DemoRank:在排序任务中选择大型语言模型的有效演示
摘要
最近,人们对应用大型语言模型(大语言模型)作为零样本段落排序器越来越感兴趣。 然而,很少有研究探索如何为段落排序任务选择合适的上下文演示,这也是本文的重点。 先前的研究主要应用演示检索器来检索演示并使用 top- 演示进行上下文学习(ICL)。 虽然有效,但这种方法忽略了演示之间的依赖性,导致少样本 ICL 在段落排序任务中表现较差。 在本文中,我们将演示选择制定为检索然后重新排序过程,并介绍了 DemoRank 框架。 在此框架中,我们首先使用大语言模型训练反馈来训练演示检索器,并构建一个新颖的依赖感知样本来训练演示重排序器,以改进少样本 ICL。 此类训练样本的构建不仅考虑了演示依赖性,而且还以有效的方式执行。 大量的实验证明了 DemoRank 在域内场景中的有效性以及对域外场景的强大泛化能力。 我们的代码可在 https://github.com/8421BCD/DemoRank 获取。
DemoRank:在排序任务中选择大型语言模型的有效演示
Wenhan Liu, Yutao Zhu, and Zhicheng Dou† Gaoling School of Artificial Intelligence, Renmin University of China lwh@ruc.edu.cn, yutaozhu94@gmail.com, dou@ruc.edu.cn
1简介
大型语言模型(大语言模型)在一系列自然语言处理(NLP)任务中表现出了卓越的性能。 最近,人们对使用大语言模型进行段落排序任务产生了浓厚的兴趣 Zhuang 等人 (2023a);孙等人 (2023);秦等人 (2023). 一种典型的方法是相关性生成,它以逐点的方式判断查询-段落对的相关性。 该方法提示大语言模型通过生成“是”或“否”等回答来评估段落与查询的相关性。 然后根据这些响应的对数似然计算相关性得分。 这种方法在之前的研究中已被证明是有效的Zhuang 等人 (2023a);梁等人 (2022).
情境学习(ICL)已被证明是大语言模型 Wei 等人 (2022) 的一种新兴能力,使他们能够通过多次任务演示来适应特定任务(即,输入输出示例)。 许多研究调查了 NLP 任务演示的最佳选择Lu 等人 (2022);张等人 (2022);李等人 (2023);王等人 (2023); Xu 等人 (2024),强调了定制演示对于实现高性能的重要性。 然而,ICL 在段落排序任务中的应用尚未得到广泛研究。 鉴于文章排名的复杂性,ICL 为提高大语言模型的性能提供了一个具有挑战性但又充满希望的机会。 因此,本研究旨在开发有效的示范选择策略,以优化 ICL 在段落排序中的应用。
一种广泛使用且有效的示范选择方法是使用大语言模型的反馈训练示范检索器 Wang 等人 (2023); Rubin 等人 (2022);李等人 (2023);程等人 (2023);斯卡拉托斯和兰 (2023);罗等人(2023)。 该方法首先利用大语言模型根据大语言模型在给定每个候选者和输入的情况下产生正确输出的可能性对一些示范训练候选者进行评分,并根据检索器的分数选择正向和负向候选者。 沿着这个技术路线,我们建议根据大语言模型的反馈训练一个针对段落排序任务的演示检索器。
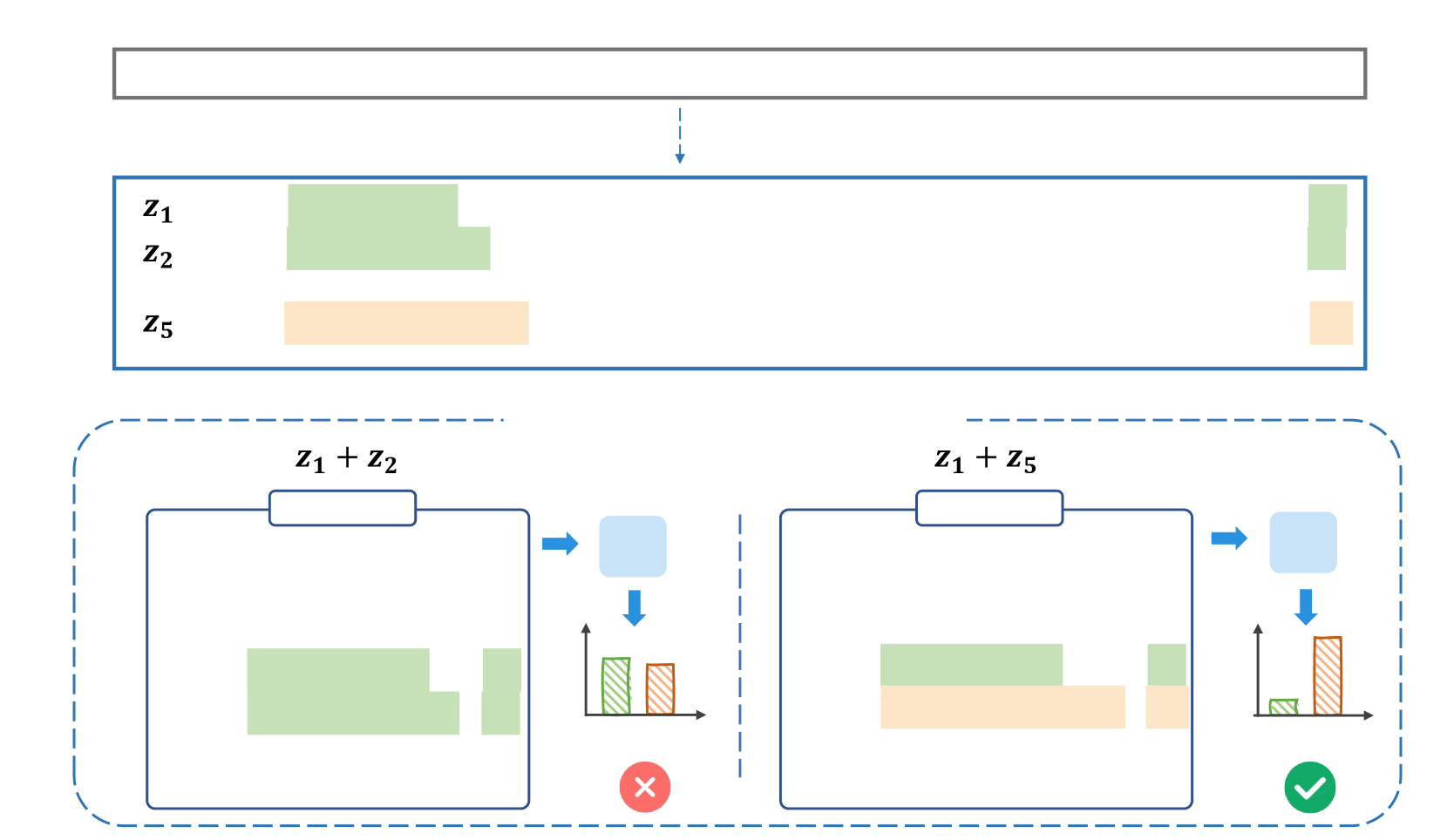
在推理阶段,常见的做法Wang等人(2023)是使用经过训练的检索器来获取演示列表,并在 ICL 提示中将检索到的最前面的列表连接在一起。 尽管它在 NLP 任务中有效,但直接将其扩展到段落排名任务中可能会导致性能次优。 主要挑战在于文章排名中查询-文章关系的复杂性,这可能需要组合多个演示来提供理解这种关系的有效信息。 图 1 显示了此类问题的示例。 当为当前输入(相关查询-段落对)选择 2-shot 演示时,现有方法 Wang 等人 (2023); Rubin 等人 (2022) 将选择检索器返回的前 2 个演示( 和 )。 但是,我们认为组合 和 更适合这种情况。 这是因为和有更多不同的查询和相反的输出(相关性标签),这为大语言模型提供了更丰富、更多样化的查询-段落关系信号,从而对相关性评估做出更多贡献。 这个例子显示了在基于LLM的少样本段落排名任务中纯粹基于相关性的演示选择的不足。 在本文中,我们将从最初检索的 演示中选择最佳 镜头演示的问题转化为演示排名问题,并提出使用大语言模型的反馈来训练新颖的依赖性感知演示重新排序器,使排名靠前的演示更适合在少样本 ICL 中进行段落排序。
