奖励重要事项:面向任务对话的逐步强化学习
摘要
强化学习 (RL) 是一种增强面向任务对话 (TOD) 系统的强大方法。 然而,现有的 RL 方法倾向于主要关注生成任务,例如对话策略学习 (DPL) 或响应生成 (RG),而忽略了用于理解的对话状态跟踪 (DST)。 这种狭隘的关注限制了系统通过忽略理解和生成之间的相互依赖性来实现全局最优性能。 此外,RL 方法面临着稀疏和延迟奖励的挑战,这使得训练和优化变得复杂。 为了解决这些问题,我们通过在整个符元生成过程中引入逐步奖励,将 RL 扩展到理解和生成任务。 理解奖励随着 DST 中填充更多槽位而增加,而生成奖励随着准确包含用户请求而增长。 我们的方法提供了一种与任务完成相一致的平衡优化。 实验结果表明,我们的方法有效地提高了 TOD 系统的性能,并在三个广泛使用的数据集上取得了新的最先进结果,包括 MultiWOZ2.0、MultiWOZ2.1 和 In-Car。 与现有模型相比,我们的方法在低资源环境中也表现出更强的少样本能力。
奖励重要事项:面向任务对话的逐步强化学习
Huifang Du* Tongji University duhuifang@tongji.edu.cn Shuqin Li* Hangzhou Dianzi University shuqinlee9683@gmail.com Minghao Wu Monash University minghao.wu@monash.edu
Xuejing Feng Tongji University fengxuejing@tongji.edu.cn Yuan-Fang Li Monash University yuanfang.li@monash.edu Haofen Wang Tongji University carter.whfcarter@gmail.com
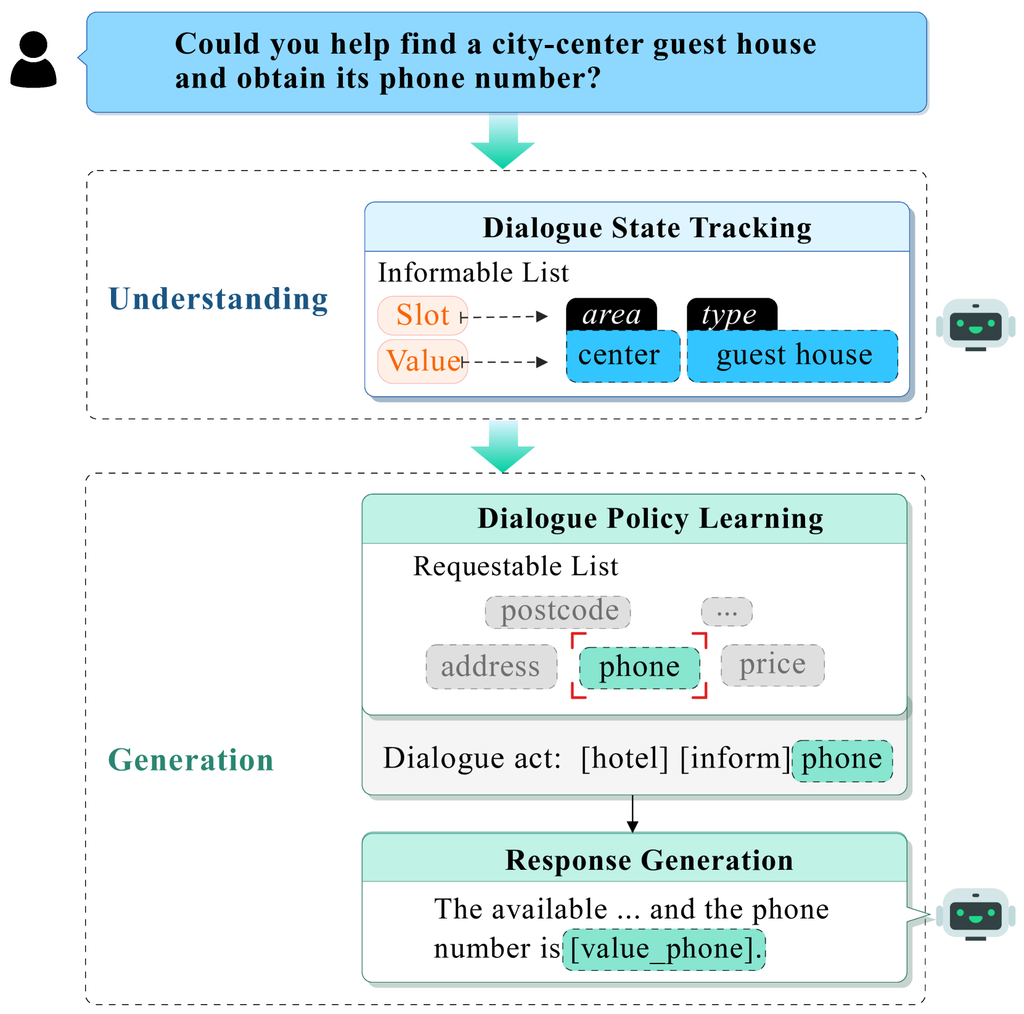
1 引言
预训练语言模型 (PLMs) 的快速发展已经极大地影响了各种现实世界中的应用 Devlin 等人 (2018);Raffel 等人 (2020);Chung 等人 (2024)。 其中,面向任务的对话 (TOD) 系统的开发尤为引人注目 Wen 等人 (2017);Hosseini-Asl 等人 (2020)。 通常,TOD 系统包含几个组件 He 等人 (2022b);Feng 等人 (2023),如 Figure 1 所示,包括用于理解用户信念状态的对话状态跟踪 (DST) Chen 等人 (2020);Guo 等人 (2023)、用于生成对话行为的对话策略学习 (DPL) Zhao 等人 (2024);Zhang 等人 (2019) 以及用于生成系统响应的响应生成 (RG) Pei 等人 (2020);Chen 等人 (2019)。 最近,人们越来越关注基于 PLMs 构建端到端 (E2E) TOD 系统,以便为模型配备所有这些基本功能 He 等人 (2022b);Hosseini-Asl 等人 (2020);Feng 等人 (2023);Yu 等人 (2023)。
基于前面讨论的 TOD 系统的进步,最近的研究探索了使用离线强化学习 (RL) 来进一步优化 TOD 系统学习面向目标的对话策略 Lu 等人 (2019);Jang 等人 (2021);Feng 等人 (2023)。 然而,当前的 RL 方法通常侧重于增强生成组件,例如生成对话行为 (DPL 任务) Li 等人 (2023) 或系统响应 (RG 任务) Yu 等人 (2023)。 这种偏向性的关注,通过忽略理解和生成之间至关重要的相互依赖关系,阻止了系统达到最佳性能。 此外,用于 TOD 系统的 RL 经常面临稀疏和延迟奖励的问题 Lu 等人 (2019);Abdulhai 等人 (2023),这些奖励仅在对话或回合级别达到目标时才会提供 Kwan 等人 (2023);Lu 等人 (2019);Abdulhai 等人 (2023)。 这导致 RL 的探索不足和训练不稳定。 虽然许多努力试图减轻这些奖励问题以提供密集奖励,但这些方法中奖励函数的设计往往很复杂,这可能会限制方法的泛化 Li 等人 (2020);Feng 等人 (2023)。
在这项工作中,我们建议设计一个简单但有效的奖励函数,以在端到端中联合优化理解和生成组件的方式来实现全局最优性能。 我们建议在每个符元生成期间组合理解奖励和生成奖励,以逐步加强学习步骤。 理解奖励是 DST 过程中正确填充的槽位的增长比例,而生成奖励则通过 DPL 和 RG 过程中正确包含用户请求来衡量。 我们使用两个模型骨干,Flan-T5 基础模型和 Flan-T5 大型模型 Chung 等人 (2024),在三个广泛使用的基准测试中进行了广泛的实验:MultiWOZ2.0、MultiWOZ2.1 和 In-Car。 结果表明,我们的方法显着提高了模型性能,优于强大的基线,并建立了新的最先进的结果。 我们还表明,我们的方法在低资源条件下优于当前模型,突出了其在数据有限的现实世界场景中的适应性。
我们对这项工作的贡献总结如下:
-
•
我们介绍了一种新方法,将 RL 整合到理解(DST)和生成(DPL 和 RG)组件中,以端到端的方式,从而促进 TOD 系统的平衡优化。
-
•
为了解决 TOD 系统中 RL 的稀疏和延迟奖励的挑战,我们提出了一种组合奖励机制,在令牌生成期间提供逐步反馈。 这种逐步奖励显着提高了效率。
-
•
实验结果表明,我们的方法在多个基准测试(MultiWOZ2.0、MultiWOZ2.1 和 In-Car)上取得了新的最先进的结果。 此外,该方法在资源匮乏的情况下表现出优越的性能。
2 相关工作
在本节中,我们将回顾利用管道和 E2E 方法的 TOD 系统的工作,强化学习 (RL) 的集成以及为 RL 设计奖励函数。 此外,我们还讨论了大型语言模型 (LLM) 在 TOD 系统中的作用。
管道和端到端方法。
管道方法的特点是其模块化结构,其中对话状态跟踪 (DST) Chen 等人(2020);Guo 等人(2023)、对话策略学习 (DPL) Zhao 等人(2024);Zhang 等人(2019) 和响应生成 (RG) Pei 等人(2020);Chen 等人(2019) 按顺序处理。 它们提供了可解释性和模块化,但通常难以捕捉对话的整体上下文 Kwan 等人(2023)。 相反,E2E 方法直接将输入话语映射到系统响应,而没有显式的中间表示 He 等人(2022b);Yang 等人(2021);He 等人(2022a)。 一些模型,例如 SPACE-3 He 等人(2022a)、UBAR Yang 等人(2021) 和 PPTOD Su 等人(2022a),通过预训练和微调将所有子任务重组为单个序列预测。 但是,监督微调 (SFT) 更侧重于在令牌级别学习,而不是特定要求,这限制了模型完成特定任务的能力。
