Murali Karthick Baskar、Andrew Rosenberg、Bhuvana Ramabhadran、Neeraj Gaur、钟猛
利用 RNNT 损失进行语音前缀调整以改善大语言模型预测
摘要
在本文中,我们重点解决将大语言模型应用于 ASR 时面临的限制。 最近的工作利用了 prefixLM 型模型,直接将语音作为 ASR 大语言模型的前缀。 我们发现优化语音前缀可以带来更好的 ASR 性能,并建议应用 RNNT 损失来执行语音前缀调整。 这是一种简单的方法,不会增加模型复杂性或改变推理管道。 我们还提出基于语言的软提示,以通过冻结的大语言模型进一步改进。 对 10 种印度语言实时测试集的实证分析表明,我们提出的语音前缀调整可以通过冻结和微调的大语言模型产生改进。 我们对 10 个印度语的平均识别结果表明,与经过微调的大语言模型的基线相比,所提出的使用 RNNT 损失进行的前缀调整导致 WER 相对提高了 12%。 我们提出的使用冻结大语言模型的方法比基本的软提示前缀LM 有了 31% 的相对改进。
索引词:语音识别、大语言模型、大语言模型、ASR、prefixLM、prompt-tuning、prefix-tuning
1简介
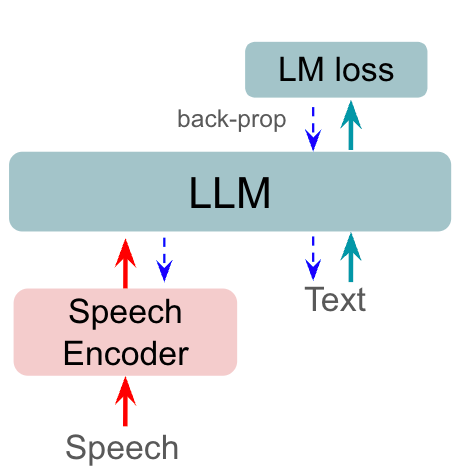
大型语言模型(大语言模型)通过解决各种类型的预测错误,正在彻底改变自动语音识别(ASR)研究。 PrefixLM 是一个大语言模型变体,其中输入文本附有前缀。 此前缀可以采用文本 [1] 或语音 [2] 或图像 [3] 的形式,为模型提供附加上下文。 当使用语音标记作为前缀时(如本研究中所示),PrefixLM 学习自回归预测文本,模仿端到端 ASR 模型 [4, 5]。 之前的工作[6]表明,通过更好的语音编码或从自监督和监督模型中提取的前缀标记,大语言模型的性能得到提高。 缩放语音编码器还增强了语音前缀[2, 7]的使用,进一步提高了LLaMA [8]等大语言模型模型的识别能力。 具有语音前缀的 PrefixLM 已针对多种任务进行了训练,包括语音识别和语音翻译[9]。 值得注意的是,这些方法直接使用预训练的大语言模型,无需对目标任务进行额外的微调。
前缀调整 [10] 提供了微调的轻量级替代方案,因为它将可训练的词符序列添加到文本输入中。 仅优化与前缀相关的参数可以使模型有效地适应下游任务。 该技术也被纳入基于图像和视频的 prefixLM 模型中。 跨模态前缀调整[11]已被提出,用于使多语言翻译模型适应双语语音翻译任务。 虽然最终的训练目标仍然只是大语言模型损失,但预训练的语音编码器用于跨模态的适应。 虽然大语言模型在识别性能方面取得了显着的进步,但它们仍然存在诸如较高的插入[12]和代码转换错误[13]等缺点。 [12] 中的作者证明,与 RNNT 相比,使用大语言模型进行 ASR 纠错有助于改善替换,但会增加插入错误。 与 RNNT 模型[13]相比,双向大语言模型的简单浅层融合导致普通话和英语之间的语码转换。 尽管有这些研究,我们的多语言实验也表明,RNNT 不会像大语言模型预测那样受到插入和语码转换的影响。 我们将 RNNT 的这种行为归因于具有稳健对齐的训练,并假设将其与大语言模型集成将导致幻觉减少和更好的预测。
我们的主要贡献如下:
-
•
语音前缀调整的 RNNT 损失:我们展示了对冻结和微调大语言模型的改进。 我们还检查了使用连接主义时间分类 (CTC) 损失(一种非自回归技术)调整语音前缀时遇到的约束。 我们将 CTC 与 RNNT 损失进行比较,突出显示与 prefixLM 相关的区别。
