![]()
UniCoder:通过通用代码扩展代码大语言模型
摘要
中间推理或行动步骤已成功改进大型语言模型(大语言模型),用于处理各种下游自然语言处理(NLP)任务。 在应用大语言模型进行代码生成时,最近的工作主要集中在指导模型阐明中间自然语言推理步骤,如思想链(CoT)提示,然后用自然语言或其他结构化中间代码输出代码步骤。 然而,这样的输出不适合代码翻译或生成任务,因为标准CoT与代码具有不同的逻辑结构和表达形式。 在这项工作中,我们引入通用代码(UniCode)作为中间表示。 它是使用混合编程语言约定(例如赋值运算符、条件运算符和循环)的算法步骤的描述。 因此,我们收集指令数据集 UniCoder-Instruct 来针对多任务学习目标训练我们的模型 UniCoder。 UniCoder-Instruct包括自然语言问题、代码解决方案以及相应的通用代码。 中间通用代码表示和最终代码解决方案之间的对齐显着提高了生成代码的质量。 实验结果表明,带有通用代码的UniCoder明显优于之前的提示方法,展示了伪代码中结构线索的有效性。111https://github.com/ASC8384/UniCoder
1简介
代码翻译和生成领域取得了显着进展Szafraniec 等人 (2023); Yan 等人 (2023) 随着特定于代码的大语言模型(大语言模型)的出现。 Code大语言模型,例如StarCoder Li 等人(2023b)和Code-Llama Rozière 等人(2023),能够通过分析自然语言提示生成可执行代码。 思想链(CoT)提示Wei等人(2022b)已成为增强大语言模型的领先技术,其中中间步骤提供了从问题陈述到解决方案的结构化路径,有效地反映了人类解决问题的过程。

考虑到编码器生成中 CoT 的精度较低,提出结构 CoT (SCoT) Li 等人 (2023a) 来最小化中间步骤与生成代码之间的差距。 更直观地说,使用通用代码作为处理多种编程语言(PL)的中间表示是有前途的。 在这里,通用代码是实现算法的蓝图,有助于使算法的设计逻辑清晰、易于理解。 此外,它在不同的编程语言中是通用的(与 PL 无关),因为它通常不遵循特定的语法并省略执行细节。 然而, 如何使用通用代码在多语言场景中进行代码翻译和生成仍有待探索。
在这项工作中,我们扩展了代码大语言模型,通过通用代码(UniCode)支持多种编程语言,它被用作关键算法原理的高效且与语言无关的中间表示。 具体来说,我们首先通过指定语法规则和提供范式来定义 UniCode,然后提示 GPT-4 OpenAI (2023) 创建指令数据集 UniCoder-Instruct由自然语言问题、代码解答以及对应的通用代码组成,如图1所示。 然后,通过对多任务学习目标进行指令调优Wei等人(2022a)来构建UniCoder模型,包括零样本问答生成(问题代码)、问题通用代码生成(问题UniCode代码)、通用代码解决方案翻译( UniCodecode)和通用思想代码(UoT)目标。 在UoT中,模型需要在生成可执行代码之前生成通用代码。
UniCoder 在 Python 基准(Humaneval Chen 等人 (2021) 和 MBPP Austin 等人 (2021))和扩展多语言基准上进行评估MultiPL-E Cassano 等人 (2022)。 结果表明,UniCoder 在所有语言中始终实现最先进的性能,显着超越了之前的基准。 此外,消融研究验证了所提出方法的有效性,并且额外的讨论提供了对我们方法的效果的见解。 贡献总结如下:
-
•
我们引入了与编程语言无关的通用代码UniCode,让大语言模型逐步掌握算法的本质。 此外,还收集并提供指令数据集UniCoder-Instruct以供后续研究。
-
•
我们提出了UniCoder,一种代码生成方法,它在UniCode的帮助下使用多任务学习目标来调节代码大语言模型。 目标包括问题答案生成 (QA)、问题通用代码生成 (QP)、通用代码答案翻译 (PA) 和通用思想代码 (UoT)。
-
•
大量实验表明,我们的方法 UniCoder 在不同基准测试(包括 HumanEval、MBPP 和 MultiPL-E)上始终优于之前的基线。为了进一步验证通用代码的有效性,我们提出UniCoder-Bench来测试大语言模型的代码能力。
2 UniCoder-指令
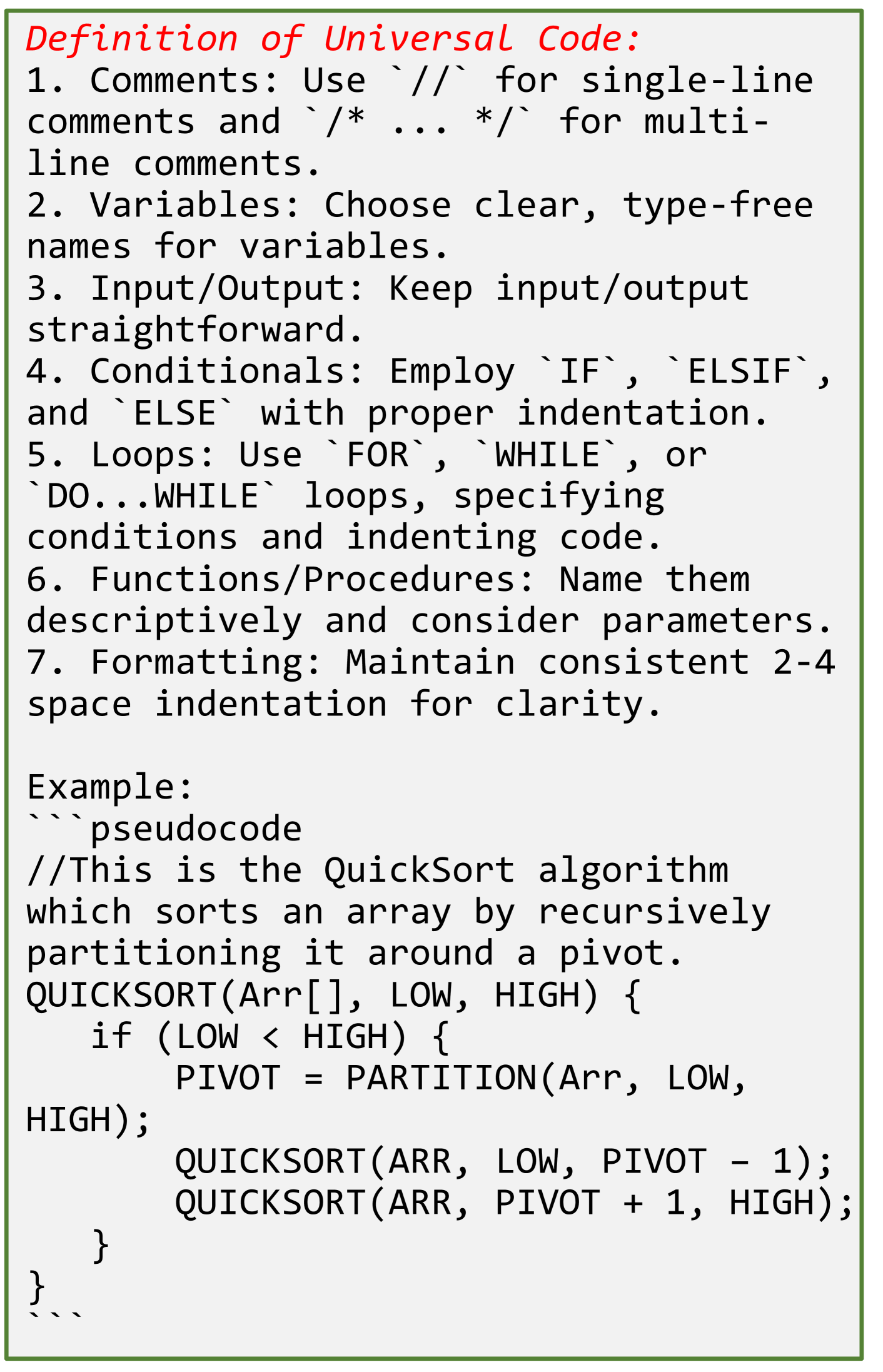

通用代码的定义。
通用代码旨在以人类易于理解的形式表达算法,将编程语言语法与自然语言描述和数学符号相结合,以概述算法的步骤,而无需复杂的完整编码细节。 它省略了特定于机器的实现,专注于核心逻辑,使其成为教育材料文档和软件开发的基础知识设计阶段的流行选择。 通过从实际代码的复杂性中抽象出来,伪代码有助于跨各种编程环境清晰地传达算法概念。 通用码的定义如图2所示,基于以下原则:
-
•
注释:为代码段提供解释和上下文,使其他人更容易理解其意图和功能。
-
•
变量:通过使用有意义的名称来传达变量的用途,而不依赖于数据类型规范,从而增强代码的可读性和可维护性。
-
•
输入/输出:简化数据进出系统的交互,确保这些操作清晰且易于追踪。
-
•
条件:通过使用定义清晰执行路径的结构化和缩进条件语句来阐明代码中的决策过程。
-
•
循环:以受控方式促进代码块的重复,并明确定义开始和结束条件,使迭代过程易于理解。
-
•
函数/过程:通过描述性地命名函数和过程以及有效地使用参数来封装功能来提高模块化和可重用性。
