LoongTrain:头语并行长序列大语言模型的高效训练
摘要。
有效训练长序列的大语言模型很重要,但也面临着大量计算和内存需求的挑战。 序列并行性已被提出来解决这些问题,但现有方法存在可扩展性或效率问题。 我们提出了 LoongTrain,这是一种有效训练大规模长序列大语言模型的新颖系统。 LoongTrain的核心是2D-Attention机制,结合了头部并行和上下文并行技术,在保持效率的同时打破可扩展性限制。 我们引入了 Double-Ring-Attention 并分析了设备放置策略的性能,以进一步加快训练速度。 我们使用ZeRO和Selective Checkpoint++混合技术来实现LoongTrain。 实验结果表明,LoongTrain 在端到端训练速度和可扩展性方面均优于最先进的基线,即 DeepSpeed-Ulysses 和 Megatron Context Parallelism,并将模型 FLOP 利用率 (MFU) 提高高达 2.88。
1. 介绍
近年来,随着大语言模型的出现,研究人员研究并提出了许多先进的分布式训练方法,例如数据并行(DP)(KrizhevskySH12, ; paszke2019pytorch, ; li2014scaling, ; li2014communication, )、张量并行性 (TP) (DeanCMCDLMRSTYN12, )、管道并行性 (PP) (GPipe, ; AthlurSSRK22, )、PyTorch FSDP (PyTorchFSDP, ) 和自动并行化框架 (Alpa, )。 最近,长序列大语言模型推动了我们日常生活中必不可少的新颖应用的开发,包括生成式人工智能(ni2023recent, )和长上下文理解(beltagy2020longformer, ; zhou2021document ,; ding2023longnet,)。 随着 ChatGPT 的日益普及,长对话处理任务对于聊天机器人应用程序来说变得比以往更加重要(touvron2023llama, )。 除了这些语言处理场景之外,基于 Transformer 的巨型模型还在计算机视觉(zhang2020span, ; arnab2021vivit, ; Yuan2021tokens, )和科学人工智能(bi2023accurate, ; ai4science , ),其中长序列输入对于视频流处理 (ruan2022survey, ) 和蛋白质特性预测 (chandra2023transformer, ) 等复杂任务至关重要。
训练长序列的大语言模型需要大量的内存资源和计算量。 为了应对这些挑战,序列并行(SP)被提出(DeepspeedUlysses,;lightseq,;BPT2,;megatroncp,),它基本上可以分为两类:头并行(HP)(DeepspeedUlysses, ) 和上下文并行性 (CP) (BPT2, ; megatroncp, )。 在注意力块中,HP 方法保持整个序列并并行计算不同头的注意力,而 CP 方法将 QKV(查询、键和值)张量沿序列维度分割成块。 然而,两者在大规模应用于超长序列大语言模型时都面临局限性。 首先,惠普遇到了可扩展性问题。 在HP中,SP的程度本质上不能超过注意力头的数量(DeepspeedUlysses, )。 因此,HP能够横向扩展的程度是有上限的。 其次,CP遇到了沟通效率低下的问题。 CP (BPT2, ; megatroncp, ) 采用点对点 (P2P) 通信原语。 但P2P存在节点内带宽利用率低、节点间网络资源利用率低的问题。 这个瓶颈使得在扩展上下文并行维度时重叠通信与计算变得具有挑战性。 例如,我们的实验表明,在序列长度为 128K 的 64 个 GPU 上运行分组查询注意 (GQA) 时,Ring-Attention 在通信上花费的时间比在计算上花费 1.8 时间(图 5(d))。
| Sequence Length (Tokens) | Sequence Parallel Size | ||
| Number of Attention Heads | Data Parallel Size | ||
| Number of KV Heads | Head Parallel Size | ||
| Hidden Dimension Size | Context Parallel Size | ||
| Global-Batch Size (Tokens) | Inner Ring Size |
为了弥补这些差距,我们提出了 LoongTrain,这是一种在大规模 GPU 集群上进行长序列大语言模型的有效训练框架。 我们的主要想法是通过引入一种新颖的2D-Attention机制来解决HP的可扩展性限制,同时缓解CP的低效率。 这种机制在 HP 和 CP 维度上并行关注。 具体来说,它根据头维度将 QKV 张量分布在 GPU 上,并将这些张量划分为 CP 维度内的块。 通过这样做,LoongTrain通过CP的集成增强了可扩展性,并通过限制CP的维度大小减少了P2P步骤的数量。 此外,这种设计为计算通信重叠提供了更多机会。
为了进一步提高Attention块在某些情况下的通信效率,我们引入了Double-Ring-Attention,它有效地利用所有节点间NIC来获得更高的点对点通信带宽。 我们还分析了不同的放置策略如何提高不同 2D-Attention 配置中的通信效率。 最后,我们实现了先进的技术,例如在 DP 和 PP 维度上应用 ZeRO 以及基于白名单的梯度检查点机制 Selective Checkpoint++ 来进一步提高端到端大语言模型训练性能。 对高达 1M 序列的训练大语言模型的评估结果表明,与现有最先进的解决方案相比,LoongTrain 可以带来高达 2.88 的性能提升。
LoongTrain已部署在我们组织内训练多个长序列大语言模型。 该系统是在我们的内部训练框架内实现的,可以通过https://github.com/InternLM/InternEvo访问该框架。
2. 背景
2.1. MHA/GQA大语言模型架构
像 GPT (GPT3, ) 和 LLaMA (LLaMA, ) 这样的大语言模型利用 Transformer 架构 (Attention, ),它由多层组成。 如图1所示,每一层都包含一个注意力块和一个前馈网络(FFN)块。 在 Attention 块中,线性模块将输入张量投影为三个张量:查询 ()、键 () 和值 (),用于注意力计算。 然后,每一层都包含一个 FFN,它在序列内的每个位置上独立运行。 ,其中都是线性模块。
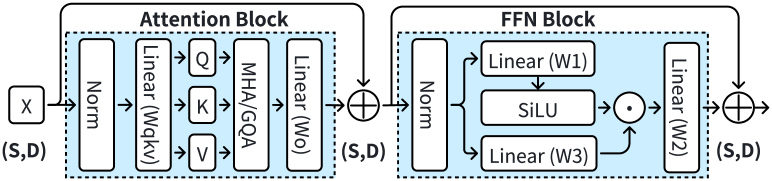
多头注意力 (MHA) (MHA, ) 将 、 和 拆分为 头。 假设原始 、 和 张量的形状为 。 它们将被重塑为。 MHA 独立地对每个头执行注意力计算,然后组合所有头的输出。 分组查询注意力 (GQA) (GQA, ) 将 查询头分为 组,每个组共享一组 KV 头。 在这种情况下,变换后的 和 张量具有 ,从而产生 的形状。 例如,LLaMA3-8B (llama3modelcard, ) 使用带有 和 的 GQA。
2.2. 分布式大语言模型训练
混合并行(Megatron-LM,)和零冗余优化器(ZeRO)(ZeRO,)通常用于大规模训练大语言模型。 具体来说,数据并行性 (DP) 将输入数据划分为块,将它们分布在多个 GPU 上以并行化训练。 张量并行 (TP) 将模型参数沿特定维度分布在 GPU 上,从而实现模型层 (TP, ) 的并行计算。 管道并行性 (PP) 将模型的各层拆分为多个阶段,并将它们分布在 GPU 上(GPipe,;pipedream,)。 每个管道阶段都依赖于前一阶段的输出,从而导致称为管道气泡的计算停顿。 先进的管道调度程序,例如 1F1B (pipedream, ) 和 ZeRO-Bubble (zerobubble, ),已被提出来减少气泡比率。 ZeRO (ZeRO, ) 解决了跨 DP 列的冗余内存使用问题。 ZeRO-1 跨 GPU 划分优化器状态,确保每个 GPU 仅存储优化器状态的一小部分。 ZeRO-2 还通过分片梯度来扩展这一点,ZeRO-3 进一步分布模型参数。
