VALL-E 2:神经编解码器语言模型是人类奇偶校验零样本文本到语音合成器
摘要
本文介绍了 VALL-E 2,它是神经编解码器语言模型的最新进展,标志着零样本文本到语音合成 (TTS) 的里程碑,首次实现了人类平等。 基于其前身 VALL-E,新迭代引入了两项重大增强功能:重复感知采样通过考虑解码历史中的词符重复来改进原始核心采样过程。 它不仅稳定了解码,还避免了无限循环问题。 分组代码建模将编解码器代码分组,有效缩短序列长度,不仅提高了推理速度,还解决了长序列建模的挑战。 我们在 LibriSpeech 和 VCTK 数据集上的实验表明,VALL-E 2 在语音鲁棒性、自然度和说话人相似度方面超越了之前的系统。 这是同类产品中第一个在这些基准上达到人类同等水平的产品。 此外,VALL-E 2 始终能够合成高质量的语音,即使对于传统上因其复杂性或重复短语而具有挑战性的句子也是如此。 这项工作的优势可能有助于做出有价值的努力,例如为失语症患者或肌萎缩侧索硬化症患者生成语音。 VALL-E 2 的演示将发布到 https://aka.ms/valle2。
1简介
文本到语音合成 (TTS) 旨在从文本输入生成具有高度清晰度和清晰度的高质量语音。 随着深度学习的进步,近年来TTS研究取得了显着的进步(沉等人,2018;李等人,2019;任等人,2019)。 一些系统使用录音室录制的干净的单说话人语音数据进行训练,单说话人语音生成的质量甚至达到了人类水平(Tan等人,2024)。 然而,零样本 TTS 仍然是一个具有挑战性的问题,它需要模型在推理过程中使用简短的注册语音样本来合成看不见的说话者的语音。
我们之前的工作VALL-E(Wang等人,2023a)标志着该领域的重大突破。 它能够仅使用 3 秒的录音来合成个性化语音,同时保留说话者的声音、情绪和声学环境。 VALL-E 是一种神经编解码器语言模型,它使用神经音频编解码器模型将语音信号表示为离散编解码器代码。 具体来说,它训练一个自回归语言模型来生成粗略编解码器代码,并训练另一个非自回归模型来生成剩余的精细编解码器代码。 VALL-E 使用随机采样进行模型推理,而不是使用不断生成静音编解码器代码的贪婪搜索。 然而,VALL-E有两个关键限制:1)稳定性:推理过程中使用的随机采样可能会导致输出不稳定,而top-p值较小的核采样可能会导致无限循环问题。 这可以通过多次采样和后续排序来缓解,但这种方法会增加计算成本。 2)效率:VALL-E的自回归架构绑定了与现成音频编解码模型相同的高帧率,且无法调整,导致推理速度较慢。
人们提出了一些后续工作来解决这些问题(Song 等人,2024;Xin 等人,2024;Borsos 等人,2023;Le 等人,2024;Ju 等人,2024) 。 为了提高稳定性,一些工作在模型训练和推理中利用文本语音对齐信息(Song等人,2024;Xin等人,2024)。 这些方法依赖于强制对齐模型,不可避免地会在对齐结果中引入错误,这可能会影响最终的性能。 它还使整体架构变得复杂,并增加了数据扩展的负担。 为了提高建模效率,一些工作探索了零样本TTS的完全非自回归方法(Borsos等人,2023;Le等人,2024;Ju等人,2024)。 然而,这些方法需要帧对齐的文本语音数据来进行模型训练,面临与之前讨论的相同的问题。 此外,非自回归模型生成具有预定持续时间结果的标记,这限制了生成语音的搜索空间并牺牲了韵律和自然度。
在这项工作中,我们提出了VALL-E 2,第一个人类零样本文本到语音合成系统。 VALL-E 2 在其前身 VALL-E 的基础上,采用神经编解码器语言建模方法进行语音合成,并包含两个关键修改:重复感知采样和分组代码建模。 重复感知采样是对VALL-E中使用的随机采样的改进,自适应地对每个时间步词符预测采用随机采样或核心采样。 这种选择是基于解码历史中的词符重复,增强了解码过程的稳定性,并规避了VALL-E中遇到的无限循环问题。另一方面,分组代码建模将编解码器代码划分为多个组,每个组在 AR 建模过程中在单个帧中建模。 这种方法不仅通过减少序列长度来加速推理,而且通过缓解长上下文建模问题来提高性能。 值得注意的是,VALL-E 2只需要简单的语音转录对数据即可进行训练,大大简化了收集和处理训练数据的过程,并促进了潜在的可扩展性。
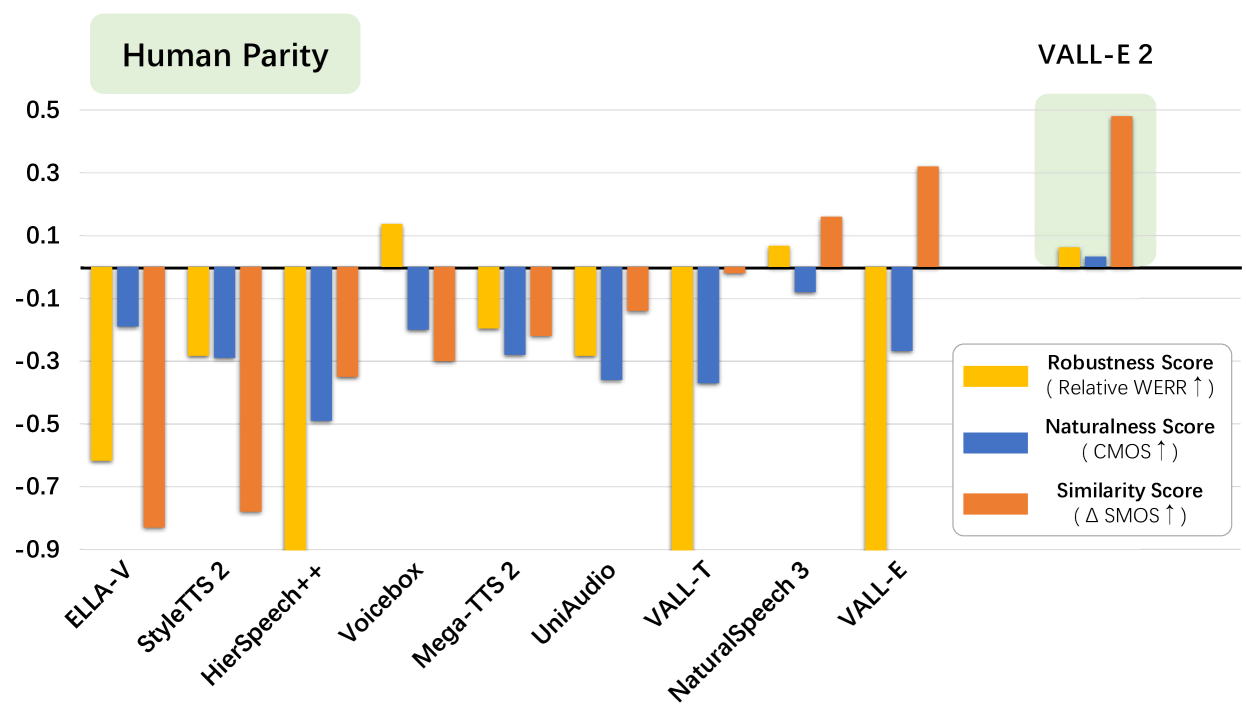
VALL-E 2 在大规模 Libriheavy 数据集(Kang 等人,2024)上进行训练。 随后的评估表明,它在域内 LibriSpeech 数据集 (Panayotov 等人,2015) 和域外 VCTK 数据集 (Veaux 等人)上均达到了与人类能力相当的性能。 ,2016)。 如图1所示,VALL-E 2在鲁棒性、自然度方面显着优于VALL-E和LibriSpeech数据集上的其他先前工作,和相似度分数,甚至达到人类同等的表现。 图1中的数字是基于论文中报告的结果的相对数字()。 在这种情况下,人类奇偶性表明 VALL-E 2 的鲁棒性、自然性和相似性指标超过了真实样本(意味着 、 和 ),这意味着 VALL-E 2 可以准确、自然地生成原始说话者的语音,可与人类的表现相媲美。 值得注意的是,这个结论仅是根据 LibriSpeech 和 VCTK 数据集的实验结果得出的。 此外,VALL-E 2可以将解码过程加速数倍,而性能几乎没有下降。 为了具体评估VALL-E 2的稳定性,我们对难以阅读或包含许多重复短语的复杂句子进行语音合成,发现VALL-E 2可以始终稳定地生成高质量的语音。 这项工作的好处可以支持有意义的举措,例如为失语症患者或肌萎缩侧索硬化症患者生成语音。 VALL-E 2 的演示将发布到 https://aka.ms/valle2。
VALL-E 2 纯粹是一个研究项目。 目前,我们没有计划将 VALL-E 2 纳入产品或扩大公众使用范围。 VALL-E 2 可以合成保持说话者身份的语音,可用于教育学习、娱乐、新闻、自创作内容、辅助功能、交互式语音应答系统、翻译、聊天机器人等。 虽然VALL-E 2可以像配音员一样用声音说话,但相似度和自然度取决于语音提示的长度和质量、背景噪音以及其他因素。 它可能会带来模型滥用的潜在风险,例如欺骗语音识别或冒充特定说话人。 我们在用户同意成为语音合成中的目标说话人的假设下进行了实验。 如果该模型被推广到现实世界中看不见的说话者,它应该包括一个协议来确保说话者批准使用他们的声音和一个合成语音检测模型。 如果您怀疑 VALL-E 2 的使用方式存在滥用或非法行为,或者侵犯您或其他人的权利,您可以在举报滥用门户网站举报。
2相关工作
2.1零镜头 TTS
零样本 TTS 的早期工作通常采用说话人适应和说话人编码方法,这通常需要额外的微调、复杂的预先设计的功能或重型结构工程(Chen 等人,2019;Wang 等人,2020;Arik等人,2018;卡萨诺瓦等人,2022)。 受自然语言处理中大语言模型成功的启发,VALL-E (Wang 等人, 2023a; Zhang 等人, 2023b) 代表语音作为具有现成神经编解码器模型的离散编解码器代码,并将 TTS 作为条件编解码器语言建模任务。 这种方法使得VALL-E能够在大规模训练数据上训练编解码语言模型,并通过提示进行零样本TTS,实现了显着的零样本TTS能力。
这一突破激发了后续研究工作,通过语言建模方法解决零样本 TTS。 例如,VALL-E X (Zhang 等人, 2023b) 通过附加语言 ID 词符将 VALL-E 扩展到跨语言 TTS 任务。 SPEAR-TTS (Kharitonov 等人, 2023) 和 Make-a-voice (Huang 等人, 2023a) 利用语音自监督模型中的语义单元作为中间体文本和声音编解码器代码之间的接口,可实现更好的训练数据效率。 Mega-TTS (Jiang 等人, 2023b) 和 Mega-TTS 2 (Jiang 等人, 2023a) 提出首先解开语音中的多个属性,然后仅对部分属性进行建模使用语言建模方法的属性。 ELLA-V (宋等人,2024)和RALL-E (辛等人,2024)提高了VALL-E的鲁棒性和通过将语音文本对齐预测纳入解码过程来提高稳定性。 UniAudio (Yang 等人, 2023b) 和 BASE TTS (Łajszczak 等人, 2024) 进一步探索将编解码器语言模型扩展到 1b 个参数和 100k 小时的训练数据。
