Sparse-DeRF: 从稀疏视图重建去模糊神经辐射场
摘要
最近的研究使用数十张模糊图像构建去模糊神经辐射场 (DeRF),如果只有有限数量的模糊图像可用,这种方法在实际应用中并不实用。 本文重点关注从稀疏视图构建 DeRF,以适应更实际的现实世界场景。 正如我们在实验中观察到的,从稀疏视图建立 DeRF 被证明是一个更具挑战性的问题,因为从稀疏视图同时优化模糊核和 NeRF 会带来固有的复杂性。 Sparse-DeRF 成功地规范了复杂的联合优化,减少了过拟合伪影,并提高了辐射场的质量。 该规范包括三个关键部分: 表面平滑度,通过利用基于模糊核的统计趋势从模糊核中推导出的未见和额外隐藏光线,帮助模型准确预测场景结构; 调制梯度缩放,帮助模型根据场景物体排列调整反向传播梯度的数量; 感知蒸馏通过克服图像去模糊的病态多视图不一致和蒸馏预过滤信息来提高感知质量,弥补了模糊图像中缺乏清晰信息的不足。 我们通过从 2 视图、4 视图和 6 视图模糊图像训练 DeRF,利用广泛的定量和定性实验结果证明了 Sparse-DeRF 的有效性。
索引词:
神经辐射场,去模糊,新视图合成,3D 合成,神经渲染,稀疏视图设置I 介绍
自从神经辐射场 (NeRF) 出现后,从多视图图像表示三维 (3D) 空间的速度迅速增长,它将连续的空间坐标映射到体积密度和辐射场。 它逼真的渲染质量和简单的架构使其在计算机视觉和图形学的各个研究领域得到广泛应用和合作。 随着 NeRF 的实际应用不断引起关注,在现实世界场景中的研究已成为一个很有前景的研究方向,例如来自噪声图像或稀疏视图的 NeRF。
在现实世界场景中,处理来自相机运动的模糊图像被认为很重要,因为用户在使用自己的设备拍摄照片时,由于曝光时间内的无意相机移动,往往会遇到图像退化问题。 为了解决这个问题,一些 NeRF 研究[1, 2, 3] 尝试通过对内部隐式模糊核和辐射场进行联合优化,从模糊图像中构建去模糊神经辐射场 (以下简称 DeRF),但它们使用数十张模糊图像进行训练,这实际上并不实用。 假设的实验环境,其中辐射场是从大约 20 到 30 张模糊图像中训练出来的,在现实中似乎不太可能发生。 因此,我们深入研究了仅使用模糊图像的情况的实际考虑因素。 我们推断,当用于重建所需 3D 空间的可用图像既非常有限又模糊时,就会出现仅使用模糊图像的情况。 遵循这一推理,我们提出了一种从模糊图像中获取辐射场的新颖实用场景,该场景从稀疏视角设置中建立 DeRF。 具体而言,我们根据对从模糊图像生成辐射场的研究的实际应用的考虑,设置了 2 视图、4 视图和 6 视图设置。
实际上,NeRF 系统本身就存在一个固有的缺点:它容易过度拟合训练视图,并且在仅提供稀疏视图输入时难以掌握正确的几何形状。 此外,我们通过实验发现,与标准 NeRF 相比,模糊图像会导致来自稀疏视图的 DeRF 更严重的过度拟合,因为模糊核引入了更复杂的优化过程。 由于复杂性的增加,当从稀疏视图训练时,DeRF 训练比一般的 NeRF 遭受更多的结构失真,如我们的实验所示,在浮动伪影的情况下表现出进一步的过度拟合。 虽然有一些工作 [4, 5, 6] 用于在稀疏视图场景中正则化辐射场,但现有的正则化方法在解决 DeRF 的复杂优化问题方面并不有效,如使用稀疏视图 NeRF 中现有的代表性正则化技术和 DeRF 的模糊核进行的比较实验所证明的那样,即 RegNeRF [6] 和 DP-NeRF [2]。 此外,在 DeRF 系统中,很难使用其他数据驱动的先验,例如预测深度监督,因为由于给定图像的固有退化,可用图像无法确保估计值的置信度。 因此,我们的目标是正则化 DeRF 的模糊核和辐射场的复杂联合优化,以增强来自稀疏模糊图像的辐射场的结构和感知质量,克服上述具有挑战性的问题。
在本文中,我们首次提出改善来自稀疏视图的 DeRF 的空间模糊并增强其清晰纹理,我们称之为 Sparse-DeRF。 我们介绍了一种新的正则化方法来缓解复杂的联合优化,该方法包括两个几何约束和一个感知先验。 提出了几何约束来预测来自稀疏视图的辐射场中的准确结构,包括表面平滑度 (SS) 和调制梯度缩放 (MGS)。 首先,SS 基于对未观察到的光线的集成进行的经典深度平滑,类似于 RegNeRF [6],从而纠正整体几何形状。 我们利用从模糊核中推导出的相机运动线索中的新颖隐藏光线作为额外的分布外未观察到的光线,以反映现实世界几何的统计平坦度,如 [7, 6] 所论证的那样。 其次,MGS 旨在灵活地调节缩放函数以补偿基于场景组件排列的梯度,这无法通过非参数化坐标系(例如归一化设备坐标 (NDC))中的单个缩放函数来处理。 它通过引入一个参数化的正弦函数作为一种新颖的缩放函数,缓解了由射线采样和 NeRF 的不成比例的梯度引起的空间模糊。 这两种几何约束即使在稀疏视图设置中没有显式深度监督的情况下,也改善了辐射场的结构场景几何。
除了几何约束,我们提出了感知蒸馏 (PD) 作为一种感知先验,以利用先前建立的图像去模糊算法来增强辐射场的详细纹理。 传统的图像去模糊随着深度学习的发展显示出显着的性能改进,展示了更多增强的细节和纹理。 我们认为,来自这些去模糊图像的清晰纹理信息可以用作额外的补充信息,以在 Sparse-DeRF 环境中实现高保真度,在该环境中,只有少数退化的图像可用于重建场景。 然而,虽然我们可以使用预先训练的基于深度学习的图像去模糊模型获取预过滤图像,但图像去模糊的独立性给直接利用去模糊图像作为像素级颜色监督带来了挑战,因为给定图像之间存在不一致。 这种不一致来自图像去模糊的固有病态特性,这种特性破坏了单个 3D 场景的多视图图像之间的几何和外观一致性。 因此,我们通过蒸馏从基于深度学习的图像特征提取器中提取的特征,将预过滤图像的感知信息传达给辐射场。 提取的特征使辐射场能够通过利用预去模糊纹理来增强感知质量。
我们的结果表明,Sparse-DeRF 从稀疏模糊图像生成高质量的渲染图像,具有改进的感知纹理质量和结构良好的场景几何。 此外,我们通过实验结果和分析证明了所提出的约束和先验的有效性。 此外,我们进行了全面的实验,以研究使用来自 Deblur-NeRF [1] 和 DP-NeRF [2] 的两种类型的代表性模糊内核的消融。 这些实验旨在展示所提出的正则化方法的优越性,并分析其根据所用内核类型的影响。
II 相关工作
II-A 神经渲染和辐射场
传统上,研究人员需要了解场景的物理属性来模拟渲染过程,以从 3D 空间生成逼真的图像。 虽然渲染模拟促进了可控的高质量图像在整个 3D 场景中的合成,但合成图像的质量在很大程度上取决于渲染过程中涉及的物理属性。 对于真实场景,需要估计属性,称为“逆向渲染”,但仅根据图像和视频等 2D 观察结果很难准确预测它们。 尽管已经尝试了几种方法来克服这些挑战,“神经渲染”最近已成为一种优越的方法,它将深度学习方法和图形渲染方法相结合,利用深度神经网络的出色表示能力。
根据一份全面的调查 [8],它很好地总结了早期神经渲染的历史,该研究领域被认为是生成对抗网络 (GAN) [9] 和图形可控图像合成的交集。 随着 GAN 的采用,神经渲染被认为是利用给定场景参数和几个 3D 场景表示的图像到图像的翻译问题,利用类似于 Pix2Pix [10] 的条件 GAN 的见解。 例如,[11, 12, 13] 通过将场景参数传递到深度神经网络来生成具有特定场景条件的高质量图像。 此外,其他工作将经典图形模块的直觉融入 GAN 中,以合成和控制图像输出,利用不可微分或可微分模块,例如使用具有密集输入条件的渲染图像 [14, 11, 15],计算机图形渲染器 [16, 17] 和照明模型 [18]。
尽管这些研究在过去几年中提出了逼真的神经渲染技术,但在神经辐射场 (NeRF) [19] 出现后,神经渲染的范式发生了巨大转变,它直接将 3D 空间位置和视角方向映射到辐照度,仅依靠多层感知器 (MLP) 和经典体积渲染方法 [20] 从多视图图像进行映射。 NeRF 使用经典的射线追踪方法隐式地表示 3D 场景,并显示出逼真的新视图合成,但仍有改进的空间。 由于其简单直观的架构,NeRF 已广泛应用于其他计算机视觉和图形任务,这引起了极大的关注,并扩展了神经渲染的研究领域。 为了增强神经表示本身的性能,一些工作使用另一种表示来表示 3D 场景,以提高训练或渲染速度,例如体素网格 [21],plenoctree [22],分解张量场 [23],hashgrid [24],plenoxels [25],光场 [26] 和 3D 高斯函数 [27]。 此外,它的隐式表示能力导致了其他图形任务的爆炸式发展,例如建模动态场景 [28, 29, 30, 31],重新照明 [32, 33],3D 重建 [34, 35] 和人体化身 [36]。
II-B 辐射场在实际场景中的应用
随着 VR 和 AR 技术重要性的提高,已经出现了大量的工作将神经表示应用于更实用的场景,例如快速渲染、射线上高效采样、场景编辑、降噪和从稀疏视图训练。 快速渲染、光线上高效采样以及场景编辑旨在通过各种方法提高推理速度、实现表面采样以及变形训练好的网格,例如烘焙 [37]、深度引导采样 [38]和表面变形 [39]。
另一个主要领域是从稀疏视图图像构建 NeRF,考虑到现实场景,这是一个实际环境。 稀疏视图图像会带来神经网络固有的缺点,即该网络更容易过度拟合到给定数据分布。 这会导致映射表示中场景几何形状不一致,通常表现为错误预测的结构信息,例如从新视图渲染的彩色和深度图像中出现的拉伸密度伪影。 几种方法已经缓解了这个问题,包括使用额外的先验知识或分布外数据。 InfoNeRF [40] 采用熵最小化来估计光线密度上密度值的概率密度函数 (PDF),以使 PDF 的形状更清晰。 RegNeRF [6] 利用真实世界几何形状的统计深度平滑度 [7] 在未观察到的光线补丁上减少伪影。 最近,FlipNeRF [5] 将表面上的翻转光线视为补充未见光线,以规范化场景几何形状。 在其他方法中,一些作品,例如 PixelNeRF [41] 和 DietNeRF [42],利用从深度图像特征提取器中提取的语义信息来利用神经网络在特征级别的代表能力。 FreeNeRF [4] 试图从优化角度缓解过度拟合问题,对频率级别施加一些限制。
除了稀疏视图设置外,从降级图像建立 NeRF 最近也开始出现,因为 NeRF 的理想图像训练条件在现实场景中经常失效。 RawNeRF [43] 对相机传感器的内部噪声进行降噪,从黑暗原始图像构建高动态范围 (HDR) 辐射场并控制相机曝光。 同样,NaN [44] 处理图像中的突发噪声,基于 IBRNet [45] 生成降噪图像,IBrNet 是另一种基于图像的渲染方法。 为了在现实世界中更实际地应用 NeRF,DeblurNeRF [1] 首次尝试处理图像中的两种类型的模糊降级,即来自相机运动和散焦的模糊,仅从模糊图像构建去模糊神经辐射场 (DeRF)。 他们模仿了模糊过程,将图像去模糊中的盲去模糊概念与 NeRF 系统集成,将模糊核建模为逐像素独立的光线变换和组合权重,以近似模糊过程。 DP-NeRF [2] 提出了另一种代表性方法,该方法通过将模糊核建模为依赖于每个视图的光线的 3D 刚性变换,在图像之间施加物理一致性,以更精确地近似相机中实际的模糊过程。 最近,也相继提出了几种方法 [46, 47, 3],试图提高构建的 DeRF 的质量。 在前面提到的这些领域中,最活跃的研究领域之一是从模糊图像中生成 NeRF,这种情况经常发生在用户用自己的设备拍照时。
然而,正如我们在第 I节中提到的,使用仅 2030 张模糊图像的实验设置(如以前的研究中所用)并不实用。 如果我们假设用户只能访问模糊图像,那么更现实的情况是,特定场景只有几张图像可用,而且所有这些图像都是模糊的。 因此,我们通过将 DeRF 与稀疏视图设置相结合,提出了一种更实用的场景,从而增强了现实世界的适用性。
III 预备知识
III-A 去模糊神经辐射场
神经辐射场 (NeRF) 是参数化的 MLP,用于将连续的 3D 位置 映射到体积密度 和视点相关的辐射颜色 。 它被公式化为近似的通用函数 ,其中 和 分别表示 NeRF MLP 的参数和射线的观察方向。 函数 是一个位置编码函数,它将每个输入 x 和 d 映射到一个高维编码特征,该特征通常定义为频率调整的正弦函数的串联,如等式 1 所示。
| (1) |
其中 表示频率范围,最大频率值为 。 在此之后,我们缩写编码函数,并将 NeRF 的函数表示为
| (2) |
NeRF 通过从多视图输入图像的像素级颜色监督进行训练,以优化 MLP,通过基于体积渲染 [48] 预测每个像素颜色 ,其中样本沿着从配对相机参数生成的射线 r。 对于给定的射线起点 o 和像素 沿的观察方向 d,沿着射线 r 的样本被均匀地划分为 个间隔,以生成具有分层采样的粗略样本。 样本定义为 在近到远的边界分区 中,如等式 3 所示,其中 表示第 i 个样本, 表示到射线起点的距离。
| (3) |
遵循 [48],粗略的像素颜色 从每个样本 的估计颜色 和密度 渲染而来,如
| (4) |
其中 和 分别表示沿射线的每个样本的透射率和相邻样本之间的距离。 层次体积采样再次利用归一化权重作为概率密度函数 (PDF) 从 作为 进行,并且通过上述渲染过程再次产生精细渲染的像素颜色 。 通过 L2 范数从输入图像中的真实像素颜色监督粗略和精细渲染的颜色,如
| (5) |
其中 是每批射线集,C(r) 是射线 r 的真实 RGB 颜色。
但是,由于在 DeRF 环境中没有用于训练 NeRF 的真实像素颜色,因此上述损失不能用于训练 DeRF。 为了解决这个问题并构建 DeRF,[1, 2] 构建了额外的 MLP 以预测 NeRF 前面的模糊核,以模仿传统的盲模糊过程,如公式 6 所示。
| (6) |
其中 、、 和 分别表示目标像素、预期模糊颜色、卷积运算符和模糊核。 为了清楚起见,我们在此后将 简称为。 预期模糊颜色 由 渲染的像素颜色 组成,这些像素颜色由模拟模糊过程的建模射线引起,如公式 7 所示。
| (7) |
其中 和 分别表示合成权重和相对于像素 的近似模糊射线索引集。 请注意, 的数量为 ,它是一个超参数,决定了模糊过程离散变换的近似质量。 最后,DeRF 使用模糊颜色的颜色重建损失进行训练,如
| (8) |
其中 、 和 分别是射线 r 的预期粗略、精细和真实模糊颜色。
模糊核在每篇论文中都作为不同类型的变换进行代表性建模,[1, 2],我们将在下一段中对此进行描述。 在同时对近似模糊核和 NeRF 进行联合训练后,他们可以通过仅评估 NeRF 来渲染干净的神经辐射场,我们将其称为去模糊的神经辐射场 (DeRF),这得益于盲去模糊的理论基础。
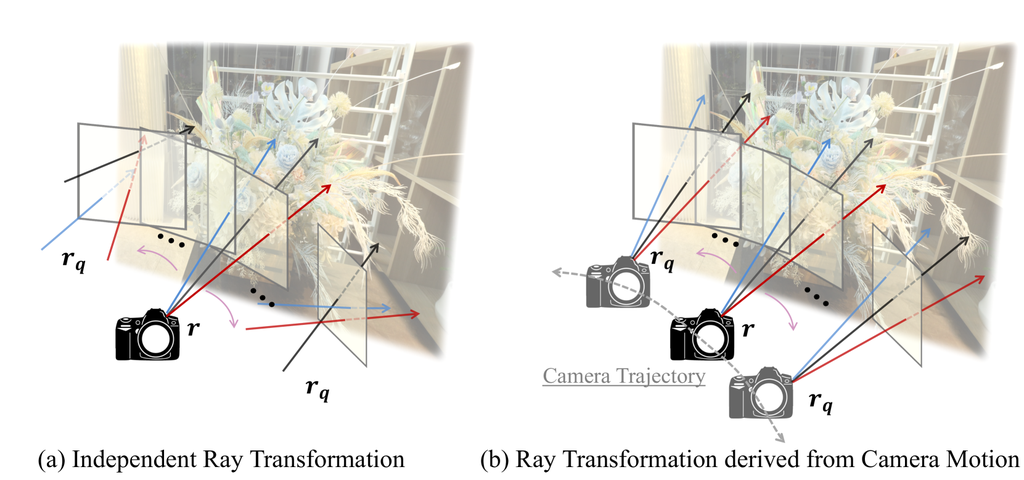
III-B 去模糊神经辐射场中的模糊核
两种论文中模糊核的核心区别在于,如 图 1 所示,考虑了整个图像中所有像素的 3D 一致性。 Deblur-NeRF [1] 将模糊核设计为可变形稀疏核 (DSK),它包含 个变换,具体取决于每个视图和图像像素位置的嵌入式潜在特征。 变换被公式化为射线原点的 3D 向量和像素坐标的 2D 向量,在图像平面上 窗口内初始化为
| (9) |
对于 ,具有参数 的 MLP 的输入是 和 ,分别是潜在嵌入像素坐标和场景信息。 这里, 定义为在特定小范围内随机初始化的规范坐标,而 表示特定场景。 3D 向量 和 变换给定射线 以生成模仿模糊过程的变换射线,如公式 10 所示。
| (10) |
其中 是通过将 应用于像素坐标来移动射线端点以变换射线方向。 然后,目标像素的模糊颜色 由每个渲染颜色 和 的加权求和组成,如公式 7 所示。
但是,DP-NeRF [2] 认为 [1] 中模糊核的逐像素独立优化会导致 3D 几何形状和外观不一致。 它们利用实际模糊图像采集在相机过程中的物理直觉作为 DeRF 的额外先验,以对构建辐射场施加约束,同时保持 3D 一致性。 为了直接将实际相机运动建模为 3D 刚性变换,它们引入了场景级 场,灵感来自 [29]、[49] 和 Rodrigues 公式 [50]。 相机在场景方面的刚性变换由估计的螺旋轴 公式化,该螺旋轴通过仅依赖于场景信息的 MLP 估计,如公式 11 所示。
| (11) |
其中 和 分别表示具有参数 的 MLP 和潜在嵌入的场景信息。 中预测的 和 通过 [50] 和 [49] 的公式分别转换为旋转矩阵 和平移矩阵 。 注意,为了清晰起见,我们省略了特定的场景指示器 。 因此,变换后的射线被公式化为射线的刚性变换,如公式 12 所示。
| (12) |
目标像素的模糊颜色 也是通过对每个渲染的颜色 和 进行加权求和来合成,与公式 7 相同。 除了使用刚性模糊核 (RBK) 对模糊过程进行建模外,[2] 还提出了一种基于变换射线和运动轴之间内在相关性的自适应权重提议网络 (AWP) 来预测每个像素的自适应合成权重 ,这弥补了深度差异带来的模糊效果。
在本文中,我们提出了一种新方法,该方法基于 Ddeblur-NeRF [1] 和 DP-NeRF [2] 中这两种类型的模糊核,通过大量实验包含几何约束和感知先验,这两种模糊核分别可以看作是灵活核和刚性核。 进行的实验表明了 Sparse-DeRF 在两种核上都有效。 此外,结果还揭示了内核灵活性的权衡,这取决于不同场景中固有的特定属性。
IV 稀疏DeRF
