使用 1,000,000,000 个角色扩展合成数据创建
摘要
我们提出了一种新颖的角色驱动数据合成方法,该方法利用大型语言模型(大语言模型)中的各种视角来创建多样化的合成数据。 为了大规模地充分利用这种方法,我们引入了 Persona Hub——根据网络数据自动整理的 10 亿个不同角色的集合。 这10亿个角色(占世界总人口的13%)作为世界知识的分布式载体,可以挖掘大语言模型中几乎所有的视角,从而促进多样化的合成数据的创建大规模用于各种场景。 通过展示 Persona Hub 在大规模合成高质量数学和逻辑推理问题、指令(即用户提示)、知识丰富的文本、游戏 NPC 和工具(函数)方面的用例,我们证明了角色驱动的数据合成是多功能的,可扩展、灵活且易于使用,有可能推动合成数据创建和实践应用的范式转变,这可能对大语言模型的研究和开发产生深远的影响。
免责声明:Persona Hub 可以促进十亿级合成数据的创建,以模拟来自各种现实世界用户的不同输入(即用例)。 如果使用该数据作为输入来查询目标大语言模型以获得其大规模输出,则有 高风险 大语言模型的知识、智能和能力将被倾销并容易被复制,从而挑战最强大的大语言模型的领先地位(例如,我们的方法允许7B大语言模型在数学上达到65%,与gpt-4-turbo-preview 的性能)。 这份技术报告是 仅供研究用途. 避免滥用并确保道德和负责任的应用至关重要。 我们在第 5 节中详细讨论了其广泛影响和潜在问题。

1简介
随着合成数据(Bauer等人,2024;Liu等人,2024)(通常指由模型或算法而不是人类直接生成的数据)变得越来越有价值(Li等人, 2023b) 对于训练大语言模型(大语言模型),人们对使用大语言模型进行数据合成越来越感兴趣:通过简单地指定数据合成提示,大语言模型有望产生所需的合成数据。
然而,在实践中,大规模创建合成数据并非易事:虽然我们可以轻松扩大合成数据的数量,但很难确保其多样性也扩大。 不考虑抽样111采样与这项工作正交。 当仅用于数据合成时,它引入的多样性通常是有限的。,在给定数据合成提示的情况下,一个大语言模型只能生成 1 个实例。 因此,要大规模创建多样化的合成数据(例如 10 亿个多样化的数学问题),需要大量多样化的提示。
先前的研究倾向于通过以下两种范式来使数据合成提示多样化,但不幸的是,这两种范式实际上都无法实现可扩展的合成数据创建:
-
•
实例驱动:这种方法通过利用种子语料库(即根据种子语料库中的实例创建新实例)来使数据合成提示多样化。 代表性研究包括Wang等人(2022)和Yu等人(2023)。 然而,在这种范式下,合成数据的多样性主要来自种子实例,很难真正扩展到种子语料库之外。 考虑到大多数实际场景中种子语料库的大小有限,这种范式扩大合成数据的创建规模具有挑战性。
-
•
关键点驱动:这种方法通过精选的关键点(或概念)综合列表使数据合成提示多样化,这些关键点(或概念)可以是主题、主题或我们期望合成数据包含的任何知识。 代表性研究包括Li 等人(2024b)和Huang 等人(2024)。 然而,这种方法在扩展合成数据创建方面也面临困难:通过枚举不同粒度级别的所有关键点来整理一个全面的列表实际上是令人望而却步的,除非仅限于狭窄且特定的领域(例如数学)。
为了切实实现大规模的多样化合成数据创建,我们提出了一种新颖的角色驱动数据合成方法。 这是受到观察的启发,只需在数据合成提示中添加角色即可引导大语言模型转向相应的视角,以创建独特的合成数据,如图1所示。 由于几乎任何大语言模型用例都可以与特定角色相关联,因此只要构建全面的角色集合,我们就可以大规模创建包罗万象的合成数据。
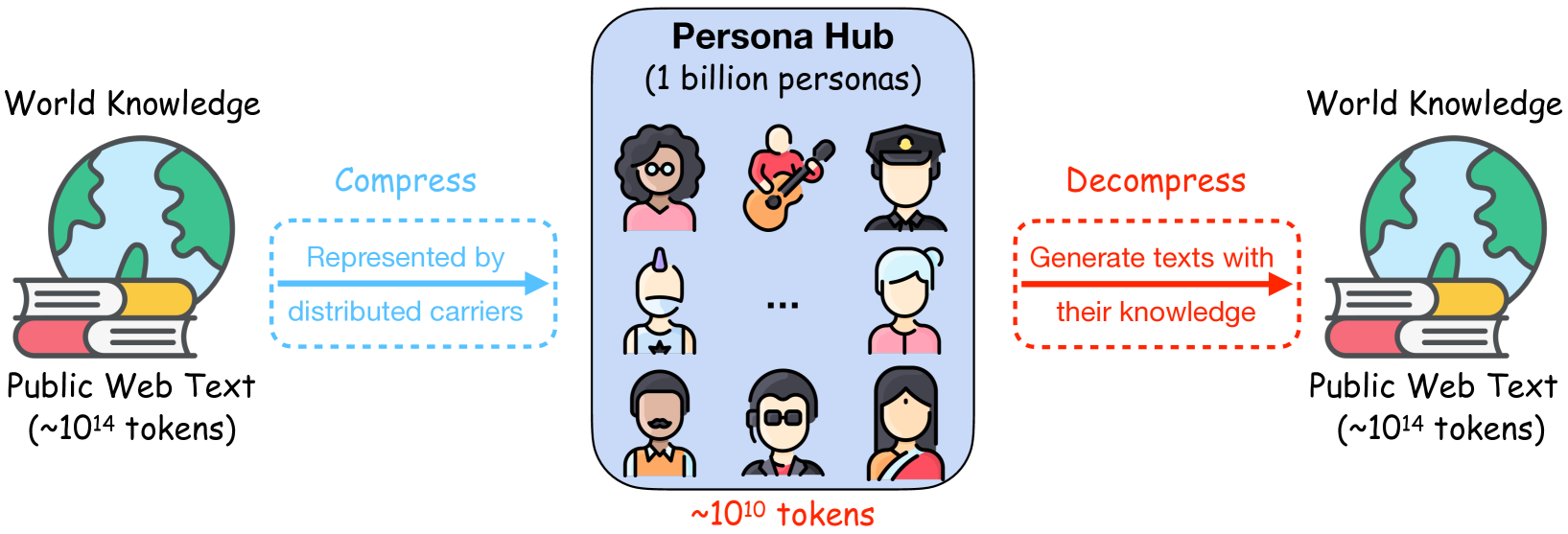
幸运的是,角色很容易扩展。 根据海量网络数据,我们自动构建 Persona Hub — 一个包含 10 亿个不同角色(占世界总人口的 13%)的角色集合。 如图2所示,这10亿个角色可以被视为世界知识的分布式载体,每个个体都可以与其独特的知识、经验、兴趣、个性和职业相关联;因此,他们可以利用大语言模型中封装的几乎所有视角来大规模创建多样化的合成数据,而不受种子语料库大小的限制。 此外,与通常与特定数据合成提示一起使用的关键点相比,人物角色可以与几乎任何数据合成提示相结合,这得益于大语言模型强大的角色扮演能力(Shanahan等人,2023;Li等人,2023a;Choi & Li,2024;Wang 等人,2024),使其普遍适用于各种数据合成场景。
我们展示了 Persona Hub 在大规模创建数学和逻辑推理问题、指令(即用户提示)、广泛覆盖的知识丰富文本、游戏 NPC 和工具(功能)开发方面的用例。 我们证明了角色驱动的数据合成是通用的、可扩展的、灵活的、易于使用的,有可能推动合成数据创建和实践应用的范式转变,这可能对大语言模型的研究和开发产生深远的影响。
