1475 研究算法/技术 所有作者均来自加州大学戴维斯分校。 电子邮件:{hyllu, ranli, ujwkal, klma}@ucdavis.edu。
GNNanatomy:图神经网络
多级解释的系统生成和评估
摘要
事实证明,图神经网络 (GNN) 在涉及图的各种机器学习 (ML) 任务中非常有效,例如节点/图分类和链接预测。 然而,由于基于图结构的聚合关系信息,导致复杂的数据转换,解释 GNN 做出的决策提出了挑战。 现有的解释 GNN 的方法在系统地探索不同的子结构和在缺乏基本事实的情况下评估结果方面常常面临局限性。 为了解决这一差距,我们引入了 GNNNatomy,这是一种与模型和数据集无关的视觉分析系统,旨在促进 GNN 多级解释的生成和评估。 在 GNNNatomy 中,我们使用 graphlet 来阐明图级分类任务中的 GNN 行为。 通过分析 GNN 分类和图基数频率之间的关联,我们制定了假设的事实和反事实解释。 为了验证假设的图基解释,我们引入了两个指标:(1)其频率与分类置信度之间的相关性,以及(2)从原始图中删除该子结构后分类置信度的变化。 为了证明 GNNNatomy 的有效性,我们对来自各个领域的真实世界和合成图数据集进行了案例研究。 此外,我们定性地将 GNNanatomy 与最先进的 GNN 解释器进行比较,展示了我们设计的实用性和多功能性。
关键词:
Graphlets、Motif、图神经网络、可解释的人工智能、视觉分析、可视化介绍
图神经网络(GNN)是一种机器学习(ML)方法,用于将图转换为向量表示,更容易用于涉及图数据的分类或预测任务。 例如,考虑一个表示为网络的团队合作场景,其中参与者是节点,两个人之间的协作形成边缘。 每个网络都可以根据历史数据进行标记,表明其结果是否成功。 通过学习团队合作结构和结果之间的关联,GNN 可以预测未来团队合作努力成功的可能性。 为了获得可行的见解,解释 GNN 行为的能力至关重要;例如,在团队合作场景中,了解不成功结果的根本原因对于实施干预措施以避免不良绩效至关重要。
为了揭开 GNN 的黑匣子,现有的可解释的 GNN 方法,例如 [33, 26],通常侧重于识别对 GNN 行为影响最大的关键子图。 然而,除了研究子图之外,许多现实世界的应用程序还需要识别图的基本构建块(即基本子结构或重复模式)并理解每个子结构的功能和重要性。 例如,在生物网络中,它是一个 6 原子碳环,它使分子具有诱变性 [3],而不是包含 6 原子碳环的特定子图。 此外,先前的文献对替代解释的探索有限。 大多数方法生成单个子图或子图集合作为解释,而不寻求潜在的替代解释。 由于这种子图级解释并不总是准确地解释 GNN 行为,因此必须能够探索不同的子结构并寻求子结构解释以得出最值得信赖的解释。
另一个挑战在于解释的粒度。 以前的 GNN 解释方法会生成实例级或模型级解释[36]。 虽然实例级解释是针对单个图[33]量身定制的,但它们限制了对 GNN 行为的整体理解。 针对这一限制,模型级解释旨在解释整个数据集或属于同一类[35,17,31]的图的 GNN 行为。 然而,通常情况下,不止一个子结构有助于使图具有可区分性。 例如,分子致突变性的分类涉及 3 原子无环子结构 和 6 原子碳环 [3]。 仅 子结构就可以将某些图标记为致突变性,而其他图仅需要碳环或两个性状的组合即可进行区分。 仅仅建议类中的公共子结构无法包含这些详细的解释,因此实例级和模型级解释都无法提供足够的粒度[27]。 因此,识别需要不同解释的图形组并确定每个组最具解释性的子结构的能力至关重要。
由于缺乏关于 GNN 应使用哪些子结构的基本事实,验证解释并不是一项简单的任务。 大多数评估指标都基于这样的直觉:当从原始图中删除解释性节点和链接时,GNN 预测[19, 8]将会发生显着变化。 然而,基于删除的方法会给图数据带来风险,因为删除子图通常会导致新图与原始图相比分布不均匀(OOD)[7,14,18,29]. 此外,度量分数通常用于不同 GNN 解释器之间的比较目的,而不是评估潜在的解释以确定最佳解释。 需要一种系统的评估方法来检查生成的解释性子结构的相关性。
考虑到这些限制和剩余的挑战,我们提出了旨在在图级分类任务的背景下解决每个问题的新方法。
-
•
为了生成子结构解释,我们使用 graphlet 作为解释元素。 每个图都表示为由图基数频率组成的向量,有助于直接从原始图导出更简单的相邻数据空间。 这种方法提供了每个图的基本子结构的摘要,不仅是为了更好地促进解释,而且适用于任何图。 随后,我们使用图基数频率向量来近似 GNN 性能。
-
•
为了提供精细的 GNN 解释,我们通过说明 GNN 分类和图基数频率之间的关系来识别需要不同分类规则的图组。 通过指定生成解释的图表组,我们解决了缺乏组级解释的问题。
-
•
为了确保可靠的评估并探索潜在的替代解释,我们从事实和反事实推理过程中得出两个指标,以系统地评估每个图作为潜在解释子结构的相关性。
-
•
通过我们的方法,我们引入了 GNNNatomy,这是一种可视化分析系统,旨在支持所需粒度的子结构解释的交互式生成和评估。
1 背景
这项工作采用 graphlet 来解释图神经网络在图级分类任务中的行为。 在本节中,我们提供有关这两种技术的简明背景信息。
1.1 图谱和图谱频率
Graphlet 是小型连通非同构图[20, 4]。 给定图基元中的特定数量的节点,则存在固定数量的图基元类型。 例如,我们在 Fig. 1 Graphlet 已用于图和网络的分析和可视化[25, 12]。
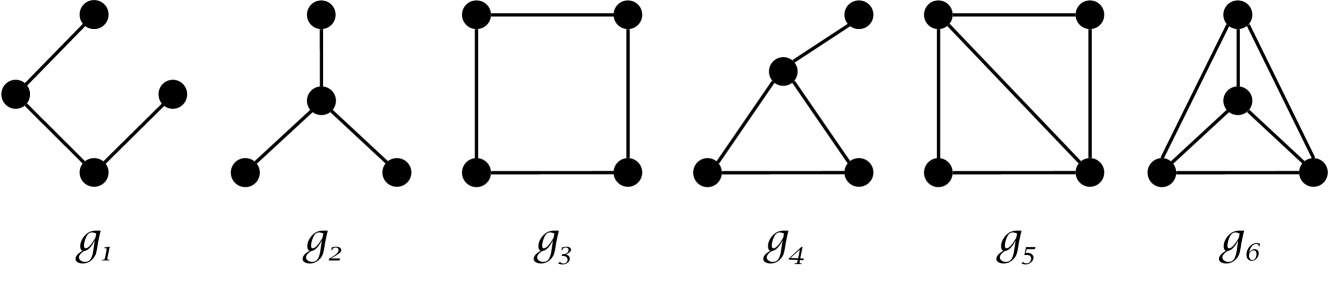
不同图基元类型的相对频率可用于表征图的拓扑结构。 对于 Fig. 1 中的 6 个小图类型 ,提取小图频率的 6D 向量 ,以表示每个图 中的小图分布:
| (1) |
在哪里
| (2) |
在实际计算图基数频率时,统计每个图基的准确出现次数太耗时,因为比较所有可能的连通子图是一个NP难题。 因此,我们在[23]中采用连通子图采样方法,计算从。对于任何图 ,我们将 3 节点图基数频率的 2D 向量、4 节点图基数频率的 6D 向量和 5 节点图基数频率的 21D 向量连接成单个 29D图基元表示。
1.2图神经网络
