MedPix 2.0:用于高级人工智能应用的综合多模式生物医学数据集
摘要
人们对在医疗领域开发人工智能应用程序的兴趣日益浓厚,但由于缺乏高质量的数据集,这主要是由于隐私相关问题。 此外,最近多模态大语言模型(MLLM)的兴起导致了对多模态医疗数据集的需求,其中临床报告和结果附加到相应的 CT 或 MR 扫描中。 本文阐述了构建 MedPix 2.0 数据集的整个工作流程。 从著名的多模态数据集 MedPix®(主要由医生、护士和医疗保健学生用于继续医学教育目的)开始,开发了一个半自动管道来提取视觉和文本数据,然后使用手动方法去除噪声样本的固化过程,从而创建 MongoDB 数据库。 除了数据集之外,我们还开发了一个 GUI,旨在高效地导航 MongoDB 实例,并获取可轻松用于训练和/或微调 MLLM 的原始数据。 为了强化这一点,我们还提出了一个基于 CLIP 的模型,在 MedPix 2.0 上训练用于扫描分类任务。
关键词:
MedPix MongoDB 生物医学数据集 MLLM CLIP 决策支持系统1简介
近年来,基于计算机的应用程序的兴起极大地促进了生物医学数据管理和分析中历史模拟过程的数字化。 反过来,基于人工智能(AI)的技术的出现促进了越来越精确的模型的开发,以支持诊断以构建个性化治疗。 事实上,在生物医学领域,不同的子领域都可以受益于基于人工智能的系统,从行政领域(例如更好地管理紧急区域的队列、集中整合医疗记录)到临床领域,这都得益于人工智能的使用人工智能可以有效地提取有用的特征以可靠地实现诊断。
这些应用程序的基本要求之一在于其可信度,这必须帮助医生充满信心,能够提供可靠的预测和分类。 然而,人工智能模型需要大量数据才能实现这些结果,这使得向生物医学领域的扩展比在其他领域的实际扩展要复杂得多。 主要问题之一在于科学界开发新的人工智能方法所需的数据集的可用性。 这个问题主要源于数据的敏感性,必须处理隐私问题,这使得构建包含图像和/或临床报告的公共数据集以供科学界使用变得困难。
为了开始克服这些障碍,欧洲共同体建立了欧洲健康数据空间(EHDS)。 这是一个特定于健康的生态系统,由通用规则、标准和实践、基础设施和治理框架组成,旨在通过增加对个人电子健康数据的数字访问和控制来增强人们的能力。 EHDS促进电子健康记录系统、相关医疗设备和高风险人工智能系统的单一市场。 最后,EHDS 旨在为利用健康数据的研究提供一个可信赖的框架来控制整个分析过程[13, 17]。 EHDS 提出的系统方法将提供共享数据和应用程序的受控池,从而使医疗领域的人工智能能够通过新一代人工智能的新坚实基础克服医疗和工程障碍,从而访问经过认证和受控的数据。基于健康的应用程序可以依靠。
鉴于 EHDS 在应用方面提供的影响,希望通过开发 MLLM 在生物医学领域开展研究的研究人员应该能够以最大限度地利用可用公共资源的方式找到并优化可用的数据集。 迄今为止,包含图像(CT 和/或 MRI)和医疗报告的数据集并不多。 最著名的数据集之一是 MedPix®111https://medpix.nlm.nih.gov/home,一个免费的开放访问在线数据库,包含医学图像、教学案例和临床主题,集成图像和文本元数据。 MedPix® 包含超过 12,000 个患者病例场景、9,000 个主题和近 59,000 张图像。 本文提出的贡献在于基于 MongoDB 的非关系数据库的新组织,它重新组织了 MedPix® 的结构,通过构建能够为训练 MLLM 创建现成的子集。 通过开发用户友好的 GUI,数据库查询得到进一步简化,该 GUI 允许用户提出她/他的查询,从而以与原始网站非常接近的方式浏览结果。 此外,我们使用 MongoDB 数据源创建一个数据集,用于训练基于 CLIP 的模型来对输入医学图像进行分类,提供有关扫描模式和所示身体部位的信息。
2相关作品
人工智能应用的医疗数据集面临着各种各样的问题,这些问题与数据和领域的特殊性有关。 首先,存在隐私问题,因为临床数据包含患者的私人信息,因此创建此类数据集的过程必须从匿名阶段开始。 为了克服这个问题,研究人员要么依靠开放获取的教科书数据,要么与医院合作创建数据集。 前两种方法依赖于匿名数据,可实现较大的可扩展性。 另一方面,与医院打交道时必须从头开始进行匿名化。 此外,与 MS-COCO [8] 等不同领域相关的其他数据集相比,多模态医疗数据存在稀缺性。
用于开发医学数据集的最常用的开放访问多模态数据库之一是 PubMed Central® (PMC)222https://www.ncbi.nlm.nih.gov/pmc/。 这是一个广泛使用的免费生物医学科学文献档案,可以通过半自动程序从中构建自己的数据集。 在 PMC 中,数据是匿名的,并且可以从图像所属的医学研究论文中提取高质量的说明文字。 从 PMC 中提取了以下多模态数据集:ROCO [12]、MedICaT [16]、PMC-OA [9]。 ROCO 包含成对的放射图像和相应的说明文字,并且它包含一个类外集以提高预测和分类性能。 MedICaT 是 ROCO 的一个不相交数据集,主要由放射学图像组成,并为子图提供手动注释。 PMC-OA 比以前的更大,它保留了各种诊断程序、疾病和结果,同时引入了子图分离。
VQA-RAD [6] 是源自 MedPix® 的数据集,它收集放射图像的子集,同时提供经域验证的问答 (QA) 对专家。
可用的高质量数据的另一个来源是教科书:PathVQA [4] 是一个视觉问答 (VQA) 数据集,它收集封闭式和开放式 QA 对,这些问答对是从病理学中提取的通过半自动化管道提供教科书和在线数字图书馆。
另一方面,像 MINIC-CXR [5]、IU-Xray [2] 和 SLAKE [10] 这样的开放获取数据集由领域专家手动注释。 MINIC-CXR和IU-Xray都是源自医院临床病例的胸片数据集。 两者都包含半结构化放射学报告,描述与之相关的图像的放射学发现。 相反,SLAKE 从不同的放射学开放数据集中收集图像,并提供由经验丰富的医生用英语和中文提供的手动注释和 QA 对。
上述数据集是多模态数据集,它们深度关注 VQA 任务。 此外,还存在一些仅提供视觉数据的专用数据集,例如 UniToChest [1] 或自由格式文本数据 [15]。 其他值得一提的作品包括将技术报告与扫描模式相结合的 UniToBrain [3],以及作为临床报告多语言数据集的 E3C 语料库 [11]。
尽管提出的 MedPix 2.0 数据集可能接近 VQA-RAD,但它们在采样策略和样本本身方面都不同。 在 Med Pix 2.0 中,我们不集成 QA 对,但可以根据数据集本身提供的结构化文本信息,遵循另一个问答对的结构来创建不同的 QA 对。 因此,可以创建更复杂的任务,例如文档摘要或理解。
对于现有的多模态数据集,MedPix 2.0:
-
1.
