0 研究
评估大语言模型 (LLM) 用于数据可视化中的自然语言话语的语义分析能力
摘要
自动生成数据可视化以响应人类对数据集的话语需要对数据话语进行深入的语义理解,包括对数据属性、可视化任务和必要的数据准备步骤的隐式和显式引用。 用于数据可视化的自然语言接口 (NLI) 已经探索了推断此类信息的方法,但由于人类语音固有的不确定性,挑战仍然存在。 大语言模型 (LLM) 的最新进展为解决这些挑战提供了一条途径,但它们提取相关语义信息的能力仍未得到探索。 在本研究中,我们评估了四个公开可用的 LLM (GPT-4、Gemini-Pro、Llama3 和 Mixtral),调查了它们即使在存在不确定性的情况下也能够理解话语并识别相关数据上下文和视觉任务的能力。 我们的发现表明,LLM 对话语中的不确定性很敏感。 尽管存在这种敏感性,但它们能够提取相关的数据上下文。 然而,LLM 难以推断可视化任务。 基于这些结果,我们重点介绍了使用 LLM 进行可视化生成的未来研究方向。 我们的补充材料已在 GitHub 上共享:https://github.com/hdi-umd/Semantic_Profiling_LLM_Evaluation。
以人为本的计算可视化可视化中的实证研究;
介绍
设计有效的数据可视化需要多个方面的考虑,例如识别相关的数据属性,通过数据整理和转换将数据集准备成正确的格式,识别分析任务或沟通目标,以及选择合适的视觉编码策略。 多年来,可视化研究人员主要专注于自动识别合适视觉编码的不同方法 [31, 16, 33],但基本上忽略了自动任务识别和数据准备等重要方面。 直到最近,研究人员才开始关注这些被忽视的问题 [32, 19, 28].
在这些努力中,自然语言接口 (NLI) 已成为可视化生成的一种流行的交互范式。 对于用户来说,用自然语言表达他们的可视化意图比使用编程结构或复杂图形用户界面更容易;对于系统构建者来说,自然语言话语提供了有关用户意图的宝贵信息,这些信息可能难以捕捉。 然而,自然语言话语可能难以处理,因为存在诸如歧义 [7] 和不足之处 [22] 等不确定性。 此外,在具有自然语言接口的可视化系统中,需要解决诸如数据准备和任务识别等问题。
大型语言模型 (LLM) 有望为针对数据可视化的自然语言接口提供基础, 因为它们能够解释和生成文本数据。 尽管有一些工具将它们用于可视化生成 [26, 9, 29, 5], 但它们往往侧重于 LLM 的低级应用,例如生成用于数据转换的代码 [29] 或只是将它们集成到管道中 [5]。 目前尚不清楚 LLM 在没有人工干预的情况下从话语中提取对可视化生成至关重要的信息的效果如何。
在这项工作中,我们开始评估 LLM 在自然语言话语的 语义分析 中的能力, 目的是 数据可视化生成。 与其他工作一致,我们使用术语“话语”来指代人们用来从 NLI 或 LLM 中获取响应的问题或指令 [23]。 通过语义分析,我们不评估由 LLM 生成的可视化,而是关注以下方面:1) 清晰度分析,它确定话语是否模棱两可、不足或要求缺失数据,2) 数据属性和转换识别,它识别相关数据列以及准备数据为可使用格式的任何必要转换,以及 3) 任务分类,它旨在揭示用户意图。
为了支持我们的研究目标,我们根据对两个 NL 数据集(NLVCorpus [23] 和 Quda [6])的评估,整理了一个包含 500 个与数据相关话语的语料库。 我们使用以下注释分析了话语:1) 诸如歧义和缺失数据引用等不确定性,2) 要求的数据属性和数据转换,以及 3) 可视化任务。 然后,我们对四个公开可用的 LLM(GPT-4、Llamma3、Mixtral 和 Gemini)在语义分析的三个方面的能力进行了系统分析。 我们的结果表明,LLM 以不同于人类的抽象级别进行推断,导致它们对话语中的不确定性过度敏感。 我们还发现,LLM 在识别话语中表达的相关数据列和数据转换方面表现得相当不错,但无法正确推断可视化任务。 我们强调了对当前 LLM 的优势和挑战的观察,并就将 LLM 用于可视化生成方面的考虑进行了讨论。
1 相关工作
用于可视化生成的自然语言界面。 自 2001 年 Cox 等人提出使用自然语言作为生成数据可视化的输入媒介以来,自然语言界面 (NLI) 领域的研究非常广泛 [4]。 从那时起,出现了大量的 NLI [7, 25, 12, 10, 14, 19]。 这些 NLI 使用词法标记或语义解析等技术来推断和转换话语中数据属性和任务的表示形式,从而生成可视化。 然而,当用户的话语缺乏明确说明时,推断正确的数据和任务表示就会变得具有挑战性。 像 DataTone 这样的工具通过允许用户使用 GUI 小部件来解决歧义来规避这种限制。 同样,Eviza [21] 和 Evizeon [10] 为用户提供了与生成的视觉效果交互并通过后续话语细化设计的能力。
