./main.bib ./juergen.bib **脚注文本:平等贡献。 通讯至yuhui.wang@kaust.edu.sa
将价值迭代网络扩展到 5000 层
以实现超长期规划
摘要
价值迭代网络 (VIN) 是一种端到端可微架构,可在潜在 MDP 上执行价值迭代,以便在强化学习 (RL) 中进行规划。 然而,VIN 很难扩展到长期和大规模的规划任务,例如导航 迷宫,这项任务通常需要数千个规划步骤才能解决。 我们观察到这种缺陷是由于两个问题造成的:潜在 MDP 的表示能力和规划模块的深度。 我们通过使用动态转换内核增强潜在 MDP 来解决这些问题,显着提高其表示能力,并且为了缓解梯度消失问题,引入“自适应高速公路损失”来构建跳跃连接以改善梯度流。 我们在 2D 迷宫导航环境和 ViZDoom 3D 导航基准测试中评估我们的方法。 我们发现我们的新方法,名为动态过渡 VIN (DT-VIN),可以轻松扩展到 5000 层,并轻松解决上述任务的挑战性版本。 总而言之,我们相信 DT-VIN 代表了在 RL 环境中执行长期大规模规划的具体一步。
1简介
规划是找到实现特定预定义目标的一系列行动的问题。 作为一些较旧的算法的目的(例如,dyna sutton191dyna,a* hart1968formal和其他schmidhuber:90diffgenau,schmidhuber:90sandiego)和许多最近的人(e.g. FNER2023Mastering, SoRB eysenbach2019search、SA-CADRL chen2017socially 和 LLM-planner Song2023llm),有效规划是人工智能 (AI) 领域长期存在的重要挑战。 在强化学习(RL)中,一种特别值得注意的方法是 tamar2016value 提出的价值迭代网络(VIN)。
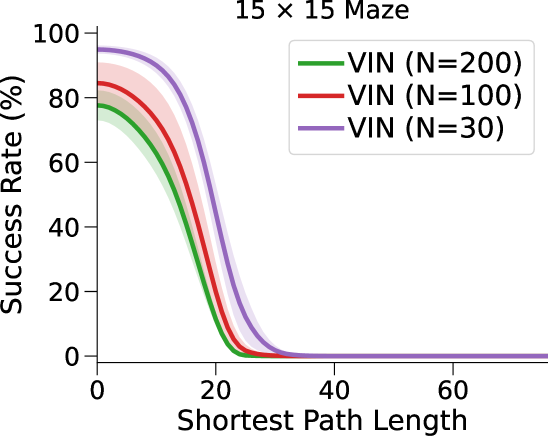
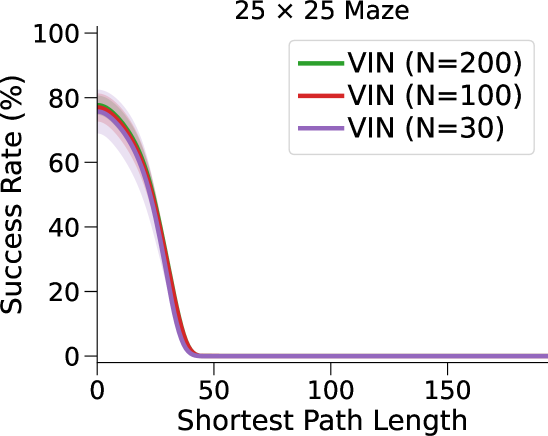
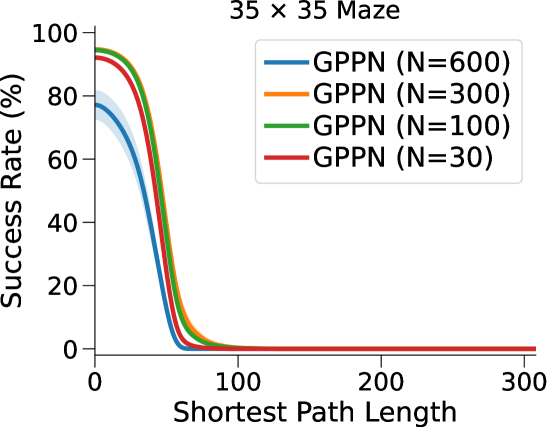
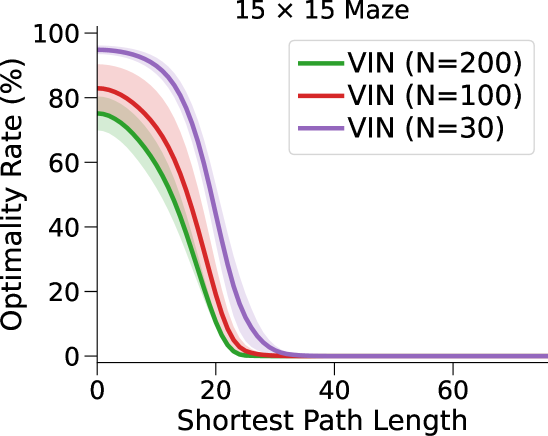
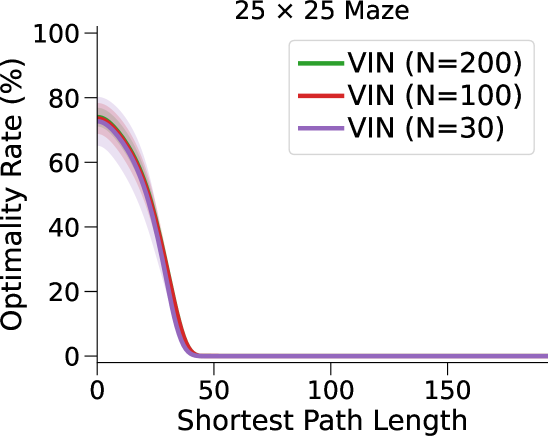
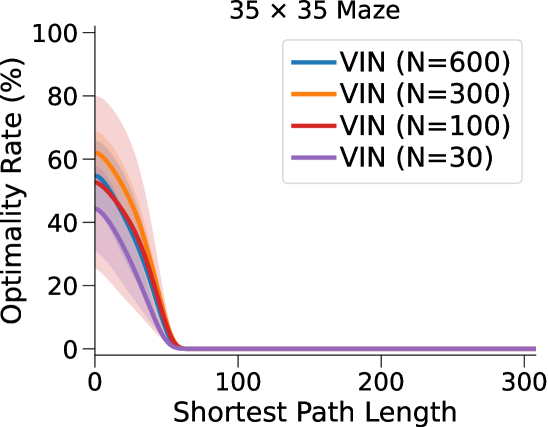
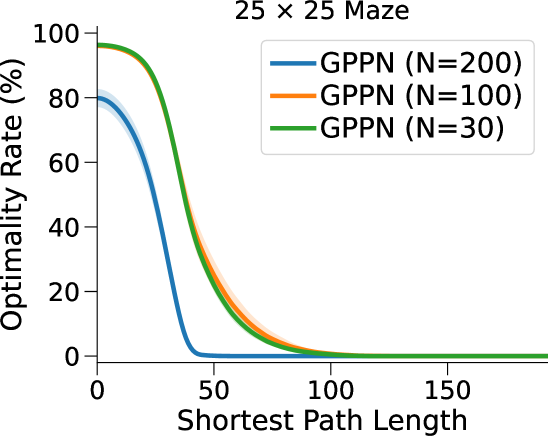
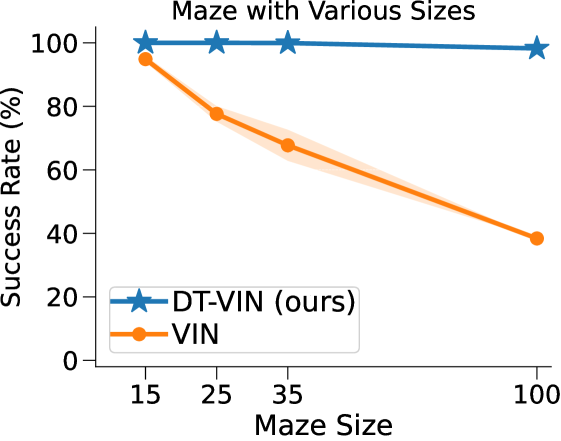
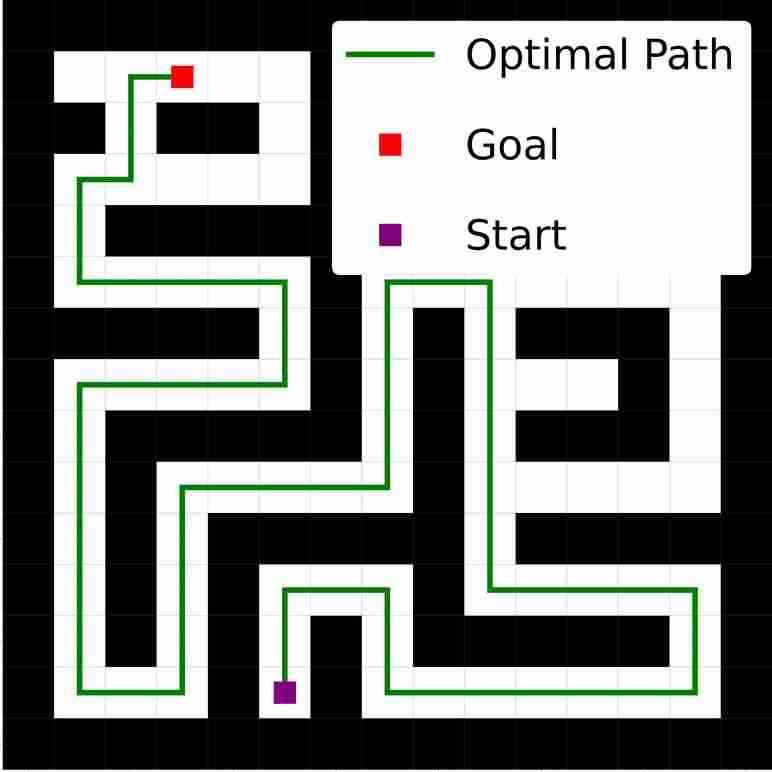
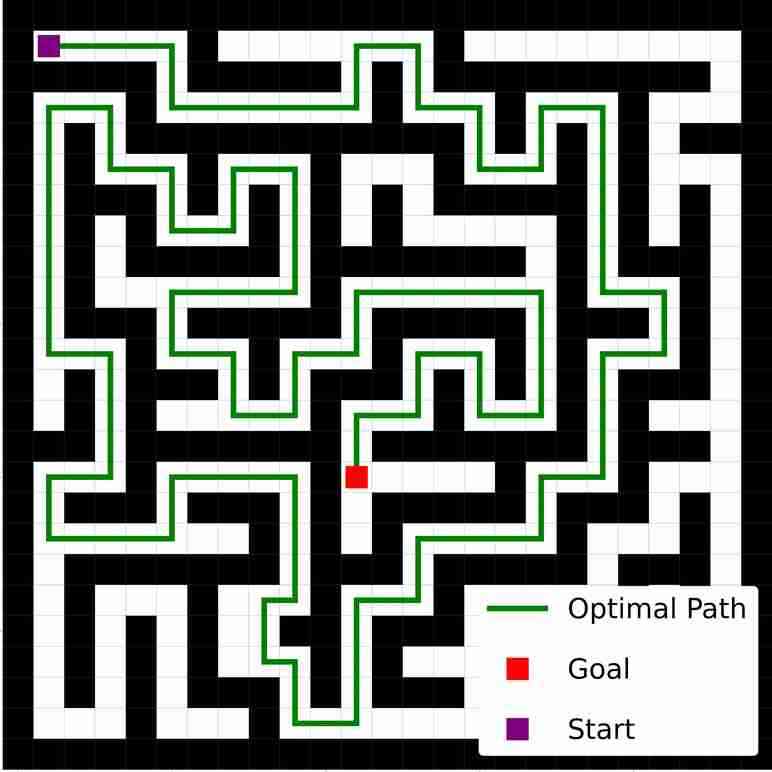
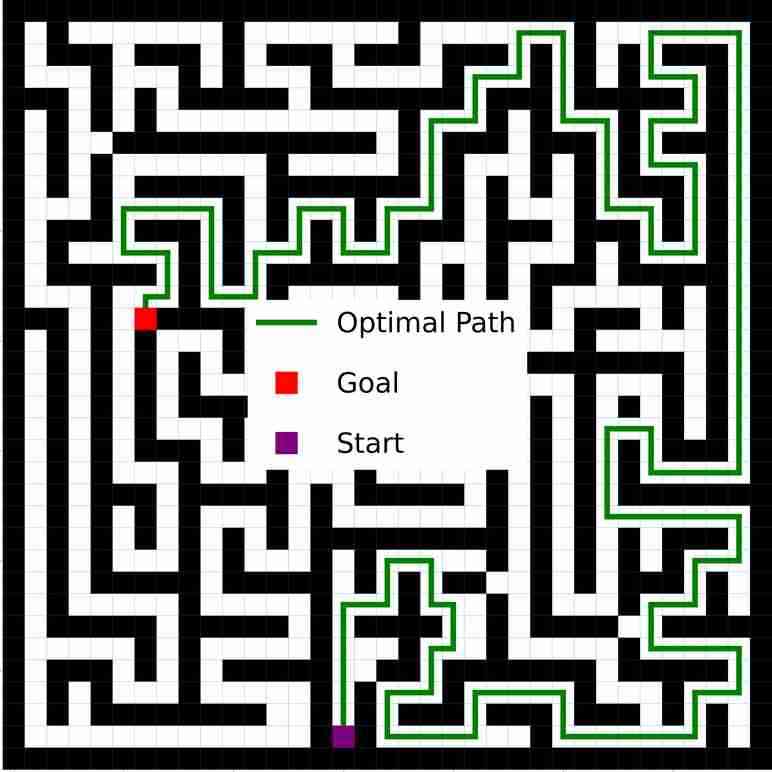
VIN 是一种专为规划而设计的人工神经网络 (NN) 架构,包含可微分的“规划模块”,可在“潜在 MDP”上执行价值迭代bellman1966dynamic。 VIN 已被证明在一些小规模短期规划情况下表现得异常出色,例如路径规划 pflueger2019rover、jin2021value、自主导航 wohlke2021hierarchies 以及动态环境中的复杂决策 li2021dynamic。 然而,他们仍然在努力解决更大规模和更长期的规划问题。 例如,在迷宫导航任务中,VIN达到目标的成功率远低于40%(参见图 1(b ))。 即使在较小的迷宫中,当所需的规划步骤超过60时,VIN的成功率也会下降至0%(参见图 1(c))。
