Ask-EDA:大语言模型、混合RAG和缩写解幻赋能的设计助手
摘要
电子设计工程师面临着为设计构建、验证和技术开发中的众多任务有效地找到相关信息的挑战。 大型语言模型(大语言模型)有潜力通过充当有效充当主题专家的对话代理来帮助提高生产力。 在本文中,我们演示了 Ask-EDA,这是一个聊天代理,旨在充当 247 的专家,为设计工程师提供指导。 Ask-EDA 利用大语言模型、混合检索增强生成 (RAG) 和缩写去幻觉 (ADH) 技术来提供更相关和更准确的响应。 我们策划了三个评估数据集,即 q2a-100、cmds-100 和 abbr-100。 每个数据集都是为了评估一个不同的方面而定制的:一般设计问题回答、设计命令处理和缩写解析。 我们证明,与不使用 RAG 相比,混合 RAG 在 q2a-100 数据集上的召回率提高了 40% 以上,在 cmds-100 数据集上的召回率提高了 60% 以上,而 ADH 在缩写上的召回率提高了 70% 以上-100 数据集。 评估结果表明Ask-EDA可以有效地响应设计相关的询问。
索引术语:
大语言模型、大语言模型、设计助手、聊天机器人、EDA、检索增强生成、RAG、混合搜索、去幻觉我简介
现代设计工程师面临着巨大的挑战。 他们面临着设计构建和验证的各种任务。 在大型组织中,找到正确的文档或主题专家进行咨询的过程经常是一个问题。 可能存在冗余文档版本,有时它们并不位于集中位置。 这个问题对于新雇用的员工或新工具上线时尤其重要。 可能会有一组必须理解的新术语和缩略语。 拥有 247 全天候为工程师提供建议的顾问将显着提高生产力。
大型语言模型(大语言模型)[1] 非常擅长提供自然语言响应。 尽管大语言模型在各种任务中表现出色,但它们的反应受到训练数据的限制。 大语言模型的训练数据经常会过时,我们的目标是避免将机密设计信息纳入其中。 当询问训练数据之外的话题时,大语言模型可能会自信地给出不正确但看似合理的反应,这种现象被称为幻觉。 检索增强生成 (RAG) [2] 通过将信息检索与精心设计的系统提示相结合来解决这些问题。 该方法将大语言模型锚定到从外部知识库检索的精确的、当前的和相关的信息。
