colorlinks=true, linkcolor=mydarkblue, citecolor=mydarkblue, filecolor=mydarkblue, urlcolor=mydarkblue, pdfview=FitH, *latexMarginpar 第 0 页已移动 *caption选项“hypcap=true”将被忽略
逐步扩散:基本教程
摘要
我们针对机器学习的扩散模型和流量匹配提供了一个易于理解的第一门课程,针对没有扩散经验的技术受众。 我们尝试尽可能地简化数学细节(有时是启发式的),同时保留足够的精度来导出正确的算法。
前言
有许多用于学习扩散模型的现有资源。 我们为什么要写另一个? 我们的目标是尽可能简单地教授扩散,以最少的数学和机器学习先决条件,但足够详细以推理其正确性。 与该主题的大多数教程不同,我们既不采用变分自动编码器 (VAE) 也不采用随机微分方程 (SDE) 方法。 事实上,对于核心思想,我们不需要任何 SDE、循证下界 (ELBO)、朗之万动力学,甚至分数的概念。 读者只需要熟悉基本的概率、微积分、线性代数和多元高斯函数。 本教程的目标受众是至少是高级本科生或研究生水平的技术读者,他们是第一次学习扩散并希望对该主题有数学理解。
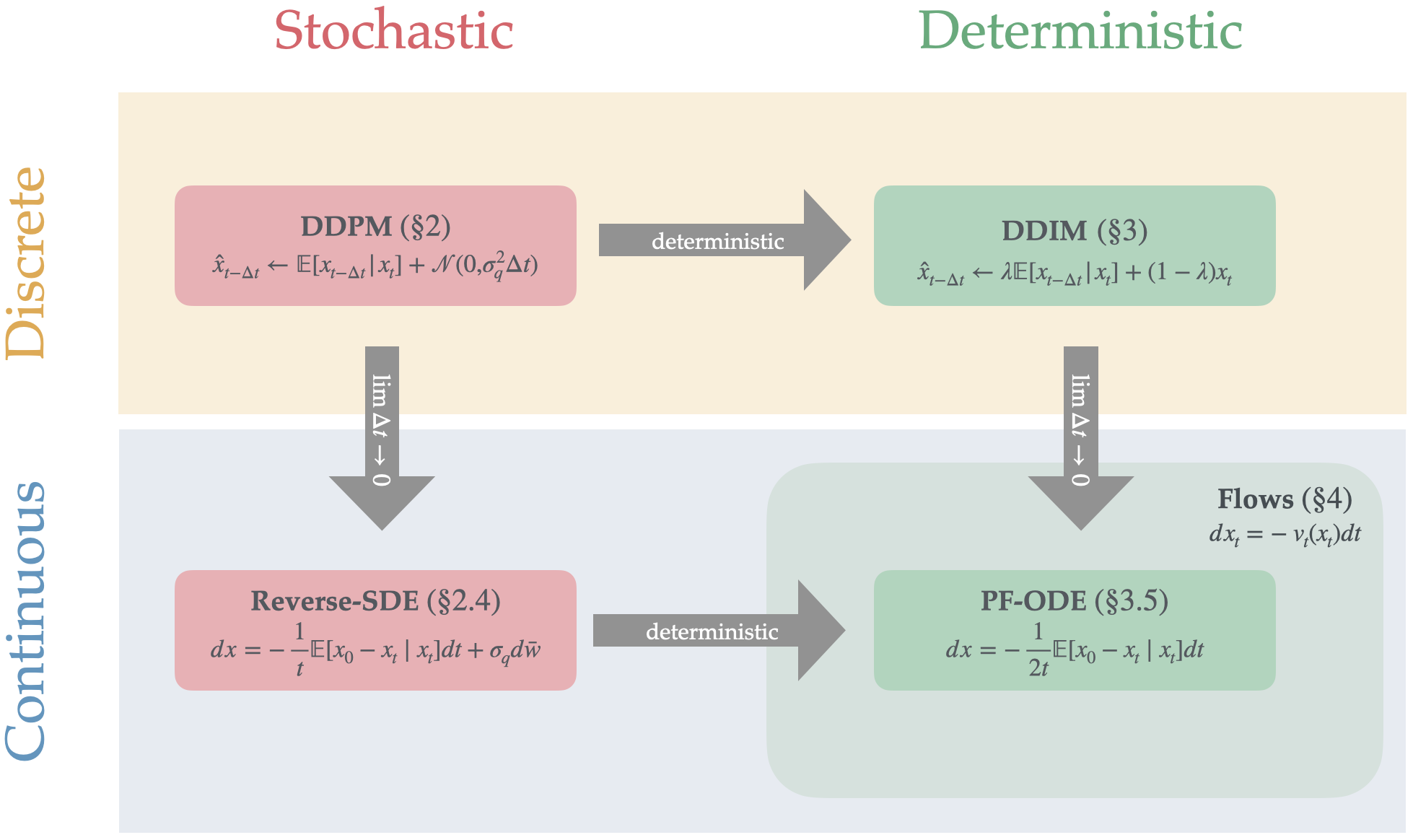
本教程有五个部分,每个部分相对独立,但涵盖密切相关的主题。 部分 1 介绍了扩散的基础知识:我们试图解决的问题以及基本方法的概述。 部分 2 和 3 分别展示如何构建随机和确定性扩散采样器,并给出为什么这些采样器正确反转前向扩散过程的直观推导。 部分 4 涵盖了密切相关的流匹配主题,它可以被认为是提供额外灵活性的扩散的概括(包括所谓的整流流或线性流)。 最后,在部分 5 我们回到扩散,并将本教程与更广泛的文献联系起来,同时强调一些在实践中最重要的设计选择,包括采样器、噪声表和参数化。
致谢
我们感谢许多人提供的有用反馈和建议,特别是:Josh Susskind、Eugene Ndiaye、Dan Busbridge、Sam Power、De Wang、Russ Webb、Sitan Chen、Vimal Thilak、Etai Littwin、Chenyang Yuan、Alex Schwing 和 Miguel安吉尔·巴蒂斯塔·马丁.
1 扩散的基础知识
生成建模的目标是:给定 i.i.d. 来自某些未知分布的样本 ,为(大约)相同的分布构造一个采样器。 例如,给定一组来自某些底层分布的狗图像训练集 ,我们想要一种从这个分布中生成新的狗图像的方法。
从高层次上来说,解决这个问题的一种方法是学习从一些易于采样的分布(例如高斯噪声)到我们的目标分布的转换. 扩散模型为学习此类转换提供了通用框架。 扩散的巧妙技巧是减少从分布中抽样的问题 转换为 更容易 的序列 抽样问题。
通过以下高斯扩散示例可以最好地解释这个想法。 我们现在将概述主要思想,在后面的部分中,我们将使用此设置来导出通常所说的 DDPM 和 DDIM 采样器111这些代表去噪扩散概率模型 (DDPM) 和去噪扩散隐式模型 (DDIM),遵循 Ho 等人 (2020) 和宋等人(2021)。,并推理它们的正确性。
1.1 高斯扩散
对于高斯扩散,令为按照目标分布分布的中的随机变量 (例如,狗的图像)。 然后构建随机变量序列 ,通过连续添加一些小尺度的独立高斯噪声:
| (1) |
这称为转发过程222 使用此特定前向过程的一个好处是计算:我们可以在恒定时间内直接对给定的 采样 。,它将数据分布转换为噪声分布。 方程(1)定义了所有的联合分布,我们让表示每个的边际分布。请注意,在步长较大时, 的分布接近高斯分布。333形式上, 在 KL 散度中与 接近,假设 具有有界矩。,所以我们大约可以从 中采样 只需对高斯进行采样。
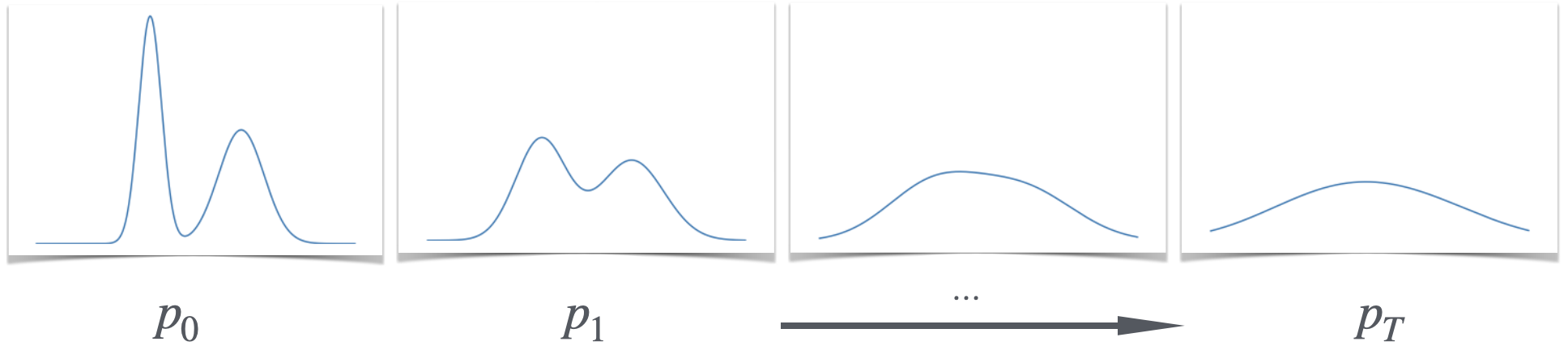
现在,假设我们可以解决以下子问题:
“给定一个边缘分布为 的样本,生成一个边缘分布为 的样本”.