基于 RL 的策略学习。
RL 可以通过将其调整为 TOD 任务的特定要求来增强模型性能。 然而,由于动作空间很大且奖励稀疏,RL 模型面临挑战 Feng 等人(2023);Zhang 等人(2019);Wu 等人(2019)。 一些研究使用深度强化学习 (DRL) 方法,例如深度 Q 网络 (DQN) Peng 等人(2018);Jang 等人(2021),以改进模拟用户交互的策略。 分层 RL (HRL) 将任务分解为子任务,创建策略层次结构 Peng 等人(2017);Liu 等人(2020),而封建 RL (FRL) 则抽象化状态和动作空间以获得更通用的策略 Gao 等人(2018);Casanueva 等人(2018)。 这些方法主要集中在对话策略学习上,采用复杂的算法设计,并且往往缺乏对用户意图的深入理解,导致性能欠佳。
TOD 的奖励设计。
最近的研究发现,离线 RL 是一种很有前景的方法,可以利用静态数据集来稳定训练 Snell 等人(2023);Feng 等人(2023)。 遵循离线原则,许多方法在实现目标时设计对话和回合级别的奖励 Kwan 等人(2023);Lu 等人(2019);Tang 等人(2018),但奖励信号仍然稀疏。 逆向强化学习 (IRL) 和奖励塑造技术已被引入以学习更密集的奖励并鼓励更快地学习 Li 等人(2020);Takanobu 等人(2019)。 然而,IRL 的计算量可能很大,如果奖励塑造设计不当,可能会导致意外行为 Arora 和 Doshi(2021);Gupta 等人(2024)。 或者,一些方法对每个符元都采用奖励,这可能缺乏对对话目标的语义意义 Yu 等人(2023);Gupta 等人(2024)。 我们的方法提供直接针对对话目标的渐进奖励。
用于 TOD 的大型语言模型。
LLM 在理解和生成各种任务的文本方面已展现出令人印象深刻的能力 Ouyang 等人(2022a);OpenAI(2023);Chowdhery 等人(2023);Wu 等人(2024c)。 然而,与专门的任务特定模型相比,LLM 的表现不佳 Hudeček 和 Dušek(2023);Li 等人(2023);Wu 等人(2024b)。 为特定任务微调 LLM 在计算上效率也很低。 所有这些原因都导致人们越来越关注提示工程方法,这些方法利用上下文学习,而无需更新参数 Wei 等人(2022);Wang 等人(2022);Yao 等人(2024);Wu 等人(2024a)。 然而,LLM 的性能仍然往往较差 Yang 等人(2024)。
3 预备知识
3.1 用于 TOD 的监督微调
TOD 任务通常被建模为一个 E2E 问题,并通过使用监督微调(SFT)的 seq2seq 模型(例如,T5)来解决。 模型的输入可以表示为 ,其中 表示连接运算符, 表示当前用户话语,、 和 分别表示第 轮的信念状态(BS)、对话行为(DA)和系统响应(SR)。 前缀指令是“将对话翻译成信念状态、对话行为和系统响应:[输入]”。 对模型进行微调以最大限度地提高在给定输入的情况下,连续生成正确 BS、DA 和 SR 的可能性:
| (1) |
其中 表示模型的参数。
3.2 用于 TOD 的强化学习
正式地说,用于 TOD 任务的 RL 方法在马尔可夫决策过程 (MDP) Kaelbling 等人 (1998) 中运行,其特征是元组 。 状态空间 可以表示为状态集 ,其中每个状态都包括对话上下文和截至当前时间步的历史记录。 对话中的每一轮都被视为一个独立的事件。 操作 是事件期间采取的第 个操作,它对应于在对话中选择下一个符号。 转移概率 是在给定操作 和状态 的情况下转移到状态 的概率。 折扣因子 用于权衡未来的奖励。 SFT 模型用于初始化策略网络 ,该策略网络随后被优化以最大限度地提高奖励 ,使用诸如近端策略优化 (PPO) Schulman 等人 (2017) 之类的算法。
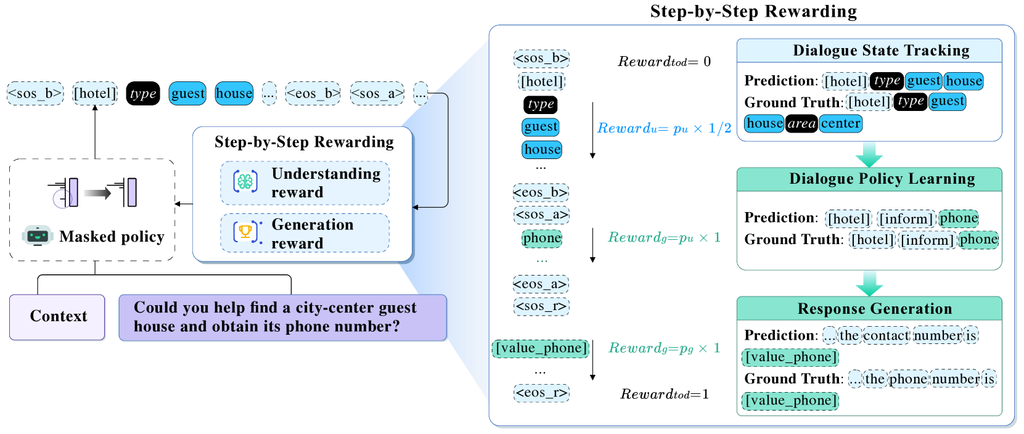
4 主要方法
我们旨在通过结合 SFT 和 RL 来增强 TOD 系统。 虽然 SFT 可以为 RL 提供一个稳定的初始基础 Ramamurthy 等人 (2023); Yu 等人 (2023); Li 等人 (2023),但它平等地对待每个地面真实符元作为目标,而没有优先考虑特定任务的目标。 我们利用 RL 来细化模型,以优化任务完成。
在 TOD 任务中,准确理解用户需求(即信念状态)对于生成适当的对话行为至关重要,而对话行为对于生成满足当前需求并有效推动对话前进的系统响应至关重要。 但是,现有的 RL 方法通常只关注优化对话策略学习 Li 等人 (2023); Takanobu 等人 (2020) 或响应生成 Yu 等人 (2023),而忽略了理解的重要性以及理解和生成之间的相互依赖性。 此外,这些方法通常在对话或轮次级别使用稀疏奖励 Kwan 等人 (2023); Lu 等人 (2019); Tang 等人 (2018); Abdulhai 等人 (2023)。
任务完成指标评估模型是否正确生成了对话模式中定义的可告知和可请求的槽值,反映了其在理解和生成任务中的性能。 策略模型的序列生成过程涉及持续满足这些列表。 受这些指标的启发,我们假设在理解和生成任务的符元生成过程中提供渐进的以任务为导向的奖励可以增强 TOD 系统。 模型架构和我们的奖励函数如图 Figure 2 所示。 在 Section 4.1 中,我们将解释如何测量这些指标以支持我们的奖励函数设计。 在 Section 4.2 中,我们将展示我们的奖励函数如何提供持续的、逐步的反馈,引导 E2E 模型完成理解和生成任务,从而构建一个更连贯、更响应的对话系统。
4.1 任务完成指标
