稳定姿势:利用 Transformer 进行姿势引导的文本到图像生成
摘要
可控文本到图像(T2I)扩散模型在通过结合各种条件生成高质量视觉内容方面表现出了令人印象深刻的性能。 然而,当前的方法在以骨架人体姿势为指导时表现出有限的性能,特别是在复杂的姿势条件下,例如人物的侧面或后部视角。 为了解决这个问题,我们提出了 Stable-Pose,这是一种新颖的适配器模型,它将从粗到细的注意力屏蔽策略引入视觉 Transformer (ViT) 中,以获得 T2I 模型的准确姿势指导。 Stable-Pose 旨在熟练处理预训练稳定扩散中的姿势条件,提供在图像合成期间对齐姿势表示的精细且有效的方法。 我们利用 ViT 的查询键自注意力机制来探索人体姿势骨骼中不同解剖部分之间的互连。 蒙版姿势图像用于以分层方式平滑地细化基于目标姿势相关特征的注意力图,从粗略级别过渡到精细级别。 此外,我们的损失函数被制定为将更多的重点分配给姿势区域,从而提高模型捕获复杂姿势细节的精度。 我们评估了五个公共数据集在各种室内和室外人体姿势场景下稳定姿势的性能。 Stable-Pose 在 LAION-Human 数据集中获得了 57.1 的 AP 分数,比现有技术 ControlNet 提高了约 13%。 项目链接和代码可在 https://github.com/ai-med/StablePose 获取。
1简介
姿势引导的文本到图像 (T2I) 生成在快速生成逼真的图像方面具有巨大的潜力,这些图像通过文本提示和姿势指令的集成来展示上下文相关性和准确的姿势。 运动学或骨骼姿势提供了一组代表人体骨骼框架的关键点(关节)(如图A.1所示)。 尽管稀疏,但骨架姿势数据为动画、机器人、体育训练和电子商务等各种应用中的 T2I 生成提供了高度灵活性和计算效率的人体姿势的足够细节,使其用户友好且非常适合真实场景时间申请Liu等人[2015]。 与其他形式的姿势信息(例如内容密集的体积姿势)相比,骨架姿势能够传达增强的关节信息,有助于对人体姿势的直观解释和灵活操纵Qi 等人 [2016], Liu 等人 [2017].
传统的姿势引导人体图像生成方法在训练期间需要源图像来指示生成图像的风格 Ma 等人 [2017], Men 等人 [2020], Tang 等人 [2020], Siarohin 等人 [ 2018],朱等人[2019]. 这些方法虽然提供了对外观的控制,但限制了输出的灵活性和多样性,并且在很大程度上取决于训练期间对源-目标数据配对的需求。 相比之下,可控T2I扩散模型的最新进展显示出消除对源图像的需求的潜力,并通过依赖文本提示和外部条件实现更高的创作自由Zhang等人[2023],Zhao等人[2024] ],黄等人[2023],牟等人[2023],李等人[2023]。 为了实现更通用的视觉内容创建,这些方法通常面临着将条件图像与稀疏表示(例如骨架姿势数据)精确对齐的挑战,特别是在处理复杂的姿势场景(例如描绘人体背面或侧面的场景时)(图1)。 此外,现有的方法也可能无法保持准确的身体比例,导致身体外观不自然。

为了解决 T2I 生成模型中稀疏姿势数据绑定不足的问题,一种潜在的策略是捕获人体姿势各个解剖部分之间的远程补丁关系。 在本文中,我们介绍了将视觉 Transformers (ViT) 集成到预训练的 T2I 扩散模型中的 Stable-Pose,例如 Stable Diffusion (SD) Rombach 等人 [2022],目标是通过捕获指定姿势的补丁关系来改进姿势控制。 在稳定姿势中,可学习注意力遵循创新的从粗到细的掩蔽方法,确保姿势调节针对相关姿势区域,同时保留整体图像的多样性。 为了进一步增强这种效果,引入了姿势掩模引导损失,以根据给定的姿势指令优化生成图像的保真度。 我们评估了五个不同数据集的稳定姿势,涵盖室内和室外图像/视频数据集。 与最先进的方法相比,Stable-Pose 在姿势依从性和生成保真度方面实现了最高的准确性和鲁棒性,使其成为增强 T2I 生成中姿势控制的有前途的解决方案。 我们进一步进行了全面的消融研究,以证明我们设计的有效性。 总之,我们的贡献是:
-
•
通过集成新颖的 ViT,解决在姿势引导 T2I 中生成逼真的人类图像的挑战,即使在具有挑战性的条件下,也能实现姿势依从性和图像保真度的高精度合成。
-
•
引入姿势掩模的分层集成以进行从粗到细的指导,并采用新颖的姿势掩模自注意力机制和姿势掩模引导损失函数来增强姿势控制。
-
•
Stable-Pose 有效地学习保留复杂的人体形状结构和准确的身体比例,在五个公开可用的数据集(包括图像和视频数据)中实现卓越的性能。
2相关工作
