LLaMAX:通过增强超过 100 种语言的翻译能力来扩展大语言模型的语言视野
摘要
大型语言模型(大语言模型)在高资源语言任务中表现出出色的翻译能力,但其在低资源语言任务中的性能受到预训练期间多语言数据不足的阻碍。 为了解决这个问题,我们投入了 35,000 个 A100-SXM4-80GB GPU 时间对 LLaMA 系列模型进行广泛的多语言持续预训练,从而实现了 100 多种语言的翻译支持。 通过对词汇扩展和数据增强等训练策略的全面分析,我们开发了 LLaMAX。 值得注意的是,与现有的开源大语言模型相比,LLaMAX 在不牺牲其泛化能力的情况下,实现了明显更高的翻译性能(高出 10 spBLEU 点以上),并且在 Flores-101 基准上的表现与专业翻译模型(M2M-100-12B)不相上下。 大量实验表明 LLaMAX 可以作为强大的多语言基础模型。 代码 111https://github.com/CONE-MT/LLaMAX/. 和模型 222https://huggingface.co/LLaMAX/. 是公开的。
1简介
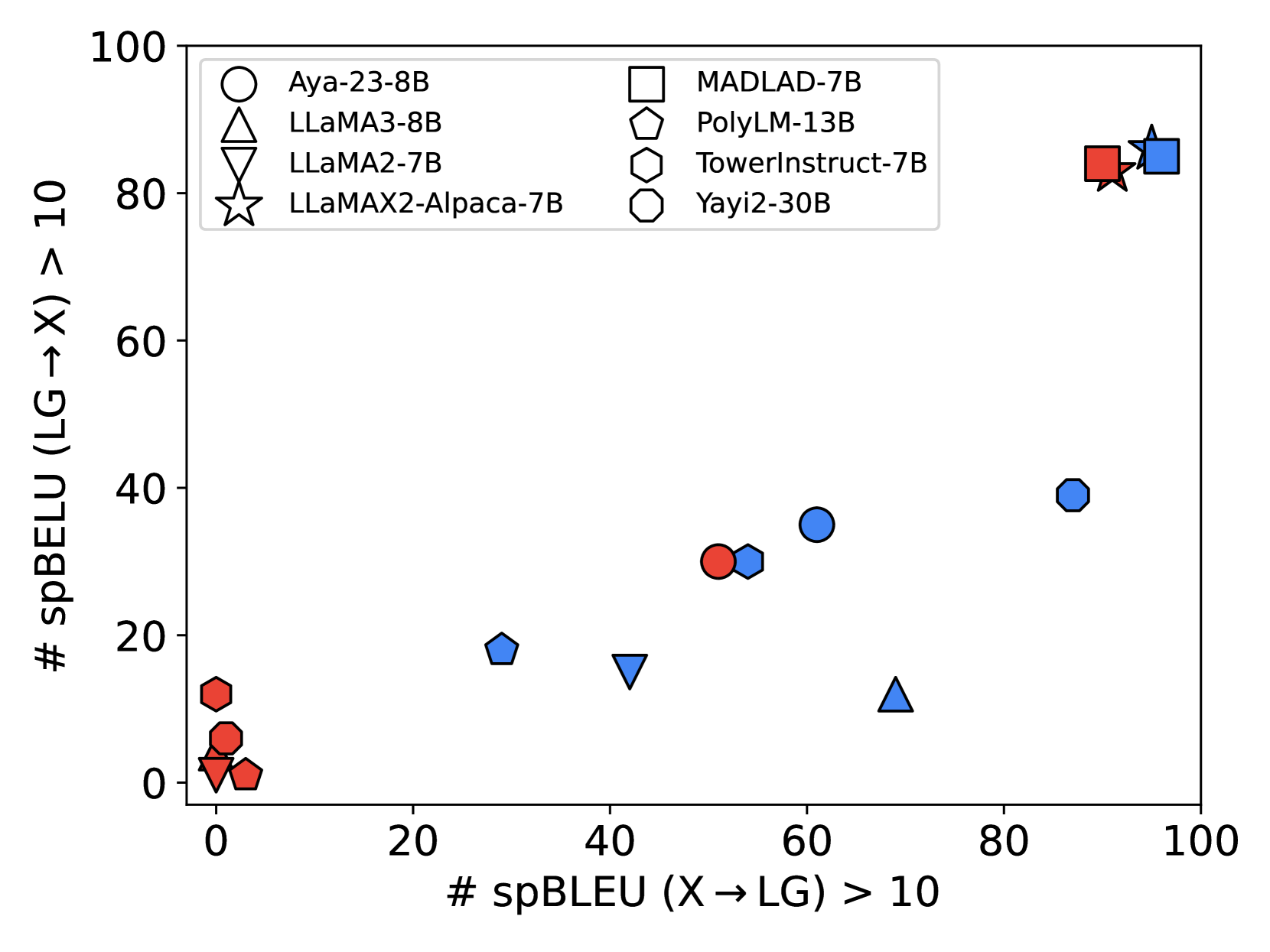
大型语言模型(大语言模型;Brown 等人,2020;Zhang 等人,2022;Chowdhery 等人,2022;OpenAI,2023;Touvron 等人,2023a,b)在翻译任务中表现出卓越的性能涉及高资源语言(Vilar 等人,2023;Zhu 等人,2024b),但其在低资源翻译中的效果并不理想(Hendy 等人,2023;Bang 等人, 2023;朱等人,2024b)。 图 1 显示了在 Flores-101 上性能超过 10 spBLEU (Goyal 等人, 2022) 分数的翻译方向数量 (Goyal 等人, 2022). 显然,大多数模型都聚集在以阿拉伯语为中心的翻译的原点周围,与以英语为中心的性能相比,表现出显着的差异。
这种差异主要是由于缺乏这些语言的预训练数据(Wei等人,2023;Yuan等人,2023b;Alves等人,2024)。 许多研究人员正在积极致力于解决这个问题。 Guo 等人 (2024) 学习教材后,通过翻译低资源语言来增强大语言模型的能力。 Zhu 等人 (2024b) 找到可以为低资源翻译提供更好的任务指导的跨语言示例。 除了在微调训练阶段的努力外,一些研究还尝试从头开始构建多语言大语言模型(Wei等人,2023),或者训练特定语言的大语言模型模型 (Faysse 等人, 2024; Alves 等人, 2024; Cui 等人, 2024)。 但这些作品涵盖的语种并不广泛(Wei 等人,2023;Alves 等人,2024;Luo 等人,2023),翻译性能仍不理想(Wei 等人,2023;Alves 等人,2024;Luo 等人,2023)等人,2023;阿尔维斯等人,2024;罗等人,2023)。
为了解决这种差异,我们对非英语语言进行了大规模的多语言持续预训练。 首先,我们对关键技术设计进行了全面分析,包括词汇扩展(3.1节)和数据增强(3.2节)。 这些分析为训练程序奠定了基础,直接影响大语言模型的效果并最终影响其表现。 随后,我们将这些策略应用到使用并行和单语数据的持续预训练中,以提高大语言模型在 Flores-101 涵盖的 102 种语言中的翻译性能,特别是对于资源匮乏的语言。
扩大语言支持的主要挑战在于确定适当的词汇(Cui等人,2024;Fujii等人,2024)。 为了面对这个问题,我们进行了定量分析,从各个角度评估添加特定于语言的标记的影响:标记化粒度、嵌入质量和模型的内部分布。 引入少量新词符会显着降低现有大语言模型的性能,而更大的新词符集会增加训练复杂性和数据要求。 令人惊讶的是,坚持大语言模型的原始词汇成为将大语言模型扩展到 102 种语言的最具成本效益的策略。
扩展语言支持的另一个巨大挑战是低资源语言的数据稀缺(Chang 等人,2023;Guo 等人,2024)。 为了缓解训练数据的稀缺性,我们深入研究了基于字典的数据增强(Pan等人,2021)并对各种增强策略进行了全面分析。 该分析考虑了不同的词典和数据源(单语或并行数据)。 我们发现数据增强的最佳方法涉及使用并行数据,字典的选择与其涵盖的目标语言实体的数量相关。
最后,我们利用上述技术对 LLaMA 系列模型进行大规模、多语言持续预训练(Touvron 等人,2023b;AI@Meta,2024),得到 LLaMAX 系列模型( LLaMAX2 和 LLaMAX3)。 LLaMAX2 使用 24 个 A100 GPU 进行了 60 多天的训练,显着增强了翻译能力,并实现了与专业翻译模型 M2M-100-12B 相当的性能(在 Flores-101 上评估)(范等人,2021)。 具体来说,我们的方法在以低资源为中心的翻译中与基线模型相比平均提高了 10 spBLEU 以上,如表 4 所示。 此外,当将我们的评估扩展到 Flores-200 (Team 等人,2022) 时,即使对于训练集中未包含的语言,它也显示出显着的性能增强。 所有这些翻译性能改进不会影响一般任务性能。 有趣的是,增强翻译能力还建立了强大的多语言基础模型基础。 在 X-CSQA (Lin 等人, 2021a)、XNLI (Conneau 等人, 2018) 上比较使用特定任务英语数据的监督微调结果时,和 MGSM (Shi 等人, 2023) 任务,我们观察到比 LLaMA2 平均提高了 5 个点。 我们的主要贡献可概括如下:
-
•
一系列开源 LLaMAX 模型增强了 100 多种语言的翻译性能。
-
•
全面分析大语言模型多语言持续预训练的关键技术,包括词汇扩展和数据增强。
-
•
对关键技术设计、跨各种模型的综合翻译基准评估、一般任务测试以及针对特定任务数据的监督微调的大量实验证明了 LLaMAX 的优越性。
2训练数据构建
为了建立强大的、支持一百种语言翻译的大语言模型,收集和构建足够的数据至关重要。
2.1 训练数据的组成
在持续关联阶段,收集到的102种语言的训练数据(参见,均为Flores-101支持的语言),主要由两部分组成:单语( )和并行()数据。 对于数据可用性有限的语言,我们使用多语言词典生成了伪并行数据集():MUSE (Lample 等人, 2018) 和 PanLex (Wang 等人,2022)。 有关支持的语言、数据集描述和数据统计的更多详细信息,请参见附录B。
单语言数据 ()。
我们的单语训练数据包括 Flores-101 支持的 94 种语言,来自 MC4 (Xue 等人, 2021) 和 MADLAD (Kudugunta 等人, 2024),总计 40,000,000 个句子。 为了保证数据的高效处理和处理,我们采取的策略是将每条单语数据分成多个条目,块大小为512。
并行数据 ()。
我们来自 Lego-MT Yuan 等人 (2023a) 的并行数据包含 102 种语言,形成总共 个语言对和 个翻译方向。 对于每个翻译方向,表示为源语言 () 到目标语言 (),我们仅使用空格作为分隔符来连接每个翻译集,以形成单个条目用于训练数据。 对于每个语言对,每个翻译方向的出现概率,例如和被设置为50%。 在训练阶段,梯度是针对整个数据输入计算的,而不是仅仅针对目标句子。 对于少于 25,000 个(受机器资源限制)句子对的语言对,我们将原始数据复制三次(Muennighoff 等人,2023)。
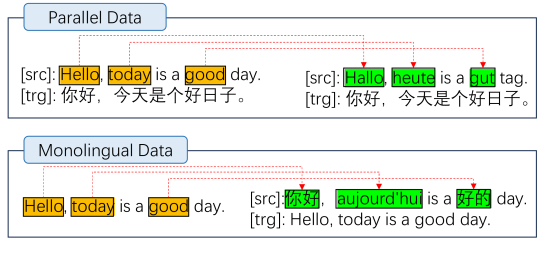
通过增强生成的数据 ()。
获取语码转换数据的方法包括两个步骤:1)构建多语言词典; 2)构造伪并行数据。 我们在图2中展示了数据增强过程。
第 1 步:建立多语言词典。
现有的多语言词典MUSE和PanLex包含多种双语词典,例如en-fr、en-de、en-zh双语词典。 字典包括许多条目,每个条目都是定义、用法并提供有其他相关信息的单词或术语。 我们迭代双语词典中的每个条目,重新格式化所有条目,并以 {entity}_{language} 格式创建条目。 例如,英语单词“hello”在三个双语词典(en-fr、en-de、en-zh)中的翻译,导致我们构建一个多语言词典条目为 hello_en、Bonjour_fr、Hallo_de、UTF8gbsn你好_zh。
| # New Token | Romanian (ro) | Bengali (bn) | ||||||||||
| fertility | cosine | R@1 | shift distance | # shift token | spBLEU | fertility | cosine | R@1 | shift distance | # shift token | spBLEU | |
| 0 | 2.25 | 0.39 | 0.37 | 0.4708 | 112 | 32.50 | 8.62 | 0.17 | 0.01 | 0.4689 | 112 | 20.12 |
| 100 | 2.19 | 0.36 | 0.34 | 0.4720 | 112 | 28.75 | 4.96 | 0.14 | 0.02 | 0.4680 | 113 | 14.02 |
| 800 | 2.02 | 0.35 | 0.36 | 0.4682 | 113 | 27.78 | 3.21 | 0.13 | 0.02 | 0.4706 | 113 | 10.18 |
| 1600 | 1.93 | 0.34 | 0.34 | 0.4690 | 113 | 26.40 | 2.78 | 0.13 | 0.02 | 0.4695 | 113 | 1.82 |
| 6,400 | 1.74 | 0.31 | 0.31 | 0.4694 | 113 | 22.66 | 2.15 | 0.12 | 0.02 | 0.4712 | 113 | 1.96 |
| 12,800 | 1.63 | 0.29 | 0.29 | 0.0205 | 1 | 21.95 | 1.95 | 0.12 | 0.02 | - | 0 | 1.84 |
| 25,600 | 1.53 | 0.27 | 0.28 | - | 0 | 19.72 | 1.80 | 0.12 | 0.02 | - | 0 | 2.58 |
| 51,200 | 1.45 | 0.26 | 0.25 | 0.0203 | 1 | 17.79 | 1.70 | 0.12 | 0.03 | - | 0 | 1.14 |
步骤2:构造伪并行数据。
构建的基础数据可以基于并行数据,也可以基于单语数据,如图2所示。 对于每个句子,我们将其转换为小写,然后使用空格将其分成多个单词(对于中文句子,使用 jieba tokenizer)。 在并行数据处理中,使用步骤 1 中创建的多语言词典,将源句子中的单词随机替换为不同语言的翻译。 在训练过程中,损失仅根据目标句子计算。 在单语言数据处理中,每个单词都被从多语言词典中随机选择的单词单独替换。 如果在另一种语言中找不到合适的替换词,则原始词保持不变。 因此,修改后的句子和原始句子可以形成伪并行数据。 在训练期间,仅根据源句子和目标句子计算损失。
我们在第3部分进一步进行了实验分析,发现基于并行数据的增强优于单语言数据。 因此,数据增强仅基于连续预训练期间的并行数据。
2.2训练算法。
给定一个基于收集的训练数据的大语言模型,其中是预训练参数,我们的目标是通过以下方式获得大语言模型:持续预训练,记为。 其中,表示更新后的参数。 的目标是保留模型在高资源语言中的通用能力,同时增强102种语言中所有翻译方向的翻译性能。 算法 1 概述了构建训练数据的过程。 我们收集每种语言的单语数据以及每个翻译方向的并行数据。 特别是,对于涉及高资源语言的翻译没有增强。 相反,我们只是利用经过训练的翻译模型(Lego-MT 模型)来补充不足的翻译数据。 然后我们训练,损失函数计算为:
| (1) |
其中 是总解码时间步长。
经过持续的预训练,我们使用 Alpaca (Taori 等人, 2023)(包含 52,000 个英语指令示例的数据集)对 LLaMAX 进行指令调优。 此过程增强了模型理解和遵循指令的能力,而无需引入额外的多语言信息,从而产生了LLaMAX-Alpaca。 我们目前正在使用羊驼毛来增强模型的指令跟随能力。 未来,我们将发布一个更强大的指令模型,并使用多语言指令数据集进行微调。
| Setting | spBLEU | # entity | similarity | |||||||
| MUSE | PanLex | MUSE | PanLex | ratio | MUSE | PanLex | ||||
| enta | 3.74 | 3.45 | -0.29 | 139,134 | 91,652 | -47,482 | 0.66 | 0.08 | 0.04 | -0.04 |
| enth | 5.45 | 6.14 | 0.69 | 21,567 | 297,573 | 276,006 | 13.80 | 0.20 | 0.06 | -0.14 |
| enfr | 44.03 | 43.85 | -0.18 | 139,134 | 568,428 | 429,294 | 4.09 | 0.31 | 0.35 | 0.04 |
| enzh | 14.65 | 16.64 | 1.99 | 139134 | 1,333,762 | 1,194,628 | 9.59 | 0.14 | 0.09 | -0.05 |
| enes | 26.98 | 27.36 | 0.38 | 142,780 | 433,468 | 290,688 | 3.04 | 0.28 | 0.32 | 0.04 |
3关键技术设计
在本节中,我们主要分析与扩展语言支持相关的两个关键挑战:确定适当的词汇表(在 3.1 节中)和提高数据增强的有效性(在 3.23.2 节中) t2>)。 更详细的分析可以参考词库中多跳翻译的选择(参见附录F)和持续预训练时并行数据格式的讨论(参见附录G)。
3.1 适当的词汇:原始词汇。
现有管道。
探索将预训练的大语言模型适应新语言而无需从头开始似乎有一个简洁的流程,产生了 ChineseLLaMA2 (Cui 等人, 2024)、Swallow (Fujii 等人, 2024 ),等等。 该管道包括三个关键步骤:1)词汇扩展:通过添加特定于该语言的新标记来扩展大语言模型的词汇,并将这些新标记初始化为现有标记 的嵌入平均值(Dobler 和 de Melo, 2023)。 2)持续预训练:在目标语言的大型文本数据语料库上持续预训练大语言模型。 3)指令调优:使模型与特定任务或指令保持一致,提高其性能。 我们不是简单地遵循管道,而是质疑词汇扩展的必要性。
环境。
我们对 LLaMA2 词汇表进行了一系列分析实验。 我们最初的重点是研究生育率与词符表征质量之间的相关性。 这里,生育率是指LLaMA2分词器生成的词符序列的长度与输入句子的长度(按空格分割)的比例(中文和日文按字符分割)。 此外,我们使用 Lego-MT 数据集中的 10,000 个 enro 和 enbn 双语句子对进行了实验。 在每个实验中,我们引入了不同数量的特定于语言的新标记,并在 Flores-101 上评估每个模型。
研究问题 1:为什么添加新标记被认为是扩展语言支持的直接方法?