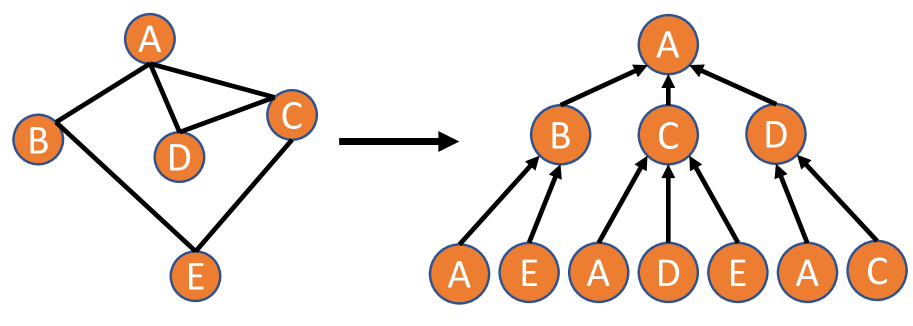
图神经网络 (GNN) 是一种机器学习模型,旨在对图结构数据进行操作,使它们能够提取图中固有的关系特征。 如图Fig. 2 以节点 为例,在第一层 中,GNN 聚合来自节点 的直接邻居(即节点 、 和 )。 然后,它将聚合消息与前一层 中 的节点表示相结合,以更新层 中 的节点表示>。 对每个后续层 中的每个节点重复此过程,在此示例中为 。 学习到的节点表示/嵌入用作在 GNN 中执行各种下游任务的结构特征,包括节点分类、边缘预测或图分类。 在节点分类任务中,节点表示用作分类器的输入,从而能够预测相应的节点标签。 在图分类任务中,所有节点的嵌入被聚合成单个图嵌入,该图嵌入作为下游分类器的输入以预测整体图标签。
2相关作品
可解释的图神经网络(GNN)领域仍处于发展的早期阶段,探索该领域的工作相对较少。 尽管如此,受到解释计算机视觉模型成功的启发,研究人员从不同的角度研究了可解释的 GNN。 在本节中,我们概述了以前的方法以及剩余的局限性和挑战。 随后,我们讨论有助于解释 GNN 的视觉分析工作。 最后,我们回顾一下用于评估 GNN 解释的常用指标。
2.1 子图解释
现有的 GNN 解释工作致力于通过查明显着影响 GNN 分类或预测的子图来阐明 GNN 性能。 基于扰动的方法,例如[33,37,6,22,28]中介绍的方法,利用经过训练的生成器来生成作为扰动应用于输入图的掩模(例如,节点或边缘掩模)。 目标是以保留重要结构信息的方式扰动图,从而保留与原始图类似的 GNN 预测。 然而,由于软掩模,这些方法经常面临潜在的偏差,软掩模会产生 0 到 1 之间的连续值,使得生成的解释难以解释。 相反,基于代理的方法[9,38,34,26]利用可解释的代理模型,使用从输入图导出的局部邻近数据来近似 GNN 预测。 尽管具有可解释性,但定义图形的相邻数据仍然是一个挑战。 相邻空间应该更容易理解并代表原始离散图,其中包含结构信息。 因此,找到图的此类相邻数据并非易事。 然而,这些方法通常会产生一个特定的子图作为解释,而在实践中,通常需要识别影响 GNN 行为的一般子结构。 例如,确定是环结构导致分子具有诱变性,比仅仅识别包含环的子图作为解释更有用。 此外,受生成子图解释设计的限制,先前的文献对潜在替代解释的探索有限。 可能存在与解释具有相似拓扑的子图,但没有充分理由说明为什么它们不如解释性子图重要。 从本质上讲,提供子结构解释而不是子图解释至关重要,并允许在确定最具解释性的子结构之前探索不同的子结构。
2.2 实例/模型级说明
Yuan 等人[36]进行的分类调查将 GNN 解释方法分类为模型级(阐明 GNN 的全局行为)或实例级(生成针对每个图实例的解释)。 虽然大多数现有的 GNN 解释工作都集中在解释为什么 GNN 对单个图实例进行预测或分类,如 Sec. 2.1,仅实例解释不足以提供对 GNN 行为的全面理解。 考虑到训练数据集中存在大量图实例,从单个实例解释中得出全局理解是不可行的。 相反,已经提出了几种模型级方法。 仅举几例,Xuanyuan 等人[31]将 GNN 中的神经元视为能够跨多个实例进行解释和泛化的单独概念检测器。 PGExplainer [17] 学习参数化模型来评估输入空间中每条边的重要性。 XGNN [35] 学习一个图生成器,它提供一组最大化目标预测的图,包含与 GNN 全局行为相关的不同重要图模式。 然而,虽然大多数现有的模型级方法旨在解释同一类的整个数据集或图表中的 GNN 行为,但它们通常缺乏粒度。 例如,在分子致突变性的分类中,虽然在某些图中单独的 6 原子碳环可能表明致突变性,但其他图中可能也需要 的存在。 这使得实例级或模型级的解释都不够。 因此,为了实现灵活的解释粒度,识别需要不同解释的图形组并确定每个图形的有效解释子结构至关重要。
2.3 解释 GNN 的视觉分析
根据最近的一项调查[13],在可解释的 GNN 中几乎没有进行视觉分析工作。 我们讨论了几种专用于 GNN 模型评估、诊断和特定领域解释的方法。 Liu等人[15]提出了一种交互式系统,将节点嵌入与拓扑邻域和节点特征连接起来以进行模型评估。 此外,开发 GNNLens [10] 是为了使用实例与其邻居之间的指标和相关性来解释和诊断预测结果。 然而,这些工作中开发的拓扑相关性和度量仅考虑 1 跳邻居,并专注于解释图中节点的预测。 Wang 等人[27]设计了一个药物再利用可视化分析系统,该系统使用GraphMask[22]提取领域专家可以理解的关键元路径。 与我们的担忧类似,这项工作也强调了领域专家需要以所需的粒度为 GNN 生成解释。 尽管如此,他们的可视化设计选择在很大程度上取决于领域偏好,这阻碍了它们对其他图数据集和 GNN 架构的适用性。
2.4 GNN解释评估指标
评估对于确保生成的解释的有效性是必要的。 某些指标,例如准确性(F1 或 ROC-AUC 分数)[33, 21],需要基本事实主题进行计算,并且通常用于评估合成图数据集的解释。 保真度 [19, 8] 指的是这样一个概念:如果删除适当的解释,将会改变 GNN 的预测。 稀疏性[19]涉及这样的想法:解释应该紧凑,并且在删除时对原始图的节点大小和边密度的影响最小。 基于这两个测量概念,可以得出各种指标[1, 16]。 然而,在评估生成的解释子结构的保真度时,基于移除的方法经常会遇到分布外 (OOD) 场景[7,14,18,29]的问题。 尽管人们努力通过新兴的基于生成的方法来缓解 OOD 问题,但它们仍然存在与原始模型行为 [5, 30] 的偏差和偏差。 其他一些著作根据推理过程来评估他们的解释,区分事实解释和反事实解释。 事实解释被认为是导致相同预测的充分子结构,而反事实解释则被视为必要子结构,一旦删除,就会改变预测。 通常导出的指标包括充分性和必要性的概率[24, 2]。 充分性衡量的是事实解释子结构单独维持 GNN 预测的图的百分比,而必要性衡量的是反事实解释子结构(如果删除)会改变 GNN 预测的图的百分比。 尽管如此,仍然没有评估 GNN 解释和解决 OOD 和模型行为偏差等其他问题的标准格式。
3方法论
如Sec. 2 本节介绍我们如何应对这些挑战。
3.1 图谱频率:拓扑总结