为了支持长序列训练,序列并行(SP)已经成为一种有效的技术来减少激活内存占用(DeepspeedUlysses,;Nvidia3,;lightseq,)。 在 SP 中,每个 Transformer 层的输入和输出张量沿着序列维度被划分为 块。 Megatron-LM 将 SP 与 TP 跨不同模块(Nvidia3,)集成。 具体来说,TP 用于并行化线性模块,而 SP 用于归一化和 dropout 模块。 为了确保计算结果的一致性,Megatron-LM 训练结合了必要的 AllGather 和 ReduceScatter 操作来在 期间转移激活。 然而,随着序列长度的增加,与传输激活相关的通信开销也会增加,从而导致重大的通信挑战(DeepspeedUlysses,;hu2024描述,)。
为了解决 SP 和 TP 集成中的这个问题,最近的方法在所有线性模块上实现 SP,并利用 ZeRO-3 来减少内存占用。 这消除了在激活时进行集体通信的需要。 他们在计算前执行AllGather来收集线性模块的参数,这些参数不会随着序列长度的增加而增加。 按照这一策略,引入了两种方法来促进分布式注意力计算:Ulysses-Attention (DeepspeedUlysses, ) 和 Ring-Attention (lightseq, ; BPT2, ),如上所述以下。
2.3. 分散注意力
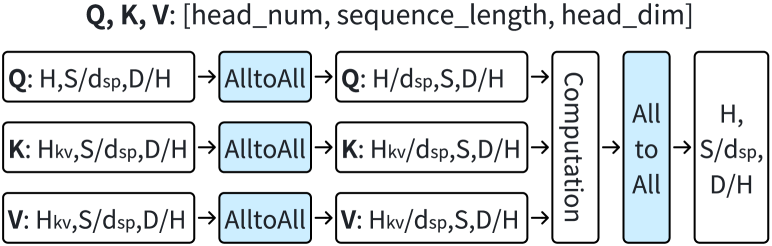
Ulysses-Attention (DeepspeedUlysses, ) 跨 GPU 执行头并行计算 (),如图 2 所示。 给定沿序列维度分割的 QKV 张量,Ulysses-Attention 首先执行 AlltoAll 以确保每个 GPU 接收 头的 QKV 完整序列。 然后,每个 GPU 并行计算不同头的注意力。 最后,另一个 AlltoAll 操作跨头维度收集结果,同时沿序列维度重新分区。
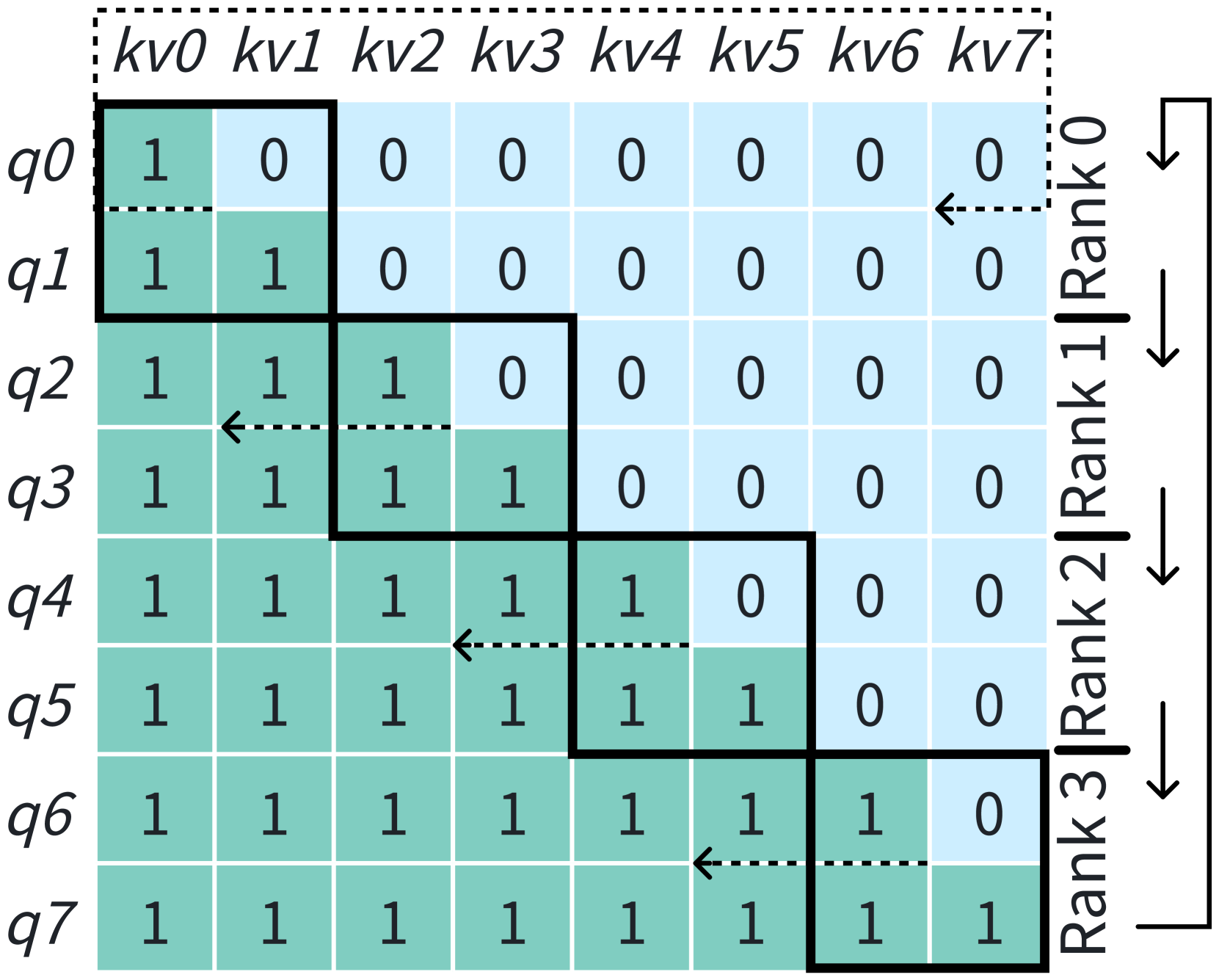
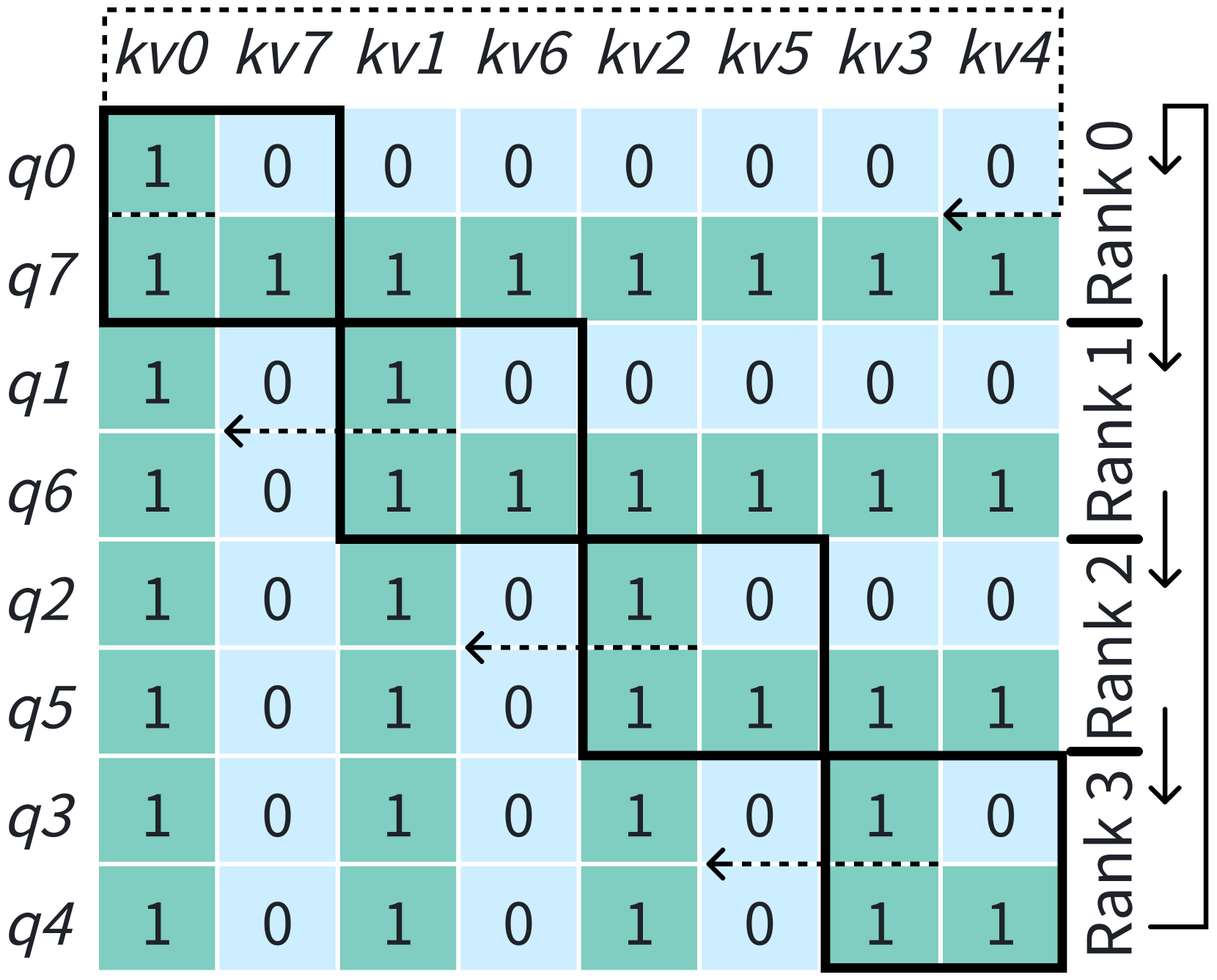
Ring-Attention (lightseq, ; BPT2, ) 利用块式注意力 (self-attnnotneedon2memory, ; BPT1, ; flashattn1, ) 并执行上下文并行计算 (),如图3所示。 该方法将 QKV 张量沿序列维度划分为块,每个 GPU 最初分配一个块。 对于每个查询块,其相应的注意力输出是通过迭代所有 KV 块来计算的。 通信以环形方式组织,每个 GPU 同时发送和接收 KV 块,从而允许通信与计算重叠。 FlashAttention (flashattn1, ) 仍可用于保持内存高效计算的 IO 感知优势。 然而,在应用因果注意掩模时,标准环注意方法不是负载平衡的,因为只需要计算矩阵的下三角部分。 为了解决这个问题,人们提出了几种方法,例如 DistFlashAttn (lightseq, ) 和 Striped-Attention (StripedAttention, )。 如图3(b)所示,Megatron-LM沿着序列维度对输入序列标记进行重新排序,以在其实现中实现负载平衡。 在本文中,Ring-Attention默认假设是负载均衡的。
3. 动机与观察
鉴于大语言模型训练的计算时间较长,尤其是长序列,因此将长序列模型扩展到大规模集群至关重要。 然而,当前的 SP 方法面临两个重大挑战:有限的可扩展性和高通信开销。
3.1. Ulysses-Attention 的可扩展性有限
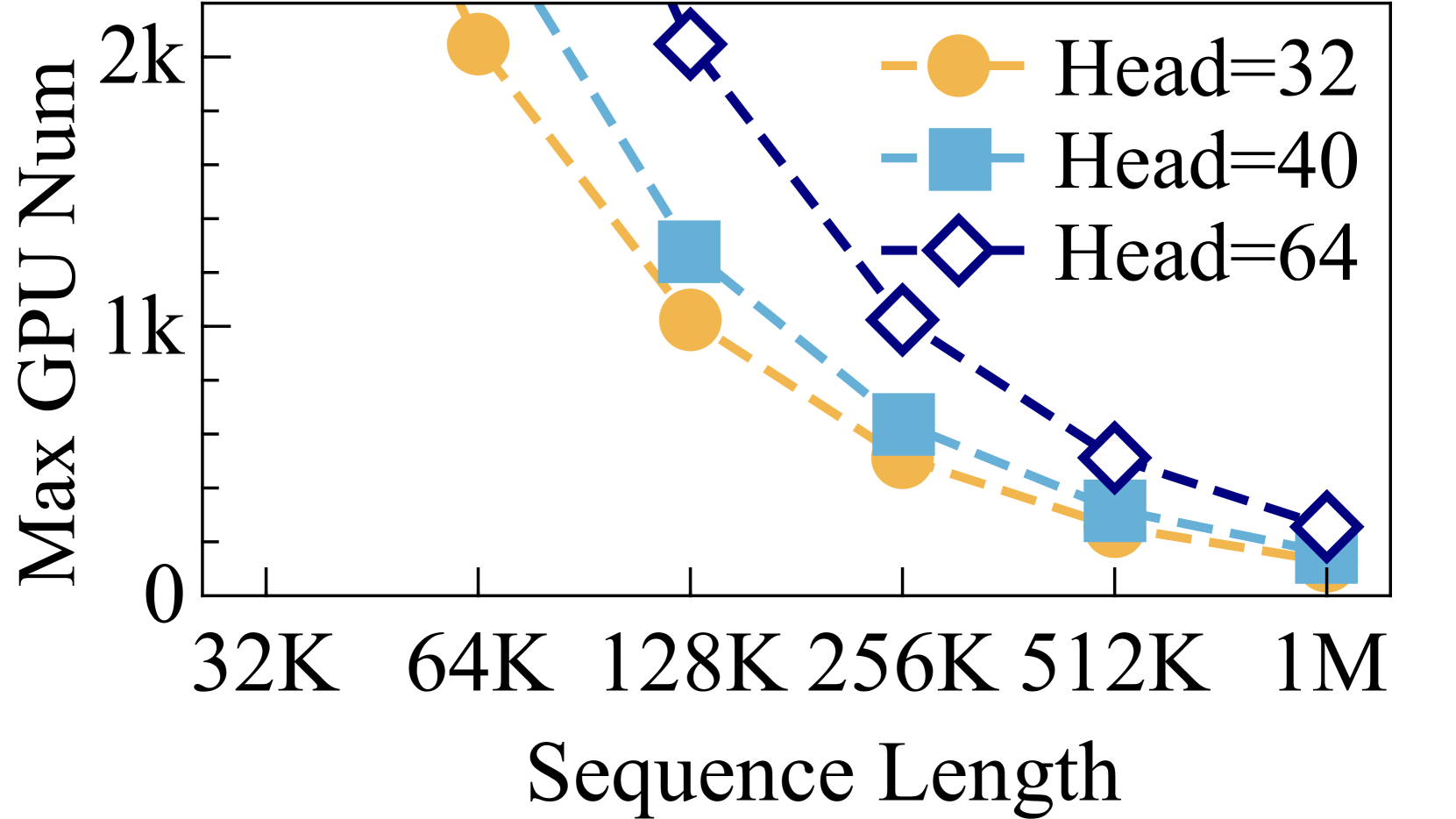
由于 SP、DP 和 PP 最大度数的限制,Ulysses-Attention 无法将长序列训练扩展到大规模集群。 首先,SP对注意力头的数量敏感。 使用MHA时,SP度不能超过注意力头的数量;而在GQA的情况下,SP度受到键/值头数量的限制。 例如,LLaMA3-8B 使用具有 8 个键/值头的 GQA,这意味着使用 Ulysses-Attention 时最大 SP 度为 8。 即使我们重复键/值头,如 4.1 节中详述,最大 SP 度仍为 32。
由于全局批量大小的限制,依靠增加 DP 的程度来扩展训练过程是不切实际的。 例如,当训练一个具有 32 个注意力头的 Transformer 模型并采用 4M 个 token 的全局批量大小(如世界模型训练 (liu2024world, ) 中所示)和 1M 个 token 的序列长度时, DP 的最大可获得程度为 4。 在这些条件下,使用 Ulysses-Attention 时,训练过程只能扩展到 128 个 GPU。 Ulysses-Attention 在 4M 全局批量大小的约束下可以使用的最大 GPU 数量如图 4 (a) 所示。
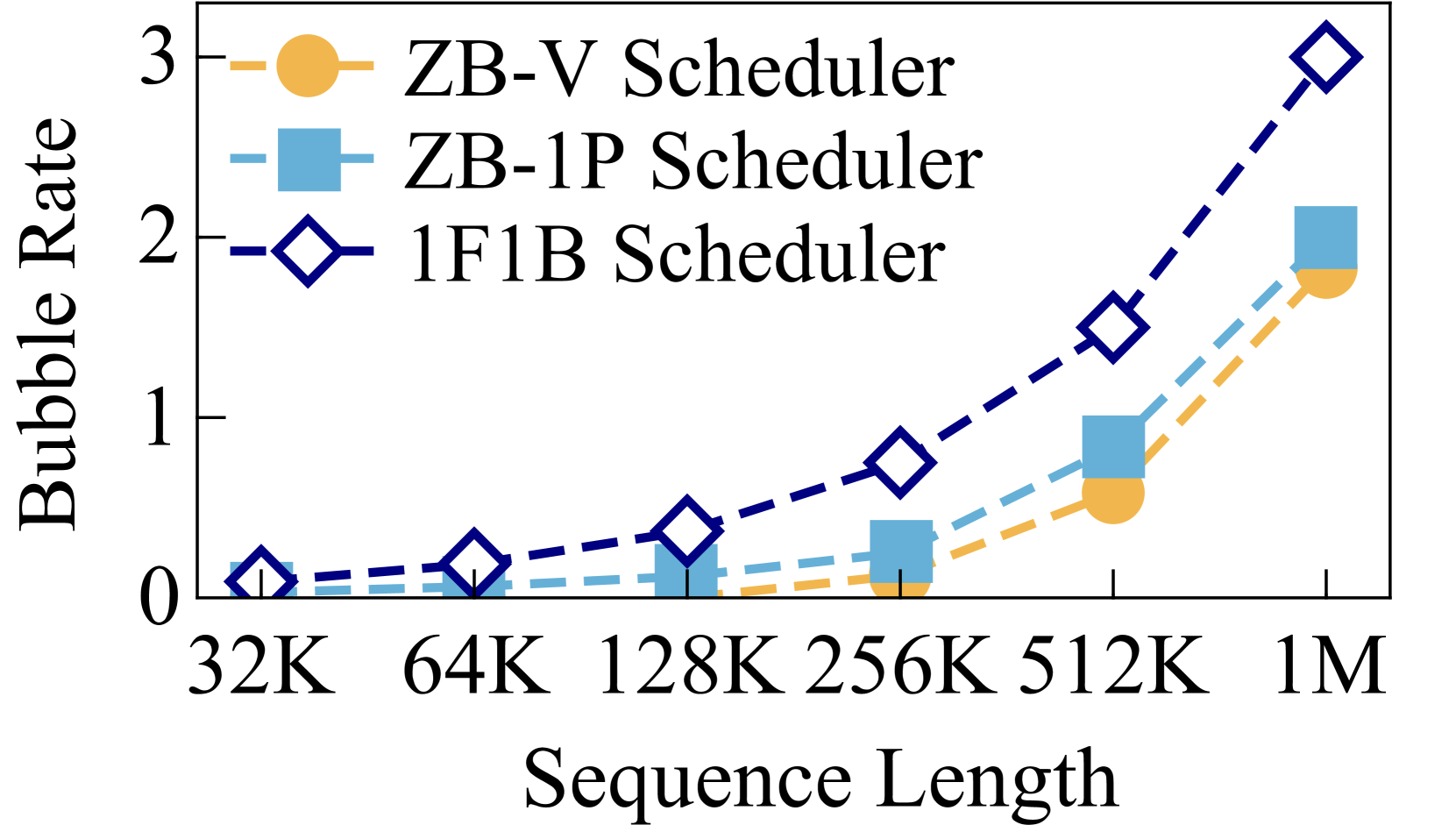
虽然我们可以通过增加 PP 程度将长序列训练扩展到更多 GPU,但它可能会导致高气泡率。 由于全局批量大小的限制,我们的微批量数量有限,这会带来显着的气泡率。 如图4(b)所示,即使在零气泡机制下,例如ZB-V和ZB-1P调度器(zerobubble, ),气泡率也达到2 。 对于有效的大语言模型训练来说,这种低效率是不可接受的。
3.2. Ring-Attention 的低效性能
虽然 Ring-Attention 展示了在很大程度上扩展 SP 的潜力,但其性能受到大量通信开销的阻碍。 我们在包含 64 个 GPU 的测试台上评估了序列长度为 128K 的 Ring-Attention 和 Ulysses-Attention 的性能111要将 1M 序列长度的训练扩展到 2048 个 GPU,受 4M Token 全局批量大小的限制, 需要缩放到512. 在这种情况下,每个查询/键/值块包含 2K 个 Token ,类似于在 64 个 GPU 上使用 128K 序列长度扩展训练。. 如图5所示,Ulysses-Attention 和 Ring-Attention 表现出相似的计算时间,随着 GPU 数量的增加几乎呈线性减少。 然而,随着 SP 程度的增加,由于通过网络传输 KV 块所需的 P2P 通信,Ring-Attention 遇到了瓶颈。 具体来说,使用 MHA,当从 32 个 GPU 扩展到 64 个 GPU 时,Ring-Attention 的总体执行时间并没有改善。 尽管 GQA 将通信量减少了 ,但在使用 64 个 GPU 时,Ring-Attention 的通信时间仍比计算时间多 1.8。
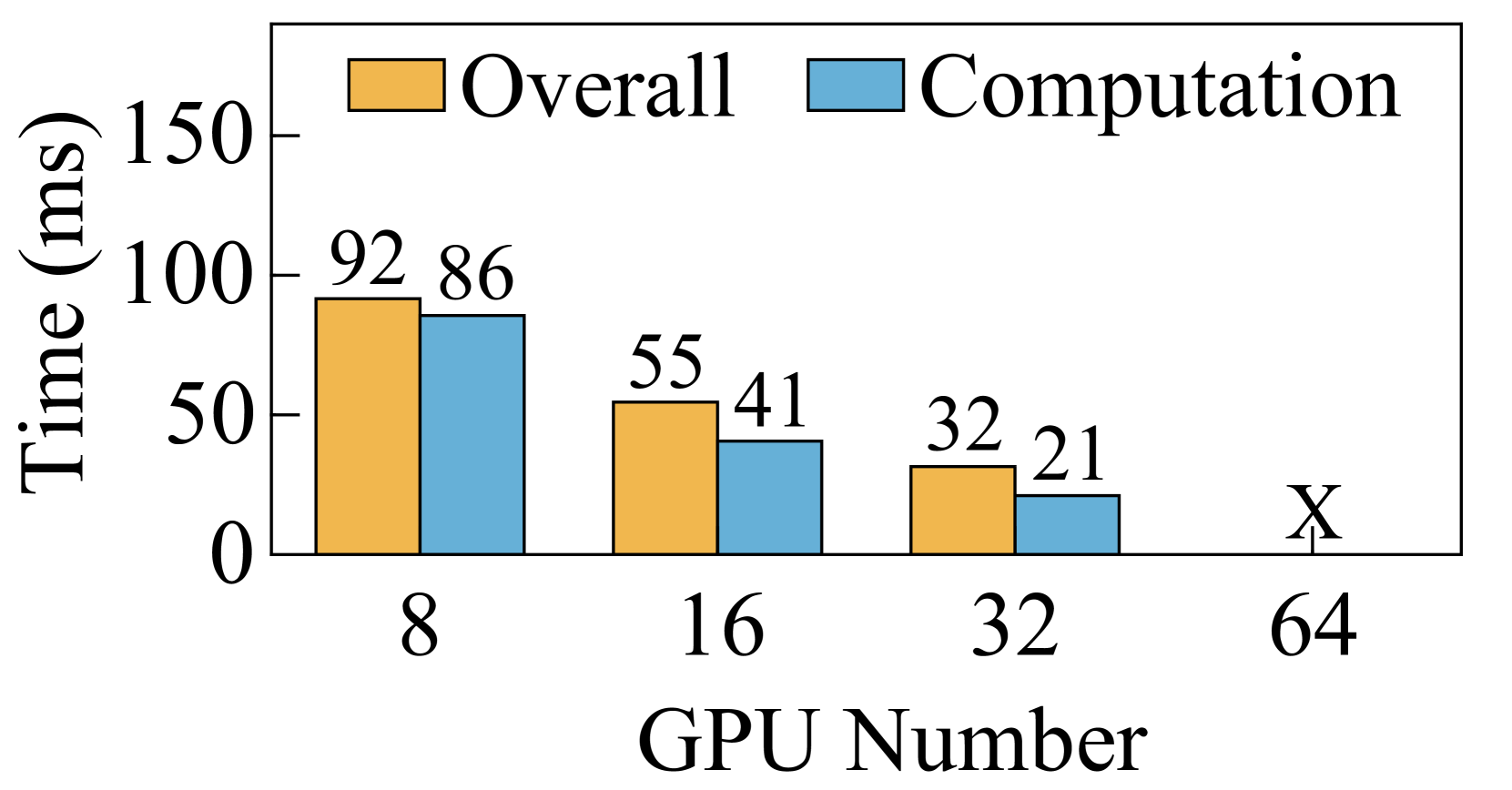
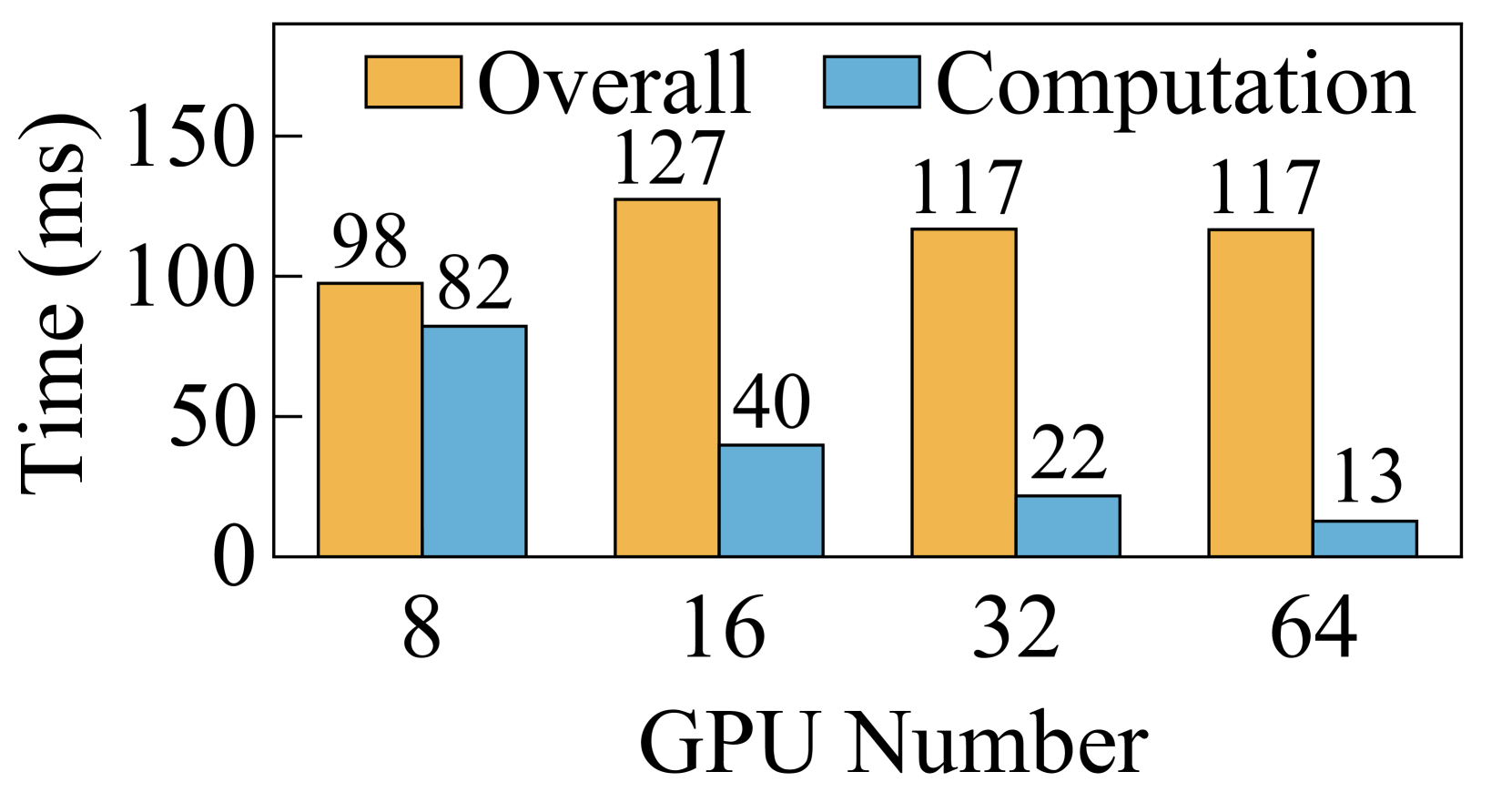
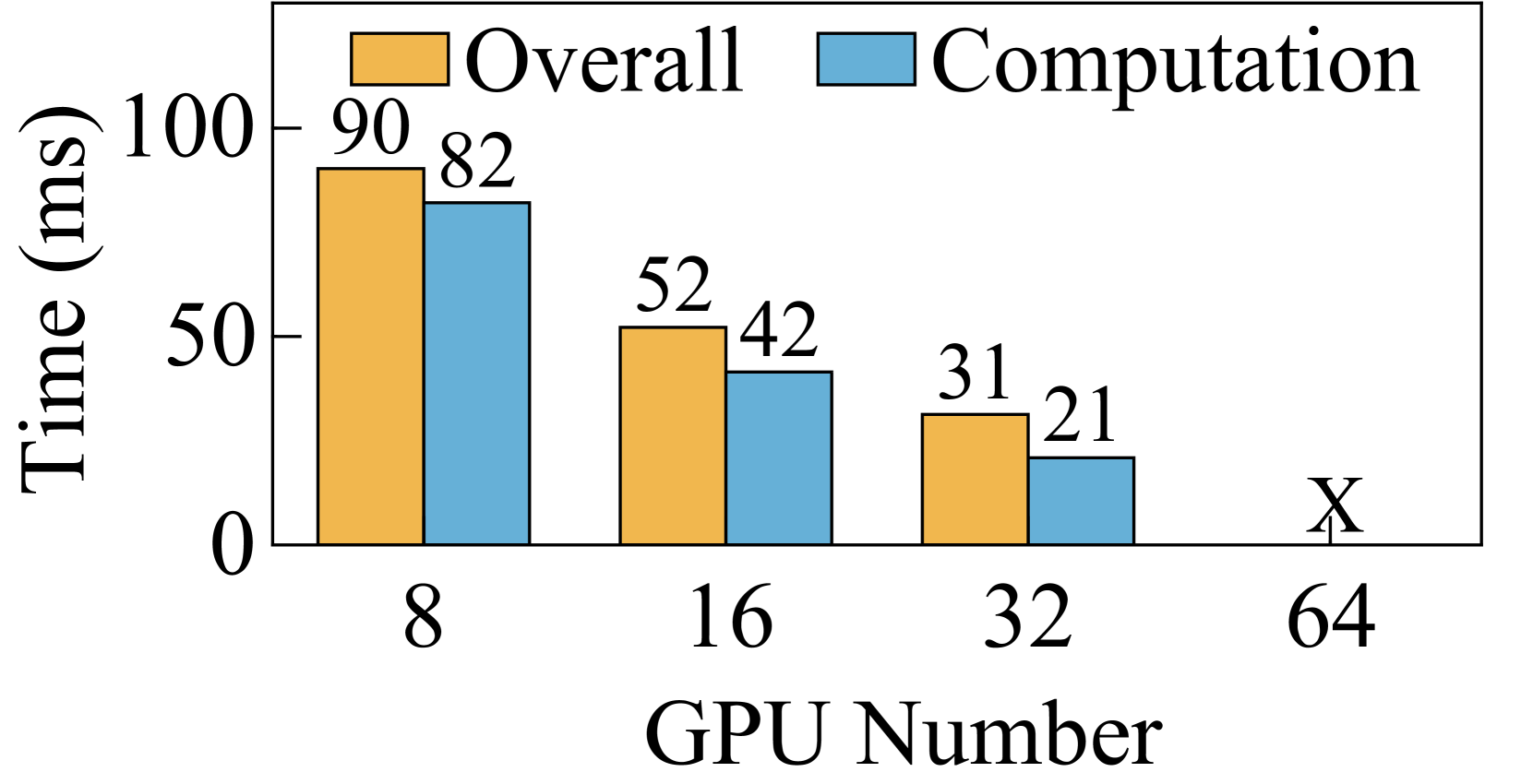
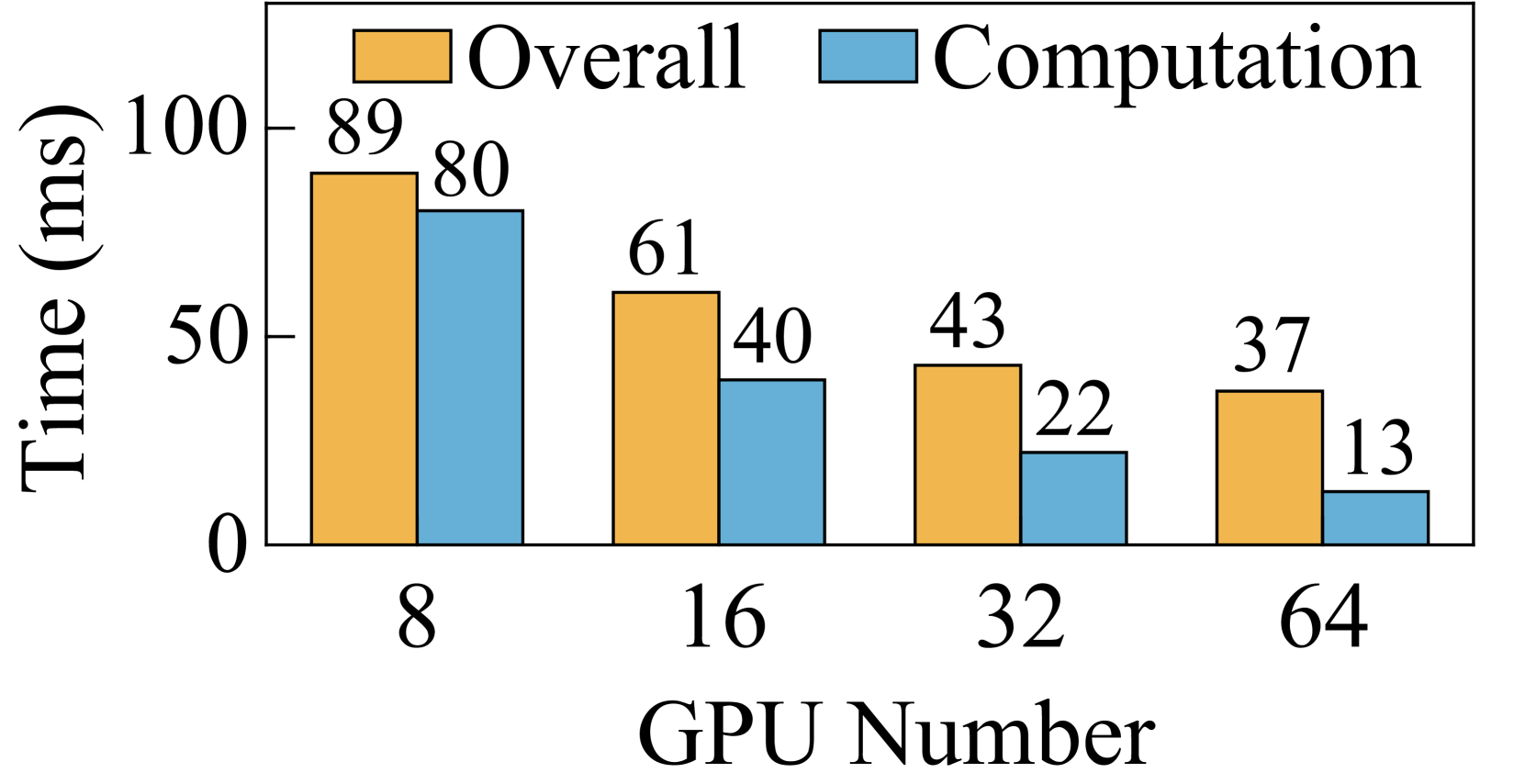
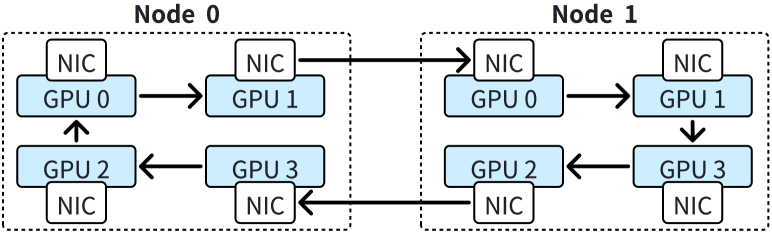
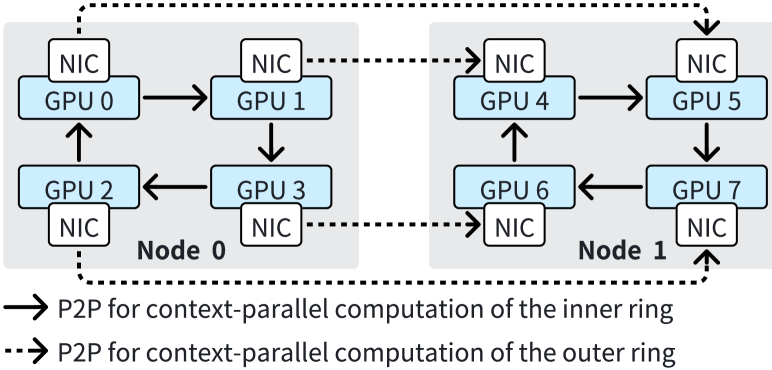
Ring-Attention 的性能低下主要源于三个因素。 首先,由于通信规模较小,通过 NVLINK 的节点内通信对通信延迟而不是带宽更敏感。 在 8 个 GPU 上运行序列长度为 128K 的 GQA 时,每步的通信量为 64MB。 这个大小并没有充分利用NVLINK的高带宽,导致无法与计算重叠的高通信延迟。 其次,当缩放 Ring-Attention 时,每步的计算时间呈二次方减少,而每步的通信量仅线性减少。 这种扩展加剧了计算和通信之间的不平衡,使通信成为性能瓶颈。 第三,Ring-Attention由于其基于环的通信设计,没有充分利用网络资源。 尽管多轨网络在 GPU 集群中广泛使用(railonly,;railarch,),Ring-Attention 使用一个 NIC 来发送 KV 块,另一块 NIC 来接收 KV 块,如图 6。 因此,在一个步骤中,所有其他等级必须使用节点间 P2P 通信等待最慢的等级。 因此,当大规模扩展 Ring-Attention 时,很难将通信与计算重叠。
