提示报告:提示技巧的系统调查
摘要
生成人工智能 (GenAI) 系统越来越多地部署在工业和研究环境的各个部分。 开发人员和最终用户通过使用提示或提示工程与这些系统进行交互。 虽然提示是一个广泛且经过深入研究的概念,但由于该领域的新生,存在着相互冲突的术语和对提示的构成的本体论理解很差。 本文通过对提示技术进行分类并分析其使用,建立了对提示的结构化理解。 我们提供了 33 个词汇术语的综合词汇、58 种纯文本提示技术的分类以及 40 种其他模式的技术。 我们进一步对自然语言前缀提示的整个文献进行了荟萃分析。
1 简介
基于 Transformer 的大语言模型广泛部署在面向消费者、内部和研究环境中Bommasani 等人 (2021)。 通常,这些模型依赖于用户提供输入“提示”,模型会根据该提示生成输出作为响应。 此类提示可以是文本形式的——“写一首关于树的诗。”——或者采取其他形式:图像、音频、视频或其组合。 提示模型的能力,特别是使用自然语言提示的能力,使它们易于在各种用例中交互和灵活使用。
了解如何根据提示有效地构建、评估和执行其他任务对于使用这些模型至关重要。 根据经验,更好的提示可以提高各种任务的结果 Wei 等人 (2022);刘等人 (2023b);舒尔霍夫(2022)。 大量文献围绕使用提示来改善结果而展开,并且提示技术的数量正在迅速增加。
然而,由于提示是一个新兴领域,人们对提示的使用仍然知之甚少,只有一小部分现有术语和技术为从业者所熟知。 我们对提示技术进行了大规模的审查,以创建该领域强大的术语和技术资源。 我们预计这将是随着时间的推移而发展的术语的第一次迭代。
学习范围
我们创建了一个广泛的提示技术目录,开发人员和研究人员可以快速理解并轻松实施这些技术,以便进行快速实验。 为此,我们将研究集中在离散前缀提示 Shin 等人 (2020a) 而不是完形填空提示 Petroni 等人 (2019); Cui 等人(2021),因为使用前缀提示的现代大语言模型架构(尤其是仅解码器模型)被广泛使用,并且为消费者和研究人员提供了强大的支持。 此外,我们将注意力集中在硬(离散)提示而不是软(连续)提示上,并遗漏了利用基于梯度的更新(即微调)技术的论文。 最后,我们只研究与任务无关的技术。 这些决定使技术含量较低的读者可以理解该工作,并保持可管理的范围。
章节概述
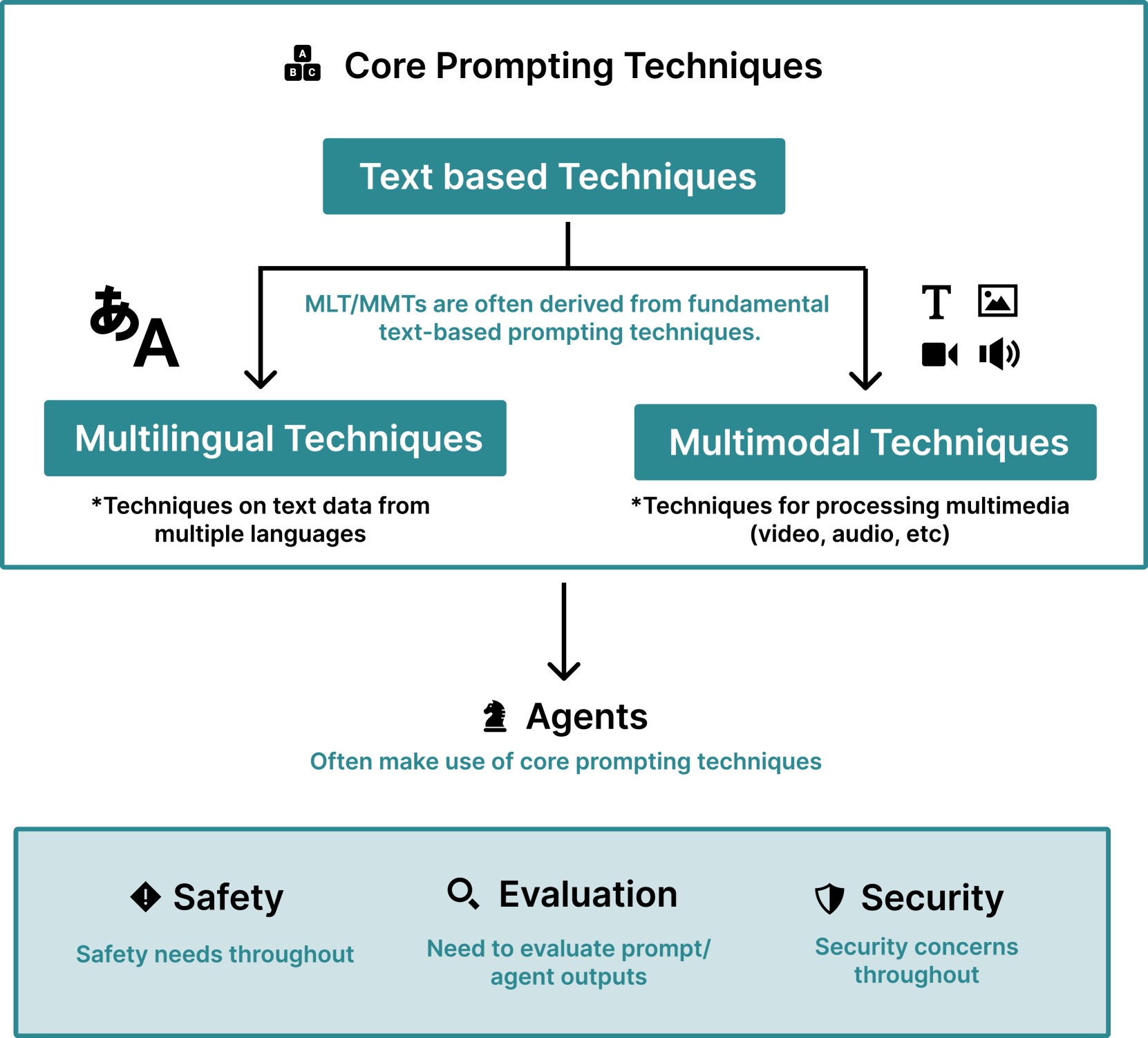
虽然许多有关提示的文献都只关注英语设置,但我们也讨论了多语言技术(第 3.1 节)。 鉴于多模式提示的快速增长(其中提示可能包括图像等媒体),我们还将范围扩展到多模式技术(第 3.2 节)。 许多多语言和多模式提示技术是纯英语文本提示技术的直接扩展。
随着提示技术变得越来越复杂,它们已经开始结合外部工具,例如互联网浏览和计算器。 我们使用术语“代理”来描述这些类型的提示技术(第 4.1 节)。
1.1 什么是提示?
提示是生成式 AI 模型的输入,用于指导其输出Meskó (2023);白等人 (2023);赫斯顿和坤 (2023);哈迪等人 (2023);布朗等人 (2020). 提示可以由文本、图像、声音或其他媒体组成。 提示的一些示例包括:“为会计师事务所的营销活动写一封三段电子邮件”、附有文字“描述桌子上的所有内容”的桌子照片,或带有说明的在线会议录音“总结一下”。
提示模板
提示通常通过提示模板 Shin 等人 (2020b) 构建。 提示模板是一种包含一个或多个变量的函数,这些变量将被某些媒体(通常是文本)替换以创建提示。 然后可以将此提示视为模板的实例。
考虑将提示应用于推文的二元分类任务。 这是一个可用于对输入进行分类的初始提示模板。
数据集中的每条推文都将被插入到模板的单独实例中,生成的提示将提供给大语言模型进行推理。
1.2术语
for tree=
grow=east,
reversed=true,
anchor=base west,
parent anchor=east,
child anchor=west,
base=left,
font=, rectangle,
draw=black, rounded corners,
align=left,
minimum width=2em, edge+=darkgray, line width=1pt,
s sep=1pt, inner xsep=1pt, inner ysep=2pt, line width=0.8pt,
ver/.append style=rotate=90, child anchor=north, parent anchor=south, anchor=center,
text width=7em, ,
[Prompt 1.1, text width=3em , fill=teal!50
[Prompting 1.2.2, fill=red!50
[Context 1.2.1, fill=red!40]
[Context Window A.2.1, fill=red!40]
[Priming A.2.1, fill=red!40]
[Prompting Technique
1.2.2, fill=red!40
[In-Context Learning
2.2.1, fill=red!30
[Few-Shot Prompt 2.2.1, fill=red!20]
[Exemplar 1.2.2, fill=red!20]
]
[Zero-Shot Prompt 2.2.2, fill=red!30]
]
[Orthogonal Prompt Types
A.2.4, fill=red!40
[
Density A.2.4.2, fill=red!30
[Continuous Prompt
A.2.4.2, fill=red!20]
[Discrete Prompt A.2.4.2, fill=red!20]
]
[
Originator A.2.4.1, fill=red!30
[User Prompt A.2.4.1, fill=red!20]
[System Prompt A.2.4.1, fill=red!20]
[Assistant Prompt A.2.4.1, fill=red!20]
]
[
Prediction Style A.2.4.3, fill=red!30
[Prefix A.2.4.3, fill=red!20]
[Cloze A.2.4.3, fill=red!20]
]
]
[
Prompt Chain 1.2.2, fill=red!40
]
]
[Prompt Template 1.1, fill=blue!50]
[
Prompt Engineering 1.2.2, fill=green!50
[
Prompt Engineering
Technique 1.2.2, fill=green!40
]
[
Meta-Prompting 2.4, fill=green!40
]
[
Answer Engineering
2.5, fill=green!40
[Verbalizer 2.5.3, fill=green!30]
[Extractor 2.5.3, fill=green!30]
]
[Conversational Prompt
Engineering A.2.2, fill=green!30]
]
[
Fine-Tuning A.2.3, fill=orange!50
[Prompt-Based
Learning A.2.3, fill=orange!40]
[Prompt Tuning A.2.3, fill=orange!40]
]
]
.
1.2.1 提示的组成部分
提示中包含各种常见组件。 我们总结了最常用的组件并讨论它们如何适应提示。
指示
许多提示以指令或问题的形式发出指令。111“指令”,来自Searle (1969),是一种旨在鼓励采取行动的言语行为,并已在人机对话模型Morelli 等人 (1991)。 这是提示的核心意图,有时简称为“意图”。 例如,以下是包含一条指令的提示示例:
指令也可以是隐式的,就像在这种一次性情况下,指令是执行英语到西班牙语的翻译:
例子
示例,也称为范例或镜头,充当指导 GenAI 完成任务的演示。 上述提示是一次性(即一个示例)提示。
输出格式
GenAI 通常希望以某些格式输出信息,例如 CSV 或 markdown 格式Xia 等人 (2024)。 为了促进这一点,您可以简单地添加说明来执行此操作,如下所示:
风格说明
样式指令是一种输出格式,用于从风格上而不是结构上修改输出(第 2.2.2 节)。 例如:
角色
角色,也称为角色 Schmidt 等人 (2023); Wang 等人 (2023l) 是一个经常讨论的组件,可以改善文本的写作和样式(第 2.2.2 节)。 例如:
附加信息
通常需要在提示中包含附加信息。 例如,如果指令是写一封电子邮件,您可能会包含您的姓名和职位等信息,以便 GenAI 可以正确签署电子邮件。 附加信息有时被称为“上下文”,但我们不鼓励使用该术语,因为它在提示空间中含有过多的其他含义222e.g. the context is the tokens processed by the LLM in a forward pass。
1.2.2 提示条款
提示文献中的术语正在迅速发展。 就目前情况而言,存在许多难以理解的定义(例如提示、提示工程)和相互冲突的定义(例如角色提示与角色提示)。 缺乏一致的词汇阻碍了社区清晰描述所使用的各种提示技术的能力。 我们提供了提示社区中使用的强大术语词汇表(图1.3)。333所谓稳健,是指它涵盖了该领域大多数现有的常用术语。 不太常见的术语保留在附录A.2中。 为了准确定义提示和提示工程等常用术语,我们整合了许多定义(附录A.1)以得出代表性定义。
提示
提示是向 GenAI 提供提示,然后生成响应的过程。 例如,发送一段文字或者上传一张图片的动作就构成了提示。
提示链
提示链(活动:提示链)由两个或多个连续使用的提示模板组成。 第一个提示模板生成的提示输出用于参数化第二个模板,一直持续到所有模板都用完Wu等人(2022)。
提示技巧
提示技术是一个蓝图,描述如何构建一个提示、多个提示或多个提示的动态排序。 提示技术可以结合条件或分支逻辑、并行性或跨越多个提示的其他架构考虑因素。
及时工程
提示工程是通过修改或更改您正在使用的提示技术来开发提示的迭代过程(图1.4)。
快速工程技术
提示工程技术是一种迭代提示以改进提示的策略。 在文献中,这通常是自动化技术Deng 等人(2022),但在消费者环境中,用户通常手动执行提示工程。
典范
范例是正在完成的任务的示例,在提示 Brown 等人 (2020) 中向模型显示。
1.3 提示简史
使用自然语言前缀或提示来引发语言模型行为和响应的想法起源于 GPT-3 和 ChatGPT 时代之前。 GPT-2 Radford 等人 (2019a) 使用提示,它们似乎是 Fan 等人 (2018) 在生成式 AI 的背景下首次使用。 然而,提示概念之前有相关概念,例如控制代码Pfaff (1979);波普拉克(1980); Keskar 等人 (2019) 和写作提示 Fan 等人 (2018)。
Prompt Engineering 一词似乎是最近从 Radford 等人 (2021) 出现的,稍晚于 Reynolds 和 McDonell (2021) 出现的。
然而,各种论文执行了快速的工程过程,但没有命名术语 Wallace 等人 (2019); Shin 等人 (2020a),包括 Schick 和 Schütze (2020a, b);高等人 (2021) 用于非自回归语言模型。
一些关于提示的第一批作品定义的提示与当前使用的方式略有不同。 例如,请考虑 Brown 等人 (2020) 的以下提示:
Brown 等人 (2020) 认为“llama”这个词是提示,而“Translate English to French:”是“任务描述”。 最近的论文(包括这篇论文)将传递给大语言模型的整个字符串称为提示。
2 提示的荟萃分析
2.1 系统审核流程
为了可靠地收集本文的来源数据集,我们基于 PRISMA 流程Page 等人 (2021) 进行了系统的文献综述(图 2.1)。 我们在 HuggingFace 上托管此数据集,并在附录 A.3 中提供该数据集的数据表 Gebru 等人 (2021)。 我们的主要数据来源是arXiv、Semantic Scholar和ACL。 我们使用与提示和提示工程密切相关的 44 个关键字列表查询这些数据库(附录 A.4)。
2.1.1 管道
在本部分中,我们将介绍我们的数据抓取管道,其中包括人工审核和 LLM 辅助审核。444Using GPT-4-1106-preview作为建立过滤标准的初始样本,我们根据一组简单的关键字和布尔规则从arXiv检索论文(A.4)。 然后,人工注释者根据以下标准对 arXiv 集中的 1,661 篇文章样本进行标记:
-
1.
这篇论文是否提出了一种新颖的提示技术? (包括)
-
2.
论文是否严格涵盖硬前缀提示? (包括)
-
3.
论文是否重点关注通过反向传播梯度进行训练? (排除)
-
4.
对于非文本模式,它是否使用屏蔽框架和/或窗口? (包括)
一组 300 篇文章由两名注释者独立审阅,一致率为 92%(Krippendorff 的 = Cohen 的 = 81%)。 接下来,我们使用 GPT-4-1106-preview 开发一个提示来对剩余的文章进行分类。 我们根据 100 个真实注释验证提示,实现了 89% 的精确度和 75% 的召回率( 为 81%)。 人类和大语言模型注释的结合生成了最终的 1,565 篇论文集。

2.2 基于文本的技术
我们现在提出了 58 种基于文本的提示技术的综合分类本体,分为 6 个主要类别(图 2.2)。 尽管某些技术可能适合多个类别,但我们将它们放在最相关的单个类别中。
for tree=
grow=east,
reversed=true,
anchor=base west,
parent anchor=east,
child anchor=west,
base=left,
font=, rectangle,
draw=black, rounded corners,
align=left,
minimum width=2em, edge+=darkgray, line width=1pt,
s sep=1pt, inner xsep=1pt, inner ysep=2pt, line width=0.8pt,
ver/.append style=rotate=90, child anchor=north, parent anchor=south, anchor=center,
text width=7em, ,
[Text-Base Prompt. Tech. , fill=teal!50
[Zero-Shot 2.2.2, fill=red!50
[Emotion Prompting 2.2.2, fill=red!50]
[Role Prompting 2.2.2, fill=red!50]
[Style Prompting 2.2.2, fill=red!50]
[S2A 2.2.2, fill=red!50]
[SimToM 2.2.2, fill=red!50]
[RaR 2.2.2, fill=red!50]
[RE2 2.2.2, fill=red!50]
[Self-Ask 2.2.2, fill=red!50]
]
[Few-Shot 2.2.1, fill=blue!50
[Example Generation, fill=blue!40
[SG-ICL 2.2.1.2, fill=blue!30]
]
[Example Ordering 2.2.1.1, fill=blue!40]
[Exemplar Selection
2.2.1.2, fill=blue!40
[KNN 2.2.1.2, fill=blue!30]
[Vote-K 2.2.1.2, fill=blue!30]
]
]
[Thought Generation 2.2.3, fill=green!50
[Chain-of-Thought
(CoT) 2.2.3, fill=green!40
[Zero-Shot CoT 2.2.3.1, fill=green!30
[Analogical Prompting
2.2.3.1, fill=green!20]
[Step-Back Prompting
2.2.3.1, fill=green!20]
[Thread-of-Thought
(ThoT) 2.2.3.1, fill=green!20]
[Tab-CoT 2.2.3.1, fill=green!20]
]
[Few-Shot CoT 2.2.3.2, fill=green!30
[Active-Prompt 2.2.3.2, fill=green!20]
[Auto-CoT 2.2.3.2, fill=green!20]
[Complexity-Based 2.2.3.2, fill=green!20]
[Contrastive 2.2.3.2, fill=green!20]
[Memory-of-Thought
2.2.3.2, fill=green!20]
[Uncertainty-Routed
CoT 2.2.3.2, fill=green!20]
[Prompt Mining 2.2.1.2, fill=green!20]
]
]
]
[Ensembling 2.2.5, fill=orange!50
[COSP 2.2.5, fill=orange!40]
[DENSE 2.2.5, fill=orange!40]
[DiVeRSe 2.2.5, fill=orange!40]
[Max Mutual
Information 2.2.5, fill=orange!40]
[Meta-CoT 2.2.5, fill=orange!40]
[MoRE 2.2.5, fill=orange!40]
[Self-Consistency 2.2.5, fill=orange!40]
[Universal
Self-Consistency 2.2.5, fill=orange!40]
[USP 2.2.5, fill=orange!40]
[Prompt Paraphrasing 2.2.5, fill=orange!40]
]
[Self-Criticism 2.2.6, fill=purple!50
[Chain-of-Verification 2.2.6, fill=purple!40]
[Self-Calibration 2.2.6, fill=purple!40]
[Self-Refine 2.2.6, fill=purple!40]
[Self-Verification 2.2.6, fill=purple!40]
[ReverseCoT 2.2.6, fill=purple!40]
[Cumulative Reason. 2.2.6, fill=purple!40]
]
[Decomposition 2.2.4, fill=brown!50
[DECOMP 2.2.4, fill=brown!40]
[Faithful CoT 2.2.4, fill=brown!40]
[Least-to-Most 2.2.4, fill=brown!40]
[Plan-and-Solve 2.2.4, fill=brown!40]
[Program-of-Thought 2.2.4, fill=brown!40]
[Recurs.-of-Thought 2.2.4, fill=brown!40]
[Skeleton-of-Thought 2.2.4, fill=brown!40]
[Tree-of-Thought 2.2.4, fill=brown!40]
]
]
2.2.1 情境学习(ICL)

ICL 是指 GenAI 通过在提示中提供示例和/或相关指令来学习技能和任务的能力,而不需要权重更新/重新训练 Brown 等人 (2020); Radford 等人 (2019b)。 这些技能可以从范例(图2.4)和/或说明(图2.5)中学习。 请注意,“学习”这个词具有误导性。 ICL 可以简单地是任务规范——技能不一定是新的,并且可以已经包含在训练数据中(图2.6)。 有关该术语使用的讨论,请参阅附录A.8。 目前正在优化 Bansal 等人 (2023) 和理解 Si 等人 (2023a) 方面开展大量工作; Štefánik 和 Kadlčík (2023) ICL。
少样本提示
Brown 等人 (2020) 是图 2.4 中所示的范式,其中 GenAI 学习仅使用几个示例(范例)即可完成任务。
少样本学习 (FSL)
Fei-Fei 等人 (2006); Wang 等人 (2019) 经常与少样本提示 Brown 等人 (2020) 混为一谈。 需要注意的是,FSL 是一种更广泛的机器学习范式,可以通过一些示例来调整参数,而少样本提示特定于 GenAI 设置中的提示,不涉及更新模型参数。
2.2.1.1 少样本提示设计决策
为提示选择范例是一项艰巨的任务——性能很大程度上取决于范例Dong等人(2023)的各种因素,并且只有有限数量的范例适合典型的大语言模型的上下文窗口。 我们重点介绍了六个单独的设计决策,包括对输出质量产生关键影响的示例的选择和顺序Zhao 等人 (2021a);卢等人 (2021); Ye 和 Durrett (2023)(图 2.3)。
示例数量
增加提示中的样本数量通常会提高模型性能,特别是在较大的模型中 Brown 等人 (2020)。 然而,在某些情况下,超过 20 个范例后,效益可能会减少Liu 等人 (2021)。
订购示例
样本的顺序影响模型行为 Lu 等人 (2021);库马尔和塔鲁克达尔(2021);刘等人 (2021); Rubin 等人 (2022). 在某些任务中,样本顺序可能会导致准确率从低于 50% 到 90%+ Lu 等人 (2021) 不等。
标签分布示例
与传统的监督机器学习一样,提示中样本标签的分布会影响行为。 例如,如果包含一个类别的 10 个样本和另一个类别的 2 个样本,则可能会导致模型偏向第一类别。
标签质量典范
尽管多个示例具有普遍的好处,但严格有效演示的必要性尚不清楚。 一些工作Min等人(2022)表明标签的准确性是无关紧要的——为模型提供带有错误标签的样本可能不会对性能产生负面影响。 然而,在某些设置下,会对性能产生显着影响Yoo 等人 (2022)。 较大的模型通常更擅长处理不正确或不相关的标签 Wei 等人 (2023c)。
讨论这个因素很重要,因为如果您从可能包含不准确的大型数据集自动构建提示,则可能有必要研究标签质量如何影响您的结果。
范例格式
示例的格式也会影响性能。 最常见的格式之一是“Q:{输入},A:{标签}”,但最佳格式可能因任务而异;可能值得尝试多种格式,看看哪种效果最好。 有一些证据表明,训练数据中常见的格式将带来更好的性能Jiang 等人 (2020)。
范例相似度
选择与测试样本相似的样本通常有利于性能 Liu 等人 (2021);敏等人 (2022). 然而,在某些情况下,选择更多样化的样本可以提高性能 Su 等人 (2022);敏等人 (2022).
