将网络空间与物理世界结合起来:对嵌入式人工智能的全面调查
摘要
嵌入式人工智能(Embodied AI)对于实现通用人工智能(AGI)至关重要,并且是连接网络空间和物理世界的各种应用的基础。 最近,多模态大型模型(MLM)和世界模型(WM)的出现因其卓越的感知、交互和推理能力而引起了极大的关注,使它们成为具身智能体大脑的有前途的架构。 然而,目前还没有针对传销时代的嵌入式人工智能的全面调查。 在本次调查中,我们全面探讨了嵌入式人工智能的最新进展。 我们的分析首先浏览了具身机器人和模拟器的代表作品的前沿,以充分了解研究重点及其局限性。 然后,我们分析了四个主要研究目标:1)具身感知,2)具身互动,3)具身主体,4)模拟到现实的适应,涵盖了最先进的方法、基本范式和综合性。数据集。 此外,我们还探讨了虚拟和真实实体代理中传销的复杂性,强调了它们在促进动态数字和物理环境中的交互方面的重要性。 最后,我们总结了嵌入式人工智能的挑战和局限性,并讨论了它们潜在的未来方向。 我们希望这项调查能够为研究界提供基础参考,并激发持续创新。 相关项目可在 https://github.com/HCPLab-SYSU/Embodied_AI_Paper_List 找到。
索引术语:
实体人工智能、网络空间、物理世界、多模态大型模型、世界模型、代理、机器人我简介
Embodied AI 最初由艾伦·图灵 (Alan Turing) 在 1950 年的《Embodied Turing Test》中提出[1],旨在确定智能体是否能够展示智能,而不仅仅局限于解决虚拟环境中的抽象问题(网络空间111代理是无形人工智能和实体人工智能的基础。 代理可以存在于网络空间和物理空间中,并与各种实体集成。 这些实体不仅包括机器人,还包括其他设备。),但这也能够应对物理世界的复杂性和不可预测性。 网络空间中的智能体通常被称为无实体人工智能,而物理空间中的智能体则被称为实体人工智能(表I)。 多模态大型模型(MLM)的最新进展为实体模型注入了强大的感知、交互和规划能力,以开发与虚拟和物理环境主动交互的通用实体代理和机器人[2]。 因此,实体代理被广泛认为是传销的最佳载体。 最近的代表性具体模型是RT-2[3]和RT-H[4]。 然而,对于当前的传销来说,长期记忆、理解复杂意图以及分解复杂任务的能力是有限的。
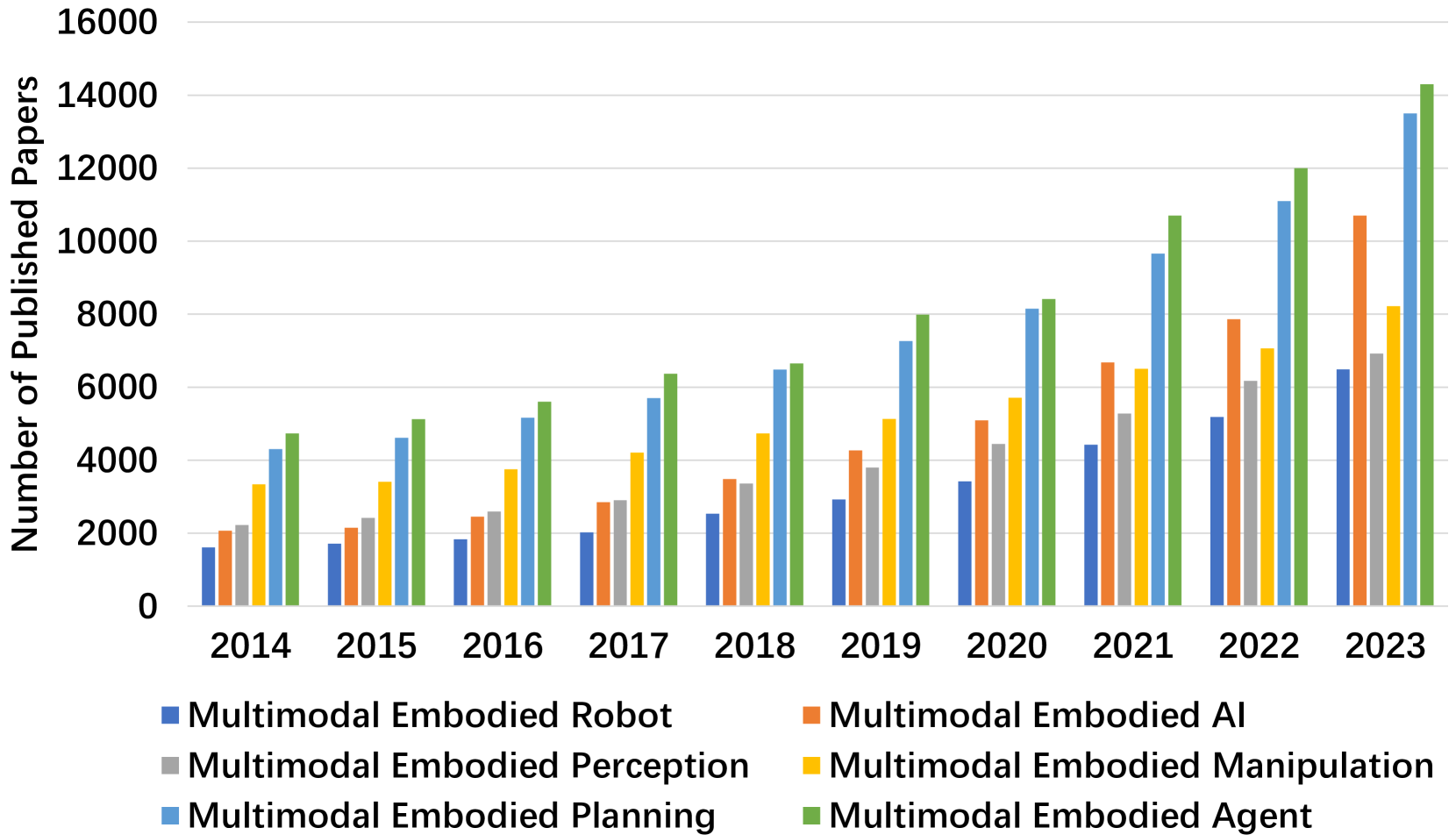
为了实现通用人工智能(AGI),嵌入式人工智能的发展是一个基本途径。 与ChatGPT等对话代理[5]不同,具身人工智能认为,真正的AGI可以通过控制物理实体并与模拟和物理环境交互来实现[6,7,8]. 当我们站在通用人工智能驱动的创新的前沿时,深入研究实体人工智能领域、揭示其复杂性、评估其当前的发展阶段并思考其未来可能遵循的潜在轨迹至关重要。 如今,具身人工智能涵盖了计算机视觉(CV)、自然语言处理(NLP)和机器人技术等领域的各种关键技术,其中最具代表性的是具身感知、具身交互、具身代理和模拟真实的机器人控制。 因此,在追求通用人工智能的过程中,必须通过全面的调查来捕捉嵌入式人工智能的演变格局。
| Type | Environment | Physical Entities | Description | Representative Agents |
|---|---|---|---|---|
| Disembodied AI | Cyber Space | No | Cognition and physical entities are disentangled | ChatGPT [9], RoboGPT [10] |
| Embodied AI | Physical Space | Robots, Cars, Other devices | Cognition is integrated into physical entities | RT-1 [11], RT-2 [3], RT-H [4] |
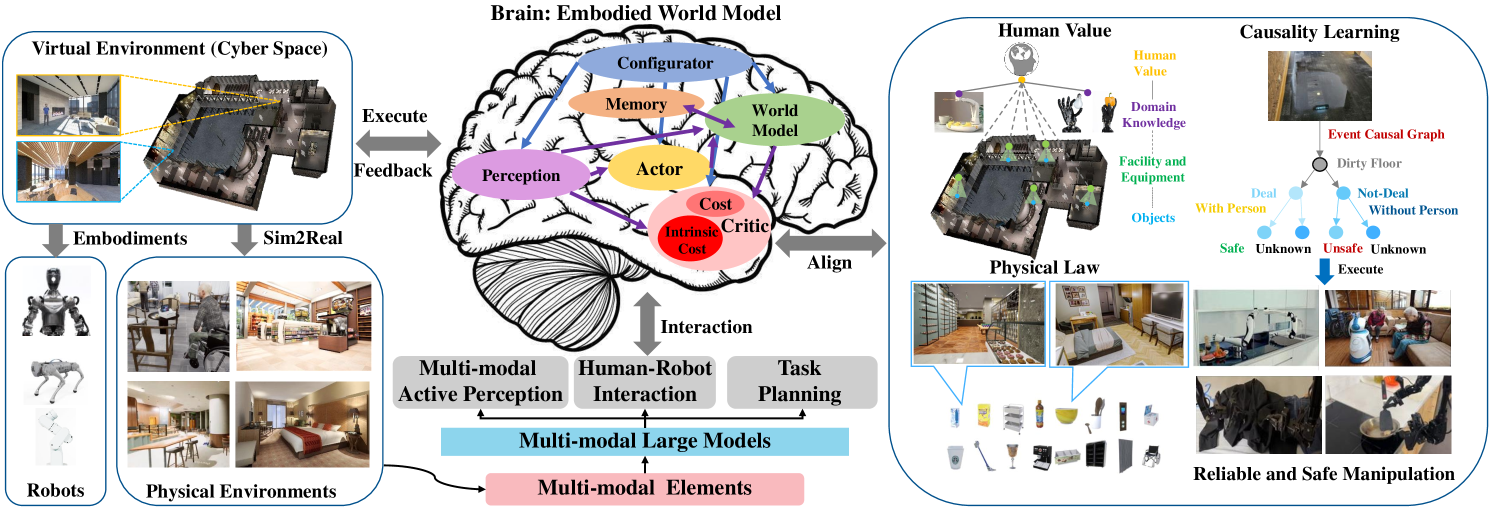
具身智能体是具身人工智能最突出的基础。 对于具体任务,具体代理必须充分理解语言指令中的人类意图,主动探索周围环境,全面感知虚拟和物理环境中的多模态元素,并针对复杂任务执行适当的动作[12 ,13],如图2所示。 与传统的深度强化学习方法相比,多模态模型的快速进展在复杂环境中表现出卓越的多功能性、灵活性和泛化性。 来自最先进视觉编码器的预训练视觉表示[14, 15]提供了对对象类别、姿态和几何形状的精确估计,这使得具体模型能够彻底感知复杂和动态的环境。 强大的大语言模型(大语言模型)使机器人更好地理解人类的语言指令。 有前途的传销提供了对齐实体机器人的视觉和语言表示的可行方法。 世界模型[16, 17]表现出卓越的模拟能力和对物理定律的良好理解,这使得具体模型能够全面理解物理和真实环境。 这些创新使实体智能体能够全面感知复杂的环境,自然地与人类交互并可靠地执行任务。
具身人工智能的发展突飞猛进,引起了研究界的高度关注(图1),被认为是实现AGI最可行的路径。 Google Scholar 报告了大量具体人工智能出版物,仅 2023 年就发表了约 10,700 篇论文。 这相当于平均每天 29 篇论文或每小时超过一篇论文。 尽管人们对从传销中获得强大的感知和推理能力有着浓厚的兴趣,但研究界缺乏一项全面的调查来帮助梳理现有的具体人工智能研究、面临的挑战以及未来的研究方向。 在传销时代,我们的目标是通过对从网络空间到物理世界的具体人工智能进行系统调查来填补这一空白。 我们从不同的角度进行调查,包括具身机器人、模拟器、四个代表性的具身任务(视觉主动感知、具身交互、多模态代理和模拟到真实的机器人控制)以及未来的研究方向。 我们相信,这项调查将为我们所取得的成就提供一个清晰的总体图景,并且我们可以沿着这个新兴但非常有前瞻性的研究方向进一步取得成就。
与之前作品的差异:虽然已经有几篇关于体现人工智能的调查论文[18,19,20,6],但其中大多数已经过时,因为它们是在传销时代于 2023 年左右开始。 据我们所知,2023 年之后只有一篇调查论文[8]仅关注视觉-语言-动作体现的人工智能模型。 然而,传销、WM 和实体代理人并未得到充分考虑。 此外,实体机器人和模拟器的最新发展也被忽视。 为了解决这个快速发展的领域缺乏综合调查论文的问题,我们提出了这项综合调查,涵盖代表性的具身机器人、模拟器和四个主要研究任务:具身感知、具身交互、具身代理和模拟到真实的机器人控制。
总之,这项工作的主要贡献有三个。 首先,它对实体人工智能进行了系统回顾,包括实体机器人、模拟器和四个主要研究任务:视觉主动感知、实体交互、实体代理和模拟到真实的机器人控制。 据我们所知,这是第一次基于 MLM 和 WM 从网络空间和物理空间协调的角度对嵌入式人工智能进行全面调查,提供了广泛的概述,并对现有研究进行了彻底的总结和分类。 其次,它研究了具体人工智能的最新进展,提供了跨多个模拟器和数据集的当前工作的全面基准测试和讨论。 第三,它确定了针对具体人工智能的通用人工智能未来研究的几个研究挑战和潜在方向。
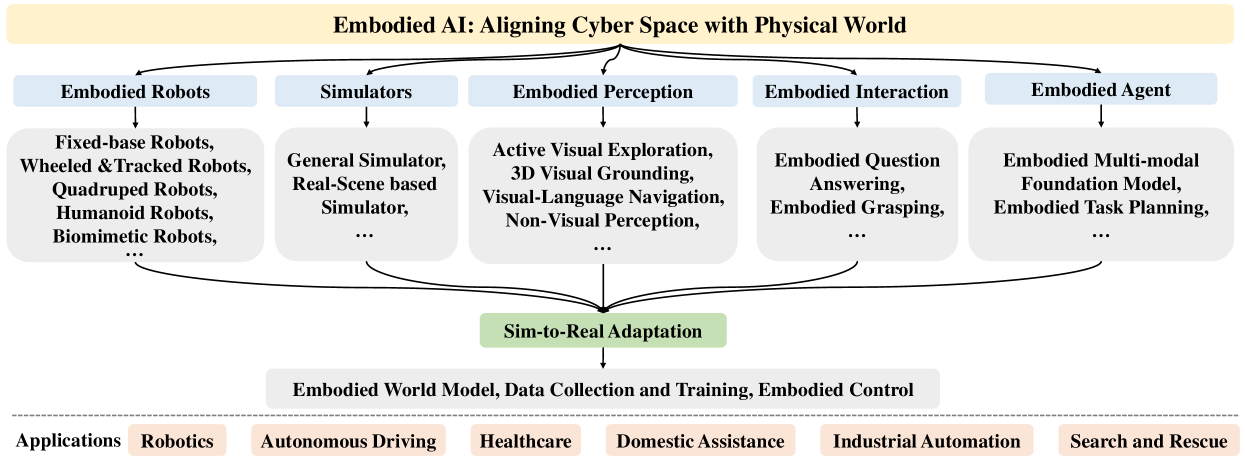
本次调查的其余部分组织如下。 第 2 节介绍了各种具体机器人。 第 3 节描述了通用模拟器和真实场景模拟器。 第 4 节介绍具身感知,包括主动视觉感知、3D 视觉基础、视觉语言导航和非视觉感知。 第 5 节介绍了具体交互。 第 6 节介绍了具体化代理,包括具体化多模态基础模型和具体化任务规划。 第 7 节介绍了模拟到现实的适应,包括具体世界模型、数据收集和训练以及具体控制。 在第 8 节中,我们讨论有前景的研究方向。

II 实体机器人
实体主体主动与物理环境交互,涵盖广泛的实体,包括机器人、智能电器、智能眼镜、自动驾驶汽车等。 其中,机器人是最突出的体现之一。 根据应用的不同,机器人被设计成各种形式,以利用其硬件特性来完成特定的任务,如图4所示。
II-A 固定底座机器人
固定底座机器人如图4(a)所示,因其结构紧凑、作业精度高而广泛应用于实验室自动化、教育训练和工业制造等领域。 这些机器人具有坚固的底座和结构,可确保操作过程中的稳定性和高精度。 它们配备高精度传感器和执行器,可实现微米级精度,适合需要高精度和可重复性的任务[21]。 此外,固定底座机器人具有高度可编程性,允许用户使其适应各种任务场景,例如 Franka(Franka Emika panda)[22]、Kuka iiwa(KUKA)[23] 和 Sawyer(重新思考机器人)[24]。 然而,固定底座机器人也有一定的缺点。 它们的固定底座设计限制了它们的操作范围和灵活性,阻止它们在大范围内移动或调整位置,并导致它们与人类和其他机器人协作。 [21]。
II-B 轮式机器人和履带式机器人
对于移动机器人来说,它们可以面对更加复杂多样的应用场景。 如图4(b)所示的轮式机器人以其高效的移动性而被广泛应用于物流、仓储、安检等领域。 轮式机器人的优点包括结构简单、成本相对较低、能源效率高以及在平面上快速移动的能力[21]。 这些机器人通常配备激光雷达和摄像头等高精度传感器,能够实现自主导航和环境感知,使其在自动化仓库管理和检查任务中非常有效,例如 Kiva 机器人 (Kiva Systems) [25] 和 Jackal 机器人 (Clearpath Robotics) [26]。 然而,轮式机器人在复杂地形和恶劣环境中,特别是在不平坦的地面上,移动性有限。 此外,它们的负载能力和机动性受到一定限制。
不同的是,履带式机器人具有强大的越野能力和机动性,在农业、建筑和灾后恢复方面显示出潜力,如图4(c)所示。 履带系统提供了更大的地面接触面积,分散了机器人的重量,并降低了在泥土和沙子等松软地形中下沉的风险。 此外,履带式机器人配备了强大的动力和悬挂系统,以在复杂地形上保持稳定性和牵引力[27]。 因此,履带式机器人也被用于军事等敏感领域。 iRobot 的 PackBot 是一款多功能军用履带式机器人,能够执行侦察、爆炸物处理和救援任务等任务[28]。 然而,由于履带系统的高摩擦力,履带式机器人常常面临能源效率低下的问题。 此外,它们在平面上的移动速度比轮式机器人慢,灵活性和可操作性也较差。
II-C 四足机器人
四足机器人以其稳定性和适应性而闻名,非常适合复杂地形探索、救援任务和军事应用。 受四足动物的启发,这些机器人可以在不平坦的表面上保持平衡和移动性,如图4(d)所示。 多关节设计使它们能够模仿生物运动,实现复杂的步态和姿势调整。 高可调节性使机器人能够自动适应不断变化的地形,增强机动性和稳定性。 LiDAR 和摄像头等传感系统可提供环境感知,使机器人能够自主导航并避开障碍物[29]。 有几种类型的四足机器人被广泛使用:Unitree Robotics、Boston Dynamics Spot 和 ANYmal C。Unitree Robotics 的 Unitree A1 和 Go1 以其成本效益和灵活性而闻名。 A1 [30]和Go1 [31]具有强大的机动性和智能避障能力,适合各种应用。 波士顿动力的 Spot 以其卓越的稳定性和操作灵活性而闻名,常用于工业检查和救援任务。 它具有强大的承载能力和适应性,能够在恶劣的环境下执行复杂的任务[32]。 ANYbotics的ANYmal C以其模块化设计和高耐用性,广泛应用于工业检测和维护。 ANYmal C具备自主导航和远程操作能力,适合长时间的户外任务甚至极端的月球任务[33]。 四足机器人的复杂设计和高昂的制造成本导致大量的初始投资,限制了它们在成本敏感领域的使用。 此外,它们在复杂环境下的电池续航能力有限,需要频繁充电或更换电池才能长时间运行[34]。
II-D 人形机器人
人形机器人以其类似人类的外形而著称,在服务业、医疗保健和协作环境等领域越来越普遍。 这些机器人可以模仿人类的动作和行为模式,提供个性化的服务和支持。 它们灵巧的手部设计使它们能够执行复杂的任务,这使它们有别于其他类型的机器人,如图4(e)所示。 这些手通常具有多个自由度和高精度传感器,使其能够模拟人手的抓取和操纵能力,这在医疗手术和精密制造等领域尤为重要[35] 。 在目前的人形机器人中,Atlas(波士顿动力公司)以其卓越的移动性和稳定性而闻名。 Atlas可以执行复杂的动态动作,例如奔跑、跳跃和滚动,展示了人形机器人在高动态环境中的潜力[36]。 HRP 系列 (AIST) 用于各种研究和工业应用,其设计注重高稳定性和灵活性,使其在复杂环境中有效,特别是与人类的协作任务[37]。 ASIMO(本田)是最著名的人形机器人之一,可以行走、跑步、爬楼梯、识别人脸和手势,非常适合接待和引导服务[38]。 此外,小型社交机器人 Pepper(Softbank Robotics)可以识别情绪并进行自然语言交流,广泛应用于客户服务和教育环境[39]。
然而,由于其复杂的控制系统,人形机器人在复杂环境下保持运行稳定性和可靠性面临挑战。 这些挑战包括稳健的双足行走控制和灵巧的手部抓取[40]。此外,基于液压系统的传统人形机器人以其结构庞大和维护成本高的特点,越来越多地被电机驱动所取代系统。 最近,特斯拉和Unitree Robotics推出了基于电机系统的人形机器人。 通过与大语言模型的集成,仿人机器人有望智能处理各种复杂的任务,填补制造业、医疗保健和服务业的劳动力缺口,从而提高效率和安全性[41]。
II-E 仿生机器人
不同的是,仿生机器人通过模拟自然生物体的高效运动和功能,在复杂和动态的环境中执行任务。 通过模拟生物实体的形态和运动机制,这些机器人在医疗保健、环境监测和生物研究等领域展现出巨大的潜力[21]。 通常,它们利用灵活的材料和结构来实现逼真、敏捷的动作并最大限度地减少对环境的影响。 重要的是,仿生设计可以通过模仿生物有机体的高效运动机制来显着提高机器人的能源效率,使其在能源消耗方面更加经济[42, 43]。 这些仿生机器人包括类鱼机器人[44, 45]、类昆虫机器人[46, 47]和软体机器人[48],如图4(f)所示。 然而,仿生机器人面临着一些挑战。 首先,其设计和制造工艺复杂且成本高昂,限制了大规模生产和广泛应用。 其次,由于采用柔性材料和复杂的运动机制,仿生机器人在极端环境下的耐用性和可靠性受到限制。
III 实体模拟器
实体模拟器对于实体人工智能至关重要,因为它们提供了经济高效的实验,通过模拟潜在危险场景来确保安全性,在不同环境中进行测试的可扩展性,快速原型设计能力,可访问更广泛的研究社区,用于精确研究的受控环境,用于精确研究的数据生成训练和评估,以及算法比较的标准化基准。 为了使智能体能够与环境交互,需要构建一个真实的模拟环境。 这需要考虑环境的物理特征、物体的属性及其相互作用。
| Simulator | Year | HFPS | HQGR | RRL | DLS | LSPC | ROS | MSS | CP | Physics Engine | Main Applications |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Isaac Sim [49] | 2023 | PhysX | Nav, AD | ||||||||
| Isaac Gym [50] | 2019 | PhysX | RL,LSPS | ||||||||
| Gazebo [51] | 2004 | ODE, Bullet, Simbody, DART | Nav,MR | ||||||||
| PyBullet [52] | 2017 | Bullet | RL,RS | ||||||||
| Webots [53] | 1996 | ODE | RS | ||||||||
| MuJoCo [54] | 2012 | Custom | RL, RS | ||||||||
| Unity ML-Agents [55] | 2017 | Custom | RL, RS | ||||||||
| AirSim [56] | 2017 | Custom | Drone sim, AD, RL | ||||||||
| MORSE [57] | 2015 | Bullet | Nav, MR | ||||||||
| CoppeliaSim (V-REP) [58] | 2013 | Bullet, ODE, Vortex, Newton | MR, RS |
本节将分两部分介绍常用的仿真平台:基于底层仿真的通用仿真器和基于真实场景的仿真器。
III-A 通用模拟器
真实环境中存在的物理交互和动态变化是不可替代的。 然而,在物理世界中部署具体模型往往会带来高昂的成本并面临众多挑战。 通用模拟器提供了一个紧密模仿物理世界的虚拟环境,允许算法开发和模型训练,从而提供显着的成本、时间和安全优势。

Isaac Sim [49] 是一个用于机器人和人工智能研究的先进仿真平台。 它具有高保真物理模拟、实时光线追踪、广泛的机器人模型库和深度学习支持。 其应用场景包括自动驾驶、工业自动化、人机交互等。Gazebo [59]是一个用于机器人研究的开源模拟器。 它拥有丰富的机器人库,并与 ROS 紧密集成。 它支持各种传感器的仿真,并提供大量预构建的机器人模型和环境。 它主要用于机器人导航和控制以及多机器人系统。PyBullet [52]是Bullet物理引擎的python接口。 它易于使用,具有多种传感器模拟和深度学习集成。 PyBullet 支持实时物理模拟,包括刚体动力学、碰撞检测和约束求解。 桌子。 II介绍了10款通用模拟器的主要特点和主要应用场景。 它们各自在实体人工智能领域具有独特的优势。 研究人员可以根据自己的具体研究需求选择最合适的模拟器,从而加速实体人工智能技术的开发和应用。 图5展示了通用模拟器的可视化效果。
III-B 基于真实场景的模拟器
在家庭活动中实现通用的具身智能体一直是具身人工智能研究领域的主要焦点。 这些实体代理需要深入了解人类的日常生活并执行复杂的实体任务,例如室内环境中的导航和交互。 为了满足这些复杂任务的需求,模拟环境需要尽可能接近现实世界,这对模拟器的复杂性和真实性提出了很高的要求。 这导致了基于现实世界环境的模拟器的创建。 这些模拟器主要从现实世界收集数据,创建逼真的 3D 资源,并使用 UE5 和 Unity 等 3D 游戏引擎构建场景。 丰富而真实的场景使得基于现实世界环境的模拟器成为研究家庭活动中的嵌入式人工智能的首选。

AI2-THOR [60]是一款基于Unity3D的室内具体场景模拟器,由艾伦人工智能研究所牵头。 作为建立在现实世界中的高保真模拟器,AI2-THOR 拥有丰富的交互式场景对象以及分配给它们的物理属性(例如打开/关闭甚至冷/热)。 AI2-THOR由两部分组成:iTHOR和RoboTHOR。 iTHOR包含120个房间,分为厨房、卧室、浴室和客厅,拥有超过2000个独特的交互对象,并支持多智能体模拟; RoboTHOR 包含 89 个模块化公寓,包含 600 多个物体,其独特之处在于这些公寓对应于现实世界中的真实场景。 迄今为止,基于AI2-THOR已经出版了一百多部作品。
Matterport 3D [61]是在R2R[62]中提出的,更常用作大规模2D-3D视觉数据集。 Matterport3D 数据集包括 90 个建筑室内场景、10,800 张全景图和 194,400 张 RGB-D 图像,并提供表面重建、相机姿态以及 2D 和 3D 语义分割注释。 Matterport3D 将 3D 场景转换为离散的“视点”,具体代理在 Matterport3D 场景中的相邻“视点”之间移动。 在每个“视点”,具体代理可以获得以“视点”为中心的 1280x1024 全景图像(18 RGB-D)。 Matterport3D 是最重要的体现导航基准之一。
Virtualhome [63]是Puig等人带来的一款包含AI的家庭活动模拟器。Virtualhome最特别的地方在于它以环境图表示的环境。 环境图表示场景中的对象及其相关关系。 用户还可以自定义和修改环境图,实现场景对象的自定义配置。 这种环境图为实体主体理解环境提供了一种新的方式。 与AI2-THOR类似,Virtualhome也提供了大量的交互对象,实体代理可以与它们交互并改变它们的状态。 Virtualhome 的另一个特点是其简单易用的 API。 体现主体的动作被简化为“操作+对象”的格式。 这一特性使得Virtualhome广泛应用于体现规划、指令分解等研究领域。
Habitat [64]是Meta推出的大规模人机交互开源模拟器。 Habitat基于Bullet物理引擎,实现了高性能、高速、并行的3D仿真,并为实体智能体的强化学习提供了丰富的接口。 人居环境具有极高的开放度。 研究人员可以在Habitat中导入并创建3D场景,也可以利用Habitat平台上丰富的开放资源进行扩展。 Habitat 拥有许多可定制的传感器,并支持多智能体模拟。 来自开放资源或定制的多个实体代理(例如人类和机器狗)可以在模拟器中合作,自由移动,并与场景进行简单的交互。 因此,栖息地越来越受到人们的关注。
| Simulation Platform | Year | Num of Scenes | Continuous Action | 3D Scene Scans | Sensors | Physics | Multiple Agents | Object States | 3D Assets |
|---|---|---|---|---|---|---|---|---|---|
| AI2-THOR [60] | 2017 | 120 | RGB-D, S | ||||||
| Matterport 3D [61] | 2018 | 90 | RGB-D, S | ||||||
| Habitat [64] | 2019 | 1000+ | RGB-D, S | ||||||
| Virtual Home [63] | 2018 | 50 | RGB-D, S | ||||||
| SAPIEN [65] | 2020 | 46 | RGB-D, S | ||||||
| iGibson [66][67] | 2021 | 15 | RGB-D, S, L | ||||||
| TDW [68] | 2021 | - | RGB-D, S, A |
与其他模拟器更注重场景不同,SAPIEN[65]更注重模拟物体的交互。 SAPIEN基于PhysX物理引擎,提供细粒度的体现控制,可以通过ROS接口实现基于力和扭矩的联合控制。 SAPIEN基于PartNet-Mobility数据集,提供包含丰富交互对象的室内模拟场景,并支持自定义资源导入。 与AI2-THOR等直接改变物体状态的模拟器不同,SAPIEN支持模拟物理交互,具身智能体可以通过物理动作控制物体的铰接部分,从而改变物体的状态。 这些特性使得SAPIEN非常适合训练具体AI的细粒度对象操作。
iGibson [66][67]是斯坦福大学推出的开源模拟器。 iGibson 基于 Bullet 物理引擎构建,提供 15 个高质量室内场景,并支持从 Gibson 和 Matterport3D 等其他数据集导入资源。 作为面向对象的模拟器,iGibson为物体赋予了丰富的可变属性,不仅限于物体的运动学属性(姿态、速度、加速度等),还包括温度、湿度、清洁度、开关状态等。 此外,除了其他模拟器标配的深度和语义传感器外,iGibson还为实体代理提供LiDAR,使代理能够轻松获取场景中的3D点云。 在具体代理配置方面,iGibson支持连续动作控制和细粒度联合控制。 这使得 iGibson 中的实体能够在自由移动的同时与物体进行微妙的交互。
TDW [68] 由麻省理工学院推出。 作为最新的实体模拟器之一,TDW结合了高保真视频和音频渲染、逼真的物理效果以及单一灵活的控制器,在模拟环境的感知和交互方面取得了一定的进步。 TDW将多个物理引擎集成到一个框架中,可以实现刚体、软体、织物、流体等多种材质的物理交互模拟,并提供与物体交互时的情境声音。 因此,与其他模拟器相比,TDW 迈出了重要的一步。 TDW支持部署多个智能代理,并为用户提供丰富的API库和资产库,允许用户根据自己的需求自由定制场景和任务,甚至是户外场景和相关任务。
表III总结了基于上述真实场景的所有模拟器。 Sapien 因其设计而脱颖而出,专门用于模拟与门、橱柜和抽屉等联合对象的交互。 VirtualHome 以其独特的环境图而闻名,它有助于基于环境的自然语言描述进行高级具体规划。 虽然AI2Thor提供了丰富的交互场景,但这些交互与VirtualHome中的交互类似,都是基于脚本的,缺乏真实的物理交互。 这种设计足以满足不需要细粒度交互的具体任务。 iGibson 和 TDW 都提供细粒度的具体控制和高度模拟的物理交互。 iGibson擅长提供丰富、真实的大型场景,适合复杂且长时间的移动操作,而TDW则允许用户更大的场景扩展自由度,并具有独特的音频和灵活的流体模拟,使其成为相关模拟场景不可或缺的组成部分。 Matterport3D 是一个基础的 2D-3D 视觉数据集,在具体人工智能基准测试中得到广泛使用和扩展。 尽管Habitat中的体现智能体缺乏交互能力,但其广泛的室内场景、友好的用户界面和开放的框架使其在体现导航领域备受推崇。