4. 分布式2D注意力
我们引入LoongTrain来解决训练长序列大语言模型的可扩展性和效率挑战。 特别是,我们提出了 2D-Attention,它通过混合策略集成了头部并行和上下文并行注意力,充分利用了两种方法的优点。 这种方法通过结合上下文并行注意力自然地克服了头部并行注意力的可扩展性限制。 为了进一步减少注意力块中的通信开销,我们设计了双环注意力机制并公开了设备放置的影响。 此外,我们还简要分析了 2D-Attention 的性能。
4.1. 2D-注意力概述
在LoongTrain中,注意力在两个维度上并行:头部并行(HP)和上下文并行(CP),称为2D-Attention。 它将 GPU组织成网格,形成大小为和 HP的CP进程组大小为 的进程组。 因此,我们有
算法1和图7说明了2D-Attention的前向传播。 在图7的配置中,每个CP进程组包含四个GPU。 输入张量 Q(查询)、K(键)和 V(值)沿序列维度划分,每个段的形状为 。 2D-Attention 处理跨 CP 组的头并行性,而上下文并行性在每个 CP 组内执行。
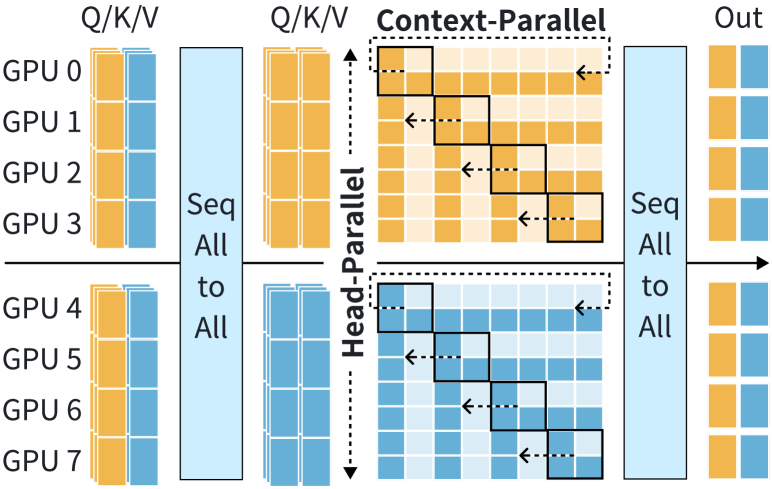
2D-Attention 中 MHA 的计算涉及三个步骤。 SeqAlltoAll 通信操作根据头维度将 QKV 张量分布在 个 GPU 上,并在 个 GPU 上沿着序列维度重新分区,从而将QKV 的形状为 。 此步骤确保每个 CP 组接收到带有 个注意力头的 QKV 的整个序列,如图 7 所示。 每个 CP 组独立执行双环注意力,如 4.3 节中详述,产生形状为 的输出张量。 在此阶段,每个 GPU 使用本地 QKV 计算注意力,并通过 P2P 通信交换分区的 KV 块,通过 NVLINK 或网络传输 元素。 最后,另一个 SeqAlltoAll 整合头部维度上的注意力输出,并重新划分序列维度,将输出张量转换为 。
在向后传递中,SeqAlltoAll 将注意力输出的梯度从形状 转换为 。 随后,每个 CP 进程组通过迭代发送和接收分区的 KV 块及其梯度来参与梯度的上下文并行计算。 最后,使用另一个SeqAlltoAll通信操作将QKV的梯度转换回。
4.2. GQA 的 KV 复制
在MHA计算中,最多可以设置为。然而,当直接计算GQA时,受到KV头数量的限制。 从开始,这个约束限制了2D-Attention中二维并行策略的搜索空间,可能会阻碍最佳性能。
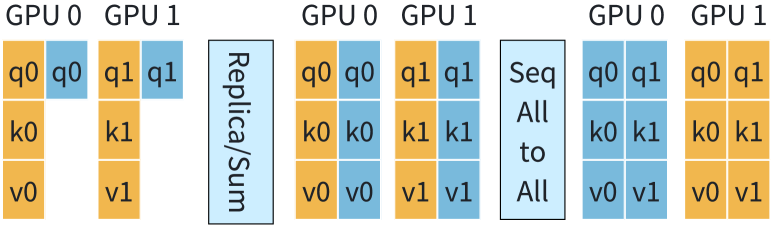
4.3. 双环注意
如果 CP 组是节点间的,如果我们直接使用 Ring-Attention 进行 CP 计算,2D-Attention 可能会产生较高的通信开销。 正如3.2节中所讨论的,由于其基于环的通信设计,Ring-Attention并没有充分利用网络资源。
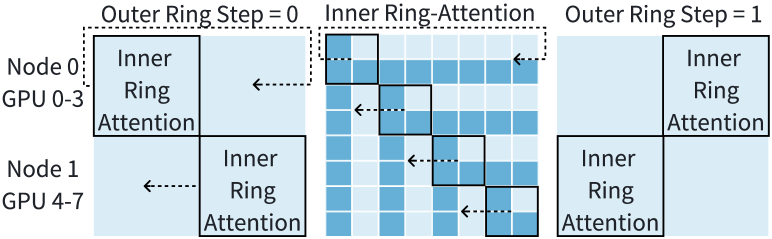
为了充分利用可用的 NIC 进行节点间通信,我们提出了 Double-Ring-Attention,它将 GPU 划分为多个内环。 如图9和算法2所示,每个CP组内的GPU形成多个内环,而内环共同形成一个外环。 假设每个内环由 个 GPU 组成,则 CP 进程组将具有 个并发内环。 让 表示第 内环中的第 个 GPU。 最初,每个内环执行传统的环注意,其中涉及 微步。 在每个微步中,GPU 使用本地 QKV 执行注意力计算,同时发送和接收后续微步所需的 KV 块。 一旦所有内环内的计算完成,外环就前进到下一步,并为每个内环启动新一轮的Ring-Attention。 总共有个外环台阶。 在新的外环步骤中,每个内环内的 GPU 使用从相邻外环的 GPU 获取的新 KV 块作为初始值。 此 P2P 通信可以与计算重叠: 将其初始 KV 块发送到 ,并同时从 接收 KV 块同时计算当前内环。
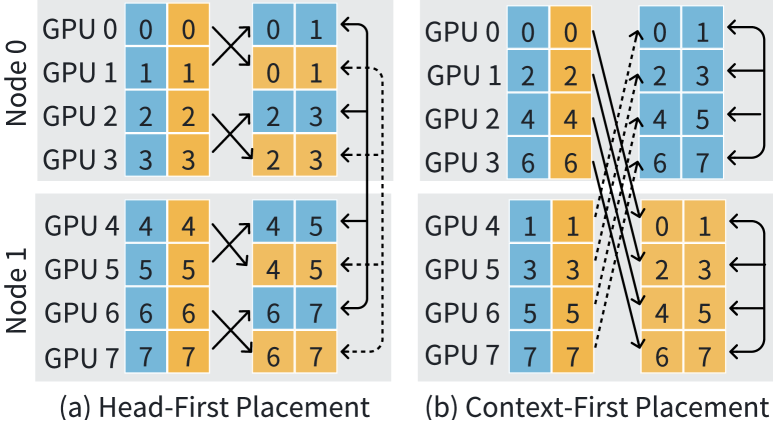
4.4. 头部优先和上下文优先的设备放置
给定和,有两种设备分配策略:头优先放置和上下文优先放置。 由于 GPU 集群中节点间和节点内带宽的差异,选择合适的放置策略至关重要。 例如,DGX-A100节点通过NVLINK提供每个GPU 600 GB/s的节点内双向带宽,而每个节点的节点间双向带宽仅为400 GB/s。 设备放置的选择直接影响 2D-Attention 中两种类型操作的节点间和节点内通信的分布:SeqAlltoAll 和 P2P。 图11显示了头部优先和上下文优先放置的示例。
在头优先放置中,同一 HP 组的 GPU 在同一节点上托管时具有较高优先级。 如图11(a)所示,GPU 0和1被分配到相同的HP组,但分配到不同的CP组。 此配置可以有效地利用 NVLINK 进行 SeqAlltoAll,因为它只需要 HP 进程组内的标准 NCCL AlltoAll。 然而,头优先放置会导致 Double-Ring-Attention 期间更高的节点间流量,因为同一 CP 组内的 GPU 更有可能分布在不同节点上,从而增加了节点间流量。
在上下文优先放置中,同一 CP 组的 GPU 优先在同一节点上共置。 如图11(b)所示,GPU 0-3被分配到同一个CP组。 因此,在此示例中,Double-Ring-Attention 仅生成节点内流量,从而显着减少每个 P2P 操作的通信延迟。 然而,当、P2P时,需要节点间互连。 幸运的是,4.3节中提出的双环方法利用多个NIC来保持高效率。 在 HP 组内维护标准 NCCL AlltoAll 的使用需要跨节点重新排序输入 QKV 张量,这会增加每个 Transformer 层的网络流量。 为了缓解这个问题,我们采用了 Megatron-LM 中使用的方法,在数据加载器中实现后处理功能,以在每个批次开始时调整输入张量的放置。 这消除了 QKV 张量的动态数据移动的需要。 即使进行了这种优化,SeqAlltoAll 仍然需要大量的节点间通信流量。
4.5. 绩效分析
4.5.1. 可扩展性分析
2D-Attention 通过混合策略集成头部并行性和上下文并行性,增强了长序列训练的可扩展性。 它通过结合上下文并行注意力,在组织为 的 GPU 网格上分配计算,克服了头部并行的限制。 这允许序列并行性扩展到无限数量的 GPU。 此外,在 GQA 的情况下,2D-Attention 可以使用 KV 复制将 扩展到 ,确保灵活的处理和较大的搜索空间以获得最佳性能。
4.5.2. 计算分析。
给定一个序列,注意力的计算复杂度为。 计算时间可以表示为,其中表示前向计算时间的比例常数。 在2D-Attention中,内环内每个微步的前向计算时间被描述为 自以来,我们有:
内环有个微步,外环有个微步。 总的前向计算时间可以表示为: 对于向后传递,每个微步的计算时间描述为:
这是因为后向计算内核自然需要额外的计算,例如 FlashAttention (flashattn1, ) 中的激活重新计算和梯度计算。
4.5.3. P2P 通信分析。
KV 块的形状定义为:,其中 MHA 中的 ,并且如果 ,则复制 KV 张量以匹配头部并行度大小。 KV chunk的大小可以计算如下:
其中因子 4 表示数据类型为 FP16 的两个张量。 使用 Double-Ring-Attention 时,给定内环大小 ,每个 GPU 都会为内环启动 P2P 通信和一个 P2P 前向阶段每个外环步骤(最后一个步骤除外)的通信。 每个P2P通信的通信大小相当于。 GPU同时发起内环和外环的P2P通信。 由于环形通信方式,每个P2P通信时间取决于最慢的等级。 考虑到通信和计算之间的重叠,每个内环的前向执行时间可以表述如下:
其中 和 定义为:
每个内环的向后执行时间可以用类似的表达式来表示。
