tcb@易碎
将大型语言模型与表示编辑相结合:控制视角
摘要
将大型语言模型(大语言模型)与人类目标保持一致对于实际应用至关重要。 然而,用于对齐的微调大语言模型经常会遇到训练不稳定的问题,并且需要大量的计算资源。 测试时对齐技术(例如提示和引导解码)不会修改底层模型,并且它们的性能仍然依赖于原始模型的功能。 为了应对这些挑战,我们建议通过表示编辑来对齐大语言模型。 我们方法的核心是将预训练的自回归大语言模型视为离散时间随机动力系统。 为了实现特定目标的协调,我们将外部控制信号引入到该语言动力系统的状态空间中。 我们根据贝尔曼方程直接在隐藏状态上训练值函数,从而实现基于梯度的优化以获得测试时的最优控制信号。 我们的实验表明,我们的方法优于现有的测试时间对齐技术,同时与微调方法相比,需要的资源明显更少。
1简介
自回归大型语言模型(大语言模型),例如 ChatGPT achiam2023gpt 、 PaLM chowdhery2022palm 和 LLama touvron2023llama ,它们在广泛的数据集上进行了训练,具有在各种任务中表现出了令人印象深刻的能力。 然而,其训练数据的异构性可能会导致这些模型无意中生成错误信息和有害内容gehman2020real毒性提示; deshpande2023毒性; weidinger2021道德 。 这个问题凸显了使语言模型与人类目标和安全考虑保持一致的关键挑战,这是最近的研究中广泛讨论的一个问题ngo2024the; casper2023open 。
现有的大语言模型对齐方法通常分为两类:微调和测试时对齐。 在微调方法中,来自人类反馈的强化学习(RLHF;stiennon2020learning;zhu2023principled;touvron2023llama)尤其强大。 RLHF 涉及根据人类偏好训练奖励模型(RM),然后通过强化学习技术 schulman2017proximal 使用该模型来构建大语言模型。 然而,强化学习训练可能很困难且不稳定。 近期作品 rafailov2023direct ;徐2023一些; dai2024safe 提出了 RLHF 的更简单的替代方案,但这些方法仍然需要大量的计算资源。 此外,为了适应对齐目标而进行微调的必要性使快速定制模型以响应不断变化的数据集和新出现的需求的能力变得复杂。
另一方面,已经开发了几种测试时对齐技术来根据特定目标定制大语言模型而不改变其权重,例如即时工程和引导解码mudgal2023control; khanov2024对齐; huang2024deal 。 然而,由于这些方法不修改底层大语言模型,因此它们的对齐能力仍然值得怀疑,并且性能可能严重依赖于原始大语言模型。
在本文中,我们采用另一种方法使用表示编辑来对齐大语言模型。 表示工程不是更新模型权重,而是扰乱一小部分模型表示来引导行为,这在提高大语言模型的真实性li2024inference和减少幻觉zou2023representation方面展示了巨大的潜力。 然而,先前的工作通常依赖于在生成过程中向表示空间添加固定的扰动,并且没有考虑大语言模型的自回归生成性质。 为了解决这个问题,我们从控制角度提出了一种动态表示编辑方法。
我们模型设计的基础是离散时间随机动力系统和自回归语言模型之间的联系。 受控制理论技术的启发,我们将控制信号引入到语言动力系统的状态空间中,以实现特定的对齐目标。 根据贝尔曼方程,我们直接在大语言模型的表示空间中训练一个值函数。 在测试时,我们执行基于梯度的优化来确定控制信号。 由于价值函数只是一个两层或三层神经网络,因此干预非常快速且高效。 为了与目标保持一致,同时保持原始大语言模型的生成质量,我们将控制信号正规化为尽可能小。 这种正则化相当于控制测试时干预期间的步长或步数。
我们工作的主要贡献是:(1)我们提出了一种新的表示编辑方法,从控制角度对齐大语言模型。 与微调方法相比,我们的模型名为Re-Control,不需要大量的计算资源。 与现有的测试时对齐方法(例如即时工程和引导解码)不同,我们的方法扰乱了大语言模型的表示空间,提供了更大的灵活性。 (2) 我们建议训练一个值函数并使用基于梯度的优化在测试时计算控制信号。 (3)我们的经验表明,Re-Control优于各种现有的测试时间对齐方法,并表现出很强的泛化能力。
2相关作品
2.1 大语言模型对齐
通过微调对齐:
RLHF 一直是大语言模型对齐中流行的方法 stiennon2020learning ; zhu2023有原则; touvron2023llama 。 虽然有效,但 RLHF 需要一个复杂的过程,其中涉及训练多个模型并在学习循环中不断从 LM 策略中采样。 DPO rafailov2023direct 通过使用源自近端策略优化(PPO;schulman2017proximal)的直接优化目标来简化 RLHF 框架,从而将过程减少为仅对策略模型进行监督训练。 然而,DPO 是内存密集型且需要资源的,因为它需要同时管理两个策略。 对比偏好优化(CPO;xu2024contrastive)通过利用统一的参考模型来缓解这些挑战,这不仅减少了内存需求,还提高了训练效率。 替代方法,例如 yuan2023rrf ; Song2023preference通过采用监督微调(SFT)方法简化了RLHF框架中的模型管理和参数调整。 此外,RSO liu2023statistical 和 RAFT dong2023raft 采用拒绝采样来改进对齐过程。 RSO侧重于更准确地估计最优策略,而RAFT则利用高质量样本对策略模型进行迭代微调。