姿势引导的人体图像生成:传统的姿势引导的人体图像生成以源图像和姿势作为输入,旨在生成特定姿势的逼真人体图像,同时保留源图像的外观。 之前的工作Ma 等人 [2017], Men 等人 [2020], Tang 等人 [2020], Siarohin 等人 [2018], Esser 等人 [2018] 主要利用生成对抗网络(GAN) )或变分自动编码器(VAE),将合成任务视为条件图像生成。 Zhu 等人 Zhu 等人 [2019] 在姿势注意力转移网络(PATN)中集成了用于外观优化的注意力机制。 张等人张等人[2022]实现了双任务姿态变换网络(DPTN),使用变换器模块合并来自两个任务的特征:辅助源图像重建任务和主要姿态变换任务引导目标图像生成任务,从而捕获双任务相关性。 随着最近扩散模型Ho等人[2020]的出现,Bhunia等人Bhunia等人[2023]提出了一种纹理扩散模块来从源图像转移纹理图案到去噪过程。 此外,应用无分类器指导 Ho 和 Salimans [2022] 来为风格和姿势提供解开的指导。 Shen 等人Shen 等人[2023]提出了一种三阶段合成管道,它通过三个扩散模型逐步执行全局特征提取、目标预测和细化。 虽然源图像提供了对外观的控制,但由于训练期间需要配对源-目标数据而产生了限制。 然而,文本消除了这种需要,并为综合提供了更高的灵活性和多样性。 因此,结合文本条件进行姿势骨架引导的人类图像生成显示出重要的前景Liu 等人[2023],Ju 等人[2023b]。
可控扩散模型:大规模T2I扩散模型Rombach 等人 [2022], Ramesh 等人 [2021, 2022], Saharia 等人 [2022], Nichol 等人 [2021] 擅长创建多样化和高质量的图像,但它们通常缺乏仅基于文本的提示的精确控制。 最近的研究旨在利用精明边缘、草图和人体姿势等各种条件来增强对 T2I 模型的控制 Huang 等人 [2023], Zhuang 等人 [2023], Mou 等人 [2023], Li 等人[2023],赵等人[2024],鞠等人[2023b],明等人[2024],邱等人[2023]。 这些方法可大致分为两类:训练整个 T2I 模型或为预训练的 T2I 模型开发插件适配器。 与第一组一样,Composer Huang 等人[2023]使用分解组合范式从头开始训练扩散模型,从而实现多控制能力。 HumanSD Ju 等人 [2023b] 使用专为姿势控制量身定制的热图引导损失来微调整个 SD 模型。 相比之下,T2I-Adapter Mou 等人 [2023] 和 GLIGEN Li 等人 [2023] 训练轻量级适配器,其输出被合并到冻结的 SD 中。 类似地,ControlNet Zhang 等人 [2023] 使用 SD 编码器的可训练副本来编码冻结 SD 的条件。 Uni-ControlNet Zhao 等人[2024]引入了一种单适配器,用于以多尺度方式将多个条件注入到可训练分支。 ControlNet++ Ming 等人[2024]提出通过显式优化生成图像和条件控制之间的循环一致性来改进可控生成。 我们的方法符合后一类,因为它的特点是减少训练时间、成本效益和通用性。
3建议的方法
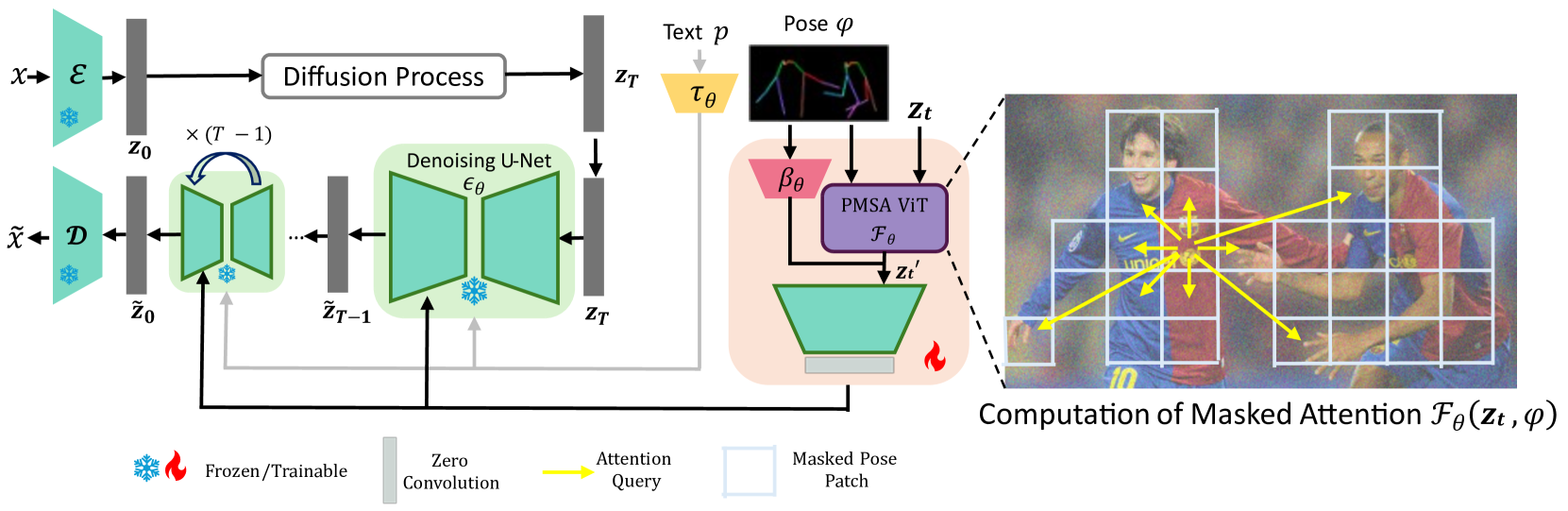
Stable-Pose 具有可训练的 ViT 单元,该单元集成到预先训练的 T2I 扩散模型中,以将扩散模型引导至条件姿势。 在潜在扩散模型(LDM)Rombach等人[2022]中,采用预训练的编码器和解码器来变换输入RGB图像 的高度 和宽度 进入具有减小空间维度的潜在空间,反之亦然。 然后,扩散过程在缩小的潜在空间中有效地进行。 在训练过程中,扩散模型中的前向过程会向已编码的 RGB 图像 中添加噪声,从而生成噪声样本 ,其高度为 ,宽度为 ,通道为 。
| (1) |

其中 是预先确定的超参数,用于控制步骤 中的噪声级别。扩散模型的逆过程,即所谓的去噪,学习每个时间步长的高斯分布的统计数据。 逆过程可表述为:
| (2) |
如图2所示,去噪网络采用UNet主干,该主干配备了Stable-Pose,用于在给定输入条件姿势图像的情况下增强潜在编码。 令 、 表示在批次上具有梯度 的 T 步去噪 UNet,并输入文本提示 。条件LDM是通过最小化通过步骤学习的,其中稳定姿势条件输入姿势上的潜在编码骨架,是将文本提示 所提出的框架详细信息如图3所示。 Stable-Pose 旨在改进 SD 的 UNet 中的冻结解码器,以在条件姿势图像 上条件化输入潜在编码 :
| (3) |
在 Stable-Pose 中,姿势图像 和给定的潜在编码 由两个名为 Pose-Masked Self-Attention (PMSA) 的主要块处理并以这样的方式构成编码器
| (4) |
其中姿势编码器 为输入姿势提供高级特征,而 PMSA 使用自注意力机制探索输入 之间的补丁关系以及姿势图像的二进制掩模版本。 PMSA 采用从粗到细的框架,为潜在编码提供额外的指导,引导其关注条件姿势。 我们将在后续部分中详细介绍每个块。 更新后的潜在编码 随后通过 SD 编码器馈送,后面是一系列零卷积块,其结构类似于 ControlNet Zhang 等人 [2023] 中采用的架构> 确保条件图像的稳健编码。
