EAGER:一种基于行为-语义协作的双流生成式推荐器
摘要。
生成式检索最近已成为序列推荐的一种很有前途的方法,将候选商品检索框架化为自回归序列生成问题。 然而,现有的生成式方法通常只关注商品信息的 行为或语义方面,而忽略了它们互补的本质,因此导致有效性有限。 为了解决这一局限性,我们引入了 EAGER,这是一种新颖的生成式推荐框架,它无缝地整合了行为和语义信息。 具体来说,我们确定了结合这两种类型信息的三大挑战:一种能够处理两种特征类型的统一生成架构,确保每种类型的充分和独立学习,以及促进微妙的交互,从而增强协作信息利用。 为了实现这些目标,我们提出了 (1) 一个双流生成架构,利用共享编码器和两个独立的解码器,通过基于置信度的排序策略对行为符元和语义符元进行解码;(2) 一种带有摘要符元的全局对比任务,以实现每种类型信息的判别式解码;(3) 一种语义引导的转移任务,旨在通过重建和估计目标来隐式地促进交叉交互。 我们在四个公开基准上验证了 EAGER 的有效性,证明了它比现有方法具有更好的性能。 我们的源代码将在 PapersWithCode.com 上公开发布。
1. 引言
推荐系统是广泛采用的解决方案,用于管理信息过载,旨在从大量的商品库中识别用户感兴趣的商品。 现代推荐系统通常集成表示学习和搜索索引构建,以细化匹配过程。 最初,用户和商品使用双塔架构(Yang 等人,2020;Wang 等人,2021) 和序列推荐模型(Kang 和 McAuley,2018;Sun 等人,2019) 等模型编码到共享潜在空间中的潜在表示中。 随后,为了有效地为用户检索 top-k 商品,使用 Faiss(Johnson 等人,2019) 和 SCANN(Guo 等人,2020) 等工具构建近似最近邻 (ANN) 搜索索引。 尽管取得了显著进展,但表示学习和索引构建的独立阶段通常是独立运行的,这给实现端到端优化带来了挑战,并因此限制了推荐系统的整体效果 (Tay 等人,2022).
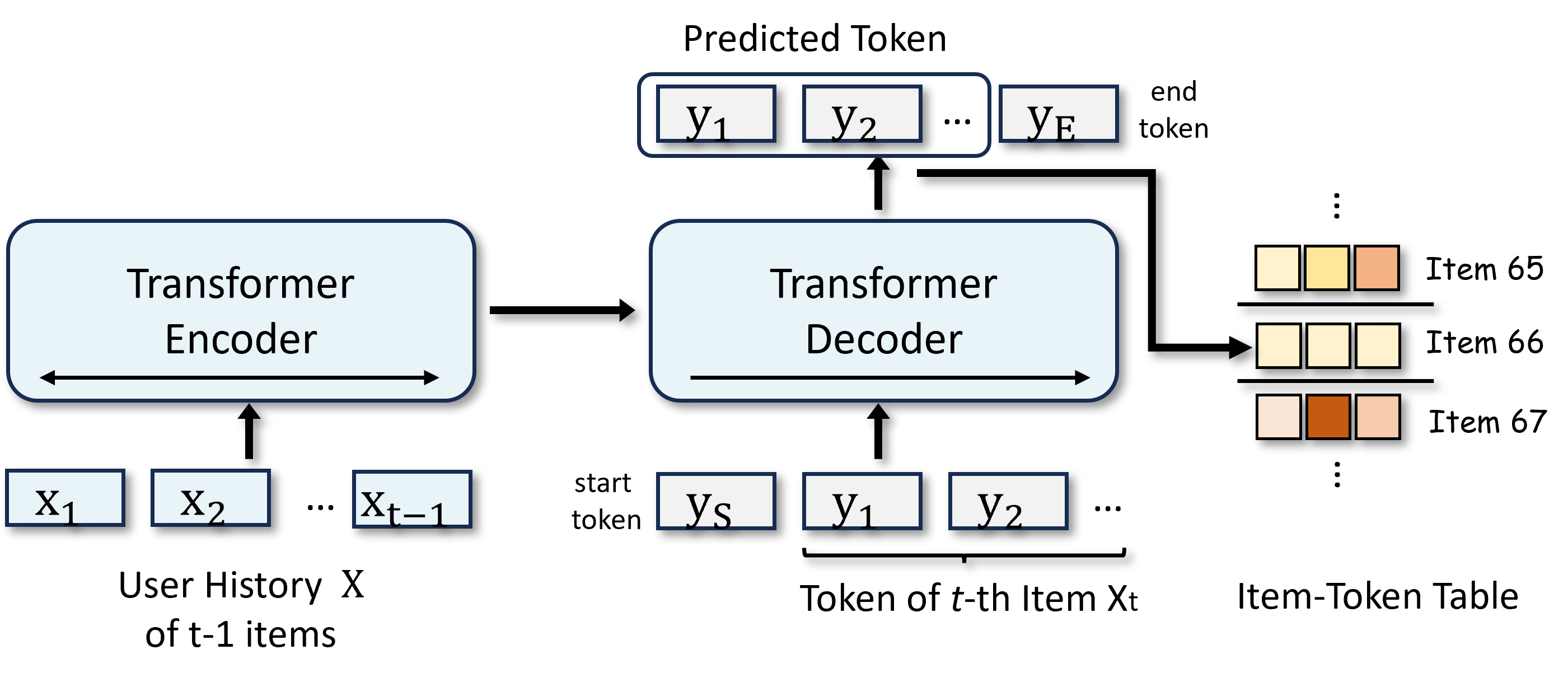
为了解决这一局限性,人们进行了许多研究努力。 一个突出的方向是构建基于树的匹配索引 (Zhu 等人,2018, 2019; Feng 等人,2022),它 为物品优化了匹配模型和树结构索引。 但是,这些方法通常面临挑战,例如由于树结构导致的推理效率低下以及物品语义信息的利用有限 (Feng 等人,2022; Si 等人,2023). 最近,生成式检索 (Li 等人,2024) 已成为信息检索的一种很有前景的新范式,它最近已被应用于生成式推荐 (Rajput 等人,2023). 与传统的基于表示的用户-物品匹配方法不同,这种范式采用了一种端到端的生成模型,该模型以自回归方式直接预测候选物品标识符。 具体而言,这些方法首先将每个物品 标记化为一组离散的语义代码 1 11注意,我们使用“代码”和“符元”可以互换。 ,然后利用编码器-解码器模型(例如 Transformer (Vaswani 等人,2017))作为端到端索引进行检索。 在这种设置中,编码器对用户和物品之间的交互历史 进行编码,而解码器预测下一个物品 的代码序列 . 整个框架如图 1 1 所示。
但是,现有的生成式推荐方法在利用物品信息方面存在一个重大缺陷,通常仅侧重于行为或语义方面的狭隘范围。 行为信息源于用户-物品交互历史,而语义信息包括物品的文本或视觉描述。 例如,RecForest (Feng 等人,2022) 利用预训练的 DIN 模型 (Zhou 等人,2018) 来提取基于行为的物品嵌入以构建语义代码,而 TIGER 利用 Sentence-T5 模型 (Ni 等人,2022) 从文本描述中得出基于语义的物品嵌入。 然而,这些方法通常只关注一个方面,而忽略了行为和语义之间的互补关系。 一方面,BERT (Devlin 等人,2018) 和 ViT (Dosovitskiy 等人,2020) 等预训练模态编码器的进步促进了多模态特征的集成,增强了先验知识,并在多模态推荐模型 (Liu 等人,2024b) 中得到了广泛应用。 另一方面,行为数据通过交互序列捕捉用户特定的偏好,使其在推荐场景中特别有效。 相反,语义信息提供了更广泛、更无偏的洞察力,了解商品特征,促进跨不同领域的泛化。
在本文中,我们提出了 EAGER,一种新颖的双流 EAm GEnerati-ve Recommender,具有行为-语义协同。 我们分析了在统一的生成框架内建模行为和语义的挑战,并从以下三个方面解决了这些挑战:
首先,处理两种不同类型信息的 统一生成架构 至关重要。 鉴于行为和语义在特征空间上的固有差异,直接通过编码器侧的特征融合来集成它们会带来挑战,正如之前的双塔模型 (Yuan 等人,2023; Shan 等人,2023) 所示。 因此,我们的方法为行为和语义构建了独立的代码,采用双流生成架构,其中每个流在解码器侧充当不同的监督信号。 该架构包括一个共享编码器,用于编码用户交互历史,以及两个独立的解码器,分别用于预测行为和语义代码,从而避免过早的特征交互。 在推断过程中,我们利用每个流的预测熵作为商品排序的置信度度量,来增强来自两个流的结果的合并,确保有效的预测。
其次,确保 充分且独立的学习 至关重要,以充分利用每种类型信息的潜在价值。 以前的工作 (Rajput 等人,2023) 通常采用自回归方法来逐个学习每个符元,专注于离散和局部信息,而不是捕捉全局洞察力。 在 EAGER 中,我们引入了带有摘要符元的全局对比任务。 此模块的灵感来自两个主要来源:(1) 传统双塔模型使用对比学习来获取有区别的商品特征。 同样,我们旨在使我们的解码器模型在自回归生成能力之外掌握全局判别能力,从而在对比范式中增强商品特征的提取;(2) Transformer 模型 (Devlin 等人,2018; Dosovitskiy 等人,2020) 利用特殊符元来封装全局信息,促使我们在符元序列的末尾附加一个摘要符元。 此符元以单向的方式总结了累积的知识,充当蒸馏的中心点。
第三,虽然单独的解码和预测重排序已被证明有效,但整合微妙的交互可以增强两种知识流的共享。 如前所述,直接的特征级交互通常会产生次优的结果 (Yuan 等人,2023)。 因此,我们引入了一个精心设计的语义引导迁移任务,以促进隐式知识交换。 具体而言,我们提出语义信息可以指导行为方面,并设计了一个具有双重目标的辅助 Transformer:重建和识别。 重建目标涉及使用全局语义特征预测掩盖的行为符元,而识别目标旨在区分行为符元是否与指定的全局语义特征一致。 通过这些目标,该模块使用 Transformer 模型间接优化行为特征和语义特征之间的交互。
总之,我们的主要贡献如下:
-
•
我们引入了 EAGER,这是一个新颖的生成推荐框架,它将行为和语义信息协同整合。
-
•
我们提出了一种统一的双流生成架构,设计了一个带有摘要符元的全局对比模块,以确保充分的独立学习,并引入了用于微妙交互的语义引导迁移模块。
-
•
在四个公开的推荐基准上进行的大量实验表明,EAGER 优于现有方法,包括生成范式和传统范式。
2. 相关工作
顺序推荐。 使用深度顺序模型来捕捉推荐系统中的用户-项目模式已发展成为一个丰富的文献。 GRU4REC (Jannach 和 Ludewig,2017) 是第一个使用基于 GRU 的 RNN 进行顺序推荐的。 SASRec (Kang 和 McAuley,2018) 采用自注意力机制,类似于仅解码器的 Transformer 模型。 受语言任务中掩码语言建模成功的启发,BERT4Rec (Sun 等人,2019) 利用带掩码策略的 Transformer 模型来执行顺序推荐任务。 -Rec (Zhou 等人,2020) 不仅依赖掩码,而且通过四个自监督任务对嵌入进行预训练,以提高项目和用户嵌入的质量。 上述方法主要依赖于近似最近邻 (ANN) 搜索索引(例如,Faiss (Johnson 等人,2019))来检索下一个项目。 此外,基于树的方法 (Feng 等人,2022;Zhu 等人,2018, 2019) 在推荐系统中表现出良好的性能。 例如,RecForest (Feng 等人,2022) 通过创建多棵树来构建一个森林,并整合一个基于 Transformer 的结构来执行路由操作。 最近,TIGER (Rajput 等人,2023) 引入了语义 ID 的概念,其中每个项目都表示为一组从其侧边信息中提取的符元,然后以 seq2seq 的方式预测下一个项目符元。 在这项工作中,我们旨在进一步探索一种双流生成架构,将其用作 top-k 项目检索的端到端索引。
