发现使用大型语言模型的偏好优化算法
摘要
离线偏好优化是提高和控制大语言模型输出质量的关键方法。 通常,偏好优化被视为使用手工制作的凸损失函数的离线监督学习任务。 虽然这些方法基于理论见解,但它们本质上受到人类创造力的限制,因此可能的损失函数的巨大搜索空间仍在探索中。 我们通过执行 LLM 驱动的客观发现来解决这个问题,以自动发现新的最先进的偏好优化算法,而无需(专家)人工干预。 具体来说,我们迭代地促使大语言模型根据先前评估的性能指标提出并实现新的偏好优化损失函数。 这个过程导致了以前未知的高性能偏好优化算法的发现。 其中表现最好的我们称之为发现偏好优化 (DiscoPOP)111代码:https://github.com/luchris429/DiscoPOP。,一种自适应混合逻辑损失和指数损失的新颖算法。 实验证明了 DiscoPOP 的最先进的性能及其成功转移到保留任务。
1简介
训练大型语言模型(大语言模型)通常涉及从在大型文本语料库上预先训练的模型开始,然后对其进行微调以符合人类的偏好。 预先训练的,甚至是经过指令微调的大语言模型,可能会产生有害、危险和不道德的完成(Carlini 等人,2021;Gehman 等人,2020)。 为了缓解这种情况并使大语言模型与人类价值观保持一致,我们通过偏好排序的完成数据来使用人类偏好对齐。 这种方法已成为行业标准,通过人类反馈强化学习 (RLHF) (Christiano 等人,2017,RLHF) 以及最近的直接偏好优化等离线偏好优化算法而得到普及(Rafailov 等人, 2023, DPO) 和序列似然校准(Zhao 等人, 2023, SLiC),将问题视为监督学习目标。 文献中已经提出了许多用于离线偏好优化的算法,但哪种算法在任务中表现最好仍然是一个悬而未决的问题。 虽然可能不存在严格占主导地位的算法,但某些算法可能表现出总体改进的性能。 迄今为止,所有现有的最先进的偏好优化算法(Rafailov等人,2023;Azar等人,2023;Zhao等人,2023)都是由人类专家开发的。 尽管取得了进步,但这些解决方案本质上受到人类局限性的限制,包括创造力、独创性和专业知识。
在这项工作中,我们的目标是通过执行 LLM 驱动的发现来解决这些限制,以便自动生成新的最先进的偏好优化算法,而无需专家在开发过程中持续干预。 虽然之前的工作(Ma 等人, 2023; Yu 等人, 2023) 使用大语言模型来设计特定于环境的强化学习奖励函数,但我们发现了可以跨各种环境使用的通用目标函数偏好优化任务。 更具体地说,我们迭代地提示大语言模型提出新的偏好优化损失函数,并使用之前提出的损失函数及其任务绩效指标对其进行评估(在我们的例子中,MT-Bench 分数 (Zheng 等人,2024) )) 作为上下文示例。 执行此自动发现过程后,我们对高性能损失函数进行了分类,并引入了一种特别强大的函数,我们称之为发现偏好优化(DiscoPOP),这是一种新算法。 为了确保超越 MT-Bench 的稳健性,我们使用 AlapacaEval 2.0 (Dubois 等人,2024) 验证 DiscoPOP,结果表明 DPO 相对于 GPT-4 的胜率有所提高。 此外,在摘要和受控生成等单独的保留任务中,使用 DiscoPOP 训练的模型表现优于现有偏好优化算法或具有竞争力。
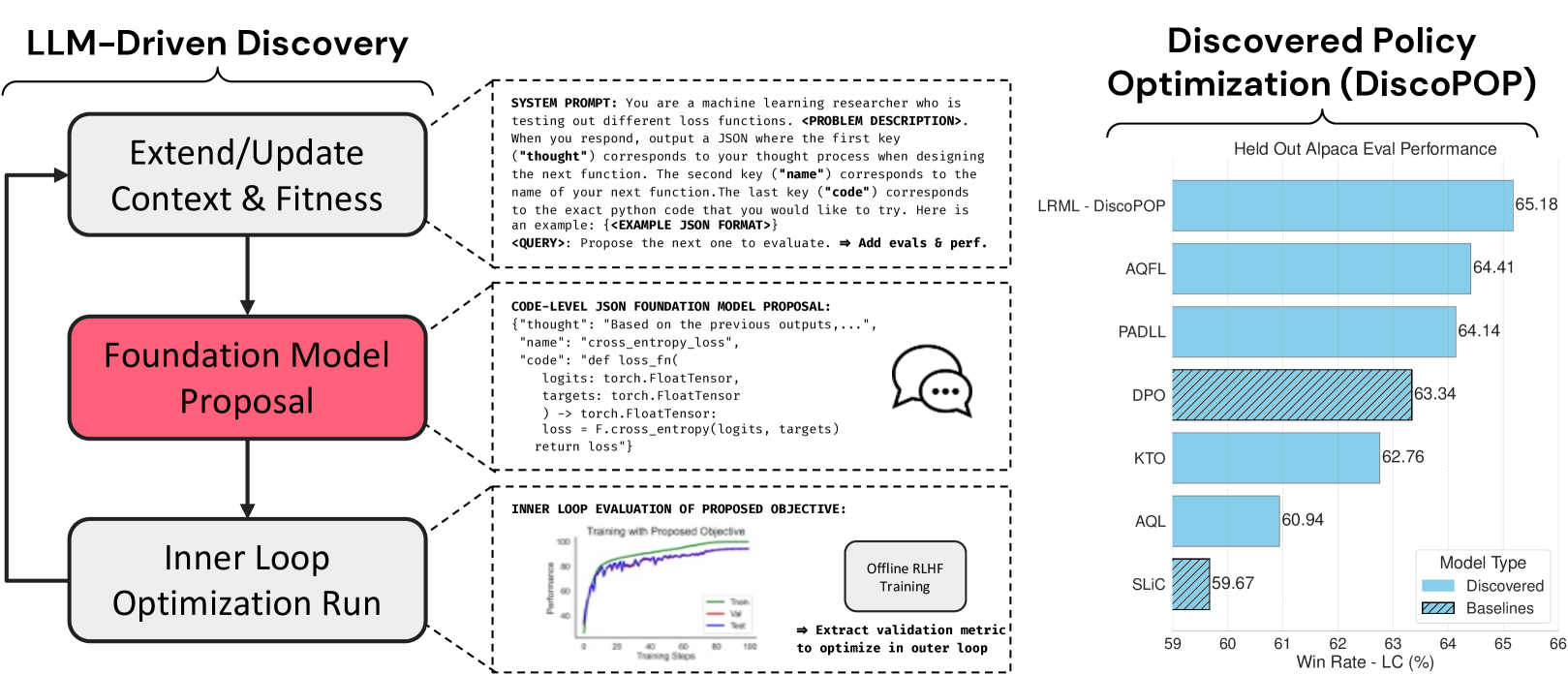
贡献: \raisebox{-0.9pt}{1}⃝ 我们提出了一个 LLM 驱动的目标发现管道来发现新颖的离线偏好优化算法 (部分 3)。 \raisebox{-0.9pt}{2}⃝ 我们发现了多个高性能偏好优化损失。 其中一个损失,我们称之为发现偏好优化(DiscoPOP),在多轮对话(AlpacaEval 2.0)、受控情绪生成(IMDb)和摘要( TL;DR) 任务。 \raisebox{-0.9pt}{3}⃝ 我们对 DiscoPOP(逻辑损失和指数损失的加权和)进行了初步分析,并发现了令人惊讶的特征。 例如,DiscoPOP 是非凸的。
2 背景
偏好优化。 考虑预训练的语言模型策略 和数据集 ,其中包含提示 以及按偏好排序的补全 和 。 在此数据集中,人类评分者更喜欢 而不是 ,表示为 。 任务是将 与这些偏好中隐含的人类价值观保持一致。 一般来说,这是通过人类反馈的强化学习(Christiano等人,2017,RLHF)来实现的,这种方法分两个阶段进行:首先是奖励建模阶段学习参数化奖励模型。 通过假设偏好的 Bradley-Terry 模型 (Bradley 和 Terry,1952),数据的概率可以表示为 ,随后简单地优化 通过最大似然原理。 策略优化的第二阶段采用强化学习算法来根据学习到的奖励来训练语言模型。 通常,模型和预强化学习参考策略之间引入KL惩罚 (Jaques等人,2019;Stiennon等人,2020) 防止过度优化,偏离原策略太远,导致最终目标:
| (1) |
尽管在前沿模型(Anthropic,2023;Gemini-Team,2023)方面取得了成功,深度强化学习仍然存在许多实现(Engstrom等人,2019)和训练挑战( Sutton,1984;Razin 等人,2023) 阻碍了它的采用。 为了简化整个过程,直接偏好优化 (Rafailov等人,2023,DPO)旨在放弃奖励建模和在线强化学习过程。 将 (1) 重写为 KL 项分解为:
| (2) |
将问题表示为熵正则化 RL bandit 任务(Ziebart 等人,2008),其中存在已知的解析解:。 通过重新安排奖励,我们可以将任务表示为基于奖励差异的二元分类问题:
| (3) |
这里,我们将对数比率差定义为。 在 DPO 中,函数 是根据 BT 模型假设得出的 sigmoid 函数的负对数。 然而,Tang 等人 (2024) 强调,更一般地,我们可以通过让 为任何标量损失函数来获得离线偏好优化算法的配方。 例如,设置,平方损失函数(Rosasco等人,2004)产生IPO(Azar等人,2023),同时采用max-margin 启发的铰链损失(Boser 等人,1992;Cortes 和 Vapnik,1995) 产生 SLiC (Zhao 等人,2023)。
算法发现的元优化。 元优化(优化优化过程)的目标是使用数据驱动的过程发现新颖的学习算法。 假设算法使用目标函数 来训练模型进行 次迭代,其中 表示一组元参数。 元优化搜索最大化预期下游性能 的目标,其中 是下游性能指标。 与之前依赖于 预定义参数化的方法不同(例如神经网络 (Hospedales 等人, 2021) 或特定领域语言 (Alet 等人, 2020)),我们利用大语言模型直接在Python中提出代码级目标函数。 这种方法消除了对精心设计的搜索空间的需要,并利用大语言模型中嵌入的广泛知识进行灵活的选择和变异。
3 LLM 驱动的目标发现
选择合适的目标函数对于向网络注入能力至关重要。 在这里,我们详细介绍了大语言模型代码级目标函数建议所促进的发现过程:
初始上下文构建。 在最初的系统提示中,我们使用代码中给出的几个已建立的目标函数及其相应的性能来“烧录”大语言模型。 此外,我们还提供问题详细信息以及 JSON 字典形式的输出响应格式示例。
大语言模型查询、解析和输出验证。 在开始训练运行之前,我们查询大语言模型,解析响应 JSON,并运行一组单元测试(例如有效的输出形状)。 如果解析或单元测试失败,我们会在向大语言模型提供错误消息作为反馈后重新采样新的解决方案。
绩效评估。 然后根据其为预定义的下游验证任务优化模型的能力来评估所提出的目标函数。 我们将生成的性能指标称为。
迭代细化。 通过使用提供的性能反馈,大语言模型迭代地完善其建议。 在每次迭代中,该模型都会综合一个新的候选损失函数,探索先前成功公式的变体和可能改进现有基准的全新公式。 该迭代过程重复指定的代数,或者直到观察到一组最佳损失函数时收敛。
小案例研究:发现监督分类损失函数。 将 CIFAR-10 数据集上的监督分类情况视为一个简单的起始示例。 我们使用 GPT-4 (OpenAI,2023) 提出的目标训练一个简单的 ResNet-18 5 个时期。 每次训练运行后,我们都会为大语言模型提供相应的验证精度,并查询下一个基于 PyTorch 的 (Paszke 等人, 2017) 候选目标函数。
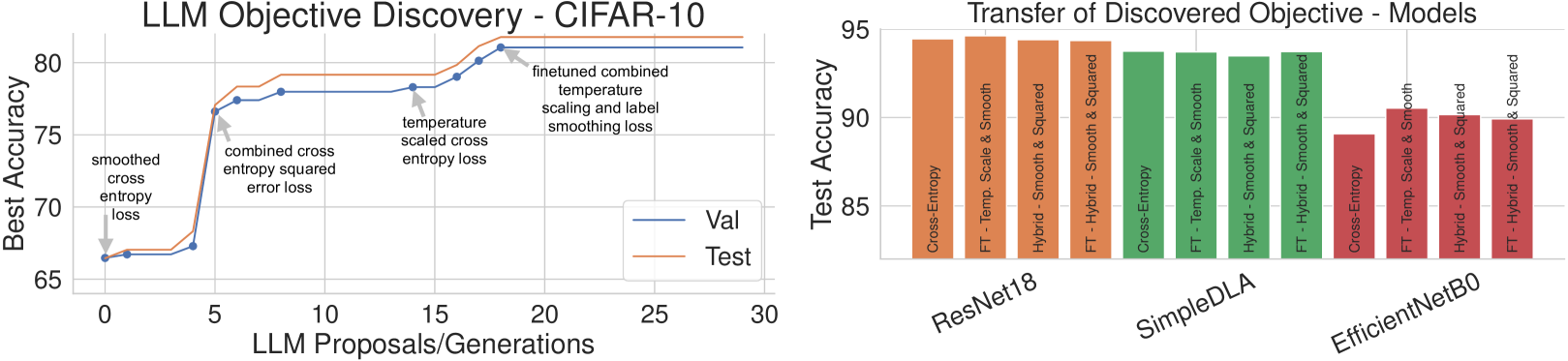
图 2描述了所提出的目标函数在整个发现过程中的性能。 不同的发现目标都优于标准交叉熵损失。 有趣的是,我们观察到 LLM 驱动的发现在几个不同的探索、微调和知识构成步骤之间交替:最初,大语言模型提出了一个标签平滑的交叉熵目标。 调整平滑温度后,它探索了平方误差损失变量,这提高了观察到的验证性能。 接下来,将两个概念上不同的目标结合起来,导致另一个显着的性能改进。 因此,大语言模型发现过程并不是对文献中先前概述的目标进行随机搜索,而是以互补的方式组合各种概念。 此外,发现的目标还可以推广到不同的架构和更长的训练运行。 在部分D.3中,我们表明这个发现过程对于采样温度的选择和提示/上下文构建是稳健的。
4发现离线偏好优化目标
在本节中,我们运行 LLM 驱动的发现来自动生成新的最先进的偏好优化算法。
4.1 发现任务-MT-Bench上的多轮对话
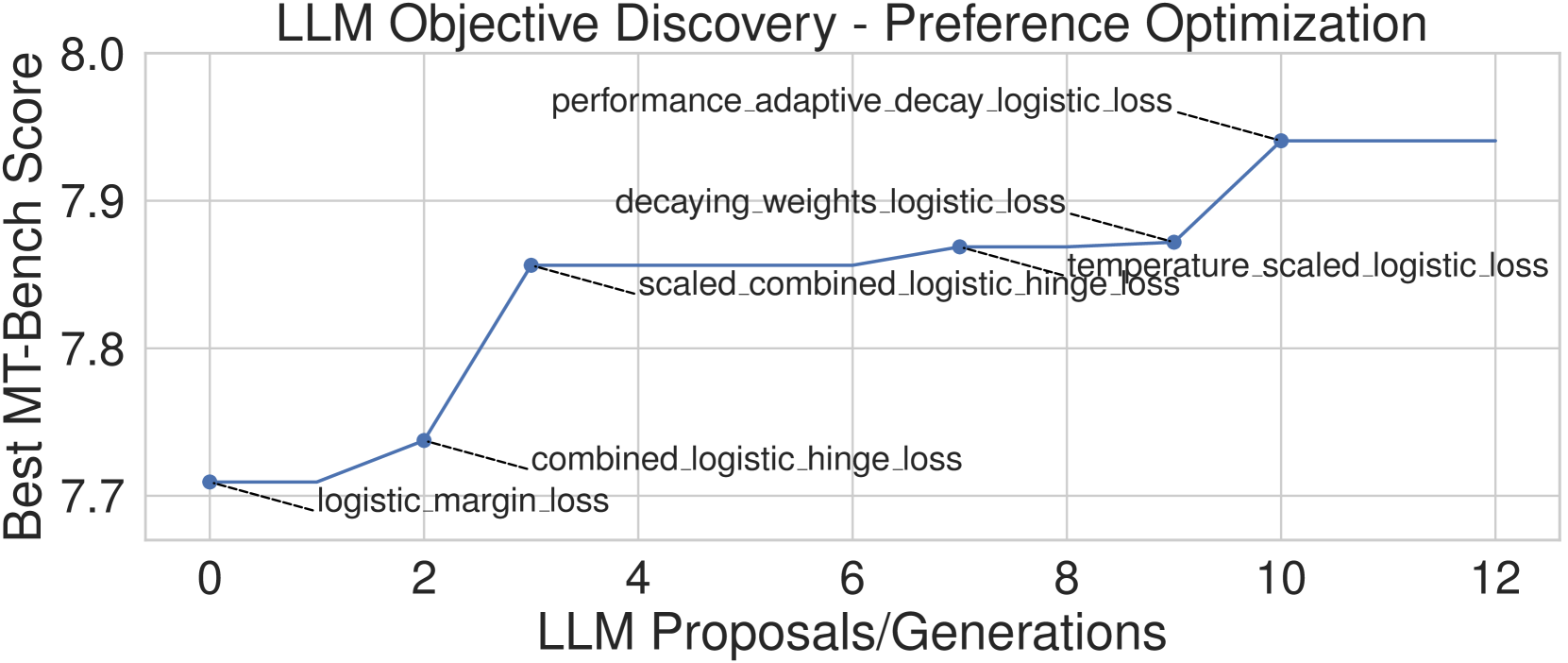
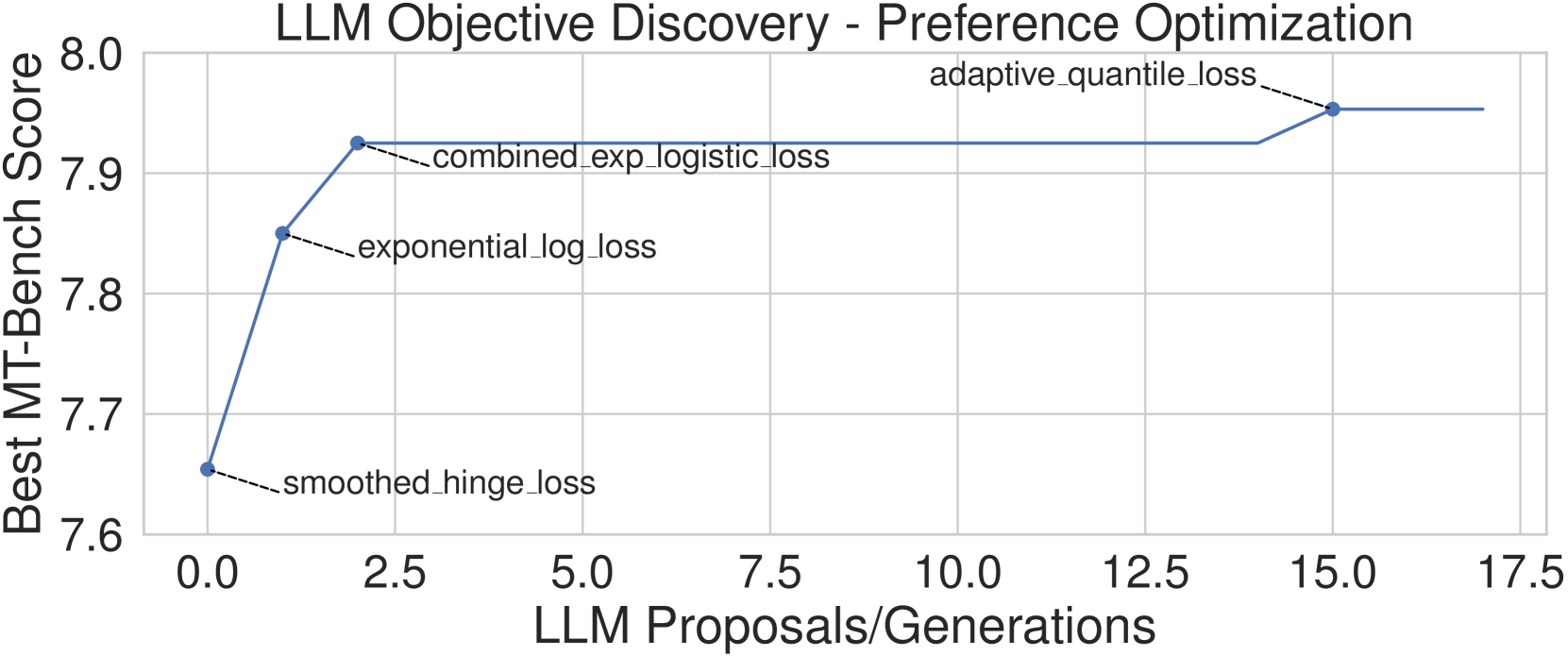
在本节中,我们使用 LLM 驱动的发现方法来发现用于离线偏好优化的新目标函数 ,如部分 2中所定义。 和方程3。 具体来说,在每一代 中,GPT-4 都会生成候选目标函数 的 PyTorch (Paszke 等人, 2017) 代码。 每个目标函数将 的变量作为输入,并返回一个标量。 对于每个建议的目标 ,我们通过单元测试检查 是否有效。
对于每个有效生成的目标函数,我们微调大语言模型,然后收集性能评估分数。 具体来说,我们在“alignment-handbook”(Tunstall 等人,2023a) 存储库的基础上构建来微调我们的模型。 值得注意的是,此存储库在使用 DPO 时会重现“Zephyr 7B Gemma”222https://huggingface.co/HuggingFaceH4/zephyr-7b-gemma-v0.1 Tunstall 和 Schmid (2024); Tunstall 等人 (2023b),在发布时,在 7B 模型的 MT-Bench 上取得了最先进的分数。 “Zephyr 7B Gemma”首先采用 gemma-7b (Gemma-Team 等人,2024) 并在“deita-10k-v0-sft”数据集 (Liu 等人,2023) 上对其进行微调) 生成“zephyr-7b-gemma-sft”333https://huggingface.co/HuggingFaceH4/zephyr-7b-gemma-sft-v0.1。 然后在“Argilla DPO Mix 7K”444https://huggingface.co/datasets/argilla/dpo-mix-7k。 在评估新的目标函数时,我们将最后一步中的 DPO 替换为生成的目标函数,并保持相同的超参数。 我们在图3中展示了示例运行,并在附录B<中提供了进一步的实验细节/t5>。
