迈向大语言模型的可扩展自动对齐:一项调查
摘要
对齐是构建满足人类需求的大型语言模型(大语言模型)中最关键的一步。 随着大语言模型的快速发展逐渐超越人类的能力,传统的基于人工标注的比对方法越来越不能满足可扩展性的需求。 因此,迫切需要探索新的自动对准信号来源和技术途径。 在本文中,我们系统地回顾了最近出现的自动对齐方法,试图探索一旦大语言模型的能力超过人类的能力,如何实现有效的、可扩展的、自动对齐。 具体来说,我们根据对齐信号的来源将现有的自动对齐方法分为4大类,并讨论了每一类的现状和潜在发展。 此外,我们还探讨了实现自动对齐的基本机制,并从对齐的基本作用出发,讨论了使自动对齐技术可行和有效的基本因素。
1简介
近年来,大语言模型的快速发展,极大地重塑了人工智能的格局(Ouyang 等人,2022;Touvron 等人,2023;OpenAI,2023b) 。 一致性是大语言模型塑造符合人类意图和价值观的行为的核心(姚等人,2023a;沉等人,2023b),例如教导大语言模型遵循“乐于助人,无害和诚实(HHH)”的回应原则(Askell 等人,2021)。 因此,人们越来越努力地调整大语言模型以满足人类的需求,这使其成为大语言模型时代的热点研究方向(王等人,2023g,2024g;季等人,2023) 。
以往的对齐研究主要依靠手动标注的对齐数据(包括人类偏好信息)对预训练模型进行后训练以实现对齐(Stiennon等人,2020)。 具体来说,对齐数据有两种主要形式:1)指令响应对,通常由查询和人工编写的黄金参考组成。 这种形式的数据常用于大语言模型的监督微调,将人类偏好信息注入到模型中(Taori 等人,2023;Peng 等人,2023;Ding 等人,2023) ; 2)偏好数据,通常包括一个查询、几个潜在的响应以及人类对这些响应的偏好(Cui等人,2024)。 偏好数据可以通过 DPO (Rafailov 等人, 2023)、IPO (Azar 等人, 2024) 和 PRO 等算法进行直接偏好优化(宋等人,2023)。 此外,它还可以用于训练奖励模型,通过提供模型响应的反馈,将目标策略大语言模型与数据中的偏好信息对齐(Stiennon 等人,2020;Bai 等人,2022a) ;欧阳等人,2022)。 然而,指令-响应对和偏好数据的构建过程需要非常昂贵、细致的人工标注和高质量标准,使得扩展这些方法的每一步都非常昂贵(Ouyang 等人, 2022; Touvron 等人, 2023 ;周等人,2023a)。
即使成本如此之高,这些依赖于人类注释的比对方法的可扩展性仍然是不可持续的。 首先,随着大语言模型的快速发展,大语言模型的能力在很多方面已经逐渐接近甚至超越人类,这使得人类产生对大语言模型有意义的比对数据变得越来越具有挑战性(Bowman等人,2022;伯恩斯等人,2023)。 事实上,许多研究发现,大语言模型生成的数据质量在很多方面已经超过了一般人类标注者标注的数据质量(Zheng 等人, 2024b; Chen 等人, 2024d; Wei 等人,2024)。 这种现象不仅显着提高了获取单个有意义的人工注释数据的成本(由于需要越来越昂贵的高质量注释器),而且还大大降低了大语言模型人工注释数据的潜在收益。 其次,随着大语言模型的能力逐渐超越人类的能力边界,人类越来越难以有效判断大语言模型生成的响应的质量。 这导致人类产生的偏好信号的质量显着下降,无法准确反映人类的需求,从而为大语言模型提供有效的指导变得具有挑战性。 因此,基于人类标注的比对方法越来越无法应对大语言模型能力的快速提升,难以实现大语言模型的可扩展监督。
为了应对这些挑战,自动对齐最近引起了人们的极大关注(Yuan 等人,2024;Chen 等人,2024g)。 与以前依赖人类标记来获取比对信号的方法不同,自动比对的目标是在最少的人为干预下构建可扩展的高质量比对系统。 因此,自动比对有潜力解决大语言模型快速发展带来的核心挑战,其中人类色素要么不可行,要么极其昂贵。 对于自动比对来说,最关键的部分是找到一种可扩展的比对信号,可以替代人类手动创建的偏好信号,并在大语言模型的快速发展中保持有效。
为此,本次调查根据构建不同比对信号的机制对快速发展的自动比对方法进行了分类,总结了每个方向当前的发展,并讨论了发展轨迹和潜在的未来方向。 具体来说,本次调查探索了以下构建对齐信号以实现自动对齐的代表性方向,包括:
此外,本次调查还探讨了实现自动对齐的底层机制(§7),并从对齐的基本作用出发,讨论了使自动对齐技术可行和有效的基本因素。
本次调查的其余部分组织如下:2 部分描述了本次调查涵盖的自动对齐范围以及我们的分类法。 3-6小节详细介绍了上述四个代表性方向在自动对齐方面的进展和局限性。 7 部分探讨了自动对齐的底层机制。 我们在8111We openly released a corresponding paper list which will be regularly updated on https://github.com/cascip/awesome-auto-alignment上公开发布了相应的论文列表,并定期更新。
对于树=分叉边缘,grow'=0,绘制,圆角,节点选项=align=center,,文本宽度=2.7cm,s sep=6pt,calign=边缘中点,,[可缩放
自动对齐,fill=gray!45,父级[归纳
偏差§3, for tree=acquisition [根据大语言模型的特征,[不确定性过滤,获取[自洽性(Wang 等人, 2023e);自强不息(黄等人, 2023a); West-of-N (Pace 等人, 2024);等等,acquisition_work] ] [自我判断/批评/提炼,获取[宪法AI (Bai 等人, 2022b);思想树(Yao 等人, 2023b);自我奖励(Yuan 等人, 2024);等等,acquisition_work ] ] [语境蒸馏、获取[对齐实验室(Askell 等人, 2021);单峰骆驼 (Sun 等人, 2023d); Llama-2-Chat (Touvron 等人, 2023); RLCD (杨等人, 2024b);等等,acquisition_work] ] [来自大语言模型的组织,[任务分解,获取[Least-to-Most (Zhou 等人, 2023b)0>; IDA (Christiano 等人, 2018)1>;等,acquisition_work] ] [自玩,获取[SPIN (Chen 等人, 2024g)2>;共识博弈(Jacob 等人, 2024)3>;等,acquisition_work] [辩论(Irving等人,2018)4>; SPAG (Cheng 等人, 2024)5>;等等,acquisition_work] ] ] ] [行为
模仿§4, for tree=representation [ 指令构建,[ 非自然指令 (Honovich 等人, 2023);自学(王等人, 2023f); Evol-Instruct (徐等人, 2024a);座头鲸 (Li 等人, 2024e);等,representation_work_2 ] ] [强到弱蒸馏,[响应引导,表示[ LLaMA-GPT4 (Peng 等人, 2023);斯坦福羊驼 (Taori 等人, 2023); Ultrachat (丁等人, 2023);等,representation_work ] ] [偏好引导,表示 [ Zephyr (Tunstall 等人, 2023); IterAlign (陈 等人, 2024e); Openchat (王等人, 2024b);等,representation_work ] ] ] [ 弱到强对齐,[ Weak2Strong (Burns 等人, 2023)0>; IaR (Somerstep 等人, 2024)1>; 刘和阿拉希 (2024)2>; Hase等人 (2024)3>;等等,representation_work_2 ] ] ] [模型
反馈§5, for tree=probing [标量奖励, [RLHF , 探测 [ InstructGPT (欧阳等人, 2022); DPRM (李等人, 2024a);等, probing_work] ] [RLAIF, 探测 [RLAIF (Lee 等人, 2023); RLCD (杨等人, 2024b);等等,probing_work]][反馈引导解码,探测[评论家驱动解码(Lango和Dusek,2023); RAD (Deng 和 Raffel,2023);等, probing_work] ] [过滤SFT数据,探测[Quark (Lu 等人, 2022); RRHF (袁 等人, 2023a); RAFT (董等人, 2023);等等, probing_work] ] ] [二进制验证器, [结果验证器, 探测 [V-STaR (Hosseini 等人, 2024); SORM (Havrilla 等人, 2024)0>;等, probing_work] ] [流程验证器,探测 [MATH-SHEPHERD (Wang 等人, 2024e)1>; MiPS (Wang 等人, 2024h)2> 等, probing_work] ] ] [文本评论家,探测 [ILF (Scheurer 等人, 2022)3>; LEMA (An 等人, 2024)4>;等等,cus_probing_work] ] ] [环境
反馈§6,针对tree=editing [社交互动,编辑[StableAlignment (Liu 等人, 2023a) ; MoralDial (Sun 等人, 2023a); SOTOPIA- (王等人, 2024f);等等,编辑工作] ] [人类
Collective Reason, editing
[Constitutional AI (Bai et al., 2022b); Collective Constitutional AI (Anthropic, 2023) etc., editing_work]
]
[Tool Execution, editing
[Self-Debugging (Qiao et al., 2024); CodeRL (Qiao et al., 2024); SelfEvlove (Jiang et al., 2023); CRITIC (Gou et al., 2024);
etc., editing_work
]
]
[Embodied Environment, editing
[GLAM (Carta et al., 2023); E2WM (Xiang et al., 2023); TWOSOME (Tan et al., 2024); etc., editing_work
]
]
]
[Mechanism §7, for tree=application
[Alignment
Mechanism, application
[LIMA (Zhou et al., 2023a); Rethinking (Ren et al., 2024); URIAL (Lin et al., 2024a); ICL&IT (Duan et al., 2023); Behavior shift (Wu et al., 2023a) etc., application_work]
]
[Inner Workings of Self-feedback,application
[GV-consistency (Li et al., 2024f); CriticBench (Lin et al., 2024b); Self-Rewarding (Yuan et al., 2024); Humback (Li et al., 2024e); LLM-as-a-Judge (Zheng et al., 2024b) etc., application_work]
]
[Feasibility of Weak-to-strong, application
[Easy2Hard (Sun et al., 2024b; Hase et al., 2024); Weak2Strong (Burns et al., 2023); Principle2Behavior (Bai et al., 2022b; Sun et al., 2023d) etc., application_work]
]
]
]
2概述
在本节中,我们将讨论本次调查中涵盖的自动对齐范围,然后描述我们的分类法。
2.1 自动对齐的范围
在快速发展的人工智能领域,对齐研究在确保机器行为符合人类价值观和期望方面发挥着关键作用。 随着人工智能系统,特别是大语言模型,变得更加复杂和强大,使这些模型与细致入微的人类标准保持一致变得越来越具有挑战性和资源密集型。 这种必要性刺激了“自动对齐”方法的发展。
自动对齐并不意味着完全没有人工参与。 相反,它的目标是最大限度地减少人为干预,同时构建严格遵守所需调整结果的可扩展的高质量系统。 自动对准的本质在于其能够通过自动化流程动态调整和响应对准标准,从而减少对持续人工监督的依赖。 根据对准信号的来源,当前自动对准的研究可分为四大类。 首先,归纳偏差涉及使用假设的概括或规则来增强模型,使它们能够在没有明确的外部指导的情况下产生更一致的响应。 其次,行为模仿技术涉及通过模仿已经对齐的模型的输出来训练人工智能系统,利用模仿学习来传播所需的行为。 第三,通过集成反馈机制支持自动对齐。 模型反馈通过结合其他模型反馈的见解来调整目标模型。 第四,环境反馈自动从操作环境本身获取对齐目标,使模型能够根据实时数据和交互进行调整。
自动对齐的演变提出了一种范式,其中人工智能系统不仅可以根据预定义的对齐协议进行自我调节,还可以通过持续学习和适应自主地发展这些协议。 这一转变有望在人工智能治理方面取得重大进展,使得更大规模地部署既有效又值得信赖的人工智能解决方案成为可能。 然而,尽管取得了这些进步,人类监督的必要性仍然至关重要,以确保人工智能系统即使获得自主权也不会偏离道德界限或社会规范。 这种自动化与战略性人类监督的结合概括了人工智能领域当前的发展轨迹和复杂性。
2.2分类
在本节中,我们将提供分类法的详细描述,如图 2 所示。
通过归纳偏置进行对齐 (§3)
讨论了通过引入额外的假设来增强模型,使其能够利用自身生成的信号来进一步改进。 目前,有两种类型的归纳偏差(Mitchell,1980)有助于大型语言模型的自我改进。 第一类包括源自大语言模型固有特征的归纳偏差。 例如,Wei 等人 (2022);小岛等人 (2022);王等人 (2023e); Wang 和 Zhou (2024) 专注于通过利用模型输出概率中的模式从大语言模型中得出更好的结果。 此外,Bai 等人 (2022b);姚等人 (2023b);桑德斯等人 (2022); Shinn 等人 (2023) 利用模型的能力来批判、判断和完善他们的反应,从而提高安全性和质量。 另一系列工作(Ganguli 等人,2022;Lin 等人,2024a)发现,只需在上下文中提供对齐的目标信号,大语言模型就可以利用其强大的上下文学习能力进行自动对齐。 第二种是由大语言模型的组织结构产生的归纳偏差。 例如,基于因子认知的假设,Khot 等人(2023);周等人 (2023b); Wang等人(2023b)利用任务分解使大语言模型能够解决复杂的任务。 此外,受 AlphaGo Zero (Silver 等人,2018)成功的启发,一些研究提出通过让大语言模型与自己进行迭代游戏来增强大语言模型(Fu 等人,2023a;Chen等人, 2024g)。
通过行为模仿进行调整 (§4)
旨在通过模仿使目标模型的行为与教师模型的行为保持一致。 根据教师模型和目标模型的特点,通过行为模仿进行对齐的研究可以分为两个主要范式:强到弱蒸馏和弱到强对齐。 具体来说,从强到弱的蒸馏涉及使用对齐良好且功能强大的大语言模型来生成训练数据,然后将目标模型的行为与响应对齐(Taori 等人,2023;Peng 等人,2023; Xu 等人, 2024a) 或教师模型的偏好(Tunstall 等人, 2023; Cui 等人, 2024)。 相比之下,弱到强对齐使用较弱的模型作为监督者,引导较强的目标模型进一步对齐(Burns等人,2023;Zheng等人,2024a;Hase等人,2024)。
通过模型反馈进行调整 (§5)
旨在通过引入其他模型的反馈来指导目标模型的对齐优化。 这种反馈通常分为三类:1)标量信号(Christiano等人,2017;Stiennon等人,2020;Ouyang等人,2022)。 这些通常由在偏好数据对上训练的奖励模型提供。 奖励模型有望从偏好数据中学习对齐信号,并推广到强化学习过程中获得的未见过的样本。 此外,奖励模型的反馈可以指导指令调优数据(Zhou 等人,2023a;Touvron 等人,2023;Yuan 等人,2023b)和模型解码(Lango 和杜塞克,2023;邓和拉斐尔,2023)。 2)二进制信号。 它们广泛用于数学推理任务,以提供有关结果正确性的二进制反馈。 鉴于大多数数学任务需要多个推理步骤来求解,二元验证器可以分为结果验证器,它估计最终结果的正确性(Zelikman 等人,2022;Singh 等人,2024;Havrilla 等人,2024) ,以及流程验证器,可以进一步提供中间步骤的反馈(Lightman等人,2023;Uesato等人,2022;Ying等人,2024;Shao等人,2024)。 3)文本信号。 这些通常由大语言模型生成,以便为人类提供更直观的反馈(Scheurer 等人,2022;Chen 等人,2024a)。
通过环境反馈进行调整 (§6)
旨在自动从现有环境中获取对齐信号或反馈,而不是训练模型,例如社交互动(Liu等人,2023a; Sun等人,2023a),舆论(Anthropic, 2023)、外部工具(乔等人, 2024;蒋等人, 2023)和具体环境(Bousmalis 等人, 2023;徐等人, 2024b)(Bousmalis 等人, 2023) t3>. 环境反馈是对先前对准信号来源的重要补充,使人工智能系统能够更好地适应现实世界的应用场景。 然而,如何有效利用环境反馈仍然是迫切需要进一步探索的研究方向。
自动对齐的底层机制 (§7)
除了回顾上述实现自动对齐的代表性技术外,我们还深入讨论了自动对齐的底层机制。 具体来说,我们致力于研究以下有关自动对齐的三个关键问题:
-
•
当前对齐的根本机制是什么?
-
•
为什么自我反馈有效?
-
•
为什么从弱到强可行?