鉴于阐明 GNN 中图结构的基本作用,而不是阐明节点/边缘特征,后者更符合非图数据的方法,因此这项工作强调辨别子结构的重要性。
如Sec. 1.1,我们的方法利用连接的非同构小图或图基元作为构建 GNN 解释的基本元素。 通过计算图中每个图基元的频率,我们得出了表示为向量的拓扑摘要。 此汇总是通过使用 节点图集(特别是 )来实现的。 以为例,我们采用[23]中详细介绍的高效采样方法从原始图中提取5节点连通子图。 对于每个采样的子图,我们确定它们与 21 个不同的 5 节点图的每个的同构。 图中每个 5 节点图基元的频率通过同构实例与总采样子图的比率来量化。 此过程类似地应用于 和 ,从而能够跨不同图基尺寸进行全面的拓扑表征。 最终,我们通过连接分别从 3、4 和 5 节点图基数的频率得出的 2D、6D 和 21D 拓扑摘要来编译 29 维 (29D) 向量。
利用图基作为解释的基本元素可以从几个方面增强可解释的 GNN 方法:首先,拓扑概括的过程普遍适用于任何图数据。 正如 Sec. 2.1 所回顾的那样,鉴于当前的 GNN 解释经常采用子图的形式,因此建立一个用于构建解释的一致框架是有益的。 这种一致性确保了解释性子结构和生成的解释之间的唯一映射,从而防止因轻微的结构差异而产生评估困难。 其次,由于其紧凑的尺寸,使用图基作为解释工具本质上是直观的。 这种简单性使得更容易理解每个子结构并将其与其他图基图区分开来,从而有助于更清晰、更直接的解释。 最后,从图谱中得出的解释提供了对 GNN 模型可能用于进行预测的一般子结构的见解。 现有方法倾向于将原始图中的特定子图确定为影响 GNN 预测的关键贡献者。 然而,在许多数据集中,在塑造 GNN 行为方面发挥关键作用的是子结构,而不是图的任何特定部分。 例如,是6原子碳环结构导致分子图具有诱变性,而不是包含碳环的特定子图。 我们的方法提取了 GNN 认为重要的一般子结构模式,从而提供了对驱动模型预测的更广泛的理解。
3.2图神经网络:图级分类
我们的方法利用 graphlet 为图级分类任务中的 GNN 提供直观的子结构解释。 图级分类任务涉及 GNN 预测图标签的潜在类别的概率分布。 这意味着 GNN 模型将整个图作为输入进行评估,并根据图数据中学习到的结构特征输出有关该图属于哪个类别或类别的预测。 典型的方法是 GNN 首先学习为每个图生成全面的嵌入。 这种嵌入封装了图的基本结构信息。 随后,该图嵌入用作简单线性层的输入,该线性层用于将嵌入的维数减少到潜在类的数量。 在此输出上应用 softmax 函数会产生一个概率分布,其中每个概率位于 0 和 1 之间,并且所有这些概率的总和等于 1。 使用简单的线性层将图嵌入降维为概率的基本原理是基于这样的前提:如果 GNN 有效地学习了嵌入,它应该从输入图中保留足够的结构信息以促进准确的预测。 因此,一个简单的线性变换就足以完成这一关键步骤,将丰富的、学习的嵌入转化为可理解的类概率。
我们坚持这种传统方法来训练我们的 GNN 模型,不仅确保准确的分类概率,而且还能保留图嵌入中的关键拓扑特征。 我们使用真实数据集和合成数据集在图分类任务上训练图卷积网络 (GCN) [11]。 优先考虑结构信息的聚合,我们丢弃任何节点或边缘属性,而是选择节点度的 one-hot 编码作为每个节点的初始向量。 我们的 GCN 架构由四层组成,后面是一个全连接层。 四个隐藏层的输出(每个隐藏层的维数均为 20)被连接起来形成节点嵌入,然后将其聚合为 80 维的图嵌入。 使用 4 层架构的决定与我们对 graphlet 的使用密切相关。 鉴于图基团的最大直径为 4(具体来说,5 节点非循环图基团),因此有必要在我们的 GNN 中使用最多 4 层。 这使得模型能够聚合来自最多 4 跳的节点的信息,并有效捕获图中最多 5 个节点的子结构。 此外,通过连接每个隐藏层的输出以形成图嵌入,我们促进了从图嵌入中的较低跳邻居捕获的子结构的表达。 这有助于减轻对 5 节点结构的任何偏好偏差,这种结构可能在网络的最后一层占主导地位。 因此,我们的方法确保了图中各种子结构的更平衡的表示。
3.3 代理模型:GNN 性能近似
为了提高解释的可解释性,我们建议使用代理模型,通过利用从输入图导出的更简单的邻近数据来近似 GNN 的行为。 具体来说,我们开发了一种机器学习(ML)编码器-解码器架构,旨在基于图频率向量重建 GNN 生成的图嵌入。 值得注意的是,尽管使用连接的图来近似 GNN 行为可能无法捕获断开的拓扑信息,但如果存在的话,这种近似与 GNN 的聚合机制一致,GNN 从直接邻居收集信息。
对于每个图,我们利用其 29 维图基数频率向量作为编码器的输入。 通过两个 20 维隐藏层,编码器输出一个 10 维瓶颈潜在向量。 然后将该 10 维潜在向量输入线性层和 softmax 函数,将维度从 10 概率降低到 2D 概率。 编码器由经过训练的 GCN 使用 L2 损失产生的概率输出进行监督,旨在重建 GCN 的性能。 解码器将10维潜在向量作为输入。 通过来自编码器的具有对称残差连接的两个20维隐藏层,它输出80维重构图嵌入。 然后,将这种重建的图嵌入输入到与 GCN 一起训练的冻结分类模型中,将 80 维嵌入转换为 2 维 softmax 概率。 解码器的训练由两个损失函数引导:图嵌入重建损失和概率重建损失(即均方误差/L2损失)。
我们通过交替训练编码器和解码器来训练编码器-解码器模型。 具体来说,我们训练编码器一步,然后冻结其权重以获得潜在向量,该向量被馈送到解码器中。 在更新一步的解码器权重后,我们冻结其权重并开始编码器的下一个训练步骤。 此训练方案确保编码器生成保留与 GCN 类似结构信息的潜在向量。 然后可以将这些潜在向量重建为相似的图嵌入,从而产生相似的分类概率。 此外,我们的架构本质上降低了过度拟合的可能性。 通过在编码器中将图基信息减少为10维潜在向量,我们创建了一个瓶颈,迫使模型学习紧凑且通用的结构表示,从而能够在解码器中成功重建。 这个瓶颈还阻止模型简单地记住图基元频率向量和图嵌入之间的映射,因为大多数原始图基元信息(即编码器的输入)被大大减少。
