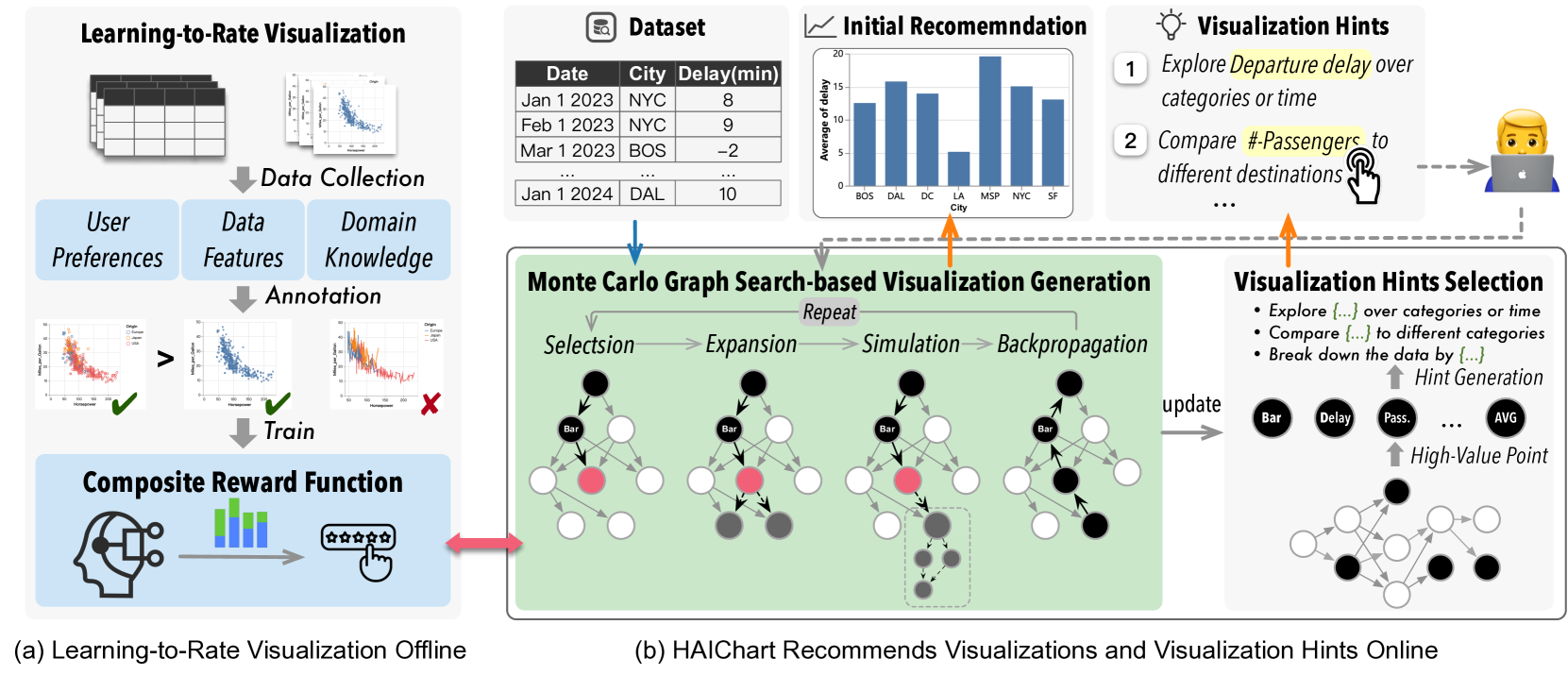
HAIChart:人类和人工智能配对可视化系统
摘要。
数据可视化在商业智能和数据科学中日益重要,强调了对能够从大型数据集有效生成有意义的可视化的工具的需求。 现有工具分为两大类:需要专家大量参与的人力工具(例如 Tableau 和 PowerBI),以及人工智能驱动的自动化工具(例如 Draco)和 Table2Charts),通常无法猜测特定的用户需求。
在本文中,我们的目标是实现两全其美。 我们的关键想法是首先自动生成一组高质量的可视化,以最大限度地减少手动工作,然后根据用户反馈迭代地完善此过程,以更紧密地满足他们的需求。 为此,我们提出了HAIChart,这是一个基于强化学习的框架,旨在通过合并用户反馈来迭代地为给定数据集推荐良好的可视化效果。 具体来说,我们提出了一种基于蒙特卡罗图搜索的可视化生成算法,与复合奖励函数相结合,以有效地探索可视化空间并自动生成良好的可视化效果。 我们设计了可视化提示机制来主动融入用户反馈,从而逐步完善可视化生成模块。 我们进一步证明了 top- 可视化提示选择问题是 NP 困难的,并设计了一种有效的算法。 我们进行了定量评估和用户研究,结果表明 HAIChart 显着优于最先进的人力工具( 在召回方面表现更好, 更快)和人工智能驱动的自动工具( 和 分别在 Hit@3 和 R10@30 方面更好)。
PVLDB 工件可用性:
源代码、数据和/或其他工件已在 https://github.com/xypkent/HAIChart 上提供。
1. 介绍
数据可视化是揭示潜在洞察的有效手段(Ward 等人,2010;Qin 等人,2020;Shen 等人,2023;Ye 等人,2024)。 随着数据可视化的重要性日益增加,如何帮助用户有效、轻松地从海量数据集中创建可视化已引起学术界的广泛关注(吴等人,2021;李等人,2021;沉等人,2022;罗等人,2020b, a) 和行业(例如 Tableau (选项卡,2024))。 根据创建可视化所需的用户工作量,现有可视化工具可大致分为两类,即人力驱动和人工智能驱动可视化工具。
人力可视化工具,包括 Voyager2 (Wongsuphasawat 等人, 2017)、DeVIL (Wu 等人, 2017) 和 Lary (Satyanarayan 和 Heer,2014),使用户能够通过手动指定数据属性、转换和视觉编码来创建所需的可视化效果,如图 1(a) 所示。 这个过程非常耗时且容易出错,因为它需要对数据集和分析任务有深入的了解。 用户通常需要尝试多次迭代才能实现最终的可视化。 因此,交互式可视化需要领域和特定于数据的专业知识,这可能会严重阻碍新手用户有效地参与可视化分析。
为了应对上述挑战,最近的研究试图通过机器算法实现可视化过程自动化。
人工智能驱动的自动可视化旨在基于预定义的约束枚举并推荐给定数据集的(top-)最佳可视化(罗等人,2018a;Li等人, 2021; Deng 等人, 2022; Luo 等人, 2022b; Moritz 等人, 2019) 或基于学习的推荐算法(Qian 等人, 2022; Zhou 等人, 2021). 例如,DeepEye (Luo 等人, 2018a) 根据可视化规则和排名模型推荐可视化,而 Table2Charts (Zhou 等人, 2021) 生成 top- 使用表到序列生成模型的可视化。 尽管这些工具通过建议“良好”的可视化为数据分析提供了有价值的起点,但它们存在以不加区别的建议误导用户的风险。 关键问题是,这些工具通常依赖于静态逻辑规则或深度学习模型,无法充分捕获用户意图或反馈,从而阻碍了定制推荐的可视化以更好地满足用户的需求。

| Types | Systems | Input | Output | Multi-round? | Learned? | Recommendation Perspectives | |||
| Domain Knowl. | User Preferences | Data Features | |||||||
| Human-powered | Voyager2 (Wongsuphasawat et al., 2017) | , | ✗ | ✗ | ✓ | ✗ | ✗ | ||
| DeVIL (Wu et al., 2017) | , | ✗ | ✗ | ✓ | ✓ | ✗ | |||
| Lary (Satyanarayan and Heer, 2014) | , | ✗ | ✗ | ✓ | ✓ | ✗ | |||
| AI-powered | DeepEye (Luo et al., 2018a) | ✗ | ✓ | ✓ | ✗ | ✓ | |||
| VizML (Hu et al., 2019) | ✗ | ✓ | ✗ | ✗ | ✓ | ||||
| Draco-Learn (Moritz et al., 2019) | ✗ | ✓ | ✓ | ✓ | ✓ | ||||
| Data2Vis (Dibia and Demiralp, 2019) | ✗ | ✓ | ✗ | ✗ | ✓ | ||||
| KG4VIS (Li et al., 2021) | , Knowl. Graph | ✗ | ✓ | ✓ | ✗ | ✗ | |||
| Table2Charts (Zhou et al., 2021) | ✗ | ✓ | ✗ | ✗ | ✓ | ||||
| VizGRank (Gao et al., 2021) | ✗ | ✗ | ✓ | ✗ | ✓ | ||||
| PVisRec (Qian et al., 2022) | ✗ | ✓ | ✗ | ✓ | ✓ | ||||
| LLM4Vis (Wang et al., 2023) | ✗ | ✓ | ✗ | ✗ | ✓ | ||||
| PI2 (Chen and Wu, 2022) | , SQL Queries | , Interface | ✓ | ✗ | ✓ | ✓ | ✗ | ||
|
HAIChart | , User Feedback | , Hints | ✓ | ✓ | ✓ | ✓ | ✓ | |
人类和人工智能配对可视化。 为了减轻上述方法的局限性,并在人力可视化和人工智能可视化之间取得平衡,我们提出了人类和人工智能配对可视化,如图1所示( C)。 我们的关键思想是首先推荐一组高质量可视化效果,然后通过向用户提供可视化提示来继续完善推荐的可视化效果以便进一步调整。 这种方法不仅简化了新手用户寻求有效可视化的过程,还使用户能够通过以人为本的反馈积极参与和指导人工智能驱动的可视化过程,如表1所示。
挑战。 我们的问题面临三个挑战。 (C1) 我们如何有效且高效地探索可视化搜索空间以推荐高质量且相关的可视化? (C2)我们如何全面评估生成的可视化的“优秀度”? (C3)如何理解并有效整合用户反馈,引导系统实现符合用户需求的可视化效果?