生成式检索。 生成式检索 (Li 等人,2024) 近来被提出作为一种新的检索范式,它包含两个主要阶段:离散语义符元化 (Liu 等人,2024a;Jin 等人,2024, 2023) 和自回归序列生成 (Tay 等人,2022;Wang 等人,2022;Rajput 等人,2023)。 在文档检索领域,研究人员已经探索使用预训练语言模型来生成各种类型的文档标识符。 值得注意的是,DSI (Tay 等人,2022) 和 NCI (Wang 等人,2022) 利用 T5 (Raffel 等人,2020) 模型来生成分层的文档 ID。 相反,SEAL (Bevilacqua 等人,2022)(使用 BART (Lewis 等人,2020) 主干)和 ULTRON (Zhou 等人,2022)(使用 T5)使用标题或子字符串作为标识符。 另一种方法,AutoTSG (Zhang 等人,2023a),采用术语集用于识别目的。 生成式文档检索也已扩展到各个领域。 例如,IRGen (Zhang 等人,2023b) 使用基于 ViT 的模型进行图像搜索,而 TIGER (Rajput 等人,2023) 利用 T5 进行推荐系统。 然而,由于预训练语言模型的资源密集型特性,这些研究往往在推荐系统中大规模项目检索方面面临挑战。 相反,我们的论文深入探讨了在这些系统中将行为和语义集成到生成式检索中。
3. 方法
3.1. 问题公式
给定用户的全部项目集 和交互项目历史 ,序列推荐系统会返回下一个项目 的项目候选列表。
在生成式推荐中,每个项目 的标识符表示为序列化代码 ,其中 是代码的长度。 生成模型的目标是学习一个映射 ,该映射将用户的交互项目序列作为输入,并生成项目代码(候选标识符)。 为了训练,模型首先将用户的行为 输入到编码器中,然后利用自回归解码器逐步生成项目代码 。 交互的概率可以通过以下公式计算:
| (1) |
在推理过程中,解码器在选择前 N 个候选者时对顺序代码执行束搜索。
3.2. 整体流程
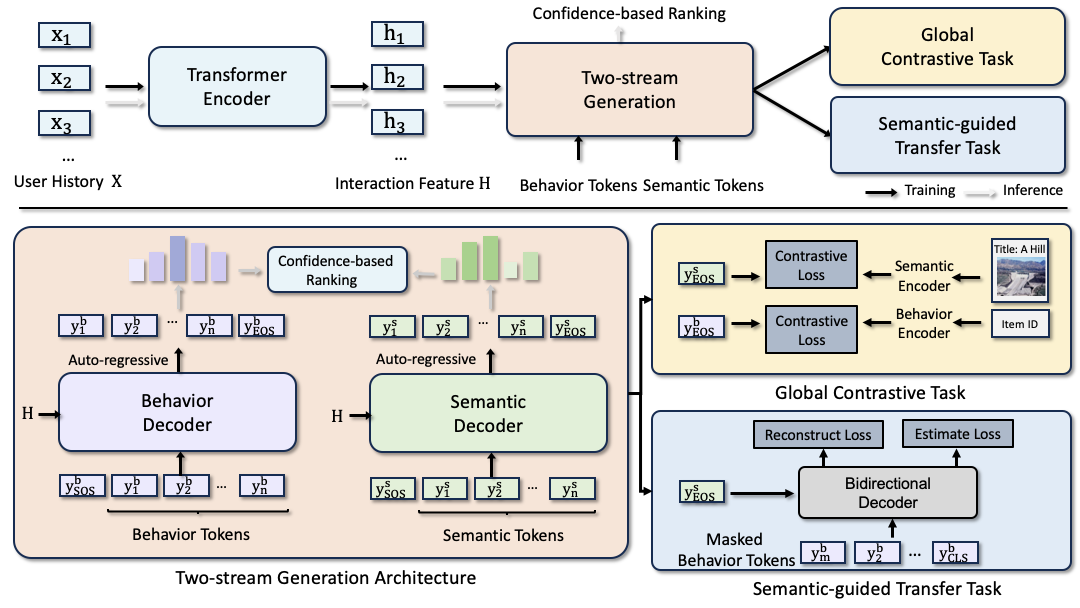
我们在 图 2 中展示了我们的整体 EAGER 框架。 EAGER 包括 (1) 一个双流生成架构,用于统一针对行为和语义信息的项目推荐,(2) 一个带有摘要符元的全局对比任务,用于捕获全局知识以改善自回归生成质量,以及 (3) 一个语义引导迁移任务,用于实现跨信息和跨解码器交互。
首先,在我们的双流生成架构中,我们对用户交互历史进行建模,并通过编码器获取交互特征。 然后,我们提取行为和语义特征以构建两个代码,并利用两个解码器以自回归的方式分别预测它们。 同时,我们在全局对比任务中优化一个摘要符元,并利用它来改进语义引导迁移任务中的跨解码器交互。 训练后,我们采用基于置信度的排序策略来合并来自两种不同预测的结果。
3.3. 双流生成架构
为了处理两种不同的信息,即行为和语义,我们利用了 Transformer 模型强大的建模能力,并设计了双流生成架构。 此框架由一个用于建模用户交互的共享编码器、两个用于双流生成的独立代码和解码器组成。
共享编码器。 用户交互历史 的序列建模基于 Transformer 中提出的堆叠多头自注意力层和前馈层。 值得注意的是,我们只采用了一个共享编码器,而不是两个编码器,这足以生成丰富的表示,以便随后进行独立解码。 我们将编码的交互历史特征表示为 。
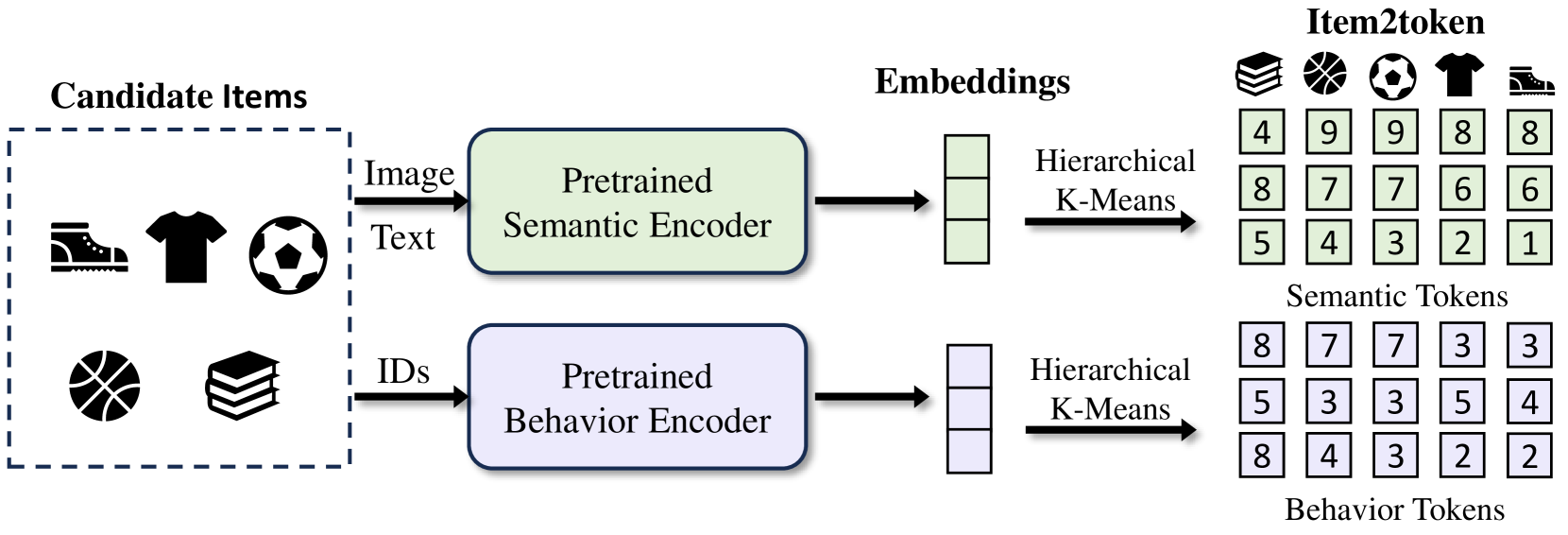
双代码。 我们首先使用两个预训练模型提取行为和语义项目嵌入 和 ,其中行为编码器是一个双塔模型(例如 DIN (Zhou et al., 2018)),它只使用 ID 序列进行推荐,而语义编码器是一个通用模态表示模型(例如 Sentence-T5)。 对于这两个提取的嵌入,我们分别对每个嵌入应用广泛使用的层次化 k 均值算法,其中每个集群被均匀地划分为 K 个子集群,直到每个子集群只包含一个单一项目。 如 图 3 所示,我们可以获得两个代码 和 ,分别对应于行为和语义。
双解码器。 为了适应两种不同的代码,我们采用两个独立的解码器来解码和生成每个代码的预测,使每个解码器专门化于一种代码。 与一个共享解码器以自回归方式生成两个标识符相比,这种设计减轻了监督差异,并通过并行生成提供了更高的效率。 对于训练,我们在代码 的开头添加一个开始符元 来构建解码器输入 并利用交叉熵损失进行预测。 总损失 是两个生成损失 和 的总和,其中每个损失由以下公式给出:
| (2) |
3.4. 全局对比任务
为了赋予每个生成解码器足够的判别能力,我们设计了一个带有摘要符元的全局对比任务来提取全局知识。
摘要符元。 对于每个解码器的输入 ,我们考虑自回归生成的从左到右顺序,并在序列末尾插入一个可学习的符元 来构建修改后的输入 。 这种设计鼓励代码中的前序符元学习更全面和更有判别力的知识,使最终的符元能够进行摘要。 在更新期间,摘要符元上的梯度可以反向传播到前序符元。
对比蒸馏。 为了使摘要符元捕获全局信息,我们采用对比学习范式来提取项目嵌入 和 从预训练的编码器。 在这里,我们采用仅正对比度度量 (Chen 和 He, 2021) 而不是常用的 Info-NCE (Chen 等人,2020) 来实现此目标。 总损失 由两个损失 和 的总和给出,其中每个损失由以下公式给出:
| (3) |
其中 对应于摘要符元 的嵌入,而 是度量函数,例如 平滑 。
3.5. 语义引导的迁移任务
通过上述组件,我们的模型可以有效地利用两种类型的信息进行预测。 然而,我们并不止步于此。 而不是完全独立的解码,我们进一步提出了一种语义引导的迁移任务,以利用语义知识来指导行为学习。
为了在避免直接交互的同时实现两侧之间的知识流动,我们构建了一个独立的双向 Transformer 解码器作为辅助模块。 我们首先在行为代码的开头添加一个标记 ,以获得序列 作为解码器的输入。 然后将语义摘要标记 的嵌入 输入到交叉注意力中,允许解码器中的每个行为标记关注语义的全局特征。 我们将输出特征表示为 。 为了进行迁移训练,我们设计了以下两个目标:重建和识别。
重建。 我们通过语义全局特征重建掩码行为代码,旨在使每个行为标记受益于语义。 对于重建训练,我们随机屏蔽行为代码中的 m% 的标记,以获得掩码代码 ,其中 表示掩码标记。 然后,我们获得相应的输出特征 并应用对比损失来通过以下方式开发重建:
| (4) | ||||
其中 是 个掩码标记的地面真值的特征, 是采样标记的特征。
识别。 此外,我们还构建了一个二元分类器来判断行为代码是否与语义全局特征相关。 对于识别训练,我们通过用采样的不相关标记随机替换行为代码中的 m% 标记来构造负样本,例如[23, 123, 32] [23, 145, 32]。 我们在 token [CLS] 的相应输出上添加一个线性层,并利用具有 sigmoid 激活的线性层来计算正/负样本的分数 。 二元交叉熵损失用于识别,由以下公式给出:
| (5) |
3.6. 训练和推理
训练。 我们将生成、对比、重建和识别损失结合起来训练我们的模型,由以下公式给出:
| (6) |
其中 和 是损失系数。
基于置信度的排序推理。 由于我们从行为流和语义流中得到了两个结果,因此我们首先通过每个流的束搜索获得前- 个预测。 利用 2* 个预测代码,我们计算代码上的对数概率作为每个预测的置信度分数,这类似于语言模型中使用的困惑度,越低的值表示更高的置信度。 最后,我们根据置信度分数对这些预测进行排名,并获得前- 个预测,这对应于 个项目。
