使用 mllm-NPU 实现每秒 1000 个 Token 的设备上
LLM 预填充
摘要。
设备上的大语言模型(大语言模型)正在催生新颖的移动应用程序,例如 UI 任务自动化和个性化电子邮件自动回复,而不会泄露用户的私人数据。 然而,由于需要长上下文来生成准确的个性化内容,以及缺乏并行计算能力,设备上的大语言模型仍然存在不可接受的长推理延迟,尤其是第一个词符(预填充阶段)的时间移动CPU/GPU。
为了实现实用的设备上大语言模型,我们推出了mllm-NPU,这是第一个有效利用设备上神经处理单元(NPU)卸载的大语言模型推理系统。 本质上,mllm-NPU是一种算法系统协同设计,解决了大语言模型架构和当代 NPU 设计之间的一些语义差距。 具体来说,它在三个级别上重新构建了提示和模型:(1)在提示级别,它将可变长度提示划分为多个固定大小的块,同时保持数据依赖关系; (2) 在张量级别,它识别并提取显着的异常值,以最小的开销在 CPU/GPU 上并行运行; (3) 在块级别,它根据硬件亲和性和对精度的敏感度,以无序方式将 Transformer 块调度到 CPU/GPU 和 NPU。 与竞争基准相比,mllm-NPU 的预填充速度平均提高 22.4,节能 30.7,节能高达 32.8 端到端实际应用程序的加速。 mllm-NPU首次实现了十亿级模型(Qwen1.5-1.8B)每秒超过1000个token的预填充,为实用的设备端大语言模型铺平了道路。
1. 介绍
随着隐私问题(gdpr,)的不断增加,人们对在移动设备上本地运行大语言模型(大语言模型)(称为设备上大语言模型)的兴趣日益浓厚,例如 Apple Intelligence (apple-intelligence, ) 和 Android AI Core (AI-Core, )。 与此同时,移动大小的语言模型(1B-10B 参数)的进步,例如 Qwen2-1.5B 和 Phi3-3.7B,已经证明了它们的性能与 GPT-3 等更大的模型相当,尽管参数减少了计数 (abdin2024phi, ; qwen2, ; MMLU-排行榜, )。 这一进展使得设备上语言模型的部署变得可行。 在不泄露隐私数据的情况下,设备上的大语言模型推理可以催化新颖的移动应用程序,例如 UI 任务自动化 (li2024personal, )(例如,将用户的语言命令翻译为 UI 操作,例如“转发给 Alice 的未读电子邮件”)和自动消息回复(电子邮件,)。
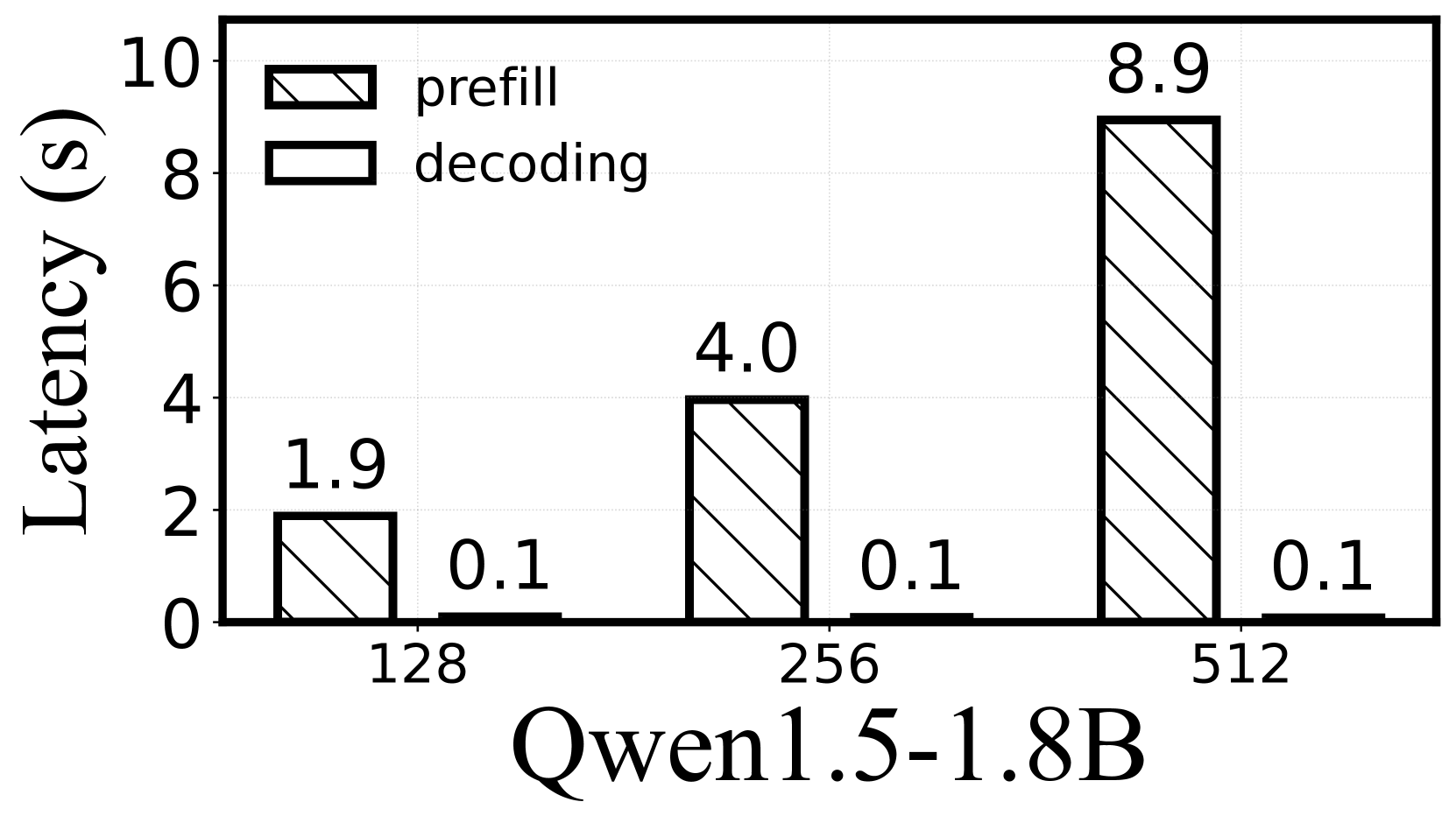
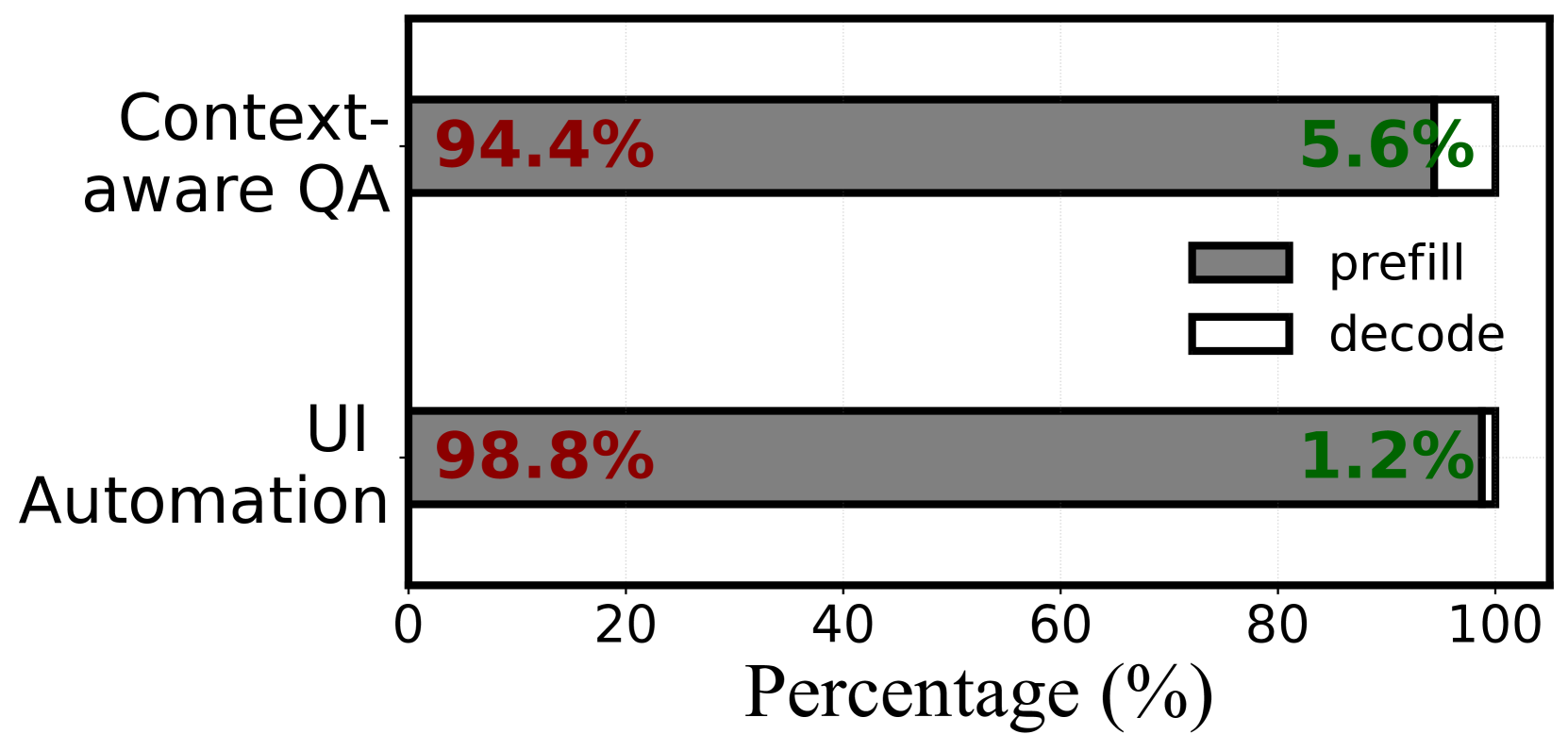
然而,高推理延迟仍然是实际设备上大语言模型的重大障碍。 为了完成一个 UI 任务,大语言模型需要摄取屏幕视图层次结构(通常是 600-800 个 token(wen2024autodroid, ; LlamaTouch, ))来逐步生成相应的 UI 操作(wen2023empowering ,)。 正如 2.1 中所示,对于 Qwen1.5-1.8B (qwen2, ),每个这样的步骤需要 8.1 秒,因此超过40 秒即可完成 5 步 UI 任务。 同样,Gemma-2B 模型根据历史电子邮件数据(包含 1500 个 Token )模仿用户的语气,需要 26.7 秒来自动回复电子邮件。 深入研究这些任务,我们发现提示处理(预填充阶段)通常主导端到端推理延迟,例如 UI 自动化任务的 94.4%–98.8%。 这是因为设备上的大语言模型任务通常涉及长上下文理解来处理个性化任务。 不幸的是,现有的研究工作主要集中在加快文本生成速度(解码阶段),例如激活稀疏性 (xue2024powerinfer, ; Song2023powerinfer, ) 和推测解码 (kim2023big, ; miao2023specinfer, ; yang2023predictive ,)。 因此,本工作主要针对提高设备端大语言模型的预填充速度。
大语言模型预填充是有计算限制的(zhong2024distserve, ; patel2023splitwise, ; wu2024loongserve, );然而,移动CPU和GPU的并行计算能力有限(yi2020heimdall, ; han2024pantheon, )。 相反,我们的动机是神经处理单元 (NPU) 在现代移动设备中无处不在,例如 Qualcomm Hexagon NPU 和 Google Edge TPU。 这些移动 NPU 在整数向量运算方面非常高效,计算能力高达 73 TOPS (8gen3, )。 在 CNN 上,它们相对于移动 CPU/GPU 的改进被证明分别高达 18/4,(xu2022mandheling, )。 与 CPU/GPU 相比,移动 NPU 也更节能,并且工作负载争用更少。
令人惊讶的是,虽然承诺具有如此多的优势,但目前还没有支持 COTS 移动 NPU 上大语言模型推理的系统。 事实上,我们的基础知识工作表明,由于以下挑战,直接使用移动 NPU 进行大语言模型推理并不能提供性能优势。
可变长度提示的准备成本很高。 移动 NPU 通常仅支持静态形状的推理,而大语言模型提示长度是动态的(具有最大上下文长度)。 在移动设备上,针对每个不同大小的提示在 NPU 上重新准备和优化大语言模型执行图的成本很高(例如,Gemma-2B 模型需要 11 秒)。 另一方面,简单地将大语言模型请求填充到相同的最大上下文长度会浪费宝贵的计算资源。
大语言模型量化算法与移动NPU设计不匹配。 由于存在异常激活(xiao2023smoothquant, ; dettmers2022gpt3, ),最先进的大语言模型量化方法通常使用每组量化来保持高精度。 它将原始激活和权重张量划分为多个具有独立量化尺度的组,以避免异常值对其他组的影响。 然而,我们的调查表明,移动 NPU 无法直接执行每组 MatMul(表2)。 相反,他们必须将 MatMul 拆分为多个组大小的子张量 MatMul,然后使用浮点求和运算来减少子张量中间结果。 此过程会影响 NPU 效率并产生高达 10.7 的性能开销。
浮点 (FP) 运算无法消除。 移动 NPU 通常提供显着的基于整数的 MatMul 加速,但在 FP 运算方面较弱。 然而,大语言模型很难以最小的精度损失量化为纯整数执行。 现有的量化大语言模型仍然依赖于LayerNorm和Attention等浮点运算符。 将这些 FP 算子调度到 NPU 之外很容易增加推理关键路径。
这项工作提出了mllm-NPU,这是第一个具有高效设备上NPU卸载功能的大语言模型推理系统。 mllm-NPU的主要设计目标是减少预填充延迟和能耗。 它针对大语言模型主流的纯解码器Transformer架构(例如LlaMA、GPT等)。 关键思想是最大限度地提高移动 NPU 上的预填充执行速度,以加速整数计算,同时在 CPU/GPU 上保留基本的浮点运算以保持准确性。 为了克服上述挑战并提高NPU卸载效率,mllm-NPU在三个层面上重新构建了提示和模型:(1)在 提示级别: mllm-NPU将可变长度的提示分为多个固定大小的块,同时保持数据依赖性; (2) 在 张量级别: mllm-NPU 识别并提取显着的异常值以在 CPU/GPU 上运行; (3) 在 块级别: mllm-NPU 根据硬件关联性和对精度的敏感度将 Transformer 块调度到 CPU/GPU 和 NPU。 相应的新技术详述如下:
块共享图 (3.2) mllm-NPU 拆分可变长度提示分成带有预先构建的子图的固定大小的“块”,从而减少图形准备时间。 然后,在具有块级因果依赖性的那些图上执行每个可变长度提示。 这种方法利用了词符生成仅依赖于仅解码器大语言模型中的先前标记的见解。 然而,同时加载多个预构建的块图会产生显着的内存开销,例如比大语言模型权重多 2-4。 为了解决这个问题,mllm-NPU 进一步识别与提示大小无关的运算符(例如 FFN),并在每个块执行中共享它们,从而将内存开销减少多达 4。
影子异常值执行 (3.3) 在不影响 NPU 效率的情况下解决了激活异常值问题。 在不更改 NPU 上每个张量 MatMul 的情况下,mllm-NPU 将激活异常值通道提取到紧凑张量中,并在 CPU/GPU 上并行执行,因为异常值非常稀疏(0.1%–0.3%)总频道数)。 由于 CPU 内存中重复的 MatMul 权重以及 CPU/GPU 和 NPU 之间的同步开销,该设计进一步引发了内存占用增加的问题。 因此,基于异常值更有可能出现在一小部分通道位置的观察结果,mllm-NPU通过仅将那些“热通道”权重保留在内存中来优化内存使用,并从内存中检索其他权重。按需磁盘。 mllm-NPU还通过测量异常值的重要性来在层级别修剪不重要的异常值,以减少同步开销。
乱序子图执行 (3.4) mllm-NPU被引导通过一个关键的见解,多个子图可以以无序的方式安排,而不需要严格遵循原始提示中的块顺序。 这显着扩大了mllm-NPU的调度空间,最大限度地减少了CPU/GPU浮点运算带来的执行气泡。 鉴于寻找最优乱序执行顺序是一个NP难题,mllm-NPU采用了微秒级在线调度算法。 该算法基于观察到NPU的工作负载较重并构成关键路径。 因此,在选择执行哪个子图时,mllm-NPU会优先考虑那些对减少NPU停顿影响更显着的子图,而不是仅仅关注子图的执行延迟。 值得注意的是,mllm-NPU的调度算法并没有最大化并行处理能力。 相反,mllm-NPU 旨在最大限度地提高 NPU 的利用率,同时最大限度地减少 CPU/GPU 工作负载的影响。
