RegMix:数据混合作为
语言模型预训练的回归
摘要
大语言模型预训练中的数据混合对性能有重大影响,但如何确定有效的混合方法尚不清楚。 我们提出 RegMix,通过将其构建为回归任务来自动识别高性能的数据混合。 RegMix 涉及使用不同的数据混合训练一组小型模型,并拟合一个回归模型来预测其各自混合的性能。 利用拟合的回归模型,我们模拟排名靠前的混合,并用它来训练一个规模更大的模型,其计算量高出几个数量级。 为了经验验证 RegMix,我们训练了 512 个具有 100 万个参数的模型,使用 10 亿个不同混合的符元来拟合回归模型并找到最佳混合。 使用这种混合,我们训练了一个具有 10 亿个参数的模型,使用 250 亿个符元(即 更大且 更长),我们发现它在 64 个其他混合的候选 10 亿参数模型中表现最佳。 此外,我们的方法展示了优于人工选择的性能,并取得了与 DoReMi 相匹配或超过其性能的结果,同时只使用了 10% 的计算预算。 我们的实验还表明:(1)数据混合对性能有重大影响,单任务性能差异高达 14.6%;(2)网络语料库比被认为是高质量的语料库(如维基百科)与下游性能具有更强的正相关性;(3)领域之间以复杂的方式相互作用,往往与常识相矛盾,因此需要像 RegMix 这样的自动方法;(4)数据混合效应超越了扩展定律,我们的方法通过将所有领域结合在一起来捕捉这种复杂性。 我们的代码可在 https://github.com/sail-sg/regmix 获取。
1 引言
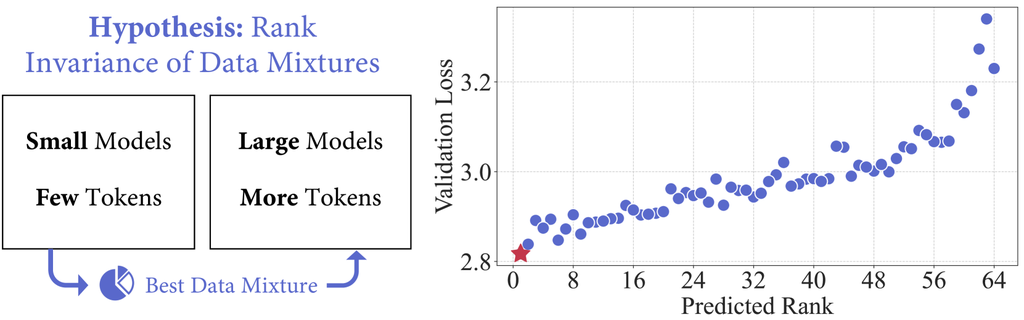
大规模公共数据集的可用性是创建大型语言模型 (LLM) 的关键因素。 大多数数据都可以在互联网上获得,包括学术论文(例如 arXiv)、书籍(例如 Project Gutenberg)和代码(例如 GitHub)。 为了创建第一个 LLM 之一,GPT-3 [7],作者已经认识到选择最佳数据进行训练的重要性,因此他们决定对维基百科进行上采样,因为它被认为具有较高的质量。 但是,这种手动数据选择不可扩展,并且可能导致次优选择 [3]。 随着用于 LLM 预训练的数据量和多样性不断增长,确定最佳数据混合变得越来越具有挑战性。 这引发了一个关键的研究问题: 我们如何以可扩展且高效的方式选择最佳数据混合?
先前的工作 [64, 16, 2] 使用小型模型(“代理模型”)来预测大型语言模型的域权重。 这些工作使用大量符元(例如,100B)训练代理模型,有时甚至与用于训练 LLM 的符元数量相同,并通过监控训练动态来动态调整数据分配策略。 然而,随着用于 LLM 预训练的训练数据量不断增长,这些方法变得效率低下。 使用当前方法训练 Llama-3 等当前模型的代理模型将需要使用高达 15T 个符元 [1],这可能过于昂贵且速度过慢,无法使其物有所值。 1 11这些方法通常会遇到稳定性问题。 详细信息可以在附录 F 中找到。 .
在这项工作中,我们认为 在有限的符元集上训练小型模型 足以预测 LLM 训练的有效数据混合。 我们的关键假设是 数据混合的秩不变性,它假设数据混合在影响模型性能方面的相对排名在不同模型大小和训练符元数量之间是一致的。 在这种假设下,关键的挑战在于从无限接近的潜在数据混合中发现排名最高的混合数据。 为此,我们将数据混合选择视为一个回归任务。 而不是用每种可能的混合物详尽地训练小型模型,我们只训练一组小型模型,每个模型都有一个独特的数据混合。 基于这些模型的性能及其混合物,我们拟合一个回归模型来预测其他数据混合物的性能。 我们的方法比以前的工作具有更大的可扩展性,因为它允许并行训练小型代理模型,而不是长时间训练单个模型。 此外,回归模型提供了对域交互的见解,可以促进理解和数据整理。
为了验证RegMix,我们训练了具有 100 万个参数和 10 亿个参数的模型 2 22本文中提到的模型大小是指非嵌入参数的数量,因为嵌入参数在较小的模型中占了不成比例的大部分。 使用不同的数据混合物。 通过在 10 亿个符元上训练 512 个具有 100 万个参数的模型 3 33训练100万个模型的估计 FLOPs 几乎是训练一个 10 亿模型所需 FLOPs 的 2%。 ,我们能够预测 64 个模型中最佳的数据混合物,这些模型更大(10 亿个参数)并且训练更长(250 亿个符元),如图1所示。 此外,使用RegMix优化后的数据混合物产生了比人工选择更好的模型,并且与旗舰 DoReMi 方法的性能相当[64],尽管它需要的总计算量更少,并允许并行训练。 我们还发现:(1) 数据混合对下游性能有重大影响,导致单任务性能差异高达 14.6%;(2) 通用网络语料库(如 CommonCrawl),而不是维基百科,与下游任务性能的提高表现出最强的正相关性; (3) 域之间的交互是复杂的,并且通常与直觉相矛盾,突出了对像RegMix这样的自动化方法的需求。 (4) 数据混合效应超越了缩放定律,而RegMix通过将所有域综合考虑来捕捉这种复杂性。
2 相关工作
数据选择和混合 关注于策划数据以优化某些目标,通常是模型性能 [29, 3]。 以前的方法可以分为:(1) 符元级 选择是最细粒度的选择级别,处理符元的过滤 [31]。 (2) 样本级 选择是关于选择单个训练示例。 它通常用于选择微调数据 [57, 13, 65, 15, 63, 33, 8, 25, 37, 49, 67]。 对于 LLM 的预训练,大多数方法依赖于启发式方法 [46, 54, 55],但也有一些使用优化算法的学习方法 [10, 40, 53, 69],模型困惑度 [35, 41],或 LLM 来告知样本选择过程 [61, 48, 72]。 (3) 组级 选择假设数据可以分组到池中,然后最佳地混合。 虽然早期的工作仍然依赖于手动混合 [18, 7],但学习混合变得更加普遍 [3]。 学习方法要么利用代理模型来确定每个组的固定权重(“离线选择”) [46, 64, 16],要么在最终模型的训练过程中动态调整权重(“在线选择”) [9]。 我们的方法,RegMix,是一种离线组级选择方法。 与此类别中的旗舰算法 DoReMi [64] 不同,RegMix 不需要为数十万步训练单个模型,而只需要为短时间训练几个小型模型。 由于这些可以并行训练,我们的方法更具可扩展性,同时也能产生更好的权重,从而导致最终模型的性能更高。
数据缩放规律 探索了数据数量、质量和混合比例的相互作用,因为 LLM 被扩展。 Muennighoff 等人 [41] 介绍了数据受限场景的缩放规律,Goyal 等人 [21] 试图将这种方法扩展到处理多个数据池。 之前的研究已经证实不同的数据集需要不同的缩放 [23, 42],因此 Ye 等人 [68] 和 Ge 等人 [20] 提出了函数关系来预测混合对语言建模损失的影响。 一些工作已经研究了在持续预训练而不是从头训练期间的最佳混合 [45, 14]。 虽然这些工作中的大多数都关注验证损失,但其他工作则调查了下游性能并开发了与损失相关的预测关系 [17, 66, 62]。 与试图找到分析标度函数 [23] 的数据标度工作不同,RegMix 使用回归模型直接优化目标指标。 RegMix 专为从头开始的预训练而设计。 与之前的研究一致,我们也发现损失与下游性能之间存在强相关性,特别是对于网络语料库上的损失。
3 RegMix: 数据混合作为回归
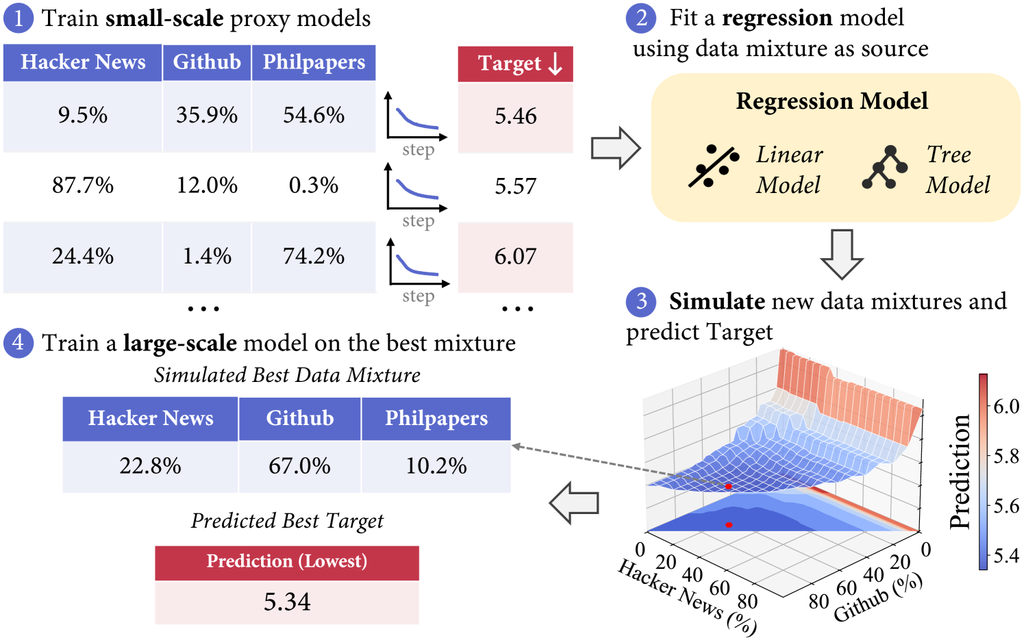
如图 2 所示,我们的方法包括四个关键步骤:(1)生成随机数据混合并在这些混合上训练小规模代理模型。 (2) 使用混合作为特征,目标值作为标签拟合线性回归模型。 (3) 在更大规模上模拟数据混合空间,并利用回归模型识别目标值的最佳混合。 (4) 使用模拟的最佳数据混合训练大规模模型。
3.1 训练小规模代理模型
第一步是在多个不同的数据混合上训练一组小规模代理模型。 为了减少所需的运行次数,我们的目标是选择一系列不同的数据混合,这些混合涵盖每个域从 0% 到 100% 的极端权重。 我们通过使用基于符元分布的狄利克雷分布来实现这一点,这使我们能够采样广泛的值,并将回归模型暴露在各种极端情况下。 同时,基于符元分布的分布确保了总体数据混合在统计上反映了数据的可用性。 例如,这可以防止任何单个域的符元计数低于 1% 被过度强调,这对于大规模训练来说是不可行的,因为该域没有足够的可用符元。 在实践中,我们将符元分布乘以 到 之间的值来构建各种稀疏和近似均匀分布,然后使用这些分布向量作为狄利克雷分布超参数 。
在对小规模代理模型进行几步训练后,我们可以获得几个训练良好的小型模型。 例如,在我们主要的实验中,每个代理模型包含 1M 个参数,并在 1B 个符元上进行训练。 然后,我们可以选择在域或基准上评估这些训练过的模型,以获得我们想要优化的目标值。 通常,目标值可以是域上的损失,如 2 图所示,用于 StackExchange 域。 一旦我们获得了这些目标值,我们就可以使用数据混合作为特征,并将目标值作为标签来拟合回归模型。
3.2 拟合回归模型
| Component | Effective Size |
|---|---|
| Pile-CC | 227.12 GiB |
| PubMed Central | 180.55 GiB |
| Books3 | 151.44 GiB |
| OpenWebText2 | 125.54 GiB |
| ArXiv | 112.42 GiB |
| Github | 95.16 GiB |
| FreeLaw | 76.73 GiB |
| Stack Exchange | 64.39 GiB |
| USPTO Backgrounds | 45.81 GiB |
| PubMed Abstracts | 38.53 GiB |
| Gutenberg (PG-19) | 27.19 GiB |
| Component | Effective Size |
|---|---|
| OpenSubtitles | 19.47 GiB |
| Wikipedia (en) | 19.13 GiB |
