ASSR-NeRF:用于高质量辐射场重建的体素网格任意尺度超分辨率
摘要
基于 NeRF 的方法通过构建具有隐式或显式表示的辐射场来重建 3D 场景。 虽然基于 NeRF 的方法可以在任意尺度上执行新视图合成 (NVS),但使用低分辨率 (LR) 优化进行高分辨率新视图合成 (HRNVS) 的性能通常会导致过度平滑。 另一方面,单图像超分辨率 (SR) 旨在将 LR 图像增强为 HR 图像,但缺乏多视图一致性。 为了解决这些挑战,我们提出了任意尺度超分辨率 NeRF (ASSR-NeRF),这是一个用于超分辨率新视图合成 (SRNVS) 的新框架。 我们提出了一个基于注意力的 VoxelGridSR 模型,以直接对优化后的体积执行 3D 超分辨率 (SR)。 我们的模型在不同的场景中进行训练,以确保泛化能力。 对于使用 LR 视图训练的未见场景,我们可以直接应用我们的 VoxelGridSR 来进一步细化体积并实现多视图一致的 SR。 我们定量和定性地证明了所提出的方法在 SRNVS 中取得了显著的性能。
关键词:
神经辐射场 超分辨率 特征蒸馏1 引言
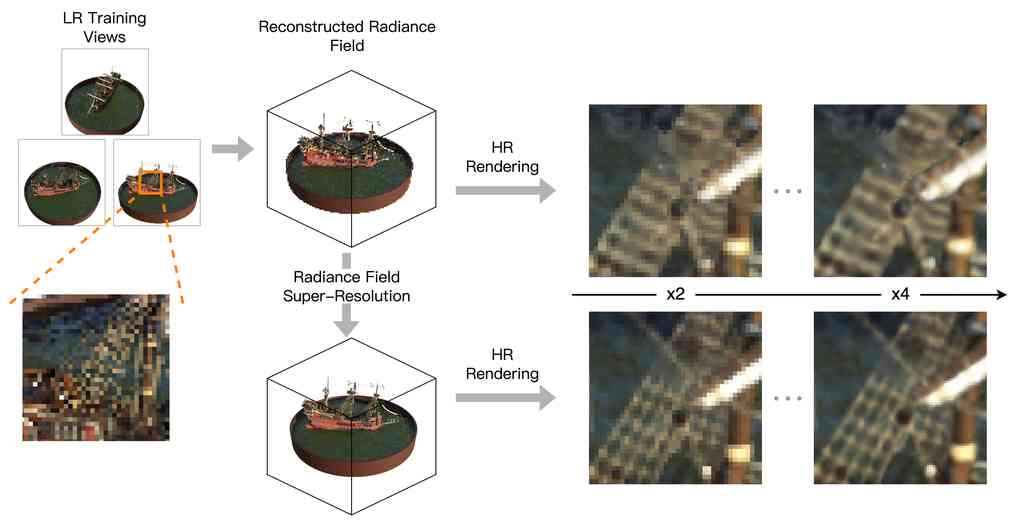
新视图合成 (NVS) 或 3D 场景重建旨在从任意视角合成 3D 场景的图像,前提是给定多视图图像和相机姿态。 NeRF [26] 通过将神经网络用作隐式体积表示来实现显着的 NVS 结果,该表示将 3D 位置和视角方向映射到与视角相关的颜色和占用率。 由于其灵活性,许多后续扩展、应用程序和改进都建立在 NeRF 的基础上。 虽然当前最先进的基于 NeRF 的方法可以准确地合成场景的几何形状和外观,但高分辨率新视角合成 (HRNVS) 对它们提出了巨大的挑战,其中高分辨率 (HR) 新视角是由从低分辨率 (LR) 训练视角构建的辐射场渲染的。 由于 LR 训练视角缺乏场景细节,渲染的 HR 新视角模糊且噪声很大。
另一方面,单图像超分辨率 (SISR) 旨在从其 LR 对应物合成 HR 图像。 与数学上采样方法(例如双线性插值)不同,SISR 方法 [9, 21, 43, 17, 20, 24, 35] 集成深度学习模型来丰富 LR 图像中缺失的细节和纹理。 最近,随着扩散模型的出现,基于生成的方法 [34, 19] 展示了令人兴奋的结果。
解决 HRNVS 上述质量问题的直接方法是直接将 SISR 方法应用于渲染的视图。 但是,在每个视图上独立应用 SISR 会导致多视图不一致,即物体的几何形状或外观在多个渲染视图之间不一致。 [33] 首先提出了用于神经辐射场超分辨率 (SR) 的 NeRF-SR。 给定一组 LR 训练视角和同一场景的 1 个 HR 参考视角,NeRF-SR 通过超采样和基于补丁的细化模块来细化渲染的 HR 视角。 虽然它显示出令人满意的结果,但要求每个场景都有一个 HR 参考视角并不实际。 具有类似想法,Super-NeRF [10] 和 CROP [39] 提议使用 SR 模块来指导 NeRF 的 HR 渲染,并且渲染的新视角可以被循环利用来指导 SR 模块,使其 SR 输出视图一致。 但是,每个场景都需要进行长时间的优化,或者 SR 的上采样因子是固定的,降低了灵活性。 一篇预印本 [1] 提议将神经辐射场分解为三平面 [6],并将预训练的 SISR 模型应用于 2D 特征平面。 虽然这种设计提高了 SR 模块的泛化能力,即在场景中训练或微调的 SR 模块可以直接应用于另一个场景,但在三平面独立应用 SR 会导致平面之间不一致。
在这项工作中,我们提出了一种任意尺度超分辨率 NeRF(ASSR-NeRF),用于在没有上述问题的情况下进行超分辨率新视角合成 (SRNVS)。 虽然 HRNVS(由常见的基于 NeRF 的模型执行)只提高了渲染视图的分辨率,而没有添加更多细节,但 SRNVS 旨在丰富新视图中的细节和纹理,并保持多视图一致性。 ASSR-NeRF 由两部分组成:一个从 LR 视图重建的基于体素的蒸馏特征场,以及一个基于注意力的 VoxelGridSR 模型,它将直接对辐射场进行超分辨率。 受 [30, 40, 41]的启发,我们首先构建了一个蒸馏特征场,以用显式体素网格表示场景。 为了让 VoxelGridSR 对有意义的特征执行注意力,部署了特征蒸馏,将提取的 2D 训练视图特征嵌入到 3D 体素网格中。 由于我们的 SR 在 3D 空间中执行,因此不会出现多视图不一致性。 VoxelGridSR 的设计灵感来自 LIIF [8],它将 SR 视为坐标与其对应 RGB 值之间的映射问题。 给定查询点的坐标,VoxelGridSR 对从其局部区域查询的蒸馏特征执行密度-距离感知注意力,并输出一个表示查询点的细化特征。 由于 3D 空间中的坐标是连续的,VoxelGridSR 能够优化任意尺度的 SR。 此外,由于 VoxelGridSR 是可泛化的,因此它可以作为一种现成的方法,可以直接应用于任何未见场景的重建特征场,用于 SRNVS。
总之,我们工作的主要贡献如下:
-
•
我们提出了一种新的框架 ASSR-NeRF,用于对辐射场进行超分辨率新视角合成 (SRNVS)。
-
•
我们将低级 2D SR 先验知识从预训练的特征提取器中蒸馏到辐射场中,以利于 3D 空间中的 SR。
-
•
我们设计了 VoxelGridSR 模型,以通过更丰富的纹理和细节来细化优化的体积,用于 SRNVS。
-
•
我们训练 VoxelGridSR 以使其可泛化,因此我们可以直接细化使用 LR 视图训练的未见场景的辐射场。
2 相关工作
2.1 图像超分辨率
图像超分辨率(SR)旨在从低分辨率(LR)图像中恢复高分辨率(HR)图像。 早期的图像 SR 方法 [9, 21, 43, 17] 采用深度卷积神经网络(CNN)来提高性能。 在注意力机制出现后,SwinIR [20] 和 ESRT [24] 等方法使用基于 Transformer 的架构实现了具有竞争力的性能。 为了进一步丰富 SR 结果中的细节,基于 GAN 和基于扩散的方法 [35, 19, 34] 分别通过对抗训练和强大的扩散模型生成更精细的细节以及丰富的纹理。 尽管在图像 SR 任务中表现出色,但大多数方法只能对一个固定尺度执行 SR,无法适应现实世界中显示设备分辨率不同的场景。 为了执行任意尺度超分辨率(ASSR),可以先适当放大输入图像,然后应用现有的图像 SR 方法。 但是,这种方法很耗时,并且当放大因子过大时会导致结果不理想。 最近,提出了一些方法 [12, 8, 18, 36, 4, 37] 来使用单个模型解决 ASSR。 LIIF [8] 使用 MLP 将任意坐标映射到 RGB 颜色,并以编码的图像潜伏为输入。 CiaoSR [4] 与 LIIF 的理念相同,进一步应用了注意力机制以扩大感受野并集成局部预测。