我们发现,基于朴素 NeRF、Deblur-NeRF [1] 或 DP-NeRF [2] 从稀疏视图设置中构建辐射场是无效的,如我们在第 V-E 节中所述。 虽然 DeRF 通常比给定视图中的朴素 NeRF 更好地恢复高频细节,但它在新的视图合成中变得更加零散,由于复杂的联合优化,产生了不准确的场景几何。 几何误差表现为映射的 RGB 纹理,类似于近处或远处深度的墙壁上的油漆,以及拉长的密度伪影,这揭示了与准确的深度值预测相关的挑战。 然而,现有的代表性正则化方法,用于从稀疏视图中获得的 NeRF [6],不能正则化 DeRF 的复杂联合优化。 我们在第 V-F1 节中展示了实验结果,这表明了先前正则化技术在从稀疏视图中获得的 DeRF 上的困难。 因此,我们在此描述了从稀疏视图中正则化 DeRF 优化的我们的方法,以缓解空间歧义,该方法包含两个几何约束和一个感知先验。 图 2 详细说明了 Sparse-DeRF 的总体架构,其中图 2 的 (a)、(b) 和 (c) 分别表示 Sparse-DeRF 的每个主要组件。 几何约束包括表面平滑度 (SS) 和调制梯度缩放 (MGS),正如我们在第 IV-A 节和第 IV-B 节中所述。 感知先验包括一个感知蒸馏 (PD),它在第 IV-C 节中进行了描述。
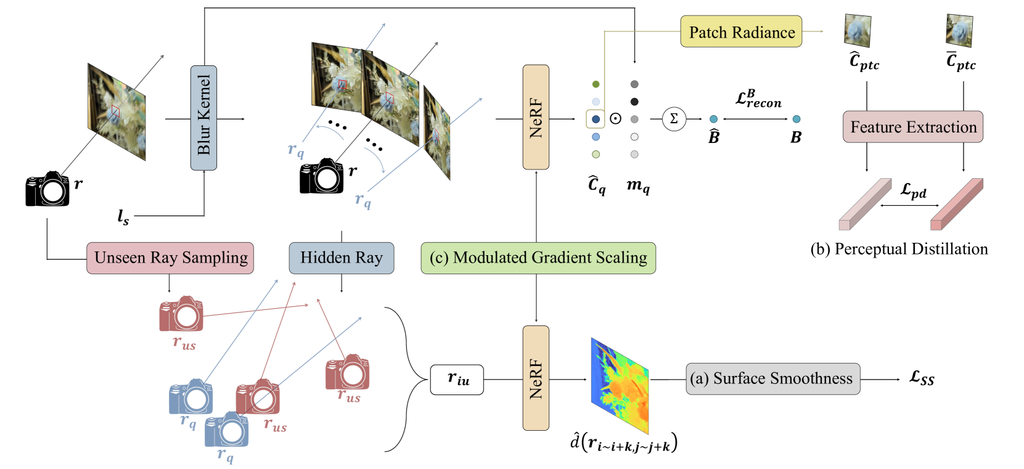
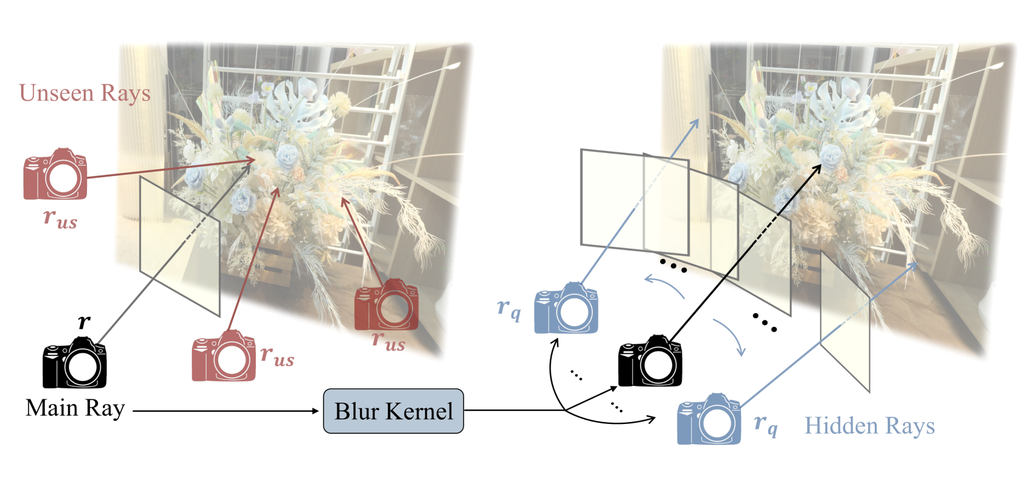
IV-A 集成未观察射线上的表面平滑度
受真实世界几何的统计趋势启发,RegNeRF [6] 中采用分段平滑作为小渲染补丁上的深度平滑正则化。 此正则化也可以解释为对表面平滑度约束的施加,该约束应用于从未见射线获得的渲染深度,这些射线定义为训练输入中未观察到的射线。 未见射线是从有限样本空间内采样的可能的相机位置生成的,受测试时渲染的目标姿态约束。 与 [6] 中介绍的方法类似,我们采用了一种方法,通过利用来自未观察射线的信息来缓解空间歧义。 然而,我们建议额外利用新的未观察射线信息,这些信息只能从模糊核中推导出,以稳定模糊核和辐射场的同步优化。 首先,我们利用未见射线作为集成未观察射线之一,以遵循 [6] 来改善空间歧义。 对于已知的相机姿态集 ,其中 ,未见射线的采样相机姿态 是从有限样本空间中的相机位置 和旋转 制定的,如下所示:
| (13) | ||||
其中 、、 和 分别表示 、、所有目标姿态的上轴的归一化均值,以及通过解决最小二乘问题获得的平均焦点。 和 分别表示相机旋转矩阵,使采样相机大致聚焦于场景的中心点,以及添加到焦点的小抖动值。 最后,采样相机姿态 制定为
| (14) |
除了利用以前未见过的射线之外,我们还利用从估计的模糊核的特征派生的隐藏射线,利用仅在模糊输入中出现的补充信息。 模糊核,在等式 6 中表示为 ,生成射线变换以近似模糊的颜色合成过程,无论内核类型如何,如 Deblur-NeRF [1] 和 DP-NeRF [2] 中所示。 受各种模糊核中颜色合成过程的共性的启发,引入了内核感应的变换射线 作为额外的未观察射线,称为隐藏射线,以强制执行深度平滑度约束。 由于隐藏射线 不会直接出现在 DeRF 系统的训练数据中,因此它们充当补充的分布外数据,用于强制执行深度平滑度,类似于上述未见射线。 此外,在隐藏射线上合并深度平滑有效地解决了指定训练视图内模糊图像的 3D 空间中的几何不一致性。 这种能力源于对估计的隐藏光线的更广泛覆盖,这是通过将相机运动信息隐式包含在模糊图像中而实现的。 因此,我们将用于深度平滑的集成未观察到的光线定义为未观察到的光线和隐藏光线的集成集合,如
| (15) |
其中 和 分别表示集成未观察到的光线和未观察到的光线。 为了更直观的理解, 和 在图 3 中进行了说明。
为了将深度平滑约束应用于 , 的预期深度按照与之前 NeRF 工作相同的公式 16 计算。
| (16) |
然后,通过添加来自 [6] 的颜色相关的加权深度平滑来重新公式化深度平滑损失,如
| (17) |
其中 和 分别表示水平和垂直加权深度差,如公式 18 所示。
| (18) | ||||
其中 表示像素级颜色差权重。
IV-B 调制梯度缩放
尽管先前的表面平滑减轻了 3D 场景中的空间模糊,但由于 NeRF 采样策略和投射体积占用率的固有缺点,仍然难以掌握准确的几何形状,如 [51] 所论述。 遵循[51],NeRF 的优化通常会失败,在近深度区域生成密度伪影,这是由于射线上样本的不平衡体积占用率导致的梯度反向传播不成比例。 [51] 通过引入梯度缩放来缓解这一限制,该缩放会根据射线起点o的距离来减少射线r上每个样本的传播梯度,如
| (19) |
其中和分别表示样本的缩放梯度值和缩放函数。 缩放函数被严格地定义为平方函数,如下所示:
| (20) |
注意,表示每个点的特征的梯度,例如 RGB 颜色c和密度。
然而,我们通过实验发现,在稀疏视图设置中,这种限制更为突出,因为可用的视角方向多样性较少,这意味着投影几何和极几何对 NeRF 优化不起作用。 因此,梯度缩放对于来自稀疏视图设置的辐射场似乎更加必要。 尽管我们尝试将该技术应用于 Sparse-DeRF,但它并没有像附录中所示那样正常工作。 原因是的固定平方函数,其下界为,不能覆盖非线性参数化空间,例如归一化设备坐标 (NDC),该坐标在我们工作中被广泛使用。 另一个原因是,函数的严格固定形状无法覆盖场景组件的排列,即使在同一数据集中,场景组件的排列也通常不同。 [51] 简要提到了雅可比行列式作为值的附加缩放因子,但他们没有对其进行实验。 此外,即使应用了附加缩放因子,缩放函数的形状也不会改变,仍然只是平方函数的形式,这无法灵活地适应场景组件的排列。 因此,我们对缩放函数的形状进行调整,以自适应地反映场景排列并适合 NDC。
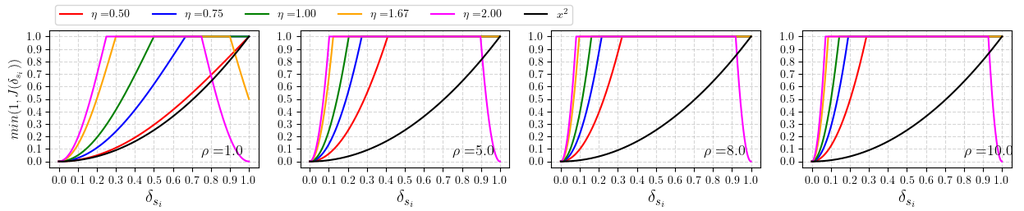
我们新颖的梯度缩放函数是基于三个条件设计的。 首先,函数应从相机原点开始增加,这是避免我们在之前提到的初始训练阶段的局部最小值的必要条件。 其次,该函数在远距离处不应为零,在我们 NDC 环境中设置为,以确保 NeRF 训练。 最后,该函数被设计为在给定的深度范围内仅增加和减少一次,这使得该函数不波动,因为考虑到 MGS 的目标是减轻近距离的不正确密度映射,这是一个直观合理的场景。 除了上述关于缩放函数形状的条件外,我们还进一步考虑了在主要物体位置集中在场景中心且密度映射误差表示为近距离或远距离的涂漆墙壁时设计函数形状。 遵循这些条件,所提出的调制梯度缩放 (MGS) 函数 被公式化为
| (21) |
其中 和 分别表示正弦函数的大小和周期。 然而,与 [51] 相反, 的距离范围被限制为 ,因为我们对数据集使用了 NDC。
为了在近距离和远距离区域都应用梯度缩放,同时最大限度地减少场景中心区域的缩放效果,我们采用正弦函数形状作为 MGS 的基础。 此外,第二个条件确定 的最大值为 2,以确保所提议函数在远距离区域的缩放值不会降至或低于 0。 图 4 左上角图像中的函数形状显示了我们上面描述的所提出的缩放函数的特征。 根据图 4 中不同的 和 值,我们展示了 和 的缩放值之间的差异。

IV-C 感知蒸馏
与之前在稀疏视图设置中与 NeRF 相关的作品相比,Sparse-DeRF 环境能够使用现成的图像处理算法,例如基于深度学习的图像去模糊网络,这是由于给定图像的降级。 除了从几何角度的改进之外,我们还旨在利用现有图像处理模块的优势来增强 DeRF 的详细纹理,从而实现高保真度。
然而,由于缺乏 3D 一致性,无法直接利用预去模糊图像作为额外的像素级颜色监督。 这种不一致是由于图像去模糊的病态性质以及跨多视图图像的独立去模糊处理造成的,这会产生不一致的去模糊结果。 在附录中,我们还讨论了这个问题,并展示了预去模糊图像和参考图像的定性比较,这些参考图像是从使用全视图训练的 DP-NeRF [2] 估计的,以揭示几何不一致问题。
为了克服预去模糊图像的固有矛盾,我们将预过滤图像视为感知先验,通过使用预训练的特征提取器从渲染的图像块和去模糊图像中提取特征来传递去模糊纹理信息。 图 5 简单地说明了我们感知蒸馏模块的流程。
具体来说,我们首先利用预训练的图像去模糊网络 为模糊训练图像 生成去模糊图像 ,为特征提取做好准备,方法是:
| (22) |
接下来,我们还从训练视图上的 中采样 大小的图像块光线 和对应的去模糊图像块 。 然后,我们使用共享的预训练图像特征提取器 从渲染的颜色图像块 (从 渲染)和预去模糊图像 中提取丰富的去模糊特征,方法是:
| (23) |
其中 和 分别表示从每个颜色图像块中提取的特征。 请注意,颜色图像块 是通过将 NeRF MLPs 正向传递(不带模糊核)来渲染的,以便将预过滤的纹理信息感知地传递到隐式清洁辐射场,这在图 2 中被称为图像块辐射度。 然后,我们应用感知损失 [52] 来提取特征信息,方法是:
| (24) |
我们最终的损失函数是对提出的损失的加权组合,方法是:
| (25) |
其中 和 表示每个损失的权重,在我们实验中均设置为 。
V 实验
V-A 数据集
Sparse-DeRF 已经在一个由 Deblur-NeRF [1] 提出的正向场景数据集上进行了实验,该数据集包含 5 个合成场景和 10 个真实场景。 具体来说,我们只使用相机运动模糊数据集,因为我们的目标是从稀疏视图设置中缓解 DeRF 中的相机运动模糊。 该数据集包含多个视图图像和配对的相机姿态,这些姿态通过使用 COLMAP [53, 54] 校准。 对于稀疏视图设置,我们手动选择 2、4 和 6 张图像作为所有场景的训练数据集,这样每个视图覆盖的整个空间尽可能宽。 此外,为了确保光照场能够合理地学习,我们选择具有可见空间的视图,这些视图尽可能少的重叠,同时避免过度极端的模糊幅度。 注意,数据集的一个固有属性是,根据每个场景,所选视图的模糊幅度可能不同,这意味着每个场景的学习难度不同。 我们在附录中附上了在我们实验中使用的所有场景的所选图像索引,以便在将来的研究中进行公平比较。
V-B 实验稀疏视图设置
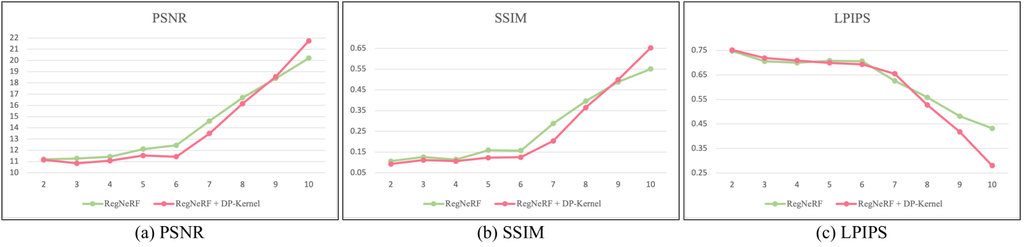
Sparse-DeRF 的场景被假定为三种设置,分别是 2 视图、4 视图和 6 视图设置下的 DeRF,这与现有的常见稀疏视图 NeRF 不同,后者通常使用 3 视图、6 视图和 9 视图设置。 原因是,当使用超过 8 张图像时,联合优化问题在 9 视图设置下更频繁地出现,如 图 6 所示。 该图展示了在 Decoration 场景中实验的图表,我们在该场景中将输入稀疏视图的数量从 2 视图更改为 10 视图。 由于篇幅限制,我们也在附录中附上了定量结果。 实验结果表明,我们的稀疏视图实验设置是有效的,因为 RegNeRF [6] 具有 DP-kernel 在 9 视图下表现不佳。
V-C 实现细节
Spare-DeRF 是基于 DP-NeRF 的公开官方代码 [2] 实现和修改的,它使用 DP-NeRF [2] 和 Deblur-NeRF [1] 的两种类型的模糊核。 为了公平比较,模糊射线的数量设置为 ,与之前的工作 [1, 2] 中的默认设置相同。 我们根据每项工作的默认参数设置模糊核的其他设置。 对于 NeRF 优化,我们使用 个粗样本和 个精样本,每条射线有 1024 个样本,并使用 Adam [55] 优化器,默认参数。 此外,从 到 应用指数权重衰减,以进行学习率调度。 我们在 2-视图、4-视图和 6-视图设置中分别对 DeRF 训练了 、 和 次迭代。 对于逐块采样,我们将块的大小设置为 和 ,分别为 和 。 然而,为了在广泛的实验中进行公平比较,尤其要考虑在表面平滑度约束中生成看不见的射线的方法。 特别是,我们从固定视图生成看不见的射线,这些视图从训练射线的剩余部分中均匀选择,以消除看不见的射线生成过程中的随机性,从而实现实验分析和公平比较。 请注意,训练射线的剩余部分不包括在训练视图或测试视图中。 我们证明这是一个合理的选择,因为选定的视图仍在我们在第 IV-A 节中定义的样本空间中。 此外,我们在附录中附上了这个问题的可视化,以证明其合理性。 每个场景的调制梯度缩放函数的超参数,幅度 和周期 ,在附录中详细介绍。 对于感知蒸馏,MPRNet [56] 被用作预训练的图像去模糊网络。 我们选择 VGG19 [57] 作为预训练的图像特征提取器 ,因为它被广泛用作基于图像的计算机视觉中的图像特征提取器。
V-D 评估指标
我们对合成数据集和真实数据集的实验结果通过一项新颖的视图合成任务,在三个量化指标和渲染图像之间的定性比较中进行评估。 与先前的研究一致,我们采用广泛使用的评估指标来比较合成的图像与相应的真实图像:峰值信噪比 (PSNR)、结构相似度指标 (SSIM) 和学习到的感知图像块相似度 (LPIPS) [58]。 这些指标分别评估了生成图像的相对清晰度、结构相似度和感知质量。 此外,我们鼓励读者参考补充视频,以更全面、更详细地展示结果。
V-E 评估
| [ 2-view ] | [ 4-view ] | [ 6-view ] | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [ Synthetic Scene ] | [ Real Scene ] | [ Synthetic Scene ] | [ Real Scene ] | [ Synthetic Scene ] | [ Real Scene ] | |||||||||||||
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| Naive NeRF [19] | 15.11 | .2999 | .5578 | 14.38 | .2635 | .6004 | 20.02 | .5327 | .4000 | 18.98 | .4860 | .4481 | 21.65 | .5985 | .3638 | 20.63 | .5513 | .4014 |
| MPR [56] + NeRF | 15.16 | .3006 | .5595 | 14.38 | .2594 | .6019 | 20.00 | .5381 | .3956 | 18.89 | .4829 | .4484 | 21.72 | .5999 | .3629 | 20.60 | .5513 | .4010 |
| Deblur-NeRF [1] | 15.14 | .2884 | .5330 | 14.41 | .2506 | .5921 | 19.99 | .5199 | .3499 | 18.89 | .4761 | .4151 | 23.12 | .6798 | .2386 | 21.36 | .6003 | .3163 |
| DP-NeRF [2] | 15.06 | .2827 | .5389 | 14.36 | .2506 | .5904 | 19.84 | .5336 | .3075 | 18.77 | .4582 | .4175 | 23.68 | .7036 | .1998 | 21.68 | .6137 | .2992 |
| RegNeRF [6] (No kernel) | 14.60 | .2849 | .5869 | 15.49 | .2997 | .5888 | 18.39 | .4600 | .4704 | 18.44 | .4326 | .4852 | 19.69 | .5249 | .4165 | 19.65 | .4790 | .4583 |
| RegNeRF [6] (w/DP-kernel) | 13.24 | .2162 | .6062 | 12.76 | .1836 | .6447 | 16.44 | .3657 | .4826 | 13.59 | .2221 | .5887 | 21.60 | .6162 | .3046 | 18.25 | .4439 | .4326 |
| Sparse-DeRF (w/DN-kernel) - Ours | 15.52 | .2966 | .5291 | 15.53 | .3112 | .5515 | 20.57 | .5565 | .3354 | 19.98 | .5231 | .3871 | 23.32 | .6903 | .2379 | 22.15 | .6248 | .3030 |
| Sparse-DeRF(w/DP-kernel) - Ours | 15.35 | .2904 | .5242 | 15.57 | .3114 | .5467 | 21.05 | .5776 | .2975 | 20.05 | .5178 | .3736 | 24.27 | .7255 | .2044 | 22.32 | .6283 | .2907 |

V-E1 定量评估
我们展示了 Sparse-DeRF 在来自 Deblur-NeRF [1] 和 DP-NeRF [2] 的两种不同类型的模糊核上的定量结果,并将这些结果与已建立的基线方法进行了比较。 表 I 中展示了我们方法的有效性,无论采用何种模糊核,该方法在所有稀疏视图设置中都取得了出色的性能。 在 Sparse-DeRF 结果中,DN-kernel 和 DP-kernel 分别表示 Deblur-NeRF [1] 和 DP-NeRF [2] 提出的模糊核。 MPRNeRF 表示仅通过 MPRNet [56] 从去模糊图像进行颜色监督训练的朴素 NeRF 模型,利用了等式 5 的重建损失 。 MPRNeRF 的结果揭示了一些有趣的观察结果,以及仅使用预去模糊图像作为直接颜色监督进行训练时,辐射场中出现的微弱改进。 这种趋势强调了预去模糊图像之间的 3D 不一致性,如第 IV-C 节所述。 此外,带有和不带有模糊核的 RegNeRF [6] 的糟糕结果表明,现有的正则化方法难以缓解模糊核和辐射场之间的复杂联合优化问题。 我们在第 V-F1 节中进一步对该优化问题进行了分析,并提供了详细的实验结果。 相反,Sparse-DeRF 在两种类型的模糊核的所有评估指标中都表现出了显著的改进,表明它具有更高的能力以更高的视觉质量表示 DeRF。 特别是,我们的结果在真实场景中表现出更显著的改进,尽管由于各种真实环境因素,存在非理想的模糊降级。 为了全面了解,我们在第 V-F 节中提供了一个广泛的消融研究,其中包含了两种类型的模糊核的结果。 此外,所有场景的详细结果都附在附录中,包括合成场景和真实场景。
V-E2 定性评估