同时,其他工作探索了完全非自回归建模方法以加快推理速度。 例如,Soundstorm (Borsos 等人, 2023) 利用基于置信度的并行解码方案 (Chang 等人, 2022) 生成具有非自回归模型。 StyleTTS 2 (Li 等人, 2024)、UniCATS (Du 等人, 2024a)、NaturalSpeech 2 (Shen 等人, 2023) 和NaturalSpeech 3 (Ju 等人, 2024) 使用扩散模型 (Ho 等人, 2020) 进行提示条件文本到语音合成。 Voicebox (Le 等人, 2024) 和 Audiobox (Vyas 等人, 2023) 使用流量匹配方法(Lipman 等人, 2022)并取得了更好的语音建模能力。 在本工作中,VALL-E 2遵循VALL-E的编解码语言建模方法,无需复杂的语音数据处理和准备即可实现稳定的解码过程,例如先前方法中使用的持续时间或音调信息。 值得注意的是,VALL-E 2 是第一个在 LibriSpeech 和 VCTK 数据集上成功实现零样本 TTS 与人类同等水平的项目。
2.2 基于编解码器的语音模型
受到零样本 TTS 中神经编解码器代码的良好性能的启发,许多后续研究工作开始探索其在更多语音任务上的有效性。 例如,PolyVoice (Dong 等人, 2023) 采用了 VALL-E 并构建了基于编解码器的语言模型用于语音到语音翻译。 SpeechX (Wang 等人, 2023c) 通过多任务学习扩展了 VALL-E,展示了在零样本 TTS、噪声抑制、目标说话人提取、语音去除和语音编辑任务。 除了语音生成之外,VioLA (Wang 等人, 2023b)进一步探索了用于语音理解任务的基于编解码器的语音模型,统一了用于语音识别、合成和翻译任务的编解码器语言模型。 AudioPaLM (Rubenstein 等人, 2023) 将编解码器 Token 融合到大语言模型 PaLM 2 (Anil 等人, 2023) 中,并在语音识别和翻译方面展示了有希望的结果任务。
这些作品通常采用最初为语音压缩而设计的 SoundStream (Zeghidour 等人, 2021) 和 Encodec (Défossez 等人, 2022) 作为神经编解码器模型。 受这些成功的启发,一些工作提出了更新颖的神经编解码器,专门用于语音处理任务。 其中包括 Vocos (Siuzdak, 2023)、SpeechTokenizer (Zhang 等人, 2023a)、AudioDec (Wu 等人, 2023)、AcademiCodec (Yang 等人, 2023a), 描述音频编解码器 (DAC) (Kumar 等人, 2024), FunCodec (Du 等人, 2024b)(Du 等人, 2024b) t5> 和 RepCodec (Huang 等人, 2023b)。 Codec-SUPERB 挑战(Wu 等人,2024) 旨在对各种语音任务中的各种编解码器代码进行基准测试。 在这项工作中,我们利用 Encodec 模型来标记语音信号,并利用 Vocos 解码器来生成目标高质量语音信号。
3 VALL-E 2
3.1 问题表述:分组编解码器语言建模
继VALL-E之后,我们使用现成的神经音频编解码器模型将语音信号表示为离散编解码器代码序列,并将TTS视为条件编解码器语言建模任务。 为了提高效率,VALL-E 2引入了分组编解码语言建模方法,将编解码代码序列划分为一定大小的组,并将每组编解码代码建模为一帧。 这样我们就可以摆脱现成的神经音频编解码模型的帧率约束,将帧率降低整数倍。 它不仅有利于推理效率,而且通过缓解长上下文建模问题也有利于整体语音质量。
通过 TTS 训练目标,VALL-E 2 被优化以最大化给定文本条件的分组代码序列的可能性。 具体来说,给定一个音频样本 及其相应的标记化文本转录 ,其中 是文本序列长度,我们首先使用预训练的神经音频编解码器模型,用于将音频样本转换为编解码器代码序列,其中是代码序列长度,(这里)是编解码器模型中量化器的数量,每个代表每个时间步的8个代码。 然后我们将其划分为分组代码序列,组大小为,代表组。 由于话语开头通常有短暂的沉默,我们可以从代码序列的开头剪掉一些代码,让代码序列长度为组大小的整数倍,而不需要删除任何代码。语音信息。 最后,我们训练 VALL-E 2 模型 以最小化以文本序列 为条件的分组代码序列 的负对数概率:
| (1) | ||||
| (2) |
其中是第组编解码器代码,是前面 组。
推理过程中,VALL-E 2根据提示执行零样本TTS任务。 给定文本输入(包含语音提示的转录和要合成的文本)和来自看不见的说话者的分组编解码器代码,作为条件和提示,该模型可以生成具有相应内容和说话者语音的目标分组编解码器代码。 具体来说,给定文本序列和未见过的说话人的登记语音样本,我们可以获得相应的分组代码序列。 然后,我们以文本序列 和代码提示 为条件生成目标分组代码序列 :
| (3) | ||||
| (4) |
最后,我们可以使用现成的神经编解码器将目标代码序列 转换为目标语音波形。
3.2 VALL-E 2架构
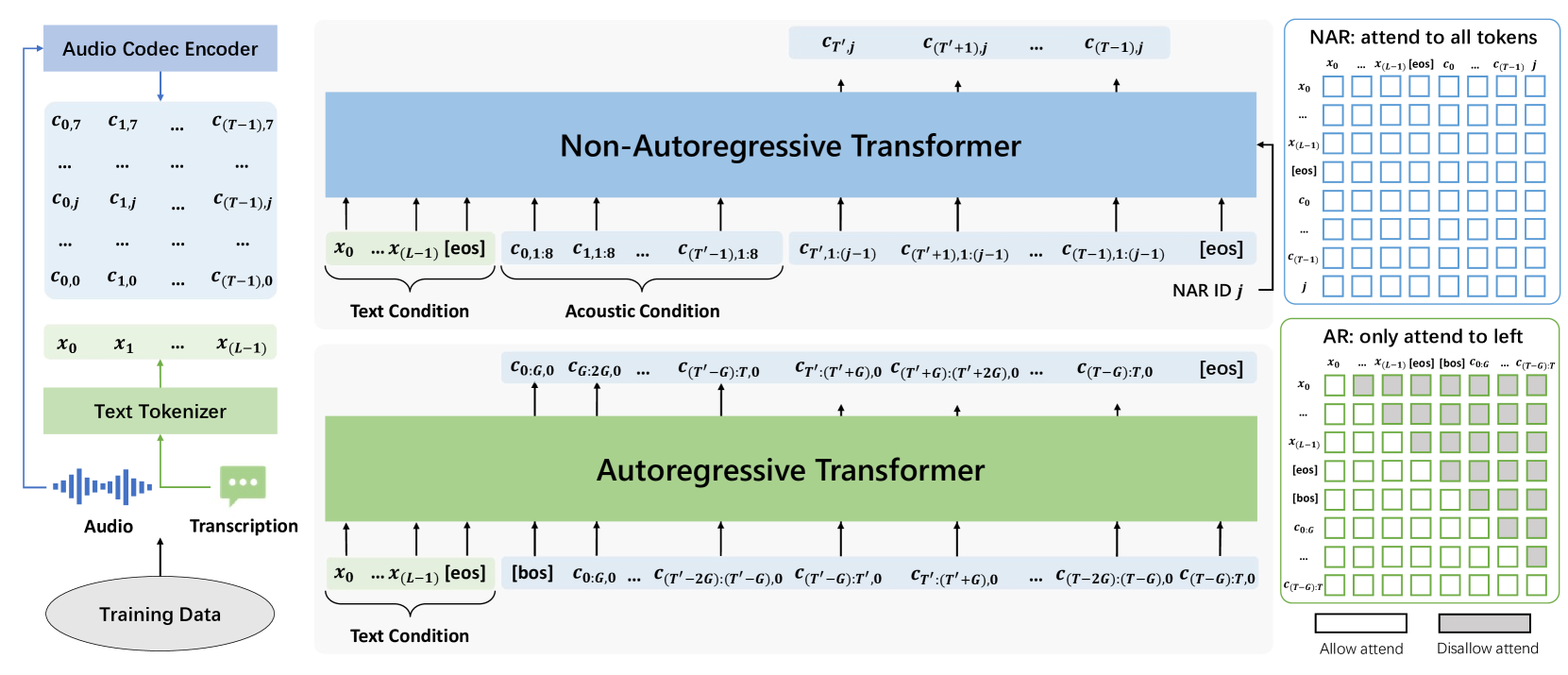
在 VALL-E 的基础上,VALL-E 2 还使用分层结构:自回归 (AR) 编解码器语言模型和非自回归 (NAR) 编解码器语言模型。 AR模型以自回归的方式生成每一帧的第一编解码器代码的序列,而NAR模型以非自回归的方式基于前面的代码序列生成每个剩余的代码序列。 两种模型都使用相同的 Transformer 架构,其中包含文本嵌入层、代码嵌入层和代码预测层。 我们对来自不同编解码器量化器的代码使用不同的嵌入,并与代码嵌入层的参数共享代码预测层的参数。 此外,AR模型还有一个组嵌入层,用于将代码嵌入投影到组嵌入,以及一个组预测层,用于预测一组中的代码。 NAR模型有一个代码ID嵌入层来指定要预测的代码序列的ID。 AR模型和NAR模型具有不同的注意力掩模策略:AR模型使用因果注意力策略,NAR模型使用完全注意力策略,如图2右部分所示。
3.3 VALL-E 2训练
图2展示了VALL-E 2模型训练的概览。 值得注意的是,VALL-E 2的训练只需要简单的语音转录对数据,不需要任何复杂的数据,例如力对齐结果或同一说话者的额外音频片段以供参考。 这极大地简化了训练数据的收集和处理过程。
具体来说,对于训练数据集中的每个音频和相应的转录,我们首先利用音频编解码器编码器和文本标记器分别获取编解码器代码 和文本序列 。 然后将它们用于 AR 模型和 NAR 模型训练。
3.3.1 自回归模型
AR 模型经过训练,以自回归方式预测以文本序列 为条件的第一个编解码器代码序列 。
如图 2 中下部分所示,我们首先利用文本嵌入矩阵 和代码嵌入矩阵 获得文本嵌入序列 和代码嵌入序列 。
| (5) | ||||
| (6) |
其中和分别表示文本序列和代码序列中每一项的索引,表示索引选择。 然后,我们将代码嵌入序列划分为大小为 的组,在隐藏维度中连接每组代码嵌入,并使用组嵌入获得组嵌入序列 矩阵。
| (7) |
我们连接文本嵌入序列 和组嵌入序列 ,在其间插入特殊标记 和 的嵌入:
| (8) |
其中表示时间维度上的串联。 然后,我们将可学习的位置嵌入分别添加到文本嵌入序列和组嵌入序列中。 AR 模型被输入 ,并使用线性映射组预测层和 softmax 代码预测层进行训练,以在末尾附加特殊词符 来预测相应的代码序列。 由于因果注意掩码策略,每个代码组的预测只能关注文本序列和前面的代码,如图2右下部分。
总的来说,AR模型的参数是通过最小化以文本序列为条件的第一个代码序列的负对数似然来优化的:
| (9) | ||||
| (10) | ||||
| (11) |
在VALL-E 2的AR模型中,组序列采用自回归方法建模,而每个组内的编解码器代码采用自回归方法建模以非自回归的方式。
3.3.2 非自回归模型训练
给定 AR 模型生成的第一个编码序列,训练 NAR 模型以非自回归方式为每个编解码器编码 ID 生成剩余编码序列 ,条件是文本序列 和前面的编码序列 ,其中 .