此外,我们的方法解决了为图定义合适的相邻数据空间的挑战,如Sec. 2.1。 通过直接从原始图中提取图基数频率,我们确保这些频率准确地表示相对于原始数据的邻近空间。 此外,现有的方法主要集中于识别局部相邻图。 相反,图基数频率向量充当每个图的全面结构摘要,适用于各种图类型。 因此,我们构建邻近空间的方法并不局限于局部表征,而是扩展到全局范围,增强了整体的综合性。
3.4事实和反事实解释评估
为了探索不同的图基子结构并制定假设的解释,我们开发了一个可视化分析系统,在Sec. 4。 通过检查 GNN 分类和图基数频率之间的关系,用户选择特定的图基数作为他们的假设解释。 随后,我们采用两种推理过程——事实和反事实——来评估这种解释的有效性。 例如,如果假设的解释是 ,它必须足以有助于 GNN 维持其当前分类的能力,才能在事实推理过程中被视为成功。 为了量化这种充分性,我们采用斯皮尔曼相关系数。 具体来说,我们分析了 GNN 分类置信度分数与用户感兴趣的所有图表中 的频率之间的相关性。 该相关系数表示 的频率与 GNN 分类概率中观察到的趋势一致的程度。 高相关系数表明 的存在或不存在会显着影响 GNN 的分类,支持其作为有意义的事实解释因素的作用。
成功的反事实解释需要证明 GNN 保留其当前分类的必要性。 这意味着删除解释性图谱应该会显着改变 GNN 的分类置信度。 为了从原始图中删除子结构,我们在图基数频率向量中引入扰动作为代理模型的输入,如Sec. 3.3。 然后我们观察这些扰动如何影响分类结果。 具体来说,我们使用经过训练的代理模型对每个图进行两次推理运行。 第一次运行采用原始的、未扰动的图基数频率向量作为输入,从代理模型获得分类置信度。 鉴于代理模型仅近似 GNN 的行为,因此初始运行对于建立基线比较标准至关重要。 第二次运行涉及输入扰动的图基数频率向量以评估其对代理模型分类置信度的影响。 扰动涉及将目标图基的频率设置为零。
为了准确地解释不同大小的图基元之间的相互依赖性,例如 4 节点和 5 节点图基元之间的相互依赖性,我们的方法仔细考虑了这些子结构的层次性质。 例如,4节点星形图是5节点星形图的子图。 这种关系需要在扰动期间调整它们的频率。 考虑扰动针对 4 节点星形图的情况。 将其频率设置为零后,必须将任何包含图基元(例如 5 节点星形)的频率也调整为零。 相反,当针对5节点星形图进行扰动时(即将5节点星形图的频率设置为零),不仅需要调整4节点星形图的频率,还需要调整其他4节点星形图的频率。节点 graphlet 相互依赖于 5 节点星。 这种调整是必要的,因为可以通过向任何相关 4 节点图基添加边和节点来形成 5 节点星形。 为了计算这种调整,我们对相关 4 节点图基团的频率使用了 softmax 函数。 该函数生成一个 softmaxed 频率向量,提供每个 4 节点相关图基对 5 节点星形图基的形成贡献的估计。 随后,对于每个相关 4 节点图基团,我们从中减去由其 softmaxed 频率加权的 5 节点星形图基团的频率。 该调整过程应用于所有相互依赖的图基元,检索并校准从 5 节点到 4 节点的依赖图基元的频率,并递归地从 4 节点到 3 节点图基元。
在向图基数频率向量引入扰动(即目标图基数去除)后,我们通过计算两次推理运行之间每个图的 L1 距离绝对值之和来比较去除前后的分类置信度。 高 L1 距离表明所选图基元作为关键子结构,极大地影响 GNN 的分类。 此外,我们利用完整的编码器-解码器模型输出的置信度分数来最初将图基团频率向量投影到与 GCN 相同的图嵌入空间。 这种方法减轻了计算两个置信度分数之间的 L1 距离时代理模型和 GCN 之间的性能差异所产生的影响。 此外,我们通过调整图基数频率向量来扰动原始图的策略,加上图基数相互依赖性的识别,解决了分布外(OOD)的挑战。 当删除子图导致残差结构偏离原始图的分布时,就会出现 OOD 问题,通常会由于这些非流形输入而导致分类不准确。 使用原始图的结构摘要(即图基元频率向量)作为比较基线可确保代理模型的行为一致。 通过考虑扰动期间图基之间的相互依赖性,我们增强了扰动图的真实性。
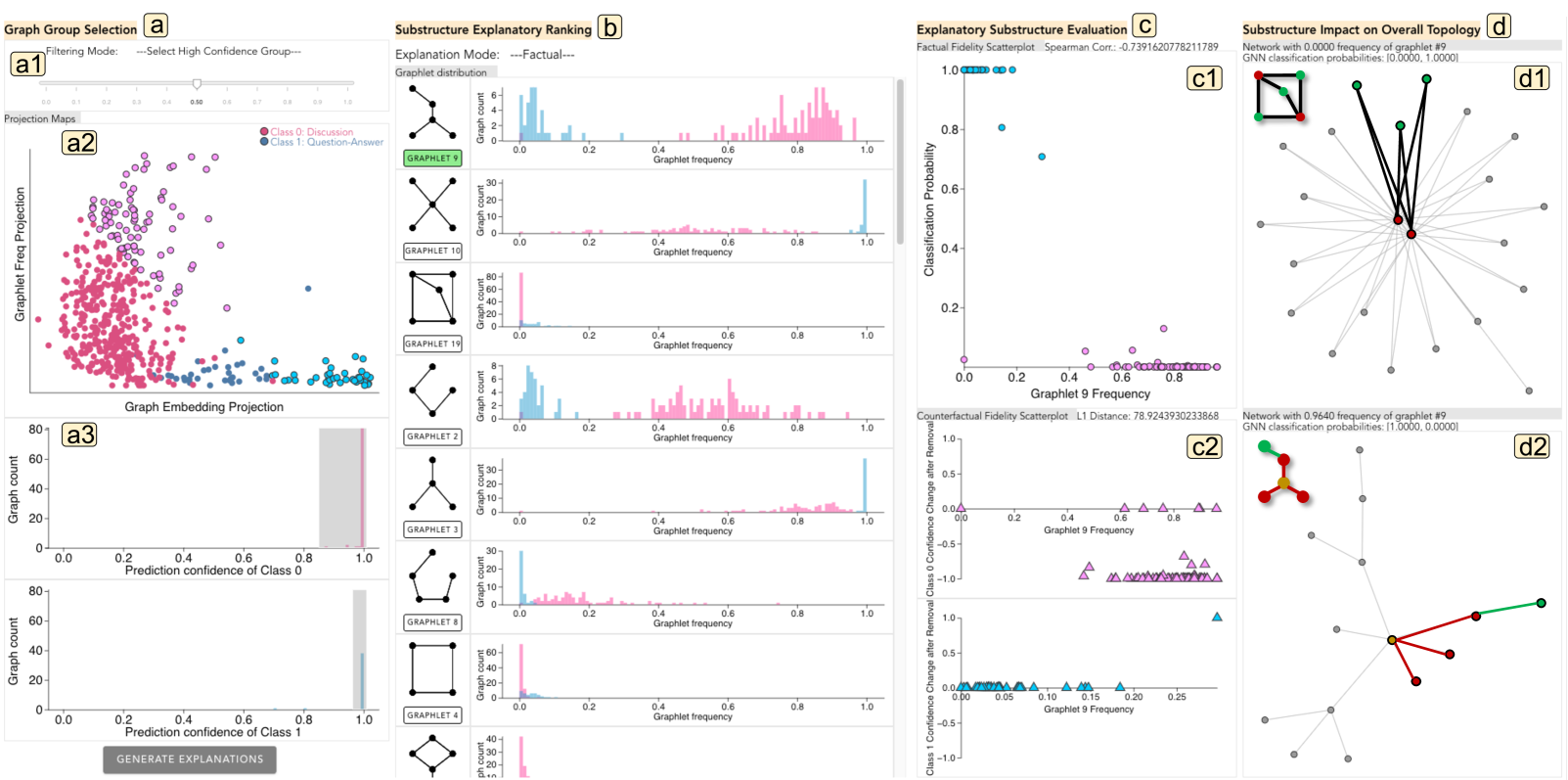
4 GNNNatomy 可视化分析
我们的可视化分析系统是交互式开发和解释评估的关键工具。 通过使用图基作为解释元素,评估指标不仅限于比较不同的解释方法,还包括检查每个子结构对 GNN 分类的贡献。 通常,现有的解释器利用通用指标进行评估,建立基线以根据所使用的指标识别最有效的方法。 然而,这种方法缺乏指标来告知用户基线本身是否足够稳健。 为了解决这一差距,我们的系统在解释制定过程中集成了一个额外的验证层。 这使用户能够仔细检查所有子结构,评估它们与 GNN 分类的相关性,并通过我们的视觉分析系统提供的定量和定性视觉辅助工具确定它们作为解释因素的潜力。
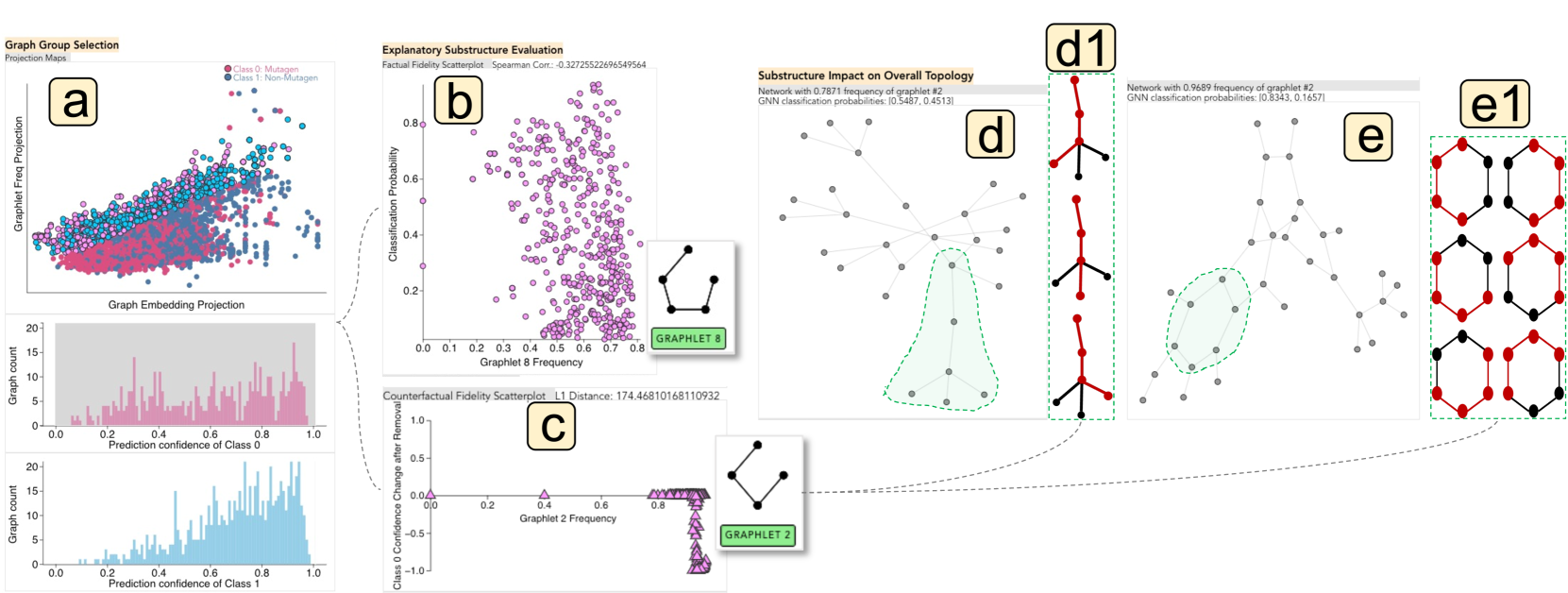
该系统由四个柱组成,可促进 GNNNatomy 的工作流程。 首先,在图组选择列中,投影图可视化图基数频率与GNN分类之间的关系,帮助用户识别感兴趣的图组。 其次,子结构解释排名列通过为每个图元提供按类别的图元分布来帮助创建解释性假设。 接下来,在解释性子结构评估列中,可以通过保真度散点图的支持来评估假设的有效性,该散点图提供了对充分性和必要性的视觉和定量见解的假设。 最后,为了演示子结构对图拓扑的整体影响,子结构对整体拓扑的影响列中提供了两个网络可视化。 值得注意的是,在该接口中,图所属类别的分类概率输出被称为“置信度”。 相反,的分类概率输出被称为“分类概率”。 例如,在讨论图中(即 ),如果 GCN 概率输出为 ,则其置信度得分为 ,分类概率为 。 在下面的段落中,我们将详细介绍这些视觉组件,突出显示它们传达的具体信息。
4.1 图组选择
如图Fig. 3 首先,合并了一个滑块,使用户能够根据他们的置信度分数过滤图表。 用户可以通过Fig. 3 剩下的图被投影到散点图上,如图Fig. 3 该投影图通过将图基数频率向量和图嵌入从高维空间投影到单个值来帮助用户辨别图基数频率向量和图嵌入之间的关联。 每个图的 x 轴值表示其图基数频率向量(即图基数频率投影)的第一主成分 (PC1),而 y 轴值编码 GNN 生成的图嵌入的 PC1(即图嵌入投影)。 在此散点图中,用户可以套索选择一组生成解释的图表,并用粉色和蓝色轮廓突出显示。 为了进一步完善选择,所选图形组被重新绘制成两个直方图,如 Fig. 3(a3)所示。 每个直方图都显示了置信度分数的图形分布,使用户能够通过刷牙选择不同类别的置信度分数的特定部分。 通过提供 GCN 分类和图基数频率之间的联系,本专栏能够在指定的粒度级别创建和评估 GNN 解释。
