使用大型语言模型的交互式文本到图像检索:
即插即用方法
摘要
在本文中,我们主要解决交互式文本到图像检索任务中对话形式上下文查询的问题。 我们的方法,PlugIR,以两种方式积极利用大语言模型的通用指令跟踪能力。 首先,通过重新制定对话形式上下文,我们消除了对现有视觉对话数据微调检索模型的必要性,从而可以使用任意黑盒模型。 其次,我们构建大语言模型提问器,根据当前上下文中检索候选图像的信息生成有关目标图像属性的非冗余问题。 这种方法减轻了生成问题中的噪音和冗余问题。 除了我们的方法之外,我们还提出了一种新颖的评估指标,即最佳对数排名积分(BRI),用于对交互式检索系统进行全面评估。 在各种基准测试中,与零样本和微调基线相比,PlugIR 表现出了卓越的性能。 此外,包括PlugIR的两种方法可以在各种情况下灵活地一起或单独应用。 我们的代码可在 https://github.com/Saehyung-Lee/PlugIR 获取。
使用大型语言模型的交互式文本到图像检索:
即插即用方法
Saehyung Lee1††thanks: Equal Contribution Sangwon Yu111footnotemark: 1 Junsung Park1 Jihun Yi1 Sungroh Yoon1,2††thanks: Corresponding Author 1Department of Electrical and Computer Engineering, Seoul National University 2Interdisciplinary Program in Artificial Intelligence, Seoul National University {halo8218, dbtkddnjs96, jerryray, t080205, sryoon}@snu.ac.kr
1简介
文本到图像检索是一项专注于在图像数据库中定位与输入文本查询相对应的目标图像的任务,由于视觉语言多模态模型的开发取得了显着的进步Radford等人(2021);李等人(2022)。 传统上,该领域的方法采用单轮检索方法,依赖于初始文本输入,这需要用户全面而详细的描述。 最近,Levy 等人 (2023a) 提出了一种基于聊天的图像检索系统,利用大语言模型(大语言模型)Radford 等人 (2019) 作为提问者,以方便多轮对话,即使用户给出简单的初始图像描述,也能提高检索效率和性能。 然而,这种基于聊天的检索框架面临着某些局限性,包括需要进行微调以熟练地编码对话式文本,这一过程既占用资源又不切实际的可扩展性。 此外,大语言模型提问者对初始描述和对话历史的依赖,无法查看候选图像,因此存在根据大语言模型的参数生成有关目标图像中不存在属性的查询的风险知识。

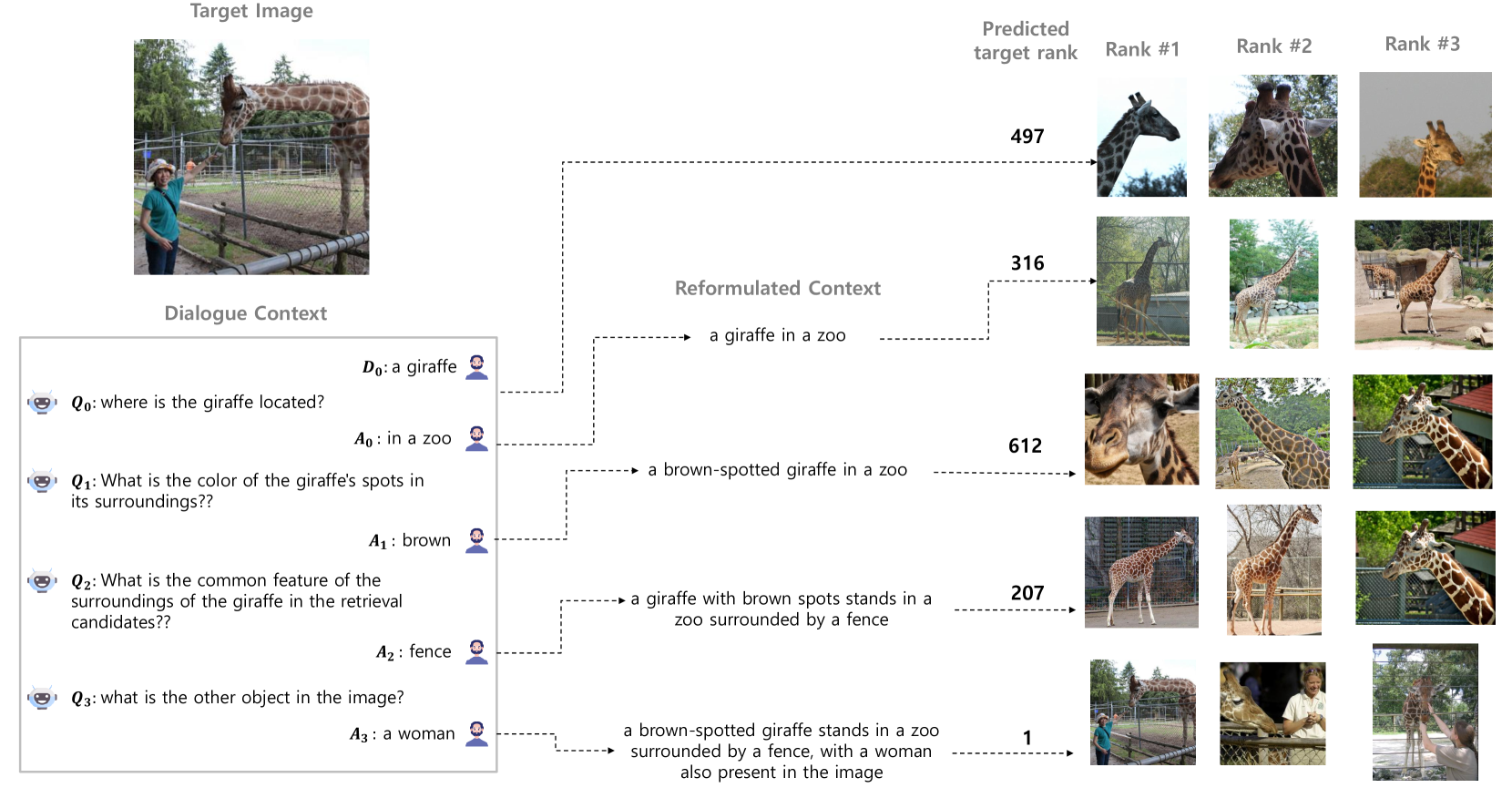
为了克服这些挑战,本文引入了 PlugIR,一种与大语言模型紧密耦合的新型即插即用交互式文本到图像检索方法。 PlugIR 包含两个关键组件:上下文重构和上下文感知对话生成。 利用大语言模型的指令跟随能力,PlugIR 将用户和提问者之间的交互上下文重新表述为与预训练视觉语言模型 Li 等人 (2022) 兼容的格式。 此过程可以直接应用一系列多模态检索模型,包括黑盒变体,而无需进一步微调。 此外,我们的方法确保大语言模型提问者的询问基于检索候选集的上下文,从而允许它提出与目标图像属性相关的问题。 在此过程中,我们以文本形式注入检索上下文作为输入上下文供大语言模型提问者参考。 随后,我们的方法还结合了一个过滤过程,选择最符合上下文的非重复问题,从而简化搜索选项。 图1说明了我们提出的交互式文本到图像检索系统的整体结构。
我们确定了评估交互式检索系统的三个关键方面:用户满意度、效率和排名改进意义。 我们展示了现有的指标,例如 Recall@K 和 Hits@K Patel 等人 (2022); Levy 等人 (2023a) 在这些方面都存在不足。 例如,Hits@K 未能考虑效率,通过更少的交互来定位目标图像会更好。 为了解决这些问题,我们引入了Best log Rank Integral (BRI)指标。 BRI 有效涵盖了所有三个基本方面,提供独立于特定排名 K 的综合评估,这与 Recall@K 或 Hits@K 不同。我们凭经验证明,与现有指标相比,BRI 更符合人类评估。
跨不同数据集的实验,包括 VisDial Das 等人 (2017)、COCO Lin 等人 (2014) 和 Flickr30k Young 等人 (2014),表明 PlugIR 显着优于使用零样本或微调模型的现有交互式检索系统Levy 等人 (2023a)。 此外,我们的方法在应用于各种检索模型(包括黑盒模型)时显示出显着的适应性。 这种兼容性扩展了我们方法的实用性,使其能够适应更广泛的应用程序和场景。 我们的贡献总结如下:
-
•
我们提出了第一个经验证据,表明零样本模型很难理解对话并引入上下文重构方法作为解决方案。 该方法不需要微调检索模型。
-
•
我们提出了一个大语言模型提问器,旨在解决由噪声和冗余问题引起的搜索瓶颈问题
-
•
我们引入了 BRI,这是一种符合人类判断的新颖指标,专门用于对交互式检索系统进行全面且可量化的评估。
-
•
我们验证了我们的框架在各种环境中的有效性,突出了其多功能的即插即用功能。
2相关工作
文本到图像检索任务 通过用户交互从图像池中检索目标图像的任务称为文本到图像检索。 已经提出了使用各种形式的用户交互来检索目标图像的各种方法 Levy 等人 (2023b);刘等人 (2021); Vo 等人 (2019);吴等人(2021)。 值得注意的是,ChatIR Levy 等人 (2023a) 引入了一种通过用户和自动化系统之间的对话进行图像检索的方法。 由于篇幅限制,进一步的相关工作在附录G中提供。
视觉语言模型
视觉语言模型(VLM)已成为人工智能研究的关键领域,旨在弥合视觉和文本理解之间的差距。 CLIP Radford 等人 (2021) 通过利用对比学习框架介绍了视觉语言景观。 通过联合嵌入图像及其相关文本描述,CLIP 展示了执行各种视觉语言任务的强大能力,特别是在跨广泛概念的零样本分类中。 随后提出的 BLIP Li 等人 (2022) 进一步引入了一种能够理解和生成任务的模型,并解决了用于预训练的网络数据中的噪声字幕问题。 因此,BLIP 在零样本图文检索方面表现出了卓越的性能。 一些开创性的模型,例如 BLIP-2 Li 等人 (2023),显着推进了这一领域的发展,在跨模式表示学习方面表现出了卓越的能力,我们利用这些 VLM 作为我们的文本-图像检索模型。
大型语言模型
从生成式预训练 Transformer (GPT)系列开始 Radford 等人(2018、2019); OpenAI (2023b),多种工作提出将语言模型的参数扩展到十亿级 Touvron 等人 (2023a, b)。 参数数量的增加不仅增强了语言模型的性能,而且还揭示了各种新兴能力Wei等人(2022a),这些能力在一系列下游任务中取得了显着的性能,包括零样本和少样本学习。 除了训练高性能大语言模型之外,诸如思想链提示Wei 等人(2022b)和自我一致性Wang 等人(2022)等技术主题从训练有素的大语言模型中有效地提取答案是活跃的研究领域。
3方法
3.1 预备知识:交互式文本到图像检索
交互式文本到图像检索是一项多轮任务,从用户提供的简单初始描述 开始。 该任务涉及用户和检索系统之间关于(目标图像)对应的图像的对话,形成上下文,用作每轮(round)目标图像的搜索查询。 在每一轮中,检索系统都会生成关于目标图像的问题,用户用答案进行响应,从而创建对话上下文 该轮。 该对话上下文经过适当的处理,例如连接所有文本元素,以形成用于该轮图像搜索的单个文本查询。 在图像搜索过程中,检索系统将连接图像池中的所有图像与文本查询进行匹配,并根据相似度得分对它们进行排名。 可以根据目标图像的检索排名来评估检索系统的性能。
为了进行评估,通常使用两个主要指标:Recall@K 和 Hits@K。当使用 Recall@K 进行评估时,如果当前轮计算的目标图像的排名位于前 K 之内,则确定成功。对于 Hits@K,成功定义为在任意一轮中出现在前 K 个结果中的目标图像当前的一个。
3.2上下文重构
零样本模型能理解对话框吗?