然而,训练这样的重新排序器是一项非常具有挑战性的任务。 如前所述,使用大语言模型对每个单独演示的反馈来训练为镜头选择而设计的重排器是不合理的,因为演示可以相互影响。 此外,构建针对 镜头选择定制的重新排名器的地面实况排名需要从检索到的 演示中找到最佳的 镜头排列。 理论上,这需要使用大语言模型来评分总分 演示排列,这是非常耗时且不切实际的。 为了克服这些挑战,我们建议为重新排序训练构建一种依赖性感知训练样本(带有排名标签的演示列表)。 具体来说,给定一个检索到的演示集,我们贪婪地从该集中选择演示,并用不同的排名标签(从最高到最低)对它们进行注释。 每次,都会选择与已选择的模型连接时最大化大语言模型反馈的演示。 这个过程不仅考虑了当前演示与之前选择的演示之间的依赖关系,而且大大减少了大语言模型的推理次数。
为此,我们提出了 DemoRank,这是一个用于通道 Rank 计算的 Demonstration 选择框架,采用两阶段 "检索-然后-再排名 "策略。 在此框架中,我们首先根据大语言模型对排序任务的反馈训练了一个演示检索器DRetriever。 然后,我们引入一个依赖项感知演示重排序器 DReranker 对检索到的演示进行重新排序。 为了解决其训练的挑战,我们提出了一种构建依赖项感知训练样本的方法,该方法不仅包含演示依赖项,而且还具有时效性。
在一系列排序数据集上的实验证明了DemoRank的有效性,特别是在少样本ICL中。 进一步的分析还证明了每个提出的组件的贡献以及 DemoRank 在不同场景下的强大能力,包括有限的训练数据、不同的演示数量、未见过的数据集等。
我们论文的主要贡献总结如下:(1)据我们所知,我们是第一个全面讨论段落排序中有效示范选择并提出DemoRank框架的人。 (2)我们提出了一种新颖的依赖感知演示训练重排序器,并设计了一种合理且有效的方法来构建其数据。 (3) 除了域内性能之外,进一步的实验还证明了 DemoRank 对未见过的数据集的泛化能力。
2相关工作
2.1 LLM 的通过排名
随着信息检索中大语言模型朱等人(2023)的发展,已有许多研究探索如何利用大语言模型来完成文章排序任务。 总的来说,这些研究可以分为三类:pointwise Liang 等人 (2022); Sachan 等人 (2022)、成对 Qin 等人 (2023) 和列表方法 Sun 等人 (2023);马等人(2023)。 逐点方法评估查询和单个段落之间的相关性。 典型的方法是相关性生成 Liang 等人 (2022); Zhuang等人(2023a),它为大语言模型提供一个查询-段落对,并指示它如果该段落与查询相关则输出“是”,否则输出“否”。 可以根据词符“是”的生成概率来计算相关性得分。 点式方法的另一种方法是查询生成 Sachan 等人 (2022); Zhuang等人(2023b),根据基于段落生成查询的对数似然来计算相关性得分。 成对方法一次比较两个段落并确定它们与查询的相对相关性,而列表方法直接对段落列表进行排名。
尽管结果令人鼓舞,但这些研究仅关注零样本场景,而较少关注如何在少样本场景中选择有效的演示。 手动编写或基于规则的选择 Drozdov 等人 (2023) 对于排序任务来说不灵活。 在本文中,我们探索了更有效的排序任务演示选择方法。 之前的研究Zhu 等人(2024)表明,与其他方法相比,逐点方法的相关性生成是最适合在开源大语言模型上进行段落排名的方法。 因此,我们打算在本文中使用相关性生成方法进行段落排名。
2.2演示检索
一种广泛使用的演示选择方法是演示检索。 先前的研究已经探索使用不同的检索器进行演示检索,可以分为两类。 一种是利用现成的猎犬,例如 BM25 Agrawal 等人 (2023) 或密集猎犬 Liu 等人 (2022)。 另一种是使用特定任务信号训练演示检索器。 例如,Rubin 等人 (2022) 提出将大语言模型的反馈提取到密集检索器 EPR 中以进行语义解析任务。 Li 等人 (2023) 和 Wang 等人 (2023) 建议在各种 NLP 任务上迭代训练检索器。 然而,这些方法的一个共同问题是它们直接选择检索最多的演示,这可能包含冗余信息,并且对大语言模型对相关性的理解贡献不大。 在本文中,我们考虑了演示依赖性,并引入了一个框架,该框架首先检索演示列表,然后以依赖性感知方式重新排名,更好地与排名任务中的少样本 ICL 保持一致。