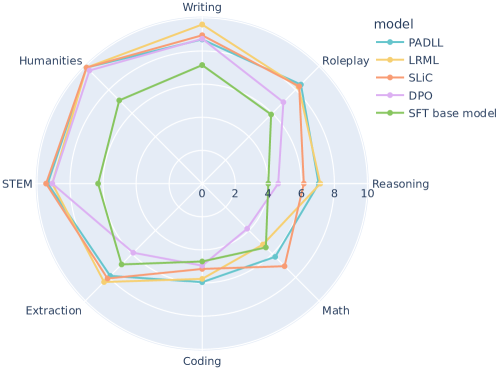
一旦我们为所提出的目标函数 训练了大语言模型,我们就可以在流行的多轮对话评估基准 MT-Bench 上评估该大语言模型(Zheng 等人,2024) 。 这是一个多轮开放式问题集,使用 GPT-4 来评估训练模型的回答质量,获得与流行的 Chatbot Arena (Zheng 等人,2024)的高度相关性。 我们在附录C中提供了进一步的评估详细信息。
4.2发现结果
在评估了大约 个目标函数后,我们在 表 1 中列出了性能最佳的目标函数。 我们在这里将高级目标形式制成表格,并在附录E中提供完整的目标损失函数及其相关代码。此外,我们还在图4中绘制了表现最佳的子任务评估。
| Name | Full Name | Objective Function | Score (/ 10) |
| DPO | Direct Preference Optimization | 7.888 | |
| DPO* | Official HuggingFace ‘zephyr-7b-gemma’ DPO model | 7.810 | |
| SLiC | Sequence Likelihood Calibration | 7.881 | |
| KTO | Pairwise Kahneman-Tversky Optimization | see (Ethayarajh et al., 2024) | 7.603 |
| DBAQL | Dynamic Blended Adaptive Quantile Loss | 7.978 | |
| AQL | Adaptive Quantile Loss | 7.953 | |
| PADLL | Performance Adaptive Decay Logistic Loss | 7.941 | |
| AQFL | Adaptive Quantile Feedback Loss | 7.931 | |
| CELL | Combined Exponential + Logistic Loss | 7.925 | |
| LRML (DiscoPOP) | Log Ratio Modulated Loss | 7.916 | |
| PFL | Policy Focused Loss | 7.900 |
5保留的评估
接下来,我们在保留任务上验证每个发现的目标函数(如 Table 1 所示)。 我们发现性能自适应衰减损失 (PADLL) 和对数比率调制损失 (LRML) 始终表现良好。 由于其非常规的特性和性能,我们将 LRML 称为我们发现的偏好优化算法,或 DiscoPOP 算法。
我们考虑三个不同的标准(Rafailov等人,2023)开放式文本生成任务,每个任务旨在评估微调的大语言模型策略的不同属性,其中每个大语言模型策略是使用我们在偏好数据集 上发现的目标函数 之一进行训练的。
5.1单轮对话-羊驼评估2.0
我们在 Alpaca Eval 2.0 上评估训练后的模型,(Li 等人, 2023; Dubois 等人, 2023, 2024)。 这是一个基于 LLM 的单轮对话自动评估,使用 GPT-4 来评估经过训练的大语言模型策略与底层 SFT 基础模型相比的胜率。 羊驼评估 2.0555https://github.com/tatsu-lab/alpaca_eval,已针对 20K 人类注释进行验证,旨在减少 Alpaca Eval 1.0 的长度偏差;其中使用长度控制 (LC) Alpaca Eval 显示与 Chatbot Area 的相关性为 0.98,使其成为与 Chatbot Arena 相关性最高的流行基准(Dubois 等人,2024)。 我们还在部分B.1中详细介绍了任务训练的详细信息。
| Function | Win Rate (%) | Win Rate - LC (%) | Win Rate (%) | Win Rate - LC (%) |
| vs. GPT-4 | vs. SFT Checkpoint | |||
| DPO | ||||
| DPO∗ | ||||
| SLiC | ||||
| KTO | ||||
| DBAQL | ||||
| AQL | ||||
| PADLL | ||||
| AQFL | ||||
| CELL | ||||
| LRML | ||||
| PFL | ||||
