*![[Uncaptioned image]](lego_block_small.png) Block Transformer:用于快速推理的全局到局部
Block Transformer:用于快速推理的全局到局部
语言建模
摘要
本文提出了 Block Transformer 架构,该架构对自回归 Transformer 采用分层全局到局部建模,以减轻自注意力的推理瓶颈。 为了应用自注意力,必须在每个解码步骤从内存中检索所有先前序列的键值(KV)缓存。 因此,这个 KV 缓存 IO 成为批量推理中的一个重要瓶颈。 我们注意到这些成本源于在全局上下文中应用自注意力,因此我们将全局建模的昂贵瓶颈隔离到较低层,并在上层应用快速局部建模 。 为了减轻较低层的剩余成本,我们将输入 Token 聚合成固定大小的块,然后在这个粗略级别应用自注意力。 上下文信息被聚合到单个嵌入中,以使上层能够解码下一个 Token 块,而无需全局关注。 由于没有全局注意力瓶颈,上层可以充分利用计算硬件来最大化推理吞吐量。 通过利用全局和本地模块,与具有同等困惑度的普通 Transformer 相比,Block Transformer 架构的推理吞吐量提高了 10-20 倍。 我们的工作引入了一种通过全局到局部建模的新颖应用来优化语言模型推理的新方法。
1简介
由于自注意力机制会关注所有先前的标记[6, 66],因此使用基于 Transformer 的自回归语言模型 (LM) 生成标记的成本很高。 为了减轻自注意力的成本,通常在自回归解码期间缓存所有层中所有 Token 的键值(KV)状态。 然而,虽然每个解码步骤只计算单个词符的 KV 状态,但它仍然需要加载所有先前词符的 KV 状态来计算自注意力分数。 随后,该 KV 缓存 IO 大部分占据了服务 LM 的推理成本。 虽然已经提出了几种技术来降低注意力组件的推理成本[20,35,69],但开发有效的基于 Transformer 的LM架构以本质上避免注意力开销仍然是一个持续的挑战。
分层的全局到局部架构[49, 31]已经显示出通过解决粗略细节的全局依赖性并捕获局部区域内的精细细节来有效地对大规模数据进行建模的巨大潜力。 受这些框架的启发,我们发现了一个独特的机会来缓解自回归 Transformer 推理中的关键瓶颈:(1)粗略的全局建模可以通过其粒度降低总体成本;但更重要的是,(2) 局部自注意力几乎可以消除注意力成本,因为不需要在小型本地上下文之外计算、存储和检索过去标记的 KV 缓存。
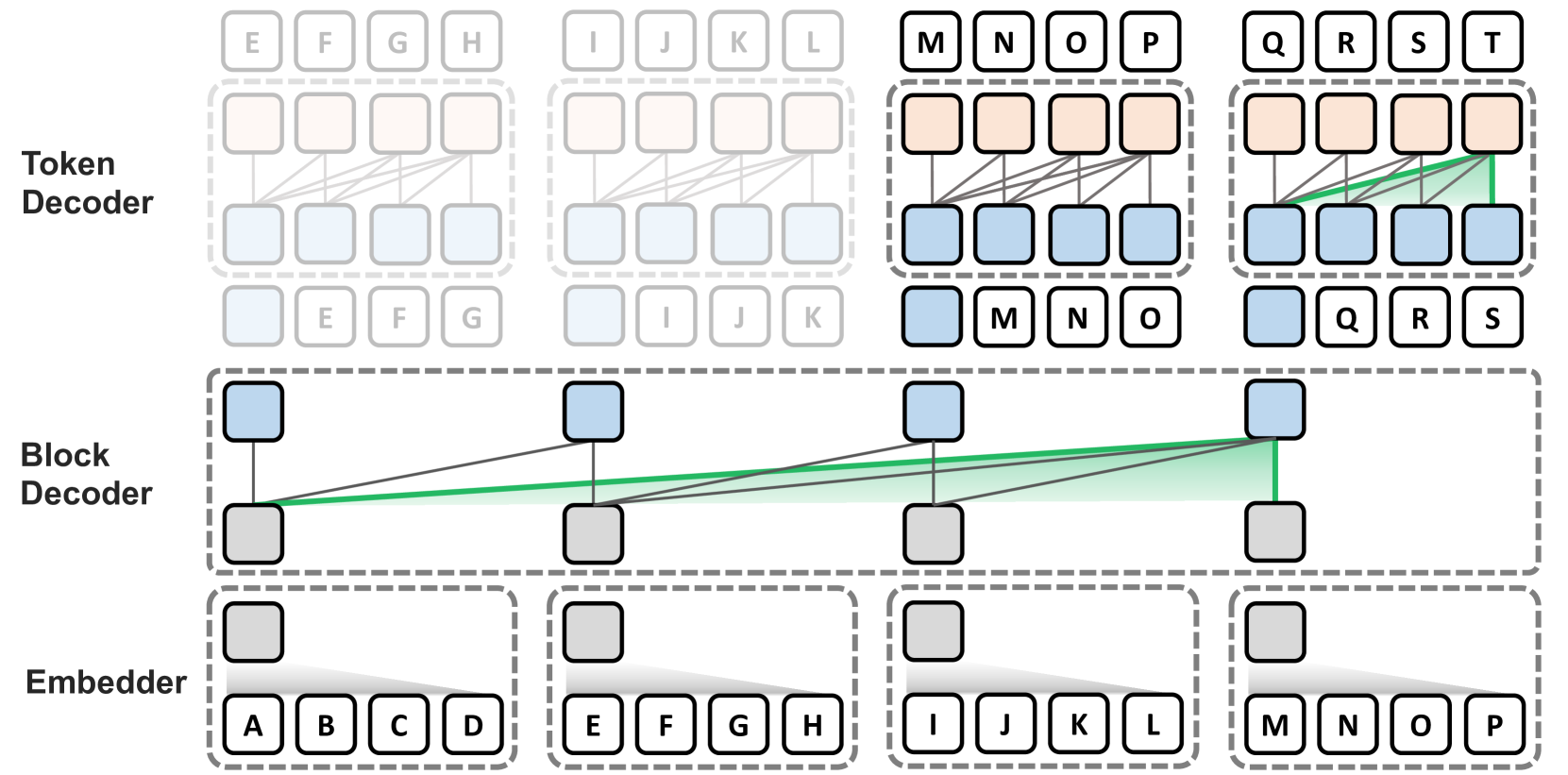
本文介绍了 Block Transformer 架构,如 Figure 1 所示,该架构通过下层粗块(每个粗块代表多个词符)之间的自我关注来模拟全局依赖关系,并对上层每个局部块内的细粒度词符进行解码。 具体来说,称为 (1) embedder 的轻量级模块首先将每个 输入标记块嵌入到输入块嵌入中。 这些成为 (2) 块解码器的输入单元,这是一个自回归 Transformer,它在块之间应用自注意力来解码上下文块嵌入,其中包含用于预测下一个块的信息堵塞。 最后,(3)词符解码器自回归解码下一个块的词符内容,仅在块内的标记之间应用局部自注意力。 虽然这使得词符解码器仅依赖输出块嵌入来获取全局上下文信息,但它极大地降低了自注意力成本,使其与总上下文长度呈线性关系,并且无需在推理过程中预填充提示标记。
虽然已经提出了类似的 Transformer 架构来处理由原始字节 [74] 组成的长序列,但先前的工作认为全局模块是主要模型,受益于粗略处理,而嵌入器和本地模块只是简单地在粗略表示和精细表示之间进行映射以减少上下文长度。 我们在 LM 中进行全局到局部建模的方法挑战了这些先前的信念,并揭示了先前工作中被忽视的实质性推理时间优势。 具体来说,我们提出全局块解码器和本地词符解码器都可以在语言建模中发挥重要作用,因此术语全局到本地语言建模。 我们的消融表明,全局和本地模块之间更平衡的参数分配可以提高性能,并且由于本地模块中的上下文长度显着缩短,因此还可以提高吞吐量。
对多达 14 亿个参数的模型进行的大量实验表明,Block Transformer 显着提高了预填充和解码密集型场景的推理吞吐量,与相比,实现了 10–20 吞吐量增益具有同等困惑度或零样本任务性能的普通 Transformer 。 尽管 Block Transformer 中的全局注意力受到架构限制,但与普通 Transformer 模型相比,我们的模型表现出了类似的利用全局上下文的能力。 此外,我们还表明,可以将预训练的普通模型升级训练到 Block Transformer 中,从而非常接近从头开始预训练的模型的性能,仅使用 10% 的适应预算。
我们的主要贡献总结如下:
-
•
我们首次认识到全局和局部建模在自回归变换器中的核心作用和推理时间优势--尤其是局部模块的重要性。
-
•
与普通 Transformer 相比,我们利用这些见解来优化架构中的推理吞吐量,从而显着扩展吞吐量的帕累托性能前沿。
2 块 Transformer
Block Transformer 通过将完整上下文和详细交互的理解分为两个不同的阶段,采用具有分层范式的全局和局部注意力机制。 准确地说,全局上下文在较低层捕获为粗块级粒度,其中每个块由聚合到单个嵌入中的固定数量的 Token 组成。 局部依赖性在上层得到解决,其中多个子字标记通过仅参与来自块解码器的上下文块嵌入以自回归方式被解码。 Block Transformer 由三个组件组成:
-
1.
嵌入器:嵌入器将每个 Token 块聚合到输入块嵌入中。
-
2.
块解码器:块解码器在整个块序列上应用自注意力来建模全局依赖性。
-
3.
词符解码器:词符解码器在每个块内应用自注意力来处理细粒度的本地依赖关系并解码各个 Token 。
2.1 为什么Block Transformer高效?