实施和评估。 我们在 MLLM (mllm, ) 和 QNN (QNN, ) 之上实现了 mllm-NPU,其中包含 10K 行 C/C++ 和汇编代码。 我们使用五个移动大小的大语言模型(Qwen1.5-1.8B (qwen2, )、Gemma-2B (gemma2b, )< 来评估 mllm-NPU /t2>、phi2-2.7B (phi2-2.7, )、LlaMA-2-7B (Llama-2-7b, ) 和 MisTrial-7B (Mistral-7B,))、四个大语言模型基准测试和两个移动设备(小米 14 和 Redmi K60 Pro)。 我们将 mllm-NPU 与五个竞争基准进行了比较,包括三个工业开源引擎(llama.cpp (llama-cpp, )、TFLite (tflite, ) 、MNN (mnn, )) 和两个最先进的研究原型 (MLC-LLM (mlc-llm, ) 和 PowerInfer-v2 (xue2024powerinfer,))。 实验表明,mllm-NPU 在预填充延迟和能耗方面始终显着优于所有基线,同时保持推理精度(与 FP16 相比损失 ¡1%)。 在 CPU 上比基准快 7.3–18.4,在 GPU 上比基准快 1.3–43.6,提示长度为1024. 它还实现了 1.9–59.5 的能耗降低。 据我们所知,mllm-NPU是第一个在数十亿规模的大语言模型上在COTS移动设备上实现1000个 Token /秒预填充速度的系统。 在端到端实际应用中,mllm-NPU 与基线相比,推理延迟(预填充+解码)减少了 1.4-32.8。
贡献总结如下:
-
•
我们深入研究了使用移动 NPU 加速大语言模型预填充的挑战和机遇。
-
•
我们提出了第一个具有高效移动 NPU 卸载的大语言模型推理引擎,具有三种新颖的技术:块共享图、影子异常值执行和乱序子图执行。
-
•
我们在 mllm-NPU 上进行了全面的实验,证明了其优于竞争基准的性能。 mllm-NPU的代码完全可以在https://github.com/UbiquitousLearning/mllm获取。
2. 背景
2.1. 设备端大语言模型推理分析
端端大语言模型越来越多地应用于Apple智能(apple-intelligence, )、UI自动化(wen2023empowering, )、邮件自动回复等前沿场景(电子邮件,),由于增强的隐私保护。 为了支持这些应用程序,已经开发了许多轻量级大语言模型,如表1所示。 然而,它们的推理延迟仍然是一个重大挑战。 例如,根据 DroidTask (wen2024autodroid, ; LlamaTouch, ) 和 LongBench 数据集 (bai2023longbench, ),这对于实际部署来说是不切实际的。
为了证实这一观察结果,我们在最先进的设备端大语言模型引擎(llama)上使用 Qwen1.5-1.8B 模型评估了 DroidTask(UI 自动化任务)和 LongBench(上下文感知生成任务)数据集.cpp),如图1所示。 结果证实,预填充阶段显着影响推理时间,占总延迟的 94.4% 至 98.8%。 随着提示长度的增加,预填充阶段占总推理时间的比例也会增加。 造成这种情况的因素有很多:(1) 移动 CPU/GPU 缺乏云 GPU (yi2020heimdall, ; han2024pantheon,) 的并行能力,主要是为处理应用程序逻辑或渲染任务而设计的。 (2) 移动大语言模型任务通常需要较长的提示才能进行个性化、上下文感知的生成。 例如,自动电子邮件回复可能需要大量的用户数据,例如历史电子邮件、日程安排和位置信息(超过 1000 个 Token ),而处理 UI 自动化的设备上大语言模型必须处理大量的 UI 标签 Token (XML 或 HTML)和用户命令。 (3) 移动大语言模型现在支持长上下文窗口。 例如,Qwen2-1.5B 等最新模型可以容纳最多 32K 个标记的上下文窗口,如表 1 所示。
| Model | Max Context | Year | Model | Max Context | Year |
|---|---|---|---|---|---|
| Opt-1.3B | 2K | 2022.5 | TinyLLaMA-1.1B | 2K | 2023.9 |
| StableLLM-3B | 4K | 2023.10 | phi-2-2.7B | 2K | 2023.12 |
| Gemma-2B | 8K | 2024.2 | Qwen1.5-1.8B | 32K | 2024.2 |
| Phi3-mini-3.8B | 128K | 2024.5 | Qwen2-1.5B | 32K | 2024.6 |
2.2. 机会:移动 NPU
为了优化预填充延迟,mllm-NPU 利用了一个关键机会:现代移动 SoC 普遍包含非常适合整数运算(例如基于 INT8 的矩阵乘法)的移动神经处理单元 (NPU)。 表2总结了主流厂商提供的知名移动NPU的规格。 例如,高通的移动 SoC 采用 Hexagon NPU,每秒可实现高达 73 万亿次 INT8 运算。 根据 AI-Benchmark (ai-benchmark, ) 的数据,小米 14 中的 Hexagon NPU 仅需 0.6 毫秒即可推理出 MobileNet-V2 模型,比手机快 23 CPU 比移动 GPU 快 3.2。
| Vendor | Latest NPU | SDK | Open | Group | INT8 Perf. | ||
| Qualcomm | Hexagon NPU (8gen3, ) | QNN (QNN, ) | 73 TOPS | ||||
| Edge TPU (edgetpu, ) | Edge TPU API (Edge-TPU-API, ) | 4 TOPS | |||||
| MediaTek | MediaTek APU 790 (APU-790, ) | NeuroPilot (neuropilot, ) | N/A | 60 TOPS | |||
| Huawei | Ascend NPU (Ascend-NPU, ) | HiAI (hiai, ) | 16 TOPS | ||||
|
|||||||
移动NPU架构和微实验。 移动 NPU 通过单指令多数据 (SIMD) 架构提供显着的性能优势。 例如,Hexagon NPU 支持 1024 位 INT8 向量运算,允许多个 SIMD 指令并行执行。 然而,与移动 GPU 相比,它们的浮点计算能力相对较弱。 移动 NPU 的时钟频率在 500 至 750 MHz 之间,比移动 CPU 和 GPU 更节能。 此外,与拥有独立物理内存的云GPU不同,移动NPU集成在移动SoC中,与移动CPU共享相同的物理内存,从而无需在NPU执行期间进行内存复制。
为了评估 INT8 MatMul 在移动 NPU 上的性能,我们使用移动大语言模型中常用的 MatMul 尺寸在小米 14 上进行了基础知识实验。 与 CPU INT8 相比,移动 NPU 上的 INT8 MatMul 实现了 4.5–5.8 加速,并且比 GPU FP16 有了显着改进。 计算工作量越大,性能提升就越明显。 然而,在移动 NPU 上执行 FP16 MatMul 导致性能比 CPU INT8 慢 159。 这些结果与移动 NPU 的 INT8 SIMD 架构一致,证实移动 NPU 最适合加速 INT8 矩阵乘法。
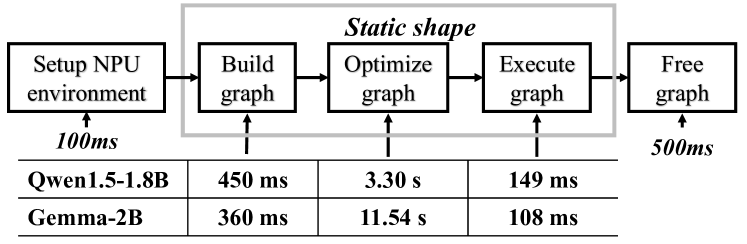
移动 NPU 上的 DNN 执行工作流程。 在移动NPU上执行DNN涉及配置NPU环境、创建计算图、优化图、执行图和释放图,如图2所示。 通常,创建和优化计算图是最耗时的,前者包括将模型转换为 NPU 所需的中间表示和内存分配,需要 300-500ms,而后者包括调整内存布局、执行顺序的优化,以及算子融合,需要很多秒。 此外,NPU SDK的闭源特性也限制了大语言模型的进一步适配。
2.3. 大语言模型与移动NPU之间的差距
鉴于其固有的优势,我们惊讶地发现现有的DNN引擎都不支持移动NPU上的大语言模型加速。 然后我们深入挖掘根本原因,发现现有移动 NPU 设计与大语言模型推理流程之间存在巨大差距。
大语言模型预填充阶段依赖于可变长度的提示,导致在构建和编译 NPU 图上花费过多的时间。 如图2所示,在移动NPU上执行计算图之前,必须对其进行构建和优化,该过程需要数十秒。 例如,使用 QNN 框架为 Gemma 2B 模型构建图需要 360 毫秒,图优化需要 11.54 秒。 与 CNN 模型不同,CNN 模型构建和优化一次,并且可以使用相同的输入形状多次执行,大语言模型预填充阶段必须处理可变长度的提示,需要为每个推理重建和重新优化计算图。 因此,在这种情况下使用移动 NPU 不会带来任何性能优势,而且速度通常比使用 CPU 慢。
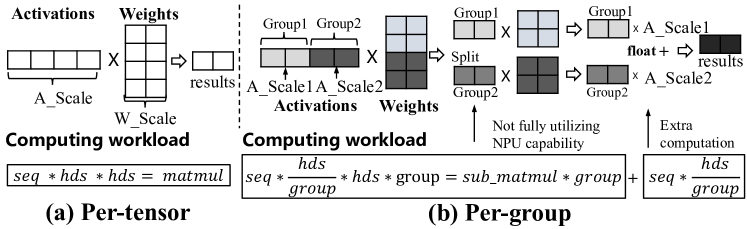
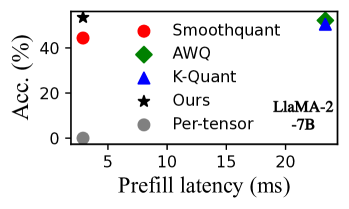
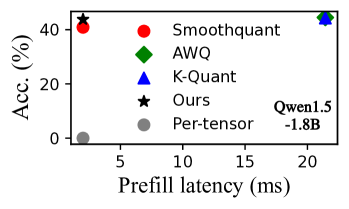
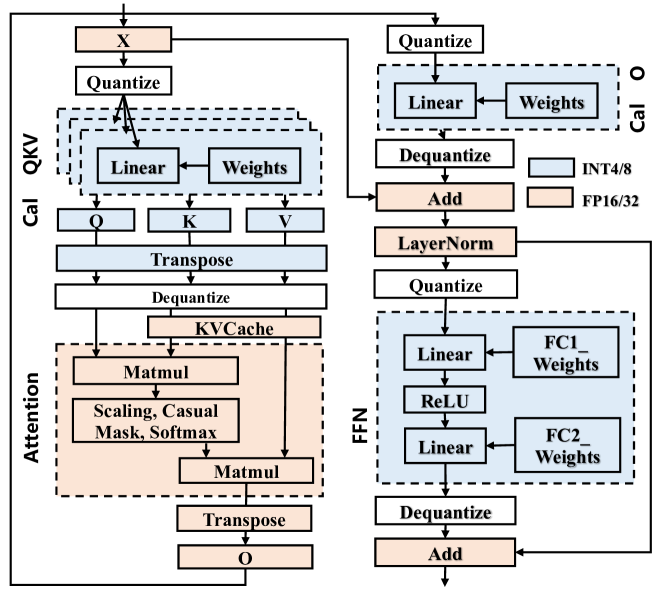
激活异常值的存在使得大语言模型难以在全张量级别上进行量化,而更细粒度的组级别量化又会阻碍NPU的效率。 我们的预备知识实验如图 4 所示,表明两种流行的量化算法(K-Quant (llama-cpp, ) 和 AWQ (lin2023awq, ))与每张量量化相比,会产生 8.1–10.7 的显着推理开销(图 3(a))。 这是因为 K-Quant 和 AWQ 等算法使用细粒度的每组量化(图3(b))来保持高精度。 这些算法将激活和权重分为多个组,每个组都有独立的量化尺度。 在NPU上,这种方法需要将MatMul操作分成多个子张量MatMul,这无法充分利用移动NPU的能力。 此外,它需要通过浮点加法来聚合中间结果,从而导致额外的浮点计算。 SmoothQuant (xiao2023smoothquant, ) 是个例外,它使用每个张量量化,但精度损失很大,例如 LlaMA-2-7B 和 HelloSwag 数据集上的精度分别下降了 3.9% 和 8.4%分别为Qwen1.5-1.8B型号。
