InternLM-XComposer-2.5:支持长上下文输入和输出的多功能大视觉语言模型
摘要
我们推出了 InternLM-XComposer-2.5 (IXC-2.5),这是一种支持长上下文输入和输出的多功能大视觉语言模型。 IXC-2.5在各种文本图像理解和合成应用中表现出色,仅用7B大语言模型后端即可实现GPT-4V级别的能力。 它经过 24K 交错图像文本上下文的训练,可以通过 RoPE 外推无缝扩展到 96K 长上下文。 这种长上下文功能使 IXC-2.5 在需要大量输入和输出上下文的任务中表现出色。 与之前的2.0版本相比,InternLM-XComposer-2.5在视觉语言理解方面有了三大升级:(1)超高分辨率理解,(2)细粒度视频理解,(3)多回合多图像对话。 除了理解之外,IXC-2.5 还扩展到两个引人注目的应用程序,使用额外的 LoRA 参数进行文本图像合成:(1) 制作网页和 (2) 撰写高质量的文本图像文章。 IXC-2.5 已在 28 个基准测试中进行了评估,在 16 个基准测试中优于现有的开源最先进模型。 它还在 16 个关键任务上超越或与 GPT-4V 和 Gemini Pro 紧密竞争。 InternLM-XComposer-2.5 可在 https://github.com/InternLM/InternLM-XComposer 上公开获取。
1简介
大型语言模型 (大语言模型) [111, 29, 146, 147, 55, 121] 的最新进展激发了人们对大型视觉语言模型 (LVLM) 开发的兴趣[112 、41、183、31、173、84]。 GPT-4 [112]、Gemini Pro 1.5 [41] 和 Claude 3 [3] 等领先范例已经取得了相当大的成功,并显着扩大了大语言模型的应用范围。 开源 LVLM 也在快速开发,并且可以在多个基准测试中与专有 API 竞争。 然而,这些开源模型在多功能性方面仍然落后于闭源领先范例。 他们缺乏执行各种视觉语言理解和写作任务的能力,这主要是由于训练语料库的多样性有限以及管理长上下文输入和输出方面的挑战。
为了进一步缩小专有 API [112, 41] 和开源大视觉语言模型之间的差距,我们推出了 InternLM-XComposer-2.5 (IXC-2.5),这是一种支持长上下文的多功能 LVLM具有不同理解和组合能力的输入和输出。 IXC-2.5 优于现有开源 LVLM,具有两个优势。 (1) 多功能性:IXC-2.5支持与理解和写作相关的广泛任务,例如自由格式的文本图像对话、OCR、视频理解、插图文章写作和网页制作。 (2) 输入和输出的长上下文能力: 它使用 24K 交错的图像文本数据进行原生训练,其上下文窗口可以通过位置编码外推[94]扩展到 96K,从而支持长期的人机交互和内容创建。
受益于长上下文能力,与之前的2.0版本[33]相比,IXC-2.5升级了三个理解能力: (1)超高分辨率理解: IXC-2.5 使用原生 560 × 560 ViT 视觉编码器增强了 IXC2-4KHD [34] 中提出的动态分辨率解决方案,支持任何长宽比的高分辨率图像。 (2)细粒度的视频理解: IXC-2.5将视频视为由数十至数百帧组成的超高分辨率合成图片,使其能够通过密集采样和每帧更高分辨率来捕捉精细细节。 (3)多轮多图对话: IXC-2.5支持自由形式的多轮多图像对话,使其能够在多轮对话中自然地与人类互动。
除了理解之外,IXC-2.5 还通过结合用于文本图像合成的额外 LoRA 参数来支持两个值得注意的应用: (1)制作网页: IXC-2.5 可轻松应用于通过按照文本图像指令编写源代码(HTML、CSS 和 JavaScript)来创建网页。 (2) 撰写高质量的图文文章: 与 IXC-2 相比,IXC-2.5 利用专门设计的思想链 (CoT) [153] 和直接偏好优化 (DPO) [124] 技术,显着提高了提高其书面内容的质量。
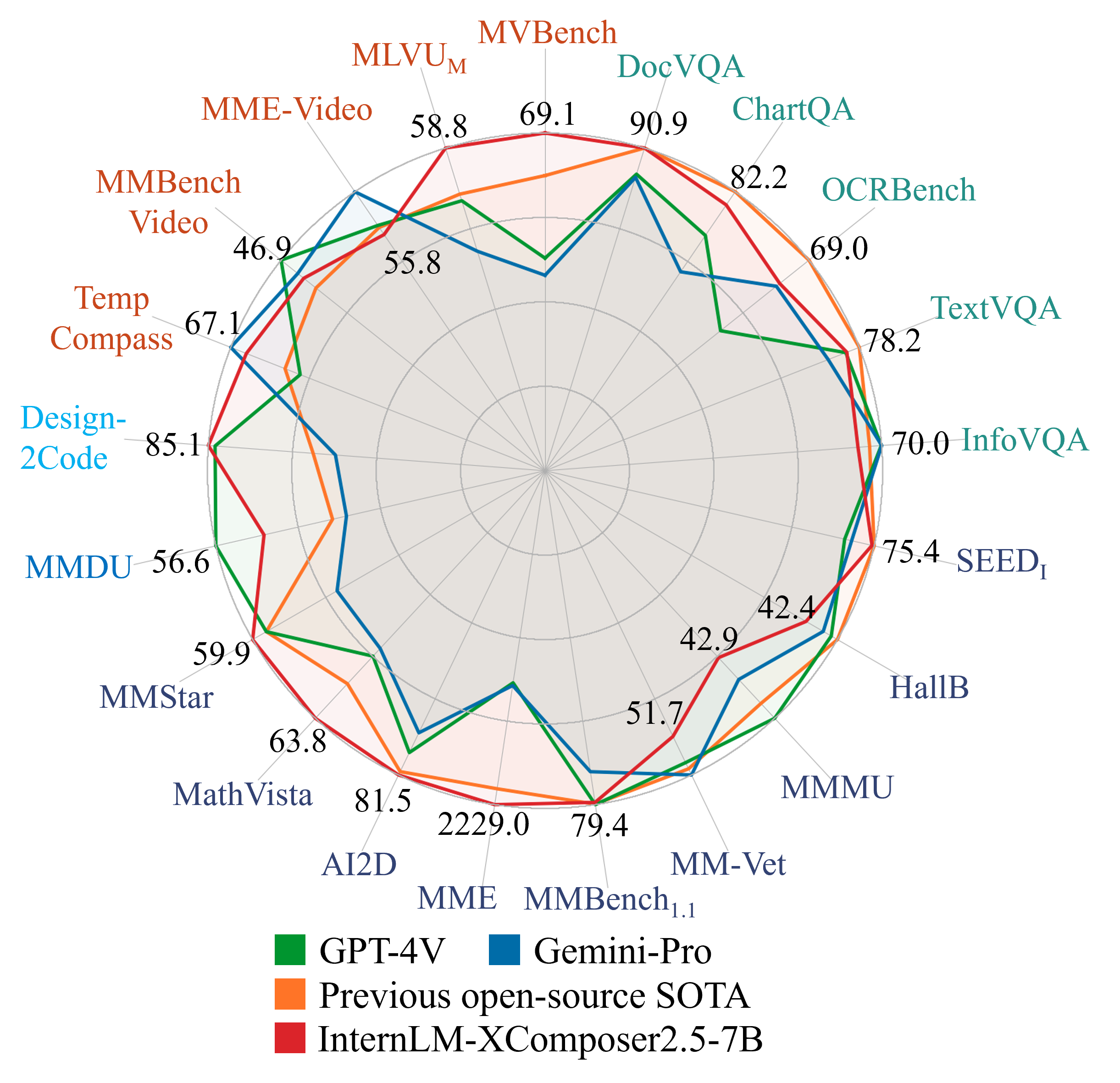
我们通过 28 个基准测试评估了 InternLM-XComposer-2.5 (IXC-2.5) 的多功能性,其中包括 5 个视频基准测试 [71, 181, 42, 38, 88]、9 个结构性高基准测试- 分辨率基准[107, 106, 108, 133, 89, 139, 117, 140, 20],十二个通用VQA基准[18, 100, 166, 61, 40, 87, 66, 164, 44, 155],一项多真多图像基准测试 [92],以及一项网页制作基准测试 [131]。 与之前的开源 LVLM 相比,IXC-2.5 在基于 InternLM2-7B [143] 后端的 28 个基准测试中的 16 个中取得了最先进的结果。 如图1所示,IXC-2.5的性能匹配甚至超越专有API,例如.、GPT-4V [ 112] 和 Gemini Pro [41],在 16 个基准测试中。
IXC-2.5 Web 演示现在支持使用开源工具[123, 179]进行音频输入和输出。 您可以在 https://huggingface.co/spaces/Willow123/InternLM-XComposer 尝试。



2相关作品
用于文本-图像对话的 LVLM。 大语言模型[12, 115, 111, 29, 60, 146, 147, 55, 143, 168, 8, 121, 13]因其令人印象深刻的性能而受到广泛关注语言理解和生成的表现。 大型视觉语言模型 (LVLM) [112, 24, 22, 23, 35, 41, 183, 31, 173, 9, 68, 118, 159, 5, 34, 78]大语言模型与视觉编码器集成开发[122, 170, 138, 169, 113, 167, 91, 25, 17, 79, 6, 150, 33, 14, 93, 26, 176] 扩展理解视觉内容的能力,实现文本图像对话的应用。 大多数现有的 LVLM 都是针对单图像多轮对话进行训练的,而一些作品[2,6,178,136,78,56]具有理解多图像输入的能力。 然而,IXC-2.5专注于提供自由形式的长上下文多轮多图像交互体验[92,86,103],这一点尚未得到解决。
用于高分辨率图像分析的 LVLM。 理解高分辨率图像具有重要的潜在应用,例如 OCR 和文档/图表分析,这在 LVLM 领域引起了越来越多的关注。 在最近的工作中,有两种主要策略来实现高分辨率理解:(1)高分辨率(HR)视觉编码器[102,151,47,74,141,177]直接支持更高的分辨率分辨率图像。 (2)补丁化:将高分辨率图像裁剪成补丁[76,90,157,158,49,79,67,79,85,158,34]。 每个补丁都使用低分辨率视觉编码器进行处理,例如。,CLIP [122],并且补丁的视觉嵌入进一步连接作为输入大语言模型后端。 IXC-4KHD [34] 首次将开源 LVLM 支持的分辨率扩展到 4K 及以上。 IXC-2.5 将这两种解决方案与经过 560x560 分辨率训练的视觉编码器和 IXC2-4KHD [34] 中提出的动态分辨率解决方案相结合,从而实现了进一步的改进。
用于视频理解的 LVLM。 除了图像理解之外,LVLM 领域在视频分析方面也取得了新进展[70,110,88,37,39,134,135]。 为了处理复杂的视频输入,现有的作品使用稀疏采样或时间池[77,104,101,52,162],压缩视频标记[69,172,57,154,73, 120],记忆库[134,45,135],以及作为视频理解桥梁的语言[59,54,171]。 除了这些特定于视频的设计之外,还可以制定视频分析来理解由采样视频帧[63,156,174]组成的高分辨率合成图片。 受益于理解超高分辨率图像和长上下文的能力,IXC-2.5 在 LVLM 的各种视频基准测试中表现出强大的性能。