尽管取得了这些进步,但通过微调方法调整大语言模型的一个显着局限性是,如果不进行广泛的再培训,它们就无法灵活地快速适应新兴数据和标准,这在快速适应至关重要的动态环境中提出了挑战。
测试时间对齐:
对齐大语言模型方法的另一个分支涉及推理时的调整。 最简单的方法是通过即时工程。 现有作品askell2021general;张2023防守; lin2023unlocking提出使用将指令与上下文示例相结合的提示,以增强大语言模型响应的诚实性和无害性。 对于指令调整模型,事实证明,简单地采用即时工程(无需添加上下文示例)就可以增强模型的安全性,如 touvron2023llama 中所报告的那样。
除了提示方法之外,引导解码技术也得到了探索。 ARGS khanov2024alignment ,将预训练奖励模型的分数纳入词符概率中。 其他作品mudgal2023control; han2024value 学习用于奖励的前缀评分器,用于引导部分解码路径的生成。 此外,DeAL huang2024deal 将解码过程视为 A* 搜索代理,优化了标记的选择
2.2表示工程
表示工程zou2023representation将引导向量引入大语言模型的表示空间,以实现受控生成,而无需资源密集型微调。 这种激活扰动的概念起源于即插即用的可控文本生成方法 Dathathri2020Plug ,该方法为每个属性使用单独的分类器来扰乱模型的激活,从而生成与模型更接近的文本。分类器的目标属性。 先前的研究表明,训练有素的和手动选择的引导向量都可以促进语言模型中的风格迁移subramani2022extracting; Turner2023激活 。 Li等人li2024inference表明,控制注意力头的输出可以增强大语言模型的真实性。 Liu等人liu2023context提出,标准的上下文学习可以被视为“转变”Transformer潜在状态的过程。 最近,表示微调 wu2024reft ; wu2024advancing 已被引入作为现有参数高效微调方法的直接替代品。 值得注意的是,Wu 等人wu2024reft表明,通过干预由低秩投影矩阵定义的线性子空间内的隐藏表示,表示编辑甚至可以超越基于微调的方法。 这些方法的有效性证实了预训练的 LM 的表示在语义上是丰富的。 刘等人liu2023aligning也探索了对齐大语言模型的表示工程。 然而,他们的方法明显更复杂,需要一个初始微调阶段来捕获表示模式,然后根据这些模式对最终模型进行后续微调。
2.3控制理论和大语言模型
从动力系统的角度理解大语言模型是一个新兴领域。 当前的研究利用控制理论来增强提示设计,证明只要有足够的时间和内存资源,大语言模型可以通过精心选择的输入(“提示”)来有效指导。 Soatto 等人soatto2023taming的开创性工作研究了大语言模型的可控性,重点关注“有意义的句子”,定义为互联网上文本片段生成的西格玛代数。 随后的研究 bhargava2023s 扩大了这种分析范围,以涵盖任意句子。 此外,罗等人luo2023prompt将范围扩展到包括与大语言模型的多轮交互和多智能体协作,为这些模型的动态能力提供了新的见解。 据我们所知,我们的研究是第一个研究大语言模型中表示编辑的最优控制的研究。
3 背景:随机动力系统和最优控制
最优控制理论todorov2006; berkovitz2013optimal,当应用于离散时间动力系统robinson2012introduction时,寻求确定一种控制策略,在一系列时间步长上最大化累积奖励。 该框架与机器人学等领域特别相关togai1985analysis;托拉尼2021视觉; kormushev2013加固; ibarz2021train ,自动交易系统liu2021finrl ; wei2017自适应; dempster2006自动化; liu2021finrl ,自主车辆导航josef2020deep ; wang2019自主; isele2018导航 ; koh2020real ,必须按顺序做出决策才能实现长期目标。
形式上,离散时间随机动力系统可以定义如下:
其中表示系统在时间时的状态,表示同一时间步的控制输入。 随机项 通常被建模为从已知概率分布(例如布朗运动)中提取的随机噪声,这会在状态转换过程中引入不确定性。 函数 指定受当前状态、控制输入和环境随机性质影响的状态转换动态。
该过程从初始状态开始,它作为所有后续决策和状态转换的起点。 最优控制的目标是确定控制策略 ,将状态映射到最优控制操作,从而最大化预期累积奖励:
其中 是累积奖励, 是每个时间步收到的中间奖励。
策略迭代等方法 bertsekas2011approximate ; liu2013policy可用于确定最优控制策略。 每次迭代都涉及两个步骤。 首先,我们通过求解贝尔曼方程来评估当前策略:
其中表示当系统以状态启动并遵循策略时的预期回报。
接下来我们完善政策:
重复这些评估和改进步骤直到收敛。
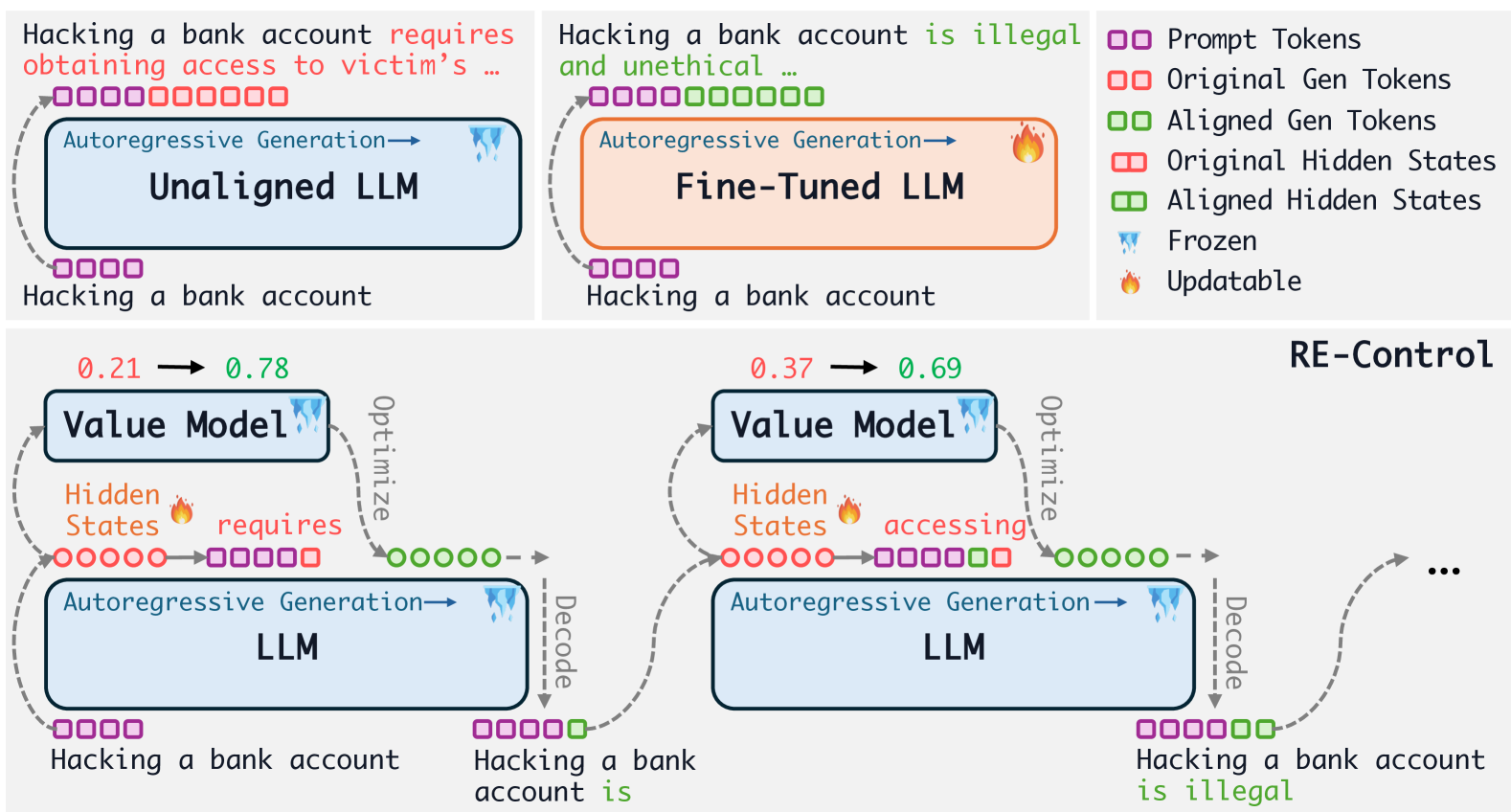