| DM Mathematics | 15.49 GiB |
| Ubuntu IRC | 11.03 GiB |
| BookCorpus2 | 9.45 GiB |
| EuroParl | 9.17 GiB |
| HackerNews | 7.80 GiB |
| YoutubeSubtitles | 7.47 GiB |
| PhilPapers | 4.76 GiB |
| NIH ExPorter | 3.79 GiB |
| Enron Emails | 1.76 GiB |
第二步是使用数据混合作为特征,并将目标值作为标签来拟合回归模型。 回归任务是一个传统的监督学习任务,它涉及根据输入特征 预测一个连续的目标变量 。 目标是找到一个函数 ,它能最好地将输入特征映射到目标变量,使得 ,其中 表示数据中的误差或噪声。 在本文的背景下,输入特征 对应于数据混合的域权重,目标变量 是我们想要优化的值。 利用这些数据,我们训练了回归模型,这些模型学习了一个函数,该函数可以在不进行进一步训练的情况下,根据任意数据混合来预测目标值。
线性回归。
线性回归模型在回归中被广泛使用。 它假设输入特征和目标变量之间存在线性关系,可以表示为:
| (1) |
其中 是截距, 是与各个输入特征 相关的系数。 系数 通常使用诸如普通最小二乘法之类的技术来估计,旨在最小化预测目标值与实际目标值之间的平方残差之和。 在实践中,我们使用具有 L2 正则化的线性回归,也称为岭回归,它对 的大小施加惩罚,以防止过拟合。
LightGBM 回归。
LightGBM [26] 是一种强大的梯度提升算法,可用于回归和分类任务。 在回归的背景下,LightGBM 学习决策树的集合来预测目标变量。 该过程由基于梯度的优化算法指导,该算法最小化指定的损失函数(例如均方误差)。 此外,LightGBM 被设计为高效且可扩展的,使其适用于大型数据集。
3.3 模拟和预测
一旦我们训练了回归模型,我们就可以有效地探索所有可能的 data mixture 空间。 通过使用训练好的模型来预测每个潜在数据混合的目标值,我们可以快速识别出产生最佳目标值的输入。 这种基于模拟的优化相对便宜,因为模拟和回归预测在计算上都很快。 例如,对 1,000,000 个数据混合进行预测只需不到 10 秒的 CPU 时间。
3.4 大规模模型训练
在通过模拟确定最佳数据混合后,我们将排名最高的混合推广到具有更多符元的大规模模型训练。 如图 2 所示,我们直接使用最佳数据混合来训练更大模型。 在实践中,为了提高回归预测的鲁棒性,我们选择排名靠前的 混合并将它们平均作为大规模训练的数据混合。
4 评估回归预测
在本节中,我们评估 RegMix 预测未见数据混合效果的能力。 首先,我们使用小模型(即 1M 参数)的训练工件来拟合回归模型,并评估小模型上的损失预测性能。 然后,为了验证我们的 排名不变假设,我们测试了学习到的回归对跨模型大小和符元数量预测排名的效果。
4.1 实验设置
数据集和模型。
我们使用表 1 中描述的 Pile 数据集 [18] 的领域进行实验。 由于版权问题,我们使用了 HuggingFace 上可用的 17 个子集 444https://huggingface.co/datasets/monology/pile-uncopyrighted,这些子集不违反版权问题。 我们同时考虑线性回归和 LightGBM 回归模型,其中目标变量 设置为 Pile-CC 域的验证损失。
| Method | 1M models with 1B tokens | 60M models with 1B tokens | 1B models with 25B tokens | ||||
|---|---|---|---|---|---|---|---|
| () | Pearson’s () | MSE () | () | Pearson’s () | () | Pearson’s () | |
| Linear | 90.08 | 87.78 | 0.13 | 89.26 | 86.79 | 88.01 | 72.57 |
| LightGBM | 98.45 | 98.57 | 0.04 | 98.64 | 98.28 | 97.12 | 94.36 |
训练和评估。
回归模型使用 100 万个模型(每个模型包含 10 亿个符元)的训练文物进行拟合,并在 未见数据混合物上进行评估,这些混合物用于 100 万个模型、6000 万个模型(每个模型都使用 10 亿个符元进行训练)和 未见数据混合物用于 10 亿个模型(每个模型都使用 250 亿个符元进行训练)。
评估指标。
我们使用三种不同的指标来对我们的回归模型进行基准测试:(1) 斯皮尔曼秩相关性 () 是一个非参数指标,用于衡量两个排序变量之间关联的强度和方向。 (2) 皮尔逊 是衡量两个变量之间线性关系的指标。 (3) 均方误差 (MSE) 是一种常用的指标,用于通过测量预测值和实际值之间的平均平方差来评估回归模型。
4.2 实验结果
模型大小之间的高度相关性。
如表 2 所示,LightGBM 模型在所有三个指标上都表现出优于线性回归模型的性能,并且在评估具有更多训练符元的较大模型时,其优势变得越来越明显。 同时,100 万个模型使用 10 亿个符元进行训练,能够在 10 亿个模型(使用 250 亿个符元进行训练)的未见混合物上实现 % 的高相关性,这直接验证了我们的 秩不变假设。
代理模型数量胜过训练符元数量。
在小规模训练中,给定相同的 FLOPs 预算,我们可以增加符元数量(即训练符元的数量)或代理模型的数量。 因此,我们研究哪种方法可以产生更好的性能。 如图 3 所示,在约 0.25B 个符元后,增加代理模型的训练符元会饱和。 相反,增加代理模型的数量会持续增强性能,特别是对于 LightGBM 模型。 值得注意的是,在 0.2B 个符元上训练的 512 个模型的性能超过了在 0.8B 个符元上训练的 128 个模型的性能,这表明增加代理模型的数量比在一定符元阈值之后增加训练符元数量更有效。
5 在下游任务上的评估
在本节中,我们将应用我们的方法来证明其在现实下游任务上的有效性。 为了评估,我们根据之前工作 [36] 中报告的性能轨迹以及我们在预训练期间的观察,排除了在性能方面表现出较大差异的特定基准(例如,RTE)。 最终,我们选择以下基准作为我们的下游任务:社交 IQA [51]、HellaSwag [70]、PiQA [5]、OpenBookQA [39]、Lambada [43]、SciQ [60]、ARC Easy [11]、COPA [52]、RACE [30]、LogiQA [32]、QQP [59]、WinoGrande [50] 和 MultiRC [27]。 这些基准涵盖了各种各样的任务,使我们能够全面评估 RegMix 对现实世界影响。 对于每个基准,如果 lm-eval-harness [19] 提供了归一化准确率,我们将使用归一化准确率作为评估指标,否则我们将使用常规准确率。
5.1 数据混合对下游性能有重大影响
| Benchmark | Worst Model | Best Model | |
|---|---|---|---|
| Social IQA [51] | 32.4 | 33.9 | 1.5 |
| HellaSwag [70] | 33.0 | 43.4 | 10.4 |
| PiQA [5] | 60.2 | 69.0 | 8.8 |
| OpenBookQA [39] | 25.8 | 31.2 | 5.4 |
| Lambada [43] | 18.9 | 33.5 | 14.6 |
| SciQ [60] | 76.7 | 82.9 | 6.2 |
| ARC Easy [11] | 44.9 | 52.2 | 7.3 |
| COPA [52] | 61.5 | 70.5 | 9.0 |
| RACE [30] | 27.9 | 32.5 | 4.6 |
| LogiQA [32] | 23.2 | 27.7 | 4.5 |
| QQP [59] | 48.0 | 59.7 | 11.7 |
| WinoGrande [50] | 50.3 | 53.2 | 2.9 |
| MultiRC [27] | 47.6 | 55.7 | 8.1 |
| Average Performance | 43.7 | 47.9 | 4.2 |
最初,我们训练了 64 个模型,每个模型都有 10 亿个参数,使用不同的数据混合。 每个模型都使用 25B Token 进行训练5 55我们根据 Chinchilla 扩展定律 [23] 设置符元数量,使其在计算方面最优。 表 3 展示了每个下游任务上表现最差和表现最好的模型的性能。 表 3 显示了每个下游任务的最差和最佳模型的性能。 报告的性能是 0-shot 到 5-shot 评估的平均值,使用 lm-eval-harness 评估框架 [19, 4] 进行评分。 我们发现数据混合对下游性能有重大影响,最大的性能 达到了 在 Lambada 任务上。 这强调了研究最佳数据混合的重要性。
5.2 网络语料库对下游性能的影响最大
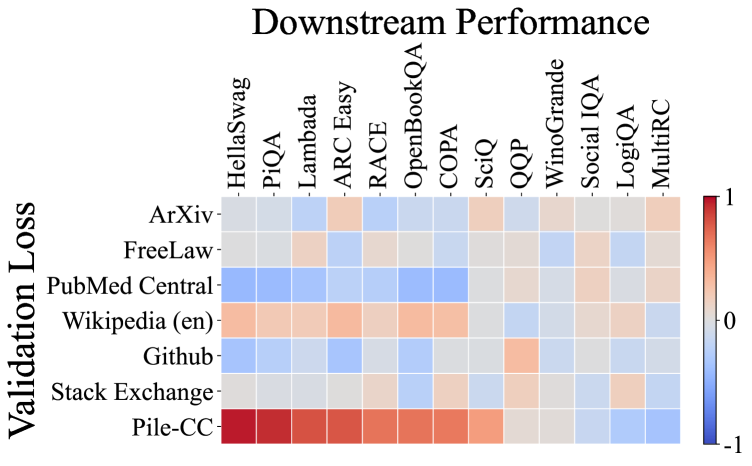
接下来,我们可视化了 64 个 10 亿模型在不同领域上的验证损失与其在各种下游任务上的性能之间的相关性,如图 4 (a) 所示。 在可视化之前,我们假设在维基百科 (en) 子集上的验证损失与大多数下游任务高度相关,因为它是一个高质量的数据集,许多下游任务都源自维基百科文本。 同样,之前的工作通常将 WikiText [38] 作为衡量语言模型性能的标准基准。
然而,令人惊讶的是,Pile-CC 数据集上的验证损失与大多数下游任务显示出最强的相关性。 例如,HellaSwag 任务与 Pile-CC 验证损失之间的相关系数非常接近 。 这一意外结果挑战了 WikiText 是评估 LLM 的最具代表性的数据集的传统假设。 此外,这一结果与之前研究 [17, 24] 的发现一致,这些研究发现,网页数据集上的验证损失与下游性能密切相关。