| Quantization | Type | Acc. | Cal QKV | Atten. | Cal O | Norm. | FFN |
|---|---|---|---|---|---|---|---|
| K-Quant (llama-cpp, ) | Per-Group | Low | INT8 | FP16 | INT8 | FP16 | INT8 |
| GPTQ (frantar2022gptq, ) | Per-Group | High | FP16 | FP16 | FP16 | FP16 | FP16 |
| AWQ (lin2023awq, ) | Per-Group | High | FP16 | FP16 | FP16 | FP16 | FP16 |
| SmoothQuant (xiao2023smoothquant, ) | Per-tensor | Low | INT8 | FP16 | INT8 | FP16 | INT8 |
| ”Atten.”:Attention; ”Norm.”: Normalization. | |||||||
3。 mllm-NPU设计
3.1. mllm-NPU概述
设计目标。 mllm-NPU旨在通过设备上的NPU卸载来减少移动大小的大语言模型的预填充延迟和能耗。 它支持设备上的各种移动大小的大语言模型,并且可以作为LLM即系统服务的一部分集成到移动操作系统或移动应用服务中(yin2024llm,;yuan2024mobile,)。
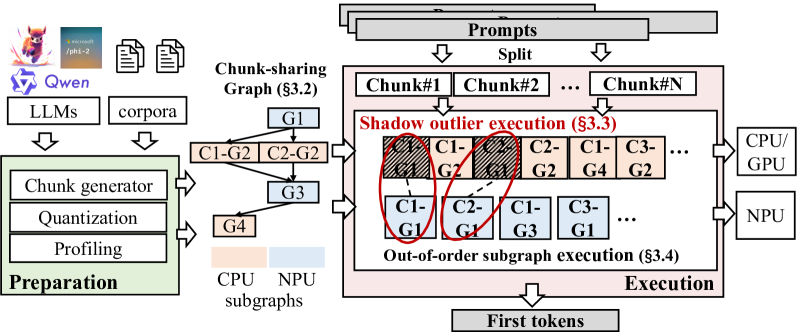
工作流程。 图6说明了mllm-NPU的工作流程。 mllm-NPU的核心思想是最大化其在移动NPU上的执行,以实现整数运算加速;同时在 CPU/GPU 上保留必要的浮点运算,以免影响精度。 为了实现更高效的 NPU 卸载,mllm-NPU 通过以下方式重新构建提示和模型: (1) 提示级别: 可变长度提示被缩减为多个固定大小的块,并保留数据依赖性; (2) 在 块级别: Transformer块根据CPU/GPU和NPU的硬件无限性和精度敏感性被调度到CPU/GPU和NPU中; (3) 在 张量级别: 识别并提取重要的异常值以在 CPU/GPU 上运行。
准备阶段。 mllm-NPU首先使用增强的每张量量化算法将大语言模型量化为W8A8格式。 量化算法与现有算法不同,因为它过滤掉最不重要的激活异常值,并将其余的提取到独立的、轻量级的算子中,与原始算子互补。 mllm-NPU 还生成固定长度的块共享图 (3.2),以有效处理可变长度的提示。
3.2. 块共享图执行
为了解决动态提示长度的挑战,一个直观的解决方案是预先设置一个固定长度的计算图并使用填充(tillet2019triton, ; olston2017tensorflow, ; FastTransformer, )。 然而,这种方法缺乏灵活性,并且过多的填充会浪费计算资源。
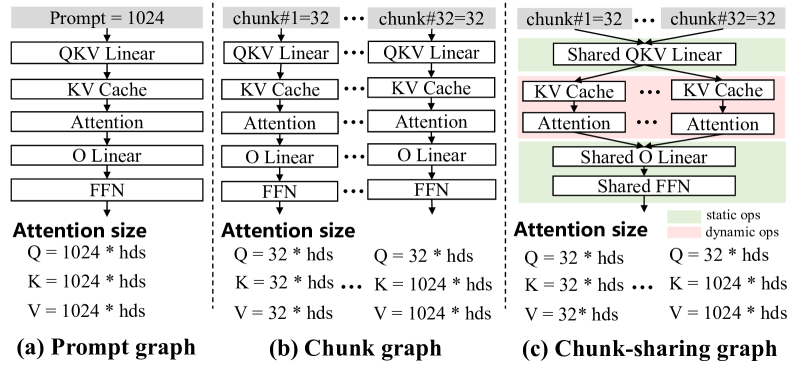
分块预填充。 为了增强灵活性并最小化可变长度提示的填充,我们认识到在大语言模型中处理长提示相当于按因果关系处理多个分割的子提示或“块”。 这是可行的,因为流行的大语言模型使用仅解码器架构,其中第词符的结果仅取决于前面的标记。 为此,mllm-NPU 首先在准备阶段预构建和预优化基于固定长度块的 NPU 计算图。 在推理过程中,mllm-NPU 将长提示拆分为多个块,并使用这些预先构建的块图对其进行处理,如图 7(b) 所示。
然而,单独使用块图是不可扩展的,因为 mllm-NPU 需要在内存中存储大量不同的块图,从而显着增加内存开销。 这是因为不同的块图具有不同大小的注意力运算符。 例如,考虑到提示长度为 1024 和块长度为 32,第一个块的注意算子的 QKV 维度大小均为 ,而最后一个块的注意算子的 QKV 维度大小分别为 、 和 ,如图 7(b)所示。
块共享图。 mllm-NPU基于大语言模型算子落入的洞察,引入了块共享图,如图7(c)所示两个不同的类别:(1)静态运算符(绿色),例如 Linear 和 LayerNorm,它们仅依赖于块长度并且可以在不同块之间共享; (2)动态算子(红色),例如Attention,它依赖于块长度和块顺序,并且不能在不同块之间共享。 因此,mllm-NPU根据算子的共享性将大语言模型划分为多个子图。 共享子图构建并优化一次,而非共享子图针对不同块单独构建。 在预填充阶段,来自不同块的激活通过相同的静态运算符子图,同时动态选择适当的特定于维度的动态运算符。 这种方法显着减少了内存开销并增强了可扩展性,因为大多数动态运算符(例如注意力)不包含权重,只需要激活缓冲区。
我们的实验表明,144 个子图中的 120 个可以在 Qwen1.5-1.8B 模型中共享,对于提示长度为 1024 和块长度为 256 的情况,内存消耗最多可减少 75% (7.2GB)。
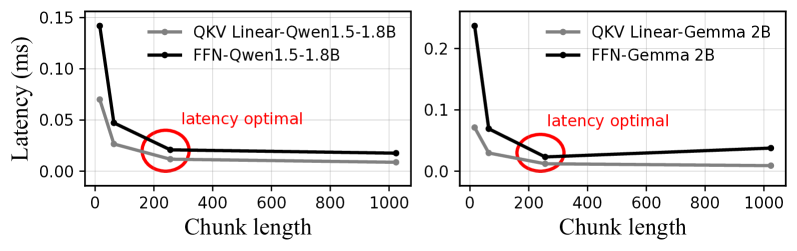
我们还进行了广泛的实验来选择合适的块长度。 两个流行的大语言模型(Qwen1.5-1.8B和Gemma-2B)在小米14设备上的结果如图8所示。 根据观察,mllm-NPU经验性地为小米14设备选择了256的块长度,这有效地利用了移动NPU的能力,同时减少了块内填充。 实际上,这种分析需要在不同的 NPU 上执行。
3.3. 影子异常值执行
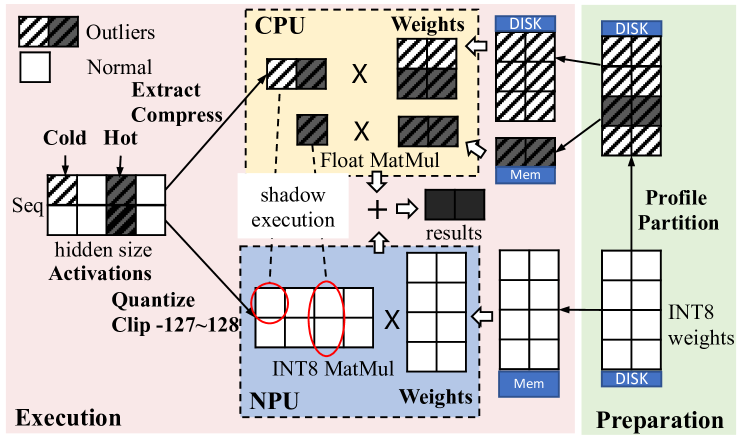
为了在不影响大语言模型精度的情况下实现 NPU 友好的每张量激活量化,mllm-NPU 采用了一种称为影子异常值执行的新颖方法。 如图9所示,mllm-NPU将运行时存在异常值的激活通道提取为更紧凑的张量,在CPU上执行,并将其合并回结果NPU 上的原始算子。 该程序可以表述如下:
| (1) | ||||
其中 、、、 和 表示原始浮动激活、INT8 权重,分别是量化比例因子、MatMul 运算和将激活异常值提取到更紧凑的张量中的函数。 具体来说,根据结合律,MatMul可以等价地分为两部分之和: (1) 适用于规模内 MatMul 的移动 NPU。 mllm-NPU首先根据比例因子将量化并舍入到-127到128的范围。然后,它通过使用权重 执行标准 W8A8 每个张量 MatMul 来获得中间结果。 (2) 用于 MatMul 的移动 CPU/GPU 超出规模。 mllm-NPU计算超过的部分值。由于这些异常值很少见,mllm-NPU 从张量中提取这些值,将它们压缩为密集张量,并使用权重 执行 MatMul。
由于异常值非常稀疏(大约 5-15 个通道,仅占总通道的 0.1%-0.3%,如图 10 所示),因此 CPU 上的 Shadow 执行速度比NPU上的原始张量,其执行时间可以通过重叠完全隐藏。 为了进一步最小化这个额外过程的开销,mllm-NPU通过离线分析大型语料库来确定异常值阈值(即等式1中的),从而可以识别异常值通过简单地将激活数与该阈值进行比较来确定异常值。 阴影异常值执行的设计与任何每张量量化算法兼容,mllm-NPU当前的原型基于简单的最大-最小对称量化(jacob2018quantization, ).
虽然影子异常值执行似乎很好地平衡了 NPU 亲和力和大语言模型准确性,但需要解决两个更关键的问题才能使其实用。 首先,虽然移动SoC对异构处理器使用统一的存储芯片,但它们使用独立的存储空间。 为了启用激活异常值的影子执行,mllm-NPU 必须在 CPU 内存空间上保留每个 MatMul 权重的另一个副本。 这使内存占用增加了近 2 倍。 其次,虽然异常值的执行即使在 CPU 上也很快,但 CPU 和 NPU 之间的降和同步仍然需要不小的开销,例如,Qwen1.5 上的端到端延迟为 29.7%,能耗为 20.1%。 1.8B。
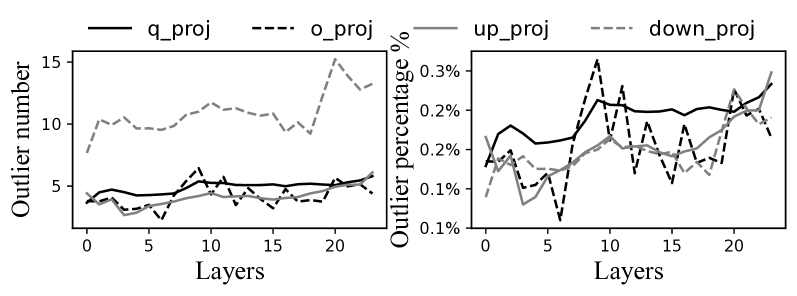
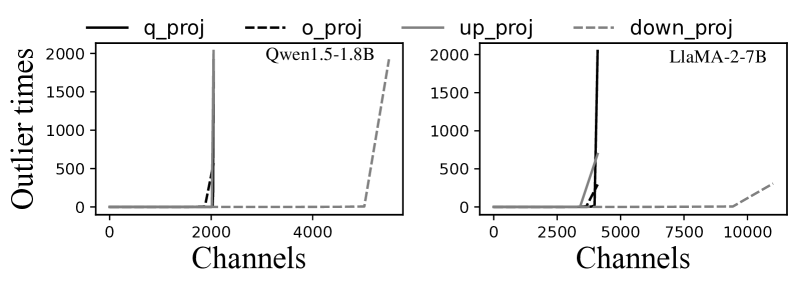
大多数异常值往往出现在一小部分通道位置中。 我们观察到,虽然在处理长提示期间(例如 78%),异常值出现在各种通道位置,但这种外观是高度倾斜的——很少有通道主导异常值的出现。 例如,如图 11 所示,在 Qwen1.5-1.8B 和 LlaMA-2-7B 模型的各种输入中,不到 3% 的通道对大多数异常值(超过 80%)有贡献。 因此,对于影子异常值执行,mllm-NPU仅将那些“热通道”需要使用的张量权重保留在CPU内存空间中,如果这些“热通道”上存在异常值,则从磁盘中检索其余部分。位置在运行时被提取(这种情况很少见)。 请注意,权重检索也可以与原始 MatMul 的 NPU 执行重叠。 这种方法将影子执行的内存开销减少了 34.3%,并且延迟可以忽略不计。
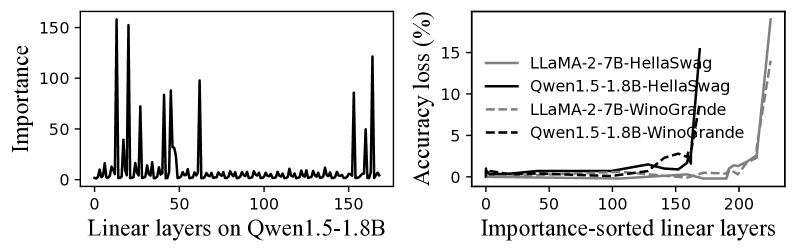
大多数异常值都可以被修剪,而不影响准确性。 令人惊讶的是,我们观察到大多数 MatMul 算子上的激活异常值对大语言模型的准确性并不重要,可以简单地删除。 这里,异常值的重要性通过最大异常值与量化尺度之间的比率来衡量(等式 1 中的 )。 比率越大表示激活分布越分散,导致量化误差越显着。 mllm-NPU 使用离线阶段的大型语料库数据来分析这些异常值的重要性(图12),并修剪大部分不重要层的异常值。 通常,我们观察到输入和输出附近的层具有更高的重要性。 这是因为靠近输入的层很容易受到 Token 差异的影响,表现出更大的波动,而靠近输出的层很容易积累来自浅层的误差。 根据观察,mllm-NPU通过离线分析修剪前85%最不重要层的异常值,从而消除CPU-NPU同步。