2.2 神经辐射场
NeRF [26] 已成为一种用于新视图合成 (NVS) 的突出方法,在多个输入视图和已知相机姿态的情况下展示了显著的结果。 具体来说,NeRF 将 3D 场景的外观和几何编码到多层感知器 (MLP) 中,该感知器以 3D 位置和视角方向为输入,并预测相应的颜色和密度。 然后,体积渲染技术沿相机射线累积查询的属性以形成像素的颜色。 许多后续工作将此想法扩展到不同的设置和场景。 一些方法通过显式结构显着提高了训练或渲染效率。 DVGO 和 Plenoxel [30, 40] 使用体素网格作为显式场景表示,从而实现快速收敛。 TensoRF [7] 使用三平面结构表示场景,大大减少了训练时间和内存使用量。 另一方面,一些方法专注于渲染质量。 Mip-NeRF [2] 利用mipmap 在不同分辨率渲染时实现抗锯齿,而 Zip-NeRF [3] 进一步整合了基于网格的表示,灵感来自 Instant-ngp [27],从而实现更快的重建和抗锯齿渲染,在 NVS 方面取得了最先进的性能。
2.3 神经辐射场的超分辨率
由于 NeRF [26] 为 NVS 学习了连续体积表示,因此它可以直接以任意分辨率渲染新视图。 但是,NeRF 采用的渲染过程使用每个像素一个射线对场景进行采样,因此在训练和渲染视图分辨率不同时,会产生混叠、模糊或伪影。 超采样,即每个像素采样多个射线,是一种有效的解决方案,但它会给 MLP 查询带来沉重的计算负担。 将现有的图像 SR 方法应用于渲染的新视图是另一种直接方法。 然而,独立地对每个视图进行超分辨率会导致多视图不一致,即物体在不同视图中的几何形状会有所不同。 已经提出了几种方法 [2, 11, 3] 来缓解此质量问题,但它们只“保留”细节,无法“丰富”LR 训练视图中遗漏的细节。 例如,给定古董花瓶的 LR 训练视图,Mip-NeRF [2] 可以生成抗锯齿的 HR 新视图,但无法恢复花瓶上的更精细图案。 NeRF-SR [33] 首次提出一个模块来使用同一场景的 HR 参考视图来细化渲染的 HR 新视图的细节。 RefSR-NeRF [13] 遵循相同的思想,执行基于参考的 SR,并实现了巨大的加速。 [39] 进一步削弱了每个场景总是有 HR 参考图像的假设,提出仅使用 LR 训练视图对新视图进行超分辨率。 虽然这些方法展示了令人印象深刻的结果,但所有 SR 模块都使用固定的上采样因子进行训练,或者需要进行每个场景的优化。
3 预备知识
NeRF [26] 通过将场景的几何形状和占用率编码到多层感知器 (MLP) 中来执行 3D 场景重建。 MLP 将 3D 位置 和视角方向 映射到相应的视角相关颜色 和密度 。 NeRF 通过遍历射线来渲染每个穿过像素的射线 的颜色 。 沿着每条射线, 点被采样以查询 MLP 的相应颜色 和密度 ,然后通过以下公式进行混合:
| (1a) | ||||
| (1b) | ||||
| (1c) | ||||
其中 是采样射线; 是累积透射率; 是不透明度; 表示在点 处终止的概率; 是到相邻点的距离。 然后可以使用光度损失训练 NeRF 模型:
| (2) |
虽然 NeRF 在新视角合成方面表现出色,但它难以处理漫长的训练和渲染时间。 后续工作 [30, 40, 27, 7] 通过用基于网格的表示替换 MLP 来提高训练效率。 我们基于 DVGO [30] 构建了超分辨率算法,其中感兴趣的模态,例如 3D 位置的密度、颜色,被明确地存储为体素特征,并且可以通过三线性插值进行查询:
| (3) |
其中 表示体素网格, 是 3D 位置, 是模态的维度, 分别表示网格的 3 个维度。 我们使用密度网格表示几何形状,使用特征网格表示外观。 此外,还使用了一个浅层 MLP 网络,称为 RGBNet,将查询的体素特征和视角方向映射到视角相关颜色。
4 方法
4.1 概述
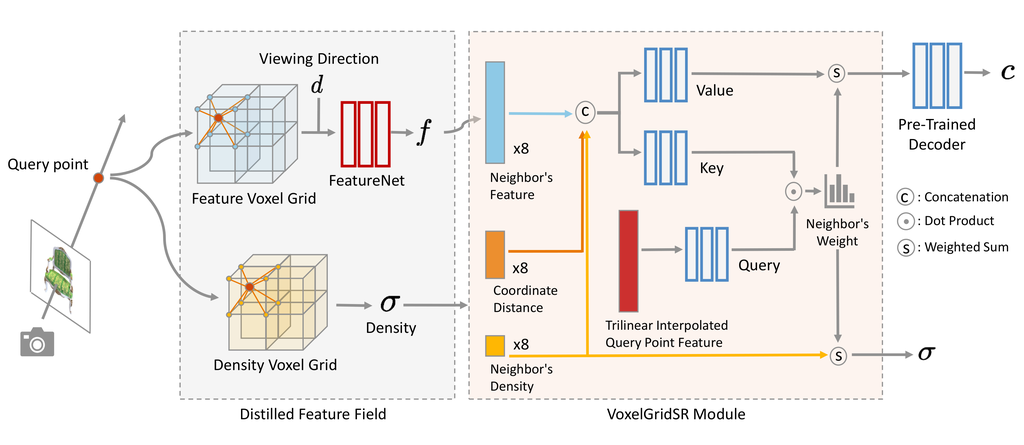
在本节中,我们描述了我们的方法,称为 ASSR-NeRF,用于任意尺度超分辨率 NeRF。 图 2 概述了我们的方法。 ASSR-NeRF 主要由两部分组成:(i) 基于体素的蒸馏特征场和 (ii) 一个可泛化的 VoxelGridSR 模块。 蒸馏确保了潜在空间对齐,以便于多场景训练和对新场景的泛化。 VoxelGridSR 学习利用蒸馏的 SR 潜在特征来细化辐射场。 以下各节组织如下:我们首先在第 4.2 节中描述了我们的蒸馏特征场,并解释了它在我们的方法中为什么至关重要。 然后在第 4.3 节中,我们介绍了可泛化的 VoxelGridSR 模块,它作为辐射场超分辨率的核心。 最后,我们在第 4.4 节中说明了 VoxelGridSR 的训练策略。
4.2 基于体素的蒸馏特征场
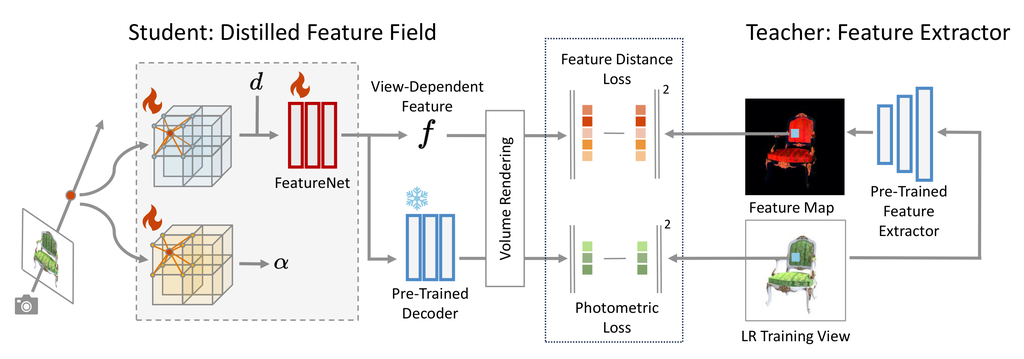
如图 2 所示,给定一个查询坐标 ,每个 最近邻居的密度 和体素特征 从体素网格中查询。 特征和密度体素网格分别明确存储外观和占用信息,并且 FeatureNet 进一步将体素特征 映射到视图相关的蒸馏特征 ,以便 VoxelGridSR 执行自注意力。 在没有特殊修改的情况下,从辐射场查询的特征只不过是高维颜色,这限制了 VoxelGridSR 自注意力的性能。 将 3D 特征提取器应用于体素特征网格是一个直接的解决方案,但用于 3D 特征提取器的训练数据的不足会导致整体性能较差。 另一方面,大量图像数据以及预训练模型可以极大地有利于 3D 任务。 受此观察的启发,我们提出了用于 ASSR-NeRF 中场景表示的蒸馏特征场,它通过特征蒸馏弥合了 2D 和 3D 数据之间的差距。