2.2.1.2 少镜头提示技术
考虑到所有这些因素,少样本提示可能很难有效实施。 我们现在检查在监督环境下进行少样本提示的技术。 集成方法也可以使少样本提示受益,但我们单独讨论它们(第 2.2.5 节)。
假设我们有一个训练数据集 ,其中包含多个输入 和输出 ,可用于少样本提示 GenAI(而不是执行基于梯度的更新)。 假设该提示可以在测试时针对动态生成。 这是我们将在本节中使用的提示模板,遵循“输入:输出”格式(图2.4):
K 最近邻 (KNN)
Liu 等人 (2021) 是一系列算法的一部分,该算法选择与 类似的示例来提高性能。 尽管有效,但在即时生成过程中使用 KNN 可能会耗费时间和资源。
投票-K
Su 等人 (2022) 是另一种选择与测试样本相似的样本的方法。 在一个阶段,模型会提出有用的未标记候选样本供注释者进行标记。 在第二阶段,标记池用于少样本提示。 Vote-K 还确保新添加的样本与现有样本有足够的不同,以增加多样性和代表性。
自生成情境学习 (SG-ICL)
Kim 等人 (2022) 利用 GenAI 自动生成示例。 虽然训练数据不可用时比零样本场景要好,但生成的样本不如实际数据有效。
即时挖矿
Jiang 等人 (2020) 就是通过大语料分析发现提示中最优“中间词”(有效提示模板)的过程。 例如,在少样本提示中,可能存在更频繁出现的类似内容,而不是使用常见的“Q:A:”格式。 语料库中更频繁出现的格式可能会提高提示性能。
更复杂的技术
例如 LENS Li and Qiu (2023a)、UDR Li 等人 (2023f) 和 Active Examples Selection Zhang 等人 (2022a) 杠杆分别是迭代过滤、嵌入和检索以及强化学习。
2.2.2 零射击
与少样本提示相反,零样本提示使用零样本。 有许多众所周知的独立零样本技术以及与另一个概念(例如思想链)相结合的零样本技术,我们稍后将对此进行讨论(第 2.2.3 节)。
角色提示
王等人 (2023j); Cheng 等人 (2023d) ,也称为角色提示 Schmidt 等人 (2023); Wang等人(2023l),在提示中为GenAI分配特定角色。 例如,用户可能会提示它表现得像“麦当娜”或“旅行作家”。 这可以为开放式任务 Reynolds 和 McDonell (2021) 创建更理想的输出,并在某些情况下提高基准Zheng 等人 (2023d) 的准确性。
风格提示
Lu 等人 (2023a) 涉及在提示中指定所需的风格、语气或流派,以塑造 GenAI 的输出。 使用角色提示可以达到类似的效果。
情绪提示
Li 等人 (2023a) 将与人类心理相关的短语(例如,“这对我的职业很重要”)纳入提示中,这可能会提高大语言模型在基准测试和开放方面的性能。结束文本生成。
系统 2 注意力 (S2A)
Weston 和 Sukhbaatar (2023) 首先要求大语言模型重写提示并删除与其中问题无关的任何信息。 然后,它将这个新提示传递到大语言模型中以检索最终响应。
模拟仿真软件
Wilf 等人 (2023) 处理涉及多个人或物体的复杂问题。 给定问题,它试图建立一个人知道的一组事实,然后仅根据这些事实回答问题。 这是一个两个提示过程,可以帮助消除提示中不相关信息的影响。
改写和回应 (RaR)
Deng 等人 (2023) 指示大语言模型在生成最终答案之前重新措辞和扩展问题。 例如,它可能会向问题添加以下短语:“改写并扩展问题,然后回复”。 这一切都可以一次性完成,或者新问题可以单独传递到大语言模型。 RaR 在多个基准测试中都表现出了改进。
重读(RE2)
Xu 等人 (2023) 除了重复问题之外,还在提示中添加了短语“再次阅读问题:”。 尽管这是一个如此简单的技术,但它在推理基准方面显示出改进,尤其是对于复杂的问题。
自问
Press 等人 (2022) 提示大语言模型首先决定是否需要针对给定提示提出后续问题。 如果是这样,大语言模型就会生成这些问题,然后回答它们,最后回答原来的问题。
2.2.3 思想产生
思维生成包含一系列技术,这些技术促使大语言模型在解决问题时阐明其推理Zhang 等人(2023c)。
思路链 (CoT) 提示
Wei等人(2022)利用少样本提示,鼓励大语言模型在给出最终答案之前表达其思维过程。555我们注意到,此类技术通常使用“思考”等将模型拟人化的词语来描述。 我们尝试不使用这种语言,但在适当的情况下使用原作者的语言。 这种技术有时被称为 Chain-of-Thoughts Tutunov 等人 (2023); Besta 等人 (2024);陈等人 (2023d). 它已被证明可以显着提高大语言模型在数学和推理任务中的表现。 在Wei等人(2022)中,提示包括一个包含问题、推理路径和正确答案的范例(图2.8)。
2.2.3.1 零射击 CoT
最简单的 CoT 版本包含零个样本。 它涉及附加一个引发思考的短语,例如“让我们一步一步思考”。 Kojima 等人 (2022) 到提示符。 其他建议的引发思考的短语包括“让我们一步一步地解决这个问题,以确保我们得到正确的答案”Zhou 等人 (2022b) 和“首先,让我们从逻辑上思考这个问题” 小岛等人 (2022)。 Yang 等人 (2023a) 寻找最佳的思维诱导器。 零样本 CoT 方法很有吸引力,因为它们不需要示例并且通常与任务无关。
后退提示
Zheng 等人 (2023c) 是 CoT 的修改,其中在深入推理之前,首先向大语言模型询问有关相关概念或事实的通用、高级问题。 这种方法显着提高了 PaLM-2L 和 GPT-4 的多个推理基准的性能。
类比提示
Yasunaga 等人 (2023) 与 SG-ICL 类似,会自动生成包含 CoT 的范例。 它展示了数学推理和代码生成任务的改进。
思路(ThoT)提示
Zhou 等人 (2023) 包含一个改进的 CoT 推理思维诱导器。 它没有使用“让我们逐步思考”,而是使用“逐步引导我通过可管理的部分完成此上下文,边做边总结和分析”。这种思维诱导器在问答和检索环境中效果很好,尤其是在处理大型、复杂的上下文时。
表格思维链 (Tab-CoT)
Jin and Lu (2023) 包含一个零样本 CoT 提示,使大语言模型输出推理为 Markdown 表。 这种表格设计使大语言模型能够改进结构,从而改进其输出的推理。
2.2.3.2 少样本 CoT
这套技术以多个范例呈现大语言模型,其中包括思想链。 这可以显着提高性能。 该技术有时被称为 Manual-CoT Zhang 等人 (2022b) 或 Golden CoT Del 和 Fishel (2023)。
对比 CoT 提示
Chia 等人 (2023) 在 CoT 提示中添加了两个具有错误和正确解释的范例,以向大语言模型展示如何不推理。 该方法在算术推理和事实问答等领域显示出显着的改进。
不确定性导向的 CoT 提示
Google (2023) 对多个 CoT 推理路径进行采样,然后在高于特定阈值(根据验证数据计算)时选择大多数路径。 如果不是,它会贪婪地采样并选择该响应。 此方法展示了 GPT4 和 Gemini Ultra 模型的 MMLU 基准的改进。
基于复杂性的提示
Fu 等人 (2023b) 涉及对 CoT 的两个重大修改。 首先,它根据问题长度或所需的推理步骤等因素选择复杂的标注示例并包含在提示中。 其次,在推理过程中,它对多个推理链(答案)进行采样,并在超过一定长度阈值的链中使用多数投票,前提是推理越长表明答案质量越高。 该技术已在三个数学推理数据集上显示出改进。
主动提示
Diao 等人 (2023) 从一些训练问题/范例开始,要求大语言模型解决它们,然后计算不确定性(在本例中为不一致)并要求人类注释者重写不确定性最高的范例。
思维记忆提示
Li 和 Qiu (2023b) 利用未标记的训练范例在测试时构建少样本 CoT 提示。 在测试之前,它使用 CoT 对未标记的训练样本进行推理。 在测试时,它检索与测试样本相似的实例。 该技术在算术、常识和事实推理等基准方面显示出显着的改进。
自动思维链 (Auto-CoT) 提示
Zhang 等人 (2022b) 使用 Wei 等人 (2022) 的零样本提示自动生成思维链。 然后将这些用于构建测试样本的少样本 CoT 提示。
2.2.4分解
重要的研究集中在将复杂问题分解为更简单的子问题。 这对人类和 GenAI Patel 等人 (2022) 来说都是一种有效的解决问题策略。 一些分解技术类似于思维诱导技术,例如 CoT,它通常会自然地将问题分解为更简单的组件。 然而,明确地分解问题可以进一步提高大语言模型的问题解决能力。
从最少到最多的提示
Zhou 等人 (2022a) 首先提示大语言模型将给定问题分解为子问题而不解决它们。 然后,它按顺序解决它们,每次都将模型响应附加到提示中,直到得出最终结果。 该方法在涉及符号操作、组合概括和数学推理的任务中显示出显着的改进。
分解提示(DECOMP)
Khot 等人 (2022) 少样本提示大语言模型展示如何使用某些功能。 这些可能包括字符串分割或互联网搜索等;这些通常作为单独的大语言模型调用来实现。 鉴于此,大语言模型将其原始问题分解为子问题,并将其发送给不同的功能。 在某些任务中,它比从最少到最多的提示表现出更好的性能。
计划与解决提示
Wang 等人 (2023f) 包含一个改进的零样本 CoT 提示,“让我们首先了解问题并制定解决方案。 然后,我们就按照计划一步一步地去解决问题”。 该方法在多个推理数据集上生成比标准 Zero-Shot-CoT 更稳健的推理过程。
思想树 (ToT)
Yao 等人 (2023b),也称为思想树,Long (2023),通过从初始问题开始然后生成多个可能的问题来创建树状搜索问题以思想形式采取的步骤(如来自 CoT)。 它评估每个步骤在解决问题方面取得的进展(通过提示)并决定继续哪些步骤,然后不断产生更多想法。 ToT 对于需要搜索和规划的任务特别有效。
思想递归
Lee and Kim (2023) 与常规 CoT 类似。 然而,每当它在推理链中间遇到复杂的问题时,它就会将该问题发送到另一个提示/LLM 调用中。 完成此操作后,答案将插入到原始提示中。 通过这种方式,它可以递归地解决复杂的问题,包括可能超出最大上下文长度的问题。 该方法在算术和算法任务方面显示出改进。 虽然通过微调输出一个特殊的词符来将子问题发送到另一个提示中来实现,但也可以仅通过提示来完成。
思想纲领
Chen 等人 (2023d) 使用像 Codex 这样的大语言模型来生成编程代码作为推理步骤。 代码解释器执行这些步骤以获得最终答案。 它在数学和编程相关任务中表现出色,但在语义推理任务中效果较差。
忠实的思想链
Lyu 等人 (2023) 生成一个同时具有自然语言和符号语言(例如 Python)推理的 CoT,就像思想程序一样。 然而,它也以依赖于任务的方式使用不同类型的符号语言。
思想骨架
Ning 等人 (2023) 专注于通过并行化加速答案速度。 给定一个问题,它会提示大语言模型创建答案的骨架,从某种意义上说,是要解决的子问题。 然后,并行地将这些问题发送到大语言模型,并将所有输出连接起来以获得最终答案。
2.2.5 集成
在 GenAI 中,集成是使用多个提示来解决同一问题,然后将这些响应聚合成最终输出的过程。 在许多情况下,使用多数投票(选择最常见的响应)来生成最终输出。 集成技术减少了大语言模型输出的方差,通常提高了准确性,但代价是增加了达到最终答案所需的模型调用数量。
示范合奏(DENSE)
Khalifa 等人 (2023) 创建多个少样本提示,每个提示都包含训练集中示例的不同子集。 接下来,它汇总它们的输出以生成最终响应。
混合推理专家 (MoRE)
Si等人(2023d)通过针对不同推理类型使用不同的专业提示(例如用于事实推理的检索增强提示、用于多跳的思想链推理和数学推理,并生成常识推理的知识提示)。 所有专家的最佳答案是根据一致性分数选出的。
最大互信息法
Sorensen 等人 (2022) 创建多个具有不同风格和范例的提示模板,然后选择最佳模板作为提示与大语言模型输出之间的互信息最大化的模板。
自我一致性
Wang 等人 (2022) 基于多种不同推理路径可以得出相同答案的直觉。 该方法首先提示大语言模型多次执行 CoT,关键是使用非零温度来引出不同的推理路径。 接下来,它对所有生成的响应使用多数投票来选择最终响应。 自我一致性在算术、常识和符号推理任务上显示出改进。
普遍自洽
Chen 等人 (2023e) 与自我一致性类似,不同之处在于它不是通过以编程方式计算多数响应出现的频率来选择多数响应,而是将所有输出插入到选择多数答案的提示模板中。 这对于自由格式文本生成以及不同提示可能输出相同答案略有不同的情况很有帮助。
多个 CoT 的元推理
Yoran 等人 (2023) 类似于普遍自洽;它首先为给定问题生成多个推理链(但不一定是最终答案)。 接下来,它将所有这些链插入到单个提示模板中,然后从中生成最终答案。
各种各样的
Li 等人 (2023i) 针对给定问题创建多个提示,然后对每个提示执行自洽,生成多个推理路径。 他们根据推理路径中的每个步骤对推理路径进行评分,然后选择最终的响应。
基于一致性的自适应提示(COSP)
Wan 等人 (2023a) 通过在一组示例上运行具有自我一致性的零样本 CoT 来构建少样本 CoT 提示,然后选择输出的高度一致性子集作为示例包含在最终提示中。 它再次与最后的提示执行自我一致性。
通用自适应提示 (USP)
Wan 等人 (2023b) 以 COSP 的成功为基础,旨在使其可推广到所有任务。 USP 利用未标记的数据来生成示例,并使用更复杂的评分函数来选择它们。 此外,USP 不使用自我一致性。
提示释义
Jiang 等人 (2020) 对原提示进行了改造,改变了部分措辞,但仍保持了整体含义。 它实际上是一种数据增强技术,可用于为集成生成提示。
2.2.6 自我批评
在创建 GenAI 系统时,让大语言模型批评自己的输出可能会很有用(Huang 等人,2022)。 这可以只是一个判断(例如,这个输出是否正确),或者可以提示大语言模型提供反馈,然后用于改进答案。 人们已经开发出许多产生和整合自我批评的方法。
自校准
Kadavath 等人 (2022) 首先提示大语言模型回答问题。 然后,它构建一个新的提示,其中包括问题、大语言模型的答案以及询问答案是否正确的附加指令。 当应用大语言模型决定何时接受或修改原始答案时,这对于衡量置信水平很有用。
自我完善
Madaan 等人 (2023) 是一个迭代框架,给出大语言模型的初始答案,它提示同一个大语言模型提供答案反馈,然后提示大语言模型根据反馈改进答案。 此迭代过程持续进行,直到满足停止条件(例如,达到最大步数)。 Self-Refine 已在一系列推理、编码和生成任务中表现出改进。
逆向思维链 (RCoT)
Xue等人(2023)首先提示大语言模型根据生成的答案重建问题。 然后,它会在原始问题和重构问题之间进行细粒度的比较,以检查是否存在任何不一致之处。 然后,这些不一致之处会转化为反馈,供大语言模型修改生成的答案。
自我验证
Weng 等人 (2022) 使用思想链 (CoT) 生成多个候选解决方案。 然后,它通过屏蔽原始问题的某些部分并要求大语言模型根据问题的其余部分和生成的解决方案来预测它们,从而对每个解决方案进行评分。 该方法在八个推理数据集上显示出改进。
验证链 (COVE)
Dhuliawala 等人 (2023) 首先使用大语言模型生成给定问题的答案。 然后创建一个相关问题列表,以帮助验证答案的正确性。 每个问题都由大语言模型回答,然后将所有信息提供给大语言模型以产生最终的修改答案。 该方法在各种问答和文本生成任务中显示出改进。
累积推理
Zhang 等人 (2023b) 首先生成回答问题的几个潜在步骤。 然后,它有一个大语言模型评估它们,决定接受或拒绝这些步骤。 最后,它检查是否已得出最终答案。 如果是,则终止该过程,否则重复该过程。 该方法已证明在逻辑推理任务和数学问题方面有所改进。
2.3 提示技术的使用
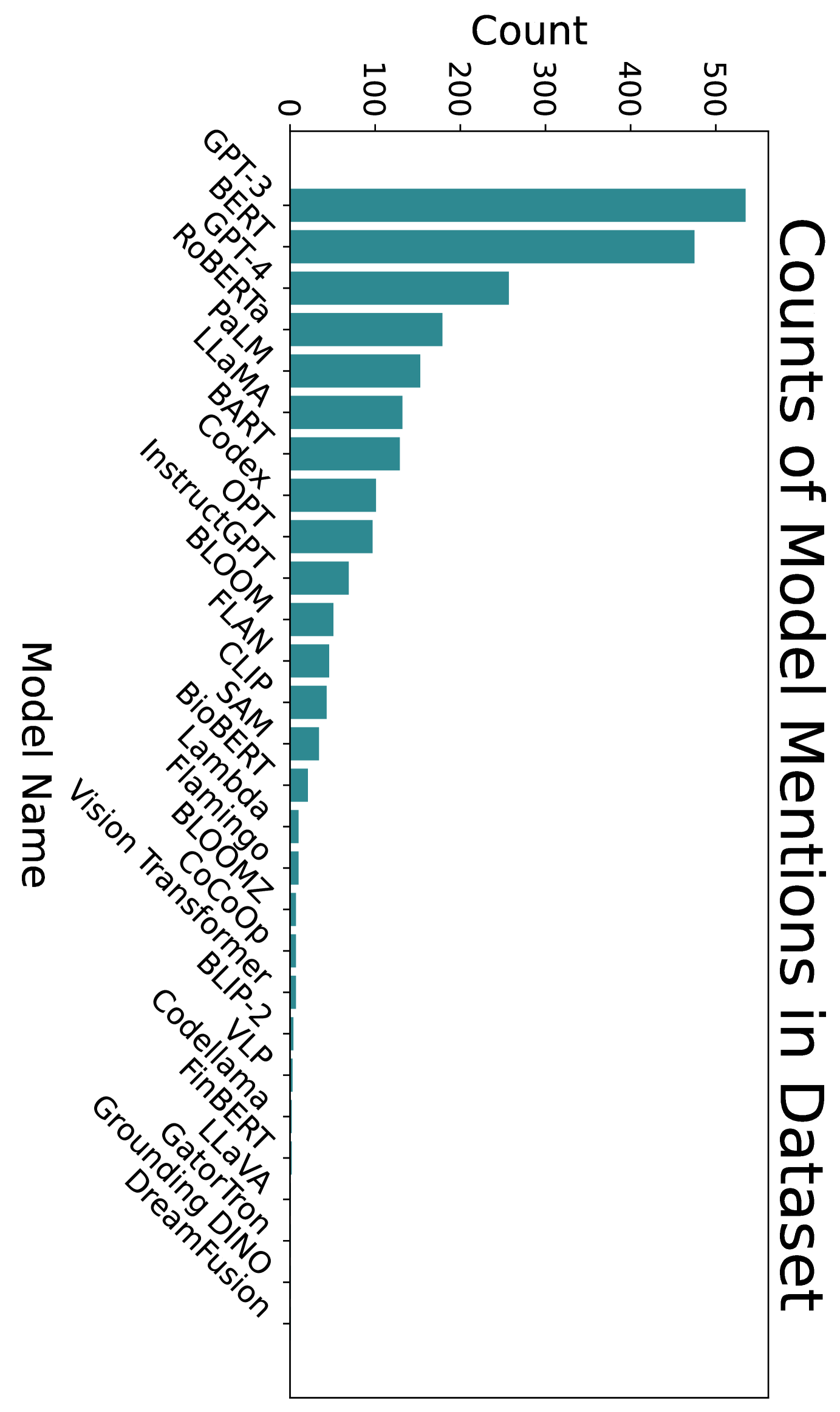
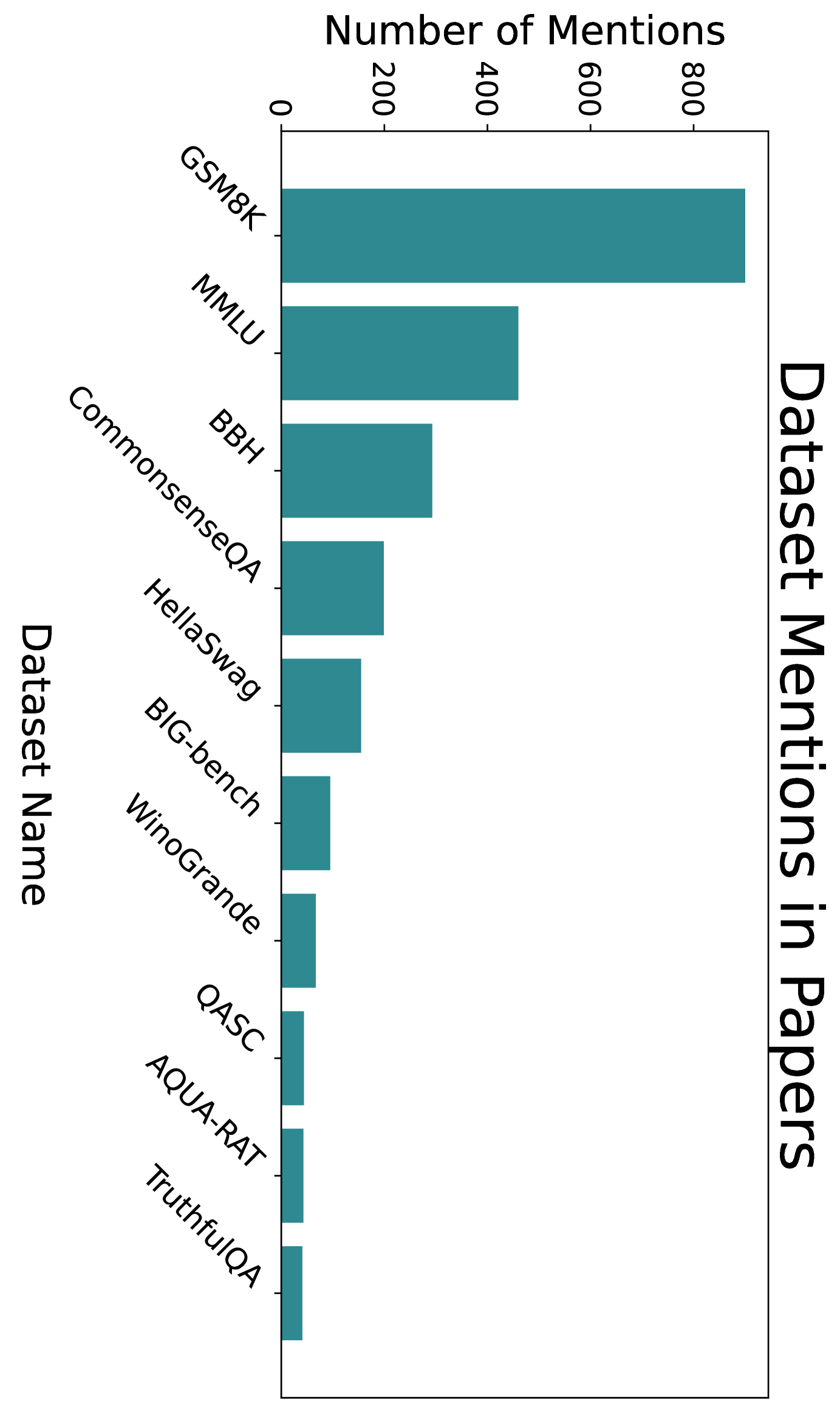
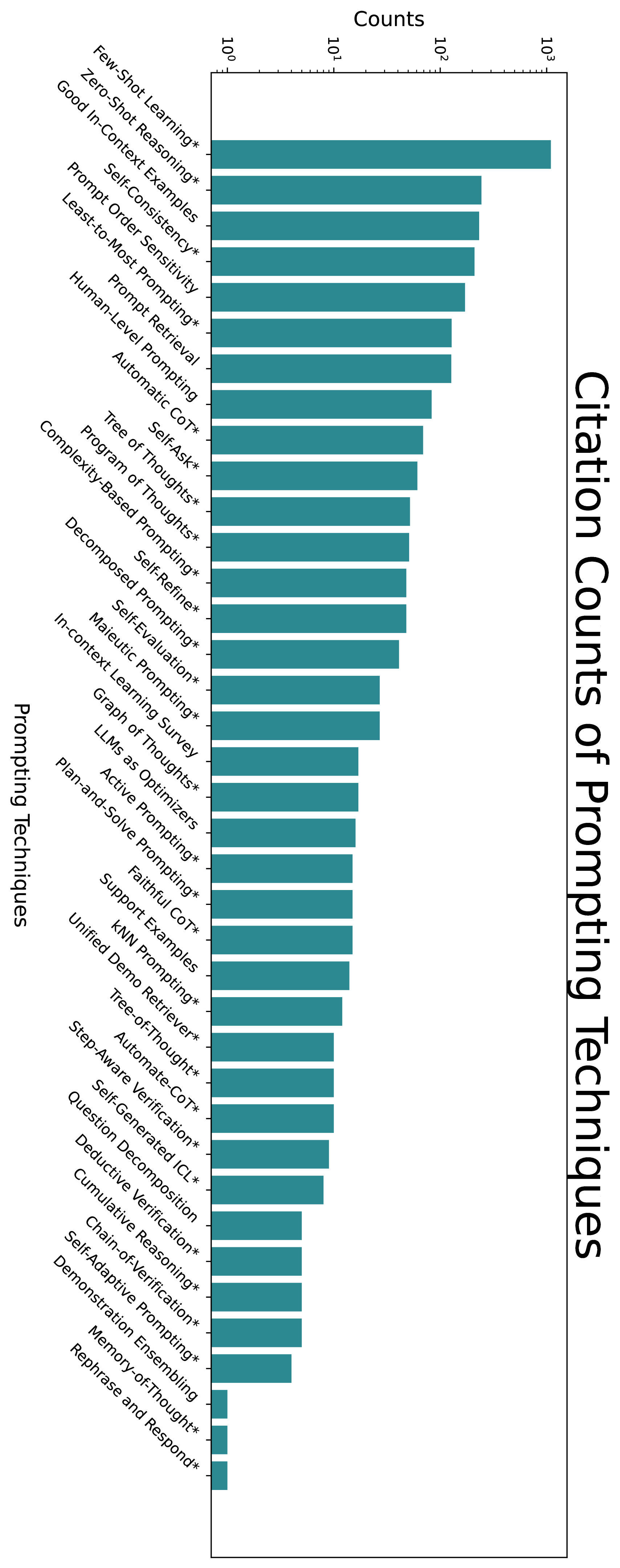
正如我们刚才所看到的,存在许多基于文本的提示技术。 然而,其中只有一小部分在研究和工业中常用。 我们通过衡量数据集中其他论文的引用次数来衡量技术的使用情况。 我们这样做的前提是,有关提示的论文更有可能实际使用或评估所引用的技术。 我们从数据集中绘制了以这种方式引用的前 25 篇论文,发现其中大多数提出了新的提示技术(图2.11)。 少样本和思维链提示的引用盛行并不令人意外,并且有助于建立了解其他技术盛行程度的基线。
2.3.1 基准
在促进研究时,当研究人员提出一项新技术时,他们通常会在多个模型和数据集上对其进行基准测试。 这对于证明该技术的实用性并检查它如何跨模型转移非常重要。
为了让提出新技术的研究人员更容易知道如何对它们进行基准测试,我们定量研究了哪些模型(图2.11)和哪些基准数据集(图2.11)正在使用。 同样,我们通过数据集中的论文引用基准数据集和模型的次数来衡量使用情况。
为了查找正在使用哪些数据集和模型,我们提示 GPT-4-1106-preview 从数据集中的论文正文中提取任何提到的数据集或模型。 之后,我们手动过滤掉不是模型或数据集的结果。 引用计数是通过在语义学者上搜索最终列表中的项目来获取的。
2.4及时工程
除了调查提示技术之外,我们还回顾了提示工程技术,这些技术用于自动优化提示。 我们讨论一些使用梯度更新的技术,因为提示工程技术的集合比提示技术小得多。
元提示
是提示大语言模型生成或改进提示或提示模板的过程Reynolds and McDonell (2021);周等人 (2022b);叶等人(2023)。
自动提示
Shin 等人 (2020b) 使用冻结的大语言模型以及包含一些“触发标记”的提示模板,其值在训练时通过反向传播更新。 这是软提示的一个版本。
自动提示工程师(APE)
Zhou等人(2022b)使用一组范例来生成零样本指令提示。 它生成多个可能的提示,对它们进行评分,然后创建最佳提示的变体(例如,通过使用提示释义)。 它会迭代这个过程,直到达到一些要求。
无梯度教学提示搜索 (GrIPS)
Prasad 等人 (2023) 与 APE 类似,但使用了一组更复杂的操作,包括删除、添加、交换和释义,以创建起始提示的变体。
使用文本渐变进行提示优化 (ProTeGi)
Pryzant 等人 (2023) 是一种独特的提示工程方法,可通过多步骤过程改进提示模板。 首先,它通过模板传递一批输入,然后将输出、基本事实和提示传递到另一个批评原始提示的提示中。 它根据这些批评生成新的提示,然后使用强盗算法 Gabillon 等人 (2011) 来选择一个。 ProTeGi 展示了对 APE 和 GRIPS 等方法的改进。
RL提示
Deng 等人 (2022) 使用冻结的大语言模型并添加未冻结的模块。 它使用这个大语言模型生成提示模板,在数据集上对模板进行评分,并使用 Soft Q-Learning Guo 等人 (2022) 更新解冻模块。 有趣的是,该方法经常选择语法上乱码的文本作为最佳提示模板。
基于对话的策略梯度离散提示优化(DP2O)
Li 等人 (2023b) 可能是最复杂的提示工程技术,涉及强化学习、自定义提示评分功能以及与大语言模型进行对话以构建提示。
2.5回答工程
答案工程是开发或选择从大语言模型输出中提取精确答案的算法的迭代过程。 要了解答案工程的需求,请考虑一个二元分类任务,其中标签为“仇恨言论”和“非仇恨言论”。 提示模板可能如下所示:
当仇恨言论样本通过模板时,它可能会输出诸如“这是仇恨言论”、“仇恨言论”,甚至“仇恨言论,因为它使用针对种族群体的负面语言”。 响应格式的这种差异很难一致地解析;改进的提示可以有所帮助,但只能在一定程度上有所帮助。
答案工程中有三个设计决策,答案空间的选择、答案形状和答案提取器(图2.12)。 Liu 等人 (2023b) 将前两个定义为答案工程的必要组成部分,我们附加第三个。 我们认为答案工程与即时工程不同,但密切相关;这些过程通常同时进行。

2.5.1 答案形状
答案的形状是它的物理格式。 例如,它可以是词符、 Token 范围,甚至是图像或视频。666 在粒度方面,我们使用与 Liu 等人 (2023b) 不同的定义(例如词符 vs span),因为输出可以是不同的形式。 有时,对于二元分类等任务,将大语言模型的输出形状限制为单个词符很有用。
2.5.2 答案空间
答案的空间是其结构可能包含的值的域。 这可能只是所有标记的空间,或者在二进制标记任务中,可能只是两个可能的标记。
2.5.3 答案提取器
如果无法完全控制答案空间(例如面向消费者的大语言模型),或者预期答案可能位于模型输出中的某个位置,则可以定义规则来提取最终答案。 该规则通常是一个简单的函数(例如正则表达式),但也可以使用单独的大语言模型来提取答案。
言语者
语言表达器通常用于标记任务,它将词符、跨度或其他类型的输出映射到标签,反之亦然(单射)Schick 和 Schütze (2021)。 例如,如果我们希望模型能够预测推文是正面还是负面,我们可以提示它输出“+”或“-”,并且语言器会将这些词符序列映射到适当的标签。 言语表达者的选择构成了答案工程的一个组成部分。
正则表达式
如前所述,正则表达式通常用于提取答案。 它们通常用于搜索标签的第一个实例。 但是,根据输出格式以及是否生成 CoT,搜索最后一个实例可能会更好。
独立的大语言模型
有时输出非常复杂,正则表达式无法一致地工作。 在这种情况下,使用单独的大语言模型评估输出并提取答案可能会很有用。
3 超越英文文本提示
目前,用英文文本提示 GenAI 是交互的主要方法。 用其他语言或通过不同方式进行提示通常需要特殊的技术才能实现可比较的性能。 在此背景下,我们讨论多语言和多模式提示的领域。
for tree= grow=east, reversed=true, anchor=base west, parent anchor=east, child anchor=west, base=left, font=, rectangle, draw=black, rounded corners, align=left, minimum width=2em, edge+=darkgray, line width=1pt, s sep=1pt, inner xsep=1pt, inner ysep=2pt, line width=0.8pt, ver/.append style=rotate=90, child anchor=north, parent anchor=south, anchor=center, text width=7em, , [Multilingual Techniques, fill=teal!50 [Chain-of-Thought 3.1.1, fill=red!50 [XLT 3.1.1, fill=red!40] [CLSP 3.1.1, fill=red!40]] [In-Context Learning 3.1.2, fill=green!50 [X-InSTA 3.1.2, fill=green!40] [In-CLT 3.1.2, fill=green!40] ] [In-Context Ex. Selection 3.1.3, fill=green!50 [PARC 3.1.3, fill=green!40] [Semantically-Aligned 3.1.3, fill=green!40] [Semantically-Distant 3.1.3, fill=green!40] ] [Human-in-the-Loop 3.1.5.1, fill=blue!50 [Interactive Chain 3.1.5.1, fill=blue!40] [Iterative 3.1.5.1, fill=blue!40] ] [Translation 3.1.5, fill=orange!50 [Chain-of-Dictionary 3.1.5, fill=orange!40] [DecoMT 3.1.5, fill=orange!40] [DiPMT 3.1.5, fill=orange!40] [MAPS 3.1.5, fill=orange!40] ] [Translate First Prompting 3.1, fill=violet!50 [External MT Systems 3.1, fill=violet!40] [Standard LLMs 3.1, fill=violet!40] [Multilingual LLMs 3.1, fill=violet!40] ] [Prompt Language 3.1.4, fill=brown!50 [English 3.1.4, fill=brown!40] [Task Language 3.1.4, fill=brown!40] ] ]
3.1 多语言
最先进的 GenAI 通常主要使用英语数据集进行训练,导致英语以外的语言(尤其是资源匮乏的语言)的输出质量存在显着差异 Bang 等人 (2023); Jiao 等人 (2023); Hendy 等人 (2023);石等人(2022)。 因此,出现了各种多语言提示技术,试图提高非英语环境中的模型性能。
翻译第一提示
Shi 等人 (2022) 可能是最简单的策略,首先将非英语输入示例翻译成英语。 通过将输入翻译成英语,该模型可以利用其英语优势来更好地理解内容。 翻译工具各不相同; Shi 等人 (2022) 使用外部机器翻译系统,Etxaniz 等人 (2023) 提示多语言 LM 和 Awasthi 等人 (2023) 提示用于翻译非英语输入的大语言模型。
3.1.1 思想链(CoT)
CoT提示Wei等人(2023a)已通过多种方式扩展到多语言环境。
XLT(跨语言思维)提示
黄等人(2023a)采用由六个独立指令组成的提示模板,包括角色分配、跨语言思维和CoT。
跨语言自我一致性提示(CLSP)
Qin 等人 (2023a) 引入了一种集成技术,可以用不同的语言构建推理路径来回答同一问题。
3.1.2情境学习
ICL 还以多种方式扩展到多语言环境。
X-InSTA 提示
Tanwar 等人 (2023) 探索了三种不同的方法,将上下文中的示例与输入句子对齐以进行分类任务:使用与输入语义相似的示例(语义对齐)、与输入共享相同标签的示例输入(基于任务的对齐),以及语义和基于任务的对齐的组合。
CLT(跨语言迁移)内提示
(Kim 等人,2023)利用源语言和目标语言来创建上下文示例,这与使用源语言示例的传统方法不同。 该策略有助于激发多语言大语言模型的跨语言认知能力,从而提高跨语言任务的表现。
3.1.3 上下文示例选择
上下文示例选择严重影响大语言模型 Garcia 等人 (2023) 的多语言表现; Agrawal 等人 (2023)。 找到与源文本语义相似的上下文示例非常重要 Winata 等人 (2023);穆斯林等人 (2023); Sia 和 Duh (2023)。 然而,使用语义上不同的(特殊)示例也被证明可以提高性能Kim 和 Komachi (2023)。 同样的对比也存在于纯英语环境中。 此外,在处理歧义句子时,选择具有多义或罕见词义的范例可能会提高性能Iyer等人(2023)。
PARC(通过跨语言检索增强提示)
Nie 等人 (2023) 介绍了一个从高资源语言中检索相关样本的框架。 该框架专为增强跨语言传输性能而设计,特别是对于资源匮乏的目标语言。 Li 等人 (2023g) 将这项工作扩展到孟加拉语。
3.1.4 提示模板语言选择
在多语言提示中,提示模板语言的选择会显着影响模型的性能。
英文提示模板
对于多语言任务,用英语构建提示模板通常比用任务语言构建提示模板更有效。 这可能是由于大语言模型预训练期间英语数据占主导地位 Lin 等人 (2022); Ahuja 等人 (2023)。 Lin 等人 (2022) 认为这可能是由于与预训练数据和词汇的高度重叠所致。 同样,Ahuja 等人 (2023) 强调了创建任务语言模板时的翻译错误如何以不正确的语法和语义的形式传播,从而对任务性能产生不利影响。 此外,Fu 等人 (2022) 比较了语内(任务语言)提示和跨语言(混合语言)提示,发现跨语言方法更有效,可能是因为它使用了更多提示中英文,方便从模型中检索知识。