我们的建议: HAI图表。 为了应对这些挑战,我们建议 HAIChart 自动、渐进地推荐一系列可视化效果,以适应随着时间的推移不断变化的用户偏好。 这个过程的特点是系统能够从用户交互和反馈中学习,迭代地完善推荐的可视化效果。 目标是在可用数据和可视化搜索空间的限制内,收敛到与用户偏好紧密一致的最终可视化集。 这种迭代优化本质上是一系列基于用户意图的决策,类似于强化学习中的关键思想。
我们采用强化学习框架来实现HAIChart。 我们将可视化视为一系列操作,例如图表类型和 / 轴配置。 因此,“状态”是当前不完整可视化序列,“动作”是指在该状态下选择后续可视化操作,“环境”是可视化系统本身。 环境评估可视化的质量并提供旨在鼓励代理改进其生成的可视化的奖励。 代理的任务是生成和推荐可视化。
我们利用蒙特卡罗图搜索 (MCGS) 算法来构建此代理,使其能够有效地导航广泛的搜索空间以发现最佳可视化(解决 C1)。 为了更准确地评估可视化,我们设计了一个综合奖励函数,考虑了数据特征、可视化领域知识和用户偏好,以确保可视化的质量(解决C2)。 此外,我们设计了一种可视化提示选择算法,用于推荐有用的提示(例如,“探索航班延误的原因”),以帮助用户进行数据探索。 这种方法可以整合用户反馈以获得更好的可视化结果(解决C3)。
贡献。 我们做出了以下显着贡献。
(1) 问题陈述。 我们正式定义了人类和人工智能配对可视化的问题(第2节)。
(2) HAIChart。
我们提出了一种基于强化学习的系统HAIChart,以整合人类洞察力和人工智能功能,以实现更好的可视化。 HAIChart 最初为用户生成一组有前景的可视化效果,并通过选择一组用于交互的可视化提示(第 3 和 4)。
(3) 学习评估可视化。 我们设计了一个复合奖励函数来评估可视化的质量,用于准确指导可视化生成过程(第5节)。
(4) 可视化提示选择。 我们设计可视化提示作为收集用户反馈的代理,证明top-可视化提示的选择是一个NP-hard问题,并设计了一种有效的算法来选择top- 提示(第 6 节)。
(5) 实验。
我们进行定量评估和用户研究,以证明 HAIChart 在准确性( 更好的召回率)和创建可视化效果的效率( 更快),并且在 Hit@3 和 R10@30 方面的有效性分别比人工智能驱动的系统高 25.1% 和 14.9%(第 7 节)。
2. 问题及解决方案概述
2.1. 问题
给定一个关系表 ,令 为所有有效可视化, 为一组“良好”可视化,两者都与 .在实践中,这组可视化通常由用户手动选择,例如仪表板中的可视化。
可视化选择。 可视化选择的问题是从所有有效可视化中选择一组可视化,最大化(即,最大化选择的良好可视化的数量)并最小化(即最小化选择的不良可视化的数量)。
当手动操作时,可视化选择非常耗时,其有效性取决于用户对数据可视化的专业知识和特定数据集的领域知识。
为了减少人类的工作量,人们研究了可视化推荐算法。 这些算法主要由机器学习方法提供支持。 然而,这些推荐算法主要是一轮的。
一轮可视化推荐。 一轮可视化推荐的问题是自动建议一组可视化并要求用户选择一个子集。
在实践中,单轮可视化推荐可能不足以支持用户的多样化意图,例如,为仪表盘选择所有图表。 因此,我们建议研究一个新问题,与用户进行多轮交互,以共同选择所有所需的良好可视化效果。
多轮可视化推荐。 多轮可视化推荐的问题是向用户推荐轮可视化。 在每一轮中,我们可以建议 可视化(可选地带有一些自然语言提示),并且用户可以在 中选择子集 可视化圆形的。 在 轮之后,用户将选择 可视化。
2.2. 解决方案概述
HAI图表概述。 如图2所示,HAIChart由两个主要组件组成:离线部分是学习评分可视化,在线部分用于自动推荐好的可视化和可视化提示用户交互。
离线:学习对可视化进行评分。 如图2(a)所示,离线部分负责理解和评估可视化质量。 为了实现这一目标,我们结合了可视化经验法则、数据特征和用户偏好来学习复合奖励函数。
在线:多轮可视化和提示推荐。 如图2(b)所示,HAIChart利用蒙特卡罗图搜索支持的代理来推荐一组有前途的可视化以及可视化指导进一步探索行动的提示。 具体来说,该代理最初有效且高效地遍历可视化搜索空间,生成可能的可视化,根据训练有素的复合奖励函数估计其质量,最后返回高质量可视化的排名列表。 此外,系统还计算从蒙特卡罗图的当前状态导出的可视化提示。 用户可以浏览推荐的可视化和提示。 一旦用户选择提示,系统将进一步探索可视化空间并推荐由所选提示引导的可视化。
3. 用于多轮可视化推荐的强化学习。
3.1. 初步知识
受之前作品(Moritz等人,2019;Luo等人,2018a,2022b)的启发,我们采用可视化查询来表示本文讨论的所有可能的可视化。
可视化查询。 给定一个具有方案 的关系表 ,可视化查询 由一系列可视化操作组成(即 操作)。 具体来说:
-
•
mark表示可视化图表的类型,包括条形图、折线图、饼图和散点图。
-
•
encoding表示数据属性的编码,包括/轴、聚合函数和配色方案。
-
•
transformation 定义数据转换:过滤、分箱、分组、排序和 top- 操作。
将可视化查询应用于表会产生相应的可视化,即 。 因此,表 的任何可视化 都可以由 中的数据属性和单元格值的组合以及可视化操作 (即 中的 操作)。
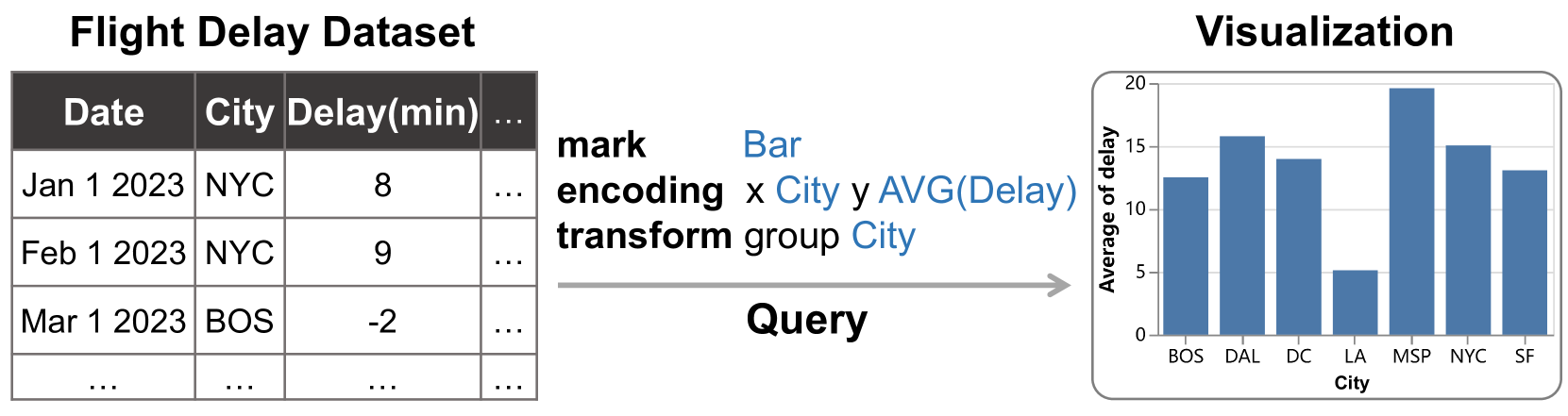
示例 3.1(可视化查询)。
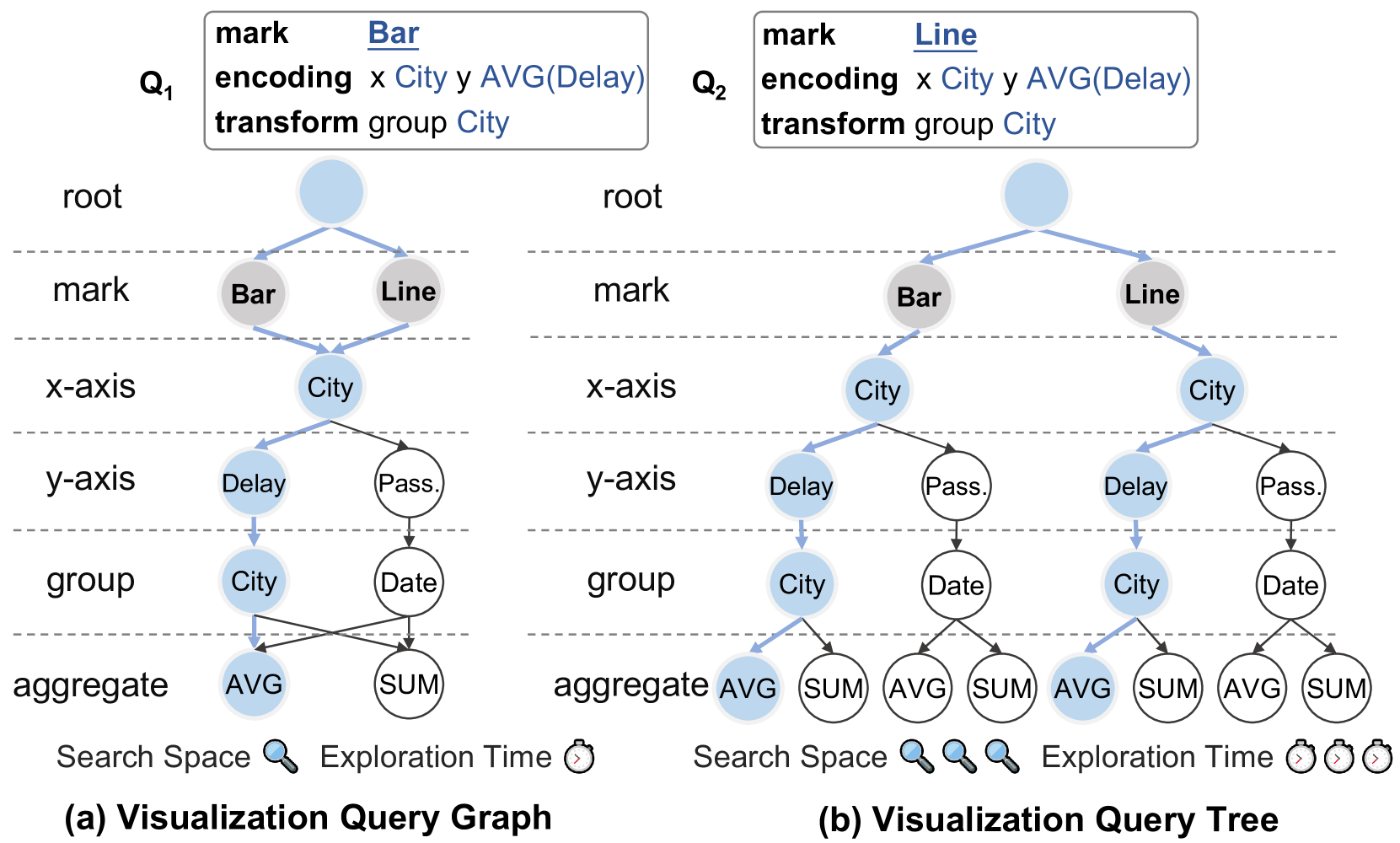
图 3 显示了应用于航班延误数据集 () 的说明性查询 ()。 该查询可视化一个条形图,其中 轴编码城市(即, City 列)和 轴显示平均延迟(即 AVG(Delay))。 条形图 () 显示平均延误趋势,显示 LA(即洛杉矶)的平均延误时间最短,而 MSP(即 明尼阿波利斯)的平均延误时间最长。
毫无疑问,可视化的搜索空间非常大,并且随着列数和可视化操作组合的增加而呈指数级增长。
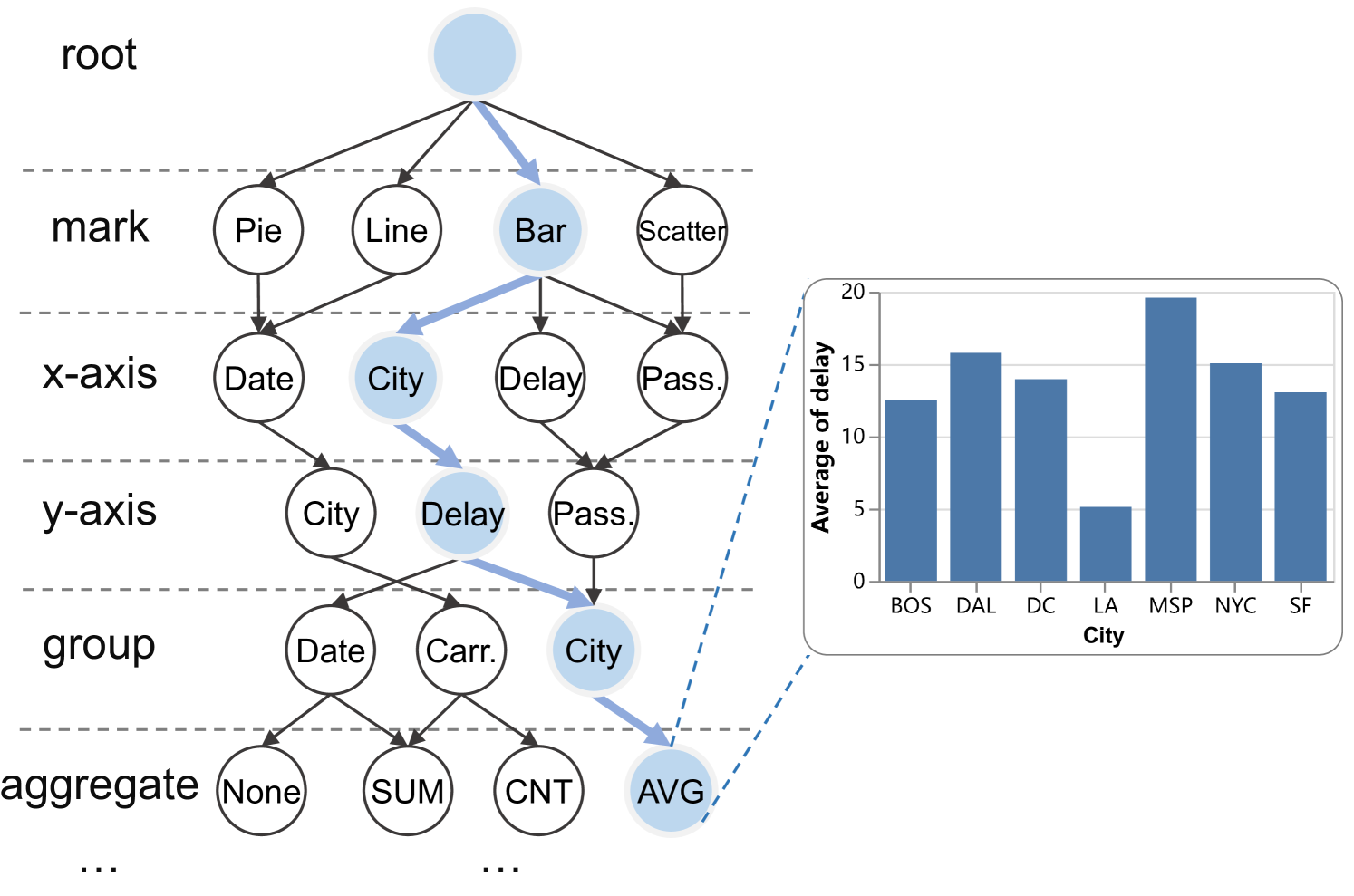
为了有效地导航这个巨大的搜索空间,我们引入了可视化查询图的概念来表示给定数据集的所有可能的可视化,定义如下:
定义 3.2(可视化查询图)。
给定表,可视化查询图被定义为有向无环图。 具体来说,每个节点代表一次可视化操作,每个有向边表示从节点到的转换。 边的权重由表示,表示从操作转换到的有效性。 该图中从根节点到结束节点的路径表示一系列可视化操作,它们一起形成候选可视化查询。
示例 3.3(可视化查询图)。
如图4所示,图表的每一层都对应于可视化操作可以采取的可能值。 例如,图表类型(mark)可以是 bar、line、scatter、pie 和 等。 以蓝色路径为例,它代表一个可视化查询 – “mark Bar encoding x City y AVG (延迟)转换</t4> 组城市”。 对数据集执行此查询后,它将创建一个条形图。
3.2. HAIChart 详细信息
给定一个用于可视化的数据集,用户通常会根据他们的基本知识理解来选择可视化类型、数据列和转换操作。 如果结果不满足他们的分析要求,他们会调整操作以优化输出。 此可视化过程是基于用户意图的一系列决策,类似于强化学习 (RL),其中来自可视化系统(即环境)的反馈有助于优化策略以实现满意的结果。
因此,我们将可视化生成和推荐问题建模为马尔可夫决策过程 (MDP)(Bellman,1957),并使用 RL 框架实现它。
HAIChart的关键强化学习组件如下:
状态。 要将 RL 框架应用于我们的问题,准确定义状态至关重要,状态可作为代理的输入并有助于在可视化生成过程中做出决策。 我们将可视化生成问题转化为一个从初始状态开始,通过一系列可视化操作/动作决策达到目标状态的过程。 每个状态对应一个由多个可视化子句组成的可视化查询,如3.1节中所述。
具体来说,可视化查询可以分为两类:
(1) 部分可视化查询。 这些查询需要进一步扩展以形成完整的查询并在蒙特卡罗图中反映历史决策路径。 例如,不完整的查询可能已指定图表类型(例如,条形图),但尚未为 - 或
(2)完整的可视化查询。 这些查询不需要额外的扩展,并且可以通过我们的奖励函数评估可视化质量。 之后,系统根据评估结果更新图的节点和边。
行动。 操作是代理可以根据其当前状态执行的操作,确定可视化查询序列中的下一步。 正如 3.1 节中所讨论的,可视化查询可以分为三种主要类型的操作:标记、编码和转换. 因此,对于给定的数据集,可用的操作空间是固定的。
代理。 该代理结合了蒙特卡罗图搜索(MCGS)算法和上置信界(UCB)(Auer等人,2002)算法来生成可视化并做出决策。 MCGS 在复杂且不确定的搜索空间中表现良好,而 UCB 算法有效地平衡了利用已知最优解和探索新可能性之间的权衡,从而优化了智能体的决策过程(参见第 4 节) >)。
奖励。 奖励函数评估 MCGS 算法创建的可视化质量,并相应地更新可视化查询图。 这指导代理生成更高质量的可视化。 奖励函数考虑三个关键因素:数据特征、可视化领域知识和用户偏好,以准确评估可视化质量(参见第5节)。
环境。 HAIChart 中的环境首先使用修剪算法在创建过程中高效生成有效的可视化查询。 其次,它评估有效查询的质量并返回奖励来指导训练过程。
4. 可视化生成
4.1. 基于蒙特卡罗图搜索的可视化生成
在第3.1节中,我们介绍了可视化查询图,其中每个可视化查询都由图中的路径表示。 查询图中所有可能的路径构成可视化的搜索空间。 我们可以使用搜索算法来探索图表并找到高质量的可视化效果。 然而,随着数据集大小的增加,搜索空间呈指数级扩展,使得有效找到良好的可视化结果变得具有挑战性。
深度优先搜索(DFS)和广度优先搜索(BFS)等传统图搜索方法在结构化搜索空间中表现良好,但在大型复杂空间中往往表现不佳,因为它们无法根据已找到的信息动态调整搜索策略。 为了解决这些限制,我们提出了一种基于蒙特卡罗图搜索的算法来有效地导航巨大的搜索空间。