网页生成。 Pix2Code [10] 提出了一种利用 CNN 和 RNN 进行 UI 到代码转换的端到端解决方案。 当应用于现实世界的 UI 时,这种方法可以应对复杂的视觉编码和广泛的文本解码带来的挑战。 在最近的进展中,Sightseer [64]、DCGen [148] 和 Design2Code [131] 等作品都采用了大视觉-在合成屏幕截图-HTML 配对数据集(例如 WebSight v0.1 或 v0.2 [64])上训练的语言模型,以促进 HTML 代码生成。 然而,合成的网页数据集因其简单性和缺乏多样性而受到批评。 这些研究通常集中在屏幕截图/草图到代码任务上。 相比之下,我们的 IXC-2.5 模型扩展了这些功能,包括屏幕截图到代码、指令感知网页生成和恢复到主页任务。 IXC-2.5 结合使用高质量的合成数据和真实网络数据进行训练。 此外,IXC-2.5能够熟练生成JavaScript代码,从而能够开发交互式前端网页。
偏好对齐。 人类反馈强化学习 (RLHF) [115] 和人工智能反馈强化学习 (RLAIF) [7] 在跨不同领域调整大语言模型方面表现出了巨大的前景,包括提高逻辑推理能力并生成有用且无害的输出。 典型的方法包括使用人类或人工智能偏好数据训练奖励模型,并使用近端策略优化 (PPO)[126] 等优化算法微调大语言模型,以最大化预期奖励函数。 或者,直接偏好优化 (DPO) [124] 和以下工作 [116, 36] 已成为隐式表示奖励分数并消除对单独的奖励模型。 基于 RLHF 和 RLAIF 在大语言模型中的成功,最近的研究成功地将 RLHF/RLAIF 算法扩展到多模态 LVLM [72, 163, 182, 180, 119] 以减少幻觉。 在这项工作中,我们研究了偏好对齐技术在文本图像文章合成任务中的应用,重点是生成高质量且稳定的响应结果。
3方法
3.1模型架构
InternLM-XComposer-2.5(以下简称IXC-2.5)的模型架构主要遵循InternLM-XComposer2 [33]和InternLM-XComposer2-4KHD [34]<的设计/t1>(为简单起见,IXC2 和 IXC2-4KHD),包括轻量级视觉编码器 OpenAI ViT-L/14 [122]、大型语言模型 InternLM2-7B [13] 和 Partial LoRA [33] 以实现高效对齐。 我们建议读者阅读 IXC2 和 IXC2-4KHD 论文以了解更多详细信息。
3.2 多模态输入
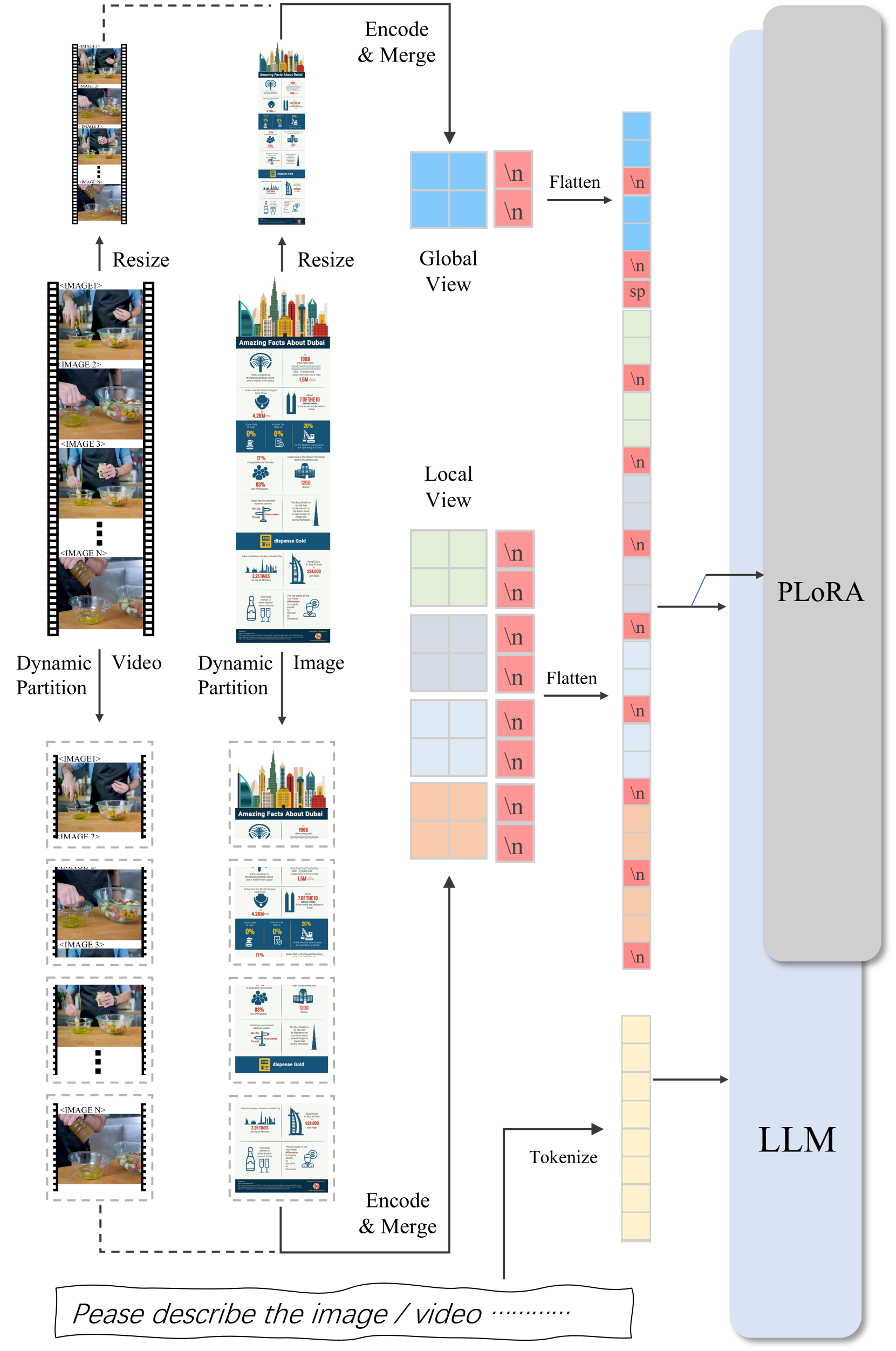
我们的 IXC-2.5 支持多种输入方式,包括文本、单/多图像和视频。 如图5所示,对于任意分辨率和长宽比的视频和多幅图像均采用统一动态图像分区策略。
图像处理。 我们主要遵循 IXC2-4KHD [34] 中使用的动态图像分区和全局本地格式设计,并进行一些修改。 对于视觉编码器,我们重用了IXC2中使用的分辨率的ViT,并进一步将其分辨率提高到,使得每个子图像有400个token。
对于高分辨率策略,我们将 IXC-4KHD 中使用的不同策略统一为缩放身份策略。 在给定最大分区编号 的情况下,大小为 的图像 被调整大小并填充为大小为 的新图像 。 此过程受到以下限制:
| (1) | ||||
| (2) | ||||
| (3) |
其中 是比例因子, 和 分别表示每行和每列中的面片数量。
对于多图像输入,我们为每个图像分配一个索引,例如 IMAGE i、 并格式化图像和交错格式的文本。
视频处理。 我们从给定视频中采样帧,并将它们沿着帧的短边连接起来,从而产生高分辨率图像。 帧索引也被写入图像中以提供时间关系。
音频处理。 IXC-2.5 Web 演示支持使用开源工具的音频输入和输出。 对于音频输入,我们使用 Whisper [123] 将音频转录为文本。 对于音频输出,我们利用 MeloTTS [179] 将文本转换回音频。
3.3预训练
| Task | Dataset |
|---|---|
| General Semantic Alignment | ShareGPT4V-PT [17], COCO [21], Nocaps [1], TextCaps [132], LAION [125], SBU [114], CC 3M [129] ALLaVA [15] |
| World Knowledge Alignment | Concept Data [173] |
| Vision Capability Enhancement | WanJuan [46], Flicker[160], MMC-Inst[82], RCTW-17[130], CTW[165], LSVT[137], ReCTs[175], ArT[28] |
在预训练阶段,大语言模型 (InternLM2-7B [143]) 被冻结,同时视觉编码器和 Partial LoRA [33] 进行微调将视觉标记与大语言模型对齐。 预训练使用的数据如表1所示。
在实践中,我们采用 IXC2 的 CLIP ViT-L-14-490 [122] 作为视觉编码器,并将其分辨率进一步提高到 。 对于统一动态映像分区策略[34],我们设置了相关的最大数量。 对于部分LoRA [33],我们为大语言模型解码器块中的所有线性层设置等级。 我们的训练过程涉及 4096 的批量大小,跨越 2 个时期。 在训练步骤的第一个 内,学习率线性增加到 。 此后,它根据余弦衰减策略减小到 。 为了保留视觉编码器的原始知识,我们应用分层学习率(LLDR)衰减策略[33],并将衰减因子设置为。
3.4 监督微调
| Task | Dataset |
|---|---|
| Caption | ShareGPT4V [17], COCO [21], Nocaps [1] |
| General QA | VQAv2 [4], GQA [53], OK-VQA [105] |
| VD [32], RD [16], VSR [81], ALLaVA-QA [15] | |
| Multi-Turn QA | MMDU [92] |
| Science QA | AI2D [61], SQA [98], TQA [62], IconQA [97] |
| Chart QA | DVQA [58], ChartQA [106], ChartQA-AUG [106] |
| Math QA | MathQA [161], Geometry3K [96], TabMWP [99], |
| CLEVR-MATH [80], Super [75] | |
| World Knowledge QA | A-OKVQA [127], KVQA [128], ViQuAE [65] |
| OCR QA | TextVQA [133], OCR-VQA [109], ST-VQA [11] |
| HD-OCR QA | InfoVQA[108], DocVQA [107], TabFact [20], |
| WTQ [117], DeepForm [139], Visual MRC [140] | |
| Video | ShareGPT4Video [19], ActivityNet [37] |
| Conversation | LLaVA-150k [84], LVIS-Instruct4V [149] |
| ShareGPT-en&zh [27], InternLM-Chat [143] |
我们使用表2中列出的数据来模拟模型。 统一动态图像分区策略的最大数量为,以处理极大的图像和视频。 对于视频数据集,IXC-2.5 使用最多 64 帧连接的大图像进行训练。 最大的训练上下文设置为 24,000 上下文窗口大小,其中 MMDU [92] 数据集可以实现此限制。 在实践中,我们通过 4000 个步骤联合训练批量大小为 2048 的所有组件。 来自多个源的数据以加权方式采样,权重基于每个源的数据数量。 最大学习率设置为,每个组件都有自己独特的学习策略。 对于视觉编码器,我们将 LLDR 训练设置为 ,这与预策略一致。 对于大语言模型,我们采用固定的学习率比例因子。 这减缓了大语言模型的更新速度,在保留其原有能力和与视觉知识保持一致之间取得了平衡。
3.5 网页生成
