RAG 与长上下文:检查环境审查文档理解的前沿大型语言模型
摘要
大型语言模型(大语言模型)已应用于各个领域的许多研究问题。 大语言模型的应用之一是提供适合不同领域用户的问答系统。 基于 LLM 的问答系统的有效性已经达到了可接受的水平,可供用户在流行和公共领域(例如琐事和文学)提出问题。 然而,它通常不会在传统上需要专业知识的利基领域建立。 为此,我们构建了NEPAQuAD1.0基准来评估三个前沿大语言模型——Claude Sonnet、Gemini和GPT-4——在回答来自美国联邦政府机构按照《环境影响报告书》编制的问题时的表现。国家环境法(NEPA)。 我们专门衡量了大语言模型在不同上下文场景下理解 NEPA 文件中法律、技术和合规相关信息的细微差别的能力。 例如,我们通过提供没有任何上下文的问题来测试大语言模型的内部先验 NEPA 知识,以及评估大语言模型如何综合长 NEPA 文档中存在的上下文信息以促进问答任务。 我们比较了长上下文大语言模型和 RAG 支持的模型在处理不同类型问题(例如解决问题、发散问题)方面的性能。 我们的结果表明,无论前沿大语言模型的选择如何,RAG 驱动的模型在答案准确性方面都显着优于长上下文模型。 我们的进一步分析表明,许多模型在回答封闭性问题时比发散性问题和解决问题的问题表现得更好。
1简介
随着大型语言模型(大语言模型)变得越来越普遍,研究人员发现这些模型对于文本生成之外的许多任务都很有用。 具体来说,大语言模型在传统上需要专门知识的利基领域(如科学)中显示出潜在的实用性,无论是在纯文本设置中Horawalavithana等人(2022); Munikoti 等人 (2024) 并通过合并各种模式的数据 Dollar 等人 (2022); Horawalavithana 等人 (2023)。 最近对这些模型进行了评估Acharya 等人 (2023); Munikoti 等人 (2023); Cai 等人 (2024) 并评估其不确定性 Wagle 等人 (2024)。 尽管进行了大量研究,但构建用于回答特定领域问题的大语言模型已被证明具有挑战性Kasneci 等人 (2023)。
当系统的任务是根据专业领域的长文档内容提供问题的答案时,基于 LLM 的问答系统就会面临这样的挑战。 现有的大语言模型允许用户将一个段落作为上下文以及问题的内容包含在内;然而,大语言模型通常将该段落的大小限制为特定数量的标记。 此限制迫使用户将冗长文档的内容截断或手动总结为简短的段落。 用户可以采取的另一种方法包括仅提交问题并依靠模型从语料库中找到正确的文档以及回答问题所需的相关内容。 这种策略通常适用于回答知名领域(例如体育或教育)的问题;然而,对于不太普遍的主题 Munikoti 等人 (2023) 来说,它并不那么成功。 由于大语言模型是数据驱动的,因此它们不太容易为不太流行、更专业的领域的问题提供准确的答案,例如法律 Kapoor 等人 (2024)) 和能源 Buster等人(2024)。
在这项工作中,我们重点评估根据国家环境政策法案 (NEPA) 进行的环境审查中的长上下文大语言模型111https://www.epa.gov/nepa。 NEPA 是旨在保护环境的美国环境法。 NEPA 第 102(2)(C) 条要求对任何严重影响环境质量的拟议重大联邦行动提供环境影响声明 (EIS)。 EIS 是一份详细文件,描述拟议行动、拟议行动的替代方案以及拟议行动和替代方案对环境的潜在影响。 EIS 包含有关环境许可和政策决定的信息,并考虑一系列合理的替代方案,分析拟议行动和替代方案产生的潜在影响,并证明遵守其他适用的环境法律和行政命令。
除了EIS文件通常很长(通常有数百页)并且由NEPA专家创建之外,阻碍大语言模型在该领域应用的另一个因素是EIS文件的开发需要NEPA专家具有各种不同的能力。多年来进行准备的主题专业知识,经常引用早在 20 世纪 90 年代的旧文章。 例如,为急救人员网络管理局项目准备的 EIS 文件第 60 页引用了 1994 年发布的第 12898 号行政命令 (EO)222https://www.energy.gov/nepa/eis-0530-nationwide-public-safety-broadband-network-programmatic-environmental-impact。 这可能对当前的大语言模型在帮助 NEPA 用户从基于 LLM 的问答系统自动检索答案方面提出重大挑战。 据我们所知,当问题涉及 EIS 文档时,没有专门针对该领域构建的真实基准来评估 QA 任务的大语言模型输出的质量。
在这项工作中,我们利用长上下文和检索增强生成(RAG)Lewis 等人(2021)来开发针对 EIS 文档问答的大语言模型能力(图1)。 我们选择前沿大语言模型进行实验:Claude Sonnet 团队与协作者、Gemini 团队与协作者(2024)、GPT-4 OpenAI (2024). 为了评估我们提出的 RAG 模型与其他上下文增强策略相比的有效性,我们还进行了严格的实验,评估大语言模型与 NEPA 文档的各种类型的上下文。 为了评估我们的方法,我们使用问题、答案和相应上下文的基本事实三元组建立了一个基准,这些问题、答案和相应上下文是通过采用 GPT-4 的半监督方法生成的。 总的来说,我们做出了以下贡献:
-
1.
创建首个基础知识基准测试(NEPAQuAD1.0),自动评估大语言模型在 EIS 文档问答任务中的表现
-
2.
评估大语言模型在长文档问答任务中的能力
-
3.
