(eccv) 包 eccv 警告:包“hyperref”加载了选项“pagebackref”,*不*建议将其用于相机就绪版本
https://jiahao620.github.io/gaussreg
GaussReg:使用高斯分布进行快速 3D 配准
摘要
点云配准是大规模3D场景扫描和重建的基本问题。 在深度学习的帮助下,注册方法有了显着的发展,达到了近乎成熟的阶段。 随着神经辐射场(NeRF)的引入,它以其强大的视图合成能力成为最流行的3D场景表示。 关于NeRF表示,大规模场景重建也需要它的配准。 然而,这个话题极其缺乏探索。 这是由于使用隐式表示对两个场景之间的几何关系进行建模存在固有的挑战。 现有的方法通常将隐式表示转换为显式表示以进一步注册。 最近,引入了采用显式 3D 高斯的高斯分布 (GS)。 该方法显着提高了渲染速度,同时保持了较高的渲染质量。 给定两个具有明确 GS 表示的场景,在这项工作中,我们探索它们之间的 3D 配准任务。 为此,我们提出了 GaussReg,一种新颖的从粗到精的框架,既快速又准确。 粗略阶段遵循现有的点云配准方法,并估计 GS 点云的粗略对齐。 我们进一步提出了一种图像引导的精细配准方法,该方法渲染来自 GS 的图像,以提供更详细的几何信息以进行精确对准。 为了支持综合评估,我们仔细构建了一个名为 ScanNet-GSReg 的场景级数据集,其中包含从 ScanNet 数据集获得的 场景,并收集了一个名为 GSReg 的野外数据集。 实验结果表明我们的方法在多个数据集上实现了最先进的性能。 我们的 GaussReg 比 Hloc(SuperPoint 作为特征提取器,SuperGlue 作为匹配器)快,并且精度相当。
关键词:
高斯泼溅配准从粗到细1简介
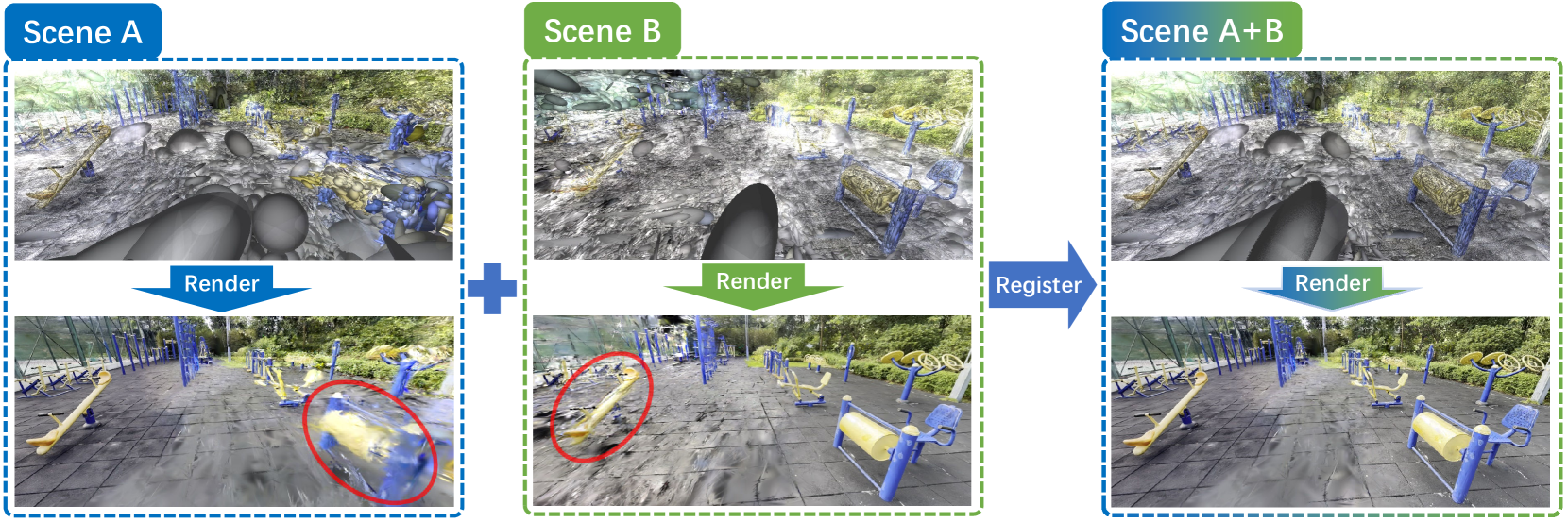
在传统的3D场景扫描和重建中,通常将大范围的场景划分为不同的块,从而产生许多独立的子场景,这些子场景可能不在同一坐标系中。 因此,它们之间的注册起着至关重要的作用。 目前,点云配准已得到广泛研究并达到相对成熟的阶段,代表性作品如ICP[4]、D3Feat[1]、Geotransformer [26]等 主流方法通常涉及从点云中提取特征并定位匹配点以计算两个输入场景之间的变换。
最近,一种新的3D表示方法——神经辐射场(NeRF)被提出,并因其强大的视图合成能力而迅速受到关注,并被广泛用于表示3D场景。 在考虑基于NeRF的大规模场景重建时,存在两个主要挑战:1)由于现实场景中存在复杂的遮挡,通常需要捕获大量图像或视频来进行大规模重建,从而导致耗时的数据收集过程。 2)用大量图像优化 NeRF 是计算密集型的。 因此,一种直接的做法是将一个大场景分割成一些较小的场景,分别重建它们,然后使用配准将所有这些小场景组合在一起。
考虑两个重叠的场景,每个场景都有自己的 NeRF 模型。 目前,配准两个重建的 NeRF 场景的方法一般可分为两类: 1)正如 NeRFuser [10] 中提出的方法,我们可以为每个场景渲染大量图像,然后从运动结构 (SfM) 中恢复所有这些图像的姿势。 然而,这种方法非常耗时; 2)如DReg-NeRF[6]方法中,我们可以通过查询两个场景的NeRF体素网格将隐式辐射场转换为显式体素,并提取特征以建立它们的匹配关系以进行配准。 但该方法面临两个问题:a)难以将无界场景的 NeRF 转化为有界体素; b)体素网格的分辨率限制使得该方法不适合较大的场景。
最近,高斯分布(GS)[16]被提出,它引入了3D高斯的显式表示,在保证高质量渲染的同时加快了渲染过程。 然后,一个有趣的问题出现了:“由于GS提供的是点状的表示,那么我们是否可以采用点云配准的方式进行GS配准呢? ”