为了促进角色驱动数据合成的研究,我们最初从 Persona Hub 发布了 200,000 个角色,并遵循我们使用各种角色创建的合成数据样本,包括:
-
•
50,000 道数学题
-
•
50,000 条指令
-
•
10000个游戏NPC
-
•
50,000道逻辑推理题
-
•
10,000 篇知识丰富的文本
-
•
5,000 个工具(功能)
当我们能够更好地评估潜在风险和担忧时,我们愿意发布更多数据,这将在第 5 节中详细讨论。
笔记: 我们提出的方法适用于几乎所有流行的大语言模型222我们主要使用公开的大语言模型,例如 GPT-4 (Achiam 等人, 2023)、Llama-3 和 Qwen (Team, 2024; qwe, 2024)我们的实验。. 本文中各图中显示的提示并不完全是我们在实验中使用的提示字符串;相反,它们被简化以适应空间并更好地说明概念。 感兴趣的读者可以使用我们发布的角色样本轻松验证我们的方法。 还值得注意的是,这项工作的主要重点是创建新的合成数据,这与之前的许多研究侧重于为特定输入(例如数学问题)生成合成输出不同。 因此,我们在整篇论文中交替使用“创造”和“合成”这两个术语。
2 角色中心
我们提出了两种可扩展的方法来派生不同的角色,以从海量网络数据构建角色中心:文本到角色和角色到角色。
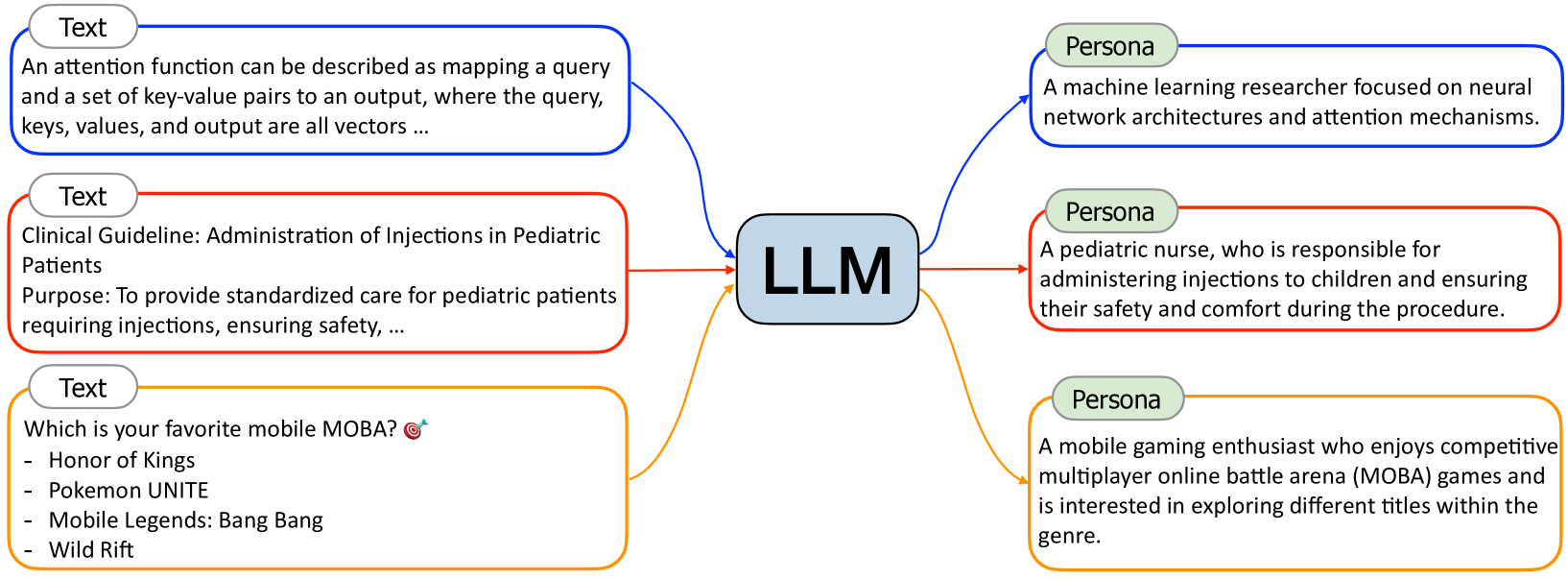
2.1 文本到角色
具有特定专业经验和文化背景的人会对阅读和写作产生独特的兴趣。 因此,从特定文本中,我们可以推断出可能[读|写|喜欢|不喜欢|…]该文本的特定角色。 鉴于网络上的文本数据实际上是无限的、包罗万象的,我们只需用这些网络文本提示大语言模型就可以获得广泛的人物角色集合,如图3所示。
有多种格式(例如,纯文本或结构化文本)来表示角色,可以在提示中进行控制。 输出角色描述的粒度也可以通过提示进行调整。 例如,在第一种情况下,粗粒度角色可能是“计算机科学家”,而细粒度角色是“专注于神经网络架构和注意力的机器学习研究人员”机制”。 在我们的实践中,我们要求大语言模型(在提示中)尽可能具体地输出角色描述。 除了在提示中指定人物描述的粒度之外,输入文本也会影响人物描述的粒度。 如图4所示,如果输入文本(例如,来自数学教科书或有关超导性的学术论文)包含许多详细元素,则生成的角色描述也将是具体且细粒度的。 因此,通过将文本到角色方法应用于海量网络文本数据,我们可以获得数十亿(甚至数万亿)个不同的角色,涵盖不同粒度的广泛方面。

2.2 角色到角色
如上所述,文本到角色是一种高度可扩展的方法,可以合成涵盖几乎所有方面的角色。 然而,它仍然可能会错过一些在网络上可见度较低的角色,因此不太可能通过文本到角色获得,例如孩子、一个乞丐,或者电影的幕后工作人员。 为了补充Text-to-Persona可能难以达到的角色,我们提出了Persona-to-Persona,它从通过Text获得的角色中派生出具有人际关系的角色-到角色。
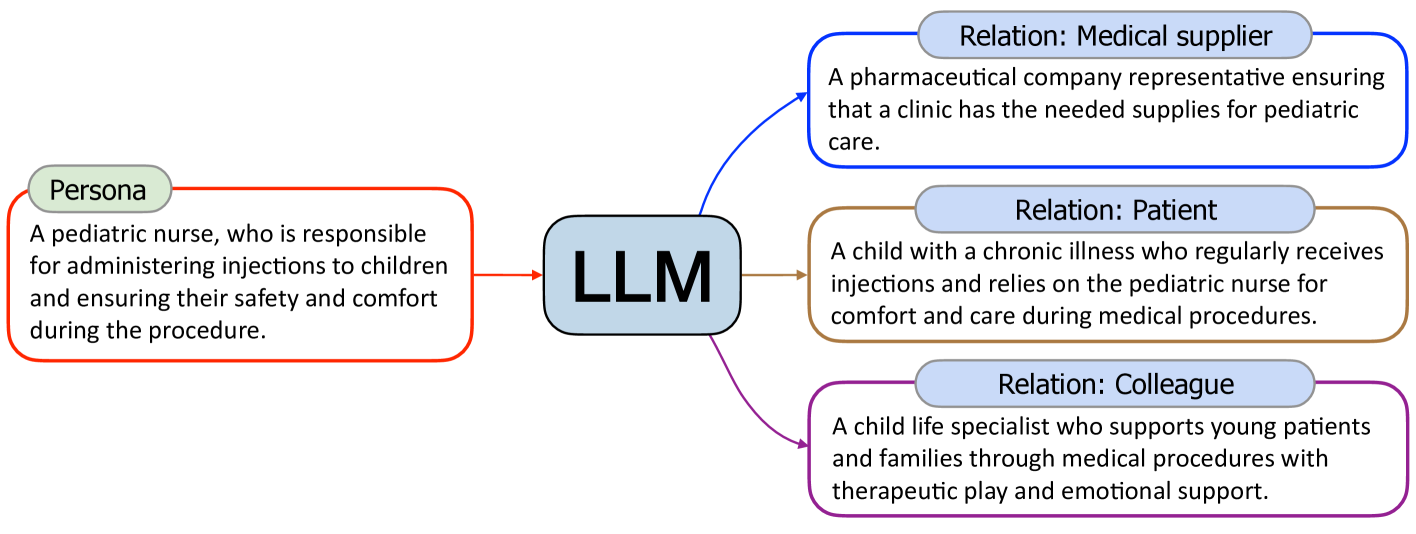
如图5所示,关于“孩子”的角色可以从儿童医院的护士角色(患者与护理人员关系)中衍生出来。 类似地,“乞丐”可以从避难所工作人员(援助关系)的角色衍生出来,“幕后电影工作人员”可以衍生出来来自电影主角的角色(同事关系)。 根据六度分离理论(Travers & Milgram,1977),我们对通过Text-to-Persona获得的每个角色进行六次角色关系扩展迭代,从而进一步丰富我们的角色收藏。
2.3重复数据删除
我们首先在 RedPajama v2 数据集 (计算机,2023) 上运行 Text-to-Persona,然后执行 Persona-to-Persona,如下所述在第 2.1 和 2.2 节中。 在获得数十亿个角色后,不可避免地会出现某些角色相同或极其相似的情况。 为了确保 Persona Hub 的多样性,我们通过两种方式对这些角色进行重复删除:
基于MinHash的重复数据删除
我们使用 MinHash (Broder, 1997) 根据角色描述的 n 元语法特征进行重复数据删除。 由于角色描述通常只有 1-2 个句子,比文档短得多,因此我们简单地使用 1-gram 和 128 的签名大小来进行 MinHash 重复数据删除。 我们以 0.9 的相似度阈值进行重复数据删除。
基于嵌入的重复数据删除
在基于表面形式(即具有n-gram特征的MinHash)的重复数据删除之后,我们还采用基于嵌入的重复数据删除。 我们使用文本嵌入模型(例如 OpenAI 的 text-embedding-3-small 模型)来计算每个角色的嵌入,然后过滤掉余弦语义相似度大于 0.9 的角色。