-
•
格式:通过应用一致的缩进来改善代码的整体视觉组织,这有助于描绘代码内的层次结构和逻辑分组。
从指令数据集构建。
从代码片段构建。
对于许多网站(例如 GitHub)上广泛存在的无监督数据(代码片段),我们还使用原始代码片段中的通用代码构建指令数据集。 具体来说,我们要求大语言模型根据原始代码片段生成问题和相应的代码答案对,提示“请根据给定的代码片段生成独立的问题和答案”。 然后,我们生成 UniCode 并构造 三元组,方式与段落 2 中相同。 此外,应用大语言模型评分器过滤掉低质量的三元组。 因此,给定不同编程语言的原始代码片段,我们可以直接从此类无监督数据构造具有通用代码的指令数据集。 最后,我们将这两个指令数据集组合起来获得,其中代表每种程序语言。
通用代码评估任务。
为了测试大语言模型从问题生成UniCode并将UniCode翻译为答案的能力,我们设计了一个代码重构任务进行评估。 给定代码段,我们需要大语言模型生成UniCode ,然后将其翻译为代码。 评估指标不是和之间的相似度,而是恢复的代码是否可以通过测试用例。 我们扩展 HumanEval 和 MBPP 数据集来创建基准 UniCoder-Bench,其中包含 HumanEval 样本和 MBPP 测试样本。
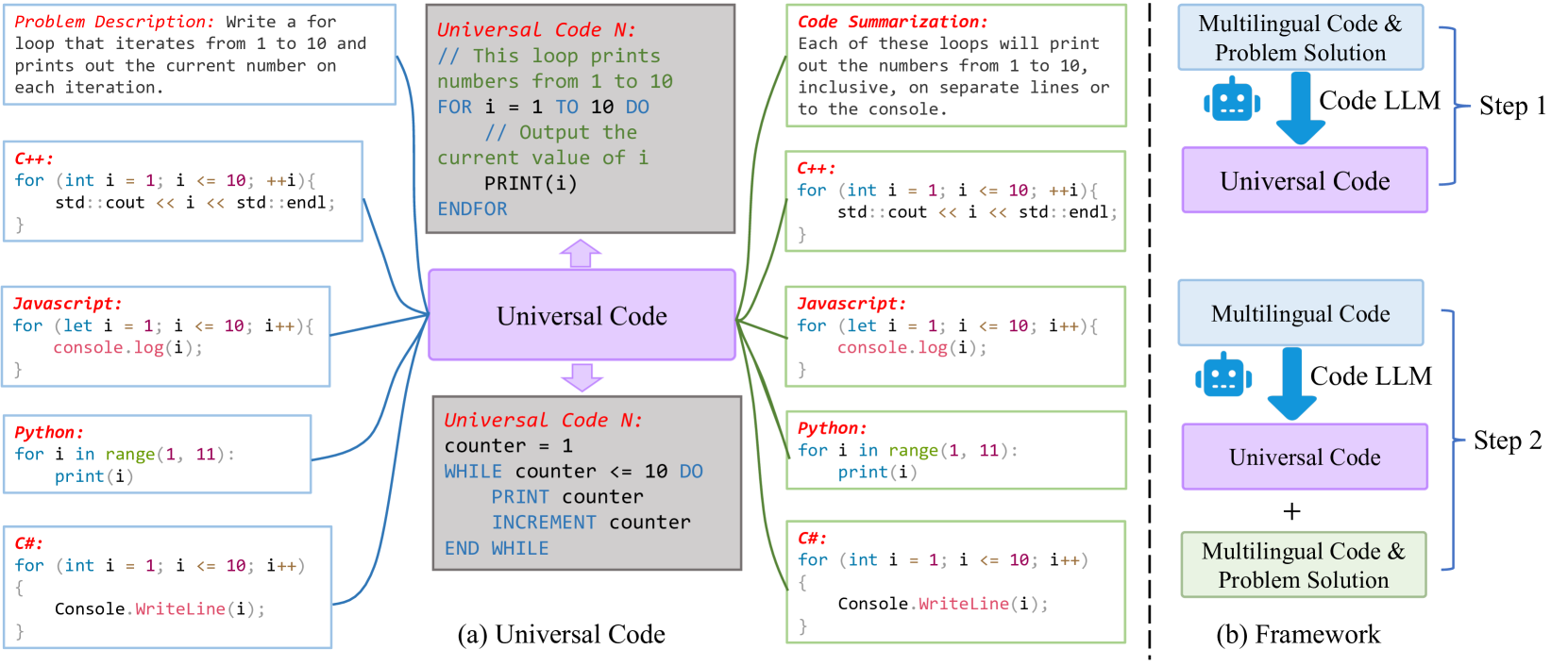
3 UniCoder
3.1模型概述
在图4中,我们首先定义了通用代码的概念及其基本组成部分,然后提示大语言模型根据通用代码生成UniCode 现有的说明数据(问题 和答案 )和原始代码片段 。 UniCode 被视为不同任务的中间表示,包括代码生成、代码翻译和代码摘要。 我们提出的模型 UniCoder 在指令数据集 上进行训练,具有多语言目标,以充分释放 UniCode 的潜力。
3.2 通用代码大语言模型
给定多语言编程语言的指令数据集,在上训练的预训练代码大语言模型可以支持Universal -思想代码(UoT)。 可以描述为:
| (1) |
其中 (问题)和 (答案)是来自 的指令对。 给定问题,大语言模型首先生成UniCode,然后输出最终答案,其中通过自然语言注释提供关键算法思想。
3.3 多任务监督微调
为了充分释放UniCode的潜力,我们设计了多个目标来增强代码大语言模型的理解和生成能力。
多任务微调。
| (2) |
其中 是问题答案生成目标, 是问题通用代码生成目标, 是通用代码答案翻译目标, 是通用思想代码 (UoT) 目标。
在这里,我们介绍所有四个训练目标。 对于以下所有目标,给出了多语言语料库。 是代码大语言模型,是编程语言的数量。
问答目标。
标准指令微调的训练目标可以描述为:
| (3) |
其中 和 是问题和答案对。
问题通用代码目标。
辅助通用代码生成任务的训练目标可以描述为:
| (4) |
其中 和 是问题,UniCode。
通用代码答案目标。
从UniCode生成可执行代码答案的训练目标可以描述为:
| (5) |
其中 和 是 UniCode 和答案。
通用思想准则目标。
生成UniCode的训练目标以及可执行代码答案可以描述为:
| (6) |
其中 、 和 分别是问题、答案和 UniCode。
4实验设置
4.1 指令数据集
使用 GPT-4 (gpt-4-1106-preview) OpenAI (2023) 作为基础模型来生成 UniCoder-Instruct。 我们从 StarCoder 数据集 Li 等人 (2023b) 中随机提取 标记内的代码片段,并让 GPT-4 将代码片段汇总为通用代码。 基于每个代码片段和相应的通用代码,创建具有正确解决方案的独立编码问题。
4.2基线
专有模型。
基于称为生成式预训练 Transformers (GPT) 的神经架构 Vaswani 等人 (2017); Radford 等人 (2018),GPT-3.5 和 GPT-4 是在文本、代码、数学方程等海量数据集上训练的大语言模型。 他们还接受了遵循指令 Ouyang 等人 (2022) 的训练,这使他们能够产生类似人类的反应。 我们使用 GPT-3.5 Turbo 和 GPT-4 作为专有模型,因为它们在各种代码理解和生成任务中表现出色。
开源模型。
为了缩小开源模型和闭源模型之间的差距,提出了一系列开源模型和指令数据集来改进代码大语言模型并引导其指令跟踪能力。 Starcoder Li 等人 (2023b)、Code Llama Rozière 等人 (2023) 和 DeepSeek-Coder Guo 等人 (2024a) 具有不同的模型尺寸被引入到基础模型中。 OctoCoder Muennighoff 等人 (2023)、WiazrdCoder Luo 等人 (2023)、MagiCoder Wei 等人 (2023) 和 WaveCoder Yu等人(2023)在这些基础代码大语言模型上进一步微调。
消除污染。
我们在训练 UniCoder 模型之前应用数据净化,通过从 HumanEval Chen 等中删除精确匹配来净化 starcoder 数据 Li 等人 (2023b) 中的代码片段人 (2021)、MBPP Austin 等人 (2021)、DS-1000 Lai 等人 (2023) 和 GSM8K Cobbe 等人 ( 2021)。
4.3评估基准
人类评估。
