Chengjie Wang,
Haokun Zhu,
Jinlong Peng,
Yue Wang,
Ran Yi
Yunsheng Wu,
Lizhuang Ma,
Jiangning ZhangC. Wang is with Shanghai Jiao Tong University and Youtu Lab, Shanghai, China.H. Zhu, Y. Wang, R. Yi, and L. Ma are with the Shanghai Jiao Tong University, Shanghai, China.J. Peng, Y. Wu, and J. Zhang are with Youtu Lab, Tencent, China.Corresponding author: Ran Yi
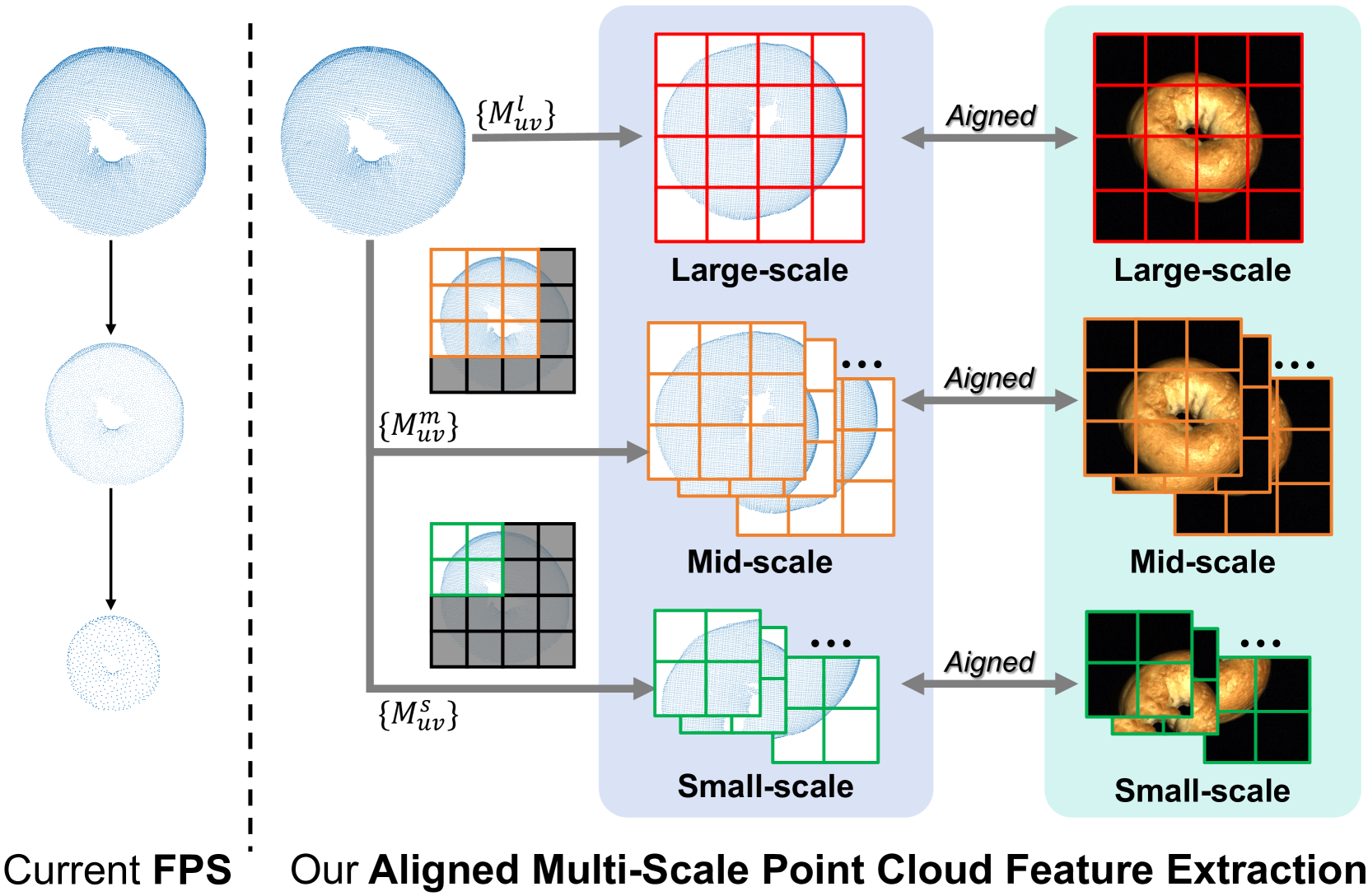
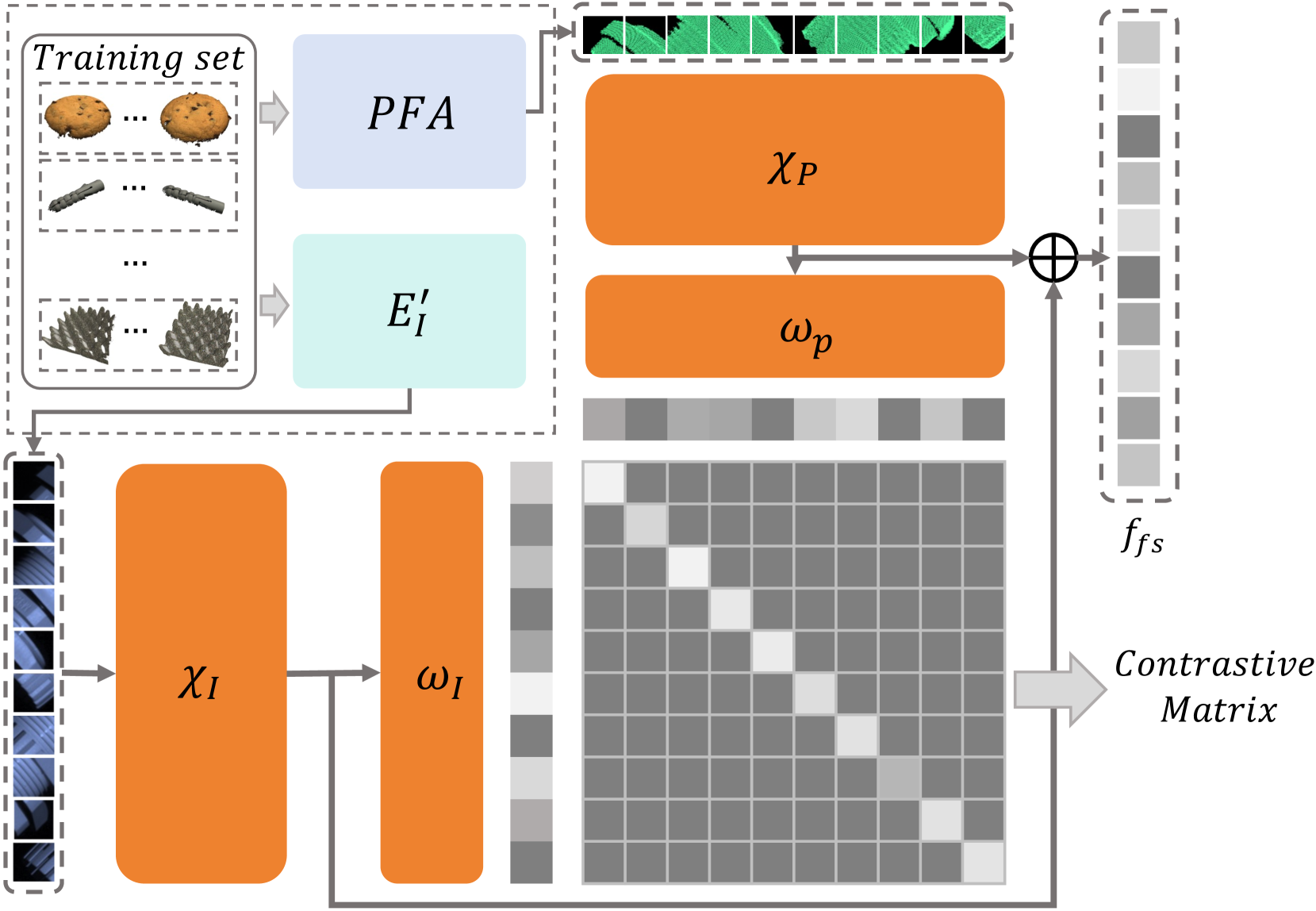
对齐的多尺度点云特征提取。正如之前的工作[9]所示,在MVTec 3D-AD [10]数据集中,许多异常现象无法仅通过RGB图像来检测。例如,在“马铃薯”类别中,名为“cut”的异常类型只能使用 3D 点云数据来识别。因此,将 3D 点云数据纳入噪声过滤过程至关重要。因此,我们建议在噪声检测中使用 3D 点云模态。
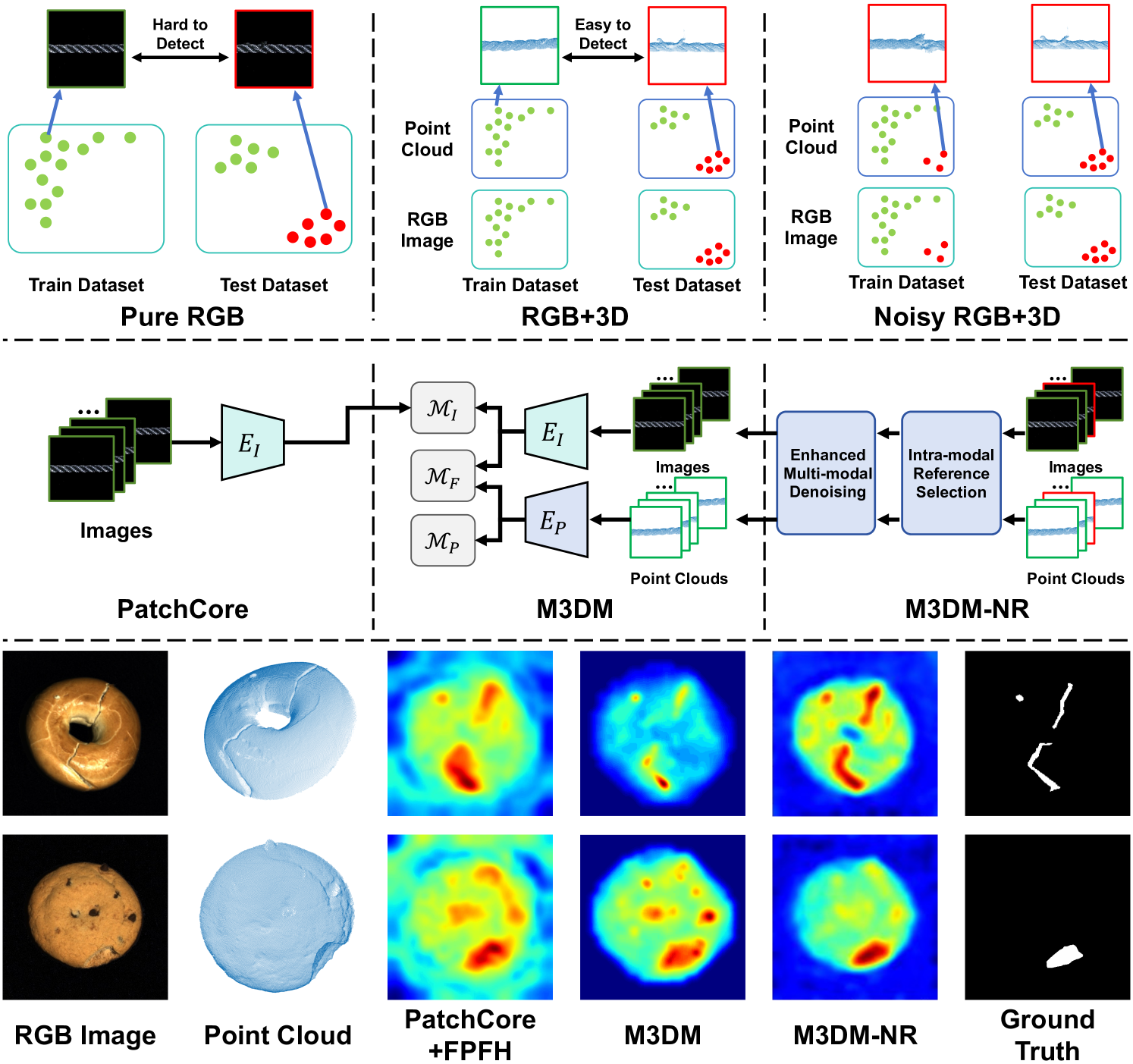
在本节中,我们将重叠设置下所有类别的 MVTec-3D AD 数据集的异常分割结果可视化。如图图7所示,我们可视化了我们的方法和PatchCore + FPFH [20]的热图结果、M3DM [9] 和具有多模态输入的形状引导 [44]。