大型语言模型知识蒸馏综述:方法、评估和应用
摘要。
大型语言模型(大语言模型)在各个领域展示了卓越的能力,引起了学术界和工业界的极大兴趣。 尽管其性能令人印象深刻,但大语言模型的巨大规模和计算需求给实际部署带来了相当大的挑战,特别是在资源有限的环境中。 在保持语言模型准确性的同时压缩语言模型已成为研究的焦点。 在各种方法中,知识蒸馏已成为一种在不极大影响性能的情况下提高推理速度的有效技术。 本文从方法、评价、应用三个方面进行了深入的探讨,探索了专门为大语言模型量身定制的知识蒸馏技术。 具体来说,我们将这些方法分为白盒 KD 和黑盒 KD,以更好地说明它们的差异。 此外,我们还探讨了不同蒸馏方法之间的评估任务和蒸馏效果,并提出了未来的研究方向。 通过深入了解最新进展和实际应用,本次调查为研究人员提供了宝贵的资源,为该领域的持续进步铺平了道路。
1. 介绍
大语言模型的出现(Touvron 等人,2023;Achiam 等人,2023;Zhao 等人,2023;Chang 等人,2024;Wang 等人,2023e)显着提高了各种生成任务中的文本生成质量,成为人工智能领域关键且广泛讨论的话题。 与它们的前辈相比,这些模型对未见过的数据表现出了卓越的泛化能力。 此外,它们还表现出了较小模型所缺乏的能力,例如多步推理(Li 等人, 2022; Magister 等人, 2022; Hsieh 等人, 2023) 和指令遵循 (王等人,2022a;彭等人,2023;吴等人,2023c)。 大语言模型的成功通常归因于训练数据的增加和模型参数数量的增加(例如,拥有 1750 亿个参数的 GPT-3(Brown 等人, 2020))。 然而,参数大小的扩展带来了显着的缺点,特别是在高推理成本和大量内存需求方面,使得实际部署具有挑战性。 例如,GPT-3 需要大约 350GB 的模型存储 (float16) 和至少 5 个 A100 GPU,每个 GPU 具有 80GB 的内存用于推理,这对碳排放有很大贡献。 为了缓解这些挑战,模型压缩(Deng等人,2020;He等人,2018)已成为一种可行的解决方案。 模型压缩旨在将大型、资源密集型模型转换为更紧凑的版本,适合在受限的移动设备上存储。 此过程可能涉及优化以减少延迟以实现更快的执行或在最小延迟和模型性能之间取得平衡。 因此,在现实场景中应用这些高容量模型的一个关键目标是压缩它们,减少参数数量,同时保持最大性能。
随着减少计算资源需求的必要性变得越来越重要,知识蒸馏(KD)(Hinton 等人,2015)成为一种有前途的技术。 KD 是一种机器学习方法,专注于通过将知识从大型复杂模型转移到更小、更高效的模型来压缩和加速模型。 该技术经常用于将大型深度神经网络模型中存储的知识压缩为较小的对应部分,从而减少计算资源需求并提高推理速度,而无需牺牲大量性能。 从根本上说,知识蒸馏利用大型模型在大量数据集上获取的广泛知识来指导较小模型的训练。 这些知识通常包括大型模型的输出概率分布、中间层表示和损失函数。 在训练过程中,较小的模型不仅旨在匹配原始数据标签,而且还模仿较大模型的行为。 对于像 GPT-4 (Achiam 等人, 2023) 这样只能通过 API 访问的高级模型,生成的指令和解释可以帮助学生模型 (Jiang 等人, 2023)。
随着知识蒸馏的最新进展,一些研究综合了各种蒸馏技术的最新进展。 具体来说,Gou et al.(Gou 等人, 2021) 对知识蒸馏进行了广泛的回顾,解决了六个关键方面:知识类别、训练方案、师生架构、蒸馏算法、性能比较和应用。 同样,Wang 等人。(Wang and Yoon,2021)全面总结了与视觉任务相关的知识蒸馏技术的研究进展和技术细节。 Alkhulaifi 等人。(Alkhulaifi 等人,2021)引入了一种称为蒸馏度量的创新度量,他们用它来评估不同的知识压缩方法。 此外,Hu等人。(Hu等人,2023a)探索了跨多个蒸馏目标的各种师生架构,提出了不同的知识表示及其相应的优化目标。 他们还提供了师生架构的系统概述,结合了代表性学习算法和有效的蒸馏方案。
现有的知识蒸馏综述为模型压缩奠定了重要基础并提供了宝贵的见解(Calderon 等人,2023;Lee 等人,2023a;Huang 等人,2023a)。 然而,大语言模型的出现给KD带来了一些新的挑战:1)大语言模型不是为文本生成等单一任务而设计的,而是为各种任务和未见数据(包括紧急能力)的广泛通用性而设计的。 因此,评估压缩大语言模型的泛化能力需要仔细、彻底的评估。 2)现有的综述只是对现有工作的总结,没有提供KD技术在现实场景中压缩和部署大语言模型的具体示例。 本案例研究可以帮助读者针对不同规模的大语言模型选择最佳的KD方案。
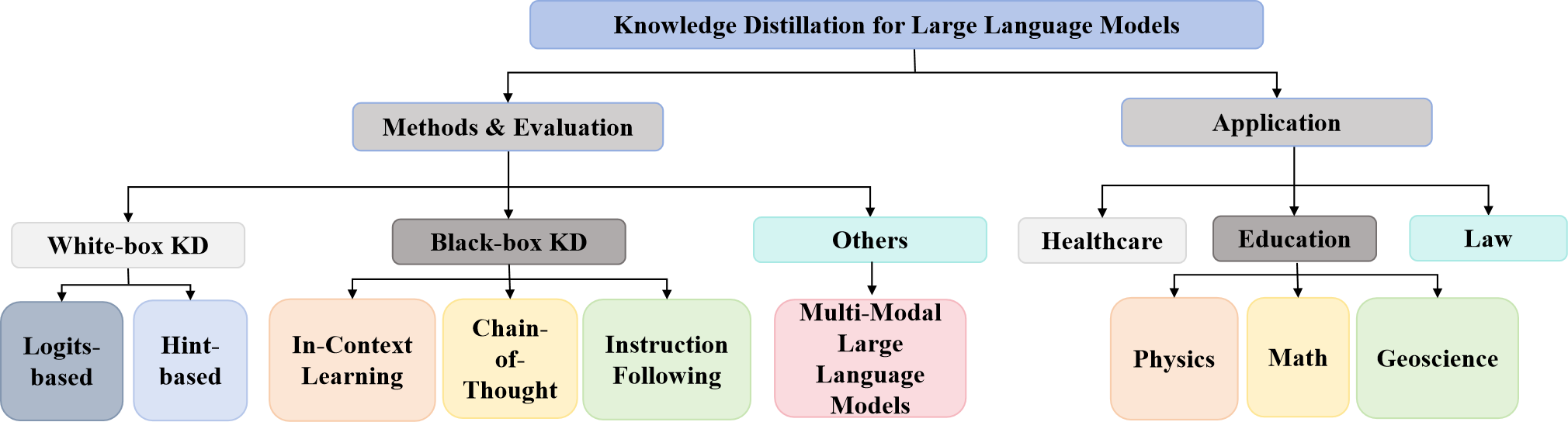
为了应对这些挑战,开发了专门为大语言模型设计的各种知识蒸馏算法。 本文旨在为这些方法提供全面且富有洞察力的指南。 我们调查的总体分类框架如图1所示,它从方法、评估和应用三个方面考察了大语言模型的蒸馏算法。 为了清楚地解释这些方法,我们将它们分为白盒 KD 和黑盒 KD。 白盒 KD 包括两种不同的类型:基于 Logits 的方法(Hinton 等人,2015),在 logits 级别传递知识,以及基于 Hint 的方法(Romero 等人,2014) ),通过中间特征传递知识。 黑盒 KD 涉及基于 API 的方法,其中只能访问教师模型的输出。 该类别通常包括三种方法:情境学习(黄等人,2022)、思想链(李等人,2022)和指令跟踪(王等人,2022a)。 此外,我们在鲁棒性基准上同时评估了上述两类蒸馏算法的有效性(Nie等人,2020a;Wang等人,2021;Tchango等人,2022)。 最后,我们讨论了不同蒸馏方法之间的关系和应用场景,并提出了未来的研究方向。
2. 知识蒸馏概述
在本节中,我们总结了每种知识蒸馏算法的优化目标。
2.1. 基于 Logits 的 KD
顾名思义,基于逻辑的 KD (Hinton 等人,2015) 是一种蒸馏范式,在教师模型中采用逻辑来进行知识转移。 我们可以将常识蒸馏损失函数表述如下:
| (1) |
| (2) |
其中,分别表示学生和教师网络的logits输出。 是调整logits平滑度的温度参数。 代表类的数量。 Kullback-Leibler divergence (KLD) (Hinton 等人, 2015) 损失也可以用其他函数代替,例如 Reverse Kullback-Leibler (RKL) (Huszár, 2015; Nowozin 等人, 2016; Chen 等人, 2018; Lee 等人, 2023b) 蒸馏, Jenson–Shannon (JS) (Tian 等人, 2021) 蒸馏等
2.2. 基于提示的 KD
鉴于学生在基于逻辑的知识蒸馏中提取知识的能力有限,研究人员努力更精确地复制教师的行为。 因此,引入了基于中间特征的知识蒸馏(Sun等人,2019;Hou等人,2020)。 该技术涉及匹配学生模型和教师模型之间的中间层的输出。 这种方法要求学生了解结果以及导致这些结果的过程。 基于特征的知识蒸馏损失函数的一般形式概述如下:
| (3) |
其中分别表示学生和教师网络的中间特征。 函数用于确保学生特征与教师特征的维度匹配。 度量函数用表示,作为例子,我们使用均方误差。
2.3. 情境学习
ICL (Brown 等人, 2020; Huang 等人, 2022)利用由任务描述或多个任务示例组成的自然语言提示作为演示。 正式地,让 表示一组 示例,其中 是将第 个任务示例转换为自然语言提示。 给定任务描述、演示集和新的输入查询,由大生成的预测输出语言模型可以用以下公式描述:
| (4) |
其中答案留空,供大语言模型预测。 学生模型用于预测大语言模型生成的结果。
2.4. 思想链
CoT (Li 等人, 2022; Magister 等人, 2022; Hsieh 等人, 2023; Wadhwa 等人, 2023) 将中间推理步骤集成到提示中,而不是仅仅依赖于简单的输入输出对正如 ICL 中所做的那样。
| (5) |
其中 表示用户提供的理由,解释为什么 的答案是 。 此时,学生模型不仅需要预测教师模型的标签,还需要模拟教师产生的原因。
2.5. 遵循指令
通过对利用自然语言描述的结构化多任务数据集进行微调,大语言模型表现出对类似以教学格式表达的未见任务的熟练程度(Sanh等人,2021;Ouyang等人,2022;Wei等人, 2021)。 通过指令调整,大语言模型可以遵循任务指南来完成新任务,而无需明确的示例,从而提高其泛化能力。 提炼指令遵循技能的过程涉及使用大语言模型生成特定于任务的指令,然后使用该指令数据集微调学生模型。
3. 大型语言模型中的知识蒸馏
Transformer 架构具有高度可扩展性,允许创建具有数十亿甚至数万亿参数的超大型模型。 它支撑着 NLP、CV 和多模态领域中许多最著名的大型模型。 例如,著名的大型语言模型,如 GPT 系列 (Brown 等人, 2020; Achiam 等人, 2023)、LLaMA (Touvron 等人, 2023) 和 Qwen (Bai 等人, 2023) 基于其仅解码器配置。 2023年之前,基于Transformer的NLP蒸馏研究(Tang等人,2019;Sanh等人,2019)主要围绕BERT架构展开。 然而,随着预训练大型语言模型(Ouyang 等人,2022;Achiam 等人,2023)的兴起,人们对提取具有十亿级参数的 Transformer 以及开发更多针对数据有限、计算成本高的场景提出高效的蒸馏方法(Ho等人,2022;Hsieh等人,2023)。 现有的蒸馏算法主要分为两类:白盒KD和黑盒KD。
3.1. 白盒知识蒸馏
白盒蒸馏依赖于需要在 期间访问教师模型内部数据的方法,利用教师模型可访问的内部信息。 在下面的讨论中,我们探讨两种不同类型的白盒知识蒸馏。 首先,基于 logits 的方法,由 Hinton et al.(Hinton 等人, 2015) 提出,在 logits 级别上传递知识,其中知识是通过教师传递的模型的逻辑。 鉴于学生在基于逻辑的知识蒸馏中获得的知识有限,研究人员的目标是更准确地复制教师的行为。 为此,Romero et al.(Romero 等人, 2014)提出基于提示的知识蒸馏,其中涉及对齐学生和教师之间中间层的特征输出楷模。 这种方法要求学生不仅了解最终结果,还要了解导致这些结果的过程。 在下面的部分中,我们从评估任务的角度详细分析每种方法的特点(如表1所示)。 此外,我们还基于鲁棒性评估了两类蒸馏算法的优缺点,为算法的适用场景提供了一定的指导。
| Models | Distillation Type | Teacher Model | Compression Rate | Evaluation Task | Comparison with Teacher Model | |||||||||
| DistillBiLSTM (Tang et al., 2019) | logits-based | BERTbase | 114 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI-m/MNLI-mm | 81.1/87.7 (92% performance) | |||||||||
| DistillBERT (Sanh et al., 2019) | logits-based | BERTbase | 2 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI/QNLI/RTE/MRPC/CoLA/STS-B/WNLI | 77.0/79.5 (97% performance) | |||||||||
| MixKD (Liang et al., 2020) | logits-based | BERTbase | 2 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI-m/MNLI-mm/QNLI/RTE/MRPC | 77.2/82.6 (93% performance) | |||||||||
| ReAugKD (Zhang et al., 2023b) | logits-based | BERTbase | 2 | GLUE(Wang et al., 2018): SST-2/QQP/QNLI/RTE/MRPC/CoLA | 81.8/82.3 (99% performance) | |||||||||
| PD (Turc et al., 2019) | logits-based | BERTbase | 2 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI/QNLI/RTE/MRPC | 82.1/81.7 (100.5% performance) | |||||||||
| MINILLM (Gu et al., 2023) | logits-based |
|
|
Dolly(Gu et al., 2023)/SelfInst(Wang et al., 2022a)/Vicuna(Chiang et al., 2023)/S-NI(Wang et al., 2022b)/UnNI(Honovich et al., 2022) |
|
|||||||||
| GKD (Agarwal et al., 2023) | logits-based | T5XL | 39 | XSum(Narayan et al., 2018)/WMT14EN-DE(Bojar et al., 2014)/GSM8K(Cobbe et al., 2021)/MMLU(Hendrycks et al., 2020)/BBH(Srivastava et al., 2023) | 14.5/26.0 (56% performance) | |||||||||
| MiniMA (Zhang et al., 2023c) | logits-based | LLaMA-27B | 2 | MMLU(Hendrycks et al., 2020)/CEval(Tunstall et al., 2023)/DROP(Dua et al., 2019)/BBH(Srivastava et al., 2023)/GSM8K(Cobbe et al., 2021) HumanEval(Chen et al., 2021) | 21.7/28.5 (76% performance) | |||||||||
| PKD (Sun et al., 2019) | hint-based | BERTbase | 2 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI-m/MNLI-mm/QNLI/RTE/MRPC | 77.7/84.9 (92% performance) | |||||||||
| MetaDistil (Zhou et al., 2022) | hint-based | BERTbase | 2 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI/QNLI/RTE/MRPC/CoLA/STS-B | 80.4/80.7 (99% performance) | |||||||||