源自免费开放获取源,并且不存在隐私相关问题;
-
2.
提供不同身体部位的均衡 CT 和 MRI 扫描;
-
3.
对于每张图像,都提供了一个完整的结构化临床病例。
由于我们为 MedPix 2.0 中的 JSON 文档选择了标注方案,最后一点使其适用于各种任务,而不仅限于文档级检索。 不幸的是,图像以 PNG 格式提供,因此限制了 DICOM 格式的原始图像的视觉处理。
3MedPix 2.0
MedPix® 是一个免费的开放访问多模式在线数据库,包含医学图像、教学案例和临床主题,由美国国立卫生研究院 (NIH) 的国家医学图书馆 (NLM) 管理。 它主要作为医生、护士和医疗保健学生继续医学教育(CME)的支持系统。 该数据库收集了超过12,000名患者的相关临床病例。 每个病例至少包含一张医学图像,以及相应的发现、讨论笔记、诊断、鉴别诊断、治疗和随访。 文本信息以半结构化格式报告。 临床病例附有主题部分,从学术和一般角度详细讨论所研究的疾病。
在图 1 中,报告了来自 MedPix® 网站的示例。
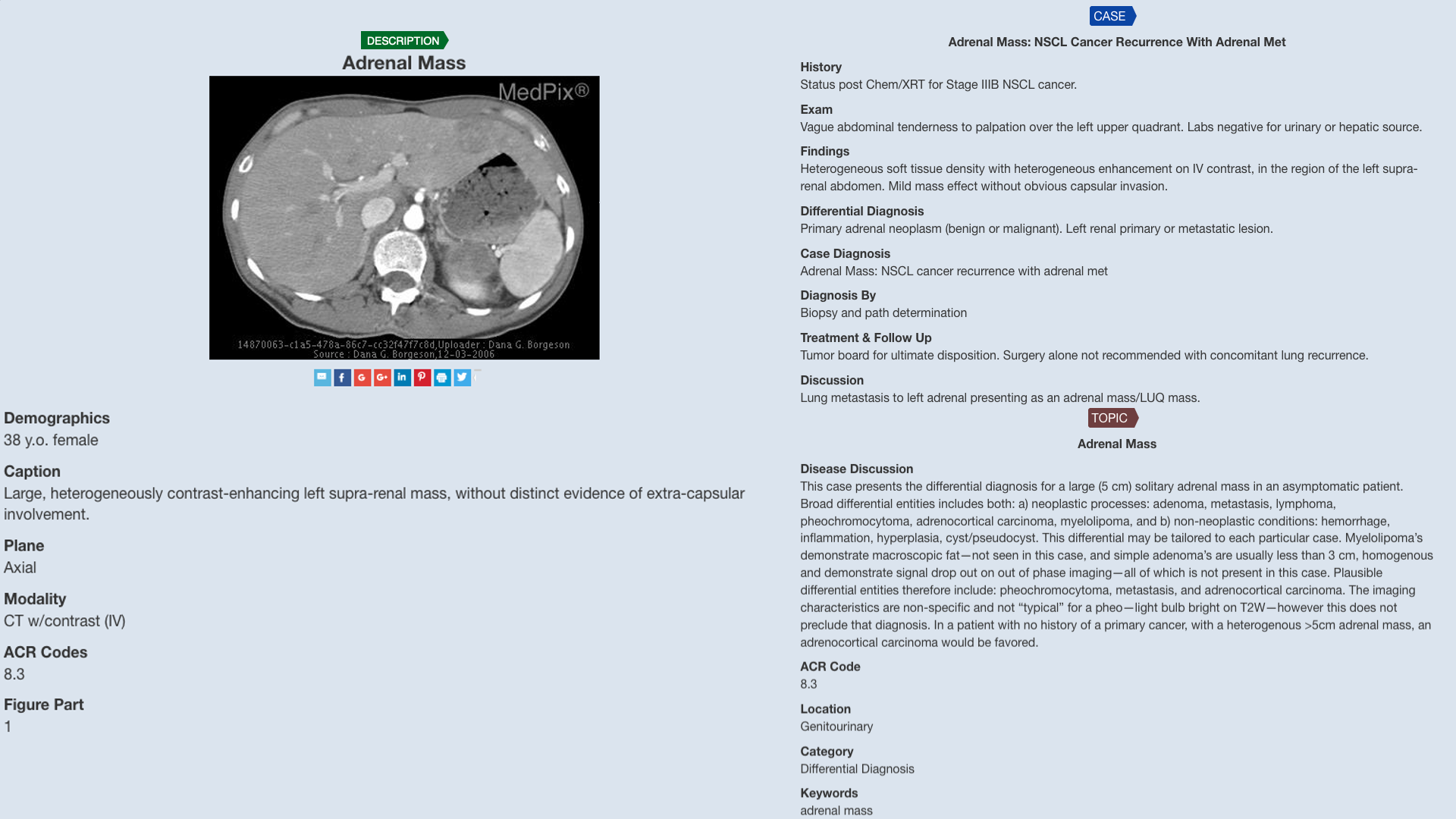
尽管数据集丰富、免费,可以添加新病例,并且可以使用关键词、身体部位或疾病来访问感兴趣的临床病例,但无法访问原始数据。 此功能限制了 MedPix® 在多模式 AI 系统中的使用。 因此,我们决定创建该数据集的全新结构化版本,因为它代表了基于人工智能的医疗应用的高质量来源。 MedPix 2.0 本质上是作为一个 MongoDB 实例构建的,它与一个合适的 GUI 一起发布,旨在通用查询和提取 AI 模型的训练数据。 参考图1,使用半自动化管道构建了 MongoDB 版本的数据集,以创建两种 JSON 文档:一种收集属于标记为 DESCRIPTION,以及收集属于标记为 CASE 和 TOPIC 的屏幕截图的信息。
3.1数据集提取
我们决定重点关注 MedPix® 的一部分,其中涉及与两种诊断方式相关的病例,即计算机断层扫描 (CT) 和磁共振成像 (MRI)。 首先,所考虑的分割中的图像是通过 Open-i® 333https://openi.nlm.nih.gov/s,以及手动删除或相应修改的噪声样本444among the downloaded images, there where pathology exams, and teaching materials like annotated slides that are useless for training a medical MLLM。 此数据清理阶段的目的是获取适合作为 MLLM 训练输入数据的图像。 实现了自动抓取管道,以使用 Selenium555https://www.selenium.dev/ 和美丽的汤666https://www.crummy.com/software/BeautifulSoup/bs4/doc/。 最后,设计了两种JSON文档来存储,分别是与图像严格相关的信息(descriptions文档)和与临床病例相关的信息(case-topic 文件)。 通过在每个描述中嵌入为病例主题文档定义的U_id,在临床病例和图像之间创建了一对多关系> 与临床病例本身相关的每张图像所附的文档。 两种 JSON 文档的示例如图 2 所示。