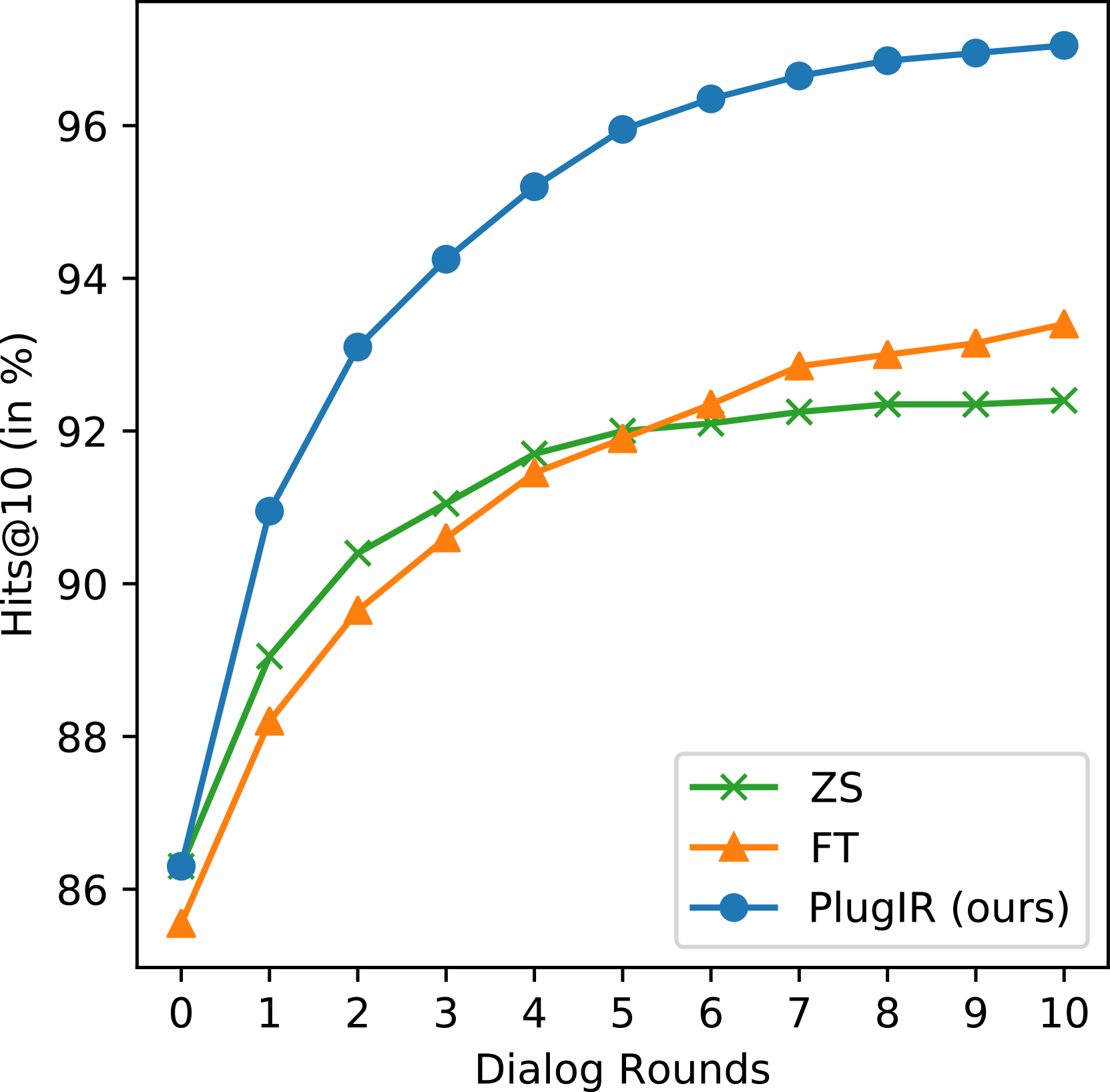
为了证明所提出方法的必要性,我们评估了零样本模型在交互式文本到图像检索任务中理解和有效使用给定对话的程度。 我们专门跟踪零样本模型的检索性能变化,其中包括三个白盒模型(CLIP、BLIP 和 BLIP-2)和一个黑盒模型111https://docs.aws.amazon.com/bedrock/latest/userguide/titan-multiemb-models.html,通过 10 轮增量提供与目标图像相关的附加问答对。 因此,在第 10 轮中,输入查询是包含一个图像标题和 10 个问答对的对话。 我们假设,如果零样本模型能够理解对话并在图像检索任务中有效地利用它们,那么与第 0 轮中的初始性能(仅涉及图像标题的使用)相比,它将在后面的几轮中表现出增强的性能。
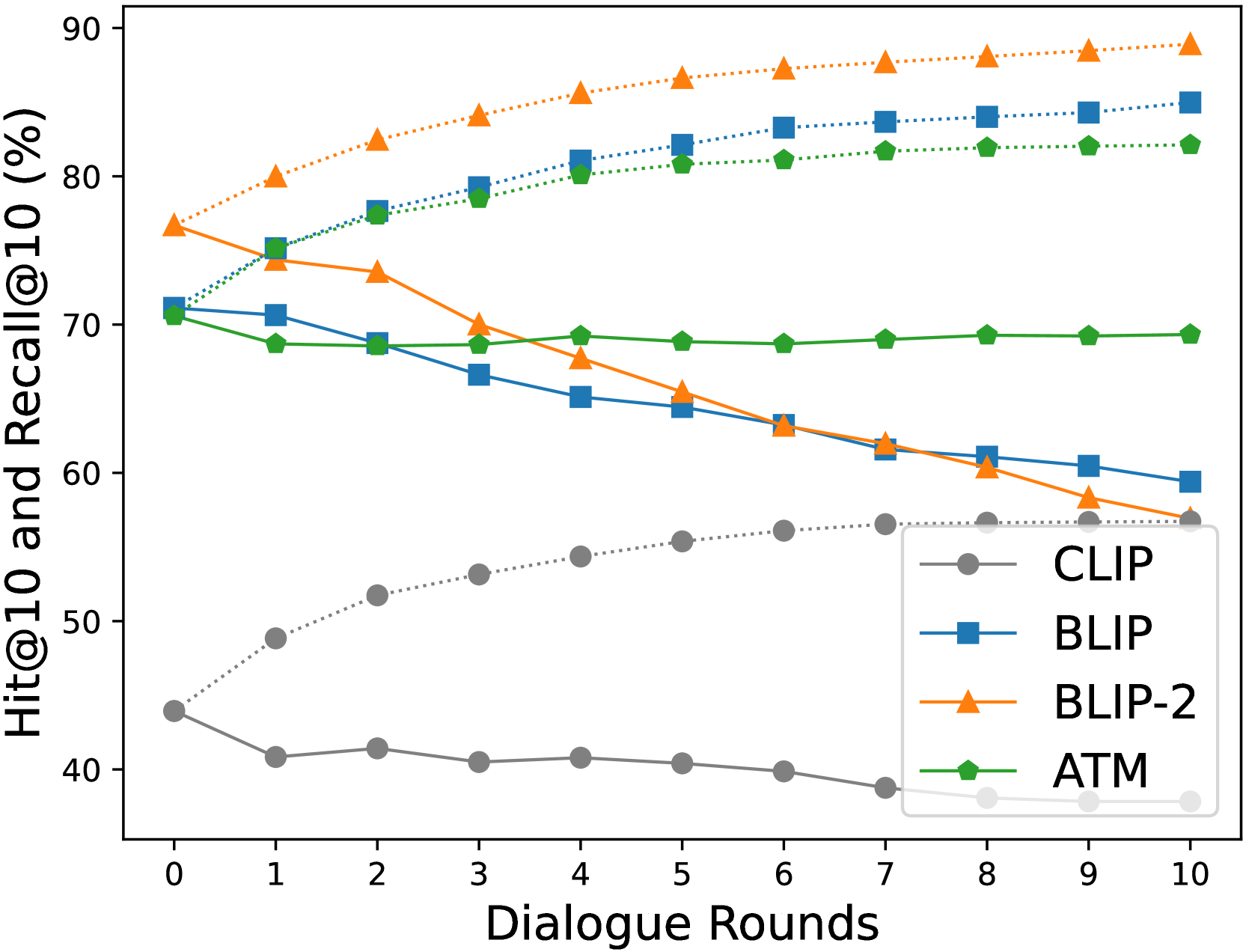
图2说明了连续几轮测试的所有零样本模型的 Hits@10 分数的逐步提高。 这种趋势表明,一些最初在检索中不成功的查询样本,随着后面几轮对话的丰富而取得了成功。 然而,我们建议不要仓促得出结论,认为对话作为仅基于这些观察的零样本模型的输入查询是有效的。 我们的分析更多地是通过 Recall@10 分数而不是 Hits@10 分数得出的,得出了不同的结论:零样本模型似乎很难理解文本到图像检索任务中的对话。
事实上,通过简单地将噪声添加到图像标题和候选图像之间的相似度矩阵中,Hits@K 分数可以在连续轮次中增加。 发生这种情况是因为 Hits@K 在每一轮的任何时间点只需要一次成功的检索尝试。 相比之下,Recall@K 反映了文本到图像检索任务中“每”轮查询中存在的信息量。 图2显示,当仅使用图像标题作为输入查询时,所研究的所有检索模型都获得了最高的 Recall@10 分数。 值得注意的是,随着回合的进行,CLIP、BLIP 和 BLIP-2 模型的 Recall@10 会有所下降。 这种趋势意味着,在这些零样本模型的背景下,附加的对话主要起到噪音的作用。 在 CLIP、BLIP 和 BLIP-2 中,随着对话长度的增加,噪声的影响变得更加明显。 Amazon Titan 多模式基础模型 (ATM) 虽然没有显示出 Recall@10 随对话时间较长而降低,但也没有表现出性能增强,这表明添加的对话可能不会对信息上下文做出实质性贡献。
即插即用的方法。
为了克服零样本检索模型在文本到图像检索任务中无法有效使用对话的挑战,一种策略可能是使用由图像和对话对组成的数据集对预先训练的检索模型进行微调。 例如,Levy 等人 (2023a) 对 VisDial 上的 BLIP 模型进行了微调,以获得更高的 Hits@K 分数。 我们在5.1节中提供了经验证据,说明该方法可以使检索模型具有理解对话的能力。 然而,这种基于调优的方法的实施取决于某些并不总是可行的条件: (i) 必须能够访问检索模型参数; (ii) 必须获得足够且合适的训练数据。 例如,该方法不适用于ATM等黑盒检索模型。
在本研究中,我们研究了一种新颖的方法,该方法可以使文本查询更好地被检索模型理解,而不是修改检索模型以适应文本查询的格式。 更具体地说,我们不是直接使用对话作为输入查询,而是利用大语言模型将对话转换为更符合检索模型数据分布的格式(例如,标题样式)。 该策略有效地绕过了与基于调整的方法相关的约束,因为它不需要对检索模型进行微调。 用于上下文重构的文本提示可以在附录A中找到。
3.3 上下文感知对话生成
对话中的附加信息
真的有效吗?