我们在表2中提供了 Alpaca Eval 2.0 结果。 作为参考策略,我们使用 GPT-4 进行绝对比较,使用 SFT 训练的模型进行相对比较。 我们观察到,发现的 LRML (DiscoPOP)、PADLL 和 AQFL 函数在正常和长度控制的获胜率上优于基线和其他发现的损失。 这些表现最好的损失之间的分数差异并不显着,除了 LC 相对于 SFT 参考模型的获胜率(其中 DiscoPOP 表现最好)。
5.2总结(TL;DR)
我们训练了一个大语言模型策略,根据 Reddit 上的论坛帖子,生成要点的摘要。 我们使用 10% 的 Reddit TL;DR 总结偏好数据集 (Völske 等人,2017) 在每个基线和发现的目标函数上对“zephyr-7b-gemma-sft”进行微调。 作为参考模型,我们再次使用“zephyr-7b-gemma-sft”。 有关训练管道的更多详细信息,请参见部分B.2。 为了评估摘要的质量,我们使用 Alpaca Eval 2.0 库,其中包含来自 TL;DR 数据集的 694 个测试样本的自定义评估数据集和自定义 GPT-4 注释器模板,如 Rafailov 等人中所述(2023)。 有关摘要评估的更多详细信息,请参阅部分C.3。
在表3中,PADLL损失和DPO损失在汇总任务的四个指标中的三个方面表现最好,彼此几乎没有差异。 此外,LRML - DiscoPOP 功能的得分略低于最佳表现者,特别是在长度控制的获胜率方面。 与单轮对话任务相比,AQFL 损失在保留评估中并未获得高分。
| Function | Win Rate (%) | Win Rate - LC (%) | Win Rate (%) | Win Rate - LC (%) |
| vs. Human Preference | vs. SFT Checkpoint | |||
| DPO | ||||
| SLiC | ||||
| KTO | ||||
| DBAQL | ||||
| AQL | ||||
| PADLL | ||||
| AQFL | ||||
| CELL | ||||
| LRML | ||||
| PFL | ||||
5.3积极情绪生成 (IMDb)
在此任务中,我们训练一个大语言模型策略来生成具有积极情绪的电影评论完成 ,其中 是来自 IMDb 数据集的电影评论开始时的提示(Maas等人,2011)。 我们从 GPT-2 (Radford 等人, 2019) 模型开始,该模型在 IMDb 数据集上进行了监督微调,然后我们使用基线和发现的目标损失函数进行偏好优化。 训练实现的详细信息可以在部分B.3中找到。 受 Rafailov 等人 (2023) 实验的启发,我们通过预先训练的情感分类器计算模型奖励,我们将其用作地面事实的代理,以及训练模型和参考模型。 部分 C.4 提供了有关此任务评估的更多详细信息。
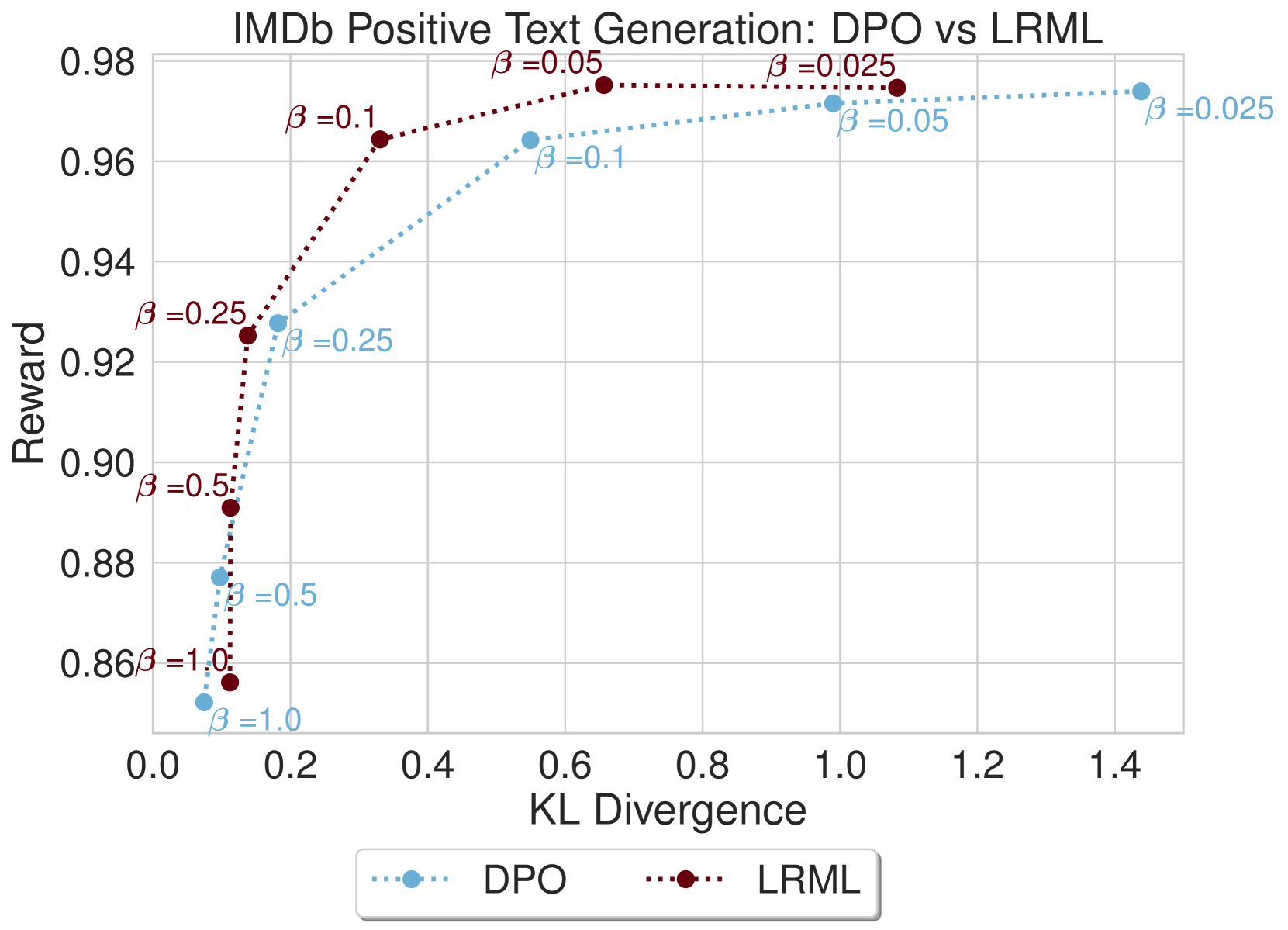
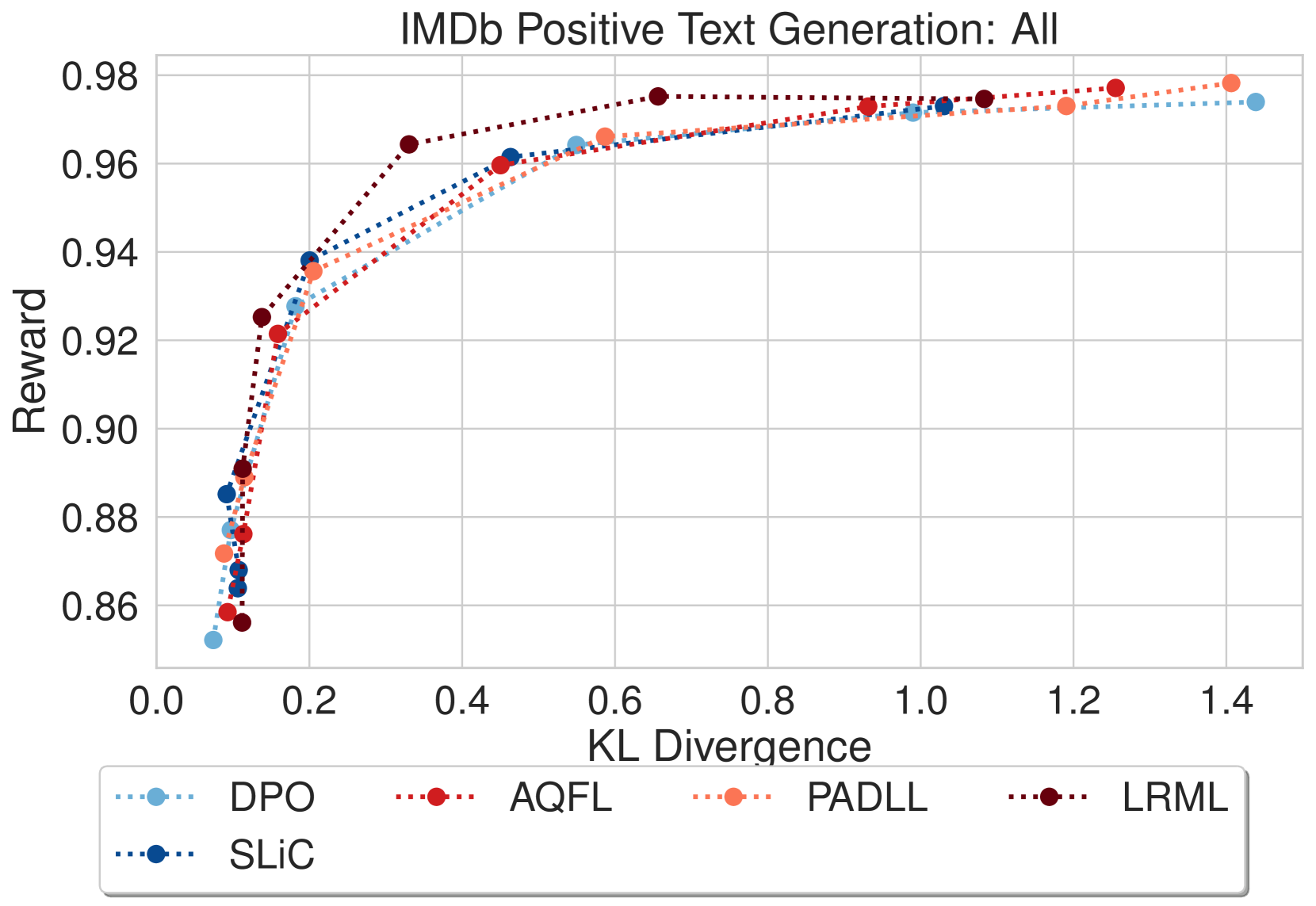
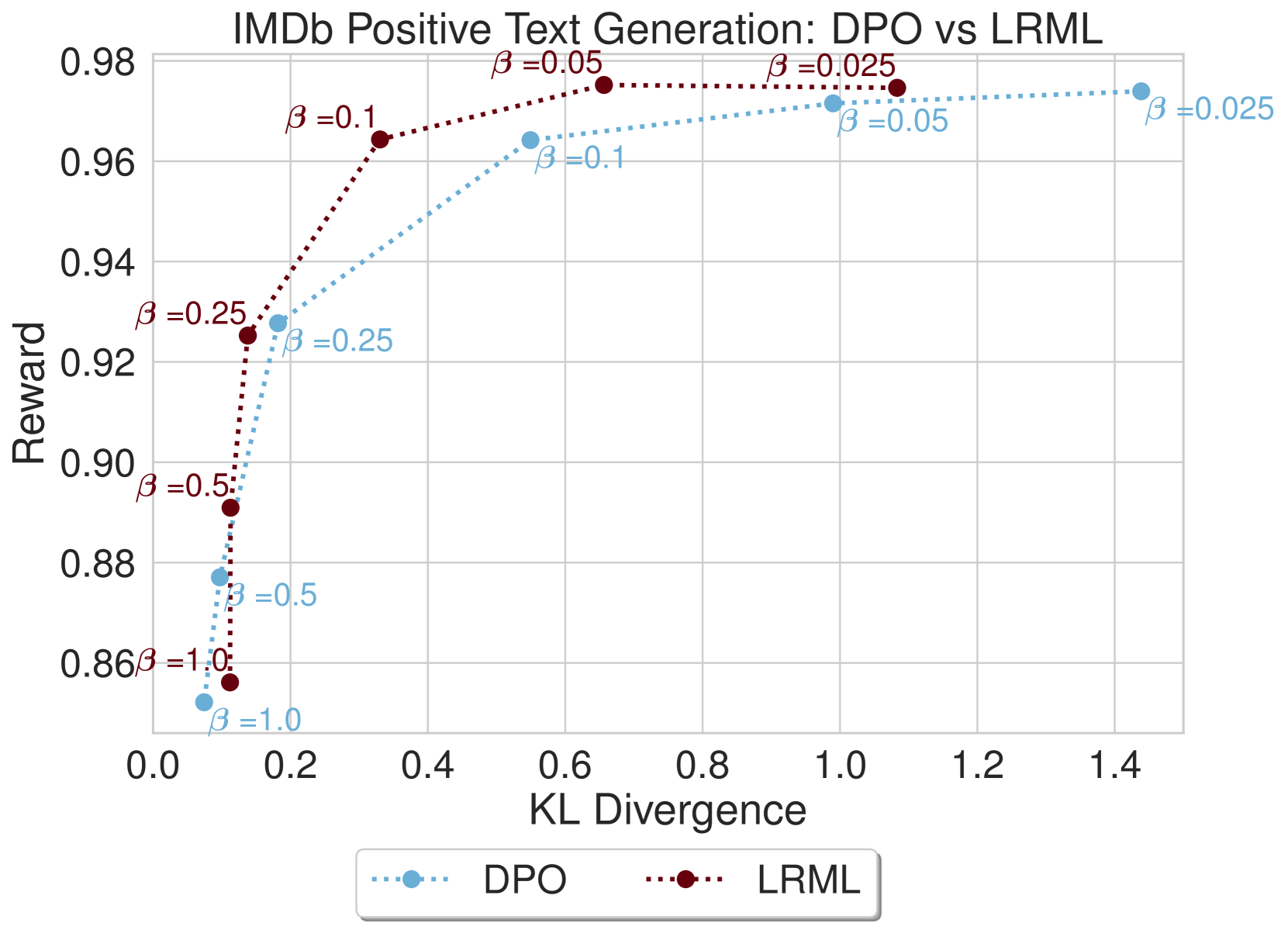
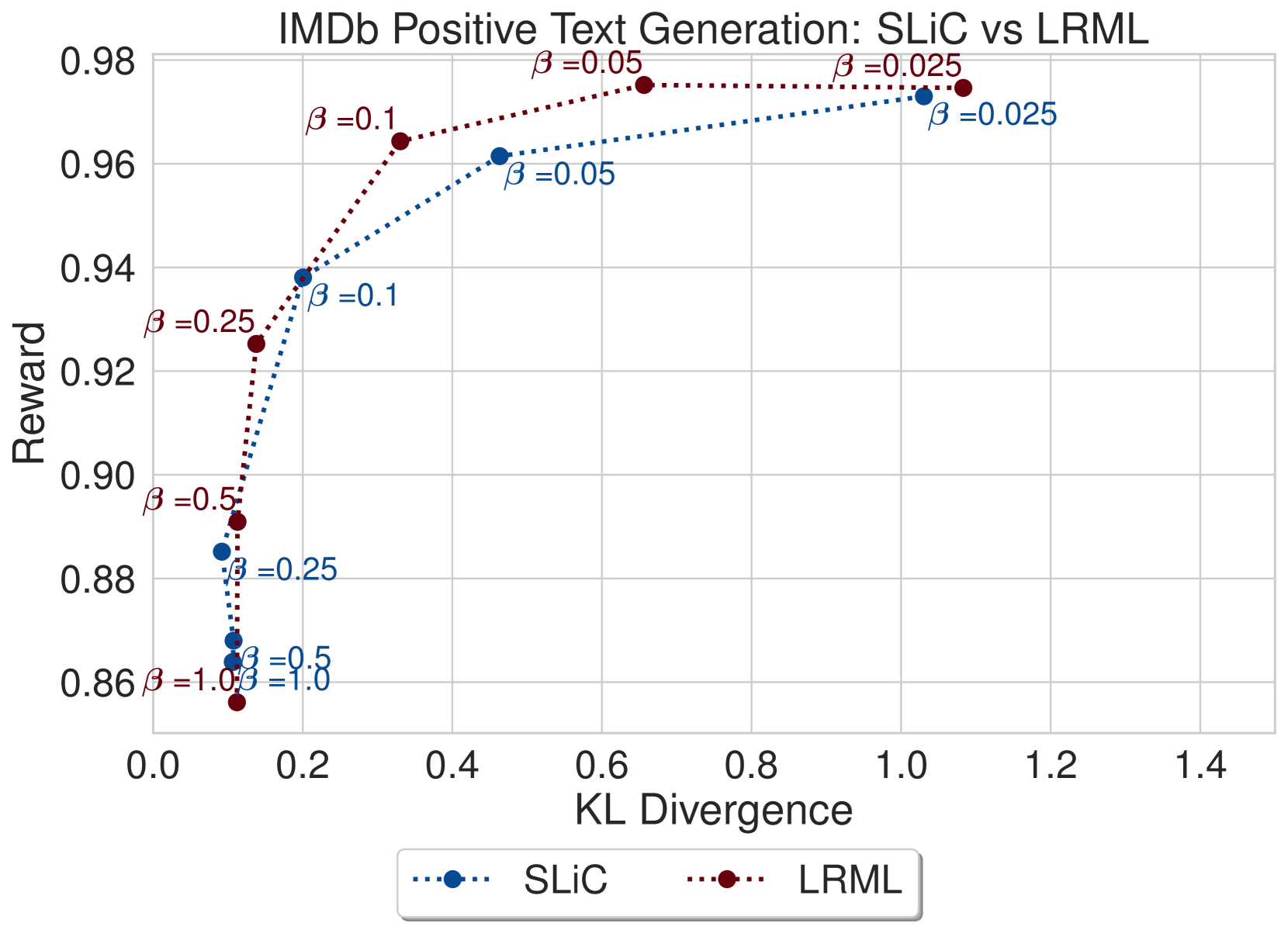
我们在 图 5 中提供了 LRML 与 DPO 和 SLiC 比较的收敛 值的模型结果,显示了模型针对参考模型的 KL 散度的奖励。 在图5(a)中,LRML训练的文本生成器在奖励和KL散度方面优于DPO模型, 值(0.025、0.05、0.1)。 在较高的 值(0.5 和 1.0)下,两种方法都显示出 KL 散度增加和奖励较低的趋势,但通常 LRML 保持比 DPO 更高的奖励。 在图5(b)中,我们注意到LRML在方面略优于DPO、SLiC、AQFL和PADLL在奖励方面。 对于较大的 值(0.5 和 1.0),LRML 显示出与其他目标函数类似的 KL 散度和奖励增加的趋势。 个别发现的损失与基线之间的更详细比较可以在附录图8中找到。
6DiscoPOP分析
我们在表1中列出了我们发现的所有目标,以及附录中的代码和数学表示> E。在本节中,我们现在分析对数比率调制损失,我们将其定义为 DiscoPOP 损失函数,因为它在所有评估任务中始终表现出色,并且我们提供了一些关于它如何优于现有状态的直观理解。 -最先进的目标。
6.1 对数比调制损失 (DiscoPOP)
对数比率调制损失是逻辑损失(如 DPO 中使用的)和指数损失的动态加权和。 每个权重是通过对数比差 () 的 sigmoid 计算来确定的。 从数学上讲,LRML 函数可以用温度参数 描述如下:
| (4) | ||||
| (5) |
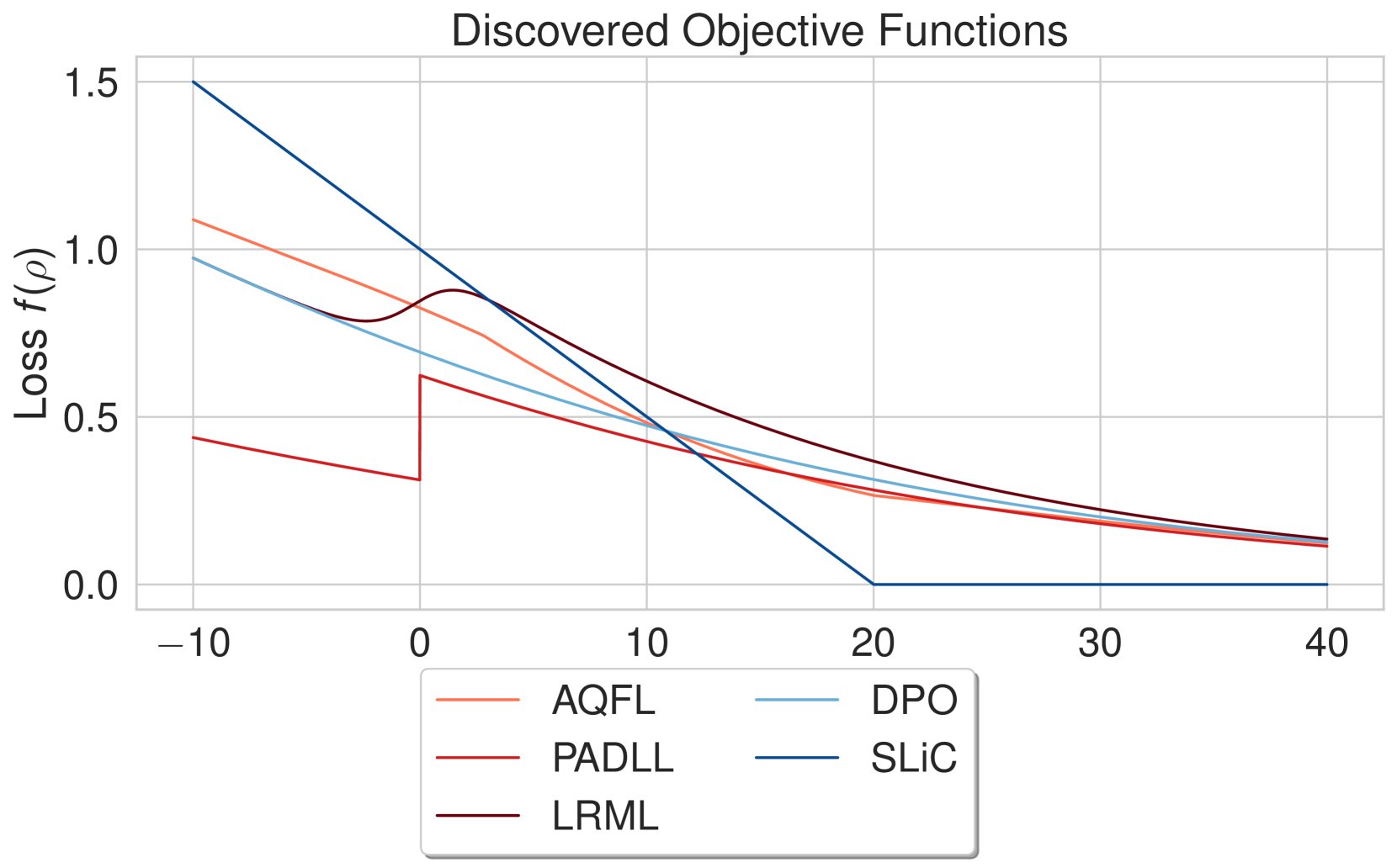
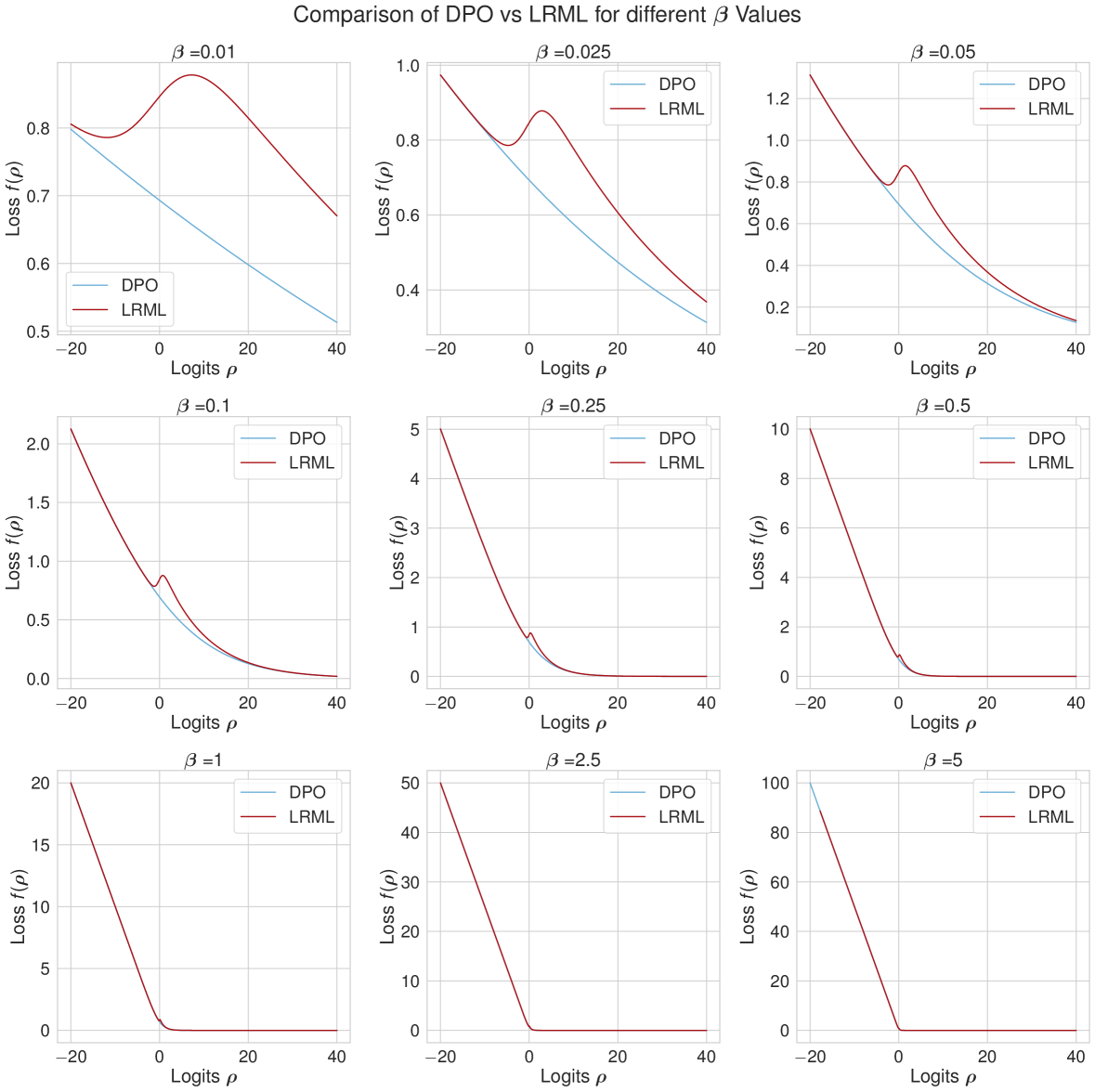
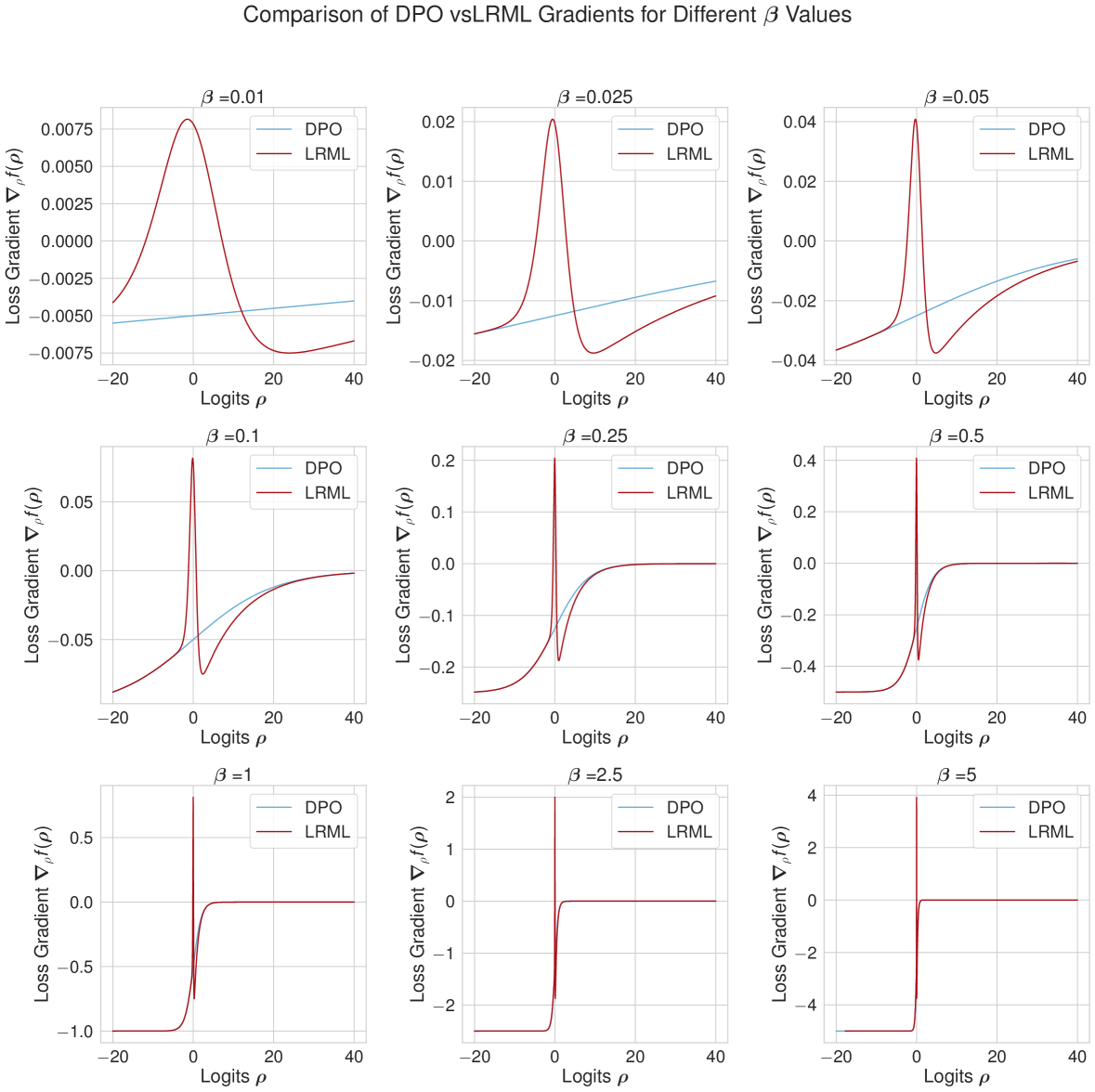
如果对数比率之差为零(,即模型策略 等于参考策略 时的开始处,那么逻辑损失和指数损失之间的损失是相等的。 如果,模型策略与参考策略不同并且选择的输出是首选,则指数项占主导地位。 这更加强调了更大的差异。 另一方面,如果,则模型策略与参考策略不同,并且拒绝的输出是首选的。 在这种情况下,逻辑损失可以很好地处理适度的差异。 基线目标损失以及 LRML、PADLL 和 AQFL 函数显示在图6中,包括它们的梯度。 令人惊讶的是,我们看到 DiscoPOP 函数在起始点 处有一个非凸段和负梯度。 这对于引入课程或随机性可能有帮助。
