自然语言到 SQL 的黎明:我们准备好了吗?
摘要。
将用户的自然语言问题转换为 SQL 查询(即 nl2sql)可显着降低访问关系数据库的障碍。 大型语言模型的出现在 nl2sql 任务中引入了一种新颖的范例,极大地增强了功能。 然而,这提出了一个关键问题: 我们是否已做好在生产中部署 nl2sql 模型的充分准备?
为了解决所提出的问题,我们提出了一个多角度的nl2sql评估框架NL2SQL360,以方便新的nl2sql方法的设计和测试研究人员。 通过NL2SQL360,我们对领先的nl2sql方法在不同数据域和sql特性等一系列应用场景进行了详细的比较,提供了对于针对特定需求选择最合适的 nl2sql 方法具有宝贵的见解。 此外,我们探索了nl2sql设计空间,利用NL2SQL360自动识别针对用户特定需求定制的最佳nl2sql解决方案。 具体来说,NL2SQL360标识了一个有效的nl2sql方法,SuperSQL,在Spider数据集下使用执行精度指标进行区分。 值得注意的是,SuperSQL 在 Spider 和 BIRD 测试集上的执行准确率分别为 87% 和 62.66%,实现了具有竞争力的性能。
PVLDB 工件可用性:
源代码、数据和/或其他工件已在 https://github.com/BugMaker-Boyan/NL2SQL360/ 上提供。
1. 介绍
Natural Language to SQL (nl2sql),它将自然语言查询 (nl) 转换为 SQL 查询 (sql),可以显着降低外行用户和专家用户在访问海量数据集和获取见解方面都存在障碍(Gu 等人,2023;Chen 等人,2023;Wang 等人,2022;Liu 等人,2022;Pourreza 和 Rafiei,2023;Gao等人,2023;李等人,2023d)。 尤其是在大型语言模型最新进展的赋能下,nl2sql解决方案的性能得到了显着提升。 数据库供应商提供nl2sql解决方案的趋势已经从神话转变为必须的。
尽管在解决nl2sql方面做出了所有这些努力,但仍然存在许多重要的问题,从我们现在的情况来看,研究人员下一步应该研究什么nl2sql研究主题,采用哪种方法?应该适用于从业者的具体应用——本文系统地审视并回答了这些问题。
Q1:我们现在在哪里? 图1描绘了过去二十年nl2sql方法的演变,从基于规则的方法、基于深度神经网络的方法、可调谐预训练语言模型(PLM) ,到巨型语言模型(大语言模型),以及诸如Spider (Yu等人,2018)和BIRD (Li等人,2023c)等基准的开发。 请注意,与 PLM 相比,大语言模型(例如 GPT-4 (OpenAI 等人, 2024) 和 Llama2 (Touvron 等人, 2023))是更大的语言模型(例如,GPT-2 (Radford 等人, 2019) 和 BART (Lewis 等人, 2019)) 并表现出高级语言理解和涌现能力 (Minaee 等人,2024)。 使用 PLM 来完成 nl2sql 任务需要对特定于任务的数据集进行微调,而利用大语言模型来完成此任务可以通过各种大语言模型或模型的提示(上下文学习)来完成仅针对开源大语言模型进行微调(即指令跟踪)(Zhao 等人,2023)。 最先进 (SOTA) 的结果是通过基于 PLM 和 LLM 的方法实现的。
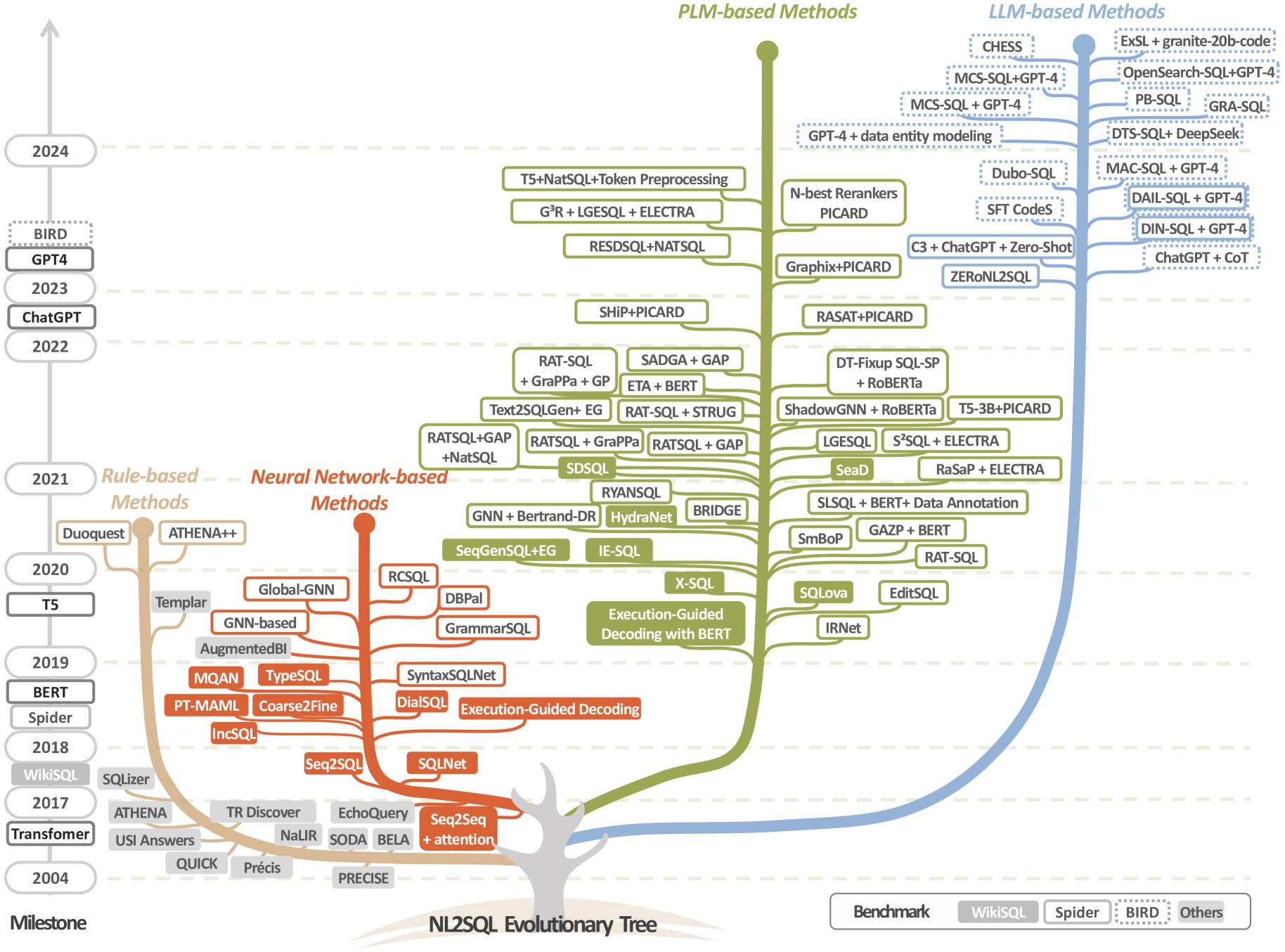
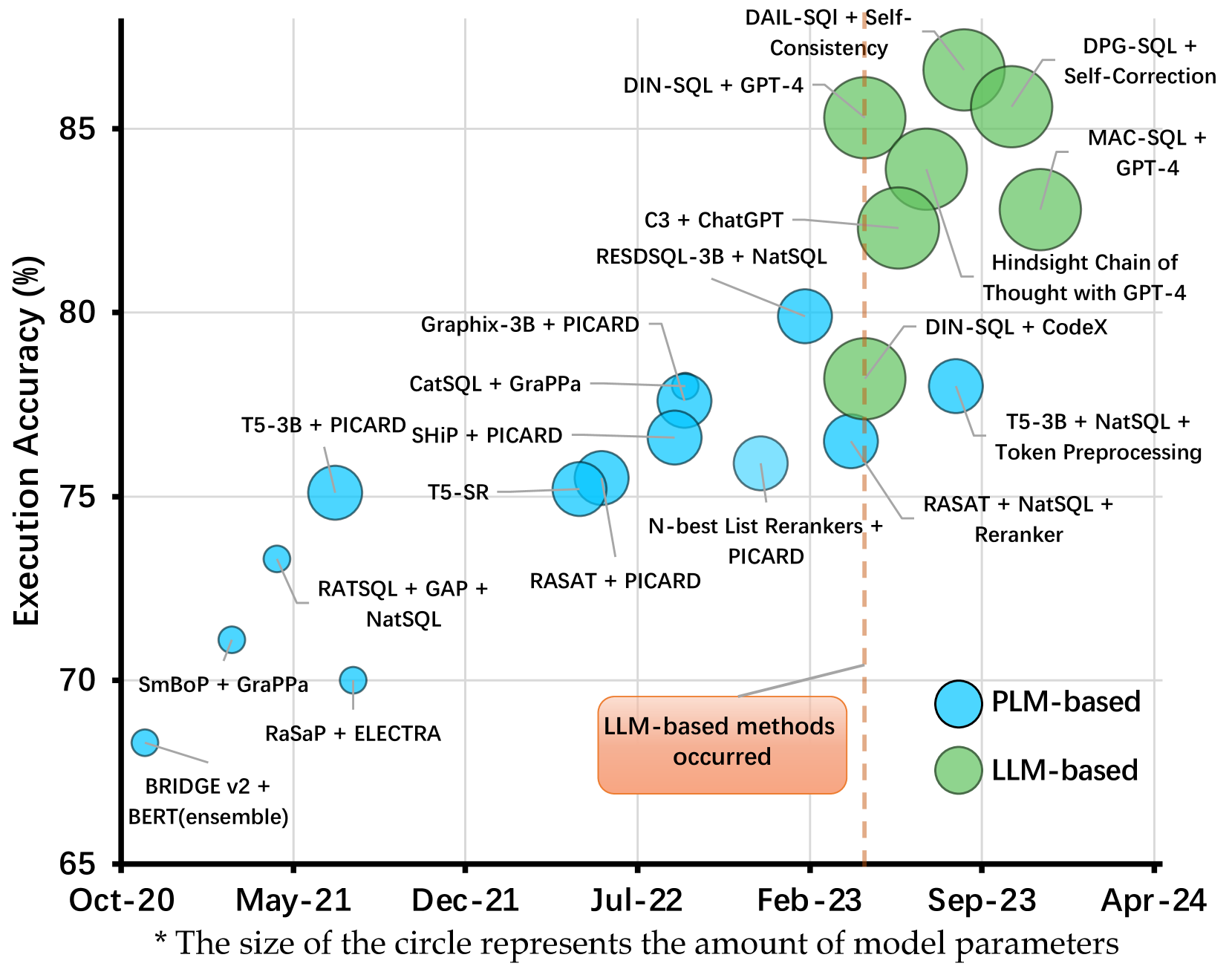
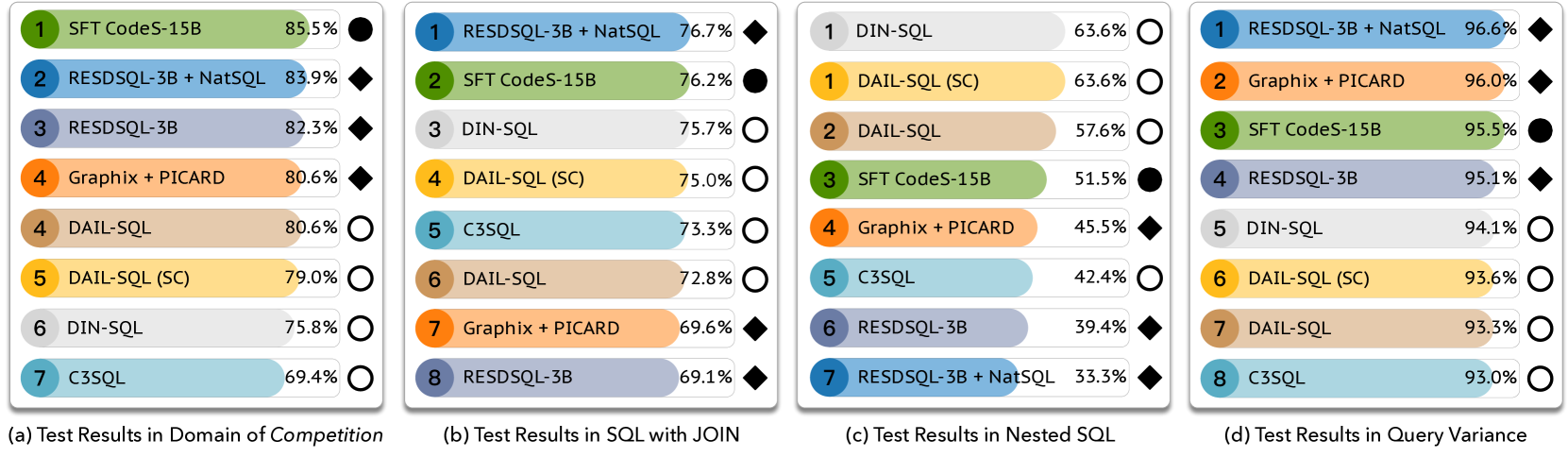
图2比较了基于PLM(蓝点)和基于LLM(绿点)nl2sql模型在Spider排行榜上的准确率(Yu等人,2018) 。 它显示基于 LLM 的 nl2sql 模型于 2023 年 2 月开始使用 (DIN-SQL CodeX),其精度与基于 PLM 的模型相当。 然而,随着大语言模型的快速发展,基于LLM和PLM的模型之间的性能差距不断扩大,凸显了基于LLM的方法的优势。
问题 2:基于 LLM 的模式是明显的赢家吗? 根据图2, 我们是否可以得出结论,基于 LLM 的模型是任何 nl2sql 应用程序的“选择”? 换句话说,选择排行榜上排名靠前的模型是否始终是最佳策略。
正确回答这个问题对于帮助研究人员和实践者设计和选择适合不同需求的正确模型至关重要。 让我们考虑一下经典的商业智能 (BI) 用例。
[各种数据域。] 像 Tableau (选项卡,[n.d.]) 这样的 BI 平台通常具有具有独特架构和术语的各种数据库域(例如电影和体育)。 理想的 nl2sql 模型必须能够跨这些不同的领域进行推广,同时适应每个特定的领域,以有效地满足临时需求。
[复杂的SQL操作。] 现实应用程序通常需要执行复杂的sql查询,涉及高级操作,例如多个JOIN、嵌套查询和聚合函数。 准确生成复杂查询的能力是评价nl2sql模型的重要标准。
[新语言现象。] 对于相同的查询意图,不同的用户可能会提出具有不同缩写、同义词和问题风格的nl问题。 因此,nl2sql 模型理解和准确解释各种 nl 查询变体的能力变得非常重要。
让我们使用实证结果更好地说明来自不同用例的不同 nl2sql 模型的比较。
示例 0。
图3在Spider开发数据集上从不同角度比较了基于SOTA PLM和LLM的模型的执行准确性指标。
各种数据域图3(a)比较了竞争域中的不同模型。 结果表明,基于微调的大语言模型/PLM 方法优于所有基于提示的大语言模型方法。 具体来说,基于 PLM 的最佳方法 RESDSQL-3BNatSQL (Li 等人, 2023d) 实现了 执行精度,优于最佳方法基于提示的大语言模型方法,DAILSQL(使用 GPT-4)(Gao 等人,2023),作者:。 上述观察结果表明,微调是增强nl2sql模型领域适应能力的关键策略。
复杂的 SQL 操作 图 3(b) 比较了仅使用 sql 查询的用例的不同模型 加入 运营商。 结果表明,基于 PLM 的方法 RESDSQL-3BNatSQL (Li 等人, 2023d) 排名第一,优于所有基于 LLM 的方法。
然而,当我们在仅使用嵌套sql查询的用例上比较不同方法时,如图3(c)所示,我们观察到基于LLM的方法通常优于PLM基于方法。
新的语言现象我们还计算了方法在不同语言现象上的平均准确度(例如,“返回总消费大于 1000 的所有客户”与“花费更多的客户列表是什么”)超过 1,000?”)。 图3(d)显示,虽然两种方法都表现良好,但nl2sql的微调大语言模型和PLM优于的提示大语言模型nl2sql。 这主要是因为微调模型可以更好地将不同的查询变体与数据库模式保持一致。
示例1.1表明一种尺寸不能适应所有情况;也就是说,即使由目前最强大的大语言模型 GPT-4 提供支持,nl2sql 模型在不同的使用场景上也没有明显的获胜者。 事实上,现实世界的场景比在公共 nl2sql 基准测试(例如 Spider 和 BIRD)中检查的情况要复杂得多。 因此,迫切需要能够在给定基准上从不同角度系统地评估nl2sql模型的工具。
Q3:我们能否结合两全其美,设计一个超级NL2SQL模型? Q1和Q2之后的问题是:如果不同场景下没有单一的赢家,我们是否可以设计一个结合优点的超级nl2sql模型PLM 和大语言模型的结合,对于不同的场景都具有鲁棒性。
贡献。 在本文中,我们从不同的角度、在不同的基准上系统地评估了不同的基于 PLM 和 LLM 的 nl2sql 模型。 在这些广泛的实验中,我们构建了一个测试平台,可以帮助研究人员和从业者在特定场景下更好地评估nl2sql模型,观察到有趣的实验结果,并设计了一个超级nl2sql模型是比 SOTA 解决方案最强大的。
我们的主要贡献总结如下。
(1)NL2SQL360:多角度NL2SQL评估。 我们设计了一个测试平台NL2SQL360,用于对nl2sql解决方案进行细粒度评估。 用户可以利用NL2SQL360根据既定基准评估不同的nl2sql方法,或根据特定标准定制评估。 这种灵活性允许在特定数据域中测试解决方案或分析 sql 查询的不同特征的性能。 (第 3 节)
| Types | Methods | Backbone Models | Example Selection (Few-shot) | Schema Linking | DB Content | SQL Generation Strategy | Post-processing Strategy | |||||
| Multi-Step |
|
Decoding Strategy | ||||||||||
| LLM-based | Prompting | DIN-SQL (Pourreza and Rafiei, 2023) | GPT-4 | Manual | ✓ | ✗ |
|
NatSQL | Greedy Search | Self-Correction | ||
|
GPT-4 | Similarity-based | ✗ | ✗ | ✗ | ✗ | Greedy Search | Self-Consistency | ||||
| MAC-SQL (Wang et al., 2023) | GPT-4 | N/A | ✓ | ✗ |
|
✗ | Greedy Search | Refiner | ||||
| C3-SQL (Dong et al., 2023) | GPT-3.5 | N/A | ✓ | ✗ | ✗ | ✗ | Greedy Search | Self-Consistency | ||||
