LoRA-GA:梯度近似的低阶自适应
摘要
就计算和内存成本而言,微调大规模预训练模型的成本极其昂贵。 LoRA 作为最流行的参数高效微调(PEFT)方法之一,通过微调参数少得多的辅助低秩模型,提供了一种经济高效的替代方案。 尽管 LoRA 在每次迭代中显着降低了计算和内存需求,但大量的经验证据表明,与完全微调相比,它的收敛速度要慢得多,最终导致整体计算量增加,并且测试性能往往更差。 在我们的论文中,我们对 LoRA 的初始化方法进行了深入研究,并表明仔细的初始化(不改变架构和训练算法)可以显着提高效率和性能。 特别是,我们引入了一种新颖的初始化方法,LoRA-GA(Low Rank Adaptation with G radient A近似),它将低秩矩阵乘积的梯度与第一步完全微调的梯度对齐。 我们的大量实验表明,LoRA-GA 实现了与完全微调相当的收敛速度(因此明显快于普通 LoRA 以及最近的各种改进),同时获得了可比甚至更好的性能。 例如,在具有 T5-Base 的 GLUE 数据集子集上,LoRA-GA 平均优于 LoRA 5.69%。 在 Llama 2-7B 等较大模型上,LoRA-GA 在 MT-bench、GSM8K 和 Human-eval 上的性能分别提高了 0.34、11.52% 和 5.05%。 此外,与普通 LoRA 相比,我们观察到收敛速度提高了 2-4 倍,验证了其在加速收敛和增强模型性能方面的有效性。 代码可在 github 获取。
1简介
微调大型语言模型(大语言模型)对于实现先进技术至关重要,例如指令微调[1]、人类反馈强化学习(RLHF)[2][2],并使模型适应特定的下游应用。 然而,与完全微调相关的计算和存储成本非常高,特别是当模型大小持续增长时。 为了应对这些挑战,参数高效微调(PEFT)方法(例如,参见[3]),例如低阶适应(LoRA)[4],已经出现并获得了极大的关注。
LoRA 不是直接更新模型的参数,而是将辅助低秩矩阵 和 合并到模型的线性层中(例如 、和自注意力块中的矩阵[5]),同时保持原始层权重固定。 修改后的层表示为,其中是该层的输入,是输出,是该层的输入。比例因子。 这种方法显着减少了需要微调的参数数量,从而降低了每个步骤的计算和内存成本。
尽管有这些好处,但大量的经验证据(例如,参见[6,7,8,9])表明,与完全微调相比,LoRA 的收敛速度明显较慢。 这种较慢的收敛通常会增加总体计算成本(以浮点运算来衡量),有时会导致测试性能变差。 在我们的实验中,我们通常观察到 LoRA 需要多 5-6 倍的迭代和 FLOP 才能在相同的学习率下达到与完全微调相同的性能,如图 1 所示。
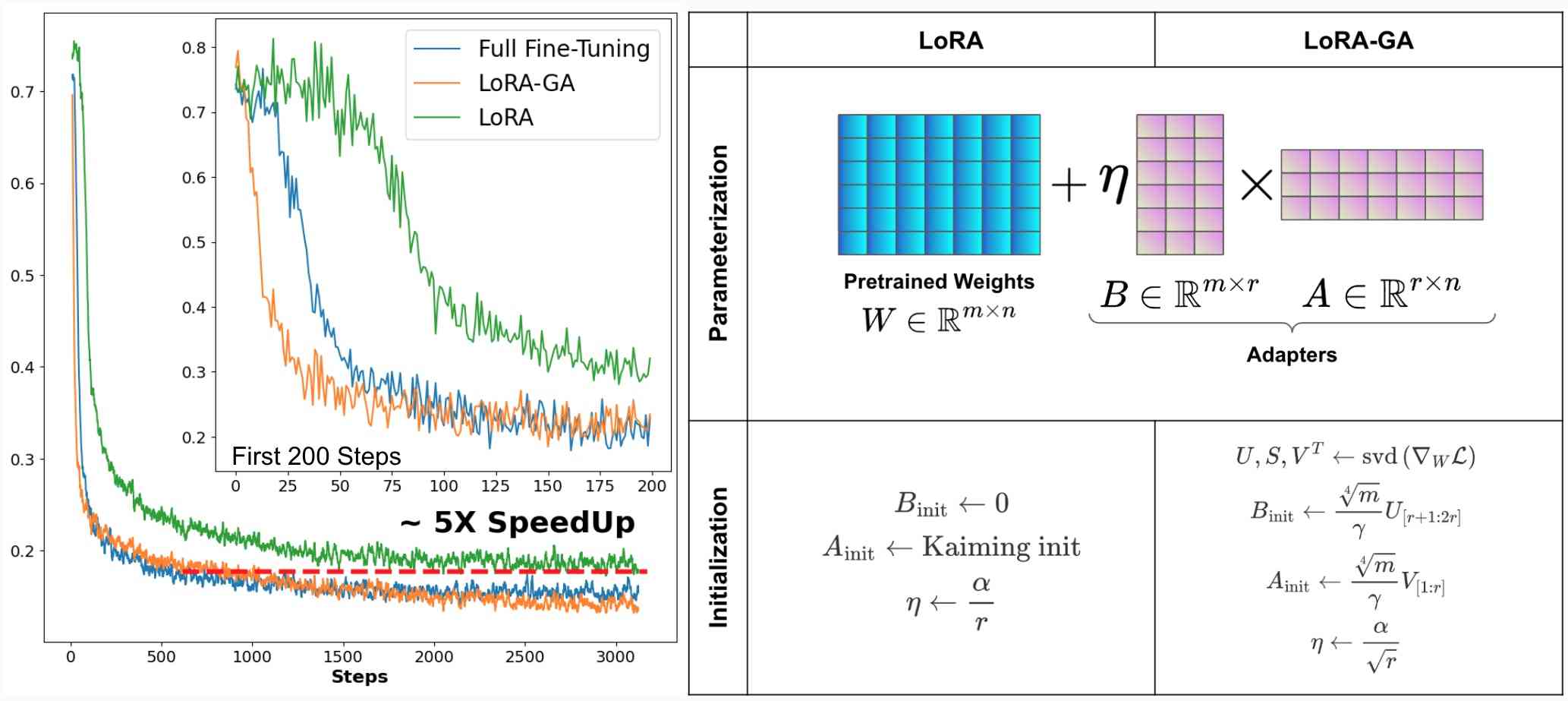
为了研究收敛缓慢的原因,我们对 LoRA 适配器权重的初始化策略进行了深入研究。 众所周知,使用相同目标(例如语言建模)微调预训练模型通常比重新初始化新参数(例如分类头)收敛得更快[10]。 这一观察结果让我们质疑普通 LoRA 的缓慢收敛是否可能归因于适配器权重的默认随机初始化(LoRA 使用 Kaiming 初始化 [11] 初始化 并设置 到零[4])。 在我们的实验中,我们发现 LoRA 的不同初始化策略会对结果产生显着影响,并且其默认初始化不是最优的。
为了追求与完全微调相当的收敛速度,我们的目标是初始化,使 的更新与 的更新紧密匹配。 之前的工作表明梯度下降在低维子空间 [12, 13] 中运行。 如果我们能够在初始步骤中逼近整个模型的梯度,那么后续步骤也可以逼近,从而有可能加速 LoRA 的收敛。
为此,我们引入了一种新颖的初始化方法,LoRA-GA (Low Rank Gradient A近似)。 通过用全梯度矩阵的特征向量初始化和,低秩乘积的梯度与全权重矩阵。从数学上来说,我们的目标是确保:
我们的贡献可总结如下:
1. 我们提出了 LoRA-GA,这是一种新颖的 LoRA 初始化方法,通过用全权重矩阵的梯度逼近低秩矩阵的梯度来加速收敛。
2. 我们确定非零初始化下的缩放因子,这确保适配器输出的方差对于适配器的等级和输入的维度是不变的。
3. 我们通过大量实验验证了 LoRA-GA,与普通 LoRA 相比,性能显着提高,收敛速度更快。 具体而言,LoRA-GA 在带有 T5-Base [15] 的 GLUE[14] 子集上比 LoRA 性能高出 5.69%,在MT-bench [16]、GSM8K [17] 和 HumanEval [18] 以及 Llama 2-7B [19],同时实现高达 2-4 倍的收敛速度。
2相关工作
2.1初始化
在初始化过程中保持方差稳定性的重要性已被广泛认可,以防止出现递减或爆炸现象。 Xavier 初始化 [20] 确保线性激活函数下网络前向和后向传递的稳定性。 他的初始化[11]将此解决方案扩展到使用 ReLU 激活的网络。 与这些不同的是,LSUV 初始化[21]选择一小批数据,执行前向传递以确定输出方差,然后对其进行归一化以确保稳定性。 张量程序(例如,参见[22])已成为一种强大的技术,用于调整大型模型的各种超参数(包括初始化)。