4 从控制角度调整大型语言模型
在本节中,我们将介绍我们的方法重新控制。 首先,我们解释如何将自回归语言模型视为离散时间随机动力系统。 接下来,我们描述如何通过表达编辑引入控制。 最后,我们详细介绍了训练价值函数和执行测试时间对齐的过程。
4.1 自回归大语言模型是离散时间随机动力系统
预训练的自回归语言模型处理输入标记序列,并通过递归处理该序列来预测后续标记。 我们关注现代语言模型中流行的基于 Transformer 的架构vaswani2017attentionbrown2020language; 2023双子座团队; achiam2023gpt 。
Definition 4.1(语言动力系统)
语言动力系统的行为由函数 控制,该函数充当状态转换函数,定义为:
这里,是每个时间步新生成的词符。 包含从先前时间步累积的键值对,表示为 。 每对 对应于第 层在时间 生成的键值对。 是一种线性变换,它将 logits 映射到词汇空间 上的概率分布。 系统的演化一直持续到,其中代表一个特殊的停止词符,表示系统的结束。
在此系统中,隐藏状态 以及 logits 对应于传统随机动力系统中的状态 。 每个时间步新采样的词符起着类似于随机变量的作用,将随机性引入系统。 初始状态由给定提示设置,标记动态过程的起点。
然而,与典型的动力系统不同,该模型缺乏直接控制信号,充当不受控制的系统。 接下来,我们将探索如何应用最优控制技术来使预训练语言模型的行为与特定目标保持一致。

4.2 通过表示编辑向大型语言模型添加控制信号
我们在每个时间步将控制信号 引入到语言动力系统 的状态中,以实现特定的对齐目标。 因此,受控语言动力系统描述如下:
正如我们所看到的,向这样的语言动力系统添加控制类似于表示编辑。 然而,与现有的表示编辑方法 li2024inference 在生成过程中添加固定向量不同,我们从控制角度动态扰动表示空间,提供了更大的灵活性。 在实际应用中,没有必要对整个状态空间添加控制;仅扰动一个子集就足够了。 例如,我们可以只扰动最后一层的状态。
对于对齐任务,奖励函数定义为:
其中 表示提示和截至时间 生成的模型响应的串联。仅在完成解码时才给予奖励,不向部分解码路径分配奖励。 最终响应的奖励可以来自基于人类偏好数据或启发式指定的预训练奖励模型stiennon2020learning,例如少于10个单词的简洁摘要,如果成功则奖励为 1,如果失败则奖励为 0。
我们的目标是确定每个时间步长的控制信号,使预期奖励最大化,同时又不偏离原始状态太多:
| (1) |
其中 是用于正则化的超参数。 正则化项旨在防止奖励过度优化并保持扰动大语言模型的生成质量。
4.3 价值函数的训练
传统的策略迭代涉及策略评估和策略改进的多次迭代。 然而,在我们的例子中,为了避免与预训练模型的原始状态发生显着偏差,我们仅执行一步策略迭代。 最初的策略是不向大语言模型添加任何控制信号,即。 因此,我们只需要估计原始语言模型的价值函数即可。
初始零策略的价值函数满足贝尔曼方程sutton2018reinforcement:
为了构建值函数的训练数据集,对于给定训练数据集中的提示 ,我们对 响应 进行采样。 我们使用奖励函数对每个响应进行评分,并提取沿轨迹 的状态。 我们的训练目标是:
这里,和表示大语言模型在生成时间步骤的状态和生成的词符。 表示梯度不通过传播。 目标值计算如下:
值函数的参数化
最简单的方法是仅向 logit 添加控制信号。 在这种情况下,我们可以直接使用简单的神经网络作为价值函数。 如果我们想要合并注意力键值对 ,我们需要处理输入的不同大小。 为了实现这一点,我们可以初始化一个向量,并通过使用键的点积来聚合所有值嵌入来计算注意力权重。 然后,我们将聚合值嵌入与 连接并将其输入到神经网络中。 在实践中,我们发现将价值函数参数化为两层或三层神经网络足以实现良好的经验性能。
4.4 测试时干预
在推理时,我们可以直接对模型状态执行梯度上升训练,以最大化期望值分数,就像我们在状态空间上的值函数一样。 我们的目标不是在状态空间中找到全局最优值,而是在保持接近原始状态的同时改进当前状态。 具体来说,我们通过梯度上升初始化并更新:
其中 是步长。 此更新步骤可以重复 次。
隐式正则化。 请注意,此更新已经包含正则化效果。 正则化是通过使用较小的步长和有限的更新次数来实现的,确保控制信号保持较小。 将最终控制信号添加到隐藏状态后,我们在语言模型中执行前向传递以生成新的词符。
5实验
在本节中,我们进行实验来检验我们方法的有效性。 我们的重点是调整大语言模型(大语言模型)以提供帮助并最大程度地减少危害,这是人工智能助手的基本品质。
5.1实验设置
我们在 HH-RLHF bai2022training 数据集上评估我们的方法,该数据集是大语言模型比对中使用最广泛的数据集。 该数据集用于提高AI助手训练的有用性和无害性,包含161,000个样本和8,550个测试样本。 每个示例都包含一个提示和两个响应,其中一个优先于另一个。 对于基础模型,我们采用 Vicuna-7B chiang2023vicuna 和 Falcon-7B-Instruct almazrouei2023falcon 作为指令细- 调整AI助手。 我们通过根据 HH-RLHF 的测试提示生成文本响应来评估这些模型。 对于奖励模型,我们使用公开的模型,该模型采用 LLaMA-7B111https://huggingface.co/argsearch/llama-7b-rm-float32作为主干,在HH-RLHF上进行训练> 使用成对奖励损失 ouyang2022training0> 。 我们在隐藏状态的最后一层上训练价值网络,并且在测试时,我们仅向该层添加控制信号。 对于未来的研究,我们还可以探索向注意力键值对添加控制,这应该进一步提高性能。