在这项工作中,我们探索使用 GS 进行快速、准确的 3D 配准来回答这个问题。 以两个场景的 GS 模型作为输入,我们首先从 GS 中提取它们的点云。 因此,最直接的方法是使点云配准方法适应这些 GS 点云之间的配准。 为此,设计了一种遵循标准点云配准管道的粗配准方法,例如 GeoTransformer [26],但特别考虑了 3D 高斯中的额外属性(例如不透明度)。
与传统收集的点云数据相比,GS 的点云仅捕获粗糙的几何结构,并且通常含有噪声。 因此,粗略的配准不能以足够的精度获得精确的结果。 我们进一步提出了一种基于粗略配准结果的新型图像引导精细配准管道。 我们的主要想法是来自观察,GS不仅包含几何信息,还包含固有的详细图像信息,可以支持更精确的对齐。 因此,我们首先借助粗配准定位重叠区域,其中一些图像借助 GS 渲染。 然后,精细配准管道将图像投影到 3D 体积特征中,以进行最终匹配和变换估计。
最终,我们提出了一种新颖的从粗到细的 GS 配准框架:GaussReg。 但目前仍缺乏GS场景级配准的评价基准。 为了支持这一点,我们构建了一个名为 ScanNet-GSReg 的数据集,其中包含 ScanNet [7] 数据集中的 1379 个场景。 此外,我们收集了一个名为 GSReg 的数据集,包括 6 个室内和 4 个室外场景,以评估我们方法的泛化能力。 我们对 ScanNet-GSReg 数据集、DReg-NeRF [6] 中使用的 Objaverse [8] 数据集以及 GSReg 数据集进行了广泛的实验,证明了我们的有效性方法。
主要贡献可概括为:
-
据我们所知,我们是第一个探索考虑高斯泼溅表示的 3D 场景配准的人。
-
我们精心设计了一种新颖的从粗到细的管道,充分考虑了 3D 高斯的特性,执行速度快且准确。
-
新提出的图像引导精细配准将 GS 的渲染图像考虑在内以进行精细对齐。 我们还相信这一策略为 GS 相关研究打开了思路。
-
还为拟议的新任务新建了一个基准,其中包括来自 ScanNet 的场景和几个自行收集的野外场景。
2相关工作
3D点云配准
3D 点云配准已经发展了几十年。 给定两个具有不同坐标系的重叠点云,该任务的目标是找到它们之间的变换。 传统方法[4,18,17,40,21,23,42]将该过程分为两个部分:对应搜索和变换估计。 对应搜索涉及寻找源点云和目标点云之间的稀疏匹配特征点。 变换估计就是利用这些对应关系来计算变换矩阵。 这两个阶段将迭代进行以找到最佳变换。 然而,这些方法需要许多复杂的策略[18,17,23,42]来克服噪声、异常值或密度变化。 为了克服这些问题,提出了深度特征提取器[35,13,41]来找到两个点云之间更鲁棒的对应关系。 3DRegNet [22] 更进一步学习点云之间的端到端转换。 最近,REGTR [38]结合了自注意力和交叉注意力机制,MAC [43]利用图网络进一步提高了端到端点云的鲁棒性登记。 GeoTransformer [26] 提出了一个几何 Transformer 来匹配超点 [9] 特征,并利用重叠感知圆损失来实现更好的收敛。 新的方法不断被提出,证明了这项任务在场景重建中的重要性。
3D场景表现