在诸如 In-Car 和 MultiWOZ 等数据集的对话目标中,通常会预先定义 可告知 列表和 可请求 列表。 可告知 列表包含表示用户需求的槽位及其值。 例如,用户对餐厅的偏好由“价格范围”槽位上的“便宜”值来表征。 Inform 指标评估系统是否准确地学习了用户需求,如 可告知 列表中定义的那样,然后提供合适的实体作为响应。 可请求 列表包含用户请求的值,例如“邮政编码”。 Success 指标衡量生成的 DAs 或 SRs 是否包含可请求列表中的所有属性。 因此,我们认为,从 可告知 列表中推导出的特定于槽位-值的奖励可以增强系统对用户需求的理解,而基于可请求列表的特定于值的奖励可以提高对用户请求的响应能力。 因此,我们介绍了一种渐进奖励函数的设计,该函数结合了 DST 的 理解 奖励以及 DPL 和 RG 的 生成 奖励。
4.2 逐步面向目标的奖励
理解奖励。
我们通过测量在符元(动作)生成过程中 可告知 列表中正确识别出的槽位-值对的比例来设计 DST 的理解奖励。 此奖励函数直接反映了系统对用户需求的理解程度,这与 DST 的目标密切相关。 形式上,我们将 表示为当前轮次的真实槽值集合,将 表示为符元生成过程中的预测槽值集合:
| (2) |
其中 表示对预测的槽值对数量与真实槽值对数量之间差异的惩罚, 是一个可调参数,用于控制此惩罚的敏感度。 该函数提供了一个密集的奖励,它逐步反映了 DST 的准确性。
生成奖励。
我们观察到,DPL 和 RG 的准确性取决于它们生成的值中有多少被正确地包含在 可请求 列表中。 因此,我们将这两个生成任务设置为相同的奖励函数。 DPL 和 RG 的奖励是在每次符元生成过程中,在用户 可请求 列表中包含的值越来越多,这衡量了系统持续满足用户请求的能力。 形式上, 是当前轮次中所有真实的用户请求值, 表示符元生成过程中的预测值:
| (3) |
其中惩罚项 对生成的值数量与真实可请求列表中的值数量之间的差异进行惩罚, 是一个可调参数,用于控制此惩罚的敏感度。 该函数提供了一个密集的奖励,它逐步反映了生成完成的程度。
TOD 奖励。
为了提供一个全面的奖励来评估理解和生成性能,我们将 TOD 奖励定义为理解奖励 和生成奖励 的加权组合:
| (4) |
综合奖励函数鼓励对理解(DST)和生成(DPL、RG)进行平衡优化,从而增强 TOD 系统的全局鲁棒性。 使用从可告知和可请求列表中得出的密集奖励,确保了在符元级生成期间的持续反馈。 与仅在对话结束时提供反馈的稀疏奖励不同,我们的方法提供了逐步奖励,从而加速了学习过程。 基于差异 和 的奖励的渐进性质有助于实现增量改进。
奖励塑造。
为了防止策略网络 偏离初始模型 太远,我们还添加了一个 KL 约束来平衡奖励。 正式来说,最终的 RL 奖励函数为:
| (5) |
其中 在训练期间动态调整。
优化。
我们使用自然语言策略优化 (NLPO) Ramamurthy 等人 (2023),它是 PPO 的扩展。 NLPO 通过参数化掩蔽方法将动作消除纳入其中。 它学习使用 top-p 采样来屏蔽掉不太相关的符元,这将符元集限制为累积概率高于指定阈值的符元。 NLPO 维持一个单独的掩蔽策略,该策略定期更新,提供额外的约束以确保选择更与任务相关的动作。
| Method | MultiWOZ2.0 | MultiWOZ2.1 | In-Car | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Inform | Succ. | BLEU | Comb. | Inform | Succ. | BLEU | Comb. | Match | SuccF1 | BLEU | Comb. | |
| E2E | ||||||||||||
| SimpleTOD | 84.4 | 70.1 | 15.0 | 92.3 | 85.0 | 70.5 | 15.2 | 93.0 | - | - | - | - |
| DoTS | 86.6 | 74.1 | 15.1 | 95.5 | 86.7 | 74.2 | 15.9 | 96.3 | - | - | - | - |
| PPTOD | 89.2 | 79.4 | 18.6 | 102.9 | 87.1 | 79.1 | 19.2 | 102.3 | - | - | - | - |
| UBAR† | 85.1 | 71.0 | 16.2 | 94.3 | 86.2 | 70.3 | 16.5 | 94.7 | - | - | - | - |
| LABES | - | - | - | - | 76.9 | 63.3 | 17.9 | 88.0 | 85.8 | 77.0 | 22.8 | 104.2 |
| SPACE-3∗∗ | 88.7 | 78.7 | 16.3 | 100.0 | 90.9 | 81.0 | 16.8 | 102.7 | 84.7 | 79.6 | 18.6 | 100.7 |
| SPACE-3 | 95.3 | 88.0 | 19.3 | 111.0 | 95.6 | 86.1 | 19.9 | 110.8 | 85.3 | 83.2 | 22.9 | 107.1 |
| GALAXY∗ | 93.1 | 81.0 | 18.4 | 105.5 | 93.5 | 81.7 | 18.3 | 105.9 | 81.9 | 83.3 | 22.0 | 104.6 |
| GALAXY | 94.4 | 85.3 | 20.5 | 110.4 | 95.3 | 86.2 | 20.0 | 110.8 | 85.3 | 83.6 | 23.0 | 107.4 |
| RL | ||||||||||||
| MinTL | 84.9 | 74.9 | 17.9 | 97.8 | - | - | - | - | - | - | - | - |
| GPT-Critic | 90.1 | 76.6 | 17.8 | 101.1 | - | - | - | - | - | - | - | - |
| FanReward | 93.1 | 83.9 | 18.0 | 106.5 | - | - | - | - | - | - | - | - |
| Oursbase | 92.1 | 88.3 | 16.6 | 106.9 | 92.7 | 88.5 | 16.2 | 106.8 | 84.3 | 83.8 | 22.8 | 106.9 |
| Ourslarge | 96.1 | 92.4 | 17.2 | 111.5 | 96.9 | 91.1 | 16.9 | 110.9 | 86.2 | 86.1 | 23.0 | 109.2 |
5 实验
5.1 数据集