图 7 分别展示了从 2 视图、 4 视图和 6 视图设置中三个场景( Parterre、 Coffee 和 Decoration)的代表性定性结果。 该图展示了新视图合成的结果,呈现了渲染的彩色和深度图像。 这些图表明,我们的模型在几何和感知保真度方面显著提高了辐射场的视觉质量。 除了上述定量结果外,定性结果还证明了预先去模糊图像的不一致性问题,以及从稀疏视图中对 DeRF 的复杂联合优化问题。 图 7 的所有结果( ii )表明,现有的代表性正则化技术 RegNeRF [6] 无法有效缓解从稀疏视图中对 DeRF 的优化问题。 此外,我们鼓励读者观看补充视频,这些视频通过从螺旋相机路径渲染的视频强调 3D 一致性。
V-F 消融研究
V-F1 问题分析和动机
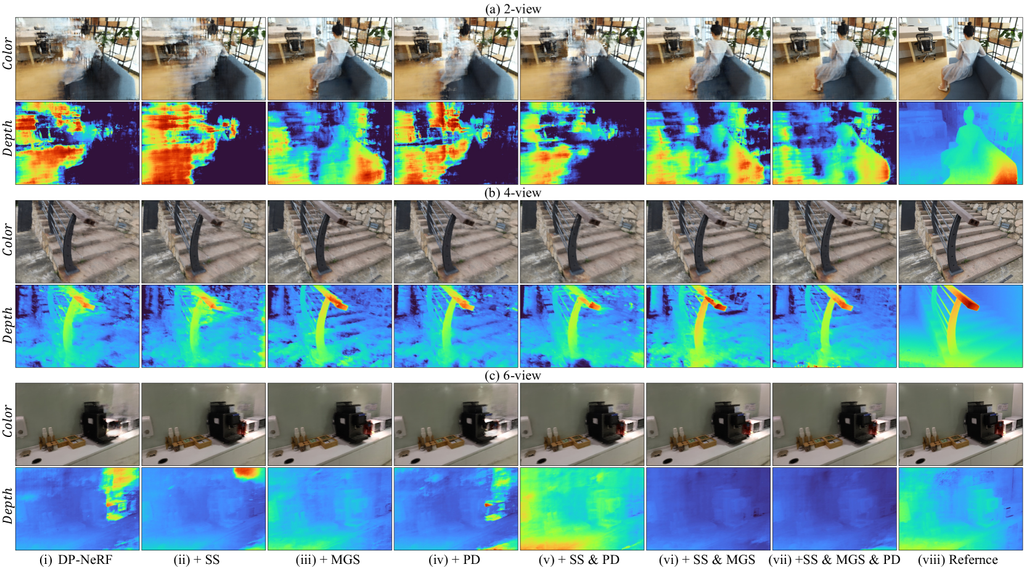
我们展示了实验结果,以描述联合优化 DeRF 以及将 NeRF 的先前正则化技术简单地应用于从稀疏视图设置中获得的 DeRF 是很困难的,我们利用了代表性现有的正则化方法 RegNeRF [6]。 我们附加了 RegNeRF [6] 在有无模糊核的情况下,从 2 视图、 4 视图和 6 视图设置中获得的实验结果,以证明如我们所述,复杂联合优化问题的难度。 表 II 和图 8 分别展示了从 2 视图、 4 视图和 6 视图中获得的定量和定性结果。 所采用的模糊核是 DP-NeRF [2] 的刚性模糊核,在表和图中被描述为 DP-kernel。 为了帮助读者将拟议的 Sparse-DeRF 的合理外观和密集几何与 Sparse-DeRF 进行比较,我们附加了我们模型的渲染颜色和深度图像。 图中结果表明,模糊核的集成在优化高频细节和整体场景几何方面存在直接的难度,正如渲染的颜色和深度图像的视觉质量所表明的那样。 虽然模糊核的存在使辐射场能够捕捉高频细节,但它会导致几何畸变,并伴随整体错误的密度映射,这类似于物体的碎片结构或外观,例如近或远深度区域的油漆墙。 这些结果和分析表明,简单地将 NeRF 的正则化从稀疏视图应用于 DeRF 是无效的。 此外,图 8 中的图像 (i) 和 (ii) 表明,尽管没有模糊核的情况下整体性能更好,但模型在建模高频细节方面仍然面临困难。 这种困难使得模糊核优化的必要性仍然很重要,导致整个场景的视觉质量模糊。 因此,受实验分析的启发,我们提出了 Sparse-DeRF,这是一种新的正则化方法,用于同时优化模糊核和辐射场。 如图 8 所示,提出的 Sparse-DeRF 呈现了具有密集几何和详细高频纹理的高质量渲染图像。
| [ 2-view ] | [ 4-view ] | [ 6-view ] | |||||||||||||||||
| [ Synthetic Scene ] | [ Real Scene ] | [ Synthetic Scene ] | [ Real Scene ] | [ Synthetic Scene ] | [ Real Scene ] | ||||||||||||||
| Blur Kernel | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| RegNeRF [6] | 14.60 | .2849 | .5869 | 15.49 | .2997 | .5888 | 18.39 | .4600 | .4704 | 18.44 | .4326 | .4852 | 19.69 | .5249 | .4165 | 19.65 | .4790 | .4583 | |
| RegNeRF [6] | DP-kernel | 13.24 | .2162 | .6062 | 12.76 | .1836 | .6447 | 16.44 | .3657 | .4826 | 13.59 | .2221 | .5887 | 21.60 | .6162 | .3046 | 18.25 | .4439 | .4326 |
| Sparse-DeRF (Ours) | DP-kernel | 15.35 | .2904 | .5242 | 15.57 | .3114 | .5467 | 21.05 | .5776 | .2975 | 20.05 | .5178 | .3736 | 24.27 | .7255 | .2044 | 22.32 | .6283 | .2907 |

| [ 2-view ] | [ 4-view ] | [ 6-view ] | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SS | MGS | PD | DP-kernel | DN-kernel | DP-kernel | DN-kernel | DP-kernel | DN-kernel | |||||||||||||
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| Synthetic Scene | 15.06 | .2827 | .5389 | 15.14 | .2884 | .5330 | 19.84 | .5336 | .3075 | 19.99 | .5199 | .3499 | 23.68 | .7036 | .1998 | 23.12 | .6798 | .2386 | |||
| ✓ | 14.88 | .2772 | .5388 | 15.25 | .2828 | .5418 | 19.93 | .5411 | .3107 | 19.89 | .5201 | .3558 | 24.15 | .7263 | .1974 | 23.59 | .6795 | .2429 | |||
| ✓ | 15.40 | .2857 | .5289 | 15.12 | .3025 | .5243 | 20.16 | .5425 | .3024 | 19.44 | .5295 | .3562 | 23.83 | .7147 | .2072 | 24.33 | .6832 | .2406 | |||
| ✓ | 15.03 | .2796 | .5391 | 14.84 | .2702 | .5454 | 19.65 | .5237 | .3311 | 19.72 | .5104 | .3630 | 23.89 | .7150 | .2052 | 23.35 | .6941 | .2341 | |||
| ✓ | ✓ | 14.52 | .2647 | .5481 | 15.11 | .2889 | .5389 | 20.91 | .5812 | .2948 | 20.03 | .5294 | .3450 | 24.28 | .7279 | .2021 | 23.41 | .6941 | .2324 | ||
| ✓ | ✓ | 15.50 | .2954 | .5215 | 15.57 | .2979 | .5319 | 19.65 | .5164 | .3334 | 19.96 | .5222 | .3547 | 23.53 | .7088 | .2153 | 22.91 | .6654 | .2560 | ||
| ✓ | ✓ | ✓ | 15.35 | .2904 | .5242 | 15.52 | .2966 | .5291 | 21.05 | .5776 | .2975 | 20.57 | .5565 | .3354 | 24.27 | .7255 | .2044 | 23.32 | .6903 | .2379 | |
| Real Scene | 14.36 | .2506 | .5904 | 14.41 | .2506 | .5921 | 18.77 | .4582 | .4175 | 18.89 | .4761 | .4151 | 21.68 | .6137 | .2992 | 21.36 | .6003 | .3163 | |||
| ✓ | 14.26 | .2414 | .5933 | 14.33 | .2495 | .5937 | 19.04 | .4760 | .4008 | 18.96 | .4839 | .4125 | 22.10 | .6214 | .2951 | 21.53 | .6044 | .3178 | |||
| ✓ | 15.46 | .3035 | .5465 | 15.44 | .3037 | .5558 | 19.75 | .4980 | .3737 | 19.06 | .4907 | .4105 | 22.07 | .6212 | .2889 | 21.76 | .6101 | .3097 | |||
| ✓ | 14.28 | .2490 | .5896 | 14.47 | .2549 | .5939 | 19.00 | .4724 | .4080 | 19.84 | .5118 | .3937 | 21.73 | .6082 | .3082 | 21.69 | .6087 | .3142 | |||
| ✓ | ✓ | 14.00 | .2587 | .5830 | 14.47 | .2563 | .5881 | 19.00 | .4760 | .4037 | 18.94 | .4861 | .4145 | 21.84 | .6105 | .3084 | 21.70 | .6129 | .3144 | ||
| ✓ | ✓ | 15.40 | .3009 | .5527 | 15.46 | .3073 | .5519 | 19.74 | .4986 | .3774 | 19.93 | .5188 | .3873 | 22.22 | .6257 | .2868 | 21.88 | .6154 | .3112 | ||
| ✓ | ✓ | ✓ | 15.57 | .3114 | .5467 | 15.53 | .3112 | .5515 | 20.05 | .5178 | .3736 | 19.98 | .5231 | .3871 | 22.32 | .6283 | .2907 | 22.15 | .6248 | .3030 | |
V-F2 各组成部分的消融
V-F3 消融分析
定量消融结果表明,我们的模型在包含所有组成部分的情况下在真实场景数据集中表现出最佳结果。 结果表明,尽管每个约束都增强了几何精度,但 MGS 在整个 2 视图、4 视图和 6 视图设置中的几何约束方面发挥着重要作用。 在9中,MGS 的重要性在定性结果中更加明显,如彩色和深度图像。 如果不应用 MGS,我们可以看到场景的几何形状没有被准确地捕捉到,或者存在很多密度伪影。 另一方面,正如我们在III和9中可以看出的那样,在 2-视图和 4-视图设置中,如果没有几何约束,PD 似乎并不有效。 原因是由于固有的 3D 不一致性,NeRF 在仅使用预先去模糊的图像预测正确的几何形状时会遇到更多困难,这使得感知先验无效。 随着视图数量的减少,这些困难变得更加严重。 我们可以证明,在应用感知蒸馏之前,应该达到一定程度的精确几何形状。
| [ 2-view ] | [ 4-view ] | [ 6-view ] | |||||||||||||||||
| [ Synthetic Scene ] | [ Real Scene ] | [ Synthetic Scene ] | [ Real Scene ] | [ Synthetic Scene ] | [ Real Scene ] | ||||||||||||||
| Blur Kernel | Gradient Scaling | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() |
| DN-kernel | + Naive [51] | 14.70 | .2483 | .5643 | 14.85 | .2860 | .5653 | 18.69 | .4321 | .4242 | 19.28 | .4909 | .4119 | 22.00 | .6002 | .3117 | 21.20 | .5877 | .3274 |
| DN-kernel | + MGS | 15.12 | .3025 | .5243 | 15.44 | .3037 | .5558 | 19.44 | .5295 | .3562 | 19.84 | .5118 | .3937 | 22.40 | .6832 | .2406 | 21.76 | .6101 | .3097 |
| DP-kernel | + Naive [51] | 14.01 | .2377 | .5743 | 14.95 | .2871 | .5591 | 17.25 | .3933 | .4221 | 18.85 | .4670 | .4014 | 21.55 | .6097 | .2838 | 21.49 | .6010 | .3111 |
| DP-kernel | + MGS | 15.40 | .2857 | .5289 | 15.46 | .3035 | .5465 | 20.16 | .5425 | .3024 | 19.75 | .5980 | .3737 | 23.83 | .7147 | .2072 | 22.07 | .6212 | .2889 |

V-F4 与朴素梯度缩放的比较
V-F5 预去模糊图像的不一致性
正如第 I节和 IV-C节中提到的,图像去模糊是针对每张图像独立进行的,并且由于其病态特性,在各个区域呈现出不一致的几何形状。 在图 11中,我们展示了定性比较,以揭示跨多视图训练图像的预去模糊图像的不一致性。 预去模糊图像通过应用MPRNet [56]获取。 此外,我们还附上了参考图像,这些图像是从使用全视图训练的DP-NeRF [2]渲染的,以帮助读者更好地理解不一致问题,并将预去模糊几何与近似真值几何进行比较。 比较每张图像的强调区域,预去模糊图像显示出每张图像中相对恢复良好的纹理,但几何形状在多个视图中不一致地恢复和扭曲。 这种不一致会对辐射场学习产生不利影响,因为它通过像素级颜色重建损失进行训练。 此外,图像去模糊的性能甚至在同一张图像中也因局部区域的结构复杂性而异,这使得学习模糊核具有挑战性。 由于这些原因,直接使用预滤波图像来训练辐射场很困难。 因此,引入了感知蒸馏,仅将预去模糊图像的感知纹理转移到辐射场。

VI 局限性和讨论
尽管在 3D 几何和外观方面取得了显著的改进,但仍然存在一些局限性。 首先是来自模糊核本身,特别是模糊核类型与每个场景属性之间的关系。 例如,在某些场景中,DP-NeRF [2] 的刚性模糊核的性能得到更多提升,但在其他场景中,Deblur-NeRF [1] 的灵活模糊核的性能提升更大。 这些依赖于内核的性能在各个场景中是不同的。 正如我们所发现的,灵活的内核会导致空间模糊性降低,但场景失真较高。 相反,刚性内核会导致精确的几何形状,但在优化场景时会遇到困难,因为场景中物体与相机的距离不同,而且由于固有的刚性,一些物体位于非常靠近相机的位置。 我们试图利用这两个内核并设计混合内核来最大化 Sparse-DeRF 的有效性,但结果并不如我们想象的那样。 无论是在去模糊神经辐射场 (DeRF) 中的稀疏视角设置,构建具有刚性和灵活特性的混合模糊内核都是一个很有前景的未来研究方向。 第二个是,尽管 MGS 极大地改善了 DeRF 从稀疏视角的 3D 几何形状,但我们必须为 MGS 设置适当的超参数来找到最有效的函数形状。 但是,根据场景中物体的排列,很难找到理想的函数形状,尤其是在我们上面提到的情况下。 我们通过将幅度 设置为一个较高的值来处理这些情况,以仅忽略非常近距离区域的梯度,该区域作为每个场景的详细超参数附加到附录中。 从这个意义上说,这种超参数的手动设置被认为是我们局限性之一。 我们相信,未来研究可以通过各种方法来缓解这一限制,例如为梯度缩放函数引入可学习的参数。 最后,虽然模糊输入的稀疏视图设置对于模糊输入来说是一个极其实用的场景,但由于输入数据中缺乏场景信息,在 2 视图设置中提高 DeRF 的性能非常困难。 2 视图设置的固有挑战是,稀疏重叠的 3D 空间通常会导致几何形状不准确,更可能被映射为在近或远深度区域的墙上绘制的纹理。 仍然有空间来提高 Sparse-DeRF 的视觉质量并通过最先进的生成方法(如扩散模型)解决这些问题,这些方法可以成为从稀疏视图构建 DeRF 的一个很好的未来方向。
VII 结论
在这项工作中,我们提出了 Sparse-DeRF,这是一种针对从稀疏视图设置中获得高质量去模糊神经辐射场的新型正则化方法,它考虑了从仅模糊图像获得辐射场的更实用的现实世界场景。 我们提出了两个几何约束,包括表面平滑度和调制梯度缩放,它们反映了现实世界的统计几何形状,并减轻了稀疏视图中去模糊神经辐射场系统中拉长的密度伪影。 此外,我们提出了一种感知蒸馏,以利用预去模糊图像作为感知先验,从而增强去模糊神经辐射场的锐利纹理。 我们通过在 2 视图、4 视图和 6 视图设置中展示大量的实验结果,证明了 Sparse-DeRF 的有效性,它改善了去模糊神经辐射场的空间歧义和结构失真。 由于去模糊神经辐射场在与神经渲染相关的研究领域引起了关注,我们相信我们的工作为未来的研究方向提供了一种方式,因为我们解决了从模糊图像获得去模糊神经辐射场的更实用场景。
致谢
这项工作得到了韩国国家研究基金会 (NRF) 的支持,该基金会由韩国政府 (MSIT) 提供资金 (RS-2024-00340745) 以及由韩国政府资助的电子通信研究院 (ETRI) 的资助 [24ZC1200,关于五感和情感体验的超现实交互技术研究]
参考文献
- [1] L. Ma, X. Li, J. Liao, Q. Zhang, X. Wang, J. Wang, and P. V. Sander, “Deblur-nerf: Neural radiance fields from blurry images,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 861–12 870.