上一节中提出的重新表述的动机是基于这样的观察:对于预先训练的检索器来说,对话形式往往更多地充当噪音,而不是有用的信息。 在本节中,我们的目标是超越上下文的形式,重点关注上下文的实际内容。 当仅依靠对话上下文来生成有关目标图像的问题时,我们确定了两个关键问题。 首先,生成的问题可能询问与目标图像无关的属性。 例如,询问不在目标图像中的物体的问题可能会引起负面反应。 这种情况本身可能会在对话上下文中充当噪音。 因此,与前几轮相比,上下文表示在检索过程中引入了更多混乱,导致检索性能下降。
第二个是生成的问题可能存在冗余。 在问题生成过程中,一般性问题如“照片中的人在做什么?”通常可以根据对话上下文中已有的信息来回答,而无需查看目标图像。 在这种情况下,问答对也无法提供有价值的附加信息,从而导致冗余。 因此,这种冗余无助于提高后续轮次的检索性能。 在接下来的章节中,我们将解决这些问题,并提出一种可以灵活应用于各种情况的提问者结构,有效解决对话中噪音和冗余的挑战。
即插即用的方法。
为了解决生成的问题涉及与目标图像不相关的属性的问题,我们将本轮的检索候选图像的信息注入作为大语言模型提问者的文本输入。 对于这个过程,我们首先从图像池中提取与嵌入空间中(重新制定的)对话上下文相似的图像,将它们建立为“检索候选者”的集合。 这些相似图像包含与当前对话上下文类似的属性,其中包括有关目标图像的一些信息,确保生成的关于这些属性的问题在某种程度上保证与目标图像相关。
我们将 K 均值聚类应用于候选图像嵌入。 随后,我们获得每个候选图像相对于其他候选图像的相似度得分分布。 对于每个簇,选择其相似度分布中熵最低的图像作为代表。 这种选择的基本原理是,相似性分布中的熵越低,表明相应的图像包含更具体和可区分的属性。 例如,在属于同一簇的图像中,与标题“家庭办公室”对应的图像表现出高熵,而与标题“有两个计算机显示器的桌子和键盘”表现出低熵。
然后,通过该方法获得的 K 个图像通过任意图像字幕模型转换为文本信息,并作为附加输入提供给大语言模型提问者。 这个检索上下文提取过程如算法1所示。 为了确保大语言模型提问者有效地根据检索候选的文本信息,我们采用了思想链(CoT)方法。 这包括向大语言模型提问者提供少量样本作为附加说明,其中涉及有效利用检索候选项。 附录A包含提供给大语言模型的CoT提示。
基于从检索搜索空间提取的附加上下文生成的问题包括与目标图像相关的属性,但仍然可能是冗余的。 为了防止此类问题的产生,我们采用了一个额外的过滤过程,如最近的工作所示(Zheng 等人,2023)。 对于提问者提出的每个问题,如果大语言模型代理无法从相应的描述和对话中得出答案,我们会提示大语言模型代理回答“不确定”,这意味着该问题没有冗余。 然后,我们只使用回答为“不确定”的问题。
过滤过程可以有效地去除无需查看目标图像即可回答的问题,但无法排除即使存在目标图像也无法回答的问题。 这些失败问题解决与候选集相关但与目标图像无关的属性。 我们观察到,使用此类不合适的问题会导致查询图像和候选图像之间的相似度分布发生相对突然的变化,从而导致检索性能下降。 因此,我们选择对话上下文的相似度分布以及与问题结合的对话上下文的分布表现出最低 Kullback-Leibler (KL) 散度的问题。 算法2展示了PlugIR的过滤过程。 以这种方式配置的上下文感知对话生成过程可以与前面部分中描述的上下文重构协同使用。 它还具有独立使用的灵活性,特别是在使用对话上下文的微调检索模型的场景中。
3.4 最佳日志排名积分指标
在评估交互式检索系统时,以下关键方面至关重要:
-
1.
用户满意度:如果系统设法在其查询预算内至少检索一次目标图像,则认为已满足。
-
2.
效率:系统效率通过成功检索所需的轮次来衡量;更少的轮次表明更好的性能。
-
3.
排名提升的意义:更高排名位置的提升本质上更具挑战性,因此在指标评估中应该更加重视。 例如,当图像的排名从 2 上升到 1 时,指标的改进应该更加显着,而不是从 100 上升到 99。 这一区别凸显了与达到最高排名相关的更大的挑战和价值。
Recall@K 通常用于非交互式检索系统评估,但未能在我们的具体环境中充分解决这三个方面。 Levy等人(2023a)推荐的交互系统Hits@K满足用户满意度的标准,但在后两个方面缺乏充分解决。 因此,本文引入了一种新颖的评估指标,旨在全面解决所有这三个考虑因素。
为了解决用户满意度方面的问题,我们将“最佳排名”定义如下:
Definition 1。
令表示与查询对应的目标图像的检索排名。 那么,第 轮查询 的最佳排名 为
最佳排名衡量每轮所有尝试中最成功的检索。 为了体现第二个和第三个方面,我们引入最佳对数排名积分(BRI),使用定义如下:
Definition 2。
令和分别为测试查询集和指定的系统查询预算。 那么,BRI 定义为
BRI 可以解释为所有查询 的回合 的 图表下的平均面积。 目标图像的排名提高得越快,图表下方的区域就越少。 该函数的对数性质导致 BRI 在接近最高排名时出现更大幅度的下降,BRI 越低意味着交互式检索系统的性能越好。 值得注意的是,BRI 的评估方法与 Recall@K 和 Hits@K 不同。 它不是根据特定等级 (K) 对数据样本进行二分,而是校准所有数据样本的结果以进行评估,使其成为更通用和更可靠的指标。
为了证明 BRI 的可靠性,我们将其与人类偏好的相关性与之前在 4.3 节中提出的指标进行了比较。 结果证实,BRI 比其他指标更符合人类评估。
4实验
4.1实验设置
我们在 VisDial、COCO 和 Flickr30k 数据集上评估我们的方法。 除非明确说明,否则使用BLIP作为默认的文本到图像检索模型,同时BLIP-2和ATM也用于适应性实验。 我们采用 ChatGPT OpenAI (2023a) 作为负责在所有实验中生成问题的语言模型,并考虑到人类回答者的不实用性,BLIP-2 代替人类回答者为生成的问题提供答案。
在本文进行的所有实验中,簇数统一设置为。 附录K介绍了不同值对性能影响的研究。
我们主要使用两个指标来报告结果:Hits@10 和我们提出的 BRI。 选择这些评估指标是因为其他指标可能会导致对交互式文本到图像检索系统性能的误解。 附录B中提供了证实这一点的示例以及进一步的实现细节。
基线和 PlugIR。
我们将我们提出的 PlugIR 与两个基线 ZS 和 FT 进行比较。
-
•
ZS:一种利用零样本检索模型的简单方法。 大语言模型提问者不符合检索上下文生成问题,对话直接作为查询进行检索。
-
•
FT:对应Levy 等人(2023a)的方法,使用微调检索模型。 其余与ZS相同。
-
•
PlugIR:我们提出的方法采用零样本检索模型。 与检索上下文相一致的大语言模型提问者生成问题,并通过上下文重新表述修改后的对话用作检索查询。
| Method | BRI | ||
| VisDial | COCO | Flickr30k | |
| ZS | 1.0006 | 0.3576 | 0.5812 |
| FT | 1.0106 | 0.3531 | 0.5793 |
| PlugIR (ours) | 0.7674 | 0.2396 | 0.3733 |
4.2结果
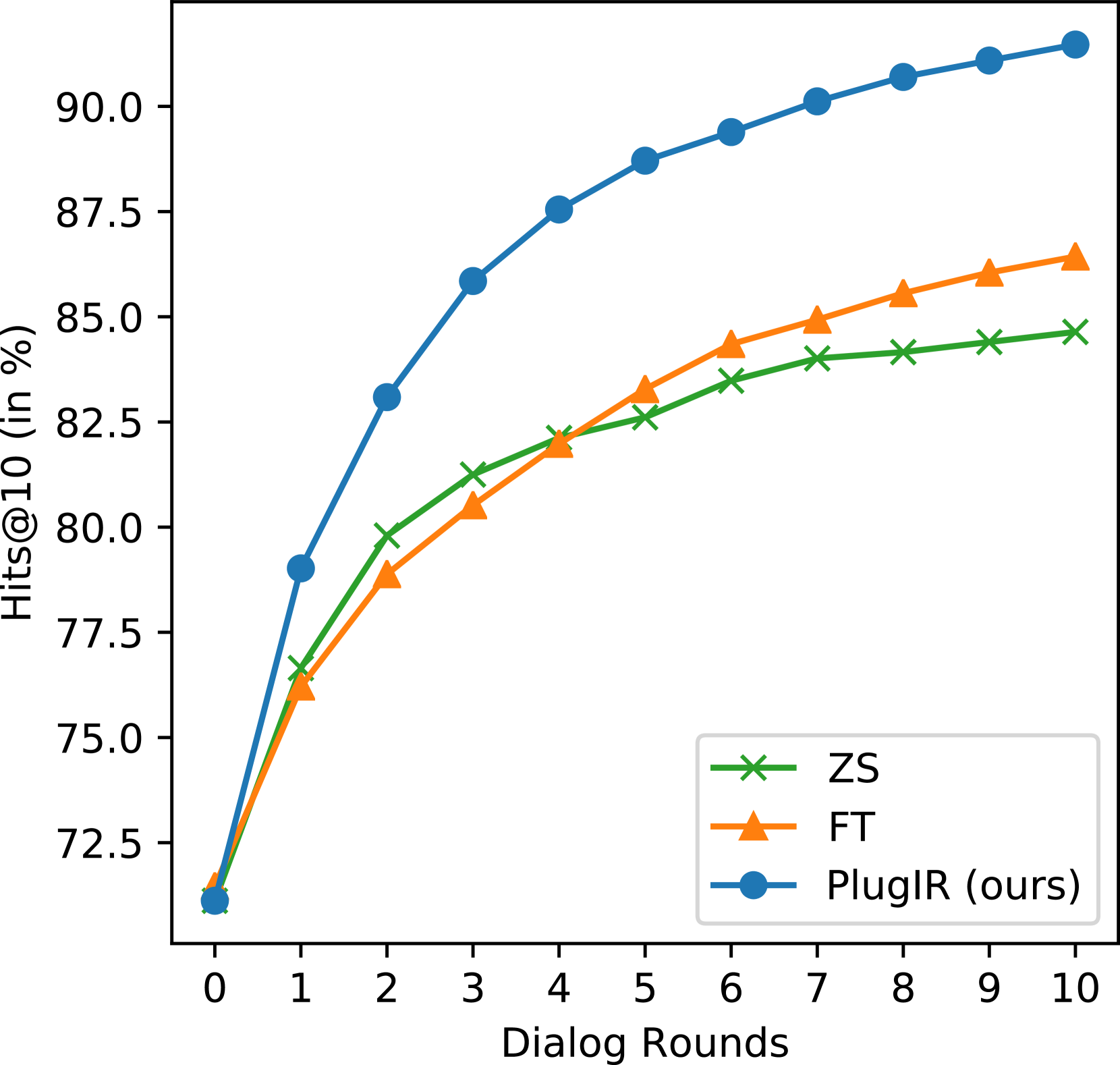
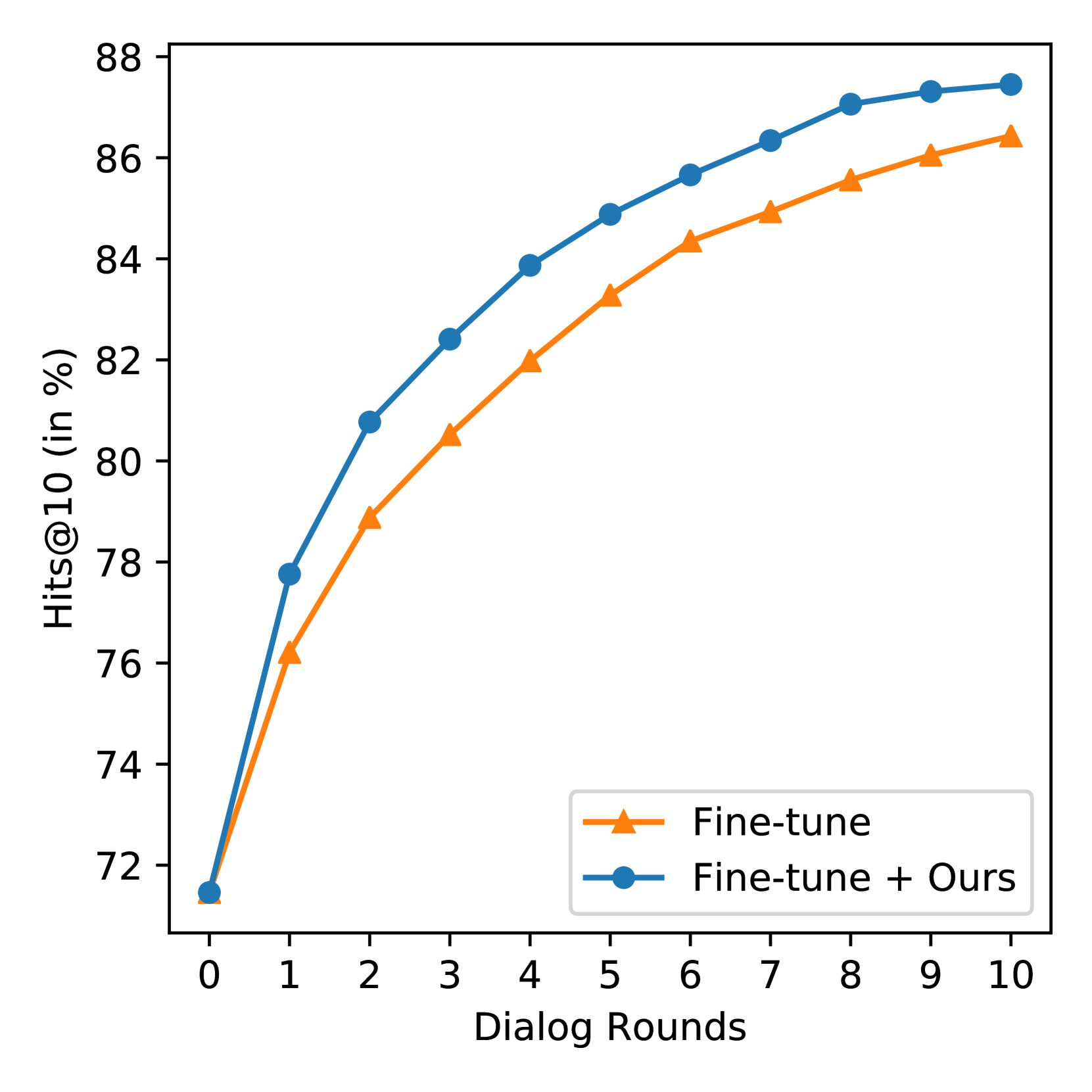
表1展示了ZS、FT和PlugIR在VisDial、COCO和Flickr30k上的BRI结果。 在所有三个数据集上,我们提出的方法都优于 ZS 和 FT 基线。 图3表明PlugIR在Hits@10分数方面在所有轮次中都超越了基线方法。