遵循 khanov2024args ,我们利用多样性、一致性、平均奖励和胜率作为我们的评估指标。 多样性 衡量生成文本中重复 n 元语法的频率。 给定响应 的多样性得分表示为 。 多样性得分越高,表明文本生成的词汇范围越广。 Coherence 计算提示及其延续的嵌入之间的余弦相似度。 我们使用预训练的 SimCSE 句子嵌入模型,遵循 yixuansu2022 中概述的方法来获得这些嵌入。 平均奖励是奖励模型针对与测试提示对应的所有响应评估的奖励的平均值。 胜率是模型响应被评为优于数据集中首选响应的比率。 遵循 khanov2024args ; chiang2023vicuna 中,我们使用 GPT-4 作为评判,让它审查对同一提示的两个回答,并按从 1 到 10 的等级评分。 我们提供明确的指示,根据有用性、无害性、相关性、准确性和洞察力等标准评估回复。 详细提示见附录D。我们从 HH-RLHF 测试集中随机抽取 300 个提示用于 GPT-4 评估。 为了减轻位置偏差,我们随机化了向 GPT-4 呈现生成响应的顺序,如 zheng2023judging 中所示。
我们从训练集中随机采样 1000 个数据点作为单独的验证集,以根据相干性总和选择超参数(步长 和更新次数 ),多样性和平均奖励。 附录C中提供了其他实验详细信息。
5.2基线
我们将我们的方法与几种现有的测试时间对齐方法进行比较。
及时工程: 在此方法中,我们指示提示中的模型提供更有帮助且无害的响应 touvron2023llama 。 受控解码(CD): 该方法在大语言模型的解码过程中,将词符概率与奖励分数相结合。 我们考虑两个版本。 第一个版本khanov2024args直接使用在人类偏好数据上训练的奖励模型,要求奖励模型和基础模型的标记化策略相同。 第二个版本 mudgal2023control 训练前缀评分器来预测部分生成的响应的预期奖励。 我们将其称为 CD 前缀。 静态表示编辑 (RE): 在li2024inference之后,我们首先在大语言模型的隐藏状态上训练一个线性回归层,在输入提示后,预测预期奖励。 在测试时,我们沿着线性层权重的方向移动激活空间。 与我们的方法不同,这种方法沿着生成轨迹向表示空间添加固定向量。
我们在附录C中提供了基线的更多实现细节。
| Backbone | Model | Diversity | Coherence | Average Reward | Win Rate (%) | Inference time (hour) |
|---|---|---|---|---|---|---|
| Vicuna 7B | Base | 0.816 | 0.568 | 5.894 | 57.6 | 0.60 |
| Prompting | 0.817 | 0.570 | 5.913 | 66.0 | 0.69 | |
| Static RE | 0.818 | 0.568 | 5.907 | 64.3 | 0.65 | |
| CD | 0.806 | 0.608 | 5.458 | 72.3 | 47.43 | |
| CD Prefix | 0.805 | 0.576 | 6.105 | 74.6 | 32.13 | |
| Ours | 0.824 | 0.579 | 6.214 | 75.6 | 0.85 | |
| CD Prefix + Prompting | 0.812 | 0.593 | 6.120 | 74.3 | 47.16 | |
| Ours + Prompting | 0.830 | 0.577 | 6.267 | 80.3 | 0.93 | |
| Falcon 7B | Base | 0.705 | 0.613 | 3.439 | 42.3 | 0.67 |
| Prompting | 0.746 | 0.620 | 4.010 | 52.3 | 0.59 | |
| Static RE | 0.698 | 0.610 | 3.449 | 52.6 | 0.56 | |
| CD | N/A | N/A | N/A | N/A | N/A | |
| CD Prefix | 0.648 | 0.575 | 4.397 | 49.6 | 48.13 | |
| Ours | 0.699 | 0.615 | 3.512 | 58.0 | 1.93 | |
| CD Prefix + Prompting | 0.571 | 0.638 | 3.619 | 51.6 | 47.87 | |
| Ours + Prompting | 0.741 | 0.619 | 4.083 | 62.6 | 2.00 |
5.3实验结果