这些问题的探索对于实现可扩展的自动对齐至关重要。 对于每个问题,我们总结现有的研究和观点,提出开放性问题,并讨论其局限性和未来方向。
3 通过归纳偏差进行对齐
我坚信,自我教育是唯一的教育方式。
艾萨克·阿西莫夫
目前,通过感应偏置进行对准是实现自动对准最有前途的方向之一。 归纳偏差(Mitchell,1980)本质上是指导模型学习和决策过程的假设或约束。 通过仔细选择和实施合适的归纳偏差,我们可以引导模型做出更有可能满足人类标准和期望的行为和决策,然后将其推广到看不见的数据分布。
与其他实现自动对准的方法相比,通过感应偏置进行对准具有两个主要优点:
-
1)
除了模型本身之外,它不需要额外的监督信号,从而避免了获取额外注释数据的高成本。 考虑到当前训练数据变得稀缺或已经耗尽的情况,这一点尤其重要 222在本文讨论的对齐背景下,我们期望模型不断提高其实用性,从而为对齐过程提供更有效的帮助。 对齐范围实际上代表了预训练后的过程,而不是引导模型。 (薛等人,2023)。
-
2)
它有可能解决可扩展的监督问题(Bowman 等人,2022)。 随着大语言模型的潜力不断扩大,人类提供超越自身知识水平的监督信号变得具有挑战性。 然而,通过归纳偏差,模型可以不断自我改进,超越人类知识的局限性。
在对相关文献进行彻底回顾后,我们发现当前仅通过语言模型本身进行自我改进的努力可以分解为一组五个归纳偏差。 这些归纳偏差分为两大类:1)源自大语言模型固有特征的归纳偏差(§3.1),2)源自大语言模型自我博弈动态的偏差(§3.2)。
对于每种类型的归纳偏差,我们将首先介绍其起源。 接下来,我们将列举使用这种归纳偏差作为单步政策改进策略的作品。 接下来,我们将讨论针对这些偏差进行迭代训练的工作,旨在持续改进。 最后,我们将解决与给定归纳偏差相关的开放研究问题。
3.1 从大语言模型特征归纳偏差
大语言模型具有可以充当归纳偏差的内在特征。 这些特征主要源自深度 Transformer 网络在大型数据集(H1、H3)上的预训练。 此外,一些偏差是由旨在提高模型有用性的初始对齐过程造成的(H2)。 在本节中,我们总结了三个关键的归纳偏差,如图 3 所示。 值得注意的是,这些归纳偏差并不是完全独立的。相反,它们代表了自动对齐的三种不同观点。
大语言模型具有可以充当归纳偏差的内在特征。 这些特征很大程度上源于深度 Transformer 网络在海量数据集上的预训练(H1、H3),而一些特征也源于旨在增强模型有用性的基础知识对齐程序(H2)。 在本节中,我们将总结三个关键的归纳偏差,如图3所示。 值得注意的是,这些归纳偏差并不是完全独立的。相反,它们代表了自动对齐的三种不同观点。
3.1.1 H1:不确定性作为有用性指标
模型的概率分布可以代表不确定性。 正如 Kadavath 等人 (2022) 发现的,当提示设计得当时,从预训练的大语言模型获得的响应可以很好地校准,并且校准的程度可以随着参数的数量和样本的数量而缩放。 换句话说,大语言模型为给定答案分配的概率越高,该答案就越有可能是正确的。 这一假设也得到了 Wang 等人 (2021) 和 He 等人 (2023) 的验证。 同样,Manakul 等人 (2023) 发现了对齐模型输出的概率与事实之间的相关性。
在机器学习文献中,这种归纳偏差的早期应用在一系列使用自我训练(Scudder,1965)进行半监督学习的作品中很明显(Nigam and Ghani,2000;阿米尼和加里纳里,2002)。 这些工作的基本范式涉及使用受监督数据训练的学习者继续从自信分类的未标记数据中学习,从而提高未标记数据的监督学习性能。 该方法已通过伪标签(Lee等人,2013;Ferreira等人,2023)和熵最小化(Grandvalet和Bengio,2004)等方法应用于分类任务。 t1>. He 等人 (2020) 将这种方法扩展到序列生成 NLP 任务,强调偏差采样和噪声扰动是这些任务中自我训练成功的关键因素。 Pace 等人 (2024) 将自我训练的范式扩展到对齐问题,通过允许奖励模型迭代地从候选者中得分最高和得分最低的答案中学习来提高奖励模型的鲁棒性为查询生成的池。
具体答案的频率也反映了不确定性。 因此,从多个采样中合成候选答案可以比依赖单个样本获得更好的性能。 当大语言模型用于需要深思熟虑的任务(例如解决数学问题)时,这种方法特别有效,作为单一的思想链(CoT)(Wei等人,2022)推理路径有时会陷入局部最优并生成看似合理但不忠实的答案。 自洽(Wang等人, 2023e)通过加权和聚合多个推理路径,可以通过边缘化模型对推理路径的可能性来缓解这个问题。 有趣的是,我们还发现,未加权的总和(即多数投票)可以实现可比较的性能,这归因于所有推理路径上的“相似可能”概率。 Wang and Zhou (2024)进一步发现,在没有任何提示技术的情况下进行推理时,CoT推理路径的存在与否与最终答案的概率相关。
为了延续这种增强,Self-Improve (Huang 等人, 2023a)将具有自我一致性的CoT视为策略改进算子,通过迭代学习大语言模型的推理能力和潜力,大幅提高大语言模型的推理能力和潜力。从自洽中获得的推理路径。 Zhang 和 Parkes (2023) 证明,LM 可以通过课程“提炼”CoT 答案到直接答案而无需明确推理,从而在大量加法问题上进行自我改进。 Quiet-STAR (Zelikman 等人, 2024) 将推出原理对后续 Token 概率的影响视为反馈信号,鼓励模型使用强化生成更有用的隐式思维过程学习技巧。
H1:讨论
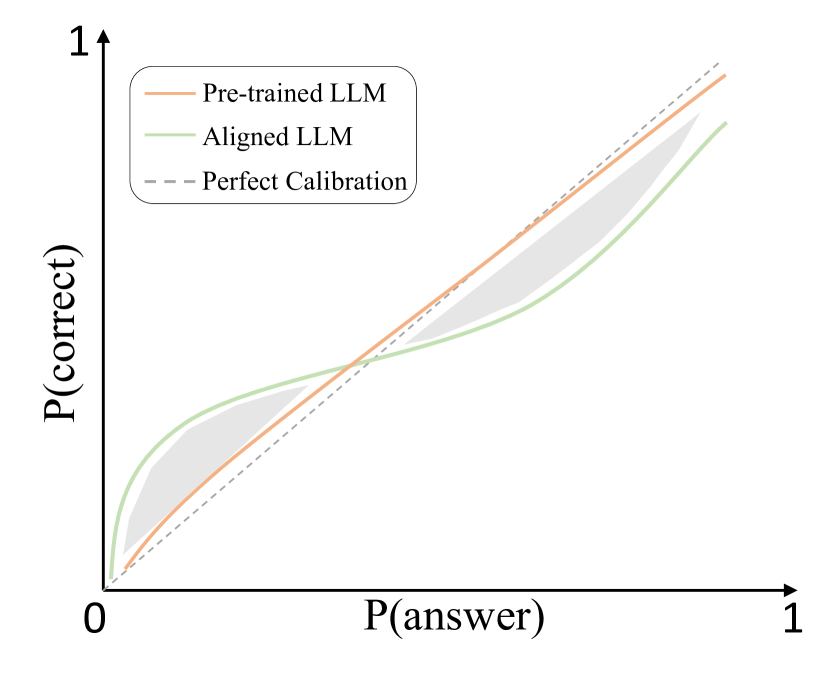
对于对齐模型来说,保持校准和不确定性仍然至关重要,因为校准错误可能会破坏迭代自我改进的潜力。 大量研究(Kadavath 等人,2022;He 等人,2023;OpenAI,2023b;Zhang 等人,2024)指出对齐过程会损害大语言模型的校准(如图4)。 这一观察结果是合理的,原因如下:1)当前的表面对齐过程旨在引导模型避免生成有害或不正确的答案。 这涉及到在某种程度上用拒绝响应的概率代替错误答案的概率,在低概率区域中创建一个灰色区域。 2)在对齐过程中,模型还学习响应格式。 对响应格式的置信度增加可能会在一定程度上影响答案本身的置信度(何等人,2023)。 此外,模型重新学习正确答案,这可能会导致过度自信(由高概率区域中的灰色区域表示)。 考虑到自对准是一个涉及自采样和训练的迭代过程,概率分布的极端化可能在自对准中更为明显。 这意味着所有 Token 已经处于非常高的概率分布中,使得它们更有可能被采样为响应。
当模型变得过度自信时,就会导致模型生成的输出的多样性和探索性下降。 为了缓解这个问题,一种有前途的方法是使用推理时间干预(例如,高温(Kadavath等人,2022),保真度(Zhang等人,2024) )以减少预期的校准误差。 另一个潜在的解决方案是过滤伪标记样本以避免有害的重复训练,这需要了解未标记样本何时有效(Grandvalet和Bengio,2004)。
3.1.2 H2:大语言模型可以判断、批评、提炼等
预先训练的大语言模型通常很难直接响应指令。 然而,模仿学习(Chiang等人,2023)和反馈学习(白等人,2022a)的广泛采用显着增强了大语言模型的零样本有用性。 利用这些普遍的帮助性改进所引发和增强的推理能力,一系列的工作已经出现,利用模型的能力通过判断、批评、提炼等来提高响应质量和安全性。
判断是指确定模型响应的质量。 这些判断标准通常作为原则或指南纳入指令中,使监管机构能够以更具可扩展性的方式监管大语言模型行为(Bai等人,2022b;Yuan等人,2024)与严重依赖相比关于人类注释者的反馈(Bai 等人,2022a)。 这种方法可以进行及时的调节,有助于语言模型的灵活和受控的对齐过程,这有助于防止迭代训练期间奖励黑客等问题(Sun等人,2023c)并促进on-policy强化学习训练(Guo 等人, 2024b)。
自我判断可以表现为两种主要形式:1)区分两个响应的相对质量(AI反馈(Bai等人,2022b)),产生以偏序表示的评估结果。 例如,Tan 等人 (2023) 使用提示来比较哪个答案更符合 HHH 原则。 然后,他们将所选选项提炼回模型中,以进一步增强其判断能力。 Bai 等人(2022b)促使模型根据抽样原则选择更优的响应,随后采用偏好过程来实现模型的帕累托改进。 2)为回答提供绝对分数(LLM-as-a-judge (Zheng 等人, 2024b)),评估结果以标量形式表示。 Yao 等人 (2023b)、Besta 等人 (2024) 和 Xie 等人 (2023) 引入了思想状态实时评估模块在推理过程中。 这些模块在搜索过程中充当先验,帮助模型探索需要深思熟虑的问题的行动空间。 类似地,RAIN(Li等人,2024g)利用二元评分提示来自我评估这一代是否可能有害,从而结合推理时间树搜索来增强响应安全性。 Yuan 等人 (2024) 采用五点判断提示对模型的指令响应输出进行评分,然后使用 DPO 将评分转换为迭代训练的偏序。
回顾H1,很明显H1是H2的基础,因为判断的准确性与大语言模型的校准直接相关。 因此,只有当 H1 有效时,H2 才会有效(Bai 等人, 2022b)。
Critique是指产生修改建议。 通过利用大语言模型本身进行批评,建议可以解决错误和不足,例如摘要错误(Saunders等人,2022)和机器翻译(Fernandes等人,2023),数学推理(Lin 等人,2024b),以及决策和编程任务(Saunders 等人,2022)。 这些建议还可以涉及摘要价值标准,例如 HHH 相关原则(Chen 等人,2024e;Bai 等人,2022b)。
Refine是指大语言模型对给定文本进行改进的能力。 大多数关于自我细化的工作都是根据critic模块提供的自然语言原因来修改响应(Bai等人,2022b;Tan等人,2023;Madaan等人,2023)。 一些研究还证明了直接根据标量奖励进行修改的可能性(Shinn等人,2023)。 信息量较少的批评家对大语言模型来说可能更具挑战性,因为他们必须通过推理自己完成更多信息。 另一项工作是使用大语言模型来完善提示本身(Fernando 等人,2023;Yang 等人,2023a)。
其他:一个有用的大语言模型可以以多种方式协助对齐过程,有效地取代人工指导。 例如,它可以对中间思维状态的质量进行投票(姚等人,2023b),根据问题中的预测条件验证结果(翁等人,2023),并自动生成、过滤(Yue 等人, 2024b),并演化指令(Wang 等人, 2023f; Li 等人, 2024e; Xu 等人, 2023a) 等任务。
关于持久化过程,这些方法的改进可以通过 SFT(即拒绝采样)、DPO、RM-RL 和其他技术进一步提炼到模型中。 此外,判断/批评-细化过程可以迭代地进行。
H2:讨论
随着判断、批判和提炼的能力越来越多地融入模型反馈和学习过程,需要对这些能力进行系统的评估研究。 在此背景下,有几个研究方向值得探索:
-
1)
根据这些原子能力对现有模型的性能进行基准测试,例如 Sun 等人 (2024a) 和 Lin 等人 (2024b) 等作品。
-
2)
对模型的判断、批判和提炼能力的形成过程进行因果研究,并研究什么形式的预训练和微调数据可以影响这些能力。
-
3)
评估分布变化对这些能力的影响。 如果模型没有经过相应的指令和响应对的训练,是否仍然具有可靠的评估和改进能力? 这与可扩展的监督问题尤其相关,该问题假设缺乏对指令的直接监督。
-
4)
收集经验证据来证明自我批判-判断-完善能力可以在公平合理的实验环境中提高模型性能。 有研究指出,改进可能来自于使用更强的模型(Sharma等人,2024)和黄金标签(Huang等人,2023a)。
3.1.3 H3:大语言模型可以有效地进行情境学习
上下文学习(ICL)是指大语言模型在推理过程中利用范例或经验初始化特定任务模型的能力(Brown等人,2020)。 鉴于某些研究(Dai等人,2023;von Oswald等人,2023)表明ICL和参数梯度下降之间存在相似之处,因此可以将其视为一种通用且有效的“学习”方法。
从自动对齐的角度来看,ICL提供了一种从预训练的大语言模型冷启动的有效方法。 在 ICL 的帮助下,只需几个上下文中的会话样本就可以产生一个稍微一致的模型(Ganguli 等人,2022;Sun 等人,2023d;Lin 等人,2024a)。 同样,通过在上下文中预先添加一些带注释的样本,ICL 也可以在一定程度上引出预训练大语言模型的判断和批判能力,或增强原始零样本能力的性能(白等人,2022b) 。 此外,ICL 还提出了一种适应不同社会规范和法规的潜在方法(Xu 等人,2023c)。
然而,在上述上下文中前置少量样本示例可能会使推理效率低下(Gim等人,2023)并干扰不相关的查询(Shi等人,2023)。 因此,从 ICL 获得的自生成标签可以直接用作伪标签,并蒸馏回仅与查询配对的大语言模型。 这种范式被称为上下文蒸馏(Askell 等人,2021)。 例如,在 Llama-2 (Touvron 等人, 2023) 的对齐过程中,使用上下文蒸馏来缓解系统提示的长期依赖问题。 在 Dromedary (Sun 训练等人, 2023d) 中,通过直接使用从多个 ICL 过程获取的样本,将基本语言模型转换为安全且有用的对齐模型,并具有最少的注释。 Padmanabhan 等人 (2023) 证明上下文蒸馏还可以通过从实体定义中学习延续来向模型注入新知识;此外,Yang 等人 (2024b) 说明了将对比上下文约束生成的偏好对提炼回模型的有效性。
此外,ICL的学习内容还可以包括探索性经验(Shinn等人,2023)和工具定义(Yao等人,2022;Tang等人,2023)。 换句话说,拥有工具和经验的代理人可能会比没有工具和经验的代理人表现更好。 这表明通过经验和工具改进的轨迹具有类似的潜力,可以不断增强同一模型。
H3:讨论
不幸的是,ICL 本身的黑盒性质对对齐提出了重大挑战(Anwar 等人,2024)。 如果没有全面了解大语言模型如何在上下文中学习,上下文蒸馏方法可能会通过潜在地放大模型在上下文中的学习过程中固有的偏差和错误来引入问题。 此外,长期情境学习的能力(Agarwal等人,2024)值得进一步探索,因为它有助于更有效的提炼,并且对于可扩展的监督设置至关重要,在这些设置中,模型需要理解冗长的专业知识文档或大量的自我对战历史。
3.2 大语言模型组织的归纳偏差
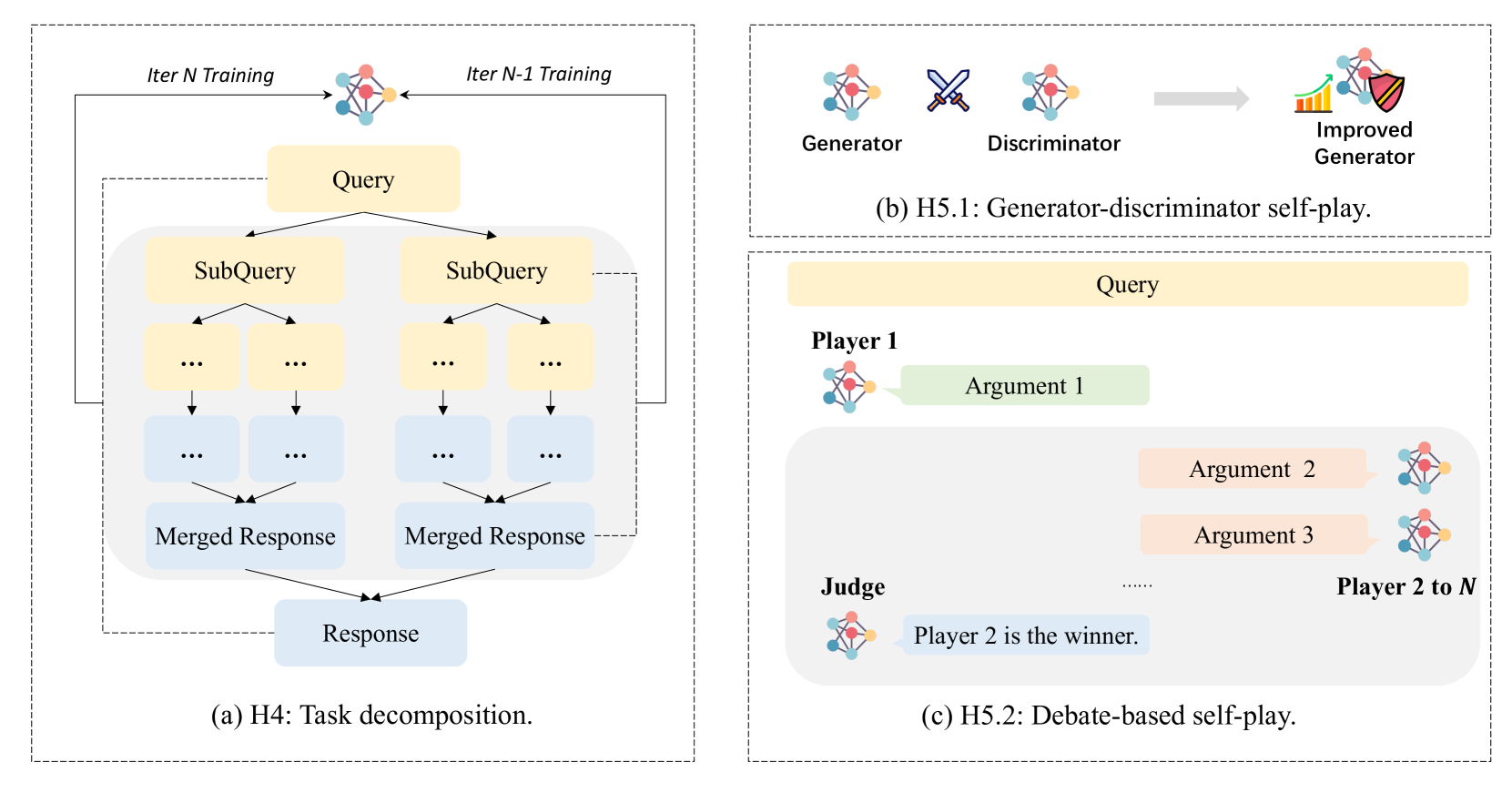
除了源于大语言模型的共同特征的归纳偏差之外,另一组偏差来自于多个大语言模型的组成或组织,如图5所示。 根据构成大语言模型之间的关系是合作还是对抗,出现了两种代表性的归纳偏差:“任务分解”和“自我博弈”。 值得注意的是,随着该领域的进展,我们预计后续文献将采用更复杂的组织和学习结构。 对抗模式和协作模式都可以构成复杂代理系统的组成部分。 然而,在现阶段,任务分解和自我游戏是实用的分类法。 后续部分将详细探讨这些概念。
3.2.1 H4:任务分解
任务分解长期以来一直被认为是更有效地解决复杂问题的有效方法。 例如,在基于集体理性的合作博弈中,联盟所获得的整体利益超过个体收益的总和(Shapley,1971)。 此外,分而治之范式和递归是算法设计中用于解决大规模和复杂问题的行之有效的手段(Hoare,1961;Wilf,2002)。
对这一范式的讨论可以追溯到因子认知的假设(Ought,2017)。 它主张认知任务可以递归分解。 如果人工智能或人类遇到难以解决的任务,它可以分解任务,将分解后的问题分配给一系列自己的副本进行并行处理,最后合并这些结果。 副本注重短期工作,独立工作。 一系列提示方法隐式或部分采用因子认知假设进行自动对齐。 例如,周等人(2023b)和王等人(2023b)提示大语言模型分解问题,然后引导其顺序解决子问题。 人们还认为,任务分解是解决从易到难的泛化(周等人,2023b)的有效方法,即在简单样本上构造分解提示并在上下文中填充它们允许大语言模型具有推广到困难样本的潜力。 Khot等人(2023)进一步实现了递归任务分解。
基于分解认知的假设,迭代蒸馏和放大(IDA)(Christiano 等人,2018)将每个分解-合并过程视为一种放大形式,并考虑学习以蒸馏的形式从最终合并结果中提取。 尽管最初的 IDA 论文以人机循环的方式构建了这个理论框架,其中人类监督初始任务分解步骤,但由于 H1、H2 和 H3 (张和帕克斯,2023)。
值得注意的是,迭代蒸馏和放大(IDA)代表了实现可扩展监督的一条有希望的途径,通过将任务分解为更容易处理的子问题,使得解决人类难以直接监督的长期任务成为可能。 例如,在现实世界中,诸如“同行评审此调查”之类的数据点标签可能需要几个月的时间才能收集。 通过因子认知可以更快地解决此类问题。 尽管一些工作部分证明了 IDA 在现实世界任务(例如书本摘要)上的有效性(吴等人,2021a),但这种意识形态仍然依赖于一组关键假设:1)它仍然是不清楚分解问题是否是解决问题最难的部分,如果认知负担不能分散,IDA可能很难发挥作用。 2)误差不会累积。 尽管这种范式并不要求智能体之间的协作高效(Christiano等人,2018),但过多的错误仍然会带来问题。 3) 任务可以并行化的程度。 如果任务解决过程很大程度上是连续的,则收集信号的时间可能会增加,但考虑到当前大语言模型的部署速度,这似乎是一个小问题。 总的来说,由于这些假设很难证明或证伪,我们主张在这个方向上进行更多的实证研究。
3.2.2 H5:自玩
复杂性源自对抗性(Bansal 等人,2018)。 自博弈是指智能体通过迭代地与自己玩游戏来学习的范式,这是一种非合作游戏的形式(Nash等人,1951),其中每个智能体其目的是实现自身效用最大化。 自对弈是许多成功的专业超人人工智能系统的基础,例如 AlphaGo Zero (Silver 等人,2018) 和 StockFish (StockFish,2023)。 鉴于这一成功,自我博弈似乎是实现大语言模型中普遍提出的超人类智能的潜在方法。 两种具有代表性的自我博弈方法是生成器-判别器方法和辩论方法,后者涉及博弈环境中的对抗生成器和一个判别器。
H5.1:生成器-判别器
在生成器-判别器自博框架中,判别器的作用是评估生成器产生的输出,确定这些输出的质量是高还是低。
正如 H2 中所讨论的,法官和批评家模型通常被认为是一种判别器。 例如,Yuan 等人 (2024) 利用 LLM-as-a-Judge 的奖励来识别生成器的高质量和低质量响应,从而优化生成器以获得更高质量的响应。 然而,判别器和生成器之间的对抗性设置是有限的,因为唯一的假设是判别器的能力可以通过一般的有用训练来提高。 在训练过程中,判别器几乎保持静态(提示不变),使得生成器有可能针对判别器进行过度优化,从而导致奖励黑客行为。 因此,与生成器一起有效改进判断和批评模块是一个关键问题。 一种合理的方法是使用在线 AIF 设置,如 Guo 等人 (2024b) 所建议。 引入更具对抗性的设置的另一种方法是在推理时优化博弈问题,正如 Jacob 等人 (2024) 的共识博弈中所演示的那样。 它采用piKL无悔学习算法迭代更新生成器和判别器的策略,收敛到纳什均衡。 然后使用这种均衡策略对候选响应进行排名,优先考虑双方都同意的响应。