-
•
语言ID(langID)软提示:该技术增强了冻结大语言模型的性能。
-
•
缩小差距:同时应用语音前缀调整和基于 langID 的软提示可以起到累加作用,并进一步缩小冻结 LM 和微调 LM 之间的性能差距。
2方法论
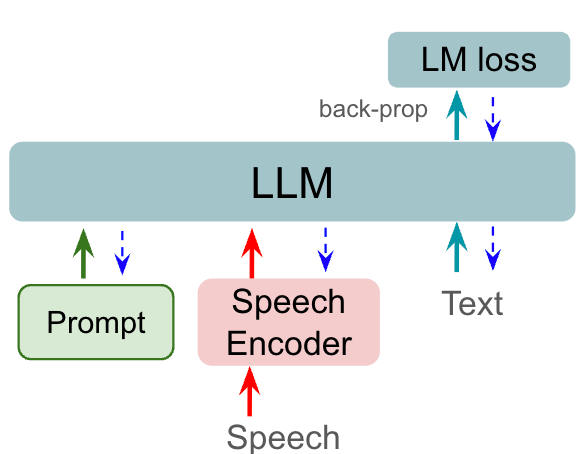
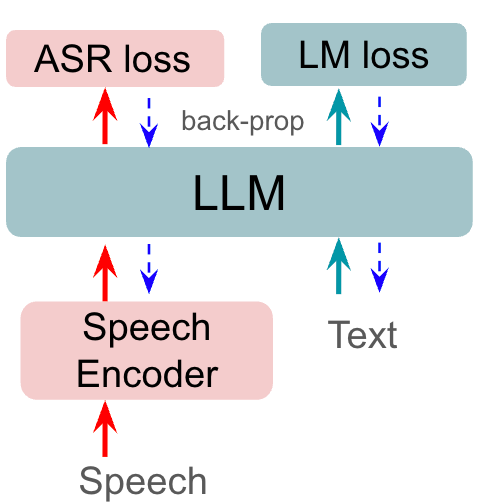
我们提出的方法侧重于使用 ASR 损失来微调 prefixLM 的语音前缀标记,以提高识别性能。 图2展示了我们提出的语音前缀调整方法的训练和评估流程。 与图 1 中的先前工作不同,仅专注于仅调整前缀嵌入,其损失与用于文本预测的损失相同,使用 RNNT 损失调整更新语音编码器和前缀嵌入,使模型能够学习更多有判别性的语音特征作为前缀标记。
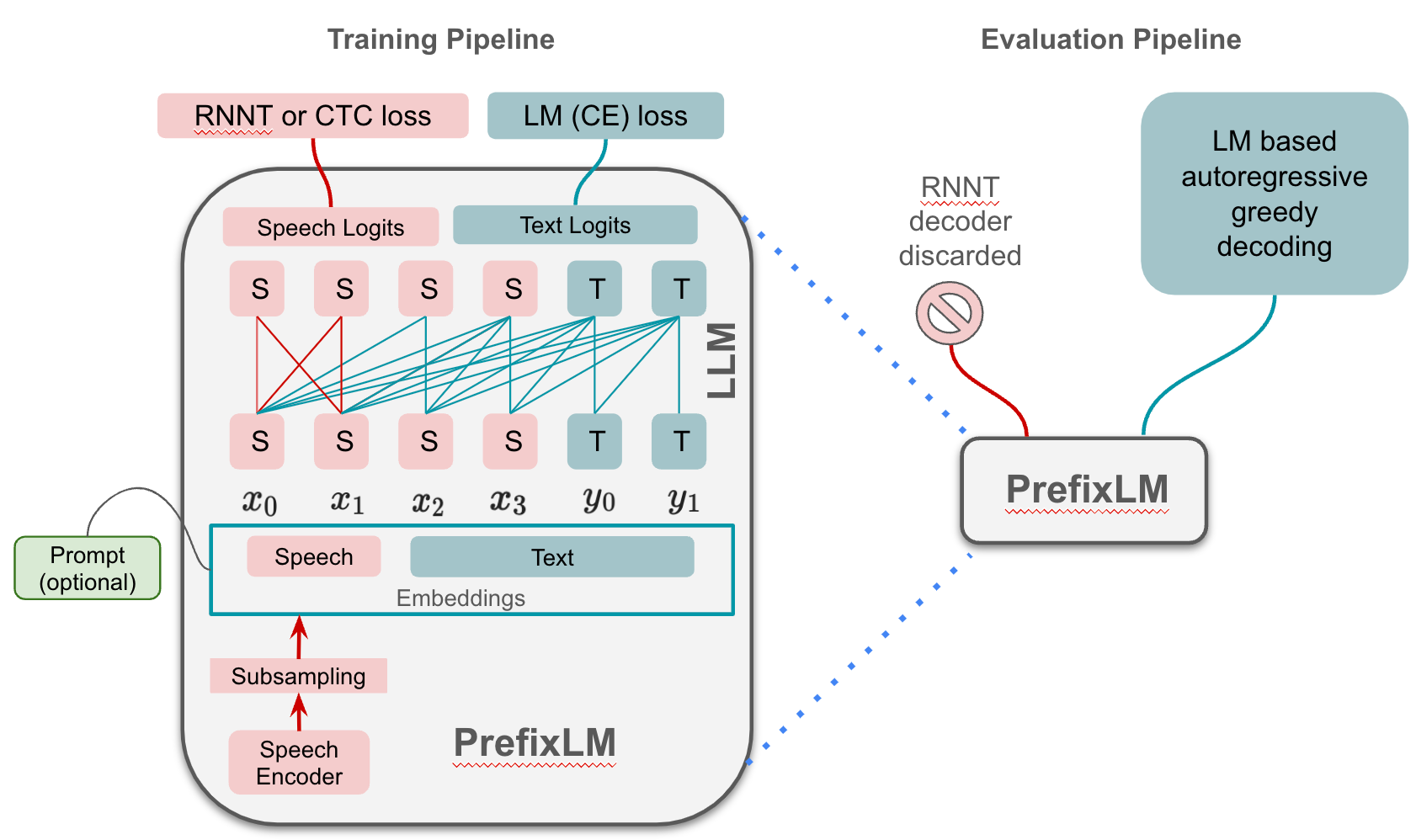
给定具有 帧的输入语音序列 和具有 长度的文本序列 ,前缀LM 接受连接的输入。
2.1前缀LM
PrefixLM [1] 是在输入到目标范例中运行的仅解码器模型。 它几乎可以被视为具有共享参数的编码器-解码器模型。 PrefixLM 作为数据量相对较小的任务的适应方法,已显示出竞争优势[14]。PrefixLM 架构 摄入 并启用对前缀序列 的双向关注。 这将作为后续对 进行预测的前缀。与声学前缀对应的输出逻辑被丢弃,并且预测文本的输出逻辑用于解码。 学习模型参数 的最终训练目标是使用 CE 损失最小化下一个文本词符预测期间的错误:
| (1) |
2.2 前缀调整
前缀调整仅微调包含前缀堆栈的嵌入层,以引导文本嵌入实现目标任务。 在使用方程 (1) 进行训练期间,前缀嵌入学习底层任务的摘要表示。 前缀嵌入在推理过程中保持固定,并从评估数据集中投影所需的信息。 前缀调整在计算上非常高效,可训练参数少得多,并且还可以避免过度拟合。
2.3RNNT解码器
RNNT [15] 是一种自回归序列到序列模型,它处理编码的语音序列,为编码器输出的每个时间步生成文本标记的分布。 然后,联合网络结合编码器信息和先前的预测来生成当前词符。 RNNT 解码器依赖于语音编码器的输出。 在我们的工作中,我们建议使用 prefixLM 语音前缀的输出 logits 作为 RNNT 解码器的输入。
2.4 使用 RNNT 损失进行语音前缀调整
基于先前 ASR 与大语言模型 [6,2,7] 的合作,我们相信拥有良好编码的语音前缀可以作为更好的上下文来驱动 LM 实现目标任务。 当语音序列长度越来越接近文本序列长度[2]时,prefixLM 能够更好地学习语音到文本的对齐。 将这种直觉扩展到序列长度之外,我们希望找到更好的语音表示来引导 LM 改进 ASR 任务。 直观上,语音前缀可以通过指导从 中提取内容来影响文本编码 ;并可以通过驱动下一个词符分布来改进文本生成。 所提出的使用 ASR 损失的目标是通过更新语音相关参数来放大语音特征的独特性。
为了执行语音前缀调整,我们将语音输出逻辑从大语言模型传播到 RNNT 解码器。 RNNT 损失学习语音到文本对齐和 预测,允许语音前缀容纳更多有关底层语音和要预测的文本的知识。 联合训练目标是:
| (2) | ||||
| (3) |
这里,是大语言模型的语音前缀输出(语音logits),如图2。
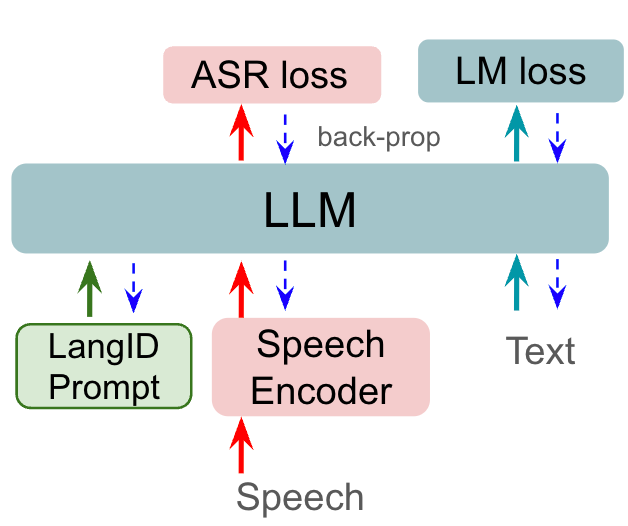
2.5 基于语言ID的软提示
2.6 LLM 训练
3实验