3 预赛
3.1 排名任务的相关性生成
段落排名旨在根据检索到的段落与查询的相关性对它们进行排名。 形式上,给定查询 和段落列表 ,我们的任务是计算每个段落的相关性得分 。 基于LLM的相关性生成方法中Liang等人(2022); Zhuang等人(2023a),向大语言模型提供由查询和段落组成的提示,并指示输出二进制标签“是”或“否”以指示该段落是否与查询与否。 然后对标记“是”和“否”的logits应用softmax函数,并将词符“是”的概率用作相关性得分:
| (1) |
其中 是任务描述。 最后,根据相关性得分按降序对段落进行排名。
3.2排名任务中的情境学习
上下文学习是一种在提示中插入一些演示以帮助大语言模型在不更新参数的情况下执行任务的技术。 在相关性生成任务中,给定上下文演示,其中是由查询、段落和二进制输出组成的三元组(“是”或“否”)表示相关性标签,相关性得分可以通过以下方式计算:
| (2) |
其中 是任务描述,在 ICL 中用于帮助大语言模型理解任务 Zhu 等人 (2024);李等人(2023)。
4 DemoRank 框架
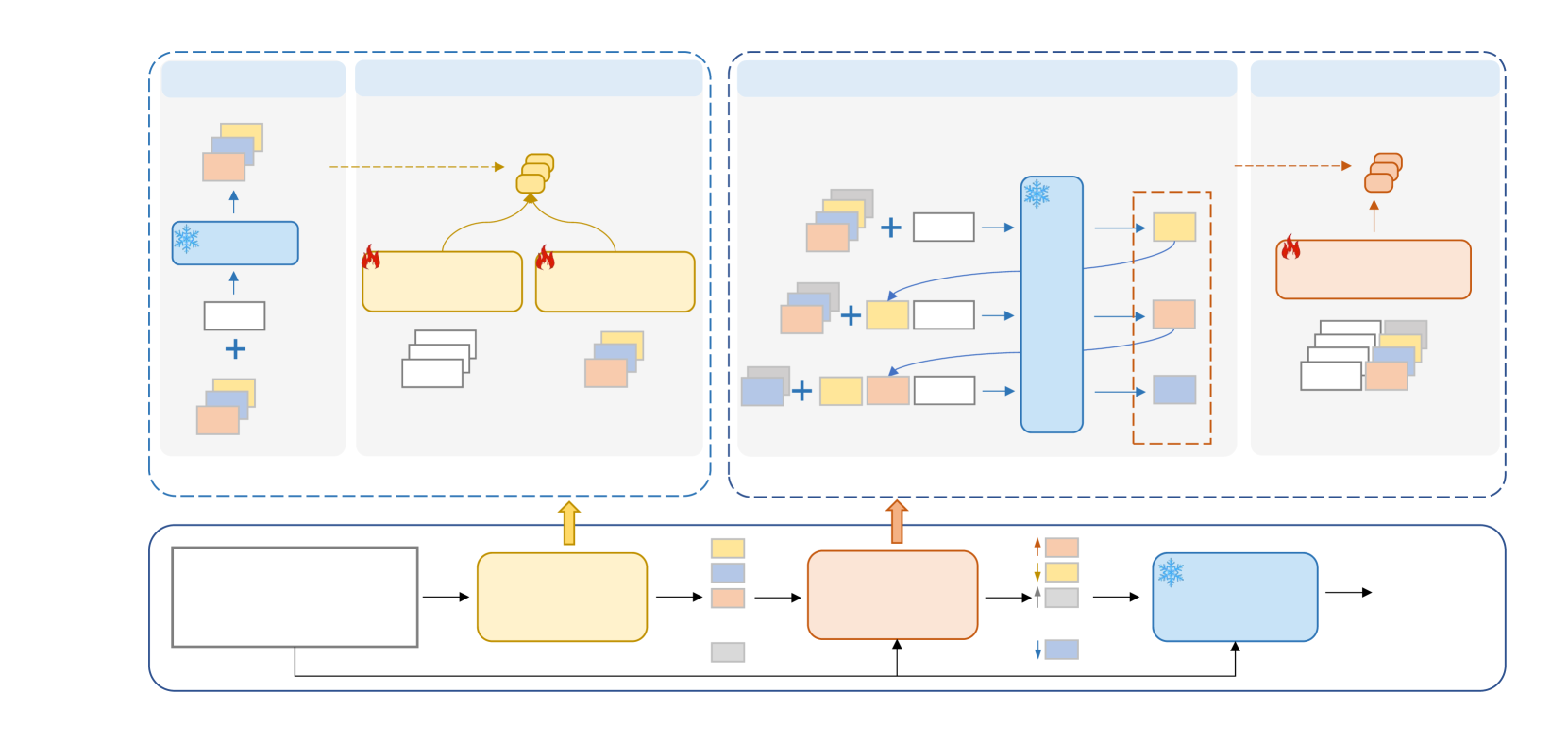
如图 2 所示,我们的 DemoRank 框架遵循演示检索过程,然后进行依赖性感知重新排名。 演示检索器 DRetriever 使用大语言模型评分的演示候选进行训练,演示重排序器 DReranker 则基于我们构建的依赖感知训练样本进行训练。 在本节中,我们将详细介绍我们的演示池构建、训练流程和推理。
4.1示范池建设。
给定一个段落排名数据集(例如,MS MARCO Nguyen 等人(2016)),我们使用其训练集来构建我们的演示池。 对于训练集中的每个查询,我们通过分别将查询与其相关和不相关的段落配对来构建正面和负面的演示。 为了维持示范池中的输出标签平衡,每个查询的负面示范数量被设置为等于其正面示范数量。
4.2演示检索器 DRetriever
在这一部分中,我们训练 DRetriever 来检索可能有用的演示,以供后续演示重新排名。 我们应用大语言模型对一组演示候选者进行评分,以获得监督信号,并使用它们通过多任务学习策略来训练检索器。
大语言模型评分
对于包含查询-段落对的训练输入 ,我们从演示池 中选择一组演示作为训练候选。 继之前的研究Wang等人(2023)之后,我们采用BM25算法来检索top-演示。 由于段落排序的复杂性,演示的效用与其与输入 Drozdov 等人 (2023) 的相似性没有直接关系。 为了包含更多潜在的有用训练演示,我们还从 中随机抽取另一个 演示。 训练候选者的总数被注释为()。
之后,我们应用冻结的大语言模型训练评分器,使用以下公式对输入 的每个演示 进行评分:
| (3) |
其中 是 中查询-段落对的相关性标签, 是标签空间, 是任务描述。 在本文中,大语言模型评分器使用与大语言模型段落排序器相同的模型。 尽管如此,我们还探讨了大语言模型评分器在不同大语言模型段落排名器上的可迁移性(参见附录C)。
训练
我们的 DRetriever 基于双编码器架构。 给定当前训练输入和候选,我们使用编码器和演示编码器分别对它们进行编码并计算相似度得分为:
| (4) |
其中两个编码器 和 共享参数并使用平均池化进行编码。
然后,我们应用对比损失 来最大化训练输入 和正向演示 之间的分数,并最小化负向演示 之间的分数>。 这里是大语言模型得分最高的演示,是其余的演示。 对比损失计算如下:
| (5) |
其中。 这里我们选择不使用批内负片。 其原因在附录D中讨论。
为了利用大语言模型反馈的细粒度监督,我们还考虑一个排名损失RankNet Burges 等人 (2005) 将候选者的排名信号注入训练中:
| (6) |
其中是按大语言模型得分降序排列时在中的排名。
最终的损失函数定义为和的加权和:
| (7) |
其中 是预定义的超参数。
4.3演示重排序器 DReranker
过往研究 Wang 等人 (2023); Rubin 等人 (2022); Li 等人 (2023) 主要使用 top- 检索到的 ICL 演示,它忽略了演示依赖性,对于排序任务可能不是最优的。 为了缓解这个问题,我们将从检索到的演示中选择最佳的 -shot 排列制定为演示重新排序问题,并以有效的方式为重新排序器的训练构建一个新颖的依赖感知样本。
// is the current ranking label.