我们架构设计的主要目标是最大限度地减少推理过程中的挂钟瓶颈。 在普通 Transformer 中,对所有先前标记的自注意力的全局处理显着阻碍了批量解码吞吐量,这主要是由于检索先前 KV 缓存 [20, 25] 的内存开销。 这还需要在解码第一个词符之前完全预填充所有提示 Token (通常相当长),从而导致延迟 [1, 25] 增加。
全局到局部方法可以通过将全局建模的昂贵瓶颈隔离到较低层并在上层的独立块内执行局部建模来减轻这些成本。 粗粒度全局建模(块级解码)通过块长度来缓解 KV 缓存瓶颈,同时保持考虑完整上下文的能力 本地解码无需预填充成本,几乎消除了 KV 缓存开销,因此受益于推理硬件上计算单元利用率的显着提高。 这使得词符解码器能够使用更多的 FLOP 进行细粒度的语言建模,同时对推理吞吐量的影响最小。 Table 1 概述了预填充和解码阶段的主要墙时间瓶颈,并总结了我们的块和词符解码器的效率增益。
尽管我们的模型需要比普通 Transformer 更多的参数来保持可比较的性能,但吞吐量的实际瓶颈是 KV 缓存开销,这使得我们的模型仍然能够实现更高的速度改进。 因此,我们专注于像云平台这样的生产系统,它可以满足更高的参数需求。 边缘设备受内存[3]限制,通常使用小批量[61]。 由于参数 IO 是一个关键瓶颈[51],因此我们将针对设备端场景的 Block Transformer 的优化留给未来的工作。
| Inference bottleneck | Relative complexity | |||||
| Metric | Name | Prefill | Decode | Vanilla | Block | |
| Memory | Parameter | - | - | | ||
| KV cache | - | - | ||||
| IO | Parameter | ✗ | ✗ | | ||
| KV cache | ✗ | ✓ | ||||
| FLOPs | Attention score | ✗ | ✓ | |||
| Linear projections | ✓ | ✗ | ||||
2.2嵌入器
考虑到我们研究中的小块长度 (2-8),我们的嵌入器设计优先考虑简单性。 我们主要使用查找表来检索和连接可训练的词符嵌入,其中词符嵌入维度设置为,与 是整个网络中使用的块表示的维度)。 虽然我们探索了小型编码器 Transformer (Appendix F)等变体,但这些并没有带来性能改进(subsection 3.4)。
2.3 块解码器
块解码器的目的是通过关注前面的块,利用嵌入器的输出作为输入来上下文化块表示。 该自回归 Transformer 在块级别运行,产生输出块嵌入(也称为上下文嵌入),使词符解码器能够自动回归解码后续块的词符内容。 给定来自嵌入器的输入块嵌入(从输入标记 派生),块解码器输出一个上下文嵌入,其中包含用于预测 的信息。
这种方法通过使用粗粒度块输入而不是单个 Token 来减轻自注意力的二次成本,同时保留全局建模能力和密集注意力硬件加速的便利性[75]。 与普通 Transformer 相比,这将给定序列的上下文长度减少了 。 就 FLOP(预填充期间的主要瓶颈)而言,所有位置计算减少了 倍,注意力分数计算减少了 [74]. 在解码过程中,KV 缓存使用量和 KV 缓存 IO(批量解码期间的主要瓶颈)分别减少 和 ,从而允许更大的批量大小和更高的计算利用率。
2.4 Token 解码器
词符解码器使用上下文块嵌入作为全局上下文信息的唯一来源来本地解码下一个块的各个标记。 词符解码器也是一个标准的自回归 Transformer,具有自己的嵌入表 和分类器。 设计词符解码器的关键在于如何将上下文嵌入融入到解码过程中,从而有效地利用词符解码器的高计算密度。
词符解码器消除了预填充(仅在块解码器中必需),因为上下文信息由输出块嵌入提供 - 因此术语上下文嵌入。 此外,批量解码过程中的主要瓶颈——KV缓存IO也几乎被消除。 虽然普通注意力的 KV 缓存 IO 与完整上下文长度 () 成二次方,但词符解码器的本地注意力在 块上每个块的成本为 ,从而导致整个上下文长度的线性成本和 的缩减因子(例如,我们的主要模型中的 )。 与普通 Transformer 相比,这可以显着提高计算单元利用率,普通 Transformer 的模型 FLOP 利用率 (MFU) [51] 约为 1%,从而使额外 FLOP 的推理时间成本相对便宜。
为了合并上下文嵌入并利用这种低成本计算,我们将上下文块嵌入投影到前缀标记中,从而进一步细化全局上下文。 扩展前缀标记的数量(前缀长度)可以拓宽词符解码器的计算宽度,并可以更好地关注上下文信息,类似于暂停标记[29]。 由于并行处理和较小的本地上下文,这些额外的前缀标记不会产生显着的墙上时间开销。 虽然我们还考虑了基于求和和交叉注意的变体(Appendix F),但事实证明这些方法不如我们的主要方法(subsection 3.4)有效。
3实验
3.1实验设置
我们使用 Pythia [8] 的 Transformer 架构,并在上下文长度为 2048 的 Pile [26, 7] 上训练 vanilla 和 Block Transformer 模型。 这些模型在 300B Token 上进行预训练,相当于大约 1.5 个 epoch。 我们采用 HuggingFace 训练框架[70]。 八个具有 40 GiB VRAM 的 A100 GPU 用于训练,而 H100 GPU 用于推理墙时间测量。 每个小节的实验细节总结在Appendix G中。
3.2 主要结果
| # Parameter | Zero-shot Eval | Memory | Throughput | |||||||||
| Models | Total | N-Emb | Loss | LD | WK | HS | PQ | ARC | ||||
| Vanilla | 31M | 5M | 3.002 | 282.7 | 78.4 | 26.47 | 57.97 | 37.10 | 355.0 | 38.5 | 10.8 | 41.6 |
| 70M | 19M | 2.820 | 67.2 | 46.9 | 27.20 | 59.73 | 40.24 | 390.0 | 76.8 | 6.9 | 19.1 | |