对 ZS 和 FT 评估结果的比较分析证实,与 Hits@10 相比,BRI 提供了更全面的评估。 具体来说,在图3(a)中,FT在第4轮之前落后于ZS,然后从第5轮开始优于ZS。 因此,在对话轮结束时,Hits@10 表明 FT 优于 ZS。 然而,在表1所示的VisDial结果中,我们发现ZS和FT在BRI方面具有可比性。 这是因为 BRI 不仅考虑了成功检索的数量(用户满意度),还考虑了成功所需的轮数(效率)。 因此,ZS 在前几轮中取得了更成功的检索,导致 BRI 得分与 FT 相似。
| Measure | Correlation coefficients with human | ||||
| Recall | MRR | NDCG | Hits | BRI (ours) | |
| Spearman | 0.46 | 0.67 | 0.67 | 0.51 | 0.88 |
| Pearson | 0.51 | 0.70 | 0.68 | 0.60 | 0.88 |
4.3“一带一路”倡议与人类评价的一致性
我们聘请了 30 名人类测试人员来测量人类对交互式文本到图像检索系统的偏好(更多详细信息,请参阅附录C),然后探讨其与召回率、平均倒数排名(MRR)的相关性、标准化贴现累积收益 (NDCG)、点击数和 BRI。 MRR 和 NDCG 是与召回率类似的指标,但另外还考虑排名改进的重要性。 使用 Spearman 和 Pearson 相关系数对相关性进行量化。 表 2 中的研究结果表明,与其他指标相比,BRI 与人类偏好的相关性明显更强。
5分析
5.1分析模型微调和上下文重构中的对话利用
| Methods | BRI | ||
| BLIP | BLIP-2 | ATM | |
| ZS | 1.0006 | 0.8520 | 1.1329 |
| PlugIR (ours) | 0.7674 | 0.6647 | 0.8236 |
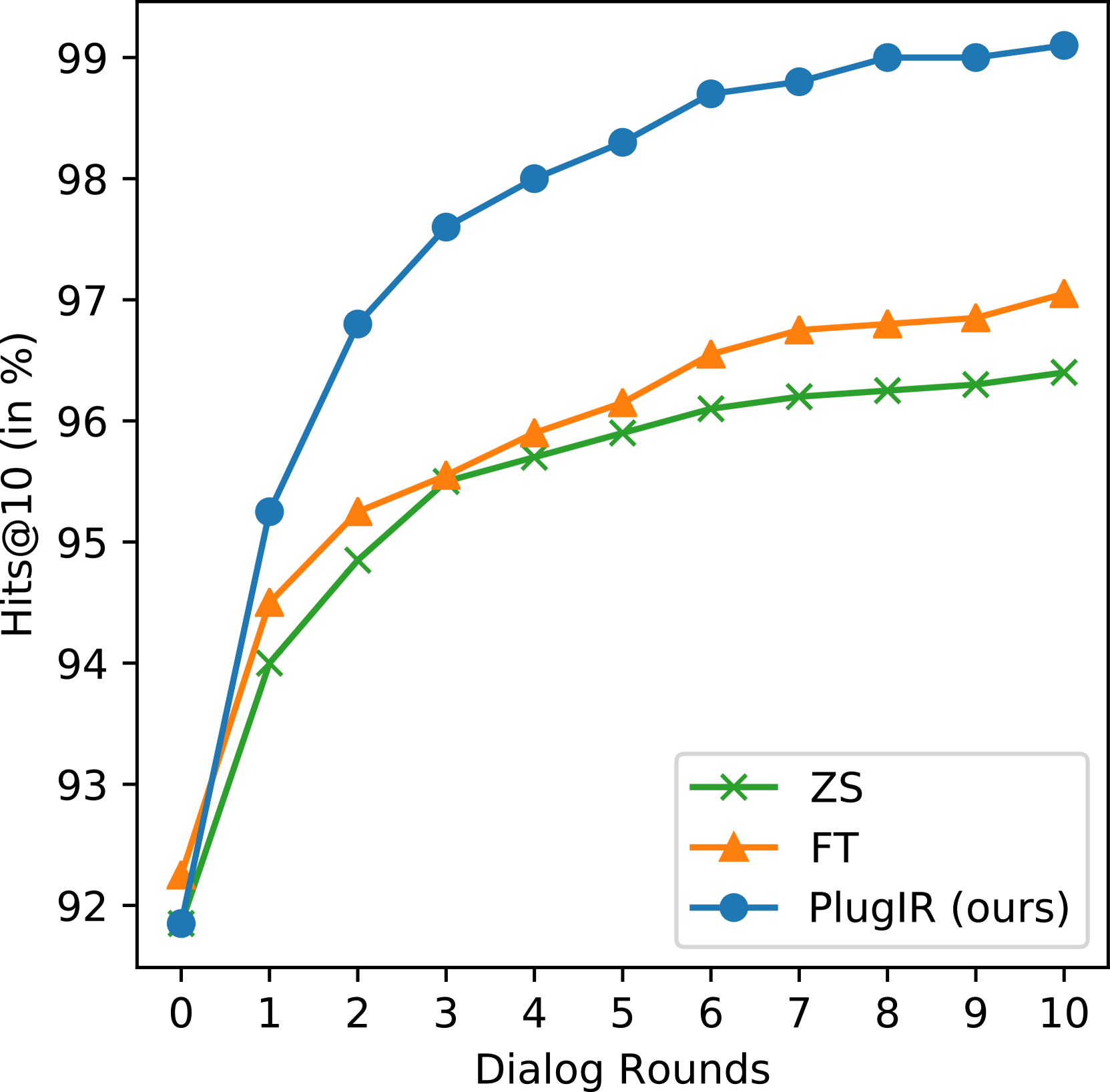
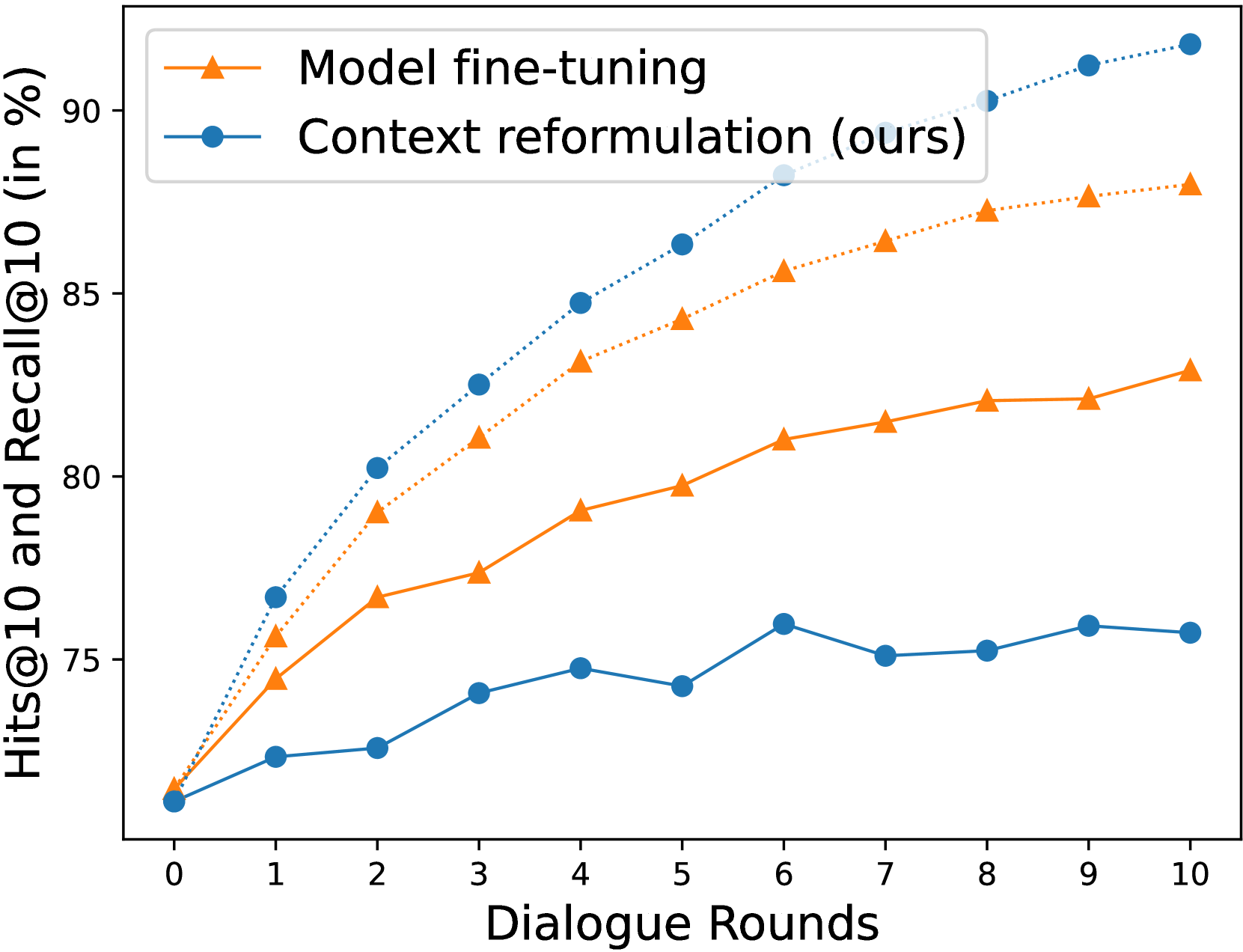
如图2所示,零样本模型在理解对话方面存在困难。 在本节中,我们研究模型微调和上下文重构是否真正增强了检索模型对对话的利用。 我们在图 4 中展示了 Recall@10 和 Hits@10,用于 VisDial 验证集上的模型微调和上下文重构。 该图显示,与图 2 中的结果不同,与仅使用图像标题(第 0 轮)相比,通过对话增强查询时,这两种方法都实现了改进的 Recall@10。 值得注意的是,我们观察到这两种方法在提高我们场景中的检索性能方面表现不同。 与上下文重构相比,模型微调实现了更高的 Recall@10 但更低的 Hits@10。 这意味着与上下文重构相比,模型微调更注重成功检索前几轮中成功的相同样本。 相反,虽然与模型微调相比,上下文重构在每轮检索方面不太成功,但通过提高整个测试查询集的对话利用率,实现了更高的 Hits@10。 在交互式文本到图像检索场景中,每轮累积的聚合检索信息比每轮单独的信息更重要。 与模型微调相比,上下文重构的 BRI 优越性反映了这一点(参见表4)。
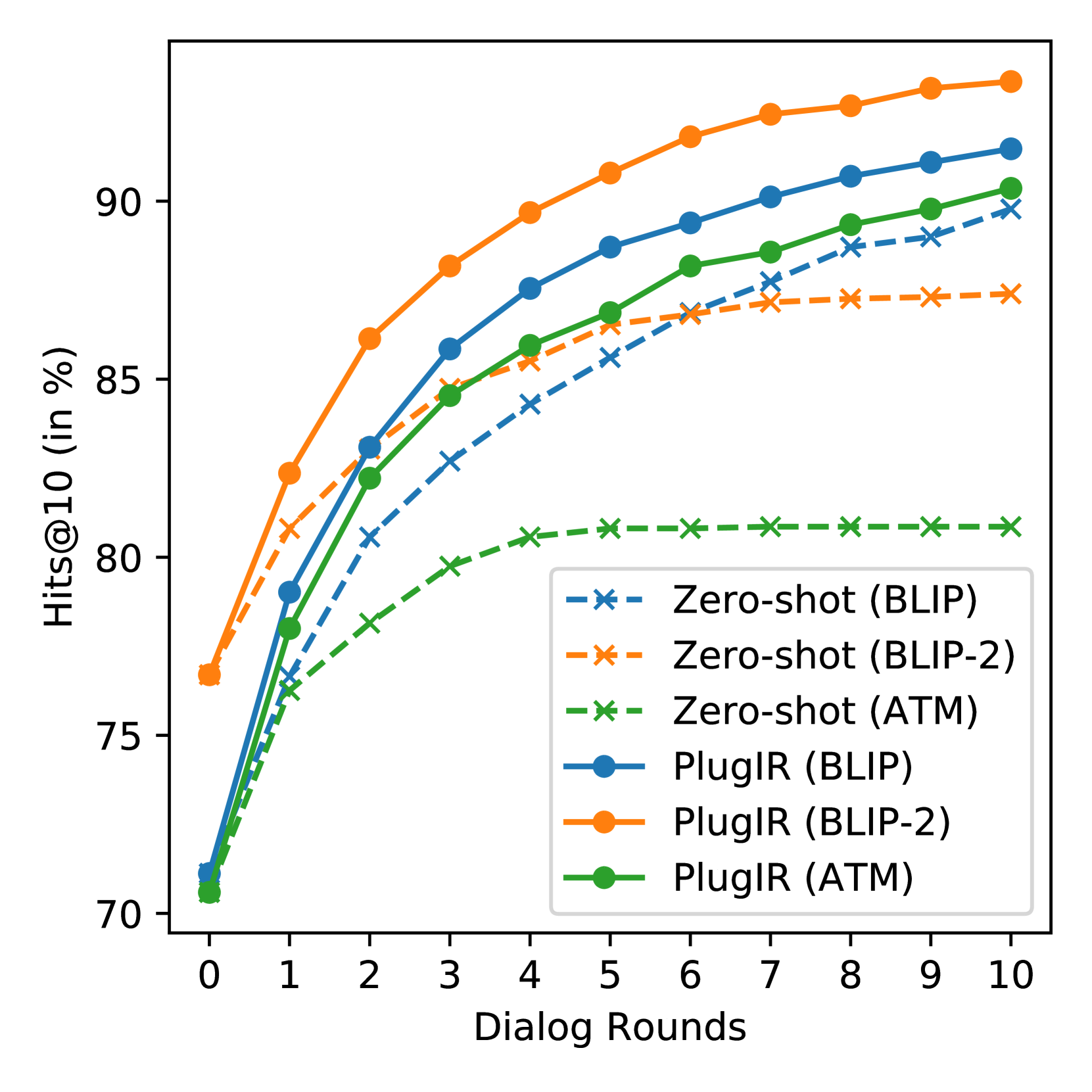
5.2对各种预训练模型的适应性
5.3 对上下文扰动的鲁棒性
| Perturb. | Method | Hits@10 | BRI | ||
| Clean | ZS | 84.98 | 0.00 | 1.0335 | 0.0000 |
| FT | 87.98 | 0.00 | 0.9987 | 0.0000 | |
| PlugIR | 91.81 | 0.00 | 0.8507 | 0.0000 | |
| Char. | ZS | 82.07 | 2.91 | 1.1255 | 0.0920 |
| FT | 84.54 | 3.44 | 1.1192 | 0.1205 | |
| PlugIR | 91.04 | 0.77 | 0.8624 | 0.0117 | |
| Infor. | ZS | 83.24 | 1.74 | 1.0721 | 0.0386 |
| FT | 87.06 | 0.92 | 1.0340 | 0.0353 | |
| PlugIR | 90.94 | 0.87 | 0.8732 | 0.0225 | |
| Slang | ZS | 82.75 | 2.23 | 1.0955 | 0.0620 |
| FT | 85.56 | 2.42 | 1.0780 | 0.0793 | |
| PlugIR | 90.26 | 1.55 | 0.9082 | 0.0575 | |
| Tech. | ZS | 81.69 | 3.29 | 1.1181 | 0.0846 |
| FT | 85.56 | 2.42 | 1.0701 | 0.0714 | |
| PlugIR | 89.78 | 2.03 | 0.9119 | 0.0612 |
在我们的场景中,用户可能有其独特的说话风格,导致检索系统的输入分布发生变化。 从这些上下文扰动的角度来看,我们将我们提出的方法与 ZS 和 FT 的鲁棒性进行了比较。为了确保公平比较,我们假设每种方法都有相同的提问者,并通过扰动固定数据集(VisDial 验证集)中的用户响应来进行实验。 实验的上下文扰动包括字符级替换和删除,以及风格转换 Reif 等人 (2022) 到“非正式”、“俚语”和“技术”风格。 我们使用 TextAttack 库 Morris 等人 (2020) 进行字符级扰动,使用 GPT-3.5 进行样式转换。 在表4中,我们观察到,与直接使用对话作为 ZS 和金融时报模型。
5.4与微调模型的兼容性
5.5消融研究
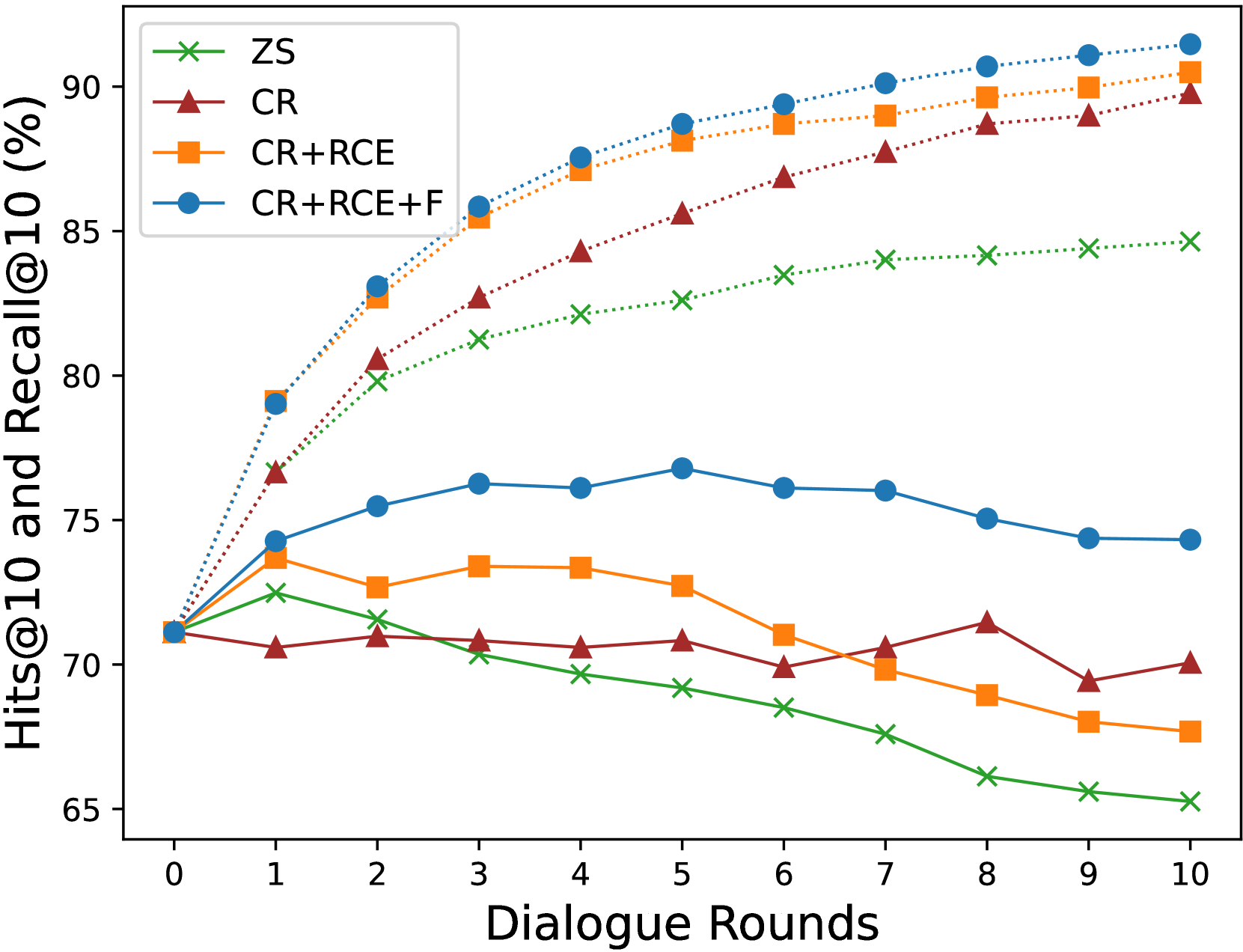
我们对 PlugIR 进行了消融研究,根据 Recall@10 和 Hits@10 对其进行了评估。 PlugIR 包括上下文重构 (CR) 和上下文感知对话生成 (CDG)。 CDG可以细分为检索上下文提取(RCE)和过滤(F)部分。 图5展示了Recall@10和Hits@10方面各种组合的比较,这是针对大语言模型提问者生成并由BLIP-2回答的对话进行的。 与 ZS 基线相比,每个组件逐渐影响 Hits@10 的性能改进。 值得注意的是,F 过程的应用导致了 Recall@10 的显着增强,这表明,如第 3 节中所述,有效减少了问题生成过程中的冗余。 BRI 性能消融研究的结果显示在附录E中。
| Methods | BRI |
| FT | 1.0106 |
| FT + CDG | 0.9457 |
6结论
我们研究了文本到图像检索背景下与大语言模型的对话形式交互。 我们提出的 PlugIR 使用大语言模型提问者和用户之间的对话逐步细化图像检索的文本查询。 具体来说,大语言模型将对话转换为检索模型更好理解的格式。 PlugIR 可以直接应用一系列多模态检索模型,包括黑盒模型,而无需进一步微调。 此外,我们新提出了最佳对数排名积分(BRI)指标,可以测量多轮任务中的综合性能。 我们验证了检索系统在各种环境中的有效性,突出了其多功能的即插即用功能。
局限性
PlugIR 将对话调整为与预先训练的检索模型兼容的格式。 这意味着实施 PlugIR 需要了解特定的检索模型。 我们的实验表明,标题式格式在所有测试的检索模型中都是有效的,并且可能适用于大多数其他模型,尽管这并不能得到普遍保证。 某些检索模型可能会从替代文本查询格式中受益,而不是从标题样式中受益。 例如,最近提出的大型视觉语言模型Liu等人(2024, 2023)的训练数据集包括各种对话格式的样本。 因此,任何利用大型视觉语言模型的交互式文本到图像检索系统可能更喜欢对话形式的查询(我们在附录I中提供了这个方向的额外实验)。 我们认为这方面既是我们当前研究的局限性,也是未来研究的途径。