3.1 数据集和模型
数据:这些实验中使用的训练数据由 [16, 17] 中所述的 YouTube 长格式数据组成,并取自 10 种印度语言。 所有数据均来自 10 种印度语言,并被分割成最大长度为 30 秒的“话语”。 语言信息是从视频中上传的语言标签中获取的,并作为辅助嵌入与语音特征一起合并。 为了进行评估,我们使用了针对 10 种印度语言的 YouTube 测试集,其中结合了涵盖从体育、娱乐到教育等广泛主题的话语。 训练和测试数据都被分割成最大长度为 30 秒的话语。 有关跨语言的训练和测试材料的分布,请参阅表 1。
| LID | Language | #Hours | #Hours |
|---|---|---|---|
| (Train) | (Test) | ||
| bn | Bengali | 3.3k | 30.2 |
| en | English | 3.5k | 22.2 |
| gu | Gujarati | 3.5k | 30.4 |
| hi | Hindi | 5.5k | 30.1 |
| kn | Kannada | 3.6k | 29.8 |
| ml | Malayalam | 3.2k | 29.3 |
| mr | Marathi | 3.7k | 30.0 |
| ta | Tamil | 4.5k | 28.7 |
| te | Telugu | 4.2k | 29.6 |
| ur | Urdu | 2.0k | 30.2 |
语音编码器:我们采用通用语音模型(USM)[18],模型复杂度为 300M (USM-S) 和 600M (USM-L) 参数。 USM-S 利用模型维度 (768) 的 24 层 Conformer,产生总共 3.335 亿个参数,而 USM-L 具有与 USM-S 相同的层数,但具有 1024 个维度。 两种 USM 架构都使用分块双向注意力,使它们能够准确地建模长音频序列(训练期间的 30 秒片段)。 基于 Mel fiterbank 的语音特征被馈送到 USM 语音编码器,并且编码输出被二次采样 4 倍(160ms 帧速率)以提高效率。 该二次采样编码器输出用作前缀嵌入。 USM 使用大量多语言数据进行训练:超过 1000 万小时的未标记音频、数百亿个文本句子、超过十万小时的监督和半监督音频。 这些数据取自一百多种语言,涵盖各种主题[18]。
大语言模型:本文使用的大语言模型基于基于 JAX 的 M4 multipod 模型[19])。 这是一个基于 Transformer 的解码器模型。 在本文中,我们展示了两种大语言模型大小(128M 和 500M 参数)的结果。 128M有8层16个头,4096个隐藏维度。 500M模型有30层,16个头和4096个隐藏维度。 前馈层配置对于 128M (LLM-S) 和 500M (LLM-L) 参数模型都是通用的,维度为 16384,注意力头大小为 64。 这两个模型都使用 800B 文本标记进行训练。 我们使用相对位置嵌入和 GELU 激活。 具有动量的 Adafactor 优化器用于批量大小为 1024、序列长度为 1k 个标记的训练。 最后,模型被量化为 bfloat16 精度,以实现高效的调整和推理。 256k 基于词汇的句子训练标记 [20] 用于 。 使用 UL2 目标 [21] 的变体执行训练,如 [22] 中所述。
4 结果与讨论
| Train decoder | Eval decoder | Avg WER (%) | |
| USM-S | USM-L | ||
