MeshAnything:使用自回归Transformer进行艺术家创作的网格生成
摘要
最近,通过重建和生成创建的3D资产在质量上已与人工制作的资产相匹配,突出了其替代人工制作的潜力。 然而,这种潜力尚未得到充分实现,因为这些资产始终需要转换为网格才能用于3D行业应用,而当前网格提取方法生成的网格质量明显低于艺术家创作的网格(AM),即由人类艺术家创建的网格。 具体而言,当前的网格提取方法依赖于密集面,并忽略了几何特征,从而导致效率低下、后期处理复杂以及表示质量下降。 为了解决这些问题,我们引入了MeshAnything,这是一种将网格提取视为生成问题的模型,能够生成与指定形状对齐的AM。 通过将任何3D表示中的3D资产转换为AM,MeshAnything可以与各种3D资产制作方法集成,从而增强其在整个3D行业的应用。 MeshAnything的架构包含一个VQ-VAE和一个形状条件解码器Transformer。 我们首先使用VQ-VAE学习一个网格词汇表,然后在这个词汇表上训练形状条件解码器Transformer,用于形状条件自回归网格生成。 我们广泛的实验表明,我们的方法生成的AM拥有少数百倍的面,显著提高了存储、渲染和模拟效率,同时实现了与先前方法相当的精度。

1 介绍
近年来,3D领域取得了快速进展,开发了多种用于自动生成高质量3D资产的方法。 这些方法,包括3D重建Mildenhall等人(2020);Yu等人(2021);Barron等人(2021;2022);Kerbl等人(2023b);Huang等人(2024)、3D生成Poole等人(2023);Liu等人(2023a);Wang等人(2023);Long等人(2023);Sun等人(2023);Hong等人(2023);Tang等人(2024);Xu等人(2024);Wei等人(2024)和扫描Daneshmand等人(2018);Haleem & Javaid(2019);Haleem等人(2022),可以生成形状和颜色质量与人工制作的资产相当的3D资产。 这些方法的成功揭示了在 3D 行业中用自动生成的 3D 模型取代人工创建的 3D 模型的潜力,包括游戏、电影和元宇宙的应用,从而显著降低时间和人工成本。
然而,这种潜力在很大程度上尚未实现,因为当前的 3D 行业主要依赖于基于网格的管道,以实现其卓越的效率和可控性,而用于生成 3D 资产的方法通常使用替代的 3D 表示来实现各种场景中的最佳结果。 因此,大量工作Lorensen & Cline (1987); Chernyaev (1995); Lorensen & Cline (1998); Shen et al. (2021b); Chen et al. (2022); Shen et al. (2023)致力于将其他 3D 表示转换为网格,并取得了一些成功。 这些方法生成的网格近似于人类艺术家创建的网格的形状质量,我们将其称为艺术家创建的网格 (AM),但它们在解决上述问题方面仍然存在不足。
这是因为所有由这些方法生成的网格Lorensen & Cline (1987); Chernyaev (1995); Lorensen & Cline (1998); Shen et al. (2021b); Chen et al. (2022); Shen et al. (2023)与 AM 相比,拓扑质量明显更差。 如图 2 所示,这些方法依赖于密集的面来重建 3D 形状,完全忽略了几何特征。 在 3D 行业中使用这些网格会导致三个重大问题: 首先,与 AM 相比,转换后的网格通常包含多数量级的面,导致存储、渲染和模拟效率低下。 此外,转换后的网格使 3D 管道中的后处理和下游任务复杂化。 由于其混乱和低效的拓扑结构,它们极大地增加了人类艺术家优化这些网格的难度。 最后,以前的方法难以表示锐利的边缘和平坦的表面,导致过度平滑和凹凸不平的伪像,如图 2 所示。

在这项工作中,我们旨在解决上述问题,以促进自动生成的 3D 资产在 3D 行业中的应用。 如前所述,所有以前的方法 Lorensen & Cline (1987); Chernyaev (1995); Lorensen & Cline (1998); Shen et al. (2021b); Chen et al. (2022); Shen et al. (2023) 以重建的方式提取具有过多密集面的三维网格,这本质上无法解决这些问题。 因此,我们首次通过将网格提取公式化为生成问题,与以前的方法背道而驰:我们教模型生成与给定三维资产对齐的艺术家创建的网格(AM)。 我们方法生成的网格模拟了人类艺术家创建的网格的形状和拓扑质量。 因此,我们的设置,即形状条件的 AM 生成,从根本上摆脱了所有以前的问题,使生成的结果能够无缝集成到 3D 行业管道中。
但是,训练这样的模型存在重大挑战。 第一个挑战是构建数据集,因为我们需要配对的形状条件和艺术家创建的网格 (AM) 用于模型训练。 形状条件必须从尽可能多的不同 3D 表示中有效地推导出来,以在推理过程中充当条件。 此外,它必须具有足够的精度才能准确地表示 3D 形状,并能够有效地处理成可以注入模型的特征。 在权衡了利弊之后,我们选择了点云,因为它们具有显式和连续的表示,易于从大多数 3D 表示中推导出来,并且可以使用成熟的点云编码器 Qi et al. (2017a; b); Zhao et al. (2024)。
我们从 Objaverse Deitke et al. (2023b; a) 和 ShapeNet Chang et al. (2015) 中过滤掉高质量的 AM。 在获取配对的形状条件时,一种简单的方法是从 AM 中直接采样点云。 但是,这会导致在推理期间产生较差的结果,因为采样的点云具有过高的精度,而自动生成的三维资产无法提供类似质量的点云,从而导致训练和推理之间的域差距。 为了解决这个问题,我们故意破坏了 AM 的形状质量。 我们首先从 AM Wang et al. (2022) 中提取符号距离函数,使用 Lorensen & Cline (1987) 将其转换为更粗糙的网格,然后从该粗糙网格中采样点云,以缩小推理和训练之间形状条件的域差距。