使用零样本提示与上下文驱动提示(即段落、PDF 和 RAG)对大语言模型进行严格比较,以评估模型性能。
本文的结构概述如下:在第 2 节中,我们描述了基准创建,以评估我们模型的质量,并与来自不同上下文的模型进行比较。 3 部分列出了我们的方法以及用于评估实施的各种背景,然后在 4 部分中详细分析了我们的表现。 5 节随后讨论了处理长上下文和长文档 RAG 的文献中的其他作品。 我们在第 6 和 7 节中总结了我们工作的结论和局限性。
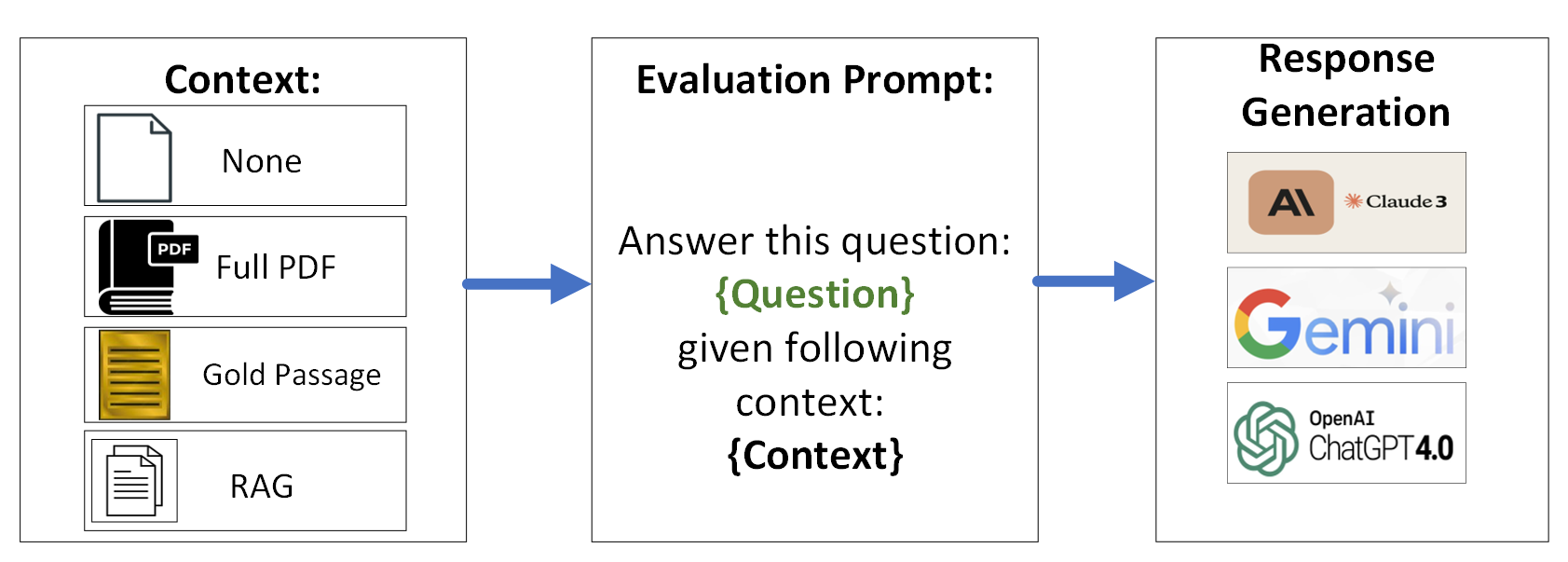
2 NEPAQuAD 基准
在本节中,我们将描述构建真实基准来评估大语言模型生成的自动响应的质量。 由于手动创建人工编写的问题和答案的成本很高,并且无法使用其他领域的真实基准,我们采用半自动方法来生成 NEPAQuAD1.0 (N国家环境环境政策政策行动ct问题问题和答复回答数据集)基准。 我们的评估基准生成过程的总体思路是从一组 EIS 文档中提取有意义的段落,然后使用 GPT-4 基于这些段落生成问题。 为了确保生成的基准的质量,本研究的两位作者(他们都是 NEPA 的主题专家)通过将提供的证据与衍生问题的原始上下文进行比较来衡量真实答案的质量。 我们生成的真实基准是一组包含问题、答案和证明的三元组(即与答案直接相关的文本,源自问题所在的上下文)。 基准生成过程如图2所示。
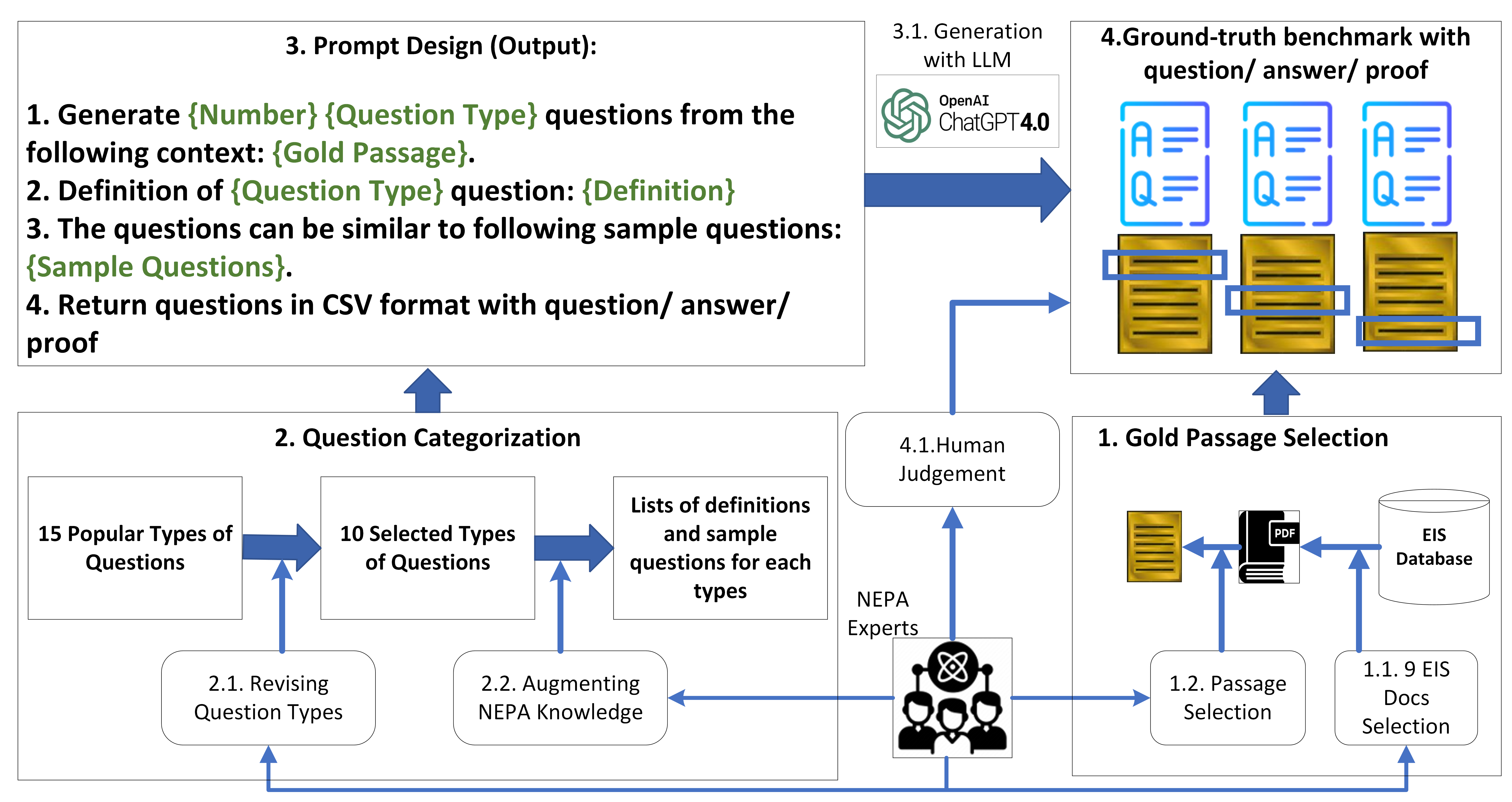
为了评估大语言模型在 EIS 问答任务中的性能,我们首先从 EIS 文档数据库中选择高质量的文档,并提取段落作为评估中使用的上下文。 然后,我们确定要用来评估模型的问题类型。 接下来,我们使用 GPT-4 OpenAI (2024) 通过精心设计的提示,根据所选上下文生成问答对。 最后,我们使用这些生成的问题来评估不同上下文中的不同大语言模型,并将生成的答案作为基本事实。 我们在下面详细描述该过程。
2.1黄金通道选择
文件选择 NEPA专家从不同政府机构挑选了最能代表各种NEPA行动的九份EIS文件。 这些文件的内容和重点因政府机构的不同而存在很大差异,因为每个机构可能会以不同的方式解释和实施 NEPA 指南。 例如,美国林务局可能会强调森林管理和野火缓解,而陆军工程兵团可能会优先考虑水资源开发和基础设施影响。 表3显示了所选文档的统计信息(参见附录)。 每个文档平均有 400 页左右,而最长的文档包含超过 600K 个标记。
摘录选择 对于九个选定文档中的每一个,我们尝试选择包含每个文档重要内容的摘录。 同样,随机提取摘录的默认方法存在导致低质量摘录的风险,例如附录的部分或图像的标题。 为了避免这种风险,NEPA 专家手动从文件中选择摘录。 他们将每个文档分为三个部分:开头、中间和结尾,然后分别从每个部分中选择 2 个、6 个和 6 个摘录,每个文档总共有 10 个摘录。 我们使用这些摘录作为事实背景,称为黄金段落,用于问题基准生成。
2.2问题类型选择
一旦我们确定了黄金段落,NEPA 专家就会选择要包含在基准中的问题类型。 我们首先列出了 15 种类型的问题333https://tinyurl.com/3akej8ct,经过广泛讨论,最终将问题范围缩小到10类。 这些类型如表1所示。 除了选择问题类型之外,NEPA 专家还为 EIS 文档域的每个类别创建了示例问题。 有关问题类型的更详细说明以及示例问题,请参阅附录A和B。
| Question Type | #Questions | |
|---|---|---|
| Closed | 789 | 49% |
| Comparison | 64 | 4% |
| Convergent | 109 | 7% |
| Divergent | 121 | 8% |
| Evaluation | 64 | 4% |
| Funnel | 127 | 8% |
| Inference | 101 | 6% |
| Problem-solving | 11 | 1% |
| Process | 108 | 7% |
| Recall | 105 | 7% |
| Total | 1599 | 100% |
2.3提示设计
下一步是设计一个提示,可以指导问题生成模型创建高质量的问题和答案。 为了确保提示能够有效地指导生成模型,我们听取了 NEPA 专家的建议来创建提示。 我们还使用 NEPA 专家创建的示例问题来增强原始提示并创建“增强”提示。 提示和基准创建过程的模板如图2所示。 我们将每个提示的输出限制为 CSV 格式,包含三个字段:问题、答案和证明。 “证明”列存储了模型选择作为问题答案证据的黄金段落部分。
2.4 地面实况基准生成
自动生成我们选择 GPT-4 作为此任务的生成模型,因为 GPT-4 已用于为农业等其他领域的文档生成问题和答案 Balaguer 等人 (2024 )。 具体来说,我们使用默认设置的 GPT-4 Azure OpenAI 服务来执行问题生成提示。 对于我们选定的 9 个文档中的每个文档,我们都有 10 个黄金段落,总共 90 个黄金段落。 对于每个黄金段落,我们为 10 种问题类型中的每一种生成了 10 组问题。 然后,我们过滤了各代中不正确的格式。 总体而言,我们针对九个选定的 EIS 文档生成了 1599 个问答证明的真实三元组的基准。 我们公开了该基准(PolicyAI,2024)。