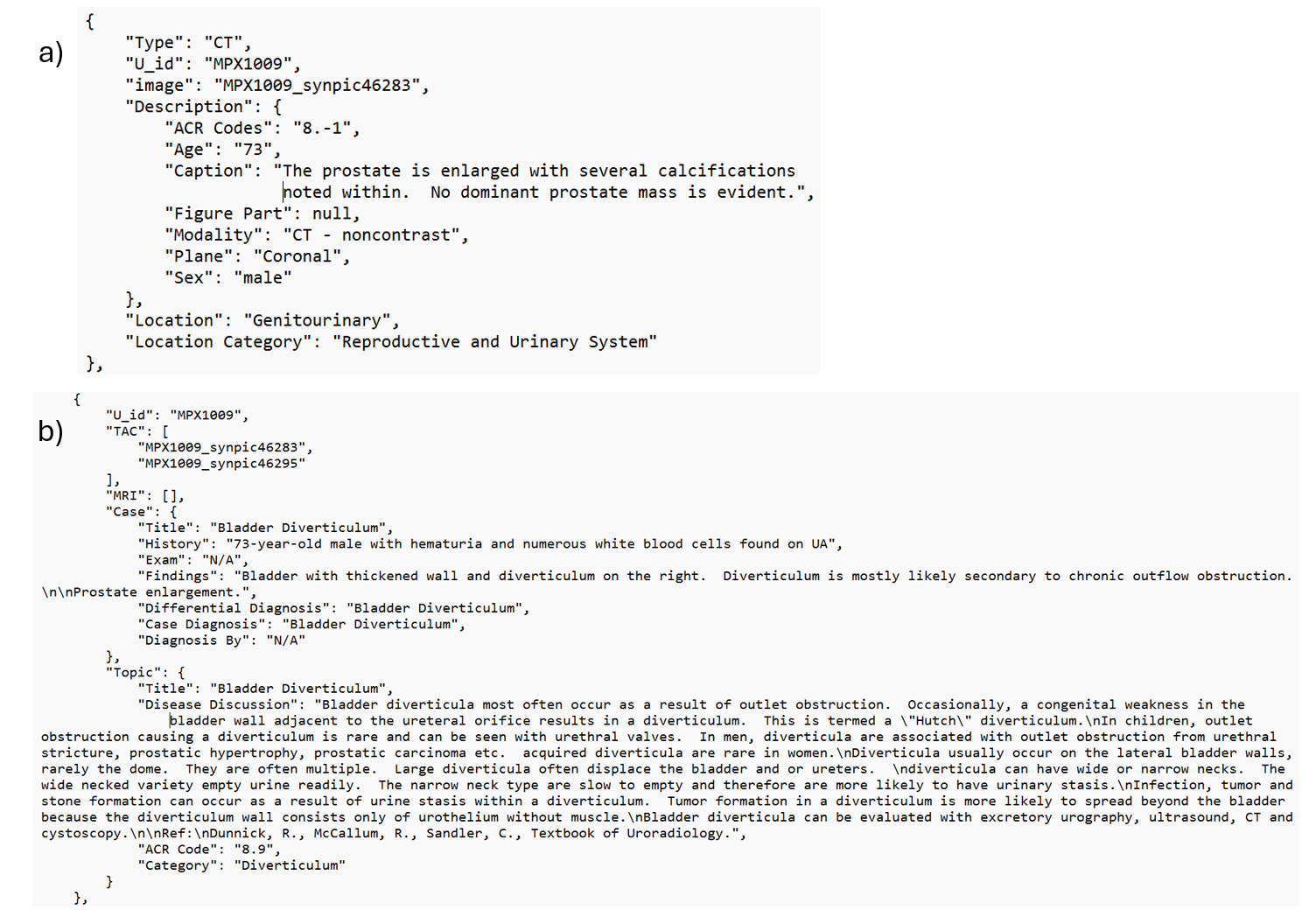
3.2MongoDB表示
为了正确处理 MedPix 2.0 中的数据,我们构建了一个 MongoDB 数据库来托管所有 JSON 文档以及图像。 架构选择不仅源于 MedPix 2.0 中数据的性质,还源于其对分布式环境的高灵活性和可扩展性的考虑,在分布式环境中,私有多模式医疗数据也可以添加到原始集合中,但不会被移走来自他们的生成站点,因为这是医院生成信息的情况。
我们构建了一个由两个集合组成的 MongoDB 实例,即包含 descriptions 文档的 Image_Descriptions 和包含所有 case-topic 的 Clinical_reports 文档。 在我们的实现中,图像存储在单独的文件夹中,并使用从 U_id 开始构建的正确 file:// URL 来访问它们。 最后,名为 Image_Reports 的视图允许通过 U_id 直接访问这两个集合。
使用 PyQt5777https://www.riverbankcomputing.com/software/pyqt/ 允许轻松访问数据库,查询数据库以获得可视化和/或下载所需的数据。 如图3(a)所示,可以选择要查询的集合或视图,并在相关字段中添加查询输入。 在图3(b)中,报告了查询答案的示例:与查询匹配的样本被报告为JSON对象列表,用户可以保存它或查看特定的临床病例和/或在查询结果列表中选择的图像。 该视图的一个示例如图4所示,其中再现了类似MedPix®的GUI,以增强原始网站用户的可用性。 在我们的 GUI 中,默认情况下会显示与文本一起抓取的精选图像,但用户可以选择下载与正在调查的临床病例相关的原始(非精选)数据。
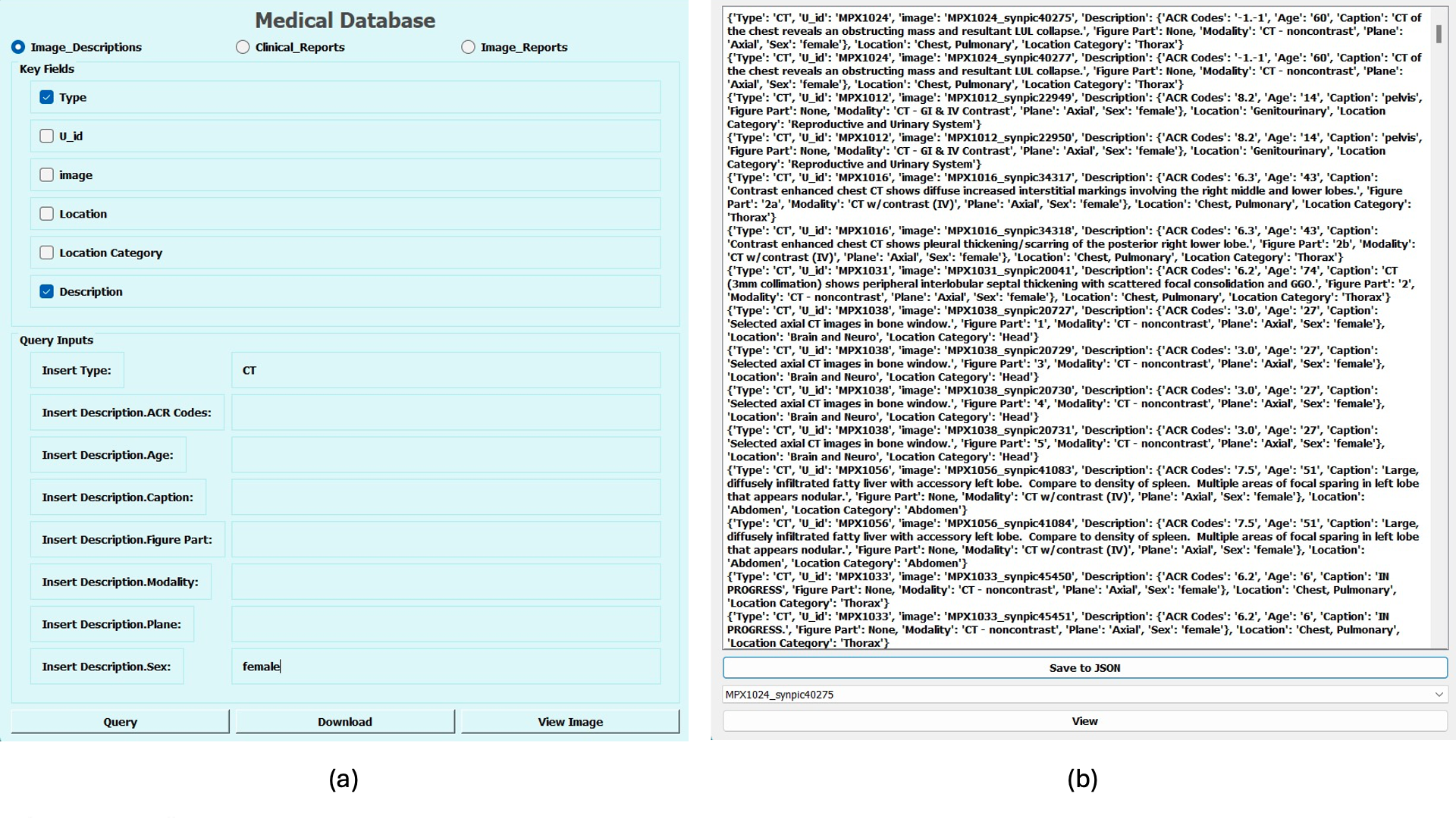
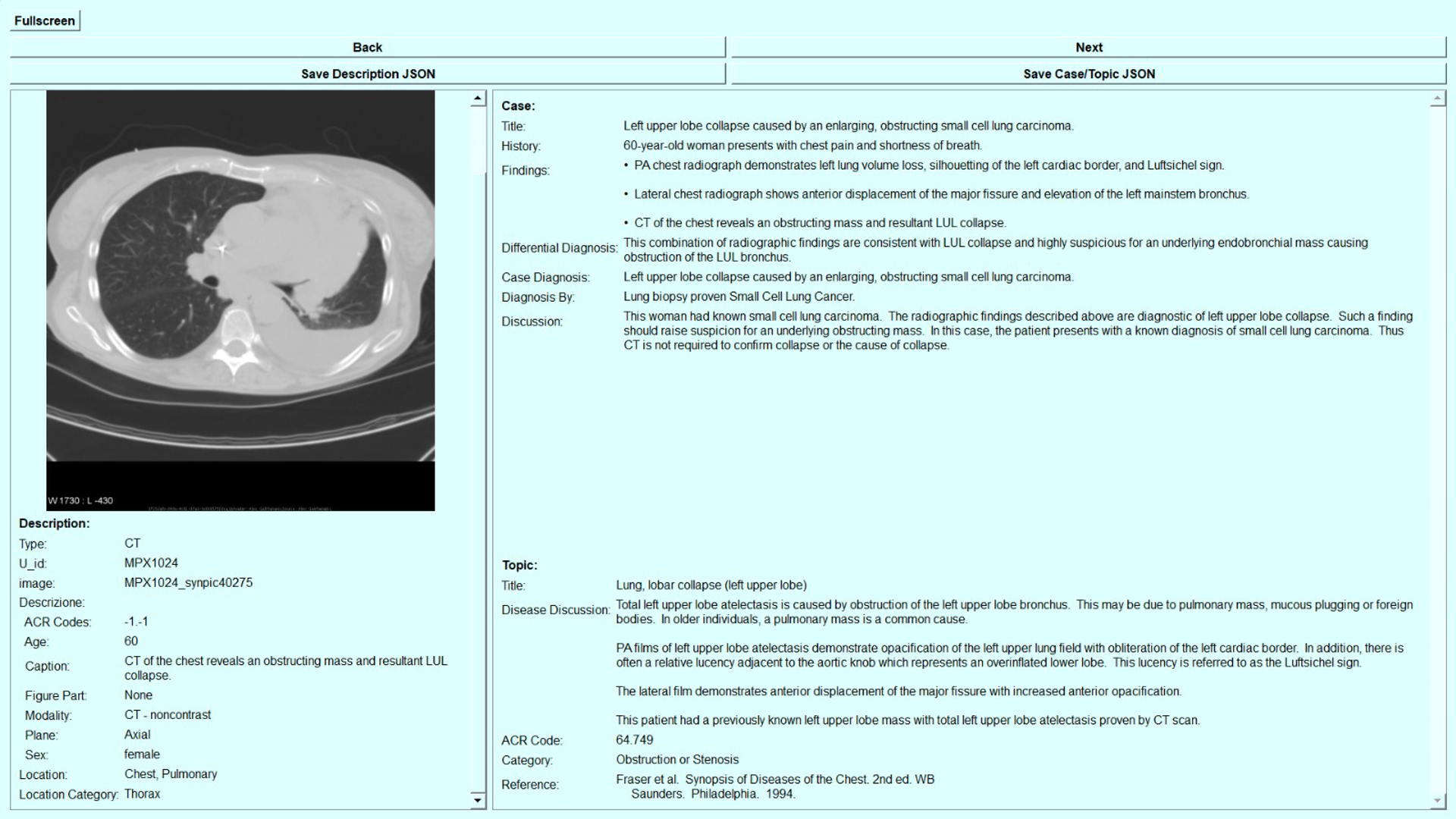
MedPix 2.0 及其查询界面对于医生和人工智能研究人员来说都是一个有效的工具,因为可以轻松下载所需的数据以供进一步应用,例如需要大量结构化数据的训练深度学习模型。 从界面下载的结构化输出可依次用于填充固定模板,并为 MLLM 提供丰富的文本提示。 如果将文本描述与相应的图像相结合,也可以解决多模态任务,正如我们将在第 4 节中演示的那样。
4 使用 MedPix 2.0 训练 MLLM