| 160M | 85M | 2.476 | 20.2 | 28.5 | 29.80 | 64.22 | 46.85 | 675.0 | 229.6 | 2.3 | 6.2 | |
| 410M | 302M | 2.224 | 10.0 | 20.1 | 35.05 | 68.10 | 51.68 | 1140.0 | 608.2 | 0.8 | 2.1 | |
| Block | 33M* | 5M | 3.578 | 2359.9 | 134.2 | 26.25 | 55.90 | 35.17 | 25.0 | 5.0 | 272.3 | 809.5 |
| 77M* | 19M | 3.181 | 390.5 | 80.1 | 27.21 | 57.69 | 38.31 | 48.9 | 9.9 | 175.3 | 421.4 | |
| 170M* | 85M | 2.753 | 67.9 | 43.7 | 28.28 | 62.22 | 43.43 | 56.3 | 29.1 | 59.0 | 134.7 | |
| 420M | 302M | 2.445 | 29.5 | 27.7 | 31.13 | 64.35 | 48.48 | 105.0 | 77.2 | 21.0 | 44.1 | |
| 1.0B | 805M | 2.268 | 16.5 | 21.4 | 34.68 | 68.18 | 52.26 | 130.2 | 102.8 | 19.8 | 42.5 | |
| 1.4B | 1.2B | 2.188 | 12.2 | 19.1 | 36.66 | 68.63 | 54.63 | 194.2 | 153.9 | 12.4 | 25.7 | |
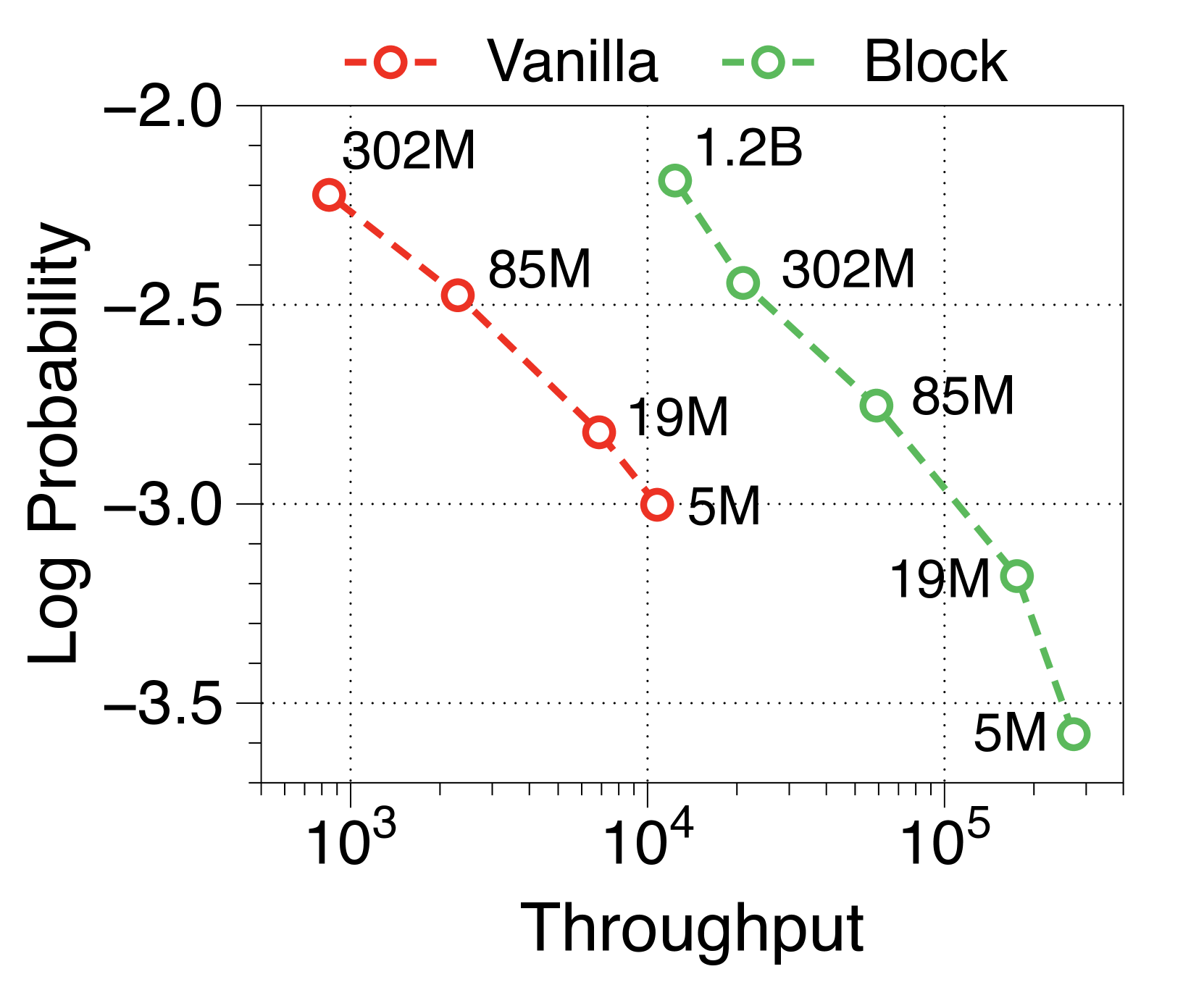
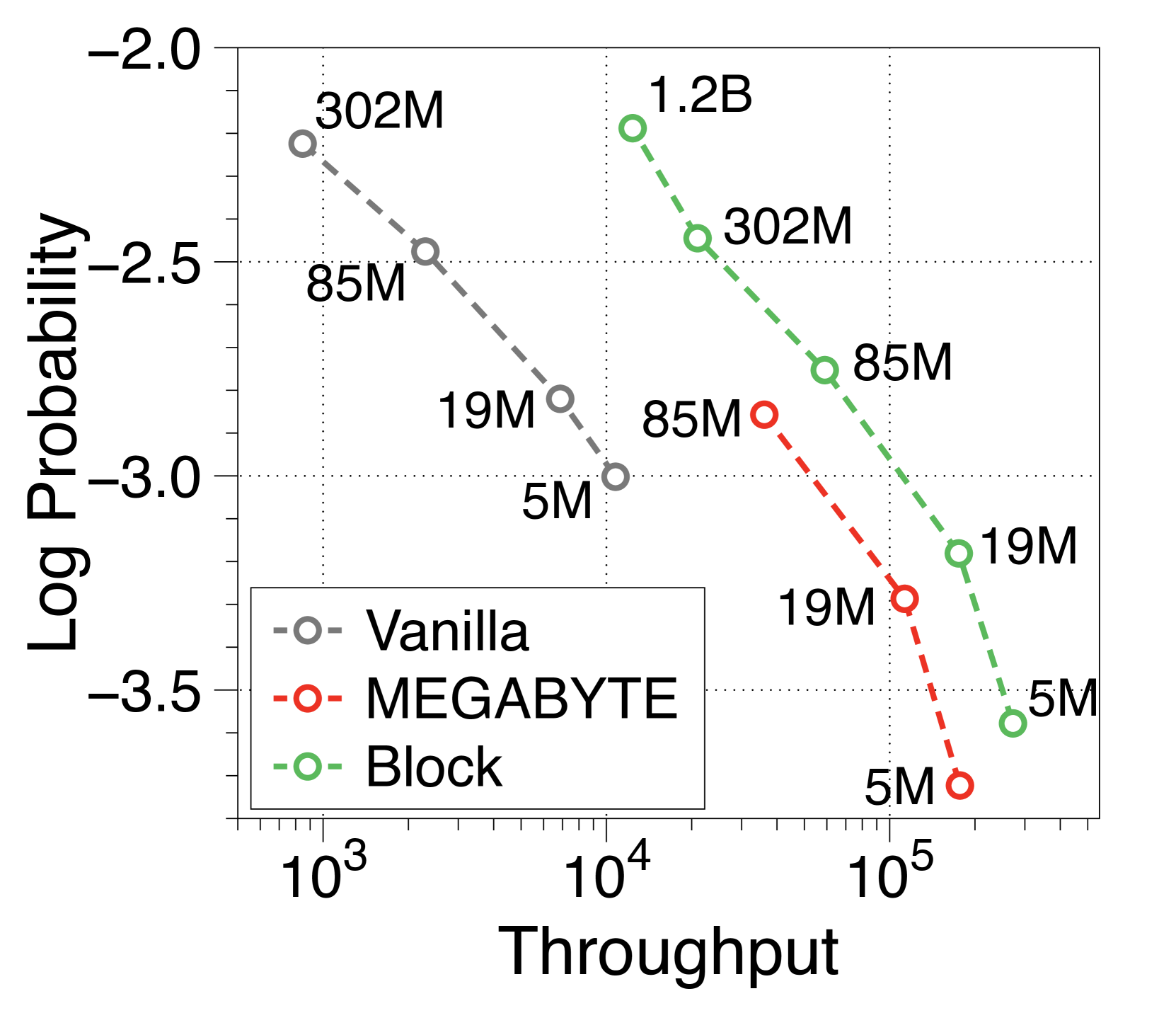
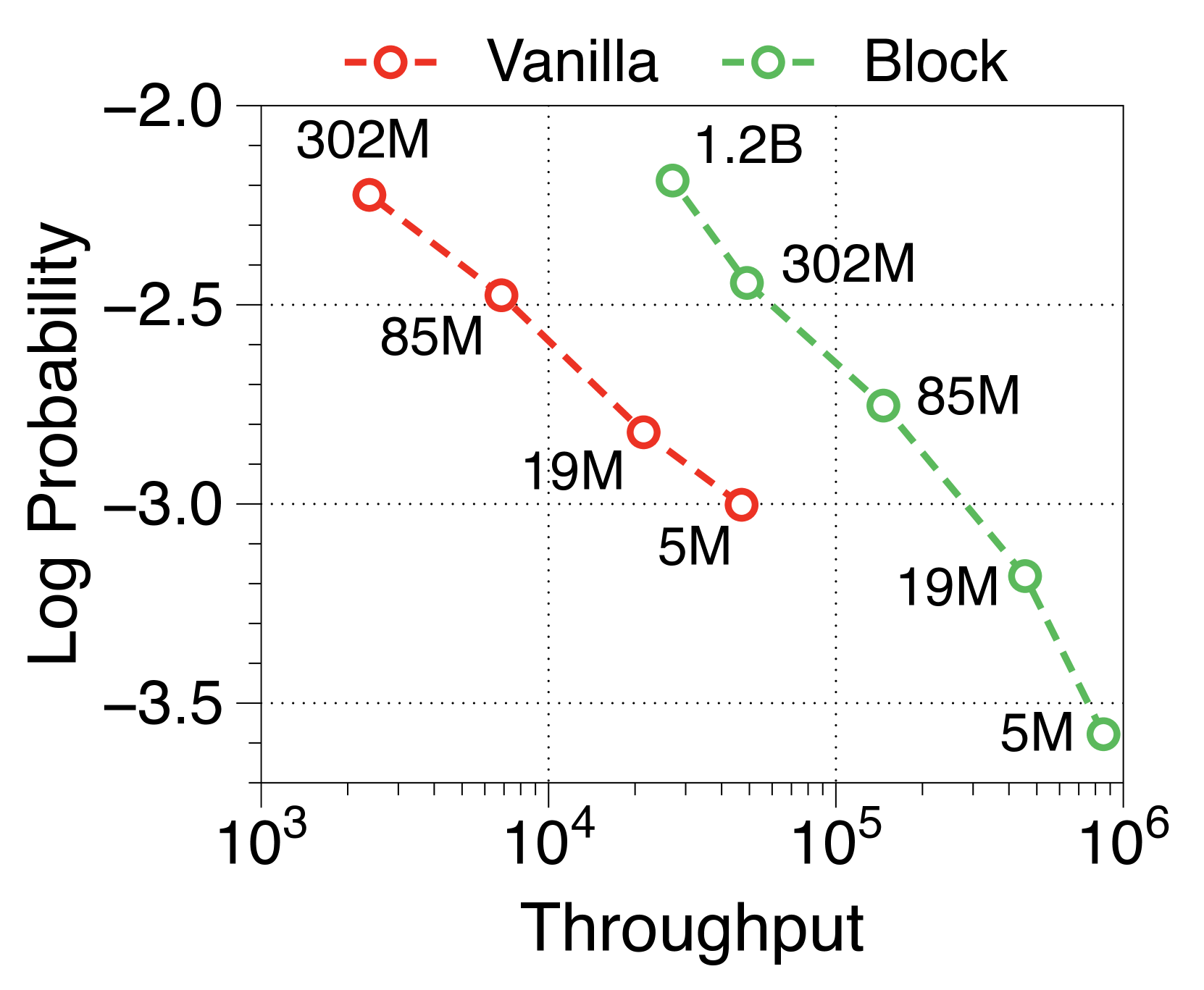
在Table 2中,我们测量了Block Transformer的语言建模性能。 块模型被缩放为具有与普通模型变体相同数量的非嵌入参数。 当我们的模型具有两倍或三倍的参数时,在五个零样本评估任务上实现了与普通模型相当的困惑度和准确性。 这是预期的结果,因为两个独立的解码器每次前向传递花费的 FLOP 更少,从而在块级将注意力复杂度降低了 倍,在 token 上将注意力复杂度降低了大约 。等级。
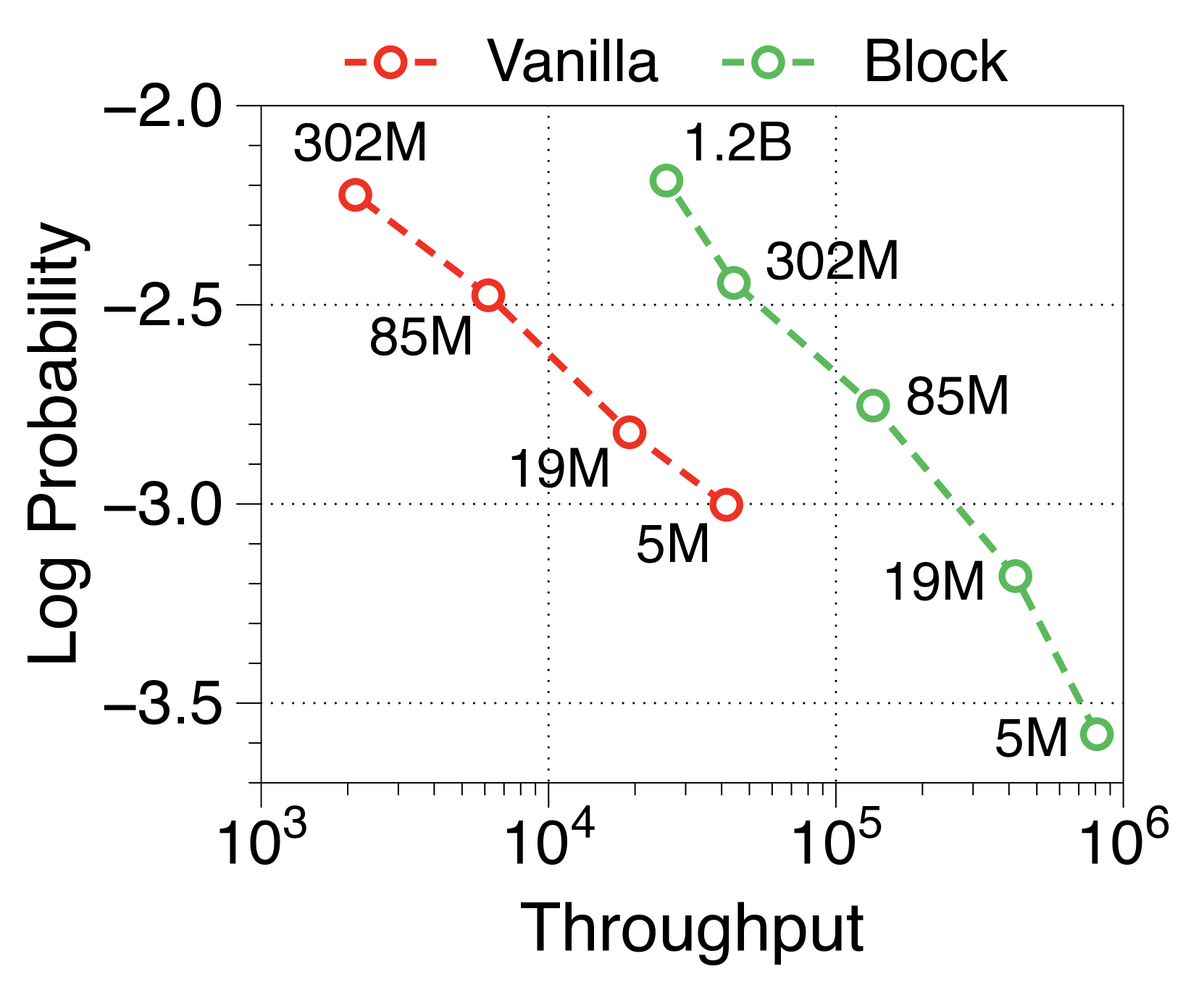
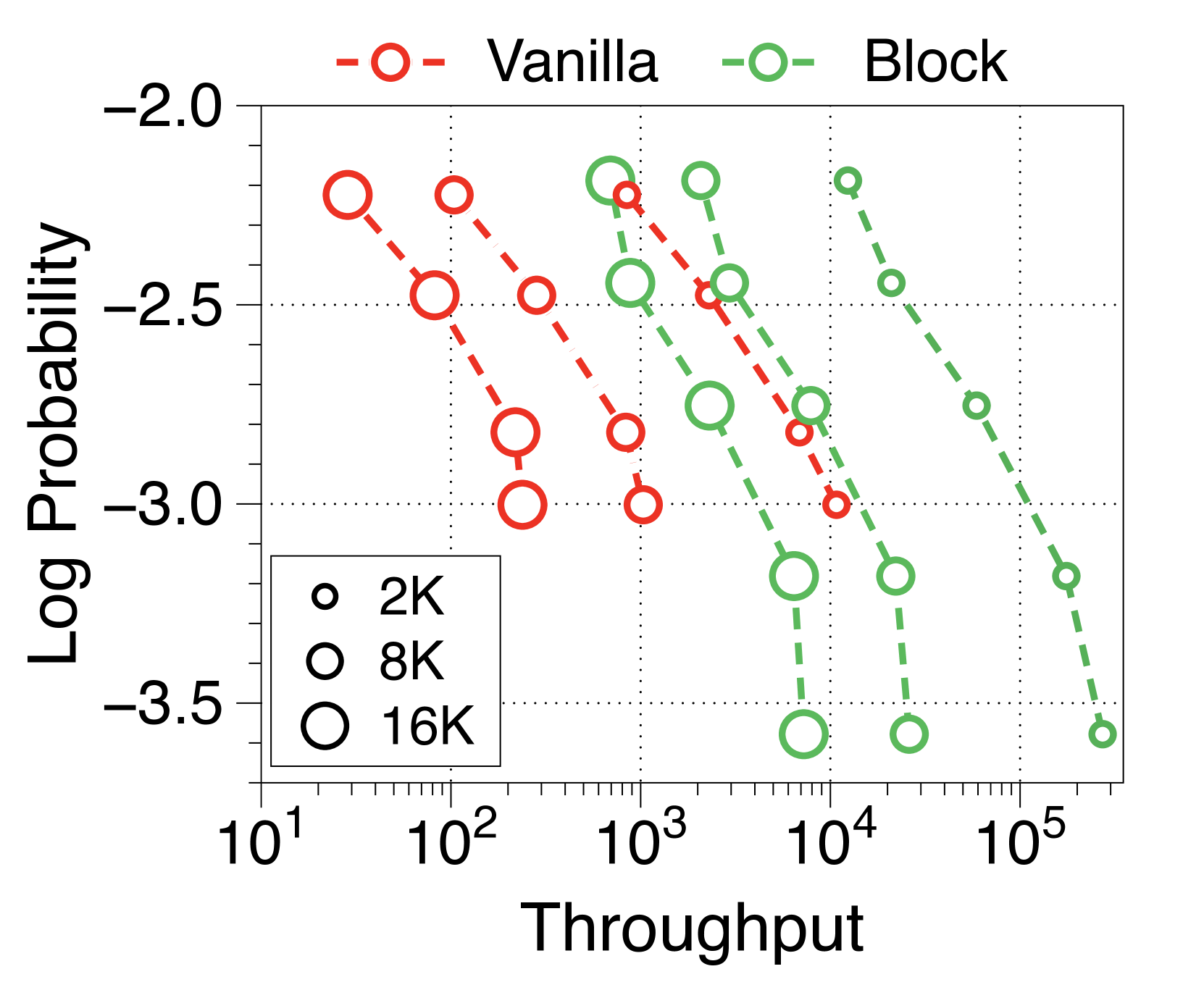
与普通模型相比,Block Transformer 的实际推理吞吐量和内存效率明显更高。 我们测量最大吞吐量[60],它使用内存允许的每个模型变体的最大批量大小。 如 2(a) 和 2(b) 所示,我们的模型实现了帕累托最优,特别是在两种情况下表现出高达 25 倍的增长:预填充-heavy 和 decode-heavy,其中输入和输出序列长度分别为 2048、128,反之亦然。 这种效率的提高归功于 KV 缓存的有效减少,这使得批量大小大约增加了六倍,如Table 2 中每个样本的内存所总结的那样。 Block Transformer 进一步减少了预填充密集设置中的延迟,因为提示的过去 KV 状态只需要缓存在块解码器中,而不会将它们转发到词符解码器。
可变固定批量大小(即 1、32 和 256)的 Pareto 前沿如Appendix I 所示。 我们发现,随着模型大小和批量大小的增加,Block Transformer 的吞吐量呈指数级增长。 考虑到实际应用中通常使用的大语言模型具有数十亿个参数,并考虑聚合多个用户请求来优化批量推理的策略[35,50,60],结果表明我们提出的架构将在实际的多租户部署场景中展示出更多的好处。
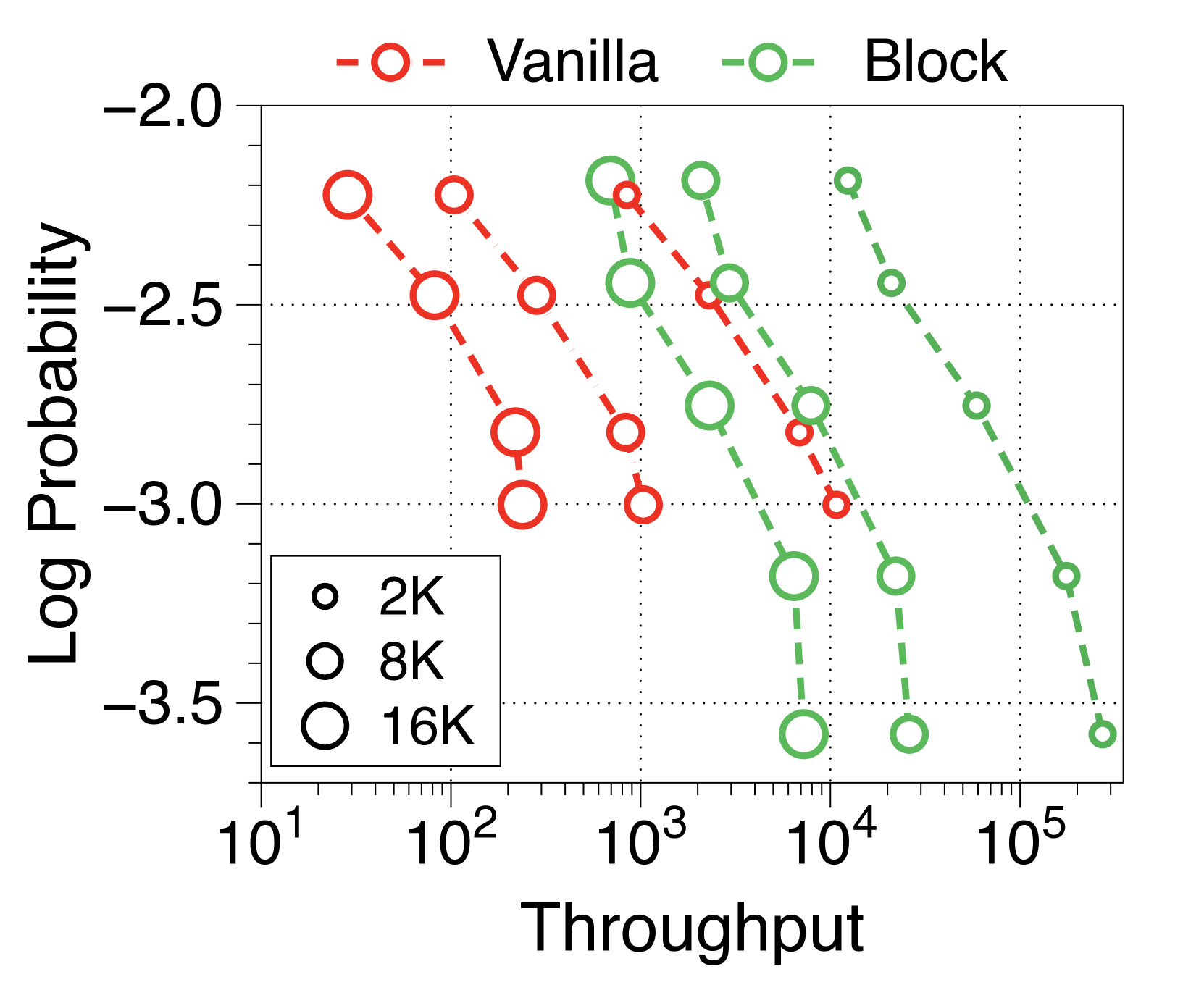
在 2(c) 中,我们观察到具有 8K 提示长度的 Block Transformer 的吞吐量超过了具有 2K 提示长度的普通模型。 这是合理的,因为块解码器的上下文长度减少了 4 倍,并且词符解码器几乎没有 KV 缓存开销。 鉴于人们对实现更长上下文长度的兴趣日益浓厚,甚至超过一百万个 Token [13,57,46],块转换器有可能进一步提高吞吐量。
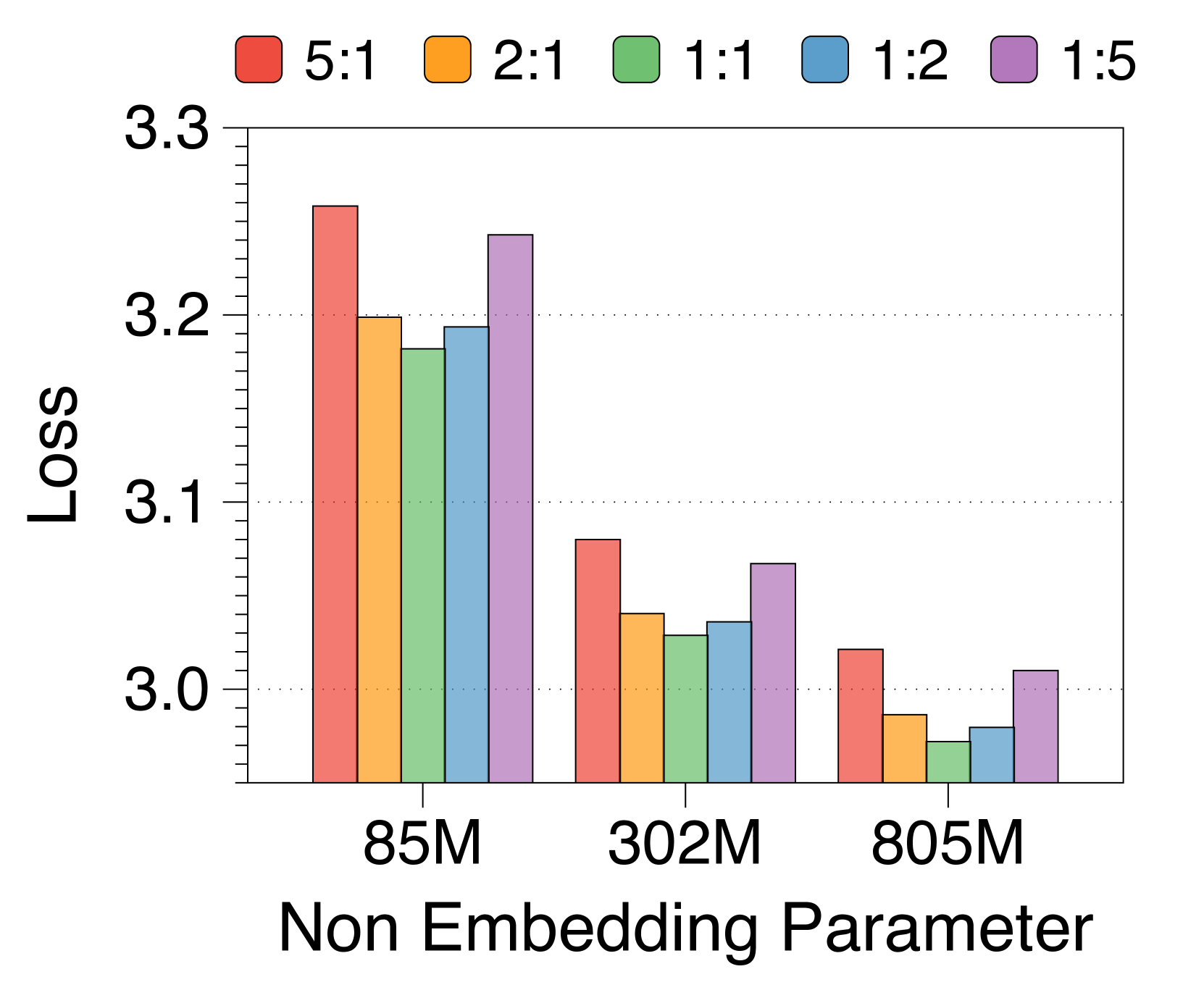
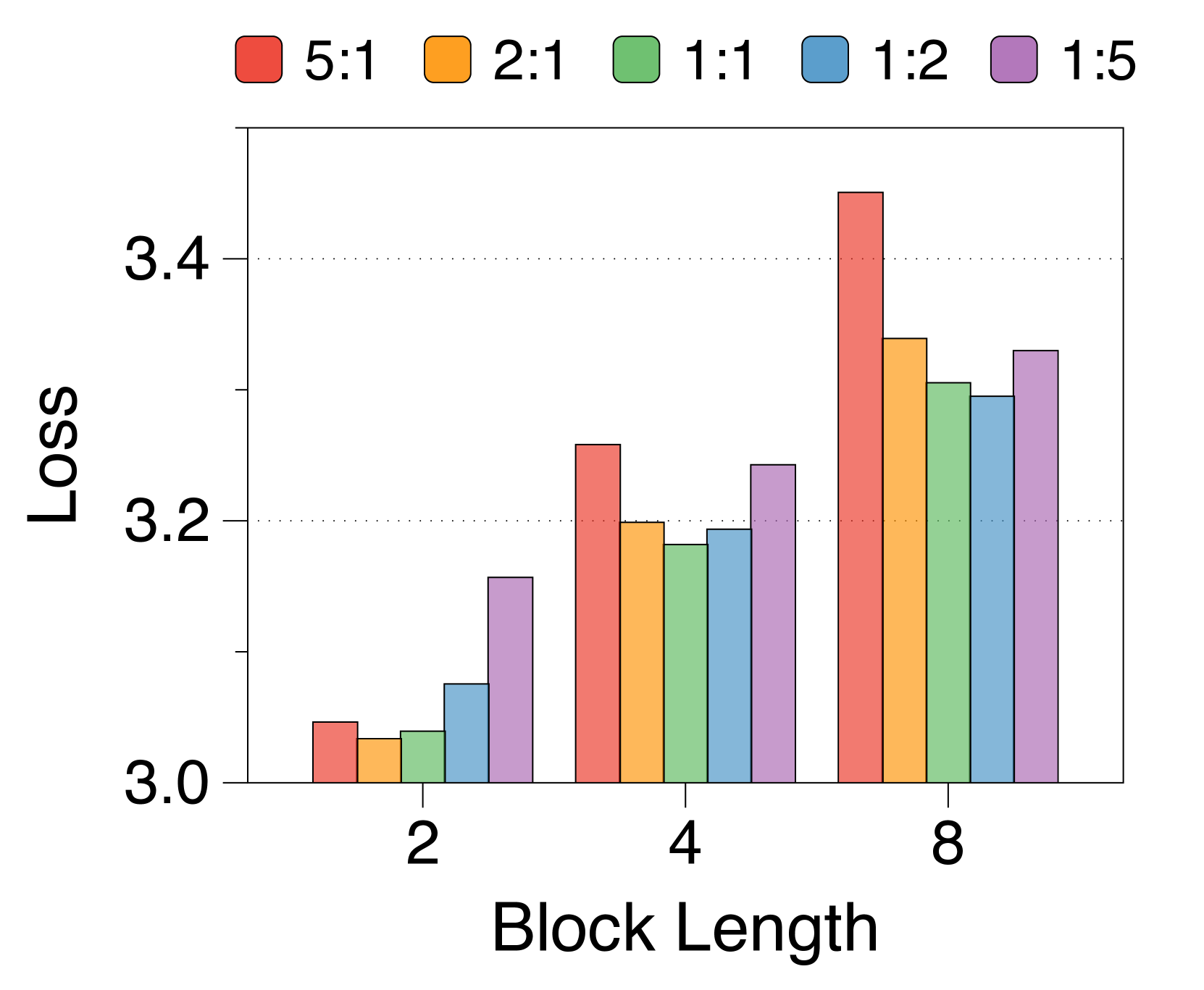
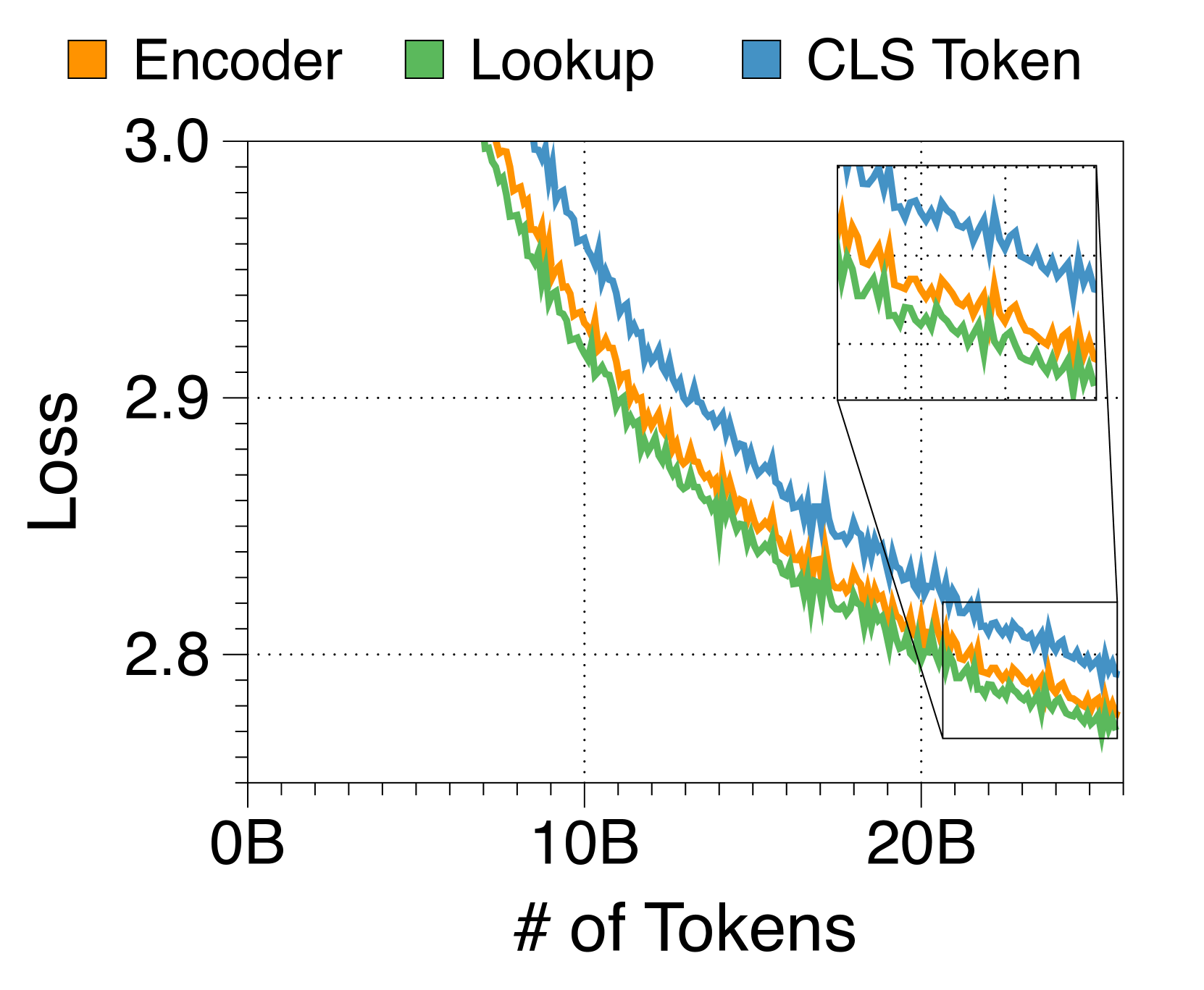
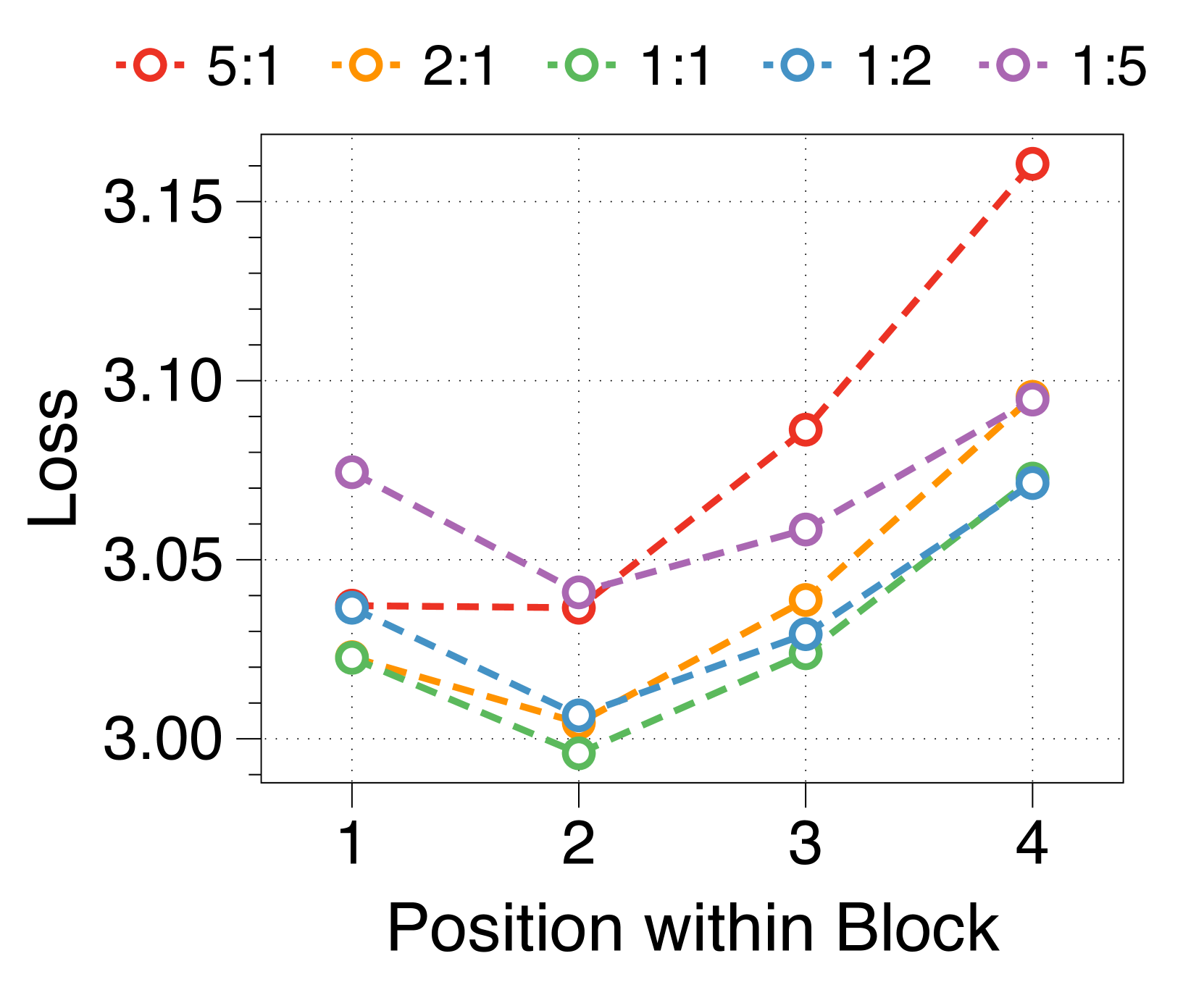


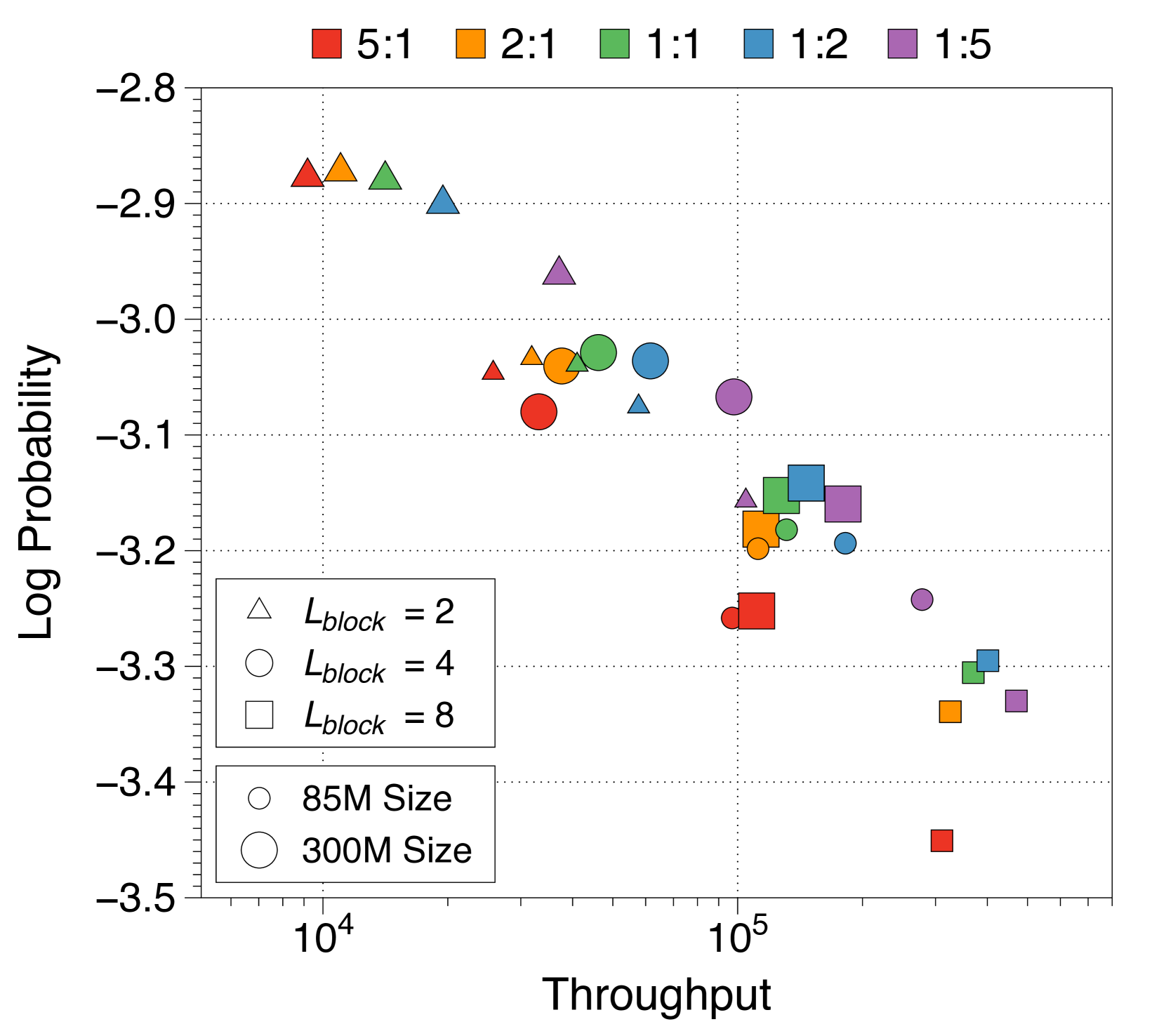
3.3参数分配比例和区块长度分析
不同分配比例下的困惑度呈现 U 形模式
我们探讨了块解码器和词符解码器之间的不同分配比例对语言建模性能的影响,同时保持非嵌入参数的总数不变。 3(a) 说明了三种模型大小的五个不同比率的训练损失。 有趣的是,所有三种模型尺寸都存在明显的 U 形权衡。 我们发现,对于所有模型尺寸中 一致的模型来说,一对一的比率是最佳的。 如果任一侧太小,性能都会明显下降。 这证明了块解码器和词符解码器在语言建模中的协同效应和同等重要性。
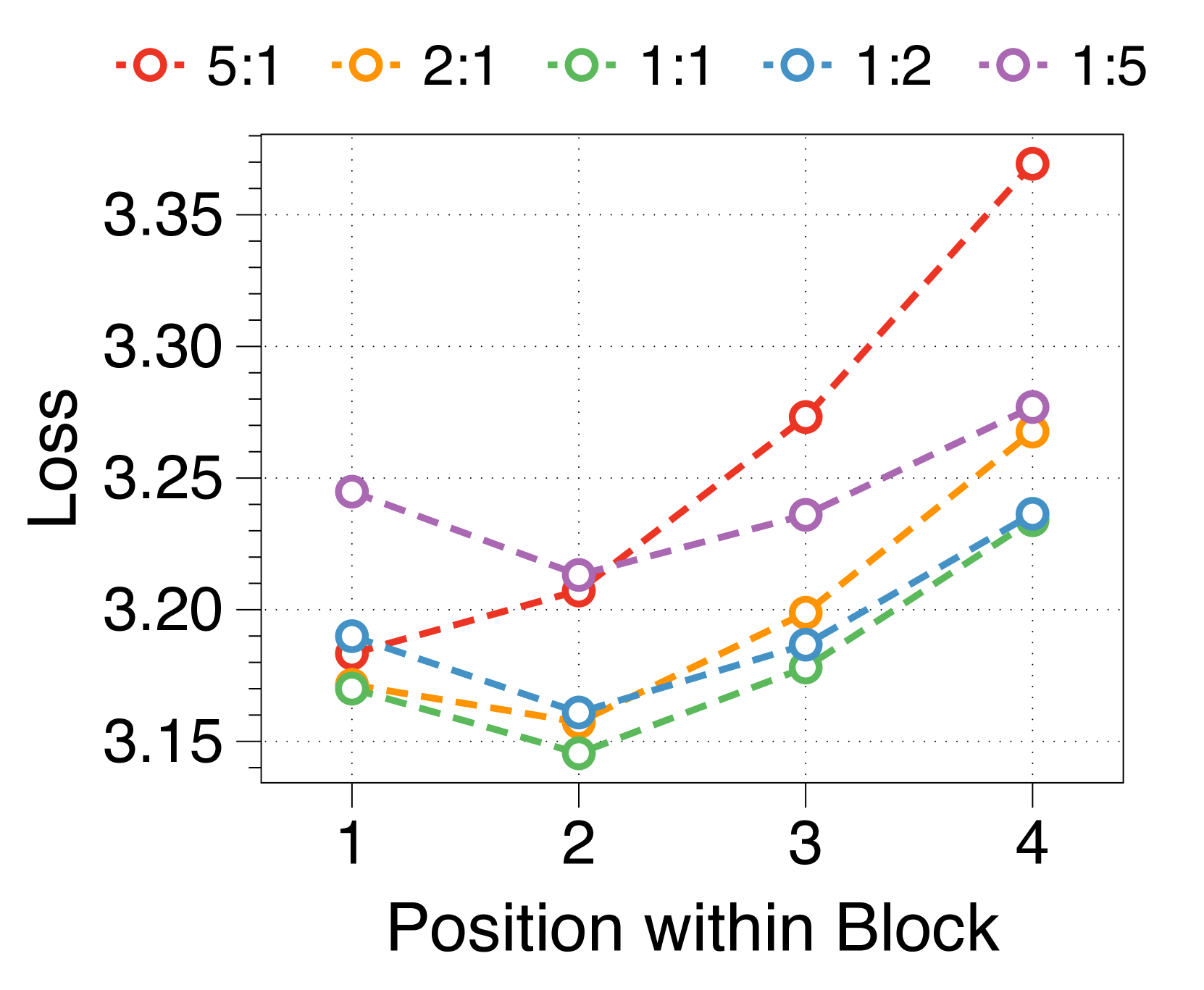
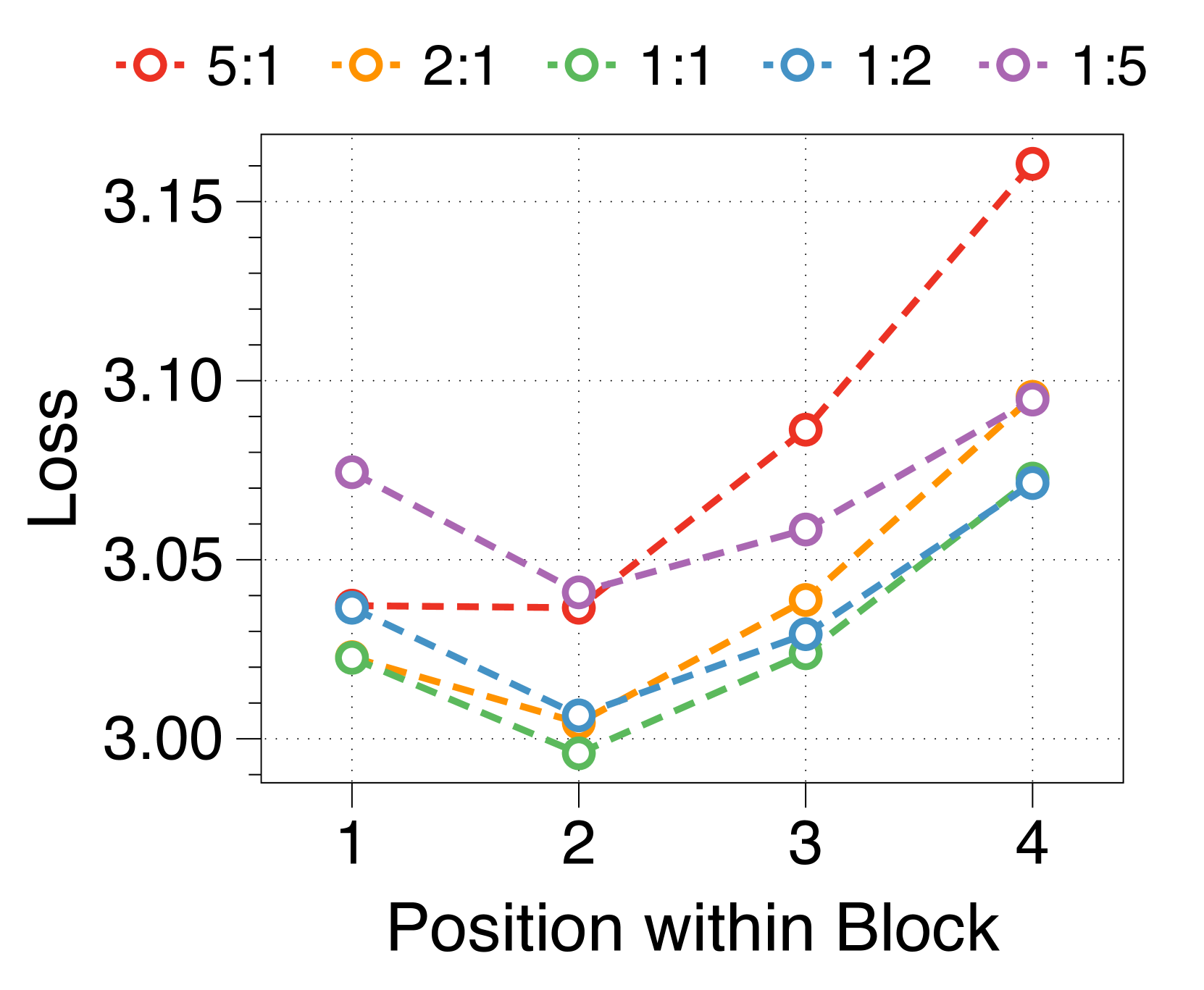
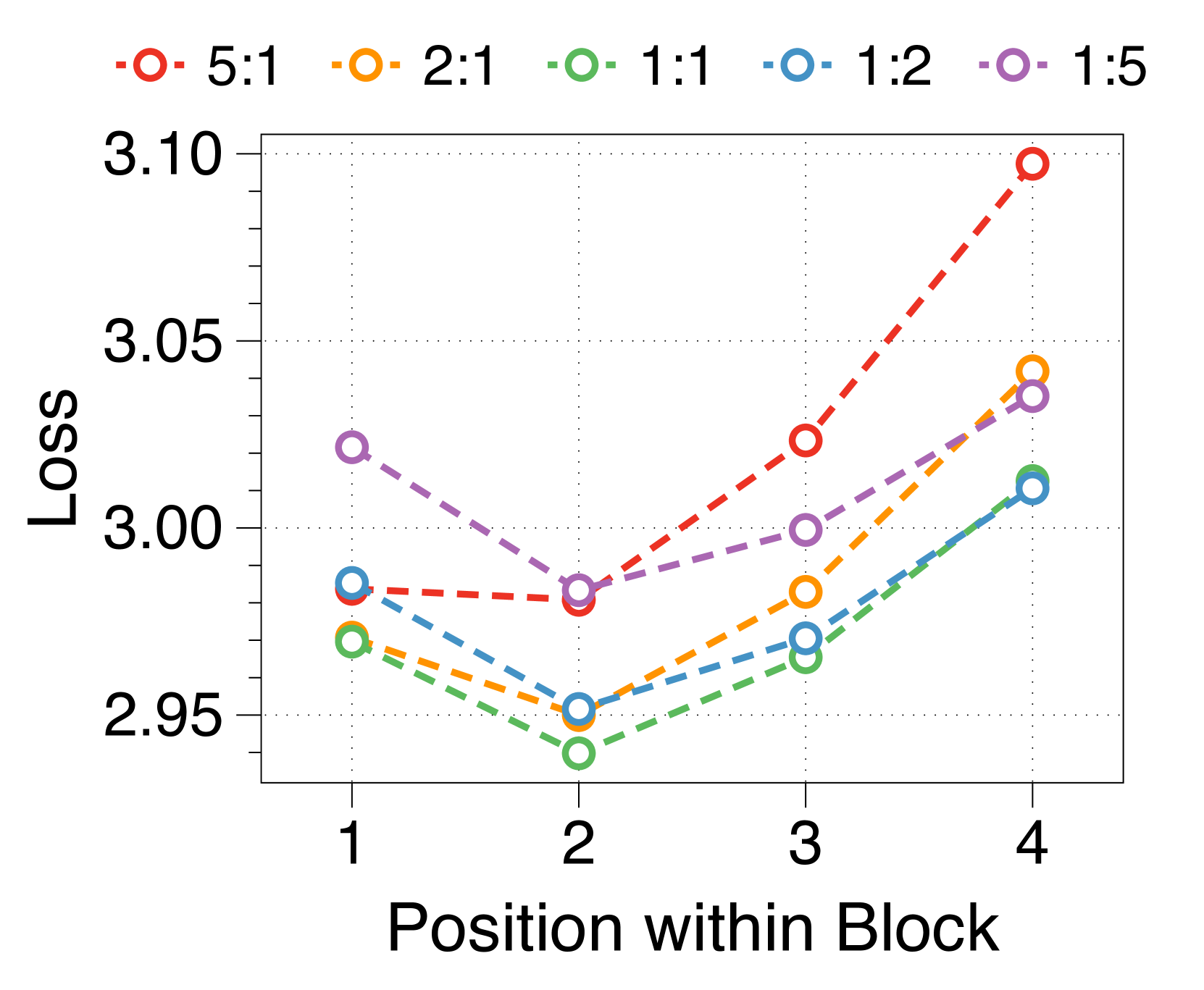
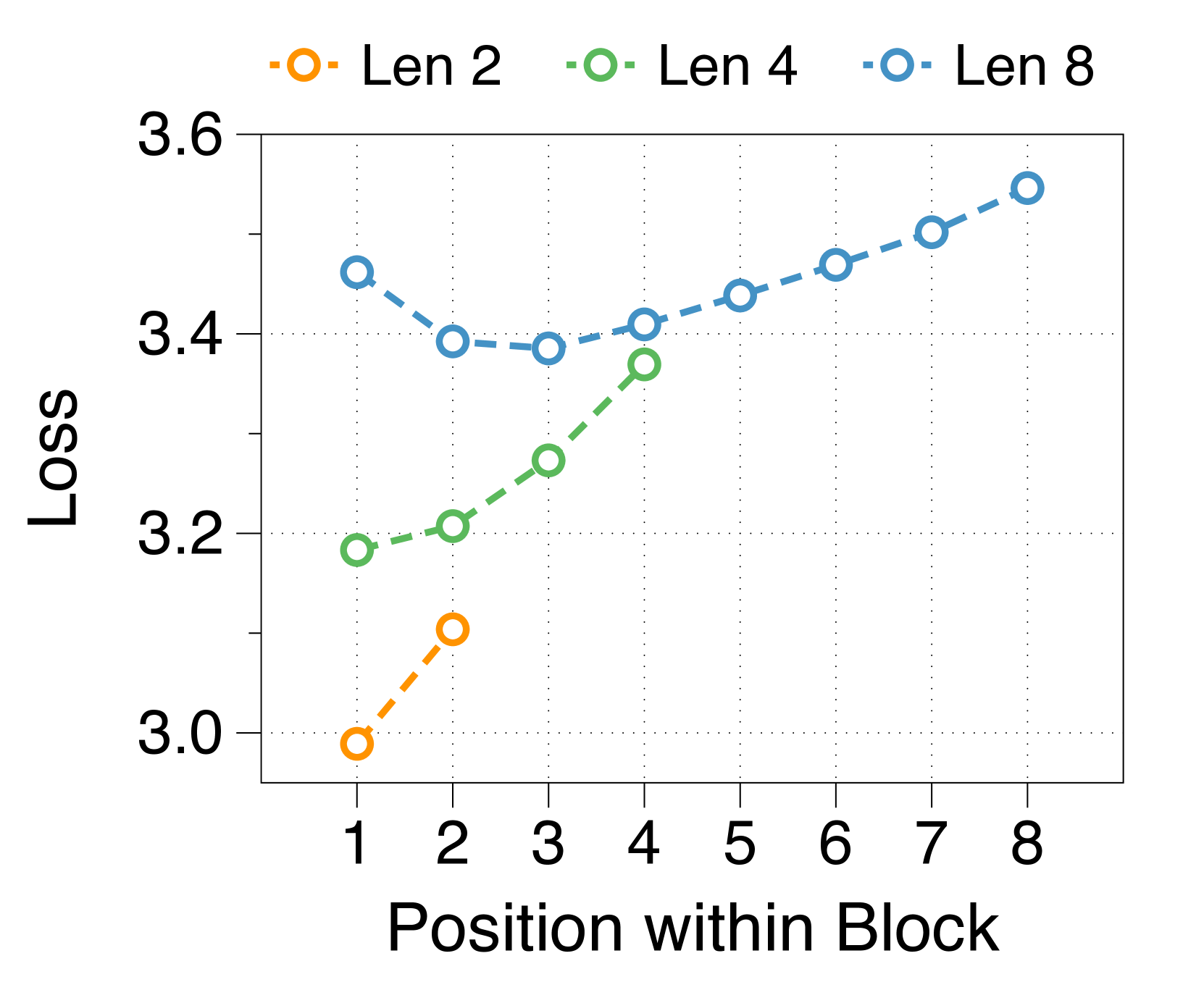
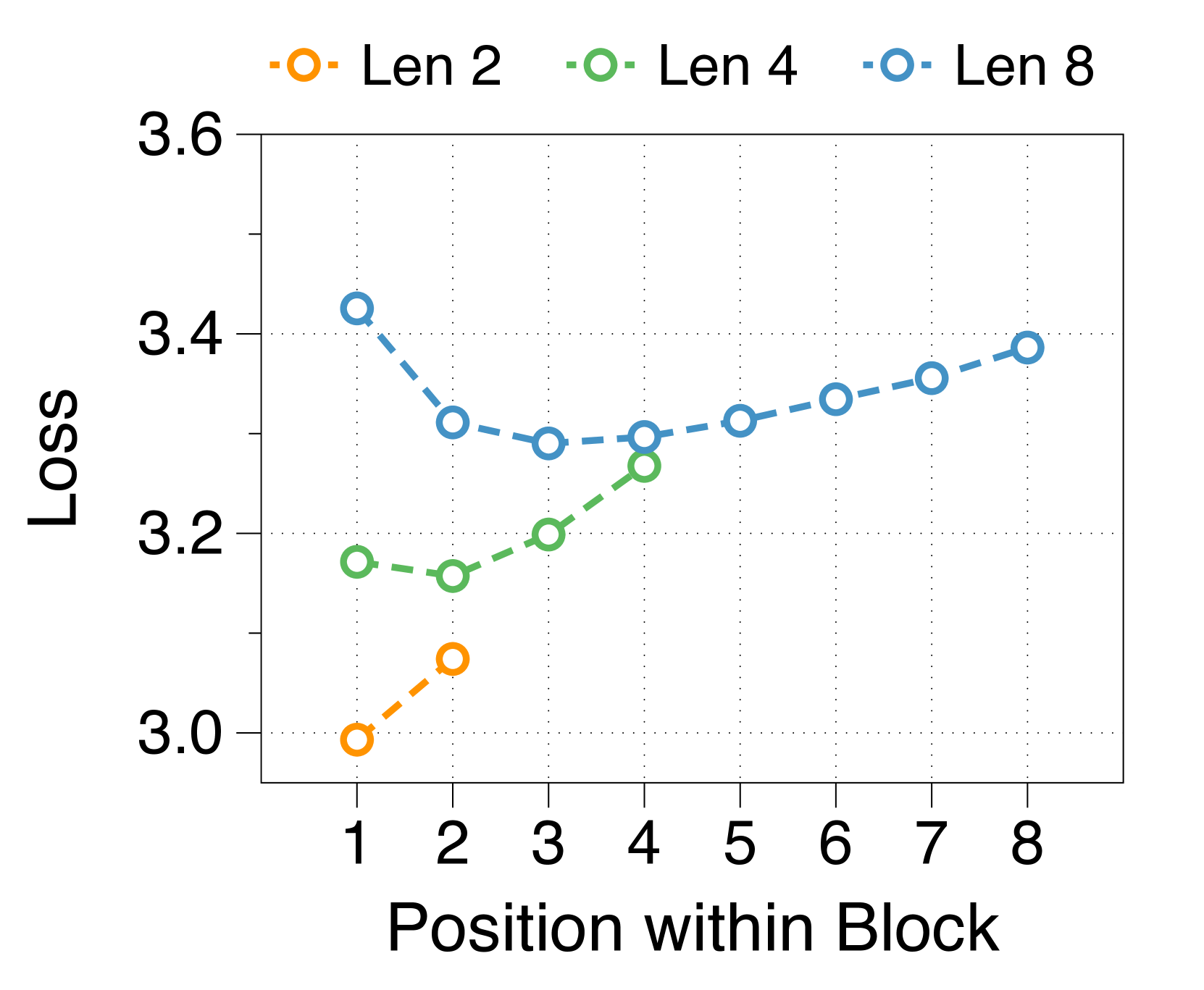
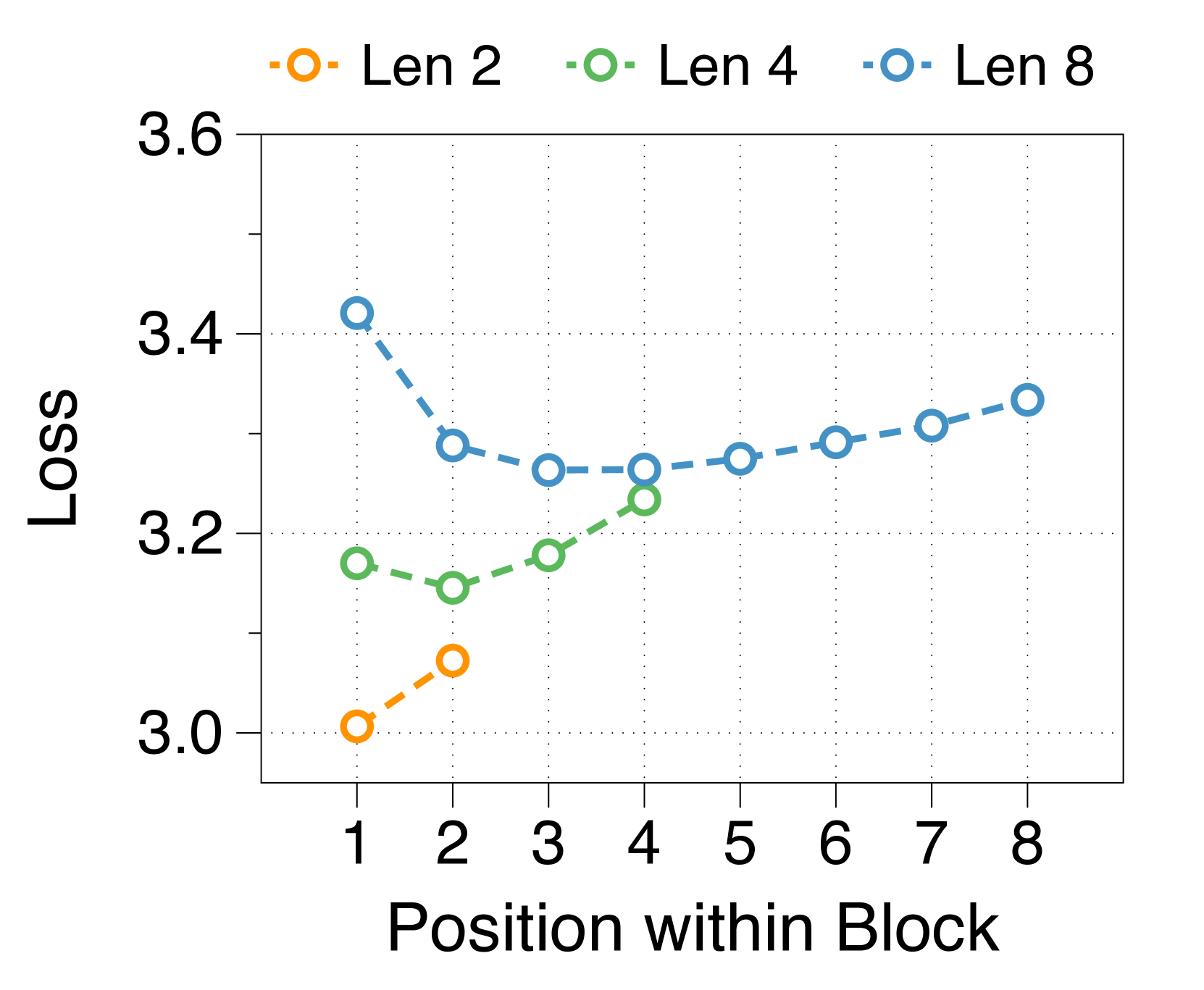