2.2参数高效微调(PEFT)
为了在有限的硬件资源的限制下使语言模型变得越来越大,研究人员开发了各种参数高效微调(PEFT)方法。 一种方法是基于适配器的方法[23,24,25,26],它将新层合并到模型的现有层中。 通过仅微调这些插入的层(通常具有很少的参数),可以显着减少资源消耗。 然而,这种方法在前向和后向传递期间都会引入额外的延迟,因为计算必须遍历新添加的层。 另一种方法是基于软提示的方法 [10, 27, 28, 29, 30],它将可学习的软标记(提示)添加到模型的输入中,以使模型适应特定任务。 这种方法利用了预训练模型的固有功能,只需要适当的提示即可适应下游任务。 尽管有效,但该方法也会产生额外的计算开销,从而导致推理期间的延迟。
2.3 LoRA 的变体
LoRA 是最流行的 PEFT 方法之一,它引入了低秩矩阵与现有层的乘积,以近似微调过程中的权重变化。 人们提出了几种方法来改进 LoRA 的结构。 AdaLoRA [31] 在使用 SVD 微调期间动态修剪不重要的权重,从而允许在固定参数预算内将更多的排名分配给重要区域。 DoRA [8] 通过向低秩矩阵乘积所做的方向调整添加可学习的幅度来增强模型的表达能力。 此外,LoHA [32] 和 LoKr [33] 分别采用哈密顿乘积和克罗内克乘积。
尽管取得了这些进步,由于其强大的库和硬件支持,vanilla LoRA 仍然是最流行的方法。 因此,在不改变LoRA结构的情况下,以低成本改进LoRA至关重要。 最近的一些方法集中在这个方面。 ReLoRA [34] 建议定期将学习到的适配器合并到权重矩阵中,以增强 LoRA 的表达能力。 LoRA+[35]提出对LoRA中的两个矩阵使用不同的学习率来提高收敛性。 rsLoRA [36] 引入了一个新的缩放因子,使输出的缩放比例与排名保持不变。 尽管我们的稳定缩放方法看起来与 rsLoRA 类似,但 rsLoRA 假设 初始化,从而使 对于更新 不变。 相反,我们的稳定尺度确保非零初始化的 从一开始就对排名和输入维度保持不变。
最近,PiSSA [37] 提出通过对 执行 SVD 来初始化 和 以逼近原始矩阵 。然而,我们的方法基于一个截然不同的想法,即近似 的梯度,这涉及对采样梯度执行 SVD 和适当缩放初始化矩阵,详见第 E 节。
3方法
在本节中,我们分析 LoRA 的初始化并介绍我们的方法 LoRA-GA。 LoRA-GA 由两个关键部分组成:(i) 近似完全微调的梯度方向;(ii) 确保初始化过程中的秩和尺度稳定性。 我们检查每个组件,然后展示它们在 LoRA-GA 中的集成。
3.1 原版 LoRA 回顾
LoRA的结构
基于微调的更新是低秩[13]的假设,LoRA[4]提出使用两个低秩矩阵的乘积来表示原始矩阵的增量部分。这里,是模型中线性层的权重矩阵。 例如,在 Transformer 中,它可以是自注意力层的 或 矩阵或 MLP 层中的权重矩阵。 具体来说,LoRA具有以下数学形式:
其中 、 和 以及 。 是预训练的权重矩阵,在微调过程中保持冻结状态,而和是可训练的。
LoRA的初始化
LoRA默认的初始化方案[4, 38]下,矩阵使用凯明统一[11]初始化,而矩阵 初始化为全零。 因此,和,确保初始参数不变。
如果附加项最初不为零(例如[37]),则可以调整冻结参数以确保初始参数不变。 这可以表示为:
其中 被冻结,并且 和 在这种情况下是可训练的。
3.2梯度近似
我们的目标是确保第一步更新 近似权重更新 的方向,即在某个非零正常数 的情况下,。 我们将在3.3节中讨论如何选择,并且现在可以将视为固定常数。
考虑学习率为的梯度下降步骤,和的更新是和 , 分别。 假设学习率较小,则第一步的更新可以表示为:
为了衡量其在完全微调中缩放权重更新的近似质量,我们使用这两个更新之间的差异的Frobenius范数作为标准:
| (1) |
Lemma 3.1。
假设损失函数为和,其中是层的输出,是输入,梯度为和是梯度的线性映射:
值得注意的是,LoRA 中的 和完全微调中的 在训练开始时是相同的。
该标准评估适配器的梯度在多大程度上接近完全微调的梯度方向,并最小化它使LoRA的梯度更接近具有比例因子的完全微调的梯度:
| (3) |
定理3.1为给定特定的和提供了适当的初始化方案。 的选择会影响更新 的缩放,将在下一节中讨论。
3.3规模稳定性
受 rsLoRA [36] 和 Kaiming 初始化[11] 的启发,我们定义稳定性:
Definition 3.1。
当时,适配器表现出两种不同类型的尺度稳定性:
1. 前向稳定性:如果适配器的输入独立同分布 (i.i.d.) 有了第二个时刻,那么输出的第二个时刻仍然是。
2. 后向稳定性:如果相对于适配器输出的损失梯度为,则相对于输入的梯度保持为。
Theorem 3.2.