由于我们在推理过程中可以访问提示的所有 8 个代码序列,为了更好地建模提示的说话人信息,在训练过程中,我们显式地将所有代码序列 拆分为声学条件 和具有随机采样长度 的目标代码序列。 然后优化模型以预测以文本序列 为条件的每个目标代码序列 ,声学条件下的所有 代码序列 和前面的目标代码序列以非自回归方式。
如图2中上部分所示,我们首先使用文本嵌入矩阵获得文本嵌入序列,如方程5。 然后,我们通过代码嵌入矩阵 获得声学条件 和目标代码序列 中的所有代码嵌入,并与代码 ID 维度相加,得到代码嵌入序列 :
| (12) |
其中 是时间步长, 是编解码器代码 ID。 接下来,我们通过代码 ID 嵌入矩阵 获取编解码器代码 ID 嵌入 。
| (13) |
我们将文本嵌入序列、代码嵌入序列和编解码器代码ID嵌入连接起来,插入特殊词符 中间:
| (14) |
然后,我们将可学习的位置嵌入分别添加到文本嵌入序列和代码嵌入序列中,类似于 AR 模型。 NAR 模型被输入 并进行训练,以使用代码预测层预测每个编解码器代码 ID 的相应代码序列 。 通过全注意力掩模策略,每个词符的预测可以关注整个输入序列,如图2右上部分所示。
总体而言,NAR 模型通过最小化以文本序列 为条件的每个 目标代码序列 的负对数似然来优化,所有代码声学条件序列和前面的目标代码序列。
| (15) | ||||
| (16) |
在实践中,为了优化训练过程中的计算效率,我们不会通过迭代的所有值并聚合相应的损失来计算训练损失,而是随机选择一个并优化使用训练损失的模型:
| (17) |
3.4 VALL-E 2 推断
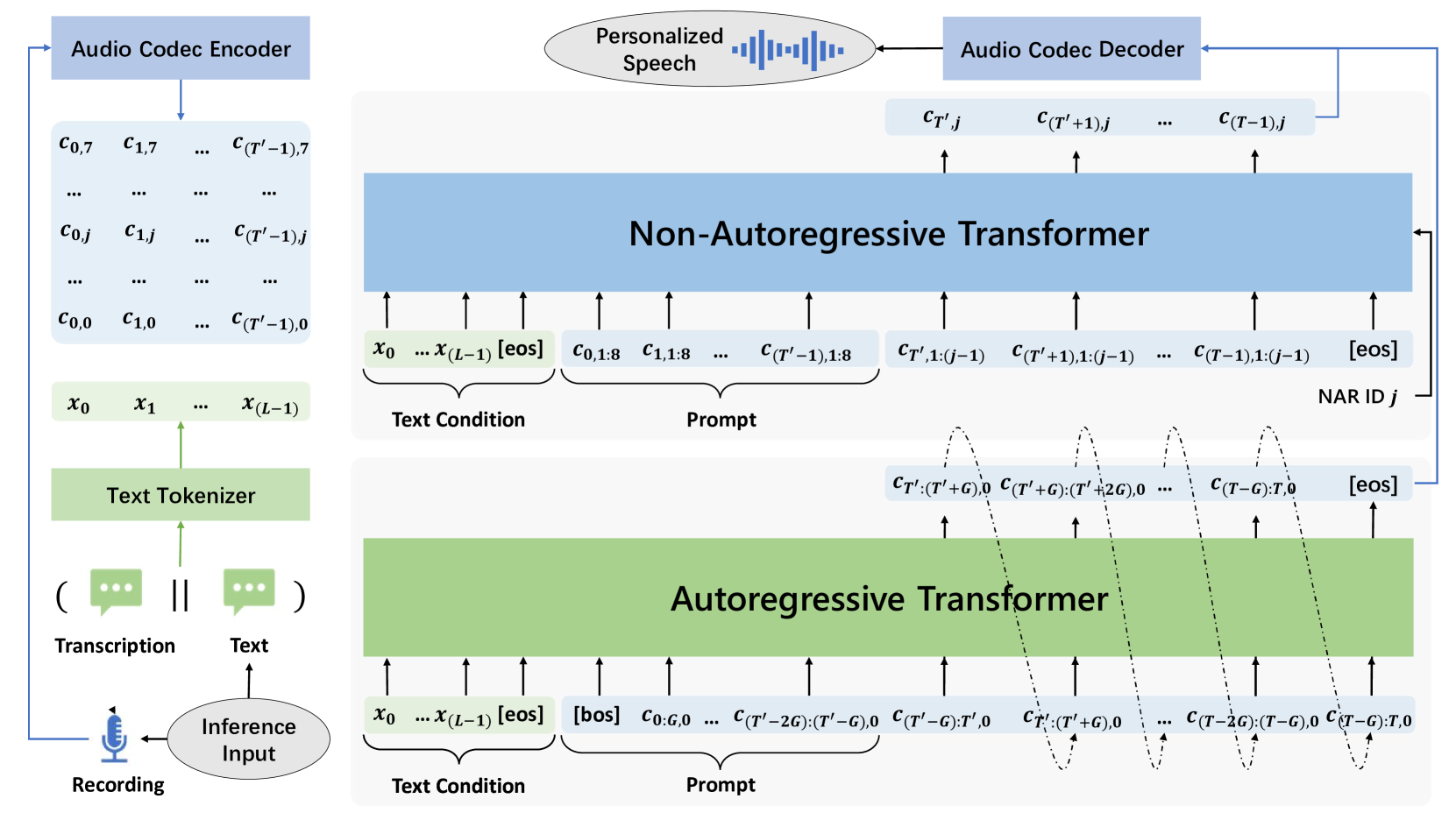
在VALL-E之后,我们在推理过程中通过提示执行零样本TTS任务。 如图3所示,给定文本句子和未见过的说话者的注册语音样本及其相应的转录,我们首先将语音转录和文本句子连接起来,编码成文本序列 使用文本标记器作为文本条件。 使用音频编解码器将语音样本转换为代码作为提示。 通过提示条件编解码语言模型,推断AR模型和NAR模型,生成目标代码。 最后,音频编解码器使用目标代码来合成目标个性化语音信号。
3.4.1 自回归模型推理
我们首先推断 AR 模型,以文本序列 和代码提示 为条件生成目标代码 的第一个代码序列。 通过分组编解码器语言建模方法,我们将分组的代码序列输入到AR模型中,并以自回归的方式生成每组目标代码:
| (18) | ||||
| (19) | ||||
| (20) |
与VALL-E中使用的随机采样方法不同,在这项工作中,我们提出了一种重复感知采样方法来增强核采样,以获得更好的解码稳定性。 如算法 1 所述,给定 AR 模型预测的概率分布 ,我们首先通过核采样生成目标代码 ,并预先定义顶 p 值 。然后,我们用窗口大小 计算词符 在前一代码序列中的重复率 。如果比率 超过了预先设定的重复阈值比率 ,我们就会从 中随机取样,替换目标代码 。 虽然一组中的编解码器代码以非自回归方式建模,但它们是自回归预测的,以计算重复率并在这两种采样方法之间切换。 采用这种重复感知采样方法,解码过程不仅可以受益于核采样的稳定性,还可以借助随机采样避免无限循环问题。 应该注意的是,这种重复感知采样不会增加解码延迟,因为与模型推理过程相比,额外采样操作的运行时成本几乎可以忽略不计。
3.4.2 非自回归模型推理
给定目标代码的第一个代码序列,我们可以使用文本条件和声学条件推断NAR模型以生成剩余代码目标代码的序列:
| (21) | ||||
| (22) |
为了生成 2-8 代码序列,我们对 NAR 模型进行了七次推理,使用贪婪解码方法一一生成。 整个代码矩阵与AR模型生成的第一编解码器代码一起用于通过相应的音频编解码器生成目标个性化语音波形。
VALL-E 2不仅可以使用未见过的说话者的参考文章作为提示,生成克隆其声音的语音,还可以进行零样本语音延续,其中,我们使用将单词的完整转录作为文本条件,前3秒前缀作为目标个性化语音生成的提示。
4实验
4.1设置
4.1.1 模型训练
我们使用 Libriheavy 语料库 (Kang 等人, 2024) 作为训练数据。 该语料库是 Librilight 语料库 (Kahn 等人,2020) 的标记版本,其中包含约 7000 个不同说话者的 5 万小时语音,这些语音源自 LibriVox 项目一部分的开源英语有声读物111https://librivox.org。 我们使用字节对编码 (BPE) 进行文本标记化,并使用预训练的开源 EnCodec 模型 (Défossez 等人,2022) 以 6K 比特率进行 24kHz 音频重建以进行语音标记化。 此外,我们使用开源的预训练 Vocos 模型(Siuzdak,2023) 作为语音生成的音频编解码器。
继VALL-E之后,AR模型和NAR模型都采用了VALL-E 2中相同的Transformer架构。 在我们的实验中,我们主要评估4个VALL-E 2模型,它们共享相同的NAR模型但不同的AR模型。 4 个 AR 模型对应的组大小为 1、2、4 和 8。 其中,组大小为1的AR模型是在没有组嵌入层和组预测层的情况下实现的,基线模型VALL-E采用相同的NAR模型和组大小为1的AR模型。 1222我们使用 Libriheavy 数据集重新训练基线 VALL-E 模型以进行公平比较。.