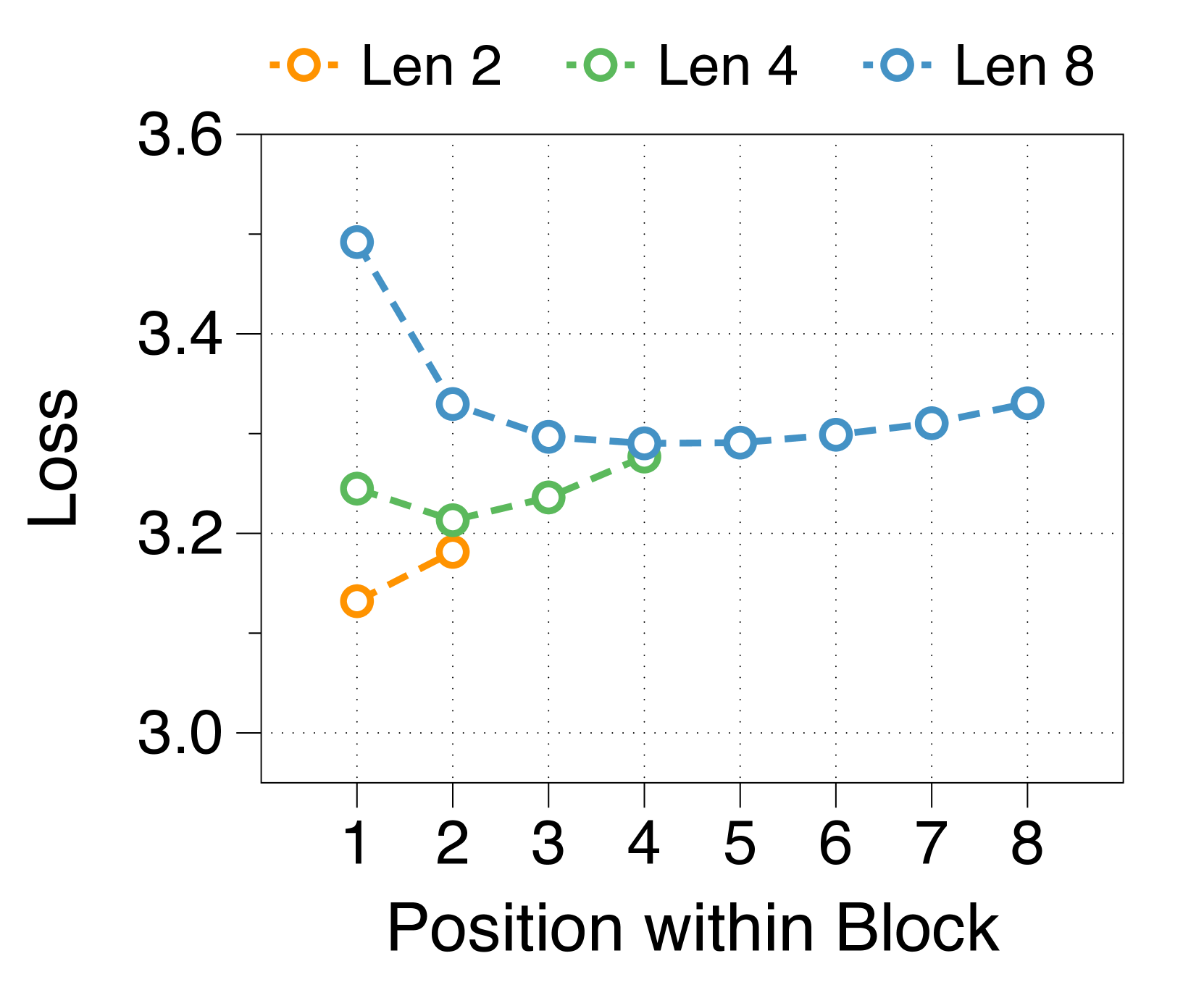
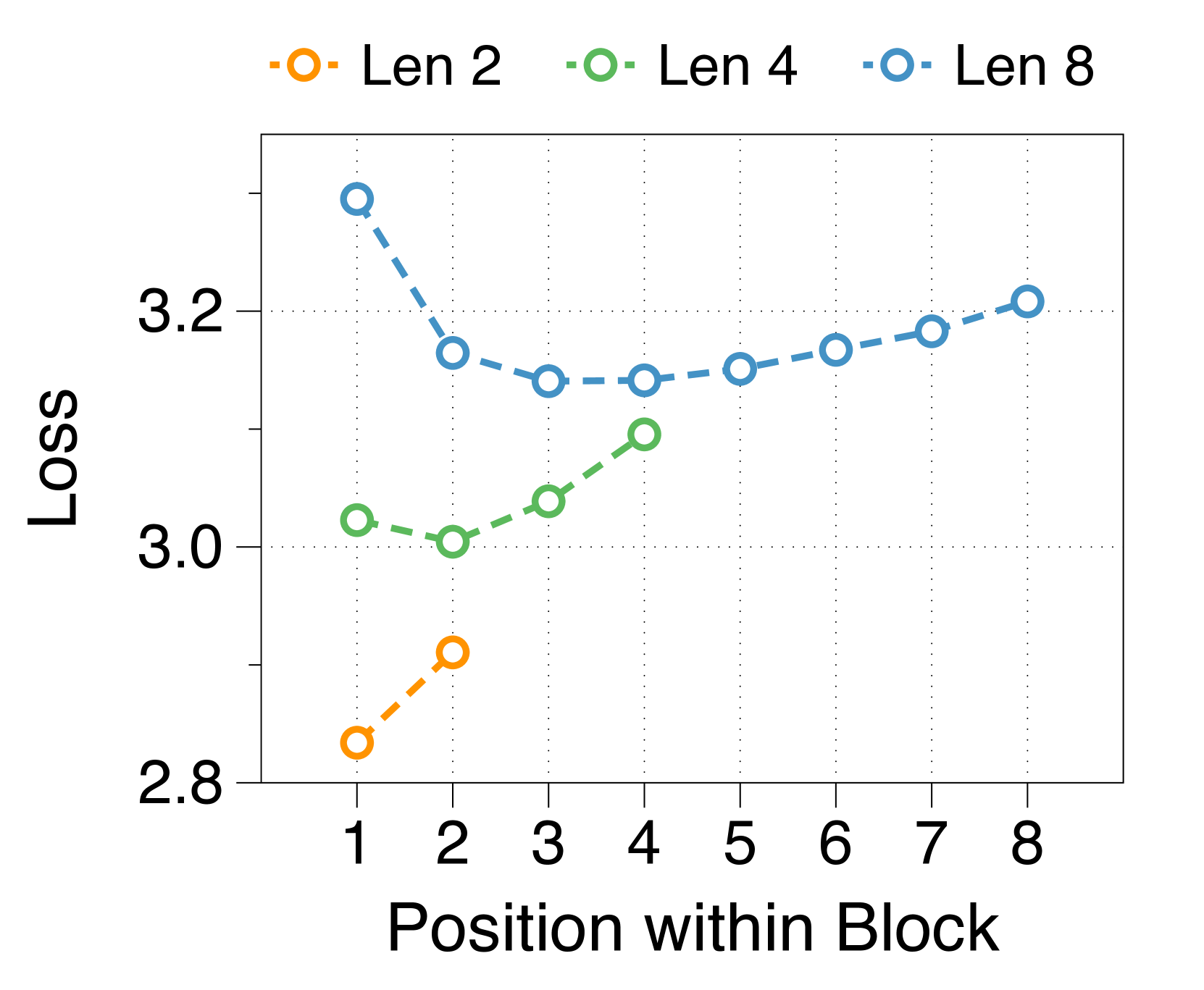
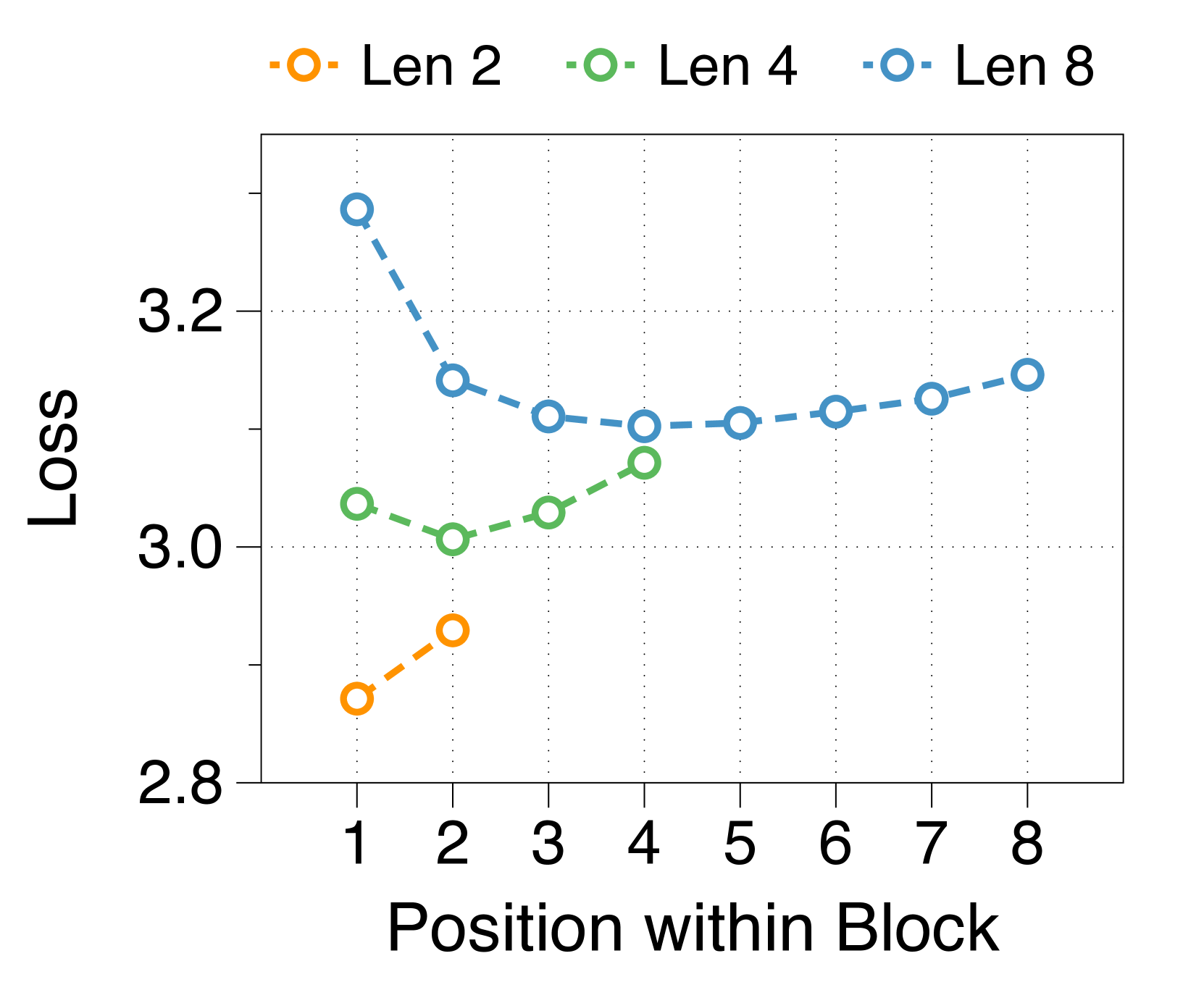
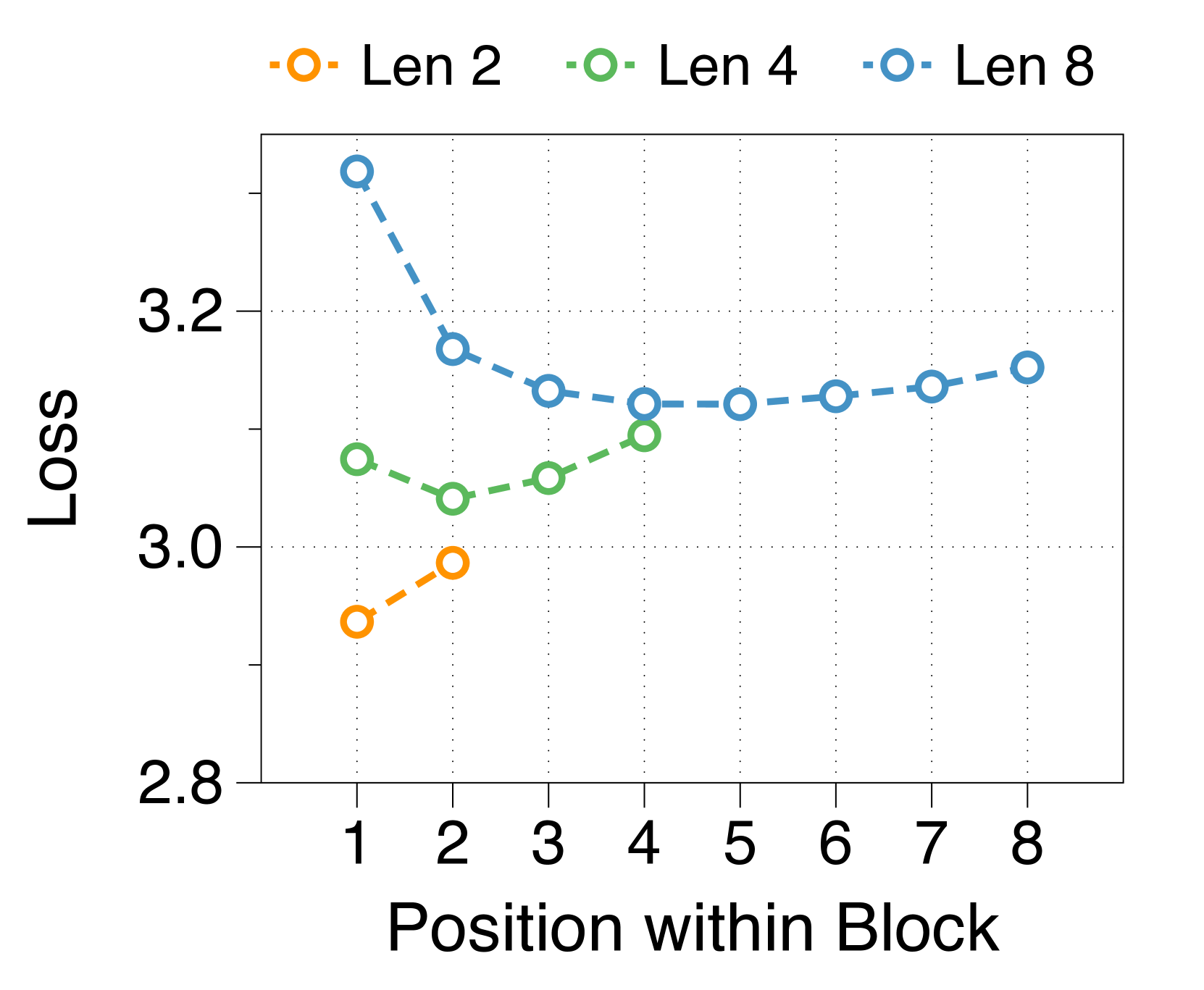
更大的块和词符解码器分别减少了初始位置和后面位置的困惑
我们测量块内每个位置的平均损失,如 3(d) 所示。 位置损失通常呈现 U 形模式,与之前的多尺度语言模型 [74] 和块并行解码方法 [62, 14, 34] 的发现相一致>。 这种趋势源于上下文嵌入中缺乏全局上下文,这增加了后续位置的不确定性。 此外,特定位置的困惑度与两个解码器的参数大小相关。 较大的块解码器可显着降低由于仅基于上下文嵌入的预测而导致的初始位置损失。 相比之下,更大的词符解码器可以通过更好地利用本地上下文来提高后续标记的预测准确性。 这些相互依赖的效应决定了最佳参数比率,在不同尺寸的模型中具有明显的相似模式,详见Appendix J。
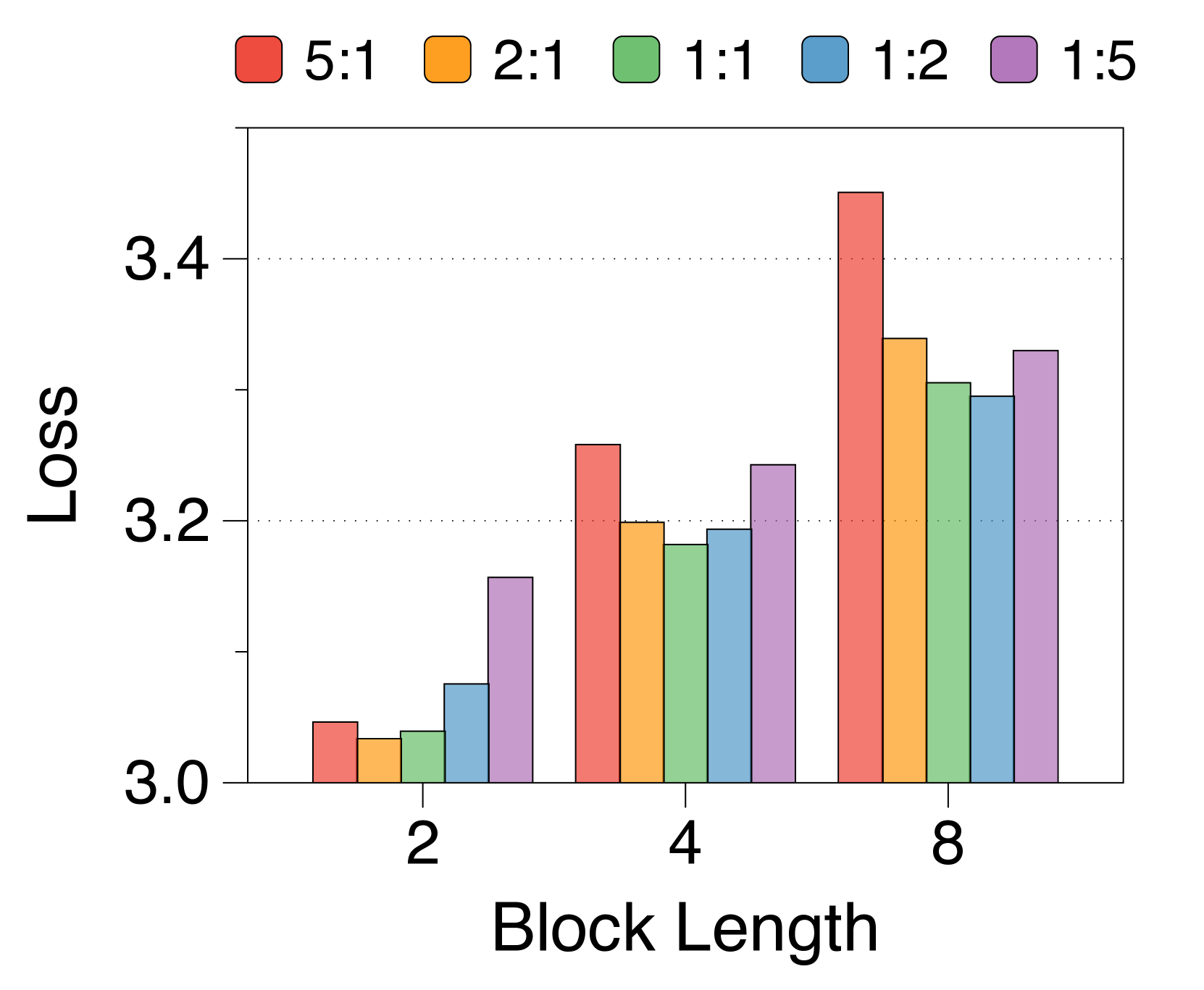
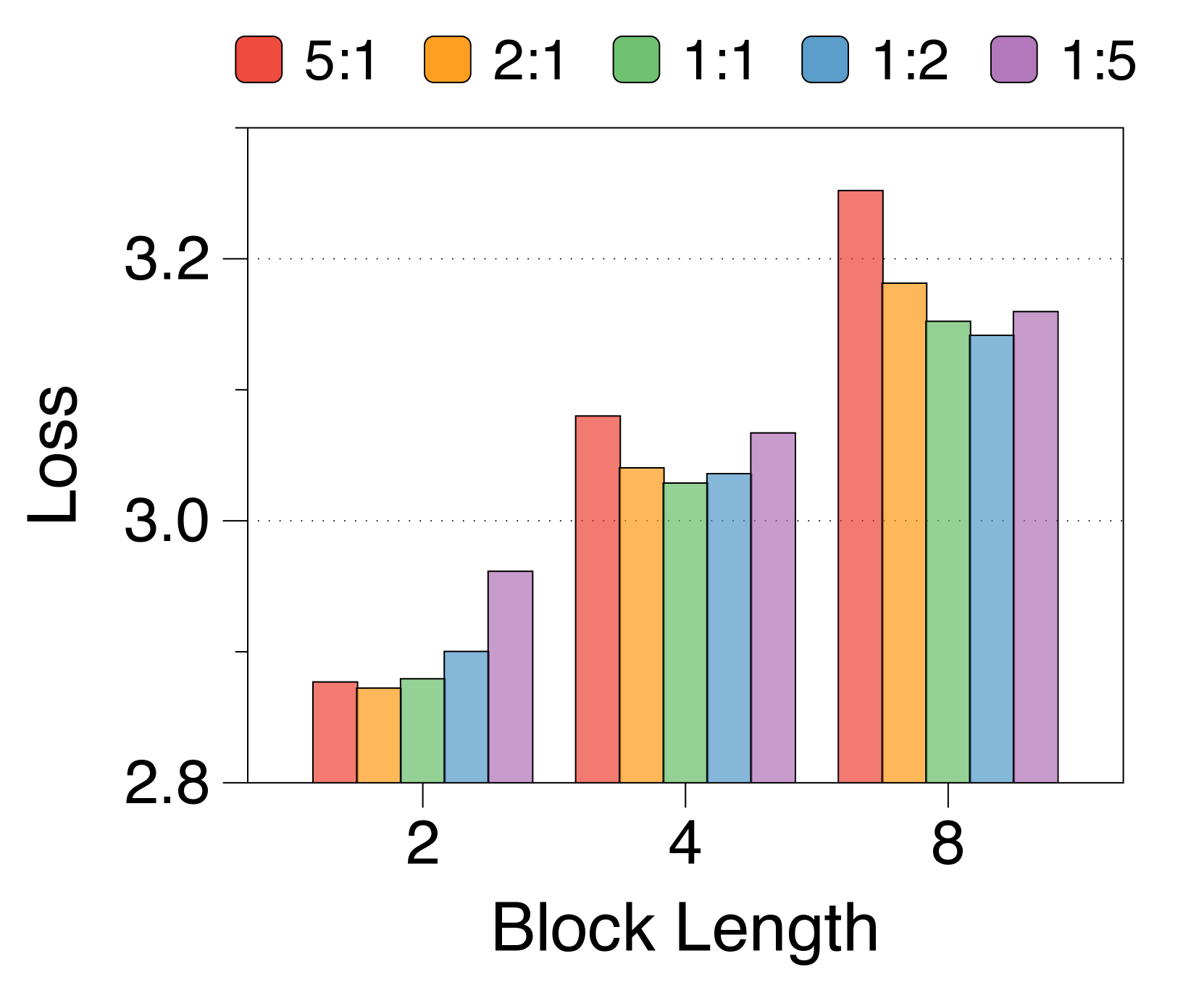
较短的块长度有利于较大的块解码器,而较长的长度则有利于词符解码器
3(b) 表明,无论区块长度如何,在不同的分配比率下,训练损失仍然遵循 U 形模式。 最佳比率随块长度而变化:较短的块受益于较大的块解码器,而较长的块在词符解码器中具有更多参数时性能更好。 这是由于块长度与块解码器的 FLOP 之间存在反比关系,从而影响模型容量[22,23,29]。 正如 3(e) 所示,随着块变短,第一位置损失显着减少,反映出块解码器容量的增加。 虽然词符解码器在不同块长度上的 FLOP 差异很小,但随着块长度的增加,它有更多机会提高后面 Token 的可能性,有利于更大的词符解码器。 这些趋势在不同的模型规模和分配比例中是一致的,详见Appendix K。
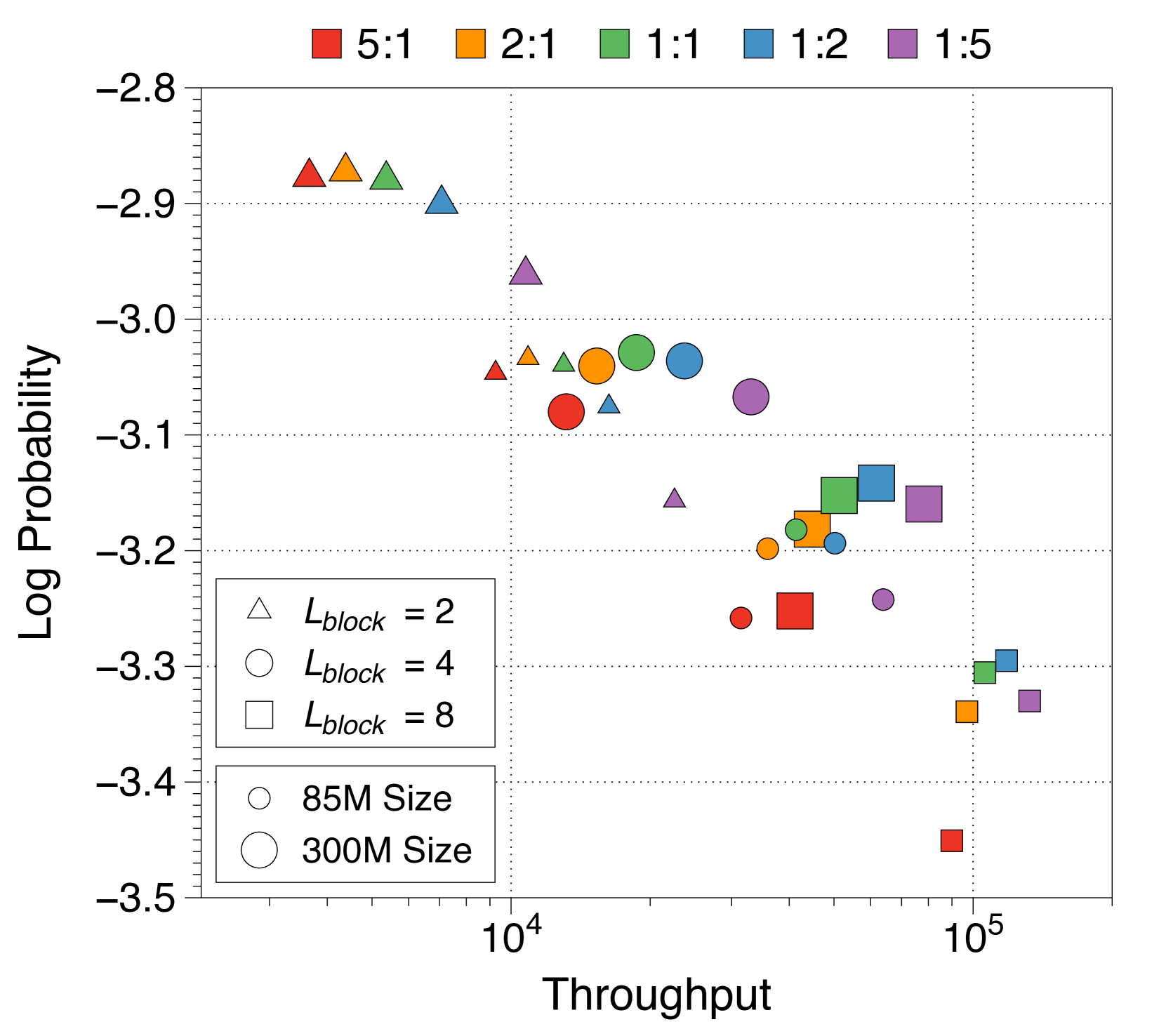
更大的词符解码器和更长的块长度有利于实现高吞吐量
我们从吞吐量的角度评估分配率和块长度,在Appendix L中总结帕累托前沿。具有较大词符解码器的模型通过以较小的性能妥协实现更高的吞吐量来达到帕累托最优。 由于 KV 缓存 IO 显着影响推理时间,因此为词符解码器分配更多参数是有利的,因为本地上下文长度受块长度限制。 此外,增加块长度可以提高吞吐量,因为块解码器中的 KV 缓存长度会成比例减少。 因此,虽然我们的主要配置使用一对一的比率和四的块长度,但选择更长的块长度和更大的词符解码器可能会导致更高吞吐量的模型。
3.4 块 Transformer 组件的烧蚀
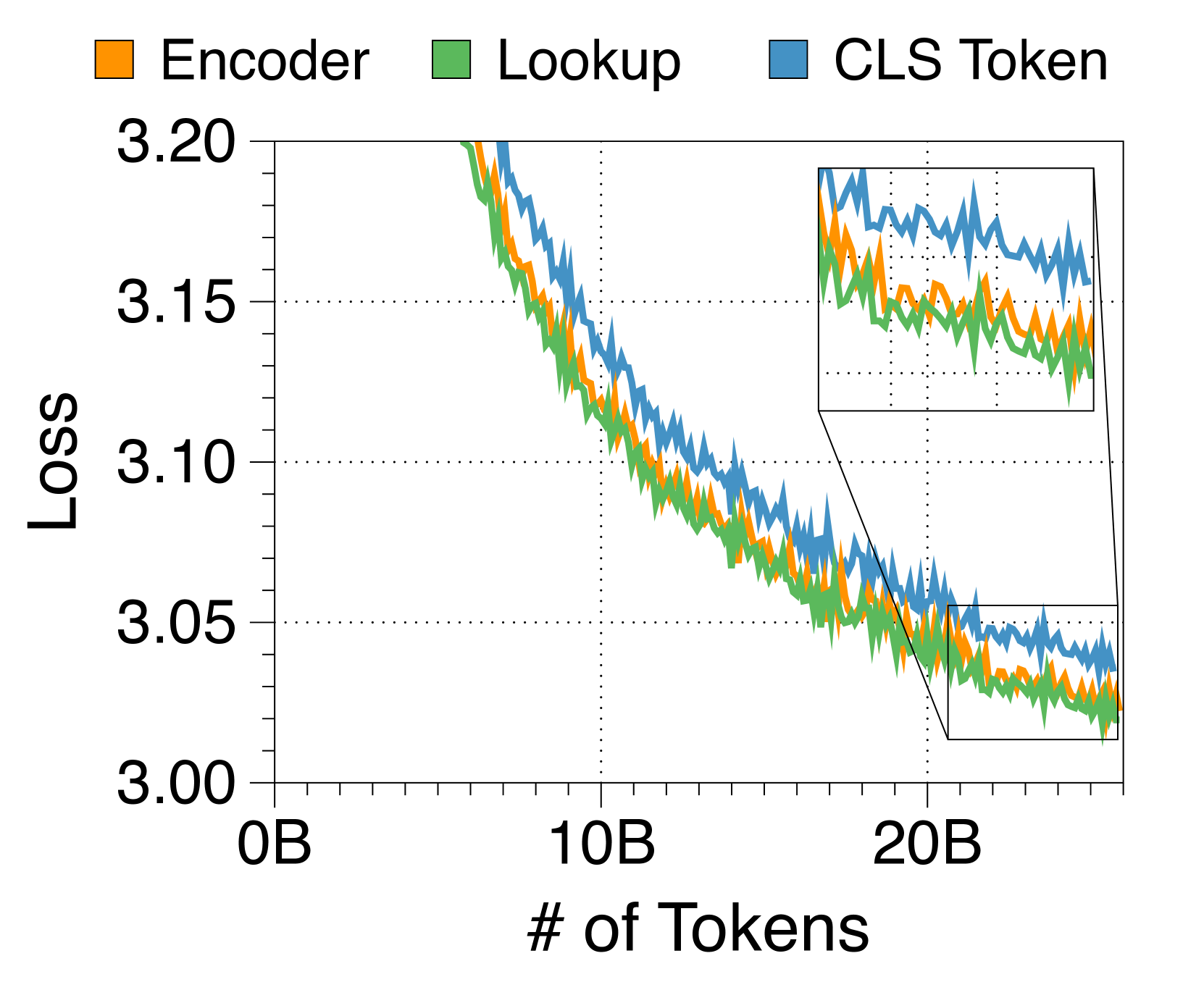
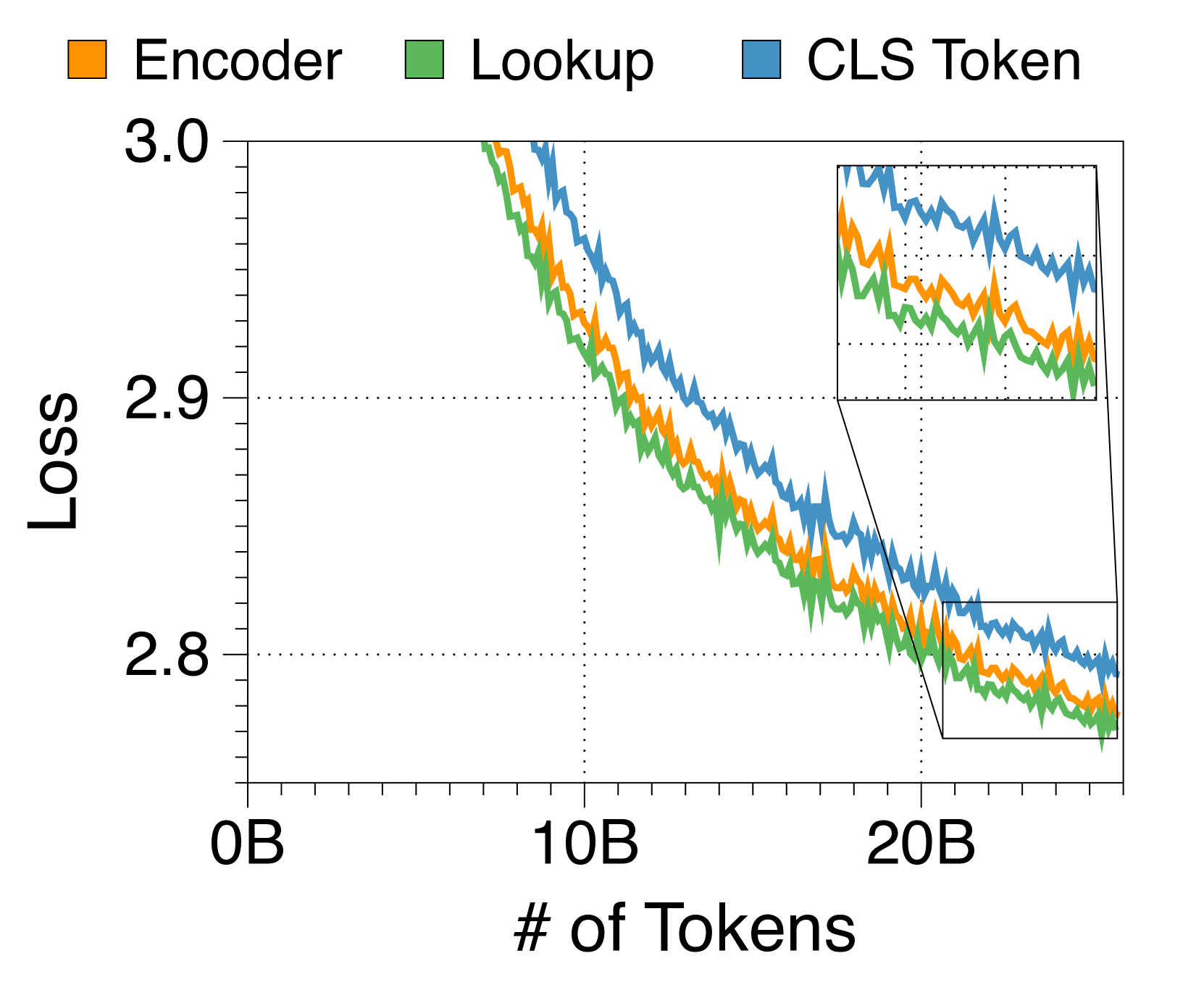
查找策略是嵌入器最有效的方法
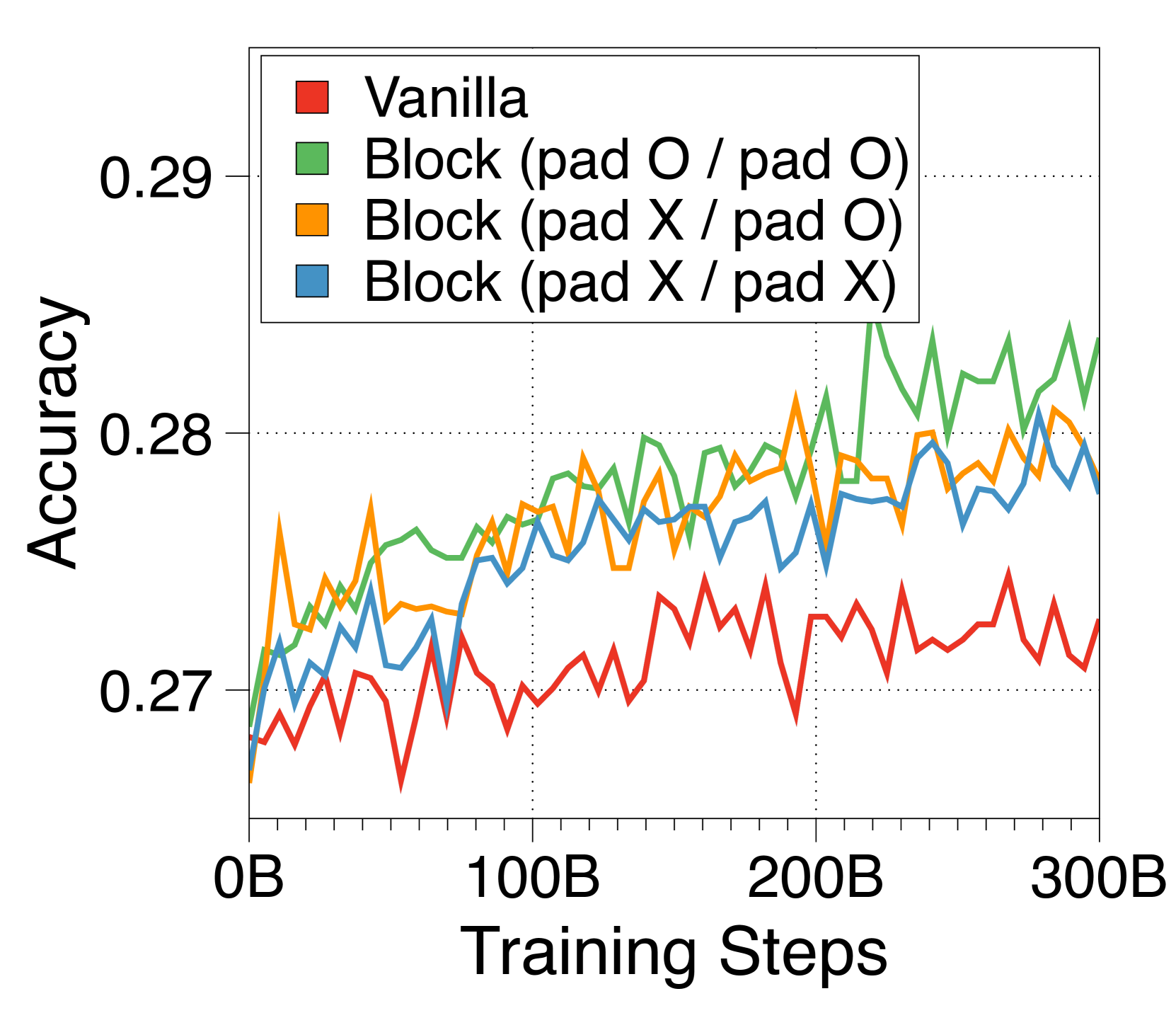
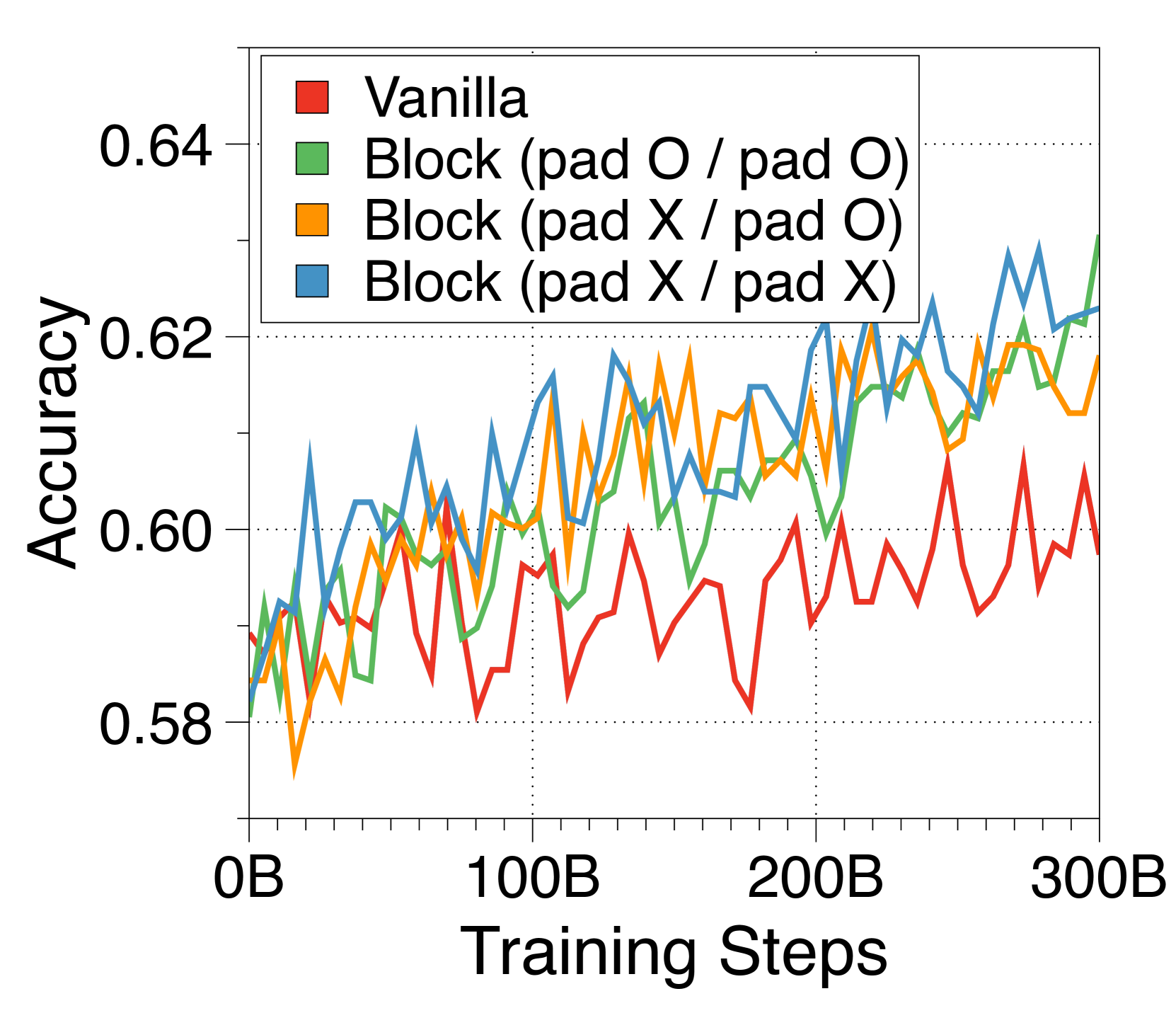
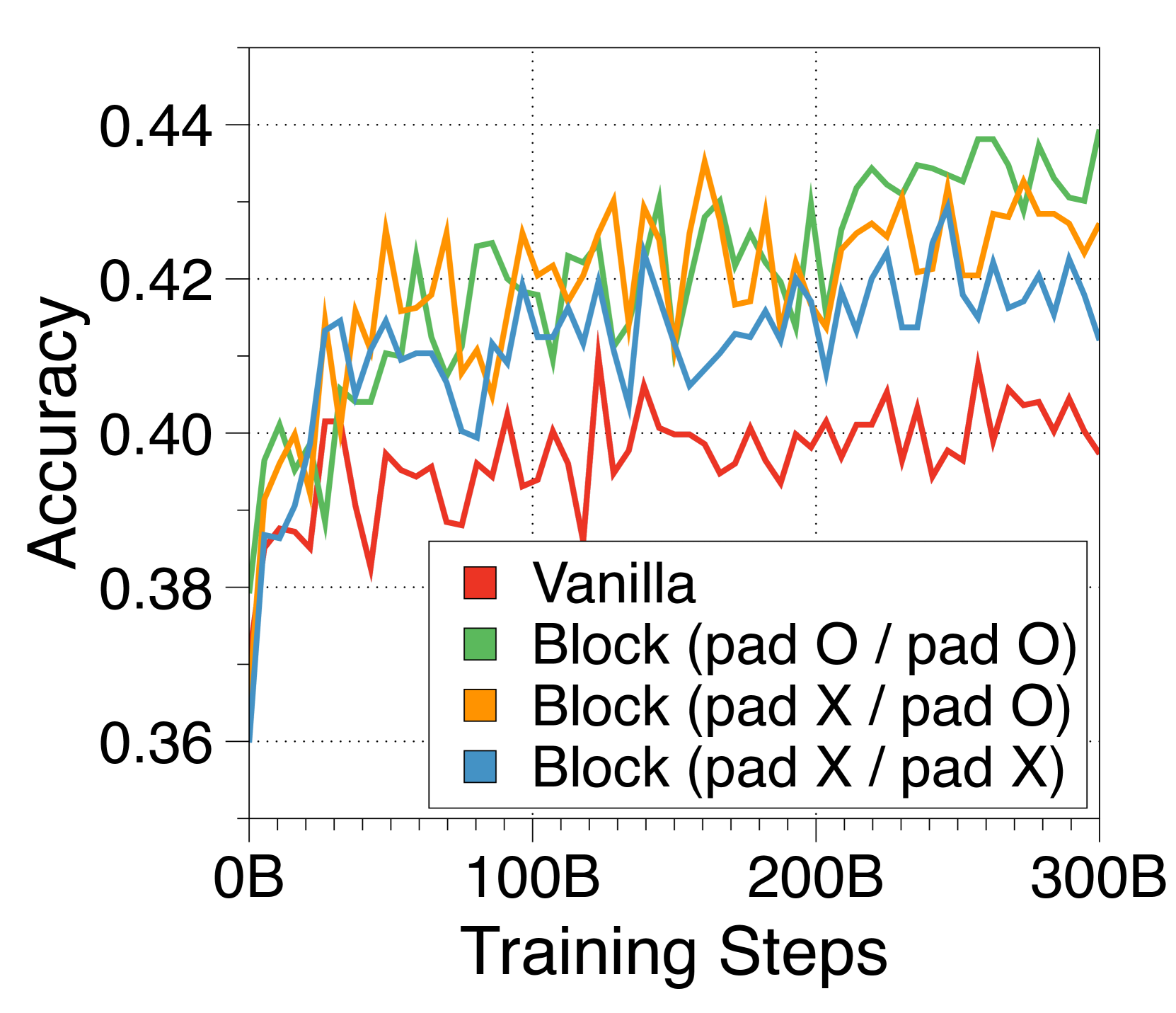
在 3(c) 中,我们尝试了三种嵌入器策略,将块 Token 捆绑到单个嵌入中。 令人惊讶的是,像 RoBERTa [40] 这样的复杂 Transformer 编码器的性能并不优于更简单的查找表策略。 此外,基于编码器的嵌入器由于额外的计算开销而降低了生成吞吐量。 因此,我们选择查找策略来简化 Block Transformer 架构。 尽管 CLS 词符方法允许块长度的灵活性,但我们将其留待将来的工作,因为它会损害语言建模性能。
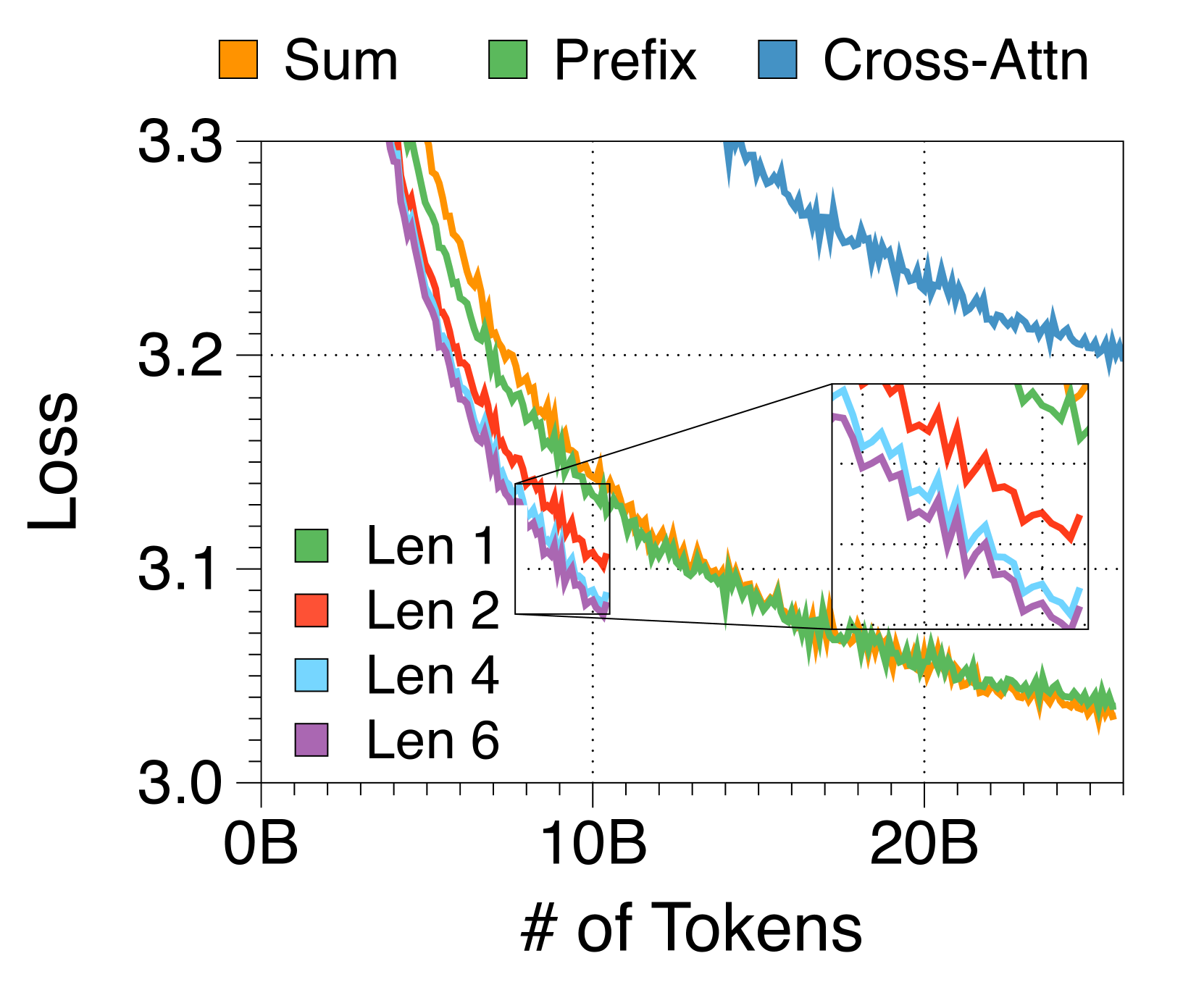
具有较长前缀的前缀词符解码器以最小的开销增强性能
3(f) 显示了三种词符解码器策略的训练损失曲线。 使用键和值序列等于块长度的交叉注意力模块会大大降低性能。 相比之下,通过自注意力操作转发上下文嵌入可以提高性能,前缀解码优于其他方法。 此外,将前缀扩展到四个标记以上可以显着提高复杂性,有效地拓宽词符解码器的计算宽度。 由于较长的前缀会增加最小的推理开销,因此我们通过平衡性能与 FLOP 来选择前缀长度为 2。 这种方法为全局到局部建模提供了新的见解,与之前的研究[74]不同,后者忽视了词符解码器中局部计算能力的潜力。 Appendix M 中总结了各种模型尺寸的详细结果。
3.5 全球到本地语言建模分析
全局到本地语言建模有效地优化了相对于性能的吞吐量
在4(a)中,我们通过调整块长度从普通过渡到块变形金刚。 随着块长度的增加,训练损失呈对数线性变化,吞吐量呈指数增长,清楚地证明了全局到局部建模的效率。 使用查找嵌入器和带有一个词符前缀的词符解码器,我们的带有 的模型与普通模型的区别仅在于删除了上层的全局注意力。 值得注意的是,在对 70% 的 Token 进行训练后,该模型实现了与普通模型相当的损失,同时吞吐量翻倍。 尽管修剪了所有过去的序列,这种强大的性能表明上下文嵌入可以保留相关信息,从而能够在全局到局部语言建模中有效地使用局部计算。
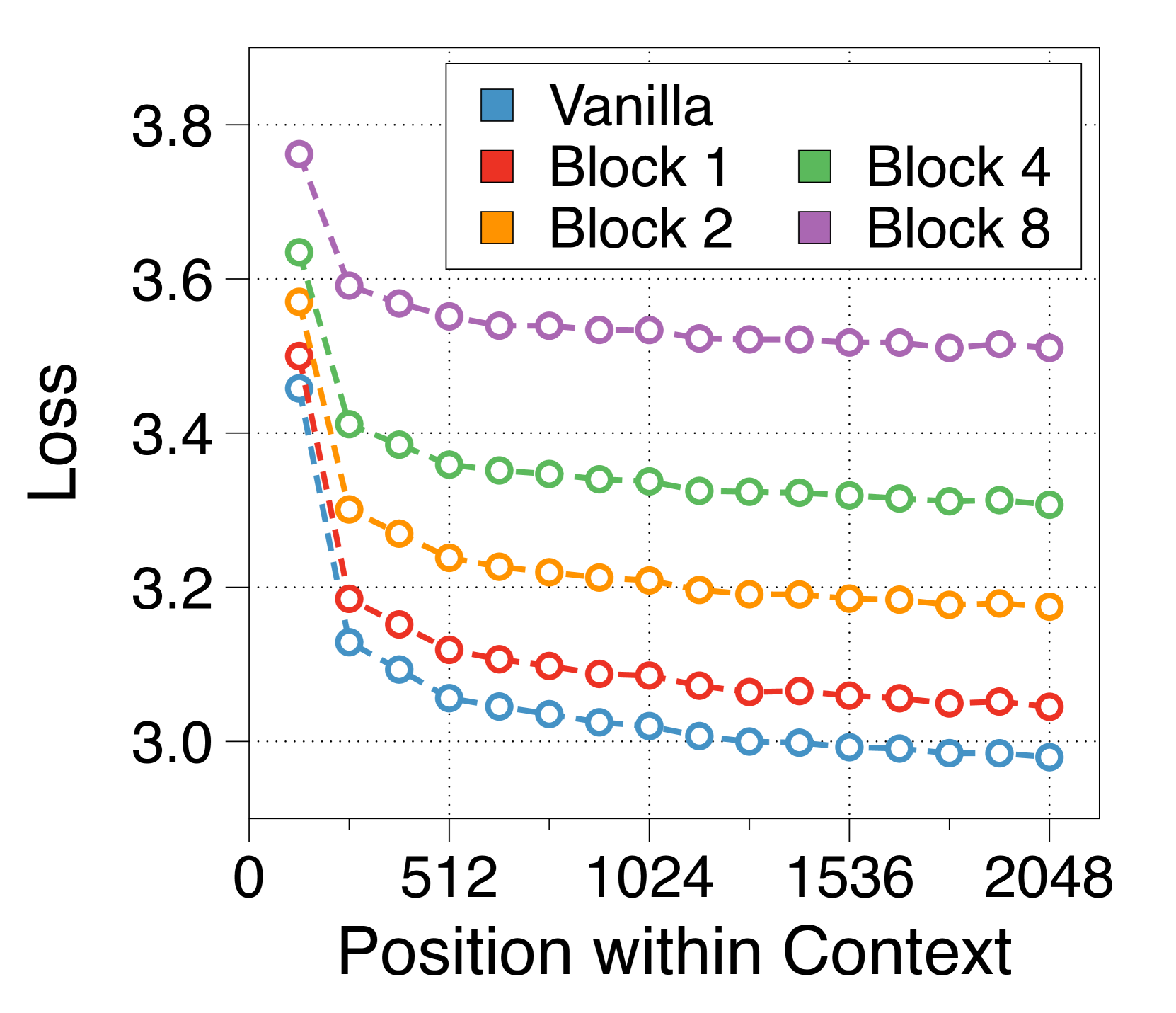
Block Transformer 可以有效地利用完整的上下文
由于词符解码器仅依赖于上下文嵌入,因此可能会担心 Block Transformer 是否充分利用上下文信息。 为了解决这个问题,我们使用 PG19 数据集 [52] 的测试集来评估 2K 上下文窗口内词符位置的损失。 4(b) 表明后面的标记始终以更高的可能性进行预测,这表明我们的架构区分了块级和标记级解码器,有效地利用了至少 2K 的上下文标记。
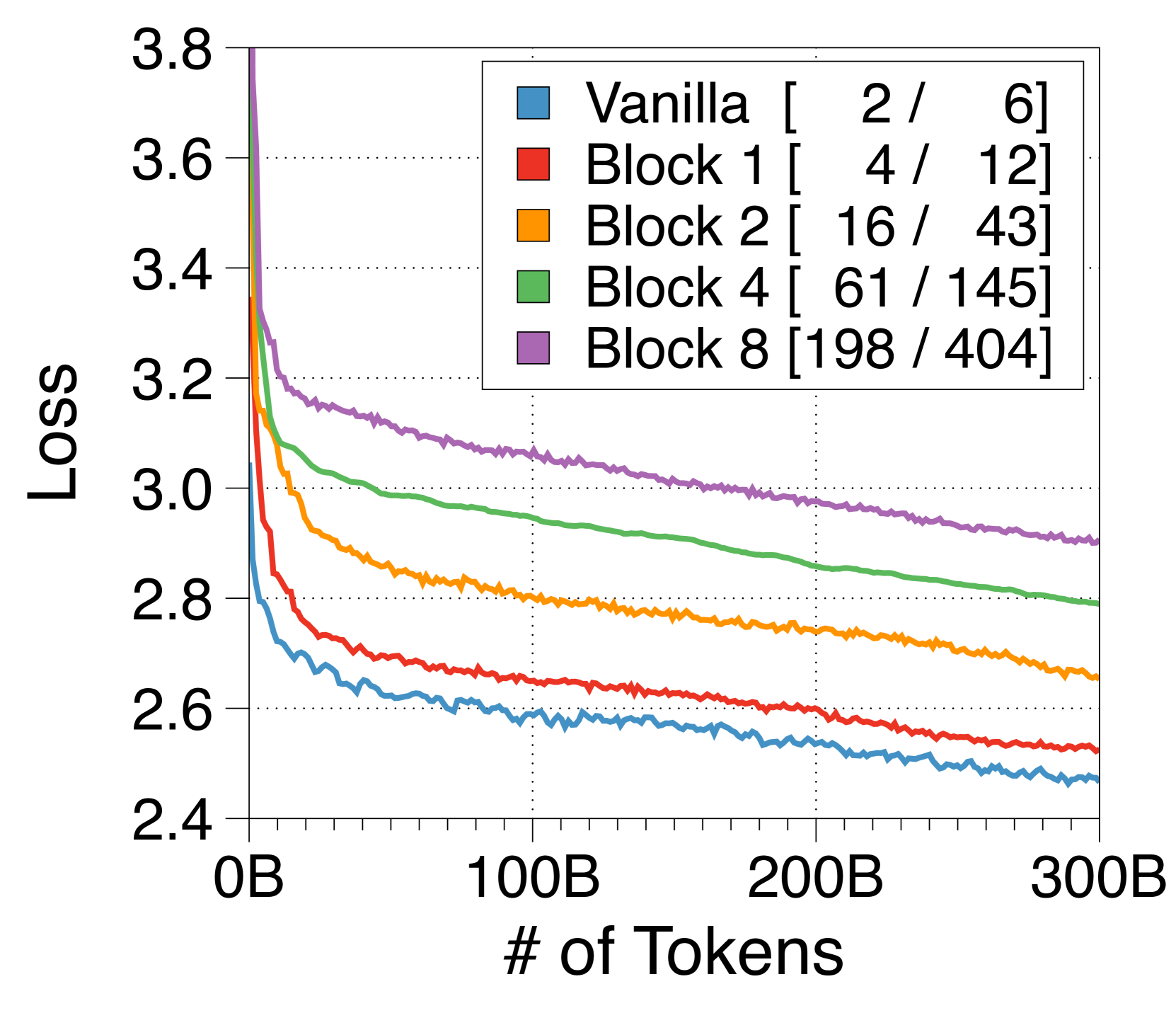
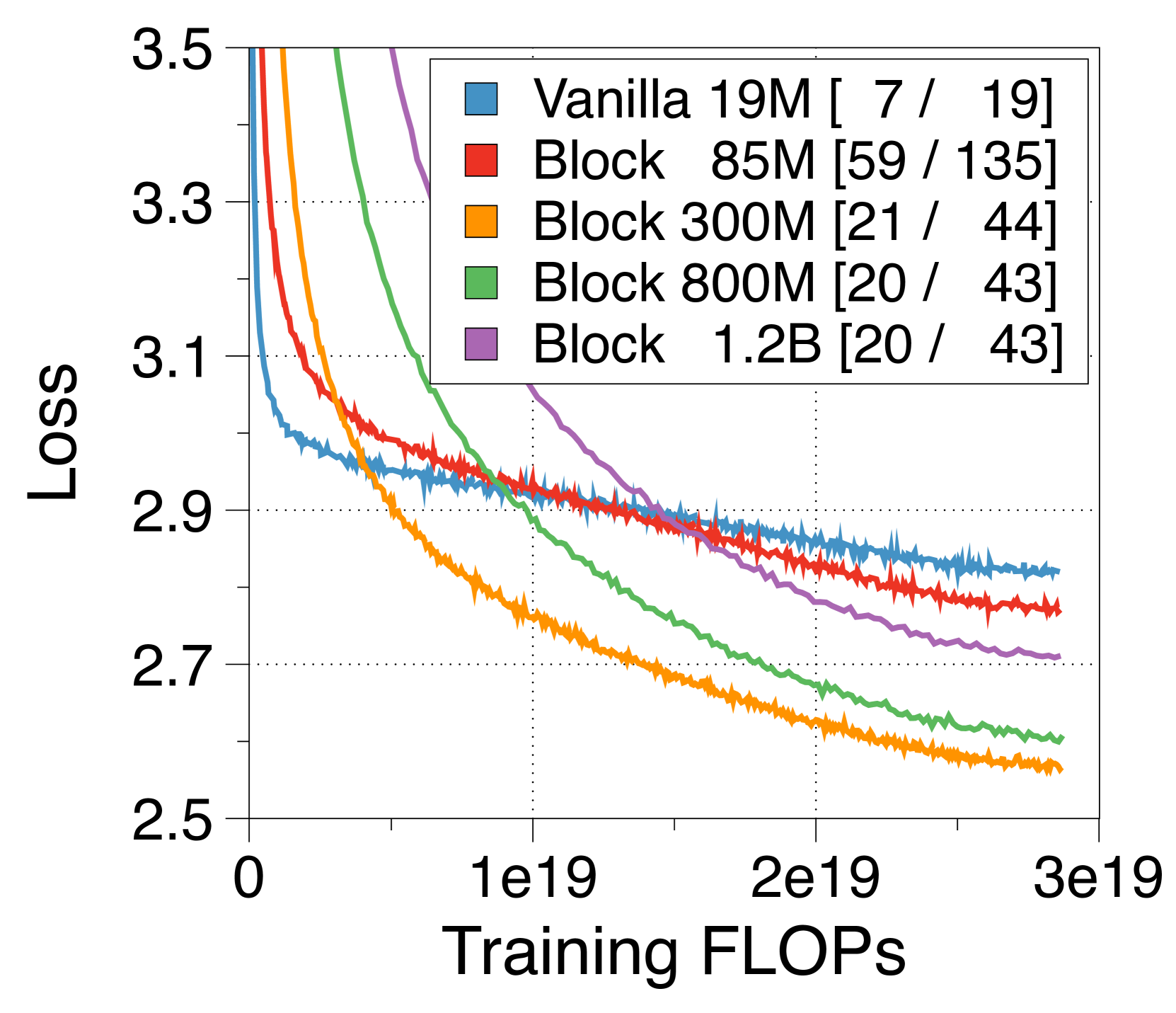
