miniGPT-Med:作为放射诊断通用接口的大型语言模型
摘要
人工智能 (AI) 的最新进展在医疗保健领域带来了重大突破,特别是在改进诊断程序方面。 然而,以前的研究往往仅限于有限的功能。 本研究介绍了 MiniGPT-Med,这是一种源自大规模语言模型并为医疗应用量身定制的视觉语言模型。 MiniGPT-Med 在各种成像模式(包括 X 射线、CT 扫描和 MRI)中表现出卓越的多功能性,从而增强了其实用性。 该模型能够执行医疗报告生成、视觉问答 (VQA) 和医学图像中的疾病识别等任务。 其对图像和文本临床数据的集成处理显着提高了诊断准确性。 我们的实证评估证实了 MiniGPT-Med 在疾病基础、医疗报告生成和 VQA 基准方面的卓越性能,代表着在缩小协助放射学实践方面的差距迈出了重要一步。 此外,它在医疗报告生成方面实现了最先进的性能,比之前的最佳模型准确率高出 19%。 MiniGPT-Med 有望成为放射学诊断的通用接口,提高各种医学成像应用的诊断效率。 我们的模型和代码已公开 https://github.com/Vision-CAIR/MiniGPT-Med
miniGPT-Med:作为放射诊断通用接口的大型语言模型
Asma Alkhaldi1,2††thanks: {asma.alkhaldi,mohamed.elhoseiny}@kaust.edu.sa, Raneem Alnajim1,2, Layan Alabdullatef1,2, Rawan Alyahya1, Jun Chen2, Deyao Zhu2, Ahmed Alsinan1, Mohamed Elhoseiny 211footnotemark: 1, 1Saudi Data and Artificial Intelligence Authority (SDAIA), 2King Abdullah University of Science and Technology (KAUST)
1简介
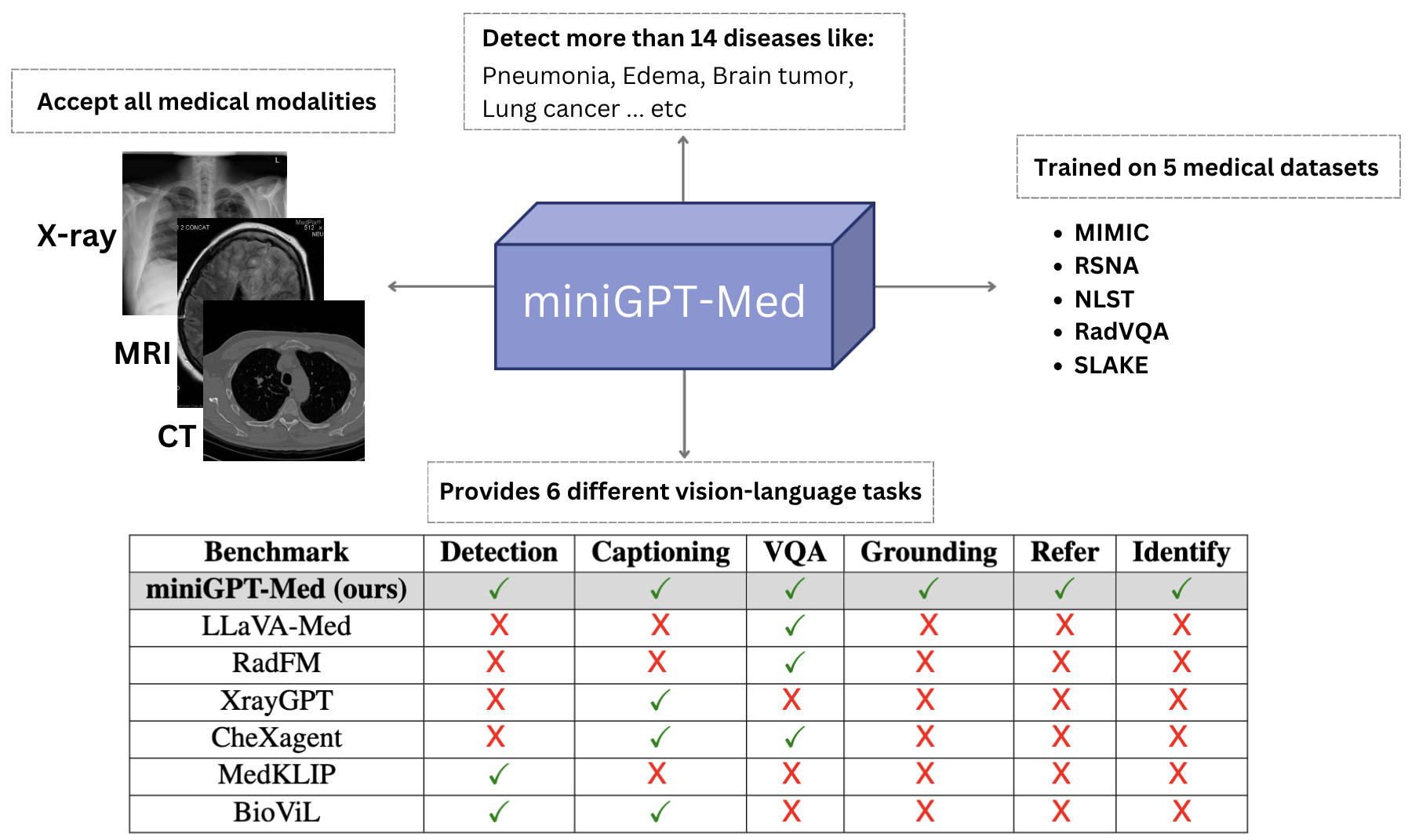
不同领域的图像文本数据量空前激增,以及视觉语言建模方面取得的进步,为生成预训练的突破性研究铺平了道路。 这个创新时代的标志是多模态模型的出现,例如 GPT-4 Achiam 等人 (2023) 和 Gemini Team 等人 (2023)。 这些进步标志着我们处理和理解复杂数据的能力的飞跃。 尽管取得了这些进展,多模态大语言模型(大语言模型)在医疗领域的采用仍然有限。 医疗领域对数据复杂性、敏感性和特异性的独特要求凸显了需要定制方法来利用大语言模型在改变医疗保健研究和实践方面的潜力。 已经推出了许多专为医疗应用而设计的模型,但它们通常表现出针对特定任务的高度专业化。 这种专业化限制了它们的多功能性,特别是在执行不同的医疗应用时。 例如,Med-Flamingo Moor 等人 (2023) 和 XrayGPT Thawkar 等人 (2023a) 等模型主要针对医疗报告生成和医学视觉问题等任务定制分别回答。 然而,他们缺乏疾病检测等基本领域的能力,这需要视觉基础技能——这是医学领域的关键组成部分。 为了解决这一缺陷,我们引入了 MiniGPT-Med,这是一个能够熟练处理接地和非接地任务的统一模型。 我们推出 MiniGPT-Med,这是一种多功能模型,专为医学领域的各种任务而设计,包括但不限于医学报告生成、医学视觉问答和疾病识别。 MiniGPT-Med 建立在大型语言模型(大语言模型)的架构之上,该模型展示了卓越的生成能力和广泛的语言学,包括医学知识。 借鉴大语言模型在广泛的视觉语言应用中的成功,如最近的研究所证明的Zhu 等人 (2023);陈 等人 (2023); Li 等人 (2024),我们的模型采用类似于 MiniGPT-v2 Chen 等人 (2023) 的设计,利用 LLaMA-2 语言模型作为通用接口。 此外,我们还结合了不同的任务标识符,以增强模型准确执行各种医学视觉语言技能的能力。 通过广泛的实验,我们证明我们的模型在一系列医学视觉语言任务中表现出强大的性能,包括医学报告生成、医学视觉问答和疾病检测。 我们将我们的模型与专门的和通用的基线模型进行了基准测试,结果表明我们的方法在所有评估的任务中都取得了良好的结果。 值得注意的是,在医疗报告生成领域,我们的模型取得了最先进的性能,在 BERT-Sim 中超过最佳基线模型 19%,在 CheXbert-Sim 中超过 5.2%。 这表明我们的模型在各种医学视觉语言任务上具有强大的生成能力。
我们的贡献如下:
-
1.
