Edresson Casanova1∗、Kelly Davis2、Eren Gölge3∗、Görkem Göknar2、Iulian Gulea2、Logan Hart3∗、Aya Aljafari1∗、Joshua Meyer2、Reuben Morais4∗、Samuel Olayemi2和 Julian Weber3∗。
XTTS:大规模多语言零样本文本转语音模型
摘要
大多数零样本多说话者 TTS (ZS-TTS) 系统仅支持单一语言。 虽然 YourTTS、VALL-E X、Mega-TTS 2 和 Voicebox 等模型探索了多语言 ZS-TTS,但它们仅限于少数高/中资源语言,限制了这些模型在大多数低/中资源语言中的应用。 在本文中,我们旨在通过提出并公开 XTTS 系统来缓解这个问题。 我们的方法建立在 Tortoise 模型的基础上,并添加了一些新颖的修改,以实现多语言训练、改进语音克隆并实现更快的训练和推理。 XTTS 接受了 16 种语言的培训,并在其中大多数语言上取得了最先进 (SOTA) 的结果。
关键词:
语音合成、文本转语音、多语言零样本、多说话人 TTS、说话人适应、跨语言 TTS1简介
近年来,由于深度学习的巨大进步,文本转语音(TTS)系统受到了广泛关注。 大多数 TTS 系统都是根据单个说话者的声音量身定制的,但目前人们对仅使用几秒钟的语音为新说话者(在训练中没有看到)合成声音感兴趣。 这种方法称为零样本多扬声器 TTS (ZS-TTS),如 (jia2018transfer, ; choi2020attentron, ; casanova2021sc, ; yourtts, ; wang2023neural, ; jian2023mega, ) 中所示。
单语ZS-TTS最早由arik2018neural提出,它扩展了DeepVoice 3模型deepvoice3。 同时,Tacotron 2 tacotron2 使用外部说话人嵌入进行了调整,允许生成类似于目标说话人 jia2018transfer 的语音; Cooper2020zero 。 SC-GlowTTS casanova2021sc 探索了一种基于流的架构,并相对于之前的研究改进了训练中看不见的说话者的语音相似性,同时保持了可比较的质量。 VALL-E wang2023neural 是探索 ZS-TTS 语言建模方法的先驱。 它是在 Encodec defossez2022high 标记上训练的文本条件语言模型。 Encodec 使用 8 个码本以 75Hz 帧速率对每个音频帧进行编码。 VALL-E 提高了看不见的说话者的声音相似度和自然度。 Tortoise tortoise 还探索了 ZS-TTS 的语言建模方法。 它经过 49,000 小时的英语语音训练,取得了令人鼓舞的 ZS-TTS 性能,增强了自然度。 StyleTTS 2 li2023styletts 基于 StyleTTS 框架构建,它利用大型语音语言模型(例如 WavLM chen2022wavlm )的风格扩散和对抗训练来实现人类级别的 TTS 和 SOTA ZS-TTS 性能。 P-Flow kim2023p 将提示文本编码器与低匹配生成解码器相结合,以有效地采样高质量的梅尔谱图。 P-Flow 在训练数据少两个数量级的情况下,与 VALL-E 模型的说话人相似度性能相匹配,并且采样速度快于。 HierSpeech++ lee2023hierspeech++ 是一个高效的分层语音合成框架,由分层语音合成器、文本转向量和语音超分辨率模型组成。 为了提高说话人的相似度,作者引入了使用 AdaLN-Zero 的双向归一化流 Transformer 网络。 为了提高音频质量,他们提出了一种双音频声学编码器来增强声学后验。 HierSpeech++ 实现了 ZS-TTS SOTA 效果,尤其提高了生成的音频质量。
大多数 ZS-TTS 模型仅支持单一语言。 然而,目前人们对多种语言的训练模型很感兴趣,这可以减少目标语言 ZS-TTS 模型所需的演讲时间和说话者的数量。 YourTTS yourtts 是第一个多语言 ZS-TTS 模型。 作者对 VITS 模型 kim2021conditional 架构提出了一些更改,以支持多语言训练和 ZS-TTS。 作者使用大约 1000 名英语使用者、5 名法语使用者和 1 名葡萄牙语使用者来训练模型。 该模型在英语方面取得了 SOTA 的结果,在法语和葡萄牙语方面也取得了可喜的结果。 它还可以进行跨语言 TTS,以目标语言生成母语口音。 YourTTS 模型展示了在只有少数发言者可用的场景中训练 ZS-TTS 模型的可行性,从而能够为低资源场景 casanova23_interspeech 生成合成数据。 