近年来,一些神经辐射场的工作在其方法中引入了特征蒸馏。 [16, 32] 为 NeRF [26] 添加了一个额外的分支来从 DINO [5] 学习语义特征,并在查询点上使用蒸馏的语义特征执行辐射场的开放集语义分割。 [14] 将多尺度 CLIP [29] 特征嵌入到辐射场中,并在 3D 空间中执行视觉接地。 虽然以上所有方法都蒸馏了高级特征,但我们建议将基于学习的低级特征蒸馏到我们的辐射场中作为 SR 先验,因为它们代表了关于场景纹理和细节的大量信息。 特征蒸馏对于我们的工作也是至关重要的,因为它保证了 VoxelGridSR 模型的泛化能力。 通过将来自相同教师提取器的特征蒸馏到辐射场中,来自不同场景的特征体素网格可以具有对齐的相同潜在空间,即,从所有辐射场查询的特征的分布保持相同。 通过这种方式,VoxelGridSR 可以在一个统一的潜在空间中进行训练,该潜在空间由来自所有场景的体素网格共享,并实现泛化能力。
我们首先遵循 [8] 中的自编码器训练范式来训练一个残差稠密网络 (RDN) [44] 作为特征提取器 和一个解码器 。 然后,我们遵循师生设置将特征蒸馏到辐射场中,如图 3 所示。 提炼的特征域基于体素网格,因此 VoxelGridSR 模块可以直接对场景表示进行超分辨率,从而保证渲染的新视图的多视角一致性。 遵循 [30, 40],我们使用两个体素网格:一个密度体素网格 和一个特征体素网格 ,分别显式地表示 3D 场景的几何形状和外观,其中 是特征空间的维度。 给定一个查询点 ,其密度 和体素特征 通过三线性插值从体素网格中查询,FeatureNet 进一步将 和视角方向 映射到视角相关的特征 。 此外, 将 解码为颜色 。 提炼的特征域通过最小化渲染特征 和教师提取的特征 之间的差异,以及渲染的颜色和地面真实像素颜色来训练。 则总损失 变成光度损失 和特征距离损失 的总和:
| (4a) | ||||
| (4b) | ||||
| (4c) | ||||
其中 是特征距离损失的权重,默认情况下设置为 0.5。 遵循 [16],我们在渲染 时对密度应用停止梯度,因为 可能不是多视角一致的。
4.3体素网格SR
我们详细介绍了 VoxelGridSR 的架构,用于细化辐射场。 受 ASSR 方法 [8, 4] 的启发,我们将我们的 VoxelGridSR 设计为一个局部 3D 隐式函数,该函数将 3D 坐标及其附近的体素特征映射到细化的特征,以便随后进行颜色解码。 为此,我们在 3D 细化过程中引入了 密度-距离感知注意力。 给定一个查询点 ,我们对相应的提炼特征 (第 4.2 节)进行三线性插值,以生成注意力查询。 我们从八个最近邻网格点位置 中收集上下文信息,每个位置包含其提炼特征 、体积密度 以及到查询点的偏移 。 然后,注意力操作中的查询、键和值可以定义为:
| (5) |
其中 、 和 在 MLPs 之前被连接起来,然后形成键矩阵 和值 矩阵。 然后可以通过缩放点积注意力来执行注意力:
| (6) |
其中 是体素特征的维度。 密度-距离感知注意力 允许 VoxelGridSR 考虑特征相关性和局部空间关系。 密度信息也有益,因为它有助于区分界面,例如,物体和空气。 从 第 4.2 节 中提取的特征使 VoxelGridSR 能够利用 SR 先验来增强场景的纹理和细节。 此外,我们还通过将网格点密度与注意力权重聚合来细化几何形状:
| (7) |
4.4 VoxelGridSR 的多场景训练
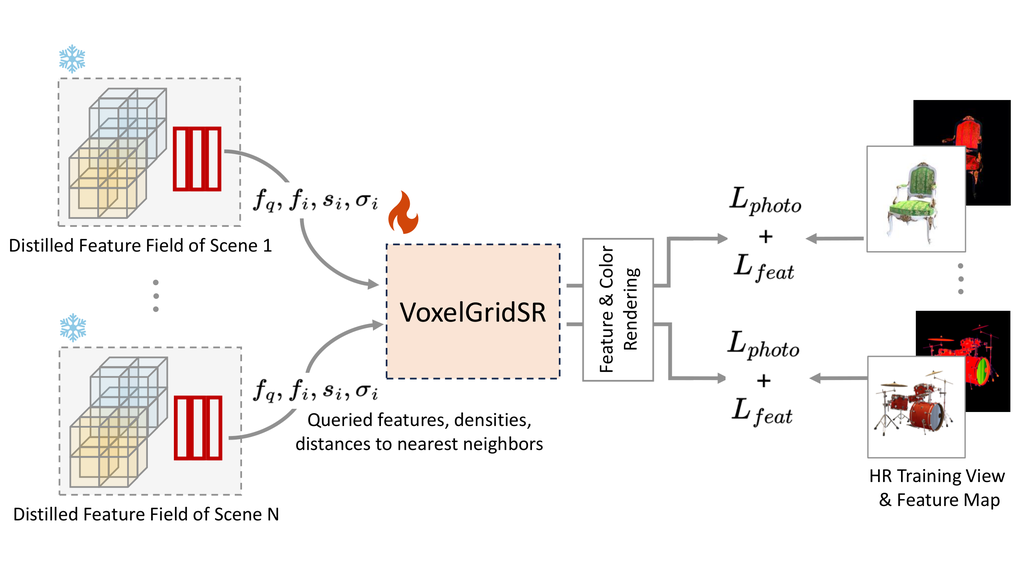
在单个场景上训练 VoxelGridSR 意义不大。 由于提取的 3D 特征与 2D 教师的 SR 潜在空间对齐,因此我们在多个场景上训练 VoxelGridSR 以实现泛化。 一旦训练完成,VoxelGridSR 模块就可以作为任何在相同潜在空间下的提取特征场的现成增强器。 图 4 描述了 VoxelGridSR 的多场景训练过程。 我们首先使用 LR 视图和提取特征场对 场景进行预训练。 随后,在跨场景训练的每次迭代中,场景 的特征域被 VoxelGridSR 通过 密度-距离-感知注意 随机选择并优化。 然后我们可以最小化渲染的 SR 视图和地面真实 HR 视图之间的光度损失 。 特征匹配损失 也被应用来确保潜空间保持一致。
5 实验
5.1 实现细节
我们使用 PyTorch [28] 实现 ASSR-NeRF。 为了有效地采样所有最近邻的密度、特征和相对距离,我们设计了自定义 CUDA 扩展。 我们为密度和特征体素网格设置了预期的体素数量 。 我们蒸馏的特征域中的 FeatureNet 基于 RDN [44],预训练的解码器由 5 个 MLP 层组成,维度为 。 FeatureNet 和解码器在 DIV2K [31] 数据集上的自编码器范式中一起训练。 为了训练 VoxelGridSR,我们以分辨率 获取 BlendedMVS [38] 数据集作为 HR 地面真实训练视图,并使用因子 降采样以生成相应的 LR 训练视图。 每个场景的蒸馏特征域经过 次迭代和 的批量大小进行训练。 我们首先从 BlendedMVS 重建了 个场景的蒸馏特征域。 在重建了 个场景的蒸馏特征域之后,我们使用蒸馏特征域训练 VoxelGridSR 模块,迭代次数为 ,批量大小为 。
5.2 比较与讨论
我们比较了 ASSR-NeRF 和其他最先进的基于 NeRF 的 NVS 方法 [30, 3],并采用了不同的设置。 其中,DVGO [30] 充当基线,因为其架构,包括体素网格和浅层 MLP 层,与我们类似。 Zip-NeRF [3] 针对抗锯齿进行了优化,因此其渲染的新视图在训练和测试分辨率差异很大的情况下仍然清晰。 我们还将我们的方法与图像 SR 方法 [20, 34] 和辐射场 SR 方法 [39] 进行比较。
5.2.1 基于 NeRF 的 NVS 方法
| x1.6 | x2 | x4 | |||||||
| Synthetic-NeRF | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS |
| DVGO [30] | 29.89 | 0.945 | 0.061 | 28.80 | 0.933 | 0.077 | 27.33 | 0.910 | 0.115 |
| TensoRF [7] | 31.36 | 0.950 | 0.060 | 29.96 | 0.947 | 0.078 | 28.07 | 0.916 | 0.118 |
| Instant-ngp [27] | 28.55 | 0.933 | 0.095 | 28.23 | 0.926 | 0.101 | 27.26 | 0.902 | 0.128 |
| Zip-NeRF [3] | 30.95 | 0.962 | 0.041 | 29.56 | 0.951 | 0.057 | 27.73 | 0.923 | 0.102 |
| ASSR-NeRF (ours) | 31.09 | 0.961 | 0.048 | 30.57 | 0.954 | 0.057 | 29.02 | 0.932 | 0.093 |
| x2 | x2.5 | x4 | |||||||
| BlendedMVS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS |
| DVGO [30] | 26.88 | 0.909 | 0.111 | 26.96 | 0.902 | 0.124 | 24.74 | 0.845 | 0.187 |
| TensoRF [7] | 27.72 | 0.921 | 0.114 | 27.78 | 0.912 | 0.131 | 25.35 | 0.852 | 0.182 |
| Instant-ngp [27] | 26.63 | 0.894 | 0.150 | 26.64 | 0.882 | 0.166 | 25.14 | 0.835 | 0.188 |
| Zip-NeRF [3] | 28.48 | 0.929 | 0.148 | 28.41 | 0.918 | 0.173 | 25.97 | 0.854 | 0.237 |
| ASSR-NeRF (ours) | 28.52 | 0.931 | 0.080 | 28.56 | 0.926 | 0.093 | 26.38 | 0.873 | 0.148 |
| PSNR | SSIM | LPIPS | |
| Zip-NeRF [3] + SwinIR [20] | 26.21 | 0.866 | 0.159 |
| Zip-NeRF [3] + StableSR [34] | 24.56 | 0.839 | 0.169 |
| CROP [39] | 26.25 | 0.879 | 0.145 |
| ASSR-NeRF (ours) | 26.38 | 0.873 | 0.148 |

在此实验中,我们将 ASSR-NeRF 与最先进的基于 NeRF 的方法进行比较,用于高分辨率新视图合成 (HRNVS)。 对于每个场景,我们使用 LR 训练视图训练一个蒸馏特征场,并直接将预训练的 VoxelGridSR 应用于蒸馏特征场以执行超分辨率新视图合成 (SRNVS)。 我们还使用 LR 训练视图训练其他方法,并执行 HRNVS。 我们在两个数据集上比较所有方法,Synthetic-NeRF [26] 和 BlendedMVS [38],并使用三种不同的比例。 请注意,在所有实验中,用于训练 VoxelGridSR 的场景与用于测试的场景之间不存在重叠。 在 Tab. 1 中,我们展示了 PSNR、SSIM 和 LPIPS 的结果。 我们看到,ASSR-NeRF 在每个比例上都超过了所有其他方法。 尽管 Zip-NeRF 在比例较低时具有一定的优势,但当比例增加时,其性能会大幅下降,揭示了基于 NeRF 的常用方法的缺点。 此结果与我们最初的观察结果一致,即在 LR 训练视图上训练的 NVS 方法在渲染 HR 新视图时性能不理想。 我们还在图 10 中展示了定性结果。 ASSR-NeRF 除了渲染出更清晰的视图外,还能生成更精细的细节和纹理。 例如,ASSR-NeRF 在人物的衣服上生成更清晰的图案,并在麦克风的边缘生成更清晰的边缘。
5.2.2 超分辨率方法
在此实验中,我们将我们的方法与图像 SR 方法以及辐射场 SR 方法进行比较。 按照 Sec. 5.2.1 中的训练设置,我们使用 LR 训练视图训练 Zip-NeRF [3]。 然后,我们以相同的比例渲染 LR 新视图,并使用最先进的图像 SR 方法 [20, 34] 对新视图进行超分辨率。 SwinIR [20] 将 Swin Transformer [23] 集成到其架构中,以便更好地提取输入图像的特征。 StableSR [34] 利用预先训练的扩散模型在 SR 结果中生成更精细的细节和纹理。 除了在渲染的新视图上使用图像 SR,我们还与一种辐射场 SR 方法 [39] 进行了比较,该方法与我们的设置类似。 CROP [39] 首先使用预训练的图像 SR 方法对 LR 训练视图进行超分辨率处理,并使用超分辨率视图来训练基于 NeRF 的 NVS 模型。 与其他需要同一场景的高分辨率参考图像的辐射场 SR 方法 [33, 13] 不同,CROP 在测试时只需要 LR 训练视图。 我们的方法不同于 CROP,我们的 VoxelGridSR 模块在任意尺度上进行了优化,而 CROP 则是在固定的放大倍率下进行训练的。 所有方法都使用放大倍率 执行 HRNVS。 在表 2 中,我们展示了 BlendedMVS [38] 上的量化结果。 虽然我们的方法在 SSIM 和 LPIPS 得分方面与 CROP 相当,但我们的方法在 PSNR 方面表现更好。
5.2.3 多视图一致性
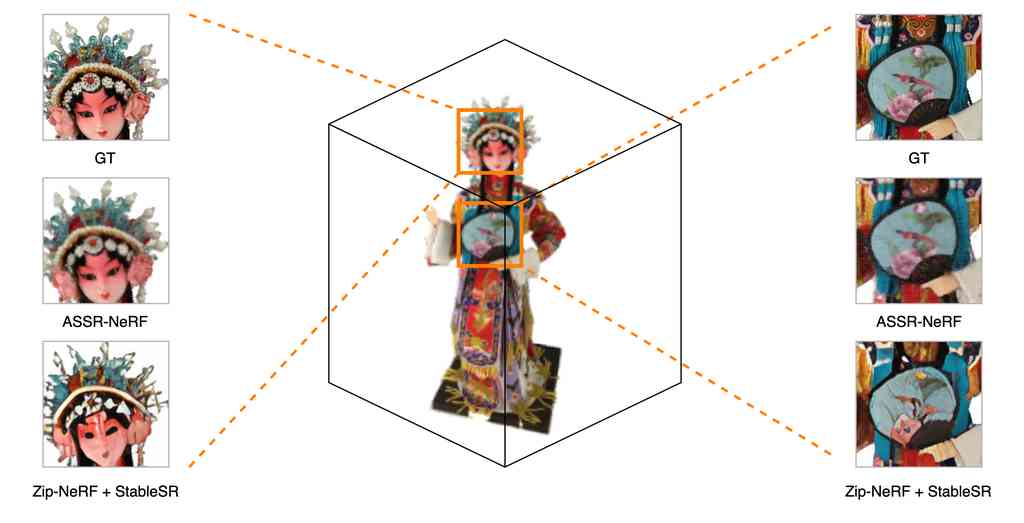
在本节中,我们将讨论多视图一致性问题。 在第 5.2.2 节中,我们进行了使用图像 SR 方法对渲染的 LR 新视图进行超分辨率处理的实验。 虽然这种方法也可以生成具有更精细细节的更清晰的 HR 新视图,但多视图不一致仍然是一个严重的问题。 如图 6 所示,使用图像超分辨率方法对渲染的低分辨率新视图进行超分辨率处理会导致不同视图之间几何形状和纹理失真。 另一方面,我们的方法从不同的相机姿态生成一致的视图。 我们的方法的这种优势来自于 ASSR-NeRF 的 SR 模块的设计。 VoxelGridSR 不是将 SR 应用于 2D 特征图,而是直接将 SR 应用于 3D 体积,即蒸馏后的特征场,保证了每个视角方向上的几何形状和外观的一致性。