我们通过 enX 翻译任务评估表示质量。 此任务识别与广泛目标数据集中相应英语句子最匹配的翻译结果,并使用顶部 1 的召回率进行评估,表示为 R@1 (Kabir 和 Carpuat,2021)。 R@1 值越高表示表示质量越稳健。 同时,我们提出了 LLaMA2 为英语和其他语言的相同句子生成的表示的余弦相似度。 在 102 种语言的实验中,更多详细信息请参阅附录 D,生育率与代表性质量之间存在很强的相关性,Spearman 相关系数约为 -0.88 证明了这一点每个评估的质量指标。
研究问题 2:添加新 Token 来降低生育率是否会促进性能提高?
扩大词汇量是降低生育率的常用方法。 然而,虽然添加新的标记确实会降低生育率,但它并不一定会增强其捕获和概括跨多种语言的语言模式的能力。 如表1所示,添加的新标记越多,翻译性能越差。
研究问题3:添加新 Token 对模型性能有何影响?
如表1所示,即使添加少量(100)个新的特定于语言的标记也可以对大语言模型的多语言性能产生重大影响。 此外,我们对KS-Lottery(袁等人,2024)原始 Token (32k)嵌入分布以及添加新 Token 前后的词符数量进行了进一步分析。 有关KS-Lottery的更多详细信息,请参阅附录E。正如表1中“shift distance”和“#shift词符”的实验结果一样,用有限的新token对整个模型进行微调,遵循与原始词汇类似的模式。 然而,过多的新标记可能会改变模型的训练重点。 无论该语言 (ro) 是否得到模型 (bn) 的良好支持,这一点都成立。 这些额外标记的影响是巨大的,这表明增强大语言模型多语言能力的过程并不像简单地扩大词汇量并用更多的多语言数据进行训练那么简单。
| Setting | Aug | en-centric | ta-centric | th-centric | zh-centric | ||||
| enX | Xen | taX | Xta | thX | Xth | zhX | Xzh | ||
| LLaMA2 | ✗ | 18.31 | 23.61 | 0.99 | 0.49 | 4.83 | 1.15 | 10.02 | 7.35 |
| ✗ | 19.06 | 25.98 | 3.20 | 0.91 | 7.66 | 3.13 | 11.32 | 7.83 | |
| + | ✗ | 19.46 | 26.40 | 4.17 | 1.76 | 7.28 | 3.02 | 11.65 | 8.82 |
| + | ✗ | 19.22 | 25.91 | 3.51 | 1.34 | 7.64 | 2.83 | 11.56 | 7.99 |
| ++ | ✗ | 19.36 | 26.47 | 4.35 | 1.82 | 7.78 | 3.49 | 11.44 | 9.14 |
| + | ✓ | 19.47 | 26.65 | 4.54 | 1.83 | 7.66 | 3.13 | 11.89 | 9.17 |
| + | ✓ | 18.59 | 25.98 | 3.61 | 1.36 | 6.72 | 2.35 | 10.81 | 6.45 |
| ++ | ✓ | 19.70 | 26.71 | 4.68 | 1.82 | 8.21 | 3.65 | 12.05 | 9.28 |
| ++ | ✓ | 19.17 | 26.58 | 4.57 | 1.95 | 7.12 | 3.12 | 11.52 | 7.73 |
| ++ | ✓ | 18.80 | 26.56 | 4.78 | 1.79 | 7.31 | 3.18 | 11.35 | 7.28 |
发现:原始词汇足以体现大语言模型的多语言性。
LLaMA 分词器采用字节级字节对编码(BBPE;Wang 等人,2019)算法,是多语言处理任务的基础。 它对所有语言的通用兼容性,加上不需要“未知”词符,优化了词汇共享(袁等人,2023b)并提高了其鲁棒性。 它允许模型使用相同的词汇理解/生成各种语言的响应。 同时,研究表明,在不平衡的以英语为中心的数据集上训练的大语言模型经常使用英语作为内部枢轴语言。 这有助于大语言模型在生成输出之前将输入映射到内部空间中更接近英语(Zhu 等人,2024a;Yoon 等人,2024)。 维护原始词汇有助于保留这种行为,这也有利于提高多语言能力。
3.2数据增强
环境。
给定一个来自 的并行数据集子集 (),其中包含 6 种语言 (en,fr,es,zh,ta,th) 的各个方向的翻译和单语言子集 ()来自 对于相同的 6 种语言。 然后,我们从 的每个方向对 12,500 个句子对进行非重复采样,分别生成并行语料库数据的两个子集 和 。 因此,我们保留 并评估增强对并行数据 或单语言数据 的影响,从而产生两个新数据集 和 ,增强后。 为了评估模型的域内和域外能力,我们使用 10 种语言(en、fr、es、pt、de、zh、ta、th、is、zu)对其进行推理,利用弗洛雷斯-101。
| en-X | zh-X | de-X | ne-X | ar-X | az-X | ceb-X | |||||||||
| System | Size | COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU |
| Encoder-Decoder Models | |||||||||||||||
| M2M-100∗ Fan et al. (2021) | 418M | 63.76 | 17.26 | 61.41 | 10.13 | 61.62 | 14.10 | 46.98 | 4.03 | 59.97 | 11.52 | 45.75 | 4.17 | 44.23 | 6.13 |
| M2M-100∗ Fan et al. (2021) | 1.2B | 70.00 | 21.54 | 67.29 | 13.13 | 67.62 | 17.73 | 56.04 | 7.14 | 62.62 | 12.57 | 52.39 | 6.06 | 52.79 | 9.46 |
| M2M-100∗ Fan et al. (2021) | 12B | 74.19 | 24.74 | 71.56 | 14.91 | 72.07 | 20.34 | 62.19 | 9.68 | 68.91 | 16.36 | 54.78 | 6.24 | 60.09 | 12.48 |
| Lego-MT∗ Yuan et al. (2023a) | 1.2B | 69.49 | 24.96 | 68.23 | 16.28 | 69.20 | 21.42 | 68.37 | 16.98 | 65.57 | 18.38 | 65.69 | 13.51 | 58.21 | 16.83 |
| NLLB-200 Team et al. (2022) | 1.3B | 81.69 | 31.77 | 78.05 | 19.61 | 79.49 | 25.99 | 81.63 | 23.65 | 78.66 | 24.32 | 78.46 | 19.18 | 76.50 | 23.71 |
| MADLAD-400 Kudugunta et al. (2024) | 7B | 77.79 | 29.19 | 74.07 | 18.23 | 74.73 | 23.15 | 72.74 | 17.74 | 74.53 | 22.14 | 61.29 | 9.92 | 64.44 | 15.29 |
| Aya-101 Üstün et al. (2024) | 13B | 77.26 | 24.30 | 75.29 | 15.50 | 76.17 | 20.86 | 77.78 | 18.65 | 74.82 | 18.44 | 75.36 | 15.46 | 71.90 | 18.76 |
| LLM based Decoder-Only Models | |||||||||||||||
| LLaMA2 Touvron et al. (2023b) | 7B | 43.95 | 4.21 | 44.62 | 0.91 | 45.26 | 2.14 | 38.22 | 0.39 | 39.43 | 0.54 | 47.43 | 0.68 | 33.50 | 1.49 |
| LLaMA2 Touvron et al. (2023b) | 13B | 31.37 | 0.24 | 34.91 | 0.25 | 31.22 | 0.10 | 35.32 | 0.21 | 32.34 | 0.11 | 36.03 | 0.17 | 30.84 | 0.17 |
| LLaMA3 AI@Meta (2024) | 8B | 45.04 | 3.84 | 45.14 | 3.50 | 42.11 | 3.27 | 44.15 | 2.65 | 39.36 | 2.36 | 43.00 | 1.86 | 36.06 | 2.43 |
| LLaMA2-Alpaca Taori et al. (2023) | 7B | 52.83 | 9.44 | 51.29 | 3.80 | 51.47 | 6.82 | 46.59 | 1.31 | 46.76 | 2.84 | 48.63 | 1.36 | 41.02 | 2.69 |
| LLaMA2-Alpaca Taori et al. (2023) | 13B | 57.16 | 11.85 | 53.93 | 6.25 | 54.70 | 9.42 | 51.47 | 3.11 | 50.73 | 5.23 | 50.68 | 2.74 | 47.86 | 4.96 |
| LLaMA3-Alpaca Taori et al. (2023) | 8B | 67.97 | 17.23 | 64.65 | 10.14 | 64.67 | 13.62 | 62.95 | 7.96 | 63.45 | 11.27 | 60.61 | 6.98 | 55.26 | 8.52 |
| PolyLM Wei et al. (2023) | 13B | 45.16 | 5.72 | 52.41 | 1.42 | 47.89 | 3.59 | 38.00 | 0.45 | 45.82 | 1.04 | 38.65 | 0.57 | 29.74 | 0.77 |
| Yayi2 Luo et al. (2023) | 30B | 54.13 | 7.80 | 55.23 | 4.38 | 56.48 | 4.72 | 47.88 | 0.92 | 49.45 | 1.73 | 53.06 | 1.23 | 36.75 | 1.87 |
| TowerInstruct Alves et al. (2024) | 7B | 58.69 | 9.41 | 57.75 | 4.15 | 58.31 | 6.79 | 51.42 | 2.07 | 50.76 | 3.35 | 48.01 | 1.79 | 41.69 | 3.36 |
| Aya-23 Aryabumi et al. (2024) | 8B | 57.91 | 11.18 | 56.65 | 7.20 | 55.69 | 9.30 | 51.78 | 3.50 | 55.49 | 8.00 | 51.45 | 3.27 | 44.14 | 4.24 |
| Qwen2-Instruct (Bai et al., 2023) | 7B | 59.64 | 9.61 | 59.70 | 6.84 | 57.44 | 7.69 | 58.62 | 4.40 | 57.22 | 6.35 | 54.49 | 3.83 | 49.61 | 3.76 |
| ChineseLLaMA2-Alpaca Cui et al. (2024) | 7B | - | - | 49.72 | 2.31 | - | - | - | - | - | - | - | - | - | - |
| LLaMAX2-Alpaca | 7B | 76.66 | 23.17 | 73.54 | 14.17 | 73.82 | 18.96 | 74.64 | 14.49 | 72.00 | 15.82 | 70.91 | 11.34 | 68.67 | 15.53 |
| LLaMAX3-Alpaca | 8B | 75.52 | 22.77 | 73.16 | 14.43 | 73.47 | 18.95 | 75.13 | 15.32 | 72.29 | 16.42 | 72.06 | 12.41 | 68.88 | 15.85 |
| X-en | X-zh | X-de | X-ne | X-ar | X-az | X-ceb | |||||||||
| System | Size | COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU |
| Encoder-Decoder Models | |||||||||||||||
| M2M-100∗ Fan et al. (2021) | 418M | 68.47 | 21.19 | 62.15 | 10.34 | 60.19 | 14.25 | 40.43 | 1.30 | 63.33 | 11.53 | 49.74 | 2.44 | 47.80 | 4.85 |
| M2M-100∗ Fan et al. (2021) | 1.2B | 73.06 | 26.26 | 67.91 | 12.94 | 67.78 | 19.33 | 42.60 | 1.40 | 60.28 | 8.57 | 55.86 | 4.58 | 55.87 | 6.83 |
| M2M-100∗ Fan et al. (2021) | 12B | 74.45 | 28.01 | 69.27 | 13.35 | 70.17 | 21.31 | 45.50 | 2.85 | 69.94 | 15.15 | 61.36 | 6.44 | 57.07 | 8.77 |
| Lego-MT∗ Yuan et al. (2023a) | 1.2B | 75.44 | 30.71 | 71.41 | 16.42 | 70.75 | 23.75 | 59.66 | 15.02 | 70.73 | 18.21 | 66.73 | 11.88 | 59.28 | 15.06 |
| NLLB-200 Team et al. (2022) | 1.3B | 84.22 | 38.60 | 76.75 | 15.27 | 79.50 | 25.71 | 73.70 | 21.84 | 79.85 | 21.80 | 80.02 | 15.55 | 69.05 | 24.72 |
| MADLAD-400 Kudugunta et al. (2024) | 7B | 83.05 | 38.14 | 78.49 | 20.48 | 77.50 | 26.79 | 61.94 | 13.93 | 77.84 | 22.25 | 75.41 | 13.85 | 51.33 | 4.24 |
| Aya-101 Üstün et al. (2024) | 13B | 80.72 | 31.92 | 78.51 | 22.49 | 77.37 | 15.43 | 69.69 | 17.13 | 77.90 | 16.54 | 78.70 | 13.51 | 67.76 | 21.58 |
| LLM Based Decoder-Only Models | |||||||||||||||
