Step-DPO:大语言模型长链推理的逐步偏好优化
摘要
由于准确性所需的广泛且精确的推理链,数学推理对大型语言模型(大语言模型)提出了重大挑战。 确保每个推理步骤的正确性至关重要。 为了解决这个问题,我们的目标是通过学习人类反馈来增强大语言模型的稳健性和真实性。 然而,直接偏好优化 (DPO) 对长链数学推理的好处有限,因为采用 DPO 的模型很难识别错误答案中的详细错误。 这种限制源于缺乏细粒度的过程监督。 我们提出了一种简单、有效且数据高效的方法,称为 Step-DPO,它将单个推理步骤视为偏好优化的单位,而不是整体评估答案。 此外,我们还为 Step-DPO 开发了数据构建管道,能够创建包含 10K 逐步偏好对的高质量数据集。 我们还观察到,在 DPO 中,由于后者的非分布性质,自行生成的数据比人类或 GPT-4 生成的数据更有效。 我们的研究结果表明,对于具有超过 70B 参数的模型,只需 10K 个偏好数据对和少于 500 个 Step-DPO 训练步骤即可将 MATH 的准确性提高近 3%。 值得注意的是,Step-DPO应用于Qwen2-72B-Instruct时,在MATH和GSM8K测试集上的得分分别达到70.8%和94.0%,超越了一系列闭源模型,包括GPT-4-1106、 Claude-3-Opus 和 Gemini-1.5-Pro。 我们的代码、数据和模型可在 https://github.com/dvlab-research/Step-DPO 获取。
1简介
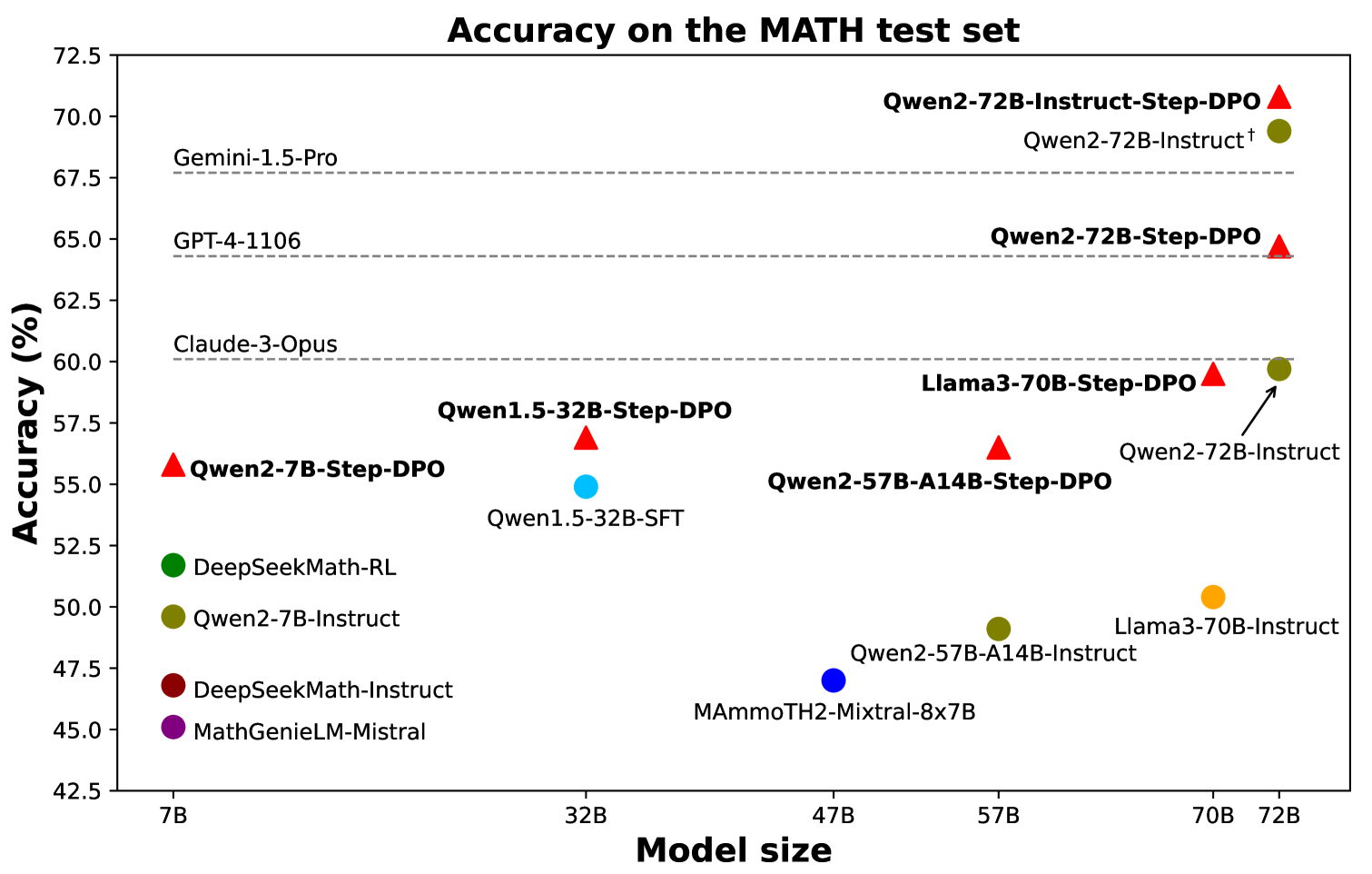
数学推理被认为是大语言模型中关键的长链推理能力。 这项任务特别具有挑战性,因为通常需要广泛的思维链,其中可能包括许多推理步骤。 这些步骤中的任何错误都可能导致最终答案不正确。
大量研究(Yu 等人, 2023; Luo 等人, 2023; Yue 等人, 2023; Liu & Yao, 2024; Lu 等人, 2024; Li 等人, 2024; Shao 等人, 2024; Xin 等人,2024;Yue等人,2024;Tang等人,2024)在监督微调(SFT)阶段提出了各种数据增强技术来增强对齐。 然而,SFT过程中的模型很容易出现幻觉,导致性能饱和。 正如 Hong 等人 (2024) 中所强调的,造成这种情况的一个潜在原因是,随着首选输出的概率增加,不良输出的概率也会增加。 这种现象使得模型在长链推理中更容易出错。 因此,有必要开发方法来抑制不良输出的可能性。
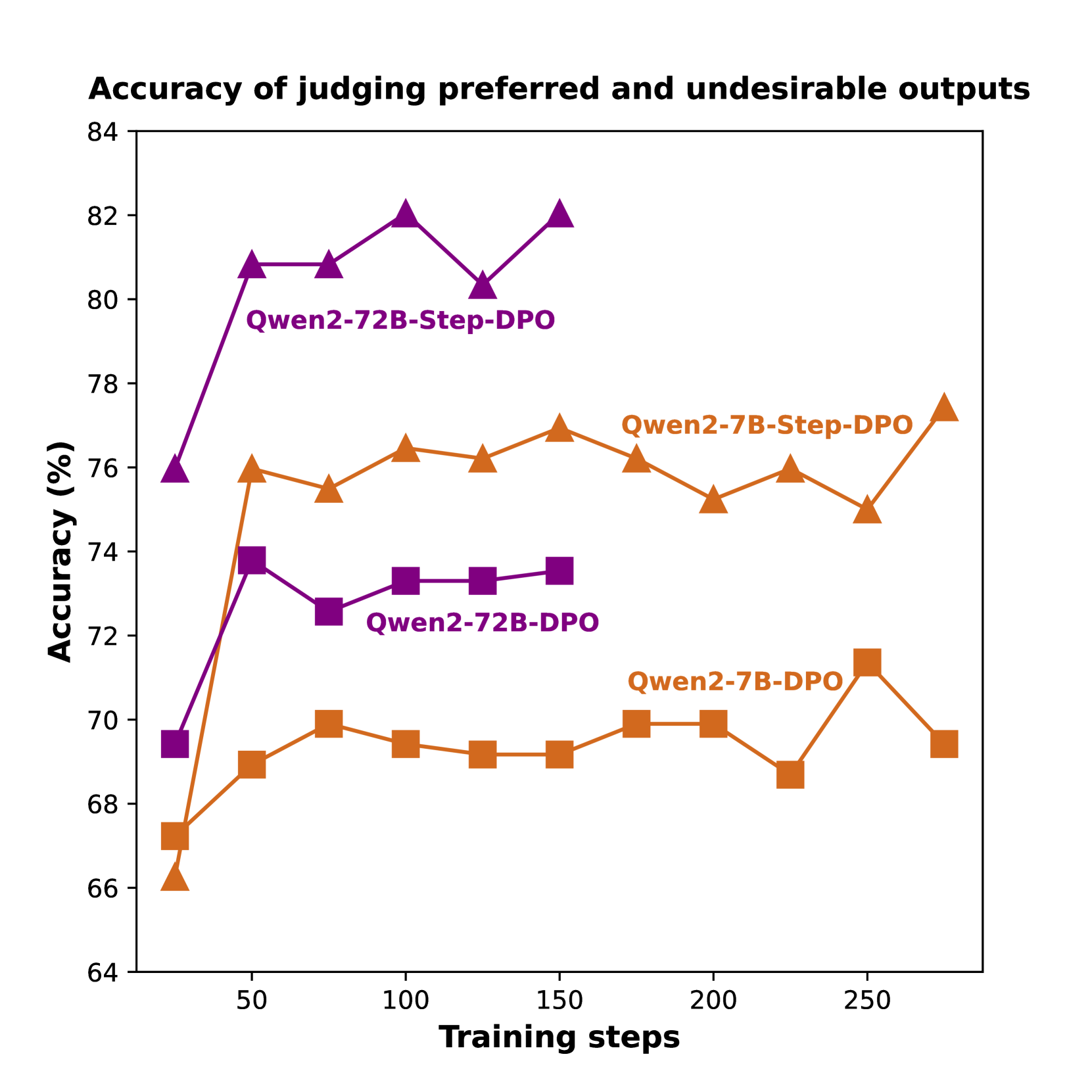
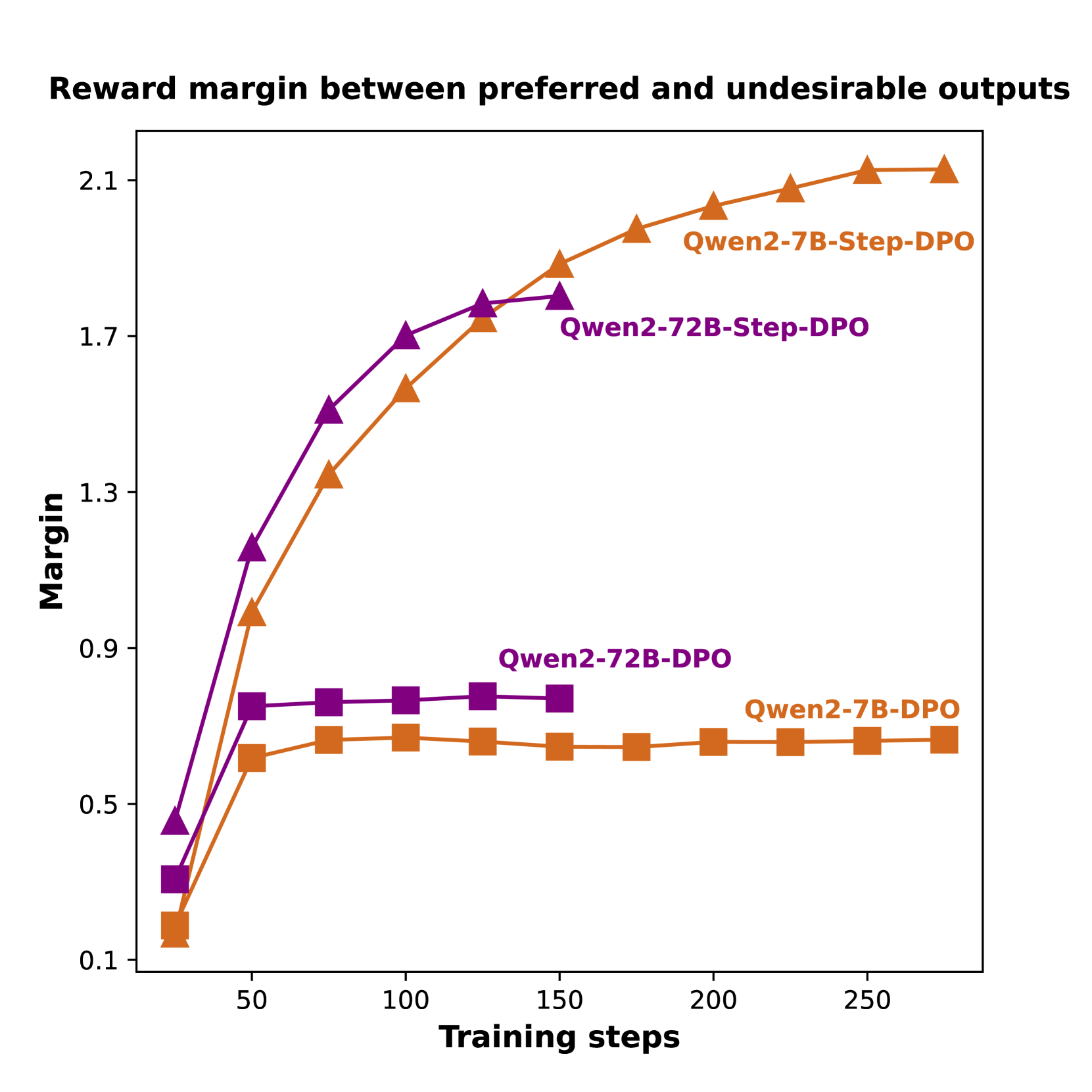
最近,直接偏好优化(DPO)(Rafailov 等人,2024) 被提出用于使用成对偏好数据进行对齐,并且由于其简单性而受到欢迎。 尽管 DPO 在聊天基准测试中非常有效(Tunstall 等人,2023;Zheng 等人,2024),但 DPO 对长链数学推理的好处微乎其微。 如图2(左)所示,使用普通 DPO 的模型在区分首选输出和不需要的输出方面表现不佳,无法识别被拒绝答案中的错误。 此外,图2(右)显示,对于使用普通 DPO 和进一步训练的高原模型,奖励裕度(即首选输出和不需要输出的奖励之间的差距)受到限制。 这些发现表明,使用普通 DPO 进行微调的模型无法查明错误答案中的详细错误,从而阻碍了推理能力的提高。
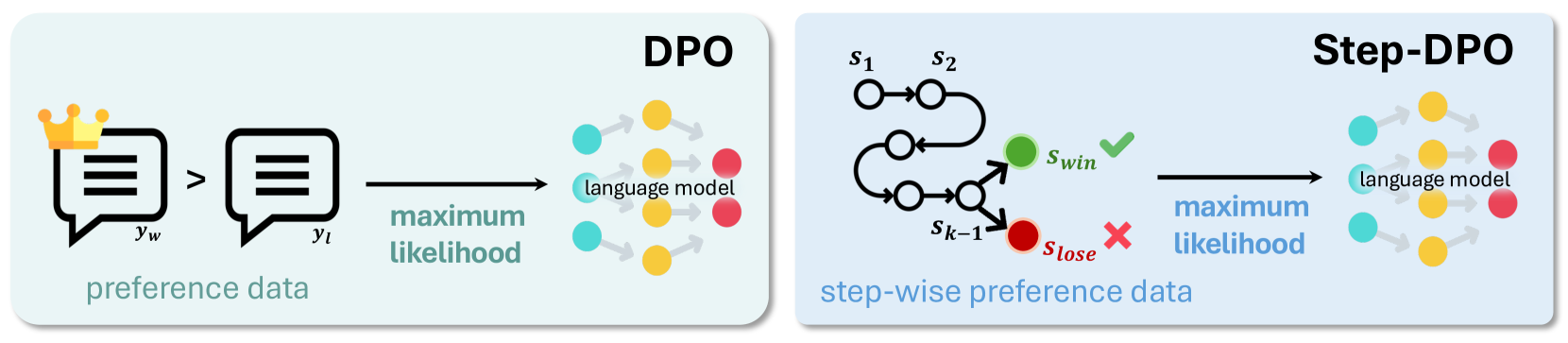