构建依赖感知训练样本。
为了与 DReranker 的目标保持一致,我们建议为训练构建一个依赖感知的训练样本。 具体来说,给定训练输入 ,我们使用经过训练的 DRetriever 从演示池中检索 top- 演示 。 然后,我们迭代地从 中选择演示,并用排名标签对每个演示进行注释,如图 2 所示。 在每次迭代中,我们从 中未选择的演示中选择与已选择的演示连接时最大化大语言模型反馈的演示。 选择演示后,我们会将其附加到训练示例中。 此过程在选择当前演示时会考虑先前的演示序列,并逐步逼近最佳的 镜头演示排列,这既省时又与少样本设置一致。 请注意,随着迭代次数的增加,大语言模型推理的计算成本也会增加。 由于计算资源有限,我们设置了最大迭代次数。第 次迭代完成后,我们根据选择顺序为训练样本中的每个演示标注从 到 1 的排名标签,并为未选中的演示标注 0 。 算法1展示了这个过程。
训练
构建依赖感知训练样本后,我们获得 中每个演示候选者的排名标签。 我们采用交叉编码器模型来训练 DReranker。 该模型将训练输入 和一个带有“[SEP]”词符的候选 串联起来作为输入,并使用以下公式输出预测分数 “[CLS]”词符的表示。 然后我们应用RankNet损失函数来优化重排序模型,类似于方程(6):
| (8) |
其中表示的排名标签。 请注意,我们的 DReranker 仅接收一个输入和一个演示,不包括依赖演示,这可能无法完全捕获依赖感知排名标签。 尽管如此,这种设计节省了推理时间,使我们的 DReranker 更加高效。 我们计划在未来探索能够有效地对多个相关演示进行建模的架构。
4.4推断
在推理过程中,我们首先使用经过训练的 DRetriever 对整个演示池 进行编码并构建索引。 然后,给定测试输入 ,我们使用 DRetriever 检索 top- 演示,并使用经过训练的 DReranker 对它们重新排名。 最后,我们会选择排名靠前的演示作为上下文中的演示,并将它们与测试输入串联起来计算相关性得分。 我们对 的所有检索到的段落执行此过程,并根据它们的相关性分数对这些段落进行排名。
5实验
5.1设置
数据集
在我们的实验中,我们在不同的排名数据集上训练和评估我们的 DemoRank,包括 HotpotQA Yang 等人 (2018)、NQ Kwiatkowski 等人 (2019)、FEVER Thorne 等人 (2018) 和 MS MARCO Nguyen 等人 (2016)。 我们分别使用他们的训练集来训练我们的模型,并在相应的测试集上评估模型(对于 MS MARCO,评估是在其开发集以及两个域内数据集 TREC DL19 Craswell 等人( 2020b) 和 TREC DL20 Craswell 等人 (2020a))。
实施细节
除非另有说明,我们使用 FLAN-T5-XL Chung 等人 (2022) 作为冷冻大语言模型进行演示评分和段落排名。 在训练阶段,检索器和重新排序器(分别为和)的演示候选数量均设置为50。 4.3节中的最大迭代次数设置为4。 在训练过程中,我们应用 e5-base-v2 Wang 等人 (2022) 和 DeBERTa-v3-base He 等人 (2023) 分别初始化我们的演示检索器和重新排序器。 继之前的研究Sun等人(2023); Zhuang等人(2023a),我们使用BM25检索到的前100个段落作为重新排序的段落。 由于篇幅有限,更多关于模型训练和推理的实现细节在附录A中列出。
基线
我们将我们的演示选择方法与一系列基线进行比较:
随机:我们为每个测试输入从演示池中随机抽取演示。
DBS Drozdov 等人 (2023):DBS 是一种基于段落排序中查询生成的基于规则的选择方法。 它选择大语言模型最难预测的演示。 在本文中,我们实现了基于相关性生成方法的算法。 我们将每个演示的分数定义为大语言模型在给定查询和段落的情况下生成相应相关性标签的概率。 应用得分最低的演示。
K-means:K-means 是另一种静态演示选择方法。 该方法将池中的所有演示聚类为簇,然后选择距离每个簇中心最近的演示进行ICL。 我们使用 E5 Wang 等人 (2022) 模型来获得聚类的演示嵌入。
BM25 Robertson 和 Zaragoza (2009):BM25 是一种广泛使用的稀疏检索器。 我们应用 BM25 来检索与测试查询最相似的演示。
SBERT Reimers 和 Gurevych (2019):我们使用 Sentence-BERT 作为现成的演示检索器,遵循 Rubin 等人 (2022)111检查点来自 https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2。. 我们使用 SBERT 对池中的所有演示进行编码并检索最相似的演示。
E5 Wang 等人 (2022):E5 是另一种现成的密集检索器。 继Wang等人(2023)之后,我们使用与SBERT相同的基于e5-base-v2检查点的检索方法222https://huggingface.co/intfloat/e5-base-v2。
| Method | HotpotQA | NQ | FEVER | DL19 | DL20 | MS MARCO | Avg | |
|---|---|---|---|---|---|---|---|---|
| Initial Order | 63.30 | 30.55 | 65.13 | 50.58 | 47.96 | 22.84 | 46.73 | |
| 0-shot | 60.65 | 48.62 | 38.92 | 66.13 | 65.57 | 33.24 | 52.19 | |
| 1-shot | Random | 59.71 | 48.69 | 38.41 | 66.76 | 65.35 | 33.53 | 52.08 |
| K-means | 59.62 | 48.68 | 37.96 | 66.45 | 65.30 | 33.59 | 51.93 | |
| DBS | 60.34 | 49.05 | 38.96 | 66.83 | 65.79 | 33.54 | 52.42 | |
| BM25 | 61.46 | 49.53 | 40.43 | 65.08 | 65.86 | 33.73 | 52.68 | |
| SBERT | 58.41 | 49.49 | 36.25 | 66.63 | 64.18 | 33.98 | 51.49 | |
| E5 | 61.70 | 49.49 | 39.96 | 66.48 | 65.20 | 33.79 | 52.77 | |
| DemoRank | 65.64 | 52.11 | 44.16 | 68.64 | 67.38 | 35.03 | 55.49 | |
| 3-shot | Random | 59.42 | 48.61 | 38.61 | 66.57 | 64.84 | 33.70 | 51.96 |
| K-means | 59.27 | 48.71 | 38.33 | 66.30 | 66.22 | 33.73 | 52.09 | |