3.6推理吞吐量约束下的IsoFLOP分析
之前的研究主要集中在计算最优模型上,以在训练 FLOP 预算内最大化性能[33, 32],同时通常忽略推理吞吐量。 然而,最近的趋势强调模型也考虑推理吞吐量约束,要么通过过度训练较小的模型[65, 64],要么通过减少模型本身的FLOPs[55]。 在 4(c) 中,当使用训练 FLOP 和普通模型的吞吐量作为预算约束时,最佳的 Block Transformer 模型实现了卓越的困惑度并使吞吐量增加了三倍。 这说明我们的模型可以有效地平衡训练效率和推理吞吐量。
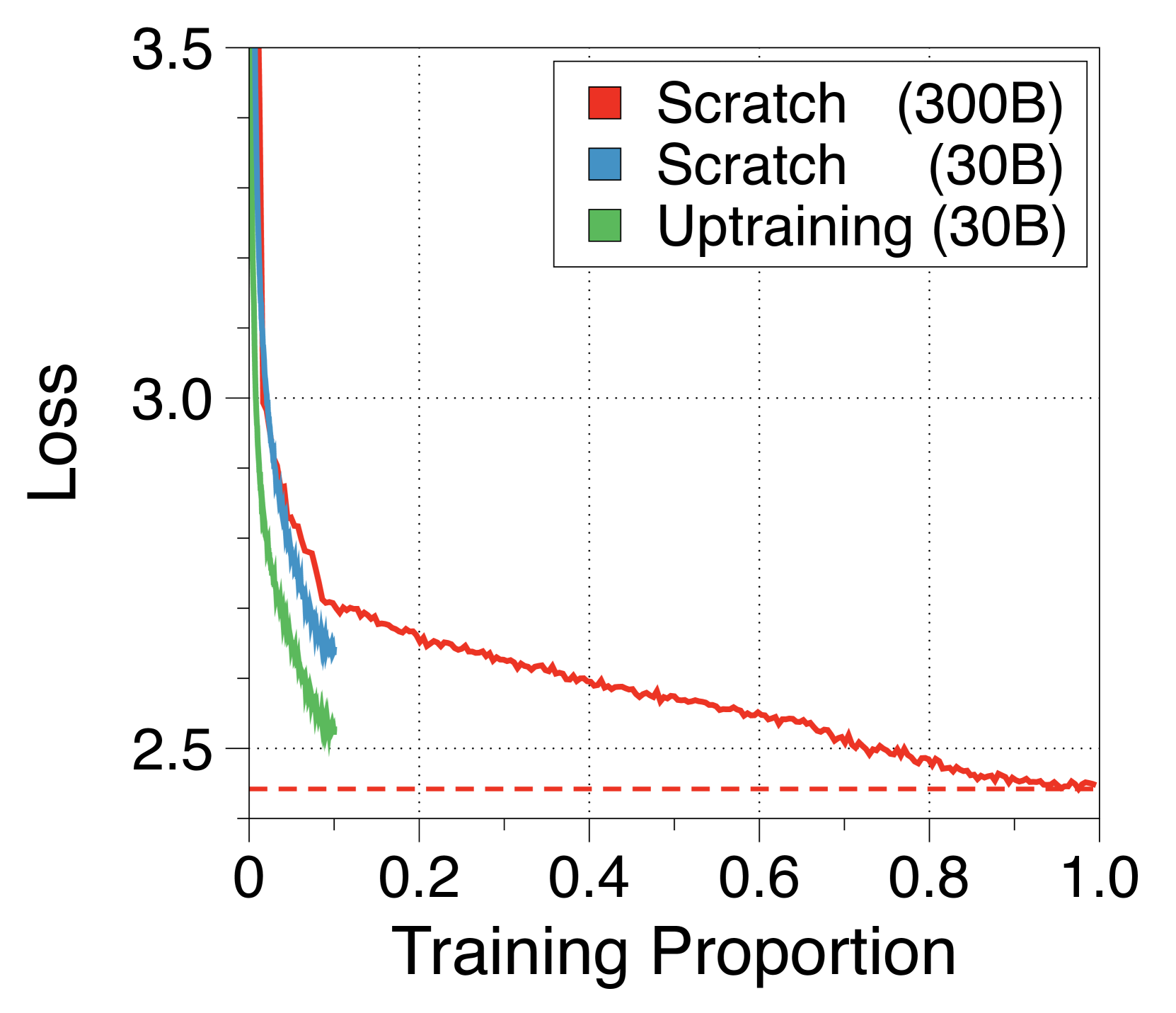
3.7 从原版 Transformer 升级
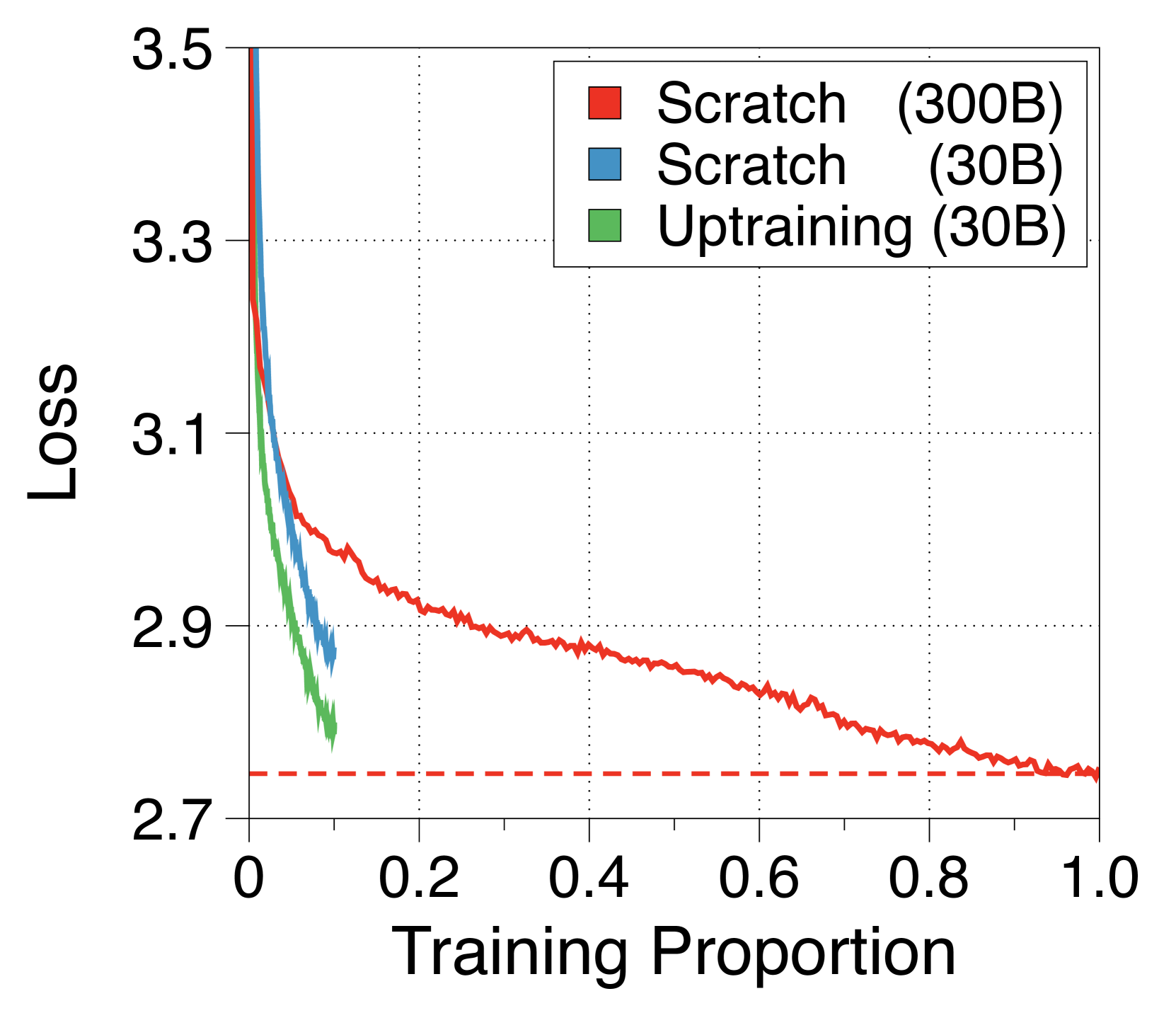
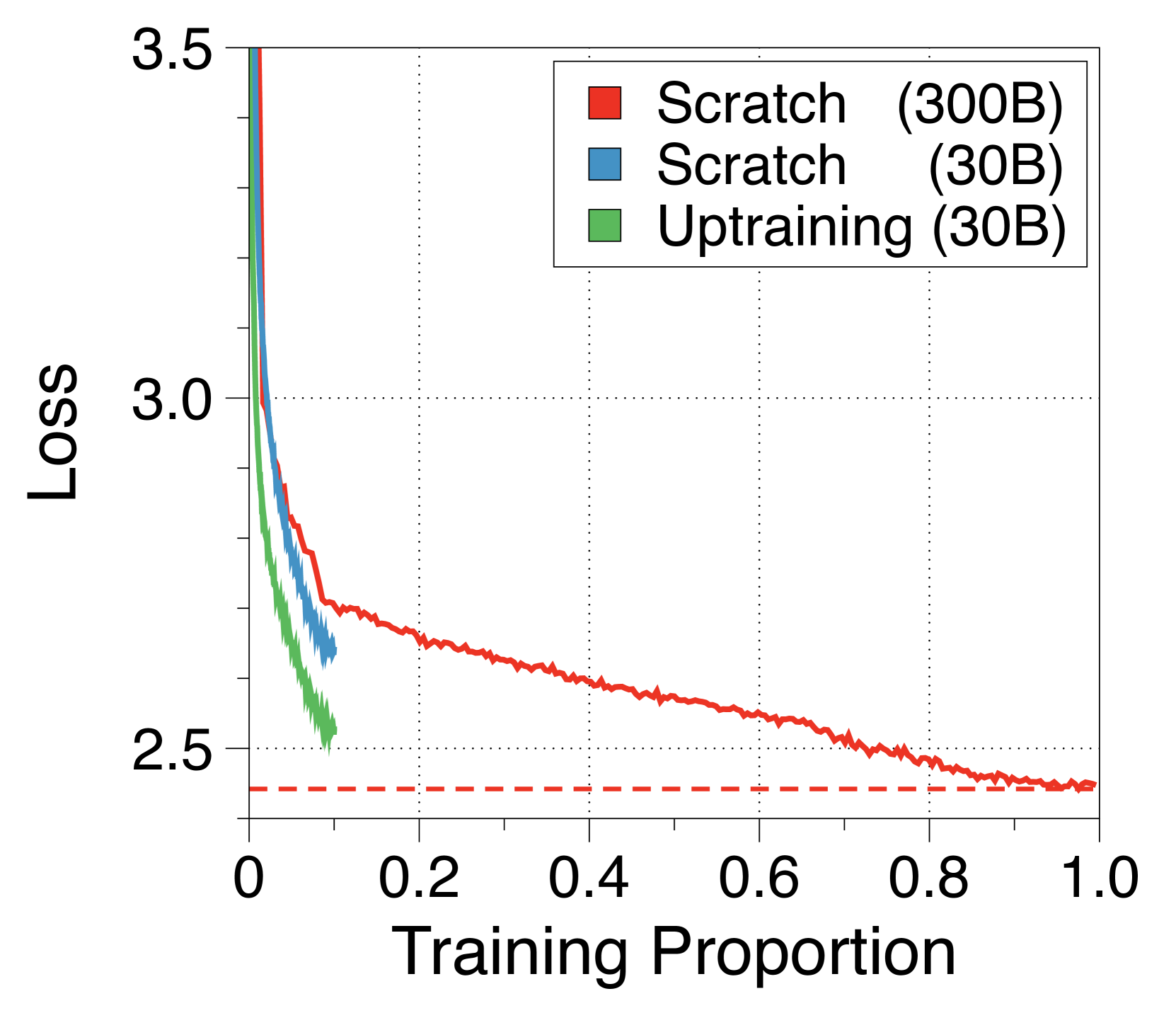
与之前的研究[74]不同,我们的子字级全局到局部架构可以利用预训练的普通 Transformer 的初始化。 这可以实现高效的训练,只需要少量的数据。 如5(a)所示,这种上训练策略只需原始训练步骤的 10% 即可实现近乎完全的性能恢复,优于随机初始化策略。 与之前的研究[2]一致,研究有意的权重初始化技术可以进一步增强性能收敛。 我们在Appendix N 中总结了详细信息。
4讨论
4.1 与相关作品的比较
与兆字节的性能比较
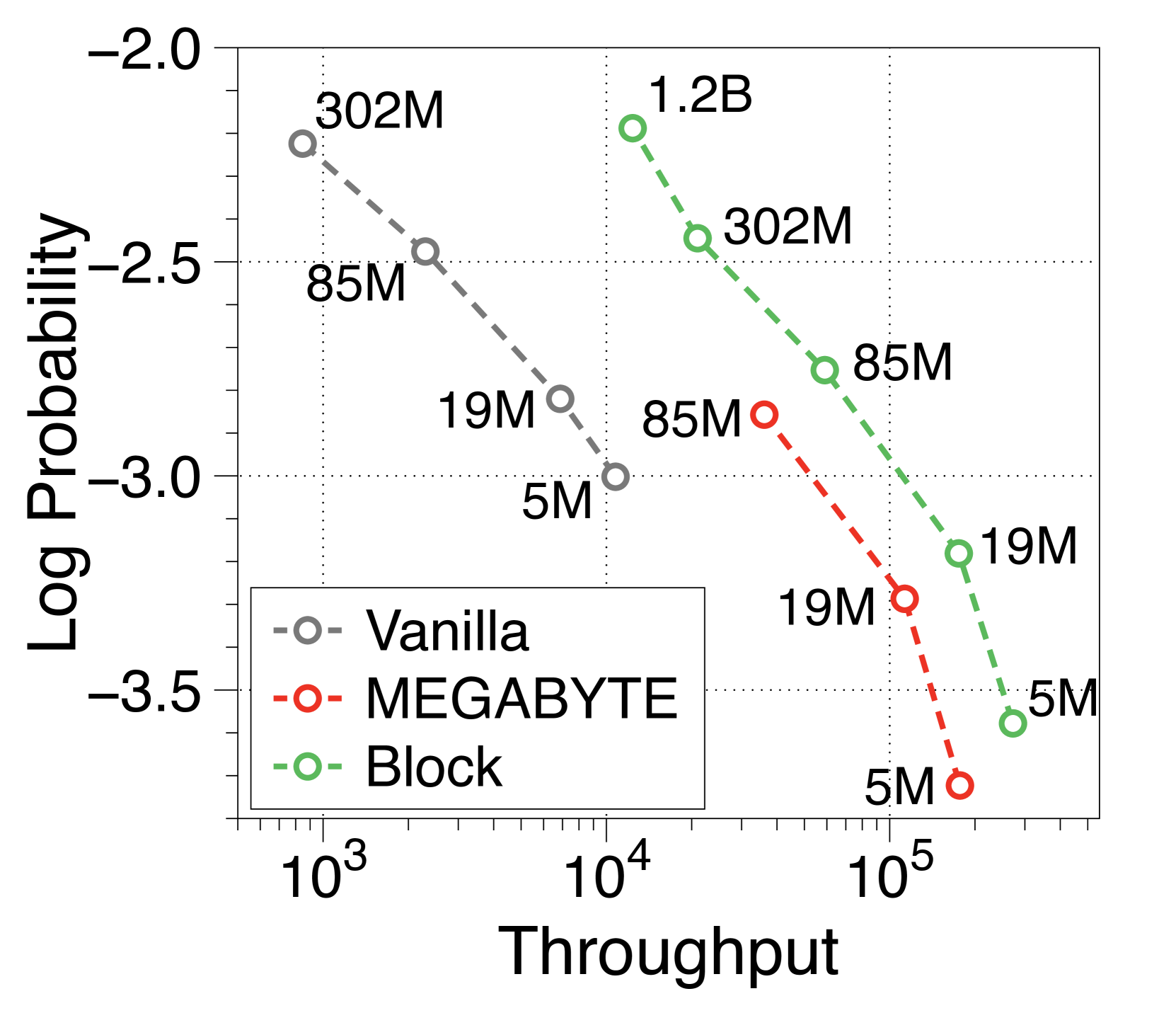
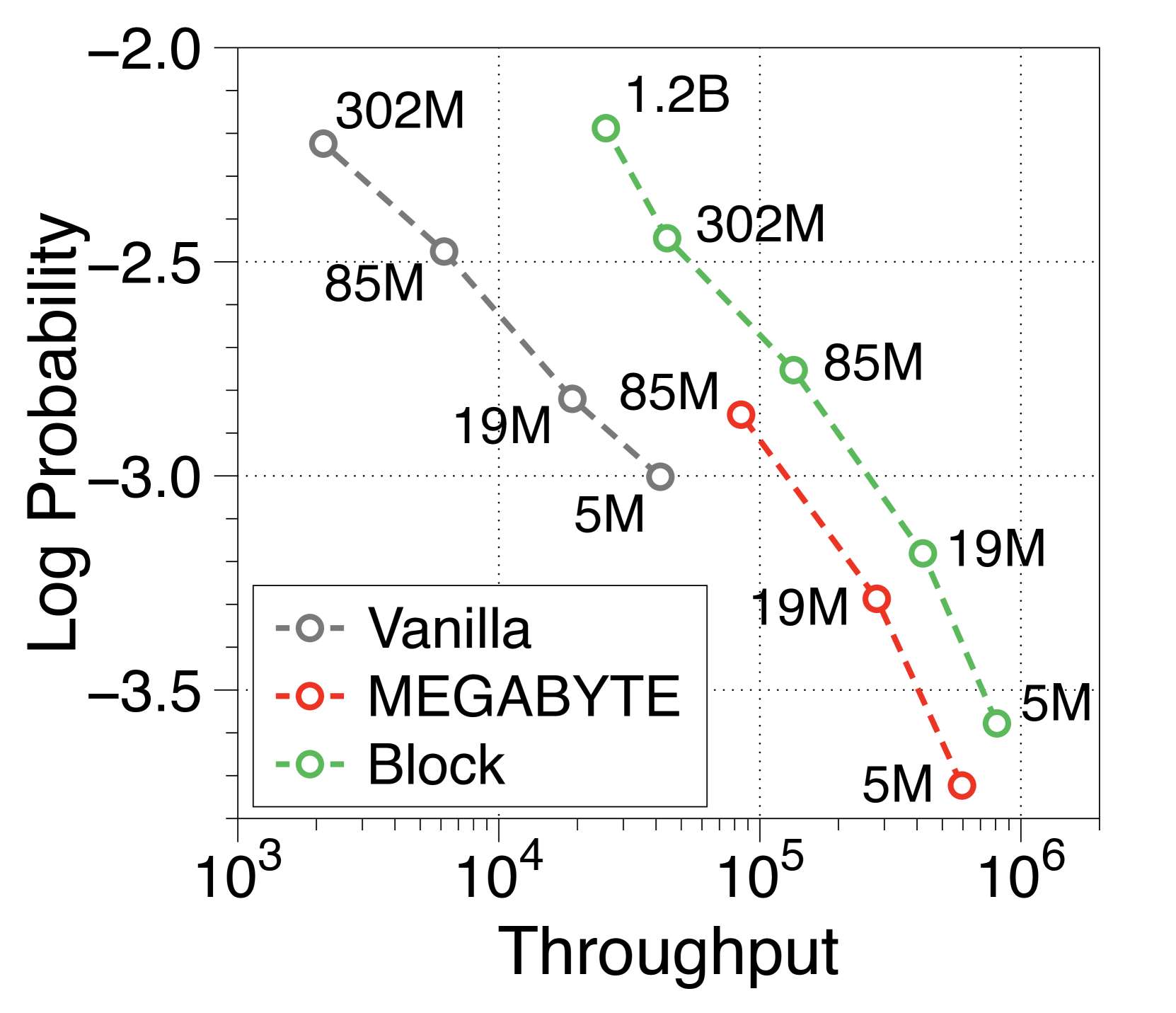
MEGABYTE模型[74]采用全局到局部的结构,但注重高效的预训练而不是推理。 因此,在训练 FLOP 预算内,他们主张基于 6:1 的最佳比率使用更大的块解码器。 如5(b)所示,我们重新实现了 Token 级MEGABYTE模型,并且通过全局到局部建模,与普通模型相比,它们还实现了显着更高的吞吐量。 尽管如此,与我们在subsection 3.3中的见解一致,我们具有增强的本地计算能力的模型显示吞吐量在兆字节之上显着增加了 1.5 倍以上。 有关详细信息,请参阅Appendix O。
与KV缓存压缩的关系
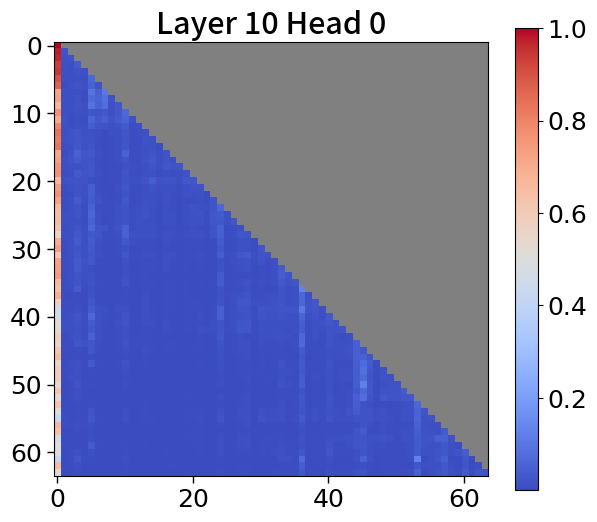
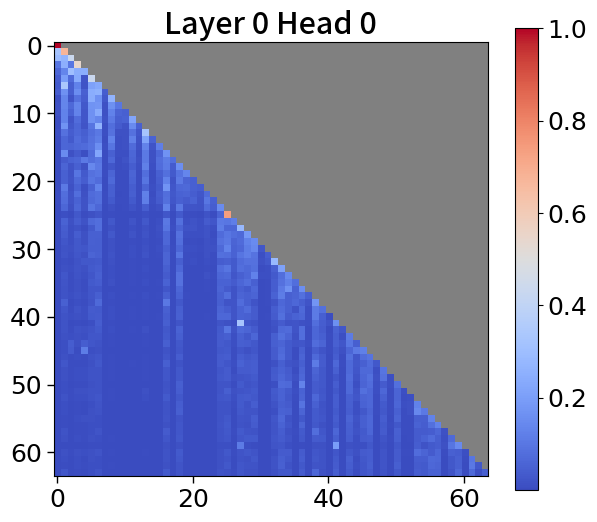
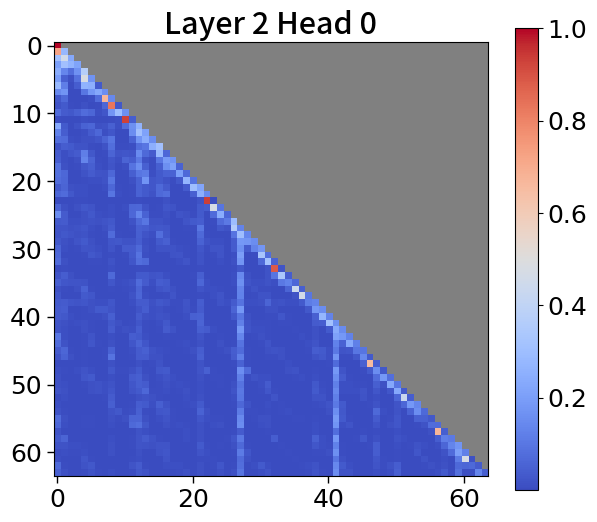
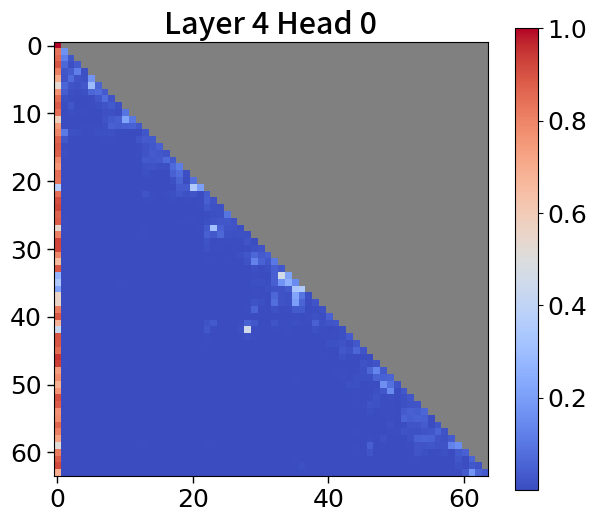
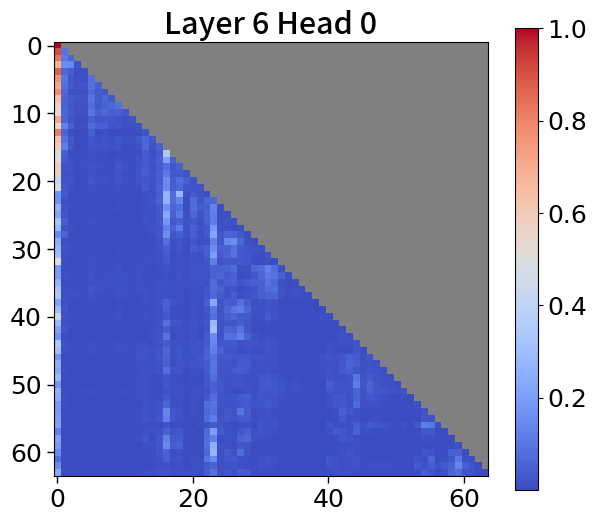
全局到局部的建模可以通过 KV 缓存压缩的视角来看待,其中过去的序列在上层被完全修剪。 最近的研究引入了仅保留有意义的标记的算法,这些标记由累积的注意力分数[67, 77]确定,并观察到大多数注意力往往集中在第一个词符[72, 28]上。 在 5(c) 中,我们的模型表现出类似的模式。 这一观察结果表明,不仅可以通过利用当前的上下文嵌入,还可以通过合并全局嵌入或前一个窗口的上下文嵌入来提高性能。 有关更多详细信息,请参阅Appendix P。
4.2 上下文信息封装在上下文块嵌入中
由于输入标记和上下文嵌入在词符解码器中共享相同的潜在空间,因此我们分析与这些块嵌入最近的标记。 有趣的是,Appendix Q 中的Table 5 揭示了上下文嵌入压缩全局上下文,而不是概述下一个块。 第二个前缀通常包含有关当前块的最后一个词符的信息,以帮助预测下一个块的第一个词符。 同时,第一个前缀通常与非直观的或EOS词符匹配,表明它们携带了更一般的信息。 有鉴于此,块解码器有效地压缩了过去的全局上下文,词符解码器利用它来进行本地语言建模。
4.3进一步提高吞吐量的技术
并行词符解码的块自回归模型
当我们预训练块解码器来预测下一个输入块嵌入时,如果块解码器的预测是精确的,则词符解码器可以并行解码所有块。 虽然 Mujika [44] 通过直接预测嵌入矩阵来提高预效率,但我们发现块解码器的 MSE 或对比损失 [16] 实际上会降低性能。 此外,需要解决块级的错误累积问题,因为块嵌入不可能实现离散化。 尽管如此,使用预训练的文本嵌入 [68, 36] 作为地面事实,而不是联合训练嵌入器,可能是有益的。
一次预测多个具有较长输出长度的块
如果模型被训练为同时预测两个或三个块,吞吐量将成比例增加。 例如,如果输入块长度为四,则可以对词符解码器进行预训练以预测八个标记,相当于两个块。 一种有效的训练方法是对原始 Block Transformer 模型进行升级训练。 为了保证性能,我们可以根据后续块的置信度自适应调整预测长度或验证这些草稿,类似于推测解码[37,15,39]。
5结论
我们引入了 Block Transformer 架构,它突出了自回归 Transformer 中全局到局部建模的推理时间优势。 我们的实证研究结果表明,全局和本地组件都发挥着至关重要的作用,并且我们认识到词符解码器的推理优势,而这在之前的工作中被忽视了。 通过战略性地设计我们的架构,与同等性能的普通 Transformer 相比,我们显着提高了吞吐量。 请参阅Appendix A 了解限制,请参阅Appendix B 了解未来工作,并参阅Appendix C 了解更广泛的影响。
致谢和资金披露
我们要感谢 Honglak Lee 对本文大纲的批评性反馈。 我们还感谢 Yujin Kim 对高效推理和相关工作的广泛讨论。 此外,我们感谢 Kyungmin Lee、Junwon Hwang、Park Sangha 和 Hyojin Jeon 在我们工作发展过程中不断提供的反馈。
参考
- Agrawal et al. [2024] Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in llm inference with sarathi-serve. arXiv preprint arXiv:2403.02310, 2024.