道德声明
PlugIR 展示了通过利用黑盒多模型文本图像模型和大型语言模型的高性能功能,在文本到图像检索任务中实现有效性能的能力。 然而,此过程在检索图像池中的单个数据时存在潜在风险。 此外,在大语言模型提问者和用户之间的交互过程中,还存在用户个人信息泄露到运行大语言模型的服务器的担忧。
致谢
这项工作得到了韩国政府(科学和信息通信技术部,MSIT)资助的韩国国家研究基金会(NRF)赠款(2022R1A3B1077720)、韩国信息与通信技术规划与评估研究所(IITP)赠款的支持政府 (MSIT)(RS-2021-II211343:人工智能研究生院计划(首尔国立大学)和 2022-0-00959)、三星电子有限公司(IO221213-04119-01)以及韩国国立大学的 BK21 FOUR 计划首尔国立大学未来 ICT 先锋教育和研究计划,2024 年。
参考
- Baldrati et al. (2022) Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Alberto Del Bimbo. 2022. Effective conditioned and composed image retrieval combining clip-based features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21466–21474.
- Das et al. (2017) Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José MF Moura, Devi Parikh, and Dhruv Batra. 2017. Visual dialog. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 326–335.
- Guo et al. (2018) Xiaoxiao Guo, Hui Wu, Yu Cheng, Steven Rennie, Gerald Tesauro, and Rogerio Feris. 2018. Dialog-based interactive image retrieval. Advances in neural information processing systems, 31.
- Karthik et al. (2023) Shyamgopal Karthik, Karsten Roth, Massimiliano Mancini, and Zeynep Akata. 2023. Vision-by-language for training-free compositional image retrieval. arXiv preprint arXiv:2310.09291.
- Levy et al. (2023a) Matan Levy, Rami Ben-Ari, Nir Darshan, and Dani Lischinski. 2023a. Chatting makes perfect–chat-based image retrieval. arXiv preprint arXiv:2305.20062.
- Levy et al. (2023b) Matan Levy, Rami Ben-Ari, Nir Darshan, and Dani Lischinski. 2023b. Data roaming and early fusion for composed image retrieval. arXiv preprint arXiv:2303.09429.
- Li et al. (2023) Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597.
- Li et al. (2022) Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR.
- Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer.
- Liu et al. (2023) Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2023. Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744.
- Liu et al. (2024) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024. Visual instruction tuning. Advances in neural information processing systems, 36.
- Liu et al. (2021) Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould. 2021. Image retrieval on real-life images with pre-trained vision-and-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2125–2134.
- Morris et al. (2020) John Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, and Yanjun Qi. 2020. Textattack: A framework for adversarial attacks, data augmentation, and adversarial training in nlp. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 119–126.
- OpenAI (2023a) OpenAI. 2023a. Chatgpt.
- OpenAI (2023b) OpenAI. 2023b. Gpt-4 technical report.
- Patel et al. (2022) Yash Patel, Giorgos Tolias, and Jiří Matas. 2022. Recall@ k surrogate loss with large batches and similarity mixup. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7502–7511.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. 2018. Improving language understanding by generative pre-training.
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