注意,虽然我们这里选择0.9作为阈值,但是我们可以根据具体需求灵活调整,以进一步去重。 例如,当实例数量要求不高(例如只需要100万个实例)但多样性需求较高时,我们可以进一步应用更严格的去重标准(例如丢弃相似度大于0.5的角色) )。
经过重复数据删除并使用简单的启发式方法过滤掉低质量的角色描述后,我们总共收获了 1,015,863,523 个角色,最终形成了我们的角色中心。
3 角色驱动的综合数据创建
我们提出的角色驱动数据合成方法简单有效,其中涉及将角色集成到数据合成提示中的适当位置。 虽然看起来很简单,但它可以显着影响大语言模型,采用角色的视角来创建合成数据。 在 Persona Hub 中 10 亿个角色的驱动下,这种方法可以轻松创建数十亿规模的多样化合成数据。

正如我们可以使用零样本或少样本方法来提示大语言模型一样,角色驱动的方法也很灵活,并且与各种形式的提示兼容以创建合成数据。 如图6所示,我们提出了三种角色驱动的数据合成提示方法:
-
•
零样本提示不利用任何现有的示例(即演示),从而充分发挥模型的创造力,而不受具体示例的限制。
-
•
少样本提示通过提供一些演示,可以更好地保证合成的数据符合要求。
-
•
角色增强少样本提示对于增强大语言模型的角色驱动数据合成能力更为有效。 但其缺点是需要事先在少样本提示中导出每个演示对应的角色。
4用例
我们展示了 Persona Hub 在各种数据合成场景中的用例,包括大规模创建数学和逻辑推理问题、指令(即用户提示)、知识丰富的文本、游戏 NPC 和工具(功能)开发。
如前所述,角色驱动方法具有通用性和通用性,只需调整数据合成提示即可轻松适应不同的数据合成场景。 因此,我们将仅针对数学问题综合(第4.1节)提供详细的技术讨论,并跳过其他用例的详细讨论。
4.1 数学问题
4.1.1演示
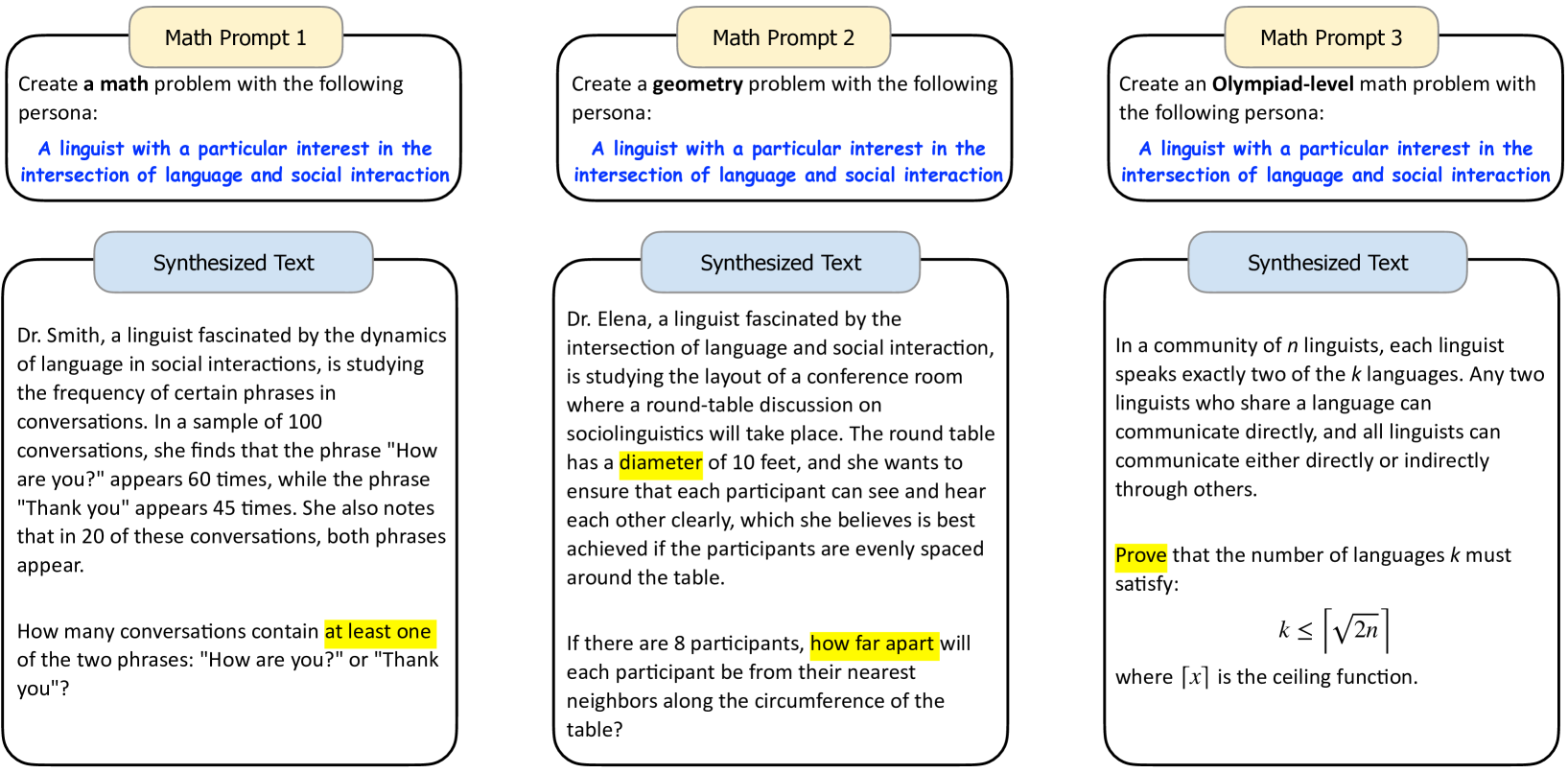
正如最初的示例(图1)所示,当提示大语言模型创建数学问题时,添加角色会导致大语言模型创建与该角色相关的数学问题。 图7(左)中的示例进一步证实了这一点:当呈现语言学家角色时,大语言模型将在计算语言学背景下创建一个数学问题。 而且,添加角色并不妨碍提示的灵活性——我们仍然可以轻松指定焦点(图7(中))或难度(图7(右)) )在提示中我们想要的数学问题。

4.1.2评估
数据
我们选择444从技术上讲,如果我们使用完整版的Persona Hub,我们可以获得一个大语言模型合成的10亿个数学问题。 然而,由于 GPT-4 API 的成本,我们将本实验的扩展限制为 109 万个角色。 来自 Persona Hub 的 109 万个角色,并采用 GPT-4 的 0-shot 提示方法来创建这些角色的数学问题,该方法不利用 MATH 等基准测试中的任何实例(Hendrycks 等人,2021)在创建数学问题的过程中。 这种方法使我们能够综合 109 万个数学问题。 由于这项工作的重点是创建新的综合数据而不是综合解决方案,因此我们简单地使用了 gpt-4o (assistant555Assistant system message in OpenAI API doc: “You are a helpful assistant.”)来生成所创建问题的解决方案。 在这 109 万道数学题中,我们随机拿出 20k 道作为综合测试集以方便评估。 剩下的1.07M问题用于训练。
测试集
我们使用以下两个测试集进行评估:
-
•
综合测试集(分布内):由于保留的20K问题集的生成方式与1.07M训练实例相同,因此可以将其视为分布内测试集。 为了确保此测试集中答案的准确性以提高评估的可靠性,我们另外使用 gpt-4o 生成解决方案 (PoT666Program of thought prompting (Chen et al., 2022))和gpt-4 -turbo(助理)以及gpt-4o(助理)生成的解决方案。 我们只保留至少两个解决方案一致的测试实例。 剩余的测试集由 11.6K 个测试实例组成。
-
•
MATH(Out-of-distribution):最广泛认可的测试大语言模型数学推理能力的基准。 其测试集包含 5,000 个竞争级别的数学问题以及参考答案。 由于我们不使用 MATH 数据集中的任何实例进行数据合成或训练,因此我们将 MATH 测试集视为分布外测试集。
平等检查
我们遵循与 OpenAI 相同的评估协议777https://github.com/openai/simple-evals 检查 MATH 基准上的答案是否相等。 对于综合测试集,我们使用类似的方法,只是我们使用 Llama-3-70B-Instruct 而不是 gpt-4-turbo-preview 作为相等检查器。
我们简单地用我们合成的 107 万个数学问题来模拟最新的开源 7B 大语言模型 – Qwen2-7B (qwe, 2024),并在上述两个测试集上评估其贪婪解码输出。