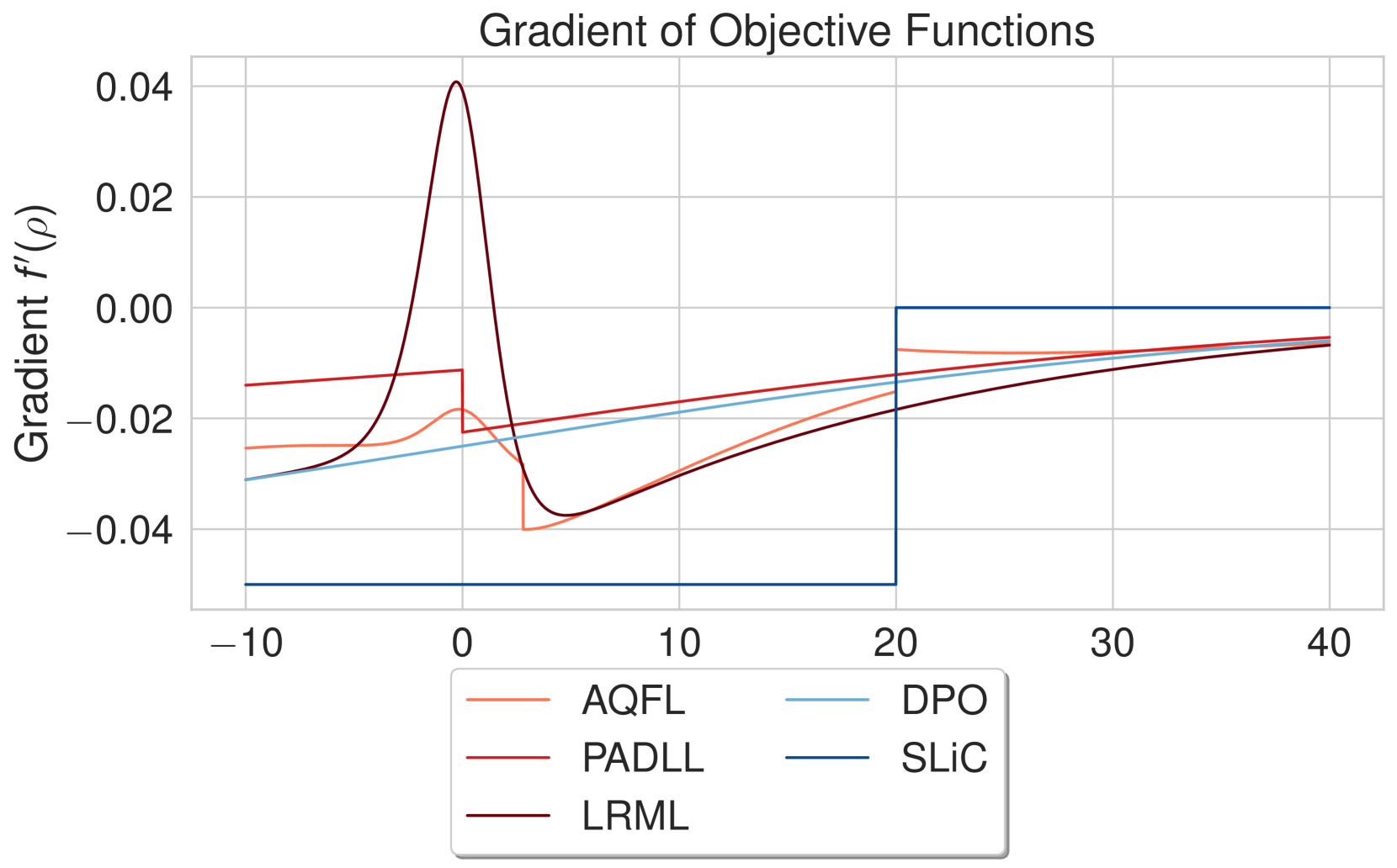
6.2 DiscoPOP 的局限性
虽然在单轮文本生成和文本摘要方面表现良好,但我们在 IMDb 实验中观察到,当 太低 () 或太高 (),可能是因为在发现过程中从未看到或使用过。
7相关工作
大型语言模型的演化和搜索。 大语言模型提供了一种快速、自动化的方式来为自然语言表述的问题创建多个候选解决方案(宋等人,2024)。 这使得它们成为推动基于群体的搜索过程(例如进化元发现)的强大工具。 最近的各种工作已将这种方法应用于编码问题(Romera-Paredes等人,2024),神经架构搜索(Chen等人,2024a),虚拟机器人设计设置(Lehman 等人,2023),和奖励函数(Ma 等人,2023;Yu 等人,2023)。 最后,最近大语言模型已证明能够充当进化策略黑盒优化的重组算子(Lange等人,2024)和质量多样性方法(Lim等)人,2024)。
机器学习的自动发现。 还有许多其他方法可以自动发现可推广的机器学习算法。 之前的一些作品使用遗传算法和手工制作的领域特定语言来探索 ML 函数的空间,用于强化学习算法(Co-Reyes 等人,2021)、好奇心算法(Alet 等)人, 2020), 和优化器(Chen 等人, 2024b)。 其他工作则使用神经网络参数化可转移的目标函数,并使用进化策略对其进行优化。 例如,Lu 等人 (2022);杰克逊等人 (2024); Houthooft 等人 (2018); Alfano 等人 (2024) 发展策略优化目标,Metz 等人 (2022) 发展神经网络优化器,Lange 等人 (2023b, a) 发展黑盒优化器。
偏好优化算法。 虽然监督学习的减少使得 DPO 和替代方案更易于使用,但其他方法也在寻求简化 RL 步骤,包括使用 REINFORCE 的变体(Ahmadian 等人,2024;Gemma-Team 等人,2024) 以及通过对推理过程中各个步骤的偏好来提供更细粒度的反馈(Wu 等人, 2024)(Uesato 等人, 2022; Lightman 等人, 2023) t2> 或奖励重新分配(Chan 等人,2024)。 其他人则使用迭代离线训练,与策略模型中的采样相结合,并获得自己的偏好排名(Xu等人,2023),另一位法官大语言模型(Guo等人,2024),或神谕(Swamy 等人,2024)。
8结论
摘要。 在本文中,我们提出并使用 LLM 驱动的目标发现来生成新颖的离线偏好优化算法。 具体来说,我们能够发现高性能的偏好优化损失,这些损失在保留的评估任务中实现了出色的性能,其中最高的性能为最佳目标可能需要拥有的内容提供了新的见解,例如逻辑和指数的混合损失,并且可能是非凸的。
局限性和未来的工作。 我们当前的方法存在多种局限性。 首先,我们只触及了如何最有效地生成大语言模型目标建议的皮毛。 使用温度采样或从最差到最佳性能排序等技术的初步探索性实验并未产生显着的改进。 但人们可以想象利用有关训练运行的更多信息并自动调整指令提示模板。 例如。通过向视觉语言模型提供完整的学习曲线图(参见图12)或通过元元优化(Lu等人,2023)大语言模型提示。 其次,性能最高的损失在传统意义上重新调整了的用途,使其影响功能行为以及模型相对于基础模型的KL惩罚。 这促使未来的工作研究不同的形式,形式中可能有多个浮点参数,每个浮点参数都可以单独调整。 尽管我们对这个单一参数进行了初步分析,并观察到导致模型训练不稳定的功能行为的一些实例,但进一步的多参数分析,重新制定目标,将有利于未来的工作。 最后,我们的工作使用闭源模型(GPT-4)来生成代码,这限制了可重复性并且运行成本高昂。 未来的工作可以使用生成的模型本身来生成代码,从而实现代码级别的自我改进。
更广泛的影响和道德考虑。 本文提出了一种由 LLM 驱动的发现上下文学习流程,用于生成性能更好的新型离线偏好优化算法。 然而,用户可能会滥用管道作为工具或训练大语言模型来产生不良、不道德或有害的输出。 此外,由于大语言模型的使用和大语言模型的训练,输出容易产生幻觉,促使大语言模型的所有输出始终对输出应用内容过滤器。 最后,这项工作朝着语言模型的代码级自我改进迈出了一小步,这可能会导致意想不到的行为。
致谢和资金披露
这项工作得到了 Microsoft AI for Good Research Lab 和 Microsoft Accelerate Foundation Models 学术研究计划授予的 Azure 赞助积分的支持。 训练所用的硬件由 GoodAI 赞助。 SH 由阿斯利康资助。 CF 由佳能医疗资助。 AJC 由 Microsoft Research 和 EPSRC ICASE 奖学金资助。 该代码也可以通过 https://github.com/samholt/DiscoPOP 访问。
参考
- Ahmadian et al. [2024] Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms. arXiv preprint arXiv:2402.14740, 2024.