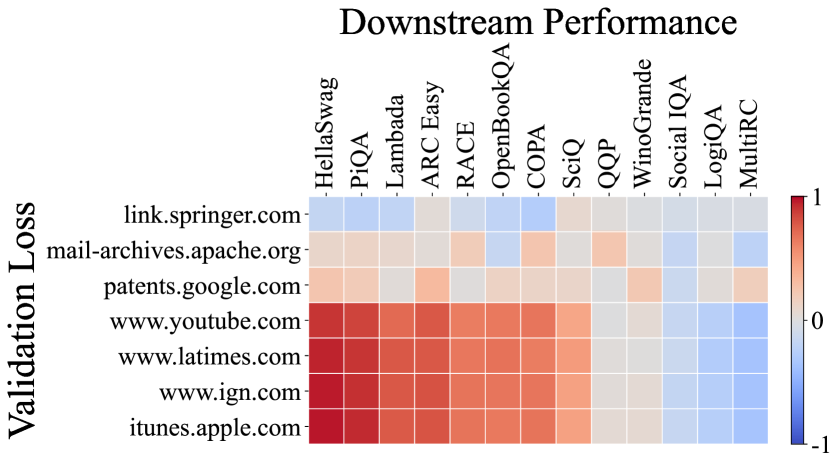
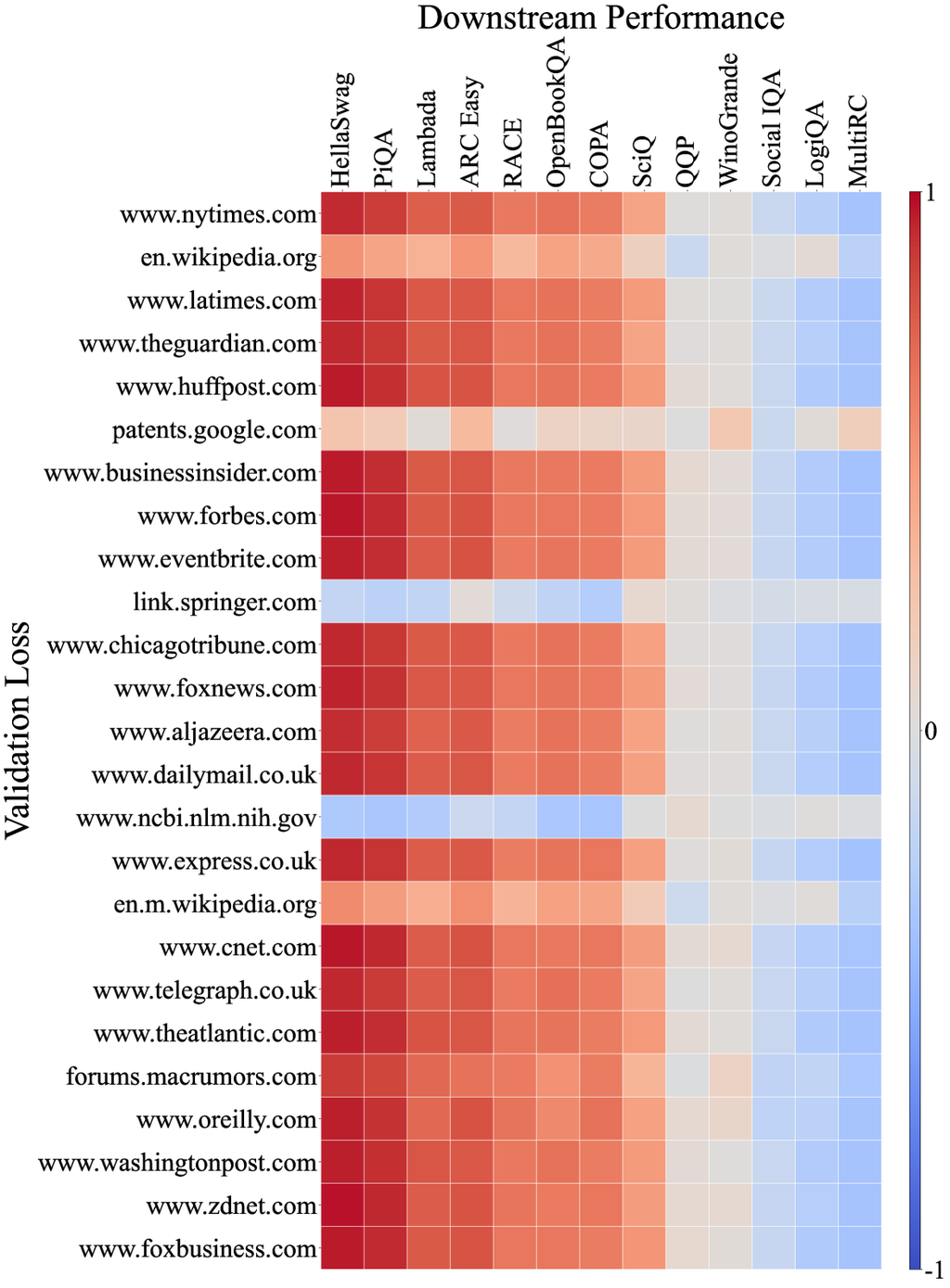
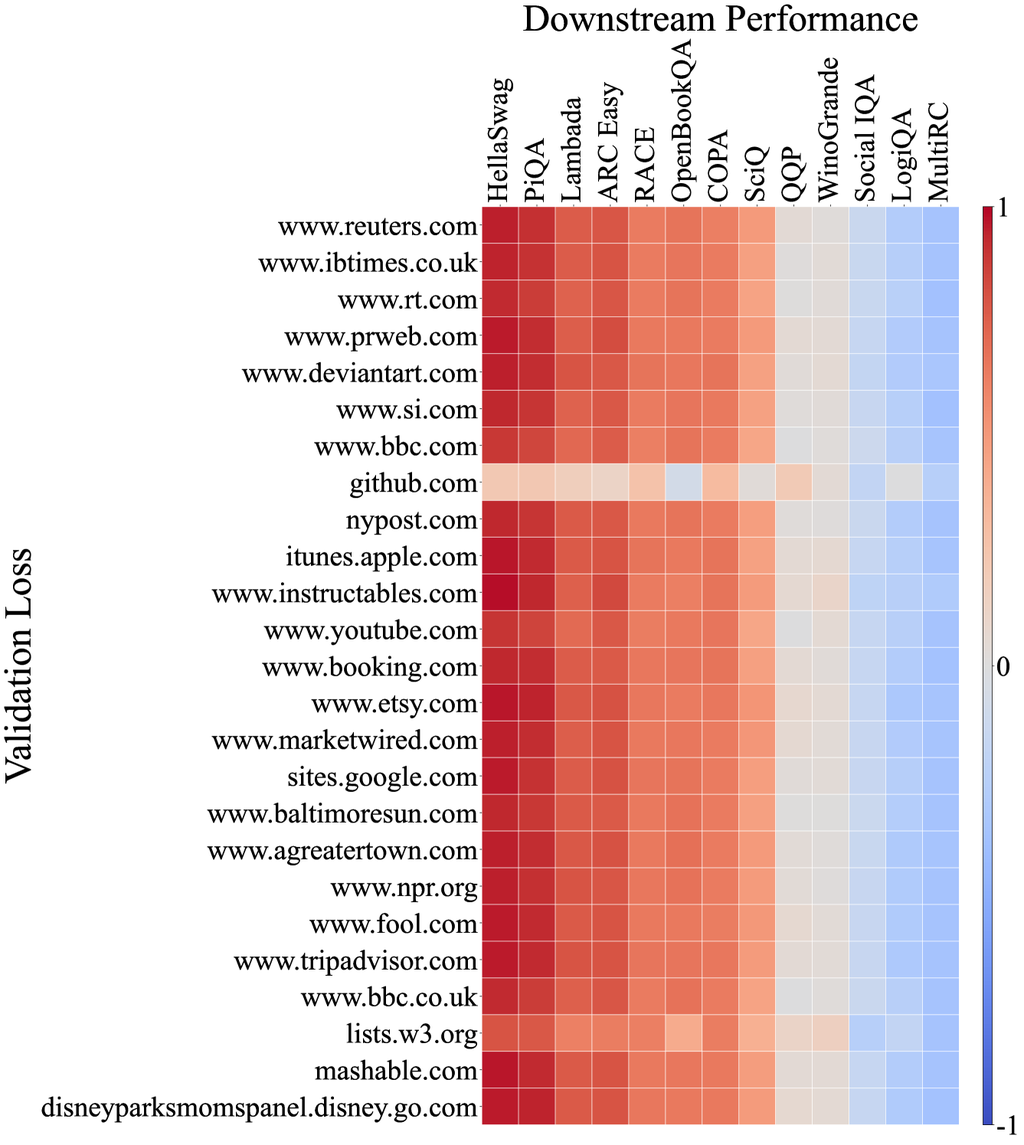
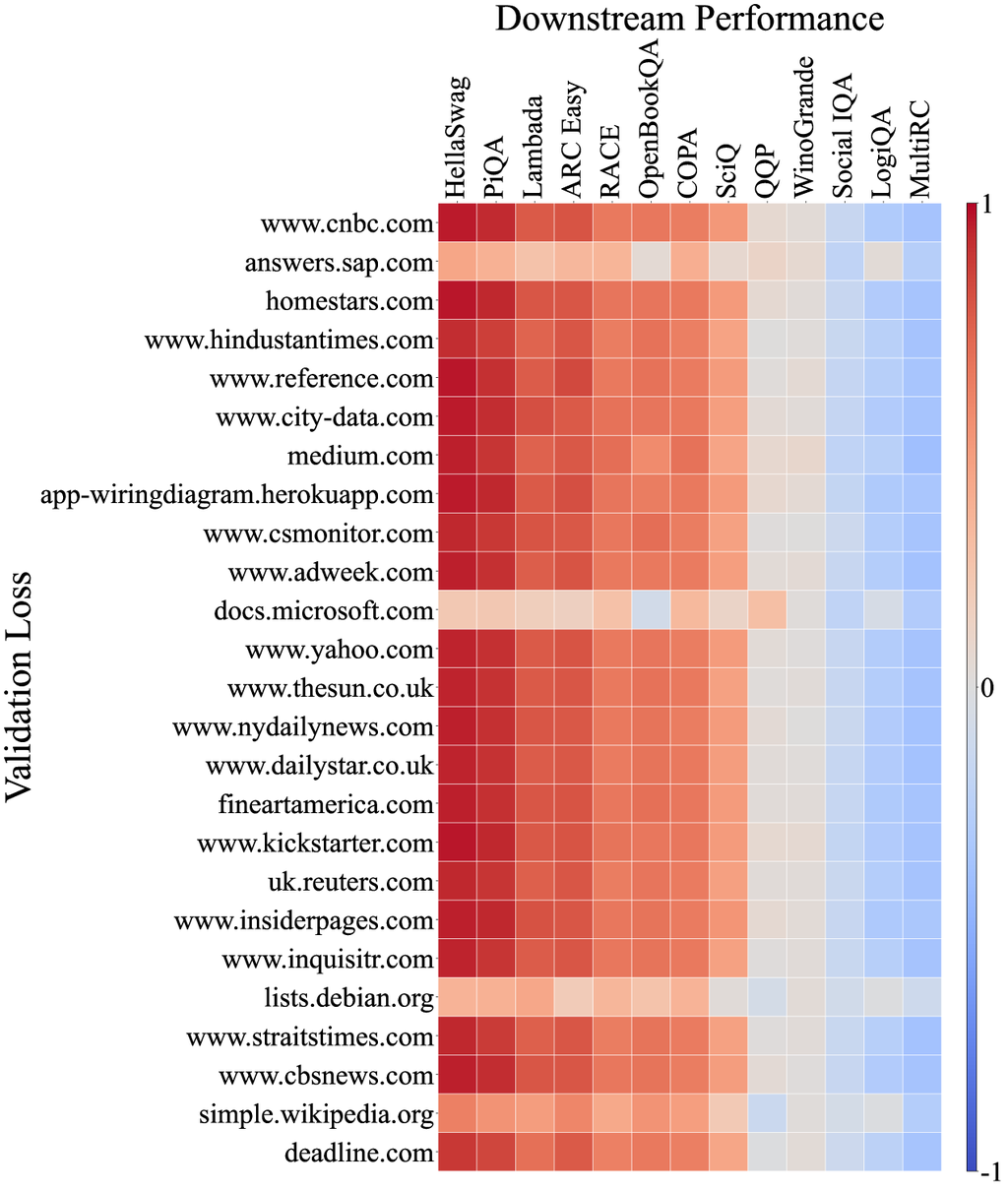
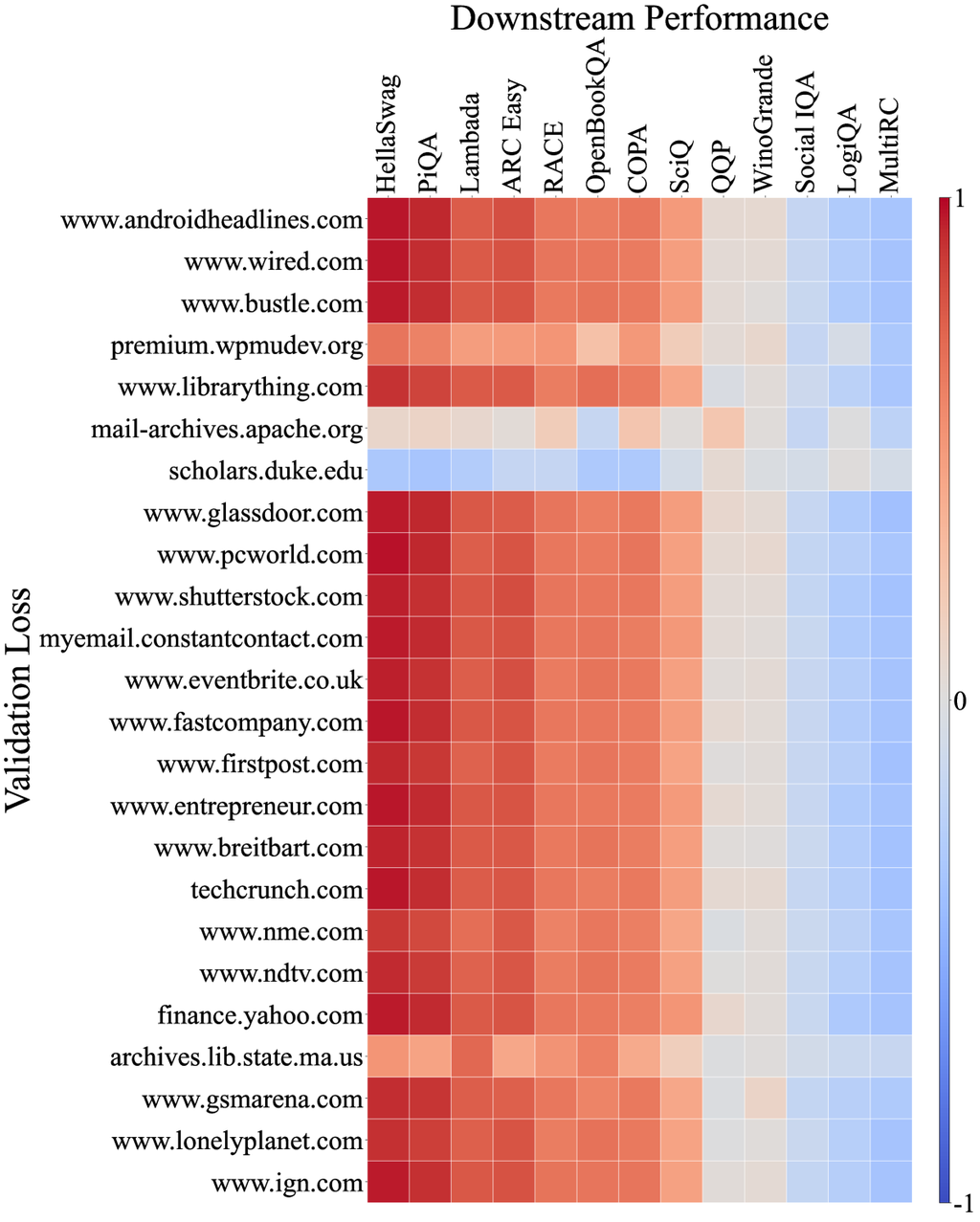
此外,我们分析了模型在 C4100Domain 验证集 [34] 上的损失与相关性,该验证集取自 C4 数据集 [47],并且应该与 Pile-CC 具有相似的分布,因为它们都源自 CommonCrawl 语料库。 由于 CommonCrawl 是一个包含各种领域的数据集,我们预计每个领域损失与下游任务之间的相关性会有所不同。 但是,令人惊讶的是,超过 85% 的领域与 Pile-CC 显示出非常强的相关性(完整相关图见附录 D)。 这以 www.ign.com 域为例,该域与 Pile-CC 的整体相关图非常相似,如图 4 (b) 所示。 这也表明,Pile-CC 与下游任务性能之间的高度相关性可能是由于其 涵盖了各种主题和领域的广泛内容。
5.3 通过 RegMix 进行的数据混合提高了下游性能
| Benchmark | Human | DoReMi | Pile-CC Only | RegMix |
|---|---|---|---|---|
| Social IQA [51] | 33.8 0.4 | 33.3 0.2 | 33.4 0.4 | 33.5 0.2 |
| HellaSwag [70] | 37.7 0.2 | 43.3 0.3 | 43.2 0.6 | 44.0 0.2 |
| PiQA [5] | 65.5 0.7 | 68.6 0.4 | 68.8 0.6 | 69.1 0.4 |
| OpenBookQA [39] | 28.5 0.4 | 30.0 0.3 | 30.5 0.4 | 29.8 0.5 |
| Lambada [43] | 28.3 1.5 | 32.4 0.7 | 34.2 1.1 | 32.9 1.4 |
| SciQ [60] | 81.5 1.1 | 83.3 1.9 | 82.4 1.0 | 82.8 0.4 |
| ARC Easy [11] | 49.9 0.9 | 52.3 1.1 | 51.8 0.4 | 52.1 0.9 |
| COPA [52] | 64.6 1.8 | 69.7 2.7 | 67.5 2.0 | 69.9 0.6 |
| RACE [30] | 29.5 0.5 | 31.1 0.2 | 31.5 0.5 | 31.2 0.4 |
| LogiQA [32] | 25.7 0.8 | 25.5 0.7 | 26.6 1.0 | 25.4 1.2 |
| QQP [59] | 55.6 2.9 | 57.3 1.4 | 58.0 1.9 | 55.7 1.9 |
| WinoGrande [50] | 52.0 1.0 | 52.1 0.3 | 51.8 0.7 | 52.1 0.7 |
| MultiRC [27] | 52.9 1.4 | 52.9 1.2 | 51.2 1.5 | 52.8 1.5 |
| Average Performance | 46.6 0.3 | 48.6 0.3 | 48.5 0.3 | 48.6 0.3 |
| Beat Human on | – | 8 / 13 | 8 / 13 | 8 / 13 |
| Estimated FLOPs | 0 | 0 |
之前的工作表明,数据混合方法可以通过使用更少的训练符元[64]来实现更小的验证损失(或困惑度),从而加速LLM预训练。 然而,一个关键问题是 应该优化哪个验证损失? 最直观的做法,也是之前工作所采用的,是将所有域的损失降到最低。 然而,根据我们对100万条训练日志的研究,我们发现这在实践中几乎不可能实现。 没有任何数据混合能够同时超越人类选择的所有域验证损失。 这表明,将所有域的损失降到最低的简单方法可能是不可行的。 因此,我们选择优化Pile-CC验证损失,以在后续任务上实现一般的性能提升,因为它与后续性能的相关性最高。
我们实现了两种方法来确定数据混合。 第一种方法依赖于人类直觉。 由于Pile-CC及其自身分布应该是最接近的匹配,我们假设仅在Pile-CC上进行预训练可能会比基线产生更好的性能。 第二种方法利用RegMix,使用Pile-CC验证损失作为目标变量。 我们使用LightGBM来预测可以最小化Pile-CC验证损失的数据混合。
我们将我们提出的方法的性能与强大的基准进行比较,包括为 Pile [18] 和 DoReMi [64] 进行的人类选择。 对于 DoReMi,我们直接从他们报告的最佳领域权重中获取数据混合,并在可用的 17 个领域中重新归一化。 这可能会导致 DoReMi 的性能低于最初报告的结果。 如表 4 所示,Pile-CC Only 和 RegMix 都展示了与基准相比的强大性能。 在广泛使用的 HellaSwag 基准测试中,RegMix 显示出比人类选择 的改进。 此外,RegMix 在 14 个案例中的 8 个案例中,在任务性能方面都击败了其他三种方法,并获得了最高的平均得分。 Pile-CC Only 令人惊讶的强大性能强化了我们上一节的结论:网络语料库在后续性能上有所帮助。 最后,RegMix 超越了表 3 中的最佳模型,证明了我们的自动数据混合方法比随机搜索更有效。
5.4 对于人类来说,理解域交互具有挑战性
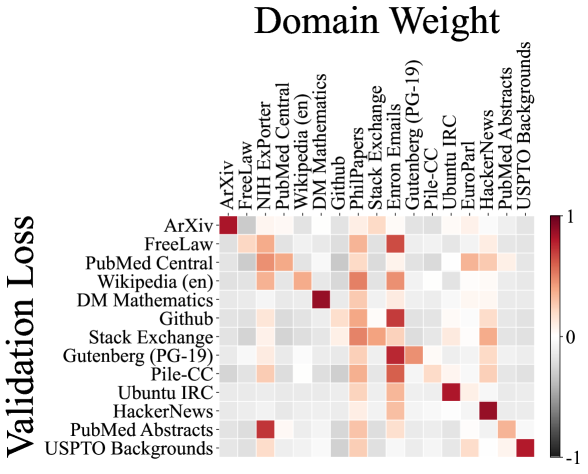
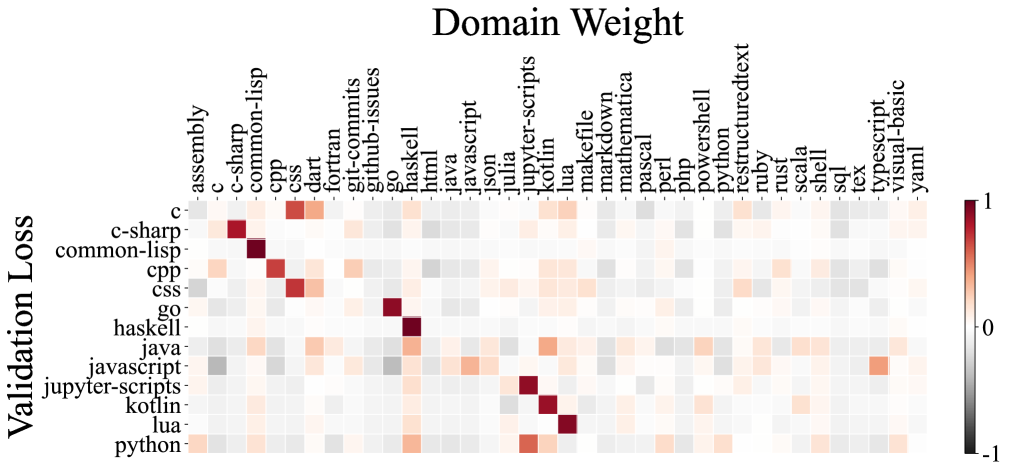
为了理解不同域彼此之间的影响,我们在图 6 中可视化了线性回归模型的系数 ()。 该可视化提供了对各种数据域如何贡献于其他域的见解,揭示了它们之间复杂的交互作用。 我们还显示了在 The Stack 数据集 [28] 上训练的每个 1M 代码模型的代码相关性图表。 令人惊讶的是,域交互可视化和代码相关性图表都显示出复杂的关系,人类专家难以完全理解。 例如,Pile 数据集中的 PhilPapers 域似乎在线性回归建模下为所有其他域提供了收益,这是一个非显而易见的发现,挑战了人类的直观理解。 这些可视化突出了确定最佳数据混合的固有复杂性,突出了我们自动化 RegMix 方法在有效识别高性能混合方面的价值,而不是仅仅依靠人类直觉。
5.5 数据混合效应超越了缩放定律
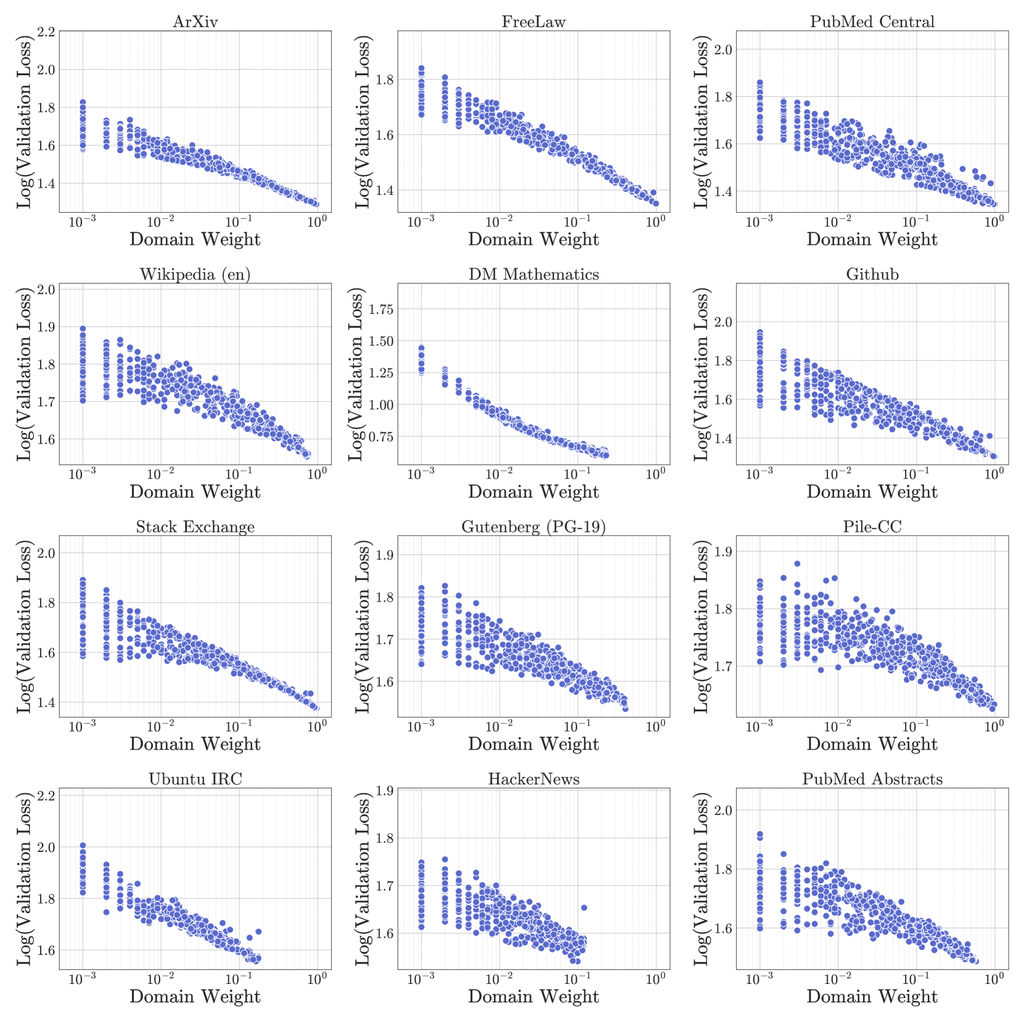
近期的研究 [68, 20] 证明了数据混合缩放定律的可行性。 但是,我们在第 5.4 节中的发现表明,域权重与验证损失之间的关系比缩放定律可能暗示的要复杂。 为了可视化这种复杂性,我们在图 7 中绘制了我们 100 万次训练日志的所有实验点。 如果数据混合的缩放定律成立,我们预计会在所有域中看到清晰的对数对数线性关系。 但是,我们的结果揭示了一幅更加细致的画面。 例如,DM 数学域,可能是由于其与其他域相比的独特分布,在损失和域权重之间表现出近似对数对数线性关系。 相反,对于大多数域(如 Pile-CC)而言,会显示出更复杂的模式,其中预测验证损失并非易事。 如图所示,域交互似乎很复杂,这使得仅根据其在混合中的权重来预测域的验证损失变得具有挑战性。 这些发现表明,虽然缩放定律提供了宝贵的见解,但它们可能无法完全捕捉数据混合动力学的复杂性。 我们的方法通过将整个数据混合作为回归模型的输入来解决这一挑战,从而提供了一个更全面的框架来理解和预测验证损失,同时考虑所有域权重。
6 结论
在本文中,我们提出了一种新方法,RegMix,用于自动选择用于预训练大型语言模型的最佳数据混合。 RegMix 将数据混合问题公式化为回归任务,并训练小型模型来预测不同数据混合的影响。 这使得能够有效地识别最佳混合,然后将其推广到大型模型训练。 RegMix 预测了 64 个 1B 模型中最佳的数据混合,证明了其有效性。 此外,我们的大规模研究提供了关于数据混合的影响、损失与下游性能之间的关系以及人类专家在确定最佳混合方面所面临的领域交互挑战的有价值的见解。
参考
- AI [2024] Meta AI. Introducing meta llama 3: The most capable openly available llm to date. https://ai.meta.com/blog/meta-llama-3/, April 2024.
- Albalak et al. [2023] Alon Albalak, Liangming Pan, Colin Raffel, and William Yang Wang. Efficient online data mixing for language model pre-training. arXiv preprint arXiv:2312.02406, 2023.
- Albalak et al. [2024] Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, et al. A survey on data selection for language models. arXiv preprint arXiv:2402.16827, 2024.
- Biderman et al. [2024] Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, et al. Lessons from the trenches on reproducible evaluation of language models. arXiv preprint arXiv:2405.14782, 2024.