质量检查为了判断生成的基准的正确性,我们随机选择100个样本问题进行验证。 验证由 NEPA 专家(两位共同作者)完成。 他们每个人都独立地检查样本问题,检查问题类型的正确性(即生成的问题是否与要求的问题类型相同)和答案的正确性。 对于每个问题,如果任何一个评估者将问题或答案标记为正确,我们就会将其标记为正确。 总体而言,我们生成的基准测试实现了答案正确性 和问题类型正确性 。
3 实验设置
在这项工作中,我们实验了三个前沿大语言模型:Claude-3 Sonnet、Gemini 和 GPT-4。 对于提供给模型的上下文,我们有四种可能的变体:无上下文、PDF 文档、银色段落(RAG 设置)或金色段落。 模型和上下文设置的组合总共产生了 12 种独特的配置(图1)。 我们在第3.1节中详细解释了这些配置,并在第3.2节中报告了评估指标。
3.1 上下文变化
无上下文: 在这种设置中,我们只需在没有提供上下文的情况下查询模型,与其他一般领域相同。 我们不提供有关问题起源的任何额外背景,因此模型预计会根据现有知识回答问题。 虽然这种策略可以很好地适用于体育或文学等流行领域,但我们假设 NEPA 领域对于大语言模型模型获得准确答案可能具有挑战性。 换句话说,这个设置可以说是对大语言模型回答非一般领域问题的考验。 因此,此设置通常预计会返回低性能。
完整 PDF 作为上下文: 在此场景中,除了问题之外,我们还为模型提供了从中提取问题上下文的 PDF(文本)文档。 由于我们没有告知模型要查看文档的哪一部分,因此生成的响应的准确性将在很大程度上取决于模型从提供的大规模文本信息中选择正确上下文的能力。 我们希望这种设置比没有上下文时产生更好的性能。
RAG 上下文(银色通道): 在RAG模型中,当输入一个问题来生成大语言模型时,相应的上下文就会从给定的EIS文档中提取为相关段落。 我们使用标准 RAG 设置,使用 BGE 嵌入模型 Xiao 等人 (2023) 对问题和检索到的段落进行编码。 我们使用余弦相似度得分来评估问题和上下文之间的相似度。 提取的排名靠前的相关段落(称为top-K银色段落)的数量设置为。
黄金通道作为背景: 在此配置中,我们在提示中包含生成问题的实际上下文以及问题内容。 虽然用户手动识别正确段落的场景在实践中很少见,但我们模拟这种场景来衡量如果我们能够以非常高的准确度提取相关段落,大语言模型的表现如何。 我们希望此设置能够发挥最佳性能。
3.2评估指标
为了评估模型在不同配置下的性能,我们比较了模型在这些不同配置下生成的响应的答案。 基于重叠的指标,例如 BLEU 分数 Papineni 等人 (2002),虽然被许多先前的作品使用,但只是简单地测量句法相似性,因此不适合执行语义更重要的评估。 因此,在我们的工作中,我们使用 Es 等人 (2023) 提出的 RAGAs 评分:答案正确性(本文称为正确性)。
答案正确性得分结合了事实正确性和语义正确性两个方面进行计算。 虽然事实正确性捕获了输入答案的短语/子句级别的正确性,但语义得分是通过使用嵌入模型比较预期答案和预测答案向量之间的相似性来获得的。 GPT-4 用于计算答案正确性,量化生成答案与真实答案 Es 等人 (2023) 之间的事实重叠。 我们使用 BGE Xiao 等人 (2023) 作为语义正确性计算的嵌入模型。 我们设置事实正确性权重为0.75,语义正确性权重为0.25来衡量答案正确性。
4性能分析
在本节中,我们将描述大语言模型在使用 NEPAQuAD1.0 评估的问答任务中的整体性能(如第 2 节所示)。 首先,我们比较了三个前沿大语言模型:Claude-3 Sonnet、Gemini 和 GPT-4 在不同 QA 上下文中的性能(第 4.1 节)。 其次,我们比较不同问题类型的模型性能(第 4.2 节)。 在第 4.3 节中,我们评估了模型对文档不同部分生成的问题的执行情况。 最后我们分析一下性能。
4.1 评估不同的 QA 环境
表 2 报告了评估中使用的各种 QA 上下文中模型的整体性能。 我们观察到,对于没有上下文的任务,Gemini 模型可以产生迄今为止最准确的结果。 然而,当 PDF 文档作为上下文提供时,这种趋势发生了逆转,GPT-4 在正确性方面超越了 Gemini。 尽管 Gemini 能够处理很长的上下文(150 万个 Token ),但令人惊讶的是,当提供 PDF 文档作为附加上下文时,其性能会下降。 这可能是由于模型难以对 EIS 文档中的大量相关和不相关内容进行推理。
总体而言,与以 PDF 文档作为附加上下文提供的模型相比,RAG 模型的性能更好。 在 RAG 设置中,尽管 Claude 模型和 GPT-4 模型的分数更接近,但 Claude 模型在正确性方面优于其他模型。 与 PDF 环境相比,Gemini 在 RAG 设置中的性能显着提高。
正如预期的那样,与其他上下文变化相比,当提供黄金通道时,所有模型的平均表现最好。 在这种情况下,模型需要合成直接包含向模型提出的问题的答案的信息。 值得注意的是,当模型提供 RAG 和黄金通道上下文时,它们的性能相当。
| Context | Claude | Gemini | GPT-4 |
|---|---|---|---|
| None | 21.50% | 50.16% | 20.28% |
| Complete PDF | 23.47% | 46.62% | 56.40% |
| Silver Passages | 68.74% | 57.06% | 66.86% |
| Gold Passage | 68.41% | 61.81% | 67.66% |
4.2 评估不同的问题类型

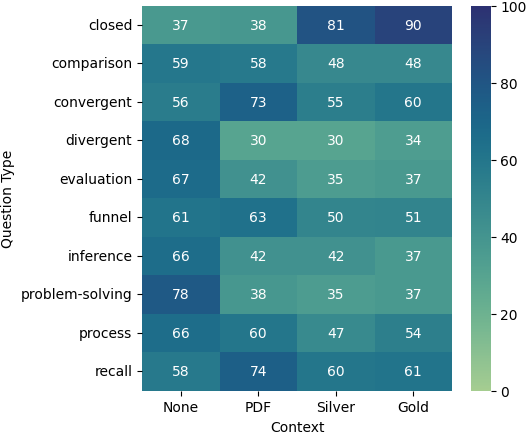