| CodeS (Li et al., 2024) | StarCoder | Similarity-based | ✓ | ✓ | ✗ | ✗ | Beam Search |
|
||||
| Fine-tuning | SFT CodeS (Li et al., 2024) | StarCoder | N/A | ✓ | ✓ | ✗ | ✗ | Beam Search |
|
|||
| PLM-based | RESDSQL + NatSQL (Li et al., 2023d) | T5 | N/A | ✓ | ✓ | Skeleton Parsing | NatSQL | Beam Search |
|
|||
| Graphix + PICARD (Li et al., 2023b) | T5 | N/A | ✓ | ✓ | ✗ | ✗ | PICARD | ✗ | ||||
| N-best Rerankers + PICARD (Zeng et al., 2023) | T5 | N/A | ✓ | ✓ | ✗ | ✗ | PICARD | N-best Rerankers | ||||
| T5 + NatSQL + Token Preprocessing (Rai et al., 2023) | T5 | N/A | ✓ | ✓ | ✗ | NatSQL | Greedy Search | ✗ | ||||
| RASAT + PICARD (Qi et al., 2022) | T5 | N/A | ✓ | ✓ | ✗ | ✗ | PICARD | ✗ | ||||
| SHiP + PICARD (Zhao et al., 2022) | T5 | N/A | ✗ | ✓ | ✗ | ✗ | PICARD | ✗ | ||||
| T5 + PICARD (Scholak et al., 2021) | T5 | N/A | ✗ | ✓ | ✗ | ✗ | PICARD | ✗ | ||||
| RATSQL + GAP + NatSQL (Gan et al., 2021) | BART | N/A | ✓ | ✓ | ✗ | NatSQL | ✗ | ✗ | ||||
| BRIDGE v2 (Lin et al., 2020) | BERT | N/A | ✗ | ✓ | ✗ | ✗ |
|
✗ | ||||
(2)新的实验发现。 我们在 Spider 和 BIRD 数据集上测试了 13 个基于 LLM 和 7 个基于 PLM 的 nl2sql 解决方案,改变了 15 种不同的设置来分析它们在各种使用场景中的性能(第 4 节) 。 主要调查结果如下:
(一) 准确性。 微调对于提高性能至关重要。 具体而言,基于 LLM 并进行微调的方法在 EX 指标方面表现出色,而基于 PLM 的方法在 EM 指标方面领先。 但是,它们可以在具有特定特征的 sql 子集中被区分为获胜者。 例如,使用 GPT-4 的方法在子查询方面的性能明显更好。
(ii) NL 查询方差。 针对不同nl查询生成相同的目标sql,针对场景数据进行微调的大语言模型和PLM表现出更强的稳定性。
(iii) 领域适应。 对于跨不同领域的 nl2sql 任务,基于 LLM 的方法和基于 PLM 的方法之间没有明显的赢家。 然而,微调过程中的域内数据对于特定域中的模型性能至关重要。
(iv) 语料库在预训练中的影响。 我们的实验表明,经过微调后,在 CodeLlama-7B、StarCoder-7B 和 Deepseek-Coder-7B 等代码特定数据集上预训练的大语言模型优于在一般文本上训练的 Llama2-7B。 nl2sql 任务。 这凸显了大语言模型的预训练数据域或其内在代码功能对其在诸如nl2sql等专门任务中的性能的显着影响。
(3)SuperSQL:一个健壮的NL2SQL模型。我们对最具代表性的进行了系统的分类和分析nl2sql 基于大语言模型和PLM的模块,突出了它们的共性和独特性。 在此探索的基础上,我们建议 SuperSQL,在 Spider 测试集上实现了 87% 的竞争执行准确率,62.66% 在 BIRD 测试集上。 (部分 5)
(4)下一步需要做什么。 基于我们的实验结果、设计空间探索以及 SuperSQL 的实现和测试,我们确定了未来的三个研究机会:i) 增强nl2sql方法的可信度,包括处理模棱两可的nl查询、诊断nl查询和预测的 SQL 之间的匹配,以及将查询结果解释为nl查询。ii) 开发具有成本效益的 nl2sql 解决方案;以及 iii) 自动和自适应地生成训练数据(nl、sql)。)根据评估结果。 (部分 6)
2. 自然语言到 SQL
设是一个nl查询,是一个关系数据库,其中有表。自然语言到 SQL(nl2sql)的问题是根据和数据库生成一个 SQL 查询。
接下来,我们通过对最近基于LLM/PLM的分类来描述相关工作nl2sql 将解决方案转化为分类法。 我们通过讨论现有作品的局限性来结束本节。
2.1. 相关作品:鸟瞰图
图1说明了nl2sql的进化树 技术,分为四个主要分支:基于规则的方法、基于神经网络的方法、基于 PLM 的方法和基于 LLM 的方法。
基于规则的方法。 我们可以观察到,早期的工作主要基于预定义的规则或语义解析器(Rajkumar等人,2022;Li和Jagadish,2014;Katsogiannis-Meimarakis和Koutrika,2023,2021)。 例如,NaLIR (Li and Jagadish, 2014) 使用句法解析器来理解 nl 查询并链接到数据库元素,然后依赖手工规则生成sql 询问。 然而,这些方法在适应性、可扩展性和泛化能力方面表现出很大的局限性。
基于神经网络的方法。 为了克服这些限制,研究人员转向使用神经网络来学习从 nl 查询到 sql 的翻译 查询。 在此期间,发布了众多大规模基准数据集,包括WikiSQL (钟等人,2017)、Spider (于等人,2018)等。 在这方面的研究中,基于序列到序列的 NL2SQL 方法(钟等人,2017;程等人,2017;肖等人,2016)被开发出来,并在当时达到了一个新的标准。 例如,IRNet (Guo 等人, 2019) 利用编码器对 nl 查询和数据库架构,然后使用解码器网络生成 sql 查询。
基于 PLM 的方法。 2017年左右,随着Transformer(Vaswani等人,2017)和Spider数据集的引入,基于神经网络的方法开始出现,并迅速成为主流方法。 BERT (Devlin 等人, 2018) 和 T5 (Raffel 等人, 2020) 等模型的出现标志着基于预训练语言模型的方法的兴起(Li 等人, 2023b, d; Scholak 等人, 2021),在基准数据集上取得了有竞争力的结果。 例如,RESDSQL (Li 等人, 2023d) 利用两阶段框架 NL2SQL. 首先,它直接从自然语言查询中识别相关的模式元素,例如表名和列。 然后,它使用这些元素构建 SQL 查询,这是 Spider 排行榜中排名最好的模型之一。
基于 LLM 的方法。 最近,像ChatGPT和GPT-4这样的巨型语言模型的出现(Achiam等人,2023)引发了新一波的解决方案。 这些基于LLM的 nl2sql方法已经成为当前最突出、最具代表性的解决方案nl2sql 景观(Pourreza和Rafiei,2023;高等人,2023;董等人,2023;李等人,2024;王等人,2023)。 例如,DAIL-SQL(高等人,2023)通过有效的即时工程方法利用GPT-4,在Spider数据集上取得了有竞争力的结果。
鉴于 nl2sql 进化树中观察到的增长趋势,我们预计基于 LLM/基于 PLM nl2sql 未来几年,方法将继续主导该领域。 因此,我们充分了解这些技术的能力、局限性和潜在的改进非常重要。 nl2sql方法。
NL2SQL 系统中的关键模块。表1对最先进的进行分类nl2sql 基于骨干模型和几个关键组件的方法。 粗略地说,最近的竞争方法采用语言模型作为骨干 NL2SQL 翻译,可以使用基于 API 的大型语言模型(例如 GPT-4),也可以使用可调语言模型(例如 T5 和 LLaMA)。
我们可以观察到模式链接模块是大多数方法不可或缺的组件,突出了其在 nl2sql 过程中的关键作用。此外,将数据库内容合并到所有基于 PLM 的方法中,表明其对提高生成的 sql 查询的准确性和相关性做出了重要贡献。这强调了理解数据库的架构和内容对于 nl2sql 任务的基础重要性。在sql生成步骤中,所有基于PLM的方法都采用类似波束搜索的策略,例如 PICARD (Scholak 等人, 2021),在以下条件下确定最佳输出 Token sql 语法规则。 相反,基于 LLM 的方法依赖于基于贪婪的策略 sql生成。在后处理步骤中,大多数基于 LLM 的方法都结合了启发式提示策略,例如自我修正和自我一致性,以细化初始输出,确保它们与预期的 sql查询。
2.2. 现有实验及其局限性
现有的实验。 有几项与我们的研究相关的实验研究。 例如,高等人(Gao 等人, 2023)评估了开源大语言模型的潜力 NL2SQL 通过即时工程完成任务。 Rajkumar 等人 (Rajkumar 等人, 2022) 探索了 Codex 语言模型在处理 NL2SQL 零样本和少样本设置下的任务。 Gkini 等人 (Gkini 等人, 2021) 对基于解析和基于关键字进行了深入评估 nl2sql。前两项研究主要侧重于评估基于 LLM 的 nl2sql 解决方案,而第三项研究则研究基于解析的 nl2sql方法。
他们的局限性。 现有的实验有几个局限性。