在这项工作中,我们引入了Step-DPO,其中每个中间推理步骤都被视为偏好优化的基本单元。 如图 3 所示,与普通 DPO 不同,后者仅考虑完整答案(即 和 )之间的偏好优化,Step-DPO 检查逐步的答案(即 )并专门针对第一个错误的推理步骤。 Step-DPO 旨在给定一个数学问题和几个初始正确推理步骤(即最大化 和最小化 ),选择正确的推理步骤并拒绝不正确的推理步骤。 这种转变使模型能够轻松定位错误的标记以进行有效的优化,从而显着增强长链推理。
此外,我们提出了一种有效且经济的管道来收集成对偏好数据,从而为 Step-DPO 提供高质量的数据集。 该数据集包含大约 10K 个样本,每个样本包含:1) 一个数学问题,2) 先验推理步骤,3) 选定的步骤,以及 4) 拒绝的步骤。 我们的数据集构建三步流程包括:1)错误收集,2)步骤本地化,以及 3)纠正。 值得注意的是,所选择的推理步骤是由模型本身生成的,因为我们发现分布内数据(即自行生成的数据)比分布外数据(例如人类或 GPT-4 编写的数据)更有效)对于Step-DPO,如表4所示。
通过这个精选的数据集,只需数百个训练步骤即可显着提高数学推理性能,如图 6 所示。 例如,通过Step-DPO微调Qwen-72B-Instruct,模型在MATH上的准确率达到70.8%,在GSM8K上的准确率达到94.0%,超越了一系列闭源模型,包括GPT-4-1106、Claude-3 -Opus 和 Gemini-1.5-Pro。
2相关作品
2.1数学推理
大型语言模型(大语言模型)表现出了强大的推理能力,这主要是由于它们的自回归性质,这使得它们能够根据上下文信息预测下一个词符。 然而,这些模型仍然难以应对长链推理任务,特别是在数学环境中。 多项先前研究(Yao 等人, 2024; Chen 等人, 2024; Yoran 等人, 2023; Li 等人, 2023; Tong 等人, 2024; Fu 等人, 2022; Zhou 等人, 2022)尝试增强思想链(CoT)推理框架(Wei等人,2022)来解决这个问题。 虽然这些努力在某些任务上带来了显着的改进,但它们并没有完全减轻常见的幻觉,并且在所有推理任务中的通用性有限。
另一个研究方向(余等人,2023;罗等人,2023;岳等人,2023;刘等人,2024;陆等人,2024;徐等人,2024;李等人,2024;邵等人, 2024; 周等人, 2024; 等人, 2024; 唐等人, 2024; ,2023) 专注于各种数据增强技术,例如用于监督微调(SFT)的改写、扩展和进化。 这些方法显着增强了大语言模型的推理能力,但一旦数据达到一定量,其性能就会趋于稳定。 此外,诸如 Wang 等人 (2023a) 提出的方法;廖等人 (2024); Toshniwal 等人 (2024); Gou等人(2023)使用Python等外部工具来大幅减少计算错误。
其他方法(Azerbayev 等人,2023;Shao 等人,2024;Lin 等人,2024;Ying 等人,2024;Wang 等人,2023c)涉及对广泛的、高水平的持续预训练。高质量的数学相关数据集,显着提高数学推理能力。 最近的研究(Xu等人,2024;Ying等人,2024)探索了强化学习来减轻数学推理中的幻觉。 作品类似于 Lightman 等人 (2023);邵 等人 (2024); Wang等人(2023b)强调了数学问题强化学习中逐步验证的重要性。 然而,这些方法仍然依赖于奖励模型的质量,并且需要 RLHF 的复杂训练流程。 基于这一研究方向,我们提出了 Step-DPO,一种更简单、更有效、更高效的方法。
2.2 根据人类反馈进行强化学习