最近的研究已朝着基于 NL 输入来促进可视化代码生成 [32, 19]、生成可视化的 NL 解释 [13] 以及推荐输入话语 [24] 方向发展。 总而言之,这些工作展示了 NLI 在可视化方面的能力。 然而,NLI 仍然难以在没有人工干预的情况下解决话语中的未充分说明问题。
用于数据可视化的大语言模型。 技术进步带来了 NLI 的改进,例如使用 BERT 将用户用 NL 表达的意图转换为可视化的特定领域语言 [3]。 最近,我们看到了大型语言模型在可视化生成方面的应用激增。 其中一个工具是 ChartLlama [9],它使用一个在从 GPT-4 [20] 生成的合成基准数据集上经过微调的开源 LLM 来 增强图表生成和理解。 一些工具开发了管道,以提示 LLM 生成用于可视化实现的相关代码 [26, 5, 17],而另一些工具则使用 LLM 来促进数据转换 [29]。
也有一些工作评估了 LLM 在不同可视化 上下文中的能力。 Li 等人评估了基于 nvbench 数据集生成可视化的提示策略 [15]。 Vázquez 还评估了 LLM 的三个方面:生成的图表类型的多样性、支持的库以及设计优化 [27]。 然而, 这些评估没有给出针对多个 LLM 的结果,并且侧重于这些 LLM 生成的视觉工件。 我们的工作基于这一研究方向,通过评估不同 LLM 在推断创建可视化所需语义信息方面的优缺点。
2 整理自然语言话语
为了促进对 LLM 提取相关数据和视觉上下文能力的评估,我们需要一组与数据相关的用户话语,作为提示提供给 LLM。 这些话语需要反映人类语言中存在的模糊程度。 为此, 我们从两个公开可用的语料库中获取了话语:
-
•
NLVCorpus: 该数据集展示了从一项在线调查中收集的 893 个话语,其中 102 名受访者被要求描述他们会输入到分析系统中的话语,以生成特定可视化 [23]。
-
•
Quda: 该数据集利用与专家数据分析师的访谈来生成 920 个话语的语料库 [6]。 这些话语通过众包研究进行了细化和改写,生成了最终包含 14,035 个不同话语的数据集。
我们对每个数据集中的话语进行了系统检查,如果话语包含 SQL 伪代码,例如,则将其过滤掉。 “按 (地区) 分组 — 对于每个地区,按 (船舶状态) 分组 — 对于每个 (地区,船舶状态),计算利润的总和”。 在我们的分析中,我们感兴趣的是检验大型语言模型 (LLM) 如何推断语义特征的必要方面,而不是显式可视化描述。 因此,我们还过滤掉了指定可视化类型或将数据映射到视觉元素的话语,例如 “给我一个以 imdb 评分为 x 轴,烂番茄评分为 y 轴的散点图”。
此选择过程首先应用于 NLVCorpus 数据集,该数据集在 3 个唯一的数据集中产生了总共 134 个话语。 然后,我们将相同的包含标准应用于 Quda 数据集的子集,以生成 32 个数据集中的剩余 309 个话语。 我们还从一个课堂活动中收集了 2 个数据集中的 54 个话语, 该活动在一所美国大学的本科数据可视化课程中进行 。 我们的最终语料库包含 37 个唯一数据集中的 500 个不同话语。
3 生成基本事实和大型语言模型响应
3.1 手动标注话语
三位作者对语料库中的话语进行了手动标注。 主要标注者拥有 5 年的可视化研究经验,而另外两位标注者至少拥有 2 年的可视化创建经验。 为了标注我们的语料库,主要作者根据对视觉任务和数据转换相关分类法的评估草拟了一个初始代码本 [2, 18]。 然后,从语料库中随机选取了五个话语,三位作者独立地检查和标注了这些话语。 随后,作者在会议中讨论了他们的代码。 然后,根据讨论更新了代码本。 三位作者在 12 周内手动标注了剩余的 495 个话语,每周举行会议以讨论和解决冲突。 在这里,我们将描述这些注释。
不确定性。 我们识别出了一些可能导致多种解释或无法根据提供的dataset进行回答的话语。 我们通过突出显示令人困惑的单词,解释其缺乏清晰度并建议解决方案来注释歧义和不足。 例如,话语“良好的空气质量记录以何种方式分布在整个监测区域?”被标记为模棱两可,因为参考dataset在每个区域的不同时间生成了空气质量读数。 因此,良好的空气质量读数可以按不同的时间段(每天每小时、每个日期)进行划分,甚至可以汇总整个dataset。 我们提供了一个解决方案来计算汇总统计数据并生成良好的空气质量的年度趋势。