遵循 Siddiqui et al. (2023),我们使用 VQ-VAE Van Den Oord et al. (2017) 来学习网格词汇表,并在该词汇表上训练仅解码器的 Transformer Vaswani et al. (2017) 以进行网格生成。 为了注入形状条件,我们从最近多模态大型语言模型 (MLLM) Wu et al. (2023); Liu et al. (2024a) 的成功中汲取灵感,其中由预训练的图像编码器编码的图像特征被投影到大型语言模型的符元空间中,以实现高效的多模态理解。 同样地,我们将从训练好的 VQ-VAE 中获得的网格符元视为 LLM 中的语言符元,并使用预训练的编码器 Zhao et al. (2024) 将点云编码为形状特征,然后将其投影到网格符元空间。 这些形状符元被放置在网格符元序列的开头,有效地作为下一个符元预测的形状条件。 预测后,这些预测的网格符元使用 VQ-VAE 解码器 Siddiqui et al. (2023) 解码回网格。
为了进一步提高网格生成的质量,我们开发了一种新颖的抗噪解码器,用于鲁棒的网格解码。 我们的观察结果是,由于 VQ-VAE 中的解码器 Van Den Oord et al. (2017) 仅用来自编码器的真实符元序列进行训练,因此在解码生成的符元序列时可能会导致域差距。 为了缓解这个问题,我们将形状条件作为辅助信息注入 VQ-VAE 解码器,用于鲁棒解码,并在 VQ-VAE 训练后对其进行微调。 此微调过程包括在网格符元序列中添加噪声,以模拟来自仅解码器 Transformer 的可能低质量符元序列,从而使解码器对这种低质量序列具有鲁棒性。
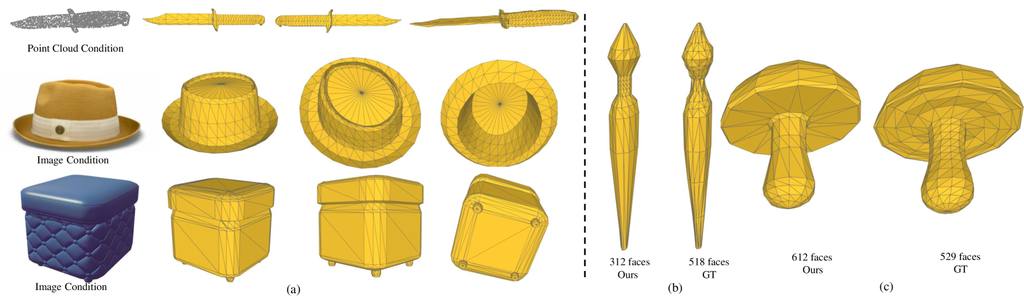
最后,我们介绍了我们的模型 MeshAnything,该模型基于上述技术进行训练。 如图 1 所示,MeshAnything 可以将各种 3D 表示中的 3D 资产转换为 AM,从而极大地促进了它们的应用。 此外,我们广泛的实验表明,我们的方法生成的 AM 具有明显更少的表面,更精细的拓扑结构,同时实现了接近或与先前方法相当的精度指标。
总之,我们的贡献如下:
-
•
我们重点介绍了当前自动生成的 3D 资产无法取代人类艺术家创建的 3D 资产的一个重要原因:当前的方法无法将这些 3D 资产转换为艺术家创建的网格 (AM)。 为了解决这个问题,我们提出了一种新颖的解决方案,称为形状条件 AM 生成,旨在生成与给定形状一致的 AM。
-
•
我们为形状条件 AM 生成引入了 MeshAnything。 MeshAnything 可以与各种 3D 资产制作方法集成,将其结果转换为 AM,以促进其在 3D 行业中的应用。
-
•
我们开发了一种新颖的抗噪解码器,以提高网格生成质量。 我们将形状条件作为辅助信息注入到解码器中,用于鲁棒解码,并使用噪声符元序列对其进行微调,以缩小训练和推理之间的域间差距。
-
•
大量实验表明,形状条件网格生成是网格生成更合适的设置,MeshAnything 显著超越了之前的网格生成方法。
2 相关工作
2.1 网格提取
从 3D 模型中提取网格的方法很多,并且是几十年来的研究课题。 遵循 Shen 等人 (2023),我们将这些方法归类为两种主要类型:等值面提取 Lorensen & Cline (1987); Bloomenthal (1988); Chernyaev (1995); Bloomenthal & Bajaj (1997); Lorensen & Cline (1998); Chen 等人 (2022) 和基于梯度的网格优化 Chen 等人 (2019); Gao 等人 (2020); Hanocka 等人 (2020); Kato 等人 (2018); Shen 等人 (2021a); Liao 等人 (2018); Shen 等人 (2023)。
传统的等值面提取方法 Lorensen & Cline (1987; 1998); Chernyaev (1995); Doi & Koide (1991); Ju 等人 (2002); Schaefer 等人 (2007); Chen & Zhang (2021); Chen 等人 (2022) 侧重于提取表示标量函数的等值面的多边形网格,这是一个在各个领域都得到广泛研究的领域。 其中最流行的方法是 Marching Cubes Lorensen & Cline (1987)。 它将空间划分为单元格,在每个单元格内创建多边形以近似表面。 Marching Cubes 由于其鲁棒性和简单性已广泛用于网格提取。 最近, Chen & Zhang (2021) 和 Chen 等人 (2022) 引入了数据驱动方法来确定基于输入场的提取网格的位置。
转向更新的发展,机器学习的出现为生成 3D 网格带来了新的技术 Chen 等人 (2019); Gao 等人 (2020); Hanocka 等人 (2020); Kato 等人 (2018); Shen 等人 (2021a); Liao 等人 (2018); Shen 等人 (2023)。 这项工作探讨了使用神经网络生成 3D 网格,其中网络参数通过在特定损失函数下的基于梯度的方法进行优化。 Shen 等人 (2021a) 采用可微分 Marching Tetrahedra 层进行网格提取。 与 Shen 等人 (2021a) 相似, Shen 等人 (2023) 通过将 3D 表面网格表示为标量场的等值面来迭代地优化它。
然而,这些方法在根本上与我们的方法不同。 它们忽略了形状的特征,本质上无法生成具有高效拓扑的网格。 相反,MeshAnything 首次将网格提取定义为一个生成问题,旨在模仿人类艺术家进行网格提取,从而生成具有数百倍更少面的艺术家创作的网格 (AM)。
2.2 3D 网格生成
3D 网格生成主要可分为两类:生成与先前网格提取方法产生的网格类似的密集网格,以及生成艺术家创作的网格 (AM)。