VALL-E X zhang2023speak基于VALL-E构建;不过,作者引入了语言 ID 来支持多语言 TTS 和语音到语音翻译。 VALL-E X 还可以进行跨语言 TTS,以目标语言产生母语口音。 Mega-TTS 2 jian2023mega是一个能够处理任意长度语音提示的ZS-TTS模型。 该模型接受了 38k 小时的英语和中文多领域语言平衡语音训练。 Mega-TTS 2 在短语音提示下实现了 SOTA 性能,在较长语音提示下也产生了更好的结果。 与我们的工作同时进行的是,Voicebox le2023voicebox 被提出。 Voicebox 是一种非自回归连续归一化流模型。 与自回归模型(例如 VALL-E)相比,Voicebox 不仅可以消耗过去的上下文,还可以消耗未来的上下文。 Voicebox 模型接受了 6 种语言的训练,在跨语言 ZS-TTS 中取得了 SOTA 的结果。
尽管有些论文探索了多语言 ZS-TTS,如 yourtts ;张2023说话; le2023语音盒; jian2023mega支持的语言数量仍然很少。 YourTTS 模型仅使用三种语言进行训练,VALL-E X 和 Mega-TTS 2 仅探索两种语言,而 Voicebox 探索六种语言。 鉴于此,当前的ZS-TTS模型仅限于少数中/高资源语言,限制了这些模型在大多数中/低资源语言中的应用。 在本文中,我们旨在通过提出一个支持 16 种语言的大规模多语言 ZS-TTS 模型来解决这个问题,包括英语 (en)、西班牙语 (es)、法语 (fr)、德语 (de)、意大利语 (it)、葡萄牙语 (pt)、波兰语 (pl)、土耳其语 (tr)、俄语 (ru)、荷兰语 (nl)、捷克语 (cs)、阿拉伯语 (ar)、中文 (zh)、匈牙利语 (hu)、韩语 (ko)、和日语(ja)。
这项工作的贡献如下:
-
•
我们推出了XTTS,一种新的多语言ZS-TTS模型,在16种语言中实现了SOTA结果;
-
•
XTTS是第一个支持中低资源语言的大规模多语言ZS-TTS模型;
-
•
我们的模型可以执行跨语言 ZS-TTS,而不需要并行训练数据集。
-
•
XTTS 模型和检查点可在 Coqui TTS111https://github.com/coqui-ai/TTS 以及 Hugging Face XTTS222https://huggingface.co/coqui/XTTS-v2/tree/v2.0.2 存储库。
我们每个实验的音频样本均可在演示网站333https://edresson.github.io/XTTS/。
2XTTS模型
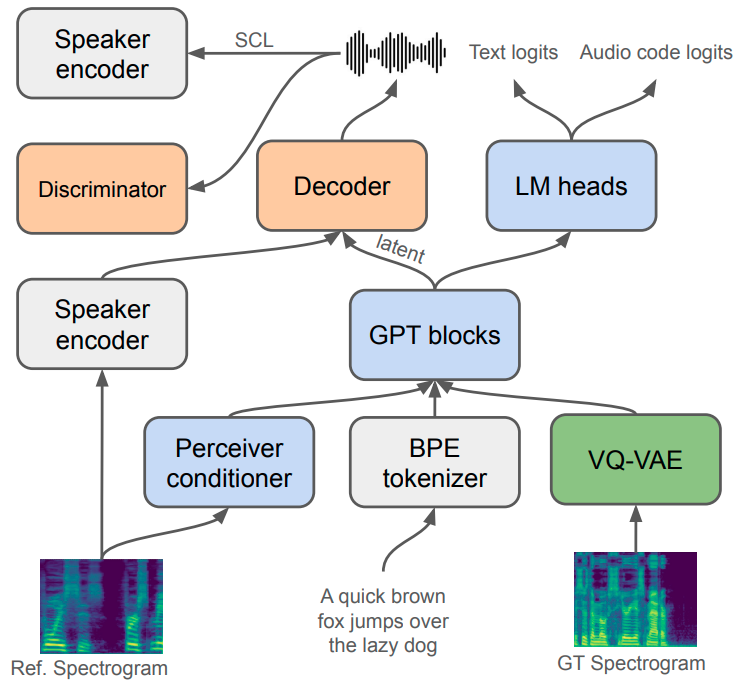
XTTS 基于 Tortoise tortoise 构建,但包含一些新颖的修改,以实现多语言训练、改进 ZS-TTS 并实现更快的训练和推理。 图1显示了XTTS架构的概述。 XTTS 由三个组件组成:
VQ-VAE: 具有 13M 参数的矢量量化变分自动编码器 (VQ-VAE) 接收梅尔频谱图作为输入,并使用由 8192 个代码组成的 1 个码本以 21.53 Hz 帧速率对每个帧进行编码。 VQ-VAE的架构和训练过程与tortoise中使用的相同;然而,在 VQ-VAE 训练之后,我们过滤了码本,仅保留前 1024 个最常见的代码。 在初步知识实验中,我们验证了过滤频率较低的代码可以提高模型的表达能力。
Encoder: GPT-2编码器是一个仅解码器的Transformer,由443M参数组成,类似于tortoise。 它接收通过 6681 个 Token 自定义字节对编码 (BPE) gage1994new Token 生成器获得的文本 Token 作为输入,并作为输出预测 VQ-VAE 音频代码。 GPT-2 编码器还受到调节编码器的调节(如下所述),该编码器接收梅尔频谱图作为输入,并为每个音频样本生成 32 个 1024 维嵌入。 条件编码器由 6 个 16 头缩放点积注意力层组成,后面跟着一个感知器重采样器 alayrac2022flamingo,以产生独立于输入音频长度的固定数量的嵌入。 请注意,在 tortoise 中,作者没有使用 Perceiver Resampler,而是仅使用单个 1024-dim 嵌入来调节 GPT-2 编码器。 在我们的基础知识实验中,我们注意到在大规模多语言训练中,使用单一嵌入会导致模型的说话人克隆能力下降。 我们还使用 Hangul-romanize444https://pypi.org/project/hangul-romanize/,肉饼555https://github.com/polm/cutlet 和 Pypinyin63>66https://pypi.org/project/pypinyin/