在注释我们语料库中的500个话语时,我们发现18个话语要求提供dataset中没有的信息。 例如,在显示美国各州预期寿命的dataset上,其中一个话语问了“显示给我欧洲国家的GDP排名”。 这个dataset不包含任何国家的信息。 因此,无法回答此类问题。 由于这些话语是从其他研究中获得的,因此不清楚这些话语是如何产生的。 虽然我们没有为这些话语提供相关数据和视觉上下文的注释,但我们仍然选择在提示LLM时包含它们,因为我们仍然有兴趣评估它们识别和解决话语中此类不确定性的能力。
数据属性和转换。 对于每个话语,我们确定了正确回答该话语所需的相关数据列。 一些话语需要数据转换才能生成可以用来回答问题的新数据表。 我们最初捕获了转换数据表所需的运算,例如折叠、展开和分组。 但是,为了正确评估这些操作是否准确,我们需要评估从这些操作生成的实际数据表。 因此,我们选择捕获用于执行数据转换的相关 pandas 代码。 使用之前关于空气质量数据集的示例话语,生成相关数据表所需的数据转换是
可视化任务。 视觉任务根据话语的推断意图进行分类。 这些任务的分类法来自 Amar 等人 [2] 和 Munzner [18] 的出版物,包括:检索值、过滤、计算派生值、查找极值、排序、确定范围、描述分布、查找异常值、聚类、关联、汇总、比较、依赖性、相似性和趋势。
3.2 生成 LLM 输出
我们评估了两个专有 LLM 和两个开源 LLM。
专有 LLM。 我们评估了 OpenAI 的 GPT4-Turbo ![]() [20] 和 Google 的 Gemini-Pro
[20] 和 Google 的 Gemini-Pro ![]() [8]。 GPT4-Turbo 的训练数据截止日期为 2023 年 12 月,Gemini-Pro 的训练数据截止日期被描述为“2023 年初” 111According to Google AI documentation。 我们利用这两个模型的应用程序编程接口 (API) 为语料库中的 500 个话语生成响应。
[8]。 GPT4-Turbo 的训练数据截止日期为 2023 年 12 月,Gemini-Pro 的训练数据截止日期被描述为“2023 年初” 111According to Google AI documentation。 我们利用这两个模型的应用程序编程接口 (API) 为语料库中的 500 个话语生成响应。
开源 LLM。
我们在 Llama 工厂代码库 [34] 上评估了两个开源 LLM,Llama3 ![]() 和 Mixtral
和 Mixtral ![]() 。 Llama3 [1] 拥有 700 亿个参数,上下文长度为 8,000 个符元,知识截止日期为 2023 年 12 月。 Mixtral-8x7B-Instruct [11] 配置了 467 亿个参数,同样在 2023 年 12 月截止知识。
。 Llama3 [1] 拥有 700 亿个参数,上下文长度为 8,000 个符元,知识截止日期为 2023 年 12 月。 Mixtral-8x7B-Instruct [11] 配置了 467 亿个参数,同样在 2023 年 12 月截止知识。
3.2.1 提示设计
我们探索了不同的提示策略(单样本 vs. 少样本)来从 LLM 中获取响应。 我们决定使用少样本提示,因为它更适合于复杂的任务,并允许模型从提供的示例中学习需求 [30]。 提供给每个模型的提示包含与我们在第 3.1 节中使用的标注者类似的指令。 对于数据转换代码,我们还指示 LLM 不要包含用于绘图或复杂分析的代码。 我们还包含了三个话语-数据集-输出样本,这些样本没有包含在我们的评估语料库中。 我们选择包含数据集的前 10 行,以概述输入数据模式。 我们还包含了样本话语的相应真实标注,以帮助模型理解预期输出。 由于空间限制,完整提示已在补充材料中提供 222Supplementary Materials。
3.2.2 获取响应的挑战。
我们预计收到总共 2000 个 LLM 响应(每个 LLM 500 个)。 然而,
我们在从 LLM 获取响应时遇到了一些问题。 我们使用专有模型的 API 的一些查询返回了空响应 (![]() : 9,
: 9, ![]() : 2)。
对于开源模型,42 个响应没有返回 JSON 标注,而是返回了对该话语的 基于文本的 答案 (
: 2)。
对于开源模型,42 个响应没有返回 JSON 标注,而是返回了对该话语的 基于文本的 答案 (![]() :20,
:20, ![]() :22)。 两种模型偶尔也会无法正确格式化 JSON 响应,将键用 ‘/,‘ ‘@,‘ 或 ‘<.‘ 括起来。错误格式化的 JSON 响应已手动解决。
最终集合包含来自 LLM 的 1947 个有效标注 (
:22)。 两种模型偶尔也会无法正确格式化 JSON 响应,将键用 ‘/,‘ ‘@,‘ 或 ‘<.‘ 括起来。错误格式化的 JSON 响应已手动解决。
最终集合包含来自 LLM 的 1947 个有效标注 (![]() : 491,