| AD-KD (Wu et al., 2023a) | hint-based | BERTbase | 2 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI/QNLI/RTE/MRPC/CoLA/STS-B | 83.4/84.1 (99% performance) | |||||||||
| XtremeDistil (Mukherjee and Hassan Awadallah, 2020) | hint-based | mBERTbase | 35 | Multilingual NER(Pan et al., 2017)/IMDB(Maas et al., 2011)/SST-2(Socher et al., 2013a)/Elec(McAuley and Leskovec, 2013)/DbPedia(Zhang et al., 2015)/Ag News(Zhang et al., 2015) | 88.6/92.7 (95% performance) | |||||||||
| TinyBERT (Jiao et al., 2020) | hint-based | BERTbase | 7 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI-m/MNLI-mm/QNLI/RTE/MRPC/CoLA/STS-B | 77.0/79.5 (97% performance) | |||||||||
| MobileBERT (Sun et al., 2020a) | hint-based | IB-BERTlarge | 4 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI-m/MNLI-mm/QNLI/RTE/MRPC/CoLA/STS-B | 77.7/78.3 (99% performance) | |||||||||
| MiniLM (Wang et al., 2020) | hint-based | BERTbase | 2 | SQuAD2(Rajpurkar et al., 2018)/ GLUE(Wang et al., 2018): SST-2/MNLI-m | 80.4/81.5 (99% performance) | |||||||||
| TED (Liang et al., 2023b) | hint-based | DeBERTaV3base | 2 | GLUE(Wang et al., 2018):SST-2/QQP/MNLI-m/MNLI-mm/QNLI/RTE/MRPC/CoLA/STS-B | 87.5/88.9 (98% performance) | |||||||||
| HomoDistil (Liang et al., 2023a) | hint-based | BERTbase | 7 | GLUE(Wang et al., 2018): SST-2/QQP/MNLI/QNLI/RTE/MRPC/CoLA/STS-B | 79.0/84.6 (93% performance) |
3.1.1. 基于 Logits 的 KD
双向长短期记忆网络(BiLSTM)的蒸馏(Tang等人,2019)标志着知识蒸馏应用于BERT的最早尝试(Kenton和Toutanova,2019)。 蒸馏的目标是最小化学生网络的逻辑与教师网络的逻辑之间的均方误差损失。 该方法已经在三个任务上进行了测试:句子分类和句子匹配。 实验结果表明,基于浅层 BiLSTM 的模型实现了与 ELMo 语言模型(Peters 等人,2018)相当的性能,但参数减少了约 100 倍,推理速度提高了 15 倍。 类似地,DistillBERT (Sanh 等人, 2019) 使用教师的参数初始化较浅的学生模型,并最小化教师和学生之间软目标概率的差异,这种技术称为单词级知识蒸馏。 它引入了三重损失,结合了语言建模、蒸馏和余弦距离损失,以利用预训练模型学到的归纳偏差。 DistilBERT 在九项任务中取得了相当于或超过 ELMo 基线的性能。 与 BERT 相比,DistilBERT 保持了 97% 的性能,同时减少了 40% 的参数数量。 MixKD (Liang 等人, 2020) 通过使用示例对的线性插值来扩展鼓励学生模仿教师 logits 的概念。 它通过使用数据增强从可用的特定于任务的数据创建额外的样本来提高知识蒸馏的有效性。 这种方法反映了学生通过提出进一步的问题来深入探索他们的答案和概念,从而更有效地向教师学习,为学生模型提供更多数据以从大规模语言模型中提取见解。 六个数据集的评估结果表明,MixKD 在压缩大型语言模型方面显着优于传统知识蒸馏和之前的方法。 ReAugKD (Zhang 等人, 2023b) 包括推理阶段和训练阶段。 在推理阶段,它聚合了教师生成的与学生嵌入非常相似的软标签。 在训练阶段,使用一种新颖的关系 KD 损失来最小化师生嵌入及其分布之间的差异。 对六个数据集的评估结果表明,ReAugKD 与基线相比取得了优异的性能,延迟开销不到基线的 3%,这凸显了集成检索信息可以显着提高泛化能力。 Turc et al.(Turc 等人, 2019)提出了一种预训练蒸馏(PD)方法,这是一种用于构建紧凑模型的通用且简单的算法。 它由三个标准训练操作序列组成,可应用于任何架构选择。 该方法还探索使用传统的基于 logits 的 KD 从大型微调模型中转移任务知识,并在六个数据集上评估其性能。 平均而言,这种预训练蒸馏方法表现最好,甚至超越了相应的教师模型。 以上蒸馏算法均以BERT为教师模型,GLUE为评估基准。 随着模型规模的不断增大,现有的蒸馏算法和评价标准已经不能满足要求
MINILLM (Gu 等人, 2023) 通过提出一种创新方法将大语言模型(大语言模型)蒸馏为较小的模型,解决传统基于 logits 的知识蒸馏方法的局限性,重点是最小化前向自由运行一代中的 Kullback-Leibler 散度。 该方法用反向KLD代替了标准KD方法的前向KLD目标,更适合在语言模型上生成KD,旨在防止学生模型高估教师分布的低概率分布。 为了进一步稳定和加速训练,引入了一种有效的优化方法,包括三个关键步骤:1)单步分解以减少方差,2)教师混合采样以减轻奖励黑客攻击,3)长度归一化以抵消长度偏差。 MINILLM适用于参数大小从120M到13B的模型。 使用 Rouge-L (Lin,2004)、人类判断和 GPT-4 反馈对五个数据集进行的实验评估一致表明,该方法优于标准 KD 基线。 进一步的研究和分析表明,MINILLM 可以减少曝光偏差并提高长响应生成性能。 与 MINILLM 类似,GKD (Agarwal 等人, 2023) 不再仅仅依赖一组固定的输出序列,学生模型可以根据教师模型的反馈生成自己的序列。 与监督 KD 方法不同,GKD 允许在学生和教师之间使用替代损失函数,这在学生模型缺乏有效模仿教师分布的表达能力时是有利的。 此外,GKD 可以无缝集成语言模型的蒸馏和强化学习 (RL) 微调。 通过提供灵活性来优化反向 KL 和广义 JSD 等替代分歧度量,GKD 允许有限的学生能力专注于生成与在教师监督下生成的样本类似的样本。 事实证明,同策略 GKD 有助于将蒸馏与 RL (Ouyang 等人,2022) 语言模型微调相结合,这是以前从未探索过的组合。 在初始学生的性能提升方面,平均而言,GKD 在不同规模的 T5 学生模型中,摘要相对增益为 2.1 倍,机器翻译相对增益为 1.7 倍,算术推理任务相对增益为 1.9 倍,凸显了 GKD 的有效性。 在初始学生的性能提升方面,GKD 在各种规模的 T5 学生模型中,摘要平均相对增益为 2.1 倍,机器翻译平均相对增益为 1.7 倍,算术推理任务平均相对增益为 1.9 倍,凸显了 GKD 的有效性。 Wen et al.(Wen 等人, 2023)提出了-DISTILL框架,该框架通过最小化广义-散度函数。 该框架引入了四种蒸馏变体,证明现有的 SeqKD (Kim 和 Rush,2016) 和 ENGINE (Tu 等人,2020) 方法是 KL 和反向 KL 蒸馏的近似。 此外,-DISTILL 方法包括逐步分解,将复杂的序列级分歧转换为更易于管理的字级损失。 这有利于更容易的计算。 该方法在四个数据集上进行了评估:用于数据到文本生成的 DART (Nan 等人, 2021)、用于摘要的 XSum (Narayan 等人, 2018)、WMT16用于机器翻译的 EN-RO (Bojar 等人, 2016) 和 Commonsense Dialogue (Zhou 等人, 2021)。 实验表明,-DISTILL 变体优于现有的分布匹配 KD 方法,与表示匹配 KD 方法结合使用时,性能得到提高。此外,结果表明对称蒸馏损失优于不对称蒸馏损失,确认极端模式平均或崩溃是次优的。 MiniMA (Zhang 等人, 2023c)发现,当学生模型大小约为教师模型大小的 40% 时,会出现最佳蒸馏效果。 它将结构化剪枝与基于 logit 的知识蒸馏相结合,使用 LLaMA2-7B (Touvron 等人, 2023) 作为教师模型来训练 3B MiniMA 模型。 结果表明,MiniMA 在知识、推理和编码方面取得了令人印象深刻的性能,同时使用与教师模型相似甚至更少数量的标记。
3.1.2. 基于提示的 KD
基于特征的知识蒸馏方法(Sun等人,2019;Hou等人,2020)从嵌入空间、Transformer层和预测层中提取知识,使学生模型能够学习教师示范全面。 例如,Sun et al.(Sun 等人, 2019)提出了一种患者知识蒸馏(PKD)方法,旨在将大规模教师模型压缩为同样有效的模型轻量级学生模型。 他们提出了两种不同的蒸馏策略: 1) PKD-Last:学生模型从教师模型的最后 层学习,基于顶层包含最多信息知识的假设。 2)PKD-Skip:学生从教师的每个层学习,这表明较低层也包含在蒸馏过程中应逐渐转移的基本信息。 在情感分类、释义相似性匹配、自然语言推理和机器阅读理解这四项任务的七个数据集上进行的实验表明,PKD 方法优于标准知识蒸馏方法。 它实现了卓越的性能和更好的泛化能力,显着提高了训练效率并降低了存储需求,同时保持了与原始大规模模型相当的精度。 MetaDistill (Zhou 等人, 2022) 通过在训练过程中保持教师模型固定,为传统 KD 方法提供了一种简单高效的替代方案。 在元学习框架内,教师网络通过提取学生表现的反馈来增强向学生网络的知识转移。 此外,还引入了试点更新机制,以提高内部学习者和元学习者之间的一致性,重点是提高内部学习者的表现。 大量的实验验证了该方法在文本和图像分类任务中的有效性和多功能性。 此外,GLUE 基准测试表明,MetaDistill 的性能显着优于传统知识蒸馏,实现了最先进的性能压缩。 AD-KD (Wu 等人, 2023a) 解决了现有知识蒸馏方法的两个关键局限性。 首先,学生模型通常只是模仿老师的行为,而没有发展自己的推理能力。 其次,这些方法通常侧重于传递特定于复杂模型的知识,而忽略特定于数据的知识。 为了克服这些问题,AD-KD引入了一种创新的归因驱动的知识蒸馏方法,该方法使用基于梯度的归因方法来计算每个输入词符的重要性得分(Sundararajan等人,2017)。 为了最大限度地减少教师输入嵌入中不太重要的维度的影响,top-K 策略会过滤掉归因分数较低的维度。 剩余的分数被汇总并标准化以反映各个标记的重要性。 此外,该方法提取所有潜在的预测归因知识,而不仅仅是最高概率的预测。 为了提高推理和泛化的知识迁移,AD-KD 探索了教师做出的所有潜在决策的多视图归因蒸馏。 GLUE 基准测试的实验结果表明,该方法在性能上超越了几种最先进的方法。
Mukherjee 等人。(Mukherjee 和 Hassan Awadallah,2020) 提出了 XtremeDistil,一种利用独立于教师架构的内部表示和参数投影的蒸馏方法。 与之前专注于单语言 GLUE 任务的方法不同,该方法使用 Transformers (mBERT) 中的多语言双向编码器表示,提炼出 41 种语言的多语言命名实体识别 (NER) (Tsai 等人,2019)作为老师的榜样。 实验结果表明,XtremeDistil 实现了更高的压缩和更快的推理速度。 此外,该研究还探讨了蒸馏的几个先前未经检验的方面,包括未标记的传输数据和标注资源的影响、多语言词嵌入的选择、架构修改和推理延迟。 该方法将教师模型的参数显着压缩了高达35倍,批量推理延迟降低了51倍,同时在大规模多语言NER中保持了95%的性能,并且在分类任务中匹配或超越了它。 TinyBERT (Jiao 等人, 2020) 将预训练蒸馏与微调蒸馏相结合,从 BERT 中捕获一般领域和特定任务的知识。 它从不同层提取多种类型的知识,包括嵌入层、隐藏状态、注意力矩阵和转换层。 在 GLUE 基准评估中,其教师模型 BERTbase 的性能超过 96.8%,同时推理速度提高了 7.5 至 9.4 倍。 MiniLM (Wang 等人,2020) 引入了一种深度自注意力蒸馏框架,用于任务无关的基于 Transformer 的语言模型(LM)蒸馏。 该方法隔离了教师模型最终 Transformer 层的自注意力模块,并使用该模块内值之间的缩放点积作为深度自注意力知识的新形式。 该技术通过将两个模型的各种维度表示转换为匹配维度的关系矩阵来解决教师和学生模型之间层对齐的挑战,而不需要额外的参数来转换学生表示。 这增强了学生模型的深度灵活性。 MiniLM 在 SQuAD 2.0 (Rajpurkar 等人,2018) 和各种 GLUE 基准任务上保留了超过 99% 的准确率,同时仅使用教师模型 50% 的 Transformer 参数和计算资源。 这证明了雇用助教(Mirzadeh 等人,2020) 在提取基于 Transformer 的大型预训练模型方面的有效性。 TED (Liang 等人,2023b) 引入了一种创新的任务感知布局蒸馏方法,旨在解决学生模型中的欠拟合问题,并从教师的隐藏表示中删除不必要的信息。 该方法对齐每个级别的学生和教师的隐藏表示,采用任务感知过滤器来提取目标任务的相关知识。 通过这样做,它缩小了模型之间的知识差距,增强了学生适应目标任务的能力。 MobileBERT (Sun 等人, 2020a) 和 HomoBERT (Liang 等人, 2023a) 主要侧重于在保持模型深度的同时调整模型的宽度。 这与 Turc et al.(Turc 等人, 2019) 形成鲜明对比,他们发现改变模型深度会显着影响性能。 MobileBERT 向教师和学生模型引入瓶颈和反向瓶颈来修改隐藏维度。 然而,这种方法可能会破坏多头注意力和前馈网络之间的参数平衡,通过使用堆叠前馈网络(FFN)方法可以缓解这种情况。 然后通过 Transformer 层的注意力和隐藏状态进行知识提取。 另一方面,HomoBERT 采用剪枝。 首先用教师模型初始化学生模型,以确保初始差异最小。 然后,它针对输入嵌入、隐藏状态、注意力矩阵和输出逻辑进行剪枝,以创建蒸馏损失函数。 在每次迭代中,根据重要性分数修剪最重要的神经元,并使用蒸馏损失来训练学生模型。 这个迭代过程持续进行,直到学生模型达到所需的大小。 虽然白盒蒸馏受到大语言模型专有性质的限制,限制了其适用性,但像 Alpaca (Taori 等人,2023) 和 Vicuna (Chiang 等人, 2023) 为白盒蒸馏的未来提供了广阔的前景。