| Dataset | #Users | #Items | #Interactions | #Density |
|---|---|---|---|---|
| Beauty | 22,363 | 12,101 | 198,360 | 0.00073 |
| Sports and Outdoors | 35,598 | 18,357 | 296,175 | 0.00045 |
| Toys and Games | 19,412 | 11,924 | 167,526 | 0.00073 |
| Yelp | 30,431 | 20,033 | 316,354 | 0.00051 |
| Dataset | Metric | Traditional | Transformer-based | Tree-based | Generative | Improv. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GRU4REC | Caser | HGN | SASRec | Bert4Rec | S^3-Rec | TDM | Recforest | TIGER | EAGER | |||
| Beauty | Recall@5 | 0.0164 | 0.0205 | 0.0325 | 0.0387 | 0.0203 | 0.0387 | 0.0442 | 0.0470∗ | 0.0454 | 0.0618 | 31.49% |
| Recall@10 | 0.0283 | 0.0347 | 0.0512 | 0.0605 | 0.0347 | 0.0647 | 0.0638 | 0.0664∗ | 0.0648 | 0.0836 | 25.90% | |
| Recall@20 | 0.0479 | 0.0556 | 0.0773 | 0.0902 | 0.0599 | 0.0994 | 0.0876 | 0.0915∗ | - | 0.1124 | 13.08% | |
| NDCG@5 | 0.0099 | 0.0131 | 0.0206 | 0.0249 | 0.0124 | 0.0244 | 0.0323 | 0.0341∗ | 0.0321 | 0.0451 | 32.26% | |
| NDCG@10 | 0.0137 | 0.0176 | 0.0266 | 0.0318 | 0.0170 | 0.0327 | 0.0376 | 0.0400∗ | 0.0384 | 0.0525 | 31.25% | |
| NDCG@20 | 0.0187 | 0.0229 | 0.0332 | 0.0394 | 0.0233 | 0.0414 | 0.0438 | 0.0464∗ | - | 0.0599 | 29.09% | |
| Sports | Recall@5 | 0.0129 | 0.0116 | 0.0189 | 0.0233 | 0.0115 | 0.0251 | 0.0127 | 0.0149∗ | 0.0264 | 0.0281 | 6.44% |
| Recall@10 | 0.0204 | 0.0194 | 0.0313 | 0.0350 | 0.0191 | 0.0385 | 0.0221 | 0.0247∗ | 0.0400 | 0.0441 | 10.25% | |
| Recall@20 | 0.0333 | 0.0314 | 0.0477 | 0.0507 | 0.0315 | 0.0607 | 0.0349 | 0.0375∗ | - | 0.0659 | 8.57% | |
| NDCG@5 | 0.0086 | 0.0072 | 0.0120 | 0.0154 | 0.0075 | 0.0161 | 0.0096 | 0.0101∗ | 0.0181 | 0.0184 | 1.66% | |
| NDCG@10 | 0.0110 | 0.0097 | 0.0159 | 0.0192 | 0.0099 | 0.0204 | 0.0110 | 0.0133∗ | 0.0225 | 0.0236 | 4.89% | |
| NDCG@20 | 0.0142 | 0.0126 | 0.0201 | 0.0231 | 0.0130 | 0.0260 | 0.0141 | 0.0164∗ | - | 0.0291 | 11.92% | |
| Toys | Recall@5 | 0.0097 | 0.0166 | 0.0321 | 0.0463 | 0.0116 | 0.0443 | 0.0305 | 0.0313∗ | 0.0521 | 0.0584 | 12.09% |
| Recall@10 | 0.0176 | 0.0270 | 0.0497 | 0.0675 | 0.0203 | 0.0700 | 0.0359 | 0.0383∗ | 0.0712 | 0.0714 | 0.28% | |
| Recall@20 | 0.0301 | 0.0420 | 0.0716 | 0.0941 | 0.0358 | 0.1065 | 0.0442 | 0.0483∗ | - | 0.1024 | -3.85% | |
| NDCG@5 | 0.0059 | 0.0107 | 0.0221 | 0.0306 | 0.0071 | 0.0294 | 0.0214 | 0.0260∗ | 0.0371 | 0.0464 | 25.07% | |
| NDCG@10 | 0.0084 | 0.0141 | 0.0277 | 0.0374 | 0.0099 | 0.0376 | 0.0230 | 0.0285∗ | 0.0432 | 0.0505 | 16.90% | |
| NDCG@20 | 0.0116 | 0.0179 | 0.0332 | 0.0441 | 0.0138 | 0.0468 | 0.0284 | 0.0310∗ | - | 0.0538 | 14.96% | |
| Yelp | Recall@5 | 0.0152 | 0.0151 | 0.0186 | 0.0162 | 0.0051 | 0.0201 | 0.0181 | 0.0220∗ | 0.0212∗ | 0.0265 | 20.45% |
| Recall@10 | 0.0263 | 0.0253 | 0.0326 | 0.0274 | 0.0090 | 0.0341 | 0.0287 | 0.0302∗ | 0.0367∗ | 0.0453 | 12.69% | |
| Recall@20 | 0.0439 | 0.0422 | 0.0535 | 0.0457 | 0.0161 | 0.0573 | 0.0422 | 0.0449∗ | 0.0552∗ | 0.0724 | 11.56% | |
| NDCG@5 | 0.0099 | 0.0096 | 0.0115 | 0.0100 | 0.0033 | 0.0123 | 0.0121 | 0.0119∗ | 0.0146∗ | 0.0177 | 3.51% | |
| NDCG@10 | 0.0134 | 0.0129 | 0.0159 | 0.0136 | 0.0045 | 0.0168 | 0.0154 | 0.0163∗ | 0.0194∗ | 0.0242 | 18.63% | |
| NDCG@20 | 0.0178 | 0.0171 | 0.0212 | 0.0182 | 0.0063 | 0.0226 | 0.0208 | 0.0210∗ | 0.0230∗ | 0.0311 | 19.62% | |
4. 实验
我们分析了提出的 EAGER 方法,并通过回答以下研究问题来证明其有效性:
-
•
RQ1:在不同的数据集之间,EAGER 的性能与现有的最佳顺序推荐方法相比如何?
