知识条件大语言模型自动临床数据提取
摘要
从临床和医学影像报告中提取肺部病变信息对于肺部相关疾病的研究和临床护理至关重要。 大语言模型(大语言模型)可以有效地解释报告中的非结构化文本,但由于缺乏特定领域的知识,它们经常产生幻觉,导致准确性降低,给临床应用带来挑战。 为了解决这个问题,我们提出了一个新颖的框架,通过上下文学习(ICL)将生成的内部知识与外部知识结合起来。 我们的框架使用检索器来识别内部或外部知识的相关单元,并使用分级器来评估检索到的内部知识规则的真实性和有用性,以调整和更新知识库。 我们的知识条件方法还通过分两个阶段处理提取任务来提高大语言模型输出的准确性和可靠性:(i)肺部病变发现检测和主要结构化字段解析,然后(ii)将病变描述文本进一步解析为附加结构化字段。 使用专家策划的测试数据集进行的实验表明,与现有 ICL 方法相比,这种 ICL 方法可以将关键字段(病变大小、边缘和坚固性)的 F1 分数平均提高 12.9%。
1简介
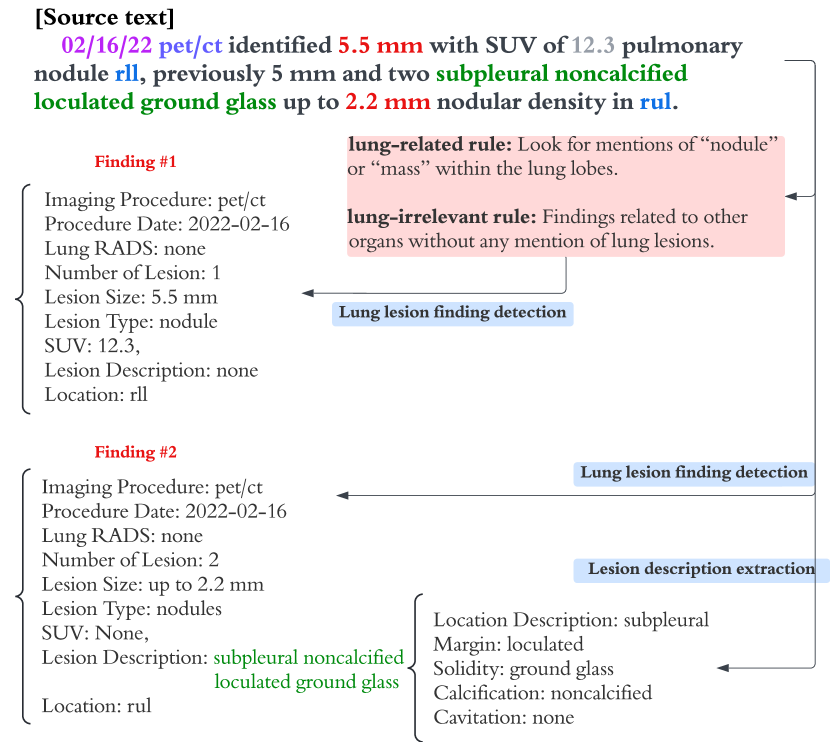
从医学影像和临床报告中提取肺部病变临床数据对于加强包括肺癌在内的肺部相关疾病的早期发现和研究起着至关重要的作用(张等人,2018;黄等人,2024)。 准确的自动提取可以减少放射科医生或医生所需的手动工作。 如图1所示,给定一份报告,任务是自动提取finding级别的信息,其中finding指的是描述文本一种或多种密切相关的病变。 由于一份报告可能有多个发现,我们的任务是检测所有发现并将它们解析为具有预定义字段的结构化模式,包括病变数量、大小、类型、位置、边距和可靠性。 (见图1和表8和9)。
然而,由于医学语言Wang等人(2018)的复杂性和可变性,解释报告中的非结构化文本提出了相当大的挑战。 针对特定医学术语创建专门的监督机器学习模型可能很有效,但通常会占用大量资源,而且此类模型可能很难训练和维护Spasic 等人 (2020)。 最近,大语言模型(大语言模型)已成为一般临床数据提取的有价值的辅助工具Singhal 等人(2023); Thirunavukarasu 等人 (2023)。
尽管如此,使用大语言模型进行临床数据提取仍面临一些挑战。 首先,大语言模型容易出错,并且经常出现“幻觉”,即返回原始报告中不存在的结果。 其次,由于大语言模型知识的静态性以及在训练中使用通用文本,他们经常难以处理需要特定领域临床知识的提取查询Ji等人(2023)。 第三,虽然大语言模型可以为基本提取任务提供高精度,但它们经常错过细粒度的细节Dagdelen等人(2024)。 这是因为提取肺部病变信息需要了解特定领域的字段(例如 margin 和 solidity),这些字段未包含在适用于更通用领域的预定义模式中语言数据联盟(2006、2008)。 最后,为了提取复杂的特定领域字段,大语言模型通常无法理解嵌套子字段 Chen 等人 (2024),因此可能会生成结构不一致的输出。
为了提供一种解决上述局限性的自动化临床数据提取方法,我们提出了一个两阶段大语言模型框架,该框架使用内部知识库,该知识库与专家衍生的迭代对齐使用上下文学习(ICL)的外部知识库。 具体来说,我们首先通过利用手动策划的医疗报告训练语料库来生成参考来创建内部知识库。 被认为与新输入报告相关的参考被转换为一组构成内部知识库的高级规则。 从报告中提取数据时,我们的系统会检索内部知识库中的规则并评分,以提高与外部知识库的一致性。 此过程通过利用与外部知识一致的相关提取模式来增强查找检测的有效性。 例如,在图 1 中,大语言模型提示中添加了两条规则,通过提供在报告中查找的具体标准和特征来帮助检测肺部病变。 最后,为了解决提取嵌套字段的挑战,我们首先为每个发现提取非结构化病变描述文本字段,然后将描述文本解析为结构化字段,作为采用更具指导性的方法的单独任务(图1)。