关键想法。 我们的关键思想是在整个搜索过程中动态积累和利用来自节点的共享信息。 最初,共享信息有限,但随着搜索的进行,探索节点积累的信息变得越来越重要,为决策提供更大的支持。 这使得算法能够逐渐减少对随机模拟的依赖,利用积累的知识来指导搜索并提高效率(Leurent and Maillard,2020)。
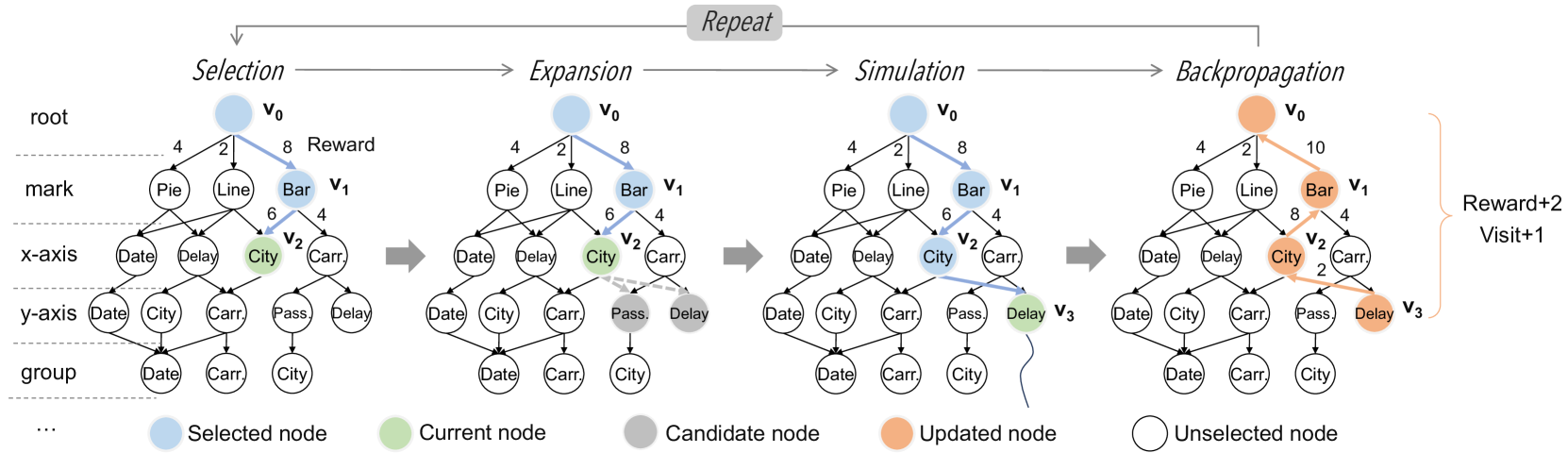
我们首先概述基于蒙特卡罗图搜索的可视化生成算法。 如算法1所示,该算法首先将数据集作为输入,旨在生成top-可视化结果。在初始阶段,算法根据数据集初始化根节点,作为图的起始节点(第1行)。
在每次迭代中,算法首先初始化可视化查询 (第 3 行),然后从根节点开始探索。 在节点选择阶段,每个选择都会添加到可视化查询(第7-8行),直到遇到未扩展的节点,然后扩展该节点(第12行)。 当可视化查询有效时,算法利用奖励函数计算查询的分数(第14行),然后执行反向传播以更新图上的信息(第 15 行)。 最后,查询被转换为相应的可视化结果并存储在中(第16-17行)。 选择 可视化后,算法返回此集合 。
选择。 在选择阶段(Algo.7 中的第 7 行) 1),算法从根节点开始,递归选择最优子节点,直到到达尚未完全展开的节点。 如图5所示,蓝色节点代表本阶段选中的节点,绿色节点代表当前选中的尚未完全展开的节点。 为了有效利用奖励函数提供的反馈信息并平衡探索和利用,我们采用了上置信界(UCB)算法。 该算法的关键思想是在每次迭代时选择具有最高置信上限的子节点。 UCB算法的具体选择策略可以用以下公式表示:
| (1) |
其中是子节点的平均奖励,是当前节点的访问次数,是访问次数对子节点 的访问次数, 是用于平衡探索和利用的常量。
扩展。 在扩展阶段(Algo.1 中的第 12 行) 1),算法根据当前状态选择下一个有效操作(即不完整的可视化查询)。 具体来说,它删除了那些语法不正确或违反可视化规则的低质量可视化(请参阅第 4.2 节)。 例如,在处理节点时(如图5),算法识别出两个高效益候选节点,并随机选择一个进行进一步扩展。
模拟。 在模拟阶段(Algo.1 中的第 13 行) 1),算法从当前节点(例如图5所示节点)开始进行仿真行动。 首先,它检查当前可视化查询是否有效。 如果查询无效,算法根据可视化语法规则随机探索下一个节点,直到构造出有效的查询。 一旦形成有效的查询,学习评分可视化部分就会分配奖励。
反向传播。 此阶段(Algo.1 中的第 15 行) 1)通过可视化查询图传播模拟结果。 如图5所示,在模拟阶段之后,节点获得的分数沿着其路径传播。 路径上的每个节点和边缘都会根据模拟结果更新其奖励值和访问计数。 我们的学习评分可视化模块评估可视化质量并更新搜索路径上的节点信息,通过将每次模拟的结果反馈到可视化查询图中,指导算法在后续探索中做出更精确的决策。
终端条件。 重复上述步骤,直到达到最大迭代次数。
MCGS 和 MCTS 的比较。 蒙特卡罗方法通过随机采样解决复杂问题,但需要对每个新节点进行模拟步骤,从而影响基于节点计数的性能(Robert等人,1999)。 传统的 MCTS 方法依赖于广泛、随机且耗时的模拟来确定下一步(石等人,2021)。 与传统的MCTS不同,我们的MCGS算法探索的是图结构而不是树结构,允许节点之间更有效地共享信息并减少节点数量,从而提高搜索效率(Tot等人,2022) 。
如图6所示,可视化查询和仅图表类型不同;其他条款相同。 在树形结构中(图6(b)),由于严格的父子层次结构,这些信息无法共享,从而导致冗余。 相比之下,图结构(图6(a))允许跨不同查询共享节点信息,减少冗余并提高搜索效率。
更具体地说,我们比较 MCGS 和 MCTS 之间的节点数量。 考虑 4 种图表类型、具有 列的数据集、同时考虑 和 轴的编码以及包括分组和 4 个聚合的数据转换运营。 在MCTS中,每条路径都是独立的,因此节点总数为。 在MCGS中,使用图结构来共享节点,总节点数为。 折减系数为。 随着 的增加,使用 MCGS 的好处变得更加显着,与 MCTS 相比,减少了节点数量。
综上所述,通过共享节点并通过图结构减少冗余计算,MCGS 显着减少了节点数量和模拟量,从而实现了更高效的搜索(Czech 等人, 2021; Shen 等人, 2018; Saffidine 等人, 2012 )。
4.2. 优化技术
基于规则的修剪。 在可视化生成过程中,节点的选择和扩展至关重要。 然而,传统的UCB算法由于缺乏可视化相关知识,可能会导致节点选择不当。 为了缓解这些问题,我们引入了基于规则的修剪算法。
该算法的关键在于集成领域知识,例如数据转换规则和可视化规则,以确保生成的可视化在语法上正确。 例如,完成GROUP BY操作后,如果需要为轴选择聚合函数,并且轴字段为分类,则 SUM、AVG 和 NONE 等函数将变得不适用。 我们的算法旨在排除这些不适当的选项,以提高搜索的效率和准确性。
此外,我们提出了一个函数,它以当前状态和候选操作集作为输入,并输出一组满足特定约束的操作,基于特定于可视化领域的知识将修剪过程形式化。
自适应随机探索策略。 在可视化生成过程中,每个选定的可视化操作(例如图表类型)都会显着影响最终的可视化。 尽管 UCB 算法旨在根据当前状态做出最佳选择,但随着模拟次数的积累,它可能会倾向于过度探索高分分支,而忽略其他可能性。 此外,UCB 算法可能倾向于次优或低效的可视化操作,特别是当奖励函数不准确地评估初始尝试时(Silver 等人,2017;Czech 等人,2021)。
为了解决这些问题,我们提出了一种自适应随机探索策略。 该策略根据已选择的子句数量调整随机选择概率,促进从利用到探索的转变。 这种方法增加了搜索空间的覆盖范围和多样性,同时避免了局部最优。 它反映了构建可视化查询时的用户行为,在初始阶段进行广泛探索,在后期根据早期尝试进行更有针对性的选择。
选择策略的优化公式如下:
| (2) |
在我们提出的决策策略中,每个节点的最终选择是基于一系列参数和函数。 节点可用的法律条款集由表示。 每个子句的平均奖励由估计,而跟踪子句被访问的次数。 当前节点的总访问次数用表示,常量用于平衡过程中的探索。
此外,策略中探索和利用之间的平衡由两个主要概率参数控制:和。 探索概率 定义为 ,其中 是做出随机选择的初始概率, 是小于 1 的常数,控制随机选择概率的衰减率。 另一方面,利用概率定义为。 随着节点中选择的子句数量的增加,随机选择的概率逐渐减小,而基于UCB算法的选择概率相应增加。
5. 学习评价可视化
与 Atari (Schrittwieser 等人, 2020) 或 Go (Silver 等人, 2016) 等游戏的轻松模拟环境不同,这些游戏存在明确的奖励和惩罚规则,但缺乏可视化评估如此清晰,如果基于单一标准,可能会产生偏差。
为了解决这个问题,我们提出了一种综合奖励函数,该函数结合了可视化最佳实践、数据特征和用户偏好来综合评估可视化质量。
5.1. 复合奖励函数
复合奖励函数结合了可视化的经验法则、数据特征和用户偏好来评估可视化结果的质量。 复合奖励函数(CRF)的公式如下:
| (3) |
其中,表示可视化领域知识的评估结果,表示基于数据特征的评分,表示用户偏好评分。 在评估可视化结果时,我们首先基于可视化领域知识进行基础知识评估。 如果结果与领域知识相符,则为 赋值 1;否则为0。 显然,当(即可视化结果与领域知识不相符)时,奖励值变为0。 反之,当时,的计算取决于和的加权组合,其中权重系数是为了平衡数据特征评分和用户偏好评分之间的重要性,根据经验设置。
5.2. 学习复合奖励函数
我们利用成熟的、人工注释的可视化语料库(Hu等人,2019;Qian等人,2022)和来自可视化社区的领域知识来学习复合奖励函数。
利用领域知识。 我们采用基于规则的方法来确保生成的可视化符合最佳实践并准确反映数据特征。 具体来说,该方法利用了 DeepEye (Luo 等人,2018a)使用的数据选择、转换和可视化规则。
例如,饼图的规则包括: (1)数据选择规则:轴应代表分类数据,而轴应代表数值数据。 (2) 数据转换规则:饼图不适合使用AVG操作聚合的数据,因为饼图主要用于显示比例。 (3) 可视化规则:轴值不应包含负值,并且应至少有两个不同的轴值来传达有意义的信息。 使用这种方法,我们为不同类型的可视化设计了 15 条规则,并使用这些规则作为严格约束来过滤掉低质量可视化。
捕获数据特征。 我们的模型在由真实用户注释的数据集(Luo等人,2018a)上进行训练,其中包含来自42个不同领域的285,236个可视化及其分数。 对于每个可视化,我们分析关键特征,包括 和 轴的数据类型、行数、极值(最大值和最小值)、值多样性(不同值的数量和唯一值的比例),以及-和-轴的数据与图表类型之间的相关性。 我们为模型训练提取了 14 个核心特征。
我们使用 LambdaMART (Wu 等人, 2008) 来训练我们的评分模型,该模型通过构建决策树来映射特征和分数之间的复杂关系。 每棵树都会评估特征,例如 轴上的数据类型,然后检查其他特征,最后输出分数。 这种方法使模型能够理解特征组合和分数之间的深层联系。 当输入新的可视化时,模型会计算其特征并使用经过训练的 LambdaMART 来预测分数。
学习常见的用户偏好。 捕获用户对可视化的偏好对于可视化推荐系统至关重要。 虽然在线推荐中考虑个人偏好是理想的选择,但这由于冷启动问题而带来了挑战——新用户通常缺乏足够的交互历史记录,尤其是在可视化场景中。 此外,为每个用户在线收集实时交互数据和微调模型可能会占用大量资源且耗时。
为了应对这些挑战,我们的目标是首先离线了解常见的用户偏好,然后根据可视化提示的反馈对 MCGS 算法进行在线调整,我们将在第 6 这种方法在推荐高质量可视化和微调推荐以更好地适合个人用户之间取得了平衡。
