PlanRAG:用于生成大型语言模型作为决策者的先计划后检索增强生成
摘要
在本文中,我们进行了一项研究,利用大语言模型作为需要复杂数据分析的决策解决方案。 我们将决策QA定义为针对决策问题、业务规则回答最佳决策的任务> 和数据库。由于没有可以检查决策 QA 的基准,我们提出决策 QA 基准,DQA。 它有两个场景:定位和建造,由两个视频游戏(Europa Universalis IV 和 Victoria 3)构建而成,其目标与决策 QA 几乎相同。 为了有效地解决决策 QA,我们还提出了一种新的 RAG 技术,称为迭代计划然后检索增强生成 (PlanRAG)。 我们基于 PlanRAG 的 LM 第一步生成决策计划,第二步检索器生成数据分析查询。 该方法在定位场景中优于最先进的迭代 RAG 方法 15.8%,在建筑场景中优于最先进的迭代 RAG 方法 7.4%。 我们在 https://github.com/myeon9h/PlanRAG 发布了我们的代码和基准测试。
PlanRAG:用于生成大型语言模型作为决策者的先计划后检索增强生成
Myeonghwa Lee∗, Seonho An∗, Min-Soo Kim† School of Computing, KAIST {myeon9h, asho1, minsoo.k}@kaist.ac.kr
1简介
在许多商业情况下,决策对于组织的成功起着至关重要的作用 Kasie 等人 (2017); Gupta等人(2002)。 在这里,决策涉及分析数据,最终选择最合适的替代方案来实现特定目标Provost 和 Fawcett (2013);迪万(2017)。 例如,我们假设制药公司“辉瑞”的目标之一是最大限度地降低生产成本,同时保持从工厂按时交付给药品分销网络中的客户Gupta等人(2002),生产成本与工厂的运转时间和员工人数成正比。 那么,辉瑞可能面临以下决策问题:(P1)应该运营或停止哪个工厂,以及(P2)每个工厂应该雇用多少员工。
一般来说,决策任务需要执行以下三个步骤:(1)制定计划,确定需要进行哪种分析来进行决策; (2) 使用查询检索必要的数据; (3)根据Troisi等人(2020)的数据做出决策(即回答);萨拉等人 (2022). 为了使步骤(2)和(3)更容易,在过去的几十年中已经开发和使用了许多决策支持系统Gupta等人(2002); Eom 和 Kim (2006);电力(2007);赫奇贝斯(2007);电力(2008); Kasie 等人 (2017). 然而,人类仍然负责最困难的部分,即步骤(1)。 本研究的目的是调查用大型语言模型(LLM)代替人类角色的可能性,使其不仅执行步骤(2)和(3),而且执行步骤(1),即所有步骤端到端。
为了实现这一目标,我们提出了Decision QA,这是一种新的语言模型决策任务。 决策 QA 被定义为 QA 风格的任务,它以一对数据库 、业务规则 和决策问题 作为输入并生成最好的决策作为输出。 图1展示了欧陆风云IV游戏中各国在大航海时代进行贸易竞争的情况,作为决策QA的一个例子。 每个国家都决定应将商人定位在哪个交易城市(即节点),以使其在其主要(即本国)交易节点上的利润最大化。 该示例显示,决策大语言模型在分析国际贸易数据库后,决定在 Doab 设立商人,以最大化 BAH 国家贸易节点德干的利润。
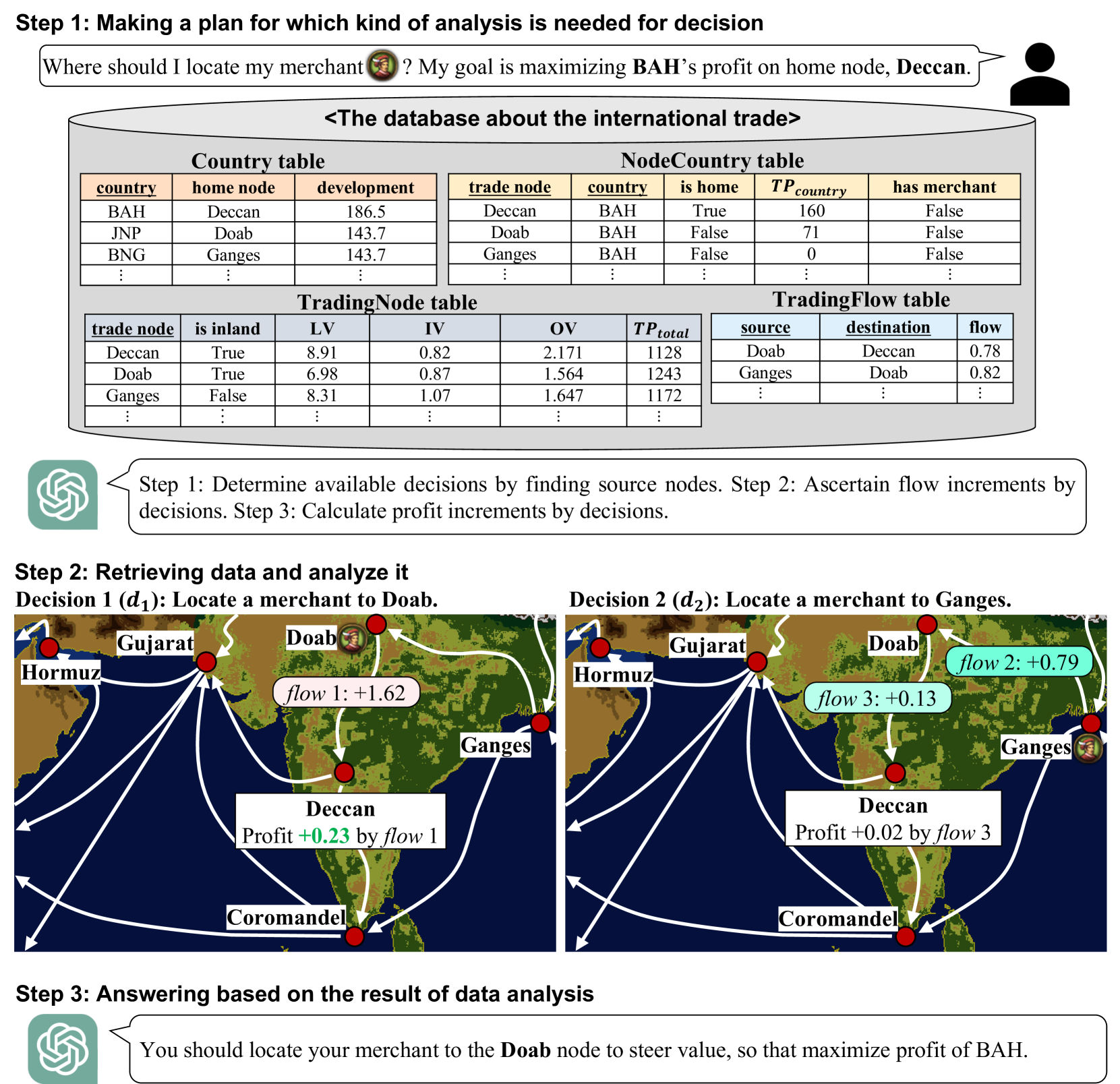
接下来,我们提出了一个称为DQA的决策QA基准,它由以下两个场景组成:定位和构建。 前一种场景包括诸如“我应该在哪个贸易节点上定位商家”之类的决策问题(类似于辉瑞的 P1)。 后者包括诸如“我应该向工厂供应多少木材”之类的问题(类似于辉瑞的P2)。 由于使用真实业务数据构建 DQA 的难度较大,我们通过从《欧陆风云 IV》和《维多利亚 3》两款游戏中提取涉及 301 个特定情况的游戏数据来构建基准测试111Grand strategy games published by Paradox Interactive推出的大策略游戏,很好地模仿了真实的商业场景。 为了消除游戏的随机性并发布我们的基准,我们开发了记录 301 种情况的决策结果的游戏模拟器。 我们利用结果作为 DQA 问题的注释。
大语言模型最近的突破是用大语言模型代替决策任务的步骤(2)和(3)成为可能,特别是基于检索增强生成(RAG)技术。 到目前为止,已经针对各种任务提出了很多基于 RAG 的方法Lewis 等人 (2020); Khandelwal 等人 (2020);伊扎卡德和格雷夫 (2021); Borgeaud 等人 (2022); Izacard 等人 (2023);安永等人 (2023);江等人 (2022a);石等人(2023)。 在这些方法中,检索器找到与问题高度相关的外部数据并将其传递给 LM,以便 LM 可以基于它生成答案 Lewis 等人 (2020)。 最近,迭代 RAG 技术也被提出来用于解决更复杂的问题,这些问题应利用检索结果来执行进一步检索Trivedi 等人(2023 年);Jiang 等人(2023 年 b)。
然而,现有的基于RAG的方法主要集中在基于知识的QA任务Karpukhin等人(2020); Trivedi 等人 (2023),但不关注决策 QA 任务。 因此,根据我们的观察,他们不太擅长处理步骤(1),即制定决策计划。 例如,在图 1 中,用于决策的 LM 应该推断需要执行哪些分析才能最大化 Deccan 的利润。 然而,现有的方法只是试图识别例如德干是什么。
为了解决这个限制,我们提出了迭代计划然后检索增强生成技术,PlanRAG,它扩展了决策 QA 的迭代 RAG 技术。 基于 PlanRAG 的 LM 首先通过检查数据模式和问题来制定需要哪种分析的计划(规划步骤)。 接下来,它通过生成和提出查询来检索分散的数据以进行分析(检索步骤)。 最后,它评估是否需要制定新计划以进行进一步分析,然后迭代地重复计划和检索步骤(重新计划步骤),或者根据数据做出决策( 应答步骤)。
为了验证 PlanRAG 在决策 QA 上的有效性,我们比较了最先进的基于迭代 RAG 的 LM 和基于 PlanRAG 的 LM 的 DQA 基准。 我们的贡献总结如下:
-
•
我们定义了一个新的具有挑战性的任务,决策 QA,它需要规划和数据分析来进行决策。
-
•
我们提出了名为 DQA 的决策 QA 基准,具有定位和构建两种场景。
-
•
我们提出了一种新的检索增强生成技术PlanRAG,可以显着增强大语言模型的决策能力。
-
•
我们证明了 PlanRAG 比决策 QA 的迭代 RAG 技术更有效。
2 决策 QA 任务
我们将决策QA定义为根据决策问题、业务规则回答最佳决策的任务,以及遵循模式的结构化数据库。这里,包含用户希望通过决策实现的文本目标,包含引用原因。
不失一般性,数据库 太大,无法一次容纳 LM 的输入。 因此,我们假设LM通过提出数据分析查询来从检索数据,下文中我们将其称为数据分析查询。
我们假设是标记属性图(LPG)数据库或关系数据库(RDB)。 例如,图1中的数据库是一个关系数据库。 这里,LPG是指具有边和节点属性的图,在业界广泛使用 Akoglu 等人 (2015);郭等人 (2020). 我们将标记属性图数据库简称为图数据库,或以下简称GDB。
3 DQA:决策 QA 基准
3.1 定位场景
当为RDB时,该场景的数据库由以下四张表组成。 通过将 TradingFlow 和 NodeCountry 中的元组视为边,将 TradingNode 和 Country 中的元组视为顶点,也可以轻松地将其表示为 GDB。
![[Uncaptioned image]](x2.png)
决策有一些业务规则。 粗体列值是根据数据库中的一些其他值和用户决策(例如商家的位置)根据规则计算得出的。 如果用户在某个国家的交易节点上找到商户,则从该交易节点到该国家的归属节点的流量就会增加。 以下规则中,为国家,为交易节点,src为源节点,dest为目的节点,是的主节点。我们还将国家/地区集表示为 ,将 TradingFlow 元组集表示为 。 TPR是指交易力比率。
| (1) | |||
| (2) | |||
| (3) |
在这种场景下,决策的目标是选择能够最大化给定目标国家的的交易节点。
3.2构建场景
当为RDB时,本场景中的数据库由以下四张表组成。 通过将 Demand 和 Supply 中的元组视为边,将 Goods 和 Buildings 中的元组视为顶点,也可以轻松地将其表示为 GDB。
![[Uncaptioned image]](x3.png)
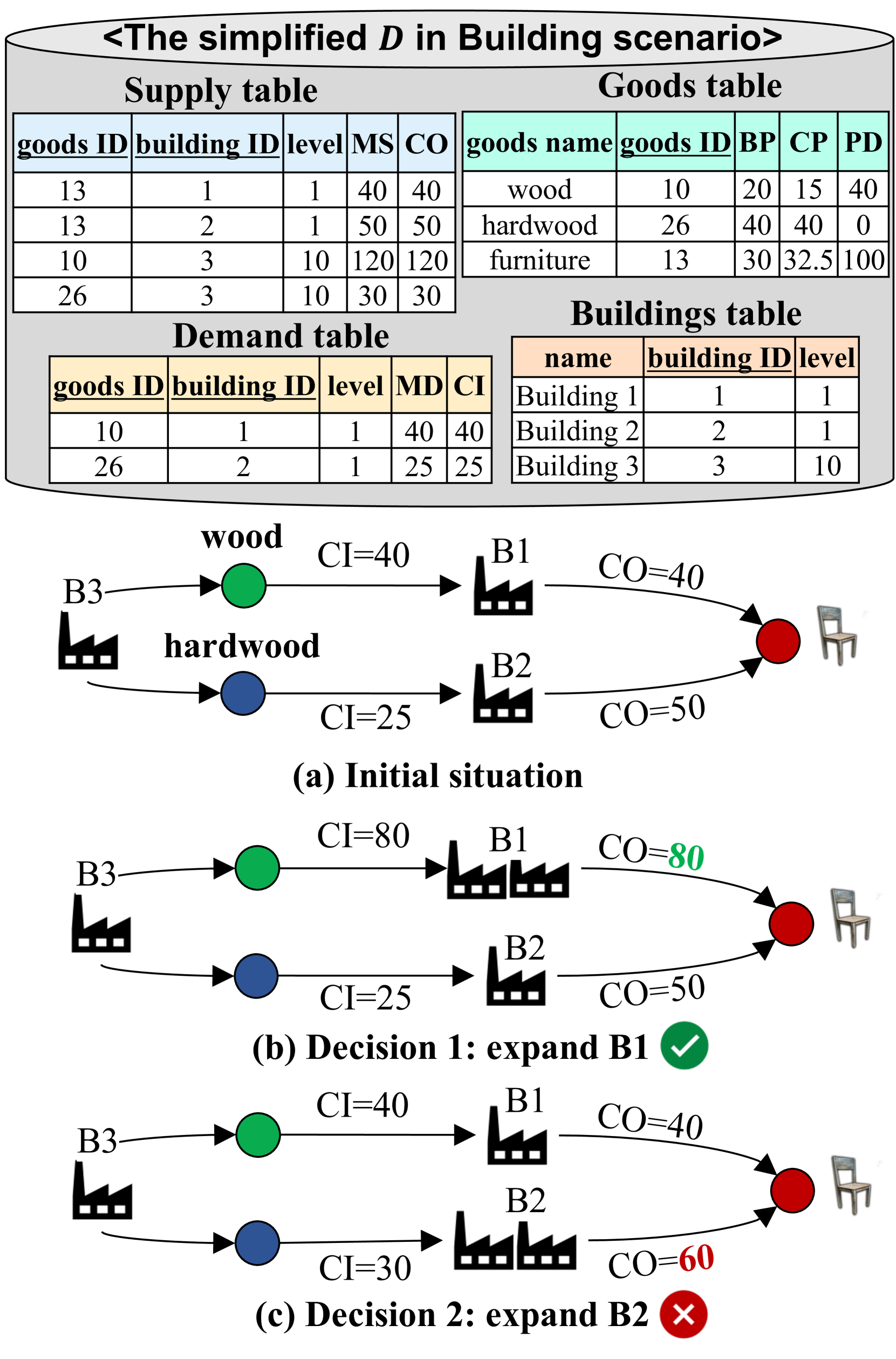
最基本的业务规则是,如果决策者扩建厂房,则任何商品的都会增加。 在下面的规则中,是货物,是建筑物。 我们还将供应集合表示为Sup,将需求集合表示为Dem。 表示总需求, 表示总供应。 其他主要业务规则如下:
| (4) | ||||
| (5) | ||||
| (6) |
在这种情况下,目标是最小化给定商品 的 。
3.3DQA统计
DQA 总共由 301 对 和 组成:(1) 200 对用于定位场景,(2) 101 对用于构建场景。 对于相同的对应问题,每个数据库同样有两个版本:RDB 和 GDB,因此,DQA 基准测试中总共提供了 602 个数据库。 我们假设 SQL 用于 RDB,而 Cypher 查询语言 (CQL) Francis 等人 (2018) 用于 GDB。 表3显示了DQA中数据库的一些统计信息。 数据收集详情参见附录A.1。
| Statistics | Locating | Building |
|---|---|---|
| # of , pairs | 200 | 101 |
| Relational DB (RDB) | ||
| Avg. rows in tables of | 2038.8 | 579.0 |
| Avg. cols in tables of | 4.5 | 4.5 |
| Graph DB (GDB) | ||
| Avg. # of edges of | 1432.3 | 374.7 |
| Avg. # of vertices of | 606.5 | 204.3 |
4方法:PlanRAG
For Decision QA, the existing RAG technique Jiang et al. (2023b); Trivedi et al. (2023) tries to answer the best decision for given ,, through a single type of reasoning that utilizes on the results retrieved from by data analysis queries. 图3(a)展示了其推理过程。 如果从的检索仅执行一次,则该过程称为单轮RAG。 否则,如果多次执行检索,则该过程称为迭代RAG。
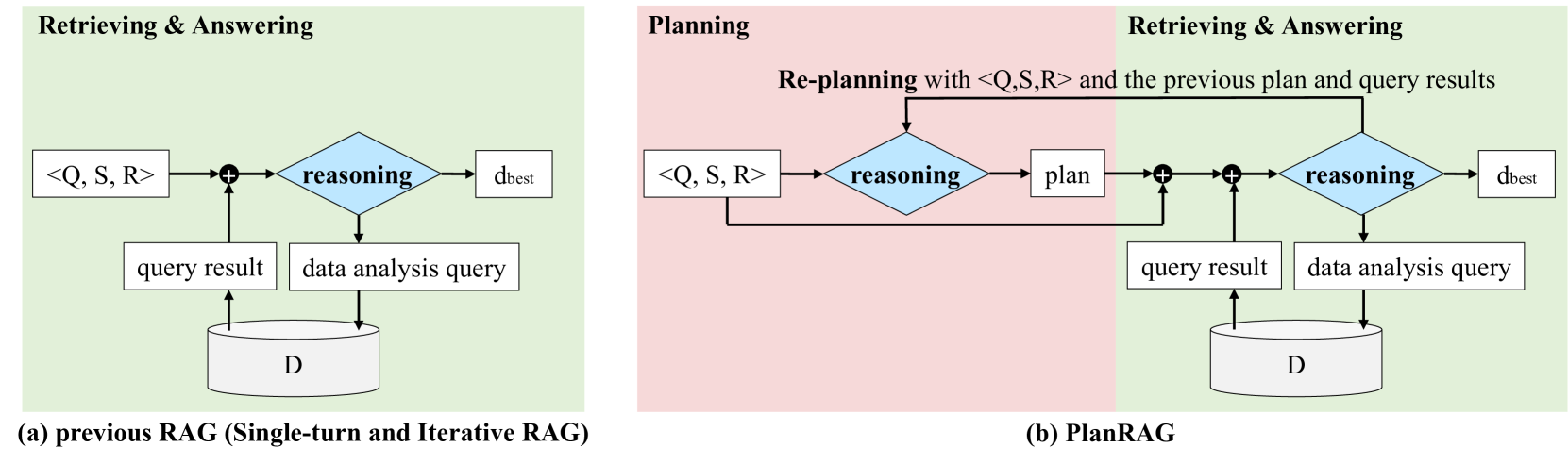
相比之下,我们的迭代计划然后检索增强生成 (PlanRAG) 技术尝试通过两种类型的推理来回答。 第一种推理是制定计划,第二种推理类似于现有RAG的推理,即根据数据分析查询从检索到的结果进行回答。 特别是,我们构建了一个可以执行两种类型推理的 LM,因为为了减少使用单独 LM 的副作用。 我们通过在 ReAct Yao 等人 (2023) 中添加“计划”和“重新计划”指令来提示 LM,详细信息参见附录。 A.6.2。 图3(b)显示了PlanRAG的推理过程,其中我们解释了(1)规划,(2)检索和回答,以及(3)重新规划的步骤,详细如下。
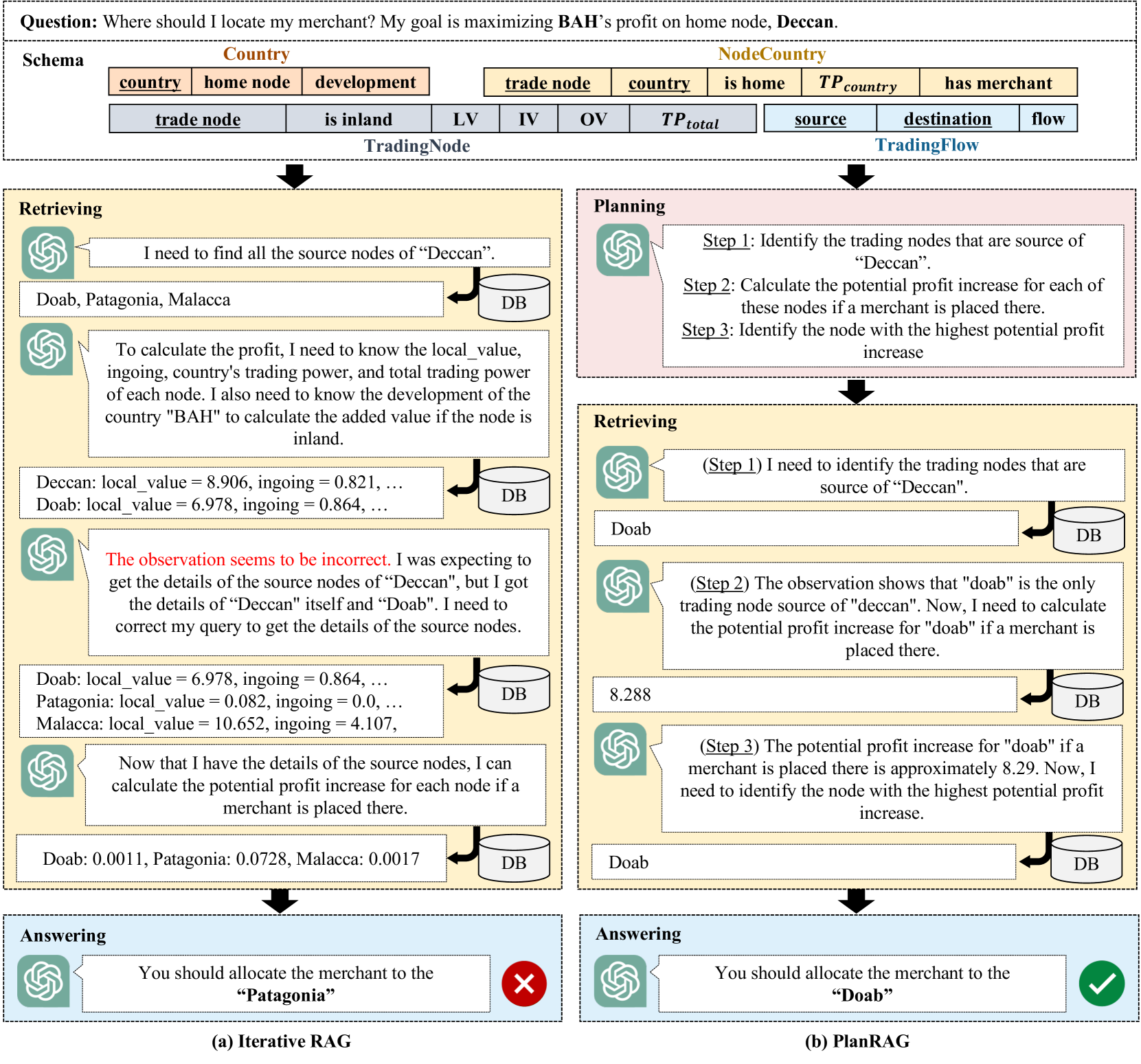
规划:在此步骤中,LM 需要 、、 作为输入,然后生成数据分析的初始计划。 初始计划描述了决策所需的一系列数据分析,因此需要在检索步骤中执行。 图4(b)中的红框显示了其示例。