前者目前是主流的研究方向。 Gao 等人 (2022);Wei 等人 (2024);Xu 等人 (2024) 等方法以直接前馈的方式生成网格,但由于它们生成具有与先前网格提取方法类似的低质量拓扑的密集网格,因此在 3D 行业应用时仍然会遇到相同的问题。
值得注意的是,许多 3D 生成方法 Poole 等人 (2023);Tang 等人 (2023b);Wang 等人 (2023);Chen 等人 (2024b);Tang 等人 (2023a);Yang 等人 (2023);Hong 等人 (2023);Fang 等人 (2023);Chen 等人 (2023a);Liu 等人 (2024b);Shi 等人 (2023);Li 等人 (2023);Chen 等人 (2023b;2024c);Tang 等人 (2024);Wang 等人 (2024);Tochilkin 等人 (2024) 也可以生成网格。 这些方法首先生成 3D 资产,然后使用类似 Lorensen & Cline (1987) 的网格提取方法将其转换为密集网格。 因此,由于其效率低下的拓扑结构,它们在应用于 3D 行业时面临挑战。
最近,一些工作集中在第二类:生成艺术家创作的网格 (AM) Nash 等人 (2020);Alliegro 等人 (2023);Siddiqui 等人 (2023);Chen 等人 (2024a)。 尽管我们的方法也侧重于 AM 生成,但它与这些方法在根本上有所不同。 由于缺乏形状调节,这些方法必须同时学习复杂的 3D 形状分布(这通常需要大量的训练 Hong 等人 (2023);Tang 等人 (2024))和 AM 的拓扑分布,导致训练过程非常具有挑战性。 相反,我们的方法消除了学习形状分布的挑战,使模型能够专注于学习拓扑分布。 这不仅显著降低了训练成本,而且还提高了模型的应用价值。
在这些方法中,与我们方法最相关的是 MeshGPT Siddiqui 等人 (2023),因为我们遵循了其架构。 Siddiqui 等人 (2023) 介绍了 VQ-VAE Van Den Oord 等人 (2017) 和自回归 Transformer 架构的组合。 它首先使用 VQ-VAE 学习一个网格词汇表,然后在学习到的词汇表上训练 Transformer 以生成网格。 然而,MeshGPT 的结果仅限于 ShapeNet 中的几个类别。 MeshGPT 需要与我们类似的训练 GPU 小时数,但我们的方法可以推广到 Objaverse 中的无限类别。 如图 3 所示,这在很大程度上是由于 MeshGPT 需要额外学习复杂的 3D 形状分布所造成的目标复杂度差异。
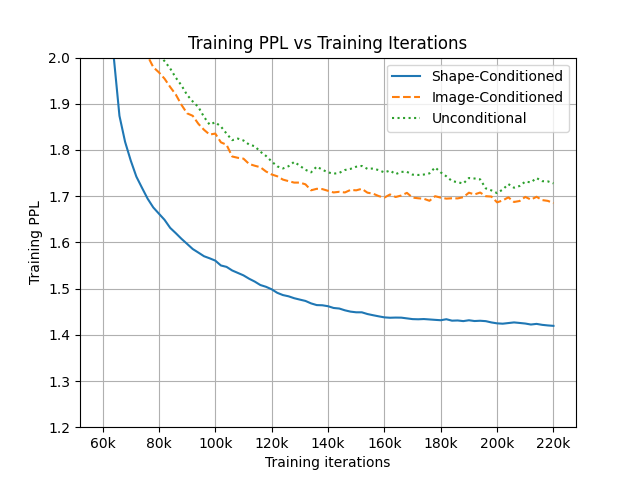
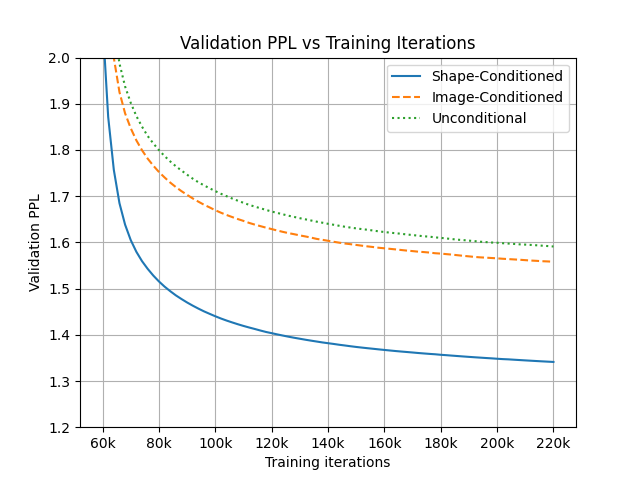
3 形状条件 AM 生成
在本节中,我们首先介绍形状条件 AM 生成的正式公式,并将其与以前的网格生成设置进行比较 Nash et al. (2020); Siddiqui et al. (2023); Alliegro et al. (2023)。 我们展示了与以前网格生成方法中的设置相比,它可以实现更好的性能和更广泛的应用范围,同时训练工作量明显减少。
形状条件 AM 生成目标是估计条件分布 。 在此公式中, 指的是艺术家创建的网格 (AM),即由人类艺术家手动建模的网格。 指的是指示 应该对齐的 3D 形状信息。 的输入形式可以多种多样,例如体素或点云。 因此,这种多功能性允许我们的方法与任何输出 的 3D 管道集成,例如 3D 重建 Mildenhall 等人 (2020); Kerbl 等人 (2023b)、生成 Poole 等人 (2023); Hong 等人 (2023) 和扫描,使这些方法更有效率地应用于 3D 行业。
与现有的 AM 生成工作相比,它们直接估计了分布 ,其中 表示条件,例如图像、文本或用于无条件生成的空集。 然而,估计 需要理解底层形状,即 ,以及复杂的拓扑结构 。 鉴于此,我们做出了以下近似:
| (1) |
根据链式法则,我们有:
| (2) |
对于分布 ,鉴于 比 更强且更直接的条件,我们可以做出以下近似:
| (3) |
| (4) |
其中 是我们形状条件网格生成的重点。 如图 3 所示,估计 比 简单得多,证明了我们的设置比以前方法中的设置更容易训练。
至于 ,在 3D 社区中,许多大型模型 团队 (2024); Tang 等人 (2024); Xu 等人 (2024); Siddiqui 等人 (2023) 旨在使用各种 3D 表示来估计并展示出色的结果。 此外,一些单场景 3D 资产制作方法 Mildenhall 等人 (2020); Kerbl 等人 (2023b); Barron 等人 (2021; 2022); Poole 等人 (2023); Liu 等人 (2023b); Sun 等人 (2023) 也可以从该分布中提供样本。 通过将我们的框架与这些现有方法集成,我们可以利用它们的功能来增强我们的网格生成过程。 这种集成允许以更节省资源的方式估计 ,与以前的方法相比,显着降低了所需的复杂性和资源。
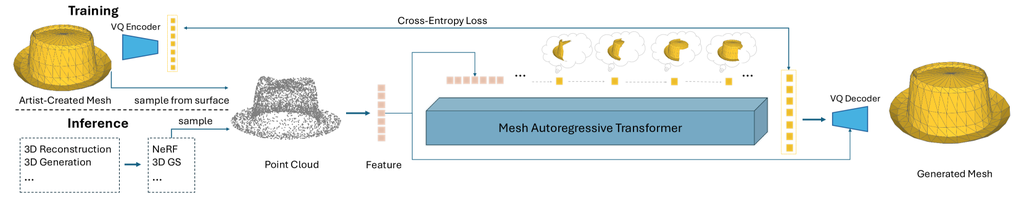
4 方法
在本节中,我们将详细介绍我们在第4.1节中的形状条件策略。 之后,我们将详细描述MeshAnything,它包括一个VQVAE,其中包含我们新提出的抗噪声解码器(第4.2节)和一个形状条件自回归Transformer(第4.3节)。
4.1 形状编码以进行条件生成
我们首先描述我们的形状条件策略。 MeshAnything的目标是学习,因此我们需要将每个网格与相应的配对,即形状条件。 为选择合适的3D表示并不容易,并且应满足以下条件:
-
1.
它应该很容易从各种3D表示中提取。 这确保了训练后的模型可以与广泛的3D资产制作管道集成Mildenhall 等人 (2020); Kerbl 等人 (2023b); Hong 等人 (2023); Poole 等人 (2023); Tang 等人 (2024)。
-
2.
它应该适合数据增强以防止过度拟合。 为了确保在训练期间的有效性,对应用的任何数据增强都必须等效地适用于。
-
3.