3.2. 白盒KD的鲁棒性评估
现有的白盒KD算法有多种评价标准,其中大部分采用BERT作为教师模型。 然而,这些蒸馏算法在大语言模型背景下的有效性仍不清楚。 在(Wang等人,2023c)中提出的工作的基础上,我们从鲁棒性的角度对这些算法进行了统一评估,特别关注对抗鲁棒性和分布外(OOD)鲁棒性。 这两种类型的鲁棒性都与输入干扰下的性能有关,这对于安全敏感的应用尤其重要。 对抗性稳健性检查模型针对对抗性和难以察觉的干扰的稳定性,而 OOD 稳健性则评估与训练数据分布不同的未见数据的性能。 为了评估对抗鲁棒性,我们采用了 AdvGLUE (Wang 等人,2021) 和 ANLI (Nie 等人,2020b) 基准,使用攻击成功率(ASR)作为公制。 为了保证 OOD 稳健性,我们使用了 Flipkart (Vaghani 和 Thummar,[n. d.]) 审查和 DDXPlus (Tchango 等人,2022) 医疗诊断数据集,其中 F1 分数( F1)作为指标。 受到 MINILLM (Gu 等人, 2023) 工作的启发,我们利用了 Dolly 111https://github.com/databrickslabs/dolly/tree/master数据集用于蒸馏,微调学生和教师模型。 我们同时评估了五种蒸馏算法和四种模型,以评估它们的稳健性。
| Params | Method | Adversarial Robustness(ASR↓) | OOD Robustness(F1↑) | |||||||
| SST-2 | QQP | MNLI | QNLI | RTE | MNLI-MM | ANLI | Flipkart | DDXPlus | ||
| 1.5B | Teacher | 54.73 | 96.15 | 86.78 | 93.92 | 80.25 | 87.65 | 87.67 | 38.55 | 0.40 |
| 120M | SFT | 57.43 | 96.15 | 91.74 | 86.49 | 61.73 | 88.89 | 96.17 | 14.26 | 0 |
| KD | 83.78 | 89.26 | 92.57 | 69.14 | 94.08 | 12.96 | 0 | |||
| SeqKD | 70.27 | 96.15 | 90.08 | 87.84 | 75.31 | 83.95 | 88.83 | 12.61 | 0 | |
| RKL | 66.89 | 98.72 | 87.60 | 85.81 | 65.43 | 93.83 | 98.08 | 7.46 | 0 | |
| JS | 100 | 94.21 | 74.07 | 95.06 | 97.83 | 20.25 | 0 | |||
| MINILLM | 64.19 | 100 | 89.26 | 90.54 | 84.57 | 95.50 | 23.32 | |||
| 340M | SFT | 70.27 | 97.44 | 92.56 | 95.27 | 83.33 | 94.00 | 46.36 | 0 | |
| KD | 63.51 | 98.72 | 84.30 | 90.54 | 72.84 | 80.86 | 92.42 | 52.12 | 0 | |
| SeqKD | 66.89 | 97.44 | 81.82 | 93.24 | 72.84 | 79.01 | 97.08 | 47.87 | 0 | |
| RKL | 62.16 | 96.15 | 95.04 | 95.27 | 70.37 | 92.59 | 96.92 | 33.64 | 0 | |
| JS | 62.16 | 96.15 | 95.04 | 95.27 | 70.37 | 92.59 | 96.92 | 32.29 | 0 | |
| MINILLM | 69.14 | 88.75 | ||||||||
| 760M | SFT | 56.76 | 97.44 | 90.91 | 92.57 | 80.25 | 91.36 | 91.75 | 28.52 | 0 |
| KD | 90.91 | 95.27 | 64.20 | 87.65 | 95.58 | 30.77 | 0 | |||
| SeqKD | 55.41 | 96.15 | 90.91 | 97.30 | 80.25 | 89.51 | 94.17 | 27.60 | 0 | |
| RKL | 64.86 | 97.44 | 90.91 | 92.57 | 85.19 | 95.06 | 98.67 | 20.53 | 0 | |
| JS | 60.14 | 98.72 | 95.04 | 94.59 | 77.78 | 96.30 | 98.58 | 19.90 | 0 | |
| MINILLM | 54.05 | 96.15 | 0 | |||||||
| Adversarial Robustness(ASR↓) | OOD Robustness(F1↑) | |||||||||
| Params | Method | SST-2 | QQP | MNLI | QNLI | RTE | MNLI-MM | ANLI | Flipkart | DDXPlus |
| 13B | Teacher | 52.70 | 94.87 | 76.03 | 91.89 | 61.73 | 70.99 | 99.58 | 54.81 | 0.18 |
| SFT | 54.05 | 94.87 | 78.51 | 94.59 | 61.73 | 77.78 | 98.00 | 51.06 | ||
| KD | 52.03 | 77.69 | 50.62 | 87.67 | 44.45 | 0 | ||||
| SeqKD | 48.65 | 93.59 | 80.17 | 85.14 | 83.95 | 75.31 | 28.85 | 0.30 | ||
| RKL | 94.87 | 92.56 | 97.30 | 74.07 | 90.12 | 99.00 | 46.41 | 0 | ||
| JS | 47.97 | 82.05 | 80.99 | 89.86 | 48.15 | 89.51 | 94.67 | 45.15 | 0 | |
| 1.3B | MINILLM | 47.30 | 94.87 | 78.51 | 79.73 | 71.60 | 89.75 | 0.13 | ||
| SFT | 51.35 | 96.15 | 92.56 | 97.30 | 69.14 | 93.83 | 98.17 | 47.86 | 0 | |
| KD | 84.62 | 83.78 | 64.20 | 41.83 | 0 | |||||
| SeqKD | 47.97 | 77.69 | 61.73 | 72.22 | 88.50 | 34.85 | 0 | |||
| RKL | 56.08 | 98.72 | 90.91 | 99.32 | 100 | 95.68 | 96.83 | 53.01 | ||
| JS | 67.57 | 96.15 | 86.78 | 97.97 | 75.31 | 89.51 | 92.25 | 46.55 | 0 | |
| 2.7B | MINILLM | 47.30 | 94.87 | 91.89 | 66.67 | 72.84 | 81.17 | 0.09 | ||
| SFT | 49.32 | 89.74 | 85.12 | 81.76 | 77.78 | 79.63 | 43.05 | 0.06 | ||
| KD | 94.87 | 80.17 | 85.14 | 58.02 | 73.46 | 81.33 | 50.99 | 0 | ||
| SeqKD | 50.68 | 92.31 | 85.95 | 77.70 | 86.42 | 80.86 | 78.17 | 32.01 | ||
| RKL | 60.81 | 91.03 | 95.87 | 88.51 | 93.21 | 97.92 | 24.16 | 0 | ||
| JS | 63.51 | 94.21 | 62.96 | 88.27 | 98.58 | 26.05 | 0 | |||
| 6.7B | MINILLM | 50.68 | 92.31 | 95.27 | 80.25 | 75.93 | 86.75 | 0 | ||
| Adversarial Robustness(ASR↓) | OOD Robustness(F1↑) | |||||||||
| Params | Method | SST-2 | QQP | MNLI | QNLI | RTE | MNLI-MM | ANLI | Flipkart | DDXPlus |
| 13B | Teacher | 41.89 | 65.38 | 76.03 | 52.70 | 56.79 | 64.20 | 66.42 | 56.01 | 9.09 |
| SFT | 47.97 | 67.95 | 71.90 | 48.65 | 46.91 | 66.67 | 67.33 | 52.65 | 2.81 | |
| KD | 43.24 | 60.26 | 73.55 | 54.73 | 56.79 | 64.20 | 66.58 | 4.32 | ||
| SeqKD | 65.38 | 49.32 | 64.81 | 66.67 | 56.58 | 5.66 | ||||
| RKL | 76.92 | 72.73 | 50.62 | 64.81 | 67.75 | 52.74 | 0.43 | |||
| JS | 43.92 | 66.67 | 73.55 | 52.70 | 56.79 | 64.20 | 67.00 | 57.35 | 3.44 | |
| LLaMA_7B | MINILLM | 42.57 | 71.90 | 51.35 | 56.79 | 64.81 | 66.92 | 52.27 | 5.21 | |
| 13B | Teacher | 54.05 | 47.44 | 65.29 | 51.35 | 46.91 | 62.96 | 71.00 | 29.76 | 0 |
| SFT | 69.23 | 75.21 | 63.51 | 61.73 | 66.05 | 69.92 | 50.76 | 0.17 | ||
| KD | 47.97 | 70.51 | 74.38 | 52.70 | 56.79 | 64.20 | 83.67 | 55.51 | 1.75 | |
| SeqKD | 49.32 | 66.67 | 75.21 | 52.70 | 56.79 | 63.59 | 84.50 | 1.67 | ||
| RKL | 52.03 | 61.54 | 73.55 | 58.02 | 63.58 | 72.33 | 55.42 | 4.37 | ||
| JS | 51.35 | 57.69 | 78.51 | 56.76 | 66.67 | 50.38 | ||||
| LLaMA2_7B | MINILLM | 50.00 | 75.64 | 75.21 | 58.78 | 48.15 | 69.75 | 83.67 | 31.94 | 0 |
评价结果如表2-4所示。 首先,我们观察到 MINILLM 在 GPT-2 中表现出卓越的整体蒸馏性能。 值得注意的是,对于 340M 大小的 GPT-2,与其他四种蒸馏算法相比,它在对抗性和非分布数据集上都取得了最先进的结果。 此外,MINILLM 在任何规模的 GPT-2 的 Flipkart 和 DDXPlus 数据集上都优于其他算法,凸显了其对分布外数据的卓越泛化能力。 其次,对于 OPT 模型,我们发现最直接的 KD 算法(使用教师分布作为每个词符步骤的监督来调节学生模型)取得了最佳的整体性能。 同样,MINILLM 的性能优于其他蒸馏算法,甚至超过了 Flipkart 数据集上任意大小的 OPT 教师模型的性能。 最后,对于LLaMA,SeqKD表现出相对较好的蒸馏效果,而对于LLaMA2,JS表现出相对优越的性能。 这表明,即使模型大小相同且模型结构相似,相同蒸馏算法的有效性也可能存在很大差异。
3.3. 白盒KD讨论
基于 Logits 的 KD 方法通常侧重于调整教师模型和学生模型之间的输出分布。 相比之下,基于提示的 KD 方法可以通过对齐中间层来传达更丰富的信息,从而获得更好的结果。 然而,实现层层知识蒸馏需要仔细设计教师模型和学生模型之间的层映射,并且需要对模型架构有深入的理解。 基于 logits 和基于提示的 KD 方法在蒸馏过程中都需要大量 GPU 内存。 尽管教师网络不需要反向传播,但前向传播过程中中间特征的激活会消耗大量的 GPU 内存。 因此,探索降低训练成本、缩短训练时间的方法至关重要。
3.4. 黑盒知识蒸馏
前面讨论的两种蒸馏技术依赖于对教师模型内部数据的访问,将它们归类为白盒蒸馏方法,在训练期间需要内部数据。 然而,许多现代大规模闭源模型不提供对内部数据的访问,这限制了我们只能使用模型预测。 仅通过教师模型的预测来转移知识的蒸馏称为黑盒知识蒸馏。 研究人员发现,当模型参数足够大时,模型表现出显着的多功能性,使其能够处理复杂的任务。 许多黑盒蒸馏方法都利用了这种能力,通常利用三种技术:上下文学习、思维链和指令跟踪。 在本节中,我们根据涌现能力的使用进一步对黑盒 KD 方法进行分类。
| Models | Distillation Type | Teacher Model | Compression Rate | Evaluation Task | Comparison with Teacher Model | ||||||||
| ILD (Huang et al., 2022) | ICL |
|
|
|
|
||||||||
| LLM-R (Wang et al., 2023d) | ICL | LLaMA13B | 2 | Commonsense/Coreference/NLI/Paraphrase/Sentiment/Data-to-text/Summarize/etc.(30) | 68.8/64.6 (107% performance) | ||||||||
| MT-CoT (Liang et al., 2020) | CoT | GPT-3text-davinci-002 | 58 | CommonsenseQA(Talmor et al., 2019)/StrategyQA(Geva et al., 2021)/OpenbookQA(Mihaylov et al., 2018) | 80.5/82.1 (98% performance) | ||||||||
| Distilling step-by-step (Hsieh et al., 2023) | CoT | PaLM540B | 2455 | e-SNLI(Camburu et al., 2018)/ANLI(Nie et al., 2020b)/CQA(Talmor et al., 2019)/SVAMP(Patel et al., 2021) | 58.4/72.3 (81% performance) | ||||||||