随着生成对抗网络(GAN)(Goodfellow 等人,2014)已经成为传统 NLP 中一类成熟的方法(Zhang 等人,2016;Wu 等人,2021b),另一种方法涉及使用类似 GAN 的判别器来区分模型的当前预测分布和黄金分布。 例如,Chen 等人 (2024g) 发现,一种特定类型的迭代 DPO 训练始终将策略生成的响应视为负面响应,将黄金响应视为正面响应,可以被视为一种自我训练。播放过程。 在此过程中,DPO 的隐式奖励充当模型预测与黄金样本之间的鉴别器。 然而,对于开放式问题,黄金分布有时仍然不是最佳的,并且这种方法排除了生成比黄金分布更好的答案的可能性。
H5.2:辩论
辩论范式(Irving等人,2018)很大程度上受到AlphaGo(Silver等人,2018)设计的启发。 在 AlphaGo 的学习算法中,集成了三个不同的组件:玩家、对手(实际上是其自身的模拟)以及评估与每个棋盘状态相关的获胜概率的价值模型。 通过采用蒙特卡罗树搜索 (MCTS),该算法进行推出,定义为一直延伸到游戏结束的模拟自我游戏序列。 这些推出通过基于结果的向后更新来提高价值估计的准确性,同时通过利用先前取得胜利的策略来完善政策。
围棋游戏与使用自然语言辩论解决可扩展的监督问题有相似之处。 在围棋的开始或中期,即使是经验丰富的专家也可能很难判断哪一方获胜的概率更高,就像人类有很小的概率判断超出人类知识水平的问题一样。 然而,当比赛接近尾声时,结果通常会变得清晰起来,即使是非专家法官也可以自信地评估围棋大师所生成的棋盘。 对于辩论比赛,获胜者通常可以由评委总结。
这为构建值得信赖的超人人工智能系统提供了可能的监督解决方案。 Irving等人(2018)通过概念验证实验表明,在辩论范式中诚实是比谎言更好的策略。 作为对此的延伸,Brown-Cohen 等人(2023)提出了一套新的辩论协议,其中诚实的策略可以通过仅涉及多项式的模拟总是成功步数。 Khan等人(2024)对大语言模型上实施辩论范式的可行性进行了深入的实证研究:发现辩论范式可以显着增强真实性,更有说服力( Anthropic,2024) 辩手会带来更真实的结果。
这为构建值得信赖的超人人工智能系统提供了潜在的解决方案。 Irving 等人 (2018) 通过概念验证实验,在辩论范式中,与欺骗相比,诚实被证明是一种更优越的策略。 在这一概念的基础上,Brown-Cohen 等人 (2023) 引入了一套新颖的辩论协议,其中诚实的方法可以始终获胜,正如仅需要多项式步骤的模拟所证明的那样。 Khan 等人(2024)对大语言模型辩论范式的实用性进行了全面的实证研究,发现辩论范式大大增强了真实性,辩手越多,结果就越真实 (人类,2024)。
除了经典的自然语言辩论之外,一系列作品都将辩论范式应用到了游戏场景中。 一个代表性的领域是讨价还价任务(Nash等人,1950)。 Fu 等人 (2023a) 专注于讨价还价的零和变体,其中气球卖方的目标是以更高的价格出售,而买方则寻求更低的价格。 他们观察到不同大语言模型之间的讨价还价能力以及从游戏经验和反馈中学习的能力存在显着差异。 Cheng 等人 (2024) 实现了对抗性语言游戏 对抗性禁忌 (Yao 等人, 2021),攻击者和防御者进行对抗以只有攻击者可见的目标词为中心的对话。 攻击者巧妙地诱导防御者无意识地说出目标词,而防御者则试图避免这样做并从上下文中猜测该词。 两名玩家通过模仿大语言模型老师的学习获得基本的游戏技能,然后通过自我对弈完善自己的策略。 有趣的是,能力较差的玩家大语言模型不仅可以通过自我对弈来提高自己在该特定游戏中的胜率,还可以增强其一般推理能力马等人(2023a)引入了红队游戏,一种更复杂的对抗性团队游戏,其中大语言模型被初始化为一组联合的红队策略,以促使目标大语言模型产生有害内容。 他们提出了一个求解器来确保最终的元策略在一定的 范围内近似纳什均衡。
3.2.3讨论
任务分解和自我博弈都需要大语言模型作为代理发挥作用。 然而,与将大语言模型对齐为聊天机器人相比,将大语言模型对齐为代理的挑战更加复杂,因为它需要考虑行为级别的对齐(Pan等人,2023),环境的动态性和自我约束(Garrabrant 和 Demski,2018;Shavit 等人,2023;Yang 等人,2024d)。 我们强调这一研究方向的重要性,并主张在这一领域加大努力。 此外,一个更复杂的问题在于证明多智能体系统的理论安全性和可信性。 尽管该领域的研究刚刚起步(Yang 和 Wang,2020;DiGiovanni 和 Zell,2021),但博弈论的进展(Hazra 和 Anjaria,2022)、自动定理证明技术(Polu 和 Sutskever,2020) 和现实世界模拟技术(Brooks 等人,2024) 可能会为应对这一挑战提供见解。
虽然对抗性自我博弈为可扩展性监督挑战提供了潜在的解决方案,但它也可能催生更具说服力和自主性的代理(Tao等人,2024)。 这种发展可能会产生重大的社会影响和道德风险,例如模型有可能生成比人类更有说服力的文章,这可能会被用来进行政治操纵。 令人鼓舞的是,几家著名的模型引擎提供商已采取措施来监控和减轻这些潜在的副作用。 例如,OpenAI 的准备团队建立了与说服力和自主性相关的基准(OpenAI,2023a)。 他们将模型风险分为低、中、高、危四个等级,规定高于高风险阈值的模型不能开发,高于中风险阈值的模型不能部署。 我们呼吁学术界和第三方组织付出更多努力,为高能力代理开发和审查强大的安全框架。
4 通过行为模仿进行调整
模仿是觉醒心灵的第一本能。
玛丽亚·蒙台梭利
通过行为模仿进行对齐是另一种广泛使用的自动对齐策略,它通过模仿另一个对齐模型的行为来对齐目标模型。 具体来说,如图6所示,该方法首先收集高质量的指令作为任务描述(Wang等人,2023f)。 然后采用监督模型生成对齐信号,通常包括指令响应对(Taori等人,2023),成对偏好数据(Cui等人,2024) t1> 和其他对齐信号(Fränken 等人,2024)。 最终,通过模仿这些产生的行为来调整目标模型。
基于监督模型和目标模型的能力比较,通过行为模仿进行对齐的研究可以分为强到弱蒸馏(§4.2)和弱到强对齐(§ 4.3)。 对于每个类别,我们都深入回顾了代表性研究,总结了当前的进展和局限性,并讨论了未来的方向。
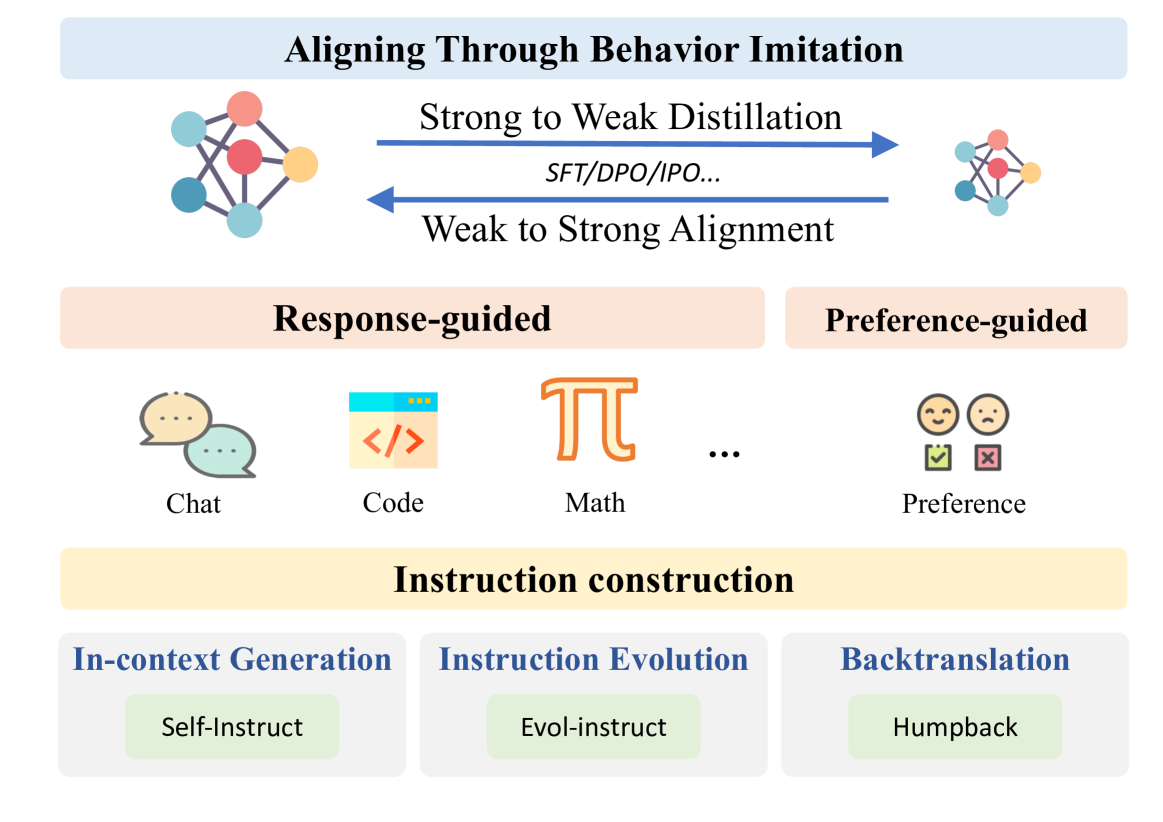
4.1 指令构建
收集高质量、多样化的大规模指令是通过行为模仿实现一致性的基础。 最直观的策略是从人工编写的指令中过滤掉高质量的数据,例如 ShareGPT 333https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered。 然而,这种方法需要大量的人力和专业知识,这也会带来显着的噪音。 因此,许多研究集中在利用大语言模型自动生成指令,从而显着减少对人类标注的依赖。 根据教学建设提供的信息,目前有代表性的策略有以下三种:
In-Context Generation,提供上下文演示来指导大语言模型生成指令。 例如,非自然指令 (Honovich 等人, 2023) 和自我指令 (Wang 等人, 2023f) 以一小组人类编写的指令开始。 这些指令是随机选择的,以创建上下文示例,提示大语言模型生成附加指令。 同样,Stanford Alpaca (Taori 等人,2023) 采用了类似的方法,使用 ChatGPT 来收集指令-响应对。
然而,初始种子指令可能缺乏多样性,这限制了生成指令的范围。 为了解决这个问题,LaMini-LM (Wu 等人, 2024) 不仅利用 gpt-3.5-turbo 进行基于上下文学习 (ICL) 的示例引导指令生成,还结合了 wiki 数据用于主题引导指令生成,从而构建大型离线精炼指令数据集。 Guo 等人 (2024a) 使用与目标域相关的高质量样本作为 ICL 的示例来生成额外样本。 Dynosaur (Yin 等人,2023) 采用 ChatGPT 通过利用现有 NLP 数据集中的元信息来生成指令,创建动态增长的指令调优数据集。 此外,LLM2LLM (Lee 等人, 2024) 通过使用学生模型的错误预测从教师模型生成新数据来增强数据集,从而提高数据集处理数据受限任务的能力。
指令演化,涉及根据预定义的手写演化原则重写现有指令的过程。 Xu 等人 (2024a) 应用指令进化范式,其中使用随机选择的手写进化原理来转换现有指令数据。 这种方法用于 GPT-3 等鲁棒模型,有助于指令重写,从而减少手动标注的需要,并增强模型管理复杂任务的能力。 以 Evol-Instruct 框架为基础,TeaMs-RL (Gu 等人, 2024) 通过强化学习训练另一个模型来生成优化的指令轨迹,从而改进了这种方法。
指令反向翻译,采用大语言模型来预测与从人类手写文本或网络文档中提取的黄金响应相对应的指令。 Humpback (Li 等人, 2024e) 和 LongForm (Köksal 等人, 2024) 利用相应的提示来标记网络文档中的文本,从而创建高质量的教学数据。 不同的是,TEGIT (Chen 等人, 2023e) 使用 ChatGPT 来注释采样文本,同时生成指令、输入和输出,以有效滤除噪声。 REInstruct (Chen 等人, 2024b) 从未标记的语料库中构建高质量的指令,并重写未标记的文本以提高其响应质量。
4.2 强到弱蒸馏
根据收集的指令,从强到弱的蒸馏试图通过模仿另一个更强且对齐良好的模型生成的响应或偏好数据来对齐较弱的目标模型。 在下面的小节中,我们将分别介绍有关响应引导和偏好引导蒸馏的代表性研究。
4.2.1 响应引导蒸馏
在响应引导蒸馏中,目标模型通过指令调整直接学习对不同指令的响应来模拟教师模型。 这种方法启发了许多研究,旨在将教师模型的各种能力提炼到目标模型。 这些能力不仅包括一般的指令遵循技能,还包括特定领域的能力,例如数学、编码和代理相关任务
遵循指令
构建教学数据后,可以轻松地从教师模型中开发出相应的响应。 使用这些指令-响应对进行训练可以模拟教师遵循指令的能力。 例如,LLaMA-GPT4 (Peng 等人, 2023) 利用 GPT-4 生成对源自 Alpaca (Taori 等人, 2023) 的指令的响应。 Ubani等人(2023)讨论了ChatGPT在资源匮乏场景下进行数据增强的零样本提示,通过设计高质量和多样化的提示来合成教学数据。 更多相关作品可以在最后一小节中找到。 除了单轮数据之外,一些研究还专注于从教师模型中收集多轮轨迹。 白泽(徐等人,2023b)和Ultrachat (丁等人,2023)采用了一个综合框架,使用两个ChatGPT API分别扮演用户和助手的角色来生成多轮对话。 Parrot (Sun 等人, 2023b) 训练模型来模拟人类生成指令,并使用这些训练好的模型与 ChatGPT 就各种主题进行多轮对话,从而收集了 40,000 个多轮对话对话。
数学
Wizardmath(罗等人,2023a)采用Evol-Instruct方法构建专门用于数学推理任务的综合数据集。 MetaMath (Yu 等人, 2024b) 利用 ChatGPT 通过从多个角度重新表述数学问题来引导数学问题,而无需引入额外的知识。 MAmmoTH (Yue 等人, 2024a) 生成一个包含数学问题和模型生成的解决方案的数据集,其特点是思维链 (CoT) 和思维程序 (PoT) 的独特组合理由。 MathCoder (Wang 等人,2024d) 使用 GPT-4 代码解释器生成创新且高质量的数学问题及其基于代码的解决方案。 MathGenie (Lu 等人, 2024) 通过问题回译过程生成多样化且可靠的数学问题。 MARIO (Liao 等人,2024) 利用 GSM8K 和 MATH 作为种子数据,产生了由 GPT 和人类专家注释的 26.9K 解决方案集合。 除了纯粹的数学数据之外,其他几项研究提出通过生成详细的 COT 响应,将基本推理能力从商业大语言模型转移到小型模型(Shridhar 等人, 2023; Fu 等人, 2023b; Hsieh 等人, 2023; Magister 等人, 2023; 何等人, 2023; 李等人, 2022, 2023a)。
编码
最先进的大语言模型,例如 GPT-4,在编码任务中表现出了卓越的性能。 除了对原始代码数据进行预训练之外,一些方法旨在通过指令调整从教师模型转移编码能力。 Code Alpaca (Chaudhary,2023) 和 WizardCoder (Luo 等人,2024) 遵循通用自动指令构建范例。 Code Alpaca 在 20K 指令跟踪数据上采用自指令,从而将 Alpaca 的功能扩展到编码领域。 WizardCoder 在编码领域采用了 Evol-Instruct 方法,从简单的编码和编程指令生成复杂的代码和程序指令。 WaveCoder (Yu 等人, 2024c) 和 Magicoder (Wei 等人, 2023) 利用开源代码数据集创建高质量的指令数据。 WaveCoder 通过开源代码片段增强了大语言模型,为编码任务生成优质的指令数据。 Magicoder 创建根据自指令技术生成的多任务数据。 OpenCodeInterpreter (Zheng 等人, 2024c) 利用 GPT-3.5 和 GPT-4 通过集成文本解释和代码片段来改进解决方案,并结合执行和反馈以实现动态代码细化。
代理人
尽管开源大语言模型在许多方面已经达到了与商业模型相当的性能,但它们在与代理相关的功能(例如工具使用和复杂任务规划)方面的能力仍然受到很大限制。 为了解决这个问题,ToolLLM(Qin等人,2023)使用ChatGPT创建了名为ToolBench的指令调优数据集,以零样本的方式获取通用工具使用能力。 类似的作品还有Graph-ToolFormer (Zhang, 2023)、Gorilla (Patil 等人, 2023)、GPT4Tools (Yang 等人, 2023b) 、 ToolAlpaca (Tang 等人, 2023) 等。 除了工具的使用之外,一些研究还关注规划任务。 例如 FIREACT (Chen 等人, 2023a)、AgentTuning (Zeng 等人, 2023)、ReAct Meets ActRe (Aksitov 等人, 2023)、ReST 满足 ReAct (Yang 等人, 2024c) 和 ETO (Song 等人, 2024b)。
4.2.2 偏好引导蒸馏
虽然响应引导蒸馏可以提升学生模型的性能(Wang等人,2022),但它并不能有效帮助学生模型符合人类偏好(Xu等人,2024c). 因此,一些工作集中于偏好引导的蒸馏,将学生模型与教师模型输出中反映的偏好保持一致。 在这种范式中,教师模型被引导以偏序对的形式生成偏好数据,然后通过直接偏好优化算法(例如 DPO (Rafailov 等人,2023))将其用于对齐学生模型。 t0>、IPO (阿扎尔等人,2024)和 PRO (宋等人,2023)。 基于构建偏序信号的方法,当前的工作主要包括三种范式:1)基于分数:涉及对响应进行评分和排名; 2)基于细化,涉及利用人工智能反馈细化现有响应; 3)基于来源,重点是了解人类对不同数据源的偏好。
基于分数
通过实施精心设计的多样化指令和模型响应,以及 GPT-4 提供的详细数字和文本反馈,UltraFeedback (Cui 等人, 2024) 生成大规模、高质量的偏好具有细粒度注释的数据集。 此外,Zephyr (Tunstall 等人, 2023) 在 UltraFeedback 上采用蒸馏直接偏好优化来开发小而高效的大语言模型。 CodeUltraFeedback (Weyssow 等人,2024) 利用 GPT 的 LLM-as-a-Judge 方法,评估来自 14 个不同大语言模型池的响应,并根据五种编码偏好对它们进行调整。
基于精炼
其他研究使用强大的模型来改善最初的反应。 Aligner (Ji 等人, 2024) 和 MetaAligner (Yang 等人, 2024a) 利用 GPT-4 等模型来修改原始响应并构建偏好数据。 IterAlign (Chen 等人, 2024e) 使用大语言模型自动发现新的构成,并优化从红队数据集生成的响应以创建偏好数据。 Safer-Instruct (Shi 等人,2024) 采用反向指令调整、指令归纳和专家模型评估,使用原始文本和 GPT-4 生成的响应来构建高质量的偏好数据。
基于源的
从单一模型学习偏好可能缺乏多样性并放大偏见。 因此,一些工作从不同的数据源构建偏序信号。 AlMoST (Kim 等人, 2023)、CycleAlign (Hong 等人, 2023) 和 Openchat (Wang 等人, 2024b) 重点关注从不同的数据源学习比较偏好。 Kim 等人 (2023) 将人类偏好转化为一系列经验先验规则,利用不同规模的大语言模型生成偏好数据。 Wang等人(2024b)将不同的数据源视为粗粒度的奖励标签,通过GPT-3和ShareGPT生成混合质量的数据。 Hong 等人 (2023) 通过比较白盒模型和黑盒模型在一系列响应中的一致性等级来对响应进行排名,并通过此排名作为上下文构建偏好数据。
4.3 弱到强对齐
正如我们在第 1 节中提到的,可扩展监管的挑战成为人工智能系统持续发展的重大障碍。 具体来说,困难在于,随着人工智能系统的能力逐渐超越人类,如何有效地进行监管。 鉴于强到弱蒸馏方法的不切实际,弱到强对齐已成为实现自动化可扩展监督的最有前途的方向之一(Burns等人,2023). 之前的研究主要集中在人类和人工智能之间的弱到强泛化上,例如迭代放大方法(Christiano等人,2018),它通过迭代放大弱专家来监督强学习器。 最近的研究已经开始探索使用较弱的模型来指导较强的模型来实现超对齐(Christiano等人,2018;Burns等人,2023;Liu和Alahi,2024)。 根据对齐信号的来源,这些工作可以分为两类:1)使用较小但对齐的模型来生成信号,2)使用较弱的模型引导较强的模型生成信号。 此外,一些研究调查模型是否可以从简单任务中的行为中学习,以提高其在更具挑战性的任务中的表现,这虽然不是经典的行为模仿,但仍然值得注意(Hase等人,2024;Sun等人,2024b) 。 在下面的小节中,我们将分别介绍每个类别的代表性研究。
Burns 等人 (2023) 以较弱的大语言模型为老师,以由弱到强的方式训练较强的大语言模型。 他们基于较小但对齐的模型生成的标签来构建较大的预训练模型,并观察到较大的目标模型始终优于较小的监督模型。 Liu 和 Alahi (2024) 不依赖单一教师,而是旨在通过与多元化专业教师共同监督强大的学生来进一步增强强大模型的一致性。 Somerstep 等人 (2024) 将弱到强泛化视为迁移学习问题,通过标签细化过程实现这一目标。 此外,Aligner (Ji 等人, 2024) 和 MetaAligner (Yang 等人, 2024a) 通过使用更小但对齐的模型来创建偏序数据,以优化来自更强的模型。
