Teola:迈向基于 LLM 的应用程序的端到端优化
摘要。
基于大语言模型(大语言模型)的应用程序由大语言模型和非LLM组件组成,每个组件都会导致端到端延迟。 尽管人们在优化大语言模型推理方面付出了巨大的努力,但端到端的工作流程优化却被忽视了。 现有框架采用任务模块的粗粒度编排,这将优化限制在每个模块内,并产生次优的调度决策。
我们提出细粒度端到端编排,它利用任务原语作为基本单元,并将每个查询的工作流程表示为原语级数据流图。 这显式地暴露了更大的设计空间,实现了跨不同模块原语的并行化和流水线优化,并增强了调度以提高应用程序级性能。 我们为基于 LLM 的应用程序构建了 Teola,一个新颖的编排框架,用于实现该方案。 综合实验表明,Teola 可以在各种流行的大语言模型应用程序中实现比现有系统高达 2.09 倍的加速。
1. 介绍
大型语言模型(大语言模型)及其多模态变体彻底改变了用户查询理解和内容生成。 这一突破改变了许多传统和新兴应用。 例如,一些搜索引擎已将大语言模型集成到其查询处理管道中,从而增强了用户体验(perplexity,; bing,)。 此外,人工智能代理作为人机交互的新范式,催生了情感陪伴(characterai,)和个性化助理(privatellm,)等新应用。
尽管大语言模型是应用程序中最智能的组件,但其本身往往无法满足多样化和复杂的用户需求。 例如知识时效性和长上下文理解,大语言模型由于其设计而无法表现良好。 如果处理不当,这些问题很容易导致众所周知的幻觉问题(huang2023Hallucination, )。 为了缓解此类问题,人们提出了许多技术,包括 RAG(检索增强生成)(lewis2020retrieval, ; liu2024iterativere, )、外部函数调用(kim2023llmcompiler, ; openaifunc, ; huang2024tool, )甚至多个大语言模型交互。 流行的框架如 Langchain (langchain, ) 和 LlamaIndex (llamaindex, ) 支持集成各种模块并构建上述端到端管道。
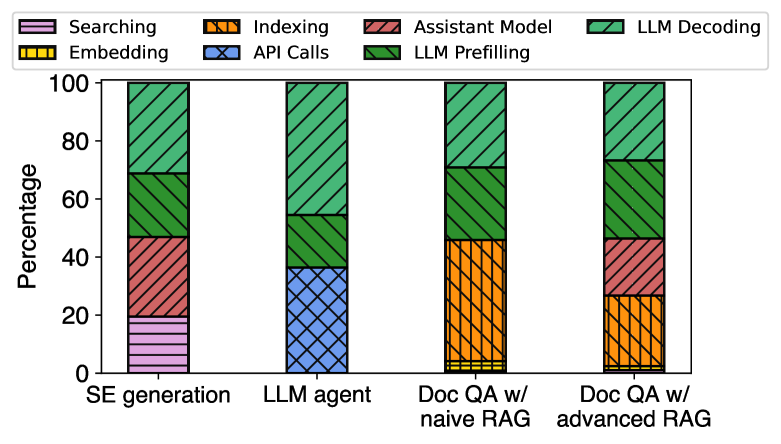




虽然人们在各个方面都做出了巨大努力来优化大语言模型推理(kwon2023vllm, ; yu2022orca, ; zhong2024distserve, ; agrawal2023sarathi, ; dao2022flashattention, ),但很少有人关注端到端由不同模块组成的基于 LLM 的应用程序的最终性能。 图 1 说明了使用 Llamaindex (llamaindex, ) 的几个流行的基于 LLM 的应用程序的执行时间细分。 非 LLM 模块占端到端延迟的很大一部分,在某些情况下(使用 RAG 进行文档问答)甚至超过 50%。 然而,优化端到端性能所面临的困难比当前编排框架(llamaindex, ; langchain, ;pairag, ; azurerag, ) 中想象的要多。 他们将工作流程组织为一个简单的基于模块的链管道(参见图 3),其中每个模块使用自己的执行引擎独立且顺序地处理高级任务(例如 vLLM (kwon2023vllm , ) 用于大语言模型推理)。 尽管易于使用,但这种粗粒度的链接方案极大地限制了跨模块工作流级联合优化的潜力,因为它们将每个模块视为黑匣子 (2.2)。 此外,前端编排和后端执行的解耦意味着请求调度无法针对应用程序的整体性能进行优化,迫使其转而优化每个请求的性能,这实际上可能会降低整体效率(2.3)。
在本文中,我们主张对基于 LLM 的应用程序进行更细粒度的阐述和编排,这可以成为端到端优化的基石。 我们没有使用基于模块的链接,而是使用基元级数据流图进行编排,其中任务基元作为基本单元。 每个原语都是图中负责特定原语操作的符号节点,并且具有元数据配置文件来存储其关键属性(2.2)。 这个基元级图允许我们利用每个基元的属性及其交互来优化图,识别具有最佳端到端延迟 (2.2) 的执行计划。 此外,该图捕获了不同原语之间的请求相关性和依赖关系及其拓扑深度,从而实现了应用程序感知的调度和批处理,并具有更好的端到端性能 (2.3)。
根据这一见解,我们构建了 Teola,一个基于原语的编排框架,用于为基于 LLM 的应用程序提供服务。 Teola 有两个主要组件:1)图形优化器:它将每个用户查询解析为特定的原始级别数据流图形,将查询的输入数据和配置以及开发人员预定义的粗粒度工作流程合并在一起。 随后,有针对性的优化过程被应用于原始图,以生成用于运行时执行的高效执行图。 2)运行时调度器:利用两层调度机制,上层调度每个查询的执行图,而下层由各个引擎调度器管理。 较低层批处理和处理请求同一引擎的查询执行图中的原语,同时考虑每个原语的请求之间的关系,以实现应用程序感知的调度。
我们主要使用 Ray (moritz2018ray, ) 来实现 Teola 的原型,用于分布式调度和执行,以及用于执行引擎的各种库。 我们使用不同的数据集和应用程序评估 Teola,包括使用简单和高级 RAG 的搜索引擎支持的生成和文档问答。 全面的测试台实验表明,与现有方案相比,Teola 可以在端到端延迟方面实现高达 2.09 倍的加速,包括我们使用 Ray 进行的 Llamaindex (llamaindex, ) 的分布式实现及其高级版本结合了模块并行化和增强的大语言模型执行。
我们的贡献总结如下:
-
•
我们确定了当前基于 LLM 的编排框架的局限性,即限制优化潜力的基于粗粒度模块的编排,以及请求级调度和端到端应用程序性能之间的不匹配。
-
•
我们提出了一种细粒度的编排,将查询工作流表示为基于基元的数据流图,为端到端优化提供更大的设计空间,包括图优化(即并行化和管道化)和应用程序感知调度。
-
•
我们设计和实施 Teola 来展示我们方法的可行性和好处。 使用流行的大语言模型应用程序进行的实验表明,Teola 的性能优于当前系统。
2. 背景和动机
2.1. 基于 LLM 的申请