-
•
RQ2:双流生成架构、全局对比任务模块和语义引导迁移任务模块都对 EAGER 的有效性有贡献吗?
-
•
RQ3:不同的消融变体和超参数设置如何影响 EAGER 的性能?
4.1. 实验设置
数据集。 我们在顺序推荐任务中常用的四个开源数据集上进行了实验。 对于所有数据集,我们按用户对交互记录进行分组,并按交互时间戳升序排列。 遵循 (Rendle 等人,2010;Zhang 等人,2019),我们只保留 5 核数据集,该数据集过滤掉交互记录少于 5 个的非热门项目和非活跃用户。 这些数据集的统计数据如表 1 所示。
-
•
亚马逊:亚马逊产品评论数据集 (McAuley 等人,2015),包含 1996 年 5 月至 2018 年 7 月的用户评论和项目元数据。 在这里,我们使用三个类别(美容、运动和户外、玩具和游戏)进行评估。
-
•
Yelp 2019222https://www.yelp.com/dataset:Yelp Challenge 发布了针对小型企业(例如餐馆)的评论数据。 遵循先前的设置 (Zhou 等人,2020),我们仅使用从 2019 年 1 月 1 日 到 2019 年 12 月 31 日 的交易记录。 我们将这些企业视为项目。
| Variants | Beauty | Toys and Games | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TSG | GCT | STT | R@5 | NDCG@5 | R@10 | NDCG@10 | R@20 | NDCG@20 | R@5 | NDCG@5 | R@10 | NDCG@10 | R@20 | NDCG@20 |
| 0.0512 | 0.0370 | 0.0699 | 0.0430 | 0.0943 | 0.0491 | 0.0436 | 0.0344 | 0.0545 | 0.0379 | 0.0657 | 0.0407 | |||
| ✓ | 0.0582 | 0.0425 | 0.0795 | 0.0496 | 0.1034 | 0.0567 | 0.0526 | 0.0428 | 0.0646 | 0.0469 | 0.0879 | 0.0510 | ||
| ✓ | ✓ | 0.0604 | 0.0439 | 0.0815 | 0.0514 | 0.1091 | 0.0587 | 0.0563 | 0.0454 | 0.0699 | 0.0497 | 0.0974 | 0.0525 | |
| ✓ | ✓ | ✓ | 0.0618 | 0.0451 | 0.0836 | 0.0525 | 0.1124 | 0.0599 | 0.0584 | 0.0464 | 0.0714 | 0.0505 | 0.1024 | 0.0538 |
评估指标。 我们采用两个广泛使用的匹配阶段标准,即。 即,召回率和归一化折扣累积增益 (NDCG)。 我们报告了在排名前 5/10/20 个推荐候选人中计算的指标。 遵循标准评估协议 (Kang 和 McAuley,2018),我们在评估中使用留一法策略。 对于每个项目序列,最后一个项目用于测试,倒数第二个项目用于验证,其余项目用于训练。 在训练期间,我们限制用户历史记录中项目的数量为 20。
实现细节。 对于双流生成架构,我们将编码器层的数量设置为 1,解码器层的数量设置为 4。 遵循之前的工作 (Feng 等人,2022;Rajput 等人,2023),我们采用预训练的 DIN 作为我们的行为编码器,Sentence-T5 作为我们的语义编码器,并将隐藏大小设置为 128,如 (Rajput 等人,2023) 中所报道。 层次 k 均值中的聚类数量 设置为 256。 对于全局对比任务,我们采用平滑 距离作为蒸馏损失。 对于语义引导的迁移任务,我们随机屏蔽 50% 的行为代码用于重建,并随机用采样的代码替换 50% 的行为代码,以构建用于识别的负样本对。 为了训练我们的模型,我们采用 Adam 优化器,学习率为 0.001,并使用预热策略来确保训练稳定。 EAGER 对 GCT 和 STT 任务的超参数并不敏感,因为这些任务收敛速度很快。 所以损失系数 均设置为 1。
4.2. 性能比较 (RQ1)
基线。 用于比较的基线方法可以分为以下四类:
(1) 对于 传统的顺序 方法,我们有:
-
•