我们推出 MiniGPT-Med,这是一种针对放射图像的异质性量身定制的模型,包括 X 射线、CT 扫描和 MRI。 该模型擅长处理各种视觉语言任务,包括疾病识别、医学视觉问答和医学报告生成。
-
2.
通过综合评估,我们评估了接地任务和非接地任务的模型,并辅以专家手动评估。 研究结果表明,MiniGPT-Med 在大多数基准测试中都提供了具有竞争力的性能,超越了通用模型和专用模型,特别是在医疗报告生成方面取得了最先进的结果,并且超出了最佳基准 19.0%。
2 背景
将视觉数据与大型语言模型结合起来: 大语言模型领域的最新进展,例如GPT-4的发布,增强了大语言模型的解释和生成能力。 LLaVALiu 等人 (2023)、FlamingoAlayrac 等人 (2022) 和 MiniGPT-v2Chen 等人 (2023) 等模型就是这一进展的例证)。 LLaVA 旨在通过多种多模式指令增强对大型语言模型中视觉内容的理解。 这种理解力的增强对于整合不同形式的数据输入至关重要。 相比之下,Flamingo 在用最少的数据快速适应新任务方面表现出了非凡的能力。 该模型有效地管理包含视觉和文本元素的序列。 另一方面,MiniGPT-v2 在单一模型框架内展示了增强的多模式功能。 这是通过特定于任务的训练和将视觉标记与大型语言模型相结合的专门架构来实现的,与 LLaVA 和 Flamingo 的目标非常一致。
集成视觉语言模型以增强医疗诊断: 最近在视觉语言模型方面的工作已经导致医疗保健应用程序的显着改进,特别是在医学图像分析和诊断报告生成方面。 在医疗诊断中使用 VLM 标志着医疗保健行业的重大进步。 模型结合了计算机视觉和语言处理,可以更好地分析 X 射线、计算机断层扫描 (CT) 和 MRI 等医学图像。 医疗领域更专业的应用,例如 LLaVA-Med Li 等人 (2024) 和 Med-BERT Rasmy 等人 (2020) 在整合结构化电子医疗方面显示出前景疾病预测任务改进的记录。 MedVQA Canepa 等人 (2023) 展示了医学视觉问答和图像分析能力。 此外,对于分类和解释任务,Med-Flamingo Moor 等人 (2023)、MedVis Shen 等人 (2008) 和 MedMCQA Pal 等人 (2022) )已经证明了少样本学习、视觉解释和特定领域问答在医学人工智能中的重要性。 LLaVA-Med 和 Med-Flamingo 都专注于医疗环境中的多模式对话人工智能和少样本学习,利用大规模数据集并展示视觉问答的熟练程度。 BioViL Bannur 等人 (2023)、BioBERT Lee 等人 (2019) 和 BioGPT Luo 等人 (2022) 都解决了更多问题特定领域语言模型预训练。 BioViL 强调文本语义以增强生物医学视觉语言处理。 MedKLIP Wu 等人 (2023a)、XrayGPT Thawkar 等人 (2023b) 和 BERTHop Monajatipoor 等人也强调了放射学应用的专用模型(2021)都展示了实现高诊断准确性的挑战。 MedKLIP 尤其进行了创新,将医学知识整合到视觉语言预训练中,以改进疾病分类。 XrayGPT 将医学视觉编码器与大型语言模型相结合,将视觉和文本分析结合起来,从放射学数据生成精确的摘要,而 BERTHop 则通过胸部 X 射线的较小数据集展示了诊断性能。 此外,CheXagent Chen 等人 (2024)、CheXNeXt Rajpurkar 等人 (2018) 和 CheXpert Irvin 等人 (2019) 的贡献为胸部病理检测设定了基准。 虽然每项工作都提出了独特的方法,但他们的共同目标是通过复杂的人工智能模型增强放射学分析。
3方法
3.1模型架构
我们的模型架构如图2所示,由三个关键组件组成:视觉主干、线性投影层和扩展语言模型。 各组件详细说明如下:
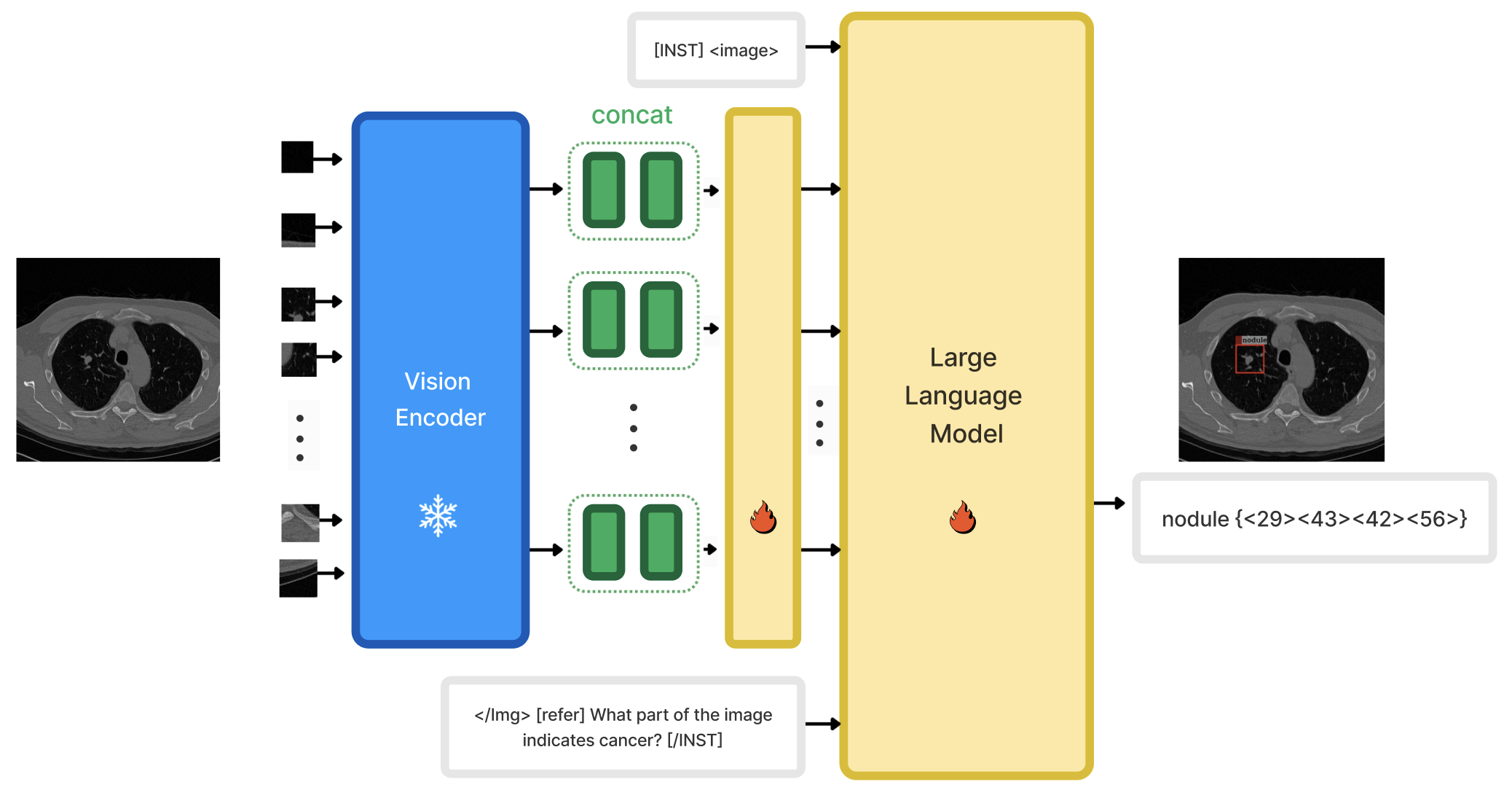
视觉编码器。 在我们的方法中,我们将 EVA Sun 等人 (2023) 作为模型的主要视觉支柱。 EVA Sun 等人 (2023) 是一种高性能视觉编码器,由于其处理复杂图像结构和变化的能力,在应用于放射数据时特别有效。 在整个训练过程中,这个视觉主干在训练过程中始终保持冻结状态。 放射图像通常具有高分辨率,我们训练图像分辨率为448448的模型。 我们还插入位置编码以适应更高的图像分辨率。
大语言模型(大语言模型)。 我们纳入了开源语言模型 LLaMA2-chat (7B)Touvron 等人 (2023) 作为主要语言模型骨干。 大语言模型已经通过学习大量的语言知识学习了广泛的医学知识,我们将其作为处理许多医学视觉语言任务的统一接口。 例如,大语言模型可以帮助生成详细的医学报告,以及医学领域肿瘤的精确定位。
视觉语言对齐。 我们采用 MiniGPT-v2 Chen 等人 (2023) 的架构,并通过连接来自视觉编码器的视觉标记来提高效率,这种技术特别有利于处理高分辨率医学图像。 该方法涉及将四个相邻的视觉标记合并为单个嵌入,然后通过线性投影层将其映射到语言模型的特征空间。
3.2提示模板。
我们采用了一个提示模板,使我们的模型能够很好地处理许多不同的医学视觉语言技能,例如视觉问答、图像字幕、引用表达理解(REC)、引用表达生成(REG)、疾病检测和接地图像字幕。 语言模型在处理许多不同的视觉语言任务时可能会经历高度的幻觉和困惑。 例如,当被要求识别潜在的肺部肿瘤时,它可能会错误地关注和描述血管或心脏的钙化区域。 因此,为了避免这些多任务环境中的歧义,我们将特定于任务的标记添加到我们的训练框架中。 我们在指令模板中遵循与 MiniGPT-v2Chen 等人 (2023) 类似的指令设计,如下所示:
[INST] Img ImageFeature /Img [任务标识符]指令[/INST]
我们在表1中提供了多种提示模板,以演示我们的模型如何通过任务标识符有效地处理不同的任务。
3.3区域接地表示。
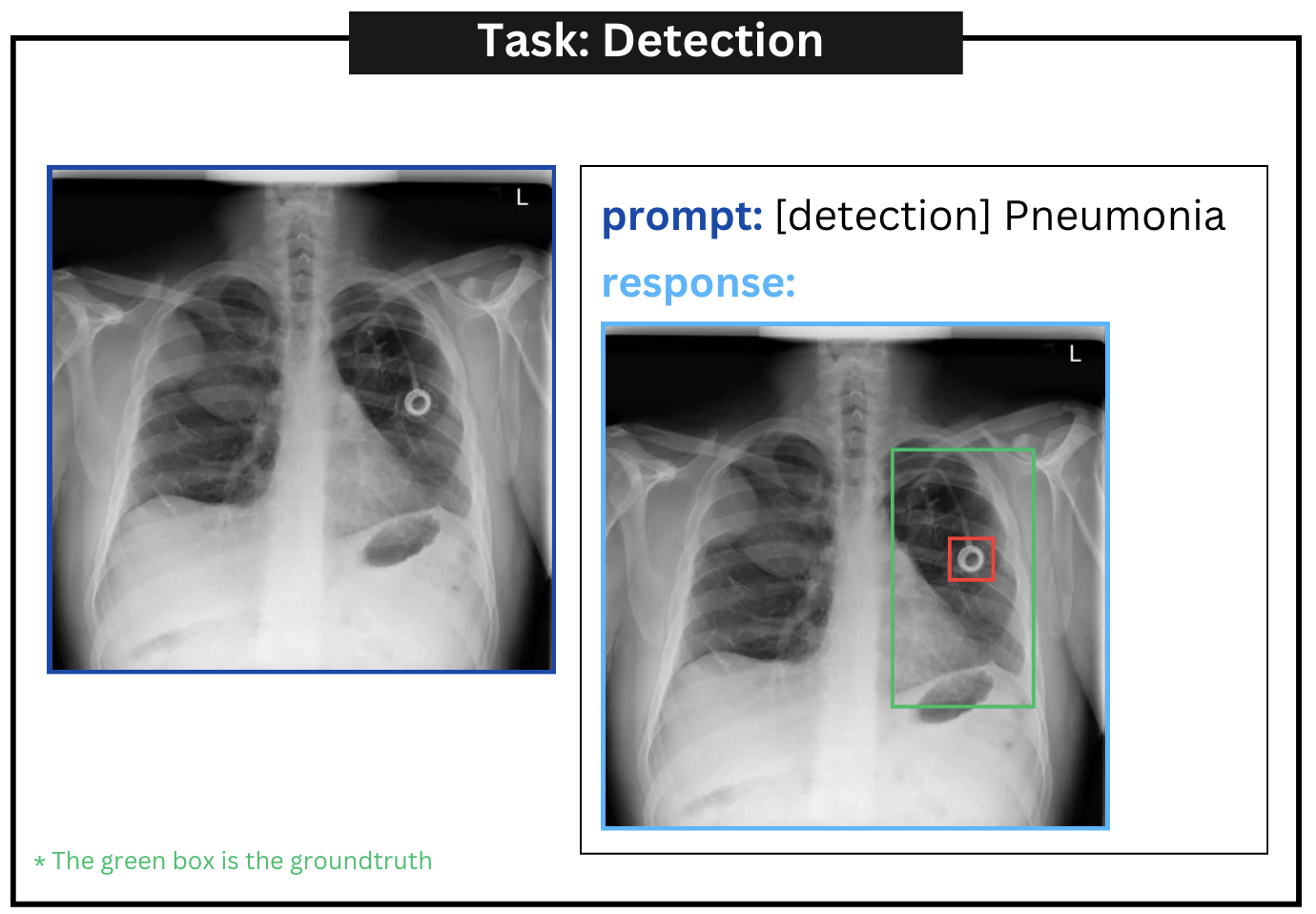