Sentence Transformer [3] 是最先进的信息检索模型之一,并迅速成为 RAG [4] 的流行选择。 句子 Transformer 将文本编码为密集向量表示,捕获语义信息并基于含义(而不仅仅是关键字匹配)实现更准确的检索。 虽然基于句子转换器的密集检索方法擅长检索相关语义上下文,但在某些情况下,设计工程师寻求包含特定技术术语的结果,而密集检索方法无法始终保证检索到这些结果。 或者,稀疏检索方法[5,6,7]允许查询术语与文档术语精确匹配,从而实现基于精确术语匹配的精确检索。 我们开发了一种混合搜索引擎,利用密集和稀疏检索算法的优势来提高搜索结果的准确性和相关性。
我们在大语言模型中遇到的另一个挑战是,当他们不知道正确的全名时,他们倾向于对缩写产生幻觉的解释。 这种现象在设计领域尤其普遍,通常使用缩写。 为了解决这个问题,我们衍生了一个缩写解幻觉(ADH)组件,它利用预先构建的缩写词典为大语言模型提供相关缩写知识。
在这项工作中,我们开发了 Ask-EDA,这是一种聊天代理,旨在支持电子设计自动化 (EDA) 并提高设计工程师的工作效率。 Ask-EDA 利用大语言模型、混合 RAG 和缩写去幻觉技术来提供更相关和更准确的响应。 我们策划了三个评估数据集来证明 Ask-EDA 的有效性,即 q2a-100、cmds-100 和 abbr-100,分别侧重于通用设计问答、设计命令回答和缩写解析方面。 虽然 ChipNeMo [4] 等现有技术已经展示了设计助理聊天机器人的功能,但我们混合 RAG 和 ADH 组件的结合展示了响应质量的显着提高,无论采用何种大语言模型模型。 此外,我们还扩展了评估范围,涵盖了解决设计领域问答中各种挑战的不同集合。 我们还使用 Slack API [8] 构建自然语言界面,允许用户与我们的聊天代理进行对话。
II 方法论
II-A 文档来源
我们的设计团队可以使用多种文档来源作为参考。 设计团队的主题专家 (SME) 为给定的芯片和方法编写指南。 我们的铸造供应商提供技术物理设计套件手册,指定设计规则。 工具和方法 SME 提供全面的工具文档,包括命令、参数和方法步骤。 DevOp SME 提供有关作业提交和持续集成程序的文档。 Slack 提供了大量有关程序和联系点的对话。 设计人员和开发人员都使用工程工作流程管理来进行迭代和发布规划、变更管理和缺陷跟踪。 在内部,我们有自己的堆栈溢出式界面和数据库,用于提出问题、提升正确答案的排名和信息检索。 目前,这些源在磁盘上消耗了大约 400 Mb,代表大约 10,200 个命令手册页、5,000 个参数、30 个松弛通道和 18,000 个常见问题/答案。
