通过锚幻觉和硬样本标签校正来学习与实例相关的噪声标签
摘要
从噪声标记数据中学习对于现实世界的应用至关重要。 传统的噪声标签学习(NLL)方法根据训练样本的损失分布将训练数据分类为干净集和噪声集。 然而,他们经常忽视干净的样品,尤其是那些具有复杂视觉图案的样品,也可能会产生巨大的损失。 这种监督在具有实例相关噪声 (IDN) 的数据集中尤其重要,其中错误标记概率与视觉外观相关。 我们的方法明确区分了干净的与噪声样本以及简单的与硬样本。 我们识别损失较小的训练样本,假设它们具有简单的模式和正确的标签。 利用这些简单的样本,我们产生多个锚点来选择硬样本进行标签校正。 校正后的困难样本和简单样本一起在后续的半监督训练中用作标记数据。 对合成和真实 IDN 数据集的实验证明了我们的方法比其他最先进的 NLL 方法具有优越的性能。
索引术语— 噪声标签学习、实例相关噪声、锚幻觉、半监督学习
1简介
深度神经网络 (DNN) 的成功在很大程度上依赖于广泛注释的数据集。 然而,数据标注通常成本高昂,并且不可避免地会带来标签噪声[1, 2]。 标签错误的校正和鲁棒表示的探索已成为近期研究的焦点[3]。 在本文中,我们考虑从带有噪声标签[2]的数据集训练图像分类模型的实际场景,其中每个图像错误标记的概率取决于其视觉外观,其特征为实例相关噪声 (IDN)。
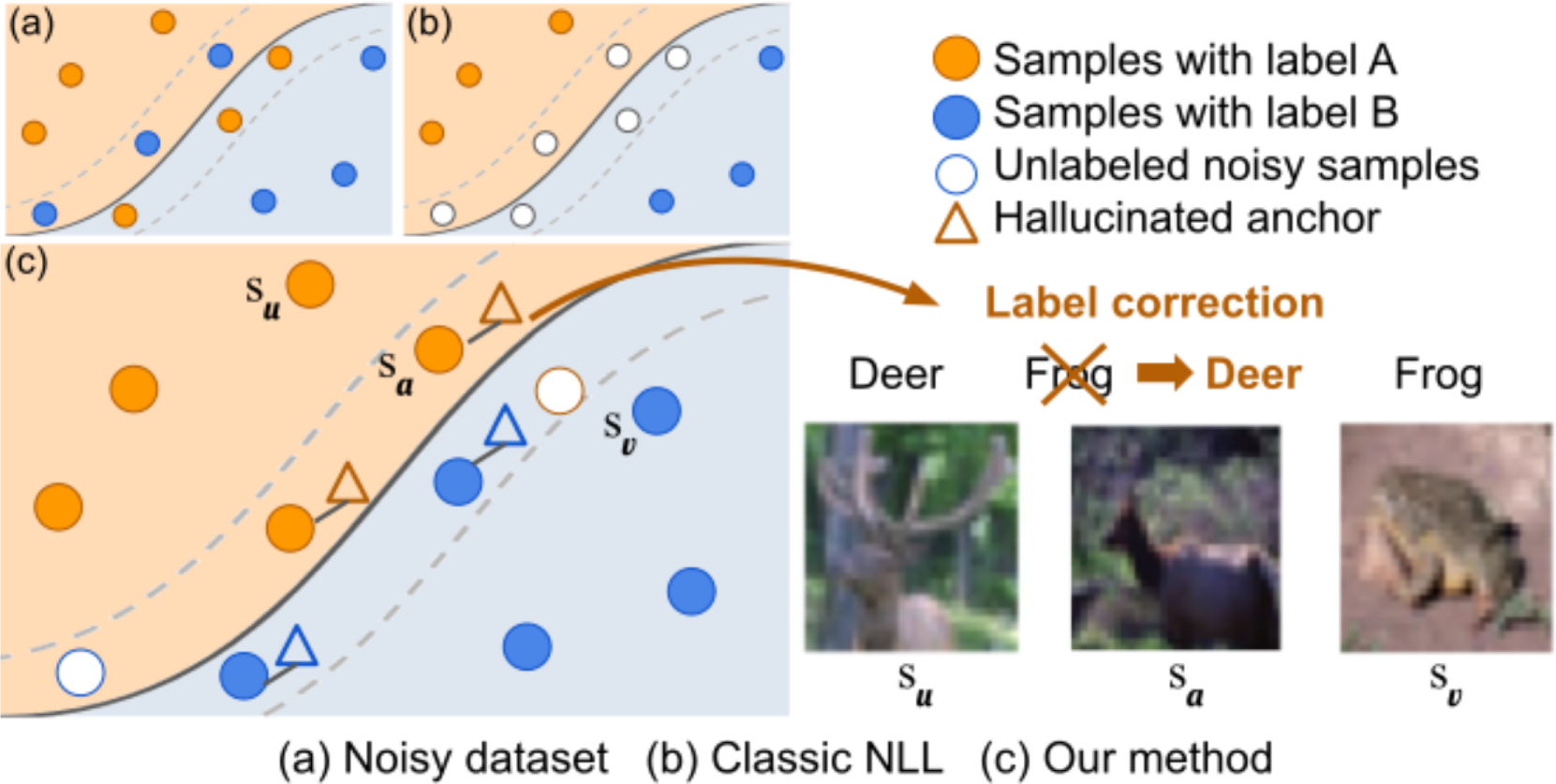
传统的噪声标签学习(NLL)方法主要依赖于样本选择[4, 5]。 这些方法通过在初始训练期间采用小损失标准来识别训练集中正确标记的(即、干净)样本。 假设分类损失较小的样本具有正确的标签,而损失较大的样本可能具有错误的标签。 然而,这种方法有一个主要缺点。 众所周知,DNN 优先学习简单模式而不是复杂模式[6]。 因此,最初识别的小损失样本可能仅代表具有简单视觉模式的干净样本的子集。 相反,分类损失较大的样本标签不一定总是有噪声;它们可能有干净的标签,但由于其复杂的视觉模式而很难学习。 例如,在 CIFAR-10 [7] 中,飞机通常在天空中,而船舶通常在水面上;但水面上也出现了一些难以分类的飞机样本。 我们认为,这些带有清晰标签的硬样本对于表征有效模型学习的决策边界非常重要。 正如典型 NLL 方法中常见的那样,简单地丢弃潜在的噪声标签会导致性能下降[8]。
为了应对这一挑战,我们的方法除了区分 clean 和 与 的样本之外,还区分了 easy 和 hard 样本。 > 嘈杂标签。 图1说明了我们的方法,从简单的样本开始识别和纠正困难样本的标签。 最初,我们使用标准的小损失标准将训练集划分为类平衡的简单样本和困难样本。 为了识别用于标签校正的硬样本,我们引入了一种新颖的锚定幻觉技术,该技术可以在特征空间中合成特征向量。 这些幻觉特征称为锚点,是从简单样本生成的,用于模拟具有复杂视觉成分的硬样本。 然后使用锚点从附近特征空间中的原始训练集中选择硬样本,见图1(c)。 由于锚点是用预先已知的标签合成的,因此它们用于通过多数投票来纠正所选硬样本的标签。 最后,经过标签校正的硬样本与初始的简单样本一起构成标记数据,而其余样本在半监督模型训练中用作未标记数据。 这有效地提高了数据和标签的利用率。
本文的贡献总结如下:
-
•