AR 和 NAR 模型均使用 16 个 NVIDIA TESLA V100 32GB GPU 进行训练。 这些模型使用 AdamW 优化器进行优化,前 32k 更新的学习率预热到学习率峰值,然后线性衰减。 对于NAR模型训练,声学条件的长度被随机采样为当前话语的一半的最大值,随机值在3s到30s之间。
4.1.2评估指标
我们采用主观评估指标,包括 SMOS 和 CMOS,分别评估合成语音的说话者相似度和比较自然度。 我们邀请 20 名以美式英语为母语的外部人士作为贡献者参与众包活动,从不同角度评估每场演讲。
SMOS(Similarity Mean Opinion Score)用于评估语音与原始提示的说话者相似度。 SMOS 等级范围为 1 至 5,增量为 0.5 分。
CMOS(比较平均意见分数)用于评估合成语音与给定参考语音的比较自然度。 CMOS标度范围从-3(表示新系统的合成语音比参考系统差很多)到3(表示新系统比参考系统好很多),间隔为1。 在我们的研究中,我们使用真实语音作为比较参考。
我们还采用包括 SIM、WER 和 DNSMOS 在内的客观评估指标来评估每个合成语音的说话者相似性、鲁棒性和整体感知质量。 为了更好地比较语音延续,我们评估整个文章,而不是仅仅关注延续部分。
SIM 用于评估原始提示和合成语音之间的说话人相似度,利用 SOTA 说话人验证模型 WavLM-TDNN 333We use the best speaker verification model released at https://github.com/microsoft/UniSpeech/tree/main/downstreams/speaker_verification#pre-trained-models (陈等人,2022)。 WavLM-TDNN预测的相似度得分在范围内,值越大表明说话人相似度越高。
WER(单词错误率)用于评估合成语音的鲁棒性。 神经 TTS 系统有时会因注意力对齐不正确而出现删除、插入和替换错误,这可能会影响其稳健性。 我们对生成的音频执行 ASR,并计算相对于原始转录的 WER。 在本实验中,我们采用开源的 Conformer-Transducer 模型444https://huggingface.co/nvidia/stt_en_conformer_transducer_xlarge (Gulati 等人, 2020) 作为 ASR 模型。
DNSMOS(深度噪声抑制平均意见得分)用于评估生成语音的整体感知质量(Reddy 等人,2021)。 具体来说,我们使用根据 ITU-T P.808 (ITU,2018)555https://github.com/microsoft/DNS-Challenge/tree/master/DNSMOS 预测 DNSMOS Score,取值范围为,值越大质量越好。
4.1.3 评估设置
我们使用 LibriSpeech test-clean (Panayotov 等人, 2015) 和 VCTK (Veaux 等人, 2016) 进行零样本 TTS 评估,确保这些语料库中没有说话人包含在训练数据中。
LibriSpeech test-clean 是 LibriSpeech 语料库的官方测试拆分,包含以 16kHz 采样的英语语音。 它与训练数据源自 LibriVox 项目的同一域,但具有不同的说话者 ID。 继 Borsos 等人 (2022) 和 Wang 等人 (2023a) 之后,我们使用 LibriSpeech test-clean 中的样本,长度在 4 到 10 秒之间,结果为 2.2 小时子集和 40 个独特的演讲者。 我们在两种设置下评估每个样本合成:3s 前缀作为提示和参考文献作为提示。 对于第一个设置,我们执行语音延续并利用语音的 3 秒前缀作为提示。 在第二种设置中,我们使用来自同一说话者的参考词作为提示。 具体来说,我们首先根据长度过滤 LibriSpeech test-clean 的官方语音列表。 对于每个说话者的有序语音列表,在第一个设置中,我们使用真实的第 语音样本的前 3 秒合成第 个语音样本,如下所示提示。 在第二个设置中,我们使用第 个样本作为提示来合成第 个语音样本,并使用最后一个样本作为提示来合成第一个语音样本。
VCTK 是一个阅读语料库,其中包含 108 位英语使用者以 48kHz 采样的语音。 与 LibriSpeech 相比,VCTK 提出了更大的挑战,因为它包含具有多种口音的说话者。 我们在三种设置下评估每个样本合成:使用长度为 3 秒、5 秒和 10 秒的提示。 具体来说,对于每个说话者,我们选择长度最接近但小于3s/5s/10s的一句话作为提示。 然后,我们随机采样另一个单词,并使用相应的转录作为语音合成的文本输入。
对于每个样本合成,我们首先使用 AR 模型进行推理,使用重复感知采样方法生成第一个代码序列(第 3.4.1 节),其中我们设置超参数 、,并选择从到的top-p值,间隔为。 接下来,我们对 NAR 模型进行七次推理,使用贪婪解码方法生成剩余的七个代码序列。 AR 模型基于采样的解码方法允许我们从同一输入生成不同的样本。 在我们的实验中,我们报告了每次语音合成的一次和五次采样的结果。 对于五次采样,我们报告了 SIM 和 WER 的排序结果以及按度量最大化的结果。
根据 SIM 和 WER 排序:我们根据说话者相似度和鲁棒性分数(以 SIM 和 WER 分数表示)对样本进行排序。 具体来说,给定五个样本 ,相应的 SIM、WER 和 DNSMOS 分数分别表示为 、 和 ,如果 SIM 分数大于 0.3,我们根据 WER 分数对它们进行排序,否则根据 SIM 分数进行排序。 这种排序方法可以表示为:
| (23) |
其中 表示查找字典顺序最大的数组 666词典秩:给定两个部分有序集合 和 ,当且仅当 或( 和 )时,笛卡儿积 的词典秩定义为 。. 生成的 SIM、WER 和 DNSMOS 分数为 、 和 。
按指标最大化:如果我们仅优化相应指标的值,我们会报告每个系统可以获得的最佳分数。 在这种情况下,生成的 SIM、WER 和 DNSMOS 分数为 、 和 。
4.2 LibriSpeech 评估
4.2.1 客观评价
| System | GroupSize | 3s Prefix as Prompt | Ref Utterance as Prompt | ||||||
| SIM | WER | DNSMOS | SIM | WER | DNSMOS | ||||
| GroundTruth | - | 0.905 | 1.6 | 3.891 | 0.779 | 1.6 | 3.891 | ||
| Codec | - | 0.823 | 1.7 | 3.886 | 0.715 | 1.7 | 3.886 | ||
| Single Sampling | |||||||||
| VALL-E | 13ms | 0.773 | 2.3 | 3.942 | 0.633 | 3.1 | 3.985 | ||
| VALL-E 2 | 0.782 | 1.6 | 3.947 | 0.643 | 1.5 | 3.987 | |||
| 0.777 | 1.5 | 3.966 | 0.635 | 1.5 | 4.000 | ||||
| 0.773 | 1.8 | 3.950 | 0.615 | 2.2 | 3.967 | ||||
| 0.766 | 2.5 | 3.937 | 0.566 | 4.2 | 3.875 | ||||
