让专家坚持到最后:稀疏架构大语言模型的专家专业微调
摘要
参数高效的微调(PEFT)对于在资源有限的情况下定制大型语言模型(大语言模型)至关重要。 尽管针对稠密结构大语言模型已有多种PEFT方法,但针对稀疏结构大语言模型的PEFT仍处于探索之中。 在这项工作中,我们研究了具有混合专家(MoE)架构的大语言模型的PEFT方法,这项工作的内容主要有三个方面:(1)我们研究了我们对定制任务中的激活专家进行了研究,发现特定任务的路由分布往往高度集中,而不同任务中激活专家的分布差异很大。 (2) 我们提出Expert-S专用Fine-Tuning,或ESFT,它调整与下游任务最相关的专家,同时冻结其他专家和模块;实验结果表明,我们的方法不仅提高了调优效率,而且达到甚至超过了全参数微调的性能。 (3)我们进一步分析MoE架构对专家专业微调的影响。 我们发现,具有更细粒度专家的 MoE 模型在选择与下游任务最相关的专家组合方面更有优势,从而提高训练效率和效果。 我们的代码可在 https://github.com/deepseek-ai/ESFT 获取。
让专家坚持到最后:稀疏架构大语言模型的专家专业微调
Zihan Wang12††thanks: Work done during internship at DeepSeek., Deli Chen1, Damai Dai1, Runxin Xu1, Zhuoshu Li1, Y. Wu1 1DeepSeek AI 2Northwestern University {zw, victorchen}@deepseek.com
1简介
随着大语言模型(大语言模型)的参数规模不断增大(Meta, 2024; Mistral, 2024a; DeepSeek, 2024; Qwen, 2024),参数-高效的微调(PEFT)方法(Han等人,2024)在使预训练的大语言模型适应下游定制任务方面变得越来越重要。 然而,现有的 PEFT 工作,如低秩适应 (LoRA) 和 P-Tuning (Hu 等人, 2021; Liu 等人, 2021) 主要集中在密集架构大语言模型上,稀疏结构大语言模型的研究还明显不足。
在这项工作中,我们重点探索混合专家 (MoE) 大语言模型 (Mistral, 2024b; Databricks, 2024) 中的 PEFT 技术,如§3.1。 与所有任务都由相同参数处理的密集模型不同,在 MoE 架构中,不同的任务由不同的激活专家处理(Lepikhin 等人,2021;Fedus 等人,2021)。 观察表明,专家系统的任务专业化是教育部大语言模型性能的关键(戴等人,2024)。 我们在§3.2中进一步说明了这种专业化,即由同一任务数据激活的专家是集中的,而不同任务的专家则差异很大,这表明MoE模型使用专门的专家组合来处理不同的任务。 受此启发,我们提出专家专业微调(ESFT),如§3.3所示。 ESFT 仅调整与任务亲和力最高的专家,同时冻结其他专家和模块的参数。
2相关工作
2.1 密集架构大语言模型的参数高效微调
参数高效微调(Han等人,2024)的目标是为下游任务高效定制大语言模型,而现有研究主要集中在密集架构大语言模型上。 密集模型的PEFT方法通常可以分为三种方法:(1)添加新参数:此类方法固定现有模型参数,并在少量新添加的参数上对模型进行调整。 适配器(Houlsby等人,2019;Pfeiffer等人,2020;He等人,2021;Wang等人,2022)和软提示(Li和Liang,2021;Liu等人, 2021;Zhang等人,2023b;Lester等人,2021)是此类方法的两个典型代表。 (2)选择现有参数:此类方法只调整现有参数的有限部分,同时保持其他大部分参数固定。 根据可训练参数空间是否连续,这些方法一般可以分为结构化训练(Guo 等人, 2020; Gheini 等人, 2021; He 等人, 2023; Vucetic 等人, 2022) 和非结构化训练 (Liao 等人, 2023; Ansell 等人, 2021; Sung 等人, 2021; Xu 等人, 2021)。 (3) 应用低秩自适应:LoRA (Hu 等人, 2021; Fomenko 等人, 2024) 是一种广泛使用的 PEFT 方法,它分解了原始权重矩阵分解为低阶分量。 后续工作(Zhang 等人,2023a;Ding 等人,2023;Lin 等人,2024;Liu 等人,2023)对原始 LoRA 方法进行了许多改进。 然而,稀疏模型中PEFT的研究仍然很少。 在这项工作中,我们根据下游任务亲和力选择和调整部分专家,作为稀疏 MoE 架构独有的独特选择维度。
2.2 粗粒度和细粒度MoE大语言模型