此外,自动化的仿真场景构建对于获得高质量的体现数据也大有裨益。 RoboGen [69]通过大语言模型从随机采样的3D资产中定制任务,从而创建场景并自动训练智能体; HOLODECK [70]可以根据人类指令自动定制AI2-THOR中对应的高质量模拟场景; PhyScene [71] 基于条件扩散生成交互式且物理一致的高质量 3D 场景。 艾伦人工智能研究所扩展了AI2-THOR,提出了ProcTHOR[72],它可以自动生成具有足够交互性、多样性和合理性的模拟场景。 这些方法提供了对具体人工智能的见解。
IV 具身感知
视觉感知未来的“北极星”是以具身为中心的视觉推理和社交智能[73]。 与仅仅识别图像中的物体不同,具有具体感知的智能体必须在物理世界中移动并与环境交互。 这需要对 3D 空间和动态环境有更深入的了解。 具身感知需要视觉感知和推理、理解场景内的 3D 关系,以及基于视觉信息预测和执行复杂的任务。
IV-A 主动视觉感知
| Function | Type | Methods |
| vSLAM | Traditional vSLAM | MonoSLAM[74], MSCKF[75], PTAM[76], |
| ORB-SLAM[77], DTAM[78], LSD-SLAM[79] | ||
| Semantic vSLAM | SLAM++[80], CubeSLAM[81], HDP-SLAM[82], QuadricSLAM[83], So-SLAM[84], | |
| DS-SLAM[85], DynaSLAM[86], SG-SLAM[87], OVD-SLAM[88], GS-SLAM[89] | ||
| 3D Scene Understanding | Projection-based | MV3D[90], PointPillars[91], MVCNN[92] |
| Voxel-based | VoxNet[93], SSCNet[94]), MinkowskiNet[95], SSCNs[96], Embodiedscan[97] | |
| Point-based | PointNet[98], PointNet++[99], PointMLP[100]), PointTransformer[101], Swin3d[102], PT2[103], | |
| PT3[104], 3D-VisTA[105], LEO[106], PQ3D[107], PointMamba[108], PCM[109], Mamba3D[110] | ||
| Active Exploration | Interacting with the environment | Pinto et al.[111], Tatiya et al.[112] |
| Changing the viewing direction | Jayaraman et al. [113], NeU-NBV[114], Hu et al.[115], Fan et al.[116] |
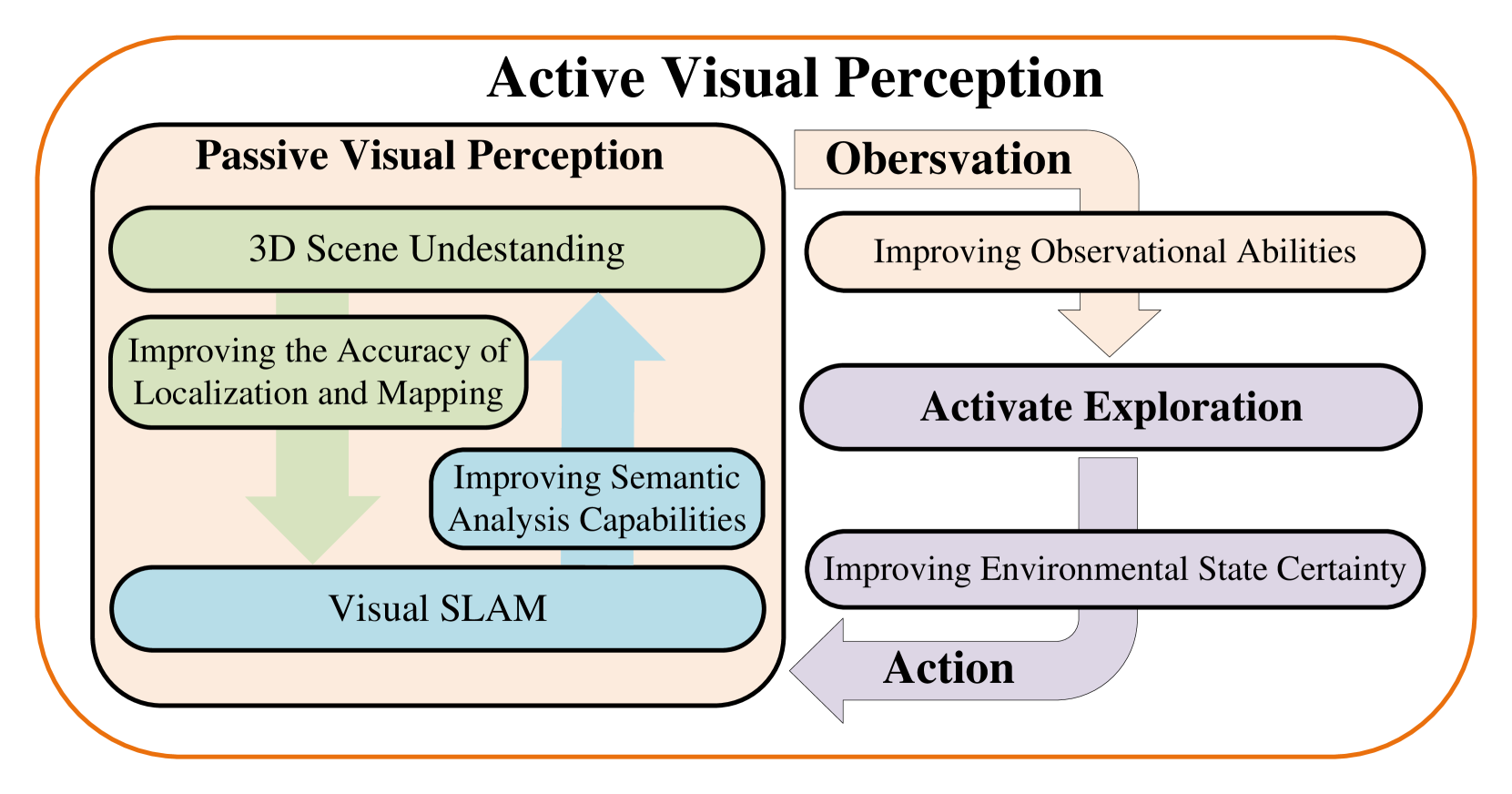
主动视觉感知系统需要状态估计、场景感知和环境探索等基本能力。 如图7所示,这些功能已在视觉同步定位与建图 (vSLAM)[117, 118]、3D 场景理解[119] 和主动探索[12]。 这些研究领域有助于开发强大的主动视觉感知系统,促进复杂动态环境中改善环境交互和导航。 我们简要介绍了这三个组件,并总结了表IV中每个部分提到的方法。
IV-A1 视觉同步定位和测绘
同步定位与建图 (SLAM) 是一种确定移动机器人在未知环境中的位置的技术,同时构建该环境的地图[120, 121]。 基于距离的 SLAM [122, 123, 124] 使用测距仪(例如激光扫描仪、雷达和/或声纳)创建点云表示,但成本高昂且提供的环境信息有限。 视觉 SLAM (vSLAM)[117, 118] 使用机载摄像头捕获帧并构建环境的表示。 它因其硬件成本低、小规模场景下精度高以及能够捕获丰富的环境信息而受到欢迎。 经典vSLAM技术可分为传统vSLAM和语义vSLAM[118]。
传统的vSLAM系统利用图像信息和多视图几何原理来估计机器人在未知环境中的位姿,构建由点云组成的低级地图(例如稀疏地图、半稠密地图和稠密地图),例如滤波器基于关键帧的方法(例如,MonoSLAM [74]、MSCKF [75])、基于关键帧的方法(例如,PTAM [76]、 ORB-SLAM [77])和直接跟踪方法(例如 DTAM [78]、LSD-SLAM [79])。 由于低级地图中的点云并不直接对应于环境中的物体,因此实体机器人很难解释和利用它们。 然而,语义概念的出现,特别是与语义信息解决方案集成的语义 vSLAM 系统,显着提高了机器人感知和导航未探索环境的能力。
早期的工作,例如 SLAM++[80],使用实时 3D 对象识别和跟踪来创建高效的对象图,从而在杂乱的环境中实现强大的闭环、重新定位和对象检测。 CubeSLAM[81]和HDP-SLAM[82]在地图中引入3D矩形来构建轻量级语义地图。 QuadricSLAM[83]采用语义3D椭球体来实现复杂几何环境中物体形状和姿态的精确建模。 So-SLAM[84]融合了室内环境中的全耦合空间结构约束(共面性、共线性和邻近性)。 为了应对动态环境的挑战,DS-SLAM[85]、DynaSLAM[86]和SG-SLAM[87]采用语义分割用于运动一致性检查和多视图几何算法来识别和过滤动态对象,确保稳定的定位和映射。 OVD-SLAM[88]利用语义、深度和光流信息来区分没有预定义标签的动态区域,从而实现更准确、更稳健的定位。 GS-SLAM[89] 利用 3D 高斯表示,通过实时可微分泼溅渲染管道和自适应扩展策略来平衡效率和准确性。
IV-A2 3D场景理解
3D 场景理解旨在区分对象的语义、识别其位置并从 3D 场景数据中推断几何属性,这对于自动驾驶[125]、机器人导航[126] 和人机交互[127] 等。可以使用 LiDAR 或 RGB-D 传感器等 3D 扫描工具将场景记录为 3D 点云。 与图像不同,点云稀疏、无序且不规则,[119]使得场景解释极具挑战性。
近年来,人们提出了许多用于3D场景理解的深度学习方法,可分为基于投影的方法、基于体素的方法和基于点的方法。 具体来说,基于投影的方法(例如 MV3D[90]、PointPillars[91]、MVCNN[92] )将 3D 点投影到各种图像平面并采用基于 CNN 的 2D 主干进行特征提取。 基于体素的方法将点云转换为规则的体素网格以方便3D卷积运算(例如VoxNet[93]、SSCNet[94]),并且一些工作提高了它们的效率通过稀疏卷积(例如,MinkowskiNet[95]、SSCNs[96]、Embodiedscan[97])。 相比之下,基于点的方法直接处理点云(例如,PointNet[98]、PointNet++[99]、PointMLP[100]) 。 最近,为了实现模型可扩展性,基于 Transformers(例如 PointTransformer[101]、Swin3d[102]、PT2[103]、PT3 [104]、3D-VisTA[105]、LEO[106]、PQ3D[107])和基于 Mamba(例如 PointMamba[108]、PCM[109]、Mamba3D[110])的架构已经出现。 值得注意的是,除了直接使用点云特征外,PQ3D[107]还无缝结合多视图像和体素特征来增强场景理解能力。
IV-A3 积极探索
前面介绍的3D场景理解方法赋予机器人以被动方式感知环境的能力。 在这种情况下,感知系统的信息获取和决策不适应不断变化的场景。 然而,被动感知是主动探索的重要基础。 鉴于机器人能够移动并与周围环境频繁互动,它们还应该能够主动探索和感知环境。 它们之间的关系如图7所示。 当前解决主动感知的方法侧重于与环境交互[111, 112]或通过改变观看方向来获取更多视觉信息[113, 114, 115, 116] 。
例如,Pinto 等人[111]提出了一种好奇的机器人,它通过与环境的物理交互来学习视觉表示,而不是仅仅依赖数据集中的类别标签。 为了解决不同形态机器人之间交互物体感知的挑战,Tatiya等人[112]提出了一种多阶段投影框架,通过学习的探索性交互传递隐性知识,使机器人能够有效地识别物体属性无需从头开始重新学习。 认识到自主捕获信息性观察的挑战,Jayaraman 等人[113]提出了一种强化学习方法,其中代理学习通过减少其环境中未观察到的部分的不确定性来主动获取信息性视觉观察,使用循环用于主动完成全景场景和 3D 物体形状的神经网络。 NeU-NBV[114] 引入了一种无地图规划框架,该框架迭代地定位 RGB 相机以捕获未知场景中信息最丰富的图像,并在基于图像的神经渲染中使用新颖的不确定性估计来指导数据收集转向最不确定的观点。 Hu 等人[115]开发了一种机器人探索算法,该算法使用状态值函数来预测未来状态的值,结合离线蒙特卡罗训练、在线时间差分自适应和基于传感器信息覆盖。 为了解决开放世界环境中的意外输入问题,范等人[116]将主动识别视为一个顺序的证据收集过程,提供逐步的不确定性量化和证据下的可靠预测组合理论,同时通过专门开发的奖励函数有效地表征开放世界环境中行动的优点。
| Type | Method | Years | Visual Input | LLM-base |
| Two-stage | ScanRefer[128] | 2020 | 3D | |
| ReferIt3D[129] | 2020 | 3D | ||
| TGNN[130] | 2021 | 3D | ||
| SAT[131] | 2021 | 3D+2D | ||
| FFL-3DOG[132] | 2021 | 3D | ||
| 3DVG-Transformer[133] | 2021 | 3D | ||
| LanguageRefer[134] | 2022 | 3D | ||
| LAR[135] | 2022 | 3D | ||
| MVT[136] | 2022 | 3D | ||
| LLM-Grounder[137] | 2023 | 3D | ||
| ZSVG3D[138] | 2023 | 3D | ||
| GPS[139] | 2024 | 3D | ||
| One-stage | 3D-SPS[140] | 2022 | 3D+2D | |
| BUTD-DETR[141] | 2022 | 3D | ||
| EDA[142] | 2023 | 3D | ||
| ReGround3D[143] | 2024 | 3D+2D |
IV-B 3D视觉基础
与在平面图像范围内运行的传统 2D 视觉基础 (VG) 不同,3D VG 融合了对象之间的深度、透视和空间关系,为代理与其环境交互提供了更强大的框架。 3D VG 的任务涉及使用自然语言描述[128, 129]在 3D 环境中定位对象。 如表V所示,近期的 3D 视觉基础方法可大致分为两类:两阶段方法和一阶段方法[144]。
IV-B1 两阶段 3D 视觉接地方法
与相应的 2D 任务[145]类似,3D 接地的早期研究主要利用两阶段检测然后匹配流程。 他们最初使用预训练的检测器[146]或分段器[147,148,149]从 3D 场景中的众多对象提案中提取特征,然后将其与语言查询融合特征来匹配目标对象。 两阶段研究的重点主要集中在第二阶段,例如探索对象提议特征和语言查询特征之间的相关性以选择最佳匹配的对象。 ReferIt3D [129] 和 TGNN [130] 不仅学习将提案特征与文本嵌入相匹配,而且还通过图神经网络对对象之间的上下文关系进行编码。 为了增强自由形式描述和不规则点云中的 3D 视觉基础,FFL-3DOG [132] 利用语言场景图进行短语相关性,使用多级 3D 建议关系图来丰富视觉特征,以及用于编码全局上下文的描述引导的 3D 视觉图。
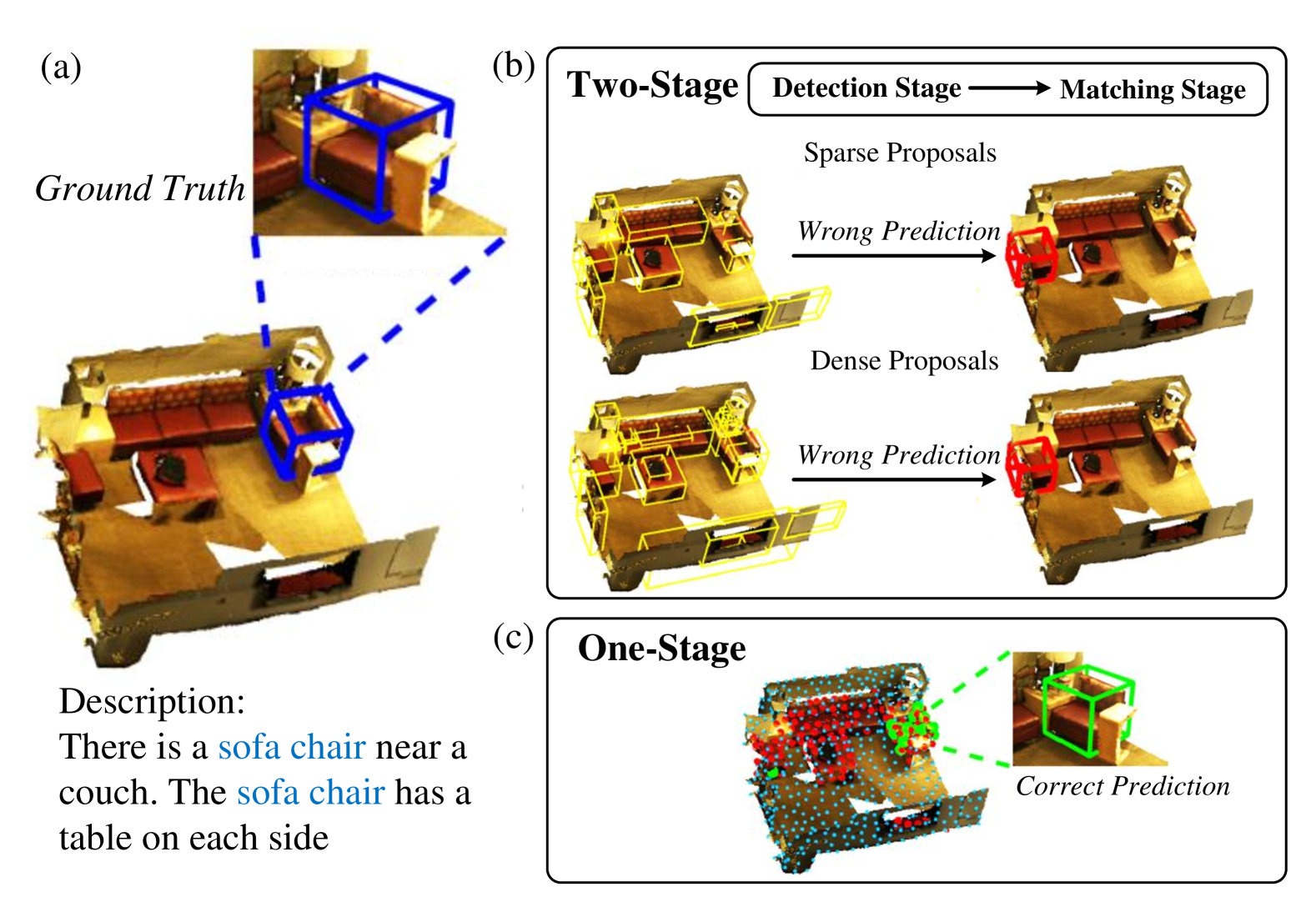
最近,随着 Transformer 架构在自然语言处理 [150, 151] 和计算机视觉任务 [152, 14] 中表现出出色的性能,研究越来越集中于使用 Transformer用于在 3D 视觉基础任务中提取和融合视觉语言特征。 例如,LanguageRefer [134] 采用基于 Transformer 的架构,结合了 3D 空间嵌入、语言描述和类标签嵌入,以实现强大的 3D 视觉基础。 3DVG-Transformer [133] 是一种用于 3D 点云的关系感知视觉基础方法,具有用于关系增强提案生成的坐标引导上下文聚合模块和用于跨模式提案的多重注意模块消歧义。 为了实现对 3D 对象和引用表达式进行更细粒度的推理,TransRefer3D [153] 使用实体和关系感知注意力增强了跨模态特征表示,结合了自我注意力、实体感知注意力和关系意识注意力。 GPS[139] 提出了一个统一的学习框架,通过利用三个级别的对比对齐学习,从百万级 3D 视觉语言数据集(即 SCENEVERSE[139])中提取知识和掩码语言建模客观学习。 上述大多数 3D VG 方法都专注于特定视点,但当视点发生变化时,学习到的视觉语言对应可能会失败。 为了学习更多视图鲁棒的视觉表示,MVT[136]提出了一种多视图 Transformer,可以学习视图无关的多模态表示。以减轻稀疏、噪声和不完整点的限制云,各种方法已经探索了如何结合捕获的(例如 SAT [131] 或合成的(例如 LAR [135])图像中的详细 2D 视觉特征来增强 3D视觉基础任务。
现有的 3D VG 方法通常依赖于大量标记数据进行训练,或者在处理复杂语言查询时表现出局限性。 受大语言模型令人印象深刻的语言理解能力的启发,LLM-Grounder[137]提出了一种不需要标记数据的开放词汇3D视觉基础管道,利用大语言模型分解查询并生成计划对象识别,然后评估空间和常识关系以选择最佳匹配对象。 为了捕获依赖于视图的查询并破译 3D 空间中的空间关系,ZSVG3D [138] 设计了零样本开放词汇 3D 视觉基础方法,该方法使用大语言模型来识别相关对象并执行推理、转换将此过程转化为脚本化可视化程序,然后转化为可执行的 Python 代码来预测对象位置。
然而,如图8(b)所示,这些两阶段方法面临着确定建议数量的困境,因为第一阶段的3D检测器需要采样关键点来表示整个3D场景并为每个关键点生成相应的建议。 稀疏的提案可能会忽略第一阶段的目标,从而使它们在第二阶段无法匹配。 相反,密集的提案可能不可避免地包含冗余对象,由于提案间关系过于复杂,导致第二阶段的目标区分困难。 此外,关键点采样策略与语言无关,这增加了检测器识别与语言相关的提案的难度。
IV-B2 一级 3D 视觉接地方法
在图8(c)中,与两阶段3D VG方法相比,一阶段3D VG方法集成了由语言查询引导的对象检测和特征提取,使得更容易定位对象。
3D-SPS[140]将3D VG任务作为关键点选择问题,避免了检测和匹配的分离。 具体来说,3D-SPS 最初通过描述感知关键点采样模块对语言相关关键点进行粗略采样。 随后,利用面向目标的渐进挖掘模块精细选择目标关键点并预测基础。 受到MDETR[154]和GLIP[155]等2D图像语言预训练模型的启发,BUTD-DETR[141]提出一个自下而上自上而下的检测 Transformer,可用于 2D 和 3D VG。 具体来说,BUTD-DETR利用带标签的自下而上的框建议和自上而下的语言描述来指导通过预测头对目标对象和相应的语言跨度进行解码。
然而,这些方法要么提取耦合所有单词的句子级特征,要么更多地关注描述中的对象名称,这会丢失单词级信息或忽略其他属性。 为了解决这些问题,EDA[142]明确地解耦了句子中的文本属性,并在细粒度语言和点云对象之间进行了密集对齐。 首先,将长文本解耦为五个语义成分,包括主宾语、辅助宾语、属性、代词和关系。 随后,密集对齐被设计为将所有与对象相关的解耦文本语义组件与视觉特征对齐。 为了根据隐式指令推理人类意图,ReGround3D [143] 设计了一个由 MLM 提供支持的以视觉为中心的推理模块,以及一个 3D 接地模块,该模块通过重新访问增强的几何形状和细粒度来准确获取对象位置3D 场景的细节。 此外,还采用了接地链机制,通过交错的推理和接地步骤来改善 3D 推理接地。
IV-C 视觉语言导航
视觉语言导航(VLN)是嵌入式人工智能的一个关键研究问题,旨在使智能体能够按照语言指令在看不见的环境中进行导航。 VLN 要求机器人能够理解复杂多样的视觉观察,同时解释不同粒度的指令。 VLN 的输入通常由两部分组成:视觉信息和自然语言指令。 视觉信息可以是过去轨迹的视频,也可以是一组历史-当前观察图像。 自然语言指令包括具体主体需要达到的目标或预期具体主体完成的任务。 实体代理必须使用上述信息从候选列表中选择一个或一系列动作来满足自然语言指令的要求。 这个过程可以表示为:
| (1) |
其中 是所选操作或候选操作列表, 是当前观察结果, 是历史信息, 是自然语言指令。
| Dataset | Year | Simulator | Environment | Feature | Size |
|---|---|---|---|---|---|
| R2R [62] | 2018 | Matterport3D | Indoor, Discrete | Step-by-step instructions | 21,567 |
| R4R [156] | 2019 | Matterport3D | Indoor, Discrete | Step-by-step instructions | 200,000+ |
| VLN-CE [157] | 2020 | Habitat | Indoor, Continuous | Step-by-step instructions | - |
| TOUCHDOWN [158] | 2019 | - | Outdoor, Discrete | Step-by-step instructions | 9,326 |
| REVERIE [159] | 2020 | Matterport3D | Indoor, Discrete | Described goal navigation | 21,702 |
| SOON [160] | 2021 | Matterport3D | Indoor, Discrete | Described goal navigation | 3,848 |
| DDN [161] | 2023 | AI2-THOR | Indoor, Continuous | Demand-driven navigation | 30,000+ |
| ALFRED [162] | 2020 | AI2-THOR | Indoor, Continuous | Navigation with interaction | 25,743 |
| OVMM [163] | 2023 | Habitat | Indoor, Continuous | Navigation with interaction | 7,892 |
| BEHAVIOR-1K[164] | 2023 | OmniGibson | Indoor, Continuous | Long-span navigation with interaction, | 1,000 |
| CVDN [165] | 2020 | Matterport3D | Indoor, Discrete | Dialog, oracle | 2,050 |
| DialFRED [166] | 2022 | AI2-THOR | Indoor, Continuous | Dialog, oracle | 53,000 |
SR(成功率)、TL(轨迹长度)和 SPL(按路径长度加权的成功)是 VLN 中最常用的指标。 其中,SR直接反映了体现智能体的导航性能,TL反映了导航效率,而SPL则结合两者来表示体现智能体的整体性能。 下面,我们分两部分介绍VLN:数据集和方法。
IV-C1 数据集
在VLN中,自然语言指令可以是一系列详细的动作描述,可以是一个完整描述的目标,也可以是一个粗略描述的任务,甚至只是人类的需求。 体现代理需要完成的任务可能只是单个导航,或者带有交互的导航,或者需要按顺序完成的多个导航任务。 这些差异给VLN带来了不同的挑战,并且建立了许多不同的数据集。 基于这些差异,我们介绍了一些重要的 VLN 数据集。
Room to Room (R2R) [62] 是基于 Matterport3D 的 VLN 数据集。 在R2R中,具体代理根据分步指令进行导航,根据视觉观察选择下一个相邻的导航图节点前进,直到到达目标位置。 实体代理需要动态跟踪进度,以使导航过程与细粒度指令保持一致。 Room-for-Room [156]将R2R中的路径延伸到更长的轨迹,这需要实体代理具有更强的长距离指令和历史对齐能力。 VLN-CE [157]将R2R和R4R扩展到连续环境,体现的代理可以在场景中自由移动。 这使得实体主体的行动决策变得更加困难。 与上述基于室内场景的数据集不同,TOUCHDOWN数据集[158]是基于Google街景创建的。 在TOUCHDOWN中,体现了代理遵循指令在纽约市的街景渲染模拟中导航以找到指定的对象。
与 R2R 类似,REVERIE 数据集[159]也是基于 Matterport3D 模拟器构建的。 REVERIE要求具身智能体能够准确定位由简洁的、人类注释的高级自然语言指令指定的远处不可见的目标物体,这意味着具身智能体需要在场景中的大量物体中找到目标物体。 在不久的[160]中,代理会收到一条从粗到细的长而复杂的指令,以在 3D 环境中找到目标对象。 在导航过程中,智能体首先搜索较大的区域,然后根据视觉场景和指令逐渐缩小搜索范围。 这使得SOON的导航具有目标导向性并且与初始位置无关。 DDN [161] 比这些数据集更进一步,仅提供人类需求,而不指定明确的对象。 代理需要在场景中导航以找到满足人类需求的对象。
ALFRED 数据集[162]基于AI2-THOR模拟器。 在ALFRED中,实体主体需要理解环境观察结果,并根据粗粒度和细粒度的指令在交互环境中完成家务任务。 OVMM [163] 的任务是在任何看不见的环境中拾取任何对象并将其放置在指定位置。 智能体需要在家庭环境中定位目标物体,导航并抓取它,然后导航到目标位置并放下该物体。 OVMM 提供了基于 Habitat 的模拟以及在现实世界中实现的框架。 Behaviour-1K 数据集[164]基于人类需求,包含 1,000 个长序列、复杂、依赖技能的日常任务,这些任务是在 OmniGibson(iGibson 模拟环境的扩展)内设计的。 智能体需要完成长跨度的导航交互任务,其中包含数千个基于视觉信息和语言指令的低级操作步骤。 这些复杂的任务需要很强的理解和记忆能力。
还有一些更特殊的数据集。 CVDN [165] 要求实体代理根据对话历史导航到目标,并在不确定时提出问题以帮助决定下一步行动。 DialFRED [166] 是 ALFRED 的扩展,允许客服人员在导航和交互过程中提出问题以获得帮助。 这些数据集都引入了额外的预言机,实体主体需要通过提问来获取更多有利于导航的信息。
IV-C2 方法
近年来,VLN取得了长足的进步,大语言模型的惊人表现,深刻影响了VLN的方向和重点。 尽管如此,VLN方法可以分为两个方向:基于记忆理解和基于未来预测。
基于记忆理解的方法侧重于对环境的感知和理解,以及基于历史观察或轨迹的模型设计,这是一种基于过去学习的方法。 基于未来预测的方法更注重对未来状态的建模、预测和理解,是一种未来学习的方法。 由于VLN可以被视为部分可观测的马尔可夫决策过程,其中未来的观测取决于智能体当前的环境和行为,历史信息对于导航决策,特别是大跨度的导航决策具有重要意义,因此基于记忆理解的方法一直是VLN的主流。 然而,基于未来预测的方法仍然具有重要意义。 其对环境的本质理解对于连续环境中的VLN具有重要价值,特别是随着世界模型概念的兴起,基于未来预测的方法越来越受到研究人员的关注。
| Method | Model | Year | Feature |
| LVERG [167] | 2020 | Graph Learning | |
| CMG [168] | 2020 | Adversarial Learning | |