4.2子结构解释排名
4.3 解释性子结构评估
如图Fig. 3
4.4子结构对整体拓扑的影响
如图Fig. 3 在事实解释模式下,顶视图(即Fig. 3(d1))展示了所选图基元频率最低的图的结构。 该图是从所选图基元的频率通常较低的类别中选择的。 例如,如果图基数频率与分类概率之间存在负相关,则所选图基数频率较低的类为。 相反,底视图(即Fig. 3(d2))显示从具有通常较高频率的类别中选择的图基元的最高频率的图。 在负相关的情况下,该图将来自。
在反事实解释模式下,顶视图显示扰动后分类置信度变化最小的网络,而底视图显示分类变化最大的图扰乱后的信心。 通过比较代表性图的结构,用户可以将子结构的影响映射到整体拓扑,使他们能够推理不同类别的图的典型外观。
5案例研究
我们通过使用真实世界和合成图数据集的案例研究来展示 GNNNatomy 的功能。 除了使用我们的事实和反事实指标定量测量图基解释的有效性之外,我们还将我们的解释与 GNNExplainer [33] 生成的解释进行比较。 我们选择与 GNNExplainer 进行比较,因为它 (1) 识别了缺乏基本事实的数据集的重要主题,(2) 它的解释性子图已被广泛用作与大多数其他解释器进行比较的基线。 GNNExplainer 提出的定量评估指标侧重于特定子图与真实值的对齐情况,这不适用于 GNNAnatomy 生成的子结构解释。 因此,我们对 GNNanatomy 和 GNNExplainer 的解释进行定性比较。
5.1数据集
5.1.1 真实世界数据集
我们利用两个现实世界的图级二元分类数据集。 Reddit-Binary [32] 包含 2000 个图表,每个图表代表从 Reddit 中提取的一个讨论线程。 在这些图中,节点对应于参与线程的用户,而边表示用户评论之间的回复。 这些图是根据线程中观察到的用户交互的性质进行标记的。 具体来说,该数据集区分了两种类型的交互:问题-答案,从 subreddits r/IAmA 和 r/AskReddit 中提取,以及讨论,从 subreddits r/TrollXChromosomes 和 r/无神论。 致突变性 [3] 由 4337 个分子图组成,每个分子图根据其对革兰氏阴性菌鼠伤寒沙门氏菌的致突变作用进行标记。
5.1.2 合成数据集
为了构建具有真实主题的图数据集,我们从 Ying 等人[33]提出的方法中汲取灵感。 他们利用 Barabasi-Albert 随机图模型 (BA) 生成包含 300 个节点的基本图。 然后通过附加 80 个房屋图案来丰富该基本图。 GNN 的任务是跨四个类执行节点分类:房屋图案顶部、中间和底部部分内的节点,以及基本图本身中的节点。 鉴于我们的解释器旨在阐明图级分类任务中的 GNN 行为,我们使用图标签创建 BA-House。 我们使用 BA 模型生成 300 个基本图,每个基本图的随机节点数范围为 10 到 40。 随后,对于其中一半的基本图,我们附加了随机数量的房屋图案,范围从 2 到 10。 基本图的大小与附加房屋主题的数量之间的比率与[33]中使用的比率保持一致(即基本图中的300个节点和80个附加房屋主题)。 然后,这 300 个合成图被标记为两类:没有任何附加房屋图案的和带有附加房屋图案的。 考虑到数据集的设计,假设对 GNN 分类至关重要的主要子结构将是附加主题,即房屋子结构。
5.2 研究 1:Reddit 二进制
实验设置。 由于与图基数频率计算相关的计算成本,我们使用少于 100 个节点的图来训练 GCN 和代理模型。 在剩下的 554 张图中,包括 101 张问答(QA)类图和 453 张讨论类图,GCN 模型实现了 的分类精度(即超过 0.5 的置信度分数) ,而代理模型输出的分类概率与 GCN 概率输出表现出 的余弦相似度。
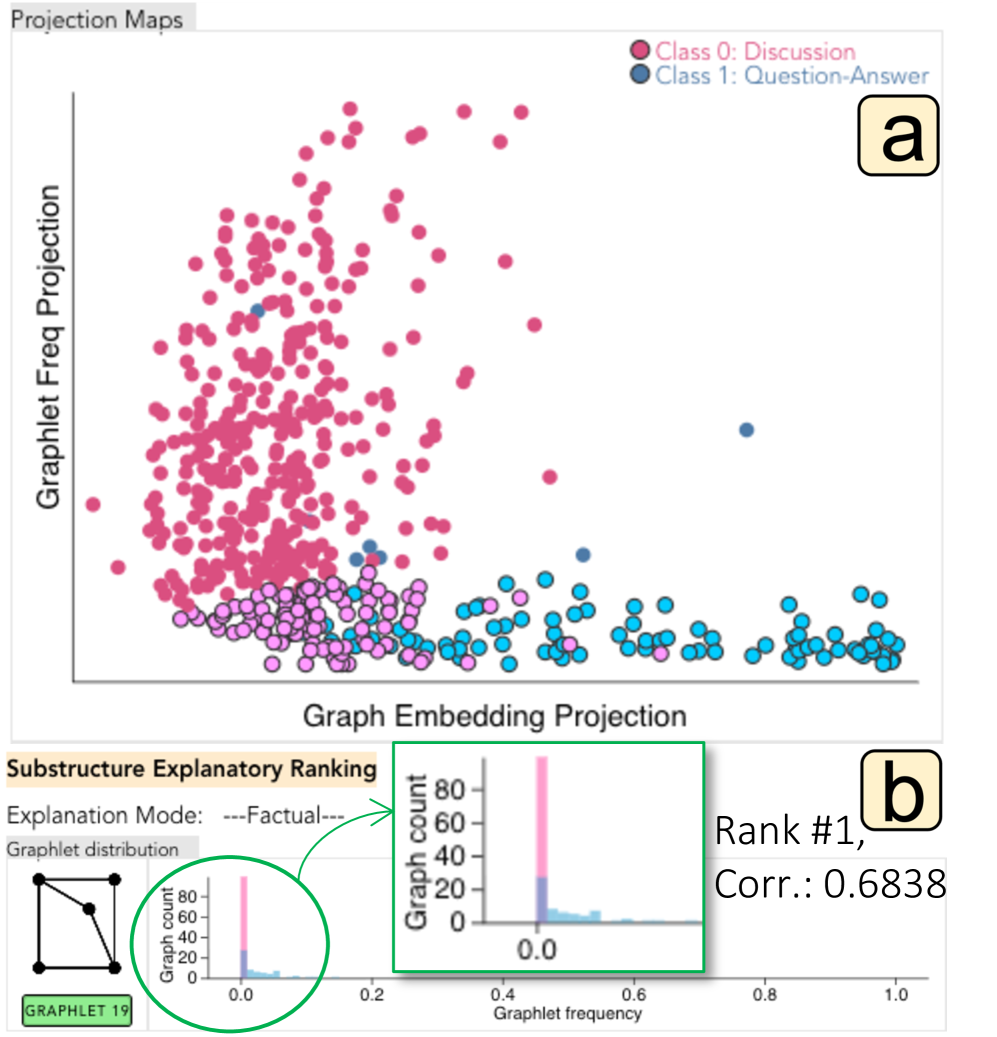
团体层面的解释。 如图Fig. 3 相比之下,问题-答案 (QA) 图的图基团频率投影仍然紧密聚集在 y 轴的底部,表明 QA 图之间的拓扑更加一致。 大多数来自不同类别的图都可以沿 x 轴分离(即图嵌入投影),这表明即使对于那些位于底部的跨类别具有相似拓扑的图,GCN 也成功地捕获了可区分的结构特征。 我们进一步探索有助于 GCN 进行此类分类的能力的潜在子结构。
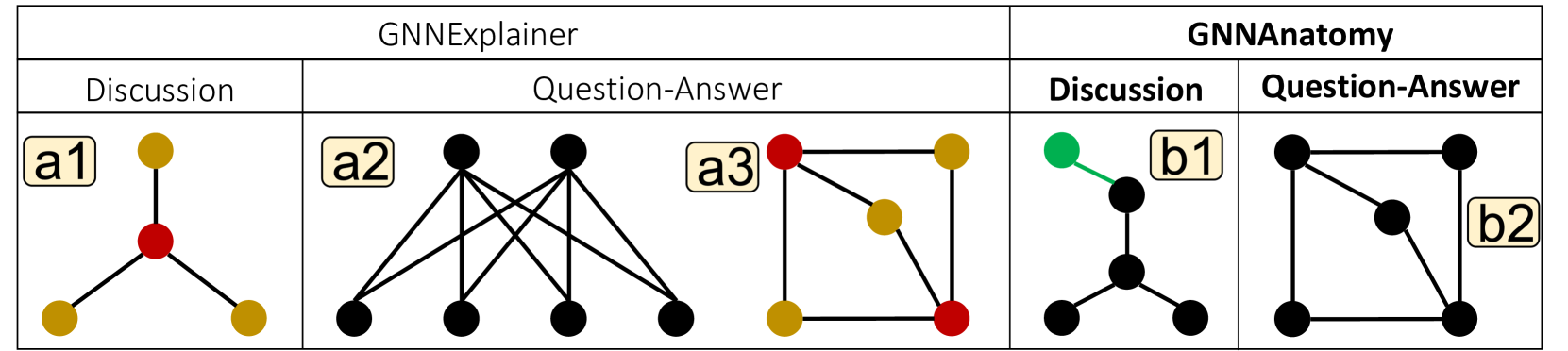
我们选择一组具有不同拓扑和图嵌入(即分离的小图频率投影和图嵌入投影)的图,如 Fig. 3(a2)所示。 此选择旨在识别与 GCN 行为相关的两个类之间的显着子结构差异。 在Fig. 3(b)所示,事实解释模式中排名最高的图基的分布表现出跨类的清晰分离。 这表明仅根据 的频率对图进行分类可能会达到与 GCN 相同的高分类精度,即 。 Fig. 3(c1)中描述的事实保真度散点图验证了强烈的负相关(Spearman correlation corr.:)在的频率和分类概率之间。 此外,在Fig. 3(c2),确认了维持当前GCN分类的必要性。 删除 后,讨论图的置信度分数会降低,而 频率异常高的 QA 图的置信度分数则会增加。 这些变化表明,当拓扑中不存在 时,GCN 倾向于将大多数图分类为 QA 图,从而验证 的解释力。 在Fig. 3(d1, d2),具有最低和最高频率 的图的可视化传达了两个类的拓扑特征:QA 图(Fig. 3) >(d1)) 往往有多个集中的个体与大多数其他人互动,而讨论图 (Fig. 3(d2)) 通常以分支讨论为特征。 Fig. 3(d2) 和 Reddit 二进制数据集的上下文表明 捕获了典型 QA 图中不存在的常见分支讨论(Fig. 3( d1))。