| Model | Model Size | Accuracy (%) |
|---|---|---|
| Open-sourced LLMs | ||
| DeepSeek LLM 67B Chat (Bi et al., 2024) | 67B | 53.2 |
| Phi-3-Mini-4K-Instruct (Abdin et al., 2024) | 3.8B | 68.3 |
| Yi-1.5-34B-Chat (Young et al., 2024) | 34B | 70.4 |
| Qwen1.5-72B-Chat (Team, 2024) | 72B | 60.7 |
| Qwen1.5-110B-Chat (Team, 2024) | 110B | 73.0 |
| Qwen2-7B-Instruct (qwe, 2024) | 7B | 72.1 |
| Qwen2-72B-Instruct (qwe, 2024) | 72B | 77.2 |
| Llama-3-8B-Instruct | 8B | 39.8 |
| Llama-3-70B-Instruct | 70B | 63.5 |
| GPT-4 | ||
| gpt-4-turbo-2024-04-09 | ? | 88.1 |
| gpt-4o-2024-05-13 | ? | 91.2 |
| This work | ||
| Qwen2-7B (fine-tuned w/ the 1.07M synthesized instances) | 7B | 79.4 |
| Model | Model Size | Accuracy (%) |
| State-of-the-art LLMs | ||
| gpt-4o-2024-05-13 | ? | 76.6 |
| gpt-4-turbo-2024-04-09 | ? | |
| gpt-4-turbo-0125-preview | ? | |
| gpt-4-turbo-1106-preview | ? | |
| gpt-4 | ? | ∗ |
| Claude 3.5 Sonnet | ? | ∗ |
| Claude 3 Opus | ? | |
| Gemini Pro 1.5 (May 2024) | ? | ∗ |
| Gemini Ultra | ? | ∗ |
| DeepSeek-Coder-V2-Instruct (Zhu et al., 2024) | 236B/21B | ∗ |
| Llama-3-70B-Instruct | 70B | |
| Qwen2-72B-Instruct | 72B | ∗ |
| Qwen2-7B-Instruct | 7B | ∗ |
| This work | ||
| Qwen2-7B (fine-tuned w/ the 1.07M synthesized instances) | 7B | 64.9 |
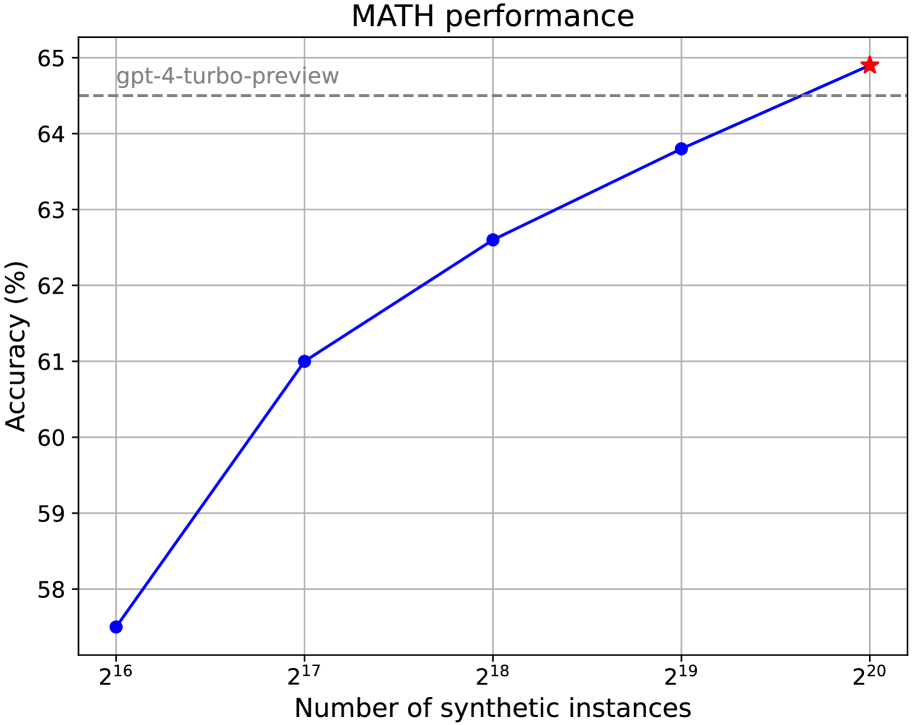
表 1 显示了 11.6K 综合测试实例的分布内 (ID) 评估结果。 在测试的开源大语言模型中,Qwen2-72B-Instruct取得了最好的结果,其他模型的排名与其在其他数学基准上报告的性能基本一致。 我们的模型在 107 万个综合数学问题的帮助下,达到了近 80% 的准确率,超越了所有开源大语言模型。 然而,考虑到综合测试中的答案并不绝对可靠,并且我们的模型可能是唯一使用ID训练数据的模型,因此该ID评估结果仅供参考。
我们在表2中列出了MATH的评估结果。 使用合成训练数据进行微调的 7B 模型仅使用贪婪解码即可在 MATH 上实现令人印象深刻的 64.9% 准确率,仅优于 gpt-4o、gpt-4-turbo-2024-04 -09、Claude 3.5 Sonnet、Gemini Pro 1.5(2024 年 5 月)和 DeepSeek-Coder-V2-Instruct。
图9展示了模型在不同尺度的综合数学问题训练时在数学上的表现。 其性能趋势总体上符合缩放定律(Kaplan等人,2020)。 与之前的研究不同,(Yu 等人, 2023; Wang 等人, 2023; Li 等人, 2024a) 对分布数据进行缩放(例如,严重依赖 MATH 训练数据来增强分布数据)分布数据),我们在数据合成或训练期间没有使用 MATH 中的任何实例。 因此,在这种分布外 (OOD) 评估设置中,在 MATH 上实现超越 gpt-4-turbo-preview (1106/0125) 的性能对于 7B 模型来说确实令人印象深刻且充满希望。
我们检查合成数学问题的质量:我们抽取了 200 个具有挑战性的问题(涉及中国高中和大学水平的数学知识点),并请两位数学专家评估其有效性。 200 个问题中只有 7 个被标记为无效(例如,由于条件不充分或冲突),可靠的有效性为 96.5%。