HumanEval 测试集 Chen 等人 (2021) 是精心设计的 164 个 Python 编程问题的集合,用于测试代码生成模型的能力。 对于每个问题,大约有 9.6 个测试用例来检查生成的代码是否按预期工作。 Humaneval 已成为衡量这些代码编写人工智能模型性能的最流行的基准之一,使其成为人工智能和机器学习编码领域的关键工具。
MBPP。
MBPP 数据集 Austin 等人 (2021) 包含来自众多贡献者的约 1,000 个 Python 编程挑战,专为编程初学者量身定制,重点关注核心原理和标准库的使用。 选择由问题组成的MBPP测试集来评估代码大语言模型的少样本推理。
多种的。
MuliPL-E 测试集 Cassano 等人 (2022) 将原始 HumanEval 测试集翻译为其他 18 种编程语言,即 Javascript、Java、Typescript、C++ 和 Rust。 我们使用MultiPL-E来评估代码大语言模型的多语言能力。
4.4评估指标
通过@k。
我们采用 Pass@k 指标 Chen 等人 (2021) 来提高评估的可靠性。 然后,我们统计成功通过测试用例的总数,记为,以计算Pass@k,从而提高性能评估的准确性和一致性。
| (7) |
其中 是每个问题生成的样本总数, 是通过所有测试用例的正确生成的代码片段的数量 ()。
4.5实现细节
我们将开源 Evol-Instruct 数据集 evol-code-alpaca-v1 Xu 等人 (2023) 的近 110K 样本扩展为具有通用代码的指令数据集。 对于从starcoderdata收集的代码片段 222https://huggingface.co/datasets/bigcode/starcoderdata,我们选择每种语言(Python、Javascript、C++、Java、Rust 和 Go)的 5K 代码片段来构建具有通用代码的合成指令数据集。 最后,我们获得包含近140K训练样本的指令数据集UniCoder-Instruct。 Code-Llama 和 DeepSeek-Coder-Base 被用作监督微调(SFT)的基础代码大语言模型。 我们在从 evol-codealpaca-v1 和 starcoder 预训练数据生成的近 150K 样本上对这些基础大语言模型进行了评估。 UniCoder 在 Standford_Alpaca333https://github.com/tatsu-lab/stanford_alpaca,配备 学习率首先通过 预热步骤增加到 ,然后采用余弦衰减调度程序。 我们采用 Adam 优化器 Kingma and Ba (2015),全局批量大小为 个样本,将句子截断为 个标记。
5 结果与讨论
lcccccc
Models Base Model Params Instruction Data Model Weight HumanEval MBPP
Proprietary Models
[0.4pt on 3pt off 3pt]-
GPT-3.5 - - - - 72.6 81.6
GPT-4 - - - - 85.4 83.0
Open-source Models
[0.4pt on 3pt off 3pt]-
StarCoder Li et al. (2023b) - 15B ✗ ✓ 33.6 43.3
WizardCoder Luo et al. (2023) StarCoder 15B ✓ ✓ 57.3 51.8
OctoCoder Muennighoff et al. (2023) StarCoder 15B ✓ ✓ 46.2 43.5
WaveCoder-SC Muennighoff et al. (2023) StarCoder 15B ✓ ✓ 50.5 51.0
[0.4pt on 3pt off 3pt]-
Code-Llama Rozière et al. (2023) - 7B ✗ ✓ 33.5 41.4
Code-Llama-Instruct Rozière et al. (2023) Code Llama 7B ✓ ✓ 34.8 44.4
WaveCoder-CL Yu et al. (2023) Code Llama 7B ✓ ✓ 48.1 47.2
Magicoder-CL Wei et al. (2023) Code Llama 7B ✓ ✓ 60.4 64.2
UniCoder (our method) Code Llama 7B ✓ ✓ 65.4 65.2
[0.4pt on 3pt off 3pt]-
DeepseekCoder Guo et al. (2024a) - 6.7B ✗ ✓ 49.4 60.6
WaveCoder-DS Yu et al. (2023) Deepseek-Coder 6.7B ✓ ✓ 64.0 62.8
UniCoder (our method) Deepseek-Coder 6.7B ✓ ✓ 70.6 64.3
@lccccccc|c@
Model Params Programming Language
Java Javascript C++ PHP Swift Rust Avg.
Proprietary models
GPT-3.5 - 69.2 67.1 63.4 60.9 - - -
GPT-4 - 81.6 78.0 76.4 77.2 - - -
Open-source models
[0.4pt on 3pt off 3pt]-
CodeLlama Rozière et al. (2023) 34B 40.2 41.7 41.4 40.4 35.3 38.7 39.6