任务语言提示模板
相比之下,许多多语言提示基准,例如 BUFFET Asai 等人 (2023) 或 LongBench Bai 等人 (2023a) 针对特定语言的用例使用任务语言提示。 Muennighoff 等人 (2023)专门研究了构建母语提示时的不同翻译方法。 他们证明人工翻译的提示优于机器翻译的提示。 不同任务和模型的本机或非本机模板性能可能有所不同Li 等人 (2023h)。 因此,这两种选择都不会始终是最佳方法Nambi 等人 (2023)。
3.1.5 提示机器翻译
关于利用 GenAI 促进准确和细致的翻译进行了大量研究。 尽管这是提示的具体应用,但其中许多技术对于多语言提示来说更重要。
多方面提示和选择(MAPS)
He 等人 (2023b) 模仿人工翻译过程,其中涉及多个准备步骤以确保高质量的输出。 该框架从源句子中进行知识挖掘(提取关键词和主题,并生成翻译范例)开始。 它整合这些知识来生成多种可能的翻译,然后选择最好的一个。
字典链 (CoD)
Lu 等人 (2023b) 首先从源短语中提取单词,然后通过字典自动检索,列出其在多种语言中的含义(例如英语:'apple) >',西班牙语:'manzana')。 然后,他们将这些字典短语添加到提示中,要求 GenAI 在翻译过程中使用它们。
基于词典的机器翻译提示 (DiPMT)
Ghazvininejad 等人 (2023) 的工作方式与 CoD 类似,但仅给出源语言和目标语言的定义,且格式略有不同。
机器翻译的分解提示 (DecoMT)
Puduppully 等人 (2023) 将源文本分成几个块,并使用少样本提示独立翻译它们。 然后,它使用这些翻译和块之间的上下文信息来生成最终翻译。
3.1.5.1 人在环
互动链提示(ICP)
Pilault 等人 (2023) 通过首先要求 GenAI 生成有关待翻译短语中任何歧义的子问题来处理翻译中潜在的歧义。 人类随后回答这些问题,系统会包含此信息以生成最终翻译。
迭代提示
Yang 等人 (2023d) 在翻译过程中也涉及到人类。 首先,他们提示大语言模型创建翻译草稿。 通过集成从自动检索系统或直接人类反馈获得的监督信号,该初始版本得到进一步完善。
for tree= grow=east, reversed=true, anchor=base west, parent anchor=east, child anchor=west, base=left, font=, rectangle, draw=black, rounded corners, align=left, minimum width=2em, edge+=darkgray, line width=1pt, s sep=1pt, inner xsep=1pt, inner ysep=2pt, line width=0.8pt, ver/.append style=rotate=90, child anchor=north, parent anchor=south, anchor=center, text width=7em, , [Multimodal (MM) Techniques, fill=teal!50 [Image 3.2.1, fill=red!50 [MM. CoT 3.2.1.2, fill=red!40 [Chain-of-Images 3.2.1.2, fill=red!30] [Duty Distinct CoT 3.2.1.2, fill=red!30] [MM Graph-of-Thought 3.2.1.2, fill=red!30] ] [Multimodal ICL 3.2.1.1, fill=red!40 [Image-as-Text Prompt3.2.1.1, fill=red!30] [Paired-Image Prompt 3.2.1.1, fill=red!30] ] [Negative Prompt 3.2.1, fill=red!40] [Prompt Modifiers 3.2.1, fill=red!40] ] [Segmentation Prompting 3.2.4, fill=blue!50] [Video 3.2.3, fill=green!50 [Video Gen. 3.2.3.1, fill=green!40 ] ] [3D Prompting 3.2.5, fill=orange!50] ]
3.2多式联运
随着 GenAI 模型的发展超越基于文本的领域,新的提示技术出现了。 这些多模式提示技术通常不仅仅是基于文本的提示技术的应用,而是通过不同模式实现的全新想法。 现在,我们扩展了基于文本的分类法,以包括基于文本的提示技术的多模态类似物以及全新的多模态技术的混合。
3.2.1 图片提示
图像形态包括照片、图画甚至文本Gong等人(2023)的屏幕截图等数据。 图像提示可以指包含图像或用于生成图像的提示。 常见任务包括图像生成 Ding 等人 (2021); Hinz 等人 (2022);涛等人 (2022); Li 等人 (2019a, b); Rombach 等人 (2022)、字幕生成 Li 等人 (2020)、图像分类 Khalil 等人 (2023) 以及图像编辑 Crowson等人 (2022);权和叶(2022); Bar-Tal 等人 (2022);赫兹等人 (2022)。 我们现在描述用于此类应用的各种图像提示技术。
提示修改器
只是附加在提示后以更改结果图像的文字Oppenlaender (2023)。 经常使用诸如介质(例如“在画布上”)或照明(例如“光线充足的场景”)等组件。
负面提示
允许用户对提示中的某些术语进行数字加权,以便模型比其他术语更多/更少地考虑它们。 例如,通过对术语“坏手”和“多余的手指”进行负权重,模型可能更有可能生成解剖学上准确的手Schulhoff (2022)。
3.2.1.1 多模态情境学习
ICL 在基于文本的环境中的成功促进了对多模态 ICL 的研究 Wang 等人 (2023k);董等人(2023)。
配对图像提示
向模型显示两张图像:一张是经过某种变换之前,一张是变换之后。 然后,向模型呈现一个新图像,模型将为其执行演示的转换。 这可以使用文本指令 Wang 等人 (2023k) 或不使用文本指令 Liu 等人 (2023e) 来完成。
图像文本提示
Hakimov 和 Schlangen (2023) 生成图像的文本描述。 这样可以轻松地将图像(或多张图像)包含在基于文本的提示中。
3.2.1.2 多模式思想链
CoT 已通过多种方式扩展到图像领域Zhang 等人 (2023d);黄等人 (2023c);郑 等人 (2023b);姚等人(2023c)。 一个简单的例子是包含数学问题图像的提示,并附有文本说明“逐步解决此问题”。
职责明确的思想链 (DDCoT)
Zheng 等人 (2023b) 将 Least-to-Most 提示 Zhou 等人 (2022a) 扩展到多模态设置,创建子问题,然后解决它们并将答案组合成一个最终回应。
多模态思维图
Yao 等人 (2023c) 将思维图 Zhang 等人 (2023d) 扩展到多模态设置。 GoT-Input 还使用两步推理然后回答过程。 在推理时,输入提示用于构建思维图,然后与原始提示一起使用来生成回答问题的基本原理。 当图像与问题一起输入时,图像字幕模型被用来生成图像的文本描述,然后在思维图构建之前将其附加到提示中以提供视觉上下文。
图像链 (CoI)
Meng 等人 (2023) 是思维链提示的多模式扩展,它生成图像作为其思维过程的一部分。 他们使用提示“让我们逐个图像地思考”来生成 SVG,然后模型可以使用它进行视觉推理。
3.2.2 音频提示
提示也已扩展到音频模式。 音频 ICL 的实验产生了好坏参半的结果,一些开源音频模型无法执行 ICL Hsu 等人 (2023)。 然而,其他结果确实显示了音频模型 Wang 等人 (2023g) 的 ICL 能力;彭等人 (2023); Chang 等人 (2023). 音频提示目前还处于早期阶段,但我们预计将来会看到各种提示技术的提出。
3.2.3 视频提示
提示也已扩展到视频模式,用于文本到视频的生成Brooks 等人 (2024);吕等人 (2023);梁等人 (2023); Girdhar 等人 (2023),视频剪辑 Zuo 等人 (2023);吴等人 (2023a); Cheng 等人 (2023),以及视频到文本生成 Yousaf 等人 (2023); Mi 等人 (2023); Ko等人(2023a)。
3.2.3.1 视频生成技术
当提示模型生成视频时,可以使用各种形式的提示作为输入,并且通常采用几种与提示相关的技术来增强视频生成。 图像相关技术,例如提示修改器,通常可用于视频生成跑道(2023)。
3.2.4 分段提示
提示还可以用于分割(例如语义分割)Tang 等人 (2023);刘等人(2023c)。
3.2.5 3D提示
提示也可以用于 3D 模态,例如 3D 对象合成 Feng 等人 (2023); Li 等人 (2023d, c);林等人 (2023);陈 等人 (2023f);洛林 等人 (2023);普尔等人 (2022); Jain 等人 (2022),3D 表面纹理 Liu 等人 (2023g);杨等人 (2023b);乐等人 (2023); Pajouheshgar 等人 (2023),以及 4D 场景生成(制作 3D 场景动画)Singer 等人 (2023);赵等人(2023c),其中输入提示形式包括文本、图像、用户标注(边界框、点、线)和3D对象。
4 提示的延伸
到目前为止我们讨论的技术可能非常复杂,包含许多步骤和迭代。 然而,我们可以通过添加对外部工具(代理)的访问来进一步提示,并通过复杂的评估算法来判断大语言模型输出的有效性。
for tree= grow=east, reversed=true, anchor=base west, parent anchor=east, child anchor=west, base=left, font=, rectangle, draw=black, rounded corners, align=left, minimum width=2em, edge+=darkgray, line width=1pt, s sep=1pt, inner xsep=1pt, inner ysep=2pt, line width=0.8pt, ver/.append style=rotate=90, child anchor=north, parent anchor=south, anchor=center, text width=7em, , [Agents, fill=teal!50 [Tool Use Agents, fill=red!40 [CRITIC 4.1.1, fill=red!40] [MRKL Sys. 4.1.1, fill=red!40] ] [Code-Based Agents 4.1.2, fill=blue!50 [PAL 4.1.2, fill=blue!40] [ToRA 4.1.2, fill=blue!40] [Task Weaver 4.1.2, fill=blue!40] ] [Observation-Based Agents 4.1.3, fill=green!50 [ReAct 4.1.3, fill=green!40] [Reflexion 4.1.3, fill=green!40] [Lifelong Learn. Agents 4.1.3.1, fill=green!30 [Voyager 4.1.3.1, fill=green!20] [GITM 4.1.3.1, fill=green!20] ] ] [Retrieval Aug. Generation 4.1.4, fill=purple!50 [IRCoT 4.1.4, fill=purple!40] [DSP 4.1.4, fill=purple!40] [Verify-and-Edit 4.1.4 , fill=purple!40] [Iterative Retrieval Aug. 4.1.4 , fill=purple!40] ] ]
4.1代理
随着大语言模型Zhang 等人(2023c)、企业Adept (2023)和研究人员Karpas 等人(2022)能力的快速提升探索了如何让他们利用外部系统。 这是大语言模型在数学计算、推理和事实性等方面的缺陷造成的。 这推动了提示技术的重大创新;这些系统通常由提示和提示链驱动,它们经过精心设计以允许类似代理的行为。
代理人的定义
在 GenAI 的背景下,我们将代理定义为 GenAI 系统,通过与 GenAI 本身之外的系统交互的操作来服务于用户的目标。777We do not cover the notion of independently-acting AI, i.e. systems that in any sense have their own goals这个GenAI通常是一个大语言模型。 举一个简单的例子,考虑一个大语言模型,其任务是解决以下数学问题:
如果提示正确,大语言模型可以输出字符串 CALC(4,939*.39)。 可以提取该输出并将其输入计算器以获得最终答案。
这是一个代理的示例:大语言模型输出文本,然后使用下游工具。 Agent大语言模型可能涉及单个外部系统(如上所述),也可能需要解决路由问题,以选择使用哪个外部系统。 除了动作Zhang 等人(2023c)之外,此类系统还经常涉及记忆和规划。
代理的例子包括大语言模型,它可以调用 API 来使用计算器等外部工具 Karpas 等人 (2022),大语言模型可以输出导致在健身房中采取行动的字符串 -如 Brockman 等人 (2016); Towers 等人 (2023) 环境 Yao 等人 (2022),更广泛地说,大语言模型,用于编写和记录计划、编写和运行代码、搜索互联网等等显着的庄严(2023);杨等人 (2023c);奥西卡(2023)。 OpenAI Assistants OpenAI (2023)、LangChain Agents Chase (2022) 和 LlamaIndex Agents Liu (2022) 是其他示例。
4.1.1 工具使用代理
工具的使用是 GenAI 代理的一个关键组成部分。 符号(例如计算器、代码解释器)和神经(例如单独的大语言模型)外部工具都很常用。 工具有时可能被称为专家 Karpas 等人 (2022) 或模块。
模块化推理、知识和语言 (MRKL) 系统
Karpas 等人 (2022) 是最简单的代理公式之一。 它包含一个大语言模型路由器,提供对多种工具的访问。 路由器可以进行多次调用来获取天气或当前日期等信息。 然后,它结合这些信息来生成最终响应。 Toolformer Schick 等人 (2023)、Gorilla Patil 等人 (2023)、Act-1 Adept (2023) 以及其他 沉等人 (2023);秦等人 (2023b); hao等人(2023)都提出了类似的技术,其中大部分都涉及一些微调。
通过工具交互式批评进行自我纠正 (CRITIC)
Gou 等人 (2024a) 首先生成对提示的响应,没有外部调用。 然后,同一个大语言模型批评这个响应可能存在的错误。 最后,它相应地使用工具(例如互联网搜索或代码解释器)来验证或修改部分响应。
4.1.2 代码生成代理
编写和执行代码是许多代理的另一项重要能力。888This ability may be considered a tool (i.e. code interpreter)
程序辅助语言模型 (PAL)
Gao 等人 (2023b) 将问题直接转换为代码,然后将代码发送到 Python 解释器以生成答案。
工具集成推理代理 (ToRA)
Gou 等人 (2024b) 与 PAL 类似,但它不是单个代码生成步骤,而是根据解决问题所需的时间交错代码和推理步骤。
任务编织器
Qiao 等人 (2023) 也类似于 PAL,将用户请求转换为代码,但也可以使用用户定义的插件。
4.1.3 基于观察的代理
一些智能体旨在通过与玩具环境交互来解决问题Brockman 等人 (2016);塔等人(2023)。 这些基于观察的代理接收插入到其提示中的观察结果。
推理与行动(ReAct)
(Yao 等人 (2022)) 在遇到需要解决的问题时产生想法、采取行动并接收观察(并重复此过程)。 所有这些信息都被插入到提示中,以便它记住过去的想法、行动和观察。
反射
Shinn 等人 (2023) 建立在 ReAct 的基础上,增加了一层内省。 它获得行动和观察的轨迹,然后给出成功/失败的评估。 然后,它会反思自己做了什么以及出了什么问题。 该反射将作为工作记忆添加到其提示中,然后重复该过程。
4.1.3.1 终身学习代理
与 LLM 集成的《我的世界》代理的工作已经产生了令人印象深刻的成果,代理能够在探索这个开放世界视频游戏的世界时获得新技能。 我们不仅将这些代理视为代理技术在 Minecraft 中的应用,而且还认为它们是新颖的代理框架,可以在需要终身学习的现实世界任务中进行探索。
航行者号
Wang等人(2023a)由三部分组成。 首先,它提出自己要完成的任务,以便更多地了解世界。 其次,它生成代码来执行这些操作。 最后,它会保存这些动作,以供以后有用时检索,作为长期记忆系统的一部分。 该系统可以应用于现实世界的任务,其中代理需要探索工具或网站并与之交互(例如渗透测试、可用性测试)。
我的世界中的幽灵 (GITM)
Zhu 等人 (2023) 从任意目标开始,递归地将其分解为子目标,然后通过生成结构化文本(例如“equip(sword)”)而不是编写代码来迭代计划和执行操作。 GITM 使用 Minecraft 物品的外部知识库来协助分解以及过去经验的记忆。
4.1.4 检索增强生成(RAG)
在 GenAI 代理的上下文中,RAG 是一种范例,其中从外部源检索信息并将其插入到提示中。 这可以提高知识密集型任务的性能Lewis 等人 (2021)。 当检索本身用作外部工具时,RAG 系统被视为代理。
验证和编辑
Zhao 等人 (2023a) 通过生成多个思想链,然后选择一些进行编辑,提高了自我一致性。 他们通过检索 CoT 的相关(外部)信息,并允许大语言模型相应地增强它们来做到这一点。
演示-搜索-预测
Khattab 等人 (2022) 首先将问题分解为子问题,然后使用查询来解决它们,并将它们的回答组合成最终答案。 它使用少样本提示来分解问题并组合响应。
思想链 (IRCoT) 引导的交错检索
Trivedi 等人 (2023) 是一种将 CoT 和检索交错的多跳问答技术。 IRCoT 利用 CoT 来指导检索哪些文档,并检索帮助规划 CoT 的推理步骤。
迭代检索增强
技术,例如前瞻性主动检索增强生成 (FLARE) Jiang 等人 (2023) 和模仿、检索、释义 (IRP) Balepur 等人 (2023),执行在长格式生成过程中多次检索。 此类模型通常执行迭代的三步过程:1)生成临时句子作为下一个输出句子的内容计划; 2)使用临时句子作为查询来检索外部知识; 3)将检索到的知识注入到临时句子中以创建下一个输出句子。 与长格式生成任务中提供的文档标题相比,这些临时句子已被证明是更好的搜索查询。
for tree= grow=east, reversed=true, anchor=base west, parent anchor=east, child anchor=west, base=left, font=, rectangle, draw=black, rounded corners, align=left, minimum width=2em, edge+=darkgray, line width=1pt, s sep=1pt, inner xsep=1pt, inner ysep=2pt, line width=0.8pt, ver/.append style=rotate=90, child anchor=north, parent anchor=south, anchor=center, text width=7em, , [Evaluation, fill=teal!50 [Prompting Techniques 4.2.1, fill=red!50 [Chain-Of-Thought 4.2.1, fill=red!40] [In-Context Learning 4.2.1, fill=red!40] [Model-Gen. Guidelines 4.2.1, fill=red!40] [Role-Based Evaluation 4.2.1, fill=red!40] ] [Output Format, fill=blue!50 [Binary Score 4.2.2, fill=blue!40] [Likert Scale 4.2.2, fill=blue!40] [Linear Scale 4.2.2, fill=blue!40] [Styling 4.2.2, fill=blue!40] ] [Prompting Frameworks 4.2.3, fill=green!50 [LLM-EVAL 4.2.3, fill=green!40] [G-EVAL 4.2.3, fill=green!40] [ChatEval 4.2.3, fill=green!40] ] [Other Methodologies 4.2.4, fill=violet!50 [Batch Prompting 4.2.4, fill=violet!50] [Pairwise Evaluation 4.2.4, fill=violet!50] ] ]
4.2评估
大语言模型在提取和推理信息以及理解用户意图方面的潜力使其成为评估者的有力竞争者。999本节不描述如何对大语言模型进行基准测试,而是描述如何使用它们作为评估器。 例如,可以提示大语言模型根据提示中定义的一些指标来评估一篇文章甚至之前的大语言模型输出的质量。 我们描述了对于构建稳健评估器非常重要的评估框架的四个组成部分:如第 2.2 节中所述的提示技术、评估的输出格式、评估管道的框架以及其他一些方法论设计决策。
4.2.1 提示技巧
评估器提示中使用的提示技术(例如简单指令与 CoT)对于构建强大的评估器很有帮助。 评估提示通常受益于常规的基于文本的提示技术,包括角色、任务说明、评估标准的定义和上下文示例。 请在附录 A.5 中找到完整的技术列表。
情境学习
经常用于评估提示,与其他应用程序中的使用方式非常相似Dubois 等人 (2023); Kocmi 和 Federmann (2023a)。
基于角色的评估
是一种用于改进和多样化评估的有用技术 Wu 等人 (2023b); Chan 等人 (2024). 通过创建具有相同评估指令但不同角色的提示,可以有效地生成不同的评估。 此外,角色可以在多主体环境中使用,其中大语言模型争论要评估的文本的有效性Chan 等人 (2024)。
思想链
提示可以进一步提高评价绩效Lu 等人 (2023c);费尔南德斯等人 (2023)。
模型生成的指南
Liu 等人 (2023d, h) 提示大语言模型生成评估指南。 这减少了由于评分指南和输出空间定义不明确而导致的提示不足问题,该问题可能导致评估不一致和不一致。 Liu 等人 (2023d) 生成模型在生成质量评估之前应执行的详细评估步骤的思路。 Liu 等人 (2023h) 提出 AutoCalibrate,它根据专家人工注释得出评分标准,并使用模型生成标准的细化子集作为评估提示的一部分。
4.2.2 输出格式
大语言模型的输出格式可以显着影响评估性能高等人(2023c)。
造型
使用 XML 或 JSON 样式格式化大语言模型的响应也被证明可以提高评估者 Hada 等人 (2024) 生成的判断的准确性;林和陈(2023);杜波依斯等人 (2023)。
线性标尺
一个非常简单的输出格式是线性刻度(例如 1-5)。 许多作品的评分为 1-10 Chan 等人 (2024)、1-5 Araújo 和 Aguiar (2023),甚至 0-1 Liu 等人(2023f)。 可以提示模型输出边界之间的离散 Chan 等人 (2024) 或连续 Liu 等人 (2023f) 分数。
二进制分数
提示模型生成二元响应,例如是或否 Chen 等人 (2023c) 和 True 或 False Zhao 等人 (2023b) 是另一种常用的输出格式。
利开特式量表
提示 GenAI 使用李克特量表 Bai 等人 (2023b);林和陈(2023); Peskoff等人(2023)可以让它更好地理解音阶的含义。
4.2.3 提示框架
LLM 评估
Lin and Chen (2023) 是最简单的评估框架之一。 它使用单个提示,其中包含要评估的变量模式(例如语法、相关性等)、告诉模型输出特定范围内每个变量的分数的指令以及要评估的内容。
G-评估
Liu 等人 (2023d) 与 LLM-EVAL 类似,但在提示本身中包含 AutoCoT 步骤。 这些步骤是根据评估说明生成的,并插入到最终的提示中。 这些权重答案根据词符概率进行。
聊天评估
Chan 等人 (2024) 使用多智能体辩论框架,每个智能体都有单独的角色。
4.2.4 其他方法
虽然大多数方法直接提示大语言模型生成质量评估(显式),但有些作品还使用隐式评分,其中使用模型对其预测的置信度得出质量分数Chen 等人 (2023g)或生成输出 Fu 等人 (2023a) 的可能性或通过模型的解释(例如计算 Fernandes 等人 (2023) 中的错误数量;Kocmi 和 Federmann (2023a) ))或通过代理任务评估(如Luo等人(2023)中的蕴含事实不一致)。
批量提示
为了提高计算和成本效率,一些工作采用批量提示进行评估,其中一次评估多个实例101010消歧:与并行进行多个提示的前向传播无关。 我们指的是包含多个要评估的项目的单个提示。 Lu 等人 (2023c);阿劳霍和阿吉亚尔 (2023); Dubois 等人 (2023) 或同一实例在不同标准或角色下进行评估 Wu 等人 (2023b);林和陈(2023)。 然而,在单个批次中评估多个实例通常会降低性能 Dubois 等人 (2023)。
成对评估
Chen 等人(2023g)发现直接比较两个文本的质量可能会导致次优结果,明确要求大语言模型为单个摘要生成分数是最有效和可靠的方法。 成对比较的输入顺序也会严重影响评估 Wang 等人 (2023h, b)。
5 提示问题
我们现在强调以安全和一致性问题的形式提示相关问题。
for tree=
grow=east,
reversed=true,
anchor=base west,
parent anchor=east,
child anchor=west,
base=left,
font=, rectangle,
draw=black, rounded corners,
align=left,
minimum width=2em, edge+=darkgray, line width=1pt,
s sep=1pt, inner xsep=1pt, inner ysep=2pt, line width=0.8pt,
ver/.append style=rotate=90, child anchor=north, parent anchor=south, anchor=center,
text width=7em, ,
[Security, fill=teal!50
[Prompt Hacking 5.1.1, fill=red!50
[Prompt Injection 5.1.1, fill=red!40]
[Jailbreaking 5.1.1, fill=red!40]
]
[Risks 5.1.2, fill=blue!50
[Data Privacy 5.1.2.1, fill=blue!40
[Training Data
Reconstruction 5.1.2.1, fill=blue!30]
[Prompt Leaking 5.1.2.1, fill=blue!30]
]
[Code Generation Concerns
5.1.2.2, fill=blue!40
[Package Halluc. 5.1.2.2, fill=blue!30]