对投影图的进一步研究促使我们研究另一组图形,如 Fig. 4(a)所示。 虽然 GCN 模型通常区分不同类别的图,但它们看起来沿着 x 轴分散。 出现这种分散的原因是一些讨论图与 y 轴底部的 QA 图共享相似的拓扑。 因此,捕获显着的结构差异可能不足以让 GCN 进行有效的分类,它还需要揭示类之间微妙的拓扑差异。 这些微妙的结构差异被编码在 GCN 学习的图嵌入中,这进一步分散了各自集群中每个类的图的投影。 因此,我们专注于选择具有相似拓扑的图来识别这些有助于 GCN 分类有效性的微妙结构差异。 如图Fig. 4(b)所示,排名靠前的的频率与GCN分类概率相关,相关系数为。 此外,在前一组图中观察到的 QA 图的典型拓扑特征由 封装,如图 Fig. 3 这表明了 GCN 的推理过程:虽然讨论图 () 的共同结构特征足以区分大多数图,但在对具有相似拓扑的图进行分类时,QA 图的共同结构特征成为下一个GCN 所依赖的指标。
总之,很明显,GCN 使用不同的子结构来对不同的图组进行分类。 GNNanatomy 不仅可以帮助用户识别这些组,还可以根据我们的事实和反事实指标对 graphlet 的相关性进行排名。 通过交互评估潜在的解释,用户可以为所选组制定令人满意的解释子结构。
定性评价。 如图Fig. 5(a1, b1),与 GNNExplainer 提出的地面实况主题相比,我们对讨论类的图形解释包含了一个额外的边和节点,以绿色突出显示。 这种差异表明我们的 graphlet 解释捕获了分支子结构的存在,这是讨论图的独特特征,但 GNNExplainer 的主题并未解决。 值得注意的是,GNNExplainer 提出的讨论主题(Fig. 5(a1))不仅在典型的讨论图中普遍存在,而且在典型的 QA 图中也很普遍。 在Fig. 3 事实上,代表性 QA 图中的这种重复出现的模式被识别为 GNNExplainer 提出的讨论主题(Fig. 5(a1)),这一事实强调了他们的方法的解释能力有限。 相反,我们对这两个类的解释(Fig. 5(b1, b2))描绘了不同的拓扑。 如图Fig. 3(d1, d2),我们的讨论解释(Fig. 5(b1))在典型的 QA 图中找不到(Fig. 3(d1) )),而我们的 QA 解释(Fig. 5(b2))不会出现在典型的讨论图中(Fig. 3(d2))。 此外,我们的解释是相互排斥的,表明分类为Fig. 5(b1)不能归类为Fig. 5(b2)基于这5个节点之间的边。 这突出了我们的方法捕获的独特子结构。 对于 QA 类,GNNExplainer 提出了一个循环子结构作为 QA 主题(Fig. 5(a2)),它可以翻译成等效的图基元表达式(Fig. 5) (a3))。 相比之下,GNNNatomy 直接以系统格式捕获相同的子结构解释(Fig. 5(b2)),无需从重复模式中进行推断。 同样重要的是要认识到,仅仅呈现每个类的拓扑特征并不能完全阐明 GNN 的行为。 正如本研究所示,不同的标准适用于不同的图表组。 GNNanatomy 可以灵活地识别最能解释指定粒度的 GNN 行为的组和子结构。
5.3研究 2:MUTAG
实验设置。 我们使用节点度的 one-hot 编码作为每个节点的初始向量来训练 GCN,丢弃该数据集中提供的任何节点和边属性。 利用纯拓扑特征,GCN 模型实现了 的分类精度,而代理模型与 GCN 概率输出的余弦相似度为 。
团体层面的解释。 在分子生物学文献中,已经确定了与致突变性相关的某些子结构,但对非诱变剂特异性子结构的讨论很有限。 因此,我们的研究旨在提取 GCN 使用的特征来将图分类为诱变图。 在Fig. 6 此选择旨在识别诱变图中导致图嵌入投影差异的结构差异(即 y 轴偏差)。
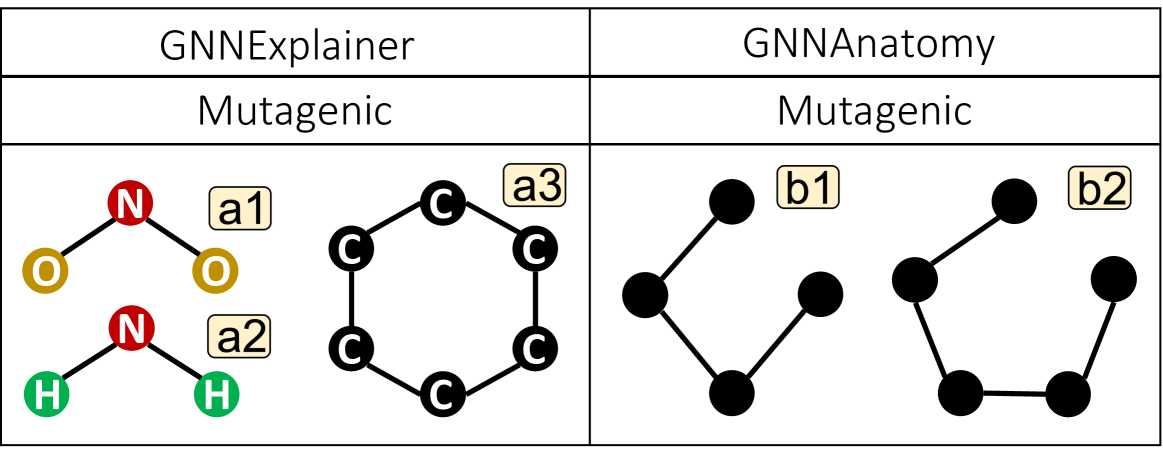
事实解释模式下排名靠前的图基团都是非循环子结构:和,如图Fig. 6 在Fig. 6(b)所示,的频率与分类概率之间的呈中度负相关,表明的频率较高的图> 有更高的机会被归类为诱变剂。 为了研究这些无环图基存在的必要性,将图分类为诱变剂,我们观察了删除 和 对置信度得分的影响。 由于和之间的相互依赖关系,选择删除会自动删除,如Sec. 3.4。 在Fig. 6 这验证了 和 的必要性,因为当拓扑中不存在这些子结构时,GCN 将图分类为诱变剂的置信度降低。
比较 Fig. 6(d)和 Fig. 6(e),可以明显看出,6 节点环形结构的存在是频率较高的 图所独有的,这表明两者之间存在关联。 为了验证这一观察结果,我们比较了可以从 6 节点非环子图和 6 节点环子图采样的 数量。 如图Fig. 6(d1, e1),我们观察到单环结构产生的 数量是非环结构的两倍。 此外,考虑到附加到环形结构的边缘,甚至可以采样更多的。 因此,GCN 将图分类为诱变剂时 和 存在的必要性可能源于 6 节点环子结构的存在。
总之,每个图数据集都可能包含 GNN 捕获的不同拓扑特征,这些特征可能很复杂且出乎意料。 GNNanatomy 提供了系统的方法和充足的视觉辅助工具来探索有助于与 GNN 分类相关的重要结构特征的基本子结构元素。
定性评价。 在Fig. 7(a1, a2, a3),GNNExplainer 提出了通常与致突变性相关的三种子结构:、 和 6 原子碳环。 然而,由于我们的方法专注于提取纯粹的结构重要性,因此我们不会直接将我们的解释与 和 进行比较,因为它们需要节点属性来指示它们的存在。 相反,我们将碳环视为简单的 6 节点环子结构进行比较。 正如Fig. 7
总之,GNNNatomy 探索了多种子结构,并使用可视化来建议 GNN 可用于分类的任何意外子结构。
5.4研究3:BA-House
实验设置。 GCN 经过训练,可以对 Barabasi-Albert 随机图模型 (BA) 生成的基本图是否附加房屋图案进行分类。 GCN 模型实现了 的分类精度,而代理模型与 GCN 概率输出的余弦相似度为 。
全局级别的解释。 由于 BA-House 数据集是合成的,并且附加的房屋主题是两个类之间已知的拓扑差异,因此我们的目标是研究 GCN 是否利用房屋主题来区分图。 我们选择了全部 300 个图来探索全局级别的解释图。
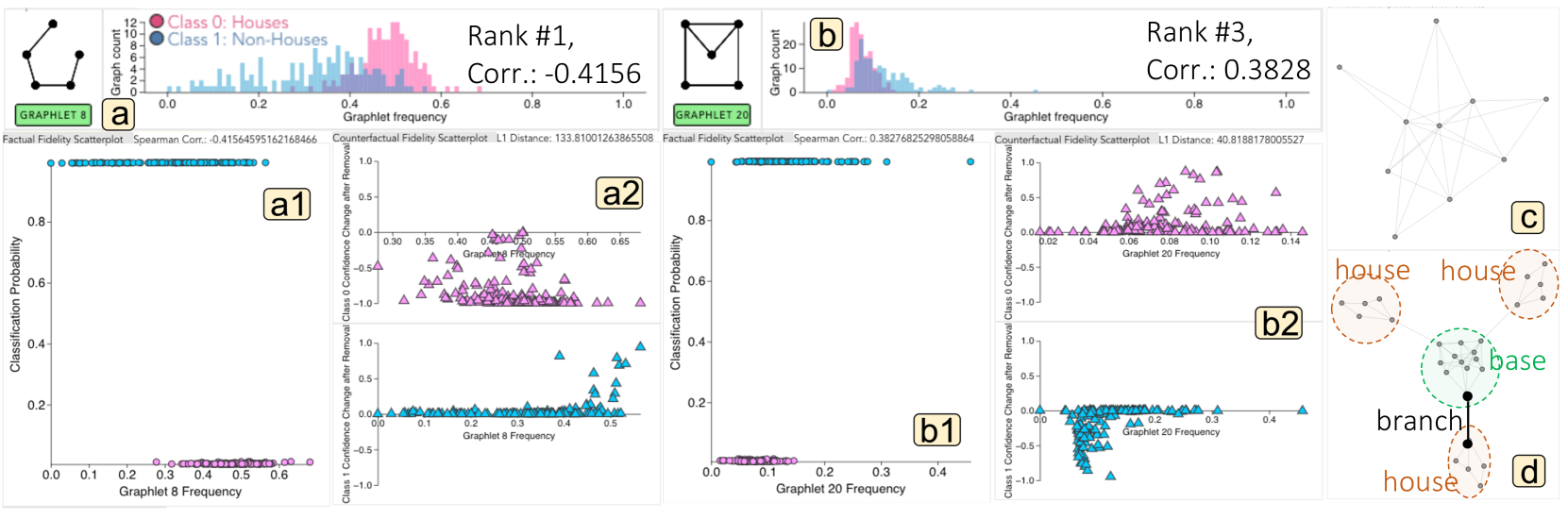