与密集大语言模型(例如,LLaMA系列,Meta,2023b,a)相比,MoE大语言模型(例如,Mixtral系列,Mistral,2024a,b)可以增加模型大小,同时节省训练和推理成本。 根据专家的粒度,现有的大型MoE模型一般可以分为两类:粗粒度专家大语言模型和细粒度专家大语言模型。 大多数现有的 MoE 大语言模型 (Lepikhin 等人, 2021; Fedus 等人, 2021; Roller 等人, 2021; Dai 等人, 2022; Shen 等人, 2024) 具有粗粒度专家,其中专家的数量非常有限。 例如,Mixtral MoE 系列(Mistral,2024a,b) 和 Grok-V1 (XAI,2024) 激活了八分之二的专家。 因此,单个专家必须同时从不同的领域任务中学习复杂的模式。 为了解决这个问题,DeepSeek MoE (Dai 等人, 2024)引入了细粒度的专家分割。 在DeepSeek-V2(DeepSeek,2024)中,有多达162个专家,其中8个活跃专家(DeepSeek-V2-Lite的66个专家中有8个是激活的)。 专家的细粒度划分,保证了专家的高度专业化。 此外,专业的专家系统可以选择与任务最相关的专家来进行高效的调整。
3方法
3.1 预备: Transformer 专家混合
Transformer 的专家混合 (MoE) 用 MoE 层取代前馈网络 (FFN)。 每个 MoE 层由多个结构与 FFN 相同的专家组成。 Token 根据亲和力分数分配给最相关的专家子集并由其处理,从而确保 MoE 层的计算效率。 第 MoE 层中第 词符的输出隐藏状态 计算如下:
| (1) |
| (2) |
| (3) |
其中, 表示专家总数, 是 -th 专家 FFN, 表示 -th 专家的门限值, 表示词符与专家的亲和度、 表示在为 -th 词符和所有 专家计算的亲和度分数中,由 最高亲和度分数组成的集合, 是 -th 专家在 -th 层中的中心点。
最近,DeepSeekMoE (Dai 等人, 2024) 提出通过多种技术对 MoE 架构进行增强,包括(1)细粒度分割,将每个专家分割成多个更小的专家,并保持相同比例的专家处理每个词符,允许专业化不同的知识类型,同时保持相同的计算成本。 (2) 共享专家隔离,利用处理所有 token 的共享专家捕获公共知识,减少参数冗余,提高效率。 DeepSeekMoE 中 MoE 层的输出为:
| (4) |
| (5) |
其中是共享专家的数量,和分别表示共享和非共享专家。 每个专家被分割成 个,与粗粒度架构相比, 和 也乘以 倍。
3.2 探索 MoE 模型中特定任务的专家专业化
尽管教育部大语言模型取得了巨大成功,但对其潜在机制的清晰理解仍然难以捉摸。 我们进行探索实验,以了解如何在各种任务中利用非共享专家。 这些任务(如第 §4.1 中详述)包括数学和代码等通用领域,以及意图识别、摘要、法律判断预测和翻译等专业领域。 这些实验从两个方面揭示了 MoE 模型的专家专业化:
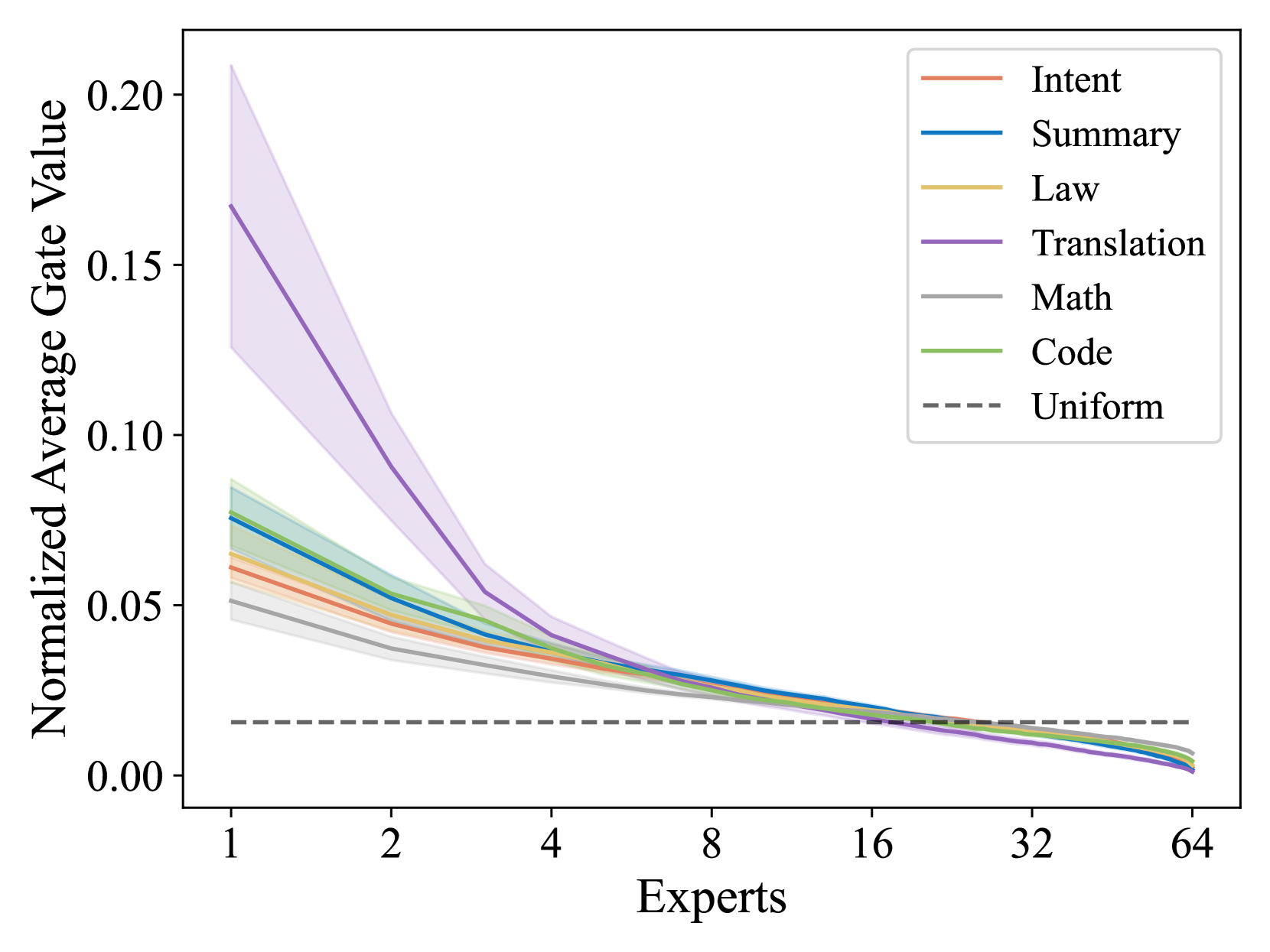
专家路由集中于同一任务
我们研究归一化门值的分布,即每个专家的所有专家 Token 门值的总和除以所有专家的总和。 图 2 显示了该分布,其中专家按标准化值从高到低排序。 该图显示一小部分专家处理大部分门值,表明模型和集中专家对特定任务的分配。
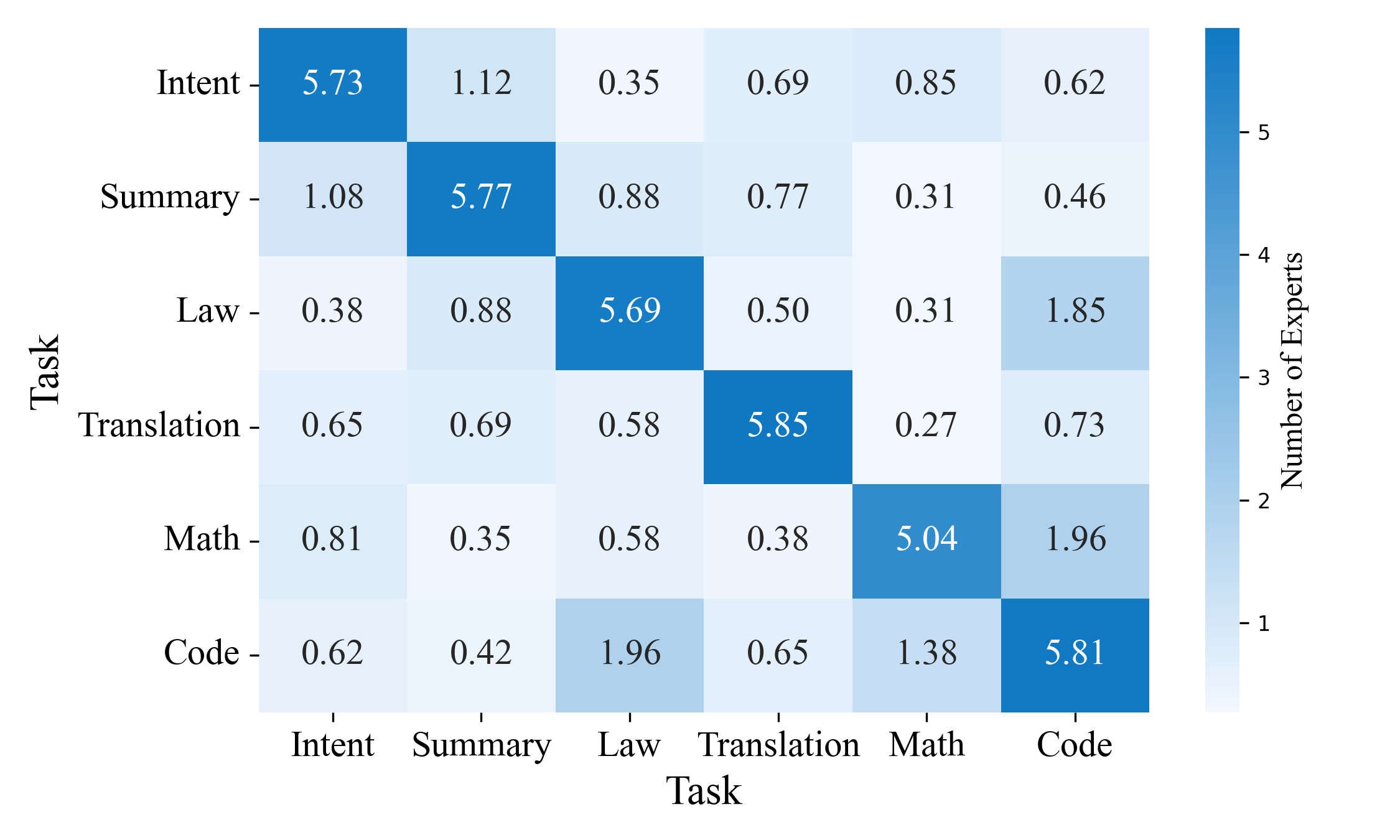
活跃专家在不同任务上存在显着差异
我们研究了专家跨任务的联合分配。 图 3 显示了每个任务的两个独立数据样本的共享 Top-6 专家跨层平均的热图。 这表明同一任务中或不同任务之间使用的专家的重叠程度。 非对角线值接近 0,对角线值接近 6,表明同一任务使用相似的专家,而不同的任务使用不同的集合。
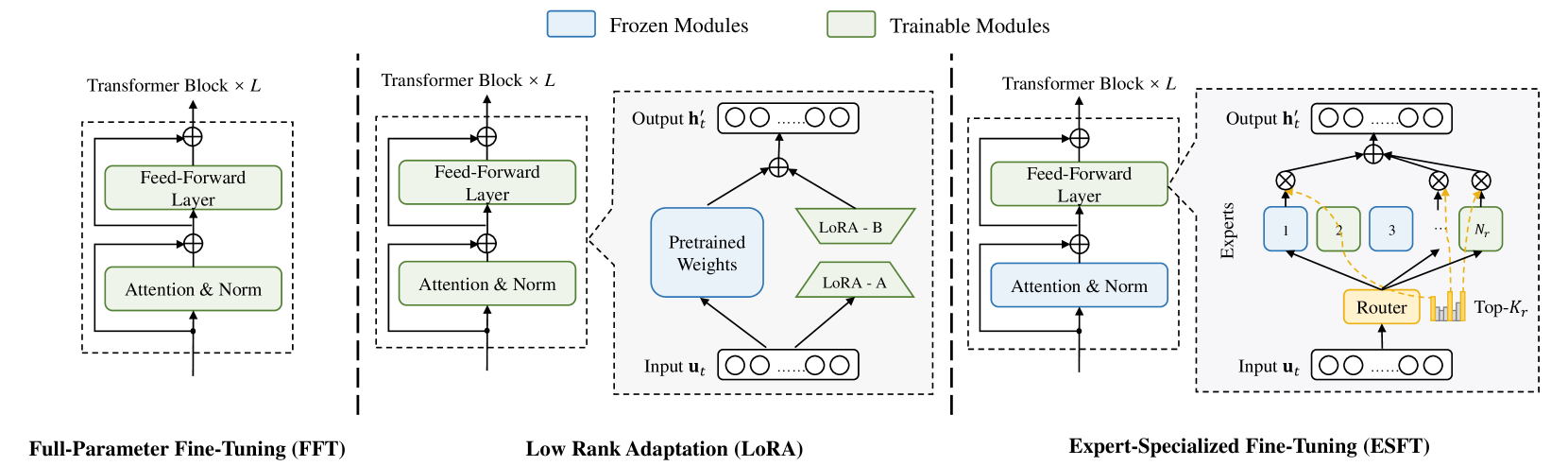
3.3专家专业微调(ESFT)
高度专业化的专家系统表明可以针对特定任务优化不同的专家。 受此启发,我们提出了用于 MoE 大语言模型定制的专家专业微调(ESFT),它有选择地微调与下游任务最相关的专家,以提高计算效率并保持专家专业化。 图1说明了我们的方法与现有方法之间的差异。 下面,我们一步步介绍我们的方法。
数据采样
我们从训练数据 中随机采样子集 进行专家选择,其中 和 分别表示输入和标签。 根据经验,我们发现 连接样本的子集(每个样本的固定长度为 )足以为任务选择最相关的专家。 我们在附录C中详细介绍了这一主张。
专家相关性评分
我们提出了两种方法来根据专家与样本标记的亲和力来计算专家与任务的相关性,分别定义为平均门得分和词符选择比。 这两种方法都会评估每个专家与下游任务的相关性,并且可以根据特定任务的实验表现进行选择。
平均门得分 (ESFT-Gate) 此得分计算专家 对采样数据中所有 Token 的平均亲和力。 它定义为:
| (6) |
其中是采样数据中输入序列的长度。
词符选择比率(ESFT-Token) 该分数计算选择专家的 Token 比率。 它定义为:
| (7) |
其中 是一个指标,如果门得分 为正,则等于 1,否则等于 0。 是每个词符选出的专家数量。
专家选拔和微调
对于每个 MoE 层 ,我们选择一个专家子集,根据他们的相关性分数进行微调。 我们将阈值 定义为一个超参数,控制要包含在所选子集中的总相关性分数的比例。 对于每一层,我们选择一组得分最高的专家,其累积相关性得分超过阈值,满足:
| (8) |
其中 是层 中专家 的相关性得分( 或 )。在训练和推理过程中,可以将 Token 分配给任何专家。 但是,只能更新每层中选定的专家;其他专家和模块仍处于冻结状态。
4实验设置
4.1主要评价