CodeLlama-Python Rozière et al. (2023) 34B 39.5 44.7 39.1 39.8 34.3 39.7 39.5
CodeLlama-Instruct Rozière et al. (2023) 34B 41.5 45.9 41.5 37.0 37.6 39.3 40.5
WizardCoder-CL Luo et al. (2023) 34B 44.9 55.3 47.2 47.2 44.3 46.2 47.5
[0.4pt on 3pt off 3pt]-
StarCoderBase Li et al. (2023b) 15B 28.5 31.7 30.6 26.8 16.7 24.5 26.5
StarCoder Li et al. (2023b) 15B 30.2 30.8 31.6 26.1 22.7 21.8 27.2
WizardCoder-SC Luo et al. (2023) 15B 35.8 41.9 39.0 39.3 33.7 27.1 36.1
[0.4pt on 3pt off 3pt]-
CodeLlama Rozière et al. (2023) 7B 29.3 31.7 27.0 25.1 25.6 25.5 27.4
CodeLlama-Python Rozière et al. (2023) 7B 29.1 35.7 30.2 29.0 27.1 27.0 29.7
UniCoder (Our method) 7B 46.4 50.2 39.2 40.4 41.2 32.4 41.6
5.1 Main Results
Python Code Generation.
Table 5 shows that UniCoder significantly beats previous strong open-source baselines using UoT, closing the gap with GPT-3.5 and GPT-4. Magicoder Wei et al. (2023) and Wavecoder Yu et al. (2023) both prove the effectiveness of instruction datasets from code snippets. Further, UniCoder outperforms the WizardCoder with 15B parameters and Evol-Instruct techniques with the help of the UniCode.
Multilingual Code Generation.
Table 5 shows that UniCoder significantly outperforms strong baselines CodeLlama and Starcoder. For the different backbones (Code Llama and Deepseek-Coder), our method beats most previous methods, especially in other languages, which demonstrates that UniCoder-Instruct can bring the capability of multilingual understanding and generation.
5.2 Discussion
Ablation Study.
To verify the efficacy of each component, we conduct the ablation study step by step on HumanEval and MBPP. In Table 3, we observe that removing the multi-tasks objective (only keeping the UoT objective: Equation 6) will have a performance drop in HumanEval and a drop in MBPP. Removing UniCode will further degrade the performance. The results support the effectiveness of each component of UniCoder.
| ID | Methods | HumanEval | MBPP |
| ① | UniCoder | 70.6 | 64.3 |
| ② | ① - Multi-tasks Objective | 67.4 | 60.2 |
| ③ | ② - Universal Code | 66.8 | 59.8 |
Effect on Universal Code.
To discuss the effect of the different formats of the universal code, we use different definitions of universal code for UniCoder. Specifically, we randomly sample 5K samples to generate the instruction dataset with different formats of UniCode.