Furukawa 和 Ponce [11] 提供了 3D 重建方法的全面分类,将其分为四种主要场景表示:体积场 [30, 24]、点云 [29]、3D 网格 [15, 39] 和深度图 [37, 31, 12]。 除了这些表示之外,NeRF [19] 还引入了一种创新方法,利用神经隐式场对场景进行建模。 NeRF 利用 MLP 网络从一组训练图像中优化 5D 函数(3d 位置加 2d 观察方向),这些图像可用于隐式地对场景进行建模。 它在图像重建和新颖的视图合成方面显示出了令人印象深刻的结果,并被广泛认为是第一个逼真的 3D 场景重建方法。 为了加速[20,5,32]和更好的渲染质量[3,2,34],人们提出了各种类型的NeRF。 另一项最新进展是 3D 高斯分布 [16] 利用显式 3D 高斯来表示场景。 每个高斯函数都具有协方差矩阵、中心点和不透明度的特征,以实现灵活的优化机制。 该模型高效的可微分光栅化实现和精心设计的训练架构可实现快速实时渲染。 此外,优化策略经过巧妙设计,可以自适应控制高斯,以确保非常高的渲染质量。 尽管场景表示的快速创新,3D配准仍然是稳定的大规模重建的一个重要问题,因此为不同的表示开发新的配准方法至关重要。
注册
神经隐式场[19]作为一种新的场景表示已被广泛接受,已经提出了几种方法来进行NeRF配准。 NeRF2NeRF [14] 利用人工注释的关键点来获得初始变换,并使用从预训练的 NeRF 中提取的表面场对其进行细化。 DReg-NeRF [6]从NeRF的占用网格中提取特征,并应用解耦模型[38]进行NeRF注册,消除了注册过程中的人工交互。 然而,由于其全局特征提取策略,很难推广到更大的场景。 NeRFuser [10] 直接使用运动方法的结构来使用 NeRF 的渲染图像来估计变换,这是非常耗时的。 CL-NeRF [36]专注于NeRF模型的持续学习,并提出了一种专家适配器,用于学习新变化的场景,而无需微调整个网络。 最近,3D 高斯分布被提出作为一种有前途的场景表示,据我们所知,我们是第一个提出 3D 高斯分布的配准方法,并以更快的配准速度和更好的渲染质量实现 SOTA 性能。 此外,可以使用我们的管道自然地完成持续学习和修改场景。
3方法
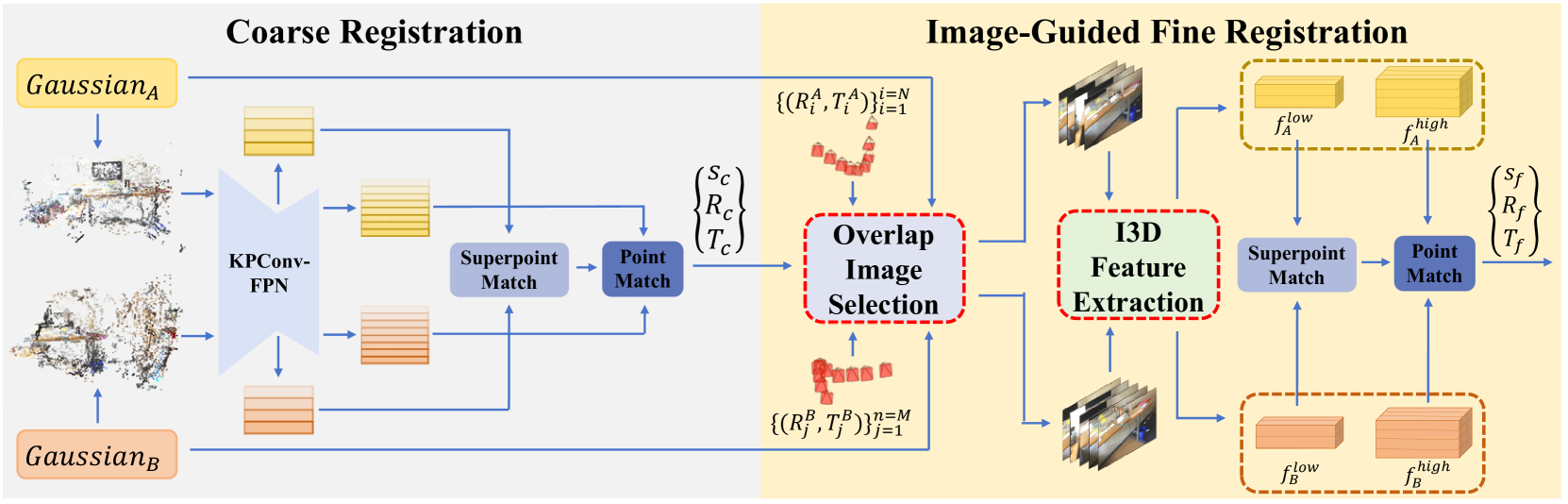
在本节中,我们提出了使用高斯分布 (GS) 进行 3D 配准的 GaussReg。 整体架构如图2所示。
3.1概述
如图2所示,所提出的GaussReg主要由两个阶段组成,包括粗配准和图像引导精细配准。 下面我们简单介绍一下整个过程。 假设两个重叠的场景 A 和 B,每个场景都有自己的 GS 模型,则仅保存和访问所有训练图像的相机姿势。 我们将 A 和 B 的所有训练图像的相机姿势分别表示为 和 。 GS 模型表示为 和 ,从 GS 模型导出的点云表示为 和 。 我们的目标是发现使场景 B 与 A 对齐的刚性变换 ,其中 表示比例因子, 表示旋转矩阵,表示平移向量。 粗配准直接接受和作为输入,并输出粗略变换。 由于从 GS 模型中提取的点云往往存在噪声和失真,因此粗对准通常需要更准确。 然后,在图像引导的精细配准中,我们首先根据粗配准结果定位高度重叠的区域。 在高度重叠的区域周围,然后分别从 和 中选择两个摄像机子集,从中渲染多个图像。 之后,采用图像引导3D(I3D)特征提取从图像中获取体积特征,用于后续的局部匹配,最终实现精确的变换输出。
3.2 粗配准
众所周知,GS模型是以3D高斯的形式存储的。 每个 3D 高斯存储位置 、不透明度 、旋转、比例和球谐系数。 首先,我们选择那些不透明度 大于阈值(根据经验选择 0.7)的置信点。 对于每个采样点,颜色 通过球谐函数确定。 最后,对于 或 中的每个点,我们使用 作为输入通道来馈入粗配准管道。
如图2所示,粗配准遵循GeoTransformer[26]的工作流程,我们通过共享的KPConv-FPN[33]。 最粗的级别点特征和用于超级点匹配,最精细的级别点特征和用于Point匹配。 超级点匹配的过程参考了Geotransformer[26]。 注意到在点匹配中,我们直接利用ICP[4]算法来获得GS之间的粗略配准结果,而不是Geotransformer中的Local-to-Global配准[26].