我们使用来自真实世界临床试验的精选数据集(其中包括医学专家的注释)通过实验验证了我们的方法。 此外,我们为肺部病变提取任务定义了一个新的领域模式,可能对相关肺部疾病研究有用。 我们的结果表明,与现有的 ICL 方法相比,使用我们的框架可以提高肺部病变临床数据提取的准确性。
2方法论
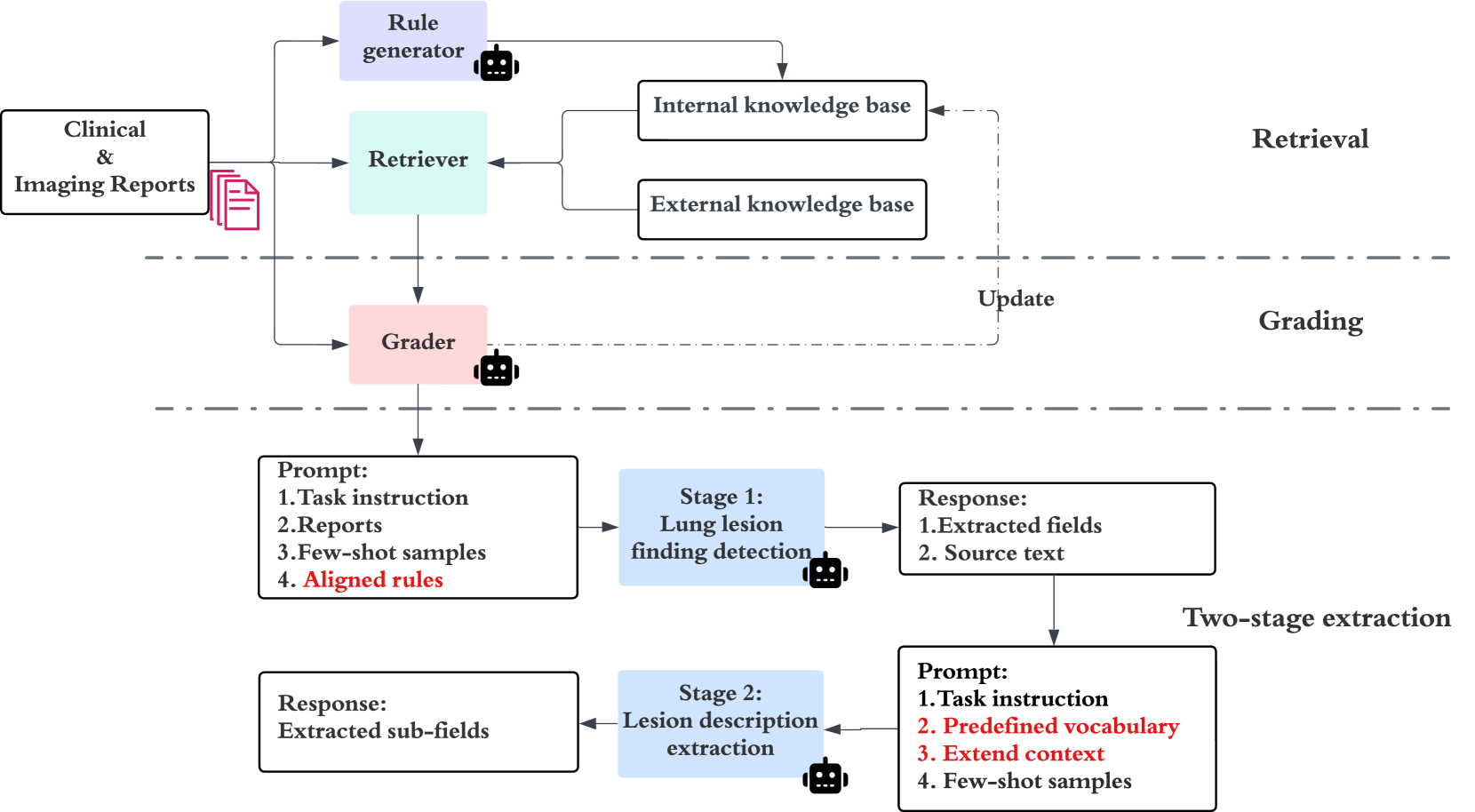
在本节中,我们首先描述该任务,然后介绍我们的两阶段临床数据提取框架,该框架采用先进的 ICL 方法,该方法以内部和外部知识库为条件。 整体框架如图2所示。
2.1 任务定义
我们的任务是从临床和影像报告中提取肺部病变结果,其中包括 CT 扫描和临床报告的诊断影像报告。 关键领域包括成像程序、病变大小、边缘、坚固性、肺叶,以及 PET/CT 的标准化摄取值 (SUV)。 表 5 中提供了有关这些字段含义的详细信息以及提取字段的完整列表。 上述字段的提取对于肿瘤学研究和支持临床护理美国癌症协会(2024)很有用。
2.2临床数据提取框架
给定输入报告 、包含 LLM 生成规则 的内部知识库 (KB) 以及专家策划的外部知识库 ,我们的系统旨在将提取的字段生成为 。
我们用于对齐 KB 的框架使用检索器 和分级器 。 检索器检索与来自的输入相关的顶级规则。 然后,分级器根据输入和从检索到的外部知识,进一步选择并尝试改进规则,从而得到,其中为知识对齐规则。 通过将改进的添加到默认提示中,大语言模型将报告中的字段提取到我们的结构化病变字段模式中。
2.3肺部病变知识库构建
我们构建了两个知识库:一个是由基于 LLM 的规则生成器模块使用小型标记训练集生成的内部知识库,另一个是使用专家知识资源的外部知识库。
内部知识库建设
使用一小组带有肺部病变和非肺部病变发现的手动注释报告的训练集,我们首先要求规则生成器(由大语言模型实现)创建参考 ,这是对手动注释的肺部和非肺部病变发现的解释。 参考采用以下形式:
- 源文本
-
“右上叶额外软组织结节密度为 1.3 厘米”
- 解释
-
“这一发现被描述为‘软组织结节密度’,测量值为 1.3 厘米。 它位于右上叶。 这可能是小肿块或结节的迹象。”
为了将这些引用转换为更通用、可重用的规则,我们接下来提示规则生成器识别引用之间的共同属性并进行推断。 肺部病变参考可能经常包含测量值,因此推断规则的一个示例是“查找包含测量值的描述(例如,‘识别出的 5.5 毫米’、‘测量值 1.8 x 1.2 厘米’),这些测量值通常表明肺部病变”。规则以多对话方式生成,生成过程如表6所示。
这些通用规则构成了内部知识库,表示为,由肺相关规则和肺相关规则组成。
外部知识库建设
我们从权威来源手动识别外部特定领域知识,包括临床指南111https://radiopaedia.org/,222https://radiologyassistant.nl/,3>35>33https://www.cancer.org/cancer/types/lung-cancer/detection-diagnosis-staging.html 收集到的信息被分成多个块。 外部知识库表示为,包含多种内容格式,包括结构化数据、文本信息和程序指南。
2.4检索器和平地机
猎犬
给定报告,检索器模块负责识别顶部相关肺相关和肺- 内部知识库 中的不相关规则。 此检索过程将输入报告与最相关的规则进行匹配,并将这些规则返回为 。
对于每个规则 ,检索器 还会从外部知识库 检索 供评分器
Input: imaging and clinical reports , retriever , grader , retrieved internal rules , external knowledge , number of iterations , thresholds.