我们在两个常见的大语言模型定制场景中对 ESFT 方法进行了评估:(1) 在模型可能已经有不错性能的领域中提高模型的特定能力;(2) 使模型适应可能狭窄但不熟悉的专门任务。
4.1.1 模型增强任务
我们选择两个特定领域的任务,即数学和代码,来评估我们的方法如何增强模型的现有能力。 这两个领域是当前大语言模型研究中广泛关注的领域,适合进行评估,因为许多预训练模型都可以表现良好,而且通过进一步训练还有很大的改进潜力。 我们通过性能提升来评估我们方法的有效性。
对于数学领域,我们使用 MetaMathQA Yu 等人 (2023) 进行训练,并使用 GSM8K Cobbe 等人 (2021) 和 MATH Hendrycks 等人 (2021a) 进行评估。 对于代码领域,我们在庞大的 evol-codealpaca 数据集 Luo 等人 (2023) 的 Python 子集上训练模型,以模拟更集中的大语言模型定制场景,并评估其在 HumanEval 上的性能Chen 等人 (2021) 和 MBPP Austin 等人 (2021)。
| Math Ability | Code Ability | Specialized Tasks | |||||||
| MATH | GSM8K | Humaneval | MBPP | Intent | Summary | Law | Translation | Average | |
| Vanilla Model | 19.6 | 55.9 | 42.1 | 44.6 | 16.8 | 58.6 | 17.1 | 14.5 | 33.6 |
| FFT | 23.4 | 66.4 | 42.1 | 42.2 | 78.8 | 69.4 | 47.0 | 38.4 | 51.0 |
| LoRA | 20.6 | 58.9 | 39.6 | 44.8 | 67.8 | 64.7 | 39.7 | 23.1 | 44.9 |
| ESFT-Token (Ours) | 22.6 | 66.0 | 41.5 | 42.6 | 75.6 | 65.4 | 45.7 | 36.2 | 49.4 |
| ESFT-Gate (Ours) | 23.2 | 64.9 | 43.3 | 41.8 | 78.6 | 65.8 | 49.1 | 35.2 | 50.2 |
4.1.2 模型适配任务
我们选择四个专门任务来评估我们的方法如何促进语言模型训练以适应不熟悉的下游任务,涵盖大多数模型在训练后可以表现出色的多种能力:(1)文本到 JSON 意图在 BDCI-21 智能 HCI NLU 挑战赛中获得认可111https://www.datafountain.cn/competitions/511,需要将文本指令转换为家电的JSON格式。 (二)BDCI-21摘要挑战赛中的文本摘要222https://www.datafountain.cn/competitions/536,总结了客户服务通话记录。 (三)BDCI-21法律事件预测挑战赛中的法律判决预测333https://www.datafountain.cn/competitions/540,其中“案件描述”和“判决”被重新用作法律判决预测任务。 (4)ChrEn数据集中的低资源翻译(Zhang等人,2020),将少数民族切罗基语翻译成英语。 任务示例如附录A所示。
为了衡量模型性能,对于文本到 JSON 任务,我们计算模型输出和参考答案之间的精确匹配;对于其他任务,我们使用 GPT-4 在给定参考答案的情况下对模型输出进行 0 到 10 的评分444我们使用的确切版本是gpt-4-1106-preview。 评估说明见附录G。. 所有评估均使用少量样本。
4.2综合能力评价
我们选择了广泛的基准来评估模型在新任务训练后保留一般能力的程度。 这些基准包括 MMLU Hendrycks 等人 (2021b)、TriviaQA Joshi 等人 (2017)、HellaSwag Zellers 等人 (2019)、ARC-挑战 Clark 等人 (2018)、IFEval Zhou 等人 (2023)、CEval Huang 等人 (2023) 和 CLUEWSC Xu等人(2020),涵盖自然语言理解、问题回答、指令遵循和常识推理等各个领域的综合模型能力评估。
| CLUEWSC | TriviaQA | IFEval | MMLU | CEval | HellaSwag | ARC | Average | |
| Vanilla Model | 81.5 | 67.7 | 42.5 | 57.5 | 59.9 | 74.0 | 53.7 | 62.4 |
| FFT | 80.9 1.1 | 65.9 0.7 | 34.2 4.1 | 55.5 1.0 | 58.8 0.9 | 67.9 3.8 | 48.4 2.4 | 58.8 1.3 |
| LoRA | 74.3 7.7 | 63.4 5.4 | 38.7 2.5 | 55.5 1.2 | 57.0 1.5 | 72.8 1.9 | 51.8 2.3 | 59.1 2.5 |
| ESFT-Token | 80.9 0.9 | 66.7 1.8 | 40.7 1.3 | 57.1 0.5 | 59.6 0.8 | 72.3 3.6 | 52.9 1.5 | 61.5 1.1 |