- Alet et al. [2020] Ferran Alet, Martin F Schneider, Tomas Lozano-Perez, and Leslie Pack Kaelbling. Meta-learning curiosity algorithms. arXiv preprint arXiv:2003.05325, 2020.
- Alfano et al. [2024] Carlo Alfano, Sebastian Towers, Silvia Sapora, Chris Lu, and Patrick Rebeschini. Meta-learning the mirror map in policy mirror descent. arXiv preprint arXiv:2402.05187, 2024.
- Anthropic [2023] Anthropic. Model card and evaluations for claude models, 2023. URL https://www-files.anthropic.com/production/images/Model-Card-Claude-2.pdf.
- Azar et al. [2023] Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. A general theoretical paradigm to understand learning from human preferences. arXiv preprint arXiv:2310.12036, 2023.
- Boser et al. [1992] Bernhard E Boser, Isabelle M Guyon, and Vladimir N Vapnik. A training algorithm for optimal margin classifiers. In Proceedings of the fifth annual workshop on Computational learning theory, pages 144–152, 1992.
- Bradley and Terry [1952] Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952.
- Carlini et al. [2021] Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), pages 2633–2650, 2021.
- Chan et al. [2024] Alex J Chan, Hao Sun, Samuel Holt, and Mihaela van der Schaar. Dense reward for free in reinforcement learning from human feedback. arXiv preprint arXiv:2402.00782, 2024.
- Chen et al. [2024a] Angelica Chen, David Dohan, and David So. Evoprompting: Language models for code-level neural architecture search. Advances in Neural Information Processing Systems, 36, 2024a.
- Chen et al. [2024b] Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, et al. Symbolic discovery of optimization algorithms. Advances in Neural Information Processing Systems, 36, 2024b.
- Christiano et al. [2017] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- Co-Reyes et al. [2021] John D Co-Reyes, Yingjie Miao, Daiyi Peng, Esteban Real, Sergey Levine, Quoc V Le, Honglak Lee, and Aleksandra Faust. Evolving reinforcement learning algorithms. arXiv preprint arXiv:2101.03958, 2021.
- Cortes and Vapnik [1995] Corinna Cortes and Vladimir Vapnik. Support-vector networks. Machine learning, 20:273–297, 1995.
- Cui et al. [2023] Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with high-quality feedback. arXiv preprint arXiv:2310.01377, 2023.
- Dubois et al. [2023] Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback, 2023.
- Dubois et al. [2024] Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475, 2024.
- Engstrom et al. [2019] Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, and Aleksander Madry. Implementation matters in deep rl: A case study on ppo and trpo. In International conference on learning representations, 2019.
- Ethayarajh et al. [2024] Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization, 2024.
- Gehman et al. [2020] Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462, 2020.
- Gemini-Team [2023] Google DeepMind Gemini-Team. Gemini: A family of highly capable multimodal models, 2023.
- Gemma-Team et al. [2024] Gemma-Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Guo et al. [2024] Shangmin Guo, Biao Zhang, Tianlin Liu, Tianqi Liu, Misha Khalman, Felipe Llinares, Alexandre Rame, Thomas Mesnard, Yao Zhao, Bilal Piot, et al. Direct language model alignment from online ai feedback. arXiv preprint arXiv:2402.04792, 2024.
- Hospedales et al. [2021] Timothy Hospedales, Antreas Antoniou, Paul Micaelli, and Amos Storkey. Meta-learning in neural networks: A survey. IEEE transactions on pattern analysis and machine intelligence, 44(9):5149–5169, 2021.
- Houthooft et al. [2018] Rein Houthooft, Yuhua Chen, Phillip Isola, Bradly Stadie, Filip Wolski, OpenAI Jonathan Ho, and Pieter Abbeel. Evolved policy gradients. Advances in Neural Information Processing Systems, 31, 2018.
- Jackson et al. [2024] Matthew Thomas Jackson, Chris Lu, Louis Kirsch, Robert Tjarko Lange, Shimon Whiteson, and Jakob Nicolaus Foerster. Discovering temporally-aware reinforcement learning algorithms. arXiv preprint arXiv:2402.05828, 2024.
- Jaques et al. [2019] Natasha Jaques, Asma Ghandeharioun, Judy Hanwen Shen, Craig Ferguson, Agata Lapedriza, Noah Jones, Shixiang Gu, and Rosalind Picard. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog. arXiv preprint arXiv:1907.00456, 2019.
- Lange et al. [2023a] Robert Lange, Tom Schaul, Yutian Chen, Chris Lu, Tom Zahavy, Valentin Dalibard, and Sebastian Flennerhag. Discovering attention-based genetic algorithms via meta-black-box optimization. In Proceedings of the Genetic and Evolutionary Computation Conference, pages 929–937, 2023a.
- Lange et al. [2023b] Robert Lange, Tom Schaul, Yutian Chen, Tom Zahavy, Valentin Dalibard, Chris Lu, Satinder Singh, and Sebastian Flennerhag. Discovering evolution strategies via meta-black-box optimization. In Proceedings of the Companion Conference on Genetic and Evolutionary Computation, pages 29–30, 2023b.
- Lange et al. [2024] Robert Tjarko Lange, Yingtao Tian, and Yujin Tang. Large language models as evolution strategies. arXiv preprint arXiv:2402.18381, 2024.
- Lehman et al. [2023] Joel Lehman, Jonathan Gordon, Shawn Jain, Kamal Ndousse, Cathy Yeh, and Kenneth O Stanley. Evolution through large models. In Handbook of Evolutionary Machine Learning, pages 331–366. Springer, 2023.
- Li et al. [2023] Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 2023.
- Lightman et al. [2023] Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, 2023.
- Lim et al. [2024] Bryan Lim, Manon Flageat, and Antoine Cully. Large language models as in-context ai generators for quality-diversity. arXiv preprint arXiv:2404.15794, 2024.
- Liu et al. [2023] Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning. arXiv preprint arXiv:2312.15685, 2023.
- Longpre et al. [2023] Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. In International Conference on Machine Learning, pages 22631–22648. PMLR, 2023.
- Loshchilov and Hutter [2017] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2017. URL https://api.semanticscholar.org/CorpusID:53592270.
- Lu et al. [2022] Chris Lu, Jakub Kuba, Alistair Letcher, Luke Metz, Christian Schroeder de Witt, and Jakob Foerster. Discovered policy optimisation. Advances in Neural Information Processing Systems, 35:16455–16468, 2022.
- Lu et al. [2023] Chris Lu, Sebastian Towers, and Jakob Foerster. Arbitrary order meta-learning with simple population-based evolution. In ALIFE 2023: Ghost in the Machine: Proceedings of the 2023 Artificial Life Conference. MIT Press, 2023.
- Ma et al. [2023] Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models. arXiv preprint arXiv:2310.12931, 2023.
- Maas et al. [2011] Andrew Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies, pages 142–150, 2011.
- Metz et al. [2022] Luke Metz, James Harrison, C Daniel Freeman, Amil Merchant, Lucas Beyer, James Bradbury, Naman Agrawal, Ben Poole, Igor Mordatch, Adam Roberts, et al. Velo: Training versatile learned optimizers by scaling up. arXiv preprint arXiv:2211.09760, 2022.
- OpenAI [2023] OpenAI. Gpt-4 technical report, 2023.
- Paszke et al. [2017] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
- Radford et al. [2019] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Rafailov et al. [2023] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- Razin et al. [2023] Noam Razin, Hattie Zhou, Omid Saremi, Vimal Thilak, Arwen Bradley, Preetum Nakkiran, Joshua Susskind, and Etai Littwin. Vanishing gradients in reinforcement finetuning of language models. arXiv preprint arXiv:2310.20703, 2023.
- Romera-Paredes et al. [2024] Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024.
- Rosasco et al. [2004] Lorenzo Rosasco, Ernesto De Vito, Andrea Caponnetto, Michele Piana, and Alessandro Verri. Are loss functions all the same? Neural computation, 16(5):1063–1076, 2004.
- Song et al. [2024] Xingyou Song, Yingtao Tian, Robert Tjarko Lange, Chansoo Lee, Yujin Tang, and Yutian Chen. Position paper: Leveraging foundational models for black-box optimization: Benefits, challenges, and future directions. arXiv preprint arXiv:2405.03547, 2024.
- Stiennon et al. [2020] Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- Sutton [1984] Richard Stuart Sutton. Temporal credit assignment in reinforcement learning. University of Massachusetts Amherst, 1984.
- Swamy et al. [2024] Gokul Swamy, Christoph Dann, Rahul Kidambi, Zhiwei Steven Wu, and Alekh Agarwal. A minimaximalist approach to reinforcement learning from human feedback. arXiv preprint arXiv:2401.04056, 2024.
- Tang et al. [2024] Yunhao Tang, Zhaohan Daniel Guo, Zeyu Zheng, Daniele Calandriello, Rémi Munos, Mark Rowland, Pierre Harvey Richemond, Michal Valko, Bernardo Ávila Pires, and Bilal Piot. Generalized preference optimization: A unified approach to offline alignment. arXiv preprint arXiv:2402.05749, 2024.
- Tunstall and Schmid [2024] Lewis Tunstall and Philipp Schmid. Zephyr 7b gemma. https://huggingface.co/HuggingFaceH4/zephyr-7b-gemma-v0.1, 2024.
- Tunstall et al. [2023a] Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Shengyi Huang, Kashif Rasul, Alexander M. Rush, and Thomas Wolf. The alignment handbook. https://github.com/huggingface/alignment-handbook, 2023a.
- Tunstall et al. [2023b] Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, and Thomas Wolf. Zephyr: Direct distillation of lm alignment, 2023b.
- Uesato et al. [2022] Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022.
- Völske et al. [2017] Michael Völske, Martin Potthast, Shahbaz Syed, and Benno Stein. Tl; dr: Mining reddit to learn automatic summarization. In Proceedings of the Workshop on New Frontiers in Summarization, pages 59–63, 2017.
- Wu et al. [2024] Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A Smith, Mari Ostendorf, and Hannaneh Hajishirzi. Fine-grained human feedback gives better rewards for language model training. Advances in Neural Information Processing Systems, 36, 2024.
- Xu et al. [2023] Jing Xu, Andrew Lee, Sainbayar Sukhbaatar, and Jason Weston. Some things are more cringe than others: Preference optimization with the pairwise cringe loss. arXiv preprint arXiv:2312.16682, 2023.
- Yu et al. [2023] Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Jan Humplik, et al. Language to rewards for robotic skill synthesis. arXiv preprint arXiv:2306.08647, 2023.