我们的工作发现,造成这种情况的主要缺陷是规划的复杂性与其所使用的相对较浅的网络的相对较弱的表示能力之间的不匹配。 尽管在学习更复杂的网络(例如 GPPN lee2018ated 和高速公路 VIN wang2024highway)方面取得了一定的成功,但到目前为止,由于长期存在的问题,能够进行长期或大规模规划的 VIN 尚未在计算上易于处理。梯度消失和爆炸——深度学习的一个基本问题 Hochreiter:91。
在这项工作中,我们的目标是通过手术纠正基于 VIN 的架构的缺陷,以实现大规模的长期规划。 具体来说,我们首先确定了 VIN 中潜在 MDP 的局限性,并提出了一个动态转换内核来显着提高网络的表示能力。 然后,我们以现有工作为基础,确定了网络深度与长期规划 wang2024highway 之间的联系,并提出了一种“自适应高速公路损失”,根据规划步骤的实际数量有选择地构建与最终损失的跳跃连接。 这种方法有助于缓解梯度消失问题,并能够训练非常深的网络。 通过这些更改,我们发现新的动态转换值迭代网络 (DT-VIN) 能够使用 层进行训练,并且可以轻松地进行训练在迷宫导航任务中扩展到个规划步骤(与原始VIN相比,它在迷宫中仅扩展到120个规划步骤)。 我们将我们的方法应用于自上而下的基于图像的迷宫导航任务和基于第一人称图像的 ViZDoom 基准 Wydmuch2019ViZDoom。 我们发现 DT-VIN 可以轻松解决这两个问题,尽管这些问题需要数百到数千个规划步骤。 总之,这些证明了我们的方法在基于视觉的任务上的实用性,而以前的方法根本无法解决这些任务。 这也凸显了我们的方法在计算能力可用性不断提高的情况下扩展到日益复杂的规划任务的潜力。
2 预赛
强化学习(RL)。
强化学习最常见的形式是马尔可夫决策过程 (MDP)bellman1957markovian。 根据 puterman2014markov,我们将 MDP 视为 元组 (),其中 是可数状态空间,是有限动作空间,表示处于状态并采取动作时转移到状态的概率, 是标量奖励函数, 是折扣因子, MDP 中人工代理的行为由其策略 定义,该策略指定在状态 下采取操作 的概率。状态价值函数是状态和遵循策略的奖励的预期贴现总和,即。 强化学习的目标通常是找到一个最优策略,以实现最高的预期奖励贴现总和。 最优策略的价值函数用表示,并且满足。 值迭代(VI)算法迭代地将以下更新应用于所有状态以获得最优值函数:,其中是迭代次数。
卷积神经网络 (CNN)。
CNN 是专门处理具有网格结构的数据的神经网络,例如图像 Fukushima:1979neocognitron、waibel1987phoneme、zhang1988shift。 CNN 前向传递通常涉及多个卷积层(其中使用可学习滤波器在输入数据上滑动并创建特征图)和最大池层(其中特征图的维度会减小)。 形式上,堆叠的最大池化层和卷积层执行以下操作:,其中是激活函数,是包含 通道, 是内核, 表示以像素 为中心的 补丁。
价值迭代网络 (VIN)。
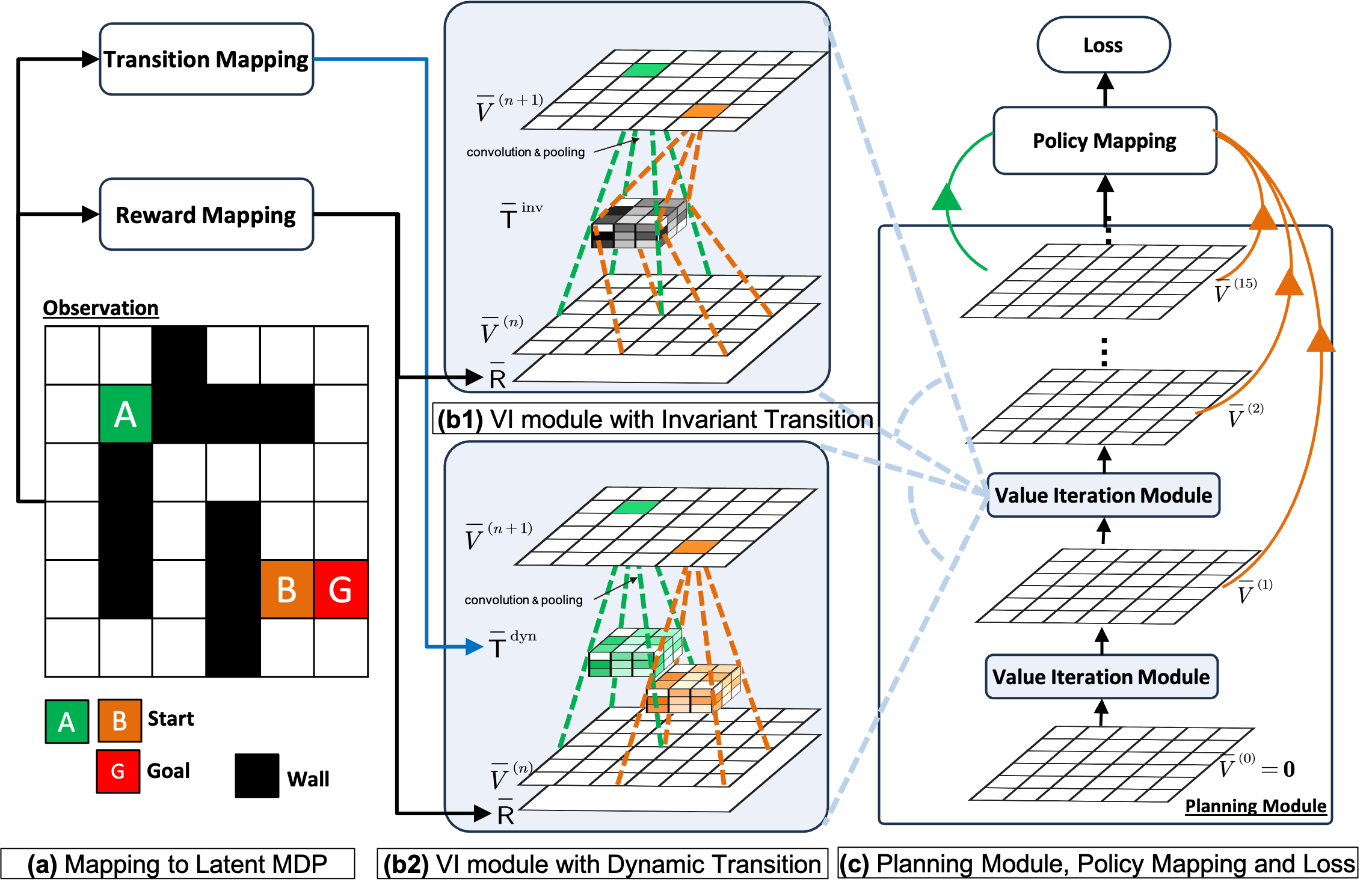
VIN 是一种用于规划的端到端可微神经网络架构,通过合并显式规划模块 tamar2016value,展示了对未见领域的强大泛化能力。 VIN 的主要思想是将观测值映射到潜在 MDP 中,然后使用嵌入式规划模块对此潜在 MDP 执行值迭代(VI)。 下面,我们使用 来表示与潜在 MDP 相关的所有术语。
对于每个决策,VIN 首先将观察结果 (例如迷宫图像和代理的当前位置)映射到 。 由潜在状态空间描述;固定的离散潜在动作空间;潜在奖励矩阵,其中是一个可学习的神经网络,称为奖励映射模块;和潜在转移矩阵(或内核)。 潜在转移矩阵是一个参数矩阵,对于每个潜在状态 都是不变,与观察无关***尽管原始 VIN 论文提出了一个通用框架,其中潜在转换内核取决于观察,即 ,但它将其实现为实际中的独立参数。 ,并且不限于满足概率属性,即其元素不需要表示概率或总和为一。 接下来,VIN 对潜在 MDP 进行 VI 以逼近潜在最优值函数 。 为了保证VI计算的可微性,提出了可微VI模块。 该模块使用可微分 CNN 运算(即卷积和最大池运算)模拟 VI 计算: . 该方程对以位置 为中心的矩阵块求和。