5.3 消融研究
本节提供消融研究来分析我们提出的方法。 我们分析了 VoxelGridSR 模块的设计,以验证 密度-距离感知注意力 的有效性。
| Model | Feature-aware | Density-aware | Distance-aware | PSNR | SSIM | LPIPS |
|---|---|---|---|---|---|---|
| A | ✓ | ✓ | ✓ | 26.38 | 0.873 | 0.148 |
| B | ✓ | ✓ | 26.20 | 0.873 | 0.157 | |
| C | ✓ | ✓ | 26.14 | 0.872 | 0.147 |
5.3.1 VoxelGridSR 的分析
5.4 讨论和局限性
实验表明,我们的框架在 SRNVS 中取得了竞争性能。 然而,其中一个局限性是渲染时间增加,因为 VoxelGridSR 对每个采样点执行自注意力。 在保持相同质量的情况下减少渲染时间将是我们未来的研究方向。 我们还注意到,目前还没有有效的基准来评估多视图一致性,我们只能通过帧级指标(如 PSNR 和定性展示)将我们的方法与其他方法进行比较。 我们认为视频质量评估 (VQA) 可能是一个有趣的研究方向,可以作为多视图一致性的评估指标。
6 结论
在这项工作中,我们提出了 ASSR-NeRF,一个用于辐射场超分辨率的新颖框架。 ASSR-NeRF 由一个用于场景表示的蒸馏特征场和一个用于辐射场 SR 的可泛化 VoxelGridSR 模块组成。 一旦从任何一组 LR 训练视图重建了一个蒸馏特征场,就可以直接应用预先训练的可泛化 VoxelGridSR 模块来进行超分辨率新视图合成 (SRNVS)。 我们的方法可以极大地有利于现实世界的应用。 例如,廉价设备捕获的低分辨率训练视图可以有效地用于高质量的新视图合成,从而减少视图捕获所需的成本和时间。 对各种基准的实验以及定性比较表明,我们的框架在提高渲染质量方面非常有效。
参考文献
- [1] Bahat, Y., Zhang, Y., Sommerhoff, H., Kolb, A., Heide, F.: Neural volume super-resolution (2023)
- [2] Barron, J.T., Mildenhall, B., Tancik, M., Hedman, P., Martin-Brualla, R., Srinivasan, P.P.: Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields (2021)
- [3] Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Zip-nerf: Anti-aliased grid-based neural radiance fields (2023)
- [4] Cao, J., Wang, Q., Xian, Y., Li, Y., Ni, B., Pi, Z., Zhang, K., Zhang, Y., Timofte, R., Gool, L.V.: Ciaosr: Continuous implicit attention-in-attention network for arbitrary-scale image super-resolution (2023)
- [5] Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers (2021)
- [6] Chan, E.R., Lin, C.Z., Chan, M.A., Nagano, K., Pan, B., Mello, S.D., Gallo, O., Guibas, L., Tremblay, J., Khamis, S., Karras, T., Wetzstein, G.: Efficient geometry-aware 3d generative adversarial networks (2022)
- [7] Chen, A., Xu, Z., Geiger, A., Yu, J., Su, H.: Tensorf: Tensorial radiance fields (2022)
- [8] Chen, Y., Liu, S., Wang, X.: Learning continuous image representation with local implicit image function (2021)
- [9] Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 38, 295–307 (2014), https://api.semanticscholar.org/CorpusID:6593498
- [10] Han, Y., Yu, T., Yu, X., Wang, Y., Dai, Q.: Super-nerf: View-consistent detail generation for nerf super-resolution (2023)
- [11] Hu, W., Wang, Y., Ma, L., Yang, B., Gao, L., Liu, X., Ma, Y.: Tri-miprf: Tri-mip representation for efficient anti-aliasing neural radiance fields (2023)
- [12] Hu, X., Mu, H., Zhang, X., Wang, Z., Tan, T., Sun, J.: Meta-sr: A magnification-arbitrary network for super-resolution (2019)
