整流器:通过大语言模型使用校正器进行代码翻译
摘要。
随着软件和社会的发展,软件迁移越来越受到人们的关注。 早期的研究主要依靠手工制定的翻译规则在两种语言之间进行翻译,翻译过程容易出错且耗时。 近年来,研究人员开始探索在代码翻译中使用预训练的大语言模型(大语言模型)。 然而,代码翻译是一项复杂的任务,大语言模型在代码翻译过程中会产生错误,它们在执行代码翻译任务时都会产生某些类型的错误,其中包括(1)编译错误,(2)运行时错误,(3)函数错误错误,以及(4)非终止执行。 我们发现这些错误的根本原因非常相似(例如导入包失败、循环边界错误、操作员错误等)。 在本文中,我们提出了一种通用校正器,即整流器,它是一种用于修复翻译错误的微观通用模型。 它从现有大语言模型产生的错误中学习,可以广泛应用于纠正任何大语言模型产生的错误。 C++、Java和Python之间的翻译任务的实验结果表明我们的模型具有有效的修复能力,交叉实验也证明了我们方法的鲁棒性。
1. 介绍
代码翻译是软件工程中的一个重要问题。 将代码从一种编程语言翻译为另一种编程语言可以实现跨语言和平台的重用和移植软件工件。 早期研究主要依靠手工翻译规则在两种语言之间进行翻译(2to,2024;C2G,2024;C2R,2024)。 翻译的可读性和正确性较差,需要额外的人工修正。 因此,翻译过程容易出错且耗时(钟等人,2010)。
近年来,随着深度学习技术的发展,基于神经机器翻译(NMT)的技术得到了广泛的研究(Chen 等人,2018;Gu 等人,2017;Roziere 等人,2020) 。 这些方法将翻译代码视为 NMT 问题,其目标是将源代码翻译为目标代码,并严重依赖从开源存储库获得的并行训练数据集。 然而,并行资源在编程语言领域比在自然语言领域更加稀缺。 手动收集双语节目数据的成本很高。 因此,将NMT技术应用于代码翻译仍然面临许多挑战。
为了克服基于 NMT 的方法的局限性,研究人员正在探索使用预训练的大语言模型(大语言模型)进行代码翻译,例如 Codex (Chen 等人,2021)、StarCoder (Li 等人, 2023)、CodeGen (Nijkamp 等人, 2022)、CodeLlama (Rozière 等人, 2023) 和 ChatGPT (OpenAI,2022),通过对大量开源代码片段进行预训练,直接根据上下文生成正确的代码。 尽管之前的工作(Pan等人,2024,2023b)在使用大语言模型进行代码翻译方面表现出了良好的前景,但缺乏了解其在这项任务中的局限性的研究。 这是一项重要的任务,因为代码翻译是一项复杂的任务,需要大语言模型同时理解代码语法(生成语法正确的代码)和语义(在翻译过程中保留功能)。 然而,大语言模型在执行代码翻译任务时会产生某些类型的错误,包括(1)编译错误、(2)运行时错误、(3)功能错误和(4)非终止执行。 我们发现这些错误的根本原因非常相似(例如导入包失败、循环边界错误、操作员错误等)。
在这项研究中,我们的目标是通过引入具有熟练纠错能力的微模型来增强代码翻译。 该模型可以普遍应用于纠正任何大语言模型所产生的错误。 为了实现这一目标,我们推出了具有以下主要贡献的整流器。 首先,我们提出了一个专为纠正翻译错误而定制的微观自动化模型。 与需要大量计算资源和相关成本的大语言模型相比,我们的微模型在 CodeT5+ 220M 上进行了微调,所需的资源比 Llama-2 13B 等更大规模的大语言模型要少得多。 随后,我们设计了一个通用模型来纠正任何大语言模型产生的错误。 我们的模型具有通用性,因为它不是为了纠正特定大语言模型特有的错误而定制的,而是针对不同大语言模型中常见的错误。 该设计与大语言模型无关,并且独立于任何特定的大语言模型体系结构运行。
