HeinrichDinkel ZhiyongYan YongqingWang JunboZhang YujunWang BinWang
为通用音频分类扩展掩码音频编码器学习
摘要
尽管音频分类取得了进展,但在语音和其他声音领域(如环境声音和音乐)之间仍然存在泛化差距。 针对语音任务训练的模型通常在环境或音乐音频任务上表现不佳,反之亦然。 虽然自监督 (SSL) 音频表示提供了一种替代方案,但针对基于 SSL 的通用音频分类,对模型和数据集规模扩展的探索有限。 我们介绍了 Dasheng,一种基于高效掩码自动编码器框架的简单 SSL 音频编码器。 Dasheng 在 272,356 小时的各种音频上以 12 亿个参数进行训练,在 HEAR 基准测试中获得了显著的性能提升。 它在 CREMA-D、LibriCount、语音命令、VoxLingua 上优于以前的工作,并在音乐和环境分类中表现出色。 如最近邻分类实验所示,Dasheng 特征天生包含丰富的语音、音乐和环境信息。
关键词:
音频分类、通用音频特征、Transformer、掩码自动编码器1 介绍
近年来,机器学习应用,尤其是在文本和视觉处理方面,取得了重大进展,这主要得益于大型模型在大型数据集上的预训练。 例如,在视觉领域,ImageNet 被广泛认为是标准的预训练数据集。 以监督方式在 ImageNet 上训练的模型在视觉领域的各种分类和分离任务中得到广泛应用。 然而,这种跨任务的视觉模型迁移能力目前在音频分类领域尚未观察到。 例如,在 [1] 中,作者表明,在 AudioSet(类似于音频领域的 ImageNet)上进行监督预训练,仅对声音分类任务有益。 相反,其他任务,如语言分类、说话人识别和意图分类,被发现受到监督 AudioSet 预训练的负面影响。
旨在开发用于通用音频分类的综合主干的最新研究,也因诸如音频嵌入整体评估 (HEAR) [2] 等基准而加速。 HEAR 基准的结果表明,在各种音频任务上的通用性能方面,自监督模型 (SSL) 可能比其监督对应模型更强大。
目前,存在各种自监督训练范式。 在诸如 Wav2Vec2 [3] 的下一个标记预测方法中,模型的任务是根据过去标记的上下文预测未来的高级音频标记。 此外,在掩码标记预测 [4, 5, 6] 中,数据段被随机擦除(归零),模型的任务是从提供的上下文中预测掩码标记。 最后,在自举自己的潜在模型 (BYOL) [7, 8] 中,学生模型的任务是预测教师模型的隐藏表示。
然而,据我们所知,在通过增加参数大小来扩展 SSL 表示编码器模型(超过 300M [9])方面,一直没有得到重视。 可能的原因之一是公开可用的大规模通用音频数据集数量有限。 近年来,5000 小时长的 AudioSet [10] 已被广泛用于大多数通用表示学习任务,而诸如 ACAV100M [11] 等更大的数据集之前尚未探索。 另一个障碍是扩大模型参数大小带来的计算开销,这需要大量的图形处理单元 (GPU) 集群。
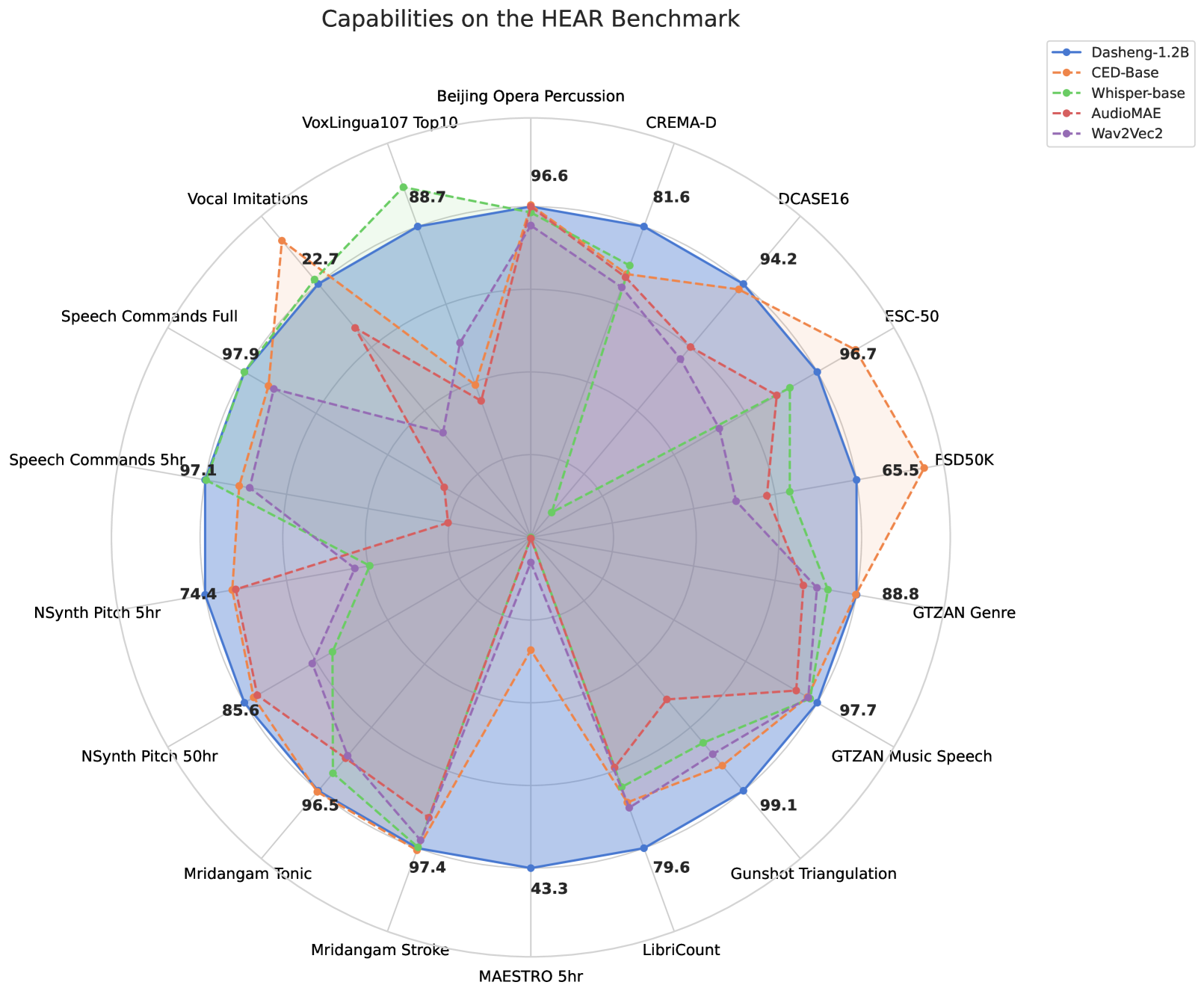
从我们的角度来看,用于可扩展预训练的最有效的 SSL 方法是使用掩码自动编码器 (MAE) [4]。 这些类型的模型偏离传统的掩码学习,方法是删除掩码掉的数据,从而大幅降低计算开销并促进模型的可扩展性。 尽管 MAEs 已被提出 [9] 并针对音频领域进行了改进 [6, 12],但以前的工作主要使用 参数模型以及上述 AudioSet 训练数据。 因此,这项工作提出了一种通用的音频分类主干,名为 Deep Audio-Signal Holistic Embeddings (Dasheng)。 Dasheng 是一种 MAE 风格的预训练编码器模型,已扩展到 12 亿个参数,并在 272,356 小时的公开数据上进行训练,在各种音频分类任务中表现出令人印象深刻的性能(图 1)。 虽然我们的主要关注点在于探索分类性能,但重要的是要注意,MAE 也可用于音频生成 [13] 和超分辨率 [14] 任务,在这两个领域都拥有最先进 (SOTA) 的性能。
2 方法