我们将调用一个执行此操作的方法反向采样器444反向采样器将在下面的1.2节中正式定义。,因为它告诉我们如何从采样,前提是我们已经可以从采样。如果我们有一个反向采样器,就可以从目标中采样,方法很简单,首先从中进行高斯采样,然后迭代应用反向采样过程,从中采样,最后从中采样。
扩散的关键见解是,学习反转每个中间步骤比学习一步从目标分布中采样更容易555 直观上,这是因为分布 已经非常接近,因此反向采样器不需要做太多事情。。构建反向采样器的方法有很多,但为了具体起见,我们首先看一下标准扩散采样器,我们将其称为 DDPM 采样器666这是Sohl-Dickstein等人(2015)最初提出的抽样策略。.k
理想的 DDPM 采样器 使用明显的策略:在时间 时,给定输入 (承诺是来自的样本),我们输出条件分布的样本
| (2) |
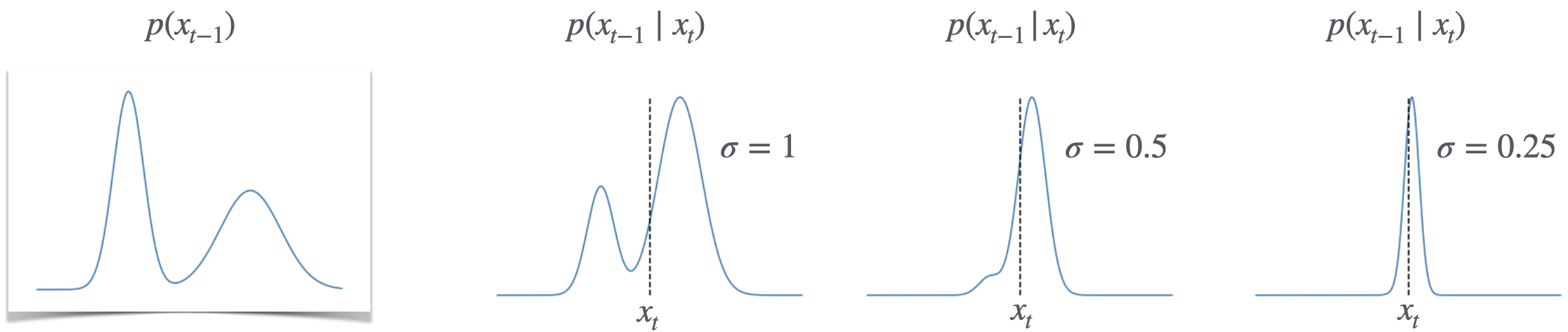
这显然是一个正确的反向采样器。 问题是,它需要学习条件分布的生成模型 对于每个 ,这可能会很复杂。 但如果每一步的噪音 足够小,那么事实证明这个条件分布变得简单:
Fact 1 (扩散反向过程)。
对于较小的 和 (1) 中定义的高斯扩散过程,条件分布 本身接近高斯分布。 也就是说,对于所有时间和条件,存在一些平均参数,使得
| (3) |
这不是一个显而易见的事实;我们将在2.1节中导出它。这一事实实现了极大的简化:我们现在不需要从头开始学习任意分布 ,而是知道该分布的所有内容,除了其均值(我们将其表示为)777 我们将平均值表示为函数,因为的平均值取决于时间 以及条件 ,如事实 1 中所述。 。图2说明,当足够小时,我们可以将后验分布近似为高斯分布。这是非常重要的一点,因此要再次重申:对于给定的时间和条件值,学习的均值就足以学习完整的条件分布。
学习 的平均值 这是一个比学习完整条件分布简单得多的问题,因为我们可以通过回归来解决它。 详细地说,我们有一个联合分布 ,我们可以轻松地从中进行采样,并且我们希望估计。这可以通过优化标准回归损失来完成888 回想一下一般事实,对于 上的任何分布,我们有: :
| (4) | ||||
| (5) | ||||
| (6) |
其中期望是从我们的目标分布中的样本获取的。999请注意,我们通过向 的样本添加噪声来模拟 的样本,如方程 1。 这个特定的回归问题在某些设置中得到了充分研究。 例如,当目标 是图像上的分布,那么对应的回归问题(方程6)就是一个图像去噪目标,可以使用熟悉的方法(例如卷积神经网络)来实现。
退一步,我们看到了一些值得注意的事情:我们将学习从任意分布采样的问题简化为标准回归问题。
1.2 摘要中的扩散
现在让我们抽象掉高斯设置,以捕获其许多实例(包括确定性采样器、离散域和流匹配)的方式定义类似扩散的模型。
抽象地说,以下是如何构建类似扩散的生成模型:我们从目标分布开始,然后选择一些基本分布 这很容易从中采样,例如标准高斯或 i.i.d 位。 然后,我们尝试构建一系列分布,在我们的目标之间进行插值 和基本分布 。也就是说,我们构建分布
| (7) |
这样 是我们的目标, 基本分布和相邻分布 在某种适当的意义上稍微“接近”。 然后,我们学习一个 反向采样器将分布转换为到. 这是关键的学习步骤,由于相邻分布“接近”,这可能会变得更容易。正式地,反向采样器定义如下。
Definition 1 (反向采样器)。
给定一系列边际分布,步骤的反向采样器是一个潜在的随机函数,这样如果,那么的边际分布恰好是:
| (8) |
有很多可能的反向采样器101010请注意,这些抽象都不是特定于高斯噪声的情况 - 事实上,它甚至不需要“添加噪声”的概念。 甚至可以在离散设置中实例化,其中我们考虑有限集合上的分布,并定义相应的“插值分布”和反向采样器。,甚至有可能构建出具有确定性的反向采样器。在本教程的剩余部分,我们将更正式地介绍三种流行的反向采样器:上文讨论过的DDPM采样器(第2.1)、确定性的 DDIM 采样器(第 3 节)和 流匹配模型系列(第 4 节)。),可以将其视为 DDIM 的推广。111111 给定一组边际分布,有许多可能的与这些边际一致的联合分布(这样的联合分布称为耦合) )。 因此,对于给定的一组边缘,没有规范的反向采样器 - 我们可以自由选择最方便的耦合。
1.3 离散化
在继续之前,我们需要更准确地了解相邻分布的含义 处于“接近”状态。 我们想要考虑顺序 作为某个(稳健的)时变函数的离散化,该函数在时间时从目标分布开始,在时间时结束于噪声分布:
| (9) |
步数 控制离散化的精细度(因此相邻分布的接近度)。121212这自然建议采用连续时间限制,我们将在 2.4 节中讨论,尽管我们的大多数论证都不需要它。
为了保证最终分布的方差,,与离散化步骤的数量无关,我们还需要更具体地了解每个增量的方差。 请注意,如果 ,然后。因此,我们需要将每个增量的方差缩放,即选择
| (10) |
哪里 是期望的终端方差。 这种选择确保了方差 无论 如何, 始终为 。 ( 缩放比例将在我们下一章中关于反向求解器正确性的论证中发挥重要作用,并且还与第 节中的 SDE 公式相关>2.4。)0>
此时,就可以方便地调整我们的记号了。 从现在开始, 将表示区间中的一个连续值(具体来说,取值为中的一个)。下标将表示时间,而不是索引,因此,例如现在将表示离散时间下的。也就是说,方程 1 变为:
| (11) |
这也意味着
| (12) |
因为截至时间(即)的总噪声也是高斯分布,均值为零且方差。
2 随机抽样:DDPM
在本节中,我们回顾一下第 1 节中讨论的类似 DDPM 的反向采样器,并启发式证明其正确性。 该采样器在概念上与流行的采样器相同 去噪扩散概率模型 (DDPM)由 Ho 等人 (2020) 提出,最初由 Sohl-Dickstein 等人 (2015) 引入,当适应我们的简化设置时。 不过,对于熟悉 Ho 等人 (2020) 的读者,请注意:虽然我们的采样器的整体策略与 Ho 等人 (2020) 相同,但某些技术细节(如常量等)略有不同131313 对于专家来说,主要区别在于我们使用“方差爆炸”扩散前向过程。 我们还使用恒定噪声计划,并且不讨论如何参数化预测器(“预测 与 与噪声 ”)。 我们在2.3节中详细阐述了后一点。 .
我们考虑第 1.3 节中的设置,其中包含一些目标分布 和噪声样本的联合分布 由方程 (11 定义)。 DDPM 采样器将需要估计以下条件期望:
| (13) |
这是一组函数,每个时间步都有一个。在训练 阶段,我们根据 i.i.d 估计这些函数。 的样本 ,通过优化去噪回归目标
| (14) |
通常使用神经网络141414 在实践中,在学习不同的回归函数时通常共享参数,而不是为每个时间步独立学习单独的函数。 这通常通过训练一个模型 来实现,该模型接受时间 作为附加参数,例如 。 参数化 。然后,在推论 阶段,我们在下面的反向采样器中使用估计函数。
[nobreak=true] 算法1:随机反向采样器(类似DDPM)
对于输入样本 和时间步 , 输出:
| (15) |
为了实际生成样本,我们首先将 作为各向同性高斯进行采样,然后运行算法 1 的迭代,直到,从而生成样本。(回想一下,在我们的离散化符号(12)中,是全噪声终端分布,迭代的步长为)。2.2节给出了这些算法的明确伪代码。
我们想要推断整个过程的正确性:为什么迭代算法 1 会从[大约]我们的目标分布中生成样本?关键的缺失部分是,我们需要证明事实1的某个版本:真正的条件可以是通过高斯函数可以很好地近似,并且随着我们缩放,这种近似会变得更好。
2.1 DDPM的正确性
Claim 1 (非正式)。
令 为 上的任意、足够平滑的密度。 考虑 的联合分布,其中 和 。 那么,对于足够小的,以下内容成立。 对于所有条件,存在,使得:
| (16) |
对于一些仅取决于 的常量 。 此外,只需采取151515专家会认为该平均值与分数相关。事实上,Tweedie 的公式意味着即使对于较大的 ,该均值也是完全正确的,无需近似。 那是, 。然而,对于较大的,分布可能会偏离高斯分布。
| (17) | ||||
| (18) |
其中 是 的边际分布。
在我们看到推导之前,有几点说明:假设1意味着,要从中采样,只需首先从中采样,然后从以为中心的高斯分布中采样。这正是公式 (15) 中 DDPM 所做的。最后,在这些注释中,我们实际上不需要等式 (18) 中的 表达式;我们只要知道这样的 就足够了。 存在,所以我们可以从样本中学习它。
索赔证明1(非正式)。
这是关于为什么分数出现在相反过程中的启发式论证。 我们本质上只是应用贝叶斯规则,然后适当地进行泰勒扩展。 我们从贝叶斯规则开始:
| (19) |
然后获取两种尺寸的日志。 在整个过程中,我们将删除日志中的所有加性常数(转化为归一化因子),并删除所有顺序项 ††[-1cm]请注意。 删除 项意味着在 的扩展中删除 ,但在 中保留 。 请注意,我们应该将 视为此推导中的常数,因为我们希望将条件概率理解为 的函数。 现在:
| 删除仅涉及 的常量。 | |||
| 自开始。 | |||
| 的定义。 | |||
| 泰勒围绕 展开并删除常数。 | |||
| 完成中的正方形,并删除仅涉及的常量。 | |||
| 对于。 |
这与均值 和方差 的正态分布的对数密度相同(最多添加因子)。 所以,
| (20) |
∎
反思这个推导,主要思想是,对于足够小的,逆过程的贝叶斯规则展开 由术语 主导,从前向过程。 这就是直观上为什么逆向过程和正向过程具有相同的函数形式(这里都是高斯)161616正向过程和反向过程之间的这种一般关系比高斯扩散更普遍;参见例如Sohl-Dickstein 等人 (2015) 中的讨论。.