大语言模型入门. 当前的大语言模型建立在 Transformer 的基础上,它依靠注意力机制来有效捕获自然语言中的长上下文(attention, )。 本文重点关注的大语言模型推理是自回归:在每次前向传递中,模型都会产生一个新的词符——语言建模的基本单位,它成为上下文的一部分,并且是作为后续迭代的输入。 为了避免在此过程中对前面的 Token 进行冗余注意计算,使用了键值(KV)缓存,这成为内存压力的关键来源(yu2022orca,; kwon2023vllm,)。
大语言模型推理涉及两个阶段:预填充和解码。 预填充通过处理所有输入标记(指令、上下文等)生成第一个输出词符,并且显然是受计算限制的。 预填充后,解码阶段基于 KV 缓存迭代生成输出的其余部分,并且受内存限制,因为在每次迭代中仅需要处理前一次迭代中的新词符。
大语言模型应用程序不仅仅是大语言模型。 尽管大语言模型具有强大的生成能力,但它并不是万能的。 他们的训练数据集不可避免地不是最新的,导致知识差距和幻觉问题(azurerag, ; lewis2020retrieval,)。 它们还缺乏与环境直接交互的能力,即它们不能直接发送电子邮件,尽管它们可以起草电子邮件(wu2023autogen, ; hong2023metagpt, ; shen2023hugginggpt, )。 因此,实际应用程序通常需要将其他工具与大语言模型集成才能实际使用。
我们在图2中展示了四个典型的基于LLM的应用程序(应用程序)。 图2(a)展示了一个搜索引擎赋能的生成应用程序,其中大语言模型利用搜索引擎来回答超出其知识范围的问题(bing, ; jeong2024adaptiverag, ; tan2024small ,)。 它采用代理和判断模型来确定是否需要调用搜索引擎。 图2(b)展示了一个通用的大语言模型代理,其中大语言模型与各种工具API交互以执行它制定的计划(例如使用用户的帐户凭据起草和发送电子邮件)(hong2023metagpt,;wu2023autogen,)。 图 2(c) 和 2(d) 分别展示了使用简单和高级 RAG 的文档问答 (QA)。 RAG 可以说是增强大语言模型应用程序的最流行技术,具有多种生产用途(pairag, ; azurerag,)。 在这里,用户上传的文档在经过嵌入模型处理后,被作为块提取到矢量数据库中作为领域知识库(lewis2020retrieval, ;pairag, ; azurerag, )。 此步骤称为索引。 大语言模型使用从向量数据库检索的相关块来生成答案。 高级版本(图2(d))利用基于LLM的查询扩展来细化和拓宽新查询(jagerman2023queryexpansion, ; gao2023retrievalsurvey, ),从而提高搜索准确性,并且随后对扩展查询的所有检索到的块进行重新排序,以合成精确的最终答案。 正如之前1中所见,大语言模型可能不是这些复杂应用程序管道的唯一性能瓶颈。 因此,仔细协调工作流程的各个组成部分至关重要。
2.2. 大语言模型App细粒度编排
许多框架,例如 LlamaIndex (llamaindex, )、Langchain (langchain, ),以及企业解决方案,例如 PAI-RAG (pairag, ) 和Azure-RAG (azurerag, ) 的出现是为了促进大语言模型应用程序的创建和编排。 他们自然地采用模块级编排,因为每个应用程序都被定义和调度为一个简单的模块链,如图3所示。 每个模块都通过后端引擎独立执行。 粗粒度模块级链接易于使用,但本质上限制了优化复杂工作流程以获得最佳性能。 它忽略了联合优化模块的更大设计空间,特别是通过利用各个模块的内部操作之间复杂的依赖关系。
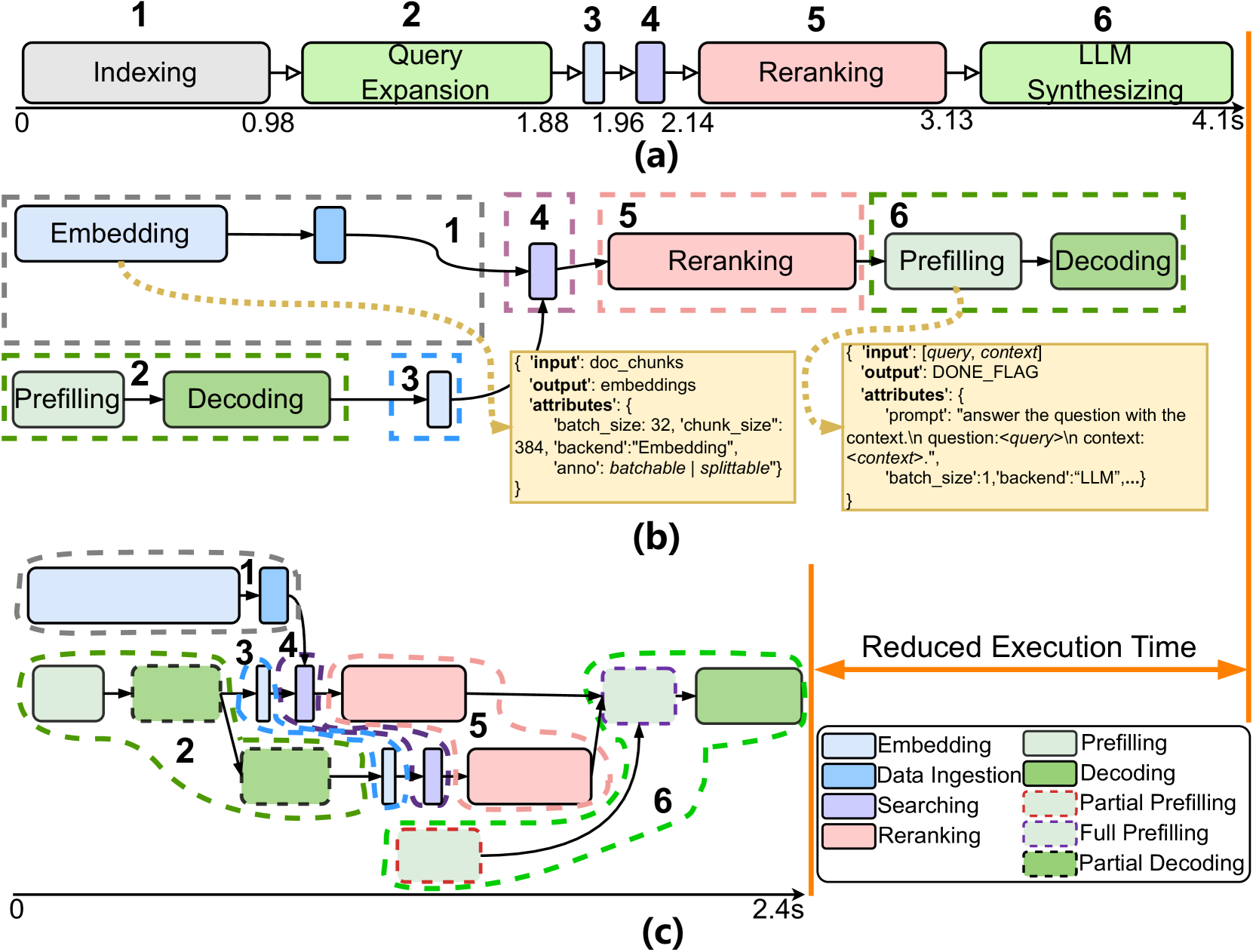
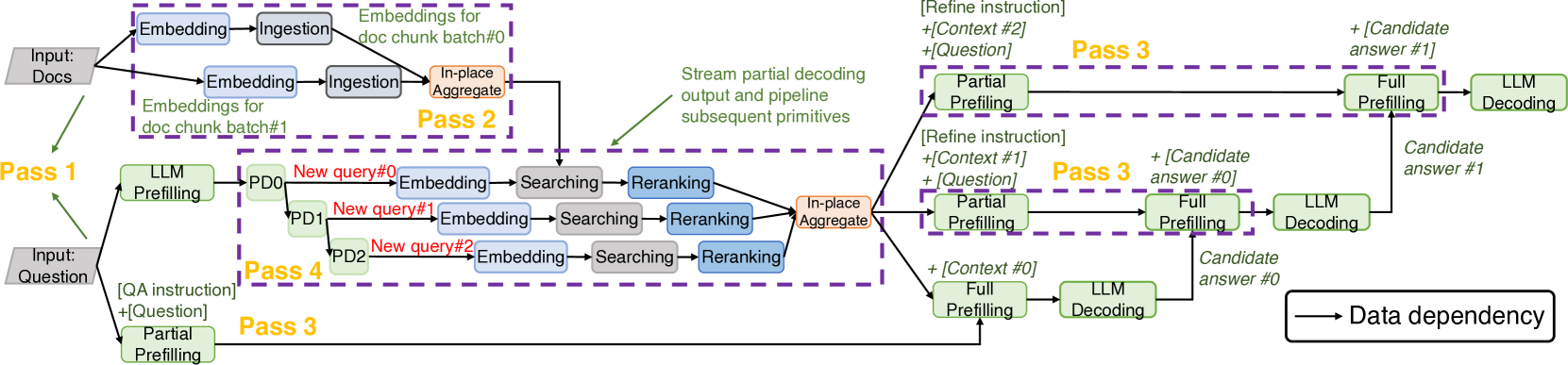
本文的中心论点是提倡对大语言模型应用进行细粒度的阐述和编排,以提高端到端的性能。 考虑图 3 中所示的同一应用程序工作流程(图 3)的替代表示。 我们不使用模块,而是将每个模块分解为细粒度的基元作为编排的基本单元(即图中的节点)。 例如,索引模块被分解为嵌入创建和数据摄取原语,查询扩展被分解为预填充和解码原语,就像大语言模型综合模块一样。
此外,这些原语之间的依赖关系在该数据流图中被明确捕获,从而能够探索跨原语和模块的更复杂的联合优化。 作为一个简单的示例,很明显,嵌入创建和数据摄取原语可以与图 3 中查询扩展的预填充和解码原语并行执行,因为它们的输入是独立的。 每个原语的输入/输出关系以及其他关键信息(有关一些示例,请参见 2.3)被编码为图中的节点属性。
然后,我们可以优化这个原始级别的数据流图,以识别整个工作流程的最佳执行计划,并具有最低的端到端延迟。 图3显示了与图3中的数据流图对应的优化执行图。 具体来说,假设查询扩展创建了多个新查询,相应的解码原语可以通过多个部分解码原语以管道方式运行,每个原语生成一个新查询并将其发送到后续原语(嵌入创建)立即,无需等待所有查询出来。 同样的词符,大语言模型综合的预填充原语可以分为先进行部分预填充,对系统指令和用户查询进行操作,可以与搜索和重排序之前的索引并行运行。
因此,基元级数据流图使我们能够探索跨基元的各种并行化和流水线机会,这在现有的基于模块的编排中是不可见的。 增益是显着的:在我们的示例中(图 3),总体执行时间从 4.1 秒减少到 2.4 秒。
2.3. 应用程序感知的调度和执行
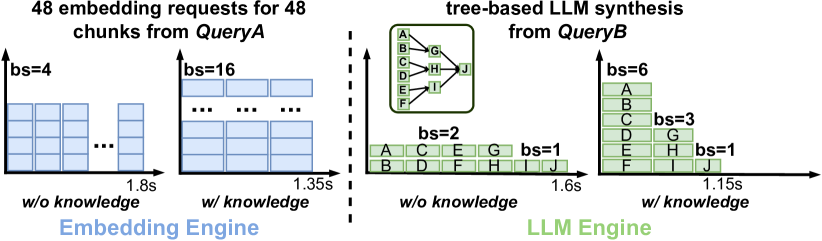
当前大语言模型应用编排的另一个局限性是后端执行引擎的请求级优化,与用户感知的应用级性能不匹配。 假设使用流行的服务引擎 Triton (tritonserver, ) 来为索引模块的嵌入模型提供服务。 Triton 引擎以固定的批量大小 4 统一处理每个请求,如图 4 所示。 如果没有任何应用程序级信息,我们只能通过合理但次优的 GPU 利用率来优化每个请求的延迟。
现在考虑到这些嵌入请求来自同一模块,很明显执行引擎应该针对总完成时间而不是每批延迟进行优化。 因此,更好的策略是使用更大的批量大小(例如 16)来充分利用 GPU。 总共 48 个请求(针对 48 个文档块),总完成时间从 1.8 秒减少到 1.35 秒,如图 4 所示,加速了 1.3 倍,尽管每批延迟为稍高一点。