- Reif et al. (2022) Emily Reif, Daphne Ippolito, Ann Yuan, Andy Coenen, Chris Callison-Burch, and Jason Wei. 2022. A recipe for arbitrary text style transfer with large language models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 837–848.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vo et al. (2019) Nam Vo, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays. 2019. Composing text and image for image retrieval-an empirical odyssey. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6439–6448.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
- Wei et al. (2022a) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. 2022a. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682.
- Wei et al. (2022b) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022b. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Wu et al. (2021) Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. 2021. Fashion iq: A new dataset towards retrieving images by natural language feedback. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11307–11317.
- Young et al. (2014) Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. 2014. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78.
- Zheng et al. (2023) Ge Zheng, Bin Yang, Jiajin Tang, Hong-Yu Zhou, and Sibei Yang. 2023. Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models. In Thirty-seventh Conference on Neural Information Processing Systems.
附录A大语言模型提示示例
附录B实验细节
B.1 评估指标
在3.2和5.1节中,我们使用Recall@10和Hits@10来评估ZS、FT和我们提出的方法的影响。 然而,Recall@10 并未包含在我们的主要评估中。 这一决定是基于这样的担忧:使用召回率作为交互式检索系统的评估指标可能会对其有效性产生误导性的看法。 我们确定了评估这些系统时需要考虑的三个关键观点。 通过说明性示例,我们依次阐述了各个角度,展示了传统指标如何可能歪曲系统性能。 对于这些示例,假设用户每轮可以查看十张图像。
用户满意度。
| Method | Retrieval rank | ||
| Round 0 | Round 1 | Round 2 | |
| A | 100 | 100 | 100 |
| B | 100 | 10 | 100 |
| Metric | A | B | Good or Bad |
| Recall@10 | 0.0 | 0.0 | Bad |
| MRR@10 | 0.0 | 0.0 | Bad |
| NDCG@10 | 0.0 | 0.0 | Bad |
| Hits@10 | 0.0 | 1.0 | Good |
| BRI | 4.6 | 2.9 | Good |
效率。
| Method | Retrieval rank | ||
| Round 0 | Round 1 | Round 2 | |
| A | 100 | 100 | 10 |
| B | 100 | 10 | 10 |
| Metric | A | B | Good or Bad |
| Recall@10 | 1.0 | 1.0 | Bad |
| MRR@10 | 0.1 | 0.1 | Bad |
| NDCG@10 | 0.3 | 0.3 | Bad |
| Hits@10 | 1.0 | 1.0 | Bad |
| BRI | 4.0 | 2.9 | Good |
排名提升意义。
| Method | Retrieval rank | |
| Round 0 | Round 1 | |
| A | 100 | 10 |
| B | 100 | 5 |
| Metric | A | B | Good or Bad |
| Recall@10 | 1.0 | 1.0 | Bad |
| MRR@10 | 0.1 | 0.2 | Good |
| NDCG@10 | 0.3 | 0.4 | Good |
| Hits@10 | 1.0 | 1.0 | Bad |
| BRI | 3.5 | 3.1 | Good |
在表10中,虽然方法A和B都在第1轮中向用户显示目标图像,但B与 A 相比,> 方法为其分配了更高的排名(更接近 1),使其检索更加直接。 表 11 显示 MRR@10、NDCG@10 和 BRI 等指标考虑了这一因素,因此对 B 的评价比 A 更积极。 然而,Recall@10 和 Hits@10 没有考虑这个特定方面。
总而言之,在评估交互式检索系统时使用 Recall@K 等传统指标可能会导致分数仅反映这些系统功能的一小部分。 基于这种不完整的指标进行系统比较和优越性评估可能会导致误导性的结论。 因此,我们选择不使用 Recall@K 作为我们的主要评估指标。 请注意,Hits@K 已在之前的研究中用于评估交互式检索系统,我们已将其纳入我们的主要评估中以方便比较。
此外,除 BRI 之外的所有分数都取决于“用户每轮可以查看的图像数量 (@K)”的超参数。然而,这个值可能变化很大,因此评估结果很容易改变。 相比之下,BRI 独立于该超参数,使其成为更加稳定可靠的评估指标。 尽管如此,我们在附录D中提供了额外的分析,仅使用传统指标,包括召回率、MRR、NDCG 和点击率。
B.2 进一步的实施细节
我们使用 gpt-3.5-turbo-0613 API 作为我们的大语言模型。 对于超参数,我们使用 0.7 的温度和 32 的最大词符长度来生成问题。 对于上下文重构,我们使用温度 0.0 和最大词符长度 512。 对于过滤,我们使用温度 0.0 和最大词符长度 10。
关于数据集,我们为 VisDial 验证集中的全部 2,064 张图像生成对话。 对于 COCO 和 Flickr30k,我们在每个数据集中的 2,000 张图像样本上生成对话。 我们设置的候选数根据实验中使用的数据集设置不同;对于 VisDial,,对于 COCO,,对于 Flickr30k,。 这相当于每个数据集的图像池(搜索空间)大小的大约 1%。
附录 C 人类评估详细信息
我们测量了 30 名接受参与人类评估的机器学习研究人员的人类偏好,如下所示:
-
1.