3.4. 子图乱序执行
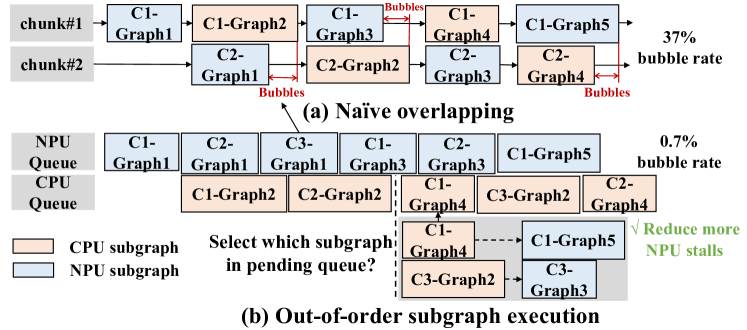
如(2.3)所述,大语言模型量化算法无法完全消除浮点运算,mllm-NPU因此将其执行流程划分为NPU以及CPU/GPU协同。 通常,LayerNorm、Attention以及阴影异常值计算都放在CPU/GPU上;而其他线性层则在 NPU 上处理。 然而,我们发现简单地重叠执行效率很低,会导致较大的执行泡沫(关键路径中的泡沫率为37%),如图13(a)所示。
无序执行。 为了减少这些执行气泡,mllm-NPU 以一个关键见解为指导,即在块和子图级别进行分区后,大语言模型子图可以以无序方式进行调度。 更具体地说,任何输入就绪的子图都可以在不严格遵循块序列的情况下执行。 例如,当 C2-Graph1 完成时,可以在冒泡期间执行第三个块 (C3-Graph1) 的第一个子图。
为了保持正确性,mllm-NPU 考虑两种类型的依赖关系:(1) 跨块依赖。 像 Attention 这样的算子依赖于之前块的数据。 这意味着 块 子图 依赖于 块的 子图:
| (2) |
(2) 块内依赖性。 LayerNorm、Linear 和 Quantize 等运算符仅依赖于同一块中的先前子图。 因此,第 块的第 子图 取决于同一块的第 子图:
| (3) |
由于移动处理器在并行性和抢占性方面较弱(yi2020heimdall, ; han2024pantheon, ; xu2022mandheling, ),为了确保效率,处理器在任何给定时间只能执行一个子图。:
| (4) |
其中 表示子图 正在处理器 上运行,时间 , 和 分别表示块和子图的最大数量。 mllm-NPU旨在找到一个执行顺序,在这些约束下最小化所有子图的总执行时间。 不幸的是,这个调度问题可以简化为经典的 NP 难旅行商问题(hoffman2013traveling, )。 而且,由于块的数量随用户提示而变化,无法离线生成最优调度策略。
相反,mllm-NPU 使用在线启发式算法。 关键思想是不要关注子图 的执行时间,而是关注执行 如何有助于减少 NPU 停顿,其动机是观察到在预填充阶段,NPU执行时间通常主导推理延迟,是关键路径。 例如,使用 Qwen1.5-1.8B 模型,提示长度为 256,NPU 执行需要 315ms,大约是 CPU 的两倍。
具体来说,我们定义子图对减少NPU停顿的贡献如下:如果子图要在CPU/GPU上执行,则让是完成后可以执行的一组新子图。 将在NPU上执行。 执行时间较长有利于减少NPU卡顿。 因此,的贡献被定义为的总执行时间。相反,如果在NPU上执行,的执行时间越短越好,的执行时间的负值为 的贡献,公式为:
| (6) |
其中 是子图执行时间。 mllm-NPU始终选择最大的子图,这意味着的子图在网络上执行时间最长NPU 或 CPU/GPU 上的最短执行时间。
简而言之,mllm-NPU 在准备阶段离线分析所有子图执行时间及其依赖关系。 在预填充阶段,它会计算所有待处理的子图 值,并选择具有最大 的子图来运行,性能开销为微秒级。
4. 实施与评估
我们已经为 Qualcomm Hexagon NPU 全面实现了 mllm-NPU,包括 10K 行 C/C++ 和汇编语言代码。 我们选择高通 SoC 作为目标平台,因为它在移动设备上的受欢迎程度和强大的 NPU 能力。 Qualcomm Hexagon也是唯一一款具有开放指令集架构的移动NPU。 mllm-NPU 建立在 MLLM (mllm, )(一种最先进的移动大语言模型引擎)和 QNN 框架 (QNN, ),高通神经处理 SDK。 支持Hugging Face (Hugging-Face, )导出的标准大语言模型格式。 为了方便大语言模型的执行,除了QNN支持的算子之外,我们还实现了KVCache、SiLU、RMSNorm、ROPE等特定算子。 为了减少 CPU/GPU 和 NPU 之间的上下文切换开销,mllm-NPU 利用共享缓冲区来同步来自不同处理器的中间结果。 对于端到端推理,mllm-NPU与任何解码引擎兼容,并利用 MLLM CPU 后端进行解码阶段,易于实现,默认块长度为 256。 离群层的默认剪枝率为 85%。
该原型还包含两项优化。 (1) 我们广泛的实验表明,移动 NPU 通常更喜欢 CNN 架构中的张量大小(例如,相等的“高度”和“宽度”)。 例如,权重为 20482048 的线性层对于 1024×1×2048 和 32322048 的输入产生相同的结果,但是使用 32322048 将执行延迟减少 1.62。 因此,mllm-NPU 在准备阶段会分析线性层的所有可能的等效形状,并选择最有效的一个。 (2) 移动 NPU 通常访问有限的内存区域(例如,Hexagon NPU 为 4GB),该内存区域可能小于大语言模型权重的大小。 为了在有限的内存内最大化预填充加速,mllm-NPU优先在 NPU 上执行计算密集型任务,例如 FFN,以提高效率。
4.1. 实验设置
硬件设置。 我们在两台配备不同 Qualcomm SoC 的智能手机上测试 mllm-NPU:小米 14(Snapdragon 8gen3,16GB 内存)和 Redmi K60 Pro(Snapdragon 8gen2,16GB 内存)。 所有设备均运行 Android OS 13。
模型和数据集。 我们使用多种典型的移动端大语言模型进行了测试:Qwen1.5-1.8B (qwen2, )、Gemma-2B (gemma2b, )、Phi2- 2.7B (phi2-2.7, )、LLaMA2-Chat-7B (Llama-2-7b, ) 和 Mistral-7B (Mistral-7B, ) 。 为了评估mllm-NPU的量化精度,我们采用了广泛认可的大语言模型基准,包括LAMBADA (lambada, )、HellaSwag (zellers2019hellaswag, )、WinoGrande (ai2:winogrande, )、OpenBookQA (OpenBookQA2018, ) 和 MMLU (hendryckstest2021, )。 对于推理速度实验,我们选择了来自 Longbench、2wikimqa 和 TriviaQA (bai2023longbench, ) 的基于检索的数据集,用于模拟上下文感知生成任务,例如自动电子邮件回复。 此外,我们还使用 DroidTask 数据集 (LlamaTouch, ) 评估了屏幕问答和将指令映射到 UI 操作场景中的 mllm-NPU,以模拟基于代理的 UI 自动化任务。

基线。 我们主要将 mllm-NPU 与 5 个基线进行比较,包括 3 个广泛使用的移动大语言模型引擎 (TFLite (tflite, )、 MNN (mnn, ) 和 llama.cpp (llama-cpp, ))。 这些引擎仅支持移动CPU和GPU; 2 个高级基线是 MLC-LLM (mlc-llm, )(用于设备上 GPU 的大语言模型编译器)和 PowerInfer-v2 ,它还利用移动 NPU 来加速预填充(xue2024powerinfer, )。 由于 PowerInfer-v2 不是开源的,我们使用其论文中报告的数据。 需要注意的是,这些基线通常仅支持我们评估的 5 个大语言模型的子集。
指标。 我们主要测量大语言模型的推理精度、预填充延迟、预填充能耗、预填充内存消耗和端到端推理延迟。 Android 操作系统中通过 /sys /class/power_supply 每 100ms 进行一次分析来获取能耗。 所有实验重复三次,我们报告平均数。
4.2. 预填充性能。
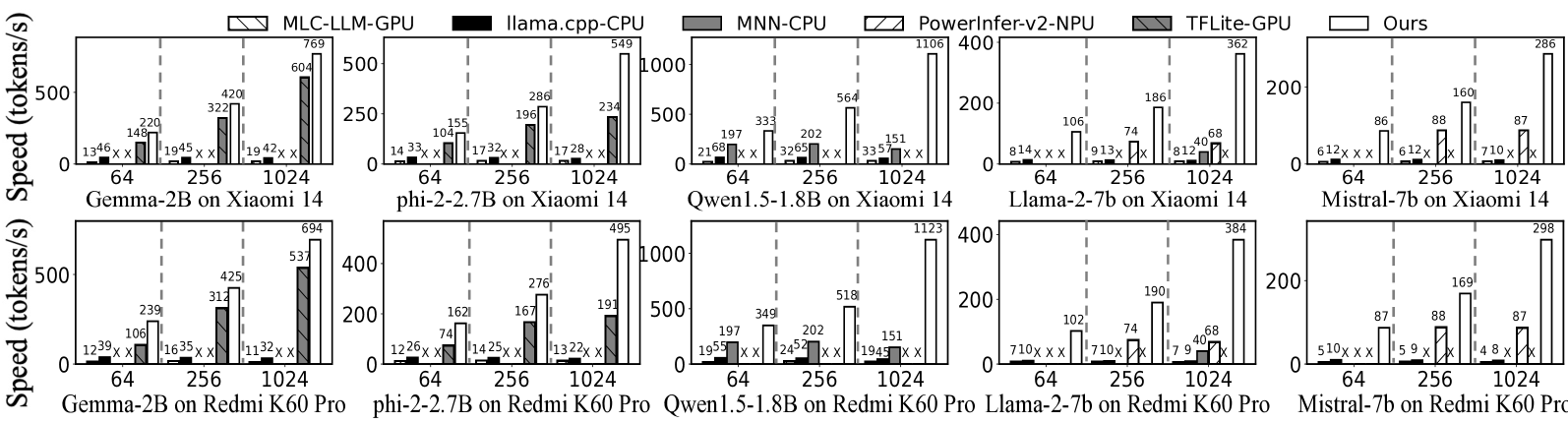
我们在两台设备上以 64、256 和 1024 个 Token 的提示长度评估 mllm-NPU 的预填充性能(速度和能耗),如图 14 所示15。 尽管数据集之间存在异常值,但对预填充性能的总体影响很小,因此我们报告了 LongBench 数据集的结果。 结果表明 神经网络处理单元 在这两个指标上始终优于所有基线,并且随着提示长度的增加,优势变得更加明显。
预充速度。 对于 1024 个 Token 的提示长度,mllm-NPU 可以将预填充延迟减少 18.17–38.4、7.3、32.5–43.6、小米 14 上分别与 llama.cpp-CPU、MNN-CPU、MLC-GPU、TFLite-GPU 相比为 1.27–2.34。 在 Redmi K60 Pro 上,这些改进为 21.3–41.3、7.43、37.2–69.3 和 1.3–2.6 分别。 这些加速归功于 mllm-NPU 使用了三种充分利用移动 NPU 的创新技术,包括阴影异常值执行、高效每张量 MatMul 和 乱序子图执行。 与同样使用 NPU 进行预填充的基线 PowerInfer-V2-NPU 相比,mllm-NPU 可以实现 3.28–5.32 和 3.4–5.6 加速通过采用 NPU 友好的 INT8 线性计算和细粒度子图调度(3.4)分别在两个设备上实现。
在提示符长度为 64 的情况下,mllm-NPU 的预填充速度比 llama 快 14.86-7.10、1.69、10.91-17.32、1.48 和 1.81-2.51。cpp-CPU、MNN-CPU、MLC-GPU、TFLite-GPU 和 PowerInfer-V2-NPU 的速度分别比 1024 个词符提示的速度平均低 10.5、4.31、2.68、1.02 和 1.96。 这是因为较短的提示可能会导致填充问题并限制 mllm-NPU 的乱序执行调度效率。