- Bisk et al. [2020] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, 2020.
- Black et al. [2022] Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, et al. Gpt-neox-20b: An open-source autoregressive language model. arXiv preprint arXiv:2204.06745, 2022.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
- Bukharin and Zhao [2023] Alexander Bukharin and Tuo Zhao. Data diversity matters for robust instruction tuning. arXiv preprint arXiv:2311.14736, 2023.
- Chen et al. [2023] Mayee F Chen, Nicholas Roberts, Kush Bhatia, Jue Wang, Ce Zhang, Frederic Sala, and Christopher Ré. Skill-it! a data-driven skills framework for understanding and training language models. arXiv preprint arXiv:2307.14430, 2023.
- Chen et al. [2024] Xuxi Chen, Zhendong Wang, Daouda Sow, Junjie Yang, Tianlong Chen, Yingbin Liang, Mingyuan Zhou, and Zhangyang Wang. Take the bull by the horns: Hard sample-reweighted continual training improves llm generalization. arXiv preprint arXiv:2402.14270, 2024.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168.
- Das and Khetan [2023] Devleena Das and Vivek Khetan. Deft: Data efficient fine-tuning for large language models via unsupervised core-set selection. arXiv preprint arXiv:2310.16776, 2023.
- Dou et al. [2024] Longxu Dou, Qian Liu, Guangtao Zeng, Jia Guo, Jiahui Zhou, Wei Lu, and Min Lin. Sailor: Open language models for south-east asia. CoRR, abs/2404.03608, 2024. doi: 10.48550/ARXIV.2404.03608. URL https://doi.org/10.48550/arXiv.2404.03608.
- Engstrom et al. [2024] Logan Engstrom, Axel Feldmann, and Aleksander Madry. Dsdm: Model-aware dataset selection with datamodels. arXiv preprint arXiv:2401.12926, 2024.
- Fan et al. [2023] Simin Fan, Matteo Pagliardini, and Martin Jaggi. Doge: Domain reweighting with generalization estimation. arXiv preprint arXiv:2310.15393, 2023.
- Gadre et al. [2024] Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean Mercat, Alex Fang, Jeffrey Li, Sedrick Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Alexandros G. Dimakis, Gabriel Ilharco, Shuran Song, Thomas Kollar, Yair Carmon, Achal Dave, Reinhard Heckel, Niklas Muennighoff, and Ludwig Schmidt. Language models scale reliably with over-training and on downstream tasks. CoRR, abs/2403.08540, 2024. doi: 10.48550/ARXIV.2403.08540. URL https://doi.org/10.48550/arXiv.2403.08540.
- Gao et al. [2021] Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling. CoRR, abs/2101.00027, 2021. URL https://arxiv.org/abs/2101.00027.
- Gao et al. [2023] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, 12 2023. URL https://zenodo.org/records/10256836.
- Ge et al. [2024] Ce Ge, Zhijian Ma, Daoyuan Chen, Yaliang Li, and Bolin Ding. Data mixing made efficient: A bivariate scaling law for language model pretraining. arXiv preprint arXiv:2405.14908, 2024.
- Goyal et al. [2024] Sachin Goyal, Pratyush Maini, Zachary C. Lipton, Aditi Raghunathan, and J. Zico Kolter. Scaling laws for data filtering - data curation cannot be compute agnostic. CoRR, abs/2404.07177, 2024. doi: 10.48550/ARXIV.2404.07177. URL https://doi.org/10.48550/arXiv.2404.07177.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ.
- Hoffmann et al. [2022] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Huang et al. [2024] Yuzhen Huang, Jinghan Zhang, Zifei Shan, and Junxian He. Compression represents intelligence linearly. arXiv preprint arXiv:2404.09937, 2024.
- Kang et al. [2024] Feiyang Kang, Hoang Anh Just, Yifan Sun, Himanshu Jahagirdar, Yuanzhi Zhang, Rongxing Du, Anit Kumar Sahu, and Ruoxi Jia. Get more for less: Principled data selection for warming up fine-tuning in llms. arXiv preprint arXiv:2405.02774, 2024.
- Ke et al. [2017] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems, 30, 2017.
- Khashabi et al. [2018] Daniel Khashabi, Snigdha Chaturvedi, Michael Roth, Shyam Upadhyay, and Dan Roth. Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 252–262, 2018.
- Kocetkov et al. [2022] Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Bahdanau, Leandro von Werra, and Harm de Vries. The stack: 3 TB of permissively licensed source code. CoRR, abs/2211.15533, 2022. doi: 10.48550/ARXIV.2211.15533. URL https://doi.org/10.48550/arXiv.2211.15533.
- Koh and Liang [2017] Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. In International conference on machine learning, pages 1885–1894. PMLR, 2017.