Dasheng 基于 MAE 框架,该框架由一个基于 Transformer 的非对称编码器-解码器组成,其中只有解码器对整个输入序列进行操作,从而实现高效的编码器训练。 给定一个大小为 的梅尔声谱图,其中 表示帧数, 表示滤波器组数,我们首先将时间轴分成大小相同的块,并通过线性变换将每个块投影到指定的维度,如:,其中 表示块数或“符元”数, 是模型的嵌入维度。 我们进一步向 添加绝对可学习的位置嵌入 。 然后,我们掩盖 并丢弃 75% 的符元,并将未掩盖的符元 送入编码器,该编码器预测嵌入 。 然后,我们通过将可学习的掩码符元附加到 中,为每个已掩盖的位置获得 。 解码器预测 。 最后,我们计算预测的掩码符元和“块化”的真实 [4] 声谱图之间的归一化均方误差 (MSE) 损失。 整个训练框架如图 2 2 所示。 训练后,我们冻结编码器的所有参数,并在各种下游任务中评估其嵌入。
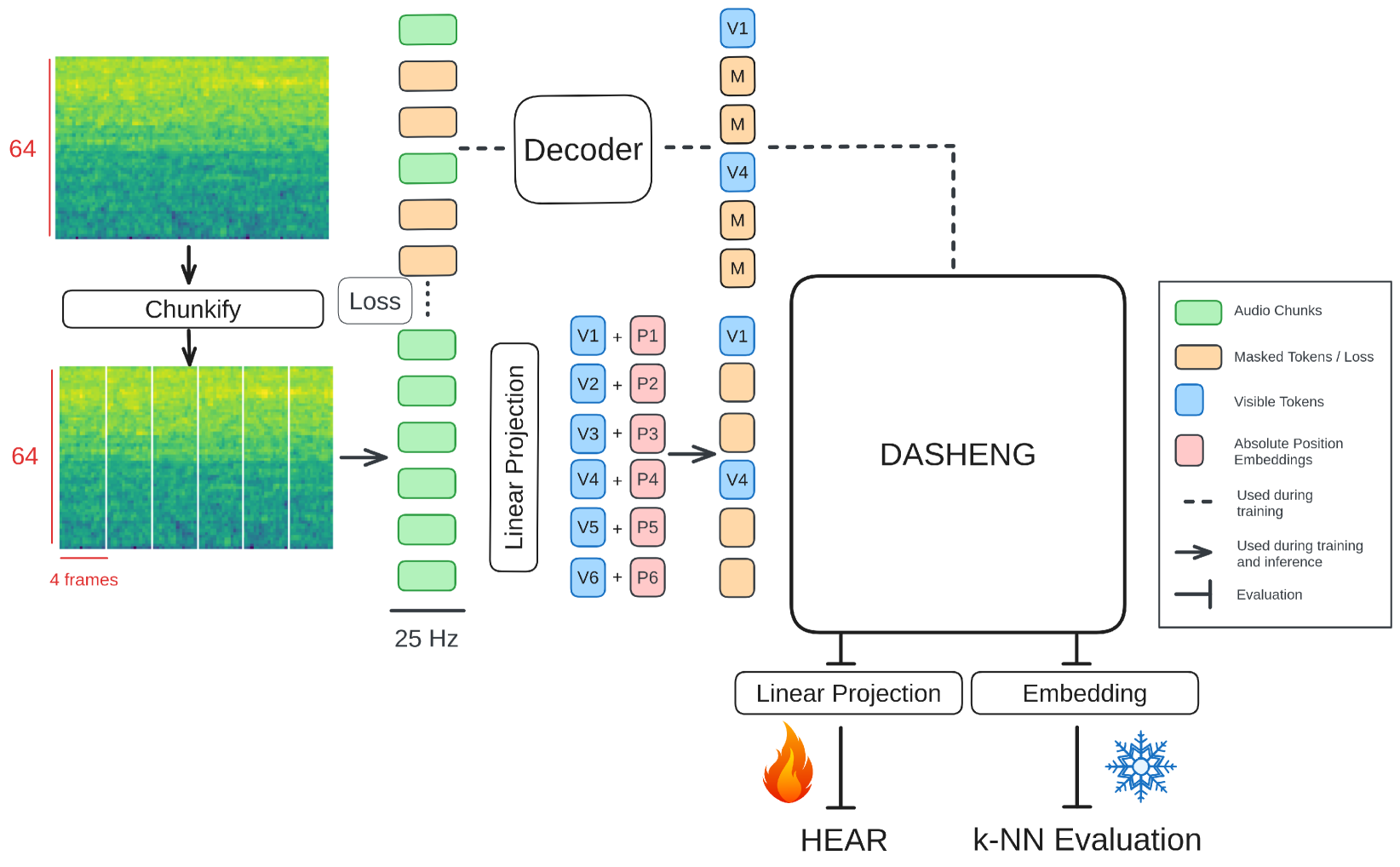
Dasheng 通过几个关键差异与之前的基于 MAE 的工作 [9] 区分开来。 值得注意的是,Dasheng 结合了可学习的绝对位置嵌入,以 25 Hz 的更高频率生成帧级嵌入(与之前方法中使用的 6.25 Hz 相比),并且对梅尔谱图帧的连续块进行操作,而不是采用早期方法中更常见的时间频率“补丁”表示。
3 实验
3.1 数据集
3.1.1 训练数据集
为了实现语音、音乐和环境声音的泛化,我们的工作利用了通用音频数据集,包括 AudioSet [10]、ACAV100M [11] 和 VGGSound [15]。 AudioSet、VGGSound 和 ACAV100M 包含来自 YouTube 视频的音频剪辑,提供了高度多样化的通用音频。 VGGSound 和 AudioSet 中的每个音频剪辑仅通过声音/视觉事件标签的存在来识别。 相反,ACAV100M 包含 1 亿个视频,这些视频是从一个更大的超集通过强大的音频-视觉相关性过滤得到的,即声音和视觉线索很可能是同步的。 由于上述数据集的部分不可用和获取困难,我们在 表 1 中提供了有关我们下载的数据集的深入信息。 本研究仅使用每个视频中包含的音频。 我们还添加了 MTG-Jamendo [16] 作为源,以进一步增强音乐任务的性能。 在训练期间,我们丢弃 MTG-Jamendo、VGGSound 和 AudioSet 中存在的任何标签,并在每个 epoch 中,我们根据 MSE 性能评估 VGGSound 的保留测试子集。
| Dataset | # Samples | Duration (h) | Type |
|---|---|---|---|
| ACAV100M | 94,934,272 | 263,000 | General |
| AudioSet | 1,904,747 | 5,100 | General |
| VGGSound | 176,819 | 488 | General |
| MTG-Jamendo | 55,701 | 3,768 | Music |
| All | 97,071,539 | 272,356 | General |
| Model | BJ | CD | D16 | E50 | F50k | GZ-Gen | GZ-M/S | Gun | LiCt | MST | Mri-S | Mri-T | NS-50 | NS-5 | SPC-5 | SPC-F | VI | VL |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CED-Base [17] | 96.6 | 69.1 | 92.2 | 96.7 | 65.5 | 88.6 | 94.4 | 89.3 | 67.9 | 14.8 | 97.4 | 96.6 | 82.8 | 68.2 | 86.9 | 89.7 | 22.7 | 38.6 |
| Whisper-base⋆ [18] | 94.5 | 71.3 | 9.2 | 77.1 | 43.1 | 81.0 | 95.3 | 80.4 | 63.9 | 0.0 | 96.5 | 89.5 | 59.3 | 36.8 | 96.8 | 97.9 | 19.7 | 88.7 |
| BYOL-S [2] | 95.3 | 65.7 | 64.2 | 80.5 | 50.9 | 83.7 | 93.9 | 85.7 | 78.5 | 0.8 | 97.3 | 92.9 | 71.2 | 39.6 | 91.4 | 94.8 | 16.0 | 45.8 |