MedPix 2.0 以训练为导向的重组使得多模态深度神经网络成为可能,而无需进一步预处理数据。 为了验证这一说法,我们使用从 MedPix 2.0 提取的数据集来训练 CLIP[14],这是最新且广泛使用的多模态模型之一。 特别是,CLIP 通过学习图像与其文本描述之间的关系[18],成功地在各种分类数据集的零样本环境中取得了有竞争力的性能。 该架构的结构是众所周知的,由图像编码器和文本编码器组成。 CLIP 的训练方案与已报道的内容保持一致,并涉及使用大型图像文本对语料库的对比预训练阶段,第二阶段是创建分类器文本标签,最后训练零样本预测。其示意图如图5所示。
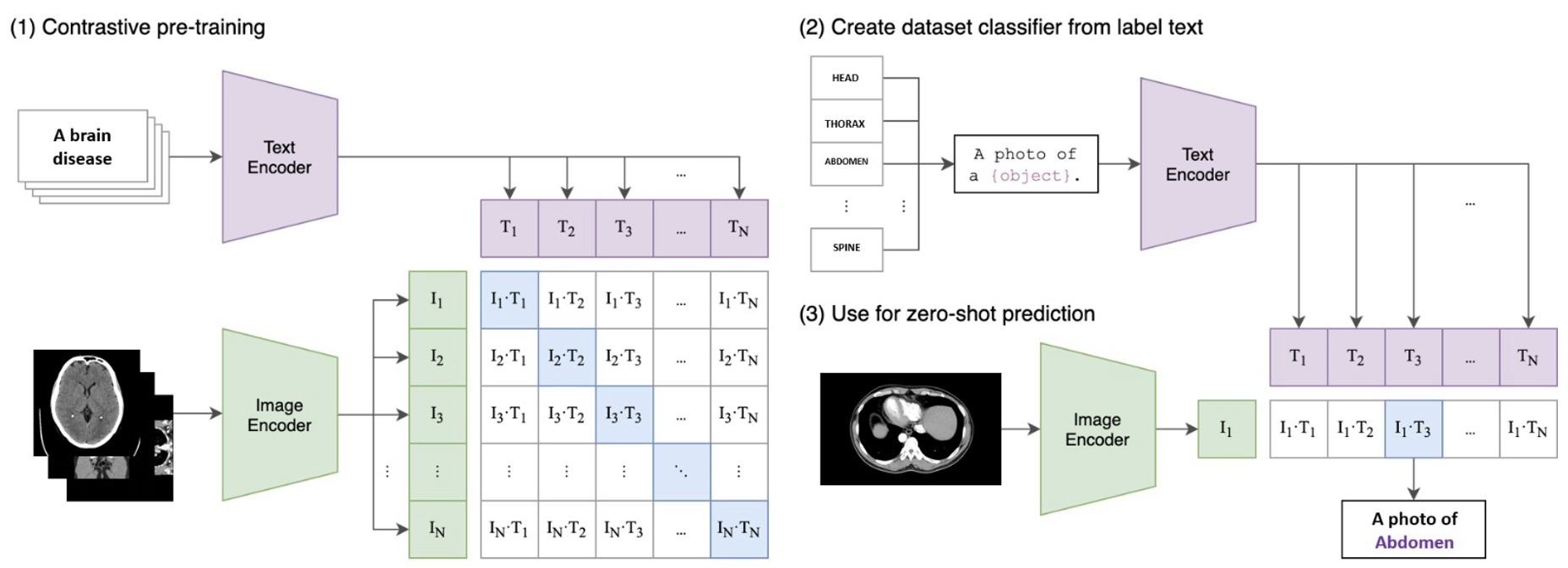
CLIP 的架构是模块化的,除了默认编码器之外,可以对视觉和文本部分使用特定的编码器。 这一特性使得 CLIP 成为一个框架,而不仅仅是一个模型。
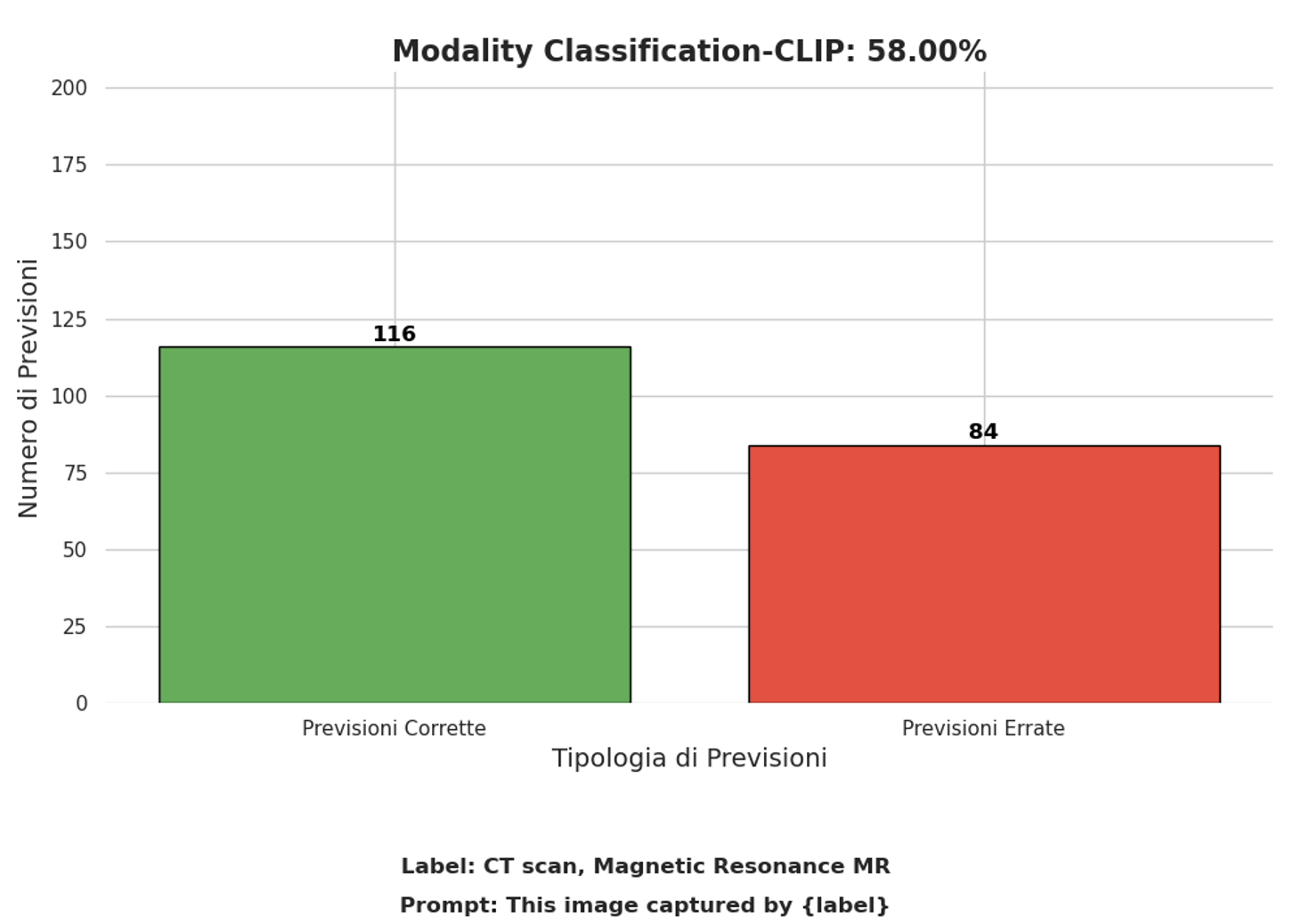
利用这一特性,我们开始了试验训练阶段,以选择最适合我们目的的视觉编码器,同时保持文本编码器不变。 具体来说,ViT-L/14 和 RN50x16 与 CLIP 的默认文本编码器结合进行了测试。 试用阶段优先使用RN50x16,并与CLIP的文本编码器进行整体测试,在扫描模态识别任务中获得了58%的准确率,如图6所示>。
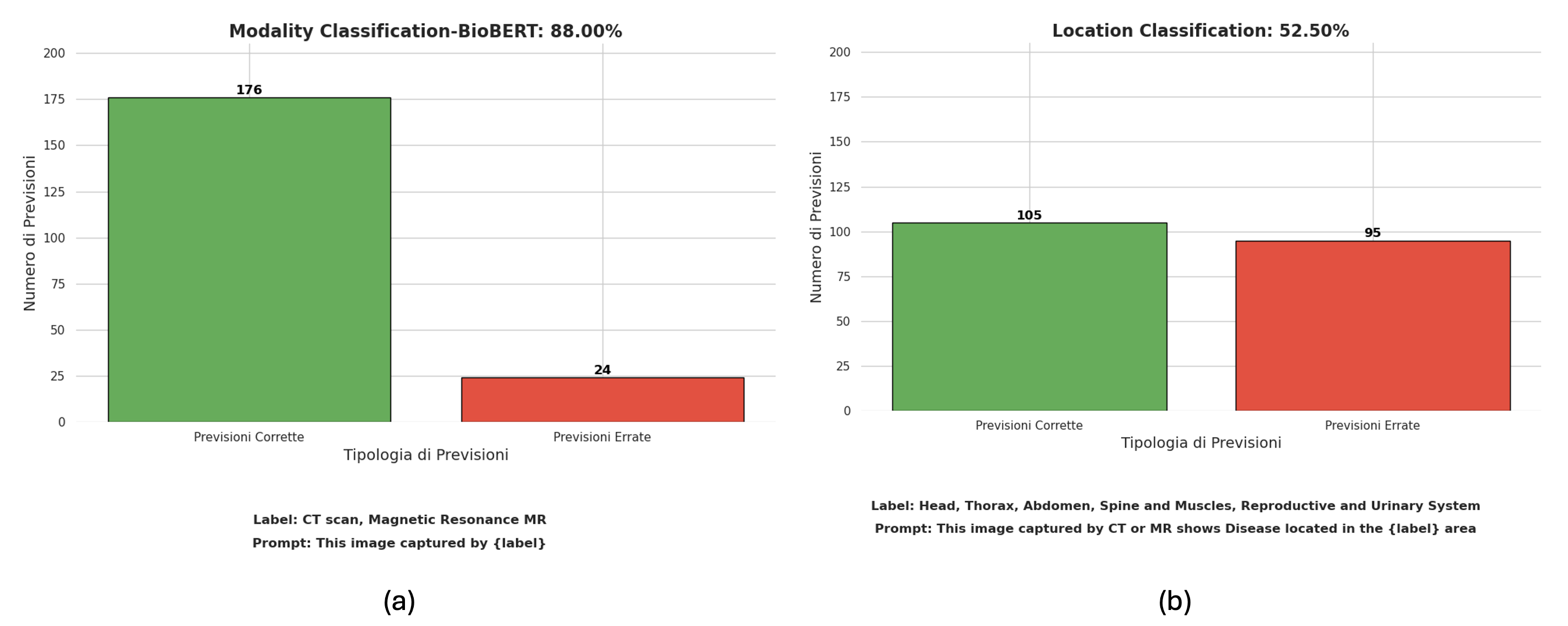
一旦确定了视觉编码器,我们就开始测试新的文本编码器 BioBERT [7],以提高整体分类性能。 BioBERT 首先使用 Mask 语言模型,通过 GUI 从 MedPix 2.0 获得的文本数据进行训练,然后与 RN50x16 编码器集成,对所选训练数据进行微调。 通过这样做,获得的性能显着提高,在扫描模态预测任务中达到了 88% 的准确率,如图7.a所示。 我们还评估了所获得的模型在位置分类任务下的性能,如图7.b所示。
5 结论和未来的工作
在本文中,我们提出了 MedPix 2.0,这是一个临床报告、CT 和 MR 扫描的多模式数据集。 我们设计了一个半自动化管道来下载和管理原始数据集中的图像,同时将文本信息构建为一组 JSON 文档集合,这些集合用于构建适当的 MongoDB 实例。 可以使用我们开发的可用 GUI 来访问和查询 NoSQL 版本的数据集。 使用 GUI,人们可以以与原始 MedPix® 相同的方式浏览数据集,并可以下载适合训练 AI 模型的查询的结构化输出。 为了证明这一点,我们开发了一个基于 CLIP 的模型,用于 CT/MR 扫描的多模式分类,涉及扫描模式和输入切片中显示的身体部位。
我们认为,所提供的数据集及其 MongoDB 界面代表了医学领域 AI 多模态模型开发的相关起点,例如为临床报告量身定制的信息提取系统、医学图像的自动分析或用于临床的生成 AI 模型报告生成作为医疗决策支持系统的一部分。 所有这些系统都可以依赖 MedPix 2.0 作为结构化数据源,其中包含有关所发现疾病的临床病例和医学解释。