我们专注于噪声标签学习(NLL)问题,特别是具有实例相关噪声(IDN)的数据。 我们主张区分简单和困难的训练样本,同时也区分它们干净的与嘈杂的标签。 该设计解决了 NLL 中的样本选择困境。
-
•
我们引入了一种锚幻觉技术,通过合成特征向量来选择硬样本并对其进行标签校正。 接下来是半监督模型训练,以最大限度地提高数据和标签利用率。
-
•
对源自 CIFAR-10 [7] 的合成 IDN 数据集以及现实世界的 CIFAR-10N/100N [2] 和 Clothing1M 进行了大量实验[1]数据集。 结果证明我们的方法优于最先进的 (SoTA) NLL 方法,包括 DivideMix [4] 和 TSCSI [9]。
2相关作品
噪声标签学习(NLL)。 在 NLL 文献中,实例无关噪声 (IIN) 是最普遍的标签噪声类型。 IIN 的特征是图像被错误标记的概率,该概率仅取决于所涉及的类对,而不管其视觉内容如何。 IIN 的著名例子包括[10]中提出的对称和非对称噪声模式,这些模式已在相关领域得到广泛采用。 基于这种噪声假设,开发了各种NLL方法,包括噪声鲁棒损失函数[11]的设计、损失校正[12]、标签校正[ 13],以及样本选择[4]。
最近有关 IIN 的著名研究将样本选择与半监督学习 (SSL) 结合起来,取得了显着进展[4, 5]。 大多数方法采用小损失标准,并将训练损失小的样本视为干净的。 随后,应用现成的 SSL 算法,例如 [14],将所选样本视为标记数据,并将其余样本视为未标记数据。 然而,这些方法经常过度拟合基于小损失标准[8]选择的简单样本的小训练子集。 这种限制阻碍了他们充分利用决策边界附近的硬样本中包含的关键标签信息的能力。 尽管它们在各种 IIN 基准测试中取得了成功,但 IDN 假设下的性能仍不清楚。
从实例相关噪声 (IDN) 数据中学习。 与 IIN 的幼稚假设相反,最近的研究[8,15,16,2,17,18,9]认为现实世界的噪声模式更有可能依赖于视觉内容,这促使转向寻址 IDN。 一些方法通过估计噪声转换矩阵 [18, 19] 来对抗 IDN,需要额外的信息并在实际数据上实现平庸的性能。 其他人采用基于选择的方法与 SSL 相结合,类似于 IIN [9] 之前的工作,并在多个 IDN 基准上达到了 SoTA 结果。 然而,有效利用具有潜在噪声标签的有价值的硬样本仍然是一个尚未解决的挑战。 我们的工作与这一研究方向一致,重点是利用简单样本中的可靠信息来:(1)识别带有噪声标签的硬样本,以及(2)执行标签校正。
3提出的方法
本文讨论了具有实例相关噪声(IDN)的数据的图像分类的噪声标签学习。 我们使用噪声训练集 ,其中 表示 -th 图像, 是 类别的相应标签。 给定的标签 可能与真实的真实标签 不同,在训练期间仍然无法观察到。 目标是在 上训练图像分类模型,使其在干净的测试集上表现良好。
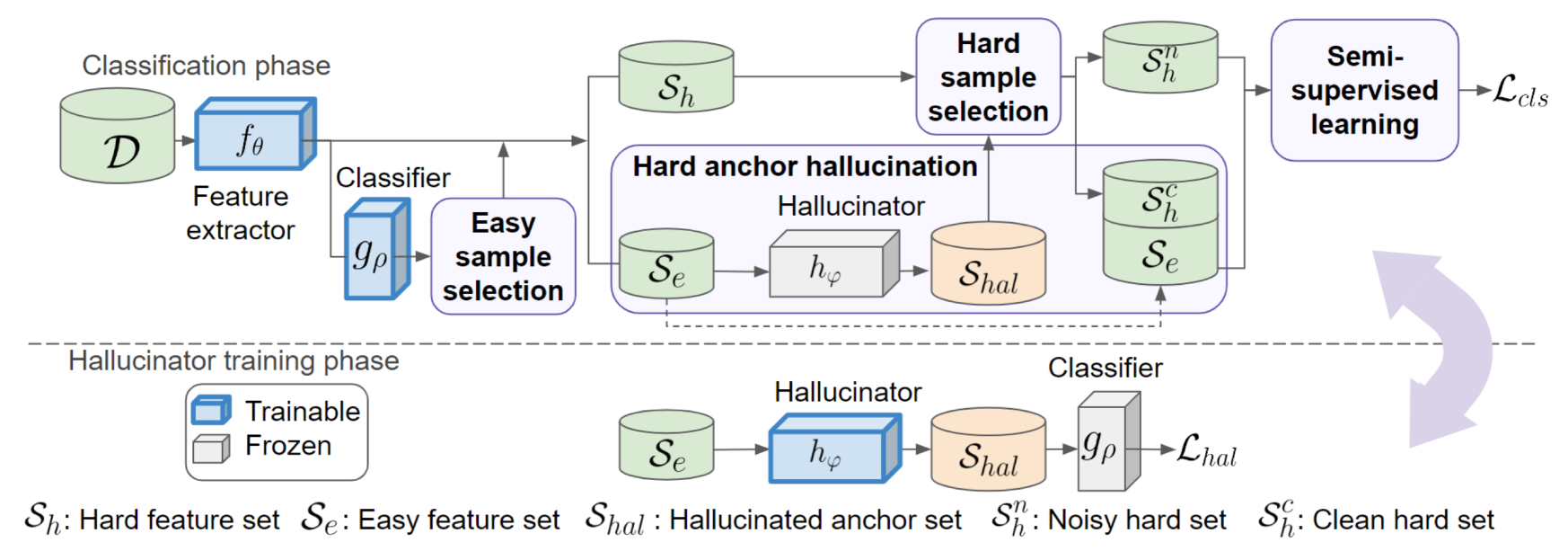
我们的方法通过区分简单和困难的训练样本来操作,使用清晰标记的简单样本来识别困难样本以进行标签校正。 这个过程是通过锚幻觉实现的,其中从简单的样本中合成特征以创建锚。 然后使用这些锚点通过多数投票来选择硬样本以进行标签校正。 总体而言,我们的模型由分类模块构成,包括特征提取器 和线性分类器 ,以及锚幻觉器 。