我们在两个广泛研究的数据集上进行了实验,即 CodeNet (Puri 等人, 2021) 和 AVATAR (Liu 等人, 2019),涵盖三种高度流行的编程语言:C++ 、Java 和 Python。 这些实验涉及四个前沿大语言模型的比较评估:ChatGPT (OpenAI, 2022)、StarCoder (Li 等人, 2023)、CodeGen ( Nijkamp 等人,2022),和 CodeLlama (Rozière 等人,2023)。
最初,我们在所有大语言模型上执行了代码翻译任务,结果非常有利于ChatGPT。 具体来说,在 CodeNet 数据集上,ChatGPT 取得了令人印象深刻的成功率,从 59.5% 到 85.5%。 同样,在 AVATAR 数据集上,ChatGPT 的成功率最高,达到 38.0% 至 73.1%,明显优于大语言模型同行 11.6% 至 61.8%。 此外,所检查的大语言模型表现出一致的翻译错误模式,主要表现为无效代码。 这些错误已被手动纠正,从而产生有效的代码实例。 这些成对的有效和无效代码集随后被用来修饰 CodeT5+ 模型。 结果证明了 CodeT5+ 模型对源自 ChatGPT、StarCoder 和 CodeGen 的错误进行微调的有效性,有效纠正了 CodeLlama 产生的总共 6 至 22 个错误。
此外,我们还进行了交叉实验,其中我们依次从 ChatGPT、StarCoder、CodeGen 和 CodeLlama 中选择错误代码翻译,利用其余模型中的错误代码进行微调。 实验结果凸显了 CodeT5+ 在大语言模型中改善翻译错误的能力(即 ChatGPT 的 4.6%43.2%、StarCoder 的 3.8%28.4%、StarCoder 的 3.9%CodeGen 的 21.3%,CodeLlama 的 6.4%24.4%)。 这强调了整个大语言模型中存在类似的错误模式,并肯定了整流器的通用性、与 LLM 无关的性质,它独立于任何特定的大语言模型架构运行。
简而言之,本文的主要贡献包括:
A。 基于LLM的代码翻译综合评价: 我们使用多个大语言模型对代码翻译进行了大规模评估。 我们考虑最近发布的大语言模型,我们的评估包括跨越 C++、Java 和 Python 的两个精心设计的基准。
B. 整流器:修复翻译错误的微观和通用模型: 我们发现这些大语言模型在翻译过程中会产生相似的错误模式,因此我们手动纠正了大语言模型产生的错误,并使用微观模型来捕获这些错误模式。 根据误差数据进行微调的模型可以普遍应用于任何未知的大语言模型。
C. 广泛的实证评估: 我们在广泛研究的 CodeNet (Puri 等人, 2021) 和 AVATAR (Ahmad 等人, 2021) 上对 4 个最先进的大语言模型进行了交叉实验> 探索整流器有效性和鲁棒性的数据集。 本文的复制品已公开发布(rep,2024)。
2. 动机示例
2.1. 动机的例子

图1显示了AVATAR数据集中的Java代码“atcoder_ABC169_D”到Python代码的翻译。 左边代表待翻译的Java代码,右边代表大语言模型(即ChatGPT、StarCoder、CodeGen、CodeLlama)的翻译结果。 这段代码是AtCoder网站上一个编程问题的解决方案。 问题给定一个正整数N,考虑对N重复应用下面的运算。首先,选择一个满足以下所有条件的正整数z: (1) z可以表示为z=,其中p是素数,e是正整数; (2) z 除以 N; (3) z 与之前操作中选择的所有整数不同。 然后,将 N 替换为 N/z。 该解决方案代码使用 类从标准输入流读取输入,并使用 语句输出答案。 这些大语言模型成功地翻译了原始Java代码的功能,但他们错误地将行翻译为,这将导致不同的循环计数和不正确的结果。 正确的转换应该从 1 开始,每次循环加 1,直到 等于 0。