给定定理3.1中提出的初始化,假设和中的正交向量是从中的单位球体中随机选择的> 和 的约束条件是向量彼此正交,而 如 rsLoRA [36] 所建议的那样。 在这些条件下,如果,则适配器向前缩放稳定;如果,则适配器向后缩放稳定。
与 Kaiming 初始化 [11] 获得的结果类似,我们观察到 或 独立工作得很好。 对于本文提出的所有模型,任何一种形式都可以确保收敛。 因此,对于所有后续实验,我们采用。
3.4LoRA-GA初始化
结合梯度近似和稳定尺度分量,我们提出了LoRA-GA初始化方法。 首先,我们使用定理3.1中的解来初始化和。 然后,根据定理3.2确定缩放因子,以确保等级和尺度的稳定性。 因此,基于定理3.1和3.2,我们提出了一种新颖的初始化方法——LoRA-GA。
LoRA-GA:
我们采用和,其中是一个超参数。 我们定义索引集和。 将的奇异值分解(SVD)表示为。 初始化如下:
4实验
在本节中,我们评估 LoRA-GA 在各种基准数据集上的性能。 最初,我们使用 GLUE 数据集 [14] 的子集和 T5-Base 模型 [15] 评估自然语言理解 (NLU) 能力。 随后,我们使用 Llama 2-7B 模型 [19] 评估对话 [16,40]、数学推理 [17,41]和编码能力 [18,42]。 最后,我们进行了消融研究以证明我们方法的有效性。
基线
我们将 LoRA-GA 与几个基线进行比较以证明其有效性:
1. Full-Finetune:用所有参数对模型进行微调,需要最多的资源。
2. Vanilla LoRA [4]:通过将低秩矩阵乘积 插入到线性层中来微调模型。 使用 Kaiming 初始化进行初始化,而 则初始化为零。
3. 具有原始结构的 LoRA 变体:这包括保留原始 LoRA 结构的几种方法:
- rsLoRA [36] 引入了一种新的稳定 LoRA 规模的缩放因子。
- LoRA+ [35]以不同的学习率更新LoRA中的两个矩阵。
- PiSSA [37] 建议在训练开始时对权重矩阵 执行 SVD,并初始化 和 基于具有较大奇异值的分量。
4. 结构修改的LoRA变体:包括修改原始LoRA结构的方法:
- DoRA [8]增强模型的表达能力通过添加可学习的幅度。
- AdaLoRA [31] 在使用 SVD 微调期间动态修剪不重要的权重,从而允许在固定参数预算内将更多的排名分配给重要区域。
4.1自然语言理解实验
模型和数据集
我们在 GLUE 基准测试的多个数据集上构建了 T5-Base 模型,包括 MNLI、SST-2、CoLA、QNLI 和 MRPC。 使用准确性作为主要指标在开发集上评估性能。
实施细节
我们在 GLUE 基准测试上利用即时调整来调整 T5-Base 模型。 这涉及将标签转换为标记(例如,“正”或“负”)并使用这些标记的归一化概率作为分类的预测标签概率。 我们在附录D.1中提供了超参数。 每个实验均使用 3 个不同的随机种子进行,并报告平均性能。
结果
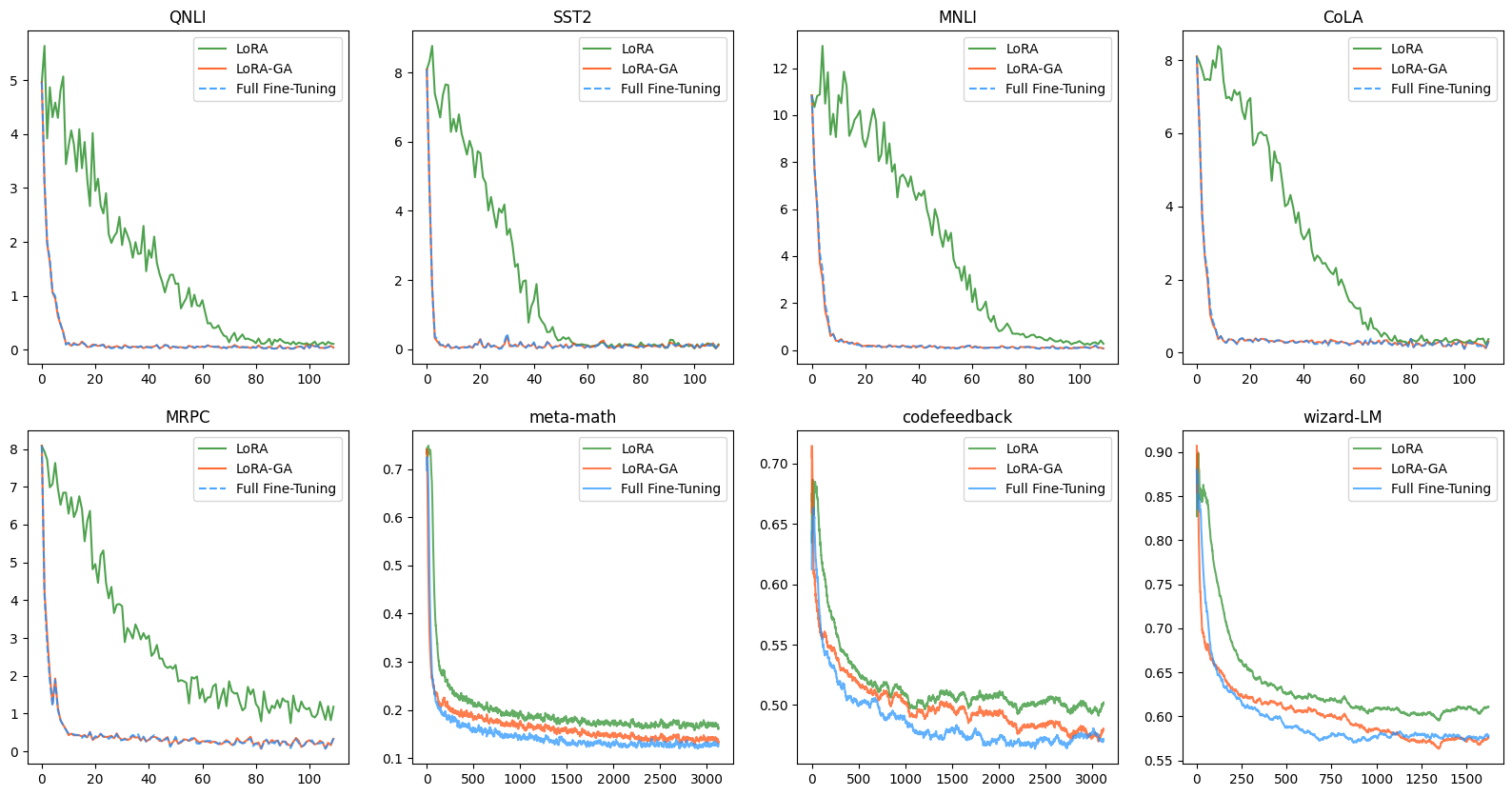
如表1所示,LoRA-GA 始终优于原始 LoRA 和其他基线方法,实现了与完全微调相当的性能。 值得注意的是,LoRA-GA 在 CoLA 和 MRPC 等较小的数据集上表现出色,展示了其更快收敛并有效利用有限训练数据的能力。