GRU4REC (Hidasi 等人,2015): 将循环神经网络引入推荐的早期尝试。
-
•
Caser (Tang 和 Wang,2018): 一种基于 CNN 的方法,通过应用水平和垂直卷积运算来捕获顺序推荐的高阶马尔可夫链。
-
•
HGN (Ma 等人,2019): 它采用分层门控网络来捕获用户的长期和短期兴趣。
(2) 对于 基于 Transformer 的 方法,我们有:
-
•
SASRec (Kang 和 McAuley,2018): SASRec 使用 Transformer 编码器来模拟用户的行为,其中多头注意力机制非常重要。
-
•
BERT4Rec (Sun 等人,2019): 它使用双向自注意力机制的闭合目标损失来进行顺序推荐。
-
•
S^3-Rec (Zhou 等人,2020): S^3-Rec 提出对自监督任务进行双向 Transformer 的预训练,以改进顺序推荐。
(3) 对于 基于树的 方法,我们有:
-
•
TDM (Zhu et al., 2018): TDM 使用树索引来组织项目(树中的每个叶子节点对应一个项目),并设计了一个基于最大堆的树模型用于检索。
-
•
RecForest (Feng et al., 2022): RecForest 构建了一个包含多个 k 分支树的森林,并集成了基于 Transformer 的结构用于路由操作。
(4) 对于 生成式 方法,我们有:
-
•
TIGER (Rajput et al., 2023): TIGER 使用预训练的 T5 为每个项目学习语义 ID,并自动回归地解码目标候选的语义 ID。
结果。 表 2 报告了四个数据集的整体性能。 所有没有上标 ∗ 的基线结果来自公开可访问的结果 (Rajput et al., 2023; Zhou et al., 2020)。 对于缺失的统计数据,我们重新实现了基线并报告了我们的实验结果。 从结果中,我们有以下观察结果:
-
•
EAGER 几乎在不同数据集上都取得了比基线模型更好的结果。 尤其是在 Beauty 基准上,EAGER 的表现明显优于第二好的基线,与 TIGER 相比,Recall@5 提高了 31.49%,NDCG@5 提高了 32.26%。 同样地,在更大的 Yelp 数据集上,EAGER 的 Recall@5 和 NDCG@5 分别提高了 20.45% 和 3.51%。 我们将这些改进归因于 EAGER 成功地将行为和语义信息整合到一个具有双重标识符的双流统一生成架构中。
-
•
EAGER 在大多数数据集上都超过了之前的生成模型。 EAGER 与现有模型的不同之处在于其双流解码器架构和多任务训练,这有助于更深入地理解行为语义关系,并捕捉代码间关键的全局信息。 这些优异的改进验证了我们设计的有效性和将行为和语义信息结合在一起的必要性。
-
•
在四个数据集上,生成模型在大多数情况下都优于其他传统的基线模型。 这种局限性可能源于使用了一种简单的内积匹配方法,这种方法可能会限制它们有效地建模复杂的用户-物品交互的能力。 此外,在实际场景中,ANN 索引的构建主要集中在实现快速匹配上,由于优化目标不一致,导致性能进一步下降。 然而,这一挑战可以通过利用束搜索策略直接预测物品代码的生成方法来克服,从而提高模型的弹性和鲁棒性。
4.3. 消融研究 (RQ2)
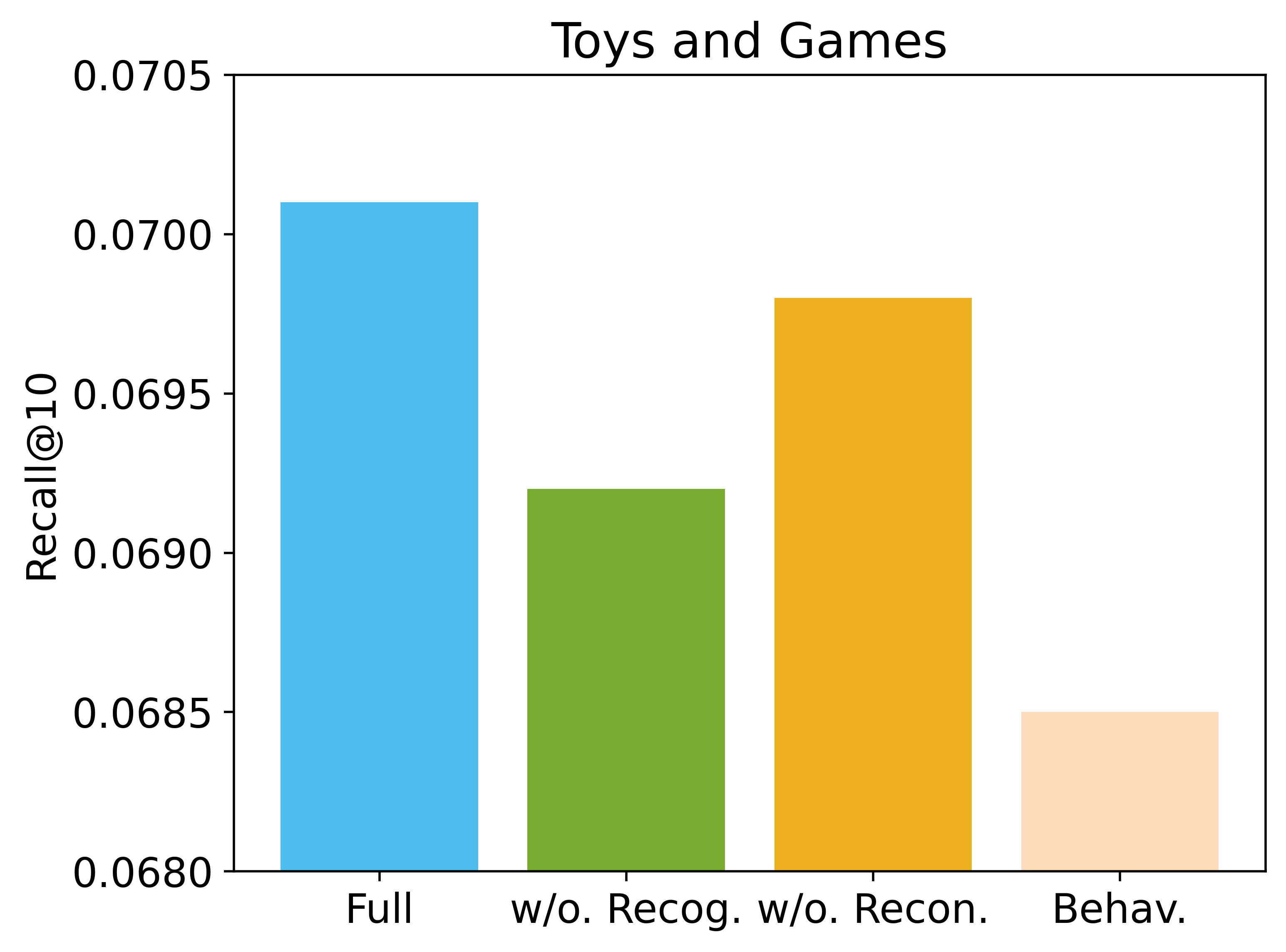
我们通过消融研究评估了 EAGER 组件对性能的影响。 具体来说,我们逐步从 EAGER 中删除语义引导迁移任务 (STT)、全局对比任务 (GCT) 和双流生成架构 (TSG),以获得消融架构。 结果如表 3 所示,我们可以观察到:
-
•
删除任何 TSG、GCT 或 STT 都会导致性能下降,而删除所有模块 (i。e。,基础模型) 则会导致不同数据集之间最差的性能。 这些结果证明了所提出的三个模块的有效性和鲁棒性,以及双流生成范式的优势。
-
•
删除 GCT 会导致比删除 STT 更多的性能下降,这表明代码间全局信息的蒸馏略微比代码内知识流更重要。 该观察结果还突出了这两个任务在使模型能够获得更强大的双重物品标识符方面的关键作用。
-
•
删除 TSG 会导致最大的性能下降,这表明基础模型可以通过整合物品的行为-语义信息来显著提高其性能。 结果再次验证了具有置信度排序的双解码器架构的优越性。
4.4. 模型分析 (RQ3)
| Dataset | Yelp | |||