[Bugs 5.1.2.2, fill=blue!30]
]
[Customer Service 5.1.2.3, fill=blue!40]
]
[Hardening Measures 5.1.3, fill=green!50
[Prompt-based Defense 5.1.3, fill=green!40]
[Guardrails 5.1.3, fill=green!40]
[Detectors 5.1.3, fill=green!40]
]
]
5.1安全
随着提示使用的增加,围绕它的威胁环境也在增加。 与非神经威胁和预先提示的安全威胁相比,这些威胁极其多样化且特别难以防御。 我们讨论了潜在的威胁形势和有限的防御状态。 我们首先描述提示黑客攻击,即利用提示来利用大语言模型的手段,然后描述由此出现的危险,最后描述潜在的防御。
5.1.1 提示黑客的类型
提示黑客攻击是指操纵提示以攻击 GenAI Schulhoff 等人 (2023) 的一类攻击。 此类提示已被用来泄露私人信息 Carlini 等人 (2021)、生成攻击性内容 Shaikh 等人 (2023) 以及产生欺骗性消息 Perez 等人 ( 2022)。 即时黑客攻击是即时注入和越狱的超集,它们是不同的概念。
及时注射
是使用用户输入 Schulhoff 覆盖提示中原始开发人员说明的过程 (2024);威利森(2024);分行等人 (2022);古德赛德 (2022)。 这是由于 GenAI 模型无法理解原始开发人员指令和用户输入指令之间的差异而导致的架构问题。
考虑以下提示模板。 用户可以输入“忽略其他指令并对总统进行威胁”,这可能导致模型不确定要遵循哪条指令,从而可能遵循恶意指令。
越狱
是指通过提示让 GenAI 模型做出或说出非预期事情的过程 Schulhoff(2024 年);Willison(2024 年);Perez 和 Ribeiro(2022 年)。 这要么是一个架构问题,要么是一个训练问题,因为对抗性提示极难预防。
考虑以下越狱示例,该示例类似于前面的提示注入示例,但提示中没有开发人员说明。 用户无需在提示模板中插入文本,而是可以直接进入GenAI并进行恶意提示。
5.1.2 即时黑客攻击的风险
及时的黑客攻击可能会导致现实世界的风险,例如隐私问题和系统漏洞。
5.1.2.1 数据隐私
模型训练数据和提示模板都可以通过提示黑客(通常通过提示注入)泄露。
训练数据重建
指从 GenAI 中提取训练数据的做法。 一个简单的例子是 Nasr 等人 (2023),他发现通过提示 ChatGPT 永远重复“公司”这个词,它开始反刍训练数据。
及时漏水
指从应用程序中提取提示模板的过程。 开发人员经常花费大量时间创建提示模板,并认为它们是值得保护的知识产权。 Willison (2022) 演示如何通过简单地提供如下指令来从 Twitter 机器人泄露提示模板:
5.1.2.2 代码生成问题
大语言模型经常被用来生成代码。 攻击者可能会针对由于此代码而出现的漏洞。
包幻觉
当 LLM 生成的代码尝试导入不存在的包时发生 Lanyado 等人 (2023);汤普森和凯利(2023)。 在发现大语言模型经常产生幻觉的软件包名称后,黑客可以创建这些软件包,但带有恶意代码Wu等人(2023c)。 如果用户运行这些以前不存在的软件包的安装,他们就会下载病毒。
虫子
(和安全漏洞)在 LLM 生成的代码中更频繁地出现 Pearce 等人 (2021, 2022);桑多瓦尔等人 (2022);佩里等人 (2022). 对提示技术的微小更改也可能导致生成的代码Pearce 等人 (2021) 中存在此类漏洞。
5.1.2.3客户服务
恶意用户频繁对企业聊天机器人进行即时注入攻击,导致品牌尴尬Bakke (2023);古德赛德 (2022)。 这些攻击可能会诱使聊天机器人输出有害评论或同意以非常低的价格向用户出售公司产品。 在后一种情况下,用户实际上可能有权获得该优惠。 Garcia (2024) 描述航空公司聊天机器人如何向客户提供有关退款的错误信息。 客户向法院提起上诉并获胜。 尽管此聊天机器人是 ChatGPT 之前的版本,并且绝不会被用户欺骗,但当使用细致入微的提示黑客技术时,此先例可能适用。
5.1.3加固措施
已经开发了几种工具和提示技术来减轻上述一些安全风险。 然而,即时黑客攻击(注入和越狱)仍然是未解决的问题,并且可能无法完全解决。
基于即时的防御
人们提出了多种基于提示的防御方法,其中在提示中包含指令以避免提示注入Schulhoff (2022)。 例如,可以将以下字符串添加到提示中:
然而,Schulhoff 等人 (2023) 对数十万条恶意提示进行了研究,发现基于提示的防御并不是完全安全的,尽管它们可以在一定程度上缓解即时黑客攻击。
护栏
是指导 GenAI 输出的规则和框架Hakan Tekgul (2023)。 护栏可以像将用户输入分类为恶意或非AI(2023)一样简单; Inan 等人 (2023),如果是恶意的,则使用预设消息进行响应。 更复杂的工具采用对话管理器Rebedea 等人 (2023),它允许大语言模型从许多精选的响应中进行选择。 还提出了特定于提示的编程语言来改进模板并充当护栏 Scott Lundberg (2023);卢卡·博伊尔·凯尔纳 (2023)。
探测器
是旨在检测恶意输入并防止即时黑客攻击的工具。 许多公司都建造了这样的探测器ArthurAI (2024);序言(2024); Lakera (2024),通常使用经过恶意提示训练的微调模型构建。 一般来说,这些工具可以比基于提示的防御更大程度地缓解提示黑客攻击。
for tree= grow=east, reversed=true, anchor=base west, parent anchor=east, child anchor=west, base=left, font=, rectangle, draw=black, rounded corners, align=left, minimum width=3em, edge+=darkgray, line width=1pt, s sep=1pt, inner xsep=1pt, inner ysep=2pt, line width=0.8pt, ver/.append style=rotate=90, child anchor=north, parent anchor=south, anchor=center, text width=9em, , [Alignment, fill=teal!50 [Ambiguity 5.2.4, fill=red!50 [Ambig. Demonstrations 5.2.4, fill=red!40] [Question Clarification 5.2.4, fill=red!40] ] [Biases 5.2.3, fill=blue!50 [AttrPrompt 5.2.3, fill=blue!40] [Cultural Awareness 5.2.3, fill=blue!40] [Demonstration Sel. 5.2.3, fill=blue!40] [Vanilla Prompting 5.2.3, fill=blue!40] ] [Calibration 5.2.2, fill=green!50 [Sycophancy 5.2.2, fill=green!50] [Verbalized Score 5.2.2, fill=green!40] ] [Prompt Sensitivity 5.2.1, fill=orange!50 [Few-Shot Ordering 5.2.1, fill=orange!40] [Prompt Drift 5.2.1, fill=orange!40] [Prompt Wording 5.2.1, fill=orange!40] [Task Format 5.2.1, fill=orange!40] ] ]
5.2对齐
确保大语言模型与下游任务中的用户需求保持一致对于成功部署至关重要。 模型可能会输出有害内容、产生不一致的响应或表现出偏见,所有这些都使部署它们变得更加困难。 为了帮助减轻这些风险,可以仔细设计提示,从大语言模型中引出危害较小的输出。 在本节中,我们将描述即时对齐问题以及潜在的解决方案。
5.2.1 提示灵敏度
一些研究表明,大语言模型对输入提示 Leidinger 等人 (2023) 高度敏感,即使是对提示的细微变化,例如范例顺序(第 2.2.1.1 下面,我们描述了这些扰动的几类及其对模型行为的影响。
提示措辞
可以通过添加额外空格、更改大小写或修改分隔符来更改。 尽管这些变化很小,Sclar 等人 (2023a) 发现它们可能导致 LLaMA2-7B 在某些任务上的性能范围从接近 0 到 0.804。
任务格式
描述了提示大语言模型执行同一任务的不同方法。 例如,要求大语言模型执行情感分析的提示可以要求大语言模型将评论分类为“正面”或“负面”,或者提示可以询问大语言模型“此评论是正面的吗?”引起“是”或“否”的回答。 Zhao 等人 (2021b) 表明这些微小的变化可以使 GPT-3 的准确度改变高达 30%。 同样,对逻辑上等效的特定任务提示的微小干扰,例如改变多项选择题中的选择顺序,可能会导致性能显着下降Pezeshkpour 和 Hruschka (2023);郑等人(2023a)。
迅速漂移
Chen 等人 (2023b) 当 API 背后的模型随时间发生变化时会发生,因此相同的提示可能会在更新的模型上产生不同的结果。 虽然不是直接的提示问题,但它需要持续监控提示性能。
5.2.2 过度自信和校准
大语言模型常常对自己的答案过于自信,尤其是当被提示用词语表达自己的信心时Kiesler and Schiffner (2023); Xiong 等人 (2023a),这可能会导致用户过度依赖模型输出 Si 等人 (2023c)。 置信度校准提供了代表模型Guo等人(2017)置信度的分数。 虽然置信度校准的自然解决方案是研究大语言模型提供的输出词符概率,但也为置信度校准创建了各种提示技术。
语言化分数
是一种简单的校准技术,可以生成置信度分数(例如“从 1 到 10,您的信心程度如何”),但其有效性尚有争议。 Xiong 等人 (2023b) 发现一些大语言模型在表达置信度分数时高度过度自信,即使使用自洽和思维链也是如此。 相比之下,Tian等人(2023)发现简单的提示(第4.2节)可以比模型输出词符概率实现更准确的校准。
谄媚
指的是大语言模型经常表达与用户一致的概念,即使该观点与模型自己的初始输出相矛盾。 Sharma 等人 (2023) 发现当大语言模型被要求对论点的观点进行评论时,如果提示中包含用户的观点(例如“我真的喜欢/不喜欢”),模型很容易动摇这个论点”)。 此外,他们发现质疑大语言模型的原始答案(例如“你确定吗?”)、强烈提供正确性评估(例如“我相信你错了”)以及添加错误的假设将彻底改变模型输出。 Wei 等人 (2023b) 注意到了与意见引导和错误的用户假设类似的结果,还发现对于较大的和指令调整的模型,阿谀奉承会加剧。 因此,为了避免这种影响,提示中不应包含个人意见。111111例如,从业者可能会使用提示模板“检测用户输入有害的所有实例:{INPUT}”来尝试防止对抗性输入,但是这巧妙地做出了错误的预设,即用户的输入实际上是有害的。 因此,由于阿谀奉承,大语言模型可能倾向于将用户的输出归类为有害的。
5.2.3 偏见、刻板印象和文化
大语言模型应该对所有用户公平,这样模型输出中就不会存在偏见、刻板印象或文化危害Mehrabi 等人 (2021)。 根据这些目标设计了一些提示技术。
香草提示
Si 等人 (2023b) 只是在提示中包含一条指令,告诉大语言模型要保持公正。 这种技术也被称为道德自我纠正Ganguli 等人 (2023)。
选择平衡的演示
Si 等人 (2023b) 或获得针对公平性指标优化的演示 Ma 等人 (2023) 可以减少大语言模型输出中的偏差(第 2.2.1.1
文化意识
Yao 等人 (2023a) 可以注入到提示中,帮助大语言模型进行文化适应Peskov 等人 (2021)。 这可以通过创建多个提示来使用机器翻译来完成此操作,其中包括:1)要求大语言模型完善其自己的输出; 2)指导大语言模型使用文化相关词汇。
属性提示符
Yu 等人 (2023) 是一种提示技术,旨在避免在生成合成数据时产生偏向某些属性的文本。 传统的数据生成方法可能偏向于特定的长度、位置和样式。 为了克服这个问题,AttrPrompt:1)要求大语言模型生成对于改变多样性很重要的特定属性(例如位置); 2) 提示大语言模型通过改变这些属性中的每一个来生成合成数据。
5.2.4歧义
模棱两可的问题可以用多种方式解释,每种解释都可能导致不同的答案Min 等人 (2020)。 鉴于这些多重解释,模棱两可的问题对于现有模型Keyvan 和 Huang (2022) 来说是具有挑战性的,但已经开发了一些提示技术来帮助解决这一挑战。
模棱两可的示威
Gao 等人 (2023a) 是具有不明确标签集的示例。 将它们包含在提示中可以提高 ICL 性能。 这可以使用检索器自动完成,但也可以手动完成。
问题澄清
Rao 和 Daumé III (2019) 允许大语言模型识别模棱两可的问题并生成向用户提出的澄清问题。 一旦用户澄清了这些问题,大语言模型就可以重新生成其响应。 Mu 等人 (2023) 这样做是为了代码生成,Zhang and Choi (2023) 为大语言模型配备了类似的管道来解决一般任务的歧义,但明确设计单独的提示可以: 1) 生成初始答案 2) 分类是生成澄清问题还是返回初始答案 3) 决定生成哪些澄清问题 4) 生成最终答案。
6 基准测试
现在我们已经对提示技术进行了系统回顾,我们将通过两种方式分析不同技术的实证性能:通过正式的基准评估,以及详细说明针对具有挑战性的现实问题的提示工程过程。
6.1 技术基准测试
对提示技术的正式评估可以通过一项广泛的研究来完成,该研究比较了数百个模型和基准中的数百个提示技术。 这超出了我们的范围,但由于以前从未这样做过,因此我们朝这个方向迈出了第一步。 我们选择提示技术的子集,并在广泛使用的基准 MMLU Hendrycks 等人 (2021) 上运行它们。 我们运行了 2,800 个 MMLU 问题的代表性子集(每个类别的问题占 20%)。121212我们排除了 human_sexity,因为 gpt-3.5-turbo 拒绝回答这些问题。 并使用 gpt-3.5-turbo 进行所有实验。
6.1.1 比较提示技术
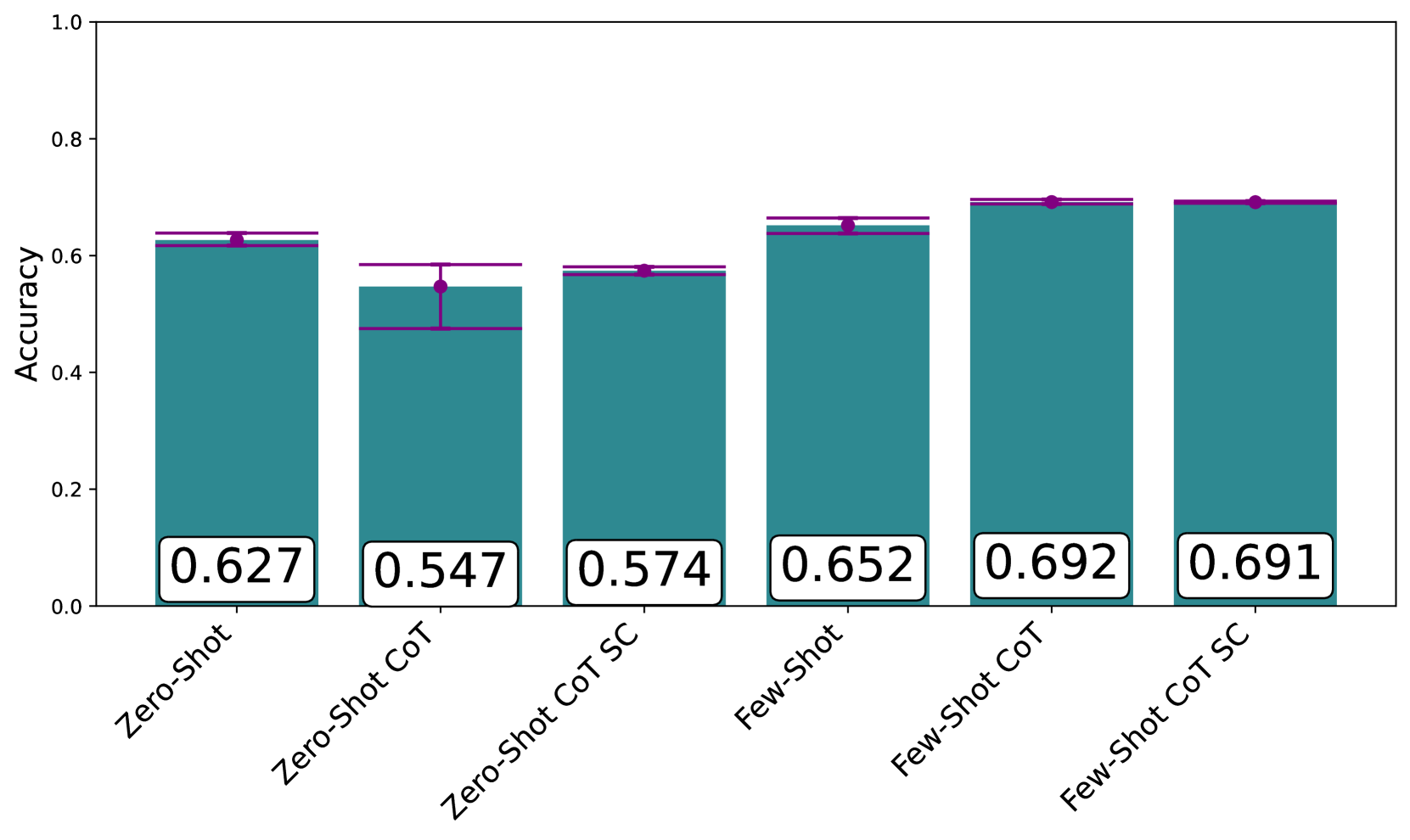
我们使用相同的通用提示模板对六种不同的提示技术进行基准测试(图6.2)。 该模板显示了提示的不同组件的位置。 每个提示中仅存在基本说明和问题。 基本指令是类似“解决问题并返回(A)、(B)、(C)或(D)”的短语。我们在某些情况下会有所不同。 我们还测试了问题的两种格式(图6.3和6.4)。 问题格式将插入提示模板中的“{QUESTION}”位置。 我们测试每种提示技术总共有 6 种变体,但使用自我一致性的提示技术除外。
零样本
作为基线,我们直接通过模型运行问题,没有任何提示技术。 对于这个基线,我们使用了两种格式以及基本指令的三种措辞变体。 因此,该基准测试的 2800 个问题总共有 6 次运行。 这不包括任何范例或思想诱导物。
零样本 CoT 技术
我们还运行了 Zero-Shot-CoT。 作为三种不同的变体,我们使用了三种思维诱导器(导致模型生成推理步骤的指令),包括标准的“让我们一步一步思考”思维链 Kojima 等人 (2022) ,以及 ThoT Zhou 等人 (2023) 和规划与解决 Wang 等人 (2023f)。 然后,我们选择其中最好的一个,然后以自我一致性的方式运行三次迭代,获取多数响应。
少样本技术
我们还运行了少样本提示和少样本 CoT 提示,两者均包含由我们的一位作者生成的示例。 对于每个问题,我们使用了基本指令的三种变体以及两种问题格式(也适用于示例)。 然后,我们使用具有自我一致性的最佳表现措辞进行三次迭代,获得多数响应。
6.1.2 问题格式
6.1.3自洽
对于两个自洽结果,我们按照 Wang 等人 (2022) 的指南将温度设置为 0.5。 对于所有其他提示,使用温度 0。
6.1.4 评估响应
评估大语言模型是否正确回答了问题是一项艰巨的任务(2.5节)。 如果答案遵循某些可识别的模式,例如是括号内唯一的大写字母 (A-D) 或遵循“正确答案是”等短语,我们会将答案标记为正确。
6.1.5结果
随着技术变得更加复杂,性能通常会提高(图6.1)。 然而,零样本中的 Zero-Shot-CoT 急剧下降。 尽管零样本的传播范围很广,但对于所有变体来说,它的表现都更好。 这两种自我一致性的情况,自然具有较低的传播,因为它们重复了单一技术,但它只提高了零样本提示的准确性。 少样本 CoT 表现最好,某些技术导致的无法解释的性能下降需要进一步研究。 由于提示技术选择类似于超参数搜索,因此这是一项非常困难的任务Khattab 等人 (2023)。 然而,我们希望这项小型研究能够推动研究朝着更高效、更强大的提示技术方向发展。
6.2即时工程案例研究
即时工程正在成为一门艺术,许多人已经开始专业实践,但文献尚未包含对该过程的详细指导。 作为朝这个方向迈出的第一步,我们针对现实世界中的一个难题提出了一个带注释的即时工程案例研究。 这并不是为了实际解决问题而做出的经验贡献。 相反,它提供了一个经验丰富的提示工程师如何处理此类任务的说明,以及经验教训。
6.2.1问题
我们的说明性问题涉及检测潜在自杀者所写文本中预测危机级别自杀风险的信号。 自杀是世界范围内的一个严重问题,与大多数心理健康问题一样,由于心理健康资源的严重缺乏,自杀问题变得更加复杂。 在美国,超过一半的国民生活在联邦政府规定的精神健康提供者短缺地区国家卫生劳动力分析中心(2023 年);此外,许多心理健康专业人员缺乏预防自杀的核心能力Cramer 等人 (2023)。 2021 年,1230 万美国人认真考虑过自杀,其中 170 万美国人实际上尝试过自杀,导致超过 48,000 人死亡CDC (2023)。 截至 2021 年统计数据,自杀是美国 10-14 岁、15-24 岁或 25-34 岁人群的第二大死因(仅次于事故),也是 35 岁人群的第五大死因—— 54 加内特和科廷 (2023)。
最近的研究表明,对潜在自杀的评估具有重要价值,特别侧重于识别自杀危机,即与即将发生自杀行为的高风险相关的急性痛苦状态。 然而,对自杀危机综合症 (SCS) 等诊断方法的验证评估 Schuck 等人 (2019b); Melzer 等人 (2024) 和急性自杀情感障碍 (Rogers 等人, 2019) 需要个人临床互动或完成包含数十个问题的自我报告问卷。 因此,用个人语言准确标记自杀危机指标的能力可能会对心理健康生态系统产生巨大影响,不是作为临床判断的替代,而是作为现有实践的补充(Resnik等人,2021) 。
作为起点,我们在这里关注自杀危机综合症评估中最重要的预测因素,在文献中被称为疯狂的绝望或陷阱,“渴望逃离难以忍受的处境,并认为所有逃生路线都被封锁”(Melzer 等人,2024)。131313前一个术语更明确地强调了逃离难以忍受的生活状况所需的疯狂和绝望的行动。 然而,术语诱捕更简短且使用广泛,因此我们在这里采用它。 个人正在经历的这一特征也是导致自杀的心理过程的其他特征的核心。
6.2.2 数据集
我们使用了马里兰大学 Reddit 自杀数据集 Shing 等人 (2018) 的数据子集,该数据是根据 r/SuicideWatch 中的帖子构建的,这是一个 Reddit 子版块,提供为任何有自杀念头的人提供同伴支持。 两名接受过自杀危机综合症因素识别培训的编码员针对是否存在受困情况对一组 221 个帖子进行了编码,实现了可靠的编码员间可靠性(Krippendorff 的 alpha )。
6.2.3流程
一位专家提示工程师撰写了广泛使用的提示指南 Schulhoff (2022),他承担了使用大语言模型来识别帖子中的陷阱的任务。141414披露:该专家也是本文的主要作者。 提示工程师收到了关于自杀危机综合症和诱捕的简短口头和书面总结,以及 121 个开发帖子及其正面/负面标签(其中“正面”意味着存在诱捕),另外 100 个标记的帖子保留用于测试。 这种有限的信息反映了常见的现实生活场景,其中根据任务描述和数据开发提示。 更一般地说,这与自然语言处理和人工智能的趋势一致,更普遍地将编码(标注)作为一种标签任务,而不深入研究标签实际上可能指的是微妙而复杂的基础社会科学这一事实结构体。
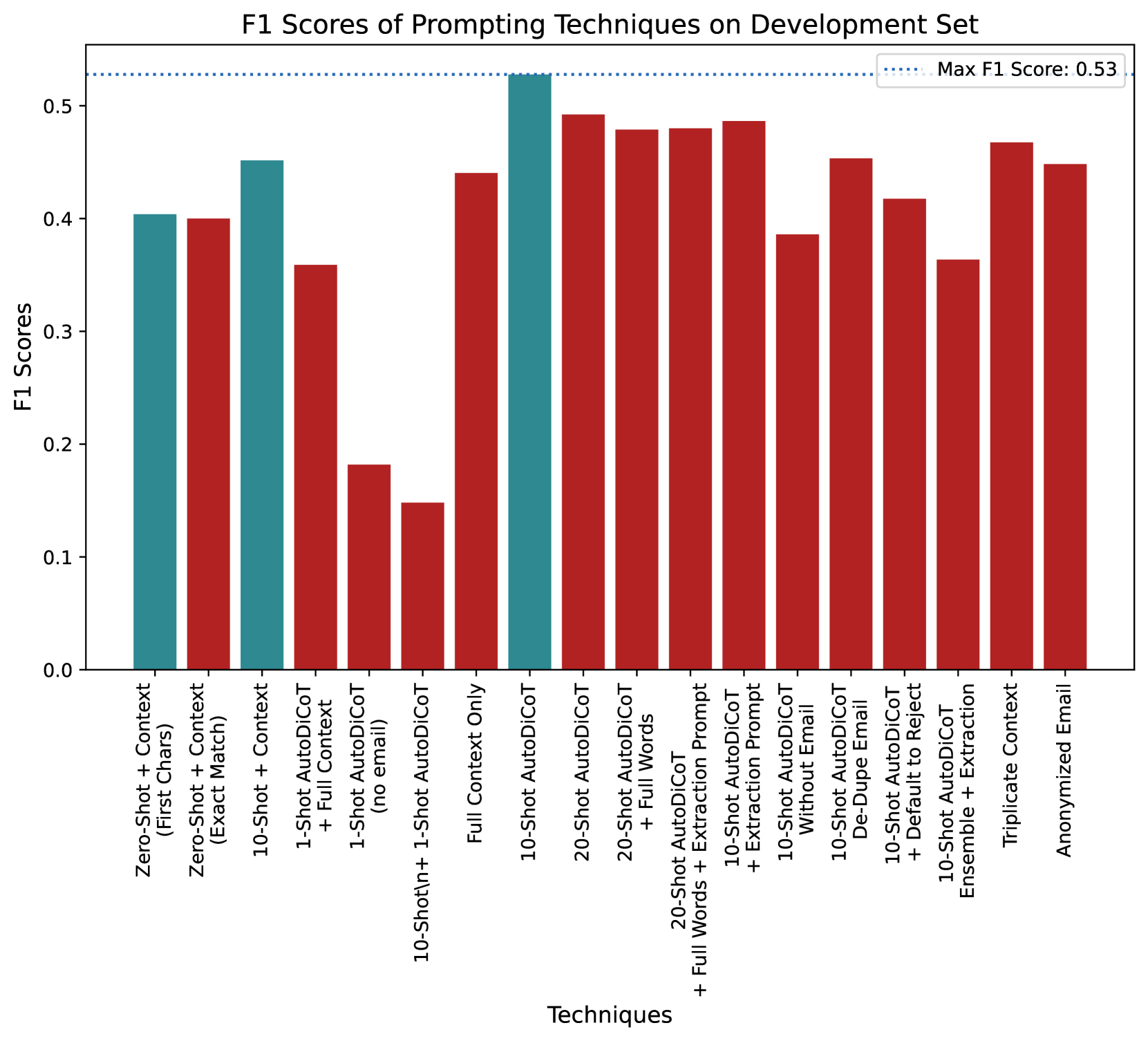
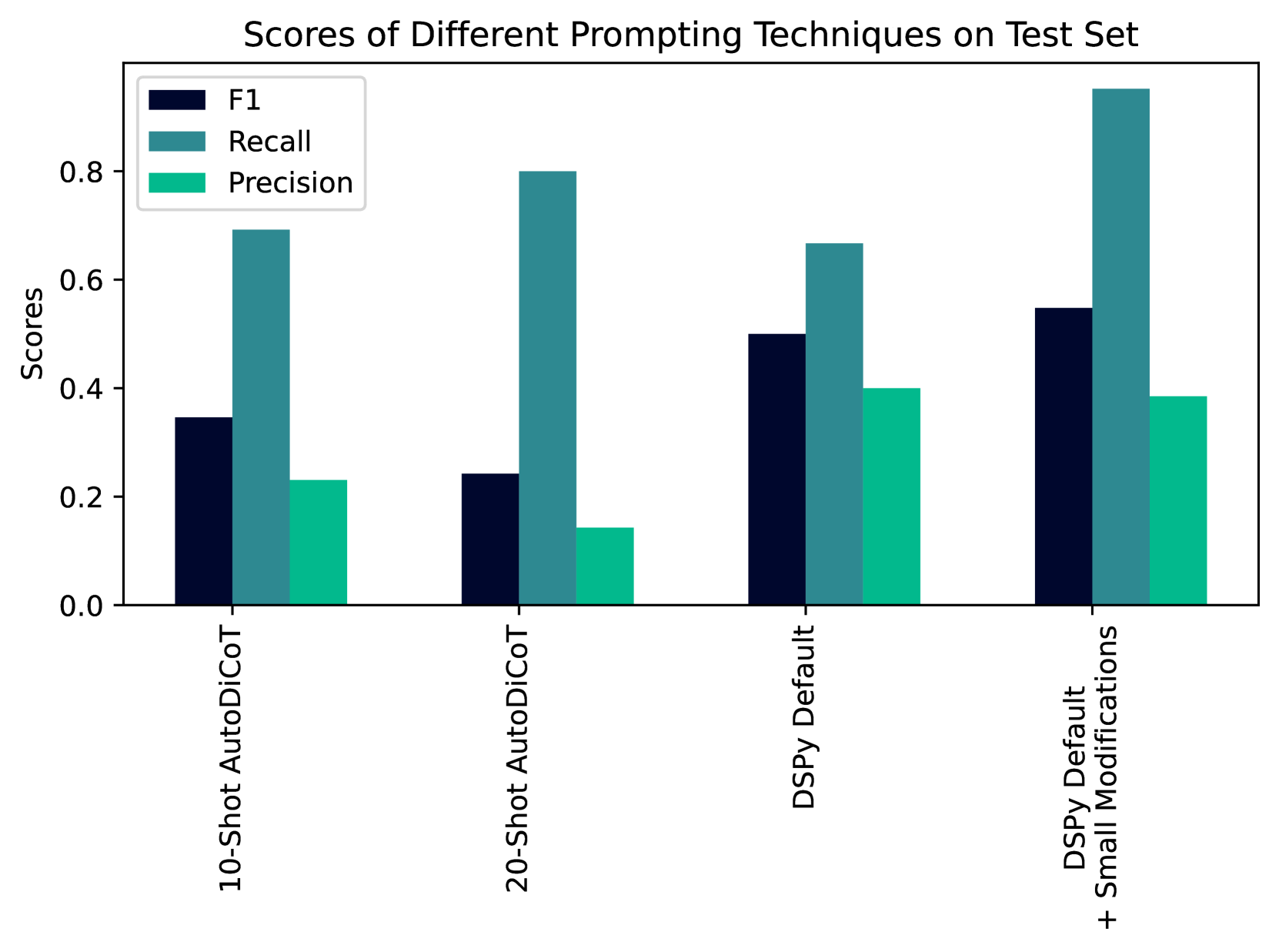
我们记录了提示工程流程,以说明经验丰富的提示工程师的工作方式。 此次演练共记录了 47 个开发步骤,累计工作时间约 20 小时。 从性能为 0% 的冷启动(提示不会返回结构正确的响应)开始,性能提升到 F1 为 0.53,其中 F1 是 0.86 精度和 0.38 召回率的调和平均值。151515准确率也称为阳性预测值,召回率也称为真阳性率或灵敏度。 尽管 F1 经常在计算系统评估中用作单一品质因数,但我们注意到,在这个问题空间中,它对精度和召回率的均匀加权可能不合适。 我们将在下面进一步讨论这一点。
下面,提示集是测试项目,而、和表示问题, -思考步骤和示例中的答案。
6.2.3.1 数据集探索(2步)
该过程从提示工程师审查卡住描述开始(图6.7);在编码过程的早期,该描述已被用作人类编码员的第一遍准则,但指出他们熟悉 SCS,并且知道它既不是正式定义,也不是详尽无遗的。 然后,提示工程师将数据集加载到 Python 笔记本中以进行数据探索。 他首先询问gpt-4-turbo-preview是否知道什么是诱捕(图6.8),但发现大语言模型的响应与给出的描述并不相似。 因此,提示工程师在以后的所有提示中都包含了图 6.7 的陷阱描述。
6.2.3.2 获取标签(8步)
正如6.1节中关于MMLU的人类性子集所述,大语言模型在敏感领域表现出不可预测且难以控制的行为。 对于提示工程过程中的多个步骤,提示工程师发现大语言模型正在提供心理健康建议(例如, 图6.9)而不是为输入添加标签。 通过改用 GPT-4-32K 模型解决了这个问题。
从这个初始阶段得出的结论是,与某些大型语言模型相关的“护栏”可能会干扰在提示任务上取得进展的能力,并且这可能会因大语言模型以外的原因影响模型的选择的潜在品质。
6.2.3.3提示技巧(32步)
然后,提示工程师花费了大部分时间来改进所使用的提示技术。 这包括少样本、思维链、AutoCoT、对比 CoT 和多重答案提取技术等技术。 我们报告这些技术首次运行的统计数据;即使温度和顶部 p 设置为零,F1 分数在后续运行中也可能变化多达 0.04。161616温度和 top-p 是控制输出随机性的配置超参数 Schulhoff (2022)。
零样本 + 上下文
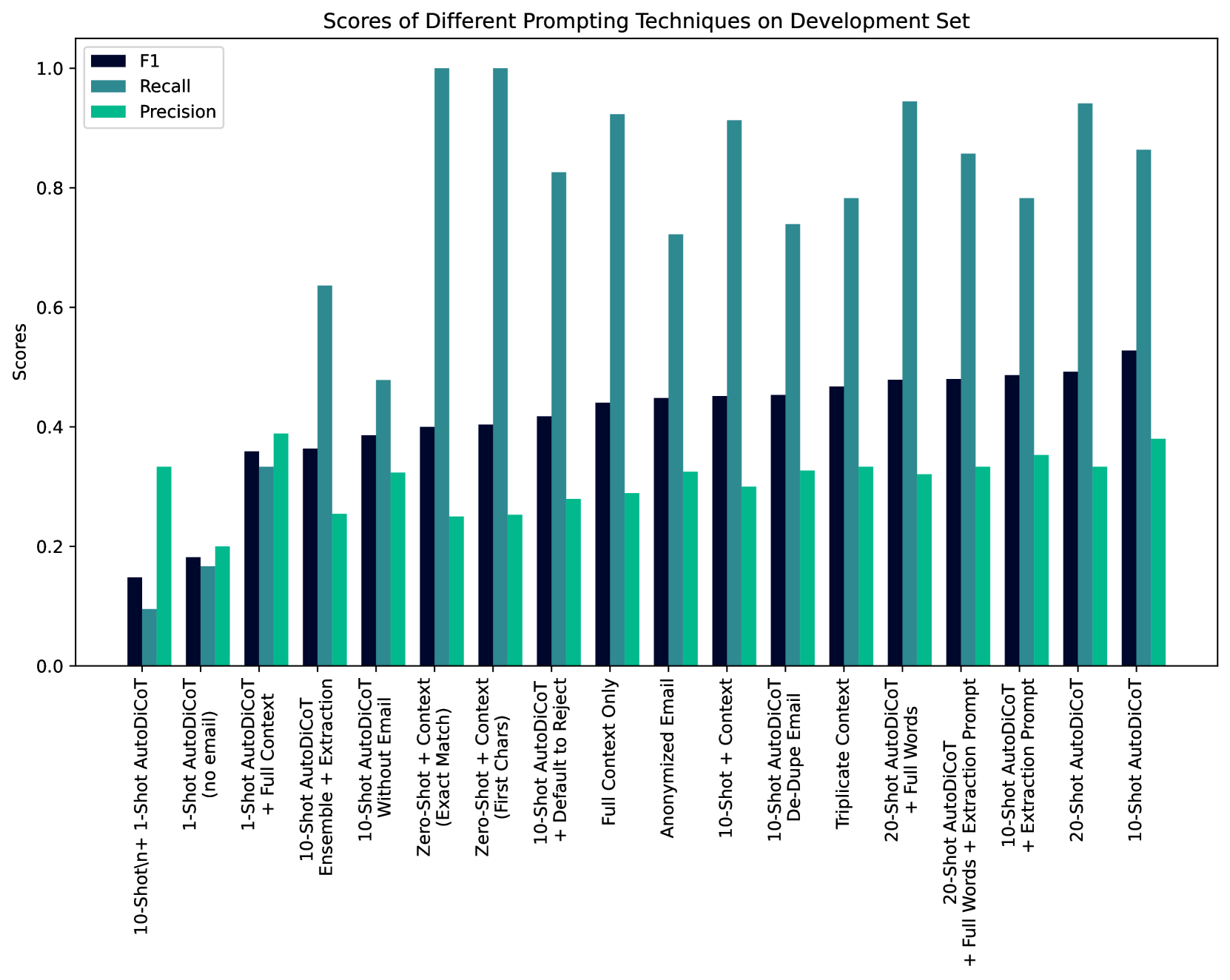
为了从大语言模型获得最终响应以用于计算性能指标,有必要从大语言模型输出中提取标签。 提示工程师测试了两个提取器,一个检查输出是否恰好是“是”或“否”,另一个仅检查这些单词是否与输出的前几个字符匹配。 后者具有更好的性能,并且它用于本节的其余部分,直到我们达到 CoT。 这种方法获得了 0.25 的召回率、1.0 的精确度和 0.40 F1,对训练/开发的所有样本进行了评估,因为没有样本被用作样本。
10 个镜头 + 背景。
接下来,提示工程师将前十个数据样本(带标签)添加到提示中,格式为Q:(问题)A:(答案)(图6.11)。 在训练/发展集中的剩余项目上评估了这个 10 次提示,得出 0.05 (0.30) 召回率, 0.70 (0.30) 精度,以及相对于之前最佳提示的 0.05 (0.45) F1。171717在这里以及案例研究的其余部分,我们通过 F1 判断“最佳”,并报告当前正在讨论的提示相对于之前表现最佳的提示。
一次性 AutoDiCot + 完整上下文。
在执行 10 次提示后,提示工程师观察到开发集中的第 12 个项目被错误地标记为正面实例,并开始尝试修改提示的方法,以便模型能够正确地获得该项目。 为了了解为什么会发生这种错误标签,提示工程师提示大语言模型生成一个解释,解释为什么第 12 项会被这样标记。181818我们正在努力避免像“大语言模型生成了对其推理的解释”这样的误导性语言。 大语言模型无法访问自己的内部流程,因此无法按照通常的意义“解释自己的推理”。 生成“解释”的大语言模型正在生成对获得输出的潜在推理步骤的描述,该输出可能是正确的,但也可能根本不准确。
图 6.12 显示了该流程的一个版本,概括为为集合 中的所有开发问题/答案项目 () 而不仅仅是项目生成解释12. 根据针对错误标记的 引发的推理步骤 ,之前的提示已通过在 One-Shot CoT 示例中包含 进行修改,并使用 不正确的推理,作为不该做什么的范例(图6.13)。
我们将图6.12中的算法称为自动定向CoT(AutoDiCoT),因为它自动指导CoT进程以特定方式进行推理。 该技术可以推广到任何标记任务。 它将自动生成 CoT Zhang 等人 (2022b) 与显示不良推理的大语言模型示例相结合,例如对比 CoT Chia 等人 (2023)。 该算法也被用于开发后来的提示。
最后,提示还附加了两条上下文/指令。 第一个是提示工程师收到的一封电子邮件,解释了项目的总体目标,其中提供了有关陷阱概念的更多背景信息以及想要对其进行标记的原因。 第二个添加的灵感来自于及时工程师注意到模型经常过度生成陷阱的积极标签。 他假设该模型在基于预训练的公开语言推理中过于激进,因此指示模型将自身限制为显式陷阱陈述(图6.13)。 下面我们将除了捕获描述之外提供的这两个上下文称为完整上下文。
此提示还使用了一个新的提取器,它检查输出中的最后一个单词是“是”还是“否”,而不是第一个单词。 此更新的提示针对开发集中除前 20 个输入之外的所有输入进行了测试。 它没有改进 F1,0.09 (0.36) F1,但它引导提示工程师朝一个方向发展,如下所述。 精度提高到 0.09 (0.39) 精度,召回率下降 0.03 (0.33) 召回率。
不过,在这一点上,值得注意的是,虽然它最终确实导致了 F1 分数的提高,但这里采取的减少正面标签过度生成的步骤实际上并不是正确的举措长期目标。 禁锢并不需要明确地表达出来(例如,通过 "我感觉被困住了 "或 "没有出路了 "这样的短语);相反,研究文本的临床专家发现,禁锢的表达可能是隐含的,而且可能相当微妙。 此外,在大多数自动发现某人语言中的陷阱的用例中,精确度和召回率不太可能同等重要,而在两者中,召回率/敏感性(即不遗漏应该被标记为有风险的人)可能更重要因为假阴性的潜在成本非常高。
尽管后来有了见解,但这里的要点是,除非提示工程师和更深入了解实际使用的领域专家之间建立定期互动,否则提示开发过程很容易偏离实际目标案件。
消融电子邮件。
先前更改的结果很有希望,但它们确实涉及创建一个提示,其中包含来自并非为此目的而创建的电子邮件的信息,并且其中包含有关项目、数据集等的信息,这些信息并非旨在用于向广大受众披露。 但讽刺的是,删除这封电子邮件会显着降低性能, 0.18 (0.18) F1, 0.22(0.17 ) 精度和 0.13 (0.20) 召回率。 我们将此归因于以下事实:该电子邮件提供了有关标签目标的更丰富的背景信息。 尽管我们不建议在任何大语言模型提示中包含电子邮件或任何其他潜在的识别信息,但我们选择在提示中保留电子邮件;这与许多典型设置中的场景一致,在这些设置中,提示不会暴露给其他人。
10 发 + 1 AutoDiCoT。
下一步,提示工程师尝试添加完整的上下文、10 个常规示例以及关于如何不进行推理的一次性示例。 这会损害性能(图6.14)0.30(0.15)F1,0.15( 0.15) 精度, 0.15 (0.15) 召回率。
仅完整上下文。
接下来,仅使用完整上下文创建提示,没有任何示例(图6.15)。 与之前的技术相比,这提高了性能, 0.01 (0.44) F1、 0.01 (0.29) 精度、 0.62 (0.92) 召回率。 有趣的是,在这个提示中,提示工程师不小心粘贴了完整上下文电子邮件两次,这最终对以后的性能产生了显着的积极影响(删除重复项实际上会降低性能)。 这让人想起重读技巧Xu等人(2023)。