预充能源消耗。 能耗评估是在唯一可 Root 的设备 Redmi K60 Pro 上进行的。 PowerInfer-V2 由于缺乏能耗数据和开源代码而被排除在外。 对于 1024 个 Token 提示,mllm-NPU 将能耗降低 35.63–59.52、35.21–59.25 和 1.85–4.32 分别与 llama.cpp-CPU、MLC-GPU 和 TFLite-GPU 进行比较。 对于 64 个 Token 提示,节省的成本分别为 10.38–14.12、10.38–17.79 和 3.22–3.67。 这些节省归功于移动 NPU 的高能效以及 mllm-NPU 的三项新技术,可最大限度地提高 NPU 性能。
| LLM | Datasets | MLC | LCPP | MNN | PI | TFLite | Ours | Speedup | Datasets | MLC | LCPP | MNN | PI | TFLite | Ours | Speedup |
| Qwen1.5-1.8B | Longbench: 2wiki -Multi-doc QA (prompt length: 1500 tokens) | 45.6 | 26.7 | 10.6 | - | - | 1.7 | 6.2-26.8 | Longbench: TriviaQA (prompt length: 1500 tokens) | 46.0 | 27.0 | 11.2 | - | - | 2.0 | 5.6-23.0 |
| Gemma-2B | 78.4 | 34.6 | - | - | 2.6 | 1.9 | 1.4-41.3 | 81.8 | 36.2 | - | - | 2.8 | 2.2 | 1.3-37.2 | ||
| Phi-2-2.7B | 87.0 | 53.3 | 13.0 | - | 6.3 | 3.1 | 2.0-28.1 | 91.4 | 56.3 | 14.7 | - | 6.8 | 3.6 | 1.9-25.4 | ||
| LlaMA-2-7B | 184.7 | 146.0 | 22.4 | 19.8 | - | 5.3 | 3.7-34.8 | 197.3 | 156.2 | 23.8 | 21.8 | - | 6.2 | 3.5-31.8 | ||
| Mistral-7b | 254.2 | 200.2 | 20.0 | - | 5.5 | 3.6-46.2 | 266.2 | 210.0 | - | 21.5 | - | 6.4 | 3.4-41.6 | |||
| Geo-mean (speedup) | 34.7 | 21.8 | 4.8 | 3.7 | 1.7 | - | 31.0 | 19.6 | 4.4 | 3.4 | 1.6 | - | ||||
| LLM | Datasets | MLC | LCPP | MNN | PI | TFLite | Ours | Speedup | Datasets | MLC | LCPP | MNN | PI | TFLite | Ours | Speedup |
| Qwen1.5-1.8B | DroidTask: clock (prompt length: 800 tokens)) | 21.0 | 10.4 | 3.9 | - | - | 1.4 | 2.8-15.0 | DroidTask: applauncher (prompt length: 600 tokens) | 16.2 | 8.1 | 3.1 | - | - | 1.1 | 2.8-14.7 |
| Gemma-2B | 39.4 | 16.5 | - | - | 2.5 | 1.2 | 2.1-32.8 | 29.4 | 12.3 | - | - | 1.9 | 0.9 | 2.1-32.7 | ||
| Phi-2-2.7B | 46.6 | 25.0 | 7.4 | - | 4.2 | 3.1 | 1.4-15.0 | 35.4 | 19.0 | 5.9 | - | 3.2 | 2.4 | 1.3-14.8 | ||
| LlaMA-2-7B | 87.7 | 60.4 | 10.6 | 11.1 | - | 4.8 | 2.2-18.3 | 63.7 | 43.9 | 7.7 | 8.2 | - | 3.6 | 2.1-17.7 | ||
| Mistral-7b | 122.3 | 68.6 | - | 12.0 | - | 4.9 | 2.4-25.0 | 90.1 | 50.6 | - | 8.9 | - | 3.8 | 2.3-23.7 | ||
| Geo-mean (speedup) | 20.2 | 10.8 | 2.4 | 2.4 | 1.7 | - | 19.7 | 10.5 | 2.5 | 2.3 | 1.7 | - | ||||
| *LCPP and PI in the first row represent llama.cpp and PowerInfer-V2, respectively. | ||||||||||||||||
4.3. 端到端性能
我们使用两种工作负载来对照基准系统评估 mllm-NPU 的实际性能:DroidTask 数据集上的 UI 自动化和 LongBench 数据集上的上下文感知自动电子邮件回复。 端到端推理延迟结果如表4所示。 我们的主要观察是 神经网络处理单元 始终在所有四个数据集上实现最低的推理延迟。
对于 LongBench 数据集,mllm-NPU 显示出显着的速度提升:比 llama.cpp-CPU 提高 23.0–46.2,比 MLC-LLM 提高 16.5–36.4 -GPU,MNN-CPU 上为 4.08–4.19,PowerInfer-V2-NPU 上为 3.51–3.73,TFLite-GPU 上为 1.27–2.03 。 这种令人印象深刻的性能主要归功于 mllm-NPU 在预填充阶段的卓越效率。 相对于 TFLite-GPU 的加速比较低,因为 mllm-NPU 目前依赖 CPU 后端进行解码,没有进行优化,而 TFLite 使用 GPU。 值得注意的是,mllm-NPU与任何解码引擎兼容,这意味着一旦TFLite开源,mllm-NPU可以将其集成为解码后端,从而有可能进一步增强性能。
对于 DroidTask 数据集,mllm-NPU 与 llama.cpp-CPU 相比,端到端推理延迟减少了 7.9-12.5;与 MLC-LLM-GPU 相比,端到端推理延迟减少了 15.0-32.8;与 MNN-CPU 相比,端到端推理延迟减少了 2.38-2.45。8,与 MLC-LLM-GPU 相比降低了 2.38-2.45,与 MNN-CPU 相比降低了 2.27-2.44,与 PowerInfer-V2-NPU 相比降低了 1.35-2.38,与 TFLite-GPU 相比降低了 1.35-2.38。 DroidTask 数据集的性能提升略小,因为 UI 自动化中的提示比电子邮件编写中的提示更短。
| LAMBADA | FP16 | SQ | INT8() | K-Quant | Ours | Ours Degrad. |
|---|---|---|---|---|---|---|
| Qwen1.5-1.8B | 71.1% | 65.6% | 71.0% | 62.7% | 71.7% | +0.6% |
| Gemma2-2B | 59.6% | 45.8% | 59.2% | 56.9% | 59.4% | -0.2% |
| Phi-2-2.7B | 72.2% | 66.1% | 71.7% | 59.3% | 67.5% | -4.7% |
| LlaMA-2-7B | 87.5% | 71.9% | 88.0% | 15.6% | 86.3% | -1.2% |
| Mistral-7b | 84.8% | 51.2% | 85.3% | 23.9% | 84.1% | -0.7% |
| Avg. Degrad. | - | -14.9% | 0% | -31.3% | -1.2% |
| HellaSwag | FP16 | SQ | INT8() | K-Quant | Ours | Ours Degrad. |
|---|---|---|---|---|---|---|
| Qwen1.5-1.8B | 43.8% | 40.9% | 43.5% | 44.3% | 43.8% | 0% |
| Gemma2-2B | 46.5% | 43.8% | 46.1% | 45.4% | 47.3% | +0.8% |
| Phi-2-2.7B | 48.2% | 46.2% | 47.7% | 47.6% | 46.9% | -1.3% |
| LlaMA-2-7B | 52.8% | 44.4% | 53.1% | 50.5% | 53.5% | +0.7% |
| Mistral-7b | 57.4% | 44.9% | 57.9% | 57.0% | 57.0% | -0.4% |
| Avg. Degrad. | - | -5.7% | -0.1% | -0.8% | -0.0% |
| WinoGrande | FP16 | SQ | INT8() | K-Quant | ours | Ours Degrad. |
|---|---|---|---|---|---|---|
| Qwen1.5-1.8B | 58.3% | 51.0% | 58.2% | 59.0% | 59.3% | +1.0% |