| MNLI | SST-2 | CoLA | QNLI | MRPC | Average | |
| Size | 393k | 67k | 8.5k | 105k | 3.7k | |
| Full | ||||||
| LoRA | ||||||
| PiSSA | ||||||
| rsLoRA | ||||||
| LoRA+ | ||||||
| DoRA | ||||||
| AdaLoRA | ||||||
| LoRA-GA |
4.2大语言模型实验
模型和数据集
为了评估 LoRA-GA 的可扩展性,我们在三个任务上训练 Llama 2-7B:聊天、数学和代码。
1. 聊天:我们在 WizardLM [40] 的 52k 子集上训练我们的模型,过滤掉以“作为 AI”或“抱歉”开头的响应。 我们在 MT-Bench 数据集 [16] 上测试我们的模型,该数据集由 80 个多轮问题组成,旨在从多个方面评估大语言模型。 响应的质量由 GPT-4 判断,我们报告第一轮得分。
2. 数学:我们在 MetaMathQA [41] 的 100k 子集上训练我们的模型,这是一个从其他数学指令调整数据集(如 GSM8K[17])引导而来的数据集> 和 MATH [43],具有更高的复杂性和多样性。 我们选择从 GSM8K 训练集中引导的数据并应用过滤。 准确度是在 GSM8K 评估集上报告的。
3. 代码:我们在代码反馈[42]的 100k 子集(一个高质量的代码指令数据集)上训练我们的模型,删除了代码块后的解释。 该模型在 HumanEval [18] 上进行测试,该模型由 180 个 Python 任务组成,我们报告了 PASS@1 指标。
实施细节
我们的模型是使用语言建模的标准监督学习进行训练的。 输入提示的损失设置为零。 详细的超参数可以参见附录D.2。 每个实验使用 3 个不同的随机种子,并报告这些运行的平均性能。
结果
排名的影响
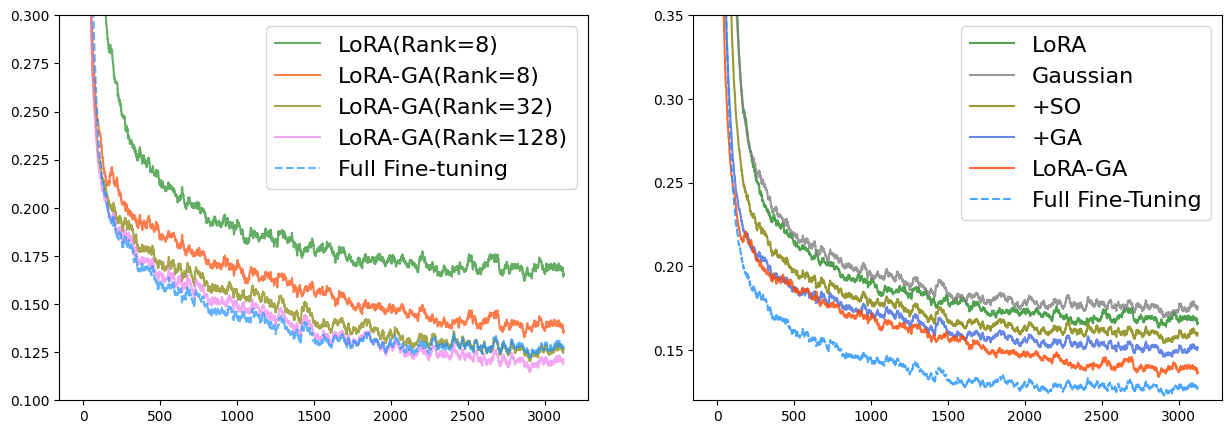
与完全微调相比,我们将 GSM8K 和人类评估数据集上的性能差异主要归因于低秩近似所施加的表征限制。 为了解决这个问题,我们尝试了更高的排名,特别是排名=32 和排名=128。 我们的研究结果表明,LoRA-GA 在不同的等级设置下保持稳定性,在某些情况下,甚至超越了完全微调的性能。 如图2(左)所示,初始化的较高等级也会导致损失曲线与完全微调的损失曲线非常相似。
| MT-Bench | GSM8K | Human-eval | |
|---|---|---|---|
| Full | |||
| LoRA | |||
| PiSSA | |||
| rsLoRA | |||
| LoRA+ | |||
| DoRA | |||
| AdaLoRA | |||
| LoRA-GA | |||
| LoRA-GA (Rank=32) | |||
| LoRA-GA (Rank=128) |
4.3消融研究
我们进行了消融研究,使用五种不同的实验设置来评估 LoRA-GA 中非零初始化、稳定输出和梯度近似的贡献。 表3中提供了每个设置的详细信息。
| Method | Initialization | Initialization | |