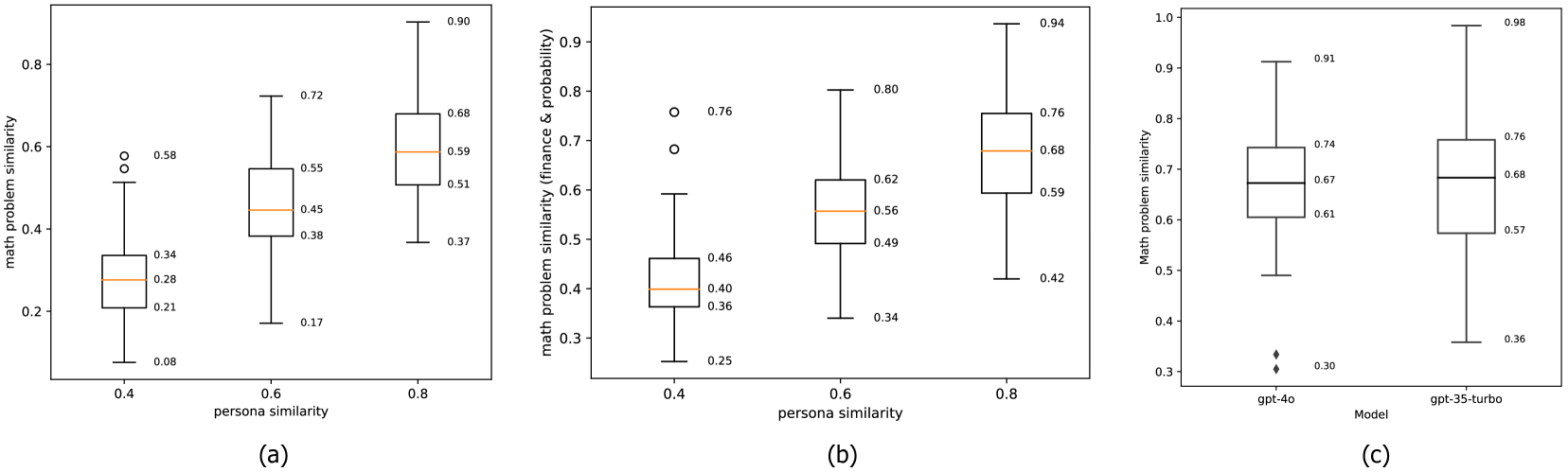
此外,我们还专门研究了提示中人物角色差异对综合数学问题的影响。 我们首先抽取 100 对具有语义相似性的角色888本实验中我们使用OpenAI的text-embedding-3-small (dim=512)来获取语义表示并计算余弦相似度。 这里,角色相似度为0.4意味着一对角色的语义相似度在0.39到0.41的范围内。 分别为 0.4、0.6 和 0.8。 对于每对角色,我们使用它们通过贪婪解码(即温度=0)创建一对数学问题。 然后,我们计算这些数学问题对的语义相似度,并在图 10 中显示结果。
我们可以清楚地观察到,综合数学问题之间的语义相似性往往与相应人物角色之间的相似性相关,但低于相似性。 当我们在提示中添加更具体的约束(例如,有关金融和概率的数学问题)时,综合数学问题之间的相似度往往会变得更高(图10(b))。 在图10(c)中,我们还使用高度相似的方法测试了gpt-4o和gpt-35-turbo创建的数学问题的相似性角色(相似度=0.9)。 结果表明,gpt-4o 和 gpt-35-turbo 创建的数学问题的语义相似度似乎没有显着差异:大多数综合数学问题的相似度都在范围为 0.6 至 0.75,远低于人物角色的相似度 (0.9)。 鉴于这些观察结果,我们相信使用 Persona Hub 中的角色可以确保合成数据的多样性——即使是十亿规模的数据。
4.2 逻辑推理问题
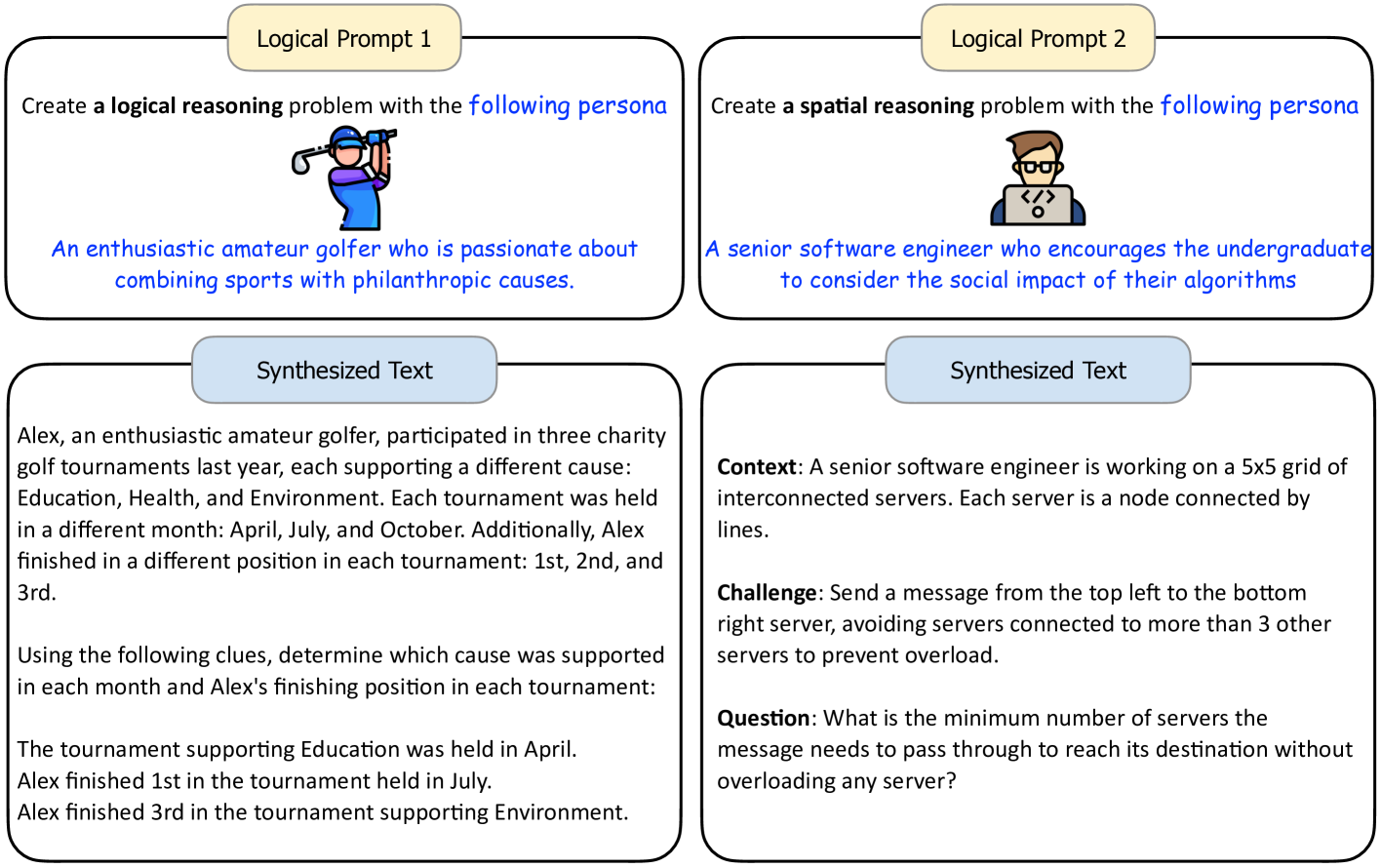
与数学问题类似,逻辑推理问题也可以很容易地综合出来。 我们在图 11 中展示了使用我们提出的人物驱动方法合成的典型逻辑推理问题的示例。

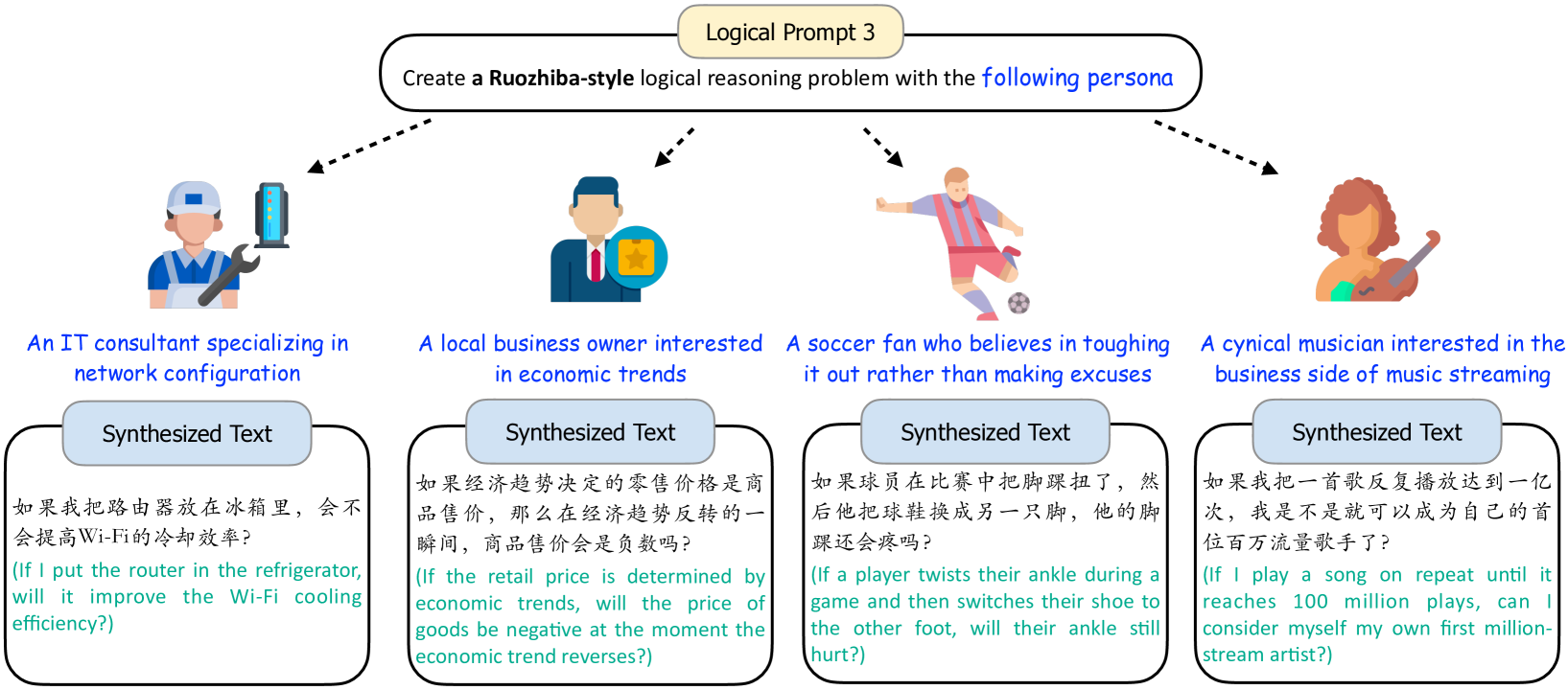
另外,我们还展示了几款若芝巴式的999若知吧是百度贴吧上的一个子论坛,以中国网友提出的众多复杂且具有挑战性的问题为特色。 这些问题结合了双关语、一词多义、因果倒置和同音词等元素,嵌入了逻辑陷阱,严格测试理解复杂汉语结构的能力。 最近的研究(Bai等人,2024)表明这些数据对大语言模型逻辑推理能力的提高有显着的帮助。 使用图 12 中的角色创建的逻辑推理问题。 所有的例子都表明,只要我们能够清楚地描述要创建的逻辑推理问题的要求,我们就可以利用多种多样的角色来引导大语言模型生成各种逻辑推理问题,这些问题不仅满足要求,而且也与人物角色高度相关,即使是对于异想天开的若智霸式问题也是如此。
更多示例请参考我们发布的 50,000 道综合推理问题。
4.3说明
大语言模型的最终用户最终是人类。 我们可以使用Persona Hub来模拟各种用户,了解他们对大语言模型帮助的典型请求,从而产生不同的指令(即用户提示)。
图13显示了两种典型的角色驱动合成指令提示,对应于3节中描述的零样本提示和角色增强少样本提示方法。 零样本方法不依赖于任何现有的指令数据集,允许大语言模型根据不同的角色生成各种指令。 相比之下,角色增强的少样本方法需要现有的指令数据集(例如,我们在实验中使用 WildChat (Zhao 等人, 2024))来采样一些指令作为演示,并涉及推断相关的角色通过2.1节中描述的Text-to-Persona方法来执行这些指令。 虽然这种方法更复杂,但它会产生更接近真实用户指令的合成指令。
通过使用 Persona Hub 创建的各种指令(通常代表用户-LLM 对话的第一轮),我们可以使用大语言模型轻松生成其后续对话轮,从而产生大量模拟的用户-LLM 对话,这将是对于增强大语言模型的听指令和会话能力具有重要意义。 此外,我们甚至可以采用类似的方法,从 Persona Hub 中选择两个角色,让大语言模型对这两个角色进行角色扮演,从而模拟两个真人之间的对话(Jandaghi 等人,2023)。
由于图 1 已经显示了使用此方法创建的一些指令,因此我们在此跳过示例。 对更多示例感兴趣的读者可以参考已发布的通过 0-shot 和角色增强 2-shot 提示合成的 50,000 条指令。
4.4知识丰富的文本
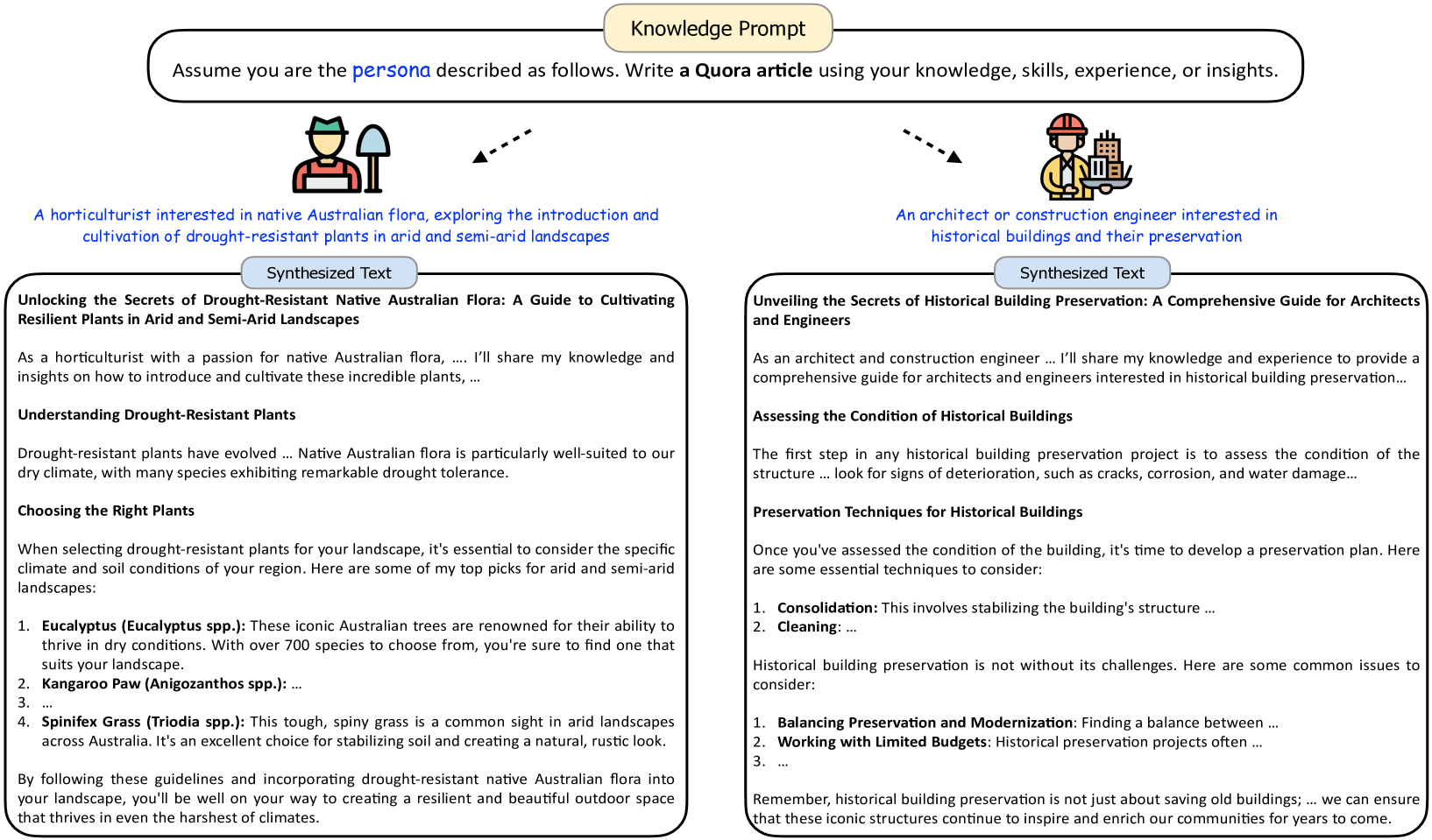
除了合成可以增强大语言模型指令调优的指令外,角色驱动方法还可以轻松地用于创建知识丰富的纯文本,有利于大语言模型的预训练和训练后。 如图14所示,我们可以提示大语言模型编写Quora101010Quora 是一个流行的问答网站,用户可以在其中就广泛的主题提出问题并提供答案。 Quora 上的文章(即帖子)通常由知识渊博的人士撰写,包括各个领域的专家,确保内容高质量、经过充分研究且内容丰富。 文章111111合成知识丰富的纯文本的方法并不局限于让大语言模型写Quora文章。 例如,我们还可以促使大语言模型合成一个角色可能感兴趣的(教育)阅读材料,从而获得大量知识丰富的文本。 使用从 Persona Hub 采样的角色。 这种方法引出了大语言模型相应的知识和视角,从而产生信息量大、知识丰富的内容。 通过在 Persona Hub 中使用 10 亿个角色来扩展这个过程,我们可以轻松获得大量知识丰富的文本,这些文本涵盖了不同粒度级别的几乎任何主题。