训练策略和损失函数
由于单目视频重建中的尺度不确定性,我们不仅对旋转和平移进行数据增强,而且对输入高斯点云进行缩放。 即使我们将输入点云的尺度标准化在一定范围内,这种数据增强仍然保留了要匹配的点云之间相对尺度差异的多样性。
我们应用 GeoTransformer [26] 中的两个损失函数(重叠感知圆损失和点匹配损失)来约束我们的粗配准网络。
3.3图像引导精细配准
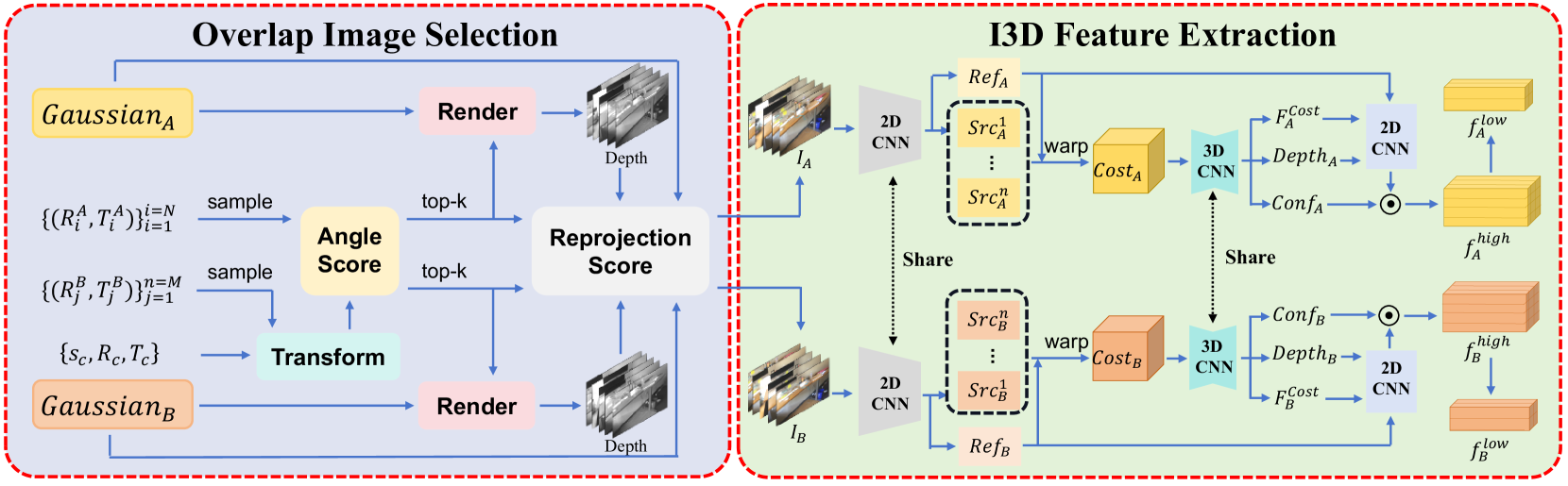
由于 GS 模型在训练过程中没有施加特定的几何约束,因此生成的点云可能会表现出一定程度的失真。 仅仅依靠 GS 模型可能无法保证准确的注册结果。 考虑到GS本质上包含详细的图像信息,提出了图像引导的精细配准。 我们的关键思想是首先找到场景 和场景 之间的重叠区域,并渲染一些覆盖该区域的训练图像,以支持更精确的几何特征以进行精细对齐。 具体来说,如图2所示,我们的图像引导精细配准主要涉及两个步骤:1)高效、准确地选择高度重叠的相机并相应地渲染图像; 2)利用这些图像构建体积特征以进行进一步的精细配准。
重叠图像选择
如图3所示,这部分的主要目标是分别从和中找到相机的两个小子集,它们共享尽可能大的相机子集。尽可能共同的视角区域。 在选择之前,我们首先对两个子集和进行均匀采样以减少计算成本,然后将应用于进行粗略采样。对齐,导致。 在我们的实验中,每个子集都包含 图像。 我们的选择遵循 3 个步骤:1)对于每对,我们计算它们的相机方向之间的角度的余弦值。 最后,将保留前 k 个最接近的对,其中在我们的实验中为 。 由于粗对齐,这一步可以准确、快速地去除许多无用的对; 2)为了实现更准确的选择,对于步骤1后剩下的每一对,我们进一步计算它们的视角共享面积。 为此,分别从 和 渲染两个低分辨率深度图 和 。 然后,我们计算从 导出的点中有多少部分可以从 中看到,从 导出的点中有多少部分可以从 中看到。 通过对平均部分的评估,我们找到最接近的对。 得益于GS的快速渲染速度,深度图渲染高效完成; 3)我们最终分别在和附近选择两个训练相机子集。 在选定的相机下,通过从和渲染获得图像集和,并将其输入到下一个特征中提取阶段。
图像引导 3D 特征提取
如图3所示,我们采用多视点立体(MVS)原理,利用图像辅助估计深度并提取参考图像的体积特征。 不失一般性,我们在下面的描述中以场景为例。 首先,我们将 输入二维卷积神经网络,得到特征 ,然后根据深度假设 通过可微分同构法将其转化为成本量 。 构建成本体积需要最小和最大距离,可以根据参考图像的渲染深度图自动计算该距离。 接下来是3DCNN正则化,从成本卷中获得概率卷和特征卷,其中是特征通道的数量,是的分辨率。 对于 上的任何像素 ,我们的网络预测概率分布 。 我们挑选出满意的:
| (1) |
其中表示像素位于深度的概率。 成本量、预测深度和置信图的特征计算如下:
| (2) | ||||
然后我们连接 、 和 ,并将它们传递给卷积层。 经过基于置信度的过滤后,我们获得高分辨率特征和低分辨率特征。 这个过程可以描述为
| (3) | ||||
和以同样的方式获得。 接下来,我们根据相应的深度图将特征投影到 坐标系中。 最后,按照与粗配准相同的过程,我们得到精配准结果。
训练策略和损失函数
重叠图像选择不参与精细配准网络的训练。 我们从 ScanNet 数据集中随机采样多对重叠的多视图图像进行训练。 在训练过程中,我们还将数据增强应用于相机外部。
我们的损失函数主要由两部分组成,深度损失和配准损失。 深度损失是一个交叉熵损失,用于监督概率量:
| (4) |
其中 和 是有效点的集合。 和 表示来自 的真实深度的 one-hot 标签。 和表示的预测概率分布。配准损失与粗配准中使用的损失函数相同。 因此,我们在罚款登记网络中的总损失是:
| (5) |
在我们的实验中,其中 。

3.4 高斯泼溅融合与滤波
获得最终的注册结果后,就到了合并两款GS车型的时候了。 为了将 转换为 的坐标系(表示为 ),我们首先转换 3D 高斯的位置:
| (6) |
不透明度对于变换 是不变的。 3D 高斯的旋转 和缩放 可以计算为:
| (7) | ||||
从球谐函数(SH)系数的性质可知,SH系数的旋转是SH系数的线性变换,且各阶SH系数的旋转可以单独进行。 因此,对于阶的SH系数,我们可以通过以下方法获得SH系数的变换: 1)选择任意2i+1个单位向量,令,其中是将方向向量投影到对应的SH值的函数; 2) 对向量应用变换,得到; 3) 为SH系数的变换矩阵。 请注意,很难选择向量来确保可逆,因此在我们的实验中,我们在计算 最后,我们将 中靠近 中心的 3D 高斯与 中靠近 中心的 3D 高斯合并> 得到。
4实验
4.1 实验设置
| Methods | RRE | RTE | RSE | Succss Ratio | Time(s) |
|---|---|---|---|---|---|
| HLoc [27]* | 2.725 | 0.099 | 0.098 | 0.756 | 212.3 |
| FGR [44] | 157.126 | 3.328 | 0.268 | 1.000 | 3.4 |
| REGTR [38] | 80.095 | 2.768 | 0.408 | 1.000 | 3.5 |
| Ours | 2.827 | 0.042 | 0.032 | 1.000 | 4.8 |
数据集
由于目前没有场景级数据集可用于我们的任务,因此我们有必要创建一个数据集来评估 GS 配准。 ScanNet [7]是室内场景常用的3D数据集,由训练场景和测试场景组成。 ScanNet 中的每个场景都包含相机内部参数、图像序列以及相应的相机外部参数和深度图。 因此,我们决定构建一个基于ScanNet的数据集,称为ScanNet-GSReg数据集。 首先,我们从每个场景中随机采样两个连续的图像序列。 每个序列包含到图像,采样间隔范围为到。 重叠率计算为两个序列之间重复图像的比例,范围从 到 。 然后,我们独立地将随机变换应用于每组相机外参,以模拟两个序列的世界坐标之间的不一致,并将这两个变换记录为它们的世界坐标之间的真实变换。 使用这些图像序列和相应的相机参数,我们分别重建 GS 模型。 每个模型都会经历 次训练迭代。 最终,在排除初始点云生成失败或GS重建失败的情况后,我们获得训练样本和测试样本。 此外,为了验证我们方法的泛化性,我们收集了 10 个真实场景进行测试,称为 GSReg 数据集,其中包括 室内和 室外场景。 对于每个场景,我们录制两个视频。 首先,我们使用HLoc [27](SuperPoint [9]作为特征提取器,SuperGlue [28]作为匹配器)来获得相机对每个视频分别进行姿态估计,然后将两个视频组合起来进行联合相机姿态估计,以获得两个 GS 模型之间的地面实况变换。 为了评估 GaussReg 在物体上的性能,我们还对 DReg-NeRF [6] 中使用的 Objaverse 数据集 [8] 进行了测试,其测试集包含 44 个对象。
公制