我们分析了大语言模型在不同类型问题上的表现,如图3所示。 在根据问题类型分析结果时,我们发现,当提供白银或黄金数据作为上下文时,所有三个模型在封闭式问题上都具有优异的性能,而 GPT-4 是唯一在这些问题上表现良好的模型,即使在仅提供 PDF 作为上下文。 对于所有其他类别,在没有上下文或 PDF 上下文的情况下,Claude 和 GPT-4 都表现出相似的行为模式,尽管 GPT4 的性能在几乎每个类别中都明显优于 Claude,这种差异在 PDF 上下文中尤其明显。
有趣的是,当没有提供任何上下文时,Gemini 的表现非常好,并且当提供 PDF 作为上下文时,除收敛和回忆问题外,所有类别的性能都会下降。 对于大多数问题类型,即使是白银或黄金数据也无法达到无上下文的水平,封闭式问题和召回问题除外。 总体而言,RAG 模型和具有其他上下文的模型在回答封闭式问题方面表现最佳,在回答发散性问题和解决问题的问题方面表现最差。
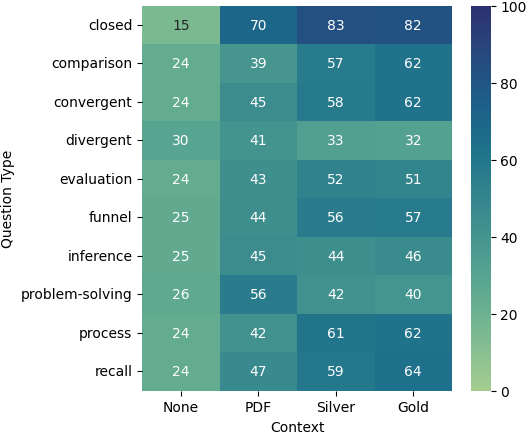
4.3 评估位置知识
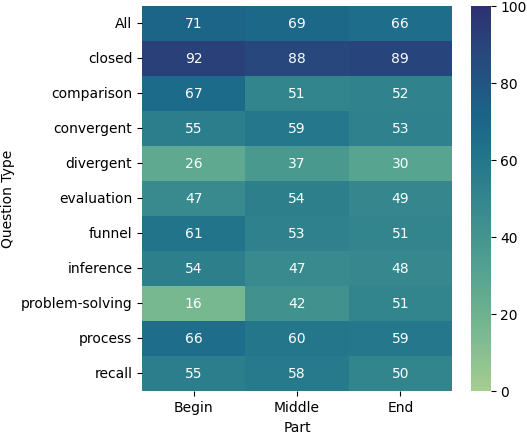
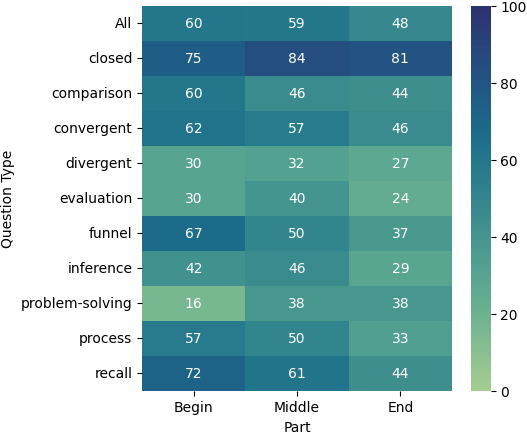
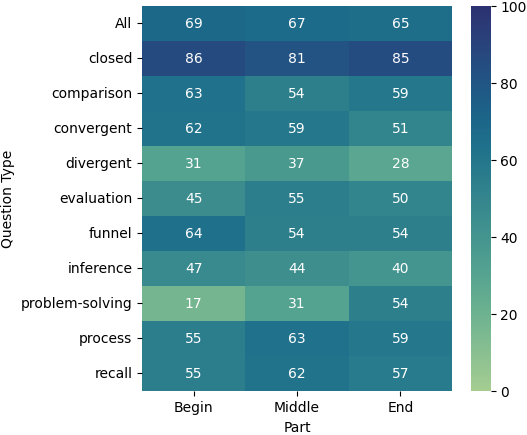
我们还根据衍生问题的文档部分分析了各种问题类型的表现,如图 4 所示。 在所有模型中,我们观察到一个总体趋势:文档中的源文本越早,模型的性能就越好。 一个值得注意的例外是解决问题的问题,当源自文档的后面部分时,其表现会更好。 这种模式适用于所有三种模型。 此外,我们注意到,从文档中间导出不同的问题会产生更好的结果。 总体而言,所有三个模型在不同的文档部分和问题类型中都表现出相似或可比较的性能模式。 这些结果表明,长上下文模型的性能不仅可能因相关信息的位置而异,还可能因问题的类型和模型必须执行的推理量而异。
4.4讨论
用于针对特定领域文档进行问答的 RAG
这项研究的结果强调了 RAG 模型作为解决特定领域问题的关键策略的重要作用。 与零样本知识和使用完整 PDF 作为上下文相比,这些模型在性能上表现出了显着的优势。 虽然在数学或生物学等成熟领域评估大语言模型可以很简单,但使用大量人工编写的真实问题和答案团队和合作者(2024),评估特定领域大语言模型需要无监督或半监督的方法来生成评估基准。 我们认识到,虽然我们的方法满足了该领域对自动化方法的需求,但它仍然面临挑战,特别是所选的问题类型可能无法代表其他研究领域。 因此,其他领域的研究人员应该仔细考虑他们想要为研究提出的问题类型。
输出模式
从这项研究中,我们得出了关于输出模式的两个总体结论。 首先,令人惊讶的是,我们没有观察到与文档元数据(例如词符计数)相关的特定正确性模式。 这一发现与我们最初的假设相矛盾,即词符计数最低的文档将达到最低的准确性,反之亦然。 我们认为造成这种情况的原因之一可能是我们从文档中只选择了90段作为黄金段落,这可能不具有代表性。 其次,我们注意到每个大语言模型模型往往具有独特的响应类型。 例如,在没有提供上下文的情况下,双子座的反应往往很直接,经常说“我没有上下文”。相比之下,Claude 和 GPT-4 更有可能尝试澄清输入问题,例如预测和提供缩写的完整内容。 我们鼓励涉及 RAG 的其他项目的研究人员分析输出模式以加强他们的工作。
长上下文推理
本研究的主要目标之一是评估可处理 128K 至 150 万个标记上下文的长上下文模型在回答长 EIS 文档中的问题时有何益处。 我们注意到这些模型很难使用长输入上下文来回答需要多个推理步骤(例如解决问题)的更困难的问题。 鉴于我们看到模型性能因问题的位置和类型而异,我们假设对检索到的文档进行有效的问题类型和复杂性感知重新排序可能有助于提高性能 Jeong 等人 (2024) 。 例如,我们可以使用另一个大语言模型来根据解题类型调整检索词块的顺序。
5相关工作
长上下文评估评估长上下文大语言模型的一种流行技术是通过简单的大海捞针分析来测试上下文检索能力Chandrayan 等人(2024)。 尽管这些测试中提出了这样的说法,但在严格的科学基准中,当前的大语言模型在处理和理解长的、上下文丰富的序列方面表现不佳Li 等人 (2024);刘等人(2024)。 例如,Li等人(2024)构建了LongICLBench基准来评估极端标签分类任务中的一组长上下文大语言模型作为长上下文学习任务。 他们表明,对于现有的大语言模型来说,长上下文理解和推理仍然是一项具有挑战性的任务。 很少有研究表明长上下文大语言模型受到输入上下文中相关信息的位置的影响 Liu 等人 (2024); Ivgi 等人 (2023)。 例如,Ivgi 等人 (2023) 表明,当相关信息放置在输入上下文的开头时,编码器-解码器模型具有显着更高的性能。 此外,Liu 等人 (2024) 表明,大语言模型在必须在长上下文中访问相关信息时表现较弱。
还有一些在多种语言和领域中提出的其他基准来评估大语言模型的长上下文理解。 Bai等人(2023)提出了LongBench,涵盖六种任务,单文档QA、多文档QA、摘要、少样本学习、合成任务以及中英文代码补全。 L-Eval Benchmark An 等人 (2023) 包含 20 个子任务、508 个长文档以及 2,000 多个人工标记的查询-响应对,这些查询-响应对具有不同的问题样式、领域和输入长度。 Li 等人 (2023) 提出了 LooGLE,其中包含跨不同领域的约 6,000 个问题,并评估了商业和开源模型。 虽然他们表明商业模型在短问答和完形填空任务中优于开源模型,但在长依赖任务中却表现不佳。 此外,基于检索的技术在回答简短问题方面显示出显着的优势,而旨在增加上下文窗口长度的方法对理解较长上下文的影响最小。 Bench Zhang 等人 (2024) 由 12 个任务组成,平均数据长度超过 100K 个 token。 他们认为,长上下文大语言模型仍然需要重大进步才能有效处理 100K+ 上下文。