- [2] D. Lee, M. Lee, C. Shin, and S. Lee, “Dp-nerf: Deblurred neural radiance field with physical scene priors,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 12 386–12 396.
- [3] P. Wang, L. Zhao, R. Ma, and P. Liu, “Bad-nerf: Bundle adjusted deblur neural radiance fields,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4170–4179.
- [4] J. Yang, M. Pavone, and Y. Wang, “Freenerf: Improving few-shot neural rendering with free frequency regularization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 8254–8263.
- [5] S. Seo, Y. Chang, and N. Kwak, “Flipnerf: Flipped reflection rays for few-shot novel view synthesis,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 883–22 893.
- [6] M. Niemeyer, J. T. Barron, B. Mildenhall, M. S. Sajjadi, A. Geiger, and N. Radwan, “Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5480–5490.
- [7] J. Huang, A. B. Lee, and D. Mumford, “Statistics of range images,” in Proceedings IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662), vol. 1. IEEE, 2000, pp. 324–331.
- [8] A. Tewari, O. Fried, J. Thies, V. Sitzmann, S. Lombardi, K. Sunkavalli, R. Martin-Brualla, T. Simon, J. Saragih, M. Nießner et al., “State of the art on neural rendering,” in Computer Graphics Forum, vol. 39, no. 2. Wiley Online Library, 2020, pp. 701–727.
- [9] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014.
- [10] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1125–1134.
- [11] S. A. Eslami, D. Jimenez Rezende, F. Besse, F. Viola, A. S. Morcos, M. Garnelo, A. Ruderman, A. A. Rusu, I. Danihelka, K. Gregor et al., “Neural scene representation and rendering,” Science, vol. 360, no. 6394, pp. 1204–1210, 2018.
- [12] A. Meka, C. Haene, R. Pandey, M. Zollhöfer, S. Fanello, G. Fyffe, A. Kowdle, X. Yu, J. Busch, J. Dourgarian et al., “Deep reflectance fields: high-quality facial reflectance field inference from color gradient illumination,” ACM Transactions on Graphics (TOG), vol. 38, no. 4, pp. 1–12, 2019.
- [13] T. Sun, J. T. Barron, Y.-T. Tsai, Z. Xu, X. Yu, G. Fyffe, C. Rhemann, J. Busch, P. Debevec, and R. Ramamoorthi, “Single image portrait relighting,” ACM Transactions on Graphics (TOG), vol. 38, no. 4, pp. 1–12, 2019.
- [14] H. Kim, P. Garrido, A. Tewari, W. Xu, J. Thies, M. Niessner, P. Pérez, C. Richardt, M. Zollhöfer, and C. Theobalt, “Deep video portraits,” ACM transactions on graphics (TOG), vol. 37, no. 4, pp. 1–14, 2018.
- [15] L. Liu, W. Xu, M. Zollhoefer, H. Kim, F. Bernard, M. Habermann, W. Wang, and C. Theobalt, “Neural rendering and reenactment of human actor videos,” ACM Transactions on Graphics (TOG), vol. 38, no. 5, pp. 1–14, 2019.
- [16] S. Lombardi, T. Simon, J. Saragih, G. Schwartz, A. Lehrmann, and Y. Sheikh, “Neural volumes: Learning dynamic renderable volumes from images,” arXiv preprint arXiv:1906.07751, 2019.
- [17] V. Sitzmann, M. Zollhöfer, and G. Wetzstein, “Scene representation networks: Continuous 3d-structure-aware neural scene representations,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [18] Z. Shu, E. Yumer, S. Hadap, K. Sunkavalli, E. Shechtman, and D. Samaras, “Neural face editing with intrinsic image disentangling,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5541–5550.
- [19] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021.
- [20] J. T. Kajiya and B. P. Von Herzen, “Ray tracing volume densities,” ACM SIGGRAPH computer graphics, vol. 18, no. 3, pp. 165–174, 1984.
- [21] L. Liu, J. Gu, K. Zaw Lin, T.-S. Chua, and C. Theobalt, “Neural sparse voxel fields,” Advances in Neural Information Processing Systems, vol. 33, pp. 15 651–15 663, 2020.
- [22] A. Yu, R. Li, M. Tancik, H. Li, R. Ng, and A. Kanazawa, “Plenoctrees for real-time rendering of neural radiance fields,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 5752–5761.
- [23] A. Chen, Z. Xu, A. Geiger, J. Yu, and H. Su, “Tensorf: Tensorial radiance fields,” in European Conference on Computer Vision. Springer, 2022, pp. 333–350.
- [24] T. Müller, A. Evans, C. Schied, and A. Keller, “Instant neural graphics primitives with a multiresolution hash encoding,” ACM Transactions on Graphics (ToG), vol. 41, no. 4, pp. 1–15, 2022.
- [25] S. Fridovich-Keil, A. Yu, M. Tancik, Q. Chen, B. Recht, and A. Kanazawa, “Plenoxels: Radiance fields without neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5501–5510.
- [26] B. Attal, J.-B. Huang, M. Zollhöfer, J. Kopf, and C. Kim, “Learning neural light fields with ray-space embedding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 19 819–19 829.
- [27] B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering,” ACM Transactions on Graphics (ToG), vol. 42, no. 4, pp. 1–14, 2023.
- [28] Z. Li, S. Niklaus, N. Snavely, and O. Wang, “Neural scene flow fields for space-time view synthesis of dynamic scenes,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 6498–6508.
- [29] K. Park, U. Sinha, J. T. Barron, S. Bouaziz, D. B. Goldman, S. M. Seitz, and R. Martin-Brualla, “Nerfies: Deformable neural radiance fields,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 5865–5874.
- [30] A. Pumarola, E. Corona, G. Pons-Moll, and F. Moreno-Noguer, “D-nerf: Neural radiance fields for dynamic scenes,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 318–10 327.
- [31] T. Li, M. Slavcheva, M. Zollhoefer, S. Green, C. Lassner, C. Kim, T. Schmidt, S. Lovegrove, M. Goesele, R. Newcombe et al., “Neural 3d video synthesis from multi-view video,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5521–5531.
- [32] S. Bi, Z. Xu, P. Srinivasan, B. Mildenhall, K. Sunkavalli, M. Hašan, Y. Hold-Geoffroy, D. Kriegman, and R. Ramamoorthi, “Neural reflectance fields for appearance acquisition,” arXiv preprint arXiv:2008.03824, 2020.
- [33] P. P. Srinivasan, B. Deng, X. Zhang, M. Tancik, B. Mildenhall, and J. T. Barron, “Nerv: Neural reflectance and visibility fields for relighting and view synthesis,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7495–7504.
- [34] P. Wang, L. Liu, Y. Liu, C. Theobalt, T. Komura, and W. Wang, “Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction,” arXiv preprint arXiv:2106.10689, 2021.
- [35] V. Rudnev, M. Elgharib, W. Smith, L. Liu, V. Golyanik, and C. Theobalt, “Nerf for outdoor scene relighting,” in European Conference on Computer Vision. Springer, 2022, pp. 615–631.
- [36] S. Peng, J. Dong, Q. Wang, S. Zhang, Q. Shuai, X. Zhou, and H. Bao, “Animatable neural radiance fields for modeling dynamic human bodies,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14 314–14 323.
- [37] P. Hedman, P. P. Srinivasan, B. Mildenhall, J. T. Barron, and P. Debevec, “Baking neural radiance fields for real-time view synthesis,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 5875–5884.
- [38] T. Neff, P. Stadlbauer, M. Parger, A. Kurz, J. H. Mueller, C. R. A. Chaitanya, A. Kaplanyan, and M. Steinberger, “Donerf: Towards real-time rendering of compact neural radiance fields using depth oracle networks,” in Computer Graphics Forum, vol. 40, no. 4. Wiley Online Library, 2021, pp. 45–59.
- [39] Y.-J. Yuan, Y.-T. Sun, Y.-K. Lai, Y. Ma, R. Jia, and L. Gao, “Nerf-editing: geometry editing of neural radiance fields,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 353–18 364.
- [40] M. Kim, S. Seo, and B. Han, “Infonerf: Ray entropy minimization for few-shot neural volume rendering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 912–12 921.
- [41] A. Yu, V. Ye, M. Tancik, and A. Kanazawa, “pixelnerf: Neural radiance fields from one or few images,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4578–4587.
- [42] A. Jain, M. Tancik, and P. Abbeel, “Putting nerf on a diet: Semantically consistent few-shot view synthesis,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 5885–5894.
- [43] B. Mildenhall, P. Hedman, R. Martin-Brualla, P. P. Srinivasan, and J. T. Barron, “Nerf in the dark: High dynamic range view synthesis from noisy raw images,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 190–16 199.
- [44] N. Pearl, T. Treibitz, and S. Korman, “Nan: Noise-aware nerfs for burst-denoising,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 672–12 681.
- [45] Q. Wang, Z. Wang, K. Genova, P. P. Srinivasan, H. Zhou, J. T. Barron, R. Martin-Brualla, N. Snavely, and T. Funkhouser, “Ibrnet: Learning multi-view image-based rendering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4690–4699.
- [46] D. Lee, J. Oh, J. Rim, S. Cho, and K. M. Lee, “Exblurf: Efficient radiance fields for extreme motion blurred images,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 639–17 648.
- [47] C. Peng and R. Chellappa, “Pdrf: progressively deblurring radiance field for fast scene reconstruction from blurry images,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 2, 2023, pp. 2029–2037.
- [48] N. Max, “Optical models for direct volume rendering,” IEEE Transactions on Visualization and Computer Graphics, vol. 1, no. 2, pp. 99–108, 1995.
- [49] K. M. Lynch and F. C. Park, Modern robotics. Cambridge University Press, 2017.
- [50] O. Rodrigues, “De l’attraction des sphéroïdes,” in Correspondence Sur l’École Impériale Polytechnique, 1816, pp. 361–385.
- [51] J. Philip and V. Deschaintre, “Floaters no more: Radiance field gradient scaling for improved near-camera training,” 2023.
- [52] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14. Springer, 2016, pp. 694–711.
- [53] J. L. Schönberger, E. Zheng, J.-M. Frahm, and M. Pollefeys, “Pixelwise view selection for unstructured multi-view stereo,” in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14. Springer, 2016, pp. 501–518.
- [54] J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4104–4113.
- [55] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [56] S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, and L. Shao, “Multi-stage progressive image restoration,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14 821–14 831.
- [57] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [58] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595.