我们参考[26]中的点云配准指标,并对其进行修改以考虑比例因子。 最后,我们使用三个指标在 ScanNet-GSReg 和 GSReg 数据集上评估 GaussReg:1)相对旋转误差(RRE),估计旋转矩阵与地面实况旋转矩阵之间的测地距离; 2)相对平移误差(RTE),估计平移向量与真实平移向量之间的欧氏距离与真实平移向量的范数之比; 3)相对尺度误差(RSE),估计比例因子和地面真实比例因子之间的欧几里得距离与地面真实比例因子的比率。 为了公平比较,我们按照 DReg-NeRF [6] 在 Objaverse 数据集上使用两个指标来评估 GaussReg:1)相对旋转误差(RRE); 2) 绝对平移误差 (ATE),估计和平移向量与真实平移向量之间的欧几里得距离。
实施细节
我们的 GaussReg 仅在 ScanNet-GSReg 训练集上进行训练,并在 ScanNet-GSReg 测试集、Objaverse 测试集和 GSReg 数据集上进行评估。 我们的方法是用 PyTorch [25] 实现的。 在粗配准网络中,我们在训练期间将输入点的数量限制为。 在图像引导的精细配准网络中,我们将每个 GS 模型的 图像渲染为输入,并将深度假设的数量设置为 。 两个网络都分别针对 时期进行训练,批量大小为 。 学习率从开始,每个时期按呈指数衰减。
| Methods | RRE | ATE |
|---|---|---|
| FGR [44] | 61.59 | 13.50 |
| REGTR [38] | 113.78 | 43.31 |
| Dreg-NeRF [6] | 9.67 | 3.85 |
| Ours w/o. fine | 2.47 | 3.46 |
| Methods | RRE | RTE | RSE |
|---|---|---|---|
| Ours w/o. fine | 6.904 | 0.074 | 0.051 |
| Ours | 2.989 | 0.065 | 0.047 |
4.2与其他方法的比较
ScanNet-GSReg 数据集的评估
由于运动结构(SFM)技术的成熟,GS 3D 配准的自然方法是渲染大量图像并利用 SFM 进行联合配准。 因此,我们选择当前的SOTA方法HLoc [27](SuperPoint [9] + SuperGlue [28])作为基线ScanNet 上的比较。 在后续讨论中,为简洁起见,我们将 Hloc [27](SuperPoint [9] + SuperGlue [28])称为 Hloc。 对于要注册的两个 GS 模型,我们统一采样每个 训练姿势来渲染图像,并使用总共 图像进行 Hloc 来估计姿势。 我们可以按照NeRFuser [10]中描述的过程获得两个GS模型的配准结果。 我们还通过输入点来评估传统点云配准方法快速全局配准(FGR)[44]和深度点云配准方法REGTR[38](在3DMatch上重新训练)来自 GS 的云。 FGR和REGTR后面还跟着ICP求解器,通过缩放来输出变换结果,并且我们还将输入点数限制为。 定量结果如表1所示,其中成功率表示注册成功的比例。 如表1所示,对于ScanNet-GSReg中的场景,HLoc仅成功注册其中,而我们的方法实现了 成功率。 对于ScanNet-GSReg中的室内场景,SuperPoint [9]有时无法提取有效关键点,导致配准失败。 我们的方法在 RTE 和 RSE 指标方面优于 HLoc,在 RRE 方面具有可比性。 值得注意的是,我们的方法明显快于 Hloc( 与 )。 FGR 和 REGTR 比我们的 GaussReg 稍快,但是,它们的性能比我们的差得多。 我们认为原因是 GS 的点云比扫描数据噪音大得多。 我们的方法在 ScanNet-GSReg 测试集上的可视化如图 4 的前两行所示。 更多视觉结果可以在补充材料中找到。 这些实验充分证明了我们方法的效率和准确性。
Objaverse 数据集的评估
为了对 DReg-NeRF 中使用的 Objaverse 数据集 [8] 进行公平比较,我们假设两个 GS 模型之间不存在 DReg-NeRF [6] 中的尺度差异>。 此外,我们不采用训练姿势,仅使用我们提出的粗配准进行比较。 如表 3 所示,我们的粗略注册方法(我们的 w/o. fine)显着优于其他没有微调的方法,展示了其对对象强大的泛化能力。
GSReg 数据集的评估
我们的 GSReg 数据集的真实配准结果是在 Hloc 成功时获得的。 如表3所示,我们的方法在没有微调的情况下获得了接近HLoc的配准结果,证明了我们的方法具有很强的通用性。 此外,我们的方法(我们的)显着优于我们的粗略配准(我们的 w./o. 罚款),证明了我们罚款登记的有效性。 我们的方法在 GSReg 数据集上的可视化显示在图 4 的最后两行中。
| Index | Methods | RRE | RTE | RSE | Succss Ratio | Time(s) |
|---|---|---|---|---|---|---|
| 1 | Hloc [27] | 2.725 | 0.099 | 0.098 | 0.756 | 212.3 |
| 2 | Ours w./o. fine | 3.403 | 0.061 | 0.034 | 1.000 | 3.7 |
| 3 | Ours w./o. fine + HLoc | 1.104 | 0.186 | 0.278 | 0.512 | 206.8 |
| 4 | Ours | 2.827 | 0.042 | 0.032 | 1.000 | 4.8 |
4.3消融研究
为了深入分析 GaussReg,我们对 ScanNet-GSReg 数据集进行了详细的消融研究,以评估所提出组件的有效性。
图像引导精细配准的有效性
Hloc 还可以利用图像信息来细化粗略配准。 因此,为了验证图像引导精细配准的有效性,我们直接将粗配准与HLoc结合起来。 获得粗配准结果后,我们使用重叠图像选择来选择两组多视图图像和,并联合使用和 用于使用 Hloc 进行姿态估计。 如表4所示,通过比较Index-2和Index-4,我们可以看到性能有所提高,这证明了我们的图像引导精细配准的有效性。 比较Index-2和Index-3,我们发现虽然HLoc显示出较低的RRE,但其成功率非常低(),而我们的精细配准不仅在RTE和RSE指标上优于HLoc,而且在更高的成功率 ()。 同时,我们的精细配准比 HLoc 更快( vs. )。 此外,我们还探讨了在重叠图像选择中保留的前 k 对相机的效果。 因此,我们将 k 从 5 更改为 30。 在表6中,当k大于10时,性能几乎没有变化,而当k小于10时,性能下降。 为了准确性和效率,我们认为k 10就足够了。
| Top-k | RRE | RTE | RSE |
|---|---|---|---|
| 5 | 3.677 | 0.115 | 0.079 |
| 10 | 2.827 | 0.042 | 0.032 |
| 20 | 2.604 | 0.063 | 0.044 |
| 30 | 2.311 | 0.091 | 0.028 |
| Index | Method | RRE | RTE | RSE | RDE |
|---|---|---|---|---|---|
| 5 | Ours w/o. I3D | 3.169 | 0.036 | 0.061 | 0.066 |
| 6 | Ours | 2.827 | 0.042 | 0.032 | 0.080 |
图像引导 3D 特征提取的有效性