| ESFT-Gate | 81.4 1.1 | 66.5 2.3 | 40.2 1.5 | 57.0 0.4 | 59.5 0.8 | 68.2 9.9 | 51.5 3.1 | 60.6 2.3 |
4.3 骨干模型和训练设置
我们使用 DeepSeek-V2-Lite DeepSeek (2024) 的主干架构进行所有实验。 该模型为每个 Transformer 层包含一组细粒度的 66 位专家。 这使得它在本研究时特别适合我们的方法,这得益于专家的专业化。 我们在精心策划的对齐数据集(不包括数学和代码数据)上训练模型,并将生成的检查点作为后续实验的普通模型。 这个对齐阶段可以激活跨各个领域的模型能力,同时将数学/代码能力作为基本能力,以更好地验证我们的方法在这两个领域的性能增益。
我们采用两个基线:全参数微调(FFT)和低秩适应(LoRA,Hu等人,2021)。 对于 LoRA,我们将低秩矩阵添加到除词符嵌入和语言建模头之外的所有训练参数中。 我们对所有方法的任务特定数据和对齐数据保持 1:1 的比例,我们发现这对于保留从 FFT 和 LoRA 对齐阶段获得的一般能力非常有效。 然而,对于我们的 ESFT 方法来说,不采用这种数据混合策略甚至可能更好地保持通用能力。 我们在附录 F 中详细介绍了这一点。所有实验均在 HFAI 集群555https://doc.hfai.high-flyer.cn/index.html 具有 2 个 8x Nvidia A100 PCIe GPU 节点。
对于超参数设置,所有方法都使用 32 的批量训练大小和 4096 的序列长度。 对于每个任务,我们将训练的最大步数设置为 500,并每 100 步评估模型。 基于 {1e-5, 3e-5, 1e-4, 3e-4 中的超参数搜索,FFT、LoRA 和 ESFT 的学习率分别设置为 3e-5、1e-4 和 1e-5 }。 LoRA 等级设置为 8,缩放比例设置为 2,遵循 Hu 等人 (2021)。 对于ESFT-Gate,阈值分别设置为0.1,对于ESFT-Token,阈值分别设置为0.2。 §6.2 展示了我们如何确定 ESFT 的阈值。
5结果
5.1基准性能结果
在定制能力评估方面,ESFT显着超越LoRA,与FFT具有竞争力。 如表1所示,ESFT-Token和ESFT-Gate在Math等模型增强任务中取得了接近最佳的结果,而ESFT-Gate在Humaneval任务中取得了最好的表现。 ESFT 在模型适应任务中也表现出色,ESFT-Gate 在 4 项任务中的 3 项中实现了接近最佳的性能。 值得注意的是,ESFT-Gate 的平均值为 50.2,与 FFT 的 51.0 相比具有竞争力,略好于 ESFT-Token 的 49.4,并显着超过 LoRA 的 44.9。 这表明寻找与任务相关的专家可以有效地调整模型以实现高效的定制。
对于一般能力评估,ESFT 的性能下降较少,始终优于 FFT 和 LoRA。 如表2所示,ESFT-token 的表现优于 ESFT-gate,平均得分分别为 61.5 和 60.6。 结果表明,在 TriviaQA 和 IFEval 等任务中具有广泛的保留能力,超过了 FFT 的 58.8 和 LoRA 的 59.1。 这两种方法都比 LoRA 和 FFT 更好地保留了性能,突出了它们在维持一般任务性能方面的有效性666 我们进一步研究了附录H中专门任务训练的模型的数学和代码性能。 FFT 和 LoRA 表现出更严重的退化,而 ESFT 表现出最小的性能下降。 . §6.3 中的分析表明,FFT 和 LoRA 一般任务的这种退化可能是由于训练共享参数造成的。
5.2计算效率结果
图6中的结果表明,ESFT在训练时间和存储空间要求方面表现出多种优势:
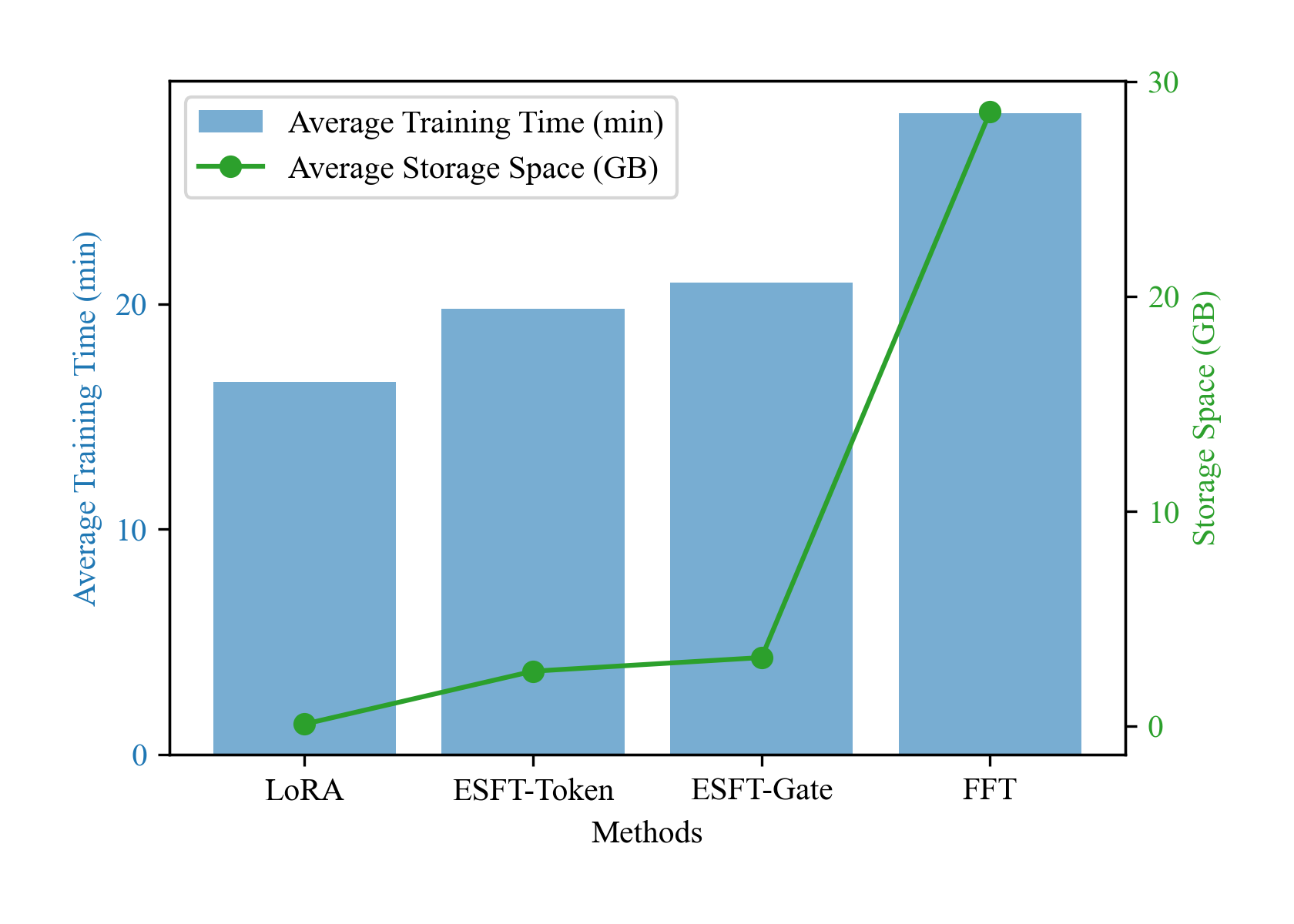
训练时间
ESFT-Token 和 ESFT-Gate 的平均训练时间分别为 19.8 分钟和 20.9 分钟。 FFT 方法花费的时间明显更长,为 28.5 分钟。 虽然 LoRA 的训练时间较短,为 16.5 分钟,但我们的方法相对接近。
存储空间
训练参数的平均存储空间:ESFT-Token 为 2.57 GB,ESFT-Gate 为 3.20 GB,而 FFT 则需要 28.6 GB。 虽然 LoRA 需要的存储较少,但 ESFT 在下游任务性能上明显优于 LoRA。
综上所述,ESFT 在训练时间和存储空间方面表现出优异的性能,显着优于 FFT。 此外,如表3所示,与 FFT 相比,ESFT 需要的可训练参数少得多,从而降低了 GPU 内存使用量。 这些优点表明ESFT对于语言模型定制和适配来说是高效且有效的。
6分析
| Non-shared Experts | Shared Experts | Non-expert Parameters | Trainable Parameters | Specialized Ability | General Ability | Average |
| ALL | 15.7B | 51.0 | 58.8 | 54.9 | ||
| Relevant | 1.85B | 49.8 | 60.7 | 55.3 | ||