除了直接从弱模型生成信号之外,实现弱到强对齐的另一种可能方法是使用弱模型指导强模型生成信号。 Li等人(2024c)发现弱大语言模型和强大语言模型感知教学难度和选择数据的能力高度一致。 因此,可以利用较小和较弱的模型来选择数据以微调较大和较强的模型。 类似地,SAMI (Fränken 等人, 2024) 采用弱模型来编写用于对齐强基线模型的宪法。
上述工作在一定程度上实现了弱到强的对齐,并研究了实现超对齐的潜在方向。 然而,较弱的模型可能无法作为更复杂任务的有效指导者。 因此,一些研究尝试使用源自更简单任务的信号来调整模型,这些信号更容易生成和学习,以提高更困难任务的性能。 例如,Hase 等人 (2024) 观察到,当前的语言模型通常可以很好地从简单数据推断到复杂数据,甚至可以与直接在复杂数据上训练的模型竞争。 Sun等人(2024b)使用在简单任务上训练的奖励模型来评估和指导更具挑战性任务的政策模型,从而实现任务泛化。
4.4讨论
当前的工作利用教师模型的响应或偏好来促进各种任务的有效泛化和可扩展性,从而显着减少手动标注的必要性。 然而,这些方法表现出明显的局限性,包括与数据质量相关的问题、教师模型固有的偏见以及对超对齐的探索不足。
数据质量
合成数据的质量仍然是一个重大问题。 大量研究强调了数据质量对于对齐的至关重要性(周等人,2023a;陈等人,2023b)。 由于模型生成固有的随机性,从教师模型导出的训练信号通常是有噪声的。 为了解决这个问题,最近的研究集中在两个主要范式上:第一,通过制定详细和细化的原则来生成高质量的数据,例如 Orcas (Mukherjee 等人, 2023; Mitra 等人, 2023) 和 AttrPrompt (Yu 等人, 2023);其次,通过建立评价指标或采用过滤范式,例如Reflection-Tuning (Li 等人, 2023b, 2024b) 和 Phis (Li 等),从现有数据集中提取相对高质量的数据。人, 2023d; 阿卜丁等人, 2023, 2024) 444由于许多研究,例如Wang等人(2024c),对数据选择进行了详细的调查,我们不深入研究这个领域这里。. 此外,一些研究表明比对算法具有一定程度的鲁棒性(Gao等人,2024)。 因此,开发更强大的训练算法可能是缓解与数据质量相关问题的另一种方法。
老师的偏见
此外,对教师模型的依赖可能会引入教师模型固有的偏差和限制,这可能会影响对齐效果。 一些研究提出引入多个教师模型来对齐学生模型(Cui等人,2024;Liu和Alahi,2024),从而降低模型过度拟合单个教师模型偏差的可能性。 利用多个教师还可以增加信号的多样性,显着提高对齐效果(宋等人,2024a)。
对超对齐理解不够
实现超级对齐仍然是一个重大挑战。 我们对超排列仍缺乏强有力的科学认识(Burns等人,2023),阻碍了对弱到强排列的进一步探索。 此外,大多数当前方法仍然需要充分对齐的“弱”模型,并且如何利用真正的弱模型进行超对齐仍然是一个问题。 一些著作提出了理解弱到强泛化的理论框架(Charikar等人,2024;Lang等人,2024;Somerstep等人,2024),但应用范围仍然有限。 一条有趣的道路是像 ExPO (Zheng 等人, 2024a),它直接从 SFT 模型和对齐模型的权重进行推断,无需额外训练即可获得更好对齐的模型,展示了从弱到强的有前景的方法到强。
总之,尽管在教学和行为构建方面取得了重大进展,但当前的方法仍然存在很大的局限性。 从强到弱的方法的核心问题是对齐上限受到教师模型的限制。 相反,关于弱到强对齐的工作仍然不发达,缺乏理论分析和通用方法。 未来必须解决几个关键问题,包括有效提高数据质量、开发更鲁棒的训练算法、实现多教师模仿以及对一般任务中的弱到强对齐进行理论分析。 应对这些挑战将为大语言模型的进一步发展铺平可行的道路。 此外,我们还在第7节中深入讨论了弱到强对齐的底层机制,这有助于更深入地理解该领域。
5 通过模型反馈进行调整
我们都需要能给我们反馈的人。 这就是我们改进的方式。
比尔盖茨
人类反馈反映了人类价值观,可用于调整大语言模型,使大语言模型能够产生有用且安全的响应,同时纠正错误和有毒输出。 不幸的是,由于效率低下且成本高昂,在训练期间获取人类反馈具有挑战性。 为了解决这个问题,引入了模型反馈作为估计人类反馈的方法。 这种方法通常用于强化学习,其中奖励模型会生成反馈。 与依赖人类生成的有限反馈数据相比,奖励模型可以在更广泛的分布上进行反馈预测,从而实现更有效的对齐。 通过自动生成的模型反馈进行对齐提供了一种将大语言模型与人类价值观对齐的有效方法,为实现自动对齐提供了一条有希望的道路。 在本节中,我们将解释如何利用模型提供的反馈来使其与人类价值观保持一致。 如图7所示,根据反馈信号的形式可以将方法分为三种类型:标量(§5.1)、二进制(§5.2) 和文本信号 (§ 5.3)。
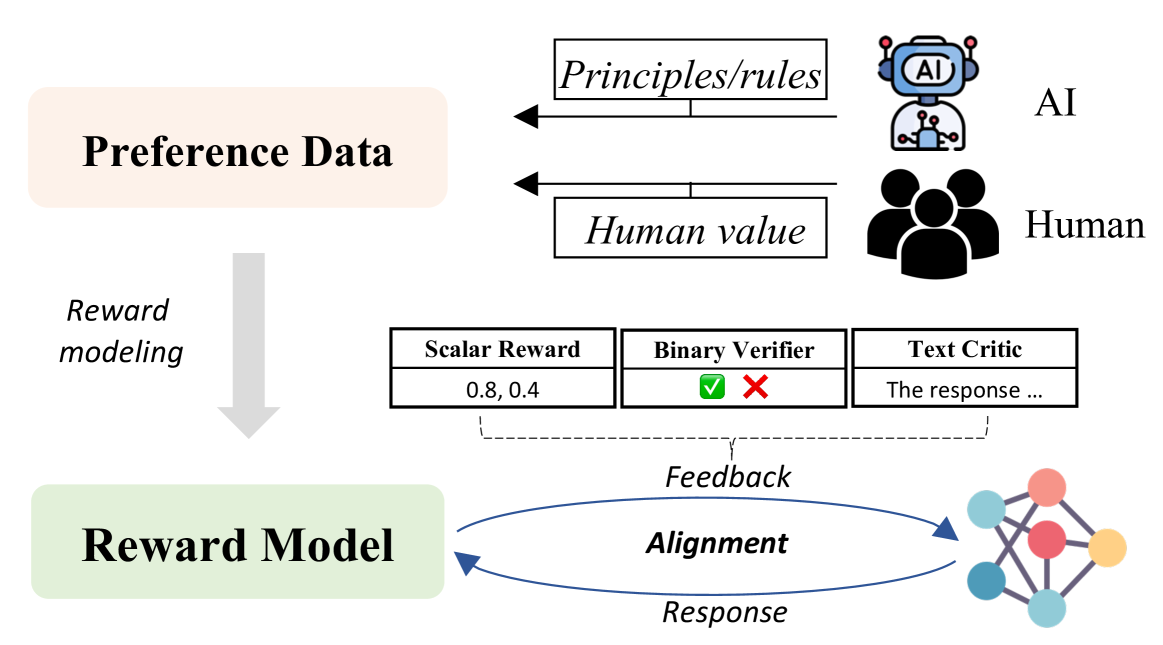
5.1 标量奖励
标量信号通常由奖励模型生成,该奖励模型以大语言模型的响应作为输入来生成标量信号以估计人类偏好。 强化学习中经常采用奖励模型来使大语言模型与人类价值观保持一致。 这样,大语言模型就可以利用奖励模型提供的大量、多样化的反馈,自动与人类价值观保持一致。 为了实现更有效的自动对齐,最近的研究重点是如何训练更高质量的奖励模型,并通过模型生成或预训练来减少奖励模型训练过程中对人类标注的依赖。 此外,奖励训练生成的标量信号还可以用于优化解码过程中大语言模型的生成以及过滤数据以进行指令调优。
5.1.1 根据人类反馈进行强化学习
人类反馈强化学习(RLHF)是将大语言模型与人类价值观结合起来的重要范式(Christiano 等人,2017;Stiennon 等人,2020;Ouyang 等人,2022)。 它通常涉及三个步骤:1)监督微调(SFT),其中大语言模型接受带注释的数据训练,以改善其对提示的响应; 2)训练奖励模型来预测人类对模型响应的反馈; 3)采用强化学习算法,例如近端策略优化(PPO)(Schulman等人,2017)来对齐模型。 在 RLHF 中,奖励模型通常根据人类注释的偏好数据进行训练,产生模仿人类反馈的标量信号,作为学习的指导信号。 奖励模型的性能决定了模型对齐的潜在上限,因此训练奖励模型至关重要(Zheng等人,2023)。 在下面的章节中,我们首先介绍增强奖励模型的相关工作。 然后我们介绍如何在无需人工干预的情况下生成偏好数据。 最后,我们介绍了奖励模型在强化学习之外的功能,包括解码阶段的对齐和 SFT 数据过滤。
5.1.2 奖励模型的改进
为了实现更有效的自动对齐,提高模型反馈的质量至关重要。 因此,最近的研究重点是学习高质量的奖励模型。 训练奖励模型的主要挑战涉及数据收集和模型优化。 收集的偏好数据通常稀疏且缺乏一致性和细节,模型优化可能会因过度拟合等问题而受到阻碍。
奖励模型预训练
由于现有数据集的数据稀疏性和人工标注的成本,很难训练出高质量的自动对齐奖励模型。 为此,Askell等人(2021)提出了奖励模型预训练。 通过从网络(包括 StackExchange、Reddit 和 Wikipedia)收集配对数据,他们构建了一个排名数据集来预训练偏好模型。 通过奖励模型预训练,减少了对人类标注的依赖(Bai等人,2022a),有利于奖励模型更高效的训练,增强自动对齐的有效性。
一致的偏好数据构建
由于人类注释者的评价原则和主观视角不同,因此反馈是多种多样的,包括多种观点。 之前的研究使用了多重模型集成(Rame等人,2023;Touvron等人,2023)、多目标学习(Zeng等人,2024)等策略来缓解多样性数据的负面影响。 与产生单一分数的奖励模型相反,Li 等人(2024a)引入了分布偏好奖励模型(DPRM)来预测偏好分布。
细粒度反馈收集
奖励模型通常很难为安全等复杂情况和推理等挑战性任务提供细粒度的反馈。 为了解决这个问题,一些研究集中于改进奖励模型的训练。 Chen 等人 (2024f) 提出了一种 Token 级别的奖励模型,能够提供词符级别的精确反馈,适用于推理等复杂任务。 Wu 等人 (2023b) 建议训练多种奖励模型,这些模型可以在文本跨度级别提供详细的反馈。
训练优化
奖励模型的学习过程通常面临过度优化的问题。 也就是说,通过学习,奖励模型反而表现不佳。 Gao等人(2023)通过实验分析了这一现象,发现了奖励模型的标度规律来指导学习。 Zhu 等人 (2023a) 对 RLHF 训练中的奖励模型进行了理论分析,并说明了训练时引入悲观主义的重要性。 此外,其他一些作品采用了各种方法来提高奖励模型的性能,包括归一化(Zheng等人,2023)和迭代学习(Touvron等人,2023)。
尽管奖励模型的目的是预测人类反馈,但奖励建模具有挑战性。 因此,如何构建更全面的奖励模型来实现自动对齐是一个重要的研究问题。
5.1.3 AI反馈强化学习
奖励模型通常使用人类反馈进行训练,但注释起来既困难又昂贵。 为了减少人力并提高对齐的自动化程度,有一些工作使用现有的大型语言模型来生成偏好数据。 AI反馈强化学习(RLAIF)(Lee等人,2023)利用大语言模型的偏好数据训练奖励模型,可以达到与RLHF相当或更好的性能。 这些方法主要分为两种类型,包括对多个模型的响应进行排序和直接生成正响应和负响应。 这样就可以在强化学习的整个过程中实现自动对齐,无需人工干预。
对多重响应进行排名
随着大语言模型能力的提高,直接用它们对多个回复进行排序可以提供偏好数据(Tunstall 等人, 2023; Hong 等人, 2023;Guo 等人, 2024b; Pace 等人, 2024; Yuan 等人,2024)。 这种排名偏好数据也可以在最少的人类监督下产生,例如通过人类定义的原则(Bai等人,2022b;Sun等人,2023c)或规则(Kim等人, 2023)。 为了提高生成的偏好数据的质量,Shi等人(2024)提出了一个精心设计的流程,包括反向指令调整、指令归纳和专家模型评估。 Liu 等人 (2024a) 提出使用对比提示对作为输入对响应进行评分,与使用单个提示直接生成反馈相比,可以获得更好的性能。
产生积极和消极的反应
一些作品利用大语言模型直接生成偏好数据,提示其输出正向响应和负向响应(陈等人,2024c)。 Yang 等人 (2024b) 使用间接方法,通过使用不同的提示分别产生积极和消极的反应。
尽管前景广阔,但其主要挑战是偏好数据的质量。 由于大语言模型在生成过程中普遍受到诸多方面的干扰,如位置偏差(郑等人,2024b;王等人,2023c),高质量偏好数据的生成仍需进一步研究勘探。 随着大语言模型的不断完善,利用大语言模型来减少人力将是未来自动对齐模型的关键策略。
5.1.4 奖励模型引导解码
除了直接从偏好数据中学习之外,大语言模型的生成还可以通过奖励模型提供的标量信号来增强。 这允许在输出中直接实现对齐,而不是通过重新加权标记的概率(Mudgal等人,2024)在模型内实现对齐。 Lango and Dusek (2023)提出了一种评论家驱动的解码方法,通过二元分类器作为评论家模型来调整生成过程中词符的概率。 Deng 和 Raffel (2023) 提出了奖励增强解码 (RAD),它采用特定于属性的奖励模型在解码时重新加权前 k 个最高概率。 为了在不同的任务中实现灵活的对齐,Liu 等人(2024b)提出了解码时重新对齐(DeRa)来控制解码期间的对齐级别。
仅在解码阶段执行自动对齐是避免消耗大量计算资源的简单方法。 然而,解码时的对齐通常需要更多的时间来进行推理,并且响应的质量仍需要进一步提高。
5.1.5 使用奖励模型过滤SFT数据
高质量的SFT对于提高大语言训练模型的性能起着至关重要的作用(周等人,2023a),因此一些研究使用奖励模型来过滤数据。 主要范式分为从最佳响应中学习和从排名结果中学习。 从最佳响应中学习通常被称为 Best of N 或拒绝采样(Touvron 等人,2023;Yuan 等人,2023b)。 这种方法通常涉及使用奖励模型从多个响应中选择高质量数据来完善模型(Dong等人,2023)。 除了从热门回复中学习之外,大语言模型还可以从排名数据中学习。 Yuan 等人 (2023a) 提出排名响应来对齐人类反馈 (RRHF),以使用排名损失来对齐大语言模型。 Lu 等人 (2022) 提出使用奖励模型根据分数对数据进行评分,并使用各种奖励 Token 来调节其生成。 这种方法有助于防止学习不良行为。
除了强化学习之外,SFT也是实现对齐的重要方式。 通过奖励模型过滤数据,大语言模型可以通过SFT自动与人类价值观保持一致。 与之前的问题类似,SFT 数据的质量高度依赖于奖励模型的质量,需要进一步研究。
5.2二进制验证器
对于一些客观任务,例如数学问题,奖励模型通常会转变为具有二进制信号的验证器。 鉴于数学问题通常需要复杂的逐步推理,验证者可以分为结果验证者和过程验证者。 结果验证器用于估计最终答案的正确性。 流程验证者访问中间步骤,需要大量的监督数据。 通过二进制验证器,大语言模型可以实现对这些目标任务的自动对齐。
结果验证者
为了提高大语言模型的推理能力,一些研究侧重于使用训练的黄金答案来选择大语言模型生成的推理路径(Zelikman等人,2022;Singh等人,2024)。 由于获取黄金答案的成本很高,因此使用结果验证器来预测生成答案的正确性。 该验证器通常使用 LLM 生成的正确和不正确的基本原理进行训练(Cobbe 等人,2021),并用于通过包括直接调优在内的不同策略来配置大语言模型(Liu 等人) , 2023c) 和迭代训练 (Hosseini 等人, 2024)。 由于结果验证者无法评估推理步骤的正确性,Havrilla 等人 (2024) 提出了逐步结果奖励模型 (SORM),用于预测某个步骤是否会得出正确答案。 除了训练之外,Yu 等人 (2024a) 提出了用于指导解码的结果监督价值模型(OVM)。
过程验证器
即使最终答案是正确的,推理过程中仍然可能存在错误,限制了结果验证器的有效性。 为了解决这个问题,采用过程验证器来评估推理步骤的正确性,以进行更详细的验证(Lightman等人,2023;Uesato等人,2022)。 过程验证器可用于训练更有效的推理器(Ying 等人, 2024; Shao 等人, 2024)。 受人类推理机制的启发,Zhu 等人 (2023b) 提出合作推理(CoRe)来生成用于推理的合成训练数据,其中过程验证器用于生成生成器生成的反馈。 由于收集逐步监督信号的困难,许多研究致力于使用自动生成的数据来训练验证器。 Wang 等人 (2024e) 和 Wang 等人 (2024h) 使用蒙特卡洛采样收集的自动构建数据来训练过程验证器。 此外,过程验证器可以应用于解码以选择正确的推理路径(Khalifa等人,2023)。 一些研究关注如何高效地完成最终的推理路径。 Ma等人(2023b)提出了一种基于验证者反馈的启发式贪婪搜索算法。 Li等人(2023c)提出使用验证器来过滤使用不同提示生成的推理步骤。
二进制验证器是在数学等客观任务中实现自动对齐的重要方法。 然而,训练验证器,特别是过程验证器是非常困难的,需要大量的注释数据。 因此,未来为了进一步实现自动化对齐,研究人员可以重点研究如何自动构建流程验证器。
5.3 文本评论家
文本信号比标量和二进制信号包含更多语义,使模型能够直观地与人类保持一致。 通过集成文本反馈,大语言模型可以提高其输出与人类的一致性。 然后,这些细化的输出可以用作监督数据,以进一步对齐大语言模型(Scheurer等人,2022;Chen等人,2024a)。 批评模型生成的文本信号显示出提高大语言模型输出的潜力,反馈通常通过提示大语言模型获得。 文本批评者可以是其他大语言模型(如GPT-4)(Koutcheme 等人, 2024; An 等人, 2024) 或大语言模型本身(即自我批评)(Saunders 等人, 2022; Wang 等人, 2023d)。 由于大语言模型的自我批评仍然是一个挑战(罗等人,2023b),用于对齐的文本信号仍然没有得到充分探索。
现有研究主要集中在利用文本批评器通过改进大语言模型的输出来实现自动对齐。 未来,探索如何使用文本批评器来实现更多样化的自动对齐,例如在训练中,是一个重要的研究方向。
6 通过环境反馈进行调整
我们不是从经验中学习……而是从反思经验中学习。
约翰·杜威
本部分涉及自动获取对齐目标或现有环境的反馈,以实现目标模型的自动对齐。 如图8所示,根据模型交互的环境类别,我们概述了本节当前研究的四个方向,并系统地回顾了每个部分的代表性工作:
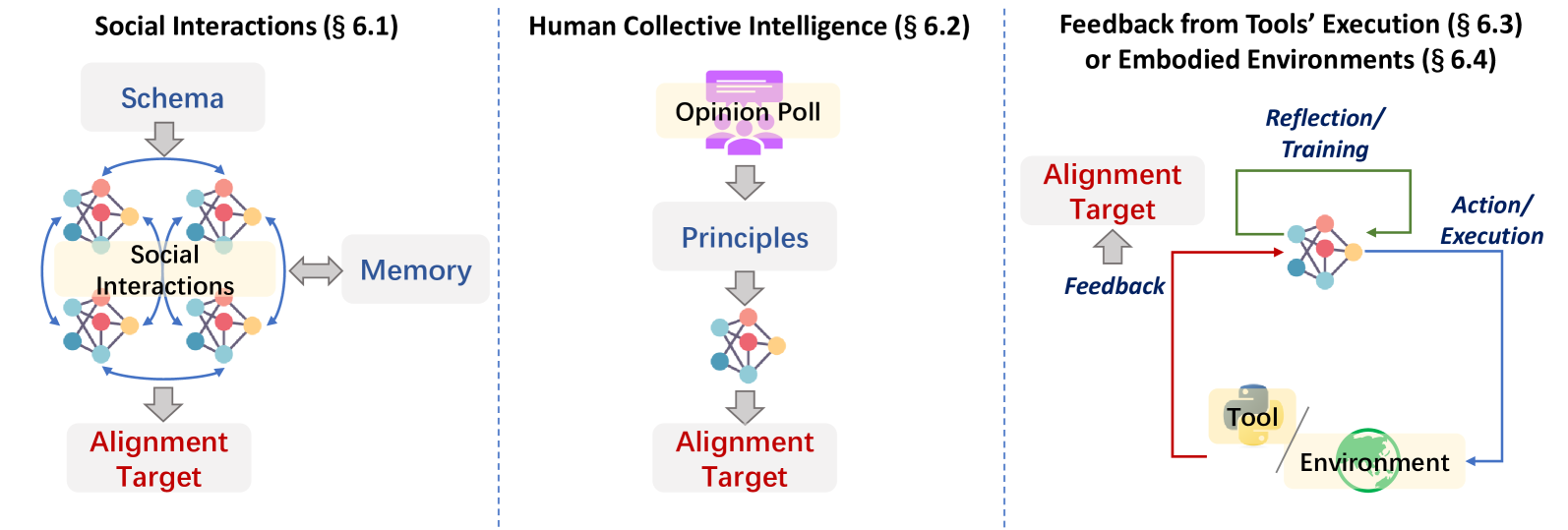
6.1 社交互动
社会互动是人类社会的基本属性之一,许多社会规范都是以隐含的方式传达和遵循的。 大语言模型的最新进展为构建基于LLM的代理系统来模拟人类社会之间的这种交互提供了机会,从而能够构建沙盒环境来收集更具可扩展性且类似于现实世界的对齐信号(Park等人, 2023)。 通过道德讨论等模拟社会互动,研究为增强人工智能系统与人类价值观和道德原则的一致性提供了有希望的途径。
例如,稳定对齐(刘等人,2023a)的灵感来自于人类如何通过讨论学习驾驭社会规范并就社会问题的价值判断达成共识。 他们引入了基于 LLM 的多智能体框架来模拟人类社会中的社会互动,并强调了包括模仿、自我批评和重新调整的三层方法。 相应地,在模拟过程中提取对准数据集。 Wang 等人(2024f)将该方法扩展到现实社交场景下的多轮交互。 他们提出了一种交互式学习方法,教语言代理通过扮演不同社会角色的角色之间的社交互动来实现目标。 基于相同的模拟社会互动方法论,其他研究作品探索了道德讨论(Sun等人,2023a)、政治辩论(Taubenfeld等人,2024)的复杂性以及面向任务的对话(Ulmer等人,2024),其中人工智能系统由一些预定义的讨论模式引导。
6.2 人类集体智慧
另一种补偿模拟社交互动的方法涉及诉诸人类的众包努力。 然而,与之前传统 NLP 或 RLHF 数据收集中的众包注释不同,对齐信号以更原始的形式收集,以实现更广泛的监督和监督的可扩展性。 这些信号通常被称为规范(Ammanabrolu等人,2022)、经验法则(RoTs)(Forbes等人,2020;Ziems等人,2022),或不同语境下的宪法(Bai 等人, 2022b)。 通过这个过程,人们可以就人工智能系统应遵循的基本原则达成共识,并通过将人类的各种价值观综合成一个目标来调整模型(Klingefjord等人,2024),从而达成集体智慧。 。
为了实现这一目标,当前的工作主要解决两个方面的研究问题。 问题之一是如何从人类价值观中提取一致性信号。 对于这个问题,宪法人工智能(CAI)(Bai等人,2022b)提供了将人工智能宪法转化为监督和偏好数据点的基本尝试。 在他们的环境中,人类监督完全依赖于一套管理人工智能行为的原则,称为宪法。 少量样本用于促使大语言模型根据这些构成原则创建SFT数据或偏好反馈。
另一个问题是如何更有效地从人类公众中获取价值观。 例如,在题为“民主对 AI 的投入”的项目中555openai.com/blog/democratic-inputs-to-ai,公开呼吁设计原型系统以促进人工智能的民主化进程。 具体来说,它致力于让具有代表性的跨界人士能够交换意见,并最终就人工智能系统应遵循的规则达成共识。 随后,在集体宪法人工智能(CCAI)项目(Anthropic,2023)中,研究人员设计了问卷,要求参与者起草人工智能系统的宪法。 通过集体起草宪法的方式,参与者可以评估现有的宪法原则,评估他们的接受分数,并提出他们认为人工智能应该遵守的新宪法原则。