- [13] Huang, X., Li, W., Hu, J., Chen, H., Wang, Y.: Refsr-nerf: Towards high fidelity and super resolution view synthesis. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8244–8253. IEEE Computer Society, Los Alamitos, CA, USA (jun 2023). https://doi.org/10.1109/CVPR52729.2023.00797, https://doi.ieeecomputersociety.org/10.1109/CVPR52729.2023.00797
- [14] Kerr, J., Kim, C.M., Goldberg, K., Kanazawa, A., Tancik, M.: Lerf: Language embedded radiance fields (2023)
- [15] Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything (2023)
- [16] Kobayashi, S., Matsumoto, E., Sitzmann, V.: Decomposing nerf for editing via feature field distillation (2022)
- [17] Ledig, C., Theis, L., Huszár, F., Caballero, J., Aitken, A.P., Tejani, A., Totz, J., Wang, Z., Shi, W.: Photo-realistic single image super-resolution using a generative adversarial network. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) pp. 105–114 (2016), https://api.semanticscholar.org/CorpusID:211227
- [18] Lee, J., Jin, K.H.: Local texture estimator for implicit representation function (2022)
- [19] Li, H., Yang, Y., Chang, M., Feng, H., hai Xu, Z., Li, Q., ting Chen, Y.: Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing 479, 47–59 (2021), https://api.semanticscholar.org/CorpusID:233476433
- [20] Liang, J., Cao, J., Sun, G., Zhang, K., Gool, L.V., Timofte, R.: Swinir: Image restoration using swin transformer. 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) pp. 1833–1844 (2021), https://api.semanticscholar.org/CorpusID:237266491
- [21] Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) pp. 1132–1140 (2017), https://api.semanticscholar.org/CorpusID:6540453
- [22] Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Li, C., Yang, J., Su, H., Zhu, J., Zhang, L.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection (2023)
- [23] Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows (2021)
- [24] Lu, Z., Li, J., Liu, H., Huang, C., Zhang, L., Zeng, T.: Transformer for single image super-resolution. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) pp. 456–465 (2021), https://api.semanticscholar.org/CorpusID:248366743
- [25] Mildenhall, B., Srinivasan, P.P., Ortiz-Cayon, R., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A.: Local light field fusion: Practical view synthesis with prescriptive sampling guidelines (2019), https://arxiv.org/abs/1905.00889
- [26] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis (2020)
- [27] Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics 41(4), 1–15 (Jul 2022). https://doi.org/10.1145/3528223.3530127, http://dx.doi.org/10.1145/3528223.3530127