姿势编码器 是一个可训练的编码器,它将输入姿势骨架图像映射到具有高度、宽度和通道的特征。为此,我们采用六个卷积层与 SiLU 激活层 Elfwing 等人 [2018] 的组合,将输入姿势图像下采样 8 倍。 最后添加一个零卷积层。 由于输入姿态图像包含稀疏信息,这种简单的姿态编码器足以准确编码骨架姿态。
PMSA 寻找潜在编码 内补丁之间的潜在关系。 人体各部分之间的相互联系表明它们之间存在着紧密的关系。 为了捕捉这一点,我们利用自注意力机制。 我们将 划分为 个大小为 的非重叠块,即 。 PMSA 通过三个可学习权重矩阵 将补丁嵌入 投影到查询 、键 和值 中分别为 t4>、 和 。 然后它通过计算所有补丁之间的注意力分数
| (5) |
在此等式中, 表示从输入姿势图像导出的二进制掩码,该掩码由 扩展以用于自注意力计算(参见图 3)。 是通过将姿态图像转换为二进制掩模并将其下采样为与潜在向量 相同大小而获得的。 然后,所得掩码通过长度为 的高斯核进行扩张。然后,扩展二进制掩码 被划分为 大小为 的非重叠补丁。 包含姿势的 patch 被标记为 1,而其他的 patch 被标记为 0。 我们通过函数 基于这些 补丁形成结果 注意力掩模。 如算法 1 所示,对于与姿势区域对应的补丁条目,掩模中相应的行和列都设置为 0。 对于与姿势无关的所有其他区域,我们分配一个非常小的整数值。 注意掩模有助于增强 PMSA 对特定姿势区域的关注。
我们实现了一系列 ViT 块,每个 ViT 块都与一个独特的姿势掩模相关联,在潜在编码上按从粗到细的顺序排列。 这种方法逐渐引导潜在编码符合指定的姿势条件。 如果表示一组高斯核,其中,则从粗到细的自注意力通过以下方式获得
| (6) | ||||
每个编码都经过前馈单元的进一步处理,将得到的集成到姿势编码器的特征中,如图3。 前馈模块由两个与 dropout 层相结合的线性变换 Ba 等人 [2016] 和 ReLU 非线性激活函数 Agarap [2018] 组成。
Pose-mask 引导损失训练:SD 模型的硬件和数据集成本很高。 因此,用于冻结 SD 模型的插件适配器(例如 Stable-Pose)可以通过消除计算梯度或维护 SD 参数优化器状态的需要来提高训练效率。 相反,优化过程的重点是改进稳定姿势参数。 稳定姿势中的损失与从粗到细的方法一致,定义如下:
| (7) | ||||
这里,表示预定的姿势掩模指导超参数,强调掩模区域内容的重要性。
4实验结果
| Dataset | Method | Pose Accuracy | Image Quality | T2I Alignment | |||||
|---|---|---|---|---|---|---|---|---|---|
| AP | CAP | PCE | FID | KID | CLIP-score | ||||
| Human-Art | SD* | 0.24 | 55.71 | 2.30 | 11.53 | 3.36 | 33.33 | ||
| T2I-Adapter | 27.22 | 65.65 | 1.75 | 11.92 | 2.73 | 33.27 | |||
| ControlNet | 39.52 | 69.19 | 1.54 | 11.01 | 2.23 | 32.65 | |||
| Uni-ControlNet | 41.94 | 69.32 | 1.48 | 14.63 | 2.30 | 32.51 | |||
| GLIGEN | 18.24 | 69.15 | 1.46 | – | – | 32.52 | |||
| HumanSD | 44.57 | 69.68 | 1.37 | 10.03 | 2.70 | 32.24 | |||
| Stable-Pose (Ours) | 48.88 | 70.83 | 1.50 | 11.12 | 2.35 | 32.60 | |||
| LAION-Human | SD* | 0.73 | 44.47 | 2.45 | 4.53 | 4.80 | 32.32 | ||
| T2I-Adapter* | 36.65 | 63.64 | 1.62 | 6.77 | 5.44 | 32.30 | |||
| ControlNet* | 44.90 | 66.74 | 1.55 | 7.53 | 6.53 | 32.31 | |||
| Uni-ControlNet | 50.83 | 66.16 | 1.41 | 6.82 | 4.52 | 32.39 | |||
| GLIGEN | 19.65 | 66.29 | 1.40 | – | – | 32.04 | |||
| HumanSD | 50.95 | 65.84 | 1.25 | 5.62 | 7.48 | 30.85 | |||