我们增强了 IXC-2.5 的功能,包括自动网页生成。 具体来说,IXC-2.5 现在能够根据视觉屏幕截图、一组自由格式指令或简历文档形式的输入,利用 HTML、CSS 和 JavaScript 自主构建网页。 当前的开源通用大型语言模型在生成 HTML 和 CSS 方面经常表现出相对于其自然语言生成能力而言的次优性能。 为了解决这个限制,我们建议使用 WebSight v0.1/v0.2 [64] 和 Stack v2 [95] 中的广泛数据集来训练屏幕截图到代码任务>。 随后,我们使用一个更小的、精心制作的数据集来构建模型,该数据集由指令感知网页生成和个人页面生成示例组成。
屏幕截图到代码。 除了 WebSight [64] 数据集之外,我们还对 Stack v2 [95] 数据集中的 HTML 和 CSS 代码进行预处理,以方便屏幕截图到代码的训练。 最初,我们将 CSS 和 HTML 代码合并到一个文件中。 随后,我们删除所有评论、JavaScript 代码和外部链接。 此外,我们消除了 HTML 代码未引用的任何 CSS 样式。 我们将所有文件转换为屏幕截图,随后丢弃那些未成功渲染的文件。 然后使用 IXC2-4KHD [34] 模型处理剩余的屏幕截图,以评估网页的质量。 排除低质量网页后,我们保留了最后一组剩余的三个约25万个高质量网页。
我们利用上述三个数据集对 LoRA 模型进行训练。 LoRA 等级设置为 512。 训练协议采用的批量大小为 512,并在单个 epoch 上执行。 最初,学习率在训练迭代的第一个 内线性增加到 。 随后,学习率按照余弦衰减时间表降低至 。
指令感知网页生成。 大型语言模型的一个关键属性在于它们遵循人类指令的能力。 为了促进基于自由格式指令的网页生成,我们建议通过查询闭源大语言模型来构造数据。 具体来说,我们利用 GPT-4 生成用于网页创建的各种指令和概念,包括类型、样式和布局等元素。 随后,利用这些指令来查询 Claude-3-sonnet [3] 以了解实际的网页生成过程。 这种方法产生了 18,000 个高质量、具有指令感知的样本。 此外,考虑到其简洁性,我们使用 Tailwind CSS 而不是传统 CSS。
恢复到主页。 除了指令感知网页生成之外,我们还引入了更实际的任务。 具体来说,给定一份简历,该模型旨在生成个人主页。 该主页不仅封装了简历中的信息,而且以结构良好且视觉上吸引人的格式呈现,从而改善了内容组织和美观布局。 为了生成相应的数据集,我们提出了一个想法-简历-主页数据生成管道。 最初,我们利用 GPT-4 来制作适合不同角色(例如研究人员、学生和工程师)的简历创意。 GPT-4 的任务是根据提供的想法以 Markdown 格式生成这些简历。 获得生成的简历后,我们会提示 Claude-3-sonnet [3] 根据这些简历创建相应的主页。 为了增强这些网页的交互性,还利用 Claude-3-sonnet 基于 HTML 代码生成 JavaScript 事件。 我们总共构建了一个包含 2,000 个样本的数据集。
在构建用于指令感知网页生成和恢复主页的数据集后,我们随后对 LoRA 模型进行了 10 个周期的微调。 所有其他实验设置均与屏幕截图到代码训练阶段采用的设置保持一致。
3.6文章撰写
生成高质量的文本图像文章(例如.、诗歌、小说、短篇故事和散文)是人工智能助手的一项重要能力,在日常生活中具有多种应用,包括教育和娱乐。 基于3.4节中的IXC-2.5 SFT模型,我们增强了生成高质量文本图像文章的创意写作能力。 然而,收集高质量的文本图像文章是一项罕见且昂贵的工作。 在大多数情况下,对稀缺指令数据进行直接微调可能会导致 LVLM 的响应不稳定。 为了克服这些挑战,我们提出了一个可扩展的管道,集成了监督微调、奖励建模、偏好数据收集和 DPO 对齐,以生成高质量和稳定的文章。
监督微调。 我们从 SFT 模型 (3.4 节)和来自 IXC2 [33] 的 5,000 个指令调优数据样本 的集合开始t4>,专注于文章写作。 由于指令数据规模有限,我们使用SFT模型,利用思想链(CoT)技术重写原始提示[152],生成分步提示将指令调整数据补充为扩充数据。 我们观察到,在使用这些增强提示时,SFT 模型在生成长格式响应方面更有效。 然后,我们通过 LoRA [51] 在增强指令调整数据上训练初始模型 ,等级为 并得到模型 建立对齐管道的起点。
| MVBench | MLVU | MME | MMB∗1 | Temp∗2 | Doc | Chart | Info | Text | OCR | WTQ | Deep | Visual | Tab | |
| Video | Video | Compass | VQA | QA | VQA | VQA | Bench | Form | MRC | Fact | ||||
| Open-Source | VideoChat | InternVL | LIVA | InternVL | Qwen-VL | InternVL | InternVL | InternVL | InternVL | GLM-4v | DocOwl | DocOwl | DocOwl | DocOwl |
| Previous SOTA | 2-7B[71] | 1.5-26B[26] | 34B[78] | 1.5-26B[26] | 7B[6] | 1.5-26B[26] | 1.5-26B[26] | 1.5-26B[26] | 1.5-26B[26] | 9B[43] | 1.5-8B[50] | 1.5-8B[50] | 1.5-8B[50] | 1.5-8B[50] |
| Performance | 60.4 | 50.4 | 59.0 | 42.0 | 58.4 | 90.9 | 83.8 | 72.5 | 80.6 | 77.6 | 40.6 | 68.8 | 246.4 | 80.2 |
| Closed-source API | ||||||||||||||
| GPT-4V [112] | 43.5 | 49.2 | 59.9 | 56.0 | — | 88.4 | 78.5 | 75.1 | 78.0 | 51.6 | — | — | — | — |
| Gemini-Pro [142] | — | — | 75.0 | 49.3 | 70.6 | 88.1 | 74.1 | 75.2 | 74.6 | 68.0 | — | — | — | — |
| IXC-2.5-7B | 69.1 | 58.8 | 55.8 | 46.9 | 67.1 | 90.9 | 82.2 | 69.9 | 78.2 | 69.0 | 53.6 | 71.2 | 307.5 | 85.2 |
| MMDU | MMStar | RealWQA | MathVista | AI2D | MMMU | MME | MMB | MMBCN | MMB1.1 | SEEDI | MM-Vet | HallB | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Open-Source | LLaVa1.6 | InternVL | WeMM | WeMM | InternVL | 360VL | InternVL | InternVL1.5 | InternVL1.5 | InternVL1.5 | WeMM | GLM-4v | WeMM |
| Previous SOTA | 8B[83] | 1.5-26B[26] | 8B[145] | 8B[145] | 1.5-26B[26] | 70B[144] | 1.5-26B[26] | 1.5-26B[26] | 1.5-26B[26] | 1.5-26B[26] | 8B[145] | 14B[43] | 8B[145] |
| Performance | 42.8 | 57.1 | 68.1 | 54.9 | 80.6 | 53.4 | 2,189.6 | 82.3 | 80.7 | 79.7 | 75.9 | 58.0 | 47.5 |
| Closed-source API | |||||||||||||
| GPT-4V [112] | 66.3 | 57.1 | 68.0 | 47.8 | 75.5 | 56.8 | 1,926.5 | 81.3 | 80.2 | 79.8 | 69.1 | 56.8 | 46.5 |