Output: aligned rules , updated internal KB .
平地机
为了提高检索规则的质量,我们引入了分级器,也是用大语言模型实现的。 评分者被分配了两个任务,并迭代这些任务以细化内部知识库 中的规则。
首先,通过比较每个,使用真实性分数(范围从1到3的整数)对中的规则进行评分对照检索到的外部知识并评估其与权威来源的一致性。 如果规则的真实性分数低于阈值,评分者会从中删除该规则,并生成修订后的规则,并将其添加回。 对于每个规则 迭代地重复此过程。其次,评分者根据中的对齐规则与输入报告的相关性为有用性分配分数。 帮助性分数是一个范围从 1 到 5 的整数。 为了评估有用性,评分者会分析每条规则对信息提取和解释的支持程度。 不满足有用性阈值的规则将从 中删除。 评估真实性和乐于助人的提示可以在表7中找到。
最终的一组高分规则用于提示病变发现提取。 此迭代过程旨在增加更新的 中的规则产生具有所需属性的输出的可能性。 完整的评分算法详见算法1。
2.5两级提取
临床数据通常包含嵌套信息。 例如,影像报告可能包括用单个短语描述的两个发现:“左下叶内有 2 个相邻的肺结节,两个中较大的一个测量为 5 毫米,SUV 为 2.39。”像这样,大语言模型经常无法检测到第二个发现,因为它与文本中的第一个发现没有很好地分开,并且因为它的特征没有被明确列举。
为了解决复杂信息提取任务中的这一已知限制Chen 等人 (2024),我们将临床数据提取任务分解为两个阶段:(i)肺部病变发现检测和初级结构化字段解析,然后是(ii)进一步解析病变描述文本。
在第一阶段,我们使用作为肺部病变发现检测的大语言模型提示的一部分,以及任务说明、输入报告和少样本(表8)。
第二阶段的目标是从病变描述文本中提取额外的结构化字段。 在第二阶段没有贡献,因为描述病变描述字段的有效术语集是有限的。 相反,我们为大语言模型提供了基于 SNOMED 本体 SNOMED (2024) 的受控词汇,这是一个全面的临床术语系统,为医疗条件和程序提供标准化代码和术语(表9)。 我们还注意到,仅病变描述通常是不够的,因为第一阶段遗漏的信息可能会导致后续提取步骤中的错误。 为了缓解此问题,第二阶段提示将提取的病变描述文本与第一阶段的完整源文本相结合,以扩展用于提取病变描述字段的上下文。
两阶段提取工作流程如图2所示。
3实验
为了评估我们提出的方法,我们首先引入肺部病变数据集,然后将我们的方法与基线方法进行比较,然后讨论迭代更新的内部知识规则如何帮助提取。
| Lesion | Total | Training | Test |
|---|---|---|---|
| Subjects | 19 | - | - |
| Clinical reports | 31 | 16 | 15 |
| Imaging reports | 30 | 14 | 16 |
| Total findings | 189 | 81 | 108 |
| Stage | Fields | Default Prompts | CoT | RAG | Ours | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| # 1 | Image procedure | 78.2 | 63.6 | 70.1 | 79.5 | 64.2 | 71.0 | 75.3 | 61.1 | 67.5 | 86.5 | 72.7 | 79.0 |
| Lesion size † | 85.9 | 82.1 | 84.0 | 87.3 | 84.2 | 85.7 | 83.0 | 78.5 | 80.7 | 92.8 | 85.8 | 89.1 | |
| SUV | 76.0 | 73.1 | 74.5 | 77.4 | 74.3 | 75.8 | 72.5 | 69.4 | 70.9 | 86.6 | 74.0 | 79.7 | |
| Lesion type | 83.7 | 67.3 | 74.6 | 85.1 | 68.7 | 76.1 | 80.2 | 63.9 | 71.2 | 88.1 | 73.6 | 80.2 | |
| Lobe | 72.7 | 60.4 | 66.0 | 74.0 | 61.5 | 67.2 | 70.0 | 57.5 | 63.0 | 81.9 | 69.6 | 75.2 | |
| #2 | Margin † | 68.4 | 65.0 | 66.7 | 68.5 | 67.5 | 67.5 | 75.0 | 63.2 | 68.6 | 90.0 | 76.3 | 82.4 |
| Solidity † | 65.0 | 35.7 | 45.7 | 67.3 | 36.9 | 47.7 | 77.1 | 27.8 | 40.7 | 96.9 | 55.6 | 69.2 | |
| Calcification | 87.7 | 61.0 | 71.6 | 89.0 | 62.1 | 73.2 | 76.0 | 62.8 | 67.5 | 88.8 | 67.8 | 75.7 | |
| Cavitation | 50.0 | 100.0 | 66.7 | 60.0 | 100.0 | 73.4 | 50.0 | 100.0 | 66.7 | 87.5 | 100.0 | 91.7 | |
3.1数据集
数据源