| DBS | 60.15 | 48.62 | 39.00 | 66.40 | 65.21 | 33.61 | 52.17 | |
| BM25 | 63.18 | 49.78 | 40.19 | 66.08 | 65.85 | 34.03 | 53.19 | |
| SBERT | 58.38 | 49.23 | 36.80 | 66.67 | 65.07 | 33.71 | 51.64 | |
| E5 | 63.42 | 49.60 | 39.71 | 66.40 | 65.33 | 34.07 | 53.09 | |
| DemoRank | 66.39 | 52.52 | 46.90 | 68.28 | 67.66 | 35.12 | 56.15 |
5.2主要结果
我们分别将 DemoRank 与 1-shot 和 3-shot ICL 中的基线进行比较。 请注意,虽然 DemoRank 主要针对少样本场景,但它也可以在 1-shot ICL 中工作,因此我们提供 1-shot ICL 的性能作为参考。 表1显示了我们实验的主要结果。 从结果中,我们得出以下观察结果:(1)我们的框架 DemoRank 在所有数据集上均显着优于所有基线。 例如,在 3-shot ICL 中,DemoRank 比 HotpotQA 上第二好的模型 E5 好 3 个点,比 FEVER 上第二好的模型 BM25 好约 7 个点。 体现了DemoRank强大的选择演示能力。 (2) 当从 1-shot 扩展到 3-shot 时,与其他基线相比,DemoRank 在 Avg 指标上显示出更大的改进,这表明我们的 DemoRank 可以更好地提高少样本场景中的 ICL 性能。 (3)基于相似度的演示选择基线(例如,E5)优于Random、K-means和DBS基线,但仍远远落后于DemoRank,这证明了基于任务特定微调的有效性关于大语言模型的反馈。
| Method | NQ | DL19 | FEVER | Avg |
| Ablation study | ||||
| - w/o DReranker | 51.69 | 68.44 | 44.40 | 54.84 |
| - w/o DTS | 52.09 | 67.12 | 46.64 | 55.28 |
| DemoRank | 52.52 | 68.28 | 46.90 | 55.90 |
| Using E5 as demonstration retriever | ||||
| E5 | 49.60 | 66.40 | 39.71 | 51.90 |
| 50.74 | 67.37 | 41.76 | 53.29 | |
5.3分析
在本节中,我们讨论 DemoRank 的不同变体,将 DemoRank 与监督模型进行比较,评估其在不同演示数上的性能,以及在未见过的数据集上的泛化。
5.3.1 DemoRank 的不同变体
为了了解 DemoRank 中每个组件的有效性,我们进一步评估 DemoRank 的不同变体。 我们用3次ICL在DL19、NQ sss和FEVER上进行了实验,如表2所示。 首先,我们删除演示重新排序器 DRanker,并仅使用演示检索器 DRetriever 检索到的演示,表示为“- w/o DRanker”。 我们可以看到,删除 DRanker 导致大约 1 分下降,这表明重新排名的演示对于 ICL 更有用。 其次,为了进一步验证我们在少样本 ICL 中的依赖感知训练样本 DTS 的有效性,我们引入了另一种变体,该变体基于大语言模型独立地对 中检索到的每个演示进行评分,表示为“- w/ o DTS”。 在不考虑演示依赖性的情况下,该变体落后于 DemoRank 0.62 个点,这证明依赖性感知训练样本与少样本 ICL 更加一致。 第三,我们还在框架中用 E5 替换了经过训练的 DRetriever,以验证 DReranker 在不同演示检索器上的训练有效性,表示为 。 从结果中我们可以看到显着提高了E5,这证明了我们的DReranker的训练是灵活的,不受特定演示检索器的限制。 此外,我们还在附录D中讨论了DRetriever训练期间排名损失和批量负数的有效性。
| Method | Robust04 | SCIDOCS | DBPedia | NEWS | FiQA | Quora | NFCorpus | Avg |
|---|---|---|---|---|---|---|---|---|
| Initial Order | 40.70 | 14.90 | 31.80 | 39.52 | 23.61 | 78.86 | 33.75 | 37.59 |
| monoBERT | 44.18 | 15.99 | 41.70 | 44.62 | 32.06 | 74.65 | 34.97 | 41.17 |
| 0-shot | 47.90 | 16.33 | 36.22 | 45.01 | 35.30 | 83.42 | 35.89 | 42.87 |
| E5 | 46.49 | 16.78 | 37.72 | 45.40 | 35.38 | 84.13 | 35.44 | 43.05 |
| DemoRank | 48.14 | 16.90 | 39.76 | 46.47 | 35.93 | 83.96 | 36.14 | 43.90 |
| QNum | Method | MS MARCO | DL19 | DL20 |
|---|---|---|---|---|
| 0 | 0-shot | 33.24 | 66.13 | 65.57 |
| 500K | monoBERT | 39.97 | 70.72 | 67.28 |
| monoT5 | 40.05 | 70.58 | 67.33 | |
| DemoRank | 35.12 | 68.28 | 67.66 | |
| 20K | monoBERT | 30.69 | 63.61 | 59.32 |
| monoT5 | 29.79 | 61.16 | 52.72 | |
| DemoRank | 34.63 | 67.25 | 66.67 |
5.3.2 与监督重排序器的比较
DemoRank 的训练主要基于训练集中的查询,也可用于微调监督模型。 在这一部分中,我们将 DemoRank 与不同训练查询量下的两个监督段落排名模型(monoBERT Nogueira and Cho (2019) 和 monoT5 Nogueira 等人 (2020))进行比较。 附录B中提供了 monoBERT 和 monoT5 的训练详细信息。 我们选择 MS MARCO 作为训练集,选择 NDCG@10 作为指标。 我们还报告了 0-shot 性能作为参考。 结果如表4所示。 我们可以看到,当提供 500K 查询时,尽管 DemoRank 在 DL20 上稍微优于 monoBERT 和 monoT5,但在 DL19 和 MS MARCO 上仍然落后于它们,这表明在有大量训练数据可用时监督模型的优势。 然而,当查询数量限制为 20K 时,DemoRank 在三个数据集上显着优于两个监督模型,并且还比 0-shot 基线有显着改进。 这表明,当训练数据有限时,DemoRank 比监督模型更有效,凸显了 DemoRank 在低资源场景中的潜力。