: 491, ![]() : 498,
: 498, ![]() : 481,
: 481, ![]() : 477)。
: 477)。
4 分析和结果
我们从三个语义分析维度分析了 LLM 的响应: 清晰度分析(即在存在不确定性的情况下对话语的理解), 正确识别相关数据上下文,以及正确推断可视化任务。
4.1 识别不确定性
摘要统计: 在我们语料库中的 500 个话语中,人工标注在 96 个话语中发现了不确定性。 在所有 LLM 中共发现了 813 个不确定性(![]() : 268,
: 268, ![]() : 192,
: 192, ![]() : 180,
: 180, ![]() : 173)。 在这 813 个不确定性中,只有 25.1%(n=204)与人工标注重叠(
: 173)。 在这 813 个不确定性中,只有 25.1%(n=204)与人工标注重叠(![]() : 74,
: 74, ![]() : 46,
: 46, ![]() : 44,
: 44, ![]() : 40)。
: 40)。
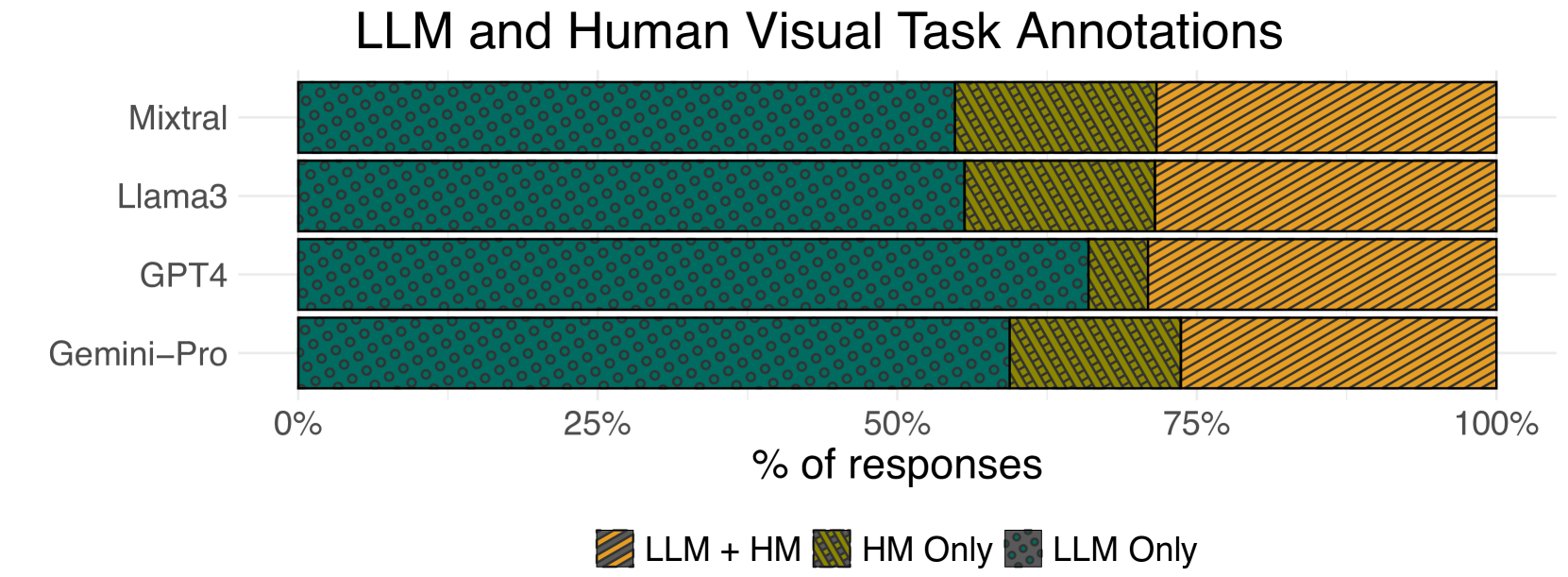
由 LLM 和人工标注者分类的不确定性的差异。 我们观察到,所有 LLM 在话语中识别出的不确定性比例都高于人工标注者识别出的比例(参见图1)。 当我们检查 LLM 识别出的一些不确定性时,我们发现它们描述了关于如何执行分析或缺少数据列值上下文的不确定性。 例如,对于话语“我们能否得出结论,更高的幸福感来自更高的自由度?”,GPT-4![]() 返回了以下歧义:“查询没有指定分析是否应该考虑可能影响幸福感的其他因素,或者是否应该只隔离幸福感和自由度。” 对于人工标注者来说,这仅仅是显示两个属性之间的相关性;因此,此话语没有不确定性标注。 同样,对于话语 “比较香港和台湾的高楼数量”,Gemini-Pro
返回了以下歧义:“查询没有指定分析是否应该考虑可能影响幸福感的其他因素,或者是否应该只隔离幸福感和自由度。” 对于人工标注者来说,这仅仅是显示两个属性之间的相关性;因此,此话语没有不确定性标注。 同样,对于话语 “比较香港和台湾的高楼数量”,Gemini-Pro![]() 将其归类为不确定,因为 “不清楚应该使用什么指标来量化建筑物的高度。 应该使用层数还是米或英尺的高度?” . 我们的人类标注者推断,建筑物的高度将是用于回答此话语的度量。
将其归类为不确定,因为 “不清楚应该使用什么指标来量化建筑物的高度。 应该使用层数还是米或英尺的高度?” . 我们的人类标注者推断,建筑物的高度将是用于回答此话语的度量。
LLM 未找到的不确定性。 在 96 个人类标注者发现不确定性的话语中,一些没有被 LLM 识别 (![]() : 14,
: 14, ![]() : 32,
: 32, ![]() : 34,
: 34, ![]() : 35)。 这些不确定性的主要原因是话语中引用的数据缺失或冲突。 一个例子是话语“如何说明艾希礼的人口分布,以显示五年内的分布情况?” 我们的标注将其标记为不确定,因为数据集只包含 2000 年至 2002 年的信息,因此无法使用数据集回答这个问题。 没有任何 LLM 将此话语标记为不确定。
: 35)。 这些不确定性的主要原因是话语中引用的数据缺失或冲突。 一个例子是话语“如何说明艾希礼的人口分布,以显示五年内的分布情况?” 我们的标注将其标记为不确定,因为数据集只包含 2000 年至 2002 年的信息,因此无法使用数据集回答这个问题。 没有任何 LLM 将此话语标记为不确定。
4.2 识别相关数据上下文
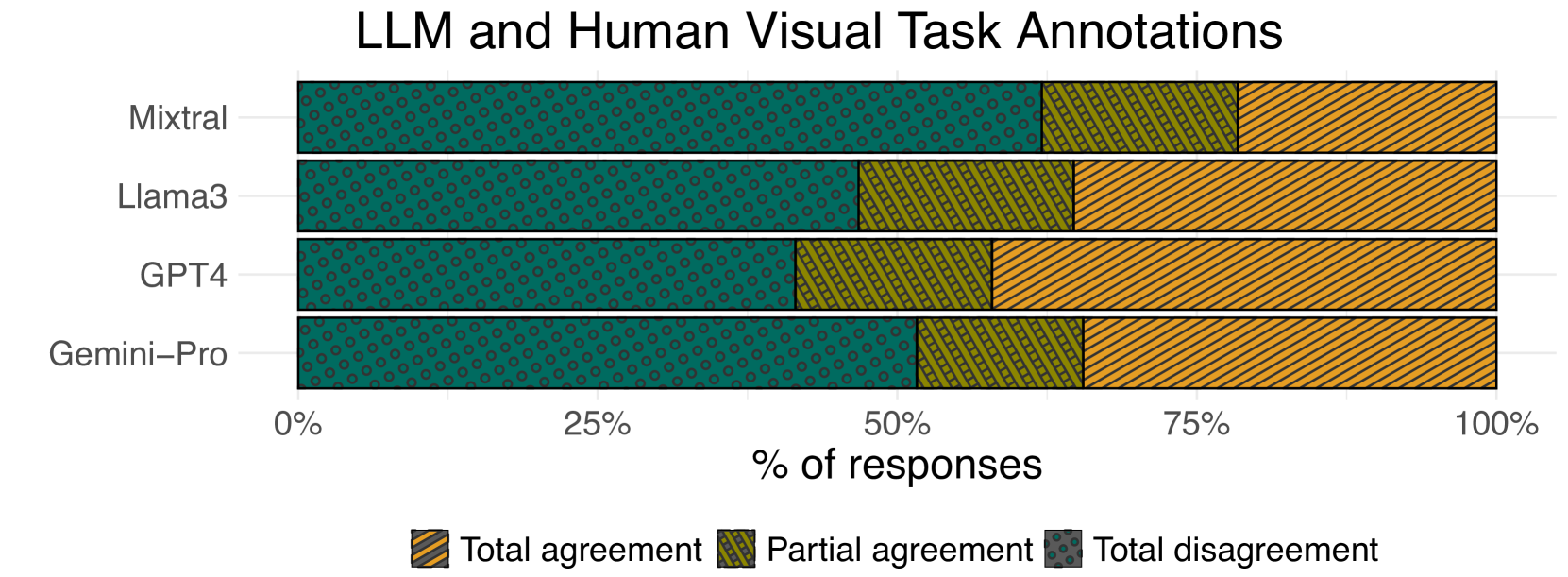
对于在 LLM 生成的响应中识别出的每个数据列,我们检查了它们是否也被人类标注者识别出来。 我们定义了 LLM 和人类标注之间三个级别的共识:1)完全一致,其中 LLM 识别所有相关数据列;2)部分一致,其中 LLM 识别部分数据列;以及 3)完全不一致,其中 LLM 未识别任何数据列。
摘要统计。 在 LLM 返回的 1947 个响应中,我们过滤掉了 53 个与人类标注者未生成数据列代码的话语相关的响应(参见第 3.1 节)。 我们还排除了另外 13 个 LLM 未生成数据列值的响应,使得用于评估数据列的总响应数为 1881。
LLM 能够为大多数话语正确推断相关数据列。
如 图 2(a) 所示,LLM 生成的有效标注中,有 57.5% 与人类标注完全一致(![]() :312,
:312,![]() :241,
:241,![]() :273,
:273,![]() :255)。 34.24% 的标注在 LLM 和人类标注之间部分一致(