| Fine-tune-CoT (Ho et al., 2022) | CoT | InstructGPT 175Btext-davinci-002 | 26 | SingleEq/AddSub/MultiArith/GSM8K/AQUA-RAT/SVAMP/StrategyQA/etc.(12) | 42.2/65.5 (64% performance) | ||||||||
| MCC-KD (Chen et al., 2023b) | CoT | GPT-3.5Turbo | / | GSM8K(Cobbe et al., 2021)/ASDiv(Miao et al., 2020)/SVAMP(Patel et al., 2021)/CommonsenseQA(Talmor et al., 2019) | 66.2/75.8 (87% performance) | ||||||||
| SCOTT (Wang et al., 2023b) | CoT | GPT-neox20B | 7 | CSQA(Talmor et al., 2019)/CREAK(Onoe et al., 2021)/QASC(Khot et al., 2020)/StrategyQA(Geva et al., 2021) | 69.6/72.3 (96% performance) | ||||||||
| LTD (Jie and Lu, 2023) | CoT | Codexcode-davinci-002 | 29 | SVAMP(Patel et al., 2021)/GSM8K(Cobbe et al., 2021)/MathQA(Amini et al., 2019) | 45.9/56.8 (81% performance) | ||||||||
| PaD (Zhu et al., 2023) | CoT | PaLM60B | 78 | SVAMP(Patel et al., 2021)/GSM8K(Cobbe et al., 2021)/ASDiv(Miao et al., 2020)/MultiArith(Roy and Roth, 2015)/BBH(Srivastava et al., 2023) | 43.9/50.2 (88% performance) | ||||||||
| Learn-to-Reason (Chae et al., 2023) | CoT | ChatGPT175B | 29 | GSM8K(Cobbe et al., 2021)/MultiArith(Roy and Roth, 2015)/SVAMP(Patel et al., 2021)/CSQA(Talmor et al., 2019)/StrategyQA(Geva et al., 2021) | 62.1/76.1 (82% performance) | ||||||||
| LaMini-LM (Wu et al., 2023c) | IF | Alpaca7B | 9 | Multiple-Choice QA/Extractive QA/Sentiment Analysis/Paraphrase Identification/etc.(15) | 60.8/62.3 (98% performance) | ||||||||
| Lion (Jiang et al., 2023) | IF | ChatGPT175B | 25 | BBH(Srivastava et al., 2023) | 32.0/48.9 (65% performance) | ||||||||
| UniNER (Zhou et al., 2023) | IF | GPT-3.5turbo-0301 | / | UNIVERSAL NER BENCHMARK (Zhou et al., 2023) | 41.7/34.9 (119% performance) |
3.4.1. 情境学习
ICL 最初在 GPT-3 (Brown 等人, 2020) 中引入,它采用自然语言提示,其中包括任务描述和多个任务示例作为演示。 该过程从任务描述开始,然后从任务数据集中选择特定实例作为示例。 然后使用预定义的模板将这些实例格式化为自然语言提示,并按特定顺序排列。 最后,将测试样本合并到大语言模型的输入中以产生输出。
在此概念的基础上,黄等人(Huang 等人, 2022)提出了In-Context Learning Distillation,旨在通过上下文学习有效地提取和迁移知识,从而增强多任务模型的少样本学习能力和语言建模目标。 这种方法引入了少样本学习的两种范例:元上下文调优和多任务上下文调优。 在 Meta-ICT (Chen 等人,2022b;Min 等人,2022a) 中,语言模型使用上下文学习目标在广泛的任务中进行元训练。 随后,它通过上下文学习来适应看不见的目标任务。 然而,情境学习的有效性很大程度上依赖于预训练(Reynolds and McDonell,2021)期间积累的知识,可能限制其充分利用训练数据中提供的输入标签对应关系的能力(Min等人,2022b)。 为了解决这个限制,提出了一种称为多任务上下文调整的替代少样本学习范例。 Meta-ICT 使学生模型能够通过情境学习和教师指导来适应新任务,而 Multitask-ICT 将所有目标任务视为训练任务,并直接利用这些任务中的示例进行情境学习提炼。 这两种少样本学习范例涉及性能和计算效率之间的权衡。 分类、自然语言推理和问答等任务的结果表明,Multitask-ICT 实现了模型大小减少 93%,同时保留了 91.4% 的教师表现。 因此,多任务-ICT 被证明更有效,尽管计算成本更高。 LLM-R (Wang 等人, 2023d) 利用预训练的冻结大语言模型来检索高质量的上下文示例,然后对这些示例进行排序以生成训练数据。 随后,它使用交叉编码器构建奖励模型来捕获排名偏好。 最后,将知识蒸馏应用于训练基于双编码器的密集检索器。 与几个可靠的基线相比,我们对不同任务的 LLM-R 的综合评估一致证明了其卓越的性能。 此外,我们的模型展示了跨不同任务规模和大语言模型架构的可扩展性。 详细分析表明,我们的方法将上下文学习性能平均提高了 7.8%,并且在不同规模的大语言模型中观察到了一致的改进。
3.4.2. 思想链
Chain-of-Thought (CoT)(Li 等人, 2022; Magister 等人, 2022; Hsieh 等人, 2023; Wadhwa 等人, 2023)代表了一种旨在增强大语言能力的高级提示策略模型处理复杂推理任务的能力。 与 ICL 中用于提示制定的输入输出对方法不同,CoT 集成了中间推理步骤,将最终输出合并到提示中。 通常,CoT 蒸馏 (Li 等人, 2022; Ho 等人, 2022; Shridhar 等人, 2023; Wang 等人, 2023b; Kang 等人, 2024; Jie 等人, 2023; Zhu 等人, 2023; Li 等人, 2023b; Chen 等人, 2023b; Chae 等人, 2023; Wang 等人, 2023a) 涉及利用大规模模型来构建专注于推理任务的丰富数据集,然后将其用于精细任务调整学生模型。 因此,首要重点是生成高质量的训练原理并确保学生有效利用这些原理(Li 等人, 2022; Hsieh 等人, 2023; Shridhar 等人, 2023; Wang 等人, 2023b ;康等人,2024)。
Li et al.(Li 等人, 2022) 率先使用大语言模型生成的解释来增强小型推理机的训练。 他们系统地探索了从大语言模型中导出解释的三种方法,并将其集成到多任务学习框架中,使紧凑模型具有强大的推理和解释能力。 在多个推理任务中,实验一致证明他们的方法在各种条件下都优于基线微调方法。 值得注意的是,经过 60 轮 Commonsense QA 微调后,它的准确率比 GPT-3 (175B) 提高了 9.5%。 他们的方法生成的高质量解释阐明了人工智能可解释预测背后的基本原理。 Hsieh et al.(Hsieh 等人, 2023) 引入了逐步蒸馏,这是一种新颖而直接的方法,旨在减少精炼和优化所需的训练数据量。将大语言模型分解为更小的模型。 他们方法的核心是范式转变:大语言模型不仅仅是噪声标签的来源,而且能够提供自然语言推理来证明他们的预测的代理。 四项 NLP 基准测试的实证结果产生了三个显着结果。 首先,与微调和传统蒸馏方法相比,他们的模型将所需的训练样本平均数量减少了 50% 以上(有些减少超过 85%),从而提高了性能。 其次,他们的模型实现了优于大语言模型的性能,同时尺寸明显更小,从而减少了部署的计算资源。 第三,他们的方法同时减少了模型大小和所需数据以优于大语言模型。 例如,他们的 770M T5 模型的最终迭代超越了 540B 参数大语言模型的性能,仅利用了 80% 的标记数据集。
此外,Ho et al.(Ho 等人, 2022)提出了微调CoT,一种利用大语言模型推理能力指导较小模型解决复杂任务的方法。 通过随机抽样从教师模型生成多个推理解决方案,他们丰富了学生模型的数据。 使用广泛可访问的模型对 12 个任务进行的评估表明,微调 CoT 在较小的模型中实现了显着的推理性能,同时保留了基于提示的 CoT 推理的大部分通用性,而以前依赖于具有超过 1000 亿个参数的模型。 因此,只有 3 亿个参数的模型在特定任务中可以胜过更大的模型,甚至超过具有 1750 亿个参数的教师模型的性能。 同样,Chen等人。(Chen等人,2023b)引入了Multi-CoT一致性知识蒸馏(MCC-KD)来有效捕获推理能力的多样性和连贯性。 在 MCC-KD 中,为每个问题生成多个基本原理,并通过最小化答案分布之间的双向 KL 散度来增强相应预测之间的一致性。 MCC-KD 的功效是根据各种模型架构的数学推理和常识推理基准进行评估的。 实证结果不仅证实了MCC-KD在分布内数据集上的优越性能,而且还强调了其在分布外数据集上强大的泛化能力。 傅 et al.(傅 等人, 2023) 傅 et al.(傅 等人, 2023)应用 CoT 专门用于多步骤数学推理任务的较小语言模型。 Shridhar 等人详细介绍了 SOCRATIC CoT 方法。(Shridhar 等人, 2023) 将原始问题分解为一系列子问题,并采用一对紧凑蒸馏模型:问题分解器和子问题求解器。 这些模型协作来分解和解决新任务中出现的复杂问题。 对各种推理数据集(包括 GSM8K、StrategyQA 和 SVAMP)的评估表明,与基线相比,这种蒸馏方法将较小模型的性能显着提高了 70% 以上。 另一方面,SCOTT(王等人,2023b)引入了利用大语言模型通过比较解码来指导正确答案的核心原理。 这种方法鼓励教师模型生成与正确答案密切相关的标记,从而提高蒸馏过程的保真度。 Jie et al.(Jie and Lu, 2023) and Zhu et al.(Zhu 等人, 2023) 通过程序蒸馏增强数学推理能力。 Chae et al.(Chae 等人, 2023) 和 Wang et al.(Wang 等人, 2023a) 提出一个交互式多循环学习框架。 在这个框架中,前者专注于使用多跳推理来训练学生,而后者则主动将他们的学习状态传达给大语言模型老师。 随后,老师针对学生的反馈进行针对性的解释,引导学生反思自己的错误。
3.4.3. 遵循指令
指令跟随能力旨在增强语言模型执行新任务的能力,而无需严重依赖有限的示例。 通过对指令指定的各种任务进行微调,语言模型展示了其准确执行以前未见过的指令中描述的任务的能力。 然而,在黑盒蒸馏中,知识转移仅依赖于数据集,因此足够大的数据集的可用性至关重要。 因此,这些方法中的协作努力(Wang 等人,2022a;Peng 等人,2023;Wu 等人,2023c;Jiang 等人,2023)涉及创建一个包含指令、输入和数据的综合数据集。输出。 该数据集使学生模型能够从教师模型中获取广泛的知识。
具体来说,Wang et al.(Wang 等人, 2022a)提出了自我指令,这是一种半自动过程,利用模型本身的指示信号来完善语言模型的指示。 该过程从一组受约束的手动任务种子开始,例如我们研究中使用的 175 个任务,以指导整个生成过程。 最初,提示模型使用这组初始指令来生成更广泛的任务描述。 此外,对于新生成的指令集,该框架会创建可用于将来监督指令调整的输入输出实例。 最后,在将剩余的有效任务合并到任务池之前,采用各种启发式方法自动过滤掉低质量或重复的指令。 这个迭代过程可以重复多次,直到获得大量任务。 该方法影响了后续研究,导致Alpaca (Taori 等人,2023)、Vicuna (Chiang 等人,2023)等13B开源模型进行了调整,和 GPT4All (Anand 等人, 2023) 遵循此范例。 Peng 等人扩展了这些想法。(Peng 等人, 2023)探索使用 GPT-4 生成指令跟踪数据以微调大语言模型。 他们整理了包含 52,000 个英文和中文指令跟随示例的数据集,以及 GPT-4 生成的反馈数据集。 他们利用这些数据集对两个学生模型 LLaMA-GPT4 和 LLaMA-GPT4-CN 进行了微调。 此外,他们开发了一个反馈模型来评估模型响应的质量。 Wu et al.(Wu 等人, 2023c)精心编制了包含 258 万条指令的数据集,确保了不同主题的覆盖。 这些指令用作使用 GPT-3.5 Turbo 生成响应的输入。 他们在 LaMini-LM 下微调了一系列模型,包括编码器-解码器和仅解码器架构。 LaMini-LM 模型性能的评估涉及在 15 个基准中应用自动指标以及手动评估。 结果表明,尽管尺寸只有十分之一,但所提出的 LaMini-LM 模型却实现了与竞争基准相当的性能。
然而,现有的方法主要集中在单向知识蒸馏上,其中学生模型的响应与教师模型的响应一致以生成指令,而不包含“反馈”机制。 为了解决这个限制,Jiang et al.(Jiang 等人,2023)引入了一种创新的对抗性蒸馏框架,该框架由三个阶段组成:模仿、辨别和生成。 该框架利用大语言模型的适应性,激励教师模型识别“具有挑战性”的指令,并为学生模型生成新的指令,从而提高知识迁移的有效性。 该方法仅使用 70,000 个训练样本即可实现与 ChatGPT 相当的开放生成能力,在零样本推理 BBH 和 AGIEval 任务上分别超越传统最先进的指令调整模型(例如 Vicuna-13B)55.4% 和 16.7% , 分别。 为了提供特定于任务的指导,Chen等人。(Chen等人,2023a)提出了一个用于代码生成指令的微调数据集,并开发了一个多轮个性化蒸馏方法。 这种方法使学生模型能够首先尝试独立解决任务,然后由教师提供适应性改进,以通过执行反馈来提高他们的表现。 与传统的知识转移方法不同,传统的知识转移方法将教师的先验知识直接传授给学生,个性化细化通过仅从错误示例中学习并迭代改进其解决方案来提供个性化的学习体验。 同时,UniversalNER (Zhou 等人, 2023) 对命名实体识别任务进行了广泛的研究。 与上述旨在增加指令多样性的方法不同,UniversalNER 专注于增强输入多样性,以增强模型在各个领域的泛化能力。
| Params | Method | Adversarial Robustness(ASR↓) | OOD Robustness(F1↑) | |||||||
| SST-2 | QQP | MNLI | QNLI | RTE | MNLI-MM | ANLI | Flipkart | DDXPlus | ||
| 1.5B | Teacher | 62.84 | 94.87 | 76.03 | 75.68 | 56.79 | 74.07 | 89.42 | 10.72 | 0 |