| Gemini-Pro [142] | — | 42.6 | 64.1 | 45.8 | 70.2 | 47.9 | 1,933.3 | 73.9 | 74.3 | 73.9 | 70.7 | 59.2 | 45.2 |
| IXC-2.5-7B | 56.6 | 59.9 | 67.8 | 63.8 | 81.5 | 42.9 | 2,229.0 | 82.2 | 80.8 | 79.4 | 75.4 | 51.7 | 42.4 |
偏好数据收集。 我们使用微调模型,使用不同的随机种子,为增强指令调整数据中的每个提示生成不同的响应。 这会产生 80,000 个提示-响应对的集合。 接下来,我们使用 GPT-4o 模型来标记 2,000 个选择或拒绝决策的响应,并给出原因,作为我们的奖励建模数据。 然后,我们在奖励建模数据上训练奖励模型 ,共享与 相同的架构。 奖励模型用于对剩余的提示响应对做出选择或拒绝的预测。 然后,使用这些选定的响应来构造数据对 ,而 、 和 引用提示、选定的响应和拒绝响应,分别。 最终,我们总共获得了 30,000 个 DPO [124] 对齐的偏好数据 。
DPO 对齐。 我们使用 DPO 算法根据偏好数据 更新目标策略上的 SFT 模型 :
| (4) | |||
在实践中,我们使用等级为的LoRA来得到DPO模型。 我们观察到,我们的模型倾向于优先考虑最小化不首选响应 的可能性,而不是最大化首选响应 的可能性,以避免生成不适当或低质量的内容。
总之,我们的可扩展管道由三个主要组件组成。 首先,我们通过将原始提示重写为增强提示来解决有限指令调整数据的挑战。 接下来,我们使用不同的随机种子生成不同的响应,从而能够探索各种创造性的可能性。 最后,我们将 DPO 算法应用于所选和拒绝的响应,以改进模型的性能。 通过我们的管道,我们的模型能够生成高质量的文章。
| Block-Match | Text | Position | Color | CLIP | Average | |
| Closed-source API | ||||||
| GPT-4V [112] | 85.8 | 97.4 | 80.5 | 73.3 | 86.9 | 84.8 |
| Gemini-Pro [142] | 80.2 | 94.6 | 72.3 | 66.2 | 83.9 | 79.4 |
| Open-source | ||||||
| WebSight VLM-8B [64] | 55.9 | 86.6 | 77.3 | 79.4 | 86.5 | 77.1 |
| CogAgent-Chat-18B [48] | 7.1 | 18.1 | 13.3 | 13.0 | 75.5 | 25.4 |
| Design2Code-18B [131] | 78.5 | 96.4 | 74.3 | 67.0 | 85.8 | 80.4 |
| IXC-2.5-7B | 81.9 | 95.6 | 80.9 | 80.8 | 86.5 | 85.1 |
4实验
在本节中,我们在监督微调后验证 InternLM-XComposer-2.5 (IXC-2.5) 的基准性能。
4.1LVLM 基准结果。
在表 3 和表 4 中,我们将 IXC-2.5 在一系列基准测试中与闭源 API 和 SOTA 开源 LVLM(模型大小相当)进行比较。 在这里,我们报告了 MVBench [71]、MLVU [181]、MME-Video [42]、MMBench-Video [38],温度罗盘[88]。 对于结构高分辨率理解,我们在 DocVQA [107]、ChartQA [106]、InfographicVQA [108]、TextVQA [133]、OCRBench [89]、DeepForm [139]、WikiTableQuestion (WTQ) [117]、Visual MRC [140] 和 TabFact [20]。 在一般视觉问题解答方面,我们报告了 MMStar [18], RealWorldQA[155], MathVista [100]、MMMU [166], AI2D [61], MME [40], MMBench (MMB) [87], MMBench-Chinese (MMBCN) [87], MMBench-v1.1 (MMBv1.1) [87], SEED-Bench Image Part (SEEDI)[66], MM-Vet [164], HallusionBench (HallB) [44]. 对于多真多图像对话,我们在 MMDU [92] 基准上评估 IXC-2.5。 对于网页制作,我们报告了一个子任务屏幕截图到代码[131],因为社区中没有其他人的基准。
评估主要在OpenCompass VLMEvalKit[30]上进行,以便统一复现结果。
视频理解基准比较。 如表 3 所示,IXC-2.5 在细粒度视频理解任务上表现出具有竞争力的性能,在 5 个基准测试中的 4 个上优于开源模型,并与闭源 API 相当。 例如,IXC-2.5 在 MVBench 上达到 69.1, 高于之前的 SOTA 方法 VideoChat2-7B,并且优于 GPT-4V,。 对于最近具有挑战性的MMBench-Video,IXC-2.5在开源模型上达到了SOTA性能,并且性能接近Gemini-Pro。
结构高分辨率基准的比较。 得益于统一的图像分区策略,IXC-2.5可以处理多种类型的图像。 表 3 报告了其在多个结构高分辨率基准上的性能。 仅 7B 参数的 IXC-2.5 的性能与当前大型开源 LVLM 和闭源 API 相当。 例如,IXC-2.5 在 DocVQA 测试集上获得 ,与 InternVL-1.5 相同,有近 个参数。 对于高度结构化的表单和表格理解任务,IXC-2.5 在 WikiTableQuestion、DeepForm 和 TableFace 上分别以 、、 优于 DocOwl 1.5-8B。
多图像多轮基准比较。 IXC-2.5能够将多个图像作为输入并基于它们进行多轮自由形式对话。 我们在新提出的 MMDU 基准[92]上对其进行定量评估。 如表4所示,IXC-2.5模型表现出优越的性能,比之前的SOTA开源模型显着领先13.8%。 这一显着的改进凸显了我们的方法在提高多图像和多轮理解能力方面的有效性。
通用视觉 QA 基准的比较。 IXC-2.5 被设计为通用 LVLM,用于处理各种多模态任务。 在这里,我们报告了它在一般视觉 QA 基准上的表现。 如表4所示,IXC-2.5 在这些基准测试中显示出卓越的性能,并且与当前大型开源 LVLM 和闭源 API 相当。 例如,IXC-2.5 在具有挑战性的 MMStar 上获得,并且优于 GPT-4V 和 Gemini-Pro。 在 RealWorldQA 上,IXC-2.5 的表现也优于 Gemini-Pro,接近 GPT-4V。
屏幕截图到代码基准的比较。 表 5 显示了 Design2Code [131] 基准测试的比较结果,该基准评估将视觉设计转化为代码实现的能力。 我们的 IXC-2.5 的平均性能甚至超过了 GPT-4v,这凸显了 IXC-2.5 在缩小视觉设计和代码实现之间差距方面的潜力。
5结论
我们推出了 InternLM-XComposer-2.5 (IXC-2.5),这是一种尖端的大视觉语言模型 (LVLM),拥有长上下文输入和输出功能,可实现超高分辨率图像理解、细粒度图像等高级功能。视频理解、多轮多图对话、网页生成、文章撰写。 我们的综合实验表明,IXC-2.5 通过相对适中的 7B 大型语言模型(大语言模型)后端实现了显着的竞争性能。
我们的模型提出了一个有前景的研究方向,可以扩展到更具上下文的多模态环境,包括长上下文视频理解(例如。,长电影)和长上下文视频理解。上下文交互历史,以更好地帮助人类进行现实世界的应用。
致谢:我们衷心感谢清华大学张超教授对音频模型和工具的建议。
参考
- Agrawal et al. [2019] Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. Flamingo: a visual language model for few-shot learning, 2022.