每个 P2P 通信时间不受 的影响(假设没有 KV 复制),因为无论 如何, 都保持不变。 然而,当增加时,每微步的计算时间线性减少。 因此,有效地重叠计算和通信变得更具挑战性,并且由于高通信开销,Ring-Attention 在大型集群中表现出较差的性能。 2D-Attention 优于 Ring-Attention,因为它通过限制 提供了更多计算通信重叠的机会。
内圈尺寸的选择。 当选择上下文优先放置时,同一CP组的等级被合并到尽可能少的节点。 在这种情况下,外环有个并发P2P通信。 为了充分利用网络资源, 应与每个节点的 NIC 数量相匹配。 当小于网卡的大小时,我们无法充分利用所有网卡进行P2P。 相反,当大于NIC时,GPU可能会共享相同的NIC进行P2P,从而导致由于拥塞而导致性能变差。
GQA 与 MHA。 在GQA的2D-Attention过程中,每次P2P传输都涉及元素,其中表示KV复制后的KV头的数量。 与 MHA 相比,GQA 在 时需要更少的通信。具体来说,当将2D-Attention应用于GQA时,会导致CP进程组中的通信量只有那么长,因为这种情况下没有应用KV复制。 但是,如果,GQA和MHA将由于KV复制而具有相同的通信量。
4.5.4. SeqAlltoAll 通信分析。
Q chunk 和输出 chunk 的大小可以计算如下:
SeqAlltoAll 在 GPU 上执行 NCCL AlltoAll。 每个GPU在前向和后向阶段发出的数据大小可以表示为:
随着的增大,也随之增大,使得运算更加充实;如果,则不需要SeqAlltoAll,但会增加。 通过头优先放置,更多与 AlltoAll 相关的流量由节点内 NVLINK 承载,对于上下文优先放置反之亦然。
因此,在 和 之间以及在 head-first 和 context-first 放置之间需要进行权衡。 LoongTrain的总体目标是尽量减少不能与计算重叠的通信时间。 该问题可以表述为:
公式中,表示SeqAlltoAll通信时间。 有内环来完成attention的执行。
4.5.5. 记忆分析。
当使用 2D-Attention 时,每个 GPU 应将其输入 QKV 块(在 SeqAlltoAll 之后)保存为激活。 因此,给定固定的序列长度,2D-Attention 还可以通过增加 来减少激活内存的使用。 与Ring-Attention类似,LoongTrain的每个GPU都维护一个的缓冲区,用于内环P2P通信。 但LoongTrain需要另外一个内存缓冲区用于外环P2P通信。 6部分的实验结果表明,这种内存开销很小,并且不妨碍可扩展性。
5. 端到端系统实施
我们使用 Hybrid ZeRO 和 selective checkpoint++ 两种技术在我们的内部框架上描述了 LoongTrain for 训练大语言模型的端到端系统实现。
5.1. 适用于标准和线性模块的混合 ZeRO
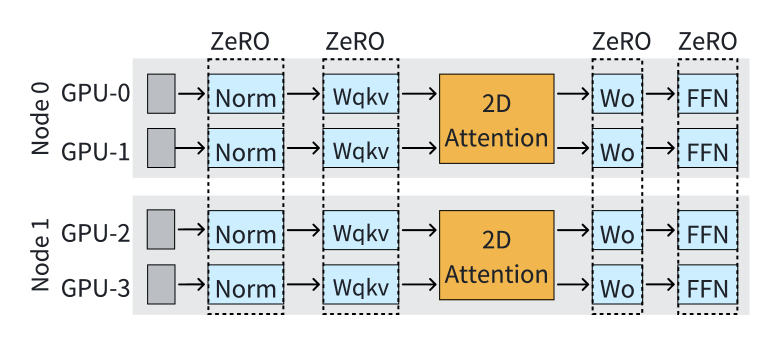
在LoongTrain中,除了attention之外的所有模块(例如Linear、LayerNorm等)都使用零(ZeRO, )。 ZeRO 最初旨在减少 DP 列中的冗余内存使用。 当直接使用ZeRO时,如图12所示,它适用于属于同一DP组的GPU-0和GPU-2,以及GPU-1和GPU-3。 GPU-0 和 GPU-1 将各自保存一半的参数或优化器状态,但这些值保持相同,从而导致冗余内存使用。
LoongTrain 通过在 DP 维度和 SP 维度上应用 ZeRO 来解决这些冗余问题。 这种混合方法在两个维度上对模型状态进行分片,将模型状态分布在更多 GPU 上。 因此,只有 模型状态保留在 GPU 内存中,从而显着减少了冗余内存使用。 这种方法也被用于 DeepSpeed-Ulysses (DeepspeedUlysses, ) 等现有框架中。 然而,集体通信操作的延迟与通信规模(sun2019gradientflow,;MiCS,)呈正相关。 因此,当扩展到数百个GPU时,通信开销变得很大。 在LoongTrain中,我们采用AMSP (amsp, )的方法,引入了三种灵活的分片策略:Full-Replica、Full-Sharding和Partial-Sharding。 这些策略使 Norm 和 Linear 模块能够在 GPU 上选择合适的分片数量,从而有效平衡 GPU 内存使用和通信开销。
| MHA (TGS) | MHA (MFU) | GQA (TGS) | GQA (MFU) | |||||||||||||
| System | 128K | 256K | 512K | 1M | 128K | 256K | 512K | 1M | 128K | 256K | 512K | 1M | 128K | 256K | 512K | 1M |
| DS-Ulysses | 629.9 | 418.3 | 243.1 | 130.6 | 0.305 | 0.341 | 0.359 | 0.365 | 629.9 | 418.3 | 243.1 | 130.6 | 0.305 | 0.341 | 0.359 | 0.365 |
| Megatron-CP | 296.8 | 300.0 | 260.1 | OOM | 0.143 | 0.244 | 0.385 | OOM | 706.2 | 476.3 | 279.6 | OOM | 0.342 | 0.388 | 0.413 | OOM |
| HP1/CP32 | 285.0 | 287.4 | 250.4 | 121.2 | 0.138 | 0.234 | 0.369 | 0.339 | 668.5 | 480.0 | 282.5 | 153.0 | 0.323 | 0.391 | 0.417 | 0.428 |
| HP2/CP16 | 311.1 | 314.9 | 267.3 | 151.6 | 0.151 | 0.256 | 0.394 | 0.423 | 740.8 | 501.3 | 290.1 | 155.9 | 0.359 | 0.408 | 0.428 | 0.436 |
| HP4/CP8 | 548.9 | 469.2 | 283.6 | 154.1 | 0.266 | 0.382 | 0.408 | 0.431 | 814.4 | 517.4 | 295.1 | 159.5 | 0.394 | 0.421 | 0.435 | 0.446 |
| HP8/CP4 | 752.4 | 498.1 | 286.1 | 154.1 | 0.364 | 0.406 | 0.418 | 0.431 | 838.1 | 528.1 | 299.5 | 160.1 | 0.406 | 0.430 | 0.442 | 0.448 |
| HP16/CP2 | 714.3 | 472.4 | 278.9 | 150.9 | 0.346 | 0.385 | 0.412 | 0.422 | 771.4 | 498.6 | 288.0 | 155.1 | 0.373 | 0.406 | 0.425 | 0.433 |
| HP32/CP1 | 700.1 | 459.3 | 268.8 | 146.0 | 0.339 | 0.374 | 0.397 | 0.408 | 717.1 | 468.4 | 262.4 | 147.5 | 0.347 | 0.381 | 0.387 | 0.412 |
5.2. 选择性检查点++
长序列训练会导致大量的内存消耗,使得梯度检查点成为一种常见的做法。 在前向传播期间,梯度检查点机制仅存储 checkpoint 函数所包装函数的输入张量。 如果在反向传播过程中需要删除的激活值,则会重新计算它们。 通常,当我们将 checkpoint 函数包装在整个 Transformer 层周围时,激活 Transformer 层所需的总内存在 FP16 中为 。
虽然保存整个模型的检查点显着减少了内存占用,但它引入了额外的计算开销(flashattn1, )。 鉴于注意力块的重新计算时间特别长,一种简单的方法是保持注意力块的激活,并通过提供的 API (Nvidia3, ) 有选择地对模型的其他部分使用检查点。 然而,该解决方案的内存效率不高。 在反向传播期间,每个注意力块需要额外的内存来保存 QKV 张量(FP16 中的大小 )和 softmax_lse(FP32 中的大小 )(chen2024internevo,)。 为了减少内存使用,DistFlashAttn (lightseq, ) 将注意力模块放置在每个 Transformer 层的末尾。 该策略消除了在后向阶段重新计算注意力模块的需要,只需要存储注意力模块的输出。