结构化 JSON 文档还编码该领域的隐式知识。 我们目前正在开发一种生成模型,该模型依赖于 MedPix 2.0 构建的知识图谱 (KG),根据一些基本知识信息生成诊断结果。 通过分析 JSON 文档的键检索到的信息可以轻松地构造为通过表示节点之间关系的边连接的节点(患者、诊断、治疗、检查等),并通过在节点或边级别添加属性来丰富信息。 这种数据的重新组织可以显示一些否则无法轻易识别的关系模式,并且除了基于人工智能的应用程序之外,医生还可以使用适当的 GUI 来浏览开发的图表以用于诊断或研究目的。 所开发的 MongoDB 数据库的可扩展性使其适合未来的扩展,可以添加必须符合隐私法规并遵循所需信息结构的新临床病例。 此外,MongoDB 固有的分布式特性允许在不同病房创建庞大的数据库,其中单个机构拥有的数据不需要明确地移出医院,从而违反隐私法规。 MedPix 2.0 的结构还可以作为开发合适的连接器以共享 EHDS 中允许的数据的指南。 新案例还可以轻松添加到知识图谱中,通过检索增强生成(RAG)方法在更复杂的管道中查询和使用知识图谱,以检索相关信息,从而通过生成大语言模型生成更精确的报告。 界面也得到了进一步的改进,为用户提供了先进的数据可视化工具,例如交互式比较类似病例的可能性,从而在诊断阶段为医生提供帮助。
5.1 数据和代码可用性
源代码可在 https://github.com/CHILab1/MedPix-2.0.git 免费获取。 用于测试和训练的数据可以通过以下链接从 zenodo 存储库免费下载 https://zenodo.org/records/12624810?token=eyJhbGciOiJIUzUxMiJ9.eyJpZCI6ImZmNjdlMjExLTc2NjQtNDRkNy1hZDU0LTRjNmVjN2YxMzE5NSIsImRh dGEiOnt9LCJyYW5kb20iOiJlMzAxNjM4MDdlZjA0Y2JjZGZhMzQzNTgwMDU5ZGQ3OCJ9.1G5h-jxdM_wy1Oq61UbXhSWVShcIw5-iq4obuX5wFh9xvKrs8LcgkdUEgR3n_YuDd zv59N156f_kILTHpDoHxw
5.1.1 致谢
这项工作得到了杯项目 B73C22000810001、项目代码 ECS_00000022“SAMOTHRACE”(西西里微纳米技术研究与创新中心)的支持。
5.1.2
作者声明,他们没有与本文所述研究相关的相关或重大经济利益。
参考
- [1] Chaudhry, H.A.H., Renzulli, R., Perlo, D., Santinelli, F., Tibaldi, S., Cristiano, C., Grosso, M., Limerutti, G., Fiandrotti, A., Grangetto, M., et al.: Unitochest: A lung image dataset for segmentation of cancerous nodules on ct scans. In: International Conference on Image Analysis and Processing. pp. 185–196. Springer (2022)