在Fig. 8(a), 排名第一,表明其与分类概率的相关性及其在 House 图中的出现率较高。 另外,在Fig. 8(a1),表明的频率与GCN分类概率呈负相关()。 这表明 频率较高的图被 GCN 分类为 House 图的机会较大。 此外,在Fig. 8(a2) 所示,删除 后,House 图的置信度分数下降,但 Non-House 图的置信度分数增加,强调了将图分类为 House 图时其存在的必要性。
研究Fig. 8(b) 所示,很明显,与带有附加房屋主题的图表相比,非房屋图表通常具有更高的房屋主题频率 ()。 另外,如图Fig. 8(b1),的频率与GCN分类概率呈正相关()。 令人惊讶的是,这意味着具有较高频率的 house 主题的图更有可能被 GCN 分类为非 House 图。 此外,如图Fig. 8
尽管房子主题确实证明了我们的假设的相关性,但它的影响似乎与我们的预期完全相反。 为了了解原因,我们检查整体图拓扑。 在Fig. 8 相反,House 图,如图 Fig. 8 如图Fig. 8(d)所示,分支边是房屋图具有普遍较低的房屋主题频率的根本原因。 每所附属房屋中只能采样一种房屋图案。 然而,将房屋连接到基础图的分支边允许计算图基数频率,以对涉及房屋和基础中的节点的附加 5 节点连接子图进行采样。 这些额外的子图样本不是房屋图案。 例如,当连接 3 个房屋时,与单个基本图相比,可以采样更多的 5 节点子图,但这些附加样本中只有 3 个是房屋主题。 我们通过计算附加房屋图案之前和之后房屋图基元的频率来验证我们的发现,这表明平均频率确实从 下降到 。
经过进一步推理,我们发现分支边缘也可能有助于成为排名最高的解释性子结构。 正如所讨论的,分支边允许跨附属房屋和基本图进行子图采样,从而增加对非循环图基团(即)进行采样的机会。 相反,由于非 House 图的高连通性,采样的 5 节点子图很少是非循环的。 总之,尽管我们根据已知的结构差异对 GCN 应该利用的内容进行了假设,但 GNNanatomy 可以通过支持可视化中提供的充足证据帮助我们识别真正的决定性因素。 这项研究还为使用我们的方法验证其他合成图数据集的假定地面真实主题铺平了道路。
定性评价。 我们假设,在附加房屋时,图基元采样机制自然会导致非循环子结构的频率更高,但会导致房屋图基团的频率较低。 这就提出了一个问题:图元采样机制是否准确反映了 GNN 行为,保证了两者结果的联系。
鉴于 GNN 聚合了每层中直接邻居的节点信息,如 Sec. 1.2,他们可以在 3 层架构中捕捉完整的房屋主题。 然而,分支边的存在使 GNN 能够聚合基本图和房屋主题的信息,这可能会阻碍 GCN 完全捕获任一组件中完整房屋拓扑的能力。 这种对邻居采样的影响反映了本研究中有关图基元采样的讨论。 本质上,在非房屋图中聚合信息会鼓励 GNN 对共同形成完整房屋主题的相邻节点进行采样。 因此,使用图基分布来描述 GNN 的行为可以表明它们的功能。
6 讨论和未来的工作
6.1 图谱频率计算的可扩展性
使用 3、4 和 5 节点图基元可确保子结构的多样化,同时保持图基元总数的可控性。 例如,在具有 94 个节点和 222 个边的图中,[23] 中提出的高效采样方法分别产生 1106、15113 和 172127 个采样的 3、4 和 5 节点子图。 为了计算每个图的每个图的频率,我们迭代这些样本,检查与目标图的同构性。 尝试从该子图池中进行随机采样,但发现会损害频率精度。 虽然此过程对于较大的网络可能非常耗时,但它是每个数据集的一次性操作。 使用图谱系统地生成和评估解释证明了所涉及的计算成本的合理性。 为了促进 GNNNatomy 与其他数据集的更有效使用,我们正在开发一个 graphlet 频率基准数据集。
6.2普遍性
其他 GNN 模型。 GNNNatomy 作为一种事后替代方法,利用经过训练的 GCN 生成的图嵌入和 softmax 概率。 这意味着它可以应用于任何能够为每个图生成图嵌入的 GNN,从而能够跨不同粒度级别解释其行为。
多类图分类任务。 尽管我们使用二元分类数据集展示了 GNNNatomy 的功能,但我们的方法可以扩展到多类分类任务。 从算法上来说,我们需要更改事实和反事实指标来计算单个类中所选图的相关性和 L1 距离。 这一调整将限制 GNNNatomy 的部分多功能性,但仍然可以允许系统地生成和评估解释性子结构。
节点分类任务。 虽然 GNNNatomy 主要是为图分类任务量身定制的,但其方法也可能适用于解释节点分类任务中的 GNN 行为。 例如,我们可以使用节点嵌入和节点分类概率,而不是利用图嵌入和图分类概率。 关于图基元频率,我们可以用特定图基元类型(例如 )中出现的节点相对于原始图中发现的所有 出现的频率来替换它。 这种方法将能够识别节点在图基表示上下文中参与整个图拓扑的情况。
具有五个以上节点的图案。 正如Sec. 5.3,考虑最多 5 个节点的 graphlet 的限制是它无法明确捕获具有超过 5 个节点的主题。 当用户期望 GNN 使用某些大主题时,可能会出现这种限制。 GNNNatomy 没有定制图基元的选择以包含这些预期的基序,而是展示了使用基本子结构元素隐式捕获这些基序的能力。 凭借充足的可视化支持,GNNNatomy 可以帮助用户在不受节点数量限制的情况下对解释性主题制定正确的推论。
6.3可扩展性
7结论
我们提出了一种新颖的 GNN 解释器,旨在促进对不同子结构的系统探索和评估,这些子结构解释了多个粒度级别的 GNN 行为。 我们的方法利用图来生成子结构解释,并集成事实和反事实推理逻辑来评估其有效性。 交互式和支持性的可视化被纳入其中,以简化制定可信解释的过程。 通过对跨越各个领域的真实世界和合成图数据集进行的案例研究,我们展示了 GNNanatomy 的功效,并将我们的解释质量与最先进的 GNN 解释器进行了比较。 在展示我们方法的多功能性和实用性的同时,我们概述了 GNNanatomy 潜在扩展的未来研究方向。
参考
- [1] M. Bajaj, L. Chu, Z. Y. Xue, J. Pei, L. Wang, P. C.-H. Lam, and Y. Zhang. Robust counterfactual explanations on graph neural networks. Advances in Neural Information Processing Systems, 34:5644–5655, 2021.