(1)忽略使用场景。 现有评估通常报告整个基准数据集的总体结果(例如 Spider)。虽然这提供了广泛的概述,但它未能提供特定数据子集的详细比较(见图 3)。例如,我们可以根据不同的 sql 特征或数据库域过滤评估的数据集,这可以对不同的相对有效性产生有价值的见解nl2sql特定模型sql0> 查询类型或特定于域的场景。
(2)缺乏直接和全面的比较。 一个主要限制是许多最近的 nl2sql 解决方案,特别是基于大语言模型和PLM的解决方案,尚未在完善的基准和定制数据集上进行系统比较。
(3)对 NL2SQL 设计空间的有限探索。当前nl2sql研究与实践的一个差距是对nl2sql设计空间的探索有限 基于大语言模型和PLM方法的框架。 缺乏全面的研究限制了我们对如何协同整合大语言模型和 PLM 的不同架构和功能模块以增强性能的理解。 nl2sql系统。
3. NL2SQL360:NL2SQL 的测试平台
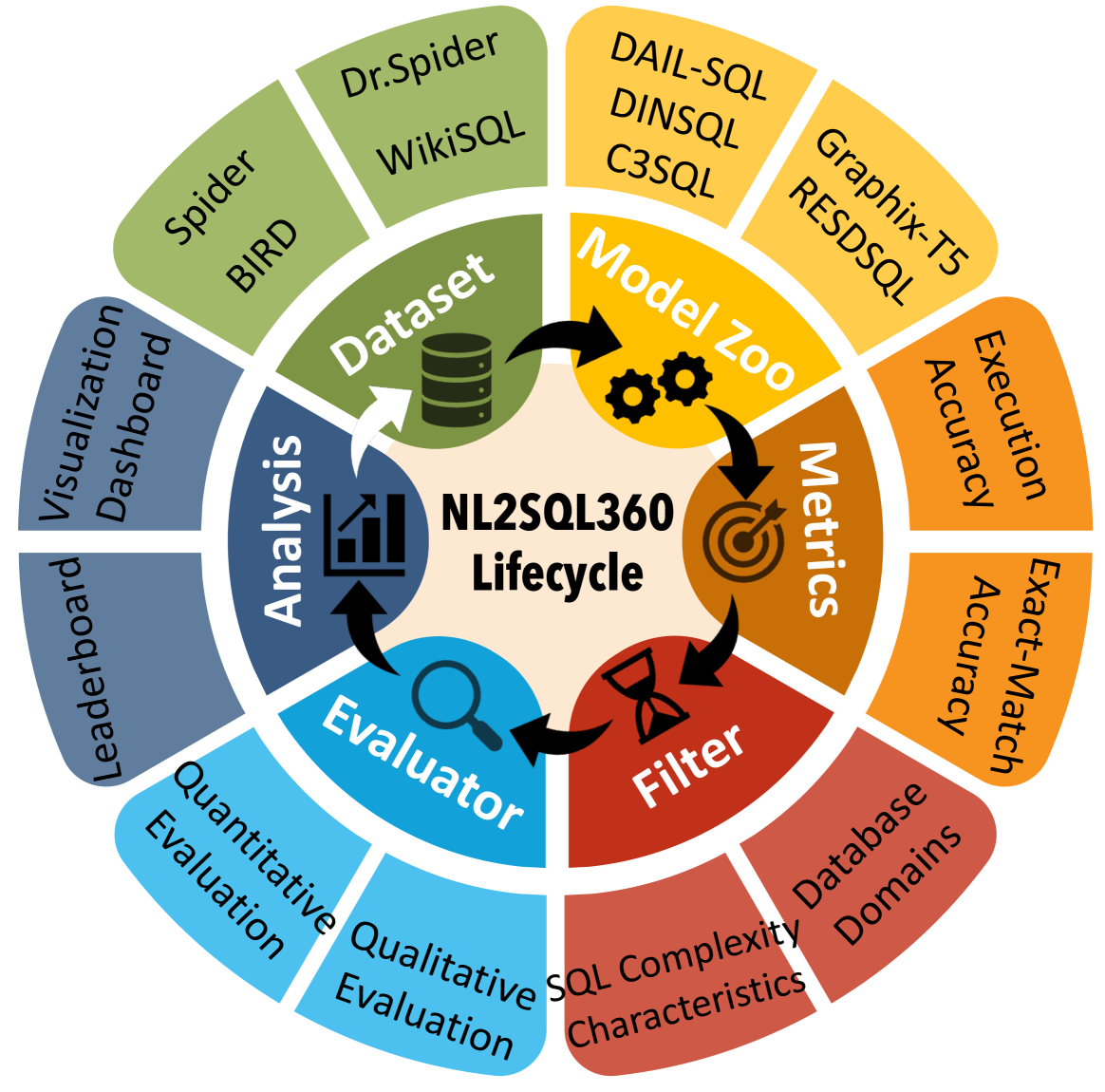
我们设计了一个测试平台,如图4所示,用于评估和分析nl2sql解决方案。 NL2SQL360可以帮助研究人员了解nl2sql系统中的设计选择比较SOTA模型,开发工作量更少,并提供实践者 结合不同类型模型在特定场景下的实验结果,推动实际应用。
图4概述了我们的测试床框架,包括六个核心组件:数据集存储库、模型动物园、数据集过滤器、评估指标、nl2sql 评估器和分析模块。
基准数据。 该模块维护广泛使用的基准:Spider (Yu 等人, 2018)、BIRD (Li 等人, 2023c)、Spider-Realistic (Deng 等人) , 2021), Dr.Spider (张等人, 2023), KaggleDBQA (李等人, 2021), WikiSQL (钟等人) ,2017)等
模型动物园。该模块托管了一系列竞争性和开源的nl2sql Spider 和 BIRD 排行榜上的型号。 主要包括基于LLM和基于PLM的方法。
数据集过滤器。 传统评估,对整个基准数据集的性能进行平均,错过了细致入微的 nl2sql 针对第 1 节中概述的各种场景的性能洞察。为了针对不同场景定制评估,我们选择特定的基准子集,包括特定数据库、nl和sql查询。这些子集突出了独特的特征,例如查询复杂性、数据库模式多样性以及独特的 sql0> 功能,例如 1>JOIN2> 操作或嵌套查询。 因此,我们在我们的模型中引入了数据集过滤机制 NL2SQL360. 这允许根据各种标准将测试数据集分成更有针对性的子集:
(1) 场景 1:SQL 复杂性。这种情况区分了sql 按复杂性进行查询,从简单的查询到具有多个子句和条件的复杂查询。 该分类遵循Spider (Yu等人,2018)制定的标准,旨在评估其分类效果 nl2sql方法处理不同级别的sql难度。
(2) 场景 2:SQL 特征。它检查主要利用特定功能的 sql 查询,例如 JOIN 操作、子查询或聚合函数。 通过根据这些特征对查询进行分类,我们可以评估 nl2sql系统管理不同sql功能的能力。 例如,商业智能平台通常使用嵌套子查询来处理分析查询。
(3) 场景 3:数据域. 此场景探讨了系统在各个数据领域(例如金融、医疗保健和零售)的性能。 按分类 NL2SQL 根据数据库的数据领域,我们提供了一个结构化框架来评估特定领域的功能和潜在限制。
(4) 场景 4:查询方差测试。它评估 nl2sql 系统在处理自然语言查询变化时的鲁棒性和灵活性。 它测试了 NL2SQL 系统对不同短语和结构的响应,衡量用户友好性和对不同语言风格的适应性。 我们使用各种自然语言查询 NL2SQL 数据集作为测试样本。
评估指标。 我们支持一组广泛接受的指标。 具体来说,我们采用 执行精度(EX)和精确匹配精度 (EM) (Yu 等人, 2018) 评估生成的 SQL 查询的有效性。 此外,我们使用 有效效率分数 (VES) (Li 等人, 2023c) 衡量生成有效数据的效率 sql查询。
为了进一步评估 nl2sql 解决方案在处理自然语言查询变化方面的稳健性和灵活性,我们提出了一个名为 查询方差的新指标测试。该指标评估模型适应不同形式的 nl 查询的能力。
给定一个sql查询,通常存在多个相应的nl查询、表示为成对:{(,),(,),..., (, )}.在评估一个 nl2sql 模型时,这些 nl 和 sql 仅当模型准确地处理其中至少一对查询对时,才会将其合并到测试集中。 这使我们能够为每个模型构建特定的测试集来计算它们的平均准确性。
计算公式QVT 准确度定义如下:
| (1) |
在哪里:
-
•
为sql总数 测试集中的查询。
-
•
是与 sql 查询 .
-
•
表示由 nl2sql 模型生成的 sql 查询 的自然语言查询变体。
-
•
是指示函数,如果里面的查询结果相等则返回1,否则返回0。
执行器和日志。用户可以定制nl2sql的评估流程 模型,设置超参数和指标等参数。 然后,测试床自动在基准测试(例如 Spider)和自定义子集(例如嵌套查询)上运行这些模型,记录每个结果。 这些日志提供了对每个模型性能的详细见解,作为模型分析的资源。
评估器。 利用日志中的数据,评估器 自动生成定量评估,以易于解释的格式(例如表格或排行榜)呈现。 此外,我们的测试台提供可视化工具和用于交互式分析的仪表板,允许用户进行比较 nl2sql跨数据库领域、sql特性等维度的解决方案。
4. 实验
4.1. 实验设置
| Dataset | #-Tables / DB | #-Columns / DB | #-Columns / Tables | #-PKs / DB | #-FKs / DB | ||||||||||||
| Min | Max | Avg | Min | Max | Avg | Min | Max | Avg | Min | Max | Avg | Min | Max | Avg | |||
|
2 | 26 | 5.4 | 6 | 352 | 27.8 | 2 | 48 | 5.1 | 0 | 18 | 4.8 | 0 | 25 | 5.0 | ||
|
2 | 65 | 7.6 | 6 | 455 | 51.3 | 1 | 62 | 6.8 | 0 | 65 | 6.7 | 0 | 61 | 6.1 | ||
|
2 | 11 | 4.1 | 7 | 56 | 22.1 | 2 | 32 | 5.4 | 1 | 10 | 3.7 | 1 | 11 | 3.2 | ||
|
3 | 13 | 6.8 | 11 | 199 | 72.5 | 2 | 115 | 10.6 | 2 | 13 | 6.5 | 1 | 29 | 9.3 | ||
数据集。 我们使用Spider (Yu等人,2018)和BIRD (Li等人,2023c)的开发集作为我们的实验数据集,其中包含1034和1534(nl,sql)分别是样本。 这 BIRD数据集中的sql结构更加复杂,包含一些Spider未涵盖的关键字,例如CASE、 IIF, ETC。 这种增加的复杂性挑战了模型的 nl2sql能力。另外,BIRD中的数据库比Spider中的数据库更加复杂,如表2所示。
方法。 我们评估最先进的基于 LLM 和 PLM 的开源nl2sql方法。
基于提示的大语言模型。 我们比较了 4 种基于提示的方法:
(1) DINSQL (Pourreza and Rafiei, 2023) 分解了 sql查询不同的子问题,并为每个子问题设计不同的提示来指示GPT-4生成最终的sql查询.
(2) DAILSQL (Gao 等人, 2023) 将问题和数据库模式编码为 sql 代码风格。 它根据结构(骨架)相似性和查询相似性来选择样本示例。 这些元素组合成一个高效的提示来指导GPT-4。
(3) DAILSQL(SC) (Gao 等人, 2023) 是 DAILSQL 的版本,采用自我一致性 (SC) 策略进行后处理。
(4) C3SQL (Dong 等人, 2023) 使用模式链接过滤和 GPT-3.5 定制的校准偏差提示 sql 查询生成,结合后处理的自一致性策略。
基于微调的大语言模型。 我们评估了 9 种基于微调的方法。
(5-8) SFT CodeS (1B/3B/7B/15B) (Li 等人, 2024):CodeS 基于 StarCoder (Li 等人, 2023a) 增量预训练 使用大型SQL相关语料库,在许多具有挑战性的问题上表现出了出色的性能 NL2SQL 基准。 在下面的实验中,我们使用 SFT CodeS,它是通过 Spider 或 BIRD 数据集进行微调的。 有 4 我们实验中的 SFT CodeS 系列模型的版本。
(9) Llama2-7B (Touvron 等人, 2023) 使用优化的 Transformer 作为自回归语言模型,由 Meta 在庞大的语料库上进行预训练。
(10) Llama3-8B (AI@Meta, 2024) 超过 15T 词符数据——训练数据集比 Llama 2 使用的数据集大 7 倍,包括多 4 倍的代码。
(11) StarCoder-7B (Li 等人, 2023a) 是一个代码大语言模型,已使用来自 GitHub 的许可数据进行训练。 这些数据涵盖广泛的内容,包括来自 80 多种编程语言的代码、Git 提交、GitHub 问题和 Jupyter Notebook。
(12) CodeLlama-7B (Rozière 等人, 2023) 是 Llama2 的增强变体,通过对代码存储库数据集的额外训练进行了改进。
(13) Deepseek-Coder-7B (Guo 等人, 2024) 在项目级代码语料库和填空任务上进行训练,以提高代码完成度。