- Ainslie et al. [2023] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023.
- Alizadeh et al. [2023] Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, Karen Khatamifard, Minsik Cho, Carlo C Del Mundo, Mohammad Rastegari, and Mehrdad Farajtabar. Llm in a flash: Efficient large language model inference with limited memory. arXiv preprint arXiv:2312.11514, 2023.
- Andonian et al. [2023] Alex Andonian, Quentin Anthony, Stella Biderman, Sid Black, Preetham Gali, Leo Gao, Eric Hallahan, Josh Levy-Kramer, Connor Leahy, Lucas Nestler, Kip Parker, Michael Pieler, Jason Phang, Shivanshu Purohit, Hailey Schoelkopf, Dashiell Stander, Tri Songz, Curt Tigges, Benjamin Thérien, Phil Wang, and Samuel Weinbach. GPT-NeoX: Large Scale Autoregressive Language Modeling in PyTorch, 9 2023. URL https://www.github.com/eleutherai/gpt-neox.
- Bae et al. [2023] Sangmin Bae, Jongwoo Ko, Hwanjun Song, and Se-Young Yun. Fast and robust early-exiting framework for autoregressive language models with synchronized parallel decoding. arXiv preprint arXiv:2310.05424, 2023.
- Bahdanau et al. [2014] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
- Biderman et al. [2022] Stella Biderman, Kieran Bicheno, and Leo Gao. Datasheet for the pile. arXiv preprint arXiv:2201.07311, 2022.
- Biderman et al. [2023] Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023.
- Bisk et al. [2020] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
- Black et al. [2022] Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, et al. Gpt-neox-20b: An open-source autoregressive language model. arXiv preprint arXiv:2204.06745, 2022.
- Brandon et al. [2024] William Brandon, Mayank Mishra, Aniruddha Nrusimha, Rameswar Panda, and Jonathan Ragan Kelly. Reducing transformer key-value cache size with cross-layer attention, 2024.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Bulatov et al. [2023] Aydar Bulatov, Yuri Kuratov, Yermek Kapushev, and Mikhail S Burtsev. Scaling transformer to 1m tokens and beyond with rmt. arXiv preprint arXiv:2304.11062, 2023.
- Cai et al. [2024] Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774, 2024.
- Chen et al. [2023] Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling. arXiv preprint arXiv:2302.01318, 2023.
- Chen et al. [2020] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020.
- Chowdhery et al. [2023] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- Dai et al. [2020] Zihang Dai, Guokun Lai, Yiming Yang, and Quoc V. Le. Funnel-transformer: Filtering out sequential redundancy for efficient language processing, 2020.
- Dao et al. [2022] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- DeepSeek-AI et al. [2024] DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J. L. Cai, Jian Liang, Jianzhong Guo, Jiaqi Ni, Jiashi Li, Jin Chen, Jingyang Yuan, Junjie Qiu, Junxiao Song, Kai Dong, Kaige Gao, Kang Guan, Lean Wang, Lecong Zhang, Lei Xu, Leyi Xia, Liang Zhao, Liyue Zhang, Meng Li, Miaojun Wang, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Mingming Li, Ning Tian, Panpan Huang, Peiyi Wang, Peng Zhang, Qihao Zhu, Qinyu Chen, Qiushi Du, R. J. Chen, R. L. Jin, Ruiqi Ge, Ruizhe Pan, Runxin Xu, Ruyi Chen, S. S. Li, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shaoqing Wu, Shengfeng Ye, Shirong Ma, Shiyu Wang, Shuang Zhou, Shuiping Yu, Shunfeng Zhou, Size Zheng, T. Wang, Tian Pei, Tian Yuan, Tianyu Sun, W. L. Xiao, Wangding Zeng, Wei An, Wen Liu, Wenfeng Liang, Wenjun Gao, Wentao Zhang, X. Q. Li, Xiangyue Jin, Xianzu Wang, Xiao Bi, Xiaodong Liu, Xiaohan Wang, Xiaojin Shen, Xiaokang Chen, Xiaosha Chen, Xiaotao Nie, Xiaowen Sun, Xiaoxiang Wang, Xin Liu, Xin Xie, Xingkai Yu, Xinnan Song, Xinyi Zhou, Xinyu Yang, Xuan Lu, Xuecheng Su, Y. Wu, Y. K. Li, Y. X. Wei, Y. X. Zhu, Yanhong Xu, Yanping Huang, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Li, Yaohui Wang, Yi Zheng, Yichao Zhang, Yiliang Xiong, Yilong Zhao, Ying He, Ying Tang, Yishi Piao, Yixin Dong, Yixuan Tan, Yiyuan Liu, Yongji Wang, Yongqiang Guo, Yuchen Zhu, Yuduan Wang, Yuheng Zou, Yukun Zha, Yunxian Ma, Yuting Yan, Yuxiang You, Yuxuan Liu, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhen Huang, Zhen Zhang, Zhenda Xie, Zhewen Hao, Zhihong Shao, Zhiniu Wen, Zhipeng Xu, Zhongyu Zhang, Zhuoshu Li, Zihan Wang, Zihui Gu, Zilin Li, and Ziwei Xie. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model, 2024.
- Dehghani et al. [2018] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. arXiv preprint arXiv:1807.03819, 2018.
- Dehghani et al. [2021] Mostafa Dehghani, Anurag Arnab, Lucas Beyer, Ashish Vaswani, and Yi Tay. The efficiency misnomer. arXiv preprint arXiv:2110.12894, 2021.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Fu [2024] Yao Fu. Challenges in deploying long-context transformers: A theoretical peak performance analysis. arXiv preprint arXiv:2405.08944, 2024.
- Gao et al. [2020] Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
- Gao et al. [2023] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, 12 2023. URL https://zenodo.org/records/10256836.
- Ge et al. [2023] Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive kv cache compression for llms. arXiv preprint arXiv:2310.01801, 2023.
- Goyal et al. [2023] Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. arXiv preprint arXiv:2310.02226, 2023.
- Graves [2016] Alex Graves. Adaptive computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983, 2016.
- Han et al. [2021] Kai Han, An Xiao, Enhua Wu, Jianyuan Guo, Chunjing Xu, and Yunhe Wang. Transformer in transformer. Advances in neural information processing systems, 34:15908–15919, 2021.
- Hoffmann et al. [2022] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Kaplan et al. [2020] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Kim et al. [2024] Taehyeon Kim, Ananda Theertha Suresh, Kishore Papineni, Michael Riley, Sanjiv Kumar, and Adrian Benton. Towards fast inference: Exploring and improving blockwise parallel drafts. arXiv preprint arXiv:2404.09221, 2024.
- Kwon et al. [2023] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023.
- Lee et al. [2024] Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, et al. Gecko: Versatile text embeddings distilled from large language models. arXiv preprint arXiv:2403.20327, 2024.
- Leviathan et al. [2023] Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR, 2023.
- Li et al. [2024a] Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. arXiv preprint arXiv:2404.14469, 2024a.
- Li et al. [2024b] Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty. arXiv preprint arXiv:2401.15077, 2024b.
- Liu et al. [2019] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Liu et al. [2024] Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. Advances in Neural Information Processing Systems, 36, 2024.
- Merity et al. [2016] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016.
- Milbauer et al. [2023] Jeremiah Milbauer, Annie Louis, Mohammad Javad Hosseini, Alex Fabrikant, Donald Metzler, and Tal Schuster. LAIT: Efficient multi-segment encoding in transformers with layer-adjustable interaction. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10251–10269, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.571. URL https://aclanthology.org/2023.acl-long.571.
- Mujika [2023] Asier Mujika. Hierarchical attention encoder decoder. arXiv preprint arXiv:2306.01070, 2023.
- Mukherjee et al. [2023] Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707, 2023.
- Munkhdalai et al. [2024] Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. Leave no context behind: Efficient infinite context transformers with infini-attention. arXiv preprint arXiv:2404.07143, 2024.
- Nair et al. [2024] Pranav Ajit Nair, Yashas Samaga, Toby Boyd, Sanjiv Kumar, Prateek Jain, Praneeth Netrapalli, et al. Tandem transformers for inference efficient llms. arXiv preprint arXiv:2402.08644, 2024.
- Paperno et al. [2016] Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: Word prediction requiring a broad discourse context. arXiv preprint arXiv:1606.06031, 2016.
- Pappagari et al. [2019] Raghavendra Pappagari, Piotr Zelasko, Jesús Villalba, Yishay Carmiel, and Najim Dehak. Hierarchical transformers for long document classification. In 2019 IEEE automatic speech recognition and understanding workshop (ASRU), pages 838–844. IEEE, 2019.
- Pham et al. [2023] Aaron Pham, Chaoyu Yang, Sean Sheng, Shenyang Zhao, Sauyon Lee, Bo Jiang, Fog Dong, Xipeng Guan, and Frost Ming. OpenLLM: Operating LLMs in production, June 2023. URL https://github.com/bentoml/OpenLLM.
- Pope et al. [2023] Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. Proceedings of Machine Learning and Systems, 5, 2023.
- Rae et al. [2019] Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive transformers for long-range sequence modelling. arXiv preprint arXiv:1911.05507, 2019.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- Rajbhandari et al. [2020] Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020.
- Raposo et al. [2024] David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Conway Humphreys, and Adam Santoro. Mixture-of-depths: Dynamically allocating compute in transformer-based language models. arXiv preprint arXiv:2404.02258, 2024.
- Rasley et al. [2020] Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3505–3506, 2020.
- Reid et al. [2024] Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- Schuster et al. [2022] Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Tran, Yi Tay, and Donald Metzler. Confident adaptive language modeling. Advances in Neural Information Processing Systems, 35:17456–17472, 2022.
- Shazeer [2019] Noam Shazeer. Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150, 2019.