:255)。 34.24% 的标注在 LLM 和人类标注之间部分一致(![]() :140,
:140,![]() :180,
:180,![]() :157,
:157,![]() :167),而 8.29% 的标注在识别的相关数据列方面完全不一致(
:167),而 8.29% 的标注在识别的相关数据列方面完全不一致(![]() :32,
:32,![]() :48,
:48,![]() :37,
:37,![]() :39)。 我们观察到,在这些完全不一致的案例中,有 43.6% 的案例存在人类标注者或 LLM 识别的的不确定性。
:39)。 我们观察到,在这些完全不一致的案例中,有 43.6% 的案例存在人类标注者或 LLM 识别的的不确定性。
4.2.1 数据转换
对于 LLM 生成的每个响应,我们执行了 LLM 生成的转换和人类标注的转换,从两种执行中提取了生成的数据表,并比较了它们的底层数据模式(即属性类型),以验证 LLM 所呈现的转换的准确性。 例如,对于话语 “风与气压之间存在什么关系,如果有的话?”,Llama3![]() 和人类标注都返回了一个具有以下模式的数据表 {}。 由于数据表具有相同数量和类型的属性,这是一个正向匹配。
和人类标注都返回了一个具有以下模式的数据表 {}。 由于数据表具有相同数量和类型的属性,这是一个正向匹配。
在评估数据转换时,我们发现了 31 个数据转换代码违反了不返回可视化图表的代码或执行复杂分析的指令的实例,这些实例被排除在我们的分析之外(![]() :1,
:1,![]() :0,
:0,![]() :15,
:15,![]() :15)。 此外,我们发现 385 个转换引发了各种错误(
:15)。 此外,我们发现 385 个转换引发了各种错误(![]() :59,
:59,![]() :96,
:96,![]() :119,
:119,![]() :111)或返回了原始值而不是数据表(
:111)或返回了原始值而不是数据表(![]() :66,
:66,![]() :90,
:90,![]() :57,
:57,![]() :52)。 由于人类标注优先考虑数据表作为数据转换的输出,我们在分析中排除了此类响应。
:52)。 由于人类标注优先考虑数据表作为数据转换的输出,我们在分析中排除了此类响应。
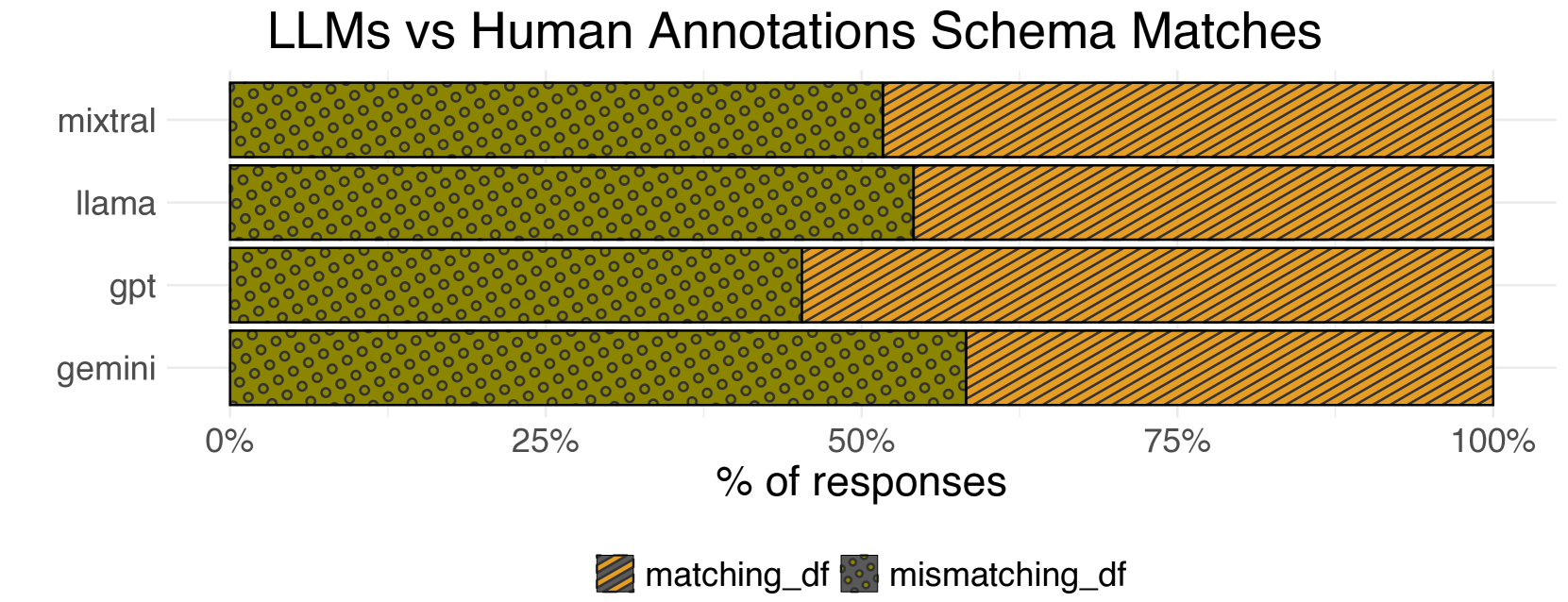
由大型语言模型 (LLM) 生成的數據轉換並不總是與人工標註者生成的數據轉換相符。 我們對數據轉換進行分析的最終數據集包含 1238 個回應 (![]() :360,
:360, ![]() :290,
:290, ![]() :292,
:292, ![]() :296)。 其中 48.1% 的回應產生的數據表架構與人工標註生成的架構相符 (見 圖 2(b))。 對於剩餘的 51.9% 數據與人工標註的代碼生成的數據不匹配的情況,我們的評估重點是數據架構之間的匹配。 因此,我們無法驗證生成的數據表是否為話語提供了有意義的答案,或者它們是否是數據轉換錯誤的結果。
:296)。 其中 48.1% 的回應產生的數據表架構與人工標註生成的架構相符 (見 圖 2(b))。 對於剩餘的 51.9% 數據與人工標註的代碼生成的數據不匹配的情況,我們的評估重點是數據架構之間的匹配。 因此,我們無法驗證生成的數據表是否為話語提供了有意義的答案,或者它們是否是數據轉換錯誤的結果。
4.3 推斷可視化任務
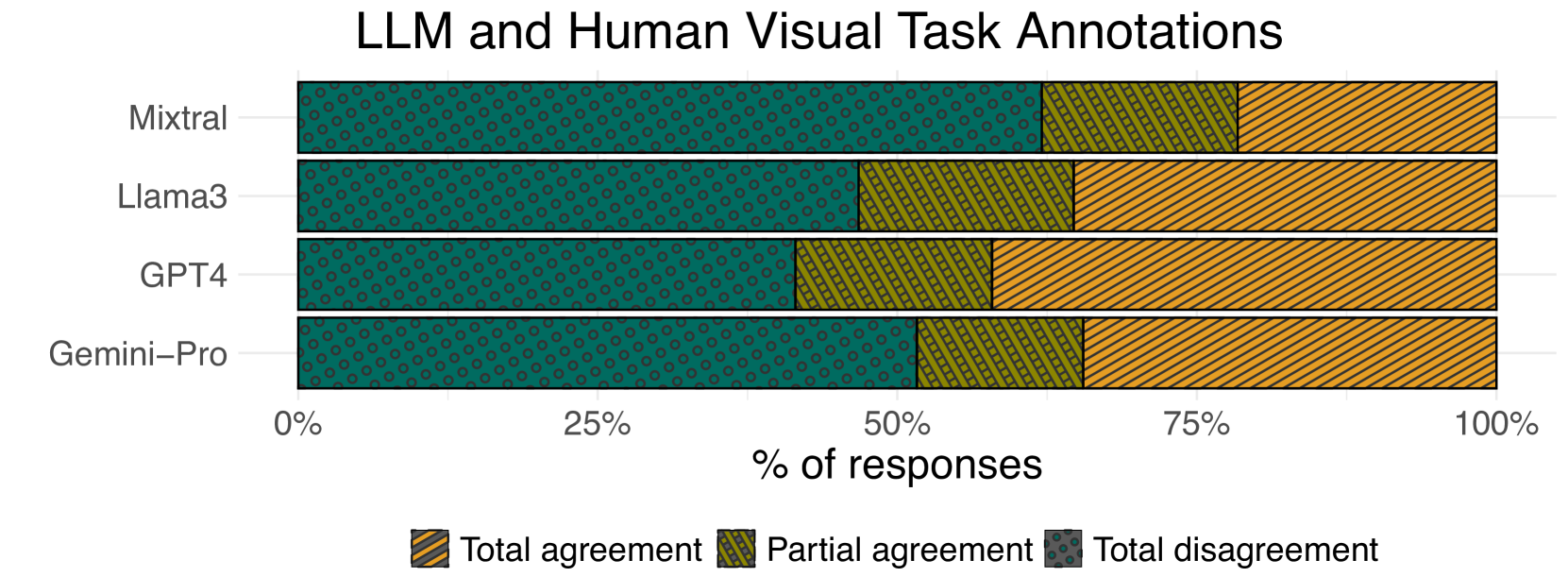
類似於數據列分析,我們識別了人類和 LLM 標註在可視化任務上的三種一致性級別。
摘要統計 在 LLM 返回的 1947 個回應中,在 1940 個回應中識別出可視化任務 (![]() :490,
:490, ![]() :494,
:494, ![]() :479,
:479, ![]() :477)。
:477)。
人類標註和 LLM 在可視化任務分類之間存在更高比例的分歧。 我們觀察到在可視化任務分類中,LLM 和人工標註之間的意見分歧程度
最高
。
如圖 2(c) 所示,50.4% 的可視化任務完全不一致 (![]() :205,
:205, ![]() :253,
:253, ![]() :224,
:224, ![]() :296)。 在 33.43% 的回應中完全一致 (
:296)。 在 33.43% 的回應中完全一致 (![]() :208,
:208, ![]() :169,
:169, ![]() :169,
:169, ![]() :103),而剩餘的 16.17% 的可視化任務部分一致 (
:103),而剩餘的 16.17% 的可視化任務部分一致 (![]() :81,