我们的训练框架包括两个迭代阶段,如图2所示。 首先,在分类阶段,我们保持固定,并通过半监督训练优化和( 3.4)使用清洁标签的简单样本和标签校正的硬样本。 该管道包括三个步骤:简易样本选择( 3.1)、硬锚幻觉( 3.2)和硬样本选择( 3.3)。 其次,在幻觉训练阶段,和保持固定,只有根据概述的幻觉损失进行更新在3.2中。 有关步骤和损失的更多详细信息将在后续部分中详细阐述。
3.1 轻松选择样本
我们的方法首先使用小损失标准[4]选择easy样本。 基于 DNN 学习简单模式比学习复杂模式更快的认识[6],我们通过分析初始训练期间分类损失的分布来识别简单的样本。 具体来说,我们计算每个样本的交叉熵损失,并使用二元高斯混合模型(GMM)拟合所有训练样本的损失分布,这在捕获拟合锐度方面提供了更大的灵活性分布[4]。 均值较小的高斯分量代表较小损失的分布。 然后,将每个样本属于该高斯分量的概率计算为该样本的轻松分数 。
随后,我们选择具有最高 轻松度分数的固定比例样本来形成 easy 训练样本集。 超参数 默认为 60,并使用小型干净验证集进行微调。 为了保持所有类别的平衡,我们确保每个类别都有足够数量的简单样本。 令表示训练集中第类的样本总数。 我们将第 类的简单样本 数量控制为:
| (1) |
因此,我们获得了具有假设的干净标签的类平衡的简单训练样本。 具有潜在噪声标签的剩余样本被视为硬样本。 接下来,我们利用特征提取器 将简单样本和困难样本嵌入到 维特征空间中,从而得到 简单特征集 和硬特征集,将用于锚幻觉、硬样本选择和标签校正。
3.2硬锚幻觉
简单的特征集 包含具有简单视觉模式和干净标签的训练样本的特征向量。 通过组合 的特征,我们可以形成复杂的视觉模式,这构成了硬锚幻觉的基础。 通过特征串联并生成跨越特征空间的大量特征锚点,我们可以采用附近锚点的多数投票来搜索硬特征集中最匹配的特征向量。
锚是通过在自动的、数据驱动的过程中聚合简单样本的特征而产生的幻觉。 具体来说,对于 类中的每个 ,我们从不同的类 中随机选择另一个特征 (其中 ) 用于混合。 随后,我们连接 和 ,并将其提供给幻觉器 以产生幻觉锚点 。 为了确保转化为所需类别的硬锚,我们根据以下两种设计制定幻觉损失。
首先,为了鼓励幻觉锚 代表 硬实例,我们通过规范化 与 和 之间的 相似性来优化幻觉锚 。 具体来说,我们将基于特征间余弦距离的相似度损失定义为,其中是控制难度级别的超参数,计算其参数间的余弦相似度。 通过最小化 ,幻觉锚点 将被鼓励驻留在特征空间中 和 之间的区域,并且因此共享 和 类的视觉模式。
其次,为了确保幻觉锚 属于已知的所需类别,我们遵循 [20] 的工作,并使用其目标标签 定义分类损失t2>。 总体幻觉损失计算如下:
| (2) |
其中 计算交叉熵损失。 最小化方程(2) 提示幻觉者生成一个锚点 ,其复杂的视觉模式位于类 和 之间的决策边界附近,同时保持在靠近的一侧。 通过对不同的 进行采样,可以从单个特征 生成多个幻觉锚点。 幻觉锚点集表示为。
3.3硬样本选择
幻觉锚点延伸到整个特征空间,具有不同程度的代表性品质。 在计算上,如果幻觉锚点 在特征空间中足够接近,则它们被认为代表真实的硬特征样本 。 我们使用余弦相似度 来测量 和 之间的接近度。 为了过滤掉代表性的,我们识别出幻觉锚点的最近的硬特征样本,表示为。 如果超过阈值,则锚点被认为是的有效代表。 超参数 可以基于带有干净标签的小型验证集进行调整。 这些有效代表分散在硬特征样本附近,可以用来匹配它们。 对于每个 ,我们最多收集 个其周围的有效代表。 这些有效代表被用来通过多数投票来确定的正确标签。