我们在两个流行的任务型对话基准上进行实验:MultiWOZ Budzianowski 等人 (2018);Eric 等人 (2020) 和 In-Car Assistant (In-Car) Eric 等人 (2017)。 MultiWOZ 数据集是评估 TOD 系统的具有挑战性的基准,它包含七个领域:景点、酒店、医院、警察、餐厅、出租车和火车。 该数据集被分成 8,438 个对话用于训练,以及 1,000 个用于验证和测试。 我们使用两个版本,即 MultiWOZ2.0 和 MultiWOZ2.1,来评估我们的模型。 In-Car 数据集包含 3,031 个跨三个特定领域的多轮对话,这些领域适合于车载助手:日历安排、天气信息检索和兴趣点导航。 In-Car 中的对话更加自然和多样。 与以前的工作一样,我们将数据集分成训练/验证/测试集,分别包含 2425/302/304 个对话。 遵循 Zhang 等人 (2020b) 中的数据预处理程序,去词汇化的响应被用于我们的工作中,以帮助模型学习可泛化的参数。
5.2 评估指标
在这项工作中,我们根据 Section 5.1 中的描述,在 MultiWOZ 和 In-Car 基准上评估我们的模型。 对于 MultiWOZ,我们报告 信息 和 成功,如 Section 4.1 中介绍的那样。 此外,我们还报告 BLEU Papineni 等人 (2002),它用于衡量生成的响应的流畅度。 因此,我们报告 (Comb),它由 (信息 + 成功) ×0.5 + BLEU 计算得出,作为整体质量度量。 我们利用 Match 来衡量系统是否能够跟踪所有正确状态以满足用户需求。 SuccF1 在 Success 的基础上进行了改进,它考虑了系统处理请求的完整程度(召回率)和准确程度(精确率)。
Inform 和 Match 都评估了系统对用户需求的理解,但 Inform 更侧重于根据理解提供正确的实体,而 Match 则确保了准确的对话状态跟踪。 同样,Success 和 SuccF1 都评估了系统满足用户请求的能力,但 Success 衡量的是是否满足了所有用户请求,而 SuccF1 则平衡了精确率和召回率,以衡量响应的准确性和完整性。 我们奖励函数的设计与对话数据集的所有这些任务完成指标相一致。
5.3 基线
我们通过将我们的方法与 MultiWOZ2.0 和 MultiWOZ2.1 数据集上的多种方法进行比较,对我们的方法进行了全面评估。 我们选择了一些著名的端到端 (E2E) 模型作为基线,包括 SimpleTOD Hosseini-Asl 等人 (2020)、DoTS Jeon 和 Lee (2021)、PPTOD Su 等人 (2022b)、UBAR Yang 等人 (2021)、GALAXY He 等人 (2022b) 和 SPACE-3 He 等人 (2022a)。 此外,我们将我们的方法与当前具有代表性的强化学习 (RL) 模型进行了比较,包括 MinTL Lin 等人 (2020)、GPT-Critic Jang 等人 (2021) 和 FanReward Feng 等人 (2023)。 这些方法证明了 RL 在 TOD 模型中的潜力,并提供了宝贵的比较视角。 我们在 In-Car 数据集上将我们的方法与几个强大的基线进行了比较,包括 LABES Zhang 等人 (2020a)、SPACE-3 He 等人 (2022a) 和 GALAXY He 等人 (2022b)。 此外,我们展示了 GALAXY 和 SPACE-3 在三个数据集上没有进行预训练的结果,以提供全面的评估。 两个预训练模型,Flan-T5-Base 和 Flan-T5-Large Chung 等人 (2024),被用作我们方法的骨干(参见 Appendix A)。
5.4 主要结果
如Section 4.2所示,我们的方法在所有数据集的组合得分(Comb)中都取得了新的最先进的结果。 这些收益主要归因于Inform和Success率的提高。 我们在 MultiWOZ 上获得了具有竞争力的BLEU得分,这可能是因为我们的方法侧重于理解和响应,而不是流畅性。 然而,我们的模型在 In-Car 数据集上表现最佳,证明了它生成流畅响应的能力。 此外,我们的模型还与两个强大的基线进行了比较,分别是 SPACE-3 和 GALAXY,它们都利用多个 TOD 数据集进行预训练,随后在 MultiWOZ 和 In-Car 数据集上进行微调。 我们的方法,没有预训练步骤,与没有预训练的结果相比,表现出显著的改进。 例如,在 MultiWOZ2.0 数据集上,我们的方法在Inform率上提高了 +3 分,在Success率上提高了 +11.4 分。 这表明我们的方法,为 RL 提供逐步奖励,有效地帮助提高了 TOD 任务完成率。
5.5 消融研究
我们在 MultiWOZ2.0 数据集上进行消融研究,以评估我们渐进式目标导向奖励机制的有效性。 如Table 2所示,当理解奖励被移除,只留下生成奖励时,组合得分显著下降至。 这种实质性的下降突出了对话状态跟踪过程中即时反馈的关键作用。 当我们移除生成奖励时,组合得分下降了分。 这表明生成奖励对于任务完成也至关重要。 如果 和 都被移除,即仅进行 SFT 的结果,性能会下降到较低的值。 总体而言,研究表明我们的渐进式奖励机制极大地提高了系统执行理解和生成任务的能力。
6 分析与讨论
在本节中,我们首先探索了我们的模型在资源匮乏环境下的表现 (Section 6.1)。 此外,我们还表明,我们的方法可以集成到最新的最先进的 LLM 中,以获得更好的性能 (Section 6.2)。 最后,我们对生成的输出进行了人工评估 (Section 6.3)。
6.1 低资源评估
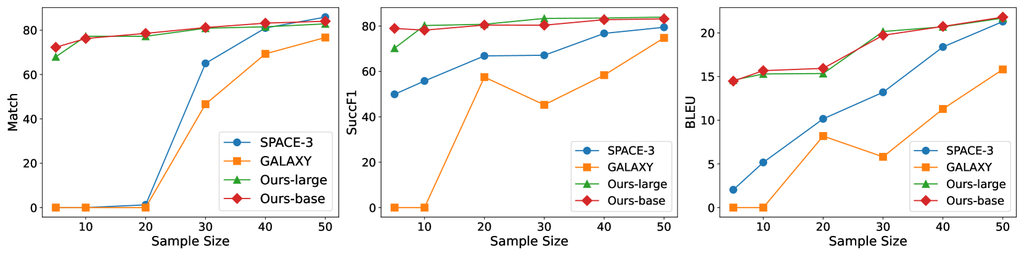
由于为现实世界应用创建广泛且标注良好的对话数据集的挑战,我们还探索了我们的方法在训练样本有限情况下的性能。 我们使用 In-Car 数据集训练模型,并随机抽取 5%、10%、20%、30%、40% 和 50% 的训练数据。 我们的方法以两个强大的基线 SPACE-3 和 GALAXY 为基准。 两个模型都使用其预训练版本进行初始化,随后使用来自 In-Car 数据集的抽样数据集进行微调。 我们的模型通过 SFT 和 RL 阶段进行训练,两种阶段都使用抽样数据。 为了确保公平性,所有模型都训练了 30 个 epoch。 Figure 3 展示了实验结果。 如图所示,在所有样本大小上,我们的方法在 Match、SuccF1 和 BLEU 指标上始终优于基线。 当训练数据有限时,性能优势尤为明显。 这表明我们的模型展示了增强的泛化能力,更适合处理新的 TOD 任务。 值得注意的是,Ours-large 和 Ours-base 之间的结果是相似的。 这可能是因为在低数据环境下,较小的模型 (Ours-base) 更好地利用了可用数据。 相反,较大的模型 (Ours-large) 可能没有完全利用有限数据进行训练,导致性能没有显著提升。