- Lai et al. [2017] Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. Race: Large-scale reading comprehension dataset from examinations. arXiv preprint arXiv:1704.04683, 2017.
- Lin et al. [2024] Zhenghao Lin, Zhibin Gou, Yeyun Gong, Xiao Liu, Yelong Shen, Ruochen Xu, Chen Lin, Yujiu Yang, Jian Jiao, Nan Duan, and Weizhu Chen. Rho-1: Not all tokens are what you need. arXiv preprint arXiv:2404.07965, 2024.
- Liu et al. [2020] Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: A challenge dataset for machine reading comprehension with logical reasoning. arXiv preprint arXiv:2007.08124, 2020.
- Liu et al. [2024] Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning. In The International Conference on Learning Representations, 2024.
- Magnusson et al. [2023] Ian Magnusson, Akshita Bhagia, Valentin Hofmann, Luca Soldaini, Ananya Harsh Jha, Oyvind Tafjord, Dustin Schwenk, Evan Pete Walsh, Yanai Elazar, Kyle Lo, Dirk Groeneveld, Iz Beltagy, Hannaneh Hajishirzi, Noah A. Smith, Kyle Richardson, and Jesse Dodge. Paloma: A benchmark for evaluating language model fit. CoRR, abs/2312.10523, 2023. doi: 10.48550/ARXIV.2312.10523. URL https://doi.org/10.48550/arXiv.2312.10523.
- Marion et al. [2023] Max Marion, Ahmet Üstün, Luiza Pozzobon, Alex Wang, Marzieh Fadaee, and Sara Hooker. When less is more: Investigating data pruning for pretraining llms at scale, 2023.
- Mehta et al. [2024] Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, and Mohammad Rastegari. Openelm: An efficient language model family with open training and inference framework. CoRR, abs/2404.14619, 2024. doi: 10.48550/ARXIV.2404.14619. URL https://doi.org/10.48550/arXiv.2404.14619.
- Mekala et al. [2024] Dheeraj Mekala, Alex Nguyen, and Jingbo Shang. Smaller language models are capable of selecting instruction-tuning training data for larger language models. arXiv preprint arXiv:2402.10430, 2024.
- Merity et al. [2016] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016.
- Mihaylov et al. [2018] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789, 2018.
- Mindermann et al. [2022] Sören Mindermann, Jan M Brauner, Muhammed T Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan N Gomez, Adrien Morisot, Sebastian Farquhar, et al. Prioritized training on points that are learnable, worth learning, and not yet learnt. In International Conference on Machine Learning, pages 15630–15649. PMLR, 2022.
- Muennighoff et al. [2023] Niklas Muennighoff, Alexander M Rush, Boaz Barak, Teven Le Scao, Nouamane Tazi, Aleksandra Piktus, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=j5BuTrEj35.
- Pandey [2024] Rohan Pandey. gzip predicts data-dependent scaling laws. arXiv preprint arXiv:2405.16684, 2024.
- Paperno et al. [2016] Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: Word prediction requiring a broad discourse context. arXiv preprint arXiv:1606.06031, 2016.
- Penedo et al. [2024] Guilherme Penedo, Hynek Kydlíček, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024. URL https://arxiv.org/abs/2406.17557.
- Que et al. [2024] Haoran Que, Jiaheng Liu, Ge Zhang, Chenchen Zhang, Xingwei Qu, Yinghao Ma, Feiyu Duan, Zhiqi Bai, Jiakai Wang, Yuanxing Zhang, Xu Tan, Jie Fu, Wenbo Su, Jiamang Wang, Lin Qu, and Bo Zheng. D-cpt law: Domain-specific continual pre-training scaling law for large language models, 2024.
- Rae et al. [2021] Jack W. Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, H. Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, Eliza Rutherford, Tom Hennigan, Jacob Menick, Albin Cassirer, Richard Powell, George van den Driessche, Lisa Anne Hendricks, Maribeth Rauh, Po-Sen Huang, Amelia Glaese, Johannes Welbl, Sumanth Dathathri, Saffron Huang, Jonathan Uesato, John Mellor, Irina Higgins, Antonia Creswell, Nat McAleese, Amy Wu, Erich Elsen, Siddhant M. Jayakumar, Elena Buchatskaya, David Budden, Esme Sutherland, Karen Simonyan, Michela Paganini, Laurent Sifre, Lena Martens, Xiang Lorraine Li, Adhiguna Kuncoro, Aida Nematzadeh, Elena Gribovskaya, Domenic Donato, Angeliki Lazaridou, Arthur Mensch, Jean-Baptiste Lespiau, Maria Tsimpoukelli, Nikolai Grigorev, Doug Fritz, Thibault Sottiaux, Mantas Pajarskas, Toby Pohlen, Zhitao Gong, Daniel Toyama, Cyprien de Masson d’Autume, Yujia Li, Tayfun Terzi, Vladimir Mikulik, Igor Babuschkin, Aidan Clark, Diego de Las Casas, Aurelia Guy, Chris Jones, James Bradbury, Matthew J. Johnson, Blake A. Hechtman, Laura Weidinger, Iason Gabriel, William Isaac, Edward Lockhart, Simon Osindero, Laura Rimell, Chris Dyer, Oriol Vinyals, Kareem Ayoub, Jeff Stanway, Lorrayne Bennett, Demis Hassabis, Koray Kavukcuoglu, and Geoffrey Irving. Scaling language models: Methods, analysis & insights from training gopher. CoRR, abs/2112.11446, 2021. URL https://arxiv.org/abs/2112.11446.
- Raffel et al. [2019] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv e-prints, 2019.
- Sachdeva et al. [2024] Noveen Sachdeva, Benjamin Coleman, Wang-Cheng Kang, Jianmo Ni, Lichan Hong, Ed H Chi, James Caverlee, Julian McAuley, and Derek Zhiyuan Cheng. How to train data-efficient llms. arXiv preprint arXiv:2402.09668, 2024.
- Sachin Parkar et al. [2024] Ritik Sachin Parkar, Jaehyung Kim, Jong Inn Park, and Dongyeop Kang. Selectllm: Can llms select important instructions to annotate? arXiv e-prints, pages arXiv–2401, 2024.
- Sakaguchi et al. [2021] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- Sap et al. [2019] Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. SocialIQA: Commonsense reasoning about social interactions. In EMNLP, 2019.
- Sarlin et al. [2020] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020.
- Shao et al. [2024] Yunfan Shao, Linyang Li, Zhaoye Fei, Hang Yan, Dahua Lin, and Xipeng Qiu. Balanced data sampling for language model training with clustering. arXiv preprint arXiv:2402.14526, 2024.
- Sharma et al. [2024] Vasu Sharma, Karthik Padthe, Newsha Ardalani, Kushal Tirumala, Russell Howes, Hu Xu, Po-Yao Huang, Shang-Wen Li, Armen Aghajanyan, and Gargi Ghosh. Text quality-based pruning for efficient training of language models. arXiv preprint arXiv:2405.01582, 2024.
- Soldaini et al. [2024] Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, et al. Dolma: An open corpus of three trillion tokens for language model pretraining research. arXiv preprint arXiv:2402.00159, 2024.
- Talmor et al. [2019] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1421. URL https://aclanthology.org/N19-1421.
- Thakkar et al. [2023] Megh Thakkar, Tolga Bolukbasi, Sriram Ganapathy, Shikhar Vashishth, Sarath Chandar, and Partha Talukdar. Self-influence guided data reweighting for language model pre-training. arXiv preprint arXiv:2311.00913, 2023.
- Touvron et al. [2023] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023. doi: 10.48550/ARXIV.2307.09288. URL https://doi.org/10.48550/arXiv.2307.09288.
- Wang et al. [2018] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
- Welbl et al. [2017] Johannes Welbl, Nelson F Liu, and Matt Gardner. Crowdsourcing multiple choice science questions. arXiv preprint arXiv:1707.06209, 2017.
- Wettig et al. [2024] Alexander Wettig, Aatmik Gupta, Saumya Malik, and Danqi Chen. Qurating: Selecting high-quality data for training language models, 2024.
- Xia et al. [2022] Mengzhou Xia, Mikel Artetxe, Chunting Zhou, Xi Victoria Lin, Ramakanth Pasunuru, Danqi Chen, Luke Zettlemoyer, and Ves Stoyanov. Training trajectories of language models across scales. arXiv preprint arXiv:2212.09803, 2022.
- Xia et al. [2024] Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. Less: Selecting influential data for targeted instruction tuning. arXiv preprint arXiv:2402.04333, 2024.
- Xie et al. [2023a] Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimizing data mixtures speeds up language model pretraining. arXiv preprint arXiv:2305.10429, 2023a.
- Xie et al. [2023b] Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. Data selection for language models via importance resampling. arXiv preprint arXiv:2302.03169, 2023b.
- Yang et al. [2024a] Chen Yang, Junzhuo Li, Xinyao Niu, Xinrun Du, Songyang Gao, Haoran Zhang, Zhaoliang Chen, Xingwei Qu, Ruibin Yuan, Yizhi Li, et al. The fine line: Navigating large language model pretraining with down-streaming capability analysis. arXiv preprint arXiv:2404.01204, 2024a.
- Yang et al. [2024b] Yu Yang, Siddhartha Mishra, Jeffrey N Chiang, and Baharan Mirzasoleiman. Smalltolarge (s2l): Scalable data selection for fine-tuning large language models by summarizing training trajectories of small models. arXiv preprint arXiv:2403.07384, 2024b.
- Ye et al. [2024] Jiasheng Ye, Peiju Liu, Tianxiang Sun, Yunhua Zhou, Jun Zhan, and Xipeng Qiu. Data mixing laws: Optimizing data mixtures by predicting language modeling performance. CoRR, abs/2403.16952, 2024. doi: 10.48550/ARXIV.2403.16952. URL https://doi.org/10.48550/arXiv.2403.16952.
- Yu et al. [2024] Zichun Yu, Spandan Das, and Chenyan Xiong. Mates: Model-aware data selection for efficient pretraining with data influence models, 2024.
- Zellers et al. [2019] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- Zhang et al. [2024a] Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. Tinyllama: An open-source small language model. arXiv preprint arXiv:2401.02385, 2024a.
- Zhang et al. [2024b] Yifan Zhang, Yifan Luo, Yang Yuan, and Andrew C Yao. Autonomous data selection with language models for mathematical texts. In ICLR 2024 Workshop on Navigating and Addressing Data Problems for Foundation Models, 2024b.