- [2] Z. Chen, F. Silvestri, J. Wang, Y. Zhang, Z. Huang, H. Ahn, and G. Tolomei. Grease: Generate factual and counterfactual explanations for gnn-based recommendations. arXiv preprint arXiv:2208.04222, 2022.
- [3] A. K. Debnath, R. L. Lopez de Compadre, G. Debnath, A. J. Shusterman, and C. Hansch. Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. correlation with molecular orbital energies and hydrophobicity. Journal of medicinal chemistry, 34(2):786–797, 1991.
- [4] K. Faust. A puzzle concerning triads in social networks: Graph constraints and the triad census. Social Networks, 32(3):221–233, 2010.
- [5] C. Frye, D. de Mijolla, T. Begley, L. Cowton, M. Stanley, and I. Feige. Shapley explainability on the data manifold. In International Conference on Learning Representations, 2020.
- [6] T. Funke, M. Khosla, and A. Anand. Hard masking for explaining graph neural networks. 2020.
- [7] G. Hooker and L. Mentch. Please stop permuting features: An explanation and alternatives. arXiv preprint arXiv:1905.03151, 2, 2019.
- [8] S. Hooker, D. Erhan, P.-J. Kindermans, and B. Kim. A benchmark for interpretability methods in deep neural networks. Advances in neural information processing systems, 32, 2019.
- [9] Q. Huang, M. Yamada, Y. Tian, D. Singh, and Y. Chang. Graphlime: Local interpretable model explanations for graph neural networks. IEEE Transactions on Knowledge and Data Engineering, 2022.
- [10] Z. Jin, Y. Wang, Q. Wang, Y. Ming, T. Ma, and H. Qu. Gnnlens: A visual analytics approach for prediction error diagnosis of graph neural networks. IEEE Transactions on Visualization and Computer Graphics, 2022.
- [11] T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- [12] O. Kwon, T. Crnovrsanin, and K. Ma. What would a graph look like in this layout? A machine learning approach to large graph visualization. IEEE Trans. Vis. Comput. Graph., 24(1):478–488, 2018. doi: 10 . 1109/TVCG . 2017 . 2743858
- [13] B. La Rosa, G. Blasilli, R. Bourqui, D. Auber, G. Santucci, R. Capobianco, E. Bertini, R. Giot, and M. Angelini. State of the art of visual analytics for explainable deep learning. In Computer Graphics Forum, vol. 42, pp. 319–355. Wiley Online Library, 2023.
- [14] H. Li, X. Wang, Z. Zhang, and W. Zhu. Out-of-distribution generalization on graphs: A survey. arXiv preprint arXiv:2202.07987, 2022.
- [15] Z. Liu, Y. Wang, J. Bernard, and T. Munzner. Visualizing graph neural networks with corgie: Corresponding a graph to its embedding. IEEE Transactions on Visualization and Computer Graphics, 28(6):2500–2516, 2022.
- [16] A. Lucic, M. A. Ter Hoeve, G. Tolomei, M. De Rijke, and F. Silvestri. CF-GNNexplainer: Counterfactual explanations for graph neural networks. In International Conference on Artificial Intelligence and Statistics, pp. 4499–4511. PMLR, 2022.
- [17] D. Luo, W. Cheng, D. Xu, W. Yu, B. Zong, H. Chen, and X. Zhang. Parameterized explainer for graph neural network. Advances in neural information processing systems, 33:19620–19631, 2020.
- [18] S. Miao, M. Liu, and P. Li. Interpretable and generalizable graph learning via stochastic attention mechanism. In International Conference on Machine Learning, pp. 15524–15543. PMLR, 2022.
- [19] P. E. Pope, S. Kolouri, M. Rostami, C. E. Martin, and H. Hoffmann. Explainability methods for graph convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10772–10781, 2019.
- [20] N. Pržulj. Biological network comparison using graphlet degree distribution. Bioinformatics, 23(2):e177–e183, 2007.
- [21] B. Sanchez-Lengeling, J. Wei, B. Lee, E. Reif, P. Wang, W. Qian, K. McCloskey, L. Colwell, and A. Wiltschko. Evaluating attribution for graph neural networks. Advances in neural information processing systems, 33:5898–5910, 2020.
- [22] M. S. Schlichtkrull, N. D. Cao, and I. Titov. Interpreting graph neural networks for {nlp} with differentiable edge masking. In International Conference on Learning Representations, 2021.
- [23] N. Shervashidze, S. Vishwanathan, T. Petri, K. Mehlhorn, and K. Borgwardt. Efficient graphlet kernels for large graph comparison. In Artificial intelligence and statistics, pp. 488–495. PMLR, 2009.
- [24] J. Tan, S. Geng, Z. Fu, Y. Ge, S. Xu, Y. Li, and Y. Zhang. Learning and evaluating graph neural network explanations based on counterfactual and factual reasoning. In Proceedings of the ACM Web Conference 2022, pp. 1018–1027, 2022.
- [25] J. Ugander, L. Backstrom, and J. Kleinberg. Subgraph frequencies: Mapping the empirical and extremal geography of large graph collections. In Proceedings of the International Conference on World Wide Web, p. 1307–1318, 2013.
- [26] M. Vu and M. T. Thai. Pgm-explainer: Probabilistic graphical model explanations for graph neural networks. Advances in neural information processing systems, 33:12225–12235, 2020.
- [27] Q. Wang, K. Huang, P. Chandak, M. Zitnik, and N. Gehlenborg. Extending the nested model for user-centric xai: A design study on gnn-based drug repurposing. IEEE Transactions on Visualization and Computer Graphics, 29(1):1266–1276, 2022.
- [28] X. Wang, Y. Wu, A. Zhang, X. He, and T.-s. Chua. Causal screening to interpret graph neural networks. 2020.
- [29] Y.-X. Wu, X. Wang, A. Zhang, X. He, and T.-S. Chua. Discovering invariant rationales for graph neural networks. arXiv preprint arXiv:2201.12872, 2022.
- [30] Y.-X. Wu, X. Wang, A. Zhang, X. Hu, F. Feng, X. He, and T.-S. Chua. Deconfounding to explanation evaluation in graph neural networks. arXiv preprint arXiv:2201.08802, 2022.
- [31] H. Xuanyuan, P. Barbiero, D. Georgiev, L. C. Magister, and P. Liò. Global concept-based interpretability for graph neural networks via neuron analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, pp. 10675–10683, 2023.
- [32] P. Yanardag and S. Vishwanathan. Deep graph kernels. In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining, pp. 1365–1374, 2015.
- [33] Z. Ying, D. Bourgeois, J. You, M. Zitnik, and J. Leskovec. GNNExplainer: Generating explanations for graph neural networks. Advances in neural information processing systems, 32, 2019.
- [34] Z. Yu and H. Gao. Motifexplainer: a motif-based graph neural network explainer. arXiv preprint arXiv:2202.00519, 2022.
- [35] H. Yuan, J. Tang, X. Hu, and S. Ji. Xgnn: Towards model-level explanations of graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 430–438, 2020.
- [36] H. Yuan, H. Yu, S. Gui, and S. Ji. Explainability in graph neural networks: A taxonomic survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [37] H. Yuan, H. Yu, J. Wang, K. Li, and S. Ji. On explainability of graph neural networks via subgraph explorations. In International conference on machine learning, pp. 12241–12252. PMLR, 2021.
- [38] Y. Zhang, D. Defazio, and A. Ramesh. Relex: A model-agnostic relational model explainer. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pp. 1042–1049, 2021.