使用多模态知识图进行多模态推理
摘要
使用大语言模型(大语言模型)的多模态推理经常会出现幻觉以及大语言模型中存在缺陷或过时的知识。 一些方法试图通过采用文本知识图来缓解这些问题,但它们单一的知识模态限制了全面的跨模态理解。 在本文中,我们提出了多模态知识图谱的多模态推理(MR-MKG)方法,该方法利用多模态知识图谱(MMKG)学习跨模态的丰富语义知识,显着增强多模态推理能力大语言模型. 特别是,利用关系图注意网络对 MMKG 进行编码,并设计跨模态对齐模块来优化图像文本对齐。 构建基于 MMKG 的数据集,通过预训练为大语言模型配备多模态推理的初步专业知识。 值得注意的是,MR-MKG 在仅使用一小部分参数(大约是大语言模型参数大小的 2.25%)进行训练的情况下实现了卓越的性能。 多模态问答和多模态类比推理任务的实验结果表明,我们的MR-MKG方法优于以前最先进的模型。 ††脚注文本:*通讯作者。
使用多模态知识图进行多模态推理
Junlin Lee1 Yequan Wang2 Jing Li1∗ Min Zhang1 1Harbin Institute of Technology, Shenzhen, China 2Beijing Academy of Artificial Intelligence, Beijing, China leejunlin27@gmail.com tshwangyequan@gmail.com jingli.phd@hotmail.com zhangmin2021@hit.edu.cn
1简介
最近,大型语言模型(大语言模型)(Chen 等人,2020;Achiam 等人,2023)在各种 NLP 任务中展示了其优越性和鲁棒性(Zhang 等人, 2024b;罗宾逊等人,2023;张等人,2024)。 为了进一步释放大语言模型的潜力,研究人员(Wu 等人, 2023a; Huang 等人, 2023; Su 等人, 2022; Li 等人, 2023b)尝试赋予其多模态能力推理能力,以视觉大语言模型为例,如 BLIP-2 (Li 等人, 2023a)、MiniGPT-4 (Zhu 等人, 2023)、LLaVA (刘等人,2023)等 尽管这些模型在使用图像和文本进行推理方面取得了重大进展,但它们仍然容易产生幻觉 (Rohrbach 等人,2018;Jones 等人,2024),通常是由于信息不充分或过时造成的。

微调大型语言模型(大语言模型)以更新其知识库通常是一个耗时且成本高昂的过程。 正如 Wu 等人 2023c 所建议的另一种策略是利用知识图谱 (KG) 作为直接用必要知识增强大语言模型的手段。 尽管最近的努力Baek等人(2023);森等人 (2023); Kim 等人 (2023); Sun等人(2024)专注于使用文本知识图谱,其单一模态限制了大语言模型处理和推理多模态信息的能力(如图1a所示)。 这种限制导致我们考虑使用多模态知识图谱(MMKG)来代替文本知识图谱(见图1b)。
在本文中,我们提出了M多模态R推理与M多模态K知识Graphs (MR-MKG)方法,旨在通过学习MMKG来扩展大语言模型的多模态知识。 特别是,MR-MKG首先使用关系图注意网络(RGAT)Ishiwatari等人(2020)对检索到的MMKG进行编码,该网络生成能够捕获复杂的图形结构。 然后,设计知识和视觉适配器层来弥合跨模态差距,分别将知识节点和视觉嵌入映射到大语言模型的词嵌入。 最后,将知识节点、图像和文本的嵌入连接起来形成提示,然后转发到大语言模型以提供指导和说明。 此外,我们引入了一种新颖的跨模式对齐模块,通过 MMKG 内的匹配任务来优化图像文本对齐。 为了让模型具备多模态推理方面的初步专业知识,我们首先在定制的 MMKG 数据集上预训练 MR-MKG,该数据集是通过匹配每个 VQA Krishna 等人 (2017)< 构建的/t1> 具有相应 MMKG 的实例,源自其图像的场景图,包含回答问题的基本知识。
为了彻底评估我们的MR-MKG方法,我们对多模态问答Lu等人(2022)和多模态类比进行了全面的实验推理 Zhang 等人 (2022) 任务,涵盖各种大语言模型大小和训练配置。 实验结果证实,MR-MKG有效地处理和利用 MMKG 的知识进行多模态推理,优于之前最先进的模型,准确率提高了 1.95%,推理能力提高了 10.4%。点击率@1 指标。 重要的是,MR-MKG冻结了大语言模型和视觉编码器,只更新了一小部分参数,大约是大语言模型参数大小的2.25%。 总而言之,我们的主要贡献有三方面:
-
•
据我们所知,我们是第一个利用 MMKG 衍生的知识来研究扩展大语言模型的多模态推理能力的问题。
-
•
我们提出了MR-MKG方法,专门用于从MMKG中提取有价值的知识并将多模态信息无缝集成到大语言模型中。 此外,我们还开发了一个基于 MMKG 的数据集,用于初步增强多模态推理。
-
•
我们在两个多模态推理任务上广泛评估MR-MKG。 MR-MKG 以显着的优势实现了最先进的性能,优于最近的基线方法。
2相关工作
2.1多模态知识图谱
MMKG 的主要好处在于将附加模式集成到传统 KG 中。 通过将实体与相关图像或文本描述相关联,MMKG 为知识库带来了有价值的视觉和文本维度,从而增强了其处理复杂任务的能力。 例如,接近Xie等人(2017); Mousselly-Sergieh 等人 (2018) 将图像与知识图谱中的实体特征相结合,显着改进了知识图谱补全和三重分类等应用的实体表示。 Zhao and Wu 2023 介绍了一种通过使用 MMKG 来增强实体感知图像字幕的方法,其中 MMKG 将视觉对象与命名实体相关联,并捕获这些实体之间的关系。 在推荐系统领域,Sun 等人 2020 采用 MMKG,结合图像和文本等各种数据模态来增强项目表示。 我们的方法与这些现有解决方案的不同之处在于,它是使用 MMKG 为大语言模型配备多模态推理能力的开创性努力,而不是将 MMKG 集成到特定任务中。
2.2 知识增强大语言模型
虽然大语言模型受益于对大量文本语料库的大量预训练,但他们仍然面临着幻觉和依赖过时知识等问题,这阻碍了他们的推理能力。 因此,最近的研究Baek等人(2023);森等人 (2023);吴等人 (2023c); Mondal 等人 (2024) 致力于将知识直接纳入大语言模型提示中以缓解这些问题,从而消除重新训练大语言模型的需要。 Baek 等人 2023 从 KG 中提取相关三元组,并使用线性语言化技术将其转换为文本。 Wu 等人 2023c 开发了一种知识图谱到文本的方法来创建高质量的提示,通过将相关三元组转换为信息更丰富的知识文本来增强大语言模型在基于知识图谱的问答中的性能。 Tian 等人 2023 观察到,直接将知识图谱中的三元组输入大语言模型可能会由于知识图谱中不相关的上下文而引入噪声。 他们提出了一种图神经提示,能够从 KG 中提取有价值的知识,以便集成到预训练的大语言模型中。 Mondal 等人 2024 将来自基于文本的知识图谱的外部知识融入到多模态思维推理链中,使模型能够实现更深入的上下文理解。 然而,这些方法主要集中在文本知识图谱上,由于模态的固有差异,这可能会限制它们在多模态推理任务中的有效性。 为了解决这个问题,我们的目标是通过整合来自 MMKG 的额外多模态信息来增强多模态推理能力。
2.3 多模态大语言模型