|---|---|---|---|---|
| Information | R@5 | NDCG@5 | R@10 | NDCG@10 |
| Behav+Text | 0.0265 | 0.0177 | 0.0453 | 0.0242 |
| Behav+Vis | 0.0259 | 0.0171 | 0.0440 | 0.0236 |
| Behav+Text+Vis | 0.0283 | 0.0187 | 0.0484 | 0.0252 |
| Dataset | Beauty | |||
|---|---|---|---|---|
| Type | R@5 | NDCG@5 | R@10 | NDCG@10 |
| Head | 0.0473 | 0.0337 | 0.0612 | 0.0401 |
| Mean | 0.0559 | 0.0431 | 0.0760 | 0.0502 |
| Tail | 0.0604 | 0.0439 | 0.0815 | 0.0514 |
| Dataset | Toys and Games | |||
| Type | R@5 | NDCG@5 | R@10 | NDCG@10 |
| Head | 0.0441 | 0.0303 | 0.0513 | 0.0343 |
| Mean | 0.0522 | 0.0406 | 0.0617 | 0.0446 |
| Tail | 0.0563 | 0.0454 | 0.0699 | 0.0497 |
| DIN | RecForest | TIGER | EAGER | |
| Speed | 0.2349 | 0.0499 | 0.0281 | 0.0325 |
| Parameters | 93 | 51 | 14 | 87 |
双流生成架构分析。 为了进一步探索双流结构在整合行为和语义方面的作用,我们在 Yelp 上进行了引入视觉特征的实验。 我们使用 ViT-B 来提取商品封面的图像特征,然后执行相同的操作来获取基于视觉的语义代码。 如表所示,我们可以看到:(1)文本语义特征和行为信息的结合比视觉语义特征的结合更有效。 这可能是因为文本包含比视觉语义更直观、更丰富的信息,而视觉语义可能过于抽象和嘈杂。 (2)此外,我们构建了一个三流架构,将文本语义、视觉语义和行为信息同时整合在一起,从而提高了性能。 这种现象进一步反映了我们的架构在无缝整合不同类型信息方面的有效性和通用性。
全局对比任务分析。 正如第 3.4 节中分析的那样,我们认为自回归解码器缺乏判别能力。 为了解决这个问题,我们设计了一个额外的全局符号,从预训练的行为/语义编码器中提取全局知识。 在本研究中,我们专注于调查不同符号类型和对比度量对模型性能的影响。
-
•
符元类型。 摘要符元的設計至關重要,因为它代表着全局信息,同時影響着代碼的自動回歸生成。 我们研究了三种符元类型:’Head’ 将符元放在代码开头,’Tail’ 将符元放在代码末尾,’Mean’ 直接使用代码特征的平均值。 表中的结果表明 ’Tail’ 实现了最佳性能,这与我们之前的讨论一致。 将符元放在开头会导致由于频繁更新而导致的自动回归生成训练不稳定,而直接平均会影响代码特征,导致与生成式训练冲突。 相反,将符元放在末尾既不会直接影响前面代码的生成,也不会通过梯度反转间接优化代码表示。
-
•
对比度量。 在实验中,我们评估了三种广泛采用的距离度量的性能,例如余弦、InfoNCE 和 Smooth ,作为损失函数。 表 7 中呈现的结果表明,仅正例对比度量,特别是余弦和 Smooth ,优于常用的 InfoNCE。 这种优势可以归因于两个主要原因:(1) 仅正例对比学习方法,结合冻结的预训练特征,缓解了表示崩溃的风险,如先前工作所支持 (Chen and He, 2021)。 (2) 数据集通常包含属于特定类别且语义多样性有限的项目,例如书籍或体育,这会为负样本引入噪声和混淆。 这些具有挑战性的负样本在有效挖掘方面存在困难,导致次优优化结果。
| Dataset | Beauty | |||
|---|---|---|---|---|
| Metric | R@5 | NDCG@5 | R@10 | NDCG@10 |
| Cosine | 0.0620 | 0.0458 | 0.0842 | 0.0535 |
| InfoNCE | 0.0611 | 0.0446 | 0.0820 | 0.0525 |