该研究使用 Freenome 的 Vallania 研究(ClinicalTrials.gov,NCT05254834)的临床和影像报告,其中包括肺癌筛查和其他临床结果。 所有个人身份信息 (PII) 均已事先经过编辑。 这些报告中的文本信息是通过 Google 的 Cloud Vision API Google Vision (2024) 使用光学字符识别 (OCR) 提取的。
标注和数据准备
3.2评估指标
对于给定的测试报告,黄金标准结果和系统检测到的结果可能在数量和/或顺序上有所不同。 为了评估提取的准确性,两组结果需要相互对齐。 为此,我们执行额外的匹配步骤并使用匈牙利算法444https://en.wikipedia.org/wiki/Hungarian_algorithm 以匹配黄金标准和系统检测到的结果。 所有提取的字段都用于构建匹配成本矩阵。 我们报告提取任务的微观精度、召回率和 F1 分数。
3.3模块实现
用于规则生成、分级、肺部病变发现检测和病变描述提取的大语言模型基于 Google 的 PaLM2 模型 Anil 等人 (2023) 的官方 API。 对于评分者,真实性和乐于助人分数的阈值设置为和 分别。 大语言模型使用的所有提示均列于附录A.2中。
我们使用检索器来获取最重要的相关内部知识规则,并根据与的语义相似性检索外部知识。 具体来说,我们使用 Google Google Vertex AI (2024) 的文本嵌入 API (text-embedding-004) 来获取 的嵌入, 和 。余弦相似度用于语义相似度得分。 对于我们系统中使用的超参数设置,请参阅表10。
3.4 比较基线
由于目前还没有使用大语言模型和我们策划的真实数据集进行肺部病变提取的工作,因此我们应用常用的上下文学习(ICL)基线方法并与以下方法进行比较:
少样本学习
这里,大语言模型提供了少量金标准示例作为基本提示的一部分,用于病灶发现检测和病灶描述提取Brown等人(2020)。 但是,提示中不包含知识库内容或其他指导。 我们将这些最小提示称为默认提示。 我们报告使用默认提示获得的结果,而其他方法则逐步建立在这些默认提示的基础上。
思想链(CoT)
默认提示中添加了额外的说明,引导大语言模型通过一步步思考将病灶发现检测任务分解为更简单、连续的步骤Wei等人(2022b). CoT 适用于第一阶段,但不适用于第二阶段病变描述文本提取,因为该任务执行起来很简单。
检索增强生成 (RAG)
RAG对基本的大语言模型查询进行了补充,它试图通过引入外部知识来改善查询Lewis等人(2020)的上下文来减少幻觉。 我们实现了一种 RAG 方法,直接从 检索信息,并将检索到的外部知识块添加到默认提示中。 此方法不使用内部 KB ()。
| Stage | Fields | w/o knowledge | w/o context | w/o grading | Ours | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| # 1 | Image procedure | 78.2 | 63.6 | 70.1 | 86.5 | 72.7 | 79.0 | 84.6 | 61.7 | 71.4 | 86.5 | 72.7 | 79.0 |
| Lesion size † | 85.9 | 82.1 | 84.0 | 92.8 | 85.8 | 89.1 | 92.4 | 85.1 | 88.5 | 92.8 | 85.8 | 89.1 | |
| SUV | 76.0 | 73.1 | 74.5 | 86.6 | 74.0 | 79.7 | 85.7 | 69.2 | 76.6 | 86.6 | 74.0 | 79.7 | |
| Lesion type | 83.7 | 67.3 | 74.6 | 88.1 | 73.6 | 80.2 | 91.2 | 69.8 | 78.9 | 88.1 | 73.6 | 80.2 | |
| Lobe | 72.7 | 60.4 | 66.0 | 81.9 | 69.6 | 75.2 | 80.8 | 63.2 | 70.8 | 81.9 | 69.6 | 75.2 | |
| # 2 | Margin † | 68.6 | 67.8 | 67.2 | 85.8 | 75.0 | 80.0 | 84.5 | 66.7 | 74.1 | 90.0 | 76.3 | 82.4 |
| Solidity † | 91.7 | 37.0 | 52.6 | 95.0 | 44.4 | 60.1 | 90.0 | 55.7 | 65.8 | 96.9 | 55.6 | 69.2 | |
| Calcification | 100.0 | 57.1 | 72.7 | 80.4 | 64.3 | 70.1 | 83.3 | 71.4 | 73.3 | 88.8 | 67.8 | 75.7 | |
| Cavitation | 55.6 | 100.0 | 71.5 | 75.0 | 100.0 | 83.4 | 66.7 | 100.0 | 77.8 | 87.5 | 100.0 | 91.7 | |
3.5结果与分析
总体结果
总体结果如表2所示。 我们对用 表示的字段特别感兴趣,其中包括 lesion size、margin 和 solidity,因为这些字段通常对癌症工作具有最大的临床意义。