| Model | Inform | Succ. | BLEU | Comb. |
|---|---|---|---|---|
| Ours | 96.1 | 92.4 | 17.2 | 111.5 |
| 91.2 | 87.0 | 16.1 | 105.2 | |
| 92.1 | 87.5 | 15.6 | 105.4 | |
| 86.0 | 81.8 | 17.2 | 101.1 |
6.2 与 LLM 的集成
近年来,LLM 在 NLP 领域取得了显著进展,展示出令人印象深刻的涌现能力。 然而,与专门用于 TOD 任务的模型相比,LLM 的性能往往较差 Hudeček 和 Dušek (2023); Li 等人 (2023)。 我们利用 MultiWOZ2.0 训练集中的少样本对话示例来提示 LLM。 如 Table 3 上半部分所示,LLM 的强大代表,包括 Codex (code-davinci-002) Chen 等人 (2021)、ChatGPT (gpt-3.5-turbo) Ouyang 等人 (2022b)、Claude (Claude 3 sonnet) Anthropic (2024) 和 GPT-4o111https://openai.com/index/hello-gpt-4o/,其性能不如我们的模型。 此外,为 TOD 系统微调 LLM 也可能资源密集且计算效率低下。 越来越多的研究兴趣集中在将 LLM 与小型模型结合起来以实现特定应用。 我们遵循近期工作 DSP Li 等人 (2023),该工作利用小型可调模型进行对话策略学习以生成对话行为。 对话行为被用作提示 LLM 生成最终响应的提示。 为了展示我们方法的优势,我们采用我们的生成奖励函数来增强小型模型的策略学习。 公平起见,我们使用与 DSP 方法相同的 数据设置 - 10% 的训练数据用于 SFT 和 RL 训练。 我们的方法在 MultiWOZ2.0 数据集上表现出优异的性能。 成功率比 DSP 在其工作中报告的结果高 8.9%。 这表明我们的方法具有优越的生成能力,从而导致更有效的任务完成。
| Method | MultiWOZ2.0 | |||
| Inform | Succ. | BLEU | Comb. | |
| Codex† | 76.7 | 41.5 | 7.7 | 66.8 |
| ChatGPT† | 71.8 | 44.1 | 10.5 | 68.4 |
| Claude | 78.3 | 41.2 | 2.9 | 62.7 |
| GPT-4o | 77.0 | 53.1 | 5.2 | 70.3 |
| DSP w/ ChatGPT† | 95.3 | 82.3 | 10.9 | 99.6 |
| Ours w/ ChatGPT | 95.1 | 91.2 | 9.8 | 102.9 |
| Ourslarge | 96.1 | 92.4 | 17.2 | 111.5 |
6.3 人工评估
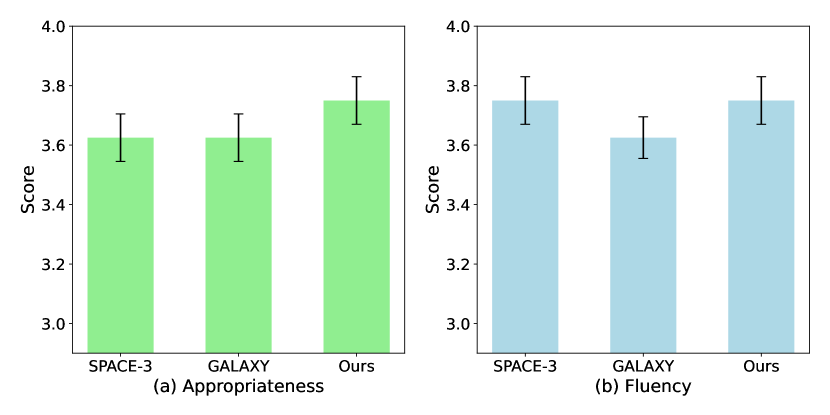
像 BLEU 这样的自动评估指标可能无法准确地评估生成质量 (Freitag 等人,2021,2022;Wu 和 Aji,2023)。 为了全面评估我们的方法,我们使用我们开发的平台对生成的响应进行人工评估。 我们将我们的模型与来自 Section 4.2 的 In-Car 数据集上的两个最佳基线,SPACE-3 和 GALAXY 进行比较。 遵循先前的工作 Zhang 等人 (2020b);Ramachandran 等人 (2022);Jang 等人 (2022),我们使用两个指标:1)适当性:响应与对话语境的匹配程度;2)流畅性:响应的清晰度和连贯性。 我们从测试集中随机选择 50 个对话回合,向 6 位评估者展示每个回合及其历史。 评估者使用 5 分制李克特量表(从 1 到 5)对每个响应进行评分,其中 1 代表最低质量,5 代表最高质量。 重要的是,评估者不知道模型身份,以确保判断的公正性。 如 Figure 4 所示,我们的模型在适当性方面优于基线,并且在流畅性方面与 SPACE-3 相匹配。 这与 Section 4.2 的结果一致,并进一步验证了我们的方法不仅可以实现优越的对话任务完成性能,还可以确保高质量的响应。
7 结论
我们介绍了一种将强化学习融入 TOD 系统的新方法。 我们的方法侧重于通过解决与稀疏和延迟奖励相关的挑战来改进理解和生成任务。 我们设计了一种逐步奖励机制,该机制在符元级别上结合了理解和生成奖励,从而促进了逐步学习。 通过使用 Flan-T5-Base 和 Flan-T5-Large 主干在标准基准上进行广泛的实验,我们证明了我们方法的有效性,并在三个广泛使用的数据集上取得了最先进的结果。
8 局限性
虽然我们提出的使用逐步奖励的方法已显示出令人鼓舞的结果,但它可能难以完全捕捉到 TOD 任务的所有细微差别。 因此,可能会无意中引入偏差,导致模型学习次优策略。 未来,开发一个基于我们的奖励函数的全面奖励模型将是有益的。 这种模型可以学习复杂的模式并增强灵活性和适应性。
此外,我们方法中的奖励设计依赖于对话模式中预定义的 可告知 和 可请求 列表。 虽然这在面向任务的对话系统中是一种常见做法,但它在扩展到开放域对话时受到限制。 开放域对话通常缺乏固定的槽位和值,这使得有效应用这种奖励机制具有挑战性。 在未来,拥有一个更通用的方法将是有价值的,该方法支持对话代理中的任务导向和开放域对话。
参考文献
- Abdulhai et al. (2023) Marwa Abdulhai, Isadora White, Charlie Snell, Charles Sun, Joey Hong, Yuexiang Zhai, Kelvin Xu, and Sergey Levine. 2023. LMRL gym: Benchmarks for multi-turn reinforcement learning with language models. CoRR, abs/2311.18232.