![[Uncaptioned image]](dogyoon_lee.jpg) |
Dogyoon Lee is a Ph.D candidate at the School of Electrical and Electronic Engineering, Yonsei University. He received his B.S. degree in Electrical and Electronic Engineering from Yonsei University, Seoul, South Korea, in 2019. His current research interests focus on 3D computer vision including Neural rendering and its applications in real-world scenarios, 3D from Images, 3D generative models, 3D reconstruction, and Image processing. |
![[Uncaptioned image]](donghyung_kim.jpeg) |
Donghyeong Kim is a Ph.D candidate at the School of Electrical and Electronic Engineering, Yonsei University. He received his B.S. degree in Electrical and Electronic Engineering from Yonsei University, Seoul, South Korea, in 2021. degree. His current research interests include anomaly detection, 3D computer vision, generative models, 3D reconstruction, and Image processing. |
![[Uncaptioned image]](jungho_lee.jpeg) |
Jungho Lee is a Ph.D candidate at the School of Electrical and Electronic Engineering, Yonsei University. He received his B.S. degree in Electrical and Electronic Engineering from Yonsei University, Seoul, Korea, in 2021. His current research interests focus on neural rendering and human motion analysis in real-world conditions, with various mathematical machine learning tools such as neural ordinary differential equations. |
![[Uncaptioned image]](minhyeok_lee.jpeg) |
Minhyeok Lee is a dedicated Computer Vision and ML/DL Researcher with a focus on segmentation, autonomous driving, detection & recognition, and novel view synthesis. Currently pursuing an Integrated M.S./Ph.D. in Electrical and Electronic Engineering at Yonsei University. His research spans various areas such as salient object detection, video object segmentation, camouflaged object detection, lane detection, and monocular depth estimation. |
![[Uncaptioned image]](Seunghoon_lee.jpeg) |
Seunghoon Lee received the B.S degree in Electronic Engineering of Inha University, Incheon, Korea in 2020. He is currently an integrated MS/Ph.D degree student in Electrical and Electronic Engineering, at Yonsei University. His research interests are video object segmentation, salient object detection, and super-resolution. |
![[Uncaptioned image]](sangyoun_lee.jpeg) |
Sangyoun Lee received his Ph.D. degree in Electrical and Computer Engineering from the Georgia Institute of Technology, Atlanta, Georgia, USA, in 1999. He is currently a professor at the School of Electrical and Electronic Engineering. His research interests include all aspects of computer vision, with a special focus on video codecs. |
附录 A 样本空间可视化
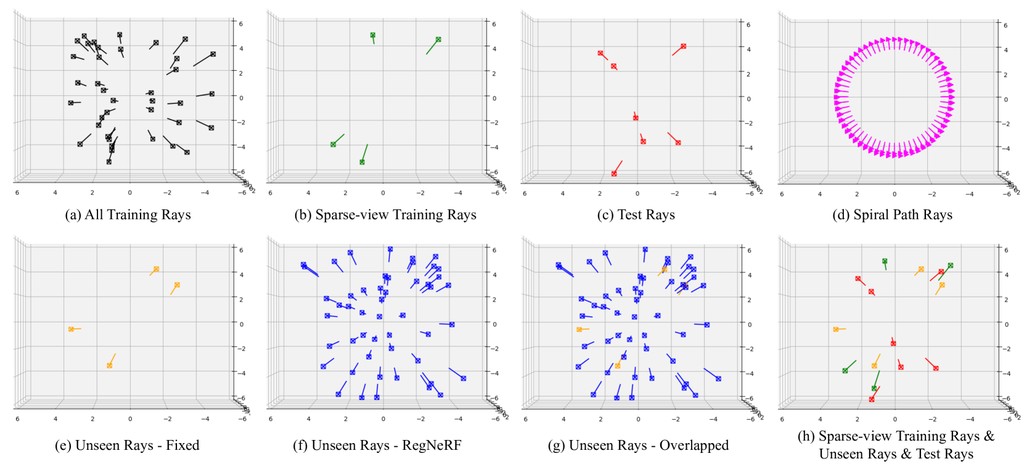
在图 12 中,我们展示了从 RegNeRF [6] 获取的未见光线的样本空间可视化以及我们固定的未见光线,这些光线用于论文中的公平比较。 由于他们在每次训练中随机从样本空间中采样相机姿态,因此我们从样本空间中采样了 个未见相机姿态来显示样本空间的近似覆盖范围。 正如我们在图 12 中看到的,用于我们实验的固定未见光线仍在 RegNeRF 的样本空间覆盖范围内。 此外,训练相机姿态和固定的未见训练光线与测试光线没有显著重叠,这也并没有打破新视图合成训练和测试规则。 因此,使用固定未见光线作为 RegNeRF 的替代未见光线并不是问题。 正如我们在主论文的第 V-C 节中提到的,我们利用固定未见光线来训练我们的模型,以便在广泛的实验中公平地评估性能,因为 RegNeRF 中未见光线生成的随机性使得难以理解每个组件的有效性。
| Real Scene | Ball | Basket | Buick | Coffee | Decoration | Girl | Heron | Parterre | Puppet | Stair |
| -view | 1, 12 | 12, 33 | 11, 39 | 3, 10 | 1, 19 | 9, 16 | 11, 35 | 8, 26 | 9, 31 | 13, 26 |
| -view | 1, 12, 18, 22 | 1, 12, 22, 33 | 5, 11, 20, 39 | 3, 10, 15, 26 | 1, 19, 22, 39 | 2, 9, 16, 32 | 4, 11, 18, 35 | 1, 8, 13, 26 | 9, 13, 21, 31 | 4, 13, 16, 26 |
| -view | 1, 5, 10, 12, 18, 22 | 1, 8, 12, 17, 22, 33 | 5, 11, 17, 20, 34, 39 | 3, 10, 11, 15, 21, 26 | 1, 14, 19, 22, 27, 39 | 2, 9, 16, 24, 32, 37 | 4, 11, 18, 23, 27, 35 | 1, 8, 13, 17, 26, 28 | 7, 9, 13, 21, 23, 31 | 2, 4, 13, 16, 26, 34 |
| Synthetic Scene | Cozyroom | Factory | Pool | Tanabata | Trolley | |||||
| -view | 2, 17 | 3, 19 | 10, 23 | 1, 7 | 13, 23 | |||||
| -view | 2, 17, 23, 29 | 3, 14, 19, 33 | 5, 10, 15, 23 | 1, 7, 11, 22 | 7, 13, 23, 31 | |||||
| -view | 2, 14, 17, 21, 23, 29 | 1, 3, 14, 19, 28, 33 | 1, 5, 10, 15, 20, 23 | 1, 7, 11, 18, 22, 27 | 7, 13, 20, 23, 27, 31 |
| Synthetic Scene | Cozyroom | Factory | Pool | Tanabata | Trolley | |||||
| 10.0 | 10.0 | 10.0 | 1.0 | 10.0 | ||||||
| 1.75 | 1.75 | 1.75 | 1.5 | 1.75 | ||||||
| Real Scene | Ball | Basket | Buick | Coffee | Decoration | Girl | Heron | Parterre | Puppet | Stair |
| 1.0 | 1.0 | 10.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 10.0 | 1.0 | |
| 1.2 | 0.67 | 1.75 | 0.67 | 0.5 | 0.5 | 0.5 | 0.5 | 1.75 | 0.5 |
附录 B 其他实现细节
B-A 训练场景索引
为了在未来的研究中进行公平比较,我们展示了在 TABLE V 中用于训练 Sparse-DeRF 的每个场景的图像索引。 这些索引是我们从每个场景的训练图像中手动选择的,正如我们在主文中提到的。 注意,2-视图和 4-视图设置的索引是 6-视图设置的子集。
B-B 整个场景的参数
在 TABLE VI 中,我们展示了 MGS 用于整个场景的超参数,包括正弦函数的周期 和幅度 。 正如我们在主文中的 Section IV-B 中指出的那样,我们将幅度 设置为一个高值,以便仅忽略非常近距离区域的梯度,例如 Buick、Puppet、Cozyroom、Factory、Pool 和 Trolley 等场景。 请参考主文中关于该函数形状根据参数变化的图形。
附录 C 其他定量结果
C-A 整个场景的定量结果
C-B 整个场景的复杂优化问题
CC 与整个场景的朴素梯度缩放比较
我们展示了整个场景的定量比较结果,比较了我们调制的梯度缩放 (MGS) 和 [51] 的朴素梯度缩放,从 2 视图、4 视图和 6 视图设置中得到的定量比较结果分别在 TABLEXVII、 XVIII 和 XIX 中。
| Synthetic Scene | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| Naive NeRF [19] | 14.24 | .2186 | .6867 | 21.07 | .6127 | .3644 | 18.59 | .3575 | .4288 | 10.84 | .1517 | .6500 | 10.82 | .1591 | .6593 | 15.11 | .2999 | .5578 |
| MPR [56]+NeRF | 14.43 | .2250 | .6858 | 21.08 | .6111 | .3671 | 18.72 | .3676 | .4228 | 11.03 | .1456 | .6553 | 10.56 | .1535 | .6663 | 15.16 | .3006 | .5595 |
| Deblur-NeRF [1] | 14.14 | .2009 | .6647 | 20.58 | .5768 | .3443 | 18.37 | .3247 | .4061 | 11.56 | .1704 | .6075 | 11.05 | .1690 | .6425 | 15.14 | .2884 | .5330 |
| DP-NeRF [2] | 14.14 | .2091 | .6540 | 20.71 | .5752 | .3487 | 18.38 | .3276 | .4127 | 11.21 | .1482 | .6247 | 10.88 | .1536 | .6543 | 15.06 | .2827 | .5389 |
| RegNeRF [6] (No kernel) | 14.57 | .2523 | .6680 | 17.13 | .4616 | .3808 | 14.23 | .1473 | .7298 | 13.01 | .2408 | .5956 | 14.04 | .3227 | .5602 | 14.60 | .2849 | .5869 |
| RegNeRF [6] (w/DP-kernel) | 14.20 | .2214 | .6412 | 18.88 | .5136 | .3476 | 13.03 | .1003 | .6845 | 9.21 | .0815 | .6920 | 10.86 | .1644 | .6657 | 13.24 | .2162 | .6062 |
| Sparse-DeRF (w/DN-kernel) - Ours | 14.27 | .2200 | .6564 | 20.57 | .5675 | .3589 | 19.81 | .3330 | .4058 | 11.67 | .1827 | .5947 | 11.28 | .1800 | .6298 | 15.52 | .2966 | .5291 |
| Sparse-DeRF (w/DP-kernel) - Ours | 14.10 | .2116 | .6413 | 18.97 | .5206 | .3417 | 20.32 | .3488 | .4056 | 12.00 | .1943 | .5902 | 11.36 | .1769 | .6422 | 15.35 | .2904 | .5242 |
| Real Scene | Ball | Basket | Buick | Coffee | Decoration | |||||||||||||
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| Naive NeRF [19] | 18.45 | .4363 | .5693 | 13.32 | .2595 | .6131 | 13.49 | .2620 | .5680 | 17.76 | .5249 | .4807 | 12.25 | .1718 | .6738 | |||
| MPR [56]+NeRF | 18.69 | .4413 | .5659 | 13.09 | .2505 | .6194 | 13.31 | .2574 | .5706 | 18.13 | .5243 | .4869 | 12.41 | .1761 | .6735 | |||
| Deblur-NeRF [1] | 18.80 | .4325 | .5521 | 12.86 | .2414 | .5947 | 13.11 | .2446 | .5609 | 18.66 | .5272 | .4696 | 12.09 | .1508 | .6722 | |||
| DP-NeRF [2] | 18.22 | .4200 | .5611 | 13.24 | .2263 | .6062 | 13.43 | .2480 | .5571 | 18.15 | .5191 | .4876 | 12.34 | .1672 | .6675 | |||
| RegNeRF [6] (No kernel) | 20.48 | .4951 | .5398 | 15.53 | .3388 | .5403 | 17.05 | .4241 | .4361 | 23.24 | .6950 | .3505 | 10.94 | .0816 | .7545 | |||
| RegNeRF [6] (w/DP-kernel) | 18.58 | .4297 | .5565 | 13.49 | .2429 | .5985 | 12.51 | .2199 | .5579 | 15.71 | .4280 | .5370 | 11.15 | .0927 | .7520 | |||
| Sparse-DeRF (w/DN-kernel) - Ours | 20.07 | .4612 | .5290 | 13.62 | .2678 | .5835 | 14.38 | .3182 | .4913 | 19.51 | .6048 | .4146 | 13.09 | .2173 | .6256 | |||
| Sparse-DeRF (w/DP-kernel) - Ours | 20.09 | .4583 | .5244 | 14.05 | .2890 | .5555 | 13.78 | .2864 | .5036 | 19.67 | .6084 | .4096 | 13.11 | .2192 | .6192 | |||
| Real Scene | Girl | Heron | Parterre | Puppet | Stair | Average | ||||||||||||
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| Naive NeRF [19] | 11.06 | .2298 | .6304 | 13.69 | .1564 | .5683 | 15.20 | .2528 | .6462 | 14.34 | .2937 | .6156 | 14.27 | .0474 | .6385 | 14.38 | .2635 | .6004 |
| MPR [56]+NeRF | 10.80 | .1977 | .6424 | 13.51 | .1538 | .5652 | 15.45 | .2667 | .6422 | 14.22 | .2844 | .6135 | 14.15 | .0414 | .6392 | 14.38 | .2594 | .6019 |
| Deblur-NeRF [1] | 10.94 | .2031 | .6436 | 13.97 | .1459 | .5499 | 15.02 | .2320 | .6431 | 14.28 | .2764 | .6036 | 14.40 | .0525 | .6313 | 14.41 | .2506 | .5921 |
| DP-NeRF [2] | 11.14 | .2151 | .6485 | 13.63 | .1473 | .5376 | 14.70 | .2226 | .6348 | 14.32 | .2887 | .5930 | 14.38 | .0521 | .6104 | 14.36 | .2506 | .5904 |
| RegNeRF [6] (No kernel) | 8.31 | .0602 | .7545 | 11.43 | .0951 | .6687 | 15.58 | .2709 | .6510 | 16.02 | .3548 | .5739 | 16.30 | .1816 | .6182 | 15.49 | .2997 | .5888 |
| RegNeRF [6] (w/DP-kernel) | 7.86 | .0419 | .7737 | 11.57 | .0783 | .6246 | 12.54 | .1524 | .7091 | 10.67 | .1331 | .6604 | 13.49 | .0170 | .6770 | 12.76 | .1836 | .6447 |
| Sparse-DeRF (w/DN-kernel) - Ours | 12.85 | .3418 | .5585 | 14.30 | .1706 | .5197 | 16.61 | .2903 | .5912 | 14.91 | .3141 | .5886 | 15.97 | .1255 | .6125 | 15.53 | .3112 | .5515 |
| Sparse-DeRF (w/DP-kernel) - Ours | 13.11 | .3707 | .5486 | 14.17 | .1669 | .5285 | 16.19 | .2527 | .5908 | 15.25 | .3277 | .5739 | 16.30 | .1343 | .6133 | 15.57 | .3114 | .5467 |
| Synthetic Scene | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| Naive NeRF [19] | 16.63 | .3494 | .5861 | 22.75 | .6935 | .2903 | 25.92 | .6419 | .2495 | 16.15 | .4408 | .4635 | 18.66 | .5380 | .4104 | 20.02 | .5327 | .4000 |
| MPR [56]+NeRF | 16.97 | .3570 | .5789 | 22.86 | .7014 | .2895 | 25.77 | .6436 | .2465 | 16.78 | .4827 | .4361 | 17.61 | .5056 | .4272 | 20.00 | .5381 | .3956 |
| Deblur-NeRF [1] | 17.26 | .3740 | .5088 | 25.51 | .7767 | .1897 | 23.38 | .5068 | .2649 | 15.91 | .4209 | .4198 | 17.91 | .5213 | .3661 | 19.99 | .5199 | .3499 |
| DP-NeRF [2] | 19.20 | .5175 | .3813 | 21.50 | .6242 | .1980 | 21.85 | .4235 | .3117 | 17.30 | .5265 | .3381 | 19.35 | .5765 | .3084 | 19.84 | .5336 | .3075 |
| RegNeRF [6] (No kernel) | 16.32 | .3441 | .5876 | 23.25 | .7155 | .2663 | 16.21 | .2040 | .6451 | 17.35 | .4915 | .4509 | 18.81 | .5447 | .4020 | 18.39 | .4600 | .4704 |
| RegNeRF [6] (w/DP-kernel) | 16.71 | .3497 | .4683 | 21.37 | .6471 | .1802 | 15.17 | .1740 | .6666 | 10.27 | .1165 | .6911 | 18.66 | .5412 | .4067 | 16.44 | .3657 | .4826 |
| Sparse-DeRF (w/DN-kernel) - Ours | 16.91 | .3693 | .5357 | 25.79 | .7872 | .1801 | 25.48 | .6042 | .2405 | 16.58 | .4705 | .3793 | 18.10 | .5514 | .3414 | 20.57 | .5565 | .3354 |
| Sparse-DeRF (w/DP-kernel) - Ours | 18.99 | .4770 | .4034 | 26.51 | .8051 | .1627 | 23.33 | .4888 | .2733 | 17.51 | .5371 | .3356 | 18.92 | .5799 | .3126 | 21.05 | .5776 | .2975 |
| Real Scene | Ball | Basket | Buick | Coffee | Decoration | |||||||||||||
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| Naive NeRF [19] | 21.61 | .5043 | .4992 | 17.23 | fv.4384 | .4746 | 19.20 | .5508 | .3579 | 23.21 | .7341 | .3281 | 14.78 | .3299 | .5640 | |||
| MPR [56]+NeRF | 21.46 | .5046 | .4992 | 16.98 | .4260 | .4766 | 19.39 | .5486 | .3629 | 22.98 | .7267 | .3284 | 14.88 | .3460 | .5532 | |||
| Deblur-NeRF [1] | 21.90 | .5182 | .4609 | 17.15 | .4331 | .4316 | 19.34 | .5278 | .3407 | 23.10 | .7302 | .2873 | 14.94 | .3201 | .5471 | |||
| DP-NeRF [2] | 23.20 | .5842 | .3847 | 17.42 | .4046 | .4658 | 19.26 | .5323 | .3374 | 24.05 | .7597 | .2624 | 14.98 | .3018 | .5618 | |||
| RegNeRF [6] (No kernel) | 21.16 | .5100 | .4952 | 18.12 | .4711 | .4569 | 20.11 | .5821 | .3412 | 26.14 | .7837 | .2965 | 11.35 | .1045 | .7030 | |||
| RegNeRF [6] (w/DP-kernel) | 19.13 | .4391 | .4042 | 17.42 | .4165 | .3746 | 13.31 | .2697 | .4715 | 16.40 | .4684 | .5239 | 11.07 | .1058 | .7089 | |||
| Sparse-DeRF (w/DN-kernel) - Ours | 22.28 | .5506 | .4334 | 18.69 | .5058 | .3774 | 19.28 | .5414 | .3371 | 26.76 | .8126 | .2419 | 17.12 | .4192 | .4761 | |||
| Sparse-DeRF (w/DP-kernel) - Ours | 23.39 | .6010 | .3806 | 20.41 | .5451 | .3305 | 19.48 | .5531 | .3251 | 27.77 | .8364 | .2049 | 16.33 | .3914 | .4950 | |||
| Real Scene | Girl | Heron | Parterre | Puppet | Stair | Average | ||||||||||||
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| Naive NeRF [19] | 15.91 | .5659 | .4161 | 18.83 | .4263 | .4086 | 20.64 | .4857 | .4822 | 18.15 | .4619 | .4470 | 20.27 | .3622 | .5033 | 18.98 | .4860 | .4481 |
| MPR [56]+NeRF | 15.60 | .5617 | .4224 | 18.91 | .4217 | .4173 | 20.76 | .4893 | .4781 | 17.96 | .4548 | .4468 | 19.94 | .3493 | .4993 | 18.89 | .4829 | .4484 |
| Deblur-NeRF [1] | 15.62 | .5351 | .4206 | 18.85 | .4350 | .3398 | 19.71 | .4318 | .4549 | 17.77 | .4400 | .4358 | 20.49 | .3901 | .4326 | 18.89 | .4761 | .4151 |
| DP-NeRF [2] | 15.40 | .5237 | .4318 | 18.68 | .4292 | .3352 | 17.62 | .2987 | .4991 | 17.61 | .4369 | .4313 | 19.44 | .3107 | .4657 | 18.77 | .4582 | .4175 |
| RegNeRF [6] (No kernel) | 10.24 | .1511 | .7199 | 18.86 | .4235 | .4194 | 18.68 | .4238 | .5163 | 18.66 | .4788 | .4327 | 21.06 | .3975 | .4706 | 18.44 | .4326 | .4852 |