| HuBERT-FUSE [2] | 94.9 | 75.2 | 82.6 | 74.4 | 41.3 | 79.6 | 93.6 | 92.9 | 68.3 | 16.6 | 97.4 | 90.9 | 68.8 | 38.2 | 94.7 | 95.7 | 18.5 | 71.4 |
| Sony-VIT [2] | 92.8 | 44.1 | 66.8 | 40.1 | 0.0 | 68.1 | 89.9 | 86.6 | 48.8 | 23.9 | 88.0 | 73.0 | 79.5 | 69.2 | 47.9 | 53.1 | 6.8 | 22.4 |
| Wav2Vec2 [2] | 90.7 | 65.6 | 66.3 | 56.1 | 34.2 | 78.0 | 94.6 | 84.8 | 69.2 | 3.3 | 94.3 | 82.8 | 65.3 | 40.2 | 83.8 | 87.9 | 8.0 | 49.3 |
| MSM-MAE [6] | 94.9 | 73.4 | 0.0 | 85.6 | 52.2 | 86.1 | 99.2 | 96.4 | 77.8 | 0.0 | 97.5 | 98.3 | 81.2 | - | - | 86.4 | 18.3 | 50.0 |
| AudioMAE⋆ [9] | 96.2 | 68.3 | 70.8 | 73.2 | 39.3 | 74.3 | 90.5 | 63.4 | 58.9 | 0.1 | 87.3 | 83.8 | 81.7 | 67.4 | 24.7 | 29.6 | 16.0 | 34.6 |
| Data2Vec⋆ [19] | 85.6 | 54.2 | 43.3 | 34.9 | 17.9 | 57.3 | 96.1 | 67.0 | 55.4 | 0.2 | 86.0 | 74.0 | 23.9 | 12.8 | 91.9 | 94.2 | 8.7 | 42.9 |
| Beats⋆ [5] | 95.8 | 68.1 | 43.0 | 81.9 | 51.4 | 87.0 | 98.5 | 90.5 | 74.6 | 0.0 | 96.1 | 96.0 | 82.0 | 68.6 | 88.2 | 91.5 | 13.5 | 43.8 |
| Beats⋆ [5] | 96.2 | 71.3 | 39.6 | 94.5 | 63.6 | 90.0 | 96.8 | 95.2 | 76.4 | 0.1 | 96.8 | 94.7 | 81.4 | 64.2 | 83.9 | 86.7 | 18.4 | 37.8 |
| ATST-Frame [20] | 95.8 | 76.7 | 95.7 | 89.0 | 55.7 | 88.3 | 100.0 | 94.3 | 78.1 | 24.4 | 97.5 | 94.1 | - | 68.6 | 92.6 | 95.1 | 22.3 | 66.9 |
| ATST-Clip [20] | 95.3 | 76.0 | 93.7 | 91.2 | 59.5 | 87.7 | 99.2 | 98.8 | 78.2 | 18.9 | 97.7 | 96.7 | - | 67.8 | 93.1 | 95.5 | 18.5 | 53.9 |
| HEAR SOTA | 97.5 | 76.7 | 95.7 | 96.7 | 65.5 | 96.7 | 100.0 | 100.0 | 78.5 | 46.9 | 97.7 | 96.7 | 90.0 | 87.8 | 97.6 | 97.8 | 22.7 | 72.2 |
| Dasheng-Base | 93.6 | 78.7 | 93.9 | 82.9 | 51.0 | 89.2 | 99.2 | 92.9 | 76.6 | 43.9 | 96.1 | 94.9 | 83.3 | 71.8 | 95.9 | 97.1 | 16.7 | 69.9 |
| Dasheng-0.6B | 94.9 | 81.2 | 94.4 | 85.9 | 53.9 | 88.6 | 97.6 | 97.6 | 80.7 | 43.5 | 96.6 | 96.2 | 85.8 | 74.6 | 97.0 | 97.5 | 17.8 | 74.7 |