- Anthropic [2024] Anthropic. Claude 3 haiku: our fastest model yet, 2024. Available at: https://www.anthropic.com/news/claude-3-haiku.
- Antol et al. [2015] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: Visual question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2015.
- Awadalla et al. [2023] Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, and Ludwig Schmidt. Openflamingo: An open-source framework for training large autoregressive vision-language models. arXiv.org, 2023.
- Bai et al. [2023] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-VL: A frontier large vision-language model with versatile abilities. arXiv.org, 2023.
- Bai et al. [2022] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- Baichuan [2023] Baichuan. Baichuan 2: Open large-scale language models. arXiv.org, 2023.
- Bavishi et al. [2023] Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, and Sağnak Taşırlar. Introducing our multimodal models, 2023.
- Beltramelli [2018] Tony Beltramelli. pix2code: Generating code from a graphical user interface screenshot. In Proceedings of the ACM SIGCHI symposium on engineering interactive computing systems, 2018.
- Biten et al. [2019] Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusinol, Ernest Valveny, CV Jawahar, and Dimosthenis Karatzas. Scene text visual question answering. In ICCV, 2019.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems (NeurIPS), 33:1877–1901, 2020.
- Cai et al. [2024] Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, Xiaoyi Dong, Haodong Duan, Qi Fan, Zhaoye Fei, Yang Gao, Jiaye Ge, Chenya Gu, Yuzhe Gu, Tao Gui, Aijia Guo, Qipeng Guo, Conghui He, Yingfan Hu, Ting Huang, Tao Jiang, Penglong Jiao, Zhenjiang Jin, Zhikai Lei, Jiaxing Li, Jingwen Li, Linyang Li, Shuaibin Li, Wei Li, Yining Li, Hongwei Liu, Jiangning Liu, Jiawei Hong, Kaiwen Liu, Kuikun Liu, Xiaoran Liu, Chengqi Lv, Haijun Lv, Kai Lv, Li Ma, Runyuan Ma, Zerun Ma, Wenchang Ning, Linke Ouyang, Jiantao Qiu, Yuan Qu, Fukai Shang, Yunfan Shao, Demin Song, Zifan Song, Zhihao Sui, Peng Sun, Yu Sun, Huanze Tang, Bin Wang, Guoteng Wang, Jiaqi Wang, Jiayu Wang, Rui Wang, Yudong Wang, Ziyi Wang, Xingjian Wei, Qizhen Weng, Fan Wu, Yingtong Xiong, Chao Xu, Ruiliang Xu, Hang Yan, Yirong Yan, Xiaogui Yang, Haochen Ye, Huaiyuan Ying, Jia Yu, Jing Yu, Yuhang Zang, Chuyu Zhang, Li Zhang, Pan Zhang, Peng Zhang, Ruijie Zhang, Shuo Zhang, Songyang Zhang, Wenjian Zhang, Wenwei Zhang, Xingcheng Zhang, Xinyue Zhang, Hui Zhao, Qian Zhao, Xiaomeng Zhao, Fengzhe Zhou, Zaida Zhou, Jingming Zhuo, Yicheng Zou, Xipeng Qiu, Yu Qiao, and Dahua Lin. Internlm2 technical report. arXiv preprint arXiv:2403.17297, 2024.
- Cao et al. [2024] Yuhang Cao, Pan Zhang, Xiaoyi Dong, Dahua Lin, and Jiaqi Wang. DualFocus: Integrating macro and micro perspectives in multi-modal large language models. arXiv preprint arXiv:2402.14767, 2024.
- Chen et al. [2024a] Guiming Hardy Chen, Shunian Chen, Ruifei Zhang, Junying Chen, Xiangbo Wu, Zhiyi Zhang, Zhihong Chen, Jianquan Li, Xiang Wan, and Benyou Wang. ALLaVA harnessing gpt4v-synthesized data for a lite vision-language model. arXiv preprint arXiv:2402.11684, 2024a.
- Chen et al. [2023a] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv.org, 2023a.
- Chen et al. [2023b] Lin Chen, Jisong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. arXiv preprint arXiv:2311.12793, 2023b.
- Chen et al. [2024b] Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Are we on the right way for evaluating large vision-language models? arXiv preprint arXiv:2403.20330, 2024b.
- Chen et al. [2024c] Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, et al. ShareGPT4Video: Improving video understanding and generation with better captions. arXiv preprint arXiv:2406.04325, 2024c.
- Chen et al. [2020] Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. TabFact: A large-scale dataset for table-based fact verification. In Proceedings of the International Conference on Learning Representations (ICLR), 2020.
- Chen et al. [2015] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollar, and C. Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server, 2015.
- Chen et al. [2023c] Xi Chen, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, Sebastian Goodman, Xiao Wang, Yi Tay, Siamak Shakeri, Mostafa Dehghani, Daniel Salz, Mario Lucic, Michael Tschannen, Arsha Nagrani, Hexiang Hu, Mandar Joshi, Bo Pang, Ceslee Montgomery, Paulina Pietrzyk, Marvin Ritter, AJ Piergiovanni, Matthias Minderer, Filip Pavetic, Austin Waters, Gang Li, Ibrahim Alabdulmohsin, Lucas Beyer, Julien Amelot, Kenton Lee, Andreas Peter Steiner, Yang Li, Daniel Keysers, Anurag Arnab, Yuanzhong Xu, Keran Rong, Alexander Kolesnikov, Mojtaba Seyedhosseini, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, and Radu Soricut. Pali-x: On scaling up a multilingual vision and language model, 2023c.
- Chen et al. [2023d] Xi Chen, Xiao Wang, Lucas Beyer, Alexander Kolesnikov, Jialin Wu, Paul Voigtlaender, Basil Mustafa, Sebastian Goodman, Ibrahim Alabdulmohsin, Piotr Padlewski, Daniel Salz, Xi Xiong, Daniel Vlasic, Filip Pavetic, Keran Rong, Tianli Yu, Daniel Keysers, Xiaohua Zhai, and Radu Soricut. Pali-3 vision language models: Smaller, faster, stronger, 2023d.
- Chen et al. [2023e] Xi Chen, Xiao Wang, Soravit Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Nan Ding, Keran Rong, Hassan Akbari, Gaurav Mishra, Linting Xue, Ashish Thapliyal, James Bradbury, Weicheng Kuo, Mojtaba Seyedhosseini, Chao Jia, Burcu Karagol Ayan, Carlos Riquelme, Andreas Steiner, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, and Radu Soricut. Pali: A jointly-scaled multilingual language-image model, 2023e.
- Chen et al. [2023f] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. arXiv preprint arXiv:2312.14238, 2023f.
- Chen et al. [2024d] Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, Ji Ma, Jiaqi Wang, Xiaoyi Dong, Hang Yan, Hewei Guo, Conghui He, Botian Shi, Zhenjiang Jin, Chao Xu, Bin Wang, Xingjian Wei, Wei Li, Wenjian Zhang, Bo Zhang, Pinlong Cai, Licheng Wen, Xiangchao Yan, Min Dou, Lewei Lu, Xizhou Zhu, Tong Lu, Dahua Lin, Yu Qiao, Jifeng Dai, and Wenhai Wang. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites, 2024d.