LoongTrain在不修改模型结构的情况下实现了选择性检查点++机制。 它将注意力模块添加到白名单中。 在前向传递过程中,当遇到白名单中的模块时,修改后的检查点函数会保存其输出。 具体来说,对于注意力,它保存大小为的注意力输出和大小为的softmax_lse。 在向后传递过程中,当遇到白名单中的模块时,checkpoint函数不会执行重新计算。 相反,它检索存储的输出并继续计算图。 这消除了在向后传递期间重新计算注意力的需要,每个 Transformer 层需要额外的 内存大小。 此外,选择性检查点++与其他卸载技术(ren2021zero, )兼容,这些技术涉及将注意力输出卸载到内存或NVMe存储。
6. 绩效评估
6.1. 实验设置
测试平台。 除非另有说明,我们在具有 8 个 GPU 服务器的集群上进行性能评估。 每台服务器均配备 8 个 NVIDIA Ampere GPU、128 个 CPU 核心、每个 GPU 80GB 内存。 在每个节点内,GPU 通过 NVLINK 互连。 节点间通信由 4 个 NVIDIA Mellanox HDR (200Gb/s) InfiniBand NIC 促进,无需 SHARP。
系统配置。 我们使用 LLaMA2-7B (LLaMA2, ) 的配置来评估 LoongTrain 的训练性能,其中 和 表示 MHA, 用于 GQA。 输入序列长度从 128K 缩放到 1M。 在所有实验中,激活检查点默认启用。 我们分析了 LoongTrain 在不同并行度设置和设备布局下的性能。
评估指标。 我们重点关注关键性能指标,包括模型 FLOP 利用率 (MFU) (palm, ) 和每秒每 GPU 的 Token 数 (TGS)。 我们使用 Megatron-LM (Megatron-LM, ) 中提供的公式来计算 FLOP 和 MFU。 值得注意的是,在这项工作中,注意力的 FLOP 减少了一半,以考虑因果掩码,这将注意力中需要计算的元素数量减少了大约一半。 这与其他作品中使用的 FLOP 和 MFU 计算不同(chen2024internevo, ; flashattn1, ; dao2023flashattention, ),但很重要,因为注意力在长序列训练中占据了大部分工作量。 如果不进行此调整,MFU 可能会超过 1,从而歪曲实际的系统性能。
基线。 我们将 LoongTrain 与两个长序列训练框架的性能进行比较:DeepSpeed-Ulysses (DS-Ulysses) (DeepspeedUlysses, ) 和 Megatron Context Parallelism (Megatron-CP) (megatroncp, ). DS-Ulysses 采用 head-parallel Attention,而 Megatron-CP 采用带有负载平衡的 Ring-Attention。 所有基线系统均与 FlashAttention-V2 (dao2023flashattention, ) 集成。 使用的版本如下: 1)DS-Ulysses:DeepSpeed V0.14.0; 2) Megatron-CP:Nemo v2.0.0rc0、NemoLauncher v24.05、Megatron-Core v0.7.0、TransformerEngine v1.6、Apex 提交 ID 810ffa。
| 128K | 256K | 512K | 1M | |||||||||||||||
| With SC++ | W/O SC++ | With SC++ | W/O SC++ | With SC++ | W/O SC++ | With SC++ | W/O SC++ | |||||||||||
| HF | CF | HF | CF | HF | CF | HF | CF | HF | CF | HF | CF | HF | CF | HF | CF | |||
| MHA | 64 | 1 | 0.092 | 0.092 | 0.070 | 0.070 | 0.159 | 0.159 | 0.122 | 0.122 | 0.290 | 0.290 | 0.221 | 0.221 | 0.452 | 0.452 | 0.357 | 0.357 |
| 32 | 2 | 0.099 | 0.158 | 0.077 | 0.126 | 0.173 | 0.278 | 0.133 | 0.219 | 0.316 | 0.434 | 0.243 | 0.353 | 0.475 | 0.486 | 0.394 | 0.406 | |
| 16 | 4 | 0.176 | 0.245 | 0.141 | 0.205 | 0.314 | 0.378 | 0.248 | 0.317 | 0.470 | 0.472 | 0.384 | 0.388 | 0.520 | 0.509 | 0.418 | 0.413 | |
| 8 | 8 | 0.283 | 0.321 | 0.236 | 0.282 | 0.434 | 0.420 | 0.361 | 0.357 | 0.502 | 0.478 | 0.409 | 0.394 | 0.527 | 0.521 | 0.424 | 0.420 | |
| 4 | 16 | 0.328 | 0.327 | 0.289 | 0.283 | 0.436 | 0.423 | 0.369 | 0.359 | 0.487 | 0.476 | 0.399 | 0.394 | 0.519 | 0.520 | 0.418 | 0.412 | |
| 2 | 32 | 0.320 | 0.329 | 0.284 | 0.293 | 0.421 | 0.421 | 0.353 | 0.357 | 0.474 | 0.478 | 0.388 | 0.394 | 0.517 | 0.517 | 0.415 | 0.406 | |
| GQA | 64 | 1 | 0.255 | 0.255 | 0.196 | 0.196 | 0.379 | 0.379 | 0.308 | 0.308 | 0.470 | 0.470 | 0.378 | 0.378 | 0.508 | 0.508 | 0.406 | 0.406 |
| 32 | 2 | 0.283 | 0.317 | 0.233 | 0.269 | 0.419 | 0.429 | 0.345 | 0.354 | 0.492 | 0.485 | 0.398 | 0.392 | 0.521 | 0.516 | 0.418 | 0.416 | |
| 16 | 4 | 0.354 | 0.338 | 0.309 | 0.294 | 0.466 | 0.437 | 0.385 | 0.373 | 0.505 | 0.494 | 0.410 | 0.404 | 0.531 | 0.526 | 0.425 | 0.426 | |
| 8 | 8 | 0.377 | 0.354 | 0.327 | 0.310 | 0.480 | 0.452 | 0.392 | 0.380 | 0.516 | 0.502 | 0.419 | 0.412 | 0.543 | 0.536 | 0.435 | 0.432 | |
| 4 | 16 | 0.354 | 0.341 | 0.310 | 0.308 | 0.457 | 0.437 | 0.377 | 0.373 | 0.500 | 0.493 | 0.409 | 0.405 | 0.532 | 0.529 | 0.428 | 0.419 | |
| 2 | 32 | 0.323 | 0.333 | 0.285 | 0.295 | 0.424 | 0.422 | 0.349 | 0.360 | 0.476 | 0.481 | 0.389 | 0.394 | 0.518 | 0.518 | 0.415 | 0.406 | |