6.3 工具执行反馈
工具对于扩展大型语言模型的功能至关重要,使它们能够超越其基本功能的限制,并更有效地与周围环境交互。 此外,来自工具执行的准确而详尽的反馈为大语言模型提供了直接信号,以验证和增强其初始输出(Chen等人,2023d;Gou等人,2024),这有助于减少依赖关于人类的反馈。 此外,学习计划和使用工具的过程可以从工具执行反馈中细化(王等人,2024a),大语言模型接收其行为的反馈并从成功和失败中学习以互动的方式。
工具的执行反馈可以作为人类劳动力语料库之外的附加信号,以教导模型更好地学习任务。 代码生成任务提供了这样的例子。 CodeRL (Le 等人, 2022) 通过代码编译器进行单元测试以接收反馈信号并使用它们来训练批评家模型,通过深度强化学习进一步训练代码生成模型。 自调试(Chen等人,2023d)通过在代码执行反馈旁边添加代码解释阶段来设计交互式代码调试管道,其中要求大型语言模型根据这些反馈来调试自己生成的代码信息。 同样,SelfEvolve (Jiang 等人, 2023) 接收来自解释器的错误消息,并根据此反馈完善答案代码。
除了代码生成之外,还有设计统一框架的研究,以使语言模型与来自多个其他来源的执行反馈保持一致。 CRITIC (Gou 等人, 2024) 利用先验证后纠正的流程从各种外部工具(包括搜索引擎、代码解释器和文本 API)获取外部反馈,从而使语言模型能够通过以下方式纠正输出:工具互动批评。 更进一步,Wang 等人(2024a)通过动态记忆机制增强了大语言模型,使大语言模型能够逐步学习如何准确使用工具。 Qiao等人(2024)提出了带有执行反馈的强化学习,用工具的执行结果来强化大语言模型。
6.4具体环境
具身智能是指智能体在一定的物理环境中感知信号并采取行动,不仅需要语言理解,还需要在大量状态的空间中进行推理和决策的能力(Roy等人,2021) 。 在具体的人工智能环境中利用大型语言模型是一项引人注目的努力,它可以带来两个方面的好处。 一方面,可以利用大语言模型强大的泛化能力,在不需要学习基础知识的情况下,用自然语言来制定行动计划。 另一方面,大型语言模型的常识知识和物理理解能力可以与来自环境的反馈信号保持一致。
最近的研究表明,大语言模型在机器人技术中用于现实世界交互的潜力,同时也对大语言模型理解物理世界的基础提出了挑战(Wang 等人,2023a;Ahn 等人,2022). 为了更好地调整尚未在具体环境中预训练的语言模型,Xiang等人(2023)采用具体模拟器作为世界模型,在大语言模型与对象交互并执行时提供反馈信号在此环境中执行的具有或不具有任务目标的操作。 然后,探索的世界状态将被收集为具体经验,随后离线配置大语言模型。 与此同时,其他研究利用在线强化学习(Carta等人,2023;Tan等人,2024)来学习或迭代离线学习框架(Song等人,2024b)通过交互环境中的反复试验来更新具体代理的策略。
6.5讨论
在本节中,我们回顾了一些当前可以从环境反馈对齐的角度统一观察的研究。 虽然大多数工作都针对特定的下游应用,但主动从环境中学习一直是人工智能的关键追求。 尽管做出了宝贵的贡献,但当前的方法仍然存在局限性,并为未来的研究留下了悬而未决的问题。 主要限制来自模拟环境与现实世界之间的差距。
当前的大多数工作都从模拟环境中获取对齐信号,而来自真实环境的反馈可能是嘈杂的或模糊的。 例如,在通过社会互动进行调整方面,刘等人(2023a)指出,当前的研究通常对社会规范采取静态的看法,而忽视了其动态和演变的本质。 事实上,社会价值观是复杂的、依赖于环境的,有时甚至是矛盾的。 以全面、连贯的方式将这些价值观编码到人工智能系统中是一项重大挑战。 因此,如何有效地弥合这些多变、分歧的社会价值观,对于与人类社会保持一致至关重要。
此外,模拟环境可能过于简单化,无法完全捕捉现实世界的复杂性,这对对齐模型的鲁棒性和泛化性提出了挑战。 对于作品的体现环境轨迹,研究往往是在沙盒环境中进行,不同的设置是相互独立的。 与具有潜在无限自由度的真实环境相比,这些模拟环境的动作空间仍然有限(Tan等人,2024)。 因此,在一种环境中训练的模型可能无法很好地推广到其他环境,并且确保模型在不同环境中保持一致仍然是一个问题。
总之,将环境反馈整合到人工智能调整中的主题开辟了一条有前景的新兴轨道,而重大的研究问题仍有待探索。 未来的研究可以集中于弥合模拟环境和真实环境之间的差距,以开发更具适应性、更可靠、更符合道德的人工智能。
7 自动对齐的底层机制
正如前面几节所讨论的,大量研究致力于提高自动对准方法的效率、有效性和可靠性。 尽管做出了这些努力,但仍然明显缺乏对对齐机制的系统研究。 例如,提出了多种方法(Liu等人,2024c;Li等人,2024d;等等)来过滤指令数据,但目前尚不清楚具体的过滤是否有效标准或过程是必要的,以及它们背后的基本原理。 同样,许多工作提出了各种弱到强的对齐算法,但我们仍然不知道弱到强泛化成功的原因以及它是否取决于特定条件。 缺乏相关研究可能会阻碍对当前对齐和自动对齐方法的理解,从而阻碍这些方法的进一步优化。
因此,在本节中,我们将对自动对齐的机制进行系统的研究。 通过系统地组织和分析自动对齐的底层机制,我们可以识别当前自动对齐方法的缺点和局限性,并阐明设计改进方法的方向。 如前所述,有大量的自动对齐技术。 在本次调查中,我们选择了以下三个核心研究问题,这对于实现可扩展的自动对齐至关重要:
-
•
问题一: 当前对齐的根本机制是什么? 对齐的基本机制是自动对齐研究的基础。 这对于理解自动对齐的可行性、边界和优化方向至关重要。
- •
-
•
问题3: 为什么从弱到强可行? 作为实现可扩展监管的一个有前途的方向,理解弱到强的可行性和底层机制对于优化和设计更有效的弱到强至关重要方法,尤其是在调整超人模型时。
对于每个研究问题,我们总结了现有的研究和观点,并讨论了这些分析工作的局限性以及仍需要探索的领域。
7.1 当前对齐的底层机制是什么?
了解当前对准的机制对于评估自动对准的潜力、检查自动对准面临的关键挑战以及引导当前自动对准方法的优化方向至关重要。 之前的工作(周等人,2023a;任等人,2024;梅克伦堡等人,2024;等)主要集中在这两个方面对齐的基本机制的两个方面:行为规范迁移和知识学习。 围绕哪一个方面更为关键展开分析和讨论。
一些研究发现,当前一致性的主要作用是行为规范的转变,而不是学习额外的世界知识。 周等人(2023a)提出“表面对齐假设”,模型的知识和能力几乎完全是在预训练过程中学习的,而对齐则教会模型在与用户交互时应使用哪种格式的子分布。 此外,后续研究采用了三种不同的分析方法来更深入地研究对齐过程中的模型行为。
基于特征的分析
Lin等人(2024a)通过比较大语言模型预测token对齐前后的概率分布(DPO&RLHF),发现分布偏移主要发生在文体token上,而知识密集型token上则出现分布偏移。显示出较小的分布偏移,并且随着预测变长,分布偏移减小,这表明对齐是关于形式对齐而不是知识注入。 同时,Duan等人(2023)发现ICL和IFT在大语言模型的隐藏层状态上表现出较高的收敛性,而与基础大语言模型的隐藏层状态表现出较低的收敛性,这表明一致性在于模型的行为规范从持续写入到响应的转变。 此外,通过采用基于梯度的输入输出归因方法并分析注意力头和前馈层,吴等人(2023a)揭示了IFT使大语言模型能够识别用户指令组件并定制响应因此,在不改变语言结构的情况下。
知识干预
Ren 等人 (2024) 引入知识干预框架来解耦 IFT 的潜在潜在因素,发现对于 IFT 来说,从世界知识的学习中获得的好处甚微,甚至不会造成额外的损害与所有同质、域内和域外评估的参数知识不一致。 而且,任等人(2024)发现,有效IFT的本质是在完成行为规范转化的同时,保持IFT前后模型参数知识的一致性。 Gekhman等人(2024)还通过观察模型通过IFT引入不同比例新知识的表现,强调了添加新事实的风险。
实证评估
LIMA (周等人, 2023a)、AlpaGasus (陈等人, 2023c)和LTD (陈等人, 2023b)提供实验支持通过使用很少的指令数据在 IFT 下实现令人印象深刻的性能来实现“表面对齐假设”。 此外,Gudibande等人(2023)表明,通过行为模仿进行对齐可以成功改善大语言模型的风格、角色和遵循指令的能力,但无法改善大语言模型在更复杂维度上的表现,例如事实性和解决问题的能力。
虽然这些研究得出了类似的结论,但它们未能描绘出受审查的模型所实现的具体一致性。 不同程度或要求之间的潜在协调机制的潜在差异仍未被探索。 此外,当前的研究主要集中在传统的 NLP 任务和一般对话场景上。 然而,一些研究(Mecklenburg等人,2024;Singhal等人,2023;等)发现特定领域的对齐确实可以提高相应领域的模型性能,这表明一致性在学习额外领域知识方面可以发挥至关重要的作用。 编码和数学等各种场景中的底层对齐机制仍然是一个悬而未决的问题。
7.2 为什么自我反馈有效?
反馈能力是指根据特定标准对给定输入提供信息或指导的能力。 正如我们上面所讨论的,这种功能广泛应用于各种自动对齐范例中。 例如,在RLAIF中,大语言模型本身替代人类评估来构建偏好数据(袁等人,2024;等)。 此外,大语言模型可以根据自我反馈不断优化其输出,这一过程称为自我优化(Bai 等人,2022b;Madaan 等人,2023; Tan等人,2023等)。 尽管如此,关于大语言模型是否以及为什么能够为他们自己的反应提供有效的反馈仍然存在很多争论。 下面,我们对各个有代表性的观点进行系统总结。
Li 等人 (2024f) 和 Lin 等人 (2024b) 表明模型拥有某些不能直接用于生成但可以用于提供反馈的知识。 Li 等人(2024f)还发现大语言模型在生成和验证答案时存在显着的生成器-验证器不一致问题。 同样,Lin等人(2024b)发现大语言模型拥有大量知识,这些知识无法通过生成和修正来表达,但可以用于批判。 此外,其他研究(Liu等人,2024a;Li等人,2024e)认为反馈能力是模型遵循指令能力的副产品。 因此,在对齐过程中,模型的反馈能力随着遵循指令的能力而提高,这一现象得到了实验证据的支持(Liu等人,2024a;Li等人,2024e)。 然而,其他一些研究认为大语言模型的反馈能力是虚幻的,这表明它可能依赖于具体数据并表现出偏差。 West等人(2023)指出,虽然当前的大语言模型通过训练获得了复制专家级输出的生成能力,但他们缺乏与批判相关的理解能力。 此外,黄等人(2023b)观察到,在推理任务中,大语言模型有时甚至会在自我修正后出现性能下降,因为他们无法正确判断推理的正确性。 此外,Zheng 等人(2024b)发现,虽然像GPT-4这样强大的大语言模型与人类评估者取得了很高的一致性,类似于人与人之间的一致性水平,但基于LLM的评估面临着各种挑战,例如立场偏见(郑等人,2024b;王等人,2023c),冗长偏见(郑等人,2024b;吴和阿吉,2023),自我增强偏见(郑等人, 2024b;刘等人, 2023b),以及在某些场景下能力有限,例如数学评分、推理题(郑等人, 2024b) 、高质量摘要(Shen 等人,2023a)等(Lan 等人,2024)。 研究人员提出了许多方法来进一步提高自反馈能力,例如元批评(孙等人,2024a),自动校准(刘等人,2023d),分裂并合并(Li 等人, 2023e)并使用外部工具(如搜索引擎、代码解释器等)交叉检查(Gou 等人, 2024) ,从而完善他们的初始反应等。
讨论虽然人们在探索模型提供自我反馈的能力方面进行了大量工作,但有关其有效性边界和根本原因的问题仍未得到解答。 此外,模型自我反馈与人类期望之间的差异和基本原理仍有待探索。 此外,自反馈和校正的两步优化模型输出(Bai等人,2022b;Madaan等人,2023;Tan等人,2023)也取得了可喜的结果。 然而,研究主要集中在前者,而后者基本上未被探索。 尽管研究人员(Lan 等人, 2024; Gou 等人, 2024)发现大语言模型具有与人类类似的能力,可以根据反馈修改自己的反应,但他们也有能力根据反馈进行纠正。他们产生的反馈仍然未知。 此外,大语言模型的整体性能提升取决于将错误答案精炼为正确答案的次数是否多于相反的次数。 目前仍缺乏对自我完善何时可以提高或损害绩效以及造成这种影响的根本原因的全面分析。
7.3 为什么从弱到强可行?
正如我们上面所讨论的,实现可扩展监管的一种有前途的方法是“从弱到强”的概念,它涉及通过有限或简化的监管来培养强大的能力。 虽然“弱到强”已经有一些成功的实践工作,但“弱到强”的底层机制仍有待进一步研究,这限制了“弱到强”的进一步优化和方法设计。 目前,一个普遍的观点是,在大型语料库上预训练的大语言模型可以利用其令人印象深刻的泛化能力,即使在有限或简化的监督下也能实现强大的能力。 下面我们将介绍这种泛化能力如何帮助大语言模型通过有限或简化的监督来实现自动对齐。
Bai 等人 (2022b)、Sun 等人 (2023d) 和 Fränken 等人 (2024) 观察到仅仅为大提供核心对齐原则语言模型使他们能够自动实现显着的对齐效果。 这说明了模型从原理推广到行为的能力。 例如,Bai 等人(2022b)提示大语言模型根据提供的原则细化和选择最佳响应,以完成IFT和RLAIF。 Sun等人(2023d)利用16条手动设计的规则来指导基础模型生成高质量的指令,然后进行自蒸馏以实现自对准。 Chen 等人(2024e)进一步采用更强大的大语言模型来自动发现这些构成。 类似地,Fränken 等人 (2024) 使用较弱的指令细化模型的构成来对齐更强的基础模型。 Burns 等人 (2023) 发现简单的方法通常可以显着提高大语言模型从弱到强的泛化能力:例如,当使用 GPT-2 级别的监督器和辅助置信度损失,GPT-4在NLP任务中可以达到接近GPT-3.5级别的性能。 这证明了模型从有限的监督泛化到更强的表现的能力。 此外,Sun 等人 (2024b) 和 Hase 等人 (2024) 发现在简单任务上训练的大语言模型可以成功泛化到困难任务。 最近的研究还讨论了理论框架下弱到强泛化的可行性(Somerstep等人,2024;Lang等人,2024;Charikar等人,2024)。
讨论 目前的大语言模型表现出很强的泛化能力。 然而,当前大语言模型与早期预训练语言模型之间泛化能力存在显着差异的根本原因仍有待探索。 此外,还需要进一步探索来划定泛化的边界,即什么可以泛化,什么不能泛化,以及理解其背后的原因,这对于识别对齐和自动对齐的关键挑战和确定未来的研究方向至关重要。
8结论
这项调查探讨了可扩展的自动对齐的各种技术,将它们分为四个主要领域:归纳偏差对齐、行为模仿、模型反馈和环境反馈。 现有的研究说明了实现自动对齐的多种途径,主要解决可扩展监督等关键挑战。 尽管取得了这些进步,但当我们研究电流对齐机制时,我们注意到显着的研究差距,特别是在自反馈的可靠性和弱到强泛化的可行性方面。 解决这些尚未探索的问题对于推进自动对齐、实现大型语言模型在现实场景中的安全有效应用至关重要。 未来的研究工作有望弥合这些差距,确保大语言模型可靠运行并符合预期的人类价值观。
参考
- Abdin et al. (2023) Marah Abdin, Jyoti Aneja, Sebastien Bubeck, Caio César Teodoro Mendes, Weizhu Chen, Allie Del Giorno, Ronen Eldan, Sivakanth Gopi, Suriya Gunasekar, Mojan Javaheripi, Piero Kauffmann, Yin Tat Lee, Yuanzhi Li, Anh Nguyen, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Michael Santacroce, Harkirat Singh Behl, Adam Taumann Kalai, Xin Wang, Rachel Ward, Philipp Witte, Cyril Zhang, and Yi Zhang. Phi-2: The surprising power of small language models., 2023. URL https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models.
- Abdin et al. (2024) Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Caio César Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary, Parul Chopra, Allie Del Giorno, Gustavo de Rosa, Matthew Dixon, Ronen Eldan, Dan Iter, Amit Garg, Abhishek Goswami, Suriya Gunasekar, Emman Haider, Junheng Hao, Russell J. Hewett, Jamie Huynh, Mojan Javaheripi, Xin Jin, Piero Kauffmann, Nikos Karampatziakis, Dongwoo Kim, Mahoud Khademi, Lev Kurilenko, James R. Lee, Yin Tat Lee, Yuanzhi Li, Chen Liang, Weishung Liu, Eric Lin, Zeqi Lin, Piyush Madan, Arindam Mitra, Hardik Modi, Anh Nguyen, Brandon Norick, Barun Patra, Daniel Perez-Becker, Thomas Portet, Reid Pryzant, Heyang Qin, Marko Radmilac, Corby Rosset, Sambudha Roy, Olatunji Ruwase, Olli Saarikivi, Amin Saied, Adil Salim, Michael Santacroce, Shital Shah, Ning Shang, Hiteshi Sharma, Xia Song, Masahiro Tanaka, Xin Wang, Rachel Ward, Guanhua Wang, Philipp Witte, Michael Wyatt, Can Xu, Jiahang Xu, Sonali Yadav, Fan Yang, Ziyi Yang, Donghan Yu, Chengruidong Zhang, Cyril Zhang, Jianwen Zhang, Li Lyna Zhang, Yi Zhang, Yue Zhang, Yunan Zhang, and Xiren Zhou. Phi-3 technical report: A highly capable language model locally on your phone, 2024.