检索与回复: 与之前的 RAG 技术不同,LM 不仅需要 、、,而且还需要初始计划作为输入。 然后,它可以比以前的 RAG 更有效地生成数据分析查询以进行决策。 图 4 显示了基于 PlanRAG 的 LM 如何生成与之前的 RAG 不同的查询。 查询实际上是通过 SQL 或 Cypher 通过 LangChain222https://langchain.readthedocs.io/en/latest 和 LlamaIndex333https://docs.llamaindex.ai/en/stable/。 查询结果被迭代地用于推理是否需要重新规划或只是进一步检索以做出更好的决策。 通过向后链接到规划过程,迭代执行规划和检索过程,直到 LM 确定不再需要进一步分析来做出决策。
重新规划:当初始计划不足以解决决策问题时,就会进行重新规划。 为了使 LM 能够决定是否重新规划,我们通过一些指令提示 LM 通过参考每个检索步骤的结果来评估当前计划(参见附录 1)。 A.6.2 了解详情)。 因此,LM 不仅采用 、、,而且还采用当前计划和查询结果作为输入并生成新计划以进行进一步分析,或纠正先前分析的方向。
5实验
5.1实验设置
为了验证所提出的 PlanRAG 对于决策 QA 任务的有效性,我们实现并比较了四种不同的决策 LM:(1)基于单轮 RAG 的 SingleRAG-LM,(2)基于迭代 RAG 的 IterRAG-LM,( 3)基于PlanRAG的PlanRAG-LM,(4)PlanRAG-LM w/o RP,这意味着没有重新规划的PlanRAG。 基于 ReAct Yao 等人 (2023) 的提示用于让这些 LM 作为决策者(详细信息参见附录 A.6)。 所有这些决策者都是由零温度的GPT-4OpenAI(2023)和LangChain库来实现的。 数据库方面,我们使用MySQL444https://www.mysql.com 对于 RDBMS 和 Neo4j555https://neo4j.com 用于 GDBMS。
所有实验均在零样本和单次运行设置中进行。 这个零样本的设置是基于以下两个原因。 首先,在大多数现实商业情况中,很难提前知道做出最佳决策的策略。 其次,在少样本设置中,我们观察到 LM 不仅过度拟合问题解决策略,而且过度拟合给定镜头中的数据库内容。
仅当决策者的答案在语义上与 DQA 上的真实最佳决策相同时,才被认为是正确的。 例如,在图4(b)中,我们认为答案是正确的,因为地面实况最佳决策是Doab。
5.2结果与分析
主要结果: 表 4 列出了实验结果,与现有的 SOTA 技术迭代 RAG Yao 相比,两种场景的决策性能均得到显着提高,定位提高了 15.8%,建筑提高了 7.4%等人(2023)。 它很好地展示了 PlanRAG 对于决策任务的有效性。 PlanRAG 在 Locating 中比在 Building 中相对更有效的原因是,Building 需要比 Locating 场景更长的遍历,并且它使规划比 Locating 更困难。 SingleRAG-LM在Building中的准确率非常低,这是因为Building场景需要生成非常复杂的查询,很难立即推理。 在超过 60% 的定位问题和 95% 的建筑问题中,SingleRAG-LM 未能从数据库检索任何结果。 表4还表明,PlanRAG 中没有重新规划会导致精度下降,特别是定位方面下降了 10.8%,建筑方面下降了 0.9%。 这一结果表明,重新规划过程对于 PlanRAG 技术的决策者 LM 的决策任务是有帮助和重要的。
| Decision makers | Locating | Building |
| Single-turn RAG | ||
| SingleRAG-LM | 30.5 | 2.5 |
| Iterative RAG | ||
| IterRAG-LM | 48.5 | 37.6 |
| PlanRAG (ours) | ||
| PlanRAG-LM | 64.3 | 45.0 |
| PlanRAG-LM w/o RP | 53.5 | 44.1 |
SR和MR分析: DQA中有相对简单的问题和相对困难的问题。 为了根据问题的难度检查 PlanRAG 的有效性,我们将 DQA 问题分为两种不同类型:(1)单检索(SR)问题,以及(2)多重检索(先生)问题。 这里,SR指的是IterRAG-LM从执行一次检索来解决问题的情况,而MR指的是它执行多次检索来解决问题的问题。 SR总共有84对、对和518对、 对 MR。我们比较了 IterRAG-LM 和 PlanRAG-LM 对于 SR 和 MR 的准确性,结果如图5所示。
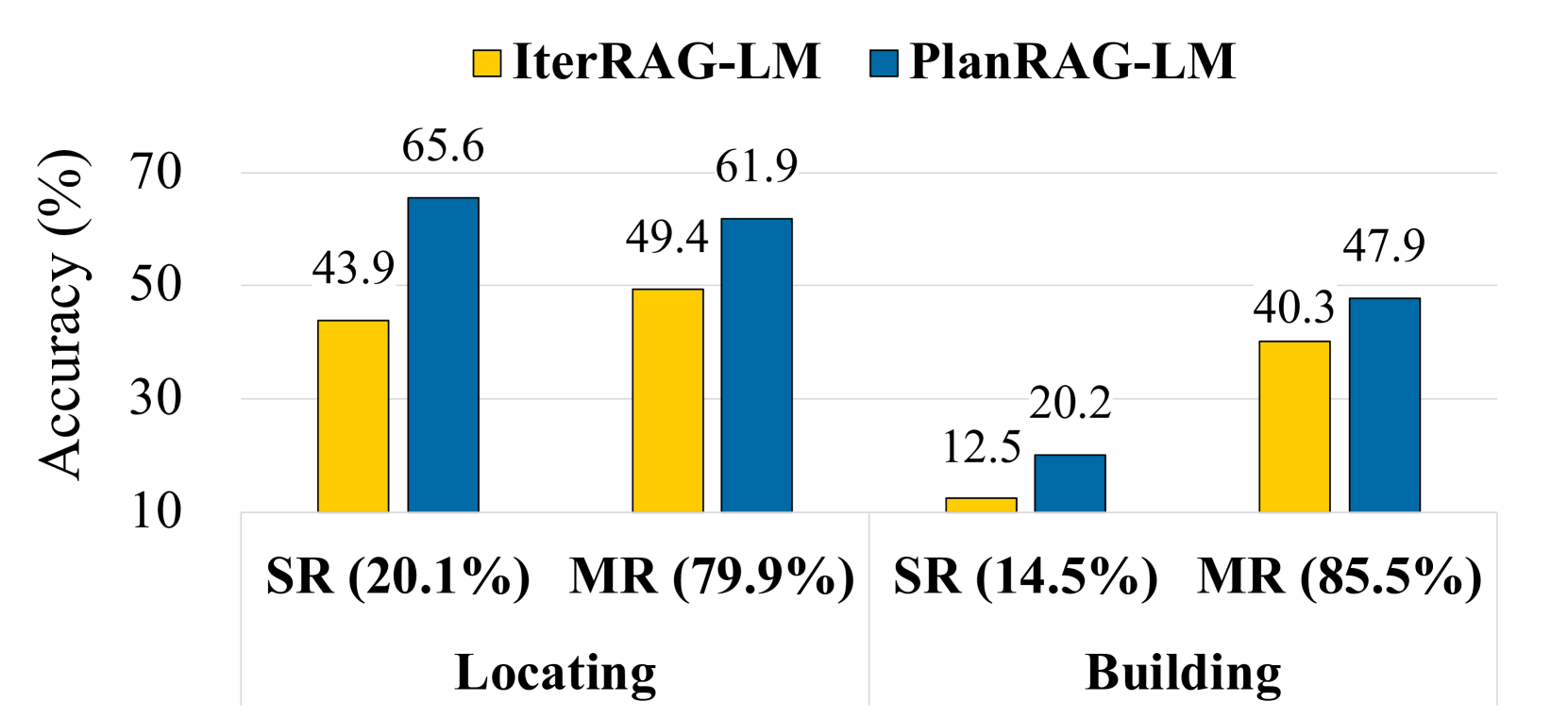
结果,PlanRAG-LM 在 SR 问题上的表现比在 MR 问题上的表现要好得多。 因为很多时候SR题其实并不那么容易。 IterRAG-LM 尝试仅通过使用单次检索来解决这些问题。 也就是说,有些是IterRAG-LM低估其难度的问题,但实际上是比较难的问题,需要多次检索。 相比之下,PlanRAG-LM 降低了它通过规划步骤了解给定问题的难度并根据计划执行多次检索的可能性。 因此,它可以显着提高准确性。 对于MR情况,PlanRAG-LM仍然比IterRAG-LM更有效,因为前者按照计划相对系统地进行数据检索,而后者相对杂乱地进行检索,如图4 (A)。
RDB和GDB分析: 表5展示了DQA中两个不同数据库RDB和GDB的LM的准确性。 结果显示,无论数据库类型(即 RDB 和 GDB)如何,PlanRAG-LM 在这两种情况下都比其他 LM 更有效。 我们注意到,在建筑场景中,PlanRAG-LM 对 GDB 比对 RDB 更有效。 这是因为构建比定位更困难,需要在 GDB 中进行更长的遍历(或者在 RDB 中进行更多的连接)来回答问题。 例如,Locating 中的问题只需要从源节点到归属节点的单跳遍历,而 Building 中的问题需要多跳遍历才能找到图2中的高供应品。
| Locating | Building | |||
|---|---|---|---|---|
| Decision makers | RDB | GDB | RDB | GDB |
| SingleRAG-LM | 25.5 | 35.5 | 2.0 | 3.0 |
| IterRAG-LM | 37.5 | 59.5 | 34.7 | 40.6 |