Table 1 显示了所有方法的性能。 我们的研究结果可概括如下:(1)在GPT-4评估的获胜率方面,Re-Control取得了最高的对齐分数。 此外,它还保持了发电质量(通过多样性和一致性来衡量)。 虽然受控解码在 Falcon-7B 上实现了最佳平均奖励,但 Re-Control 在其他三个指标方面优于它。 这表明受控解码可能会遇到奖励过度优化。 (2)最强基线是受控解码。 然而,受控解码比Re-Control慢20倍。 这是因为受控解码需要评估多个候选 Token 并重复执行整个奖励模型的前向传递,而Re-Control只需要通过一个两层或三层神经网络的值函数进行优化网络,使其速度更快。 (3) 将即时工程与Re-Control相结合,可以进一步提高平均奖励和GPT-4评估方面的对齐性能。 具体来说,就 GPT-4 胜率而言,它比最强基线高出 5.5% 和 9.7%。 相比之下,带有提示的受控解码仅显示出微小的改进。 这可能是因为重新控制扰乱了大语言模型的激活空间,这比仅仅改变最终词符概率更加灵活。 (4) Re-Control 在 Vicuna-7B 上显着优于静态表示编辑 11.7%,在 Falcon-7B 上显着优于静态表示编辑 9.7%。 这是因为 Re-Control 在自回归生成过程中动态调整表示,提供更多控制。 相比之下,静态表达编辑采用固定移位,更加严格。
在表 2 中,我们提供了一个定性示例,演示了 Re-Control 如何引导基本模型输出更有帮助且无害的响应。 在此示例中,用户询问有关向组织撒谎的建议。 基本模型提供了各种策略,而Re-Control拒绝提供此类建议,并强调说谎会损害组织内的关系和信任。
6进一步分析
6.1 与训练时间对齐的比较

在上一节中,我们将Re-Control与不需要大量计算资源的测试时对齐方法进行了比较。 当我们需要模型快速适应不同的需求时,这个功能至关重要,因为它只涉及训练一个只有两层或三层的简单价值网络。 在本小节中,我们进一步将重新控制与基于微调的方法进行比较。 图 3展示了重新控制、近端策略优化(PPO)和直接偏好优化之间的比较( DPO) rafailov2023direct 。 所有模型均使用Vicuna-7B作为基础模型。 C 中提供了 PPO 和 DPO 的训练详细信息。我们观察到,与 PPO 和 DPO 相比,Re-Control 实现了更高的 GPT-4 获胜率和平均奖励。 此外,Re-Control 在多样性和一致性方面也优于这些方法。 总的来说,结果表明我们的方法是微调方法的有竞争力的替代方案。
6.2 推广到新的输入分布
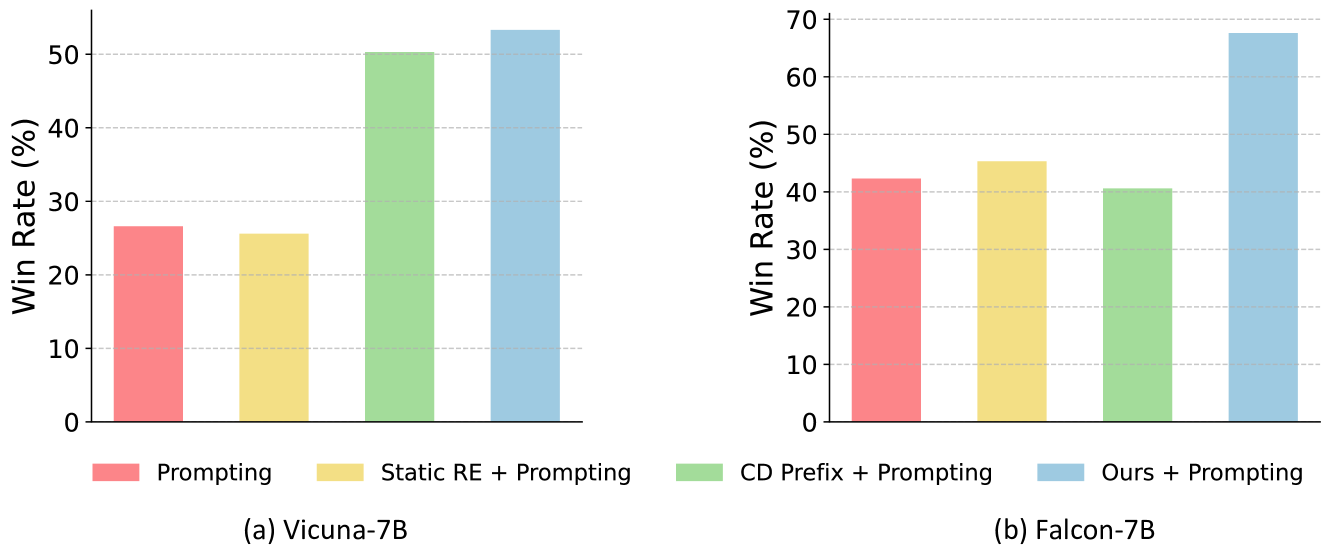
一个重要的问题是我们的方法如何推广到与训练的价值函数不同的新输入分布。 为了研究这个问题,我们进一步测试了分布外(OOD)数据集 HarmfulQA bhardwaj2023red 。 HarmfulQA 的测试部分包含有害问题,用于评估语言模型针对红队尝试的性能。 我们重点关注 GPT-4 评估,因为奖励模型对于 OOD 数据并不准确。 我们将重新控制 + 提升与其他测试时间对齐方法 + 提示进行比较。 图 4展示了结果。 如图所示,Re-Control + Prompting 在 Vicuna-7B 和 上的 GPT-4 获胜率方面实现了最高性能>Falcon-7B。 这是一项重要的能力,尤其是当我们想要在开放世界中部署大语言模型时。
6.3 超参数研究
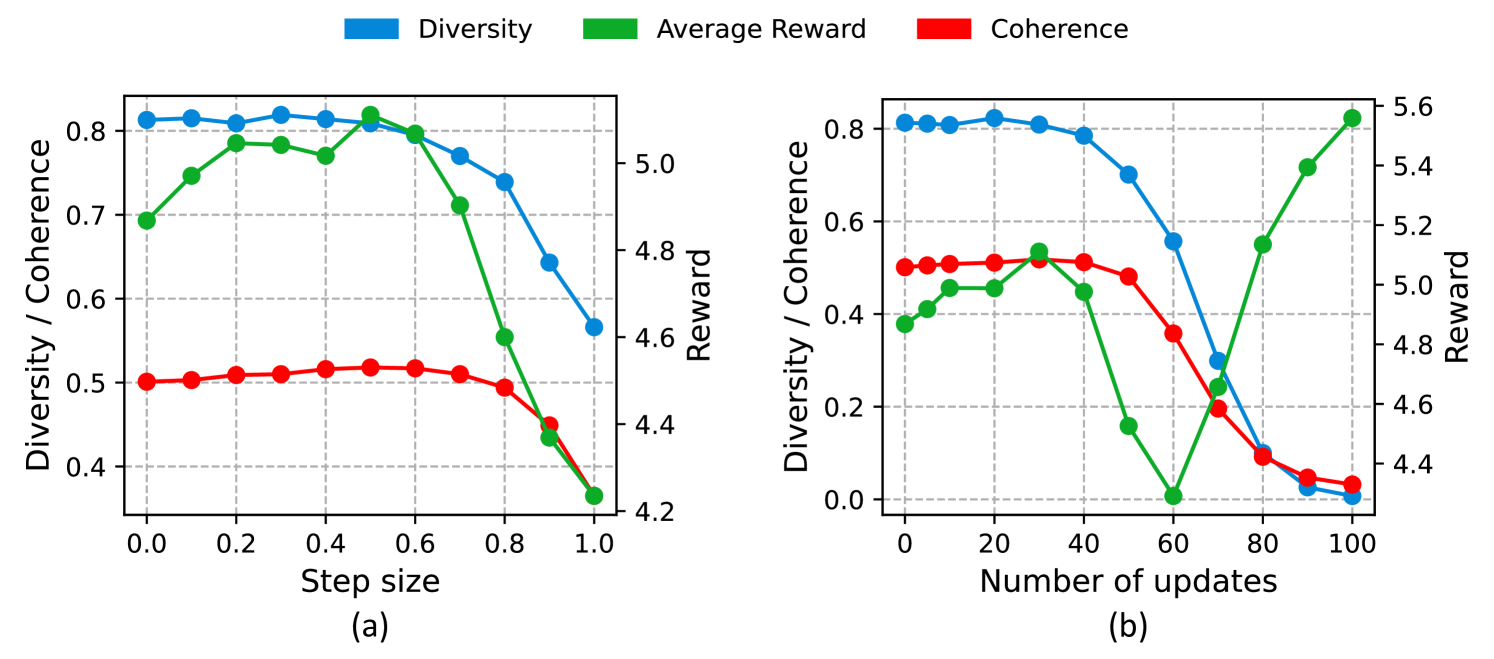
为了更好地理解Re-Control的特征,我们改变了测试时干预的两个超参数——步长和更新次数 ——并衡量关键绩效统计数据。 图 5显示了在HH-RLHF。
正如我们所看到的,增加步长 最初会提高奖励,但超过某个点后,较大的步长无法准确计算控制信号,导致奖励减少。 更新次数的影响显示出更复杂的模式:奖励首先提高,然后减少,然后再次提高,表明从逃离局部最小值到走向另一个最小值的过渡。 一致性和多样性指标下降到接近零,这是奖励过度优化的证据。 因此,进行正则化以防止与原始状态的显着偏差至关重要。 在实践中,我们根据验证集上所有三个指标的总和来选择这两个超参数。
7 结论、局限性和未来的工作
在本文中,我们提出Re-Control在测试时使用表示编辑来对齐大型语言模型(大语言模型)。 我们将自回归语言模型视为离散时间随机动力系统,并将控制信号引入其表示空间。 在整个生成过程中,表示空间会被动态扰动以获得更高的价值分数。 我们的方法不需要对大语言模型进行微调,并且比现有的测试时对齐方法(例如提示和引导解码)提供了更大的灵活性。 我们的经验表明,Re-Control 优于现有的测试时间对齐方法,并表现出很强的泛化能力。 由于篇幅限制,我们在附录A中讨论限制和未来的工作。
参考
- (1) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- (2) Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, et al. The falcon series of open language models. arXiv preprint arXiv:2311.16867, 2023.