- Agarwal et al. (2024) Rishabh Agarwal, Avi Singh, Lei M Zhang, Bernd Bohnet, Stephanie Chan, Ankesh Anand, Zaheer Abbas, Azade Nova, John D Co-Reyes, Eric Chu, et al. Many-shot in-context learning. ArXiv preprint, abs/2404.11018, 2024. URL https://arxiv.org/abs/2404.11018.
- Ahn et al. (2022) Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao, Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan, and Andy Zeng. Do as i can, not as i say: Grounding language in robotic affordances, 2022.
- Aksitov et al. (2023) Renat Aksitov, Sobhan Miryoosefi, Zonglin Li, Daliang Li, Sheila Babayan, Kavya Kopparapu, Zachary Fisher, Ruiqi Guo, Sushant Prakash, Pranesh Srinivasan, Manzil Zaheer, Felix Yu, and Sanjiv Kumar. Rest meets react: Self-improvement for multi-step reasoning llm agent, 2023.
- Amini and Gallinari (2002) Massih-Reza Amini and Patrick Gallinari. Semi-supervised logistic regression. In ECAI, volume 2, page 11, 2002.
- Ammanabrolu et al. (2022) Prithviraj Ammanabrolu, Liwei Jiang, Maarten Sap, Hannaneh Hajishirzi, and Yejin Choi. Aligning to social norms and values in interactive narratives. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5994–6017, Seattle, United States, 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.439. URL https://aclanthology.org/2022.naacl-main.439.
- An et al. (2024) Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou, and Weizhu Chen. Learning from mistakes makes llm better reasoner, 2024.
- Anthropic (2023) Anthropic. Training socially aligned language models on simulated social interactions, 2023. URL https://www.anthropic.com/news/collective-constitutional-ai-aligning-a-language-model-with-public-input.
- Anthropic (2024) Anthropic. Measuring the persuasiveness of language models, 2024. https://www.anthropic.com/research/measuring-model-persuasiveness/.
- Anwar et al. (2024) Usman Anwar, Abulhair Saparov, Javier Rando, Daniel Paleka, Miles Turpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner, Stephen Casper, Oliver Sourbut, et al. Foundational challenges in assuring alignment and safety of large language models. ArXiv preprint, abs/2404.09932, 2024. URL https://arxiv.org/abs/2404.09932.
- Askell et al. (2021) Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment. ArXiv preprint, abs/2112.00861, 2021. URL https://arxiv.org/abs/2112.00861.
- Azar et al. (2024) Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. In International Conference on Artificial Intelligence and Statistics, pages 4447–4455. PMLR, 2024.
- Bai et al. (2022a) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. ArXiv preprint, abs/2204.05862, 2022a. URL https://arxiv.org/abs/2204.05862.
- Bai et al. (2022b) Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. ArXiv preprint, abs/2212.08073, 2022b. URL https://arxiv.org/abs/2212.08073.
- Bansal et al. (2018) Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, and Igor Mordatch. Emergent complexity via multi-agent competition. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018. URL https://openreview.net/forum?id=Sy0GnUxCb.
- Besta et al. (2024) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17682–17690, 2024.
- Bousmalis et al. (2023) Konstantinos Bousmalis, Giulia Vezzani, Dushyant Rao, Coline Devin, Alex X. Lee, Maria Bauza, Todor Davchev, Yuxiang Zhou, Agrim Gupta, Akhil Raju, Antoine Laurens, Claudio Fantacci, Valentin Dalibard, Martina Zambelli, Murilo Martins, Rugile Pevceviciute, Michiel Blokzijl, Misha Denil, Nathan Batchelor, Thomas Lampe, Emilio Parisotto, Konrad Żołna, Scott Reed, Sergio Gómez Colmenarejo, Jon Scholz, Abbas Abdolmaleki, Oliver Groth, Jean-Baptiste Regli, Oleg Sushkov, Tom Rothörl, José Enrique Chen, Yusuf Aytar, Dave Barker, Joy Ortiz, Martin Riedmiller, Jost Tobias Springenberg, Raia Hadsell, Francesco Nori, and Nicolas Heess. Robocat: A self-improving generalist agent for robotic manipulation, 2023.
- Bowman et al. (2022) Samuel R Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, Kamilė Lukošiūtė, Amanda Askell, Andy Jones, Anna Chen, et al. Measuring progress on scalable oversight for large language models. ArXiv preprint, abs/2211.03540, 2022. URL https://arxiv.org/abs/2211.03540.
- Brooks et al. (2024) Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024. URL https://openai.com/research/video-generation-models-as-world-simulators.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
- Brown-Cohen et al. (2023) Jonah Brown-Cohen, Geoffrey Irving, and Georgios Piliouras. Scalable ai safety via doubly-efficient debate. ArXiv preprint, abs/2311.14125, 2023. URL https://arxiv.org/abs/2311.14125.
- Burns et al. (2023) Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, and Jeff Wu. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision, 2023. URL https://arxiv.org/abs/2312.09390.
- Carta et al. (2023) Thomas Carta, Clément Romac, Thomas Wolf, Sylvain Lamprier, Olivier Sigaud, and Pierre-Yves Oudeyer. Grounding large language models in interactive environments with online reinforcement learning, 2023.
- Charikar et al. (2024) Moses Charikar, Chirag Pabbaraju, and Kirankumar Shiragur. Quantifying the gain in weak-to-strong generalization, 2024.
- Chaudhary (2023) Sahil Chaudhary. Code alpaca: An instruction-following llama model for code generation. https://github.com/sahil280114/codealpaca, 2023.
- Chen et al. (2024a) Angelica Chen, Jérémy Scheurer, Jon Ander Campos, Tomasz Korbak, Jun Shern Chan, Samuel R. Bowman, Kyunghyun Cho, and Ethan Perez. Learning from natural language feedback. Transactions on Machine Learning Research, 2024a. ISSN 2835-8856. URL https://openreview.net/forum?id=xo3hI5MwvU.
- Chen et al. (2023a) Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, and Shunyu Yao. Fireact: Toward language agent fine-tuning, 2023a.
- Chen et al. (2023b) Hao Chen, Yiming Zhang, Qi Zhang, Hantao Yang, Xiaomeng Hu, Xuetao Ma, Yifan Yanggong, and Junbo Zhao. Maybe only 0.5% data is needed: A preliminary exploration of low training data instruction tuning. arXiv preprint arXiv:2305.09246, 2023b.
- Chen et al. (2023c) Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, and Hongxia Jin. Alpagasus: Training a better alpaca with fewer data, 2023c. URL https://arxiv.org/abs/2307.08701.
- Chen et al. (2024b) Shu Chen, Xinyan Guan, Yaojie Lu, Hongyu Lin, Xianpei Han, and Le Sun. Reinstruct: Building instruction data from unlabelled corpus. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024b.
- Chen et al. (2024c) Weixin Chen, Dawn Song, and Bo Li. Grath: Gradual self-truthifying for large language models, 2024c.
- Chen et al. (2024d) Xiaoyang Chen, Ben He, Hongyu Lin, Xianpei Han, Tianshu Wang, Boxi Cao, Le Sun, and Yingfei Sun. Spiral of silences: How is large language model killing information retrieval?–a case study on open domain question answering. arXiv preprint arXiv:2404.10496, 2024d.
- Chen et al. (2023d) Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug, 2023d.
- Chen et al. (2024e) Xiusi Chen, Hongzhi Wen, Sreyashi Nag, Chen Luo, Qingyu Yin, Ruirui Li, Zheng Li, and Wei Wang. Iteralign: Iterative constitutional alignment of large language models. ArXiv preprint, abs/2403.18341, 2024e. URL https://arxiv.org/abs/2403.18341.
- Chen et al. (2023e) Yongrui Chen, Haiyun Jiang, Xinting Huang, Shuming Shi, and Guilin Qi. Tegit: Generating high-quality instruction-tuning data with text-grounded task design, 2023e.
- Chen et al. (2024f) Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, and Ji-Rong Wen. Improving large language models via fine-grained reinforcement learning with minimum editing constraint, 2024f.
- Chen et al. (2024g) Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. ArXiv preprint, abs/2401.01335, 2024g. URL https://arxiv.org/abs/2401.01335.
- Cheng et al. (2024) Pengyu Cheng, Tianhao Hu, Han Xu, Zhisong Zhang, Yong Dai, Lei Han, and Nan Du. Self-playing adversarial language game enhances llm reasoning. ArXiv preprint, abs/2404.10642, 2024. URL https://arxiv.org/abs/2404.10642.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Christiano et al. (2018) Paul Christiano, Buck Shlegeris, and Dario Amodei. Supervising strong learners by amplifying weak experts. ArXiv preprint, abs/1810.08575, 2018. URL https://arxiv.org/abs/1810.08575.
- Christiano et al. (2017) Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 4299–4307, 2017. URL https://proceedings.neurips.cc/paper/2017/hash/d5e2c0adad503c91f91df240d0cd4e49-Abstract.html.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021.
- Cui et al. (2024) Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with high-quality feedback, 2024. URL https://openreview.net/forum?id=pNkOx3IVWI.
- Dai et al. (2023) Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 4005–4019, Toronto, Canada, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.247. URL https://aclanthology.org/2023.findings-acl.247.
- Deng and Raffel (2023) Haikang Deng and Colin Raffel. Reward-augmented decoding: Efficient controlled text generation with a unidirectional reward model. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11781–11791, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.721. URL https://aclanthology.org/2023.emnlp-main.721.
- DiGiovanni and Zell (2021) Anthony DiGiovanni and Ethan C Zell. Survey of self-play in reinforcement learning. ArXiv preprint, abs/2107.02850, 2021. URL https://arxiv.org/abs/2107.02850.
- Ding et al. (2023) Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3029–3051, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.183. URL https://aclanthology.org/2023.emnlp-main.183.
- Dong et al. (2023) Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, KaShun SHUM, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=m7p5O7zblY.
- Duan et al. (2023) Hanyu Duan, Yixuan Tang, Yi Yang, Ahmed Abbasi, and Kar Yan Tam. Exploring the relationship between in-context learning and instruction tuning, 2023. URL https://arxiv.org/abs/2311.10367.
- Fernandes et al. (2023) Patrick Fernandes, Daniel Deutsch, Mara Finkelstein, Parker Riley, André Martins, Graham Neubig, Ankush Garg, Jonathan Clark, Markus Freitag, and Orhan Firat. The devil is in the errors: Leveraging large language models for fine-grained machine translation evaluation. In Philipp Koehn, Barry Haddow, Tom Kocmi, and Christof Monz, editors, Proceedings of the Eighth Conference on Machine Translation, pages 1066–1083, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.wmt-1.100. URL https://aclanthology.org/2023.wmt-1.100.
- Fernando et al. (2023) Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. Promptbreeder: Self-referential self-improvement via prompt evolution. ArXiv preprint, abs/2309.16797, 2023. URL https://arxiv.org/abs/2309.16797.
- Ferreira et al. (2023) Rafael EP Ferreira, Yong Jae Lee, and João RR Dórea. Using pseudo-labeling to improve performance of deep neural networks for animal identification. Scientific Reports, 13(1):13875, 2023. URL https://doi.org/10.1038/s41598-023-40977-x.
- Forbes et al. (2020) Maxwell Forbes, Jena D. Hwang, Vered Shwartz, Maarten Sap, and Yejin Choi. Social chemistry 101: Learning to reason about social and moral norms. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 653–670, Online, 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.48. URL https://aclanthology.org/2020.emnlp-main.48.
- Fränken et al. (2024) Jan-Philipp Fränken, Eric Zelikman, Rafael Rafailov, Kanishk Gandhi, Tobias Gerstenberg, and Noah D. Goodman. Self-supervised alignment with mutual information: Learning to follow principles without preference labels, 2024. URL https://arxiv.org/abs/2404.14313.
- Fu et al. (2023a) Yao Fu, Hao Peng, Tushar Khot, and Mirella Lapata. Improving language model negotiation with self-play and in-context learning from ai feedback. ArXiv preprint, abs/2305.10142, 2023a. URL https://arxiv.org/abs/2305.10142.
- Fu et al. (2023b) Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. Specializing smaller language models towards multi-step reasoning, 2023b.
- Ganguli et al. (2022) Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. ArXiv preprint, abs/2209.07858, 2022. URL https://arxiv.org/abs/2209.07858.
- Gao et al. (2023) Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 10835–10866. PMLR, 2023. URL https://proceedings.mlr.press/v202/gao23h.html.
- Gao et al. (2024) Yang Gao, Dana Alon, and Donald Metzler. Impact of preference noise on the alignment performance of generative language models, 2024.
- Garrabrant and Demski (2018) Scott Garrabrant and Abram Demski. Embedded agency, 2018. URL https://www.alignmentforum.org/s/Rm6oQRJJmhGCcLvxh/p/i3BTagvt3HbPMx6PN.
- Gekhman et al. (2024) Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, and Jonathan Herzig. Does fine-tuning llms on new knowledge encourage hallucinations?, 2024. URL https://arxiv.org/abs/2405.05904.
- Gim et al. (2023) In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference. ArXiv preprint, abs/2311.04934, 2023. URL https://arxiv.org/abs/2311.04934.
- Goodfellow et al. (2014) Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. In Zoubin Ghahramani, Max Welling, Corinna Cortes, Neil D. Lawrence, and Kilian Q. Weinberger, editors, Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pages 2672–2680, 2014. URL https://proceedings.neurips.cc/paper/2014/hash/5ca3e9b122f61f8f06494c97b1afccf3-Abstract.html.
- Gou et al. (2024) Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing, 2024. URL https://arxiv.org/abs/2305.11738.
- Grandvalet and Bengio (2004) Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Advances in Neural Information Processing Systems 17 [Neural Information Processing Systems, NIPS 2004, December 13-18, 2004, Vancouver, British Columbia, Canada], pages 529–536, 2004. URL https://proceedings.neurips.cc/paper/2004/hash/96f2b50b5d3613adf9c27049b2a888c7-Abstract.html.
- Gu et al. (2024) Shangding Gu, Alois Knoll, and Ming Jin. Teaching LLMs to teach themselves better instructions via reinforcement learning, 2024. URL https://openreview.net/forum?id=wlRp8IdLkN.
- Gudibande et al. (2023) Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, and Dawn Song. The false promise of imitating proprietary llms, 2023. URL https://arxiv.org/abs/2305.15717.
- Guo et al. (2024a) Hongyi Guo, Yuanshun Yao, Wei Shen, Jiaheng Wei, Xiaoying Zhang, Zhaoran Wang, and Yang Liu. Human-instruction-free llm self-alignment with limited samples, 2024a.
- Guo et al. (2024b) Shangmin Guo, Biao Zhang, Tianlin Liu, Tianqi Liu, Misha Khalman, Felipe Llinares, Alexandre Rame, Thomas Mesnard, Yao Zhao, Bilal Piot, et al. Direct language model alignment from online ai feedback. ArXiv preprint, abs/2402.04792, 2024b. URL https://arxiv.org/abs/2402.04792.
- Hase et al. (2024) Peter Hase, Mohit Bansal, Peter Clark, and Sarah Wiegreffe. The unreasonable effectiveness of easy training data for hard tasks, 2024. URL https://arxiv.org/abs/2401.06751.
- Havrilla et al. (2024) Alex Havrilla, Sharath Raparthy, Christoforus Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, and Roberta Railneau. Glore: When, where, and how to improve llm reasoning via global and local refinements, 2024.
- Hazra and Anjaria (2022) Tanmoy Hazra and Kushal Anjaria. Applications of game theory in deep learning: a survey. Multimedia Tools and Applications, 81(6):8963–8994, 2022.
- He et al. (2023) Guande He, Peng Cui, Jianfei Chen, Wenbo Hu, and Jun Zhu. Investigating uncertainty calibration of aligned language models under the multiple-choice setting. ArXiv preprint, abs/2310.11732, 2023. URL https://arxiv.org/abs/2310.11732.
- He et al. (2020) Junxian He, Jiatao Gu, Jiajun Shen, and Marc’Aurelio Ranzato. Revisiting self-training for neural sequence generation. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020. URL https://openreview.net/forum?id=SJgdnAVKDH.
- Ho et al. (2023) Namgyu Ho, Laura Schmid, and Se-Young Yun. Large language models are reasoning teachers. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14852–14882, Toronto, Canada, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.830. URL https://aclanthology.org/2023.acl-long.830.
- Hoare (1961) Charles Antony Richard Hoare. Algorithm 64: quicksort. Communications of the ACM, 4(7):321, 1961.
- Hong et al. (2023) Jixiang Hong, Quan Tu, Changyu Chen, Xing Gao, Ji Zhang, and Rui Yan. Cyclealign: Iterative distillation from black-box llm to white-box models for better human alignment, 2023.
- Honovich et al. (2023) Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. Unnatural instructions: Tuning language models with (almost) no human labor. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14409–14428, Toronto, Canada, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.806. URL https://aclanthology.org/2023.acl-long.806.
- Hosseini et al. (2024) Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, and Rishabh Agarwal. V-star: Training verifiers for self-taught reasoners, 2024.
- Hsieh et al. (2023) Cheng-Yu Hsieh, Chun-Liang Li, Chih-kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 8003–8017, Toronto, Canada, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.507. URL https://aclanthology.org/2023.findings-acl.507.
- Huang et al. (2023a) Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. Large language models can self-improve. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023a. URL https://openreview.net/forum?id=uuUQraD4XX.
- Huang et al. (2023b) Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet, 2023b. URL https://arxiv.org/abs/2310.01798.
- Irving et al. (2018) Geoffrey Irving, Paul Christiano, and Dario Amodei. Ai safety via debate. ArXiv preprint, abs/1805.00899, 2018. URL https://arxiv.org/abs/1805.00899.
- Jacob et al. (2024) Athul Paul Jacob, Yikang Shen, Gabriele Farina, and Jacob Andreas. The consensus game: Language model generation via equilibrium search. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=n9xeGcI4Yg.
- Ji et al. (2023) Jiaming Ji, Tianyi Qiu, Boyuan Chen, Borong Zhang, Hantao Lou, Kaile Wang, Yawen Duan, Zhonghao He, Jiayi Zhou, Zhaowei Zhang, Fanzhi Zeng, Kwan Yee Ng, Juntao Dai, Xuehai Pan, Aidan O’Gara, Yingshan Lei, Hua Xu, Brian Tse, Jie Fu, Stephen McAleer, Yaodong Yang, Yizhou Wang, Song-Chun Zhu, Yike Guo, and Wen Gao. AI Alignment: A Comprehensive Survey, 2023. URL https://arxiv.org/abs/2310.19852.
- Ji et al. (2024) Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Juntao Dai, and Yaodong Yang. Aligner: Achieving efficient alignment through weak-to-strong correction, 2024.
- Jiang et al. (2023) Shuyang Jiang, Yuhao Wang, and Yu Wang. Selfevolve: A code evolution framework via large language models, 2023.
- Kadavath et al. (2022) Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know. ArXiv preprint, abs/2207.05221, 2022. URL https://arxiv.org/abs/2207.05221.
- Khalifa et al. (2023) Muhammad Khalifa, Lajanugen Logeswaran, Moontae Lee, Honglak Lee, and Lu Wang. GRACE: Discriminator-guided chain-of-thought reasoning. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, pages 15299–15328, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.1022. URL https://aclanthology.org/2023.findings-emnlp.1022.
- Khan et al. (2024) Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R Bowman, Tim Rocktäschel, and Ethan Perez. Debating with more persuasive llms leads to more truthful answers. ArXiv preprint, abs/2402.06782, 2024. URL https://arxiv.org/abs/2402.06782.
- Khot et al. (2023) Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. Decomposed prompting: A modular approach for solving complex tasks. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=_nGgzQjzaRy.
- Kim et al. (2023) Sungdong Kim, Sanghwan Bae, Jamin Shin, Soyoung Kang, Donghyun Kwak, Kang Yoo, and Minjoon Seo. Aligning large language models through synthetic feedback. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13677–13700, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.844. URL https://aclanthology.org/2023.emnlp-main.844.
- Klingefjord et al. (2024) Oliver Klingefjord, Ryan Lowe, and Joe Edelman. What are human values, and how do we align ai to them?, 2024.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- Koutcheme et al. (2024) Charles Koutcheme, Nicola Dainese, Sami Sarsa, Arto Hellas, Juho Leinonen, and Paul Denny. Open source language models can provide feedback: Evaluating llms’ ability to help students using gpt-4-as-a-judge, 2024.
- Köksal et al. (2024) Abdullatif Köksal, Timo Schick, Anna Korhonen, and Hinrich Schütze. Longform: Effective instruction tuning with reverse instructions, 2024.
- Lan et al. (2024) Tian Lan, Wenwei Zhang, Chen Xu, Heyan Huang, Dahua Lin, Kai Chen, and Xian-ling Mao. Criticbench: Evaluating large language models as critic, 2024. URL https://arxiv.org/abs/2402.13764.