技术细节[可选]。
细心的读者可能会注意到声明1 显然不足以暗示整个 DDPM 算法的正确性。 问题是:当我们缩小规模时 ,每步近似的误差(方程16) 减少,但所需的总步骤数增加。 因此,如果每步误差下降得不够快(作为 ),那么这些误差可能会在最后一步累积为不可忽略的误差。 因此,我们需要量化每步误差衰减的速度。 引理 下面的 1 是量化这一点的一种方法:它指出如果步长(即每步噪声的方差)为 ,则每步高斯近似的KL误差为。这个衰减速度足够快,因为步数只会增长171717 KL 的链式法则意味着我们可以将这些每步误差相加:最终样本的近似误差受到所有每步误差之和的限制。步骤错误。 。
Lemma 1.
令 为 上的任意密度,具有有界的一阶到四阶导数。 考虑联合分布 ,其中 和 。 然后,对于任何条件 ,我们有
| (21) |
在哪里
| (22) |
2.2 算法
伪代码清单 1 和 2 给出明确的 DDPM 训练损失和采样代码。 去训练181818请注意,训练过程通过采样 同时优化所有时间步 的 统一在第 2 行。网络,我们必须最小化伪代码输出的预期损失1,通常通过反向传播。
2.3 方差减少:预测
到目前为止,我们已经训练扩散模型来预测:这正是算法 1 所要求的,也是伪代码1的训练过程所产生的。然而,许多实际的扩散实现实际上是训练预测,即预测初始点的期望值,而不是预测前一个点的期望值。结果发现,这种差异只是方差减小 技巧,它估计期望中的相同数量。 形式上,这两个量的关系如下:
Claim 2。
这个说法意味着,如果我们想要估计,我们可以估计,然后本质上除以通过 ,这是迄今为止采取的步数。 DDPM 训练和采样算法的方差减少版本正是这样做的;我们将它们包含在附录中 B.9.
![[Uncaptioned image]](predict_eps_dt.png)
主张 2 背后的直觉。 给定 ,最终噪声步骤 的分布与所有其他噪声步骤相同,直观地说,因为我们只知道总和 。 主张2背后的直觉如图2所示:首先,请注意,在给定的情况下预测相当于预测最后一个噪声步骤,即等式(11)前向过程中的。但是,如果我们只给出最后的,那么之前所有的噪声步骤都会被忽略。 直觉上“看起来一样”——例如,我们无法区分最后一步添加的噪声和第五步添加的噪声。 通过这种对称性,我们可以得出结论,所有单独的噪声步骤都是分布的 相同(尽管不是独立的)给定。因此,我们可以等效地估计所有先前噪声步骤的平均值,而不是估计单个噪声步骤,其方差要低得多。 有 按时间计算经过的噪声步数,因此我们将总噪声除以公式中的该量23 计算平均值。 参见附录 B.8 以获得正式证明。
警告:扩散模型应始终经过训练来估计期望。特别是,当我们训练一个模型来预测时,我们不应该不认为这是在尝试学习“如何从分布中采样”。例如,如果我们训练图像扩散模型,那么最优模型将输出 这看起来像是模糊的图像混合(例如 Karras 等人 (2022) 中的图 1b) — 它看起来不像实际的图像样本。 最好记住,当扩散论文通俗地讨论模型“预测 ”,它们并不意味着生成看起来像 实际样本的东西。
2.4 作为 SDE 的扩散 [可选]
在本节中,我们将迄今为止讨论的离散时间过程与随机微分方程(SDE)联系起来。 在连续极限下,如 ,我们的离散扩散过程变成了随机微分方程。 SDE 还可以代表许多其他扩散变体(对应于不同的漂移和扩散项),提供设计选择的灵活性,例如缩放和噪声调度。 SDE 观点非常强大,因为现有理论为时间反演 SDE 提供了通用的封闭式解。 我们特定扩散的逆时 SDE 的离散化立即产生了我们在本节中导出的采样器,但其他扩散变体的逆时 SDE 也可用 自动(然后可以使用任何现成的或自定义的 SDE 求解器进行求解),从而实现更好的训练和采样策略,我们将在第 5. 尽管我们在这里只是简单地提到这些联系,但 SDE 的观点对该领域产生了重大影响。 如需更详细的讨论,我们推荐宋杨的博文(宋,2021)。
极限 SDE
回想一下我们的离散更新规则:
在此限制为,这对应于零漂移 SDE:
| (25) |
哪里 是布朗运动。 布朗运动是一个具有独立同分布的随机过程。 高斯增量,其方差与 。191919有关布朗运动和 Itô 公式的高级概述,请参阅 Eldan (2024)。 另请参阅 Evans (2012) 了解温和的入门教材,以及 Kloeden 和 Platen (2011) 了解数值方法。 非常启发式,我们可以想到,从而“推导”(25) 通过
更一般地说,扩散的不同变体相当于具有不同漂移和扩散项选择的 SDE:
| (26) |
SDE (25) 仅具有 和 。不过,这个公式包含许多其他可能性,对应于 、 在 SDE 中。 我们将在部分中回顾 5,这种灵活性对于开发有效的算法非常重要。 实践中做出的两个重要选择是调整噪声调度和缩放 ;这些一起可以帮助控制 的方差,并控制我们对不同噪音水平的关注程度。 采用灵活的噪声时间表 代替固定时间表 对应SDE (宋等人, 2020)
如果我们还希望将每个缩放一个因子, Karras 等人 (2022) 表明这对应于 SDE 202020作为如何产生的一个草图,让我们忽略噪音并注意:
这些只是灵活的 SDE (26) 实现的丰富且有用的设计空间的几个示例。
反时SDE
SDE 的时间反转运行进程时间向后. 反时 SDE 是 DDPM 等采样器的连续时间模拟。 Anderson (1982)(并在Winkler (2021)中很好地重新推导)得出的深刻结果表明,SDE 的时间反转(26) 是(谁)给的:
| (27) |
也就是说,SDE (27) 告诉我们如何运行 (26 形式的任何 SDE)时间倒退! 这意味着我们不必在每种情况下重新推导反转,并且我们可以选择任何 SDE 求解器来生成实用的采样器。 但没有什么是免费的:我们仍然无法使用(27)直接向后采样,因为项--实际上就是之前出现在方程18中的分数--一般来说是未知的,因为它取决于。但是,如果我们能够学习 得分,然后我们就可以求解逆SDE。 这类似于离散扩散,其中 正向过程很容易建模(它只会增加噪音),而反向 过程必须要学习。
让我们花点时间讨论一下分数,,起着核心作用。 直观上,由于分数“指向更高的概率”,因此它有助于逆转扩散过程,从而在向前运行时“压平”概率。 分数也与条件期望有关 给定。回想一下,在离散情况下
类似地,在连续情况下我们有212121我们可以通过应用 Tweedie 公式直接看到这一点,该公式指出: 由于 Tweedie 与 给出:
| (28) |
3 确定性采样:DDIM
我们现在将展示确定性 高斯扩散的反向采样器——它看起来与上一节的随机采样器类似,但在概念上有很大不同。 该采样器相当于DDIM222222DDIM代表去噪扩散隐式模型,反映了宋等人(2021)原始推导中使用的视角。 我们的推导遵循不同的视角,“隐含”方面对我们来说并不重要。 宋等人 (2021) 的更新,适应我们的简化设置。
我们考虑与上一节相同的高斯扩散设置,具有联合分布和条件期望函数 反向采样器定义如下,并在伪代码中明确列出3。
我们如何证明这定义了一个有效的反向采样器? 由于算法 2 是 确定性,认为它从采样是没有意义的。,正如我们所主张的类似 DDPM 的随机采样器。 相反,我们将直接证明方程(31)实现了边际分布和之间有效的传输映射。也就是说,如果让成为方程(31)的更新:
| (32) | ||||
| (33) |
那么我们想证明232323 符号表示的分布。 这被函数称为的前推。
| (34) |
证明概述:证明这一点的通常方法是使用随机微积分工具,但我们将提出一个基本推导。 我们的策略是首先证明算法 2 在最简单的点质量分布情况下是正确的,然后通过适当的边缘化将该结果提升到完全分布。 对于专家来说,这类似于“流程匹配”证明。
3.1 案例1:单点
让我们首先了解一个简单的情况,其中目标分布是中的单个点质量。不失一般性242424因为我们可以“移动”坐标来实现这一点。 形式上,我们的整个设置(包括方程 33)是平移对称的。,我们可以假设该点位于. 在这种情况下算法 2 正确吗? 为了推断正确性,我们要考虑以下分布 和 用于任意步骤 。根据扩散前向过程(方程11),在时间相关随机变量为0>252525为了符号简单起见,我们省略了这些协方差中的单位矩阵。 读者可以假设维度而不失一般性。
的边际分布为,的边际分布为。
让我们首先找到一些确定性函数,使得。有许多可能的功能可以工作262626例如,我们始终可以向任何有效地图添加围绕原点的旋转。,但这是显而易见的:
| (35) |
上面的函数只是重新缩放的高斯分布,以匹配高斯分布的方差。事实证明,这个 与步骤 完全相同 我们现在将展示算法 2。
证明。
要应用 ,我们需要计算简单分布的 。 由于 是共同高斯变量,因此††[-2cm]回顾两个共同高斯随机变量 的条件期望为 、其中 是各自的均值, 是 的交叉协方差和 的协方差。 由于 和 以 为中心,因此我们有 。 对于协方差项,由于 我们有 。 类似地,。
| (37) |
3.2 速度场和气体
的物理直觉是:想象一种由非相互作用粒子组成的气体,其密度场为。然后,假设位置处的粒子沿方向移动。生成的气体将具有密度场。我们把这个过程写成0>
| (40) |
在小步长的限制下,通俗地说,我们可以将视为速度场 — 根据 DDIM 算法指定粒子移动的瞬时速度。
![[Uncaptioned image]](x1.png)
3.3 案例2:两点
现在让我们证明当目标分布是两点混合时算法 2 是正确的:
| (41) |
对于一些。根据扩散前向过程,时刻的分布将是高斯混合分布282828前向过程的线性(相对于)在这里很重要。 也就是说,粗略地说,扩散分布相当于独立扩散该分布中的每个单独的点;这些点不相互作用。 :
| (42) |
我们想要证明,通过这些分布,DDIM速度场(方程38) 传输 。
让我们首先尝试构建某个速度场,使得。根据我们在3.1节中的结果--DDIM 更新对单点有效--我们已经知道了单独传输每个混合物成分的速度场。也就是说,我们知道定义为的速度场。
| (43) |
运输292929请特别注意我们对哪些分布进行期望! 方程 (43) 中的期望是 w.r.t. 单点分布 ,但我们对 DDIM 算法的定义及其方程 (38) 中的向量场始终与单点分布 相关。 目标分布。 在我们的例子中,目标分布是方程 (41) 的 。
| (44) |
对于也类似。
我们现在需要某种方法将这两个速度场组合成一个速度,输送混合物:
| (45) |
我们可能只想取平均速度场,但这是不正确的。 正确的组合速度 是各个速度场的加权平均值,由相应的密度场加权。303030请注意,我们可以将密度写为。.