对于涉及对象空间位置的基础技能,例如疾病检测和基础图像字幕,我们采用边界框的文本表示。 这种表示方式使我们能够将空间位置集成到输入语言模型的文本中。 我们将边界框坐标标准化在 [0,100] 范围内。 每个空间位置用以下格式表示:
4实验
该实验旨在评估 MiniGPT-Med 的功效,重点是其准确分析和描述复杂医学成像数据的能力,适用于肺癌检测、报告生成和问答功能等应用。 我们使用全面的放射图像数据集(包括 X 射线、MRI 和 CT 扫描)对 MiniGPT-v2 的第 3 阶段进行了微调,涵盖了各种技能的广泛医疗状况。
4.1 数据集设置
缺乏高质量的医学数据集是医学成像深度学习领域的一个重大挑战。 为了解决这个问题,我们优先收集专注于放射学(特别是肺部疾病)以及一般医疗信息的综合数据集。 我们的目标是收集多样化且广泛的医学图像,包括 X 射线、CT 扫描和 MRI 图像。 此外,我们的目标是通过将图像与边界框、具有问答格式的数据集以及用于报告生成的数据集合并来增强数据集。 这些新增内容将支持模型训练和开发的所有必要技能。
| Task Types | [Identifier] Instruction |
|---|---|
| Caption | [caption] Could you describe the contents of this image for me? |
| VQA | [vqa] What plane is the image in? |
| Detection | [detection] pneumonia |
| Refer | [refer] the nodule in the left lung |
| Grounding | [grounding] describe this image in detail |
| Identify | [identify] what is this { <56><16><84><58>} |
收集的数据集包括 MIMIC Johnson 等人 (2019)、NLST The Cancer Imaging Archive (2023) 和 SLAKE Medical Visual Question Answering (2023) (Med-VQA) )、RSNA 北美放射学会 (2018) 和 RadVQA OSF (2023s)。这些医学数据集的详细信息如下:MIMIC 该数据集包含 377,110 张图像和 227,835 份医疗报告。 在我们的研究中,我们从XrayGPT Thawkar等人(2023a)获得了预处理的MIMIC数据集,其中包括114,539张JPG格式的去识别化胸部X射线图像,每张都附有相应的放射学报告。 其中,171,085 张图像和报告分配用于训练,43,454 张图像和报告分配用于测试。 该数据集用于报告生成的任务。
NLST 该数据集用于检测任务,包含 7,625 张经过精心注释的肺癌低剂量 CT 扫描图像,并专门标记以精确定位结节位置。 从完整的 3D 体积中,我们提取了显示结节的 2D CT 切片。 这些用于训练的注释源自 Sybil Mikhael 等人 (2023) 的工作。
SLAKE 该数据集用于训练基础和 VQA 任务,其中包含 579 张描绘各种身体器官的放射学图像,以及用于训练的 3,543 个不同的问答对集。
北美放射学会。 我们使用 RSNA 数据集来评估肺炎检测任务。 RSNA 数据集包含 1,218 名患有至少一种或多种肺炎疾病的患者。 我们对该数据集进行零样本评估以进行疾病检测任务。
RadVQA 包括 315 个放射学图像,均匀分布在头部、胸部和腹部,每个图像都与多个问题配对,并产生 2,248 个问答对。 这些问题分为 11 个不同的类别:异常、属性、形态、器官系统、颜色、计数、物体或条件的存在、大小、平面和位置推理。 一半的答复是封闭式的(即是/否),而其余的是开放式的,通常需要一个词或简短的短语答复。 我们对 RadVQA 数据集进行零样本评估。
4.2培训详情
在我们的实验中,我们使用 MiniGPT-v2 Chen 等人 (2023) 预训练权重(第 3 阶段之后)初始化模型,并在整个训练过程中保持视觉编码器冻结。 我们对线性投影层进行微调,并使用 LoRA(低秩适应)Hu 等人 (2021) 来微调 LLaMA-2 Touvron 等人 (2023) 大语言模型。 该模型使用交叉熵损失函数进行训练,并使用 AdamW 优化器进行优化。 我们的数据集包含 124,276 张医学图像,每张图像的分辨率为 448x448 像素,并且未应用数据增强。 整个训练在单个 NVIDIA A100 GPU 上执行了 100 多个 epoch,最大学习率为 1e-5。 训练时间约为22小时。
4.3 基准模型
在这项研究中,我们对 MiniGPT-Med 在三个不同任务上的表现进行了评估:医学报告生成、疾病检测和医学视觉问答 (VQA)。 我们将我们的模型与专家模型和通才模型进行了比较。 专家模型代表那些只能完成接地或非接地任务的人。 通才模型代表那些可以执行各种任务(包括基础任务和非基础任务)的模型。
– 对于医疗报告生成任务,我们将 MiniGPT-Med 与包括 Med-Flamingo Moor 等人 (2023) 和 LLaVA-Med Li 等人在内的专业模型进行了比较(2024),以其在视觉语言任务和情境学习能力方面的实力而闻名。 此外,我们还将 MiniGPT-Med 与专为放射学量身定制的 RadFM Wu 等人 (2023b) 以及 XrayGPT Thawkar 等人 (2023a) 进行了比较,这是一种新颖的视觉-专为胸部放射线照片分析而设计的语言模型。 此外,我们还针对 CheXagent Chen 等人 (2024) 评估了 MiniGPT-Med,这是一个专注于改善胸部 X 射线解释的基础模型。 此外,我们还与 MiniGPT-v2 和 Qwen-VL Bai 等人 (2023) 等通用模型进行了比较,这些模型在通用视觉语言数据上进行了训练,展示了在各种以视觉为中心的理解基准上的卓越性能。