上述玩具示例利用了单个基元的请求相关性。 我们可以利用的另一种信息是原语之间的请求依赖性。 考虑大语言模型综合模块,它以基于树的综合模式进行一系列大语言模型调用,如图4所示。 在传统请求级调度中,这些请求以批量大小 2 执行,同样是为了优化每个请求的延迟。 相比之下,考虑到它们形成深度为 2 的依赖树,大语言模型执行引擎可以以不同的批量大小处理相同深度的请求,尽管每批延迟较长,但整体加速达 1.4 倍。
综上所述,细粒度编排还弥补了执行引擎请求级优化的差距,并通过使用原始数据流图(作为节点属性)中的请求相关性和依赖信息(作为节点属性)来进一步优化端到端,从而实现应用程序感知调度。终端性能。
3. 设计概述
3.1. 建筑学
Teola 是一种新颖的编排框架,用于优化以原始操作为基本单元的基于 LLM 的应用程序的执行。
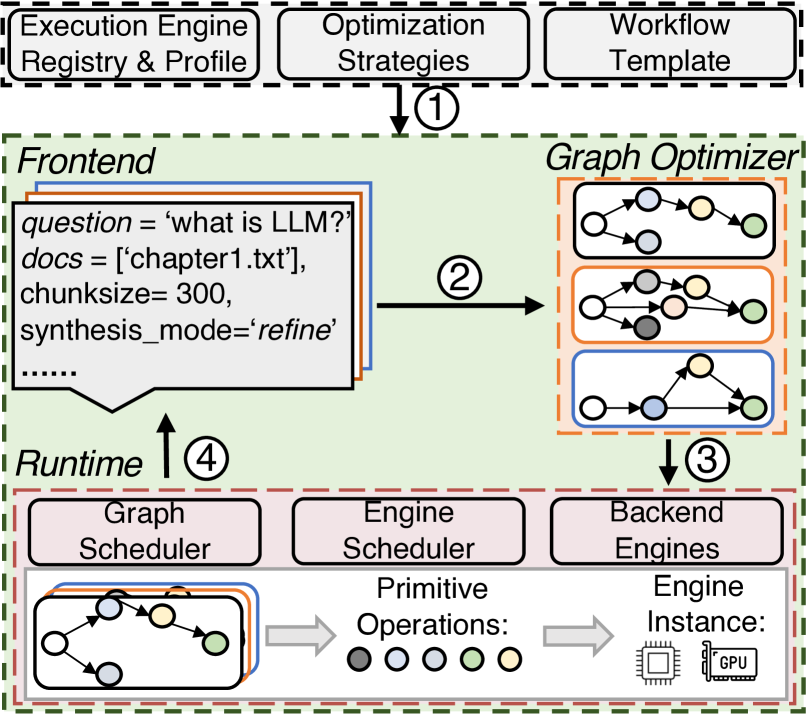
图5描绘了Teola的架构。 在离线阶段①,开发人员注册应用程序的执行引擎,例如嵌入模型、大语言模型和数据库操作的执行引擎,以及各种输入大小(例如批量大小和序列长度)的延迟配置文件。 他们还提供了一个工作流程模板,概述了应用程序的组件(例如查询扩展和大语言模型生成)及其执行顺序,类似于当前框架中的任务模块(llamaindex,; langchain,)。 或者,开发人员可以为某些原始操作指定优化策略。 配置和部署应用程序后,系统就可以提供在线服务了。
在在线阶段,在收到具有特定输入数据和工作流配置的查询后,Teola 创建基于原语的数据流图(p-graph)②,应用相关优化来生成执行图(e-graph),并将e-graph提交给运行时③。 运行时准确地跟踪并有效地安排电子图原语在适当后端的执行。 最后完成④后将结果返回给前端。
3.2. 蜜蜂
列表 LABEL:lst:code 提供了 Teola 的简化使用示例,突出显示了其主要组件,如下所述。
执行引擎。 执行引擎处理来自工作流组件的模型或操作请求(第 5 行)。 它们可以是无模型的或基于模型的。 无模型引擎,例如数据库,主要基于 CPU,不涉及 DNN 模型。 另一方面,基于模型的引擎可以部署各种 DNN 模型,包括用于嵌入的 BERT 系列模型(devlin2018bert, )和用于生成的大语言模型。 单个引擎可以服务于具有不同目的的多个组件,例如图2(d)中用于查询扩展和大语言模型综合的共享大语言模型引擎。
工作流程模板。 工作流模板定义应用程序的基本组件及其执行流程(第 8-20 行)。 开发人员指定工作流程中涉及的组件,概述所需的引擎、角色和输入输出配置。 这些组件可以使用优化提示进一步注释,例如batchable(用于独立操作的批量输入)和splittable(用于可分为独立部分输出的输出)。 运算符建立组件之间的执行顺序,确保数据流的正确性。 生成的模板可作为为具有不同配置的查询构建和优化更细粒度图的基础。
图形优化。 对于每个查询,基于特定于查询的数据、配置和预定义的工作流模板(第 22 行)构建具有原始节点的更细粒度的 p 图。 然后,Teola 利用原始操作和模式的内置优化通道来识别优化的执行计划并生成用于执行的电子图 (4)。 开发人员还可以通过提供的界面(第 7 行)注册自定义优化。
声明式查询。 提供了一个声明性接口,用于向已部署的应用程序提交查询。 除了指定查询(即问题和上下文)之外,用户还可以自定义工作流程(图5),允许对组件进行参数调整(例如,用于索引的文档块大小、大语言模型提示模板和大语言模型提示模板)。语言模型合成模式)满足性能预期。
4. 图优化器
图优化器通过结合查询信息和工作流模板来生成细粒度的每个查询表示(p-graph)。 该 p 图由符号基元节点组成,支持优化策略以生成高效的e-graph 来执行。
4.1。 p-图
原语。 如 2.2 中所述,仅依赖高级组件可能会过度简化操作之间复杂的关系,并暴露有限的信息和灵活性。 为了解决这个问题,我们引入了一个精炼的抽象:任务原语(简称原语)。 类似于 TensorFlow (tensorflow, ) 中的操作节点,工作流级别的符号原语增强了表示的粒度,并为执行前的优化提供了有价值的信息。
具体来说,如表1所示,原语可以对应于已注册执行引擎内的标准操作的功能(例如,嵌入引擎中的嵌入创建或重新排名引擎中的上下文排名)或表示精细的操作。 - 粒度分解操作。 例如,大语言模型推理被分解为预填充和解码,其中部分预填充和完全预填充构成大语言模型语言模型预填充,以及管理完整解码的不同部分的部分解码。 此外,原语可以是控制流操作,例如聚合或条件分支(即聚合和条件)。 每个基元都包含一个元数据配置文件,详细说明其输入、输出、父节点和子节点,形成图构建的基础。 该配置文件还包含关键属性,例如 DNN 的批量大小或大语言模型的提示,以及目标执行引擎。
| Type | Description | ||
|---|---|---|---|
| Reranking |
|
||
| Ingestion | Store embedding vectors into vector database | ||
| Searching | Perform vector searching in the database | ||
| Embedding | Create embedding vectors for docs or questions | ||
| Prefilling | The prefilling part of LLM inference | ||
| Decoding | The decoding part of LLM inference | ||
| Partial Prefilling |
|
||
| Full Prefilling | Prefilling for rest part of a prompt after a partial prefilling | ||