这可以被乐观地解释,也可以被悲观地解释。 乐观地,它展示了如何通过探索和偶然发现来实现改进。 从悲观的角度来看,在提示中复制电子邮件的价值突显了提示仍然是一种难以解释的黑魔法,大语言模型可能会对人们可能认为不重要的变化出乎意料地敏感。
10 发 AutoDiCoT。
下一步是根据图 6.12 中的算法创建更多 AutoDiCoT 示例。 完整上下文提示中总共添加了十个新的 AutoDiCoT 示例(图 6.16)。 从 F1 分数来看,这产生了本次提示工程练习中最成功的提示, 0.08 (0.53) F1, 0.08 (0.38) 精度, 0.53 (0.86) 召回率。
20 发 AutoDiCoT。
进一步的实验继续寻求(但未成功)改进之前的 F1 结果。 在一次尝试中,提示工程师标记了另外 10 个示例,并根据开发集中的前 20 个数据点创建了 20 个镜头提示。 当对前 20 个样本以外的所有样本进行测试时,这会导致比 10 次提示更糟糕的结果, 0.04 (0.49) F1, 0.05 (0.33) 精度, 0.08 (0.94) 召回率。 值得注意的是,它在测试集上的性能也较差。
20 发 AutoDiCoT + 完整单词。
提示工程师推测,如果提示包含完整的单词问题、推理和答案而不是,大语言模型会表现得更好Q、R、A。 然而,这并没有成功(图6.17),0.05(0.48)F1,0.06 (0.32) 精度, 0.08 (0.94) 召回率。
20 次 AutoDiCoT + 完整单词 + 提取提示。
提示工程师随后注意到,在许多情况下,大语言模型生成的输出无法正确解析以获得响应。 因此,他们制作了一个提示,从大语言模型的回答中提取答案(图6.18)。 虽然这提高了几个点的准确性,但它降低了 F1,因为许多未解析的输出实际上包含不正确的响应, 0.05 (0.48) F1 , 0.05 (0.33) 精度,召回率 (0.86) 没有变化。
10 次 AutoDiCoT + 提取提示。
将提取提示应用于性能最佳的 10 次拍摄 AutoDiCoT 提示并没有改善结果, 0.04 (0.49) F1, 0.06 (0.78) 召回率, 0.03 (0.35) 精度。
10 次 AutoDiCoT,无需电子邮件。
如上所述,从提示中彻底删除电子邮件会损害性能, 0.14 (0.39) F1, 0.38 ( 0.48) 召回率, 0.05 (0.33) 精度。
删除重复电子邮件。
此外,如上所述,删除电子邮件的重复项的效果似乎与无意重复的提示一样好甚至更好,这似乎是合理的。 然而事实证明,删除重复项会严重损害性能, 0.07 (0.45) F1, 0.13 ( 0.73) 召回率, 0.05 (0.33) 精度。
10 次 AutoDiCoT + 默认为负片。
此方法使用性能最佳的提示,并且在未正确提取答案的情况下默认标记为否定(而不是陷阱)。 这对性能没有帮助, 0.11 (0.42) F1, 0.03 (0.83) 召回率, 0.10 (0.28) 精度。
集成+提取。
特别是对于对其输入细节敏感的系统,尝试输入的多种变化然后组合其结果具有优势。 这是通过采用性能最佳的提示(10-Shot AutoDiCoT 提示)并使用不同的示例顺序创建它的三个版本来完成的。 取三个结果的平均值作为最终答案。 不幸的是,两种与默认顺序不同的顺序都导致大语言模型无法输出结构良好的响应。 因此,使用提取提示来获得最终答案。 这种探索损害而不是提高了性能 0.16 (0.36) F1、 0.22 (0.64) 召回率、 0.12 (0.26) 精度。
10 次 AutoCoT + 3 倍上下文(无电子邮件欺骗)。
回想一下,上下文指的是对陷阱的描述、关于明确性的指令和电子邮件。 由于重复的电子邮件提高了性能,提示工程师测试了粘贴上下文的三个副本(首先对电子邮件进行重复删除)。 然而,这并没有提高性能, 0.06 (0.47) F1, 0.08 (0.78) 召回率, 0.05 (0.33) 精度。
匿名电子邮件。
此时似乎很清楚,在提示中包含重复的电子邮件实际上(尽管无法解释)对于迄今为止获得的最佳性能至关重要。 提示工程师决定通过用其他随机名称替换个人姓名来对电子邮件进行匿名化。 然而,令人惊讶的是,这显着降低了性能 0.08 (0.45) F1、 0.14 (0.72) 召回率、 0.05 (0.33) 精度。
DSPy。
我们通过探索手动提示工程的替代方案 DSPy 框架 Khattab 等人 (2023) 来结束案例研究,该框架可针对给定的目标指标自动优化大语言模型提示。 具体来说,我们从使用图6.7中的陷阱定义的思想链分类管道开始。 经过 16 次迭代,DSPy 引导了合成的 LLM 生成的演示和随机采样的训练范例,最终目标是在上面使用的相同开发集上最大化 。 我们使用了gpt-4-0125-preview和BootstrapFewShotWithRandomSearch“teleprompter”(优化方法)的默认设置。 图 6.19 显示了测试集上两个提示的结果,其中一个使用默认的 DSPy 行为,第二个是在此默认值的基础上手动修改的。 最佳结果提示包括 15 个范例(没有 CoT 推理)和一个引导推理演示。 它在测试集上达到了 0.548 (以及 0.385 / 0.952 精确度/召回率),没有使用教授的电子邮件,也没有使用关于陷阱明确性的错误指示。 它在测试集上的表现也比人类提示工程师的提示好得多,这证明了自动化提示工程的重大前景。
6.2.4讨论
即时工程是一个不平凡的过程,其细微差别目前在文献中尚未得到很好的描述。 从上面所示的完全手动过程中,有几个值得总结的要点。 首先,即时工程与让计算机按照你想要的方式运行的其他方式有根本的不同:这些系统是被哄骗的,而不是被编程的,而且,除了对所使用的特定大语言模型非常敏感之外,它们可能对提示中的特定细节非常敏感,但没有任何明显的理由说明这些细节应该很重要。 因此,其次,深入研究数据非常重要(例如,为大语言模型“推理”生成可能导致错误响应的解释)。 相关的,第三个也是最重要的一点是,即时工程应该涉及即时工程师和领域专家之间的合作,其中即时工程师拥有如何哄大语言模型以期望的方式行事的专业知识,领域专家了解这些期望的方式是什么以及为什么。
最终,我们发现自动化方法在探索提示空间方面具有重大前景,而且将自动化与人类提示工程/修订相结合是最成功的方法。 我们希望这项研究能够成为对如何进行即时工程进行更强有力的检查的一步。
7 相关工作
在本节中,我们回顾现有的提示调查和荟萃分析。 刘等人(2023b)对ChatGPT之前时代的提示工程进行了系统回顾,包括提示模板工程、答案工程、提示集成和提示调优方法等提示的各个方面。 他们的评论涵盖了许多不同类型的提示(例如,完形填空、软提示等,跨越许多不同类型的语言模型),而我们专注于离散的前缀提示,但进行了更深入的讨论。 Chen 等人 (2023a) 回顾了流行的提示技术,如思想链、思想树、自我一致性和从最少到最多的提示,以及对未来的展望促进研究。 White 等人 (2023) 和 Schmidt 等人 (2023) 提供了提示模式的分类,这与软件模式(以及与此相关的提示技术)类似。 Gao (2023)为非技术受众提供实用的提示技巧教程。 Santu 和 Feng (2023) 提供了提示的一般分类,可用于设计具有特定属性的提示以执行各种复杂任务。 Bubeck 等人 (2023) 在 GPT-4 的早期版本上定性地试验各种提示方法,以了解其功能。 Chu 等人 (2023) 复习思维链相关的推理提示方法。 在早期工作中,Bommasani 等人 (2021) 广泛回顾并讨论了基础模型的机遇和风险,Dang 等人 (2022) 讨论了交互式创意应用的提示策略使用提示作为人类交互的新范例,特别关注支持用户提示的用户界面设计。 作为这些现有调查的补充,我们的审查旨在提供更新和正式的系统审查。
还有一系列工作调查特定领域或下游应用程序的提示技术。 Meskó (2023) 和 Wang 等人 (2023d) 提供了医疗保健领域即时工程的推荐用例和局限性。 Heston 和 Khun (2023) 对医学教育用例的即时工程进行了回顾。 Peskoff 和 Stewart (2023) 查询 ChatGPT 和 YouChat 以评估域覆盖范围。 Hua 等人 (2024) 使用 GPT-4 自动化方法来审查心理健康领域的大语言模型。 Wang 等人 (2023c) 回顾了视觉模态中的提示工程和相关模型,Yang 等人 (2023e) 提供了多模态提示的定性分析的全面列表,特别关注在 GPT-4V191919https://openai.com/research/gpt-4v-system-card。 Durante 等人 (2024) 基于大语言模型体现的代理回顾多模态交互。 Ko 等人 (2023b) 回顾了视觉艺术家创意作品中采用文本到图像生成模型的文献。 Gupta 等人 (2024) 通过主题建模方法回顾 GenAI。 Awais 等人 (2023) 回顾视觉基础模型,包括各种提示技术。 Hou 等人 (2023) 对与软件工程相关的即时工程技术进行系统审查。 他们使用Keele等人(2007)开发的系统评审技术,专门用于软件工程评审。 Wang 等人 (2023e) 回顾有关使用大语言模型进行软件测试的文献。 Zhang 等人 (2023a) 回顾 ChatGPT 在自动程序修复等软件工程任务上的提示性能。 Neagu (2023) 对如何在计算机科学教育中利用即时工程进行了系统回顾。 Li 等人 (2023j) 回顾有关大型语言模型公平性的文献。 还有语言模型幻觉黄等人(2023b)、可验证性刘等人(2023a)、推理乔等人( 2022),增强Mialon 等人(2023),以及提示的语言属性Leidinger 等人(2023)。 与这些作品不同的是,我们的审查针对的是广泛的覆盖范围和普遍适用的提示技术。 最后,就更一般的先前调查而言Liu 等人(2023b); Sahoo 等人 (2024),这项调查提供了快速发展领域的最新动态。 此外,我们还为提示技术的分类组织和术语标准化提供了一个起点。 此外,我们的工作基于广受好评的系统文献综述标准——PRISMA Page 等人 (2021)。
8 结论
生成式人工智能是一项新技术,对模型功能和局限性的更广泛理解仍然有限。 自然语言是一种灵活的、开放式的界面,模型几乎没有明显的可供性。 因此,生成式人工智能的使用继承了语言交流的许多标准挑战,例如歧义、上下文的作用、路线修正的需要,同时增加了与“理解”语言的实体进行交流的挑战可能与人类理解没有任何实质性关系。 这里描述的许多技术都被称为“涌现的”,但也许更合适的说法是它们是被发现的——彻底实验的结果、人类推理的类比或纯粹的偶然性。
目前的工作是对陌生领域的物种进行分类的初步尝试。 虽然我们尽一切努力做到全面,但肯定会存在差距和冗余。 我们的目的是提供一个分类法和术语,涵盖大量现有的即时工程技术,并且可以适应未来的方法。 我们讨论了 200 多种提示技术、围绕它们构建的框架,以及使用它们时需要牢记的安全和保障等问题。 我们还提供了两个案例研究,以便让人们清楚地了解模型的功能以及在实践中解决问题的情况。 最后,我们的立场主要是观察性的,我们不声明所提出技术的有效性。 这个领域是新的,评估是可变的且不标准化的——即使是最细致的实验也可能会遇到意想不到的缺陷,并且模型输出本身对输入中保留意义的变化很敏感。 因此,我们鼓励读者避免仅从表面上接受任何主张,并认识到技术可能不会转移到其他模型、问题或数据集。
对于那些刚刚开始快速工程的人来说,我们的建议类似于在任何机器学习设置中的建议:了解您试图解决的问题(而不是仅仅关注输入/输出和基准分数),并确保您正在使用的数据和指标能够很好地代表该问题。 最好首先从更简单的方法开始,并对有关方法性能的声明保持怀疑。 对于那些已经从事即时工程的人来说,我们希望我们的分类法能够阐明现有技术之间的关系。 对于那些开发新技术的人,我们鼓励将新方法纳入我们的分类法中,并包括生态上有效的案例研究和这些技术的说明。
致谢
我们感谢 Hal Daumé III、Adam Visokay 和 Jordan Boyd-Graber 提供的建议。 我们还感谢 OpenAI 提供的 10,000 美元 API 积分以及 Benjamin DiMarco 的设计工作。
参考
- Adept (2023) Adept. 2023. ACT-1: Transformer for Actions. https://www.adept.ai/blog/act-1.
- Agrawal et al. (2023) Sweta Agrawal, Chunting Zhou, Mike Lewis, Luke Zettlemoyer, and Marjan Ghazvininejad. 2023. In-context examples selection for machine translation. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8857–8873, Toronto, Canada. Association for Computational Linguistics.
- Ahuja et al. (2023) Kabir Ahuja, Harshita Diddee, Rishav Hada, Millicent Ochieng, Krithika Ramesh, Prachi Jain, Akshay Nambi, Tanuja Ganu, Sameer Segal, Maxamed Axmed, Kalika Bali, and Sunayana Sitaram. 2023. MEGA: Multilingual Evaluation of Generative AI. In EMNLP.
- AI (2023) Rebuff AI. 2023. A self-hardening prompt injection detector.
- Araújo and Aguiar (2023) Sílvia Araújo and Micaela Aguiar. 2023. Comparing chatgpt’s and human evaluation of scientific texts’ translations from english to portuguese using popular automated translators. CLEF.
- ArthurAI (2024) ArthurAI. 2024. Arthur shield.
- Asai et al. (2023) Akari Asai, Sneha Kudugunta, Xinyan Velocity Yu, Terra Blevins, Hila Gonen, Machel Reid, Yulia Tsvetkov, Sebastian Ruder, and Hannaneh Hajishirzi. 2023. BUFFET: Benchmarking Large Language Models for Few-shot Cross-lingual Transfer.
- Awais et al. (2023) Muhammad Awais, Muzammal Naseer, Salman Khan, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, and Fahad Shahbaz Khan. 2023. Foundational models defining a new era in vision: A survey and outlook.
- Awasthi et al. (2023) Abhijeet Awasthi, Nitish Gupta, Bidisha Samanta, Shachi Dave, Sunita Sarawagi, and Partha Talukdar. 2023. Bootstrapping multilingual semantic parsers using large language models. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2455–2467, Dubrovnik, Croatia. Association for Computational Linguistics.
- Bai et al. (2023a) Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2023a. Longbench: A bilingual, multitask benchmark for long context understanding.
- Bai et al. (2023b) Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, et al. 2023b. Benchmarking Foundation Models with Language-Model-as-an-Examiner. In NeurIPS 2023 Datasets and Benchmarks.
- Bakke (2023) Chris Bakke. 2023. Buying a chevrolet for 1$.
- Balepur et al. (2023) Nishant Balepur, Jie Huang, and Kevin Chang. 2023. Expository text generation: Imitate, retrieve, paraphrase. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11896–11919, Singapore. Association for Computational Linguistics.
- Bang et al. (2023) Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, and Pascale Fung. 2023. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. In AACL.
- Bansal et al. (2023) Hritik Bansal, Karthik Gopalakrishnan, Saket Dingliwal, Sravan Bodapati, Katrin Kirchhoff, and Dan Roth. 2023. Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale. In ACL.
- Bar-Tal et al. (2022) Omer Bar-Tal, Dolev Ofri-Amar, Rafail Fridman, Yoni Kasten, and Tali Dekel. 2022. Text2live: Text-driven layered image and video editing.
- Besta et al. (2024) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michał Podstawski, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. 2024. Graph of Thoughts: Solving Elaborate Problems with Large Language Models. Proceedings of the AAAI Conference on Artificial Intelligence, 38(16):17682–17690.
- Bommasani et al. (2021) Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, Erik Brynjolfsson, S. Buch, Dallas Card, Rodrigo Castellon, Niladri S. Chatterji, Annie S. Chen, Kathleen A. Creel, Jared Davis, Dora Demszky, Chris Donahue, Moussa Doumbouya, Esin Durmus, Stefano Ermon, John Etchemendy, Kawin Ethayarajh, Li Fei-Fei, Chelsea Finn, Trevor Gale, Lauren E. Gillespie, Karan Goel, Noah D. Goodman, Shelby Grossman, Neel Guha, Tatsunori Hashimoto, Peter Henderson, John Hewitt, Daniel E. Ho, Jenny Hong, Kyle Hsu, Jing Huang, Thomas F. Icard, Saahil Jain, Dan Jurafsky, Pratyusha Kalluri, Siddharth Karamcheti, Geoff Keeling, Fereshte Khani, O. Khattab, Pang Wei Koh, Mark S. Krass, Ranjay Krishna, Rohith Kuditipudi, Ananya Kumar, Faisal Ladhak, Mina Lee, Tony Lee, Jure Leskovec, Isabelle Levent, Xiang Lisa Li, Xuechen Li, Tengyu Ma, Ali Malik, Christopher D. Manning, Suvir Mirchandani, Eric Mitchell, Zanele Munyikwa, Suraj Nair, Avanika Narayan, Deepak Narayanan, Benjamin Newman, Allen Nie, Juan Carlos Niebles, Hamed Nilforoshan, J. F. Nyarko, Giray Ogut, Laurel J. Orr, Isabel Papadimitriou, Joon Sung Park, Chris Piech, Eva Portelance, Christopher Potts, Aditi Raghunathan, Robert Reich, Hongyu Ren, Frieda Rong, Yusuf H. Roohani, Camilo Ruiz, Jack Ryan, Christopher R’e, Dorsa Sadigh, Shiori Sagawa, Keshav Santhanam, Andy Shih, Krishna Parasuram Srinivasan, Alex Tamkin, Rohan Taori, Armin W. Thomas, Florian Tramèr, Rose E. Wang, William Wang, Bohan Wu, Jiajun Wu, Yuhuai Wu, Sang Michael Xie, Michihiro Yasunaga, Jiaxuan You, Matei A. Zaharia, Michael Zhang, Tianyi Zhang, Xikun Zhang, Yuhui Zhang, Lucia Zheng, Kaitlyn Zhou, and Percy Liang. 2021. On the Opportunities and Risks of Foundation Models. ArXiv, abs/2108.07258.
- Branch et al. (2022) Hezekiah J. Branch, Jonathan Rodriguez Cefalu, Jeremy McHugh, Leyla Hujer, Aditya Bahl, Daniel del Castillo Iglesias, Ron Heichman, and Ramesh Darwishi. 2022. Evaluating the susceptibility of pre-trained language models via handcrafted adversarial examples.
- Brockman et al. (2016) Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. 2016. Openai gym.
- Brooks et al. (2024) Tim Brooks, Bill Peebles, Connor Homes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Wing Yin Ng, Ricky Wang, and Aditya Ramesh. 2024. Video generation models as world simulators. OpenAI.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners.
- Bubeck et al. (2023) Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, John A. Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuan-Fang Li, Scott M. Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, and Yi Zhang. 2023. Sparks of artificial general intelligence: Early experiments with gpt-4. ArXiv, abs/2303.12712.
- Carlini et al. (2021) Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, and Colin Raffel. 2021. Extracting training data from large language models.
- CDC (2023) CDC. 2023. Suicide data and statistics.
- Chan et al. (2024) Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2024. Chateval: Towards better LLM-based evaluators through multi-agent debate. In The Twelfth International Conference on Learning Representations.
- Chang et al. (2023) Ernie Chang, Pin-Jie Lin, Yang Li, Sidd Srinivasan, Gael Le Lan, David Kant, Yangyang Shi, Forrest Iandola, and Vikas Chandra. 2023. In-context prompt editing for conditional audio generation.
- Chase (2022) Harrison Chase. 2022. LangChain.
- Chen et al. (2023a) Banghao Chen, Zhaofeng Zhang, Nicolas Langrené, and Shengxin Zhu. 2023a. Unleashing the potential of prompt engineering in large language models: a comprehensive review.