|---|---|---|---|
| LoRA | 0 | ||
| Gaussian | |||
| +SO | |||
| +GA | |||
| LoRA-GA |
| MT-Bench | GSM8K | Human-eval | Average of GLUE | |
|---|---|---|---|---|
| Full | ||||
| LoRA | ||||
| Gaussian | ||||
| + SO | ||||
| + GA | ||||
| LoRA-GA |
消融结果
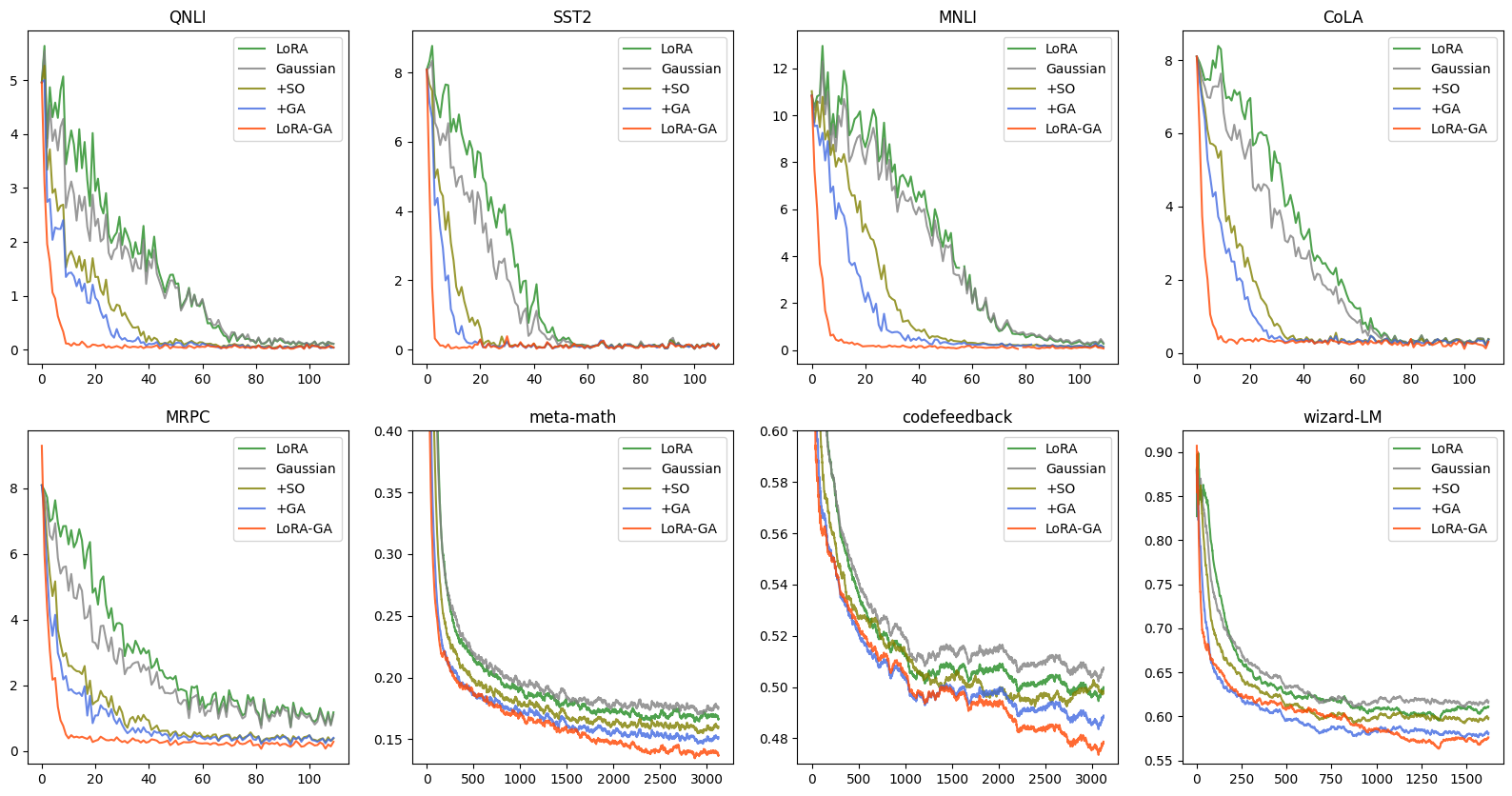
结果如表4和6所示。 对于小型和大型模型,我们观察到简单地将 LoRA 的初始化更改为高斯不会产生任何性能提升,并且可能会导致性能轻微下降。 然而,当与“+SO”(稳定输出)或“+GA”(梯度近似)结合使用时,性能会比 LoRA 有所提高。 LoRA-GA 集成了这两种技术,其性能优于其他方法。 如图2(左)和图4所示,+SO和+GA也提高了收敛速度,当两者结合时,训练损失曲线更接近也就是全面微调。 这表明输出稳定性和梯度近似都有助于 LoRA 的改进,分别解决模型性能的不同方面。
4.4 内存成本和运行时间
我们在单个 RTX 3090 24GB GPU、128 核 CPU 和 256GB RAM 上对 LoRA-GA 进行了基准测试。 如表5所示,我们的新方法的内存消耗不超过LoRA使用的内存消耗,表明不需要额外的内存。 此外,与后续的微调过程相比,此操作的时间成本相对可以忽略不计。 例如,在Code-Feedback任务中,训练过程大约需要10个小时,而初始化只需要大约1分钟,这是微不足道的。
| Parameters | Time(LoRA-GA) | Memory(LoRA-GA) | LoRA | Full-FT | |
|---|---|---|---|---|---|
| T5-Base | 220M | 2.8s | 1.69G | 2.71G | 3.87G |
| Llama 2-7B | 6738M | 74.7s | 18.77G | 23.18G | 63.92G |
5结论
在本文中,我们提出了一种新颖的低秩适应(LoRA)初始化方案,其目标是加速其收敛。 通过检查 LoRA 的初始化方法和更新过程,我们开发了一种新的初始化方法 LoRA-GA,该方法从第一步开始就用完全微调的梯度来近似低秩矩阵乘积的梯度。
通过大量的实验,我们证明 LoRA-GA 实现了与完全微调相当的收敛速度,同时提供类似甚至更优越的性能。 由于 LoRA-GA 仅修改 LoRA 的初始化,而不改变架构或训练算法,因此它提供了一种易于实现的高效且有效的方法。 此外,它还可以与其他 LoRA 变体合并。 例如,ReLoRA [34] 定期将适配器合并为冻结权重 ,这可能允许 LoRA-GA 展示其相对于更多步骤的优势。 我们将其作为一个有趣的未来方向。
参考
- [1] Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, et al. Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792, 2023.