纯文本大语言模型的能力无法满足不断发展的需求,导致大量的研究工作(Wu 等人, 2023a; Huang 等人, 2023; Su 等人, 2022; Koh 等人, 2023) 旨在开发精通处理多模式输入和任务的大语言模型。 当前研究趋势Wu 等人 (2023b); Zhu等人(2023)主要关注集成适配器或投影层,以将各种模态编码器的嵌入空间与大语言模型的文本嵌入空间对齐。 例如,流行的视觉大语言模型如 LLaVA (Liu 等人, 2023) 和 MiniGPT-4 (Zhu 等人, 2023) 通过冻结大语言模型来实现这一点并训练视觉投影来解释视觉数据。 这种方法在其他多模态大语言模型中得到了体现,包括听觉大语言模型 Zhang 等人 (2023a) 和视频大语言模型 Zhang 等人 (2023b)。 最近,PandaGPT Su 等人 (2023) 集成了多模态编码器 ImageBind Girdhar 等人 (2023),能够理解和处理六种不同的模态。 同样,NExT-GPT Wu 等人 (2023b) 展示了跨四种不同模式理解和生成内容的熟练程度。 然而,这些多模态大语言模型仍然容易产生幻觉。 虽然它们增强了模式之间的一致性,但它们不会获取新知识,并且可能会引入新的噪音。 我们的MR-MKG方法与上述方法的不同之处在于,MMKG的结合不仅为大语言模型提供了额外的相关信息,而且还有望减轻在转换和对齐过程中产生的噪声。多模态数据。
3方法
在本节中,我们首先概述MR-MKG,然后详细描述其架构设计和训练方法。
3.1MR-MKG概述
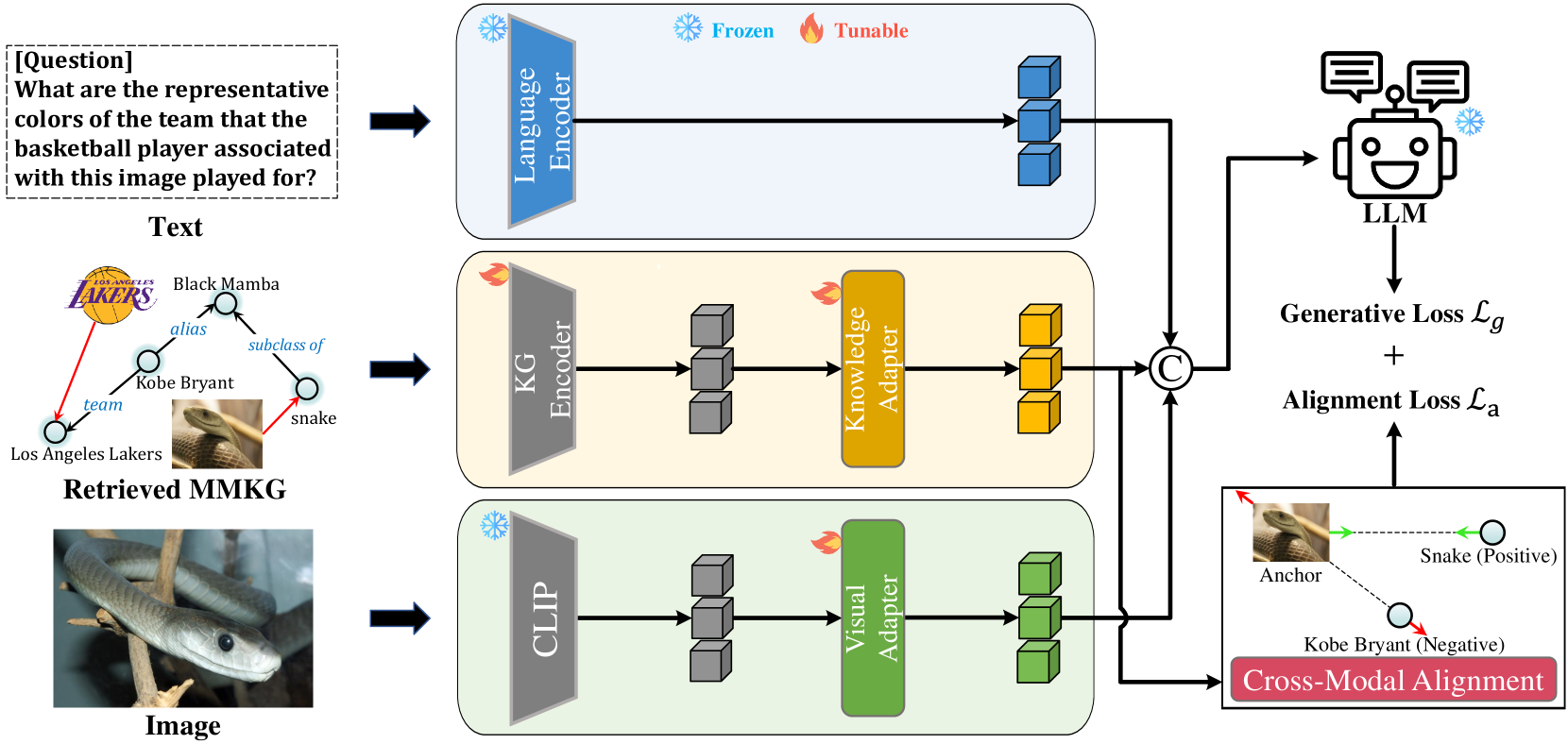
我们方法的主要目标是有效利用视觉编码器的功能和从 MMKG 衍生的多模态知识来增强大语言模型的多模态推理能力。 可视化工作流程如图2所示。 文本、多模态知识图和图像分别使用语言编码器、KG编码器和视觉编码器独立嵌入。 视觉和知识适配器旨在将视觉和知识图谱编码器的嵌入空间与大语言模型的文本嵌入空间对齐。 跨模式对齐模块专门设计用于通过利用 MMKG 中的匹配任务来改进图像文本对齐。
3.2MR-MKG架构
MR-MKG由五个组件组成:语言编码器、视觉编码器、KG编码器、知识适配器和跨模态对齐模块。
语言编码器。
我们采用 LLaMA 和 T5 等现成的大语言模型中的嵌入层作为语言编码器,在训练和推理阶段保持固定。 形式上,文本由语言编码器处理,产生文本嵌入。
视觉编码器。
对于输入图像,我们采用预先训练的视觉编码器,例如 CLIP Radford 等人 (2021),它将图像转换为视觉特征 。 为了确保视觉和语言空间之间的兼容性,使用线性层实现的视觉适配器将视觉特征转换为视觉语言嵌入,与大语言模型的词嵌入向量。 随后,利用单头注意力网络通过以下函数获得与文本嵌入相关的最终视觉特征:
| (1) |
| (2) |
其中表示的维度,表示可训练的视觉适配器矩阵。
公斤编码器。
给定文本或图像,MR-MKG 首先通过从 MMKG 中检索子图 来识别相关知识,该子图包含 Top- 最相关的三元组。 然而,检索到的子图也可能包含不相关的三元组,从而可能引入噪声。 因此,如果将所有这些三元组直接输入到提示中,噪声就会阻碍大语言模型有效处理基本知识的能力。 此外,顺序提示不能有效捕获 MMKG 中的结构关系。 因此,考虑到的复杂结构,我们采用关系图注意网络(RGAT)Ishiwatari等人(2020)来嵌入知识节点。 具体来说,我们首先使用 CLIP 来初始化节点和关系嵌入。 接下来,我们使用 RGAT 网络对 进行编码,生成知识节点嵌入 。 流程如下:
| (3) |
知识适配器。
为了使大语言模型能够理解多模态知识节点嵌入,我们引入了一个知识适配器,将 转换为大语言模型可以理解的文本嵌入。 该知识适配器旨在弥合多模式知识和文本之间的固有差距,促进更加无缝的结合。 具体来说,节点嵌入 通过以下方式映射到知识语言嵌入 :
| (4) |
| (5) |
其中 表示可训练的知识适配器矩阵, 对应于 或 ,具体取决于当前的具体场景。
跨模式对齐。
该模块涉及从 中随机选择一组图像实体,并提示模型将它们与相应的文本实体准确匹配。 与所选图像对应的知识节点嵌入表示为,其关联文本节点的嵌入表示为。 我们使用三元组损失 Schroff 等人 (2015) 进行对齐。 当一个图像实体的嵌入作为锚点时,其对应的文本实体嵌入作为正样本 。 同时,其他文本实体嵌入充当负样本。 对齐的目标是最小化正样本与锚样本之间的距离,同时最大化负样本与锚样本之间的距离。 对齐损失的定义如下:
| (6) |
其中表示欧氏距离,是选中的图像实体的数量,是一个常量,用于保证正数距离之间有一定的余量和反面例子。
3.3培训目标
自回归训练目标侧重于训练大语言模型以准确预测后续标记。 具体来说,我们通过以下方式计算生成目标答案的概率:
| (7) |
其中是目标答案的长度,是视觉嵌入、知识嵌入 和文本嵌入 。 表示适应参数。最终目标函数定义为和的组合:
| (8) |
其中是平衡两个损失的权衡权重。 MR-MKG 的训练分为两个阶段。 在第一阶段,模型接受预训练,以发展基础视觉能力并熟练地理解 MMKG。 第二阶段涉及将模型应用于需要高级多模态推理的特定场景。 值得注意的是,在这两个阶段中,大语言模型和视觉编码器的权重都保持不变。
4实验
4.1设置
评估数据集。
我们对多模态问答和多模态类比推理任务进行实验,即 ScienceQA 和 MARS。 有关更多详细信息,请参阅附录A.1。
-
•
科学QA。 该数据集是一个大规模多模态科学问答数据集Lu等人(2022),每个多项选择题都伴有文本或视觉上下文。 该数据集并非纯粹的多模态,只有 48.7% 的数据包含图像。
-
•
火星。 MARS Zhang 等人 (2022) 是一个新颖的数据集,旨在评估多模态知识图 MarKG 上的多模态类比推理。
多模态知识图。
理论上,任何知识丰富的 MMKG 都可以应用于多个基准测试。 然而,合适的 MMKG 将根据基准测试的领域而有所不同。 特别是,MMKG 与 ScienceQA 结合使用,而 MarKG 用于支持 MARS。 原因在附录A.2中给出。
-
•
MMKG。 该数据集 Liu 等人 (2019) 提取自 FreeBase Bordes 等人 (2013)、DBpedia Auer 等人 (2007) 和 YAGO Suchanek 等人 (2007) 分别。 每个实体都与来自 Google 的大约 36 个相应图像相关联。
-
•
MarKG。 MarKG Zhang 等人 (2022) 是一个多模态知识图谱数据集,由 E-KAR Chen 等人 (2022a) 和 BAT Gladkova 等中的种子实体和关系开发而成人(2016)。 它旨在支持MARS进行多模态类比推理,与MARS共享相同的实体和关系。
预训练设置。
我们提取每个数据实例的图像、QA 对和修改后的场景图,以构建基于 Visual Genome Krishna 等人 (2017) 的 MMKG 数据集进行预训练。 具体来说,原始场景图中的对象实体分别通过“图像”和“属性”关系链接到其对应的图像和属性。 附录A.3中提供了更多详细信息。 这个修改后的场景图用作预训练中的MMKG。
基线。
对于 ScienceQA,我们将我们的方法与四种基线进行比较,包括零和少样本 GPT 模型 Lu 等人 (2022)、SOTA 方法 MM-Cot Zhang 等人 (2023c) 、代表性的端到端多模态大语言模型LLaVA (Liu 等人, 2023),以及参数高效的方法如LLaMA-Adapter Zhang 等人(2024a) ) 和 LaVIN Luo 等人 (2023)。 对于 MARS,我们将我们的方法与两种基线进行比较,MKGE 方法如 IKRL Xie 等人 (2017)、TransAE Wang 等人 (2019) 和 RSME Wang 等人 (2021)、多模预训练 Transformer 模型(MPT)、VisualBERT Li 等人 (2019)、ViLT Kim 等人 (2021)、MKGformer Chen 等人 (2022b) 等。每个基线都经过 MarKG 的预训练,为其配备有关实体和关系的必要先验知识,以增强多模态推理。
执行。