解码器:解码器基于HiFi-GAN声码器kong2020hifi,具有26M参数。 它接收来自 GPT-2 编码器的潜在向量。 由于 VQ-VAE 的高压缩率,直接从 VQ-VAE 代码重建音频会导致发音问题和伪影。 为了避免这个问题,我们遵循tortoise,并使用GPT-2编码器潜在空间作为解码器的输入,而不是VQ-VAE代码。 我们提出的解码器还以 H/ASP 模型 heo2020clova 中的扬声器嵌入为条件。 通过线性投影将扬声器嵌入添加到每个上采样层中。 受 yourtts 的启发,为了提高说话人的相似度,我们还添加了说话人一致性损失(SCL)。
为了加快推理速度,我们使用 22.5 kHz 音频信号训练 VQ-VAE 和编码器。 然而,我们通过将输入向量线性上采样到正确的长度来训练解码器,以产生 24khz 音频。
3实验
3.1XTTS数据集
XTTS 数据集由公共数据集和内部数据集组成。 我们的大部分内部数据都是英文的,多种语言仅使用公共数据。 表 1 显示了 XTTS 数据集中每种语言的小时数。 对于英语,我们使用了 LibriTTS-R koizumi23_interspeech 的 541.7 小时和 LibriLight kahn2020libri 的 1812.7 小时。 其余的英语数据来自内部数据集,该数据集主要由类似有声读物的数据组成。 对于其他语言,大部分数据来自 Common Voice ardila2020common 数据集。
| Language | Hours | Language | Hours |
| English | 14,513.1 | Czech | 52.4 |
| German | 3,584.4 | Korean | 539.1 |
| Spanish | 1,514.3 | Hungarian | 62.0 |
| French | 2,215.5 | Japanese | 57.3 |
| Italian | 1,296.6 | Turkish | 165.3 |
| Portuguese | 2,386.8 | Arabic | 240.9 |
| Russian | 147.1 | Chinese | 233.9 |
| Dutch | 74.1 | Polish | 198.8 |
| Total | 27,281.6 | ||
3.2实验设置
以前的作品 li2023styletts ; wang23c_interspeech ; wang2023神经;探索单语言 ZS-TTS 的 kim2023p 使用作者发布的多语言检查点将他们的模型与 YourTTS 模型进行了比较。 这种比较是不公平的,因为在 ZS-TTS 模型中,语音训练的小时数和说话者的数量非常重要。 尽管 YourTTS 多语言模型已经接受了超过 1000 名讲英语的人的训练,但该模型只接受了 5 名讲法语的人和 1 名讲葡萄牙语的人的训练。 考虑到 YourTTS 作者使用了语言批次平衡器,这意味着在训练期间,批次的 66% 将仅由来自 6 个说话者的样本组成。 这可能会导致过度拟合,从而降低英语语言的性能(有关更多详细信息,请参阅第 4.1 节)。
在本文中,我们在 LibriTTS zen2019libritts 和 XTTS 数据集上训练 YourTTS 以避免这些问题。 通过这种方式,我们可以将仅在 LibriTTS 上训练的 YourTTS 与当前的英语 ZS-TTS SOTA 进行比较。 我们还可以将其与原始的多语言 YourTTS 检查点进行比较,以展示与以前的作品进行比较时存在的问题。 我们还可以将使用 16 种语言的 XTTS 数据集训练的 YourTTS 与我们的提案模型进行公平比较。 对于使用 XTTS 数据集训练的 XTTS 和 YourTTS,我们使用了语言批量平衡器。
我们进行了三个训练实验:
-
•
实验一: 您的 TTS 模型仅使用 LibriTTS train-clean-460 子集(与 li2023styletts 中使用的数据相同)进行英语训练,并修复了 SCL 上的错误777https://github.com/Edresson/YourTTS#erratum。 我们对模型进行了 405k 步训练;
-
•
实验2: YourTTS 使用 XTTS 数据集对 16 种语言进行训练,SCL 固定为 196 万步;
-
•
实验3: 使用 XTTS 数据集训练 XTTS 模型约 250 万步。
3.3训练设置
对于 YourTTS 训练,我们使用了 Coqui TTS 存储库888https://github.com/coqui-ai/TTS。 XTTS 和 YourTTS 使用配备 80 GB GPU 的 NVIDIA A100 进行训练。 您的 TTS 实验在单个 GPU 上运行。 XTTS 在 4 个 GPU 上进行训练。