– 在疾病检测任务中,MiniGPT-Med 与 BioVil Bannur 等人 (2023)、MedKLIP Wu 等人 (2023a) 等专业模型进行了比较t2> 和 GLoRIA Huang 等人 (2021),均在视觉语言医学数据集以及包括 MiniGPT-v2 和 Qwen-VL 在内的通用模型上进行了预训练。
– 在医疗 VQA 任务中,我们将 MiniGPT-Med 与 MedVINT Zhang 等人 (2023)、OpenFlamingo Awadalla 等人 (2023) 等专业模型进行了比较t2> 和 Med-Flamingo Moor 等人 (2023) 专门利用 RadVQA 数据集解决医学 VQA 的挑战,特别是在零样本场景中。 此外,我们的工作与 MiniGPT-v2 和 Qwen-VL 等通用模型进行了比较,以对 MiniGPT-Med 的性能进行全面评估。
| Method | Model’s type | MIMIC-CXR | |
|---|---|---|---|
| BERT-Sim | CheXbert-Sim | ||
| MedFlamingo | 10.4 | 3.2 | |
| LLaVA-Med | 6.2 | 17.5 | |
| RadFM | Specialist Models | 45.7 | 17.5 |
| XrayGPT | 44.0 | 24.2 | |
| CheXagent | 50.4 | 24.9 | |
| MiniGPT-v2 | 53.0 | 21.1 | |
| Qwen-VL | Generalist Models | 51.9 | 20.3 |
| Ours | 72.0 | 30.1 | |
| Method | Model’s type | RSNA IoU |
|---|---|---|
| BioViL | 0.30 | |
| MedKLIP | Specialist | 0.31 |
| GLoRIA | 0.21 | |
| Qwen-VL | 0.10 | |
| MiniGPT-v2 | Generalist | 0.13 |
| Ours | 0.26 |
4.4评估指标
在我们的研究中,我们调整了评估方法,以适应使用 MiniGPT-Med 解释放射学图像所需的独特技能。 为了评估模型生成放射学报告的能力,我们使用了两个指标:BERT 相似度 (BERTsim) 和 CheXbert 相似度 (CheXbert-Sim)。 BERTsim 用于评估模型生成的放射图像描述与专家提供的地面实况注释之间的语义相似性。 这涉及使用 BERT 模型来嵌入地面事实和生成的句子,然后计算这些嵌入之间的余弦相似度。 相反,选择 CheXbert-Sim 是因为它在评估模型复制专业医疗报告标准的准确性方面具有相关性。 它是 BERT 模型的专门版本,针对临床文本进行了微调,计算编码后每个对应句子对的嵌入之间的余弦相似度。 对于视觉问答(VQA)方面,我们专门使用 BERTsim 来衡量模型响应的语义准确性。 此外,我们还使用交集比并集 (IoU) 进行接地,这是一种定量测量模型在定位和识别放射图像中特定特征或异常(例如 RSNA 数据集中的肺炎)方面的精度的指标。
4.5医疗报告生成
在我们的综合研究中,我们利用综合 MIMIC 数据集 Johnson 等人 (2019) 评估了 MiniGPT-Med 模型在生成医疗报告方面的功效。 表 5 中列出的评估结果表明,MiniGPT-Med 模型超越了专门的和通用的基线模型。 最值得注意的是,MiniGPT-Med 表现出了领先的专业模型 CheXagent Chen 等人 (2024) 的显着优势,在 BERT-Sim 和 CheXbert-Sim 指标上分别具有 21.6 和 5.2 的显着优势。 这一表现不仅展示了 MiniGPT-Med 在医疗报告生成方面的霸主地位,还强调了其大幅超越顶级通才模型的能力——在 BERT-Sim 上领先 19 分,在 CheXbert-Sim 上领先 9 分。 这些发现巩固了 MiniGPT-Med 作为尖端工具的地位,证明了其在医疗报告生成方面的有效性。
4.6疾病检测
表 3 中显示的数据表明,与一系列全面的基线模型相比,MiniGPT-Med 以其竞争性能脱颖而出。 MiniGPT-Med 的交集比并集 (IoU) 得分为 0.26,不仅超出了通用模型 16% 的能力,而且还获得了与专业模型相当的性能指标。 这些专业模型的 IoU 分数峰值为 0.31。 我们的 MiniGPT-Med 取得了具有竞争力的结果,并且在所有基线模型中表现出了良好的疾病检测性能,凸显了其作为医疗领域多功能且有效工具的潜力。
4.7医学视觉问答
本研究使用 RadVQA OSF (2023s) 基准对照各种基线模型评估我们的模型 MiniGPT-Med,如表 4 所示。 MiniGPT-Med 取得了 0.58 的显着性能指标,超越了 MiniGPT-v2 Chen 等人 (2023) 等通用模型和 OpenFlamingo Awadalla 等人 (2023) 等专业模型> 和 Med-Flamingo Moor 等人 (2023)。 这一性能不仅证明了 MiniGPT-Med 相对于多种模型的优越性,而且还表明它可以取得与领先的专业模型 MedVIN Zhang 等人 (2023) 相媲美的结果,该模型具有准确率0.62。 MiniGPT-Med 超越或匹配多种专业和通用模型性能的能力突显了其作为高级医学视觉问答模型开发基础的巨大潜力。
| Method | Model’s type | RadVQA |
| BERT-Sim | ||
| MedVIN | 0.62 | |
| OpenFlamingo | Specialist | 0.49 |
| Med-Flamingo | 0.48 | |
| Qwen-VL | 0.13 | |
| MiniGPT-v2 | Generalist | 0.55 |
| Ours | 0.58 |
4.8放射科专家评估