在上面之后,通过堆叠 层的 VI 模块,然后通过 将潜在值函数馈送到策略映射模块,以表示适用于实际 MDP 的策略。 最后,模型可以通过标准 RL 和 IL 算法进行训练,一般损失如下:,其中 是训练数据, 是观察结果,是标签,是样本损失函数。 这些项目的具体含义因任务而异,例如,在模仿学习中,标签 是最优动作, 是交叉熵损失。
3方法
在本节中,我们讨论如何为长期大规模规划任务训练可扩展的 VIN。 我们的方法解决了 VIN 的两个被认为阻碍其可扩展性的关键问题:潜在 MDP 表示的容量和规划模块的深度。
3.1 增加潜在MDP的表示能力
动机。
VIN利用VI和CNN之间的计算相似性,通过基于CNN的VI模块直接实现VI,如部分2中所述。 然而,基于CNN的VI模块和一般的VI计算过程之间存在差异。
基于 CNN 的 VIN 使用不变潜在转换内核作为可学习参数,该参数对于每个潜在状态都是相同的,并且与当前观察无关,例如迷宫地图。 这严重限制了潜在 MDP 的表征能力,为了有效,潜在 MDP 应该模拟实际 MDP 的复杂且依赖于状态的转换函数。 例如,在图1(a)所示的迷宫导航问题中,如果相邻单元是墙,则转移概率有很大不同与空单元格相比。 此外,由于 VIN 的潜在转变内核独立于真实观测,VIN 无法利用观测中的任何信息来同时模拟不同环境的不同转变动态。 在迷宫示例中,这意味着它将非常困难,因为该模型用于规划完全不同的迷宫。
总而言之,这种表示能力的缺乏并不影响 VIN 在小规模、短期规划任务中的表现(正如在原始工作中测试的那样),其中状态空间有限,只需要几个步骤即可达到目标。 然而,我们发现它是 VIN 在大规模、长期规划任务中发挥作用的主要障碍。 正如我们在图1(c)中所示,VIN在大规模迷宫导航任务和长时间任务中失败。 - 需要 60 多个步骤的短期计划任务。
方法。
由于上述原因,我们的目标是提高 VIN 潜在 MDP 的表示能力。 为此,我们提出了一种称为动态转换 VIN (DT-VIN) 的新架构。 DT-VIN 没有使用不变的潜在转换内核,而是采用动态潜在转换内核 ,它将观察结果输入到可学习的转换映射模块 并动态输出每个潜在状态的潜在转换内核。 增强动态转换VI模块计算如下:
| (1) |
转换映射模块可以是任何类型的神经网络,例如CNN或全连接网络。 在我们的迷宫导航任务中,仅包含一个内核大小为的卷积层,它迭代地将迷宫的每个局部补丁映射到潜在的每个潜在状态的转换内核。 与原始 VIN 的 相比,此架构需要 个参数。 请注意,在实践中,使用 的较小内核大小 足以产生强大的性能。 因此,这个替代模块极大地提高了 VIN 的表示能力,但通常不会导致训练成本发生显着变化。
3.2增加规划模块的深度
动机。
最近对高速公路 VIN 的研究证明了 VIN 规划模块的深度与其规划能力 wang2024highway 之间的关系。 更深的规划模块意味着价值迭代过程的更多次迭代,这被证明可以更准确地估计最优价值函数(参见定理 1.12 agarwal2019reinforcement)。 然而,由于梯度消失或爆炸问题 Hochreiter:91,训练非常深的神经网络具有挑战性。 高速公路 VIN 通过在强化学习的背景下合并跳跃连接来解决这个问题,显示出与分类任务 srivastava2015training、he2016deep 的现有工作的相似之处。 尽管高速公路 VIN 可以进行多达 300 层的训练,但它们在更大规模和更长期的规划任务中仍然无法获得完美的分数,并且需要更复杂的实现。 在这里,我们提出了一种更简单、易于实现的方法来训练非常深的 VIN。