| Gemma2-2B | 58.3% | 54.8% | 59.0% | 58.5% | 59.5% | +1.2% |
| Phi-2-2.7B | 72.2% | 68.9% | 72.4% | 72.5% | 70.2% | -2.0% |
| LlaMA-2-7B | 65.2% | 56.9% | 66.2% | 67.4% | 65.1% | -0.1% |
| Mistral-7b | 73.5% | 59.1% | 73.3% | 73.5% | 73.1% | -0.4% |
| Avg. Degrad. | - | -7.4% | +0.3% | +0.7% | -0.1% |
| OpenBookQA | FP16 | SQ | INT8() | K-Quant | ours | Ours Degrad. |
|---|---|---|---|---|---|---|
| Qwen1.5-1.8B | 28.8% | 23.0% | 28.5% | 28.0% | 26.6% | -2.2% |
| Gemma2-2B | 33.7% | 28.0% | 34.2% | 33.0% | 38.4% | +4.7% |
| Phi-2-2.7B | 41.0% | 35.9% | 40.2% | 39.5% | 37.7% | -3.3% |
| LlaMA-2-7B | 32.7% | 25.0% | 32.0% | 31.5% | 31.1% | -1.6% |
| Mistral-7b | 39.4% | 25.6% | 39.3% | 37.9% | 39.3% | -0.1% |
| Avg. Degrad. | - | -7.6% | -0.3% | -1.1% | -0.5% |
| MMLU | FP16 | SQ | INT8() | K-Quant | ours | Ours Degrad. |
|---|---|---|---|---|---|---|
| Qwen1.5-1.8B | 29.7% | 27.9% | 29.1% | 29.8% | 30.8% | +1.1% |
| Gemma2-2B | 35.7% | 32.1% | 35.1% | 35.1% | 36.4% | +0.7% |
| Phi-2-2.7B | 35.4% | 35.3% | 35.6% | 35.7% | 36.7% | +1.3% |
| LlaMA-2-7B | 37.8% | 29.2% | 38.1% | 34.4% | 36.9% | -0.9% |
| Mistral-7b | 42.1% | 30.9% | 41.4% | 42.3% | 41.0% | -1.1% |
| Avg. Degrad. | - | -5.1% | -0.3% | -0.7% | +0.2% |
4.4. 推理准确率
我们在五个大语言模型基准上研究了 mllm-NPU 的推理精度:LAMBADA (lambada, )、HellaSwag (zellers2019hellaswag, )、WinoGrande (ai2:winogrande, )、OpenBookQA (OpenBookQA2018, ) 和 MMLU (hendryckstest2021, )。 为了进行比较,我们评估了 4 个替代方案:FP16(非量化)、K-Quant (llama-cpp, )(在 llama.cpp 中使用)、SmoothQuant (xiao2023smoothquant, ) (最先进的每张量方法)和大语言模型.Int8() (dettmers2022gpt3, ) (最先进的浮点数方法)异常值处理方法)。 mllm-NPU的精度损失可以忽略不计,并且显着优于其他量化算法,如表5所示
具体来说,mllm-NPU 的平均准确度仅比 FP16 低 1%,但其准确度比 SmoothQuant 提高了 32.9%,比 K-Quant 提高了 70.9%。 SmoothQuant 使用静态分析将离群值平滑至正常值,这一改进归功于 mllm-NPU 通过 CPU 浮点精度动态处理离群值位置。 mllm-NPU 在元素级别解决异常值,提供比使用组级别量化尺度的 K-Quant 更高的精度。 此外,mllm-NPU 实现了与大语言模型.Int8() 相当的精度(平均损失 0.1%),因为两者都以浮点精度处理异常值。 但mllm-NPU更好地利用了NPU特有的计算特性,保持了高精度和NPU效率。
4.5. 内存消耗
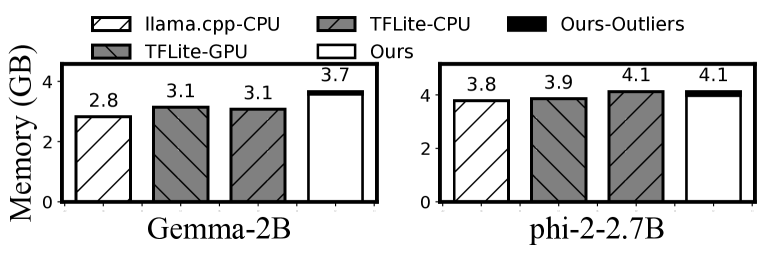
我们将 mllm-NPU 与 INT8 权重基线进行比较,因为移动 NPU 仅支持 INT8 权重计算。 使用 512-token 提示的 Redmi K60 Pro 上的内存消耗结果如图16所示。 mllm-NPU 比 llama.cpp 和 TFLite 多消耗 1.32 内存。 开销是由于 MLLM 和 QNN 框架造成的,它们为每个运算符分配独立的激活缓冲区以提高速度。 mllm-NPU 引入的微小额外内存开销是其 3.3 影子异常值执行 技术(黑色),它将微小的浮点权重加载到内存中,仅占总内存的0.6%–1%。
4.6. 消融研究。
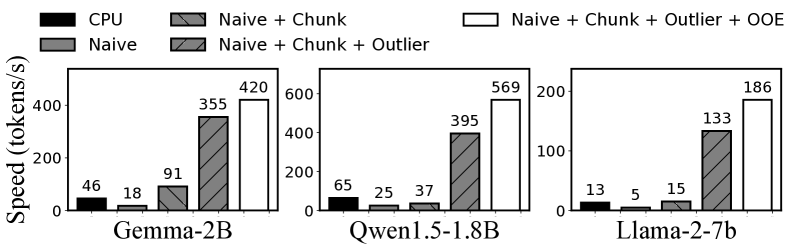
我们利用Qwen1.5-1.8B、Gemma-2B、LlaMA2-7B模型对mllm-NPU各项技术带来的收益进行了全面的细分分析,如图17。 最左边的条代表使用 llama.cpp 在 CPU 上的预填充速度。 第二个条显示了移动 NPU 上的简单实现,然后是我们三种技术的结合,最右边的条代表 mllm-NPU。 这三种技术分别用chunk (3.2)、outlier (3.3 和 OOE (3.4。 我们观察到 神经网络处理单元 的三种技术对整体改进做出了重大贡献。
首先,由于大语言模型与移动 NPU 之间存在巨大差距,直接将大语言模型预填充工作负载卸载到移动 NPU 会导致 2.55–2.68 的延迟,具体参见 2.3。 此外,块共享图通过减少图构建和优化延迟,将预填充速度提高了 1.46–5.09。 Gemma-2B 模型实现了最高的加速比,因为它需要更多的时间来构建和优化。 此外,阴影离群值执行将预填充延迟减少了 3.91–8.68,允许每个张量 MatMul 操作以最小的 CPU/GPU 开销充分利用移动 NPU。 最后,乱序子图执行通过减少 NPU 内的执行气泡,将预填充延迟减少了 18%–44%。
5. 相关工作
设备端大语言模型优化。 大语言模型非常消耗资源,尤其是需要长上下文时(xu2024survey, ; zeng2024cap, )。 为了减少设备上大语言模型推理的大量内存消耗,人们提出了各种压缩技术,包括量化和知识蒸馏(yao2022zeroquant, ; frantar2022gptq, ; guan2021cocopie, ; niu2020patdnn, ; wang2020minilm, ; huynh2017deepmon, ; you2022speechmoe2 , ; yi2023edgemoe, ; mllm-npu,)。 为了最大限度地减少设备上的大语言模型计算,研究人员引入了词符剪枝 (wang2021spatten, ; cai2022enable, ; kim2022learned, ; rao2021dynamicvit, ; bolya2022token, ),它会剪掉不必要的词符推理过程中的标记。 推测解码是一种通过将任务卸载到较小的大语言模型来加速词符生成的方法,已在开源框架(llama-cpp,;FastTransformer,)中广泛采用,并得到广泛研究(kim2023big, ; miao2023specinfer, ; yang2023predictive, ; he2023rest, ; fu2024break, ; cai2024medusa, )。 除了推理之外,设备上的大语言模型训练(尤其是微调)也在移动研究中受到关注(cai2022fedadapter, ; xu2024fwdllm, ) 作为系统优化,mllm-NPU 是正交的并且与这些算法级优化兼容。
ML 的片上卸载。 对此进行了深入研究,通过利用 GPU 和 NPU 等异构移动处理器(kim2019mulayer, ; zeng2021energy, ; ha2021acceleating, ; Lane2016deepx, ; han2019mosaic, ; zhang2020mobipose, ; lee2019mobisr, ; georgiev2014dsp, ; xu2022曼特宁,; xue2024powerinfer,;niu2024smartmem,;niu2024sod,)。 MobiSR (lee2019mobisr, ) 利用移动 NPU 来加速超分辨率计算。 然而,这些方法并没有解决LLM特定的功能,并且不适合设备上的大语言模型场景。 最相关的工作是PowerInfer-V2 (xue2024powerinfer, ),它也利用移动NPU进行预填充,但主要侧重于设备内存不足的大语言模型推理。 mllm-NPU 受到这些努力的启发,是第一个具有高效、端到端设备上 NPU 卸载的大语言模型推理框架。
移动NPU执行优化。 随着移动 NPU 在智能手机中的重要性日益增加,人们在优化其执行效率方面做出了巨大努力(root2023fast, ; thomas2024automatic, ; niu2022gcd, ; vocke2017extending, ; ragan2013halide, ; franchetti2008generating, )。 Pitchfork (root2023fast, ) 定义了可移植的定点中间表示以优化定点执行效率。 Isaria (thomas2024automatic, ) 提出了一个框架,用于自动生成 DSP 架构的矢量化编译器,为移动 NPU 创建高效的运算符代码。 作为一个系统框架,mllm-NPU是正交的,可以利用它们生成更高效的算子库作为执行后端,进一步提升性能。