针对长文档的 RAG RAG 模型提供了一种有前途的方法,使大语言模型能够从冗长的文档或广泛的集合中搜索和提取相关信息。 正如最近的研究 Barnett 等人 (2024) 所强调的那样,将文档分割成更小、更易于管理的块以适应大语言模型上下文窗口的常见策略有其局限性。 这些限制包括模型无法准确提取答案,即使答案存在于所提供的上下文中,特别是当存在过多噪音或矛盾信息时。 为了应对这些挑战,研究人员提出了新技术。 HippoRAG 是一种受神经生物学启发的长期记忆系统,专为大语言模型设计,可以更有效地处理长文档,旨在减轻当前 RAG 模型 Gutiérrez 等人 (2024) 的局限性。 Gao等人(2023)对RAG方法进行了全面的概述,将其分为三种范式:Naive RAG、Advanced RAG和Modular RAG。 作者强调了 Modular RAG 卓越的适应性,它允许模块替换或重新配置以应对特定的挑战,超越了 Naive 和 Advanced RAG 的固定结构。 模块化RAG集成新模块或调整现有模块之间的交互流程,增强其在不同任务中的适用性。 该调查还讨论了 RAG 中自适应检索的概念,例如 Flare Jiang 等人 (2023) 和 Self-RAG Asai 等人 (2023) 等方法。 这些方法通过使大语言模型能够主动确定检索的最佳时刻和内容来完善 RAG 框架,从而提高来源信息的效率和相关性。 尽管取得了这些进步,Gao 等人(2023)强调,需要进一步的研究来充分理解将 RAG 应用于长文档的复杂性,并开发更稳健和可靠的方法。
6结论
在本研究中,我们对大语言模型在《国家环境政策法》及其相关文件范围内的表现进行了初步调查。 为了实现这一目标,我们引入了 NEPAQuAD,这是一个问答基准,旨在评估模型理解 NEPA 文件中的法律、技术和合规相关内容的能力。 我们评估了三个旨在处理广泛上下文的前沿大语言模型——Claude Sonnet、Gemini 和 GPT-4——跨不同的上下文设置。 我们的综合分析表明,NEPA 文档对大语言模型提出了重大挑战,特别是在理解复杂语义和有效处理冗长文档方面。 研究结果表明,使用 RAG 技术增强的模型超越了那些仅提供 PDF 内容作为长上下文的大语言模型。 这表明,结合更多相关的知识检索过程可以显着提高大语言模型在复杂文档理解任务(例如 NEPA 领域中的任务)上的性能。 此外,我们注意到这些大语言模型很难使用长输入上下文来回答需要多个推理步骤的更困难的问题。 例如,模型在回答封闭式问题时表现最好,而在回答发散性问题和解决问题的问题时表现最差。
7 限制
与大语言模型的其他应用类似,我们提出的 EIS 长文档系统也有一些局限性。 我们将这些限制列出如下:
对完整 PDF 上下文的词符限制。 虽然我们能够使用词符长度为 150 万的 Gemini 模型,但我们每次查询只能使用 128K 个 Token 来使用 Claude 和 GPT-4 生成响应。 因此,我们需要截断Full PDF的内容来运行这两个大语言模型模型。 这可能会导致包含 EIS 文档问题的完整 PDF 上下文的性能下降。 在未来的工作中,我们应该更仔细地分析词符截断对完整 PDF 上下文的影响。
大语言模型生成的响应的不确定性。 由于预算限制,我们仅在不同配置中进行了一阶段的响应生成。 这引入了不确定输出的风险,这意味着即使输入相同,大语言模型每次也可能产生不同的响应,正如另一项研究 Wagle 等人 (2024) 所证明的那样。 在未来的工作中,我们计划多次运行大语言模型并分析这种不确定性对响应生成的影响。
人类判断力的挑战。 目前,我们利用人类评估作为基准定性分析的基本知识代理衡量标准。 在未来的工作中,我们计划以更系统的方式让更多的NEPA专家参与进来,用人类判断结果扩展数据集,并在NEPA专家之间进行适当的裁决会议以协调相互矛盾的结果。
自动评估中的偏差 由于使用 GPT-4 来评估各种模型的输出,答案正确性评估过程中可能存在潜在偏差。 有人担心,在事实正确性评估中,GPT-4 可能本质上更喜欢同一模型生成的输出而不是其他模型。 这可能会导致评估结果出现偏差,即 GPT-4 的输出得到更有利的评价,不一定是因为它们更优秀,而是因为评估模型 (GPT-4) 中固有的偏差。
为了解决答案正确性评估过程中的潜在偏差,我们评估评估中的事实和语义正确性。 为了语义正确性,我们利用 BGE Xiao 等人 (2023) 作为嵌入模型,并独立于 GPT-4 自己的评估机制来计算模型输出和真实答案之间的语义相似度。 通过结合事实和语义正确性,我们的目标是准确反映包括 GPT-4 在内的各种模型的真实性能。
8道德考虑
通常认为以前发表的作品可以按原样使用,而不必考虑继承的道德问题。 然而,在当今时代,研究人员不应“简单地假设[...]研究将对世界产生净积极影响”Hecht 等人 (2021)。 我们承认这不仅适用于新工作,也适用于以我们已经完成的方式使用现有工作时。
在开展该项目时,我们已注意确保所有数据都是匿名的,并且所使用的数据中不存在个人身份信息 (PII)。 在整个过程中,我们的团队中有领域专家,从而确保他们了解所有潜在的风险和收益。