我们选择 ViT-L/32 Radford 等人 (2021) 作为视觉编码器,并选择 RGAT 作为这两个数据集的知识嵌入模型。 在ScienceQA中,我们采用FLAN-T5 3B和FLAN-T5 11B (Chung 等人, 2022)作为大语言模型,并实现Multimodal-CoT提示方法Zhang 等人(2023c) 。 为了验证 MR-MKG 的通用性,还使用 FLAN-UL2 19B Chung 等人 (2022) 作为主干。 对于 MARS,选择 LLaMA-2 7B Touvron 等人 (2023) 来初始化我们的模型。 对于知识三元组检索,我们将三元组的数量设置为10或20,并且三元组检索的跳跃距离保持为1。 所有实验均在 NVIDIA 8A800-SXM4-80GB 机器上进行。 附录A.7提供了更多详细信息。
| Method | #T-Param | Subject | Context Modality | Grade | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | |||
| Human Lu et al. (2022) | - | 90.23 | 84.97 | 87.48 | 89.60 | 87.50 | 88.10 | 91.59 | 82.42 | 88.40 |
| GPT-3.5 (CoT) Lu et al. (2022) | - | 75.44 | 70.87 | 78.09 | 74.68 | 67.43 | 79.93 | 78.23 | 69.68 | 75.17 |
| GPT-4 Liu et al. (2023) | - | 84.06 | 73.45 | 87.36 | 81.87 | 70.75 | 90.73 | 84.69 | 79.10 | 82.69 |
| UnifiedQABase Lu et al. (2022) | 223M | 71.00 | 76.04 | 78.91 | 66.42 | 66.53 | 81.81 | 77.06 | 68.82 | 74.11 |
| UnifiedQABase(MM-CoT) Zhang et al. (2023c) | 223M | 87.52 | 77.17 | 85.82 | 87.88 | 82.90 | 86.83 | 84.65 | 85.37 | 84.91 |
| UnifiedQALarge(MM-CoT) Zhang et al. (2023c) | 738M | 95.91 | 82.00 | 90.82 | 95.26 | 88.80 | 92.89 | 92.44 | 90.31 | 91.68 |
| LLaVA Liu et al. (2023) | 13B | 90.36 | 95.95 | 88.00 | 89.49 | 88.00 | 90.66 | 90.93 | 90.90 | 90.92 |
| LLaMA-Adapter Zhang et al. (2024a) | 1.8M | 84.37 | 88.30 | 84.36 | 83.72 | 80.32 | 86.90 | 85.83 | 84.05 | 85.19 |
| LaVIN-7B Luo et al. (2023) | 3.8M | 89.25 | 94.94 | 85.24 | 88.51 | 87.46 | 88.08 | 90.16 | 88.07 | 89.41 |
| LaVIN-13B Luo et al. (2023) | 5.4M | 89.88 | 94.49 | 89.82 | 88.95 | 87.61 | 91.85 | 91.45 | 89.72 | 90.83 |
| MR-MKG (FLAN-T5-3B) | 77M | 90.67 | 85.38 | 86.45 | 90.96 | 87.46 | 87.39 | 90.27 | 85.23 | 88.47 |
| MR-MKG (FLAN-T5-11B) | 248M | 94.93 | 90.1 | 90.55 | 94.53 | 92.12 | 92.2 | 93.83 | 90.9 | 92.78 |
| MR-MKG (FLAN-UL2-19B) | 248M | 95.74 | 90.33 | 92.00 | 95.50 | 92.41 | 93.31 | 93.98 | 93.01 | 93.63 |
4.2 主要结果
多模式问答的结果。
表1报告了ScienceQA上的实验结果。 我们可以做出以下观察:
首先,我们的 MR-MKG 方法在平均准确度方面优于所有基线方法。 表的第二部分显示了零样本和少样本方法,即使应用于像 GPT 这样的流行大语言模型,仍然没有达到人类水平的性能。 值得注意的是,GPT-4 凭借其增强的多模态功能和更大的参数大小,比 GPT-3.5 显示出相当大的改进。 UnifiedQALarge(MM-CoT)虽然达到了之前的SOTA,但需要全参数训练,导致训练成本较高。 相比之下,MR-MKG只需要训练一小部分参数,仍然可以获得优异的结果。 例如,MR-MKG(FLAN-T5 3B)仅训练了 77M 个参数,但性能比 UnifiedQABase 提高了 3.56%,几乎达到了人类的性能。 MR-MKG (FLAN-T5 11B) 的可训练参数数量 (249M) 与 UnifiedQABase (223M) 相当,绝对提升了 7.87% 。 这表明我们的方法在性能和训练效率之间实现了更有利的平衡。
其次,虽然 LLaVA 在 SOC 类别中取得了最佳性能,但 MR-MKG 在所有其他类别中都超越了 LLaVA,平均精度增益为 +1.86%。 重要的是,我们的 MR-MKG 方法 (FLAN-T5-11B) 仅在 248M 个参数上进行训练,而 LLaVA 则在更大规模的 130 亿个参数上进行训练。 我们将此归因于 MR-MKG 利用从 MMKG 衍生的多模态知识,可以有效增强多模态推理。
| Method | Hits@1 | Hits@3 | Hits@5 | Hits@10 | MRR |
|---|---|---|---|---|---|
| IKRL Xie et al. (2017) | 0.266 | 0.294 | 0.301 | 0.310 | 0.283 |
| TransAE Wang et al. (2019) | 0.261 | 0.285 | 0.289 | 0.293 | 0.276 |
| RSME Wang et al. (2021) | 0.266 | 0.298 | 0.307 | 0.311 | 0.285 |
| MarT_VisualBERT Li et al. (2019) | 0.261 | 0.292 | 0.308 | 0.321 | 0.284 |
| MarT_ViLT Kim et al. (2021) | 0.245 | 0.275 | 0.287 | 0.303 | 0.266 |
| MarT_ViLBERT Lu et al. (2019) | 0.256 | 0.312 | 0.327 | 0.347 | 0.292 |
| MarT_FLAVA Singh et al. (2022) | 0.264 | 0.303 | 0.309 | 0.319 | 0.288 |
| MarT_MKGformer Chen et al. (2022b) | 0.301 | 0.367 | 0.380 | 0.408 | 0.341 |
| Visual_LLaMA-2 7B | 0.286 | 0.373 | 0.409 | 0.457 | 0.347 |
| MR-MKG (Visual_LLaMA-2 7B) | 0.405 | 0.465 | 0.497 | 0.531 | 0.449 |