6. 结论
本文提出了mllm-NPU,这是第一个利用设备上NPU卸载来减少预填充延迟和能耗的大语言模型推理系统。 mllm-NPU采用了新技术:块共享图、影子离群值执行和乱序子图执行,以提高 NPU 卸载效率。 大量实验已证明 mllm-NPU 具有卓越的性能优势,例如高达 43.6 的加速和 59.5 的节能。
参考
- [1] AI Core. https://developer.android.com/ai/aicore. Accessed: [2023.7].
- [2] Apple Intelligence. https://www.apple.com/apple-intelligence/. Accessed: [2023.7].
- [3] Gboard - the Google Keyboard - Apps on Google Play — play.google.com. https://github.com/NVIDIA/FasterTransformer. [Accessed 22-Oct-2023].
- [4] Winogrande: An adversarial winograd schema challenge at scale. 2019.
- [5] General data protection regulation. https://gdpr-info.eu/, 2021.
- [6] Ascend NPU. https://www.hisilicon.com/en/products/Kirin/Kirin-flagship-chips/Kirin-9000, 2023.
- [7] Edge TPU API. https://coral.ai/docs/edgetpu/inference/#general-purpose-operating-systems, 2023.
- [8] Gemma-2B. https://huggingface.co/google/gemma-2b, 2023.
- [9] HiAI Engine. https://developer.huawei.com/consumer/cn/doc/hiai-References/overview-0000001053824513, 2023.
- [10] Llama-2-7b. https://huggingface.co/meta-llama/Llama-2-7b-chat-hf, 2023.
- [11] MediaTek APU 790. https://corp.mediatek.com/news-events/press-releases/mediateks-new-all-big-core-design-for-flagship-dimensity-9300-chipset-maximizes-smartphone-performance-and-efficiency, 2023.
- [12] Mistral-7B. https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3, 2023.
- [13] Neuro Pilot. https://neuropilot.mediatek.com/, 2023.
- [14] Phi-2. https://https://huggingface.co/microsoft/phi-2, 2023.
- [15] Snapdragon 8gen3 soc. https://www.qualcomm.com/products/mobile/snapdragon/smartphones/snapdragon-8-series-mobile-platforms/snapdragon-8-gen-3-mobile-platform, 2023.
- [16] Ai benchmark. https://ai-benchmark.com/ranking_detailed.html, 2024.
- [17] Edgetpu. https://cloud.google.com/edge-tpu, 2024.
- [18] Gpt-based email writer. https://hix.ai/ai-email-writer-email-generator, 2024.
- [19] Hugging face. https://huggingface.co/, 2024.
- [20] Llamatouch. https://github.com/LlamaTouch/LlamaTouch, 2024.
- [21] Mllm. https://github.com/UbiquitousLearning/mllm, 2024.
- [22] Mmlu leader board. https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu, 2024.
- [23] Qnn. https://www.qualcomm.com/developer/software/qualcomm-ai-engine-direct-sdk, 2024.
- [24] Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024.
- [25] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- [26] Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508, 2023.
- [27] Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461, 2022.
- [28] Dongqi Cai, Yaozong Wu, Shangguang Wang, Felix Xiaozhu Lin, and Mengwei Xu. Fedadapter: Efficient federated learning for modern nlp. arXiv preprint arXiv:2205.10162, 2022.
- [29] Han Cai, Ji Lin, Yujun Lin, Zhijian Liu, Haotian Tang, Hanrui Wang, Ligeng Zhu, and Song Han. Enable deep learning on mobile devices: Methods, systems, and applications. ACM Transactions on Design Automation of Electronic Systems (TODAES), 27(3):1–50, 2022.
- [30] Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774, 2024.
- [31] Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in Neural Information Processing Systems, 35:30318–30332, 2022.
- [32] Franz Franchetti and Markus Püschel. Generating simd vectorized permutations. In International Conference on Compiler Construction, pages 116–131. Springer, 2008.
- [33] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
- [34] Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of llm inference using lookahead decoding. arXiv preprint arXiv:2402.02057, 2024.
- [35] Petko Georgiev, Nicholas D Lane, Kiran K Rachuri, and Cecilia Mascolo. Dsp. ear: Leveraging co-processor support for continuous audio sensing on smartphones. In Proceedings of the 12th ACM Conference on Embedded Network Sensor Systems, pages 295–309, 2014.
- [36] Hui Guan, Shaoshan Liu, Xiaolong Ma, Wei Niu, Bin Ren, Xipeng Shen, Yanzhi Wang, and Pu Zhao. Cocopie: Enabling real-time ai on off-the-shelf mobile devices via compression-compilation co-design. Communications of the ACM, 64(6):62–68, 2021.