- Anthropic (2024) AI Anthropic. 2024. The claude 3 model family: Opus, sonnet, haiku. Claude-3 Model Card.
- Arora and Doshi (2021) Saurabh Arora and Prashant Doshi. 2021. A survey of inverse reinforcement learning: Challenges, methods and progress. Artificial Intelligence, 297:103500.
- Budzianowski et al. (2018) Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gašić. 2018. MultiWOZ - a large-scale multi-domain Wizard-of-Oz dataset for task-oriented dialogue modelling. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 5016–5026, Brussels, Belgium. Association for Computational Linguistics.
- Casanueva et al. (2018) Iñigo Casanueva, Paweł Budzianowski, Pei-Hao Su, Stefan Ultes, Lina M Rojas Barahona, Bo-Hsiang Tseng, and Milica Gasic. 2018. Feudal reinforcement learning for dialogue management in large domains. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 714–719.
- Chen et al. (2020) Lu Chen, Boer Lv, Chi Wang, Su Zhu, Bowen Tan, and Kai Yu. 2020. Schema-guided multi-domain dialogue state tracking with graph attention neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7521–7528.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating large language models trained on code. CoRR, abs/2107.03374.
- Chen et al. (2019) Xiuyi Chen, Jiaming Xu, and Bo Xu. 2019. A working memory model for task-oriented dialog response generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2687–2693.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Chung et al. (2024) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2024. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Eric et al. (2020) Mihail Eric, Rahul Goel, Shachi Paul, Abhishek Sethi, Sanchit Agarwal, Shuyang Gao, Adarsh Kumar, Anuj Kumar Goyal, Peter Ku, and Dilek Hakkani-Tür. 2020. Multiwoz 2.1: A consolidated multi-domain dialogue dataset with state corrections and state tracking baselines. In Proceedings of The 12th Language Resources and Evaluation Conference, LREC 2020, Marseille, France, May 11-16, 2020, pages 422–428. European Language Resources Association.
- Eric et al. (2017) Mihail Eric, Lakshmi Krishnan, Francois Charette, and Christopher D Manning. 2017. Key-value retrieval networks for task-oriented dialogue. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 37–49.
- Feng et al. (2023) Yihao Feng, Shentao Yang, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, and Huan Wang. 2023. Fantastic rewards and how to tame them: A case study on reward learning for task-oriented dialogue systems. arXiv preprint arXiv:2302.10342.
- Freitag et al. (2021) Markus Freitag, George Foster, David Grangier, Viresh Ratnakar, Qijun Tan, and Wolfgang Macherey. 2021. Experts, errors, and context: A large-scale study of human evaluation for machine translation. Transactions of the Association for Computational Linguistics, 9:1460–1474.
- Freitag et al. (2022) Markus Freitag, Ricardo Rei, Nitika Mathur, Chi-kiu Lo, Craig Stewart, Eleftherios Avramidis, Tom Kocmi, George Foster, Alon Lavie, and André F. T. Martins. 2022. Results of WMT22 metrics shared task: Stop using BLEU – neural metrics are better and more robust. In Proceedings of the Seventh Conference on Machine Translation (WMT), pages 46–68, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics.
- Gao et al. (2018) Jianfeng Gao, Michel Galley, and Lihong Li. 2018. Neural approaches to conversational ai. In The 41st international ACM SIGIR conference on research & development in information retrieval, pages 1371–1374.
- Guo et al. (2023) Jinyu Guo, Kai Shuang, Kaihang Zhang, Yixuan Liu, Jijie Li, and Zihan Wang. 2023. Learning to imagine: distillation-based interactive context exploitation for dialogue state tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 12845–12853.
- Gupta et al. (2024) Dhawal Gupta, Yash Chandak, Scott Jordan, Philip S Thomas, and Bruno C da Silva. 2024. Behavior alignment via reward function optimization. Advances in Neural Information Processing Systems, 36.
- He et al. (2022a) Wanwei He, Yinpei Dai, Min Yang, Jian Sun, Fei Huang, Luo Si, and Yongbin Li. 2022a. Unified dialog model pre-training for task-oriented dialog understanding and generation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 187–200.
- He et al. (2022b) Wanwei He, Yinpei Dai, Yinhe Zheng, Yuchuan Wu, Zheng Cao, Dermot Liu, Peng Jiang, Min Yang, Fei Huang, Luo Si, et al. 2022b. Galaxy: A generative pre-trained model for task-oriented dialog with semi-supervised learning and explicit policy injection. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 10749–10757.
- Hosseini-Asl et al. (2020) Ehsan Hosseini-Asl, Bryan McCann, Chien-Sheng Wu, Semih Yavuz, and Richard Socher. 2020. A simple language model for task-oriented dialogue. Advances in Neural Information Processing Systems, 33:20179–20191.
- Hudeček and Dušek (2023) Vojtěch Hudeček and Ondřej Dušek. 2023. Are large language models all you need for task-oriented dialogue? In Proceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 216–228.
- Jang et al. (2021) Youngsoo Jang, Jongmin Lee, and Kee-Eung Kim. 2021. Gpt-critic: Offline reinforcement learning for end-to-end task-oriented dialogue systems. In International Conference on Learning Representations.
- Jang et al. (2022) Youngsoo Jang, Jongmin Lee, and Kee-Eung Kim. 2022. GPT-critic: Offline reinforcement learning for end-to-end task-oriented dialogue systems. In International Conference on Learning Representations.
- Jeon and Lee (2021) Hyunmin Jeon and Gary Geunbae Lee. 2021. Domain state tracking for a simplified dialogue system. arXiv preprint arXiv:2103.06648.
- Kaelbling et al. (1998) Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. 1998. Planning and acting in partially observable stochastic domains. Artificial intelligence, 101(1-2):99–134.
- Kwan et al. (2023) Wai-Chung Kwan, Hong-Ru Wang, Hui-Min Wang, and Kam-Fai Wong. 2023. A survey on recent advances and challenges in reinforcement learning methods for task-oriented dialogue policy learning. Machine Intelligence Research, 20(3):318–334.
- Li et al. (2023) Zekun Li, Baolin Peng, Pengcheng He, Michel Galley, Jianfeng Gao, and Xifeng Yan. 2023. Guiding large language models via directional stimulus prompting. In Advances in Neural Information Processing Systems, volume 36, pages 62630–62656. Curran Associates, Inc.