附录 A 局限性
尽管在理解和优化数据混合以提高性能方面取得了进展,但我们的方法仍然存在一些局限性。
模型参数的最大值。
我们已经验证了小型模型可用于预测针对具有高达 1B 参数的大规模运行的最佳数据混合。 然而,通常使用 7B 或 70B 参数训练更大的模型 [58]。 由于计算限制,我们将 RegMix 在更大规模上的验证留待将来工作。
基准测试覆盖率。
由于 Pile 语料库中相关数据的稀缺以及我们 1B 规模模型的相对较小尺寸,它们在 MMLU 基准测试 [22] 上的性能几乎是随机的,在 GSM8K [12] 上可以忽略不计。 因此,我们没有计算验证损失与这些具有挑战性的基准测试得分之间的相关性。
无限数据假设。
大多数现有的数据混合方法假设每个领域都有无限的数据可用。 虽然我们在第 5.3 节的无 Pile-CC 实验中考虑了这个问题,但将可用数据的影响系统地整合到方法中仍然具有挑战性。 将我们的方法与 Muennighoff 等人 [41] 提出的数据重用的衰减系数相结合,可能是未来探索的一个有趣的课题,有可能解决数据可用性有限的情况。
域假设。
现有数据混合方法(包括我们的方法)的一个常见假设是,每个示例所属的域是已知的。 然而,情况并非总是如此,需要首先获取域。 将示例分配到域是一个困难的任务,这可能使我们在域边界不明确的情况下应用我们的方法变得具有挑战性。
分词器假设。
所有现有的数据混合方法都需要使用代理模型来获取域权重。 然而,这些方法的一个基本假设是,代理模型使用与大型模型相同的分词器和词汇量。 在不同的分词器之间推广权重带来了重大挑战。
附录 B 伦理声明
优化用于 LLM 预训练的数据混合会引发一些伦理问题。 首先,优化后的数据混合可能偏向于某些域,这对实现更好的性能有利。 然而,某些域可能被低估或错误地表示,导致训练后的模型在这些域上表现不佳或产生有偏见的结果。 其次,虽然我们的方法旨在有效地优化数据混合,但寻找最佳数据混合仍然需要计算资源,导致高能耗和环境影响。 有必要探索如何进一步降低计算成本。
附录 C 附加结果
C.1 回归预测可视化
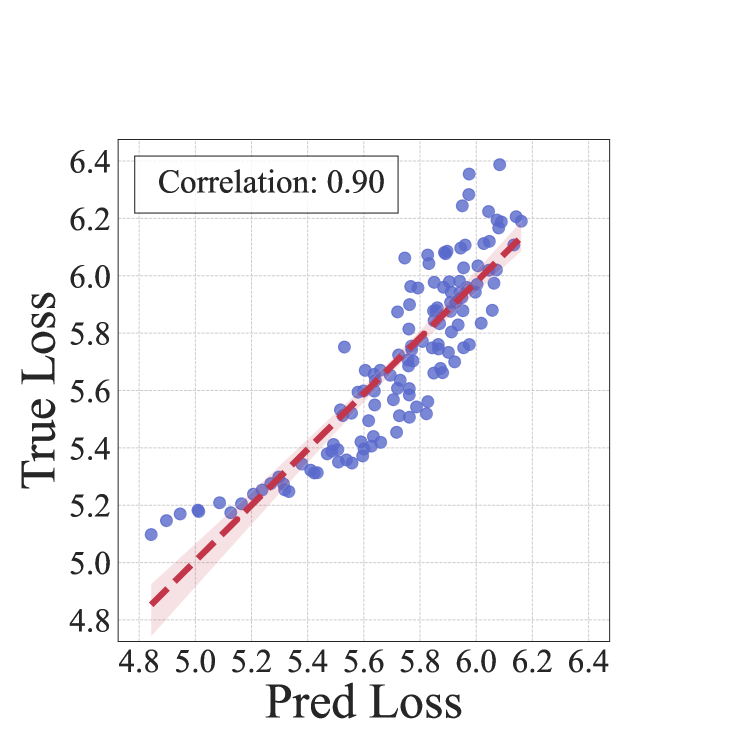
如图 8 所示,我们在 1M 模型上可视化了线性模型和 LightGBM 模型的预测和真实损失对。 LightGBM 模型的性能优于线性模型,实现了接近 100% 的斯皮尔曼等级相关性 。
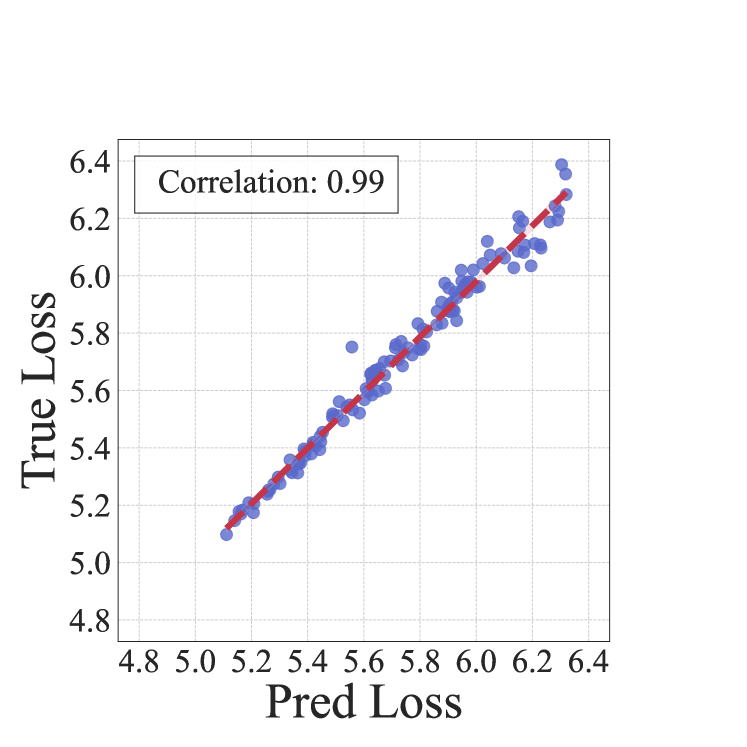
C.2 小模型在非分布设置下的损失和排名预测
在第 5 节中,我们验证了我们的方法在非分布场景中的有效性,在这种场景中,我们完全从预训练语料库中排除了 Pile-CC 域,并使用剩余域来找到最小化 Pile-CC 验证损失的最佳数据混合。 我们还在图 5 中提供了此设置下回归评估的结果。 同样,LightGBM 模型优于线性模型,并实现了接近 100% 的斯皮尔曼等级相关性 。
| Method | 1M models with 1B tokens | ||
|---|---|---|---|
| () | Pearson’s () | MSE () | |
| Linear | 83.00 | 84.18 | 0.08 |
| LightGBM | 95.47 | 95.48 | 0.04 |
C.3 派生的数据混合
表 6 展示了不同方法的派生数据混合权重。 如图所示,RegMix 将 0.87 的高权重分配给 Pile-CC 数据集,这与人类直觉相一致。
| Domain Weights | Human† | DoReMi† | Pile-CC Only | RegMix |
|---|---|---|---|---|
| ArXiv | 0.134 | 0.004 | 0.0 | 0.001 |
| FreeLaw | 0.049 | 0.005 | 0.0 | 0.001 |
| NIH ExPorter | 0.007 | 0.008 | 0.0 | 0.001 |
| PubMed Central | 0.136 | 0.006 | 0.0 | 0.003 |
| Wikipedia (en) | 0.117 | 0.086 | 0.0 | 0.016 |
| DM Mathematics | 0.025 | 0.002 | 0.0 | 0.0 |
| Github | 0.054 | 0.022 | 0.0 | 0.0 |
| PhilPapers | 0.003 | 0.034 | 0.0 | 0.0 |
| Stack Exchange | 0.118 | 0.019 | 0.0 | 0.0 |
| Enron Emails | 0.004 | 0.009 | 0.0 | 0.002 |
| Gutenberg (PG-19) | 0.025 | 0.009 | 0.0 | 0.002 |
| Pile-CC | 0.142 | 0.743 | 1.0 | 0.87 |
| Ubuntu IRC | 0.009 | 0.011 | 0.0 | 0.064 |
| EuroParl | 0.005 | 0.008 | 0.0 | 0.0 |
| HackerNews | 0.01 | 0.016 | 0.0 | 0.012 |
| PubMed Abstracts | 0.107 | 0.014 | 0.0 | 0.024 |
| USPTO Backgrounds | 0.053 | 0.004 | 0.0 | 0.002 |
C.4 使用 LightEval 的评估结果
| Benchmark | Human | DoReMi | Pile-CC Only | RegMix |
|---|---|---|---|---|
| ARC Easy [11] | 45.3 0.4 | 46.6 0.7 | 47.1 0.6 | 47.2 0.9 |
| ARC Challenge [11] | 25.5 0.8 | 25.9 0.8 | 25.6 0.5 | 25.6 0.5 |
| CommonsenseQA [56] | 31.8 1.2 | 34.1 0.7 | 34.9 0.3 | 35.0 0.5 |
| HellaSwag [70] | 36.5 0.2 | 41.5 0.3 | 39.7 0.5 | 42.1 0.3 |
| OpenBookQA [39] | 29.8 0.6 | 31.0 0.8 | 31.5 0.4 | 31.8 0.8 |
| PiQA [5] | 65.4 0.6 | 68.7 0.3 | 69.0 0.5 | 69.4 0.5 |
| Social IQA [51] | 41.7 0.3 | 42.0 0.2 | 42.7 0.3 | 42.6 0.7 |
| WinoGrande [50] | 51.1 1.0 | 51.2 0.4 | 50.7 1.0 | 50.9 0.4 |
| MMLU [22] | 28.6 0.2 | 28.9 0.4 | 28.5 0.2 | 28.7 0.3 |
| Average Performance | 39.5 0.3 | 41.1 0.3 | 41.2 0.3 | 41.5 0.2 |
| Beat Human on | – | 5 / 9 | 6 / 9 | 6 / 9 |
| Estimated FLOPs | 0 | 0 |
遵循 FineWeb [44] 的方法,我们使用 LightEval 666https://github.com/huggingface/lighteval 库来评估我们的模型,使用一组基准,这些基准因其稳定性和适用性而被选中。 所选基准具有三个主要特征:不同数据样本之间的得分方差低,训练期间得分单调提高,以及 10 亿参数范围内模型的基线得分高于随机。 表 7 显示了评估结果。 我们的方法 RegMix 在 6 个基准上始终优于人类基线。 此外,RegMix 在与 DoReMi 和 Pile-CC Only 方法相比时,展示出优越的平均性能。
附录 D URL 域名关联图
附录 E 实现细节
我们利用 Zhang 等人 [71] 提出的模型架构,并通过修改层数、注意力头数以及符元嵌入和隐藏状态的维度来创建不同的模型变体,如图 8 所示。 对于分词,我们采用 GPTNeoX 分词器 [6],它拥有 50,432 个词汇。
对于参数量为 1M 和 60M 的模型,我们将训练迭代次数设置为 1000,批次大小设置为 1M 个符元,这意味着训练预算为 1B 个符元。 同样,我们用 25000 次训练迭代和相同的批次大小训练参数量为 1B 的更大模型,因此总共消耗了 25B 个符元。 我们将学习率设置为 4e-4 并使用余弦学习率调度器。
对于线性回归,我们采用 5 折交叉验证与岭回归来确定从集合 [1e-3, 1e-2, 1e-1, 1e0, 1e1, 1e2, 1e3] 中的最佳 。 对于 LightGBM,我们手动将迭代次数设置为 1000,学习率设置为 1e-2。 将所有其他超参数保留其默认值。
| Model | 1M | 60M | 1B |
|---|---|---|---|
| Vocabulary Size | 50432 | 50432 | 50432 |
| 2 | 10 | 22 | |
| 8 | 8 | 16 | |
| 256 | 768 | 2048 | |
| 512 | 1536 | 5632 |
附录 F 我们方法的稳定性
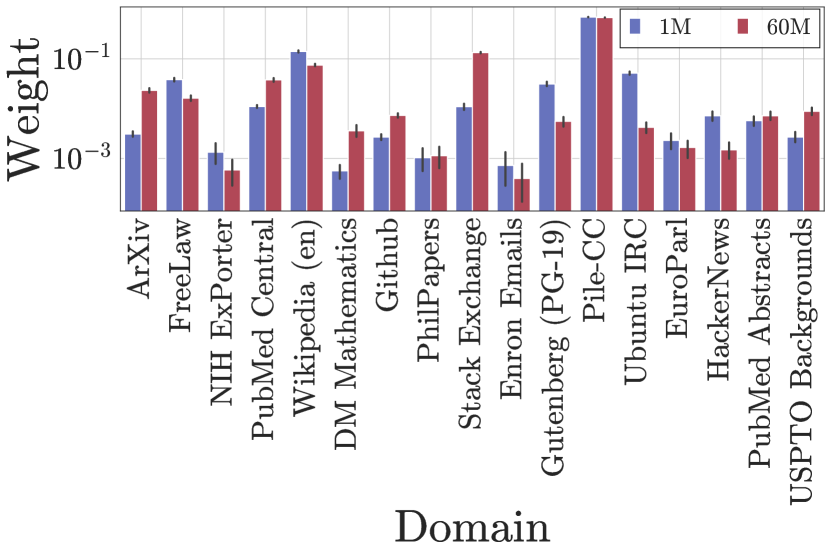
之前研究 [64, 16, 2] 已经使用在大量符元上训练的小规模代理模型来预测大型语言模型的最佳数据混合。 但是,这些方法通常存在稳定性问题。 例如,DoReMi [64] 报告说,不同的代理模型大小会导致预测的数据混合有很大差异。 他们的发现(图 8,附录)表明,使用 280M 代理模型导致 Pile-CC 权重为 0.67,而使用 1B 代理模型导致 Pile-CC 权重低于 0.20。 这种巨大的差异突出了之前方法中潜在的不稳定性。 为了评估 RegMix 对这种不稳定性的鲁棒性,我们使用两个不同的模型规模进行了比较实验:1M 代理模型和 60M 代理模型。 我们使用它们各自的训练日志来拟合回归模型,然后模拟了前 1024 个预测结果。 所得分布如图 13所示。 我们的结果表明,尽管 1M 和 60M 模型的预测分布并不完全相同,但它们表现出非常相似的模式。 这种一致性表明,即使改变代理训练模型的规模,RegMix 也比以前的方法实现了更好的稳定性。
附录 G 详细的实验结果
为了便于未来的研究,我们分享了所有数据混合以及 64 个具有 10 亿个参数的训练模型的相应下游性能。
| Model Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Pre-training Domain Weights | ||||||||
| ArXiv | 0.123 | 0.066 | 0.055 | 0.059 | 0.201 | 0.036 | 0.042 | 0.126 |
| FreeLaw | 0.065 | 0.071 | 0.052 | 0.083 | 0.004 | 0.212 | 0.113 | 0.21 |
| NIH ExPorter | 0.0 | 0.0 | 0.004 | 0.0 | 0.014 | 0.0 | 0.0 | 0.0 |
| PubMed Central | 0.126 | 0.211 | 0.177 | 0.174 | 0.243 | 0.153 | 0.089 | 0.123 |
| Wikipedia (en) | 0.036 | 0.013 | 0.02 | 0.177 | 0.01 | 0.005 | 0.022 | 0.055 |
| DM Mathematics | 0.0 | 0.0 | 0.011 | 0.0 | 0.03 | 0.047 | 0.007 | 0.008 |
| Github | 0.034 | 0.153 | 0.095 | 0.194 | 0.017 | 0.205 | 0.028 | 0.008 |
| PhilPapers | 0.0 | 0.033 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Stack Exchange | 0.039 | 0.097 | 0.18 | 0.0 | 0.103 | 0.075 | 0.011 | 0.129 |
| Enron Emails | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Gutenberg (PG-19) | 0.0 | 0.0 | 0.016 | 0.0 | 0.002 | 0.0 | 0.217 | 0.035 |
| Pile-CC | 0.27 | 0.101 | 0.381 | 0.192 | 0.359 | 0.209 | 0.232 | 0.288 |
| Ubuntu IRC | 0.0 | 0.0 | 0.001 | 0.005 | 0.0 | 0.0 | 0.08 | 0.0 |
| EuroParl | 0.0 | 0.0 | 0.0 | 0.109 | 0.0 | 0.001 | 0.117 | 0.0 |
| HackerNews | 0.0 | 0.011 | 0.005 | 0.0 | 0.0 | 0.0 | 0.018 | 0.0 |
| PubMed Abstracts | 0.0 | 0.136 | 0.0 | 0.005 | 0.014 | 0.002 | 0.011 | 0.016 |
| USPTO Backgrounds | 0.307 | 0.106 | 0.003 | 0.0 | 0.002 | 0.055 | 0.011 | 0.0 |
| Downstream Performance (%) | ||||||||
| Social IQA | 33.27 | 33.33 | 33.62 | 33.53 | 33.49 | 33.56 | 33.62 | 33.55 |
| HellaSwag | 40.58 | 36.86 | 40.58 | 36.06 | 40.07 | 37.85 | 37.93 | 39.59 |
| PiQA | 67.29 | 65.14 | 67.97 | 64.66 | 67.03 | 65.36 | 66.0 | 66.55 |
| OpenBookQA | 28.63 | 27.87 | 29.33 | 29.1 | 29.23 | 28.33 | 29.13 | 28.73 |
| Lambada | 29.17 | 26.86 | 31.55 | 27.11 | 29.16 | 28.92 | 31.53 | 30.92 |
| SciQ | 80.68 | 79.98 | 81.05 | 80.8 | 82.4 | 79.88 | 78.67 | 79.7 |
| COPA | 70.5 | 63.83 | 69.17 | 65.0 | 67.5 | 66.0 | 66.67 | 68.67 |
| RACE | 29.47 | 30.0 | 32.11 | 28.82 | 31.13 | 30.06 | 29.9 | 30.75 |
| ARC Easy | 50.03 | 48.72 | 50.01 | 46.64 | 51.06 | 47.46 | 46.75 | 48.39 |
| LogiQA | 23.76 | 24.17 | 25.29 | 25.29 | 24.55 | 25.96 | 25.45 | 26.32 |
| QQP | 55.71 | 55.9 | 54.84 | 56.52 | 54.01 | 56.34 | 52.35 | 54.2 |
| WinoGrande | 51.54 | 51.59 | 51.39 | 50.91 | 53.13 | 52.26 | 51.26 | 51.45 |
| MultiRC | 52.65 | 53.39 | 51.89 | 50.92 | 49.03 | 53.09 | 53.64 | 50.23 |
| Avg | 47.18 | 45.97 | 47.60 | 45.80 | 47.06 | 46.54 | 46.38 | 46.85 |
| Model Index | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| Pre-training Domain Weights | ||||||||
| ArXiv | 0.184 | 0.226 | 0.107 | 0.139 | 0.101 | 0.099 | 0.251 | 0.147 |
| FreeLaw | 0.009 | 0.046 | 0.276 | 0.048 | 0.047 | 0.002 | 0.024 | 0.046 |
| NIH ExPorter | 0.0 | 0.0 | 0.0 | 0.0 | 0.001 | 0.022 | 0.0 | 0.0 |
| PubMed Central | 0.094 | 0.261 | 0.157 | 0.184 | 0.119 | 0.501 | 0.101 | 0.196 |
| Wikipedia (en) | 0.035 | 0.001 | 0.009 | 0.032 | 0.049 | 0.003 | 0.17 | 0.14 |
| DM Mathematics | 0.007 | 0.001 | 0.0 | 0.001 | 0.092 | 0.0 | 0.0 | 0.008 |
| Github | 0.106 | 0.189 | 0.024 | 0.055 | 0.078 | 0.017 | 0.048 | 0.237 |
| PhilPapers | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.043 | 0.019 | 0.0 |
| Stack Exchange | 0.142 | 0.077 | 0.051 | 0.109 | 0.002 | 0.065 | 0.007 | 0.06 |
| Enron Emails | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Gutenberg (PG-19) | 0.0 | 0.01 | 0.001 | 0.0 | 0.051 | 0.091 | 0.0 | 0.012 |
| Pile-CC | 0.341 | 0.114 | 0.273 | 0.354 | 0.283 | 0.055 | 0.339 | 0.111 |
| Ubuntu IRC | 0.0 | 0.003 | 0.0 | 0.0 | 0.057 | 0.0 | 0.017 | 0.0 |