II-B 混合RAG
我们使用检索增强生成(RAG)为大语言模型生成提供相关上下文。 我们开发了一个混合搜索引擎,将句子转换器和 BM25 结合起来,以提高搜索结果的准确性和相关性。 以下是有关摄取和检索阶段的详细信息。
II-B1 食入
每个源文档可以采用不同的格式,因此,我们使用langchain [9]文档加载器来读取图1中的文档。 它支持逗号和制表符分隔值文件、json、pdf、docx、pptx、markdown 和纯文本格式。 目前,文档被分成大小均匀的块。 每个块都被输入到句子 Transformer 以创建密集的嵌入向量。 我们使用 ChromaDB [10] 作为我们的密集向量数据库。 相同的块也被馈送到 BM25 [5] 以计算 BM25 索引。 它们一起形成一个混合数据库,供以后检索使用。
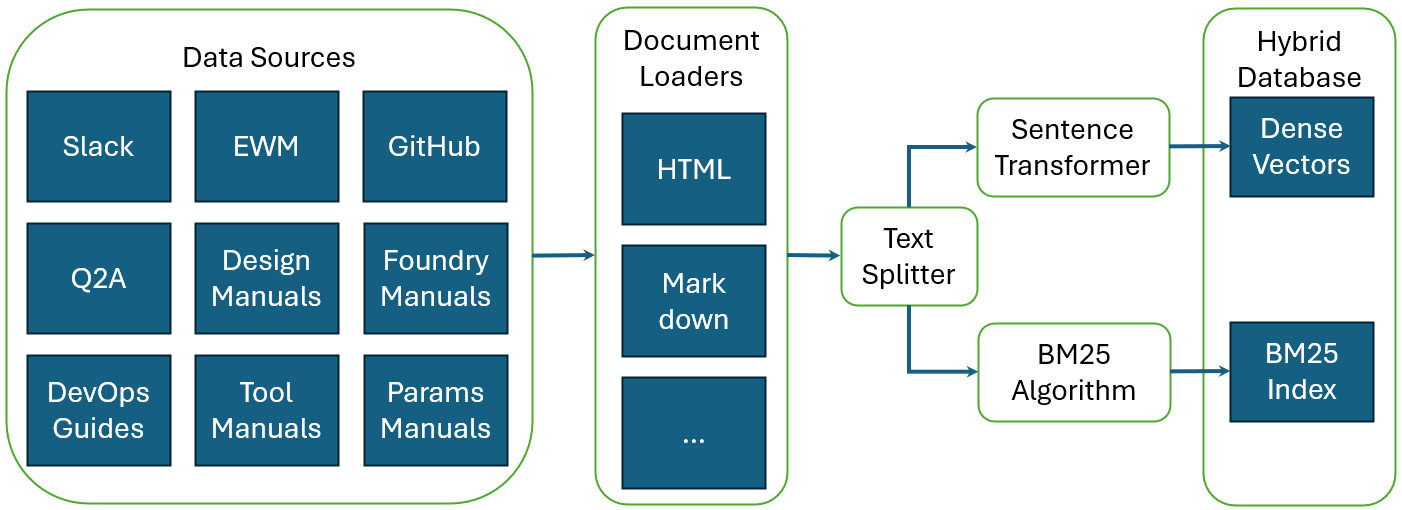
II-B2 恢复
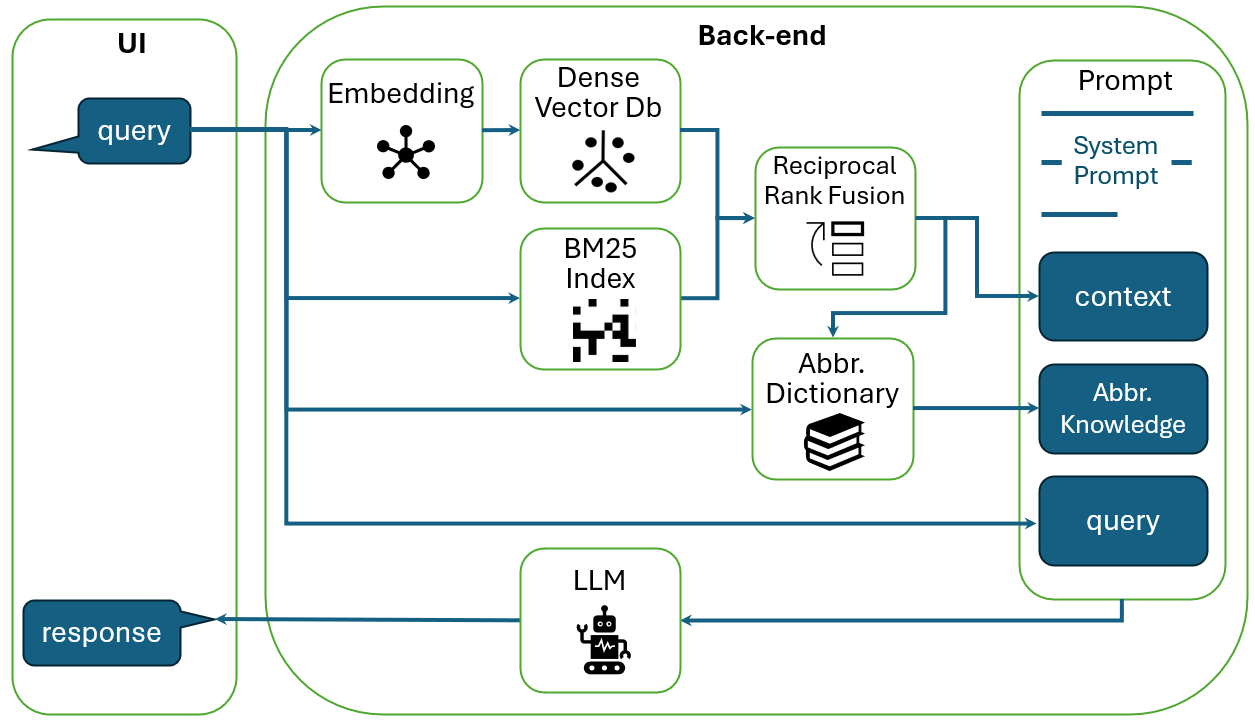
当用户进行查询时,我们在摄取阶段使用相同的句子 Transformer 对查询进行编码,并将其嵌入与具有余弦相似度的密集向量数据库中最近的嵌入进行匹配。 这为我们提供了语义最相关的顶级 文本块。 我们还根据预先计算的 BM25 索引找到最相关的 文本块。 然后将密集方法和稀疏方法的结果与倒数秩融合(RRF)[11]相结合。 RRF 分数计算如下:
| (1) |
其中 是顶部 和顶部 候选文本块的并集, 是一个候选文本。 是一种排名方法(根据其相关性分数排序的密集或稀疏方法)的排名索引, 是来自不同排名方法的排名集合。 是一个有助于平衡高低排名的常数,在我们的研究中设置为 60。 文本块集合将根据其 RRF 分数重新排序,并且具有最高 RRF 分数的前 文本块将被选择作为大语言模型提示中的上下文。 这些文本块按升序排序,以便最相关的上下文更接近大语言模型提示中的用户查询。
II-C 缩写 解除幻觉