虽然我们预计这里介绍的新颖工作本身不会引入新的伦理问题,但我们确实认识到,我们在本文中使用的数据、模型和方法也可能存在预先存在的担忧和问题。 特别是,我们发现大语言模型,就像本作品中使用的模型一样,表现出各种各样的偏见——宗教、性别、种族、职业和文化——并且经常生成不正确的、厌恶女性的、反犹太主义的答案,且一般有毒 Abid 等人 (2021); Buolamwini 和 Gebru (2018);梁 等人 (2021); Nadeem 等人 (2021); Welbl 等人 (2021)。 然而,当在本文详细介绍的实验参数内使用时,我们没有在任何模型中看到这种行为。 据我们所知,当按预期使用时,我们的模型不会比任何其他大语言模型造成更多的道德问题。
9致谢
这项工作得到了美国能源部政策办公室和西北太平洋国家实验室的支持,该实验室由美国能源部巴特尔纪念研究所根据合同 DE-AC05-76RLO1830 运营。 本文已被 PNNL 批准公开发布,编号为 PNNL-SA-199339。
参考
- Abid et al. (2021) Abubakar Abid, Maheen Farooqi, and James Zou. 2021. Persistent anti-muslim bias in large language models. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pages 298–306.
- Acharya et al. (2023) Anurag Acharya, Sai Munikoti, Aaron Hellinger, Sara Smith, Sridevi Wagle, and Sameera Horawalavithana. 2023. Nuclearqa: A human-made benchmark for language models for the nuclear domain. arXiv preprint arXiv:2310.10920.
- An et al. (2023) Chenxin An, Shansan Gong, Ming Zhong, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. 2023. L-eval: Instituting standardized evaluation for long context language models. arXiv preprint arXiv:2307.11088.
- Asai et al. (2023) Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-rag: Learning to retrieve, generate, and critique through self-reflection. Preprint, arXiv:2310.11511.
- Bai et al. (2023) Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. 2023. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508.
- Balaguer et al. (2024) Angels Balaguer, Vinamra Benara, Renato Luiz de Freitas Cunha, Roberto de M. Estevão Filho, Todd Hendry, Daniel Holstein, Jennifer Marsman, Nick Mecklenburg, Sara Malvar, Leonardo O. Nunes, Rafael Padilha, Morris Sharp, Bruno Silva, Swati Sharma, Vijay Aski, and Ranveer Chandra. 2024. Rag vs fine-tuning: Pipelines, tradeoffs, and a case study on agriculture. Preprint, arXiv:2401.08406.
- Barnett et al. (2024) Scott Barnett, Stefanus Kurniawan, Srikanth Thudumu, Zach Brannelly, and Mohamed Abdelrazek. 2024. Seven failure points when engineering a retrieval augmented generation system. arXiv preprint arXiv:2401.05856.
- Buolamwini and Gebru (2018) Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency, pages 77–91. PMLR.
- Buster et al. (2024) Grant Buster, Pavlo Pinchuk, Jacob Barrons, Ryan McKeever, Aaron Levine, and Anthony Lopez. 2024. Supporting energy policy research with large language models. arXiv preprint arXiv:2403.12924.