基于 PLM 的 NL2SQL。 我们评估了 7 种最先进的方法:
(1) Graphix-3B+PICARD (Li 等人, 2023b) 将预先训练的 T5-3B Transformer 与图形感知增强功能集成在一起, NL2SQL 任务,利用 PICARD (Scholak 等人,2021) 来提高性能。
(2-4) RESDSQL(Base/Large/3B) (Li 等人, 2023d) 引入了排名增强编码和骨架感知解码,以将模式链接与骨架解析分开。
(5-7)RESDSQL(基本/大型/3B)NatSQL (Li 等人, 2023d) 是与 NatSQL (Gan 等人, 2021) 合并的版本,以获得更好的性能。 实验中使用了 6 个版本的 RESDSQL 系列模型。
指标。 我们评估了精确匹配精度 (EM)、执行精度 (EX)、查询方差测试 (QVT)、有效效率 Socre (VES)、词符效率和延迟指标的不同方法。
硬件和平台。 所有实验均在配备 512GB RAM 和两个 40 核 Intel(R) Xeon(R) Platinum 8383C CPU @ 2.70GHz 的 Ubuntu 22.04.3 LTS 服务器上进行。 为了对大语言模型实验进行监督微调,我们使用 8 个 NVIDIA A800 (80GB) GPU 来对模型进行调节。
4.2. 评估准确性的实验
Exp-1:基准的总体准确性。 我们跨 sql 评估基于 LLM 和 PLM 的方法的性能 不同复杂程度的查询。 我们在 Spider 和 BIRD 开发集上运行所有方法并计算它们的执行精度(EX)和精确匹配准确度(EM)指标。 请注意,我们在 BIRD 训练集上从头开始重新训练了基于 PLM 的官方方法 RESDSQL。 由于 NatSQL 的完整代码未公开,因此我们的模型没有包含 NatSQL。 另外,由于GPT资源的限制,我们没有在BIRD上重现DINSQL方法。 桌子 3和表4 报告结果。
最先进的 (SOTA) EX 和 EM 在特定 SQL 复杂性方面是标记为橙色和蓝色 分别在表中。
| Types | Methods | Metrics | Spider-Dev | |||||||||||||
| Easy | Med. | Hard | Extra | All | ||||||||||||
| LLM-based | Prompting | C3SQL | EX | 92.7 | 85.2 | 77.6 | 62.0 | 82.0 | ||||||||
| EM | 80.2 | 43.5 | 35.6 | 18.1 | 46.9 | |||||||||||
| DINSQL | EX | 92.3 | 87.4 | 76.4 | 62.7 | 82.8 | ||||||||||
| EM | 82.7 | 65.5 | 42.0 | 30.7 | 60.1 | |||||||||||
| DAILSQL | EX | 91.5 | 89.2 | 77.0 | 60.2 | 83.1 | ||||||||||
| EM | 89.5 | 74.2 | 55.5 | 45.2 | 70.0 | |||||||||||
| DAILSQL(SC) | EX | 91.5 | 90.1 | 75.3 | 62.7 | 83.6 | ||||||||||
| EM | 88.3 | 73.5 | 54.0 | 41.6 | 68.7 | |||||||||||
| Fine-tuning | SFT CodeS-1B | EX | 92.3 | 83.6 | 70.1 | 49.4 | 77.9 | |||||||||
| EM | 91.5 | 74.4 | 65.5 | 41.0 | 71.7 | |||||||||||
| SFT CodeS-3B | EX | 94.8 | 88.3 | 75.3 | 60.8 | 83.3 | ||||||||||
| EM | 94.4 | 80.7 | 67.8 | 49.4 | 76.8 | |||||||||||
| SFT CodeS-7B | EX | 94.8 | 91.0 | 75.3 | 66.9 | 85.4 | ||||||||||
| EM | 92.7 | 85.2 | 67.8 | 56.0 | 79.4 | |||||||||||
| SFT CodeS-15B | EX | 95.6 | 90.4 | 78.2 | 61.4 | 84.9 | ||||||||||
| EM | 93.1 | 83.4 | 67.2 | 54.2 | 78.3 | |||||||||||
| PLM-based | RESDSQL-3B | EX | 94.8 | 87.7 | 73.0 | 56.0 | 81.8 | |||||||||
| EM | 94.0 | 83.0 | 66.7 | 53.0 | 78.0 | |||||||||||
| RESDSQL-3B + NatSQL | EX | 94.4 | 87.9 | 77.0 | 66.3 | 84.1 | ||||||||||
| EM | 93.1 | 83.0 | 70.1 | 65.7 | 80.5 | |||||||||||
| Graphix-3B + PICARD | EX | 92.3 | 86.3 | 73.6 | 57.2 | 80.9 | ||||||||||
| EM | 91.9 | 82.3 | 65.5 | 53.0 | 77.1 | |||||||||||
| Hybird | SuperSQL | EX | 94.4 |
|
|
|
|
|||||||||
| EM | 90.3 | 76.7 | 61.5 | 44.0 | 72.1 | |||||||||||
| Types | Methods | Metrics | BIRD-Dev | ||||||||
| Simple | Moderate | Challenging | All | ||||||||
| LLM-based | Prompt- ing | C3SQL | EX | 58.9 | 38.5 | 31.9 | 50.2 | ||||
| DAILSQL | EX | 62.5 | 43.2 | 37.5 | 54.3 | ||||||
| DAILSQL(SC) | EX | 63.0 | 45.6 | 43.1 | 55.9 | ||||||
| Fine-tuning | SFT CodeS-1B | EX | 58.7 | 37.6 | 36.8 | 50.3 | |||||
| SFT CodeS-3B | EX | 62.8 | 44.3 | 38.2 | 54.9 | ||||||
| SFT CodeS-7B | EX | 64.6 | 46.9 | 40.3 | 57.0 | ||||||
| SFT CodeS-15B | EX | 65.8 | 48.8 | 42.4 | 58.5 | ||||||
| PLM- based | RESDSQL-Base | EX | 42.3 | 20.2 | 16.0 | 33.1 | |||||
| RESDSQL-Large | EX | 46.5 | 27.7 | 22.9 | 38.6 | ||||||
| RESDSQL-3B | EX | 53.5 | 33.3 | 16.7 | 43.9 | ||||||
| Hybird | SuperSQL | EX |
|
46.5 |
|
58.5 | |||||
基于 EX 指标的见解。如表3和表4,我们发现基于 LLM 的方法的 EX 在不同难度子集中都超过了基于 PLM 的方法。 特别是,表中 4,DAILSQL(SC)在Challenging子集上优于基于LLM的SOTA方法SFT CodeS-15B,这可能受益于GPT-4更强的推理能力。
基于 EM 指标的见解。在表中3,我们发现经过监督微调后基于 LLM 的方法通常比基于提示的大语言模型方法具有更高的 EM 性能。 经过微调后,基于 LLM 和 PLM 的模型的输出与特定数据集的数据分布更加一致,从而可以预测 sql 结构与该数据集中的结构相似。
发现 1. 微调是提高性能的重要策略。 具体而言,经过微调的基于 LLM 的方法在 EX 指标上实现了最佳总体结果,而基于 PLM 的方法在 EM 指标上总体表现最佳。
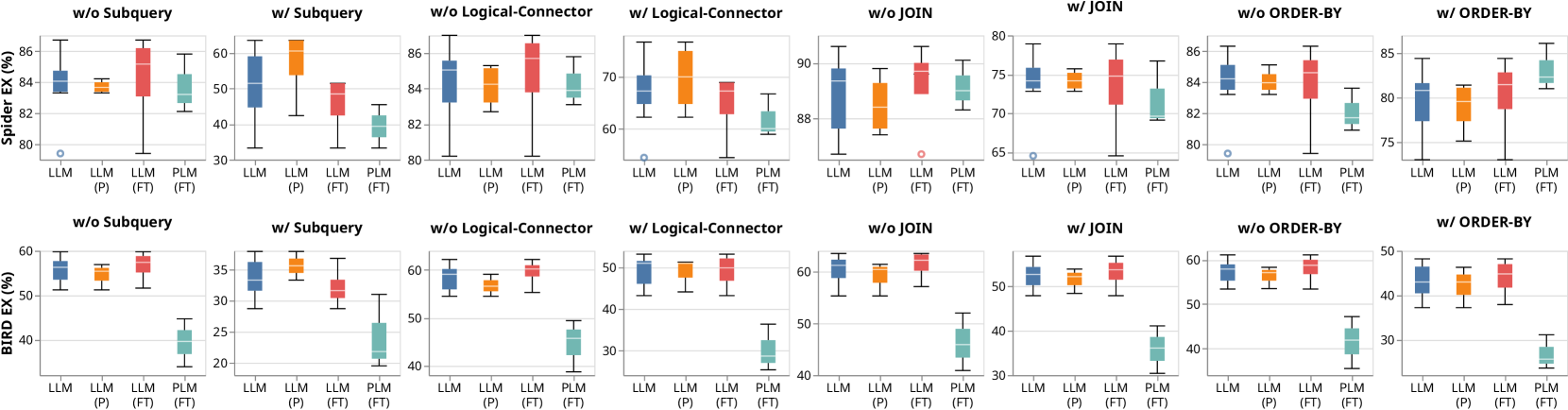
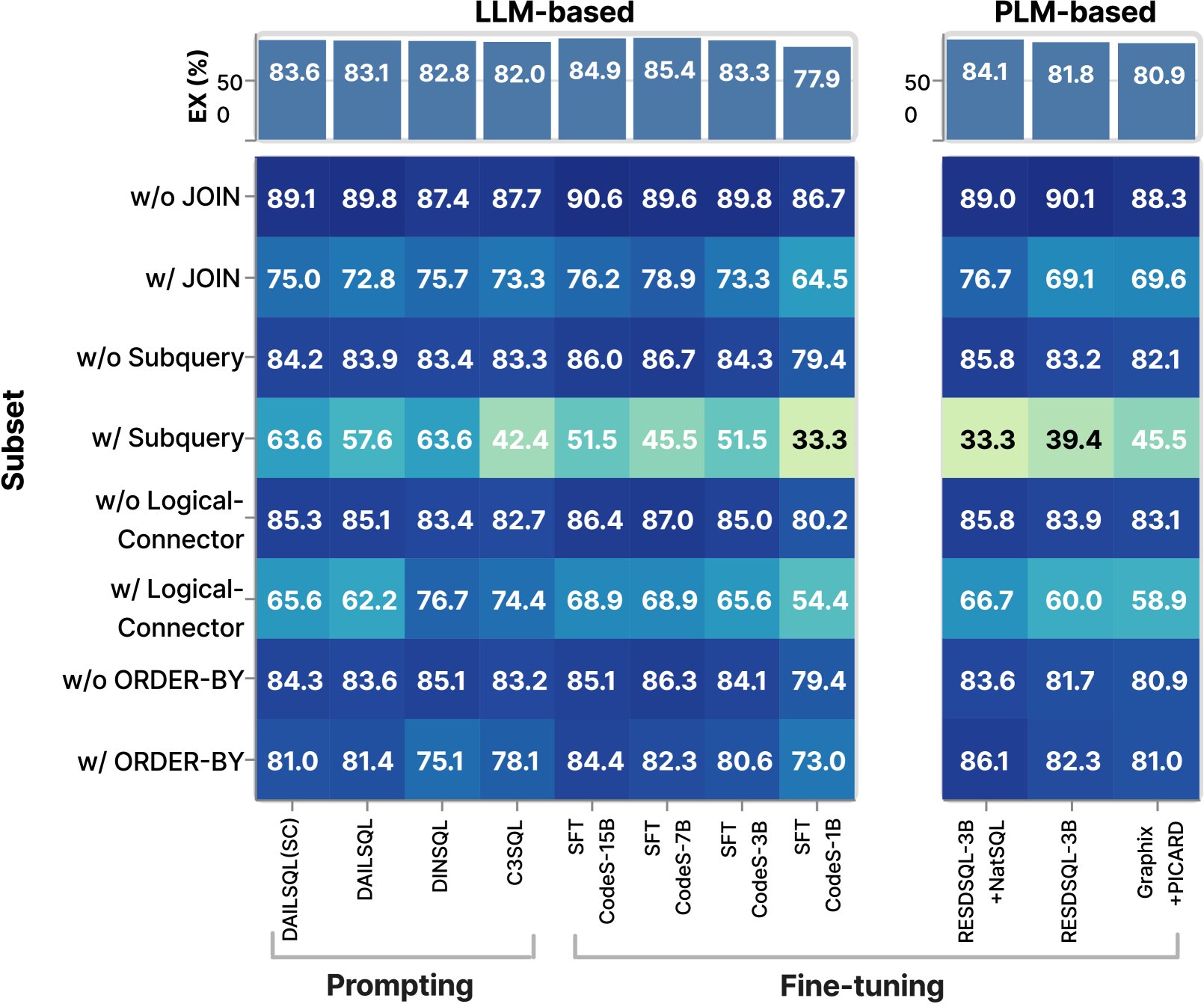
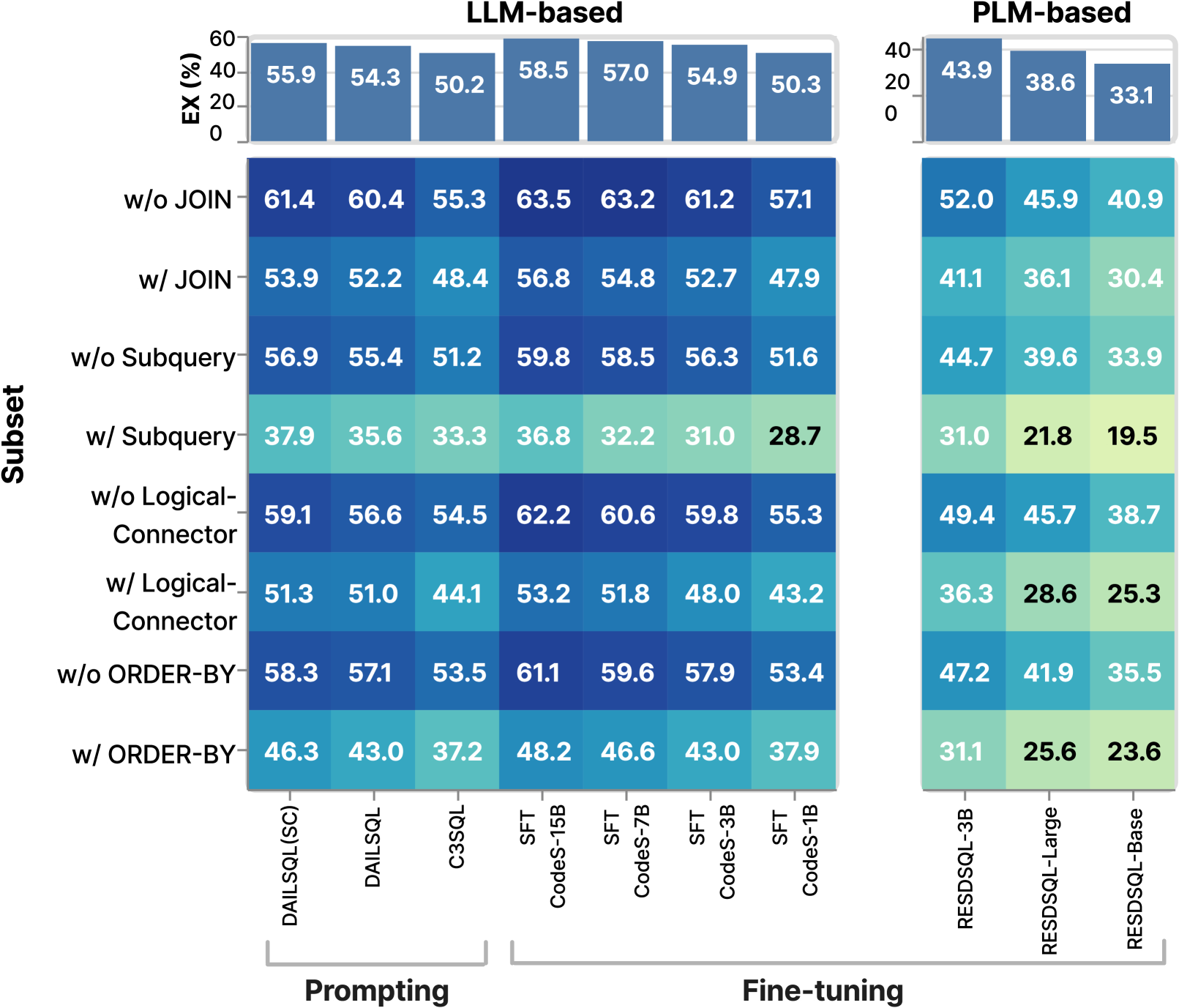
Exp-2:准确性与 SQL 特征。 实际应用程序通常需要生成 sql 查询,涉及高级操作,例如子查询、逻辑连接器、ORDER BY 和多个 JOIN。因此,我们将评估nl2sql模型准确生成sql的能力 具有不同特征的查询。
为此,我们根据四个标准对 sql 查询进行分类:(1) 子查询的存在,(2) 逻辑连接器的数量,(3) ORDER BY 和 (4) 的使用以及 JOIN 的数量。请注意,我们的NL2SQL360支持基于单个0>sql的sql查询过滤> 子句、它们的组合或用户定义的条件。 然而,由于篇幅限制,我们只展示了四个有代表性的方面。 我们在这四个子集上运行所有方法 sql 查询并计算其 EX 指标。
我们进一步将基于LLM的方法分为基于提示的和基于微调的大语言模型。 数字 5 可视化 Spider 和 BIRD 数据集不同子集的 EX 性能分布。 数字 7和图7 进一步显示不同子集的各种方法的详细结果。 条形图显示了每种方法的总体 EX。 在热图中,x 轴代表不同的方法,y 轴代表不同的子集。