观察1。 大语言模型在代码翻译过程中也会产生类似的错误模式。 多年来,多个最先进的大语言模型(OpenAI, 2022; Li 等人, 2023; Nijkamp 等人, 2022; Wang 等人, 2023; Touvron 等人, 2023; Rozière 等人,2023;Chen 等人,2021;Zheng 等人,2023) 已被提出,并通过使用来自开源项目的数百万代码片段进行预训练,显示出强大的翻译能力。 然而,它们在执行代码翻译任务时都会产生某些类型的错误,其中包括(1)编译错误,(2)运行时错误,(3)功能错误和(4)非终止执行。 我们发现这些错误的根本原因非常相似(例如导入包失败、循环边界错误、操作员错误等)。 通过识别代码中重复出现的常见错误类型,我们可以使用统一的纠错操作来修复这些错误,使纠错过程更加自动化和可靠。
观察2。 现有的基于神经机器翻译(NMT-based)的模型不具备普遍纠正错误的能力,而使用大语言模型纠正错误的成本相对较高。 几个基于 SOTA NMT 的模型(Jiang 等人,2023;Meng 等人,2023;Ye 等人,2022b,a;Jiang 等人,2021)通过大量训练显示出强大的错误修复能力的标记数据。 然而,它们都不具备强大的分析推理能力来自动修复图1所示的错误。 如果他们有限的训练数据中没有类似的修复模式,就很难正确修复错误,因为他们都无法理解并推理在代码中添加新的逻辑来修复。 与当前使用有限训练数据的基于 NMT 的模型不同,大语言模型是直接使用来自开源项目的数百万个代码片段进行预训练的。 通过利用高质量的提示或微调,它可以理解代码中的翻译错误并执行修复(Xia等人,2023;Xia和Zhang,2023)。 然而,使用大语言模型来纠正翻译错误需要大量的计算资源,成本很高。
2.2. 关键想法
基于上述观察,我们通过大语言模型设计了带有自动校正器的代码翻译框架,即Rectifier,其主要思想如下。
(1) 紧凑纠错模型。 我们提出了一种有效的纠错模型,能够吸收从大语言模型生成的翻译错误中收集到的纠正模式。 该模型表现出自动纠正由不同大语言模型引起的类似错误的能力。 与需要大量计算资源和相关成本的大语言模型相比,我们的紧凑模型在 CodeT5+ 220M 上进行了微调,所需的资源比大语言模型的对应模型(例如 Llama 2 13B)要少得多。
(2) 带校正器的通用翻译模型。 当一个小说大语言模型进行代码翻译时,它往往会表现出类似的翻译错误模式。 我们的模型吸收了这些模式,并且可以应用于纠正一系列大语言模型产生的错误。 从本质上讲,我们的模型具有普遍的适用性,因为它不是为了纠正任何特定大语言模型中的错误而定制的,而是解决各种大语言模型中表现出的常见错误模式。 这强调了其与 LLM 无关的设计范式。
3. 整流器:通过大语言模型使用校正器进行代码翻译
3.1. 收集阶段
此阶段的目的是从大语言模型的输出中收集错误翻译。 这些错误将作为识别后续阶段错误模式的基础。 为此,我们需要解决三项任务:(1)及时准备,(2)翻译收集,(3)错误纠正。
3.1.1. 任务 1:及时准备
我们遵循与每个模型相关的工件、论文或技术报告中类似的提示(Nijkamp 等人,2022;Li 等人,2023;Rozière 等人,2023)。 大语言模型使用的提示包含三个重要组成部分,如图2所示:
-
•
源代码(标记为①)。 我们在代码翻译任务中为大语言模型提供了需要翻译不同语言(即Java、C++和Python)的代码。
-
•
任务描述(标记为②)。 大语言模型的描述构造为“将上述$SOURCE_LANG代码翻译为$TARGET_LANG。”。 翻译任务中使用的任务描述根据我们使用的源编程语言和目标编程语言而有所不同。
-
•
指示器(标记为③)。 ChatGPT 在推理过程中会输出大量描述性文本。 因此,我们需要一个严格的提示模板,让 ChatGPT 专注于翻译代码而不是描述性文本。 在本文中,我们遵循之前工作(Pan等人,2023a)中的最佳实践,并采用名为的相同提示''仅打印$TARGET_LANG代码,以“|End- of-Code|".''。 其他模型被指示生成“$TARGET_LANG”。