对于 YourTTS 生成器训练和声码器 HiFi-GAN 的辨别,我们使用 AdamW 优化器,具有 beta 和 、权重衰减 和初始值 的学习率按 的 gamma 呈指数衰减。 我们使用的批量大小等于。 为了加速 YourTTS 实验,我们使用了来自 Cmltts2023 上公开的检查点的迁移学习。
对于 XTTS 训练,我们使用 AdamW 优化器,其测试版 和 、权重衰减 以及初始学习率为 每个 GPU 的批量大小等于 ,梯度累积等于 步。 按照 tortoise 的方法,我们只对权重应用了权重衰减,我们还使用 MultiStepLR 以 的伽马值衰减了学习率,使用的里程碑是 、 和 。
4 结果与讨论
我们将我们的模型与 SOTA ZS-TTS 模型进行了比较:StyleTTS 2、Tortoise、YourTTS、HierSpeech++ 和 Mega-TTS 2。 我们还将我们的模型与在我们的多语言 ZS-TTS 数据集上训练的 YourTTS 模型进行了比较。 为了使我们的工作更具可重复性,评估代码和所有音频样本均可在 ZS-TTS-Evaluation999https://github.com/Edresson/ZS-TTS-Evaluation存储库。
为了比较模型,我们使用了 FLORES+ nllb-22 中每种支持语言的 240 个句子。 这些句子是从 子集中随机选择的。 我们选择了 FLORES+ 数据集,因为它具有我们模型支持的所有语言的并行翻译。 这样,我们就可以比较使用相同词汇的所有语言结果。 为了测试 ZS-TTS 功能,我们决定使用 DAPS 数据集干净子集中的所有 20 个扬声器(10M 和 10F)101010https://zenodo.org/records/4660670。 对于每个说话者,我们随机选择一个 3 到 8 秒之间的音频片段作为测试句子生成过程中的参考。 我们使用这些样本来评估所有语言,这样对于非英语语言,模型就会以跨语言的方式进行比较。
对于 YourTTS 推理,我们使用了等于 的长度尺度、等于 的噪声尺度和等于 的持续时间预测器噪声尺度。 对于 XTTS 推理,我们使用的温度等于 ,长度惩罚等于 ,重复惩罚等于 ,顶部 k 等于 ,顶部 p 等于 。 对于Tortoise推理,我们使用开源可用的检查点,参数等于,等于,并且对于其余参数,我们使用默认值。 对于 StyleTTS 2,我们使用了开源检查点111111https://github.com/yl4579/StyleTTS2#inference 在 LibriTTS train-clean-460 子集上进行训练,对于推理,我们使用了默认参数。 对于 HierSpeech++,我们使用了作者在 GitHub 上发布的原始模型121212https://github.com/sh-lee-prml/HierSpeechpp,为了推理,我们使用了默认参数。 对于 Mega-TTS 2,我们使用了作者善意提供的示例。
为了进行客观评估,按照lee2023hierspeech++,我们使用UTMOS模型saeki2022utmos来预测自然度平均意见得分(nMOS)。 在 lee2023hierspeech++ 中,作者使用了开源版本的 UTMOS131313https://github.com/tarepan/SpeechMOS,人类 nMOS 和 UTMOS 给出的结果几乎一致。 虽然这不能被视为绝对的评估指标,但它可以用来轻松地比较模型的质量。 为了比较合成语音与原始说话人之间的相似度,我们使用 SOTA ECAPA2 thienpondt2024ecapa2 说话人编码器计算说话人编码器余弦相似度 (SECS) casanova2021sc。 继之前的作品 wang2023neural ;金2023p; lee2023hierspeech++,我们使用ASR模型评估发音准确性。 为此,我们使用 Whisper Large v3 radford2022whisper 模型计算了字符错误率 (CER)。
对于主观评估,我们通过将 XTTS 与之前的模型进行比较来测量用户偏好得分。
4.1英语评测
| Model | Hours | CER() | UTMOS() | SECS() | ||||
|---|---|---|---|---|---|---|---|---|
| Ground truth | - | - | 4.2775 0.15 | 0.8952 | ||||
| Tortoise tortoise |
|
1.0934 | 4.0883 0.31 | 0.5492 | ||||
| StyleTTS 2 li2023styletts | 245 | 0.6789 | 4.4260 0.07 | 0.4728 | ||||