Exp-2.1:#-子查询。如图7和图7,所有方法在有子查询的情况下表现最差,这表明通过子查询进行推理是一项具有挑战性的任务。 数字 5 结果表明,在没有子查询的场景中,基于 LLM 的方法在 Spider 上略优于基于 PLM 的方法,在 BIRD 上平均显着优于基于 PLM 的方法。 在带有子查询的场景中,基于 LLM 的方法在这两个数据集上都表现出色。
这是因为使用子查询生成sql需要模型首先考虑子查询,然后生成整个sql,要求较强的推理能力。 我们发现所有基于 LLM 的方法,尤其是那些由 GPT-4 提示的方法,在子查询中表现更好,超过了基于 LLM 的微调方法和基于 PLM 的方法。 这表明模型固有的推理能力对于处理至关重要 sql 带有子查询。
发现2. 在涉及子查询的场景中,基于LLM的方法总体优于基于PLM的方法,其中使用GPT-4(即基于提示的大语言模型)的方法表现出特别更好的性能。 这些模型固有的推理能力可能对于成功预测子查询至关重要。
Exp-2.2:#-逻辑连接器。 逻辑连接器(例如, AND、OR)用于链接条件、过滤查询结果以及执行其他操作,因此了解模型在逻辑连接器方面的性能至关重要。
无逻辑连接器场景,如图5,在 Spider 数据集上,基于 LLM 的方法与基于 PLM 的方法相比没有显着优势。 然而,在 BIRD 数据集上,基于 LLM 的方法优于基于 PLM 的方法,这可能是由于 BIRD 数据集的复杂性较高,如表所示 2. 在需要逻辑连接器的场景中,基于 LLM 的方法在两个数据集上始终优于基于 PLM 的方法。
发现3. 在需要逻辑连接器的场景中,基于LLM的方法比基于PLM的方法更好。
Exp-2.3:#-JOIN。在很多使用场景中,我们需要生成sql带有JOIN的查询跨多个表。 这挑战了模型正确理解复杂数据库模式的能力。
没有 JOIN 的 SQL。如图5,没有JOIN的场景 运营方面,基于 LLM 和基于 PLM 的方法在 Spider 和 BIRD 上表现出不一致的性能,没有明显的赢家。 数字 7和图7 提供类似的见解。
SQL 与 JOIN。但是,对于需要JOIN的场景 在这两个数据集上,基于 LLM 的方法均优于基于 PLM 的方法。 这可能是由于 加入 运营需要理解复杂的数据库模式,大语言模型通常因其卓越的上下文理解能力而表现出色。
NatSQL 的影响。在图7中,对于sql使用JOIN的查询>,DINSQL 在基于提示的方法中效果最好,而 RESDSQL-3B+NatSQL 在基于 PLM 的方法中效果最好。 两者都利用 NatSQL (Gan 等人, 2021) 作为中间表示,可能受益于其省略的简化形式 JOIN关键字并减少模式项预测,从而简化sql在JOIN场景中的预测。
发现4. 在涉及JOIN操作的场景中,基于LLM的方法优于基于PLM的方法。 采用 NatSQL 作为中间表示降低了预测 JOIN 操作的复杂性,并有可能提高模型性能。
Exp-2.4:#-ORDER BY。如图5所示,我们观察到没有ORDER BY 条款中,基于 LLM 的方法在 Spider 和 BIRD 数据集上均优于基于 PLM 的方法。 然而,随着 订购依据 子句中,与基于 PLM 的方法相比,基于 LLM 的方法在 Spider 数据集上的性能较差,而在 BIRD 数据集上的性能优于基于 PLM 的方法。 这种差异可能是因为 BIRD 数据集比 Spider 数据集更复杂。
发现5. 在包含 ORDER BY 子句的场景中,基于 LLM 和基于 PLM 的方法的性能因不同数据集而异。 总的来说,基于LLM的方法表现出更强的泛化能力。
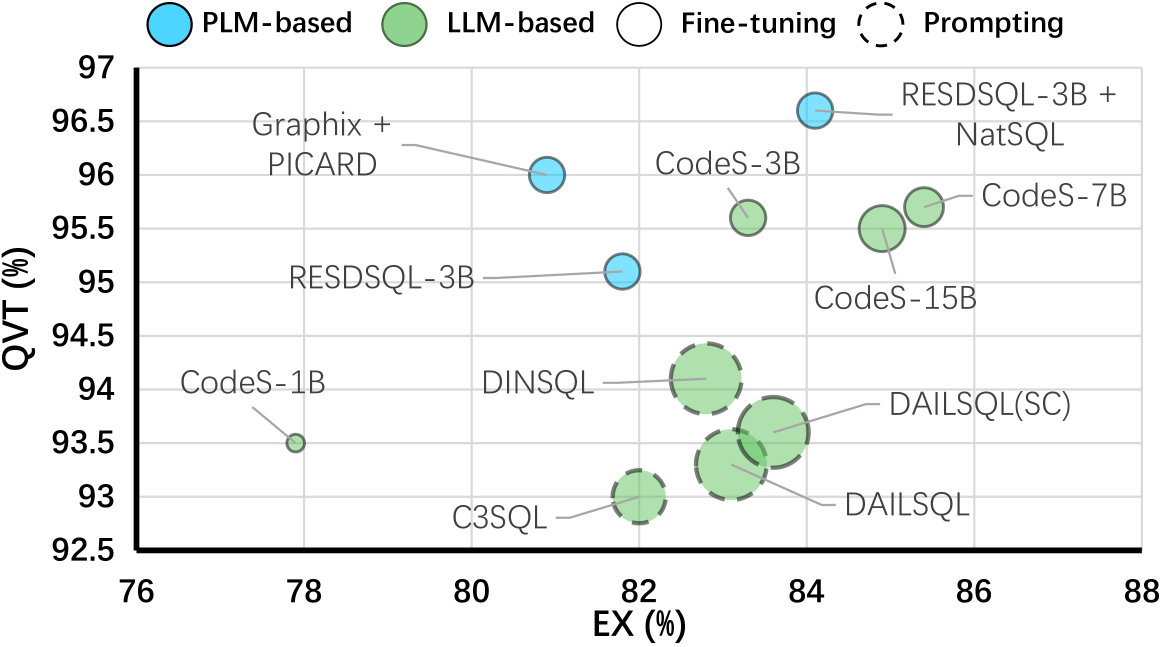
Exp-3:查询方差测试。我们评估nl2sql 系统对不同自然语言短语和结构的适应性,反映了实际应用中预期的多样性。 请注意,很少有 sql有多个对应的查询nl BIRD 数据集中的查询。 因此,我们使用 Spider Dev 集构建 QVT 数据集,因为它包含 469 sqls对应两个以上不同的nl 查询,与 QVT 的目的保持一致。 我们根据方程(1)。
如图8,就 QVT 而言,基于 LLM 的方法和基于 PLM 的方法之间没有明显的赢家。 然而,微调大语言模型通常表现出比提示大语言模型更高的QVT。 这种改进可能是由于微调后模型输入与特定数据分布的一致性,减少了 NL 变化对性能的影响。 值得注意的是,尽管与所有基于提示的方法相比,Graphix+PICARD 方法在总体 EX 中表现不佳,但在 QVT 中超过了它们。
发现 6. QVT 中基于 LLM 的方法和基于 PLM 的方法之间没有明显的赢家。 使用特定于任务的数据集微调模型可能有助于稳定其针对 nl 变化的性能。
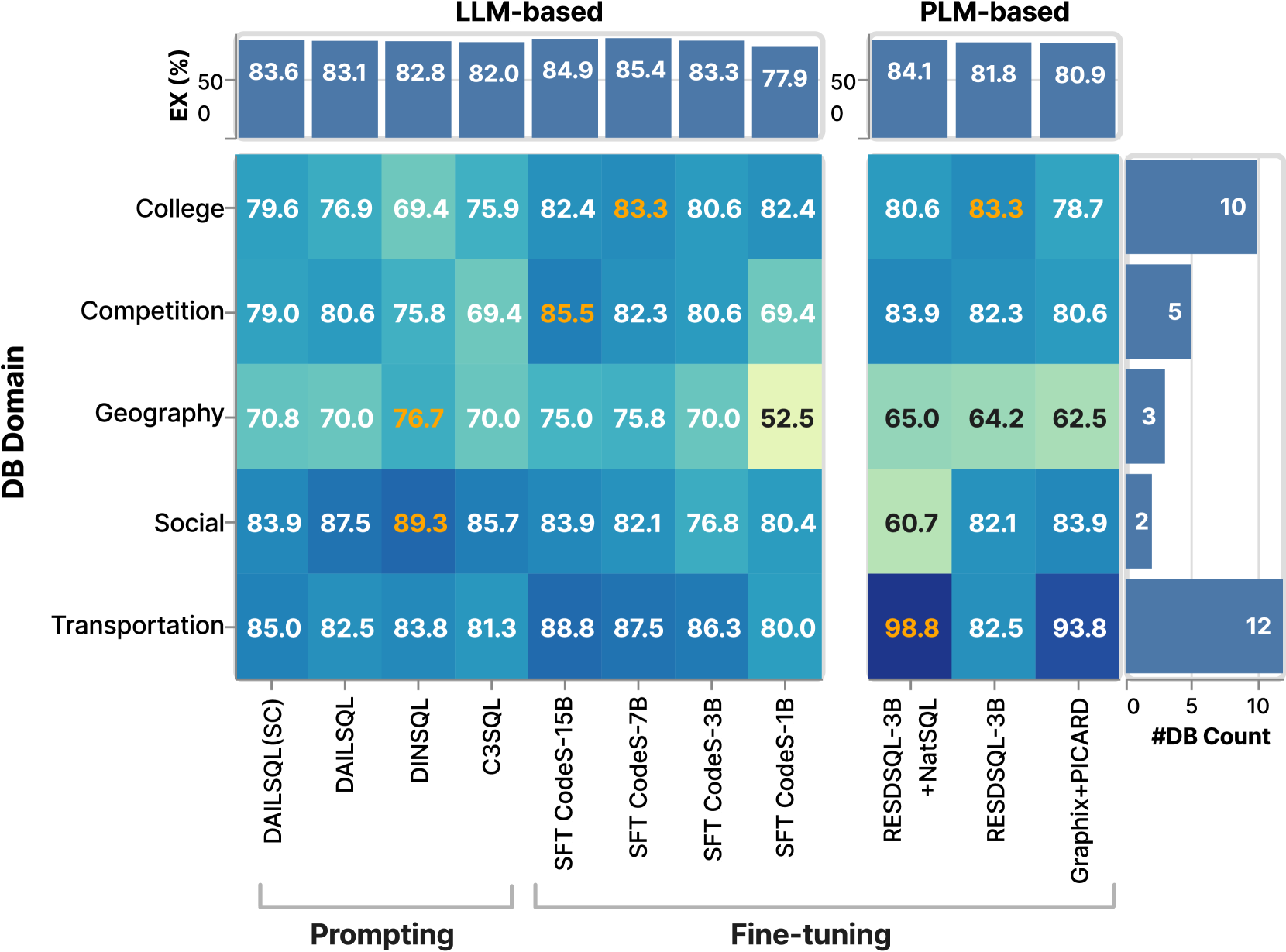

Exp-4:数据库域适应。实际nl2sql 应用程序、场景通常涉及特定领域的数据库,例如电影或体育,每个数据库都有独特的模式设计和术语。 评估不同领域方法的详细性能对于有效的模型应用至关重要。 我们将Spider训练集中的140个数据库和开发集中的20个数据库分为33个领域。 所有基于微调的大语言模型和PLM都是使用该集进行调整的。 数字 9(a) 显示了 Spider 数据集中不同数据库域的 EX 性能。 数字 9(b) 显示总体性能。
如图9(a)所示,我们发现不同的nl2sql 方法对不同领域表现出不同的偏见,并且基于 LLM 和基于 PLM 的方法之间没有明显的赢家。
但是,如图9(b),我们观察到基于微调的方法在训练数据库较多的领域(大学、竞赛、交通)表现更好。 相反,在训练数据库较少的领域,基于提示的方法表现出色。 这表明微调过程中的域内训练数据对于增强特定领域的模型性能至关重要。
发现 7. 不同的方法对不同的领域表现出不同的偏见,并且基于 LLM 和基于 PLM 的方法之间没有明显的赢家。 然而,微调过程中的域内训练数据对于特定领域的模型性能至关重要。

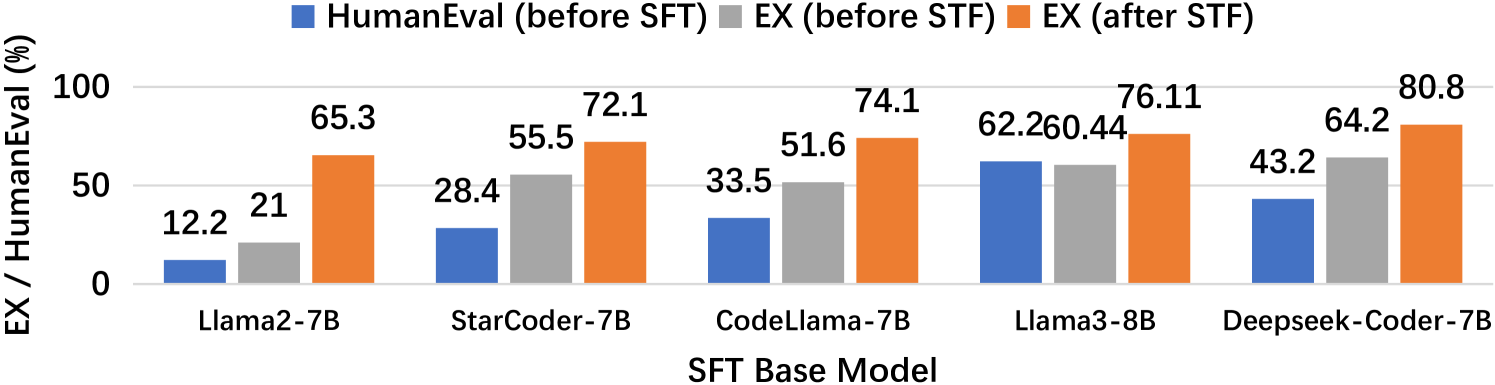
Exp-5:基于 LLM 的方法的监督微调。我们研究了开源大语言模型的监督微调(SFT)nl2sql 任务。 DAILSQL (Gao 等人, 2023) 检查 SFT 期间不同镜头和提示表示的影响,但没有解决 哪个开源大语言模型最适合nl2sql任务中的SFT。 DAILSQL发现SQL风格的提示是有益的,因此我们在零样本设置中采用了类似的提示方法,如图10所示。鉴于 nl2sql 是一项与代码相关的任务,我们选择了五个具有不同代码能力的开源大语言模型,使用 HumanEval (Pass@1) 指标(Chen 等人, 2021) 进行评估。 为了确保公平比较并考虑硬件限制,所有选择的大语言模型都具有相似的参数。 型号名称中的后缀,例如 7B,表示模型有 70 亿个参数。
设置。我们比较4.1节中介绍的5个基于微调的大语言模型。我们使用指令调整方法,即 羊驼(Taori 等人,2023)。 我们使用 Adam 优化器,学习率为 1e-5,并且没有权重衰减。 在训练结束时,学习率遵循余弦衰减为零。 我们在单个 epoch 中使用 16 的全局批量大小进行训练,以减轻过度拟合风险。 SFT 之后,使用 EX 指标在 Spider Dev 集上评估大语言模型。
结果。如图11,SFT 后,性能 (EX) 有所提高,但不同基础模型之间差异很大。 重要的是,在 SFT 之前观察到这些性能变化与模型的内在编码能力 (HumanEval) 之间存在正相关性。 这表明 选择具有高级编码能力的大语言基础模型有利于nl2sql任务的适配。
发现8. 对开源大语言模型的nl2sql任务进行有监督微调(SFT)后,我们发现SFT后的性能与SFT前模型固有的编码能力呈正相关。 这表明具有高级编码能力的基础大语言模型对于适应nl2sql任务非常重要。
4.3. 评估效率的实验
Exp-6:基于 LLM 的方法的经济性。基于提示的大语言模型方法利用商业GPT API接口来完成nl2sql 任务。 截至 2024 年 6 月,与 GPT-3.5-turbo 相比,GPT-4 的 API 接口对于输入 Token 来说要贵 60 倍,对于输出 Token 来说要贵 40 倍。 在实际应用中,我们关注的不仅仅是性能 NL2SQL 方法包括成本考虑。 在这个实验中,我们根据 Spider 和 BIRD 的开发集计算每个基于提示的方法的几个指标。 其中包括 Token 数量和每个 Token 的成本(以美元为单位) nl2sql 任务。如表5所示,我们还计算了EX与Average Cost的比率,这表明了nl2sql的成本效益> 某种程度上的方法。
尽管 C3SQL 在两个数据集上的 EX 得分最低,但其 EX 与平均成本之比最高,这得益于 GPT-3.5-turbo 接口的成本低于 GPT-4。 在使用 GPT-4 的方法中,DINSQL 的成本效益最低,而 DAILSQL 的成本效益最高。 尽管 DAILSQL(SC) 在两个数据集上都优于 DAILSQL,但它带来了更高的成本。
发现9. 根据执行准确率(EX)与每个nl2sql任务的平均成本的比率,我们观察到调用GPT-3.5-turbo的基于提示的大语言模型方法提供了更高的成本效益。 尽管 DAILSQL(SC) 在 Spider 和 BIRD 数据集上显示出相对于 DAILSQL 的 EX 改进,但它引入了更高的成本,降低了其成本效益。