:81, ![]() :68,
:68, ![]() :86,
:86, ![]() :78)。
當我們檢查部分完全不一致的案例時,我們觀察到一些問題是衝突的解釋造成的。 例如,對於話語 “影響不同狀態 (風、時間、壓力等) 的主要因素是什麼?” Gemini
:78)。
當我們檢查部分完全不一致的案例時,我們觀察到一些問題是衝突的解釋造成的。 例如,對於話語 “影響不同狀態 (風、時間、壓力等) 的主要因素是什麼?” Gemini![]() 將其分類為“相關性”,而人工標註將話語分類為“依賴性”,因為在類別屬性和數字屬性之間無法計算相關性。 我們還看到 LLM 將數據轉換與可視化任務混合的示例,例如,對於話語 “每個內容評級和創意類型的平均預算是多少,以多個柱狀圖表示?” Mixtral
將其分類為“相關性”,而人工標註將話語分類為“依賴性”,因為在類別屬性和數字屬性之間無法計算相關性。 我們還看到 LLM 將數據轉換與可視化任務混合的示例,例如,對於話語 “每個內容評級和創意類型的平均預算是多少,以多個柱狀圖表示?” Mixtral![]() 將話語分類為“聚合、分類和關係”。
將話語分類為“聚合、分類和關係”。
5 讨论和未来工作
我们评估了四个公开可用的 LLM 在自然语言话语语义分析方面的能力,以进行数据可视化。 我们的结果为未来的研究提供了有趣的见解。
使用不确定性来促进更深入的数据探索和分析。 我们的研究结果表明,与我们的标注人员相比,LLM 在话语中发现了更多的不确定性。 人类和 LLM 可能在不同的抽象层级上识别不确定性,因为人类能够更深入地解释语境并做出更好的推断。 在第 4.1 节中提供的“最高建筑”示例中可以观察到这种差异的一个实例。 因此,LLM 可能对话语中的不确定性更加敏感。 但是,这可能不是限制,因为它们对不确定性的敏感性可以用来向分析师提出问题,并帮助他们深入思考其分析问题或方法。 在 NLI 中促进这种交互是一个有趣的研究方向。
改善基于编程的话语响应。 我们观察到,LLM 也能够推断出超过一半话语的适当数据列和转换。 然而,对于许多数据转换,我们发现在 LLM 返回的代码中存在一些问题。 此问题已知,并且工具通过提示多个代码脚本并过滤掉错误脚本来规避此问题 [5, 29]。 虽然这些错误的响应可以通过反馈和微调提示得到改进,但需要进一步研究如何改进为可视化上下文生成相关代码。
改善可视化任务推断以促进探索。 我们还发现,LLM 难以从话语中正确推断出适当的可视化任务。 尽管如此,仍然需要探索方法来提高 LLM 正确推断可视化任务的能力。 这一点很重要,因为这些任务通常会影响可视化设计的选择,例如使用条形图进行比较或使用小提琴图来描述分布 [2, 18, 19]。 正确推断可视化上下文还可以促进类似于 Voyager 系统 [31] 的横向数据探索。 例如,如果用户正在处理电影数据集,而 LLM 可以推断出他们试图在 IMDB 评分中 寻找异常值,它可以根据相关任务推荐潜在的有趣话语, 例如 比较 不同创意任务的 IMDB 评分或查找 IMDB 和 Rotten Tomato 评分之间的 相关性。
6 结论
我们评估了四种公开可用的
LLM(GPT-4![]() 、Gemini
、Gemini![]() 、Llama3
、Llama3![]() 和 Mixtral
和 Mixtral![]() )在正确推断自然语言话语的语义特征以进行数据可视化生成方面的能力。 我们的发现揭示了 LLM 在识别话语中的不确定性和推断相关数据列方面的优势。 我们还强调了 LLM 在生成数据转换代码和推断可视化任务方面的当前局限性。 基于我们的发现,我们提出了 LLM 用于可视化生成方面的未来研究方向。
)在正确推断自然语言话语的语义特征以进行数据可视化生成方面的能力。 我们的发现揭示了 LLM 在识别话语中的不确定性和推断相关数据列方面的优势。 我们还强调了 LLM 在生成数据转换代码和推断可视化任务方面的当前局限性。 基于我们的发现,我们提出了 LLM 用于可视化生成方面的未来研究方向。
致谢。
感谢 Human-Data Interaction Group 的反馈和支持。 这项工作得到了 NSF 资助 IIS-2239130 的支持。参考文献
- [1] AI@Meta. Llama 3 model card. 2024.
- [2] R. Amar, J. Eagan, and J. Stasko. Low-level components of analytic activity in information visualization. In Proceedings of the Proceedings of the 2005 IEEE Symposium on Information Visualization, INFOVIS ’05, p. 15. IEEE Computer Society, USA, 2005. doi: 10 . 1109/INFOVIS . 2005 . 24