- Zhao et al. [2023] Yao Zhao, Rishabh Joshi, Tianqi Liu, Misha Khalman, Mohammad Saleh, and Peter J Liu. Slic-hf: Sequence likelihood calibration with human feedback. arXiv preprint arXiv:2305.10425, 2023.
- Zheng et al. [2024] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2024.
- Ziebart et al. [2008] Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, Anind K Dey, et al. Maximum entropy inverse reinforcement learning. In Aaai, volume 8, pages 1433–1438. Chicago, IL, USA, 2008.
附录
附录 ALLM 驱动的目标发现实施细节
A.1提示
我们使用以下系统提示来生成模型响应:
然后我们提供第一个用户提示,如下所示:
在测试生成的代码时,如果遇到错误,我们会提供以下提示,其中“error”是包含系统错误的文本:
成功完成后,我们返回以下用户提示,其中“val”是 MT-Bench 分数:
附录 B培训详情
B.1 发现任务-单轮对话
对于每个有效生成的目标函数,我们将其用于大语言模型,然后收集性能评估分数。 具体来说,我们在训练和评估所有目标函数时遵循相同的过程,从“zephyr-7b-gemma-sft”的预训练监督微调(SFT)70亿gemma模型开始,这是一个70亿基本版本gemma [Gemma-Team 等人, 2024] 在“deita-10k-v0-sft”数据集上对模型进行监督微调[Liu 等人, 2023]。 从这个模型开始,我们在“Argilla DPO Mix 7K”的成对偏好数据集上对其进行训练;它尝试通过仅过滤来自多轮数据集、指令遵循数据集[Longpre等人,2023]的数据集以及多样化偏好数据集的高评价选择响应来创建高质量的偏好数据集涵盖诚实、诚实和乐于助人[Cui 等人, 2023]。 对于每次训练运行,我们使用固定的 训练起始模型的所有参数。 除非明确说明,否则我们对所有训练运行使用相同的固定超参数。 具体来说,我们使用了 5e-7 的学习率、bfloat16 浮点格式、两个 epoch、每个设备的批量大小为 2、梯度累积步长为 8、余弦学习率调度程序和 AdamW 优化算法 [洛什奇洛夫和哈特,2017]。 我们使用流行的 TRL 转换器库 [vonwerra2022trl],调整离线偏好优化目标函数来训练所有模型。 这些模型在 8 个 nvidia A100 GPU 上进行训练。 一次单独训练大约需要 30 分钟。 我们在图7中提供了发现的目标函数的训练和评估统计数据。

B.2 TL;DR 总结
为了确定所发现的目标函数是否也可以很好地推广到其他任务,我们使用它们来优先优化用于文本摘要的大语言模型。 具体来说,我们再次从“zephyr-7b-gemma-sft”的预训练监督微调 (SFT) 70 亿 gemma 模型开始,并在子样本上使用目标函数 对其进行优化Reddit TL;DR 总结偏好数据集 [Völske 等人, 2017]666https://huggingface.co/datasets/CarperAI/openai_summarize_comparisons。 更准确地说,我们使用数据集的前 10% 进行偏好优化,总计约 8'000 个训练样本。 在训练过程中,超参数与单轮对话任务中的超参数保持相同,如 B.1 小节中所述,不同之处在于大语言模型使用梯度累积步骤 16 来训练 4 个 nvidia A100 GPU。 一次单独训练大约需要 1.5 小时。
B.3 IMDb 正面文本生成
偏好优化的另一个流行的泛化任务[Rafailov 等人, 2023] 是根据 IMDb 情感数据集[Maas 等微调一个小型大语言模型来生成电影评论的正面文本。人,2011]777https://huggingface.co/datasets/ZHZisZZ/imdb_preference。 作为起始模型,我们使用 GPT2 模型 [Radford 等人, 2019],该模型在 IMDb 数据集上进行了监督微调888https://huggingface.co/lvwerra/gpt2-imdb。 随后,我们应用基线并发现目标函数进行偏好优化。 大语言模型的目标是给出一个2-8个标记的简短提示,表明电影评论的开始,以产生积极的评论。 由于我们对 对奖励和 KL 散度的影响感兴趣,因此我们在 范围内训练目标函数。 每个大语言模型都训练了3个epoch,使用AdamW优化器,初始学习率为5.0e-5,预热调度器为0.1,余弦学习率调度器。 这些模型在 4 个 nvidia A100 GPU 上进行训练,梯度累积步长为 8,每个设备的批量大小为 2。 训练时间约为 30 分钟。
附录C评估指标
C.1 MT 工作台
为了评估发现阶段发现的偏好优化损失函数的适应性,我们在 MT-Bench [Zheng 等人, 2024] 基准上评估训练好的大语言模型。 评估基准由来自不同学科的 80 个多轮高质量问题组成。 目标是评估大语言模型遵循指令并保持对话流畅的能力。 然后使用更大的大语言模型(在我们的例子中为 GPT-4)作为评判,以 0(最低)到 10(最高)的数字对答案的质量进行评分。 根据大语言模型第一轮答案(单轮)以及第一轮和第二轮(多轮)的质量给出分数。 最后,MT-Bench 得分是单圈和多圈得分的平均值。 为了生成和评估答案,我们使用了 FastChat 库999https://github.com/lm-sys/FastChat及其标准采样和温度参数,由Zheng等人[2024]提供。