| (46) | ||||
| (47) |
明确地,在一点的权重是是从初始点生成的,而不是。0>
凭直觉确信这一点313131时间步长必须足够小才能使这个类比成立,因此 DDIM 更新本质上是无穷小的步长。 否则,如果步长很大,则可能无法单独将两个传输图与“局部”(即逐点)操作结合起来。,考虑图3中所示的有关气体的相应问题。假设我们有两种重叠的气体,一种密度为 和速度 的红色气体,以及密度 < 的蓝色气体。 /t7> 和速度 . 我们想知道,混合气体的有效速度是多少(就好像我们只在灰度中看到一样)? 我们应该明确采取 加权 - 各个气体速度的平均值,按各自的密度加权 - 正如方程(47)。

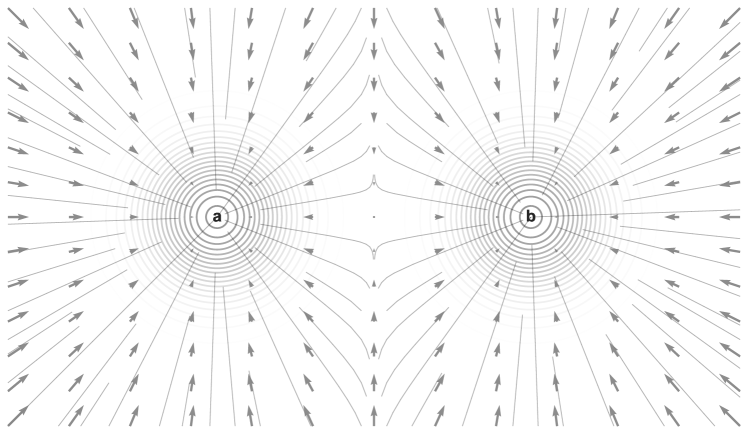
我们现在已经解决了本节的主要子问题:我们已经找到了 一个特定的矢量场,对于我们的两点分布,它将传送到。我们还需要证明,等价于算法 2 的速度场(来自公式38)。
3.4 情况 3:任意分布
现在我们知道如何处理两个点,我们可以将这个想法推广到 的任意分布. 我们不会在这里详细讨论,因为一般证明将包含在后续部分中。
事实证明,我们算法 2 的整体证明策略可以显着推广到其他类型的扩散,而无需做太多工作。 这就产生了流匹配的想法,我们将在下一节中看到。 一旦我们开发了流机制,实际上就可以直接从简单的单点缩放算法方程(35):参见附录B.5。
3.4.1 概率流 ODE [可选]
最后,我们将离散时间确定性采样器推广到称为概率流 ODE 的常微分方程 (ODE)概率流 ODE (宋等人,2020)。 以下部分基于我们对 SDE 作为扩散连续极限的讨论 2.4。正如2.4节的逆时SDE 提供了离散随机采样器的灵活连续时间推广,因此我们将看到离散确定性采样器推广到 ODE。 ODE 公式既提供了观察扩散的有用理论镜头,也提供了实际优势,例如可以从各种现成和自定义 ODE 求解器中进行选择以改进采样(如流行的 DPM++ 方法、章节中讨论 5)。
Song 等人 (2020) 表明可以将此 SDE 转换为 确定性 等价称为概率流 ODE (PF-ODE): 333333校样草图位于附录B.2中。 它涉及将 SDE 噪声项重写为确定性分数(回想一下等式 (18) 中噪声和分数之间的联系)。 尽管它是确定性的,但分数是未知的,因为它取决于 。
| (54) |
SDE (26) 和 ODE (54) 是等价的,即通过求解获得的轨迹PF-ODE 在每个时间点都具有与 SDE 轨迹相同的边际分布343434使用气体类比:SDE 描述气体中单个粒子的(布朗)运动,而 PF-ODE 描述气体速度场的流线。 也就是说,PF-ODE 描述了气体传输的“测试粒子”的运动,就像风中的羽毛一样。。但是,请注意,分数再次出现在此处,就像在反向 SDE 中一样 (27);就像逆向 SDE 一样,我们必须学习分数才能生成 ODE (54)实用。
3.5 讨论:DDPM 与 DDIM
上面定义的两个反向采样器(DDPM 和 DDIM)在概念上有显着不同:一个是确定性的,另一个是随机性的。 为了进行审查,这些采样器使用以下策略:
-
1.
DDPM 理想地实现了随机映射,使得输出逐点是来自条件分布。
-
2.
DDIM 理想地实现确定性映射 ,使得输出 为 边际分布为。即,。1>
尽管他们都朝着同一个方向迈出了一步353535步数与成比例。(给定相同的输入),这两种算法最终的演变非常不同。 为了看到这一点,让我们考虑一下每个采样器从相同的初始点开始时的理想行为 并迭代完成。
DDPM 理想情况下会从 生成样本。如果前向过程充分混合(即,对于我们设置中的较大 ),那么最终点 将接近独立 从初始点开始。 因此 ,所以理想的DDPM的分布输出根本不依赖363636 实际的 DDPM 可能对初始点 有很小的依赖性,因为它们没有完美混合(即最终分布 不是完美的高斯分布)。 因此,随机化初始点可能有助于实践中的样本多样性。在起点。相反,DDIM 是确定性的,因此它始终会为给定的 生成固定值,因此将非常强烈地依赖于 .
要记住的图片是,DDIM 定义了确定性映射,从高斯分布中采样到我们的目标分布。 在这个层面上,DDIM 映射听起来可能与其他生成模型类似——毕竟,GAN 和归一化流也定义了从高斯噪声到真实分布的映射。 DDIM图的特别之处在于,它不允许任意:目标分布 准确地确定了理想的 DDIM 映射(我们训练模型来模拟)。 这张地图“不错”;例如,如果我们的目标分布是平滑的,我们期望它是平滑的。 相比之下,GAN 可以自由学习噪声和图像之间的任意映射。 扩散模型的这一特征可能会使学习问题在某些情况下变得更容易(因为它是有监督的),或者在其他情况下变得更困难(因为可能存在其他方法可以找到的更容易学习的地图)。
3.6 关于泛化的评论
在本教程中,我们没有讨论扩散模型的学习理论方面:在仅给定有限样本和有界计算的情况下,我们如何学习基础分布的属性? 这些是学习的基本方面,但扩散模型尚未完全理解;这是一个活跃的研究领域373737 我们推荐引入 Chen 等人 (2022) 和 Chen 等人 (2024b)最近学习理论结果的概述。 这一系列工作包括例如De Bortoli 等人 (2021);德博尔托利 (2022); Lee 等人 (2023);陈等人(2023, 2024a)。 .
为了理解这里的微妙之处,假设我们使用经验风险最小化(ERM)的经典策略学习扩散模型:我们从基础分布中采样有限训练集,并优化所有回归函数。 这种经验分布。 问题是,我们不应该 完美地最小化经验风险,因为这会产生一个仅重现训练样本的扩散模型383838 这并非特定于扩散模型:经验分布的任何完美生成模型都将始终输出均匀随机点,这远非最佳。 真实的基础分布。.
在一般学习中,扩散模型必须被正则化隐式或显式地防止训练数据的过度拟合和记忆。 当我们训练用于扩散模型的深度神经网络时,这种正则化通常会隐式发生:有限模型大小和优化随机性等因素会阻止训练模型完美记住其训练集。 我们将在第 1 节中重新审视这些因素(作为错误来源) 5.