我们的方法通过生成更准确的分割图并对数据集噪声表现出更大的弹性来优于以前的方法。虽然早期的方法经常被数据集中的噪声样本所混淆,但这一点在 PatchCore + FPFH 的电缆密封套、销钉、泡沫和桃子结果以及形状引导的泡沫和绳索结果中尤其明显。更多非重叠设置下的可视化结果参见Visualization results of Non-Overlap setiing。
4.5 消融研究
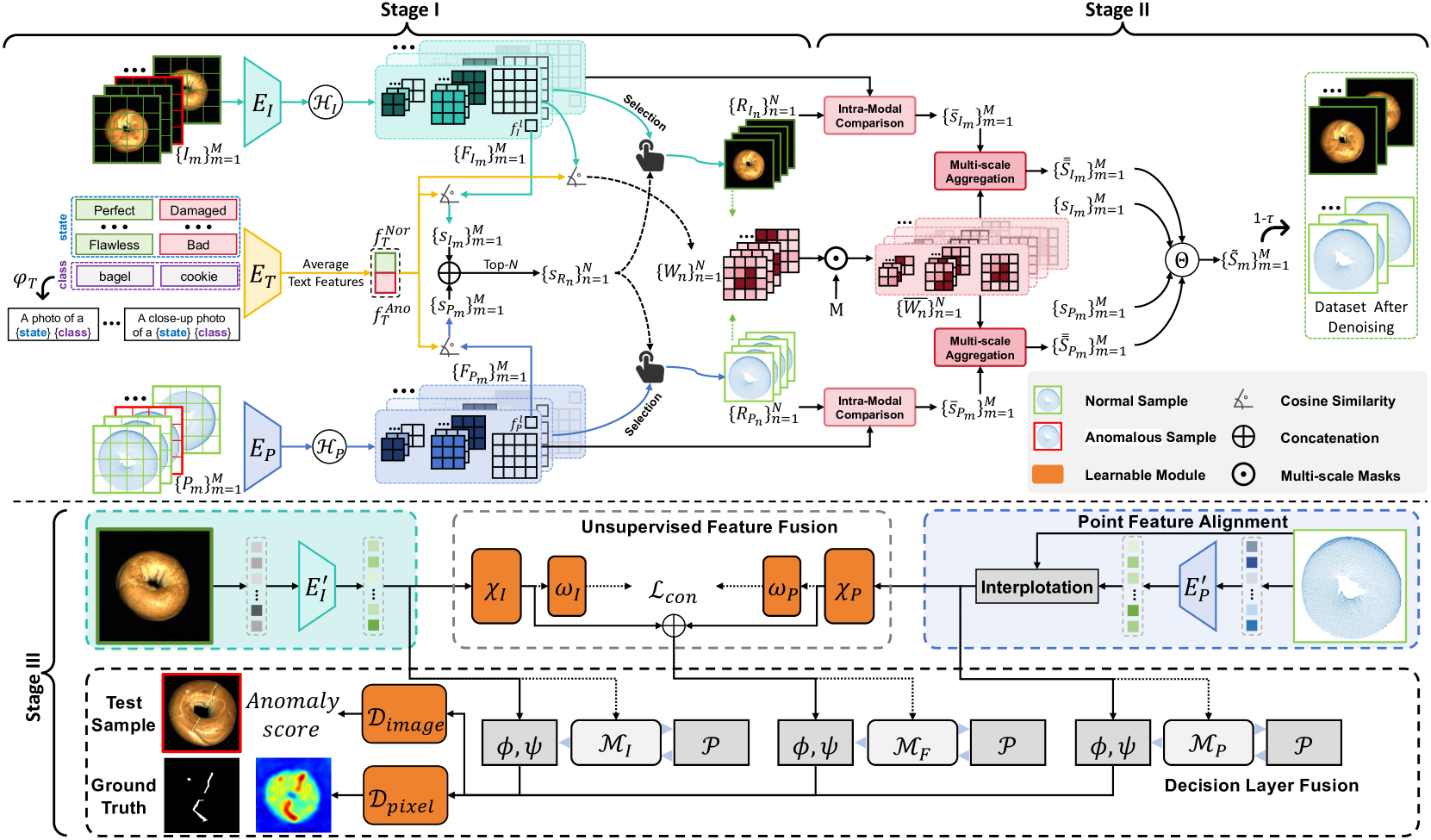
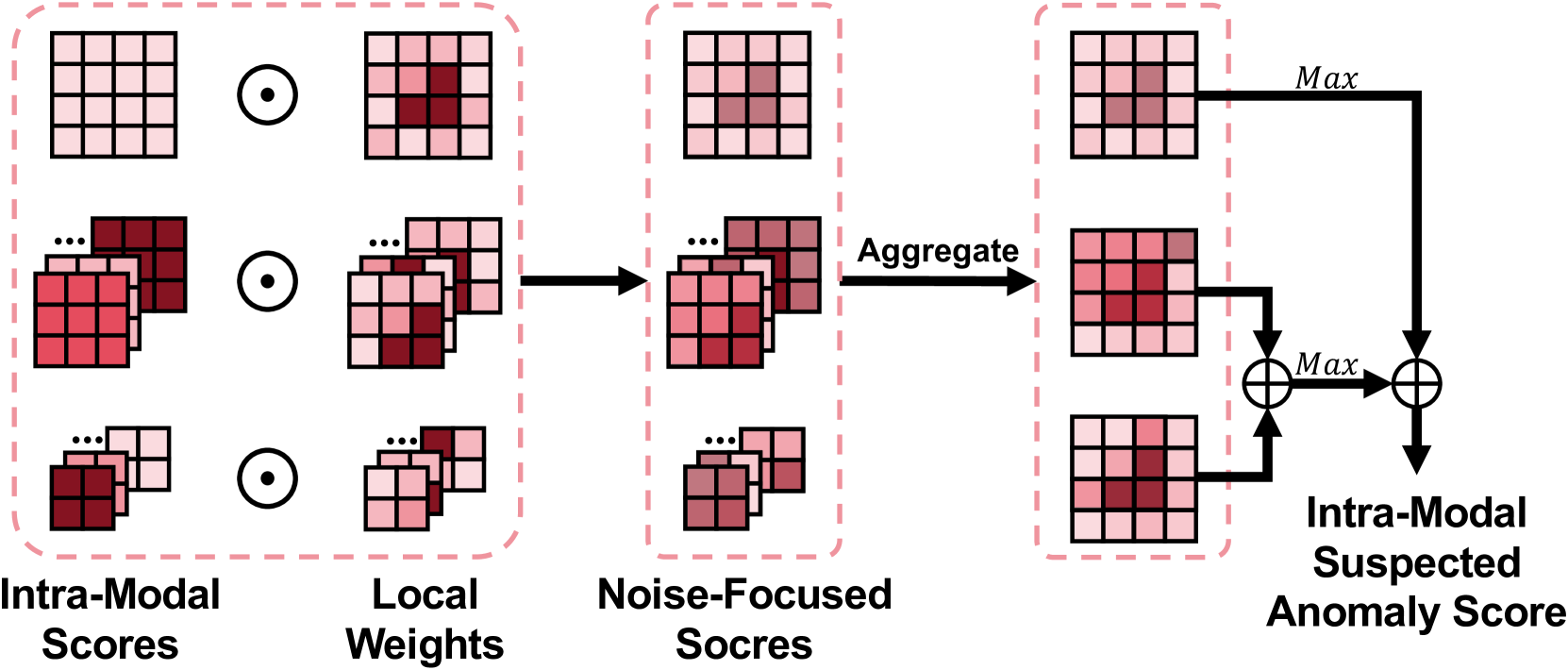
我们对Sec.3中介绍的主要组件进行了消融研究,即Stage I & II两阶段样本级去噪、intra -模态参考、对齐的多尺度点云特征提取和以噪声为中心的聚合。结果显示在选项卡。七.据观察,每个组件的增量包含导致了在重叠和非重叠设置下的I-AUROC、P-AUROC和AUPRO的改进,特别是在更具挑战性的重叠设置。除了这些指标之外,噪声级别指标还清楚地表明,随着每个模块的添加,模型的样本级去噪能力逐渐增强。
[1]Y. Cao, X. Xu, J. Zhang, Y. Cheng, X. Huang, G. Pang, and W. Shen, “A survey on visual anomaly detection: Challenge, approach, and prospect,” arXiv preprint arXiv:2401.16402, 2024.
[2]J. Liu, G. Xie, J. Wang, S. Li, C. Wang, F. Zheng, and Y. Jin, “Deep industrial image anomaly detection: A survey,” Machine Intelligence Research, vol.21, no.1, pp.104–135, 2024.