通过以这种方式识别具有正确标签的硬样本,分类模块(和)根据硬样本中包含的更有价值的标签信息进行训练,从而提高性能。
3.4半监督学习
带有正确标签的硬样本集,表示为,与简单特征集相结合,形成模型训练的标记数据集,而剩余的噪声硬特征,表示为,构成半监督学习(SSL)的未标记数据集。
我们采用经典的 SSL 方法 MixMatch [14] 来增强 和 中的样本。 我们从两个增强副本的模型预测平均值中获得 中样本的伪标签。 类似地,我们通过使用 中给定标签的线性组合以及两个增强图像的模型预测平均值来细化 中样本的标签。 分配给给定标签的权重由 3.1 的轻松度分数 确定。
获得精炼后的伪标签后,我们使用组合分类损失执行 SSL:
| (3) |
其中是标记数据的交叉熵损失,是未标记数据的均方误差,是通过验证设置的超参数。 通过最小化方程。 (3),由特征提取器和线性分类器组成的最终图像分类器将变得更加鲁棒,因为它结合了来自关键硬样本的信息和干净的信息。训练期间的标签。
3.5 迭代模型训练
4实验
4.1 数据集和 IDN 噪声生成
我们遵循之前的 NLL 从带有 IDN 标签 [15,8,17,9] 的数据集学习的工作,在合成和真实的 IDN 数据集上进行实验。
综合 IDN 数据集。 我们对根据 CIFAR-10 数据集 [7] 创建的合成 IDN 数据集进行实验,该数据集包含来自 10 个注释清晰的类的 50,000 个训练图像和 10,000 个测试图像。 我们考虑了两种生成IDN噪声的方法:1)部分相关标签噪声(PTD)[15],它是根据多个噪声转移矩阵的组合生成的图像的不同部分; 2) 基于分类的标签噪声 [8],它是通过使用在多个时期的所有训练数据上训练的标准 CNN 对训练期间收集的 softmax 输出进行平均而生成的。
真实世界的 IDN 数据集。 为了评估我们的方法在真实世界 IDN 数据集上的有效性,我们使用 CIFAR-10N/100N [2] 和真实世界 Clothing1M [1] 进行了实验数据集。 CIFAR-10N/100N 是通过 Amazon Mechanical Turk 从每个训练图像的三个人工注释中收集标签,从 CIFAR-10/100 生成的。 每幅图像的三个噪声标签表示为随机1/2/3,并通过多数投票(表示为聚合)和随机选择一个错误来进一步聚合标签(如果有的话)(表示为最差)。 Clothing1M 数据集包含在线收集的 14 种不同类型服装的超过 100 万张训练图像,并从图像周围的文本中提取标签。 我们使用 14K clean 验证集进行超参数调整,并使用 10K clean 测试集来评估模型性能。 这些 IDN 数据集呈现了具有各种噪声源的真实场景,从而为将我们的方法与 SoTA 方法进行比较提供了合适的测试平台。
4.2 基线和实施细节
