基于 LLM 的代理工作流程和 LLM 概要组件的调查
摘要
大型语言模型(大语言模型)的最新进展促进了复杂代理工作流程的发展,提供了对传统单路径、思想链(CoT)提示技术的改进。 这项调查总结了常见的工作流程,特别关注 LLM 组件 (LMPC) 和对非 LLM 组件的忽略。 这种探索背后的原因是为了更清楚地理解大语言模型角色,并了解 LMPC 的可重用性。
基于 LLM 的代理工作流程和 LLM 概要组件的调查
Xinzhe Li School of IT, Deakin University, Australia lixinzhe@deakin.edu.au
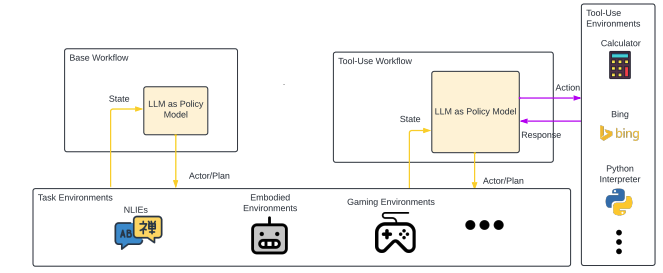
1简介
生成性大语言模型(GLM或大语言模型)已经获得了广泛的常识和类人推理能力(Santurkar等人,2023;Wang等人,2022;Zhong等人,2022,2023) ,将它们定位为构建称为基于 LLM 的代理的 AI 代理的关键。 在本次调查中,基于 LLM 的代理是根据其与外部工具(例如维基百科)或环境(例如家庭环境)积极交互的能力来定义的,并且被设计为作为代理的组成部分发挥作用,包括行动、规划,并进行评估。
调查目的
这项调查背后的动机源于观察到许多基于 LLM 的代理都采用了类似的工作流程和组件,尽管存在各种技术和概念挑战,例如搜索算法(Yao等人,2023a)、树结构(Hao等人,2023)和强化学习(RL)组件(Shinn等人,2023)。 (Wu 等人,2023)提供了模块化方法,但缺乏与流行的代理工作流程的集成。 Wang 等人 (2024) 对大语言模型智能体进行了全面的回顾,探索了它们在分析、记忆、规划和行动方面的能力。 相比之下,我们的调查并不试图全面涵盖 LLM 代理的所有组成部分。 相反,我们专注于大语言模型在代理工作流程中的参与,并旨在阐明大语言模型在代理实现中的角色。 我们创建了包含可重复使用的 LLM-Profiled 组件 (LMPC) 的通用工作流程,如图 1 所示。
贡献
我们总结了四种与任务无关的 LMPC(参与者、规划器、评估器和动态模型)和其他任务相关的 LMPC(例如语言器)。 所有现有作品,如ReAct (Yao 等人, 2023b)、Reflexion (Shinn 等人, 2023) 和Tree-of-Thoughts (Yao 等人, 2023a) 由这些工作流程和 LMPC 以及一些特定的非 LLM 组件组成。 我们对三种类型的模块化工作流程进行了分类和详细说明:仅策略工作流程、基于搜索的工作流程和反馈学习工作流程。 此外,§3 描述了四种与任务无关的 LMPC(参与者、规划器、评估器和动态模型),并介绍了特定于任务的 LMPC。 §4 和表 2 展示了这些组件与非 GLM 元素一起集成到 ReAct、Reflexion 和 Tree-of-Thoughts 等著名模型中的情况。 这些工作流程和常见 LMPC 的描述具有以下几个优点:1)它增强了对现有基于 LLM 的代理工作流程的理解。 2) 它支持工作流级和组件级实现的重用和适应,以构建复杂的代理。 3) 它简化了现有工作流程的修改和扩展,因为它们通常包含一个或多个这些组件。 §5 还包括 LMPC 的常见实现以支持进一步扩展。
| Env Types | Entities Interacted With by Agent | Action Properties | Examples of Action Instances | Examples of Env Instances |
| Task Environments | ||||
|
Gaming
Environments |
Virtual game elements (objects, avatars, other characters), and possibly other players or game narratives |
Discrete,
Executable, Deterministic |
Move(Right) | BlocksWorld, CrossWords |
|
Embodied
Environments |
Physical world (through sensors and actuators) |
Discrete,
Executable, Deterministic |
Pick_Up[Object] |
AlfWorld (Shridhar et al., 2021),
VirtualHome, Minecraft (Fan et al., 2022) |
| NLIEs | Humans (through conversation or text) |
Free-form,
Discrete, Deterministic (Single-step QA) Stochastic (Multi-step) |
The answer is Answer
Finish[Answer] |
GSM8K,
HotpotQA |
| Tool Environments ( Nested with Task Environments) | ||||
| Retrieval | Retrieval |
Discrete,
Executable, Deterministic, Non-State-Altering |
Wiki_Search[Entity] | A Wikipedia API (Goldsmith, 2023) (used by ReAct (Yao et al., 2023b)) |
| Calculator | Calculator |
Executable,
Deterministic, Non-State-Altering |
2 x 62 = << Calculator >> | Python’s eval function (used by MultiTool-CoT (Inaba et al., 2023)) |