| Methods | LLMs | Avg. Tokens / Query | Avg. Cost / Query | EX(%) | EX / Avg. Cost | ||||
| Spider | BIRD | Spider | BIRD | Spider | BIRD | Spider | BIRD | ||
| C3SQL | GPT-3.5 | 5702 | 5890 | 0.0103 | 0.0104 | 82.0 | 50.2 | 7961 | 4825 |
| DINSQL | GPT-4 | 9571 | - | 0.2988 | - | 82.8 | - | 277 | - |
| DAILSQL | GPT-4 | 930 | 1559 | 0.0288 | 0.0486 | 83.1 | 54.3 | 2885 | 1117 |
| DAILSQL(SC) | GPT-4 | 1063 | 1886 | 0.0377 | 0.0683 | 83.6 | 55.9 | 2218 | 819 |
| SuperSQL | GPT-4 | 942 | 1412 | 0.0354 | 0.0555 | 87.0 | 58.5 | 2458 | 1053 |
| Methods | Parameters | EX (%) |
|
|
||||
| RESDSQL-Base | 220M | 77.9 | 1.10 | 3.87 | ||||
| RESDSQL-Base + NatSQL | 220M | 80.2 | 1.01 | 3.59 | ||||
| RESDSQL-Large | 770M | 80.1 | 1.71 | 7.55 | ||||
| RESDSQL-Large + NatSQL | 770M | 81.9 | 1.57 | 6.83 | ||||
| RESDSQL-3B | 3B | 81.8 | 1.91 | 24.66 | ||||
| RESDSQL-3B + NatSQL | 3B | 84.1 | 1.97 | 21.59 |
| Types | Methods | Spider-Dev | |||||||||||||
| Easy | Medium | Hard | Extra | All | |||||||||||
| LLM-based | Prompting | C3SQL | 104.68 | 96.04 | 84.55 | 69.63 | 91.94 | ||||||||
| DINSQL | 102.99 | 97.49 | 84.05 | 67.81 | 91.78 | ||||||||||
| DAILSQL | 102.73 | 100.36 | 86.15 | 66.10 | 93.04 | ||||||||||
| DAILSQL(SC) | 103.86 | 102.73 | 86.40 | 71.59 | 95.25 | ||||||||||
| Fine-tuning | SFT CodeS-1B | 103.23 | 94.13 | 80.37 | 55.02 | 87.72 | |||||||||
| SFT CodeS-3B | 106.17 | 99.72 | 80.80 | 68.10 | 93.01 | ||||||||||
| SFT CodeS-7B | 108.77 | 102.90 | 84.05 | 73.42 | 96.41 | ||||||||||
| SFT CodeS-15B | 107.91 | 103.02 | 87.10 | 68.92 | 96.04 | ||||||||||
| PLM-based | RESDSQL-3B | 106.22 | 98.61 | 83.06 | 61.60 | 91.88 | |||||||||
| RESDSQL-3B + NatSQL | 106.91 | 97.98 | 86.78 | 73.83 | 94.36 | ||||||||||
| Graphix + PICARD | 108.92 | 102.71 | 83.64 | 68.61 | 95.51 | ||||||||||
| Hybird | SuperSQL | 107.54 |
|
|
|
|
|||||||||
| Types | Methods | BIRD-Dev | ||||||||
| Simple | Moderate | Challenging | All | |||||||
| LLM-based | Prompt- ing | C3SQL | 59.82 | 41.68 | 31.93 | 51.70 | ||||
| DAILSQL | 65.04 | 43.35 | 39.33 | 56.05 | ||||||
| DAILSQL(SC) | 66.54 | 46.14 | 45.18 | 58.35 | ||||||
| Fine-tuning | SFT CodeS-1B | 61.11 | 39.89 | 37.38 | 52.45 | |||||
| SFT CodeS-3B | 64.96 | 50.98 | 38.99 | 58.28 | ||||||
| SFT CodeS-7B | 66.88 | 49.53 | 58.42 | 60.83 | ||||||
| SFT CodeS-15B | 67.87 | 51.69 | 52.71 | 61.54 | ||||||
| PLM- based | RESDSQL-Base | 42.75 | 22.16 | 16.54 | 34.05 | |||||
| RESDSQL-Large | 47.21 | 30.00 | 34.67 | 40.81 | ||||||
| RESDSQL-3B | 53.35 | 35.49 | 28.84 | 45.64 | ||||||
| Hybird | SuperSQL |
|
50.55 | 49.08 |
|
|||||
Exp-7:基于 PLM 的方法的效率。在实际应用中,必须要兼顾性能和效率nl2sql 方法,包括每个样本的延迟。 不同的方法有不同的硬件要求,特别是 GPU 内存,它往往会随着模型大小的增加而增加。 选择合适的 NL2SQL 基于可用硬件资源和延迟要求的方法是一个常见的挑战。 我们评估了六个模型的三个指标:RESDSQL-Base/Large/3B 和 RESDSQL-Base/Large/3B + NatSQL,重点关注执行精度 (EX)、每个样本的延迟和使用的 GPU 内存,并利用 Spider 开发集进行评估。 请注意,由于模型效率与数据集无关,因此由于空间限制,我们省略了 BIRD 数据集上的实验。
表6 结果表明,随着模型参数大小的增加,同一方法所需的 GPU 内存和延迟也会增加。 然而,我们发现具有 220M 参数的 RESDSQL-Base+NatSQL 和具有 770M 参数的 RESDSQL-Large 实现了相似的 EX 分数(分别为 80.2% 和 80.1%),前者每个样本的延迟较低,并且需要更少的 GPU 内存。 将 RESDSQL-Large+NatSQL 与 RESDSQL-3B 进行比较时,可以得到类似的观察结果。 因此,尽管不同的型号可能具有相似的 EX 分数,但它们在延迟和硬件要求方面可能存在显着差异。 在实际场景中,应根据时延要求和可用的硬件资源来选择合适的模型。
找到10. 对于相同的方法,随着模型参数大小的增加,延迟和硬件资源需求也会相应增加。 此外,具有相似性能的模型在延迟和硬件资源要求方面可能有所不同。
Exp-8:SQL 效率 - 有效效率分数。在实际场景中,不仅仅关注sql的正确性至关重要 模型生成的查询还取决于其执行效率。 BIRD (Li 等人, 2023c)引入了有效效率分数(VES)来评估正确生成的执行效率 sql 查询。VES 分数是通过将地面实况sql查询的执行时间除以预测的sql查询的执行时间确定的。我们使用 VES 指标对 Spider 和 BIRD 的开发集上的不同方法进行了评估,以比较 sql 的执行效率。 通过不同的方法生成。
表7 报告实验结果。 最高的 VES 分数突出显示在 橙子 在表中。 在不同难度的子集上具有最佳 VES 的方法并不一致,并且基于 LLM 和基于 PLM 的方法之间没有明显的赢家。 对于相同的方法,它在更困难的子集上往往具有较低的 VES,可能是由于复杂性的增加 sqls 以及相关的预测挑战和执行时间。
发现 11. 根据 VES 指标,基于 LLM 的方法和基于 PLM 的方法之间没有明显的赢家。 对于相同的方法,在更困难的子集上往往具有较低的 VES。
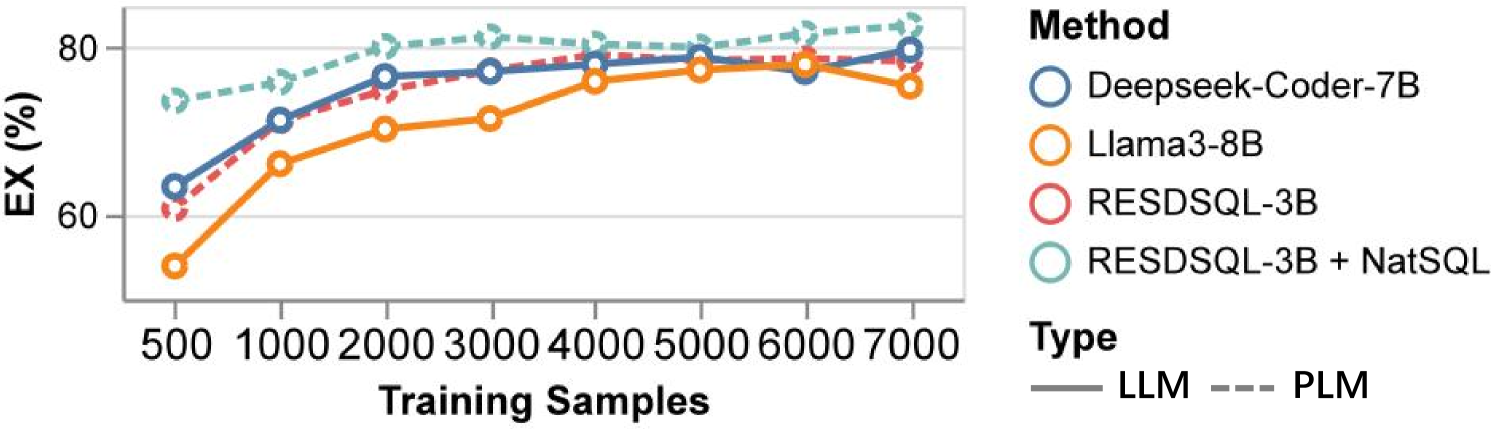
Exp-9:#-训练样本的影响。 在现实场景中,有限的域内数据通常会影响性能。 我们在 Spider 训练集上进行实验,随机采样大小增量为 1000 的子集,以及大小为 500 的较小子集。 在这些子集上训练不同的方法,并在 Spider 开发集上评估它们的 EX 性能。 RESDSQL-3B和RESDSQL-3B+NatSQL的训练超参数与(Li等人, 2023d)相同,其他方法与 Exp-5。
图12的结果表明,基于PLM的和微调的大语言模型方法都随着更多nl2sql的改进而改进> 训练数据并通过 4000 个训练样本达到可接受的性能。 然而,随着数据集大小的增加,EX 性能增益会降低。
发现12. 基于 PLM 和基于 LLM 的方法都可以通过更多的 nl2sql 数据来改进训练。 然而,随着数据集大小的增加,EX 性能增益会降低。 如果数据隐私是一个问题或者有足够的标记数据可用,那么微调大语言模型/PLM 是有希望的。