方法。
为了便于训练非常深的 VIN,我们还采用了跳跃连接结构,但实现方式不同。 我们的中心见解是,与长期规划任务相比,短期规划任务通常需要更少的价值迭代迭代。 这是因为当距离较短时,从目标位置到起始位置的信息传播到起始位置的步数较少。 因此,当任务只需要几个步骤时,我们建议直接向较浅的层添加额外的损失。 我们通过引入以下自适应高速公路损失来实现这一目标:
| (2) |
这里,、是指标函数,是超参数,是实际需要的规划步骤数。任务,可以从训练数据中推断出来。 例如,在迷宫导航任务的模仿学习中,对于数据集中的每个迷宫,是提供的从起点到目标的最短路径的长度。
正如 Equation 2 所暗示的那样,它为隐藏层构建了跳跃连接以增强信息流,类似于 Highway Nets 和 Residual Nets 等现有工作srivastava2015年训练,他2016年深度。 然而,我们将隐藏层直接连接到最终损失,而现有的工作通常连接中间层之间的跳过连接。 请注意,我们为每个层 而不是在特定层 构建跳过连接。 这是因为深度 的相对较深的 VIN 也有利于在短期规划任务中输出正确的操作。 此外,在执行阶段,实际的规划步骤是未知的,因此仅使用VIN最后一层的输出。 请注意,这种额外的损失不会改变值迭代过程的固有结构,并将在执行阶段被删除。 此外,为了降低计算复杂度,我们仅将自适应高速公路损失应用于满足条件的层。
为了避免梯度爆炸问题,我们对每个潜在状态 的潜在转换内核的值强制执行 softmax 操作。 这为潜在转换内核提供了统计语义。 这个改变很简单,但对训练稳定性至关重要,如部分4.1和图<的实验结果所示/t4> 4(d)。
4实验
我们进行了多项实验来测试我们对 VIN 规划模块的修改是否允许为大规模长期规划任务训练非常深的 DT-VIN。 与之前的工作(例如 lee2018ated)一致,我们评估了 2D 迷宫和 3D ViZDoom Wydmuch2019ViZDoom 环境中导航任务的规划算法。 每个任务都包括一个起始位置和一个目标位置,代理通过在四个基本方向中的任何一个方向上一次移动一步来导航四个相邻的单元格。 我们的实验着眼于每种方法在多个版本的任务中的有效性,不同版本具有不同的最短路径长度 (SPL)。 SPL 是使用 Dijkstra 算法预先计算的,可以作为规划任务复杂性的良好代理度量。 如果代理在预定步数内生成从起始位置到目标位置的路径(在我们的论文中为),我们就说代理成功完成了任务。 如果相应的路径具有最小长度,我们进一步说智能体已经找到了最佳路径。 我们遵循 GPPN 并将其用于成功率 (SR)(算法在任务中成功的比率)和最优率 (OR)(即是算法生成最佳路径的速率。
在上述任务上,我们将我们的 DT-VIN 方法与为规划任务设计的几种先进神经网络进行比较,包括原始的 VIN tamar2016value、GPPNs lee2018ated 和 Highway VIN wang2024highway。 使用标记数据集通过模仿学习来训练模型。 然后,我们根据验证数据集上的结果确定性能最佳的模型,并在单独的测试数据集上对其进行评估。 遵循 GPPN 论文中的方法,我们对每种算法使用三种不同的随机种子进行评估。 由于我们在任务中观察到的标准偏差较低,这足以在这里提供可靠的性能估计。 显示学习曲线的所有图表均报告测试集的平均值和标准差。
4.1 2D迷宫导航
环境。