- Li et al. (2020) Ziming Li, Julia Kiseleva, and Maarten de Rijke. 2020. Rethinking supervised learning and reinforcement learning in task-oriented dialogue systems. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3537–3546.
- Lin et al. (2020) Zhaojiang Lin, Andrea Madotto, Genta Indra Winata, and Pascale Fung. 2020. MinTL: Minimalist transfer learning for task-oriented dialogue systems. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3391–3405, Online. Association for Computational Linguistics.
- Liu et al. (2020) Jianfeng Liu, Feiyang Pan, and Ling Luo. 2020. Gochat: Goal-oriented chatbots with hierarchical reinforcement learning. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1793–1796.
- Lu et al. (2019) Keting Lu, Shiqi Zhang, and Xiaoping Chen. 2019. Goal-oriented dialogue policy learning from failures. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 2596–2603.
- OpenAI (2023) OpenAI. 2023. GPT-4 technical report. CoRR, abs/2303.08774.
- Ouyang et al. (2022a) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022a. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744.
- Ouyang et al. (2022b) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022b. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
- Pei et al. (2020) Jiahuan Pei, Pengjie Ren, Christof Monz, and Maarten de Rijke. 2020. Retrospective and prospective mixture-of-generators for task-oriented dialogue response generation. In ECAI 2020, pages 2148–2155. IOS Press.
- Peng et al. (2018) Baolin Peng, Xiujun Li, Jianfeng Gao, Jingjing Liu, Kam-Fai Wong, and Shang-Yu Su. 2018. Deep dyna-q: Integrating planning for task-completion dialogue policy learning. arXiv preprint arXiv:1801.06176.
- Peng et al. (2017) Baolin Peng, Xiujun Li, Lihong Li, Jianfeng Gao, Asli Celikyilmaz, Sungjin Lee, and Kam-Fai Wong. 2017. Composite task-completion dialogue policy learning via hierarchical deep reinforcement learning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2231–2240, Copenhagen, Denmark. Association for Computational Linguistics.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67.
- Ramachandran et al. (2022) Govardana Sachithanandam Ramachandran, Kazuma Hashimoto, and Caiming Xiong. 2022. [CASPI] causal-aware safe policy improvement for task-oriented dialogue. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 92–102, Dublin, Ireland. Association for Computational Linguistics.
- Ramamurthy et al. (2023) Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, and Yejin Choi. 2023. Is reinforcement learning (not) for natural language processing: Benchmarks, baselines, and building blocks for natural language policy optimization. In The Eleventh International Conference on Learning Representations.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
- Snell et al. (2023) Charlie Victor Snell, Ilya Kostrikov, Yi Su, Sherry Yang, and Sergey Levine. 2023. Offline rl for natural language generation with implicit language q learning. In The Eleventh International Conference on Learning Representations.
- Su et al. (2022a) Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai, and Yi Zhang. 2022a. Multi-task pre-training for plug-and-play task-oriented dialogue system. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4661–4676, Dublin, Ireland. Association for Computational Linguistics.
- Su et al. (2022b) Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai, and Yi Zhang. 2022b. Multi-task pre-training for plug-and-play task-oriented dialogue system. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4661–4676, Dublin, Ireland. Association for Computational Linguistics.
- Takanobu et al. (2020) Ryuichi Takanobu, Runze Liang, and Minlie Huang. 2020. Multi-agent task-oriented dialog policy learning with role-aware reward decomposition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pages 625–638. Association for Computational Linguistics.
- Takanobu et al. (2019) Ryuichi Takanobu, Hanlin Zhu, and Minlie Huang. 2019. Guided dialog policy learning: Reward estimation for multi-domain task-oriented dialog. arXiv preprint arXiv:1908.10719.
- Tang et al. (2018) Da Tang, Xiujun Li, Jianfeng Gao, Chong Wang, Lihong Li, and Tony Jebara. 2018. Subgoal discovery for hierarchical dialogue policy learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2298–2309.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837.
- Wen et al. (2017) Tsung-Hsien Wen, David Vandyke, Nikola Mrkšić, Milica Gasic, Lina M Rojas Barahona, Pei-Hao Su, Stefan Ultes, and Steve Young. 2017. A network-based end-to-end trainable task-oriented dialogue system. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 438–449.
- Wu and Aji (2023) Minghao Wu and Alham Fikri Aji. 2023. Style over substance: Evaluation biases for large language models. CoRR, abs/2307.03025.
- Wu et al. (2024a) Minghao Wu, Thuy-Trang Vu, Lizhen Qu, George F. Foster, and Gholamreza Haffari. 2024a. Adapting large language models for document-level machine translation. CoRR, abs/2401.06468.
- Wu et al. (2024b) Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, and Alham Fikri Aji. 2024b. LaMini-LM: A diverse herd of distilled models from large-scale instructions. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 944–964, St. Julian’s, Malta. Association for Computational Linguistics.
- Wu et al. (2024c) Minghao Wu, Yulin Yuan, Gholamreza Haffari, and Longyue Wang. 2024c. (perhaps) beyond human translation: Harnessing multi-agent collaboration for translating ultra-long literary texts. arXiv preprint arXiv:2405.11804.
- Wu et al. (2019) Yuexin Wu, Xiujun Li, Jingjing Liu, Jianfeng Gao, and Yiming Yang. 2019. Switch-based active deep dyna-q: Efficient adaptive planning for task-completion dialogue policy learning. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 7289–7296.
- Yang et al. (2024) Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Shaochen Zhong, Bing Yin, and Xia Hu. 2024. Harnessing the power of llms in practice: A survey on chatgpt and beyond. ACM Transactions on Knowledge Discovery from Data, 18(6):1–32.
- Yang et al. (2021) Yunyi Yang, Yunhao Li, and Xiaojun Quan. 2021. Ubar: Towards fully end-to-end task-oriented dialog system with gpt-2. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14230–14238.
- Yao et al. (2024) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2024. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36.
- Yu et al. (2023) Xiao Yu, Qingyang Wu, Kun Qian, and Zhou Yu. 2023. Krls: Improving end-to-end response generation in task oriented dialog with reinforced keywords learning. In The 2023 Conference on Empirical Methods in Natural Language Processing.
- Zhang et al. (2020a) Yichi Zhang, Zhijian Ou, Min Hu, and Junlan Feng. 2020a. A probabilistic end-to-end task-oriented dialog model with latent belief states towards semi-supervised learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9207–9219, Online. Association for Computational Linguistics.
- Zhang et al. (2020b) Yichi Zhang, Zhijian Ou, and Zhou Yu. 2020b. Task-oriented dialog systems that consider multiple appropriate responses under the same context. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 9604–9611.
- Zhang et al. (2019) Zhirui Zhang, Xiujun Li, Jianfeng Gao, and Enhong Chen. 2019. Budgeted policy learning for task-oriented dialogue systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3742–3751.
- Zhao et al. (2024) Yangyang Zhao, Mehdi Dastani, and Shihan Wang. 2024. Bootstrapped policy learning: Goal shaping for efficient task-oriented dialogue policy learning. In Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pages 2615–2617.
- Ziegler et al. (2019) Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul F. Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences. CoRR, abs/1909.08593.