| 120M | ANLI | 74.36 | 73.55 | 92.75 | 0 | |||||
| CQA | 85.81 | 96.15 | 95.87 | 96.62 | 98.77 | 93.83 | 94.17 | 8.56 | 0 | |
| e-SNLI | 99.32 | 60.81 | 58.02 | 71.60 | 1.38 | 0 | ||||
| SVAMP | 80.41 | 93.59 | 85.95 | 90.54 | 93.83 | 82.72 | 95.42 | 3.98 | ||
| 340M | ANLI | 58.78 | 78.51 | 46.91 | 68.52 | 87.08 | 27.39 | 0 | ||
| CQA | 52.70 | 87.18 | 88.43 | 94.59 | 97.53 | 91.36 | 94.08 | 0 | ||
| e-SNLI | 99.32 | 71.79 | 80.99 | 65.54 | 4.61 | 0 | ||||
| SVAMP | 69.23 | 80.17 | 77.03 | 64.20 | 77.78 | 76.08 | 25.60 | 0 | ||
| 760M | ANLI | 89.19 | 89.74 | 88.43 | 75.68 | 93.83 | 86.42 | 92.83 | 6.48 | 0 |
| CQA | 90.08 | 75.00 | 83.95 | 94.44 | 98.83 | 0 | ||||
| e-SNLI | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 1.38 | 0 | |
| SVAMP | 64.19 | 70.51 | 87.60 | 85.19 | 85.19 | 96.75 | 9.84 | 0 | ||
| Params | Method | Adversarial Robustness(ASR↓) | OOD Robustness(F1↑) | |||||||
| SST-2 | QQP | MNLI | QNLI | RTE | MNLI-MM | ANLI | Flipkart | DDXPlus | ||
| 13B | Teacher | 68.24 | 80.77 | 74.38 | 50.68 | 56.79 | 69.75 | 72.33 | 32.04 | 0 |
| 1.3B | ANLI | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 0 | 0 |
| CQA | 50.00 | 85.90 | 66.89 | 96.00 | 36.00 | 0 | ||||
| e-SNLI | 75.00 | 93.59 | 81.82 | 83.78 | 67.90 | 79.63 | 97.33 | 2.93 | 0 | |
| SVAMP | 92.31 | 78.51 | 78.38 | 53.09 | 75.93 | 99.33 | ||||
| 2.7B | ANLI | 100 | 100 | 100 | 100 | 100 | 97.53 | 98.50 | 0 | 0 |
| CQA | 87.18 | 80.99 | 75.00 | 81.92 | 31.15 | |||||
| e-SNLI | 87.84 | 79.49 | 90.91 | 87.84 | 86.42 | 86.42 | 96.50 | 3.48 | 0 | |
| SVAMP | 51.35 | 61.49 | 66.67 | 64.20 | 0.08 | |||||
| 6.7B | ANLI | 100 | 100 | 99.17 | 100 | 100 | 100 | 99.83 | 0 | 0 |
| CQA | 98.72 | 85.12 | 83.78 | 64.20 | 93.83 | 97.08 | 0 | |||
| e-SNLI | 100 | 91.74 | 84.46 | 70.37 | 85.80 | 94.75 | 0.87 | 0 | ||
| SVAMP | 58.78 | 84.62 | 76.03 | 94.59 | 86.42 | 72.84 | 82.83 | 31.77 | ||
3.5. 黑盒KD的鲁棒性评估
受(Hsieh等人,2023)工作的启发,我们从鲁棒性角度对基于CoT的逐步蒸馏算法进行了统一评估。 由于PaLM 540B模型的闭源性质,我们遵循(Hsieh等人,2023)中的实验设置,并使用生成的CoT解释来解释学生模型。 实验结果如表6-8所示。 对于具有 120M 和 340M 参数的 GPT-2 模型,使用 ANLI 和 e-SNLI 数据集的解释进行蒸馏产生了更好的结果。 然而,随着模型规模的增加,这两个数据集的解释力会减弱,并且在 OPT 模型中也观察到类似的趋势。 对于各种大小的 OPT 模型,ANLI 和 e-SNLI 产生的解释性蒸馏效果并不理想。 这表明常识数据(CQA)和数学数据(SVAMP)更有利于OPT模型中的CoT蒸馏。 无论是 LLaMA 还是 OPT,在 Flipkart 和 DDXPlus 上使用 CQA 和 SVAMP 进行的 CoT 蒸馏都优于使用其他两个数据集进行的蒸馏。 这表明数学能力和常识知识的提炼增强了模型推广到分布外的能力。
| Adversarial Robustness(ASR↓) | OOD Robustness(F1↑) | |||||||||
| Params | Method | SST-2 | QQP | MNLI | QNLI | RTE | MNLI-MM | ANLI | Flipkart | DDXPlus |
| 13B | Teacher | 50.68 | 69.23 | 62.81 | 58.78 | 46.91 | 77.78 | 69.83 | 49.16 | 5.74 |
| ANLI | 60.26 | 54.32 | 71.08 | 2.16 | 4.80 | |||||
| CQA | 46.62 | 66.12 | 53.38 | 46.91 | 64.81 | 77.42 | 41.37 | |||
| e-SNLI | 49.32 | 84.62 | 57.85 | 58.11 | 61.73 | 63.58 | 70.33 | 1.38 | 1.46 | |
| LLaMA_7B | SVAMP | 46.62 | 74.36 | 72.73 | 52.70 | 61.73 | 67.90 | 77.75 | 32.44 | 1.46 |
| 13B | Teacher | 53.38 | 50.00 | 71.07 | 45.95 | 50.62 | 62.35 | 71.83 | 33.76 | 18.92 |
| ANLI | 64.19 | 61.54 | 52.70 | 56.79 | 61.11 | 23.88 | 1.02 | |||
| CQA | 48.72 | 66.94 | 50.00 | 43.21 | 66.05 | 66.50 | 8.19 | |||
| e-SNLI | 61.49 | 74.38 | 67.33 | 5.48 | 4.71 | |||||
| LLaMA2_7B | SVAMP | 58.11 | 53.85 | 78.51 | 56.08 | 61.73 | 69.14 | 70.42 | 27.01 | 11.67 |
3.6. 黑盒KD讨论
大语言模型通常使用基于黑盒的 KD 方法来生成解释或指令对来调节学生模型。 在这种方法中,只有教师模型生成数据,并且只有学生模型参与训练,从而节省内存。 然而,当前大多数方法都依赖于闭源教师模型,并且生成额外数据的成本可能很高。 此外,许多方法没有开源数据生成技术或涉及闭源生成数据,这给这些基于黑盒的蒸馏算法的公平评估带来了挑战。
3.7. 其他的
随着大型语言模型的显着进步,其固有的局限性在于无法理解视觉信息,因为它们主要是为处理离散文本而设计的。 因此,研究人员越来越多地探索如何将语言模型的能力转移到多模态领域,其中文本和图像数据被集成以实现更广泛的任务(Yang等人,2023;Driess等人,2023;Gong等人,2023)。 从预训练的多模态模型中提取知识以增强紧凑多模态语言模型的性能和泛化已成为该领域的关注焦点。
3.7.1. 多模态大语言模型
多模式大型模型的知识蒸馏仍处于初级阶段,主要侧重于改进指令跟踪能力。 Li 等人.(Li 等人, 2023d) 开创了一种新颖的框架,该框架具有在多模态大型模型中提取知识的两个阶段。 初始阶段涉及多模态预训练,以通过投影层对齐多模态特征。 第二阶段称为多模式竞争蒸馏,建立双向反馈循环,包括:1)多模式教学调整,以确保学生的反应与教师提供的多模式指令保持一致。 2) 多模态评估以识别具有挑战性的多模态指令。 3)多模态增强,生成新的指令训练并与原始图像相结合,为学生模型创建新的多模态指令数据集。 对 ScienceQA (Lu 等人, 2022)、SEED-Bench (Li 等人, 2023e) 和 LLaVA 测试集 (Liu 等人, 2024) 证明 CoMD 在推理任务和零样本设置方面超越了现有模型。 Park et al.(Park 等人, 2023)通过从大语言模型中采样局部常识知识,开发了局部视觉常识模型。 用户可以指定区域作为输入,单独训练的批评模型会选择高质量的示例。 零样本设置中的经验结果和人工评估表明,与简单地将生成的参考表达式传递到基线大语言模型相比,这种蒸馏方法可以产生更准确的 VL 推理模型。 类似地,Hu et al.(Hu 等人, 2023b) 引入了用于 Visual Program Distillation (VPD) 的指令配置。 VPD利用大语言模型的推理能力,对多个候选程序进行采样、执行和验证,并将正确的程序翻译成推理步骤的语言描述,进行VLM蒸馏。 大量实验表明,VPD 增强了 VLM 的计数、空间关系理解和组合推理能力,在 MMBench 等具有挑战性的视觉任务中实现了最先进的性能(Liu 等人,2023) 、OK-VQA (Marino 等人, 2019)、A-OKVQA (Schwenk 等人, 2022)、TallyQA (Acharya 等人, 2019) t3>、POPE (Li 等人, 2023a) 和 Hateful Memes (Kiela 等人, 2020)。
4. 应用领域
在本节中,我们将简要探讨大语言模型蒸馏在医疗保健、教育和法律等各个关键领域的应用。
| Models | Distillation Scenario | Teacher Model | Compression Rate | Evaluation Task | Comparison with Teacher Model |
|---|---|---|---|---|---|
| HuatuoGPT (Zhang et al., 2023a) | Healthcare | GPT-3.5turbo | / | cMedQA2(Zhang et al., 2018)/webMedQA(He et al., 2019)/Huatuo-26M(Li et al., 2023f) | 25.1/18.6 (135% performance) |
| Chatdoctor (Li et al., 2023c) | Healthcare | GPT-3.5turbo | / | HealthCareMagic100k(Li et al., 2023c) | 84.5/84.1 (100% performance) |
| PMC-LLaMA (Wu et al., 2023b) | Healthcare | ChatGPT | / | PubMedQA(Jin et al., 2019)/MedMCQA(Pal et al., 2022)/USMLE(Jin et al., 2021) | 64.4/55.0 (117% performance) |
| DARWIN (Xie et al., 2023) | Education | GPT-3175B | 25 | SciQ(Welbl et al., 2017)/FAIR(Scheffler et al., 2022) | 93.6/82.7 (113% performance) |
| WizardMath (Luo et al., 2023) | Education | ChatGPT | / | GSM8k(Cobbe et al., 2021)/MATH(Hendrycks et al., 2021) | 52.2/57.5 (91% performance) |
| K2 (Deng et al., 2023) | Education | LLaMA7B | 1750 | GeoBench(Deng et al., 2023) | 34.6/24.6 (141% performance) |
| LawyerLLaMA (Huang et al., 2023b) | Law | GPT-3.5turbo | / | C3(Sun et al., 2020b)/CMNLI(Xu et al., 2020)/SciQ(Welbl et al., 2017)/PIQA(Bisk et al., 2020) | / |
| ChatLaw (Cui et al., 2023) | Law | Ziya-LLaMA13B | / | Legal Multiple-choice Questions(Cui et al., 2023) | / |
4.1. 卫生保健
医疗保健是与人类福祉密切相关的关键领域。 自 ChatGPT 诞生以来,许多人都在努力利用 ChatGPT 和其他大语言模型在医学领域的实力。 例如,张等人。(张等人,2023a)介绍了华佗GPT,一个专为医疗咨询而设计的大语言模型。 通过从 ChatGPT 中提取数据,并通过监督微调整合医生对现实世界的见解,HuatuoGPT 整合了一个奖励模型,旨在协同两个数据集的优势。 实证结果表明,HuatuoGPT 在医疗咨询方面实现了最先进的性能,在 GPT-4 上评估的各种指标(包括手动评估和医疗基准数据集)上均优于 GPT-3.5turbo。 Li et al.(Li 等人, 2023c)强调了专门针对医学领域的大语言模型的稀缺性。 使用LLaMA作为开发和评估平台,他们探索了两种增强策略:模型微调和知识整合,以增强大语言模型作为医疗聊天机器人的功效。 他们在来自在线医疗咨询平台的 10 万患者生理对话数据集上对对话模型进行微调,实验表明 Chatdoctor 模型在准确性和 F1 分数方面超越了 ChatGPT。 此外,Wu等人。(Wu等人,2023b)引入了PMC-LLaMA,它合并了480万篇生物医学学术论文和3万本医学教科书,注入以数据为中心的知识,加上针对特定领域指令进行的详尽微调。 PMC-LLaMA 的参数数量适中,为 13B,表现出出色的性能,在各种公共医疗问答基准测试中超越了 ChatGPT。
4.2. 教育