-
•
UniCode 1: It describes the naming conventions, variable declaration, operators, conditional statements, loops, and function structure that pseudocode should have.
-
•
UniCode 2: It separates the first set of standards and provides code examples for each, instead of applying them all together in the examples.
-
•
UniCode 3: It describes the code structure, variable rules, control structures, functions, comments, and assignment rules that pseudocode should have.
-
•
UniCode 4: It is similar to the first standard but specifies type-free names for variables.
-
•
UniCode 5: It provides an abstract, high-level architectural description, without setting standards for the code itself.
-
•
UniCode 6: It uses latex algorithm and algorithmic packages for description.
| ID | Methods | HumanEval | MBPP |
| ① | UniCode 1 | 53.2 | 51.5 |
| ② | UniCode 2 | 52.8 | 51.2 |
| ③ | UniCode 3 | 53.5 | 50.5 |
| ④ | UniCode 4 | 53.8 | 49.5 |
| ⑤ | UniCode 5 | 49.5 | 50.2 |
| ⑥ | UniCode 6 | 48.2 | 48.4 |
| ⑦ | UniCode 14 | 55.5 | 52.2 |
In Table 4, we can observe that the evaluation results of UniCode 1UniCode 4 have better performance. Compared to the universal code format UniCode 5 and UniCode 6, UniCode 1UniCode 4 has a clear definition and common structure, which brings more support for code generation. Notably, the experiment ⑦ performs the best by combing the training data of ①④. The experimental results show that the concrete definition of UniCode and the combination of it can effectively improve the model performance.
5.3 Code-UniCode-Code
To compare the capabilities of different code LLMs, we create a test set (denoted as UniCoder-Bench) by prompting the code LLM to generate UniCode and translate it into the executable code. We check the correctness of each translated code with the test cases, denoted as Pass@1 of the universal code. Code-Llama-7B is fine-tuned on the Code Alpaca dataset and our dataset UniCoder-Instruct separately. The results of fine-tuned Code-Llama models on UniCoder-Bench are shown in Table 5. Our method UniCoder is more accurate in passing the test cases than the Code-Llama baselines, demonstrating its excellent code understanding and generation abilities.
| Method | Params | Python | Other Languages |
| Code-Llama-Instruct | 7B | 33.3 | 26.2 |
| Code-Llama-Alpaca | 7B | 44.2 | 29.1 |
| UniCoder | 7B | 45.2 | 31.3 |
6 Related Work
Code Understanding and Generation.
Code understanding and generation as the key tasks to substantially facilitate the project development process, including code generation Chen et al. (2021); Austin et al. (2021); Zhang et al. (2023); Chai et al. (2024a); Deng et al. (2024), code translation Szafraniec et al. (2023), automated testing Deng et al. (2023), bug fixing Muennighoff et al. (2023), code refinement Liu et al. (2023c), code question answering Liu and Wan (2021), and code summarization Ahmad et al. (2020). Researchers Chai et al. (2023) have undertaken extensive endeavors to bridge natural language and programming languages. With less ambiguous prompt styles, Mishra et al. (2023) using pseudocode improves the performance of NLP tasks. Oda et al. (2015) uses traditional machine learning to achieve code to pseudocode conversion. Jiang et al. (2022) also shows that designers and programmers can speed up the prototyping process, and ground communication between collaborators via prompt-based prototyping. To verify that the generated code is correct, there are some code synthesis evaluation frameworks, including EvalPlus Liu et al. (2023b), HumanEval Chen et al. (2021), HumanEval-X Zheng et al. (2023), and MBPP Austin et al. (2021).
Large Language Models for Code.
Since CodeBERT Feng et al. (2020) first connected code tasks with pre-trained models, large language models for code have developed rapidly, demonstrating extraordinary performance on almost all code tasks, rather than a single task. Prominent large models include Codex Chen et al. (2021), AlphaCode Li et al. (2022), SantaCoder Allal et al. (2023), Starcoder Li et al. (2023b), WizardCoder Luo et al. (2023), InCoder Fried et al. (2022), CodeT5 Wang et al. (2021), CodeGeeX Zheng et al. (2023), Code Llama Rozière et al. (2023), and Code-QWen Bai et al. (2023). To improve the performance of code generation, researchers used optimized prompts Liu et al. (2023a); Reynolds and McDonell (2021); Zan et al. (2023); Beurer-Kellner et al. (2023), bring test cases Chen et al. (2023) and collaborative roles Dong et al. (2023). There are also some related studies on using large language models for other code tasks, such as dynamic programming Dagan et al. (2023), compiler optimization Cummins et al. (2023), multilingual prompts Di et al. (2023), and program of thoughts Chen et al. (2022) (PoT).
Chain-of-Thought Prompting.
To unleash the potential of LLMs Zhang et al. (2024); Liu et al. (2024); Que et al. (2024); Du et al. (2024) in addressing complex reasoning tasks, chain-of-thought (CoT) prompting Wei et al. (2022b); Kojima et al. (2022) extends in-context learning with step-by-step reasoning processes, which handles complex reasoning tasks in the field of the code and mathematics by encouraging them to engage in step-by-step reasoning processes. Following this line of research, X-of-Thought (XoT) reasoning (CoT and its structural variants further) Chai et al. (2024b); Yao et al. (2023); Li et al. (2023a); Lei et al. (2023); Guo et al. (2023); Ji et al. (2024); Guo et al. (2024b) further expands the capabilities and applications of LLMs in complex reasoning and planning scenarios.
Intermediate Repersentation
In the field of natural language processing, there exist many works using intermediate representation Gan et al. (2021); Yang et al. (2022, 2024, 2019, 2020b, 2020a); Liang et al. (2024), such as text generation and translation. The universal code is used as the intermediate representation, which typically omits details that are essential for the machine implementation of the algorithm. We perform the coarse-to-fine pattern for the code generation and translation, where the universal code first summarizes the algorithm process and then the programming language gives the accurate solution. The Unicode provides explicit help for code generation such as Chain-of-thought in LLM.