4.5游戏 NPC
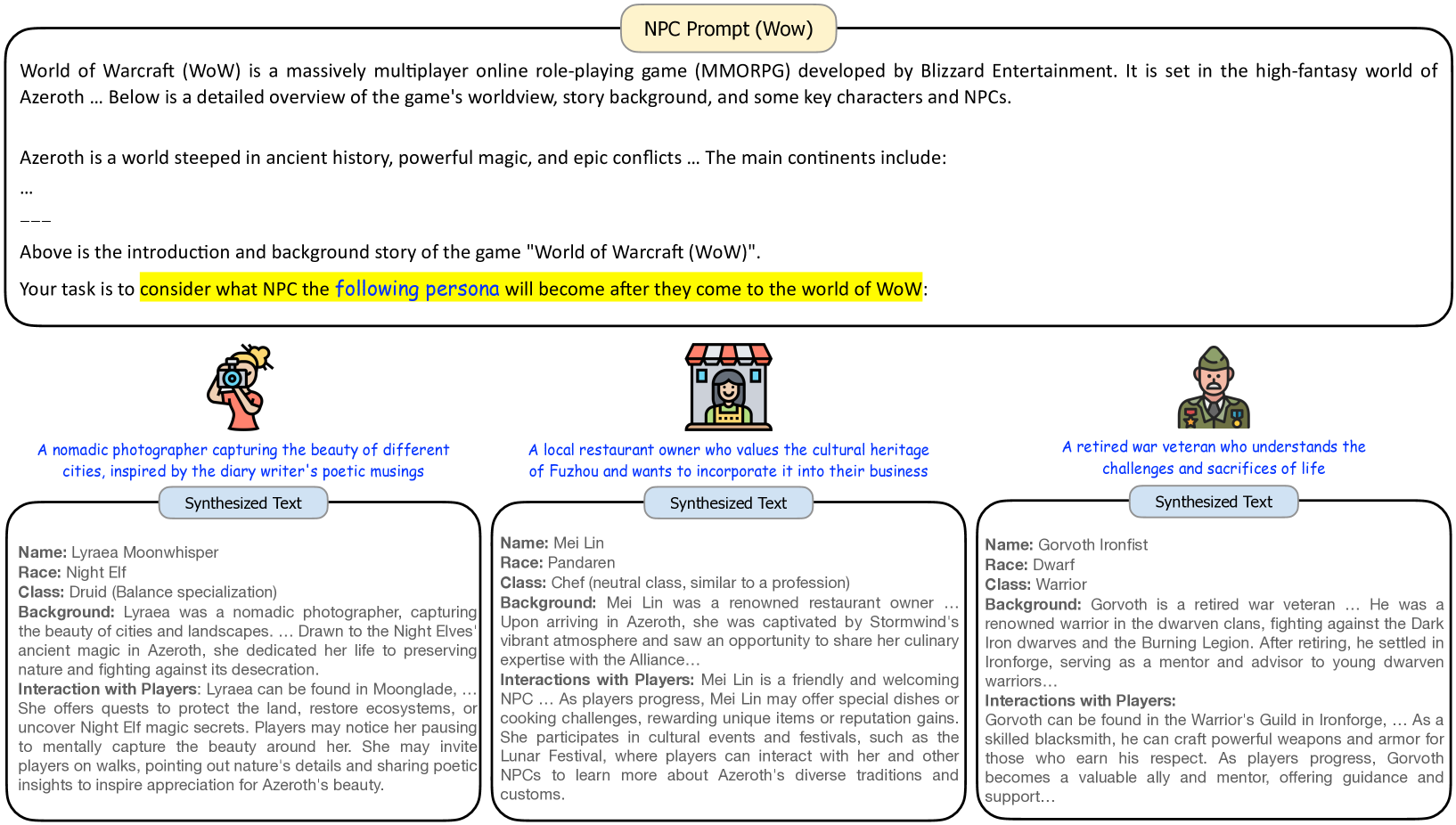
Persona Hub 的一个简单实用的应用是为游戏大规模创建不同的 NPC(非玩家角色)。 只要我们能够向大语言模型提供游戏的背景和世界构建信息,我们就可以促使大语言模型将Persona Hub中的角色(通常是现实世界的角色)投射到游戏世界中的角色中。 这样,我们就可以大大减少游戏设计过程中NPC头脑风暴的工作量。
UTF8gkai
图15和16显示了我们使用Persona Hub中的角色为《魔兽世界》游戏创建游戏NPC的具体示例121212魔兽世界由暴雪娱乐开发,是一款极具影响力的MMORPG,自上线以来,在全球拥有数百万活跃玩家,遍布100多个国家。 2004年发布。”和“月光之刃131313天涯明月刀是一款由腾讯开发的3D武侠题材MMORPG,于7月1日在中国正式上线, 2016年。”。

4.6工具(功能)开发
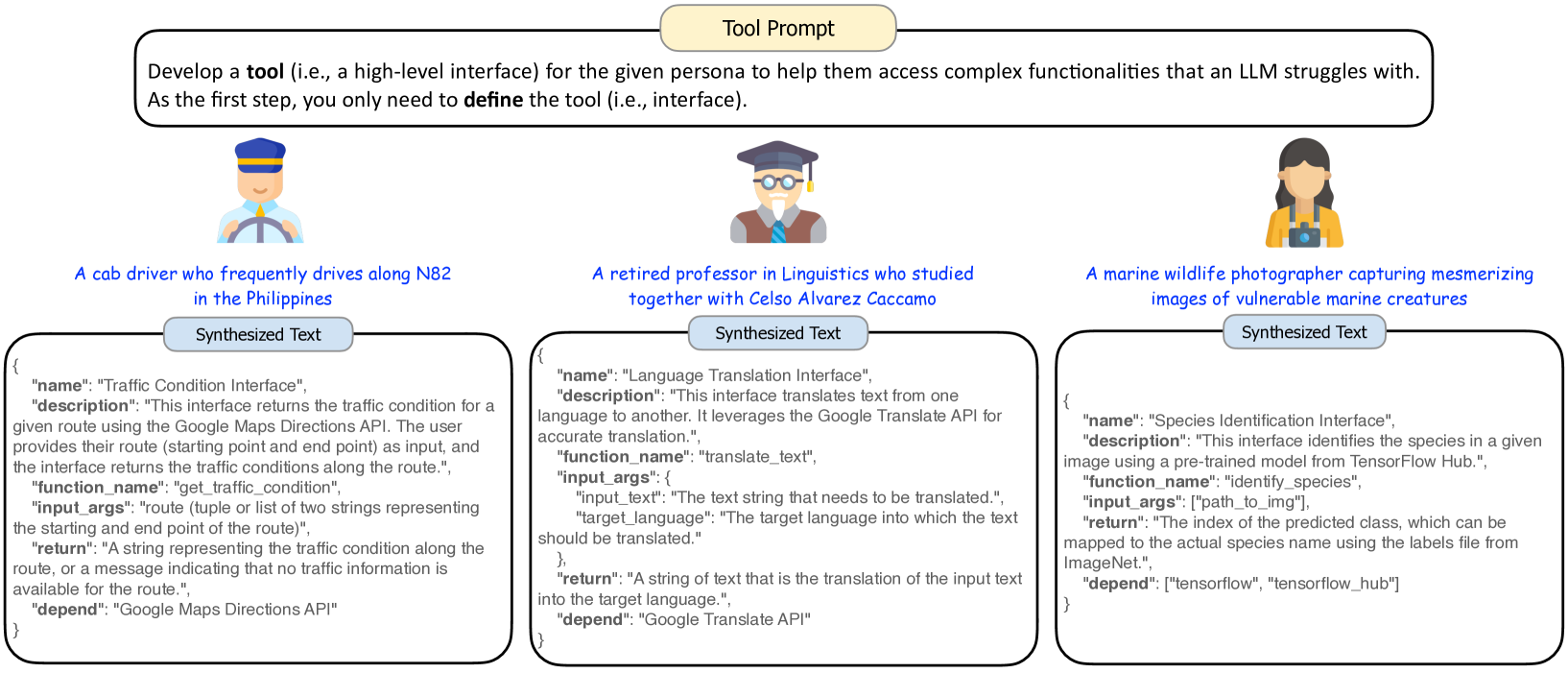
正如 4.3 节所演示的,Persona Hub 可用于模拟各种真实用户,以预测他们对大语言模型可能的请求(即指令)。 同样,我们可以使用Persona Hub来预测用户可能需要的工具(Cai等人,2023;Schick等人,2024),以便我们可以预先构建这些工具(功能)。 当真实用户提出类似的请求时,大语言模型可以直接调用这些预先构建的工具来返回结果,而不必每次都从头开始构建工具。 Persona Hub引入的这一范式是一种全新的解决方案,可以让大语言模型更好地服务用户。 我们相信,随着大语言模型变得更加民主化和多功能化,它在未来将具有巨大的潜力。
图17显示了使用各种角色创建的工具示例。 这些工具提供了角色可能需要的功能(例如出租车司机需要检查交通状况)但大语言模型无法访问,极大地扩展了大语言模型提供的服务范围。 请注意,虽然图17中的工具只是接口定义,但这些定义可以轻松转换为代码实现,如图18所示。

5 广泛的影响和道德问题
5.1广泛影响
5.1.1 人类和大语言模型数据创建的范式转变
传统上,人们普遍认为,虽然大语言模型擅长处理数据(例如重写、标注或针对特定输入生成输出/解决方案),但它们并不特别擅长创建新数据。 因此,数据创建的任务在很大程度上仍然是人类的领域,而人类与大语言模型之间的协作范式始终是人类创建数据并大语言模型处理它(Maini等人,2024). 然而,我们提出的角色驱动方法的引入可能会彻底改变这种范式。 有了Persona Hub,大语言模型不再局限于处理现有数据;他们现在可以从多个角度创建各种类型的新数据,就像世界上不同的人口一样。
虽然目前大语言模型的能力可能还无法完全取代人类完成数据创建的使命——无论是在数据质量还是广度方面,但大语言模型能力的不断进步预示着未来大语言模型将越来越擅长:数据创建。 随着大语言模型的不断完善,其能够创建的数据的质量和广度也可能会提高,从而使大语言模型可以完全承担数据创建的作用。 当这一天到来时,我们将不再受制于(Villalobos 等人,2024)受限于人类生成的有限的高质量现实世界数据141414https://lilianweng.github.io/posts/2024-02-05-human-data-quality/。 Persona Hub 确保了合成数据的多样性和覆盖范围,显着减轻了人们对合成数据对模型训练的负面影响(Shumailov 等人,2023;Dohmatob 等人,2024)的担忧。 这可以有效消除数据瓶颈,从而将缩放定律推向极限。
5.1.2现实模拟
在4.3和4.6节中,我们证明了Persona Hub可以用其10亿个角色来代表大量现实世界的个人。 通过利用这些角色来模拟和推断真实用户的潜在需求和行为,我们不仅可以让大语言模型自主地为即将到来的用例(查询)做准备,还可以为大语言模型有效模仿真实用户铺平道路。世界,从而创造许多新的机会。 例如,公司可以使用这种方法来预测不同类型的用户对新产品发布的反应;考虑到不同的人口群体,政府可以预见公众对新立法的反应;在需要用户分析和行为建模的在线服务中,Persona Hub可以方便地模拟多样化的用户行为,显着缓解冷启动挑战。