- [28] Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Köpf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: Pytorch: An imperative style, high-performance deep learning library (2019)
- [29] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision (2021)
- [30] Sun, C., Sun, M., Chen, H.T.: Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction (2022)
- [31] Timofte, R., Agustsson, E., Gool, L.V., Yang, M.H., Zhang, L., Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M., Wang, X., Tian, Y., Yu, K., Zhang, Y., Wu, S., Dong, C., Lin, L., Qiao, Y., Loy, C.C., Bae, W., Yoo, J., Han, Y., Ye, J.C., Choi, J.S., Kim, M., Fan, Y., Yu, J., Han, W., Liu, D., Yu, H., Wang, Z., Shi, H., Wang, X., Huang, T.S., Chen, Y., Zhang, K., Zuo, W., Tang, Z., Luo, L., Li, S., Fu, M., Cao, L., Heng, W., Bui, G., Le, T., Duan, Y., Tao, D., Wang, R., Lin, X., Pang, J., Xu, J., Zhao, Y., Xu, X., Pan, J., Sun, D., Zhang, Y., Song, X., Dai, Y., Qin, X., Huynh, X.P., Guo, T., Mousavi, H.S., Vu, T.H., Monga, V., Cruz, C., Egiazarian, K., Katkovnik, V., Mehta, R., Jain, A.K., Agarwalla, A., Praveen, C.V.S., Zhou, R., Wen, H., Zhu, C., Xia, Z., Wang, Z., Guo, Q.: Ntire 2017 challenge on single image super-resolution: Methods and results. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 1110–1121 (2017). https://doi.org/10.1109/CVPRW.2017.149
- [32] Tschernezki, V., Laina, I., Larlus, D., Vedaldi, A.: Neural feature fusion fields: 3d distillation of self-supervised 2d image representations (2022)
- [33] Wang, C., Wu, X., Guo, Y.C., Zhang, S.H., Tai, Y.W., Hu, S.M.: Nerf-sr: High quality neural radiance fields using supersampling. In: Proceedings of the 30th ACM International Conference on Multimedia. MM ’22, ACM (Oct 2022). https://doi.org/10.1145/3503161.3547808, http://dx.doi.org/10.1145/3503161.3547808
- [34] Wang, J., Yue, Z., Zhou, S., Chan, K.C.K., Loy, C.C.: Exploiting diffusion prior for real-world image super-resolution (2023)
- [35] Wang, X., Yu, K., Wu, S., Gu, J., Liu, Y., Dong, C., Loy, C.C., Qiao, Y., Tang, X.: Esrgan: Enhanced super-resolution generative adversarial networks. In: ECCV Workshops (2018), https://api.semanticscholar.org/CorpusID:52154773
- [36] Wei, M., Zhang, X.: Super-resolution neural operator (2023)
- [37] Yao, J.E., Tsao, L.Y., Lo, Y.C., Tseng, R., Chang, C.C., Lee, C.Y.: Local implicit normalizing flow for arbitrary-scale image super-resolution (2023)
- [38] Yao, Y., Luo, Z., Li, S., Zhang, J., Ren, Y., Zhou, L., Fang, T., Quan, L.: Blendedmvs: A large-scale dataset for generalized multi-view stereo networks (2020)