为了实现这一目标,我们的系统利用生成对抗网络(GAN)(Goodfellow 等人,2020),特别是 IRecGAN (Bai 等人,2019),来学习常见的使用真实世界可视化语料库的用户偏好。 该语料库包含从 Plotly 社区收集的用户交互日志(Qian 等人,2022)。 该数据集包含 17,469 个用户的历史交互记录,平均每个用户有 5.41 个数据集和 1.85 个可视化,每个数据集平均包含 24.39 个属性。 为了跨数据集和可视化有效学习用户偏好,我们从原始数据集中提取了 606 个可视化配置,灵感来自于(Qian 等人,2022)。 每个配置都包括与数据集无关的设计选择,例如图表类型、颜色和大小,使模型能够在没有直接数据集关联的情况下学习偏好,并从设计选择中识别模式。 通过聚合不同数据集的数据、用户和可视化训练特征,我们生成了 15,531 个样本来训练 IRecGAN 模型(Bai 等人,2019)。
在第一轮可视化推荐中,从经过训练的IRecGAN模型获得的评估是一般用户偏好的关键指标。 在交互阶段(例如第二轮),HAIChart根据用户选择的可视化提示细化和优化推荐策略,详见第6。
6. 可视化提示选择
虽然基于 MCGS 的可视化生成算法可以推荐高质量的可视化,但它可能并不总是符合个人偏好。 相反,像 Voyager2 (Wongsuphasawat 等人,2017) 这样的交互式工具提供了灵活的探索选项,但其复杂性可能会让用户不知所措。 这些工具要求用户筛选密集的控制面板和众多的可视化选项,就像解决具有挑战性的“填空”难题一样。
为了解决这些问题,我们引入了可视化提示模块。 可视化提示代表我们的系统导出的高级可视化意图,如图7所示。 该模块将可视化创建的复杂决策过程简化为简单、用户友好的选择,类似于“多项选择题”。 该方法收集用户意图,使我们的 MCGS 算法能够在线微调,以更好地适应个人用户。
定义 6.1(可视化提示)。
可视化提示对应于可视化操作或动作,例如选择数据字段、应用聚合操作以及选择图表类型。 它以易于理解的自然语言表达。 每个提示 都与一组可视化 相关联,这些可视化根据复合奖励函数的值进行排名,以对高价值可视化进行优先级排序。
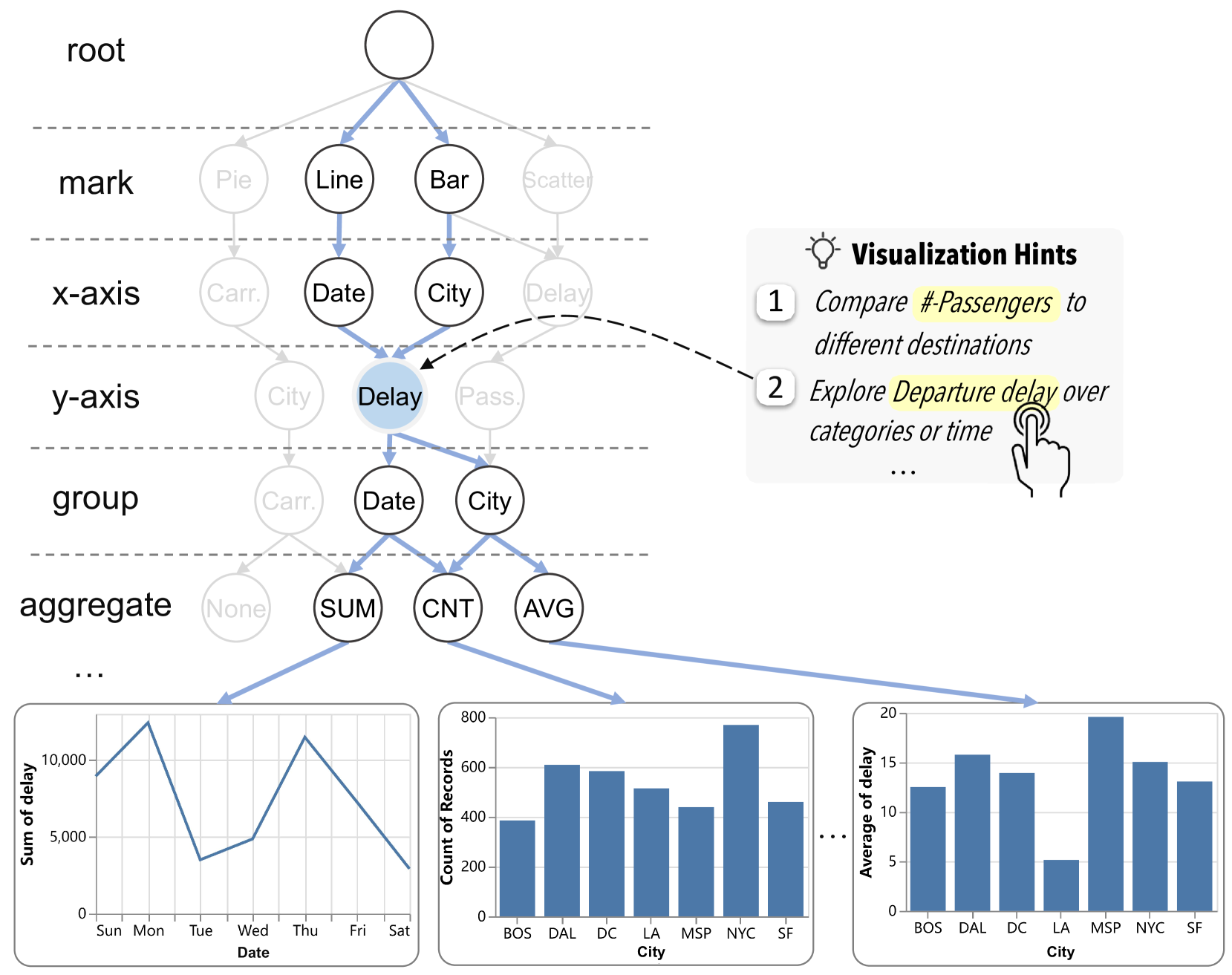
如图7所示,考虑基于数据字段的提示:“探索数据字段名称 overcategoriesortime”,这个提示本质上定义了与数据字段相关的部分可视化查询。 因此,用户可以浏览这些提示并选择所需的提示进行可视化。 接下来,HAIChart 将通过 MCGS 流程根据所选提示生成一组相关可视化效果。 这种方法不仅简化了用户定义可视化查询的步骤,而且还通过有意义的提示引导用户快速探索和理解数据,从而加快了获取数据洞察的过程。
我们的目标是选择 top- 可视化提示,不仅涵盖不同方面,而且确保高质量的可视化,同时保持适当数量的可视化。
定义 6.2(顶部-可视化提示选择)。
给定一组提示 ,其中每个提示 与一组可视化 关联,并且每个可视化 都有一个关联奖励值,目标是选择由提示组成的子集。 选择必须最大化子集的总奖励值,同时确保中的可视化总数不超过预定义的预算。 优化问题可以表述如下:
| (4) |
| (5) |
其中表示与提示关联的可视化数量,是所选子集的总奖励值, 是所选提示的数量, 是可视化数量的预算上限。
然而,选择提示的问题是NP困难的,因为它相当于一个已知的NP困难问题——预算最大覆盖问题(Khuller等人,1999)。 为了解决这个问题,我们提出了一种有效的算法来选择 top- 可视化提示。 为了实现有效的提示选择,第一步是构建一套全面的提示并评估每个提示的好处。 这个初始阶段的目的是确保在后续的选择过程中,能够从这个评估集中选出最好的提示,从而最大化奖励值。 这样,算法主要包括两个步骤:候选提示生成和top-提示选择。
候选可视化提示生成。 我们从可视化查询图中识别高价值节点(即可视化操作)来选择候选提示。 在计算每个提示的奖励时,考虑到相同的可视化出现在不同的提示中可能会降低其独特性,我们引入了衰减系数来调整每个可视化的评分权重。 衰减系数定义为:,其中是提示总数,是提示数量包含特定的可视化。 该系数反映了可视化的频率,可视化越频繁,衰减系数越高,从而降低了总体得分。 将该分数乘以可视化的奖励值后,就确定了其最终值。 因此,在收集所有提示后,我们计算每个可视化出现的频率,并将其与衰减系数相结合来计算其分数。
顶部-可视化提示选择。 我们的目标是选择最佳的提示子集,在预定义的预算内最大化总奖励。算法2显示了伪代码。 它首先选择成本不超过预算的所有提示,形成候选提示集(第2行)。 然后,它根据复合奖励函数计算出的相应平均可视化分数对有效提示进行排序(第 3 行)。 算法继续遍历这个排序集,挑选提示添加到最终选择集中,直到满足两个条件之一:所选提示的数量达到预定义的 ,或者添加更多提示导致总成本超出预算(第5-10行)。 这样,算法在保持预算约束的同时优先考虑高分提示,从而在给定预算下最大化总奖励值。
用户反馈进行细化。 HAIChart 利用用户选择的可视化提示来指导 MCGS 过程中的节点探索策略。 当用户选择特定提示时,他们会引导搜索图向某个方向扩展。 例如,如图7所示,如果用户点击提示“探索延迟类别或时间”,系统将重点关注将数据字段“delay”应用于轴。 在搜索过程中,系统会冻结其他节点,只搜索与“delay”相关的节点,确保生成的结果与目标字段相关。 因此,该方法可以使搜索过程与用户偏好保持一致,并有效地修剪搜索空间,从而提高基于MCGS的可视化推荐的效率和准确性。
7. 实验
| Datasets | #-Tables | #-Vis. | Avg(#-Vis.) | Avg(#-Rows) | Avg(#-Col.) | Max(#-Col.) |
|---|---|---|---|---|---|---|
| VizML | 79,475 | 162,905 | 2 | 2,817.8 | 3.3 | 25 |
| KaggleBench | 8 | 252 | 31.5 | 32,585.9 | 9.1 | 15 |
| Datasets | #-Rows | #-Columns | #-Vis. | |
|---|---|---|---|---|
| D1 | StudentPerformance | 1,000 | 8 | 34 |
| D2 | AirplaneCrashes | 5,191 | 6 | 22 |
| D3 | VideoGame | 6,825 | 15 | 48 |
| D4 | GooglePlayStore | 9,659 | 11 | 33 |
| D5 | AvocadosPrice | 18,249 | 7 | 20 |
| D6 | SuicideRates | 27,820 | 9 | 25 |
| D7 | Zomato | 51,717 | 11 | 49 |
| D8 | GunViolence | 140,226 | 6 | 21 |
7.1. 实验设置
数据集。 表2显示了两个用于实验的真实数据集。
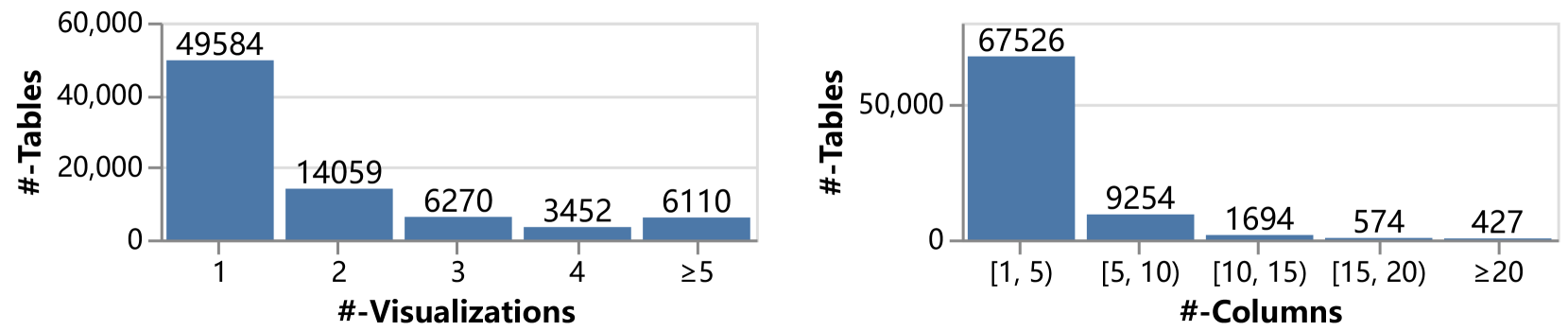
(1) VizML (Hu 等人, 2019),源自 Plotly 社区,拥有由真实用户创建的约 120,000 个数据集可视化对。 通过删除缺少表格或图表数据的条目并清理无效字符来完善该数据集。 该数据集有四种类型的图表,即条形图、饼图、折线图和散点图可视化,最终形成 79,475 个有效的数据集可视化对。 这些数据按 7:1:2 的比例随机分为训练集、验证集和测试集,分配 55,632 对用于训练,7,947 对用于验证,15,896 对用于测试。 数据集的统计信息如图8所示,覆盖范围广泛,包括不同领域和任务的用户使用的各种表格和可视化。
(2) KaggleBench (Gao 等人, 2021)是一个公共基准,旨在评估可视化推荐的有效性。 其数据主要来自众多数据竞赛以及Kaggle平台提供的相应可视化效果。 通过过滤掉低质量数据集、删除缺失数据的行以及修复无效字符,对该数据集进行了细化。 最终,我们获得了8个用于评估的数据集,如表3所示。
我们仅使用 VizML 数据集来训练或配置所有方法。 我们使用上述两个数据集来测试不同的方法。
| D | Tasks | Metrics | The State-of-the-Art Methods | Our Methods | |||||||
| Data2Vis (Dibia and Demiralp, 2019) | VizGRank (Gao et al., 2021) | DeepEye (Luo et al., 2018a) | PVisRec (Qian et al., 2022) | VizML (Hu et al., 2019) | LLM4Vis (Wang et al., 2023) | MCTS | HAIChart- | HAIChart | |||
| VizML | Data Queries | Hit@1 | 47.5% | 57.6% | 52.4% | 52.3% | - | - | 78.3% | 79.7% | 79.3% |
| Hit@3 | 51.3% | 67.2% | 67.6% | 58.7% | - | - | 88.2% | 91.3% | 91.9% | ||
| Design Choices | Hit@1 | 41.7% | 34.9% | 34.1% | 28.9% | 28.7% | 47.9% | 42.4% | 50.6% | 48.7% | |
| Hit@3 | 43.7% | 42.9% | 40.7% | 51.3% | - | - | 77.1% | 81.8% | 81.5% | ||
| Overall | Hit@1 | 24.3% | 25.6% | 25.7% | 21.8% | - | - | 33.1% | 37.9% | 36.9% | |
| Hit@3 | 26.9% | 30.1% | 33.9% | 42.3% | - | - | 64.7% | 68.4% | 67.4% | ||
| KaggleBench | Data Queries | P@10 | 41.2% | 58.7% | 62.5% | 42.5% | - | - | 52.2% | 60.0% | 63.8% |