大语言模型角色扮演、智能体协作(Liu 等人,2023;Wang 等人,2024)、策略推理(Gandhi 等人,2023;Zhang 等人,2024)<当然,Persona Hub 中庞大且多样化的角色可以促进 /t1> 和相关领域的发展。 更雄心勃勃的是,这 10 亿个角色甚至可以在虚拟世界中维持一个组织良好的社会,例如沙盒环境(Park 等人,2023)、在线游戏、平行世界或元宇宙,使用使用4.5节中讨论的方法来模拟强大的大语言模型的操作。 这个虚拟社会可以作为新政策、激进举措和社会动态的试验场,在现实世界实施之前提供有价值的见解。 通过创建一个不同角色互动的受控环境,我们可以在无风险的环境中观察突发行为、测试假设并完善策略。 这不仅可以帮助加深我们对复杂系统的理解,还可以通过促进快速迭代和实验来加速创新。
5.1.3 大语言模型全内存访问
当我们在特定场景下与大语言模型交互时,我们只能引出它的一小部分记忆和能力,而无法完全访问大语言模型中封装的大量知识。 然而,Persona Hub 有可能提供对大语言模型的完整内存的访问,因为 Persona Hub 中的 10 亿个角色可以利用大语言模型中编码的几乎每个视角和信息。
通过利用这10亿个角色,我们可以创建多样化的查询并从目标大语言模型中获得解决方案,从而将大语言模型的综合记忆(参数)转化为文本形式的合成数据。 如果我们将大语言模型视为世界知识的参数化压缩,那么Persona Hub可以视为基于分布式载体的压缩151515如图2所示,Persona Hub具有个 Token ,相当于一个 公共网络文本的压缩( 标记)。 世界知识,如图2所示。 这种基于载体的分布式压缩为我们提供了将大语言模型的参数解压缩回其所学过的世界知识和信息的机会(例如,使用4.4节中讨论的方法)。
但考虑到目前的Persona Hub还处于非常初级的知识阶段,而今天的大语言模型由于不可避免的幻觉还无法将记忆无损地转化为合成数据(徐等人,2024),通过这种方法生成的合成数据的广度和质量仍然有限。 尽管如此,随着Persona Hub的不断改进和规模化,以及大语言模型变得更加强大(幻觉更少),我们可以期待有一天可以几乎无损地将大语言模型的全部记忆提取到其中。纯文本。
5.2 道德问题
5.2.1 训练数据安全及对当前大语言模型主导地位的威胁
正如 5.1.3 节中所讨论的,Persona Hub 提供了访问目标大语言模型的完整内存的机会。 然而,这也带来了一个重大问题:训练数据的安全性。 通过目标大语言模型合成的所有数据本质上代表了其所看到的训练数据的一种形式。 因此,大规模提取目标大语言模型记忆的过程本质上是转储其训练数据,尽管这个过程通常是有损的。
此外,如果我们采用4.3节中描述的方法来综合几乎涵盖所有用例的指令(即用户提示)来查询目标大语言模型以大规模获取其输出,则有目标大语言模型的知识、智能和能力被提取和复制的风险很高。 这对最强大的大语言模型的领先地位提出了挑战,我们在4.1节中已经通过数学推理验证了这一点。
鉴于当前的大语言模型普遍具有相似的架构,并且其性能优势主要在于数据,这项工作很可能会影响当前的实践,并可能成为一个转折点,加速大语言模型的竞争格局从一种严重依赖数据优势的技术转变为专注于更先进技术的技术。
5.2.2 其他
合成数据引起了人们对错误信息和虚假新闻的普遍担忧,这在之前的研究中经常被讨论(Pan 等人,2023)。 Persona Hub 可能会放大这个问题,因为不同的角色带来不同的写作风格,使得机器生成的文本与人类生成的内容更难区分(Chakraborty 等人,2023)。 检测难度的增加可能会加剧与数据污染相关的问题,其中合成数据与真实数据混合,可能会扭曲研究结果和公共信息。
6 结论和未来工作
我们提出了一种新颖的角色驱动数据合成方法,并提出了 Persona Hub,这是根据网络数据自动整理的 10 亿个不同角色的集合。 我们表明,这种方法可以促进跨各种场景的合成数据创建的扩展,展示其彻底改变合成数据的创建和应用的潜力,及其作为研究和实践的通用数据合成引擎的前景。
作为Persona Hub的第一个版本,虽然它已经包含了10亿个角色,但这些角色的描述只集中于主要方面,缺乏细粒度的细节(例如,对颜色和数字的偏好;特定的家庭背景、历史背景和生活经历)。 我们计划在 Persona Hub 的后续版本中完善角色,旨在使它们的描述与维基百科有关个人的文章中的描述一样详细。 这些更详细的角色描述将使每个角色更加独特,从而扩大角色中心并为合成数据创建提供更多机会,同时还支持个性化对话等实际应用(例如,character.ai)。
此外,虽然这项工作仅探索基于文本的大语言模型的数据合成,但该方法也应该适用于多模态大语言模型。 因此,我们将探索多模式合成数据创建作为未来的方向。 此外,鉴于特定的角色可以从大语言模型中引出相应的视角,我们很好奇利用一些超级角色来引导大语言模型探索现有知识范围之外的可能性。 这或许为挖掘大语言模型的超智能提供了一种新的途径,值得今后研究。
参考
- qwe (2024) Qwen2 technical report. 2024.