| Relevant | 1.4B | 49.4 | 61.5 | 55.4 | ||
| 450M | 47.4 | 61.2 | 54.3 | |||
| 1.3B | 49.0 | 60.0 | 54.5 | |||
| Relevant | 2.7B | 50.8 | 60.3 | 55.6 | ||
| - | 33.8 | 62.4 | 48.1 |
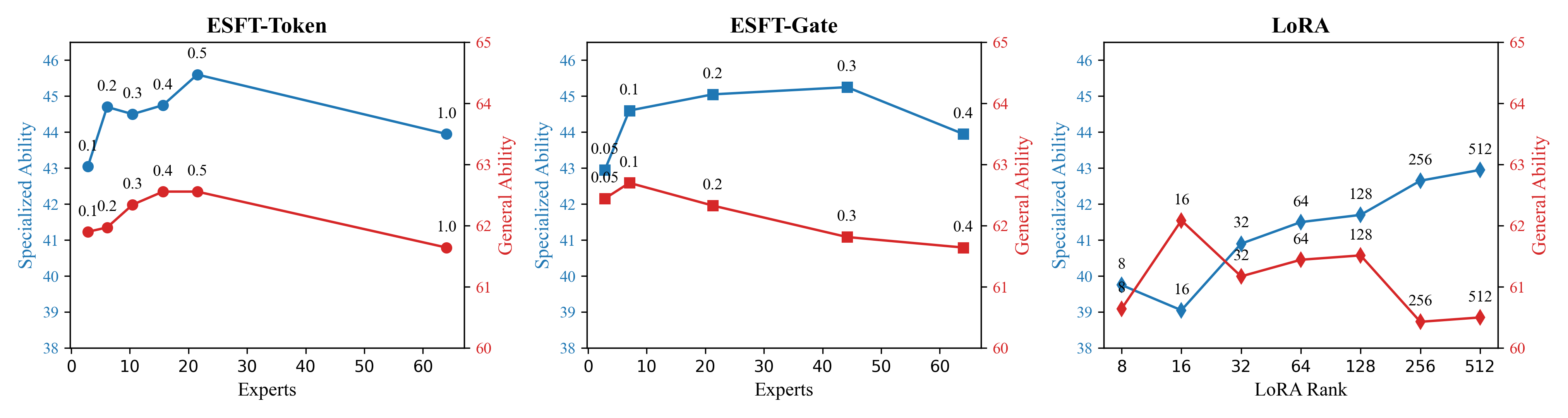
在本节中,我们研究§6.1中ESFT的专家选择过程,并在§6.2中演示ESFT和LoRA在不同计算约束下的性能。 我们在§6.3中分析了训练共享和非共享参数的影响,并在§6.4中进行了消融研究,以验证我们的专家相关性得分和模型结构的重要性细粒度的专家。
6.1ESFT有效利用专业专家
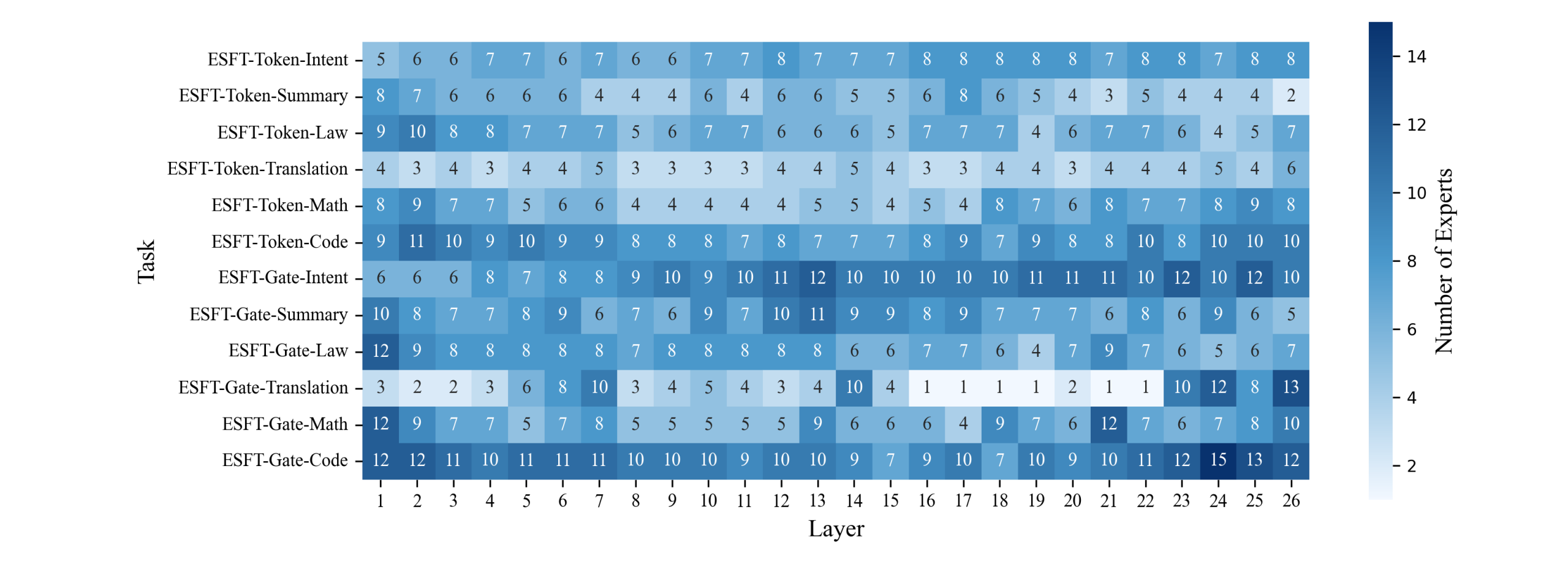
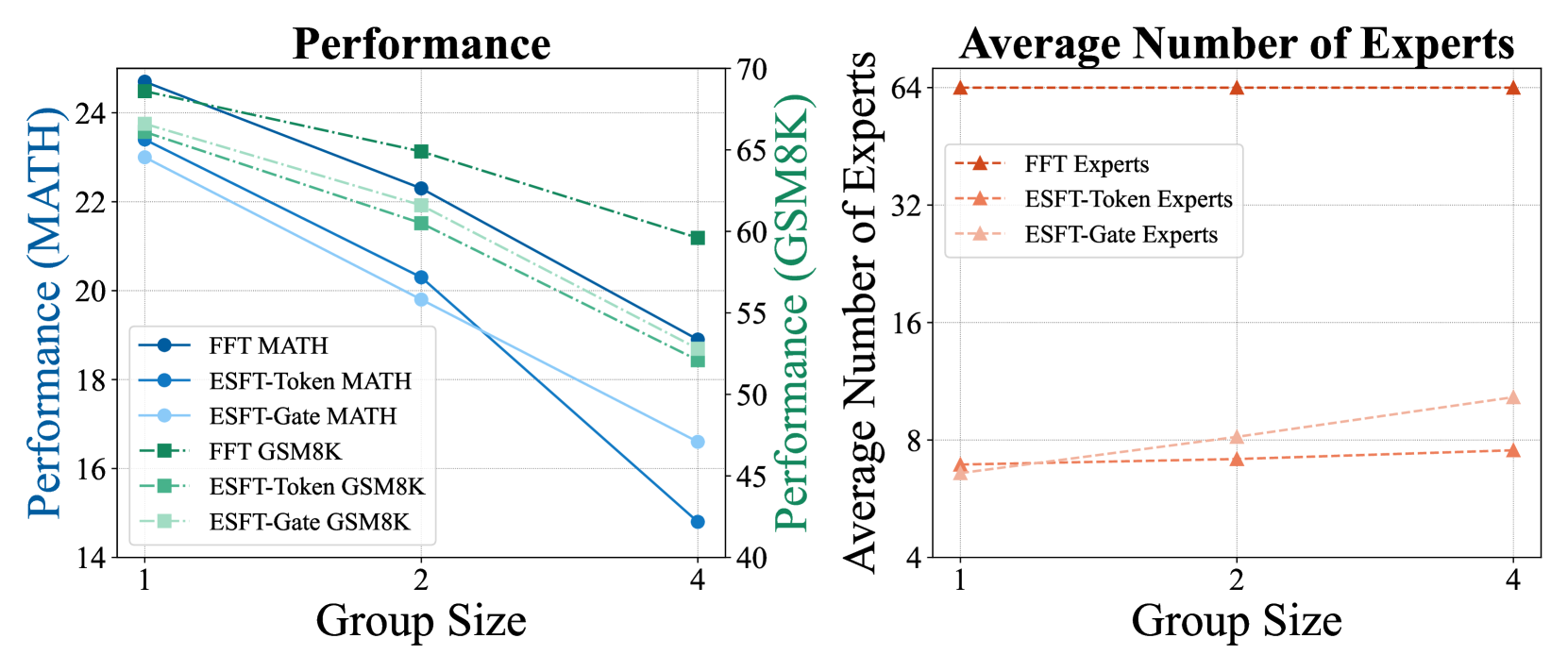
我们分析了 ESFT 跨任务和层级培训的专家数量,以了解其专家选择过程。 结果如图4所示。
从结果中,我们有以下几个观察结果:(1)跨层每个任务使用的专家平均数量为 66 个中的 2 到 15 个,这表明 ESFT 的可训练参数比 FFT 少 75%-95%。 (2) ESFT-Token 通常雇用较少的专家,同时更好地保持一般性能,与数学、意图和法律等任务中的 ESFT-Gate 相当。 (3) 专家的数量因任务而异,数学和翻译等更专业的任务使用的专家较少;我们的方法在这些任务上的性能在最大程度上超过了 LoRA,这表明我们的方法特别适合更专业的任务。 (4)对于大多数任务,中间层选择的专家很少,表明专家分布更集中在这些层。
6.2 ESFT高效利用训练资源
| Math Ability | Code Ability | Specialized Tasks | |||||||
| MATH | GSM8K | Humaneval | MBPP | Intent | Summary | Law | Translation | Average | |
| ESFT-Token | 22.6 | 66.0 | 41.5 | 42.6 | 75.6 | 65.4 | 45.7 | 36.2 | 49.4 |
| of rand | -1.0 | -3.7 | -2.5 | 0.2 | -2.6 | -1.7 | 1.3 | -13.5 | -2.8 |
| ESFT-Gate | 23.2 | 64.9 | 43.3 | 41.8 | 78.6 | 65.8 | 49.1 | 35.2 | 50.2 |
| of rand | -1.7 | -3.2 | -4.3 | 1.6 | -5.0 | 0.3 | -2.9 | -20.4 | -4.4 |
ESFT 和 LoRA 都有训练效率超参数(ESFT 为 ,LoRA 为排名)。 增加其价值将增加计算资源的使用并可能提高性能。 为了了解 ESFT 和 LoRA 在不同效率设置下的表现,我们评估了数学任务的基准性能。 我们为 LoRA 设置排名 512,因为较高的值将导致比 FFT 更多的可训练参数。 图6说明了不同效率设置下的专业能力和通用能力的训练。
从结果中,我们可以得出结论:(1)所有三种方法都显示了训练效率和性能之间的权衡。 在某个点之前增加训练参数(ESFT 的 和 LoRA 的排名)可以提高性能。 (2)ESFT-Token和ESFT-Gate在任何一点上都优于LoRA,表现出更高的专业能力和更稳定的通用能力。 (3) ESFT-Token 专业能力和通用能力的峰值均为 =0.5,而 ESFT-Gate 专业能力和通用能力的峰值为 =0.3,= 0.1为一般能力。 (4) ESFT-Token 和 ESFT-Gate 性能分别在 =0.2 和 =0.1 处饱和,表明大多数专家选择可能与任务性能不太相关。 我们在附录E中对此进行了更深入的研究。
6.3 选择性训练非共享参数是ESFT的关键
在我们提出的 ESFT 方法中,我们只影响非共享专家的子集。 本节详细讨论了我们方法的几种变体,这些变体也可以训练共享参数。 变量基于:
-
•
是否训练所有非共享专家或其中任务相关子集(我们使用词符选择比率并设置=0.2) 。
-
•
共享专家是否经过培训。
-
•
是否训练其他参数,包括门、注意力层和嵌入。
随着可训练参数的增加,专业性能也会提高。 可训练参数的等级从450M到15.7B与专业能力的等级从47.4到51.0高度一致。 这表明增加可训练参数可以有效提高专业性能。
随着可训练共享参数的增加,总体性能会下降。 无论相关非共享专家是否接受过培训,当我们共享专家和/或非专家参数时,总体性能分别从 61.5 下降到 60.3,或从 62.4 下降到 60.0。 随着整套非共享专家的训练,总体表现进一步从 60.3 下降到 58.8。 这表明与训练非共享参数相比,训练共享参数更有可能导致下游任务的过度拟合和一般任务的遗忘。
它高度优先于培训与任务相关的非共享专家。 训练相关专家至少达到55.3,而其他设置最多达到54.9,即使有高达15.7B参数的更高要求。 因此,对这些专家进行微调是模型定制的重中之重。
基于这些结论,我们提出了两种主要的训练策略:
-
1.