在我们的实验中,CoT 的好处是有限的,它可能更适合更传统的多步骤推理任务,而不太适合我们专门的提取任务 Wei 等人 (2022a)。 此外,缺乏对知识库的访问限制了其正确提取高度特定领域领域的能力。
我们的 RAG 实现在肺部病变提取任务中也表现不佳——甚至比默认提示更糟糕。 这可能是由于仅基于语义相似性搜索错误地检索了外部知识,导致提示中增加了噪音。 这表明,如果不首先尝试将外部知识 () 与特定的提取任务保持一致,那么外部知识 () 的效用可能会受到限制。
与 RAG 不同,我们的方法首先生成与特定提取任务相关的内部知识。 然后,外部知识仅用于调整和更新内部知识。 表 2 中的结果表明,这提高了我们方法生成的规则的质量。
我们的模型在所有领域都优于所有 ICL 基线,特别是在 领域表现出色,F1 分数平均提高了 12.9%。 具体来说,它的病灶大小提高了3.4%,边缘提高了13.8%以上,硬度提高了21.5%。
消融研究
为了评估我们方法的每个组件的贡献,我们通过删除每个主要模块来进行消融测试。 消融结果列于表3中。
值得注意的是,不使用知识库(“w/o 知识”)的模型的性能显着下降,这表明合并领域知识的重要性。 此外,因为当忽略KB时病灶发现提取质量会降低,所以第二阶段病灶描述提取的质量也会降低。
省略为第 2 阶段病变描述提取提供扩展上下文和 SNOMED 受控词汇表(“无上下文”)的模型在第 2 阶段字段中表现较差。 这表明第二阶段提示中的扩展上下文可以帮助防止第一阶段的错误传播,并且受控词汇标准化了病变描述字段的提取。
最后,我们观察到,不使用评分器进行知识对齐(“不评分”)的模型的性能在运行中存在显着差异,这表明评分器的对齐作用提高了一致性并减少了噪音。
| Category | Rule # | Picked Rule |
|---|---|---|
| Lung-related | #1 | { "pattern": "solid | partly solid | groundglass", "rule": "Clinical notes mentioning ‘solid’, ‘partly solid’, ‘groundglass’ could indicate pulmonary nodule findings." } |
| #2 | { "pattern": "nodule", "rule": "Look for descriptions that mention ‘nodule’, which often indicate lung lesions." } | |
| #3 | { "pattern": "mass", "rule": "Look for descriptions that mention ‘mass’ which often indicate lung lesions." } | |
| Lung-irrelevant | #4 | { "pattern": "liver | kidney | other organs", "rule": "Findings related to other organs (e.g., liver, kidney) without any mention of lung lesions." } |
3.6讨论
内部知识案例研究
在我们的知识条件模型中,如果规则的真实性得分低于阈值(我们实验中的超参数),则分级器会迭代更新内部知识。
为了更好地了解内部知识库中对齐规则的影响,我们从测试集中识别出最常挑选的与肺相关和与肺无关的规则(表4)。 关于结节和肿块的规则经常被选择,因为这是肺部病变类型的两个常用术语。 (参见表4中的规则#2和#3。) 我们还观察到,大语言模型往往更擅长检测具有明确病变大小的肺部病变发现,并使用这些作为锚点来提取完整的发现。 临床数据中的坚固性信息很少,但在很多情况下,研究结果没有大小信息,但它描述了坚固性。 实心、部分实心和磨砂玻璃等术语通常指的是实心场。 表4中的规则#1有助于大语言模型检测参考病变坚固性的病变发现的能力。
对于与肺无关的规则,首选规则与其他器官(例如肝脏和肾脏)的发现相关,但没有提及肺。 显然,这种类型的规则有助于区分相关和不相关的发现。
猎犬顶部的效果-
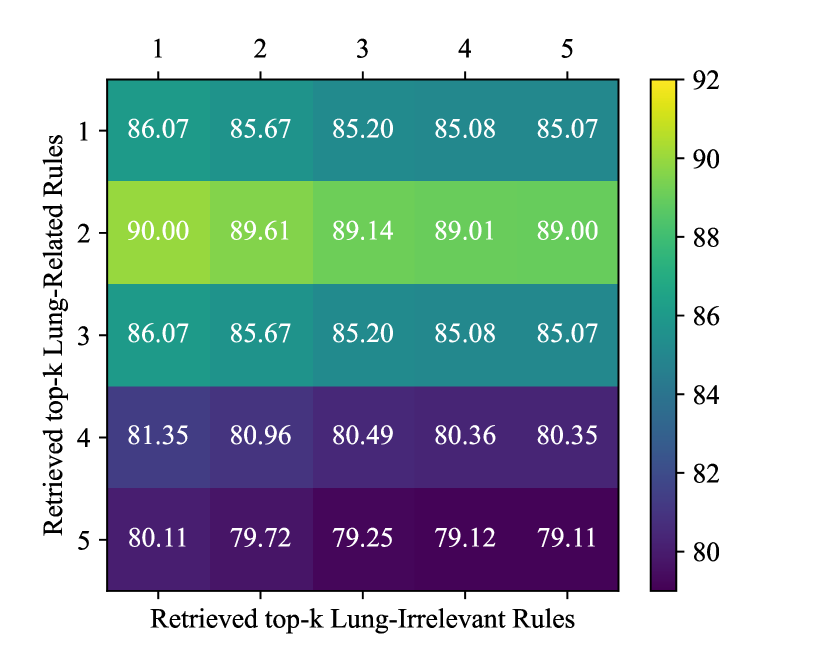
为了确定内部知识检索的最佳值,我们使用训练集执行网格搜索,评估病变大小提取的性能。 与肺相关和与肺无关的规则都考虑 的不同值。 如图3所示,当用于肺部相关规则和用于肺部无关规则时,观察到最佳提取性能。 我们使用这些最佳 值在测试集中进行提取。 一个有趣的发现是,仅使用少量规则即可显着提高病变大小提取性能。
4相关工作
在本节中,我们讨论以前在临床信息提取、知识感知模型和参考引导提取方法方面的工作。
4.1临床信息提取
临床信息提取的早期工作侧重于基于规则的系统和基于字典的方法Savova 等人 (2010);王等人(2018). 这些方法依赖于手动制定的规则和词典,这些规则和词典的创建需要大量劳动力,并且需要一个缺乏可扩展性的流程。 随着更强大的机器学习 (ML) 方法的出现,研究人员探索了监督学习技术,例如支持向量机 (SVM) 和条件随机场 (CRF),用于临床领域的命名实体识别和信息提取任务巴雷特等人 (2013);丹尼等人 (2010); Mehrabi 等人 (2015);罗伯茨等人 (2012);李等人(2015).