它应该作为条件有效且方便地输入模型。 为了确保模型理解形状信息并保持高效训练,必须易于有效地编码为特征。
考虑到第一和第二点,应该以显式表示形式存在。 进一步考虑到第三点,主要的显式 3D 表示形式,可以轻松地被编码为特征,是体素和点云。 两种表示形式都适用,但体素通常需要高分辨率才能准确地表示形状,而将高分辨率体素处理成特征在计算上开销很大。 此外,体素作为离散表示,与点云相比,在数据增强方面精度较低。 因此,我们选择点云作为的表示。 为了增强点云的表达能力,我们还将法线纳入点云表示中。
为了从训练的真实网格中获得点云, 我们可以简单地直接从表面采样点云。 但是,这会在推理过程中产生问题:自动生成的 3D 资产的表面通常比 AM 的表面更粗糙。 例如,在 AM 中,我们会在平面上采样一系列点,而自动生成的 3D 资产会具有不均匀的表面,导致训练和推理之间存在领域差距。
因此,我们需要确保在训练期间从真实中提取的与在推理期间提取的具有相似的领域。 为了使它们的领域更接近,我们有意地从 AM 中构建粗略的网格。 我们首先使用Wang et al. (2022)从中提取符号距离函数,然后使用 Marching Cubes Lorensen & Cline (1987)将其转换为相对粗略的网格,以破坏真实拓扑结构。 最后,我们从粗略网格中采样点云及其法线。 这种方法还有助于避免过拟合,因为 AM 通常具有较少的表面,并且每个表面通常可以采样多个点。 网络可以通过确定点是否位于同一平面上来轻松识别真实拓扑结构。
由于几乎所有 3D 表示都可以使用 Marching Cubes Lorensen & Cline (1987) 转换为粗略网格或采样为点云,这确保了 的域在训练和推理过程中始终保持一致。 我们将提取为 的点云与 配对,以创建用于训练的数据项 。
4.2 具有抗噪解码器的 VQ-VAE
遵循 MeshGPT Siddiqui et al. (2023),我们首先训练一个 VQ-VAE Van Den Oord et al. (2017) 来学习几何嵌入的词汇表,以便更好地进行 Transformer Vaswani et al. (2017) 学习。 与 MeshGPT 不同,MeshGPT 使用图卷积网络 Wu et al. (2019) 和 ResNet He et al. (2016) 作为编码器和解码器,我们分别对编码器和解码器使用具有相同结构的 Transformer。 在训练 VQ-VAE 时,网格被离散化并作为三角形面的序列输入:
| (5) |
其中 是每个面的顶点的坐标, 是 中面的数量。 编码器 然后提取每个面的特征向量:
| (6) |
其中 是 的特征向量。
然后将提取的面量化为具有代码簿 的量化特征 :
| (7) |
最后,重建的网格通过解码器 从 解码,方法是预测每个顶点坐标的 logits:
| (8) |
VQ-VAE 通过交叉熵损失在预测的顶点坐标 logits 上进行端到端训练,并进行向量量化的承诺损失 Van Den Oord et al. (2017)。 在训练 VQ-VAE 之后,VQ-VAE 的编码器-解码器被视为自动回归 Transformer 训练的标记器和去标记器。
但是,如图 7 所示,生成结果中可能存在缺陷。 为了解决这个问题,鉴于我们对形状条件的 AM 生成的设置,VQ-VAE 解码器也可以将形状条件作为输入。 Transformer 生成的标记序列中的微小缺陷可以通过形状感知解码器进行潜在的修正。 因此,在完成普通 VQ-VAE 训练后,我们添加了一个额外的解码器微调阶段,将形状信息注入到 Transformer 解码器中。 然后,我们在码本采样 logits 中添加随机 Gumbel 噪声,以模拟 Transformer 在推理过程中生成的符元序列中潜在的缺陷。 然后,使用相同的交叉熵损失独立更新解码器,以训练它即使在面对不完美的符元序列时也能生成细化的网格。 我们在表 3 和表 4 中的实验表明,我们的方法有效地增强了解码器的抗噪性,提高了网格生成质量。
4.3 形状条件自动回归 Transformer
为了在 Transformer 中添加形状条件,受到多模态大型语言模型成功的启发 Wu et al. (2023); Liu et al. (2024a); Xu et al. (2023); Guo et al. (2023),我们首先使用点云编码器 将点云编码为固定长度的符元序列,然后将其与来自 VQ-VAE 的嵌入序列连接起来,作为 Transformer 的最终输入嵌入序列:
| (9) |
是 Transformer 的训练输入。
我们借用了来自 Zhao et al. (2024) 的预训练点编码器,并添加了一个线性投影层,以将其输出特征投影到与 相同的潜在空间。 在训练期间,来自 Zhao et al. (2024) 的原始点编码器被冻结;我们只更新新添加的投影层和使用交叉熵损失的自动回归 Transformer。
| Method | Shape | Topology |
|---|---|---|
| PolyGen | 12.7% | 11.1% |
| MeshGPT | 24.1% | 28.2% |
| MeshAnything | 63.2% | 60.7% |
| Method | Shape | Topology |
|---|---|---|
| MarchingCubes | 38.1% | 10.2% |
| Shape As Points | 17.3% | 6.2% |
| MeshAnything | 44.6% | 83.6% |
在推理过程中,我们将 输入到 Transformer,并要求它生成后续序列 。 然后输入到抗噪解码器中以重建网格:
| (10) |
其中 是最终生成的 AM。
我们使用标准的下一个符元预测损失来训练形状条件 Transformer。 对于每个序列,我们在点云符元之后添加一个 <bos> 符元,在网格符元之后添加一个 <eos> 符元,以标识 3D 网格的结束。
5 实验
5.1 数据准备
数据选择。 现有的 AM 生成工作仅限于少数类别。 但是,我们的方法的目标是在一般形状上运行。 MeshAnything 在 Objaverse Deitke et al. (2023b) 和 ShapeNet Chang et al. (2015) 的组合数据集上进行了训练,以选择它们的互补特性。 我们选择 Objaverse,因为它包含大量没有类别限制的 AM。 另一方面,ShapeNet 在有限的类别中提供了更高的数据质量。
我们从这两个数据集中过滤掉面数超过 800 个的网格。 此外,我们手动过滤掉了低质量的网格。 我们最终过滤后的数据集包含来自 Objaverse 的 51k 个网格和来自 ShapeNet 的 5k 个网格。 我们随机选择这个数据集的 10% 作为评估数据集,其余 90% 用作我们所有实验的训练集。
数据处理和增强。 遵循 PolyGen Nash 等人 (2020) 和 MeshGPT Siddiqui 等人 (2023) 的策略,我们根据面片的最低顶点索引对它们进行排序,然后是下一个最低顶点索引,以此类推。 顶点根据其 z-y-x 坐标按升序排序,其中 z 代表垂直轴。 在每个面片内,我们对索引进行排列,以确保最低索引排在第一位。 在训练期间,我们应用动态缩放、平移和旋转增强,将每个网格归一化为 到 之间的单位边界框。
5.2 实施细节
VQ-VAE 的编码器和解码器都使用 BERT Devlin 等人 (2018) 的编码器,而我们选择 OPT-350M Zhang 等人 (2022) 作为我们的自回归 Transformer 架构。 剩余向量量化 Zeghidour 等人 (2021) 深度设置为 3,码本大小为 8,192。
我们的点编码器基于 Zhao 等人 (2024) 的预训练点编码器,该编码器已在 Objaverse 上进行过训练,因此可以处理一般形状。 该点编码器输出一个固定长度的符元序列,包含 257 个符元,其中 256 个符元主要包含形状信息,而额外的头部符元包含有关形状的语义信息。 我们为每个点云采样 4096 个点。
VQ-VAE 和 Transformer 的训练批次大小分别设置为每个 GPU 8 个。 VQ-VAE 在 8 个 A100 GPU 上训练 12 小时,之后我们分别将 VQ-VAE 的解码器部分微调为抗噪声解码器,如第 4.2 节所述。 接着,Transformer 在 8 个 A100 GPU 上训练 4 天。
| Method | COV | MMD | 1-NNA | FID | KID |
|---|---|---|---|---|---|
| PolyGen | 23.2 | 6.22 | 88.2 | 48.8 | 27.7 |
| MeshGPT | 41.7 | 3.83 | 67.3 | 25.1 | 6.11 |
| MeshAnything | 53.1 | 2.72 | 55.7 | 14.5 | 1.89 |
5.3 定性实验
5.4 定量实验
从生成模型的角度来看,MeshAnything 是一个形状条件网格生成模型。 从网格提取的角度来看,它从点云中提取艺术家创建的网格。 因此,我们将 MeshAnything 与这两种类型的模型进行比较。 附录部分 A.2 中提供了其他实验。
用户研究。 如表 1 所示,我们进行了两项用户研究,分别与网格生成基准 Nash 等人 (2020); Siddiqui 等人 (2023) 和网格提取基准 Lorensen & Cline (1987); Peng 等人 (2021) 进行比较。 网格生成基准在 ShapeNet 上进行训练,为了确保公平比较,我们使用与 MeshAnything 相同的 Transformer 模型在 Objaverse 上重新训练它们。 由于网格生成基准都是无条件网格生成方法,而 MeshAnything 是一种形状条件网格生成方法,因此我们从 Objaverse 的评估集中随机采样形状作为 MeshAnything 的输入,而对于基准方法,我们直接执行随机采样。
在网格提取基准中,由于我们的方法也可以被视为点云到网格方法,因此我们包括了 Peng 等人 (2021),一种点云到网格方法,作为基准。 此外,我们使用 Blender 重新网格化方法 Blender Development Team (2024) 优化了网格提取基准的结果,以简化拓扑结构。