有监督微调(SFT)可以使模型与人类偏好保持一致。 然而,随着首选输出的概率增加,不良输出的可能性也会增加,从而导致幻觉。 为了生成更可靠的输出,引入了人类反馈强化学习(RLHF)(Christiano 等人,2017;Ouyang 等人,2022)来进行大语言模型对齐。 这种方法涉及使用比较数据训练奖励模型,然后使用该奖励模型来优化策略模型。 最终的性能在很大程度上取决于奖励模型的质量,并且训练流程相当复杂。
为了简化这个过程,提出了直接偏好优化(DPO)(Rafailov等人,2024),它直接使用成对的偏好数据进行模型优化。 这一转变显着简化了训练流程。 虽然 DPO 已被证明在聊天基准测试中有效,但它仅为数学推理提供边际效益。 Step-DPO继承了DPO的原理,专为长链推理而设计,在解决数学应用题方面表现出显着的性能提升。
3步骤-DPO
在本节中,我们将详细阐述拟议的 Step-DPO。 首先,我们在第二节中提出逐步公式。 3.1,一种基于 DPO 的新颖方法,旨在增强长链推理能力。 接下来,在第二节。 3.2,我们展示了为 Step-DPO 构建逐步偏好数据集的管道。 这两个组件对于实现所需的性能改进都是必不可少的。
3.1逐步制定
初步知识。
人类反馈强化学习(RLHF)(Christiano 等人,2017)是增强大语言模型鲁棒性、真实性和安全性的有效方法(Ouyang 等人,2022). RLHF 包含两个训练阶段:1)奖励模型训练,2)策略模型训练。 然而,RLHF 的最终性能对两个阶段的各种超参数都高度敏感,需要仔细调整。
为了避免这种复杂的训练流程,Rafailov 等人 (2024) 提出了直接偏好优化(DPO),它直接使用成对偏好数据来优化具有等效优化目标的策略模型。 具体来说,给定输入提示 和偏好数据对 ,DPO 的目标是最大化首选输出 的概率并最小化不良输出的概率输出。 优化目标表述为:
| (1) |
其中是成对偏好数据集,是sigmoid函数,是要优化的策略模型,是训练过程中保持不变的参考模型,超参数控制与参考模型的距离。
我们的解决方案。
虽然 DPO 在聊天基准测试中已被证明是有效的,但它对于数学问题等长链推理任务仅带来了边际改进,如图2和表3所示。 出现这种限制是因为这些任务中大多数不需要的答案最初并不包含错误;第一个错误经常出现在推理过程的中途。 在 DPO 中拒绝整个不需要的答案也可能会丢弃前面的正确推理步骤,从而引入显着的噪声并对训练产生负面影响。
类似于教师如何通过查明特定错误而不是忽略整个答案来纠正学生,我们提出的 Step-DPO 通过识别特定的错误推理步骤来提供更详细的监督。 这种精细的焦点使模型能够快速定位、纠正并避免错误的步骤。
具体来说,答案可以分解为一系列推理步骤,其中是第推理步骤。 如图3所示,给定提示和一系列初始正确推理步骤,Step-DPO的目标是最大化纠正下一个推理步骤并最小化错误的概率。 该目标可以表述为:
| (2) |
3.2分布内数据构建
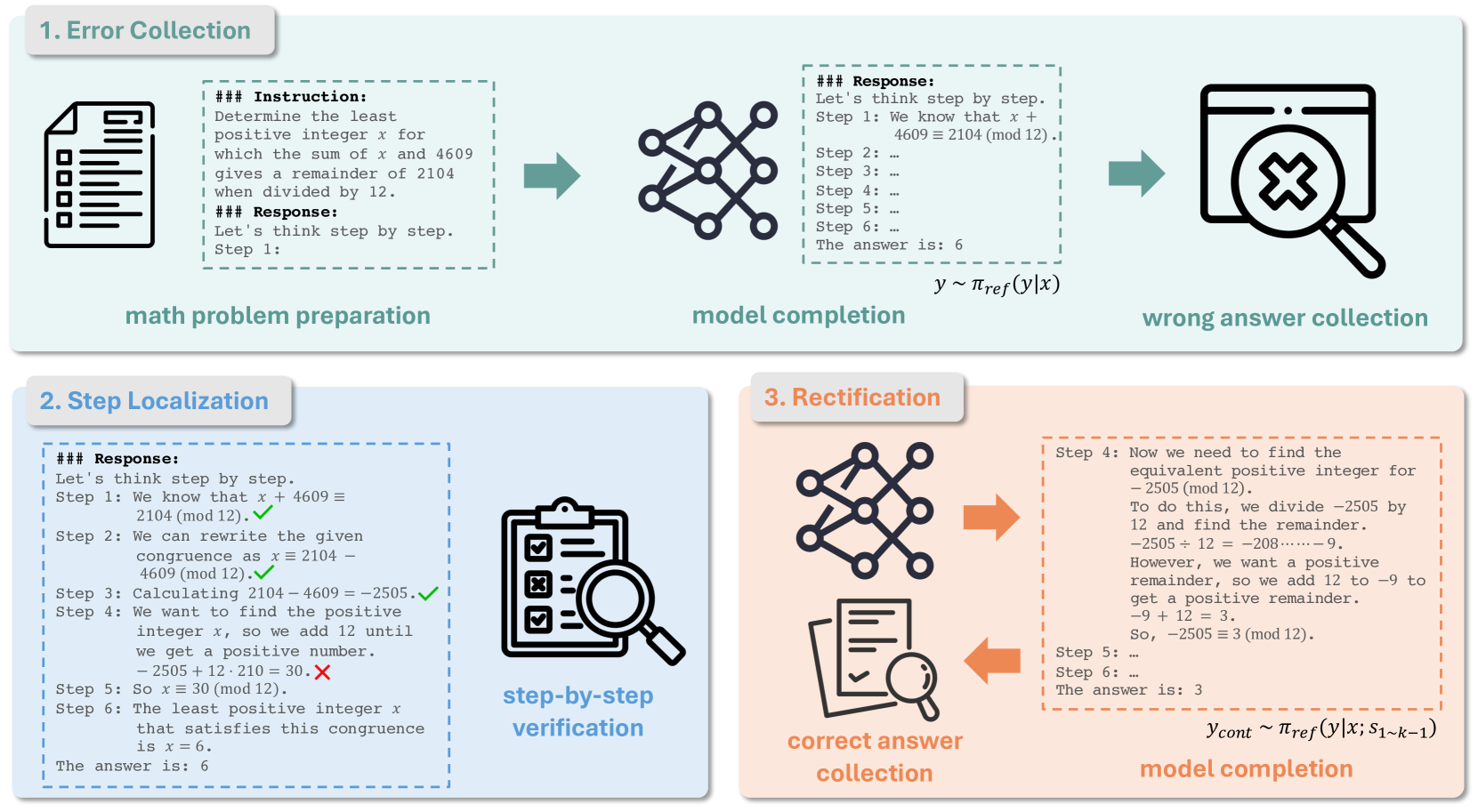

根据Step-DPO的优化目标,我们需要创建相应的高质量配对偏好数据集。 每个数据样本应包含四个条目: 1) 提示; 2)初始推理步骤; 3)优选推理步骤; 4)不良推理步骤,如图5所示。 为了获得高质量的数据集,我们提出了如图4所示的数据构建流程,其中包括以下三个步骤。
错误集合。
首先,我们收集一组 数学问题 以及真实答案 。 然后,每个数学问题 都会用作使用初始模型 推断答案的提示。 在推理之前,我们添加逐步的思想链(CoT)前缀进行提示,即 “我们一步步思考吧。 步骤1:”. 这确保了模型的推理结果被构造为多个推理步骤,每个步骤明确地以“步骤i:”开始。 推理完成后,我们获得每个数学问题的模型答案。 然后,我们选择最终答案 与基本事实 不同的实例,从而产生错误推理结果的数据集,表示为 。