我们将我们的框架与最近的 SoTA NLL 工作进行比较,包括那些专注于 IIN 数据集(例如 DivideMix [4])的框架,以及那些专注于 IDN 数据集(例如 TSCSI [9])的框架。 值得注意的是,DivideMix 和 TSCSI 都以协同训练的方式使用两个网络来进行模型集成,因此会产生更高的计算成本,而我们的框架在大多数实验设置中仅训练单个网络(除了 Clothing1M)。 对于带有 IDN 的 CIFAR-10 和 CIFAR-10N/100N 数据集,我们遵循之前的工作[2, 9]并采用 ResNet-34 网络作为我们的分类模块,以及两层 Multi-Layer感知器(MLP)作为我们的幻觉器。 我们在干净的测试集上评估我们的方法,并报告三次运行的平均最佳测试准确性。 对于 Clothing1M,我们根据之前的工作 [4, 9] 采用 ImageNet 预训练的 ResNet-50 网络,同时还将 实现为两层 MLP。 我们还采用与 DivideMix 中使用的相同程序来选择简单样本(基于 GMM 的选择,无需类平衡)以进行更好的比较。 在训练过程中,我们使用14K clean验证集来选择最佳模型,并将其应用于10K clean测试以获得测试精度。 补充材料中提供了更多实施细节。
4.3定量结果
PTD 标签噪声的结果。 表1显示了在带有PTD噪声[15]的CIFAR-10数据集上的实验结果。 与先前最先进的方法相比,我们提出的方法在 20% 和 40% 噪声比下实现了显着的性能改进。 我们的模型还显示了针对 PTD 下不断增加的噪声率的鲁棒性。
Method PTD 20% PTD 40% Forward T [10] 87.221.60 79.372.72 Co-teaching [21] 88.870.24 73.001.24 Co-teaching+ [22] 89.800.28 73.781.39 JoCoR [23] 88.780.15 71.643.09 DivideMix [4] 93.330.14 95.070.11 CAL [17] 92.010.75 84.961.25 TSCSI [9] 93.680.12 94.970.09 Ours 94.260.19 95.280.10
Method 10% 20% 40% CE (Standard) 91.250.27 86.340.11 75.680.29 Forward [10] 91.060.02 86.350.11 71.120.47 Co-teaching [21] 91.220.25 87.280.20 78.820.47 DAC [24] 90.940.09 86.160.13 74.800.32 SEAL [8] 91.320.14 87.790.09 82.980.05 TSCSI [9] 91.390.08 88.360.11 84.180.40 Ours 93.680.47 92.980.11 92.470.41
CIFAR-10N CIFAR-100N Method Random1 Random2 Random3 Worst Noisy CE (Standard) 85.020.65 86.461.79 85.160.61 77.691.55 55.500.66 Forward T [10] 86.880.50 86.140.24 87.040.35 79.790.46 57.011.03 Co-teaching+ [22] 89.700.27 89.470.18 89.540.22 83.260.17 57.880.24 DivideMix [4] 95.160.19 95.230.07 95.210.14 