| EuroParl | 0.0 | 0.0 | 0.003 | 0.003 | 0.0 | 0.006 | 0.0 | 0.0 |
| HackerNews | 0.002 | 0.0 | 0.034 | 0.0 | 0.0 | 0.0 | 0.0 | 0.001 |
| PubMed Abstracts | 0.005 | 0.039 | 0.009 | 0.075 | 0.061 | 0.007 | 0.0 | 0.01 |
| USPTO Backgrounds | 0.075 | 0.033 | 0.056 | 0.0 | 0.057 | 0.088 | 0.024 | 0.032 |
| Downstream Performance (%) | ||||||||
| Social IQA | 33.43 | 33.21 | 33.31 | 33.17 | 33.28 | 32.43 | 33.57 | 33.7 |
| HellaSwag | 40.05 | 35.89 | 39.55 | 39.89 | 38.63 | 36.18 | 39.52 | 35.94 |
| PiQA | 66.6 | 64.74 | 66.29 | 66.27 | 66.9 | 64.05 | 66.7 | 64.51 |
| OpenBookQA | 28.87 | 26.6 | 29.33 | 28.73 | 29.4 | 27.87 | 29.67 | 27.83 |
| Lambada | 31.39 | 27.37 | 30.32 | 30.31 | 31.38 | 26.25 | 29.86 | 26.95 |
| SciQ | 81.1 | 79.12 | 79.97 | 82.85 | 79.42 | 81.4 | 81.38 | 81.23 |
| COPA | 67.0 | 64.5 | 66.83 | 69.5 | 67.33 | 65.83 | 69.5 | 66.33 |
| RACE | 30.57 | 29.63 | 30.49 | 30.85 | 30.35 | 28.66 | 31.21 | 29.57 |
| ARC Easy | 50.66 | 47.74 | 47.47 | 50.18 | 49.92 | 49.52 | 50.73 | 48.65 |
| LogiQA | 23.6 | 25.65 | 26.37 | 23.81 | 25.58 | 26.29 | 25.86 | 25.12 |
| QQP | 54.89 | 54.79 | 54.2 | 55.23 | 53.69 | 57.09 | 53.95 | 54.24 |
| WinoGrande | 50.83 | 51.84 | 51.05 | 51.83 | 52.12 | 52.0 | 51.01 | 51.82 |
| MultiRC | 54.18 | 54.48 | 50.17 | 52.12 | 51.42 | 52.69 | 51.87 | 53.48 |
| Avg | 47.17 | 45.81 | 46.57 | 47.29 | 46.88 | 46.17 | 47.30 | 46.11 |
| Model Index | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| Pre-training Domain Weights | ||||||||
| ArXiv | 0.228 | 0.0 | 0.501 | 0.101 | 0.047 | 0.031 | 0.078 | 0.068 |
| FreeLaw | 0.016 | 0.019 | 0.005 | 0.03 | 0.014 | 0.073 | 0.024 | 0.181 |
| NIH ExPorter | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PubMed Central | 0.204 | 0.084 | 0.156 | 0.272 | 0.163 | 0.053 | 0.302 | 0.126 |
| Wikipedia (en) | 0.02 | 0.159 | 0.17 | 0.021 | 0.218 | 0.129 | 0.027 | 0.07 |
| DM Mathematics | 0.036 | 0.009 | 0.0 | 0.099 | 0.0 | 0.0 | 0.0 | 0.001 |
| Github | 0.02 | 0.012 | 0.022 | 0.124 | 0.137 | 0.066 | 0.04 | 0.195 |
| PhilPapers | 0.004 | 0.0 | 0.017 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Stack Exchange | 0.002 | 0.052 | 0.062 | 0.113 | 0.173 | 0.12 | 0.007 | 0.24 |
| Enron Emails | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Gutenberg (PG-19) | 0.0 | 0.001 | 0.002 | 0.054 | 0.001 | 0.089 | 0.002 | 0.0 |
| Pile-CC | 0.244 | 0.361 | 0.061 | 0.154 | 0.19 | 0.057 | 0.499 | 0.023 |
| Ubuntu IRC | 0.0 | 0.296 | 0.002 | 0.0 | 0.029 | 0.001 | 0.0 | 0.0 |
| EuroParl | 0.004 | 0.0 | 0.0 | 0.001 | 0.007 | 0.0 | 0.0 | 0.0 |
| HackerNews | 0.0 | 0.0 | 0.0 | 0.0 | 0.011 | 0.031 | 0.0 | 0.0 |
| PubMed Abstracts | 0.196 | 0.001 | 0.0 | 0.011 | 0.008 | 0.351 | 0.0 | 0.059 |
| USPTO Backgrounds | 0.026 | 0.007 | 0.002 | 0.02 | 0.001 | 0.001 | 0.021 | 0.036 |
| Downstream Performance (%) | ||||||||
| Social IQA | 33.89 | 33.31 | 33.53 | 33.38 | 33.75 | 33.24 | 33.56 | 33.71 |
| HellaSwag | 38.68 | 39.9 | 34.67 | 37.12 | 37.44 | 36.07 | 42.15 | 34.67 |
| PiQA | 66.83 | 67.39 | 63.33 | 64.83 | 65.0 | 63.68 | 67.8 | 62.99 |
| OpenBookQA | 28.13 | 30.67 | 28.03 | 29.4 | 27.67 | 27.77 | 29.37 | 25.83 |
| Lambada | 28.78 | 28.56 | 24.13 | 29.41 | 27.67 | 28.03 | 33.47 | 24.04 |
| SciQ | 79.6 | 78.83 | 77.42 | 78.98 | 78.95 | 78.72 | 81.83 | 79.12 |
| COPA | 65.17 | 68.17 | 65.33 | 67.33 | 67.67 | 62.67 | 69.83 | 65.83 |
| RACE | 28.74 | 30.03 | 29.76 | 29.49 | 30.77 | 29.76 | 31.21 | 27.91 |
| ARC Easy | 48.86 | 49.42 | 47.9 | 48.3 | 47.88 | 46.68 | 50.92 | 45.24 |
| LogiQA | 25.91 | 26.34 | 26.24 | 25.76 | 26.11 | 26.24 | 24.17 | 25.91 |
| QQP | 53.35 | 53.18 | 50.61 | 51.49 | 54.27 | 54.99 | 52.77 | 55.19 |
| WinoGrande | 52.54 | 51.17 | 52.01 | 51.09 | 52.13 | 52.03 | 52.5 | 50.28 |
| MultiRC | 51.49 | 52.45 | 55.4 | 54.87 | 51.73 | 49.49 | 50.61 | 50.29 |
| Avg | 46.30 | 46.88 | 45.26 | 46.27 | 46.23 | 45.34 | 47.71 | 44.69 |
| Model Index | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 |
| Pre-training Domain Weights | ||||||||
| ArXiv | 0.074 | 0.076 | 0.05 | 0.067 | 0.244 | 0.073 | 0.234 | 0.08 |
| FreeLaw | 0.214 | 0.085 | 0.039 | 0.052 | 0.023 | 0.087 | 0.015 | 0.134 |
| NIH ExPorter | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.026 | 0.0 | 0.0 |
| PubMed Central | 0.135 | 0.214 | 0.049 | 0.221 | 0.064 | 0.175 | 0.086 | 0.255 |
| Wikipedia (en) | 0.011 | 0.005 | 0.068 | 0.052 | 0.151 | 0.017 | 0.287 | 0.058 |
| DM Mathematics | 0.0 | 0.0 | 0.019 | 0.0 | 0.0 | 0.101 | 0.026 | 0.037 |
| Github | 0.121 | 0.127 | 0.042 | 0.101 | 0.073 | 0.1 | 0.04 | 0.171 |
| PhilPapers | 0.006 | 0.0 | 0.0 | 0.0 | 0.0 | 0.019 | 0.0 | 0.0 |
| Stack Exchange | 0.024 | 0.204 | 0.146 | 0.001 | 0.02 | 0.054 | 0.022 | 0.015 |
| Enron Emails | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Gutenberg (PG-19) | 0.001 | 0.147 | 0.01 | 0.265 | 0.017 | 0.0 | 0.0 | 0.045 |
| Pile-CC | 0.088 | 0.138 | 0.302 | 0.214 | 0.383 | 0.12 | 0.134 | 0.182 |
| Ubuntu IRC | 0.001 | 0.002 | 0.0 | 0.026 | 0.01 | 0.134 | 0.0 | 0.0 |
| EuroParl | 0.0 | 0.0 | 0.008 | 0.0 | 0.0 | 0.037 | 0.0 | 0.0 |
| HackerNews | 0.004 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PubMed Abstracts | 0.132 | 0.001 | 0.01 | 0.002 | 0.007 | 0.053 | 0.022 | 0.016 |
| USPTO Backgrounds | 0.189 | 0.001 | 0.255 | 0.0 | 0.007 | 0.002 | 0.134 | 0.008 |
| Downstream Performance (%) | ||||||||
| Social IQA | 33.51 | 33.4 | 33.59 | 33.52 | 33.53 | 33.49 | 33.16 | 33.56 |
| HellaSwag | 36.75 | 36.97 | 40.81 | 38.25 | 40.28 | 35.71 | 37.37 | 37.39 |
| PiQA | 64.09 | 64.74 | 67.97 | 66.15 | 66.88 | 63.84 | 64.47 | 65.05 |
| OpenBookQA | 29.47 | 28.7 | 29.57 | 29.77 | 29.5 | 29.13 | 29.47 | 28.0 |
| Lambada | 26.69 | 33.0 | 31.6 | 33.08 | 31.49 | 27.69 | 26.99 | 29.54 |
| SciQ | 80.03 | 79.17 | 80.12 | 80.22 | 81.92 | 78.23 | 77.42 | 80.87 |
| COPA | 67.67 | 65.5 | 69.0 | 65.67 | 68.33 | 63.33 | 64.67 | 67.17 |
| RACE | 30.05 | 30.19 | 30.96 | 30.37 | 30.08 | 29.62 | 30.13 | 29.92 |
| ARC Easy | 47.5 | 46.9 | 50.26 | 48.57 | 50.55 | 46.96 | 48.77 | 48.79 |
| LogiQA | 27.24 | 25.55 | 25.86 | 24.37 | 25.32 | 25.12 | 26.4 | 24.3 |
| QQP | 49.68 | 55.43 | 50.94 | 50.91 | 51.99 | 53.53 | 49.53 | 51.36 |
| WinoGrande | 51.68 | 52.12 | 51.93 | 51.5 | 52.32 | 51.67 | 52.13 | 52.63 |
| MultiRC | 51.24 | 51.91 | 50.33 | 52.42 | 52.52 | 54.04 | 52.05 | 53.04 |
| Avg | 45.82 | 46.43 | 47.15 | 46.52 | 47.29 | 45.57 | 45.58 | 46.28 |
| Model Index | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 |
| Pre-training Domain Weights | ||||||||
| ArXiv | 0.105 | 0.295 | 0.142 | 0.279 | 0.052 | 0.251 | 0.239 | 0.157 |
| FreeLaw | 0.007 | 0.029 | 0.122 | 0.01 | 0.07 | 0.007 | 0.087 | 0.062 |
| NIH ExPorter | 0.0 | 0.0 | 0.001 | 0.0 | 0.253 | 0.007 | 0.0 | 0.0 |
| PubMed Central | 0.407 | 0.061 | 0.065 | 0.184 | 0.4 | 0.331 | 0.223 | 0.039 |
| Wikipedia (en) | 0.045 | 0.124 | 0.0 | 0.0 | 0.003 | 0.107 | 0.029 | 0.096 |
| DM Mathematics | 0.054 | 0.0 | 0.001 | 0.0 | 0.0 | 0.0 | 0.0 | 0.007 |
| Github | 0.017 | 0.006 | 0.006 | 0.108 | 0.033 | 0.13 | 0.049 | 0.057 |
| PhilPapers | 0.0 | 0.0 | 0.003 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Stack Exchange | 0.126 | 0.006 | 0.001 | 0.097 | 0.019 | 0.021 | 0.202 | 0.174 |
| Enron Emails | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Gutenberg (PG-19) | 0.009 | 0.047 | 0.014 | 0.039 | 0.0 | 0.001 | 0.0 | 0.015 |
| Pile-CC | 0.167 | 0.364 | 0.618 | 0.198 | 0.031 | 0.006 | 0.156 | 0.181 |
| Ubuntu IRC | 0.0 | 0.0 | 0.001 | 0.0 | 0.0 | 0.12 | 0.0 | 0.0 |
| EuroParl | 0.007 | 0.026 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.089 |
| HackerNews | 0.0 | 0.004 | 0.0 | 0.0 | 0.018 | 0.0 | 0.0 | 0.012 |
| PubMed Abstracts | 0.047 | 0.0 | 0.0 | 0.083 | 0.002 | 0.005 | 0.012 | 0.016 |
| USPTO Backgrounds | 0.008 | 0.037 | 0.025 | 0.002 | 0.119 | 0.014 | 0.001 | 0.095 |
| Downstream Performance (%) | ||||||||
| Social IQA | 33.48 | 33.28 | 33.35 | 33.29 | 33.63 | 33.61 | 33.21 | 33.61 |
| HellaSwag | 38.0 | 40.18 | 43.37 | 37.69 | 32.96 | 32.98 | 37.31 | 37.79 |
| PiQA | 65.3 | 66.68 | 69.04 | 66.46 | 62.25 | 60.17 | 65.24 | 65.32 |
| OpenBookQA | 29.43 | 30.37 | 30.43 | 27.63 | 26.43 | 26.83 | 27.97 | 28.7 |
| Lambada | 26.59 | 31.46 | 31.71 | 30.21 | 18.92 | 20.29 | 28.1 | 28.58 |