| RCM [169] | 2021 | Reinforcement learning | |
| FILM [170] | 2022 | Semantic Map | |
| Memory- | LM-Nav [171] | 2022 | Graph Learning |
| Understanding | HOP [172] | 2022 | History Modeling |
| Based | NaviLLM [173] | 2024 | Large Model |
| FSTT [174] | 2024 | Test-Time Augmentation | |
| DiscussNav [175] | 2024 | Large Model | |
| GOAT [176] | 2024 | Causal Learning | |
| VER [177] | 2024 | Environment Encoder | |
| NaVid [178] | 2024 | Large Model | |
| LookBY [179] | 2018 | Reinforcement Learning | |
| Future- | NvEM [180] | 2021 | Environment Encoder |
| Prediction | BGBL [181] | 2022 | Graph Learning |
| Based | Mic [182] | 2023 | Large Model |
| HNR [183] | 2024 | Environment Encoder | |
| ETPNav [184] | 2024 | Graph Learning | |
| Others | MCR-Agent [185] | 2023 | Multi-Level Model |
| OVLM [186] | 2023 | Large Model |
基于记忆理解。 基于图的学习是基于记忆理解的方法的重要组成部分。 基于图的学习通常以图的形式表示导航过程,其中实体代理在每个时间步获得的信息被编码为图的节点。 实体代理获取全局或部分导航图信息作为历史轨迹的表示。 LVERG [167]分别编码每个节点的语言信息和视觉信息,设计新的语言和视觉实体关系图来建模文本和视觉之间的模态间关系以及模态内关系视觉实体之间。 LM-Nav [171]使用目标条件距离函数来推断原始观察集之间的联系并构建导航图,并通过大语言模型从指令中提取地标,使用视觉语言模型将它们与导航图的节点进行匹配。 HOP[172]虽然不是基于图学习,但其方法与图类似,要求模型对不同粒度的时间有序信息进行建模,从而实现对历史轨迹和记忆的深刻理解。
导航图离散化环境,但同时理解和编码环境也很重要。 FILM [170] 使用 RGB-D 观察和语义分割在导航过程中逐渐从 3D 体素构建语义图。 VER [177]通过2D-3D采样将物理世界量化为结构化3D单元,提供细粒度的几何细节和语义。
不同的学习方案探索如何更好地利用历史轨迹和记忆。 通过对抗性学习,CMG[168]在模仿学习和探索激励方案之间交替,有效加强了对指令和历史轨迹的理解,缩短了训练和推理之间的差异。 GOAT [176]通过后门调整因果学习(BACL)和前门调整因果学习(FACL)直接训练无偏模型,与视觉、导航历史及其组合到指令进行对比学习,使代理能够以更充分地利用信息。 RCM[169]提出的增强型跨模态匹配方法,利用面向目标的外部奖励和面向指令的内部奖励,在全局和局部进行跨模态落地,并通过自身的历史良好决策学习自监督模仿学习。 FSTT[174]将TTA引入到VLN中,并在时间步和任务两个尺度上对模型的梯度和模型参数进行优化,有效提高了模型性能。
大模型在基于记忆理解的方法中的具体应用是理解历史记忆的表示,并基于其广泛的世界知识来理解环境和任务。 NaviLLM [173]通过视觉编码器将历史观测序列整合到嵌入空间中,将融合编码的多模态信息输入到大语言模型中并进行微调,达到状态-在多个基准测试中都是最先进的。 NaVid[178]对历史信息的编码进行了改进,通过不同程度的池化实现对历史观测值和当前观测值的不同程度的信息保留。 DiscussNav [175]将不同能力的大模型专家分配到不同的角色,驱动大模型在导航动作之前进行讨论,完成导航决策,在零样本VLN中取得了优异的性能。
基于未来预测。 基于图的学习也广泛应用于基于未来预测的方法中。 BGBL [181] 和 ETPNav [184] 使用类似的方法设计了一个航路点预测器,可以根据对当前导航的观察来预测连续环境中的可移动路径点图节点。 他们的目标是将连续环境中的复杂导航迁移到离散环境中的节点到节点导航,从而缩小从离散环境到连续环境的性能差距。
通过环境编码提高对未来环境的理解和感知也是预测和探索未来的研究方向之一。 NvEM [180]使用主题模块和参考模块从全局和局部角度对邻居视图进行融合编码。 这实际上是对未来观察的理解和学习。 HNR[183]使用大规模预训练的分层神经辐射表示模型来直接预测未来环境的视觉表示,而不是使用三维特征空间编码的像素级图像,并构建基于未来环境表示的可导航的未来路径树。 它们从不同层面预测未来环境,为导航决策提供有效参考。
一些强化学习方法也被应用于预测和探索未来状态。 LookBY [179] 采用强化预测来使预测模块能够模仿世界并预测未来的状态和奖励。 这使得智能体能够直接将“当前观察”和“未来观察的预测”映射到行动,从而实现当时最先进的性能。 丰富的世界知识和大型模型的零样本性能为基于未来预测的方法提供了许多可能性。 MiC[182]要求大语言模型直接根据指令预测目标及其可能位置,并通过场景感知的描述提供导航指令。 这种方法需要大语言模型充分发挥“想象力”,通过提示构建想象的场景。
此外,还有一些既借鉴过去又面向未来的方法。 MCR-Agent[185]设计了一个三层动作策略,要求模型根据指令预测目标,预测要交互的目标的像素级掩模,并从先前的导航决策; OVLM [186]需要大语言模型来预测指令的相应操作和标志序列。 在导航过程中,视觉语言地图将不断更新和维护,操作将链接到地图上的航点。
IV-D 非视觉感知:触觉
触觉传感器为代理提供详细信息,例如质地、硬度和温度。 对于同一个动作,从视觉和触觉传感器学到的知识可能是相关和互补的,让机器人完全掌握手上的高精度任务。 因此,触觉感知对于物理世界中的主体至关重要,并且无疑可以增强人机交互[187, 188, 189]。
对于触觉感知任务,智能体需要从物理世界收集触觉信息,然后执行复杂的任务。 在本节中,如图10所示,我们首先介绍现有的触觉传感器类型及其数据集,然后讨论触觉感知中的三个主要任务:估计、识别和操纵。
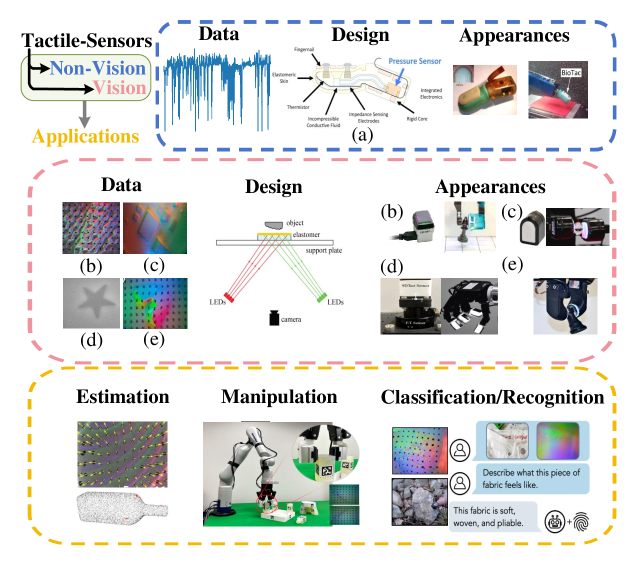
IV-D1 传感器设计
人体触觉的原理是皮肤在触摸时发生形状变化,其丰富的神经细胞发出电信号,这也是设计触觉传感器的基础。 触觉传感器设计方法可分为三类:基于非视觉、基于视觉和多模态。 基于非视觉的触觉传感器,主要利用电气和机械原理,主要记录基本的低维感觉输出,例如力、压力、振动和温度[190,191,192,193,194,195] 。 著名的代表之一是 BioTac [196] 及其模拟器[197]。 基于视觉的触觉传感器基于光学原理。 使用凝胶变形图像作为触觉信息,基于视觉的触觉传感器,例如 GelSight[198]、Gelslim[199]、DIGIT[200]、9DTact[201]、TacTip[202]、GelTip[203] 和 AllSight[204]已被用于许多应用。 TACTO[205] 和 Taxim[206] 等模拟也很受欢迎。 最近的工作重点是降低成本[201]和集成到机器人手[200,207,208]。 受人体皮肤启发的多模态触觉传感器采用灵活的材料和模块化设计,结合了压力、接近度、加速度和温度等多模态信息。
IV-D2 数据集
非视觉传感器的数据集主要由BioTac系列[196]收集,包含电极值、力矢量和接触位置。 由于任务主要是力和抓取细节的估计,因此数据集中的对象通常是力和抓取样本。 基于视觉的传感器具有变形凝胶的高分辨率图像,更注重更高的估计、纹理识别和操作。 数据集由 Geisight 传感器、DIGIT 传感器及其模拟器[198,200,205,201]收集,包括家居物品、野生动物环境、不同材料和抓握物品。 由于图像信息可以轻松地与其他模态(图像、语言、音频等)对齐和绑定[14, 209],因此实体主体的触觉感知主要围绕基于视觉的传感器。 我们介绍了十个主要的触觉数据集,总结在表八中。
| Dataset | Year | Sensor | Data Format | Type | Real/ | Sensor/ | Size | Continuous |
| Types | Simulated | Simulator | ||||||
| The Feeling of Success[210] | 2017 | Vision | Tac, Vision, Label | Daily Necessities | Real | Gelsight | 106 Objects | |
| SynTouch[197] | 2019 | Non-vision | Tac, Force, Location | - | Real | BioTac | 300k Readings | - |
| Decoding the BioTac[211] | 2020 | Non-vision | Tac, Force, Location | - | Real | BioTac | 50k Points | |
| ObjectFolder 1.0[212] | 2021 | Vision | Tac, Vision, Audio | Household Object | Simulate | TACTO | 100 Objects | |
| ObjectFolder 2.0[213] | 2022 | Vision | Tac, Vision, Audio | Household Object | Simulate | Taxim | 1000 Objects | |
| SSVTP[214] | 2022 | Vision | Tac, Vision | Clothings&Materials | Real | DIGIT | 4500 Pairs | |
| YCB-Slide[215] | 2022 | Vision | Tac, Vision, Other | Daily Necessities | Both | TACTO&DIGIT | 10 Objects | |
| ObjectFolder Real[216] | 2023 | Vision | Tac, Vision, Audio | Household Objects | Real | Gelslim | 100 Objects | |
| TVL[217] | 2024 | Vision | Tac, Vision, Text | Clothings&Materials | Real | DIGIT | 44K Pairs | |
| TaRF[218] | 2024 | Vision | Tac, Vision | Full Scene | Simulate | DIGIT | 19.3k | - |
IV-D3 方法
触觉感知有很多应用,可以分为三种类型:估计、精确的机器人操作和多模态识别任务。
预估
早期的估计工作主要集中在形状、力和滑移测量的基本算法[219,220,201]。 研究人员只是根据触觉图像的颜色和不同帧下标记分布的变化,使用阈值或应用卷积神经网络(CNN)来解决这些任务。 估计工作的重点主要是第二阶段,触觉图像的生成和物体的重建。 触觉图像[221,222,223,224]的生成旨在从视觉数据生成触觉图像。 首先它应用深度学习模型,以 RGB-D 图像作为输入并输出触觉图像[221, 222]。 近年来,随着图像生成技术的快速发展,Higuera等人[223]和Yang等人[224]将扩散模型应用于触觉生成,并取得了良好的效果。 物体的重建可分为2D重建[225, 226]和3D重建[227, 228, 201, 229, 230, 231, 232, 233, 234, 235, 218、236、237、238、239、240]。 2D重建主要关注物体的形状和分割,而3D则关注物体的表面和姿态,甚至是全场景感知。 这些任务首先采用数学方法、自动编码器方法和神经网络方法将视觉(有时是点云)和触觉特征融合在一起。 最近,Comi等人[235]和Dou等人[218]等研究人员将基于神经辐射场(NeRF)和3D高斯分布(3DGS)的新方法应用于触觉重建工作。
机器人操作
在触觉任务中,弥合模拟与真实的差距非常重要。 人们提出了强化学习和基于 GAN 的方法来解决准确、准时的机器人操作任务的变化。
强化学习方法。 Visuotactile-RL[241]对现有的强化学习方法提出了多种方法,包括触觉门控、触觉数据增强和视觉退化。 Rotateit[242] 是一个通过利用多模态感官输入实现基于指尖的对象沿多个轴旋转的系统。 它通过使用特权信息的强化学习策略来训练网络并启用在线推理。 [243]提出了一种仅使用触觉感知来推动物体的深度强化学习方法。 它提出了一个目标条件公式,允许无模型和基于模型的强化学习获得准确的策略,将对象推向目标。 AnyRotate[244] 专注于手动操作。 它是一个重力不变的多轴手持物体旋转系统,使用密集的模拟到真实触摸功能,构建连续的接触特征表示,为模拟中的训练策略提供触觉反馈,并引入执行零样本的方法通过训练观察模型来弥合模拟与现实之间的差距来进行政策转移。
基于 GAN 的方法。 ACTNet[245]提出了一种无监督对抗域适应方法来缩小像素级触觉感知任务的域差距。 引入了自适应相关注意机制来改进生成器,该生成器能够利用全局信息并关注显着区域。 然而,像素级域自适应会导致错误累积、性能下降、结构复杂性和训练成本增加。 相比之下,STR-Net[246]提出了一种用于触觉图像的特征级无监督框架,缩小了特征级触觉感知任务的领域差距。 此外,一些方法侧重于模拟到真实。 例如,触觉健身房 2.0 [247]。 但由于其复杂性和成本较高,给实际应用带来了挑战。
认出
触觉表征学习侧重于材料分类和多模态理解,可分为两类:传统方法和大语言模型&VLM方法。
传统方法。 各种传统方法已被用来增强触觉表征学习。 自动编码器框架在开发紧凑的触觉数据表示方面发挥了重要作用。 Polic 等人[248]使用卷积神经网络自动编码器对基于光学的触觉传感器图像进行降维。 高等人[249]创建了一个有监督的循环自动编码器来处理异构传感器数据集,而曹等人[250]创建了TacMAE,使用屏蔽自动编码器来处理不完整的触觉数据。 张等人[251]介绍了MAE4GM,一种集成视觉触觉数据的多模态自动编码器。 由于触觉是其他模式的补充,因此联合训练方法用于融合多种模式。 Yuan 等人[252]使用包括深度、视觉和触觉数据的模式训练 CNN。 类似地,Lee 等人[253]对力传感器系列和末端执行器指标等模式使用了变分贝叶斯方法。 为了更好的学习表征,对比学习等自监督方法也是将模式结合在一起的关键技术。 研究的不同之处在于对比方法 Lin 等人 [254] 简单地将触觉输入与多个视觉输入配对,而 Yang 等人 [255] 采用视觉-触觉对比多视图特征。 Kerr 等人 [214] 使用了 InfoNCE 损失,而 Guzey 等人 [256] 使用了 BYOL。 这些传统方法为触觉表征学习奠定了坚实的基础。
大语言模型&VLM方法。 大语言模型和VLM最近表现出了对跨模态交互的惊人理解和强大的零样本性能。 Yang 等人[188]、Fu 等人[217]和Yu 等人[257]的最新作品对触觉数据进行了编码和对齐通过对比预训练方法进行视觉和语言模式。 然后像LLaMA这样的大语言模型将被应用,使用张力方法来适应触觉描述等任务。 大语言模型和 VLM 技术的出现进一步推动了该领域的发展,实现了更全面、更强大的跨模式触觉表示。
IV-D4 困难
a)不同传感器类型的缺点:传统传感器提供简单且低维的数据,对多模态学习提出了挑战。 基于视觉的传感器和电子皮肤虽然精度很高,但价格昂贵。 b) 数据采集挑战:尽管在开发简化的收集设备方面取得了一些进展,但收集数据,特别是同时收集触觉和视觉数据,仍然很困难。 c) 不一致的标准:触觉传感器的运行标准和原理不一致,阻碍了大规模学习并限制了公共数据集的有用性。 需要标准化和广泛的数据集。
V 具体互动
具身交互任务是指智能体在物理或模拟空间中与人类和环境交互的场景。 典型的具身交互任务是具身问答(EQA)和具身抓取。
V-A 体现问答
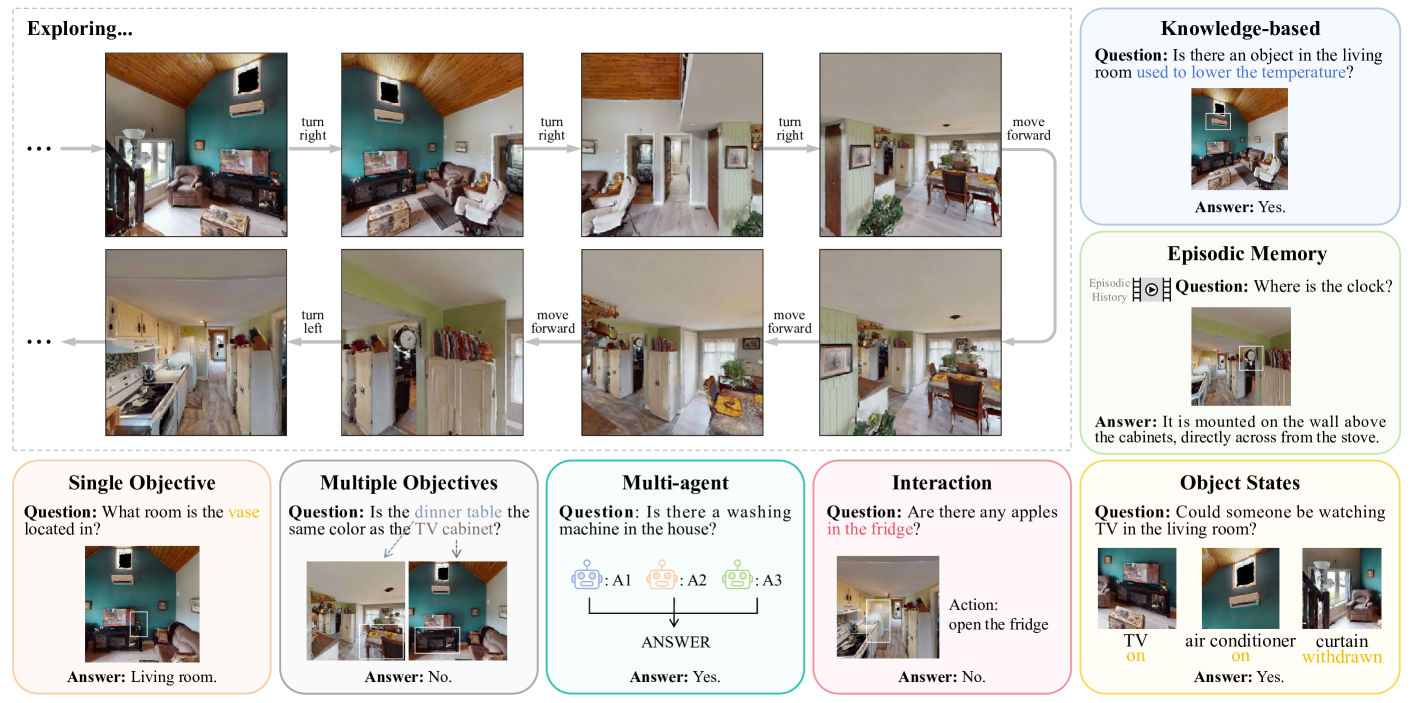
对于 EQA 任务,智能体需要从第一人称视角探索环境,以收集回答给定问题所需的信息。 具有自主探索和决策能力的智能体不仅要考虑采取哪些行动来探索环境,还要确定何时停止探索以回答问题。 现有的工作侧重于不同类型的问题,其中一些如图11所示。 在本节中,我们将介绍现有的数据集,讨论相关方法,描述用于评估模型性能的指标,并解决此任务的其余限制。
V-A1 数据集
在真实环境中进行机器人实验通常受到场景和机器人硬件的限制。 作为虚拟实验平台,模拟器为构建具体问答数据集提供了合适的环境条件。 在模拟器中创建的数据集上训练和测试模型可以显着降低实验成本并提高在真机上部署模型的成功率。 我们简要介绍了几个具体的问答数据集,这些数据集总结在表IX中。
| Dataset | Year | Type | Data Sources | Simulator | Query Creation | Answer | Size |
|---|---|---|---|---|---|---|---|
| EQA v1[258] | 2018 | Active EQA | SUNCG | House3D | Rule-Based | open-ended | 5,000+ |
| MT-EQA[259] | 2019 | Active EQA | SUNCG | House3D | Rule-Based | open-ended | 19,000+ |
| MP3D-EQA[260] | 2019 | Active EQA | MP3D | Simulator based on MINOS | Rule-Based | open-ended | 1,136 |
| IQUAD V1[261] | 2018 | Interactive EQA | - | AI2THOR | Rule-Based | multi-choice | 75,000+ |
| VideoNavQA[262] | 2019 | Episodic Memory EQA | SUNCG | House3D | Rule-Based | open-ended | 101,000 |
| SQA3D[263] | 2022 | QA only | ScanNet | - | Manual | multi-choice | 33,400 |
| K-EQA[264] | 2023 | Active EQA | - | AI2THOR | Rule-Based | open-ended | 60,000 |
| OpenEQA[265] | 2024 | Active EQA, Episodic Memory EQA | ScanNet, HM3D | Habitat | Manual | open-ended | 1,600+ |
| HM-EQA[266] | 2024 | Active EQA | HM3D | Habitat | VLM | multi-choice | 500 |
| S-EQA[267] | 2024 | Active EQA | - | VirtualHome | LLM | binary | - |
EQA v1[258] 是第一个专为 EQA 设计的数据集。 EQA v1 基于 House3D[268] 模拟器中 SUNCG 数据集[94]的合成 3D 室内场景构建,包含四种类型的问题:位置、颜色、color_room 和介词。 它包含分布在 750 多个环境中的 5,000 多个问题。 这些问题是通过功能程序执行构建的,使用模板来选择和组合基本操作。
与EQA v1类似,MT-EQA[259]是使用SUNCG通过执行由一些基本操作组成的功能程序在House3D中构建的。 然而,它进一步将单对象问答任务扩展到多对象设置。 设计了六种类型的问题,涉及多个物体之间的颜色、距离和大小的比较。 该数据集包含 588 个环境中的 19,287 个问题。
MP3D-EQA[260] 是基于 MINOS[269] 使用 Matterport3D 数据集[270]<开发的模拟器构建的/t3>,将问答任务扩展到现实的 3D 环境。 参考 EQA v1,MP3D-EQA 使用三种类型的模板:位置、颜色和 color_room,在 83 个家庭环境中总共生成 1,136 个问题。
IQUAD V1[261] 基于 AI2-THOR 构建,由三类问题组成:存在、计数和空间关系。 它使用一组预先编写的模板来生成超过 75,000 个多项选择题,每个问题都配有独特的场景配置。 与其他数据集不同,回答 IQUAD V1 问题需要智能体充分了解可供性并与动态环境交互。
VideoNavQA[262] 将视觉推理与 EQA 问题的导航方面解耦。 在此任务中,代理访问与探索轨迹相对应的视频,并提供足够的信息来回答问题。 仍然参考 EQA v1,VideoNavQA 根据功能、模板式表示生成问题。 它还渲染最短的轨迹来模拟接近最佳的导航路径,创建与代理在探索环境时看到的内容相对应的视频。 VideoNavQA 使用 SUNCG 在 House3D 环境中生成约 101,000 对视频和问题,涵盖存在、计数、定位等 8 个类别的 28 类问题。
SQA3D[263] 简化了协议(仅限 QA),同时仍然保留基准测试体现场景理解的功能,从而实现更复杂、知识密集型的问题和更大规模的数据收藏。 具体来说,SQA3D 基于 ScanNet[271] 场景提供了一个数据集,其中包含约 6,800 个独特情况、20,400 个描述以及针对这些情况的 33,400 个不同推理问题。
与之前的数据集在问题中明确指定目标对象不同,K-EQA[264] 的特点是包含逻辑子句和知识相关短语的复杂问题,需要先验知识才能回答。 它是在 AI2Thor 中构建的,包括四种类型的问题:存在、计数、枚举和比较。 将每个实体映射到知识库,并进一步构建知识图谱。 在这项工作中,IQA[261]和MT-EQA中提供的模板被扩展为一组语法。 在指定对象和逻辑关系后,引入知识图、场景图等来生成问题并计算真实答案。 生成的 K-EQA 数据集包含 6000 个不同环境设置中的 60,000 个问题。
OpenEQA[265] 是 EQA 的第一个开放词汇数据集,支持情景记忆和主动探索案例。 情景记忆 EQA (EM-EQA) 任务涉及代理从情景记忆中发展对环境的理解以回答问题,类似于 VideoNavQA。 在主动 EQA (A-EQA) 任务中,智能体通过采取探索性行动来收集必要的信息来回答问题。 使用 ScanNet 和 HM3D[272],人类注释者从 Habitat 的 180 多个现实世界环境中构建了 1,600 多个高质量问题。
利用GPT4-V,使用HM3D在栖息地模拟器中构建HM-EQA[266]。 它包含 267 个不同场景的 500 个问题,大致可分为识别、计数、存在、状态和位置。 为了保持一致性,每个问题有四个多项选择。
S-EQA[267]利用VirtualHome中的GPT-4进行数据生成,并通过余弦相似度计算来决定是否保留生成的数据,从而增强数据集多样性。 在 S-EQA 中,回答问题需要评估一系列共识对象和状态,以得出存在的“是/否”答案。
V-A2 方法
体现问答任务主要涉及导航和问答子任务,实现方法大致分为基于神经网络和基于大语言模型/VLMs两种。
神经网络方法。 在早期工作中,研究人员主要通过构建深度神经网络来解决具体问答任务。 他们使用模仿学习和强化学习等技术来训练和微调这些模型,以提高性能。
EQA任务最早由Das等人[258]提出。 在他们的工作中,代理由四个主要模块组成:视觉、语言、导航和应答。 这些模块主要使用传统的神经构建块构建:卷积神经网络(CNN)和循环神经网络(RNN)。 他们分两个阶段进行训练。 最初,导航和响应模块使用模仿或监督学习在自动生成的专家导航演示上进行独立训练。 随后,在第二阶段,使用策略梯度对导航架构进行微调。 后续的一些作品[273, 274]保留了Das等人[258]提出的问答模块等模块,并对模型进行了改进。 此外,Wu 等人[274]提出将导航和QA模块集成到统一的SGD训练管道中进行联合训练,从而避免采用深度强化学习来同时训练单独训练的导航和问答模块。