| CTC | CTC | 35.9 | 33.0 |
| PrefixLM (finetuned) | LM | 36.7 | 32.2 |
| PrefixLM (prefix-tuned with CTC) | CTC | 33.8 | 31.8 |
| PrefixLM (prefix-tuned with CTC) | LM | 33.7 | 31.8 |
| RNNT | RNNT | 31.5 | 29.4 |
| PrefixLM (prefix-tuned with RNNT) | RNNT | 29.8 | 28.4 |
| PrefixLM (prefix-tuned with RNNT) | LM | 29.8 | 28.3 |
| LLM | Tune | bn | en | gu | hi | kn | ml | mr | ta | te | ur | Avg |
| USM-L + frozen LLM-L | - | 33.5 | 16.6 | 51.1 | 49.4 | 57.6 | 54.6 | 30.3 | 52.2 | 45.7 | 45.7 | 43.6 |
| Prompt | 33.5 | 15.2 | 50.2 | 45.1 | 52.3 | 51.1 | 30.4 | 52.0 | 44.6 | 41.0 | 41.5 | |
| Prefix | 22.0 | 14.1 | 37.8 | 15.5 | 37.6 | 40.1 | 27.3 | 42.0 | 33.0 | 21.4 | 29.1 | |
| Prefix+Prompt | 20.9 | 14.5 | 37.6 | 15.3 | 37.4 | 39.7 | 26.9 | 42.2 | 32.7 | 21.3 | 28.9 | |
| Prefix+LangIDPrompt | 20.5 | 14.3 | 37.0 | 15.2 | 37.2 | 39.4 | 26.4 | 41.1 | 32.4 | 21.0 | 28.5 | |
| USM-L + finetuned LLM-L | - | 27.5 | 17.4 | 40.7 | 18.3 | 40.6 | 42.8 | 29.9 | 44.0 | 35.6 | 25.6 | 32.2 |
| Prefix | 20.2 | 13.7 | 37.1 | 15.2 | 37.2 | 39.5 | 26.5 | 41.5 | 32.4 | 21.0 | 28.3 |
4.1 带有 CTC 和 RNNT 的 PrefixLM
RNNT 或 CTC 解码器的引入以及 PrefixLM ASR 模型的相应损失表明了明显的改进。 使用 CTC 辅助损失,USM-L 的 WER 从 32.2 下降到 31.8,而 USM-S 的表现则从 36.7 下降到 33.7(相对 8%)。 单独的 RNNT 是比表 2 中第 1 行和第 5 行给出的 CTC 更好的 ASR 模型(29.4 比 33.0)。 这也体现在它与PrefixLM的结合上。 RNNT 解码器的引入和 PrefixLM 的损失在 USM-S 和 USM-L 上分别产生了 5.4% 和 3.7% 的相对胜利。
4.2 基于语言的提示允许冻结LM
表 2 中的结果更新了完整的 PrefixLM 模型(图 2),包括语音编码器和 LM。 然而,更新大语言模型的计算成本很高。 在本节中,我们将探索上下文提示技术,通过更新语音编码器同时保持大语言模型冻结来实现类似的性能。