在我们的评估中,我们使用尺寸 设置为 、、 和 其中许多迷宫需要数百或数千个规划步骤才能解决。 为了评估每种算法的性能,我们测试了各种神经网络深度。具体来说,对于大小为 和 的迷宫,我们检查 中的深度。 对于,我们检查中的深度。 对于最大的迷宫 ,我们检查 的深度,但 GPPN 除外,由于 GPU 资源限制,其仅限于 。 对于每个迷宫大小,我们按照 GPPN lee2018ated 中的方法生成一个数据集。 每个样本都有一个起始位置、 地图的直观表示以及指示目标位置的 矩阵。 有关更多详细信息,请参阅部分B.1。
结果与讨论。
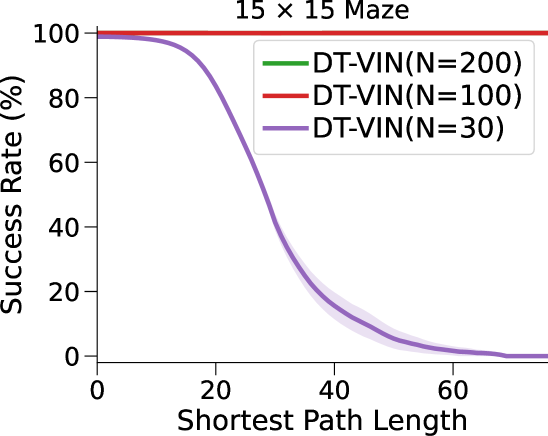
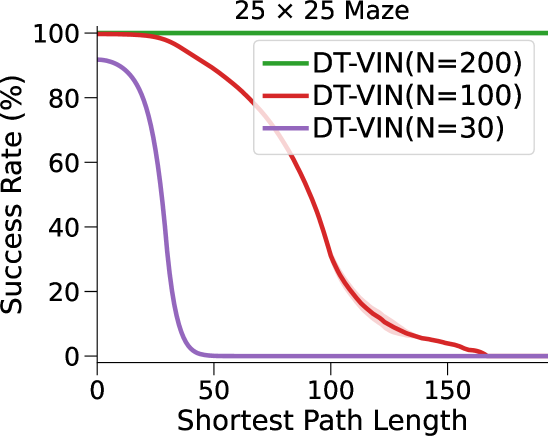
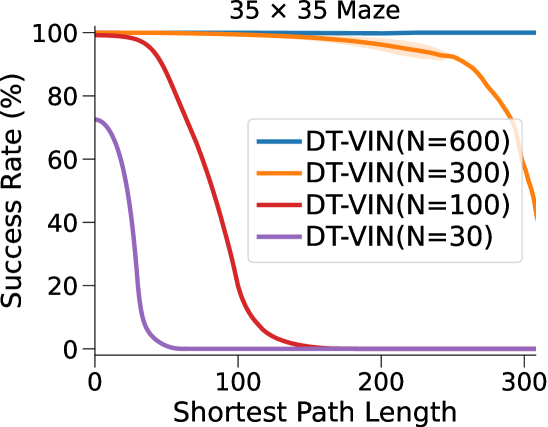
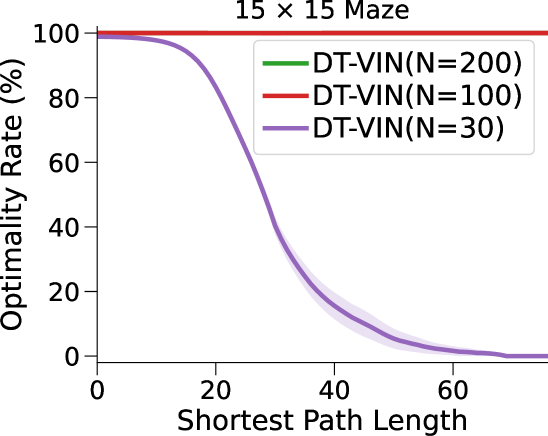
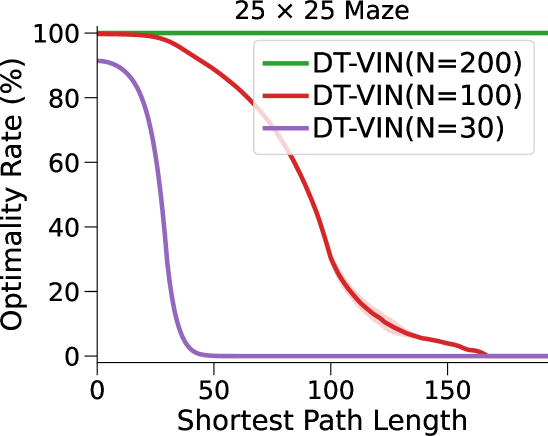
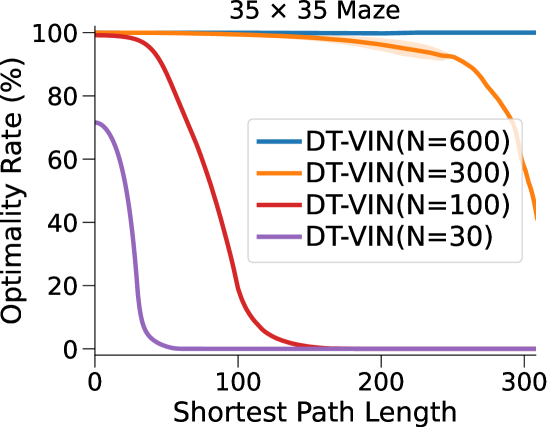
图3(a)和表1显示我们的方法和基线方法的成功率 (SR),作为 SPL 的函数。 对于每种算法和环境配置,我们报告在上一段指定的范围内具有最佳深度 的 NN 的性能(参见图 7 附录 C中的(对于的其他值)。
| Maze Size | ||||||
| SPL | [1,100] | [100, 200] | [200, 300] | [1,600] | [600, 1200] | [1200, 1800] |
| VIN tamar2016value | ||||||
| GPPN lee2018gated | ||||||
| Highway VIN wang2024highway | ||||||
| DT-VIN (ours) | ||||||

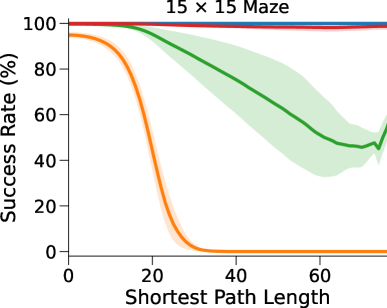
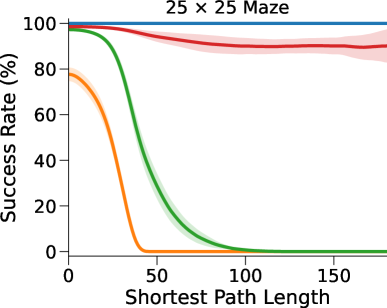
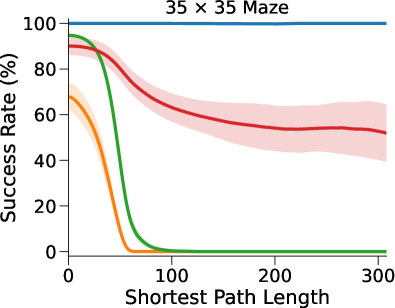
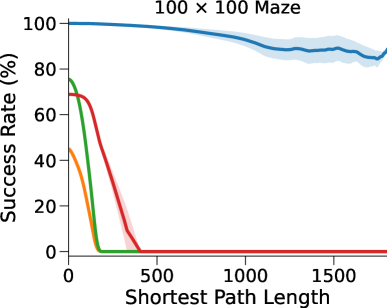
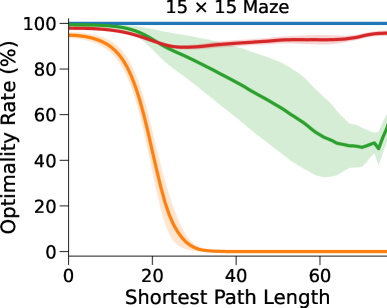
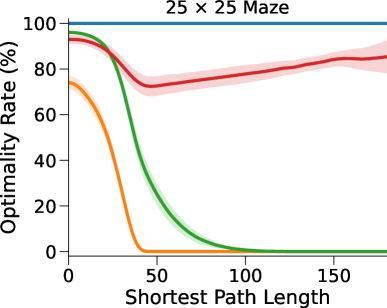
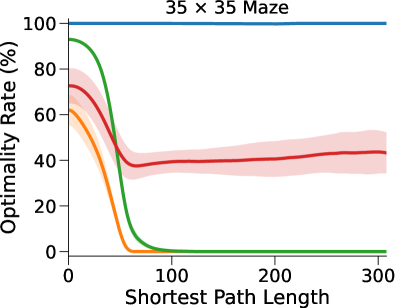
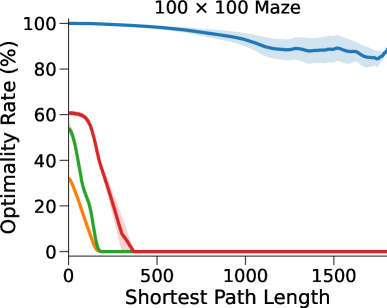
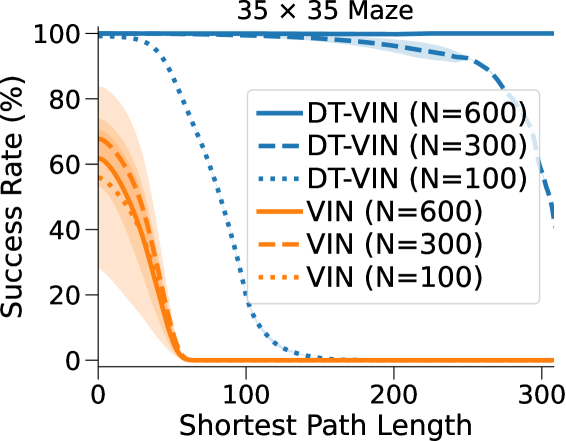
在这里,DT-VIN 在所有不同大小 和 SPL 下的所有迷宫导航任务上都优于所有其他方法。 值得注意的是,在 大小的小型迷宫中,DT-VIN 在所有任务上实现了大约 100% 的 SR。 对于具有 的最具挑战性的环境,DT-VIN 在完整的 层上表现最佳,并且在 SPL 范围内的短期规划任务上保持大约 100% 的 SR ,对于 SPL 超过 的任务,SR 约为 88%。
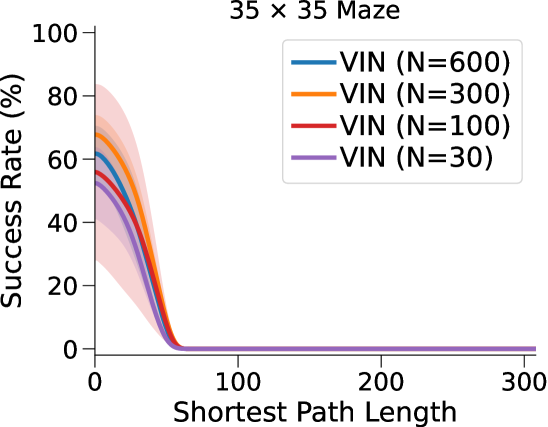
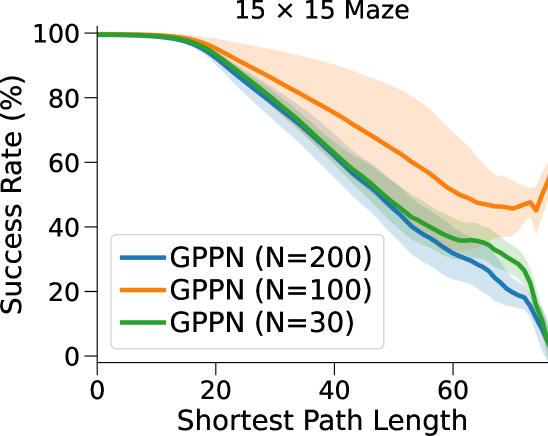
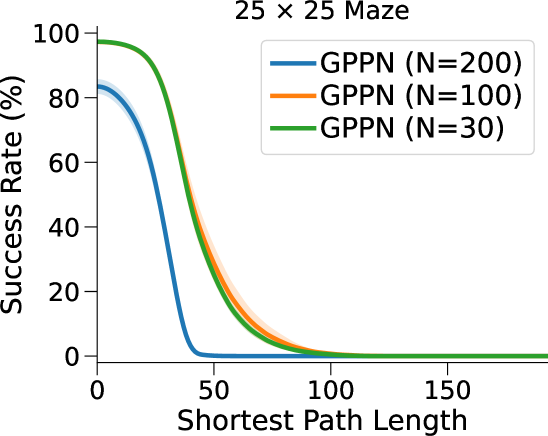
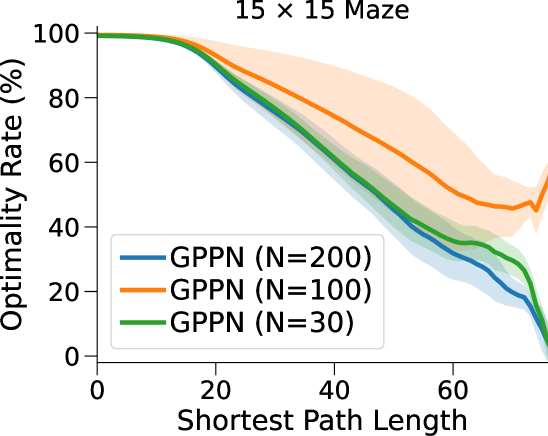
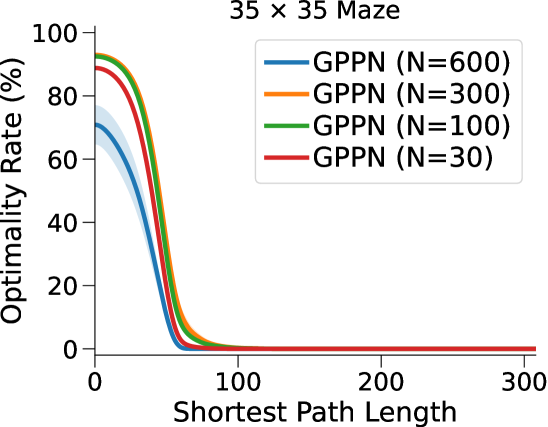
相比之下,VIN 在小规模和短期规划任务上表现良好。 然而,即使在尺寸为 的小规模迷宫中,当 SPL 超过 时,VIN 的 SR 也会下降至 0%。 此外,当迷宫大小增加到 时,VIN 只能实现不到 40% 的 SR,即使是在 SPL 在 范围内的短期规划任务中也是如此。 GPPN 在短期规划任务上表现良好,但在长期规划任务上却不能很好地泛化,随着 SPL 的增加,长期规划任务的 SR 也会下降到 0%。 在 的小规模迷宫中,高速公路 VIN 在各种 SPL 的任务中表现良好。 然而,它仍然显示出 在大规模迷宫任务中的性能下降。