- Sheng et al. [2023] Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. Flexgen: High-throughput generative inference of large language models with a single gpu. In International Conference on Machine Learning, pages 31094–31116. PMLR, 2023.
- Spector and Re [2023] Benjamin Spector and Chris Re. Accelerating llm inference with staged speculative decoding. arXiv preprint arXiv:2308.04623, 2023.
- Stern et al. [2018] Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Blockwise parallel decoding for deep autoregressive models. Advances in Neural Information Processing Systems, 31, 2018.
- Sun et al. [2024] Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, and Furu Wei. You only cache once: Decoder-decoder architectures for language models, 2024.
- Team et al. [2024] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Touvron et al. [2023] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wang et al. [2021] Hanrui Wang, Zhekai Zhang, and Song Han. Spatten: Efficient sparse attention architecture with cascade token and head pruning. In 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 97–110. IEEE, 2021.
- Wang et al. [2022] Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022.
- Wang et al. [2020] Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- Wolf et al. [2020] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45, 2020.
- Wu and Tu [2024] Haoyi Wu and Kewei Tu. Layer-condensed kv cache for efficient inference of large language models, 2024.
- Xiao et al. [2023] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023.
- Yang et al. [2024] Dongjie Yang, XiaoDong Han, Yan Gao, Yao Hu, Shilin Zhang, and Hai Zhao. Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference, 2024.
- Yu et al. [2024] Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, and Mike Lewis. Megabyte: Predicting million-byte sequences with multiscale transformers. Advances in Neural Information Processing Systems, 36, 2024.
- Zaheer et al. [2020] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33:17283–17297, 2020.
- Zellers et al. [2019] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- Zhang et al. [2024] Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36, 2024.
附录 A限制
与困惑等效的普通模型相比,我们研究中考虑的 Block Transformer 变体需要更多参数和失败次数。 尽管参数和 FLOP 要求较高,但由于内存开销较低且词符解码器中省略了预填充,我们的块转换器仍实现了较高的推理吞吐量。 然而,这种优势在训练过程中会减弱——与普通变形金刚相比,导致训练时的成本更高。 大参数要求还阻碍了块 Transformer 在硬内存限制(例如设备上使用)的情况下的适用性。 我们注意到,这些部分是我们关注推理吞吐量而不是架构限制的结果。 有许多有希望的途径可以最大限度地减少参数和 FLOP(训练成本)要求,只需对架构或超参数进行细微调整。 在下一节中,我们将讨论其中的一些内容以供将来的工作使用。
附录 B 未来的工作
B.1 优化参数或 FLOP 的超参数
我们可以优化 Block Transformer 架构的超参数,以最大限度地减少参数或 FLOP 要求,这与我们主要实验中的推理吞吐量不同。 首先,我们可以减少块长度以提高性能,同时保持相同的参数数量。 我们对块长度的消融表明,较短的块长度可以显着提高困惑度,同时会因块解码器中的 FLOP 增加而损害推理吞吐量。 因此,为了实现可比的困惑度,我们可以使用更少的参数,这抵消了由于缩短的块长度而导致的吞吐量下降。
其次,我们发现,由于词符解码器的 FLOP 密集型性质,增加块解码器的比例可以显着降低 FLOP 要求,同时性能略有下降。 然而,由于块解码器的 KV 缓存瓶颈,这是以增加推理时间为代价的。 需要进一步的实验来精确确定与这些超参数选择相关的各种成本指标的权衡。
B.2 具有更长块嵌入的块解码器的致密化
另一种无需额外参数即可提高块转换器性能的方法是更好地利用块解码器中已有的参数,即通过它们传递更多 Token 。 我们可以通过表示具有更长输入块嵌入的单个块(例如 )来实现这一点,而不是一个。 我们将这些称为子块 Token 。 在单个解码步骤中, 输入标记将被投影到 子块标记中。 然后,这些将被传递到块解码器并并行转发。
这将有效地保留块解码器的计算宽度[29],即输入的总嵌入维度,相当于相同宽度和深度的普通 Transformer。 4(a) 中的普通 Transformer 和带有 的 Block Transformer 之间的困惑度存在微小差异,表明当计算宽度相同时,Block Transformer 可以接近相同大小的普通 Transformer 的性能块解码器的结构是相同的。
虽然这需要与普通 Transformer 相同的 FLOP,但由于并行执行,我们预计解码时间会减少大约 倍,因为参数和之前的 KV 缓存每个块只需要获取一次,而不是每次输入词符一次。 请注意,总 KV 缓存存储将与普通 Transformer 相同,因为输入 Token 和子块 Token 的数量将相同(这就是为什么我们期望 KV 缓存 IO 减少 而不是 就像我们原来的块解码器一样)。
B.3 减轻词符解码器的局部性以提高性能
在我们的实验中,我们将传递给词符解码器的全局信息限制为单个上下文嵌入。 这样做是为了简单起见,并强调全局到局部建模的可行性,其中局部模块对全局上下文的访问受到限制。 然而,我们认为词符解码器可以通过消除这种相当极端的限制,以最小的额外成本获得性能提升。
可以在词符解码器中使用额外的上下文嵌入来促进上下文信息的传播,如subsection 4.1中所述。 我们可以利用先前输出块嵌入的一个小窗口,而不是仅将最后一个输出块嵌入投影到词符解码器。 这可以解决词符解码器中后面位置由于上下文信息不足而导致的困惑度的增加,而词符解码器中的 FLOP 和 KV 缓存开销仅略有增加。
B.4 进一步扩展和高级训练方案
与上一代前沿模型[12, 17]相比,我们论文中的实验规模也相对较小。 虽然我们的实验表明 Block Transformer 的推理吞吐量优势可在两个数量级上积极扩展,但还需要进一步的实验来验证超过 10 亿个参数。
我们可以将上行训练视为此分析的一种经济有效的训练方法,它有效地利用现有的预训练普通 Transformer 来最大限度地降低块 Transformer 的训练成本。 例如,我们可以考虑一种渐进式适应方法,其中普通 Transformer 首先适应块长度为 1 的 Block Transformer,以最大限度地提高兼容性,然后使用更大的块长度逐步进行训练。 此外,探索权重初始化方法(例如平均层或识别产生类似激活的权重),而不是简单地分割预训练的普通 Transformer 的层来初始化块和词符解码器,可以显着提高性能。
B.5 动态计算分配的自适应块长度
如果我们可以动态分配计算以更快地生成“简单” Token ,但在“硬” Token 上思考更长时间会怎么样? 这是之前几篇关于动态计算分配的研究的核心问题[30,58,5,55]。 Block Transformer 架构的多尺度性质为在自回归语言模型中实现这一目标提供了一种新颖的途径——根据块内容的“难度”动态设置块的输入和输出长度。 对于嵌入器和词符解码器,我们可以分别使用基于 CLS Token 和前缀词符的设计,并且可以使用填充来在训练期间维持静态计算。 训练模型以动态确定最佳输入和输出块长度仍然是一个挑战。
附录 C 更广泛的影响
最近的语言模型已经显着扩展以实现类似人类的训练能力,从而导致巨大的成本。 在现实世界的服务中部署这些巨大的模型会产生大量的计算开销。 此外,与大型语言模型相关的计算成本不断上升正在引发环境问题。 我们的模型提高了内存利用率和推理吞吐量,有可能缓解这些问题。 Block Transformer 架构带来的效率提升可以降低部署语言模型的成本。 此外,子字级别的全局到局部建模有助于从现有预训练模型到 Block Transformer 的高效上训练,从而提供有效的训练增强途径。 我们鼓励进一步研究以充分探索这些影响,确保负责任地开发和部署 Block Transformer。
附录D相关工作
D.1 全局到局部建模
虽然先前的研究已经探索了各种模式的全局到局部建模,但尚未在自回归语言模型中利用它来优化推理效率。 局部模块已合并到视觉变换器中,以最小的计算开销增强细粒度局部特征的编码[31]。 基于 BERT 的编码器 LM 中也使用了类似的方法,通过首先独立编码每个固定大小的片段[49,19,43]来有效地对长文档进行分类。 这与我们强调局部词符解码器的方式类似,但我们将局部性应用于上层的解码器 LM,而不是下层的编码器 LM。
字节级分层模型
有关字节级建模的几项工作将类似的架构应用于我们的块转换器[74, 44]。 然而,虽然我们试图通过将语言建模任务隔离为全局和局部组件来减轻全局注意力的瓶颈,但先前的工作主要利用层次结构来减轻来自各种模态的字节级数据的长上下文长度。标记化。 与块 Transformer 中局部模块的核心作用相反,先前的工作将局部模型的作用视为“将隐藏状态映射到可能的补丁上的分布”,并建议“更小的模型可以用于内部模型”。 -补丁建模'[74]并且可能'停止对整体性能做出贡献'[44]。 Similarly, while Yu et al. [74] finds that it is optimal to assign more parameters to the global module under same training-time constraint, we find that a more balanced allocation, e.g., 1:1 for , is optimal under fixed parameter constraints, and that even larger token decoders are beneficial for inference throughput, further highlighting the benefits of the local module. 我们认为解释和发现的这些差异源于输入单元粒度(即字节与子字)以及所考虑的成本指标(即训练时间与推理成本)的差异。
D.2 KV缓存压缩
KV 缓存压缩的最新进展旨在通过有选择地保留必要的键值对[72,77,28,73,38]来优化内存使用。 Scissorhands [28] 和 H2O [77] 通过利用注意力分数仅保留 KV 缓存的关键组件来增强压缩。 FastGen [41] 通过对每个注意力头采用不同的策略来完善这种方法。 StreamingLLM [72] 仅维护最近的上下文窗口和一些初始标记作为“注意力接收器”,从而丢弃其他过去的上下文。 SnapKV [38] 专注于修剪输入提示中的标记,以响应增加的输入长度。 PyramidInfer [73] 在预填充期间修剪 KV 头,计算每一层,以解决此阶段的内存使用问题。 虽然已经提出了各种方法来智能地修剪相对不太重要的标记,但这些方法本质上永久地丢弃可能在未来上下文中再次变得相关的信息。 相反,Block Transformer 保留对块解码器中所有先前上下文的访问。 KV缓存压缩方法也可以应用于块解码器以提高效率。
D.3 优化KV缓存的架构
最近的工作修改了注意力块的设计,使得多个查询头可以关注相同的共享 KV 头,显着减少唯一 KV 头的数量,同时将性能下降最小化。 多查询关注 (MQA) [59] 允许多个查询头关注共享键/值对,从而减少存储开销。 分组查询注意力(GQA)[2]通过将查询头组织成共享单个 KV 头的组来概括这一点,以实现相同的目标。 几个并发的工作进一步发展了这个想法,通过在相邻层之间共享 KV 头 [11] 或在大多数层之间共享顶层的 KV 头 [71] 。 最近的架构[21]引入了多头潜在注意(MLA)来联合量化KV状态。 通过采用标准 Transformer 架构,我们的 Block Transformer 也可以从这些技术中受益,以减轻块解码器中剩余的 KV 缓存瓶颈。
有几件作品对整体建筑的表述采用了新颖的方法。 串联 Transformer [47]在大块级编码器和小 Token 级解码器之间交替。 YOCO [63] 是一种解码器-解码器架构,在上层采用基于交叉注意力的解码器,所有解码器都从单个中间层引用 KV 缓存,从而减少了 KV 缓存存储。 相比之下,我们采用不同的方法,将上下文信息压缩为单个上下文嵌入,以实现本地建模,几乎没有 KV 缓存存储和访问成本,从而缓解推理吞吐量的关键瓶颈。
附录EBlock Transformer推理效率分析
E.1 背景:推理阶段和主要瓶颈
为了生成对输入提示的响应,有必要预填充并缓存所有输入标记的 KV 值,因为它们在全局自注意力下会受到后续标记的关注。 (1) 预填充阶段是计算密集型的,因为所有输入 Token 都可以在一次前向传递过程中并行处理。 相反,当生成新 Token 时,每个前向传递只能处理一个词符,因为需要前一个词符的输出作为下一个词符的输入。 虽然线性投影 FLOP 在上下文长度较短的情况下占主导地位,但由于二次缩放,自注意力 FLOP 在上下文长度非常大的情况下超过了线性投影 FLOP。 (2) 解码阶段受内存访问限制,因为所有模型参数和先前的 KV 缓存都必须在每次前向传递时从内存加载。 为了实现高计算利用率和吞吐量,生产服务系统通常利用批处理来分摊参数 IO [1, 45] 的成本。 因此,在大批量(和足够长的上下文)下,KV缓存IO成为解码[51]的主要瓶颈。
E.2 块和词符解码器的推理时间优势
块解码器将预填充计算减少 ,将 IO 解码减少
块解码器保持与普通转换器类似的全局注意力,但在更粗糙的块级别上运行,与原始 Token 级别序列相比,将上下文长度减少 。 与相同尺寸的普通 Transformer 相比,这种减少减少了预填充期间的位置计算。 批量解码期间的主要瓶颈,即 KV 缓存 IO,减少了 ,因为它是上下文长度的二次方。 同样的节省也适用于注意力计算,随着上下文长度的增长,这可能成为预填充期间的瓶颈。 解码期间 GPU 内存中的 KV 缓存存储也线性减少 ,从而实现更大的批量大小和更高的并行度。
词符解码器完全跳过预填充,几乎消除了解码 IO
词符解码器不使用全局注意力,而是依赖于全局上下文信息的单个上下文嵌入,在每个独立块内应用局部上下文的注意力。 因此,词符解码器不需要保留或检索先前块中的 KV 缓存值,消除了预填充输入 Token 的需要。 这也几乎消除了解码期间的 KV 缓存 IO 开销,因为二次缩放适用于 的小型本地上下文,而不是全局上下文 。与普通 Transformer 中 的 KV 缓存 IO 复杂度相比,词符解码器在 块中每个块的复杂度为 ,整体降低了 。 对于我们具有 和 的主要模型,这会导致 KV 缓存 IO 开销减少 256 倍。 渐近地,这将 KV 缓存 IO 开销从相对于上下文长度的二次方降低为线性,解决了扩展到超长上下文的关键挑战[25]。 KV 缓存存储也减少了相同的因素,从而实现了更大的批量大小。 这显着提高了推理硬件的利用率,在普通 Transformer [51] 中,推理硬件的利用率通常低至 1% 的模型 FLOP 利用率 (MFU)。 因此,我们可以在词符解码器中应用更多的 FLOP 来提高性能,同时对推理吞吐量的影响最小。
附录F架构细节
F.1 嵌入器方法
抬头
对于我们的主要嵌入器设计,我们只需从查找表中检索 Token 级嵌入并将它们连接起来以获得输入块嵌入。 Token 级嵌入维度设置为主模型维度的。
编码器
为了消除向嵌入器添加编码功能的影响,我们使用基于 RoBERTa 的小型编码器对块的输入标记进行编码。 我们使用尺寸大小为 256 和 3 个隐藏层的固定大小编码器。 我们连接输出隐藏状态并应用线性投影来获得输入块嵌入。
CLS词符
为了研究可以接受各种输入块长度的嵌入器的可行性,我们使用之前用于提取句子嵌入的 CLS 标记 [24]。 我们使用与 RoBERTa 模型相同的模型大小,并将信息编码为 3 个 CLS Token ,以增加嵌入维度,同时最小化嵌入器的模型维度。 与 RoBERTa 嵌入器类似,我们连接 CLS Token 的输出隐藏状态并应用线性投影来获得输入块嵌入。
F.2 Token 解码器方法
字首
对于主要的词符解码器设计,我们通过将块解码器中的上下文嵌入投影为前缀词符嵌入来合并它们。 词符解码器可以通过注意力从前缀标记中检索上下文信息,并进一步对上下文信息进行编码。 我们可以使用多个前缀标记,即增加前缀长度,以增加词符解码器的计算宽度[29],以通过额外的FLOPs来提高性能,在推理时间方面相对便宜词符解码器。
求和
我们还考虑了先前工作[74]中使用的求和方法。 这里,上下文嵌入被投影到维度 的 嵌入,并添加到词符解码器每个输入位置的词符嵌入。 这并没有受益于词符解码器中上下文信息的额外计算。
交叉注意力
最后,我们考虑一种使用交叉注意力的方法,将输出上下文嵌入视为编码器-解码器 Transformer [53] 中编码器的输出隐藏状态。 具体来说,我们将上下文嵌入到 隐藏状态中,每个隐藏状态的维度为 ,并在词符解码器中的每个 Transformer 层的自注意力和前馈操作之间应用交叉注意力。 这也没有受益于词符解码器中上下文信息的额外计算。
附录G实验设置
G.1 整体设置
我们使用与 Pythia [8] 相同的 Transformer 架构,利用开源 GPT-NeoX 库 [4]。 我们在 Pile [26, 7] 上同时训练 vanilla 和 Block Transformer 模型,Pile 是专门为训练大型语言模型而开发的英语数据集。 我们使用专为 Pile 数据集 [10] 定制的 BPE 分词器,词汇量为 50,304。 这些模型在大约 3000 亿个 Token 上进行了预训练,考虑到去重后的 Pile 包含 2070 亿个 Token ,这相当于大约 1.5 个训练周期。 为了评估各种零样本任务的模型,我们使用语言模型评估框架[27]。 我们采用 HuggingFace 训练框架 [70],并通过 DeepSpeed 库 [ 中的混合精度训练和零冗余优化器 (ZeRO) [54] 来提高内存效率56]。 我们使用 8 个具有 40 GiB 训练 VRAM 的 A100 进行训练,同时使用 H100 GPU 测量推理延迟。
G.2 模型大小和超参数
我们的模型经过六种不同大小的训练,参数范围从 3300 万 (M) 到 14 亿 (B) 不等,以探索性能如何随模型大小而变化。 我们训练了四个与我们的 Block Transformer 模型相对应的普通模型。 我们在Table 3中总结了详细的模型配置和训练超参数。
| Token Decoder | Block Decoder | ||||||||||||
| Models | Size | Method | Dim | Head | Dim | Head | LR | Batch | |||||
| Vanilla | 5M | - | 2048 | 6 | 256 | 8 | - | - | - | - | - | 1e-3 | 256 |
| 19M | - | 2048 | 6 | 512 | 8 | - | - | - | - | - | 1e-3 | 256 | |
| 85M | - | 2048 | 12 | 768 | 12 | - | - | - | - | - | 6e-4 | 256 | |