为了帮助减轻大语言模型对缩写产生的幻觉反应,我们创建了一个缩写(Abbr.) 词典,包含249个常见的设计相关缩写术语。 这些术语主要特定于 IBM 芯片设计,其中大约 25% 为电子设计自动化行业所普遍认可。 所有缩写项都有全名,249 个术语中有 148 个有附加详细描述。 五位设计专家为这本词典的编写做出了贡献。 当用户进行查询时,首先通过混合搜索和RRF获得相关上下文。 然后,我们搜索查询和上下文,根据精确的术语匹配在词典中查找相关缩写。 如果找到相关缩写,则从词典中提取其相关全名和描述(如果有)并添加到提示中,为大语言模型提供缩写知识。 在我们的实现中,缩写知识被添加到上下文和查询之间。 对于每个缩写术语,其知识以“通常缩写为,即”的格式添加。当其描述可用时,“ 通常是 的缩写。”当其描述不存在时,其中 是缩写术语, 是其全名, 是其描述。
II-D 大语言模型一代
最后,我们在提示符的开头添加了一个系统提示符,以指导大语言模型的行为并确保生成的输出符合我们的预期目标。 我们使用的系统提示将在本文的后续部分中提供。 最后的提示被输入到大语言模型中并生成响应。 大语言模型响应连同相关文档作为完整响应返回给用户。 我们的管道如图2所示。
II-E 聊天界面
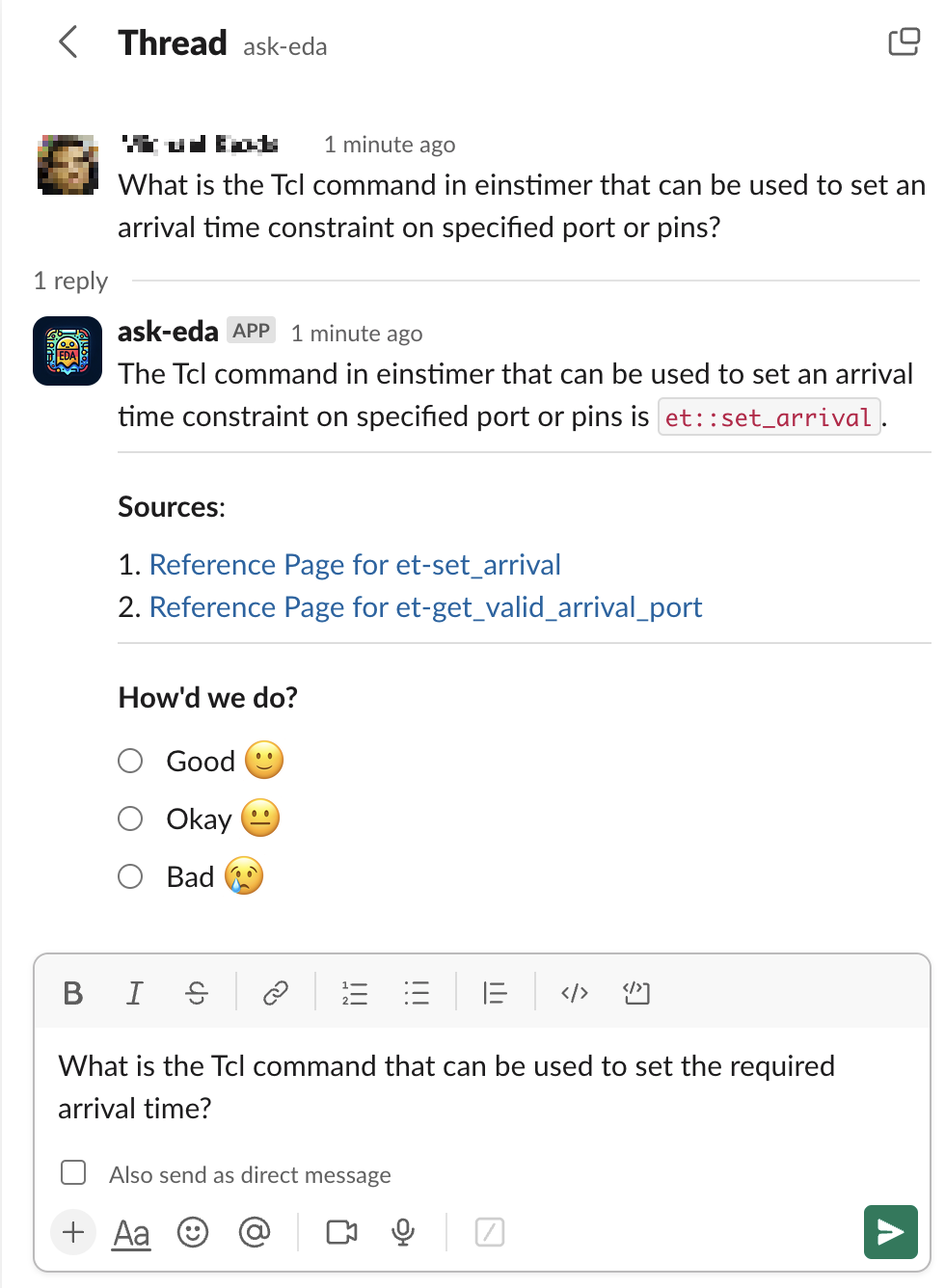
Slack 常被工程师用于沟通,是进行对话的自然界面。 我们通过 Slack API 创建了一个代理。 用户向代理发送消息,代理将在线程中创建响应。 聊天历史记录继续对话,我们包括最近的先前问题的历史背景以供后续查询。 我们还提供了一个界面,使用户能够查看 RAG 提供的来源,并就 Ask-EDA 响应的质量提供反馈。 请注意,本文的评估研究中不使用聊天记录和反馈数据。 我们的界面截图示例如图A.1所示。
III评估
III-A 数据集
为了评估 Ask-EDA 的性能,我们策划了三个用于评估的数据集,即 q2a-100、cmds-100 和 abbr-100。 每篇文章的内容都是特定于 IBM 芯片设计和方法的领域。
III-A1 q2a-100 数据集
我们有一个堆栈溢出类型的系统,工程师可以提出问题,其他中小企业可以评论和回答。 有一个投票系统,可以标记最佳答案。 使用这些针对常见问题的专家答案代表了带有真实标记数据的集体知识。 我们提取了这些问题和答案作为要摄取的数据源。 基于这个数据库,我们创建了一个包含 100 个问题和答案的子集作为评估数据集。