图 3(b)显示了算法的最优率(OR),它衡量模型输出最优路径的速率。 与 SR 相比,我们的 DT-VIN 保持一致的 OR。 然而,其他一些方法(尤其是高速公路 VIN)表现出 OR 的明显下降,这表明虽然这些模型可以生成可以实现目标的路径,但该路径通常不是最佳的。
消融研究。
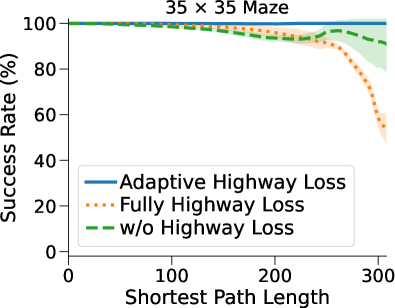
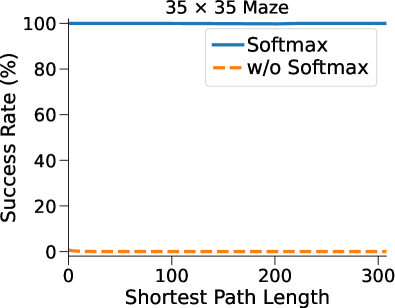
我们使用 迷宫和深度 的神经网络进行多项消融研究,以评估 (1) 动态潜在转换内核对 DT-VIN 的影响,如 节 3.1; (2) 网络深度,如部分3.2所述; (3) 适应性高速公路损失,同样包含在节3.20>中; (4)潜在转换核上的softmax函数,如部分2>3.23>1>中所述。 除非另有说明,否则所有这些元素都包括在内。
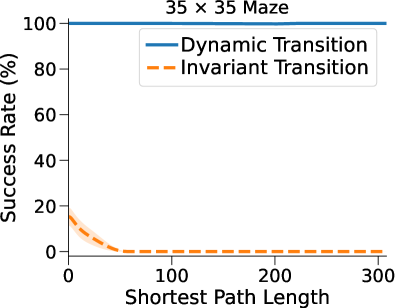
动态潜在转换内核。 图 4(a)显示了我们的方法的SR,以及所提出的动态和原始不变潜在转移内核。 不变过渡的性能显着下降,凸显了动态过渡的重要性。 值得注意的是,该变体在原始 VIN 中加入了额外的自适应高速公路损失,当潜在 MDP 的表示能力有限时,这会对性能产生不利影响。
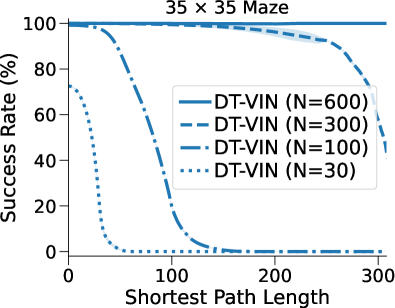
规划模块的深度。 图 4(b)显示了我们的DT-VIN在不同深度下的SR。 在这里,增加深度可以极大地增强长期规划能力。 例如,对于 SPL 为 的任务,深度为 的变体比深度为 的变体表现得更好。 此外,对于 SPL 为 的任务,深度为 的更深变体表现更好。 当深度增加时,VIN 和 GPPN 等其他方法并未显示出明显的性能改进。 图 7中的附录 C显示了其他方法在所有深度上的性能。
适应性高速公路损失。 我们评估了 DT-VIN 的两个变体,第一个没有高速公路损失,第二个有“完全高速公路损失”,后者对每个隐藏层强制实施高速公路损失,而无需根据实际规划步骤进行自适应调整。 如图图 4(c)所示,没有高速公路损失的变体性能下降,而完全高速公路损失的变体性能下降表现更差。 这些结果意味着,在不进行任何调整的情况下对隐藏层施加额外的损失可能会损害性能。
Softmax 潜在转换内核。 如图图4(d)所示,对潜在转换内核没有进行softmax操作的变体在所有任务上都失败了。 这种失败是由于梯度爆炸,梯度变得非常大,最终导致模型的参数溢出并变成NaN(非数字)值。
4.23D ViZDoom 导航
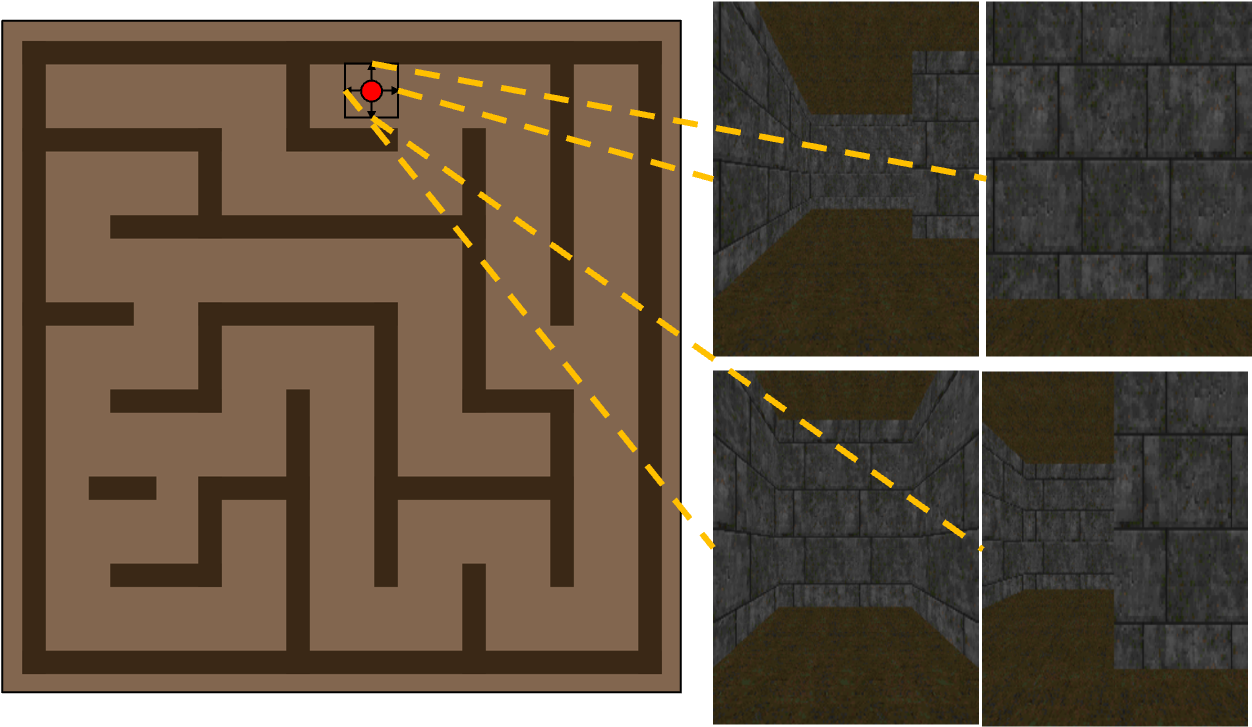
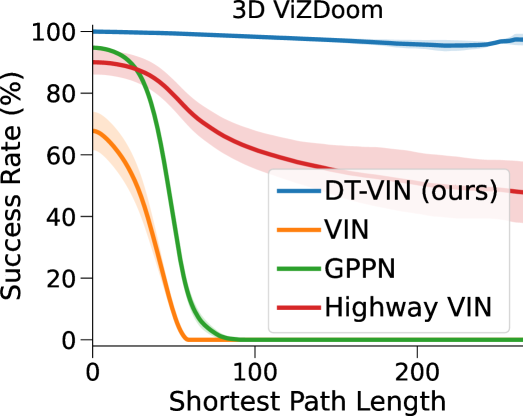
按照 GPPN 论文的方法,我们在 3D ViZDoom Wydmuch2019ViZDoom 环境中测试我们的方法。 在这里,我们没有像之前的实验那样直接使用自上而下的二维迷宫,而是使用由捕获环境的第一人称视角的 RGB 图像组成的观察,如图图所示5(a)。 然后,训练 CNN 来根据第一人称观察来预测迷宫图。 然后,使用与 2D 迷宫环境相同的架构和超参数,将地图作为规划模型的输入(请参阅部分 B.2了解更多实施细节)。 对于每种算法,我们选择不同网络深度的最佳结果。 我们发现DT-VIN的最佳深度是,GPPN的最佳深度是,VIN的最佳深度是,高速公路的VIN的最佳深度是. 图5(b)显示了大小为的3D ViZDoom迷宫上的SR。 可以预见的是,由于预测引入了额外的噪声,与 2D 迷宫环境相比,所有基线的性能都会下降。 在这里,与所有不同 SPL 的任务相比,DT-VIN 的性能优于所有方法。