在小图像数据集上训练的扩散模型中,已经在“野外”看到了记忆训练数据的问题,并且观察到,记忆随着训练集大小的增加而减少 (Somepalli 等人, 2023; Gu 等人,2023)。 此外,记忆被认为是神经网络的潜在安全和版权问题,如 Carlini 等人 (2023) 中的作者发现,他们可以在正确的提示下从稳定扩散中恢复训练数据。
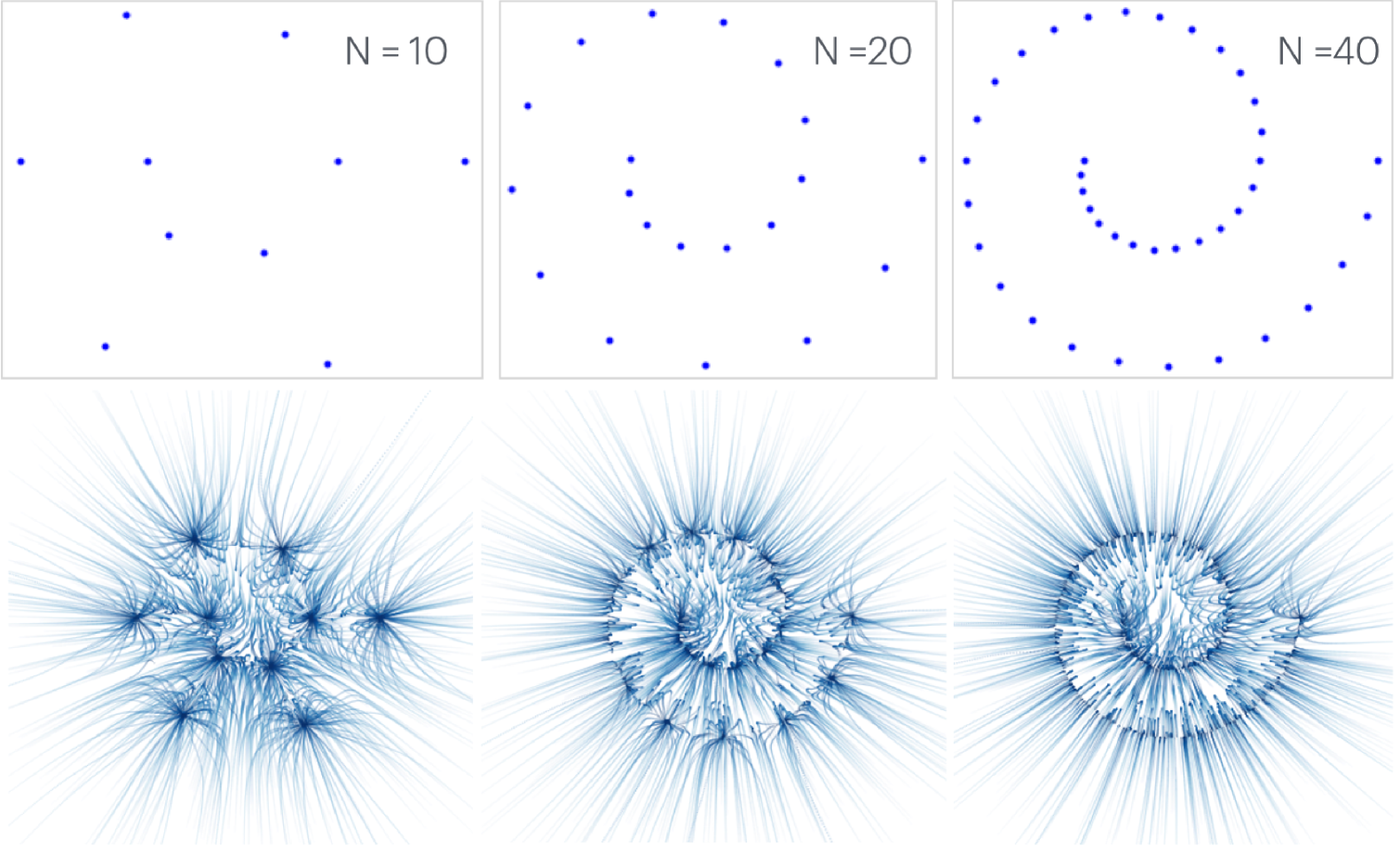
图4 演示了训练集大小的影响,并显示了使用 3 层 ReLU 网络训练的扩散模型的 DDIM 轨迹。 我们看到扩散模型 样本“记住”它的训练集:它的轨迹全部崩溃到训练点之一,而不是产生底层的螺旋分布。 随着我们添加更多样本,模型开始泛化:轨迹收敛到底层螺旋流形。 轨迹也开始变得更加垂直于底层流形,这表明正在学习低维结构。 我们还注意到,在 在扩散模型失败的情况下,人类根本无法从这些样本中识别出“正确”的模式,因此泛化的期望可能过高。
4 流量匹配
![[Uncaptioned image]](x5.png)
运行从环形分布(顶部)生成螺旋分布(底部)的流。
现在我们介绍流匹配的框架(Lipman等人,2023;Albergo等人,2023;Liu等人,2022)。 流匹配可以被认为是 DDIM 的推广,它允许在设计生成模型时具有更大的灵活性,例如包括 整流流(有时称为线性流)由稳定扩散 3 (Liu 等人,2022;Esser 等人,2024)使用。
实际上,在3节中对 DDIM 的分析中,我们已经了解了流匹配背后的主要思想。在较高的层面上,以下是我们在第 3 节中构建生成模型的方式:
-
1.
首先,我们定义了如何生成单点。 具体来说,我们构建了向量场 ,当应用于所有时间步长时,将标准高斯分布转换为任意 delta 分布。
-
2.
其次,我们确定如何将两个矢量场组合成单个有效矢量场。 这让我们可以构建从标准高斯到 两个点(或者更一般地说,到一个分布 超过点——我们的目标分布)。
这些步骤都不需要特别需要高斯基分布或高斯前向过程(方程1)。 例如,组合矢量场的第二步对于任意两个任意矢量场保持相同。
所以让我们放弃所有的高斯假设。 相反,我们将从基本层面思考如何在任意两点之间进行映射 和。然后,我们看看从任意分布 (数据)和 中采样两个点时会发生什么 (基地),分别。 我们将看到这种观点将 DDIM 作为一个特例,但它更为普遍。
4.1 流量
Let us first define the central notion of a flow. A flow is simply a collection of time-indexed vector fields . We should think of this as the velocity-field of a gas at each time , as we did earlier in Section 3.2. Any flow defines a trajectory taking initial points to final points , by transporting the initial point along the velocity fields .
形式上,对于流 和初始点 ,考虑 ODE††[] 相应的离散时间模拟是迭代: ,从 开始,初始点为 。
| (57) |
初始条件为,时间为。我们写
| (58) |
表示在时间处的流动 ODE(方程57)的解,终止于最终点。也就是说,RunFlow 是将点沿着流传输到时间的结果。
正如流定义起始点和终点之间的映射一样,它们也定义整个分布之间的传输分布,通过沿着轨迹“推动”源分布中的点。 如果 是初始点的分布393939符号警告:大多数流匹配文献使用反向时间约定,因此 是目标分布。 我们让 为目标分布,以与 DDPM 约定保持一致。,然后应用流程产生最终点的分布404040 我们可以等效地将其写为前推 。
| (59) |
我们将此过程表示为,表示流程传输初始分配最终分发414141 在我们的气体类比中,这意味着如果我们从根据 分布的粒子气体开始,并且每个粒子遵循由,那么最终的粒子分布就是。 。
4.2 逐点流
我们的基本构件将是一个点向流,它只是将一个点传送到一个点。直观地说,给定一条连接 和 的任意路径,点向流通过给出沿途每个点的速度来描述这条轨迹(见图4.2)。形式上,和之间的点向流是满足公式57的任何流,其边界条件分别为和,时间分别为。我们将这些流表示为。点向流并不是唯一的:在 和 之间有许多不同的路径选择。
![[Uncaptioned image]](x6.png)
将传输到的逐点流。
4.3 边际流量
假设对于所有点对,我们都可以构建一个显式点向流,将源点传送到目标点。例如,我们可以让沿着一条直线从到达。,或沿着任何其他显式路径。 回想一下我们的气体类比,这对应于在之间移动的单个粒子 和。现在,让我们尝试建立一个单个粒子集合,使粒子在处按照分布,在处按照分布。这其实很容易做到:我们可以选择任何耦合434343 和 之间的 耦合 ,指定如何联合采样源点和目标点对 ,使得 边缘分布为 , 边缘分布为 最基本的耦合是独立耦合,对应于独立采样。 在和之间,并考虑与点状流相对应的粒子. 这为我们提供了点状流(即粒子轨迹的集合)的分布,并且总体上具有所需的行为。
我们希望以某种方式组合所有这些逐点流,以获得在分布之间实现相同传输的单个流444444 为什么我们会喜欢这个? 正如我们稍后将看到的,它简化了我们的学习问题:我们不必学习所有单独轨迹的分布,而是只需学习代表其整体演化的一个速度场。。我们之前的讨论454545与 3 部分中的公式 (47) 进行比较。 附录B.4给出了如何组合流的正式声明。节中的3告诉了我们如何做到这一点:要确定有效速度,我们应该对所有单个粒子速度进行加权平均,并根据处的粒子是由点状流产生的概率进行加权。最终结果为464646 从高层次查看此结果的另一种方法是:我们从传输增量分布的点向流 开始: (60) 然后方程 (62) 为我们提供了一种奇特的方法,“对 和 上的这些流量进行平均”,以获得流量 运输 (61)
| (62) |
其中期望是 w.r.t. 的联合分布 由采样引起,并让。
至此,我们原则上已经有了生成建模问题的“解决方案”,但仍然存在一些重要问题以使其在实践中有用:
-
•
哪个点向流与耦合 我们应该选择吗?