我们的研究使用严格的人类主观协议与两名高级放射科医生一起评估了 MiniGPT-Med。 他们评估了 MIMIC 数据集测试套件中的 50 个随机样本,重点关注模型的稳健性、粒度和准确性。 评估围绕三个问题,Q1:生成的报告与您的专家判断的吻合程度如何? Q2:生成的报告的医疗内容有多详细? Q3:生成的报告在诊断病理方面的准确性如何? 我们在附表5中列出了结果。 结果显示,高达 76% 的人工医疗报告被判定为高质量。 另外 19% 被归类为中等质量,而只有 5% 被认为质量较差。 这种分布强调了该模型合成医疗报告的能力,这些报告不仅符合专业标准,而且还表现出高度的细节和诊断准确性。 这些发现强调了 MiniGPT-Med 作为增强医疗报告流程的宝贵工具的潜力,表明其在生成临床相关报告方面具有极高的可靠性和有效性。
| Radiologist Evaluation | ||
|---|---|---|
| Quality | Percentage | |
| Good | 76% | |
| Medium | 19% | |
| Poor | 5% |
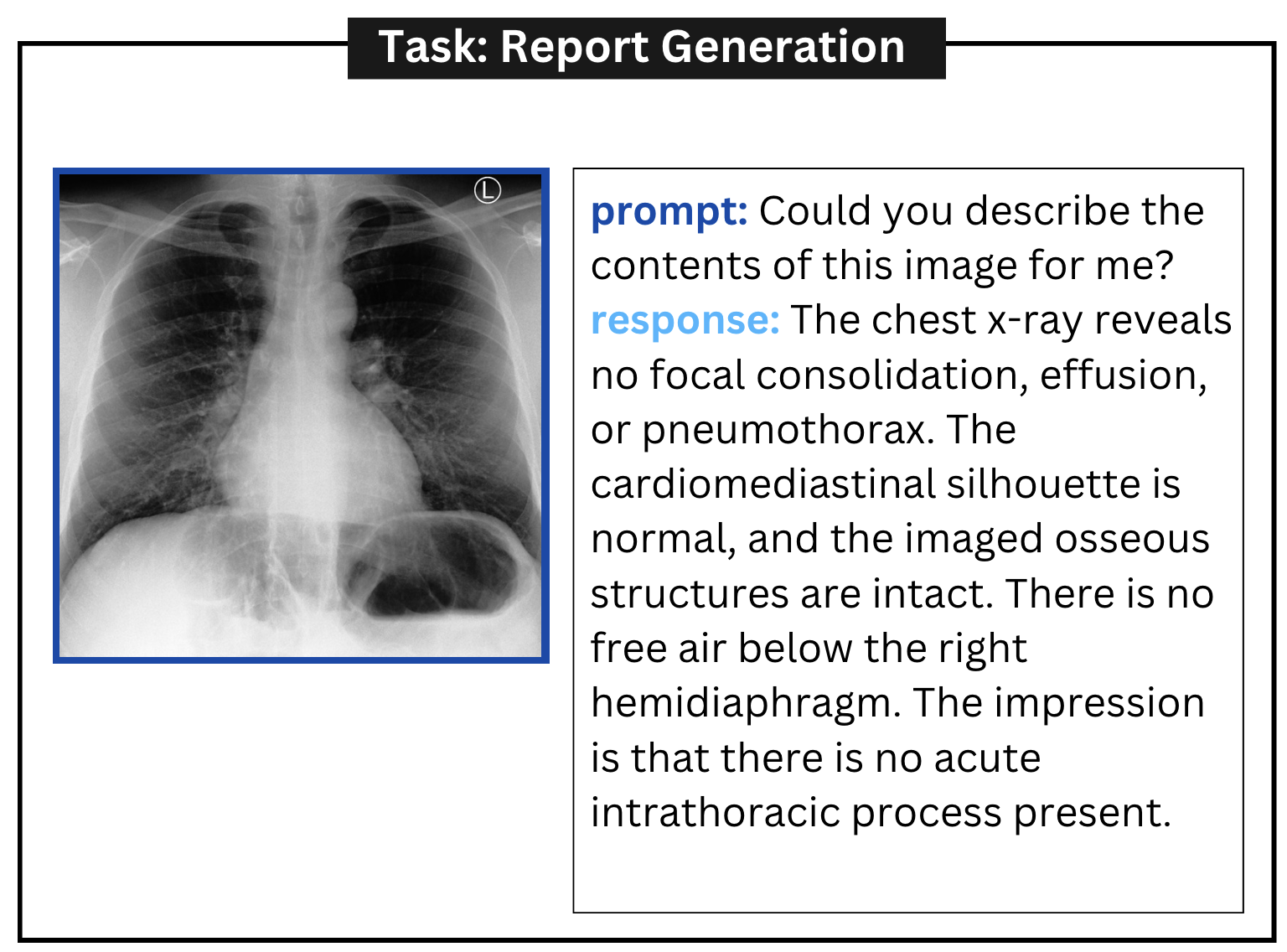
4.9定性评估
5限制
由于缺乏多样化和高质量的训练数据集,MiniGPT-Med 面临着挑战,限制了其覆盖范围较窄的疾病。 为了改进,需要更丰富、更多样化的数据集,以及先进的视觉主干和底层大语言模型的增强。 该模型有时会生成不准确的医疗报告,并将症状与疾病错误地联系起来,这种现象称为幻觉。 此外,它很难区分异常现象和包括人体植入设备的医学图像。 图5展示了MiniGPT-Med未能正确识别肺炎位置的数据样本。 绿色边界框下的对象是真实检测,红色边界框下的对象是错误检测。 该模型很容易将设备植入物误认为是异常。 这一缺点常常导致误诊。 具体来说,当人工智能遇到带有植入物的 X 射线或 MRI 时,它可能会错误地将这些识别为异常。
6 结论
在本研究中,我们介绍了 MiniGPT-Med,这是一种专为放射诊断应用而设计的专用多模式。 它处理各种医学视觉语言任务,例如生成医学报告、检测疾病和回答基于视觉的医学问题,并使用不同的任务标识符有效地导航这些任务。 MiniGPT-Med 在接地和非接地任务中均优于基线模型,在 MIMIC-CXR 医疗报告生成任务中实现了最先进的性能。 放射科医生评估显示,生成的报告中约 76% 具有首选质量,凸显了该模型的优越性。 未来的计划包括纳入更多样化的医学数据集,提高对复杂医学术语的理解,增强可解释性和可靠性,并进行广泛的临床验证研究,以确保在真实医疗环境中的有效性和安全性。
致谢
这项工作得到了 KAUST-SDAIA 资金的支持。 Asma、Raneem 和 Layan 作为 KAUST VisionCAIR 的访问研究工程师开始从事该项目。 我们衷心感谢 KAUST HPC/Ibex 集群团队在本研究项目训练模型期间提供的宝贵帮助和支持。
参考
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Alayrac et al. (2022) Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. 2022. Flamingo: a visual language model for few-shot learning. In Advances in Neural Information Processing Systems.
- Awadalla et al. (2023) Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. 2023. Openflamingo: An open-source framework for training large autoregressive vision-language models. arXiv preprint arXiv:2308.01390.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966.
- Bannur et al. (2023) Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Perez-Garcia, Maximilian Ilse, Daniel C Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anja Thieme, et al. 2023. Learning to exploit temporal structure for biomedical vision-language processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15016–15027.
- Canepa et al. (2023) Louisa Canepa, Sonit Singh, and Arcot Sowmya. 2023. Visual question answering in the medical domain. Preprint, arXiv:2309.11080.
- Chen et al. (2023) Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. 2023. Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478.
- Chen et al. (2024) Zhihong Chen, Maya Varma, Jean-Benoit Delbrouck, Magdalini Paschali, Louis Blankemeier, et al. 2024. Chexagent: Towards a foundation model for chest x-ray interpretation. arXiv preprint arXiv:2401.12208.