步骤本地化。
鉴于每个错误的推理结果都明确地表示为一系列推理步骤,我们继续验证每个推理步骤的正确性,直到找到第一个错误并记录其步骤号。此过程可以手动完成或使用 GPT-4 完成。 我们选择作为错误推理步骤,从而得到包含错误步骤的数据集,表示为。
整改。
要为 中的每个样本获取相应的正确推理步骤,我们需要通过提示 和前面的正确推理步骤 来推断模型 ,从而对多个输出 进行采样。 该过程表述为:
| (3) |
我们保留最终答案与基本事实相符的输出。 在剩余的输出中,我们选择中的第一个推理步骤作为,得到最终的数据集。 图 5 显示了结果数据样本的示例。
值得注意的是,某些情况可能有正确的最终答案,但中间推理步骤是错误的。 因此,我们可能需要进一步过滤掉不正确的样本,这可以手动完成,也可以通过GPT-4完成。 为了简单起见,我们在符号中省略了这个过程,附录中提供了更多细节。
值得注意的是,数据管道是用户友好的。 在这个数据管道中,人类或GPT-4只需要定位错误并对答案进行排序,而不需要自己编写答案或纠正。
我们还注意到,分布内数据的使用至关重要。 选择 时,我们使用模型 生成的输出,而不是由人类或 GPT-4 纠正的答案。 由于人类或 GPT-4 纠正答案 对于模型 来说是分布外 (OOD) 的,因此输出 的对数概率(即,)明显低于分布内(ID)输出。 此外,由于梯度衰减问题(详见附录),策略模型学习增加的概率具有挑战性。 因此,采用自行生成的分布内数据作为首选答案被证明是符合人类偏好的更有效方法。
4实验
在本节中,我们首先介绍第二节中的实验设置。 4.1。 然后,我们在第二节中介绍主要结果。 4.2,其中包括详尽的性能比较。 此外,我们在 Sec 中进行了广泛的消融研究。 4.3。 最后,第 2 节中显示了一些演示。 4.4进一步了解Step-DPO。
4.1 实验设置
网络架构。
我们的实验基于各种基础模型,包括Qwen2和Qwen1.5系列(Bai等人,2023),Meta-Llama-3-70B(Touvron等人,2023) 和 deepseek-math-7b-base (邵等人,2024)。
| Model | size | general | open | MATH (%) | GSM8K (%) |
|---|---|---|---|---|---|
| GPT-3.5-Turbo | - | ✓ | ✗ | 42.5 | 92.0 |
| Gemini-1.5-Pro (Feb) (Reid et al., 2024) | - | ✓ | ✗ | 58.5 | 91.7 |
| Gemini-1.5-Pro (May) (Reid et al., 2024) | - | ✓ | ✗ | 67.7 | 90.8 |
| Claude-3-Opus | - | ✓ | ✗ | 60.1 | 95.0 |
| GPT-4-1106 (Achiam et al., 2023) | - | ✓ | ✗ | 64.3 | 91.4 |
| GPT-4-Turbo-0409 (Achiam et al., 2023) | - | ✓ | ✗ | 73.4 | 93.7 |
| GPT-4o-0513 | - | ✓ | ✗ | 76.6 | 95.8 |
| Llama-3-8B-Instruct (Touvron et al., 2023) | 8B | ✓ | ✓ | 30.0 | 79.6 |
| Qwen2-7B-Instruct (Bai et al., 2023) | 7B | ✓ | ✓ | 49.6 | 82.3 |