- (3) Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861, 2021.
- (4) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, Ben Mann, and Jared Kaplan. Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022.
- (5) Leonard David Berkovitz. Optimal control theory, volume 12. Springer Science & Business Media, 2013.
- (6) Dimitri P Bertsekas. Approximate policy iteration: A survey and some new methods. Journal of Control Theory and Applications, 9(3):310–335, 2011.
- (7) Rishabh Bhardwaj and Soujanya Poria. Red-teaming large language models using chain of utterances for safety-alignment. arXiv preprint arXiv:2308.09662, 2023.
- (8) Aman Bhargava, Cameron Witkowski, Manav Shah, and Matt Thomson. What’s the magic word? a control theory of llm prompting. arXiv preprint arXiv:2310.04444, 2023.
- (9) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- (10) Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. Open problems and fundamental limitations of reinforcement learning from human feedback. Transactions on Machine Learning Research, 2023.
- (11) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023.
- (12) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arxiv 2022. arXiv preprint arXiv:2204.02311, 10, 2022.
- (13) Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe RLHF: Safe reinforcement learning from human feedback. In The Twelfth International Conference on Learning Representations, 2024.
- (14) Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation. In International Conference on Learning Representations, 2020.
- (15) Michael AH Dempster and Vasco Leemans. An automated fx trading system using adaptive reinforcement learning. Expert systems with applications, 30(3):543–552, 2006.
- (16) Ameet Deshpande, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. Toxicity in chatgpt: Analyzing persona-assigned language models. arXiv preprint arXiv:2304.05335, 2023.
- (17) Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767, 2023.
- (18) Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, 2020.
- (19) Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman. Finding alignments between interpretable causal variables and distributed neural representations. In Causal Learning and Reasoning, pages 160–187. PMLR, 2024.
- (20) Nyoman Gunantara. A review of multi-objective optimization: Methods and its applications. Cogent Engineering, 5(1):1502242, 2018.
- (21) Seungwook Han, Idan Shenfeld, Akash Srivastava, Yoon Kim, and Pulkit Agrawal. Value augmented sampling for language model alignment and personalization. arXiv preprint arXiv:2405.06639, 2024.
- (22) James Y Huang, Sailik Sengupta, Daniele Bonadiman, Yi-an Lai, Arshit Gupta, Nikolaos Pappas, Saab Mansour, Katrin Kirchoff, and Dan Roth. Deal: Decoding-time alignment for large language models. arXiv preprint arXiv:2402.06147, 2024.
- (23) Julian Ibarz, Jie Tan, Chelsea Finn, Mrinal Kalakrishnan, Peter Pastor, and Sergey Levine. How to train your robot with deep reinforcement learning: lessons we have learned. The International Journal of Robotics Research, 40(4-5):698–721, 2021.
- (24) David Isele, Reza Rahimi, Akansel Cosgun, Kaushik Subramanian, and Kikuo Fujimura. Navigating occluded intersections with autonomous vehicles using deep reinforcement learning. In 2018 IEEE international conference on robotics and automation (ICRA), pages 2034–2039. IEEE, 2018.
- (25) Shirel Josef and Amir Degani. Deep reinforcement learning for safe local planning of a ground vehicle in unknown rough terrain. IEEE Robotics and Automation Letters, 5(4):6748–6755, 2020.
- (26) Maxim Khanov, Jirayu Burapacheep, and Yixuan Li. Alignment as reward-guided search. In The Twelfth International Conference on Learning Representations, 2024.
- (27) Maxim Khanov, Jirayu Burapacheep, and Yixuan Li. Args: Alignment as reward-guided search. arXiv preprint arXiv:2402.01694, 2024.
- (28) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- (29) Songsang Koh, Bo Zhou, Hui Fang, Po Yang, Zaili Yang, Qiang Yang, Lin Guan, and Zhigang Ji. Real-time deep reinforcement learning based vehicle navigation. Applied Soft Computing, 96:106694, 2020.
- (30) Petar Kormushev, Sylvain Calinon, and Darwin G Caldwell. Reinforcement learning in robotics: Applications and real-world challenges. Robotics, 2(3):122–148, 2013.
- (31) Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36, 2023.
- (32) Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavatula, and Yejin Choi. The unlocking spell on base llms: Rethinking alignment via in-context learning. arXiv preprint arXiv:2312.01552, 2023.
- (33) Derong Liu and Qinglai Wei. Policy iteration adaptive dynamic programming algorithm for discrete-time nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 25(3):621–634, 2013.
- (34) Sheng Liu, Lei Xing, and James Zou. In-context vectors: Making in context learning more effective and controllable through latent space steering. arXiv preprint arXiv:2311.06668, 2023.
- (35) Tianqi Liu, Yao Zhao, Rishabh Joshi, Misha Khalman, Mohammad Saleh, Peter J Liu, and Jialu Liu. Statistical rejection sampling improves preference optimization. arXiv preprint arXiv:2309.06657, 2023.
- (36) Wenhao Liu, Xiaohua Wang, Muling Wu, Tianlong Li, Changze Lv, Zixuan Ling, Jianhao Zhu, Cenyuan Zhang, Xiaoqing Zheng, and Xuanjing Huang. Aligning large language models with human preferences through representation engineering. arXiv preprint arXiv:2312.15997, 2023.
- (37) Xiao-Yang Liu, Hongyang Yang, Jiechao Gao, and Christina Dan Wang. Finrl: Deep reinforcement learning framework to automate trading in quantitative finance. In Proceedings of the second ACM international conference on AI in finance, pages 1–9, 2021.