| LLaMA2 Touvron et al. (2023b) | 7B | 55.46 | 11.80 | 43.50 | 0.55 | 43.10 | 3.22 | 34.41 | 0.42 | 39.13 | 0.25 | 43.98 | 0.59 | 41.64 | 1.16 |
| LLaMA2 Touvron et al. (2023b) | 13B | 38.25 | 0.75 | 37.06 | 0.22 | 31.73 | 0.25 | 30.13 | 0.15 | 33.68 | 0.06 | 33.47 | 0.08 | 37.49 | 0.20 |
| LLaMA3 AI@Meta (2024) | 8B | 67.66 | 19.81 | 42.52 | 1.37 | 49.42 | 6.61 | 33.38 | 0.52 | 34.12 | 0.49 | 37.27 | 0.79 | 37.97 | 1.41 |
| LLaMA2-Alpaca Taori et al. (2023) | 7B | 65.85 | 16.44 | 56.53 | 4.46 | 56.76 | 9.01 | 34.96 | 1.03 | 44.10 | 2.18 | 40.67 | 0.63 | 45.69 | 1.73 |
| LLaMA2-Aplaca Taori et al. (2023) | 13B | 68.72 | 19.69 | 64.46 | 8.80 | 62.86 | 12.57 | 38.88 | 2.16 | 52.08 | 4.48 | 41.18 | 0.87 | 48.47 | 2.51 |
| LLaMA3-Alpaca Taori et al. (2023) | 8B | 77.43 | 26.55 | 73.56 | 13.17 | 71.59 | 16.82 | 46.56 | 3.83 | 66.49 | 10.20 | 58.30 | 4.81 | 52.68 | 4.18 |
| PolyLM Wei et al. (2023) | 13B | 50.98 | 7.75 | 42.60 | 1.20 | 43.95 | 3.69 | 33.69 | 0.36 | 42.27 | 1.67 | 40.24 | 0.44 | 39.29 | 0.96 |
| Yayi2 Luo et al. (2023) | 30B | 68.06 | 19.37 | 57.81 | 6.07 | 53.82 | 5.62 | 40.95 | 0.48 | 46.61 | 0.52 | 49.29 | 0.71 | 45.50 | 1.71 |
| TowerInstruct Alves et al. (2024) | 7B | 65.37 | 18.87 | 64.26 | 10.37 | 60.73 | 12.81 | 38.80 | 0.62 | 44.72 | 0.39 | 47.17 | 0.71 | 47.15 | 2.24 |
| Aya-23 Aryabumi et al. (2024) | 8B | 67.53 | 20.57 | 66.11 | 11.20 | 63.09 | 14.09 | 44.33 | 2.69 | 63.59 | 11.84 | 46.97 | 1.19 | 45.17 | 2.29 |
| Qwen2-Instruct (Bai et al., 2023) | 7B | 73.25 | 19.04 | 72.52 | 13.52 | 64.61 | 11.33 | 41.41 | 2.27 | 64.94 | 8.50 | 47.96 | 1.66 | 55.45 | 3.00 |
| ChineseLLaMA2-Alpaca Cui et al. (2024) | 7B | - | - | 55.06 | 6.15 | - | - | - | - | - | - | - | - | - | - |
| LLaMAX2-Alpaca | 7B | 80.55 | 30.63 | 75.52 | 13.53 | 74.47 | 19.26 | 67.36 | 15.47 | 75.40 | 15.32 | 72.03 | 10.27 | 65.05 | 16.11 |
| LLaMAX3-Alpaca | 8B | 81.28 | 31.85 | 78.34 | 16.46 | 76.23 | 20.64 | 65.83 | 14.16 | 75.84 | 15.45 | 70.61 | 9.32 | 63.35 | 12.66 |
| System | Size | TED (en-X) | TED (X-en) | TICO (en-X) | WMT23 (en-X) | WMT23 (X-en) | |||||
| COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU | COMET | BLEU | ||
| LLaMA2 Touvron et al. (2023b) | 7B | 52.15 | 3.34 | 61.54 | 8.66 | 39.63 | 3.45 | 51.55 | 2.96 | 65.68 | 14.87 |
| LLaMA2 Touvron et al. (2023b) | 13B | 34.66 | 0.17 | 40.87 | 0.49 | 31.65 | 0.42 | 33.74 | 0.43 | 41.18 | 0.85 |
| LLaMA3 AI@Meta (2024) | 8B | 44.72 | 2.09 | 53.56 | 6.04 | 40.02 | 4.82 | 47.44 | 2.61 | 55.18 | 7.84 |
| LLaMA2-Alpaca Taori et al. (2023) | 7B | 62.04 | 9.15 | 68.62 | 12.67 | 44.73 | 8.60 | 73.17 | 17.23 | 75.82 | 24.97 |
| LLaMA2-Alpaca Taori et al. (2023) | 13B | 65.62 | 11.40 | 70.74 | 14.54 | 48.64 | 10.79 | 77.93 | 21.60 | 77.90 | 28.67 |
| LLaMA3-Alpaca Taori et al. (2023) | 8B | 73.20 | 14.13 | 75.03 | 16.83 | 56.73 | 14.49 | 80.05 | 24.11 | 79.22 | 29.76 |
| PolyLM Wei et al. (2023) | 13B | 50.18 | 5.53 | 55.16 | 7.28 | 40.36 | 7.17 | 62.67 | 10.62 | 69.15 | 19.09 |
| Yayi2 Luo et al. (2023) | 30B | 61.53 | 8.54 | 70.92 | 14.09 | 47.02 | 7.91 | 65.69 | 10.76 | 75.60 | 20.47 |
| TowerInstruct Alves et al. (2024) | 7B | 64.83 | 8.22 | 70.91 | 15.29 | 50.48 | 10.14 | 74.03 | 18.42 | 80.08 | 30.03 |
| Qwen2-Instruct (Bai et al., 2023) | 7B | 66.68 | 8.84 | 71.83 | 13.37 | 55.16 | 11.47 | 75.11 | 18.86 | 77.48 | 25.61 |
| Aya-23 Aryabumi et al. (2024) | 8B | 68.06 | 10.69 | 72.87 | 16.44 | 52.44 | 12.98 | 83.29 | 27.15 | 82.00 | 31.21 |
| LLaMAX2-Alpaca | 7B | 75.58 | 16.12 | 76.18 | 17.81 | 68.33 | 19.79 | 80.17 | 23.91 | 79.55 | 30.30 |
| LLaMAX3-Alpaca | 8B | 74.95 | 15.15 | 76.99 | 18.47 | 67.71 | 20.06 | 79.96 | 24.49 | 79.88 | 30.34 |
发现:词典的选择与词典中该语言的实体数量有关。
如表2所示,以 en/ta/th/zh 为中心的翻译没有观察到明显的词典偏好,最佳性能随机分布在两个词典中。 此外,我们还对 MUSE 和 PanLex 词典进行了深入分析,以将 en 翻译为其他 5 种语言。 我们比较了端到端翻译性能(spBLEU)、词典中目标语言实体的数量(#entity)以及从训练模型中提取的实体嵌入的相似度(与实体词符嵌入的简单平均)。 并发现翻译性能和#entity 之间存在明显的相关性。
4 基准测试结果
在本节中,我们将展示多语言基准测试结果,以全面展示 LLaMAX2 的潜力。 我们使用 spBLEU (Goyal 等人, 2022) 和 COMET-22 (Rei 等人, 2020) 评估大语言模型和翻译模型的翻译质量。 有关 LLaMAX2 的训练详细信息和基线模型的描述,请参阅附录 C。
| Knowledge | Commonsense Reasoning | Math Reasoning | Code | Avg. | ||||||
| MMLU | BBH | NQ | HellaSwag | Winogrande | GSM8K | Math | HumanEval | MBPP | ||
| LLaMA2-Alpaca | 44.22 | 37.95 | 24.32 | 31.12 | 61.09 | 14.03 | 3.82 | 14.63 | 27.63 | 28.76 |
| LLaMAX2-Alpaca | 44.60 | 38.25 | 23.21 | 33.75 | 61.48 | 12.21 | 3.74 | 12.20 | 25.29 | 28.30 |
我们通过大量的多语言持续预训练,显着增强了基础 LLaMA2 模型的多语言翻译能力。
我们持续预训练的好处是增强基础大语言模型的多语言翻译能力。 Flores-101基准评估结果如表4所示。 通过将我们的多语言增强模型与指令调整版本中的基本 LLaMA2 模型(LLaMAX2-Alpaca 与 LLaMA2-Alpaca)进行比较,我们一致观察到以英语为中心和非以英语为中心的翻译的性能显着提高。 除了 Flores-101 之外,我们还对一系列不同的翻译基准进行评估(表5)。 我们的多语言持续预训练带来的性能提升在这些基准测试中是一致的。
LLaMAX 在多语言翻译方面远远优于其他仅开源解码器的大语言模型。
LLaMAX 也有利于看不见的长尾低资源语言。
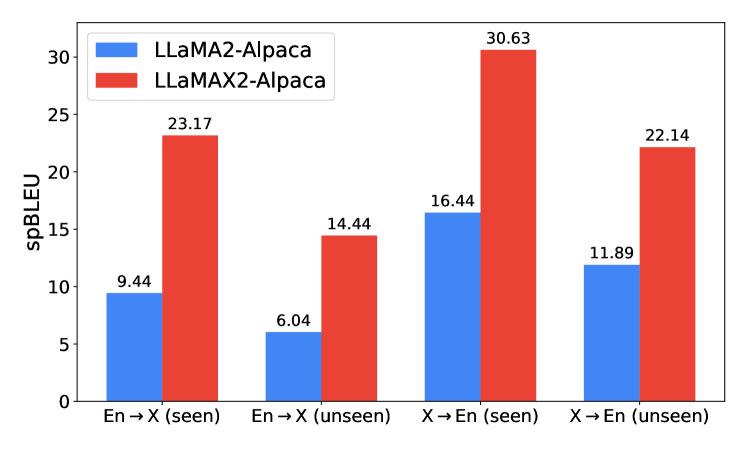
多语言增强的一个重大挑战是收集稀缺多语言资源的巨大成本使得覆盖大量语言变得令人望而却步。 虽然我们的多语言预训练语料库已经涵盖了 102 种语言,但我们承认,仍然有一大群长尾、资源匮乏的语言没有得到很好的覆盖。 为了评估 LLaMAX2 的泛化能力,我们在 Flores-200 数据集上对其进行评估,并观察其在这些未见过的语言上的性能(图4)。 我们发现,对于训练中未遇到的语言,LLaMAX2 仍然取得了显着的改进,展示了我们大规模持续预训练的泛化能力。
LLaMAX 正在缩小开源大语言模型翻译器和专业编码器-解码器翻译系统之间的性能差距。
虽然 LLaMAX2 在仅开源解码器的大语言模型中实现了最先进的翻译性能,但下一个关键问题是我们是否可以缩小大语言模型与专用编码器-解码器翻译系统之间的差距。 表4提供了全面的比较,显示LLaMAX2已经达到了M2M-100-12B模型的水平。 未来需要优化语言扩展框架,以匹配先进翻译系统(例如 MADLAD-400)的性能。
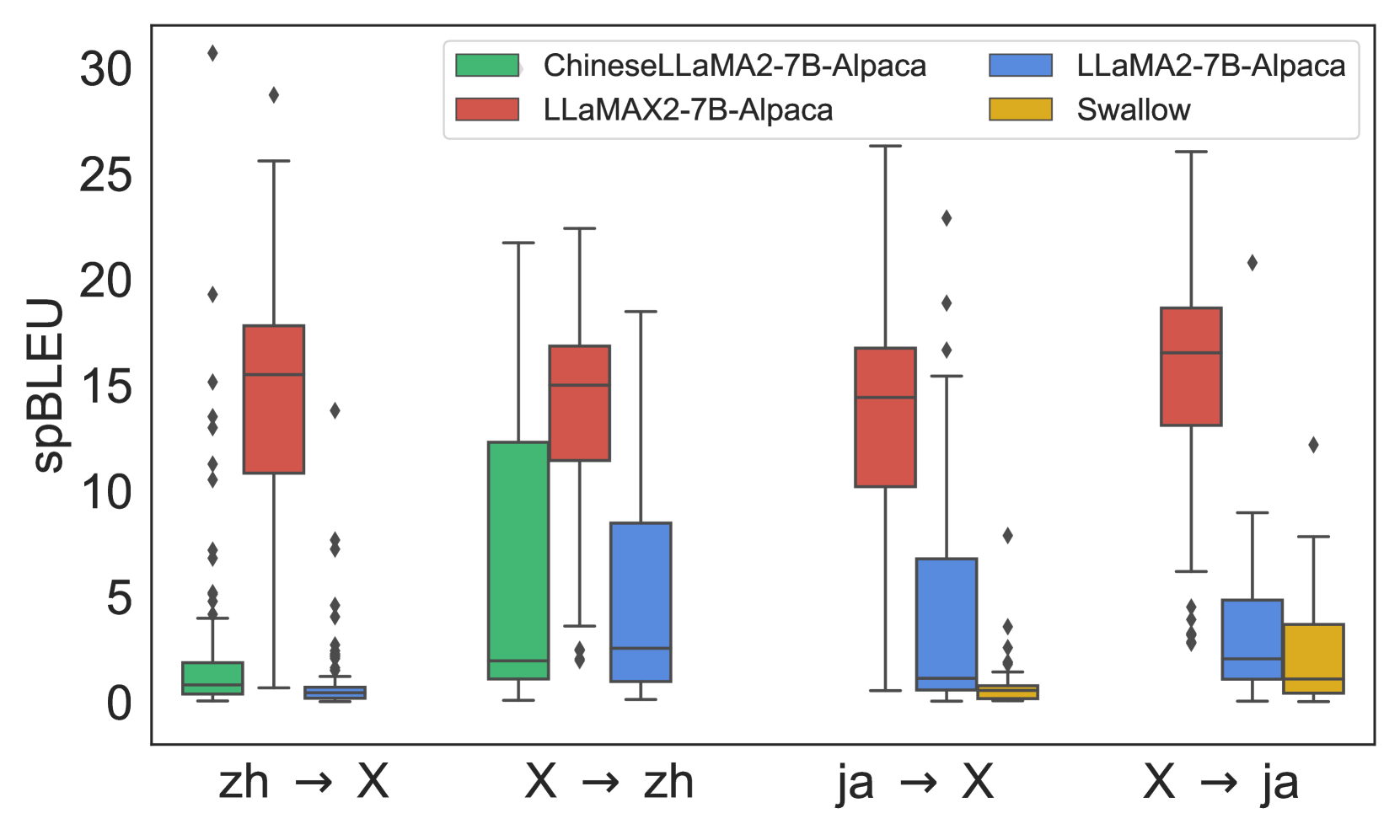
| X | LLaMA2-Alpaca | ChineseLLaMA2-Alpaca | LLaMAX2-Alpaca | X | LLaMA2-Alpaca | ChineseLLaMA2-Alpaca | LLaMAX2-Alpaca | ||||||
| af | 0.20 | 28.36 | 31.32 | 0.10 | 0.30 | 79.84 | ln | 0.30 | 0.00 | 66.40 | 0.00 | 0.00 | 0.00 |
| am | 1.09 | 40.12 | 67.29 | 21.15 | 0.00 | 89.23 | lo | 1.38 | 32.71 | 89.03 | 0.10 | 0.00 | 58.30 |
| ar | 2.17 | 81.23 | 72.92 | 24.70 | 0.00 | 99.80 | lt | 1.09 | 14.13 | 50.69 | 24.31 | 0.20 | 96.34 |
| as | 8.40 | 0.59 | 84.39 | 0.30 | 0.00 | 76.78 | luo | 5.83 | 0.00 | 87.65 | 0.00 | 1.38 | 0.00 |
| ast | 0.30 | 0.20 | 18.77 | 0.10 | 0.00 | 33.20 | lv | 0.30 | 15.51 | 52.67 | 15.42 | 0.20 | 97.73 |
| az | 0.20 | 18.87 | 39.23 | 4.25 | 0.00 | 96.44 | mi | 0.49 | 0.00 | 59.58 | 0.00 | 0.00 | 0.00 |
| be | 0.10 | 49.11 | 2.96 | 2.87 | 0.00 | 99.70 | mk | 0.40 | 17.19 | 7.31 | 21.94 | 0.00 | 99.31 |
| bg | 2.37 | 44.66 | 29.74 | 30.24 | 0.30 | 98.62 | ml | 8.20 | 12.15 | 79.55 | 7.51 | 0.49 | 51.88 |
| bn | 3.95 | 44.96 | 78.75 | 17.79 | 0.10 | 99.60 | mn | 1.58 | 17.49 | 85.67 | 1.48 | 0.00 | 99.51 |
| bs | 0.40 | 2.17 | 8.10 | 1.98 | 0.10 | 4.25 | mr | 0.40 | 19.86 | 31.42 | 1.58 | 0.00 | 99.01 |
| ca | 0.30 | 90.12 | 5.14 | 79.84 | 0.00 | 98.91 | ms | 0.59 | 5.93 | 20.36 | 3.95 | 0.00 | 43.18 |
| ceb | 0.20 | 21.94 | 6.72 | 16.01 | 0.00 | 95.55 | mt | 0.20 | 63.44 | 29.15 | 25.00 | 0.00 | 97.13 |
| cs | 0.20 | 54.55 | 24.90 | 38.14 | 0.30 | 94.76 | my | 1.78 | 47.33 | 38.74 | 29.74 | 0.00 | 99.90 |
| cy | 0.30 | 19.66 | 20.55 | 44.66 | 0.00 | 98.81 | ne | 0.49 | 35.77 | 71.64 | 3.06 | 0.00 | 98.72 |