| Dasheng-1.2B | 96.2 | 81.6 | 94.2 | 85.3 | 54.2 | 88.8 | 97.7 | 99.1 | 79.6 | 43.3 | 96.8 | 96.1 | 85.6 | 74.4 | 97.1 | 97.9 | 19.4 | 78.7 |
3.1.2 下游数据集
该研究主要在 HEAR 基准 [2] 上评估其结果。 HEAR 包含 19 个任务,广泛分为语音、音乐和环境。 语音类别中的任务包括 SpeechCommands (SPC) 5h/Full、Voxlingua (VL)、LibriCount (LiCt)、Vocal Imitations (VI) 和 CREMA-D (CD)。 在音乐类别中,任务包括京剧 (BJ)、GTZAN Genre (GZ-Gen)、GTZAN Music/Speech (GZ-M/S)、Mridangam Tonic (Mri-T)、Mridangam Stroke (Mri-S)、MEASTRO 5h (MST) 和 NSynth (NS) Pitch 5h/50h。 最后,与环境相关的任务包括 Beehive、DCASE16 (D16)、ESC-50 (E50) 和 FSD50k (F50k)。 此外,可以将这些任务分为 17 个片段级和 2 个帧级 (D16, MST) 分类任务。 HEAR 基准测试在冻结嵌入的基础上训练了一个浅层多层感知器 (MLP) 分类器。 有关数据集的更多信息,请参阅 [2]。 遵循先前的工作 [21],我们放弃了“Beehive”子任务,因为它的话语过于长,样本量过小,导致结果不一致。
3.1.3 嵌入提取
对于所有下游任务,我们使用最后一层的输出作为代表性嵌入,以 25 Hz 的频率提取。 在需要单个片段级嵌入的情况下,我们会对这些帧级嵌入进行平均池化。
3.2 设置
在数据处理方面,我们将所有数据集重新采样到 16 kHz,并每 提取 64 维对数梅尔谱图,窗口大小为 ,片段长度为 。 在训练期间,我们采用分组掩蔽策略来解决梅尔谱图的最后一帧包含未来帧信息的问题,具体来说,在本例中是接下来的三帧。 为了提高整体训练稳定性,我们在训练期间系统地丢弃至少两个连续的块(相当于 80 毫秒的音频)。 模型训练使用 8 位 AdamW 优化器 [22] ,并使用余弦衰减调度器,从 0.0003 的学习率和 0.01 的权重衰减开始。 较大的 1.2B 模型使用 0.0002 的学习率,不使用权重衰减。 一个训练时期涉及采样 15,000 个批次,训练持续时间为 100 个时期,相当于在我们训练数据集上进行 4 个完整的数据时期。 每个 GPU 的批次大小为 32,分布在八个 A100 GPU 上,训练大约需要四天才能完成 1.2B 模型的训练。 我们为学习率添加了 3 个时期的预热,然后在训练期间将其衰减到最大值的 10%。 Dasheng 每次最多可以处理 的音频。 在涉及较长输入的下游评估场景中,我们将音频分割成 块。 然后这些片段分别通过模型传递,并将得到的嵌入连接起来。 神经网络后端是在 Pytorch [23] 中实现的,源代码和预训练检查点已公开发布111https://github.com/RicherMans/Dasheng。
| Model | # Param | Depth | Embed | MLP | #Heads |
|---|---|---|---|---|---|
| Base | 12 | 768 | 3072 | 12 | |
| 0.6B | 32 | 1024 | 4096 | 16 | |
| 1.2B | 40 | 1536 | 6144 | 24 | |
| Dec-25M | 8 | 512 | 2048 | 16 | |
| Dec-56M | 8 | 768 | 3072 | 24 |
为了展示 MAEs 的扩展能力,我们训练了三个不同大小的模型,如 表 3 所示。 Dasheng-Base 代表文献中最常用的模型参数大小,我们在此基础上增加了 0.6B 和 1.2B 参数模型。 所有模型都与常见的视觉 Transformer (ViT) [24] 的设置相同,使用预归一化和 GeLU 激活。 在训练阶段,我们将 Dec-25M 附加到 Base 和 0.6B 编码器,而更大的 Dec-56M 用于 1.2B 模型。
4 结果
4.1 HEAR