2 任务环境和工具环境
本节探讨任务环境和工具环境,与传统人工智能和强化学习 (RL) 代理框架相比,它们呈现出不同的设置(Russell 和 Norvig,2010;Sutton 和 Barto,2018)。 在简要概述基于标准逻辑的游戏和模拟体现环境之后,我们重点关注两个特定领域:自然语言交互环境(NLIE)和工具环境。
2.1 典型任务环境
通常,有两种常见类型的任务环境: 1)基于规则的游戏环境:这些环境是确定性的且完全可观察的,包括各种抽象策略游戏(例如国际象棋和围棋)以及逻辑诸如《24的游戏》(姚等人,2023a)和《积木世界》(郝等人,2023)等谜题。 他们需要深刻的逻辑推理和战略规划来导航和解决问题。 2) 模拟具体环境:这些设置模拟现实世界的物理交互和空间关系。 它们要求代理参与导航、对象操作和其他复杂的物理任务,反映物理环境的变化。
2.2 自然语言交互环境
随着大语言模型主体的兴起,NLP研究人员越来越倾向于将典型的NLP任务重新语境化为主体环境(姚等人,2023b;郝等人,2023;姚等人,2023a)。 在我们的调查中,这些设置被称为自然语言交互环境。
在 NLIE 中,环境保持静态,直到智能体采取行动。 与自然语言作为中介的典型任务环境不同,在 NLIE 中,状态和动作都是用语言定义的,使得状态概念化,而动作通常是模糊且广泛定义的。
用于问答的单步 NLIE
许多作品(Yao 等人,2023b;Shinn 等人,2023)将传统的 QA 设置表述为单步决策过程,其中代理针对问题生成答案。 该过程以问题作为初始状态开始,并以答案作为操作提供时结束。
有意的多步骤 NLIE
对于“没有明确定义中间步骤”的任务,一些研究已将 NLP 任务转化为马尔可夫决策过程,以促进代理工作流程。 例如,Hao 等人 (2023) 将 QA 任务中的子问题重新表述为操作,从而能够通过多步骤过程响应用户查询。 这种方法允许初始问题作为一系列状态转换的开始。 操作可能有所不同,从在单步 QA 中提供直接、自由形式的答案,到战略性地制定子问题,引导代理通过顺序更新获得全面的解决方案。 这种方法与顺序决策过程更加一致,使其适合部署在基于规划的代理系统中。 此外,Wan 等人 (2024) 建议“将输出序列拆分为标记可能是有条理地定义多步骤 NLIE 的一个不错的选择”。 此外,Yao 等人(2023a)通过将问题解决过程分为不同的规划和执行阶段,制定了创意写作的两步NLIE。
2.3工具环境
现代大语言模型智能体通常通过外部工具进行增强,以提高其解决问题的能力(Inaba 等人,2023;Yao 等人,2023b)。 这些工具的设计和集成增加了复杂性,需要仔细考虑大语言模型如何与任务环境以及这些辅助工具交互。 通常,工具环境中的操作涉及与不受这些交互影响的资源的交互。 例如,从维基百科检索数据构成“只读”操作,不会修改维基百科数据库。 此功能将此类工具使用操作与传统任务环境或典型强化学习 (RL) 设置中的操作区分开来,在这些操作中,操作通常会改变环境状态。 然而,重要的是要认识到工具环境可以是动态的,可以经历外部变化。 这方面反映了工具应被视为外部环境而不是代理的内部流程的本质。
嵌套 NLIE-QA + 工具环境
工具环境通常与 NLIE 一起建立,以帮助解决 QA 任务。 Shinn 等人 (2023); Yao 等人 (2023b) 采用工具来增强回复的真实性。 它们定义类似命令的操作,例如“搜索”和“查找”以与维基百科交互,“搜索”建议相关维基页面中前 5 个相似实体,“查找”则模拟浏览器中的 Ctrl+F 功能。 除了简单的检索之外,Thoppilan 等人 (2022) 还包括一个语言翻译器和一个用于对话任务的计算器。 同样,Inaba 等人 (2023) 使用使用 Python eval 函数实现的计算器来解决 NumGLUE 基准中的数字查询。
3 LLM 型组件
本节探讨大语言模型通常描述的常见代理角色。 这些组件利用大语言模型的内部常识知识和推理能力来生成行动、计划、估计值 111值是指与在某种状态下采取某种行动相关的估计奖励(对结果的成功或可取性的定量衡量),广泛用于典型的强化学习中和 MDP 设置来学习执行所需行为的策略模型。,并推断后续状态。
通用 LLM 型组件
具体来说,以下与任务无关的组件经过分析并在各种工作流程中常用。 1) LLM-Profiled Policy :策略模型旨在生成决策,决策可以是在外部环境中执行或在搜索和规划算法中使用的一个操作或一系列操作(计划)。 222请注意,规划算法可用于构建计划的计划;例如,思想树采用树搜索,其中每个节点可能代表单个操作或整个计划。 典型的强化学习政策模型通过反复试验来学习最大化累积奖励,与此相反,LLM 描述的政策模型(表示为 )利用从大量文本数据中得出的预先训练的知识和常识。 我们区分两种类型的 :参与者 直接将状态映射到操作,而规划器 从给定状态生成一系列操作。 2) LLM 型评估者:提供对不同工作流程至关重要的反馈。 他们评估基于搜索的工作流程中的动作和状态(Hao等人,2023;Yao等人,2023a)并修改反馈学习工作流程中的决策(Shinn等人,2023;Wang等人,2023b)(更多详情请参阅§4)。 这些评估者是直接行动评估和更广泛的战略调整不可或缺的一部分。 3)LLM-Profiled动态模型:它们预测或描述环境的变化。 一般来说,动态模型通过从当前状态和动作预测下一个状态来构成综合世界模型的一部分。 典型的强化学习使用概率分布 来建模潜在的下一个状态,而基于 LLM 的动态模型直接预测下一个状态 。
任务相关的 LLM 概要组件
除了通用组件之外,某些 LLM 描述的组件是针对特定任务量身定制的。 例如,言语表达器在具体环境中至关重要,但在 NLIE 中则不必要。 语言表达者将行动和观察转化为规划者的输入;例如,在 Planner-Actor-Reporter 工作流程 (Wang 等人, 2023a) 中,微调的视觉语言模型 (VLM) 与 将像素状态转换为文本输入。 类似地,如果环境反馈与状态一起可被感知,则可能需要语言器将这种反馈转换为 的语言描述,类似于 RL 中的奖励塑造,其中为政策学习生成数字刺激。 大语言模型被描述为言语者, (Shinn 等人, 2023),通常根据指定的标准指导描述。