-
•
我们如何计算边际流量?我们无法直接根据方程 (62) 计算它,因为这需要从 中对给定点 ,一般来说可能会很复杂。
我们将在下一节中回答这些问题。
4.4 逐点流的简单选择
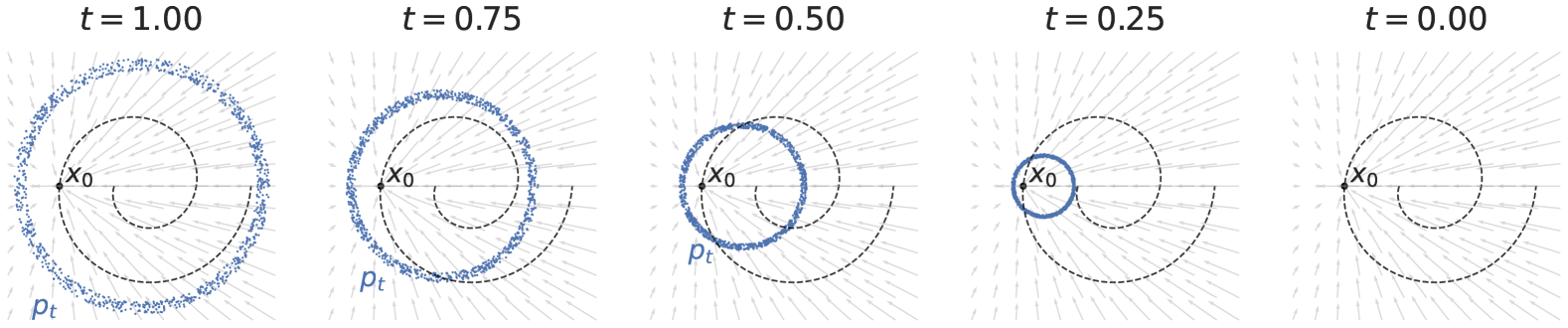
我们需要明确选择:逐点流、基本分布和耦合。有很多简单的选择都可行474747 扩散提供了一种可能的构造,我们将在后面的 4.6 节中看到。.
基本分布 本质上可以是任何易于采样的分布。 高斯是一种流行的选择,但肯定不是唯一的选择——图 4 例如,使用环形基础分布。 至于联轴器 在基础分布和目标分布之间,最简单的选择是独立耦合,即从和独立。
4.5 流量匹配
现在,唯一剩下的问题是使用方程(62)天真地评估需要从 对于给定的 。如果我们知道如何做到这一点 ,我们就已经解决了生成建模问题!
幸运的是,我们可以利用 DDPM 中的相同技巧:我们能够从联合分布中进行采样,然后求解回归问题。 与DDPM类似,方程中的条件期望函数(62) 可以写成回归量494949这个结果类似于Lipman等人(2023)中的定理2,但我们的结果是针对双边流的。:
| (65) | ||||
| (66) |
(通过使用通用事实)。
概括
总而言之,以下是如何学习目标分布的流匹配生成模型。
这些成分。
我们首先选择:
-
1.
源代码分发,我们可以从中有效地采样(例如标准高斯)。
-
2.
耦合之间的和,它指定了一种对源点和目标点进行联合采样的方法,其边距分别为和。标准的选择是独立耦合,即独立采样 和 。
-
3.
对于所有点对,显式逐点流 将 传输到 。我们必须能够有效地计算向量场0> 在所有点。
理论上,这些成分决定了边缘向量场,它将传输到:
| (67) |
其中期望是 w.r.t. 联合分布:
训练。
通过反向传播由伪代码计算的随机损失函数来训练神经网络 4. 该预期损失的最优函数是: 。
采样。
运行伪代码5从(大约)目标分布生成样本.
4.6 DDIM 作为流量匹配 [可选]
第3节的DDIM算法3 可以看作是流匹配的特殊情况,针对点流和耦合的特定选择。 我们在这里描述了确切的对应关系,这将使我们注意到 DDIM 和线性流之间的有趣关系。
4.7 附加备注和参考文献 [可选]
[1厘米]![[Uncaptioned image]](x8.png) 图4中各个样本的流动轨迹。
图4中各个样本的流动轨迹。
-
•
见图6 查看本教程中描述的不同方法及其关系的图表。
-
•
我们强烈推荐 Fjelde 等人 (2024) 的流匹配教程,其中包括有用的流可视化,并使用与当前文献更一致的符号。
-
•
出于好奇,请注意,我们从来不需要像高斯扩散那样为流匹配定义明确的“前向过程”。 相反,定义适当的“反向流程”(通过流程)就足够了。
-
•
我们所说的逐点流也称为双边条件流 在文献中,并在Albergo 和 Vanden-Eijnden (2022) 中开发; Pooladian 等人 (2023);刘等人 (2022);童等人(2023)。
-
•
Albergo 等人 (2023)定义随机插值框架随机插值,可以认为是考虑随机点向流,而不仅仅是确定性流。 他们的框架严格概括了 DDPM 和 DDIM。
-
•
有关非标准流程的有趣示例,请参阅 Stark 等人 (2024)。 他们通过嵌入连续空间(概率单纯形)来导出离散空间的生成模型,然后在这些单纯形上构建特殊的流。
5 实践中的传播
最后,我们提到了扩散的一些方面,这些方面在实践中很重要,但本教程未涵盖。
实践中的采样器。
我们的 DDPM 和 DDIM 采样器(算法 2 和 3)分别对应于 Ho 等人 (2020) 和 Song 等人 (2021) 中提出的采样器,但具有不同的时间表和参数化选择(参见脚注 13)。 DDPM 和 DDIM 是实践中最早使用的采样器之一,但从那时起,更少步骤生成的采样器取得了重大进展(这一点至关重要,因为每个步骤都需要通常昂贵的模型前向传递)。545454即使最好的采样器仍然需要大约 采样步骤,这可能不切实际。 各种时间蒸馏方法寻求训练单步生成器学生模型以匹配扩散教师模型的输出,目标是通过一步(或几个步骤)进行高质量采样。 一些例子包括一致性模型(Song等人,2023b)和对抗性蒸馏方法(Lin等人,2024;Xu等人,2023;Sauer等人,2024)。 但请注意,蒸馏模型不再是扩散模型,它们的采样器(即使是多步)也不再是扩散采样器。 在 2.4 和 3.4.1 部分中,我们证明了 DDPM 和 DDIM 可以分别看作逆 SDE 和概率流 ODE 的离散化。 SDE 和 ODE 视角自动导致许多采样器对应于不同的黑盒 SDE 和 ODE 数值求解器(例如 Euler、Heun 和 Runge-Kutta)。 还可以利用扩散常微分方程的特定结构来改进黑盒求解器(Lu等人,2022a,b;Zhang和Chen,2023)。
噪音表。
噪声表通常指的是,它确定在时间添加的噪声量> 的扩散过程。 简单扩散(1) 具有 和 。请注意 的方差 在每个时间步都增加。555555Song 等人 (2020) 在比较 SMLD 时区分了“方差爆炸”(VE) 和“方差保留”(VP) 计划(Song 和 Ermon,2019) 和 DDPM (Ho 等人, 2020)。 术语 VE 和 VP 通常分别特指 SMLD 和 DDPM。 我们的扩散(1)也可以称为方差爆炸计划,尽管我们的噪声计划与 Song 和 Ermon (2019) 中最初提出的计划不同。
在实践中,通常首选具有受控方差的时间表。 Ho 等人 (2020) 中引入了最流行的计划之一,它使用依赖于时间的方差和缩放,使得方差为 仍然有界。 他们的离散更新是
| (72) |
其中选择 以便 是(非常接近)干净的数据 和 处的纯噪声。
可能性解释和 VAE。
扩散模型的一种流行且有用的解释是变分自动编码器 (VAE) 视角565656这实际上是推导扩散目标函数的原始方法,参见 Sohl-Dickstein 等人 (2015) 和 何等人(2020)。. 简而言之,扩散模型可以被视为深层分层 VAE 的特例,其中每个扩散时间步长对应于 VAE 解码器的一个“层”。 相应的 VAE 编码器由前向扩散过程给出,该过程产生噪声序列 作为输入的“潜在”. 值得注意的是,与通常的 VAE 不同,这里的 VAE 编码器不是学习的。 由于潜在变量的马尔可夫结构,VAE 解码器的每一层都可以单独训练,无需前向/后向遍历所有先前层;这有助于解决深度 VAE 众所周知的训练不稳定问题。 我们推荐 Turner (2021) 和 Luo (2022) 的教程,了解有关 VAE 视角的更多详细信息。
VAE 解释的一个优点是,它为我们提供了数据可能性的估计 在我们的生成模型下,通过使用 VAE 的标准循证下界 (ELBO)。 这使我们能够直接使用最大似然目标来训练扩散模型。 事实证明,扩散 VAE 的 ELBO 精确地减少了我们提出的 L2 回归损失,但具有特定的 时间加权,在不同时间步长对回归损失进行不同的加权。比如大时候的回归误差 (即在高噪声水平下)可能需要与小时间的错误进行不同的加权,以便整体损失正确反映可能性。575757 另请参阅 Kadkhodaie 等人 (2024) 中的方程 (5),了解真实分布与生成分布之间 KL 散度的简单界限,就回归超额风险而言。然而,实践中时间加权的最佳选择仍然存在争议:VAE 解释所告知的“原则性”选择并不总是能产生最佳生成样本585858 例如,Ho 等人 (2020) 删除了时间加权项,只是对所有时间步进行统一加权。. 有关不同权重及其效果的详细讨论,请参阅 Kingma 和 Gau (2023)。
参数化: / / v -预测。
另一个重要的实际选择是我们要求网络预测几个密切相关的量(部分去噪数据、完全去噪数据或噪声本身)中的哪一个。595959更准确地说,网络始终预测这些数量的条件期望。 回想一下,在 DDPM 训练(算法 1)中,我们要求网络学习预测 通过最小化 . 然而,其他参数化也是可能的。 例如,回想起 ,我们看到
是一个(几乎)等效的问题,通常称为-预测。606060这对应于方差减少算法 (6)。 目标的区别仅在于时间权重因子。类似地,定义噪声 ,我们发现我们可以选择要求网络预测 :这通常称为。另一种参数化1>v-prediction2>要求模型预测3> (Salimans 和 Ho,2022) – 主要预测高噪声水平的数据,主要预测低噪声水平的噪声。 所有参数化仅在时间权重方面有所不同(参见附录 B.10 更多细节)。
尽管不同的时间权重不会影响最佳解决方案,但它们确实会影响训练,如上所述。 此外,即使调整时间权重以产生原则上相同的问题,不同的参数化在实践中也可能表现不同,因为学习并不完美并且某些目标可能对错误更稳健。 例如, -预测与对低噪声水平给予很大重视的时间表相结合,在实践中可能效果不佳,因为对于低噪声,恒等函数可以实现相对较低的目标值,但显然不是我们想要的。
错误来源。
最后,在实践中使用扩散和流动模型时,存在许多误差源,导致学习的生成模型无法准确生成目标分布。 这些可以大致分为训练时间误差和采样时间误差。
-
1.