关于 HEAR 基准测试的结果可以在 表 2 中看到。 此外,我们展示了通过监督预训练方法获得的顶级结果,特别是利用 CED-Base [17] 用于环境/音乐任务,利用 Whisper-base [18] 用于语音。 此外,我们还纳入了许多当前最先进的 SSL 嵌入 [20, 5] 以及常用的音频表示,如 Wav2Vec2 和 BYOL。 Dasheng 1.2B 在大多数任务中取得了令人印象深刻的性能,在 18 个任务中的 13 个任务中得分超过 80。 值得注意的是,它在情绪识别 (CD)、语言识别 (VL) 和关键词识别 (SPC) 方面表现出色,而 Dasheng 0.6B 在说话人计数 (LiCt) 方面表现突出。 对于情绪识别,Dasheng 1.2B 显著优于之前的尝试 (76.7 81.6)。 尤其值得注意的是,它在语言识别方面的准确率达到了 78.7%,超过了在 100,000 小时多语言语音上训练的 Wav2Vec2。 值得强调的是,VL 上报道的最佳结果 (Whisper,88.7%) 包括使用 小时的监督多语言语音训练数据。 另一个值得注意的结果是在 NS-50 上的音高估计,其中提出的模型可以达到高达 85 的分数。 这略低于当前 SOTA 得分 90,该得分由专门的音高估计器实现。 在帧级分类任务中,提出的模型表现出色,在 D16 中达到 94.4,在 MST 中达到 43.9,分别略低于 SOTA 性能 95.7 和 46.9。 为了直观地了解 HEAR 的能力,请参考 图 1。
4.2 跨域能力
在本节中,我们对 表 2 中的发现进行了总结,并将它们分为三个音频类别:环境 (Env)、语音和音乐,通过对每个子任务的得分进行平均,结果在 表 4 中给出。 值得注意的是,在环境分类中,Dasheng 被 CED-Base 超越,但 CED-Base 在语音分类中表现不佳。 Dasheng 在语音相关任务中表现出色,超过了 Whisper-Base 和 Wav2Vec2。 最后,可能是由于音乐相关训练数据的数量,所有提出的模型在音乐相关任务中都显著优于之前的工作。 平均而言,提出的模型优于之前的工作,证明了其在音频领域的通用性。
| Model | Env | Speech | Music | Average |
|---|---|---|---|---|
| CED-Base | 85.90 | 62.47 | 79.91 | 76.09 |
| Whisper-Base | 52.45 | 73.06 | 69.10 | 64.87 |
| Wav2Vec2 | 60.35 | 60.63 | 68.65 | 63.21 |
| MSM-MAE | 78.07 | 61.18 | 69.65 | 69.63 |
| AudioMAE | 61.66 | 38.68 | 72.66 | 57.67 |
| Data2Vec | 40.77 | 57.87 | 54.48 | 51.04 |
| Beats | 66.68 | 63.28 | 78.00 | 69.32 |
| Beats | 73.23 | 62.40 | 77.52 | 71.05 |
| ATST-Frame | 83.68 | 71.95 | 71.09 | 75.57 |
| ATST-Clip | 85.80 | 69.20 | 70.41 | 75.14 |
| Dasheng-Base | 80.15 | 72.48 | 84.01 | 78.88 |
| Dasheng-0.6B | 82.38 | 74.89 | 84.04 | 80.44 |
| Dasheng-1.2B | 83.20 | 75.71 | 84.86 | 81.25 |
4.3 K-最近邻分类