| Involved Workflows |
Generative-LLM
Components |
Non-Generative-LLM
Components |
Applied
Environments |
|
|---|---|---|---|---|
| ToT (Yao et al., 2023a) |
Search-based
(Fixed value models) |
, ,
(only for NLIEs-Writing) |
Search Tree | Gaming; NLIEs-Writing |
| Tree-BeamSearch (Xie et al., 2023) |
Search-based
(Fixed value models) |
, | Search Tree | NLIE-QA |
| RAP (Hao et al., 2023) |
Search-based
(Adaptive Value Estimate) |
, , | Search Tree | Gaming; NLIEs-QA |
| LLM Planner (Huang et al., 2022) | Direct | MLM for action translation | Embodied Env | |
| DEPS (Wang et al., 2023b) | Direct | ,, | Immediate actor, VLM+GLM as verbalizer | Embodied Env |
| Planner-Actor-Reporter (Dasgupta et al., 2022) | Direct | RL actor, Trained classifier+Hard code as verbalizer | Embodied Env | |
| Plan-and-solve (Wang et al., 2023a) | Direct | / | NLIEs-QA | |
| MultiTool-CoT (Inaba et al., 2023) | Tool-Use | / | NLIEs | |
| ReAct (Yao et al., 2023b) | Tool-Use | / | NLIEs | |
| Direct | / | Embodied Env | ||
| Guan et al. (2023) |
Feedback Learning
(from Tools & Humans) |
, | Domain Experts, Domain-independent Planner | Embodied Env |
| CRITIC (Gou et al., 2024) |
Feedback Learning
(from Tool & Self) |
/ | NLIEs | |
| Reflexion (Shinn et al., 2023) |
Feedback Learning
(from Self), Tool-Use |
, , | / | NLIEs-QA |
|
Feedback Learning
(from Task Env & Self), |
, , | Embodied Env | ||
| Self-refine (Madaan et al., 2023) |
Feedback Learning
(from Self) |
, , | / | NLIEs |
4 基于LLM的代理的工作流程
本节说明如何使用各种 LLM 组件,如图 1 所示。
4.1 仅限策略的工作流程
基础和工具使用工作流程仅需要将大语言模型描述为策略模型。 在具体任务领域,许多项目使用部署基础工作流,以使用大语言模型代理生成计划,例如大语言模型规划器(黄等人,2022) 、规划者-行动者-报告者(Dasgupta 等人, 2022) 和 DEPS (Wang 等人, 2023b)。 计划与解决方法(Wang 等人,2023a)将基本工作流程应用于NLIE。 相比之下, 的工具使用工作流程始终应用于 NLIE,例如 ReAct (Yao 等人, 2023b)、Reflexion (Shinn 等人, 2023) 和 MultiTool-CoT (Inaba 等人,2023)。
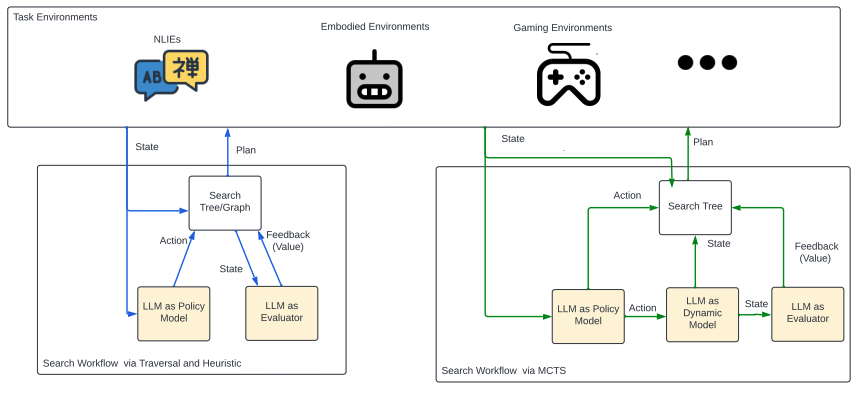
4.2 搜索工作流程
与的基础智能体不同,基础智能体在一代中为计划生成一系列动作,动作可以组织成树(Yao等人,2023a;Hao等人,2023) 和图(Liu 等人, 2023) 进行探索。 这种具有搜索功能的规划代理可以以非线性方式探索状态。 树(或解决方案)是通过添加节点来构建的,每个节点代表带有输入和到目前为止的想法/行动序列的部分解决方案。 使用这些数据结构可以使用波束搜索(Xie等人,2023)、深度/广度优先搜索(DFS和BFS)等算法对多个推理路径生成的动作进行策略性搜索(Yao 等人, 2023a) 和蒙特卡洛树搜索 (MCTS) (Hao 等人, 2023)。
LMPC 用于探索实现目标的路径。 不是直接在外部环境上应用操作,而是生成多个操作样本以方便搜索过程的操作选择,而 用于计算探索期间操作/状态评估的值(姚等人,2023a;陈等人,2024)。
通过遍历和启发式搜索
ToT 工作流程(Yao 等人, 2023a) 使用 在树和图上扩展节点, 提供固定值估计来选择进一步扩展的节点。 为了扩展树,Tree-BeamSearch 工作流程(Xie 等人,2023) 采用束搜索,而 ToT 应用深度/广度优先搜索(DFS 和 BFS)。 然而,BFS 确实是使用 波束的波束搜索,因为单位模型 生成的值用于维护 最有希望的节点。 通常,BFS 不使用实用模型来决定扩展哪些节点,因为它系统地探索每个深度的所有可能节点。 的 CoT 实现将对结果状态进行推理,并产生值来“确定要继续探索哪些状态以及按什么顺序”Yao 等人 (2023a)。