| Llama-3-70B-Instruct (Touvron et al., 2023) | 70B | ✓ | ✓ | 50.4 | 93.0 |
| DeepSeek-Coder-V2-Instruct (Zhu et al., 2024) | 236B | ✗ | ✓ | 75.7 | 94.9 |
| Code-Llama-7B (Roziere et al., 2023) | 7B | ✗ | ✓ | 13.0 | 25.2 |
| MAmooTH-CoT (Yue et al., 2023) | 7B | ✗ | ✓ | 10.4 | 50.5 |
| WizardMath (Luo et al., 2023) | 7B | ✗ | ✓ | 10.7 | 54.9 |
| MetaMath (Yu et al., 2023) | 7B | ✗ | ✓ | 19.8 | 66.5 |
| MetaMath-Mistral-7B (Yu et al., 2023) | 7B | ✗ | ✓ | 28.2 | 77.7 |
| MathScale-Mistral Tang et al. (2024) | 7B | ✗ | ✓ | 35.2 | 74.8 |
| InternLM-Math-7B (Ying et al., 2024) | 7B | ✗ | ✓ | 34.6 | 78.1 |
| Xwin-Math-Mistral-7B (Li et al., 2024) | 7B | ✗ | ✓ | 43.7 | 89.2 |
| MAmmoTH2-7B-Plus (Yue et al., 2024) | 7B | ✗ | ✓ | 45.0 | 84.7 |
| MathGenieLM-Mistral (Lu et al., 2024) | 7B | ✗ | ✓ | 45.1 | 80.5 |
| InternLM-Math-20B (Ying et al., 2024) | 20B | ✗ | ✓ | 37.7 | 82.6 |
| MathGenieLM-InternLM2 (Lu et al., 2024) | 20B | ✗ | ✓ | 55.7 | 87.7 |
| DeepSeekMath-Instruct (Shao et al., 2024) | 7B | ✗ | ✓ | 46.8 | 82.9 |
| DeepSeekMath-RL (Shao et al., 2024) | 7B | ✗ | ✓ | 51.7 | 88.2 |
| DeepSeekMath-RL + Step-DPO | 7B | ✗ | ✓ | 53.2 (+1.5) | 88.7 (+0.5) |
| DeepSeekMath-Base-SFT† | 7B | ✗ | ✓ | 52.9 | 86.7 |
| DeepSeekMath-Base-SFT + Step-DPO | 7B | ✗ | ✓ | 54.1 (+1.2) | 86.7 (+0.0) |
| Qwen2-7B-SFT† | 7B | ✗ | ✓ | 54.8 | 88.2 |
| Qwen2-7B-SFT + Step-DPO | 7B | ✗ | ✓ | 55.8 (+1.0) | 88.5 (+0.3) |
| Qwen1.5-32B-SFT† | 32B | ✗ | ✓ | 54.9 | 90.0 |
| Qwen1.5-32B-SFT + Step-DPO | 32B | ✗ | ✓ | 56.9 (+2.0) | 90.9 (+0.9) |