92.560.42 71.130.48 Negative-LS [25] 90.290.32 90.370.12 90.130.19 82.990.36 58.590.98 VolMinNet [26] 88.300.12 88.270.09 88.190.41 80.530.20 57.800.31 CAL [17] 90.930.31 90.750.30 90.740.24 85.360.16 61.730.42 PES [27] 95.060.15 95.190.23 95.220.13 92.680.22 70.360.33 Ours 95.210.05 95.310.10 95.250.17 93.520.49 70.790.06
基于分类的标签噪声的结果。 表2提供了CIFAR-10与基于分类的标签噪声[8]在不同噪声水平下的性能比较。 基于分类的标签噪声被认为具有挑战性,因为它源自分类模型[9]。 与以前的方法相比,我们的方法在所有噪声水平上始终表现出显着优越的性能。 我们的方法对基于分类的标签噪声表现出对更高水平的标签噪声 (40%) 的显着抵抗力,而其他方法则遭受显着的性能下降。
Method Co-teaching JoCoR DivideMix CAL TSCSI Ours [21] [23] [4] [17] [9] Accuracy 69.21 70.30 74.400.08 74.17 75.40 74.620.14
Easy sample sel. Hard sample corr. Test accuracy - - 86.240.90 - 89.771.45 92.470.41
CIFAR-N 上的结果。 表 3 显示了 CIFAR-10N/CIFAR-100N 数据集 [2] 上的性能比较。 在 CIFAR-10N 上,我们的方法在 随机 1、随机 2、随机 3 和 最差 等所有噪声设置下,始终优于其他方法。 值得注意的是,我们的方法在仅训练单个网络的情况下,在 CIFAR-100N 上实现了与 DivideMix [4] 相当的性能。 这证明了我们的方法在从现实世界的 IDN 数据集中学习的有效性。
Clothing1M 上的结果。 表 4 显示了 Clothing1M 数据集上的性能比较。 与 TSCSI 相比,我们的方法取得了有竞争力的结果,并且优于 DivideMix 和其他方法。 由于我们的方法在简单样本选择方面采用了与 DivideMix 类似的策略 ( 3.1),因此与 DivideMix 相比的优越性能表明了我们基于幻觉的硬样本选择的有效性 ( 3.2 和 3.3)从如此大规模的 IDN 数据集进行学习。
消融研究。 为了评估每个设计组件的有效性,我们在具有 40% 基于分类的 IDN 的 CIFAR-10 数据集上对我们提出的框架进行了消融分析。 我们比较了三种不同设置的性能:(1) 基于普通 GMM 选择的方法,本质上是没有协同训练和模型集成的 DivideMix [4],(2) 我们的方法仅使用简单的 3.1中描述的样本选择阶段,以及(3)我们的方法,在 3.3。 表5列出了比较结果。 从表中可以看出,这两个阶段的设计都有助于我们框架的性能提升。 值得注意的是,简单样本选择阶段对性能提升的贡献最大,这表明获得类平衡的简单子集对于有效模型训练的重要性。 第二阶段硬样本选择进一步将性能提升至的SoTA水平。 这验证并证实了我们的建议,即硬样本中包含的信息对于模型学习稳健的表示很有价值。