6.2. 与 DS-Ulysses 和 Megatron-CP 的比较
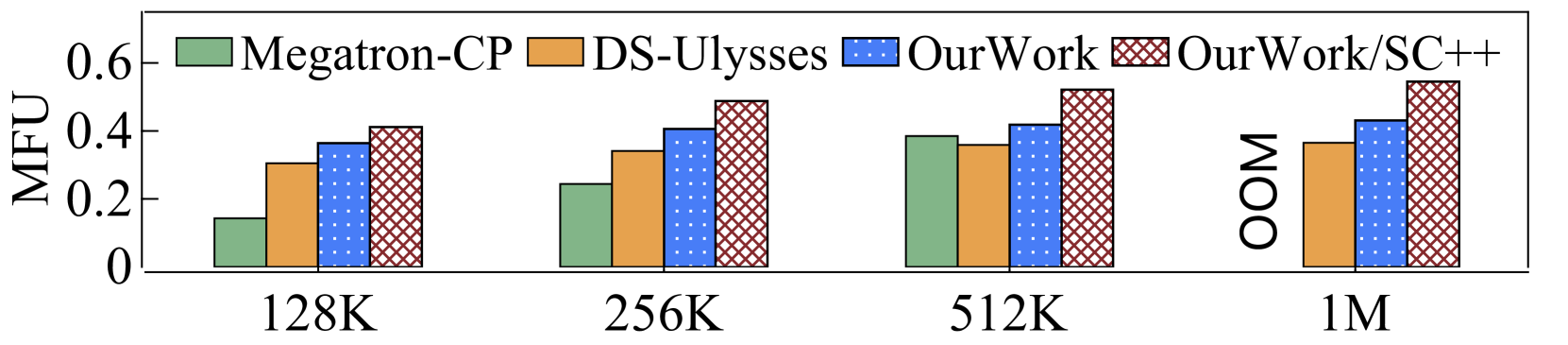
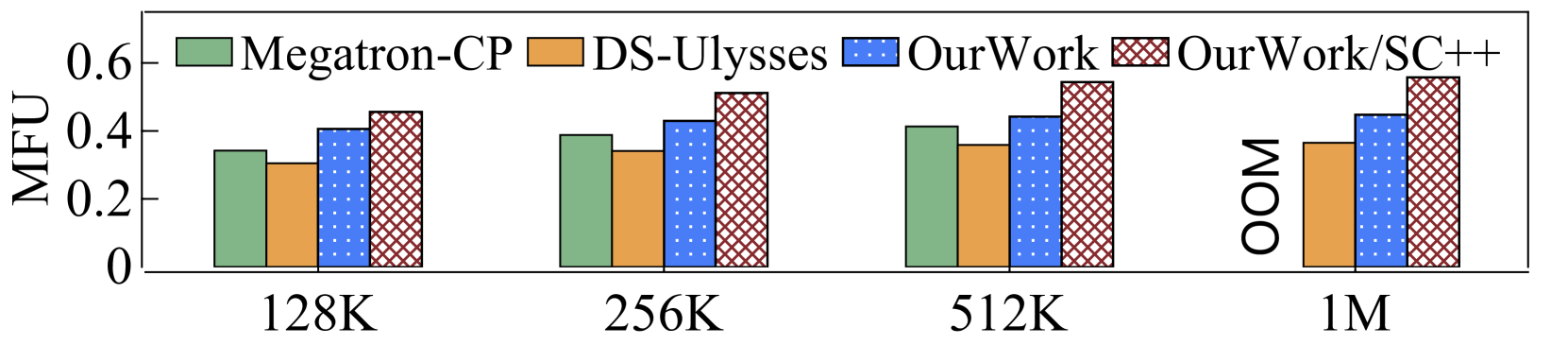
理论上,时的2D-Attention相当于DS-Ulysses,时的2D-Attention相当于Megatron-CP。 为了验证我们的 LoongTrain 实现与理论分析一致,我们使用 LoongTrain、DS-Ulysses 和 Megatron-CP 在 32 个 GPU 上使用不同的序列长度测量了 7B-MHA 和 7B-GQA 时的 TGS 和 MFU。 比较仅限于 32 个 GPU,因为 DS-Ulysses 仅支持头并行性,而这受到注意力头数量的限制。 为了确保公平比较,所有系统都在 32 个 GPU 上的 Norm 和 Linear 模块上应用了 ZeRO-1,并且没有使用Selective Checkpoint++。 结果如表2所示。
当时,LoongTrain优于DS-Ulysses,因为其在Norm和Linear模块的后向阶段通信和计算之间具有优越的重叠能力。 当时,LoongTrain在MHA中表现出略低于Megatron-CP的性能,但在GQA中表现出较高的性能。 我们的分析表明两个系统在注意力计算方面表现相似。 主要的性能差异源于计算和通信运营商的不同选择。 值得注意的是,在处理 1M 序列长度时,Megatron-CP 由于参数和梯度的预分配 GPU 内存需求增加而遇到内存不足错误。
对于128K和256K的序列长度,Megatron-CP在MHA中表现不佳,因为P2P通信无法与计算有效重叠。 然而,在序列长度为 512K 和 1M 的情况下,Megatron-CP 和 LoongTrain-HP1/CP32 都比 DS-Ulysses 对于 MHA 表现出更好的性能。 此外,在 GQA 中,每微步的通信量减少了 4 倍。 因此,Megatron-CP 和 LoongTrain-HP1/CP32 在 GQA 的所有评估序列长度上始终优于 DS-Ulysses。
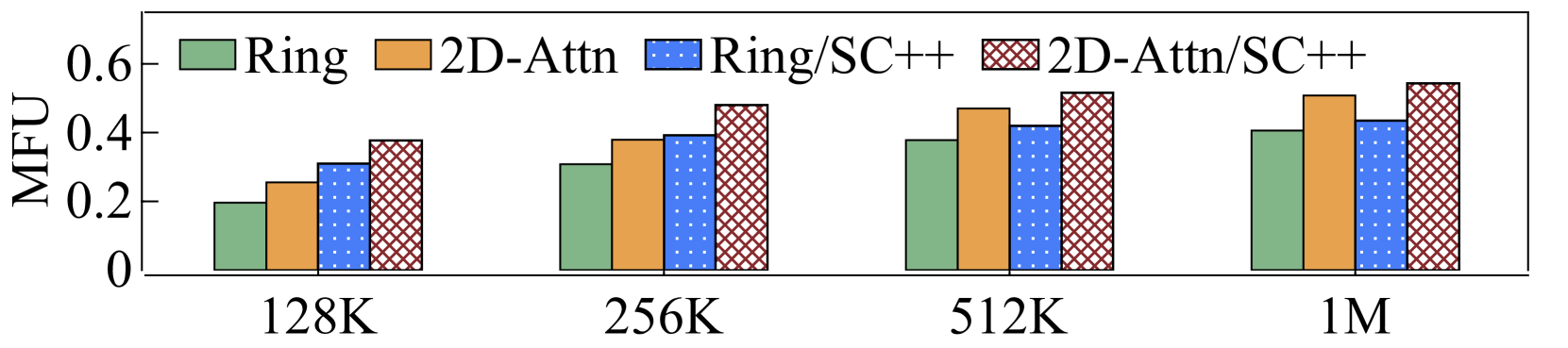
然后,我们比较完整 LoongTrain 和基线的端到端性能。 使用了混合 ZeRO 和 Selective Checkpoint++ 等所有技术。 如图13所示,LoongTrain具有更大的MFU。 本实验中和的配置效率更高。 与DS-Ulysses相比,LoongTrain将MHA和GQA的训练性能分别提高了和。 与Megatron-CP相比,LoongTrain将MHA和GQA的性能分别提升了和。
6.3. LoongTrain性能分析
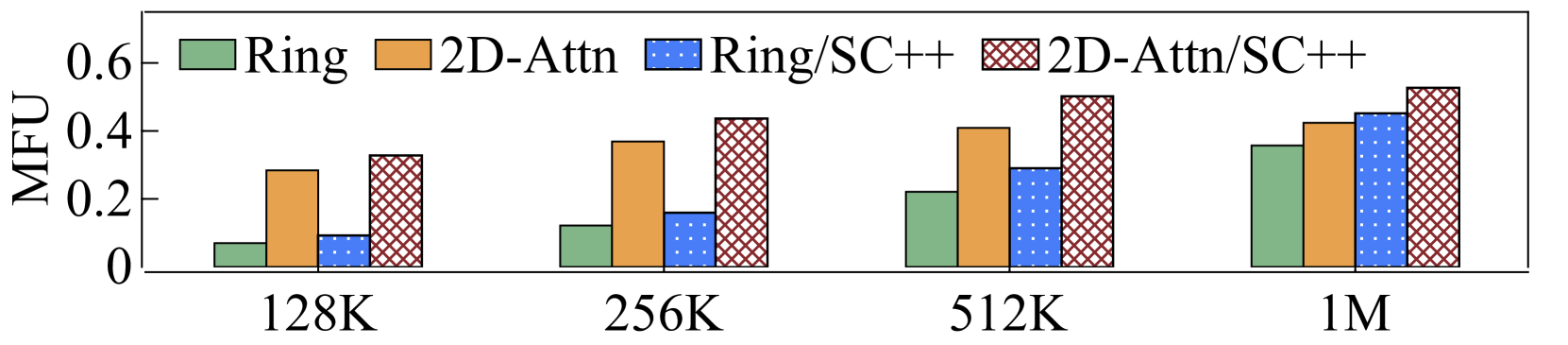
为了分析每种设计可以带来多少性能提升,我们评估了 LoongTrain 在具有不同序列长度和配置的 64 个 GPU 上训练 7B-MHA 和 7B-GQA 模型的性能。 评价结果如表3所示。 我们不显示 的结果,因为 不能超过注意力头的数量,即 32。 端到端评估表明,LoongTrain的设计(例如2D-Attention)和实现技术(例如Selective Checkpoint++)显着提高了所有情况下的训练性能。 图14显示了端到端MFU结果,详细信息列于表3中。
| MHA (Head-First) | MHA (Context-First) | GQA (Head-First) | GQA (Context-First) | |||||||||||||||
| 128K | 256K | 512K | 1M | 128K | 256K | 512K | 1M | 128K | 256K | 512K | 1M | 128K | 256K | 512K | 1M | |||
| Overall | 64 | 1 | 296.4 | 597.8 | 1210 | 2897 | 296.4 | 597.8 | 1210 | 2897 | 86.0 | 225.1 | 713.5 | 2681 | 86.0 | 225.1 | 713.5 | 2681 |
| 32 | 2 | 273.6 | 546.8 | 1106 | 2745 | 162.4 | 328.7 | 782.5 | 2663 | 75.4 | 198.5 | 679.5 | 2607 | 64.9 | 187.1 | 683.5 | 2589 | |
| 16 | 4 | 137.0 | 275.8 | 708.1 | 2595 | 87.4 | 213.8 | 691.5 | 2617 | 55.4 | 172.1 | 659.4 | 2559 | 59.9 | 179.1 | 668.3 | 2543 | |
| 8 | 8 | 72.2 | 187.9 | 658.3 | 2557 | 62.2 | 185.6 | 675.3 | 2539 | 52.1 | 166.2 | 644.1 | 2494 | 56.8 | 175.2 | 656.1 | 2495 | |
| 4 | 16 | 58.4 | 179.8 | 671.9 | 2575 | 60.1 | 182.6 | 680.6 | 2549 | 55.8 | 173.6 | 659.6 | 2530 | 57.3 | 177.2 | 661.7 | 2510 | |
| 2 | 32 | 60.8 | 186.0 | 684.9 | 2573 | 59.4 | 183.0 | 677.1 | 2553 | 60.8 | 185.8 | 683.9 | 2579 | 59.3 | 183.1 | 677.5 | 2555 | |
| SeqAlltoAll | 64 | 1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 32 | 2 | 2.23 | 3.20 | 5.49 | 10.00 | 7.19 | 13.27 | 25.10 | 49.26 | 1.89 | 2.51 | 3.92 | 6.58 | 4.92 | 8.65 | 16.29 | 31.59 | |
| 16 | 4 | 2.45 | 3.52 | 5.80 | 10.53 | 10.31 | 19.25 | 37.37 | 73.74 | 2.15 | 2.76 | 4.08 | 6.76 | 6.90 | 12.55 | 23.82 | 46.87 | |
| 8 | 8 | 3.00 | 4.15 | 6.27 | 11.22 | 12.05 | 22.26 | 42.82 | 83.30 | 2.64 | 3.24 | 4.43 | 7.31 | 8.13 | 14.60 | 27.51 | 53.35 | |
| 4 | 16 | 9.11 | 15.99 | 29.02 | 55.38 | 12.95 | 23.97 | 45.52 | 90.28 | 7.23 | 12.85 | 22.56 | 42.44 | 10.12 | 18.91 | 34.94 | 71.51 | |
| 2 | 32 | 13.42 | 23.43 | 42.73 | 81.47 | 14.56 | 25.41 | 48.25 | 100.0 | 13.40 | 23.35 | 42.85 | 81.76 | 14.31 | 25.75 | 48.43 | 106.8 | |
当时,LoongTrain表现出与MHA的Ring-Attention类似的较差性能:序列长度为128K时,MFU小于10%。 当序列长度增加到1M时,计算量增大,在没有Selective Checkpoint++的情况下,MFU仅为35.7%。 对于 GQA,与 MHA 相比,Ring-Attention 涉及更少的通信量,从而导致比 MHA 更高的 MFU。 具体来说,在Ring-Attention中,当序列长度为128K时,MFU达到19.6%,当序列长度为1M时,MFU增加到40.6%。