在这里,我们还报告了相对深度误差(RDE),它是估计深度和真实深度之间的欧几里德距离与真实深度之间的比率。 如表6所示,在Index-5中,我们删除了图像引导的3D(I3D)特征提取。 相反,我们使用 MVSNet [12] 计算深度并投影深度图以获得两个点云,这两个点云作为 KPConv-FPN [33] 的输入来提取特征登记细化。 比较 Index-5 和 Index-6,我们观察到虽然 Index-5 具有更好的深度估计精度,但配准结果很差,证明从图像中提取几何信息补充了特征描述符提取。
4.4高斯泼溅融合和滤波结果
在图5中,我们展示了 GSReg 数据集上的一些定量结果,以证明我们的 GS 融合和过滤的有效性。 有关动态演示,请参阅补充材料中的视频附件。 我们的 GS 融合和过滤策略成功地合并了两个 GS 模型。
5讨论

局限性和未来的工作
我们只采用简单的策略来融合和过滤两个GS模型。 对于一些比较复杂的情况,我们的融合方式是不完善的。 例如,当在不同时间捕获两个场景时,照明的变化可能会导致两个场景的外观不同。 因此,通过我们的策略获得的融合 GS 模型可能会在融合边界处表现出不一致。 未来的工作可以进一步探索解决这个问题。
结论
神经辐射场 (NeRF) 的出现改变了 3D 场景表示的格局,需要改进配准方法。 然而,由于隐式建模几何关系固有的复杂性,大规模场景的 NeRF 表示配准仍未得到充分探索。 最近引入的 Gaussian Splatting (GS) 通过引入显式 3D 高斯显着增强了 NeRF,在保持高质量的同时促进快速渲染。 在本研究中,我们介绍了 GaussReg,这是一种开创性的从粗到精的框架,利用 GS 进行 3D 配准。 粗略阶段利用现有的点云配准方法为输入的 GS 点云建立初步知识对齐。 我们创新地设计了一种图像引导的精细配准策略,该策略结合了这些高斯点的渲染图像,丰富了几何细节以实现精确对准。 为了全面评估我们的方法,我们构建了一个由 ScanNet 场景和几个野外场景组成的基准。 我们的实验结果显示了 GaussReg 在多个数据集上的最先进的性能。
参考
- [1] Bai, X., Luo, Z., Zhou, L., Fu, H., Quan, L., Tai, C.L.: D3feat: Joint learning of dense detection and description of 3d local features. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
- [2] Barron, J.T., Mildenhall, B., Tancik, M., Hedman, P., Martin-Brualla, R., Srinivasan, P.P.: Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 5835–5844 (2021). https://doi.org/10.1109/ICCV48922.2021.00580
- [3] Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5460–5469 (2022). https://doi.org/10.1109/CVPR52688.2022.00539
- [4] Besl, P., McKay, N.D.: A method for registration of 3-d shapes. IEEE Transactions on Pattern Analysis and Machine Intelligence 14(2), 239–256 (1992). https://doi.org/10.1109/34.121791
- [5] Chen, A., Xu, Z., Geiger, A., Yu, J., Su, H.: Tensorf: Tensorial radiance fields. In: European Conference on Computer Vision (ECCV) (2022)
- [6] Chen, Y., Lee, G.H.: Dreg-nerf: Deep registration for neural radiance fields. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22703–22713 (October 2023)
- [7] Dai, A., Nießner, M., Zollöfer, M., Izadi, S., Theobalt, C.: Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface re-integration. ACM Transactions on Graphics 2017 (TOG) (2017)
- [8] Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., VanderBilt, E., Kembhavi, A., Vondrick, C., Gkioxari, G., Ehsani, K., Schmidt, L., Farhadi, A.: Objaverse-xl: A universe of 10m+ 3d objects. arXiv preprint arXiv:2307.05663 (2023)
- [9] DeTone, D., Malisiewicz, T., Rabinovich, A.: Superpoint: Self-supervised interest point detection and description. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops (June 2018)
- [10] Fang, J., Lin, S., Vasiljevic, I., Guizilini, V., Ambrus, R., Gaidon, A., Shakhnarovich, G., Walter, M.R.: Nerfuser: Large-scale scene representation by nerf fusion (2023)
- [11] Furukawa, Y., Ponce, J.: Accurate, dense, and robust multiview stereopsis. IEEE Transactions on Pattern Analysis and Machine Intelligence 32(8), 1362–1376 (2010). https://doi.org/10.1109/TPAMI.2009.161
- [12] Goesele, M., Curless, B., Seitz, S.: Multi-view stereo revisited. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06). vol. 2, pp. 2402–2409 (2006). https://doi.org/10.1109/CVPR.2006.199
- [13] Gojcic, Z., Zhou, C., Wegner, J.D., Andreas, W.: The perfect match: 3d point cloud matching with smoothed densities. In: International conference on computer vision and pattern recognition (CVPR) (2019)