第三,LLaMA-Adapter 和 LaVIN 代表了参数高效的训练方法,重点关注轻量级适配器来吸收不同的模态信息。 相比之下,MR-MKG (FLAN-T5-11B) 表现出明显优于这些模型的优势,分别实现了 7.59% 和 3.37% 的绝对改进。
| Settings | NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | Average |
|---|---|---|---|---|---|---|---|---|---|
| Visual_FLAN-T5-11B | 88.45 | 81.89 | 84.09 | 88.47 | 86.51 | 85.51 | 86.75 | 84.64 | 86.08(+0.00) |
| + KG | 93.78 | 88.64 | 89.55 | 93.35 | 90.47 | 91.08 | 92.77 | 89.65 | 91.74(+5.66) |
| + MMKG | 94.23 | 89.20 | 90.00 | 93.94 | 91.77 | 91.43 | 93.39 | 89.85 | 92.21(+6.13) |
| + Alignment | 94.40 | 89.54 | 90.09 | 94.18 | 91.98 | 91.50 | 93.32 | 90.38 | 92.36(+6.28) |
| + Pre-training | 94.93 | 90.10 | 90.55 | 94.53 | 92.12 | 92.20 | 93.83 | 90.90 | 92.78(+6.70) |
| Settings | Accuracy (%) on samples |
|---|---|
| Visual_FLAN-T5-11B | 86.59(+0.00) |
| + KG | 90.37(+3.78) |
| + MMKG | 91.78(+5.19) |
| + Alignment | 92.32(+5.73) |
第四,为了评估 MR-MKG 在不同骨干网络上的泛化能力,我们尝试了各种大小和类型的大语言模型。 表 1 中的结果表明,将 FLAN-T5 模型的参数从 3B 扩展到 13B 会带来显着的性能提升,具体来说提高了 +4.31%。 这表明较大的模型从我们的方法中受益更多。 然而,当主干模型及其参数都发生变化时,就像 FLAN-UL2-19B 一样,我们观察到了最先进的性能,尽管改进幅度相对较小。 这可能归因于训练参数数量的一致或在已经高度准确的模型中实现更高准确度改进的固有挑战。
多模态类比推理的结果。
为了进一步评估我们的MR-MKG方法的普遍性,我们将实验扩展到不同的任务,即多模态类比推理。 实验结果如表2所示,清楚地表明MR-MKG在MARS数据集上显着优于所有其他方法。 值得注意的是,多模态知识图嵌入方法和多模态预训练 Transformer 模型的性能具有相当的可比性,其中 MKGformer 凭借优越的性能脱颖而出。 相比之下,视觉 LLaMA-2 7B 模型在配备视觉适配器时,取得了与 MKGformer 相当的结果,尽管 Hits@1 分数略低,但在其他指标上显示出改进。
这强调了视觉适配器组件的有效性和精心设计。 值得注意的是,当使用 MR-MKG 进行增强时,视觉 LLaMA-2 7B 在 Hits@1 分数方面表现出 10.4% 的提高,同时其他指标也有显着改进。
| Settings | Hits@1 on MARS |
|---|---|
| Visual_LLaMA-2 7B | 0.286(+0.000) |
| + KG | 0.352(+0.066) |
| + MMKG | 0.381(+0.095) |
| + Alignment | 0.394(+0.108) |
4.3消融研究
为了了解 MR-MKG 方法中每个组件的影响,我们在 ScienceQA 上进行了消融研究。 如表3所示,每个组件都是独立添加的,并分析了它们各自的贡献。 表3中的结果清楚地说明了每个组件对增强多模态推理的有益效果。
最值得注意的是,包含从 KG 中提取的知识带来了最实质性的改进,性能提高了 5.66%。 这凸显了 KG 增强推理在该方法中的关键作用。 当结合 MMKG 的多模态知识时,性能进一步提高,从 91.74% 上升到 92.21%。 这表明多模态知识有效地用附加信息补充了推理过程。
在跨模态对齐模块中添加图像文本匹配任务使得准确率小幅提高至 92.36%,强调了其在完善大语言模型对跨模态信息的理解方面的实用性。 最后,在基于 MMKG 的数据集上对我们的模型进行预训练,平均准确率提高了 +0.42%,从而证明了预训练的优势。 总之,这些消融研究明显验证了 MR-MKG 方法中每个组件的有效性,显示了它们如何共同促进整体性能的提高。
| LLM | Method | ScienceQA |
|---|---|---|
| FLAN-T5-11B | Text-Only | 92.78 |
| Image-Only | 91.58 | |
| Text + Image | 92.03 |
| Model | Design | ScienceQA | MARS |
|---|---|---|---|
| FLAN-T5-11B /LLaMA-2 7B | GNN | 92.23 | 39.1 |
| GAT | 91.94 | 39.6 | |
| RGAT | 92.78 | 40.5 |
然而,我们观察到 MMKG 和跨模式对齐的影响相对较小。 这是因为 ScienceQA 主要是面向文本的。 作为 QA 数据集,其核心问题和选择以文本形式呈现,从而减少了需要视觉知识来回答的问题。 此外,ScienceQA 并不完全是多模态的,只有 48.7% 的数据包含图像,这进一步削弱了 MMKG 和跨模态对齐的真正有效性。 此外,当模型达到更高的准确度时,进一步提高准确度就变得具有挑战性,从而导致变化不太明显。
为了证明MMKG和跨模态比对的真正有效性,我们手动从ScienceQA中选择了1973个样本。 这些样本都包含图像,其主题是社会科学或自然科学。 我们假设这些样本需要视觉知识来推理答案。
表4显示了这些样本的额外消融研究结果。 我们可以观察到,使用 KG 使性能提高了 3.78%,使用 MMKG 使性能提高了 1.41%。 跨模式对齐的添加导致性能提高了 0.54%。 与原始消融研究中使用 MMKG (0.47%) 和跨模态对齐 (0.15%) 的改进相比,这些样本的性能提升 (1.41% 和 0.54%) 更为显着。 这证实了 MMKG 和跨模态对齐的真正有效性。
此外,我们还补充了MARS上的消融研究结果。 表5显示,当使用MMKG和跨模态对齐时,模型的性能显着提高(2.9%和1.3%)。 相对于使用 KG 的改进(6.6%),这些改进也很明显。 因此,当模型性能较低时,性能增益相对显着。 相反,当模型的性能已经很高时,提高性能就会变得更具挑战性。
4.4进一步分析
在本节中,我们定量研究各种架构选择的影响。
不同子图检索方法的影响。
实验结果如表6所示,表明纯文本检索策略最有效,其次是文本和图像组合策略,而纯图像方法产生的结果最差。 这种模式可以归因于 ScienceQA 数据集的特征。 这一发现强调了根据当前问题的具体性质调整检索策略的重要性,而不是仅仅依赖于一种特定的模式。
不同知识图嵌入方法的影响。
我们尝试了三种不同的 KGE 架构:GNN Scarselli 等人 (2008)、GAT Veličković 等人 (2017) 和 RGAT Ishiwatari 等人 (2020). 如表7所示,GNN 和 GAT 在这两个任务中的性能相当,尽管稍微落后于 RGAT。 值得注意的是,RGAT 在这两项任务中都表现出了最佳性能,突显了其作为广泛采用的 GNN 架构在图数据中显式建模关系的功效。
不同数量的知识三元组的影响。