| Stable-Pose (Ours) | 57.11 | 67.78 | 1.37 | 6.25 | 4.50 | 32.38 | |||
数据集。 我们评估了所提出的 Stable-Pose 以及竞争方法在五个以人类为中心的大型数据集上的性能,包括 Human-Art Ju 等人 [2023a]、LAION-Human Ju 等人 [2023b]、UBC Fashion Zablotskaia 等人 [2019]、Dance Track Sun 等人 [2022] 以及 DAVIS Perazzi 等人 [ 2016]数据集。 数据集和处理步骤的详细信息可以在第 2 节中找到。 A.1。
实施细节。 与之前的工作Zhang 等人[2023],Mou 等人[2023],Zhao 等人[2024]类似,我们在1.5版本的SD上微调了我们的模型。 我们使用 Adam Kingma 和 Ba [2014] 优化器,学习率为 。 对于我们提出的 PMSA ViT 模块,我们采用深度 2 和补丁大小 2,其中使用两个高斯滤波器生成从粗到细的姿势掩模,每个滤波器的 sigma 值为 3,但内核大小不同为 23 和分别为13。 我们将在第 2 节中更详细地探讨这些超参数的影响。 4.2。 在姿势掩模引导损失函数中,我们将 设置为 5 作为引导因子。 我们还按照Zhang等人[2023]以0.5的概率将文本提示随机替换为空字符串,旨在加强对姿势输入的控制。 在推理过程中,没有删除任何文本提示,并使用时间步长为 50 的 DDIM 采样器 Song 等人 [2020] 来生成图像。 在 Human-Art 数据集上,我们对所有技术(包括我们的技术)进行了 10 个 epoch 的训练,以确保公平的比较。 在 LAION-Human 子集上,我们训练了 Stable-Pose、HumanSD Ju 等人 [2023b]、GLIGEN Li 等人 [2023] 和 Uni-ControlNet Zhao等人 [2024] 10 个时期,而由于计算限制,我们使用了其他技术发布的检查点。 该训练使用两个 NVIDIA A100 GPU 执行,我们的方法对于 Human-Art 数据集需要 15 小时,对于 LAION-Human 子集需要 70 小时。 与 SOTA 技术相比,这意味着 GPU 时间大幅减少。 例如,T2I-Adapter 需要大约 300 个 GPU 小时才能在大型数据集上进行训练。 相比之下,我们的方法只需要不到四分之一的时间,并且仍然提供卓越的性能。
评估指标。 我们采用六个指标进行评估,涵盖姿势准确性、图像质量和文本图像对齐。 对于姿势精度,我们采用平均精度(AP)、基于姿势余弦相似度的 AP (CAP) cap 和人数计数误差 (PCE) Cheong 等人 [2022],测量提供的姿势与预训练姿势估计器HigherHRNet Cheng 等人[2020]从生成图像中提取的姿势结果之间的准确性。 对于图像质量,我们使用 Fréchet 起始距离 (FID) Heusel 等人 [2017] 和内核起始距离 (KID) Bińkowski 等人 [2018]。 这两个指标都衡量生成图像的多样性和保真度,并广泛用于图像合成任务。 对于文本-图像对齐,我们包含了 CLIP 分数 Radford 等人 [2021],它表明 CLIP 模型认为文本描述图像的程度。 评估指标的详细信息可以在第 2 节中找到。 A.2。
4.1结果
定量和定性结果。 表1报告了不同方法在两个数据集上的定量结果。 我们报告了平均精度 (AP)、基于姿态余弦相似度的 AP (CAP)、人数计数误差 (PCE)、Fréchet 起始距离 (FID)、内核起始距离 (KID) 和 CLIP 相似度 (CLIP-score) 。 为了便于阅读,Human-Art 的 KID 乘以 100,LAION-Human 的 KID 乘以 1000。 表1显示,Stable-Pose 取得了最高的 AP(Human-Art 为 48.87,LAION-Human 为 57.41)和 CAP(Human-Art 为 71.04,LAION-Human 为 68.06),超过了 SOTA方法提高了10%以上。 这凸显了稳定姿势在姿势对齐方面的优越性。 在图像质量和文本图像对齐方面,Stable-Pose 取得了与其他方法相当的结果,FID/KID 分数仅存在微小差异,但差异可以忽略不计,并且结果质量仍然很高。 总体而言,这些结果强调了 Stable-Pose 在姿势控制和视觉保真度方面的卓越准确性和鲁棒性。
Human-Art Ju 等人 [2023a] 和 LAION-Human Ju 等人 [2023b] 获得的定性结果如图 4 所示。 与定量结果一致,即使在涉及复杂姿势的场景中,Stable-Pose 与其他 SOTA 方法相比,在姿势精度和文本对齐方面都表现出优越的控制能力(图 4 的第一行,这是一个图的后视图)和多个个体(图4的第三行),而其他方法无法一致地保持原始姿势指令的完整性。 这在动态姿势(例如瑜伽姿势和体育活动)中尤其明显,其中稳定姿势能够比其他姿势更忠实地捕捉姿势动态。