3.1.2. 任务2:翻译收集
通过语言模型(大语言模型)与修饰提示的交互,它遵循任务描述,以生成与所提供的源代码相对应的翻译代码。 值得注意的是,这些生成的翻译可能包含无关的对话和描述性文本。 为了隔离基本的代码段,我们使用正则表达式。 结果,任务2的执行产生了所有大语言模型翻译代码的编译。
3.1.3. 任务 3:纠正错误
我们利用数据集中的测试用例来验证大语言模型生成的代码的准确性。 如果翻译后的代码成功通过所有测试用例,则视为有效翻译;否则,标记为无效。 翻译错误分为四类:(1) 编译错误、(2) 运行时错误、(3) 功能错误和 (4) 非终止执行。
随后,我们对无效代码进行较小的更正,以确保它通过所有测试用例,从而产生我们所说的有效代码。 大语言模型产生的许多错误可以通过直接调整来纠正,例如添加包、修改运算符或调整边界条件。 有效代码和无效代码的区分因素在于特定的错误语句,这有助于模型从错误中学习。 这些有效和无效代码对随后用于后续阶段的错误模式学习。
3.2. 参数和推理阶段
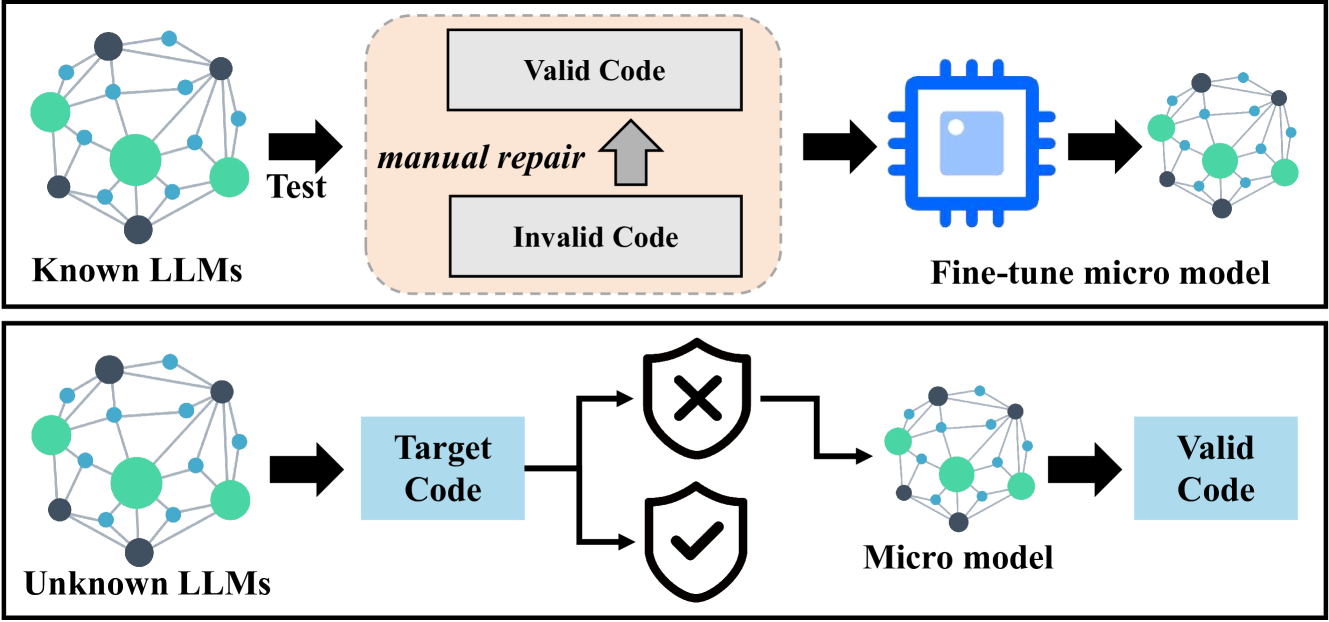
如图3所示,我们利用收集阶段获得的有效和无效代码对来生成生成的模型。 微调的目的是为了同化已建立的大语言模型产生的错误模式。 该生成模型的输入包括大语言模型生成的错误翻译,输出是正确的代码。
在我们的研究中,我们使用 CodeT5+ 模型(Wang 等人,2023) 作为底层大语言模型,尽管它可以很容易地替换为各种其他生成的大语言模型,例如 Llama 2 (Touvron 等人,2023)。 详细的微调过程在4.3节中阐述。
经过微调,CodeT5+ 可以有效地学习代码翻译中与大语言模型相关的错误模式,尤其是在集合内。 随后,我们利用微调后的CodeT5+来纠正测试集中的无效代码,其中包括CodeT5+以前未遇到过的模型(即未知的大语言模型,如图3所示) 。 在这里,我们将未知模型生成的错误翻译输入到经过微调的 CodeT5+ 中,然后 CodeT5+ 利用学习到的校正模式来找到当前错误翻译的解决方案,最终生成正确的代码。
4. 实验方法
4.1. 数据集收集和预处理
为了确保我们关于大语言模型翻译错误性质的研究结果的彻底性和有效性,我们利用了两个广泛认可的代码翻译基准:CodeNet 数据集(Puri 等人,2021) 和AVATAR 数据集(Ahmad 等人,2021)。 这些数据集之前已用于研究(Pan 等人,2023a;Szafraniec 等人,2022),涵盖三种非常流行的编程语言,即 C++、Java 和 Python。 这些选定数据集的详细特征及其各自的统计数据如表1所示。 每个数据集都配备了旨在验证代码翻译的测试用例。 具体来说,对于 CodeNet 和 AVATAR,测试包括输入数据和相应的预期输出。
| Dataset | Source Language | # Number | # Testcase | Target Language | # Translation |
| CodeNet | C++ | 200 | 200 | Java, Python | 400 |
| Java | 200 | 200 | C++, Python | 400 | |
| Python | 200 | 200 | C++, Java | 400 | |
| AVATAR | Java | 249 | 6255 | C++, Python | 498 |
| Python | 250 | 6255 | C++, Java | 500 | |
| # Total | - | 1099 | 13110 | - | 2198 |
4.2. 研究基线模型