最近,深度学习模型,特别是循环神经网络(RNN)和基于 Transformer 的架构,在临床信息提取Zhong等人(2022)方面显示出了前景。 这些模型减少了对大量特征工程的需求,但它们依赖于高质量的注释数据。 针对医学术语的专门监督机器学习模型虽然有效,但训练需要占用大量资源,并且难以维护Spasic 等人 (2020)。
近年来,大语言模型已应用于临床信息提取Goel 等人 (2023); Wornow 等人 (2024). 大语言模型可以同时提取多个字段,而不需要为每个字段提供标记的训练数据。 虽然早期结果表明大语言模型可以加速临床数据提取,但错误率足够高,幻觉也足够常见,但结果仍然需要大量的人工审核以保证准确性。
我们的工作提出了一种完全自动化的方法,并使用新颖的技术来提高准确性,并至少部分缓解当前大语言模型的局限性,例如幻觉。 此外,针对肺部病变临床数据提取的具体问题,我们定义了一个领域相关的模式,可能对实际应用和进一步的 ML 模型开发有用。
4.2 知识感知语言模型
大多数现有语言模型都侧重于一般领域知识,因此,在处理临床或其他专业文本的细微差别和复杂性时,它们面临挑战Sushil 等人 (2021)。 为了解决通用语言模型遇到的特定领域知识差距,研究人员探索了各种整合外部知识源(知识库、本体、特定领域语料库等)的技术。 Yuan 等人 (2021);苏希尔 等人 (2021);杨等人 (2023);徐等人(2023)。 知识感知语言模型是使用知识蒸馏、知识注入和检索增强等技术开发的Xie等人(2022)。 这些方法旨在通过提供特定领域的知识来提高性能,使模型能够更好地理解和推理专业领域。 我们的方法就是这一策略的一个例子。
4.3 参考引导提取
使用外部参考或知识源来指导信息提取的想法已经在各个领域进行了探索,包括临床 NLP Demner-Fushman 和 Lin (2005)。 研究人员研究了使用医学本体、知识库和特定领域语料库来提高临床信息提取系统的性能Goswami 等人 (2019);金等人 (2022); Kiritchenko 等人 (2010)。 这些方法通常涉及将外部知识源合并到模型架构中,或者在训练或推理过程中将它们用作辅助输入。 然而,现有方法可能无法充分利用临床参考文献中丰富且不断发展的知识。 Yan 等人 (2024). 相比之下,我们的系统动态地调整和细化与外部知识的参考,当额外的外部知识可用时,其更新方式很简单。
5结论
在本文中,我们提出了一种使用大语言模型从临床和影像报告中提取肺部病变信息的新框架。 我们提出了一种新方法,通过 ICL 将内部知识和外部知识结合起来,以提高提取信息的可靠性和准确性。 通过动态选择和更新内部知识以及仅使用外部知识进行内部知识更新,我们的方法优于常用的 ICL 方法和 RAG 技术。 它在准确检测和提取临床上最相关的病变信息(病变大小、边缘和硬度)方面表现尤其出色。
局限性
Grader Fine-Tuning 我们方法的一个限制是,Grader 模块目前依赖于预训练的大语言模型,没有任何微调。 使用特定领域的数据对分级器模块进行微调可能会提高其评估检索知识的真实性和有用性的性能,从而提高整体提取准确性。
数据集大小 用于训练和评估的真实临床试验数据集的大小很小,尽管考虑到获取黄金标准、临床相关内容的高成本和难度,这并不奇怪。 机器学习模型的性能通常受到可用数据量的影响,因此更大、更多样化的数据集可以增强我们的模型泛化到新报告的能力。
依赖权威的外部知识我们的模型依赖权威的外部知识来验证和更新内部知识库。 即使最好的外部知识来源也不可避免地包含不准确之处,或者它们可能不是最新的。 模型的性能可能会因此降低。 我们方法的一个优点是可以轻松合并外部知识的改进版本或该知识的更新版本,而不需要对核心架构进行任何更改。
道德声明
我们认识到在整个工作中满足所有道德和法律标准的重要性,特别是在处理敏感医疗数据和 PII 方面。
数据集伦理问题 本研究中使用的临床数据不得共享或分发。 用于这项工作的数据中的所有 PII 均经过完全编辑,以保护患者身份并严格遵守所有相关法规、法律和指南。
更广泛的影响虽然此处描述的方法可以应用于任何 NLP 领域,但我们的工作特别关注与肺部相关疾病的早期检测相关的数据 - 以有利于研究或临床结果的方式,以及还减少了医疗保健专业人员的工作量。
致谢
这项工作得到了 Freenome 的支持。 我们感谢 Chuanbo Xu 协助获取影像和临床报告,感谢 Nasibeh Vatankhah 提供临床见解并帮助开发肺部病变野图。
参考
- American Cancer Society (2024) American Cancer Society. 2024. Lung cancer early detection, diagnosis, and staging. https://www.cancer.org/content/dam/CRC/PDF/Public/8705.00.pdf.
- Anil et al. (2023) Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. 2023. Palm 2 technical report. arXiv preprint arXiv:2305.10403.
- Barrett et al. (2013) Neil Barrett, Jens H Weber-Jahnke, and Vincent Thai. 2013. Engineering natural language processing solutions for structured information from clinical text: extracting sentinel events from palliative care consult letters. In MEDINFO 2013, pages 594–598. IOS Press.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Chen et al. (2024) Ruirui Chen, Chengwei Qin, Weifeng Jiang, and Dongkyu Choi. 2024. Is a large language model a good annotator for event extraction? In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17772–17780.
- Dagdelen et al. (2024) John Dagdelen, Alexander Dunn, Sanghoon Lee, Nicholas Walker, Andrew S Rosen, Gerbrand Ceder, Kristin A Persson, and Anubhav Jain. 2024. Structured information extraction from scientific text with large language models. Nature Communications, 15(1):1418.
- Demner-Fushman and Lin (2005) Dina Demner-Fushman and Jimmy Lin. 2005. Knowledge extraction for clinical question answering: Preliminary results. In Proceedings of the AAAI-05 Workshop on Question Answering in Restricted Domains, pages 9–13. AAAI Press (American Association for Artificial Intelligence) Pittsburgh, PA.
- Denny et al. (2010) Joshua C Denny, Marylyn D Ritchie, Melissa A Basford, Jill M Pulley, Lisa Bastarache, Kristin Brown-Gentry, Deede Wang, Dan R Masys, Dan M Roden, and Dana C Crawford. 2010. Phewas: demonstrating the feasibility of a phenome-wide scan to discover gene–disease associations. Bioinformatics, 26(9):1205–1210.
- Goel et al. (2023) Akshay Goel, Almog Gueta, Omry Gilon, Chang Liu, Sofia Erell, Lan Huong Nguyen, Xiaohong Hao, Bolous Jaber, Shashir Reddy, Rupesh Kartha, et al. 2023. Llms accelerate annotation for medical information extraction. In Machine Learning for Health (ML4H), pages 82–100. PMLR.
- Google Vertex AI (2024) Google Vertex AI. 2024. Vertex ai generative ai documentation: Text embeddings. https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/text-embeddings. Accessed: 2024-06-14.
- Google Vision (2024) Google Vision. 2024. Cloud vision documentation. https://cloud.google.com/vision/docs. Accessed: 2024-06-14.
- Goswami et al. (2019) Raxit Goswami, Vatsal Shah, Nehal Shah, and Chetan Moradiya. 2019. Ontological approach for knowledge extraction from clinical documents. In 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 1487–1491. IEEE.
- Huang et al. (2024) Jingwei Huang, Donghan M Yang, Ruichen Rong, Kuroush Nezafati, Colin Treager, Zhikai Chi, Shidan Wang, Xian Cheng, Yujia Guo, Laura J Klesse, et al. 2024. A critical assessment of using chatgpt for extracting structured data from clinical notes. npj Digital Medicine, 7(1):106.
- Ji et al. (2023) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
- Jin et al. (2022) Qiao Jin, Zheng Yuan, Guangzhi Xiong, Qianlan Yu, Huaiyuan Ying, Chuanqi Tan, Mosha Chen, Songfang Huang, Xiaozhong Liu, and Sheng Yu. 2022. Biomedical question answering: a survey of approaches and challenges. ACM Computing Surveys (CSUR), 55(2):1–36.