- Chiang et al. [2023] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, 2023.
- Chng et al. [2019] Chee Kheng Chng, Yuliang Liu, Yipeng Sun, Chun Chet Ng, Canjie Luo, Zihan Ni, ChuanMing Fang, Shuaitao Zhang, Junyu Han, Errui Ding, et al. Icdar2019 robust reading challenge on arbitrary-shaped text-rrc-art. In International Conference on Document Analysis and Recognition (ICDAR), 2019.
- Chowdhery et al. [2022] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv.org, 2022.
- Contributors [2023] OpenCompass Contributors. Opencompass: A universal evaluation platform for foundation models. https://github.com/open-compass/opencompass, 2023.
- Dai et al. [2023] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- Das et al. [2017] Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, José M.F. Moura, Devi Parikh, and Dhruv Batra. Visual Dialog. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- Dong et al. [2024a] Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Xilin Wei, Songyang Zhang, Haodong Duan, Maosong Cao, Wenwei Zhang, Yining Li, Hang Yan, Yang Gao, Xinyue Zhang, Wei Li, Jingwen Li, Kai Chen, Conghui He, Xingcheng Zhang, Yu Qiao, Dahua Lin, and Jiaqi Wang. Internlm-xcomposer2: Mastering free-form text-image composition and comprehension in vision-language large model. arXiv preprint arXiv:2401.16420, 2024a.
- Dong et al. [2024b] Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Songyang Zhang, Haodong Duan, Wenwei Zhang, Yining Li, Hang Yan, Yang Gao, Zhe Chen, Xinyue Zhang, Wei Li, Jingwen Li, Wenhai Wang, Kai Chen, Conghui He, Xingcheng Zhang, Jifeng Dai, Yu Qiao, Dahua Lin, and Jiaqi Wang. Internlm-xcomposer2-4khd: A pioneering large vision-language model handling resolutions from 336 pixels to 4k hd. arXiv preprint arXiv:2404.06512, 2024b.
- Driess et al. [2023] Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. Palm-e: An embodied multimodal language model. In arXiv preprint arXiv:2303.03378, 2023.
- Ethayarajh et al. [2024] Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. KTO: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306, 2024.
- Fabian Caba Heilbron and Niebles [2015] Bernard Ghanem Fabian Caba Heilbron, Victor Escorcia and Juan Carlos Niebles. ActivityNet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
- Fang et al. [2024a] Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, and Kai Chen. MMBench-Video: A long-form multi-shot benchmark for holistic video understanding. arXiv preprint arXiv:2406.14515, 2024a.
- Fang et al. [2024b] Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, and Kai Chen. Mmbench-video: A long-form multi-shot benchmark for holistic video understanding, 2024b.
- Fu et al. [2023a] Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394, 2023a.
- Fu et al. [2023b] Chaoyou Fu, Renrui Zhang, Zihan Wang, Yubo Huang, Zhengye Zhang, Longtian Qiu, Gaoxiang Ye, Yunhang Shen, Mengdan Zhang, Peixian Chen, Sirui Zhao, Shaohui Lin, Deqiang Jiang, Di Yin, Peng Gao, Ke Li, Hongsheng Li, and Xing Sun. A challenger to gpt-4v? early explorations of gemini in visual expertise. arXiv preprint arXiv:2312.12436, 2023b.
- Fu et al. [2024] Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075, 2024.
- GLM et al. [2024] Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, et al. ChatGLM: A family of large language models from glm-130b to glm-4 all tools. arXiv preprint arXiv:2406.12793, 2024.
- Guan et al. [2023] Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. Hallusionbench: An advanced diagnostic suite for entangled language hallucination & visual illusion in large vision-language models, 2023.
- He et al. [2024] Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. arXiv preprint arXiv:2404.05726, 2024.
- He et al. [2023] Conghui He, Zhenjiang Jin, Chaoxi Xu, Jiantao Qiu, Bin Wang, Wei Li, Hang Yan, Jiaqi Wang, and Da Lin. Wanjuan: A comprehensive multimodal dataset for advancing english and chinese large models. ArXiv, abs/2308.10755, 2023.
- Hong et al. [2023] Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. arXiv preprint arXiv:2312.08914, 2023.
- Hong et al. [2024] Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. CogAgent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
- Hu et al. [2024a] Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Chen Li, Ji Zhang, Qin Jin, Fei Huang, et al. mplug-docowl 1.5: Unified structure learning for ocr-free document understanding. arXiv preprint arXiv:2403.12895, 2024a.
- Hu et al. [2024b] Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Chen Li, Ji Zhang, Qin Jin, Fei Huang, et al. mPLUG-DocOwl 1.5: Unified structure learning for ocr-free document understanding. arXiv preprint arXiv:2403.12895, 2024b.
- Hu et al. [2022] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In Proceedings of the International Conference on Learning Representations (ICLR), 2022.
- Huang et al. [2024] Suyuan Huang, Haoxin Zhang, Yan Gao, Yao Hu, and Zengchang Qin. From image to video, what do we need in multimodal llms? arXiv preprint arXiv:2404.11865, 2024.
- Hudson and Manning [2019] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Islam et al. [2024] Md Mohaiminul Islam, Ngan Ho, Xitong Yang, Tushar Nagarajan, Lorenzo Torresani, and Gedas Bertasius. Video recap: Recursive captioning of hour-long videos. arXiv preprint arXiv:2402.13250, 2024.
- Jiang et al. [2023] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023.
- Jiang et al. [2024] Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning, 2024.
- Jin et al. [2023] Peng Jin, Ryuichi Takanobu, Caiwan Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. arXiv preprint arXiv:2311.08046, 2023.
- Kafle et al. [2018] Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan. DVQA: Understanding data visualizations via question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- Kahatapitiya et al. [2024] Kumara Kahatapitiya, Kanchana Ranasinghe, Jongwoo Park, and Michael S Ryoo. Language repository for long video understanding. arXiv preprint arXiv:2403.14622, 2024.
- Kaplan et al. [2020] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Kembhavi et al. [2016] Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In Proceedings of the European Conference on Computer Vision (ECCV), 2016.
- Kembhavi et al. [2017] Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Hajishirzi. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- Kim et al. [2024] Wonkyun Kim, Changin Choi, Wonseok Lee, and Wonjong Rhee. An image grid can be worth a video: Zero-shot video question answering using a vlm, 2024.
- Laurençon et al. [2024] Hugo Laurençon, Léo Tronchon, and Victor Sanh. Unlocking the conversion of web screenshots into html code with the websight dataset. arXiv preprint arXiv:2403.09029, 2024.
- Lerner et al. [2022] Paul Lerner, Olivier Ferret, Camille Guinaudeau, Hervé Le Borgne, Romaric Besançon, José G Moreno, and Jesús Lovón Melgarejo. Viquae, a dataset for knowledge-based visual question answering about named entities. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3108–3120, 2022.
- Li et al. [2023a] Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension, 2023a.
- Li et al. [2023b] Bo Li, Peiyuan Zhang, Jingkang Yang, Yuanhan Zhang, Fanyi Pu, and Ziwei Liu. Otterhd: A high-resolution multi-modality model, 2023b.
- Li et al. [2023c] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning. arXiv.org, 2023c.
- Li et al. [2023d] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023d.
- Li et al. [2023e] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. arXiv preprint arXiv:2311.17005, 2023e.
- Li et al. [2024a] Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024a.
- Li et al. [2023f] Lei Li, Zhihui Xie, Mukai Li, Shunian Chen, Peiyi Wang, Liang Chen, Yazheng Yang, Benyou Wang, and Lingpeng Kong. Silkie: Preference distillation for large visual language models. arXiv preprint arXiv:2312.10665, 2023f.
- Li et al. [2023g] Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. arXiv preprint arXiv:2311.17043, 2023g.
- Li et al. [2024b] Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-Gemini: Mining the potential of multi-modality vision language models. arXiv preprint arXiv:2403.18814, 2024b.
- Li et al. [2023h] Zhuowan Li, Xingrui Wang, Elias Stengel-Eskin, Adam Kortylewski, Wufei Ma, Benjamin Van Durme, and Alan L Yuille. Super-clevr: A virtual benchmark to diagnose domain robustness in visual reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023h.
- Li et al. [2023i] Zhang Li, Biao Yang, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu, and Xiang Bai. Monkey: Image resolution and text label are important things for large multi-modal models. arXiv preprint arXiv:2311.06607, 2023i.
- Lin et al. [2023a] Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. arXiv preprint arXiv:2311.10122, 2023a.
- Lin et al. [2024] Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models, 2024.
- Lin et al. [2023b] Ziyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen, et al. Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. arXiv preprint arXiv:2311.07575, 2023b.
- Lindström and Abraham [2022] Adam Dahlgren Lindström and Savitha Sam Abraham. Clevr-math: A dataset for compositional language, visual and mathematical reasoning. arXiv preprint arXiv:2208.05358, 2022.