教育是大语言模型显示出巨大前景的另一个关键领域。 目前的研究表明,大语言模型可以在物理和计算机科学等各个数学学科的标准化考试中达到与学生相当的水平(Achiam 等人,2023)。 Xie 等人。(Xie 等人,2023)介绍了 DARWIN,这是一个旨在通过加速和丰富发现过程的自动化来增强自然科学的框架。 这种方法结合了科学指令生成(SIG)模型,该模型集成了来自公共数据集和文献的结构化和非结构化科学知识。 通过消除手动提取或特定领域知识图的需要,DARWIN 在不同的科学任务中实现了最先进的性能。 Luo et al.(Luo 等人, 2023)提出了WizardMath,利用Evol-Instruct Feedback强化学习(RLEIF)技术来增强LLaMA的数学推理能力-2 (Touvron 等人, 2023)。 该方法采用数学专用的 Evol-Instruct 来生成各种数学指令数据,随后训练指令奖励模型(IRM)和过程监督奖励模型(PRM)(Yuan 等人,2023)。 IRM 评估进化指令的质量,而 PRM 在解决方案过程的每一步接收反馈。 通过对 GSM8k (Cobbe 等人, 2021) 和 MATH (Hendrycks 等人, 2021) 两个数学推理基准的大量实验,WizardMath 明显优于其他开源大语言模型。 此外,邓等人。(邓等人,2023)引入了为地学量身定制的大语言模型K2,并建立了第一个地学基准GeoBench来评估大语言模型就属于这个领域。
4.3. 法律
法律是一个专业知识丰富的领域,最近采用大语言模型来解决各种法律任务,例如法律文档分析(Blair-Stanek等人,2023)和法律文档生成( Choi等人,2021)。 Huang et al.(Huang 等人, 2023b)通过精心设计的监督微调任务,将法律专业知识融入到 LLaMA 的连续训练阶段。 这些任务旨在向模型传授专业技能,同时减轻模型产生的错觉问题。 为了增强训练,他们引入了一个检索模块,可以在模型生成响应之前提取相关的法律文章。 同样,Cui et al.(Cui 等人, 2023) 将法律特定数据集成到 LLaMA 中,从而创建了 ChatLaw。 考虑到法律数据集参考检索的准确性,他们开发了一种结合矢量数据库检索和基于关键字检索的混合方法。 这种方法通过实施自我注意机制解决了幻觉问题并提高了准确性。 这种机制增强了大型模型纠正参考数据中错误的能力,从而提高了法律背景下的一致性并增强了解决问题的能力。
5. 挑战和未来方向
5.1. 统一评估基准
现有评估知识蒸馏的基准主要分为四类: 1)通用语言理解评估(GLUE)基准(王等人,2018):该基准由九个句子级分类任务组成,包括语言可接受性(Warstadt 等人, 2019)、情感分析(Socher 等人, 2013b)、文本相似度(Cer 等人, 2017) 、蕴含检测(Dolan and Brockett,2005)和自然语言推理(Rajpurkar等人,2016)。 它通常用于评估采用 BERT 作为教师模型的蒸馏方法。 2)多模态多任务学习理解(MMLU)基准(Hendrycks等人,2020):该基准作为评估大语言模型多任务知识理解能力的通用评估工具。 它涵盖数学、计算机科学、人文科学和社会科学等各个领域,具有从基础到高级的不同难度级别的任务。 3)BIG Bench (Srivastava 等人,2023):共同努力创建一个综合评估基准,探索现有大语言模型在各种任务中的能力。 它包括 204 项任务,涵盖语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等。 4)人类评估语言模型(HELM)基准(Liang等人,2022):这是一个整体评估基准,包含16个核心场景和7个指标类别。 它集成了先前提出的各种评估基准,以提供大语言模型性能的整体评估。 这些基准测试共同涵盖了广泛的主流大语言模型评估任务。 此外,还有针对特定任务量身定制的专门评估基准,例如用于评估多语言知识利用率的 TyDiQA (Clark 等人,2020)和 MGSM (Shi 等人,2022)用于评估多语言数学推理。 随着大型模型的不断发展,评估标准不断更新,为知识蒸馏制定统一的评估标准仍然是一个有前途的研究途径。
5.2. 先进的算法
当前的方法主要旨在为学生模型配备特定的能力。 例如,符号知识蒸馏(West等人, 2022)利用大语言模型来收集和过滤数据,提取高质量的常识图用于训练常识模型。 同样,DISCO (Chen 等人, 2022a)采用大语言模型获取反事实数据,然后使用大型教师自然语言推理模型进行过滤,以提高学生在自然语言推理任务中的熟练程度。 随着开源大语言模型的不断发展,探索大语言模型的白盒蒸馏算法可能被证明是集成多种能力的有效方法。 此外,目前MLLM蒸馏的发展速度落后于大语言模型。 因此,研究更先进的 MLLM 蒸馏算法可以更有效地促进多种模式的集成。
5.3. 可解释性
Stanton et al.(Stanton 等人, 2021)探讨了知识蒸馏的可解释性,并引入匹配度的概念来增强其可靠性。 他们的研究揭示了几个重要的见解:1)学生模型的泛化性能和匹配度之间的关系并不完全一致。 排除自蒸馏,具有最佳泛化性能的模型并不总是表现出最高的保真度。 2)学生模型的保真度与蒸馏过程的校准之间存在显着的相关性。 尽管最忠实的学生模型可能并不总是达到最高的准确度,但它始终表现出卓越的校准能力。 3)知识蒸馏过程中的优化具有挑战性,导致保真度较低。 同样,在大语言模型时代,知识蒸馏也面临着类似的困难。 例如,当前的方法很难阐明 CoT 蒸馏如何将 CoT 能力赋予学生语言模型,或确定微调指令所需的数据量。 因此,将可解释性融入到流程中对于推进大语言模型知识蒸馏至关重要。 这种集成不仅有助于评估模型蒸馏,还增强了生产中模型的可靠性和可预测性
6. 结论
在本次调查中,我们从方法、评估和应用三个角度系统地研究了知识蒸馏算法。 与较小的模型相比,较大模型中的蒸馏面临更多挑战。 尽管现有算法为应对这些挑战做出了巨大努力,但许多算法仍然依赖最初为压缩较小模型而定制的框架,而压缩大型模型的挑战仍然存在。 未来,在保证大语言模型的通用性和泛化性的同时,深入研究开发更高效、更有效的压缩算法势在必行。 这项调查旨在提供有价值的参考,阐明当前的情况,并倡导对这一关键主题的持续探索,以便在师生框架内有效设计、学习和应用各种蒸馏目标。
参考
- (1)
- Acharya et al. (2019) Manoj Acharya, Kushal Kafle, and Christopher Kanan. 2019. TallyQA: answering complex counting questions. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence. 8076–8084.
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
- Agarwal et al. (2023) Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. 2023. Generalized knowledge distillation for auto-regressive language models. arXiv preprint arXiv:2306.13649 (2023).
- Alkhulaifi et al. (2021) Abdolmaged Alkhulaifi, Fahad Alsahli, and Irfan Ahmad. 2021. Knowledge distillation in deep learning and its applications. PeerJ Computer Science 7 (2021), e474.
- Amini et al. (2019) Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. 2019. MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2357–2367.
- Anand et al. (2023) Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, and Andriy Mulyar. 2023. Gpt4all: Training an assistant-style chatbot with large scale data distillation from gpt-3.5-turbo. GitHub (2023).
- Bai et al. (2023) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609 (2023).
- Bisk et al. (2020) Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. 2020. PIQA: Reasoning about Physical Commonsense in Natural Language. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 7432–7439.
- Blair-Stanek et al. (2023) Andrew Blair-Stanek, Nils Holzenberger, and Benjamin Van Durme. 2023. Can GPT-3 Perform Statutory Reasoning?. In Proceedings of the Nineteenth International Conference on Artificial Intelligence and Law (ICAIL ’23). 22–31.
- Bojar et al. (2014) Ondřej Bojar, Christian Buck, Christian Federmann, Barry Haddow, Philipp Koehn, Johannes Leveling, Christof Monz, Pavel Pecina, Matt Post, Herve Saint-Amand, et al. 2014. Findings of the 2014 workshop on statistical machine translation. In Proceedings of the ninth workshop on statistical machine translation. 12–58.
- Bojar et al. (2016) Ondrej Bojar, Rajen Chatterjee, Christian Federmann, Yvette Graham, Barry Haddow, Matthias Huck, Antonio Jimeno Yepes, Philipp Koehn, Varvara Logacheva, Christof Monz, et al. 2016. Findings of the 2016 conference on machine translation (wmt16). In First conference on machine translation. Association for Computational Linguistics, 131–198.
- Brown et al. (2020) Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems. 1877–1901.
- Calderon et al. (2023) Nitay Calderon, Subhabrata Mukherjee, Roi Reichart, and Amir Kantor. 2023. A Systematic Study of Knowledge Distillation for Natural Language Generation with Pseudo-Target Training. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 14632–14659.
- Camburu et al. (2018) Oana-Maria Camburu, Tim Rocktäschel, Thomas Lukasiewicz, and Phil Blunsom. 2018. e-SNLI: natural language inference with natural language explanations. In Proceedings of the 32nd International Conference on Neural Information Processing Systems. 9560–9572.
- Cer et al. (2017) Daniel Cer, Mona Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. 2017. SemEval-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). 1–14.
- Chae et al. (2023) Hyungjoo Chae, Yongho Song, Kai Ong, Taeyoon Kwon, Minjin Kim, Youngjae Yu, Dongha Lee, Dongyeop Kang, and Jinyoung Yeo. 2023. Dialogue Chain-of-Thought Distillation for Commonsense-aware Conversational Agents. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 5606–5632.
- Chang et al. (2024) Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. 2024. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology (2024).
- Chen et al. (2023a) Hailin Chen, Amrita Saha, Steven Hoi, and Shafiq Joty. 2023a. Personalized Distillation: Empowering Open-Sourced LLMs with Adaptive Learning for Code Generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 6737–6749.
- Chen et al. (2023b) Hongzhan Chen, Siyue Wu, Xiaojun Quan, Rui Wang, Ming Yan, and Ji Zhang. 2023b. MCC-KD: Multi-CoT Consistent Knowledge Distillation. In Findings of the Association for Computational Linguistics: EMNLP 2023. 6805–6820.