不同姿势方向的结果。 我们的实验表明,当前的 SOTA 方法在以不太常见的方向(例如侧面或背部姿势)创建人类图像时常常会出现问题。 为了研究这些方法在渲染非典型姿势方面的能力,我们从 UBC 时尚数据集 Zablotskaia 等人 [2019] 中收集了约 2,650 张图像,其中仅包含正面、侧面和背面姿势。 我们评估了 LAION-Human 数据集中每种技术的检查点,以评估姿势对齐。 如表2所示,Stable-Pose 在识别和生成所有姿势方向的人体方面显着优于其他方法,特别是对于侧面和后视图中的罕见姿势,在美联社。 这进一步验证了Stable-Pose的鲁棒可控性。
| Orientation | T2I-Adapter | ControlNet | Uni-ControlNet | GLIGEN | HumanSD | Stable-Pose (Ours) |
|---|---|---|---|---|---|---|
| Front | 72.20 | 74.64 | 79.47 | 73.97 | 76.83 | |
| Side | 36.80 | 52.83 | 58.26 | 45.32 | 57.09 | |
| Back | 6.03 | 23.68 | 19.97 | 4.45 | 11.05 |
| Method | DAVIS | Dance Track | ||
|---|---|---|---|---|
| AP | CAP | AP | CAP | |
| T2I-Adapter | 20.28 | 60.76 | 10.36 | 72.38 |
| ControlNet | 30.13 | 60.81 | 16.45 | 73.16 |
| Uni-ControlNet | 37.64 | 60.57 | 25.22 | 73.62 |
| GLIGEN | 12.17 | 59.87 | 5.61 | 72.57 |
| HumanSD | 38.32 | 60.59 | 24.13 | 69.93 |
| Stable-Pose (Ours) | 42.87 | 62.43 | 28.58 | 74.97 |
室外和室内姿势的结果。 我们扩展了对室外和室内姿势引导 T2I 生成的评估。 我们从 DAVIS 数据集 Perazzi 等人 [2016] 中选择了大约 2,000 帧,其中包含人类户外活动的视频,作为我们的户外姿势评估。 此外,我们从 Dance Track 数据集中随机选择了约 2000 张图像Sun 等人[2022],其特点是群舞视频,大多数视频是在室内拍摄的,多人且姿势复杂,如下室内姿势对齐评估。 如表 3 所示,Stable-Pose 取得的一致最高 AP 和 CAP 分数证明了其在不同环境中生成姿势控制 T2I 的稳健性,凸显了其作为姿势引导视频生成骨干的潜力。
4.2消融研究
我们在 Human-Art 数据集上对 Stable-Pose 进行了全面的消融研究,包括姿势掩模的有效性、从粗到细的设计、姿势掩模引导强度以及 PMSA 及其 ViT 主干的有效性。
姿势蒙版的有效性。 为了评估姿势掩模作为我们提出的 PMSA 和姿势掩模引导损失函数的输入的影响,我们与从 PMSA 和/或相关损失函数中删除它们进行了比较。 如表4所示,在 PMSA 和损失函数中加入姿势掩模显着增强了姿势对齐和图像质量的性能。
| Pose mask | AP | CAP | PCE | FID | KID | CLIP-score | |
|---|---|---|---|---|---|---|---|
| in PMSA | in loss | ||||||
| ✗ | ✗ | 39.40 | 69.18 | 1.55 | 13.94 | 2.56 | 32.63 |
| ✓ | ✗ | 44.50 | 70.51 | 1.51 | 14.24 | 2.61 | 32.58 |
| ✗ | ✓ | 45.39 | 70.18 | 1.56 | 13.17 | 2.62 | 32.65 |
| ✓ | ✓ | 48.88 | 70.83 | 1.50 | 11.12 | 2.35 | 32.60 |
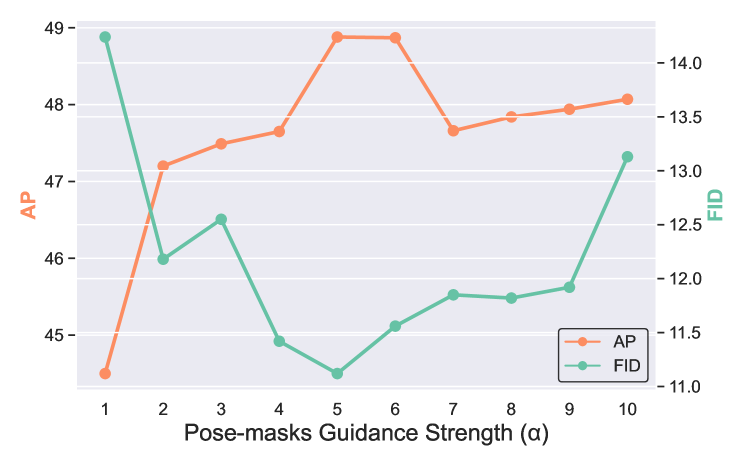
从粗到细的掩蔽指南。 姿势掩模的粒度由高斯滤波器中的高斯内核指定,其中较大的内核生成较粗糙的姿势掩模。 我们比较了恒定粒度、从细到粗以及从粗到细设置的结果。 所有实验均基于具有 PMSA 且深度为 2 的 ViT 以及具有固定 sigma 的高斯滤波器。 如表 5 所示,从粗到细的方法始终能够在姿势对齐和图像质量指标上提供最佳性能。 这种改进可能是由于其姿势区域中从粗粒度到细粒度的逐步细化。 通过有条不紊地将焦点缩小到更精确的可控区域,该策略平稳地提高了姿态调整的准确性和生成图像的整体质量。