训练时间误差:学习群体最优回归函数时的回归误差。 回归目标是边际流量 流量匹配中的,或者分数 在扩散模型中。 每个固定时间 ,这是一种标准的统计误差。 它取决于神经网络架构和大小以及样本数量,并且可以以通常的方式进一步分解为近似误差和估计误差(例如参见Advani等人(2020,第4节) 将2层网络分解为近似误差和过拟合误差)。
-
2.
采样时间误差:使用有限步长产生的离散化误差. 该误差正是采样中使用的 ODE 或 SDE 求解器的离散化误差。 这些错误以不同的方式表现出来:对于 DDPM,这反映了使用逆过程的高斯近似时的错误(即 事实 1 打破了大 )。 对于DDIM和流匹配来说,它反映了在离散时间上模拟连续时间流的误差。
这些错误以非平凡的方式相互作用和复合,目前尚未完全理解。 例如,尚不清楚回归估计中的训练时间误差如何转化为整个生成模型的分布误差。 (这个问题本身很复杂,因为我们在实践中并不总是清楚我们关心什么类型的分布分歧)。 有趣的是,这些“错误”也可以对小型训练集产生有益的影响,因为它们充当了一种 正则化,防止扩散模型仅仅记住样本(如第3.6节中所述)。
结论
我们现在已经介绍了扩散模型和流量匹配的基础知识。 这是一个活跃的研究领域,有许多我们没有涉及的有趣方面和开放性问题(参见第 A 供推荐阅读)。 我们希望这里的基础知识能够帮助读者了解扩散建模中更高级的主题,并可能为研究本身做出贡献。
附录A 其他资源
其他一些对学习扩散有用的资源(教程、博客、论文),大致按所需数学背景的顺序排列。
-
1.
对扩散的看法。
迪勒曼(2023)。 (网页。)对扩散和技术的多种解释的概述。
-
2.
成像和视觉扩散模型教程。
陈 (2024)。 (49 页。)更注重直觉和应用。
-
3.
使用欧几里得距离函数解释和改进扩散模型。
Permenter 和 Yuan (2023)。 (网页。)距离场解释。 请参阅随附的博客,其中包含简单代码(元,2024)。
-
4.
关于扩散模型的数学。
麦卡莱斯特(2023)。 (4 页。)简短且易于理解。
-
5.
从头开始构建扩散模型的理论
Das (2024)。 (网页。)ICLR 2024 博客文章轨道。 关注SDE和分数匹配的观点。
-
6.
去噪扩散模型:生成学习大爆炸。
宋、孟和 Vahdat (2023a)。 (视频,3 小时。)CVPR 2023 教程,带录音。
-
7.
从头开始的扩散模型。
段(2023)。 (网页,10 个部分。)主题相当完整,包括:DDPM、DDIM、Karras 等人 (2022)、SDE/ODE 求解器。 包括实用注释和代码。
-
8.
了解扩散模型:统一的视角。
罗(2022)。 (22 页。)专注于 VAE 解释,具有明确的数学细节。
-
9.
揭秘变分扩散模型。
里贝罗和格洛克 (2024)。 (44 页。)专注于 VAE 解释,具有明确的数学细节。
-
10.
扩散和基于分数的生成模型。
歌曲(2023)。 (视频,1.5 小时。)讨论几种解释、应用以及与其他生成建模方法的比较。
-
11.
使用非平衡热力学的深度无监督学习
Sohl-Dickstein、Weiss、Maheswaranathan 和 Ganguli (2015)。 (9 页 + 附录)介绍机器学习扩散模型的原始论文。 包括离散扩散的统一描述(即离散状态空间上的扩散)。
-
12.
流量匹配简介。
Fjelde、Mathieu 和 Dutordoir (2024)。 (网页。)富有洞察力的图形和动画,以及严格的数学阐述。
-
13.
阐明基于扩散的生成模型的设计空间。
卡拉斯、艾塔拉、艾拉和莱恩 (2022)。 (10 页 + 附录。)讨论各种设计选择的影响,例如噪声调度、参数化、ODE 求解器等。提出了一个捕获多种选择的通用框架。
-
14.
去噪扩散模型
Peyré (2023)。 (4 页。)为已经熟悉朗之万动力学和 SDE 的读者提供快速通读数学知识的机会。
-
15.
通过估计数据分布的梯度进行生成建模。
Song、Sohl-Dickstein、Kingma、Kumar、Ermon 和 Poole (2020)。 (9 页 + 附录。)介绍 SDE、ODE、DDIM 和 DDPM 之间的联系。
-
16.
随机插值:流动和扩散的统一框架。
Albergo、Boffi 和 Vanden-Eijnden (2023)。 (46 页 + 附录。)提出了一个捕获许多扩散变体和学习目标的通用框架。 适合熟悉 SDE 的读者
-
17.
采样、扩散和随机定位。
蒙塔纳里(2023)。 (22 页 + 附录。)将扩散呈现为“随机定位”的一个特例,这是一种在高维统计中用于建立马尔可夫链混合的技术。
附录B 省略的推导
B.1 逆过程高斯逼近中的KL误差
这里我们证明引理1,重述如下。
Lemma 2.
令 为 上的任意密度,具有有界的一阶到四阶导数。 考虑联合分布 ,其中 和 。 然后,对于任何条件 我们有
| (73) |
在哪里
| (74) |
证明。
WLOG,我们可以取。 我们想要估计 KL:
| (75) |
现在我们让 是任意的。
让和。 我们有。 这意味着:
| (76) |
让我们首先展开我们正在比较的两个分布的日志:
| (77) | |||
| (78) | |||
| (79) | |||
| (80) |
并且:
| (82) |
现在我们可以扩展 KL:
| (83) | |||
| (84) | |||
| (85) | |||
| (86) | |||
| (work) | |||
| (87) | |||
| (88) | |||
| (89) | |||
| (90) | |||
| (91) |
我们现在将估计第一项 :
| (92) | ||||
| (93) | ||||
| (94) | ||||
| (95) | ||||
| (Taylor expand around ) | ||||
| (96) |
要计算 的导数,请观察:
| (97) | ||||
| (98) | ||||
| (99) | ||||
| (100) | ||||
| (101) |
我们现在可以将 的估计值插入到 Line (91) 中。 为了简单起见,我们省略了 中的参数 :
| (103) | |||
| (104) | |||
| (105) | |||
| (106) | |||
| (107) |
到目前为止, 是任意的。 我们现在设置
| (108) |
并继续:
| (109) | |||
| (110) | |||
| (111) | |||
| (112) |
如预期的。
∎
请注意,我们在上述证明中选择的至关重要;例如,如果我们设置了 ,则 行中的项 (111)不会被取消。
B.2 SDE 证明草图
下面是 SDE 和概率流 ODE 等价性证明的草图,它依赖于 SDE 与 Fokker-Planck 方程的等价性。 (完整证明参见Song 等人 (2020)。)
证明。
∎
SDE 和 Fokker-Planck 方程的等价性源自 Itô 公式和分部积分。 这是 1d 中的简化情况的概述,其中 是常数(完整证明请参见 Winkler (2023)):
证明。
| 伊藤公式 | ||||
| 分部分集成 | ||||
| 福克一普朗克 |
∎
B.3 DDIM 点质量声明
这是权利要求的一个版本3,其中是任意点的增量 。
Claim 5。
假设目标分布是 处的点质量,即 。 定义函数
| (113) |
那么我们显然有,而且
| (114) |
因此算法2为目标分布定义了一个有效的反向采样器
B.4 流组合引理
在这里,我们提供了方程(62)中所示的边际流量结果的更正式的表述。
公式 (62) 源自一个更一般的 Lemma(Lemma 3),它将第 3节中的 "气体组合 "类比形式化。这个两难的动机是,我们需要一种组合气流的方法:将几种不同的气流组合在一起,产生一种 "有效气流"。作为该 Lemma 的热身,假设我们有 不同的流,每个流都有自己的初始和最终分布::
我们可以将它们想象为不同气体的流动,其中气体具有初始密度和最终密度。现在我们要构建一个整体流程 将平均初始密度转化为平均最终密度:
| (115) |
要构建,我们必须取各个矢量场的平均值,并根据流在上的概率质量加权,时间为。(这与图 3 完全类似)。
[没有休息]
Lemma 3 (流组合引理)。
令 为流 对 及其关联的初始分布 上的任意联合分布。 设表示初始分布由流传输时的最终分布,因此
对于固定的 ,请考虑通过以下方式生成的 上的联合分布:
然后,考虑所有的期望。 这种联合分布,流量定义为
| (116) | ||||
| (117) |
被称为的边际流量,并且传输:
| (118) |
B.5 使用流派生 DDIM
现在我们已经掌握了流动机制,通过从单点质量情况扩展我们的简单缩放算法,“从头开始”推导 DDIM 算法相当容易。
B.6 DDIM 的两个逐点流给出相同的轨迹
B.7 DDIM 与时间重新参数化线性流
B.8 权利要求证明草图2
我们将证明,在第1部分的前向扩散设置中:
| (125) |
证明草图。
回想一下。 因此,根据期望的线性:
| (126) | ||||
| (127) |
现在,我们声称对于给定的 ,条件分布 对于所有 都是相同的。要看到这一点,请注意,根据前向过程的定义,联合分布函数 在 中是对称的,因此条件分布函数 在 中也是对称的。因此,所有 具有相同的条件期望:
| (128) |
由于有 个,
| (129) |
现在从127行继续,
| (130) | ||||
| (131) | ||||
| (132) |
如预期的。 ∎
B.9 方差减少算法
B.10 和 - 和 - 预测的等价性
我们将在通常的简化设置中讨论这个问题:
在一般情况下,缩放因子更加复杂(例如,参见 Luo (2022) 的 VP 扩散),但想法是相同的。 DDPM 训练算法 1具有客观最优值
即网络学习预测. 然而,我们可以要求网络预测其他相关量,如下所示。 注意到
我们得到以下等效问题:
参考
- Advani et al. [2020] Madhu S Advani, Andrew M Saxe, and Haim Sompolinsky. High-dimensional dynamics of generalization error in neural networks. Neural Networks, 132:428–446, 2020.