| RegNeRF [6] (w/DP-kernel) | 9.52 | .1304 | .7119 | 11.56 | .0595 | .6149 | 13.61 | .1721 | .7245 | 11.10 | .1342 | .6914 | 12.73 | .0249 | .6610 | 13.59 | .2221 | .5887 |
| Sparse-DeRF (w/DN-kernel) - Ours | 16.95 | .5975 | .3823 | 19.04 | .4558 | .3315 | 20.74 | .4916 | .4323 | 18.11 | .4616 | .4202 | 20.80 | .3948 | .4386 | 19.98 | .5231 | .3871 |
| Sparse-DeRF (w/DP-kernel) - Ours | 16.47 | .5855 | .3835 | 19.09 | .4624 | .3194 | 18.36 | .3375 | .4715 | 17.97 | .4612 | .4206 | 21.25 | .4045 | .4044 | 20.05 | .5178 | .3736 |
| Synthetic Scene | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| Naive NeRF [19] | 17.12 | .3663 | .5663 | 23.12 | .7160 | .2713 | 28.42 | .7463 | .2106 | 19.92 | .5889 | .3866 | 19.68 | .5749 | .3853 | 21.65 | .5985 | .3638 |
| MPR [56]+NeRF | 17.21 | .3754 | .5649 | 23.06 | .7087 | .2749 | 28.38 | .7461 | .2093 | 20.23 | .5966 | .3783 | 19.71 | .5728 | .3870 | 21.72 | .5999 | .3629 |
| Deblur-NeRF [1] | 18.77 | .5048 | .3890 | 26.67 | .8214 | .1475 | 27.50 | .7116 | .1783 | 21.10 | .6693 | .2517 | 21.58 | .6921 | .2263 | 23.12 | .6798 | .2386 |
| DP-NeRF [2] | 21.63 | .6402 | .2984 | 27.63 | .8475 | .1224 | 25.36 | .6227 | .1861 | 21.27 | .6818 | .2023 | 22.49 | .7259 | .1899 | 23.68 | .7036 | .1998 |
| RegNeRF [6] (No kernel) | 17.04 | .3690 | .5729 | 23.40 | .7205 | .2649 | 18.05 | .3610 | .4870 | 20.33 | .5980 | .3745 | 19.63 | .5760 | .3833 | 19.69 | .5249 | .4165 |
| RegNeRF [6] (w/DP-kernel) | 21.03 | .6273 | .3076 | 27.73 | .8455 | .1238 | 18.04 | .3173 | .4987 | 21.84 | .7246 | .2022 | 19.36 | .5661 | .3908 | 21.60 | .6162 | .3046 |
| Sparse-DeRF (w/DN-kernel) - Ours | 18.33 | .5144 | .4004 | 26.63 | .8184 | .1513 | 28.16 | .7344 | .1755 | 22.06 | .6988 | .2245 | 21.43 | .6855 | .2380 | 23.32 | .6903 | .2379 |
| Sparse-DeRF (w/DP-kernel) - Ours | 21.29 | .6179 | .3261 | 27.34 | .8340 | .1298 | 28.19 | .7365 | .1606 | 22.30 | .7233 | .2017 | 22.21 | .7159 | .2036 | 24.27 | .7255 | .2044 |
| Real Scene | Ball | Basket | Buick | Coffee | Decoration | |||||||||||||
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| Naive NeRF [19] | 22.12 | .5359 | .4818 | 21.39 | .6253 | .3328 | 21.21 | .6197 | .3100 | 22.73 | .7163 | .3397 | 19.14 | .5118 | .4460 | |||
| MPR [56]+NeRF | 22.15 | .5365 | .4745 | 21.39 | .6261 | .3294 | 21.11 | .6192 | .3063 | 22.56 | .7087 | .3435 | 18.31 | .4837 | .4735 | |||
| Deblur-NeRF [1] | 24.47 | .6473 | .3342 | 23.63 | .7204 | .2108 | 21.45 | .6285 | .2625 | 23.70 | .7604 | .2588 | 17.74 | .4790 | .4296 | |||
| DP-NeRF [2] | 24.73 | .6651 | .3107 | 23.24 | .6643 | .2494 | 21.65 | .6418 | .2445 | 25.51 | .7949 | .2170 | 17.48 | .4725 | .4457 | |||
| RegNeRF [6] (No kernel) | 21.98 | .5312 | .4677 | 21.67 | .6129 | .3406 | 21.16 | .6215 | .3051 | 25.67 | .7716 | .3105 | 12.45 | .1569 | .7061 | |||
| RegNeRF [6] (w/DP-kernel) | 25.02 | .6719 | .2953 | 22.95 | .6554 | .2501 | 21.57 | .6456 | .2462 | 23.38 | .7393 | .2341 | 11.43 | .1247 | .6932 | |||
| Sparse-DeRF (w/DN-kernel) - Ours | 23.76 | .6184 | .3607 | 23.39 | .7155 | .2329 | 21.66 | .6405 | .2585 | 27.84 | .8388 | .2068 | 19.98 | .5553 | .3644 | |||
| Sparse-DeRF (w/DP-kernel) - Ours | 24.80 | .6643 | .3200 | 23.32 | .6789 | .2455 | 21.27 | .6234 | .2662 | 28.91 | .8525 | .1902 | 19.69 | .5440 | .3672 | |||
| Real Scene | Girl | Heron | Parterre | Puppet | Stair | Average | ||||||||||||
| PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| Naive NeRF [19] | 18.43 | .6500 | .3335 | 18.91 | .4204 | .4307 | 21.82 | .5487 | .4351 | 19.52 | .5242 | .3933 | 21.01 | .3602 | .5111 | 20.63 | .5513 | .4014 |
| MPR [56]+NeRF | 18.61 | .6580 | .3324 | 18.97 | .4220 | .4287 | 21.78 | .5477 | .4358 | 19.84 | .5357 | .3793 | 21.27 | .3758 | .4070 | 20.60 | .5513 | .4010 |
| Deblur-NeRF [1] | 18.09 | .6582 | .3055 | 19.40 | .4709 | .3166 | 21.92 | .5557 | .3872 | 20.58 | .5834 | .3226 | 22.60 | .4993 | .3349 | 21.36 | .6003 | .3163 |
| DP-NeRF [2] | 18.16 | .6622 | .3020 | 19.58 | .4991 | .2905 | 22.36 | .5879 | .3350 | 20.65 | .5868 | .2988 | 23.40 | .5624 | .2986 | 21.68 | .6137 | .2992 |
| RegNeRF [6] (No kernel) | 11.06 | .1966 | .7091 | 18.96 | .4218 | .4292 | 21.83 | .5526 | .4353 | 20.07 | .5309 | .3827 | 21.69 | .3938 | .4963 | 19.65 | .4790 | .4583 |
| RegNeRF [6] (w/DP-kernel) | 10.38 | .1434 | .7200 | 12.83 | .1019 | .5757 | 21.34 | .5159 | .3415 | 20.49 | .5799 | .3113 | 13.08 | .2613 | .6581 | 18.25 | .4439 | .4326 |
| Sparse-DeRF (w/DN-kernel) - Ours | 18.86 | .6860 | .2769 | 19.63 | .5011 | .2992 | 22.15 | .5703 | .3787 | 20.81 | .5882 | .3149 | 23.42 | .5340 | .3374 | 22.15 | .6248 | .3030 |
| Sparse-DeRF (w/DP-kernel) - Ours | 18.96 | .6887 | .2744 | 19.59 | .5051 | .2808 | 22.57 | .5994 | .3317 | 20.60 | .5756 | .3124 | 23.48 | .5509 | .3189 | 22.32 | .6283 | .2907 |
| Kernel Type | Synthetic Scene | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||||
| SS | MGS | PD | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DP-kernel | 14.14 | .2091 | .6540 | 20.71 | .5752 | .3487 | 18.38 | .3276 | .4127 | 11.21 | .1482 | .6247 | 10.88 | .1536 | .6543 | 15.06 | .2827 | .5389 | |||
| ✓ | 14.09 | .2008 | .6550 | 19.57 | .5321 | .3544 | 18.49 | .3178 | .4271 | 11.21 | .1552 | .6243 | 11.04 | .1801 | .6331 | 14.88 | .2772 | .5388 | |||
| ✓ | 14.33 | .2088 | .6496 | 18.89 | .5032 | .3577 | 20.30 | .3467 | .4017 | 11.69 | .1748 | .6067 | 11.78 | .1948 | .6289 | 15.40 | .2857 | .5289 | |||
| ✓ | 14.19 | .2035 | .6620 | 19.82 | .5404 | .3451 | 18.96 | .3350 | .4125 | 11.16 | .1457 | .6408 | 11.02 | .1733 | .6350 | 15.03 | .2796 | .5391 | |||
| ✓ | ✓ | 13.95 | .1963 | .6629 | 18.81 | .5010 | .3637 | 18.57 | .3404 | .4148 | 11.00 | .1501 | .6259 | 10.25 | .1357 | .6730 | 14.52 | .2647 | .5481 | ||
| ✓ | ✓ | 14.24 | .2228 | .6439 | 20.16 | .5560 | .3391 | 20.37 | .3526 | .4004 | 11.55 | .1710 | .5999 | 11.16 | .1744 | .6241 | 15.50 | .2954 | .5215 | ||
| ✓ | ✓ | ✓ | 14.10 | .2116 | .6413 | 18.97 | .5206 | .3417 | 20.32 | .3488 | .4056 | 12.00 | .1943 | .5902 | 11.36 | .1769 | .6422 | 15.35 | .2904 | .5242 | |
| DN-kernel | 14.14 | .2009 | .6647 | 20.58 | .5768 | .3443 | 18.37 | .3247 | .4061 | 11.56 | .1704 | .6075 | 11.05 | .1690 | .6425 | 15.14 | .2884 | .5330 | |||
| ✓ | 14.21 | .2177 | .6650 | 20.33 | .5663 | .3591 | 18.74 | .3200 | .4093 | 11.13 | .1547 | .6191 | 10.78 | .1554 | .6566 | 15.04 | .2828 | .5418 | |||
| ✓ | 14.20 | .2107 | .6686 | 21.02 | .5999 | .3326 | 19.64 | .3330 | .3950 | 11.55 | .1804 | .5903 | 11.48 | .1883 | .6351 | 15.12 | .3025 | .5243 | |||
| ✓ | 14.11 | .2096 | .6588 | 18.78 | .5094 | .3928 | 19.76 | .3464 | .3901 | 10.58 | .1206 | .6565 | 10.99 | .1648 | .6289 | 14.84 | .2702 | .5454 | |||
| ✓ | ✓ | 14.24 | .2222 | .6619 | 21.02 | .5918 | .3544 | 18.77 | .3197 | .4115 | 11.12 | .1642 | .6217 | 10.41 | .1467 | .6452 | 15.11 | .2889 | .5389 | ||
| ✓ | ✓ | 14.14 | .2189 | .6622 | 20.10 | .5555 | .3761 | 20.11 | .3372 | .3939 | 11.49 | .1753 | .5975 | 11.99 | .2026 | .6299 | 15.57 | .2979 | .5319 | ||
| ✓ | ✓ | ✓ | 14.27 | .2200 | .6564 | 20.57 | .5675 | .3589 | 19.81 | .3330 | .4058 | 11.67 | .1827 | .5947 | 11.28 | .1800 | .6298 | 15.52 | .2966 | .5291 | |
| Real Scene | Ball | Basket | Buick | Coffee | Decoration | ||||||||||||||||
| SS | MGS | PD | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| DP-kernel | 18.22 | .4200 | .5611 | 13.24 | .2263 | .6062 | 13.43 | .2480 | .5571 | 18.15 | .5191 | .4876 | 12.34 | .1672 | .6675 | ||||||
| ✓ | 18.76 | .4329 | .5521 | 12.68 | .2189 | .6301 | 13.05 | .2269 | .5657 | 17.51 | .4792 | .4907 | 12.28 | .1638 | .6619 | ||||||
| ✓ | 19.80 | .4544 | .5273 | 14.08 | .2706 | .5509 | 13.96 | .3028 | .4992 | 19.72 | .6115 | .4035 | 13.14 | .2198 | .6201 | ||||||
| ✓ | 18.28 | .4191 | .5591 | 12.95 | .2281 | .5951 | 13.49 | .2654 | .5464 | 17.92 | .5030 | .4875 | 12.04 | .1491 | .6700 | ||||||
| ✓ | ✓ | 18.50 | .4341 | .5537 | 12.92 | .2407 | .5938 | 13.64 | .2564 | .5427 | 18.09 | .5263 | .4689 | 12.42 | .1669 | .6689 | |||||
| ✓ | ✓ | 19.80 | .4412 | .5346 | 14.28 | .2913 | .5520 | 13.82 | .2920 | .5013 | 18.81 | .5712 | .4363 | 13.04 | .2166 | .6203 | |||||
| ✓ | ✓ | ✓ | 20.09 | .4583 | .5244 | 14.05 | .2890 | .5555 | 13.78 | .2864 | .5036 | 19.67 | .6084 | .4096 | 13.11 | .2192 | .6192 | ||||
| DN-kernel | 18.80 | .4325 | .5521 | 12.86 | .2414 | .5947 | 13.11 | .2446 | .5609 | 18.66 | .5272 | .4696 | 12.09 | .1508 | .6722 | ||||||
| ✓ | 18.88 | .4388 | .5519 | 13.03 | .2516 | .6018 | 13.36 | .2533 | .5523 | 18.04 | .5145 | .4847 | 12.38 | .1736 | .6545 | ||||||
| ✓ | 19.95 | .4596 | .5394 | 13.52 | .2534 | .5871 | 14.11 | .3087 | .5051 | 19.33 | .6003 | .4133 | 13.13 | .2153 | .6222 | ||||||
| ✓ | 18.70 | .4235 | .5673 | 13.24 | .2505 | .5931 | 13.52 | .2520 | .5438 | 18.15 | .5031 | .4949 | 12.32 | .1683 | .6617 | ||||||
| ✓ | ✓ | 18.36 | .4140 | .5667 | 13.14 | .2482 | .5975 | 13.40 | .2549 | .5461 | 17.90 | .5098 | .4857 | 12.37 | .1634 | .6658 | |||||
| ✓ | ✓ | 20.06 | .4637 | .5299 | 13.56 | .2593 | .5828 | 14.51 | .3204 | .4869 | 19.40 | .5956 | .4198 | 13.07 | .2189 | .6230 | |||||
| ✓ | ✓ | ✓ | 20.07 | .4612 | .5290 | 13.62 | .2678 | .5835 | 14.38 | .3182 | .4913 | 19.51 | .6048 | .4146 | 13.09 | .2173 | .6256 | ||||
| Real Scene | Girl | Heron | Parterre | Puppet | Stair | Average | |||||||||||||||
| SS | MGS | PD | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DP-kernel | 11.14 | .2151 | .6485 | 13.63 | .1473 | .5376 | 14.70 | .2226 | .6348 | 14.32 | .2887 | .5930 | 14.38 | .0521 | .6104 | 14.36 | .2506 | .5904 | |||
| ✓ | 10.75 | .1816 | .6600 | 14.05 | .1553 | .5467 | 15.17 | .2340 | .6205 | 14.13 | .2770 | .5934 | 14.24 | .0442 | .6120 | 14.26 | .2414 | .5933 | |||
| ✓ | 12.89 | .3465 | .5645 | 14.48 | .1677 | .5209 | 16.20 | .2511 | .5927 | 14.48 | .2941 | .5819 | 15.81 | .1167 | .6039 | 15.46 | .3035 | .5465 | |||
| ✓ | 11.09 | .2039 | .6398 | 13.52 | .1381 | .5553 | 14.73 | .2355 | .6403 | 14.37 | .2918 | .5857 | 14.49 | .0555 | .6165 | 14.28 | .2490 | .5896 | |||
| ✓ | ✓ | 11.19 | .2311 | .6275 | 13.86 | .1524 | .5365 | 15.44 | .2498 | .6124 | 14.03 | .2771 | .6020 | 14.40 | .0518 | .6231 | 14.00 | .2587 | .5830 | ||
| ✓ | ✓ | 12.78 | .3357 | .5685 | 14.45 | .1741 | .5228 | 16.36 | .2643 | .5939 | 14.56 | .2958 | .5918 | 16.11 | .1267 | .6054 | 15.40 | .3009 | .5527 | ||
| ✓ | ✓ | ✓ | 13.11 | .3707 | .5486 | 14.17 | .1669 | .5285 | 16.19 | .2527 | .5908 | 15.25 | .3277 | .5739 | 16.30 | .1343 | .6133 | 15.57 | .3114 | .5467 | |
| DN-kernel | 10.94 | .2031 | .6436 | 13.97 | .1459 | .5499 | 15.02 | .2320 | .6431 | 14.28 | .2764 | .6036 | 14.40 | .0525 | .6313 | 14.41 | .2506 | .5921 | |||
| ✓ | 10.43 | .1696 | .6654 | 13.10 | .1336 | .5652 | 15.09 | .2075 | .6536 | 14.66 | .3000 | .5950 | 14.36 | .0528 | .6122 | 14.33 | .2495 | .5937 | |||
| ✓ | 12.55 | .3184 | .5736 | 14.51 | .1850 | .5217 | 16.65 | .2830 | .5953 | 14.68 | .2944 | .5924 | 15.93 | .1189 | .6081 | 15.44 | .3037 | .5558 | |||
| ✓ | 11.19 | .2214 | .6475 | 13.95 | .1421 | .5508 | 14.30 | .2189 | .6739 | 14.99 | .3117 | .5894 | 14.35 | .0574 | .6164 | 14.47 | .2549 | .5939 | |||
| ✓ | ✓ | 11.55 | .2299 | .6195 | 13.93 | .1543 | .5382 | 14.92 | .2291 | .6399 | 14.74 | .3042 | .6001 | 14.43 | .0556 | .6211 | 14.47 | .2563 | .5881 | ||
| ✓ | ✓ | 12.70 | .3438 | .5627 | 14.57 | .1779 | .5200 | 16.51 | .2872 | .5825 | 14.24 | .2848 | .6097 | 16.02 | .1216 | .6018 | 15.46 | .3073 | .5519 | ||
| ✓ | ✓ | ✓ | 12.85 | .3418 | .5585 | 14.30 | .1706 | .5197 | 16.61 | .2903 | .5912 | 14.91 | .3141 | .5886 | 15.97 | .1255 | .6125 | 15.53 | .3112 | .5515 | |
| Kernel Type | Synthetic Scene | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||||
| SS | MGS | PD | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DP-kernel | 19.20 | .5175 | .3813 | 21.50 | .6242 | .1980 | 21.85 | .4235 | .3117 | 17.30 | .5265 | .3381 | 19.35 | .5765 | .3084 | 19.84 | .5336 | .3075 | |||
| ✓ | 19.01 | .4914 | .4082 | 21.69 | .6356 | .1889 | 22.62 | .4520 | .3013 | 16.61 | .4789 | .3771 | 17.82 | .5385 | .3475 | 19.55 | .5193 | .3246 | |||
| ✓ | 18.22 | .4638 | .4144 | 22.48 | .6603 | .1762 | 23.11 | .4709 | .2791 | 18.18 | .5517 | .3124 | 18.83 | .5657 | .3299 | 20.16 | .5425 | .3024 | |||
| ✓ | 18.79 | .4972 | .3974 | 22.59 | .6760 | .2314 | 22.41 | .4348 | .3011 | 16.88 | .4913 | .3606 | 17.59 | .5194 | .3652 | 19.65 | .5237 | .3311 | |||
| ✓ | ✓ | 19.09 | .5253 | .3889 | 25.83 | .7796 | .1709 | 24.13 | .5229 | .2474 | 16.95 | .5017 | .3501 | 18.56 | .5764 | .3167 | 20.91 | .5812 | .2948 | ||
| ✓ | ✓ | 17.62 | .4227 | .4615 | 23.43 | .7266 | .1688 | 22.71 | .4454 | .2850 | 15.64 | .4150 | .4308 | 18.84 | .5722 | .3209 | 19.65 | .5164 | .3334 | ||
| ✓ | ✓ | ✓ | 18.99 | .4770 | .4034 | 26.51 | .8051 | .1627 | 23.33 | .4888 | .2733 | 17.51 | .5371 | .3356 | 18.92 | .5799 | .3126 | 21.05 | .5776 | .2975 | |