| Partial Decoding | Part of full decoding for partial output | ||
| Condition | Decide the conditional branch | ||
| Aggregate | Aggregate the results from multiple primitives |
p-图构造。 The optimizer converts the original workflow template with query-specific configuration into a more granular p-graph as outlined in Algorithm 1, where represents components, dependencies, and user configurations. 该过程根据配置将每个模板组件分解为显式符号基元,创建具有明确定义的依赖关系的子基元级图。 例如,具有3个上下文块的refine模式的大语言模型综合模块被转换为一个子图,其中3对Prefilling和Decoding 原语被链接并配置有相应的元数据。 最终生成的 p 图保留了原始工作流程依赖关系,同时提供了工作流程内部运作的更详细视图。
4.2. 优化
正如 2.2 中提到的,Teola 专注于最大化分布式执行中的并行性,而不是单点优化或加速(正交并在 9 中讨论)。 具体来说,优化器采用一组静态的、基于规则的优化来识别原始并行性(并行化)和管道并行性(管道化)的机会。
可利用的机会。 首先,从工作流模板继承的原始依赖关系仅描述组件的高级序列,可能会在细粒度 p 图中引入冗余。 为了最大化并行化,必须分析和修剪不必要的依赖关系,从而释放独立原语并创建并行数据流分支(通道 1)。 此外,在可行的情况下,计算密集型原语可以分解为多个流水线阶段,使它们能够与后续原语同时执行(通道 2)。
此外,我们观察到工作流程的核心大语言模型具有可利用的特殊属性。 具体来说,可以利用两个关键属性:(1)因果预填充:这允许大语言模型的预填充被分割成依赖部分,从而实现部分预填充与前面原语的并行化(通过3)和(2)流式解码输出:特定大语言模型解码的自回归和部分输出可以预先通信作为下游原语的输入,从而创建额外的流水线机会(通过 4)。
优化通过。 基于上述分析,集成了以下优化过程,并且可以将其应用于p图来优化端到端工作流执行:
-
第 1 遍:依赖性修剪。 为了增加并行化潜力,我们消除了不必要的依赖关系,并通过检查每个任务原语的输入及其当前的上游原语来识别并发执行的独立数据流分支。 冗余边被修剪,确保剩余边仅表示数据依赖关系,这可能会将某些任务原语与原始依赖关系结构分离。 例如,查询扩展和嵌入模块中的原语被分离以形成图3中的新分支。
-
第 2 遍:阶段分解。 对于处理超过引擎最大有效批量大小(即吞吐量不会增加的大小)的数据的batchable原语,它们被分解为多个阶段,每个阶段处理一个子微批量和流水线与下游batchable原语。 虽然更积极的分割可能会增加流水线程度,但找到最佳分割大小非常耗时。 此外,相邻的可批处理基元会导致指数搜索空间,这对于延迟敏感的场景是不切实际的。 为了平衡资源利用率和执行效率,只有当原语的输入大小达到最大有效批量大小时,我们才将原语显式分割为多个阶段。 在管道末尾添加一个Aggregate原语,以在必要时显式同步和聚合结果。
-
第三关:大语言模型预填充分割。 在大语言模型预填充中,完整的提示由系统/用户指令、问题和上下文等组件组成。 在工作流程中,某些提示部分可能提前可用(例如,用户指令或问题),而其他提示部分可能不可用(例如,从 RAG 中的数据库检索上下文)。 不必等待所有组件,而是可以在提示的可用组件准备好时对其进行预先计算,同时尊重注意计算的因果属性,从而实现部分预填充并行化。
-
第4关:大语言模型解码流水线。 在大语言模型的解码过程中, Token 是增量生成的。 一旦有一致的输出(例如,查询扩展中的新重写句子)可用,它就可以立即转发到下游可批处理原语,避免与等待完全解码相关的延迟。 为了实现这种优化,大语言模型调用必须被注释为splittable,表明它的输出可以在语义上分为不同的部分。 相应的解析器监视解码过程的渐进式结构化输出(例如 JSON),一旦部分解码可用,就提取完整的部分解码并将其转发给后继者。
优化程序。 优化器迭代地遍历 p 图,将原始节点与每个优化过程的模式进行匹配。 当找到匹配时,将应用相应的通道,并相应地修改相关原语,如算法 1 中所述。 此过程将持续进行,直到无法进一步优化为止。 为了减少开销,可以使用缓存来存储和重用优化子图的结果。
5. 运行时调度
Teola 在运行时利用两层调度机制。 上层图调度程序调度每个查询的优化电子图的原始节点。 下层由引擎调度程序组成,用于管理引擎实例并融合来自查询的原始请求以实现高效执行。 将图调度和操作执行分开可以增强 Teola 的可伸缩性和可扩展性。
5.1. 图调度器
图调度程序密切跟踪每个查询的电子图的状态,并在满足其依赖性时发出原始节点。 它评估节点入度,并在入度达到零时将节点分派到适当的引擎调度程序。 请注意,图调度程序调度节点本身而不是其关联的请求,确保较低的调度程序可以识别源自原语的请求,而不是像现有框架中那样独立处理它们(请参阅2.3)。 原语执行完成后,调度线程会通过 RPC 调用收到通知,并传输输出。 然后,线程递减下游基元的入度,为它们的执行做好准备。
此外,专用的每个查询对象存储管理中间输出。 该存储既充当待处理原语的输入存储库,又提供一定程度的容错能力,防止操作失败。

5.2. 发动机调度程序
执行引擎实例由专用引擎调度程序管理,使得映射到不同引擎类型的原语节点能够独立执行。 主要挑战是有效地融合请求相同引擎的原语。 通过优化的电子图,查询可以同时将多个基元节点分派给引擎调度程序,或者在队列中拥有多个待处理的基元节点,特别是当组件共享同一引擎时,例如图2(a)或图2(d)中使用相同大语言模型的查询扩展和大语言模型综合模块。