| PlanRAG-LM | 64.5 | 64.0 | 40.6 | 49.5 |
数据分析漏检率: 在每个场景中,都需要查询或计算一些关键值才能回答问题。 例如,“Locating”的值包括和,“Building”的值包括和。 为了分析为什么 PlanRAG 比 IterRAG-LM 更有效,我们测量了查询或计算此类值的数据分析丢失率。 我们使用 和 作为定位条件,使用 和 作为标准。 表6显示PlanRAG-LM的比率较低,为1.3%和21.8%,而IterRAG-LM的比率较高,为3.3%和33.2%。 这意味着 IterRAG-LM 的准确率低于 PlanRAG-LM,尽管它可以完美地进行推理。 根据表6,PlanRAG-LM的定位精度可能达到98.7%,但表4中的实际精度要低于该精度。 因为除了错过数据分析之外,推理(包括规划)本身就非常具有挑战性。
| Decision makers | Locating | Building |
|---|---|---|
| IterRAG-LM | 3.3% | 33.2% |
| PlanRAG-LM | 1.3% | 21.8% |
失败案例分析: 我们将每个失败案例分为以下五个错误类别:(1)CAN,这意味着LM未能通过考虑不正确的候选者来解决问题(例如,Deccan的dest)图1)并回答; (2)MIS,漏掉的数据分析; (3) DEEP,不当使用检索到的数据或方程; (4) QUR,查询生成错误; (5) OTH,其他错误(例如超出词符长度限制)。 例如,我们将4(a)分类为DEEP,因为LM误用了一些方程,因此低估了Doab的利润。 我们根据这些类别比较 IterRAG-LM 和 PlanRAG-LM 完成的失败案例,如图 6 所示。
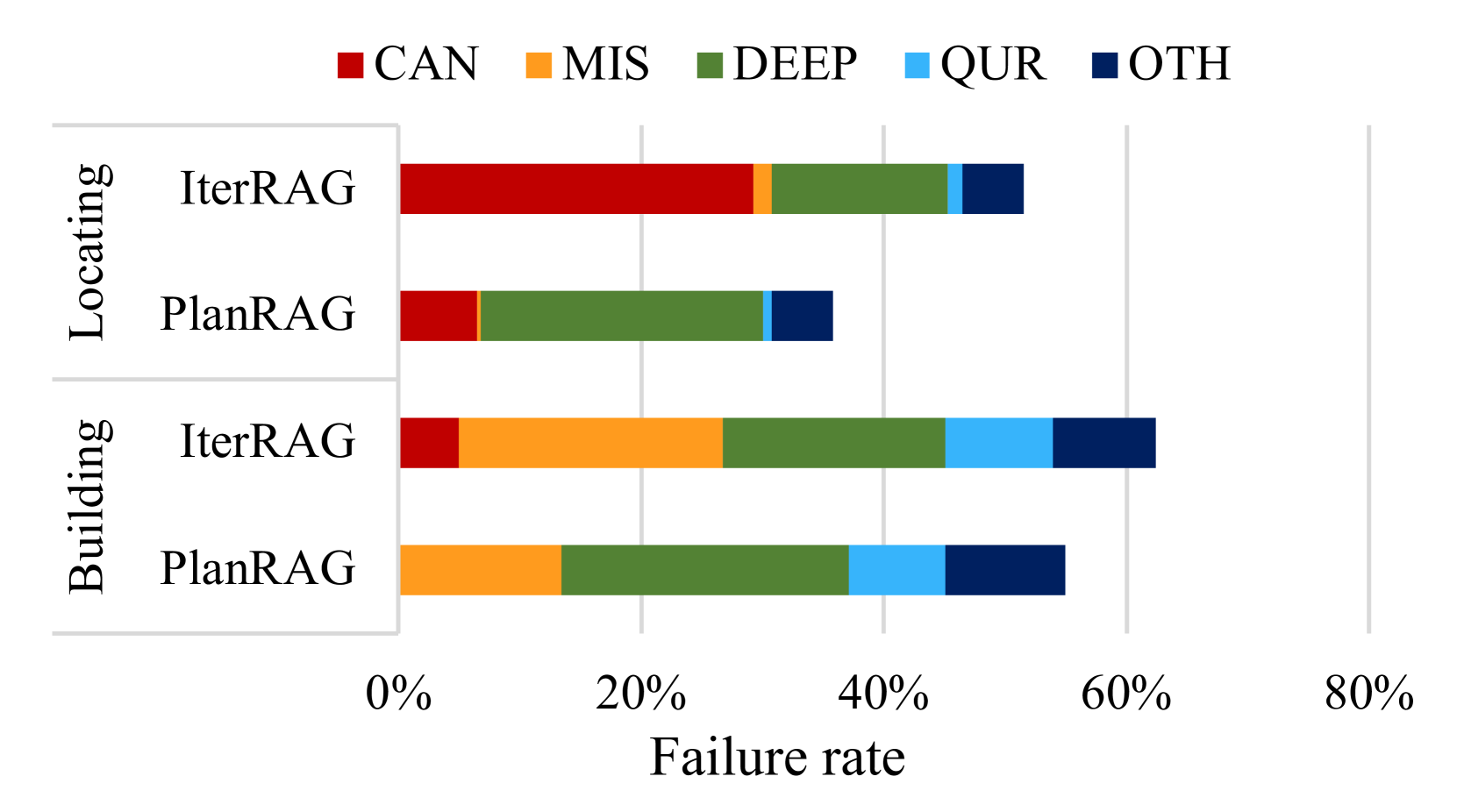
结果,PlanRAG-LM 显着减少了这两种情况下的 CAN 和 MIS 错误。 这意味着 PlanRAG-LM 比 IterRAG-LM 可以更好地理解决策 QA 问题并更好地查询该问题的关键数据。 我们还注意到,对于这两种情况,PlanRAG-LM 的 DEEP 案例都比 IterRAG-LM 稍多。 根据我们的观察,只有在没有 CAN 或 MIS 错误的情况下才会出现 DEEP 错误。 例如,在图 4(a) 中,当 LM 未能将 Doab 作为候选者之一(即,使CAN 错误)。 因此,我们可以说 PlanRAG-LM 中 DEEP 案例的增加来自于减少 CAN 和 MIS 案例的副作用。
重新规划分析: PlanRAG-LM 对某些 DQA 问题执行重新规划。 表7展示了基于PlanRAG-LM重新规划次数的问题分布以及重新规划提高的准确性。 重新规划的详细案例和统计数据见附录A.8。
| No. of re-plannings | Locating | Building |
|---|---|---|
| 0 | 376 (66.8%) | 125 (57.6%) |
| 1 | 0 (-) | 0 (-) |
| 2 | 12 (41.7%) | 24 (41.7%) |
| 3 | 5 (20.0%) | 23 (21.7%) |
| more than 4 | 7 (0.0%) | 30 (13.3%) |
| Total | 400 (64.3%) | 202 (45.0%) |
结果,PlanRAG-LM 在建筑场景中比在定位场景中更频繁地重新规划。 PlanRAG-LM 重新规划定位中 400 个问题中的 24 个问题(占问题的 6%),但重新规划建筑中 202 个问题中的 77 个问题(占问题的 38%)。 此外,Building 中重新规划超过 4 次的题目比例(30 题,14.85%)远高于 Locating 题目(7 题,1.75%)。 我们注意到,如果原始计划不充分,LM 就会重新计划,正如我们在第 4 节中所解释的那样。 因此,结果表明 LM 很难在 Building 中制定计划(初始规划和重新规划),并解释了 PlanRAG-LM 与 Building 中其他技术之间相对较小的差距,如表 4 。 这也与表7的结果一致,随着重新规划次数的增加,重新规划提高的精度降低。
6相关工作
使用结构化数据的 NLP 任务 已经提出了许多用于结构化数据推理的基准,例如 Table NLI benchmarks Chen 等人 (2020a); Gupta 等人 (2020); Jena 等人 (2022) 和表格 QA Iyyer 等人 (2017);陈 等人 (2020b);朱 等人 (2021); Chen 等人 (2021b, a);李等人 (2022); Nan 等人 (2022). 表格 QA 是一项基于给定表格数据回答问题的任务,而表格 NLI 是一项根据给定表格数据确定假设是蕴含、矛盾或中性的任务。 然而,此类基准测试没有考虑业务规则,也没有考虑 LM 对大型结构化数据库的查询。 桌子 8 显示上述基准测试中每个表的行数比我们的 DQA 基准测试中的小得多。
| Benchmarks | Avg. rows |
|---|---|
| Tabular QA | |
| HybridQA Chen et al. (2020b) | 15.7 |
| TAT-QA Zhu et al. (2021) | 9.5 |
| FinQA Chen et al. (2021b) | 6.26 |
| WikiTableQA Zhu et al. (2021) | 30 |
| Table NLI | |
| TabFact Chen et al. (2020a) | 14.5 |
| ToTTo-TNLI Jena et al. (2022) | 35.8 |
| Decision QA (ours) | |
| Building with RDB | 579.0 |
| Locating with RDB | 2038.8 |