- Liu et al. [2023a] Fangyu Liu, Guy Edward Toh Emerson, and Nigel Collier. Visual spatial reasoning. Transactions of the Association for Computational Linguistics (TACL), 2023a.
- Liu et al. [2023b] Fuxiao Liu, Xiaoyang Wang, Wenlin Yao, Jianshu Chen, Kaiqiang Song, Sangwoo Cho, Yaser Yacoob, and Dong Yu. Mmc: Advancing multimodal chart understanding with large-scale instruction tuning. arXiv preprint arXiv:2311.10774, 2023b.
- Liu et al. [2023c] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744, 2023c.
- Liu et al. [2023d] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv.org, 2023d.
- Liu et al. [2024a] Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, 2024a.
- Liu et al. [2024b] Shuo Liu, Kaining Ying, Hao Zhang, Yue Yang, Yuqi Lin, Tianle Zhang, Chuanhao Li, Yu Qiao, Ping Luo, Wenqi Shao, et al. Convbench: A multi-turn conversation evaluation benchmark with hierarchical capability for large vision-language models. arXiv preprint arXiv:2403.20194, 2024b.
- Liu et al. [2023e] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhnag, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player? arXiv:2307.06281, 2023e.
- Liu et al. [2024c] Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. TempCompass: Do video llms really understand videos? arXiv preprint arXiv:2403.00476, 2024c.
- Liu et al. [2024d] Yuliang Liu, Zhang Li, Biao Yang, Chunyuan Li, Xucheng Yin, Cheng lin Liu, Lianwen Jin, and Xiang Bai. On the hidden mystery of ocr in large multimodal models, 2024d.
- Liu et al. [2024e] Yuliang Liu, Biao Yang, Qiang Liu, Zhang Li, Zhiyin Ma, Shuo Zhang, and Xiang Bai. Textmonkey: An ocr-free large multimodal model for understanding document. arXiv preprint arXiv:2403.04473, 2024e.
- Liu et al. [2022] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s, 2022.
- Liu et al. [2024f] Ziyu Liu, Tao Chu, Yuhang Zang, Xilin Wei, Xiaoyi Dong, Pan Zhang, Zijian Liang, Yuanjun Xiong, Yu Qiao, Dahua Lin, et al. MMDU: A multi-turn multi-image dialog understanding benchmark and instruction-tuning dataset for lvlms. arXiv preprint arXiv:2406.11833, 2024f.
- Liu et al. [2024g] Ziyu Liu, Zeyi Sun, Yuhang Zang, Wei Li, Pan Zhang, Xiaoyi Dong, Yuanjun Xiong, Dahua Lin, and Jiaqi Wang. RAR: Retrieving and ranking augmented mllms for visual recognition. arXiv preprint arXiv:2403.13805, 2024g.
- LocalLLaMA [2023] LocalLLaMA. Dynamically scaled rope further increases performance of long context llama with zero fine-tuning, 2023.
- Lozhkov et al. [2024] Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. Starcoder 2 and the stack v2: The next generation. arXiv preprint arXiv:2402.19173, 2024.
- Lu et al. [2021a] Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. In The 59th Annual Meeting of the Association for Computational Linguistics (ACL), 2021a.
- Lu et al. [2021b] Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning. arXiv preprint arXiv:2110.13214, 2021b.
- Lu et al. [2022a] Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In Advances in Neural Information Processing Systems (NeurIPS), 2022a.
- Lu et al. [2022b] Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, and Ashwin Kalyan. Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. arXiv preprint arXiv:2209.14610, 2022b.
- Lu et al. [2024] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In International Conference on Learning Representations (ICLR), 2024.
- Luo et al. [2023] Ruipu Luo, Ziwang Zhao, Min Yang, Junwei Dong, Minghui Qiu, Pengcheng Lu, Tao Wang, and Zhongyu Wei. Valley: Video assistant with large language model enhanced ability. arXiv preprint arXiv:2306.07207, 2023.
- Lv et al. [2023] Tengchao Lv, Yupan Huang, Jingye Chen, Lei Cui, Shuming Ma, Yaoyao Chang, Shaohan Huang, Wenhui Wang, Li Dong, Weiyao Luo, Shaoxiang Wu, Guoxin Wang, Cha Zhang, and Furu Wei. Kosmos-2.5: A multimodal literate model, 2023.
- Ma et al. [2024] Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, Pan Zhang, Jiang Yu-Gang Pan, Liangming, Jiaqi Wang, Yixin Cao, and Aixin Sun. MMLongBench-Doc: Benchmarking long-context document understanding with visualizations. arXiv preprint arXiv:2407.01523, 2024.
- Maaz et al. [2023] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424, 2023.
- Marino et al. [2019] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3195–3204, 2019.
- Masry et al. [2022] Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. arXiv preprint arXiv:2203.10244, 2022.
- Mathew et al. [2021] Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. In Proc. of the IEEE Winter Conference on Applications of Computer Vision (WACV), 2021.
- Mathew et al. [2022] Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. Infographicvqa. In Proc. of the IEEE Winter Conference on Applications of Computer Vision (WACV), 2022.
- Mishra et al. [2019] Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. OCR-VQA: Visual question answering by reading text in images. In International Conference on Document Analysis and Recognition (ICDAR), 2019.
- Ning et al. [2023] Munan Ning, Bin Zhu, Yujia Xie, Bin Lin, Jiaxi Cui, Lu Yuan, Dongdong Chen, and Li Yuan. Video-bench: A comprehensive benchmark and toolkit for evaluating video-based large language models. arXiv preprint arXiv:2311.16103, 2023.
- OpenAI [2022] OpenAI. Chatgpt. https://openai.com/blog/chatgpt, 2022.
- OpenAI [2023] OpenAI. Gpt-4 technical report, 2023.
- Oquab et al. [2024] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, and Piotr Bojanowski. Dinov2: Learning robust visual features without supervision, 2024.
- Ordonez et al. [2011] Vicente Ordonez, Girish Kulkarni, and Tamara L. Berg. Im2text: Describing images using 1 million captioned photographs. In Advances in Neural Information Processing Systems (NeurIPS), 2011.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems (NeurIPS), 2022.
- Pal et al. [2024] Arka Pal, Deep Karkhanis, Samuel Dooley, Manley Roberts, Siddartha Naidu, and Colin White. Smaug: Fixing failure modes of preference optimisation with dpo-positive. arXiv preprint arXiv:2402.13228, 2024.
- Pasupat and Liang [2015] Panupong Pasupat and Percy Liang. Compositional semantic parsing on semi-structured tables. In The Annual Meeting of the Association for Computational Linguistics (ACL), 2015.
- Peng et al. [2023] Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. arXiv.org, 2023.
- Pi et al. [2024] Renjie Pi, Tianyang Han, Wei Xiong, Jipeng Zhang, Runtao Liu, Rui Pan, and Tong Zhang. Strengthening multimodal large language model with bootstrapped preference optimization. arXiv preprint arXiv:2403.08730, 2024.
- Qian et al. [2024] Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuangrui Ding, Dahua Lin, and Jiaqi Wang. Streaming long video understanding with large language models, 2024.
- Qwen [2023] Qwen. Introducing Qwen-7B: Open foundation and human-aligned models (of the state-of-the-arts), 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine learning (ICML), 2021.
- Radford et al. [2022] Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. arxiv 2022. arXiv preprint arXiv:2212.04356, 10, 2022.
- Rafailov et al. [2024] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems (NeurIPS), 2024.
- Schuhmann et al. [2021] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- Schulman et al. [2017] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Schwenk et al. [2022] Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A-okvqa: A benchmark for visual question answering using world knowledge. In Proceedings of the European Conference on Computer Vision (ECCV), 2022.
- Shah et al. [2019] Sanket Shah, Anand Mishra, Naganand Yadati, and Partha Pratim Talukdar. Kvqa: Knowledge-aware visual question answering. In Proceedings of the Conference on Artificial Intelligence (AAAI), 2019.
- Sharma et al. [2018] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In The Annual Meeting of the Association for Computational Linguistics (ACL), 2018.
- Shi et al. [2017] Baoguang Shi, Cong Yao, Minghui Liao, Mingkun Yang, Pei Xu, Linyan Cui, Serge Belongie, Shijian Lu, and Xiang Bai. Icdar2017 competition on reading chinese text in the wild (rctw-17). In International Conference on Document Analysis and Recognition (ICDAR), 2017.
- Si et al. [2024] Chenglei Si, Yanzhe Zhang, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: How far are we from automating front-end engineering? arXiv preprint arXiv:2403.03163, 2024.
- Sidorov et al. [2020] Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. Textcaps: a dataset for image captioning with reading comprehension. In Proceedings of the European Conference on Computer Vision (ECCV), 2020.
- Singh et al. [2019] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Song et al. [2023] Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Xun Guo, Tian Ye, Yan Lu, Jenq-Neng Hwang, et al. Moviechat: From dense token to sparse memory for long video understanding. arXiv preprint arXiv:2307.16449, 2023.