- (38) Yifan Luo, Yiming Tang, Chengfeng Shen, Zhennan Zhou, and Bin Dong. Prompt engineering through the lens of optimal control. arXiv preprint arXiv:2310.14201, 2023.
- (39) Sidharth Mudgal, Jong Lee, Harish Ganapathy, YaGuang Li, Tao Wang, Yanping Huang, Zhifeng Chen, Heng-Tze Cheng, Michael Collins, Trevor Strohman, et al. Controlled decoding from language models. arXiv preprint arXiv:2310.17022, 2023.
- (40) Richard Ngo, Lawrence Chan, and Sören Mindermann. The alignment problem from a deep learning perspective. In The Twelfth International Conference on Learning Representations, 2024.
- (41) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- (42) Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- (43) Rex Clark Robinson. An introduction to dynamical systems: continuous and discrete, volume 19. American Mathematical Soc., 2012.
- (44) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- (45) Stefano Soatto, Paulo Tabuada, Pratik Chaudhari, and Tian Yu Liu. Taming ai bots: Controllability of neural states in large language models. arXiv preprint arXiv:2305.18449, 2023.
- (46) Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. Preference ranking optimization for human alignment. arXiv preprint arXiv:2306.17492, 2023.
- (47) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- (48) Yixuan Su, Tian Lan, Yan Wang, Dani Yogatama, Lingpeng Kong, and Nigel Collier. A contrastive framework for neural text generation. Advances in Neural Information Processing Systems, 2022.
- (49) Nishant Subramani, Nivedita Suresh, and Matthew E Peters. Extracting latent steering vectors from pretrained language models. In Findings of the Association for Computational Linguistics: ACL 2022, pages 566–581, 2022.
- (50) Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT press, 2018.
- (51) Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- (52) Emanuel Todorov. Optimal control theory. Bayesian Brain, 2006.
- (53) Masaki Togai and Osamu Yamano. Analysis and design of an optimal learning control scheme for industrial robots: A discrete system approach. In 1985 24th IEEE Conference on Decision and Control, pages 1399–1404. IEEE, 1985.
- (54) Varun Tolani, Somil Bansal, Aleksandra Faust, and Claire Tomlin. Visual navigation among humans with optimal control as a supervisor. IEEE Robotics and Automation Letters, 6(2):2288–2295, 2021.
- (55) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- (56) Alex Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248, 2023.
- (57) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- (58) Chao Wang, Jian Wang, Yuan Shen, and Xudong Zhang. Autonomous navigation of uavs in large-scale complex environments: A deep reinforcement learning approach. IEEE Transactions on Vehicular Technology, 68(3):2124–2136, 2019.
- (59) Zhikang T. Wang and Masahito Ueda. Convergent and efficient deep q learning algorithm. In International Conference on Learning Representations, 2022.
- (60) Boyi Wei, Kaixuan Huang, Yangsibo Huang, Tinghao Xie, Xiangyu Qi, Mengzhou Xia, Prateek Mittal, Mengdi Wang, and Peter Henderson. Assessing the brittleness of safety alignment via pruning and low-rank modifications. arXiv preprint arXiv:2402.05162, 2024.
- (61) Qinglai Wei, Guang Shi, Ruizhuo Song, and Yu Liu. Adaptive dynamic programming-based optimal control scheme for energy storage systems with solar renewable energy. IEEE Transactions on Industrial Electronics, 64(7):5468–5478, 2017.
- (62) Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, et al. Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359, 2021.
- (63) Muling Wu, Wenhao Liu, Xiaohua Wang, Tianlong Li, Changze Lv, Zixuan Ling, Jianhao Zhu, Cenyuan Zhang, Xiaoqing Zheng, and Xuanjing Huang. Advancing parameter efficiency in fine-tuning via representation editing. arXiv preprint arXiv:2402.15179, 2024.
- (64) Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D Manning, and Christopher Potts. Reft: Representation finetuning for language models. arXiv preprint arXiv:2404.03592, 2024.
- (65) Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation. arXiv preprint arXiv:2401.08417, 2024.
- (66) Jing Xu, Andrew Lee, Sainbayar Sukhbaatar, and Jason Weston. Some things are more cringe than others: Preference optimization with the pairwise cringe loss. arXiv preprint arXiv:2312.16682, 2023.
- (67) Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. Rrhf: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302, 2023.
- (68) Zhexin Zhang, Junxiao Yang, Pei Ke, and Minlie Huang. Defending large language models against jailbreaking attacks through goal prioritization. arXiv preprint arXiv:2311.09096, 2023.
- (69) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- (70) Banghua Zhu, Michael Jordan, and Jiantao Jiao. Principled reinforcement learning with human feedback from pairwise or k-wise comparisons. In International Conference on Machine Learning, pages 43037–43067. PMLR, 2023.
- (71) Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405, 2023.