| R10@30 | 25.0% | 50.0% | 48.7% | 67.5% | - | - | 73.6% | 80.1% | 83.7% | ||
| Design Choices | P@10 | 88.7% | 87.5% | 93.7% | 91.9% | Hit@2:78.3% | Hit@2:87.6% | 93.8% | 96.3% | 96.3% | |
| R10@30 | 95.0% | 81.3% | 95.0% | 85.0% | - | - | 92.5% | 96.2% | 96.2% | ||
| Overall | P@10 | 28.7% | 43.7% | 48.7% | 36.7% | - | - | 45.4% | 51.3% | 55.0% | |
| R10@30 | 13.8% | 41.3% | 33.7% | 60.0% | - | - | 63.8% | 72.5% | 74.9% | ||
方法。 我们评估以下方法。
(一)人工智能驱动的可视化方法:
(1) Data2Vis (Dibia 和 Demiralp,2019) 使用序列到序列模型将数据集转换为可视化查询。
(2)VizGRank(高等人,2021)通过将可视化之间的关系建模为图,并使用基于图的排序算法来实现可视化推荐。
(3)DeepEye(罗等人,2018a)将数据特征与领域知识相结合,推荐top-好的可视化效果。
(4) PVisRec (Qian 等人, 2022) 通过学习用户偏好来推荐一组可视化。
(5) VizML (Hu 等人, 2019)使用深度学习模型进行可视化推荐。 它专注于五种特定类型的任务,不包括数据查询。 我们的评估将评估 VizML 在推荐设计选择方面的有效性。
(6) LLM4Vis (Wang 等人, 2023) 使用上下文学习与 ChatGPT 交互来推荐可视化。 与 VizML 一样,它不包括数据查询任务。 因此,我们的比较重点是设计选择,使用与 LLM4Vis 相同的 Hit@ 指标进行评估。
(二)人力可视化方法:
(7) Voyager2 (Wongsuphasawat 等人, 2017) 是一个交互式系统,允许用户通过基于点击的交互来创建和探索可视化。
(III) 人类和人工智能配对可视化方法:
(8) HAIChart(我们的)是基于 MCGS 和复合奖励函数的完整实现,如本文所述。
(9) HAIChart-(我们的)在复合奖励函数中与 HAIChart 不同,其中捕获数据特征模型是在 VizML 语料库上训练的。
(10) LLM4Vis+(我们的)是LLM4Vis (Wang等人,2023)的改进版本。 我们增强了 LLM4Vis 以支持数据查询和 top- 可视化。
(11) 基于 MCTS 的基线(我们的)遵循与 HAIChart 相同的实现,只是它使用基于 MCTS 的方法来推荐可视化。
指标。 根据之前评估自动可视化系统的研究(Zhou 等人,2021;Dibia 和 Demiralp,2019;Hu 等人,2019;Luo 等人,2023),我们采用 Hit@、P@ 和 Rt@ 作为评估指标。 鉴于创建可视化涉及数据查询、设计选择和最终集成,我们的评估分为三个任务。 指标定义如下:
(1) Hit@: 该指标评估基本事实是否出现在前结果中。 我们将其应用于 VizML 数据集,并将 设置为 3,因为每个用户通常平均创建大约 2 个可视化。
(2) P@: 该指标衡量顶部结果中有多少真实值。 对于 KaggleBench 数据集,考虑到每个数据集通常包含超过 20 个可视化,我们将 设置为 10。
(3) R@: 该指标评估顶部覆盖了多少顶部-地面事实- 结果。 我们对 KaggleBench 数据集使用 R10@30,分析模型返回的前 30 个结果中包含前 10 个基本事实中的多少个。
实验环境。 实验在配备双 Intel Xeon 8383C CPU、512GB RAM 和 8 个 NVIDIA RTX 4090 GPU 的 Ubuntu 22.04 Server LTS 上进行。
7.2. 实验结果
7.2.1. Exp-1:第一轮建议的有效性。
本实验评估HAIChart第一轮可视化推荐的有效性。 我们在 VizML 和 KaggleBench 数据集上测试了所有方法。 对于 VizML,每个数据集平均有 2.05 个可视化,我们使用了 Hit@ 指标。 对于 KaggleBench,每个数据集平均有 31.5 个可视化,我们使用 P@ 和 Rt@ 指标。
表4显示了结果,我们有以下发现。
(1) 总体而言,我们的方法(HAIChart 和 HAIChart-)在所有指标上均显着优于所有最先进的方法,显示了我们框架的有效性。 HAIChart- 和 HAIChart 之间的性能差距主要是由于捕获数据特征模块造成的:HAIChart- 在 VizML 训练集上进行训练,而HAIChart 在更加多样化的语料库上进行训练(罗等人,2018a)。
(2)在VizML数据集上,HAIChart在整个任务上实现了36.9%的Hit@1和67.4%的Hit@3,分别超过了竞争方法DeepEye和PVisRec 11.2%和25.1%。 在 KaggleBench 数据集上,HAIChart 在整个任务上实现了 55% P@10 和 74.9% R10@30,比 DeepEye 和 PVisRec 分别高出 6.3% 和 14.9%。 这些结果证明了 HAIChart 在利用 MCGS 算法和复合奖励函数在大型搜索空间中查找高质量可视化方面的有效性。
(3) DeepEye 使用基于规则的方法在 P@10 指标上表现良好,而 PVisRec 在具有个性化推荐的 Rt@30 指标上表现出色。 通过融合可视化规则、用户偏好和数据特征,HAIChart 在 P@10 和 Rt@30 指标上均取得了优异的成绩。
| Tasks | Metrics | DeepEye | Voyager2 | LLM4Vis+ (ours) | HAIChart (ours) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Iter. 1 | Iter. 1 | Iter. 2 | Iter. 3 | Iter. 1 | Iter. 2 | Iter. 3 | Iter. 1 | Iter. 2 | Iter. 3 | ||
| Data Queries | P@10 | 62.5% | 45.0% | 55.1% | 58.0% | 47.2% | 65.0% | 74.3% | 63.8% | 69.5% | 79.2% |
| Design Choices | P@10 | 93.7% | 78.7% | 96.3% | 97.4% | 75.6% | 91.5% | 97.2% | 96.3% | 97.6% | 99.3% |
| Overall | P@10 | 48.7% | 40.0% | 44.9% | 45.7% | 41.0% | 55.6% | 65.3% | 55.0% | 58.2% | 68.8% |
| Dataset | Metrics | Round 1 | Round 2 | Round 3 |
|---|---|---|---|---|
| KaggleBench | Hit@1 | 64.7% | 65.2% | 69.1% |
| Hit@3 | 79.4% | 82.2% | 85.7% | |
| Hit@5 | 88.2% | 89.6% | 92.1% |
7.2.2. Exp-2:多轮建议的有效性。
本实验的目标是:(1)验证HAIChart在多轮用户交互后是否增强了其可视化推荐的有效性,以及(2)验证可视化提示是否有效地帮助用户并提高了他们的体验数据探索的效率。 为此,我们设计了一项有 17 名参与者的用户研究,将 HAIChart 与最先进的方法进行比较:DeepEye (Luo 等人, 2018a)、Voyager2 (Wongsuphasawat 等人, 2017),以及 LLM4Vis+。
参与者。 我们邀请了 17 名参与者(7 名女性,10 名男性,年龄 21-33 岁)参与我们的研究,其中包括 12 名专家和 5 名非专家。 专家中包括6名博士。计算机科学专业的候选人、4名硕士生和2名本科生,都具有不同程度的数据分析经验。 大多数专家至少使用一种数据可视化工具(例如Tableau)超过一年。 非专家来自非技术背景,具有基本的数据处理经验,主要使用 Excel 完成简单任务。
任务。 我们的研究让参与者使用 HAIChart、DeepEye、LLM4Vis+ 和 Voyager2 来处理 8 个 KaggleBench 数据集(表 3)。 每个数据集都包含特定的分析任务,例如检查学生学科分数并将表现与 StudentsPerformance 数据集中的背景因素相关联。 此外,参与者还进行了开放式探索,以评估这些工具在非结构化任务中的适应性和效率。
过程。 (1)准备:首先,我们向参与者介绍了研究的背景和数据集。 我们还通过示例向他们展示了如何使用HAIChart、DeepEye、LLM4Vis+和Voyager2,让他们有时间进行探索。 此步骤确保他们在开始实验之前熟悉两个系统的功能、数据集和任务。 (2) 实验:在实验过程中,鼓励参与者在使用系统时分享他们的想法和问题。 我们记录了他们的交互、跟踪所花费的时间、交互计数、选定的提示或字段以及每次会话期间生成的可视化效果。 每轮交互结束后,HAIChart 都会提供新的可视化建议以及顶部 提示,以引导用户进行下一步探索。 (3) 用户反馈:实验结束后,参与者根据易学性、易用性、结果质量、探索帮助性等方面对HAIChart、LLM4Vis+和Voyager2进行了评估和响应速度。 选择这些标准是为了从多个角度评估用户体验和系统性能(Li等人,2024),并采用李克特五点量表进行评级(Allen和Seaman,2007) t1>从1(强烈不同意)到5(强烈同意)。 我们还进行了访谈来收集参与者的反馈,鼓励对所使用工具的任何方面发表评论,并记录这些评论以供分析。