RAG技术 RAG 是使用外部数据增强 LM 生成的最常见方法。 语言模型检索与输入(例如问题)相关的数据,然后根据检索到的观察结果生成响应(例如答案)。 他们中的大多数以单轮(即非迭代)方式运行 Guu 等人 (2020); Izacard 等人 (2023);伊扎卡德和格雷夫 (2021);江等人 (2022b);石等人 (2023); Borgeaud 等人 (2022); Lewis 等人 (2020) 等在需要多跳推理的复杂任务中具有明显的局限性。 为了解决这个问题,人们提出了几种方法来通过迭代执行检索然后生成的过程来增强生成 Jiang 等人 (2023b);邵 等人 (2023); Trivedi 等人 (2023);蒋等人(2023a)。 它在需要多次数据访问才能生成响应的各种任务上表现出了成功的性能 Yang 等人 (2018);索恩等人 (2018);何等人 (2020); Aly 等人 (2021),但在我们的实验中还不足以很好地解决决策任务。
7结论
在本文中,我们探讨了大语言模型作为决策解决方案的能力。 我们提出了新的决策任务, 决策质量保证,它回答了给定复杂决策问题的最佳决策,该问题需要考虑大型数据库(RDB 或 GDB)中表示的业务规则和业务情况。 我们建立了决策 QA 基准,称为 数据质量保证,通过从两个模拟需要决策的真实业务情况的流行视频游戏中提取 301 组数据库(RDB 和 GDB 中)、问题和答案(ground Truth)。 我们还提出了新的 RAG 技术,称为 计划RAG,如果初始计划不够好,它会在检索之前执行计划并重新计划。 通过大量实验,我们证明 PlanRAG 在决策 QA 任务中显着优于 SOTA 迭代 RAG。
8 限制
在本文中,我们探讨了大语言模型作为决策解决方案的能力。 然而,我们的研究仍然存在一些局限性。
首先,在本研究中,我们重点关注使用图数据库或关系数据库的决策 QA。 未来的研究可以探索基于其他数据库的决策,例如数据库和矢量数据库的混合形式。
接下来,我们从高级 RAG 技术角度提出了解决决策 QA 时应考虑的技术。 因此,我们在本文中不关注解决决策 QA 的低级方法。 例如,创建一个可有效生成 Cypher 查询的微调模型可能有利于使用 GDB 解决决策 QA。 这些领域也应该在未来的工作中得到解决。
最后,我们设计了 PlanRAG 方法并使用单个 LM 实现了 PlanRAG-LM,而一些研究建议使用多个 LM 的语言模型框架。 PlanRAG 在多个 LM 框架中的有效性不是本文的重点,留待进一步研究。
9 道德考虑
语言模型存在幻觉问题,可能会产生有偏见的答案。 我们讨论的 RAG 方法可以在一定程度上缓解这些问题,但这并不意味着这些问题不会发生。 因此,当我们的研究应用于现实世界时,有必要仔细检查生成的决策是否是基于幻觉或有偏见的知识推断出来的。
在根据 Europa Universalis IV 和 Victoria 3 游戏构建基准测试和模拟器之前,我们已考虑最终用户许可协议 (EULA)666https://legal.paradoxplaza.com/eula?locale=en 他们的游戏发行商 Paradox Interactive。 我们的基准测试和模拟器对应于 EULA 第 5 节中用户生成内容 (UGC) 的游戏玩法和脚本,因此我们的内容应该是开源的。 因此,我们在 MIT 许可证下开放我们的基准测试和模拟器。 此外,在我们的论文中使用来自这些游戏的所有图标在 EULA 第 6 节中被归类为流式 Paradox 游戏。 根据 EULA,如果我们的论文没有付费墙,我们可以自由使用图标。
我们用来构建 DQA 的视频游戏描述了历史情况。 因此,我们基于这些游戏的数据集包含与当代常识相矛盾的知识,并且可能对某些群体具有攻击性。 例如,在我们基准的定位场景中,特定国家应该影响特定地区的正确答案可能对特定国家或地区具有攻击性。 为了避免这些问题,我们将国家名称匿名化为三个字母的代码,而不是直接提及他们的名字。 例如,不要使用术语 Bahmanis Sultanate777https://en.wikipedia.org/wiki/Bahmani_Sultanate, we employed the term BAH, and instead of The Papel States888https://en.wikipedia.org/wiki/Papal_States, we used PAP 作为术语。
致谢
这项工作得到了韩国政府(MSIT)资助的韩国国家研究基金会(NRF)资助(No. 2018R1A5A1060031,RS-2023-00281635)和韩国政府(MSIT)资助的信息与通信技术规划与评估研究所(IITP)赠款(编号:2018R1A5A1060031,RS-2023-00281635) 2019-0-01267,基于GPU的超快多类型图数据库引擎软件)。
参考
- Akoglu et al. (2015) Leman Akoglu, Hanghang Tong, and Danai Koutra. 2015. Graph based anomaly detection and description: a survey. Data mining and knowledge discovery, 29:626–688.
- Aly et al. (2021) Rami Aly, Zhijiang Guo, Michael Sejr Schlichtkrull, James Thorne, Andreas Vlachos, Christos Christodoulopoulos, Oana Cocarascu, and Arpit Mittal. 2021. The fact extraction and VERification over unstructured and structured information (FEVEROUS) shared task. In Proceedings of the Fourth Workshop on Fact Extraction and VERification (FEVER), pages 1–13, Dominican Republic. Association for Computational Linguistics.