| da | 0.30 | 49.01 | 22.73 | 39.72 | 0.49 | 91.80 | nl | 0.30 | 65.81 | 4.55 | 65.22 | 0.10 | 94.76 |
| de | 0.79 | 70.55 | 10.97 | 75.69 | 0.30 | 96.94 | no | 0.99 | 32.21 | 22.53 | 28.06 | 0.20 | 88.74 |
| el | 0.69 | 21.25 | 52.67 | 28.26 | 0.00 | 100.00 | ns | 0.20 | 0.00 | 38.74 | 0.00 | 0.10 | 0.00 |
| en | 0.00 | 100.00 | 0.30 | 99.70 | 0.00 | 100.00 | ny | 0.59 | 0.00 | 60.08 | 0.00 | 0.20 | 0.00 |
| es | 0.10 | 96.94 | 4.74 | 93.08 | 0.00 | 99.51 | oc | 0.10 | 0.79 | 20.55 | 0.30 | 0.40 | 59.39 |
| et | 2.27 | 8.50 | 75.49 | 2.96 | 0.10 | 96.34 | om | 0.20 | 0.00 | 38.04 | 0.00 | 0.20 | 0.00 |
| fa | 0.40 | 45.95 | 34.49 | 57.61 | 0.00 | 98.12 | or | 1.28 | 37.35 | 62.65 | 1.78 | 0.00 | 99.80 |
| ff | 0.49 | 0.00 | 73.81 | 0.00 | 0.59 | 0.00 | pa | 1.28 | 49.41 | 39.62 | 5.43 | 0.00 | 100.00 |
| fi | 3.95 | 55.43 | 65.22 | 17.59 | 0.30 | 97.13 | pl | 0.20 | 64.33 | 12.55 | 58.50 | 0.00 | 98.42 |
| fr | 0.10 | 94.17 | 3.46 | 92.98 | 0.00 | 98.72 | ps | 0.99 | 20.16 | 39.03 | 0.49 | 0.00 | 97.83 |
| ga | 0.20 | 19.37 | 8.70 | 6.82 | 0.00 | 93.08 | pt | 0.30 | 84.39 | 5.34 | 79.84 | 0.10 | 98.42 |
| gl | 0.20 | 0.89 | 26.19 | 0.10 | 0.20 | 83.99 | ro | 0.10 | 19.57 | 26.98 | 42.39 | 0.20 | 87.15 |
| gu | 0.59 | 36.96 | 45.65 | 29.74 | 0.00 | 99.60 | ru | 0.69 | 79.74 | 46.64 | 37.06 | 0.10 | 99.01 |
| ha | 0.79 | 0.00 | 67.98 | 0.00 | 0.10 | 0.00 | sd | 0.89 | 7.41 | 41.70 | 0.20 | 0.00 | 95.16 |
| he | 1.68 | 58.70 | 65.51 | 31.03 | 0.00 | 100 | sk | 0.40 | 20.26 | 25.40 | 3.56 | 0.10 | 97.23 |
| hi | 0.79 | 50.79 | 55.83 | 23.81 | 0.00 | 98.91 | sl | 1.19 | 37.25 | 49.60 | 16.21 | 0.69 | 91.90 |
| hr | 0.49 | 41.60 | 20.95 | 20.36 | 0.10 | 69.66 | sn | 0.49 | 0.00 | 34.58 | 0.00 | 0.10 | 0.00 |
| hu | 0.40 | 64.33 | 27.47 | 38.74 | 0.10 | 97.13 | so | 0.30 | 8.70 | 58.70 | 0.20 | 0.10 | 57.71 |
| hy | 4.74 | 47.13 | 79.15 | 12.15 | 0.00 | 99.60 | sr | 0.59 | 12.45 | 17.89 | 18.87 | 0.20 | 48.02 |
| id | 0.49 | 81.92 | 16.21 | 60.38 | 0.00 | 95.85 | sv | 0.10 | 47.33 | 46.94 | 25.00 | 0.10 | 96.94 |
| ig | 0.20 | 0.00 | 51.48 | 0.00 | 0.10 | 0.00 | sw | 0.20 | 39.23 | 36.86 | 22.73 | 0.00 | 94.66 |
| is | 0.40 | 35.08 | 40.02 | 28.46 | 0.20 | 92.98 | ta | 1.48 | 24.41 | 55.24 | 34.09 | 0.00 | 98.62 |
| it | 0.49 | 79.55 | 3.36 | 77.57 | 0.10 | 98.42 | te | 1.38 | 38.93 | 69.47 | 28.56 | 0.00 | 99.60 |
| ja | 48.02 | 16.70 | 28.36 | 70.95 | 6.62 | 92.00 | tg | 1.28 | 2.77 | 44.86 | 7.61 | 0.20 | 97.04 |
| jv | 0.20 | 0.00 | 13.83 | 0.00 | 0.00 | 64.62 | th | 1.28 | 58.60 | 71.25 | 28.56 | 0.00 | 100.00 |
| ka | 3.56 | 31.72 | 70.06 | 4.74 | 0.00 | 99.80 | tl | 0.20 | 66.7 | 32.91 | 45.75 | 0.00 | 98.91 |
| kam | 0.99 | 0.00 | 65.51 | 0.00 | 1.58 | 0.00 | tr | 0.89 | 37.94 | 48.02 | 31.42 | 0.00 | 95.65 |
| kea | 0.59 | 0.00 | 35.47 | 0.00 | 0.40 | 0.00 | uk | 0.49 | 71.54 | 10.38 | 28.06 | 0.49 | 98.62 |
| kk | 0.99 | 45.95 | 37.06 | 29.45 | 0.00 | 98.32 | umb | 0.59 | 0.00 | 54.94 | 0.00 | 0.30 | 0.00 |
| km | 1.58 | 29.25 | 58.89 | 28.26 | 0.00 | 100.00 | ur | 1.68 | 19.86 | 75.49 | 14.82 | 0.10 | 96.54 |
| kn | 3.16 | 38.24 | 75.59 | 14.72 | 0.00 | 100.00 | uz | 0.20 | 30.24 | 58.99 | 2.77 | 0.10 | 89.92 |
| ko | 3.85 | 71.94 | 75.69 | 23.52 | 0.00 | 98.02 | vi | 0.10 | 92.69 | 13.44 | 81.13 | 0.00 | 99.70 |
| ku | 0.10 | 14.13 | 31.72 | 0.00 | 0.40 | 75.20 | wo | 0.30 | 0.00 | 56.62 | 0.00 | 0.49 | 0.00 |
| ky | 1.19 | 25.99 | 48.62 | 4.35 | 0.00 | 99.11 | xh | 0.20 | 0.00 | 40.51 | 0.00 | 0.10 | 0.00 |
| lb | 0.10 | 24.21 | 30.73 | 0.40 | 0.59 | 89.53 | yo | 0.10 | 3.56 | 57.91 | 0.40 | 0.10 | 15.81 |
| lg | 10.57 | 0.00 | 79.35 | 0.00 | 6.13 | 0.00 | zhtrad | 98.12 | 0.00 | 98.42 | 0.00 | 99.51 | 0.00 |
| zu | 0.20 | 0.00 | 45.55 | 0.00 | 0.10 | 0.00 | |||||||
LLaMAX 为英语任务数据的专门指令调整提供了更好的起点。
最后,我们演示了持续预训练模型 (LLaMAX2) 在翻译以外的任务中的用法。 虽然在之前的实验中,我们使用基本的羊驼指令数据来教大语言模型遵循翻译指令,但现在我们表明,我们发布的检查点可以处理除翻译之外的更多多语言任务。 图3展示了三个示例任务,我们使用专门的指令数据来解锁LLaMAX2在特定任务上的能力,例如数学推理和常识推理。 我们发现,在所有三个任务中,指令调整的 LLaMAX2 模型在非英语性能方面均优于其对应的 LLaMA2 模型,这表明该模型为使用特定于任务的数据进行指令调整提供了更好的起点。
| Direct | BLEU | COMET | ||||||
| LLaMA3-Alpaca | LLaMAX2-Alpaca | LLaMA3-Alpaca | LLaMAX2-Alpaca | |||||
| srctrg | srcentrg | srctrg | srcentrg | srctrg | srcentrg | srctrg | srcentrg | |
| zhx | 10.14 | 11.34 | 14.17 | 15.54 | 64.65 | 66.61 | 73.54 | 74.74 |
| xzh | 13.17 | 15.37 | 13.53 | 15.11 | 73.56 | 75.66 | 75.52 | 77.21 |
| dex | 13.62 | 14.24 | 18.96 | 19.38 | 64.67 | 65.79 | 73.82 | 74.36 |
| xde | 16.82 | 18.08 | 19.26 | 20.71 | 71.59 | 73.11 | 74.47 | 76.04 |
| arx | 11.27 | 12.60 | 15.82 | 17.10 | 63.45 | 65.33 | 72.00 | 73.17 |
| xar | 10.20 | 10.88 | 15.32 | 16.00 | 66.49 | 69.54 | 75.40 | 76.32 |
| nex | 7.96 | 10.29 | 14.49 | 16.16 | 62.95 | 67.87 | 74.64 | 76.86 |
| xne | 3.83 | 7.08 | 15.47 | 16.86 | 46.56 | 58.89 | 67.36 | 69.47 |
| azx | 6.98 | 9.52 | 11.34 | 13.54 | 60.61 | 65.16 | 70.91 | 73.60 |
| xaz | 4.81 | 6.96 | 10.27 | 11.44 | 58.30 | 67.52 | 72.03 | 75.60 |
| cebx | 8.52 | 10.69 | 15.53 | 16.98 | 55.26 | 60.71 | 68.67 | 70.76 |
| xceb | 4.18 | 7.17 | 16.11 | 18.94 | 52.68 | 59.55 | 65.05 | 66.52 |
| Avg. | 9.29 | 11.19 | 15.02 | 16.48 | 61.73 | 66.31 | 71.95 | 73.72 |
LLaMAX 规避了灾难性遗忘问题。
LLaMAX2-Alpaca 与特定语言大语言模型的比较。
超越以英语为中心的翻译更加高效和有效。
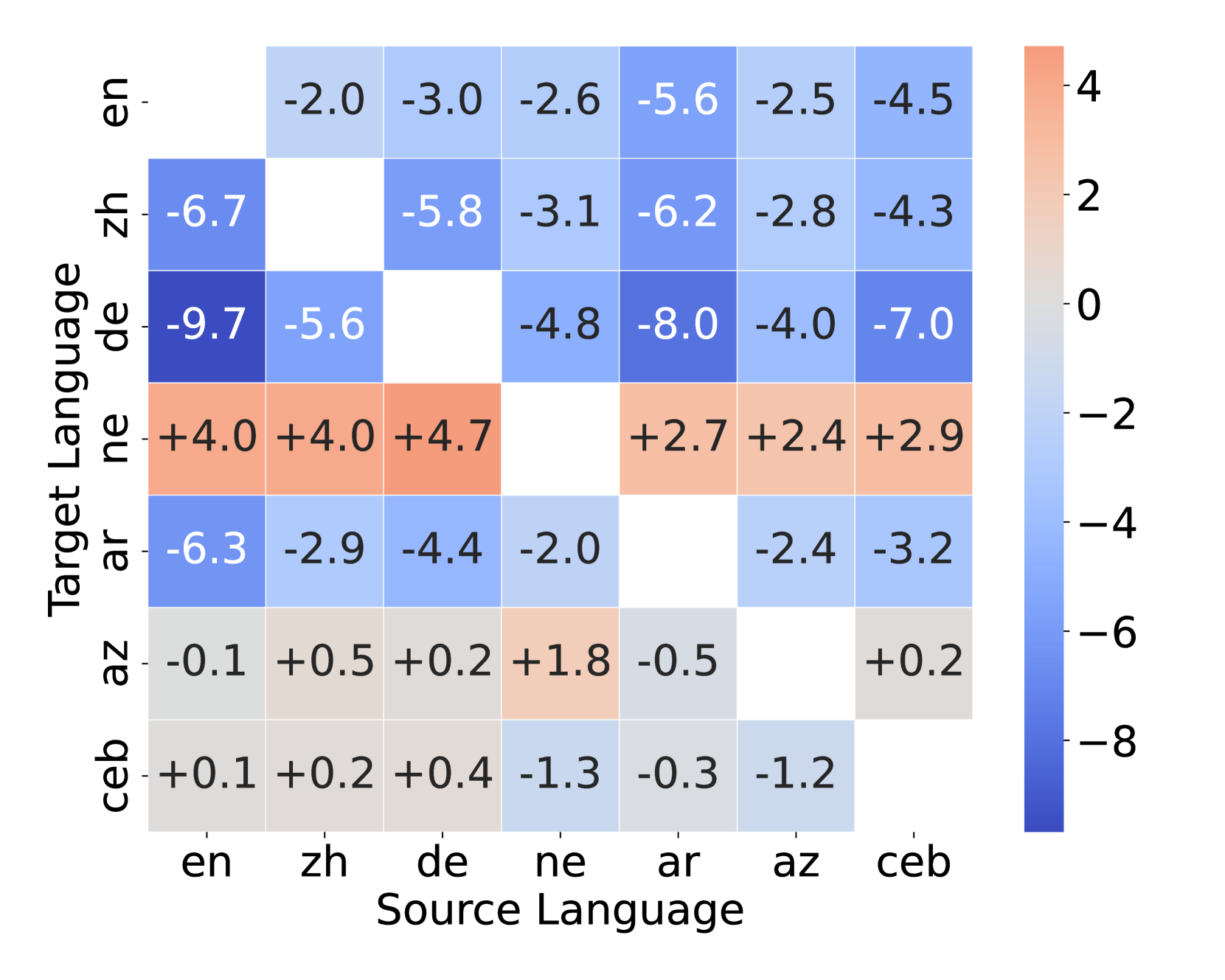
我们进一步研究了以英语为中心的大语言模型的多语言增强的必要性和可行性。 我们可以有效地将一个翻译任务(srctrg)从源语言(src)到目标语言(trg)转换为 srcen 和 entrg,它使我们能够利用英语作为中心语言的力量,促进跨不同语言对的无缝沟通和理解。 我们将此实验设置称为枢轴翻译实验。 如表8所示,实验结果表明枢轴翻译实验有效地利用了英语的力量来提升翻译性能(对比srcen trg 到 srctrg 在同一模型上),尽管它仍然低于大规模多语言连续预训练模型(LLaMA3-Alpaca srcentrg 与 LLaMAX2-Alpaca srctrg)。 有趣的是,基于 LLaMAX2-Alpaca 进行枢轴翻译实验揭示了翻译性能显着提高的潜力(LLaMAX2-Alpaca srcentrg 与 LLaMAX2-Alpaca srctrg)。
5相关工作
多语言大语言模型。
大语言模型(大语言模型;OpenAI, 2023;Zhang 等人, 2022;Brown 等人, 2020;Chowdhery 等人, 2022;Touvron 等人, 2023a, b)以英语为中心进行训练数据也可以解决各种非英语任务(Hendrycks 等人, 2021a, b; Srivastava 等人, 2022; Kwiatkowski 等人, 2019; Hendrycks 等人, 2021c),但是非英语任务之间的表现英英明显大Yuan等人(2023b)。 通过两种不同的方式开发更多的多语言大语言模型:从头开始用多种多语言数据重新训练大语言模型(Wei等人,2023);或使用特定于语言的数据对预训练模型进行连续训练,并可选择扩展词汇量(Zhao 等人, 2024a; Cui 等人, 2024; Faysse 等人, 2024; Alves 等人, 2024). 持续预训练不是从头开始训练,而是用新数据更新预训练模型,使过程更加高效且更具成本效益 (Gupta 等人, 2023; Alves 等人, 2024; Xie 等人, 2023)。
大语言模型中的多语言性。
最近的研究揭示了大语言模型的多语言能力。 Huang 等人 (2024) 的综合调查讨论了大语言模型中多语言的各个方面,包括训练和推理方法、模型安全性、语言文化的多领域,并强调了语言的必要性——辉科技. Yuan 等人(2023b)从词汇共享方面分析大语言模型的多语言性。 Zhao 等人 (2024b) 深入研究大语言模型的架构,了解大语言模型如何处理多语言。 最近,Li 等人(2024)量化了大语言模型的多语言性能。 这些研究为大语言模型的多语言能力以及LLaMAX持续预训练的关键技术设计提供了有价值的见解。
6结论
在这项工作中,我们通过持续的预训练增强了 LLaMA 翻译性能的系列模型对 102 种语言的性能,创建了 LLaMAX。 我们在多个基准测试中将 LLaMAX 的翻译能力与其他仅解码器的大语言模型和编码器-解码器模型进行比较。 LLaMAX 还针对一般任务进行评估,并根据特定任务的指令进行微调。 我们的结果表明,LLaMAX 在保持一般功能的同时提高了翻译质量,可以作为下游多语言应用程序的强大基础模型。
致谢
本文作者衷心感谢黄子贤、孙秋实、徐方志、胡汉旭、金川阳、杜一超和丁子晨对本文先前版本提出的许多有益的评论。
参考
- AI@Meta (2024) AI@Meta. 2024. Llama 3 model card.