- Chen et al. (2018) Liqun Chen, Shuyang Dai, Yunchen Pu, Erjin Zhou, Chunyuan Li, Qinliang Su, Changyou Chen, and Lawrence Carin. 2018. Symmetric variational autoencoder and connections to adversarial learning. In International Conference on Artificial Intelligence and Statistics. PMLR, 661–669.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021).
- Chen et al. (2022b) Yanda Chen, Ruiqi Zhong, Sheng Zha, George Karypis, and He He. 2022b. Meta-learning via Language Model In-context Tuning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 719–730.
- Chen et al. (2022a) Zeming Chen, Qiyue Gao, Kyle Richardson, Antoine Bosselut, and Ashish Sabharwal. 2022a. DISCO: Distilling Phrasal Counterfactuals with Large Language Models. arXiv preprint arXiv:2212.10534 (2022).
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. (2023).
- Choi et al. (2021) Jonathan H Choi, Kristin E Hickman, Amy B Monahan, and Daniel Schwarcz. 2021. ChatGPT goes to law school. J. Legal Educ. 71 (2021), 387.
- Clark et al. (2020) Jonathan H Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki. 2020. TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages. Transactions of the Association for Computational Linguistics 8 (2020), 454–470.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021).
- Cui et al. (2023) Jiaxi Cui, Zongjian Li, Yang Yan, Bohua Chen, and Li Yuan. 2023. Chatlaw: Open-source legal large language model with integrated external knowledge bases. arXiv preprint arXiv:2306.16092 (2023).
- Deng et al. (2023) Cheng Deng, Tianhang Zhang, Zhongmou He, Yi Xu, Qiyuan Chen, Yuanyuan Shi, Luoyi Fu, Weinan Zhang, Xinbing Wang, Chenghu Zhou, et al. 2023. K2: A foundation language model for geoscience knowledge understanding and utilization. arXiv preprint arXiv:2306.05064 (2023).
- Deng et al. (2020) Lei Deng, Guoqi Li, Song Han, Luping Shi, and Yuan Xie. 2020. Model compression and hardware acceleration for neural networks: A comprehensive survey. Proc. IEEE 108, 4 (2020), 485–532.
- Dolan and Brockett (2005) William B Dolan and Chris Brockett. 2005. Automatically Constructing a Corpus of Sentential Paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005).
- Driess et al. (2023) Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. 2023. Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023).
- Dua et al. (2019) Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. 2019. DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2368–2378.
- Fu et al. (2023) Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. 2023. Specializing Smaller Language Models towards Multi-Step Reasoning. arXiv preprint arXiv:2301.12726 (2023).
- Geva et al. (2021) Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Transactions of the Association for Computational Linguistics 9 (2021), 346–361.
- Gong et al. (2023) Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. 2023. Multimodal-gpt: A vision and language model for dialogue with humans. arXiv preprint arXiv:2305.04790 (2023).
- Gou et al. (2021) Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. 2021. Knowledge Distillation: A Survey. International Journal of Computer Vision 129, 6 (2021), 1789–1819.
- Gu et al. (2023) Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2023. MiniLLM: Knowledge distillation of large language models. In The Twelfth International Conference on Learning Representations.
- He et al. (2019) Junqing He, Mingming Fu, and Manshu Tu. 2019. Applying deep matching networks to Chinese medical question answering: a study and a dataset. BMC medical informatics and decision making 19, 2 (2019), 91–100.
- He et al. (2018) Yihui He, Ji Lin, Zhijian Liu, Hanrui Wang, Li-Jia Li, and Song Han. 2018. Amc: Automl for model compression and acceleration on mobile devices. In Proceedings of the European conference on computer vision (ECCV). 784–800.
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring Massive Multitask Language Understanding. In International Conference on Learning Representations.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021).
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015).
- Ho et al. (2022) Namgyu Ho, Laura Schmid, and Se-Young Yun. 2022. Large language models are reasoning teachers. arXiv preprint arXiv:2212.10071 (2022).
- Honovich et al. (2022) Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. 2022. Unnatural instructions: Tuning language models with (almost) no human labor. arXiv preprint arXiv:2212.09689 (2022).
- Hou et al. (2020) Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, and Qun Liu. 2020. DynaBERT: dynamic BERT with adaptive width and depth. In Proceedings of the 34th International Conference on Neural Information Processing Systems. 9782–9793.
- Hsieh et al. (2023) Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. 2023. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. arXiv preprint arXiv:2305.02301 (2023).
- Hu et al. (2023a) Chengming Hu, Xuan Li, Dan Liu, Haolun Wu, Xi Chen, Ju Wang, and Xue Liu. 2023a. Teacher-student architecture for knowledge distillation: A survey. arXiv preprint arXiv:2308.04268 (2023).
- Hu et al. (2023b) Yushi Hu, Otilia Stretcu, Chun-Ta Lu, Krishnamurthy Viswanathan, Kenji Hata, Enming Luo, Ranjay Krishna, and Ariel Fuxman. 2023b. Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models. arXiv preprint arXiv:2312.03052 (2023).
- Huang et al. (2023b) Quzhe Huang, Mingxu Tao, Zhenwei An, Chen Zhang, Cong Jiang, Zhibin Chen, Zirui Wu, and Yansong Feng. 2023b. Lawyer LLaMA Technical Report. arXiv preprint arXiv:2305.15062 (2023).
- Huang et al. (2023a) Tianyu Huang, Weisheng Dong, Fangfang Wu, Xin Li, and Guangming Shi. 2023a. Uncertainty-Driven Knowledge Distillation for Language Model Compression. IEEE/ACM Trans. Audio, Speech and Lang. Proc. (2023), 2850–2858.
- Huang et al. (2022) Yukun Huang, Yanda Chen, Zhou Yu, and Kathleen McKeown. 2022. In-context Learning Distillation: Transferring Few-shot Learning Ability of Pre-trained Language Models. arXiv preprint arXiv:2212.10670 (2022).
- Huszár (2015) Ferenc Huszár. 2015. How (not) to train your generative model: Scheduled sampling, likelihood, adversary? arXiv preprint arXiv:1511.05101 (2015).
- Jiang et al. (2023) Yuxin Jiang, Chunkit Chan, Mingyang Chen, and Wei Wang. 2023. Lion: Adversarial distillation of closed-source large language model. arXiv preprint arXiv:2305.12870 (2023).
- Jiao et al. (2020) Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. TinyBERT: Distilling BERT for Natural Language Understanding. In Findings of the Association for Computational Linguistics: EMNLP 2020. 4163–4174.
- Jie and Lu (2023) Zhanming Jie and Wei Lu. 2023. Leveraging training data in few-shot prompting for numerical reasoning. arXiv preprint arXiv:2305.18170 (2023).
- Jin et al. (2021) Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences 11, 14 (2021), 6421.
- Jin et al. (2019) Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. PubMedQA: A Dataset for Biomedical Research Question Answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2567–2577.
- Kang et al. (2024) Minki Kang, Seanie Lee, Jinheon Baek, Kenji Kawaguchi, and Sung Ju Hwang. 2024. Knowledge-augmented reasoning distillation for small language models in knowledge-intensive tasks. In Advances in Neural Information Processing Systems, Vol. 36.
- Kenton and Toutanova (2019) Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of NAACL-HLT. 4171–4186.
- Khot et al. (2020) Tushar Khot, Peter Clark, Michal Guerquin, Peter Jansen, and Ashish Sabharwal. 2020. QASC: A Dataset for Question Answering via Sentence Composition. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 8082–8090.
- Kiela et al. (2020) Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine. 2020. The hateful memes challenge: detecting hate speech in multimodal memes. In Proceedings of the 34th International Conference on Neural Information Processing Systems. 2611–2624.
- Kim and Rush (2016) Yoon Kim and Alexander M Rush. 2016. Sequence-Level Knowledge Distillation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 1317–1327.
- Lee et al. (2023a) Hayeon Lee, Rui Hou, Jongpil Kim, Davis Liang, Sung Ju Hwang, and Alexander Min. 2023a. A Study on Knowledge Distillation from Weak Teacher for Scaling Up Pre-trained Language Models. In Findings of the Association for Computational Linguistics: ACL 2023. 11239–11246.
- Lee et al. (2023b) Hyoje Lee, Yeachan Park, Hyun Seo, and Myungjoo Kang. 2023b. Self-knowledge distillation via dropout. Computer Vision and Image Understanding 233 (2023), 103720.
- Li et al. (2023e) Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. 2023e. Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125 (2023).
- Li et al. (2023f) Jianquan Li, Xidong Wang, Xiangbo Wu, Zhiyi Zhang, Xiaolong Xu, Jie Fu, Prayag Tiwari, Xiang Wan, and Benyou Wang. 2023f. Huatuo-26M, a Large-scale Chinese Medical QA Dataset. arXiv preprint arXiv:2305.01526 (2023).
- Li et al. (2023b) Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, and Yejin Choi. 2023b. Symbolic Chain-of-Thought Distillation: Small Models Can Also” Think” Step-by-Step. arXiv preprint arXiv:2306.14050 (2023).
- Li et al. (2022) Shiyang Li, Jianshu Chen, Yelong Shen, Zhiyu Chen, Xinlu Zhang, Zekun Li, Hong Wang, Jing Qian, Baolin Peng, Yi Mao, et al. 2022. Explanations from large language models make small reasoners better. arXiv preprint arXiv:2210.06726 (2022).
- Li et al. (2023d) Xinwei Li, Li Lin, Shuai Wang, and Chen Qian. 2023d. Unlock the power: Competitive distillation for multi-modal large language models. arXiv preprint arXiv:2311.08213 (2023).
- Li et al. (2023a) Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023a. Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355 (2023).
- Li et al. (2023c) Yunxiang Li, Zihan Li, Kai Zhang, Ruilong Dan, Steve Jiang, and You Zhang. 2023c. ChatDoctor: A Medical Chat Model Fine-Tuned on a Large Language Model Meta-AI (LLaMA) Using Medical Domain Knowledge. Cureus 15, 6 (2023).
- Liang et al. (2023a) Chen Liang, Haoming Jiang, Zheng Li, Xianfeng Tang, Bin Yin, and Tuo Zhao. 2023a. Homodistil: Homotopic task-agnostic distillation of pre-trained transformers. arXiv preprint arXiv:2302.09632 (2023).
- Liang et al. (2023b) Chen Liang, Simiao Zuo, Qingru Zhang, Pengcheng He, Weizhu Chen, and Tuo Zhao. 2023b. Less is more: Task-aware layer-wise distillation for language model compression. In International Conference on Machine Learning. PMLR, 20852–20867.
- Liang et al. (2020) Kevin J Liang, Weituo Hao, Dinghan Shen, Yufan Zhou, Weizhu Chen, Changyou Chen, and Lawrence Carin. 2020. MixKD: Towards Efficient Distillation of Large-scale Language Models. In International Conference on Learning Representations.
- Liang et al. (2022) Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. 2022. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110 (2022).
- Lin (2004) Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out. 74–81.
- Liu et al. (2024) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2024. Visual instruction tuning. In Advances in neural information processing systems, Vol. 36.
- Liu et al. (2023) Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. 2023. Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281 (2023).
- Lu et al. (2022) Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering. In Advances in Neural Information Processing Systems, Vol. 35. 2507–2521.
- Luo et al. (2023) Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. 2023. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583 (2023).
- Maas et al. (2011) Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. 142–150.
- Magister et al. (2022) Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. 2022. Teaching small language models to reason. arXiv preprint arXiv:2212.08410 (2022).
- Marino et al. (2019) Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. 2019. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/cvf conference on computer vision and pattern recognition. 3195–3204.
- McAuley and Leskovec (2013) Julian McAuley and Jure Leskovec. 2013. Hidden factors and hidden topics: understanding rating dimensions with review text (RecSys ’13). 165–172.
- Miao et al. (2020) Shen-Yun Miao, Chao-Chun Liang, and Keh-Yih Su. 2020. A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 975–984.
- Mihaylov et al. (2018) Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2381–2391.
- Min et al. (2022a) Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2022a. MetaICL: Learning to Learn In Context. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2791–2809.
- Min et al. (2022b) Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022b. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 11048–11064.
- Mirzadeh et al. (2020) Seyed Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, Nir Levine, Akihiro Matsukawa, and Hassan Ghasemzadeh. 2020. Improved knowledge distillation via teacher assistant. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 5191–5198.
- Mukherjee and Hassan Awadallah (2020) Subhabrata Mukherjee and Ahmed Hassan Awadallah. 2020. XtremeDistil: Multi-stage Distillation for Massive Multilingual Models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2221–2234.
- Nan et al. (2021) Linyong Nan, Dragomir Radev, Rui Zhang, Amrit Rau, Abhinand Sivaprasad, Chiachun Hsieh, Xiangru Tang, Aadit Vyas, Neha Verma, Pranav Krishna, et al. 2021. DART: Open-Domain Structured Data Record to Text Generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 432–447.
- Narayan et al. (2018) Shashi Narayan, Shay B Cohen, and Mirella Lapata. 2018. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 1797–1807.
- Nie et al. (2020a) Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. 2020a. Adversarial NLI: A New Benchmark for Natural Language Understanding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 4885–4901.
- Nie et al. (2020b) Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. 2020b. Adversarial NLI: A New Benchmark for Natural Language Understanding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics.
- Nowozin et al. (2016) Sebastian Nowozin, Botond Cseke, and Ryota Tomioka. 2016. f-GAN: training generative neural samplers using variational divergence minimization. In Proceedings of the 30th International Conference on Neural Information Processing Systems. 271–279.