| Mega-TTS 2 jiang2023mega |
|
1.4269 | 4.184 0.17 | 0.6428 | ||||
| HierSpeech++ lee2023hierspeech++ | 2.7k | 0.7741 | 4.457 0.06 | 0.6530 | ||||
|
|
2.8736 | 3.6034 0.29 | 0.4621 | ||||
| YourTTS (Exp. 1) | 245 | 1.091 | 4.102 0.25 | 0.7120 | ||||
| YourTTS (Exp. 2) |
|
3.4803 | 3.6821 0.29 | 0.5651 | ||||
| XTTS (Exp. 3) |
|
0.5425 | 4.007 0.25 | 0.6423 |
表 2 列出了我们所有英语实验和相关工作的 CER、UTMOS 和 SECS。 YourTTS 单语(Exp. 1) 在说话者相似度 (SECS) 方面呈现出更好的结果,在 CER 和 UTMOS 指标方面也显示出有竞争力的结果。 然而,它在单语言模型中取得了最差的 CER。 事实上,YourTTS 韵律并不是很好,因为它有时会产生不自然的持续时间。 比较单语 YourTTS(Exp. 1)通过原来的多语言YourTTS,我们可以看到巨大的改进。 通过这种方式,确认了过度拟合问题,并表明以前的模型错误地将其模型与 YourTTS 进行了比较。 比较单语 YourTTS(Exp. 1) 使用在 XTTS 数据集上训练的 YourTTS(实验 1) 2)我们可以看到所有指标中存在巨大差距,表明将多语言模型与单语言模型进行比较是不公平的。 它还表明 YourTTS 很难学好所有 16 种语言。 XTTS 模型(Exp. 3)取得了更好的CER,并且在所有其他指标上都取得了有竞争力的结果。 令人印象深刻的是,我们的模型接受了 16 种语言的训练,并且我们正在将其与仅使用英语训练的相关作品进行比较。 考虑到单语相关的工作,HierSpeech++取得了更好的结果。 它实现了更好的 UTMOS,还实现了第二更好的 SECS 和第三更好的 CER。 考虑到多语言相关的作品,Mega-TTS 2 在英语方面比原来的 YourTTS 取得了更好的效果。
我们还通过将 XTTS 与 HierSpeech++ 和 Mega-TTS 2 模型进行比较来衡量用户偏好得分。 在kim2023p之后,我们使用比较平均意见得分(CMOS)来评估对自然度、音质和人类相似性的偏好。 使用比较说话人相似度平均意见得分 (SMOS) 报告说话人相似度的偏好测试。 SMOS 评估器提供了用于生成模型输出的说话者参考。 CMOS 和 SMOS 值的范围逐渐变化,从 -2(表示 XTTS 比其他型号差)到 +2(表示相反)。 我们从每个评估者至少 8 个样本中获得评估分数,每个比较实验至少有 15 个评估者。 表3表明XTTS在自然度、音质和人体相似度(CMOS)方面比以前的作品表现出明显更好的结果。 它还表明,XTTS 在说话人相似度(SMOS)方面比之前的模型要差一些。 我们认为,由于大规模多语言训练的复杂性,这是预料之中的。 这些结果也与表2中呈现的客观评估一致。
| Comparison | CMOS() | SMOS() |
|---|---|---|
| XTTS vs HierSpeech++ | 0.41 0.26 | -0.31 0.36 |
| XTTS vs Mega-TTS2 | 0.92 0.22 | -0.39 0.38 |
4.2多语言评估
对于多语言评估,我们比较了在 XTTS 数据集上训练的 YourTTS 和 XTTS(分别为 Exp. 2 和实验。 3) 与原来的Mega-TTS 2 模型。 表 4 显示了 XTTS、YourTTS 和 Mega-TTS 2 模型的 CER 和 SECS。 XTTS 模型能够在几乎所有语言中实现更好的 CER 和说话人相似度。
| Lang. | YourTTS | XTTS | Mega-TTS 2 | |||
|---|---|---|---|---|---|---|
| CER() | SECS() | CER() | SECS() | CER() | SECS() | |
| ar | 11.1713 | 0.4400 | 3.3503 | 0.5007 | - | - |
| cs | 4.0174 | 0.4496 | 1.3295 | 0.4655 | - | - |
| de | 2.2411 | 0.4612 | 3.1694 | 0.5175 | - | - |
| en | 2.9727 | 0.5651 | 0.5425 | 0.6423 | 1.4269 | 0.6428 |