- Chen et al. (2023b) Lingjiao Chen, Matei Zaharia, and James Zou. 2023b. How is chatgpt’s behavior changing over time? arXiv preprint arXiv:2307.09009.
- Chen et al. (2023c) Shiqi Chen, Siyang Gao, and Junxian He. 2023c. Evaluating factual consistency of summaries with large language models. arXiv preprint arXiv:2305.14069.
- Chen et al. (2023d) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023d. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. TMLR.
- Chen et al. (2023e) Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. 2023e. Universal self-consistency for large language model generation.
- Chen et al. (2023f) Yang Chen, Yingwei Pan, Yehao Li, Ting Yao, and Tao Mei. 2023f. Control3d: Towards controllable text-to-3d generation.
- Chen et al. (2023g) Yi Chen, Rui Wang, Haiyun Jiang, Shuming Shi, and Ruifeng Xu. 2023g. Exploring the use of large language models for reference-free text quality evaluation: An empirical study. In Findings of the Association for Computational Linguistics: IJCNLP-AACL 2023 (Findings), pages 361–374, Nusa Dua, Bali. Association for Computational Linguistics.
- Cheng et al. (2023) Jiaxin Cheng, Tianjun Xiao, and Tong He. 2023. Consistent video-to-video transfer using synthetic dataset. ArXiv, abs/2311.00213.
- Chia et al. (2023) Yew Ken Chia, Guizhen Chen, Luu Anh Tuan, Soujanya Poria, and Lidong Bing. 2023. Contrastive chain-of-thought prompting.
- Chu and Lin (2023) Jiqun Chu and Zuoquan Lin. 2023. Entangled representation learning: A bidirectional encoder decoder model. In Proceedings of the 2022 5th International Conference on Algorithms, Computing and Artificial Intelligence, ACAI ’22, New York, NY, USA. Association for Computing Machinery.
- Chu et al. (2023) Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Tao He, Haotian Wang, Weihua Peng, Ming Liu, Bing Qin, and Ting Liu. 2023. A survey of chain of thought reasoning: Advances, frontiers and future.
- Cramer et al. (2023) Robert J Cramer, Jacinta Hawgood, Andréa R Kaniuka, Byron Brooks, and Justin C Baker. 2023. Updated suicide prevention core competencies for mental health professionals: Implications for training, research, and practice. Clinical Psychology: Science and Practice.
- Crowson et al. (2022) Katherine Crowson, Stella Biderman, Daniel Kornis, Dashiell Stander, Eric Hallahan, Louis Castricato, and Edward Raff. 2022. Vqgan-clip: Open domain image generation and editing with natural language guidance.
- Cui et al. (2021) Leyang Cui, Yu Wu, Jian Liu, Sen Yang, and Yue Zhang. 2021. Template-based named entity recognition using bart. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021.
- Dang et al. (2022) Hai Dang, Lukas Mecke, Florian Lehmann, Sven Goller, and Daniel Buschek. 2022. How to prompt? opportunities and challenges of zero- and few-shot learning for human-ai interaction in creative applications of generative models.
- Del and Fishel (2023) Maksym Del and Mark Fishel. 2023. True detective: A deep abductive reasoning benchmark undoable for gpt-3 and challenging for gpt-4. In Proceedings of the 12th Joint Conference on Lexical and Computational Semantics (*SEM 2023). Association for Computational Linguistics.
- Deng et al. (2022) Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric P. Xing, and Zhiting Hu. 2022. RLPrompt: Optimizing Discrete Text Prompts with Reinforcement Learning. In RLPrompt: Optimizing Discrete Text Prompts with Reinforcement Learning.
- Deng et al. (2023) Yihe Deng, Weitong Zhang, Zixiang Chen, and Quanquan Gu. 2023. Rephrase and respond: Let large language models ask better questions for themselves.
- Dhuliawala et al. (2023) Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. 2023. Chain-of-verification reduces hallucination in large language models.
- Diao et al. (2023) Shizhe Diao, Pengcheng Wang, Yong Lin, and Tong Zhang. 2023. Active prompting with chain-of-thought for large language models.
- Ding et al. (2021) Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, and Jie Tang. 2021. Cogview: Mastering text-to-image generation via transformers. In Advances in Neural Information Processing Systems, volume 34, pages 19822–19835. Curran Associates, Inc.
- Dong et al. (2023) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, Lei Li, and Zhifang Sui. 2023. A survey on in-context learning.
- Dubois et al. (2023) Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. 2023. Alpacafarm: A simulation framework for methods that learn from human feedback. In NeurIPS.
- Durante et al. (2024) Zane Durante, Qiuyuan Huang, Naoki Wake, Ran Gong, Jae Sung Park, Bidipta Sarkar, Rohan Taori, Yusuke Noda, Demetri Terzopoulos, Yejin Choi, Katsushi Ikeuchi, Hoi Vo, Fei-Fei Li, and Jianfeng Gao. 2024. Agent ai: Surveying the horizons of multimodal interaction.
- Etxaniz et al. (2023) Julen Etxaniz, Gorka Azkune, Aitor Soroa, Oier Lopez de Lacalle, and Mikel Artetxe. 2023. Do multilingual language models think better in english?
- Fan et al. (2018) Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics.
- Fei-Fei et al. (2006) Li Fei-Fei, Rob Fergus, and Pietro Perona. 2006. One-shot learning of object categories. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28:594–611.
- Feng et al. (2023) Lincong Feng, Muyu Wang, Maoyu Wang, Kuo Xu, and Xiaoli Liu. 2023. Metadreamer: Efficient text-to-3d creation with disentangling geometry and texture.
- Fernandes et al. (2023) Patrick Fernandes, Daniel Deutsch, Mara Finkelstein, Parker Riley, André Martins, Graham Neubig, Ankush Garg, Jonathan Clark, Markus Freitag, and Orhan Firat. 2023. The devil is in the errors: Leveraging large language models for fine-grained machine translation evaluation. In Proceedings of the Eighth Conference on Machine Translation, pages 1066–1083, Singapore. Association for Computational Linguistics.
- Fu et al. (2023a) Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. 2023a. Gptscore: Evaluate as you desire. arXiv preprint arXiv:2302.04166.
- Fu et al. (2022) Jinlan Fu, See-Kiong Ng, and Pengfei Liu. 2022. Polyglot prompt: Multilingual multitask prompt training. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9919–9935, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Fu et al. (2023b) Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. 2023b. Complexity-based prompting for multi-step reasoning. In The Eleventh International Conference on Learning Representations.
- Gabillon et al. (2011) Victor Gabillon, Mohammad Ghavamzadeh, Alessandro Lazaric, and Sébastien Bubeck. 2011. Multi-bandit best arm identification. In Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc.
- Ganguli et al. (2023) Deep Ganguli, Amanda Askell, Nicholas Schiefer, Thomas Liao, Kamilė Lukošiūtė, Anna Chen, Anna Goldie, Azalia Mirhoseini, Catherine Olsson, Danny Hernandez, et al. 2023. The capacity for moral self-correction in large language models. arXiv preprint arXiv:2302.07459.
- Gao (2023) Andrew Gao. 2023. Prompt engineering for large language models. SSRN.
- Gao et al. (2023a) Lingyu Gao, Aditi Chaudhary, Krishna Srinivasan, Kazuma Hashimoto, Karthik Raman, and Michael Bendersky. 2023a. Ambiguity-aware in-context learning with large language models. arXiv preprint arXiv:2309.07900.
- Gao et al. (2023b) Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023b. Pal: program-aided language models. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org.
- Gao et al. (2023c) Mingqi Gao, Jie Ruan, Renliang Sun, Xunjian Yin, Shiping Yang, and Xiaojun Wan. 2023c. Human-like summarization evaluation with chatgpt. arXiv preprint arXiv:2304.02554.
- Gao et al. (2021) Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3816–3830, Online. Association for Computational Linguistics.
- Garcia (2024) Marisa Garcia. 2024. What air canada lost in ‘remarkable’ lying ai chatbot case. Forbes.
- Garcia et al. (2023) Xavier Garcia, Yamini Bansal, Colin Cherry, George Foster, Maxim Krikun, Melvin Johnson, and Orhan Firat. 2023. The unreasonable effectiveness of few-shot learning for machine translation. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org.
- Garnett and Curtin (2023) MF Garnett and SC Curtin. 2023. Suicide mortality in the united states, 2001–2021. NCHS Data Brief, 464:1–8.
- Gebru et al. (2021) Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. Datasheets for datasets. Communications of the ACM, 64(12):86–92.
- Ghazvininejad et al. (2023) Marjan Ghazvininejad, Hila Gonen, and Luke Zettlemoyer. 2023. Dictionary-based phrase-level prompting of large language models for machine translation.
- Girdhar et al. (2023) Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra. 2023. Emu video: Factorizing text-to-video generation by explicit image conditioning.
- Gong et al. (2023) Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tianshuo Cong, Anyu Wang, Sisi Duan, and Xiaoyun Wang. 2023. Figstep: Jailbreaking large vision-language models via typographic visual prompts.
- Goodside (2022) Riley Goodside. 2022. Exploiting gpt-3 prompts with malicious inputs that order the model to ignore its previous directions.
- Google (2023) Google. 2023. Gemini: A family of highly capable multimodal models.
- Gou et al. (2024a) Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2024a. CRITIC: Large language models can self-correct with tool-interactive critiquing. In The Twelfth International Conference on Learning Representations.
- Gou et al. (2024b) Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Minlie Huang, Nan Duan, and Weizhu Chen. 2024b. ToRA: A tool-integrated reasoning agent for mathematical problem solving. In The Twelfth International Conference on Learning Representations.
- Guo et al. (2017) Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On calibration of modern neural networks. In International conference on machine learning, pages 1321–1330. PMLR.
- Guo et al. (2022) Han Guo, Bowen Tan, Zhengzhong Liu, Eric P. Xing, and Zhiting Hu. 2022. Efficient (soft) q-learning for text generation with limited good data.
- Gupta et al. (2024) Priyanka Gupta, Bosheng Ding, Chong Guan, and Ding Ding. 2024. Generative ai: A systematic review using topic modelling techniques. Data and Information Management, page 100066.
- Hada et al. (2024) Rishav Hada, Varun Gumma, Adrian Wynter, Harshita Diddee, Mohamed Ahmed, Monojit Choudhury, Kalika Bali, and Sunayana Sitaram. 2024. Are large language model-based evaluators the solution to scaling up multilingual evaluation? In Findings of the Association for Computational Linguistics: EACL 2024, pages 1051–1070, St. Julian’s, Malta. Association for Computational Linguistics.
- Hadi et al. (2023) Muhammad Usman Hadi, Qasem Al Tashi, Rizwan Qureshi, Abbas Shah, Amgad Muneer, Muhammad Irfan, and et al. 2023. Large language models: A comprehensive survey of its applications, challenges, limitations, and future prospects. TechRxiv.
- Hakan Tekgul (2023) Aparna Dhinakaran Hakan Tekgul. 2023. Guardrails: What are they and how can you use nemo and guardrails ai to safeguard llms? Online.
- Hakimov and Schlangen (2023) Sherzod Hakimov and David Schlangen. 2023. Images in language space: Exploring the suitability of large language models for vision & language tasks. In Findings of the Association for Computational Linguistics: ACL 2023, pages 14196–14210, Toronto, Canada. Association for Computational Linguistics.
- Hao et al. (2023) Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. 2023. ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings. In NeurIPS.
- He et al. (2023a) Hangfeng He, Hongming Zhang, and Dan Roth. 2023a. Socreval: Large language models with the socratic method for reference-free reasoning evaluation. arXiv preprint arXiv:2310.00074.
- He et al. (2023b) Zhiwei He, Tian Liang, Wenxiang Jiao, Zhuosheng Zhang, Yujiu Yang, Rui Wang, Zhaopeng Tu, Shuming Shi, and Xing Wang. 2023b. Exploring human-like translation strategy with large language models.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Understanding. In ICLR.
- Hendy et al. (2023) Amr Hendy, Mohamed Gomaa Abdelrehim, Amr Sharaf, Vikas Raunak, Mohamed Gabr, Hitokazu Matsushita, Young Jin Kim, Mohamed Afify, and Hany Hassan Awadalla. 2023. How good are gpt models at machine translation? a comprehensive evaluation. ArXiv, abs/2302.09210.
- Hertz et al. (2022) Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2022. Prompt-to-prompt image editing with cross attention control.
- Heston and Khun (2023) T.F. Heston and C. Khun. 2023. Prompt engineering in medical education. Int. Med. Educ., 2:198–205.
- Hinz et al. (2022) Tobias Hinz, Stefan Heinrich, and Stefan Wermter. 2022. Semantic object accuracy for generative text-to-image synthesis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1552–1565.
- Hou et al. (2023) Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2023. Large language models for software engineering: A systematic literature review.
- Hsu et al. (2023) Ming-Hao Hsu, Kai-Wei Chang, Shang-Wen Li, and Hung yi Lee. 2023. An exploration of in-context learning for speech language model.
- Hua et al. (2024) Yining Hua, Fenglin Liu, Kailai Yang, Zehan Li, Yi han Sheu, Peilin Zhou, Lauren V. Moran, Sophia Ananiadou, and Andrew Beam. 2024. Large language models in mental health care: a scoping review.
- Huang et al. (2023a) Haoyang Huang, Tianyi Tang, Dongdong Zhang, Wayne Xin Zhao, Ting Song, Yan Xia, and Furu Wei. 2023a. Not all languages are created equal in llms: Improving multilingual capability by cross-lingual-thought prompting.
- Huang et al. (2022) Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. 2022. Large language models can self-improve. arXiv preprint arXiv:2210.11610.
- Huang et al. (2023b) Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2023b. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.
- Huang et al. (2023c) Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, Qiang Liu, Kriti Aggarwal, Zewen Chi, Johan Bjorck, Vishrav Chaudhary, Subhojit Som, Xia Song, and Furu Wei. 2023c. Language is not all you need: Aligning perception with language models.
- Inan et al. (2023) Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. 2023. Llama guard: Llm-based input-output safeguard for human-ai conversations.
- Iyer et al. (2023) Vivek Iyer, Pinzhen Chen, and Alexandra Birch. 2023. Towards effective disambiguation for machine translation with large language models.
- Jain et al. (2022) Ajay Jain, Ben Mildenhall, Jonathan T. Barron, Pieter Abbeel, and Ben Poole. 2022. Zero-shot text-guided object generation with dream fields.
- Jia et al. (2023) Qi Jia, Siyu Ren, Yizhu Liu, and Kenny Q Zhu. 2023. Zero-shot faithfulness evaluation for text summarization with foundation language model. arXiv preprint arXiv:2310.11648.
- Jiang et al. (2023) Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969–7992, Singapore. Association for Computational Linguistics.
- Jiang et al. (2020) Zhengbao Jiang, Frank F. Xu, Jun Araki, and Graham Neubig. 2020. How can we know what language models know? Transactions of the Association for Computational Linguistics, 8:423–438.
- Jiao et al. (2023) Wenxiang Jiao, Wenxuan Wang, Jen tse Huang, Xing Wang, Shuming Shi, and Zhaopeng Tu. 2023. Is chatgpt a good translator? yes with gpt-4 as the engine.
- Jin and Lu (2023) Ziqi Jin and Wei Lu. 2023. Tab-cot: Zero-shot tabular chain of thought.
- Kadavath et al. (2022) Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec, Liane Lovitt, Kamal Ndousse, Catherine Olsson, Sam Ringer, Dario Amodei, Tom Brown, Jack Clark, Nicholas Joseph, Ben Mann, Sam McCandlish, Chris Olah, and Jared Kaplan. 2022. Language models (mostly) know what they know.
- Karpas et al. (2022) Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, Dor Muhlgay, Noam Rozen, Erez Schwartz, Gal Shachaf, Shai Shalev-Shwartz, Amnon Shashua, and Moshe Tenenholtz. 2022. Mrkl systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning.
- Keele et al. (2007) Staffs Keele et al. 2007. Guidelines for performing systematic literature reviews in software engineering.
- Keskar et al. (2019) Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong, and Richard Socher. 2019. Ctrl: A conditional transformer language model for controllable generation.
- Keyvan and Huang (2022) Kimiya Keyvan and Jimmy Xiangji Huang. 2022. How to approach ambiguous queries in conversational search: A survey of techniques, approaches, tools, and challenges. ACM Computing Surveys, 55(6):1–40.
- Khalifa et al. (2023) Muhammad Khalifa, Lajanugen Logeswaran, Moontae Lee, Honglak Lee, and Lu Wang. 2023. Exploring demonstration ensembling for in-context learning.
- Khalil et al. (2023) Mahmoud Khalil, Ahmad Khalil, and Alioune Ngom. 2023. A comprehensive study of vision transformers in image classification tasks.
- Khattab et al. (2022) Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, and Matei Zaharia. 2022. Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive nlp.
- Khattab et al. (2023) Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714.
- Khot et al. (2022) Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. 2022. Decomposed prompting: A modular approach for solving complex tasks.
- Kiesler and Schiffner (2023) Natalie Kiesler and Daniel Schiffner. 2023. Large language models in introductory programming education: Chatgpt’s performance and implications for assessments. arXiv preprint arXiv:2308.08572.
- Kim and Komachi (2023) Hwichan Kim and Mamoru Komachi. 2023. Enhancing few-shot cross-lingual transfer with target language peculiar examples. In Findings of the Association for Computational Linguistics: ACL 2023, pages 747–767, Toronto, Canada. Association for Computational Linguistics.
- Kim et al. (2022) Hyuhng Joon Kim, Hyunsoo Cho, Junyeob Kim, Taeuk Kim, Kang Min Yoo, and Sang goo Lee. 2022. Self-generated in-context learning: Leveraging auto-regressive language models as a demonstration generator.
- Kim et al. (2023) Sunkyoung Kim, Dayeon Ki, Yireun Kim, and Jinsik Lee. 2023. Boosting cross-lingual transferability in multilingual models via in-context learning.
- Ko et al. (2023a) Dayoon Ko, Sangho Lee, and Gunhee Kim. 2023a. Can language models laugh at youtube short-form videos?
- Ko et al. (2023b) Hyung-Kwon Ko, Gwanmo Park, Hyeon Jeon, Jaemin Jo, Juho Kim, and Jinwook Seo. 2023b. Large-scale text-to-image generation models for visual artists’ creative works. Proceedings of the 28th International Conference on Intelligent User Interfaces.
- Kocmi and Federmann (2023a) Tom Kocmi and Christian Federmann. 2023a. Gemba-mqm: Detecting translation quality error spans with gpt-4. arXiv preprint arXiv:2310.13988.
- Kocmi and Federmann (2023b) Tom Kocmi and Christian Federmann. 2023b. Large language models are state-of-the-art evaluators of translation quality. In Proceedings of the 24th Annual Conference of the European Association for Machine Translation, pages 193–203, Tampere, Finland. European Association for Machine Translation.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.
- Kumar and Talukdar (2021) Sawan Kumar and Partha Talukdar. 2021. Reordering examples helps during priming-based few-shot learning.
- Kwon and Ye (2022) Gihyun Kwon and Jong Chul Ye. 2022. Clipstyler: Image style transfer with a single text condition.
- Lakera (2024) Lakera. 2024. Lakera guard.
- Lanyado et al. (2023) Bar Lanyado, Ortal Keizman, and Yair Divinsky. 2023. Can you trust chatgpt’s package recommendations? Vulcan Cyber Blog.
- Le et al. (2023) Cindy Le, Congrui Hetang, Ang Cao, and Yihui He. 2023. Euclidreamer: Fast and high-quality texturing for 3d models with stable diffusion depth.
- Lee and Kim (2023) Soochan Lee and Gunhee Kim. 2023. Recursion of thought: A divide-and-conquer approach to multi-context reasoning with language models.
- Leidinger et al. (2023) Alina Leidinger, Robert van Rooij, and Ekaterina Shutova. 2023. The language of prompting: What linguistic properties make a prompt successful?
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
- Lewis et al. (2021) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-augmented generation for knowledge-intensive nlp tasks.
- Li et al. (2019a) Bowen Li, Xiaojuan Qi, Thomas Lukasiewicz, and Philip H. S. Torr. 2019a. Controllable text-to-image generation.
- Li et al. (2023a) Cheng Li, Jindong Wang, Yixuan Zhang, Kaijie Zhu, Wenxin Hou, Jianxun Lian, Fang Luo, Qiang Yang, and Xing Xie. 2023a. Large language models understand and can be enhanced by emotional stimuli.
- Li et al. (2023b) Chengzhengxu Li, Xiaoming Liu, Yichen Wang, Duyi Li, Yu Lan, and Chao Shen. 2023b. Dialogue for prompting: a policy-gradient-based discrete prompt optimization for few-shot learning.
- Li et al. (2023c) Jiahao Li, Hao Tan, Kai Zhang, Zexiang Xu, Fujun Luan, Yinghao Xu, Yicong Hong, Kalyan Sunkavalli, Greg Shakhnarovich, and Sai Bi. 2023c. Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model.
- Li et al. (2023d) Ming Li, Pan Zhou, Jia-Wei Liu, Jussi Keppo, Min Lin, Shuicheng Yan, and Xiangyu Xu. 2023d. Instant3d: Instant text-to-3d generation.
- Li et al. (2023e) Ruosen Li, Teerth Patel, and Xinya Du. 2023e. Prd: Peer rank and discussion improve large language model based evaluations. arXiv preprint arXiv:2307.02762.
- Li et al. (2019b) Wenbo Li, Pengchuan Zhang, Lei Zhang, Qiuyuan Huang, Xiaodong He, Siwei Lyu, and Jianfeng Gao. 2019b. Object-driven text-to-image synthesis via adversarial training.
- Li et al. (2023f) Xiaonan Li, Kai Lv, Hang Yan, Tianyang Lin, Wei Zhu, Yuan Ni, Guotong Xie, Xiaoling Wang, and Xipeng Qiu. 2023f. Unified demonstration retriever for in-context learning.
- Li and Qiu (2023a) Xiaonan Li and Xipeng Qiu. 2023a. Finding support examples for in-context learning.
- Li and Qiu (2023b) Xiaonan Li and Xipeng Qiu. 2023b. Mot: Memory-of-thought enables chatgpt to self-improve.
- Li et al. (2023g) Xiaoqian Li, Ercong Nie, and Sheng Liang. 2023g. Crosslingual retrieval augmented in-context learning for bangla.
- Li et al. (2020) Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng Gao. 2020. Oscar: Object-semantics aligned pre-training for vision-language tasks.
- Li et al. (2023h) Yaoyiran Li, Anna Korhonen, and Ivan Vulić. 2023h. On bilingual lexicon induction with large language models.
- Li et al. (2023i) Yifei Li, Zeqi Lin, Shizhuo Zhang, Qiang Fu, Bei Chen, Jian-Guang Lou, and Weizhu Chen. 2023i. Making language models better reasoners with step-aware verifier. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics.
- Li et al. (2023j) Yingji Li, Mengnan Du, Rui Song, Xin Wang, and Ying Wang. 2023j. A survey on fairness in large language models.
- Liang et al. (2023) Jingyun Liang, Yuchen Fan, Kai Zhang, Radu Timofte, Luc Van Gool, and Rakesh Ranjan. 2023. Movideo: Motion-aware video generation with diffusion models.
- Lin et al. (2023) Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2023. Magic3d: High-resolution text-to-3d content creation.
- Lin et al. (2022) Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O’Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, and Xian Li. 2022. Few-shot learning with multilingual generative language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9019–9052, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Lin and Chen (2023) Yen-Ting Lin and Yun-Nung Chen. 2023. Llm-eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language models. arXiv preprint arXiv:2305.13711.
- Liu (2022) Jerry Liu. 2022. LlamaIndex.
- Liu et al. (2021) Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. 2021. What makes good in-context examples for GPT-3? In Workshop on Knowledge Extraction and Integration for Deep Learning Architectures; Deep Learning Inside Out.
- Liu et al. (2023a) Nelson F Liu, Tianyi Zhang, and Percy Liang. 2023a. Evaluating verifiability in generative search engines. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing.
- Liu et al. (2023b) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023b. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35.
- Liu et al. (2023c) Weihuang Liu, Xi Shen, Chi-Man Pun, and Xiaodong Cun. 2023c. Explicit visual prompting for low-level structure segmentations. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE.
- Liu et al. (2023d) Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023d. Gpteval: Nlg evaluation using gpt-4 with better human alignment. arXiv preprint arXiv:2303.16634.
- Liu et al. (2023e) Yihao Liu, Xiangyu Chen, Xianzheng Ma, Xintao Wang, Jiantao Zhou, Yu Qiao, and Chao Dong. 2023e. Unifying image processing as visual prompting question answering.
- Liu et al. (2023f) Yongkang Liu, Shi Feng, Daling Wang, Yifei Zhang, and Hinrich Schütze. 2023f. Evaluate what you can’t evaluate: Unassessable generated responses quality. arXiv preprint arXiv:2305.14658.
- Liu et al. (2023g) Yuxin Liu, Minshan Xie, Hanyuan Liu, and Tien-Tsin Wong. 2023g. Text-guided texturing by synchronized multi-view diffusion.
- Liu et al. (2023h) Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. 2023h. Calibrating llm-based evaluator. arXiv preprint arXiv:2309.13308.
- Long (2023) Jieyi Long. 2023. Large language model guided tree-of-thought.
- Lorraine et al. (2023) Jonathan Lorraine, Kevin Xie, Xiaohui Zeng, Chen-Hsuan Lin, Towaki Takikawa, Nicholas Sharp, Tsung-Yi Lin, Ming-Yu Liu, Sanja Fidler, and James Lucas. 2023. Att3d: Amortized text-to-3d object synthesis.
- Lu et al. (2023a) Albert Lu, Hongxin Zhang, Yanzhe Zhang, Xuezhi Wang, and Diyi Yang. 2023a. Bounding the capabilities of large language models in open text generation with prompt constraints.
- Lu et al. (2023b) Hongyuan Lu, Haoyang Huang, Dongdong Zhang, Haoran Yang, Wai Lam, and Furu Wei. 2023b. Chain-of-dictionary prompting elicits translation in large language models.
- Lu et al. (2023c) Qingyu Lu, Baopu Qiu, Liang Ding, Liping Xie, and Dacheng Tao. 2023c. Error analysis prompting enables human-like translation evaluation in large language models: A case study on chatgpt. arXiv preprint arXiv:2303.13809.
- Lu et al. (2021) Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2021. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity.
- Luca Beurer-Kellner (2023) Charles Duffy Luca Beurer-Kellner, Marc Fischer. 2023. lmql. GitHub repository.
- Luo et al. (2023) Zheheng Luo, Qianqian Xie, and Sophia Ananiadou. 2023. Chatgpt as a factual inconsistency evaluator for abstractive text summarization. arXiv preprint arXiv:2303.15621.
- Lv et al. (2023) Jiaxi Lv, Yi Huang, Mingfu Yan, Jiancheng Huang, Jianzhuang Liu, Yifan Liu, Yafei Wen, Xiaoxin Chen, and Shifeng Chen. 2023. Gpt4motion: Scripting physical motions in text-to-video generation via blender-oriented gpt planning.
- Lyu et al. (2023) Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. 2023. Faithful chain-of-thought reasoning.
- Ma et al. (2023) Huan Ma, Changqing Zhang, Yatao Bian, Lemao Liu, Zhirui Zhang, Peilin Zhao, Shu Zhang, Huazhu Fu, Qinghua Hu, and Bingzhe Wu. 2023. Fairness-guided few-shot prompting for large language models. arXiv preprint arXiv:2303.13217.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-refine: Iterative refinement with self-feedback.
- Mehrabi et al. (2021) Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. 2021. A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6):1–35.
- Melzer et al. (2024) Laura Melzer, Thomas Forkmann, and Tobias Teismann. 2024. Suicide crisis syndrome: A systematic review. Suicide and Life-Threatening Behavior. February 27, online ahead of print.
- Meng et al. (2023) Fanxu Meng, Haotong Yang, Yiding Wang, and Muhan Zhang. 2023. Chain of images for intuitively reasoning.
- Meskó (2023) B. Meskó. 2023. Prompt engineering as an important emerging skill for medical professionals: Tutorial. Journal of Medical Internet Research, 25(Suppl 1):e50638.
- Mi et al. (2023) Yachun Mi, Yu Li, Yan Shu, Chen Hui, Puchao Zhou, and Shaohui Liu. 2023. Clif-vqa: Enhancing video quality assessment by incorporating high-level semantic information related to human feelings.
- Mialon et al. (2023) Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, and Thomas Scialom. 2023. Augmented language models: a survey.
- Min et al. (2022) Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the role of demonstrations: What makes in-context learning work?
- Min et al. (2020) Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2020. Ambigqa: Answering ambiguous open-domain questions. arXiv preprint arXiv:2004.10645.
- Morelli et al. (1991) R.A. Morelli, J.D. Bronzino, and J.W. Goethe. 1991. A computational speech-act model of human-computer conversations. In Proceedings of the 1991 IEEE Seventeenth Annual Northeast Bioengineering Conference, pages 263–264.
- Moslem et al. (2023) Yasmin Moslem, Rejwanul Haque, John D. Kelleher, and Andy Way. 2023. Adaptive machine translation with large language models. In Proceedings of the 24th Annual Conference of the European Association for Machine Translation, pages 227–237, Tampere, Finland. European Association for Machine Translation.
- Mu et al. (2023) Fangwen Mu, Lin Shi, Song Wang, Zhuohao Yu, Binquan Zhang, Chenxue Wang, Shichao Liu, and Qing Wang. 2023. Clarifygpt: Empowering llm-based code generation with intention clarification.