通过 MCTS 搜索
RAP工作流程(Hao等人,2023)也通过搜索构建树,并包含来扩展节点。 然而,通过使用MCTS,选择扩展的节点是基于动态值估计,这不仅由确定,还由动态模型和用于更新构建的反向传播短语确定。在MCTS中。 具体来说,用于模拟给定和的下一个状态(向前看下一个状态),然后作为奖励模型,评估并输出反馈,例如数字分数或口头判断。 推出轨迹后,轨迹沿线节点的值(期望奖励)将会更新。
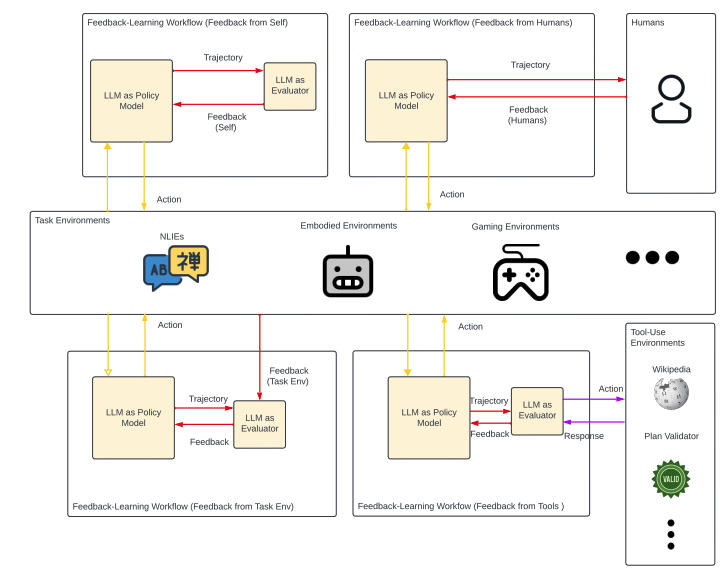
4.3 反馈学习工作流程
不同工作流程中的反馈来源差异很大。 反馈主要有四个来源:(内部反馈)、人员、任务环境和工具。
Reflexion (Shinn 等人, 2023) 和 Self-Refine (Madaan 等人, 2023) 利用 glmeval反思前几代的glmpolicy,使glmpolicy能够从这样的反思中学习。 与基于搜索的工作流程不同,在基于搜索的工作流程中,glmeval评估树扩展中操作选择的操作或状态,在这里,反馈用于修改决策,从而允许glm策略重新生成行动或计划。 在涉及物理交互的任务中,Reflexion 中的 glmeval 还集成了来自任务环境的外部信息(Shinn 等人,2023)。 同样,glmeval 可以从工具接收信息以生成反馈,如 CRITIC 工作流程(Gou 等人,2024) 中所示。 在此设置中,工具环境反馈的必要性由 glmeval 自动确定,而在 Reflexion 中,反馈传输由工作流设计硬编码。 表15说明了如何配置glmeval以在必要时激活工具。 正如 Guan 等人(2023 年) 的工作流程所指出的,人类可以向 glm 政策 提供直接反馈,而无需 glmeval 。
| Zero-shot CoT | Few-shot CoT | |
|---|---|---|
| MultiTool-CoT (Inaba et al., 2023) |
ReAct (Yao et al., 2023b),
Reflexion (Shinn et al., 2023), RAP (Hao et al., 2023) |
|
|
Plan-and-Solve (Wang et al., 2023a),
LLM Planner (Huang et al., 2022) |
DEPS (Wang et al., 2023b), Planner-Actor-Reporter (Dasgupta et al., 2022) | |
| / |
RAP (Hao et al., 2023),
Tree-BeamSearch (Xie et al., 2023), Reflexion (Shinn et al., 2023), CRITIC (Gou et al., 2024) |
| Task Formulation | Feedback Types | Applicable Workflows | Example Works |
|---|---|---|---|
| Text Generation | Free-form reflection | Feedback-learning workflows | Self-Refine (Madaan et al., 2023), Reflexion (Shinn et al., 2023), CRITIC (Gou et al., 2024) |
|
Binary/Multi-class
Classification |
Discrete values | Search workflows |
RAP (Hao et al., 2023),
Tree-BeamSearch (Xie et al., 2023) ToT (Yao et al., 2023a) |
| Binary Classification | Continuous values (logits) | Search workflows for MCTS | RAP (Hao et al., 2023) |
| Multi-choice QA | Choices of top-N actions | Search workflows via traversal and heuristic | ToT (Yao et al., 2023a) |
5 LMPC 的实现
在本节中,我们将探讨 LMPC 的不同实现方法,涵盖独立于特定工作流程和任务的策略、专门为某些任务设计的实现以及针对特定工作流程定制的实现。
5.1 通用实现
一般可以通过以下提示方式对大语言模型进行剖析:
-
•
输入输出(IO)提示:在这种方法中,大语言模型仅接收当前任务实例并生成相应的动作。
-
•
CoT 提示:为了便于创建中间推理步骤,实现了两种类型的提示:
-
–
零样本 CoT:提示在任务说明中包含思维链 (CoT) 触发器,例如“让我们逐步思考”(Kojima 等人,2022)。
-
–
少样本 CoT:手动制作的推理步骤集成在少样本学习上下文中(Wei 等人,2022)。
-
–
表3根据提示方法对LLM描述的组件进行分类。 一些研究(Inaba等人,2023;Wang等人,2023a)采用零样本CoT方法,但大多数(Yao等人,2023b;Shinn等人,2023;Hao等人, 2023)通过少样本CoT提示实现大语言模型政策模型,如表5和7中的示例。 零样本 CoT 实施 通常无法制定长期计划,这与提示 的少样本 CoT 不同(Wang 等人,2023b)。 虽然有效,但少样本提示需要手动编译带有推理序列的演示,从而导致手动工作和计算资源的使用增加。 像 Auto CoTs (Zhang 等人,2023) 这样自动生成少量样本演示的方法可以缓解这一挑战。