[3]P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger, “Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp.9592–9600.
[4]C. Wang, W. Zhu, B.-B.Gao, Z. Gan, J. Zhang, Z. Gu, S. Qian, M. Chen, and L. Ma, “Real-iad: A real-world multi-view dataset for benchmarking versatile industrial anomaly detection,” in CVPR, 2024.
[5]K. Roth, L. Pemula, J. Zepeda, B. Schölkopf, T. Brox, and P. Gehler, “Towards total recall in industrial anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp.14 318–14 328.
[6]D. Gudovskiy, S. Ishizaka, and K. Kozuka, “Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp.98–107.
[7]Y. Zheng, X. Wang, R. Deng, T. Bao, R. Zhao, and L. Wu, “Focus your distribution: Coarse-to-fine non-contrastive learning for anomaly detection and localization,” in 2022 IEEE International Conference on Multimedia and Expo (ICME).IEEE, 2022, pp.1–6.
[8]X. Jiang, J. Liu, J. Wang, Q. Nie, K. Wu, Y. Liu, C. Wang, and F. Zheng, “Softpatch: Unsupervised anomaly detection with noisy data,” Advances in Neural Information Processing Systems, vol.35, pp.15 433–15 445, 2022.
[9]Y. Wang, J. Peng, J. Zhang, R. Yi, Y. Wang, and C. Wang, “Multimodal industrial anomaly detection via hybrid fusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp.8032–8041.
[10]P. Bergmann, X. Jin, D. Sattlegger, and C. Steger, “The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization,” in Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, VISIGRAPP 2022, Volume 5: VISAPP, Online Streaming, February 6-8, 2022, G. M. Farinella, P. Radeva, and K. Bouatouch, Eds.SCITEPRESS, 2022, pp.202–213.[Online].Available: https://doi.org/10.5220/0010865000003124
[11]E. Horwitz and Y. Hoshen, “Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp.2967–2976.
[12]D. Gong, L. Liu, V. Le, B. Saha, M. R. Mansour, S. Venkatesh, and A. v. d. Hengel, “Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp.1705–1714.
[13]V. Zavrtanik, M. Kristan, and D. Skočaj, “Reconstruction by inpainting for visual anomaly detection,” Pattern Recognition, vol.112, p. 107706, 2021.
[14]——, “Draem-a discriminatively trained reconstruction embedding for surface anomaly detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp.8330–8339.