通过 2D-Attention,LoongTrain 显着提高了 MHA 的训练性能。 与 Ring-Attention 相比,2D-Attention 将 MFU 提高了 4.1、3.0、1.8 和 1.2序列长度分别为128K、256K、512K和1M。 通过 Selective Checkpoint++,LoongTrain 的训练性能进一步提升 1.15、1.18、1.22 和 1.24序列长度。 因此,图14(a)显示LoongTrain的整体训练性能提高了5.2、3.6、2.3、和 1.5 分别。 此外,我们观察到,为了实现更高的 MHA 训练性能,LoongTrain 倾向于对 128K 和 256K 的序列长度使用更高的头并行度大小。 对于512K和1M的序列长度,LoongTrain倾向于使用平衡的头部和上下文并行度大小。
2D-Attention 对于 GQA 也很有效。 与Ring-Attention的性能相比,LoongTrain对128K、256K、512K、1M序列的MFU分别提升了1.58、1.27、1.11 和 1.07 分别。 结合 Selective Checkpoint++,LoongTrain 的性能进一步提升 1.21、1.22、1.23 和 1.25序列长度。 因此,图14(b)显示整体训练性能提高了1.9、1.5、1.3、和 1.3 分别。 对于 GQA,平衡的头和上下文并行度大小是更有效的配置。
6.4. 2D-Attention 分析
我们通过测量各种配置下单个 2D-Attention 前向操作的平均总体执行时间和 SeqAlltoAll 通信时间来评估 2D-Attention。 结果如表4所示。
| MHA (CP=64, HP=1) | MHA (CP=16, HP=4) | GQA (CP=64, HP=1) | GQA (CP=16, HP=4) | |||||||||||||
| Inner Ring Size | 128K | 256K | 512K | 1M | 128K | 256K | 512K | 1M | 128K | 256K | 512K | 1M | 128K | 256K | 512K | 1M |
| 1 | 295.9 | 597.7 | 1214 | 2913 | 86.3 | 213.8 | 697.9 | 2621 | 94.2 | 226.7 | 713.5 | 2668 | 60.7 | 180.6 | 673.3 | 2567 |
| 2 | 184.5 | 401.3 | 917.1 | 2823 | 72.6 | 205.7 | 710.7 | 2611 | 83.2 | 218.9 | 730.5 | 2650 | 60.8 | 182.6 | 671.2 | 2530 |
| 4 | 140.6 | 316.3 | 842.7 | 2754 | 69.1 | 199.4 | 704.4 | 2610 | 78.4 | 210.3 | 719.7 | 2669 | 60.3 | 182.0 | 675.2 | 2535 |
| 8 | 214.9 | 415.1 | 869.9 | 2815 | 77.4 | 198.7 | 705.3 | 2621 | 83.4 | 211.6 | 723.1 | 2674 | 61.0 | 183.1 | 677.4 | 2537 |
序列长度研究。 正如4.5节中所讨论的,在固定的序列并行度下,较长的序列长度为计算通信重叠提供了更多的机会。 当 和序列长度从 128K 增加到 1M 时,尽管计算工作量增加了 ,但 MHA 的总体关注时间只增加了 ,从 296.4ms 增加到 2897ms。 在此配置中,没有SeqAlltoAll操作,表明主要性能瓶颈在于P2P操作。 在 GQA 的情况下,整体注意力时间从 86.0ms 增加到 2681ms。 在所有序列长度上,由于通信量减少,GQA 与 MHA 相比执行时间更短。
MHA 研究。 在表4中最合适的配置下,MHA的执行时间可以显着减少。 具体来说,对于128K序列长度,当LoongTrain将头并行度增加到16时,执行时间从296.4ms减少到58.4ms。 当处理1M长度的序列时,当LoongTrain将头部并行度提高到8时,整体执行时间从2681ms减少到2555ms。 如4.5节所述,每次P2P操作的通信量不受的影响(只要保持不变) ),但每微步的计算时间随着 的增加而线性增加。 因此,LoongTrain可以通过增加来更有效地将P2P通信与计算重叠,即使这样的配置引入了更多的SeqAlltoAll通信时间。
GQA 研究。 与 MHA 相比,GQA 引入的通信量较少,并且对 的敏感度较低。 例如,使用 处理 128K 序列,每个 GQA 操作的执行时间为 86.0ms,比 MHA 短 3.4。 LoongTrain通过增加进一步减少GQA执行时间,从而增强P2P通信与计算重叠的能力。 通过将增加到8,LoongTrain将128K序列长度的GQA执行时间从86.0ms减少到56.8ms,将1M序列长度的GQA执行时间从2681ms减少到2495ms。 然而,将 增加到超过 8 并不会进一步减少 GQA 执行时间,因为 SeqAlltoAll 通信时间显着增加。 例如,当从8增加到32时,处理头先放置的128K序列的SeqAlltoAll通信时间从2.64ms增加到13.40ms。 综上所述,为了高效处理 GQA, 和 的配置避免了较大的 SeqAlltoAll 开销,并有效地与 P2PP2P 计算重叠。 t3> 沟通。
设备布局研究。 正如4.5节中分析的那样,在选择放置策略时,需要在SeqAlltoAll时间和总执行时间之间进行权衡。 表 4 显示,当 很大时(例如 ),单个 Attention 操作可以从上下文优先放置中受益。 虽然上下文优先策略增加了SeqAlltoAll时间,但由于减少了P2P通信时间,总体时间更具优势。 然而,随着 变大,头部优先的放置效果会更好。 在这些情况下,增加的大型 SeqAlltoAll 卷成为整体执行时间的瓶颈。 因此,只有SeqAlltoAll利用节点内高带宽NVLINK,LoongTrain才能获得更好的整体性能。
双环注意力研究。 我们在表5中比较了不同内环尺寸的2D-Attention的执行时间。 正如预期的那样,使用 MHA 和较短的序列长度,P2P 通信无法与计算有效重叠。 在这些情况下,双环注意力机制可以实现更高的加速。 例如,当序列长度为 128K 且 时,即使已经应用了 2D-Attention,Double-Ring-Attention 也会进一步将注意力操作时间减少 1.2 倍。 然而,随着序列长度的增加,由于计算工作量的增加,P2P通信可能会重叠更多,限制了双环注意力机制的改进。
7. 结论
我们提出了LoongTrain,一种高效的长序列大语言模型训练框架。 我们设计了 2D-Attention,结合了头部并行和上下文并行方法,在保持高效率的同时打破了可扩展性限制。 我们引入了双环注意力和设备放置策略来进一步提高训练效率。 我们通过混合并行和先进的梯度检查点技术实现了 LoongTrain 系统。 实验结果表明,与 DeepSpeed-Ulysses 和 Megatron CP 等现有系统相比,LoongTrain 提供了显着的性能提升。
8. 致谢
我们对腾讯的朱紫琳表示感谢。 我们的研究受益于他的 GitHub 存储库“ring-flash-attention”,该存储库使用 FlashAttention 实现了 Ring-Attention。 此外,我们感谢来自腾讯的 Jiarui Fang 和 Shangchun Zhu 在集成 Ulysses 和 Ring-Attention 方面所做的开创性工作,正如开源项目 Yunchang (fang2024unified, ) 中所展示的那样。 他们的指导对于完成这项工作发挥了重要作用。 我们还要感谢清华大学的杨浩宇和翟继东为提高我们的实施绩效提供的帮助。
参考
- [1] AI@Meta. Llama 3 model card. 2024.