III-A2 cmds-100 数据集
工具团队创建手册页来记录我们的物理构建和验证系统的命令。 这些是一个工具包,设计人员可以在其中增强方法流程以满足特殊需求。 这些命令中的每一个都代表一个数据源,开发人员经常从中查询命令和选项。 此内容是从工具源代码生成的 HTML。 我们同样将其提取为设计源。 我们通过将命令的一行概要转化为问题并提供命令名称作为真实答案,进一步收集了 100 个命令作为测试数据集。
III-A3 abbr-100 数据集
我们从前面描述的缩写词典中派生出 abbr-100 数据集作为子集。 我们从缩写词词典中随机抽取100个缩写词,并分别以“代表什么?”、“”的格式创建问题和答案。 请注意,在此评估集中,问答对中仅包含缩写及其全名,而不考虑描述。 在表中。 I我们展示了上述每个评估数据集中的一个示例。
| Dataset | Example | |||
|---|---|---|---|---|
| q2a-100 |
|
|||
| cmds-100 |
|
|||
| abbr-100 |
|
III-B 实施细节
我们在研究中评估了两个大语言模型。 Granite-13b-chat-v2.1 [12, 13] 是由 IBM 开发和训练的纯解码器和纯英语基础模型。 大语言模型训练数据和我们摄取的数据之间没有重叠。 我们还评估了 Llama2-13b-chat,它被认为是 13b 参数规模最先进的开源聊天模型之一。 对于这两个模型,上下文长度均为 8192,最大新 Token 为 4096。 对于 Granite-13b-chat-v2.1 和 Llama2-13b-chat,我们使用其相应的提示格式,但使用相同的系统提示:“你是一个有用的 AI 语言模型。 您的主要功能是帮助用户回答问题、生成文本和参与对话。 给定长文档和问题的以下提取部分,创建最终答案。 如果请求命令,请只返回第一个命令。”我们使用 all-MiniLM-L6-v2 [14] 作为文本嵌入器。 摄取时的块大小为 2048,块重叠为 256。 检索候选数、和均设置为3。
III-C 结果
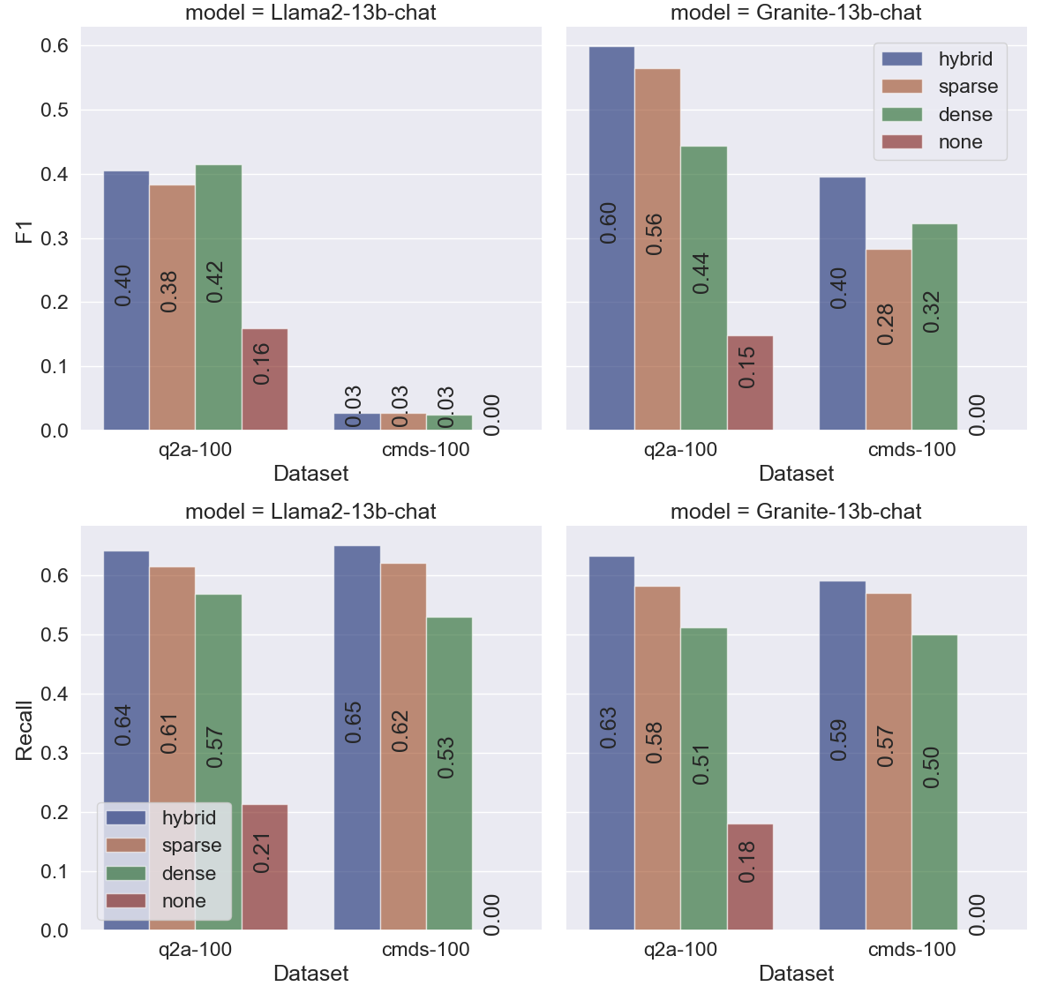