| Qwen2-57B-A14B-SFT† | 57B | ✗ | ✓ | 54.6 | 89.8 |
| Qwen2-57B-A14B-SFT + Step-DPO | 57B | ✗ | ✓ | 56.5 (+1.9) | 90.0 (+0.2) |
| Llama-3-70B-SFT† | 70B | ✗ | ✓ | 56.9 | 92.2 |
| Llama-3-70B-SFT + Step-DPO | 70B | ✗ | ✓ | 59.5 (+2.6) | 93.3 (+1.1) |
| Qwen2-72B-SFT† | 72B | ✗ | ✓ | 61.7 | 92.9 |
| Qwen2-72B-SFT + Step-DPO | 72B | ✗ | ✓ | 64.7 (+3.0) | 93.9 (+1.0) |
| Qwen2-72B-Instruct (Bai et al., 2023) | 72B | ✓ | ✓ | 59.7 | 91.1 |
| Qwen2-72B-Instruct ‡ | 72B | ✓ | ✓ | 69.4 | 92.4 |
| Qwen2-72B-Instruct + Step-DPO ‡ | 72B | ✓ | ✓ | 70.8 (+1.4) | 94.0 (+1.6) |
-
•
Supervised fine-tuned models with our 299K SFT data based on the open-source base model.
-
•
Reproduced using our prompt
| Model | size | open | AIME | Odyssey-MATH (%) |
| Gemini-1.5-Pro (Reid et al., 2024) | - | ✗ | 2 / 30 | 45.0 |
| Claude-3-Opus | - | ✗ | 2 / 30 | 40.6 |
| GPT-4-1106 (Achiam et al., 2023) | - | ✗ | 1 / 30 | 49.1 |
| GPT-4-Turbo-0409 (Achiam et al., 2023) | - | ✗ | 3 / 30 | 46.8 |
| GPT-4o-0513 | - | ✗ | 2 / 30 | 53.2 |
| DeepSeek-Coder-V2-Lite-Instruct (Zhu et al., 2024) | 16B | ✓ | 0 / 30 | 44.4 |
| Llama-3-70B-Instruct (Touvron et al., 2023) | 70B | ✓ | 1 / 30 | 27.9 |
| DeepSeek-Coder-V2-Instruct (Zhu et al., 2024) | 236B | ✓ | 4 / 30 | 53.7 |
| Qwen2-72B-SFT† | 72B | ✓ | 1 / 30 | 44.2 |
| Qwen2-72B-SFT + Step-DPO | 72B | ✓ | 3 / 30 | 47.0 (+2.8) |
| Qwen2-72B-Instruct (Bai et al., 2023) | 72B | ✓ | 5 / 30 | 47.0 |
| Qwen2-72B-Instruct + Step-DPO | 72B | ✓ | 4 / 30 | 50.1 (+3.1) |
-
•
Supervised fine-tuned models with our 299K SFT data based on the open-source base model.