还有一些作品试图增加问答任务的复杂性和完整性。 从任务奇异性的角度来看,一些工作[259, 275]将任务分别扩展到包括多目标和多智能体,这使得模型需要存储和整合任务所获得的信息。智能体通过特征提取和场景重建等方法进行探索。 考虑到智能体与动态环境之间的交互,Gordon等人[261]引入了分层交互式记忆网络。 控制在负责任务选择的规划器和执行任务执行的低级控制器之间交替进行。 在此过程中,利用以自我为中心的空间 GRU (esGRU) 来存储空间内存,使代理能够导航并提供答案。 以前的工作还存在一个限制,即智能体无法使用外部知识来回答复杂的问题,并且缺乏对场景中已探索部分的了解。 为了解决这个问题,Tan等人[264]提出了一个框架,利用神经程序合成方法以及从知识和3D场景图转换而来的表格,允许动作规划者访问与对象相关的信息。 此外,基于蒙特卡罗树搜索(MCTS)的方法用于确定代理要移动到的下一个位置。
大语言模型/VLM 方法。 近年来,大语言模型和VLM不断进步,在各个领域展现了卓越的能力。 因此,研究人员尝试应用这些模型来解决具体的问答任务,而无需任何额外的微调。
Majumdar等人[265]探索了使用大语言模型和VLM进行情景记忆EQA(EM-EQA)任务和主动EQA(A-EQA)任务。 对于EM-EQA任务,他们考虑了盲大语言模型、具有情景记忆语言描述的苏格拉底大语言模型、具有构建场景图描述的苏格拉底大语言模型以及处理多个场景帧的VLM。 A-EQA 任务通过基于边界的探索 (FBE)[276] 扩展了 EM-EQA 方法,以实现与问题无关的环境探索。 其他一些作品[266, 277]也采用基于前沿的探索方法来识别后续探索的区域并构建语义地图。 他们利用保形预测或图像文本匹配提前结束了探索,以避免过度探索。 Patel 等人[278]强调了任务的问答方面。 他们利用多个基于 LLM 的代理来探索环境,并使他们能够独立回答“是”或“否”的问题。 这些单独的响应用于训练中央答案模型,负责聚合响应并生成可靠的答案。
V-A3 指标
性能通常基于两个方面进行评估:导航和问题回答。 在导航方面,很多作品都沿用了达斯等人[258]提出的方法,利用了导航完成后到目标物体的距离()等指标,从初始位置到最终位置 () 到目标的距离的变化以及该事件中任何点到目标的最小距离 (),以评估模型的性能。 它们在距离目标 10、30 或 50 个动作时进行测试。 也有基于轨迹长度、目标对象的交集得分()等指标来衡量的作品。对于问答来说,评估主要涉及平均排名()答案列表中的真实答案以及答案的准确性。 最近,Majumdar 等人[265]引入了基于聚合LLM正确性度量(LLM-Match)的概念来评估开放词汇答案的准确性。 此外,他们通过将代理路径的标准化长度作为正确性指标的权重来评估效率。
V-A4 局限性
a) 数据集:构建数据集需要大量的人力和资源。 此外,大规模数据集仍然很少,并且不同数据集评估模型性能的指标也不同,这使得性能的测试和比较变得复杂。b)模型:尽管大语言模型带来了进步,但这些模型的性能仍然存在问题。明显落后于人类水平。 未来的工作可能会更多地侧重于有效存储智能体探索的环境信息,并指导他们根据环境记忆和问题来规划行动,同时增强其行动的可解释性。
V-B 具身把握
具身交互除了与人类进行问答交互外,还涉及根据人类指令进行操作,例如抓取、放置物体,从而完成机器人、人类和物体之间的交互。 具身抓取需要全面的语义理解、场景感知、决策和鲁棒的控制规划。 具体抓取方法将传统机器人运动学抓取与大语言模型[279]和视觉语言基础模型[14]等大型模型相结合,使智能体能够执行抓取操作多感官感知下的任务,包括视觉主动感知、语言理解和推理。 图12 (b) 展示了人-智能体-物体交互的概述,其中智能体完成具体的抓取任务。
| Dataset | Year | Type | Modality | Grasp Label | Gripper Finger | Objects | Grasps | Scenes | Language |
|---|---|---|---|---|---|---|---|---|---|
| Cornell [280] | 2011 | Real | RGB-D | Rect. | 2 | 240 | 8K | Single | × |
| Jacquard [281] | 2018 | Sim | RGB-D | Rect. | 2 | 11K | 1.1M | Single | × |
| 6-DOF GraspNet [282] | 2019 | Sim | 3D | 6D | 2 | 206 | 7.07M | Single | × |
| ACRONYM [283] | 2021 | Sim | 3D | 6D | 2 | 8872 | 17.7M | Multi | × |
| MultiGripperGrasp [284] | 2024 | Sim | 3D | - | 2-5 | 345 | 30.4M | Single | × |
| OCID-Grasp [285] | 2021 | Real | RGB-D | Rect. | 2 | 89 | 75K | Multi | × |
| OCID-VLG [286] | 2023 | Real | RGB-D,3D | Rect. | 2 | 89 | 75K | Multi | |
| ReasoingGrasp [287] | 2024 | Real | RGB-D | 6D | 2 | 64 | 99.3M | Multi | |
| CapGrasp [288] | 2024 | Sim | 3D | - | 5 | 1.8K | 50K | Single |
V-B1 夹爪
目前抓取技术的研究热点是二指平行手爪和五指灵巧手。 对于两指平行夹具,抓取姿势通常分为两种类型:4-DOF和6-DOF[289]。 4-DOF 抓取合成 [285, 281, 280] 使用三维位置和自上而下的手部方向(偏航)定义抓取,通常称为“自上而下抓取” 。 相比之下,六自由度抓取合成[290,291,283]通过六维位置和方向定义抓取姿势。 对于五指灵巧手来说,ShadowHand是一种广泛使用的五指机器人灵巧手,具有26个自由度(DOF)。 这种高维度显着增加了生成有效抓取姿势和规划执行轨迹的复杂性。
V-B2 数据集
最近,已经生成了大量的抓取数据集[280,281,282,283,284]。 这些数据集通常包含基于图像(RGB、深度)、点云或 3D 场景的带注释的抓取数据。 随着 MLM 的出现以及基础语言模型在机器人抓取中的应用,迫切需要包含语言文本的数据集。 因此,现有数据集已被扩展或重构以创建语义抓取数据集[286,287,292,288]。 这些数据集有助于研究基于语言的抓取模型,使代理能够对语义产生广泛的理解。
传统抓取数据集包含单个对象[280]和杂乱场景[285]的数据,提供符合运动学的稳定抓取注释(4-DOF或6-DOF)对于每个对象。 这些数据可以从真实桌面环境[280]收集,通常包括RGB、深度和点云数据,也可以从虚拟环境[283]收集,其中包括图像数据、点云或场景模型。 虽然这些数据集对于掌握模型很有用,但它们缺乏语义信息。 为了弥补这一差距,这些数据集已通过语义表达 [286, 293] 进行了扩充或扩展,从而将语言、视觉和抓取联系起来。 通过整合语义信息,智能体可以更好地理解和执行抓取任务。 这一增强功能允许开发更复杂和语义感知的抓取模型,促进与环境更直观、更有效的交互。 表X展示了上述数据集,包括传统的抓取数据集和基于语言的抓取数据集。
V-B3 语言引导的抓取
语言引导抓取的概念[286,293,287]就是从这种集成演变而来的,它结合了MLM,为智能体提供语义场景推理的能力。 这允许代理根据隐式或显式的人类指令执行抓取操作。 图12(c)展示了近年来语言引导抓取主题的发表趋势。 随着大语言模型的不断进步,研究者们对这一课题表现出越来越浓厚的兴趣。 目前,抓取研究越来越关注开放世界场景,强调开放集泛化[294]方法。 通过利用 MLM 的泛化能力,机器人可以在开放世界环境中以更高的智能和效率执行抓取任务。
在语言引导的抓取中,语义可以源自显式指令[294, 295]和隐式指令[287, 288]。 明确的指令清楚地指定了要抓取的物体的类别,例如香蕉或苹果。 然而,隐式指令需要推理来识别要抓握的物体或物体的一部分,涉及空间推理和逻辑推理。
空间推理[286]是指可能包含要抓取的物体或部分的空间关系的指令,需要根据场景内物体的空间关系来推断抓取姿势。 例如,“抓住棕色纸巾盒右侧的键盘”涉及理解和推断物体的空间排列。 另一方面,逻辑推理[287]涉及可能包含逻辑关系的指令,需要推理来辨别人类意图并随后掌握目标。 例如,“我渴了,能给我喝点东西吗?”会提示代理人可能会递出一杯水或一瓶饮料。 代理必须确保交接过程中液体不会溢出,从而产生合理的抓取姿势。
在这两种情况下,语义理解与空间和逻辑推理的集成使智能体能够有效、准确地执行复杂的抓取任务。 图12(a)描述了各种类型的语言引导的抓取任务。
V-B4 端到端方法
CLIPORT [293] 是一种语言条件模仿学习代理,它将视觉语言预训练模型 CLIP 与 Transporter Net 相结合,创建端到端双流架构,用于语义理解和把握一代。 它使用从虚拟环境中收集的大量专家演示数据进行训练,使代理能够执行语义引导的抓取。 基于 OCID 数据集,CROG[286]提出了视觉语言抓取数据集,并引入了有竞争力的端到端基线。 它利用 CLIP 的视觉基础功能直接从图像文本对学习掌握合成。 Reasoning Grasping[287]基于GraspNet-10亿数据集引入了第一个推理抓取基准数据集,并提出了端到端的推理抓取模型。 该模型将多模态大语言模型与基于视觉的机器人抓取框架集成,以生成基于语义和视觉的抓取。 SemGrasp [288] 是一种基于语义的抓取生成方法,它将语义信息合并到抓取表示中以生成灵巧的手抓取姿势。 它引入了一种将抓取空间与语义空间对齐的离散表示,从而能够根据语言指令生成抓取姿势。 为了便于训练,提出了一个大规模抓取文本对齐数据集 CapGrasp。
V-B5 模块化方法
F3RM [294] 试图将 CLIP 的文本图像先验提升到 3D 空间,使用提取的特征进行语言本地化,然后进行抓取生成。 它将精确的 3D 几何与 2D 基础模型的丰富语义相结合,利用从 CLIP 中提取的特征来指定通过自由文本自然语言进行操作的对象。 它展示了泛化到未见过的表达式和新对象类别的能力。 GaussianGrasper [295] 利用 3D 高斯场来实现语言引导的抓取任务。 所提出的方法首先构建 3D 高斯场,然后进行特征蒸馏。 随后,使用提取的特征执行基于语言的本地化。 最后,基于SOTA预训练抓取网络[296]进行抓取姿势生成。 它将开放词汇语义与精确几何相结合,实现基于语言指令的抓取。
这些方法通过利用端到端和模块化框架推进了语言引导抓取领域,从而增强了机器人代理通过自然语言指令理解和执行复杂抓取任务的能力。 具身抓取使机器人能够与物体交互,从而提高其在家庭服务和工业制造中的智能性和实用性。 然而,现有的体现抓取方法存在局限性,例如依赖广泛的数据以及对未见过的数据的泛化能力差。 未来的研究将集中于提高智能体的通用性,使机器人能够理解更复杂的语义,抓取更广泛的看不见的物体,并完成复杂的抓取任务。
VI 具体代理
代理被定义为能够感知其环境并采取行动以实现特定目标的自主实体。 传销的最新进展进一步将代理的应用扩展到实际场景。 当这些基于MLM的主体体现在物理实体中时,它们可以有效地将其能力从虚拟空间转移到物理世界,从而成为体现主体[297]。
为了使实体智能体能够在信息丰富且复杂的现实世界中运行,实体智能体被开发为具有强大的多模态感知、交互和规划能力,如图13所示。 为了完成一项任务,具体化智能体通常涉及以下过程:1)将抽象任务和复杂任务分解为特定的子任务,这被称为高级具体化任务规划。 2)通过有效利用体现感知和体现交互模型或利用基础模型的政策功能(称为低级体现行动规划)来逐步实施这些子任务。 值得注意的是,任务规划涉及行动之前的思考,因此通常在网络空间中考虑。 相反,行动规划必须考虑与环境的有效交互,并将此信息反馈给任务规划者以调整任务规划。 因此,对于实体主体来说,将其能力从网络空间调整到物理世界至关重要。
VI-A 体现多模态基础模型
实体代理需要以视觉方式识别其环境,以听觉方式理解指令,并理解自己的状态以实现复杂的交互和操作。 这需要一个集成多种感官模式和自然语言处理能力的模型,通过综合不同的数据类型来增强代理的理解和决策。 因此,体现多模式基础模型正在出现。 最近,Google DeepMind 发现利用基础模型和大型、多样化的数据集是最佳策略。 他们开发了一系列基于机器人 Transformer (RT)[11]的作品,为未来的实体代理研究提供了重要的见解。
基础机器人模型已经取得了重大进展,从 SayCan [298] 的初始方法发展而来,该方法使用三个独立的模型进行规划、可供性和低级策略。 Q-Transformer [299] 后来统一了可供性和低级策略,PaLM-E [300] 集成了规划和可供性。 然后,RT-2 [301] 通过将所有三个功能整合到一个模型中实现了突破,实现了联合缩放和正迁移。 这代表了机器人基础模型的重大进步。 RT-2 引入了视觉-语言-动作(VLA)模型,具有“思维链”推理能力,可以实现多步骤语义推理,例如在各种上下文中选择替代工具或饮料。 最终,RT-H [4] 实现了一个具有动作层次结构的端到端机器人 Transformer,以在细粒度级别上推理任务规划。
为了解决体现模型的泛化局限性,Google 与 33 个领先学术机构合作创建了综合性 Open X-Embodiment 数据集[302],集成了 22 种不同的数据类型。 他们利用这个数据集训练了通用大型模型 RT-X。 这也促进了更多机器人领域的开源VLM的参与,例如基于LLaVA的EmbodiedGPT[303]和基于Flamingo的RoboFlamingo[304]。 尽管 Open X-Embodiment 提供了大量数据集,但鉴于实体机器人平台的快速发展,构建数据集仍然是一个挑战。 为了解决这个问题,AutoRT[305]创建了一个在新环境中部署机器人来收集训练数据的系统,利用大语言模型通过更全面和多样化的数据来增强学习能力。
此外,基于 Transformer 的架构还面临效率低下的问题,因为实体模型需要较长的上下文,其中包括来自视觉、语言和实体状态的信息,以及与当前执行任务相关的内存。 例如,RT-2尽管性能强大,但推理频率仅为1-3Hz。 我们已经做出了一些努力,例如通过量化和蒸馏来部署模型。 此外,改进模型框架是另一个可行的方法。 SARA-RT [306] 采用更高效的线性注意力,而 RoboMamba [307] 采用 mamba 架构,对于长序列任务更有效。 这使其推理速度比现有的机器人 MLM 快七倍。
基于生成模型的 RT 在高层任务理解和规划方面表现出色,但由于生成模型无法精确生成动作参数以及高层任务规划和低层动作执行之间的差距,因此在低层行动规划方面存在局限性。 为了解决这个问题,Google 推出了 RT-Trajectory [308],它通过自动添加机器人轨迹来为学习机器人控制策略提供低级视觉提示。 类似地,基于 RT-2 框架,具有动作层次结构的机器人 Transformer (RT-H) 结合了分层动作框架,通过中间语言动作将高级任务描述与低级机器人运动联系起来[4]. 此外,VLA 模型仅在与 VLM 相关的高级规划和可供性任务中表现出紧急功能。 他们无法在低水平的身体互动中展示新技能,并且受到数据集中技能类别的限制,导致行动笨拙。 未来的研究应该将强化学习融入大型模型的训练框架中,以提高泛化能力,使VLA模型能够在现实环境中自主学习和优化低级物理交互策略,从而更灵活、更准确地执行各种物理动作。
VI-B 体现任务计划
如前所述,任务“将苹果放在盘子上”,任务规划器会将其划分为子任务“找到苹果,摘苹果”,“找到盘子” ,“放下苹果”。 由于如何寻找(导航任务)或拾取/放下动作(抓取任务)不在任务规划的范围内。 这些操作通常是在模拟器中预定义的,或者使用预先训练的策略模型在现实场景中执行,例如使用 CLIPort[293] 来执行抓取任务。
传统的具体任务规划方法通常基于显式规则和逻辑推理。 例如,STRIPS [309] 和 PDDL[310] 等符号规划算法,以及 MCTS [311] 和 A* 等搜索算法[312],用于生成计划。 然而,这些方法通常依赖于僵化的预定义规则、约束和启发式方法,可能无法很好地适应环境中的动态或不可预见的变化。 随着大语言模型的流行,许多著作尝试使用大语言模型进行规划,或者将传统方法与大语言模型相结合,利用其中蕴藏的丰富的世界知识进行推理和规划,而不需要手工定义,大大提高了大语言模型的效率。模型的泛化能力。
VI-B1 利用大语言模型的应急能力进行规划
在自然语言模型规模化之前,任务规划器类似地通过 BERT 等训练模型在 Alfred [313] 和 Alfworld [314] 等具体指令数据集上实现,正如电影[315]所证明的那样。 然而,这种方法受到训练集中示例的限制,无法有效地与物理世界保持一致。 如今,借助大语言模型的新兴能力,他们可以利用内部世界知识和思维链推理来分解抽象任务,类似于人类在行动之前通过任务完成步骤进行推理的方式。 例如,Translated LM [316] 和 Inner Monologue [317] 可以将复杂的任务分解为可管理的步骤,并使用其内部逻辑和知识系统设计解决方案,而无需额外的训练,例如 ReAct [318]。 类似地,提出了多智能体协作框架ReAd[319],用于通过不同的提示有效地自我完善计划。 此外,一些方法将过去的成功示例抽象为存储在记忆库中的一系列技能,以便在推理过程中考虑并提高计划成功率[320,321,322]。 有些作品使用代码而不是自然语言作为推理媒介。 其中任务规划是基于可用 API 库[323, 324, 325]生成的代码。 此外,多轮推理可以有效纠正任务规划中潜在的幻觉,这是许多基于 LLM 的代理研究的重点。 例如,苏格拉底模型[326]和苏格拉底规划器[327]使用苏格拉底提问来得出可靠的规划。
然而,在任务规划过程中,执行过程中可能会出现潜在的失败,这通常是由于规划者没有充分考虑现实环境的复杂性和任务执行的难度[317, 328]造成的。 由于缺乏视觉信息,计划的子任务可能会偏离实际场景,导致任务失败。 因此,在执行过程中将视觉信息整合到规划或重新规划中是必要的。 这种方法可以显着提高任务规划的准确性和可行性,更好地应对现实环境的挑战。
VI-B2 利用来自具体感知模型的视觉信息进行规划
基于上述讨论,进一步将视觉信息融入到任务规划(或重新规划)中显得尤为重要。 在此过程中,视觉输入提供的对象标签、位置或描述可以为大语言模型的任务分解和执行提供关键参考。 通过视觉信息,大语言模型可以更准确地识别当前环境中的目标物体和障碍物,从而优化任务步骤或修改子任务目标。 有些作品使用对象检测器来查询任务执行过程中环境中存在的对象,并将这些信息反馈给大语言模型,使其能够修改当前计划中不合理的步骤[328,326,329]. RoboGPT 考虑了同一任务内相似对象的不同名称,进一步提高了重新规划[10]的可行性。 然而,标签提供的信息仍然太有限。 能否提供更多场景信息? SayPlan [330] 建议使用分层 3D 场景图来表示环境,有效缓解大型、多层和多房间环境中任务规划的挑战。 同样,ConceptGraphs[331]也采用3D场景图为大语言模型提供环境信息。 与SayPlan相比,它提供了更详细的开放世界对象检测,并以基于代码的格式呈现任务规划,更加高效,更适合复杂任务的需求。
然而,有限的视觉信息可能会导致智能体对其环境的理解不足。 虽然大语言模型提供了视觉提示,但它们往往无法捕捉环境的复杂性和动态变化,从而导致误解和任务失败。 例如,如果毛巾被锁在浴室柜子里,代理可能会重复搜索浴室而不考虑这种可能性[10]。 为了解决这个问题,必须开发更强大的算法来集成多个感官数据,增强智能体对环境的理解。 此外,即使视觉信息有限,利用历史数据和上下文推理也可以帮助智能体做出合理的判断和决策。 这种多模态集成和基于上下文的推理方法不仅提高了任务执行的成功率,而且为实体人工智能的进步提供了新的视角。
VI-B3 利用 VLM 进行规划
与使用外部视觉模型将环境信息转换为文本相比,VLM 模型可以捕获潜在空间中的视觉细节,特别是难以用对象标签表示的上下文信息。 VLM 可以辨别视觉现象背后的规则;例如,即使毛巾在环境中不可见,也可以推断该毛巾可能存放在柜子中。 这个过程本质上演示了如何在潜在空间中更有效地对齐摘要视觉特征和结构化文本特征。 在 EmbodiedGPT [303] 中,Embodied-Former 模块对齐体现、视觉和文本信息,在任务规划过程中有效考虑智能体的状态和环境信息。 与直接使用第三人称视角图像的 EmbodiedGPT 不同,LEO [332] 将 2D 自我中心图像和 3D 场景编码为视觉标记。 该方法有效地感知3D世界信息并相应地执行任务。 同样,EIF-Unknow 模型利用从体素特征中提取的语义特征图作为视觉标记,将其与文本标记一起输入到经过训练的 LLaVA 模型中以进行任务规划[333]。 此外,在 RT 系列 [11, 301]、PaLM-E [300] 等研究中,具体化多模态基础模型(VLA 模型)已使用大型数据集进行了广泛的训练和 Matcha [334] 来实现具体场景中视觉和文本特征的对齐。
然而,任务规划只是智能体完成指令任务的第一步;后续的行动计划决定了任务能否完成。 在RoboGPT[10]的实验中,任务规划的准确率达到了96%,但总体任务完成率仅为60%,受限于低级规划器的性能。 因此,实体主体能否从“想象如何完成任务”的网络空间过渡到“与环境交互并完成任务”的物理世界,取决于有效的行动规划。
VI-C 具体行动计划
VI-B 节讨论任务规划和行动规划之间的定义和区别。 显然,行动规划必须解决现实世界的不确定性,因为任务规划提供的子任务的粒度不足以指导代理进行环境交互。 一般来说,智能体可以通过两种方式实现行动规划:1)使用预先训练的体现感知和体现干预模型作为工具,通过API逐步完成任务规划指定的子任务,2)利用VLA模型的固有能力导出行动规划。 此外,行动规划器执行的结果会反馈给任务规划器,以调整和改进任务规划。
VI-C1 利用 API 的操作
一种典型的方法是向大语言模型提供各种训练有素的策略模型的定义和描述作为上下文,使它们能够理解这些工具并确定如何以及何时调用它们来执行特定任务[298, 328]. 此外,通过生成代码,可以将一系列更细粒度的工具抽象为函数库进行调用,而不是直接将子任务所需的参数传递给导航和抓取模型[325]。 考虑到环境的不确定性,Reflexion可以在执行过程中进一步调整这些工具,以实现更好的泛化[335]。 优化这些工具可以增强代理的鲁棒性,并且可能需要新的工具来完成未知的任务。 DEPS在零样本学习的前提下,赋予大语言模型多种角色设置,在与环境交互的同时学习多种技能。 在后续的交互过程中,大语言模型可以学习选择和组合这些技能来开发新的技能[336]。
这种分层规划范式使代理能够专注于高级任务规划和决策,同时将具体的操作执行委托给策略模型,从而简化了开发过程。 任务规划器和行动规划器的模块化可以实现独立开发、测试和优化,增强系统的灵活性和可维护性。 该方法允许代理通过调用不同的行动规划器并促进修改来适应各种任务和环境,而不需要对代理的结构进行重大更改。 然而,调用外部策略模型可能会引入延迟,从而可能影响响应时间和效率,尤其是在实时任务中。 代理的表现很大程度上取决于策略模型的质量。 如果策略模型无效,智能体的整体性能将会受到影响。
VI-C2 利用VLA模型的动作
与之前在同一系统中执行任务规划和行动执行的方法不同,该范例利用具体多模式基础模型的功能来规划和执行行动,减少通信延迟并提高系统响应速度和效率。 在VLA模型中,感知、决策和执行模块的紧密集成使得系统能够更有效地处理复杂的任务并适应动态环境的变化。 这种集成还有助于实时反馈,使代理能够自我调整策略,从而增强任务执行的鲁棒性和适应性[3,303,302]。 然而,这种范式无疑更加复杂和昂贵,特别是在处理复杂或长期的任务时。 此外,一个关键问题是,如果没有具体的世界模型,行动规划器无法仅使用大语言模型的内部知识来模拟物理定律。 这种限制阻碍了智能体准确有效地完成物理世界中的各种任务,阻碍了从网络空间到物理世界的无缝转移。