5.3.3不同的演示编号
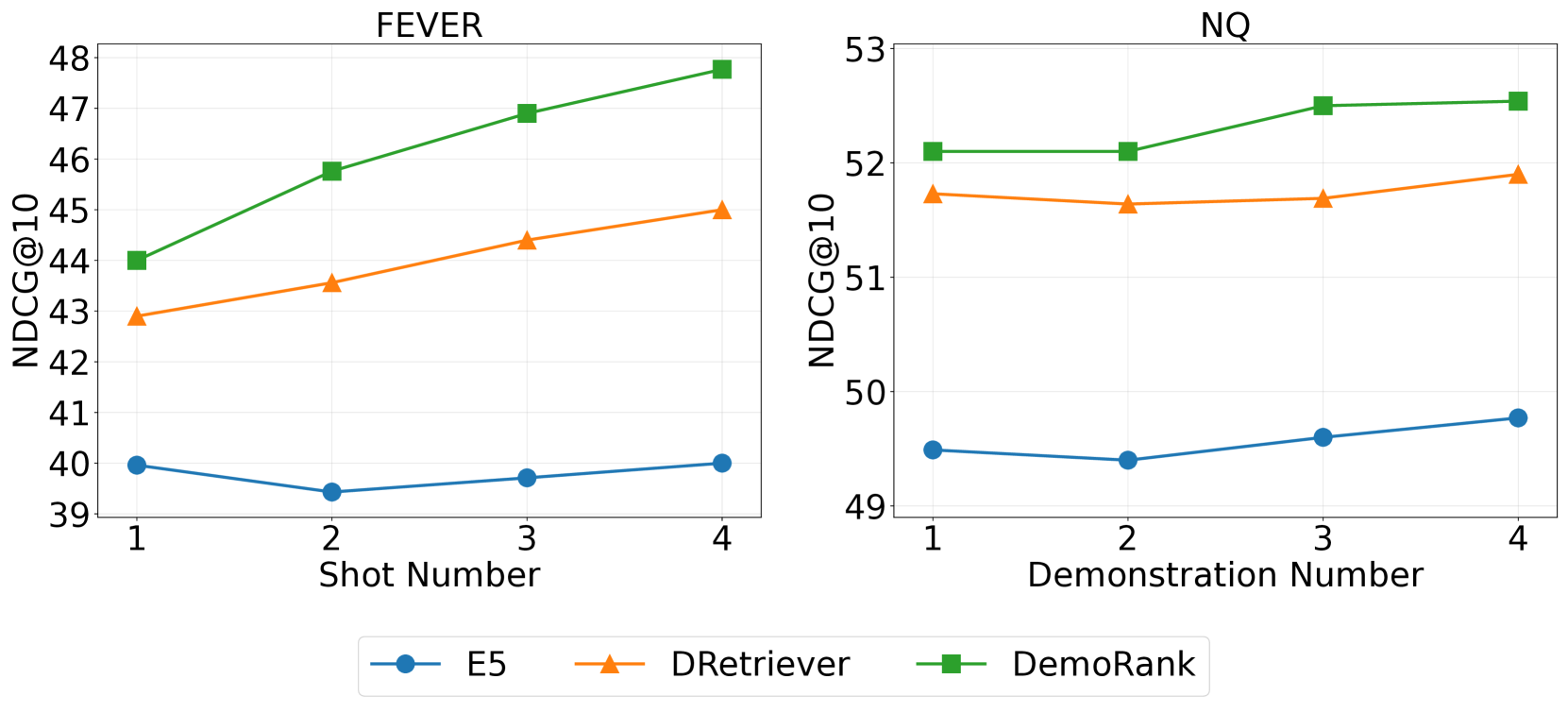
演示次数通常被认为是影响 ICL 的关键因素。 在这一部分中,我们讨论模型在不同演示次数下的性能。 我们使用 NDCG@10 作为指标,在 FEVER 和 NQ 数据集上将 DemoRank 与 E5 基线进行比较。 我们还与 DRetriever 进行比较,以更好地了解 DReranker 的性能。 结果如图3所示。 我们可以看到,DRetriever 和 DemoRank 在不同的演示数据中始终优于 E5,证明了我们模型的有效性和鲁棒性。 此外,我们可以观察到,随着演示数量的增加,DemoRank 和 DRetriever 之间的差距变得更加明显(尤其是在 FEVER 上),证明了依赖感知演示重排序在少样本 ICL 中的有效性。
5.3.4 未见数据集的泛化
DemoRank的应用场景之一是对未见过的数据集的泛化。 为了证明这一点,我们在一系列 BEIR 数据集上评估了在 MS MARCO 数据集上训练的 DemoRank。 我们选择 0-shot、E5 演示检索器和监督段落排序器 MonoBERT Nogueira 和 Cho (2019)(它也在 MS MARCO 数据集上进行过训练)进行比较。 由于大多数 BEIR 数据集中缺乏训练集,我们使用 MS MARCO 的演示池。 如表3所示,DemoRank比第二好的模型E5平均高出约1分,证明了其泛化能力。 此外,我们还得出一个有趣的观察结果:尽管使用了 MS MARCO 的演示,但 DemoRank 改进了所有数据集的 0-shot 基线,这表明 ICL 中跨数据集演示的潜力。
6结论
在本文中,我们探讨了如何为段落排名任务选择演示并提出 DemoRank。 我们首先根据大语言模型的反馈来训练一个具有多任务学习功能的示范检索器。 然后,提出了一种合理有效的方法来构造依赖感知训练样本,作为演示重排序器的训练数据。 在各种排名数据集上的实验证明了DemoRank的有效性。 进一步的分析显示了所提出的每个组件的有效性、与监督模型相比的优势以及 BEIR 的泛化等。
局限性
在本文中,我们介绍了一种新颖的用于段落排序任务的演示选择框架 DemoRank。 我们承认本文中的一些局限性为未来的工作提供了机会。 首先,由于计算资源有限,我们无法进行更大的大语言模型的实验,例如30B甚至70B参数的模型。 其次,我们的框架仅限于逐点段落排名,缺乏关于如何在成对和列表段落排名中选择演示的讨论,这可能是一个有前途的探索方向。
参考
- Agrawal et al. (2023) Sweta Agrawal, Chunting Zhou, Mike Lewis, Luke Zettlemoyer, and Marjan Ghazvininejad. 2023. In-context examples selection for machine translation. In Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 8857–8873. Association for Computational Linguistics.
- Burges et al. (2005) Christopher J. C. Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Gregory N. Hullender. 2005. Learning to rank using gradient descent. In Machine Learning, Proceedings of the Twenty-Second International Conference (ICML 2005), Bonn, Germany, August 7-11, 2005, volume 119 of ACM International Conference Proceeding Series, pages 89–96. ACM.
- Cheng et al. (2023) Daixuan Cheng, Shaohan Huang, Junyu Bi, Yuefeng Zhan, Jianfeng Liu, Yujing Wang, Hao Sun, Furu Wei, Weiwei Deng, and Qi Zhang. 2023. UPRISE: universal prompt retrieval for improving zero-shot evaluation. In EMNLP, pages 12318–12337. Association for Computational Linguistics.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Y. Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. 2022. Scaling instruction-finetuned language models. CoRR, abs/2210.11416.
- Craswell et al. (2020a) Nick Craswell, Bhaskar Mitra, Emine Yilmaz, and Daniel Campos. 2020a. Overview of the TREC 2020 deep learning track. In TREC, volume 1266 of NIST Special Publication. National Institute of Standards and Technology (NIST).
- Craswell et al. (2020b) Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, and Ellen M. Voorhees. 2020b. Overview of the TREC 2019 deep learning track. CoRR, abs/2003.07820.
- Drozdov et al. (2023) Andrew Drozdov, Honglei Zhuang, Zhuyun Dai, Zhen Qin, Razieh Rahimi, Xuanhui Wang, Dana Alon, Mohit Iyyer, Andrew McCallum, Donald Metzler, and Kai Hui. 2023. PaRaDe: Passage ranking using demonstrations with LLMs. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 14242–14252, Singapore. Association for Computational Linguistics.