| Pose mask granularity | AP | CAP | PCE | FID | KID | CLIP-score |
|---|---|---|---|---|---|---|
| Constant (23, 23) | 48.10 | 70.77 | 1.59 | 12.55 | 2.59 | 32.62 |
| Fine-to-coarse (13, 23) | 47.86 | 70.84 | 1.57 | 12.48 | 2.54 | 32.54 |
| Coarse-to-fine (23, 13) | 48.88 | 70.83 | 1.50 | 11.12 | 2.35 | 32.60 |
PMSA 及其 ViT 支柱的有效性。 我们的 PMSA 包含额外的姿势蒙版,这些蒙版源自使用高斯滤波器扩展的姿势骨架。 为了评估 PMSA 的有效性,我们仅将这些增强姿势掩模集成到 ControlNet 中,而没有 PMSA 模块。 我们探索了两种配置:一种配置是原始姿势骨架与一个粗略放大的姿势蒙版连接,称为 ControlNet-PM1,另一种配置是与粗略放大和精细放大的姿势蒙版连接,称为 ControlNet-PM2。 表6表明,扩大的姿势掩模在ControlNet中仅产生微小的改进,这表明在Stable-Pose中观察到的实质性增强主要归因于PMSA的创新设计,而不是额外的姿势掩模输入。
| Method | AP | CAP | PCE | FID | KID | CLIP-score |
|---|---|---|---|---|---|---|
| ControlNet | 39.52 | 69.19 | 1.54 | 11.01 | 2.23 | 32.65 |
| ControlNet-PM1 | 39.24 | 68.45 | 1.50 | 11.52 | 2.26 | 32.70 |
| ControlNet-PM2 | 40.73 | 69.27 | 1.49 | 11.63 | 2.24 | 32.67 |
| PMSA w/ ResNet | 45.24 | 70.09 | 1.56 | 13.48 | 2.60 | 32.58 |
| PMSA w/ ViT (Ours) | 48.88 | 70.83 | 1.50 | 11.12 | 2.35 | 32.60 |
此外,为了验证 PMSA(PMSA w/ ViT)中 ViT 主干的有效性,我们将其替换为在残差块之间运行的传统姿态屏蔽自注意力模块(PMSA w/ ResNet)。 我们在两种配置中集成了相同的姿势蒙版,以确保公平的比较。 表6表明PMSA中的ViT设计明显优于传统方法。 这证实了 ViT 捕获人体姿势各个解剖部分之间的长距离、分块交互以增强姿势对齐的卓越能力。
5讨论与结论
我们推出了 Stable-Pose,这是一种新颖的适配器,它利用视觉变换器和从粗到细的姿势屏蔽自注意力策略,专门设计用于在 T2I 生成期间有效管理精确的姿势控制。 Stable-Pose 在五个不同的公共数据集上优于当前的可控 T2I 生成方法,在不同环境和各种姿势场景中展示了高生成鲁棒性。 值得注意的是,在涉及罕见姿势(例如侧视图或后视图以及多个人物)的复杂场景中,稳定姿势在姿势和视觉保真度方面都表现出了卓越的性能。 这可以归因于其通过我们复杂的调节设计捕获人体姿势图像的不同解剖部分之间的远程补丁关系的先进能力。 因此,稳定姿势在要求高姿势精度的应用中具有巨大的潜力。 Stable-Pose 的局限性之一是其推理时间稍长,这主要是由于 ViT 中自注意力机制的集成所致。 此外,尽管在姿势控制方面表现出色,但稳定姿势尚未使用边缘图等其他条件进行评估。 尽管如此,它的设计可以直接适应各种外部条件,这表明其具有广泛的应用潜力。
更广泛的影响:Stable-Pose 出色的姿势控制使其成为创作各种艺术作品、动画、电影和体育训练节目的宝贵工具。 此外,它可以成为医疗保健和康复领域的可靠工具,用于纠正姿势和预防患者出现肌肉骨骼问题。 然而,也存在滥用生成伪造图像或视频的风险,这可能会造成负面的社会担忧。 解决这些问题需要结合技术保障、监管框架和道德准则。
致谢
这项工作得到了慕尼黑机器学习中心 (MCML) 和德国研究基金会 (DFG) 的支持。 作者衷心感谢莱布尼茨超级计算中心提供的计算和数据资源。
参考
- [1] Posenet similarity. URL https://github.com/freshsomebody/posenet-similarity.
- Agarap [2018] A. F. Agarap. Deep learning using rectified linear units (relu). arXiv preprint arXiv:1803.08375, 2018.