用户研究结果。 我们进行定量和定性分析。
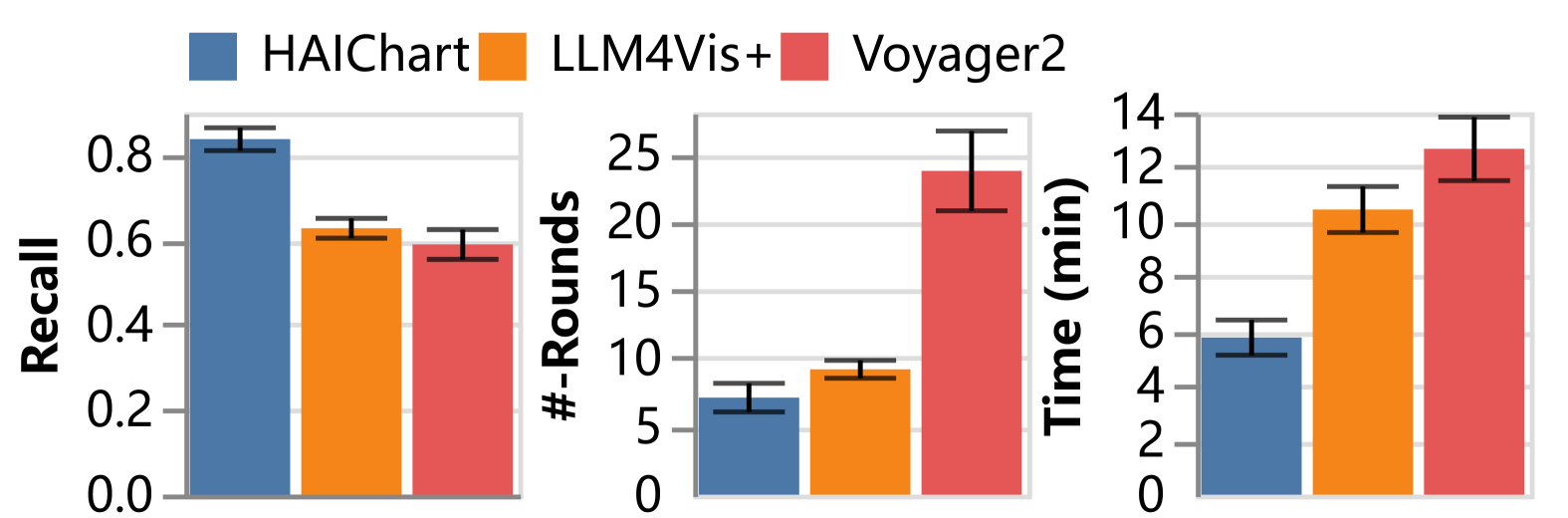
(1)如表5所示,HAIChart通过用户反馈改进了可视化推荐。 经过两轮交互后,P@10从55%增加到68.8%,分别优于LLM4Vis+和Voyager2 3.5%和23.1%。 与 Voyager2 的手动探索不同,HAIChart 的可视化提示可以有效地引导用户。 LLM4Vis+ 需要耗时的自然语言查询和领域知识。 DeepEye 在第一轮中取得了 48.7% 的成绩,缺乏多轮推荐支持,并且没有通过额外的交互来提高。
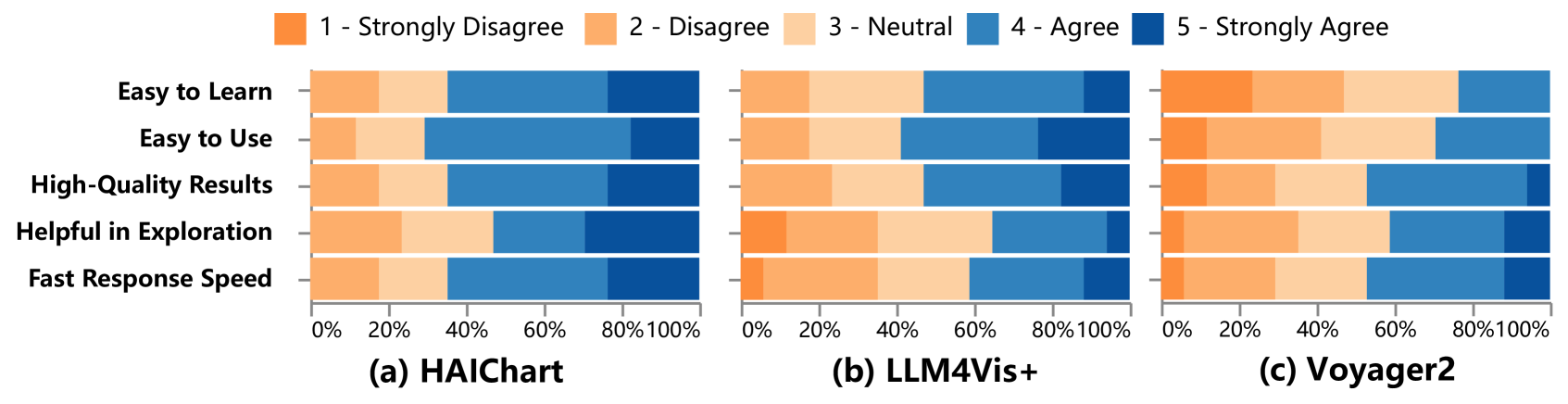
(2)此外,如图10所示,HAIChart在交互次数和时间方面优于LLM4Vis+和Voyager2,分别快了1.8倍和2.2倍。 平均召回率为83.7%,比LLM4Vis+和Voyager2分别高出21%和24.8%。 这说明HAIChart以较低的交互成本满足了用户的分析需求。 最后,用户反馈(图10)表明HAIChart易于学习和使用,帮助用户更有效地探索并获得高质量的可视化结果。
(3) 与参与者的对话为HAIChart在数据探索方面的实用性提供了富有洞察力的反馈。 参与者广泛认可HAIChart通过提供有用的提示简化了数据探索任务并提高了效率。 例如,参与者 P1 指出:“Voyager2 缺乏对初学者的友好性,使得选择用于分析的数据字段变得复杂。 相比之下,HAIChart通过可视化提示简化了探索,使数据字段和操作的决策变得更加容易”。此外,学员P5还指出了LLM4Vis+的一个局限性:“自然语言交互简化了初始可视化的创建,但微调具有挑战性。 大语言模型经常误解我的意图,需要反复调整却达不到预期的效果。 提示或控制面板更加直观和方便。” 这表明自然语言歧义可能会导致数据探索过程中与大语言模型的“通信”问题。 直观的控制面板或提示等探索指导将增强用户体验。
尽管如此,用户反馈也揭示了HAIChart的局限性。 例如,参与者P10建议,“HAIChart的提示点击交互适合初学者,但添加自定义字段选择的控制面板会增加灵活性。”此外,与会者P15指出,“HAI图表 仅支持常见图表类型。 未来的版本应该包括更复杂的类型,例如地图和桑基图,以满足广泛的分析需求”。
7.2.3. Exp-3:可视化的有效性提示选择。
本实验通过多轮推荐实验 (Exp-2) 分析 17 位用户关于 HAIChart 的交互日志,以验证使用 Hit@ 指标进行提示选择的有效性。
表6的结果显示,第一轮推荐的Hit@1为64.7%,证明了系统能够准确预测用户最感兴趣的提示。 随着交互轮数的增加,推荐准确率进一步提高。 到了第三轮,Hit@3值增加到85.7%。 这些结果证明了系统在优先考虑用户所需信息方面的有效性以及提示选择在指导用户决策过程中的有效性。
7.2.4. Exp-4:MCGS 优化技术的消融研究
我们提出了几种 MCGS 优化技术,包括基于规则的剪枝和自适应随机探索策略。 我们使用 VizML 和 KaggleBench 数据集进行消融研究,以评估它们对整体性能的影响。
表 7 中的结果表明,从任一数据集中删除任何优化技术都会导致性能下降,这证实了它们的重要性。 具体来说,在 VizML 数据集中,删除自适应随机探索策略会将 Hit@1 到 Hit@3 的改进从 30.5% 降低到 8.7%,这表明该策略增强了结果多样性并避免了局部最优,从而提高了性能。
7.2.5. Exp-5:复合奖励函数的消融研究
我们的复合奖励函数由三个部分组成:数据特征、可视化领域知识和用户偏好。 我们使用 VizML 和 KaggleBench 数据集进行消融研究,以评估它们对整体性能的影响。
表 7 显示了以下观察结果。
总体而言,删除任何组件都会降低 HAIChart 的性能。 当删除领域知识或用户偏好时,性能下降更为显着,这表明这些方面对于使可视化与用户需求保持一致至关重要。 综上所述,将数据特征、可视化知识和用户偏好集成到复合奖励函数中可以增强可视化推荐的有效性。
| Methods | VizML | KaggleBench | |||
|---|---|---|---|---|---|
| Hit@1 | Hit@3 | P@10 | R10@30 | ||
| HAIChart | 36.9% | 67.4% | 55.0% | 74.9% | |
| Opt. Tech. | w/o Rule-based Pruning | 34.6% | 65.3% | 37.4% | 40.0% |
| w/o Adapt. Random Exploration | 33.4% | 42.1% | 45.7% | 65.0% | |
| Composite Reward Func. | w/o Domain Knowl. | 26.3% | 60.2% | 31.0% | 33.8% |
| w/o User Preferences | 30.8% | 64.2% | 40.7% | 54.9% | |
| w/o Data Features | 34.2% | 64.1% | 36.0% | 68.7% | |
7.2.6. Exp-6:参数的敏感性分析
我们对HAIChart的关键参数进行了实验分析:(1)对于MCGS,我们评估了迭代次数和平衡参数 通常, 设置为 (Gray 等人, 2023)。 因此,在本实验中,我们将 从 0.5 更改为 2.5,将 从 25 次迭代更改为 125 次迭代。 (2) 对于 top- 可视化提示选择,我们评估了不同 值(范围从 3 到 15)和预算 (范围从10 到 50)关于选择提示。 我们还测试了仅显示每个提示的前 可视化结果(其中 范围从 1 到 10)如何影响整体性能。
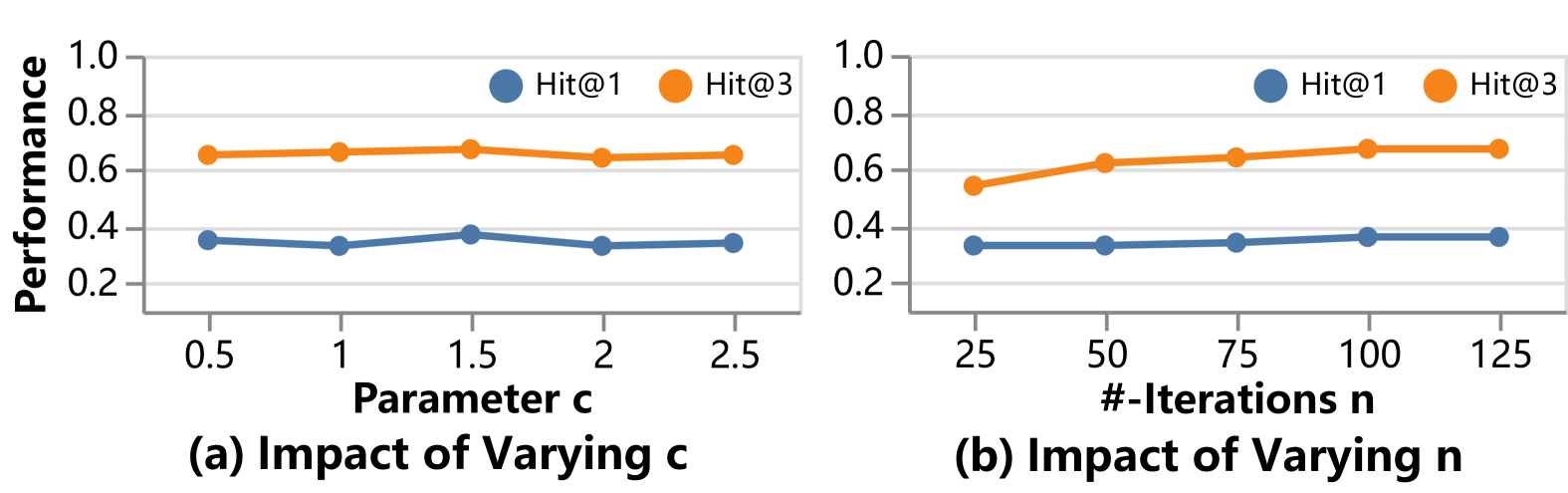
(1)平衡参数的不同取值会影响推荐的质量,但总体而言,HAIChart表现良好且稳定。 我们发现 的值为 1.5 可在探索和利用之间实现良好的平衡,从而获得更好的结果。
(2) 增加迭代次数通常可以通过探索更多高价值可视化来提高性能。 然而,将迭代次数从 100 次增加到 125 次在延长搜索时间的同时显示出最小的改进。 因此,设置合适的迭代次数可以平衡准确性和效率。
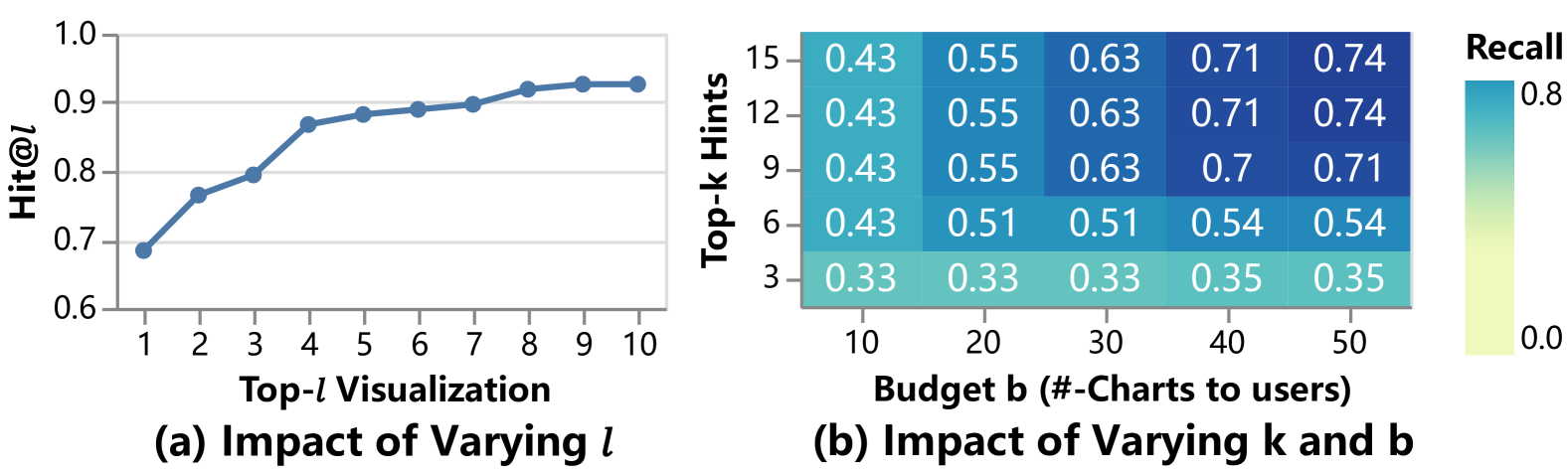
(3) 图12(a)显示,当每个提示显示top-可视化时,增加可以提高命中率,体现了我们的可视化排名。 较低的 (例如 1)在捕获用户兴趣方面表现不佳。 当为8以上时,命中率稳定在90%以上,没有进一步明显的提升。 因此,应在适当的范围内选择,以满足用户的需求。
(4) 对于top-可视化提示选择,图12(b)显示增加和值可以改善推荐质量。 然而,当达到9并且达到40时,性能提升速度减慢。 这表明选择合适的和值可以平衡成本和效果。
7.2.7. Exp-7:HAIChart 的效率。
我们使用 KaggleBench 数据集比较了 HAIChart 和现有方法的效率,该数据集包括八个不同大小的表(D1 到 D8)。
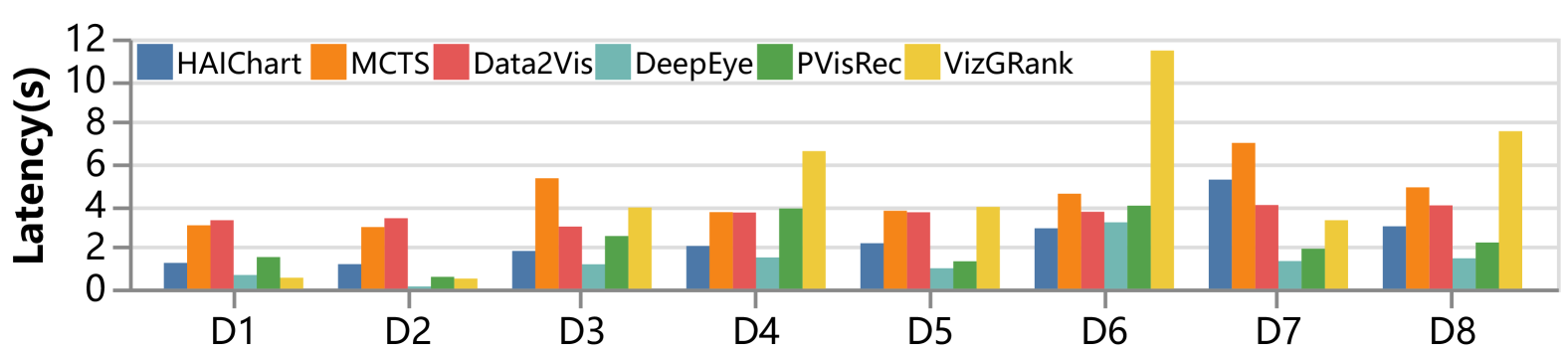
图13显示了具有以下观察结果的结果:
(1)HAIChart可视化生成时间为1~5秒,平均2.4秒,提示生成仅需1~3毫秒,验证了其快速可视化探索的能力。
(2) HAIChart 平均比 MCTS 快 1.8 倍,特别是对于多列数据集。 例如,在 D3 数据集(15 列)中,HAIChart 的基于图的结构比 MCTS 的基于树的结构性能高出 2.9 倍。
总体而言,HAIChart 对于数据可视化来说足够高效。
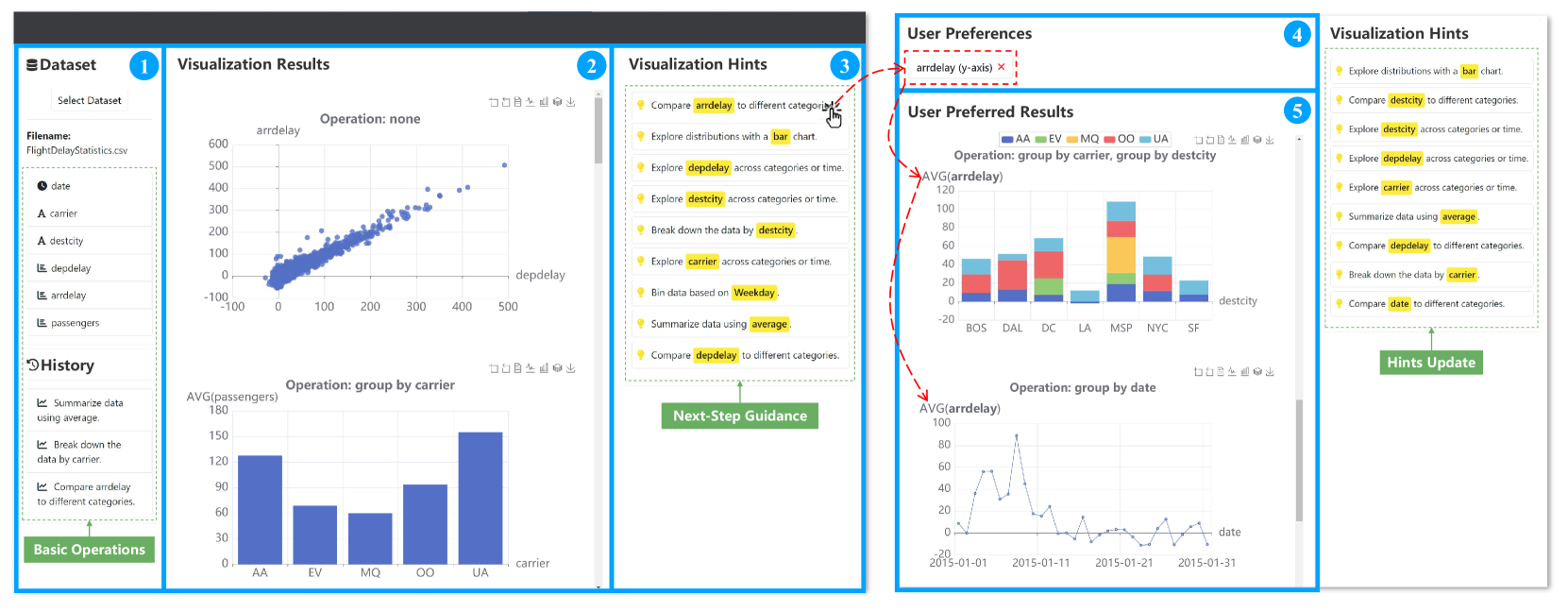
7.3. 系统演示
我们实现了HAIChart,这是一个基于网络的界面,旨在促进可视化探索,如图14所示。 在此界面中,我们演示了两个主要场景:(1)首轮可视化推荐,以及(2)基于提示的多轮可视化推荐。
数据集。 我们利用航班延误统计数据集,其中包含日期、航空公司、目的地城市(destcity)、出发延误(depdelay)等记录,到达延迟 (arrdelay) 和乘客数量。 该数据集使我们能够分析导致航班延误的各种因素。
第一轮可视化建议。 最初,用户上传他们的数据集。 然后,HAIChart 显示表格的数据字段,允许用户通过单击感兴趣的字段来进一步探索。 HAIChart还记录用户的历史操作,方便检索之前的分析,如图14-❶所示。
上传数据集后,HAIChart采用由复合奖励函数引导的蒙特卡罗图搜索算法,自动推荐一系列高质量的可视化效果。 如图14-❷所示,初始建议包括一个散点图,揭示了航班到达延误(arrdelay)和出发延误(depdelay)之间的关系>),以及显示承运商和乘客之间关系的条形图。 这些可视化帮助用户快速掌握数据集中的关键信息,为导致航班延误的各种因素提供直观的分析视角。
为了增强用户体验,HAIChart支持可视化的交互操作,例如缩放、切换图表类型、查看底层数据(图14-❷)。 这些功能丰富了可视化编辑体验,并支持对数据进行彻底的探索和分析,揭示潜在的见解。
基于提示的多轮可视化推荐。 现有的交互式可视化工具,例如 Voyager2 (Wongsuphasawat 等人,2017),需要用户通过复杂的控制面板迭代地完善可视化。 相比之下,HAIChart 通过可视化提示简化了数据探索。 该功能推荐提示,使用户能够绕过繁琐的决策,通过多选的形式探索数据,降低数据探索的障碍。
8. 相关工作
人力可视化工具,例如 Tableau、Voyager 和 Polaris (tab, 2024; exc, 2024; Wongsuphasawat 等人, 2015; Stolte 等人, 2008; Wu 等人, 2017; Satyanarayan 和 Heer,2014) 允许用户选择或调整数据源、图表类型和数据转换操作以实现数据可视化。 例如,Tableau (tab, 2024) 提供了一个无代码界面,用于通过单击并拖动操作创建可视化效果。 然而,这些工具高度依赖于用户技能,带来了诸如陡峭的学习曲线等挑战。