- Alves et al. (2024) Duarte M Alves, José Pombal, Nuno M Guerreiro, Pedro H Martins, João Alves, Amin Farajian, Ben Peters, Ricardo Rei, Patrick Fernandes, Sweta Agrawal, et al. 2024. Tower: An open multilingual large language model for translation-related tasks. arXiv preprint arXiv:2402.17733.
- Anastasopoulos et al. (2020) Antonios Anastasopoulos, Alessandro Cattelan, Zi-Yi Dou, Marcello Federico, Christian Federmann, Dmitriy Genzel, Franscisco Guzmán, Junjie Hu, Macduff Hughes, Philipp Koehn, Rosie Lazar, Will Lewis, Graham Neubig, Mengmeng Niu, Alp Öktem, Eric Paquin, Grace Tang, and Sylwia Tur. 2020. TICO-19: the translation initiative for COvid-19. In Proceedings of the 1st Workshop on NLP for COVID-19 (Part 2) at EMNLP 2020, Online. Association for Computational Linguistics.
- Aryabumi et al. (2024) Viraat Aryabumi, John Dang, Dwarak Talupuru, Saurabh Dash, David Cairuz, Hangyu Lin, Bharat Venkitesh, Madeline Smith, Kelly Marchisio, Sebastian Ruder, et al. 2024. Aya 23: Open weight releases to further multilingual progress. arXiv preprint arXiv:2405.15032.
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609.
- Bang et al. (2023) Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, Quyet V. Do, Yan Xu, and Pascale Fung. 2023. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity.
- Bowman et al. (2015) Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 632–642, Lisbon, Portugal. Association for Computational Linguistics.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Cettolo et al. (2012) Mauro Cettolo, Christian Girardi, and Marcello Federico. 2012. WIT3: Web inventory of transcribed and translated talks. In Proceedings of the 16th Annual conference of the European Association for Machine Translation, pages 261–268, Trento, Italy. European Association for Machine Translation.
- Chang et al. (2023) Tyler A. Chang, Catherine Arnett, Zhuowen Tu, and Benjamin K. Bergen. 2023. When is multilinguality a curse? language modeling for 250 high- and low-resource languages.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating large language models trained on code.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Conneau et al. (2018) Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel R. Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. Xnli: Evaluating cross-lingual sentence representations. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
- Contributors (2023) OpenCompass Contributors. 2023. Opencompass: A universal evaluation platform for foundation models. https://github.com/open-compass/opencompass.
- Cui et al. (2024) Yiming Cui, Ziqing Yang, and Xin Yao. 2024. Efficient and effective text encoding for chinese llama and alpaca.
- Dobler and de Melo (2023) Konstantin Dobler and Gerard de Melo. 2023. FOCUS: Effective embedding initialization for monolingual specialization of multilingual models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13440–13454, Singapore. Association for Computational Linguistics.
- Fan et al. (2021) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, et al. 2021. Beyond english-centric multilingual machine translation. Journal of Machine Learning Research (JMLR).
- Faysse et al. (2024) Manuel Faysse, Patrick Fernandes, Nuno M. Guerreiro, António Loison, Duarte M. Alves, Caio Corro, Nicolas Boizard, João Alves, Ricardo Rei, Pedro H. Martins, Antoni Bigata Casademunt, François Yvon, André F. T. Martins, Gautier Viaud, Céline Hudelot, and Pierre Colombo. 2024. Croissantllm: A truly bilingual french-english language model.
- Fujii et al. (2024) Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Hiroki Iida, Masanari Ohi, Kakeru Hattori, Hirai Shota, Sakae Mizuki, Rio Yokota, and Naoaki Okazaki. 2024. Continual pre-training for cross-lingual llm adaptation: Enhancing japanese language capabilities.
- Goodfellow et al. (2013) Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. 2013. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv preprint arXiv:1312.6211.
- Goyal et al. (2022) Naman Goyal, Cynthia Gao, Vishrav Chaudhary, Peng-Jen Chen, Guillaume Wenzek, Da Ju, Sanjana Krishnan, Marc’Aurelio Ranzato, Francisco Guzmán, and Angela Fan. 2022. The Flores-101 evaluation benchmark for low-resource and multilingual machine translation. Transactions of the Association for Computational Linguistics, 10:522–538.
- Guo et al. (2024) Ping Guo, Yubing Ren, Yue Hu, Yunpeng Li, Jiarui Zhang, Xingsheng Zhang, and Heyan Huang. 2024. Teaching large language models to translate on low-resource languages with textbook prompting. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 15685–15697, Torino, Italia. ELRA and ICCL.
- Gupta et al. (2023) Kshitij Gupta, Benjamin Thérien, Adam Ibrahim, Mats L. Richter, Quentin Anthony, Eugene Belilovsky, Irina Rish, and Timothée Lesort. 2023. Continual pre-training of large language models: How to (re)warm your model?
- Hendrycks et al. (2021a) Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. 2021a. Aligning ai with shared human values. Proceedings of the International Conference on Learning Representations (ICLR).
- Hendrycks et al. (2021b) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021b. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR).
- Hendrycks et al. (2021c) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021c. Measuring mathematical problem solving with the math dataset. NeurIPS.
- Hendy et al. (2023) Amr Hendy, Mohamed Abdelrehim, Amr Sharaf, Vikas Raunak, Mohamed Gabr, Hitokazu Matsushita, Young Jin Kim, Mohamed Afify, and Hany Hassan Awadalla. 2023. How good are gpt models at machine translation? a comprehensive evaluation.
- Huang et al. (2024) Kaiyu Huang, Fengran Mo, Hongliang Li, You Li, Yuanchi Zhang, Weijian Yi, Yulong Mao, Jinchen Liu, Yuzhuang Xu, Jinan Xu, Jian-Yun Nie, and Yang Liu. 2024. A survey on large language models with multilingualism: Recent advances and new frontiers.
- Joulin et al. (2016) Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, H’erve J’egou, and Tomas Mikolov. 2016. Fasttext.zip: Compressing text classification models. arXiv preprint arXiv:1612.03651.
- Kabir and Carpuat (2021) Tasnim Kabir and Marine Carpuat. 2021. The UMD submission to the explainable MT quality estimation shared task: Combining explanation models with sequence labeling. In Proceedings of the 2nd Workshop on Evaluation and Comparison of NLP Systems, pages 230–237, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Kocmi and Federmann (2023) Tom Kocmi and Christian Federmann. 2023. GEMBA-MQM: Detecting translation quality error spans with GPT-4. In Proceedings of the Eighth Conference on Machine Translation, pages 768–775, Singapore. Association for Computational Linguistics.
- Kudugunta et al. (2024) Sneha Kudugunta, Isaac Caswell, Biao Zhang, Xavier Garcia, Derrick Xin, Aditya Kusupati, Romi Stella, Ankur Bapna, and Orhan Firat. 2024. Madlad-400: A multilingual and document-level large audited dataset. Advances in Neural Information Processing Systems (NeurIPS).
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey, Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association of Computational Linguistics.
- Lample et al. (2018) Guillaume Lample, Alexis Conneau, Ludovic Denoyer, and Marc’Aurelio Ranzato. 2018. Unsupervised machine translation using monolingual corpora only. In International Conference on Learning Representations.
- Li et al. (2024) Zihao Li, Yucheng Shi, Zirui Liu, Fan Yang, Ninghao Liu, and Mengnan Du. 2024. Quantifying multilingual performance of large language models across languages.
- Lin et al. (2021a) Bill Yuchen Lin, Seyeon Lee, Xiaoyang Qiao, and Xiang Ren. 2021a. Common sense beyond english: Evaluating and improving multilingual language models for commonsense reasoning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pages 1274–1287. Association for Computational Linguistics.
- Lin et al. (2021b) Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O’Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona T. Diab, Veselin Stoyanov, and Xian Li. 2021b. Few-shot learning with multilingual language models. CoRR, abs/2112.10668.
- Luo et al. (2023) Yin Luo, Qingchao Kong, Nan Xu, Jia Cao, Bao Hao, Baoyu Qu, Bo Chen, Chao Zhu, Chenyang Zhao, Donglei Zhang, et al. 2023. Yayi 2: Multilingual open-source large language models. arXiv preprint arXiv:2312.14862.
- Muennighoff et al. (2023) Niklas Muennighoff, Alexander M. Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. 2023. Scaling data-constrained language models.
- Muennighoff et al. (2022) Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng-Xin Yong, Hailey Schoelkopf, Xiangru Tang, Dragomir Radev, Alham Fikri Aji, Khalid Almubarak, Samuel Albanie, Zaid Alyafeai, Albert Webson, Edward Raff, and Colin Raffel. 2022. Crosslingual generalization through multitask finetuning.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Pan et al. (2021) Xiao Pan, Mingxuan Wang, Liwei Wu, and Lei Li. 2021. Contrastive learning for many-to-many multilingual neural machine translation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 244–258, Online. Association for Computational Linguistics.
- Ponti et al. (2020) Edoardo Maria Ponti, Goran Glavaš, Olga Majewska, Qianchu Liu, Ivan Vulić, and Anna Korhonen. 2020. XCOPA: A multilingual dataset for causal commonsense reasoning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2362–2376, Online. Association for Computational Linguistics.
- Rei et al. (2020) Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. COMET: A neural framework for MT evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685–2702, Online. Association for Computational Linguistics.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Shi et al. (2023) Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, and Jason Wei. 2023. Language models are multilingual chain-of-thought reasoners. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Srivastava et al. (2022) Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, Alice Xiang, Alicia Parrish, Allen Nie, Aman Hussain, Amanda Askell, Amanda Dsouza, Ambrose Slone, Ameet Rahane, Anantharaman S. Iyer, Anders Andreassen, Andrea Madotto, Andrea Santilli, Andreas Stuhlmüller, Andrew Dai, Andrew La, Andrew Lampinen, Andy Zou, Angela Jiang, Angelica Chen, Anh Vuong, Animesh Gupta, Anna Gottardi, Antonio Norelli, Anu Venkatesh, Arash Gholamidavoodi, Arfa Tabassum, Arul Menezes, Arun Kirubarajan, Asher Mullokandov, Ashish Sabharwal, Austin Herrick, Avia Efrat, Aykut Erdem, Ayla Karakaş, B. Ryan Roberts, Bao Sheng Loe, Barret Zoph, Bartłomiej Bojanowski, Batuhan Özyurt, Behnam Hedayatnia, Behnam Neyshabur, Benjamin Inden, Benno Stein, Berk Ekmekci, Bill Yuchen Lin, Blake Howald, Cameron Diao, Cameron Dour, Catherine Stinson, Cedrick Argueta, César Ferri Ramírez, Chandan Singh, Charles Rathkopf, Chenlin Meng, Chitta Baral, Chiyu Wu, Chris Callison-Burch, Chris Waites, Christian Voigt, Christopher D. Manning, Christopher Potts, Cindy Ramirez, Clara E. Rivera, Clemencia Siro, Colin Raffel, Courtney Ashcraft, Cristina Garbacea, Damien Sileo, Dan Garrette, Dan Hendrycks, Dan Kilman, Dan Roth, Daniel Freeman, Daniel Khashabi, Daniel Levy, Daniel Moseguí González, Danielle Perszyk, Danny Hernandez, Danqi Chen, Daphne Ippolito, Dar Gilboa, David Dohan, David Drakard, David Jurgens, Debajyoti Datta, Deep Ganguli, Denis Emelin, Denis Kleyko, Deniz Yuret, Derek Chen, Derek Tam, Dieuwke Hupkes, Diganta Misra, Dilyar Buzan, Dimitri Coelho Mollo, Diyi Yang, Dong-Ho Lee, Ekaterina Shutova, Ekin Dogus Cubuk, Elad Segal, Eleanor Hagerman, Elizabeth Barnes, Elizabeth Donoway, Ellie Pavlick, Emanuele Rodola, Emma Lam, Eric Chu, Eric Tang, Erkut Erdem, Ernie Chang, Ethan A. Chi, Ethan Dyer, Ethan Jerzak, Ethan Kim, Eunice Engefu Manyasi, Evgenii Zheltonozhskii, Fanyue Xia, Fatemeh Siar, Fernando Martínez-Plumed, Francesca Happé, Francois Chollet, Frieda Rong, Gaurav Mishra, Genta Indra Winata, Gerard de Melo, Germán Kruszewski, Giambattista Parascandolo, Giorgio Mariani, Gloria Wang, Gonzalo Jaimovitch-López, Gregor Betz, Guy Gur-Ari, Hana Galijasevic, Hannah Kim, Hannah Rashkin, Hannaneh Hajishirzi, Harsh Mehta, Hayden Bogar, Henry Shevlin, Hinrich Schütze, Hiromu Yakura, Hongming Zhang, Hugh Mee Wong, Ian Ng, Isaac Noble, Jaap Jumelet, Jack Geissinger, Jackson Kernion, Jacob Hilton, Jaehoon Lee, Jaime Fernández Fisac, James B. Simon, James Koppel, James Zheng, James Zou, Jan Kocoń, Jana Thompson, Jared Kaplan, Jarema Radom, Jascha Sohl-Dickstein, Jason Phang, Jason Wei, Jason Yosinski, Jekaterina Novikova, Jelle Bosscher, Jennifer Marsh, Jeremy Kim, Jeroen Taal, Jesse Engel, Jesujoba Alabi, Jiacheng Xu, Jiaming Song, Jillian Tang, Joan Waweru, John Burden, John Miller, John U. Balis, Jonathan Berant, Jörg Frohberg, Jos Rozen, Jose Hernandez-Orallo, Joseph Boudeman, Joseph Jones, Joshua B. Tenenbaum, Joshua S. Rule, Joyce Chua, Kamil Kanclerz, Karen Livescu, Karl Krauth, Karthik Gopalakrishnan, Katerina Ignatyeva, Katja Markert, Kaustubh D. Dhole, Kevin Gimpel, Kevin Omondi, Kory Mathewson, Kristen Chiafullo, Ksenia Shkaruta, Kumar Shridhar, Kyle McDonell, Kyle Richardson, Laria Reynolds, Leo Gao, Li Zhang, Liam Dugan, Lianhui Qin, Lidia Contreras-Ochando, Louis-Philippe Morency, Luca Moschella, Lucas Lam, Lucy Noble, Ludwig Schmidt, Luheng He, Luis Oliveros Colón, Luke Metz, Lütfi Kerem Şenel, Maarten Bosma, Maarten Sap, Maartje ter Hoeve, Maheen Farooqi, Manaal Faruqui, Mantas Mazeika, Marco Baturan, Marco Marelli, Marco Maru, Maria Jose Ramírez Quintana, Marie Tolkiehn, Mario Giulianelli, Martha Lewis, Martin Potthast, Matthew L. Leavitt, Matthias Hagen, Mátyás Schubert, Medina Orduna Baitemirova, Melody Arnaud, Melvin McElrath, Michael A. Yee, Michael Cohen, Michael Gu, Michael Ivanitskiy, Michael Starritt, Michael Strube, Michał Swędrowski, Michele Bevilacqua, Michihiro Yasunaga, Mihir Kale, Mike Cain, Mimee Xu, Mirac Suzgun, Mo Tiwari, Mohit Bansal, Moin Aminnaseri, Mor Geva, Mozhdeh Gheini, Mukund Varma T, Nanyun Peng, Nathan Chi, Nayeon Lee, Neta Gur-Ari Krakover, Nicholas Cameron, Nicholas Roberts, Nick Doiron, Nikita Nangia, Niklas Deckers, Niklas Muennighoff, Nitish Shirish Keskar, Niveditha S. Iyer, Noah Constant, Noah Fiedel, Nuan Wen, Oliver Zhang, Omar Agha, Omar Elbaghdadi, Omer Levy, Owain Evans, Pablo Antonio Moreno Casares, Parth Doshi, Pascale Fung, Paul Pu Liang, Paul Vicol, Pegah Alipoormolabashi, Peiyuan Liao, Percy Liang, Peter Chang, Peter Eckersley, Phu Mon Htut, Pinyu Hwang, Piotr Miłkowski, Piyush Patil, Pouya Pezeshkpour, Priti Oli, Qiaozhu Mei, Qing Lyu, Qinlang Chen, Rabin Banjade, Rachel Etta Rudolph, Raefer Gabriel, Rahel Habacker, Ramón Risco Delgado, Raphaël Millière, Rhythm Garg, Richard Barnes, Rif A. Saurous, Riku Arakawa, Robbe Raymaekers, Robert Frank, Rohan Sikand, Roman Novak, Roman Sitelew, Ronan LeBras, Rosanne Liu, Rowan Jacobs, Rui Zhang, Ruslan Salakhutdinov, Ryan Chi, Ryan Lee, Ryan Stovall, Ryan Teehan, Rylan Yang, Sahib Singh, Saif M. Mohammad, Sajant Anand, Sam Dillavou, Sam Shleifer, Sam Wiseman, Samuel Gruetter, Samuel R. Bowman, Samuel S. Schoenholz, Sanghyun Han, Sanjeev Kwatra, Sarah A. Rous, Sarik Ghazarian, Sayan Ghosh, Sean Casey, Sebastian Bischoff, Sebastian Gehrmann, Sebastian Schuster, Sepideh Sadeghi, Shadi Hamdan, Sharon Zhou, Shashank Srivastava, Sherry Shi, Shikhar Singh, Shima Asaadi, Shixiang Shane Gu, Shubh Pachchigar, Shubham Toshniwal, Shyam Upadhyay, Shyamolima, Debnath, Siamak Shakeri, Simon Thormeyer, Simone Melzi, Siva Reddy, Sneha Priscilla Makini, Soo-Hwan Lee, Spencer Torene, Sriharsha Hatwar, Stanislas Dehaene, Stefan Divic, Stefano Ermon, Stella Biderman, Stephanie Lin, Stephen Prasad, Steven T. Piantadosi, Stuart M. Shieber, Summer Misherghi, Svetlana Kiritchenko, Swaroop Mishra, Tal Linzen, Tal Schuster, Tao Li, Tao Yu, Tariq Ali, Tatsu Hashimoto, Te-Lin Wu, Théo Desbordes, Theodore Rothschild, Thomas Phan, Tianle Wang, Tiberius Nkinyili, Timo Schick, Timofei Kornev, Timothy Telleen-Lawton, Titus Tunduny, Tobias Gerstenberg, Trenton Chang, Trishala Neeraj, Tushar Khot, Tyler Shultz, Uri Shaham, Vedant Misra, Vera Demberg, Victoria Nyamai, Vikas Raunak, Vinay Ramasesh, Vinay Uday Prabhu, Vishakh Padmakumar, Vivek Srikumar, William Fedus, William Saunders, William Zhang, Wout Vossen, Xiang Ren, Xiaoyu Tong, Xinran Zhao, Xinyi Wu, Xudong Shen, Yadollah Yaghoobzadeh, Yair Lakretz, Yangqiu Song, Yasaman Bahri, Yejin Choi, Yichi Yang, Yiding Hao, Yifu Chen, Yonatan Belinkov, Yu Hou, Yufang Hou, Yuntao Bai, Zachary Seid, Zhuoye Zhao, Zijian Wang, Zijie J. Wang, Zirui Wang, and Ziyi Wu. 2022. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca.