数据集。
在监督微调(SFT)中,我们使用 MetaMath (Yu 等人,2023) 和 MMIQC (Liu & Yao,2024) 中的增强数学问题来推断步骤 - DeepSeekMath 中使用的 SFT 数据(Shao 等人,2024) 未公开,因此无法通过 DeepSeekMath 进行逐步响应。 过滤掉最终答案错误的响应后,我们获得了 374K SFT 数据。 其中,299K 用于 SFT,剩余部分用于进一步的 Step-DPO 训练。
在Step-DPO阶段,除了剩余的SFT数据外,我们还合并了AQuA的子集(Ling等人,2017)。 这些数据集按照第 2 节中所述进行处理。 3.2,生成 Step-DPO 的 10K 成对偏好数据。
为了进行评估,我们使用广泛采用的 MATH (Hendrycks 等人, 2021) 和 GSM8K (Cobbe 等人, 2021) 数据集。 这些数据集的准确性作为评估指标。 MATH 测试集包含 5000 个数学问题,涵盖 5 个难度级别和 7 个科目,包括代数、计数和概率、几何、中级代数、数论、初级代数和初级微积分。 GSM8K 测试集包括 1319 个数学问题,每个问题都有逐步解决方案和真实答案。 GSM8K 中的问题通常比 MATH 中的问题容易。 此外,我们还使用美国数学邀请赛(AIME)(MAA,2024)和Odyssey-MATH (Netmind.AI,2024)中的完成级别问题来评估解决难题的数学推理能力。
实施细节。
首先,我们使用299K SFT数据对基础模型进行监督微调,得到SFT模型。 我们在 3 个 epoch 中训练 7B 个模型,在 2 个 epoch 中训练大于 30B 的模型。 全局批量大小设置为256,学习率设置为5e-6。 我们使用 AdamW 优化器和线性衰减学习率调度器,将预热比率设置为 0.03。 具有 CPU 卸载功能的 DeepSpeed ZeRO3 用于减少训练期间 GPU 内存的使用。
接下来,我们基于 SFT 模型执行 Step-DPO。 对于 Step-DPO,我们在 8 个 epoch 中训练 7B 个模型,在 4 个 epoch 中训练大于 30B 的模型。 全局批量大小设置为128,学习率设置为5e-7。 超参数对于72B模型设置为0.5,对于其他模型设置为0.4。 我们使用 AdamW 优化器和余弦学习率调度器,并将预热比率设置为 0.1。
4.2结果
| Model | Qwen2-7B-SFT | Qwen2-7B-SFT + DPO (5K) | Qwen2-7B-SFT + Step-DPO (5K) |
|---|---|---|---|
| MATH (%) | 54.8 | 55.0 | 55.8 |
| Model | Qwen2-72B-SFT | Qwen2-72B-SFT + DPO (5K) | Qwen2-72B-SFT + Step-DPO (5K) |
| MATH (%) | 61.7 | 62.5 | 64.1 |
| Model | Qwen2-7B-SFT | Qwen2-7B-SFT + Step-DPO (OOD) | Qwen2-7B-SFT + Step-DPO (ID) |
|---|---|---|---|
| MATH (%) | 54.8 | 55.1 | 55.8 |
适用于开源指导模型。
表1展示了各种模型的综合比较,包括开源模型和闭源模型。 值得注意的是,Step-DPO 可以直接集成到开源指令模型中,例如 DeepSeekMath-RL 和 Qwen2-72B-Instruct,即使在之前的 RLHF 训练阶段之后也能显着提高性能。 这表明Step-DPO有效地补充了RLHF。 具体来说,当应用于 Qwen2-72B-Instruct 时,Step-DPO 在 MATH 和 GSM8K 测试集上分别取得了 70.8% 和 94.0% 的成绩,超越了一系列闭源模型,包括 GPT-4-1106、Claude- 3-Opus 和 Gemini-1.5-Pro。
适用于 SFT 型号。
为了进一步证实Step-DPO的功效,我们将其应用于SFT模型。 最初,我们对第 2 节中提到的 299K SFT 数据集进行了监督微调。 4.1,产生 DeepSeekMath-Base-SFT、Qwen2-7B-SFT、Qwen1.5-32B-SFT、Llama3-70B-SFT 和 Qwen2-72B-SFT 等模型。 事实证明,Step-DPO 非常有效,在各种模型尺寸上都取得了显着的改进。 特别是,对于超过 70B 参数的模型(即 Llama-3-70B-SFT 和 Qwen-2-72B-SFT),Step-DPO 在 MATH 测试集上实现了约 3% 的性能提升。
有趣的是,较大的模型从 Step-DPO 中表现出更大的性能提升。 我们假设较大的模型具有 Step-DPO 可以利用的未开发潜力。 如果通过监督微调(SFT)未达到性能上限,Step-DPO 可以帮助模型接近最佳性能。
数学竞赛问题的结果。
为了进一步说明Step-DPO在数学推理方面的优越性,我们在竞赛级数学问题上对模型进行了评估,特别是AIME 2024和Odyssey-MATH,如图2所示。 尽管与 MATH 和 GSM8K 相比,这些问题的难度有所增加,但 Step-DPO 显着增强了性能。 在 Odyssey-MATH 上,应用于 Qwen2-72B-Instruct 的 Step-DPO 达到了 50.1% 的准确率,缩小了与 GPT-4o 的性能差距。
值得注意的是,这些模型对于这些竞赛级别的问题和普通难度的问题使用了相同的 Step-DPO 训练数据,凸显了 Step-DPO 强大的泛化能力。
4.3消融研究
为了验证 Step-DPO 及其数据构建过程的有效性,我们进行了广泛的消融研究。
DPO 与 Step-DPO。
分布外数据与分布内数据。
4.4演示

如图6所示,我们展示了Qwen2-72B-Instruct和Qwen2-72B-Instruct-Step-DPO之间的比较示例。 事实证明,Step-DPO 在纠正以前模型中的小错误方面做得很好。 附录中提供了更多比较。
5结论
在这项工作中,我们提出了一种简单、有效且数据高效的方法,称为 Step-DPO。 与比较整体答案之间的偏好的 DPO 不同,Step-DPO 使用单个推理步骤作为偏好比较的基本单位。 这种转变可以对大语言模型进行细粒度的流程监督,有助于快速定位错误答案中的错误。 此外,我们还引入了 Step-DPO 的数据构建管道,创建包含 10K 偏好数据对的数据集。 我们的结果证明了 Step-DPO 和 10K 数据集取得了显着的改进,特别是对于大型模型。 我们希望 Step-DPO 能够为长链推理问题的模型对齐提供新的见解。
参考
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv:2303.08774, 2023.
- Azerbayev et al. (2023) Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An open language model for mathematics. arXiv:2310.10631, 2023.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report. arXiv:2309.16609, 2023.
- Chen et al. (2024) Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. Alphamath almost zero: process supervision without process. arXiv:2405.03553, 2024.
- Christiano et al. (2017) Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. NeurIPS, 2017.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv:2110.14168, 2021.
- Fu et al. (2022) Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. Complexity-based prompting for multi-step reasoning. In ICLR, 2022.
- Gou et al. (2023) Zhibin Gou, Zhihong Shao, Yeyun Gong, Yujiu Yang, Minlie Huang, Nan Duan, Weizhu Chen, et al. Tora: A tool-integrated reasoning agent for mathematical problem solving. arXiv:2309.17452, 2023.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv:2103.03874, 2021.
- Hong et al. (2024) Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model. arXiv:2403.07691, 2024.
- Li et al. (2024) Chen Li, Weiqi Wang, Jingcheng Hu, Yixuan Wei, Nanning Zheng, Han Hu, Zheng Zhang, and Houwen Peng. Common 7b language models already possess strong math capabilities. arXiv:2403.04706, 2024.