重新控制的附录
[章节] [章节]l1
附录 A局限性和未来的工作
我们讨论Re-Control的局限性和可能的扩展。 (1) 将归纳偏差注入控制策略。 在我们当前的工作中,我们仅在模型隐藏空间的最后一层训练一个值函数。 但是,我们可以遵循 li2024inference 中的方法,首先在所有中间隐藏层上使用多个值函数,然后选择在验证集上实现最佳准确率的层。 此外,我们可以借鉴 geiger2024finding 中的方法; wu2024ref; wei2024评估仅扰动表示空间的低阶子空间。 (2) 多目标对齐。 在本文中,我们考虑单一奖励模型的目标。 然而,在实践中,协调可能涉及多个可能相互冲突的目标。 在测试时利用多目标优化技术gunantara2018review来获得此类设置的表示空间中的帕累托前沿将会很有趣。 (3) 更高级的训练算法。 目前,我们使用简单的一次迭代策略迭代方法来训练价值函数。 探索增加迭代次数是否可以进一步改善价值函数的训练是很有趣的。 此外,我们可以考虑使用训练价值函数的算法来提供可证明的收敛性 wang2022convergent 。
附录 B更广泛的影响
将大型语言模型(大语言模型)与人类偏好保持一致至关重要。 我们期望本文引入的测试时间对齐方法将有助于防止大语言模型生成有害内容,从而对社会产生积极影响。 然而,必须确保价值函数的训练不涉及负面目标。 必须小心防止这种滥用。
附录C实验细节
C.1 计算基础设施
我们在配备 NVIDIA A100 (80GB VRAM) GPU 的服务器上进行实验。 我们使用 NVIDIA CUDA 工具包版本 12.4。 所有实验均使用Python 3.12.2和PyTorch框架版本2.2.2实现。
C.2 HH-RLHF
我们在 HH-RLHF bai2022training 数据集上评估我们的方法,该数据集是大语言模型比对中使用最广泛的数据集。 该数据集用于提高AI助手训练的有用性和无害性,包含161,000个样本和8,550个测试样本。 每个示例都包含一个提示和两个响应,其中一个优先于另一个。 对于基础模型,我们采用 Vicuna-7B222https://huggingface.co/lmsys/vicuna-7b-v1.5 chiang2023vicuna 和 Falcon-7B-Instruct333https://huggingface.co/tiiuae/falcon-7b almazrouei2023falcon 作为指令微调的人工智能助手。 我们通过根据 HH-RLHF 的测试提示生成文本响应来评估这些模型。 按照标准做法,我们将提示和生成的延续的最大长度分别限制为 和 标记。
对于奖励模型,我们使用公开的模型,该模型采用 LLaMA-7B444https://huggingface.co/argsearch/llama-7b-rm-float32作为主干,在HH-RLHF上进行训练> 使用成对奖励损失 ouyang2022training0> 。
重新控制。
在为值函数构建训练数据集时,我们仅对 HH-RLHF 的每个训练提示采样一个响应,即 。 对于Vicuna-7B和Falcon-7B,我们在隐藏状态的最后一层上训练价值网络,并在测试时,我们仅将控制信号添加到这一层。 对于未来的研究,我们还可以探索向注意力键值对添加控制,这应该进一步提高性能。
对于Vicuna-7B,价值函数是一个三层网络,隐藏维度为4096。 对于Falcon-7B,价值函数是一个隐藏维度为4096的两层网络。
为了训练 Re-Control 的价值函数,我们采用 Adam 优化器 kingma2014adam 。 价值网络的训练超参数总结在表3中。
| Backbone | Parameters | Value |
|---|---|---|
| Vicuna | Number of epochs | 100 |
| Learning rate | ||
| batch size | 512 | |
| Floating point format | fp16 (Half-precision) | |
| Number of Layers | 3 | |
| Hidden Dimension | 4096 | |
| Falcon | Number of epochs | 100 |
| Learning rate | ||
| batch size | 512 | |
| Floating point format | fp16 (Half-precision) | |
| Number of Layers | 2 | |
| Hidden Dimension | 4096 |
我们从 HH-RLHF 训练集中随机采样 1000 个数据点作为单独的验证集。 在验证集上选择步长 和更新次数 ,以最大化一致性、多样性和平均奖励的总和。 推理参数总结在表4中。
| Backbone | Parameters | Value |
| Vicuna | Step size | 0.5 |
| Number of updates | 30 | |
| batch size | 30 | |
| Floating point format | fp16 (Half-precision) | |
| Maximum lengths of the prompt | 2048 | |
| Maximum lengths of genearted continuation | 128 | |
| Falcon | Step size | 0.2 |
| Number of updates | 200 | |
| batch size | 60 | |
| Floating point format | fp16 (Half-precision) | |
| Maximum lengths of the prompt | 2048 | |
| Maximum lengths of genearted continuation | 128 |
提示工程。
我们指示模型提供更有帮助且无害的响应。 提示模板如下:
静态表示编辑。
在输入提示后,我们首先在大型语言模型(大语言模型)的隐藏状态上训练线性回归层,以预测预期奖励,如 li2024inference 。 为了公平比较,我们使用与Re-Control相同的隐藏状态层。 在测试时,我们使用基于验证集选择的干预强度参数 沿权重方向移动激活空间。 表5总结了训练和测试阶段使用的超参数。
受控解码。
我们使用代码库555https://github.com/deeplearning-wisc/args 来自 khanov2024args 。 我们采用论文和存储库中建议的默认超参数。 奖励模型排名的候选者数量设置为10,控制大语言模型文本目标和奖励之间权衡的权重为1。 对于使用值函数的受控解码,我们将Re-Control的值函数堆叠在大语言模型的隐藏状态之上作为前缀评分器,确保与我们的方法进行公平比较。
| Backbone | Parameters | Value |
|---|---|---|
| Vicuna | Number of epochs | 100 |
| Learning rate | ||
| Training batch size | 512 | |
| Testing batch size | 30 | |
| Intervention strength | 2.5 | |
| Falcon | Number of epochs | 100 |
| Learning rate | ||
| Training batch size | 512 | |
| Testing batch size | 60 | |
| Intervention strength | 2.0 |
PPO 的训练配置
对于涉及近端策略优化 (PPO) 的实验,我们使用 Huggingface 的 Transformer 强化学习 (TRL) 存储库以及 PPO 训练器模块。 配置值详见表6。
| Parameters | Value | |
|---|---|---|
| Vicuna | Max number of PPO update steps | 10000 |
| Generation batch | 1 | |
| PPO batch size | 16 | |
| PPO minibatch size | 8 | |
| Lora rank | 8 | |
| Learning rate | ||
| Batch size | 4 | |
| Gradient accumulation steps | 2 | |
| Input maximum length | 512 | |
| Output maximum length | 256 | |
| Weight decay | 0.001 |
DPO 的训练配置
对于涉及直接策略优化 (DPO) 的实验,我们使用 Huggingface 的 Transformer 强化学习 (TRL) 存储库以及 DPO Trainer 模块。 配置值详见表7。
| Parameters | Value | |
|---|---|---|
| Vicuna | Max number of training steps | 10000 |
| Learning rate | ||
| Lora rank | 8 | |
| Warmup steps | 100 | |
| Batch size | 4 | |
| Gradient accumulation steps | 4 | |
| Maximum sequence length | 1024 | |
| Weight decay | 0.05 | |
| Regularization parameter | 0.1 |
C.3 有害的QA
此数据集666https://huggingface.co/datasets/declare-lab/HarmfulQA包含1,960个专门用于评估语言模型性能的有害问题。 此外,它还包括一个对话集,其中包含 9,536 个无害对话和 7,356 个有害对话,用于模型对齐目的。 在我们的实验中,我们仅关注 HarmfulQA 数据集的评估部分来测试我们方法的性能。
附录 D GPT-4 评估
关注 chiang2023vicuna ; khanov2024args 中,我们使用 GPT-4 作为判断者,让它以 1 到 10 的等级对同一提示的两个回答进行审查和评分。 我们提供明确的指示,根据有用性、无害性、相关性、准确性、深度、创造力和详细程度等标准评估回复。 详细提示见8。 现有的作品zheng2023judging表明GPT-4的判断在80%以上的时间里与人类的评估一致。 我们从 RLHF 测试集中随机抽取 300 个提示。 为了减轻位置偏差,我们随机化了向 GPT-4 呈现生成响应的顺序,如 zheng2023judging 中所示。