图3展示了Granite-13b-chat-v2.1和Llama2-13b-chat模型在q2a-100和cmds-100数据集上的结果。 对于每个大语言模型模型,我们比较了不同的RAG技术,包括:混合检索(hybrid)、仅BM25稀疏检索(sparse)、仅句子变换器密集检索(dense)和无RAG(none)。 此时不包括缩写去幻觉 (ADH) 组件。 我们使用 ROUGE-Lsum [15] F1 和召回率作为我们的评估指标。 从图3我们可以看到,在q2a-100上,Granite-13b-chat-v2.1在F1分数方面比Llama2-13b-chat产生了明显更好的响应,同时提供了可比较的响应就召回率而言。 对于这两种模型,与不使用 RAG 相比,使用 RAG 产生的结果明显更优。 使用 Granite-13b-chat-v2.1,混合检索实现了最高性能,其次是稀疏和密集检索。 然而,在 Llama2-13b-chat 中,这种模式仅在召回率方面观察到,而在 F1 方面却没有。 鉴于其相对较低的 F1 性能,尽管混合搜索提供了潜在的改进,但 Llama2-13b-chat 可能难以有效地从上下文中提取最终答案。
在 cmds-100 数据集上,Llama2-13b-chat 的召回率比 Granite-13b-chat-v2.1 稍好,但就 F1 而言,Granite-13b-chat-v2.1 的响应远远优于 Llama2-13b-chat分数。 值得注意的是,由于大语言模型缺乏对这些设计命令的了解,无 RAG 模型的召回分数为 0。 在这里,混合搜索 RAG 再次优于仅稀疏 RAG 和仅密集 RAG。
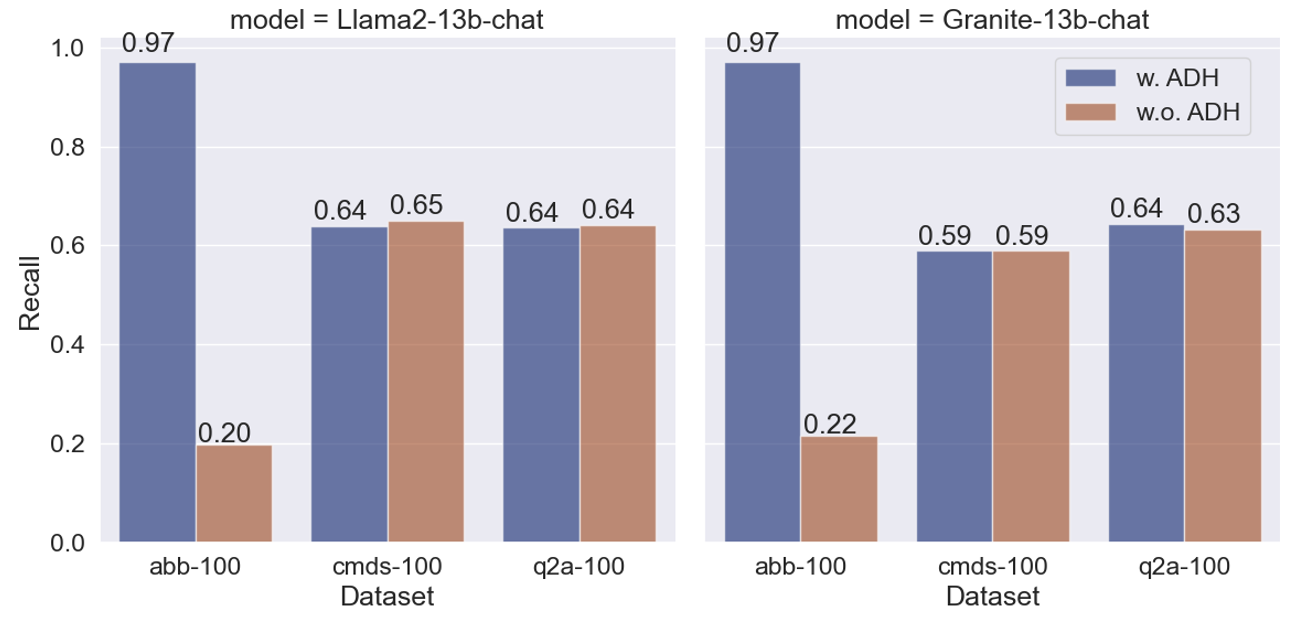
图4显示了添加缩写去幻觉(ADH)组件后的对比结果。 这里仅使用混合 RAG。 我们在这里专门报告 Recall 表现,因为 abbr-100 中的答案由简短且明确表述的完整缩写名称组成,而大语言模型有时会产生带有描述性解释的冗长答案,这可能会导致 F1 分数受到惩罚。 可以看出,ADH 组件的添加显着提高了两个大语言模型模型在 abbr-100 上的性能。 