- Ba et al. [2016] J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Bhunia et al. [2023] A. K. Bhunia, S. Khan, H. Cholakkal, R. M. Anwer, J. Laaksonen, M. Shah, and F. S. Khan. Person image synthesis via denoising diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5968–5976, 2023.
- Bińkowski et al. [2018] M. Bińkowski, D. J. Sutherland, M. Arbel, and A. Gretton. Demystifying mmd gans. arXiv preprint arXiv:1801.01401, 2018.
- Cheng et al. [2020] B. Cheng, B. Xiao, J. Wang, H. Shi, T. S. Huang, and L. Zhang. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5386–5395, 2020.
- Cheong et al. [2022] S. Y. Cheong, A. Mustafa, and A. Gilbert. Kpe: Keypoint pose encoding for transformer-based image generation. arXiv preprint arXiv:2203.04907, 2022.
- Elfwing et al. [2018] S. Elfwing, E. Uchibe, and K. Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural networks, 107:3–11, 2018.
- Esser et al. [2018] P. Esser, E. Sutter, and B. Ommer. A variational u-net for conditional appearance and shape generation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8857–8866, 2018.
- Heusel et al. [2017] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Ho and Salimans [2022] J. Ho and T. Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- Ho et al. [2020] J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Huang et al. [2023] L. Huang, D. Chen, Y. Liu, Y. Shen, D. Zhao, and J. Zhou. Composer: Creative and controllable image synthesis with composable conditions. arXiv preprint arXiv:2302.09778, 2023.
- Ju et al. [2023a] X. Ju, A. Zeng, J. Wang, Q. Xu, and L. Zhang. Human-art: A versatile human-centric dataset bridging natural and artificial scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 618–629, 2023a.
- Ju et al. [2023b] X. Ju, A. Zeng, C. Zhao, J. Wang, L. Zhang, and Q. Xu. Humansd: A native skeleton-guided diffusion model for human image generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15988–15998, 2023b.
- Kingma and Ba [2014] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Li et al. [2023] Y. Li, H. Liu, Q. Wu, F. Mu, J. Yang, J. Gao, C. Li, and Y. J. Lee. Gligen: Open-set grounded text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22511–22521, 2023.
- Liu et al. [2023] D. Liu, L. Wu, F. Zheng, L. Liu, and M. Wang. Verbal-person nets: Pose-guided multi-granularity language-to-person generation. IEEE Transactions on Neural Networks and Learning Systems, 34(11):8589–8601, 2023.
- Liu et al. [2017] J. Liu, G. Wang, L.-Y. Duan, K. Abdiyeva, and A. C. Kot. Skeleton-based human action recognition with global context-aware attention lstm networks. IEEE Transactions on Image Processing, 27(4):1586–1599, 2017.
- Liu et al. [2015] Z. Liu, J. Zhu, J. Bu, and C. Chen. A survey of human pose estimation: the body parts parsing based methods. Journal of Visual Communication and Image Representation, 32:10–19, 2015.
- Ma et al. [2017] L. Ma, X. Jia, Q. Sun, B. Schiele, T. Tuytelaars, and L. Van Gool. Pose guided person image generation. Advances in neural information processing systems, 30, 2017.
- Men et al. [2020] Y. Men, Y. Mao, Y. Jiang, W.-Y. Ma, and Z. Lian. Controllable person image synthesis with attribute-decomposed gan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5084–5093, 2020.
- Ming et al. [2024] L. Ming, Y. Taojiannan, K. Huafeng, W. Jie, W. Zhaoning, X. Xuefeng, and C. Chen. Controlnet++: Improving conditional controls with efficient consistency feedback. arXiv preprint arXiv:2404.07987, 2024.
- Mou et al. [2023] C. Mou, X. Wang, L. Xie, Y. Wu, J. Zhang, Z. Qi, Y. Shan, and X. Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453, 2023.
- Nichol et al. [2021] A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741, 2021.
- Perazzi et al. [2016] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. V. Gool, M. Gross, and A. Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Qi et al. [2016] C. R. Qi, H. Su, M. Nießner, A. Dai, M. Yan, and L. J. Guibas. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5648–5656, 2016.
- Qiu et al. [2023] Z. Qiu, W. Liu, H. Feng, Y. Xue, Y. Feng, Z. Liu, D. Zhang, A. Weller, and B. Schölkopf. Controlling text-to-image diffusion by orthogonal finetuning. In NeurIPS, 2023.
- Radford et al. [2021] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Ramesh et al. [2021] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever. Zero-shot text-to-image generation. In International conference on machine learning, pages 8821–8831. Pmlr, 2021.
- Ramesh et al. [2022] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
- Rombach et al. [2022] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Saharia et al. [2022] C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35:36479–36494, 2022.
- Schuhmann et al. [2022] C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
- Shen et al. [2023] F. Shen, H. Ye, J. Zhang, C. Wang, X. Han, and W. Yang. Advancing pose-guided image synthesis with progressive conditional diffusion models. arXiv preprint arXiv:2310.06313, 2023.
- Siarohin et al. [2018] A. Siarohin, E. Sangineto, S. Lathuiliere, and N. Sebe. Deformable gans for pose-based human image generation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3408–3416, 2018.
- Song et al. [2020] J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
- Sun et al. [2022] P. Sun, J. Cao, Y. Jiang, Z. Yuan, S. Bai, K. Kitani, and P. Luo. Dancetrack: Multi-object tracking in uniform appearance and diverse motion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- Szegedy et al. [2016] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016.