| DN-kernel | 17.26 | .3740 | .5088 | 25.51 | .7767 | .1897 | 23.38 | .5068 | .2649 | 15.91 | .4209 | .4198 | 17.91 | .5213 | .3661 | 19.99 | .5199 | .3499 | |||
| ✓ | 16.89 | .3611 | .5353 | 25.82 | .7876 | .1770 | 22.92 | .4820 | .2809 | 15.52 | .4381 | .4173 | 18.07 | .5317 | .3684 | 19.89 | .5201 | .3558 | |||
| ✓ | 16.33 | .3387 | .5636 | 25.55 | .7813 | .1874 | 24.28 | .5544 | .2649 | 16.60 | .4635 | .3781 | 17.96 | .5095 | .3870 | 19.44 | .5295 | .3562 | |||
| ✓ | 16.49 | .3444 | .5691 | 25.40 | .7674 | .1982 | 21.87 | .4194 | .3203 | 16.48 | .4798 | .3830 | 18.38 | .5412 | .3445 | 19.72 | .5104 | .3630 | |||
| ✓ | ✓ | 17.11 | .3766 | .5195 | 25.43 | .7770 | .1891 | 22.41 | .4585 | .2864 | 16.63 | .4792 | .3826 | 18.57 | .5559 | .3476 | 20.03 | .5294 | .3450 | ||
| ✓ | ✓ | 16.22 | .3389 | .5637 | 25.12 | .7566 | .1950 | 23.00 | .4792 | .2810 | 17.37 | .5088 | .3661 | 18.08 | .5275 | .3677 | 19.96 | .5222 | .3547 | ||
| ✓ | ✓ | ✓ | 16.91 | .3693 | .5357 | 25.79 | .7872 | .1801 | 25.48 | .6042 | .2405 | 16.58 | .4705 | .3793 | 18.10 | .5514 | .3414 | 20.57 | .5565 | .3354 | |
| Real Scene | Ball | Basket | Buick | Coffee | Decoration | ||||||||||||||||
| SS | MGS | PD | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| DP-kernel | 23.20 | .5842 | .3847 | 17.42 | .4046 | .4658 | 19.26 | .5323 | .3374 | 24.05 | .7597 | .2624 | 14.98 | .3018 | .5618 | ||||||
| ✓ | 23.55 | .6053 | .3685 | 18.32 | .4442 | .4292 | 19.35 | .5340 | .3339 | 23.17 | .7442 | .2670 | 16.14 | .3739 | .5082 | ||||||
| ✓ | 22.52 | .5522 | .3689 | 20.31 | .5388 | .3364 | 19.16 | .5203 | .3430 | 25.62 | .7884 | .2082 | 17.33 | .4081 | .4777 | ||||||
| ✓ | 23.18 | .5817 | .3878 | 17.63 | .4194 | .4475 | 19.53 | .5441 | .3325 | 24.85 | .7885 | .2467 | 14.99 | .3407 | .5267 | ||||||
| ✓ | ✓ | 23.30 | .5893 | .3904 | 18.49 | .4615 | .3926 | 19.14 | .5385 | .3408 | 24.05 | .7716 | .2494 | 15.25 | .3458 | .5274 | |||||
| ✓ | ✓ | 22.36 | .5504 | .3612 | 19.61 | .5134 | .3661 | 19.27 | .5458 | .3316 | 27.55 | .8167 | .2242 | 16.53 | .3902 | .4867 | |||||
| ✓ | ✓ | ✓ | 23.39 | .6010 | .3806 | 20.41 | .5451 | .3305 | 19.48 | .5531 | .3251 | 27.77 | .8364 | .2049 | 16.33 | .3914 | .4950 | ||||
| DN-kernel | 21.90 | .5182 | .4609 | 17.15 | .4331 | .4316 | 19.34 | .5278 | .3407 | 23.10 | .7302 | .2873 | 14.94 | .3201 | .5471 | ||||||
| ✓ | 21.94 | .5220 | .4571 | 17.38 | .4464 | .4298 | 19.26 | .5401 | .3418 | 23.03 | .7264 | .2830 | 14.82 | .3293 | .5363 | ||||||
| ✓ | 21.85 | .5168 | .4514 | 17.87 | .4641 | .4014 | 19.23 | .5289 | .3467 | 26.91 | .8082 | .2473 | 16.69 | .4031 | .4859 | ||||||
| ✓ | 21.85 | .5313 | .4392 | 16.97 | .4301 | .4228 | 19.45 | .5443 | .3403 | 23.78 | .7679 | .2754 | 15.18 | .3549 | .5112 | ||||||
| ✓ | ✓ | 22.06 | .5319 | .4481 | 16.75 | .4308 | .4333 | 19.34 | .5421 | .3373 | 23.44 | .7421 | .2943 | 14.86 | .3429 | .5299 | |||||
| ✓ | ✓ | 22.09 | .5299 | .4477 | 17.81 | .4854 | .3812 | 19.31 | .5400 | .3384 | 27.40 | .8263 | .2353 | 16.93 | .4023 | .4879 | |||||
| ✓ | ✓ | ✓ | 22.28 | .5506 | .4334 | 18.69 | .5058 | .3774 | 19.28 | .5414 | .3371 | 26.76 | .8126 | .2419 | 17.12 | .4192 | .4761 | ||||
| Real Scene | Girl | Heron | Parterre | Puppet | Stair | Average | |||||||||||||||
| SS | MGS | PD | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DP-kernel | 15.40 | .5237 | .4318 | 18.68 | .4292 | .3352 | 17.62 | .2987 | .4991 | 17.61 | .4369 | .4313 | 19.44 | .3107 | .4657 | 18.77 | .4582 | .4175 | |||
| ✓ | 15.67 | .5342 | .4274 | 18.44 | .4145 | .3322 | 17.37 | .2900 | .4935 | 18.49 | .4765 | .3982 | 19.85 | .3433 | .4503 | 19.04 | .4760 | .4008 | |||
| ✓ | 17.03 | .6045 | .3636 | 18.90 | .4526 | .3185 | 18.38 | .3323 | .4575 | 17.89 | .4408 | .4333 | 20.33 | .3416 | .4297 | 19.75 | .4980 | .3737 | |||
| ✓ | 14.80 | .4950 | .4538 | 18.83 | .4336 | .3308 | 17.81 | .3089 | .4915 | 18.12 | .4505 | .4205 | 20.23 | .3615 | .4422 | 19.00 | .4724 | .4080 | |||
| ✓ | ✓ | 15.57 | .5297 | .4349 | 19.04 | .4578 | .3278 | 17.88 | .3094 | .4887 | 17.84 | .4461 | .4329 | 19.47 | .3102 | .4522 | 19.00 | .4760 | .4037 | ||
| ✓ | ✓ | 16.78 | .5919 | .3806 | 18.99 | .4575 | .3166 | 18.28 | .3333 | .4630 | 17.63 | .4272 | .4243 | 20.36 | .3594 | .4201 | 19.74 | .4986 | .3774 | ||
| ✓ | ✓ | ✓ | 16.47 | .5855 | .3835 | 19.09 | .4624 | .3194 | 18.36 | .3375 | .4715 | 17.97 | .4612 | .4206 | 21.25 | .4045 | .4044 | 20.05 | .5178 | .3736 | |
| DN-kernel | 15.62 | .5351 | .4206 | 18.85 | .4350 | .3398 | 19.71 | .4318 | .4549 | 17.77 | .4400 | .4358 | 20.49 | .3901 | .4326 | 18.89 | .4761 | .4151 | |||
| ✓ | 15.04 | .5147 | .4312 | 18.75 | .4291 | .3585 | 20.73 | .4841 | .4379 | 18.15 | .4647 | .4248 | 20.45 | .3825 | .4249 | 18.96 | .4839 | .4125 | |||
| ✓ | 17.13 | .6103 | .3623 | 18.96 | .4527 | .3366 | 20.47 | .4735 | .4464 | 18.39 | .4694 | .4156 | 20.94 | .3914 | .4432 | 19.84 | .5118 | .3937 | |||
| ✓ | 15.17 | .5215 | .4383 | 18.97 | .4367 | .3480 | 20.57 | .4833 | .4463 | 18.24 | .4620 | .4252 | 20.42 | .3752 | .4578 | 19.06 | .4907 | .4105 | |||
| ✓ | ✓ | 15.48 | .5272 | .4282 | 19.00 | .4430 | .3458 | 20.37 | .4801 | .4401 | 18.08 | .4577 | .4276 | 20.05 | .3635 | .4601 | 18.94 | .4861 | .4145 | ||
| ✓ | ✓ | 17.07 | .6081 | .3706 | 18.95 | .4514 | .3254 | 20.64 | .4854 | .4385 | 18.03 | .4510 | .4298 | 21.05 | .4086 | .4182 | 19.93 | .5188 | .3873 | ||
| ✓ | ✓ | ✓ | 16.95 | .5975 | .3823 | 19.04 | .4558 | .3315 | 20.74 | .4916 | .4323 | 18.11 | .4616 | .4202 | 20.80 | .3948 | .4386 | 19.98 | .5231 | .3871 | |
| Kernel Type | Synthetic Scene | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||||
| SS | MGS | PD | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DP-kernel | 21.63 | .6402 | .2984 | 27.63 | .8475 | .1224 | 25.36 | .6227 | .1861 | 21.27 | .6818 | .2023 | 22.49 | .7259 | .1899 | 23.68 | .7036 | .1998 | |||
| ✓ | 21.84 | .6556 | .2947 | 27.48 | .8419 | .1272 | 26.73 | .6891 | .1687 | 22.57 | .7289 | .1950 | 22.15 | .7160 | .2015 | 24.15 | .7263 | .1974 | |||
| ✓ | 19.30 | .5628 | .3553 | 27.56 | .8408 | .1262 | 28.10 | .7374 | .1544 | 21.83 | .7128 | .2074 | 22.34 | .7197 | .1928 | 23.83 | .7147 | .2072 | |||
| ✓ | 20.52 | .5994 | .3224 | 27.29 | .8322 | .1349 | 27.07 | .7002 | .1719 | 22.50 | .7306 | .1958 | 22.07 | .7127 | .2011 | 23.89 | .7150 | .2052 | |||
| ✓ | ✓ | 21.27 | .6104 | .3191 | 27.39 | .8376 | .1301 | 28.54 | .7518 | .1608 | 22.32 | .7290 | .1966 | 21.87 | .7109 | .2037 | 24.28 | .7279 | .2021 | ||
| ✓ | ✓ | 18.43 | .5407 | .3738 | 27.44 | .8399 | .1313 | 27.89 | .7321 | .1596 | 22.02 | .7197 | .2071 | 21.87 | .7118 | .2046 | 23.53 | .7088 | .2153 | ||
| ✓ | ✓ | ✓ | 21.29 | .6179 | .3261 | 27.34 | .8340 | .1298 | 28.19 | .7365 | .1606 | 22.30 | .7233 | .2017 | 22.21 | .7159 | .2036 | 24.27 | .7255 | .2044 | |
| DN-kernel | 18.77 | .5048 | .3890 | 26.67 | .8214 | .1475 | 27.50 | .7116 | .1783 | 21.10 | .6693 | .2517 | 21.58 | .6921 | .2263 | 23.12 | .6798 | .2386 | |||
| ✓ | 17.87 | .4554 | .4370 | 26.76 | .8239 | .1462 | 28.12 | .7316 | .1735 | 21.69 | .6979 | .2282 | 21.61 | .6887 | .2294 | 23.59 | .6795 | .2429 | |||
| ✓ | 18.06 | .4849 | .4104 | 26.54 | .8159 | .1486 | 28.09 | .7392 | .1725 | 20.97 | .6866 | .2394 | 21.71 | .6895 | .2320 | 24.33 | .6832 | .2406 | |||
| ✓ | 19.22 | .5397 | .3756 | 26.52 | .8184 | .1514 | 27.72 | .7242 | .1828 | 21.67 | .6961 | .2306 | 21.64 | .6920 | .2300 | 23.35 | .6941 | .2341 | |||
| ✓ | ✓ | 19.77 | .5461 | .3692 | 26.63 | .8192 | .1480 | 28.17 | .7353 | .1733 | 21.08 | .6878 | .2367 | 21.39 | .6821 | .2347 | 23.41 | .6941 | .2324 | ||
| ✓ | ✓ | 17.50 | .4349 | .4613 | 26.72 | .8226 | .1491 | 27.40 | .7046 | .1848 | 21.73 | .6962 | .2369 | 21.20 | .6688 | .2477 | 22.91 | .6654 | .2560 | ||
| ✓ | ✓ | ✓ | 18.33 | .5144 | .4004 | 26.63 | .8184 | .1513 | 28.16 | .7344 | .1755 | 22.06 | .6988 | .2245 | 21.43 | .6855 | .2380 | 23.32 | .6903 | .2379 | |
| Real Scene | Ball | Basket | Buick | Coffee | Decoration | ||||||||||||||||
| SS | MGS | PD | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| DP-kernel | 24.73 | .6651 | .3107 | 23.24 | .6643 | .2494 | 21.65 | .6418 | .2445 | 25.52 | .7949 | .2170 | 17.48 | .4725 | .4457 | ||||||
| ✓ | 24.93 | .6697 | .3054 | 22.91 | .6688 | .2453 | 21.48 | .6400 | .2580 | 28.12 | .8224 | .1987 | 18.34 | .4934 | .4226 | ||||||
| ✓ | 24.21 | .6412 | .3094 | 22.82 | .6631 | .2508 | 21.17 | .6251 | .2681 | 28.39 | .8448 | .1722 | 19.82 | .5485 | .3697 | ||||||
| ✓ | 24.92 | .6661 | .3111 | 22.27 | .6326 | .2860 | 21.30 | .6234 | .2710 | 26.62 | .7973 | .2259 | 18.07 | .4926 | .4230 | ||||||
| ✓ | ✓ | 24.86 | .6598 | .3181 | 21.29 | .6094 | .3065 | 21.40 | .6359 | .2584 | 28.58 | .8332 | .1910 | 17.78 | .4869 | .4352 | |||||
| ✓ | ✓ | 25.01 | .6691 | .3007 | 23.19 | .6706 | .2481 | 21.12 | .6212 | .2662 | 28.23 | .8410 | .1798 | 19.88 | .5550 | .3606 | |||||
| ✓ | ✓ | ✓ | 24.80 | .6643 | .3200 | 23.32 | .6789 | .2455 | 21.27 | .6234 | .2662 | 28.91 | .8525 | .1902 | 19.69 | .5440 | .3672 | ||||
| DN-kernel | 24.47 | .6473 | .3342 | 23.63 | .7204 | .2108 | 21.45 | .6285 | .2625 | 23.70 | .7604 | .2588 | 17.74 | .4790 | .4296 | ||||||
| ✓ | 23.02 | .5757 | .3964 | 22.96 | .7128 | .2230 | 21.72 | .6389 | .2595 | 26.90 | .8004 | .2354 | 17.21 | .4774 | .4346 | ||||||
| ✓ | 24.15 | .6343 | .3465 | 22.59 | .6894 | .2365 | 21.30 | .6185 | .2678 | 26.41 | .7947 | .2300 | 19.38 | .5272 | .3908 | ||||||
| ✓ | 23.68 | .6175 | .3572 | 22.90 | .7035 | .2255 | 20.95 | .6172 | .2716 | 27.18 | .8083 | 2336 | 18.53 | .5030 | .4084 | ||||||
| ✓ | ✓ | 24.60 | .6530 | .3439 | 22.96 | .7132 | .2296 | 21.43 | .6360 | .2642 | 26.13 | .8178 | .2159 | 18.07 | .4784 | .4420 | |||||
| ✓ | ✓ | 23.93 | .6332 | .3464 | 23.89 | .7342 | .2188 | 21.11 | .6247 | .2747 | 26.88 | .8074 | .2403 | 19.53 | .5383 | .3855 | |||||
| ✓ | ✓ | ✓ | 23.76 | .6184 | .3607 | 23.39 | .7155 | .2329 | 21.66 | .6405 | .2585 | 27.84 | .8388 | .2068 | 19.98 | .5553 | .3644 | ||||
| Real Scene | Girl | Heron | Parterre | Puppet | Stair | Average | |||||||||||||||
| SS | MGS | PD | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DP-kernel | 18.16 | .6622 | .3020 | 19.58 | .4991 | .2905 | 22.36 | .5879 | .3350 | 20.65 | .5868 | .2988 | 23.40 | .5624 | .2986 | 21.68 | .6137 | .2992 | |||
| ✓ | 18.79 | .6771 | .2890 | 19.56 | .4967 | .2903 | 22.53 | .5972 | .3318 | 20.41 | .5765 | .3101 | 23.96 | .5723 | .2997 | 22.10 | .6214 | .2951 | |||
| ✓ | 18.77 | .6833 | .2703 | 19.58 | .4998 | .2856 | 22.27 | .5801 | .3440 | 20.48 | .5790 | .3043 | 23.23 | .5468 | .3149 | 22.07 | .6212 | .2889 | |||
| ✓ | 18.50 | .6650 | .2956 | 19.59 | .4895 | .3003 | 22.45 | .5926 | .3344 | 20.29 | .5687 | .3230 | 23.33 | .5545 | .3120 | 21.73 | .6082 | .3082 | |||
| ✓ | ✓ | 18.36 | .6628 | .2989 | 19.57 | .4920 | .3006 | 22.69 | .6015 | .3296 | 20.38 | .5774 | .3211 | 23.47 | .5462 | .3244 | 21.84 | .6105 | .3084 | ||
| ✓ | ✓ | 19.20 | .6872 | .2695 | 19.45 | .4947 | .2871 | 22.33 | .5833 | .3438 | 20.46 | .5800 | .3035 | 23.34 | .5550 | .3082 | 22.22 | .6257 | .2868 | ||
| ✓ | ✓ | ✓ | 18.96 | .6887 | .2744 | 19.59 | .5051 | .2808 | 22.57 | .5994 | .3317 | 20.60 | .5756 | .3124 | 23.48 | .5509 | .3189 | 22.32 | .6283 | .2907 | |
| DN-kernel | 18.09 | .6582 | .3055 | 19.40 | .4709 | .3166 | 21.92 | .5557 | .3872 | 20.58 | .5834 | .3226 | 22.60 | .4993 | .3349 | 21.36 | .6003 | .3163 | |||
| ✓ | 18.19 | .6615 | .3009 | 19.42 | .4879 | .3052 | 22.18 | .5758 | .3733 | 20.49 | .5823 | .3167 | 23.18 | .5312 | .3330 | 21.53 | .6044 | .3178 | |||
| ✓ | 18.93 | .6856 | .2748 | 19.58 | .4904 | .3122 | 21.91 | .5570 | .3853 | 20.44 | .5810 | .3232 | 22.90 | .5231 | .3294 | 21.76 | .6101 | .3097 | |||
| ✓ | 18.18 | .6538 | .3005 | 19.65 | .4962 | .3083 | 22.34 | .5834 | .3608 | 20.41 | .5785 | .3305 | 23.08 | .5257 | .3458 | 21.69 | .6087 | .3142 | |||
| ✓ | ✓ | 18.74 | .6782 | .2855 | 19.74 | .4948 | .3153 | 22.25 | .5796 | .3658 | 20.45 | .5771 | .3183 | 22.63 | .5009 | .3637 | 21.70 | .6129 | .3144 | ||
| ✓ | ✓ | 18.53 | .6646 | .2923 | 19.45 | .4859 | .3182 | 21.62 | .5510 | .3909 | 20.71 | .5819 | .3126 | 23.18 | .5332 | .3325 | 21.88 | .6154 | .3112 | ||
| ✓ | ✓ | ✓ | 18.86 | .6860 | .2769 | 19.63 | .5011 | .2992 | 22.15 | .5703 | .3787 | 20.81 | .5882 | .3149 | 23.42 | .5340 | .3374 | 22.15 | .6248 | .3030 | |
| Decoration Scene | # of views | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR() | Blur Kernel | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| RegNeRF [6] | 11.20 | 11.28 | 11.43 | 12.11 | 12.45 | 14.61 | 16.69 | 18.41 | 20.21 | |
| RegNeRF [6] | DP-kernel | 11.15 | 10.84 | 11.07 | 11.54 | 11.43 | 13.50 | 16.16 | 18.56 | 21.75 |
| SSIM() | Blur Kernel | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| RegNeRF [6] | .1064 | .1262 | .1139 | .1589 | .1569 | .2876 | .3956 | .4880 | .5508 | |