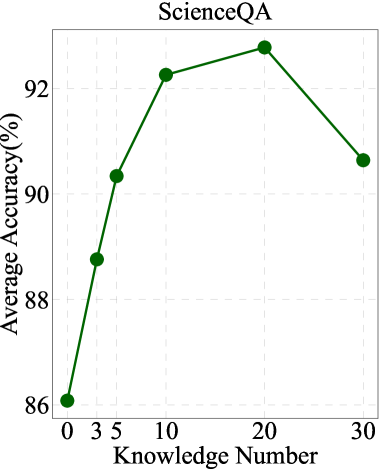
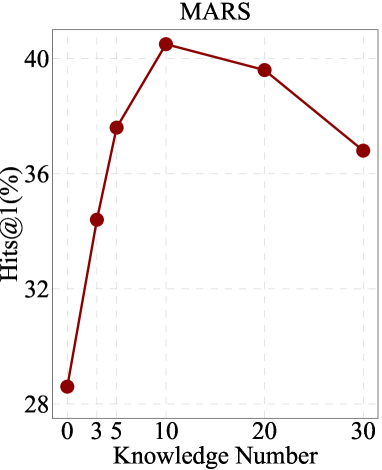
如图3所示,我们观察到随着三元组的数量从0增加到10,两个模型的性能都有成比例的提高。 然而,随着三胞胎的数量超过 20 至 30 个,出现了一个有趣的趋势。 在此范围内,我们注意到两种模型的性能均有所下降。 这种下降意味着 MMKG 中有用知识三元组的数量是有限的,过多的三元组可能会引入不相关的信息。
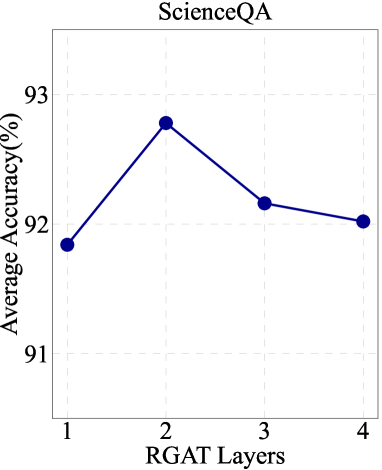
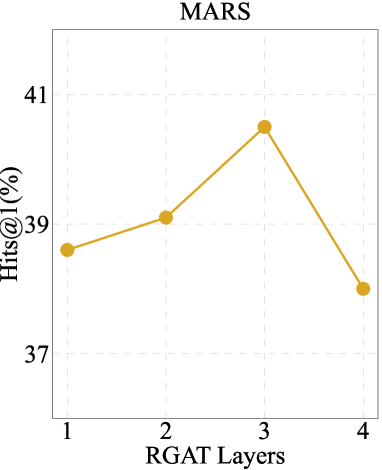
不同数量的 KGE 层的影响。
图 4 展示了我们对 RGAT 中不同层数影响的探索。 这一趋势表明,RGAT 层的适当堆叠可以对图结构的编码和知识的表示产生积极影响。
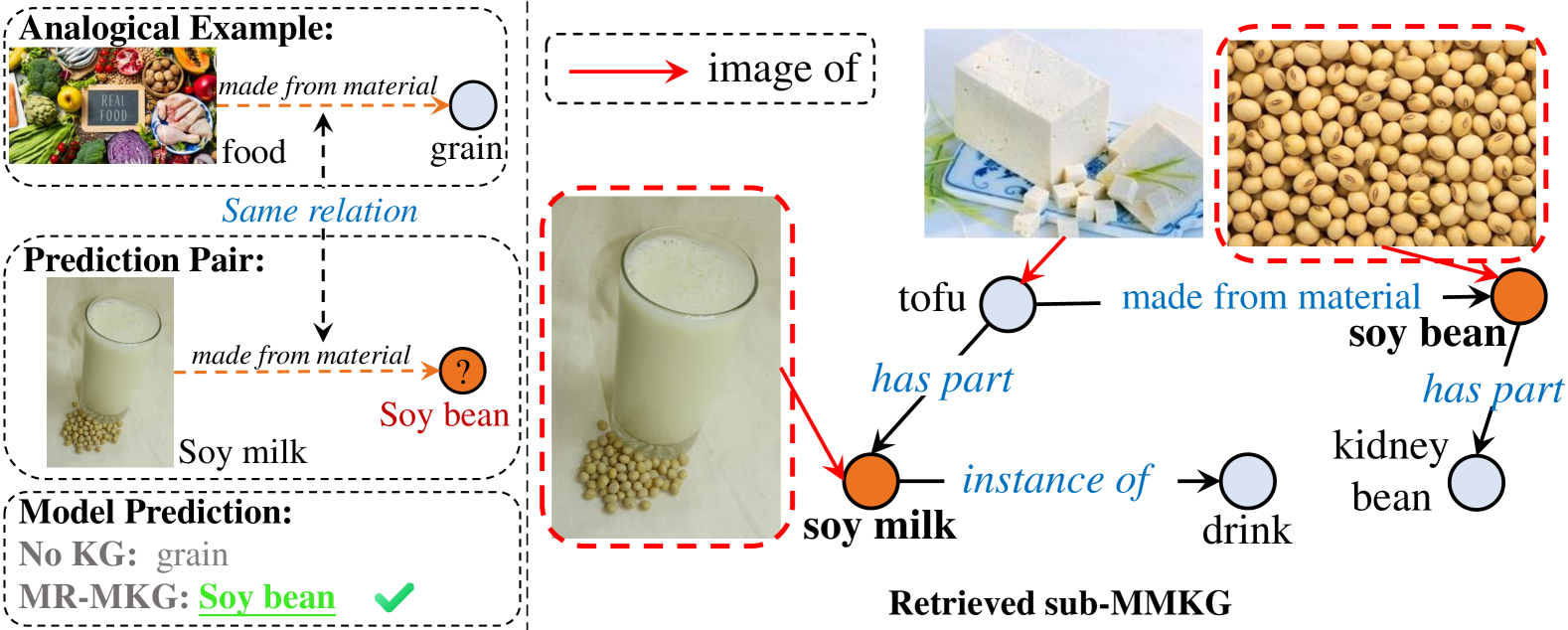
4.5定性分析
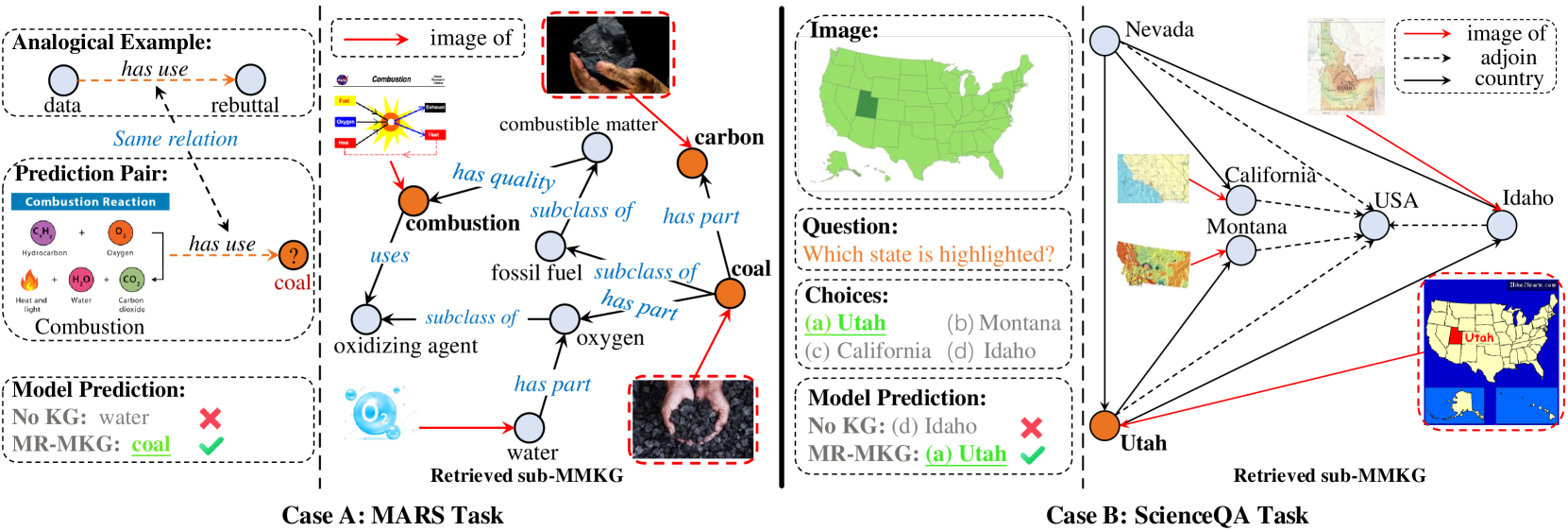
图5(以及附录中的图7和8)可视化每个任务检索到的子MMKG。 为了视觉清晰,我们仅显示相关实体和关系。 在 MARS 中,模型旨在根据燃烧图像和(数据,反驳)的示例来预测“煤”。 我们的 MR-MKG 方法从图像中识别并检索“燃烧”、“碳”、“水”和“氧气”等实体。 子MMKG提供了“燃烧”与“煤炭”之间的间接联系。 碳和煤炭图像之间的相似性指导模型正确预测“煤炭”,证明了 MMKG 多模态知识的关键作用。
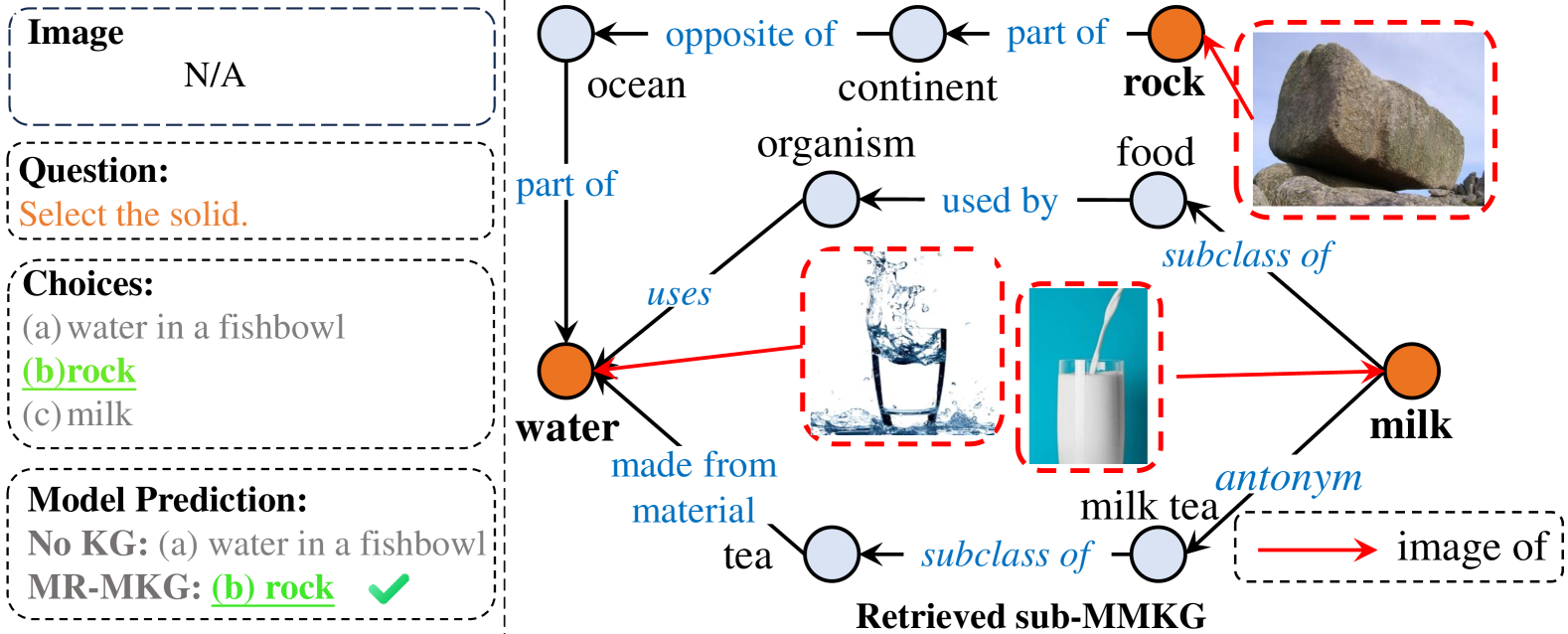
在 ScienceQA 示例中,问题是“哪个状态突出显示?”,模型必须识别这种状态的形状。 由于缺乏足够的内在知识,没有 KG 的模型无法准确地预测“Idaho”。 然而,在 MR-MKG 下检索到的子 MMKG 包含有关选项中不同州形状的关键信息,直接告知模型有关犹他州的形状。 这两个例子都证明了源自 MMKG 的多模态知识的有效性。
5结论
在本研究中,我们解决了通过使用多模态知识图来增强大语言模型的多模态推理能力的挑战。 我们提出的方法称为MR-MKG,旨在通过利用MMKG中包含的丰富知识(图像、文本和知识三元组)来赋予大语言模型先进的多模态推理技能。 对多模态问答和多模态类比推理任务的综合实验证明了我们的MR-MKG方法的有效性,实现了新的状态-这些任务的艺术结果。 此外,我们还进行了一系列消融研究、分析检查和案例研究,以提供额外的有效性证据。
致谢
这项工作得到了国家自然科学基金委员会(U23B2055)、深圳市高校稳定支持计划(GXWD20231128103232001)、广东省科技厅(2024A1515011540)、国家科技重大专项(2022ZD0116314)和国家自然科学基金委员会(62106249)的部分支持。
局限性
在本节中,我们忠实地讨论了我们希望在未来工作中改进的局限性。
首先,检索的子多模态知识图的有效性取决于所采用的知识检索策略的成功。 如果检索方案被证明无效或表现不佳,则可能无法获得所提出问题的相关知识。 这种缺陷直接降低了大语言模型产生准确响应的概率(有关此类错误的实例,请参阅附录中的图9和表6)。 因此,未来研究的一个关键方向是完善检索方案,以确保它能够提供多模态推理任务所必需的、更精确的知识。
其次,由于计算资源的限制,我们的评估仅限于两个多模态推理任务(ScienceQA 和 MARS)的四个大语言模型。 然而,仍有许多参数量较大的大语言模型,例如 LLaMA-2 70B Touvron 等人 (2023)。 因此,未来的工作之一是将我们的方法扩展到更大的模型尺寸,并评估其在更广泛的多模态推理任务上的性能。
道德考虑
由于知识检索能力有限以及可能出现错误或过时的知识,我们的MR-MKG方法的性能尚不完美。 我们的方法已在两个公开可用的数据集 ScienceQA 和 MARS 上进行了评估。 我们明确声称我们的方法和研究结果的适用性可能仅限于类似的数据集或领域。 我们的方法在其他特定数据集或领域上的性能仍然不确定。 因此,将我们的方法应用于隐私敏感或高风险数据集时存在潜在风险。 我们应该谨慎并验证该方法是否生成正确的答案。
参考
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Auer et al. (2007) Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives. 2007. Dbpedia: A nucleus for a web of open data. In Proceedings of the International Semantic Web Conference (ISWC), pages 722–735. Springer.
- Baek et al. (2023) Jinheon Baek, Alham Fikri Aji, and Amir Saffari. 2023. Knowledge-augmented language model prompting for zero-shot knowledge graph question answering. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL).
- Bordes et al. (2013) Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. Advances in neural information processing systems (NeurIPS), 26.
- Chang et al. (2024) Yapei Chang, Kyle Lo, Tanya Goyal, and Mohit Iyyer. 2024. Booookscore: A systematic exploration of book-length summarization in the era of llms. In Proceedings of the International Conference on Learning Representations (ICLR).
- Chen et al. (2022a) Jiangjie Chen, Rui Xu, Ziquan Fu, Wei Shi, Zhongqiao Li, Xinbo Zhang, Changzhi Sun, Lei Li, Yanghua Xiao, and Hao Zhou. 2022a. E-kar: A benchmark for rationalizing natural language analogical reasoning. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL).
- Chen et al. (2020) Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey E Hinton. 2020. Big self-supervised models are strong semi-supervised learners. Advances in neural information processing systems (NeurIPS), 33:22243–22255.