4.4硬锚幻觉的可视化
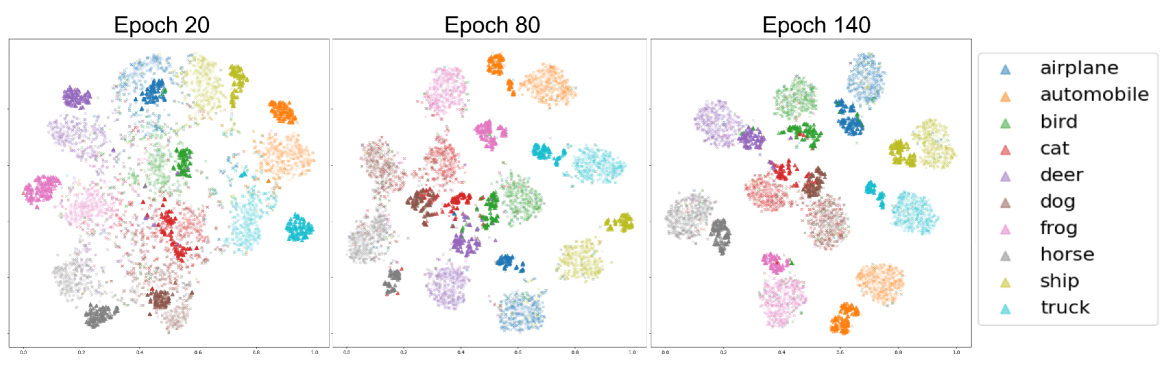
为了证明我们方法的有效性,图 3 展示了我们在 CIFAR-10 数据集上的幻觉的 t-SNE 可视化,在不同的训练时期中具有 40% 基于分类的标签噪声。 为简单起见,我们将从 中随机采样的每个类别的显示限制为 25 个幻觉样本和 500 个真实样本。 较深色调的颜色表示带有与相应较浅色调相匹配的伪标签的幻觉锚点。 观察每个类别的幻觉锚点的特征与相应的真实特征簇是否一致。 这表明我们的幻觉锚可以使用适当的伪标签有效地模拟所需的硬样本,这可以促进后续的硬样本选择以改进决策边界训练。 我们在补充材料中提供了关于硬锚点的额外可视化。
5结论
在本文中,我们提出了一种新颖的框架来解决经典的基于选择的噪声标签学习(NLL)方法中硬样本的低估问题。 通过利用简单的样本来产生硬锚的幻觉,我们的方法在存在实例相关噪声的情况下从硬样本中捕获关键信息。 虽然我们无法涵盖所有可能的工作,但我们与最相似的工作进行了比较,并在几个基准数据集上证明了我们的模型的有效性,与最先进的方法相比,实现了卓越的性能。 我们相信,我们的工作为标签噪声下训练模型中硬样本的重要性提供了一个新的视角,而标签噪声是传统 NLL 方法经常忽视的一个因素。 我们证明,利用干净的硬样本中的关键标签信息可以增强决策边界的稳健性。 其他领域也可能从我们的建议中受益,例如主动学习,它也侧重于有效利用数据信息。
限制。 我们的框架识别困难样本并通过硬锚幻觉纠正其标签,假设所选的简单特征集(以及幻觉锚集)跨越感兴趣的类别。 因此,所提出的幻觉过程可能不适用于高度不平衡的数据集。
未来的工作。 在更大的现实世界数据集上对所提出的框架进行彻底的调查和评估将最好产生新的见解来改进当前的解决方案。 我们还计划将所提出的框架集成到图像分类之外的其他领域,以增强我们工作的普遍性。
参考
- [1] T. Xiao, T. Xia, Y. Yang, C. Huang, and X. Wang, “Learning from massive noisy labeled data for image classification,” in CVPR, 2015.
- [2] J. Wei, Z. Zhu, H. Cheng, T. Liu, G. Niu, and Y. Liu, “Learning with noisy labels revisited: A study using real-world human annotations,” in ICLR, 2022.
- [3] H. Song, M. Kim, D. Park, Y. Shin, and J.-G. Lee, “Learning from noisy labels with deep neural networks: A survey,” in TNNLS, 2022.
- [4] J. Li, R. Socher, and S.C.H. Hoi, “DivideMix: Learning with noisy labels as semi-supervised learning,” in ICLR, 2020.