- [39] Yoon, Y., Yoon, K.: Cross-guided optimization of radiance fields with multi-view image super-resolution for high-resolution novel view synthesis. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 12428–12438. IEEE Computer Society, Los Alamitos, CA, USA (jun 2023). https://doi.org/10.1109/CVPR52729.2023.01196, https://doi.ieeecomputersociety.org/10.1109/CVPR52729.2023.01196
- [40] Yu, A., Fridovich-Keil, S., Tancik, M., Chen, Q., Recht, B., Kanazawa, A.: Plenoxels: Radiance fields without neural networks (2021)
- [41] Yu, A., Li, R., Tancik, M., Li, H., Ng, R., Kanazawa, A.: Plenoctrees for real-time rendering of neural radiance fields (2021)
- [42] Zhang, K., Riegler, G., Snavely, N., Koltun, V.: Nerf++: Analyzing and improving neural radiance fields (2020)
- [43] Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.R.: Image super-resolution using very deep residual channel attention networks. ArXiv abs/1807.02758 (2018), https://api.semanticscholar.org/CorpusID:49657846
- [44] Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image super-resolution. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2472–2481 (2018). https://doi.org/10.1109/CVPR.2018.00262
补充材料
7 其他实现细节
7.1 特征提取器和预训练解码器
如主论文第 4 节所述,我们使用预训练特征提取器 为辐射场提供 SR 先验信息,并使用预训练解码器 将体素特征映射到提取的特征。 我们遵循 [8] 中的训练流程来共同训练 和 。 在自动编码器范式下,形状为 的输入图像 首先由 编码成形状为 的像素对齐特征图 ,其中 和 是输入图像的高度和宽度, 是特征的维度。 然后,解码器 将像素对齐特征映射到 RGB 值。 然后可以训练模型以最小化解码器输出与输入图像 之间的 L1 损失。 我们选择 RDN [44] 作为 ,因为它与其他架构相比,在训练效率和性能方面具有良好的平衡,并使用 5 个具有 ReLU 激活函数的 MLP 层作为解码器 。
7.2 数据集预处理

我们使用 BlendedMVS [38] 数据集训练所有实验中通用的 VoxelGridSR 模型,并按照所有先前工作在 5 个场景的子集上测试我们的方法。 在训练 VoxelGridSR 模型之前,我们首先从 BlendedMVS 中重建了 40 个场景的辐射场。 我们发现,BlendedMVS 主要包含复杂物体以及复杂背景的场景,这可能会影响重建的辐射场的质量。 为了确保 VoxelGridSR 使用重建良好的辐射场进行训练,我们设计了一个预处理流程来细化 BlendedMVS 数据。 给定场景 的原始训练视图,我们首先使用 Grounding DINO [22] 来标记目标对象的边界框。 然后,使用一个分割任何事物模型 (SAM) [15] 来分割该对象并生成具有对象掩码的训练视图。 然后,使用处理后的图像和相机姿态重建辐射场,用于训练 VoxelGridSR。 预训练的 Grounding DINO 和 SAM 直接用于此过程。
8 多视图一致性
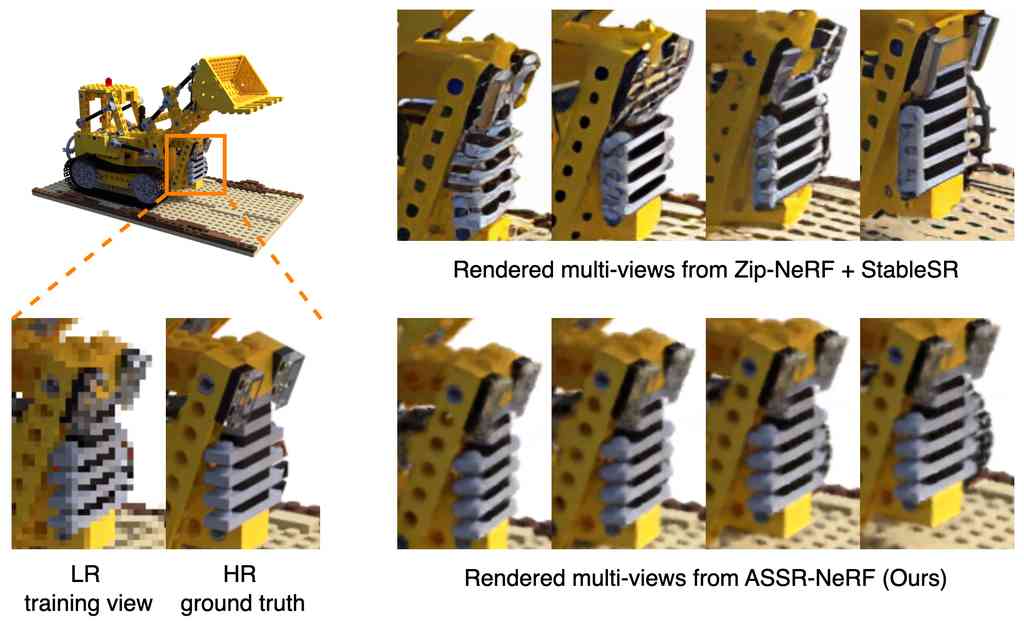
我们在图 8 中提供了关于多视图一致性的额外定性比较。 虽然对来自 Zip-NeRF [3] 的渲染 LR 新视图进行超分辨率处理会导致更清晰的结果,但会导致多视图不一致,即来自相邻相机姿态的视图之间的几何形状和外观差异很大。 另一方面,我们的方法以极高的一致性执行超分辨率新视图合成 (SRNVS)。
9 特征蒸馏分析

10 其他结果
10.1 边界场景

在第 5.2 节。 在主要论文中,我们提供了与 DVGO [30] 和 Zip-NeRF [3] 的定性比较。 在这里,我们提供了更多模型的额外定性结果,包括 TensoRF [7] 和 Instant-ngp [27],在 Synthetic-NeRF [26] 和 BlendedMVS [38] 上。 图 10 显示,我们的方法可以渲染具有更丰富和更清晰细节的高分辨率新视图。
10.2 面向前的场景
在主论文中,我们对有限场景数据集进行了实验。 这些场景以物体为中心,背景简单 [26, 38]。 在本节中,我们提供了关于 LLFF [25] 的结果,这是一个包含具有复杂物体和背景的正向场景的数据集。 遵循第 5.2 节的相同实验设置。 主论文,我们在 LLFF 上将我们的方法与 Zip-NeRF 进行比较。 如表 4 所示,ASSR-NeRF 在高放大倍数 (x4) 下优于 Zip-NeRF。 图 11 还表明,即使在重建具有复杂背景和物体的场景时,我们的方法也能有效地改善几何形状并获得更清晰的外观。
| x4 | PSNR | SSIM | LPIPS |
|---|---|---|---|
| Zip-NeRF | 23.351 | 0.690 | 0.419 |
| Ours(ASSR-NeRF) | 23.801 | 0.725 | 0.361 |
|
Zip-NeRF |
 |
 |
 |
|---|---|---|---|
|
Ours |
 |
 |
 |