[15]H. Deng and X. Li, “Anomaly detection via reverse distillation from one-class embedding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp.9737–9746.
[16]P. Perera, R. Nallapati, and B. Xiang, “Ocgan: One-class novelty detection using gans with constrained latent representations,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp.2898–2906.
[17]J. Yu, Y. Zheng, X. Wang, W. Li, Y. Wu, R. Zhao, and L. Wu, “Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows,” arXiv preprint arXiv:2111.07677, 2021.
[18]M. Rudolph, T. Wehrbein, B. Rosenhahn, and B. Wandt, “Asymmetric student-teacher networks for industrial anomaly detection,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp.2592–2602.
[19]T. Defard, A. Setkov, A. Loesch, and R. Audigier, “Padim: a patch distribution modeling framework for anomaly detection and localization,” in International Conference on Pattern Recognition.Springer, 2021, pp.475–489.
[20]E. Horwitz and Y. Hoshen, “An empirical investigation of 3d anomaly detection and segmentation,” arXiv preprint arXiv:2203.05550, 2022.
[21]A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning.PMLR, 2021, pp.8748–8763.
[22]Z. Guo, R. Zhang, X. Zhu, Y. Tang, X. Ma, J. Han, K. Chen, P. Gao, X. Li, H. Li et al., “Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following,” arXiv preprint arXiv:2309.00615, 2023.
[23]L. Bonfiglioli, M. Toschi, D. Silvestri, N. Fioraio, and D. De Gregorio, “The eyecandies dataset for unsupervised multimodal anomaly detection and localization,” in Proceedings of the Asian Conference on Computer Vision, 2022, pp.3586–3602.
[24]C.-L. Li, K. Sohn, J. Yoon, and T. Pfister, “Cutpaste: Self-supervised learning for anomaly detection and localization,” in CVPR, 2021.
[25]G. Zhang, K. Cui, T.-Y.Hung, and S. Lu, “Defect-gan: High-fidelity defect synthesis for automated defect inspection,” in CACV, 2021.
[26]Z. Liu, Y. Zhou, Y. Xu, and Z. Wang, “Simplenet: A simple network for image anomaly detection and localization,” in CVPR, 2023.
[27]M. Yang, P. Wu, and H. Feng, “Memseg: A semi-supervised method for image surface defect detection using differences and commonalities,” Engineering Applications of Artificial Intelligence, 2023.
[28]T. D. Tien, A. T. Nguyen, N. H. Tran, T. D. Huy, S. Duong, C. D. T. Nguyen, and S. Q. Truong, “Revisiting reverse distillation for anomaly detection,” in CVPR, 2023.
[29]L. Chen, Z.You, N. Zhang, J. Xi, and X.Le, “Utrad: Anomaly detection and localization with u-transformer,” Neural Networks, 2022.
[30]Y. Liang, J. Zhang, S. Zhao, R. Wu, Y. Liu, and S. Pan, “Omni-frequency channel-selection representations for unsupervised anomaly detection,” TIP, 2023.
[31]J. Zhang, X. Chen, Y. Wang, C. Wang, Y. Liu, X. Li, M.-H. Yang, and D. Tao, “Exploring plain vit reconstruction for multi-class unsupervised anomaly detection,” arXiv preprint arXiv:2312.07495, 2023.
[32]H. He, Y. Bai, J. Zhang, Q.He, H. Chen, Z. Gan, C. Wang, X. Li, G. Tian, and L. Xie, “Mambaad: Exploring state space models for multi-class unsupervised anomaly detection,” arXiv, 2024.
[33]J. Zhang, X. Li, G. Tian, Z. Xue, Y. Liu, G. Pang, and D. Tao, “Learning feature inversion for multi-class unsupervised anomaly detection under general-purpose coco-ad benchmark,” arXiv, 2024.
[34]H. He, J. Zhang, H. Chen, X. Chen, Z. Li, X. Chen, Y. Wang, C. Wang, and L. Xie, “Diad: A diffusion-based framework for multi-class anomaly detection,” arXiv preprint arXiv:2312.06607, 2023.
[35]Q. Wan, L. Gao, X. Li, and L. Wen, “Unsupervised image anomaly detection and segmentation based on pretrained feature mapping,” TII, 2022.
[36]Y. Cao, X. Xu, Z. Liu, and W. Shen, “Collaborative discrepancy optimization for reliable image anomaly localization,” TII, 2023.
[37]J. Lei, X. Hu, Y. Wang, and D. Liu, “Pyramidflow: High-resolution defect contrastive localization using pyramid normalizing flow,” in CVPR, 2023.
[38]M. Salehi, N. Sadjadi, S. Baselizadeh, M. H. Rohban, and H. R. Rabiee, “Multiresolution knowledge distillation for anomaly detection,” in CVPR, 2021.