- [2] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- [3] Zeyu Han, Chao Gao, Jinyang Liu, Sai Qian Zhang, et al. Parameter-efficient fine-tuning for large models: A comprehensive survey. arXiv preprint arXiv:2403.14608, 2024.
- [4] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021.
- [5] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [6] Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence, 5(3):220–235, 2023.
- [7] Rui Pan, Xiang Liu, Shizhe Diao, Renjie Pi, Jipeng Zhang, Chi Han, and Tong Zhang. Lisa: Layerwise importance sampling for memory-efficient large language model fine-tuning, 2024.
- [8] Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation, 2024.
- [9] Dan Biderman, Jose Gonzalez Ortiz, Jacob Portes, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, et al. Lora learns less and forgets less. arXiv preprint arXiv:2405.09673, 2024.
- [10] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35, 2023.
- [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, 2015.
- [12] Guy Gur-Ari, Daniel A Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace. arXiv preprint arXiv:1812.04754, 2018.
- [13] Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv preprint arXiv:2012.13255, 2020.
- [14] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
- [15] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- [16] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2024.
- [17] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [18] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [19] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [20] Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010.
- [21] Dmytro Mishkin and Jiri Matas. All you need is a good init. arXiv preprint arXiv:1511.06422, 2015.
- [22] Greg Yang, Edward J Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer. arXiv preprint arXiv:2203.03466, 2022.
- [23] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International conference on machine learning, pages 2790–2799. PMLR, 2019.
- [24] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning, 2022.
- [25] Yaqing Wang, Sahaj Agarwal, Subhabrata Mukherjee, Xiaodong Liu, Jing Gao, Ahmed Hassan Awadallah, and Jianfeng Gao. Adamix: Mixture-of-adaptations for parameter-efficient model tuning. arXiv preprint arXiv:2205.12410, 2022.
- [26] Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. arXiv preprint arXiv:2005.00247, 2020.
- [27] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning, 2021.
- [28] Anastasia Razdaibiedina, Yuning Mao, Rui Hou, Madian Khabsa, Mike Lewis, Jimmy Ba, and Amjad Almahairi. Residual prompt tuning: Improving prompt tuning with residual reparameterization, 2023.
- [29] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. Gpt understands, too. AI Open, 2023.
- [30] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190, 2021.
- [31] Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter-efficient fine-tuning, 2023.
- [32] Nam Hyeon-Woo, Moon Ye-Bin, and Tae-Hyun Oh. Fedpara: Low-rank hadamard product for communication-efficient federated learning. arXiv preprint arXiv:2108.06098, 2021.
- [33] Ali Edalati, Marzieh Tahaei, Ivan Kobyzev, Vahid Partovi Nia, James J Clark, and Mehdi Rezagholizadeh. Krona: Parameter efficient tuning with kronecker adapter. arXiv preprint arXiv:2212.10650, 2022.
- [34] Vladislav Lialin, Namrata Shivagunde, Sherin Muckatira, and Anna Rumshisky. Relora: High-rank training through low-rank updates, 2023.
- [35] Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models, 2024.
- [36] Damjan Kalajdzievski. A rank stabilization scaling factor for fine-tuning with lora, 2023.
- [37] Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models, 2024.
- [38] Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022.
- [39] Kai Lv, Yuqing Yang, Tengxiao Liu, Qinghui Gao, Qipeng Guo, and Xipeng Qiu. Full parameter fine-tuning for large language models with limited resources. arXiv preprint arXiv:2306.09782, 2023.
- [40] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions, 2023.
- [41] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models, 2024.
- [42] Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. Opencodeinterpreter: Integrating code generation with execution and refinement, 2024.
- [43] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset, 2021.
- [44] Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank. Psychometrika, 1(3):211–218, 1936.
- [45] Leon Mirsky. Symmetric gauge functions and unitarily invariant norms. The quarterly journal of mathematics, 11(1):50–59, 1960.
- [46] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019.
附录A定理证明
A.1 定理证明3.1
引理3.1。
假设损失函数为和,其中是层的输出,是输入,梯度为适配器和是梯度的线性映射:
值得注意的是,LoRA中的梯度和完全微调中的梯度在训练开始时是相等的。
证明。
对于 LoRA 中的梯度,
在训练开始时,LoRA和全微调都有和相同的,因此,
∎
定理3.1。
考虑以下优化问题:
如果的奇异值分解(SVD)为,则该优化问题的解为:
其中 是索引集。
证明。
由于和,我们可以断言矩阵有。
在这个给定的解决方案下,
根据 Eckart-Young 定理[44, 45],关于 Frobenius 范数的最优低秩近似为:
这与我们所得到的相同。 因此,这是最优解。 ∎
A.2 定理证明3.2
Lemma A.1.
在 中,如果我们随机选择 的向量 ,我们有:
-
1.
、和;
-
2.
;
-
3.
;
-
4.
;
证明。
相当于从内的单位球体中均匀采样随机点。
对于属性 1, 由对称性可知。 自从 并且均匀分布,每个条目都有相同的期望,,。 。
对于性质2,也可以通过对称性来证明:我们总能找到包含的向量 也位于球体上。 所以, 。
对于属性 3,。
对于性质4,同样可以通过对称性来证明:我们总能找到包含的向量 也位于球体上。 所以, 。 ∎
Lemma A.2.