在本节中,我们有兴趣进一步探索嵌入的性能,这些嵌入不进行参数化、监督微调,因此,我们在九个任务上执行简单的 k-最近邻 (k-NN) 分类。 我们特别使用 Fluent Speech Commands (FSC) [25]、UrbanSound8k (US8k) [26]、NSynth Instrument (NS) [27]、VoxCeleb1 [28]、RAVDESS-Speech [29]、FSDKaggle2018 [30] (FSDK18)、Speechcommands 1 和 2 (10/35 类) 和 ESC-50 [31]。 所有任务都在片段级别进行评估,方法是将所有帧级表示进行平均池化,采用与一致的设置进行评估,准确率作为主要指标。 RAVDESS、US8k 和 ESC-50 的性能通过 k 折交叉验证进行评估,而其他任务使用保留的测试集。 为了比较,我们包含 AudioMAE [9] 基线。 表 5 中的结果表明 Dasheng 嵌入本质上是用于一般音频分类任务的强大表示。 值得注意的是,对于两个关键字识别任务 (SPC1/2),Dasheng 1.2B 分别实现了 95% 和 90.7% 的惊人准确率,显著优于 AudioMAE 基线。 此外,NS 上的乐器分类实现了 71.2% 的准确率,表明其在音乐分类方面具有很强的能力。 令人惊讶的是,说话人识别 (VoxCeleb1) 的结果表明,Dasheng 中存在说话人信息,实现了高达 39.4% 的准确率,显著优于基线。 这一令人惊讶的结果促使我们在 VoxCeleb1 上进行线性评估,分别针对 Base、0.6B 和 1.2B 模型实现了 82.5%、89.4% 和 92.5% 的准确率。 未来,我们旨在对 Dasheng 进行进一步实验,重点关注语音识别和说话人识别。
| Domain | Task | AudioMAE | Dasheng | ||
|---|---|---|---|---|---|
| Base | 0.6B | 1.2B | |||
| Env | ESC50 | 53.1 | 61.9 | 66.6 | 68.6 |
| FSDK18 | 43.4 | 70.3 | 72.1 | 72.1 | |
| US8k | 58.2 | 73.9 | 75.9 | 77.7 | |
| Music | NS | 67.2 | 70.0 | 70.9 | 71.2 |
| Speech | SPC1 | 56.9 | 93.6 | 93.4 | 95.9 |
| SPC2 | 5.9 | 86.0 | 87.3 | 90.9 | |
| VoxCeleb1 | 2.9 | 34.2 | 37.8 | 39.4 | |
| RAVDESS | 28.7 | 58.1 | 61.8 | 61.9 | |
| FSC | 7.6 | 52.3 | 57.6 | 62.4 | |
4.4 扩展对性能的影响
在这里,我们评估了数据集和模型大小扩展对性能的影响。 在此实验中,我们使用部分 3.2中概述的设置在 AudioSet 上进行了 30 个轮次的训练。 结果显示在表 6中。 正如我们所见,在 AS 上进行训练时,增加模型大小始终可以提高性能。 然而,同时增加数据集大小和模型大小会导致显著的性能提升, 分别使 Base、0.6B 和 1.2B 模型的平均性能提高了 6.37、8.69 和 8.45 个点。
| Model | Training data | Difference | |
|---|---|---|---|
| AS | Ours | ||
| Base | 70.43 | 78.88 | +8.45 |
| 0.6B | 71.75 | 80.44 | +8.69 |
| 1.2B | 74.87 | 81.25 | +6.37 |
5 结论
我们介绍了 Dasheng,一个用于音频分类任务的通用模型。 Dasheng 基于高效的 MAE 框架,这使得在有限的大型 GPU 集群访问的情况下,在 272,356 小时的数据上训练一个 12 亿参数模型成为可能。 HEAR 基准测试中的 MLP 评估结果表明,在 18 个任务中表现出色,同时在四个任务中也优于之前的尝试。 值得注意的是,Dasheng 在关键词识别、语言识别、说话人计数和情绪分类方面取得了优异的性能,同时能够进行音符和流派分类,并且在环境声音事件分类方面具有竞争力。 进一步的 k-NN 评估表明,Dasheng 特征可以直接用于各种下游任务的分类任务,无需参数化。 最重要的是,本文提供了经验证据,表明使用 MAE 框架对音频表示进行大规模预训练会导致性能大幅提升。
参考文献