5相关工作
价值迭代网络 (VIN) 的变体。
近年来,人们提出了 VIN tamar2016value 的几种变体。 门控路径规划网络采用门控循环机制来减少 VIN lee2018ated 中出现的训练不稳定性和超参数敏感性。 为了减轻高估偏差(这对这里的学习不利),提出了 dVIN 并使用加权双估计器作为最大算子 jin2021 值的替代方案。 为了解决不规则空间图的挑战,广义VIN采用图卷积算子,扩展了VIN niu2018generalized中使用的传统卷积算子。 为了提高可扩展性,AVIN 引入了一个抽象模块,可以从环境和目标 schleich2019value 中提取更高级别的信息。 对于迁移学习,迁移 VIN 解决了将 VIN 泛化到动作空间或环境特征与训练环境 shen2020transfer 不同的目标域的问题。 最近,VIRN 被提出,并采用更大的卷积核来进行规划,使用更少的迭代次数以及自注意力将信息从每一层传播到网络 cai2022value 的最终输出。 类似地,GS-VIN 也使用更大的卷积核,但为了稳定训练,还包含门控汇总模块,可减少值迭代 cai2023value 期间的累积误差。
与 DT-VIN 最相关的是最近的其他工作,重点是为长期规划开发非常深的 VIN。 具体来说,高速公路VIN wang2024highway结合了高速公路强化学习wang2023highway的理论,为长期规划任务创建了多达300层的深度规划网络。 Highway VIN 通过引入探索模块来修改 VIN 的规划模块,该模块在前向传递中注入随机性,并使用门控机制允许选择性信息流通过网络层。 然而,我们的方法通过在潜在 MDP 中合并动态转换矩阵并自适应地加权每个层与最终输出的连接来实现更深入的规划。
具有深层架构的神经网络。
开发超深度神经网络 (NN) 有着悠久的历史。 对于顺序数据,这主要包括长短期记忆(LSTM)架构及其门控残差连接,这有助于缓解“梯度消失问题”Hochreiter:97lstm,Hochreiter:91。 对于前馈神经网络,高速公路网络 srivastava2015 训练中使用了类似的门控残差连接架构,后来在 ResNet 架构 he2016deep 中使用,其中门保持打开状态。 这种残差连接在现代语言架构中仍然普遍存在,例如生成预训练 Transformer (GPT)achiam2023gpt。 我们的方法动态地采用从选择的隐藏层到最终损失的跳跃连接,利用状态和观察图相关的转换内核。 这种方法与真实 VI 算法的计算更加一致。 类似的内核依赖于输入图像 chen2020dynamic 或图像 liu2018intriguing 的坐标,以前已在计算机视觉中使用过。
6 结论
规划是人工智能及其子领域(强化学习)中长期存在的挑战。 之前的工作提出 VIN 作为该任务的端到端可微神经网络架构。 虽然 VIN 在短期小规模规划方面取得了成功,但随着规划范围和规模的增长,它们开始很快失败。 我们观察到,这种性能下降主要是由于(1)网络的表征能力和(2)深度的限制。 为了缓解这些问题,我们提出了对架构的一些修改,包括用于增加表示能力的动态转换内核和用于简化非常深模型的训练的自适应高速公路损失函数。 总而言之,这些修改使我们能够训练具有 层的网络。 根据之前的工作,我们评估了我们提出的动态过渡 VIN (DT-VIN) 在 2D 迷宫环境和 3D ViZDoom 环境中的功效。 我们发现,与之前的尝试相比,DT-VIN 可解决更长期、更大规模的规划问题。 据我们所知,在发布时,DT-VIN 是针对这些特定环境的当前最先进的规划解决方案。