- Abdin et al. (2024) Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024.
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Bai et al. (2024) Yuelin Bai, Xinrun Du, Yiming Liang, Yonggang Jin, Ziqiang Liu, Junting Zhou, Tianyu Zheng, Xincheng Zhang, Nuo Ma, Zekun Wang, et al. Coig-cqia: Quality is all you need for chinese instruction fine-tuning. arXiv preprint arXiv:2403.18058, 2024.
- Bauer et al. (2024) André Bauer, Simon Trapp, Michael Stenger, Robert Leppich, Samuel Kounev, Mark Leznik, Kyle Chard, and Ian Foster. Comprehensive exploration of synthetic data generation: A survey. arXiv preprint arXiv:2401.02524, 2024.
- Bi et al. (2024) Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954, 2024.
- Broder (1997) Andrei Z Broder. On the resemblance and containment of documents. In Proceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No. 97TB100171), pp. 21–29. IEEE, 1997.
- Cai et al. (2023) Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, and Denny Zhou. Large language models as tool makers. arXiv preprint arXiv:2305.17126, 2023.
- Chakraborty et al. (2023) Souradip Chakraborty, Amrit Singh Bedi, Sicheng Zhu, Bang An, Dinesh Manocha, and Furong Huang. On the possibilities of ai-generated text detection. arXiv preprint arXiv:2304.04736, 2023.
- Chen et al. (2022) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, 2022.
- Choi & Li (2024) Hyeong Kyu Choi and Yixuan Li. Picle: Eliciting diverse behaviors from large language models with persona in-context learning. In Forty-first International Conference on Machine Learning, 2024.
- Computer (2023) Together Computer. Redpajama: an open dataset for training large language models, 2023. URL https://github.com/togethercomputer/RedPajama-Data.
- Delétang et al. (2023) Grégoire Delétang, Anian Ruoss, Paul-Ambroise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau-Moya, Li Kevin Wenliang, Matthew Aitchison, Laurent Orseau, et al. Language modeling is compression. arXiv preprint arXiv:2309.10668, 2023.
- Dohmatob et al. (2024) Elvis Dohmatob, Yunzhen Feng, Pu Yang, Francois Charton, and Julia Kempe. A tale of tails: Model collapse as a change of scaling laws. arXiv preprint arXiv:2402.07043, 2024.
- Gandhi et al. (2023) Kanishk Gandhi, Dorsa Sadigh, and Noah D Goodman. Strategic reasoning with language models. arXiv preprint arXiv:2305.19165, 2023.
- Ge et al. (2024) Tao Ge, Hu Jing, Lei Wang, Xun Wang, Si-Qing Chen, and Furu Wei. In-context autoencoder for context compression in a large language model. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=uREj4ZuGJE.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
- Huang et al. (2024) Yiming Huang, Xiao Liu, Yeyun Gong, Zhibin Gou, Yelong Shen, Nan Duan, and Weizhu Chen. Key-point-driven data synthesis with its enhancement on mathematical reasoning. arXiv preprint arXiv:2403.02333, 2024.
- Jandaghi et al. (2023) Pegah Jandaghi, XiangHai Sheng, Xinyi Bai, Jay Pujara, and Hakim Sidahmed. Faithful persona-based conversational dataset generation with large language models. arXiv preprint arXiv:2312.10007, 2023.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Li et al. (2024a) Chen Li, Weiqi Wang, Jingcheng Hu, Yixuan Wei, Nanning Zheng, Han Hu, Zheng Zhang, and Houwen Peng. Common 7b language models already possess strong math capabilities. arXiv preprint arXiv:2403.04706, 2024a.
- Li et al. (2024b) Haoran Li, Qingxiu Dong, Zhengyang Tang, Chaojun Wang, Xingxing Zhang, Haoyang Huang, Shaohan Huang, Xiaolong Huang, Zeqiang Huang, Dongdong Zhang, et al. Synthetic data (almost) from scratch: Generalized instruction tuning for language models. arXiv preprint arXiv:2402.13064, 2024b.
- Li et al. (2023a) Junyi Li, Ninareh Mehrabi, Charith Peris, Palash Goyal, Kai-Wei Chang, Aram Galstyan, Richard Zemel, and Rahul Gupta. On the steerability of large language models toward data-driven personas. arXiv preprint arXiv:2311.04978, 2023a.
- Li et al. (2023b) Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463, 2023b.
- Liu et al. (2024) Ruibo Liu, Jerry Wei, Fangyu Liu, Chenglei Si, Yanzhe Zhang, Jinmeng Rao, Steven Zheng, Daiyi Peng, Diyi Yang, Denny Zhou, et al. Best practices and lessons learned on synthetic data for language models. arXiv preprint arXiv:2404.07503, 2024.
- Liu et al. (2023) Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization. arXiv preprint arXiv:2310.02170, 2023.
- Maini et al. (2024) Pratyush Maini, Skyler Seto, He Bai, David Grangier, Yizhe Zhang, and Navdeep Jaitly. Rephrasing the web: A recipe for compute and data-efficient language modeling. arXiv preprint arXiv:2401.16380, 2024.
- Pan et al. (2023) Yikang Pan, Liangming Pan, Wenhu Chen, Preslav Nakov, Min-Yen Kan, and William Yang Wang. On the risk of misinformation pollution with large language models. arXiv preprint arXiv:2305.13661, 2023.
- Park et al. (2023) Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pp. 1–22, 2023.
- Schick et al. (2024) Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36, 2024.
- Shanahan et al. (2023) Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role play with large language models. Nature, 623(7987):493–498, 2023.
- Shumailov et al. (2023) Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. The curse of recursion: Training on generated data makes models forget. arXiv preprint arXiv:2305.17493, 2023.
- Team (2024) Qwen Team. Introducing qwen1.5, February 2024. URL https://qwenlm.github.io/blog/qwen1.5/.
- Travers & Milgram (1977) Jeffrey Travers and Stanley Milgram. An experimental study of the small world problem. In Social networks, pp. 179–197. Elsevier, 1977.
- Villalobos et al. (2024) Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? limits of llm scaling based on human-generated data. In Forty-first International Conference on Machine Learning, 2024.
- Wang et al. (2023) Ke Wang, Houxing Ren, Aojun Zhou, Zimu Lu, Sichun Luo, Weikang Shi, Renrui Zhang, Linqi Song, Mingjie Zhan, and Hongsheng Li. Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning. arXiv preprint arXiv:2310.03731, 2023.
- Wang et al. (2022) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. arXiv preprint arXiv:2212.10560, 2022.
- Wang et al. (2024) Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi-persona self-collaboration. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 257–279, 2024.
- Xu et al. (2024) Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. Hallucination is inevitable: An innate limitation of large language models. arXiv preprint arXiv:2401.11817, 2024.
- Young et al. (2024) Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, et al. Yi: Open foundation models by 01. ai. arXiv preprint arXiv:2403.04652, 2024.
- Yu et al. (2023) Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- Zhang et al. (2024) Yadong Zhang, Shaoguang Mao, Tao Ge, Xun Wang, Adrian de Wynter, Yan Xia, Wenshan Wu, Ting Song, Man Lan, and Furu Wei. Llm as a mastermind: A survey of strategic reasoning with large language models. arXiv preprint arXiv:2404.01230, 2024.
- Zhao et al. (2024) Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatGPT interaction logs in the wild. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Bl8u7ZRlbM.
- Zhu et al. (2024) Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y Wu, Yukun Li, Huazuo Gao, Shirong Ma, et al. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence. arXiv preprint arXiv:2406.11931, 2024.