对于随机选择的正交矩阵,我们从中随机选取两个不同的列向量和。 对于这两个向量,我们有以下内容:
-
1.
;
-
2.
;
证明。
相当于先从内的单位球体中均匀选取一个随机向量,然后选取另一个 与 正交。
对于属性 1,。
对于属性 2,考虑 ,并且给定 ,我们总能找到 也是一个正交向量。 所以, 。 ∎
附录 B其他实验结果
B.1 收敛速度
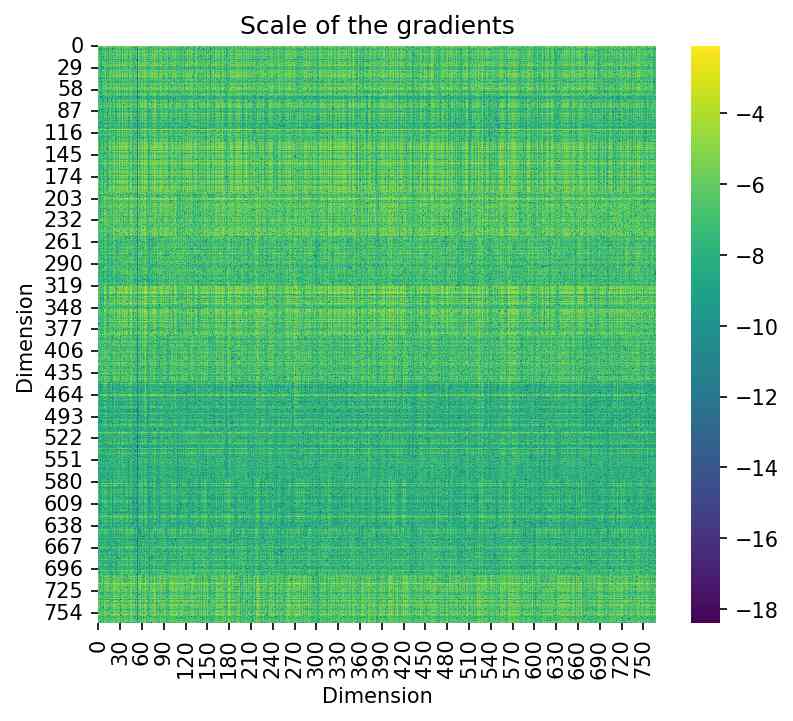
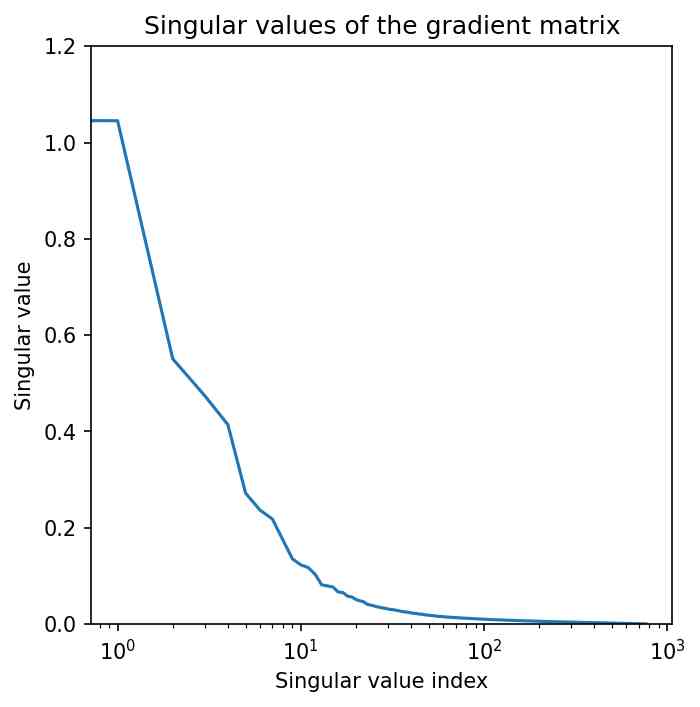
B.2 评估梯度矩阵的秩
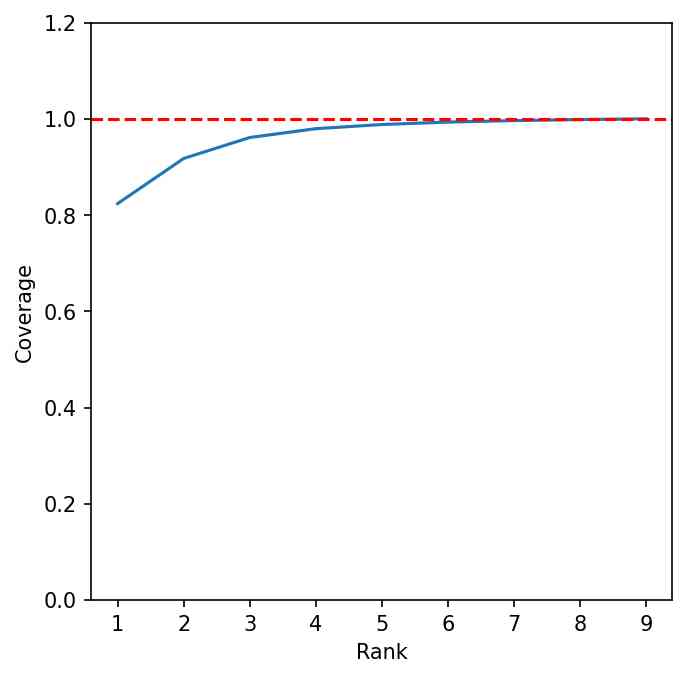
定理3.1表明梯度矩阵的秩越接近,梯度越接近,从而增强我们初始化的理论有效性。 数字 5 说明了梯度矩阵的低秩性质。 左图描绘了权重矩阵梯度中的网格状图案,表示低阶结构。 中间面板显示了奇异值急剧下降的曲线,反映了梯度矩阵的高度低秩性质。 右图显示了奇异值平方的累积曲线,表明少数秩几乎解释了梯度矩阵的所有奇异值。 具体来说,右侧面板中的覆盖范围定义为
哪里 是 LoRA-GA 中使用的 LoRA 秩,指示有多少低秩矩阵可以通过该秩来近似。
B.3GLUE的详细烧蚀研究结果
表6显示了 GLUE 子集的消融研究的完整结果,表中简要报告了平均分数4。如表6 事实证明,LoRA-GA 优于所有其他消融模型,而“+SO”和“+GA”方法都从普通 LoRA 和简单的非零初始化“高斯”中获得了一些改进。 这说明LoRA-GA中的两个组件对性能的提高都有积极的贡献。
| MNLI | SST-2 | CoLA | QNLI | MRPC | Average | |
|---|---|---|---|---|---|---|
| Trainset | 393k | 67k | 8.5k | 105k | 3.7k | |
| Full | ||||||
| LoRA | ||||||
| Gaussian | ||||||
| + SO | ||||||
| + GA | ||||||
| LoRA-GA |
B.4 不同学习率的实验结果
| MT-Bench | GSM8K | Human-eval | |
|---|---|---|---|
| Full | |||
| LoRA | |||
| PiSSA | |||
| rsLoRA | |||
| LoRA+ | |||
| LoRA-GA |
| MT-Bench | GSM8K | Human-eval | |
|---|---|---|---|
| Full | |||
| LoRA | |||
| PiSSA | |||
| rsLoRA | |||
| LoRA+ | |||
| LoRA-GA |
附录 C LoRA-GA 梯度累积初始化
附录D超参数
D.1 自然语言理解实验
我们在 T5-Base 中使用以下超参数。
-
•
训练算法:AdamW [46] 与 ,, 权重衰减为 0。 对于完全微调,LoRA 及其变体,学习率为 ,预热比为 0.03,并采用余弦衰减。 对于 DoRA [8],学习率为 使用,而对于Adalora,学习率为 应用,两者都具有相同的预热比和余弦衰减,遵循各自的论文。
-
•
LoRA 超参数:LoRA 排名 、. LoRA目标是除了嵌入层、层规范和语言模型头之外的所有线性模块。
-
•
LoRA-GA 超参数: ,采样批量大小
-
•
其他超参数:序列长度、训练批量大小、训练epoch数。精密FP32
D.2 大语言模型实验
我们对 Llama 2-7B 使用以下超参数。
-
•
训练算法: AdamW [46] with with ,, 权重衰减为 0。 对于完全微调,LoRA 及其变体,学习率为 [37],采用 0.03 的预热比和余弦衰减。 对于 DoRA [8],学习率为 使用,而对于Adalora,学习率为 应用,两者都具有相同的预热比和余弦衰减,遵循各自的论文。