我们从每种方法中收集了 结果,并要求用户根据形状质量和拓扑质量投票选出最佳结果。 共有 名用户参与,提供了 1,230 次有效比较。 两项用户研究都证明了我们方法的优越性。 重新训练的 MeshGPT 和 MeshAnything 之间的唯一区别是它们是否受形状条件限制,这进一步证明了形状条件网格生成设置的优势。
指标。 我们遵循 Chen 等人 (2022);Siddiqui 等人 (2023) 的指标设置。 我们将在附录部分详细介绍此设置。 A.1。
与网格生成管道的比较。 我们使用用户研究中相同的重新训练模型进行比较。 如表 2 所示,MeshAnything 显著优于先前方法 Nash 等人 (2020);Siddiqui 等人 (2023),表明它在形状和拓扑质量方面均处于领先地位。 由于重新训练的 MeshGPT 和 MeshAnything 之间的唯一区别是是否包含形状条件,因此 MeshAnything 的出色性能进一步证明了形状条件网格生成是更适合网格生成的设置。
6 结论
在这项工作中,我们提出了一种用于改进网格提取和网格生成的新方法,即形状条件艺术家创作网格 (AM) 生成。 遵循此设置,我们引入了 MeshAnything,它是一种能够生成符合给定 3D 资产的 AM 的模型。 MeshAnything 可以将任何 3D 表示形式的 3D 资产转换为 AM,因此可以与多种 3D 资产制作方法集成,以促进其在 3D 行业的应用。 此外,我们引入了一种抗噪声解码器架构,以提高生成质量,使模型能够处理由自回归 Transformer 生成的低质量符元序列。 最后,大量的实验表明了我们方法的优越性能,突出了其扩展到 3D 行业应用的潜力,以及相对于先前方法的优势。
参考文献
- Alliegro et al. (2023) Antonio Alliegro, Yawar Siddiqui, Tatiana Tommasi, and Matthias Nießner. Polydiff: Generating 3d polygonal meshes with diffusion models. arXiv preprint arXiv:2312.11417, 2023.
- Barron et al. (2021) Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5855–5864, 2021.
- Barron et al. (2022) Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. CVPR, 2022.
- Blender Development Team (2024) Blender Development Team. Blender (version 4.1.0) [computer software], 2024. Available from https://docs.blender.org/manual/en/latest/modeling/modifiers/generate/remesh.html.
- Bloomenthal (1988) Jules Bloomenthal. Polygonization of implicit surfaces. Computer Aided Geometric Design, 5(4):341–355, 1988.
- Bloomenthal & Bajaj (1997) Jules Bloomenthal and Chandrajit Bajaj. Introduction to implicit surfaces. Morgan Kaufmann, 1997.
- Chang et al. (2015) Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012, 2015.
- Chen et al. (2024a) Sijin Chen, Xin Chen, Anqi Pang, Xianfang Zeng, Wei Cheng, Yijun Fu, Fukun Yin, Yanru Wang, Zhibin Wang, Chi Zhang, et al. Meshxl: Neural coordinate field for generative 3d foundation models. arXiv preprint arXiv:2405.20853, 2024a.
- Chen et al. (2019) Wenzheng Chen, Huan Ling, Jun Gao, Edward Smith, Jaakko Lehtinen, Alec Jacobson, and Sanja Fidler. Learning to predict 3d objects with an interpolation-based differentiable renderer. Advances in neural information processing systems, 32, 2019.
- Chen et al. (2023a) Yiwen Chen, Zilong Chen, Chi Zhang, Feng Wang, Xiaofeng Yang, Yikai Wang, Zhongang Cai, Lei Yang, Huaping Liu, and Guosheng Lin. Gaussianeditor: Swift and controllable 3d editing with gaussian splatting. arXiv preprint arXiv:2311.14521, 2023a.
- Chen et al. (2024b) Yiwen Chen, Chi Zhang, Xiaofeng Yang, Zhongang Cai, Gang Yu, Lei Yang, and Guosheng Lin. It3d: Improved text-to-3d generation with explicit view synthesis. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 1237–1244, 2024b.
- Chen & Zhang (2021) Zhiqin Chen and Hao Zhang. Neural marching cubes. ACM Transactions on Graphics (TOG), 40(6):1–15, 2021.
- Chen et al. (2022) Zhiqin Chen, Andrea Tagliasacchi, Thomas Funkhouser, and Hao Zhang. Neural dual contouring. ACM Transactions on Graphics (TOG), 41(4):1–13, 2022.
- Chen et al. (2023b) Zilong Chen, Feng Wang, and Huaping Liu. Text-to-3d using gaussian splatting. arXiv preprint arXiv:2309.16585, 2023b.
- Chen et al. (2024c) Zilong Chen, Yikai Wang, Feng Wang, Zhengyi Wang, and Huaping Liu. V3d: Video diffusion models are effective 3d generators. arXiv preprint arXiv:2403.06738, 2024c.
- Chernyaev (1995) Evgeni Chernyaev. Marching cubes 33: Construction of topologically correct isosurfaces. Technical report, 1995.
- Community (2018) Blender Online Community. Blender - a 3D modelling and rendering package. Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018. URL http://www.blender.org.
- Daneshmand et al. (2018) Morteza Daneshmand, Ahmed Helmi, Egils Avots, Fatemeh Noroozi, Fatih Alisinanoglu, Hasan Sait Arslan, Jelena Gorbova, Rain Eric Haamer, Cagri Ozcinar, and Gholamreza Anbarjafari. 3d scanning: A comprehensive survey. arXiv preprint arXiv:1801.08863, 2018.
- Deitke et al. (2023a) Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects. arXiv preprint arXiv:2307.05663, 2023a.
- Deitke et al. (2023b) Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In CVPR, pp. 13142–13153, 2023b.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Doi & Koide (1991) Akio Doi and Akio Koide. An efficient method of triangulating equi-valued surfaces by using tetrahedral cells. IEICE TRANSACTIONS on Information and Systems, 74(1):214–224, 1991.
- Fang et al. (2023) Jiemin Fang, Junjie Wang, Xiaopeng Zhang, Lingxi Xie, and Qi Tian. Gaussianeditor: Editing 3d gaussians delicately with text instructions. arXiv preprint arXiv:2311.16037, 2023.