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
- Huang et al. (2021) Shih-Cheng Huang, Liyue Shen, Matthew P Lungren, and Serena Yeung. 2021. Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3942–3951.
- Irvin et al. (2019) Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, Jayne Seekins, David A. Mong, Safwan S. Halabi, Jesse K. Sandberg, Ricky Jones, David B. Larson, Curtis P. Langlotz, Bhavik N. Patel, Matthew P. Lungren, and Andrew Y. Ng. 2019. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. Preprint, arXiv:1901.07031.
- Johnson et al. (2019) Alistair Johnson, Matt Lungren, Yifan Peng, Zhiyong Lu, Roger Mark, Seth Berkowitz, and Steven Horng. 2019. Mimic-cxr-jpg-chest radiographs with structured labels. PhysioNet.
- Lee et al. (2019) Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2019. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240.
- Li et al. (2024) Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. 2024. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems, 36.
- Liu et al. (2023) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual instruction tuning. arXiv preprint arXiv:2304.08485.
- Luo et al. (2022) Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. 2022. Biogpt: generative pre-trained transformer for biomedical text generation and mining. Briefings in Bioinformatics, 23.
- Medical Visual Question Answering (2023) (Med-VQA) Medical Visual Question Answering (Med-VQA). 2023. The slake dataset. https://www.med-vqa.com/slake/.
- Mikhael et al. (2023) Peter G Mikhael, Jeremy Wohlwend, Adam Yala, Ludvig Karstens, Justin Xiang, Angelo K Takigami, Patrick P Bourgouin, PuiYee Chan, Sofiane Mrah, Wael Amayri, et al. 2023. Sybil: A validated deep learning model to predict future lung cancer risk from a single low-dose chest computed tomography. Journal of Clinical Oncology, 41(12):2191–2200.