| es | 1.0926 | 0.4879 | 1.4606 | 0.5371 | - | - |
| fr | 3.3965 | 0.4376 | 1.4937 | 0.4799 | - | - |
| hu | 4.5098 | 0.4819 | 1.4622 | 0.4570 | - | - |
| it | 1.7010 | 0.4520 | 0.7982 | 0.5008 | - | - |
| ja | 10.2808 | 0.4873 | 5.3748 | 0.5207 | - | - |
| ko | 8.8567 | 0.4836 | 4.0647 | 0.4760 | - | - |
| nl | 3.4228 | 0.4269 | 0.946 | 0.4825 | - | - |
| pl | 1.5925 | 0.4561 | 0.7593 | 0.4833 | - | - |
| pt | 1.5481 | 0.4693 | 1.1068 | 0.5033 | - | - |
| ru | 2.8566 | 0.4606 | 0.932 | 0.5012 | - | - |
| tr | 2.6367 | 0.4855 | 1.042 | 0.5031 | - | - |
| zh-cn | 14.4220 | 0.4825 | 5.2016 | 0.5023 | 6.1031 | 0.4529 |
| Avg. | 4.7949 | 0.4704 | 2.0646 | 0.5046 | - | - |
5 说话者适应
不同的录音条件对 ZS-TTS 模型 yourtts 的泛化是一个挑战。 声音与训练中看到的声音有很大不同的说话者也会成为一个挑战 tan2021survey 。 尽管如此,为了展示 XTTS 模型适应新的说话者/录音条件的潜力,我们从不同语言的知名或独特风格的声音(例如耳语声)中选择了大约 10 分钟的语音样本。 我们选择 3 名讲英语的人、3 名讲葡萄牙语的人、1 名讲中文的人和 1 名讲阿拉伯语的人。 我们使用这些说话者进行微调,并使用 4 节中使用的跨语言方法评估模型;然而,我们用选定的扬声器替换了 DAPS 扬声器。 当以跨语言方式克隆这些语音时,微调模型将 SECS 从 0.5852 提高到 0.7166。 这表明XTTS微调在跨语言说话人迁移设置中极大地提高了说话人相似度。 结果可在演示页面141414https://edresson.github.io/XTTS。
6 结论和未来的工作
在这项工作中,我们提出了 XTTS,它在 16 种语言的多语言零样本多说话人 TTS 中取得了 SOTA 结果。 此外,我们还表明,XTTS 可以用一小部分语音进行微调,并在韵律和风格模仿方面取得令人印象深刻的结果,能够模仿所有 16 种语言的耳语语音风格,尽管它只接受了 10 分钟的训练。低语的英语声音。 XTTS 模型也比 VALL-E 更快,因为我们的编码器以 21.53 Hz 帧速率生成 Token ,而 VALL-E 模型的帧速率为 75Hz。 在未来的工作中,我们打算寻求对 VQ-VAE 组件的改进,以便能够使用 VQ-VAE 解码器生成语音,而不是使用当前的 XTTS 解码器组件。 我们还打算解开说话者和韵律信息,以便能够进行跨说话者韵律传输。
7致谢
我们要感谢所有 Coqui TTS151515https://github.com/coqui-ai/TTS 贡献者,这项工作的完成得益于所有人的努力。 此外,我们还要感谢 HierSpeech++、Tortoise 和 StyleTTS 2 作者将他们的作品开源并易于社区访问。 此外,我们要感谢 Ziyue Jiang 慷慨地生成了本文中使用的 Mega-TTS 2 模型样本。
参考
- (1) Y. Jia, Y. Zhang, R. Weiss, Q. Wang, J. Shen, F. Ren, P. Nguyen, R. Pang, I. L. Moreno, Y. Wu et al., “Transfer learning from speaker verification to multispeaker text-to-speech synthesis,” in Advances in neural information processing systems, 2018, pp. 4480–4490.
- (2) S. Choi, S. Han, D. Kim, and S. Ha, “Attentron: Few-Shot Text-to-Speech Utilizing Attention-Based Variable-Length Embedding,” in Proc. Interspeech 2020, 2020, pp. 2007–2011.