- Cai et al. (2024) Hengxing Cai, Xiaochen Cai, Junhan Chang, Sihang Li, Lin Yao, Changxin Wang, Zhifeng Gao, Yongge Li, Mujie Lin, Shuwen Yang, et al. 2024. Sciassess: Benchmarking llm proficiency in scientific literature analysis. arXiv preprint arXiv:2403.01976.
- Chandrayan et al. (2024) Kedar Chandrayan, Lance Martin, gkamradt, Lazaro Hurtado, arkadyark cohere, Ikko Eltociear Ashimine, Pavel Kral, and Prabha Arivalagan. 2024. Needle in a haystack - pressure testing llms.
- Dollar et al. (2022) Orion Walker Dollar, Sameera Horawalavithana, Scott Vasquez, W James Pfaendtner, and Svitlana Volkova. 2022. Moljet: multimodal joint embedding transformer for conditional de novo molecular design and multi-property optimization.
- Es et al. (2023) Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. 2023. Ragas: Automated evaluation of retrieval augmented generation. Preprint, arXiv:2309.15217.
- Gao et al. (2023) Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
- Gutiérrez et al. (2024) Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. Hipporag: Neurobiologically inspired long-term memory for large language models. arXiv preprint arXiv:2405.14831.
- Hecht et al. (2021) Brent Hecht, Lauren Wilcox, Jeffrey P Bigham, Johannes Schöning, Ehsan Hoque, Jason Ernst, Yonatan Bisk, Luigi De Russis, Lana Yarosh, Bushra Anjum, et al. 2021. It’s time to do something: Mitigating the negative impacts of computing through a change to the peer review process. arXiv preprint arXiv:2112.09544.
- Horawalavithana et al. (2022) Sameera Horawalavithana, Ellyn Ayton, Shivam Sharma, Scott Howland, Megha Subramanian, Scott Vasquez, Robin Cosbey, Maria Glenski, and Svitlana Volkova. 2022. Foundation models of scientific knowledge for chemistry: Opportunities, challenges and lessons learned. In Proceedings of BigScience Episode# 5–Workshop on Challenges & Perspectives in Creating Large Language Models, pages 160–172.
- Horawalavithana et al. (2023) Sameera Horawalavithana, Sai Munikoti, Ian Stewart, and Henry Kvinge. 2023. Scitune: Aligning large language models with scientific multimodal instructions. arXiv preprint arXiv:2307.01139.
- Ivgi et al. (2023) Maor Ivgi, Uri Shaham, and Jonathan Berant. 2023. Efficient long-text understanding with short-text models. Transactions of the Association for Computational Linguistics, 11:284–299.
- Jeong et al. (2024) Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park. 2024. Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity. arXiv preprint arXiv:2403.14403.
- Jiang et al. (2023) Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. Preprint, arXiv:2305.06983.
- Kapoor et al. (2024) Sayash Kapoor, Peter Henderson, and Arvind Narayanan. 2024. Promises and pitfalls of artificial intelligence for legal applications. arXiv preprint arXiv:2402.01656.
- Kasneci et al. (2023) Enkelejda Kasneci, Kathrin Sessler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan Günnemann, Eyke Hüllermeier, Stephan Krusche, Gitta Kutyniok, Tilman Michaeli, Claudia Nerdel, Jürgen Pfeffer, Oleksandra Poquet, Michael Sailer, Albrecht Schmidt, Tina Seidel, Matthias Stadler, Jochen Weller, Jochen Kuhn, and Gjergji Kasneci. 2023. Chatgpt for good? on opportunities and challenges of large language models for education. Learning and Individual Differences, 103:102274.
- Lewis et al. (2021) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-augmented generation for knowledge-intensive nlp tasks. Preprint, arXiv:2005.11401.
- Li et al. (2023) Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. 2023. Loogle: Can long-context language models understand long contexts? arXiv preprint arXiv:2311.04939.
- Li et al. (2024) Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, and Wenhu Chen. 2024. Long-context llms struggle with long in-context learning. arXiv preprint arXiv:2404.02060.
- Liang et al. (2021) Paul Pu Liang, Chiyu Wu, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2021. Towards understanding and mitigating social biases in language models. In International Conference on Machine Learning, pages 6565–6576. PMLR.
- Liu et al. (2024) Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173.
- Munikoti et al. (2023) Sai Munikoti, Anurag Acharya, Sridevi Wagle, and Sameera Horawalavithana. 2023. Evaluating the effectiveness of retrieval-augmented large language models in scientific document reasoning. arXiv preprint arXiv:2311.04348.
- Munikoti et al. (2024) Sai Munikoti, Anurag Acharya, Sridevi Wagle, and Sameera Horawalavithana. 2024. Atlantic: Structure-aware retrieval-augmented language model for interdisciplinary science. In Proceedings of the Workshop on AI to Accelerate Science and Engineering (AI2ASE), Vancouver, Canada. Held in conjunction with the 38th AAAI Conference on Artificial Intelligence (AAAI 2024).
- Nadeem et al. (2021) Moin Nadeem, Anna Bethke, and Siva Reddy. 2021. StereoSet: Measuring stereotypical bias in pretrained language models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 5356–5371, Online. Association for Computational Linguistics.
- OpenAI (2024) OpenAI. 2024. Gpt-4 technical report. Preprint, arXiv:2303.08774.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
- PolicyAI (2024) PolicyAI. 2024. Llm for environmental review.
- (35) Anthropic Team and Collaborators. Article about claude 3 models. https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf. Accessed: 2024-05-06.
- Team and Collaborators (2024) Gemini Team and Collaborators. 2024. Gemini: A family of highly capable multimodal models. Preprint, arXiv:2312.11805.
- Wagle et al. (2024) Sridevi Wagle, Sai Munikoti, Anurag Acharya, Sara Smith, and Sameera Horawalavithana. 2024. Empirical evaluation of uncertainty quantification in retrieval-augmented language models for science. In Proceedings of the Workshop on Scientific Document Understanding (SDU), Vancouver, Canada. Held in conjunction with the 38th AAAI Conference on Artificial Intelligence (AAAI 2024).
- Welbl et al. (2021) Johannes Welbl, Amelia Glaese, Jonathan Uesato, Sumanth Dathathri, John Mellor, Lisa Anne Hendricks, Kirsty Anderson, Pushmeet Kohli, Ben Coppin, and Po-Sen Huang. 2021. Challenges in detoxifying language models. arXiv preprint arXiv:2109.07445.
- Xiao et al. (2023) Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. 2023. C-pack: Packaged resources to advance general chinese embedding. Preprint, arXiv:2309.07597.
- Zhang et al. (2024) Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Khai Hao, Xu Han, Zhen Leng Thai, Shuo Wang, Zhiyuan Liu, et al. 2024. bench: Extending long context evaluation beyond 100k tokens. arXiv preprint arXiv:2402.13718.
附录 A问题定义
NEPA 专家审查并创建了每个问题类型的定义如下。
-
1.
封闭式问题: 封闭式问题有两种可能的答案,具体取决于您的表达方式:“是”或“否”或“正确”或“错误”。
-
2.