人工智能驱动的可视化。 人工智能驱动的自动可视化(罗等人,2018a;胡等人,2019;李等人,2021;周等人,2021;高等人,2021;钱等人,2022;罗等人,2022a ,2018b,2020a;Qin等人,2018;Chai等人,2023)使用算法自动生成和推荐有意义的数据集可视化。 例如,DeepEye (Luo 等人, 2018a) 使用机器学习根据数据特征和领域知识推荐良好的可视化效果。 PVisRec (Qian 等人, 2022) 根据用户过去的交互推荐个性化可视化。 然而,随着新用户或缺乏历史信息的数据集,其性能会下降。
可视化大型语言模型 (LLM4VIS)。 LLM4VIS 利用大型语言模型将自然语言查询转化为数据可视化(Luo 等人, 2022b, 2021c, 2021b, 2021a; Wang 等人, 2022; Tian 等人, 2023; Wang 等人, 2023; Tang 等人,2022)。 例如,ChartGPT (Tian 等人, 2023) 采用大语言模型从自然语言查询生成可视化,而 LLM4Vis (Wang 等人, 2023) 使用少样本学习建议可视化类型并用文本解释它们。 这些方法依赖于用户提供清晰的查询描述,并且可能难以通过自然语言准确地修改可视化。 我们的方法通过提供可视化提示和易于调整的功能来补充 LLM4VIS,减少用户输入并使可视化创建过程更加高效。
强化学习是一种以试错探索为特征的学习范式,其中代理从其环境中接收反馈,这通常应用于序列生成任务,例如项目推荐(Wang等人,2021)。 最近的研究还针对可视化任务采用了强化学习(Zhou 等人,2021;Chen 和 Wu,2022;Wu 等人,2020;Deng 等人,2022)。 例如,PI2(Chen and Wu,2022;Tao等人,2022)采用MCTS从SQL日志生成交互式UI小部件,帮助开发人员理解分析任务所需的查询。 与 PI2 需要用户提供 SQL 查询不同,HAIChart 自动为数据集推荐良好的可视化效果。 虽然 PI2 允许用户通过 UI 小部件优化查询结果,但 HAIChart 引入了可视化提示来指导数据探索。 这两个系统都旨在促进数据探索,但应用场景有所不同。
9. 结论
我们推出了 HAIChart,它将人类洞察力与人工智能功能相结合,通过用户反馈逐步和迭代提高可视化质量。 HAIChart 利用基于蒙特卡罗图搜索的可视化算法来自动推荐高质量的可视化。 它还配备了可视化提示机制,可以主动合并用户反馈,从而迭代地改进可视化生成算法。 HAIChart 已经过验证其在创建符合用户偏好的高质量可视化效果方面的有效性。 未来的研究可以探索将大语言模型集成到我们的框架中以生成和评估可视化,从而有可能增强各种应用的通用性和鲁棒性。
参考
- (1)
- exc (2024) 2024. Excel. https://www.microsoft.com/en-us/microsoft-365/excel
- tab (2024) 2024. Tableau. https://www.tableau.com/
- Allen and Seaman (2007) I Elaine Allen and Christopher A Seaman. 2007. Likert scales and data analyses. Quality progress 40, 7 (2007), 64–65.
- Auer et al. (2002) Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. 2002. Finite-time analysis of the multiarmed bandit problem. Machine learning 47 (2002), 235–256.
- Bai et al. (2019) Xueying Bai, Jian Guan, and Hongning Wang. 2019. A Model-Based Reinforcement Learning with Adversarial Training for Online Recommendation. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada. 10734–10745. https://proceedings.neurips.cc/paper/2019/hash/e49eb6523da9e1c347bc148ea8ac55d3-Abstract.html
- Bellman (1957) Richard Bellman. 1957. A Markovian decision process. Journal of mathematics and mechanics (1957), 679–684.
- Chai et al. (2023) Chengliang Chai, Nan Tang, Ju Fan, and Yuyu Luo. 2023. Demystifying Artificial Intelligence for Data Preparation. In SIGMOD Conference Companion. ACM, 13–20.
- Chen and Wu (2022) Yiru Chen and Eugene Wu. 2022. PI2: End-to-end Interactive Visualization Interface Generation from Queries. In SIGMOD ’22: International Conference on Management of Data, Philadelphia, PA, USA, June 12 - 17, 2022. ACM, 1711–1725. https://doi.org/10.1145/3514221.3526166
- Czech et al. (2021) Johannes Czech, Patrick Korus, and Kristian Kersting. 2021. Improving AlphaZero Using Monte-Carlo Graph Search. In Proceedings of the Thirty-First International Conference on Automated Planning and Scheduling, ICAPS 2021, Guangzhou, China (virtual), August 2-13, 2021. AAAI Press, 103–111. https://ojs.aaai.org/index.php/ICAPS/article/view/15952
- Deng et al. (2022) Dazhen Deng, Aoyu Wu, Huamin Qu, and Yingcai Wu. 2022. Dashbot: Insight-driven dashboard generation based on deep reinforcement learning. IEEE Transactions on Visualization and Computer Graphics 29, 1 (2022), 690–700.
- Dibia and Demiralp (2019) Victor Dibia and Çağatay Demiralp. 2019. Data2vis: Automatic generation of data visualizations using sequence-to-sequence recurrent neural networks. IEEE computer graphics and applications 39, 5 (2019), 33–46.
- Gao et al. (2021) Qianfeng Gao, Zhenying He, Yinan Jing, Kai Zhang, and X. Sean Wang. 2021. VizGRank: A Context-Aware Visualization Recommendation Method Based on Inherent Relations Between Visualizations. In Database Systems for Advanced Applications - 26th International Conference, DASFAA 2021, Taipei, Taiwan, April 11-14, 2021, Proceedings, Part III (Lecture Notes in Computer Science, Vol. 12683). Springer, 244–261. https://doi.org/10.1007/978-3-030-73200-4_16
- Goodfellow et al. (2020) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2020. Generative adversarial networks. Commun. ACM 63, 11 (2020), 139–144.
- Gray et al. (2023) Robert C Gray, Jichen Zhu, and Santiago Ontañón. 2023. Beyond UCT: MAB Exploration Improvements for Monte Carlo Tree Search. In 2023 IEEE Conference on Games (CoG). IEEE, 1–8.