- Team et al. (2022) NLLB Team, Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews, Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, and Jeff Wang. 2022. No language left behind: Scaling human-centered machine translation. ArXiv.
- Tikhonov and Ryabinin (2021) Alexey Tikhonov and Max Ryabinin. 2021. It’s all in the heads: Using attention heads as a baseline for cross-lingual transfer in commonsense reasoning.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023a. Llama: Open and efficient foundation language models.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Cantón Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony S. Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel M. Kloumann, A. V. Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023b. Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288.
- Üstün et al. (2024) Ahmet Üstün, Viraat Aryabumi, Zheng-Xin Yong, Wei-Yin Ko, Daniel D’souza, Gbemileke Onilude, Neel Bhandari, Shivalika Singh, Hui-Lee Ooi, Amr Kayid, et al. 2024. Aya model: An instruction finetuned open-access multilingual language model. arXiv preprint arXiv:2402.07827.
- Vilar et al. (2023) David Vilar, Markus Freitag, Colin Cherry, Jiaming Luo, Viresh Ratnakar, and George Foster. 2023. Prompting PaLM for translation: Assessing strategies and performance. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15406–15427, Toronto, Canada. Association for Computational Linguistics.
- Wang et al. (2019) Changhan Wang, Kyunghyun Cho, and Jiatao Gu. 2019. Neural machine translation with byte-level subwords.
- Wang et al. (2022) Xinyi Wang, Sebastian Ruder, and Graham Neubig. 2022. Expanding pretrained models to thousands more languages via lexicon-based adaptation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 863–877, Dublin, Ireland. Association for Computational Linguistics.
- Wei et al. (2023) Xiangpeng Wei, Haoran Wei, Huan Lin, Tianhao Li, Pei Zhang, Xingzhang Ren, Mei Li, Yu Wan, Zhiwei Cao, Binbin Xie, et al. 2023. Polylm: An open source polyglot large language model. arXiv preprint arXiv:2307.06018.
- Williams et al. (2018) Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistics.
- Xie et al. (2023) Yong Xie, Karan Aggarwal, and Aitzaz Ahmad. 2023. Efficient continual pre-training for building domain specific large language models.
- Xue et al. (2021) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mT5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 483–498, Online. Association for Computational Linguistics.
- Yoon et al. (2024) Dongkeun Yoon, Joel Jang, Sungdong Kim, Seungone Kim, Sheikh Shafayat, and Minjoon Seo. 2024. Langbridge: Multilingual reasoning without multilingual supervision.
- Yuan et al. (2023a) Fei Yuan, Yinquan Lu, Wenhao Zhu, Lingpeng Kong, Lei Li, Yu Qiao, and Jingjing Xu. 2023a. Lego-MT: Learning detachable models for massively multilingual machine translation. In Findings of the Association for Computational Linguistics: ACL 2023, pages 11518–11533, Toronto, Canada. Association for Computational Linguistics.
- Yuan et al. (2024) Fei Yuan, Chang Ma, Shuai Yuan, Qiushi Sun, and Lei Li. 2024. Ks-lottery: Finding certified lottery tickets for multilingual language models.
- Yuan et al. (2023b) Fei Yuan, Shuai Yuan, Zhiyong Wu, and Lei Li. 2023b. How multilingual is multilingual llm?
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.
- Zhang et al. (2022) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022. Opt: Open pre-trained transformer language models.
- Zhao et al. (2024a) Jun Zhao, Zhihao Zhang, Luhui Gao, Qi Zhang, Tao Gui, and Xuanjing Huang. 2024a. Llama beyond english: An empirical study on language capability transfer.
- Zhao et al. (2024b) Yiran Zhao, Wenxuan Zhang, Guizhen Chen, Kenji Kawaguchi, and Lidong Bing. 2024b. How do large language models handle multilingualism?
- Zhu et al. (2024a) Wenhao Zhu, Shujian Huang, Fei Yuan, Shuaijie She, Jiajun Chen, and Alexandra Birch. 2024a. Question translation training for better multilingual reasoning.
- Zhu et al. (2024b) Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. 2024b. Multilingual machine translation with large language models: Empirical results and analysis. In Findings of the Association for Computational Linguistics: NAACL 2024.
大纲
附录 A限制
这项工作重点讨论一些关键技术,例如词汇表的使用和数据增强方案的确定。 然而,它并没有深入研究开源数据质量的进一步处理。 我们承认文献中关于开源数据质量的全面评估存在差距,这表明未来研究有机会改进数据预处理方法,以获得更好的模型训练结果。
附录B数据信息
| Family | ISO | Language | # Mono. | # Para. | # Direct. | Family | ISO | Language | # Mono. | # Para. | # Direct. |
| Afro-Asiatic | ha | Hausa | 420,964 | 3,147,704 | 96 | Indo-European | ne | Nepali | 702,334 | 8,907,527 | 97 |
| om | Oromo | 18,895 | 191,319 | 96 | or | Odia | 100,530 | 812,235 | 97 | ||
| so | Somali | 697,864 | 3,804,551 | 97 | pa | Punjabi | 513,987 | 3,737,780 | 97 | ||
| am | Amharic | 269,171 | 4,031,552 | 97 | sd | Sindhi | 472,217 | 821,996 | 95 | ||
| ar | Arabic | 716,063 | 9,940,756 | 97 | ur | Urdu | 711,354 | 4,137,619 | 97 | ||
| he | Hebrew | 300,000 | 3,928,938 | 96 | fa | Persian | 721,307 | 4,111,536 | 97 | ||
| mt | Maltese | 671,716 | 1,518,533 | 94 | ku | Kurdish | 517,239 | 3,597,863 | 97 | ||
| Austroasiatic | km | Khmer | 687,690 | 4,044,652 | 97 | ps | Pashto | 588,340 | 3,717,480 | 97 | |
| vi | Vietnamese | 760,472 | 4,112,089 | 97 | tg | Tajik | 700,237 | 4,131,709 | 97 | ||
| Austronesian | jv | Javanese | 505,619 | 2,799,761 | 97 | ast | Asturian | 0 | 1,535,714 | 96 | |
| id | Indonesian | 707,962 | 4,243,235 | 97 | ca | Catalan | 724,597 | 4,145,004 | 97 | ||
| ms | Malay | 711,895 | 4,121,713 | 97 | es | Spanish | 706,307 | 4,258,477 | 98 | ||
| mi | Maori | 180,678 | 3,437702 | 97 | fr | French | 787,316 | 4,290,003 | 99 | ||
| ceb | Cebuano | 418,058 | 2,217,926 | 91 | gl | Galician | 726,512 | 3,131,730 | 96 | ||
| tl | Tagalog | 0 | 3,927,576 | 97 | it | Italian | 846,107 | 4,233,108 | 96 | ||
| Dravidian | te | Telugu | 708,459 | 4,219,702 | 97 | oc | Occitan | 36,379 | 1,752,951 | 95 | |
| kn | Kannada | 712,832 | 3,592,636 | 97 | pt | Portuguese | 795,818 | 4,258,604 | 97 | ||
| ml | Malayalam | 715,387 | 4,516,012 | 97 | ro | Romanian | 702,002 | 4,219,414 | 97 | ||
| ta | Tamil | 711,863 | 4,444,734 | 97 | Japonic | ja | Japanese | 726,455 | 4,207,728 | 97 | |
| Indo-European | hy | Armenian | 712,835 | 3,677,780 | 97 | Kartvelian | ka | Georgian | 703,515 | 4,182,651 | 97 |
| lt | Lithuanian | 718,382 | 3,946,735 | 96 | Koreanic | ko | Korean | 711,406 | 4,234,653 | 97 | |
| lv | Latvian | 700,889 | 4,011,628 | 97 | Kra–Dai | lo | Lao | 357,758 | 2,642,799 | 97 | |
| be | Belarusian | 708,288 | 4,169,719 | 95 | th | Thai | 707,719 | 4,437,476 | 97 | ||
| bg | Bulgarian | 711,500 | 4,131,053 | 97 | Mongolic | mn | Mongolian | 701,304 | 3,894,353 | 97 | |
| bs | Bosnian | 300,000 | 2,953,912 | 97 | Niger–Congo | wo | Wolof | 871 | 802,521 | 97 | |
| cs | Czech | 711,179 | 4,135,944 | 97 | ln | Lingala | 3,325 | 159,684 | 96 | ||
| hr | Croatian | 300,000 | 4,106,335 | 97 | ns | Northern Sotho | 0 | 96,288 | 88 | ||
| mk | Macedonian | 702,035 | 4,009,787 | 97 | lg | Luganda | 13,030 | 216,135 | 95 | ||
| pl | Polish | 792,829 | 4,200,001 | 98 | ny | Nyanja | 226,940 | 3,104,349 | 92 | ||
| ru | Russian | 853,407 | 4,204,365 | 97 | sn | Shona | 386,588 | 3,140,063 | 97 | ||
| sk | Slovak | 715,540 | 4,100,272 | 98 | sw | Swahili | 700,422 | 3,775,394 | 97 | ||
| sl | Slovenian | 731,613 | 4,073,213 | 97 | umb | Umbundu | 0 | 54 | 2 | ||
| sr | Serbian | 711,535 | 4,033,130 | 97 | xh | Xhosa | 122,720 | 3,955,426 | 97 | ||
| uk | Ukrainian | 714,181 | 4,070,250 | 97 | yo | Yoruba | 98,281 | 3,364,040 | 96 | ||
| cy | Welsh | 703,507 | 3,777,953 | 97 | zu | Zulu | 470,403 | 2,899,738 | 97 | ||
| ga | Irish | 693,460 | 2,814,912 | 96 | ig | Igbo | 147,319 | 3,314,731 | 96 | ||
| is | Icelandic | 704,159 | 4,088,886 | 97 | kam | Kamba | 0 | 8 | 1 | ||
| sv | Swedish | 726,893 | 4,213,939 | 97 | ff | Fulani | 26 | 313,870 | 97 | ||
| da | Danish | 721,543 | 4,194,587 | 97 | Nilo-Saharan | luo | Dholuo | 0 | 91 | 6 | |
| no | Norwegian | 721,715 | 4,045,571 | 97 | Portuguese | kea | Kabuverdianu | 0 | 0 | 0 | |
| af | Afrikaans | 703,546 | 4,143,358 | 98 | Sino-Tibetan | zh | Chinese | 726,112 | 14,215,583 | 96 | |
| de | German | 881,553 | 10,273,597 | 97 | zhtrad | Chinese | 0 | 3,747,297 | 96 | ||
| en | English | 846,712 | 19,548,583 | 100 | my | Burmese | 579,160 | 3,887,841 | 97 | ||
| lb | Luxembourgish | 574,166 | 1,035,619 | 94 | Turkic | uz | Uzbek | 723,096 | 2,344,375 | 95 | |
| nl | Dutch | 769,778 | 4,199,773 | 96 | kk | Kazakh | 701,849 | 3,836,259 | 97 | ||
| el | Greek | 707,751 | 4,081,607 | 97 | ky | Kyrgyz | 704,438 | 3,725,583 | 97 | ||
| bn | Bengali | 707,099 | 4,560,978 | 97 | az | Azerbaijani | 712,947 | 8,080,151 | 97 | ||
| as | Assamese | 33,825 | 1,656,861 | 97 | tr | Turkish | 727,711 | 4,169,259 | 97 | ||
| gu | Gujarati | 704,619 | 3,761,401 | 97 | Uralic | et | Estonian | 706,720 | 4,056,200 | 97 | |
| hi | Hindi | 715,691 | 4,186,127 | 97 | fi | Finnish | 719,416 | 40,76,885 | 97 | ||
| mr | Marathi | 702,382 | 4,295,708 | 97 | hu | Hungarian | 731,479 | 4,154,132 | 97 |
B.1 训练数据集
该数据集由三个不同的开源数据集编译而成,有关数据统计和支持的语言的详细信息如表9所示。
MC4 (薛等人, 2021)
是 C4 数据集的多语言变体,包含源自 Common Crawl 网络抓取的 101 种语言的自然文本。 引入它是为了支持大规模多语言预训练文本到文本转换器(如 mT5)的训练。
MADLAD-400 (Kudugunta 等人, 2024)
是基于 CommonCrawl 的手动审核的通用领域单语言数据集,涵盖 419 种语言,专为文档级分析而设计。 它以其广泛的语言覆盖范围和创建过程中涉及的严格审核过程而闻名。
Lego-MT Yuan 等人 (2023a)
是大规模多语言机器翻译的基准,具有基于高效训练配方的可拆卸模型。 它包括一个全面的翻译基准,其数据来自 OPUS,涵盖 433 种语言和 13 亿个并行数据点。