- Kiritchenko et al. (2010) Svetlana Kiritchenko, Berry De Bruijn, Simona Carini, Joel Martin, and Ida Sim. 2010. Exact: automatic extraction of clinical trial characteristics from journal publications. BMC medical informatics and decision making, 10:1–17.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
- Li et al. (2015) Qi Li, Stephen Andrew Spooner, Megan Kaiser, Nataline Lingren, Jessica Robbins, Todd Lingren, Huaxiu Tang, Imre Solti, and Yizhao Ni. 2015. An end-to-end hybrid algorithm for automated medication discrepancy detection. BMC medical informatics and decision making, 15:1–12.
- Linguistic Data Consortium (2006) Linguistic Data Consortium. 2006. Ace 2005 multilingual training corpus.
- Linguistic Data Consortium (2008) Linguistic Data Consortium. 2008. ACE (automatic content extraction) English annotation guidelines for relations v6.2. https://www.ldc.upenn.edu/sites/www.ldc.upenn.edu/files/english-relations-guidelines-v6.2.pdf.
- Mehrabi et al. (2015) Saeed Mehrabi, Anand Krishnan, Alexandra M Roch, Heidi Schmidt, DingCheng Li, Joe Kesterson, Chris Beesley, Paul Dexter, Max Schmidt, Mathew Palakal, et al. 2015. Identification of patients with family history of pancreatic cancer-investigation of an nlp system portability. Studies in health technology and informatics, 216:604.
- Roberts et al. (2012) Kirk Roberts, Bryan Rink, Sanda M Harabagiu, Richard H Scheuermann, Seth Toomay, Travis Browning, Teresa Bosler, and Ronald Peshock. 2012. A machine learning approach for identifying anatomical locations of actionable findings in radiology reports. In AMIA Annual Symposium Proceedings, volume 2012, page 779. American Medical Informatics Association.
- Savova et al. (2010) Guergana K Savova, Jin Fan, Zi Ye, Sean P Murphy, Jiaping Zheng, Christopher G Chute, and Iftikhar J Kullo. 2010. Discovering peripheral arterial disease cases from radiology notes using natural language processing. In AMIA Annual Symposium Proceedings, volume 2010, page 722. American Medical Informatics Association.
- Singhal et al. (2023) Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. 2023. Large language models encode clinical knowledge. Nature, 620(7972):172–180.
- SNOMED (2024) SNOMED. 2024. Snomed ct. https://www.snomed.org/. Accessed: 2024-06-14.
- Spasic et al. (2020) Irena Spasic, Goran Nenadic, et al. 2020. Clinical text data in machine learning: systematic review. JMIR medical informatics, 8(3):e17984.
- Sushil et al. (2021) Madhumita Sushil, Simon Suster, and Walter Daelemans. 2021. Are we there yet? exploring clinical domain knowledge of bert models. In Proceedings of the 20th Workshop on Biomedical Language Processing, pages 41–53.
- Thirunavukarasu et al. (2023) Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. 2023. Large language models in medicine. Nature medicine, 29(8):1930–1940.
- Wang et al. (2018) Yanshan Wang, Liwei Wang, Majid Rastegar-Mojarad, Sungrim Moon, Feichen Shen, Naveed Afzal, Sijia Liu, Yuqun Zeng, Saeed Mehrabi, Sunghwan Sohn, et al. 2018. Clinical information extraction applications: a literature review. Journal of biomedical informatics, 77:34–49.
- Wei et al. (2022a) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022a. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Associates, Inc.
- Wei et al. (2022b) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022b. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837.
- Wornow et al. (2024) Michael Wornow, Alejandro Lozano, Dev Dash, Jenelle Jindal, Kenneth W. Mahaffey, and Nigam H. Shah. 2024. Zero-shot clinical trial patient matching with llms.
- Xie et al. (2022) Tianbao Xie, Chen Henry Wu, Peng Shi, Ruiqi Zhong, Torsten Scholak, Michihiro Yasunaga, Chien-Sheng Wu, Ming Zhong, Pengcheng Yin, Sida I Wang, et al. 2022. Unifiedskg: Unifying and multi-tasking structured knowledge grounding with text-to-text language models. arXiv preprint arXiv:2201.05966.
- Xu et al. (2023) Ran Xu, Hejie Cui, Yue Yu, Xuan Kan, Wenqi Shi, Yuchen Zhuang, Wei Jin, Joyce Ho, and Carl Yang. 2023. Knowledge-infused prompting: Assessing and advancing clinical text data generation with large language models.
- Yan et al. (2024) Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. 2024. Corrective retrieval augmented generation. arXiv preprint arXiv:2401.15884.
- Yang et al. (2023) Linyao Yang, Hongyang Chen, Zhao Li, Xiao Ding, and Xindong Wu. 2023. Chatgpt is not enough: Enhancing large language models with knowledge graphs for fact-aware language modeling. arXiv preprint arXiv:2306.11489.
- Yuan et al. (2021) Zheng Yuan, Yijia Liu, Chuanqi Tan, Songfang Huang, and Fei Huang. 2021. Improving biomedical pretrained language models with knowledge. arXiv preprint arXiv:2104.10344.
- Zhang et al. (2018) Junjie Zhang, Yong Xia, Hengfei Cui, and Yanning Zhang. 2018. Pulmonary nodule detection in medical images: a survey. Biomedical Signal Processing and Control, 43:138–147.
- Zhong et al. (2022) Yizhen Zhong, Jiajie Xiao, Thomas Vetterli, Mahan Matin, Ellen Loo, Jimmy Lin, Richard Bourgon, and Ofer Shapira. 2022. Improving precancerous case characterization via transformer-based ensemble learning. arXiv preprint arXiv:2212.05150.