然而,我们还观察到,Granite-13b-chat-v2.1 和 Llama2-13b-chat 都没有达到 1.0 的召回分数,即使我们验证了与查询匹配的缩写包含在查询文本之前的增强提示中。 目前,我们得出的结论是,大语言模型中的一些内在局限性(由于复杂的基于 RAG 的上下文而加剧)阻碍了它们成功回忆所有缩写。 我们还展示了合并 ADH 组件后 cmds-100 和 q2a-100 的结果,证明使用额外的缩写知识增强提示不会对这两个评估数据集的性能产生不利影响。
四讨论
在本文中,我们证明,与不使用 RAG 相比,使用 RAG 可以获得显着更好的结果。 我们还表明,混合 RAG 比仅稀疏 RAG 和仅密集 RAG 表现出显着增强。 我们未来的方向之一涉及微调更复杂的稀疏 [6, 7] 和密集 [16] 检索模型,以进一步增强 RAG。 我们还将探索通过对设计数据进行扩展微调来进一步改进大语言模型。 此外,我们的目标是根据我们从 Slack GUI 收集的反馈数据(如图所示),利用人类反馈强化学习 (RLHF)[17] 技术,使我们的聊天代理更符合人类偏好。 A.1)响应。
V 结论
在这项工作中,我们引入了 Ask-EDA,这是一款专为提高设计工程师的工作效率而定制的聊天代理。 借助大语言模型、混合 RAG 和缩写去幻觉技术,Ask-EDA 可以提供相关且准确的响应。 我们评估了 Ask-EDA 在三个不同数据集上的性能,证明了其在不同领域的有效性。 最后,我们集成了 Slack API,创建了一个用户友好的自然语言界面,以便与我们的聊天代理无缝交互。
六致谢
我们衷心感谢 Ehsan Degan、Vandana Mukherjee 和 Leon Stok 作为管理层在本文准备过程中提供的宝贵支持和指导。
参考
- [1] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
- [2] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel et al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,” Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020.