Strawman 解决方案和限制:盲批处理。 处理不同原始节点的一个简单方法是统一对待它们。 引擎调度程序使用 FIFO 策略动态批处理来自待处理队列的关联原语请求,达到预定义的最大批处理大小或超时,类似于现有系统(crankshaw2017clipper,; tritonserver,)。 然后该批次被分派到引擎实例。 然而,这种简单化的方法忽略了并非来自同一查询的所有原始节点对图进展的贡献相同。
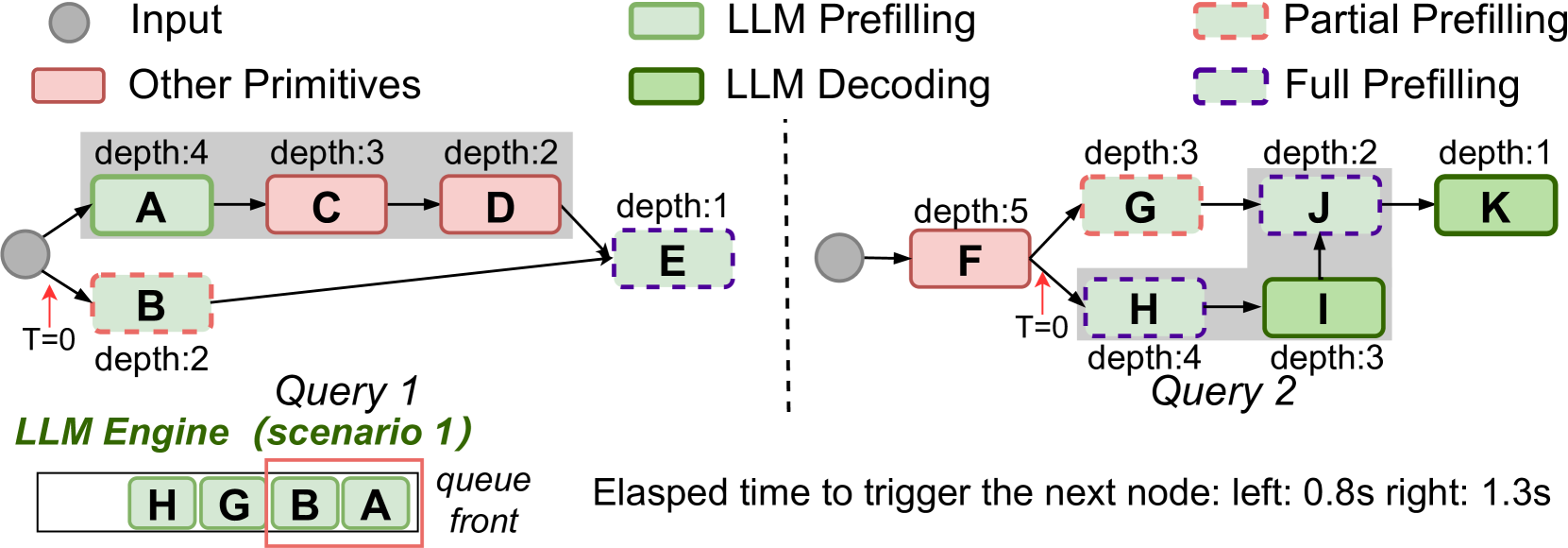
如图7所示,对于查询1,请求大语言模型引擎的原语A和B与查询2中的原语G和H一起进入队列。 盲批处理会批处理 A 和 B,而让 G 和 H 等待。 然而,此时执行原语 B 几乎没有什么好处,因为由于 E 的另一个未触发的父级 D,B 的子级 E 无法稍后发出。相反,批处理 A 和 H 会推进两个查询的图形执行,而 B 的延迟不会成为查询 1 的瓶颈。
我们的解决方案:拓扑感知批处理。 该示例强调了盲批处理的局限性,它忽略了每个基元对查询图进展的独特贡献。 图中的原始节点的拓扑深度各不相同;延迟较低深度的节点可以为更有贡献的节点保留资源,从而增强整体执行力。 此外,与现有编排所采用的方法(如2.3中讨论的)不同,必须考虑请求之间的相关性和依赖性。 结合这些见解,我们提出了拓扑感知批处理,这是一种启发式解决方案,利用原始节点的深度及其关系来智能地指导批处理形成。
具体来说,该方法有两个主要好处。 首先,对于单个查询,深度信息自然地捕获不同原语之间的依赖性,从而能够利用每个原语中固有的请求相关性对调度首选项进行直接调整(参见2.3)。 例如,可以以最大有效批量大小执行相同深度的基元,以优化吞吐量并推进图形。 其次,虽然由于实际执行中不可预测的延迟,深度信息可能无法查明确切的关键路径,但它可以指导查询的原始优先级(见图7),从而促进跨多个查询的高效资源利用。
算法2显示了拓扑感知批处理的过程。 获得查询的电子图后,对原始节点进行反向拓扑排序并记录其深度,输出节点具有最小深度(事件 1)。 调度时,引擎调度程序队列中同一查询的原语被分组到存储桶中。 在每个桶中,基元按深度排序,优先考虑深度较高的基元。 然后根据每个桶内最早到达时间对桶进行排序。 给定一个槽号(代表确保最佳吞吐量效率的预定最大批量大小(或大语言模型的最大词符大小)),调度程序将迭代每个存储桶。 对于每个存储桶,它检查最高优先级的基元节点,如果有空闲槽可用,则将相关请求从基元移至候选节点(事件 2)。
6. 执行
我们用大约 5,300 行 Python 代码实现了 Teola 的原型。 具体来说,我们利用几个现有的库:(1)Ray(moritz2018ray,)用于分布式调度和执行; (2) LlamaIndex (llamaindex, ) 用于预处理任务,例如文本分块和 HTML/PDF 解析; (3) postgresql (postgresql, ) 作为默认数据库; (4) pgvector(pgvector, )作为向量搜索引擎; (5) Google自定义搜索(googlesearch, )作为搜索引擎,支持单次请求和批量请求; (6) vLLM (kwon2023vllm, ) 作为大语言模型服务引擎,我们对其进行了额外修改以支持部分预填充和完全预填充表1。
对于前端,我们通过 FastAPI (Fastapi, ) 提供用户界面来提交查询和用户配置。 对于后端,图调度器维护一个线程池,为每个新查询分配专用线程,以便构建、优化和调度电子图。 除了5中的讨论之外,每个引擎调度器还根据各种负载指标(主要是通用引擎的执行请求数和大语言模型占用的KV缓存槽数)来管理不同实例之间的负载平衡。
减少通信开销。 为了减少中央调度程序中的通信开销,我们对具有大量数据交互或相同执行引擎的相邻原语使用依赖预调度机制。 这允许同时发出两个相关原语,即 A 和 B,其中 B 等待 A 的输出。 除了将 A 的结果发送到调度程序之外,RPC 调用还将 A 的输出直接发送到 B 的执行引擎。 这避免了在发布 B 之前通过调度器中继结果,因此可以减少通信开销。
7. 评估
测试台设置。 我们分别为基于模型的引擎(例如大语言模型)和无模型引擎分配 GPU 和仅 CPU 资源。 用于嵌入或其他非 LLM 模型的每个引擎实例均托管在单个 NVIDIA 3090 24GB GPU 上。 对于大语言模型,llama-2-7B 和 llama-2-13B (touvron2023llama2model, ) 的每个实例分别部署在 1 个和 2 个 NVIDIA 3090 GPU 上。 llama-30B (touvron2023llamamodel, ) 的每个实例都部署在 2 个 NVIDIA A800 80GB GPU 上。 任何物理服务器之间的网络带宽为 100 Gbps。
基线。 据我们所知,很少有研究专门关注在分布式环境中优化基于 LLM 的工作流程。 因此,我们基于 LlamaIndex (llamaindex, ) 将 Teola 与以下框架进行比较:
-
•
LlamaDist:我们使用 Ray 实现的 LlamaIndex 的分布式版本,定义任务模块链来构建应用程序管道。 每个任务模块调用对不同分布式后端引擎的请求。 该实现将 Ray 与 LlamaIndex 的编排方法集成在一起,利用与 Teola 相同的引擎,但编排的粒度有所不同。
-
•
LlamaDistPC(并行和缓存重用):一种高级 LlamaDist 变体,它检查预定义的管道并手动并行化独立模块以实现并发执行。 它还结合了大语言模型的前缀缓存,以避免提示中部分指令的重新计算,正如之前的一些作品(zheng2023sglang,;liu2024optimizingquery,;gim2023promptcache,)中所建议的那样。
对于已部署引擎的请求调度,我们比较了两种方法:
-
•
面向每次调用(PO):我们从编排端稍微修改了调用,并在调用中以捆绑形式发出请求(本质上是添加 Teola 中利用的额外相关信息来增强基线)。 引擎一次调度每个包,优先考虑每个调用的延迟首选项。
-
•