| RegNeRF [6] | DP-kernel | .0927 | .1115 | .1058 | .1228 | .1247 | .2034 | .3645 | .4986 | .6526 |
| LPIPS() | Blur Kernel | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| RegNeRF [6] | .7475 | .7059 | .6995 | .7078 | .7061 | .6258 | .5588 | .4818 | .4322 | |
| RegNeRF [6] | DP-kernel | .7520 | .7191 | .7089 | .6992 | .6932 | .6547 | .5277 | .4178 | .2804 |
| Synthetic Scene | Blur Kernel | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| RegNeRF [6] | 14.57 | .2523 | .6680 | 17.13 | .4616 | .3808 | 14.23 | .1473 | .7298 | 13.01 | .2408 | .5956 | 14.04 | .3227 | .5602 | 14.60 | .2849 | .5869 | |
| RegNeRF [6] | DP-kernel | 14.20 | .2214 | .6412 | 18.88 | .5136 | .3476 | 13.03 | .1003 | .6845 | 9.21 | .0815 | .6920 | 10.86 | .1644 | .6657 | 13.24 | .2162 | .6062 |
| Sparse-DeRF(Ours) | DP-kernel | 14.10 | .2116 | .6413 | 18.97 | .5206 | .3417 | 20.32 | .3488 | .4056 | 12.00 | .1943 | .5902 | 11.36 | .1769 | .6422 | 15.35 | .2904 | .5242 |
| Real Scene | Blur Kernel | Ball | Basket | Buick | Coffee | Decoration | |||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| RegNeRF [6] | 20.48 | .4951 | .5398 | 15.53 | .3388 | .5403 | 17.05 | .4241 | .4361 | 23.24 | .6950 | .3505 | 10.94 | .0816 | .7545 | ||||
| RegNeRF [6] | DP-kernel | 18.58 | .4297 | .5565 | 13.49 | .2429 | .5985 | 12.51 | .2199 | .5579 | 15.75 | .4280 | .5370 | 11.15 | .0927 | .7520 | |||
| Sparse-DeRF(Ours) | DP-kernel | 20.09 | .4583 | .5244 | 14.05 | .2890 | .5555 | 13.78 | .2864 | .5036 | 19.67 | .6084 | .4096 | 13.11 | .2192 | .6192 | |||
| Real Scene | Blur Kernel | Girl | Heron | Parterre | Puppet | Stair | Average | ||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| RegNeRF [6] | 8.31 | .0602 | .7545 | 11.43 | .0951 | .6687 | 15.58 | .2709 | .6510 | 16.02 | .3548 | .5739 | 16.30 | .1816 | .6182 | 15.49 | .2997 | .5888 | |
| RegNeRF [6] | DP-kernel | 7.86 | .0419 | .7737 | 11.57 | .0783 | .6246 | 12.54 | .1524 | .7091 | 10.67 | .1331 | .6604 | 13.49 | .0170 | .6770 | 12.76 | .1836 | .6447 |
| Sparse-DeRF(Ours) | DP-kernel | 13.11 | .3707 | .5486 | 14.17 | .1669 | .5285 | 16.19 | .2527 | .5908 | 15.25 | .3277 | .5739 | 16.30 | .1343 | .6133 | 15.57 | .3114 | .5467 |
| Synthetic Scene | Blur Kernel | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| RegNeRF [6] | 16.32 | .3441 | .5876 | 23.25 | .7155 | .2663 | 16.21 | .2040 | .6451 | 17.35 | .4915 | .4509 | 18.81 | .5447 | .4020 | 18.39 | .4600 | .4704 | |
| RegNeRF [6] | DP-kernel | 16.71 | .3497 | .4683 | 21.37 | .6471 | .1802 | 15.17 | .1740 | .6666 | 10.27 | .1165 | .6911 | 18.66 | .5412 | .4067 | 16.44 | .3657 | .4826 |
| Sparse-DeRF(Ours) | DP-kernel | 18.99 | .4770 | .4034 | 26.51 | .8051 | .1627 | 23.33 | .4888 | .2733 | 17.51 | .5371 | .3356 | 18.92 | .5799 | .3126 | 21.05 | .5776 | .2975 |
| Real Scene | Blur Kernel | Ball | Basket | Buick | Coffee | Decoration | |||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| RegNeRF [6] | 21.16 | .5100 | .4952 | 18.12 | .4711 | .4569 | 20.11 | .5821 | .3412 | 26.14 | .7837 | .2965 | 11.35 | .1045 | .7030 | ||||
| RegNeRF [6] | DP-kernel | 19.13 | .4391 | .4042 | 17.42 | .4165 | .3746 | 13.31 | .2697 | .4715 | 16.40 | .4684 | .5239 | 11.07 | .1058 | .7089 | |||
| Sparse-DeRF(Ours) | DP-kernel | 23.39 | .6010 | .3806 | 20.41 | .5451 | .3305 | 19.48 | .5531 | .3251 | 27.77 | .8364 | .2049 | 16.33 | .3914 | .4950 | |||
| Real Scene | Blur Kernel | Girl | Heron | Parterre | Puppet | Stair | Average | ||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| RegNeRF [6] | 10.24 | .1511 | .7199 | 18.86 | .4235 | .4194 | 18.68 | .4238 | .5163 | 18.66 | .4788 | .4327 | 21.06 | .3975 | .4706 | 18.44 | .4326 | .4852 | |
| RegNeRF [6] | DP-kernel | 9.52 | .1304 | .7119 | 11.56 | .0595 | .6149 | 13.61 | .1721 | .7245 | 11.10 | .1342 | .6914 | 12.73 | .0249 | .6610 | 13.59 | .2221 | .5887 |
| Sparse-DeRF(Ours) | DP-kernel | 16.47 | .5855 | .3835 | 19.09 | .4624 | .3194 | 18.36 | .3375 | .4715 | 17.97 | .4612 | .4206 | 21.25 | .4045 | .4044 | 20.05 | .5178 | .3736 |
| Synthetic Scene | Blur Kernel | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| RegNeRF [6] | 17.04 | .3690 | .5729 | 23.40 | .7205 | .2649 | 18.05 | .3610 | .4870 | 20.33 | .5980 | .3745 | 19.63 | .5760 | .3833 | 19.69 | .5249 | .4165 | |
| RegNeRF [6] | DP-kernel | 21.03 | .6273 | .3076 | 27.73 | .8455 | .1238 | 18.04 | .3173 | .4987 | 21.84 | .7246 | .2022 | 19.36 | .5661 | .3908 | 21.60 | .6162 | .3046 |
| Sparse-DeRF(Ours) | DP-kernel | 21.29 | .6179 | .3261 | 27.34 | .8340 | .1298 | 28.19 | .7365 | .1606 | 22.30 | .7233 | .2017 | 22.21 | .7159 | .2036 | 24.27 | .7255 | .2044 |
| Real Scene | Blur Kernel | Ball | Basket | Buick | Coffee | Decoration | |||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| RegNeRF [6] | 21.98 | .5312 | .4677 | 21.67 | .6129 | .3406 | 21.16 | .6215 | .3051 | 25.67 | .7716 | .3105 | 12.45 | .1569 | .7061 | ||||
| RegNeRF [6] | DP-kernel | 25.02 | .6719 | .2953 | 22.95 | .6554 | .2501 | 21.57 | .6456 | .2462 | 23.38 | .7393 | .2341 | 11.43 | .1247 | .6932 | |||
| Sparse-DeRF(Ours) | DP-kernel | 24.80 | .6643 | .3200 | 23.32 | .6789 | .2455 | 21.27 | .6234 | .2662 | 28.91 | .8525 | .1902 | 19.69 | .5440 | .3672 | |||
| Real Scene | Blur Kernel | Girl | Heron | Parterre | Puppet | Stair | Average | ||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| RegNeRF [6] | 11.06 | .1966 | .7091 | 18.96 | .4218 | .4292 | 21.83 | .5526 | .4353 | 20.07 | .5309 | .3827 | 21.69 | .3938 | .4963 | 19.65 | .4790 | .4583 | |
| RegNeRF [6] | DP-kernel | 10.38 | .1434 | .7200 | 12.83 | .1019 | .5757 | 21.34 | .5159 | .3415 | 20.49 | .5799 | .3113 | 13.08 | .2613 | .6581 | 18.25 | .4439 | .4326 |
| Sparse-DeRF(Ours) | DP-kernel | 18.96 | .6887 | .2744 | 19.59 | .5051 | .2808 | 22.57 | .5994 | .3317 | 20.60 | .5756 | .3124 | 23.48 | .5509 | .3189 | 22.32 | .6283 | .2907 |
| Synthetic Scene | Gradient Scaling | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DN-kernel | Naive [51] | 11.93 | .1340 | .6835 | 17.82 | .4573 | .4827 | 18.89 | .3131 | .4237 | 11.45 | .1603 | .6107 | 11.12 | .1769 | .6207 | 14.70 | .2483 | .5643 |
| DN-kernel | MGS | 14.20 | .2107 | .6686 | 21.02 | .5999 | .3326 | 20.30 | .3467 | .4017 | 11.55 | .1804 | .5903 | 11.48 | .1883 | .6351 | 15.12 | .3025 | .5243 |
| DP-kernel | Naive [51] | 11.98 | .1378 | .6799 | 16.54 | .3988 | .5360 | 19.08 | .3135 | .4275 | 11.30 | .1653 | .5992 | 11.14 | .1731 | .6291 | 14.01 | .2377 | .5743 |
| DP-kernel | MGS | 14.33 | .2088 | .6496 | 18.89 | .5032 | .3577 | 19.64 | .3330 | .3950 | 11.69 | .1748 | .6067 | 11.78 | .1948 | .6289 | 15.40 | .2857 | .5289 |
| Real Scene | Gradient Scaling | Ball | Basket | Buick | Coffee | Decoration | |||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| DN-kernel | Naive [51] | 17.96 | .4198 | .5715 | 13.27 | .2431 | .5864 | 13.88 | .2982 | .5075 | 19.17 | .5960 | .4223 | 12.08 | .2076 | .6294 | |||
| DN-kernel | MGS | 19.95 | .4596 | .5394 | 13.52 | .2534 | .5871 | 14.11 | .3087 | .5051 | 19.33 | .6003 | .4133 | 13.13 | .2153 | .6222 | |||
| DP-kernel | Naive [51] | 17.85 | .4053 | .5819 | 13.43 | .2445 | .5694 | 13.97 | .3061 | .5014 | 19.36 | .6070 | .4123 | 12.81 | .2071 | .6238 | |||
| DP-kernel | MGS | 19.80 | .4544 | .5273 | 14.08 | .2706 | .5509 | 13.96 | .3028 | .4992 | 19.72 | .6115 | .4035 | 13.14 | .2198 | .6201 | |||
| Real Scene | Gradient Scaling | Girl | Heron | Parterre | Puppet | Stair | Average | ||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DN-kernel | Naive [51] | 12.40 | .2923 | .5883 | 13.46 | .1458 | .5483 | 16.52 | .2778 | .5930 | 13.76 | .2670 | .5948 | 15.99 | .1122 | .6118 | 14.85 | .2860 | .5653 |
| DN-kernel | MGS | 12.55 | .3184 | .5736 | 14.51 | .1850 | .5217 | 16.65 | .2830 | .5953 | 14.68 | .2944 | .5924 | 15.93 | .1189 | .6081 | 15.44 | .3037 | .5558 |
| DP-kernel | Naive [51] | 12.84 | .3408 | .5621 | 14.32 | .1672 | .5234 | 16.22 | .2547 | .5963 | 12.85 | .2309 | .6045 | 15.80 | .1072 | .6159 | 14.95 | .2871 | .5591 |
| DP-kernel | MGS | 12.89 | .3465 | .5645 | 14.48 | .1677 | .5209 | 16.20 | .2511 | .5927 | 14.48 | .2941 | .5819 | 15.81 | .1167 | .6039 | 15.46 | .3035 | .5465 |
| Synthetic Scene | Gradient Scaling | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DN-kernel | Naive [51] | 12.80 | .1949 | .6631 | 23.41 | .7202 | .2517 | 23.54 | .5069 | .2508 | 14.22 | .3275 | .5065 | 15.41 | .4109 | .4487 | 18.69 | .4321 | .4242 |
| DN-kernel | MGS | 16.33 | .3387 | .5636 | 25.55 | .7813 | .1874 | 24.28 | .5544 | .2649 | 16.60 | .4635 | .3781 | 17.96 | .5095 | .3870 | 19.44 | .5295 | .3562 |
| DP-kernel | Naive [51] | 11.89 | .1392 | .6831 | 22.26 | .6676 | .2354 | 22.36 | .4721 | .2616 | 14.14 | .3024 | .4953 | 15.62 | .3850 | .4351 | 17.25 | .3933 | .4221 |
| DP-kernel | MGS | 18.22 | .4638 | .4144 | 22.48 | .6603 | .1762 | 23.11 | .4709 | .2791 | 18.18 | .5517 | .3124 | 18.83 | .5657 | .3299 | 20.16 | .5425 | .3024 |
| Real Scene | Gradient Scaling | Ball | Basket | Buick | Coffee | Decoration | |||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| DN-kernel | Naive [51] | 21.01 | .4947 | .4699 | 16.89 | .4274 | .4394 | 18.79 | .5123 | .3654 | 26.36 | .7986 | .2604 | 16.77 | .4036 | .4896 | |||
| DN-kernel | MGS | 21.85 | .5168 | .4514 | 17.87 | .4641 | .4014 | 19.23 | .5289 | .3467 | 26.91 | .8082 | .2473 | 16.69 | .4031 | .4859 | |||
| DP-kernel | Naive [51] | 20.06 | .4560 | .4361 | 18.23 | .4615 | .3970 | 18.65 | .5074 | .3611 | 24.80 | .7541 | .2497 | 16.32 | .3843 | .4878 | |||
| DP-kernel | MGS | 22.52 | .5522 | .3689 | 20.31 | .5388 | .3364 | 19.16 | .5203 | .3430 | 25.62 | .7884 | .2082 | 17.33 | .4081 | .4777 | |||
| Real Scene | Gradient Scaling | Girl | Heron | Parterre | Puppet | Stair | Average | ||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DN-kernel | Naive [51] | 16.83 | .5976 | .3730 | 18.60 | .4154 | .3632 | 20.10 | .4602 | .4612 | 16.90 | .4247 | .4646 | 20.53 | .3749 | .4319 | 19.28 | .4909 | .4119 |
| DN-kernel | MGS | 17.13 | .6103 | .3623 | 18.96 | .4527 | .3366 | 20.47 | .4735 | .4464 | 18.39 | .4694 | .4156 | 20.94 | .3914 | .4432 | 19.84 | .5118 | .3937 |
| DP-kernel | Naive [51] | 16.31 | .5787 | .3874 | 18.85 | .4481 | .3152 | 18.21 | .3274 | .4750 | 16.74 | .4101 | .4634 | 20.32 | .3421 | .4415 | 18.85 | .4670 | .4014 |
| DP-kernel | MGS | 17.03 | .6045 | .3636 | 18.90 | .4526 | .3185 | 18.38 | .3323 | .4575 | 17.89 | .4408 | .4333 | 20.33 | .3416 | .4297 | 19.75 | .4980 | .3737 |
| Synthetic Scene | Gradient Scaling | Factory | Cozyroom | Pool | Tanabata | Trolley | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DN-kernel | Naive [51] | 14.70 | .2560 | .6091 | 26.13 | .8080 | .1658 | 27.24 | .7167 | .1810 | 20.29 | .6379 | .2816 | 18.48 | .5824 | .3208 | 22.00 | .6002 | .3117 |
| DN-kernel | MGS | 18.06 | .4849 | .4104 | 26.54 | .8159 | .1486 | 28.09 | .7392 | .1725 | 20.97 | .6866 | .2394 | 21.71 | .6895 | .2320 | 22.40 | .6832 | .2406 |
| DP-kernel | Naive [51] | 14.47 | .2649 | .5744 | 26.71 | .8233 | .1456 | 27.90 | .7330 | .1598 | 20.04 | .6253 | .2528 | 18.63 | .6020 | .2865 | 21.55 | .6097 | .2838 |
| DP-kernel | MGS | 19.30 | .5628 | .3553 | 27.56 | .8408 | .1262 | 28.10 | .7374 | .1544 | 21.83 | .7128 | .2074 | 22.34 | .7197 | .1928 | 23.83 | .7147 | .2072 |
| Real Scene | Gradient Scaling | Ball | Basket | Buick | Coffee | Decoration | |||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | ||||
| DN-kernel | Naive [51] | 22.07 | .5574 | .4040 | 21.76 | .6780 | .2515 | 21.03 | .6107 | .2837 | 27.69 | .8236 | .2275 | 19.72 | .5396 | .3770 | |||
| DN-kernel | MGS | 24.15 | .6343 | .3465 | 22.59 | .6894 | .2365 | 21.30 | .6185 | .2678 | 26.41 | .7947 | .2300 | 19.38 | .5272 | .3908 | |||
| DP-kernel | Naive [51] | 24.04 | .6385 | .3293 | 21.29 | .6075 | .3275 | 20.07 | .6133 | .2724 | 28.42 | .8342 | .1931 | 19.60 | .5366 | .3727 | |||
| DP-kernel | MGS | 24.21 | .6412 | .3094 | 22.82 | .6631 | .2508 | 21.17 | .6251 | .2681 | 28.39 | .8448 | .1722 | 19.82 | .5485 | .3697 | |||
| Real Scene | Gradient Scaling | Girl | Heron | Parterre | Puppet | Stair | Average | ||||||||||||
| Kernel Type | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | PSNR() | SSIM() | LPIPS() | |
| DN-kernel | Naive [51] | 18.68 | .6777 | .2824 | 19.41 | .4885 | .3078 | 21.67 | .5481 | .3963 | 18.24 | .5173 | .3792 | 21.75 | .4360 | .3543 | 21.20 | .5877 | .3274 |
| DN-kernel | MGS | 18.93 | .6856 | .2748 | 19.58 | .4904 | .3122 | 21.91 | .5570 | .3853 | 20.44 | .5810 | .3232 | 22.90 | .5231 | .3294 | 21.76 | .6101 | .3097 |
| DP-kernel | Naive [51] | 18.70 | .6770 | .2789 | 19.13 | .4822 | .2918 | 21.97 | .5665 | .3548 | 18.36 | .5114 | .3739 | 23.27 | .5432 | .3167 | 21.49 | .6010 | .3111 |
| DP-kernel | MGS | 18.77 | .6833 | .2703 | 19.58 | .4998 | .2856 | 22.27 | .5801 | .3440 | 20.48 | .5790 | .3043 | 23.23 | .5468 | .3149 | 22.07 | .6212 | .2889 |