比较问题: 比较问题是高阶问题,要求听众比较两个事物,例如物体、人、想法、故事或理论。
-
3.
收敛问题: 收敛性问题旨在尝试帮助您找到问题的解决方案或对问题的单一回答。
-
4.
发散的问题: 不同的问题没有正确或错误的答案,而是鼓励公开讨论。 虽然它们与开放式问题类似,但发散式问题的不同之处在于它们邀请听众分享意见,尤其是与未来可能性相关的意见。
-
5.
评价问题: 评估问题有时称为关键评估问题或 KEQ,是用于指导评估的高级问题。 好的评估问题将深入了解您想了解的有关您的计划、政策或服务的核心内容。
-
6.
漏斗问题: 漏斗问题始终是一系列问题。 他们的顺序模仿了漏斗结构,从开放式问题开始,然后转向封闭式问题。
-
7.
推理题: 推理问题要求学习者使用归纳或演绎推理来消除答案或批判性地评估陈述。
-
8.
解决问题的问题。 解决问题的问题向学生展示一个场景或问题,并要求他们制定解决方案。
-
9.
流程问题: 过程问题可以让演讲者更详细地评估听众的知识。
-
10.
回忆问题: 回忆问题要求听者回忆一个特定的事实。
附录 B示例问题
在本节中,我们列出了用于每种类型问题的示例问题集。
B.1 封闭式问题
-
•
[项目] 50 英里半径内是否有联邦认可的部落?
-
•
[项目] 50 英里半径内是否存在联邦认可的受关注物种?
-
•
[机构] 是否批准了许可行动
-
•
EIS 是否考虑过[主题]?
B.2 比较问题
-
•
[项目 1] 中咨询了哪些部落,而 [项目 2] 中没有咨询哪些部落,反之亦然?
-
•
[研究 1] 和 [研究 2] 之间有哪些差异可以解释 [SPECIES] 的物种计数差异?
-
•
将[项目 1] 中考虑的替代方案与[项目 2] 中的替代方案进行比较。
-
•
将新反应堆 EIS 的调查结果与 [RPOJECT] 的许可证更新 EIS 进行比较。
B.3 收敛问题
-
•
从逻辑上讲,还有哪些值得关注的物种可能位于 [项目] 周围 50 英里半径范围内?
-
•
在对空气质量的影响被评定为高之前,可以建设多少类似的项目?
-
•
如果拟议行动的影响范围增加 50%,还需要解决哪些联邦关注物种?
B.4 发散的问题
-
•
[机构] 在文件中应该考虑但没有考虑哪些考虑因素?
B.5评估问题
-
•
根据在[项目]附近进行的 NEPA 评估,历史和文化资源部分的结论是否适当地权衡了部落领导人的担忧?
-
•
使用本次 NEPA 评估和其他 NEPA 评估进行推断,附近 [SPECIES] 的长期前景如何?
-
•
[机构] NEPA 审查随着时间的推移趋势如何?这次审查在 10 年前或 10 年后会产生相同的结果吗?
-
•
在[项目]的许可证续订 EIS 中,哪些影响与初始 EIS 相比发生了变化,原因是什么?
B.6 漏斗问题
-
•
[项目] 50 英里半径内有哪些联邦认可的部落? 哪些部落参与了本次 EIS? 参与部落的担忧是什么? 采取了哪些缓解措施?
-
•
[项目] 50 英里半径范围内有哪些联邦认可的关注物种? 为预测这些物种采取了哪些缓解措施(如果有)?
-
•
讨论了哪些替代方案? 考虑了哪些? 为什么没有考虑[替代方案]?
-
•
文件的受影响环境部分讨论了哪些资源领域?
-
•
拟议的行动对[主题]有何影响?
-
•
[机构]在评估[主题]时是否考虑了[X]?
B.7 推理题
-
•
如果联邦认可的[部落]在[项目1]附近拥有土地,就像在[项目2]附近一样,那么[部落]可能会对[项目1]有什么顾虑?
-
•
如果过去针对[项目类型]的[物种]的主要迁移是[缓解],那么您期望[项目]的缓解是什么?
-
•
如果[机构 1] 和[机构 2] 通常就影响水平达成一致,并且[机构 1] 发现附近地区的一项行动对陆地生态产生巨大影响,那么[机构 2] 会发现什么?
-
•
如果[项目 1] 的空气质量缓解措施有效,并且相同的缓解措施适用于[项目 2],我们假设[项目 2] 的结果是什么?
B.8解决问题的问题
-
•
根据以下参考资料,评估 [SITE] 的新核电站对附近文化和历史资源的影响。
-
•
给定[项目]的位置,创建一份可能存在于 50 英里半径范围内的水生物种列表。
-
•
为 [项目] 撰写摘要
-
•
给定[项目 1] 的[部分]中的参考列表,创建适用于[项目 2] 的参考列表。 提供超链接和 ML 编号(如果有)。
B.9 处理问题
-
•
本文件如何定义与部落协商的 NEPA 流程?
-
•
[机构] 如何定义拟议行动的影响范围?
B.10 回忆问题
-
•
[机构] 在评估申请人提议的行动对 [物种] 的影响时使用了哪些参考资料?
-
•
哪些资源领域表明拟议行动会产生中等或较大的影响?
附录 C EIS 数据集
表3报告了用于创建基准的EIS数据的统计数据。
| Document Title | Agency | #Pages | #Tokens |
|---|---|---|---|
| Continental United States Interceptor Site | Missile Defense Agency, Department of Defense | 74 | 41,742 |
| Supplement Analysis of the Final Tank Closure and Waste Management for the Hanford Site, Richland, Washington, Offsite Secondary Waste Treatment and Disposal | Hanford Site Office, Department of Energy | 63 | 43,167 |
| Nationwide Public Safety Broadband Network Final Programmatic Environmental Impact Statement for the Southern United States | Department of Commerce | 86 | 43,985 |
| T-7A Recapitalization at Columbus Air Force Base, Mississippi | United States Department of the Air Force (DAF), Air Education and Training Command (AETC). | 472 | 179,697 |
| Oil and Gas Decommissioning Activities on the Pacific Outer Continental Shelf | The Bureau of Safety and Environmental Enforcement (BSEE) and Bureau of Ocean Energy Management (BOEM) | 404 | 271,545 |
| Final Environmental Impact Statement for the Land Management Plan Tonto National Forest | Department of Agriculture, Forest Service | 472 | 325,641 |
| Final Environmental Impact Statement for Nevada Gold Mines LLC’s Goldrush Mine Project, Lander and Eureka Counties, NV | Bureau of Land Management, Interior. | 454 | 413,083 |
| Addressing Heat and Electrical Upgrades at Fort Wainwright, Alaska | Department of the Army, Department of Defense | 618 | 514,003 |
| Sea Port Oil Terminal Deepwater Port Project | The U.S. Coast Guard (USCG) and Maritime Administration (MARAD), Department oF Transportation | 890 | 613,214 |