面向吞吐量(TO):我们预先调整每个引擎的最大批次/ Token 大小(即,将 DNN 的批次大小或大语言模型的词符大小增加 2 的幂,直到不再观察到吞吐量增益)并采用动态批处理策略(tritonserver,;crankshaw2017clipper,;kwon2023vllm,)。 这最大化了总体吞吐量,但忽略了请求之间的任何关系。
应用程序、模型和工作负载。 我们的实验涵盖三个应用:
-
•
搜索引擎赋能生成(图2(a)):搜索引擎协助核心大语言模型生成答案。 一个较小的大语言模型(llama-2-7B)充当代理和判断者,制定启发式答案并确定是否需要搜索。 任何搜索结果(前 4 个实体)都会输入到核心大语言模型中以综合最终答案。 工作负载请求是使用基于泊松分布的 web_question (webquestion, ) 和 HotpotQA (yang2018hotpotqa, ) 数据集综合生成的。
-
•
使用朴素 RAG 进行文档 QA(图2(c)):用户随问题输入文档或网页。 应用程序将文档分割成块(默认块大小:256,块重叠:30),使用 bge-large-en-v1.5 模型 (xiao2023bgeembedding, ) 嵌入它们,并将它们存储在矢量数据库(postgresql 和 pgvector)。 它检索最相关的块(默认:前 3 个)以生成具有基于树模式的响应。 工作负载(即问题和文档/网页)是使用泊松分布从 Finqabench (Finqabench, ) 和 TruthfulQA (lin2021truthfulqa, ) 数据集合成的。
- •
如无特殊说明,均采用上述默认配置。 所有模型均以半精度部署,并对不同核心大语言模型(7B、13B和30B)进行了实验。
7.1. 端到端性能
我们在相同的资源分配下使用不同的方案评估各种应用程序的性能。 每个非LLM引擎配备一个实例,而每个大语言模型配备两个实例。
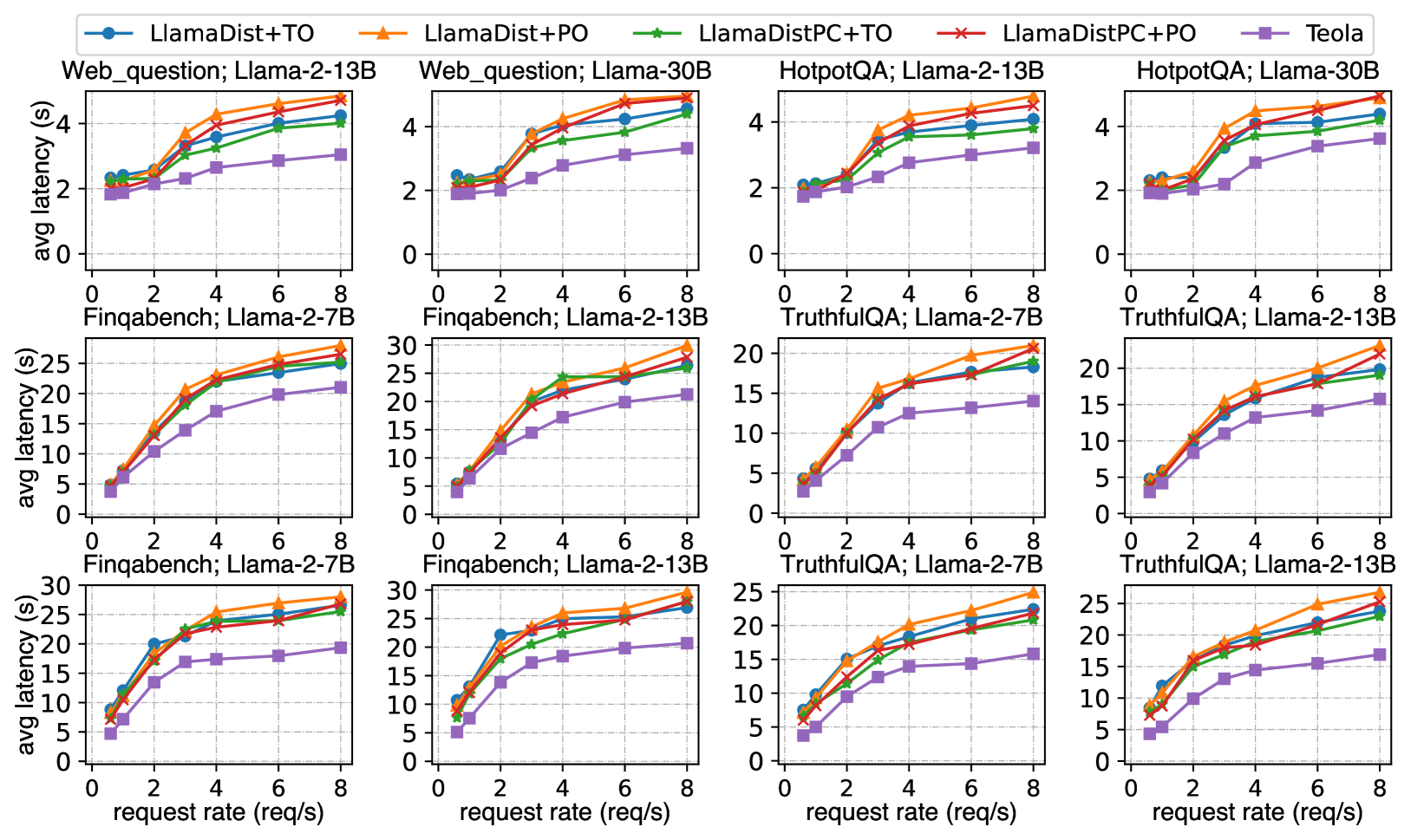
搜索引擎赋能的一代。 图8(顶行)显示 Teola 的性能比其他四种方案高出 1.79 倍。 Teola 的效率归功于法官和核心大语言模型的指令和问题的可并行部分预填充,以及不同引擎的有效批处理协调。 相比之下,LlamaDist 按顺序执行模块,并且难以处理多个查询的请求调度。 PO 关注每次调用延迟,导致在高请求率下队列时间更长,而 TO 在这些场景中通常表现更好。 由于缺乏跨模块的显式并行化,LlamaDistPC 无法从并行化中受益。 它对部分指令(通常大约 60 个标记)的前缀缓存提供的好处有限,因为当前缀明显较长(promptflow,; zheng2023sglang,)时,前缀缓存最有利。
使用朴素的 RAG 记录 QA。 图8(中行)表明,Teola 在低请求率下的性能比其他四种方案高出 1.62 倍,在高请求率下高出 1.46 倍。 LlamaDist 按顺序执行模块,无需进行特定优化,而 LlamaDistPC 实现有限的并行化(索引和查询嵌入模块)和部分指令 KV 缓存重用,性能略好于 LlamaDist。 在调度方面,PO 在低请求率下优于 TO,因为它注重每次调用延迟,但在高请求率下性能会受到影响。 此外,该应用程序引入了复杂的请求关系。 索引和查询嵌入模块都利用嵌入模型。 同时,大语言模型综合模块发出三个初始请求,随后提出构建树综合的后续请求。 如果忽视,这些可能会导致批处理效率低下,从而导致产出减少,与 TO 类似。 相反,Teola 利用电子图,结合管道来分割计算量大的任务,例如文档块的大型嵌入,同时还探索更多并行化机会,例如四个部分预填充。 此外,Teola 的拓扑感知批处理可捕获链接到不同原语的请求之间的依赖性和相关性,从而促进每个引擎的有效批处理。
使用高级 RAG 记录 QA。 该应用程序是我们设置中最复杂的应用程序,但它提供了充足的机会来展示 Teola 的有效性。 它利用积极的优化技术,例如不同级别的并行化(例如,独立的数据流分支和不同大语言模型调用的部分预填充)和流水线(例如,将大型嵌入分解为较小的嵌入并将查询扩展中的解码过程拆分为三个部分解码) ),如图6所示。 相比之下,LlamaDist 采用简单的运行到完成范例按顺序运行,错过了减少端到端延迟的机会。 LlamaDistPC 改进了索引和查询扩展模块的并行化,并重用了部分 KV 缓存,但仍然未能像 Teola 那样探索完整的优化潜力。 此外,与朴素的 RAG 类似,LlamaDist 和 LlamaDistPC 都很难有效地协调 PO 或 TO 中的请求,而 Teola 表现良好。 总体而言,Teola 在低请求率下的性能比其他产品高出 2.09 倍,在高请求率下的性能高出 1.68 倍,如图 8(底行)所示。
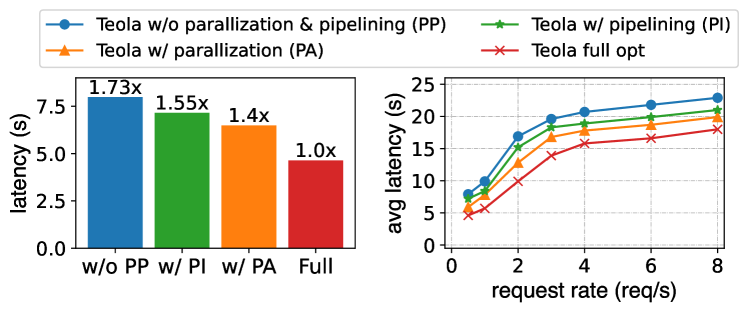
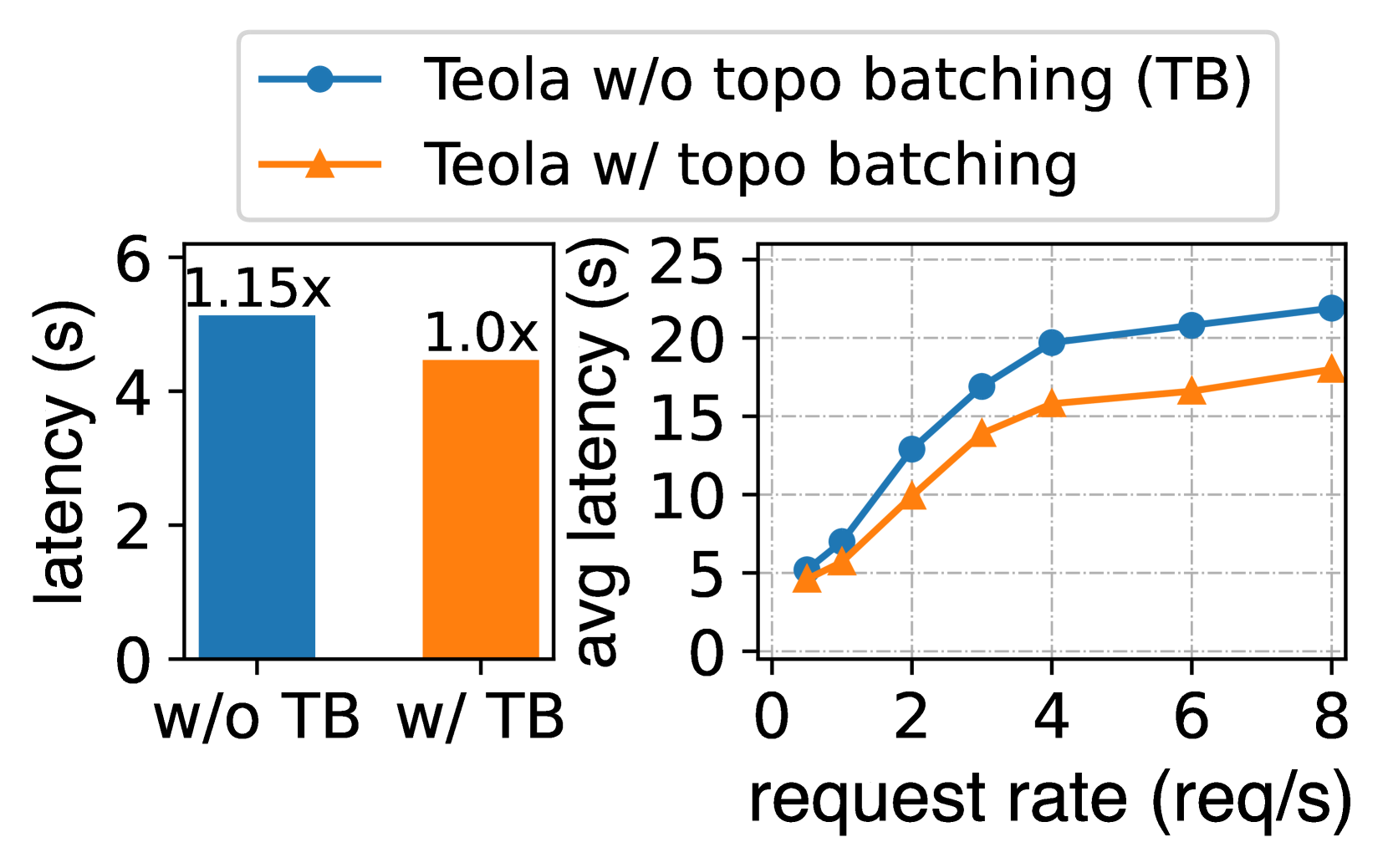
7.2. 消融研究
我们从图优化和运行时调度的角度展示了 Teola 主要组件的有效性。
7.3. 开销分析
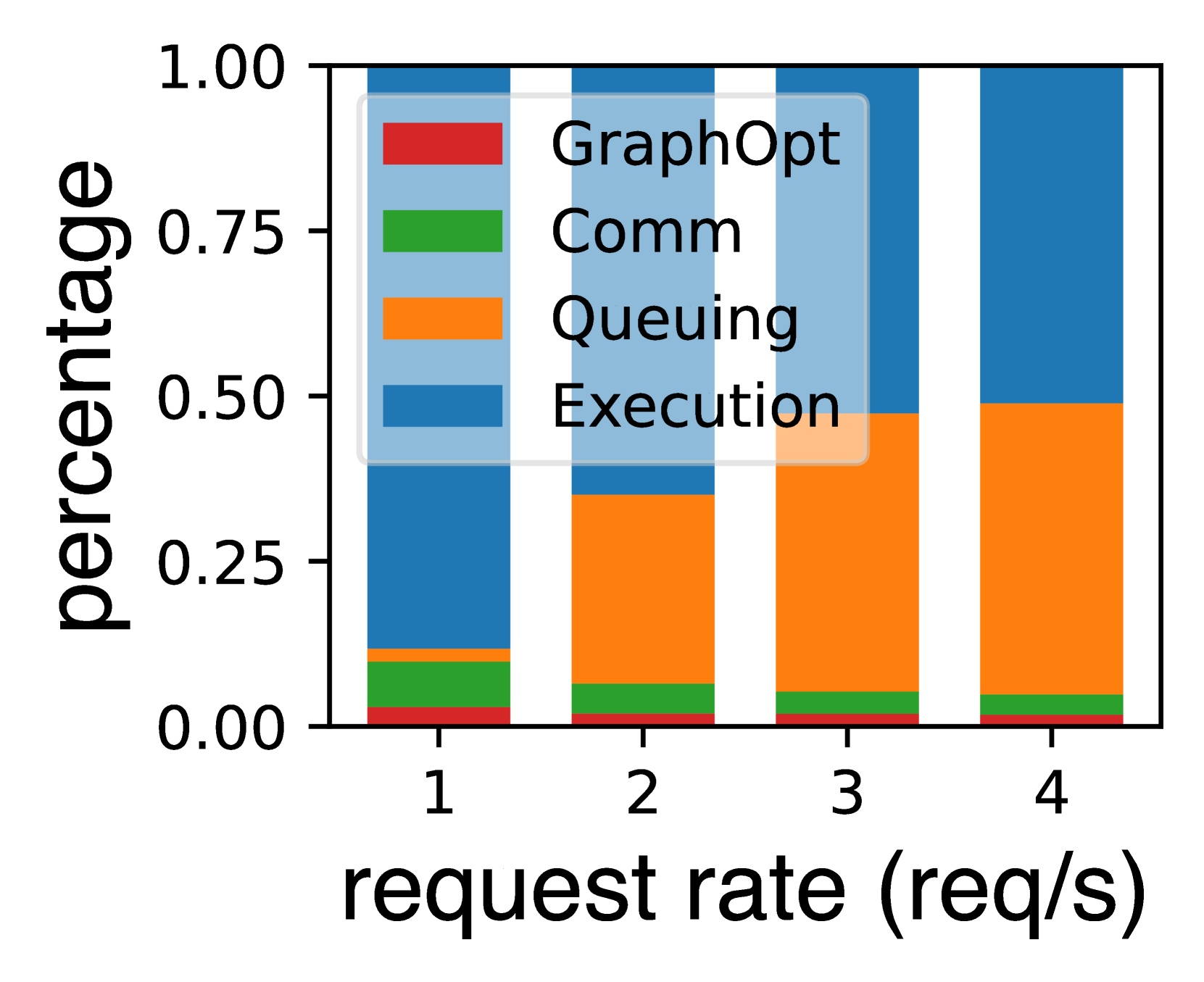
为了证明 Teola 产生的开销,我们通过分析实际关键执行路径中的不同部分来提供延迟细分。 该分析涵盖了不同请求率下在 TruthfulQA 数据集上使用高级 RAG 进行的文档 QA。 它包括图形优化、通信、排队和原始执行的延迟测量。 结果清楚地表明,通过优化缓存重用,图优化开销最小(1.3% ~3%),并且与总延迟相比,通信开销较低(3.1% ~6.2%)。 随着请求率的增加,某些操作的排队时间会导致更多的延迟。 这些表明 Teola 产生的开销可以忽略不计。
8. 局限性和未来的工作。
动态图。 虽然 Teola 的提前图优化带来了好处,但它可以适应动态模式,例如反射生成 (madaan2024selfreflection, )、RAG 中的迭代检索 (liu2024iterativere, ) 和代理- 确定的工作流程(kim2023llmcompiler, ; shen2023hugginggpt, ) 具有挑战性,因为它们的模式不可预测,并且在执行之前捕获整个基元级图很困难。