- Gao et al. (2020) Jun Gao, Wenzheng Chen, Tommy Xiang, Alec Jacobson, Morgan McGuire, and Sanja Fidler. Learning deformable tetrahedral meshes for 3d reconstruction. Advances in neural information processing systems, 33:9936–9947, 2020.
- Gao et al. (2022) Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. Get3d: A generative model of high quality 3d textured shapes learned from images. NeurIPS, 35:31841–31854, 2022.
- Guo et al. (2023) Ziyu Guo, Renrui Zhang, Xiangyang Zhu, Yiwen Tang, Xianzheng Ma, Jiaming Han, Kexin Chen, Peng Gao, Xianzhi Li, Hongsheng Li, et al. Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following. arXiv preprint arXiv:2309.00615, 2023.
- Haleem & Javaid (2019) Abid Haleem and Mohd Javaid. 3d scanning applications in medical field: a literature-based review. Clinical Epidemiology and Global Health, 7(2):199–210, 2019.
- Haleem et al. (2022) Abid Haleem, Mohd Javaid, Ravi Pratap Singh, Shanay Rab, Rajiv Suman, Lalit Kumar, and Ibrahim Haleem Khan. Exploring the potential of 3d scanning in industry 4.0: An overview. International Journal of Cognitive Computing in Engineering, 3:161–171, 2022.
- Hanocka et al. (2020) Rana Hanocka, Gal Metzer, Raja Giryes, and Daniel Cohen-Or. Point2mesh: A self-prior for deformable meshes. arXiv preprint arXiv:2005.11084, 2020.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Hong et al. (2023) Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400, 2023.
- Huang et al. (2024) Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically accurate radiance fields. arXiv preprint arXiv:2403.17888, 2024.
- Ju et al. (2002) Tao Ju, Frank Losasso, Scott Schaefer, and Joe Warren. Dual contouring of hermite data. In Proceedings of the 29th annual conference on Computer graphics and interactive techniques, pp. 339–346, 2002.
- Kato et al. (2018) Hiroharu Kato, Yoshitaka Ushiku, and Tatsuya Harada. Neural 3d mesh renderer. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3907–3916, 2018.
- Kerbl et al. (2023a) Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (ToG), 42(4):1–14, 2023a.
- Kerbl et al. (2023b) Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 42(4), July 2023b. URL https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/.
- Li et al. (2023) Jiahao Li, Hao Tan, Kai Zhang, Zexiang Xu, Fujun Luan, Yinghao Xu, Yicong Hong, Kalyan Sunkavalli, Greg Shakhnarovich, and Sai Bi. Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model. arXiv preprint arXiv:2311.06214, 2023.
- Liao et al. (2018) Yiyi Liao, Simon Donne, and Andreas Geiger. Deep marching cubes: Learning explicit surface representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2916–2925, 2018.
- Liu et al. (2024a) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024a.
- Liu et al. (2024b) Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Mukund Varma T, Zexiang Xu, and Hao Su. One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization. Advances in Neural Information Processing Systems, 36, 2024b.
- Liu et al. (2023a) Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object. https://arxiv.org/abs/2303.11328, 2023a.
- Liu et al. (2023b) Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object. arXiv preprint arXiv:2303.11328, 2023b.
- Long et al. (2023) Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Single image to 3d using cross-domain diffusion. arXiv preprint arXiv:2310.15008, 2023.
- Lorensen & Cline (1987) William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. ACM siggraph computer graphics, 21(4):163–169, 1987.
- Lorensen & Cline (1998) William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. In Seminal graphics: pioneering efforts that shaped the field, pp. 347–353. 1998.
- Mildenhall et al. (2020) Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
- Nash et al. (2020) Charlie Nash, Yaroslav Ganin, SM Ali Eslami, and Peter Battaglia. Polygen: An autoregressive generative model of 3d meshes. In International conference on machine learning, pp. 7220–7229. PMLR, 2020.
- Peng et al. (2021) Songyou Peng, Chiyu Jiang, Yiyi Liao, Michael Niemeyer, Marc Pollefeys, and Andreas Geiger. Shape as points: A differentiable poisson solver. Advances in Neural Information Processing Systems, 34:13032–13044, 2021.
- Poole et al. (2023) Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=FjNys5c7VyY.
- Qi et al. (2017a) Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In CVPR 2017, pp. 652–660, 2017a.
- Qi et al. (2017b) Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems, 30, 2017b.
- Schaefer et al. (2007) Scott Schaefer, Tao Ju, and Joe Warren. Manifold dual contouring. IEEE Transactions on Visualization and Computer Graphics, 13(3):610–619, 2007.
- Shen et al. (2021a) Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis. In Advances in Neural Information Processing Systems (NeurIPS), 2021a.
- Shen et al. (2021b) Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis. Advances in Neural Information Processing Systems, 34:6087–6101, 2021b.
- Shen et al. (2023) Tianchang Shen, Jacob Munkberg, Jon Hasselgren, Kangxue Yin, Zian Wang, Wenzheng Chen, Zan Gojcic, Sanja Fidler, Nicholas Sharp, and Jun Gao. Flexible isosurface extraction for gradient-based mesh optimization. ACM Transactions on Graphics (TOG), 42(4):1–16, 2023.
- Shi et al. (2023) Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d generation. arXiv preprint arXiv:2308.16512, 2023.
- Siddiqui et al. (2023) Yawar Siddiqui, Antonio Alliegro, Alexey Artemov, Tatiana Tommasi, Daniele Sirigatti, Vladislav Rosov, Angela Dai, and Matthias Nießner. Meshgpt: Generating triangle meshes with decoder-only transformers. arXiv preprint arXiv:2311.15475, 2023.
- Sun et al. (2023) Jingxiang Sun, Bo Zhang, Ruizhi Shao, Lizhen Wang, Wen Liu, Zhenda Xie, and Yebin Liu. Dreamcraft3d: Hierarchical 3d generation with bootstrapped diffusion prior. arXiv preprint arXiv:2310.16818, 2023.
- Tang et al. (2023a) Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for efficient 3d content creation. arXiv preprint arXiv:2309.16653, 2023a.
- Tang et al. (2024) Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. arXiv preprint arXiv:2402.05054, 2024.
- Tang et al. (2023b) Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior. arXiv preprint arXiv:2303.14184, 2023b.
- Team (2024) Deemos Team. Deemos rodin. https://hyperhuman.deemos.com/rodin, 2024.
- Tochilkin et al. (2024) Dmitry Tochilkin, David Pankratz, Zexiang Liu, Zixuan Huang, Adam Letts, Yangguang Li, Ding Liang, Christian Laforte, Varun Jampani, and Yan-Pei Cao. Triposr: Fast 3d object reconstruction from a single image. arXiv preprint arXiv:2403.02151, 2024.
- Van Den Oord et al. (2017) Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wang et al. (2022) Peng-Shuai Wang, Yang Liu, and Xin Tong. Dual octree graph networks for learning adaptive volumetric shape representations. ACM Transactions on Graphics (TOG), 41(4):1–15, 2022.
- Wang et al. (2023) Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. arXiv preprint arXiv:2305.16213, 2023.
- Wang et al. (2024) Zhengyi Wang, Yikai Wang, Yifei Chen, Chendong Xiang, Shuo Chen, Dajiang Yu, Chongxuan Li, Hang Su, and Jun Zhu. Crm: Single image to 3d textured mesh with convolutional reconstruction model. arXiv preprint arXiv:2403.05034, 2024.