- Chen et al. (2022b) Xiang Chen, Ningyu Zhang, Lei Li, Shumin Deng, Chuanqi Tan, Changliang Xu, Fei Huang, Luo Si, and Huajun Chen. 2022b. Hybrid transformer with multi-level fusion for multimodal knowledge graph completion. In Proceedings of the International Conference on Research and Development in Information Retrieva (SIGIR), pages 904–915.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Girdhar et al. (2023) Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. 2023. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15180–15190.
- Gladkova et al. (2016) Anna Gladkova, Aleksandr Drozd, and Satoshi Matsuoka. 2016. Analogy-based detection of morphological and semantic relations with word embeddings: what works and what doesn’t. In Proceedings of the Student Research Workshop, SRW@HLT-NAACL 2016, pages 8–15.
- Huang et al. (2023) Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, Qiang Liu, Kriti Aggarwal, Zewen Chi, Johan Bjorck, Vishrav Chaudhary, Subhojit Som, Xia Song, and Furu Wei. 2023. Language is not all you need: Aligning perception with language models. arXiv preprint arXiv:2302.14045.
- Ishiwatari et al. (2020) Taichi Ishiwatari, Yuki Yasuda, Taro Miyazaki, and Jun Goto. 2020. Relation-aware graph attention networks with relational position encodings for emotion recognition in conversations. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7360–7370.
- Jones et al. (2024) Erik Jones, Hamid Palangi, Clarisse Simões, Varun Chandrasekaran, Subhabrata Mukherjee, Arindam Mitra, Ahmed Awadallah, and Ece Kamar. 2024. Teaching language models to hallucinate less with synthetic tasks. In Proceedings of the International Conference on Learning Representations (ICLR).
- Kim et al. (2023) Jiho Kim, Yeonsu Kwon, Yohan Jo, and Edward Choi. 2023. Kg-gpt: A general framework for reasoning on knowledge graphs using large language models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Kim et al. (2021) Wonjae Kim, Bokyung Son, and Ildoo Kim. 2021. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the International Conference on Machine Learning (ICML), volume 139, pages 5583–5594.
- Koh et al. (2023) Jing Yu Koh, Daniel Fried, and Ruslan Salakhutdinov. 2023. Generating images with multimodal language models. Advances in Neural Information Processing Systems (NeurIPS).
- Krishna et al. (2017) Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. 2017. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision, 123:32–73.
- Li et al. (2023a) Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. 2023a. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning (ICML), pages 19730–19742.
- Li et al. (2023b) Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. 2023b. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355.
- Li et al. (2019) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. 2019. Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557.
- Liu et al. (2023) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. Advances in Neural Information Processing Systems (NeurIPS).
- Liu et al. (2019) Ye Liu, Hui Li, Alberto Garcia-Duran, Mathias Niepert, Daniel Onoro-Rubio, and David S Rosenblum. 2019. Mmkg: multi-modal knowledge graphs. In Proceedings of the Extended Semantic Web Conference (ESWC), pages 459–474. Springer.
- Lu et al. (2019) Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Advances in Neural Information Processing Systems (NeurIPS), pages 13–23.
- Lu et al. (2022) Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems (NeurIPS), 35:2507–2521.