- Borgeaud et al. (2022) Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack W. Rae, Erich Elsen, and Laurent Sifre. 2022. Improving language models by retrieving from trillions of tokens. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pages 2206–2240. PMLR.
- Chen et al. (2021a) Wenhu Chen, Ming-Wei Chang, Eva Schlinger, William Yang Wang, and William W. Cohen. 2021a. Open question answering over tables and text. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net.
- Chen et al. (2020a) Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. 2020a. Tabfact: A large-scale dataset for table-based fact verification. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
- Chen et al. (2020b) Wenhu Chen, Hanwen Zha, Zhiyu Chen, Wenhan Xiong, Hong Wang, and William Yang Wang. 2020b. HybridQA: A dataset of multi-hop question answering over tabular and textual data. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1026–1036, Online. Association for Computational Linguistics.
- Chen et al. (2021b) Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. 2021b. FinQA: A dataset of numerical reasoning over financial data. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3697–3711, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Diván (2017) Mario José Diván. 2017. Data-driven decision making. In 2017 international conference on Infocom technologies and unmanned systems (trends and future directions)(ICTUS), pages 50–56. IEEE.
- Eom and Kim (2006) Sean Eom and E Kim. 2006. A survey of decision support system applications (1995–2001). Journal of the Operational Research Society, 57:1264–1278.
- Francis et al. (2018) Nadime Francis, Alastair Green, Paolo Guagliardo, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Stefan Plantikow, Mats Rydberg, Petra Selmer, and Andrés Taylor. 2018. Cypher: An evolving query language for property graphs. In Proceedings of the 2018 international conference on management of data, pages 1433–1445.
- Guo et al. (2020) Qingyu Guo, Fuzhen Zhuang, Chuan Qin, Hengshu Zhu, Xing Xie, Hui Xiong, and Qing He. 2020. A survey on knowledge graph-based recommender systems. IEEE Transactions on Knowledge and Data Engineering, 34(8):3549–3568.
- Gupta et al. (2002) Vijay Gupta, Emmanuel Peters, Tan Miller, and Kelvin Blyden. 2002. Implementing a distribution-network decision-support system at pfizer/warner-lambert. Interfaces, 32(4):28–45.
- Gupta et al. (2020) Vivek Gupta, Maitrey Mehta, Pegah Nokhiz, and Vivek Srikumar. 2020. INFOTABS: Inference on tables as semi-structured data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2309–2324, Online. Association for Computational Linguistics.