| 302M | - | 2048 | 24 | 1024 | 16 | - | - | - | - | - | 3e-4 | 256 | |
| Block | 5M | Prefix | 2 + 4 | 3 | 256 | 8 | 4 | 512 | 3 | 256 | 8 | 1e-3 | 256 |
| 19M | Prefix | 2 + 4 | 3 | 512 | 8 | 4 | 512 | 3 | 512 | 8 | 1e-3 | 256 | |
| 85M | Prefix | 2 + 4 | 6 | 768 | 12 | 4 | 512 | 6 | 768 | 12 | 6e-4 | 256 | |
| 302M | Prefix | 2 + 4 | 12 | 1024 | 16 | 4 | 512 | 12 | 1024 | 16 | 3e-4 | 256 | |
| 805M | Prefix | 2 + 4 | 8 | 2048 | 16 | 4 | 512 | 8 | 2048 | 16 | 3e-4 | 512 | |
| 1.2B | Prefix | 2 + 4 | 12 | 2048 | 16 | 4 | 512 | 12 | 2048 | 16 | 2e-4 | 512 | |
G.3 subsection 3.2
每个模型都针对 3000 亿个 Token 进行训练,上下文长度为 2048。 对于Block Transformer模型,我们将块长度设置为4,并利用长度为2的前缀解码和查找方法分别作为词符解码器和嵌入器组件。 为了测量分配的内存和吞吐量,我们使用合成样本,其中所有提示都填充到目标长度。
G.4 subsection 3.3
除非另有说明,我们使用具有 302M 非嵌入参数的模型的默认设置,为块解码器和词符解码器分配相同大小的参数。 对于嵌入器和词符解码器组件的默认策略,我们使用 RoBERTa 模型中的三个 CLS Token ,分别由维度为 256 的三层和长度为 1 的前缀组成。 大量的实验表明,找到最佳值需要最小的开销,因为在各种模型大小的早期训练阶段,消融之间的排名趋势保持一致。 因此,我们只用 80 亿个 Token 来训练模型。
G.5 subsection 3.4
每个模型都在 260 亿个 Token 上使用长度为 4 的块进行训练,块和词符解码器的参数平均分配。 我们实验了85M和302M非嵌入参数两种模型大小。 我们将嵌入器的默认策略设置为利用 RoBERTa 模型中的三个 CLS Token ,由维度为 256 的三层组成,并将词符解码器的默认策略设置为长度为 1 的前缀解码。
G.6 subsection 3.5
我们使用普通 Transformer 和块 Transformer ,非嵌入参数为 85M。 所有模型都在上下文长度为 2K 的 3000 亿个 Token 上进行了完全预训练。 对于 Block Transformer 模型,我们使用查找策略和长度为 1 的前缀解码,以促进从普通模型到 Block Transformer 的平滑过渡。
G.7 subsection 3.6
我们使用普通 70M 模型的训练 FLOP 和推理吞吐量作为约束来训练 Block Transformer 变体。 所有模型都从头开始进行预训练,并调整训练步骤以匹配各自的 FLOP。 在训练步骤结束时,学习率已完全衰减。
G.8 subsection 3.7
为了利用普通 Transformer 模型的预训练层权重,我们将参数平均分配给块和词符解码器,保留整体非嵌入参数大小。 此外,在连接普通模型查找表中的四个词符嵌入后,我们引入了一个全连接层将其映射到块解码器的隐藏维度中。 我们评估了具有 8500 万和 3.02 亿个非嵌入参数的两个模型,并在 300 亿个 token(原始训练数据的 10%)上训练它们。
G.9 subsection 4.1
与兆字节的性能比较
我们重新实现了 MEGABYTE 模型的几种变体,其配置详见Table 4。 MEGABYTE 的模型尺寸基于 GPT-3 模型配置[12],并认为在考虑训练 FLOP 预算时,大约 6:1 的块和词符解码器参数比是最佳的。 我们在 3000 亿个 Token 上从头开始对这些模型进行预训练。
| Token Decoder | Block Decoder | ||||||||||||
| Models | Size | Method | Dim | Head | Dim | Head | LR | Batch | |||||
| MEGABTYE | 5M | Sum | 4 | 4 | 128 | 4 | 4 | 512 | 5 | 256 | 8 | 1e-3 | 256 |
| 19M | Sum | 4 | 4 | 256 | 8 | 4 | 512 | 5 | 512 | 8 | 1e-3 | 256 | |
| 85M | Sum | 4 | 4 | 512 | 8 | 4 | 512 | 11 | 768 | 12 | 6e-4 | 256 | |
与KV缓存压缩的关系
为了探索注意力分数,我们利用具有 1.2B 非嵌入参数的预训练 Block Transformer 模型。 注意力分数是从随机选择的样本中提取的。 此外,我们关注块解码器和词符解码器中 12 层中每一层的第一个注意力头。
附录H预训练期间的随机长度填充
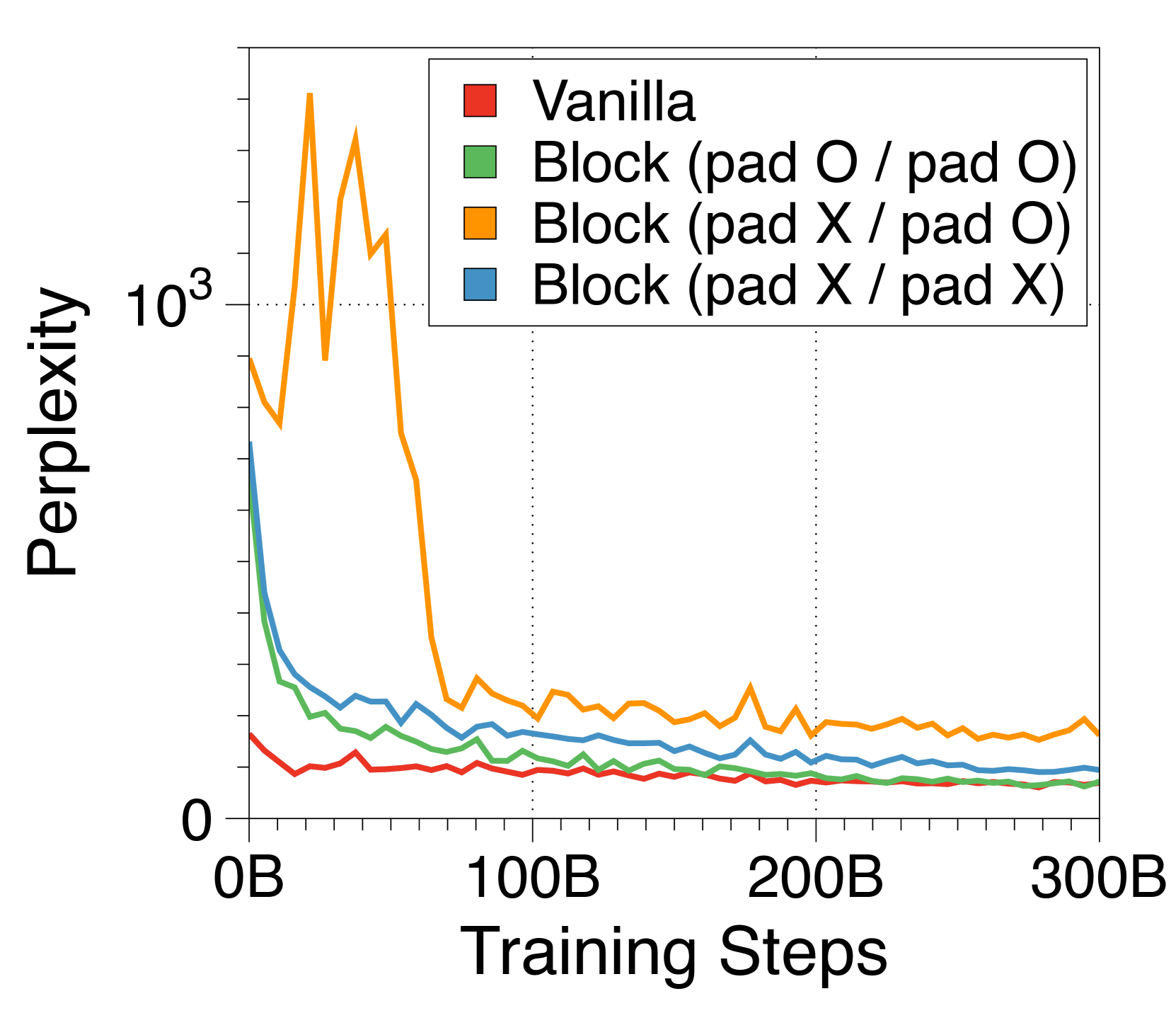
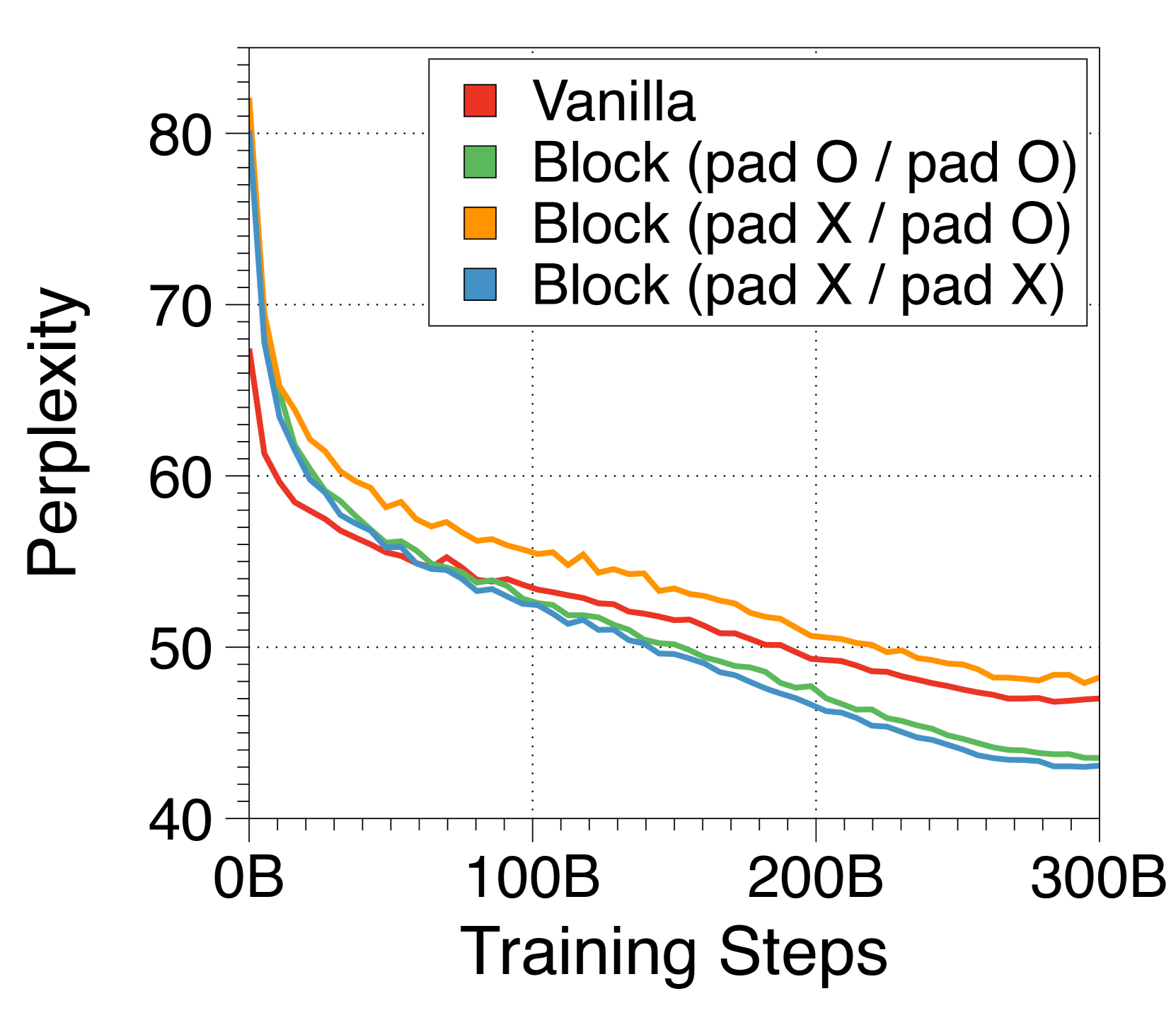
要对长度不是 倍数的提示应用推理,我们需要向提示添加填充标记以填充输入块。 与普通 Transformer 中的填充标记不同,由于我们的嵌入方法的固定大小性质(CLS 词符变体除外),这些填充标记实际上在输入块嵌入的计算中被考虑。 因此,在预训练期间应用输入打包时,我们在每个文档的开头添加长度在 0 到 之间的随机填充标记。 我们还在每个文档的最后一个块中填充未填充的标记,以防止多个文档包含在单个块中。 请注意,这是在我们的主要实验之后应用的,因此并未应用于Table 2 中我们最大的模型。 我们认为这对一些下游任务绩效评估产生了不利影响。
附录一可变批量大小和上下文长度的帕累托前沿
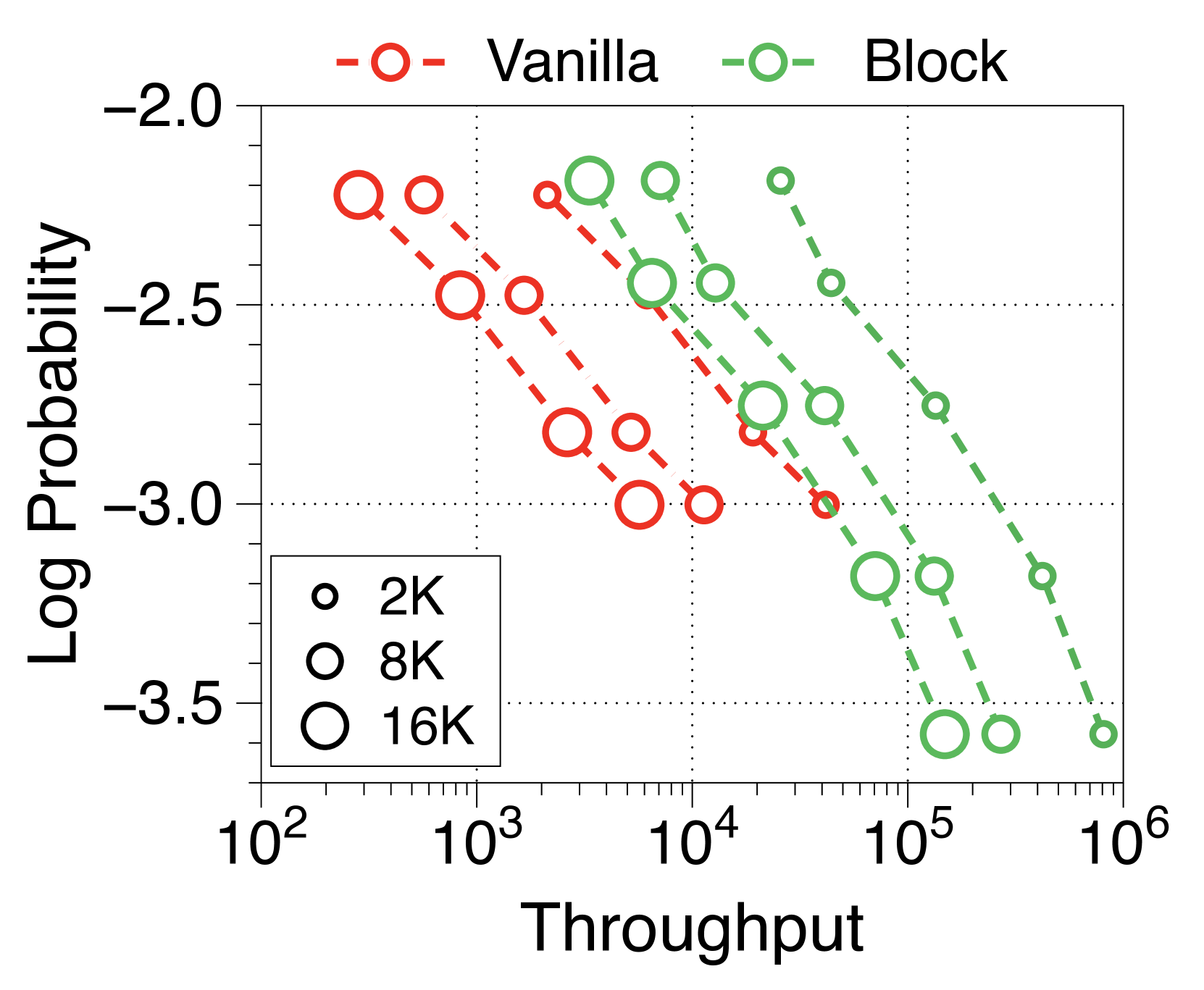
在Figure 7 和Figure 8 中,我们测量了三种不同批量大小的预填充密集型和解码密集型设置下的吞吐量。 在批量大小为 1 时,参数 IO 与 KV 缓存 IO 相比对吞吐量的影响要大得多,导致 Block Transformer 的吞吐量略低。 然而,当模型大小增加超过某个点时,KV 缓存内存的增加会导致这种趋势发生逆转。 当批量大小为 32 时,我们的模型实现了显着更高的吞吐量。 为了确保解码密集型设置的改进不仅仅归因于预填充阶段不需要转发词符解码器的增益,我们还尝试了一种没有提示的设置。 Figure 9 中总结的结果显示了一致的性能改进。
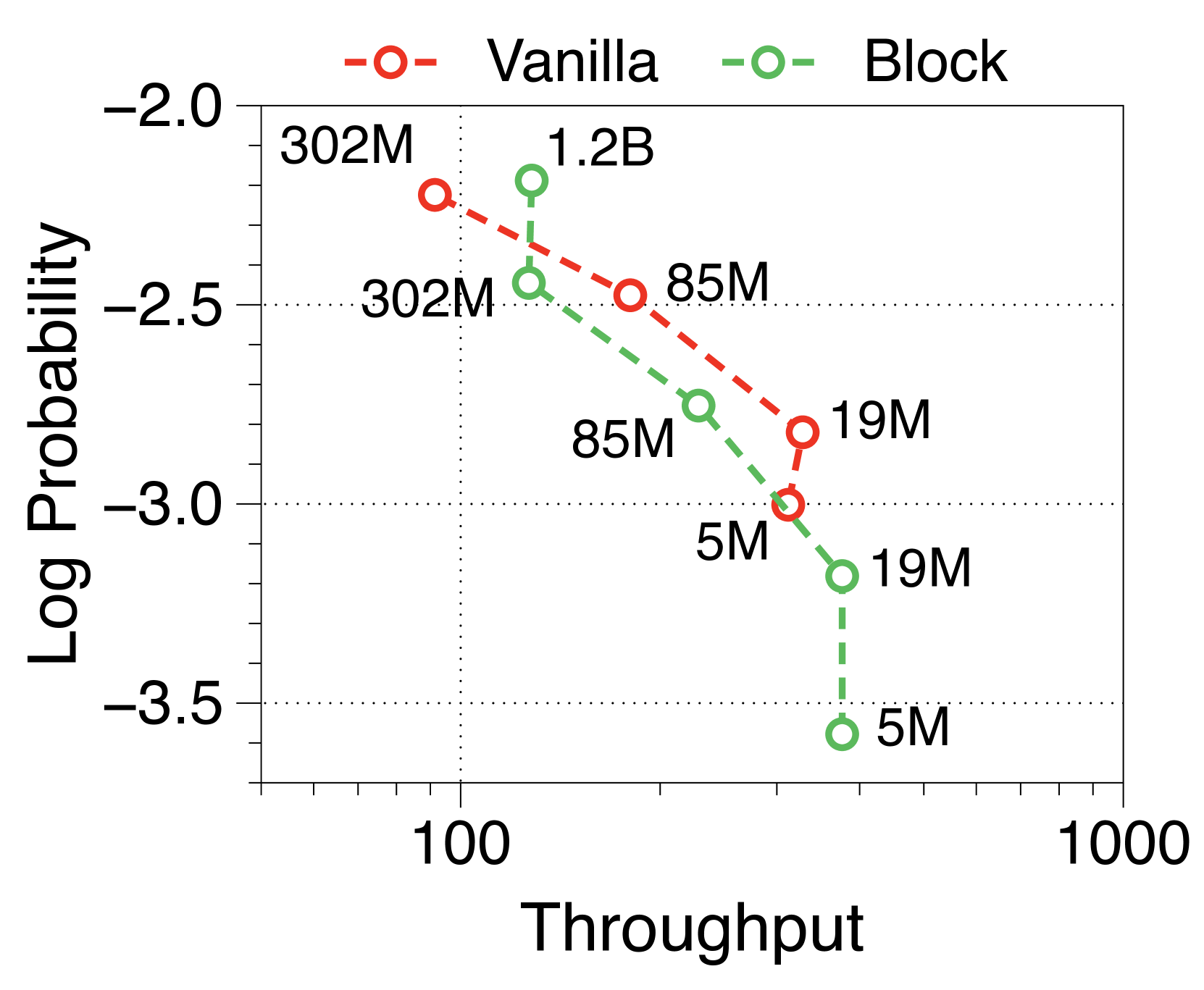
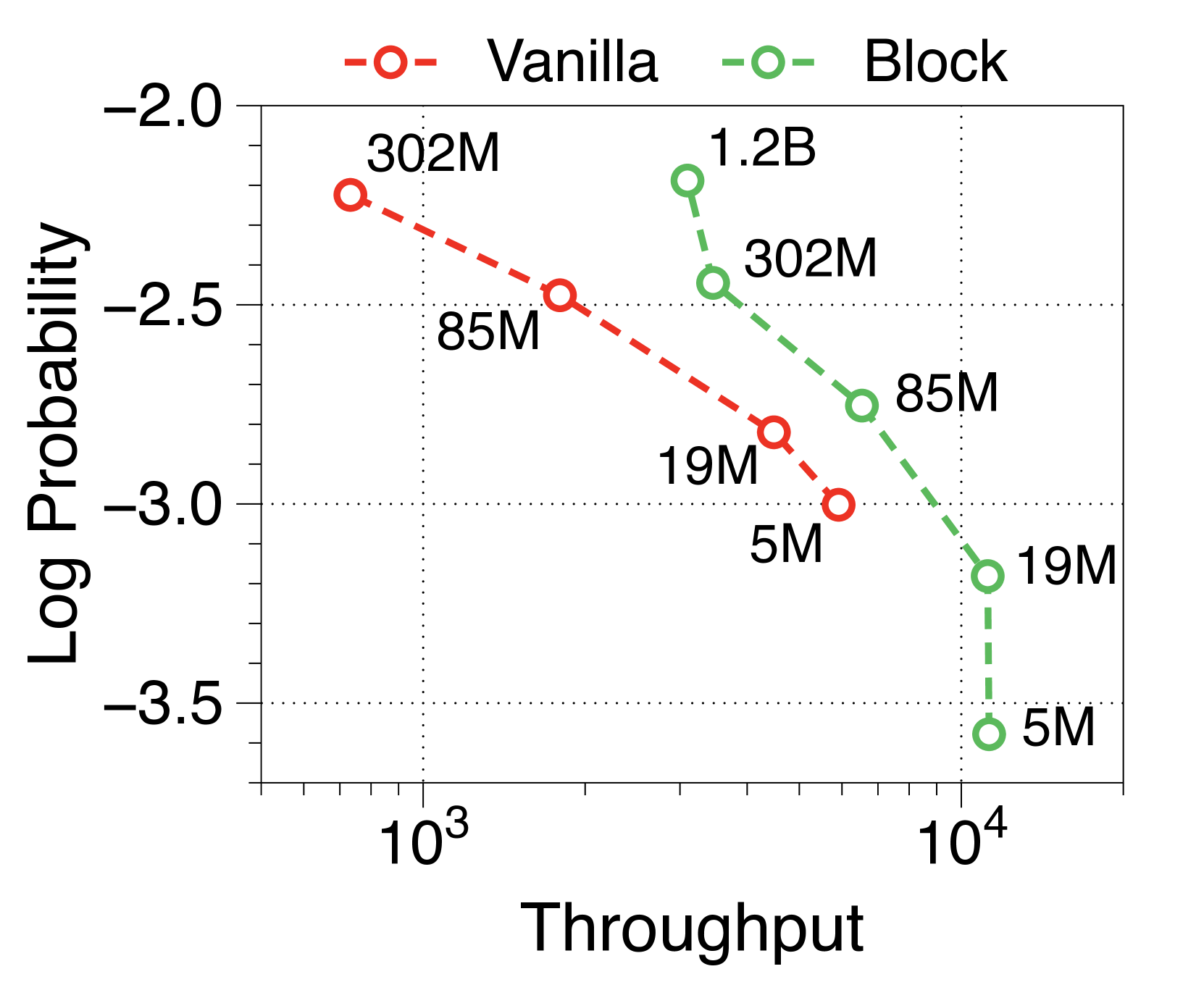
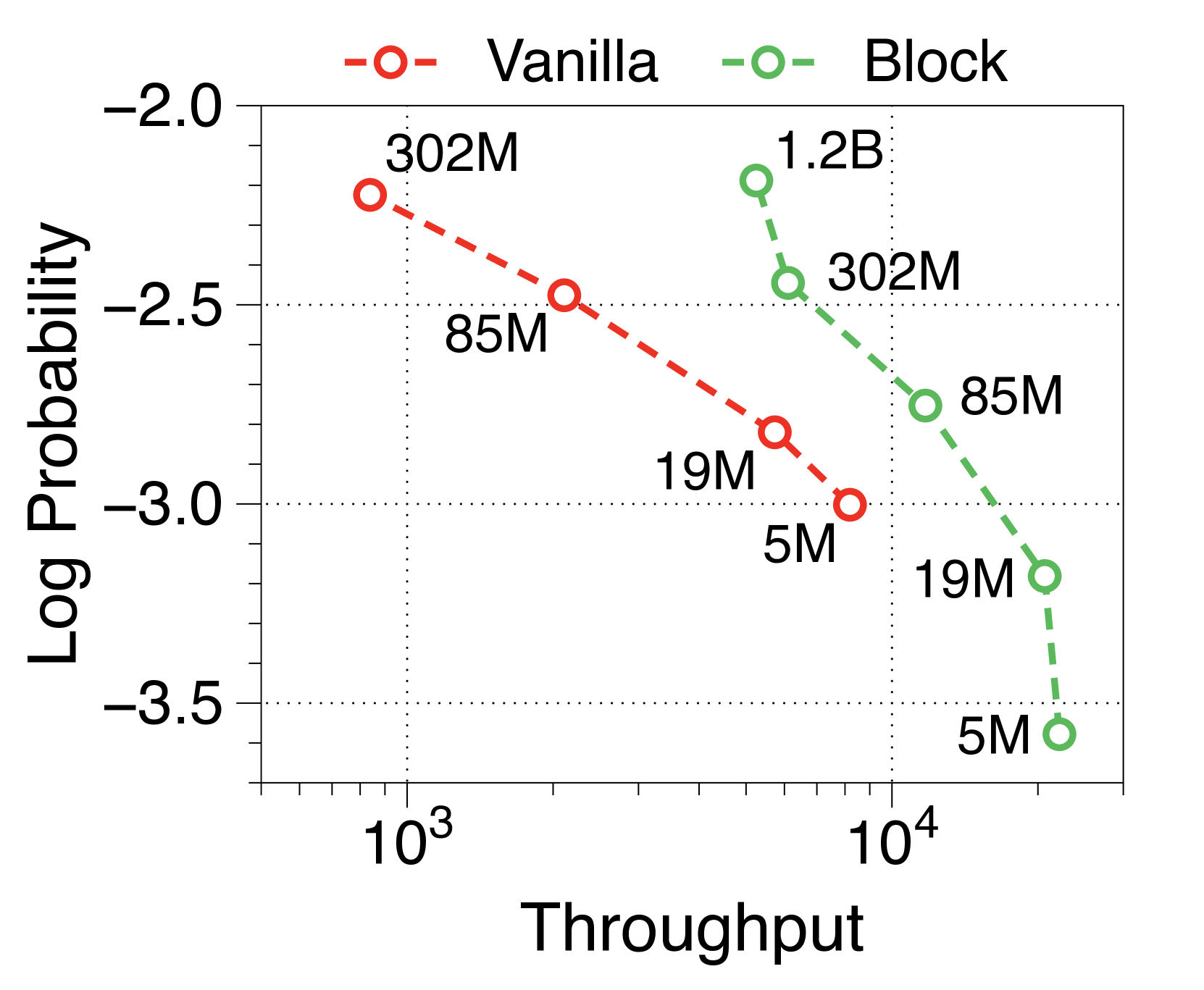
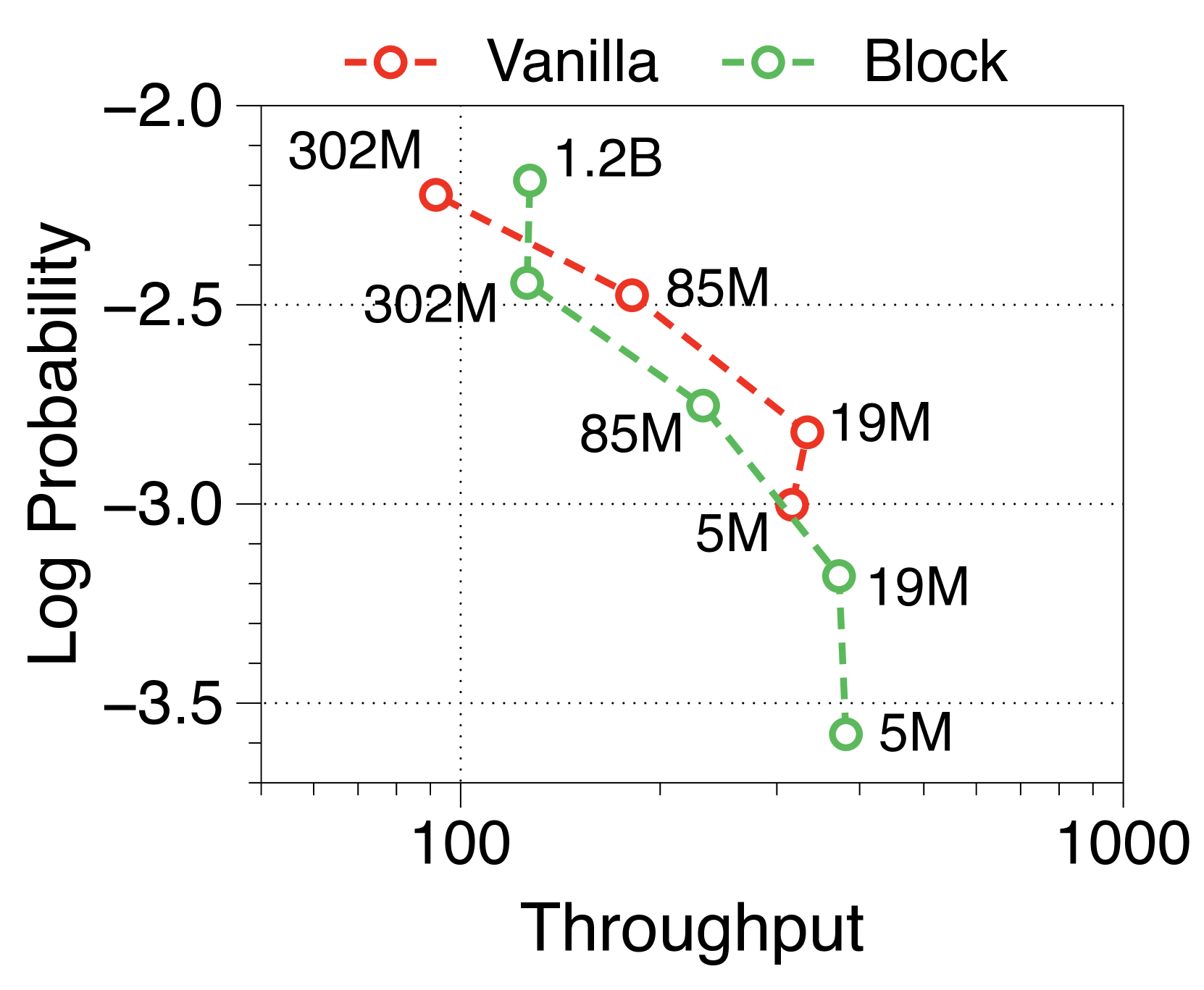
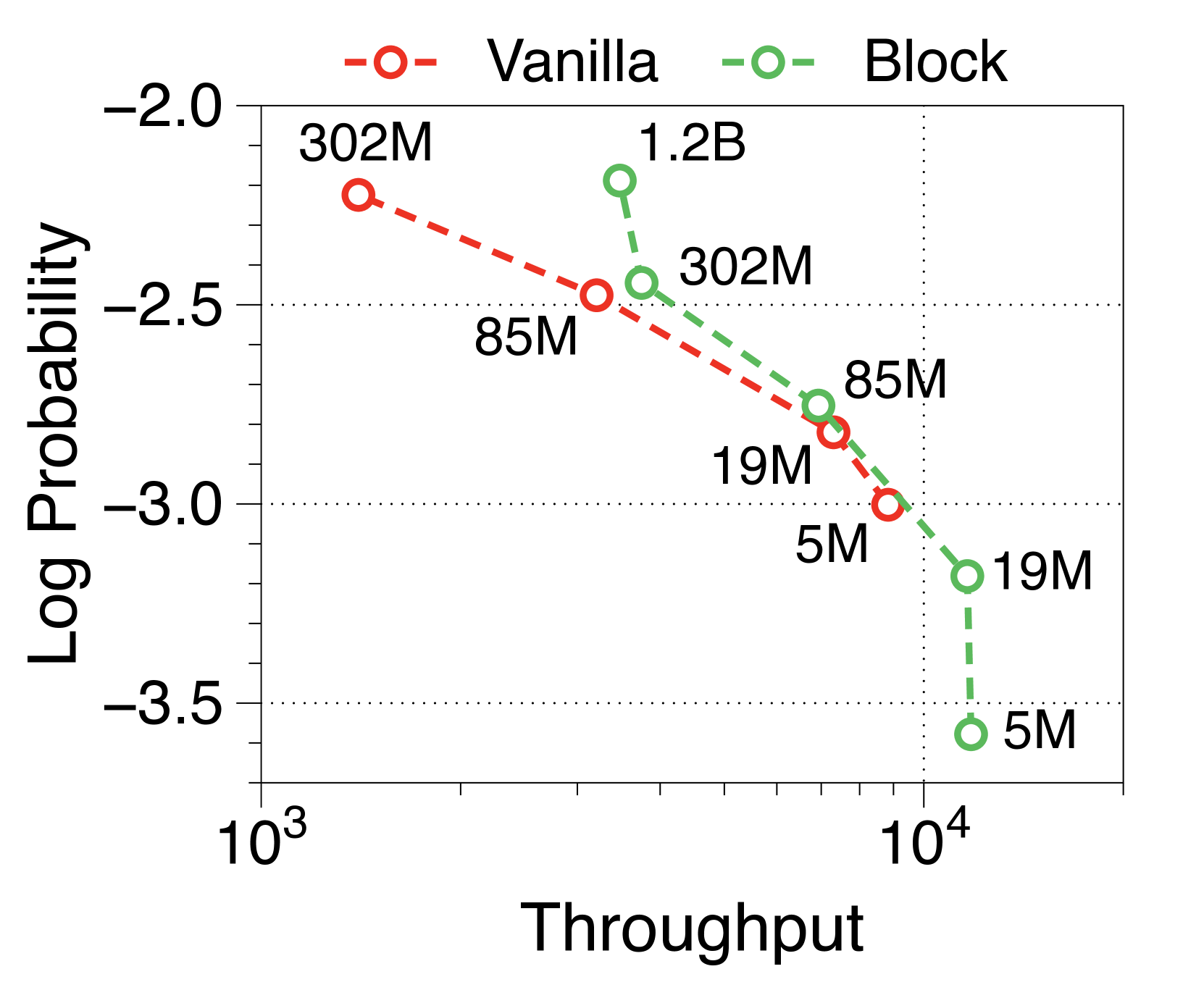
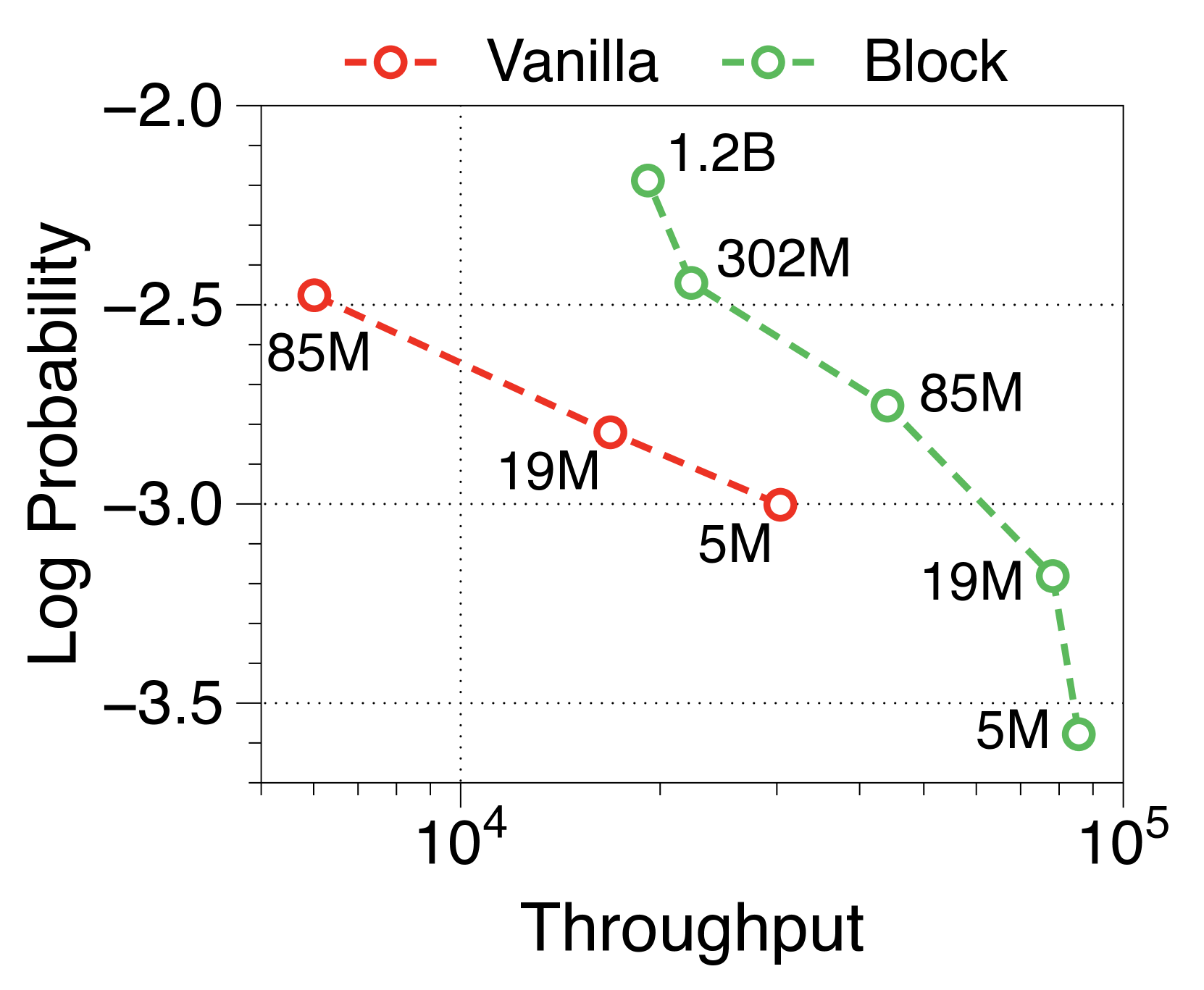
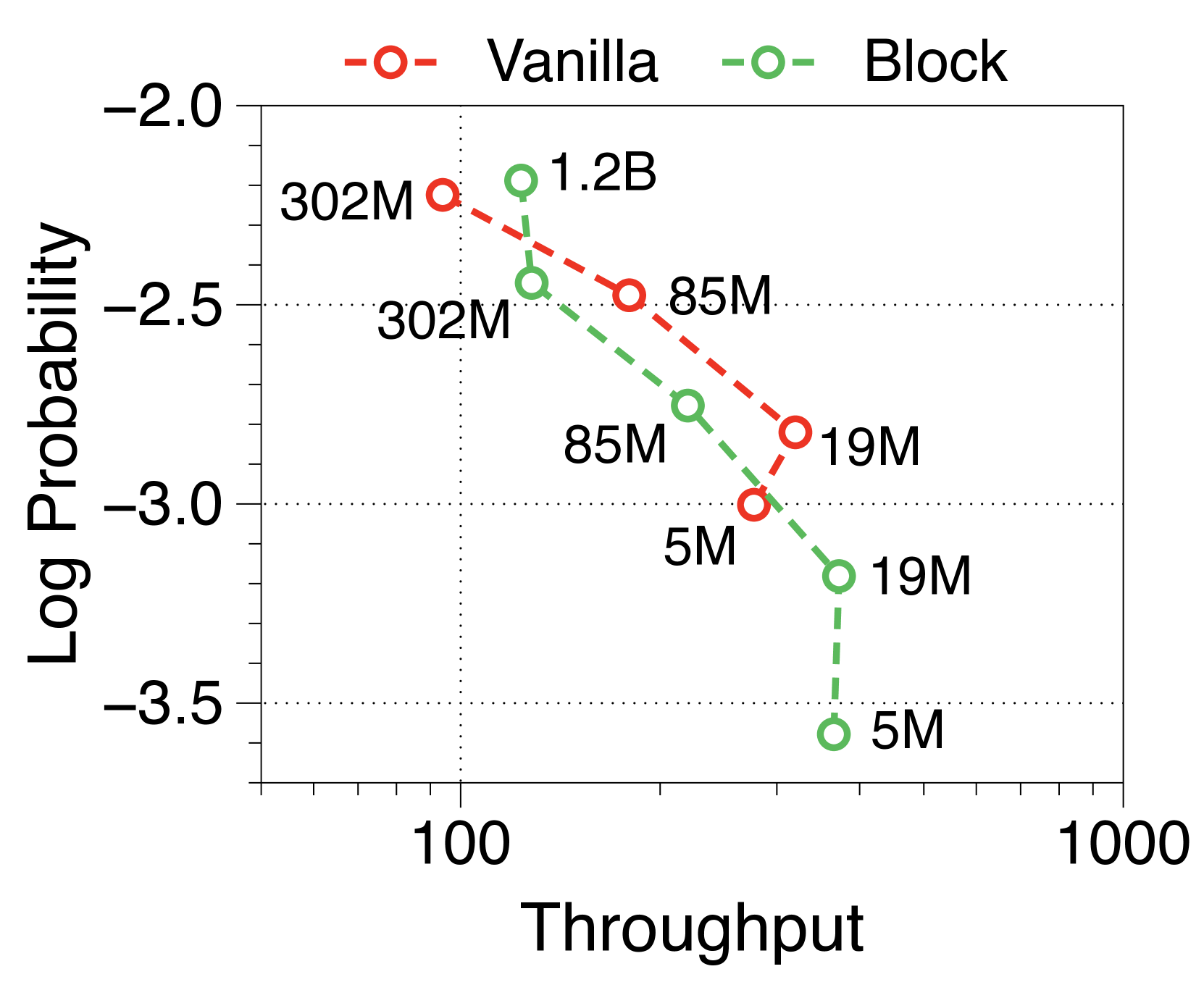
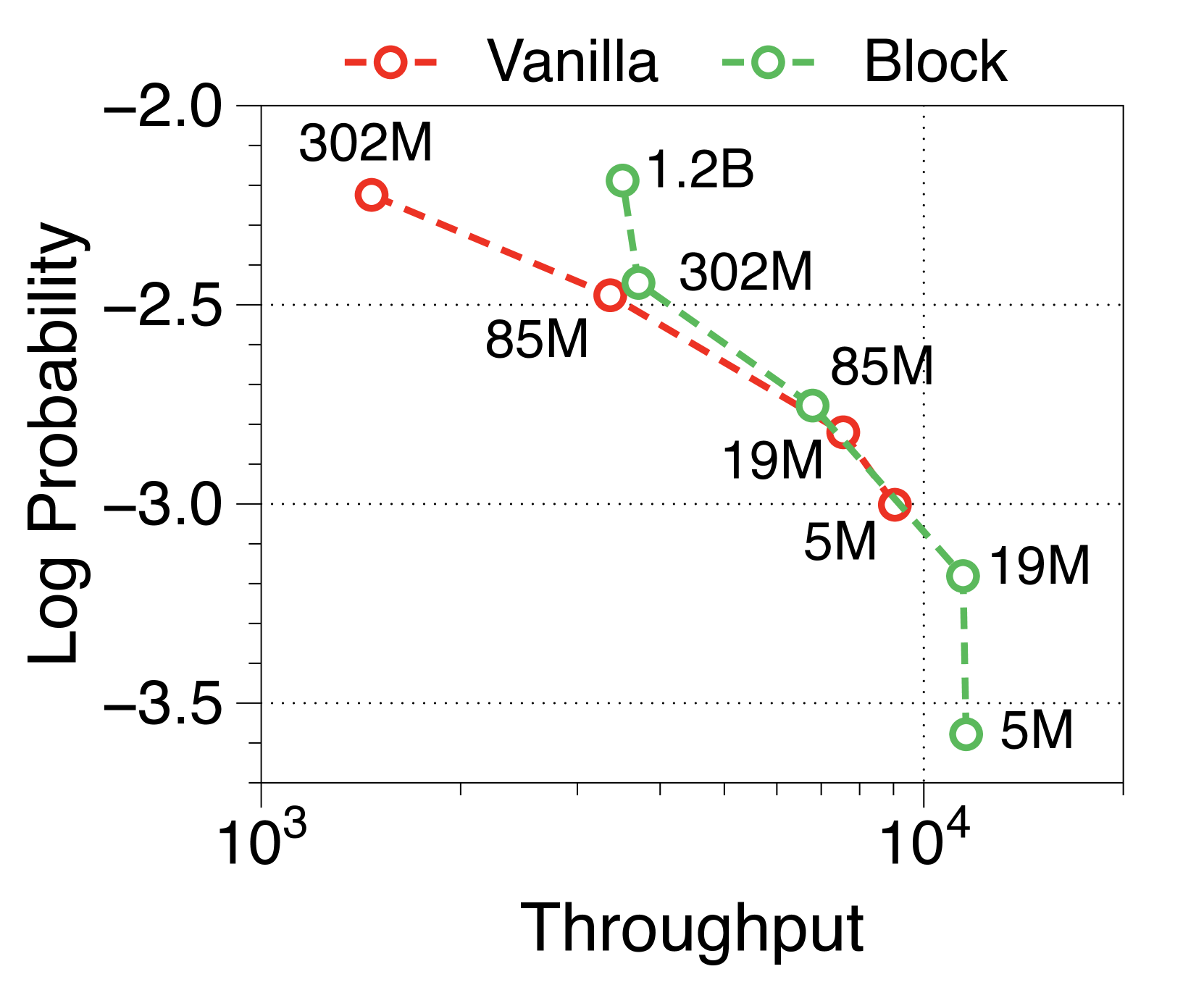
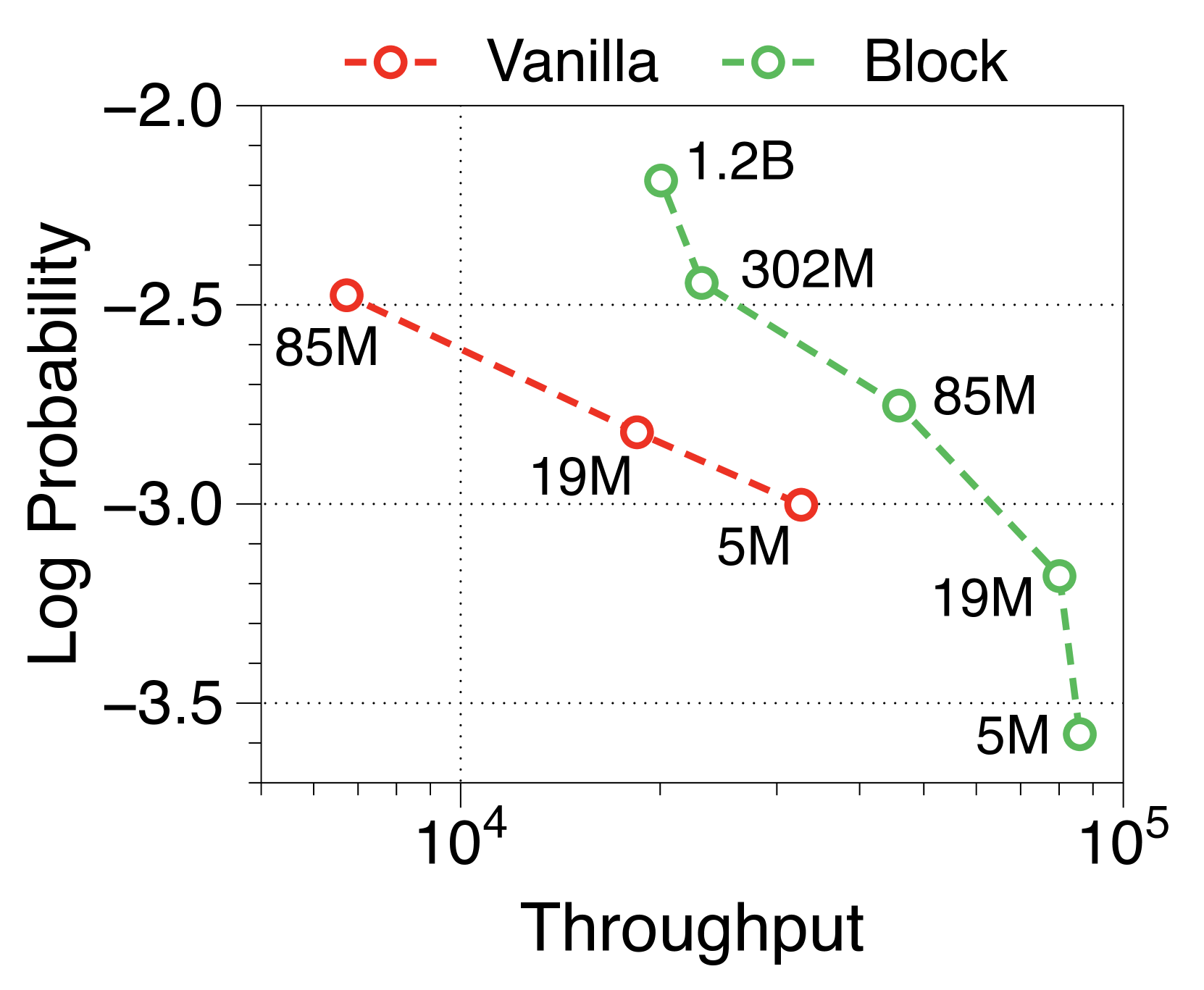
此外,我们还比较了两种场景下不同上下文长度下普通模型和 Block Transformer 模型的吞吐量。 在Figure 10中,每个点对应于相同顺序的模型尺寸。 我们的模型展示了显着的速度改进,即使上下文长度增加了四倍或八倍,它们的性能也优于上下文长度为 2K 的普通模型。 通过将块解码器处的上下文长度减少为块长度的一个因子,我们的模型即使在上下文长度更长的情况下也能实现更快的生成速度。
附录 J参数分配比例造成的位置损失
我们在Figure 11 中总结了三种不同模型大小的位置损失。 我们确认,更改模型大小不会改变整体趋势,根据词符位置呈现 U 形图案。 此外,我们观察到较大的块解码器始终提高了较早标记的可能性,而较大的词符解码器则提高了较晚标记的可能性。
附录K按分配比例和区块长度划分的损失趋势
我们分析了Figure 12中的平均损失以及Figure 13和Figure 14中的位置损失,调整了三个区块长度和五个分配比率两种型号尺寸。 令人惊讶的是,所有实验结果都显示出相同的趋势。 值得注意的是,较短的块长度有利于较大的块解码器,而较长的块长度则受益于较大的词符解码器。 通过检查位置方面的困惑,特别是通过观察第一个词符的损失变化和后来的词符的损失变化,这种趋势背后的基本原理变得显而易见。 我们相信,我们广泛的消融研究将有助于确定适合块 Transformer 设计的特定场景的参数比率。



附录 L 按分配率和块长度划分的吞吐量帕累托前沿
虽然我们从复杂度的角度分析了最佳参数比率和块长度,但我们还从吞吐量的角度评估了哪些设置表现最好。 Figure 15 描绘了所有模型变体的帕累托前沿。 尽管吞吐量和性能之间存在权衡,但从广泛的组合中得出了两个明确的结论。 首先,词符解码器越大,吞吐量提升就越高。 尽管词符解码器消耗更多的 FLOP,但显着缩短的上下文长度并不会增加实际生成速度的开销。 相反,与词符解码器相比,块解码器的上下文长度更长,随着其大小的增加,吞吐量会受到阻碍。 第二个观察结果是,较长的块长度显着提高了吞吐量,因为它们有效地减少了上下文长度。 总之,为了优化推理吞吐量,应扩大词符解码器,并增加块长度。 然而,为了考虑复杂度,需要对模型总大小、分配比例和块长度进行微调。
附录MBlock Transformer组件的烧蚀研究
M.1嵌入器设计
我们在Figure 16 中比较了作为嵌入器组件的三种方法。 令人惊讶的是,使用嵌入表的查找策略显示出比基于 Transformer 的编码器更快的收敛速度,尽管最终通过延长训练达到了相同的性能水平。 尽管增加编码器层数可能会提高性能,但我们选择不这样做,因为它会对推理吞吐量产生不利影响。 使用固定数量的 CLS Token 可以灵活调整每个块的长度。 从根据预测难度自适应分配计算成本的研究中汲取灵感[58, 5],在设计能够处理自适应输出长度的 Block Transformer 时,可以有效地利用该策略。
M.2Token解码器设计
在Figure 17中,我们比较了词符解码器优化设计的三个组件。 前缀解码优于其他策略,特别是当前缀长度增加时,导致性能显着提升。 考虑到词符解码器的上下文长度较短,扩展前缀长度并不会显着降低实际生成速度。 然而,由于FLOPs成比例增加,我们将前缀长度设置为2作为主要配置,以保持性能和计算效率之间的平衡。

附录 N 提高效率的训练策略
Ainslie 等人[2]证明了权重初始化对于有效上训练模型的重要性。 我们广泛的消融研究揭示了 Block Tramsformers 的最佳策略:(1)将普通 Transformer 层分成两半并将每一半分别分配给块解码器和词符解码器,其性能优于将所选层的相同权重分配给两者。 (2) 将输入块嵌入初始化为块内词符嵌入的平均值,可以提高性能。 (3)通过复制上下文嵌入来初始化词符解码器前缀,增强收敛性。 如Figure 18所示,这些初始化技术使向上训练的模型几乎与完全预训练的模型相匹配。 虽然较大的模型通常需要更长的上训练时间,但与随机初始化相比,这种方法仍然收敛得更快并且恢复性能更好。
附录O与MEGABYTE的性能比较
MEGABYTE提出了一种与我们类似的全局到局部的架构,但他们对高效训练的强调导致了不同的结论。 例如,他们声称块解码器比词符解码器大六倍的模型结构是最佳的,而忽视了词符解码器内本地计算的重要性。 然而,我们的观察表明,增加块解码器的大小不利于吞吐量,并且显着减少词符解码器会严重影响语言建模性能。 这一点在Figure 19 中很明显,根据他们报告的结果,我们对 MEGABYTE 的重新实现表明,在预填充密集型和解码密集型设置中,生成速度和性能都比我们的基准模型低得多。 有鉴于此,我们相信我们的研究结果专注于有效推理,将为全球到本地的语言模型开辟新的方向。
附录 PBlock Transformer 中注意力分数的可视化
我们在Figure 20和Figure 21中可视化来自块和词符解码器的注意力分数。 在块解码器中,我们观察到类似的注意力集中到第一个词符的模式。 之前的研究已经利用了这一点,将第一个词符保留为全局词符,以防止在压缩过去标记的长序列时性能下降。 我们相信这种方法也能让 Block Transformers 受益。 此外,词符解码器中的注意力图表明,后来的标记强烈关注上下文嵌入。 这表明全球背景在其中被有效压缩,这与subsection 4.2中的见解一致。
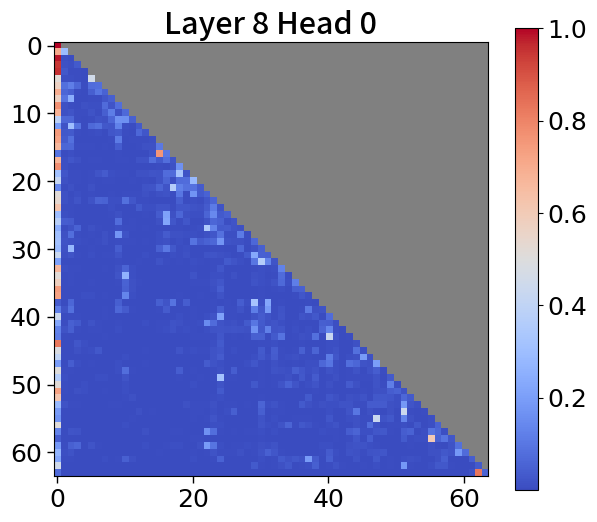
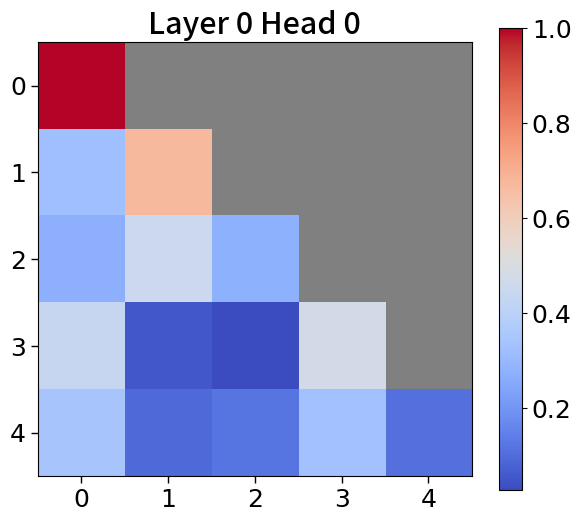
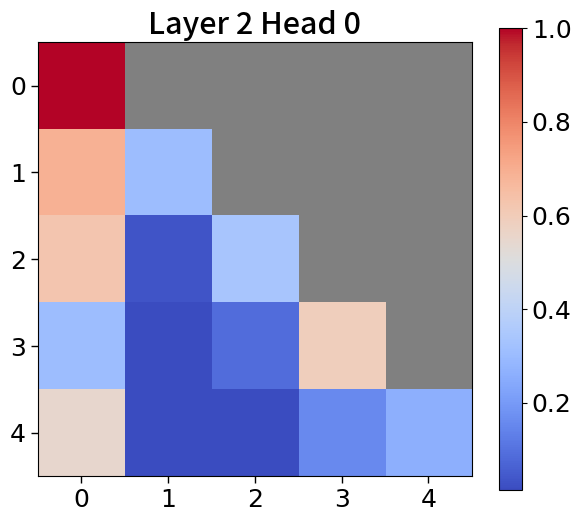
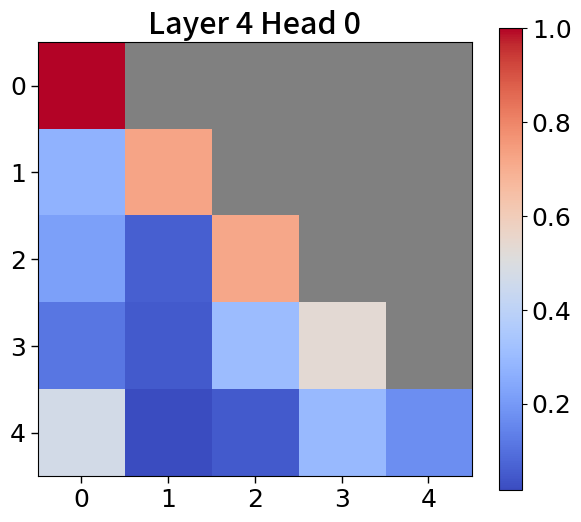
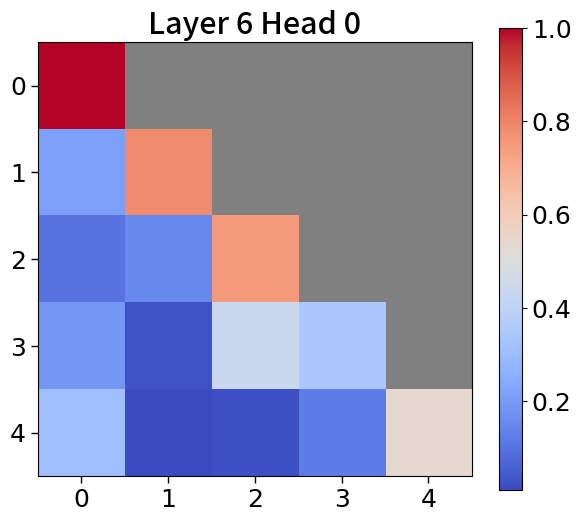
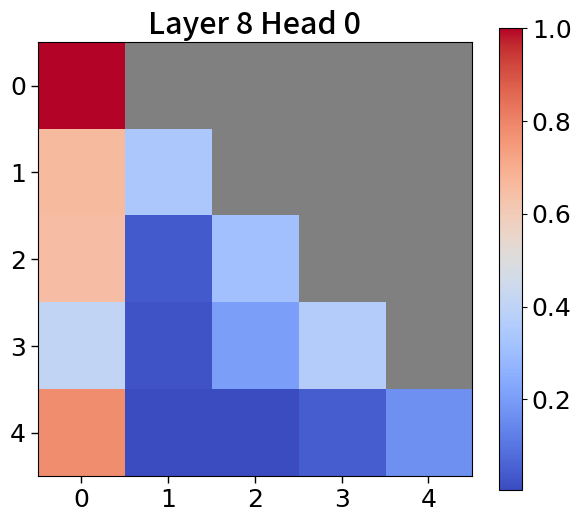
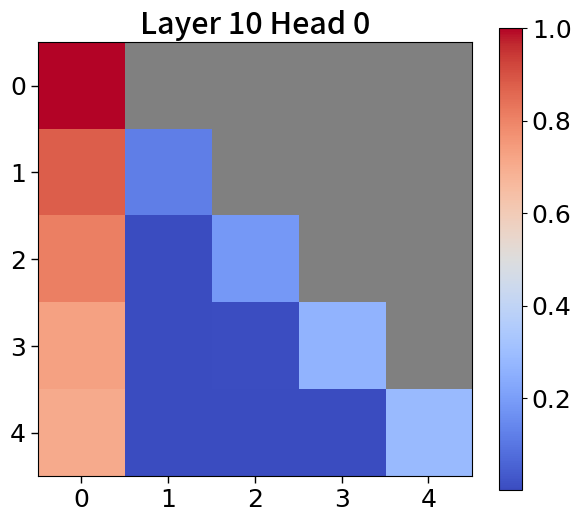
附录Q上下文块嵌入分析
为了研究全局到本地语言建模是否利用完整上下文,我们检查存储在上下文块嵌入中的信息。 具体来说,考虑到输入词符和上下文嵌入在词符解码器中共享相同的潜在空间,我们分析了从上下文嵌入投影的三个最接近前缀的词汇术语,如Table 5. 我们使用具有 12 亿个非嵌入参数的 Block Transformer 和前缀长度为 2 的前缀解码。 有几个有趣的发现。 第二个前缀通常包含有关当前块的最后一个词符的信息。 这表明块解码器合并了有关特定词符的信息,而不是先前的序列,以更好地预测下一个块的第一个词符。 相反,上下文嵌入的第一个前缀包含无法解释的标记,表明它主要用于尽可能多地捕获全局上下文。 Figure 21进一步支持了这一点,它表明词符解码器中的后续标记倾向于更多地关注此前缀。
| Sample | Tokens | Top-k | Block # 0 | Block # 1 | Block # 2 | Block # 3 | Block # 4 |
| #0 | Input | - | iff The | exuberant capital | of Wales, compact | Cardiff has recently | |
| Nearest | =1 | (‘<|endoftext|>’, ‘ Card’) | (‘ the’, ‘The’) | (‘ guarantee’, ‘ captial’) | (‘ guranteee’, ‘ compact’) | (‘ the’, ‘ has’) | |
| =2 | (‘the’, ‘Card’) | (‘<|endoftext|>’, ‘ the’) | (‘ocardial’, ‘captial’) | (‘ the’, ‘,’) | (‘,’, ‘ recently’) | ||
| =3 | (‘.’, ‘card’) | (‘219’, ‘ The’) | (‘28’, ‘ Capital’) | (‘ unfamiliar’, ‘compact’) | (‘.’, ‘ve’) | ||
| #1 | Input | - | the medieval Jewish community | , who were not | allowed to bury their | dead within the city | , would take bodies |
| Nearest | =1 | (‘ and’, ‘ community’) | (‘ the’, ‘ not’) | (‘maybe’, ‘ their’) | (‘ LOSS’, ‘City’) | (‘ deteriorated’, ‘ body’) | |
| =2 | (‘,’, ‘ Community’) | (‘ and’, ‘ were’) | (‘ LOSS’, ‘Their’) | (‘ removed’, ‘ City’) | (‘iding’, ‘ bodies’) | ||
| =3 | (‘ the’, ‘community’) | (‘.’, ‘ are’) | (‘ and’, ‘ Their’) | (‘otten’, ‘ city’) | (‘pped’, ‘Body’) | ||
| #2 | Input | - | to six daily | Fort William (£28 | .20, 3 | ¾ hours, four | to five daily), |
| Nearest | =1 | (‘<|endoftext|>’, ‘,’) | (‘ fiercely’, ‘ 28’) | (‘ijing’, ‘ 3’) | (‘ulsions’, ‘ four’) | (‘illes’, ‘,’) | |
| =2 | (‘ the’, ‘),’) | (‘ foe’, ‘28’) | (‘n ’, ‘3’) | (‘ fierecely’, ‘ 4’) | (‘yscall’, ‘),’) | ||
| =3 | (‘ and’, ‘]]’) | (‘illes’, ‘ 30’) | (‘ῦ’, ‘ 4’) | (‘n ’, ‘ three’) | (‘boats’, ‘!),’) | ||
| #3 | Input | - | can get almost anywhere | in Britain without having | to drive.n | nThe main public | transport options are train |
| Nearest | =1 | (‘<|endoftext|>’, ‘ anywhere’) | (‘uin’, ‘ having’) | (‘ the’, ‘.’) | (‘ the’, ‘ public’) | (‘onet’, ‘ train’) | |
| =2 | (‘ the’, ‘ anything’) | (‘ […]’, ‘ without’) | (‘ and’, ‘Ċ’) | (‘.’, ‘ Public’) | (‘stuff’, ‘train’) | ||
| =3 | (‘.’, ‘anything’) | (‘ the’, ‘ have’) | (‘,’, ‘?).’) | (‘ in’, ‘Public’) | (‘atisfaction’, ‘ Train’) | ||
| #4 | Input | - | nn**Length | ** : 2 miles | ; two to four | hoursnnIt | ’s fitting to start |
| Nearest | =1 | (‘ the’, ‘length’) | (‘ the’, ‘ miles’) | (‘ the’, ‘ four’) | (‘ the’, ‘It’) | (‘ the’, ‘ start’) | |
| =2 | (‘<|endoftext|>’, ‘ length’) | (‘ and’, ‘km’) | (‘079’, ‘ two’) | (‘ in’, ‘ It’) | (‘305’, ‘ started’) | ||
| =3 | (‘ and’, ‘Length’) | (‘ in’, ‘ mile’) | (‘ and’, ‘ 4’) | (‘ and’, ‘ it’) | (‘,’, ‘ starts’) | ||
| #5 | Input | - | the English church. | If this is the | only cathedral you visit | in England, you | ’ll still walk away |
| Nearest | =1 | (‘<|endoftext|>’, ‘.’) | (‘ the’, ‘ the’) | (‘zione’, ‘ visit’) | (‘zione’, ‘ you’) | (‘aciones’, ‘ away’) | |
| =2 | (‘ and’, ‘ ).’) | (‘cción’, ‘The’) | (‘icions’, ‘ visiting’) | (‘ Heather’, ‘ You’) | (‘ 326’, ‘ walk’) | ||
| =3 | (‘ the’, ‘)$.’) | (‘ and’, ‘ this’) | (‘opsis’, ‘ visits’) | (‘icions’, ‘You’) | (‘ the’, ‘ walked’) | ||
| #6 | Input | - | nnStart at | the 1 **Store | y Arms car park | ** off the A | 470. A clear |
| Nearest | =1 | (‘<|endoftext|>’, ‘ at’) | (‘ the’, ‘ Store’) | (‘ãĤĬ’, ‘ Park’) | (‘ and’, ‘ A’) | (‘etus’, ‘ clear’) | |
| =2 | (‘ the’, ‘At’) | (‘ãĤĬ’, ‘Store’) | (‘ and’, ‘Park’) | (‘ the’, ‘A’) | (‘ the’, ‘ Clear’) | ||
| =3 | (‘,’, ‘ At’) | (‘ and’, ‘ store’) | (‘ishops’, ‘park’) | (‘.’, ‘ a’) | (‘ção’, ‘Clear’) |