[39]Y. Cao, Q. Wan, W. Shen, and L. Gao, “Informative knowledge distillation for image anomaly segmentation,” KBS, 2022.
[40]R. Chen, G. Xie, J. Liu, J. Wang, Z. Luo, J. Wang, and F. Zheng, “Easynet: An easy network for 3d industrial anomaly detection,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp.7038–7046.
[41]V. Zavrtanik, M. Kristan, and D. Skočaj, “Keep dræming: Discriminative 3d anomaly detection through anomaly simulation,” Pattern Recognition Letters, 2024.
[42]W. Li and X. Xu, “Towards scalable 3d anomaly detection and localization: A benchmark via 3d anomaly synthesis and a self-supervised learning network,” arXiv preprint arXiv:2311.14897, 2023.
[43]Y. Cao, X. Xu, and W. Shen, “Complementary pseudo multimodal feature for point cloud anomaly detection,” arXiv preprint arXiv:2303.13194, 2023.
[44]Y.-M. Chu, L. Chieh, T.-I.Hsieh, H.-T. Chen, and T.-L. Liu, “Shape-guided dual-memory learning for 3d anomaly detection,” 2023.
[45]Y. Tu, B. Zhang, L. Liu, Y. Li, C. Xu, J. Zhang, Y. Wang, C. Wang, and C. R. Zhao, “Self-supervised feature adaptation for 3d industrial anomaly detection,” arXiv preprint arXiv:2401.03145, 2024.
[46]B. Zhao, Q. Xiong, X. Zhang, J. Guo, Q. Liu, X. Xing, and X. Xu, “Pointcore: Efficient unsupervised point cloud anomaly detector using local-global features,” arXiv preprint arXiv:2403.01804, 2024.
[47]P. Bergmann and D. Sattlegger, “Anomaly detection in 3d point clouds using deep geometric descriptors,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp.2613–2623.
[48]Z. Gu, J. Zhang, L. Liu, X. Chen, J. Peng, Z. Gan, G. Jiang, A. Shu, Y. Wang, and L. Ma, “Rethinking reverse distillation for multi-modal anomaly detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol.38, no.8, 2024, pp.8445–8453.
[49]Z. Hu, Z. Yang, X. Hu, and R. Nevatia, “Simple: Similar pseudo label exploitation for semi-supervised classification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp.15 099–15 108.
[50]K. Sohn, D. Berthelot, N. Carlini, Z. Zhang, H. Zhang, C. A. Raffel, E. D. Cubuk, A. Kurakin, and C.-L. Li, “Fixmatch: Simplifying semi-supervised learning with consistency and confidence,” Advances in neural information processing systems, vol.33, pp.596–608, 2020.
[51]J. Li, R. Socher, and S. C. Hoi, “Dividemix: Learning with noisy labels as semi-supervised learning,” arXiv preprint arXiv:2002.07394, 2020.
[52]M. Xu, Z. Zhang, H. Hu, J. Wang, L. Wang, F. Wei, X. Bai, and Z. Liu, “End-to-end semi-supervised object detection with soft teacher,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp.3060–3069.
[53]Y.-C. Liu, C.-Y.Ma, Z.He, C.-W. Kuo, K. Chen, P. Zhang, B. Wu, Z. Kira, and P. Vajda, “Unbiased teacher for semi-supervised object detection,” arXiv preprint arXiv:2102.09480, 2021.
[54]F. Yang, K. Wu, S. Zhang, G. Jiang, Y. Liu, F. Zheng, W. Zhang, C. Wang, and L. Zeng, “Class-aware contrastive semi-supervised learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp.14 421–14 430.
[55]S. Han, X. Hu, H. Huang, M. Jiang, and Y. Zhao, “Adbench: Anomaly detection benchmark,” Advances in Neural Information Processing Systems, vol.35, pp.32 142–32 159, 2022.
[56]G. Pang, C. Yan, C. Shen, A. v. d. Hengel, and X. Bai, “Self-trained deep ordinal regression for end-to-end video anomaly detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp.12 173–12 182.
[57]B. Liu, D. Wang, K. Lin, P.-N. Tan, and J. Zhou, “Rca: A deep collaborative autoencoder approach for anomaly detection,” in IJCAI: proceedings of the conference, vol.2021.NIH Public Access, 2021, p. 1505.
[58]C. Zhou and R. C. Paffenroth, “Anomaly detection with robust deep autoencoders,” in Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, 2017, pp.665–674.
[59]S. Wu, J. Zhao, and G. Tian, “Understanding and mitigating data contamination in deep anomaly detection: A kernel-based approach.” in IJCAI, 2022, pp.2319–2325.
[60]J.-B.Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds et al., “Flamingo: a visual language model for few-shot learning,” Advances in neural information processing systems, vol.35, pp.23 716–23 736, 2022.