- Wei et al. (2024) Xinyue Wei, Kai Zhang, Sai Bi, Hao Tan, Fujun Luan, Valentin Deschaintre, Kalyan Sunkavalli, Hao Su, and Zexiang Xu. Meshlrm: Large reconstruction model for high-quality mesh. arXiv preprint arXiv:2404.12385, 2024.
- Wu et al. (2019) Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. In International conference on machine learning, pp. 6861–6871. PMLR, 2019.
- Wu et al. (2023) Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and S Yu Philip. Multimodal large language models: A survey. In 2023 IEEE International Conference on Big Data (BigData), pp. 2247–2256. IEEE, 2023.
- Xu et al. (2024) Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models. arXiv preprint arXiv:2404.07191, 2024.
- Xu et al. (2023) Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. arXiv preprint arXiv:2308.16911, 2023.
- Yang et al. (2023) Xiaofeng Yang, Yiwen Chen, Cheng Chen, Chi Zhang, Yi Xu, Xulei Yang, Fayao Liu, and Guosheng Lin. Learn to optimize denoising scores for 3d generation: A unified and improved diffusion prior on nerf and 3d gaussian splatting. arXiv preprint arXiv:2312.04820, 2023.
- Yu et al. (2021) Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. In CVPR, pp. 4578–4587, 2021.
- Zeghidour et al. (2021) Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2021.
- Zhang et al. (2022) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- Zhao et al. (2024) Zibo Zhao, Wen Liu, Xin Chen, Xianfang Zeng, Rui Wang, Pei Cheng, Bin Fu, Tao Chen, Gang Yu, and Shenghua Gao. Michelangelo: Conditional 3d shape generation based on shape-image-text aligned latent representation. Advances in Neural Information Processing Systems, 36, 2024.
附录 A 附录

| Noise Level | CD() | ECD() | NC | |||
|---|---|---|---|---|---|---|
| W/O NR | W/ NR | W/O NR | W/ NR | W/O NR | W/ NR | |
| 0.0 | 0.011 | 0.007 | 0.035 | 0.023 | 0.987 | 0.993 |
| 0.1 | 0.187 | 0.028 | 0.613 | 0.138 | 0.973 | 0.991 |
| 0.5 | 1.167 | 0.639 | 2.538 | 1.329 | 0.964 | 0.981 |
| 1.0 | 2.131 | 1.798 | 4.317 | 2.316 | 0.952 | 0.969 |
| Method | CD | ECD | NC |
|---|---|---|---|
| () | () | ||
| W/O NR | 2.423 | 6.414 | 0.883 |
| W/ NR | 2.256 | 6.245 | 0.902 |
| Method | CD | ECD | NC | #V | #F | V_R | F_R |
|---|---|---|---|---|---|---|---|
| () | () | () | () | ||||
| (a) Marching Cubes | 1.532 | 6.733 | 0.954 | 73.22 | 146.0 | 440.2 | 462.2 |
| (b) MC+Remesh (0.005) | 2.174 | 7.813 | 0.912 | 127.8 | 167.9 | 748.1 | 534.6 |
| (c) MC+Remesh (0.010) | 2.083 | 7.578 | 0.929 | 39.01 | 41.78 | 225.4 | 132.3 |
| (d) MC+Remesh (0.030) | 2.915 | 8.329 | 0.863 | 5.848 | 4.410 | 34.38 | 14.05 |
| (e) MC+Remesh (0.050) | 4.179 | 8.138 | 0.814 | 2.299 | 1.538 | 13.64 | 4.920 |
| (f) MC+Remesh (0.100) | 7.312 | 10.771 | 0.748 | 0.625 | 0.359 | 3.735 | 1.149 |
| (g) FC | 1.190 | 6.121 | 0.967 | 59.12 | 121.1 | 378.2 | 391.1 |
| (h) FC+Remesh (0.010) | 1.861 | 6.940 | 0.933 | 37.98 | 40.19 | 205.5 | 124.2 |
| (i) SAP | 1.771 | 7.112 | 0.939 | 79.12 | 152.3 | 481.2 | 489.3 |
| (j) SAP+Remesh (0.010) | 2.367 | 7.862 | 0.925 | 39.17 | 42.87 | 239.1 | 136.6 |
| (k) MeshAnything | 2.256 | 6.245 | 0.902 | 0.172 | 0.318 | 0.888 | 0.871 |
A.1 指标
我们在网格生成实验中遵循 Siddiqui et al. (2023) 的评估指标设置,在网格提取实验中遵循 Chen et al. (2022) 的设置。
我们通过从真实网格和预测网格的面部均匀采样 100K 个点,然后计算一组指标来评估重建的各个方面,从而定量评估网格质量。
对于网格提取,我们报告以下指标:Chamfer 距离 (CD) 用于评估重建网格的整体质量;边缘 Chamfer 距离 (ECD) 用于通过采样靠近锋利边缘和角点的点来评估锋利边缘的保留情况;以及法线一致性 (NC) 用于评估表面法线的质量。 此外,我们报告了网格顶点数 (#V) 和网格面数 (#F)。 我们还提供了估计顶点数与真实顶点数之比 (#V_R) 以及面数的相同比率 (#F_R)。
对于网格生成,覆盖率 (COV) 捕获了生成网格的多样性,并且对模式丢失敏感,但它并不反映结果的质量。 最小匹配距离 (MMD) 测量参考集与其在生成集中的最近邻居之间的平均距离,尽管它对低质量输出缺乏敏感性。 1-最近邻精度 (1-NNA) 评估了生成集和参考集之间的质量和多样性。 为了评估拓扑质量,我们渲染了地面实况网格和生成的网格,并可视化了它们的线框。 然后,我们对渲染的图像使用 Fréchet inception 距离 (FID) 和 Kernel inception 距离 (KID)。 MMD 和 KID 分数按 的因子进行缩放。