- Tang et al. [2020] H. Tang, S. Bai, L. Zhang, P. H. Torr, and N. Sebe. Xinggan for person image generation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV 16, pages 717–734. Springer, 2020.
- Zablotskaia et al. [2019] P. Zablotskaia, A. Siarohin, B. Zhao, and L. Sigal. Dwnet: Dense warp-based network for pose-guided human video generation. arXiv preprint arXiv:1910.09139, 2019.
- Zhang et al. [2023] L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023.
- Zhang et al. [2022] P. Zhang, L. Yang, J.-H. Lai, and X. Xie. Exploring dual-task correlation for pose guided person image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7713–7722, 2022.
- Zhao et al. [2024] S. Zhao, D. Chen, Y.-C. Chen, J. Bao, S. Hao, L. Yuan, and K.-Y. K. Wong. Uni-controlnet: All-in-one control to text-to-image diffusion models. Advances in Neural Information Processing Systems, 36, 2024.
- Zhu et al. [2019] Z. Zhu, T. Huang, B. Shi, M. Yu, B. Wang, and X. Bai. Progressive pose attention transfer for person image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2347–2356, 2019.
附录 A 附录/补充材料

A.1 数据集和预处理
我们的方法和其他技术在五个不同的数据集上进行训练和评估,如下所示:
Human-Art Ju等人[2023a]:Human-Art数据集包含分布在19个场景中的38,000张图像,包括自然场景、2D人工场景和3D人工场景。 我们采用与作者建议的相同的训练验证分割。 Human-Art 中的注释属于国际数字经济学院 (IDEA),并根据署名-非商业-相同方式共享 4.0 国际许可证 (CC-BY-NC-SA 4.0) 获得许可。
LAION-Human Ju 等人[2023b]:LAION-Human源自LAION-5B数据集Schuhmann 等人[2022],由大约 100 万张经过人类估计置信度分数过滤的图像组成。 我们随机选择 200,000 张图像的子集进行训练,并随机选择 20,000 张图像进行验证。 该数据集根据 Creative Common CC-BY 4.0 许可证获得许可,没有特殊限制。 这些图像受其版权保护。
UBC Fashion Zablotskaia 等人 [2019]:UBC Fashion 数据集包含展示时装模特执行转身的序列。 我们提取了代表不同方向的帧:正面、侧面和背面,以严格测试我们的模型处理复杂和不常见姿势的能力。 该数据集产生大约 1100 个正面帧、450 个侧面帧和 1100 个背面帧。 该数据集根据知识共享署名-非商业 4.0 国际公共许可证获得许可。
Dance Track Sun 等人[2022]:Dance Track 数据集呈现集体舞蹈片段,以多个主体和复杂的姿势为代表。 我们从 Dance Track 验证集中精选了 20 个视频,并总共提取了 2000 个帧来评估我们的模型。 DanceTrack 的注释已获得 Creative Commons Attribution 4.0 许可证的许可,并且 DanceTrack 的数据集仅可用于非商业研究目的。
DAVIS Perazzi 等人[2016]:DAVIS 数据集是广泛用于视频相关任务的数据集。 我们从 DAVIS Test-Dev 2017 集中和 DAVIS Test-Challenge 2017 集中随机选择了 26 个以人为中心的场景,提供了大约 2000 个帧用于评估。 DAVIS 数据集是在 BSD 许可证下发布的。
所有数据集都遵循标准化协议,遵循 COCO 和 Human-Art,具有 17 个关键点和每张图像最多 10 个人。 尽管 ControlNet 和 T2I-Adapter 的原始检查点锚定在 OpenPose 关键点协议中,但在不损失准确性的情况下在不同风格之间转换关键点是可行的。 在预处理网络输入数据集时,我们应用 0.05 的分数阈值来过滤关键点并连接相应的关键点,遵循 Human-Art 作者概述的过程。 每条连接线都以不同的颜色描绘,如图A.1所示,使网络能够学习每条线与特定身体部位之间的关联。 请注意,本文中呈现的姿势骨架的颜色仅用于可视化目的,与实验中使用的颜色并不对应。 在训练过程中,我们采用了一致的数据增强,包括 512 像素的随机裁剪、随机旋转、随机颜色偏移和随机亮度对比度。 这些增强被统一应用于所有技术。
值得注意的是,LAION-Human子集的规模及其数据分布与SOTA工作中报告的数据密切相关,例如ControlNet Zhang等人[2023],它是在200,000张图像上进行训练的来源于互联网。 因此,确保公平比较是可能的。 由于上述视频数据集都没有使用姿势或文本描述进行注释,因此我们使用 GPT-4 API 来生成提示,并使用 HighHRNet Cheng 等人 [2020] 来推导姿势标签。
A.2评估指标
我们在这里详细定义评估指标。 FID 假设 Inception v3 模型 Szegedy 等人 [2016] 从真实图像和生成图像中提取的特征遵循高斯分布。 它测量这些分布之间的 Fréchet 距离。 然而,KID 放宽了高斯分布的假设,并使用多项式核计算真实图像和生成图像的 Inception 特征之间的平方最大平均差异 (MMD)。 平均精度 (AP) 计算真实图像和生成图像中关键点之间的对齐情况。 生成图像的姿势由相同的人检测考虑到图像可能包含多人,我们将人数计数错误(PCE)Cheong 等人[2022]作为指标,测量生成图像时的误报率以多人为特色。 CLIP 分数衡量生成的图像和文本提示的嵌入之间的相似性,两者均由 CLIP 编码。