VII 模拟到真实的适应
嵌入式人工智能中的模拟到真实适应是指将模拟环境(网络空间)中学到的能力或行为转移到现实世界场景(物理世界)的过程。 它涉及验证和提高仿真中开发的算法、模型和控制策略的有效性,以确保它们在物理环境中稳健可靠地执行。 为了实现模拟到现实的适应,具体世界模型、数据收集和训练方法以及具体控制算法是三个基本组成部分。
VII-A 具身世界模型
Sim-to-Real 涉及在模拟中创建与现实世界环境非常相似的世界模型,帮助算法在迁移时更好地泛化。 世界模型方法旨在构建一个端到端模型,通过以生成或预测的方式预测下一个状态来做出决策,将愿景映射到行动,甚至将任何事物映射到任何事物。 此类世界模型与 VLA 模型之间的最大区别在于,VLA 模型首先在大规模互联网数据集上进行训练,以实现高水平的紧急能力,然后与现实世界的机器人数据进行协同微调。 相比之下,世界模型是根据物理世界数据从头开始训练的,随着数据量的增加逐渐发展出高级能力。 然而,它们仍然是低级物理世界模型,有点类似于人类神经反射系统的机制。 这使得它们更适合输入和输出都相对结构化的场景,例如自动驾驶(输入:视觉,输出:油门、刹车、方向盘)或物体分类(输入:视觉、指令、数值传感器,输出:抓取)目标对象并将其放置在目标位置)。 它们不太适合泛化到非结构化、复杂的具体任务。
| Type | Method | Years | Main tasks |
| Generation-based | World Models[337] | 2018 | Car Racing |
| Sora [17] | 2024 | Video Generation | |
| Pandora[338] | 2024 | Real-time Controllable Video Generation | |
| 3D-VLA[339] | 2024 | Embodied Reasoning and Localization, Multimodal Goal Generation, Robot Planning | |
| DWM[340] | 2024 | D4RL Offline RL | |
| Prediction-based | I-JEPA[16] | 2023 | Visual Representation Learning, Image Classification, Object Counting, Depth Prediction |
| MC-JEPA[341] | 2023 | Visual Representation Learning, Optical Flow Estimation, Instance Segmentation, Video Segmentation | |
| A-JEPA[342] | 2023 | Audio Representation Learning, Audio and Speech Classification | |
| IWM[343] | 2024 | Visual Representation Learning, Image Classification, Image Segmentation | |
| iVideoGPT[344] | 2024 | Video Prediction, Visual Planning, Visual Model-based RL | |
| IRASim[345] | 2024 | Trajectory to Video Generation | |
| STP[346] | 2024 | Robotic Motor Control | |
| MuDreamer[347] | 2024 | DeepMind Visual Control Suite, Natural Background Setting | |
| Knowledge-driven | Lionel et al. [348] | 2023 | Probabilistic Reasoning, Relational Reasoning, Perceptual and Physical Reasoning, Social Reasoning |
| ElastoGen[349] | 2024 | 4D Elastodynamics Generation | |
| Liu et al.[350] | 2024 | Single-image 3D Reconstruction | |
| Holodeck[70] | 2024 | 3D Environments Generation | |
| LEGENT[351] | 2024 | 3D Environments Generation | |
| GRUtopia [352] | 2024 | Language Instruction, Task Generation, Navigation, Social Interaction, Manipulation |
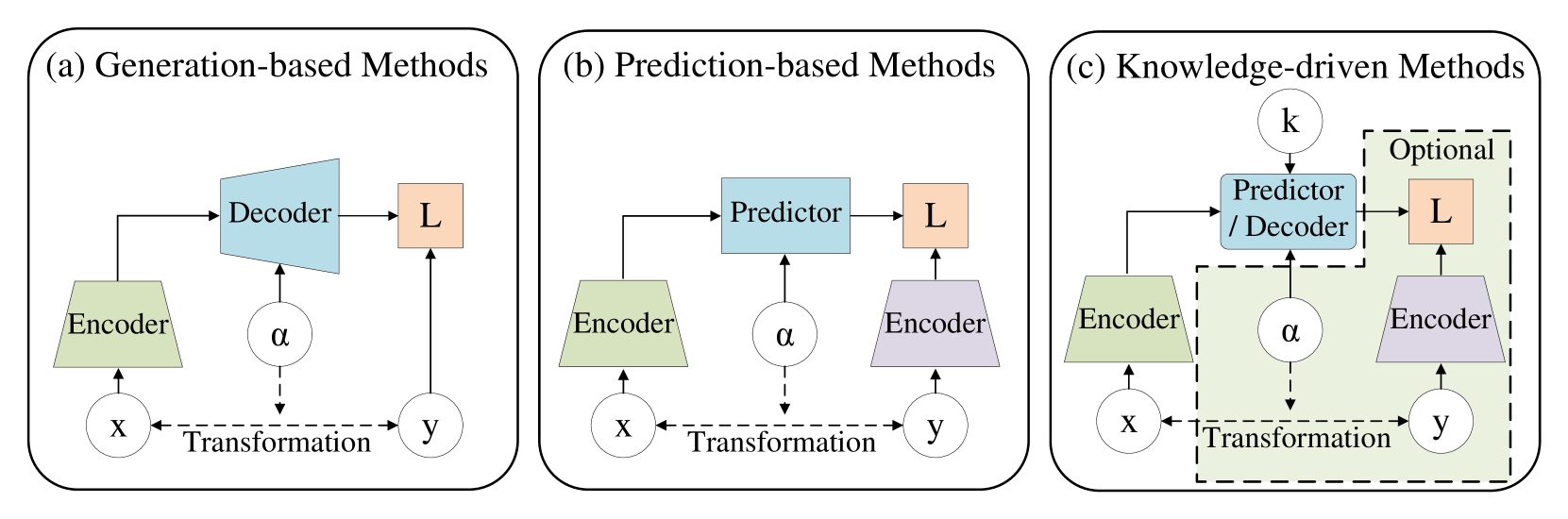
学习世界模型在物理模拟领域很有前景。 与传统的仿真方法相比,它具有显着的优势,例如能够推理与不完整信息的交互,满足实时计算要求,并随着时间的推移提高预测精度。 这种世界模型的预测能力至关重要,它使机器人能够发展在人类世界中运行所需的物理直觉。 如图15所示,根据世界环境的学习管道,可以分为基于生成的方法、基于预测的方法和知识驱动的方法。 我们简要总结了表XI中提到的方法。
VII-A1 基于生成的方法
随着模型和数据规模的逐渐增加,生成模型已经证明了理解和生成图像(例如,世界模型[337])、视频(例如,Sora [17]、Pandora [338])、点云(例如 3D-VLA [339])或其他格式的数据(例如 DWM [340 ])符合物理定律。 这种能力表明生成模型可以学习和内化世界知识。 具体来说,生成模型在接触海量数据后,不仅可以捕获数据的统计特性,还可以通过其内在的结构和机制来模拟现实世界的物理和因果关系。 因此,这些生成模型可以被认为不仅仅是简单的模式识别工具:它们表现出世界模型的特征。 因此,可以利用生成模型中嵌入的世界知识来增强其他模型的性能。 通过挖掘和利用生成模型所代表的世界知识,我们可以提高模型的泛化性和鲁棒性。 这种方法不仅增强了模型对新环境的适应性,还提高了其对未知数据的预测准确性[339, 338]。 然而,生成模型也有一定的局限性和缺点。 例如,当数据分布存在明显偏差或训练数据不足时,生成模型可能会产生不准确或扭曲的输出。 此外,这些模型的训练过程通常需要大量的计算资源和时间,并且模型通常缺乏可解释性,这使得它们的实际应用变得复杂。 总体而言,虽然生成模型在理解和生成符合物理定律的内容方面显示出巨大潜力,但为了有效应用,必须解决一些技术和实践挑战。 这些挑战包括提高模型效率、增强可解释性以及解决与数据偏差相关的问题。 随着不断的研究和开发,生成模型有望在未来的应用中展现出更大的价值和潜力。
VII-A2 基于预测的方法
基于预测的世界模型通过构建和利用内部表示来预测和理解环境。 通过根据提供的条件重建潜在空间中的相应特征,它捕获更深层次的语义和相关的世界知识。 该模型将输入信息映射到潜在空间,并在该空间内进行操作以提取和利用高级语义信息,从而使机器人能够感知世界环境的基本表示(例如,I-JEPA[16]、MC-JEPA[341]、A-JEPA[342]、点-JEPA[353]、IWM [343])并更准确地执行具体的下游任务(例如,iVideoGPT[344]、IRASim[345])、STP[346] ,MuDreamer[347])。 与像素级信息相比,潜在特征可以对各种形式的知识进行抽象和解耦,使模型能够更有效地处理复杂的任务和场景,提高泛化能力[354]。 例如,在时空建模中,世界模型需要根据对象的当前状态和交互的性质来预测对象的交互后状态,并将这些信息与其内部知识相结合。 具体来说,具体世界模型通过整合感知信息和先验知识来生成环境的动态预测。 这种方法不仅依赖于感知数据,还依赖于固有的世界知识来推断和预测环境变化,从而产生更准确的时空预测[344, 346, 347]。 此过程考虑对象的当前状态及其历史数据和上下文信息。
同样,利用其表征中嵌入的世界知识可以进一步增强模型的感知和鲁棒性[16, 341, 355, 343]。 通过在潜在空间中运行,机器人有望以较低的成本在不同的环境中保持高性能[347]。 这种方法的关键在于抽象处理和知识解耦,从而能够有效地适应复杂的情况。 然而,在处理以前未见过的环境和条件时,此类模型可能会表现出局限性和不稳定性。 此外,潜在空间中解耦的世界知识可能存在可解释性问题。
VII-A3 知识驱动方法
知识驱动的世界模型将人工构建的知识注入模型中,赋予模型世界知识。 该方法在实体人工智能领域显示出广泛的应用潜力。 例如,在 real2sim2real 方法[356]中,现实世界的知识用于构建符合物理的模拟器,然后用于训练机器人,增强模型的鲁棒性和泛化能力。 此外,人工构建常识或符合物理的知识并将其应用于生成模型或模拟器是一种常见策略(例如,ElastoGen [349]、One-2-3-45 [350 ],PLoT [348])。 这种方法对模型施加了更物理上准确的约束,增强了其在生成任务中的可靠性和可解释性。 这些约束确保模型的知识既准确又一致,减少了训练和应用过程中的不确定性。 一些方法将人工创建的物理规则与大语言模型或 MLM 结合起来。 通过利用大语言模型和 MLM 的常识性功能,这些方法(例如 Holodeck[70]、LEGENT[351]、GRUtopia [352])通过自动空间布局优化生成多样化且语义丰富的场景。 通过在新颖且多样化的环境中训练通用实体代理,极大地促进了它们的开发。
VII-B 数据收集与训练
对于模拟到真实的适应,高质量的数据非常重要。 传统的数据采集方法需要昂贵的设备、精确的操作、费时费力、往往缺乏灵活性。 最近,人们提出了一些有效且具有成本效益的方法来进行高质量的演示数据收集和训练。 本节将讨论在现实世界和模拟环境中收集数据的各种方法。 图16展示了来自真实环境和模拟环境的演示数据。
VII-B1 真实世界数据
在大容量、丰富的数据集上训练大型、高容量的模型在有效解决下游应用程序方面表现出了卓越的能力和巨大的成功。 例如ChatGPT、GPT-4、LLaMA等大语言模型不仅在NLP领域表现出色,而且为下游任务提供了优秀的问题解决能力。 因此,是否有可能在机器人领域训练一个具体的大型模型,通过训练使其具有很强的泛化能力,并且能够适应新的场景和机器人任务。 这需要大量的具体数据集来为模型训练提供数据。 Open X-Embodiment [302] 是来自 22 个不同机器人的体现数据集,具有 527 项技能和 160,266 项任务。 收集的数据包括机器人的真实演示数据,通过记录执行操作的过程获得。 该数据集主要关注家庭和厨房环境,涉及家具、食物和餐具等物品。 这些操作主要围绕拾放任务,一小部分涉及更复杂的操作。 在此数据集上训练的高容量模型 RT-X 表现出了出色的传输能力。 UMI[357]提出了数据收集和政策学习框架。 他们设计了一个手持式夹具和一个优雅的数据收集界面,实现了便携式、低成本和信息丰富的数据收集,以应对具有挑战性的双手和动态演示数据。 通过简单地修改训练数据,机器人就可以实现零样本通用、双手精确的任务。 Mobile ALOHA[358]是一种低成本的全身移动操控系统。 可用于采集全身移动下双手操作的任务数据,例如煎虾、上菜等。 使用该系统收集的数据和静态 ALOHA 训练智能体可以提高移动操纵任务的性能。 这些代理人可以充当家庭助理或工作助理。 在人机协作[359]中,人类和代理在数据收集过程中共同学习,从而减少人工工作量、加速数据获取并提高数据质量。 具体来说,在具体场景中,在数据收集期间,人类提供初始动作输入。 随后,智能体通过迭代扰动和去噪过程完善这些动作,逐步优化它们以产生精确、高质量的操作演示。 整个过程可以概括为:人类在操作中贡献直觉和多样性,而代理负责优化和稳定性,减少对操作员的依赖,能够执行更复杂的任务,并收集更高质量的数据。
VII-B2 模拟数据
上述数据收集方法涉及直接收集现实世界中的演示数据以用于代理训练。 这种收集方式往往需要大量的人力、物力和时间,效率低下。 因此,在大多数情况下,研究人员可以选择在模型的模拟环境中收集训练数据集。 在模拟环境中收集数据不需要大量资源,通常可以通过程序自动化,从而节省大量时间。 CLIPORT [293] 和 Transporter Networks [360] 从 Pybullet 模拟器收集了端到端网络模型训练的演示数据,并成功将模型从模拟转移到现实世界。 GAPartNet[361]构建了一个大规模的以零件为中心的交互数据集GAPartNet,为感知和交互任务提供了丰富的零件级注释。 他们提出了一种用于域广义 3D 零件分割和姿态估计的管道,该管道可以很好地泛化到模拟器和现实世界中未见过的对象类别。 SemGrasp [288] 构建了一个大规模的文本对齐抓取数据集 CapGrasp,这是一个来自虚拟环境的语义丰富的灵巧手抓取数据集。
VII-B3 模拟到真实范式
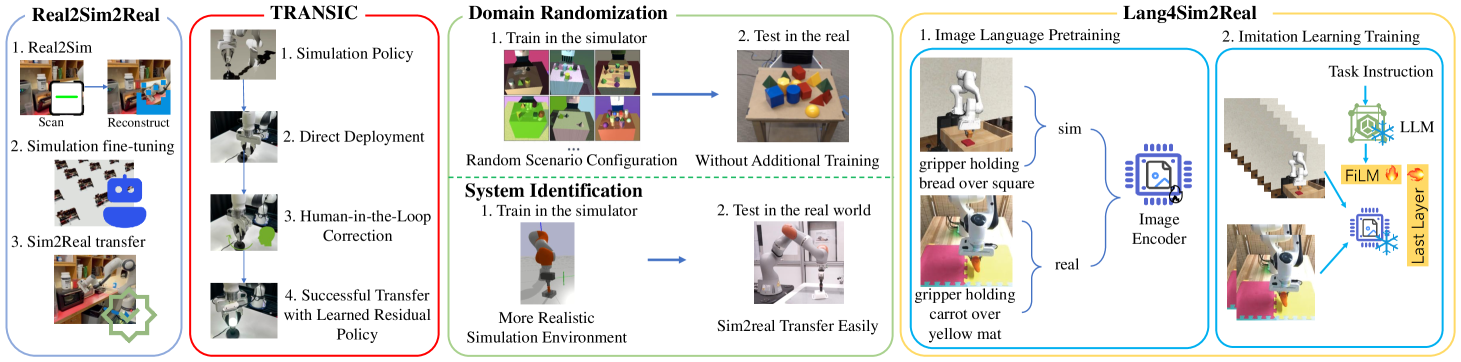
最近,引入了几种从模拟到真实的范式,通过在模拟环境中进行广泛的学习,然后迁移到现实世界的设置,来减轻对广泛且昂贵的现实世界演示数据的需求。 本节概述了模拟到真实传输的五种范式,如图17所示。
Real2Sim2real [362] 通过利用在“数字孪生”模拟环境中训练的强化学习 (RL),增强了现实场景中的模仿学习。 该方法涉及通过模拟中广泛的强化学习来强化策略,然后将这些策略转移到现实世界中,以解决数据稀缺问题并实现有效的机器人操作模仿学习。 最初,使用NeRF和VR进行场景扫描和重建,并将构建的场景资产导入模拟器中以实现真实与模拟的保真度。 随后,强化学习在模拟中对从现实世界中收集的稀疏专家演示中得出的初始策略进行微调。 最后,将细化的策略转移到现实世界的环境中。
TRANSIC [363] 通过实现实时人工干预来纠正现实场景中的机器人行为,缩小了模拟与真实的差距。 它通过几个步骤增强模拟到真实的传输性能:首先,使用强化学习对机器人进行训练,以在模拟环境中建立基础策略。 然后,这些策略在真实的机器人上实施,当出现错误时,人类通过远程控制实时干预和纠正行为。 从这些干预措施中收集的数据用于训练剩余政策。 集成基础策略和剩余策略可确保在模拟到真实传输后的实际应用中轨迹更加平滑。 这种方法显着减少了对现实世界数据收集的需求,从而减轻了负担,同时实现了有效的模拟到真实的传输。
域随机化[364,365,366]通过在模拟过程中引入参数随机化,增强了在模拟环境中训练的模型到现实场景的泛化能力。 虽然模拟环境和真实环境都涉及通过相机获取的视觉图像进行感知,但物体摩擦力和光泽度等差异使得准确的模拟具有挑战性。 模拟训练期间的随机化参数涵盖了广泛的条件,可能包含现实环境中可能发生的变化。 这种方法提高了经过训练的模型的稳健性,从而能够从模拟部署到真实环境。
系统识别[367, 368]构建了现实环境中物理场景的精确数学模型,包含动态和视觉渲染等参数。 它的目的是使模拟环境与现实世界的设置非常相似,从而促进在模拟中训练的模型顺利过渡到真实环境。
Lang4sim2real [369] 使用自然语言作为桥梁,通过使用图像的文本描述作为跨域统一信号来解决模拟与真实的差距。 这种方法有助于学习域不变的图像表示,从而提高模拟和真实环境中的泛化性能。 最初,编码器对用跨域语言描述注释的图像数据进行预训练。 随后,使用域不变表示,训练多域、多任务语言条件行为克隆策略。 该方法通过丰富的模拟数据中的附加信息来补偿现实世界数据的稀缺性,从而增强模拟到真实的传输。
VII-C 体现控制
具身控制通过与环境的交互进行学习,并利用奖励机制优化行为以获得最优策略,从而避免了传统物理建模方法的弊端。 体现控制方法可分为两类:
1)深度强化学习(DRL)。 DRL可以处理高维数据并学习复杂的行为模式,使其适合决策和控制。 针对双足运动提出了混合动态策略梯度(HDPG)[370],允许通过多个标准动态同时优化控制策略。 DeepGait [371] 是一种用于地形感知运动的神经网络策略,它结合了基于模型的运动规划和强化学习的方法。 它包括一个地形感知规划器,用于生成步态序列和引导机器人朝目标方向的基本运动,以及一个步态和基本运动控制器,用于在保持平衡的同时执行这些序列。 规划器和控制器都使用神经网络函数逼近器进行参数化,并使用深度强化学习算法进行优化。

2)模仿学习。 DRL 的缺点是需要来自大量试验的大量数据。 为了解决这个问题,引入了模仿学习,其目的是通过收集高质量的演示来最大限度地减少数据使用。 为了提高数据效率,提出了Offline RL + Online RL,以降低交互成本并确保安全。 该方法首先采用离线强化学习从静态、预先收集的大型数据集中学习策略。 然后将这些策略部署到真实环境中进行实时交互和探索,并根据反馈进行调整。 人类示范的代表性模仿学习方法是 ALOHA [372] 和 Mobile ALOHA [358]。
尽管实体人工智能包含高级算法、模型和规划模块,但其最基本和最重要的组成部分是实体控制。 因此,如何控制物理实体并赋予其物理智能势在必行。 具身控制与硬件密切相关,例如控制关节运动、末端执行器位置和行走速度。 对于机械臂来说,知道末端执行器的位置,如何规划关节轨迹以将手臂移动到目标? 对于仿人机器人来说,知道了运动模式,如何控制关节以达到目标姿势? 这些都是需要在控制中解决的关键问题。 一些工作专注于机器人控制,增强机器人动作的灵活性。 [373]提出了一种基于视觉的全身控制框架。 通过连接机械臂和机器狗,利用全自由度(腿部12个关节、手臂6个关节、夹具1个关节),跟踪机器狗的速度和机器臂末端执行器的位置,实现控制更灵活。 一些作品[374, 375]采用传统方法来控制双足机器人行走。 麻省理工学院的 Cheetah 3 [376]、ANYmal [377] 和 Atlas [378] 使用强大的步行控制器来管理机器人。 这些机器人可用于更敏捷的运动任务,例如跳跃或克服各种障碍[379,380,381,382,383]。 其他作品[384, 385]专注于控制人形机器人,像人类一样执行各种动作并模仿人类行为。 图18说明了一些示例。
具身控制集成了强化学习和模拟真实技术,通过环境交互来优化策略,从而能够探索未知领域,有可能超越人类的能力,并适应非结构化环境。 虽然机器人可以模仿许多人类行为,但有效完成任务通常需要基于环境反馈的强化学习训练。 最具挑战性的场景包括接触密集型任务,其中操作需要根据被操作对象的状态、变形、材料和力等反馈进行实时调整。 在这种情况下,强化学习是必不可少的。 在 MLM 时代,这些模型拥有对场景语义的普遍理解,为 RL 提供了强大的奖励函数。 此外,强化学习对于使大型模型与其预期任务保持一致至关重要。 未来,经过预训练和微调后,强化学习仍然需要与物理世界保持一致,确保在现实环境中的有效部署。
八挑战和未来方向
尽管嵌入式人工智能发展迅速,但它面临着一些挑战,并提出了令人兴奋的未来方向。
高质量的机器人数据集:获取足够的现实世界机器人数据仍然是一个重大挑战。 收集这些数据既耗时又耗费资源。 仅仅依赖模拟数据会使模拟与真实的差距问题变得更加严重。 创建多样化的现实世界机器人数据集需要各个机构之间密切而广泛的合作。 此外,开发更真实、更高效的模拟器对于提高模拟数据的质量至关重要。 目前的工作 RT-1 [11] 使用基于机器人图像和自然语言命令的预训练模型。 RT-1在导航和抓取任务中取得了良好的效果,但获取现实世界的机器人数据集非常具有挑战性。 为了构建能够在机器人领域进行跨场景和跨任务应用的通用体现模型,必须构建大规模数据集,利用高质量的模拟环境数据来辅助现实世界数据。
人类演示数据的有效利用:人类演示数据的有效利用涉及利用人类演示的动作和行为来训练和改进机器人系统。 这个过程包括收集、处理和学习大规模、高质量的数据集,人类在这些数据集中执行机器人要学习的任务。 当前的工作R3M[386]使用动作标签和人类演示数据来学习具有较高成功率的泛化表示,但复杂任务的效率仍然需要提高。 因此,有效利用大量非结构化、多标签、多模态的人类演示数据与动作标签数据相结合来训练能够在相对较短的时间内学习各种任务的具体模型非常重要。 通过有效利用人类演示数据,机器人系统可以实现更高水平的性能和适应性,使其更有能力在动态环境中执行复杂的任务。
复杂环境认知:复杂环境认知是指实体或虚拟环境中的实体感知、理解和导航复杂的现实世界环境的能力。 Say-Can[298]基于广泛的常识知识,利用预训练的大语言模型模型的任务分解机制,严重依赖大量的常识知识来进行简单的任务规划,但缺乏对复杂环境下的长期任务。 对于非结构化的开放环境,当前的工作通常依赖于预先训练的大语言模型的任务分解机制,利用广泛的常识知识进行简单的任务规划,而缺乏具体的场景理解。 增强复杂环境下的知识迁移和泛化能力至关重要。 一个真正多功能的机器人系统应该能够在不同的和看不见的场景中理解和执行自然语言指令。 这就需要开发适应性强且可扩展的具体代理架构。
长视野任务执行:执行单个指令通常会给机器人带来长视野任务,例如“打扫厨房”等命令,其中涉及重新排列物体、扫地、擦桌子等活动,和更多。 成功完成此类任务需要机器人能够在较长的时间跨度内规划和执行一系列低级动作。 虽然当前的高级任务规划器已经取得了初步的成功,但由于缺乏对具体任务的调整,它们在不同的场景中往往表现不足。 应对这一挑战需要培养具备强大感知能力和大量常识知识的高效规划者。
因果关系发现:现有的数据驱动的实体代理根据数据内的内在相关性做出决策。 然而,这种建模方法不允许模型真正理解知识、行为和环境之间的因果关系,从而导致策略出现偏差。 这使得很难确保它们能够以可解释、稳健且可靠的方式在现实环境中运行。 因此,实体主体必须由世界知识驱动,能够进行自主因果推理,这一点非常重要。 通过交互来理解世界,并通过溯因推理来学习其运作方式,我们可以进一步增强多模态实体在复杂的现实环境中的适应性、决策可靠性和泛化能力。 对于具体任务,需要通过交互指令和状态预测来建立跨模态的时空因果关系[387]。 此外,智能体需要了解物体的可供性,以实现动态场景中的自适应任务规划和长距离自主导航。 优化决策需要结合反事实和因果干预策略[388],从反事实和因果干预的角度追溯因果关系,减少探索迭代,优化决策。 基于世界知识构建因果图,通过主动因果推理驱动智能体从模拟到现实的转移,将形成实体人工智能的统一框架。
持续学习:在机器人应用中,持续学习[389]对于在不同环境中部署机器人学习策略至关重要,但它仍然是一个很大程度上未经探索的领域。 虽然最近的一些研究探讨了持续学习的子主题,例如增量学习、快速运动适应和人机循环学习,但这些解决方案通常是针对单个任务或平台设计的,尚未考虑基础模型。 开放研究问题和可行的方法包括:1)在对最新数据进行微调时混合不同比例的先验数据分布,以减轻灾难性遗忘[390],2)根据先验分布或课程开发有效的原型对于学习新任务中的任务推理,3)提高在线学习算法的训练稳定性和样本效率,4)确定将大容量模型无缝整合到控制框架中的原则性方法,可能通过分层学习或慢速控制来实现实时时间推断。
统一评估基准:虽然存在许多用于评估低级控制策略的基准,但它们评估的技能往往存在很大差异。 此外,这些基准测试中包含的对象和场景通常受到模拟器约束的限制。 为了全面评估具体模型,需要使用真实模拟器来制定包含各种技能的基准。 对于高级任务规划者,许多基准测试侧重于通过问答任务评估规划能力。 然而,更理想的方法是同时评估高级任务规划器和低级控制策略,以执行长期任务并衡量成功率,而不是仅仅依赖于规划器的孤立评估。 这种综合方法可以对具体人工智能系统的功能进行更全面的评估。
九结论
具身人工智能允许智能体感知、感知网络空间和物理世界的各种物体并与之交互,这对实现通用人工智能具有重要意义。 这项调查广泛回顾了具身机器人、模拟器、四个代表性的具身任务:视觉主动感知、具身交互、具身代理和模拟到真实的机器人控制,以及未来的研究方向。 对具身机器人、模拟器、数据集和方法的比较总结,清晰地展示了具身人工智能的最新发展情况,这对未来沿着这一新兴且有前景的研究方向的研究大有裨益。
致谢
我们衷心感谢罗景洲、宋新帅、蒋凯旋、李志达和赵甘龙的贡献。
参考
- [1] C. Machinery, “Computing machinery and intelligence-am turing,” Mind, vol. 59, no. 236, p. 433, 1950.