附录 A 实施细节
SFT 细节。
在监督微调阶段,我们使用 8 的训练批次大小和 16 的评估批次大小。 我们将学习率设置为 并训练模型共 30 个 epochs。 对于推理的生成设置,MultiWOZ 数据集的令牌最大长度设置为 256,In-Car 数据集的令牌最大长度分别设置为 168。 In-Car 数据集的较短最大长度是由于与 MultiWOZ 数据集相比,其中的话语相对较短。 重要的是要注意,In-Car 数据集不包含对话行为标注。 因此,我们只预测信念状态和系统响应,将输入格式化为 。
RL 细节。
策略网络经过 20k 个 episodes 训练,每个批次有 5 个 epochs 用于强化学习。 批次大小设置为 8,学习率为 。 我们在训练期间采用 top-k 值为 50 的采样。 遵循 Ziegler 等人 (2019),Equation 5 中的 KL 系数 在训练期间动态调整:
| (6) |
| (7) |
其中 是初始模型 和当前策略 之间的 KL 散度。 最初设置为 0.01。 是更新率,我们在实验中将其设置为 0.2。
模型和实现细节。
我们使用 Flan-T5 基础模型 (250M 参数) 和 Flan-T5 大型模型 (780M 参数) 作为主干,它们是 T5 模型的扩展,旨在增强其在各种自然语言处理任务上的性能。 我们的所有实验都在配备了 8 个 NVIDIA A800 的服务器上运行。
附录 B 奖励曲线
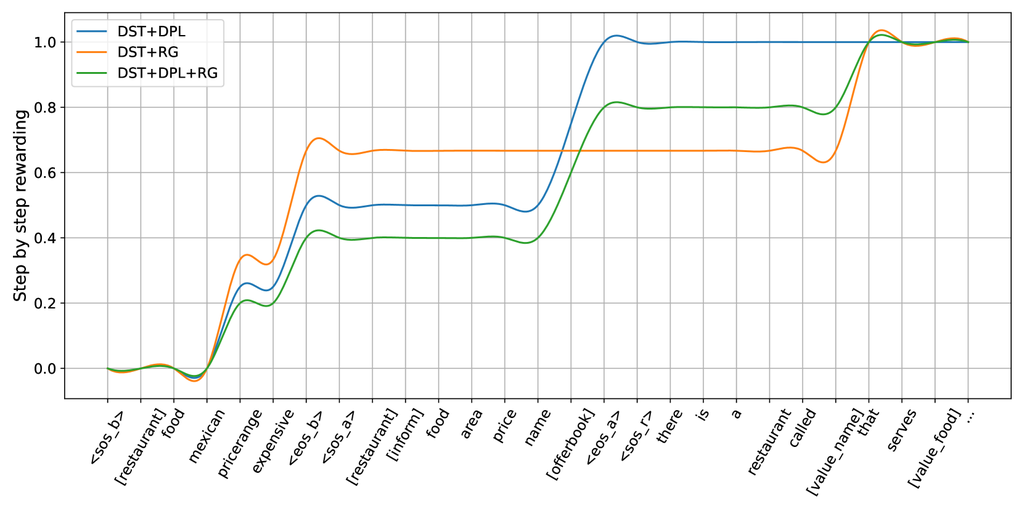
Figure 5 显示了在完成槽值或值时,逐个符元生成过程中奖励如何逐步增加。 平台阶段代表生成完整槽值或值的进程。 我们展示了三个任务的奖励模式:DSP、DPL 和 RG。 曲线表明,我们的方法为端到端模型提供了逐渐增加的密集奖励,有效地支持理解和生成任务。
附录 C 案例研究
为了评估我们对话系统的有效性,我们使用 Streamlit222https://streamlit.io/ 开发了一个用户界面,如 Figure 6 所示。 该界面允许用户选择一个对话目标,并根据该目标与系统进行交互。 用户利用Section 6.3中详细介绍的评估方法评估系统的响应。
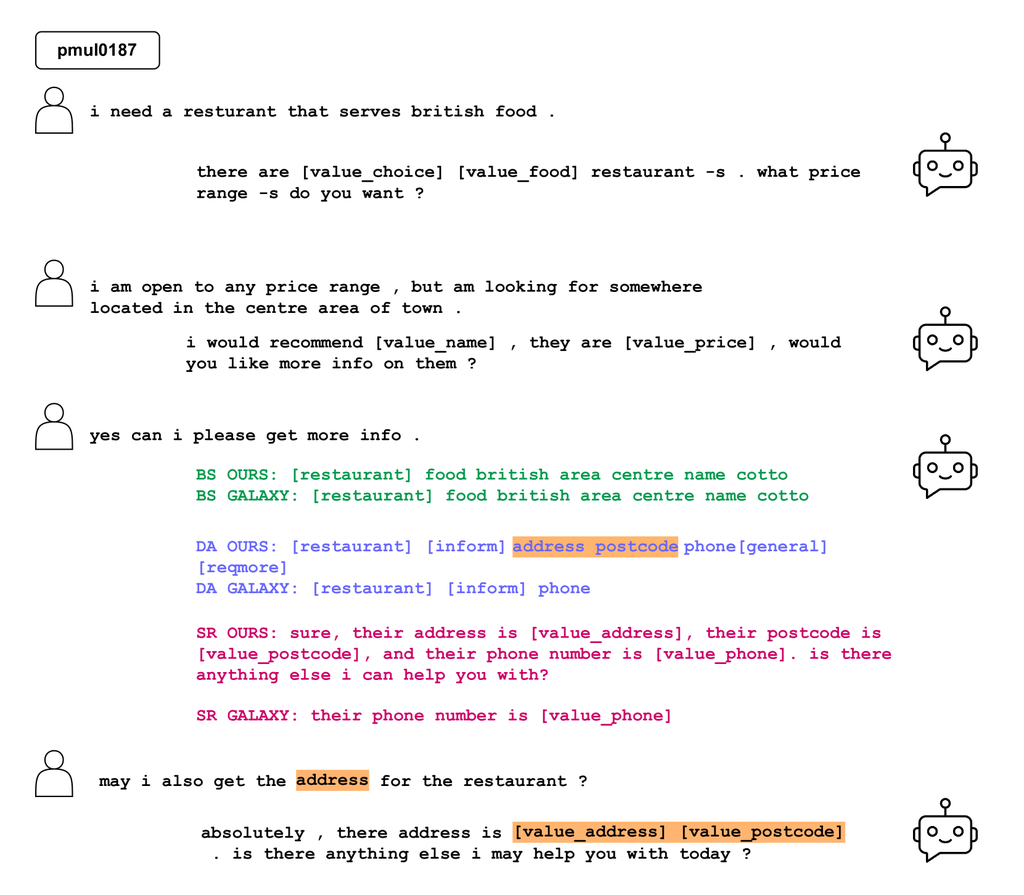
我们在Figure 7中提供了一个来自我们的模型和 GALAXY 的示例比较。 它说明了一个场景,在这个场景中,与 GALAXY 相比,我们的模型生成了更准确和更全面的结果。

附录 D 错误示例
我们在Figure 8中展示了我们预测结果中的一个代表性错误示例。 我们观察到,我们的模型的响应包含了任务所需的所有价值信息,但它缺乏对话流畅性。 这表明我们设计的奖励函数优先考虑任务完成效率而不是对话自然度。 未来工作可以探索将 BLEU 等指标集成到奖励函数中,以增强任务完成和对话流畅性。