| Five-Time Sampling (Sort on SIM and WER) | |||||||||
| VALL-E | 13ms | 0.802 | 1.0 | 3.944 | 0.676 | 0.8 | 3.987 | ||
| VALL-E 2 | 0.807 | 1.0 | 3.943 | 0.687 | 0.7 | 3.994 | |||
| 0.803 | 1.0 | 3.967 | 0.679 | 0.6 | 3.997 | ||||
| 0.799 | 1.1 | 3.954 | 0.662 | 0.7 | 3.973 | ||||
| 0.790 | 1.0 | 3.938 | 0.616 | 1.0 | 3.898 | ||||
| Five-Time Sampling (Metric-Wise Maximization) | |||||||||
| VALL-E | 13ms | 0.806 | 1.0 | 4.055 | 0.686 | 0.7 | 4.124 | ||
| VALL-E 2 | 0.809 | 1.0 | 4.042 | 0.691 | 0.6 | 4.116 | |||
| 0.805 | 1.0 | 4.059 | 0.683 | 0.6 | 4.130 | ||||
| 0.802 | 1.1 | 4.046 | 0.669 | 0.7 | 4.105 | ||||
| 0.795 | 1.0 | 4.035 | 0.630 | 1.0 | 4.041 | ||||
表 1 展示了 LibriSpeech test-clean 数据集上的客观评估结果,其中 VALL-E 2 在所有设置下均显着优于 VALL-E,甚至通过单次采样获得比地面实况语音更好的 WER 和 DNSMOS 分数。
计算真实语音的 SIM、WER 和 DNSMOS 分数作为上限。 当使用现成的神经音频编解码器模型进行语音重建时,我们观察到 SIM 的性能下降以及 WER 和 DNSMOS 的类似性能。 基线VALL-E可以通过五次采样获得令人印象深刻的整体结果,但单次采样缺乏鲁棒性,这可能归因于随机采样解码过程的不稳定。
相比之下,VALL-E 2在鲁棒性方面表现出显着的提高,尤其是在单采样场景中。 通过重复感知采样,VALL-E 2 可以成功实现更好的解码稳定性,导致所有三个指标的性能提高,甚至获得比地面真实语音更低的 WER 分数。 这表明我们的合成语音高度忠实于提供的文本和注册的语音。
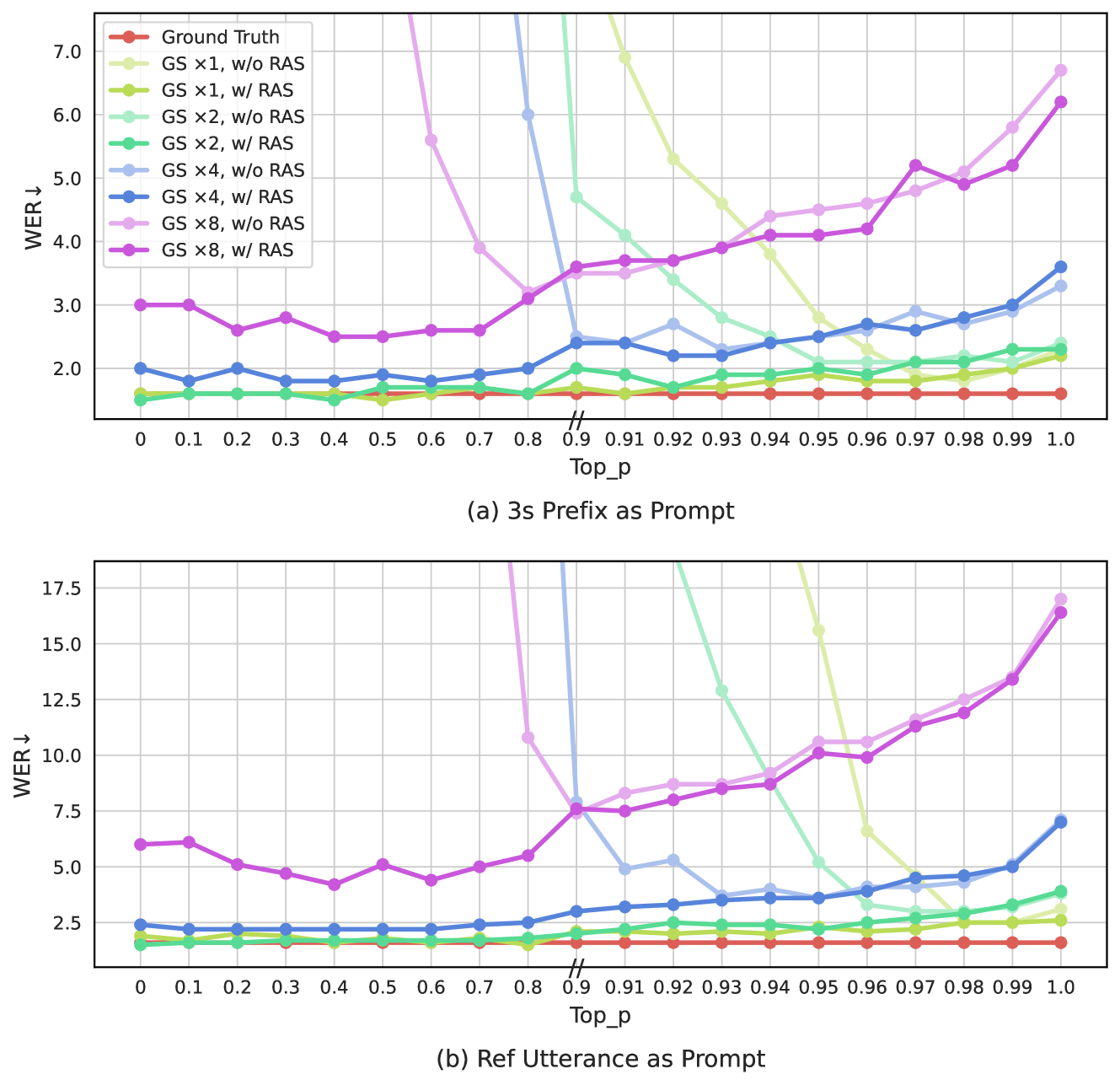
通过分组代码建模,VALL-E 2 在 AR 模型中组大小为 2 时可以获得更好的 WER 和 DNSMOS 分数。 结果表明,该方法不仅可以通过减少代码序列长度来提高推理效率,还可以通过缓解长上下文建模问题来提高模型性能。 即使组大小为 4,我们仍然可以获得与基线模型相似或更好的结果,同时通过将代码序列长度减少 4 倍,大大提高了推理效率。 图4进一步展示了VALL-E 2优越的解码稳定性。 无论组大小设置如何,重复感知采样方法都显着增强了解码稳定性。 它使 VALL-E 2 能够使用非常小的 top-p(甚至 0)进行推理,与使用大的 top-p 进行解码相比,这往往会引入更少的错误并生成更鲁棒的语音编解码器代码。 这是使用小top-p获得良好WER分数的关键,甚至低于groundtruth语音的分数。
4.2.2主观评价
| System | GroupSize | SMOS | CMOS | ||
| GroundTruth | - | 4.13±0.32 | 0.00 | ||
| VALL-E | 13ms | 4.45±0.28 | -0.268 | ||
| VALL-E 2 | 4.61±0.19 | 0.033 | |||
| 4.51±0.26 | -0.167 |
表2展示了LibriSpeech test-clean的主观评价结果。 对于主观评估,使用官方语音列表中的先前话语作为提示,为 LibriSpeech test-clean 数据集中的每个说话者生成当前话语,从而产生 40 个测试用例。
从表中可以看出,VALL-E 2在说话人相似度SMOS和语音质量CMOS方面都可以成功超越VALL-E,甚至比地面真实语音有更好的表现。 这表明我们提出的方法可以在 LibriSpeech 基准测试中实现与人类同等的零样本 TTS 性能。 通过组代码建模方法,对于 AR 模型的推理,VALL-E 2 也可以比组大小为 2 的 VALL-E 获得更好的性能。
4.2.3 消融研究
| AR Model | NAR Model | 3s Prefix as Prompt | Ref Utterance as Prompt | ||||||||
| Prompt Input | Text Input | Prompt Input | SIM | WER | DNSMOS | SIM | WER | DNSMOS | |||
| Single Sampling | |||||||||||
| ✓ | ✓ | ✓ | 0.779 | 1.6 | 3.956 | 0.639 | 1.9 | 4.013 | |||
| ✗ | ✓ | ✓ | n/a | n/a | n/a | 0.169 | 2.8 | 4.001 | |||
| ✓ | ✓ | ✦ | 0.731 | 1.6 | 3.957 | 0.530 | 1.9 | 4.018 | |||
| ✓ | ✓ | ✗ | n/a | n/a | n/a | 0.385 | 1.8 | 4.015 | |||
| ✓ | ✗ | ✓ | 0.774 | 5.6 | 3.958 | 0.619 | 10.0 | 4.016 | |||
| Five-Time Sampling | |||||||||||
| ✓ | ✓ | ✓ | 0.804 | 1.0 | 3.952 | 0.684 | 0.7 | 4.016 | |||
| ✗ | ✓ | ✓ | n/a | n/a | n/a | 0.305 | 2.0 | 4.018 | |||
| ✓ | ✓ | ✦ | 0.765 | 1.0 | 3.956 | 0.583 | 0.7 | 4.020 | |||
| ✓ | ✓ | ✗ | n/a | n/a | n/a | 0.457 | 1.0 | 4.019 | |||
| ✓ | ✗ | ✓ | 0.793 | 1.8 | 3.960 | 0.647 | 3.0 | 4.018 | |||
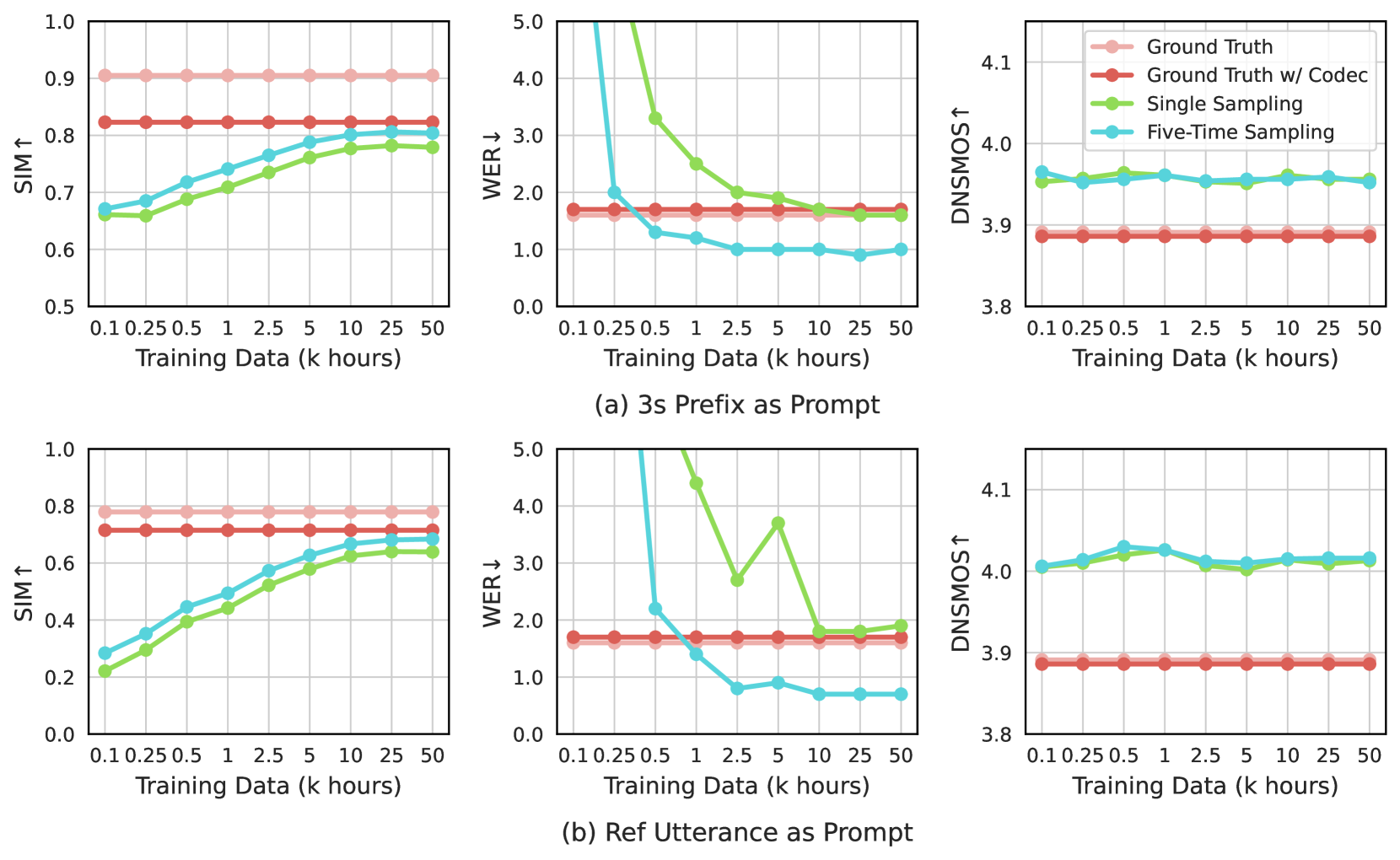
我们在 LibriSpeech test-clean 上对 VALL-E 2 进行了多项消融研究。 我们使用组大小为 1 的 VALL-E 2 模型,并给出每个语音合成的单次采样和五次采样的结果。 对于五次采样,我们根据 SIM 和 WER 分数对 5 个样本进行排序来选择最佳候选,如公式 23 所示。
模型输入的消融:在表3中,我们研究了AR和NAR模型中文本和提示输入的影响。 在 AR 或 NAR 模型中删除提示会导致说话者相似度分数显着降低,这强调了提示在保留说话者身份方面的关键作用。 尽管 NAR 模型可以访问提示,但 AR 模型的提示仍然对说话者相似度有显着贡献。 对于 NAR 模型,我们还发现在训练期间显式分割声学条件对于提高最终说话人相似度得分至关重要,因为 NAR 模型可以从提示的整个 8 个代码序列中提取更多说话人信息。 有趣的是,我们发现 AR 模型中的提示也提高了生成语音的鲁棒性,较低的 WER 分数就证明了这一点。 这可以归因于提示能够限制一对多语音合成任务的搜索空间,从而实现更稳定和鲁棒的语音生成。 此外,文本输入在 NAR 模型中对于获得较低的 WER 分数也至关重要,尽管它在 AR 模型中使用。