- [14] Goli, L., Rebain, D., Sabour, S., Garg, A., Tagliasacchi, A.: nerf2nerf: Pairwise registration of neural radiance fields. In: International Conference on Robotics and Automation (ICRA). IEEE (2023)
- [15] Hernández Esteban, C., Schmitt, F.: Silhouette and stereo fusion for 3d object modeling. Computer Vision and Image Understanding 96(3), 367–392 (Dec 2004). https://doi.org/10.1016/j.cviu.2004.03.016, http://dx.doi.org/10.1016/j.cviu.2004.03.016
- [16] Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics 42(4) (July 2023), https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
- [17] Li, J., Hu, Q., Ai, M.: Point cloud registration based on one-point ransac and scale-annealing biweight estimation. IEEE Transactions on Geoscience and Remote Sensing 59(11), 9716–9729 (2021). https://doi.org/10.1109/TGRS.2020.3045456
- [18] Mellado, N., Dellepiane, M., Scopigno, R.: Relative scale estimation and 3d registration of multi-modal geometry using growing least squares. IEEE Transactions on Visualization and Computer Graphics 22(9), 2160–2173 (2016). https://doi.org/10.1109/TVCG.2015.2505287
- [19] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020)
- [20] Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. 41(4), 102:1–102:15 (Jul 2022). https://doi.org/10.1145/3528223.3530127, https://doi.org/10.1145/3528223.3530127
- [21] Myronenko, A., Song, X.: Point set registration: Coherent point drift. IEEE Transactions on Pattern Analysis and Machine Intelligence 32(12), 2262–2275 (2010). https://doi.org/10.1109/TPAMI.2010.46
- [22] Pais, G.D., Ramalingam, S., Govindu, V.M., Nascimento, J.C., Chellappa, R., Miraldo, P.: 3dregnet: A deep neural network for 3d point registration. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7191–7201 (2020). https://doi.org/10.1109/CVPR42600.2020.00722
- [23] Pan, Y., Yang, B., Liang, F., Dong, Z.: Iterative global similarity points: A robust coarse-to-fine integration solution for pairwise 3d point cloud registration. In: 2018 International Conference on 3D Vision (3DV). pp. 180–189 (2018). https://doi.org/10.1109/3DV.2018.00030
- [24] Paris, S., Sillion, F.X., Quan, L.: A surface reconstruction method using global graph cut optimization. International Journal of Computer Vision 66(2), 141–161 (Feb 2006). https://doi.org/10.1007/s11263-005-3953-x, https://doi.org/10.1007/s11263-005-3953-x
- [25] Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., Lerer, A.: Automatic differentiation in pytorch (2017)
- [26] Qin, Z., Yu, H., Wang, C., Guo, Y., Peng, Y., Xu, K.: Geometric transformer for fast and robust point cloud registration. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11133–11142 (2022). https://doi.org/10.1109/CVPR52688.2022.01086
- [27] Sarlin, P.E., Cadena, C., Siegwart, R., Dymczyk, M.: From coarse to fine: Robust hierarchical localization at large scale. In: CVPR (2019)
- [28] Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: SuperGlue: Learning feature matching with graph neural networks. In: CVPR (2020), https://arxiv.org/abs/1911.11763