- [2] Demner-Fushman, D., Kohli, M.D., Rosenman, M.B., Shooshan, S.E., Rodriguez, L., Antani, S., Thoma, G.R., McDonald, C.J.: Preparing a collection of radiology examinations for distribution and retrieval. Journal of the American Medical Informatics Association 23(2), 304–310 (2016)
- [3] Gava, U., D’Agata, F., Bennink, E., Tartaglione, E., Perlo, D., Vernone, A., Bertolino, F., Ficiarà, E., Cicerale, A., Pizzagalli, F., Guiot, C., Grangetto, M., Bergui, M.: Unitobrain (2021). https://doi.org/10.21227/x8ea-vh16, https://dx.doi.org/10.21227/x8ea-vh16
- [4] He, X., Zhang, Y., Mou, L., Xing, E., Xie, P.: Pathvqa: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286 (2020)
- [5] Johnson, A.E., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Mark, R.G., Horng, S.: Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data 6(1), 317 (2019)
- [6] Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific data 5(1), 1–10 (2018)
- [7] Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C.H., Kang, J.: Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 36(4), 1234–1240 (Feb 2020). https://doi.org/10.1093/bioinformatics/btz682, arXiv:1901.08746 [cs]
- [8] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. pp. 740–755. Springer (2014)
- [9] Lin, W., Zhao, Z., Zhang, X., Wu, C., Zhang, Y., Wang, Y., Xie, W.: Pmc-clip: Contrastive language-image pre-training using biomedical documents. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 525–536. Springer (2023)
- [10] Liu, B., Zhan, L.M., Xu, L., Ma, L., Yang, Y., Wu, X.M.: Slake: A semantically-labeled knowledge-enhanced dataset for medical visual question answering. In: 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI). pp. 1650–1654. IEEE (2021)
- [11] Magnini, B., Altuna, B., Lavelli, A., Speranza, M., Zanoli, R.: The e3c project: Collection and annotation of a multilingual corpus of clinical cases. Proceedings of the Seventh Italian Conference on Computational Linguistics CLiC-it 2020 (2020), https://api.semanticscholar.org/CorpusID:229293442
- [12] Pelka, O., Koitka, S., Rückert, J., Nensa, F., Friedrich, C.M.: Radiology objects in context (roco): a multimodal image dataset. In: Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis: 7th Joint International Workshop, CVII-STENT 2018 and Third International Workshop, LABELS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 16, 2018, Proceedings 3. pp. 180–189. Springer (2018)