5.2 特定于任务的实现
实现
对于本质上涉及顺序决策的任务(例如,“将凉番茄放入微波炉”), 通常需要后处理步骤。 当使用 CoT 方法时,会提示大语言模型生成导致决策的推理路径。 随后,调用以提取 的可执行操作,如反射 (Shinn 等人, 2023) 中所示。 对于,生成的计划通常包含必须进一步转换为原始操作的高级操作(HLA)。 随后,必须将原始动作提取为可执行动作。 另一点需要考虑的是,虽然没有被提示生成计划,但它可能在决定当前行动之前的推理阶段自主制定计划(Shinn等人,2023;Yao等人, 2023b)(参见表 LABEL:tab:alfred_world_actor 中的示例)。 这些生成的计划作为内部状态进行维护,并且不充当与其他组件的通信信号。 对于从 NLIE 派生的任务,一个显着的特征是计划生成和执行都可能发生在单个大语言模型生成中,如表 5 中的示例所示。
实现
5.3 特定于工作流程的实现
实现
对于工具使用和反馈学习工作流程(从工具接收反馈),可以采用两种不同的实现来使触发大语言模型的工具使用:
- 1.
-
2.
推理-行动策略:由ReAct (姚等人,2023b)引入,此工作流程根据任务略有不同。 对于问答 (QA),推理和行动顺序是预先定义的,并交替提示思考和行动,如表 LABEL:tab:glm_actor_reflexion_hotpotqa 中所示。 相比之下,下一步是否继续思考或行动则由自主决定,如表8所示。
实现
可以针对各种评估任务进行定制,从而产生特定于特定工作流程的不同类型的反馈,如表 4 中详述: 1) 生成自由形式反射:这种反思性输出经常被集成到反馈学习工作流程中的提示中(Shinn 等人,2023;Gou 等人,2024)。 大语言模型旨在反思先前的状态和动作,作为基本反馈学习工作流程的一部分,通常结合来自任务或工具环境的外部输入来丰富反思过程。 2)二元/多类分类:从离散输出标记获得反馈,通常为“否”或“是”。这些可以转换为 0/1 值,作为 MCTS (Hao 等人,2023) 基于搜索的工作流程中的奖励,或直接用于在 DFS 和 BFS 基于搜索的工作流程中选择操作(姚等人,2023a)。 3)标量值二元分类:这种方法与前一种方法不同,它使用标记的logit值来计算标量反馈值。 例如,“是”响应的概率使用以下公式计算:
其中 和 分别是“yes”和“no”标记的 logits。 333请注意, 的此类实现无法通过黑盒大语言模型访问。 然后,这些标量值可以用作 MCTS 基于搜索的工作流程中的奖励。 4) 多选 QA:用于需要从多个选项中进行选择的环境,支持涉及从前 N 个可能操作中进行选择的任务,如基于搜索的操作选择工作流程中所使用的(姚等人,2023a)。
6 未来的工作
随着我们深入研究 LMPC 和代理工作流程,确定了未来研究的几个关键方向,以推动跨各种任务的完全自主代理的开发。
通用工具使用
通用工具使用:一个方向是超越针对特定任务的预定义工具使用,并制定策略,使大语言模型能够根据手头任务的具体要求自主确定工具的使用。 另一个方向是整合政策模型和评估者的工具使用。 换句话说,大语言模型应该对工具在各种任务中的使用进行推理,并且能够在不同的角色之间灵活地跳转。 附录E展示了对这种可能性的洞察
跨任务的统一工作流程
正如第 §5 中所详述的,尽管某些工作流在概念上集成了各种视角,但所有工作流都具有特定于任务的实现。 例如,ReAct(推理与行动策略)旨在协调工具使用环境和任务环境的基本工作流程之间的操作。 然而,这些工作流程对于不同的任务仍然表现出不同的特征444For instance, hardcoded reasoning and acting steps in NLIE-QA versus autonomously determined reasoning and acting steps in embodied environments。 同样,虽然 Reflexion 中的反馈学习循环在理论上是统一的,但实际上,外部反馈仅在具体环境中生成,而不是在 NLIE-QA 中生成。
减少带宽
有几种潜在的策略可以减少大语言模型推理所需的带宽 555Here, bandwidth refers to the volume of information processed during a single LLM generation期间处理的信息量,包括使用随机(详细信息参见附录F)。
7结论
该调查总结了常见工作流程和 LLM 概要组件,以鼓励重用这些组件,并通过集成特定于任务的 LMPC 和非 LLM 组件来扩展现有工作流程。 这种方法旨在促进代理工作流程的开发和可重复性。
局限性
This survey specifically omits discussions on memory design 666Refer to Appendix G for details on memory in LLM-based agents and the integration of peripheral components into agentic workflows 777These are concisely summarized in Table 2, as our focus is solely on the involvement of LLM-profiled components within these workflows. 这使我们的工作与其他调查明显不同。
参考
- Chen et al. (2024) Sijia Chen, Baochun Li, and Di Niu. 2024. Boosting of thoughts: Trial-and-error problem solving with large language models. In The Twelfth International Conference on Learning Representations.