- [2] L. Londoño, J. V. Hurtado, N. Hertz, P. Kellmeyer, S. Voeneky, and A. Valada, “Fairness and bias in robot learning,” Proceedings of the IEEE, 2024.
- [3] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” arXiv preprint arXiv:2307.15818, 2023.
- [4] S. Belkhale, T. Ding, T. Xiao, P. Sermanet, Q. Vuong, J. Tompson, Y. Chebotar, D. Dwibedi, and D. Sadigh, “Rt-h: Action hierarchies using language,” arXiv preprint arXiv:2403.01823, 2024.
- [5] T. Wu, S. He, J. Liu, S. Sun, K. Liu, Q.-L. Han, and Y. Tang, “A brief overview of chatgpt: The history, status quo and potential future development,” IEEE/CAA Journal of Automatica Sinica, vol. 10, no. 5, pp. 1122–1136, 2023.
- [6] J. Duan, S. Yu, H. L. Tan, H. Zhu, and C. Tan, “A survey of embodied ai: From simulators to research tasks,” IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 6, no. 2, pp. 230–244, 2022.
- [7] Z. Xu, K. Wu, J. Wen, J. Li, N. Liu, Z. Che, and J. Tang, “A survey on robotics with foundation models: toward embodied ai,” arXiv preprint arXiv:2402.02385, 2024.
- [8] Y. Ma, Z. Song, Y. Zhuang, J. Hao, and I. King, “A survey on vision-language-action models for embodied ai,” arXiv preprint arXiv:2405.14093, 2024.
- [9] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
- [10] Y. Chen, W. Cui, Y. Chen, M. Tan, X. Zhang, D. Zhao, and H. Wang, “Robogpt: an intelligent agent of making embodied long-term decisions for daily instruction tasks,” arXiv preprint arXiv:2311.15649, 2023.
- [11] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu et al., “Rt-1: Robotics transformer for real-world control at scale,” arXiv preprint arXiv:2212.06817, 2022.
- [12] Y. Hu, Q. Xie, V. Jain, J. Francis, J. Patrikar, N. Keetha, S. Kim, Y. Xie, T. Zhang, Z. Zhao et al., “Toward general-purpose robots via foundation models: A survey and meta-analysis,” arXiv preprint arXiv:2312.08782, 2023.
- [13] R. McCarthy, D. C. Tan, D. Schmidt, F. Acero, N. Herr, Y. Du, T. G. Thuruthel, and Z. Li, “Towards generalist robot learning from internet video: A survey,” arXiv preprint arXiv:2404.19664, 2024.
- [14] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [15] J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in International conference on machine learning. PMLR, 2023, pp. 19 730–19 742.
- [16] M. Assran, Q. Duval, I. Misra, P. Bojanowski, P. Vincent, M. Rabbat, Y. LeCun, and N. Ballas, “Self-supervised learning from images with a joint-embedding predictive architecture,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 619–15 629.
- [17] Z. Zhu, X. Wang, W. Zhao, C. Min, N. Deng, M. Dou, Y. Wang, B. Shi, K. Wang, C. Zhang et al., “Is sora a world simulator? a comprehensive survey on general world models and beyond,” arXiv preprint arXiv:2405.03520, 2024.
- [18] R. Pfeifer and F. Iida, “Embodied artificial intelligence: Trends and challenges,” Lecture notes in computer science, pp. 1–26, 2004.
- [19] J. Haugeland, Artificial intelligence: The very idea. MIT press, 1989.
- [20] R. Pfeifer and J. Bongard, How the body shapes the way we think: a new view of intelligence. MIT press, 2006.
- [21] B. Siciliano, O. Khatib, and T. Kröger, Springer handbook of robotics. Springer, 2008, vol. 200.
- [22] S. Haddadin, S. Parusel, L. Johannsmeier, S. Golz, S. Gabl, F. Walch, M. Sabaghian, C. Jähne, L. Hausperger, and S. Haddadin, “The franka emika robot: A reference platform for robotics research and education,” IEEE Robotics & Automation Magazine, vol. 29, no. 2, pp. 46–64, 2022.
- [23] C. Li, S. Zhu, Z. Sun, and J. Rogers, “Bas optimized elm for kuka iiwa robot learning,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 68, no. 6, pp. 1987–1991, 2020.
- [24] M. Kennedy, K. Schmeckpeper, D. Thakur, C. Jiang, V. Kumar, and K. Daniilidis, “Autonomous precision pouring from unknown containers,” IEEE Robotics and Automation Letters, vol. 4, no. 3, pp. 2317–2324, 2019.
- [25] P. R. Wurman, R. D’Andrea, and M. Mountz, “Coordinating hundreds of cooperative, autonomous vehicles in warehouses,” AI magazine, vol. 29, no. 1, pp. 9–9, 2008.
- [26] B. Reily, P. Gao, F. Han, H. Wang, and H. Zhang, “Real-time recognition of team behaviors by multisensory graph-embedded robot learning,” The International Journal of Robotics Research, vol. 41, no. 8, pp. 798–811, 2022.
- [27] A. Ugenti, R. Galati, G. Mantriota, and G. Reina, “Analysis of an all-terrain tracked robot with innovative suspension system,” Mechanism and Machine Theory, vol. 182, p. 105237, 2023.
- [28] B. M. Yamauchi, “Packbot: a versatile platform for military robotics,” in Unmanned ground vehicle technology VI, vol. 5422. SPIE, 2004, pp. 228–237.
- [29] M. Raibert, K. Blankespoor, G. Nelson, and R. Playter, “Bigdog, the rough-terrain quadruped robot,” IFAC Proceedings Volumes, vol. 41, no. 2, pp. 10 822–10 825, 2008.
- [30] G. Bellegarda, Y. Chen, Z. Liu, and Q. Nguyen, “Robust high-speed running for quadruped robots via deep reinforcement learning,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2022, pp. 10 364–10 370.
- [31] S. Le Cleac’h, T. A. Howell, S. Yang, C.-Y. Lee, J. Zhang, A. Bishop, M. Schwager, and Z. Manchester, “Fast contact-implicit model predictive control,” IEEE Transactions on Robotics, 2024.
- [32] A. Bouman, M. F. Ginting, N. Alatur, M. Palieri, D. D. Fan, T. Touma, T. Pailevanian, S.-K. Kim, K. Otsu, J. Burdick et al., “Autonomous spot: Long-range autonomous exploration of extreme environments with legged locomotion,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2020, pp. 2518–2525.
- [33] P. Arm, G. Waibel, J. Preisig, T. Tuna, R. Zhou, V. Bickel, G. Ligeza, T. Miki, F. Kehl, H. Kolvenbach et al., “Scientific exploration of challenging planetary analog environments with a team of legged robots,” Science robotics, vol. 8, no. 80, p. eade9548, 2023.
- [34] T. F. Nygaard, C. P. Martin, J. Torresen, K. Glette, and D. Howard, “Real-world embodied ai through a morphologically adaptive quadruped robot,” Nature Machine Intelligence, vol. 3, no. 5, pp. 410–419, 2021.
- [35] A. K. Vaskov, P. P. Vu, N. North, A. J. Davis, T. A. Kung, D. H. Gates, P. S. Cederna, and C. A. Chestek, “Surgically implanted electrodes enable real-time finger and grasp pattern recognition for prosthetic hands,” IEEE Transactions on Robotics, vol. 38, no. 5, pp. 2841–2857, 2022.
- [36] S. Maniatopoulos, P. Schillinger, V. Pong, D. C. Conner, and H. Kress-Gazit, “Reactive high-level behavior synthesis for an atlas humanoid robot,” in IEEE international conference on robotics and automation. IEEE, 2016, pp. 4192–4199.
- [37] D. J. Agravante, A. Cherubini, A. Sherikov, P.-B. Wieber, and A. Kheddar, “Human-humanoid collaborative carrying,” IEEE Transactions on Robotics, vol. 35, no. 4, pp. 833–846, 2019.
- [38] S. Shigemi, A. Goswami, and P. Vadakkepat, “Asimo and humanoid robot research at honda,” Humanoid robotics: A reference, vol. 55, p. 90, 2018.
- [39] F. Tanaka, K. Isshiki, F. Takahashi, M. Uekusa, R. Sei, and K. Hayashi, “Pepper learns together with children: Development of an educational application,” in IEEE-RAS 15th International Conference on Humanoid Robots, 2015, pp. 270–275.
- [40] Y. Tong, H. Liu, and Z. Zhang, “Advancements in humanoid robots: A comprehensive review and future prospects,” IEEE/CAA Journal of Automatica Sinica, vol. 11, no. 2, pp. 301–328, 2024.
- [41] J. Xiang, T. Tao, Y. Gu, T. Shu, Z. Wang, Z. Yang, and Z. Hu, “Language models meet world models: Embodied experiences enhance language models,” Advances in neural information processing systems, vol. 36, 2024.
- [42] Y. Yang, Z. He, P. Jiao, and H. Ren, “Bioinspired soft robotics: How do we learn from creatures?” IEEE Reviews in Biomedical Engineering, 2022.
- [43] M. Ilami, H. Bagheri, R. Ahmed, E. O. Skowronek, and H. Marvi, “Materials, actuators, and sensors for soft bioinspired robots,” Advanced Materials, vol. 33, no. 19, p. 2003139, 2021.
- [44] R. K. Katzschmann, J. DelPreto, R. MacCurdy, and D. Rus, “Exploration of underwater life with an acoustically controlled soft robotic fish,” Science Robotics, vol. 3, no. 16, p. eaar3449, 2018.
- [45] F. Berlinger, M. Gauci, and R. Nagpal, “Implicit coordination for 3d underwater collective behaviors in a fish-inspired robot swarm,” Science Robotics, vol. 6, no. 50, p. eabd8668, 2021.
- [46] G. C. de Croon, J. Dupeyroux, S. B. Fuller, and J. A. Marshall, “Insect-inspired ai for autonomous robots,” Science robotics, vol. 7, no. 67, p. eabl6334, 2022.
- [47] X. Zhou, X. Wen, Z. Wang, Y. Gao, H. Li, Q. Wang, T. Yang, H. Lu, Y. Cao, C. Xu et al., “Swarm of micro flying robots in the wild,” Science Robotics, vol. 7, no. 66, p. eabm5954, 2022.
- [48] N. R. Sinatra, C. B. Teeple, D. M. Vogt, K. K. Parker, D. F. Gruber, and R. J. Wood, “Ultragentle manipulation of delicate structures using a soft robotic gripper,” Science Robotics, vol. 4, no. 33, p. eaax5425, 2019.
- [49] NVIDIA, “Nvidia isaac sim: Robotics simulation and synthetic data,” 2023. [Online]. Available: https://developer.nvidia.com/isaac-sim
- [50] V. Makoviychuk, L. Wawrzyniak, Y. Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa et al., “Isaac gym: High performance gpu-based physics simulation for robot learning,” arXiv preprint arXiv:2108.10470, 2021.
- [51] N. Koenig and A. Howard, “Design and use paradigms for gazebo, an open-source multi-robot simulator,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, vol. 3, 2004, pp. 2149–2154.
- [52] E. Coumans and Y. Bai, “Pybullet, a python module for physics simulation for games, robotics and machine learning,” 2016.
- [53] Cyberbotics, “Webots: open-source robot simulator.” [Online]. Available: https://github.com/cyberbotics/webots
- [54] E. Todorov, T. Erez, and Y. Tassa, “Mujoco: A physics engine for model-based control,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2012, pp. 5026–5033.
- [55] A. Juliani, V.-P. Berges, E. Teng, A. Cohen, J. Harper, C. Elion, C. Goy, Y. Gao, H. Henry, M. Mattar, and D. Lange, “Unity: A general platform for intelligent agents,” arXiv preprint arXiv:1809.02627, 2020.
- [56] S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelity visual and physical simulation for autonomous vehicles,” in Field and Service Robotics, 2017.
- [57] ISAE-SUPAERO, “Morse: the modular open robots simulator engine.”
- [58] E. Rohmer, S. P. Singh, and M. Freese, “V-rep: A versatile and scalable robot simulation framework,” in IEEE/RSJ international conference on intelligent robots and systems, 2013, pp. 1321–1326.
- [59] N. Koenig and A. Howard, “Design and use paradigms for gazebo, an open-source multi-robot simulator,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, vol. 3, 2004, pp. 2149–2154.
- [60] E. Kolve, R. Mottaghi, D. Gordon, Y. Zhu, A. Gupta, and A. Farhadi, “Ai2-thor: An interactive 3d environment for visual ai,” arXiv: Computer Vision and Pattern Recognition,arXiv: Computer Vision and Pattern Recognition, Dec 2017.
- [61] A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niebner, M. Savva, S. Song, A. Zeng, and Y. Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,” in 2017 International Conference on 3D Vision (3DV), Oct 2017.
- [62] P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. Sunderhauf, I. Reid, S. Gould, and A. van den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2018.
- [63] X. Puig, K. Ra, M. Boben, J. Li, T. Wang, S. Fidler, and A. Torralba, “Virtualhome: Simulating household activities via programs,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2018.
- [64] M. Savva, A. Kadian, O. Maksymets, Y. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V. Koltun, J. Malik, D. Parikh, and D. Batra, “Habitat: A platform for embodied ai research,” in IEEE/CVF International Conference on Computer Vision, Oct 2019.
- [65] F. Xiang, Y. Qin, K. Mo, Y. Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y. Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, and H. Su, “Sapien: A simulated part-based interactive environment,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2020.
- [66] B. Shen, F. Xia, C. Li, R. Martín-Martín, L. Fan, G. Wang, C. Pérez-D’Arpino, S. Buch, S. Srivastava, L. Tchapmi, M. Tchapmi, K. Vainio, J. Wong, L. Fei-Fei, and S. Savarese, “igibson 1.0: A simulation environment for interactive tasks in large realistic scenes,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2021, pp. 7520–7527.
- [67] C. Li, F. Xia, R. Martín-Martín, M. Lingelbach, S. Srivastava, B. Shen, K. E. Vainio, C. Gokmen, G. Dharan, T. Jain, A. Kurenkov, K. Liu, H. Gweon, J. Wu, L. Fei-Fei, and S. Savarese, “igibson 2.0: Object-centric simulation for robot learning of everyday household tasks,” in Proceedings of the 5th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, A. Faust, D. Hsu, and G. Neumann, Eds., vol. 164. PMLR, 08–11 Nov 2022, pp. 455–465.
- [68] C. Gan, J. Schwartz, S. Alter, M. Schrimpf, J. Traer, J. Freitas, J. Kubilius, A. Bhandwaldar, N. Haber, M. Sano, K. Kim, E. Wang, D. Mrowca, M. Lingelbach, A. Curtis, K. Feigelis, D. Bear, D. Gutfreund, D. Cox, J. DiCarlo, J. McDermott, J. Tenenbaum, and D. Yamins, “Threedworld: A platform for interactive multi-modal physical simulation,” Neural Information Processing Systems 2021, Dec 2021.
- [69] Y. Wang, Z. Xian, F. Chen, T.-H. Wang, Y. Wang, K. Fragkiadaki, Z. Erickson, D. Held, and C. Gan, “Robogen: Towards unleashing infinite data for automated robot learning via generative simulation,” arXiv:2311.01455, Nov 2023.
- [70] Y. Yang, F.-Y. Sun, L. Weihs, E. VanderBilt, A. Herrasti, W. Han, J. Wu, N. Haber, R. Krishna, L. Liu et al., “Holodeck: Language guided generation of 3d embodied ai environments,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 227–16 237.
- [71] Y. Yang, B. Jia, P. Zhi, and S. Huang, “Physcene: Physically interactable 3d scene synthesis for embodied ai,” in Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
- [72] M. Deitke, E. VanderBilt, A. Herrasti, L. Weihs, J. Salvador, K. Ehsani, W. Han, E. Kolve, A. Farhadi, A. Kembhavi, and R. Mottaghi, “ProcTHOR: Large-Scale Embodied AI Using Procedural Generation,” in NeurIPS, 2022, outstanding Paper Award.
- [73] L. Fei-Fei and R. Krishna, “Searching for computer vision north stars,” Daedalus, vol. 151, no. 2, pp. 85–99, 2022.
- [74] A. J. Davison, I. D. Reid, N. D. Molton, and O. Stasse, “Monoslam: Real-time single camera slam,” IEEE transactions on pattern analysis and machine intelligence, vol. 29, no. 6, pp. 1052–1067, 2007.
- [75] A. I. Mourikis and S. I. Roumeliotis, “A multi-state constraint kalman filter for vision-aided inertial navigation,” in IEEE International Conference on Robotics and Automation. IEEE, 2007, pp. 3565–3572.
- [76] G. Klein and D. Murray, “Parallel tracking and mapping for small ar workspaces,” in 2007 6th IEEE and ACM international symposium on mixed and augmented reality. IEEE, 2007, pp. 225–234.
- [77] R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “Orb-slam: a versatile and accurate monocular slam system,” IEEE transactions on robotics, vol. 31, no. 5, pp. 1147–1163, 2015.
- [78] R. A. Newcombe, S. J. Lovegrove, and A. J. Davison, “Dtam: Dense tracking and mapping in real-time,” in 2011 international conference on computer vision. IEEE, 2011, pp. 2320–2327.
- [79] J. Engel, T. Schöps, and D. Cremers, “Lsd-slam: Large-scale direct monocular slam,” in European conference on computer vision. Springer, 2014, pp. 834–849.
- [80] R. F. Salas-Moreno, R. A. Newcombe, H. Strasdat, P. H. Kelly, and A. J. Davison, “Slam++: Simultaneous localisation and mapping at the level of objects,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 1352–1359.
- [81] S. Yang and S. Scherer, “Cubeslam: Monocular 3-d object slam,” IEEE Transactions on Robotics, vol. 35, no. 4, pp. 925–938, 2019.
- [82] J. Zhang, M. Gui, Q. Wang, R. Liu, J. Xu, and S. Chen, “Hierarchical topic model based object association for semantic slam,” IEEE transactions on visualization and computer graphics, vol. 25, no. 11, pp. 3052–3062, 2019.
- [83] L. Nicholson, M. Milford, and N. Sünderhauf, “Quadricslam: Dual quadrics from object detections as landmarks in object-oriented slam,” IEEE Robotics and Automation Letters, vol. 4, no. 1, pp. 1–8, 2018.
- [84] Z. Liao, Y. Hu, J. Zhang, X. Qi, X. Zhang, and W. Wang, “So-slam: Semantic object slam with scale proportional and symmetrical texture constraints,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 4008–4015, 2022.
- [85] C. Yu, Z. Liu, X.-J. Liu, F. Xie, Y. Yang, Q. Wei, and Q. Fei, “Ds-slam: A semantic visual slam towards dynamic environments,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2018, pp. 1168–1174.
- [86] B. Bescos, J. M. Fácil, J. Civera, and J. Neira, “Dynaslam: Tracking, mapping, and inpainting in dynamic scenes,” IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 4076–4083, 2018.
- [87] S. Cheng, C. Sun, S. Zhang, and D. Zhang, “Sg-slam: A real-time rgb-d visual slam toward dynamic scenes with semantic and geometric information,” IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–12, 2022.
- [88] J. He, M. Li, Y. Wang, and H. Wang, “Ovd-slam: An online visual slam for dynamic environments,” IEEE Sensors Journal, 2023.
- [89] C. Yan, D. Qu, D. Xu, B. Zhao, Z. Wang, D. Wang, and X. Li, “Gs-slam: Dense visual slam with 3d gaussian splatting,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 595–19 604.
- [90] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3d object detection network for autonomous driving,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 1907–1915.
- [91] A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12 705.
- [92] H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller, “Multi-view convolutional neural networks for 3d shape recognition,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 945–953.
- [93] D. Maturana and S. Scherer, “Voxnet: A 3d convolutional neural network for real-time object recognition,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2015, pp. 922–928.
- [94] S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and T. Funkhouser, “Semantic scene completion from a single depth image,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1746–1754.
- [95] C. Choy, J. Gwak, and S. Savarese, “4d spatio-temporal convnets: Minkowski convolutional neural networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3075–3084.
- [96] B. Graham, M. Engelcke, and L. Van Der Maaten, “3d semantic segmentation with submanifold sparse convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9224–9232.
- [97] T. Wang, X. Mao, C. Zhu, R. Xu, R. Lyu, P. Li, X. Chen, W. Zhang, K. Chen, T. Xue et al., “Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 757–19 767.
- [98] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660.
- [99] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” Advances in neural information processing systems, vol. 30, 2017.
- [100] X. Ma, C. Qin, H. You, H. Ran, and Y. Fu, “Rethinking network design and local geometry in point cloud: A simple residual mlp framework,” arXiv preprint arXiv:2202.07123, 2022.
- [101] H. Zhao, L. Jiang, J. Jia, P. H. Torr, and V. Koltun, “Point transformer,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 16 259–16 268.
- [102] Y.-Q. Yang, Y.-X. Guo, J.-Y. Xiong, Y. Liu, H. Pan, P.-S. Wang, X. Tong, and B. Guo, “Swin3d: A pretrained transformer backbone for 3d indoor scene understanding,” arXiv preprint arXiv:2304.06906, 2023.
- [103] X. Wu, Y. Lao, L. Jiang, X. Liu, and H. Zhao, “Point transformer v2: Grouped vector attention and partition-based pooling,” Advances in Neural Information Processing Systems, vol. 35, pp. 33 330–33 342, 2022.
- [104] X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y. Qiao, W. Ouyang, T. He, and H. Zhao, “Point transformer v3: Simpler faster stronger,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4840–4851.
- [105] Z. Zhu, X. Ma, Y. Chen, Z. Deng, S. Huang, and Q. Li, “3d-vista: Pre-trained transformer for 3d vision and text alignment,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2911–2921.
- [106] J. Huang, S. Yong, X. Ma, X. Linghu, P. Li, Y. Wang, Q. Li, S.-C. Zhu, B. Jia, and S. Huang, “An embodied generalist agent in 3d world,” in Proceedings of the International Conference on Machine Learning (ICML), 2024.
- [107] Z. Zhu, Z. Zhang, X. Ma, X. Niu, Y. Chen, B. Jia, Z. Deng, S. Huang, and Q. Li, “Unifying 3d vision-language understanding via promptable queries,” arXiv preprint arXiv:2405.11442, 2024.
- [108] D. Liang, X. Zhou, X. Wang, X. Zhu, W. Xu, Z. Zou, X. Ye, and X. Bai, “Pointmamba: A simple state space model for point cloud analysis,” arXiv preprint arXiv:2402.10739, 2024.
- [109] T. Zhang, X. Li, H. Yuan, S. Ji, and S. Yan, “Point could mamba: Point cloud learning via state space model,” arXiv preprint arXiv:2403.00762, 2024.
- [110] X. Han, Y. Tang, Z. Wang, and X. Li, “Mamba3d: Enhancing local features for 3d point cloud analysis via state space model,” arXiv preprint arXiv:2404.14966, 2024.
- [111] L. Pinto, D. Gandhi, Y. Han, Y.-L. Park, and A. Gupta, “The curious robot: Learning visual representations via physical interactions,” in European Conference on Computer Vision, 2016, pp. 3–18.
- [112] G. Tatiya, J. Francis, and J. Sinapov, “Transferring implicit knowledge of non-visual object properties across heterogeneous robot morphologies,” in IEEE International Conference on Robotics and Automation. IEEE, 2023, pp. 11 315–11 321.
- [113] D. Jayaraman and K. Grauman, “Learning to look around: Intelligently exploring unseen environments for unknown tasks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1238–1247.
- [114] L. Jin, X. Chen, J. Rückin, and M. Popović, “Neu-nbv: Next best view planning using uncertainty estimation in image-based neural rendering,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2023, pp. 11 305–11 312.
- [115] Y. Hu, J. Geng, C. Wang, J. Keller, and S. Scherer, “Off-policy evaluation with online adaptation for robot exploration in challenging environments,” IEEE Robotics and Automation Letters, 2023.
- [116] L. Fan, M. Liang, Y. Li, G. Hua, and Y. Wu, “Evidential active recognition: Intelligent and prudent open-world embodied perception,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 351–16 361.
- [117] S. Mokssit, D. B. Licea, B. Guermah, and M. Ghogho, “Deep learning techniques for visual slam: A survey,” IEEE Access, vol. 11, pp. 20 026–20 050, 2023.
- [118] K. Chen, J. Zhang, J. Liu, Q. Tong, R. Liu, and S. Chen, “Semantic visual simultaneous localization and mapping: A survey,” arXiv preprint arXiv:2209.06428, 2022.
- [119] P. K. Vinodkumar, D. Karabulut, E. Avots, C. Ozcinar, and G. Anbarjafari, “A survey on deep learning based segmentation, detection and classification for 3d point clouds,” Entropy, vol. 25, no. 4, p. 635, 2023.
- [120] H. Durrant-Whyte and T. Bailey, “Simultaneous localization and mapping: part i,” IEEE robotics & automation magazine, vol. 13, no. 2, pp. 99–110, 2006.
- [121] T. Bailey and H. Durrant-Whyte, “Simultaneous localization and mapping (slam): Part ii,” IEEE robotics & automation magazine, vol. 13, no. 3, pp. 108–117, 2006.