7 Conclusion
In this work, we put forth a state-of-the-art framework UniCoder for both code translation and code generation. Using the universal code UniCode as the intermediate representation, we effectively bridge different programming languages and facilitate code tasks. In addition, we collect a dataset UniCoder-Instruct with 140K instruction instances from existing instruction datasets and the raw code snippets. After being fine-tuned on UniCoder-Instruct with multi-task learning objectives, our model generates UniCode and translates it into the final answer (executable code). The evaluation results on code translation and generation tasks demonstrate that our method significantly improves the generalization ability, showing the efficacy and superiority of UniCoder.
Limitations
We acknowledge the following limitations of this study: (1) The evaluation focuses on benchmark datasets (Humaneval, MBPP, and MultiPL-E), and the model’s effectiveness in real-world programming scenarios or industry applications is not fully explored. (2) Our method is developed and evaluated primarily on programming language benchmarks. Its effectiveness in other domains or for non-programming-related tasks is not assessed, which limits the generalizability of our findings.
Acknowledege
This work was supported in part by the National Natural Science Foundation of China (Grant Nos. U1636211, U2333205, 61672081, 62302025, 62276017), a fund project: State Grid Co., Ltd. Technology R&D Project (ProjectName: Research on Key Technologies of Data Scenario-based Security Governance and Emergency Blocking in Power Monitoring System, Proiect No.: 5108-202303439A-3-2-ZN), the 2022 CCF-NSFOCUS Kun-Peng Scientific Research Fund and the Opening Project of Shanghai Trusted Industrial Control Platform and the State Key Laboratory of Complex & Critical Software Environment (Grant No. SKLSDE-2021ZX-18).
References
- Ahmad et al. (2020) Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2020. A transformer-based approach for source code summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pages 4998–5007. Association for Computational Linguistics.
- Allal et al. (2023) Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, et al. 2023. SantaCoder: Don’t reach for the stars! arXiv preprint arXiv:2301.03988.
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609, abs/2309.16609.
- Beurer-Kellner et al. (2023) Luca Beurer-Kellner, Marc Fischer, and Martin T. Vechev. 2023. Prompting is programming: A query language for large language models. Proc. ACM Program. Lang., 7(PLDI):1946–1969.
- Cassano et al. (2022) Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q Feldman, et al. 2022. Multipl-e: A scalable and extensible approach to benchmarking neural code generation. arXiv preprint arXiv:2208.08227.
- Chai et al. (2024a) Linzheng Chai, Shukai Liu, Jian Yang, Yuwei Yin, Ke Jin, Jiaheng Liu, Tao Sun, Ge Zhang, Changyu Ren, Hongcheng Guo, et al. 2024a. Mceval: Massively multilingual code evaluation. arXiv e-prints, pages arXiv–2406.
- Chai et al. (2024b) Linzheng Chai, Jian Yang, Tao Sun, Hongcheng Guo, Jiaheng Liu, Bing Wang, Xinnian Liang, Jiaqi Bai, Tongliang Li, Qiyao Peng, and Zhoujun Li. 2024b. xcot: Cross-lingual instruction tuning for cross-lingual chain-of-thought reasoning. arXiv preprint arXiv:2401.07037, abs/2401.07037.
- Chai et al. (2023) Yekun Chai, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, and Hua Wu. 2023. Ernie-code: Beyond english-centric cross-lingual pretraining for programming languages. In Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 10628–10650. Association for Computational Linguistics.
- Chen et al. (2023) Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2023. Codet: Code generation with generated tests. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, abs/2107.03374.
- Chen et al. (2022) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2022. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, abs/2211.12588.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Cummins et al. (2023) Chris Cummins, Volker Seeker, Dejan Grubisic, Mostafa Elhoushi, Youwei Liang, Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Kim M. Hazelwood, Gabriel Synnaeve, and Hugh Leather. 2023. Large language models for compiler optimization. arXiv preprint arXiv:2309.07062, abs/2309.07062.
- Dagan et al. (2023) Gautier Dagan, Frank Keller, and Alex Lascarides. 2023. Dynamic planning with a LLM. arXiv preprint arXiv:2308.06391, abs/2308.06391.
- Deng et al. (2024) Ken Deng, Jiaheng Liu, He Zhu, Congnan Liu, Jingxin Li, Jiakai Wang, Peng Zhao, Chenchen Zhang, Yanan Wu, Xueqiao Yin, et al. 2024. R2c2-coder: Enhancing and benchmarking real-world repository-level code completion abilities of code large language models. arXiv preprint arXiv:2406.01359.
- Deng et al. (2023) Yinlin Deng, Chunqiu Steven Xia, Chenyuan Yang, Shizhuo Dylan Zhang, Shujing Yang, and Lingming Zhang. 2023. Large language models are edge-case fuzzers: Testing deep learning libraries via fuzzgpt. arXiv preprint arXiv:2304.02014, abs/2304.02014.
- Di et al. (2023) Peng Di, Jianguo Li, Hang Yu, Wei Jiang, Wenting Cai, Yang Cao, Chaoyu Chen, Dajun Chen, Hongwei Chen, Liang Chen, Gang Fan, Jie Gong, Zi Gong, Wen Hu, Tingting Guo, Zhichao Lei, Ting Li, Zheng Li, Ming Liang, Cong Liao, Bingchang Liu, Jiachen Liu, Zhiwei Liu, Shaojun Lu, Min Shen, Guangpei Wang, Huan Wang, Zhi Wang, Zhaogui Xu, Jiawei Yang, Qing Ye, Gehao Zhang, Yu Zhang, Zelin Zhao, Xunjin Zheng, Hailian Zhou, Lifu Zhu, and Xianying Zhu. 2023. Codefuse-13b: A pretrained multi-lingual code large language model. arXiv preprint arXiv:2310.06266, abs/2310.06266.
- Dong et al. (2023) Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li. 2023. Self-collaboration code generation via chatgpt. arXiv preprint arXiv:2304.07590, abs/2304.07590.
- Du et al. (2024) Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Binhang Yuan, Wenhu Chen, Jie Fu, and Ge Zhang. 2024. Chinese tiny llm: Pretraining a chinese-centric large language model.
- Feng et al. (2020) Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. Codebert: A pre-trained model for programming and natural languages. In Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, volume EMNLP 2020 of Findings of ACL, pages 1536–1547. Association for Computational Linguistics.
- Fried et al. (2022) Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida I. Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen tau Yih, Luke Zettlemoyer, and Mike Lewis. 2022. Incoder: A generative model for code infilling and synthesis. arXiv preprint arXiv:2204.05999, abs/2204.05999.