表 3 还显示了使用习得的软提示和语言条件提示的结果,如 2.5 节中所述,使用 LLM-L 和 USM-L 作为语音编码器。 使用冷冻大语言模型的平均 %WER 性能明显较差,为 43.6,而微调大语言模型为 28.3。 及时调整表明它平均提高了 2.1%。 我们提出的语音前缀调整将平均 %WER 降至 29.1。 调整语音前缀和提示嵌入是互补的,并且显示出边际收益。 我们假设语音前缀+提示调整的这种边际改进是由于使用单个提示嵌入来建模多语言输入数据的限制。 通过使用 langID 提示调整将提示扩展到特定于语言,能够将冻结大语言模型的性能提高到表 3 中最佳性能完全更新模型的 0.2% WER 以内 (28.5对比 28.3)。 这导致模型中大约一半的参数不需要更新,对质量的影响非常小。
4.3 语音前缀调谐误差分析
| Lang | Error | RNNT | PrefixLM | PrefixLM |
|---|---|---|---|---|
| (finetuned) | (prefix-tuned with RNNT) | |||
| bn | D | 3.6 | 3.6 | 4.6 |
| I | 2.0 | 6.7 | 1.9 | |
| S | 14.6 | 17.2 | 13.6 | |
| en | D | 3.1 | 3.0 | 3.6 |
| I | 2.7 | 5.4 | 2.3 | |
| S | 11.6 | 9.0 | 7.8 | |
| gu | D | 5.4 | 5.5 | 5.5 |
| I | 8.8 | 11.7 | 8.6 | |
| S | 23.7 | 23.5 | 23.0 | |
| hi | D | 3.8 | 3.5 | 3.1 |
| I | 2.2 | 3.8 | 2.1 | |
| S | 23.7 | 11.0 | 10.0 | |
| kn | D | 5.8 | 5.7 | 5.6 |
| I | 4.1 | 6.7 | 4.3 | |
| S | 27.8 | 28.2 | 27.3 | |
| ml | D | 5.3 | 6.1 | 5.3 |
| I | 7.4 | 9.3 | 7.2 | |
| S | 27.2 | 27.5 | 26.1 | |
| mr | D | 5.4 | 6.0 | 6.5 |
| I | 2.6 | 5.5 | 2.4 | |
| S | 18.7 | 18.4 | 17.6 | |
| ta | D | 6.1 | 5.4 | 5.5 |
| I | 5.5 | 7.6 | 5.7 | |
| S | 31.0 | 31.1 | 30.3 | |
| te | D | 4.5 | 4.4 | 4.7 |
| I | 5.4 | 7.7 | 5.4 | |
| S | 23.0 | 23.5 | 22.3 | |
| ur | D | 3.4 | 4.0 | 3.1 |
| I | 6.2 | 7.6 | 6.3 | |
| S | 19.4 | 13.9 | 11.7 |
4.4 语码转换分析
如果没有语言 ID 信息,多语言 ASR 模型往往会产生多种语言(有时是多种文字)的假设。 其中一些是有意设计的,因为印度语言中的语音经常是代码混合的。 然而,这也是错误的来源,其中假设可能在声学上“正确”,但以意想不到的脚本产生。 在这里,我们使用 [23] 中表示的代码混合指数 (CMI) 度量来测量不同方法的代码混合行为:
| (4) |