5. 结合两全其美
5.1. 设计空间探索
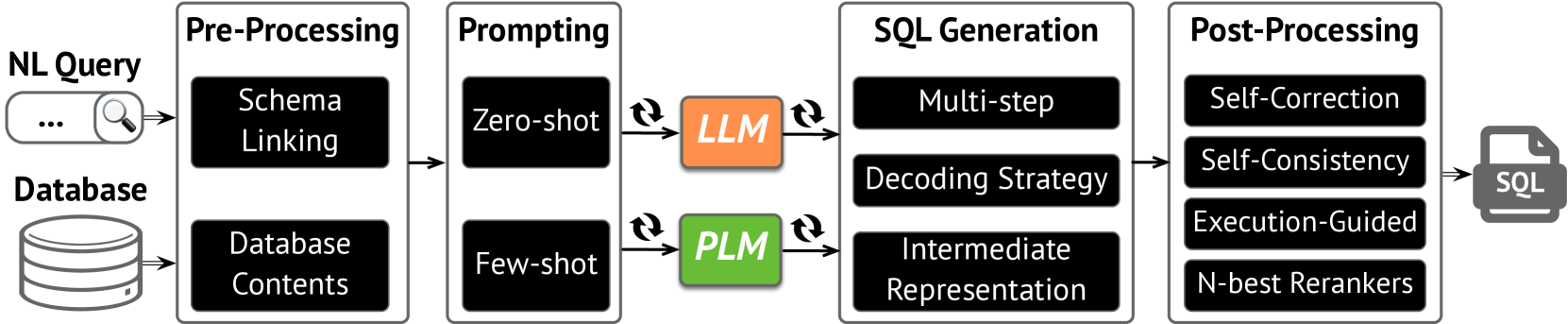
我们探索由语言模型支持的nl2sql解决方案的设计空间,如图13所示。
(1) 预处理:预处理模块包括模式链接和数据库内容。 模式链接图 NL 对数据库模式元素(表、列)的查询引用,增强跨域通用性和复杂查询生成(雷等人,2020)。 这种方法被领先的基于 LLM 的(Dong 等人,2023;Pourreza 和 Rafiei,2023) 和基于 PLM 的方法(Li 等人,2023d,b) 采用。 此外,数据库内容模块将查询条件与数据库内容对齐,通常通过字符串匹配(Lin等人,2020)来丰富列详细信息。 详见表 1,虽然在基于 PLM 的方法中很流行,但很少在基于 LLM 的方法中使用。
(2) 提示策略:提示策略属于零样本,其中没有nl2sql 示例包含在模型输入中,并且包含此类示例的少样本,根据使用的示例数量表示为“3-shot”、“5-shot”等。 桌子 1 显示基于 PLM 的方法通常使用零样本,而基于 LLM 的方法则有所不同:C3SQL (Dong 等人, 2023) 使用零样本,而 DAILSQL(Gao 等人, 2023) 使用零样本t1> 和 DINSQL(Pourreza 和 Rafiei,2023) 使用少量样本。 DINSQL 的少样本示例是手动设计和固定的,而 DAILSQL 的少样本示例是根据目标问题和训练集示例之间的相似性动态选择的。
(3) SQL生成策略:语言模型采用各种策略来生成sql,分为三个关键方面:多步骤、解码策略和中间表示。
(a) 多步骤 类似于思想链 (COT) 过程,涉及分阶段生成 SQL 查询,对于复杂查询特别有用(Wei 等人,2022)。 我们包括两种类型的多步骤策略:“sql骨架 - sql”来自基于 PLM 的 RESDSQL (Li 等人, 2023d) 和“子查询 - sql”来自 DINSQL (Pourreza 和 Rafiei,2023)。
(b) 解码策略 涉及模型的解码过程以确保输出的有效性。 基于 PLM 的 PICARD (Scholak 等人, 2021) 强制执行 sql 其输出中的语法合规性,而基于 LLM 的方法,利用 OpenAI 的 API,缺乏这种解码级别的限制。
(c) 中间表示策略探索模型是否采用中间查询形式将自然语言处理为sql 翻译的不匹配问题,其中sql关系数据库的设计并不与自然语言语义直接相关。 已经推出了(Guo等人,2019)和NatSQL(Gan等人,2021)等各种解决方案。 如表所示 1、基于 LLM 的 DINSQL 等模型(Pourreza 和 Rafiei,2023) 和几种基于 PLM 的方法(Li 等人,2023d;Rai 等人,2023;Gan 等人,2021) 采用 NatSQL。 在我们的设置中,我们仅包含 NatSQL 以进行简化。
(4) 后处理:我们考虑以下策略。
(a) 自我修正 是在 DINSQL (Pourreza 和 Rafiei,2023) 中提出的。 它提供了生成的 sql 修复潜在问题的模型。
(b) 自一致性涉及对单个执行各种有效的sql查询nl查询,对结果使用投票机制来确定最一致的sql 作为最终的选择。 用于 C3SQL (Dong 等人, 2023) 和 DAILSQL (Gao 等人, 2023)。
(c) 执行引导的 SQL 选择器 是一个模块 (Li 等人, 2023d),它顺序执行模型生成的 SQL 查询,将第一个无错误的执行识别为有效的 SQL。
(d) N个最佳重新排序对多个候选排序sql 查询以选择最可能的一个作为最终查询(Zeng 等人, 2023)。
5.2. NL2SQL360 促进更好的 NL2SQL
将不同的方法分类到统一的模块化框架中后,很明显不同的方法使用或提出新的模块(仍在我们的统一工作流程中)来增强nl2sql的性能 解决方案。 这就提出了一个问题: 是否可以通过组合来自不同nl2sql系统的不同模块来获得更强的性能?
为了解决这个问题,受神经架构搜索(NAS)算法(Xie and Yuille,2017)的启发,我们设计了一个 nl2sql自动架构搜索算法(NL2SQL360-AAS)在我们的 NL2SQL360 框架内。 背后的关键直觉 NL2SQL360-AAS是自动探索即预定义搜索空间) >nl2sql 解决方案。 因此,我们采用标准遗传算法(GA)(Alam等人,2020)来实现这一目标。
有一些与我们的 NL2SQL360-AAS 相关的关键概念。
(1) 搜索空间。这包括nl2sql中使用的各种模块,例如sql生成策略、后处理模块、以及提示技巧,如图13。
(2) 个人。搜索空间中不同模块的有效组合,即即有效的nl2sql解决方案是一个个人。
(3) 目标指标。 我们的目标是根据指定数据集上的执行准确性 (EX)、精确匹配准确性 (EM) 和有效效率得分 (VES) 等目标指标来选择更好的个体。
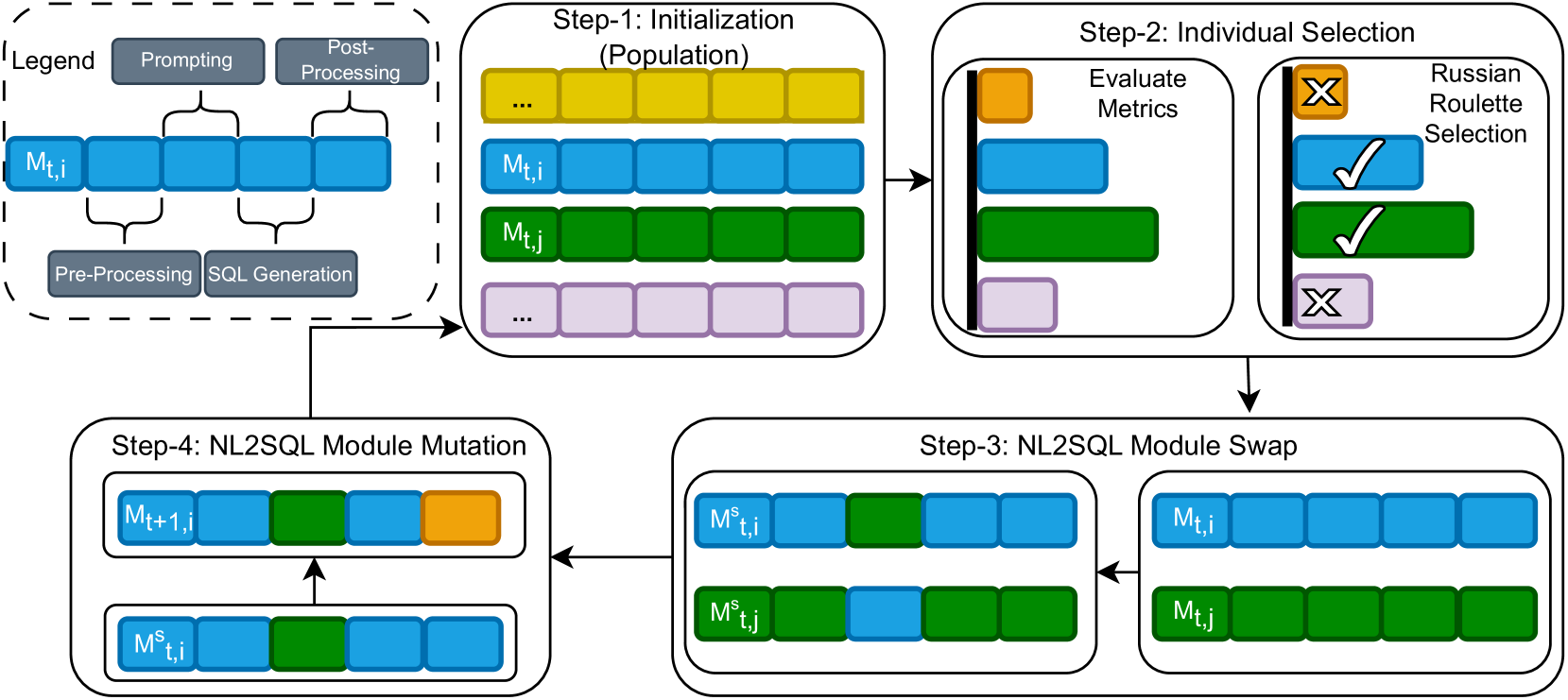
NL2SQL360-AAS:概述。如图14所示,我们的算法由四个主要步骤组成,即初始化、个体化选择、nl2sql模块交换和nl2sql 模块突变。 注意, 是 中的第 个个体第 代人口。
步骤 1:初始化。我们初始化随机nl2sql系统个体 由随机模块组成,如图13,结果为第 代人口。
步骤 2:个人选择。我们使用目标指标评估指定数据集(例如蜘蛛)上的个体的种群(例如 EX)。我们实现了俄罗斯轮盘赌流程 (Xie 和 Yuille,2017) 用于个人选择。 此过程根据目标指标分布对个体进行概率抽样,确保目标指标较高的个体被选中的可能性更大,同时不断淘汰表现最差的人员。
步骤 3:nl2sql 模块交换。从上一步中选择的两个个体将根据模块交换概率交换他们的nl2sql模块。例如,如果个人 有自我纠正模块,并且个人 在交换之前的后处理层中有一个自一致性模块,这两个模块可以交换。 图中 14,模块交换后的个体被标记为和, 分别。
步骤 4:nl2sql 模块突变。 接下来,个体(类似)将在每一层中进行模块突变( 例如,预处理层)基于模块突变概率。例如,如果预处理层为 不使用 DB Contents 模块,成功的突变将导致包含该模块。 突变后,个体被标记为 并将进入下一代人口。 我们重复步骤2、3和4,直到获得完整的下一代种群 ,标记整个种群迭代。
5.3. NL2SQL360-AAS 案例研究

在本节中,我们验证NL2SQL360-AAS算法的有效性。搜索空间定义如图13. 请注意,为了简化,我们在提示策略中仅使用 DAILSQL 中的少样本模块。 此外,由于我们使用 GPT 作为主干,我们无法控制模型的解码行为,因此我们在解码策略中仅采用贪婪搜索。 我们使用Spider开发集作为目标数据集,以执行精度(EX)作为目标 nl2sql度量。种群大小设为 10,种群代数设为 20,nl2sql模块交换和nl2sql模块突变的概率、和设为 0。,分别设置为 0.5 和 0.2。 为了节省成本,我们使用 GPT-3.5-turbo 作为骨干模型。
SuperSQL。 因此,从算法产生的最终生成中,我们选择执行精度最高的个体作为我们最终搜索的nl2sql解决方案,即SuperSQL。我们发现SuperSQL的组成 如下:(1)在预处理层,利用RESDSQL的Schema Linking模块和BRIDGE v2的DB Contents模块; (2)在Prompting层,它使用DAILSQL的少样本模块,根据相似度动态选择上下文中的示例; (3)在SQL Generation层,使用OpenAI默认的Greedy-decoding策略,不包括Multi-step或NatSQL中间表示; (4)在Post-Processing层,融合了DAILSQL的Self-Consistency模块。 我们探索了这篇作文的提示组织,如图所示 15. 在这种组合下,基于DAILSQL提示,使用RESDSQL模式链接模块过滤掉不相关的模式项。 此外,它还结合了 BRIDGE v2 方法中的 DB 内容模块,采用字符串匹配算法来匹配 NL 查询数据库中的内容。 然后在提示中相应栏目后面添加相关内容作为注释,从而丰富栏目信息。 然后,我们用 GPT-4 替换主干模型以获得更强大的性能。
从NL2SQL360-AAS生成的最终一代中,我们选择 EX 指标最高的个体作为最终 nl2sql解决方案,即SuperSQL。
SuperSQL 的有效性。 我们在 Spider 开发集上评估 SuperSQL,在 EX 中达到 87.0%,优于其他竞争方法(表 3 )。对于不同硬度的sql查询,SuperSQL 在中、硬和超硬度级别子集中取得了最佳结果,证明了其有效性。 此外,在 BIRD 开发集上, SuperSQL 显示出具有竞争力的性能(表4)。
我们还评估SuperSQL 在 Spider 和 BIRD 测试集上。 SuperSQL在Spider测试集上达到87.0% EX,排名第二 排行榜上,在 BIRD 测试集上 EX 率为 62.66%,排名第九。 注意 超级SQL 超越其设计空间内的所有基线。 具体来说, SuperSQL 优于最强的基线—DAILSQL(SC) — 在 BIRD 测试集上的 EX 指标中提高了 5.25%。 这一改进主要归功于我们 NL2SQL360-AAS,根据不同基线有效搜索优质模块组合 在设计空间中。 我们期望包括更强大的 设计空间中的基线将通过NL2SQL360-AAS进一步增强我们的SuperSQL系统.