基线。 为了全面比较现有工作的性能,在本文中,我们考虑了四种最先进的大语言模型,即 ChatGPT (OpenAI, 2022)、StarCoder (Li 等)人, 2023)、CodeGen (Nijkamp 等人, 2022) 和 CodeLlama (Rozière 等人, 2023),对于错误模式校正器,我们选择CodeT5+ (Wang 等人, 2023) 用于我们的整流器。 在这里,我们简要介绍这些方法,以使我们的论文自成体系。
OpenAI (OpenAI,2022)提出的ChatGPT是一个大型预训练语言模型,并通过人类反馈强化学习(RLHF)方法进行了微调。 它进行多轮自然对话,理解历史并产生连贯的响应。 ChatGPT 代表高级语言建模和对话式人工智能。 它的主要优势包括常识推理和对话连贯性。
李等人(李等人,2023)提出的StarCoder是专门为代码设计的大型预训练语言模型。 它使用大量代码数据进行预训练,以获取编程知识,并使用来自 GitHub 的许可数据进行训练,包括 80 多种编程语言、Git 提交、GitHub 问题和 Jupyter Notebook。 StarCoder 可以执行代码编辑任务、理解自然语言提示并生成符合 API 的代码。 StarCoder 代表了在编程中应用大型语言模型的进步。
CodeGen由Nijkamp等人(Nijkamp等人, 2022)提出,是一个从自然语言生成代码的人工智能系统。 它利用根据编程数据进行微调的大型预训练语言模型。 CodeGen 可以将自然语言描述翻译成多种语言的工作代码。 CodeGen可用于合成与指定功能匹配的代码并将生成的代码集成到项目中。
Rozière 等人提出的 CodeLlama (Rozière 等人, 2023) 是一组基于 Llama 2 构建的大型预训练代码语言模型。 它们在代码任务的开放模型中实现了最先进的性能,提供填充功能,支持大型输入上下文,并演示针对编程问题的零样本指令。 CodeLlama 是通过使用增加的代码数据采样进一步训练 Llama 2 创建的。 与 Llama 2 一样,作者对经过微调的 CodeLlama 版本应用了广泛的安全缓解措施。
Wang等人提出的CodeT5+(Wang等人,2023)是一系列代码编码器-解码器模型。 其组件模块可以通过多种方式组合以适应各种下游代码任务。 这种灵活性来自于作者设计的预训练目标的组合,以减少预训练和微调之间的差距。 这些目标包括针对跨语言代码和文本的单模态和双模态跨语言模型预训练任务,例如跨度去噪、对比学习和文本代码匹配。
4.3. 实验过程
数据分割。 我们将大语言模型分为两组(即用于错误模式校正器的大语言模型和用于代码翻译器的大语言模型)。 对于用于收集误差的大语言模型,我们采用数据分割方式:80%:10%:10%。 更准确地说,整个数据集分为 80% 的训练数据、10% 的验证数据和 10% 的测试数据。 对于用于推理的大语言模型,我们将大语言模型产生的所有错误作为测试数据。
模型实施。 对于StarCoder、CodeGen和CodeLlama,我们利用他们公开的源代码,并使用其原始代码中提供的默认参数进行推理。 所有这些模型都是使用 PyTorch (Paszke 等人, 2019) 框架实现的,完全采用 Huggingface (hug, 2024) 上托管的预训练模型。 微调过程在 NVIDIA RTX 3090 显卡上进行。 考虑到 ChatGPT 的代码不公开,我们通过 API 支持封装 ChatGPT 功能,以 Python 实现翻译(chatgptendpoint,2023),并遵守最佳实践指南(Shieh,2023) 对于每个提示。 我们使用 ChatGPT 系列中的 GPT-3.5-Turbo-0301 模型,这是我们实验中统一使用的版本。
5. 实验结果
为了研究不同大语言模型在代码翻译中的错误模式并使用校正器评估我们的代码翻译框架,我们的实验重点关注以下研究问题:
-
•
RQ-1大语言模型在代码翻译中的有效性。 最先进的代码大语言模型在各种基准测试中的代码翻译表现如何?