- Song et al. [2024] Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, and Gaoang Wang. Moviechat+: Question-aware sparse memory for long video question answering. arXiv preprint arXiv:2404.17176, 2024.
- Sun et al. [2024a] Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiying Yu, Zhengxiong Luo, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative multimodal models are in-context learners, 2024a.
- Sun et al. [2019] Yipeng Sun, Zihan Ni, Chee-Kheng Chng, Yuliang Liu, Canjie Luo, Chun Chet Ng, Junyu Han, Errui Ding, Jingtuo Liu, Dimosthenis Karatzas, et al. Icdar 2019 competition on large-scale street view text with partial labeling-rrc-lsvt. In International Conference on Document Analysis and Recognition (ICDAR), 2019.
- Sun et al. [2024b] Zeyi Sun, Ye Fang, Tong Wu, Pan Zhang, Yuhang Zang, Shu Kong, Yuanjun Xiong, Dahua Lin, and Jiaqi Wang. Alpha-CLIP: A clip model focusing on wherever you want. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024b.
- Svetlichnaya [2020] S. Svetlichnaya. DeepForm: Understand structured documents at scale., 2020.
- Tanaka et al. [2021] Ryota Tanaka, Kyosuke Nishida, and Sen Yoshida. VisualMRC: Machine reading comprehension on document images. In Proceedings of the Conference on Artificial Intelligence (AAAI), 2021.
- Tang et al. [2024] Jingqun Tang, Chunhui Lin, Zhen Zhao, Shu Wei, Binghong Wu, Qi Liu, Hao Feng, Yang Li, Siqi Wang, Lei Liao, Wei Shi, Yuliang Liu, Hao Liu, Yuan Xie, Xiang Bai, and Can Huang. Textsquare: Scaling up text-centric visual instruction tuning, 2024.
- Team [2023a] Gemini Team. Gemini: A family of highly capable multimodal models, 2023a.
- Team [2023b] InternLM Team. Internlm: A multilingual language model with progressively enhanced capabilities. https://github.com/InternLM/InternLM, 2023b.
- Team [2024a] 360VL Team. 360vl, 2024a.
- Team [2024b] WeMM Team. Wemm, 2024b.
- Touvron et al. [2023a] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv.org, 2023a.
- Touvron et al. [2023b] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models, 2023b.
- Wan et al. [2024] Yuxuan Wan, Chaozheng Wang, Yi Dong, Wenxuan Wang, Shuqing Li, Yintong Huo, and Michael R Lyu. Automatically generating ui code from screenshot: A divide-and-conquer-based approach. arXiv preprint arXiv:2406.16386, 2024.
- Wang et al. [2023a] Junke Wang, Lingchen Meng, Zejia Weng, Bo He, Zuxuan Wu, and Yu-Gang Jiang. To see is to believe: Prompting gpt-4v for better visual instruction tuning. arXiv preprint arXiv:2311.07574, 2023a.
- Wang et al. [2023b] Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, and Jie Tang. Cogvlm: Visual expert for pretrained language models, 2023b.
- Wei et al. [2023a] Haoran Wei, Lingyu Kong, Jinyue Chen, Liang Zhao, Zheng Ge, Jinrong Yang, Jianjian Sun, Chunrui Han, and Xiangyu Zhang. Vary: Scaling up the vision vocabulary for large vision-language models. arXiv preprint arXiv:2312.06109, 2023a.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2022.
- Wei et al. [2023b] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023b.
- Weng et al. [2024] Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang. Longvlm: Efficient long video understanding via large language models. arXiv preprint arXiv:2404.03384, 2024.
- XAI [2024] XAI. Grok-1.5 vision preview. 2024.
- Xu et al. [2024a] Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava : Parameter-free llava extension from images to videos for video dense captioning, 2024a.
- Xu et al. [2024b] Ruyi Xu, Yuan Yao, Zonghao Guo, Junbo Cui, Zanlin Ni, Chunjiang Ge, Tat-Seng Chua, Zhiyuan Liu, Maosong Sun, and Gao Huang. Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images. arXiv preprint arXiv:2403.11703, 2024b.
- Ye et al. [2023a] Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Guohai Xu, Chenliang Li, Junfeng Tian, Qi Qian, Ji Zhang, et al. Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model. arXiv preprint arXiv:2310.05126, 2023a.
- Ye et al. [2023b] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv.org, 2023b.
- Young et al. [2014] Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics (TACL), 2014.
- Yu et al. [2023a] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023a.
- Yu et al. [2024a] Shoubin Yu, Jaemin Cho, Prateek Yadav, and Mohit Bansal. Self-chained image-language model for video localization and question answering. In Advances in Neural Information Processing Systems (NeurIPS), 2024a.
- Yu et al. [2024b] Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al. RLHF-V: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024b.
- Yu et al. [2023b] Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023b.
- Yuan et al. [2019] Tai-Ling Yuan, Zhe Zhu, Kun Xu, Cheng-Jun Li, Tai-Jiang Mu, and Shi-Min Hu. A large chinese text dataset in the wild. Journal of Computer Science and Technology, 34(3):509–521, 2019.
- Yue et al. [2023] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. arXiv preprint arXiv:2311.16502, 2023.
- Zang et al. [2023] Yuhang Zang, Wei Li, Jun Han, Kaiyang Zhou, and Chen Change Loy. Contextual object detection with multimodal large language models. arXiv preprint arXiv:2305.18279, 2023.
- Zeng et al. [2023] Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, Weng Lam Tam, Zixuan Ma, Yufei Xue, Jidong Zhai, Wenguang Chen, Zhiyuan Liu, Peng Zhang, Yuxiao Dong, and Jie Tang. GLM-130b: An open bilingual pre-trained model. In Proceedings of the International Conference on Learning Representations (ICLR), 2023.
- Zhai et al. [2023] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training, 2023.
- Zhang et al. [2024a] Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-CLIP: Unlocking the long-text capability of clip. arXiv preprint arXiv:2403.15378, 2024a.
- Zhang et al. [2023a] Ce Zhang, Taixi Lu, Md Mohaiminul Islam, Ziyang Wang, Shoubin Yu, Mohit Bansal, and Gedas Bertasius. A simple llm framework for long-range video question-answering. arXiv preprint arXiv:2312.17235, 2023a.
- Zhang et al. [2023b] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023b.
- Zhang et al. [2023c] Pan Zhang, Xiaoyi Dong Bin Wang, Yuhang Cao, Chao Xu, Linke Ouyang, Zhiyuan Zhao, Shuangrui Ding, Songyang Zhang, Haodong Duan, Hang Yan, et al. Internlm-xcomposer: A vision-language large model for advanced text-image comprehension and composition. arXiv preprint arXiv:2309.15112, 2023c.
- Zhang et al. [2024b] Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024b.
- Zhang et al. [2019] Rui Zhang, Yongsheng Zhou, Qianyi Jiang, Qi Song, Nan Li, Kai Zhou, Lei Wang, Dong Wang, Minghui Liao, Mingkun Yang, et al. Icdar 2019 robust reading challenge on reading chinese text on signboard. In International Conference on Document Analysis and Recognition (ICDAR), 2019.
- Zhang et al. [2024c] Tao Zhang, Xiangtai Li, Hao Fei, Haobo Yuan, Shengqiong Wu, Shunping Ji, Chen Change Loy, and Shuicheng Yan. Omg-llava: Bridging image-level, object-level, pixel-level reasoning and understanding, 2024c.
- Zhang et al. [2024d] Yi-Fan Zhang, Qingsong Wen, Chaoyou Fu, Xue Wang, Zhang Zhang, Liang Wang, and Rong Jin. Beyond llava-hd: Diving into high-resolution large multimodal models, 2024d.
- Zhao et al. [2023a] Haozhe Zhao, Zefan Cai, Shuzheng Si, Xiaojian Ma, Kaikai An, Liang Chen, Zixuan Liu, Sheng Wang, Wenjuan Han, and Baobao Chang. Mmicl: Empowering vision-language model with multi-modal in-context learning. arXiv.org, 2023a.
- Zhao et al. [2023b] Wenliang Zhao, Xumin Yu, and Zengyi Qin. Melotts: High-quality multi-lingual multi-accent text-to-speech, 2023b.
- Zhao et al. [2023c] Zhiyuan Zhao, Bin Wang, Linke Ouyang, Xiaoyi Dong, Jiaqi Wang, and Conghui He. Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization. arXiv preprint arXiv:2311.16839, 2023c.
- Zhou et al. [2024a] Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. MLVU: A comprehensive benchmark for multi-task long video understanding. arXiv preprint arXiv:2406.04264, 2024a.
- Zhou et al. [2024b] Yiyang Zhou, Chenhang Cui, Rafael Rafailov, Chelsea Finn, and Huaxiu Yao. Aligning modalities in vision large language models via preference fine-tuning. arXiv preprint arXiv:2402.11411, 2024b.
- Zhu et al. [2023] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv.org, 2023.