- [122] X. Zhang, J. Lai, D. Xu, H. Li, and M. Fu, “2d lidar-based slam and path planning for indoor rescue using mobile robots,” Journal of Advanced Transportation, vol. 2020, no. 1, p. 8867937, 2020.
- [123] D. Droeschel and S. Behnke, “Efficient continuous-time slam for 3d lidar-based online mapping,” in IEEE International Conference on Robotics and Automation. IEEE, 2018, pp. 5000–5007.
- [124] J. Ruan, B. Li, Y. Wang, and Z. Fang, “Gp-slam+: real-time 3d lidar slam based on improved regionalized gaussian process map reconstruction,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2020, pp. 5171–5178.
- [125] V. Mittal, “Attngrounder: Talking to cars with attention,” in ECCV. Springer, 2020, pp. 62–73.
- [126] X. Wang, Q. Huang, A. Celikyilmaz, J. Gao, D. Shen, Y.-F. Wang, W. Y. Wang, and L. Zhang, “Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6629–6638.
- [127] C. Bermejo, L. H. Lee, P. Chojecki, D. Przewozny, and P. Hui, “Exploring button designs for mid-air interaction in virtual reality: A hexa-metric evaluation of key representations and multi-modal cues,” Proceedings of the ACM on Human-Computer Interaction, vol. 5, no. EICS, pp. 1–26, 2021.
- [128] D. Z. Chen, A. X. Chang, and M. Nießner, “Scanrefer: 3d object localization in rgb-d scans using natural language,” in European conference on computer vision. Springer, 2020, pp. 202–221.
- [129] P. Achlioptas, A. Abdelreheem, F. Xia, M. Elhoseiny, and L. Guibas, “Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes,” in ECCV. Springer, 2020, pp. 422–440.
- [130] P.-H. Huang, H.-H. Lee, H.-T. Chen, and T.-L. Liu, “Text-guided graph neural networks for referring 3d instance segmentation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 2, 2021, pp. 1610–1618.
- [131] Z. Yang, S. Zhang, L. Wang, and J. Luo, “Sat: 2d semantics assisted training for 3d visual grounding,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1856–1866.
- [132] M. Feng, Z. Li, Q. Li, L. Zhang, X. Zhang, G. Zhu, H. Zhang, Y. Wang, and A. Mian, “Free-form description guided 3d visual graph network for object grounding in point cloud,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3722–3731.
- [133] L. Zhao, D. Cai, L. Sheng, and D. Xu, “3dvg-transformer: Relation modeling for visual grounding on point clouds,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2928–2937.
- [134] J. Roh, K. Desingh, A. Farhadi, and D. Fox, “Languagerefer: Spatial-language model for 3d visual grounding,” in Conference on Robot Learning. PMLR, 2022, pp. 1046–1056.
- [135] E. Bakr, Y. Alsaedy, and M. Elhoseiny, “Look around and refer: 2d synthetic semantics knowledge distillation for 3d visual grounding,” Advances in neural information processing systems, vol. 35, pp. 37 146–37 158, 2022.
- [136] S. Huang, Y. Chen, J. Jia, and L. Wang, “Multi-view transformer for 3d visual grounding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 15 524–15 533.
- [137] J. Yang, X. Chen, S. Qian, N. Madaan, M. Iyengar, D. F. Fouhey, and J. Chai, “Llm-grounder: Open-vocabulary 3d visual grounding with large language model as an agent,” arXiv preprint arXiv:2309.12311, 2023.
- [138] Z. Yuan, J. Ren, C.-M. Feng, H. Zhao, S. Cui, and Z. Li, “Visual programming for zero-shot open-vocabulary 3d visual grounding,” arXiv preprint arXiv:2311.15383, 2023.
- [139] B. Jia, Y. Chen, H. Yu, Y. Wang, X. Niu, T. Liu, Q. Li, and S. Huang, “Sceneverse: Scaling 3d vision-language learning for grounded scene understanding,” arXiv preprint arXiv:2401.09340, 2024.
- [140] J. Luo, J. Fu, X. Kong, C. Gao, H. Ren, H. Shen, H. Xia, and S. Liu, “3d-sps: Single-stage 3d visual grounding via referred point progressive selection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 454–16 463.
- [141] A. Jain, N. Gkanatsios, I. Mediratta, and K. Fragkiadaki, “Bottom up top down detection transformers for language grounding in images and point clouds,” in European Conference on Computer Vision. Springer, 2022, pp. 417–433.
- [142] Y. Wu, X. Cheng, R. Zhang, Z. Cheng, and J. Zhang, “Eda: Explicit text-decoupling and dense alignment for 3d visual grounding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 231–19 242.
- [143] C. Zhu, T. Wang, W. Zhang, K. Chen, and X. Liu, “Empowering 3d visual grounding with reasoning capabilities,” arXiv preprint arXiv:2407.01525, 2024.
- [144] Y. Lei, Z. Wang, F. Chen, G. Wang, P. Wang, and Y. Yang, “Recent advances in multi-modal 3d scene understanding: A comprehensive survey and evaluation,” arXiv preprint arXiv:2310.15676, 2023.
- [145] Y. Zhan, Z. Xiong, and Y. Yuan, “Rsvg: Exploring data and models for visual grounding on remote sensing data,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–13, 2023.
- [146] Y. Zhou and O. Tuzel, “Voxelnet: End-to-end learning for point cloud based 3d object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4490–4499.
- [147] Z. Ding, X. Han, and M. Niethammer, “Votenet: A deep learning label fusion method for multi-atlas segmentation,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part III 22. Springer, 2019, pp. 202–210.
- [148] L. Jiang, H. Zhao, S. Shi, S. Liu, C.-W. Fu, and J. Jia, “Pointgroup: Dual-set point grouping for 3d instance segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and Pattern recognition, 2020, pp. 4867–4876.
- [149] J. Schult, F. Engelmann, A. Hermans, O. Litany, S. Tang, and B. Leibe, “Mask3d: Mask transformer for 3d semantic instance segmentation,” in IEEE International Conference on Robotics and Automation. IEEE, 2023, pp. 8216–8223.
- [150] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [151] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
- [152] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [153] D. He, Y. Zhao, J. Luo, T. Hui, S. Huang, A. Zhang, and S. Liu, “Transrefer3d: Entity-and-relation aware transformer for fine-grained 3d visual grounding,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 2344–2352.
- [154] A. Kamath, M. Singh, Y. LeCun, G. Synnaeve, I. Misra, and N. Carion, “Mdetr-modulated detection for end-to-end multi-modal understanding,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1780–1790.
- [155] L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y. Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwang et al., “Grounded language-image pre-training,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10 965–10 975.
- [156] V. Jain, G. Magalhaes, A. Ku, A. Vaswani, E. Ie, and J. Baldridge, “Stay on the path: Instruction fidelity in vision-and-language navigation,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Jan 2019.
- [157] J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments, Jan 2020, p. 104–120.
- [158] H. Chen, A. Suhr, D. Misra, N. Snavely, and Y. Artzi, “Touchdown: Natural language navigation and spatial reasoning in visual street environments,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2019.
- [159] Y. Qi, Q. Wu, P. Anderson, X. Wang, W. Y. Wang, C. Shen, and A. van den Hengel, “Reverie: Remote embodied visual referring expression in real indoor environments,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2020.
- [160] F. Zhu, X. Liang, Y. Zhu, Q. Yu, X. Chang, and X. Liang, “Soon: Scenario oriented object navigation with graph-based exploration,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2021.
- [161] H. Wang, A. G. H. Chen, X. Li, M. Wu, and H. Dong, “Find what you want: Learning demand-conditioned object attribute space for demand-driven navigation,” Advances in Neural Information Processing Systems, 2023.
- [162] M. Shridhar, J. Thomason, D. Gordon, Y. Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “Alfred: A benchmark for interpreting grounded instructions for everyday tasks,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2020.
- [163] S. Yenamandra, A. Ramachandran, K. Yadav, A. Wang, M. Khanna, T. Gervet, T.-Y. Yang, V. Jain, A. Clegg, J. Turner, Z. Kira, M. Savva, A. Chang, D. Chaplot, D. Batra, R. Mottaghi, Y. Bisk, and C. Paxton, “Homerobot: Open-vocabulary mobile manipulation,” in NeurIPS, Jun 2023.
- [164] C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Martín-Martín, C. Wang, G. Levine, M. Lingelbach, J. Sun et al., “Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation,” in Conference on Robot Learning. PMLR, 2023, pp. 80–93.
- [165] J. Thomason, M. Murray, M. Cakmak, and L. Zettlemoyer, “Vision-and-dialog navigation,” in Conference on Robot Learning. PMLR, 2020, pp. 394–406.
- [166] X. Gao, Q. Gao, R. Gong, K. Lin, G. Thattai, and G. Sukhatme, “Dialfred: Dialogue-enabled agents for embodied instruction following,” arXiv:2202.13330, 2022.
- [167] Y. Hong, C. Rodriguez, Y. Qi, Q. Wu, and S. Gould, “Language and visual entity relationship graph for agent navigation,” vol. 33, 2020, pp. 7685–7696.
- [168] W. Zhang, C. Ma, Q. Wu, and X. Yang, “Language-guided navigation via cross-modal grounding and alternate adversarial learning,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, pp. 3469–3481, 2020.
- [169] X. Wang, Q. Huang, A. Celikyilmaz, J. Gao, D. Shen, Y.-F. Wang, W. Y. Wang, and L. Zhang, “Vision-language navigation policy learning and adaptation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 12, pp. 4205–4216, 2021.
- [170] S. Y. Min, D. S. Chaplot, P. K. Ravikumar, Y. Bisk, and R. Salakhutdinov, “FILM: Following instructions in language with modular methods,” in International Conference on Learning Representations, 2022.
- [171] D. Shah, B. Osinski, B. Ichter, and S. Levine, “Lm-nav: Robotic navigation with large pre-trained models of language, vision, and action,” in Conference on Robot Learning, 2022.
- [172] Y. Qiao, Y. Qi, Y. Hong, Z. Yu, P. Wang, and Q. Wu, “Hop: History-and-order aware pretraining for vision-and-language navigation,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 15 397–15 406.
- [173] D. Zheng, S. Huang, L. Zhao, Y. Zhong, and L. Wang, “Towards learning a generalist model for embodied navigation,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2024.
- [174] J. Gao, X. Yao, and C. Xu, “Fast-slow test-time adaptation for online vision-and-language navigation,” 2024.
- [175] Y. Long, X. Li, W. Cai, and H. Dong, “Discuss before moving: Visual language navigation via multi-expert discussions,” in IEEE International Conference on Robotics and Automation, 2024.
- [176] R. D. M. S. C. L. Q. C. Liuyi Wang, Zongtao He, “Vision-and-language navigation via causal learning,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2024.
- [177] Y. Y. Rui Liu, Wenguan Wang, “Volumetric environment representation for vision-language navigation,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024, Jun 2024.
- [178] J. Zhang, K. Wang, R. Xu, G. Zhou, Y. Hong, X. Fang, Q. Wu, Z. Zhang, and W. He, “Navid: Video-based vlm plans the next step for vision-and-language navigation,” ArXiv, vol. abs/2402.15852, 2024.
- [179] X. E. Wang, W. Xiong, H. Wang, and W. Y. Wang, “Look before you leap: Bridging model-free and model-based reinforcement learning for planned-ahead vision-and-language navigation,” in European Conference on Computer Vision, 2018.
- [180] D. An, Y. Qi, Y. Huang, Q. Wu, L. Wang, and T. Tan, “Neighbor-view enhanced model for vision and language navigation,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 5101–5109.
- [181] Y. Hong, Z. Wang, Q. Wu, and S. Gould, “Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 15 418–15 428.
- [182] Y. Qiao, Y. Qi, Z. Yu, J. Liu, and Q. Wu, “March in chat: Interactive prompting for remote embodied referring expression,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, October 2023, pp. 15 758–15 767.
- [183] Z. Wang, X. Li, J. Yang, Y. Liu, J. Hu, M. Jiang, and S. Jiang, “Lookahead exploration with neural radiance representation for continuous vision-language navigation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- [184] D. An, H. Wang, W. Wang, Z. Wang, Y. Huang, K. He, and L. Wang, “Etpnav: Evolving topological planning for vision-language navigation in continuous environments,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
- [185] S. Bhambri, B. Kim, and J. Choi, “Multi-level compositional reasoning for interactive instruction following,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 1, 2023, pp. 223–231.
- [186] C. Xu, H. T. Nguyen, C. Amato, and L. L. Wong, “Vision and language navigation in the real world via online visual language mapping,” ArXiv, vol. abs/2310.10822, 2023.
- [187] T. Lin, Y. Zhang, Q. Li, H. Qi, B. Yi, S. Levine, and J. Malik, “Learning visuotactile skills with two multifingered hands,” arXiv preprint arXiv:2404.16823, 2024.
- [188] F. Yang, C. Feng, Z. Chen, H. Park, D. Wang, Y. Dou, Z. Zeng, X. Chen, R. Gangopadhyay, A. Owens et al., “Binding touch to everything: Learning unified multimodal tactile representations,” arXiv preprint arXiv:2401.18084, 2024.
- [189] P. Achenbach, S. Laux, D. Purdack, P. N. Müller, and S. Göbel, “Give me a sign: Using data gloves for static hand-shape recognition,” Sensors, vol. 23, no. 24, p. 9847, 2023.
- [190] S. J. Lederman and R. L. Klatzky, “Hand movements: A window into haptic object recognition,” Cognitive psychology, vol. 19, no. 3, pp. 342–368, 1987.
- [191] M. R. Cutkosky, R. D. Howe, and W. R. Provancher, “Force and tactile sensors,” Springer Handbook of Robotics, pp. 455–476, 2008.
- [192] S. J. Lederman and R. L. Klatzky, “Haptic perception: A tutorial,” Attention, Perception, & Psychophysics, vol. 71, no. 7, pp. 1439–1459, 2009.
- [193] S. Stassi, V. Cauda, G. Canavese, and C. F. Pirri, “Flexible tactile sensing based on piezoresistive composites: A review,” Sensors, vol. 14, no. 3, pp. 5296–5332, 2014.
- [194] Z. Kappassov, J.-A. Corrales, and V. Perdereau, “Tactile sensing in dexterous robot hands,” Robotics and Autonomous Systems, vol. 74, pp. 195–220, 2015.
- [195] Y. Zhou, Z. Yan, Y. Yang, Z. Wang, P. Lu, P. F. Yuan, and B. He, “Bioinspired sensors and applications in intelligent robots: a review,” Robotic Intelligence and Automation, vol. 44, no. 2, pp. 215–228, 2024.
- [196] J. A. Fishel and G. E. Loeb, “Sensing tactile microvibrations with the biotac—comparison with human sensitivity,” in 2012 4th IEEE RAS & EMBS international conference on biomedical robotics and biomechatronics (BioRob). IEEE, 2012, pp. 1122–1127.
- [197] P. Ruppel, Y. Jonetzko, M. Görner, N. Hendrich, and J. Zhang, “Simulation of the syntouch biotac sensor,” in Intelligent Autonomous Systems 15: Proceedings of the 15th International Conference IAS-15. Springer, 2019, pp. 374–387.
- [198] W. Yuan, S. Dong, and E. H. Adelson, “Gelsight: High-resolution robot tactile sensors for estimating geometry and force,” Sensors (Basel, Switzerland), vol. 17, 2017.
- [199] I. H. Taylor, S. Dong, and A. Rodriguez, “Gelslim 3.0: High-resolution measurement of shape, force and slip in a compact tactile-sensing finger,” in International Conference on Robotics and Automation, 2022, pp. 10 781–10 787.
- [200] M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V. R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, D. Jayaraman, and R. Calandra, “Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation,” IEEE Robotics and Automation Letters, vol. 5, no. 3, p. 3838–3845, Jul. 2020.
- [201] C. Lin, H. Zhang, J. Xu, L. Wu, and H. Xu, “9dtact: A compact vision-based tactile sensor for accurate 3d shape reconstruction and generalizable 6d force estimation,” IEEE Robotics and Automation Letters, 2023.
- [202] B. Ward-Cherrier, N. Pestell, L. Cramphorn, B. Winstone, M. E. Giannaccini, J. Rossiter, and N. F. Lepora, “The tactip family: Soft optical tactile sensors with 3d-printed biomimetic morphologies,” Soft robotics, vol. 5, no. 2, pp. 216–227, 2018.
- [203] D. F. Gomes, Z. Lin, and S. Luo, “Geltip: A finger-shaped optical tactile sensor for robotic manipulation,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2020, pp. 9903–9909.
- [204] O. Azulay, N. Curtis, R. Sokolovsky, G. Levitski, D. Slomovik, G. Lilling, and A. Sintov, “Allsight: A low-cost and high-resolution round tactile sensor with zero-shot learning capability,” IEEE Robotics and Automation Letters, vol. 9, no. 1, pp. 483–490, 2023.
- [205] S. Wang, M. Lambeta, P.-W. Chou, and R. Calandra, “Tacto: A fast, flexible, and open-source simulator for high-resolution vision-based tactile sensors,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3930–3937, 2022.
- [206] Z. Si and W. Yuan, “Taxim: An example-based simulation model for gelsight tactile sensors,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2361–2368, 2022.
- [207] S. Athar, G. Patel, Z. Xu, Q. Qiu, and Y. She, “Vistac towards a unified multi-modal sensing finger for robotic manipulation,” IEEE Sensors Journal, 2023.
- [208] Y. Ma, E. Adelson et al., “Gellink: A compact multi-phalanx finger with vision-based tactile sensing and proprioception,” arXiv preprint arXiv:2403.14887, 2024.
- [209] R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V. Alwala, A. Joulin, and I. Misra, “Imagebind: One embedding space to bind them all,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 15 180–15 190.
- [210] R. Calandra, A. Owens, M. Upadhyaya, W. Yuan, J. Lin, E. H. Adelson, and S. Levine, “The feeling of success: Does touch sensing help predict grasp outcomes?” arXiv preprint arXiv:1710.05512, 2017.
- [211] B. Sundaralingam, A. S. Lambert, A. Handa, B. Boots, T. Hermans, S. Birchfield, N. Ratliff, and D. Fox, “Robust learning of tactile force estimation through robot interaction,” in International Conference on Robotics and Automation, 2019, pp. 9035–9042.
- [212] R. Gao, Y.-Y. Chang, S. Mall, L. Fei-Fei, and J. Wu, “Objectfolder: A dataset of objects with implicit visual, auditory, and tactile representations,” arXiv preprint arXiv:2109.07991, 2021.
- [213] R. Gao, Z. Si, Y.-Y. Chang, S. Clarke, J. Bohg, L. Fei-Fei, W. Yuan, and J. Wu, “Objectfolder 2.0: A multisensory object dataset for sim2real transfer,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 598–10 608.
- [214] J. Kerr, H. Huang, A. Wilcox, R. Hoque, J. Ichnowski, R. Calandra, and K. Goldberg, “Self-supervised visuo-tactile pretraining to locate and follow garment features,” arXiv preprint arXiv:2209.13042, 2022.
- [215] S. Suresh, Z. Si, S. Anderson, M. Kaess, and M. Mukadam, “Midastouch: Monte-carlo inference over distributions across sliding touch,” in Conference on Robot Learning, 2023, pp. 319–331.
- [216] R. Gao, Y. Dou, H. Li, T. Agarwal, J. Bohg, Y. Li, L. Fei-Fei, and J. Wu, “The objectfolder benchmark: Multisensory learning with neural and real objects,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 276–17 286.
- [217] L. Fu, G. Datta, H. Huang, W. C.-H. Panitch, J. Drake, J. Ortiz, M. Mukadam, M. Lambeta, R. Calandra, and K. Goldberg, “A touch, vision, and language dataset for multimodal alignment,” arXiv preprint arXiv:2402.13232, 2024.
- [218] Y. Dou, F. Yang, Y. Liu, A. Loquercio, and A. Owens, “Tactile-augmented radiance fields,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 529–26 539.
- [219] S. Dong, W. Yuan, and E. H. Adelson, “Improved gelsight tactile sensor for measuring geometry and slip,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2017, pp. 137–144.
- [220] W. Yuan, S. Dong, and E. H. Adelson, “Gelsight: High-resolution robot tactile sensors for estimating geometry and force,” Sensors, vol. 17, no. 12, p. 2762, 2017.
- [221] K. Patel, S. Iba, and N. Jamali, “Deep tactile experience: Estimating tactile sensor output from depth sensor data,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2020, pp. 9846–9853.
- [222] S. Zhong, A. Albini, O. P. Jones, P. Maiolino, and I. Posner, “Touching a nerf: Leveraging neural radiance fields for tactile sensory data generation,” in Conference on Robot Learning. PMLR, 2023, pp. 1618–1628.
- [223] C. Higuera, B. Boots, and M. Mukadam, “Learning to read braille: Bridging the tactile reality gap with diffusion models,” arXiv preprint arXiv:2304.01182, 2023.
- [224] F. Yang, J. Zhang, and A. Owens, “Generating visual scenes from touch,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 070–22 080.
- [225] M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V. R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer et al., “Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation,” IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 3838–3845, 2020.
- [226] N. F. Lepora, A. Church, C. De Kerckhove, R. Hadsell, and J. Lloyd, “From pixels to percepts: Highly robust edge perception and contour following using deep learning and an optical biomimetic tactile sensor,” IEEE Robotics and Automation Letters, vol. 4, no. 2, pp. 2101–2107, 2019.
- [227] S. Wang, Y. She, B. Romero, and E. Adelson, “Gelsight wedge: Measuring high-resolution 3d contact geometry with a compact robot finger,” in IEEE International Conference on Robotics and Automation. IEEE, 2021, pp. 6468–6475.
- [228] C. Lin, Z. Lin, S. Wang, and H. Xu, “Dtact: A vision-based tactile sensor that measures high-resolution 3d geometry directly from darkness,” in IEEE International Conference on Robotics and Automation. IEEE, 2023, pp. 10 359–10 366.
- [229] S. Wang, J. Wu, X. Sun, W. Yuan, W. T. Freeman, J. B. Tenenbaum, and E. H. Adelson, “3d shape perception from monocular vision, touch, and shape priors,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2018, pp. 1606–1613.
- [230] M. Bauza, O. Canal, and A. Rodriguez, “Tactile mapping and localization from high-resolution tactile imprints,” in International Conference on Robotics and Automation, 2019, pp. 3811–3817.
- [231] E. Smith, R. Calandra, A. Romero, G. Gkioxari, D. Meger, J. Malik, and M. Drozdzal, “3d shape reconstruction from vision and touch,” Advances in Neural Information Processing Systems, vol. 33, pp. 14 193–14 206, 2020.
- [232] E. Smith, D. Meger, L. Pineda, R. Calandra, J. Malik, A. Romero Soriano, and M. Drozdzal, “Active 3d shape reconstruction from vision and touch,” Advances in Neural Information Processing Systems, vol. 34, pp. 16 064–16 078, 2021.
- [233] S. Suresh, Z. Si, J. G. Mangelson, W. Yuan, and M. Kaess, “Shapemap 3-d: Efficient shape mapping through dense touch and vision,” in International Conference on Robotics and Automation, 2022, pp. 7073–7080.
- [234] Y. Chen, A. E. Tekden, M. P. Deisenroth, and Y. Bekiroglu, “Sliding touch-based exploration for modeling unknown object shape with multi-fingered hands,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2023, pp. 8943–8950.
- [235] M. Comi, A. Tonioni, M. Yang, J. Tremblay, V. Blukis, Y. Lin, N. F. Lepora, and L. Aitchison, “Snap-it, tap-it, splat-it: Tactile-informed 3d gaussian splatting for reconstructing challenging surfaces,” arXiv preprint arXiv:2403.20275, 2024.
- [236] M. B. Villalonga, A. Rodriguez, B. Lim, E. Valls, and T. Sechopoulos, “Tactile object pose estimation from the first touch with geometric contact rendering,” in Conference on Robot Learning, 2021, pp. 1015–1029.
- [237] S. Dikhale, K. Patel, D. Dhingra, I. Naramura, A. Hayashi, S. Iba, and N. Jamali, “Visuotactile 6d pose estimation of an in-hand object using vision and tactile sensor data,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2148–2155, 2022.
- [238] M. Comi, A. Church, K. Li, L. Aitchison, and N. F. Lepora, “Implicit neural representation for 3d shape reconstruction using vision-based tactile sensing,” 2023.
- [239] Y. Gao, S. Matsuoka, W. Wan, T. Kiyokawa, K. Koyama, and K. Harada, “In-hand pose estimation using hand-mounted rgb cameras and visuotactile sensors,” IEEE Access, vol. 11, pp. 17 218–17 232, 2023.
- [240] G. M. Caddeo, N. A. Piga, F. Bottarel, and L. Natale, “Collision-aware in-hand 6d object pose estimation using multiple vision-based tactile sensors,” in IEEE International Conference on Robotics and Automation, 2023, pp. 719–725.
- [241] J. Hansen, F. Hogan, D. Rivkin, D. Meger, M. Jenkin, and G. Dudek, “Visuotactile-rl: Learning multimodal manipulation policies with deep reinforcement learning,” in International Conference on Robotics and Automation, 2022, pp. 8298–8304.
- [242] H. Qi, B. Yi, S. Suresh, M. Lambeta, Y. Ma, R. Calandra, and J. Malik, “General in-hand object rotation with vision and touch,” in Proceedings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., vol. 229. PMLR, 06–09 Nov 2023, pp. 2549–2564.
- [243] M. Yang, Y. Lin, A. Church, J. Lloyd, D. Zhang, D. A. Barton, and N. F. Lepora, “Sim-to-real model-based and model-free deep reinforcement learning for tactile pushing,” IEEE Robotics and Automation Letters, 2023.
- [244] M. Yang, C. Lu, A. Church, Y. Lin, C. Ford, H. Li, E. Psomopoulou, D. A. Barton, and N. F. Lepora, “Anyrotate: Gravity-invariant in-hand object rotation with sim-to-real touch,” arXiv preprint arXiv:2405.07391, 2024.
- [245] X. Jing, K. Qian, T. Jianu, and S. Luo, “Unsupervised adversarial domain adaptation for sim-to-real transfer of tactile images,” IEEE Transactions on Instrumentation and Measurement, 2023.
- [246] B. Duan, K. Qian, Y. Zhao, D. Zhang, and S. Luo, “Feature-level sim2real regression of tactile images for robot manipulation.”
- [247] Y. Lin, J. Lloyd, A. Church, and N. F. Lepora, “Tactile gym 2.0: Sim-to-real deep reinforcement learning for comparing low-cost high-resolution robot touch,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 754–10 761, 2022.
- [248] M. Polic, I. Krajacic, N. Lepora, and M. Orsag, “Convolutional autoencoder for feature extraction in tactile sensing,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 3671–3678, 2019.
- [249] R. Gao, T. Taunyazov, Z. Lin, and Y. Wu, “Supervised autoencoder joint learning on heterogeneous tactile sensory data: Improving material classification performance,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2020, pp. 10 907–10 913.
- [250] G. Cao, J. Jiang, D. Bollegala, and S. Luo, “Learn from incomplete tactile data: Tactile representation learning with masked autoencoders,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2023, pp. 10 800–10 805.
- [251] Z. Zhang, G. Zheng, X. Ji, G. Chen, R. Jia, W. Chen, G. Chen, L. Zhang, and J. Pan, “Mae4gm: Visuo-tactile learning for property estimation of granular material using multimodal autoencoder.”
- [252] W. Yuan, S. Wang, S. Dong, and E. Adelson, “Connecting look and feel: Associating the visual and tactile properties of physical materials,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5580–5588.