- Monajatipoor et al. (2021) Masoud Monajatipoor, Mozhdeh Rouhsedaghat, Liunian Harold Li, Aichi Chien, C. C. Jay Kuo, Fabien Scalzo, and Kai-Wei Chang. 2021. Berthop: An effective vision-and-language model for chest x-ray disease diagnosis. Preprint, arXiv:2108.04938.
- Moor et al. (2023) Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. 2023. Med-flamingo: a multimodal medical few-shot learner. In Machine Learning for Health (ML4H), pages 353–367. PMLR.
- OSF (2023s) OSF. 2023s. Osf project: Radvqa. https://osf.io/89kps/.
- Pal et al. (2022) Ankit Pal, Logesh Umapathi, and Malaikannan Sankarasubbu. 2022. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering.
- Radiological Society of North America (2018) Radiological Society of North America. 2018. Rsna pneumonia detection challenge 2018. https://www.rsna.org/rsnai/ai-image-challenge/rsna-pneumonia-detection-challenge-2018.
- Rajpurkar et al. (2018) Pranav Rajpurkar, Jeremy Irvin, Robyn Ball, Kaylie Zhu, Brandon Yang, Hershel Mehta, Tony Duan, Daisy Ding, Aarti Bagul, Curtis Langlotz, Bhavik Patel, Kristen Yeom, Katie Shpanskaya, Francis Blankenberg, Jayne Seekins, Timothy Amrhein, David Mong, Safwan Halabi, Evan Zucker, and Matthew Lungren. 2018. Deep learning for chest radiograph diagnosis: A retrospective comparison of the chexnext algorithm to practicing radiologists. PLOS Medicine, 15:e1002686.
- Rasmy et al. (2020) Laila Rasmy, Yang Xiang, Ziqian Xie, Cui Tao, and Degui Zhi. 2020. Med-bert: pre-trained contextualized embeddings on large-scale structured electronic health records for disease prediction. CoRR, abs/2005.12833.
- Shen et al. (2008) Rui Shen, Pierre Boulanger, and Michelle Noga. 2008. Medvis: A real-time immersive visualization environment for the exploration of medical volumetric data. In 2008 Fifth International Conference BioMedical Visualization: Information Visualization in Medical and Biomedical Informatics, pages 63–68. IEEE.