- [2] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023.
- [3] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6836–6846, 2021.
- [4] Sanjith Athlur, Nitika Saran, Muthian Sivathanu, Ramachandran Ramjee, and Nipun Kwatra. Varuna: scalable, low-cost training of massive deep learning models. In Proceedings of 17th European Conference on Computer Systems, EuroSys 2022, pages 472–487, 2022.
- [5] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- [6] Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Accurate medium-range global weather forecasting with 3d neural networks. Nature, 619(7970):533–538, 2023.
- [7] William Brandon, Aniruddha Nrusimha, Kevin Qian, Zachary Ankner, Tian Jin, Zhiye Song, and Jonathan Ragan-Kelley. Striped attention: Faster ring attention for causal transformers. arXiv preprint arXiv:2311.09431, 2023.
- [8] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [9] Abel Chandra, Laura Tünnermann, Tommy Löfstedt, and Regina Gratz. Transformer-based deep learning for predicting protein properties in the life sciences. Elife, 12:e82819, 2023.
- [10] Qiaoling Chen, Diandian Gu, Guoteng Wang, Xun Chen, YingTong Xiong, Ting Huang, Qinghao Hu, Xin Jin, Yonggang Wen, Tianwei Zhang, et al. Internevo: Efficient long-sequence large language model training via hybrid parallelism and redundant sharding. arXiv preprint arXiv:2401.09149, 2024.
- [11] Qiaoling Chen, Qinghao Hu, Guoteng Wang, Yingtong Xiong, Ting Huang, Xun Chen, Yang Gao, Hang Yan, Yonggang Wen, Tianwei Zhang, and Peng Sun. Amsp: Reducing communication overhead of zero for efficient llm training, 2023.
- [12] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- [13] Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691, 2023.
- [14] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- [15] Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao, Marc’Aurelio Ranzato, Andrew W. Senior, Paul A. Tucker, Ke Yang, and Andrew Y. Ng. Large scale distributed deep networks. In Proceedings of 26th Annual Conference on Neural Information Processing Systems, NeurIPS 2012., pages 1232–1240, 2012.
- [16] Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, and Furu Wei. Longnet: Scaling transformers to 1,000,000,000 tokens. arXiv preprint arXiv:2307.02486, 2023.
- [17] Jiarui Fang and Shangchun Zhao. A unified sequence parallelism approach for long context generative ai. arXiv preprint arXiv:2405.07719, 2024.
- [18] Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Seshadri, Nikhil Devanur, Greg Ganger, and Phil Gibbons. Pipedream: Fast and efficient pipeline parallel dnn training, 2018. URL https://arxiv. org/abs, 1806.
- [19] Qinghao Hu, Zhisheng Ye, Zerui Wang, Guoteng Wang, Meng Zhang, Qiaoling Chen, Peng Sun, Dahua Lin, Xiaolin Wang, Yingwei Luo, et al. Characterization of large language model development in the datacenter. In USENIX Symposium on Networked Systems Design and Implementation (NSDI’24), 2024.
- [20] Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. volume 32, 2019.
- [21] Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models. arXiv preprint arXiv:2309.14509, 2023.
- [22] Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. Reducing activation recomputation in large transformer models. Proceedings of Machine Learning and Systems, 5, 2023.
- [23] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Proceedings of 26th Annual Conference on Neural Information Processing Systems, NeurIPS 2012., pages 1106–1114, 2012.
- [24] Dacheng Li, Rulin Shao, Anze Xie, Eric P Xing, Joseph E Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. Lightseq: Sequence level parallelism for distributed training of long context transformers. arXiv preprint arXiv:2310.03294, 2023.
- [25] Mu Li, David G Andersen, Jun Woo Park, Alexander J Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J Shekita, and Bor-Yiing Su. Scaling distributed machine learning with the parameter server. In Proceedings of 11th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2014, pages 583–598, 2014.
- [26] Mu Li, David G. Andersen, Alexander J. Smola, and Kai Yu. Communication efficient distributed machine learning with the parameter server. In Proceedings of 28th Annual Conference on Neural Information Processing Systems, NeurIPS 2014., pages 19–27, 2014.
- [27] Hao Liu and Pieter Abbeel. Blockwise parallel transformers for large context models. Advances in Neural Information Processing Systems, 36, 2024.
- [28] Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with ringattention. arXiv preprint arXiv:2402.08268, 2024.
- [29] Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near-infinite context. arXiv preprint arXiv:2310.01889, 2023.
- [30] Microsoft Azure Quantum Microsoft Research AI4Science. The impact of large language models on scientific discovery: a preliminary study using gpt-4. arXiv preprint arXiv:2311.07361, 2023.
- [31] Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, et al. Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–15, 2021.
- [32] Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, et al. Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–15, 2021.
- [33] Jinjie Ni, Tom Young, Vlad Pandelea, Fuzhao Xue, and Erik Cambria. Recent advances in deep learning based dialogue systems: A systematic survey. Artificial intelligence review, 56(4):3055–3155, 2023.
- [34] NVDIA. Megatron context parallelism, 2024.
- [35] NVIDIA. Nvidia dgx superpod: Next generation scalable infrastructure for ai leadership: Reference architecture. 2023.
- [36] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. arXiv preprint arXiv:1912.01703, 2019.
- [37] Penghui Qi, Xinyi Wan, Guangxing Huang, and Min Lin. Zero bubble pipeline parallelism. arXiv preprint arXiv:2401.10241, 2023.
- [38] Markus N Rabe and Charles Staats. Self-attention does not need memory. arXiv preprint arXiv:2112.05682, 2021.
- [39] Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020.
- [40] Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. Zero-offload: Democratizing billion-scale model training. In 2021 USENIX Annual Technical Conference (USENIX ATC 21), pages 551–564, 2021.
- [41] Ludan Ruan and Qin Jin. Survey: Transformer based video-language pre-training. AI Open, 3:1–13, 2022.
- [42] Peng Sun, Yonggang Wen, Ruobing Han, Wansen Feng, and Shengen Yan. Gradientflow: Optimizing network performance for large-scale distributed dnn training. IEEE Transactions on Big Data, 8(2):495–507, 2019.
- [43] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [44] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023.
- [45] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [46] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. volume 30, 2017.
- [47] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [48] Weiyang Wang, Manya Ghobadi, Kayvon Shakeri, Ying Zhang, and Naader Hasani. Optimized network architectures for large language model training with billions of parameters. arXiv preprint arXiv:2307.12169, 2023.
- [49] Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Zi-Hang Jiang, Francis EH Tay, Jiashi Feng, and Shuicheng Yan. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF international conference on computer vision, pages 558–567, 2021.
- [50] Hao Zhang, Aixin Sun, Wei Jing, and Joey Tianyi Zhou. Span-based localizing network for natural language video localization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6543–6554, 2020.
- [51] Zhen Zhang, Shuai Zheng, Yida Wang, Justin Chiu, George Karypis, Trishul Chilimbi, Mu Li, and Xin Jin. Mics: near-linear scaling for training gigantic model on public cloud. Proceedings of the VLDB Endowment, 16:37–50, 2022.
- [52] Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: Experiences on scaling fully sharded data parallel. Proceedings of the VLDB Endowment, 16(12):3848–3860, 2023.
- [53] Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P Xing, et al. Alpa: Automating inter-and Intra-Operator parallelism for distributed deep learning. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 559–578, 2022.
- [54] Wenxuan Zhou, Kevin Huang, Tengyu Ma, and Jing Huang. Document-level relation extraction with adaptive thresholding and localized context pooling. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 14612–14620, 2021.
9. 附录
表 6 显示了 7B-MHA 和 7B-GQA 在使用 的 64 个 GPU 上的训练性能 (TGS)。
| 128K | 256K | 512K | 1M | |||||||||||||||
| With SC++ | W/O SC++ | With SC++ | W/O SC++ | With SC++ | W/O SC++ | With SC++ | W/O SC++ | |||||||||||
| HF | CF | HF | CF | HF | CF | HF | CF | HF | CF | HF | CF | HF | CF | HF | CF | |||
| MHA | 64 | 1 | 190.2 | 190.2 | 145.3 | 145.3 | 195.4 | 195.4 | 149.4 | 149.4 | 196.8 | 196.8 | 149.9 | 149.9 | 161.7 | 161.7 | 127.6 | 127.6 |
| 32 | 2 | 203.9 | 327.1 | 158.8 | 260.4 | 212.0 | 340.8 | 163.6 | 269.2 | 214.2 | 294.3 | 164.7 | 239.3 | 169.8 | 173.9 | 140.8 | 145.2 | |
| 16 | 4 | 363.2 | 505.9 | 290.4 | 422.5 | 386.0 | 464.6 | 304.7 | 389.1 | 318.7 | 319.7 | 260.0 | 262.7 | 185.7 | 182.1 | 149.3 | 147.5 | |
| 8 | 8 | 585.6 | 662.6 | 486.9 | 582.2 | 533.5 | 515.6 | 443.6 | 437.8 | 340.1 | 324.0 | 277.1 | 266.8 | 188.4 | 186.1 | 151.7 | 150.2 | |
| 4 | 16 | 676.9 | 675.9 | 596.3 | 585.0 | 535.2 | 519.5 | 452.4 | 441.1 | 329.9 | 323.0 | 270.4 | 266.8 | 185.5 | 185.9 | 149.3 | 147.2 | |
| 2 | 32 | 661.0 | 679.9 | 586.7 | 605.7 | 516.4 | 517.2 | 433.6 | 438.7 | 321.3 | 323.8 | 263.2 | 267.2 | 185.0 | 185.0 | 148.4 | 145.0 | |
| GQA | 64 | 1 | 526.0 | 526.0 | 404.8 | 404.8 | 465.4 | 465.4 | 377.6 | 377.6 | 318.7 | 318.7 | 256.5 | 256.5 | 181.6 | 181.6 | 145.3 | 145.3 |
| 32 | 2 | 585.3 | 655.0 | 480.6 | 555.4 | 514.6 | 527.2 | 424.0 | 435.1 | 333.5 | 328.5 | 270.0 | 265.9 | 186.4 | 184.6 | 149.5 | 148.9 | |
| 16 | 4 | 732.1 | 698.8 | 637.6 | 606.6 | 571.6 | 537.0 | 473.1 | 457.6 | 342.4 | 334.8 | 277.7 | 273.6 | 189.7 | 187.9 | 152.1 | 152.4 | |
| 8 | 8 | 779.7 | 730.6 | 676.0 | 640.8 | 588.9 | 554.7 | 481.3 | 466.4 | 349.8 | 340.6 | 284.3 | 279.2 | 194.0 | 191.6 | 155.6 | 154.3 | |
| 4 | 16 | 731.2 | 705.1 | 641.0 | 636.5 | 561.1 | 536.1 | 463.1 | 458.5 | 339.1 | 334.2 | 277.0 | 274.3 | 190.1 | 189.2 | 152.9 | 149.8 | |
| 2 | 32 | 666.4 | 687.5 | 589.2 | 609.7 | 520.3 | 517.6 | 428.1 | 441.6 | 322.8 | 325.9 | 264.0 | 267.3 | 185.1 | 185.1 | 148.3 | 145.0 | |