- [1] H. Dinkel, Z. Yan, Y. Wang, J. Zhang, and Y. Wang, “An empirical study of weakly supervised audio tagging embeddings for general audio representations,” in Odyssey 2022: The Speaker and Language Recognition Workshop, 28 June - 1 July 2022, Beijing, China, T. F. Zheng, Ed. ISCA, 2022, pp. 390–395. [Online]. Available: https://doi.org/10.21437/Odyssey.2022-54
- [2] J. Turian, J. Shier, H. R. Khan, B. Raj, B. W. Schuller, C. J. Steinmetz, C. Malloy, G. Tzanetakis, G. Velarde, K. McNally et al., “Hear: Holistic evaluation of audio representations,” in NeurIPS 2021 Competitions and Demonstrations Track. PMLR, 2022, pp. 125–145.
- [3] A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020.
- [4] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009.
- [5] S. Chen, Y. Wu, C. Wang, S. Liu, D. Tompkins, Z. Chen, and F. Wei, “Beats: Audio pre-training with acoustic tokenizers,” arXiv preprint arXiv:2212.09058, 2022.
- [6] D. Niizumi, D. Takeuchi, Y. Ohishi, N. Harada, and K. Kashino, “Masked spectrogram modeling using masked autoencoders for learning general-purpose audio representation,” in HEAR: Holistic Evaluation of Audio Representations (NeurIPS 2021 Competition), ser. Proceedings of Machine Learning Research, vol. 166. PMLR, 13–14 Dec 2022, pp. 1–24.
- [7] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar et al., “Bootstrap your own latent-a new approach to self-supervised learning,” Advances in neural information processing systems, vol. 33, pp. 21 271–21 284, 2020.
- [8] D. Niizumi, D. Takeuchi, Y. Ohishi, N. Harada, and K. Kashino, “BYOL for Audio: Exploring pre-trained general-purpose audio representations,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, p. 137–151, 2023. [Online]. Available: http://dx.doi.org/10.1109/TASLP.2022.3221007
- [9] P.-Y. Huang, H. Xu, J. Li, A. Baevski, M. Auli, W. Galuba, F. Metze, and C. Feichtenhofer, “Masked autoencoders that listen,” Advances in Neural Information Processing Systems, vol. 35, pp. 28 708–28 720, 2022.