这里, = 任何语言中出现的最高单词数(超过 1 种语言可以具有相同的最高单词数), = 话语中的标记数量 , = 赋予其他语言标签的标记数量。
| Model | # words | # maxwords in ta | CMI |
|---|---|---|---|
| RNNT | 137257 | 136788 | 34.2% |
| PrefixLM (finetuned) | 137394 | 136888 | 36.8% |
| Proposed | 137299 | 136849 | 32.8% |
在表 5 中,我们看到,对于泰米尔语 (ta),PrefixLM 比提出的语音前缀调整 模型生成更多的代码混合假设。 %CMI 从 36.8 提高到 32.8,这表明与基线相比,预测的非泰米尔语单词数量较少。 在其他印度语言中也观察到了这种行为。
5相关作品
就在过去的几年里,在 ASR 中使用大语言模型方面做了很多工作。 其中包括 Flamingo [24]、PrefixLM [1] 和 SLM [9]。 其他一些著名的作品[25,26,27],将预训练的语音编码器与基于预训练的文本的大语言模型合并来执行 ASR 和其他语音相关任务。 考虑到进展速度,这必然是一个不完整的列表。 这些工作大多数依赖于具有匹配域的良好预训练语音编码器[18]来实现更好的识别性能。 另一方面,大语言模型通过执行完整的微调 [28, 29] 或其他轻量级方法(例如提示调整 [30, 6, 31])来适应目标域]。
在这项工作中,我们证明这两种技术可以通过使用联合 RNNT 和 LM 损失执行语音前缀调整来统一,从而提供更好的前缀嵌入并执行轻量级微调。 为了进一步减少可调参数,我们在2.5节中提出了基于langID的软提示,通过使用条件信息来学习软提示,而不是为此条件手工制作硬提示。
6 结论
传统 RNNT 损失的包含成功地补充了基于 PrefixLM 的 ASR 的成功。 整体质量保持较高水平,同时平衡插入率。 此外,代码混合输出的速率也降低了。 我们还证明了以语言 ID 为条件的学习软提示的价值,作为消除对 LM 微调的需要的途径,从而大大减少了该技术获得高质量结果所需的训练。
参考
- [1] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” The Journal of Machine Learning Research, vol. 21, no. 1, pp. 5485–5551, 2020.
- [2] Y. Fathullah, C. Wu, E. Lakomkin, J. Jia, Y. Shangguan, K. Li, J. Guo, W. Xiong, J. Mahadeokar, O. Kalinli et al., “Prompting large language models with speech recognition abilities,” arXiv preprint arXiv:2307.11795, 2023.
- [3] R. Mokady, A. Hertz, and A. H. Bermano, “Clipcap: Clip prefix for image captioning,” arXiv preprint arXiv:2111.09734, 2021.