- Guu et al. (2020) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. In International conference on machine learning, pages 3929–3938. PMLR.
- Hedgebeth (2007) Darius Hedgebeth. 2007. Data-driven decision making for the enterprise: an overview of business intelligence applications. Vine, 37(4):414–420.
- Ho et al. (2020) Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. In Proceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625.
- Iyyer et al. (2017) Mohit Iyyer, Wen-tau Yih, and Ming-Wei Chang. 2017. Search-based neural structured learning for sequential question answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1821–1831, Vancouver, Canada. Association for Computational Linguistics.
- Izacard and Grave (2021) Gautier Izacard and Edouard Grave. 2021. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880, Online. Association for Computational Linguistics.
- Izacard et al. (2023) Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research, 24(251):1–43.
- Javaheripi et al. (2023) Mojan Javaheripi, Sébastien Bubeck, Marah Abdin, Jyoti Aneja, Sebastien Bubeck, Caio César Teodoro Mendes, Weizhu Chen, Allie Del Giorno, Ronen Eldan, Sivakanth Gopi, et al. 2023. Phi-2: The surprising power of small language models. Microsoft Research Blog.
- Jena et al. (2022) Aashna Jena, Vivek Gupta, Manish Shrivastava, and Julian Eisenschlos. 2022. Leveraging data recasting to enhance tabular reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 4483–4496, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Jiang et al. (2023a) Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Wayne Xin Zhao, and Ji-Rong Wen. 2023a. Structgpt: A general framework for large language model to reason over structured data. arXiv preprint arXiv:2305.09645.
- Jiang et al. (2022a) Zhengbao Jiang, Luyu Gao, Zhiruo Wang, Jun Araki, Haibo Ding, Jamie Callan, and Graham Neubig. 2022a. Retrieval as attention: End-to-end learning of retrieval and reading within a single transformer. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2336–2349, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Jiang et al. (2022b) Zhengbao Jiang, Luyu Gao, Zhiruo Wang, Jun Araki, Haibo Ding, Jamie Callan, and Graham Neubig. 2022b. Retrieval as attention: End-to-end learning of retrieval and reading within a single transformer. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2336–2349.
- Jiang et al. (2023b) Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023b. Active retrieval augmented generation. arXiv preprint arXiv:2305.06983.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online. Association for Computational Linguistics.
- Kasie et al. (2017) Fentahun Moges Kasie, Glen Bright, and Anthony Walker. 2017. Decision support systems in manufacturing: a survey and future trends. Journal of Modelling in Management, 12(3):432–454.
- Khandelwal et al. (2020) Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. 2020. Generalization through memorization: Nearest neighbor language models. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
- Kwon et al. (2023) Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
- Li et al. (2022) Moxin Li, Fuli Feng, Hanwang Zhang, Xiangnan He, Fengbin Zhu, and Tat-Seng Chua. 2022. Learning to imagine: Integrating counterfactual thinking in neural discrete reasoning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 57–69, Dublin, Ireland. Association for Computational Linguistics.
- Nan et al. (2022) Linyong Nan, Chiachun Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kryściński, Hailey Schoelkopf, Riley Kong, Xiangru Tang, Mutethia Mutuma, Ben Rosand, Isabel Trindade, Renusree Bandaru, Jacob Cunningham, Caiming Xiong, Dragomir Radev, and Dragomir Radev. 2022. FeTaQA: Free-form table question answering. Transactions of the Association for Computational Linguistics, 10:35–49.
- OpenAI (2023) R OpenAI. 2023. Gpt-4 technical report. arXiv, pages 2303–08774.
- Power (2007) Daniel J Power. 2007. A brief history of decision support systems. DSSResources. com, 3.
- Power (2008) Daniel J Power. 2008. Understanding data-driven decision support systems. Information Systems Management, 25(2):149–154.
- Provost and Fawcett (2013) Foster Provost and Tom Fawcett. 2013. Data science and its relationship to big data and data-driven decision making. Big data, 1(1):51–59.
- Sala et al. (2022) Roberto Sala, Fabiana Pirola, Giuditta Pezzotta, and Sergio Cavalieri. 2022. Data-driven decision making in maintenance service delivery process: A case study. Applied Sciences, 12(15):7395.
- Shao et al. (2023) Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. 2023. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy. arXiv preprint arXiv:2305.15294.
- Shi et al. (2023) Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. 2023. Replug: Retrieval-augmented black-box language models. arXiv preprint arXiv:2301.12652.
- Thorne et al. (2018) James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a large-scale dataset for fact extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 809–819, New Orleans, Louisiana. Association for Computational Linguistics.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Trivedi et al. (2023) Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10014–10037, Toronto, Canada. Association for Computational Linguistics.
- Troisi et al. (2020) Orlando Troisi, Gennaro Maione, Mara Grimaldi, and Francesca Loia. 2020. Growth hacking: Insights on data-driven decision-making from three firms. Industrial Marketing Management, 90:538–557.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Computational Linguistics.
- Yao et al. (2023) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Yasunaga et al. (2023) Michihiro Yasunaga, Armen Aghajanyan, Weijia Shi, Richard James, Jure Leskovec, Percy Liang, Mike Lewis, Luke Zettlemoyer, and Wen-Tau Yih. 2023. Retrieval-augmented multimodal language modeling. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pages 39755–39769. PMLR.
- Zhu et al. (2021) Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. 2021. TAT-QA: A question answering benchmark on a hybrid of tabular and textual content in finance. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3277–3287, Online. Association for Computational Linguistics.
附录A附录
A.1数据收集
收集,我们首先从每个游戏中选择提供的保存文件,并通过游戏保存文件解析器提取相关数据。 提取的数据存储在 根据每个场景的数据库模式。 接下来,我们生成 通过应用 的组件 为每个场景预先定义问题格式。 为了控制基准的质量,我们考虑以下几点:
-
•
对于定位场景,我们为每个国家创建一个问题。 作为 利润由决定,我们忽略了低利润的国家 因为它们对决策的影响很小。
-
•
对于建筑场景,我们过滤了具有多个答案的问题。
A.2 数据实例
对于这两种场景,实例共享相同的业务规则。一些实例共享相同的数据库,但并非所有人都使用相同的。 这里,每个数据库 具有不同的行数和不同的列值(例如,LV、建筑物的大小、商品的当前价格)。
在定位场景中,每个实例都有不同的目标,问题模板中具有不同的 {COUNTRY_NODE} 和 {HOME_NODE} 对“我应该在哪里找到我的商人? 我的目标是最大化 {COUNTRY_NODE}在主节点上的利润,{HOME_NODE}”。
在建筑场景中,每个实例在问题模板中都有不同的{GOODS}“我们应该将哪个建筑ID提高5级,以最大程度地降低市场价格” >{商品}?”。
两种场景中的实例都被设计为LM应该检索不同的中间节点和边来计算值,例如用于定位的TPR和TS 对于建筑,需要做出最佳决定。
A.3 标注模拟器
虽然将每个决策应用于真实游戏并比较结果是注释最佳决策的最可信方法,但由于游戏的以下特征,这是不可能的:(1)随机性和(2)不开源。 因此,我们为 DQA 上的每个场景开发模拟器,以确定性地计算决策结果。
A.4模拟器的算法
| Symbol | Description |
| Locating | |
| obj_n | The node we should calculate its flow |
| Nodes | The set of nodes |
| Countries | The set of countries |
| NodeCountry | The set of NodeCountry relationships |
| Simulated_n | The set of nodes which are simulated |
| Building | |
| Goods | The set of goods |
| Buildings | The set of buildings |
| cycle_cnt | # of hops that a building affects |
| Minimum value between and | |
| For , An average of the set |
A.4.1 定位模拟器算法
算法1 描述了定位模拟器的机制。 定位模拟器中有三个不同的函数:“trading_power_estimate”、“flow_estimate”和“find_top_n”。
-
•
trading_power_estimate将数据库作为输入,计算并更新所有的和,并返回更新后的.。
-
•
flow_estimation takes the database and an objective node obj_n as inputs, calculates and updates flow(obj_n, dest) and IV(dest) for all dest such that by using Eq. (2), and returns updated .