- Luo et al. (2023) Gen Luo, Yiyi Zhou, Tianhe Ren, Shengxin Chen, Xiaoshuai Sun, and Rongrong Ji. 2023. Cheap and quick: Efficient vision-language instruction tuning for large language models. Advances in Neural Information Processing Systems (NeurIPS).
- Mondal et al. (2024) Debjyoti Mondal, Suraj Modi, Subhadarshi Panda, Rituraj Singh, and Godawari Sudhakar Rao. 2024. Kam-cot: Knowledge augmented multimodal chain-of-thoughts reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 18798–18806.
- Mousselly-Sergieh et al. (2018) Hatem Mousselly-Sergieh, Teresa Botschen, Iryna Gurevych, and Stefan Roth. 2018. A multimodal translation-based approach for knowledge graph representation learning. In Proceedings of the Joint Conference on Lexical and Computational Semantics, pages 225–234.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML), pages 8748–8763.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551.
- Robinson et al. (2023) Joshua Robinson, Christopher Michael Rytting, and David Wingate. 2023. Leveraging large language models for multiple choice question answering. In Proceedings of the International Conference on Learning Representations (ICLR).
- Rohrbach et al. (2018) Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. Object hallucination in image captioning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Scarselli et al. (2008) Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. 2008. The graph neural network model. IEEE transactions on neural networks, 20(1):61–80.
- Schroff et al. (2015) Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 815–823.
- Schuhmann et al. (2022) Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. 2022. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems (NeurIPS), 35:25278–25294.
- Sen et al. (2023) Priyanka Sen, Sandeep Mavadia, and Amir Saffari. 2023. Knowledge graph-augmented language models for complex question answering. In The Workshop on Natural Language Reasoning and Structured Explanations (NLRSE), pages 1–8.
- Singh et al. (2022) Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. 2022. FLAVA: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15617–15629.
- Su et al. (2023) Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. 2023. Pandagpt: One model to instruction-follow them all. arXiv preprint arXiv:2305.16355.
- Su et al. (2022) Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lingpeng Kong, and Nigel Collier. 2022. Language models can see: Plugging visual controls in text generation. arXiv preprint arXiv:2205.02655.
- Suchanek et al. (2007) Fabian M Suchanek, Gjergji Kasneci, and Gerhard Weikum. 2007. Yago: a core of semantic knowledge. In Proceedings of the International Conference on World Wide Web (WWW), pages 697–706.
- Sun et al. (2024) Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Heung-Yeung Shum, and Jian Guo. 2024. Think-on-graph: Deep and responsible reasoning of large language model with knowledge graph. In Proceedings of the International Conference on Learning Representations (ICLR).
- Sun et al. (2020) Rui Sun, Xuezhi Cao, Yan Zhao, Junchen Wan, Kun Zhou, Fuzheng Zhang, Zhongyuan Wang, and Kai Zheng. 2020. Multi-modal knowledge graphs for recommender systems. In Proceedings of the ACM International Conference on Information & Knowledge Management (CIKM), pages 1405–1414.
- Tay et al. (2022) Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Steven Zheng, et al. 2022. Ul2: Unifying language learning paradigms. In Proceedings of the International Conference on Learning Representations (ICLR).
- Tian et al. (2023) Yijun Tian, Huan Song, Zichen Wang, Haozhu Wang, Ziqing Hu, Fang Wang, Nitesh V Chawla, and Panpan Xu. 2023. Graph neural prompting with large language models. Advances in Neural Information Processing Systems (NeurIPS).
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Veličković et al. (2017) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks. arXiv preprint arXiv:1710.10903.
- Wang et al. (2021) Meng Wang, Sen Wang, Han Yang, Zheng Zhang, Xi Chen, and Guilin Qi. 2021. Is visual context really helpful for knowledge graph? A representation learning perspective. In Proceedings of the ACM International Conference on Multimedia (MM), pages 2735–2743.
- Wang et al. (2019) Zikang Wang, Linjing Li, Qiudan Li, and Daniel Zeng. 2019. Multimodal data enhanced representation learning for knowledge graphs. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), pages 1–8.
- Wu et al. (2023a) Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. 2023a. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671.
- Wu et al. (2023b) Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. 2023b. Next-gpt: Any-to-any multimodal llm. arXiv preprint arXiv:2309.05519.
- Wu et al. (2023c) Yike Wu, Nan Hu, Guilin Qi, Sheng Bi, Jie Ren, Anhuan Xie, and Wei Song. 2023c. Retrieve-rewrite-answer: A kg-to-text enhanced llms framework for knowledge graph question answering. arXiv preprint arXiv:2309.11206.
- Xie et al. (2017) Ruobing Xie, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2017. Image-embodied knowledge representation learning. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), pages 3140–3146.