SuperSQL 的效率。我们计算VES指标来评估sql Spider 和 BIRD 开发集的效率。 根据表 7,SuperSQL 总体 VES 得分分别为 99.18 和 61.99,优于其他方法。
SuperSQL 的经济性。此外,我们考虑了我们方法的经济性,结果如表5所示. 与其他基于 GPT-4 的方法相比,我们的方法使用更少的 Token 和更低的成本,同时实现更高的 EX。
6. 研究机会
我们根据实验结果讨论研究机会。
使 NL2SQL 方法值得信赖。 当前方法可能会生成不正确的sql结果,这可能归因于:1)不明确且未指定nl 查询,2)不明确的数据库模式和脏内容,以及3)模式链接能力不足。
处理不明确和未指定的 nl 查询。 我们可以探索以下策略来缓解这些问题。 (i) 查询重写器旨在自动优化给定的nl 查询并确保其清晰。 (ii) 查询自动完成 通过建议与数据库良好匹配的候选标记来帮助制定用户查询。
解释 NL2SQL 解决方案。 (i) NL2SQL 调试器可以检测不正确的sql查询,并允许用户单步执行sql生成过程,识别错误或不匹配,并理解生成的sql背后的逻辑。 (ii) SQL和查询结果解释方法帮助用户了解生成的sql 并且查询结果满足他们的要求。
开发经济高效的 NL2SQL 方法。基于LLMnl2sql 方法很有前途,但就词符消耗而言成本高昂,影响成本和推理时间。 探索提高准确性同时尽量减少词符使用的方法至关重要。 具体来说,模块化的潜在好处 NL2SQL 解决方案和多代理框架正变得越来越清晰。 将大语言模型与这些方法相结合有可能优化准确性和效率,特别是对于复杂查询,同时节省标记。
自适应训练数据生成。nl2sql的有效性nl2sql 方法很大程度上取决于训练数据的质量和覆盖范围。 这些方法通常很难适应看不见的数据库。 一个有前途的研究方向是自动生成(nl,sql)基于模型评估反馈进行配对。 关键思想是我们动态合成(nl, sql) 对,解决了领域适应的挑战和对高质量、多样化训练数据的需求,通过利用从 nl2sql 获得的见解 绩效评估。
7. 结论
我们提出了一个多角度测试平台,命名为NL2SQL360,用于从不同角度评估nl2sql方法,比如处理各种特性的能力sql 和数据库域,以细粒度的方式。 我们利用了我们的 NL2SQL360 评估 13 个基于 LLM 和 7 个基于 PLM 的nl2sql 方法基于 2 个广泛使用的基准,改变 15 种设置并得出一组新发现。 此外,我们还利用了我们的 NL2SQL360 分析 nl2sql 解决方案的设计空间,并自动搜索最佳解决方案之一,名为 超级SQL,根据用户的具体需求量身定制。 我们新的 SuperSQL 交错基于 LLM 和基于 PLM 的模块,实现了 87% 和 62.66% 分别在 Spider 和 BIRD 测试集上的执行准确性。
参考
- (1)
- tab ([n.d.]) [n.d.]. TABLEAU SOFTWARE, LLC, A SALESFORCE COMPANY. https://www.tableau.com/. Accessed: 2024-2-22.
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
- AI@Meta (2024) AI@Meta. 2024. Llama 3 Model Card. (2024). https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md
- Alam et al. (2020) Tanweer Alam, Shamimul Qamar, Amit Dixit, and Mohamed Benaida. 2020. Genetic Algorithm: Reviews, Implementations, and Applications. CoRR abs/2007.12673 (2020). arXiv:2007.12673 https://arxiv.org/abs/2007.12673
- Chang et al. (2023) Shuaichen Chang, Jun Wang, Mingwen Dong, Lin Pan, Henghui Zhu, Alexander Hanbo Li, Wuwei Lan, Sheng Zhang, Jiarong Jiang, Joseph Lilien, Steve Ash, William Yang Wang, Zhiguo Wang, Vittorio Castelli, Patrick Ng, and Bing Xiang. 2023. Dr.Spider: A Diagnostic Evaluation Benchmark towards Text-to-SQL Robustness. In ICLR. OpenReview.net.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating Large Language Models Trained on Code. CoRR abs/2107.03374 (2021). arXiv:2107.03374 https://arxiv.org/abs/2107.03374
- Chen et al. (2023) Ziru Chen, Shijie Chen, Michael White, Raymond J. Mooney, Ali Payani, Jayanth Srinivasa, Yu Su, and Huan Sun. 2023. Text-to-SQL Error Correction with Language Models of Code. In ACL (2). Association for Computational Linguistics, 1359–1372.
- Cheng et al. (2017) Jianpeng Cheng, Siva Reddy, Vijay Saraswat, and Mirella Lapata. 2017. Learning structured natural language representations for semantic parsing. arXiv preprint arXiv:1704.08387 (2017).
- Deng et al. (2021) Xiang Deng, Ahmed Hassan Awadallah, Christopher Meek, Oleksandr Polozov, Huan Sun, and Matthew Richardson. 2021. Structure-Grounded Pretraining for Text-to-SQL. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tür, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou (Eds.). Association for Computational Linguistics, 1337–1350. https://doi.org/10.18653/V1/2021.NAACL-MAIN.105
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Dong et al. (2023) Xuemei Dong, Chao Zhang, Yuhang Ge, Yuren Mao, Yunjun Gao, Jinshu Lin, Dongfang Lou, et al. 2023. C3: Zero-shot Text-to-SQL with ChatGPT. arXiv preprint arXiv:2307.07306 (2023).
- Gan et al. (2021) Yujian Gan, Xinyun Chen, Jinxia Xie, Matthew Purver, John R Woodward, John Drake, and Qiaofu Zhang. 2021. Natural SQL: Making SQL easier to infer from natural language specifications. arXiv preprint arXiv:2109.05153 (2021).
- Gao et al. (2023) Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2023. Text-to-sql empowered by large language models: A benchmark evaluation. arXiv preprint arXiv:2308.15363 (2023).
- Gkini et al. (2021) Orest Gkini, Theofilos Belmpas, Georgia Koutrika, and Yannis E. Ioannidis. 2021. An In-Depth Benchmarking of Text-to-SQL Systems. In SIGMOD Conference. ACM, 632–644.
- Gu et al. (2023) Zihui Gu, Ju Fan, Nan Tang, Lei Cao, Bowen Jia, Sam Madden, and Xiaoyong Du. 2023. Few-shot Text-to-SQL Translation using Structure and Content Prompt Learning. Proc. ACM Manag. Data 1, 2 (2023), 147:1–147:28.
- Guo et al. (2024) Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence. CoRR abs/2401.14196 (2024). https://doi.org/10.48550/ARXIV.2401.14196 arXiv:2401.14196
- Guo et al. (2019) Jiaqi Guo, Zecheng Zhan, Yan Gao, Yan Xiao, Jian-Guang Lou, Ting Liu, and Dongmei Zhang. 2019. Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation. CoRR abs/1905.08205 (2019). arXiv:1905.08205 http://arxiv.org/abs/1905.08205
- Katsogiannis-Meimarakis and Koutrika (2021) George Katsogiannis-Meimarakis and Georgia Koutrika. 2021. A Deep Dive into Deep Learning Approaches for Text-to-SQL Systems. In SIGMOD Conference. ACM, 2846–2851.
- Katsogiannis-Meimarakis and Koutrika (2023) George Katsogiannis-Meimarakis and Georgia Koutrika. 2023. A survey on deep learning approaches for text-to-SQL. VLDB J. 32, 4 (2023), 905–936.
- Lee et al. (2021) Chia-Hsuan Lee, Oleksandr Polozov, and Matthew Richardson. 2021. KaggleDBQA: Realistic Evaluation of Text-to-SQL Parsers. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (Eds.). Association for Computational Linguistics, 2261–2273. https://doi.org/10.18653/V1/2021.ACL-LONG.176
- Lei et al. (2020) Wenqiang Lei, Weixin Wang, Zhixin Ma, Tian Gan, Wei Lu, Min-Yen Kan, and Tat-Seng Chua. 2020. Re-examining the Role of Schema Linking in Text-to-SQL. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Linguistics, Online, 6943–6954. https://doi.org/10.18653/v1/2020.emnlp-main.564
- Lewis et al. (2019) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2019. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv:1910.13461 [cs.CL]
- Li and Jagadish (2014) Fei Li and Hosagrahar V Jagadish. 2014. NaLIR: an interactive natural language interface for querying relational databases. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD ’14). Association for Computing Machinery, New York, NY, USA, 709–712. https://doi.org/10.1145/2588555.2594519
- Li et al. (2023d) Haoyang Li, Jing Zhang, Cuiping Li, and Hong Chen. 2023d. RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL. arXiv:2302.05965 [cs.CL]
- Li et al. (2024) Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, and Hong Chen. 2024. CodeS: Towards Building Open-source Language Models for Text-to-SQL. CoRR abs/2402.16347 (2024). https://doi.org/10.48550/ARXIV.2402.16347 arXiv:2402.16347
- Li et al. (2023b) Jinyang Li, Binyuan Hui, Reynold Cheng, Bowen Qin, Chenhao Ma, Nan Huo, Fei Huang, Wenyu Du, Luo Si, and Yongbin Li. 2023b. Graphix-t5: Mixing pre-trained transformers with graph-aware layers for text-to-sql parsing. arXiv preprint arXiv:2301.07507 (2023).
- Li et al. (2023c) Jinyang Li, Binyuan Hui, Ge Qu, Binhua Li, Jiaxi Yang, Bowen Li, Bailin Wang, Bowen Qin, Rongyu Cao, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin Chen-Chuan Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023c. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. CoRR abs/2305.03111 (2023). https://doi.org/10.48550/ARXIV.2305.03111 arXiv:2305.03111
- Li et al. (2023a) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Logesh Kumar Umapathi, Jian Zhu, Benjamin Lipkin, Muhtasham Oblokulov, Zhiruo Wang, Rudra Murthy V, Jason Stillerman, Siva Sankalp Patel, Dmitry Abulkhanov, Marco Zocca, Manan Dey, Zhihan Zhang, Nour Moustafa-Fahmy, Urvashi Bhattacharyya, Wenhao Yu, Swayam Singh, Sasha Luccioni, Paulo Villegas, Maxim Kunakov, Fedor Zhdanov, Manuel Romero, Tony Lee, Nadav Timor, Jennifer Ding, Claire Schlesinger, Hailey Schoelkopf, Jan Ebert, Tri Dao, Mayank Mishra, Alex Gu, Jennifer Robinson, Carolyn Jane Anderson, Brendan Dolan-Gavitt, Danish Contractor, Siva Reddy, Daniel Fried, Dzmitry Bahdanau, Yacine Jernite, Carlos Muñoz Ferrandis, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries. 2023a. StarCoder: may the source be with you! CoRR abs/2305.06161 (2023). https://doi.org/10.48550/ARXIV.2305.06161 arXiv:2305.06161
- Lin et al. (2020) Xi Victoria Lin, Richard Socher, and Caiming Xiong. 2020. Bridging textual and tabular data for cross-domain text-to-sql semantic parsing. arXiv preprint arXiv:2012.12627 (2020).
- Liu et al. (2022) Aiwei Liu, Xuming Hu, Li Lin, and Lijie Wen. 2022. Semantic Enhanced Text-to-SQL Parsing via Iteratively Learning Schema Linking Graph. In KDD. ACM, 1021–1030.
- Minaee et al. (2024) Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. 2024. Large Language Models: A Survey. arXiv:2402.06196 [cs.CL]
- OpenAI et al. (2024) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Jan Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David Mély, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O’Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr H. Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine B. Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cerón Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, CJ Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. 2024. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
- Pourreza and Rafiei (2023) Mohammadreza Pourreza and Davood Rafiei. 2023. Din-sql: Decomposed in-context learning of text-to-sql with self-correction. arXiv preprint arXiv:2304.11015 (2023).
- Qi et al. (2022) Jiexing Qi, Jingyao Tang, Ziwei He, Xiangpeng Wan, Yu Cheng, Chenghu Zhou, Xinbing Wang, Quanshi Zhang, and Zhouhan Lin. 2022. Rasat: Integrating relational structures into pretrained seq2seq model for text-to-sql. arXiv preprint arXiv:2205.06983 (2022).
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research 21, 1 (2020), 5485–5551.
- Rai et al. (2023) Daking Rai, Bailin Wang, Yilun Zhou, and Ziyu Yao. 2023. Improving Generalization in Language Model-Based Text-to-SQL Semantic Parsing: Two Simple Semantic Boundary-Based Techniques. arXiv preprint arXiv:2305.17378 (2023).
- Rajkumar et al. (2022) Nitarshan Rajkumar, Raymond Li, and Dzmitry Bahdanau. 2022. Evaluating the Text-to-SQL Capabilities of Large Language Models. CoRR abs/2204.00498 (2022).
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, and Gabriel Synnaeve. 2023. Code Llama: Open Foundation Models for Code. CoRR abs/2308.12950 (2023). https://doi.org/10.48550/ARXIV.2308.12950 arXiv:2308.12950
- Scholak et al. (2021) Torsten Scholak, Nathan Schucher, and Dzmitry Bahdanau. 2021. PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models. arXiv:2109.05093 [cs.CL]
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023. Llama 2: Open Foundation and Fine-Tuned Chat Models. CoRR abs/2307.09288 (2023). https://doi.org/10.48550/ARXIV.2307.09288 arXiv:2307.09288
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Wang et al. (2023) Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Qian-Wen Zhang, Zhao Yan, and Zhoujun Li. 2023. MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL. CoRR abs/2312.11242 (2023). https://doi.org/10.48550/ARXIV.2312.11242 arXiv:2312.11242
- Wang et al. (2022) Lihan Wang, Bowen Qin, Binyuan Hui, Bowen Li, Min Yang, Bailin Wang, Binhua Li, Jian Sun, Fei Huang, Luo Si, and Yongbin Li. 2022. Proton: Probing Schema Linking Information from Pre-trained Language Models for Text-to-SQL Parsing. In KDD. ACM, 1889–1898.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, Quoc Le, and Denny Zhou. 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models. CoRR abs/2201.11903 (2022). arXiv:2201.11903 https://arxiv.org/abs/2201.11903
- Xiao et al. (2016) Chunyang Xiao, Marc Dymetman, and Claire Gardent. 2016. Sequence-based structured prediction for semantic parsing. In Annual meeting of the Association for Computational Linguistics (ACL). 1341–1350.
- Xie and Yuille (2017) Lingxi Xie and Alan L. Yuille. 2017. Genetic CNN. CoRR abs/1703.01513 (2017). arXiv:1703.01513 http://arxiv.org/abs/1703.01513
- Yu et al. (2018) Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir R. Radev. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In EMNLP. Association for Computational Linguistics, 3911–3921.
- Zeng et al. (2023) Lu Zeng, Sree Hari Krishnan Parthasarathi, and Dilek Hakkani-Tur. 2023. N-best hypotheses reranking for text-to-sql systems. In 2022 IEEE Spoken Language Technology Workshop (SLT). IEEE, 663–670.
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2023. A Survey of Large Language Models. arXiv:2303.18223 [cs.CL]
- Zhao et al. (2022) Yiyun Zhao, Jiarong Jiang, Yiqun Hu, Wuwei Lan, Henry Zhu, Anuj Chauhan, Alexander Li, Lin Pan, Jun Wang, Chung-Wei Hang, et al. 2022. Importance of synthesizing high-quality data for text-to-sql parsing. arXiv preprint arXiv:2212.08785 (2022).
- Zhong et al. (2017) Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2sql: Generating structured queries from natural language using reinforcement learning. arXiv preprint arXiv:1709.00103 (2017).