优先考虑专业能力: 训练所有共享参数和与任务相关的非共享专家,以最大限度地提高专业性能。
-
2.
平衡专业能力和通用能力以及计算效率: 仅训练与任务相关的非共享专家,以最大限度地降低参数成本,同时最大限度地维持通用能力。
6.4ESFT关键模块分析
在本节中,我们分析并证明我们方法的有效性在于两个模块:(1)我们提出的专家相关性评分函数和(2)MoE模型架构的细粒度专家分割。
专家相关性评分函数
在这项工作中,我们提出平均门得分和词符选择比作为专家相关性得分函数,以过滤不同任务的相关专家。 为了证明其有效性,我们用随机专家替换了从这些函数中获得的专家,同时保持每层激活的专家数量相同。 表 4 中的结果表明,用随机专家替换相关专家会显着降低任务绩效,证明了我们提出的相关性评分的有效性。
MoE 模型的细粒度专家细分
7结论
在这项工作中,我们研究了具有专家混合(MoE)架构的稀疏大型语言模型的参数高效微调方法。 我们首先观察到来自不同领域的任务是由不同的专家组合处理的。 然后,我们建议使用两个指标为下游任务选择最相关的专家:平均门得分和词符选择率。 实验结果表明,我们的方法显着降低了训练成本,同时匹配或超越了全参数微调结果。 进一步的分析证实,我们的方法增强了 MoE 架构内专家系统的专业化。
局限性
首先,由于其他细粒度 MoE 模型可用性的限制,我们的方法仅在 DeepSeek-V2-Lite MoE 模型上进行了测试。 从该模型得出的结论在应用于其他情况时需要进一步验证。 此外,由于缺乏不同专家粒度的参数化和结构一致的MoE模型,我们采用了绑定多组专家的模拟方法来比较粗粒度和细粒度的MoE方法。
参考
- Ansell et al. (2021) Alan Ansell, Edoardo Maria Ponti, Anna Korhonen, and Ivan Vulić. 2021. Composable sparse fine-tuning for cross-lingual transfer. arXiv preprint arXiv:2110.07560.
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Trevor Cai, Anselm Levskaya, Charles Sutton, et al. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Maarten Dehghani, Pieter Abbeel, Deepak Pathak, Brandon Sanders, Vishal Katarkar, Zareen Xu, et al. 2021. Evaluating large language models trained on code. In NeurIPS.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the AI2 reasoning challenge. CoRR, abs/1803.05457.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Gsm8k: A dataset for grade school math problem solving. In NeurIPS.
- Dai et al. (2024) Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y. K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. 2024. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. CoRR, abs/2401.06066.
- Dai et al. (2022) Damai Dai, Li Dong, Shuming Ma, Bo Zheng, Zhifang Sui, Baobao Chang, and Furu Wei. 2022. Stablemoe: Stable routing strategy for mixture of experts. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 7085–7095. Association for Computational Linguistics.
- Databricks (2024) Databricks. 2024. Dbrx: Resources and code examples.
- DeepSeek (2024) DeepSeek. 2024. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. CoRR, abs/2405.04434.
- Ding et al. (2023) Ning Ding, Xingtai Lv, Qiaosen Wang, Yulin Chen, Bowen Zhou, Zhiyuan Liu, and Maosong Sun. 2023. Sparse low-rank adaptation of pre-trained language models. arXiv preprint arXiv:2311.11696.
- Fedus et al. (2021) William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. CoRR, abs/2101.03961.
- Fomenko et al. (2024) Vlad Fomenko, Han Yu, Jongho Lee, Stanley Hsieh, and Weizhu Chen. 2024. A note on lora. arXiv preprint arXiv:2404.05086.
- Gheini et al. (2021) Mozhdeh Gheini, Xiang Ren, and Jonathan May. 2021. Cross-attention is all you need: Adapting pretrained transformers for machine translation. arXiv preprint arXiv:2104.08771.
- Guo et al. (2020) Demi Guo, Alexander M Rush, and Yoon Kim. 2020. Parameter-efficient transfer learning with diff pruning. arXiv preprint arXiv:2012.07463.
- Han et al. (2024) Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. 2024. Parameter-efficient fine-tuning for large models: A comprehensive survey. CoRR, abs/2403.14608.
- He et al. (2023) Haoyu He, Jianfei Cai, Jing Zhang, Dacheng Tao, and Bohan Zhuang. 2023. Sensitivity-aware visual parameter-efficient fine-tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11825–11835.
- He et al. (2021) Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. 2021. Towards a unified view of parameter-efficient transfer learning. arXiv preprint arXiv:2110.04366.
- Hendrycks et al. (2021a) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021a. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874.
- Hendrycks et al. (2021b) Dan Hendrycks, Collin Burns, Steven Basart, et al. 2021b. Measuring massive multitask language understanding. In International Conference on Learning Representations (ICLR).
- Houlsby et al. (2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
- Huang et al. (2023) Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, et al. 2023. C-Eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322.
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv e-prints, arXiv:1705.03551.
- Lepikhin et al. (2021) Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2021. Gshard: Scaling giant models with conditional computation and automatic sharding. In 9th International Conference on Learning Representations, ICLR 2021. OpenReview.net.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190.
- Liao et al. (2023) Baohao Liao, Yan Meng, and Christof Monz. 2023. Parameter-efficient fine-tuning without introducing new latency. arXiv preprint arXiv:2305.16742.
- Lin et al. (2024) Yang Lin, Xinyu Ma, Xu Chu, Yujie Jin, Zhibang Yang, Yasha Wang, and Hong Mei. 2024. Lora dropout as a sparsity regularizer for overfitting control. arXiv preprint arXiv:2404.09610.
- Liu et al. (2023) Qidong Liu, Xian Wu, Xiangyu Zhao, Yuanshao Zhu, Derong Xu, Feng Tian, and Yefeng Zheng. 2023. Moelora: An moe-based parameter efficient fine-tuning method for multi-task medical applications. arXiv preprint arXiv:2310.18339.
- Liu et al. (2021) Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. 2021. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602.
- Luo et al. (2023) Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2023. Wizardcoder: Empowering code large language models with evol-instruct.
- Meta (2023a) Meta. 2023a. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288.
- Meta (2023b) Meta. 2023b. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Meta (2024) Meta. 2024. Llama 3 model card.
- Mistral (2024a) Mistral. 2024a. Cheaper, better, faster, stronger: Continuing to push the frontier of ai and making it accessible to all.
- Mistral (2024b) Mistral. 2024b. Mixtral of experts. CoRR, abs/2401.04088.
- Pfeiffer et al. (2020) Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. 2020. Adapterfusion: Non-destructive task composition for transfer learning. arXiv preprint arXiv:2005.00247.
- Qwen (2024) Qwen. 2024. Introducing qwen1.5.
- Roller et al. (2021) Stephen Roller, Sainbayar Sukhbaatar, Arthur Szlam, and Jason Weston. 2021. Hash layers for large sparse models. CoRR, abs/2106.04426.
- Shen et al. (2024) Yikang Shen, Zhen Guo, Tianle Cai, and Zengyi Qin. 2024. Jetmoe: Reaching llama2 performance with 0.1m dollars. CoRR, abs/2404.07413.
- Sung et al. (2021) Yi-Lin Sung, Varun Nair, and Colin A Raffel. 2021. Training neural networks with fixed sparse masks. Advances in Neural Information Processing Systems, 34:24193–24205.
- Vucetic et al. (2022) Danilo Vucetic, Mohammadreza Tayaranian, Maryam Ziaeefard, James J Clark, Brett H Meyer, and Warren J Gross. 2022. Efficient fine-tuning of bert models on the edge. In 2022 IEEE International Symposium on Circuits and Systems (ISCAS), pages 1838–1842. IEEE.
- Wang et al. (2022) Yaqing Wang, Subhabrata Mukherjee, Xiaodong Liu, Jing Gao, Ahmed Hassan Awadallah, and Jianfeng Gao. 2022. Adamix: Mixture-of-adapter for parameter-efficient tuning of large language models. arXiv preprint arXiv:2205.12410, 1(2):4.
- XAI (2024) XAI. 2024. Grok open release.
- Xu et al. (2020) Liang Xu, Hai Hu, Xuanwei Zhang, et al. 2020. Clue: A chinese language understanding evaluation benchmark. arXiv preprint arXiv:2004.05986.
- Xu et al. (2021) Runxin Xu, Fuli Luo, Zhiyuan Zhang, Chuanqi Tan, Baobao Chang, Songfang Huang, and Fei Huang. 2021. Raise a child in large language model: Towards effective and generalizable fine-tuning. arXiv preprint arXiv:2109.05687.