- Dasgupta et al. (2022) Ishita Dasgupta, Christine Kaeser-Chen, Kenneth Marino, Arun Ahuja, Sheila Babayan, Felix Hill, and Rob Fergus. 2022. Collaborating with language models for embodied reasoning. In Second Workshop on Language and Reinforcement Learning.
- Fan et al. (2022) Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. 2022. Minedojo: Building open-ended embodied agents with internet-scale knowledge. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Goldsmith (2023) Jonathan Goldsmith. 2023. Wikipedia: A python library that makes it easy to access and parse data from wikipedia. Python Package Index.
- Gou et al. (2024) Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2024. CRITIC: Large language models can self-correct with tool-interactive critiquing. In The Twelfth International Conference on Learning Representations.
- Guan et al. (2023) Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. 2023. Leveraging pre-trained large language models to construct and utilize world models for model-based task planning. In Thirty-seventh Conference on Neural Information Processing Systems.
- Hao et al. (2023) Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. 2023. Reasoning with language model is planning with world model. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8154–8173, Singapore. Association for Computational Linguistics.
- Huang et al. (2022) Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. 2022. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International Conference on Machine Learning, pages 9118–9147. PMLR.
- Inaba et al. (2023) Tatsuro Inaba, Hirokazu Kiyomaru, Fei Cheng, and Sadao Kurohashi. 2023. MultiTool-CoT: GPT-3 can use multiple external tools with chain of thought prompting. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1522–1532, Toronto, Canada. Association for Computational Linguistics.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems.
- Liu et al. (2023) Hanmeng Liu, Zhiyang Teng, Leyang Cui, Chaoli Zhang, Qiji Zhou, and Yue Zhang. 2023. Logicot: Logical chain-of-thought instruction-tuning.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2023. Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651.
- Manakul et al. (2023) Potsawee Manakul, Adian Liusie, and Mark JF Gales. 2023. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. arXiv preprint arXiv:2303.08896.
- Russell and Norvig (2010) Stuart J Russell and Peter Norvig. 2010. Artificial intelligence a modern approach. London.
- Santurkar et al. (2023) Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. 2023. Whose opinions do language models reflect? arXiv preprint arXiv:2303.17548.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning.
- Shridhar et al. (2021) Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cote, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2021. {ALFW}orld: Aligning text and embodied environments for interactive learning. In International Conference on Learning Representations.
- Sutton and Barto (2018) Richard S Sutton and Andrew G Barto. 2018. Reinforcement learning: An introduction. MIT press.
- Thoppilan et al. (2022) Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. 2022. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239.
- Wan et al. (2024) Ziyu Wan, Xidong Feng, Muning Wen, Ying Wen, Weinan Zhang, and Jun Wang. 2024. Alphazero-like tree-search can guide large language model decoding and training.
- Wang et al. (2024) Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. 2024. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6):1–26.
- Wang et al. (2023a) Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. 2023a. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2609–2634, Toronto, Canada. Association for Computational Linguistics.
- Wang et al. (2022) Siyuan Wang, Zhongkun Liu, Wanjun Zhong, Ming Zhou, Zhongyu Wei, Zhumin Chen, and Nan Duan. 2022. From lsat: The progress and challenges of complex reasoning. IEEE/ACM Trans. Audio, Speech and Lang. Proc., 30:2201–2216.
- Wang et al. (2023b) Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian Ma, and Yitao Liang. 2023b. Describe, explain, plan and select: Interactive planning with LLMs enables open-world multi-task agents. In Thirty-seventh Conference on Neural Information Processing Systems.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems.
- Willard and Louf (2023) Brandon T Willard and Rémi Louf. 2023. Efficient guided generation for llms. arXiv preprint arXiv:2307.09702.
- Wu et al. (2023) Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155.
- Xie et al. (2023) Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, Junxian He, and Qizhe Xie. 2023. Self-evaluation guided beam search for reasoning. In Thirty-seventh Conference on Neural Information Processing Systems.
- Yao et al. (2023a) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023a. Tree of thoughts: Deliberate problem solving with large language models.
- Yao et al. (2023b) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023b. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations.
- Zhang et al. (2023) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2023. Automatic chain of thought prompting in large language models. In The Eleventh International Conference on Learning Representations (ICLR 2023).
- Zhong et al. (2023) Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. 2023. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364.