- Gan et al. (2021) Shiwei Gan, Yafeng Yin, Zhiwei Jiang, Lei Xie, and Sanglu Lu. 2021. Skeleton-aware neural sign language translation. In MM ’21: ACM Multimedia Conference, Virtual Event, China, October 20 - 24, 2021, pages 4353–4361. ACM.
- Guo et al. (2024a) Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y Wu, YK Li, et al. 2024a. Deepseek-coder: When the large language model meets programming–the rise of code intelligence. arXiv preprint arXiv:2401.14196.
- Guo et al. (2023) Hongcheng Guo, Jian Yang, Jiaheng Liu, Liqun Yang, Linzheng Chai, Jiaqi Bai, Junran Peng, Xiaorong Hu, Chao Chen, Dongfeng Zhang, Xu Shi, Tieqiao Zheng, Liangfan Zheng, Bo Zhang, Ke Xu, and Zhoujun Li. 2023. OWL: A large language model for IT operations. CoRR, abs/2309.09298.
- Guo et al. (2024b) Hongcheng Guo, Wei Zhang, Anjie Le, Jian Yang, Jiaheng Liu, Zhoujun Li, Tieqiao Zheng, Shi Xu, Runqiang Zang, Liangfan Zheng, et al. 2024b. Lemur: Log parsing with entropy sampling and chain-of-thought merging. arXiv preprint arXiv:2402.18205.
- Ji et al. (2024) Hangyuan Ji, Jian Yang, Linzheng Chai, Chaoren Wei, Liqun Yang, Yunlong Duan, Yunli Wang, Tianzhen Sun, Hongcheng Guo, Tongliang Li, et al. 2024. Sevenllm: Benchmarking, eliciting, and enhancing abilities of large language models in cyber threat intelligence. arXiv preprint arXiv:2405.03446.
- Jiang et al. (2022) Ellen Jiang, Kristen Olson, Edwin Toh, Alejandra Molina, Aaron Donsbach, Michael Terry, and Carrie J. Cai. 2022. Promptmaker: Prompt-based prototyping with large language models. In CHI ’22: CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April 2022 - 5 May 2022, Extended Abstracts, pages 35:1–35:8. ACM.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Lai et al. (2023) Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-Tau Yih, Daniel Fried, Sida I. Wang, and Tao Yu. 2023. DS-1000: A natural and reliable benchmark for data science code generation. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pages 18319–18345. PMLR.
- Lei et al. (2023) Bin Lei, Pei-Hung Lin, Chunhua Liao, and Caiwen Ding. 2023. Boosting logical reasoning in large language models through a new framework: The graph of thought. arXiv preprint arXiv:2308.08614, abs/2308.08614.
- Li et al. (2023a) Jia Li, Ge Li, Yongmin Li, and Zhi Jin. 2023a. Structured chain-of-thought prompting for code generation. arXiv preprint arXiv:2305.06599.
- Li et al. (2023b) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Logesh Kumar Umapathi, Jian Zhu, Benjamin Lipkin, Muhtasham Oblokulov, Zhiruo Wang, Rudra Murthy V, Jason Stillerman, Siva Sankalp Patel, Dmitry Abulkhanov, Marco Zocca, Manan Dey, Zhihan Zhang, Nour Moustafa-Fahmy, Urvashi Bhattacharyya, Wenhao Yu, Swayam Singh, Sasha Luccioni, Paulo Villegas, Maxim Kunakov, Fedor Zhdanov, Manuel Romero, Tony Lee, Nadav Timor, Jennifer Ding, Claire Schlesinger, Hailey Schoelkopf, Jan Ebert, Tri Dao, Mayank Mishra, Alex Gu, Jennifer Robinson, Carolyn Jane Anderson, Brendan Dolan-Gavitt, Danish Contractor, Siva Reddy, Daniel Fried, Dzmitry Bahdanau, Yacine Jernite, Carlos Muñoz Ferrandis, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries. 2023b. StarCoder: May the source be with you! arXiv preprint arXiv:2305.06161, abs/2305.06161.
- Li et al. (2022) Yujia Li, David H. Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu, and Oriol Vinyals. 2022. Competition-level code generation with AlphaCode. arXiv preprint arXiv:2203.07814, abs/2203.07814.
- Liang et al. (2024) Yaobo Liang, Quanzhi Zhu, Junhe Zhao, and Nan Duan. 2024. Machine-created universal language for cross-lingual transfer. In Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver, Canada, pages 18617–18625. AAAI Press.
- Liu et al. (2023a) Chao Liu, Xuanlin Bao, Hongyu Zhang, Neng Zhang, Haibo Hu, Xiaohong Zhang, and Meng Yan. 2023a. Improving chatgpt prompt for code generation. arXiv preprint arXiv:2305.08360, abs/2305.08360.
- Liu and Wan (2021) Chenxiao Liu and Xiaojun Wan. 2021. CodeQA: A question answering dataset for source code comprehension. In Findings of the Association for Computational Linguistics: EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 16-20 November, 2021, pages 2618–2632. Association for Computational Linguistics.
- Liu et al. (2024) Jiaheng Liu, Zhiqi Bai, Yuanxing Zhang, Chenchen Zhang, Yu Zhang, Ge Zhang, Jiakai Wang, Haoran Que, Yukang Chen, Wenbo Su, Tiezheng Ge, Jie Fu, Wenhu Chen, and Bo Zheng. 2024. E2-llm: Efficient and extreme length extension of large language models. ArXiv, abs/2401.06951.
- Liu et al. (2023b) Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023b. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. arXiv preprint arXiv:2305.01210, abs/2305.01210.
- Liu et al. (2023c) Yue Liu, Thanh Le-Cong, Ratnadira Widyasari, Chakkrit Tantithamthavorn, Li Li, Xuan-Bach Dinh Le, and David Lo. 2023c. Refining ChatGPT-generated code: Characterizing and mitigating code quality issues. arXiv preprint arXiv:2307.12596, abs/2307.12596.
- Luo et al. (2023) Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2023. WizardCoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568.
- Mishra et al. (2023) Mayank Mishra, Prince Kumar, Riyaz Bhat, Rudra Murthy V, Danish Contractor, and Srikanth Tamilselvam. 2023. Prompting with pseudo-code instructions. arXiv preprint arXiv:2305.11790, abs/2305.11790.