- [3] Q. Chen, S. Pailoor, C. Barnaby, A. Criswell, C. Wang, G. Durrett, and I. Dillig. Type-directed synthesis of visualizations from natural language queries. Proc. ACM Program. Lang., 6(OOPSLA2), article no. 144, 28 pages, oct 2022. doi: 10 . 1145/3563307
- [4] K. Cox, R. E. Grinter, S. L. Hibino, L. J. Jagadeesan, and D. Mantilla. A multi-modal natural language interface to an information visualization environment. International Journal of Speech Technology, 4:297–314, 2001. doi: 10 . 1023/A:1011368926479
- [5] V. Dibia. LIDA: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models. In D. Bollegala, R. Huang, and A. Ritter, eds., Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pp. 113–126. Association for Computational Linguistics, Toronto, Canada, July 2023. doi: 10 . 18653/v1/2023 . acl-demo . 11
- [6] S. Fu, K. Xiong, X. Ge, S. Tang, W. Chen, and Y. Wu. Quda: Natural language queries for visual data analytics, 2020.
- [7] T. Gao, M. Dontcheva, E. Adar, Z. Liu, and K. G. Karahalios. Datatone: Managing ambiguity in natural language interfaces for data visualization. In Proc., UIST ’15, 12 pages, p. 489–500. Association for Computing Machinery, New York, NY, USA, 2015. doi: 10 . 1145/2807442 . 2807478
- [8] Google. Gemini api docs and reference — google ai for developers.
- [9] Y. Han, C. Zhang, X. Chen, X. Yang, Z. Wang, G. Yu, B. Fu, and H. Zhang. Chartllama: A multimodal llm for chart understanding and generation, 2023.
- [10] E. Hoque, V. Setlur, M. Tory, and I. Dykeman. Applying pragmatics principles for interaction with visual analytics. IEEE Transactions on Visualization and Computer Graphics, 24(1):309–318, 2018. doi: 10 . 1109/TVCG . 2017 . 2744684
- [11] A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de las Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M.-A. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed. Mixtral of experts, 2024.