- [4] J. Cho, M. K. Baskar, R. Li, M. Wiesner, S. H. Mallidi, N. Yalta, M. Karafiát, S. Watanabe, and T. Hori, “Multilingual sequence-to-sequence speech recognition: Architecture, transfer learning, and language modeling,” in 2018 IEEE Spoken Language Technology Workshop (SLT), 2018, pp. 521–527.
- [5] M. Kim, K. Sung-Bin, and T.-H. Oh, “Prefix tuning for automated audio captioning,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [6] Z. Ma, G. Yang, Y. Yang, Z. Gao, J. Wang, Z. Du, F. Yu, Q. Chen, S. Zheng, S. Zhang, and X. Chen, “An Embarrassingly Simple Approach for LLM with Strong ASR Capacity,” arXiv e-prints, p. arXiv:2402.08846, Feb. 2024.
- [7] E. Lakomkin, C. Wu, Y. Fathullah, O. Kalinli, M. L. Seltzer, and C. Fuegen, “End-to-end speech recognition contextualization with large language models,” arXiv preprint arXiv:2309.10917, 2023.
- [8] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al., “Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
- [9] M. Wang, W. Han, I. Shafran, Z. Wu, C.-C. Chiu, Y. Cao, N. Chen, Y. Zhang, H. Soltau, P. K. Rubenstein et al., “Slm: Bridge the thin gap between speech and text foundation models,” in 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8.
- [10] X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 4582–4597.
- [11] Y. Ma, T. H. Nguyen, and B. Ma, “Cpt: Cross-modal prefix-tuning for speech-to-text translation,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6217–6221.
- [12] R. Ma, M. Qian, P. Manakul, M. Gales, and K. Knill, “Can generative large language models perform asr error correction?” arXiv preprint arXiv:2307.04172, 2023.