- Li et al. (2023) Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for” mind” exploration of large language model society. NeurIPS, 2023.
- Liao et al. (2024) Minpeng Liao, Wei Luo, Chengxi Li, Jing Wu, and Kai Fan. Mario: Math reasoning with code interpreter output–a reproducible pipeline. arXiv:2401.08190, 2024.
- Lightman et al. (2023) Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. arXiv:2305.20050, 2023.
- Lin et al. (2024) Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Yelong Shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, et al. Rho-1: Not all tokens are what you need. arXiv:2404.07965, 2024.
- Ling et al. (2017) Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. arXiv:1705.04146, 2017.
- Liu & Yao (2024) Haoxiong Liu and Andrew Chi-Chih Yao. Augmenting math word problems via iterative question composing. arXiv:2401.09003, 2024.
- Liu et al. (2023) Yixin Liu, Avi Singh, C Daniel Freeman, John D Co-Reyes, and Peter J Liu. Improving large language model fine-tuning for solving math problems. arXiv:2310.10047, 2023.
- Lu et al. (2024) Zimu Lu, Aojun Zhou, Houxing Ren, Ke Wang, Weikang Shi, Junting Pan, Mingjie Zhan, and Hongsheng Li. Mathgenie: Generating synthetic data with question back-translation for enhancing mathematical reasoning of llms. arXiv:2402.16352, 2024.
- Luo et al. (2023) Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv:2308.09583, 2023.
- MAA (2024) MAA. American invitational mathematics examination, 2024. URL https://maa.org/math-competitions/american-invitational-mathematics-examination-aime.
- Mitra et al. (2024) Arindam Mitra, Hamed Khanpour, Corby Rosset, and Ahmed Awadallah. Orca-math: Unlocking the potential of slms in grade school math. arXiv:2402.14830, 2024.
- Netmind.AI (2024) Netmind.AI. Odyssey-math. https://github.com/protagolabs/odyssey-math/tree/main, 2024. Accessed: April 22, 2024.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. NeurIPS, 2022.
- Rafailov et al. (2024) Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. NeurIPS, 2024.
- Reid et al. (2024) Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530, 2024.
- Roziere et al. (2023) Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. Code llama: Open foundation models for code. arXiv:2308.12950, 2023.
- Shao et al. (2024) Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, YK Li, Y Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv:2402.03300, 2024.
- Tang et al. (2024) Zhengyang Tang, Xingxing Zhang, Benyou Wan, and Furu Wei. Mathscale: Scaling instruction tuning for mathematical reasoning. arXiv:2403.02884, 2024.
- Tong et al. (2024) Yongqi Tong, Dawei Li, Sizhe Wang, Yujia Wang, Fei Teng, and Jingbo Shang. Can llms learn from previous mistakes? investigating llms’ errors to boost for reasoning. arXiv:2403.20046, 2024.
- Toshniwal et al. (2024) Shubham Toshniwal, Ivan Moshkov, Sean Narenthiran, Daria Gitman, Fei Jia, and Igor Gitman. Openmathinstruct-1: A 1.8 million math instruction tuning dataset. arXiv:2402.10176, 2024.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv:2302.13971, 2023.
- Tunstall et al. (2023) Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, et al. Zephyr: Direct distillation of lm alignment. arXiv:2310.16944, 2023.
- Wang et al. (2023a) Ke Wang, Houxing Ren, Aojun Zhou, Zimu Lu, Sichun Luo, Weikang Shi, Renrui Zhang, Linqi Song, Mingjie Zhan, and Hongsheng Li. Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning. arXiv:2310.03731, 2023a.
- Wang et al. (2023b) Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Y Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. CoRR, abs/2312.08935, 2023b.
- Wang et al. (2023c) Zengzhi Wang, Rui Xia, and Pengfei Liu. Generative ai for math: Part i–mathpile: A billion-token-scale pretraining corpus for math. arXiv:2312.17120, 2023c.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS, 2022.
- Xin et al. (2024) Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. Deepseek-prover: Advancing theorem proving in llms through large-scale synthetic data. arXiv:2405.14333, 2024.
- Xu et al. (2024) Yifan Xu, Xiao Liu, Xinghan Liu, Zhenyu Hou, Yueyan Li, Xiaohan Zhang, Zihan Wang, Aohan Zeng, Zhengxiao Du, Wenyi Zhao, et al. Chatglm-math: Improving math problem-solving in large language models with a self-critique pipeline. arXiv:2404.02893, 2024.
- Yao et al. (2024) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. NeurIPS, 2024.
- Ying et al. (2024) Huaiyuan Ying, Shuo Zhang, Linyang Li, Zhejian Zhou, Yunfan Shao, Zhaoye Fei, Yichuan Ma, Jiawei Hong, Kuikun Liu, Ziyi Wang, et al. Internlm-math: Open math large language models toward verifiable reasoning. arXiv:2402.06332, 2024.
- Yoran et al. (2023) Ori Yoran, Tomer Wolfson, Ben Bogin, Uri Katz, Daniel Deutch, and Jonathan Berant. Answering questions by meta-reasoning over multiple chains of thought. arXiv:2304.13007, 2023.
- Yu et al. (2023) Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv:2309.12284, 2023.
- Yuan et al. (2023) Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Chuanqi Tan, and Chang Zhou. Scaling relationship on learning mathematical reasoning with large language models. arXiv:2308.01825, 2023.
- Yue et al. (2023) Xiang Yue, Xingwei Qu, Ge Zhang, Yao Fu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mammoth: Building math generalist models through hybrid instruction tuning. arXiv:2309.05653, 2023.
- Yue et al. (2024) Xiang Yue, Tuney Zheng, Ge Zhang, and Wenhu Chen. Mammoth2: Scaling instructions from the web. arXiv:2405.03548, 2024.
- Zheng et al. (2024) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. NeurIPS, 2024.
- Zhou et al. (2022) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv:2205.10625, 2022.
- Zhou et al. (2024) Kun Zhou, Beichen Zhang, Jiapeng Wang, Zhipeng Chen, Wayne Xin Zhao, Jing Sha, Zhichao Sheng, Shijin Wang, and Ji-Rong Wen. Jiuzhang3. 0: Efficiently improving mathematical reasoning by training small data synthesis models. arXiv:2405.14365, 2024.
- Zhu et al. (2024) Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y Wu, Yukun Li, Huazuo Gao, Shirong Ma, et al. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence. arXiv:2406.11931, 2024.