| Smooth | 0.0618 | 0.0451 | 0.0836 | 0.0525 |
| Dataset | Toys and Games | |||
| Metric | R@5 | NDCG@5 | R@10 | NDCG@10 |
| Cosine | 0.0578 | 0.0448 | 0.0686 | 0.0488 |
| InfoNCE | 0.0558 | 0.0440 | 0.0663 | 0.0478 |
| Smooth | 0.0584 | 0.0464 | 0.0714 | 0.0505 |
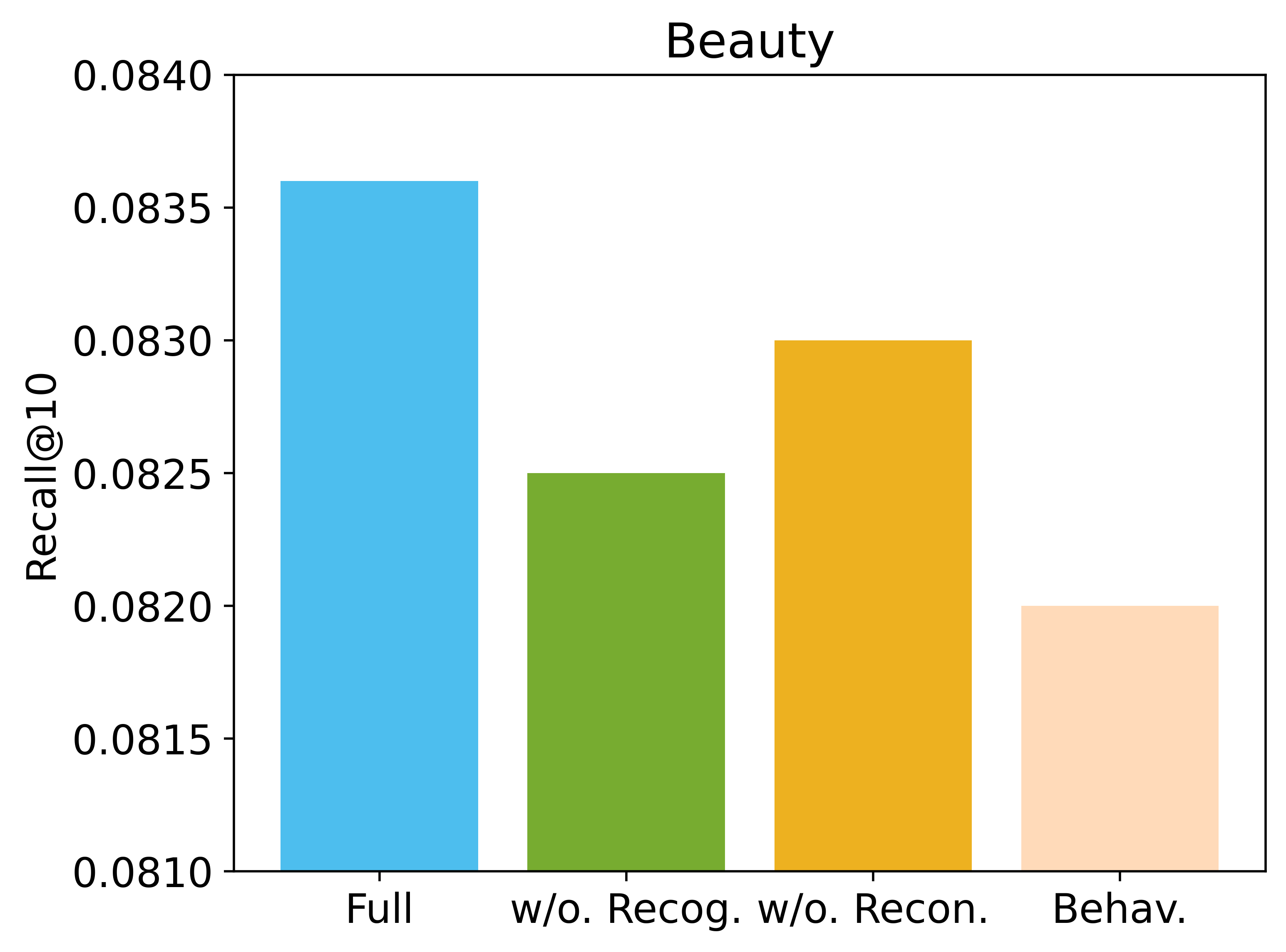
语义引导迁移任务分析。 我们分析了语义引导迁移任务中的目标和方向。
-
•
迁移目标。 我们设计了两个迁移目标,即重建和识别。 如图 4 所示,移除任何一个目标都会导致一定程度的性能下降,其中识别发挥着更重要的作用。 我们假设这是因为识别任务比局部重建执行了更高层次的知识迁移。
-
•
迁移方向。 此外,我们还通过交换引导方向来研究行为引导迁移。 可以观察到,结果比语义引导差,这是合理的,因为语义信息可以提供更多与项目本身相关的先验知识。
4.5. 超参数分析 (RQ3)
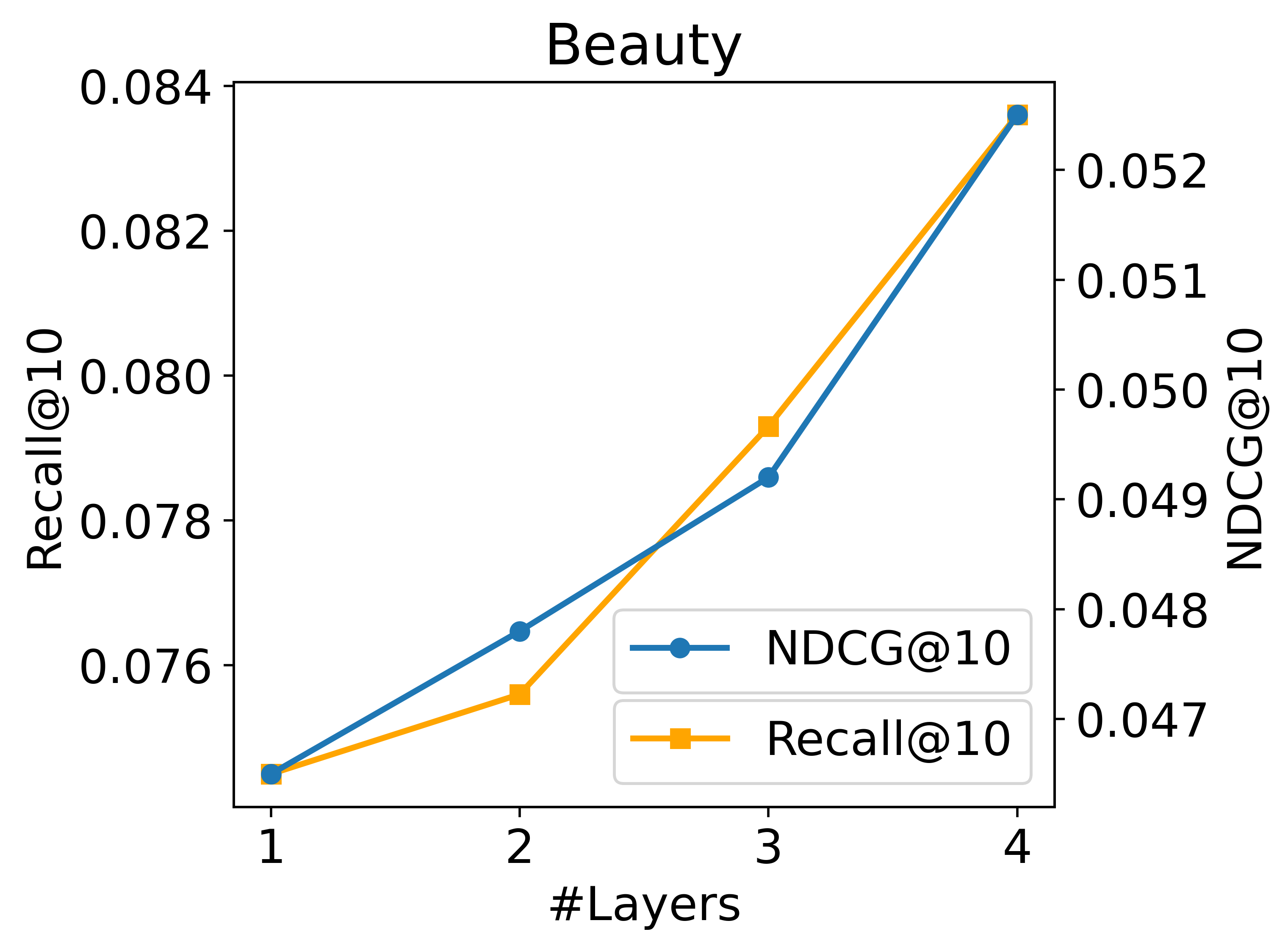
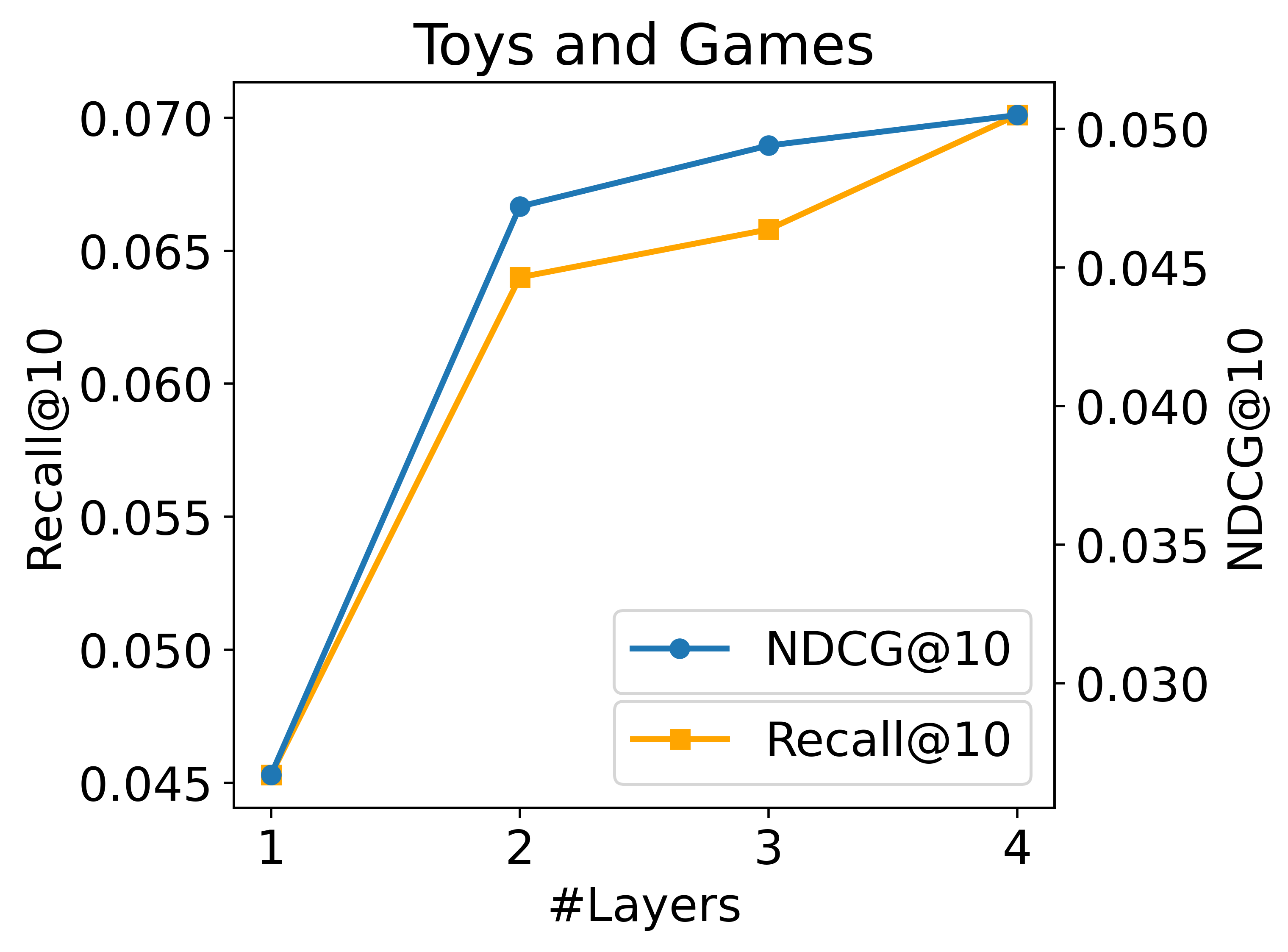
层数。 在我们的实践中,我们发现编码器层的数量对性能的影响微不足道,而解码器层的数量则有更大的影响。 这表明解码器在我们 EAGER 中起着更重要的作用。 因此,我们在此重点关注解码器层。 为了研究解码器层数量对模型性能的影响,我们通过改变层规模来分析两个数据集上 Recall@10 和 NDCG@10 的变化。 如图 5 所示,通过增加层数,模型性能在两个数据集上都有持续提高。 这可以归因于更大的参数可以增强模型的表达能力。 然而,模型越深,推理速度越慢。
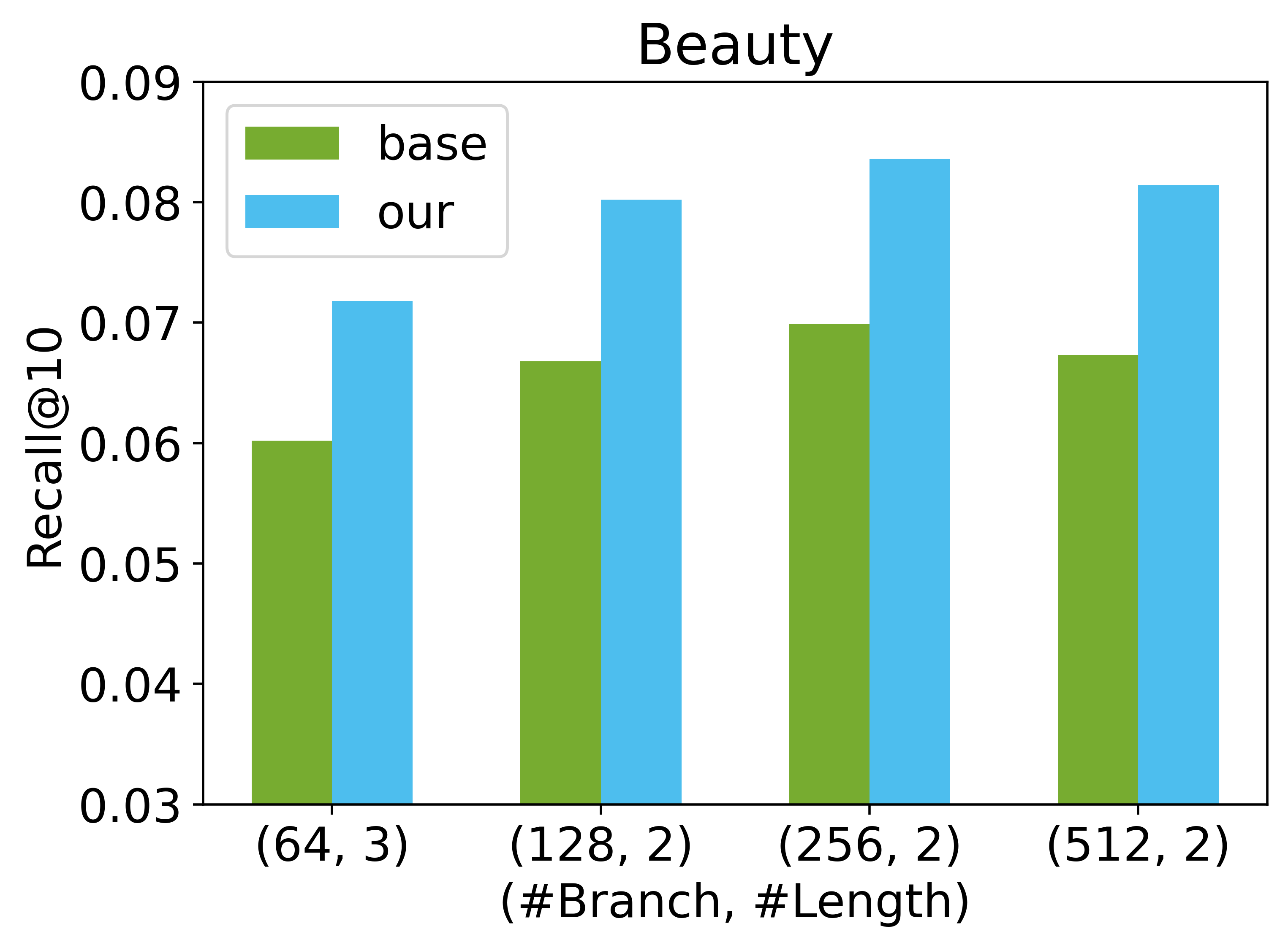
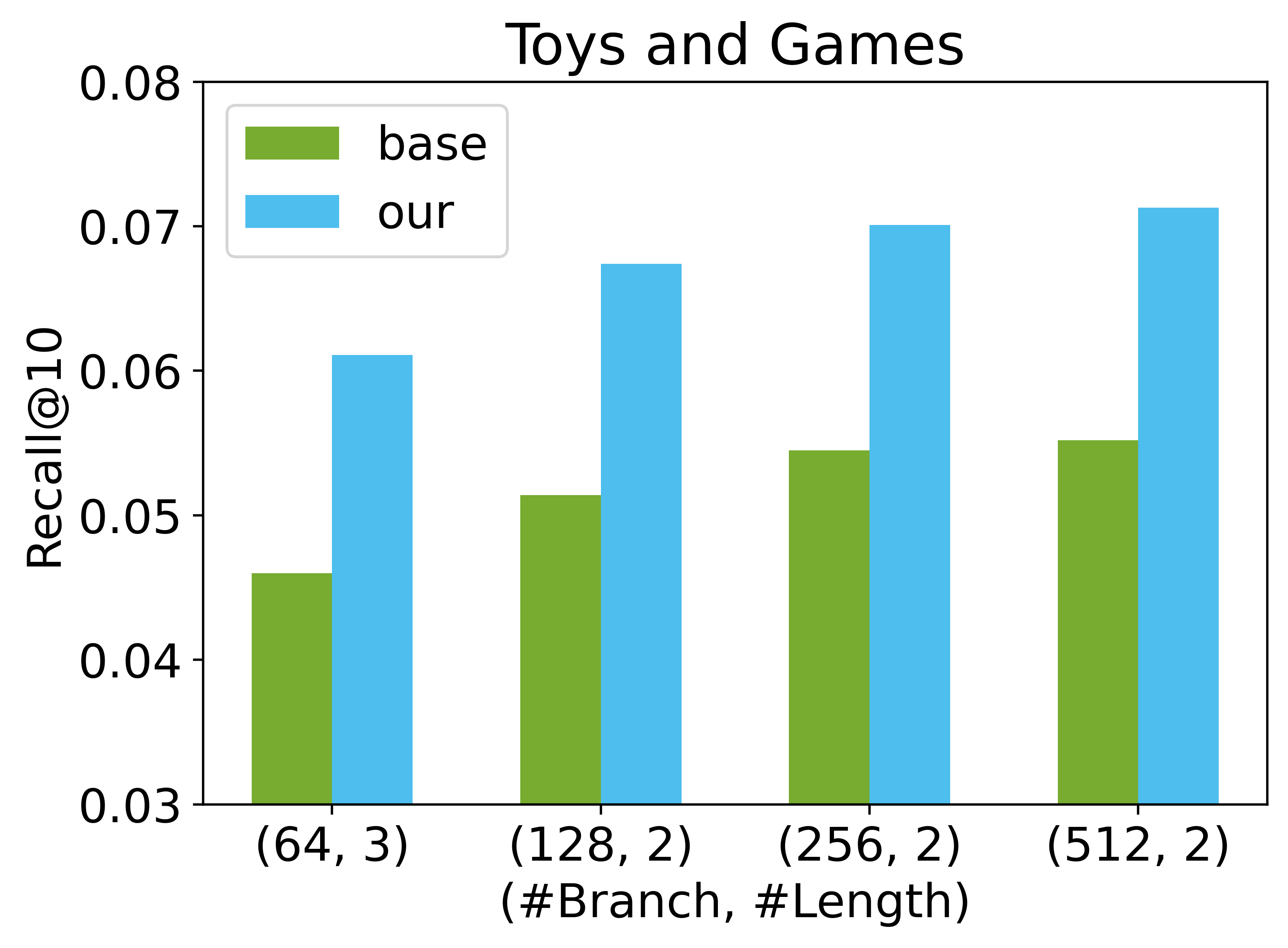
集群数量。 我们研究了采用不同分支数量 对模型性能的影响。 分支数量 的增加导致项目标识符的长度 随着项目总数的增加而相应减少。 实验在两个数据集上进行,分别是 Beauty 和 Toys。 a结果如图 6 所示。 我们观察到,当 从 64 增加到 512 时,基础模型和我们的模型在 Toys 数据集上的模型性能都单调增加。 然而,在 Beauty 数据集上出现了一个有趣的趋势,我们观察到当 从 256 增加到 512 时,性能下降。 由于 的增加而导致的性能提升可以归因于标识符长度 的减少,但过大的 会导致模型性能下降并增加推理时间。 此外,我们的方法始终优于基础方法,这表明双解码器架构的优越性。
5. 结论与未来工作
本文介绍了一个新的框架 EAGER,旨在将行为和语义信息集成到统一的生成式推荐中。 EAGER 包含三个关键部分:(1) 双流生成架构,将行为和语义信息相结合,以增强商品推荐;(2) 带有摘要符元的全局对比任务,以捕获全局知识,从而提高自回归生成的质量;(3) 语义引导的迁移任务,促进两个解码器及其特征之间的交互。 与最先进方法的广泛比较和详细分析证明了 EAGER 的有效性和鲁棒性。 在未来的工作中,我们计划通过整合大型语言模型和多模态 AI 技术来进一步增强生成式推荐模型 (Dong 等人,2023)。
致谢。
感谢 MindSpore333https://www.mindspore.cn 对这项工作的部分支持,MindSpore 是一种新的深度学习计算框架。参考文献
- (1)
- Bevilacqua et al. (2022) Michele Bevilacqua, Giuseppe Ottaviano, Patrick Lewis, Scott Yih, Sebastian Riedel, and Fabio Petroni. 2022. Autoregressive search engines: Generating substrings as document identifiers. Advances in Neural Information Processing Systems 35 (2022), 31668–31683.