- Yu et al. (2023) Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2023. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 4791–4800. Association for Computational Linguistics.
- Zhang et al. (2023a) Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. 2023a. Adaptive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv:2303.10512.
- Zhang et al. (2020) Shiyue Zhang, Benjamin Frey, and Mohit Bansal. 2020. Chren: Cherokee-english machine translation for endangered language revitalization. In EMNLP2020.
- Zhang et al. (2023b) Zhen-Ru Zhang, Chuanqi Tan, Haiyang Xu, Chengyu Wang, Jun Huang, and Songfang Huang. 2023b. Towards adaptive prefix tuning for parameter-efficient language model fine-tuning. arXiv preprint arXiv:2305.15212.
- Zhou et al. (2023) Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2023. Instruction-following evaluation for large language models. Preprint, arXiv:2311.07911.
![[Uncaptioned image]](table5.jpg)
| Non-shared | Shared | Non-expert | CLUEWSC | TriviaQA | IFEval | MMLU | CEval | HellaSwag | ARC | Average |
| ALL | 80.9 2.2 | 65.9 1.5 | 34.2 8.1 | 55.5 1.9 | 58.8 1.7 | 67.9 7.4 | 48.4 4.7 | 58.8 2.5 | ||
| Relevant | 80.9 2.1 | 66.1 4.4 | 42.4 3.0 | 56.8 1.0 | 58.9 1.6 | 67.8 20.4 | 52.1 5.7 | 60.7 4.4 | ||
| Relevant | 80.9 1.8 | 66.7 3.5 | 40.7 2.6 | 57.1 1.0 | 59.6 1.5 | 72.3 7.0 | 52.9 3.0 | 61.5 2.3 | ||
| 81.1 3.4 | 66.7 4.2 | 41.2 1.6 | 56.9 1.2 | 58.9 1.6 | 71.3 14.1 | 52.6 5.6 | 61.2 3.3 | |||
| 79.5 4.4 | 65.8 5.0 | 41.4 3.2 | 56.2 1.6 | 58.6 1.7 | 67.5 20.7 | 51.2 4.1 | 60.0 4.4 | |||
| Relevant | 80.4 4.1 | 66.3 4.1 | 41.1 5.0 | 56.7 1.2 | 59.0 1.9 | 67.5 20.3 | 51.5 4.6 | 60.3 4.6 | ||
| 81.5 | 67.7 | 42.5 | 57.5 | 59.9 | 74.0 | 53.7 | 62.4 |
| Non-shared | Shared | Non-expert | Math Ability | Code Ability | Specialized Tasks | ||||||
| MATH | GSM8K | Humaneval | MBPP | Intent | Summary | Law | Translation | Average | |||
| ALL | 23.4 | 66.4 | 42.1 | 42.2 | 78.8 | 69.4 | 47.0 | 38.4 | 51.0 | ||
| Relevant | 23.8 | 65.7 | 40.2 | 43.8 | 80.4 | 67.3 | 42.4 | 35.1 | 49.8 | ||
| Relevant | 22.6 | 66.0 | 41.5 | 42.6 | 75.6 | 65.4 | 45.7 | 36.2 | 49.4 | ||
| 22.7 | 64.5 | 37.2 | 44.0 | 73.6 | 68.3 | 42.7 | 26.0 | 47.4 | |||
| 23.4 | 66.6 | 41.5 | 44.4 | 81.0 | 66.7 | 39.0 | 29.5 | 49.0 | |||
| Relevant | 24.8 | 66.0 | 42.1 | 43.2 | 82.2 | 69.5 | 46.4 | 32.2 | 50.8 | ||
| 19.6 | 55.9 | 42.1 | 44.6 | 16.8 | 58.6 | 17.1 | 14.5 | 33.6 | |||
| Math Ability | Code Ability | ||||
| MATH | GSM8K | HumanEval | MBPP | Average | |
| Vanilla Model | 19.6 | 55.9 | 42.1 | 44.6 | 40.5 |
| FFT | 15.1 0.3 | 40.3 5.3 | 30.2 4.4 | 40.6 3.9 | 31.5 2.5 |
| LoRA | 11.8 0.6 | 36.1 4.4 | 27.9 2.3 | 36.6 2.6 | 28.1 2.0 |
| ESFT-Token | 19.4 0.8 | 55.2 0.7 | 39.5 1.0 | 44.8 0.8 | 39.7 0.4 |
| ESFT-Gate | 19.5 0.3 | 55.1 1.3 | 39.3 1.3 | 45.3 0.6 | 39.8 0.6 |
| Math Ability | Code Ability | Specialized Tasks | |||||||
| MATH | GSM8K | HumanEval | MBPP | Intent | Service | Law | Translation | Average | |
| FFT | 26.1 | 70.4 | 51.2 | 42.6 | 78.8 | 72.8 | 45.6 | 34.4 | 52.7 |
| + mix data | -2.7 | -4.0 | -9.1 | -0.4 | 0.0 | -3.4 | 1.4 | 4.0 | -1.7 |
| LoRA | 21.8 | 57.8 | 42.1 | 42.6 | 78.2 | 66.4 | 46.0 | 21.8 | 47.1 |
| + mix data | -1.2 | 1.1 | -2.5 | 2.2 | -10.4 | -1.7 | -6.3 | 1.3 | -2.2 |
| ESFT-Token | 25.2 | 64.8 | 42.1 | 43.8 | 78.0 | 67.4 | 47.2 | 31.9 | 50.0 |
| + mix data | -2.6 | 1.2 | -0.6 | -1.2 | -2.4 | -2.0 | -1.5 | 4.3 | -0.6 |
| ESFT-Gate | 24.1 | 64.9 | 42.1 | 44.6 | 77.2 | 68.4 | 43.6 | 32.8 | 49.7 |
| + mix data | -0.9 | 0.0 | 0.0 | -2.8 | 1.4 | -2.6 | 0.9 | 2.4 | 0.5 |
| CLUEWSC | TriviaQA | IFEval | MMLU | CEval | HellaSwag | ARC | Average | |
| Vanilla Model | 81.5 | 67.7 | 42.5 | 57.5 | 59.9 | 74.0 | 53.7 | 62.4 |
| FFT | 76.8 1.7 | 62.4 10 | 28.4 5.1 | 55.5 1.1 | 58.4 0.4 | 74.6 3.2 | 53.6 3.1 | 58.5 2.5 |
| + mix data | 4.1 | 3.5 | 5.8 | 0.0 | 0.4 | -6.7 | -5.2 | 0.3 |
| LoRA | 60.2 27 | 61.2 4.0 | 33.4 6.1 | 52.3 3.3 | 55.3 2.3 | 71.5 2.5 | 50.7 2.2 | 55.0 4.6 |