- Zhong et al. (2022) Wanjun Zhong, Siyuan Wang, Duyu Tang, Zenan Xu, Daya Guo, Yining Chen, Jiahai Wang, Jian Yin, Ming Zhou, and Nan Duan. 2022. Analytical reasoning of text. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 2306–2319, Seattle, United States. Association for Computational Linguistics.
|
Q: In a dance class of 20 students, enrolled in contemporary dance, of the remaining enrolled in jazz dance, and the rest enrolled in hip-hop dance. What percentage of the entire students enrolled in hip-hop dance?
A: Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step. Plan: Therefore, the answer (arabic numerals) is |
| Use the following tools at your disposal and answer some questions: |
| - <<Calculator >> |
| - <<Chemical reaction predictor >> |
| - <<Molar mass list >> |
| Q: Find the amount of formed on combining 2 moles of and 2 moles of . |
| A: First, use the chemical reaction predictor to determine the chemical equation for the reaction. |
| Reactants: |
| Products: ? |
| <<Chemical reaction predictor >> |
| Second, use the molar mass list to determine the molar mass of . Molar mass list |
| Third, use the calculator to calculate the amount of 2 moles of . Calculator |
| Therefore, of is formed. |
| Q: Find the amount of Calcium hydroxide that is required to react with 2 moles of Carbon dioxide to form 2 moles of Calcium carbonate along with 2 moles of Water. |
| A: |
|
Q: Julie is reading a 120-page book. Yesterday, she was able to read 12 pages and today, she read twice as many pages as yesterday. If she wants to read half of the remaining pages tomorrow, how many pages should she read?
A: Julie read twice as many pages as yesterday, so she read 12 * 2 = 24 pages today. Since yesterday, Julie read 12 + 24 = 36 pages. So, there are 120 - 36 = 84 pages left to be read. Since she wants to read half of the remaining pages, she should read 84 / 2 = 42 pages. The answer is 42. Q: Ken created a care package to send to his brother, who was away at boarding school. Ken placed a box on a scale, and then he poured into the box enough jelly beans to bring the weight to 2 pounds. Then, he added enough brownies to cause the weight to triple. Next, he added another 2 pounds of jelly beans. And finally, he added enough gummy worms to double the weight once again. What was the final weight of the box of goodies, in pounds? A: Ken poured jelly beans into the box until the weight was 2 pounds, so the weight of the box was 2 pounds at first. Then Ken added enough brownies to cause the weight to triple, so the weight of the box was 2 * 3 = 6 pounds. After Ken added another 2 pounds of jelly beans, the weight of the box was 6 + 2 = 8 pounds. Finally, he added enough gummy worms to double the weight once again, so the weight of the box was 8 * 2 = 16 pounds. The answer is 16. Q: James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year? A: James writes a 3-page letter to 2 different friends twice a week, so he writes 3 * 2 * 2 = 12 pages every week. There are 52 weeks in a year, so he writes 12 * 52 = 624 pages a year. The answer is 624. Q: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? A: Natalia sold 48 clips in April and half as many clips in May, so she sold 48 / 2 = 24 clips in May. Altogether, she sold 48 + 24 = 72 clips. The answer is 72. Q: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? A:" |
|
Interact with a household to solve a task. Here are two examples.
You are in the middle of a room. Looking quickly around you, you see a cabinet 9, a cabinet 8, a cabinet 7, a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a drawer 9, a drawer 8, a drawer 7, a drawer 6, a drawer 5, a drawer 4, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1.
Your task is to: put a cool mug in shelf. > think: To solve the task, I need to find and take a mug, then cool it with fridge, then put it in shelf. OK. > think: First I need to find a mug. A mug is more likely to appear in countertop (1-3), coffeemachine (1), cabinet (1-9), shelf (1-3), drawer (1-9). I can check one by one, starting with countertop 1. OK. > go to countertop 1 On the countertop 1, you see a knife 1, a pan 2, a pan 1, and a plate 1. … > think: Now I cool the mug. Next, I need to put it in/on shelf 1. OK. > go to shelf 1 On the shelf 1, you see a cup 2, a cup 1, a peppershaker 1, and a saltshaker 1. > put mug 3 in/on shelf 1 You put the mug 3 in/on the shelf 1. Here is the task: You are in the middle of a room. Looking quickly around you, you see a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: put a cool tomato in microwave. > OK. > OK. > On the countertop 1, you see a dishsponge 1, and a mug 2. … |
| Solve a question answering task by having a Thought, then Finish with your answer. Thought can reason about the current situation. Finish[answer] returns the answer and finishes the task. |
| Here are some examples: |
| Question 1: What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into? |
| Thought: Let’s think step by step. The eastern sector of Colorado orogeny extends into the High Plains. High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft. |
| Action: Finish[1,800 to 7,000 ft] |
| … |
| Question 6: Were Pavel Urysohn and Leonid Levin known for the same type of work? |