训练数据的消融:在图5中,我们探讨了训练数据大小对零样本TTS性能的影响。 我们发现,我们的模型在 LibriSpeech test-clean 上使用 10k 训练数据已经可以达到与 50k 数据相似的性能。 额外的 40k 数据仅在说话者相似性和鲁棒性方面带来轻微的性能改进。 然而,如果我们将训练数据减少到 10k 以下,我们会观察到性能下降,特别是对于设置参考文献作为提示。 值得注意的是,这个结论是基于当前有声读物领域的实验设置。
4.3VCTK评估
4.3.1 客观评价
| System | GroupSize | 3s Prompt | 5s Prompt | 10s Prompt | |||||||||
| SIM | WER | DNSMOS | SIM | WER | DNSMOS | SIM | WER | DNSMOS | |||||
| GroundTruth | - | 0.623 | 0.3 | 3.635 | 0.679 | 0.3 | 3.635 | 0.709 | 0.3 | 3.635 | |||
| Codec | - | 0.563 | 0.3 | 3.609 | 0.616 | 0.3 | 3.609 | 0.644 | 0.3 | 3.609 | |||
| Single Sampling | |||||||||||||
| VALL-E | 13ms | 0.430 | 2.4 | 3.667 | 0.455 | 3.1 | 3.664 | 0.533 | 5.8 | 3.575 | |||
| VALL-E 2 | 0.447 | 0.9 | 3.666 | 0.487 | 1.9 | 3.674 | 0.558 | 3.3 | 3.667 | ||||
| 0.426 | 1.5 | 3.599 | 0.481 | 0.9 | 3.598 | 0.557 | 2.3 | 3.617 | |||||
| 0.417 | 1.8 | 3.470 | 0.457 | 2.1 | 3.537 | 0.521 | 2.9 | 3.547 | |||||
| 0.375 | 5.0 | 3.438 | 0.415 | 4.8 | 3.387 | 0.499 | 8.0 | 3.420 | |||||
| Five-Time Sampling (Sort on SIM and WER) | |||||||||||||
| VALL-E | 13ms | 0.497 | 0.3 | 3.599 | 0.534 | 0.3 | 3.666 | 0.607 | 1.5 | 3.591 | |||
| VALL-E 2 | 0.508 | 0.0 | 3.684 | 0.552 | 0.3 | 3.699 | 0.620 | 1.5 | 3.694 | ||||
| 0.494 | 1.0 | 3.616 | 0.547 | 0.1 | 3.617 | 0.606 | 0.4 | 3.621 | |||||
| 0.487 | 0.9 | 3.547 | 0.531 | 0.4 | 3.588 | 0.592 | 1.6 | 3.559 | |||||
| 0.444 | 2.4 | 3.454 | 0.499 | 0.5 | 3.429 | 0.563 | 1.3 | 3.430 | |||||
| Five-Time Sampling (Metric-Wise Maximization) | |||||||||||||
| VALL-E | 13ms | 0.504 | 0.1 | 3.867 | 0.541 | 0.3 | 3.864 | 0.615 | 1.5 | 3.850 | |||
| VALL-E 2 | 0.513 | 0.0 | 3.860 | 0.555 | 0.3 | 3.868 | 0.621 | 1.5 | 3.855 | ||||
| 0.499 | 0.1 | 3.842 | 0.550 | 0.1 | 3.833 | 0.606 | 0.4 | 3.821 | |||||
| 0.490 | 0.5 | 3.760 | 0.537 | 0.3 | 3.783 | 0.595 | 1.4 | 3.772 | |||||
| 0.454 | 1.0 | 3.673 | 0.505 | 0.4 | 3.658 | 0.571 | 1.3 | 3.683 | |||||
表4展示了VCTK数据集上的客观评估结果,其中VALL-E 2表现出优于VALL-E的零样本TTS性能,特别是就语音鲁棒性得分 WER 而言。 它表明,重复感知采样方法还可以有效稳定具有不同口音的说话者的具有挑战性的 VCTK 数据的解码过程。 在单次采样场景中,它大约可以降低 WER 分数的一半。 通过五次采样,我们可以有效过滤掉低质量样本并选择最好的样本作为输出,使VALL-E能够生成鲁棒性更好的语音,并缩小WER的差距分数介于 VALL-E 和 VALL-E 2 之间。
当比较不同的提示长度时,我们发现分组代码建模方法甚至可以进一步提高较长提示的 WER 分数。 原因可能是过长的提示对 Transformer 架构的长序列建模提出了挑战,并且往往会由于不正确的注意力对齐而产生一些生成错误,而分组代码建模方法可以通过减少序列长度同时增强性能来缓解这一问题。 AR建模。
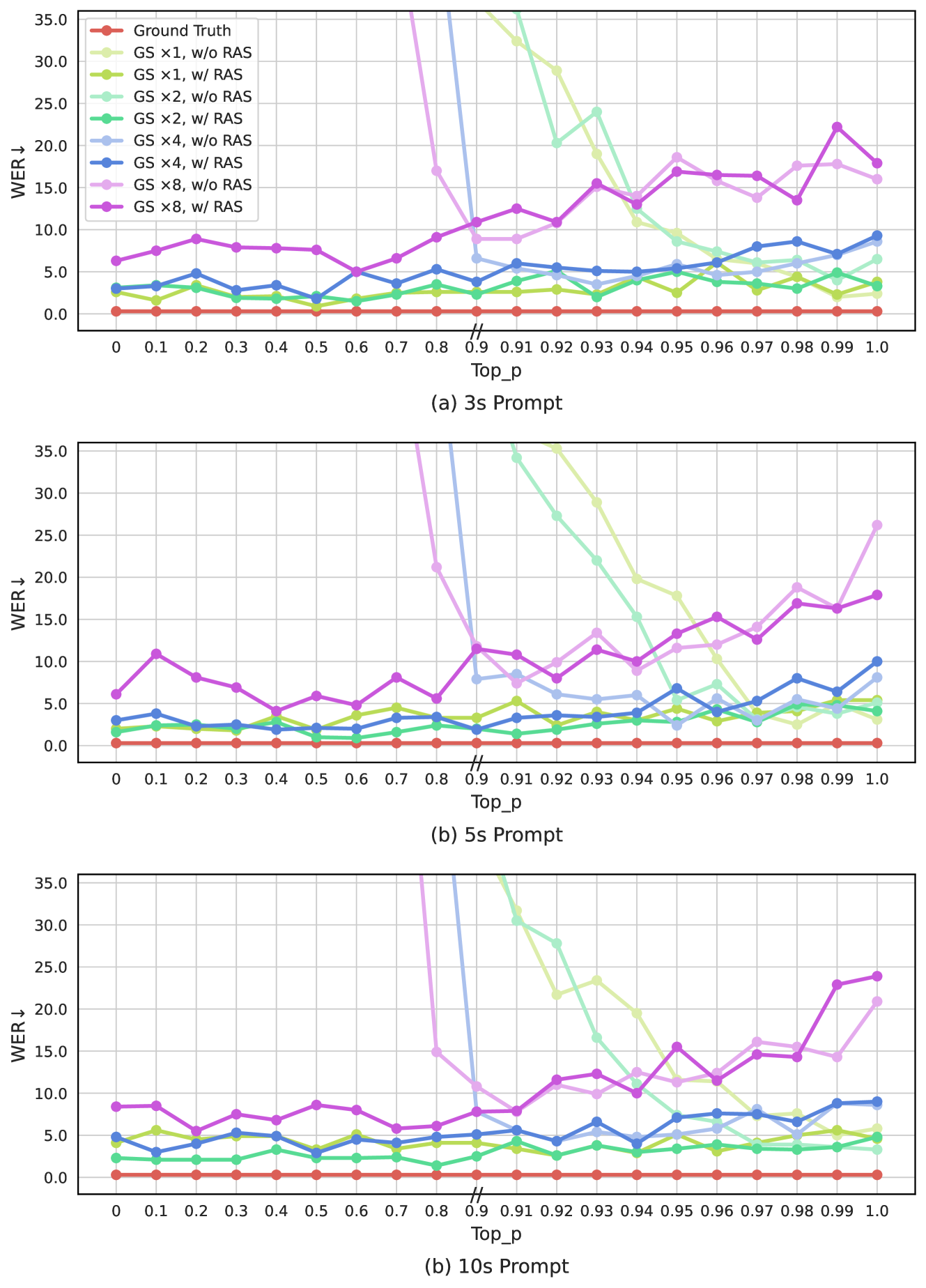
我们在图6中进一步展示了VALL-E 2卓越的解码稳定性。 正如在 LibriSpeech 数据集中发现的那样,重复感知采样方法显着增强了解码稳定性,并且能够生成具有相对较小的 top-p 值的更鲁棒性的语音信号。
4.3.2主观评价
| System | GroupSize | 3s Prompt | 5s Prompt | 10s Prompt | ||||||
| SMOS | CMOS | SMOS | CMOS | SMOS | CMOS | |||||
| GroundTruth | - | 4.47±0.13 | 0.00 | 4.53±0.14 | 0.00 | 4.74±0.17 | 0.00 | |||
| VALL-E | 13ms | 4.32±0.16 | 0.028 | 4.05±0.20 | 0.144 | 3.50±0.49 | 0.094 | |||
| VALL-E 2 | 4.42±0.15 | 0.207 | 4.28±0.16 | 0.079 | 3.95±0.10 | 0.117 | ||||
| 4.47±0.13 | 0.163 | 4.14±0.17 | 0.217 | 4.26±0.42 | 0.109 | |||||
表5给出了VCTK数据集上的主观评价结果。 我们使用来自 60 个不同说话者的 60 个测试用例进行主观评估。
考虑到 VCTK 数据集中说话者口音的多样性,零样本 TTS 比 LibriSpeech 数据集上的零样本 TTS 更具挑战性。 表5中的比较结果表明,VALL-E 2在说话人相似度和语音质量方面都可以成功超越VALL-E,即使仅使用 3 秒提示时,性能与真实语音相同或更好。 这强调了 VALL-E 在零样本 TTS 中针对多种口音场景的人类同等性能。