- Sun et al. (2023) Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. 2023. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389.
- Team et al. (2023) Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
- Thawkar et al. (2023a) Omkar Thawkar, Abdelrahman Shaker, Sahal Shaji Mullappilly, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Jorma Laaksonen, and Fahad Shahbaz Khan. 2023a. Xraygpt: Chest radiographs summarization using medical vision-language models. arXiv preprint arXiv:2306.07971.
- Thawkar et al. (2023b) Omkar Thawkar, Abdelrahman Shaker, Sahal Shaji Mullappilly, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Jorma Laaksonen, and Fahad Shahbaz Khan. 2023b. Xraygpt: Chest radiographs summarization using medical vision-language models. Preprint, arXiv:2306.07971.
- The Cancer Imaging Archive (2023) The Cancer Imaging Archive. 2023. The cancer imaging archive (tcia) national lung screening trial (nlst) wiki page. https://wiki.cancerimagingarchive.net/display/NLST.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Wu et al. (2023a) Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2023a. Medklip: Medical knowledge enhanced language-image pre-training. arXiv preprint arXiv:2301.02228.
- Wu et al. (2023b) Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2023b. Towards generalist foundation model for radiology. arXiv preprint arXiv:2308.02463.
- Zhang et al. (2023) Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2023. Pmc-vqa: Visual instruction tuning for medical visual question answering. arXiv preprint arXiv:2305.10415.
- Zhu et al. (2023) Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592.
附录A定性示例
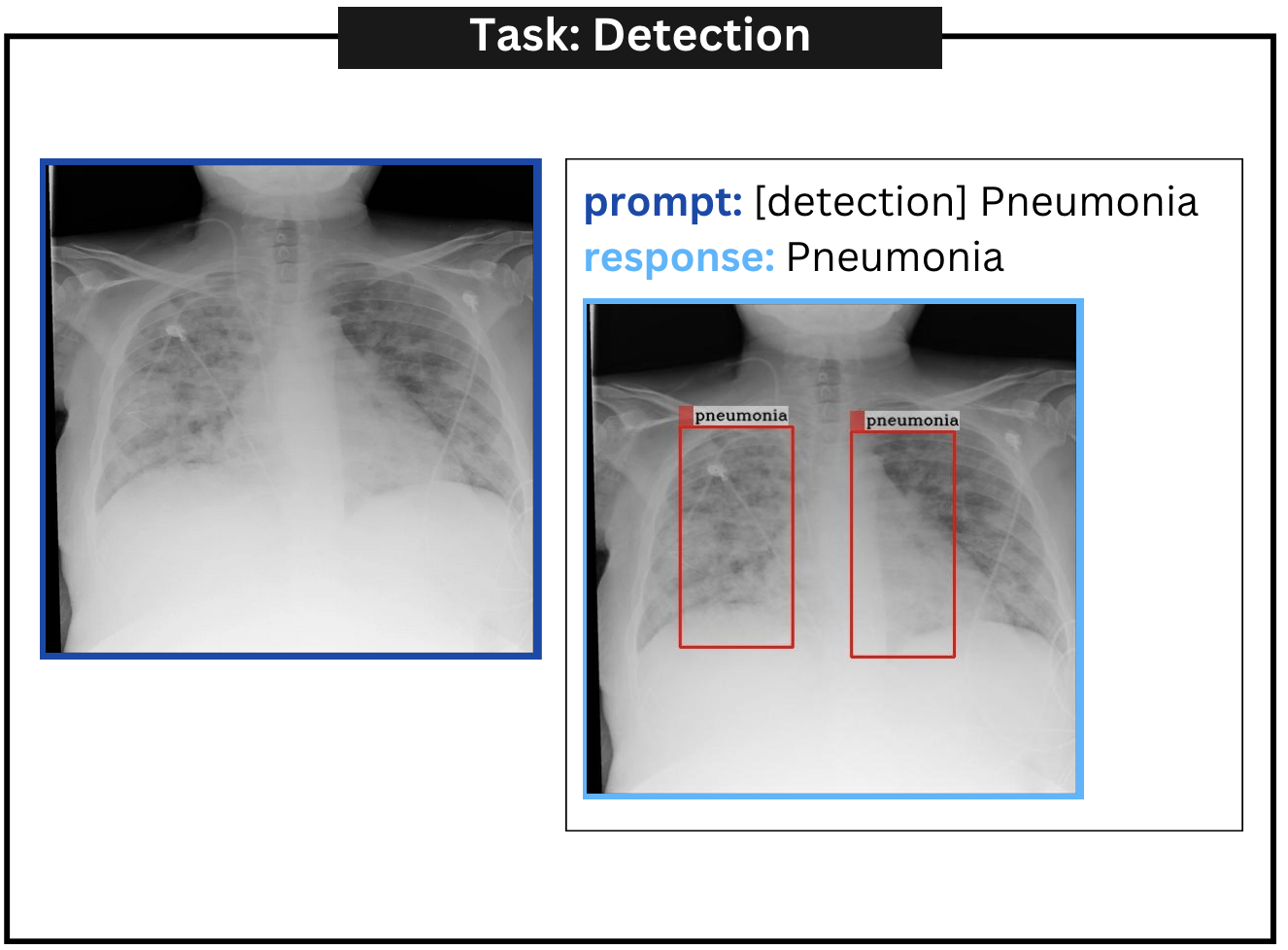
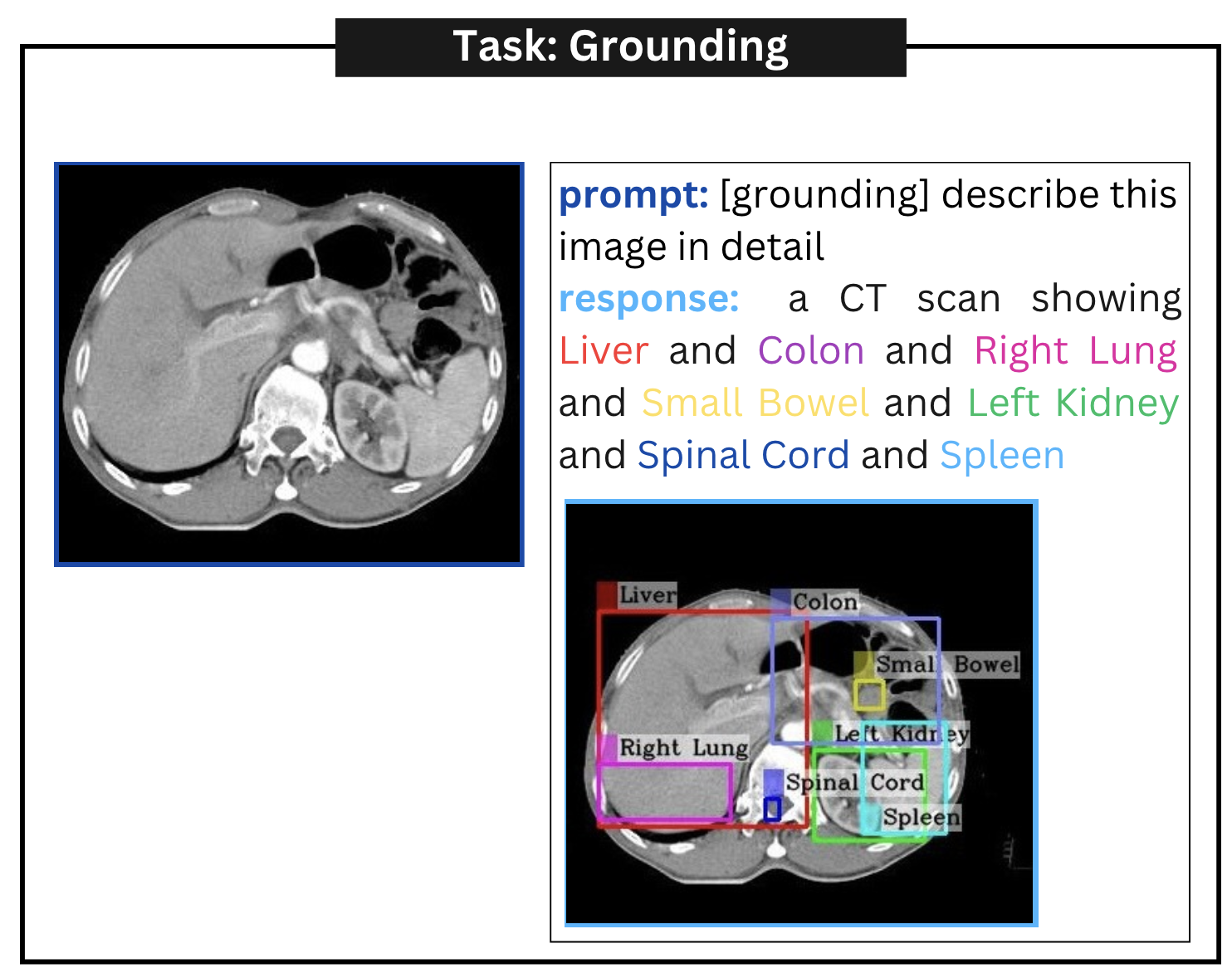
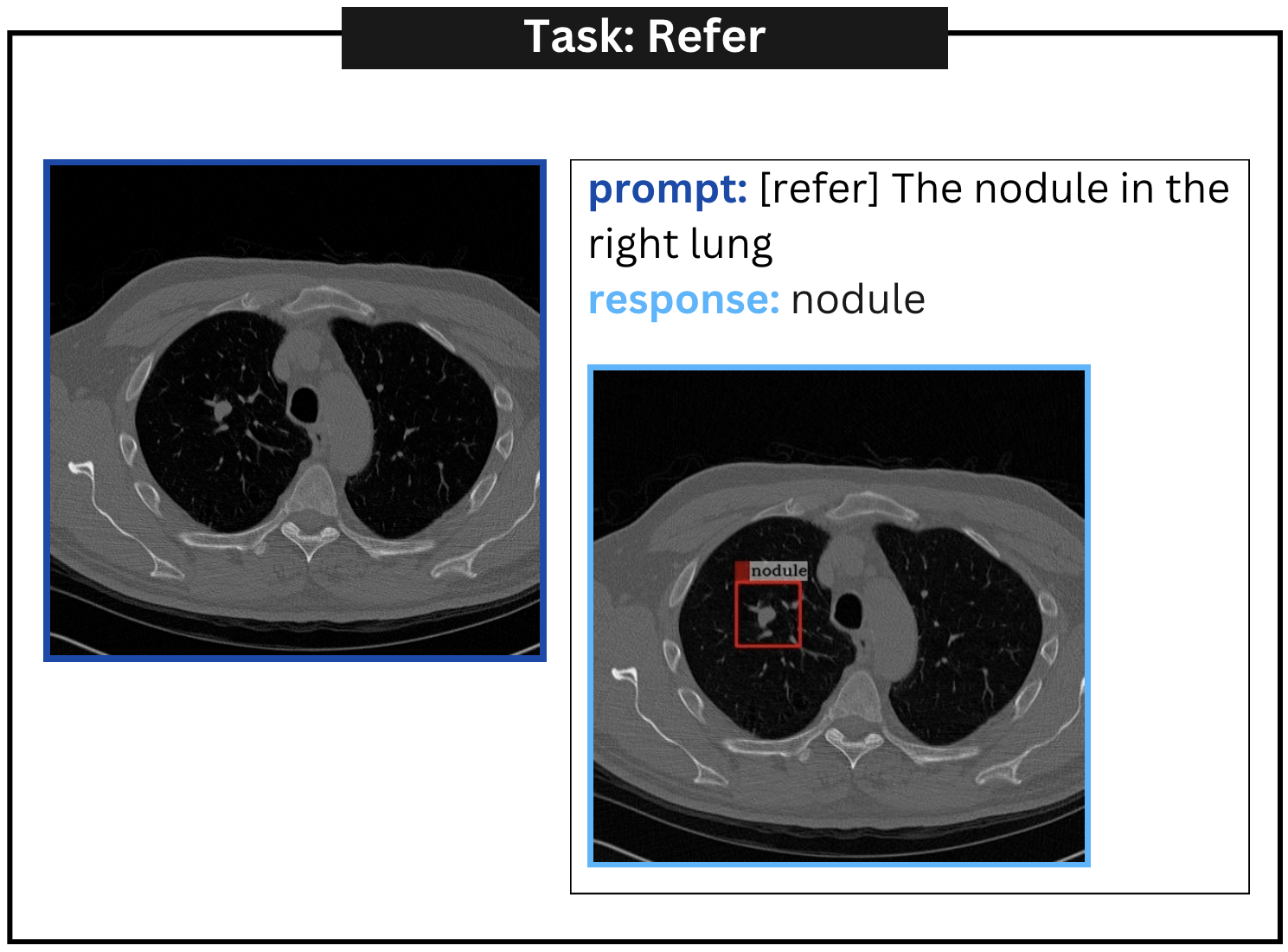
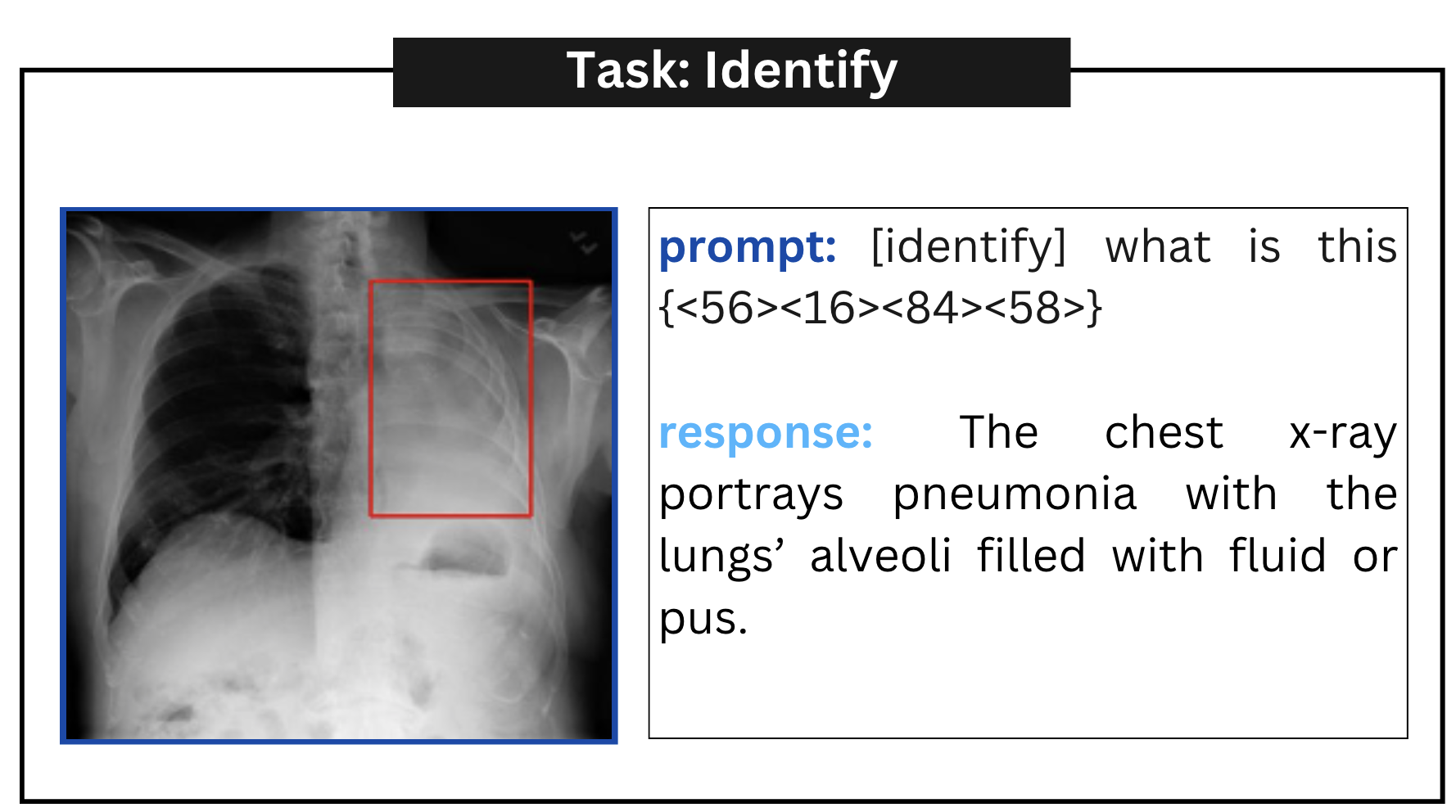
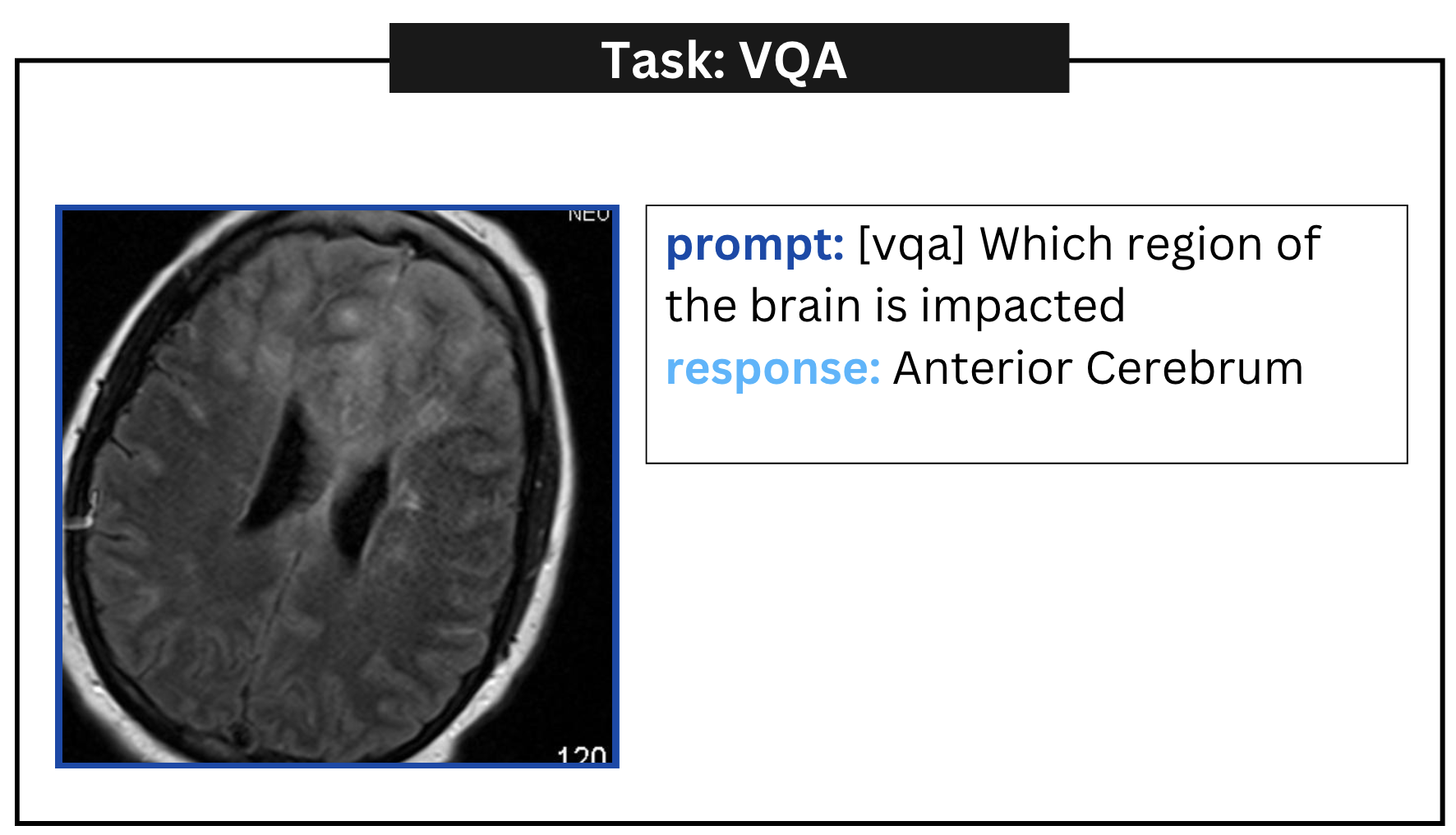
附录 B误报示例