- (3) E. Casanova, C. Shulby, E. Gölge, N. M. Müller, F. S. de Oliveira, A. Candido Jr., A. da Silva Soares, S. M. Aluisio, and M. A. Ponti, “SC-GlowTTS: An Efficient Zero-Shot Multi-Speaker Text-To-Speech Model,” in Proc. Interspeech 2021, 2021, pp. 3645–3649.
- (4) E. Casanova, J. Weber, C. D. Shulby, A. C. Junior, E. Gölge, and M. A. Ponti, “Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone,” in International Conference on Machine Learning. PMLR, 2022, pp. 2709–2720.
- (5) C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li et al., “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023.
- (6) Z. Jiang, J. Liu, Y. Ren, J. He, Z. Ye, S. Ji, Q. Yang, C. Zhang, P. Wei, C. Wang, X. Yin, Z. MA, and Z. Zhao, “Mega-tts 2: Boosting prompting mechanisms for zero-shot speech synthesis,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=mvMI3N4AvD
- (7) S. Arik, J. Chen, K. Peng, W. Ping, and Y. Zhou, “Neural voice cloning with a few samples,” in Advances in Neural Information Processing Systems, 2018, pp. 10 019–10 029.
- (8) W. Ping, K. Peng, A. Gibiansky, S. O. Arik, A. Kannan, S. Narang, J. Raiman, and J. Miller, “Deep voice 3: 2000-speaker neural text-to-speech,” in International Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=HJtEm4p6Z
- (9) J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y. Zhang, Y. Wang, R. Skerrv-Ryan et al., “Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4779–4783.
- (10) E. Cooper, C.-I. Lai, Y. Yasuda, F. Fang, X. Wang, N. Chen, and J. Yamagishi, “Zero-shot multi-speaker text-to-speech with state-of-the-art neural speaker embeddings,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6184–6188.
- (11) A. Défossez, J. Copet, G. Synnaeve, and Y. Adi, “High fidelity neural audio compression,” Transactions on Machine Learning Research, 2023, featured Certification, Reproducibility Certification. [Online]. Available: https://openreview.net/forum?id=ivCd8z8zR2
- (12) J. Betker, “Better speech synthesis through scaling,” arXiv preprint arXiv:2305.07243, 2023.