[61]C. Jia, Y. Yang, Y. Xia, Y.-T. Chen, Z. Parekh, H. Pham, Q.Le, Y.-H.Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” in International conference on machine learning.PMLR, 2021, pp.4904–4916.
[62]R. Taori, A. Dave, V. Shankar, N. Carlini, B. Recht, and L. Schmidt, “Measuring robustness to natural distribution shifts in image classification,” Advances in Neural Information Processing Systems, vol.33, pp.18 583–18 599, 2020.
[63]G. Goh, N. Cammarata, C. Voss, S. Carter, M. Petrov, L. Schubert, A. Radford, and C. Olah, “Multimodal neurons in artificial neural networks,” Distill, vol.6, no.3, p. e30, 2021.
[64]Y. Rao, W. Zhao, G. Chen, Y. Tang, Z. Zhu, G. Huang, J. Zhou, and J. Lu, “Denseclip: Language-guided dense prediction with context-aware prompting,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp.18 082–18 091.
[65]Y. Zhong, J. Yang, P. Zhang, C. Li, N. Codella, L. H. Li, L. Zhou, X. Dai, L. Yuan, Y. Li et al., “Regionclip: Region-based language-image pretraining,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp.16 793–16 803.
[66]C. Zhou, C. C. Loy, and B. Dai, “Extract free dense labels from clip,” in European Conference on Computer Vision.Springer, 2022, pp.696–712.
[67]J. Jeong, Y. Zou, T. Kim, D. Zhang, A. Ravichandran, and O. Dabeer, “Winclip: Zero-/few-shot anomaly classification and segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp.19 606–19 616.
[68]X. Chen, Y. Han, and J. Zhang, “A zero-/few-shot anomaly classification and segmentation method for cvpr 2023 vand workshop challenge tracks 1&2: 1st place on zero-shot ad and 4th place on few-shot ad,” arXiv preprint arXiv:2305.17382, 2023.
[69]Y. Cao, X. Xu, C. Sun, Y. Cheng, Z.Du, L. Gao, and W. Shen, “Segment any anomaly without training via hybrid prompt regularization,” arXiv preprint arXiv:2305.10724, 2023.
[70]X. Chen, J. Zhang, G. Tian, H. He, W. Zhang, Y. Wang, C. Wang, Y. Wu, and Y. Liu, “Clip-ad: A language-guided staged dual-path model for zero-shot anomaly detection,” arXiv preprint arXiv:2311.00453, 2023.
[71]J. Zhang, X. Chen, Z. Xue, Y. Wang, C. Wang, and Y. Liu, “Exploring grounding potential of vqa-oriented gpt-4v for zero-shot anomaly detection,” arXiv preprint arXiv:2311.02612, 2023.
[72]R. Zhang, Z. Guo, W. Zhang, K. Li, X. Miao, B. Cui, Y. Qiao, P. Gao, and H. Li, “Pointclip: Point cloud understanding by clip,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp.8552–8562.
[73]X. Zhu, R. Zhang, B.He, Z. Guo, Z. Zeng, Z. Qin, S. Zhang, and P. Gao, “Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp.2639–2650.
[74]L. Xue, M. Gao, C. Xing, R. Martín-Martín, J. Wu, C. Xiong, R. Xu, J. C. Niebles, and S. Savarese, “Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp.1179–1189.
[75]Y. Zheng, X. Wang, Y. Qi, W. Li, and L. Wu, “Benchmarking unsupervised anomaly detection and localization,” 2022.
[76]G. Wang, S. Han, E. Ding, and D. Huang, “Student-teacher feature pyramid matching for anomaly detection,” in 32nd British Machine Vision Conference 2021, BMVC 2021, Online, November 22-25, 2021.BMVA Press, 2021, p. 306.[Online].Available: https://www.bmvc2021-virtualconference.com/assets/papers/1273.pdf
[77]M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,” Communications of the ACM, vol.24, no.6, pp.381–395, 1981.
[78]J. Deng, W. Dong, R. Socher, L.-J.Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition.Ieee, 2009, pp.248–255.
[79]M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp.9650–9660.
[80]H. Zhao, L. Jiang, J. Jia, P. H. Torr, and V. Koltun, “Point transformer,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp.16 259–16 268.
[81]Y. Pang, W. Wang, F. E. H. Tay, W. Liu, Y. Tian, and L. Yuan, “Masked autoencoders for point cloud self-supervised learning,” 2022.
[82]A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su et al., “Shapenet: An information-rich 3d model repository,” arXiv preprint arXiv:1512.03012, 2015.
[83]B. Schölkopf, J. C. Platt, J. Shawe-Taylor, A. J. Smola, and R. C. Williamson, “Estimating the support of a high-dimensional distribution,” Neural computation, vol.13, no.7, pp.1443–1471, 2001.
[84]A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems, vol.32, 2019.