我们准备了包含用户和交互式文本到图像检索系统之间交互的实例。 每个实例包括一个目标图像、一个 5 轮对话以及每轮的前 5 个图像。 为了方便测试人员进行评估(并且可以一目了然地轻松识别总体结果),我们决定在单个目标图像的五轮中每轮显示五张图像。
-
2.
向 30 名人类测试人员每人展示了 60 个实例,并附有以下说明:
“交互式图像检索是系统通过交互找到用户想要的目标图像的过程。 当您进行评估时,该场景涉及用户最初向系统提供目标图像的简短描述。 然后系统根据此描述制定问题以正确识别目标图像,并且用户回答这些问题。 该过程从第 0 轮开始,用户在系统中输入简短的描述。 从第一轮开始,每一轮系统都会根据前几轮与用户交换的信息询问有关目标图像的问题,然后用户做出相应的回答。 每轮结束时,系统会根据目前收集到的信息,搜索五张候选目标图像,并按排名顺序呈现给用户。 用户可以选择在任何一轮结束时结束与系统的交互。 此外,每一轮都会产生金钱和时间成本。 您将根据左侧的交互日志来评估系统的有用性,该日志记录了与系统的五轮交互。”
-
3.
对于每个实例,人类测试人员都需要回答以下问题:
“假设您使用的系统具有以下日志:
Q1. 该系统将发挥作用。
(是:5,否:1)Q2。 该系统将是高效的。
(是:5,否:1)”我们的问题旨在从有效性和效率方面评估系统,这在系统评估中通常会考虑,而不会对人类测试人员的偏好产生偏见。
-
4.
分配给每个实例的平均分数用作人类偏好分数。
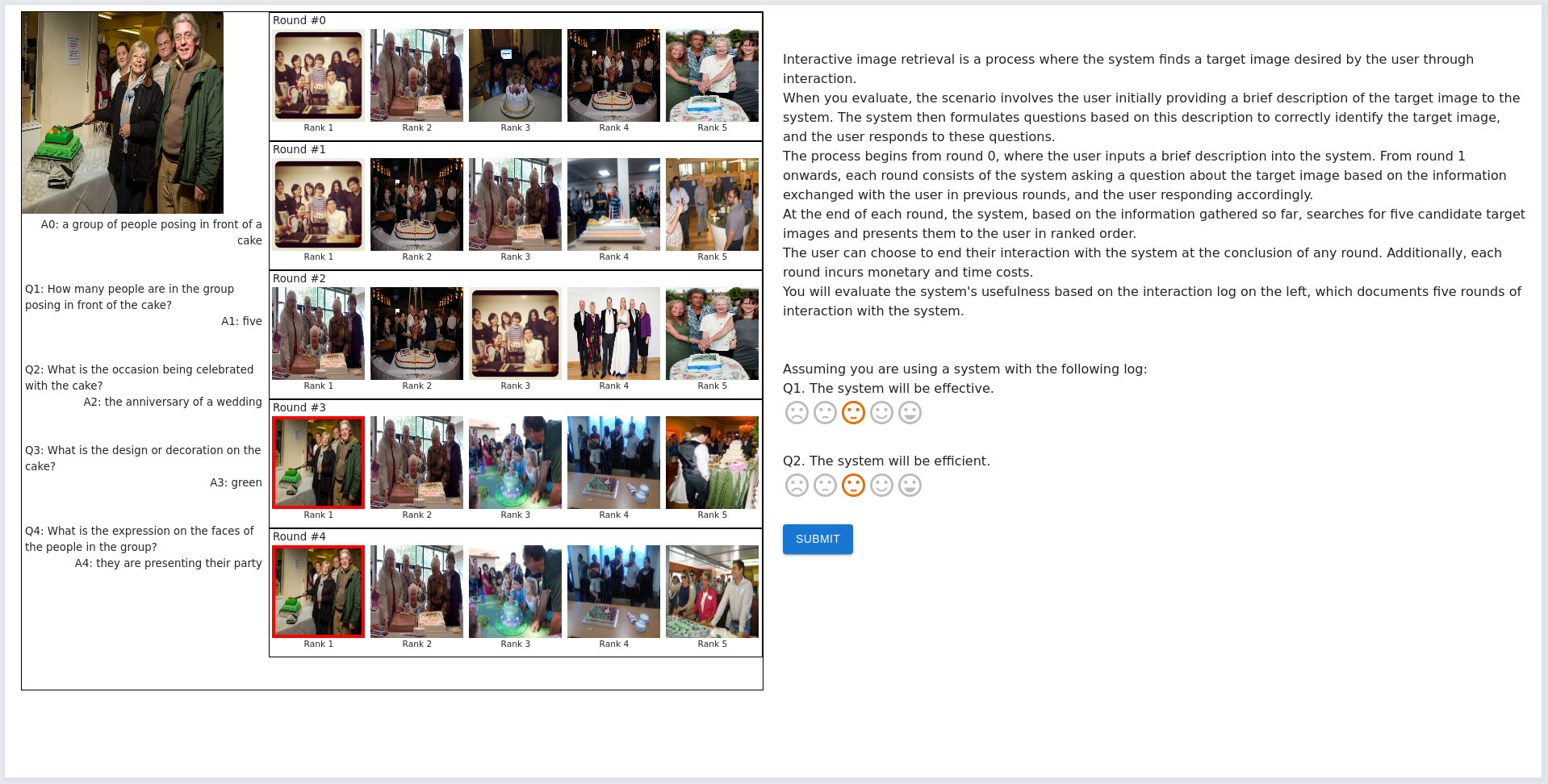
我们在图7中提供了测试的屏幕截图。
附录 D 使用传统指标的其他分析
我们以类似于手稿第 5.1 节的方式比较 FT 和我们提出的方法。 此比较使用 Recall@10、MRR@10、NDCG@10、Hits@10 等指标以及成功检索所需的平均轮数。
| Metrics | Methods | Round | ||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| Recall@10 | FT | 71.5 | 73.9 | 74.9 | 75.3 | 76.0 | 77.5 | 78.2 | 78.3 | 78.8 | 79.4 | 79.5 |
| Ours | 71.1 | 74.3 | 75.5 | 76.3 | 76.1 | 76.8 | 76.1 | 76.0 | 75.1 | 74.4 | 74.3 | |
| MRR@10 | FT | 0.50 | 0.53 | 0.54 | 0.56 | 0.56 | 0.56 | 0.57 | 0.58 | 0.58 | 0.58 | 0.58 |
| Ours | 0.51 | 0.53 | 0.56 | 0.56 | 0.57 | 0.57 | 0.56 | 0.56 | 0.56 | 0.55 | 0.54 | |
| NDCG@10 | FT | 0.55 | 0.58 | 0.59 | 0.60 | 0.60 | 0.61 | 0.62 | 0.63 | 0.63 | 0.63 | 0.63 |
| Ours | 0.56 | 0.58 | 0.61 | 0.61 | 0.62 | 0.62 | 0.61 | 0.61 | 0.60 | 0.60 | 0.59 | |
| Hits@10 | FT | 71.5 | 76.2 | 78.9 | 80.5 | 82.0 | 83.3 | 84.4 | 84.9 | 85.6 | 86.1 | 86.4 |
| Ours | 71.1 | 79.0 | 83.1 | 85.9 | 87.6 | 88.7 | 89.4 | 90.1 | 90.7 | 91.1 | 91.5 | |
MRR 和 NDCG 通过纳入排名改进意义的概念来增强召回的概念。 然而,FT 的 MRR 和 NDCG 分数高于 PlugIR,如第 6 轮后表 12 的 MRR@10 和 NDCG@10 结果所示,不应得出 FT 在以下方面优于 PlugIR 的结论:排名提升意义重大。 需要警惕这种解释,因为 Recall@10、MRR@10 和 NDCG@10 结果中存在明显的一致趋势。 换句话说,FT 的 MRR 和 NDCG 分数相对于 PlugIR 的优越性很大程度上受召回因素影响,而不是排名提升显着性。 我们手稿的 3.2 和 5.1 节对这些有关召回的方法进行了深入分析,如下所示:FT 实现了较高的 Recall@10 但较低的 Hits@10与我们提出的方法相比。 这意味着与我们相比,FT 更注重成功检索前几轮中成功的相同样本。 相反,虽然与 FT 相比,所提出的方法在每轮检索方面不太成功,但通过提高整个测试查询集的对话利用率,实现了更高的 Hits@10。 在交互式文本到图像检索场景中,每轮累积的聚合检索信息比每轮单独的信息更重要。 PlugIR 相对于 FT 优越的 BRI 反映了这一点。
尽管如此,我们通过比较表 12 中 Recall@10、MRR@10 和 NDCG@10 的结果,提供了以下新的分析(未在我们的手稿中提供):
- 在表12第0轮的结果中,FT的召回率略高于PlugIR,但MRR和NDCG较低。 这意味着在视觉对话数据集上微调检索模型可能会破坏字幕与其相应图像之间的精确匹配。
- 在表12的第4轮和第5轮结果中,虽然FT与PlugIR相比显示出相似或略高的召回率,但其MRR和NDCG较低。 这表明PlugIR在排名提升意义方面超越了FT。
附录 E其他分析
| Methods | BRI |
| ZS | 1.0006 |
| CR | 0.8907 |
| CR + RCE | 0.7829 |
| CR + RCE + F | 0.7674 |
附录 FPlugIR 示例
我们在图 9 中展示了 PlugIR 的示例。
附录G相关工作
在本节中,我们探索为图像检索任务量身定制的潜在基线和最先进的方法,并讨论现有方法在方法论方面与我们的方法有何不同。
虽然交互式文本到图像检索的主题很流行,但该领域的现有方法采用了与我们的方法不同的方法。 值得注意的是,Guo 等人 (2018) 和 Wu 等人 (2021) 依赖于用户的片面反馈,这与我们关注用户之间的问答对话形成鲜明对比。系统和用户。 因此,由于实验设置不同,将这些工作的性能与我们的方法进行比较具有挑战性。 相反,我们从方法论的角度进行比较。 Guo 等人 (2018) 和 Wu 等人 (2021) 仅依赖用户反馈而没有提问者系统,可能会导致基于个人用户的显着性能差异。 此外,系统中的用户承担着思考和提供反馈的负担,导致用户严重疲劳。 相比之下,我们的方法涉及系统主动制定图像检索的最佳问题。 用户只需提供答案即可,大大减少了用户的疲劳度。 此外,我们的方法可以最大限度地减少不同用户造成的性能差异。 这种方法上的区别强调了我们设置的实际优势,提供了更加用户友好和一致的交互式文本到图像搜索体验。
另一方面,在组合图像检索(CIR)领域,最近出现了与交互式图像检索相关的论文。 CIR 方法通常不仅涉及文本信息,还涉及参考图像,以促进目标图像的检索。 例如 Baldrati 等人 (2022) 和 Karthik 等人 (2023)。 特别是,Karthik 等人 (2023) 与我们利用大语言模型的方法有共同点。 然而,由于 CIR 和文本到图像检索这两个任务之间存在根本差异,因此与 CIR 方法的性能比较提出了挑战,因为 CIR 还结合了参考图像的使用。
经过彻底调查,我们的方法和基线 ChatIR Levy 等人 (2023a) 似乎是当前文本到图像检索领域中唯一利用问答对话的两种方法。 我们相信,我们对问答对话的关注使我们的方法有别于现有方法,在交互式文本到图像检索领域提供了独特的角度。
附录 H 效率比较:Fine-Tuned 与 PlugIR
| Methods | #ARNSR |
| FT | 3.41 |
| PlugIR (ours) | 2.85 |
我们对我们提出的方法 PlugIR 的效率进行了分析。 虽然 PlugIR 的高 BRI 分数可能无法直接反映其效率,但由于 BRI 还包含除效率之外的一系列重要因素,我们将注意力转向更直观的效率衡量标准:成功检索所需的平均轮数。 表 14 的结果表明 PlugIR 比基于调整的方法更有效。 此外,与 FT 相比,PlugIR 的 Hits@10 分数更高,表明我们的方法不仅比 FT 更快地找到目标图像,而且检索成功率更高。
附录一评估大型视觉语言模型中的查询风格偏好:字幕与对话
| Rounds | Dialogue | Caption |
| 1 | 492 | 1572 |
| 2 | 675 | 1389 |
| 3 | 853 | 1211 |
| 4 | 923 | 1141 |
| 5 | 992 | 1072 |
| 6 | 989 | 1075 |
| 7 | 967 | 1097 |
| 8 | 923 | 1141 |
| 9 | 846 | 1218 |
| 10 | 800 | 1264 |
我们进行了以下实验,以调查经过指令调整的大型视觉语言模型是否也表现出对字幕或对话形式的偏好:
-
1.
我们为 VisDial 验证数据集中的每张图像创建多项选择题,每个问题都有一个问题和两个选择。
-
2.
问题如下:“什么与照片更相关?”
-
3.
第一个选择(对话形式)是:“标题:<标题>。 对话:<对话>。”这里,“<标题>”是图像的标题,<对话>是 VisDial 示例中的对话。
-
4.
第二个选择(标题形式)是:“标题:<我们的标题>”。在这里,“<我们的标题>”是通过我们对第一个选择的标题和对话进行上下文重新表述而创建的标题。
-
5.
为了消除选择顺序中的偏差,我们改变顺序并将 VQA 样本输入模型。
我们在 LLaVA-1.6-7B222https://huggingface.co/liuhaotian/llava-v1.6-vicuna-7b,结果总结在表15中。 表15中,“轮次”表示对话的长度,每轮增加一组问题和答案。 从表15中我们可以看到LLaVA模型也更喜欢标题形式。 尽管在某些时间间隔中偏好看起来相似(第 5-7 轮),但我们可以看到,随着提供更多信息,对字幕的偏好再次增加。
附录 J上下文感知对话生成中的幻觉问题
在本节中,我们讨论 PlugIR 中大语言模型代理中出现的幻觉问题,其中大语言模型在管道的三个步骤中使用:上下文重构、问题生成和过滤。 我们偶尔会发现在上下文重构过程中省略对话中部分内容的问题。 此外,在过滤过程中,我们还发现了一些情况,尽管大语言模型能够通过对话历史进行回答,但它仍将某些问题归类为非冗余问题,根据现有对话内容认为它们无法回答。 这两个例子都与大语言模型推理过程中的幻觉问题有关,其中一些输入内容被忽略。
此外,我们还观察到一个现象,即大语言模型生成的问题格式倾向于符合提示中提供的例题结构。 例如,如果提示中的例句主要询问“什么”,则大语言模型生成的问题大多是“照片中物体的颜色是什么?”等形式。当对如何在添加的思想链 (CoT) 示例中使用检索候选进行具体解释时,这种现象变得尤其明显。 解释越详细,大语言模型提问者在该示例中就越有根据,使其能够更有效地使用检索候选项来生成问题。 然而,这也导致了一个问题,即生成的问题强烈遵循示例问题的格式,因为大语言模型提问者不仅以解释为基础,而且以示例的问题格式为基础。 我们认为这与幻觉问题有关,即大语言模型基于给定上下文中被视为噪音的内容,分散了推理过程的注意力。
附录K不同簇的影响
| 5 | 10 | 15 | 20 | |
| BRI | 0.8742 | 0.8456 | 0.8280 | 0.8246 |
增加簇的数量()对应于增加注入大语言模型提问者的标题数量,允许大语言模型提问者从检索候选集中引用更多样化的特征集。 然而,如果簇的数量增加超过一定水平,共享重叠特征的标题可能会变得多余,并可能阻碍大语言模型提问者生成正确问题的能力。
我们进一步研究 BRI 的性能如何随着 的不同值而变化。表 16 显示了 PlugIR 的结果,该结果仅应用利用 2024.02 版本 ChatGPT 的上下文重构 (CR) 和检索上下文提取 (RCE)。 我们观察到,随着集群数量的增加,BRI 性能会提高。 然而,超过某个阈值,改进的程度就变得微乎其微( 与 比较)。 这表明,虽然增加集群数量最初可以有助于增强“一带一路”倡议,但存在收益递减点,进一步增加集群数量不会带来显着改善。