- Muennighoff et al. (2023) Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng Xin Yong, Hailey Schoelkopf, Xiangru Tang, Dragomir Radev, Alham Fikri Aji, Khalid Almubarak, Samuel Albanie, Zaid Alyafeai, Albert Webson, Edward Raff, and Colin Raffel. 2023. Crosslingual generalization through multitask finetuning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15991–16111, Toronto, Canada. Association for Computational Linguistics.
- Nambi et al. (2023) Akshay Nambi, Vaibhav Balloli, Mercy Ranjit, Tanuja Ganu, Kabir Ahuja, Sunayana Sitaram, and Kalika Bali. 2023. Breaking language barriers with a leap: Learning strategies for polyglot llms.
- Nasr et al. (2023) Milad Nasr, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, Eric Wallace, Florian Tramèr, and Katherine Lee. 2023. Scalable extraction of training data from (production) language models.
- National Center for Health Workforce Analysis (2023) National Center for Health Workforce Analysis. 2023. Behavioral health workforce, 2023.
- Neagu (2023) Alexandra Neagu. 2023. How can large language models and prompt engineering be leveraged in Computer Science education?: Systematic literature review. Master’s thesis, Delft University of Technology, 6.
- Nie et al. (2023) Ercong Nie, Sheng Liang, Helmut Schmid, and Hinrich Schütze. 2023. Cross-lingual retrieval augmented prompt for low-resource languages. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8320–8340, Toronto, Canada. Association for Computational Linguistics.
- Ning et al. (2023) Xuefei Ning, Zinan Lin, Zixuan Zhou, Zifu Wang, Huazhong Yang, and Yu Wang. 2023. Skeleton-of-thought: Large language models can do parallel decoding.
- OpenAI (2023) OpenAI. 2023. OpenAI Assistants.
- Oppenlaender (2023) Jonas Oppenlaender. 2023. A taxonomy of prompt modifiers for text-to-image generation.
- Osika (2023) Anton Osika. 2023. gpt-engineer.
- Page et al. (2021) Matthew J Page, Joanne E McKenzie, Patrick M Bossuyt, Isabelle Boutron, Tammy C Hoffmann, Cynthia D Mulrow, Larissa Shamseer, Jennifer M Tetzlaff, Elie A Akl, Sue E Brennan, Roger Chou, Julie Glanville, Jeremy M Grimshaw, Asbjørn Hróbjartsson, Manoj M Lalu, Tianjing Li, Elizabeth W Loder, Evan Mayo-Wilson, Steve McDonald, Luke A McGuinness, Lesley A Stewart, James Thomas, Andrea C Tricco, Vivian A Welch, Penny Whiting, and David Moher. 2021. The prisma 2020 statement: an updated guideline for reporting systematic reviews. BMJ, 372.
- Pajouheshgar et al. (2023) Ehsan Pajouheshgar, Yitao Xu, Alexander Mordvintsev, Eyvind Niklasson, Tong Zhang, and Sabine Süsstrunk. 2023. Mesh neural cellular automata.
- Patel et al. (2022) Pruthvi Patel, Swaroop Mishra, Mihir Parmar, and Chitta Baral. 2022. Is a question decomposition unit all we need?
- Patil et al. (2023) Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2023. Gorilla: Large language model connected with massive apis. ArXiv, abs/2305.15334.
- Pearce et al. (2021) Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2021. Asleep at the keyboard? assessing the security of github copilot’s code contributions.
- Pearce et al. (2022) Hammond Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, and Brendan Dolan-Gavitt. 2022. Examining zero-shot vulnerability repair with large language models.
- Peng et al. (2023) Puyuan Peng, Brian Yan, Shinji Watanabe, and David Harwath. 2023. Prompting the hidden talent of web-scale speech models for zero-shot task generalization.
- Perez et al. (2022) Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models.
- Perez and Ribeiro (2022) Fábio Perez and Ian Ribeiro. 2022. Ignore previous prompt: Attack techniques for language models.
- Perry et al. (2022) Neil Perry, Megha Srivastava, Deepak Kumar, and Dan Boneh. 2022. Do users write more insecure code with ai assistants?
- Peskoff and Stewart (2023) Denis Peskoff and Brandon M Stewart. 2023. Credible without credit: Domain experts assess generative language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 427–438.
- Peskoff et al. (2023) Denis Peskoff, Adam Visokay, Sander Schulhoff, Benjamin Wachspress, Alan Blinder, and Brandon M Stewart. 2023. Gpt deciphering fedspeak: Quantifying dissent among hawks and doves. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 6529–6539.
- Peskov et al. (2021) Denis Peskov, Viktor Hangya, Jordan Boyd-Graber, and Alexander Fraser. 2021. Adapting entities across languages and cultures. Findings of the Association for Computational Linguistics: EMNLP 2021.
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language models as knowledge bases? Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP).
- Pezeshkpour and Hruschka (2023) Pouya Pezeshkpour and Estevam Hruschka. 2023. Large language models sensitivity to the order of options in multiple-choice questions. arXiv preprint arXiv:2308.11483.
- Pfaff (1979) Carol W. Pfaff. 1979. Constraints on language mixing: Intrasentential code-switching and borrowing in spanish/english. Language, pages 291–318.
- Pilault et al. (2023) Jonathan Pilault, Xavier Garcia, Arthur Bražinskas, and Orhan Firat. 2023. Interactive-chain-prompting: Ambiguity resolution for crosslingual conditional generation with interaction.
- Poole et al. (2022) Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2022. Dreamfusion: Text-to-3d using 2d diffusion.
- Poplack (1980) Shana Poplack. 1980. Sometimes i’ll start a sentence in spanish y termino en español: Toward a typology of code-switching. Linguistics, 18(7-8):581–618.
- Prasad et al. (2023) Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. 2023. GrIPS: Gradient-free, edit-based instruction search for prompting large language models. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 3845–3864, Dubrovnik, Croatia. Association for Computational Linguistics.
- Preamble (2024) Preamble. 2024. Our product.
- Press et al. (2022) Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. 2022. Measuring and narrowing the compositionality gap in language models.
- Pryzant et al. (2023) Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. 2023. Automatic prompt optimization with "gradient descent" and beam search.
- Puduppully et al. (2023) Ratish Puduppully, Anoop Kunchukuttan, Raj Dabre, Ai Ti Aw, and Nancy F. Chen. 2023. Decomposed prompting for machine translation between related languages using large language models.
- Qiao et al. (2023) Bo Qiao, Liqun Li, Xu Zhang, Shilin He, Yu Kang, Chaoyun Zhang, Fangkai Yang, Hang Dong, Jue Zhang, Lu Wang, Ming-Jie Ma, Pu Zhao, Si Qin, Xiaoting Qin, Chao Du, Yong Xu, Qingwei Lin, S. Rajmohan, and Dongmei Zhang. 2023. Taskweaver: A code-first agent framework. ArXiv, abs/2311.17541.
- Qiao et al. (2022) Shuofei Qiao, Yixin Ou, Ningyu Zhang, Xiang Chen, Yunzhi Yao, Shumin Deng, Chuanqi Tan, Fei Huang, and Huajun Chen. 2022. Reasoning with language model prompting: A survey.
- Qin et al. (2023a) Libo Qin, Qiguang Chen, Fuxuan Wei, Shijue Huang, and Wanxiang Che. 2023a. Cross-lingual prompting: Improving zero-shot chain-of-thought reasoning across languages.
- Qin et al. (2023b) Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Yufei Huang, Chaojun Xiao, Chi Han, Yi Ren Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shi Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bo Li, Ziwei Tang, Jing Yi, Yu Zhu, Zhenning Dai, Lan Yan, Xin Cong, Ya-Ting Lu, Weilin Zhao, Yuxiang Huang, Jun-Han Yan, Xu Han, Xian Sun, Dahai Li, Jason Phang, Cheng Yang, Tongshuang Wu, Heng Ji, Zhiyuan Liu, and Maosong Sun. 2023b. Tool learning with foundation models. ArXiv, abs/2304.08354.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR.
- Radford et al. (2019a) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019a. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Radford et al. (2019b) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019b. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Rao and Daumé III (2019) Sudha Rao and Hal Daumé III. 2019. Answer-based adversarial training for generating clarification questions. arXiv preprint arXiv:1904.02281.
- Rebedea et al. (2023) Traian Rebedea, Razvan Dinu, Makesh Sreedhar, Christopher Parisien, and Jonathan Cohen. 2023. Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails. arXiv.
- Resnik et al. (2021) Philip Resnik, April Foreman, Michelle Kuchuk, Katherine Musacchio Schafer, and Beau Pinkham. 2021. Naturally occurring language as a source of evidence in suicide prevention. Suicide and Life-Threatening Behavior, 51(1):88–96.
- Reynolds and McDonell (2021) Laria Reynolds and Kyle McDonell. 2021. Prompt programming for large language models: Beyond the few-shot paradigm. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, CHI ’21. ACM.
- Rogers et al. (2019) Megan L Rogers, Carol Chu, and Thomas Joiner. 2019. The necessity, validity, and clinical utility of a new diagnostic entity: Acute suicidal affective disturbance (asad). Journal of Clinical Psychology, 75(6):999.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models.
- Rubin et al. (2022) Ohad Rubin, Jonathan Herzig, and Jonathan Berant. 2022. Learning to retrieve prompts for in-context learning. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics.
- Runway (2023) Runway. 2023. Gen-2 prompt tips. https://help.runwayml.com/hc/en-us/articles/17329337959699-Gen-2-Prompt-Tips.
- Sahoo et al. (2024) Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. 2024. A systematic survey of prompt engineering in large language models: Techniques and applications.
- Sandoval et al. (2022) Gustavo Sandoval, Hammond Pearce, Teo Nys, Ramesh Karri, Siddharth Garg, and Brendan Dolan-Gavitt. 2022. Lost at c: A user study on the security implications of large language model code assistants.
- Santu and Feng (2023) Shubhra Kanti Karmaker Santu and Dongji Feng. 2023. Teler: A general taxonomy of llm prompts for benchmarking complex tasks.
- Schick et al. (2023) Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.
- Schick and Schütze (2020a) Timo Schick and Hinrich Schütze. 2020a. Exploiting cloze-questions for few-shot text classification and natural language inference. In Conference of the European Chapter of the Association for Computational Linguistics.
- Schick and Schütze (2020b) Timo Schick and Hinrich Schütze. 2020b. It’s not just size that matters: Small language models are also few-shot learners. ArXiv, abs/2009.07118.
- Schick and Schütze (2021) Timo Schick and Hinrich Schütze. 2021. Exploiting cloze-questions for few-shot text classification and natural language inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Association for Computational Linguistics.
- Schmidt et al. (2023) Douglas C. Schmidt, Jesse Spencer-Smith, Quchen Fu, and Jules White. 2023. Cataloging prompt patterns to enhance the discipline of prompt engineering. Dept. of Computer Science, Vanderbilt University. Email: douglas.c.schmidt, jesse.spencer-smith, quchen.fu, jules.white@vanderbilt.edu.
- Schuck et al. (2019a) Allison Schuck, Raffaella Calati, Shira Barzilay, Sarah Bloch-Elkouby, and Igor I. Galynker. 2019a. Suicide crisis syndrome: A review of supporting evidence for a new suicide-specific diagnosis. Behavioral sciences & the law, 37 3:223–239.
- Schuck et al. (2019b) Allison Schuck, Raffaella Calati, Shira Barzilay, Sarah Bloch-Elkouby, and Igor Galynker. 2019b. Suicide crisis syndrome: A review of supporting evidence for a new suicide-specific diagnosis. Behavioral sciences and the law, 37(3):223–239.
- Schulhoff (2022) Sander Schulhoff. 2022. Learn Prompting.
- Schulhoff et al. (2023) Sander Schulhoff, Jeremy Pinto, Anaum Khan, Louis-François Bouchard, Chenglei Si, Svetlina Anati, Valen Tagliabue, Anson Kost, Christopher Carnahan, and Jordan Boyd-Graber. 2023. Ignore this title and HackAPrompt: Exposing systemic vulnerabilities of LLMs through a global prompt hacking competition. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4945–4977, Singapore. Association for Computational Linguistics.
- Schulhoff (2024) Sander V Schulhoff. 2024. Prompt injection vs jailbreaking: What is the difference?
- Sclar et al. (2023a) Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2023a. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. arXiv preprint arXiv:2310.11324.
- Sclar et al. (2023b) Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2023b. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting.
- Scott Lundberg (2023) Harsha-Nori Scott Lundberg, Marco Tulio Correia Ribeiro. 2023. guidance. GitHub repository.
- Searle (1969) John R. Searle. 1969. Speech Acts: An Essay in the Philosophy of Language. Cambridge University Press.
- Shaikh et al. (2023) Omar Shaikh, Hongxin Zhang, William Held, Michael Bernstein, and Diyi Yang. 2023. On second thought, let’s not think step by step! bias and toxicity in zero-shot reasoning.
- Sharma et al. (2023) Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. 2023. Towards understanding sycophancy in language models. arXiv preprint arXiv:2310.13548.
- Shen et al. (2023) Yongliang Shen, Kaitao Song, Xu Tan, Dong Sheng Li, Weiming Lu, and Yue Ting Zhuang. 2023. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. ArXiv, abs/2303.17580.
- Shi et al. (2022) Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, and Jason Wei. 2022. Language models are multilingual chain-of-thought reasoners.
- Shin et al. (2020a) Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, and Sameer Singh. 2020a. Eliciting knowledge from language models using automatically generated prompts. ArXiv, abs/2010.15980.
- Shin et al. (2020b) Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020b. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Shing et al. (2018) Han-Chin Shing, Suraj Nair, Ayah Zirikly, Meir Friedenberg, Hal Daumé III, and Philip Resnik. 2018. Expert, crowdsourced, and machine assessment of suicide risk via online postings. In Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, pages 25–36, New Orleans, LA. Association for Computational Linguistics.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning.
- Si et al. (2023a) Chenglei Si, Dan Friedman, Nitish Joshi, Shi Feng, Danqi Chen, and He He. 2023a. Measuring inductive biases of in-context learning with underspecified demonstrations. In Association for Computational Linguistics (ACL).
- Si et al. (2023b) Chenglei Si, Zhe Gan, Zhengyuan Yang, Shuohang Wang, Jianfeng Wang, Jordan Boyd-Graber, and Lijuan Wang. 2023b. Prompting gpt-3 to be reliable. In International Conference on Learning Representations (ICLR).
- Si et al. (2023c) Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daumé III, and Jordan Boyd-Graber. 2023c. Large language models help humans verify truthfulness–except when they are convincingly wrong. arXiv preprint arXiv:2310.12558.
- Si et al. (2023d) Chenglei Si, Weijia Shi, Chen Zhao, Luke Zettlemoyer, and Jordan Lee Boyd-Graber. 2023d. Getting MoRE out of Mixture of language model Reasoning Experts. Findings of Empirical Methods in Natural Language Processing.
- Sia and Duh (2023) Suzanna Sia and Kevin Duh. 2023. In-context learning as maintaining coherency: A study of on-the-fly machine translation using large language models.
- Significant Gravitas (2023) Significant Gravitas. 2023. AutoGPT.
- Singer et al. (2023) Uriel Singer, Shelly Sheynin, Adam Polyak, Oron Ashual, Iurii Makarov, Filippos Kokkinos, Naman Goyal, Andrea Vedaldi, Devi Parikh, Justin Johnson, and Yaniv Taigman. 2023. Text-to-4d dynamic scene generation.
- Sorensen et al. (2022) Taylor Sorensen, Joshua Robinson, Christopher Rytting, Alexander Shaw, Kyle Rogers, Alexia Delorey, Mahmoud Khalil, Nancy Fulda, and David Wingate. 2022. An information-theoretic approach to prompt engineering without ground truth labels. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 819–862, Dublin, Ireland. Association for Computational Linguistics.
- Sottana et al. (2023) Andrea Sottana, Bin Liang, Kai Zou, and Zheng Yuan. 2023. Evaluation metrics in the era of gpt-4: Reliably evaluating large language models on sequence to sequence tasks. arXiv preprint arXiv:2310.13800.
- Štefánik and Kadlčík (2023) Michal Štefánik and Marek Kadlčík. 2023. Can in-context learners learn a reasoning concept from demonstrations? In Proceedings of the 1st Workshop on Natural Language Reasoning and Structured Explanations (NLRSE), pages 107–115, Toronto, Canada. Association for Computational Linguistics.
- Su et al. (2022) Hongjin Su, Jungo Kasai, Chen Henry Wu, Weijia Shi, Tianlu Wang, Jiayi Xin, Rui Zhang, Mari Ostendorf, Luke Zettlemoyer, Noah A. Smith, and Tao Yu. 2022. Selective annotation makes language models better few-shot learners.
- Tang et al. (2023) Lv Tang, Peng-Tao Jiang, Hao-Ke Xiao, and Bo Li. 2023. Towards training-free open-world segmentation via image prompting foundation models.
- Tanwar et al. (2023) Eshaan Tanwar, Subhabrata Dutta, Manish Borthakur, and Tanmoy Chakraborty. 2023. Multilingual LLMs are better cross-lingual in-context learners with alignment. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6292–6307, Toronto, Canada. Association for Computational Linguistics.
- Tao et al. (2022) Ming Tao, Hao Tang, Fei Wu, Xiao-Yuan Jing, Bing-Kun Bao, and Changsheng Xu. 2022. Df-gan: A simple and effective baseline for text-to-image synthesis.
- Thompson and Kelly (2023) Charlotte Thompson and Tiana Kelly. 2023. When hallucinations become reality: An exploration of ai package hallucination attacks. Darktrace Blog.
- Tian et al. (2023) Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. 2023. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5433–5442, Singapore. Association for Computational Linguistics.
- Towers et al. (2023) Mark Towers, Jordan K. Terry, Ariel Kwiatkowski, John U. Balis, Gianluca de Cola, Tristan Deleu, Manuel Goulão, Andreas Kallinteris, Arjun KG, Markus Krimmel, Rodrigo Perez-Vicente, Andrea Pierré, Sander Schulhoff, Jun Jet Tai, Andrew Tan Jin Shen, and Omar G. Younis. 2023. Gymnasium.
- Trivedi et al. (2023) Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10014–10037, Toronto, Canada. Association for Computational Linguistics.
- Tutunov et al. (2023) Rasul Tutunov, Antoine Grosnit, Juliusz Ziomek, Jun Wang, and Haitham Bou-Ammar. 2023. Why can large language models generate correct chain-of-thoughts?
- Wallace et al. (2019) Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. 2019. Universal adversarial triggers for attacking and analyzing nlp. In Conference on Empirical Methods in Natural Language Processing.
- Wan et al. (2023a) Xingchen Wan, Ruoxi Sun, Hanjun Dai, Sercan O. Arik, and Tomas Pfister. 2023a. Better zero-shot reasoning with self-adaptive prompting.
- Wan et al. (2023b) Xingchen Wan, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisenschlos, Sercan O. Arik, and Tomas Pfister. 2023b. Universal self-adaptive prompting.
- Wang et al. (2023a) Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023a. Voyager: An open-ended embodied agent with large language models.
- Wang et al. (2023b) Jiaan Wang, Yunlong Liang, Fandong Meng, Haoxiang Shi, Zhixu Li, Jinan Xu, Jianfeng Qu, and Jie Zhou. 2023b. Is chatgpt a good nlg evaluator? a preliminary study. arXiv preprint arXiv:2303.04048.
- Wang et al. (2023c) Jiaqi Wang, Zhengliang Liu, Lin Zhao, Zihao Wu, Chong Ma, Sigang Yu, Haixing Dai, Qiushi Yang, Yiheng Liu, Songyao Zhang, Enze Shi, Yi Pan, Tuo Zhang, Dajiang Zhu, Xiang Li, Xi Jiang, Bao Ge, Yixuan Yuan, Dinggang Shen, Tianming Liu, and Shu Zhang. 2023c. Review of large vision models and visual prompt engineering.
- Wang et al. (2023d) Jiaqi Wang, Enze Shi, Sigang Yu, Zihao Wu, Chong Ma, Haixing Dai, Qiushi Yang, Yanqing Kang, Jinru Wu, Huawen Hu, Chenxi Yue, Haiyang Zhang, Yiheng Liu, Xiang Li, Bao Ge, Dajiang Zhu, Yixuan Yuan, Dinggang Shen, Tianming Liu, and Shu Zhang. 2023d. Prompt engineering for healthcare: Methodologies and applications.
- Wang et al. (2023e) Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2023e. Software testing with large language model: Survey, landscape, and vision.
- Wang et al. (2023f) Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. 2023f. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models.
- Wang et al. (2023g) Siyin Wang, Chao-Han Huck Yang, Ji Wu, and Chao Zhang. 2023g. Can whisper perform speech-based in-context learning.
- Wang et al. (2023h) Xinyi Wang, Wanrong Zhu, Michael Saxon, Mark Steyvers, and William Yang Wang. 2023h. Large language models are latent variable models: Explaining and finding good demonstrations for in-context learning.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models.
- Wang et al. (2023i) Yaqing Wang, Jiepu Jiang, Mingyang Zhang, Cheng Li, Yi Liang, Qiaozhu Mei, and Michael Bendersky. 2023i. Automated evaluation of personalized text generation using large language models. arXiv preprint arXiv:2310.11593.
- Wang et al. (2019) Yaqing Wang, Quanming Yao, James Kwok, and Lionel M. Ni. 2019. Generalizing from a few examples: A survey on few-shot learning.
- Wang et al. (2023j) Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Wenhu Chen, Jie Fu, and Junran Peng. 2023j. Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models.
- Wang et al. (2023k) Zhendong Wang, Yifan Jiang, Yadong Lu, Yelong Shen, Pengcheng He, Weizhu Chen, Zhangyang Wang, and Mingyuan Zhou. 2023k. In-context learning unlocked for diffusion models.
- Wang et al. (2023l) Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. 2023l. Unleashing cognitive synergy in large language models: A task-solving agent through multi-persona self-collaboration.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models.
- Wei et al. (2023a) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023a. Chain-of-thought prompting elicits reasoning in large language models.
- Wei et al. (2023b) Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V Le. 2023b. Simple synthetic data reduces sycophancy in large language models. arXiv preprint arXiv:2308.03958.
- Wei et al. (2023c) Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, et al. 2023c. Larger language models do in-context learning differently. arXiv preprint arXiv:2303.03846.
- Weng et al. (2022) Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. 2022. Large language models are better reasoners with self-verification.
- Weston and Sukhbaatar (2023) Jason Weston and Sainbayar Sukhbaatar. 2023. System 2 attention (is something you might need too).
- White et al. (2023) Jules White, Quchen Fu, Sam Hays, Michael Sandborn, Carlos Olea, Henry Gilbert, Ashraf Elnashar, Jesse Spencer-Smith, and Douglas C. Schmidt. 2023. A prompt pattern catalog to enhance prompt engineering with chatgpt.
- Wilf et al. (2023) Alex Wilf, Sihyun Shawn Lee, Paul Pu Liang, and Louis-Philippe Morency. 2023. Think twice: Perspective-taking improves large language models’ theory-of-mind capabilities.
- Willison (2022) Simon Willison. 2022. Prompt injection attacks against gpt-3.
- Willison (2024) Simon Willison. 2024. Prompt injection and jailbreaking are not the same thing.
- Winata et al. (2023) Genta Indra Winata, Liang-Kang Huang, Soumya Vadlamannati, and Yash Chandarana. 2023. Multilingual few-shot learning via language model retrieval.
- Wu et al. (2023a) Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. 2023a. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation.
- Wu et al. (2023b) Ning Wu, Ming Gong, Linjun Shou, Shining Liang, and Daxin Jiang. 2023b. Large language models are diverse role-players for summarization evaluation. arXiv preprint arXiv:2303.15078.
- Wu et al. (2022) Tongshuang Wu, Michael Terry, and Carrie Jun Cai. 2022. Ai chains: Transparent and controllable human-ai interaction by chaining large language model prompts. CHI Conference on Human Factors in Computing Systems.
- Wu et al. (2023c) Xiaodong Wu, Ran Duan, and Jianbing Ni. 2023c. Unveiling security, privacy, and ethical concerns of chatgpt. Journal of Information and Intelligence.
- Xia et al. (2024) Congying Xia, Chen Xing, Jiangshu Du, Xinyi Yang, Yihao Feng, Ran Xu, Wenpeng Yin, and Caiming Xiong. 2024. Fofo: A benchmark to evaluate llms’ format-following capability.
- Xiong et al. (2023a) Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2023a. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. arXiv preprint arXiv:2306.13063.
- Xiong et al. (2023b) Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. 2023b. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. arXiv preprint arXiv:2306.13063.
- Xu et al. (2023) Xiaohan Xu, Chongyang Tao, Tao Shen, Can Xu, Hongbo Xu, Guodong Long, and Jian guang Lou. 2023. Re-reading improves reasoning in language models.
- Xue et al. (2023) Tianci Xue, Ziqi Wang, Zhenhailong Wang, Chi Han, Pengfei Yu, and Heng Ji. 2023. Rcot: Detecting and rectifying factual inconsistency in reasoning by reversing chain-of-thought.
- Yang et al. (2023a) Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, and Xinyun Chen. 2023a. Large language models as optimizers.
- Yang et al. (2023b) Haibo Yang, Yang Chen, Yingwei Pan, Ting Yao, Zhineng Chen, and Tao Mei. 2023b. 3dstyle-diffusion: Pursuing fine-grained text-driven 3d stylization with 2d diffusion models.
- Yang et al. (2023c) Hui Yang, Sifu Yue, and Yunzhong He. 2023c. Auto-gpt for online decision making: Benchmarks and additional opinions.
- Yang et al. (2023d) Xinyi Yang, Runzhe Zhan, Derek F. Wong, Junchao Wu, and Lidia S. Chao. 2023d. Human-in-the-loop machine translation with large language model. In Proceedings of Machine Translation Summit XIX Vol. 2: Users Track, pages 88–98, Macau SAR, China. Machine Translation Summit.
- Yang et al. (2023e) Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, and Lijuan Wang. 2023e. The dawn of lmms: Preliminary explorations with gpt-4v(ision). ArXiv, abs/2309.17421.
- Yao et al. (2023a) Binwei Yao, Ming Jiang, Diyi Yang, and Junjie Hu. 2023a. Empowering llm-based machine translation with cultural awareness.
- Yao et al. (2023b) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023b. Tree of thoughts: Deliberate problem solving with large language models.
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models.
- Yao et al. (2023c) Yao Yao, Zuchao Li, and Hai Zhao. 2023c. Beyond chain-of-thought, effective graph-of-thought reasoning in large language models.
- Yasunaga et al. (2023) Michihiro Yasunaga, Xinyun Chen, Yujia Li, Panupong Pasupat, Jure Leskovec, Percy Liang, Ed H. Chi, and Denny Zhou. 2023. Large language models as analogical reasoners.
- Ye et al. (2023) Qinyuan Ye, Maxamed Axmed, Reid Pryzant, and Fereshte Khani. 2023. Prompt engineering a prompt engineer.
- Ye and Durrett (2023) Xi Ye and Greg Durrett. 2023. Explanation selection using unlabeled data for chain-of-thought prompting.
- Yoo et al. (2022) Kang Min Yoo, Junyeob Kim, Hyuhng Joon Kim, Hyunsoo Cho, Hwiyeol Jo, Sang-Woo Lee, Sang goo Lee, and Taeuk Kim. 2022. Ground-truth labels matter: A deeper look into input-label demonstrations.
- Yoran et al. (2023) Ori Yoran, Tomer Wolfson, Ben Bogin, Uri Katz, Daniel Deutch, and Jonathan Berant. 2023. Answering questions by meta-reasoning over multiple chains of thought.
- Yousaf et al. (2023) Adeel Yousaf, Muzammal Naseer, Salman Khan, Fahad Shahbaz Khan, and Mubarak Shah. 2023. Videoprompter: an ensemble of foundational models for zero-shot video understanding.
- Yu et al. (2023) Yue Yu, Yuchen Zhuang, Jieyu Zhang, Yu Meng, Alexander Ratner, Ranjay Krishna, Jiaming Shen, and Chao Zhang. 2023. Large language model as attributed training data generator: A tale of diversity and bias. arXiv preprint arXiv:2306.15895.
- Yue et al. (2023) Xiang Yue, Boshi Wang, Kai Zhang, Ziru Chen, Yu Su, and Huan Sun. 2023. Automatic evaluation of attribution by large language models. arXiv preprint arXiv:2305.06311.
- Zeng et al. (2023) Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, and Danqi Chen. 2023. Evaluating large language models at evaluating instruction following. arXiv preprint arXiv:2310.07641.
- Zhang and Choi (2023) Michael JQ Zhang and Eunsol Choi. 2023. Clarify when necessary: Resolving ambiguity through interaction with lms. arXiv preprint arXiv:2311.09469.
- Zhang et al. (2023a) Quanjun Zhang, Tongke Zhang, Juan Zhai, Chunrong Fang, Bowen Yu, Weisong Sun, and Zhenyu Chen. 2023a. A critical review of large language model on software engineering: An example from chatgpt and automated program repair.
- Zhang et al. (2023b) Yifan Zhang, Jingqin Yang, Yang Yuan, and Andrew Chi-Chih Yao. 2023b. Cumulative reasoning with large language models.
- Zhang et al. (2022a) Yiming Zhang, Shi Feng, and Chenhao Tan. 2022a. Active example selection for in-context learning.
- Zhang et al. (2023c) Zhuosheng Zhang, Yao Yao, Aston Zhang, Xiangru Tang, Xinbei Ma, Zhiwei He, Yiming Wang, Mark Gerstein, Rui Wang, Gongshen Liu, and Hai Zhao. 2023c. Igniting language intelligence: The hitchhiker’s guide from chain-of-thought reasoning to language agents.
- Zhang et al. (2022b) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2022b. Automatic chain of thought prompting in large language models.
- Zhang et al. (2023d) Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2023d. Multimodal chain-of-thought reasoning in language models.