| Thought: Let’s think step by step. Pavel Urysohn is a mathematician. Leonid Levin is a mathematician and computer scientist. So Pavel Urysohn and Leonid Levin have the same type of work. |
| Action: Finish[Yes] |
| END OF EXAMPLES) |
| Question: VIVA Media AG changed itś name in 2004. What does their new acronym stand for? |
| Thought: |
| Action: |
| Given a question, please decompose it into sub-questions. For each sub-question, please answer it in a complete sentence, ending with "The answer is". When the original question is answerable, please start the subquestion with "Now we can answer the question:" |
| Question 1: James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year? |
| Question 1.1: How many pages does he write every week? |
| Answer 1.1: James writes a 3-page letter to 2 different friends twice a week, so he writes 3 * 2 * 2 = 12 pages every week. The answer is 12. |
| Question 1.2: How many weeks are there in a year? |
| Answer 1.2: There are 52 weeks in a year. The answer is 52. |
| Question 1.3: Now we can answer the question: How many pages does he write a year? |
| Answer 1.3: James writes 12 pages every week, so he writes 12 * 52 = 624 pages a year. The answer is 624. |
| … |
| Question 5: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? |
| Question 5.1: |
附录A示例:大语言模型Actor的提示工作流程
A.1 直接代理
A.2 基于搜索的代理
在 RAP 工作流程中的 MCTS 扩展阶段需要一个参与者。 提示和预期生成如表10所示。
附录B大语言模型评估者提示
大语言模型被描述为基于分类的评估器,如表11和LABEL:tab:value24game所示。
| Given a question and some sub-questions, determine whether the last sub-question is useful to answer the question. Output ’Yes’ or ’No’, and a reason. |
| Question 1: Four years ago, Kody was only half as old as Mohamed. If Mohamed is currently twice as 30 years old, how old is Kody? |
| Question 1.1: How old is Mohamed? |
| Question 1.2: How old was Mohamed four years ago? |
| New question 1.3: How old was Kody four years ago? |
| Is the new question useful? Yes. We need the answer to calculate how old is Kody now. |
| … |
| Question 5: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? |
| New question 5.1: Now we can answer the question: How much in dollars does she make every day at the farmers’ market? |
| Is the new question useful? |
|
Evaluate if given numbers can reach 24 (sure/likely/impossible)
10 14 10 + 14 = 24 sure … 1 3 3 1 * 3 * 3 = 9 (1 + 3) * 3 = 12 1 3 3 are all too small impossible {input} |
| Factuality |
Context: …
Sentence: … Is the sentence supported by the context above? Answer Yes or No: |
| Usefulness |
Given a question and some sub-questions, determine whether the last sub-question is useful to answer the question. Output ’Yes’ or ’No’, and a reason.
Question 1: Four years ago, Kody was only half as old as Mohamed. If Mohamed is currently twice as 30 years old, how old is Kody? Question 1.1: How old is Mohamed? Question 1.2: How old was Mohamed four years ago? New question 1.3: How old was Kody four years ago? Is the new question useful? Yes. We need the answer to calculate how old is Kody now. … Question 5: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? New question 5.1: How much in dollars does she make every day at the farmers’ market? Is the new question useful? Yes/No [Provide your reasoning here]. |
附录 C LLM 作为动态模型
| Given a question, please decompose it into sub-questions. For each sub-question, please answer it in a complete sentence, ending with "The answer is". When the original question is answerable, please start the subquestion with "Now we can answer the question: ". |
| Question 1: Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn? |
| Question 1.1: How much does Weng earn per minute? |
| Answer 1.1: Since Weng earns $12 an hour for babysitting, she earns $12 / 60 = $0.2 per minute. The answer is 0.2. |
| Question 1.2: Now we can answer the question: How much did she earn? |
| Answer 1.2: Working 50 minutes, she earned $0.2 x 50 = $10. The answer is 10. |
| … |
| Question 5: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? |
| Question 5.1: How many eggs does Janet have left after eating three for breakfast and using four for muffins? |
| Answer 5.1: |
附录D演员+评估者
| … |
| Question: Serianna is a band of what genre that combines elements of heavy metal and hardcore punk? |
| Proposed Answer: Let’s think step by step. Serianna is a band of metalcore genre. Metalcore is a subgenre of heavy metal and hardcore punk. So Serianna is a band of heavy metal and hardcore punk. So the answer is: heavy metal and hardcore punk. |
| 1. Plausibility: [Metalcore - Wikipedia] Metalcore is a fusion music genre that combines elements of extreme metal and hardcore punk. |
| [Serianna - Wikipedia] Serianna was a metalcore band from Madison, Wisconsin. The band formed in 2006… |
附录E创建与任务无关的工具环境
以前的工作总是将工具限制在 NLIE-QA 等特定应用程序中,未来的工作应该致力于建立一个全面的工具环境,其中包含适合各种任务的各种工具。 这里的一个主要挑战是调整单个参与者以有效地利用这样的环境。 虽然代内策略受到限制,因为触发器通常仅适用于具有简单参数的基本工具,但推理-行动策略可能会提供更多希望。 尽管如此,定义工具仍然是一个挑战,特别是在高效的上下文学习或工具利用率的微调方面。
附录 F 随机
通常,单个动作是从 glmactor 的输出中采样的。 探索随机 glmactor(提供可能操作的分布)可以增强 glm 策略 的随机性> 并提高效率。 这种方法可能包括研究约束生成技术(Willard 和 Louf,2023)。 此外,使用这样的分布可以有效地作为所有可能操作的奖励,从而可能消除在某些工作流程中对单独的 glmeval 进行奖励建模的需要。 这种方法允许在一个生成步骤中同时扩展多个潜在节点,而不是在基于搜索的工作流中单独扩展每个节点(Hao等人,2023)。
附录G内存
所审查的作品中的记忆实现通常是直接且任意的。 通常,静态信息(例如,分析消息)是手动构建和存储的,而动态信息(例如,反馈)是在每个工作流内的交互期间通过运行时数据结构进行处理的。 虽然混合记忆系统的管理(需要对短期和长期记忆进行显式处理和管理)在王等人(2024)之前的一项调查中进行了广泛讨论,但这种记忆管理方面这些超出了本次调查的重点,本次调查的重点是基于 LLM 的工作流程。