A.2 实验
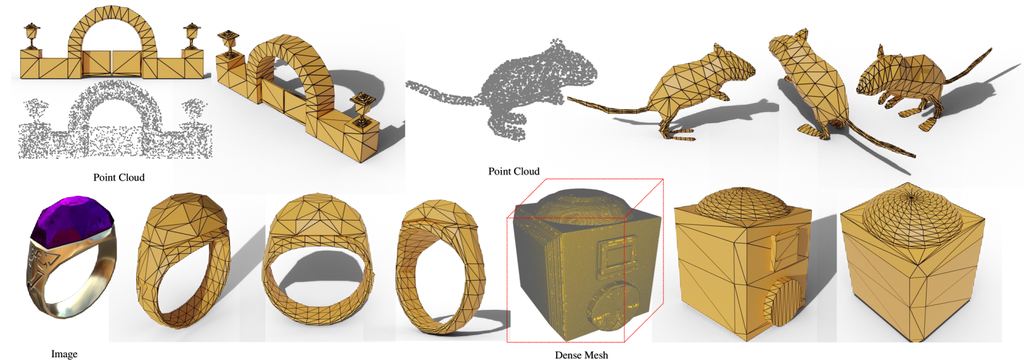
其他定性实验 我们在本文中展示了 MeshAnything 的更多定性结果。 如图 5 和图 6 所示,MeshAnything 有效地从各种 3D 表示中生成 AM。 当与不同的 3D 资产生产管道集成时,我们的方法有效地实现了具有不同条件的网格生成。
接下来,图 6 证明了 MeshAnything 并不仅仅是过度拟合,而是理解如何生成具有有效拓扑的网格,以符合给定的形状。 为了证明这一点,我们使用手动创建的网格作为地面实况,并使用它们的形状作为条件来测试我们的模型是否可以生成具有可比较拓扑的网格。 为了有效地将地面实况用作条件,我们首先使用 Marching Cubes Lorensen & Cline (1987) 将它们转换为密集网格,以破坏它们的表面结构。 然后,我们从密集网格中采样带有法线的点云,作为形状条件。 图 6 中的实验结果表明,MeshAnything 能够生成与人类艺术家建模的网格相当甚至超越的网格,展示了多样化和强大的 3D 建模能力。
与网格提取基线比较。 我们的方法与各种网格提取方法相关 Lorensen & Cline (1987); Chen & Zhang (2021); Chen et al. (2022); Shen et al. (2023); Peng et al. (2021),因为我们也将其他 3D 表示转换为网格。 但是,需要注意的是,以前的方法是重建类方法,生成密集网格,而我们的方法是生成式的,创建艺术家创作网格 (AM),这些网格比密集网格更复杂。 因此,严格来说,我们的方法不能被认为与这些基于重建的网格提取方法相同。 此比较的主要目的是使用这些网格提取方法作为参考,根据形状评估 MeshAnything 生成的网格的质量。 我们将 MeshAnything 与 Lorensen & Cline (1987); Shen et al. (2023); Peng et al. (2021) 进行了比较。 其中,MarchingCubes 是最流行的网格提取方法,FlexiCubes 代表了网格提取领域的最新技术,Shape as Points 是从点云提取网格的领先方法。
我们还将这些方法与重新网格化技术结合起来,以测试它们是否可以在保持形状质量的同时显著减少面的数量。 我们使用 Blender Remesh 的体素模式 Community (2018); Blender Development Team (2024),特别是使用 Blender 版本 4.1 作为重新网格化方法。 由于我们的评估数据集包含非封闭网格,我们首先使用 Wang et al. (2022) 提取所有地面真实网格的符号距离场 (SDF),它可以处理非封闭网格。 然后,我们在这些 SDF 上以 128 的分辨率应用 Marching Cubes。 接下来,我们将 Blender remesh Blender Development Team (2024) 应用于不同的体素大小,以应用于 Marching Cubes 结果,因为重新网格化方法和我们的方法都能够简化拓扑。 此外,Marching Cubes 结果被用作 MeshAnything 的形状条件输入以获得我们的结果。 Shen et al. (2023) 和 Peng et al. (2021) 的设置遵循其论文。
如表 5 所示,我们发现这些方法需要多出数百倍的面数才能实现与我们方法相当的结果。 比较 (a)、(g)、(i) 和 (k),我们的方法在 Chamfer 距离 (CD) 和法线一致性 (NC) 方面落后,这主要是由于我们的方法作为生成模型固有的失败案例,使其不如这些基于重建的网格提取方法稳健。 当与重新网格化方法进行比较时,我们观察到它们在实现与我们相似的面数方面会产生高成本。 将 (f) 和 (k) 进行比较,我们发现即使当重新网格化方法达到可比的面数时,顶点数仍然是我们方法的几倍,这表明重新网格化方法的拓扑效率远远低于我们的方法,因为它们完全忽略了 3D 资产的形状特征。 重要的是要注意,网格提取中的指标只能反映形状对齐的质量,不能有效地反映我们方法的拓扑优势。 此外,我们惊讶地发现,我们的方法可以产生比地面实况更少的面数的结果,这表明 MeshAnything 并没有过度拟合数据,而是学习了有效的拓扑表示,偶尔超过了地面实况网格。
抗噪声条件解码器的消融研究。 我们进行消融实验以验证抗噪声解码器的有效性。 我们从一个没有任何噪声或条件的 VQ-VAE 开始。 然后,我们在两种设置之间进行消融:一种设置是解码器保持不变且不知道形状条件,另一种设置是将形状条件注入 Transformer,如第 4.2 节所述。 接下来,我们在矢量量化过程中从 Gumbel 分布中随机采样噪声并将其添加到代码本采样 logits 中,以模拟 Transformer 生成的潜在低质量符元序列。 我们通过缩放添加的噪声来控制噪声水平。
| Method | CD | ECD | NC | #V | #F | V_R | F_R |
|---|---|---|---|---|---|---|---|
| () | () | () | () | ||||
| (a) Noise scale 0.005 | 2.351 | 6.412 | 0.897 | 0.175 | 0.321 | 0.895 | 0.880 |
| (b) Noise scale 0.020 | 2.980 | 6.970 | 0.881 | 0.180 | 0.330 | 0.901 | 0.910 |
| (c) Noise scale 0.050 | 4.910 | 8.556 | 0.755 | 0.162 | 0.284 | 0.811 | 0.802 |
| (d) Rodin | 2.552 | 6.622 | 0.833 | 0.185 | 0.342 | 0.919 | 0.923 |
| (e) MeshAnything | 2.256 | 6.245 | 0.902 | 0.172 | 0.318 | 0.888 | 0.871 |
在将两个模型训练足够多的 epochs 后,我们测试它们在相同噪声水平下的性能。 如表 3 所示,随着添加噪声强度的增加,具有形状条件的抗噪声解码器明显获得了更好的重建结果。 这表明形状条件有助于解码器识别和纠正输入符元序列中的缺陷。
接下来,我们验证抗噪声解码器是否确实增强了 Transformer 在推理过程中的性能。 测试方法使用从损坏的 GT 网格派生的密集网格作为生成新网格的条件。 然后评估生成的网格与条件形状的形状对齐情况。 如表 4 所示,使用抗噪声解码器的模型取得了更好的结果。
输入点云质量对生成结果的影响实验。 MeshAnything 以点云作为输入,其对点云质量的鲁棒性决定了其在各种应用中的通用性。 我们设计了两个实验来评估其对输入点云质量的容忍度:首先,在保持其他评估设置不变的情况下,我们对输入点云坐标和法线应用高斯噪声。 具体来说,对于每个点,我们从标准分布中随机采样高斯噪声,将其按噪声因子进行缩放,并将其添加到点的坐标中。 对法线采用相同的方法,但在添加噪声后应用归一化。 其次,我们使用 Rodin 的生成结果作为真值网格,从该网格中采样点云作为输入,并评估生成结果与真值之间的偏差。
如表 6 所示,MeshAnything 在 (a) 和 (b) 中没有出现明显的性能下降,表明其对点云中的噪声具有弹性,仅在 (c) 中出现了明显的性能下降。 值得注意的是,输入点云被归一化为 [-1,1] 范围,(c) 中的噪声尺度已经相当大。 (d) 中的实验进一步证明了 MeshAnything 可以容忍生成的点云,并有效地与 3D 生成模型集成。
A.3 局限性
我们的方法无法生成超过最大面数限制的网格,因此无法将大型场景和特别复杂的物体转换为网格。 此外,由于其生成性,我们的方法不如基于重建的网格提取方法稳定,例如 Lorensen & Cline (1987); Shen et al. (2023)。
A.4 社会影响
我们的方法指出了自动生成艺术家创建的网格的一种很有前景的方法,这有可能大幅降低 3D 行业的劳动力成本,从而促进游戏、电影和元宇宙等行业的进步。 然而,获取 3D 艺术家创建的网格的成本降低也可能导致潜在的犯罪活动。