- Lang et al. (2024) Hunter Lang, David Sontag, and Aravindan Vijayaraghavan. Theoretical analysis of weak-to-strong generalization, 2024.
- Lango and Dusek (2023) Mateusz Lango and Ondrej Dusek. Critic-driven decoding for mitigating hallucinations in data-to-text generation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2853–2862, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.172. URL https://aclanthology.org/2023.emnlp-main.172.
- Le et al. (2022) Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven C. H. Hoi. Coderl: Mastering code generation through pretrained models and deep reinforcement learning, 2022.
- Lee et al. (2013) Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on challenges in representation learning, ICML, volume 3, page 896. Atlanta, 2013.
- Lee et al. (2023) Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. Rlaif: Scaling reinforcement learning from human feedback with ai feedback, 2023.
- Lee et al. (2024) Nicholas Lee, Thanakul Wattanawong, Sehoon Kim, Karttikeya Mangalam, Sheng Shen, Gopala Anumanchipali, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami. Llm2llm: Boosting llms with novel iterative data enhancement, 2024.
- Li et al. (2023a) Chengpeng Li, Zheng Yuan, Hongyi Yuan, Guanting Dong, Keming Lu, Jiancan Wu, Chuanqi Tan, Xiang Wang, and Chang Zhou. Query and response augmentation cannot help out-of-domain math reasoning generalization, 2023a.
- Li et al. (2024a) Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, Ruiming Tang, and Yong Liu. Aligning crowd feedback via distributional preference reward modeling, 2024a.
- Li et al. (2023b) Ming Li, Lichang Chen, Jiuhai Chen, Shwai He, and Tianyi Zhou. Reflection-tuning: Recycling data for better instruction-tuning. In NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023b. URL https://openreview.net/forum?id=xaqoZZqkPU.
- Li et al. (2024b) Ming Li, Lichang Chen, Jiuhai Chen, Shwai He, Jiuxiang Gu, and Tianyi Zhou. Selective reflection-tuning: Student-selected data recycling for llm instruction-tuning, 2024b.
- Li et al. (2024c) Ming Li, Yong Zhang, Shwai He, Zhitao Li, Hongyu Zhao, Jianzong Wang, Ning Cheng, and Tianyi Zhou. Superfiltering: Weak-to-strong data filtering for fast instruction-tuning, 2024c.
- Li et al. (2024d) Ming Li, Yong Zhang, Zhitao Li, Jiuhai Chen, Lichang Chen, Ning Cheng, Jianzong Wang, Tianyi Zhou, and Jing Xiao. From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning, 2024d. URL https://arxiv.org/abs/2308.12032.
- Li et al. (2022) Shiyang Li, Jianshu Chen, Yelong Shen, Zhiyu Chen, Xinlu Zhang, Zekun Li, Hong Wang, Jing Qian, Baolin Peng, Yi Mao, Wenhu Chen, and Xifeng Yan. Explanations from large language models make small reasoners better, 2022.
- Li et al. (2024e) Xian Li, Ping Yu, Chunting Zhou, Timo Schick, Omer Levy, Luke Zettlemoyer, Jason E Weston, and Mike Lewis. Self-alignment with instruction backtranslation. In The Twelfth International Conference on Learning Representations, volume abs/2308.06259, 2024e. URL https://openreview.net/forum?id=1oijHJBRsT.
- Li et al. (2024f) Xiang Lisa Li, Vaishnavi Shrivastava, Siyan Li, Tatsunori Hashimoto, and Percy Liang. Benchmarking and improving generator-validator consistency of language models. In The Twelfth International Conference on Learning Representations, volume abs/2310.01846, 2024f. URL https://openreview.net/forum?id=phBS6YpTzC.
- Li et al. (2023c) Yifei Li, Zeqi Lin, Shizhuo Zhang, Qiang Fu, Bei Chen, Jian-Guang Lou, and Weizhu Chen. Making language models better reasoners with step-aware verifier. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5315–5333, Toronto, Canada, 2023c. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.291. URL https://aclanthology.org/2023.acl-long.291.
- Li et al. (2023d) Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. Textbooks are all you need ii: phi-1.5 technical report, 2023d.
- Li et al. (2024g) Yuhui Li, Fangyun Wei, Jinjing Zhao, Chao Zhang, and Hongyang Zhang. RAIN: Your language models can align themselves without finetuning. In The Twelfth International Conference on Learning Representations, volume abs/2309.07124, 2024g. URL https://openreview.net/forum?id=pETSfWMUzy.
- Li et al. (2023e) Zongjie Li, Chaozheng Wang, Pingchuan Ma, Daoyuan Wu, Shuai Wang, Cuiyun Gao, and Yang Liu. Split and merge: Aligning position biases in large language model based evaluators, 2023e. URL https://arxiv.org/abs/2310.01432.
- Liao et al. (2024) Minpeng Liao, Wei Luo, Chengxi Li, Jing Wu, and Kai Fan. Mario: Math reasoning with code interpreter output – a reproducible pipeline, 2024.
- Lightman et al. (2023) Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023.
- Lin et al. (2024a) Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavatula, and Yejin Choi. The unlocking spell on base LLMs: Rethinking alignment via in-context learning. In The Twelfth International Conference on Learning Representations, volume abs/2312.01552, 2024a. URL https://openreview.net/forum?id=wxJ0eXwwda.
- Lin et al. (2024b) Zicheng Lin, Zhibin Gou, Tian Liang, Ruilin Luo, Haowei Liu, and Yujiu Yang. Criticbench: Benchmarking llms for critique-correct reasoning. ArXiv preprint, abs/2402.14809, 2024b. URL https://arxiv.org/abs/2402.14809.
- Liu et al. (2024a) Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, and Lijie Wen. Direct large language model alignment through self-rewarding contrastive prompt distillation, 2024a. URL https://arxiv.org/abs/2402.11907.
- Liu et al. (2023a) Ruibo Liu, Ruixin Yang, Chenyan Jia, Ge Zhang, Denny Zhou, Andrew M. Dai, Diyi Yang, and Soroush Vosoughi. Training socially aligned language models on simulated social interactions, 2023a.
- Liu et al. (2024b) Tianlin Liu, Shangmin Guo, Leonardo Bianco, Daniele Calandriello, Quentin Berthet, Felipe Llinares, Jessica Hoffmann, Lucas Dixon, Michal Valko, and Mathieu Blondel. Decoding-time realignment of language models, 2024b.
- Liu et al. (2024c) Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning. In The Twelfth International Conference on Learning Representations, 2024c. URL https://openreview.net/forum?id=BTKAeLqLMw.
- Liu et al. (2023b) Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment, 2023b. URL https://arxiv.org/abs/2303.16634.
- Liu et al. (2023c) Yixin Liu, Avi Singh, C. Daniel Freeman, John D. Co-Reyes, and Peter J. Liu. Improving large language model fine-tuning for solving math problems, 2023c.
- Liu and Alahi (2024) Yuejiang Liu and Alexandre Alahi. Co-supervised learning: Improving weak-to-strong generalization with hierarchical mixture of experts, 2024.
- Liu et al. (2023d) Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. Calibrating llm-based evaluator, 2023d. URL https://arxiv.org/abs/2309.13308.
- Lu et al. (2022) Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, and Yejin Choi. Quark: Controllable text generation with reinforced unlearning, 2022.
- Lu et al. (2024) Zimu Lu, Aojun Zhou, Houxing Ren, Ke Wang, Weikang Shi, Junting Pan, Mingjie Zhan, and Hongsheng Li. Mathgenie: Generating synthetic data with question back-translation for enhancing mathematical reasoning of llms, 2024.
- Luo et al. (2023a) Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct, 2023a.
- Luo et al. (2023b) Liangchen Luo, Zi Lin, Yinxiao Liu, Lei Shu, Yun Zhu, Jingbo Shang, and Lei Meng. Critique ability of large language models, 2023b.
- Luo et al. (2024) Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=UnUwSIgK5W.
- Ma et al. (2023a) Chengdong Ma, Ziran Yang, Minquan Gao, Hai Ci, Jun Gao, Xuehai Pan, and Yaodong Yang. Red teaming game: A game-theoretic framework for red teaming language models. ArXiv preprint, abs/2310.00322, 2023a. URL https://arxiv.org/abs/2310.00322.
- Ma et al. (2023b) Qianli Ma, Haotian Zhou, Tingkai Liu, Jianbo Yuan, Pengfei Liu, Yang You, and Hongxia Yang. Let’s reward step by step: Step-level reward model as the navigators for reasoning, 2023b.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. In Thirty-seventh Conference on Neural Information Processing Systems, volume 36, pages 46534–46594, 2023. URL https://openreview.net/forum?id=S37hOerQLB.
- Magister et al. (2023) Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. Teaching small language models to reason. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1773–1781, Toronto, Canada, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-short.151. URL https://aclanthology.org/2023.acl-short.151.
- Manakul et al. (2023) Potsawee Manakul, Adian Liusie, and Mark Gales. SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.557. URL https://aclanthology.org/2023.emnlp-main.557.
- Mecklenburg et al. (2024) Nick Mecklenburg, Yiyou Lin, Xiaoxiao Li, Daniel Holstein, Leonardo Nunes, Sara Malvar, Bruno Silva, Ranveer Chandra, Vijay Aski, Pavan Kumar Reddy Yannam, Tolga Aktas, and Todd Hendry. Injecting new knowledge into large language models via supervised fine-tuning, 2024. URL https://arxiv.org/abs/2404.00213.
- Mitchell (1980) Tom M Mitchell. The need for biases in learning generalizations. 1980.
- Mitra et al. (2023) Arindam Mitra, Luciano Del Corro, Shweti Mahajan, Andres Codas, Clarisse Simoes, Sahaj Agarwal, Xuxi Chen, Anastasia Razdaibiedina, Erik Jones, Kriti Aggarwal, Hamid Palangi, Guoqing Zheng, Corby Rosset, Hamed Khanpour, and Ahmed Awadallah. Orca 2: Teaching small language models how to reason, 2023.
- Mudgal et al. (2024) Sidharth Mudgal, Jong Lee, Harish Ganapathy, YaGuang Li, Tao Wang, Yanping Huang, Zhifeng Chen, Heng-Tze Cheng, Michael Collins, Trevor Strohman, Jilin Chen, Alex Beutel, and Ahmad Beirami. Controlled decoding from language models, 2024.
- Mukherjee et al. (2023) Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4, 2023.
- Nash et al. (1950) John F Nash et al. The bargaining problem. Econometrica, 18(2):155–162, 1950.
- Nash et al. (1951) John F Nash et al. Non-cooperative games. page 286–295, 1951.
- Nigam and Ghani (2000) Kamal Nigam and Rayid Ghani. Analyzing the effectiveness and applicability of co-training. In Proceedings of the ninth international conference on Information and knowledge management, pages 86–93, 2000.
- OpenAI (2023a) OpenAI. Preparedness framework (beta), 2023a. URL https://cdn.openai.com/openai-preparedness-framework-beta.pdf.
- OpenAI (2023b) OpenAI. GPT-4 Technical Report, 2023b. URL https://arxiv.org/abs/2303.08774.
- Ought (2017) Ought. Factored cognition, 2017. https://ought.org/research/factored-cognition.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback, 2022. URL https://arxiv.org/abs/2203.02155.
- Pace et al. (2024) Alizée Pace, Jonathan Mallinson, Eric Malmi, Sebastian Krause, and Aliaksei Severyn. West-of-n: Synthetic preference generation for improved reward modeling. ArXiv preprint, abs/2401.12086, 2024. URL https://arxiv.org/abs/2401.12086.
- Padmanabhan et al. (2023) Shankar Padmanabhan, Yasumasa Onoe, Michael JQ Zhang, Greg Durrett, and Eunsol Choi. Propagating knowledge updates to LMs through distillation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=DFaGf3O7jf.
- Pan et al. (2023) Alexander Pan, Jun Shern Chan, Andy Zou, Nathaniel Li, Steven Basart, Thomas Woodside, Hanlin Zhang, Scott Emmons, and Dan Hendrycks. Do the rewards justify the means? measuring trade-offs between rewards and ethical behavior in the machiavelli benchmark. In International Conference on Machine Learning, pages 26837–26867. PMLR, 2023.
- Park et al. (2023) Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior, 2023.
- Patil et al. (2023) Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis, 2023.
- Peng et al. (2023) Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4, 2023.
- Polu and Sutskever (2020) Stanislas Polu and Ilya Sutskever. Generative language modeling for automated theorem proving. ArXiv preprint, abs/2009.03393, 2020. URL https://arxiv.org/abs/2009.03393.
- Qiao et al. (2024) Shuofei Qiao, Honghao Gui, Chengfei Lv, Qianghuai Jia, Huajun Chen, and Ningyu Zhang. Making language models better tool learners with execution feedback, 2024.
- Qin et al. (2023) Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. Toolllm: Facilitating large language models to master 16000+ real-world apis, 2023.
- Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct Preference Optimization: Your Language Model is Secretly a Reward Model, 2023. URL https://arxiv.org/abs/2305.18290.
- Rame et al. (2023) Alexandre Rame, Guillaume Couairon, Corentin Dancette, Jean-Baptiste Gaya, Mustafa Shukor, Laure Soulier, and Matthieu Cord. Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=lSbbC2VyCu.
- Ramesh et al. (2021) Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In International conference on machine learning, pages 8821–8831. Pmlr, 2021.
- Ren et al. (2024) Mengjie Ren, Boxi Cao, Hongyu Lin, Cao Liu, Xianpei Han, Ke Zeng, Guanglu Wan, Xunliang Cai, and Le Sun. Learning or self-aligning? rethinking instruction fine-tuning, 2024. URL https://arxiv.org/abs/2402.18243.
- Roy et al. (2021) Nicholas Roy, Ingmar Posner, Tim D. Barfoot, Philippe Beaudoin, Yoshua Bengio, Jeannette Bohg, Oliver Brock, Isabelle Depatie, Dieter Fox, Daniel E. Koditschek, Tomás Lozano-Pérez, Vikash Mansinghka, Christopher J. Pal, Blake A. Richards, Dorsa Sadigh, Stefan Schaal, Gaurav S. Sukhatme, Denis Thérien, Marc Toussaint, and Michiel van de Panne. From machine learning to robotics: Challenges and opportunities for embodied intelligence. ArXiv preprint, abs/2110.15245, 2021. URL https://arxiv.org/abs/2110.15245.
- Saunders et al. (2022) William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. Self-critiquing models for assisting human evaluators. ArXiv preprint, abs/2206.05802, 2022. URL https://arxiv.org/abs/2206.05802.
- Scheurer et al. (2022) Jérémy Scheurer, Jon Ander Campos, Jun Shern Chan, Angelica Chen, Kyunghyun Cho, and Ethan Perez. Training language models with language feedback, 2022.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017.
- Scudder (1965) H. Scudder. Probability of error of some adaptive pattern-recognition machines. IEEE Transactions on Information Theory, 11(3):363–371, 1965. doi: 10.1109/TIT.1965.1053799.
- Shao et al. (2024) Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024.
- Shapley (1971) Lloyd S Shapley. Cores of convex games. International journal of game theory, 1:11–26, 1971.
- Sharma et al. (2024) Archit Sharma, Sedrick Keh, Eric Mitchell, Chelsea Finn, Kushal Arora, and Thomas Kollar. A critical evaluation of ai feedback for aligning large language models. ArXiv preprint, abs/2402.12366, 2024. URL https://arxiv.org/abs/2402.12366.
- Shavit et al. (2023) Yonadav Shavit, Sandhini Agarwal, Miles Brundage, Steven Adler, Cullen O’Keefe, Rosie Campbell, Teddy Lee, Pamela Mishkin, Tyna Eloundou, Alan Hickey, et al. Practices for governing agentic ai systems. 2023.
- Shen et al. (2023a) Chenhui Shen, Liying Cheng, Xuan-Phi Nguyen, Yang You, and Lidong Bing. Large language models are not yet human-level evaluators for abstractive summarization. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, pages 4215–4233, Singapore, 2023a. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.278. URL https://aclanthology.org/2023.findings-emnlp.278.
- Shen et al. (2023b) Tianhao Shen, Renren Jin, Yufei Huang, Chuang Liu, Weilong Dong, Zishan Guo, Xinwei Wu, Yan Liu, and Deyi Xiong. Large Language Model Alignment: A Survey, 2023b. URL https://arxiv.org/abs/2309.15025.
- Shi et al. (2023) Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning, pages 31210–31227. PMLR, 2023.
- Shi et al. (2024) Taiwei Shi, Kai Chen, and Jieyu Zhao. Safer-instruct: Aligning language models with automated preference data, 2024.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023.
- Shridhar et al. (2023) Kumar Shridhar, Alessandro Stolfo, and Mrinmaya Sachan. Distilling reasoning capabilities into smaller language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 7059–7073, Toronto, Canada, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.441. URL https://aclanthology.org/2023.findings-acl.441.
- Silver et al. (2018) David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science, 362(6419):1140–1144, 2018.
- Singh et al. (2024) Avi Singh, John D Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron T Parisi, Abhishek Kumar, Alexander A Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Fathy Elsayed, Hanie Sedghi, Igor Mordatch, Isabelle Simpson, Izzeddin Gur, Jasper Snoek, Jeffrey Pennington, Jiri Hron, Kathleen Kenealy, Kevin Swersky, Kshiteej Mahajan, Laura A Culp, Lechao Xiao, Maxwell Bileschi, Noah Constant, Roman Novak, Rosanne Liu, Tris Warkentin, Yamini Bansal, Ethan Dyer, Behnam Neyshabur, Jascha Sohl-Dickstein, and Noah Fiedel. Beyond human data: Scaling self-training for problem-solving with language models. Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=lNAyUngGFK. Expert Certification.
- Singhal et al. (2023) Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, Mike Schaekermann, Amy Wang, Mohamed Amin, Sami Lachgar, Philip Mansfield, Sushant Prakash, Bradley Green, Ewa Dominowska, Blaise Aguera y Arcas, Nenad Tomasev, Yun Liu, Renee Wong, Christopher Semturs, S. Sara Mahdavi, Joelle Barral, Dale Webster, Greg S. Corrado, Yossi Matias, Shekoofeh Azizi, Alan Karthikesalingam, and Vivek Natarajan. Towards expert-level medical question answering with large language models, 2023. URL https://arxiv.org/abs/2305.09617.
- Somerstep et al. (2024) Seamus Somerstep, Felipe Maia Polo, Moulinath Banerjee, Ya’acov Ritov, Mikhail Yurochkin, and Yuekai Sun. A statistical framework for weak-to-strong generalization, 2024.
- Song et al. (2023) Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. Preference Ranking Optimization for Human Alignment, 2023. URL https://arxiv.org/abs/2306.17492.
- Song et al. (2024a) Feifan Song, Bowen Yu, Hao Lang, Haiyang Yu, Fei Huang, Houfeng Wang, and Yongbin Li. Scaling data diversity for fine-tuning language models in human alignment. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue, editors, Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 14358–14369, Torino, Italia, 2024a. ELRA and ICCL. URL https://aclanthology.org/2024.lrec-main.1251.
- Song et al. (2024b) Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. Trial and error: Exploration-based trajectory optimization for llm agents, 2024b.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. Learning to summarize with human feedback. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/1f89885d556929e98d3ef9b86448f951-Abstract.html.
- StockFish (2023) StockFish. Stockfish - open source chess engine, 2023. https://stockfishchess.org/.
- Sun et al. (2023a) Hao Sun, Zhexin Zhang, Fei Mi, Yasheng Wang, Wei Liu, Jianwei Cui, Bin Wang, Qun Liu, and Minlie Huang. MoralDial: A framework to train and evaluate moral dialogue systems via moral discussions. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2213–2230, Toronto, Canada, 2023a. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.123. URL https://aclanthology.org/2023.acl-long.123.
- Sun et al. (2024a) Shichao Sun, Junlong Li, Weizhe Yuan, Ruifeng Yuan, Wenjie Li, and Pengfei Liu. The critique of critique. ArXiv preprint, abs/2401.04518, 2024a. URL https://arxiv.org/abs/2401.04518.
- Sun et al. (2023b) Yuchong Sun, Che Liu, Jinwen Huang, Ruihua Song, Fuzheng Zhang, Di Zhang, Zhongyuan Wang, and Kun Gai. Parrot: Enhancing multi-turn chat models by learning to ask questions, 2023b.
- Sun et al. (2023c) Zhiqing Sun, Yikang Shen, Hongxin Zhang, Qinhong Zhou, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. Salmon: Self-alignment with principle-following reward models, 2023c. URL https://openreview.net/forum?id=xJbsmB8UMx.
- Sun et al. (2023d) Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. Principle-driven self-alignment of language models from scratch with minimal human supervision. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 2511–2565. Curran Associates, Inc., 2023d. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/0764db1151b936aca59249e2c1386101-Paper-Conference.pdf.
- Sun et al. (2024b) Zhiqing Sun, Longhui Yu, Yikang Shen, Weiyang Liu, Yiming Yang, Sean Welleck, and Chuang Gan. Easy-to-hard generalization: Scalable alignment beyond human supervision, 2024b. URL https://arxiv.org/abs/2403.09472.
- Tan et al. (2024) Weihao Tan, Wentao Zhang, Shanqi Liu, Longtao Zheng, Xinrun Wang, and Bo An. True knowledge comes from practice: Aligning llms with embodied environments via reinforcement learning, 2024.