| + mix data | 14.1 | 2.2 | 5.3 | 3.2 | 1.7 | 1.3 | 1.1 | 4.1 |
| ESFT-Token | 80.0 2.5 | 67.5 0.3 | 41.9 0.8 | 57.3 0.2 | 60.2 0.5 | 74.5 0.7 | 54.9 0.7 | 62.3 0.5 |
| + mix data | 0.9 | -0.8 | -1.2 | -0.2 | -0.6 | -2.2 | -2.0 | -0.8 |
| ESFT-Gate | 80.2 1.6 | 67.6 0.3 | 40.8 2.4 | 57.3 0.3 | 59.9 0.4 | 74.3 0.9 | 55.1 0.9 | 62.2 0.5 |
| + mix data | 1.2 | -1.1 | -0.6 | -0.3 | -0.4 | -6.1 | -3.6 | -1.6 |
UTF8gbsn
| Task | Evaluation Instruction |
| Summary | 请你进行以下电话总结内容的评分。请依据以下标准综合考量,以确定预测答案与标准答案之间的一致性程度。满分为10分,根据预测答案的准确性、完整性和相关性来逐项扣分。请先给每一项打分并给出总分,再给出打分理由。总分为10分减去每一项扣除分数之和,最低可扣到0分。请以“内容准确性扣x分,详细程度/完整性扣x分,…,总分是:x分"为开头。 1. 内容准确性: - 预测答案是否准确反映了客户问题或投诉的核心要点。 - 是否有任何关键信息被错误陈述或误解。 2. 详细程度/完整性: - 预测答案中包含的细节是否充分,能否覆盖标准答案中所有重要点。 - 对于任何遗漏的关键信息,应相应减分。 3. 内容冗余度: - 预测答案是否简洁明了,和标准答案风格一致,不存在冗余信息。 - 如果预测答案过长或与标准答案风格不一致,需相应减分。 4. 行动指令正确性: - 预测答案对后续处理的建议或请求是否与标准答案相符。 - 如果处理建议发生改变或丢失,需相应减分。 预测答案:{prediction} 参考答案:{ground_truth} |
| Law | 请你进行以下法案判决预测内容的评分。请依据以下标准综合考量,以确定预测答案与标准答案之间的一致性程度。满分为10分,根据预测答案的准确性、完整性和相关性来逐项扣分。请先给每一项打分并给出总分,再给出打分理由。总分为10分减去每一项扣除分数之和,最低可扣到0分。请以“相关性扣x分,完整性扣x分,…,总分是:x分"为开头。 1. 相关性:预测答案与标准答案的相关程度是最重要的评分标准。如果预测的判决情况与标准答案完全一致,即所有事实和结果都被精确复制或以不同但等效的方式表述,则应给予高分。若只有部分一致或存在偏差,则根据一致的程度适当扣分。如果没有预测判决内容,扣10分。 2. 完整性:评估预测答案是否涵盖了所有标准答案中提到的关键点,包括但不限于当事人、具体金额、责任判定、费用承担等。如果遗漏重要信息,则应相应扣分。 3. 准确性:检查预测答案中提及的细节、数字、日期和法律依据是否与标准答案保持一致。任何错误信息均需扣分,并且严重错误应该导致更多的扣分。 4. 客观性与专业性:预测答案应客观反映法案内容并使用恰当的法律术语。主观臆断或非专业表达需酌情扣分。 预测答案:{prediction} 参考答案:{ground_truth} |
| Translation | You are an expert master in machine translation. Please score the predicted answer against the standard answer out of 10 points based on the following criteria: Content accuracy: Does the predicted answer accurately reflect the key points of the reference answer? Level of detail/completeness: Does the predicted answer cover all important points from the standard answer? Content redundancy: Is the predicted answer concise and consistent with the style of the standard answer? Respond following the format: "Content accuracy x points, level of detail/completeness x points, …, total score: x points". The total score is the average of all the scores. Do not give reasons for your scores. Predicted answer: {prediction} Reference answer: {ground_truth} |
附录
附录 A专门任务的示例
表5以提示形式呈现任务示例以及每个专门任务的相应参考响应,包括意图识别、文本摘要、法律判断预测和低资源翻译。
附录B专家分组策略
为了将专家分组并模拟粗粒度专家混合 Transformer 模型,我们计算专家相似度并通过使用贪婪搜索算法最大化组内相似度来对专家进行分组。
我们从比对数据集中采样数据,其中包含 32 个样本,每个样本的序列长度为 4096,以计算专家之间的相似度。 我们将所有专家对的共现矩阵初始化为零矩阵。 对于词符的 Top-6 专家选择中同时出现的每一对专家,我们在矩阵中将他们的分数加 1。 在对数据集进行迭代后,我们使用矩阵中 行和 行向量之间的余弦相似度来计算每对专家 和专家 之间的相似度。
为了通过贪婪搜索获得专家分组策略,我们计算所有可能的 K 个专家组的平均组内相似度(组内所有专家的平均成对相似度)(其中 K 是组大小,为 2 或 4)每层 66 名专家中的 64 名非共享专家。 然后我们选择得分最高的 K 专家组。 对于剩余的未选定的专家,我们重复此过程,直到所有专家都被选定并分组。
附录C专家亲和力样本量分析
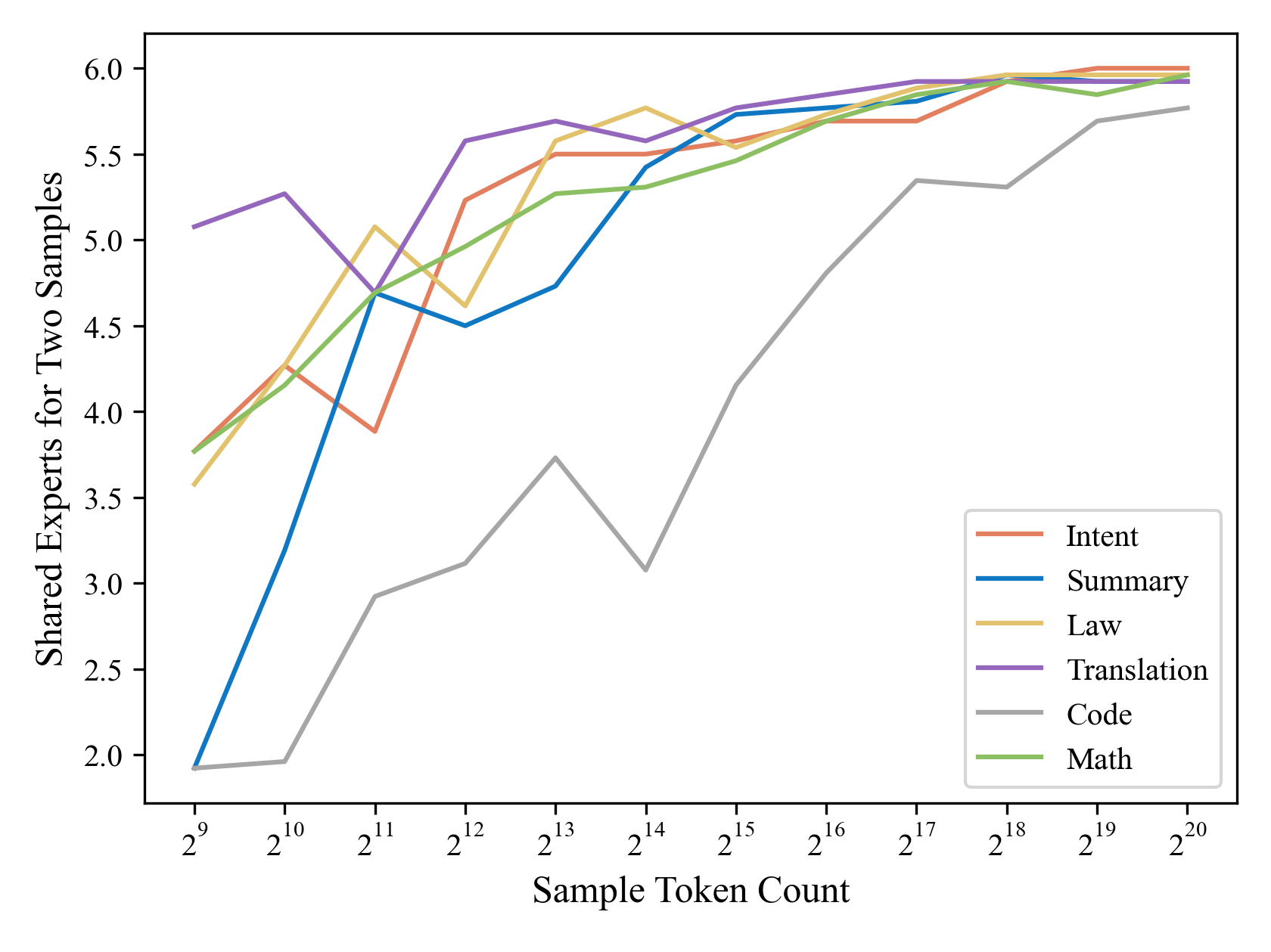
为了评估识别任务最相关的训练专家所需的数据量,我们从六个任务中的每一个任务的数据集中独立采样两组数据,并计算两组之间共享的 Top-6 专家。 结果如图8所示。 当样本量达到 (即 32 个样本,序列长度为 4096)时,所有任务在两个样本之间都表现出大量共享专家。 这表明样本量足够大,足以为任务选择最相关的专家。
附录 D训练共享参数消融的详细结果
附录E专家选择的定性示例
我们在图 LABEL:fig:qualitative 中提供了每个任务的所有 Token 中路由专家可训练数量的定性示例。 每个子图都演示了从任务中提取的示例。 更深的 Token 表示所有 26 层中可训练的专家更多(每层前 6 个专家)。 词符选择比例参数设置为0.2。 结果表明,我们的方法即使只处理大约 20% 的专家选择,也涵盖了广泛的与关键任务相关的单词。
UTF8gbsn 例如,在Intent识别任务中,最深的token是“意图”(Intent);在法律判断任务中,最深的标记包括“婚后”、“要求”、“原告”和“被告”;在数学任务中,最深的标记主要是“3”、“5”、“6”和“7”等数字标记;在代码任务中,最深的标记是“const”等关键词,或者“获取 ID 列表”等重要注释词。
附录 F混合对齐数据对训练的影响
我们对所有方法的下游任务数据和对齐训练数据采用 1:1 的比例,以更好地保持一般任务性能。 该手动比率保持恒定,以避免因微调每个任务的比率而产生大量额外成本。
结果表明,FFT 和 LoRA 受益于包含对齐数据,从而提高了一般任务的性能,而下游任务的性能仅略有下降。 相反,我们的 ESFT 方法没有表现出相同的优势。 具体来说,混合对齐数据不会导致一般或下游任务的性能提高。 研究结果表明,即使没有添加对齐数据,ESFT 本质上也能够适应下游任务,而不会在一般任务中显着降低性能。 这凸显了 ESFT 在不同任务设置中的稳健性和适应性。
附录G专门任务的评估说明
表11列出了评估专业任务的详细标准,包括文本摘要、法律判决预测和低资源翻译。 每项任务都包括根据参考答案评估预测答案的具体说明,重点关注内容准确性、完整性、相关性和一致性等方面。
附录 H 将数学和代码作为一般任务进行评估
我们研究了在适应任务(即意图、摘要、法律、翻译)上训练的模型的数学和代码性能,因为这些领域反映了模型的一般能力(如果没有专门训练的话)。 我们仅在下游任务数据上报告带有训练设置的数字。 表8中的结果表明,FFT和LoRA会导致数学和代码领域的性能显着下降,平均性能分别下降9.0和12.4。 值得注意的是,与 FFT 和 LoRA 相比,我们的 ESFT 方法保留了明显更好的性能,平均性能下降小于 1。