- Onoe et al. (2021) Yasumasa Onoe, Michael JQ Zhang, Eunsol Choi, and Greg Durrett. 2021. CREAK: A dataset for commonsense reasoning over entity knowledge. arXiv preprint arXiv:2109.01653 (2021).
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, Vol. 35. 27730–27744.
- Pal et al. (2022) Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2022. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Conference on Health, Inference, and Learning. PMLR, 248–260.
- Pan et al. (2017) Xiaoman Pan, Boliang Zhang, Jonathan May, Joel Nothman, Kevin Knight, and Heng Ji. 2017. Cross-lingual Name Tagging and Linking for 282 Languages. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1946–1958.
- Park et al. (2023) Jae Sung Park, Jack Hessel, Khyathi Chandu, Paul Pu Liang, Ximing Lu, Peter West, Youngjae Yu, Qiuyuan Huang, Jianfeng Gao, Ali Farhadi, et al. 2023. Localized Symbolic Knowledge Distillation for Visual Commonsense Models. In Thirty-seventh Conference on Neural Information Processing Systems.
- Patel et al. (2021) Arkil Patel, Satwik Bhattamishra, and Navin Goyal. 2021. Are NLP Models really able to Solve Simple Math Word Problems?. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2080–2094.
- Peng et al. (2023) Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. 2023. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277 (2023).
- Peters et al. (2018) Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of NAACL-HLT. 2227–2237.
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language Models as Knowledge Bases?. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2463–2473.
- Rajpurkar et al. (2018) Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know What You Don’t Know: Unanswerable Questions for SQuAD. Cornell University - arXiv,Cornell University - arXiv (Jun 2018).
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2383–2392.
- Reynolds and McDonell (2021) Laria Reynolds and Kyle McDonell. 2021. Prompt programming for large language models: Beyond the few-shot paradigm. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems. 1–7.
- Romero et al. (2014) Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. 2014. Fitnets: Hints for thin deep nets. arXiv preprint arXiv:1412.6550 (2014).
- Roy and Roth (2015) Subhro Roy and Dan Roth. 2015. Solving General Arithmetic Word Problems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 1743–1752.
- Sanh et al. (2019) Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108 (2019).
- Sanh et al. (2021) Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, et al. 2021. Multitask Prompted Training Enables Zero-Shot Task Generalization. In International Conference on Learning Representations.
- Scheffler et al. (2022) Matthias Scheffler, Martin Aeschlimann, Martin Albrecht, Tristan Bereau, Hans-Joachim Bungartz, Claudia Felser, Mark Greiner, Axel Groß, Christoph T Koch, Kurt Kremer, et al. 2022. FAIR data enabling new horizons for materials research. Nature 604, 7907 (2022), 635–642.
- Schwenk et al. (2022) Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. 2022. A-okvqa: A benchmark for visual question answering using world knowledge. In European Conference on Computer Vision. Springer, 146–162.
- Shi et al. (2022) Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, et al. 2022. Language models are multilingual chain-of-thought reasoners. In The Eleventh International Conference on Learning Representations.
- Shridhar et al. (2023) Kumar Shridhar, Alessandro Stolfo, and Mrinmaya Sachan. 2023. Distilling reasoning capabilities into smaller language models. In Findings of the Association for Computational Linguistics: ACL 2023. 7059–7073.
- Socher et al. (2013a) Richard Socher, John Bauer, Christopher D. Manning, and Andrew Y. Ng. 2013a. Parsing with Compositional Vector Grammars. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 455–465.
- Socher et al. (2013b) Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013b. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing. 1631–1642.
- Srivastava et al. (2023) Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. 2023. Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research (2023).
- Stanton et al. (2021) Samuel Stanton, Pavel Izmailov, Polina Kirichenko, Alexander A Alemi, and Andrew G Wilson. 2021. Does knowledge distillation really work?. In Advances in Neural Information Processing Systems, Vol. 34. 6906–6919.
- Sun et al. (2020b) Kai Sun, Dian Yu, Dong Yu, and Claire Cardie. 2020b. Investigating Prior Knowledge for Challenging Chinese Machine Reading Comprehension. Transactions of the Association for Computational Linguistics 8 (2020), 141–155.
- Sun et al. (2019) Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. 2019. Patient Knowledge Distillation for BERT Model Compression. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 4323–4332.
- Sun et al. (2020a) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou. 2020a. MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2158–2170.
- Sundararajan et al. (2017) Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70 (Sydney, NSW, Australia) (ICML’17). 3319–3328.
- Talmor et al. (2019) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 4149–4158.
- Tang et al. (2019) Raphael Tang, Yao Lu, Linqing Liu, Lili Mou, Olga Vechtomova, and Jimmy Lin. 2019. Distilling task-specific knowledge from bert into simple neural networks. arXiv preprint arXiv:1903.12136 (2019).
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model. GitHub repository (2023).
- Tchango et al. (2022) Arsene Fansi Tchango, Rishab Goel, Zhi Wen, Julien Martel, and Joumana Ghosn. 2022. DDXPlus: A New Dataset For Automatic Medical Diagnosis. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Tian et al. (2021) Xudong Tian, Zhizhong Zhang, Shaohui Lin, Yanyun Qu, Yuan Xie, and Lizhuang Ma. 2021. Farewell to mutual information: Variational distillation for cross-modal person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1522–1531.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- Tsai et al. (2019) Henry Tsai, Jason Riesa, Melvin Johnson, Naveen Arivazhagan, and Amelia Archer. 2019. Small and Practical BERT Models for Sequence Labeling. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 3632–3636.
- Tu et al. (2020) Lifu Tu, Richard Yuanzhe Pang, Sam Wiseman, and Kevin Gimpel. 2020. ENGINE: Energy-Based Inference Networks for Non-Autoregressive Machine Translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2819–2826.
- Tunstall et al. (2023) Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, et al. 2023. Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944 (2023).
- Turc et al. (2019) Iulia Turc, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Well-read students learn better: On the importance of pre-training compact models. arXiv preprint arXiv:1908.08962 (2019).
- Vaghani and Thummar ([n. d.]) Nirali Vaghani and Mansi Thummar. [n. d.]. Flipkart product reviews with sentiment dataset, 2023. URL https://www. kaggle. com/dsv/4940809 ([n. d.]).
- Wadhwa et al. (2023) Somin Wadhwa, Silvio Amir, and Byron C Wallace. 2023. Revisiting relation extraction in the era of large language models. arXiv preprint arXiv:2305.05003 (2023).
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. 353–355.
- Wang et al. (2021) Boxin Wang, Chejian Xu, Shuohang Wang, Zhe Gan, Yu Cheng, Jianfeng Gao, Ahmed Hassan Awadallah, and Bo Li. 2021. Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
- Wang et al. (2023c) Jindong Wang, HU Xixu, Wenxin Hou, Hao Chen, Runkai Zheng, Yidong Wang, Linyi Yang, Wei Ye, Haojun Huang, Xiubo Geng, et al. 2023c. On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective. In ICLR 2023 Workshop on Trustworthy and Reliable Large-Scale Machine Learning Models.
- Wang et al. (2023d) Liang Wang, Nan Yang, and Furu Wei. 2023d. Learning to retrieve in-context examples for large language models. arXiv preprint arXiv:2307.07164 (2023).
- Wang and Yoon (2021) Lin Wang and Kuk-Jin Yoon. 2021. Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks. IEEE transactions on pattern analysis and machine intelligence 44, 6 (2021), 3048–3068.
- Wang et al. (2023b) Peifeng Wang, Zhengyang Wang, Zheng Li, Yifan Gao, Bing Yin, and Xiang Ren. 2023b. SCOTT: Self-consistent chain-of-thought distillation. arXiv preprint arXiv:2305.01879 (2023).
- Wang et al. (2020) Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. MINILM: deep self-attention distillation for task-agnostic compression of pre-trained transformers. In Proceedings of the 34th International Conference on Neural Information Processing Systems. 5776–5788.
- Wang et al. (2022a) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022a. Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560 (2022).
- Wang et al. (2022b) Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. 2022b. Benchmarking generalization via in-context instructions on 1,600+ language tasks. arXiv e-prints (2022), arXiv–2204.
- Wang et al. (2023e) Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, et al. 2023e. PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization. arXiv preprint arXiv:2306.05087 (2023).
- Wang et al. (2023a) Zhaoyang Wang, Shaohan Huang, Yuxuan Liu, Jiahai Wang, Minghui Song, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, et al. 2023a. Democratizing Reasoning Ability: Tailored Learning from Large Language Model. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 1948–1966.
- Warstadt et al. (2019) Alex Warstadt, Amanpreet Singh, and Samuel Bowman. 2019. Neural Network Acceptability Judgments. Transactions of the Association for Computational Linguistics 7 (2019), 625–641.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2021. Finetuned Language Models are Zero-Shot Learners. In International Conference on Learning Representations.
- Welbl et al. (2017) Johannes Welbl, Nelson F Liu, and Matt Gardner. 2017. Crowdsourcing Multiple Choice Science Questions. In Proceedings of the 3rd Workshop on Noisy User-generated Text. 94–106.
- Wen et al. (2023) Yuqiao Wen, Zichao Li, Wenyu Du, and Lili Mou. 2023. f-Divergence Minimization for Sequence-Level Knowledge Distillation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10817–10834.
- West et al. (2022) Peter West, Chandra Bhagavatula, Jack Hessel, Jena Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, and Yejin Choi. 2022. Symbolic Knowledge Distillation: from General Language Models to Commonsense Models. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 4602–4625.
- Wu et al. (2023b) Chaoyi Wu, Weixiong Lin, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2023b. Pmc-llama: Towards building open-source language models for medicine. arXiv preprint arXiv:2305.10415 6 (2023).
- Wu et al. (2023c) Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, and Alham Fikri Aji. 2023c. Lamini-lm: A diverse herd of distilled models from large-scale instructions. arXiv preprint arXiv:2304.14402 (2023).
- Wu et al. (2023a) Siyue Wu, Hongzhan Chen, Xiaojun Quan, Qifan Wang, and Rui Wang. 2023a. AD-KD: Attribution-Driven Knowledge Distillation for Language Model Compression. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
- Xie et al. (2023) Tong Xie, Yuwei Wan, Wei Huang, Zhenyu Yin, Yixuan Liu, Shaozhou Wang, Qingyuan Linghu, Chunyu Kit, Clara Grazian, Wenjie Zhang, et al. 2023. Darwin series: Domain specific large language models for natural science. arXiv preprint arXiv:2308.13565 (2023).
- Xu et al. (2020) Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, et al. 2020. CLUE: A Chinese Language Understanding Evaluation Benchmark. In Proceedings of the 28th International Conference on Computational Linguistics. 4762–4772.
- Yang et al. (2023) Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. 2023. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381 (2023).
- Ye et al. (2021) Qinyuan Ye, Bill Yuchen Lin, and Xiang Ren. 2021. CrossFit: A Few-shot Learning Challenge for Cross-task Generalization in NLP. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 7163–7189.
- Yuan et al. (2023) Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Chuanqi Tan, and Chang Zhou. 2023. Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825 (2023).
- Zhang et al. (2023c) Chen Zhang, Dawei Song, Zheyu Ye, and Yan Gao. 2023c. Towards the law of capacity gap in distilling language models. arXiv preprint arXiv:2311.07052 (2023).
- Zhang et al. (2023a) Hongbo Zhang, Junying Chen, Feng Jiang, Fei Yu, Zhihong Chen, Jianquan Li, Guiming Chen, Xiangbo Wu, Zhiyi Zhang, Qingying Xiao, et al. 2023a. HuatuoGPT, towards Taming Language Model to Be a Doctor. arXiv preprint arXiv:2305.15075 (2023).
- Zhang et al. (2023b) Jianyi Zhang, Aashiq Muhamed, Aditya Anantharaman, Guoyin Wang, Changyou Chen, Kai Zhong, Qingjun Cui, Yi Xu, Belinda Zeng, Trishul Chilimbi, and Yiran Chen. 2023b. ReAugKD: Retrieval-Augmented Knowledge Distillation For Pre-trained Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 1128–1136.
- Zhang et al. (2018) Sheng Zhang, Xin Zhang, Hui Wang, Lixiang Guo, and Shanshan Liu. 2018. Multi-scale attentive interaction networks for chinese medical question answer selection. IEEE Access 6 (2018), 74061–74071.
- Zhang et al. (2015) Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. In Proceedings of the 28th International Conference on Neural Information Processing Systems-Volume 1. 649–657.
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223 (2023).
- Zhou et al. (2021) Pei Zhou, Karthik Gopalakrishnan, Behnam Hedayatnia, Seokhwan Kim, Jay Pujara, Xiang Ren, Yang Liu, and Dilek Hakkani-Tur. 2021. Commonsense-Focused Dialogues for Response Generation: An Empirical Study. In Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue. 121–132.
- Zhou et al. (2022) Wangchunshu Zhou, Canwen Xu, and Julian McAuley. 2022. BERT Learns to Teach: Knowledge Distillation with Meta Learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7037–7049.
- Zhou et al. (2023) Wenxuan Zhou, Sheng Zhang, Yu Gu, Muhao Chen, and Hoifung Poon. 2023. Universalner: Targeted distillation from large language models for open named entity recognition. arXiv preprint arXiv:2308.03279 (2023).
- Zhu et al. (2023) Xuekai Zhu, Biqing Qi, Kaiyan Zhang, Xingwei Long, and Bowen Zhou. 2023. PaD: Program-aided Distillation Specializes Large Models in Reasoning. arXiv preprint arXiv:2305.13888 (2023).