- [29] Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4104–4113 (2016). https://doi.org/10.1109/CVPR.2016.445
- [30] Slabaugh, G., Schafer, R., Malzbender, T., Culbertson, B.: A survey of methods for volumetric scene reconstruction from photographs. In: Mueller, K., Kaufman, A.E. (eds.) Volume Graphics 2001. pp. 81–100. Springer Vienna, Vienna (2001)
- [31] Strecha, C., Fransens, R., Van Gool, L.: Combined depth and outlier estimation in multi-view stereo. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06). vol. 2, pp. 2394–2401 (2006). https://doi.org/10.1109/CVPR.2006.78
- [32] Sun, C., Sun, M., Chen, H.T.: Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5459–5469 (June 2022)
- [33] Thomas, H., Qi, C.R., Deschaud, J.E., Marcotegui, B., Goulette, F., Guibas, L.J.: Kpconv: Flexible and deformable convolution for point clouds. Proceedings of the IEEE International Conference on Computer Vision (2019)
- [34] Wang, P., Liu, Y., Chen, Z., Liu, L., Liu, Z., Komura, T., Theobalt, C., Wang, W.: F2-nerf: Fast neural radiance field training with free camera trajectories. CVPR (2023)
- [35] Wang, Y., Solomon, J.M.: Deep closest point: Learning representations for point cloud registration. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
- [36] Wu, X., Dai, P., DENG, W., Chen, H., Wu, Y., Cao, Y.P., Shan, Y., QI, X.: CL-neRF: Continual learning of neural radiance fields for evolving scene representation. In: Thirty-seventh Conference on Neural Information Processing Systems (2023), https://openreview.net/forum?id=uZjpSBTPik
- [37] Yao, Y., Luo, Z., Li, S., Fang, T., Quan, L.: Mvsnet: Depth inference for unstructured multi-view stereo. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision – ECCV 2018. pp. 785–801. Springer International Publishing, Cham (2018)
- [38] Yew, Z.J., Lee, G.H.: Regtr: End-to-end point cloud correspondences with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6677–6686 (June 2022)
- [39] Zaharescu, A., Boyer, E., Horaud, R.: Transformesh : A topology-adaptive mesh-based approach to surface evolution. In: Yagi, Y., Kang, S.B., Kweon, I.S., Zha, H. (eds.) Computer Vision – ACCV 2007. pp. 166–175. Springer Berlin Heidelberg, Berlin, Heidelberg (2007)
- [40] Zang, Y., Lindenbergh, R., Yang, B., Guan, H.: Density-adaptive and geometry-aware registration of tls point clouds based on coherent point drift. IEEE Geoscience and Remote Sensing Letters 17(9), 1628–1632 (2020). https://doi.org/10.1109/LGRS.2019.2950128
- [41] Zeng, A., Song, S., Nießner, M., Fisher, M., Xiao, J., Funkhouser, T.: 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In: CVPR (2017)
- [42] Zhang, J., Yao, Y., Deng, B.: Fast and robust iterative closest point. IEEE Transactions on Pattern Analysis and Machine Intelligence 44(7), 3450–3466 (2022). https://doi.org/10.1109/TPAMI.2021.3054619
- [43] Zhang, X., Yang, J., Zhang, S., Zhang, Y.: 3d registration with maximal cliques. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17745–17754 (2023)
- [44] Zhou, Q.Y., Park, J., Koltun, V.: Fast global registration. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision – ECCV 2016. pp. 766–782. Springer International Publishing, Cham (2016)