- [13] K. Hu, T. N. Sainath, B. Li, N. Du, Y. Huang, A. M. Dai, Y. Zhang, R. Cabrera, Z. Chen, and T. Strohman, “Massively multilingual shallow fusion with large language models,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5.
- [14] N. Ding, T. Levinboim, J. Wu, S. Goodman, and R. Soricut, “Causallm is not optimal for in-context learning,” in The Twelfth International Conference on Learning Representations, 2023.
- [15] M. Ghodsi, X. Liu, J. Apfel, R. Cabrera, and E. Weinstein, “Rnn-transducer with stateless prediction network,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7049–7053.
- [16] H. Liao, E. McDermott, and A. Senior, “Large scale deep neural network acoustic modeling with semi-supervised training data for youtube video transcription,” in 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, 2013, pp. 368–373.
- [17] T. Chen, C. Allauzen, Y. Huang, D. Park, D. Rybach, W. R. Huang, R. Cabrera, K. Audhkhasi, B. Ramabhadran, P. J. Moreno, and M. Riley, “Large-scale language model rescoring on long-form data,” in ICASSP, 2023.
- [18] Y. Zhang, W. Han, J. Qin, Y. Wang, A. Bapna, Z. Chen, N. Chen, B. Li, V. Axelrod, G. Wang et al., “Google usm: Scaling automatic speech recognition beyond 100 languages,” arXiv e-prints, pp. arXiv–2303, 2023.
- [19] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann et al., “Palm: Scaling language modeling with pathways,” Journal of Machine Learning Research, vol. 24, no. 240, pp. 1–113, 2023.
- [20] T. Kudo and J. Richardson, “Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2018, pp. 66–71.
- [21] Y. Tay, M. Dehghani, V. Q. Tran, X. Garcia, D. Bahri, T. Schuster, H. S. Zheng, N. Houlsby, and D. Metzler, “Unifying language learning paradigms,” arXiv e-prints, pp. arXiv–2205, 2022.
- [22] X. Garcia, Y. Bansal, C. Cherry, G. Foster, M. Krikun, M. Johnson, and O. Firat, “The unreasonable effectiveness of few-shot learning for machine translation,” in International Conference on Machine Learning. PMLR, 2023, pp. 10 867–10 878.
- [23] B. Gambäck and A. Das, “On measuring the complexity of code-mixing,” in Proceedings of the 11th international conference on natural language processing, Goa, India, 2014, pp. 1–7.
- [24] J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynolds et al., “Flamingo: a visual language model for few-shot learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 23 716–23 736, 2022.
- [25] Q. Chen, Y. Chu, Z. Gao, Z. Li, K. Hu, X. Zhou, J. Xu, Z. Ma, W. Wang, S. Zheng et al., “Lauragpt: Listen, attend, understand, and regenerate audio with gpt,” arXiv preprint arXiv:2310.04673, 2023.
- [26] D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y. Zhou, and X. Qiu, “Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities,” arXiv preprint arXiv:2305.11000, 2023.
- [27] W. Yu, C. Tang, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “Connecting speech encoder and large language model for asr,” arXiv preprint arXiv:2309.13963, 2023.
- [28] J. Wu, Y. Gaur, Z. Chen, L. Zhou, Y. Zhu, T. Wang, J. Li, S. Liu, B. Ren, L. Liu et al., “On decoder-only architecture for speech-to-text and large language model integration,” in 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8.
- [29] C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, M. Zejun, and C. Zhang, “Salmonn: Towards generic hearing abilities for large language models,” in The Twelfth International Conference on Learning Representations, 2023.
- [30] H. Yu, H. Zheng, Y. Zhang, S. Xie, X. Cao, and Z. Fang, “Prompt tuning is all we need?” 2024. [Online]. Available: https://openreview.net/forum?id=eBTtShIjxu
- [31] X. Liu, K. Ji, Y. Fu, Z. Du, Z. Yang, and J. Tang, “P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks,” CoRR, vol. abs/2110.07602, 2021. [Online]. Available: https://arxiv.org/abs/2110.07602