- [10] J. F. Gemmeke, D. P. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 776–780.
- [11] S. Lee, J. Chung, Y. Yu, G. Kim, T. Breuel, G. Chechik, and Y. Song, “Acav100m: Automatic curation of large-scale datasets for audio-visual video representation learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 274–10 284.
- [12] D. Niizumi, D. Takeuchi, Y. Ohishi, N. Harada, and K. Kashino, “Masked modeling duo: Learning representations by encouraging both networks to model the input,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [13] H. Liu, Q. Tian, Y. Yuan, X. Liu, X. Mei, Q. Kong, Y. Wang, W. Wang, Y. Wang, and M. D. Plumbley, “Audioldm 2: Learning holistic audio generation with self-supervised pretraining,” arXiv preprint arXiv:2308.05734, 2023.
- [14] S.-B. Kim, S.-H. Lee, H.-Y. Choi, and S.-W. Lee, “Audio super-resolution with robust speech representation learning of masked autoencoder,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 1012–1022, 2024.
- [15] H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “Vggsound: A large-scale audio-visual dataset,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 721–725.
- [16] D. Bogdanov, M. Won, P. Tovstogan, A. Porter, and X. Serra, “The mtg-jamendo dataset for automatic music tagging,” in Machine Learning for Music Discovery Workshop, International Conference on Machine Learning (ICML 2019), Long Beach, CA, United States, 2019. [Online]. Available: http://hdl.handle.net/10230/42015
- [17] H. Dinkel, Y. Wang, Z. Yan, J. Zhang, and Y. Wang, “Ced: Consistent ensemble distillation for audio tagging,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
- [18] A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International Conference on Machine Learning. PMLR, 2023, pp. 28 492–28 518.
- [19] A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “Data2vec: A general framework for self-supervised learning in speech, vision and language,” in International Conference on Machine Learning. PMLR, 2022, pp. 1298–1312.
- [20] X. Li, N. Shao, and X. Li, “Self-supervised audio teacher-student transformer for both clip-level and frame-level tasks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024.
- [21] J. Anton, H. Coppock, P. Shukla, and B. W. Schuller, “Audio barlow twins: Self-supervised audio representation learning,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
- [22] T. Dettmers, M. Lewis, S. Shleifer, and L. Zettlemoyer, “8-bit optimizers via block-wise quantization,” 9th International Conference on Learning Representations, ICLR, 2022.
- [23] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “PyTorch: An Imperative Style, High-Performance Deep Learning Library,” in Advances in Neural Information Processing Systems 32, H. Wallach, H. Larochelle, A. Beygelzimer, F. Alché-Buc, E. Fox, and R. Garnett, Eds. Curran Associates, Inc., 2019, pp. 8026–8037.
- [24] A. Kolesnikov, A. Dosovitskiy, D. Weissenborn, G. Heigold, J. Uszkoreit, L. Beyer, M. Minderer, M. Dehghani, N. Houlsby, S. Gelly, T. Unterthiner, and X. Zhai, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021.
- [25] L. Lugosch, M. Ravanelli, P. Ignoto, V. S. Tomar, and Y. Bengio, “Speech model pre-training for end-to-end spoken language understanding,” arXiv preprint arXiv:1904.03670, 2019.
- [26] J. Salamon, C. Jacoby, and J. P. Bello, “A dataset and taxonomy for urban sound research,” in Proceedings of the 22nd ACM international conference on Multimedia, 2014, pp. 1041–1044.
- [27] J. Engel, C. Resnick, A. Roberts, S. Dieleman, M. Norouzi, D. Eck, and K. Simonyan, “Neural audio synthesis of musical notes with wavenet autoencoders,” in International Conference on Machine Learning. PMLR, 2017, pp. 1068–1077.
- [28] A. Nagrani, J. S. Chung, and A. Zisserman, “Voxceleb: a large-scale speaker identification dataset,” arXiv preprint arXiv:1706.08612, 2017.
- [29] S. R. Livingstone, K. Peck, and F. A. Russo, “Ravdess: The ryerson audio-visual database of emotional speech and song,” in Annual meeting of the canadian society for brain, behaviour and cognitive science, 2012, pp. 205–211.
- [30] E. Fonseca, J. Pons Puig, X. Favory, F. Font Corbera, D. Bogdanov, A. Ferraro, S. Oramas, A. Porter, and X. Serra, “Freesound datasets: a platform for the creation of open audio datasets,” in Proceedings of the 18th ISMIR Conference, p. 486-93. International Society for Music Information Retrieval (ISMIR), 2017.
- [31] K. J. Piczak, “Esc: Dataset for environmental sound classification,” in Proceedings of the 23rd ACM international conference on Multimedia, 2015, pp. 1015–1018.