-
•
find_top_n将数据库和Simulated_n作为输入,并返回一个节点,使得。如果,则返回空。
A.4.2建筑模拟器算法
我们在算法2中提供了定位模拟器的机制。我们将 初始化为 的总和 避免出现商品价格跌至当地最低价的情况。 我们还限制最大 周期_cnt 为 10 以使我们的模拟器更加高效。
A.5 DQA 中的业务规则
(A) “交易节点”有“local_value”、“total_power”、“outgoing”、“ingoing”以及**是否在内陆**。 一个“国家”有“名称”、“发展”和“home_node”(主节点)。 在“交易节点”之间,可以存在有向边[来源]。 它从较高的节点连接到较低的节点。 “国家”可以与交易节点建立非定向连接。 每个连接对于每个节点都有一个唯一的“base_trading_power”。 如果某个特定节点是某个国家的主节点,则该国家从该节点赚取利润。 利润与“local_value”加上“ingoing”以及该国交易力与该节点总交易力的比率成正比。 即(本地值+流入)*(国家交易功率/总交易功率) 如果某个特定节点是某个国家的本地节点的来源,则该国家将一个值移动到目标节点,该值与该国家的交易力与该节点总交易力的比率和(local_value + ingoing)成正比。 在目标节点中,移动的值增加 1.05 倍并添加到传入的值中。 一个“商人”属于一个国家,可以被分配到特定的交易节点。 属于某个交易节点的“商人”,该国交易节点的交易力增加2,放大1.05倍。 *如果其中一条边有内陆节点,则增加值变为 2+max(development/3, 50)。 (可选)* 如果某个特定的交易节点有多个目的节点,并且没有该节点作为其本国节点的国家在该交易节点上放置了一个“商人”,它可以决定将“商人”移动到哪个目的节点当前值”到。 也就是说,该国可以将与其交易力成比例的“current_value”移动到特定的目标节点。 如果没有放置商户,当目的地节点超过一个时,他们就失去了决定方向的权利。 换句话说,该国的“current_value”与其交易能力成正比,并与其他流向目标节点的资金成正比。 如果只有一个目标节点,那也没关系。 (二) 商品有“名称”、相应的“代码”、“base_price”、“current_price”和“pop_demand”。 建筑物具有唯一的“id”以及与其类型相对应的“名称”和“级别”。 存在一种称为从建筑物到货物的供应的关系。 供应有“max_supply”、“current_output”和“level”。 这里的高度与建筑物的高度相同。 此外,max_supply与level呈正比关系。 存在一种称为商品与建筑物需求的关系。 需求有“max_demand”、“current_input”和“level”。 另外,max_demand 和 level 存在比例关系。 商品的需求定义为商品的“pop_demand”加上与商品相关的所有需求的“max_demand”之和。 商品的供应量由连接到商品的所有供应品的“current_output”之和定义。 需求的“current_input”由连接建筑物的“max_demand”与连接商品的需求之比决定,并乘以商品的供应量。 Supply 的“current_output”由连接建筑物的“current_input”与连接货物“max_demand”的平均比率决定,并乘以 Supply 的“max_supply”。 商品的“current_price”由base_price*(1+0.75(demand-supply)/max(demand,supply))确定。
A.6 DQA 提示
A.6.1 以前基于 RAG 的 LM
图8和9 显示在使用 GDB 设置的定位场景中用于基于 RAG 的单轮决策者 SingleRAG-LM 的提示示例。 数字 10 显示在使用 GDB 设置定位场景中用于基于 RAG 的迭代决策者 IterRAG-LM 的提示示例。 这些提示基于 ReAct 的结构,“思想”-“行动”-“观察”。



A.6.2 基于PlanRAG的LM
用于实现我们基于 PlanRAG 的决策器 PlanRAG-LM 的提示具有“计划”-“思考”-“行动”-“观察”-“重新计划”的结构。 数字 11 显示使用 GDB 设置定位场景的提示示例。 提示结构是通过在两个 DQA 场景中进行的实验凭经验设计的。
在实验中,我们还考虑了提示结构的以下两种变体:(1)在规划后无需对当前步骤进行额外推理即可采取行动(即“计划”-“行动”-“观察”-“重新计划”) ,(2)提前计划的原因(即“想法”-“计划”-“行动”-“观察”-“重新计划”)。 实验采用与 5.1 节相同的设置进行,使用零温度的 GPT-4 作为零样本设置中的基础 LM。
表10 显示了 PlanRAG-LM 的提示结构、上述两种变体以及 IterRAG 的 ReAct 提示结构对于每个 DQA 场景中 10% 问题的实验结果。 在这里,在每个场景中,我们从每个数据库设置中以 10% 的比例随机抽取问题。 结果中,PlanRAG-LM 的提示结构在两种 DQA 场景中均优于其他基线。 与此同时,一种使用“想法”-“计划”-“行动”-“观察”-“重新计划”提示结构的PlanRAG-LM变体未能证明其有效性。 PlanRAG-LM 的另一种变体显示出比 ReAct 结构稍好的性能。 这两个结果之间的差异在于是否要推理每次迭代时要采取的下一步行动(“想法”),或者根据通过规划过程建立的计划(“计划”)采取行动。 “思考”过程的重要性和有效性已在多项研究中得到充分讨论 Yao 等人 (2023);魏等人(2022)。 因此,这些结果可以显示规划过程在决策质量保证等决策任务中的重要性。

| Prompt structure | Locating | Building |
| IterRAG-LM | ||
| Thou-Act-Obs | 37.5 | 30 |
| PlanRAG-LM | ||
| Plan-Thou-Act-Obs-Replan | 57.5 | 50 |
| PlanRAG-LM variations | ||
| Plan-Act-Obs-Replan | 40 | 40 |
| Thou-Plan-Act-Obs-Replan | 27.5 | 30 |
A.7 尝试其他模型
在本节中,我们通过四种不同的模型实现 IterRAG-LM 和 PlanRAG-LM:(1)GPT-3.5999gpt-3.5-turbo-0125,这是最新的gpt-3.5型号。 (2) Llama 2 (70B)、(3) Llama 2 (13B) Touvron 等人 (2023)、(4) Phi-2 Javaheripi 等人 (2023)。 所有实验均在配备 8 个 Nvidia A100 (80GB) GPU 的单台机器上进行。 为了加快推理速度,我们利用 vLLM Kwon 等人 (2023) 库进行开放模型推理。 我们将 GPT-3.5-turbo 和其他开放模型的温度分别设置为 0 和 0.1。 其他设置与章节描述一致 5。我们在表 11 中提供了四种模型的 PlanRAG-LM 和 IterRAG-LM 的结果. 结果,Llama-2 和 Phi-2 模型的 PlanRAG-LM 和 IterRAG-LM 无法解决 DQA 中的任何问题。 通过 GPT-3.5,IterRAG-LM 显示出比 PlanRAG-LM 更好的性能。 这是因为 PlanRAG 的提示过于复杂,GPT-3.5 无法理解指令并生成正确的答案。
| Locating | Building | |||
|---|---|---|---|---|
| Models | RDB | GDB | RDB | GDB |
| GPT-3.5 | ||||
| IterRAG-LM | 8.0 | 2.5 | 22.8 | 3.96 |
| PlanRAG-LM | 0 | 4.0 | 1.0 | 1.0 |
| Llama 2 (70B) | ||||
| IterRAG | 0 | 0 | 0 | 0 |
| PlanRAG | 0 | 0 | 0 | 0 |
| Llama 2 (13B) | ||||
| IterRAG | 0 | 0 | 0 | 0 |
| PlanRAG | 0 | 0 | 0 | 0 |
| Phi-2 | ||||
| IterRAG | 0 | 0 | 0 | 0 |
| PlanRAG | 0 | 0 | 0 | 0 |
A.8重新规划案例
表12 提供 PlanRAG-LM 进行的重新规划的统计数据和示例。 我们将所有重新规划案例分为三组: (1)增加、(2)相同、(3)减少,其中“Increase”表示重新规划后的步数相对于原规划增加,“Same”表示步数与原规划的步数相同,“Decrease”表示步数重新规划后步数减少。
每个类别又分为以下子类别:
-
•
重新订购 包括安排一系列步骤的情况。
-
•
代替 包括一些步骤被新步骤替换的情况。
-
•
改变目标 包括查找或计算等操作目标发生变化的情况。
-
•
添加查找 包括将新查找操作添加到原始计划的情况。
-
•
添加计算 包括将新的计算操作添加到原始计划的情况。
-
•
添加两个操作 包括通过单个重新规划过程将查找和计算操作添加到原始计划的情况。
-
•
划分为子步骤 包括将原始计划的单个步骤分解为详细行动而将其分为子步骤的情况。
-
•
删除 包括从原始计划中删除某些步骤的情况。
-
•
合并 包括将某些步骤汇总或合并为单个步骤的情况。
如表7,由于某些问题需要重新规划两次以上,因此它们可以属于多个类别。 在定位场景中,PlanRAG-LM主要执行“添加查找”的重新规划。 就建筑而言,我们发现“划分为子步骤”是大多数情况下重新规划的主要策略。
![[Uncaptioned image]](x13.png)