同样,将检索候选集的大小()设置得太小可能无法准确掌握检索任务的上下文,而设置太大则可能会增加检索中与目标图像无关的信息比例。图像池。 因此,为用户使用的图像池找到最佳的 和 也将是成功应用我们的工作的一个有意义的元素。
附录LAI写作辅助的使用
这篇论文是在人工智能助手 ChatGPT 的语言帮助下撰写的,其中包括对作者原始内容的释义和拼写检查。
| System (Task Description) | You are a proficient question generator tasked with aiding in the retrieval of a target image. Your role is to generate questions about the target image of the description via leveraging two key information sources: [Description]: This is a concise explanation of the target image. [Dialogue]: Comprising question and answer pairs that seek additional details about the target image. Your generated question about the description must be clear, succinct, and concise, while differing from prior questions in the [Dialogue]. |
| User (Train Example) | [Description] a man is doing a trick on a skateboard [Dialogue] Question: What type of trick is the man performing on the skateboard? Answer: a jump Question: What is the location of the jump trick being performed? Answer: a skate park Question: |
| Assistant (Train Example) | what is the outfit of the man performing the jump trick at a skate park? |
| User (Query) | [Description] {Initial Description} [Dialogue] {Dialogues} Question: |
| System (Task Description) | You are a proficient question generator tasked with aiding in the retrieval of a target image. Your role is to generate questions about the target image of the description via leveraging three key information sources: [Retrieval Candidates]: These are captions of images which are the candidates of the retrieval task for the target image described in [Description]. [Description]: This is a concise explanation of the target image. [Dialogue]: Comprising question and answer pairs that seek additional details about the target image. You should craft a question that narrows down the options for the attributes of the target image through drawing the information from the retrieval candidates. The generated question about the target image must be clear, succinct, and concise. Also, the question should only be asked about common objects in the description and candidates, which cannot be answered only from the description and the dialogue. Please explain how did you utilize the information sources for generating a question. |
| User (Train Example) | [Retrieval Candidates] 0. man in yellow shirt 1. a boy in a skateboard park 2. the biker is performing a trick 3. a man in a green hat doing half-pipe with a skateboard 4. a skateboarding man catches the air in the midst of a trick [Description] a man is doing a trick on a skateboard [Dialogue] Question: what type of trick is the man performing on the skateboard? Answer: a jump Question: what is the location of the jump trick being performed? Answer: a skate park Question: |
| Assistant (Train Example) | what is the outfit of the man performing the jump trick at a skate park? Explanation: To generate a question about the description, I will utilize the retrieval candidates that mention the outfit of the man. Candidates 0 and 3 provide information about the man’s wearing. The description mentions the man’s trick on a skateboard, and the dialogue mentions the type and the location of the trick. Since the attribute about the outfit does not appear in the description and the dialogue, the generated question cannot be answered from the information in the description and the dialogue about the target image. Also, the generated question is asking for the common objective, man, in the descriptions and candidates, not for the different objective from the description and the retrieval candidates 0 and 3, for example, a shirt and a half-pipe. |
| User (Query) | [Retrieval Candidates] {Retrieval Context} [Description] {Initial Description} [Dialogue] {Dialogues} Question: |
| System (Task Description) | Answer the question only according to the given context. If you cannot determine the answer or there are no objects that are asked by the question in the context , answer "Uncertain". |
| User (Query) | [Context] {Context} [Question] {Question} [Answer] |
| System (Task Description) | Your role is to reconstruct the [Caption] with the additional information given by following [Dialogue]. The reconstructed [New Caption] should be concise and in appropriate form to retrieve a target image from a pool of candidate images. |
| User (Train Example) | [Caption]: a woman sits on a bench holding a guitar in her lap [Dialogue]: is this in a park? yes, i believe it is, are there others around? no, she is alone, does she have a collection bucket? no, is her hair long? yes, pretty long, is she wearing a dress? i don’t think so, hard to tell, does she have shoes on? yes, flip flops, is there grass nearby? yes, everywhere, is it a sunny day? yes, are there trees? in the background there are trees, is the guitar new? i don’t think so [New Caption]: |
| Assistant (Train Example) | a woman with pretty long hair sits alone on a grassy bench in a park on a sunny day, holding a guitar in her lap without a collection bucket, wearing flip flops, with trees in the background, with a slightly worn guitar |
| User (Query) | [Caption]: {caption} [Dialogue]: {dialogue} [New Caption]: |