- [37] Donghee Ha, Mooseop Kim, KyeongDeok Moon, and Chi Yoon Jeong. Accelerating on-device learning with layer-wise processor selection method on unified memory. IEEE Sensors, 21(7):2364, 2021.
- [38] Lixiang Han, Zimu Zhou, and Zhenjiang Li. Pantheon: Preemptible multi-dnn inference on mobile edge gpus. In Proceedings of the 22nd Annual International Conference on Mobile Systems, Applications and Services, pages 465–478, 2024.
- [39] Myeonggyun Han, Jihoon Hyun, Seongbeom Park, Jinsu Park, and Woongki Baek. Mosaic: Heterogeneity-, communication-, and constraint-aware model slicing and execution for accurate and efficient inference. In 2019 28th International Conference on Parallel Architectures and Compilation Techniques, pages 165–177. IEEE, 2019.
- [40] Zhenyu He, Zexuan Zhong, Tianle Cai, Jason D Lee, and Di He. Rest: Retrieval-based speculative decoding. arXiv preprint arXiv:2311.08252, 2023.
- [41] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- [42] Karla L Hoffman, Manfred Padberg, Giovanni Rinaldi, et al. Traveling salesman problem. Encyclopedia of operations research and management science, 1:1573–1578, 2013.
- [43] Loc N Huynh, Youngki Lee, and Rajesh Krishna Balan. Deepmon: Mobile gpu-based deep learning framework for continuous vision applications. In Proceedings of the 15th Annual International Conference on Mobile Systems, Applications, and Services, pages 82–95, 2017.
- [44] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2704–2713, 2018.
- [45] Xiaotang Jiang, Huan Wang, Yiliu Chen, Ziqi Wu, Lichuan Wang, Bin Zou, Yafeng Yang, Zongyang Cui, Yu Cai, Tianhang Yu, et al. Mnn: A universal and efficient inference engine. arXiv preprint arXiv:2002.12418, 2020.
- [46] Sehoon Kim, Karttikeya Mangalam, Jitendra Malik, Michael W Mahoney, Amir Gholami, and Kurt Keutzer. Big little transformer decoder. arXiv preprint arXiv:2302.07863, 2023.
- [47] Sehoon Kim, Sheng Shen, David Thorsley, Amir Gholami, Woosuk Kwon, Joseph Hassoun, and Kurt Keutzer. Learned token pruning for transformers. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 784–794, 2022.
- [48] Youngsok Kim, Joonsung Kim, Dongju Chae, Daehyun Kim, and Jangwoo Kim. layer: Low latency on-device inference using cooperative single-layer acceleration and processor-friendly quantization. In Proceedings of the Fourteenth EuroSys Conference 2019, pages 1–15, 2019.
- [49] Nicholas D Lane, Sourav Bhattacharya, Petko Georgiev, Claudio Forlivesi, Lei Jiao, Lorena Qendro, and Fahim Kawsar. Deepx: A software accelerator for low-power deep learning inference on mobile devices. In 2016 15th ACM/IEEE International Conference on Information Processing in Sensor Networks, pages 1–12. IEEE, 2016.
- [50] Royson Lee, Stylianos I Venieris, Lukasz Dudziak, Sourav Bhattacharya, and Nicholas D Lane. Mobisr: Efficient on-device super-resolution through heterogeneous mobile processors. In The 25th Annual International Conference on Mobile Computing and Networking, pages 1–16, 2019.
- [51] Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guohong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, et al. Personal llm agents: Insights and survey about the capability, efficiency and security. arXiv preprint arXiv:2401.05459, 2024.
- [52] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. arXiv preprint arXiv:2306.00978, 2023.
- [53] TensorFlow Lite. Deploy machine learning models on mobile and iot devices, 2019.
- [54] llama.cpp. Port of Facebook’s LLaMA model in C/C++ Resources. https://github.com/ggerganov/llama.cpp, Year of publication. Accessed: [2023.7].
- [55] Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Accelerating generative llm serving with speculative inference and token tree verification. arXiv preprint arXiv:2305.09781, 2023.
- [56] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In EMNLP, 2018.
- [57] Wei Niu, Gagan Agrawal, and Bin Ren. Sod2: Statically optimizing dynamic deep neural network. arXiv preprint arXiv:2403.00176, 2024.
- [58] Wei Niu, Jiexiong Guan, Xipeng Shen, Yanzhi Wang, Gagan Agrawal, and Bin Ren. Gcd 2: A globally optimizing compiler for mapping dnns to mobile dsps. In 2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 512–529. IEEE, 2022.
- [59] Wei Niu, Xiaolong Ma, Sheng Lin, Shihao Wang, Xuehai Qian, Xue Lin, Yanzhi Wang, and Bin Ren. Patdnn: Achieving real-time dnn execution on mobile devices with pattern-based weight pruning. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, pages 907–922, 2020.
- [60] Wei Niu, Md Musfiqur Rahman Sanim, Zhihao Shu, Jiexiong Guan, Xipeng Shen, Miao Yin, Gagan Agrawal, and Bin Ren. Smartmem: Layout transformation elimination and adaptation for efficient dnn execution on mobile. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, pages 916–931, 2024.
- [61] Christopher Olston, Noah Fiedel, Kiril Gorovoy, Jeremiah Harmsen, Li Lao, Fangwei Li, Vinu Rajashekhar, Sukriti Ramesh, and Jordan Soyke. Tensorflow-serving: Flexible, high-performance ml serving. arXiv preprint arXiv:1712.06139, 2017.
- [62] Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernandez. The LAMBADA dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1525–1534, Berlin, Germany, August 2016. Association for Computational Linguistics.
- [63] Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Aashaka Shah, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. arXiv preprint arXiv:2311.18677, 2023.
- [64] Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe. Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. Acm Sigplan Notices, 48(6):519–530, 2013.
- [65] Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural information processing systems, 34:13937–13949, 2021.
- [66] Alexander J Root, Maaz Bin Safeer Ahmad, Dillon Sharlet, Andrew Adams, Shoaib Kamil, and Jonathan Ragan-Kelley. Fast instruction selection for fast digital signal processing. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 4, pages 125–137, 2023.
- [67] Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. Powerinfer: Fast large language model serving with a consumer-grade gpu. arXiv preprint arXiv:2312.12456, 2023.
- [68] MLC team. MLC-LLM. https://github.com/mlc-ai/mlc-llm, 2023.
- [69] Samuel Thomas and James Bornholt. Automatic generation of vectorizing compilers for customizable digital signal processors. 2024.
- [70] Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019.
- [71] Sander Vocke, Henk Corporaal, Roel Jordans, Rosilde Corvino, and Rick Nas. Extending halide to improve software development for imaging dsps. ACM Transactions on Architecture and Code Optimization (TACO), 14(3):1–25, 2017.
- [72] Hanrui Wang, Zhekai Zhang, and Song Han. Spatten: Efficient sparse attention architecture with cascade token and head pruning. In 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 97–110. IEEE, 2021.
- [73] Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. Advances in Neural Information Processing Systems, 33:5776–5788, 2020.
- [74] Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. Empowering llm to use smartphone for intelligent task automation. arXiv preprint arXiv:2308.15272, 2023.
- [75] Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. Autodroid: Llm-powered task automation in android. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, pages 543–557, 2024.
- [76] Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. Loongserve: Efficiently serving long-context large language models with elastic sequence parallelism. arXiv preprint arXiv:2404.09526, 2024.
- [77] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning, pages 38087–38099. PMLR, 2023.
- [78] Daliang Xu, Mengwei Xu, Qipeng Wang, Shangguang Wang, Yun Ma, Kang Huang, Gang Huang, Xin Jin, and Xuanzhe Liu. Mandheling: Mixed-precision on-device dnn training with dsp offloading. In Proceedings of the 28th Annual International Conference on Mobile Computing And Networking, pages 214–227, 2022.
- [79] Daliang Xu, Hao Zhang, Liming Yang, Ruiqi Liu, Mengwei Xu, and Xuanzhe Liu. Wip: Efficient llm prefilling with mobile npu. In Proceedings of the Workshop on Edge and Mobile Foundation Models, EdgeFM ’24, page 33–35, New York, NY, USA, 2024. Association for Computing Machinery.
- [80] Mengwei Xu, Dongqi Cai, Yaozong Wu, Xiang Li, and Shangguang Wang. Fwdllm: Efficient federated finetuning of large language models with perturbed inferences. 2024.
- [81] Mengwei Xu, Wangsong Yin, Dongqi Cai, Rongjie Yi, Daliang Xu, Qipeng Wang, Bingyang Wu, Yihao Zhao, Chen Yang, Shihe Wang, et al. A survey of resource-efficient llm and multimodal foundation models. arXiv preprint arXiv:2401.08092, 2024.
- [82] Zhenliang Xue, Yixin Song, Zeyu Mi, Le Chen, Yubin Xia, and Haibo Chen. Powerinfer-2: Fast large language model inference on a smartphone. arXiv preprint arXiv:2406.06282, 2024.
- [83] Seongjun Yang, Gibbeum Lee, Jaewoong Cho, Dimitris Papailiopoulos, and Kangwook Lee. Predictive pipelined decoding: A compute-latency trade-off for exact llm decoding. arXiv preprint arXiv:2307.05908, 2023.
- [84] Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. Zeroquant: Efficient and affordable post-training quantization for large-scale transformers. Advances in Neural Information Processing Systems, 35:27168–27183, 2022.
- [85] Juheon Yi and Youngki Lee. Heimdall: mobile gpu coordination platform for augmented reality applications. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, pages 1–14, 2020.
- [86] Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, and Mengwei Xu. Edgemoe: Fast on-device inference of moe-based large language models. arXiv preprint arXiv:2308.14352, 2023.
- [87] Wangsong Yin, Mengwei Xu, Yuanchun Li, and Xuanzhe Liu. Llm as a system service on mobile devices. arXiv preprint arXiv:2403.11805, 2024.
- [88] Zhao You, Shulin Feng, Dan Su, and Dong Yu. Speechmoe2: Mixture-of-experts model with improved routing. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7217–7221. IEEE, 2022.
- [89] Jinliang Yuan, Chen Yang, Dongqi Cai, Shihe Wang, Xin Yuan, Zeling Zhang, Xiang Li, Dingge Zhang, Hanzi Mei, Xianqing Jia, et al. Mobile foundation model as firmware. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, pages 279–295, 2024.
- [90] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
- [91] Pai Zeng, Zhenyu Ning, Jieru Zhao, Weihao Cui, Mengwei Xu, Liwei Guo, Xusheng Chen, and Yizhou Shan. The cap principle for llm serving. arXiv preprint arXiv:2405.11299, 2024.
- [92] Qunsong Zeng, Yuqing Du, Kaibin Huang, and Kin K Leung. Energy-efficient resource management for federated edge learning with cpu-gpu heterogeneous computing. IEEE Transactions on Wireless Communications, 20(12):7947–7962, 2021.
- [93] Jinrui Zhang, Deyu Zhang, Xiaohui Xu, Fucheng Jia, Yunxin Liu, Xuanzhe Liu, Ju Ren, and Yaoxue Zhang. Mobipose: Real-time multi-person pose estimation on mobile devices. In Proceedings of the 18th Conference on Embedded Networked Sensor Systems, pages 136–149, 2020.
- [94] Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving. arXiv preprint arXiv:2401.09670, 2024.