| SciQ | 79.82 | 80.58 | 82.13 | 80.83 | 76.73 | 77.9 | 79.12 | 79.6 |
| COPA | 64.33 | 69.33 | 67.0 | 67.83 | 61.5 | 62.67 | 64.67 | 66.0 |
| RACE | 30.03 | 30.16 | 32.47 | 30.49 | 29.27 | 28.12 | 30.11 | 30.21 |
| ARC Easy | 48.86 | 49.88 | 52.22 | 48.32 | 44.86 | 45.54 | 48.15 | 48.86 |
| LogiQA | 25.91 | 24.3 | 23.35 | 24.96 | 26.19 | 27.68 | 25.47 | 25.37 |
| QQP | 56.06 | 56.56 | 52.57 | 56.7 | 52.54 | 48.04 | 49.81 | 57.12 |
| WinoGrande | 50.92 | 50.97 | 52.39 | 52.7 | 52.3 | 51.68 | 51.42 | 52.8 |
| MultiRC | 53.09 | 49.97 | 52.18 | 49.05 | 53.78 | 52.27 | 51.45 | 55.68 |
| Avg | 46.29 | 47.21 | 47.86 | 46.63 | 43.95 | 43.67 | 45.54 | 46.90 |
| Model Index | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 |
| Pre-training Domain Weights | ||||||||
| ArXiv | 0.422 | 0.466 | 0.027 | 0.063 | 0.121 | 0.041 | 0.033 | 0.114 |
| FreeLaw | 0.213 | 0.075 | 0.041 | 0.089 | 0.008 | 0.025 | 0.048 | 0.116 |
| NIH ExPorter | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PubMed Central | 0.08 | 0.07 | 0.116 | 0.219 | 0.093 | 0.111 | 0.22 | 0.081 |
| Wikipedia (en) | 0.019 | 0.006 | 0.021 | 0.001 | 0.008 | 0.092 | 0.027 | 0.038 |
| DM Mathematics | 0.001 | 0.0 | 0.001 | 0.05 | 0.016 | 0.062 | 0.002 | 0.031 |
| Github | 0.026 | 0.044 | 0.067 | 0.291 | 0.012 | 0.121 | 0.169 | 0.109 |
| PhilPapers | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Stack Exchange | 0.003 | 0.078 | 0.137 | 0.002 | 0.408 | 0.124 | 0.082 | 0.001 |
| Enron Emails | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Gutenberg (PG-19) | 0.01 | 0.0 | 0.001 | 0.0 | 0.006 | 0.0 | 0.057 | 0.021 |
| Pile-CC | 0.026 | 0.2 | 0.549 | 0.238 | 0.156 | 0.214 | 0.312 | 0.428 |
| Ubuntu IRC | 0.0 | 0.0 | 0.002 | 0.0 | 0.013 | 0.129 | 0.0 | 0.001 |
| EuroParl | 0.0 | 0.0 | 0.0 | 0.001 | 0.001 | 0.006 | 0.0 | 0.0 |
| HackerNews | 0.0 | 0.0 | 0.0 | 0.001 | 0.0 | 0.012 | 0.0 | 0.0 |
| PubMed Abstracts | 0.101 | 0.028 | 0.002 | 0.045 | 0.005 | 0.012 | 0.0 | 0.031 |
| USPTO Backgrounds | 0.099 | 0.031 | 0.037 | 0.0 | 0.153 | 0.052 | 0.05 | 0.029 |
| Downstream Performance (%) | ||||||||
| Social IQA | 33.49 | 33.43 | 33.07 | 33.28 | 33.44 | 33.08 | 33.78 | 33.17 |
| HellaSwag | 34.51 | 37.59 | 42.69 | 37.37 | 38.31 | 38.3 | 39.67 | 41.07 |
| PiQA | 62.24 | 65.58 | 68.05 | 66.62 | 66.54 | 65.52 | 66.98 | 67.21 |
| OpenBookQA | 27.1 | 28.77 | 28.9 | 28.07 | 28.07 | 27.6 | 31.17 | 29.73 |
| Lambada | 22.78 | 26.99 | 31.34 | 29.51 | 27.87 | 29.47 | 30.34 | 32.71 |
| SciQ | 77.78 | 80.25 | 79.47 | 80.25 | 80.7 | 79.72 | 81.35 | 81.77 |
| COPA | 64.0 | 66.33 | 67.0 | 67.0 | 67.33 | 68.33 | 67.17 | 67.67 |
| RACE | 28.33 | 28.82 | 30.78 | 30.8 | 30.08 | 30.24 | 30.24 | 30.67 |
| ARC Easy | 45.48 | 48.64 | 51.49 | 46.99 | 48.79 | 48.05 | 49.58 | 49.49 |
| LogiQA | 24.83 | 24.96 | 24.76 | 23.25 | 26.06 | 25.55 | 24.32 | 24.68 |
| QQP | 50.27 | 54.73 | 53.96 | 57.0 | 53.73 | 51.19 | 57.52 | 56.91 |
| WinoGrande | 51.79 | 51.63 | 51.32 | 50.76 | 53.18 | 52.45 | 50.72 | 52.24 |
| MultiRC | 54.03 | 53.96 | 48.91 | 50.74 | 53.01 | 50.89 | 47.63 | 53.84 |
| Avg | 44.35 | 46.28 | 47.06 | 46.28 | 46.7 | 46.18 | 46.96 | 47.78 |
| Model Index | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 |
| Pre-training Domain Weights | ||||||||
| ArXiv | 0.082 | 0.091 | 0.194 | 0.011 | 0.039 | 0.294 | 0.012 | 0.25 |
| FreeLaw | 0.12 | 0.084 | 0.04 | 0.022 | 0.063 | 0.119 | 0.16 | 0.058 |
| NIH ExPorter | 0.0 | 0.0 | 0.022 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PubMed Central | 0.051 | 0.343 | 0.126 | 0.37 | 0.079 | 0.186 | 0.311 | 0.104 |
| Wikipedia (en) | 0.067 | 0.0 | 0.046 | 0.006 | 0.0 | 0.023 | 0.014 | 0.044 |
| DM Mathematics | 0.034 | 0.174 | 0.028 | 0.0 | 0.002 | 0.005 | 0.0 | 0.0 |
| Github | 0.205 | 0.144 | 0.048 | 0.14 | 0.482 | 0.023 | 0.117 | 0.028 |
| PhilPapers | 0.0 | 0.0 | 0.01 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Stack Exchange | 0.036 | 0.009 | 0.099 | 0.058 | 0.012 | 0.001 | 0.004 | 0.06 |
| Enron Emails | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Gutenberg (PG-19) | 0.0 | 0.019 | 0.04 | 0.216 | 0.0 | 0.002 | 0.236 | 0.0 |
| Pile-CC | 0.371 | 0.122 | 0.229 | 0.101 | 0.269 | 0.213 | 0.037 | 0.363 |
| Ubuntu IRC | 0.0 | 0.001 | 0.0 | 0.033 | 0.0 | 0.023 | 0.007 | 0.0 |
| EuroParl | 0.0 | 0.003 | 0.002 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| HackerNews | 0.0 | 0.001 | 0.0 | 0.002 | 0.0 | 0.0 | 0.0 | 0.0 |
| PubMed Abstracts | 0.029 | 0.006 | 0.089 | 0.026 | 0.002 | 0.024 | 0.007 | 0.086 |
| USPTO Backgrounds | 0.004 | 0.004 | 0.027 | 0.015 | 0.052 | 0.088 | 0.094 | 0.007 |
| Downstream Performance (%) | ||||||||
| Social IQA | 33.53 | 33.74 | 33.37 | 33.41 | 32.96 | 33.88 | 33.75 | 33.79 |
| HellaSwag | 39.09 | 35.65 | 38.68 | 36.07 | 37.68 | 38.53 | 35.4 | 40.5 |
| PiQA | 66.81 | 64.58 | 65.68 | 63.99 | 65.85 | 65.76 | 64.51 | 66.89 |
| OpenBookQA | 29.13 | 27.57 | 28.27 | 29.1 | 29.43 | 28.73 | 28.3 | 29.87 |
| Lambada | 30.23 | 26.19 | 30.29 | 30.84 | 29.76 | 29.03 | 28.63 | 30.74 |
| SciQ | 79.9 | 80.83 | 78.4 | 80.03 | 81.38 | 80.92 | 77.75 | 82.07 |
| COPA | 68.17 | 61.83 | 67.0 | 66.0 | 66.17 | 63.17 | 66.33 | 64.0 |
| RACE | 31.42 | 29.35 | 30.41 | 31.08 | 30.77 | 29.73 | 30.8 | 31.42 |
| ARC Easy | 49.54 | 47.71 | 49.02 | 47.64 | 48.38 | 49.36 | 46.96 | 51.22 |
| LogiQA | 24.99 | 24.58 | 25.32 | 24.91 | 25.17 | 26.22 | 24.63 | 24.91 |
| QQP | 54.06 | 56.48 | 50.96 | 56.62 | 56.45 | 53.86 | 53.85 | 53.26 |
| WinoGrande | 50.51 | 50.26 | 51.83 | 51.33 | 52.18 | 51.89 | 51.59 | 50.5 |
| MultiRC | 50.25 | 54.37 | 50.94 | 52.38 | 51.21 | 55.34 | 54.52 | 50.5 |
| Avg | 46.74 | 45.63 | 46.17 | 46.42 | 46.72 | 46.65 | 45.92 | 46.90 |
| Model Index | 57 | 58 | 59 | 60 | 61 | 62 | 63 | 64 |
| Pre-training Domain Weights | ||||||||
| ArXiv | 0.137 | 0.176 | 0.471 | 0.081 | 0.107 | 0.278 | 0.119 | 0.131 |
| FreeLaw | 0.085 | 0.007 | 0.038 | 0.153 | 0.016 | 0.141 | 0.085 | 0.006 |
| NIH ExPorter | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.027 | 0.03 |
| PubMed Central | 0.085 | 0.05 | 0.218 | 0.17 | 0.218 | 0.257 | 0.294 | 0.075 |
| Wikipedia (en) | 0.059 | 0.122 | 0.005 | 0.017 | 0.003 | 0.099 | 0.02 | 0.0 |
| DM Mathematics | 0.0 | 0.001 | 0.0 | 0.033 | 0.0 | 0.009 | 0.073 | 0.093 |
| Github | 0.039 | 0.088 | 0.097 | 0.041 | 0.238 | 0.041 | 0.038 | 0.369 |
| PhilPapers | 0.0 | 0.069 | 0.0 | 0.048 | 0.0 | 0.0 | 0.0 | 0.0 |
| Stack Exchange | 0.017 | 0.05 | 0.016 | 0.077 | 0.113 | 0.027 | 0.046 | 0.06 |
| Enron Emails | 0.009 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.001 | 0.0 |
| Gutenberg (PG-19) | 0.007 | 0.0 | 0.018 | 0.001 | 0.0 | 0.0 | 0.026 | 0.002 |
| Pile-CC | 0.435 | 0.339 | 0.112 | 0.268 | 0.272 | 0.128 | 0.232 | 0.188 |
| Ubuntu IRC | 0.0 | 0.006 | 0.017 | 0.095 | 0.001 | 0.0 | 0.0 | 0.001 |
| EuroParl | 0.0 | 0.012 | 0.0 | 0.0 | 0.0 | 0.0 | 0.001 | 0.003 |
| HackerNews | 0.001 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.017 |
| PubMed Abstracts | 0.004 | 0.004 | 0.001 | 0.0 | 0.02 | 0.0 | 0.013 | 0.016 |
| USPTO Backgrounds | 0.122 | 0.077 | 0.006 | 0.016 | 0.013 | 0.02 | 0.025 | 0.009 |
| Downstream Performance (%) | ||||||||
| Social IQA | 33.24 | 33.3 | 33.56 | 33.54 | 33.42 | 33.84 | 33.32 | 33.55 |
| HellaSwag | 41.74 | 39.63 | 35.36 | 38.83 | 38.53 | 36.46 | 38.8 | 36.43 |
| PiQA | 68.07 | 67.31 | 64.44 | 66.38 | 66.5 | 64.74 | 66.54 | 64.87 |
| OpenBookQA | 29.2 | 29.5 | 28.1 | 27.97 | 27.83 | 27.37 | 28.83 | 27.87 |
| Lambada | 31.79 | 31.11 | 27.32 | 30.17 | 28.75 | 26.22 | 30.38 | 26.25 |
| SciQ | 80.42 | 79.83 | 80.85 | 79.6 | 78.93 | 80.05 | 79.5 | 78.65 |
| COPA | 66.17 | 69.0 | 64.0 | 64.83 | 67.0 | 64.0 | 66.0 | 66.83 |
| RACE | 31.39 | 29.82 | 29.67 | 30.08 | 29.98 | 29.46 | 30.37 | 29.19 |
| ARC Easy | 51.14 | 49.24 | 47.13 | 47.88 | 48.2 | 47.09 | 49.09 | 46.9 |
| LogiQA | 25.19 | 25.93 | 23.68 | 25.17 | 25.7 | 25.52 | 26.5 | 26.65 |
| QQP | 55.37 | 54.46 | 52.73 | 53.17 | 59.65 | 58.15 | 57.5 | 55.31 |
| WinoGrande | 53.21 | 51.46 | 50.83 | 52.16 | 52.37 | 51.41 | 51.63 | 51.85 |
| MultiRC | 53.58 | 52.31 | 52.22 | 53.03 | 50.41 | 52.17 | 52.27 | 51.5 |
| Avg | 47.73 | 47.15 | 45.38 | 46.37 | 46.71 | 45.88 | 46.98 | 45.84 |