B.2评估基准
Flores-101 (Goyal 等人, 2022)
是机器翻译评估的基准,包含源自英语维基百科并由专业翻译人员制作的多路数据集。
Flores-200 (团队等人,2022)
是 Flores-101 数据集的扩展,也可作为机器翻译的基准。 该数据集包含 200 种语言的并行句子,每种语言由其 ISO 639-3 代码((例如 eng))和描述脚本的附加代码(例如“eng_Latn”)标识。
WMT-23 (Kocmi 和 Federmann,2023)
也是2023年提出的综合翻译评估基准。 我们将此数据集纳入我们的评估中,以降低大语言模型中数据泄露的风险。 基于基准,我们评估了以英语为中心的翻译任务性能,包括 deen、encs、ende、enhe、enja、enru、enuk、enzh、heen、jaen、ruen、uken、zhen。
TICO Anastasopoulos 等人 (2020)
数据集代表了针对 COVID-19 材料的联合翻译工作,是与学术界、行业利益相关者和无国界翻译者组织合作开发的。 它包含翻译记忆库、翻译的 COVID-19 术语词汇表,并作为翻译相关评估的基准。 所有评估的翻译为 en{am, bn, din, fa, fuv, hi, km, ku, ln, ms, ne, om, ps, ru, so, ta, ti_ER, tl, zh、ar、ckb、es_LA、fr、ha、id、kr、lg、mr、my、nus、prs、pt_BR、rw、sw、ti、ti_ET、ur、zu}。
TED Cettolo 等人 (2012)
是一个源自 TED 演讲笔录的大规模多语言数据集,涵盖 60 种语言以及并行的语言和文本数组。 它专为自然语言处理任务而设计,并过滤掉丢失或不完整的翻译。 我们还评估了以英语为中心的翻译性能。 翻译方向涵盖全部60种语言,包括en{af, am, ar, arq, art-x-bork, as, ast, az, be, bg, bi, bn, bo, bs, ca、ceb、cnh、cs、da、de、el、eo、es、et、eu、fa、fi、fil、fr、fr-ca、ga、gl、gu、ha、he、hi、hr、ht、 hu、hup、hy、id、ig、inh、is、it、ja、ka、kk、km、kn、ko、ku、ky、la、lb、lo、lt、ltg、lv、mg、mk、ml、 mn、先生、女士、mt、my、nb、ne、nl、nn、oc、pa、pl、ps、pt、pt-br、ro、ru、rup、sh、si、sk、sl、so、sq、 sr、srp、sv、sw、szl、ta、te、tg、th、tl、tlh、tr、tt、ug、uk、ur、uz、vi、zh、zh-cn、zh-tw}
X-CSQA Lin 等人 (2021a)
是常识问答 (CSQA) 数据集的多语言扩展,专为常识推理研究而设计。 它有助于在常识推理任务中评估和改进多语言语言模型。
XStoryCloze (Lin 等人, 2021b)
是一个基准数据集,由专业翻译的英语 StoryCloze 数据集(2016 年春季版)组成 10 种非英语语言。 它旨在评估多语言语言模型的零样本和少样本学习能力。
| Setting | Dictionary | en-centric | ta-centric | th-centric | zh-centric | ||||
| enx | xen | tax | xta | thx | xth | zhx | xzh | ||
| ++ | MUSE: 1-hop | 18.80 | 26.56 | 4.78 | 1.79 | 7.31 | 3.18 | 11.35 | 7.28 |
| ++ | MUSE: 2-hop | 18.70 | 26.50 | 4.47 | 1.83 | 7.08 | 3.26 | 10.74 | 6.68 |
| ++ | PanLex: 1-hop | 19.33 | 26.54 | 4.40 | 1.83 | 7.57 | 3.31 | 10.86 | 8.08 |
| 1-hop translation | 2-hop translation | ||
| Direction | Example | Direction | Example |
| enfr | dog chien | enfrde | dog chien Hund |
| frde | chien Hund | ||
XCOPA (Ponti 等人, 2020)
是一个基准数据集,用于评估机器学习模型跨语言迁移常识推理的能力。 它是英语 COPA 数据集的扩展,包含来自不同语系和地理区域的 11 种语言。
XWinograd (Muennighoff 等人, 2022; Tikhonov 和 Ryabinin, 2021)
这是一个基准数据集,由 Winograd 模式的多语言集合组成,旨在评估涵盖六种语言的跨语言常识推理能力。
XNLI (Conneau 等人, 2018)
是 SNLI (Bowman 等人, 2015)/MultiNLI (Williams 等人, 2018) 的跨语言扩展,由翻译成 14 个英文示例的子集组成不同的语言。 它用于评估文本蕴涵和分类任务,其目标是确定一个句子是否暗示、矛盾或与另一个句子是中性的
MGSM (石等人, 2023)
小学数学问题的数据集,每个问题都由人工注释者翻译成 10 种语言。 它源自 GSM8K (Cobbe 等人, 2021) 数据集,旨在支持需要多步推理的基本数学问题的问答。
MMLU (Hendrycks 等人, 2021a, b)
是评估语言模型跨不同领域的语言理解和推理能力的基准。 它由涵盖 57 个学术科目的约 16,000 个多项选择题组成,旨在衡量在零样本和少样本设置中预训练期间获得的知识。
BBH (Srivastava 等人, 2022)
是 BIG-Bench 的一个子集,专注于当前语言模型难以执行的 23 项具有挑战性的任务,在这些任务中它们的表现并不优于人类评估者的平均水平。 它作为一个严格的评估套件来测试语言模型的能力极限。
HellaSwag (Zellers 等人, 2019)
这是一个旨在评估高级自然语言理解和常识推理的数据集,它引入了更多的复杂性和多样性,对人工智能模型预测不完整叙述的结局提出了挑战。
WinoG (坂口等人, 2021)
是一个包含 44k 问题的大型数据集,灵感来自 Winograd Schema Challenge,旨在提高共指解析任务的规模和难度。 它提出了带有二元选项的填空题,测试模型理解细致入微的人类语言的能力。
NQ (Kwiatkowski 等人, 2019)
是用于问答研究的数据集,包含超过 300,000 个示例,每个示例由真实的用户查询和相应的维基百科页面组成。 它旨在通过模拟人们搜索信息的方式来训练和评估自动问答系统。
HumanEval (Chen 等人, 2021)
旨在评估大型语言模型的代码生成能力,具有 164 个手工编程挑战,包括函数签名、文档字符串、主体和单元测试。 平均而言,每个问题都伴随着 7.7 次测试来评估功能正确性。
MBPP (Austin 等人, 2021)
包含大约 1,000 个众包的 Python 编程问题,针对入门级程序员,涵盖编程基础知识和标准库功能。 每个问题都包括任务描述、代码解决方案和三个自动化测试用例。
GSM8K (Cobbe 等人, 2021)
由人类问题作者创建的 8.5K 个高质量、语言多样的小学数学应用题组成。 它旨在支持需要多步骤推理的基本数学问题的问答。
数学 (Hendrycks 等人, 2021c)
是从数学竞赛中衍生出来的 12,500 个复杂问题的集合。 数学数据集中的每个问题都包含带有分步指导的综合解决方案,可作为训练模型的资源来生成详细的答案理由和解释。
附录C型号信息
| Setting | Translation Tasks | General Tasks | Multilingual Tasks | |||||
| cebx | xceb | QNLI | QQP | MRPC | XStoryCloze | XCOPA | XWinograd | |
| splited-parallel + mono | 3.36 | 2.74 | 49.46 | 36.82 | 68.38 | 59.20 | 56.82 | 73.72 |
| connected-parallel + mono | 4.45 | 3.68 | 49.46 | 36.82 | 68.38 | 59.10 | 56.80 | 74.07 |
| Setting | cebca | cebde | ceben | cebes | cebfr | cebit | cebpt | cebru |
| splited-parallel + mono | 10.32 | 8.94 | 23.19 | 13.30 | 15.96 | 10.01 | 12.66 | 8.05 |
| connected-parallel + mono | 10.97 | 11.37 | 27.06 | 14.91 | 18.04 | 12.03 | 15.55 | 10.26 |
| Setting | caceb | deceb | enceb | esceb | frceb | itceb | ptceb | ruceb |
| splited-parallel + mono | 5.90 | 4.91 | 7.44 | 5.14 | 6.02 | 5.54 | 6.12 | 4.24 |
| connected-parallel + mono | 7.62 | 6.92 | 9.88 | 6.41 | 7.39 | 6.91 | 7.62 | 6.54 |
C.1 大型语言模型
LLaMA2 (Touvron 等人, 2023b)
是一个仅包含解码器的语言模型,它根据有序标记的输入序列来预测下一个词符,具有一系列经过预训练和微调的模型,参数范围从 70 亿到 700 亿个参数。 LLaMA2 7B 模型是我们的基础模型。 除非另有说明,否则对 LLaMA 或 LLaMA2 的任何引用都是 LLaMA2 7B 型号。 该模型利用字节级字节对编码(BBPE;Wang 等人,2019)分词器,这是一种在字节级别进行分词的高效子词分词器,使其能够处理任何语言并对噪声具有鲁棒性在数据中。 BBPE 分词器对于词汇量大和生僻字很多的语言特别有用。
拉马克斯2
遵循 LLaMA2 的模型架构,没有词汇扩展。 我们利用 24 个 A100 80GB GPU,并将收集的数据的预训练时间延长了 60 多天。 我们将每个设备的训练批量大小设置为 32,学习率设置为 2e-5,纪元数设置为 1.0。
PolyLM (Wei 等人, 2023)
是一个开源多语言大型语言模型(大语言模型),在 6400 亿个 Token 上进行训练,有两种模型大小:1.7B 和 13B。 它精通 15 种主要非英语语言,采用先进的训练技术来增强其语言处理能力。
Yayi2 (罗等人, 2023)
是一个多语言开源大型语言模型,在包含 2.65 万亿个 Token 的语料库上从头开始进行预训练。 它通过监督微调和根据人类反馈进行强化学习,与人类价值观保持一致。
TowerInstruct (Alves 等人, 2024)
是针对翻译相关任务进行微调的 7B 参数语言模型,支持英语、葡萄牙语、西班牙语、法语等多种语言。 它专为机器翻译、自动译后编辑和释义生成等任务而设计。 在我们的论文中,我们评估了指令调整模型 TowerInstruct-7B-v0.2。
Aya-23 (Aryabumi 等人, 2024)
是一个开放权重研究版本的指令微调解码器模型,具有先进的多语言功能,可服务 23 种语言。 它将高性能的预训练 Command 系列模型与 Aya Collection 配对,以执行强大的语言处理任务。
ChineseLLaMA2-Alpaca Cui 等人 (2024)
建立在LLaMA2的基础上,并增强了广泛的中文词汇,专注于中文。 这是使用羊驼(Taori等人,2023)数据的ChineseLLaMA2的微调版本。
LLaMA2-SFT (Taori 等人, 2023)
是 LLaMA2 模型的微调版本,利用 Alpaca 中的一组 52,000 条多样化的英文指令(Taori 等人,2023) 来增强模型的指令跟随能力。
Qwen2-7B-指示(白等人, 2023)
是 Qwen2 系列的一部分,它是一个指令调整的语言模型。 它在多语言基准测试中展示了与专有模型的竞争力。
燕子(Fujii 等人, 2024)
是一个基于LLaMA2的增强日语能力的大型语言模型。 它通过用日语字符扩展词汇量并在日语语料库上进行持续的预训练来实现这一目标,与其他大语言模型相比,在英语和日语任务中都有更出色的表现。 在我们的论文中,我们评估了指令调整模型 Swallow-7B-Instruct-v0.1。
C.2 翻译模型
| X | LLaMA2-Alpaca | Swallow | LLaMAX2-Alpaca | X | LLaMA2-Alpaca | Swallow | LLaMAX2-Alpaca | ||||||
| af | 0.20 | 35.28 | 72.23 | 0.00 | 0.59 | 75.69 | lo | 0.30 | 37.85 | 75.89 | 0.10 | 0.00 | 54.55 |
| am | 0.20 | 61.96 | 77.67 | 0.10 | 0.69 | 90.91 | lt | 4.74 | 32.41 | 70.85 | 4.55 | 3.66 | 94.76 |
| ar | 0.69 | 93.97 | 64.72 | 13.93 | 0.00 | 99.90 | luo | 0.49 | 0.00 | 71.25 | 0.00 | 0.89 | 0.00 |
| as | 3.66 | 1.38 | 74.01 | 0.00 | 0.10 | 73.22 | lv | 1.09 | 39.92 | 66.80 | 5.53 | 1.68 | 95.36 |
| ast | 0.20 | 1.48 | 71.44 | 0.00 | 0.20 | 34.19 | mi | 0.20 | 0.00 | 61.46 | 0.00 | 0.20 | 0.00 |
| az | 0.20 | 26.58 | 69.57 | 5.53 | 0.30 | 97.43 | mk | 0.30 | 17.98 | 78.46 | 0.00 | 0.49 | 98.81 |
| be | 0.40 | 60.18 | 72.92 | 0.00 | 0.20 | 99.11 | ml | 1.28 | 36.17 | 74.41 | 1.68 | 0.49 | 70.75 |
| bg | 1.09 | 60.28 | 77.67 | 0.30 | 0.89 | 98.02 | mn | 0.59 | 35.18 | 75.59 | 1.48 | 0.00 | 99.31 |
| bn | 1.78 | 64.62 | 75.69 | 1.78 | 0.00 | 99.90 | mr | 0.59 | 35.87 | 76.88 | 0.00 | 0.10 | 99.01 |
| bs | 0.69 | 1.38 | 73.52 | 0.00 | 1.98 | 3.16 | ms | 0.10 | 5.53 | 61.86 | 0.20 | 0.00 | 39.92 |
| ca | 0.40 | 89.92 | 65.02 | 11.07 | 0.49 | 98.12 | mt | 0.40 | 60.08 | 68.38 | 3.16 | 0.69 | 94.07 |
| ceb | 0.10 | 33.30 | 44.57 | 3.56 | 0.00 | 95.06 | my | 1.68 | 56.03 | 78.85 | 1.48 | 0.10 | 99.90 |
| cs | 1.19 | 61.46 | 72.13 | 5.24 | 1.68 | 93.38 | ne | 0.20 | 50.00 | 70.45 | 0.00 | 0.00 | 99.01 |
| cy | 0.20 | 30.83 | 66.90 | 2.47 | 0.20 | 98.52 | nl | 0.40 | 76.78 | 61.36 | 22.33 | 0.20 | 92.09 |
| da | 0.79 | 57.51 | 70.06 | 4.64 | 0.59 | 91.80 | no | 1.38 | 44.47 | 69.57 | 3.16 | 0.69 | 86.66 |
| de | 1.28 | 83.40 | 57.41 | 29.25 | 1.28 | 94.17 | ns | 1.58 | 0.00 | 62.55 | 0.00 | 1.38 | 0.00 |
| el | 1.09 | 42.00 | 75.20 | 7.41 | 0.00 | 100.00 | ny | 0.49 | 0.00 | 72.53 | 0.00 | 0.79 | 0.00 |
| en | 0.00 | 100.00 | 67.29 | 32.41 | 0.00 | 100.00 | oc | 0.20 | 1.09 | 68.97 | 0.00 | 0.59 | 58.10 |
| es | 0.40 | 97.04 | 57.81 | 20.26 | 0.10 | 99.21 | om | 0.30 | 0.00 | 72.53 | 0.00 | 2.57 | 0.00 |
| et | 0.69 | 14.03 | 68.48 | 8.70 | 4.35 | 89.13 | or | 0.69 | 61.86 | 79.45 | 0.00 | 1.09 | 98.52 |
| fa | 0.30 | 83.89 | 75.79 | 4.35 | 0.00 | 98.42 | pa | 0.40 | 77.67 | 72.04 | 1.78 | 0.79 | 98.91 |
| ff | 0.69 | 0.00 | 73.12 | 0.00 | 11.96 | 0.00 | pl | 0.79 | 73.32 | 71.54 | 8.40 | 0.49 | 98.02 |
| fi | 3.36 | 74.11 | 66.01 | 17.39 | 2.37 | 96.25 | ps | 0.20 | 43.28 | 75.40 | 0.00 | 0.00 | 98.22 |
| fr | 0.49 | 97.04 | 52.47 | 34.29 | 0.00 | 99.70 | pt | 1.09 | 90.71 | 63.14 | 8.20 | 0.20 | 98.22 |
| ga | 0.20 | 26.98 | 64.23 | 2.96 | 0.00 | 94.07 | ro | 0.30 | 45.95 | 68.97 | 4.25 | 0.30 | 89.53 |
| gl | 0.10 | 1.58 | 63.34 | 3.56 | 0.20 | 83.30 | ru | 0.30 | 83.10 | 71.44 | 12.45 | 0.20 | 99.41 |
| gu | 0.30 | 67.59 | 77.47 | 0.99 | 1.48 | 96.64 | sd | 0.89 | 2.47 | 74.31 | 0.00 | 0.00 | 92.59 |
| ha | 0.59 | 0.00 | 70.06 | 0.00 | 0.99 | 0.00 | sk | 0.49 | 27.27 | 65.42 | 7.81 | 0.59 | 94.57 |
| he | 1.78 | 76.19 | 63.34 | 16.60 | 0.00 | 100.00 | sl | 0.79 | 58.79 | 61.66 | 3.56 | 1.38 | 91.11 |
| hi | 0.69 | 70.75 | 67.98 | 7.91 | 0.00 | 99.90 | sn | 0.40 | 0.00 | 68.18 | 0.00 | 1.58 | 0.00 |
| hr | 0.89 | 54.55 | 69.37 | 1.28 | 1.19 | 66.60 | so | 0.10 | 7.71 | 74.31 | 0.20 | 0.99 | 59.19 |
| hu | 0.40 | 69.96 | 71.44 | 10.67 | 0.30 | 93.87 | sr | 1.48 | 15.22 | 75.49 | 1.48 | 1.98 | 44.07 |
| hy | 0.69 | 77.08 | 79.55 | 1.09 | 0.00 | 99.90 | sv | 2.57 | 49.90 | 66.01 | 13.34 | 1.68 | 95.16 |
| id | 0.20 | 84.98 | 70.65 | 7.61 | 0.00 | 97.04 | sw | 0.20 | 48.32 | 67.49 | 0.99 | 0.59 | 94.76 |
| ig | 0.10 | 0.00 | 74.80 | 0.00 | 0.20 | 0.00 | ta | 0.30 | 53.46 | 74.31 | 1.98 | 0.00 | 99.80 |
| is | 0.30 | 55.34 | 58.20 | 19.76 | 0.20 | 95.06 | te | 0.20 | 73.12 | 75.79 | 2.47 | 0.00 | 99.80 |
| it | 0.59 | 85.47 | 55.24 | 24.11 | 0.00 | 97.63 | tg | 0.69 | 6.23 | 74.01 | 0.00 | 0.40 | 97.33 |