附录A附录
A.1 肺病变标注图式
根据 Lung-RADS 指南 555https://www.acr.org/-/media/ACR/Files/RADS/Lung-RADS/Lung-RADS-2022.pdf,完整的标注模式如表 5 所示。
| Field | Description |
|---|---|
| Evaluator Signed On | The medical expert who signs the report, such as a physician, medical examiner, or pathologist. The expert’s signature verifies the report and confirms their agreement with the findings and opinions. |
| Date of Report Signed | The date the medical expert signs the report. |
| Imaging Procedure | The imaging procedure identifying the pulmonary lesion, including documentation or comparisons of previous procedures. |
| Date of Imaging Procedure Performed | The date the imaging procedure is performed. |
| Lesion SeqNo | An auxiliary variable to help track the number of lesions described in a report, listed in chronological order if dates are available. |
| Number of Lesions | Indicates whether the lesions are solitary or multiple. |
| Lesion Size (mm) | Size can be reported in diameter, area, or all three dimensions (width, height, depth). Usually measured in millimeters; convert from centimeters if necessary. |
| SUV | The reported standard uptake value of the nodule, which may be provided even if lesion size is not mentioned. |
| Lesion Type | Terms used in medical imaging to describe small growths in the lungs, differing mainly in size. A pulmonary nodule is a rounded opacity 3 cm in diameter, while a pulmonary mass is > 3 cm. A pulmonary cyst is an air- or fluid-filled sac within lung tissue. |
| Lobe | The lobe of the lung where the nodule is located. |
| Lesion Description | Detailed description of the pulmonary lesion. |
| Margin | Describes the edge characteristics of the lesion, such as ‘spiculated’, ‘well-defined’, or ‘irregular’. |
| Solidity (Morphology) | Refers to the shape and structure of the lesion, such as ‘ground glass’, ‘partly-solid’, or ‘solid’. • For solid and part-solid nodules, the size threshold for an actionable nodule or positive screen is 6 mm. • For nonsolid (ground-glass) nodules, the size threshold is 20 mm. • On follow-up screening CT exams, the size cutoff is 4 mm for solid and part-solid nodules and/or an interval growth of 1.5 mm of preexisting nodule(s). |
| Calcification | Indicates if the pulmonary nodules are calcified. |
| Cavitation | A gas-filled space within the lung tissue. |
| Lung RADS Score | Lung-RADS is a classification system for findings in low-dose CT (LDCT) screening exams for lung cancer. Examples include ‘4A’, ‘4B’, and ‘4X’. |
A.2提示
| Role | Prompt |
|---|---|
| System | You are a pulmonary radiologist. Your task is to extract key findings from the clinical or imaging reports. |
| User | How many findings of Lung Lesions are present in the following text: {text} |
| System | {lesion_number} |
| User | Please provide detailed explanations. |
| System | {detailed_explanations} |
| User | Only {num_findings} findings should be classified as Lung Lesions, explain why they are and why the remaining findings are not. Return in JSON format of: {"lung lesion findings": ["referred text": "reason of being lung lesion finding"], "none lung lesion findings": ["referred text": "reason of not being lung lesion finding"]} |
| System | {references} |
| User | Transform the references into generalized, reusable rules by abstracting common properties. Format the output in the following JSON structure: ["pattern": "example pattern", "rule": "example rule description"] |
| System | {lung-relevant rules, lung-irrelevant rules} |
| You are a grader assessing the helpfulness and truthfulness of retrieved rules related to pulmonary (lung) lesions in the context of pulmonary lesion findings.. |
|---|
| Given the clinical or imaging report, please evaluate the helpfulness of each rule on a scale from 1 to 5, where: 1 means not helpful at all 2 means slightly helpful 3 means moderately helpful 4 means very helpful 5 means extremely helpful |
| Below is the clinical or imaging report: |
| {input_query} |
| Additionally, evaluate the truthfulness of each rule based on the retrieved knowledge on a scale from 1 to 3, where: 1 means not truthful at all 2 means partially truthful 3 means completely truthful |
| Provide a brief explanation indicating how the rule can help in the extraction of pulmonary lesion characteristics and how the retrieved knowledge supports or refutes the rule. |
| Below is the retrieved external knowledge: |
| {external_knowledge} |
| You are a pulmonary radiologist. Extract key findings from the clinical or imaging report and organize them into the provided JSON structure. |
|---|
| Use the following JSON template as a guide: |
| [ { "Imaging Procedure": "Enter imaging procedure here or ’None’", "Procedure Date": "Enter date in YYYY-MM-DD format here or ’None’", "Lung RADS": "Enter Lung RADS category here or ’None’", "Number of Lesion": "Enter number of lesion here or ’None’", "Lagest Lesion Size": "Enter lesion size here", "Lesion Type": "Enter lesion type here", "SUV": "Enter SUV here or ’None’", "Location": "Enter location here or ’None’", "Lesion Description": "Enter Lesion Description here or ’None’", "Text Source": "Enter text source here or ’None’", }, { // Add additional finding as needed }, ] // Lung Lesion Findings |
| Below is the clinical or imaging report: |
| {input_query} |
| Below are some examples for reference: |
| {few_shot_samples} |
| Below are some lung-related rules for reference: |
| {corrected_rules} |
| Below are some lung-irrelevant rules for reference: |
| {corrected_rules} |
| You are a pulmonary radiologist. Please extract location description, margin, solidity, calcification, cavitation from lesion description and organize them into the provided JSON structure. |
|---|
| Use the following JSON template with preferred vocabularies as a guide: |
| { "location description": "Enter location description here or ’None’", "margin": "Enter margin description here, preferably from the vocabulary [’spiculated’, ’rounded’, ’ill-defined’, ’irregular’, ’lobulated’] or ’None’" "solidity": "Enter solidity description only from the fixed vocabulary [’solid’, ’partly solid’, ’groundglass’, ’ground-glass’, ’groundglass and consolidative’] or ’None’", "calcification": "Enter calcification description here, preferably from [’noncalcified’] or ’None’", "cavitation": "Enter cavitation description here, preferably from [’mildly cavitary’, ’cavitary’] or ’None’" } |
| Below is the lesion description text: |
| {lesion_description_text} |
| Below is the full text of report containing the finding for reference: |
| {source_text} |
| Below are some examples for reference: |
| {few_shot_samples} |
A.3 超参数
所有模块的超参数设置如表10所示。
| Module | Hyper-parameter | Value |
| Rule generator | temperature | 0.9 |
| top_p | 1 | |
| Retriever | retrival threshold for external knowledge | 0.9 |
| retrieved top- lung-related rule | 2 | |
| retrieved top- lung-irrelevant rule | 1 | |
| Grader | number of interations | 3 |
| truthfulness threshold | 2 | |
| helpfulness threshold | 4 | |
| Lesion finding detection | temperature | 0.2 |
| Lesion description extraction | temperature | 0.2 |