得益于组码建模方法的长上下文建模能力,我们还在10s的长提示下实现了显着的性能提升,特别是对于说话人相似度。
4.3.3 消融研究
| AR Model | NAR Model | 3s Prompt | 5s Prompt | 10s Prompt | |||||||||||
| Prompt Input | Text Input | Prompt Input | SIM | WER | DNSMOS | SIM | WER | DNSMOS | SIM | WER | DNSMOS | ||||
| Single Sampling | |||||||||||||||
| ✓ | ✓ | ✓ | 0.450 | 2.6 | 3.698 | 0.486 | 2.0 | 3.692 | 0.567 | 4.1 | 3.684 | ||||
| ✗ | ✓ | ✓ | 0.139 | 3.0 | 3.685 | 0.144 | 2.9 | 3.686 | 0.159 | 3.5 | 3.672 | ||||
| ✓ | ✓ | ✦ | 0.347 | 2.3 | 3.684 | 0.396 | 2.4 | 3.672 | 0.489 | 4.4 | 3.688 | ||||
| ✓ | ✓ | ✗ | 0.224 | 2.3 | 3.686 | 0.245 | 2.4 | 3.679 | 0.284 | 3.8 | 3.690 | ||||
| ✓ | ✗ | ✓ | 0.426 | 14.1 | 3.698 | 0.478 | 11.9 | 3.705 | 0.556 | 11.5 | 3.677 | ||||
| Five-Time Sampling | |||||||||||||||
| ✓ | ✓ | ✓ | 0.513 | 0.0 | 3.678 | 0.550 | 0.0 | 3.694 | 0.618 | 1.6 | 3.703 | ||||
| ✗ | ✓ | ✓ | 0.271 | 1.6 | 3.787 | 0.282 | 2.3 | 3.741 | 0.303 | 3.1 | 3.725 | ||||
| ✓ | ✓ | ✦ | 0.418 | 0.4 | 3.665 | 0.472 | 1.0 | 3.700 | 0.550 | 1.5 | 3.675 | ||||
| ✓ | ✓ | ✗ | 0.306 | 1.4 | 3.658 | 0.327 | 2.1 | 3.678 | 0.361 | 3.8 | 3.677 | ||||
| ✓ | ✗ | ✓ | 0.476 | 3.0 | 3.705 | 0.527 | 1.5 | 3.719 | 0.605 | 2.4 | 3.725 | ||||
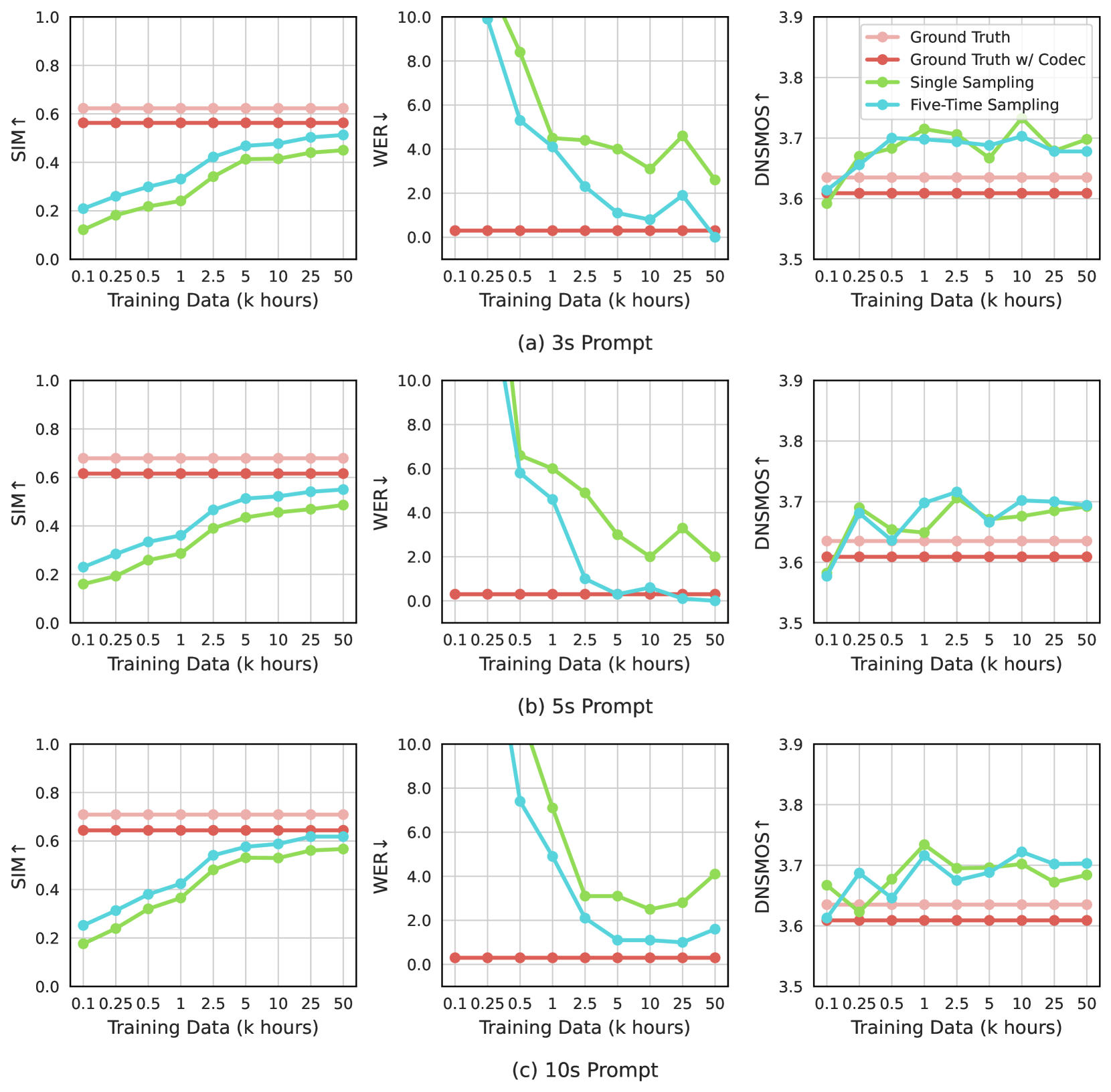
我们进一步在 VCTK 数据集上对 VALL-E 2 进行消融研究。 我们使用组大小为 1 的 VALL-E 2 模型,并给出每个语音合成的单次采样和五次采样的结果。 对于五次采样,我们使用公式23对多个样本进行排序。
模型输入的消融:如表6所示,与LibriSpeech评估中的观察结果一致,提示在说话人信息建模的AR和NAR模型中都至关重要。 当我们删除提示输入时,说话者相似度得分会显着下降。 虽然文本输入在 AR 模型中被消耗,但 NAR 模型也需要它来合成鲁棒的语音。
训练数据的消融:如图7所示,不同的推理提示和指标,训练数据的最佳大小有所不同。 SIM 分数始终受益于更大的训练数据,它提供了更多样化的说话者语音模式。 3 秒提示下的最佳 WER 分数需要比 5 秒提示和 10 秒提示更多的训练数据,因为仅 3 秒注册语音的零样本 TTS 的挑战更大。 有趣的是,最好的 DNSMOS 分数并不是通过最大的训练数据来实现的。 一种可能的解释是,在模型容量有限的情况下,我们的模型以感知质量的轻微损失为代价实现了更好的说话人相似性和鲁棒性。
5结论
我们推出了VALL-E 2,这是一种语言建模方法,首次实现了人类同等的零样本文本到语音合成(TTS)。 基于VALL-E的成功,VALL-E 2引入了两种简单但有效的方法:重复感知采样以提高解码稳定性和分组代码建模以提高建模效率。 此外,我们的观察表明,VALL-E 2 能够可靠地合成复杂句子的语音,包括那些难以阅读或包含大量重复短语的句子。
更广泛的影响: 由于VALL-E 2可以合成保持说话人身份的语音,因此可能存在模型滥用的潜在风险,例如欺骗语音识别或冒充特定说话人。 我们在用户同意成为语音合成中的目标说话人的假设下进行实验。 如果该模型被推广到现实世界中看不见的说话者,它应该包括一个协议来确保说话者批准使用他们的声音和一个合成语音检测模型。 此外,还可以建立一个检测模型来区分音频片段是否是由VALL-E 2合成的。 我们还将把 Microsoft AI 原则777https://www.microsoft.com/ai/responsible-ai 付诸实践。
参考
- Anil et al. (2023) Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Arik et al. (2018) Sercan Ömer Arik, Jitong Chen, Kainan Peng, Wei Ping, and Yanqi Zhou. Neural voice cloning with a few samples. In NeurIPS, pages 10040–10050, 2018.
- Borsos et al. (2022) Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matthew Sharifi, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. Audiolm: a language modeling approach to audio generation. CoRR, abs/2209.03143, 2022.
- Borsos et al. (2023) Zalán Borsos, Matt Sharifi, Damien Vincent, Eugene Kharitonov, Neil Zeghidour, and Marco Tagliasacchi. Soundstorm: Efficient parallel audio generation. arXiv preprint arXiv:2305.09636, 2023.
- Casanova et al. (2022) Edresson Casanova, Julian Weber, Christopher D Shulby, Arnaldo Candido Junior, Eren Gölge, and Moacir A Ponti. Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone. In ICML, pages 2709–2720. PMLR, 2022.
- Chang et al. (2022) Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11315–11325, 2022.
- Chen et al. (2022) Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022.