与后端耦合。 为了实现更细粒度的编排,我们必须修改几个引擎端机制,例如支持分解的原始操作和某些批处理策略。 与 LlamaIndex (llamaindex, ) 和 Langchain (langchain, ) 等现有框架相比,这些修改需要额外的工程工作,这些框架解耦编排和执行并与可插入引擎一起使用。 然而,这些额外的努力可以提高性能。 此外,在界面层面,Teola对用户隐藏了优化细节,以方便用户使用。
关键路径的利用。 可以进一步利用电子图中的关键路径信息。 对于资源分配,我们可以根据工作负载模式调整关键和非关键路径上的操作资源,以最大限度地提高利用率。 对于请求调度,对特定查询的关键节点进行优先级排序可以增强当前的拓扑批处理,但这需要对关键路径和协调复杂性进行准确的在线预测。
多应用程序协同编排。 当前的设计侧重于单个应用程序,但有可能扩展到协同编排在集群内共享通用引擎的多个应用程序,例如 RAG 和大语言模型对话应用程序。 通过分析它们独特的数据流图和需求,我们可以实现更广泛的系统范围优化。 优化跨应用程序的性能是未来的工作。
9. 相关工作
大语言模型推理优化。 大语言模型推理引起了广泛关注,大量研究集中在各个优化方向,包括内核加速(xiao2023smoothquant, ; dao2022flashattention, ; hong2023flashdecoding++, )、请求调度(yu2022orca, ; agrawal2024taming, ; agrawal2023sarathi, ; sheng2023fairness, ), 模型并行(li2023alpaserve, ; zhong2024distserve, ; miao2023spotserve, ), 语义缓存(bang2023gptcache, ; zhu2023optimalcache, ), KV缓存管理(kwon2023vllm, ; wu2024loongserve, ; lin2024infinite, ),KV缓存复用(kwon2023vllm, ; zheng2023sglang, ; gim2023promptcache, ; liu2024optimrelation, ; jin2024ragcache, ) 和先进的解码算法(ou2024losslessdecoding,;liu2023onlinespec,;miao2024specinfer,)。 最近的工作(patel2023splitwise, ; zhong2024distserve, ; hu2024inferencewithoutinterference, )分解了预填充和解码阶段的部署以提高吞吐量。 这一理念与 Teola 的分解方法非常吻合,并且可以无缝集成。 虽然大多数工作都提供大语言模型领域的单点解决方案,但 Teola 采取整体视角,优化整个应用程序工作流程并促进不同组件之间的合作。 因此,大语言模型推理的优化将补充 Teola 的努力。
基于 LLM 的应用程序的框架。 除了(llamaindex, ; langchain, ;promptflow, )等框架之外,一些研究(kim2023llmcompiler, ; khattab2023dspy, ; zheng2023sglang, ; lin2024parrot, )专注于优化复杂的大语言涉及多个大语言模型调用的模型任务。 他们通过开发特定的编程接口或编译器来探索并行性和共享等机会。 此外,多个人工智能代理框架(langgraph, ; wu2023autogen, ; shen2023hugginggpt, ; hong2023metagpt, ; khattab2023dspy, ; hong2024data, ; lin2024parrot, )使大语言模型能够自主控制工作流程、做出决策、选择工具、并与其他大语言模型交互,减少了人工干预的需要,但引入了特定的挑战。 Teola 更类似于(llamaindex, ; langchain, ;promptflow, ),使用原始级别的图来维护具有人工定义流程的各种组件的应用程序,同时关注端到端的执行效率。 Parrot (lin2024parrot, ) 还使用提示结构捕获多个大语言模型请求的应用程序级关联性,以方便联合调度。 正交,Teola 专注于涉及大语言模型和非 LLM 部分的应用程序的完整执行图优化。
机器学习分析系统。 现有的机器学习分析系统,例如 VideoStorm (zhang2017live, )、Jellybean (wu2022servingmlworkflow, )、Llama (romero2021llama, ) 和 Vulcan (zhang2024vulcan, ),专注于通过跨异构资源配置和放置组件来优化视频分析管道。 虽然它们与基于 LLM 的工作流程类似,但后者涉及更复杂的请求模式和灵活的配置。 此外,视频系统通常为所有查询维护统一的管道,而忽略前端编排和后端调度之间的协调。 Teola 通过构建更细粒度的数据流图进行编排、增强执行和调度效率以及利用 LLM 特定属性来解决这些限制。
10. 结论
我们推出 Teola,这是一个针对基于 LLM 的应用程序的细粒度编排框架。 核心思想是使用原始级别的数据流图进行编排。 这显式地公开了原始操作及其交互的属性,从而能够自然地探索并行执行的工作流级优化。 通过利用图中的原语关系,Teola 采用拓扑感知批处理启发式方法来智能地融合来自原语的请求以进行执行。 测试床实验表明,Teola 在不同应用中的性能优于现有方案。
参考
- [1] LlamaIndex. https://github.com/jerryjliu/llama_index, 2022.
- [2] Promptflow. https://https://github.com/microsoft/promptflow, 2023.
- [3] Bing Copilot. https://www.bing.com/chat, 2024.