- He et al. (2023) Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2023. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing. In ICLR. OpenReview.net.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick S. H. Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In EMNLP (1), pages 6769–6781. Association for Computational Linguistics.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: a benchmark for question answering research. Trans. Assoc. Comput. Linguistics, 7:452–466.
- Li et al. (2023) Xiaonan Li, Kai Lv, Hang Yan, Tianyang Lin, Wei Zhu, Yuan Ni, Guotong Xie, Xiaoling Wang, and Xipeng Qiu. 2023. Unified demonstration retriever for in-context learning. In ACL (1), pages 4644–4668. Association for Computational Linguistics.
- Liang et al. (2022) Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu Ren, Huaxiu Yao, Jue Wang, Keshav Santhanam, Laurel J. Orr, Lucia Zheng, Mert Yüksekgönül, Mirac Suzgun, Nathan Kim, Neel Guha, Niladri S. Chatterji, Omar Khattab, Peter Henderson, Qian Huang, Ryan Chi, Sang Michael Xie, Shibani Santurkar, Surya Ganguli, Tatsunori Hashimoto, Thomas Icard, Tianyi Zhang, Vishrav Chaudhary, William Wang, Xuechen Li, Yifan Mai, Yuhui Zhang, and Yuta Koreeda. 2022. Holistic evaluation of language models. CoRR, abs/2211.09110.
- Liu et al. (2022) Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. 2022. What makes good in-context examples for gpt-3? In DeeLIO@ACL, pages 100–114. Association for Computational Linguistics.
- Lu et al. (2022) Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In ACL (1), pages 8086–8098. Association for Computational Linguistics.
- Luo et al. (2023) Man Luo, Xin Xu, Zhuyun Dai, Panupong Pasupat, Seyed Mehran Kazemi, Chitta Baral, Vaiva Imbrasaite, and Vincent Y. Zhao. 2023. Dr.icl: Demonstration-retrieved in-context learning. CoRR, abs/2305.14128.
- Ma et al. (2023) Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. 2023. Zero-shot listwise document reranking with a large language model. CoRR, abs/2305.02156.
- Nguyen et al. (2016) Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A human generated machine reading comprehension dataset. In Proceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, December 9, 2016, volume 1773 of CEUR Workshop Proceedings. CEUR-WS.org.
- Nogueira and Cho (2019) Rodrigo Frassetto Nogueira and Kyunghyun Cho. 2019. Passage re-ranking with BERT. CoRR, abs/1901.04085.
- Nogueira et al. (2020) Rodrigo Frassetto Nogueira, Zhiying Jiang, Ronak Pradeep, and Jimmy Lin. 2020. Document ranking with a pretrained sequence-to-sequence model. In Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, volume EMNLP 2020 of Findings of ACL, pages 708–718. Association for Computational Linguistics.
- Qin et al. (2023) Zhen Qin, Rolf Jagerman, Kai Hui, Honglei Zhuang, Junru Wu, Jiaming Shen, Tianqi Liu, Jialu Liu, Donald Metzler, Xuanhui Wang, and Michael Bendersky. 2023. Large language models are effective text rankers with pairwise ranking prompting. CoRR, abs/2306.17563.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. CoRR, abs/1908.10084.
- Robertson and Zaragoza (2009) Stephen E. Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 3(4):333–389.
- Rubin et al. (2022) Ohad Rubin, Jonathan Herzig, and Jonathan Berant. 2022. Learning to retrieve prompts for in-context learning. In NAACL-HLT, pages 2655–2671. Association for Computational Linguistics.
- Sachan et al. (2022) Devendra Singh Sachan, Mike Lewis, Mandar Joshi, Armen Aghajanyan, Wen-tau Yih, Joelle Pineau, and Luke Zettlemoyer. 2022. Improving passage retrieval with zero-shot question generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 3781–3797. Association for Computational Linguistics.
- Scarlatos and Lan (2023) Alexander Scarlatos and Andrew S. Lan. 2023. Reticl: Sequential retrieval of in-context examples with reinforcement learning. CoRR, abs/2305.14502.
- Sun et al. (2023) Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is chatgpt good at search? investigating large language models as re-ranking agents. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 14918–14937. Association for Computational Linguistics.
- Thorne et al. (2018) James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a large-scale dataset for fact extraction and verification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 1 (Long Papers), pages 809–819. Association for Computational Linguistics.
- Wang et al. (2022) Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text embeddings by weakly-supervised contrastive pre-training. CoRR, abs/2212.03533.
- Wang et al. (2023) Liang Wang, Nan Yang, and Furu Wei. 2023. Learning to retrieve in-context examples for large language models. CoRR, abs/2307.07164.
- Wei et al. (2022) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. 2022. Emergent abilities of large language models. Trans. Mach. Learn. Res., 2022.
- Xu et al. (2024) Zhe Xu, Daoyuan Chen, Jiayi Kuang, Zihao Yi, Yaliang Li, and Ying Shen. 2024. Dynamic demonstration retrieval and cognitive understanding for emotional support conversation. CoRR, abs/2404.02505.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In EMNLP, pages 2369–2380. Association for Computational Linguistics.
- Zhang et al. (2022) Yiming Zhang, Shi Feng, and Chenhao Tan. 2022. Active example selection for in-context learning. In EMNLP, pages 9134–9148. Association for Computational Linguistics.
- Zhu et al. (2023) Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Zhicheng Dou, and Ji-Rong Wen. 2023. Large language models for information retrieval: A survey. CoRR, abs/2308.07107.
- Zhu et al. (2024) Yutao Zhu, Peitian Zhang, Chenghao Zhang, Yifei Chen, Binyu Xie, Zhicheng Dou, Zheng Liu, and Ji-Rong Wen. 2024. INTERS: unlocking the power of large language models in search with instruction tuning. CoRR, abs/2401.06532.
- Zhuang et al. (2023a) Honglei Zhuang, Zhen Qin, Kai Hui, Junru Wu, Le Yan, Xuanhui Wang, and Michael Bendersky. 2023a. Beyond yes and no: Improving zero-shot LLM rankers via scoring fine-grained relevance labels. CoRR, abs/2310.14122.
- Zhuang et al. (2023b) Shengyao Zhuang, Bing Liu, Bevan Koopman, and Guido Zuccon. 2023b. Open-source large language models are strong zero-shot query likelihood models for document ranking. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pages 8807–8817. Association for Computational Linguistics.