- Hu et al. (2019) Kevin Hu, Michiel A Bakker, Stephen Li, Tim Kraska, and César Hidalgo. 2019. Vizml: A machine learning approach to visualization recommendation. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems. 1–12.
- Khuller et al. (1999) Samir Khuller, Anna Moss, and Joseph Naor. 1999. The Budgeted Maximum Coverage Problem. Inf. Process. Lett. 70, 1 (1999), 39–45. https://doi.org/10.1016/S0020-0190(99)00031-9
- Lee et al. (2021) Doris Jung-Lin Lee, Dixin Tang, Kunal Agarwal, Thyne Boonmark, Caitlyn Chen, Jake Kang, Ujjaini Mukhopadhyay, Jerry Song, Micah Yong, Marti A Hearst, et al. 2021. Lux: always-on visualization recommendations for exploratory dataframe workflows. arXiv preprint arXiv:2105.00121 (2021).
- Leurent and Maillard (2020) Edouard Leurent and Odalric-Ambrym Maillard. 2020. Monte-Carlo Graph Search: the Value of Merging Similar States. In Proceedings of The 12th Asian Conference on Machine Learning, ACML 2020, 18-20 November 2020, Bangkok, Thailand (Proceedings of Machine Learning Research, Vol. 129). PMLR, 577–592. http://proceedings.mlr.press/v129/leurent20a.html
- Li et al. (2024) Guozheng Li, Runfei Li, Yunshan Feng, Yu Zhang, Yuyu Luo, and Chi Harold Liu. 2024. CoInsight: Visual Storytelling for Hierarchical Tables with Connected Insights. IEEE Transactions on Visualization and Computer Graphics (2024).
- Li et al. (2021) Haotian Li, Yong Wang, Songheng Zhang, Yangqiu Song, and Huamin Qu. 2021. KG4Vis: A knowledge graph-based approach for visualization recommendation. IEEE Transactions on Visualization and Computer Graphics 28, 1 (2021), 195–205.
- Luo et al. (2020a) Yuyu Luo, Chengliang Chai, Xuedi Qin, Nan Tang, and Guoliang Li. 2020a. Interactive Cleaning for Progressive Visualization through Composite Questions. In ICDE. IEEE, 733–744.
- Luo et al. (2020b) Yuyu Luo, Chengliang Chai, Xuedi Qin, Nan Tang, and Guoliang Li. 2020b. VisClean: Interactive Cleaning for Progressive Visualization. Proc. VLDB Endow. 13, 12 (2020), 2821–2824.
- Luo et al. (2022a) Yuyu Luo, Xuedi Qin, Chengliang Chai, Nan Tang, Guoliang Li, and Wenbo Li. 2022a. Steerable Self-Driving Data Visualization. IEEE Trans. Knowl. Data Eng. 34, 1 (2022), 475–490.
- Luo et al. (2018a) Yuyu Luo, Xuedi Qin, Nan Tang, and Guoliang Li. 2018a. DeepEye: Towards Automatic Data Visualization. In 34th IEEE International Conference on Data Engineering, ICDE 2018, Paris, France, April 16-19, 2018. IEEE Computer Society, 101–112. https://doi.org/10.1109/ICDE.2018.00019
- Luo et al. (2018b) Yuyu Luo, Xuedi Qin, Nan Tang, Guoliang Li, and Xinran Wang. 2018b. DeepEye: Creating Good Data Visualizations by Keyword Search. In SIGMOD Conference. ACM, 1733–1736.
- Luo et al. (2021a) Yuyu Luo, Jiawei Tang, and Guoliang Li. 2021a. nvBench: A Large-Scale Synthesized Dataset for Cross-Domain Natural Language to Visualization Task. NLVIZ, IEEE Visualization Conference Companion abs/2112.12926 (2021).
- Luo et al. (2021b) Yuyu Luo, Jiawei Tang, Guoliang Li, and Chengliang Chai. 2021b. Empowering natural language to visualization neural translation using synthesized benchmarks. IEEE Visualization Conference (2021).
- Luo et al. (2021c) Yuyu Luo, Nan Tang, Guoliang Li, Chengliang Chai, Wenbo Li, and Xuedi Qin. 2021c. Synthesizing Natural Language to Visualization (NL2VIS) Benchmarks from NL2SQL Benchmarks. In SIGMOD Conference. ACM, 1235–1247.
- Luo et al. (2022b) Yuyu Luo, Nan Tang, Guoliang Li, Jiawei Tang, Chengliang Chai, and Xuedi Qin. 2022b. Natural Language to Visualization by Neural Machine Translation. IEEE Trans. Vis. Comput. Graph. 28, 1 (2022), 217–226.
- Luo et al. (2023) Yuyu Luo, Yihui Zhou, Nan Tang, Guoliang Li, Chengliang Chai, and Leixian Shen. 2023. Learned Data-aware Image Representations of Line Charts for Similarity Search. Proc. ACM Manag. Data 1, 1 (2023), 88:1–88:29.
- Moritz et al. (2019) Dominik Moritz, Chenglong Wang, Gregory Nelson, Halden Lin, Adam M. Smith, Bill Howe, and Jeffrey Heer. 2019. Formalizing Visualization Design Knowledge as Constraints: Actionable and Extensible Models in Draco. IEEE Trans. Visualization & Comp. Graphics (Proc. InfoVis) (2019). http://idl.cs.washington.edu/papers/draco
- Qian et al. (2022) Xin Qian, Ryan A Rossi, Fan Du, Sungchul Kim, Eunyee Koh, Sana Malik, Tak Yeon Lee, and Nesreen K Ahmed. 2022. Personalized visualization recommendation. ACM Transactions on the Web (TWEB) 16, 3 (2022), 1–47.
- Qin et al. (2018) Xuedi Qin, Yuyu Luo, Nan Tang, and Guoliang Li. 2018. Deepeye: An automatic big data visualization framework. Big data mining and analytics 1, 1 (2018), 75–82.
- Qin et al. (2020) Xuedi Qin, Yuyu Luo, Nan Tang, and Guoliang Li. 2020. Making data visualization more efficient and effective: a survey. VLDB J. 29, 1 (2020), 93–117.
- Robert et al. (1999) Christian P Robert, George Casella, Christian P Robert, and George Casella. 1999. Monte carlo integration. Monte Carlo statistical methods (1999), 71–138.
- Saffidine et al. (2012) Abdallah Saffidine, Tristan Cazenave, and Jean Méhat. 2012. UCD: Upper Confidence bound for rooted Directed acyclic graphs. Knowledge-Based Systems 34 (2012), 26–33.
- Satyanarayan and Heer (2014) Arvind Satyanarayan and Jeffrey Heer. 2014. Lyra: An Interactive Visualization Design Environment. Comput. Graph. Forum 33, 3 (2014), 351–360.
- Schrittwieser et al. (2020) Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy P. Lillicrap, and David Silver. 2020. Mastering Atari, Go, chess and shogi by planning with a learned model. Nat. 588, 7839 (2020), 604–609. https://doi.org/10.1038/S41586-020-03051-4
- Shen et al. (2023) Leixian Shen, Enya Shen, Yuyu Luo, Xiaocong Yang, Xuming Hu, Xiongshuai Zhang, Zhiwei Tai, and Jianmin Wang. 2023. Towards Natural Language Interfaces for Data Visualization: A Survey. IEEE Trans. Vis. Comput. Graph. 29, 6 (2023), 3121–3144.
- Shen et al. (2022) Leixian Shen, Enya Shen, Zhiwei Tai, Yun Wang, Yuyu Luo, and Jianmin Wang. 2022. GALVIS: Visualization Construction through Example-Powered Declarative Programming. In CIKM. ACM, 4975–4979.
- Shen et al. (2018) Yelong Shen, Jianshu Chen, Po-Sen Huang, Yuqing Guo, and Jianfeng Gao. 2018. M-walk: Learning to walk over graphs using monte carlo tree search. Advances in Neural Information Processing Systems 31 (2018).
- Shi et al. (2021) Danqing Shi, Xinyue Xu, Fuling Sun, Yang Shi, and Nan Cao. 2021. Calliope: Automatic Visual Data Story Generation from a Spreadsheet. IEEE Trans. Vis. Comput. Graph. 27, 2 (2021), 453–463. https://doi.org/10.1109/TVCG.2020.3030403
- Silver et al. (2016) David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Vedavyas Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy P. Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. 2016. Mastering the game of Go with deep neural networks and tree search. Nat. 529, 7587 (2016), 484–489. https://doi.org/10.1038/NATURE16961
- Silver et al. (2017) David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy P. Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, and Demis Hassabis. 2017. Mastering the game of Go without human knowledge. Nat. 550, 7676 (2017), 354–359. https://doi.org/10.1038/NATURE24270
- Stolte et al. (2008) Chris Stolte, Diane Tang, and Pat Hanrahan. 2008. Polaris: a system for query, analysis, and visualization of multidimensional databases. Commun. ACM 51, 11 (2008), 75–84.
- Tang et al. (2022) Jiawei Tang, Yuyu Luo, Mourad Ouzzani, Guoliang Li, and Hongyang Chen. 2022. Sevi: Speech-to-Visualization through Neural Machine Translation. In SIGMOD Conference. ACM, 2353–2356.
- Tao et al. (2022) Jeffrey Tao, Yiru Chen, and Eugene Wu. 2022. Demonstration of PI2: Interactive Visualization Interface Generation for SQL Analysis in Notebook. In SIGMOD Conference. ACM, 2365–2368.
- Tian et al. (2023) Yuan Tian, Weiwei Cui, Dazhen Deng, Xinjing Yi, Yurun Yang, Haidong Zhang, and Yingcai Wu. 2023. Chartgpt: Leveraging llms to generate charts from abstract natural language. arXiv preprint arXiv:2311.01920 (2023).
- Tot et al. (2022) Marko Tot, Michelangelo Conserva, Diego Perez Liebana, and Sam Devlin. 2022. Turning Zeroes into Non-Zeroes: Sample Efficient Exploration with Monte Carlo Graph Search. In IEEE Conference on Games, CoG 2022, Beijing, China, August 21-24, 2022. IEEE, 300–306. https://doi.org/10.1109/COG51982.2022.9893579
- Wang et al. (2021) Kai Wang, Zhene Zou, Qilin Deng, Jianrong Tao, Runze Wu, Changjie Fan, Liang Chen, and Peng Cui. 2021. Reinforcement Learning with a Disentangled Universal Value Function for Item Recommendation. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021. AAAI Press, 4427–4435. https://doi.org/10.1609/AAAI.V35I5.16569
- Wang et al. (2023) Lei Wang, Songheng Zhang, Yun Wang, Ee-Peng Lim, and Yong Wang. 2023. LLM4Vis: Explainable Visualization Recommendation using ChatGPT. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: EMNLP 2023 - Industry Track, Singapore, December 6-10, 2023. Association for Computational Linguistics, 675–692. https://aclanthology.org/2023.emnlp-industry.64
- Wang et al. (2022) Xingbo Wang, Furui Cheng, Yong Wang, Ke Xu, Jiang Long, Hong Lu, and Huamin Qu. 2022. Interactive data analysis with next-step natural language query recommendation. arXiv preprint arXiv:2201.04868 (2022).
- Ward et al. (2010) Matthew O Ward, Georges Grinstein, and Daniel Keim. 2010. Interactive data visualization: foundations, techniques, and applications. CRC press.
- Wongsuphasawat et al. (2015) Kanit Wongsuphasawat, Dominik Moritz, Anushka Anand, Jock Mackinlay, Bill Howe, and Jeffrey Heer. 2015. Voyager: Exploratory analysis via faceted browsing of visualization recommendations. IEEE transactions on visualization and computer graphics 22, 1 (2015), 649–658.
- Wongsuphasawat et al. (2017) Kanit Wongsuphasawat, Zening Qu, Dominik Moritz, Riley Chang, Felix Ouk, Anushka Anand, Jock Mackinlay, Bill Howe, and Jeffrey Heer. 2017. Voyager 2: Augmenting visual analysis with partial view specifications. In Proceedings of the 2017 chi conference on human factors in computing systems. 2648–2659.
- Wu et al. (2020) Aoyu Wu, Wai Tong, Tim Dwyer, Bongshin Lee, Petra Isenberg, and Huamin Qu. 2020. Mobilevisfixer: Tailoring web visualizations for mobile phones leveraging an explainable reinforcement learning framework. IEEE Transactions on Visualization and Computer Graphics 27, 2 (2020), 464–474.
- Wu et al. (2021) Aoyu Wu, Yun Wang, Mengyu Zhou, Xinyi He, Haidong Zhang, Huamin Qu, and Dongmei Zhang. 2021. MultiVision: Designing analytical dashboards with deep learning based recommendation. IEEE Transactions on Visualization and Computer Graphics 28, 1 (2021), 162–172.
- Wu et al. (2017) Eugene Wu, Fotis Psallidas, Zhengjie Miao, Haoci Zhang, and Laura Rettig. 2017. Combining Design and Performance in a Data Visualization Management System. In CIDR. www.cidrdb.org.
- Wu et al. (2008) Qiang Wu, Chris JC Burges, Krysta M Svore, and Jianfeng Gao. 2008. Ranking, boosting, and model adaptation. Technical Report. Citeseer.
- Ye et al. (2024) Yilin Ye, Jianing Hao, Yihan Hou, Zhan Wang, Shishi Xiao, Yuyu Luo, and Wei Zeng. 2024. Generative AI for visualization: State of the art and future directions. Visual Informatics (2024).
- Zhou et al. (2021) Mengyu Zhou, Qingtao Li, Xinyi He, Yuejiang Li, Yibo Liu, Wei Ji, Shi Han, Yining Chen, Daxin Jiang, and Dongmei Zhang. 2021. Table2Charts: Recommending charts by learning shared table representations. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2389–2399.