- [12] J.-F. Kassel and M. Rohs. Valletto: A multimodal interface for ubiquitous visual analytics. In Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, CHI EA ’18, 6 pages, p. 1–6. Association for Computing Machinery, New York, NY, USA, 2018. doi: 10 . 1145/3170427 . 3188445
- [13] D. H. Kim, E. Hoque, and M. Agrawala. Answering questions about charts and generating visual explanations. In Proc., CHI ’20, 13 pages, p. 1–13. Association for Computing Machinery, New York, NY, USA, 2020. doi: 10 . 1145/3313831 . 3376467
- [14] A. Kumar, J. Aurisano, B. Di Eugenio, A. Johnson, A. Gonzalez, and J. Leigh. Towards a dialogue system that supports rich visualizations of data. In R. Fernandez, W. Minker, G. Carenini, R. Higashinaka, R. Artstein, and A. Gainer, eds., Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pp. 304–309. Association for Computational Linguistics, Los Angeles, Sept. 2016. doi: 10 . 18653/v1/W16-3639
- [15] G. Li, X. Wang, G. Aodeng, S. Zheng, Y. Zhang, C. Ou, S. Wang, and C. H. Liu. Visualization generation with large language models: An evaluation, 2024.
- [16] J. Mackinlay, P. Hanrahan, and C. Stolte. Show me: Automatic presentation for visual analysis. IEEE Transactions on Visualization and Computer Graphics, 13(6):1137–1144, 2007. doi: 10 . 1109/TVCG . 2007 . 70594
- [17] P. Maddigan and T. Susnjak. Chat2vis: Fine-tuning data visualisations using multilingual natural language text and pre-trained large language models, 2023.
- [18] T. Munzner. Visualization analysis and design. CRC press, 2014. doi: 10 . 1201/b17511
- [19] A. Narechania, A. Srinivasan, and J. Stasko. Nl4dv: A toolkit for generating analytic specifications for data visualization from natural language queries. IEEE Transactions on Visualization and Computer Graphics, 27(2):369–379, 2021. doi: 10 . 1109/TVCG . 2020 . 3030378
- [20] OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- [21] V. Setlur, S. E. Battersby, M. Tory, R. Gossweiler, and A. X. Chang. Eviza: A natural language interface for visual analysis. In Proc., UIST ’16, 13 pages, p. 365–377. Association for Computing Machinery, New York, NY, USA, 2016. doi: 10 . 1145/2984511 . 2984588
- [22] V. Setlur, M. Tory, and A. Djalali. Inferencing underspecified natural language utterances in visual analysis. In Proceedings of the 24th International Conference on Intelligent User Interfaces, IUI ’19, 12 pages, p. 40–51. Association for Computing Machinery, New York, NY, USA, 2019. doi: 10 . 1145/3301275 . 3302270
- [23] A. Srinivasan, N. Nyapathy, B. Lee, S. M. Drucker, and J. Stasko. Collecting and characterizing natural language utterances for specifying data visualizations. In Proc., CHI ’21, article no. 464, 10 pages. Association for Computing Machinery, New York, NY, USA, 2021. doi: 10 . 1145/3411764 . 3445400
- [24] A. Srinivasan and V. Setlur. Snowy: Recommending utterances for conversational visual analysis. In Proc., UIST ’21, 17 pages, p. 864–880. Association for Computing Machinery, New York, NY, USA, 2021. doi: 10 . 1145/3472749 . 3474792
- [25] Y. Sun, J. Leigh, A. Johnson, and S. Lee. Articulate: A semi-automated model for translating natural language queries into meaningful visualizations. In Smart Graphics: 10th International Symposium on Smart Graphics, Banff, Canada, June 24-26, 2010 Proceedings 10, pp. 184–195. Springer, 2010. doi: 10 . 1007/978-3-642-13544-6_18
- [26] Y. Tian, W. Cui, D. Deng, X. Yi, Y. Yang, H. Zhang, and Y. Wu. Chartgpt: Leveraging llms to generate charts from abstract natural language. IEEE Transactions on Visualization and Computer Graphics, pp. 1–15, 2024. doi: 10 . 1109/TVCG . 2024 . 3368621
- [27] P.-P. Vázquez. Are llms ready for visualization?, 2024.
- [28] C. Wang, Y. Feng, R. Bodik, I. Dillig, A. Cheung, and A. J. Ko. Falx: Synthesis-powered visualization authoring. In Proc., CHI ’21, article no. 106, 15 pages. Association for Computing Machinery, New York, NY, USA, 2021. doi: 10 . 1145/3411764 . 3445249
- [29] C. Wang, J. Thompson, and B. Lee. Data formulator: Ai-powered concept-driven visualization authoring. IEEE Transactions on Visualization and Computer Graphics, 30(1):1128–1138, 2024. doi: 10 . 1109/TVCG . 2023 . 3326585
- [30] J. Wei, X. Wang, D. Schuurmans, M. Bosma, brian ichter, F. Xia, E. H. Chi, Q. V. Le, and D. Zhou. Chain of thought prompting elicits reasoning in large language models. In A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, eds., Advances in Neural Information Processing Systems, 2022.
- [31] K. Wongsuphasawat, D. Moritz, A. Anand, J. Mackinlay, B. Howe, and J. Heer. Voyager: Exploratory analysis via faceted browsing of visualization recommendations. IEEE Transactions on Visualization and Computer Graphics, 22(1):649–658, 2016. doi: 10 . 1109/TVCG . 2015 . 2467191
- [32] Z. Wu, V. Le, A. Tiwari, S. Gulwani, A. Radhakrishna, I. Radiček, G. Soares, X. Wang, Z. Li, and T. Xie. Nl2viz: natural language to visualization via constrained syntax-guided synthesis. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, 12 pages, p. 972–983. Association for Computing Machinery, New York, NY, USA, 2022. doi: 10 . 1145/3540250 . 3549140
- [33] J. Zhao, M. Fan, and M. Feng. Chartseer: Interactive steering exploratory visual analysis with machine intelligence. IEEE Transactions on Visualization and Computer Graphics, 28(3):1500–1513, 2022. doi: 10 . 1109/TVCG . 2020 . 3018724
- [34] Y. Zheng, R. Zhang, J. Zhang, Y. Ye, Z. Luo, and Y. Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models. arXiv preprint arXiv:2403.13372, 2024.