- Chen et al. (2019) Yutian Chen, Yannis M. Assael, Brendan Shillingford, David Budden, Scott E. Reed, Heiga Zen, Quan Wang, Luis C. Cobo, Andrew Trask, Ben Laurie, Çaglar Gülçehre, Aäron van den Oord, Oriol Vinyals, and Nando de Freitas. Sample efficient adaptive text-to-speech. In ICLR ,, 2019.
- Défossez et al. (2022) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438, 2022.
- Dong et al. (2023) Qianqian Dong, Zhiying Huang, Chen Xu, Yunlong Zhao, Kexin Wang, Xuxin Cheng, Tom Ko, Qiao Tian, Tang Li, Fengpeng Yue, et al. Polyvoice: Language models for speech to speech translation. arXiv preprint arXiv:2306.02982, 2023.
- Du et al. (2024a) Chenpeng Du, Yiwei Guo, Feiyu Shen, Zhijun Liu, Zheng Liang, Xie Chen, Shuai Wang, Hui Zhang, and Kai Yu. Unicats: A unified context-aware text-to-speech framework with contextual vq-diffusion and vocoding. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17924–17932, 2024a.
- Du et al. (2024b) Zhihao Du, Shiliang Zhang, Kai Hu, and Siqi Zheng. Funcodec: A fundamental, reproducible and integrable open-source toolkit for neural speech codec. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 591–595. IEEE, 2024b.
- Gulati et al. (2020) Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, et al. Conformer: Convolution-augmented transformer for speech recognition. 2020.
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Huang et al. (2023a) Rongjie Huang, Chunlei Zhang, Yongqi Wang, Dongchao Yang, Luping Liu, Zhenhui Ye, Ziyue Jiang, Chao Weng, Zhou Zhao, and Dong Yu. Make-a-voice: Unified voice synthesis with discrete representation. arXiv preprint arXiv:2305.19269, 2023a.
- Huang et al. (2023b) Zhichao Huang, Chutong Meng, and Tom Ko. Repcodec: A speech representation codec for speech tokenization. arXiv preprint arXiv:2309.00169, 2023b.
- ITU (2018) Rec ITU. P. 808: Subjevtive evaluation of speech quality with a crowdsoucing approach. International Telecommunication Standardization Sector (ITU-T), 2018.
- Jiang et al. (2023a) Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Chen Zhang, Zhenhui Ye, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, et al. Mega-tts 2: Zero-shot text-to-speech with arbitrary length speech prompts. arXiv preprint arXiv:2307.07218, 2023a.
- Jiang et al. (2023b) Ziyue Jiang, Yi Ren, Zhenhui Ye, Jinglin Liu, Chen Zhang, Qian Yang, Shengpeng Ji, Rongjie Huang, Chunfeng Wang, Xiang Yin, et al. Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias. arXiv preprint arXiv:2306.03509, 2023b.
- Ju et al. (2024) Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, et al. Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models. arXiv preprint arXiv:2403.03100, 2024.
- Kahn et al. (2020) Jacob Kahn, Morgane Rivière, Weiyi Zheng, Evgeny Kharitonov, Qiantong Xu, Pierre-Emmanuel Mazaré, Julien Karadayi, Vitaliy Liptchinsky, Ronan Collobert, Christian Fuegen, et al. Libri-light: A benchmark for asr with limited or no supervision. In ICASSP, pages 7669–7673. IEEE, 2020.
- Kang et al. (2024) Wei Kang, Xiaoyu Yang, Zengwei Yao, Fangjun Kuang, Yifan Yang, Liyong Guo, Long Lin, and Daniel Povey. Libriheavy: a 50,000 hours asr corpus with punctuation casing and context. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 10991–10995. IEEE, 2024.
- Kharitonov et al. (2023) Eugene Kharitonov, Damien Vincent, Zalán Borsos, Raphaël Marinier, Sertan Girgin, Olivier Pietquin, Matt Sharifi, Marco Tagliasacchi, and Neil Zeghidour. Speak, read and prompt: High-fidelity text-to-speech with minimal supervision. Transactions of the Association for Computational Linguistics, 11:1703–1718, 2023.
- Kumar et al. (2024) Rithesh Kumar, Prem Seetharaman, Alejandro Luebs, Ishaan Kumar, and Kundan Kumar. High-fidelity audio compression with improved rvqgan. Advances in Neural Information Processing Systems, 36, 2024.
- Łajszczak et al. (2024) Mateusz Łajszczak, Guillermo Cámbara, Yang Li, Fatih Beyhan, Arent van Korlaar, Fan Yang, Arnaud Joly, Álvaro Martín-Cortinas, Ammar Abbas, Adam Michalski, et al. Base tts: Lessons from building a billion-parameter text-to-speech model on 100k hours of data. arXiv preprint arXiv:2402.08093, 2024.
- Le et al. (2024) Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, et al. Voicebox: Text-guided multilingual universal speech generation at scale. Advances in neural information processing systems, 36, 2024.
- Li et al. (2019) Naihan Li, Shujie Liu, Yanqing Liu, Sheng Zhao, and Ming Liu. Neural speech synthesis with transformer network. In AAAI, pages 6706–6713. AAAI, 2019.
- Li et al. (2024) Yinghao Aaron Li, Cong Han, Vinay Raghavan, Gavin Mischler, and Nima Mesgarani. Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models. Advances in Neural Information Processing Systems, 36, 2024.
- Lipman et al. (2022) Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022.
- Panayotov et al. (2015) Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In ICASSP, pages 5206–5210. IEEE, 2015.
- Reddy et al. (2021) Chandan KA Reddy, Vishak Gopal, and Ross Cutler. Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6493–6497. IEEE, 2021.
- Ren et al. (2019) Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Fastspeech: Fast, robust and controllable text to speech. In NeurIPS, pages 3165–3174, 2019.
- Rubenstein et al. (2023) Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. Audiopalm: A large language model that can speak and listen. arXiv preprint arXiv:2306.12925, 2023.
- Shen et al. (2018) Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ-Skerrv Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, and Yonghui Wu. Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions. In ICASSP, pages 4779–4783. IEEE, 2018.
- Shen et al. (2023) Kai Shen, Zeqian Ju, Xu Tan, Eric Liu, Yichong Leng, Lei He, Tao Qin, Jiang Bian, et al. Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers. In The Twelfth International Conference on Learning Representations, 2023.
- Siuzdak (2023) Hubert Siuzdak. Vocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis. arXiv preprint arXiv:2306.00814, 2023.
- Song et al. (2024) Yakun Song, Zhuo Chen, Xiaofei Wang, Ziyang Ma, and Xie Chen. Ella-v: Stable neural codec language modeling with alignment-guided sequence reordering. arXiv preprint arXiv:2401.07333, 2024.
- Tan et al. (2024) Xu Tan, Jiawei Chen, Haohe Liu, Jian Cong, Chen Zhang, Yanqing Liu, Xi Wang, Yichong Leng, Yuanhao Yi, Lei He, Sheng Zhao, Tao Qin, Frank Soong, and Tie-Yan Liu. Naturalspeech: End-to-end text-to-speech synthesis with human-level quality. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6):4234–4245, 2024. doi: 10.1109/TPAMI.2024.3356232.
- Veaux et al. (2016) Christophe Veaux, Junichi Yamagishi, Kirsten MacDonald, et al. Superseded-cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit. 2016.
- Vyas et al. (2023) Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, et al. Audiobox: Unified audio generation with natural language prompts. arXiv preprint arXiv:2312.15821, 2023.
- Wang et al. (2023a) Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023a.
- Wang et al. (2020) Tao Wang, Jianhua Tao, Ruibo Fu, Jiangyan Yi, Zhengqi Wen, and Rongxiu Zhong. Spoken content and voice factorization for few-shot speaker adaptation. In Interspeech, pages 796–800. ISCA, 2020.
- Wang et al. (2023b) Tianrui Wang, Long Zhou, Ziqiang Zhang, Yu Wu, Shujie Liu, Yashesh Gaur, Zhuo Chen, Jinyu Li, and Furu Wei. Viola: Unified codec language models for speech recognition, synthesis, and translation. arXiv preprint arXiv:2305.16107, 2023b.
- Wang et al. (2023c) Xiaofei Wang, Manthan Thakker, Zhuo Chen, Naoyuki Kanda, Sefik Emre Eskimez, Sanyuan Chen, Min Tang, Shujie Liu, Jinyu Li, and Takuya Yoshioka. Speechx: Neural codec language model as a versatile speech transformer. arXiv preprint arXiv:2308.06873, 2023c.
- Wu et al. (2024) Haibin Wu, Ho-Lam Chung, Yi-Cheng Lin, Yuan-Kuei Wu, Xuanjun Chen, Yu-Chi Pai, Hsiu-Hsuan Wang, Kai-Wei Chang, Alexander H. Liu, and Hung yi Lee. Codec-superb: An in-depth analysis of sound codec models, 2024.
- Wu et al. (2023) Yi-Chiao Wu, Israel D Gebru, Dejan Marković, and Alexander Richard. Audiodec: An open-source streaming high-fidelity neural audio codec. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023.
- Xin et al. (2024) Detai Xin, Xu Tan, Kai Shen, Zeqian Ju, Dongchao Yang, Yuancheng Wang, Shinnosuke Takamichi, Hiroshi Saruwatari, Shujie Liu, Jinyu Li, et al. Rall-e: Robust codec language modeling with chain-of-thought prompting for text-to-speech synthesis. arXiv preprint arXiv:2404.03204, 2024.
- Yang et al. (2023a) Dongchao Yang, Songxiang Liu, Rongjie Huang, Jinchuan Tian, Chao Weng, and Yuexian Zou. Hifi-codec: Group-residual vector quantization for high fidelity audio codec. arXiv preprint arXiv:2305.02765, 2023a.
- Yang et al. (2023b) Dongchao Yang, Jinchuan Tian, Xu Tan, Rongjie Huang, Songxiang Liu, Xuankai Chang, Jiatong Shi, Sheng Zhao, Jiang Bian, Xixin Wu, et al. Uniaudio: An audio foundation model toward universal audio generation. arXiv preprint arXiv:2310.00704, 2023b.
- Zeghidour et al. (2021) Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2021.
- Zhang et al. (2023a) Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu. Speechtokenizer: Unified speech tokenizer for speech large language models. arXiv preprint arXiv:2308.16692, 2023a.
- Zhang et al. (2023b) Ziqiang Zhang, Long Zhou, Chengyi Wang, Sanyuan Chen, Yu Wu, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Speak foreign languages with your own voice: Cross-lingual neural codec language modeling. arXiv preprint arXiv:2303.03926, 2023b.