- Yasunaga et al. (2022) Michihiro Yasunaga, Antoine Bosselut, Hongyu Ren, Xikun Zhang, Christopher D Manning, Percy S Liang, and Jure Leskovec. 2022. Deep bidirectional language-knowledge graph pretraining. In Advances in neural information processing systems (NeurIPS).
- Zhang et al. (2023a) Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. 2023a. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. arXiv preprint arXiv:2305.11000.
- Zhang et al. (2023b) Hang Zhang, Xin Li, and Lidong Bing. 2023b. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858.
- Zhang et al. (2022) Ningyu Zhang, Lei Li, Xiang Chen, Xiaozhuan Liang, Shumin Deng, and Huajun Chen. 2022. Multimodal analogical reasoning over knowledge graphs. Proceedings of the International Conference on Learning Representations (ICLR).
- Zhang et al. (2024a) Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. 2024a. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. Proceedings of the International Conference on Learning Representations (ICLR).
- Zhang et al. (2024b) Tianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeown, and Tatsunori B Hashimoto. 2024b. Benchmarking large language models for news summarization. Transactions of the Association for Computational Linguistics, 12:39–57.
- Zhang et al. (2023c) Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2023c. Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923.
- Zhao and Wu (2023) Wentian Zhao and Xinxiao Wu. 2023. Boosting entity-aware image captioning with multi-modal knowledge graph. IEEE Transactions on Multimedia.
- Zhu et al. (2023) Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592.
附录 A 其他实验设置
A.1 数据集
我们提供了两个多模态推理数据集的更多详细信息,即 ScienceQA 和 MARS。
科学质量保证。
ScienceQA 分为训练集、验证集和测试集,分别由 12,726、4,241 和 4,241 个实例组成。 该数据集包含丰富的注释,为答案提供讲座和解释,并为问题提供上下文。 该数据集的独特之处在于它结合了多模态问题(文本和图像上下文)以及广泛覆盖 26 个主题、127 个类别和 379 项技能。
火星。
MARS 融合了视觉和文本模式,并以多模式知识图 MarKG 为基础。 MARS包含2063个实体和27个关系,每个实体都有对应的图像。 它包括 10,685 个训练、1,228 个验证和 1,415 个测试实例。
A.2 多模态知识图
| Settings | Hits@1 on MARS |
|---|---|
| MR-MKG (with MarKG) | 0.405(0.000) |
| MR-MKG (with MMKG) | 0.384(-0.021) |
| Base (no MMKG) | 0.286(-0.119) |
MMKG。
MMKG Liu 等人(2019)以FB15K为模板构建,生成多模态知识图谱。 FB15K 中的实体与其他知识图中的实体的对齐是通过使用 sameAs 链接实现的,从而生成 DB15K 和 YAGO15K。 总共 14,951 个实体和 1,345 个关系中有 812,899 个三元组。 大多数实体都有相应的图像。
马克·KG。
MarKG Zhang 等人 (2022) 包含 11,292 个实体、192 个关系和 76,424 个图像。 图像数据通过 Google 搜索和多模态数据 Laion-5B Schuhmann 等人 (2022) 的查询获取,使用实体的文本描述。
选择MarKG来支持MARS进行多模态类比推理,是因为MarKG和MARS来自同一篇作品Zhang等人(2022)。 它们具有相同的数据源和构建方法,共享相同的实体和关系。 因此,我们假设MarKG中包含的知识与MARS高度兼容,并且与MMKG Liu 等人(2019)相比更适合MARS。 此外,我们用 MMKG 替换 MarKG 以验证这一假设。
表8显示,当MarKG替换为MMKG时,模型性能从40.5%下降到38.4%。 这表明MarKG中包含的知识对于MARS来说更为重要,但这并不意味着MMKG无效,它仍然显着提高了模型的性能。 因此任何知识丰富的 MMKG 都可以应用于多个基准测试。 然而,它们对特定任务的增强可能不如特定MMKG那么有效,但它们仍然可以在一定程度上改进模型。 因此,MMKG的唯一选择标准是任务所需的知识是否足够。 对于ScienceQA,我们直接使用MMKG来支持。
A.3 基于MMKG的数据集构建
Visual Genome Krishna 等人 (2017) 是一个大规模图像语义理解数据集。 每个数据由五个主要部分组成:问答对、区域描述、区域图、场景图和图像。 每个图像被分割成多个区域,每个区域都被单独描述。 提取图像中的所有对象和关系来构建场景图。 注释了两种类型的 QA 对: 1. 基于整个图像(不指定区域)的自由形式QA,以及2. 基于区域的 QA 基于图像中选定的区域。
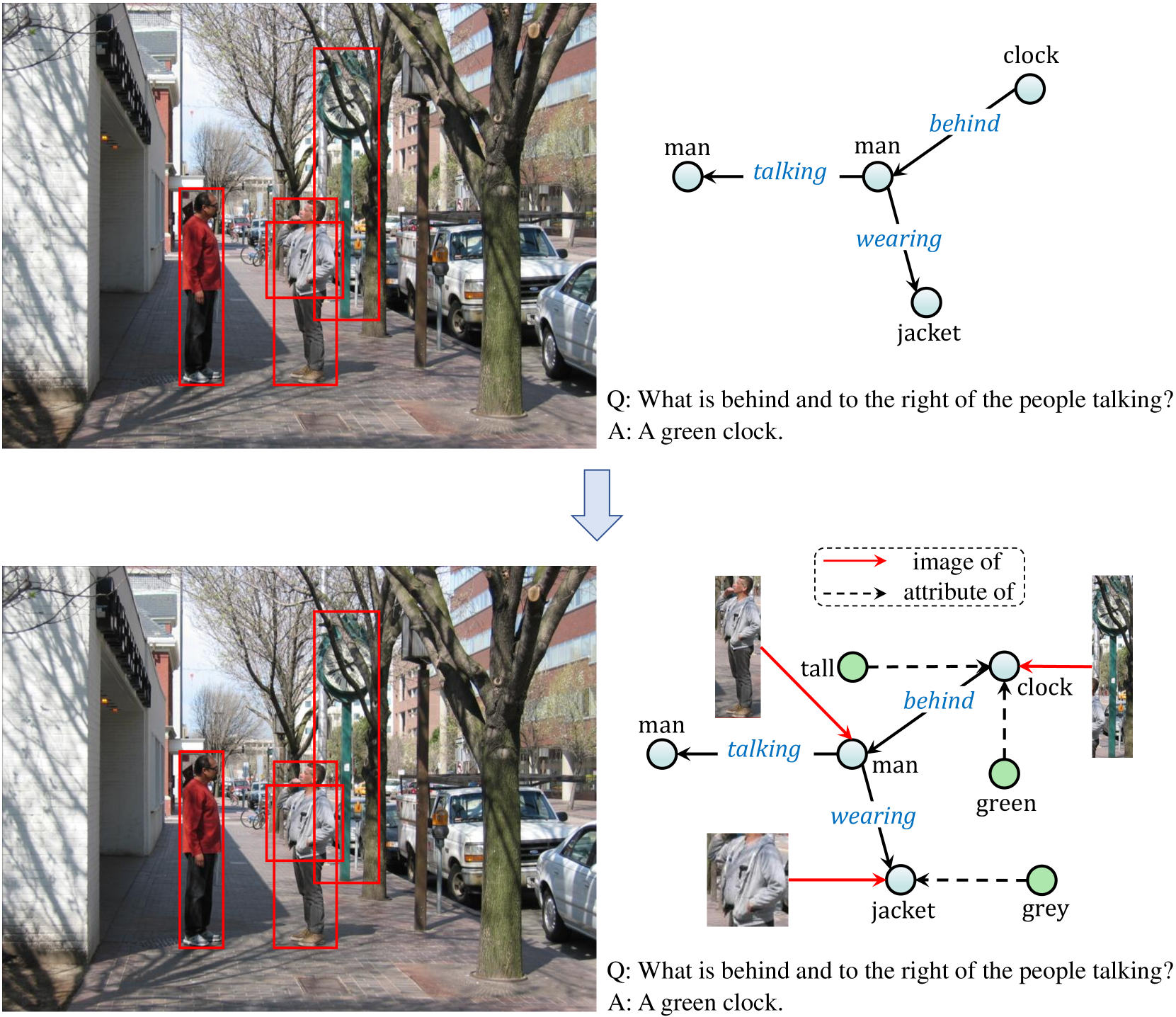
我们通过提取每个数据实例的图像、QA 对和修改后的场景图来构建基于 MMKG 的数据集。 在这种情况下,图像和相关问题和答案的组合构成了视觉问答(VQA)任务,代表多模态推理。 修改后的场景图充当多模态知识图,包含有关图像中对象的知识(如图6所示)。 具体来说,我们根据对象的边界框裁剪出对象的图像,并使用“image of”关系将它们链接到相应的对象实体。 此外,对象属性与其各自的实体之间通过“attribute of”关系建立连接。 最后,我们专门选择基于区域的 QA 数据,因为相应的多模态场景图包含推理出答案的关键知识。 我们总共构建了 18,448 个实例。
| Hyper-parameters | MarKG | MARS |
|---|---|---|
| epoch | 3 | 3 |
| sequence length | 96 | 128 |
| learning rate | 2e-5 | 5e-6 |
| batch size | 8 | 4 |
| optimizer | AdamW | AdamW |
| Weight decay | 0.01 | 0.01 |
A.4 大型语言模型
我们描述了用于评估的大型语言模型(大语言模型)的具体细节。
法兰-T5。
T5 Raffel 等人 (2020) 是一个编码器-解码器模型。 对于相同数量的参数,FLAN-T5 Chung 等人 (2022) 在 T5 的基础上在涵盖更广泛语言的 1000 多个附加任务上进行了微调。
法兰-UL2。
FLAN-UL2 Chung 等人 (2022) 在 FLAN-T5 的基础上进行扩展,采用统一框架 UL2 Tay 等人 (2022) 的升级预训练流程对于预训练模型。
LLaMA-2。
LLaMA-2 Touvron 等人 (2023) 是一个免费且开源的仅限解码器的模型。
A.5详细评估指标
对于 ScienceQA 数据集,我们仅使用准确性作为评估指标。 对于 MARS 数据集,我们使用 Hits@k 和 MRR 作为我们的评估指标。 这些指标都在 [0,1] 范围内。 值越高表示性能越好。 Hits@k 指标是通过计算正确实体出现在预测中前 k 个位置的次数来获得的。 将三元组的正确实体的等级表示为,等级的倒数为1/。 平均倒数排名 (MRR) 是多模态知识图中所有三元组的倒数排名的平均值:
| (9) |
其中 是训练集的总数。
A.6知识检索方案
根据文本或图像信息检索子MMKG。 这涉及将文本或图像信息以及 MMKG 中的所有三元组嵌入到表示空间中。 然后计算它们之间的余弦相似度,并且Top-相关三元组的所有实体形成。 随后,根据中的实体检索,包括它们的一跳邻居以及连接它们的关系Yasunaga等人(2022)。 最后,我们根据余弦相似度在 中选择 Top- 最相关的三元组。
A.7实施细节
科学质量保证。
我们在 ScienceQA 任务中使用 Multimodal-CoT 提示。 它是一个两阶段框架,将基本原理生成和答案推理分开。 在每次预测中,模型首先生成一个基本原理,然后根据问题和基本原理预测最终答案。 相关子 MMKG 是根据文本特征检索的,这些文本特征由问题、上下文和选项连接起来。 我们将模型进行了最多 3 个 epoch,学习率为 4e-5。 我们设置大语言模型输入和输出词符长度的最大数量为512。 批量大小为 1,优化器为 AdamW,权重衰减为 0.01。

火星。
最初,我们在 MarKG 数据集上预训练模型,重点关注实体预测和关系预测等任务。 它可以获得实体和关系嵌入矩阵。 随后,我们进一步对 MARS 上的模型进行了仿真。 超参数详细信息如表9所示。 根据问题实体检索相关子MMKG,并根据其模式对所有实体进行嵌入和转换。
MMKG 接地数据集。
我们首先在基于 MMKG 的数据集上预训练我们的 MR-MKG 方法,最多 2 个 epoch,学习率为 5e-5。 我们设置大语言模型的最大输入词符长度为512个,输出词符长度为128个。 批量大小为 2,优化器为 AdamW,权重衰减为 0.01。 根据问题检索相关子 MMKG。
附录 B案例研究的其他示例
为了更好地理解MR-MKG的行为,我们提供了额外的示例进行案例分析。
其他案例研究。
误差分析。
我们还进行了错误案例研究,如图9所示。 在这种情况下,问题是“哪种鱼的嘴也适合撕开肉?”。 然而,MR-MKG检索到的子MMKG不包含任何有用的信息。 具体来说,它包含有关其他鱼类的知识,甚至包含两部与鱼类相关的名称的电影。 我们可以看到MR-MKG方法的困难: 1)知识不足:所利用的MMKG本身缺乏相关信息,阻碍了其为多模态推理提供有效知识的能力。 2)知识的模糊性:知识本身固有的模糊性可能会导致检索到不相关的知识。 在这个例子中,“BIG FISH”不是指鱼,而是指电影,从而产生了歧义。