- (13) Y. A. Li, C. Han, V. Raghavan, G. Mischler, and N. Mesgarani, “Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- (14) S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
- (15) S. Kim, K. J. Shih, R. Badlani, J. F. Santos, E. Bakhturina, M. T. Desta, R. Valle, S. Yoon, and B. Catanzaro, “P-flow: A fast and data-efficient zero-shot tts through speech prompting,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- (16) S.-H. Lee, H.-Y. Choi, S.-B. Kim, and S.-W. Lee, “Hierspeech++: Bridging the gap between semantic and acoustic representation of speech by hierarchical variational inference for zero-shot speech synthesis,” arXiv preprint arXiv:2311.12454, 2023.
- (17) J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” in International Conference on Machine Learning. PMLR, 2021, pp. 5530–5540.
- (18) E. Casanova, C. Shulby, A. Korolev, A. C. Junior, A. da Silva Soares, S. Aluísio, and M. A. Ponti, “ASR data augmentation in low-resource settings using cross-lingual multi-speaker TTS and cross-lingual voice conversion,” in Proc. INTERSPEECH 2023, 2023, pp. 1244–1248.
- (19) Z. Zhang, L. Zhou, C. Wang, S. Chen, Y. Wu, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li et al., “Speak foreign languages with your own voice: Cross-lingual neural codec language modeling,” arXiv preprint arXiv:2303.03926, 2023.
- (20) M. Le, A. Vyas, B. Shi, B. Karrer, L. Sari, R. Moritz, M. Williamson, V. Manohar, Y. Adi, J. Mahadeokar et al., “Voicebox: Text-guided multilingual universal speech generation at scale,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- (21) P. Gage, “A new algorithm for data compression,” C Users Journal, vol. 12, no. 2, pp. 23–38, 1994.
- (22) J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds et al., “Flamingo: a visual language model for few-shot learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 23 716–23 736, 2022.
- (23) J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” arXiv preprint arXiv:2010.05646, 2020.
- (24) H. S. Heo, B.-J. Lee, J. Huh, and J. S. Chung, “Clova baseline system for the voxceleb speaker recognition challenge 2020,” arXiv preprint arXiv:2009.14153, 2020.
- (25) Y. Koizumi, H. Zen, S. Karita, Y. Ding, K. Yatabe, N. Morioka, M. Bacchiani, Y. Zhang, W. Han, and A. Bapna, “LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus,” in Proc. INTERSPEECH 2023, 2023, pp. 5496–5500.
- (26) J. Kahn, M. Rivière, W. Zheng, E. Kharitonov, Q. Xu, P.-E. Mazaré, J. Karadayi, V. Liptchinsky, R. Collobert, C. Fuegen et al., “Libri-light: A benchmark for asr with limited or no supervision,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7669–7673.
- (27) R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” in Proceedings of the 12th Language Resources and Evaluation Conference, 2020, pp. 4218–4222.
- (28) W. Wang, Y. Song, and S. Jha, “Generalizable Zero-Shot Speaker Adaptive Speech Synthesis with Disentangled Representations,” in Proc. INTERSPEECH 2023, 2023, pp. 4454–4458.
- (29) H. Zen, V. Dang, R. Clark, Y. Zhang, R. J. Weiss, Y. Jia, Z. Chen, and Y. Wu, “Libritts: A corpus derived from librispeech for text-to-speech,” Interspeech 2019, 2019.
- (30) F. S. Oliveira, E. Casanova, A. C. Junior, A. S. Soares, and A. R. Galvão Filho, “Cml-tts: A multilingual dataset for speech synthesis in low-resource languages,” in Text, Speech, and Dialogue, K. Ekštein, F. Pártl, and M. Konopík, Eds. Cham: Springer Nature Switzerland, 2023, pp. 188–199.
- (31) NLLB Team, M. R. Costa-jussà, J. Cross, O. Çelebi, M. Elbayad, K. Heafield, K. Heffernan, H. Kalbassi, …, and J. Wang, “No language left behind: Scaling human-centered machine translation,” 2022.
- (32) T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022,” Interspeech 2022, 2022.
- (33) J. Thienpondt and K. Demuynck, “Ecapa2: A hybrid neural network architecture and training strategy for robust speaker embeddings,” arXiv preprint arXiv:2401.08342, 2024.
- (34) A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” 2022.
- (35) X. Tan, T. Qin, F. Soong, and T.-Y. Liu, “A survey on neural speech synthesis,” arXiv preprint arXiv:2106.15561, 2021.