- [5] N. Karim, M.N. Rizve, N. Rahnavard, A. Mian, and M. Shah, “UNICON: Combating label noise through uniform selection and contrastive learning,” in CVPR, 2022.
- [6] D. Arpit, S. Jastrzebski, N. Ballas, D. Krueger, E. Bengio, M.S. Kanwal, T. Maharaj, A. Fischer, A. Courville, Y. Bengio, and S. Lacoste-Julien, “A closer look at memorization in deep networks,” in ICML, 2017.
- [7] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” in Master’s thesis, University of Toronto, 2009.
- [8] P. Chen, J. Ye, G. Chen, J. Zhao, and P.-A. Heng, “Beyond class-conditional assumption: A primary attempt to combat instance-dependent label noise.,” in AAAI, 2021.
- [9] G. Zhao, G. Li, Y. Qin, F. Liu, and Y. Yu, “Centrality and consistency: Two-stage clean samples identification for learning with instance-dependent noisy labels,” in ECCV, 2022.
- [10] G. Patrini, A. Rozza, A. Menon, R. Nock, and L. Qu, “Making deep neural networks robust to label noise: a loss correction approach,” in CVPR, 2017.
- [11] X. Ma, H. Huang, Y. Wang, S. Romano, S. Erfani, and J. Bailey, “Normalized loss functions for deep learning with noisy labels,” in ICML, 2020.
- [12] Z. Wang, G. Hu, and Q. Hu, “Training noise-robust deep neural networks via meta-learning,” in CVPR, 2020.
- [13] X. Wang, Y. Hua, E. Kodirov, D.A. Clifton, and N.M. Robertson, “ProSelfLC: Progressive self label correction for training robust deep neural networks,” in CVPR, 2021.
- [14] D. Berthelot, N. Carlini, I. Goodfellow, N. Papernot, A. Oliver, and C.A. Raffel, “MixMatch: A holistic approach to semi-supervised learning,” in NeurIPS, 2019.
- [15] X. Xia, T. Liu, B. Han, N. Wang, M. Gong, H. Liu, G. Niu, D. Tao, and M. Sugiyama, “Part-dependent label noise: Towards instance-dependent label noise,” in NeurIPS, 2020.
- [16] Y. Zhang, S. Zheng, P. Wu, M. Goswami, and C. Chen, “Learning with feature-dependent label noise: A progressive approach,” in ICLR, 2021.
- [17] Z. Zhu, T. Liu, and Y. Liu, “A second-order approach to learning with instance-dependent label noise,” in CVPR, 2021.
- [18] D. Cheng, T. Liu, Y. Ning, N. Wang, B. Han, G. Niu, X. Gao, and M. Sugiyama, “Instance-dependent label-noise learning with manifold-regularized transition matrix estimation,” in CVPR, 2022.
- [19] A. Berthon, B. Han, G. Niu, T. Liu, and M. Sugiyama, “Confidence scores make instance-dependent label-noise learning possible,” in ICML, 2021.
- [20] W. Zhang and Y.-X. Wang, “Hallucination improves few-shot object detection,” in CVPR, 2021.
- [21] B. Han, Q. Yao, X. Yu, G. Niu, M. Xu, W. Hu, I.W. Tsang, and M. Sugiyama, “Co-teaching: Robust training of deep neural networks with extremely noisy labels,” in NeurIPS, 2018.
- [22] X. Yu, B. Han, J. Yao, G. Niu, I.W. Tsang, and M. Sugiyama, “How does disagreement help generalization against label corruption?,” in ICML, 2019.
- [23] H. Wei, L. Feng, X. Chen, and B. An, “Combating noisy labels by agreement: A joint training method with co-regularization,” in CVPR, 2020.
- [24] S. Thulasidasan, T. Bhattacharya, J. Bilmes, G. Chennupati, and J. Mohd-Yusof, “Combating label noise in deep learning using abstention,” in ICML, 2019.
- [25] J. Wei, H. Liu, T. Liu, G. Niu, and Y. Liu, “To smooth or not? when label smoothing meets noisy labels,” in ICML, 2022.
- [26] X. Li, T. Liu, B. Han, G. Niu, and M. Sugiyama, “Provably end-to-end label-noise learning without anchor points,” in ICML. PMLR, 2021, pp. 6403–6413.
- [27] Y. Bai, E. Yang, B. Han, Y. Yang, J. Li, Y. Mao, G. Niu, and T. Liu, “Understanding and improving early stopping for learning with noisy labels,” in NeurIPS, 2021.