| jv | 1.38 | 0.10 | 66.90 | 0.00 | 0.89 | 67.79 | th | 0.00 | 84.39 | 70.75 | 12.15 | 0.00 | 100.00 |
| ka | 1.28 | 63.14 | 65.91 | 16.01 | 0.00 | 100.00 | tl | 0.20 | 73.62 | 62.94 | 6.72 | 0.10 | 99.31 |
| kam | 0.30 | 0.00 | 73.22 | 0.00 | 3.56 | 0.00 | tr | 0.79 | 42.39 | 67.69 | 11.86 | 0.40 | 95.26 |
| kea | 0.20 | 0.00 | 71.25 | 0.00 | 0.99 | 0.00 | uk | 0.59 | 89.53 | 74.31 | 3.36 | 0.49 | 98.12 |
| kk | 0.10 | 55.93 | 76.48 | 0.49 | 0.10 | 99.21 | umb | 0.69 | 0.00 | 68.68 | 0.00 | 1.38 | 0.00 |
| km | 0.40 | 53.66 | 80.34 | 0.69 | 0.00 | 99.90 | ur | 1.19 | 25.49 | 76.19 | 2.77 | 0.30 | 97.92 |
| kn | 3.06 | 49.60 | 78.56 | 1.09 | 0.10 | 99.90 | uz | 0.40 | 32.71 | 74.51 | 0.20 | 1.78 | 86.36 |
| ko | 1.58 | 94.17 | 60.57 | 21.84 | 0.10 | 99.51 | vi | 0.00 | 95.85 | 56.42 | 13.24 | 0.10 | 99.70 |
| ku | 0.20 | 28.06 | 60.28 | 0.49 | 2.77 | 72.73 | wo | 1.09 | 0.00 | 73.32 | 0.00 | 2.96 | 0.00 |
| ky | 0.40 | 40.71 | 75.79 | 0.00 | 0.10 | 99.41 | xh | 0.20 | 0.00 | 70.55 | 0.00 | 0.59 | 0.00 |
| lb | 0.69 | 31.23 | 66.11 | 0.00 | 2.27 | 87.75 | yo | 0.10 | 3.95 | 67.00 | 0.00 | 0.10 | 13.93 |
| lg | 1.38 | 0.00 | 74.11 | 0.00 | 12.65 | 0.00 | zh | 23.22 | 70.16 | 37.15 | 35.67 | 5.93 | 93.08 |
| ln | 0.30 | 0.00 | 71.84 | 0.00 | 0.79 | 0.00 | zhtrad | 32.41 | 0.00 | 43.87 | 0.00 | 7.31 | 0.00 |
| zu | 0.10 | 0.00 | 67.39 | 0.00 | 1.38 | 0.00 | |||||||
M2M-100 (范等人,2021)
包含多语言机器翻译模型,旨在直接在 100 种语言中的任意对之间进行翻译,无需英语作为中介。 M2M-100系列包括不同尺寸的型号,具体为418M、1.2B和12B参数。 这些模型是机器翻译领域突破性方法的一部分,旨在提高多种语言的直接翻译效率。
乐高-MT (元 等人, 2023a)
是一种大规模多语言机器翻译的新颖方法,具有可分离的模型,每种语言或语言组都有单独的分支。 该设计支持即插即用的训练和推理,增强了语言处理任务的灵活性和效率。
MADLAD-400 (Kudugunta 等人, 2024)
是一种利用 T5 架构的多语言机器翻译模型,并在包含 2500 亿个标记的庞大语料库上进行了训练,涵盖了 450 多种语言。
Aya-101 (Aryabumi 等人, 2024)
是一个开源的大规模多语言生成语言模型,运行在 mT5(薛等人,2021)架构上,覆盖 101 种语言,旨在弥补非主流语言的性能差距。 它包含 13B 参数库,并经过指令微调,以在其广泛的语言范围内实现高性能。
附录D生育率与代表性质量之间的相关性。
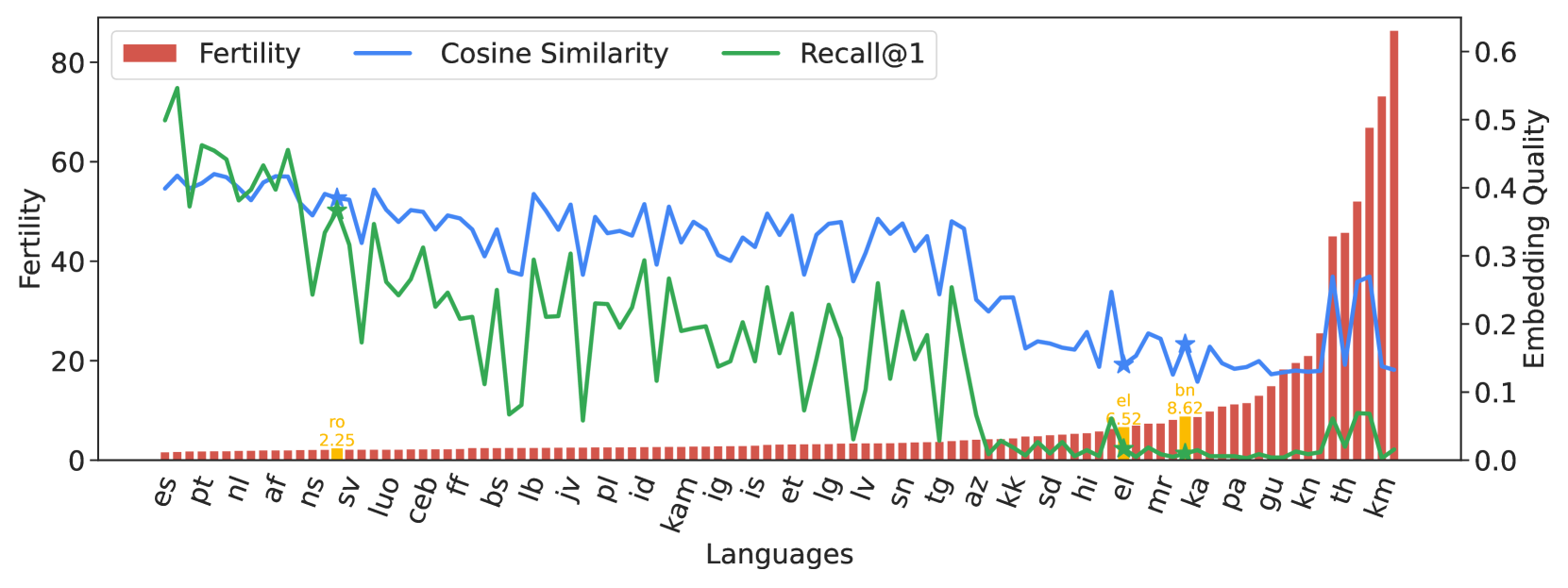
我们在 Flores-101 上进行了实验。 生育率定义为 与 的比率,其中 是空格分隔的语言和其他语言的字符数, 是应用 LLaMA2 tokenizer 后的 token 数量。 LLaMA 在 Flores-101 测试中的质量评估。 余弦相似度关注英语和其他语言中同一句子的句子表示中 LLaMA 表达的相似性。 Recall@1 通常用于信息检索的背景下,它衡量表示的质量。 实验结果如图6所示,生育率与表征质量具有高度相关性。
| Model | Templates |
| LLaMAX- Alpaca | Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: Translate the following sentences from English to Chinese Simpl ### Input: "We now have 4-month-old mice that are non-diabetic that used to be diabetic," he added. ### Response:UTF8gbsn他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。” |
| LLaMA Series Models | Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: Translate the following sentences from English to Chinese Simpl ### Input: "We now have 4-month-old mice that are non-diabetic that used to be diabetic," he added. ### Response:UTF8gbsn他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。” |
| yayi2 | Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: Translate the following sentences from English to Chinese Simpl ### Input: "We now have 4-month-old mice that are non-diabetic that used to be diabetic," he added. ### Response:UTF8gbsn他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。” |
| polylm | "We now have 4-month-old mice that are non-diabetic that used to be diabetic," he added. Translate this sentence English to Chinese Simpl. UTF8gbsn他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。” |
| TowerInstruct | <|im_start|>user Translate the following text from English into Chinese. English: "We now have 4-month-old mice that are non-diabetic that used to be diabetic," he added. Chinese:<|im_end|> <|im_start|>assistant UTF8gbsn他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。” |
| aya23 | <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Translate the following sentences from English to Chinese: "We now have 4-month-old mice that are non-diabetic that used to be diabetic," he added.<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>UTF8gbsn他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。”<|END_OF_TURN_TOKEN|> |
| Qwen2 instruct | system You are a helpful assistant. user Translate the following sentences from English to Chinese Simpl: "We now have 4-month-old mice that are non-diabetic that used to be diabetic," he added. assistant UTF8gbsn他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。” |
| ChineseAlpaca-2 | [INST] <<SYS>> You are a helpful assistant. UTF8gbsn你是一个乐于助人的助手。 <</SYS>> Translate the following sentences from English to Chinese Simpl: "We now have 4-month-old mice that are non-diabetic that used to be diabetic," he added. [/INS T] UTF8gbsn他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。” |
| Swallow | [INST] <<SYS>> UTF8gbsnあなたは誠実で優秀な日本人のアシスタントです。 <</SYS>> Translate the following sentences from Japanese to Chinese Simpl: UTF8gbsn「我々が飼っている生後4か月のマウスはかつて糖尿病でしたが現在は糖尿病ではない、」 UTF8gbsnと彼は付け加えました。 [/INST] 「他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。”」 |
| Madlad | ’<2zh> "We now have 4-month-old mice that are non-diabetic that used to be diabetic," he added.’ UTF8gbsn他补充道:“我们现在有 4 个月大没有糖尿病的老鼠,但它们曾经得过该病。” |
Appendix E Introduction to KS-Lottery.
KS-Lottery is a technique designed to identify a small, highly effective subset of parameters within LLMs for multilingual capability transfer. The core concept of this method involves utilizing the Kolmogorov-Smirnov Test to examine the distribution shift of parameters before and after fine-tuning. This approach helps in pinpointing the “winning tickets” or the most impactful parameters that contribute significantly to the model’s performance in multilingual tasks.
Appendix F 1-hop translation in data augmentation is enough.
Given a parallel dataset subset () from that contains translations in all directions for 6 languages (en,fr,es,zh,ta,th) and a monolingual subset () from for the same 6 languages. We then perform non-repetitive sampling 12,500 sentence pairs from in each direction to generate two subsets of parallel corpus data and , respectively. Consequently, we preserve and evaluate the effect of augmentation on parallel data or monolingual data , resulting in two new dataset, and , post-augmentation. To assess both the in-domain and out-of-domain capabilities of the model, we perform inference on it using 10 languages (en, fr, es, pt, de, zh, ta, th, is, zu), utilizing the Flores-101.
We use two different multilingual dictionaries MUSE provided by Lample et al. (2018) 333https://github.com/facebookresearch/MUSE., and PanLex Wang et al. (2022). In the context of a multilingual dictionary, we can use “1-hop” and “2-hop” to characterize the translation relationship among different languages, an example shown in Table 10.
We use the MUSE dictionary to perform data augmentation on both parallel and monolingual data, utilizing 1-hop and 2-hop translations. As shown in Table 10, using different hop translation for augmentation does not significantly impact the final translation performance. Multi-hop translation sometimes can even result in poorer performance.
Appendix G Design of parallel format
The Usage of Parallel Data.
Parallel data can be utilized in two distinct ways: split-parallel or connected-parallel. Split-Parallel: Consider the source language data and target language data involved in parallel data as two distinct monolingual datasets, which are randomly shuffled throughout the entire training set. Connected-Parallel: In the training process, we treat each pair of source and target language sentences from the parallel dataset as a single data point by concatenating them.
Based on different forms of parallel data, supervised fine-tuning (SFT) is conducted separately on ceb-centric using both parallel and monolingual datasets. As indicated in Table 12, we observed that the form of parallel data primarily impacts translation performance, with no significant difference in general tasks and cross-lingual general tasks; however, the disparity in translation is pronounced. We specifically highlighted some high-resource translation directions and found that such gaps are quite significant.
Appendix H Comparison Results Between Our Model and GPT-4
In Figure 7, we compare the performance gap between our model and GPT-4. Considering the API cost of evaluating GPT-4, we only evaluate the mutual translation performance among seven languages (en, zh, de, ne, ar, az, ceb). Experiment results show that while our model lags behind in high-resource translation directions, it achieves on-par or even superior performance in low-resource translation.
Appendix I Comparison LLaMAX2-Alpaca with language-specific LLMs.
We perform further comparisons between LLaMAX2-Alpaca and Japanese-specific LLMs-Swallow. After using LLaMAX2-Alpaca and Swallow to generate translations from Japanese (ja) to any language in Flores-101, we apply langdetect to determine the language of each translation result and calculate the proportion of Japanese and target translated language respectively. The experimental result, as shown in Table 13, indicates that the Japanese-specific LLM tends to output Japanese, whereas LLaMAX2-Alpaca performs more accurately in producing the target language.
Appendix J Prompt Templates
We offer a comprehensive collection of prompt instruction templates, as illustrated in Table D, which are utilized for all evaluated LLMs. These templates are meticulously designed based on existing LLMs, playing a crucial role in obtaining accurate model results and ensuring fairness in comparisons. Our goal in providing these templates is to promote transparency and make it easier to reproduce our findings.