- [4] Character.ai/. https://character.ai/, 2024.
- [5] Fastapi. https://fastapi.tiangolo.com/, 2024.
- [6] Finqabench Dataset. https://huggingface.co/datasets/lighthouzai/finqabench, 2024.
- [7] Google custom search. https://programmablesearchengine.google.com/, 2024.
- [8] Gpt-rag. https://github.com/Azure/GPT-RAG, 2024.
- [9] Langchain. https://github.com/langchain-ai/langchain, 2024.
- [10] LangGraph. https://python.langchain.com/docs/langgraph/, 2024.
- [11] Openai function calling. https://platform.openai.com/docs/guides/function-calling, 2024.
- [12] Pairag. https://github.com/aigc-apps/PAI-RAG, 2024.
- [13] Perplexity ai. https://www.perplexity.ai/, 2024.
- [14] Pgvector. https://github.com/pgvector/pgvector, 2024.
- [15] Postgresql. https://www.postgresql.org/, 2024.
- [16] Privatellm. https://privatellm.app/en, 2024.
- [17] Triton inference server. https://github.com/triton-inference-server, 2024.
- [18] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: A system for Large-Scale machine learning. In Proc. USENIX OSDI, 2016.
- [19] Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in llm inference with sarathi-serve. arXiv preprint arXiv:2403.02310, 2024.
- [20] Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, and Ramachandran Ramjee. Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills. arXiv preprint arXiv:2308.16369, 2023.
- [21] Fu Bang. Gptcache: An open-source semantic cache for llm applications enabling faster answers and cost savings. In Proc. the 3rd Workshop for Natural Language Processing Open Source Software, 2023.
- [22] Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on Freebase from question-answer pairs. In Proc. EMNLP, October 2013.
- [23] Daniel Crankshaw, Xin Wang, Guilio Zhou, Michael J Franklin, Joseph E Gonzalez, and Ion Stoica. Clipper: A Low-Latency online prediction serving system. In Proc. USENIX NSDI, 2017.
- [24] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. In Proc. NeurIPS, 2022.
- [25] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proc. ACL, 2018.
- [26] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.
- [27] In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference. arXiv preprint arXiv:2311.04934, 2023.
- [28] Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Hanyu Dong, and Yu Wang. Flashdecoding++: Faster large language model inference on gpus. In Proc. Machine Learning and Systems, 2023.
- [29] Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, Li Zhang, Lingyao Zhang, Min Yang, Mingchen Zhuge, Taicheng Guo, Tuo Zhou, Wei Tao, Wenyi Wang, Xiangru Tang, Xiangtao Lu, Xiawu Zheng, Xinbing Liang, Yaying Fei, Yuheng Cheng, Zongze Xu, and Chenglin Wu. Data interpreter: An llm agent for data science. arXiv preprint arXiv:2402.18679, 2024.
- [30] Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for a multi-agent collaborative framework. arXiv preprint arXiv:2308.00352, 2023.
- [31] Cunchen Hu, Heyang Huang, Liangliang Xu, Xusheng Chen, Jiang Xu, Shuang Chen, Hao Feng, Chenxi Wang, Sa Wang, Yungang Bao, et al. Inference without interference: Disaggregate llm inference for mixed downstream workloads. arXiv preprint arXiv:2401.11181, 2024.
- [32] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232, 2023.
- [33] Zhongzhen Huang, Kui Xue, Yongqi Fan, Linjie Mu, Ruoyu Liu, Tong Ruan, Shaoting Zhang, and Xiaofan Zhang. Tool calling: Enhancing medication consultation via retrieval-augmented large language models. arXiv preprint arXiv:2404.17897, 2024.
- [34] Rolf Jagerman, Honglei Zhuang, Zhen Qin, Xuanhui Wang, and Michael Bendersky. Query expansion by prompting large language models. arXiv preprint arXiv:2305.03653, 2023.
- [35] Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park. Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity. arXiv preprint arXiv:2403.14403, 2024.
- [36] Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Xin Liu, Xuanzhe Liu, and Xin Jin. Ragcache: Efficient knowledge caching for retrieval-augmented generation. arXiv preprint arXiv:2404.12457, 2024.
- [37] Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, et al. Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714, 2023.
- [38] Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. An llm compiler for parallel function calling. arXiv preprint arXiv:2312.04511, 2023.
- [39] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proc. ACM SOSP, 2023.
- [40] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2020.
- [41] Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, et al. AlpaServe: Statistical multiplexing with model parallelism for deep learning serving. In Proc. USENIX OSDI, 2023.
- [42] Bin Lin, Tao Peng, Chen Zhang, Minmin Sun, Lanbo Li, Hanyu Zhao, Wencong Xiao, Qi Xu, Xiafei Qiu, Shen Li, et al. Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache. arXiv preprint arXiv:2401.02669, 2024.
- [43] Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. Parrot: Efficient serving of llm-based applications with semantic variable. In Proc. USENIX OSDI, 2024.
- [44] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
- [45] Shu Liu, Asim Biswal, Audrey Cheng, Xiangxi Mo, Shiyi Cao, Joseph E Gonzalez, Ion Stoica, and Matei Zaharia. Optimizing llm queries in relational workloads. arXiv preprint arXiv:2403.05821, 2024.
- [46] Shu Liu, Asim Biswal, Audrey Cheng, Xiangxi Mo, Shiyi Cao, Joseph E Gonzalez, Ion Stoica, and Matei Zaharia. Optimizing llm queries in relational workloads. arXiv preprint arXiv:2403.05821, 2024.
- [47] Xiaoxuan Liu, Lanxiang Hu, Peter Bailis, Ion Stoica, Zhijie Deng, Alvin Cheung, and Hao Zhang. Online speculative decoding. arXiv preprint arXiv:2310.07177, 2023.
- [48] Yanming Liu, Xinyue Peng, Xuhong Zhang, Weihao Liu, Jianwei Yin, Jiannan Cao, and Tianyu Du. Ra-isf: Learning to answer and understand from retrieval augmentation via iterative self-feedback. arXiv preprint arXiv:2403.06840, 2024.
- [49] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. In Proc. NeurIPS, 2024.
- [50] Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, et al. Specinfer: Accelerating large language model serving with tree-based speculative inference and verification. In Proc. ACM ASPLOS, 2024.
- [51] Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. Spotserve: Serving generative large language models on preemptible instances. In Proc. ACM ASPLOS, 2024.
- [52] Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I Jordan, et al. Ray: A distributed framework for emerging AI applications. In Proc. USENIX OSDI, 2018.
- [53] Jie Ou, Yueming Chen, and Wenhong Tian. Lossless acceleration of large language model via adaptive n-gram parallel decoding. arXiv preprint arXiv:2404.08698, 2024.
- [54] Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Aashaka Shah, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. arXiv preprint arXiv:2311.18677, 2023.
- [55] Francisco Romero, Mark Zhao, Neeraja J Yadwadkar, and Christos Kozyrakis. Llama: A heterogeneous & serverless framework for auto-tuning video analytics pipelines. In Proc. ACM SoCC, 2021.
- [56] Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. In Proc. NeurIPS, 2023.
- [57] Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E Gonzalez, and Ion Stoica. Fairness in serving large language models. arXiv preprint arXiv:2401.00588, 2023.
- [58] Jiejun Tan, Zhicheng Dou, Yutao Zhu, Peidong Guo, Kun Fang, and Ji-Rong Wen. Small models, big insights: Leveraging slim proxy models to decide when and what to retrieve for llms. arXiv preprint arXiv:2402.12052, 2024.
- [59] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [60] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [61] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In Proc. NeurIPS, 2017.
- [62] Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. Loongserve: Efficiently serving long-context large language models with elastic sequence parallelism. arXiv preprint arXiv:2404.09526, 2024.
- [63] Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155, 2023.
- [64] Yongji Wu, Matthew Lentz, Danyang Zhuo, and Yao Lu. Serving and optimizing machine learning workflows on heterogeneous infrastructures. arXiv preprint arXiv:2205.04713, 2022.
- [65] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In Proc. ICML, 2023.
- [66] Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighof. C-pack: Packaged resources to advance general chinese embedding. arXiv preprint arXiv:2309.07597, 2023.
- [67] Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proc. EMNLP, 2018.
- [68] Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for Transformer-Based generative models. In Proc. USENIX OSDI, 2022.
- [69] Haoyu Zhang, Ganesh Ananthanarayanan, Peter Bodik, Matthai Philipose, Paramvir Bahl, and Michael J Freedman. Live video analytics at scale with approximation and Delay-Tolerance. In Proc. USENIX NSDI, 2017.
- [70] Yiwen Zhang, Xumiao Zhang, Ganesh Ananthanarayanan, Anand Iyer, Yuanchao Shu, Victor Bahl, Z Morley Mao, and Mosharaf Chowdhury. Vulcan: Automatic query planning for live ml analytics. In Proc. USENIX NSDI, 2024.
- [71] Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Efficiently programming large language models using sglang. arXiv preprint arXiv:2312.07104, 2023.
- [72] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving. arXiv preprint arXiv:2401.09670, 2024.
- [73] Banghua Zhu, Ying Sheng, Lianmin Zheng, Clark Barrett, Michael I Jordan, and Jiantao Jiao. On optimal caching and model multiplexing for large model inference. arXiv preprint arXiv:2306.02003, 2023.