- [13] Penedo, A.C.: The regulation of data spaces under the eu data strategy: Towards the ‘act-ification’ of the fifth european freedom for data? European Journal of Law and Technology 15(1) (May 2024), https://www.ejlt.org/index.php/ejlt/article/view/995
- [14] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
- [15] Schulz, S., Ševa, J., Rodriguez, S., Ostendorff, M., Rehm, G.: Named entities in medical case reports: Corpus and experiments. In: Proceedings of the Twelfth Language Resources and Evaluation Conference. pp. 4495–4500. European Language Resources Association, Marseille, France (May 2020), https://aclanthology.org/2020.lrec-1.553
- [16] Subramanian, S., Wang, L.L., Mehta, S., Bogin, B., van Zuylen, M., Parasa, S., Singh, S., Gardner, M., Hajishirzi, H.: Medicat: A dataset of medical images, captions, and textual references. arXiv preprint arXiv:2010.06000 (2020)
- [17] Terzis, P., Echeverria, E.O.S.: Interoperability and governance in the european health data space regulation. Medical Law International (Apr 2023). https://doi.org/10.1177/09685332231165692, https://journals.sagepub.com/doi/full/10.1177/09685332231165692
- [18] Van, M.H., Verma, P., Wu, X.: On large visual language models for medical imaging analysis: An empirical study (arXiv:2402.14162) (Feb 2024). https://doi.org/10.48550/arXiv.2402.14162, http://arxiv.org/abs/2402.14162, arXiv:2402.14162 [cs]