- Chen et al. (2020) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. In International conference on machine learning. PMLR, 1597–1607.
- Chen and He (2021) Xinlei Chen and Kaiming He. 2021. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15750–15758.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Dong et al. (2023) Zhenhua Dong, Jieming Zhu, Weiwen Liu, and Ruiming Tang. 2023. Ten Challenges in Industrial Recommender Systems. CoRR abs/2310.04804 (2023).
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
- Feng et al. (2022) Chao Feng, Wuchao Li, Defu Lian, Zheng Liu, and Enhong Chen. 2022. Recommender Forest for Efficient Retrieval. Advances in Neural Information Processing Systems 35 (2022), 38912–38924.
- Guo et al. (2020) Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating large-scale inference with anisotropic vector quantization. In International Conference on Machine Learning. PMLR, 3887–3896.
- Hidasi et al. (2015) Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2015. Session-based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939 (2015).
- Jannach and Ludewig (2017) Dietmar Jannach and Malte Ludewig. 2017. When recurrent neural networks meet the neighborhood for session-based recommendation. In Proceedings of the eleventh ACM conference on recommender systems. 306–310.
- Jin et al. (2023) Bowen Jin, Hansi Zeng, Guoyin Wang, Xiusi Chen, Tianxin Wei, Ruirui Li, Zhengyang Wang, Zheng Li, Yang Li, Hanqing Lu, Suhang Wang, Jiawei Han, and Xianfeng Tang. 2023. Language Models As Semantic Indexers. CoRR abs/2310.07815 (2023).
- Jin et al. (2024) Mengqun Jin, Zexuan Qiu, Jieming Zhu, Zhenhua Dong, and Xiu Li. 2024. Contrastive Quantization based Semantic Code for Generative Recommendation. CoRR abs/2404.14774 (2024).
- Johnson et al. (2019) Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with gpus. IEEE Transactions on Big Data 7, 3 (2019), 535–547.
- Kang and McAuley (2018) Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197–206.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 7871–7880.
- Li et al. (2024) Xiaoxi Li, Jiajie Jin, Yujia Zhou, Yuyao Zhang, Peitian Zhang, Yutao Zhu, and Zhicheng Dou. 2024. From Matching to Generation: A Survey on Generative Information Retrieval. CoRR abs/2404.14851 (2024).
- Liu et al. (2024a) Qijiong Liu, Hengchang Hu, Jiahao Wu, Jieming Zhu, Min-Yen Kan, and Xiao-Ming Wu. 2024a. Discrete Semantic Tokenization for Deep CTR Prediction. In Companion Proceedings of the ACM on Web Conference (WWW). 919–922.
- Liu et al. (2024b) Qijiong Liu, Jieming Zhu, Yanting Yang, Quanyu Dai, Zhaocheng Du, Xiao-Ming Wu, Zhou Zhao, Rui Zhang, and Zhenhua Dong. 2024b. Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey. CoRR abs/2404.00621 (2024).
- Ma et al. (2019) Chen Ma, Peng Kang, and Xue Liu. 2019. Hierarchical gating networks for sequential recommendation. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 825–833.
- McAuley et al. (2015) Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. 2015. Image-based recommendations on styles and substitutes. In Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52.
- Ni et al. (2022) Jianmo Ni, Gustavo Hernandez Abrego, Noah Constant, Ji Ma, Keith Hall, Daniel Cer, and Yinfei Yang. 2022. Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models. In Findings of the Association for Computational Linguistics: ACL 2022. 1864–1874.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research 21, 1 (2020), 5485–5551.
- Rajput et al. (2023) Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan H Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q Tran, Jonah Samost, et al. 2023. Recommender Systems with Generative Retrieval. arXiv preprint arXiv:2305.05065 (2023).
- Rendle et al. (2010) Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th international conference on World wide web. 811–820.
- Shan et al. (2023) Hongyu Shan, Qishen Zhang, Zhongyi Liu, Guannan Zhang, and Chenliang Li. 2023. Beyond Two-Tower: Attribute Guided Representation Learning for Candidate Retrieval. In Proceedings of the ACM Web Conference 2023. 3173–3181.
- Si et al. (2023) Zihua Si, Zhongxiang Sun, Jiale Chen, Guozhang Chen, Xiaoxue Zang, Kai Zheng, Yang Song, Xiao Zhang, and Jun Xu. 2023. Generative Retrieval with Semantic Tree-Structured Item Identifiers via Contrastive Learning. arXiv preprint arXiv:2309.13375 (2023).
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Tang and Wang (2018) Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommendation via convolutional sequence embedding. In Proceedings of the eleventh ACM international conference on web search and data mining. 565–573.
- Tay et al. (2022) Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, et al. 2022. Transformer memory as a differentiable search index. Advances in Neural Information Processing Systems 35 (2022), 21831–21843.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Wang et al. (2021) Jinpeng Wang, Jieming Zhu, and Xiuqiang He. 2021. Cross-Batch Negative Sampling for Training Two-Tower Recommenders. In The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). 1632–1636.
- Wang et al. (2022) Yujing Wang, Yingyan Hou, Haonan Wang, Ziming Miao, Shibin Wu, Qi Chen, Yuqing Xia, Chengmin Chi, Guoshuai Zhao, Zheng Liu, et al. 2022. A neural corpus indexer for document retrieval. Advances in Neural Information Processing Systems 35 (2022), 25600–25614.
- Yang et al. (2020) Ji Yang, Xinyang Yi, Derek Zhiyuan Cheng, Lichan Hong, Yang Li, Simon Xiaoming Wang, Taibai Xu, and Ed H. Chi. 2020. Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations. In Companion of The Web Conference (WWW). 441–447.
- Yuan et al. (2023) Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to go next for recommender systems? id-vs. modality-based recommender models revisited. arXiv preprint arXiv:2303.13835 (2023).
- Zhang et al. (2023a) Peitian Zhang, Zheng Liu, Yujia Zhou, Zhicheng Dou, and Zhao Cao. 2023a. Term-Sets Can Be Strong Document Identifiers For Auto-Regressive Search Engines. arXiv preprint arXiv:2305.13859 (2023).
- Zhang et al. (2019) Tingting Zhang, Pengpeng Zhao, Yanchi Liu, Victor S Sheng, Jiajie Xu, Deqing Wang, Guanfeng Liu, Xiaofang Zhou, et al. 2019. Feature-level Deeper Self-Attention Network for Sequential Recommendation.. In IJCAI. 4320–4326.
- Zhang et al. (2023b) Yidan Zhang, Ting Zhang, Dong Chen, Yujing Wang, Qi Chen, Xing Xie, Hao Sun, Weiwei Deng, Qi Zhang, Fan Yang, et al. 2023b. IRGen: Generative Modeling for Image Retrieval. arXiv preprint arXiv:2303.10126 (2023).
- Zhou et al. (2018) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068.
- Zhou et al. (2020) Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In Proceedings of the 29th ACM international conference on information & knowledge management. 1893–1902.
- Zhou et al. (2022) Yujia Zhou, Jing Yao, Zhicheng Dou, Ledell Wu, Peitian Zhang, and Ji-Rong Wen. 2022. Ultron: An ultimate retriever on corpus with a model-based indexer. arXiv preprint arXiv:2208.09257 (2022).
- Zhu et al. (2019) Han Zhu, Daqing Chang, Ziru Xu, Pengye Zhang, Xiang Li, Jie He, Han Li, Jian Xu, and Kun Gai. 2019. Joint optimization of tree-based index and deep model for recommender systems. Advances in Neural Information Processing Systems 32 (2019).
- Zhu et al. (2018) Han Zhu, Xiang Li, Pengye Zhang, Guozheng Li, Jie He, Han Li, and Kun Gai. 2018. Learning tree-based deep model for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1079–1088.