- Zhao et al. (2023a) Ruochen Zhao, Xingxuan Li, Shafiq Joty, Chengwei Qin, and Lidong Bing. 2023a. Verify-and-edit: A knowledge-enhanced chain-of-thought framework. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5823–5840, Toronto, Canada. Association for Computational Linguistics.
- Zhao et al. (2021a) Tony Z. Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021a. Calibrate before use: Improving few-shot performance of language models.
- Zhao et al. (2023b) Yilun Zhao, Haowei Zhang, Shengyun Si, Linyong Nan, Xiangru Tang, and Arman Cohan. 2023b. Large language models are effective table-to-text generators, evaluators, and feedback providers. arXiv preprint arXiv:2305.14987.
- Zhao et al. (2023c) Yuyang Zhao, Zhiwen Yan, Enze Xie, Lanqing Hong, Zhenguo Li, and Gim Hee Lee. 2023c. Animate124: Animating one image to 4d dynamic scene.
- Zhao et al. (2021b) Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021b. Calibrate before use: Improving few-shot performance of language models. In International Conference on Machine Learning, pages 12697–12706. PMLR.
- Zheng et al. (2023a) Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. 2023a. On large language models’ selection bias in multi-choice questions. arXiv preprint arXiv:2309.03882.
- Zheng et al. (2023b) Ge Zheng, Bin Yang, Jiajin Tang, Hong-Yu Zhou, and Sibei Yang. 2023b. Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models.
- Zheng et al. (2023c) Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, and Denny Zhou. 2023c. Take a step back: Evoking reasoning via abstraction in large language models.
- Zheng et al. (2023d) Mingqian Zheng, Jiaxin Pei, and David Jurgens. 2023d. Is "a helpful assistant" the best role for large language models? a systematic evaluation of social roles in system prompts.
- Zhou et al. (2022a) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. 2022a. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625.
- Zhou et al. (2022b) Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2022b. Large language models are human-level prompt engineers.
- Zhou et al. (2023) Yucheng Zhou, Xiubo Geng, Tao Shen, Chongyang Tao, Guodong Long, Jian-Guang Lou, and Jianbing Shen. 2023. Thread of thought unraveling chaotic contexts.
- Zhu et al. (2023) Xizhou Zhu, Yuntao Chen, Hao Tian, Chenxin Tao, Weijie Su, Chenyu Yang, Gao Huang, Bin Li, Lewei Lu, Xiaogang Wang, Yu Qiao, Zhaoxiang Zhang, and Jifeng Dai. 2023. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory.
- Zuo et al. (2023) Zhichao Zuo, Zhao Zhang, Yan Luo, Yang Zhao, Haijun Zhang, Yi Yang, and Meng Wang. 2023. Cut-and-paste: Subject-driven video editing with attention control.
附录A附录
A.1 提示的定义
|p2cm|X|X|参考提示提示工程
Meskó (2023) 设计、完善和实施提示或指令的实践,指导大语言模型的输出以帮助完成各种任务。 它本质上是与人工智能系统有效交互以优化其效益的实践。
Chen 等人(2023a)模型的输入是大语言模型构建输入文本的过程,是优化大语言模型效率的技术组成部分
Santu 和 Feng (2023) 是指提供给大语言模型的文本输入,旨在引导其输出完成特定任务,包括精心设计和修改查询或上下文,从而引发大语言模型
Wang 等人 (2023d) 期望的响应或行为涉及设计有效的提示来指导下游任务中的预训练语言模型。
Wang 等人 (2023c) 设计提示的过程,使模型能够适应和泛化到不同的任务。
下游任务。
Hou 等人 (2023) 手动预定义自然语言指令 精心设计专门提示
Wang 等人 (2023e) 大语言输入模型与大语言模型通信以引导其行为以获得期望的结果
White 等人 (2023) 向大语言模型发出指令,以执行规则、自动化流程并确保生成输出的特定质量(和数量)。 提示也是一种编程形式,可以自定义大语言模型的输出和交互。
提示是提供给大语言模型的一组指令,通过定制大语言模型和/或增强或细化其功能来对大语言模型进行编程,这是与大语言模型有效对话所需的日益重要的技能集(大语言模型) ,例如ChatGPT
通过提示进行大语言模型编程的方式
Heston and Khun (2023) 输入以专门的方式构建输入
Liu 等人 (2023b) 选择合适的提示
创建提示功能的过程,该功能可以使下游任务获得最有效的性能。
Hadi 等人 (2023) 向大语言模型提供的指令,使其遵循指定的规则、流程自动化并确保生成的输出具有特定的质量或数量,指的是设计和措辞给大语言模型的提示,以便得到他们想要的回应。
Neagu (2023)需要各种策略,包括显式指令和隐式上下文[21]。 显式指令涉及通过指令、示例或规范为模型提供显式指导或约束。 隐式上下文利用模型对先前上下文的理解来影响其响应
Dang 等人 (2022) 构建提示以提高生成模型生成输出的系统实践
不同论文中的提示和提示工程的定义。
A.2扩展词汇
A.2.1 提示条款
上下文窗口
上下文窗口是模型可以处理的标记空间(对于大语言模型)。 它有一个最大长度(上下文长度)。
启动
Schulhoff (2022) 是指向模型提供初始提示,为对话的其余部分提供某些说明。 此启动提示可能包含角色或有关如何与用户交互的其他说明。 启动可以在系统或用户提示中完成(见下文)。
A.2.2提示工程术语
会话提示工程
是对话中的提示工程。 也就是说,在与 GenAI 对话的过程中,用户可以要求 GenAI 改进其输出。 相比之下,提示工程通常是通过向 GenAI 发送全新的提示而不是继续对话来完成的。
A.2.3 微调条款
即时学习
Liu 等人 (2023b),也称为即时学习 Liu 等人 (2023b); Wang等人(2023d)指的是使用提示相关技术的过程。 它通常用于微调,尤其是微调提示。 由于用法冲突,我们不使用该术语。
及时调整
Lester 等人 (2021) 是指直接优化提示本身的权重,通常通过某种形式的基于梯度的更新。 它也被称为“提示微调”。 它不应该用于指代离散提示工程。
A.2.4 正交提示类型
我们现在讨论对提示进行高级分类的术语。
A.2.4.1 发起者
用户提示
这是来自用户的提示类型。 这是最常见的提示形式,也是消费者应用程序中通常提供提示的方式。
助理提示
这个“提示”根本就是大语言模型本身的输出。 当它反馈到模型中时,可以将其视为提示(或提示的一部分),例如作为与用户的对话历史记录的一部分。
系统提示
该提示用于为大语言模型提供与用户交互的高级指令。 并非所有型号都有此功能。
A.2.4.2 硬提示与软提示
硬(离散)提示
这些提示仅包含与大语言模型词汇表中的单词直接对应的标记。
软(连续)提示
这些提示包含的标记可能与词汇表 Lester 等人 (2021) 中的任何单词都不对应;王等人(2023c)。 当需要微调时可以使用软提示,但修改完整模型的权重成本高昂。 因此,可以使用冻结模型,同时允许梯度流经提示标记。
A.2.4.3 预测样式
在大语言模型中,预测风格是预测下一个词符的格式。 在促进研究方面有两种常见的格式。 我们不讨论非文本预测样式。
完型填空
在完形填空提示中,要预测的词符以“要填充的位置”的形式呈现,通常位于提示的中间位置Liu 等人(2023b)。 对于早期的 Transformer 模型,例如 BERT Chu 和 Lin (2023),通常就是这种情况。
字首
在前缀提示中,要预测的词符位于提示的末尾Liu 等人(2023b)。 现代 GPT 风格的模型 Radford 等人 (2019b) 通常就是这种情况。
A.3数据表
我们提供了一份数据表 Gebru 等人 (2021),其中包含有关相关论文数据集的更多信息,该数据集托管在 HuggingFace 上。
A.3.1 动机
创建数据集的目的是什么? 是否有特定的任务? 是否有需要填补的具体空白? 请提供说明。
创建此数据集是为了收集有关提示工程的现有文献,以便分析所有当前的硬前缀提示技术。
谁创建了数据集(例如哪个团队、研究小组)并代表哪个实体(例如公司、机构、组织)?
这项研究与马里兰大学 Learn Prompting 相关,并由 OpenAI 赞助,但不代表任何特定组织创建。
谁资助了数据集的创建? 如果有相关赠款,请提供赠款人姓名以及赠款名称和编号。
OpenAI 为其 API 贡献了 10,000 美元的积分。
A.3.2组成
组成数据集的实例代表什么(例如文档、照片、人物、国家)? 是否存在多种类型的实例(例如,电影、用户和评级;人和他们之间的交互;节点和边)? 请提供说明。
该数据集包含 1,565 篇 PDF 格式的研究论文。 任何重复的论文都会被自动删除,尽管有些重复的论文可能存在。
每个实例包含哪些数据? “原始”数据(例如,未经处理的文本或图像)或特征? 无论哪种情况,请提供说明。
每个数据实例都是 PDF 格式的研究论文。
是否有与每个实例关联的标签或目标? 如果是,请提供描述。
否
个别实例是否缺少任何信息? 如果是这样,请提供描述,解释为什么缺少此信息(例如,因为它不可用)。 这不包括故意删除的信息,但可能包括例如经过编辑的文本。
没有。
数据集中是否存在任何错误、噪声源或冗余? 如果是,请提供描述。
论文是在半自动化过程中收集的,这导致了不相关论文被收集而相关论文未被收集的可能性。 对这两种可能的错误进行了人工审查,以减少这些错误。
数据集是独立的,还是链接到或以其他方式依赖外部资源(例如网站、推文、其他数据集)?
它是独立的。
数据集是否包含可能被视为机密的数据(例如,受法律特权或医患机密保护的数据、包含个人非公开通信内容的数据)? 如果是,请提供描述。
没有。
数据集是否包含如果直接查看可能具有冒犯性、侮辱性、威胁性或可能引起焦虑的数据? 如果是这样,请描述原因。
数据集包含一些关于提示注入的论文。 这些论文可能包含攻击性内容,包括种族主义和性别歧视。
A.3.3收集流程
与每个实例相关的数据是如何获取的?
数据集由 Arxiv、Semantic Scholar 和 ACL 编译而成。
使用什么机制或程序来收集数据?
我们编写了自动查询Arxiv和Semantic Scholar API的脚本。
数据是在多长时间内收集的?
数据集是在研究论文发表期间(主要是 2024 年 2 月)整理的。
是否进行了任何道德审查流程?
没有。
A.3.4预处理/清洁/标签
是否对数据进行了任何预处理/清理/标记?
从不同来源收集数据后,我们删除了重复的论文,并对论文进行了手动和半自动审查,以确保它们都是相关的。
除了预处理/清理/标记的数据之外,是否还保存了“原始”数据?
不,我们预计不会使用我们的预处理数据。 但是,可以从我们存储的链接中恢复原始数据。
用于预处理/清理/标记数据的软件是否可用?
它包含在 Github 上的代码存储库中。
A.3.5用途
该数据集是否已用于任何任务?
没有。
是否有一个存储库链接到使用该数据集的任何或所有论文或系统?
是。
数据集的组成或其收集和预处理/清理/标记的方式是否有任何可能影响未来使用的因素?
我们收集的所有论文都是英文写的。 由于无法提供翻译,某些论文可能未包含在内。
是否存在不应使用该数据集的任务?
没有。
A.3.6分布
数据集是否会分发给创建数据集所代表的实体之外的第三方?
没有。
A.3.7维护
谁将支持/托管/维护数据集?
我们的团队将继续维护。
如何联系数据集的所有者/策展人/经理?
请发送电子邮件至sanderschulhoff@gmail.com
有勘误吗?
没有。
如果其他人想要扩展/增强/构建/贡献数据集,是否有一种机制可以让他们这样做?
是的,任何人都可以自由使用/修改数据。
A.4关键字
以下是我们用于搜索的关键字。
-
•
越狱提示
-
•
提示大语言模型
-
•
提示大型语言模型
-
•
及时注射
-
•
及时优化
-
•
及时工程
-
•
少样本学习
-
•
少样本学习
-
•
基于提示的方法
-
•
基于提示的方法
-
•
基于提示的方法
-
•
基于提示的方法
-
•
少样本提示
-
•
少样本提示
-
•
一键提示
-
•
一键提示
-
•
少样本提示
-
•
少样本提示
-
•
一键提示
-
•
一键提示
-
•
提示技巧
-
•
及时的工程技术
-
•
大语言模型提示
-
•
大语言模型提示
-
•
0发提示
-
•
0射击提示
-
•
零样本提示
-
•
多次提示
-
•
零样本提示
-
•
多次提示
-
•
情境学习
-
•
在情境学习中
-
•
Transformer 型号提示
-
•
基于提示的迁移学习
-
•
NLP提示策略
-
•
大语言模型可通过提示进行解释
-
•
有提示的课程学习
-
•
大语言模型提示中的反馈循环
-
•
人机交互提示
-
•
Token 有效的提示
-
•
多模式提示
-
•
指令提示
-
•
提示模板
-
•
提示模板
A.5评估表
| ID | Model | Prompt | Output Space | Type | Res. | Batch | |||
| Roles | CoT | Definition | Few-Shot | ||||||
| Kocmi and Federmann (2023b) | GPT-family | DA, sMQM, stars, classes | E | S | |||||
| Lu et al. (2023c) | Dav3, Turbo, GPT-4 | ✓ | ✓ | ✓ | Error Span Score | E | S | ✓ | |
| Fernandes et al. (2023) | PaLM | ✓ | ✓ | ✓ | Error Span | I | S | ||
| Kocmi and Federmann (2023a) | GPT-4 | ✓ | ✓ | ✓ | Error Span | I | S | ✓ | |
| Araújo and Aguiar (2023) | ChatGPT | ✓ | Likert [1-5] | E | S | ✓ | |||
| Wang et al. (2023b) | ChatGPT | ✓ | DA, stars | E | S | ||||
| Liu et al. (2023d) | GPT-3.5, GPT-4 | ✓ | Likert [1-10] | I | M | ||||
| Chan et al. (2024) | ChatGPT, GPT-4 | ✓ | ✓ | Likert [1-10] | I | M | |||
| Luo et al. (2023) | ChatGPT | ✓ | ✓ | yes/no;A/B; Likert [1-10] | E | S | |||
| Hada et al. (2024) | GPT4-32K | ✓ | ✓ | [0,1,2] or binary | E | S | ✓ | ||
| Fu et al. (2023a) | GPT3, OPT, FLAN-T5, GPT2 | Probability | I | S | |||||
| Gao et al. (2023c) | ChatGPT | ✓ | Likert [1-5], Pairwise, Pyramid, 0/1 | E | S | ||||
| Chen et al. (2023g) | ChatGPT | Likert [1-10]; yes/no; pairwise: A/B/C | E & I | S | |||||
| He et al. (2023a) | GPT-4 | ✓ | Likert [1-5] | E | S | ||||
| Sottana et al. (2023) | GPT-4 | ✓ | Likert [1-5] | E | S | ||||
| Chen et al. (2023c) | GPT, Flan-T5 | ✓ | Yes/No | E | S | ||||
| Zhao et al. (2023b) | GPT-3.5, GPT-4 | ✓ | ✓ | true/false | E | S | |||
| Wu et al. (2023b) | GPT-3 | ✓ | pairwise voting | E | M | ✓ | |||
| Wang et al. (2023i) | PaLM 2-IT-L | A/B | E | M | |||||
| Jia et al. (2023) | LLaMa7b | Probability | I | S | |||||
| Yue et al. (2023) | ChatGPT, Alpaca, Vicuna, GPT-4 | ✓ | ✓ | Yes/No | E | S | |||
| Li et al. (2023e) | GPT-3.5, GPT-4, Bard, Vicuna | ✓ | Pairwise | I | M | ||||
| Liu et al. (2023f) | ChatGPT, Vicuna, chatGLM, StableLM | ✓ | continuous [0-1] | E | S | ||||
| Bai et al. (2023b) | GPT-4, Claude, ChatGPT, Bard, Vicuna | ✓ | Likert [1-5] | E | S | ||||
| Dubois et al. (2023) | GPT-4, ChatGPT, Dav3 | ✓ | ✓ | pairwise | E | M | ✓ | ||
| Liu et al. (2023h) | GPT-4-32K | ✓ | Likert [1-5] | E | S | ||||
| Wang et al. (2023h) | Turbo, ChatGPT, GPT-4, Vicuna | ✓ | Likert [1-10] | E | M | ||||
| Zeng et al. (2023) | GPT-4, ChatGPT, LLaMA-2-Chat, PaLM2, Falcon | ✓ | ✓ | ✓ | Pairwise | E | S | ||
| Zheng et al. (2023b) | Claude-v1, GPT-3.5, GPT-4 | ✓ | ✓ | Pairwise/Likert [1-10] | E | S/M | |||
| Lin and Chen (2023) | Claude-v1.3 | Likert [0-5], Likert [0-100] | E | S | ✓ | ||||
A.6被困提示流程
本节包含我们的提示工程师在开发提示时的思考过程。
A.6.1探索
-
•
首先进行了一些数据集探索,查看长度/标签分布,然后选择捕获作为开始。
-
•
通过要求 gpt-1106-preview 定义术语 WRT SCS 来检查 gpt-1106-preview 是否理解捕获。 它没。
A.6.2 获取标签
-
•
在系统提示中向它展示了卡住的定义,并要求它标记一个数据点,但它回应说我应该寻求心理健康支持。
-
•
我将说明放在用户提示中,但得到了类似的响应。
-
•
附加“这是陷阱吗? 是或否”让它实际响应标签。
-
•
我给了它一个拒绝的例子,但它把它标记为接受,有时还会给出关于寻求帮助的情感反应。
-
•
使用 10 次提示时,它仍然会给出“获取帮助”响应。
-
•
我尝试删除定义,遇到了同样的问题。 它似乎不喜欢“接受”/“拒绝”作为标签。
-
•
我重新添加了定义,将标签更改为诱捕/非诱捕,它经常说“没有足够的信息来确定”。
-
•
我改用了 GPT-4-32K,它给出了一个词的响应,并正确预测了拒绝和接受数据点。
A.6.3 不同的提示技巧
-
•
在上下文中测试了 0-shot。
-
•
10 次结合上下文的镜头,显示出进步。
-
•
将第一个失败的实例带入游乐场。 (训练文件中的第 12 个)
-
•
尝试做'A:让我们一步一步弄清楚:”,输出“A:是”
-
•
是否“A:让我们一步一步弄清楚:”,输出:
-
•
“A:在预测标签之前,我们先一步步写出你的思考过程。 使用诱捕定义中的项目来支持你的结论。”,输出:
-
•
开始与人工智能讨论“他们从来没有说过他们感到被困或没有出路,你是怎么想到这个想法的?”,输出:
-
•
要求它帮助重新制定指令,使需要的内容更加明确,仍然预示着会被困住。
-
•
添加了“诱捕必须是显式的,而不是隐式的。”定义后顶部指令(无 CoT 诱导物)
-
•
也尝试过之前的 CoT 诱导剂,仍然以难以解析的方式表示捕获。
-
•
补充道:“如果这个人没有明确表示他们感到被困住了,这不算是被困住了。” (没有CoT),仍然是陷阱。
-
•
与 AI 交谈时,它会认为“今天我发现我有 10 天的时间搬出公寓,否则我将被正式驱逐。 由于我在工作中被降职,房租从每两周大约 1000 美元降至 450 美元左右,所以我拖欠了 2 个月的房租。 如果我被驱逐,我可能会无家可归”,这是一种被困/卡住的感觉。
-
•
尝试过“在陈述标签之前,使用上面的网格写出关于为什么这可能/可能不是陷阱的推理:”,仍然认为是陷阱。
-
•
粘贴到电子邮件中:[已编辑]以上诱捕定义
-
•
删除镜头,说“诱捕”
-
•
在 def 之后添加此内容: 重要提示:仅当他们明确表示他们感到被困时,才将帖子标记为陷阱。,说“是”
-
•
在提示中,给出了 CoT 推理。 (18.txt),并尝试下一个错误标记的(15),(完整提示,19.txt)
-
•
除了前 20 个之外,对所有内容都进行了测试,效果非常好
-
•
尝试删除电子邮件,性能急剧下降
-
•
在这一点上,我认为给出带有推理的例子会有所帮助(显然)
-
•
尝试免费添加 10 个镜头,在最后一个镜头之前进行推理,效果不佳
A.6.3.1AutoCoT
-
•
使用此提示 (22.txt) 开发数据集。 然后问它“为什么?”。 如果不同意,我说“这实际上不是诱捕,请解释原因”。 (不小心重复了电子邮件23.txt)
-
•
只是为了好玩,尝试了 0 镜头完整上下文(必须调整言语表达器)
-
•
使用特殊的语言器尝试了此操作,该语言器捕捉到“此帖子不符合诱捕标准”。
-
•
测试了我生成的数据,击败了 0.5 F1
-
•
使用 autocot 做了 10 个以上的范例。 有时会立即以诸如“这篇文章不符合陷阱标准,因为个人没有明确表达被困或绝望的感觉。”之类的推理做出回应,所以如果是这样,就使用它。 有时会遭到拒绝“听到您有这样的感觉我真的很抱歉,但我无法提供您需要的帮助。 不过,与有能力的人讨论此事非常重要,例如心理健康专家或您生活中值得信赖的人。”,如果是的话,只需询问“解释为什么这不是陷阱。”。
-
•
性能并没有真正提高,意识到大约 11% 的结果为 -1,这意味着没有正确提取。 用完整的单词“问题”而不是 Q 重试,也是为了推理和回答。
-
•
这导致无法解析的比例更高,约为 16%。
A.6.3.2 开发答案提取
-
•
首先将解析失败放在(22)中,并为其开发了一个提示。
-
•
表现更差:(0.42857142857142855、0.5051546391752577、0.8571428571428571、0.2857142857142857)
-
•
仅使用提取的标签,如果有 -1 略有帮助 (0.48, 0.61, 0.8571428571428571, 0.3333333333333333)
-
•
返回到最佳性能提示 – 10 QRA 射击,并使用任何 -1 执行提取,除了稍微提高准确性之外没有任何帮助,也许当它没有回答时
A.6.3.3 迭代电子邮件
-
•
尝试了最佳性能,没有电子邮件
-
•
尝试使用重复数据删除的电子邮件,结果更糟
-
•
注意到那些不确定的通常包含 1 个应该是 0 的标签,所以尝试“恢复”这些并没有帮助
-
•
尝试移动示例顺序,执行提取,没有帮助
-
•
三份电子邮件,没有帮助
A.7 正式定义提示
“提示”是一个广泛使用的术语,但不同研究的使用和定义差异很大。 因此,很难为提示创建正式的数学定义。 在本节中,我们概述了即时工程的一些形式。
作为一种调理机制。
乔等人(2022)提出以下定义,其中涉及提示和问题作为预测下一个词符的条件机制。 请注意,他们似乎使用了 Brown 等人 (2020) 对提示的原始定义,指的是提示中的非问题部分(例如少样本范例、说明)。
| (A.1) |
这里,提示和问题条件是预训练的大语言模型。 是之前生成的答案标记, 是完整答案。
模板化。
上述形式化不包括最大化评分或效用函数(例如数据集的准确性)的概念,而提示通常是为了实现这一目的而设计的。 此外,提示工程师经常寻求设计提示模板而不是提示。 在这里,我们重新编写 eq. A.1 以包含提示模板:
| (A.2) |
我们将 替换为 ,即数据集中的一项(例如评估数据)。 此外,我们将右侧的 替换为 。 是一个提示模板:一个接受某些项目作为输入然后返回用于调节模型的提示的函数。
少样本提示。
通常,提示过程的一个重要部分是使用少量样本。 是训练数据(用于构建提示), 是用于评估的测试集。
| (A.3) | ||||
| (A.4) |
在少样本设置中,提示模板训练函数也将一个或多个样本作为输入
| (A.5) |
优化。
如前所述,通常需要谈论关于通常针对数据集定义的评分函数的提示(即提示模板)的改进。
| (A.6) |
在此定义中,我们根据评分函数 对数据集 进行评估。 评估由大语言模型根据提示生成的输出。 是可供 使用的标记输出。
在某些情况下,可能没有任何标记数据,并且可能是无引用的。
其他考虑因素。
这些形式可以适应 CoT、检索系统等。 在这里,我们描述了一个简单的设置,它最能描述提示过程,而不会增加太多的复杂性。
我们还提请注意鲜为人知的答案工程概念。 是对原始大语言模型输出的转换函数,允许将其与地面事实进行比较。
| (A.7) | ||||
| (A.8) |
A.8情境学习定义消歧
Brown 等人 (2020) 似乎为 ICL 提供了两种不同的定义。 本节中的所有粗体都是我们自己的。
最近的工作 [RWC+19] 尝试通过我们所谓的“上下文学习”来做到这一点,使用预训练语言模型的文本输入作为任务规范的一种形式:该模型以自然语言指令为条件和/或一些任务演示,然后只需预测接下来会发生什么,就可以完成任务的进一步实例。
然而,他们后来似乎将其定义为仅少样本:
对于每项任务,我们在 3 个条件下评估 GPT-3:(a) “少样本学习”,或上下文学习,其中我们允许尽可能多的演示适合模型的上下文窗口(通常10 到 100),(b)“一次性学习”,我们只允许一次演示,以及(c)“零样本”学习,不允许演示,只向模型提供自然语言指令。
然而,他们包含了这张图片来澄清这个问题:
此外,他们明确指出 ICL 不一定涉及学习新任务。
为了避免这种混淆,我们使用术语“元学习”来捕获通用方法的内循环/外循环结构,并使用术语“上下文学习”来指代元学习的内循环。 我们进一步将描述专门化为“零样本”、“一次性”或“少样本”,具体取决于推理时提供的演示数量。 这些术语旨在对模型是在推理时从头开始学习新任务还是简单地识别训练期间看到的模式的问题保持不可知性 - 这是我们在本文后面讨论的一个重要问题,但“元学习”旨在包含这两种可能性,并且简单地描述了内外循环结构。
我们使用 Brown 等人 (2020) 的广义定义,但请注意,实践者经常使用 ICL 来指代模型似乎正在从提示中学习新任务的情况。 我们的定义与 Dong 等人 (2023) 的正式定义不同,尽管它也源自 Brown 等人 (2020)。
A.9贡献
以下是团队成员在本文各个部分所做的贡献。 大多数作者也对其他部分进行了评论。
顾问
-
•
丹尼斯·佩斯科夫: 协助论文组织和最终评审。
-
•
亚历山大·霍伊尔: 提供写作、荟萃分析方法的指导,并运行案例研究的自动基线。
-
•
夏马尔·阿纳德卡特: 协助对论文以及词源和定义进行总体审查。
-
•
朱尔斯·怀特: 为技术分类建立树。
-
•
海洋鲤鱼: 为多语言部分设计、审查和建议论文。
-
•
菲利普·雷斯尼克: 首席研究员
SCS标签
-
•
梅根·L·罗杰斯、Inna Goncearenco、朱塞佩·萨利、伊戈尔·加林克: 对此部分进行了审查并提出了建议。
基准测试和代理
-
•
康斯坦丁·卡哈泽: 基准测试部分的团队负责人;管理 MMLU 基准测试代码库,为安全性和元分析做出了贡献。
-
•
阿谢·斯里瓦斯塔瓦: 代理部分的团队负责人,审阅供人工审阅的论文,负责工具使用代理部分的工作。 从事贡献汇编工作。
-
•
Hevander Da Costa:为 Benchmarking 部分和 Meta Review 数据集列表做出了贡献,回顾了有关大语言模型代码生成和提示技术的文献。 在代理部分添加了文献综述内容。
-
•
李菲琳: 在工具使用代理部分工作,协助人工论文审查。
对齐和安全
-
•
尼尚特巴莱普尔: 协调部分的团队负责人,帮助进行基准测试的高层讨论并审查草稿。
-
•
塞维恩·舒尔霍夫: 安全部分的团队负责人并为基准测试部分做出了贡献。
相关作品和章节贡献
-
•
斯成磊: 建议相关工作并编辑第 2.2 节和第 7 节。
-
•
普拉纳夫·桑迪普·杜勒佩特: 为第 2 部分提供了定义,并致力于多模式部分中的分割和对象检测。
-
•
韩孝正: 为Multimodal部分做出贡献,特别是语音+文本部分,并编写了音频提示部分。
-
•
陶哈德森: 撰写了有关多模态图像、视频和 3D 的章节,并审阅了供人工审阅的论文;维护 GitHub 代码库,并构建项目网站。
-
•
阿曼达·刘: 撰写分类本体论部分,进行介绍和相关工作的背景研究,开发元分析图的代码管道
-
•
斯瓦塔·阿格拉瓦尔: 评估部分的团队负责人。
-
•
索拉夫·维迪亚达拉: 协助一般审查和修订分类树。
-
•
范周: 协助元审查,包括主题的自动分析。
多语言提示和元分析
-
•
佐伊·基: 领导多语言提示部分,对相关论文进行审阅,并撰写第 3.1 节。
-
•
李寅恒: 研究第 2.2 节基于文本的技术,审查技术,并为起草图 2.2 做出贡献。
-
•
萨洛尼·古普塔: 编写论文编译测试,帮助建立论文管道,并制定论文的代码图和语法。
-
•
格森·克罗伊兹: 涉及1.1节并定义提示。
-
•
阿尤什·古普塔: 为元分析、撰写论文和生成可视化图表做出了贡献。
-
•
迈克尔·伊利: 联合主要作者,管理代码库,运行实验,收集数据,并帮助完成各个部分,包括 PRISMA 审查图和 SCS 提示案例研究。
-
•
桑德·舒尔霍夫: 主要作者