我们注意到这种方法的上限(即网络的规模,以及随之而来的规划能力的规模)仍然未知。 由于我们的实验主要受到计算成本和未观察到的不稳定性的限制,我们预计随着可用计算能力的增长,我们的方法将扩展到更长期和更大规模的规划。
7 局限性和未来的工作
与 VIN 和高速公路 VIN 相比,我们工作的主要限制是计算成本增加(参见部分B.3)。 这是网络规模的结果。 过去几十年来,人工智能一直以扩展系统的趋势为主[sutton2019bitter],因此这不太可能是一个长期问题。 其他限制包括需要知道高速公路损失中最短路径 的长度。 在一般的强化学习问题中,这样的数量可以在线估计。 未来的工作将探索更复杂的转换映射模块(本工作为此使用单个 CNN 层)在更具挑战性的现实应用中的影响,例如动态和不可预测的环境中的实时机器人导航。
致谢
这项工作得到了欧洲研究理事会(ERC,高级拨款号 742870)的支持。 作者还要感谢 NVIDIA 公司捐赠一台 DGX-1 作为人工智能研究先锋奖的一部分,以及 IBM 捐赠一台 Minsky 机器。
附录 A 广泛影响
我们的工作主要涉及基础研究,不会产生超过所有科学进步所带来的明显负面社会影响。
附录B实验细节
以下小节详细介绍了有关实验的具体信息,这些信息被认为太小而无法出现在正文中。
B.1 2D迷宫导航
B.23D ViZDoom
B.3计算复杂性
正如我们在部分3.1中讨论的,我们的方法只需要参数,其中我们设置 和 在我们的实验中。 表 4显示了英伟达 A100 GPU 在使用 层和训练 30 次 迷宫时,DT-VIN 和基线的 GPU 内存消耗和训练时间。
| Hyperparameter | Value | ||||
| Transition Mapping Module | Conv with kernel | ||||
| Reward Mapping Module | Conv with kernel | ||||
| Latent Transition Kernel Size () | 3 | ||||
| Latent Action Space Size () | 4 | ||||
| Optimizer | RMSprop | ||||
| Learning Rate | 1e-3 | ||||
| Batch Size | 32 | ||||
| Skip Size for Adaptive Highway Loss | 10 | ||||
| Depth of Planning Module |
|
| Hyperparameter | Value |
| Batch Size () | 32 |
| Image Directions () | 4 |
| Image Channels () | 3 |
| Image Width () | 24 |
| Image Height () | 32 |
| Input Size | |
| Layer 1 (Convolution) | |
| Layer 2 (Convolution) | |
| Layer 3 (Linear) | |
| Layer 4 (Convolution) | |
| Layer 5 (Convolution) | |
| Output Size | |
| Optimizer | Adam |
| Learning Rate | 1e-3 |
| Betas |
| Method | GPU Memory (GB) | Training Time (hours) |
| VIN | 4.2 | 8.4 |
| GPPN | 182 | 4.2 |
| Highway VIN | 41.3 | 14.3 |
| DT-VIN | 53.3 | 12.1 |
附录 C其他实验结果