-
•
精度:主干模型使用bf16精度,而训练时LoRA的和 矩阵使用 fp32 精度,遵循 PEFT [38] 的实现。
-
•
LoRA-GA 超参数: ,微采样批量大小 梯度累积为32。
-
•
LoRA 超参数:LoRA 等级 和 对于所有实验。
-
•
生成超参数:所有生成均使用和温度执行。
-
•
其他超参数:训练周期数、训练微批量大小 梯度累积为32。 序列长度
附录ELoRA-GA与PiSSA的比较
LoRA-GA 和 PiSSA [37] 都专注于 LoRA 的初始化,并在预训练模型上利用 SVD。 虽然它们表面上看起来相似,但它们之间存在显着差异。
首先,LoRA-GA 和 PiSSA 背后的动机根本不同。 正如第 1 节中所讨论的 3.2,LoRA-GA的动机是LoRA更新的近似和充分的微调。 我们在梯度上使用 SVD 仅仅是因为可以精确地获得梯度逼近问题的最优解(如定理中所述) 3.1)。 相反,PiSSA 在预训练权重具有较低内在等级的假设下采用 SVD,因此权重的 SVD 可以提供原始权重的准确表示。 本质上,LoRA-GA 强调梯度并将其分解,而 PiSSA 专注于权重并将其分解。
其次,LoRA-GA 和 PiSSA 采用不同规模的初始化。 在部分 3.3,LoRA-GA 通过考虑初始化方案的前向和后向稳定性得出适当的缩放因子。 另一方面,PiSSA 使用最大的 奇异值直接作为正交矩阵的大小。
附录 F限制
在本文中,我们证明了 LoRA-GA 可以在 T5-Base (220M) 和 Llama 2-7B 模型上实现与完全微调相当的性能,同时显着减少参数数量和相关成本。 然而,由于计算资源限制,我们尚未在较大的预训练模型(例如 Llama 2-70B)上验证 LoRA-GA。
另一个限制与我们的评估范围有关。 虽然我们提供了 MTBench、GSM8K 和 Human-eval 的评估,但我们没有在其他数据集上评估我们的方法。 因此,我们不能完全保证我们的发现在所有基准中普遍一致。
此外,我们没有在与我们的改进正交的其他 LoRA 变体上实现我们的方法(例如,ReLoRA [34])。 因此,我们无法确定 LoRA-GA 是否能与其他 LoRA 架构/改进一样表现良好。
最后,与原始 LoRA 相比,LoRA-GA 需要双倍的检查点存储,因为它需要存储初始适配器检查点( 和 )和最终适配器检查点(和)。
附录 G计算资源
在本文中,我们使用了两种类型的GPU:RTX 3090 24GB GPU,支持128核CPU和256GB RAM(以下简称“RTX 3090”),以及A100 80GB GPU(以下简称“RTX 3090”)。 “A100”)。
附录 H 更广泛的影响
在本文中,我们确定了普通 LoRA 的一些局限性,并提出了一种更高效且有效的 LoRA 初始化方法,即 LoRA-GA。 LoRA-GA 比普通 LoRA 收敛得更快,并且始终获得更好的评估结果。
我们相信这项工作将会产生积极的社会影响。 主要原因如下: 训练和微调大型模型的高成本是当今的重大挑战。 LoRA-GA 提供了一种用更少的参数和更低的计算成本来调节参数的方法,同时仍能实现相当的性能。 这将降低模型微调的成本,进而减少电力等能源消耗,有助于实现低碳环境的目标。 此外,随着大语言模型规模的不断增长,个人或小型组织开发自己的大语言模型变得越来越困难。 不过,在LoRA-GA和开源大模型的帮助下,该领域的硬件进入门槛大大降低。 这将促进大模型领域的民主化,防止少数公司的垄断和独裁。
另一方面,我们的方法可能会让训练生成假新闻或误导性信息的语言模型变得更容易。 这强调了设计有效的检测器来识别大语言模型(大语言模型)生成的内容的必要性。 确保负责任地使用这项技术对于减轻与滥用高级语言模型相关的风险至关重要。