- Tan et al. (2023) Xiaoyu Tan, Shaojie Shi, Xihe Qiu, Chao Qu, Zhenting Qi, Yinghui Xu, and Yuan Qi. Self-criticism: Aligning large language models with their understanding of helpfulness, honesty, and harmlessness. In Mingxuan Wang and Imed Zitouni, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 650–662, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-industry.62. URL https://aclanthology.org/2023.emnlp-industry.62.
- Tang et al. (2023) Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases. ArXiv preprint, abs/2306.05301, 2023. URL https://arxiv.org/abs/2306.05301.
- Tao et al. (2024) Zhengwei Tao, Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li, Zhi Jin, Fei Huang, Dacheng Tao, and Jingren Zhou. A survey on self-evolution of large language models. arXiv preprint arXiv:2404.14387, 2024.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Taubenfeld et al. (2024) Amir Taubenfeld, Yaniv Dover, Roi Reichart, and Ariel Goldstein. Systematic biases in llm simulations of debates, 2024.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. ArXiv preprint, abs/2307.09288, 2023. URL https://arxiv.org/abs/2307.09288.
- Tunstall et al. (2023) Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, and Thomas Wolf. Zephyr: Direct distillation of lm alignment, 2023.
- Ubani et al. (2023) Solomon Ubani, Suleyman Olcay Polat, and Rodney Nielsen. Zeroshotdataaug: Generating and augmenting training data with chatgpt, 2023.
- Uesato et al. (2022) Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback, 2022.
- Ulmer et al. (2024) Dennis Ulmer, Elman Mansimov, Kaixiang Lin, Justin Sun, Xibin Gao, and Yi Zhang. Bootstrapping llm-based task-oriented dialogue agents via self-talk, 2024.
- von Oswald et al. (2023) Johannes von Oswald, Eyvind Niklasson, Maximilian Schlegel, Seijin Kobayashi, Nicolas Zucchet, Nino Scherrer, Nolan Miller, Mark Sandler, Max Vladymyrov, Razvan Pascanu, et al. Uncovering mesa-optimization algorithms in transformers. ArXiv preprint, abs/2309.05858, 2023. URL https://arxiv.org/abs/2309.05858.
- Wang et al. (2024a) Boshi Wang, Hao Fang, Jason Eisner, Benjamin Van Durme, and Yu Su. Llms in the imaginarium: Tool learning through simulated trial and error, 2024a.
- Wang et al. (2024b) Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song, and Yang Liu. Openchat: Advancing open-source language models with mixed-quality data. In The Twelfth International Conference on Learning Representations, 2024b. URL https://openreview.net/forum?id=AOJyfhWYHf.
- Wang et al. (2023a) Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models, 2023a.
- Wang et al. (2024c) Jiahao Wang, Bolin Zhang, Qianlong Du, Jiajun Zhang, and Dianhui Chu. A survey on data selection for llm instruction tuning, 2024c.
- Wang et al. (2024d) Ke Wang, Houxing Ren, Aojun Zhou, Zimu Lu, Sichun Luo, Weikang Shi, Renrui Zhang, Linqi Song, Mingjie Zhan, and Hongsheng Li. Mathcoder: Seamless code integration in LLMs for enhanced mathematical reasoning. In The Twelfth International Conference on Learning Representations, 2024d. URL https://openreview.net/forum?id=z8TW0ttBPp.
- Wang et al. (2023b) Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2609–2634, Toronto, Canada, 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.147. URL https://aclanthology.org/2023.acl-long.147.
- Wang et al. (2023c) Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators, 2023c. URL https://arxiv.org/abs/2305.17926.
- Wang et al. (2024e) Peiyi Wang, Lei Li, Zhihong Shao, R. X. Xu, Damai Dai, Yifei Li, Deli Chen, Y. Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations, 2024e.
- Wang et al. (2024f) Ruiyi Wang, Haofei Yu, Wenxin Zhang, Zhengyang Qi, Maarten Sap, Graham Neubig, Yonatan Bisk, and Hao Zhu. Sotopia-: Interactive learning of socially intelligent language agents, 2024f.
- Wang et al. (2021) Shuohang Wang, Yang Liu, Yichong Xu, Chenguang Zhu, and Michael Zeng. Want to reduce labeling cost? GPT-3 can help. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4195–4205, Punta Cana, Dominican Republic, 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-emnlp.354. URL https://aclanthology.org/2021.findings-emnlp.354.
- Wang et al. (2023d) Tianlu Wang, Ping Yu, Xiaoqing Ellen Tan, Sean O’Brien, Ramakanth Pasunuru, Jane Dwivedi-Yu, Olga Golovneva, Luke Zettlemoyer, Maryam Fazel-Zarandi, and Asli Celikyilmaz. Shepherd: A critic for language model generation, 2023d. URL https://arxiv.org/abs/2308.04592.
- Wang et al. (2024g) Xinpeng Wang, Shitong Duan, Xiaoyuan Yi, Jing Yao, Shanlin Zhou, Zhihua Wei, Peng Zhang, Dongkuan Xu, Maosong Sun, and Xing Xie. On the Essence and Prospect: An Investigation of Alignment Approaches for Big Models, 2024g. URL https://arxiv.org/abs/2403.04204.
- Wang and Zhou (2024) Xuezhi Wang and Denny Zhou. Chain-of-thought reasoning without prompting. ArXiv preprint, abs/2402.10200, 2024. URL https://arxiv.org/abs/2402.10200.
- Wang et al. (2023e) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, 2023e. URL https://openreview.net/forum?id=1PL1NIMMrw.
- Wang et al. (2022) Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, Eshaan Pathak, Giannis Karamanolakis, Haizhi Lai, Ishan Purohit, Ishani Mondal, Jacob Anderson, Kirby Kuznia, Krima Doshi, Kuntal Kumar Pal, Maitreya Patel, Mehrad Moradshahi, Mihir Parmar, Mirali Purohit, Neeraj Varshney, Phani Rohitha Kaza, Pulkit Verma, Ravsehaj Singh Puri, Rushang Karia, Savan Doshi, Shailaja Keyur Sampat, Siddhartha Mishra, Sujan Reddy A, Sumanta Patro, Tanay Dixit, and Xudong Shen. Super-NaturalInstructions: Generalization via declarative instructions on 1600+ NLP tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5085–5109, Abu Dhabi, United Arab Emirates, 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.340.
- Wang et al. (2023f) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13484–13508, Toronto, Canada, 2023f. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.754. URL https://aclanthology.org/2023.acl-long.754.
- Wang et al. (2023g) Yufei Wang, Wanjun Zhong, Liangyou Li, Fei Mi, Xingshan Zeng, Wenyong Huang, Lifeng Shang, Xin Jiang, and Qun Liu. Aligning Large Language Models with Human: A Survey, 2023g. URL https://arxiv.org/abs/2307.12966.
- Wang et al. (2024h) Zihan Wang, Yunxuan Li, Yuexin Wu, Liangchen Luo, Le Hou, Hongkun Yu, and Jingbo Shang. Multi-step problem solving through a verifier: An empirical analysis on model-induced process supervision, 2024h.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- Wei et al. (2024) Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, et al. Long-form factuality in large language models. arXiv preprint arXiv:2403.18802, 2024.
- Wei et al. (2023) Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Source code is all you need, 2023.
- Weng et al. (2023) Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. Large language models are better reasoners with self-verification. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, pages 2550–2575, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.167. URL https://aclanthology.org/2023.findings-emnlp.167.
- West et al. (2023) Peter West, Ximing Lu, Nouha Dziri, Faeze Brahman, Linjie Li, Jena D. Hwang, Liwei Jiang, Jillian Fisher, Abhilasha Ravichander, Khyathi Chandu, Benjamin Newman, Pang Wei Koh, Allyson Ettinger, and Yejin Choi. The generative ai paradox: ”what it can create, it may not understand”, 2023. URL https://arxiv.org/abs/2311.00059.
- Weyssow et al. (2024) Martin Weyssow, Aton Kamanda, and Houari Sahraoui. Codeultrafeedback: An llm-as-a-judge dataset for aligning large language models to coding preferences, 2024.
- Wilf (2002) Herbert S Wilf. Algorithms and complexity. AK Peters/CRC Press, 2002.
- Wu et al. (2021a) Jeff Wu, Long Ouyang, Daniel M Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, and Paul Christiano. Recursively summarizing books with human feedback. ArXiv preprint, abs/2109.10862, 2021a. URL https://arxiv.org/abs/2109.10862.
- Wu and Aji (2023) Minghao Wu and Alham Fikri Aji. Style over substance: Evaluation biases for large language models, 2023. URL https://arxiv.org/abs/2307.03025.
- Wu et al. (2024) Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, and Alham Aji. LaMini-LM: A diverse herd of distilled models from large-scale instructions. In Yvette Graham and Matthew Purver, editors, Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 944–964, St. Julian’s, Malta, 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.eacl-long.57.
- Wu et al. (2021b) Qingyang Wu, Lei Li, and Zhou Yu. Textgail: Generative adversarial imitation learning for text generation. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, pages 14067–14075. AAAI Press, 2021b. URL https://ojs.aaai.org/index.php/AAAI/article/view/17656.
- Wu et al. (2023a) Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, and Dong Yu. From language modeling to instruction following: Understanding the behavior shift in llms after instruction tuning, 2023a. URL https://arxiv.org/abs/2310.00492.
- Wu et al. (2023b) Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, and Hannaneh Hajishirzi. Fine-grained human feedback gives better rewards for language model training. In Thirty-seventh Conference on Neural Information Processing Systems, 2023b. URL https://openreview.net/forum?id=CSbGXyCswu.
- Xiang et al. (2023) Jiannan Xiang, Tianhua Tao, Yi Gu, Tianmin Shu, Zirui Wang, Zichao Yang, and Zhiting Hu. Language models meet world models: Embodied experiences enhance language models, 2023.
- Xie et al. (2023) Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, Junxian He, and Qizhe Xie. Self-evaluation guided beam search for reasoning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=Bw82hwg5Q3.
- Xu et al. (2023a) Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. ArXiv preprint, abs/2304.12244, 2023a. URL https://arxiv.org/abs/2304.12244.
- Xu et al. (2024a) Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. WizardLM: Empowering large pre-trained language models to follow complex instructions. In The Twelfth International Conference on Learning Representations, 2024a. URL https://openreview.net/forum?id=CfXh93NDgH.
- Xu et al. (2023b) Canwen Xu, Daya Guo, Nan Duan, and Julian McAuley. Baize: An open-source chat model with parameter-efficient tuning on self-chat data. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6268–6278, Singapore, 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.385. URL https://aclanthology.org/2023.emnlp-main.385.
- Xu et al. (2023c) Chunpu Xu, Steffi Chern, Ethan Chern, Ge Zhang, Zekun Wang, Ruibo Liu, Jing Li, Jie Fu, and Pengfei Liu. Align on the fly: Adapting chatbot behavior to established norms. ArXiv preprint, abs/2312.15907, 2023c. URL https://arxiv.org/abs/2312.15907.
- Xu et al. (2024b) Jie Xu, Hanbo Zhang, Xinghang Li, Huaping Liu, Xuguang Lan, and Tao Kong. Sinvig: A self-evolving interactive visual agent for human-robot interaction, 2024b.
- Xu et al. (2024c) Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi Zhou. A survey on knowledge distillation of large language models, 2024c.
- Xue et al. (2023) Fuzhao Xue, Yao Fu, Wangchunshu Zhou, Zangwei Zheng, and Yang You. To repeat or not to repeat: Insights from scaling llm under token-crisis. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 59304–59322. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/b9e472cd579c83e2f6aa3459f46aac28-Paper-Conference.pdf.
- Yang et al. (2023a) Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. ArXiv preprint, abs/2309.03409, 2023a. URL https://arxiv.org/abs/2309.03409.
- Yang et al. (2024a) Kailai Yang, Zhiwei Liu, Qianqian Xie, Tianlin Zhang, Nirui Song, Jimin Huang, Ziyan Kuang, and Sophia Ananiadou. Metaaligner: Conditional weak-to-strong correction for generalizable multi-objective alignment of language models, 2024a.
- Yang et al. (2024b) Kevin Yang, Dan Klein, Asli Celikyilmaz, Nanyun Peng, and Yuandong Tian. RLCD: Reinforcement learning from contrastive distillation for LM alignment. In The Twelfth International Conference on Learning Representations, 2024b. URL https://openreview.net/forum?id=v3XXtxWKi6.
- Yang et al. (2023b) Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. Gpt4tools: Teaching large language model to use tools via self-instruction. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 71995–72007. Curran Associates, Inc., 2023b. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/e393677793767624f2821cec8bdd02f1-Paper-Conference.pdf.
- Yang and Wang (2020) Yaodong Yang and Jun Wang. An overview of multi-agent reinforcement learning from game theoretical perspective. ArXiv preprint, abs/2011.00583, 2020. URL https://arxiv.org/abs/2011.00583.
- Yang et al. (2024c) Zonghan Yang, Peng Li, Ming Yan, Ji Zhang, Fei Huang, and Yang Liu. React meets actre: When language agents enjoy training data autonomy, 2024c.
- Yang et al. (2024d) Zonghan Yang, An Liu, Zijun Liu, Kaiming Liu, Fangzhou Xiong, Yile Wang, Zeyuan Yang, Qingyuan Hu, Xinrui Chen, Zhenhe Zhang, et al. Towards unified alignment between agents, humans, and environment. ArXiv preprint, abs/2402.07744, 2024d. URL https://arxiv.org/abs/2402.07744.
- Yao et al. (2023a) Jing Yao, Xiaoyuan Yi, Xiting Wang, Jindong Wang, and Xing Xie. From Instructions to Intrinsic Human Values – A Survey of Alignment Goals for Big Models, 2023a. URL https://arxiv.org/abs/2308.12014.
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, 2022.
- Yao et al. (2023b) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik R Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Thirty-seventh Conference on Neural Information Processing Systems, 2023b. URL https://openreview.net/forum?id=5Xc1ecxO1h.
- Yao et al. (2021) Yuan Yao, Haoxi Zhong, Zhengyan Zhang, Xu Han, Xiaozhi Wang, Kai Zhang, Chaojun Xiao, Guoyang Zeng, Zhiyuan Liu, and Maosong Sun. Adversarial language games for advanced natural language intelligence. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, pages 14248–14256. AAAI Press, 2021. URL https://ojs.aaai.org/index.php/AAAI/article/view/17676.
- Yin et al. (2023) Da Yin, Xiao Liu, Fan Yin, Ming Zhong, Hritik Bansal, Jiawei Han, and Kai-Wei Chang. Dynosaur: A dynamic growth paradigm for instruction-tuning data curation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4031–4047, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.245. URL https://aclanthology.org/2023.emnlp-main.245.
- Ying et al. (2024) Huaiyuan Ying, Shuo Zhang, Linyang Li, Zhejian Zhou, Yunfan Shao, Zhaoye Fei, Yichuan Ma, Jiawei Hong, Kuikun Liu, Ziyi Wang, Yudong Wang, Zijian Wu, Shuaibin Li, Fengzhe Zhou, Hongwei Liu, Songyang Zhang, Wenwei Zhang, Hang Yan, Xipeng Qiu, Jiayu Wang, Kai Chen, and Dahua Lin. Internlm-math: Open math large language models toward verifiable reasoning, 2024.
- Yu et al. (2024a) Fei Yu, Anningzhe Gao, and Benyou Wang. Ovm, outcome-supervised value models for planning in mathematical reasoning, 2024a.
- Yu et al. (2024b) Longhui Yu, Weisen Jiang, Han Shi, Jincheng YU, Zhengying Liu, Yu Zhang, James Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. In The Twelfth International Conference on Learning Representations, 2024b. URL https://openreview.net/forum?id=N8N0hgNDRt.
- Yu et al. (2023) Yue Yu, Yuchen Zhuang, Jieyu Zhang, Yu Meng, Alexander J Ratner, Ranjay Krishna, Jiaming Shen, and Chao Zhang. Large language model as attributed training data generator: A tale of diversity and bias. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 55734–55784. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ae9500c4f5607caf2eff033c67daa9d7-Paper-Datasets_and_Benchmarks.pdf.
- Yu et al. (2024c) Zhaojian Yu, Xin Zhang, Ning Shang, Yangyu Huang, Can Xu, Yishujie Zhao, Wenxiang Hu, and Qiufeng Yin. Wavecoder: Widespread and versatile enhanced instruction tuning with refined data generation, 2024c.
- Yuan et al. (2023a) Hongyi Yuan, Zheng Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. RRHF: Rank responses to align language models with human feedback. In Thirty-seventh Conference on Neural Information Processing Systems, 2023a. URL https://openreview.net/forum?id=EdIGMCHk4l.
- Yuan et al. (2024) Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. ArXiv preprint, abs/2401.10020, 2024. URL https://arxiv.org/abs/2401.10020.
- Yuan et al. (2023b) Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models, 2023b.
- Yue et al. (2024a) Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. MAmmoTH: Building math generalist models through hybrid instruction tuning. In The Twelfth International Conference on Learning Representations, 2024a. URL https://openreview.net/forum?id=yLClGs770I.
- Yue et al. (2024b) Xiang Yue, Tuney Zheng, Ge Zhang, and Wenhu Chen. Mammoth2: Scaling instructions from the web. ArXiv preprint, abs/2405.03548, 2024b. URL https://arxiv.org/abs/2405.03548.
- Zelikman et al. (2022) Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 15476–15488. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/639a9a172c044fbb64175b5fad42e9a5-Paper-Conference.pdf.
- Zelikman et al. (2024) Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D Goodman. Quiet-star: Language models can teach themselves to think before speaking. ArXiv preprint, abs/2403.09629, 2024. URL https://arxiv.org/abs/2403.09629.
- Zeng et al. (2023) Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. Agenttuning: Enabling generalized agent abilities for llms, 2023.
- Zeng et al. (2024) Dun Zeng, Yong Dai, Pengyu Cheng, Longyue Wang, Tianhao Hu, Wanshun Chen, Nan Du, and Zenglin Xu. On diversified preferences of large language model alignment, 2024.
- Zhang and Parkes (2023) Hugh Zhang and David Parkes. Chain-of-thought reasoning is a policy improvement operator. In NeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023. URL https://openreview.net/forum?id=bH64KCBzqS.
- Zhang (2023) Jiawei Zhang. Graph-toolformer: To empower llms with graph reasoning ability via prompt augmented by chatgpt, 2023.
- Zhang et al. (2024) Mozhi Zhang, Mianqiu Huang, Rundong Shi, Linsen Guo, Chong Peng, Peng Yan, Yaqian Zhou, and Xipeng Qiu. Calibrating the confidence of large language models by eliciting fidelity. ArXiv preprint, abs/2404.02655, 2024. URL https://arxiv.org/abs/2404.02655.
- Zhang et al. (2016) Yizhe Zhang, Zhe Gan, and Lawrence Carin. Generating text via adversarial training. In NIPS workshop on Adversarial Training, volume 21, pages 21–32. Academia. edu, 2016.
- Zheng et al. (2024a) Chujie Zheng, Ziqi Wang, Heng Ji, Minlie Huang, and Nanyun Peng. Weak-to-strong extrapolation expedites alignment, 2024a.
- Zheng et al. (2024b) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36:46595–46623, 2024b. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/91f18a1287b398d378ef22505bf41832-Abstract-Datasets_and_Benchmarks.html.
- Zheng et al. (2023) Rui Zheng, Shihan Dou, Songyang Gao, Yuan Hua, Wei Shen, Binghai Wang, Yan Liu, Senjie Jin, Qin Liu, Yuhao Zhou, Limao Xiong, Lu Chen, Zhiheng Xi, Nuo Xu, Wenbin Lai, Minghao Zhu, Cheng Chang, Zhangyue Yin, Rongxiang Weng, Wensen Cheng, Haoran Huang, Tianxiang Sun, Hang Yan, Tao Gui, Qi Zhang, Xipeng Qiu, and Xuanjing Huang. Secrets of rlhf in large language models part i: Ppo, 2023.
- Zheng et al. (2024c) Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. Opencodeinterpreter: Integrating code generation with execution and refinement, 2024c.
- Zhou et al. (2023a) Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, LILI YU, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. Lima: Less is more for alignment. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 55006–55021. Curran Associates, Inc., 2023a. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ac662d74829e4407ce1d126477f4a03a-Paper-Conference.pdf.
- Zhou et al. (2023b) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V Le, and Ed H. Chi. Least-to-most prompting enables complex reasoning in large language models. In The Eleventh International Conference on Learning Representations, 2023b. URL https://openreview.net/forum?id=WZH7099tgfM.
- Zhu et al. (2023a) Banghua Zhu, Michael Jordan, and Jiantao Jiao. Principled reinforcement learning with human feedback from pairwise or k-wise comparisons. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 43037–43067. PMLR, 2023a. URL https://proceedings.mlr.press/v202/zhu23f.html.
- Zhu et al. (2023b) Xinyu Zhu, Junjie Wang, Lin Zhang, Yuxiang Zhang, Yongfeng Huang, Ruyi Gan, Jiaxing Zhang, and Yujiu Yang. Solving math word problems via cooperative reasoning induced language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4471–4485, Toronto, Canada, 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.245. URL https://aclanthology.org/2023.acl-long.245.
- Ziems et al. (2022) Caleb Ziems, Jane Yu, Yi-Chia Wang, Alon Halevy, and Diyi Yang. The moral integrity corpus: A benchmark for ethical dialogue systems. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3755–3773, Dublin, Ireland, 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.261. URL https://aclanthology.org/2022.acl-long.261.