- Muennighoff et al. (2023) Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro von Werra, and Shayne Longpre. 2023. OctoPack: Instruction tuning code large language models. arXiv preprint arXiv:2308.07124, abs/2308.07124.
- Oda et al. (2015) Yusuke Oda, Hiroyuki Fudaba, Graham Neubig, Hideaki Hata, Sakriani Sakti, Tomoki Toda, and Satoshi Nakamura. 2015. Learning to generate pseudo-code from source code using statistical machine translation (T). In 30th IEEE/ACM International Conference on Automated Software Engineering, ASE 2015, Lincoln, NE, USA, November 9-13, 2015, pages 574–584. IEEE Computer Society.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Que et al. (2024) Haoran Que, Jiaheng Liu, Ge Zhang, Chenchen Zhang, Xingwei Qu, Yinghao Ma, Feiyu Duan, Zhiqi Bai, Jiakai Wang, Yuanxing Zhang, et al. 2024. D-cpt law: Domain-specific continual pre-training scaling law for large language models. arXiv preprint arXiv:2406.01375.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. 2018. Improving language understanding by generative pre-training. OpenAI blog.
- Reynolds and McDonell (2021) Laria Reynolds and Kyle McDonell. 2021. Prompt programming for large language models: Beyond the few-shot paradigm. In CHI ’21: CHI Conference on Human Factors in Computing Systems, Virtual Event / Yokohama Japan, May 8-13, 2021, Extended Abstracts, pages 314:1–314:7. ACM.
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code Llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Szafraniec et al. (2023) Marc Szafraniec, Baptiste Rozière, Hugh Leather, Patrick Labatut, François Charton, and Gabriel Synnaeve. 2023. Code translation with compiler representations. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008.
- Wang et al. (2021) Yue Wang, Weishi Wang, Shafiq Joty, and Steven CH Hoi. 2021. CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. arXiv preprint arXiv:2109.00859.
- Wei et al. (2022a) Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. 2022a. Finetuned language models are zero-shot learners. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
- Wei et al. (2022b) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022b. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Wei et al. (2023) Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. 2023. Magicoder: Source code is all you need. arXiv preprint arXiv:2312.02120, abs/2312.02120.
- Xu et al. (2023) Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. 2023. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244.
- Yan et al. (2023) Weixiang Yan, Yuchen Tian, Yunzhe Li, Qian Chen, and Wen Wang. 2023. Codetransocean: A comprehensive multilingual benchmark for code translation. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pages 5067–5089. Association for Computational Linguistics.
- Yang et al. (2024) Jian Yang, Hongcheng Guo, Yuwei Yin, Jiaqi Bai, Bing Wang, Jiaheng Liu, Xinnian Liang, Linzheng Chai, Liqun Yang, and Zhoujun Li. 2024. m3p: Towards multimodal multilingual translation with multimodal prompt. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation, LREC/COLING 2024, 20-25 May, 2024, Torino, Italy, pages 10858–10871. ELRA and ICCL.
- Yang et al. (2020a) Jian Yang, Shuming Ma, Dongdong Zhang, Zhoujun Li, and Ming Zhou. 2020a. Improving neural machine translation with soft template prediction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pages 5979–5989. Association for Computational Linguistics.
- Yang et al. (2020b) Jian Yang, Shuming Ma, Dongdong Zhang, Shuangzhi Wu, Zhoujun Li, and Ming Zhou. 2020b. Alternating language modeling for cross-lingual pre-training. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pages 9386–9393. AAAI Press.
- Yang et al. (2022) Jian Yang, Yuwei Yin, Shuming Ma, Dongdong Zhang, Shuangzhi Wu, Hongcheng Guo, Zhoujun Li, and Furu Wei. 2022. UM4: unified multilingual multiple teacher-student model for zero-resource neural machine translation. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, pages 4454–4460. ijcai.org.
- Yang et al. (2019) Ze Yang, Wei Wu, Jian Yang, Can Xu, and Zhoujun Li. 2019. Low-resource response generation with template prior. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pages 1886–1897. Association for Computational Linguistics.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, abs/2305.10601.
- Yu et al. (2023) Zhaojian Yu, Xin Zhang, Ning Shang, Yangyu Huang, Can Xu, Yishujie Zhao, Wenxiang Hu, and Qiufeng Yin. 2023. Wavecoder: Widespread and versatile enhanced instruction tuning with refined data generation. arXiv preprint arXiv:2312.14187, abs/2312.14187.
- Zan et al. (2023) Daoguang Zan, Ailun Yu, Bo Shen, Jiaxin Zhang, Taihong Chen, Bing Geng, Bei Chen, Jichuan Ji, Yafen Yao, Yongji Wang, and Qianxiang Wang. 2023. Can programming languages boost each other via instruction tuning? arXiv preprint arXiv:2308.16824, abs/2308.16824.
- Zhang et al. (2023) Fengji Zhang, Bei Chen, Yue Zhang, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. 2023. RepoCoder: Repository-level code completion through iterative retrieval and generation. arXiv preprint arXiv:2303.12570, abs/2303.12570.
- Zhang et al. (2024) Ge Zhang, Scott Qu, Jiaheng Liu, Chenchen Zhang, Chenghua Lin, Chou Leuang Yu, Danny Pan, Esther Cheng, Jie Liu, Qunshu Lin, Raven Yuan, Tuney Zheng, Wei Pang, Xinrun Du, Yiming Liang, Yinghao Ma, Yizhi Li, Ziyang Ma, Bill Lin, Emmanouil Benetos, Huan Yang, Junting Zhou, Kaijing Ma, Minghao Liu, Morry Niu, Noah Wang, Quehry Que, Ruibo Liu, Sine Liu, Shawn Guo, Soren Gao, Wangchunshu Zhou, Xinyue Zhang, Yizhi Zhou, Yubo Wang, Yuelin Bai, Yuhan Zhang, Yuxiang Zhang, Zenith Wang, Zhenzhu Yang, Zijian Zhao, Jiajun Zhang, Wanli Ouyang, Wenhao Huang, and Wenhu Chen. 2024. Map-neo: Highly capable and transparent bilingual large language model series. arXiv preprint arXiv: 2405.19327.
- Zheng et al. (2023) Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. 2023. Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x. arXiv preprint arXiv:2303.17568, abs/2303.17568.