C.2 羊驼毛评估
目前,Alpaca Eval 2.0 [Li 等人, 2023, Dubois 等人, 2023, 2024]也是一个流行的评估大语言模型的基准。 这是一个基于 LLM 的单轮对话自动评估,使用更强大的大语言模型(这里是 GPT-4 Turbo)来评估经过训练的大语言模型策略完成的胜率,与 GPT-4 或底层 SFT 相比基础模型。 具体来说,Alpaca Eval 2.0已经针对20K人类注释进行了验证,旨在减少Alpaca Eval的长度偏差;其中使用长度控制 (LC) Alpaca Eval 显示与 Chatbot Arena 的相关性为 0.98,使其成为与 Chatbot Arena 相关性最高的流行基准[Dubois 等人,2024]。 Alpaca 评估数据集由来自不同数据集的 841 条高质量指令组成。 库101010https://github.com/tatsu-lab/alpaca_eval 由 Dubois 等人 [2024] 提供,计算获胜率(经过训练的策略优于参考策略的百分比,首次在 Alpaca Eval 1.0 中引入) ,以及长度控制的获胜率,其中拟合线性模型以消除提示长度和指令难度的偏差。 为了生成答案,我们使用 0.7 的温度、采样和最大新 Token 数 1024。 此外,该库还提供平均值的标准误差,这表明了胜率和 LC 胜率的置信度。
C.3 TL;DR 总结胜率
为了评估所发现的目标函数泛化到摘要任务的效果,我们使用 Alpaca Eval 2.0 库,类似于 C.2 小节。 我们没有使用 Alpaca 评估数据集,而是创建了一个自定义数据集,其中包含来自 IMDb 偏好测试数据集的 694 个样本。 此外,我们更改了注释器大语言模型的提示,以适应Rafailov等人[2023]中描述的“总结GPT-4胜率提示(C)”。 (LC) 胜率是根据现有的人类选择的测试样本或 SFT 参考模型生成的摘要来计算的。 对于摘要生成,我们应用 0.7 的温度参数、采样和最多 256 个新 Token 。 而且,我们在“\n”词符之后停止总结,避免无意义的生成。 此外,由于我们无法计算长度控制获胜率的指令难度,因此我们从线性模型中省略了此项(这对指标影响很小)。 除了胜率之外,我们还提供标准误差作为置信度的衡量标准。
C.4 IMDb 奖励与 KL-Divergence
对于正向文本生成,与 MT-Bench、Alpaca Eval 2.0 和 TL;DR 评估相比,我们不需要大语言模型判断,因为我们采用预先训练的情感分类器111111https://huggingface.co/siebert/sentiment-roberta-large-english 作为地面实况奖励记分器。 对于正向文本生成,大语言模型采用采样,最多 60 个新标记。 奖励和 KL 散度是经过训练的大语言模型 10 个不同代的平均值。
附录 D其他结果
D.1 预期奖励边界与 KL 分歧
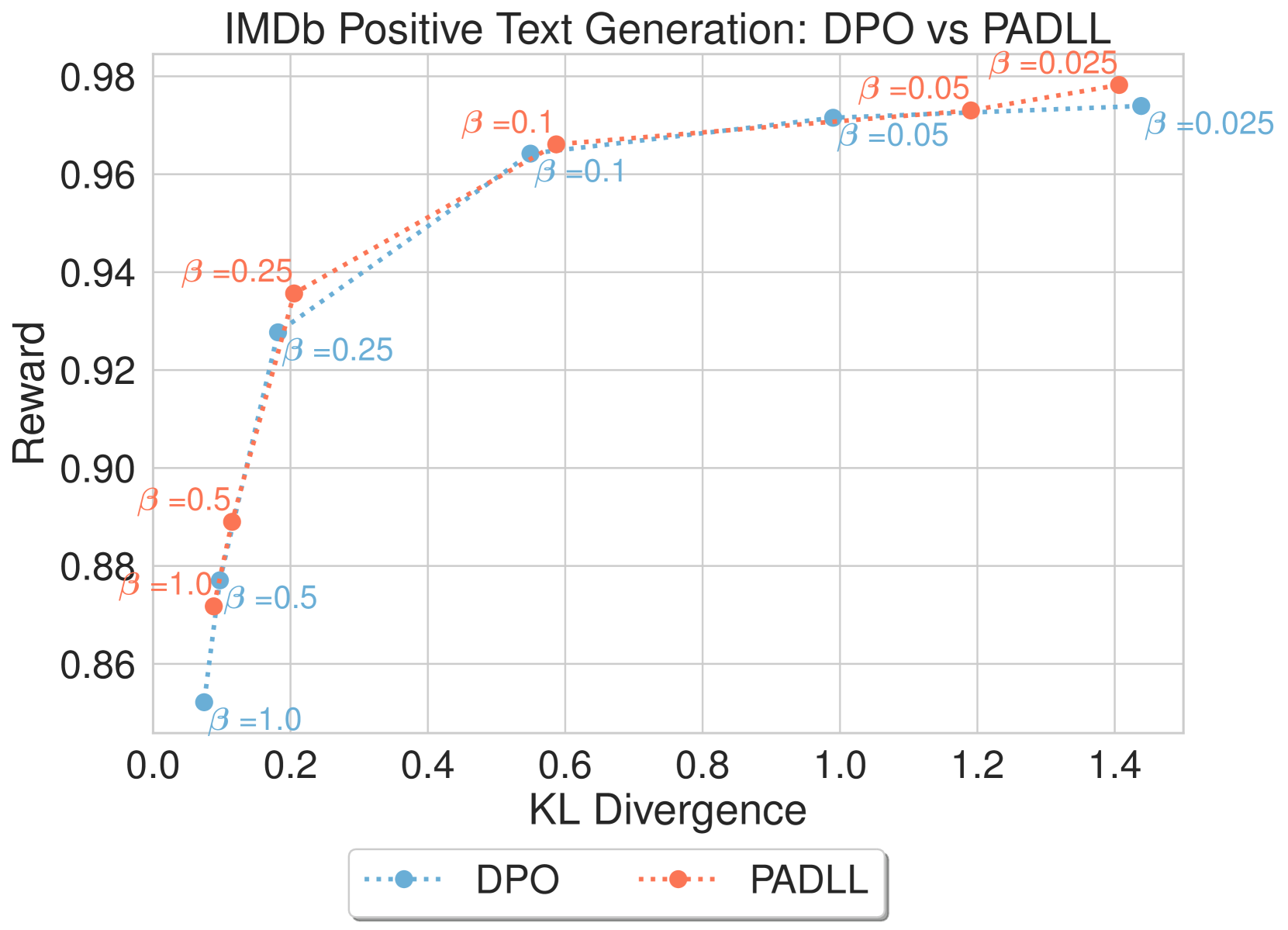
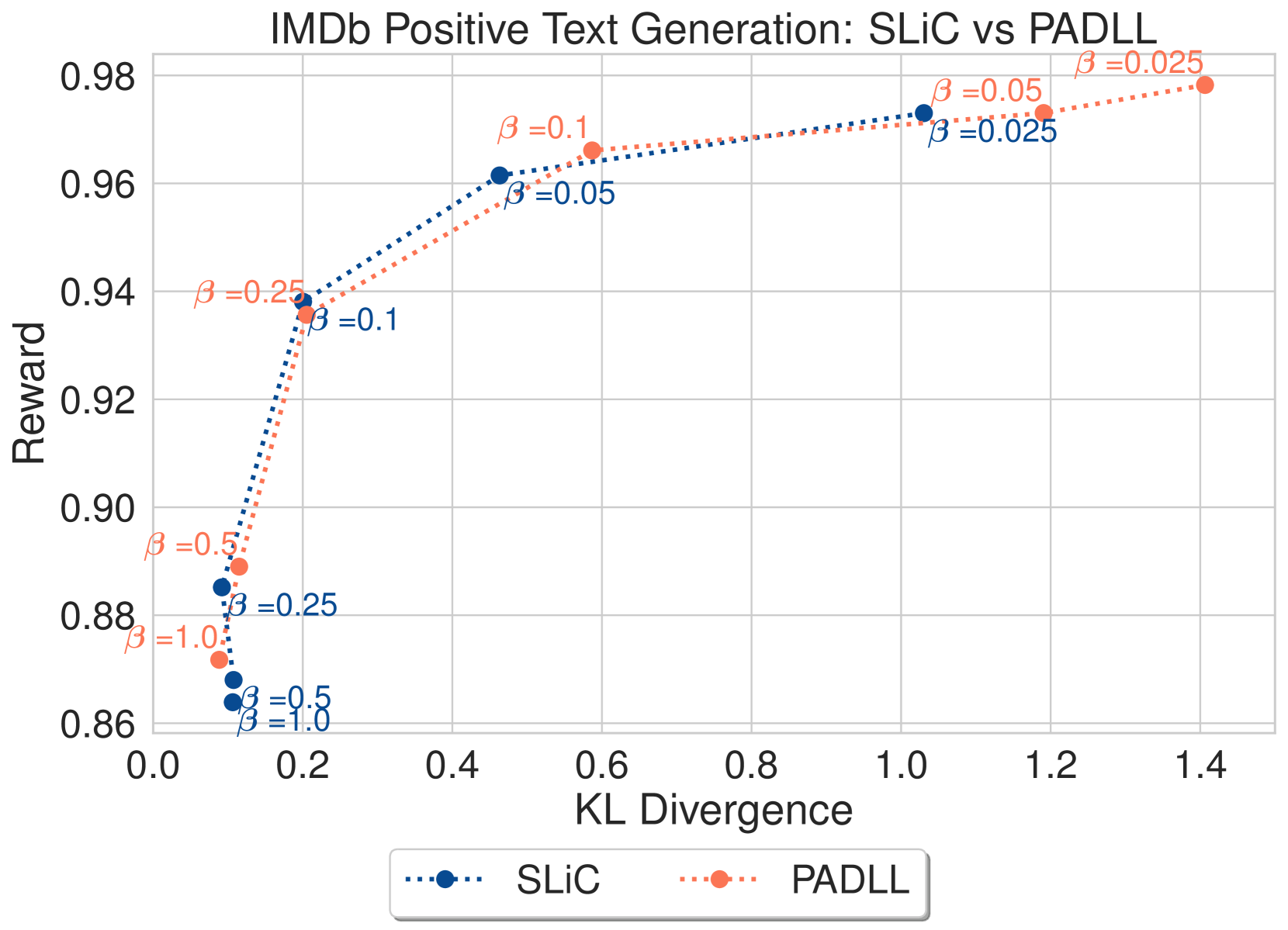
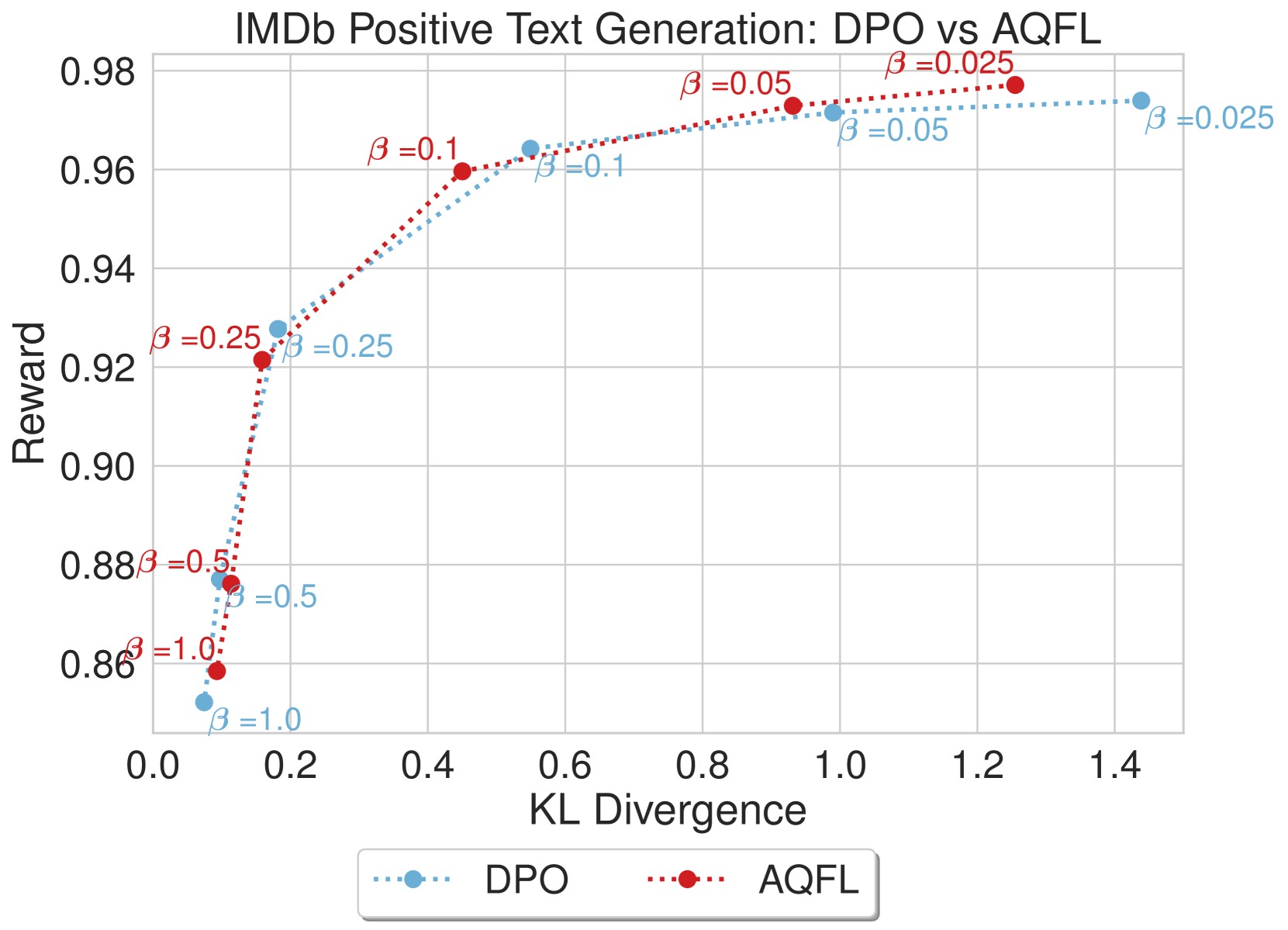
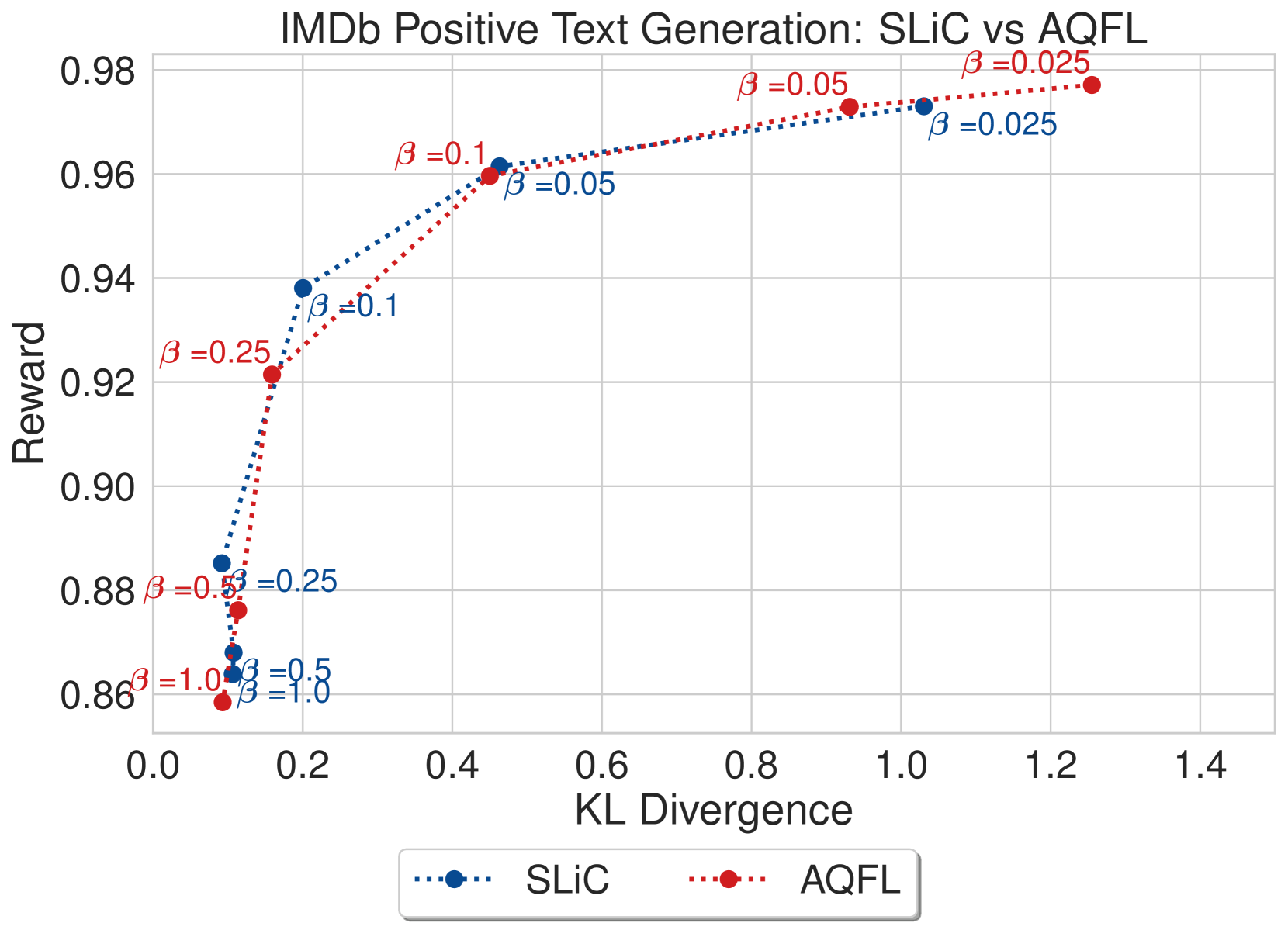
D.2 不同参数的损耗扫描
D.3 发现大语言模型超参数的鲁棒性
D.4 用于目标发现的视觉语言模型
附录E发现的目标函数
为了从数学上描述发现的损失,我们在这里定义了三个现有的偏好优化损失:
| (6) |
| (7) |
| (8) |
此外,我们还显示了大语言模型输出的已发现损失的代码。 此外,我们提供了每个的数学表示,我们已对其进行了调整,以与作为 KL 散度正则化参数的 保持一致。 这是因为,LRML、DBAQL、AQL、AQFL 和 PFL 生成的代码不支持 应该在任何进一步计算之前乘以对数比率的差值。 如果不坚持这一点,它可能会导致损失函数根据 KL 正则化项改变形状,因此模型无法收敛,或者可能崩溃。 在未来的工作中,我们应该限制探索大语言模型以支持 与输入的乘法,然后再使用对数比率 的差异进行任何其他计算。 由于元探索是使用一组 完成的,并且我们希望与这种正则化规模保持一致,因此我们通过将中间计算中使用的 值除以标量 。
在部分5的IMDb实验中,我们根据所提供的数学表示,使用了已发现损失的修正代码版本,因为我们最感兴趣的是 KL 散度与模型奖励相比的影响。
E.1 DBAQL:动态混合自适应分位数损失
MT 基准分数:7.978
| (9) | ||||
| (10) |
E.2 AQL:自适应分位数损失
MT 基准分数:7.953
| (11) | ||||
| (12) | ||||
| (13) | ||||
| (14) |
E.3 PADLL:性能自适应衰减逻辑损失
MT 基准分数:7.941
| (15) | ||||
| (16) | ||||
| (17) | ||||
| (18) |
这个损失也可以改写为:
| (19) |
E.4 AQFL:自适应分位数反馈损失
MT 基准分数:7.931
| (20) | ||||
| (21) | ||||
| (22) | ||||
| (23) | ||||
| (24) | ||||
| (25) |
E.5 CELL:组合指数 + 逻辑损失
MT 基准分数:7.925
| (26) |
E.6 LRML:对数比率调制损失
MT 基准分数:7.916
| (27) | ||||
| (28) |
E.7 PFL:以政策为重点的损失
MT 基准分数:7.900
有趣的是,PFL 生成的函数代码在损失函数中不包含任何 beta 值。 我们已将其添加到 IMDb 实验的更正代码中,以及下面的数学表达式中
| (29) |
附录F完整运行日志
我们在下面提供了完整的运行,并进行了格式化以便于阅读。