附录ADemoRank的实现细节
附录B监督模型的训练细节
为了与 DemoRank 进行公平比较,我们通过将每个查询分别与一个相关段落和一个不相关段落配对来构建训练数据。 至于 monoBERT Nogueira and Cho (2019),我们从 bert-large-uncased 模型开始,并使用二元分类损失来优化模型。 对于 monoT5 Nogueira 等人 (2020),我们使用基于 T5 的模型初始化模型,并使用生成损失对模型进行微调。 训练参数与原论文相同。
| Retriever Model | Reranker Model | |
| Initialization | e5-base-v2 | DeBERTa-v3-base |
| Optimizer | AdamW | AdamW |
| Learning Rate | 3e-5 | 1e-5 |
| Batch Size | 8 | 8 |
| Warmup Steps | 400 | 400 |
| Train Epochs | 2 | 2 |
| 0.2 | - |
| Query Number | |
|---|---|
| FEVER | 150K |
| NQ | 150K |
| HotpotQA | 150K |
| MS MARCO | 200K |
| Dataset | Instruction |
|---|---|
| FEVER | Given an article and a claim, predict whether the article is relevant to the claim by outputting either Yes or No. If the article is relevant to the claim, output Yes; otherwise, output No. |
| NQ | Given a passage and a question, predict whether the passage is relevant to the question by outputting either Yes or No. If the passage is relevant to the question, output Yes; otherwise, output No. |
| HotpotQA | Given a passage and a question, predict whether the passage is relevant to the question by outputting either Yes or No. If the passage is relevant to the question, output Yes; otherwise, output No. |
| TREC DL19 | Given a passage and a query, predict whether the passage is relevant to the query by outputting either Yes or No. If the passage is relevant to the query, output Yes; otherwise, output No. |
| TREC DL20 | Given a passage and a query, predict whether the passage is relevant to the query by outputting either Yes or No. If the passage is relevant to the query, output Yes; otherwise, output No. |
| MS MARCO | Given a passage and a query, predict whether the passage is relevant to the query by outputting either Yes or No. If the passage is relevant to the query, output Yes; otherwise, output No. |
| Dataset | Demonstration Format |
|---|---|
| FEVER | Article: #{ARTICLE}\nClaim: #{CLAIM}\nIs the Article relevant to the Claim?\nOutput: |
| NQ | Passage: #{PASSAGE}\nQuestion: #{QUESTION}\nIs the Passage relevant to the Question?\nOutput: |
| HotpotQA | Passage: #{PASSAGE}\nQuestion: #{QUESTION}\nIs the Passage relevant to the Question?\nOutput: |
| TREC DL19 | Passage: #{PASSAGE}\nQuery: #{QUERY}\nOutput: |
| TREC DL20 | Passage: #{PASSAGE}\nQuery: #{QUERY}\nOutput: |
| MS MARCO | Passage: #{PASSAGE}\nQuery: #{QUERY}\nOutput: |
附录C不同大语言模型Ranker之间的可迁移性
在之前的实验中,我们使用相同的大语言模型(Flan-T5-XL)作为演示评分器和段落排序器。 尚不清楚在推理阶段是否可以用其他大语言模型替换段落排序器。 在本节中,我们在多个数据集上评估 DemoRank 在不同大语言模型排序器之间的可迁移性,并与多个基线进行比较,包括 0-shot、Random、K-means、BM25 和 E5。 我们尝试使用 Flan-T5-XXL333https://huggingface.co/google/flan-t5-xxl(较大型号)和 Llama-3-8B-Instruct444https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct(不同模型架构),结果如表9 从结果中,我们可以得出以下结论:(1)当使用 Flan-T5-XXL 和 Llama-3-8B-Instruct 作为大语言模型排名器时,DemoRank 在 Avg 指标上优于所有基线,证明了其强大的跨语言可移植性。不同的大语言模型排名。 (2) 我们观察到,当使用 Flan-T5-XXL 作为大语言模型 Ranker 时,与 Flan-T5-XL(46.90、表1中分别为68.28和35.12)。 这显示了 DemoRank 通过更大规模的大语言模型排名器提高文章排名的潜在能力。 (3) 比较 Flan-T5-XL(见表1)、Flan-T5-XXL 和 Llama-3-8B-Instruct 的整体 0-shot 性能,可以明显看出 FlanT5 模型的表现平均而言更好。 这表明FlanT5模型更适合段落排序任务,与之前的研究结果庄等人(2023b)的结果类似。
| HotpotQA | NQ | FEVER | DL19 | DL20 | MS MARCO | Avg | |
|---|---|---|---|---|---|---|---|
| Initial Order | 63.30 | 30.55 | 65.13 | 50.58 | 47.96 | 22.84 | 46.73 |
| Flan-T5-XXL | |||||||
| 0-shot | 56.64 | 47.61 | 37.38 | 66.22 | 64.30 | 34.29 | 51.07 |
| Random | 58.31 | 48.51 | 39.56 | 67.47 | 65.31 | 35.15 | 52.39 |
| K-means | 58.75 | 48.86 | 39.37 | 67.40 | 65.47 | 35.24 | 52.52 |
| BM25 | 60.66 | 50.47 | 43.89 | 66.82 | 65.67 | 35.15 | 53.78 |
| E5 | 60.74 | 50.14 | 43.86 | 66.45 | 65.44 | 34.84 | 53.58 |
| DemoRank | 62.25 | 51.68 | 49.56 | 68.74 | 65.90 | 35.90 | 55.67 |
| Llama-3-8B-Instruct | |||||||
| 0-shot | 55.93 | 36.24 | 27.53 | 58.47 | 55.10 | 28.09 | 43.56 |
| Random | 49.45 | 36.34 | 29.03 | 59.18 | 56.26 | 28.11 | 43.06 |
| K-means | 57.01 | 35.28 | 34.73 | 57.63 | 53.30 | 26.51 | 44.08 |
| BM25 | 60.18 | 35.31 | 29.22 | 59.24 | 57.28 | 26.71 | 44.66 |
| E5 | 60.09 | 36.76 | 28.64 | 57.36 | 53.09 | 26.98 | 43.82 |
| DemoRank | 60.89 | 35.47 | 45.24 | 60.36 | 56.45 | 28.54 | 47.83 |
附录DDRetriever训练讨论
在这一部分中,我们进行了实验来验证 Dretriever 训练的原理。 首先,我们从训练中删除排名损失(方程(6))(表示为“- w/o ”)并找到一个显着的损失三个数据集的性能下降。 这表明示范候选中的排名信号对于示范寻回犬训练是有用的。 此外,正如我们在4.2节中提到的,我们在计算对比损失时不应用批量负数,这与之前的研究Wang等人不同( 2023);李等人 (2023); Karpukhin 等人 (2020)。 为了验证其基本原理,我们将批量负数纳入对比损失的计算中,表示为“-w/IBN”。 从结果中我们可以看出,批内阴性并没有带来显着的改善,甚至损害了猎犬在 DL19 上的表现。 这是因为排序任务中演示的效用与其与训练输入的相似性没有直接关系,并且随机采样的批量演示仍然可能包含有价值的信息并充当积极的候选者,这与段落检索中的假设不同Karpukhin 等人 (2020)。 因此,直接使用批内负数可能会在训练过程中引入额外的噪声。
| Method | NQ | DL19 | FEVER | Avg |
|---|---|---|---|---|
| - w/o | 50.60 | 67.65 | 43.65 | 53.97 |
| - w/ IBN | 51.68 | 67.14 | 44.43 | 54.42 |
| DRetriever | 51.69 | 68.44 | 44.40 | 54.84 |