- [253] M. A. Lee, Y. Zhu, P. Zachares, M. Tan, K. Srinivasan, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg, “Making sense of vision and touch: Learning multimodal representations for contact-rich tasks,” IEEE Transactions on Robotics, vol. 36, no. 3, pp. 582–596, 2020.
- [254] J. Lin, R. Calandra, and S. Levine, “Learning to identify object instances by touch: Tactile recognition via multimodal matching,” in International Conference on Robotics and Automation, 2019, pp. 3644–3650.
- [255] F. Yang, C. Ma, J. Zhang, J. Zhu, W. Yuan, and A. Owens, “Touch and go: Learning from human-collected vision and touch,” arXiv preprint arXiv:2211.12498, 2022.
- [256] I. Guzey, B. Evans, S. Chintala, and L. Pinto, “Dexterity from touch: Self-supervised pre-training of tactile representations with robotic play,” arXiv preprint arXiv:2303.12076, 2023.
- [257] S. Yu, K. Lin, A. Xiao, J. Duan, and H. Soh, “Octopi: Object property reasoning with large tactile-language models,” arXiv preprint arXiv:2405.02794, 2024.
- [258] A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Batra, “Embodied question answering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1–10.
- [259] L. Yu, X. Chen, G. Gkioxari, M. Bansal, T. L. Berg, and D. Batra, “Multi-target embodied question answering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6309–6318.
- [260] E. Wijmans, S. Datta, O. Maksymets, A. Das, G. Gkioxari, S. Lee, I. Essa, D. Parikh, and D. Batra, “Embodied question answering in photorealistic environments with point cloud perception,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6659–6668.
- [261] D. Gordon, A. Kembhavi, M. Rastegari, J. Redmon, D. Fox, and A. Farhadi, “Iqa: Visual question answering in interactive environments,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 4089–4098.
- [262] C. Cangea, E. Belilovsky, P. Liò, and A. Courville, “Videonavqa: Bridging the gap between visual and embodied question answering,” arXiv preprint arXiv:1908.04950, 2019.
- [263] X. Ma, S. Yong, Z. Zheng, Q. Li, Y. Liang, S.-C. Zhu, and S. Huang, “Sqa3d: Situated question answering in 3d scenes,” in International Conference on Learning Representations, 2023.
- [264] S. Tan, M. Ge, D. Guo, H. Liu, and F. Sun, “Knowledge-based embodied question answering,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [265] A. Majumdar, A. Ajay, X. Zhang, P. Putta, S. Yenamandra, M. Henaff, S. Silwal, P. Mcvay, O. Maksymets, S. Arnaud et al., “Openeqa: Embodied question answering in the era of foundation models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16 488–16 498.
- [266] A. Z. Ren, J. Clark, A. Dixit, M. Itkina, A. Majumdar, and D. Sadigh, “Explore until confident: Efficient exploration for embodied question answering,” arXiv preprint arXiv:2403.15941, 2024.
- [267] V. S. Dorbala, P. Goyal, R. Piramuthu, M. Johnston, D. Manocha, and R. Ghanadhan, “S-eqa: Tackling situational queries in embodied question answering,” arXiv preprint arXiv:2405.04732, 2024.
- [268] Y. Wu, Y. Wu, G. Gkioxari, and Y. Tian, “Building generalizable agents with a realistic and rich 3d environment,” arXiv preprint arXiv:1801.02209, 2018.
- [269] M. Savva, A. X. Chang, A. Dosovitskiy, T. Funkhouser, and V. Koltun, “Minos: Multimodal indoor simulator for navigation in complex environments,” arXiv preprint arXiv:1712.03931, 2017.
- [270] A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y. Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,” arXiv preprint arXiv:1709.06158, 2017.
- [271] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5828–5839.
- [272] S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang et al., “Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai,” arXiv preprint arXiv:2109.08238, 2021.
- [273] A. Das, G. Gkioxari, S. Lee, D. Parikh, and D. Batra, “Neural modular control for embodied question answering,” in Conference on Robot Learning. PMLR, 2018, pp. 53–62.
- [274] Y. Wu, L. Jiang, and Y. Yang, “Revisiting embodiedqa: A simple baseline and beyond,” IEEE Transactions on Image Processing, vol. 29, pp. 3984–3992, 2020.
- [275] S. Tan, W. Xiang, H. Liu, D. Guo, and F. Sun, “Multi-agent embodied question answering in interactive environments,” in European Conference on Computer Vision, 2020, pp. 663–678.
- [276] B. Yamauchi, “A frontier-based approach for autonomous exploration,” in Proceedings IEEE International Symposium on Computational Intelligence in Robotics and Automation CIRA’97.’Towards New Computational Principles for Robotics and Automation’, 1997, pp. 146–151.
- [277] K. Sakamoto, D. Azuma, T. Miyanishi, S. Kurita, and M. Kawanabe, “Map-based modular approach for zero-shot embodied question answering,” arXiv preprint arXiv:2405.16559, 2024.
- [278] B. Patel, V. S. Dorbala, and A. S. Bedi, “Embodied question answering via multi-llm systems,” arXiv preprint arXiv:2406.10918, 2024.
- [279] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- [280] Y. Jiang, S. Moseson, and A. Saxena, “Efficient grasping from rgbd images: Learning using a new rectangle representation,” in IEEE International Conference on Robotics and Automation. IEEE, 2011, pp. 3304–3311.
- [281] A. Depierre, E. Dellandréa, and L. Chen, “Jacquard: A large scale dataset for robotic grasp detection,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2018, pp. 3511–3516.
- [282] A. Mousavian, C. Eppner, and D. Fox, “6-dof graspnet: Variational grasp generation for object manipulation,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 2901–2910.
- [283] C. Eppner, A. Mousavian, and D. Fox, “Acronym: A large-scale grasp dataset based on simulation,” in IEEE International Conference on Robotics and Automation. IEEE, 2021, pp. 6222–6227.
- [284] L. F. C. Murrilo, N. Khargonkar, B. Prabhakaran, and Y. Xiang, “Multigrippergrasp: A dataset for robotic grasping from parallel jaw grippers to dexterous hands,” arXiv preprint arXiv:2403.09841, 2024.
- [285] S. Ainetter and F. Fraundorfer, “End-to-end trainable deep neural network for robotic grasp detection and semantic segmentation from rgb,” in IEEE International Conference on Robotics and Automation. IEEE, 2021, pp. 13 452–13 458.
- [286] G. Tziafas, Y. Xu, A. Goel, M. Kasaei, Z. Li, and H. Kasaei, “Language-guided robot grasping: Clip-based referring grasp synthesis in clutter,” arXiv preprint arXiv:2311.05779, 2023.
- [287] S. Jin, J. Xu, Y. Lei, and L. Zhang, “Reasoning grasping via multimodal large language model,” arXiv preprint arXiv:2402.06798, 2024.
- [288] K. Li, J. Wang, L. Yang, C. Lu, and B. Dai, “Semgrasp: Semantic grasp generation via language aligned discretization,” arXiv preprint arXiv:2404.03590, 2024.
- [289] R. Newbury, M. Gu, L. Chumbley, A. Mousavian, C. Eppner, J. Leitner, J. Bohg, A. Morales, T. Asfour, D. Kragic et al., “Deep learning approaches to grasp synthesis: A review,” IEEE Transactions on Robotics, 2023.
- [290] J. Varley, C. DeChant, A. Richardson, J. Ruales, and P. Allen, “Shape completion enabled robotic grasping,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2017, pp. 2442–2447.
- [291] H.-S. Fang, C. Wang, M. Gou, and C. Lu, “Graspnet-1billion: A large-scale benchmark for general object grasping,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 444–11 453.
- [292] J. Xu, S. Jin, Y. Lei, Y. Zhang, and L. Zhang, “Reasoning tuning grasp: Adapting multi-modal large language models for robotic grasping,” in 2nd Workshop on Language and Robot Learning: Language as Grounding, 2023.
- [293] M. Shridhar, L. Manuelli, and D. Fox, “Cliport: What and where pathways for robotic manipulation,” in Conference on robot learning. PMLR, 2022, pp. 894–906.
- [294] W. Shen, G. Yang, A. Yu, J. Wong, L. P. Kaelbling, and P. Isola, “Distilled feature fields enable few-shot language-guided manipulation,” in 7th Annual Conference on Robot Learning, 2023.
- [295] Y. Zheng, X. Chen, Y. Zheng, S. Gu, R. Yang, B. Jin, P. Li, C. Zhong, Z. Wang, L. Liu et al., “Gaussiangrasper: 3d language gaussian splatting for open-vocabulary robotic grasping,” arXiv preprint arXiv:2403.09637, 2024.
- [296] H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y. Xie, and C. Lu, “Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,” IEEE Transactions on Robotics, 2023.
- [297] Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou et al., “The rise and potential of large language model based agents: A survey,” arXiv preprint arXiv:2309.07864, 2023.
- [298] A. Brohan, Y. Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian et al., “Do as i can, not as i say: Grounding language in robotic affordances,” in Conference on robot learning. PMLR, 2023, pp. 287–318.
- [299] Y. Chebotar, Q. Vuong, K. Hausman, F. Xia, Y. Lu, A. Irpan, A. Kumar, T. Yu, A. Herzog, K. Pertsch et al., “Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions,” in Conference on Robot Learning. PMLR, 2023, pp. 3909–3928.
- [300] D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu et al., “Palm-e: an embodied multimodal language model,” in Proceedings of the 40th International Conference on Machine Learning, 2023, pp. 8469–8488.
- [301] B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” in Conference on Robot Learning. PMLR, 2023, pp. 2165–2183.
- [302] Q. Vuong, S. Levine, H. R. Walke, K. Pertsch, A. Singh, R. Doshi, C. Xu, J. Luo, L. Tan, D. Shah et al., “Open x-embodiment: Robotic learning datasets and rt-x models,” in Towards Generalist Robots: Learning Paradigms for Scalable Skill Acquisition@ CoRL2023, 2023.
- [303] Y. Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y. Qiao, and P. Luo, “Embodiedgpt: Vision-language pre-training via embodied chain of thought,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [304] X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wu, C. Cheang, Y. Jing, W. Zhang, H. Liu et al., “Vision-language foundation models as effective robot imitators,” in The Twelfth International Conference on Learning Representations, 2024.
- [305] M. Ahn, D. Dwibedi, C. Finn, M. G. Arenas, K. Gopalakrishnan, K. Hausman, B. Ichter, A. Irpan, N. Joshi, R. Julian et al., “Autort: Embodied foundation models for large scale orchestration of robotic agents,” arXiv preprint arXiv:2401.12963, 2024.
- [306] I. Leal, K. Choromanski, D. Jain, A. Dubey, J. Varley, M. Ryoo, Y. Lu, F. Liu, V. Sindhwani, Q. Vuong et al., “Sara-rt: Scaling up robotics transformers with self-adaptive robust attention,” arXiv preprint arXiv:2312.01990, 2023.
- [307] J. Liu, M. Liu, Z. Wang, L. Lee, K. Zhou, P. An, S. Yang, R. Zhang, Y. Guo, and S. Zhang, “Robomamba: Multimodal state space model for efficient robot reasoning and manipulation,” arXiv preprint arXiv:2406.04339, 2024.
- [308] J. Gu, S. Kirmani, P. Wohlhart, Y. Lu, M. G. Arenas, K. Rao, W. Yu, C. Fu, K. Gopalakrishnan, Z. Xu et al., “Rt-trajectory: Robotic task generalization via hindsight trajectory sketches,” arXiv preprint arXiv:2311.01977, 2023.
- [309] R. E. Fikes and N. J. Nilsson, “Strips: A new approach to the application of theorem proving to problem solving,” Artificial Intelligence, vol. 2, no. 3, pp. 189–208, 1971.
- [310] D. McDermott, M. Ghallab, A. E. Howe, C. A. Knoblock, A. Ram, M. M. Veloso, D. S. Weld, and D. E. Wilkins, “Pddl-the planning domain definition language,” 1998.
- [311] N. C. Metropolis and S. M. Ulam, “The monte carlo method.” Journal of the American Statistical Association, vol. 44 247, pp. 335–41, 1949.
- [312] P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,” IEEE Trans. Syst. Sci. Cybern., vol. 4, pp. 100–107, 1968.
- [313] M. Shridhar, J. Thomason, D. Gordon, Y. Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “Alfred: A benchmark for interpreting grounded instructions for everyday tasks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 740–10 749.
- [314] M. Shridhar, X. Yuan, M.-A. Côté, Y. Bisk, A. Trischler, and M. Hausknecht, “Alfworld: Aligning text and embodied environments for interactive learning,” arXiv preprint arXiv:2010.03768, 2020.
- [315] S. Y. Min, D. S. Chaplot, P. Ravikumar, Y. Bisk, and R. Salakhutdinov, “Film: Following instructions in language with modular methods,” arXiv preprint arXiv:2110.07342, 2021.
- [316] W. Huang, P. Abbeel, D. Pathak, and I. Mordatch, “Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,” in International conference on machine learning. PMLR, 2022, pp. 9118–9147.
- [317] W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar et al., “Inner monologue: Embodied reasoning through planning with language models,” in Conference on Robot Learning. PMLR, 2023, pp. 1769–1782.
- [318] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023.
- [319] Y. Zhang, S. Yang, C. Bai, F. Wu, X. Li, X. Li, and Z. Wang, “Towards efficient llm grounding for embodied multi-agent collaboration,” arXiv preprint arXiv:2405.14314, 2024.
- [320] G. Sarch, Y. Wu, M. Tarr, and K. Fragkiadaki, “Open-ended instructable embodied agents with memory-augmented large language models,” in Findings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 3468–3500.
- [321] G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anandkumar, “Voyager: An open-ended embodied agent with large language models,” arXiv preprint arXiv:2305.16291, 2023.
- [322] P. Sharma, A. Torralba, and J. Andreas, “Skill induction and planning with latent language,” in Annual Meeting of the Association for Computational Linguistics, 2021.
- [323] I. Singh, V. Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg, “Progprompt: Generating situated robot task plans using large language models,” in IEEE International Conference on Robotics and Automation, 2023, pp. 11 523–11 530.
- [324] S. Vemprala, R. Bonatti, A. F. C. Bucker, and A. Kapoor, “Chatgpt for robotics: Design principles and model abilities,” IEEE Access, vol. 12, pp. 55 682–55 696, 2023.
- [325] J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. R. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” IEEE International Conference on Robotics and Automation, pp. 9493–9500, 2022.
- [326] A. Zeng, M. Attarian, K. M. Choromanski, A. Wong, S. Welker, F. Tombari, A. Purohit, M. S. Ryoo, V. Sindhwani, J. Lee et al., “Socratic models: Composing zero-shot multimodal reasoning with language,” in The Eleventh International Conference on Learning Representations, 2023.
- [327] S. Shin, J. Kim, G.-C. Kang, B.-T. Zhang et al., “Socratic planner: Inquiry-based zero-shot planning for embodied instruction following,” arXiv preprint arXiv:2404.15190, 2024.
- [328] C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y. Su, “Llm-planner: Few-shot grounded planning for embodied agents with large language models,” IEEE/CVF International Conference on Computer Vision, pp. 2986–2997, 2022.
- [329] Z. Wu, Z. Wang, X. Xu, J. Lu, and H. Yan, “Embodied task planning with large language models,” arXiv preprint arXiv:2307.01848, 2023.
- [330] K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. D. Reid, and N. Sünderhauf, “Sayplan: Grounding large language models using 3d scene graphs for scalable task planning,” in Conference on Robot Learning, 2023.
- [331] Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa, C. Gan, C. M. de Melo, J. B. Tenenbaum, A. Torralba, F. Shkurti, and L. Paull, “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” ArXiv, vol. abs/2309.16650, 2023.
- [332] J. Huang, S. Yong, X. Ma, X. Linghu, P. Li, Y. Wang, Q. Li, S.-C. Zhu, B. Jia, and S. Huang, “An embodied generalist agent in 3d world,” in Forty-first International Conference on Machine Learning, 2024.
- [333] Z. Wu, Z. Wang, X. Xu, J. Lu, and H. Yan, “Embodied instruction following in unknown environments,” 2024.
- [334] X. Zhao, M. Li, C. Weber, M. B. Hafez, and S. Wermter, “Chat with the environment: Interactive multimodal perception using large language models,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2023, pp. 3590–3596.
- [335] N. Shinn, B. Labash, and A. Gopinath, “Reflexion: an autonomous agent with dynamic memory and self-reflection,” ArXiv, vol. abs/2303.11366, 2023.
- [336] Z. Wang, S. Cai, A. Liu, X. Ma, and Y. Liang, “Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents,” ArXiv, vol. abs/2302.01560, 2023.
- [337] D. Ha and J. Schmidhuber, “World models,” arXiv preprint arXiv:1803.10122, 2018.
- [338] J. Xiang, G. Liu, Y. Gu, Q. Gao, Y. Ning, Y. Zha, Z. Feng, T. Tao, S. Hao, Y. Shi et al., “Pandora: Towards general world model with natural language actions and video states,” arXiv preprint arXiv:2406.09455, 2024.
- [339] H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y. Du, Y. Hong, and C. Gan, “3d-vla: A 3d vision-language-action generative world model,” arXiv preprint arXiv:2403.09631, 2024.
- [340] Z. Ding, A. Zhang, Y. Tian, and Q. Zheng, “Diffusion world model,” arXiv preprint arXiv:2402.03570, 2024.
- [341] A. Bardes, J. Ponce, and Y. LeCun, “Mc-jepa: A joint-embedding predictive architecture for self-supervised learning of motion and content features,” arXiv preprint arXiv:2307.12698, 2023.
- [342] Z. Fei, M. Fan, and J. Huang, “A-jepa: Joint-embedding predictive architecture can listen,” arXiv preprint arXiv:2311.15830, 2023.
- [343] Q. Garrido, M. Assran, N. Ballas, A. Bardes, L. Najman, and Y. LeCun, “Learning and leveraging world models in visual representation learning,” arXiv preprint arXiv:2403.00504, 2024.
- [344] J. Wu, S. Yin, N. Feng, X. He, D. Li, J. Hao, and M. Long, “ivideogpt: Interactive videogpts are scalable world models,” arXiv preprint arXiv:2405.15223, 2024.
- [345] F. Zhu, H. Wu, S. Guo, Y. Liu, C. Cheang, and T. Kong, “Irasim: Learning interactive real-robot action simulators,” arXiv preprint arXiv:2406.14540, 2024.
- [346] J. Yang, B. Liu, J. Fu, B. Pan, G. Wu, and L. Wang, “Spatiotemporal predictive pre-training for robotic motor control,” arXiv preprint arXiv:2403.05304, 2024.
- [347] M. Burchi and R. Timofte, “Mudreamer: Learning predictive world models without reconstruction,” arXiv preprint arXiv:2405.15083, 2024.
- [348] L. Wong, G. Grand, A. K. Lew, N. D. Goodman, V. K. Mansinghka, J. Andreas, and J. B. Tenenbaum, “From word models to world models: Translating from natural language to the probabilistic language of thought,” arXiv preprint arXiv:2306.12672, 2023.
- [349] Y. Feng, Y. Shang, X. Feng, L. Lan, S. Zhe, T. Shao, H. Wu, K. Zhou, H. Su, C. Jiang et al., “Elastogen: 4d generative elastodynamics,” arXiv preprint arXiv:2405.15056, 2024.
- [350] M. Liu, C. Xu, H. Jin, L. Chen, M. Varma T, Z. Xu, and H. Su, “One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [351] Z. Cheng, Z. Wang, J. Hu, S. Hu, A. Liu, Y. Tu, P. Li, L. Shi, Z. Liu, and M. Sun, “Legent: Open platform for embodied agents,” arXiv preprint arXiv:2404.18243, 2024.
- [352] H. Wang, J. Chen, W. Huang, Q. Ben, T. Wang, B. Mi, T. Huang, S. Zhao, Y. Chen, S. Yang et al., “Grutopia: Dream general robots in a city at scale,” arXiv preprint arXiv:2407.10943, 2024.
- [353] A. Saito and J. Poovvancheri, “Point-jepa: A joint embedding predictive architecture for self-supervised learning on point cloud,” arXiv preprint arXiv:2404.16432, 2024.
- [354] Y. LeCun, “A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27,” Open Review, vol. 62, no. 1, pp. 1–62, 2022.
- [355] A. Dawid and Y. LeCun, “Introduction to latent variable energy-based models: A path towards autonomous machine intelligence,” arXiv preprint arXiv:2306.02572, 2023.
- [356] V. Lim, H. Huang, L. Y. Chen, J. Wang, J. Ichnowski, D. Seita, M. Laskey, and K. Goldberg, “Real2sim2real: Self-supervised learning of physical single-step dynamic actions for planar robot casting,” in International Conference on Robotics and Automation, 2022, pp. 8282–8289.
- [357] C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song, “Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots,” arXiv preprint arXiv:2402.10329, 2024.
- [358] Z. Fu, T. Z. Zhao, and C. Finn, “Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation,” arXiv preprint arXiv:2401.02117, 2024.
- [359] S. Luo, Q. Peng, J. Lv, K. Hong, K. R. Driggs-Campbell, C. Lu, and Y.-L. Li, “Human-agent joint learning for efficient robot manipulation skill acquisition,” arXiv preprint arXiv:2407.00299, 2024.
- [360] A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V. Sindhwani et al., “Transporter networks: Rearranging the visual world for robotic manipulation,” in Conference on Robot Learning. PMLR, 2021, pp. 726–747.
- [361] H. Geng, H. Xu, C. Zhao, C. Xu, L. Yi, S. Huang, and H. Wang, “Gapartnet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7081–7091.
- [362] M. Torne, A. Simeonov, Z. Li, A. Chan, T. Chen, A. Gupta, and P. Agrawal, “Reconciling reality through simulation: A real-to-sim-to-real approach for robust manipulation,” arXiv preprint arXiv:2403.03949, 2024.
- [363] Y. Jiang, C. Wang, R. Zhang, J. Wu, and L. Fei-Fei, “Transic: Sim-to-real policy transfer by learning from online correction,” arXiv preprint arXiv:2405.10315, 2024.
- [364] J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2017, pp. 23–30.
- [365] O. M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray et al., “Learning dexterous in-hand manipulation,” The International Journal of Robotics Research, vol. 39, no. 1, pp. 3–20, 2020.
- [366] J. Matas, S. James, and A. J. Davison, “Sim-to-real reinforcement learning for deformable object manipulation,” in Conference on Robot Learning. PMLR, 2018, pp. 734–743.
- [367] M. Kaspar, J. D. M. Osorio, and J. Bock, “Sim2real transfer for reinforcement learning without dynamics randomization,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2020, pp. 4383–4388.
- [368] W. Yu, J. Tan, C. K. Liu, and G. Turk, “Preparing for the unknown: Learning a universal policy with online system identification,” arXiv preprint arXiv:1702.02453, 2017.
- [369] A. Yu, A. Foote, R. Mooney, and R. Martín-Martín, “Natural language can help bridge the sim2real gap,” arXiv preprint arXiv:2405.10020, 2024.
- [370] C. Huang, G. Wang, Z. Zhou, R. Zhang, and L. Lin, “Reward-adaptive reinforcement learning: Dynamic policy gradient optimization for bipedal locomotion,” IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 6, pp. 7686–7695, 2022.
- [371] V. Tsounis, M. Alge, J. Lee, F. Farshidian, and M. Hutter, “Deepgait: Planning and control of quadrupedal gaits using deep reinforcement learning,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3699–3706, 2020.
- [372] T. Z. Zhao, V. Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” arXiv preprint arXiv:2304.13705, 2023.
- [373] M. Liu, Z. Chen, X. Cheng, Y. Ji, R. Yang, and X. Wang, “Visual whole-body control for legged loco-manipulation,” arXiv preprint arXiv:2403.16967, 2024.
- [374] H. Miura and I. Shimoyama, “Dynamic walk of a biped,” The International Journal of Robotics Research, vol. 3, no. 2, pp. 60–74, 1984.
- [375] K. Sreenath, H.-W. Park, I. Poulakakis, and J. W. Grizzle, “A compliant hybrid zero dynamics controller for stable, efficient and fast bipedal walking on mabel,” The International Journal of Robotics Research, vol. 30, no. 9, pp. 1170–1193, 2011.
- [376] G. Bledt, M. J. Powell, B. Katz, J. Di Carlo, P. M. Wensing, and S. Kim, “Mit cheetah 3: Design and control of a robust, dynamic quadruped robot,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2018, pp. 2245–2252.
- [377] M. Hutter, C. Gehring, D. Jud, A. Lauber, C. D. Bellicoso, V. Tsounis, J. Hwangbo, K. Bodie, P. Fankhauser, M. Bloesch et al., “Anymal-a highly mobile and dynamic quadrupedal robot,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2016, pp. 38–44.
- [378] S. Feng, E. Whitman, X. Xinjilefu, and C. G. Atkeson, “Optimization based full body control for the atlas robot,” in 2014 IEEE-RAS International Conference on Humanoid Robots, 2014, pp. 120–127.
- [379] Q. Nguyen, M. J. Powell, B. Katz, J. Di Carlo, and S. Kim, “Optimized jumping on the mit cheetah 3 robot,” in International Conference on Robotics and Automation, 2019, pp. 7448–7454.
- [380] C. Nguyen, L. Bao, and Q. Nguyen, “Continuous jumping for legged robots on stepping stones via trajectory optimization and model predictive control,” in IEEE 61st Conference on Decision and Control, 2022, pp. 93–99.
- [381] C. Gehring, S. Coros, M. Hutter, C. D. Bellicoso, H. Heijnen, R. Diethelm, M. Bloesch, P. Fankhauser, J. Hwangbo, M. Hoepflinger et al., “Practice makes perfect: An optimization-based approach to controlling agile motions for a quadruped robot,” IEEE Robotics & Automation Magazine, vol. 23, no. 1, pp. 34–43, 2016.
- [382] Q. Nguyen, A. Agrawal, X. Da, W. C. Martin, H. Geyer, J. W. Grizzle, and K. Sreenath, “Dynamic walking on randomly-varying discrete terrain with one-step preview.” in Robotics: Science and Systems, vol. 2, no. 3, 2017, pp. 384–399.
- [383] R. Antonova, A. Rai, and C. G. Atkeson, “Deep kernels for optimizing locomotion controllers,” in Conference on Robot Learning. PMLR, 2017, pp. 47–56.
- [384] X. Cheng, Y. Ji, J. Chen, R. Yang, G. Yang, and X. Wang, “Expressive whole-body control for humanoid robots,” arXiv preprint arXiv:2402.16796, 2024.
- [385] M. Chignoli, D. Kim, E. Stanger-Jones, and S. Kim, “The mit humanoid robot: Design, motion planning, and control for acrobatic behaviors,” in 2020 IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids). IEEE, 2021, pp. 1–8.
- [386] S. Nair, A. Rajeswaran, V. Kumar, C. Finn, and A. Gupta, “R3m: A universal visual representation for robot manipulation,” arXiv preprint arXiv:2203.12601, 2022.
- [387] B. Schölkopf, F. Locatello, S. Bauer, N. R. Ke, N. Kalchbrenner, A. Goyal, and Y. Bengio, “Toward causal representation learning,” Proceedings of the IEEE, vol. 109, no. 5, pp. 612–634, 2021.
- [388] Y. Liu, G. Li, and L. Lin, “Cross-modal causal relational reasoning for event-level visual question answering,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 10, pp. 11 624–11 641, 2023.
- [389] S. V. Mehta, D. Patil, S. Chandar, and E. Strubell, “An empirical investigation of the role of pre-training in lifelong learning,” Journal of Machine Learning Research, vol. 24, no. 214, pp. 1–50, 2023.
- [390] A. Kumar, A. Raghunathan, R. M. Jones, T. Ma, and P. Liang, “Fine-tuning can distort pretrained features and underperform out-of-distribution,” in International Conference on Learning Representations, 2022.