- Albergo et al. [2023] Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions, 2023.
- Albergo and Vanden-Eijnden [2022] Michael Samuel Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. In The Eleventh International Conference on Learning Representations, 2022.
- Anderson [1982] Brian DO Anderson. Reverse-time diffusion equation models. Stochastic Processes and their Applications, 12(3):313–326, 1982.
- Carlini et al. [2023] Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. In 32nd USENIX Security Symposium (USENIX Security 23), pages 5253–5270, 2023.
- Chan [2024] Stanley H. Chan. Tutorial on diffusion models for imaging and vision, 2024.
- Chen et al. [2023] Hongrui Chen, Holden Lee, and Jianfeng Lu. Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions. In International Conference on Machine Learning, pages 4735–4763. PMLR, 2023.
- Chen et al. [2022] Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru Zhang. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. In The Eleventh International Conference on Learning Representations, 2022.
- Chen et al. [2024a] Sitan Chen, Sinho Chewi, Holden Lee, Yuanzhi Li, Jianfeng Lu, and Adil Salim. The probability flow ode is provably fast. Advances in Neural Information Processing Systems, 36, 2024a.
- Chen et al. [2024b] Sitan Chen, Vasilis Kontonis, and Kulin Shah. Learning general gaussian mixtures with efficient score matching. arXiv preprint arXiv:2404.18893, 2024b.
- Das [2024] Ayan Das. Building diffusion model’s theory from ground up. In ICLR Blogposts 2024, 2024. URL https://iclr-blogposts.github.io/2024/blog/diffusion-theory-from-scratch/. https://iclr-blogposts.github.io/2024/blog/diffusion-theory-from-scratch/.
- De Bortoli [2022] Valentin De Bortoli. Convergence of denoising diffusion models under the manifold hypothesis. arXiv preprint arXiv:2208.05314, 2022.
- De Bortoli et al. [2021] Valentin De Bortoli, James Thornton, Jeremy Heng, and Arnaud Doucet. Diffusion schrödinger bridge with applications to score-based generative modeling. Advances in Neural Information Processing Systems, 34:17695–17709, 2021.
- Dieleman [2023] Sander Dieleman. Perspectives on diffusion, 2023. URL https://sander.ai/2023/07/20/perspectives.html.
- Duan [2023] Tony Duan. Diffusion models from scratch, 2023. URL https://www.tonyduan.com/diffusion/index.html.
- Eldan [2024] Ronen Eldan. Lecture notes - from stochastic calculus to geometric inequalities, 2024. URL https://www.wisdom.weizmann.ac.il/ ronene/GFANotes.pdf.
- Esser et al. [2024] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. arXiv preprint arXiv:2403.03206, 2024.
- Evans [2012] Lawrence C Evans. An introduction to stochastic differential equations, volume 82. American Mathematical Soc., 2012.
- Fjelde et al. [2024] Tor Fjelde, Emile Mathieu, and Vincent Dutordoir. An introduction to flow matching, January 2024. URL https://mlg.eng.cam.ac.uk/blog/2024/01/20/flow-matching.html.
- Gu et al. [2023] Xiangming Gu, Chao Du, Tianyu Pang, Chongxuan Li, Min Lin, and Ye Wang. On memorization in diffusion models. arXiv preprint arXiv:2310.02664, 2023.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Kadkhodaie et al. [2024] Zahra Kadkhodaie, Florentin Guth, Eero P Simoncelli, and Stéphane Mallat. Generalization in diffusion models arises from geometry-adaptive harmonic representations. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ANvmVS2Yr0.
- Karras et al. [2022] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models, 2022.
- Kingma and Gao [2023] Diederik P Kingma and Ruiqi Gao. Understanding diffusion objectives as the ELBO with simple data augmentation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=NnMEadcdyD.
- Kloeden and Platen [2011] P.E. Kloeden and E. Platen. Numerical Solution of Stochastic Differential Equations. Stochastic Modelling and Applied Probability. Springer Berlin Heidelberg, 2011. ISBN 9783540540625. URL https://books.google.com/books?id=BCvtssom1CMC.
- Lee et al. [2023] Holden Lee, Jianfeng Lu, and Yixin Tan. Convergence of score-based generative modeling for general data distributions. In International Conference on Algorithmic Learning Theory, pages 946–985. PMLR, 2023.
- Lin et al. [2024] Shanchuan Lin, Anran Wang, and Xiao Yang. Sdxl-lightning: Progressive adversarial diffusion distillation. arXiv preprint arXiv:2402.13929, 2024.
- Lipman et al. [2023] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t.
- Liu et al. [2022] Xingchao Liu, Chengyue Gong, et al. Flow straight and fast: Learning to generate and transfer data with rectified flow. In The Eleventh International Conference on Learning Representations, 2022.
- Lu et al. [2022a] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. Advances in Neural Information Processing Systems, 35:5775–5787, 2022a.
- Lu et al. [2022b] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. arXiv preprint arXiv:2211.01095, 2022b.
- Luo [2022] Calvin Luo. Understanding diffusion models: A unified perspective, 2022.
- McAllester [2023] David McAllester. On the mathematics of diffusion models, 2023.
- Montanari [2023] Andrea Montanari. Sampling, diffusions, and stochastic localization, 2023.
- Permenter and Yuan [2023] Frank Permenter and Chenyang Yuan. Interpreting and improving diffusion models using the euclidean distance function. arXiv preprint arXiv:2306.04848, 2023.
- Peyré [2023] Gabriel Peyré. Denoising diffusion models, 2023. URL https://mathematical-tours.github.io/book-sources/optim-ml/OptimML-DiffusionModels.pdf.
- Pooladian et al. [2023] Aram-Alexandre Pooladian, Heli Ben-Hamu, Carles Domingo-Enrich, Brandon Amos, Yaron Lipman, and Ricky TQ Chen. Multisample flow matching: Straightening flows with minibatch couplings. In International Conference on Machine Learning, pages 28100–28127. PMLR, 2023.
- Ribeiro and Glocker [2024] Fabio De Sousa Ribeiro and Ben Glocker. Demystifying variational diffusion models, 2024.
- Salimans and Ho [2022] Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022.
- Sauer et al. [2024] Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. arXiv preprint arXiv:2403.12015, 2024.
- Sohl-Dickstein et al. [2015] Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. CoRR, abs/1503.03585, 2015. URL http://arxiv.org/abs/1503.03585.
- Somepalli et al. [2023] Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Diffusion art or digital forgery? investigating data replication in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6048–6058, 2023.
- Song et al. [2021] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=St1giarCHLP.
- Song et al. [2023a] Jiaming Song, Chenlin Meng, and Arash Vahdat. Cvpr 2023 tutorial: Denoising diffusion models: A generative learning big bang, 2023a. URL https://cvpr2023-tutorial-diffusion-models.github.io.
- Song [2021] Yang Song. Generative modeling by estimating gradients of the data distribution, 2021. URL https://yang-song.net/blog/2021/score/.
- Song [2023] Yang Song. Diffusion and score-based generative models, 2023. URL https://www.youtube.com/watch?v=wMmqCMwuM2Q.
- Song and Ermon [2019] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019.
- Song et al. [2020] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020. URL https://arxiv.org/pdf/2011.13456.pdf.
- Song et al. [2023b] Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. arXiv preprint arXiv:2303.01469, 2023b.
- Stark et al. [2024] Hannes Stark, Bowen Jing, Chenyu Wang, Gabriele Corso, Bonnie Berger, Regina Barzilay, and Tommi Jaakkola. Dirichlet flow matching with applications to dna sequence design, 2024.
- Tong et al. [2023] Alexander Tong, Nikolay Malkin, Kilian Fatras, Lazar Atanackovic, Yanlei Zhang, Guillaume Huguet, Guy Wolf, and Yoshua Bengio. Simulation-free schr” odinger bridges via score and flow matching. arXiv preprint arXiv:2307.03672, 2023.
- Turner [2021] Angus Turner. Diffusion models as a kind of vae, June 2021. URL https://angusturner.github.io/generative_models/2021/06/29/diffusion-probabilistic-models-I.html.
- Winkler [2021] Ludwig Winkler. Reverse time stochastic differential equations [for generative modeling], 2021. URL https://ludwigwinkler.github.io/blog/ReverseTimeAnderson/.
- Winkler [2023] Ludwig Winkler. Fokker, planck, and ito, 2023. URL https://ludwigwinkler.github.io/blog/FokkerPlanck/.
- Xu et al. [2023] Yanwu Xu, Yang Zhao, Zhisheng Xiao, and Tingbo Hou. Ufogen: You forward once large scale text-to-image generation via diffusion gans. arXiv preprint arXiv:2311.09257, 2023.
- Yuan [2024] Chenyang Yuan. Diffusion models from scratch, from a new theoretical perspective, 2024. URL https://www.chenyang.co/diffusion.html.
- Zhang and Chen [2023] Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=Loek7hfb46P.