- [3] N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019.
- [4] M. Liu, T.-D. Ene, R. Kirby, C. Cheng, N. Pinckney, R. Liang, J. Alben, H. Anand, S. Banerjee, I. Bayraktaroglu et al., “Chipnemo: Domain-adapted llms for chip design,” arXiv preprint arXiv:2311.00176, 2023.
- [5] S. Robertson, H. Zaragoza et al., “The probabilistic relevance framework: Bm25 and beyond,” Foundations and Trends® in Information Retrieval, vol. 3, no. 4, pp. 333–389, 2009.
- [6] T. Formal, B. Piwowarski, and S. Clinchant, “Splade: Sparse lexical and expansion model for first stage ranking,” in Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2021, pp. 2288–2292.
- [7] L. Gao, Z. Dai, and J. Callan, “COIL: Revisit exact lexical match in information retrieval with contextualized inverted list,” in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, K. Toutanova, A. Rumshisky, L. Zettlemoyer, D. Hakkani-Tur, I. Beltagy, S. Bethard, R. Cotterell, T. Chakraborty, and Y. Zhou, Eds. Online: Association for Computational Linguistics, Jun. 2021, pp. 3030–3042. [Online]. Available: https://aclanthology.org/2021.naacl-main.241
- [8] Slack. (2024). [Online]. Available: https://github.com/slackapi/bolt-python/
- [9] LangChain. (2024). [Online]. Available: https://github.com/langchain-ai/langchain
- [10] Chroma. (2024). [Online]. Available: https://github.com/chroma-core/chroma/
- [11] G. V. Cormack, C. L. Clarke, and S. Buettcher, “Reciprocal rank fusion outperforms condorcet and individual rank learning methods,” in Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, 2009, pp. 758–759.
- [12] IBM Research, “Granite foundation models,” Available online, 4 2024. [Online]. Available: https://www.ibm.com/downloads/cas/X9W4O6BM
- [13] M. Mishra, M. Stallone, G. Zhang, Y. Shen, A. Prasad, A. M. Soria, M. Merler, P. Selvam, S. Surendran, S. Singh et al., “Granite code models: A family of open foundation models for code intelligence,” arXiv preprint arXiv:2405.04324, 2024.
- [14] W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,” Advances in Neural Information Processing Systems, vol. 33, pp. 5776–5788, 2020.
- [15] C.-Y. Lin, “ROUGE: A package for automatic evaluation of summaries,” in Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81. [Online]. Available: https://aclanthology.org/W04-1013
- [16] L. Shi, T. Syeda-mahmood, and T. Baldwin, “Improving neural models for radiology report retrieval with lexicon-based automated annotation,” in Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, M. Carpuat, M.-C. de Marneffe, and I. V. Meza Ruiz, Eds. Seattle, United States: Association for Computational Linguistics, Jul. 2022, pp. 3457–3463. [Online]. Available: https://aclanthology.org/2022.naacl-main.253
- [17] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022.
附录A聊天界面
图A.1显示了我们的 Slack 界面的示例屏幕截图。 该界面使用户能够查看 RAG 提供的来源,并对 Ask-EDA 的响应质量提供反馈。