-
•
RQ-2 翻译错误类别。 不成功的翻译有哪些不同类型的错误模式?
-
•
RQ-3整流器在错误修复中的有效性。 (1)从现有错误中学到的模式可以用来修复未知大语言模型产生的错误吗? (2)不同的误差源如何影响模型的整体性能(即模型的鲁棒性)?
5.1. RQ-1:大语言模型在代码翻译中的有效性
RQ1-分析程序。 在这项研究中,我们描述了四类翻译错误:(1)编译错误,(2)运行时错误,(3)功能错误和(4)非终止执行实例。 我们刻意排除了静态评估指标,例如精确匹配、语法匹配、数据流匹配(任等人,2020)、CodeBLEU (任等人,2020)和CrystalBLEU (Eghbali 和 Pradel,2022),因为我们的主要目标是通过编译和执行来验证翻译的可行性。 值得注意的是,静态指标在代码合成的背景下可能会产生误导(Chen 等人,2021)。 具体来说,语言模型可能在这些指标上产生看似不错的分数,但生成的代码由于编译或运行时问题而被证明无法执行(Ahmad 等人,2021;Chen 等人,2021)。
RQ1-结果。 大语言模型翻译代码的性能。 表2显示了大语言模型代码翻译的详细结果。 我们可以观察到:(1)ChatGPT、StarCoder 和 CodeLlama 的表现远优于 CodeGen,尤其是 ChatGPT 表现最好(CodeNet 数据集上的 Java Python 翻译除外),翻译成功率为 38.0 %85.5%。 (2) 大语言模型在翻译 C++ Java 或 Java C++ 时,通常会取得较好的翻译效果,如在 CodeNet 数据集上翻译 C++ Java(即 85.0%),在 CodeNet 数据集上翻译 Java C++(即 85.5%),在 AVATAR 数据集上翻译 Java C++(即 73.1%)、85.5%),以及在 AVATAR 数据集上翻译 Java C++ (即 73.1%),这表明大语言模型在翻译同类型语言(如 Java 和 C++ 都是静态语言)时表现更佳。 (3)大语言模型在AVATAR数据集上的翻译性能低于CodeNet数据集上的翻译性能,这是由于翻译成功率与数据集中的测试用例数量(即200个测试用例)之间存在很强的相关性CodeNet 数据集中有 6,255 个测试用例,AVATAR 数据集中有 6,255 个测试用例,如表1所示)。 也就是说,现有的测试套件越严格,对翻译是否成功保留功能的评估就越好。
| Dataset | Source Language | Target Language | # Number | % Successful Translation | |||
| ChatGPT | StarCoder | CodeGen | CodeLlama | ||||
| CodeNet | C++ | Java | 200 | 85.0% | 63.5% | 3.5% | 67.0% |
| C++ | Python | 200 | 62.0% | 33.0% | 6.0% | 36.0% | |
| Java | C++ | 200 | 85.5% | 60.0% | 32.0% | 65.5% | |
| Java | Python | 200 | 57.5% | 25.0% | 6.0% | 43.0% | |
| Python | C++ | 200 | 80.5% | 57.0% | 35.5% | 62.5% | |
| Python | Java | 200 | 59.5% | 61.0% | 0.5% | 55.0% | |
| AVATAR | Java | C++ | 249 | 73.1% | 35.7% | 12.4% | 47.4% |
| Java | Python | 249 | 62.2% | 16.1% | 0.4% | 31.7% | |
| Python | C++ | 250 | 38.8% | 26.8% | 7.2% | 24.8% | |
| Python | Java | 250 | 38.0% | 26.4% | 1.6% | 24.8% | |
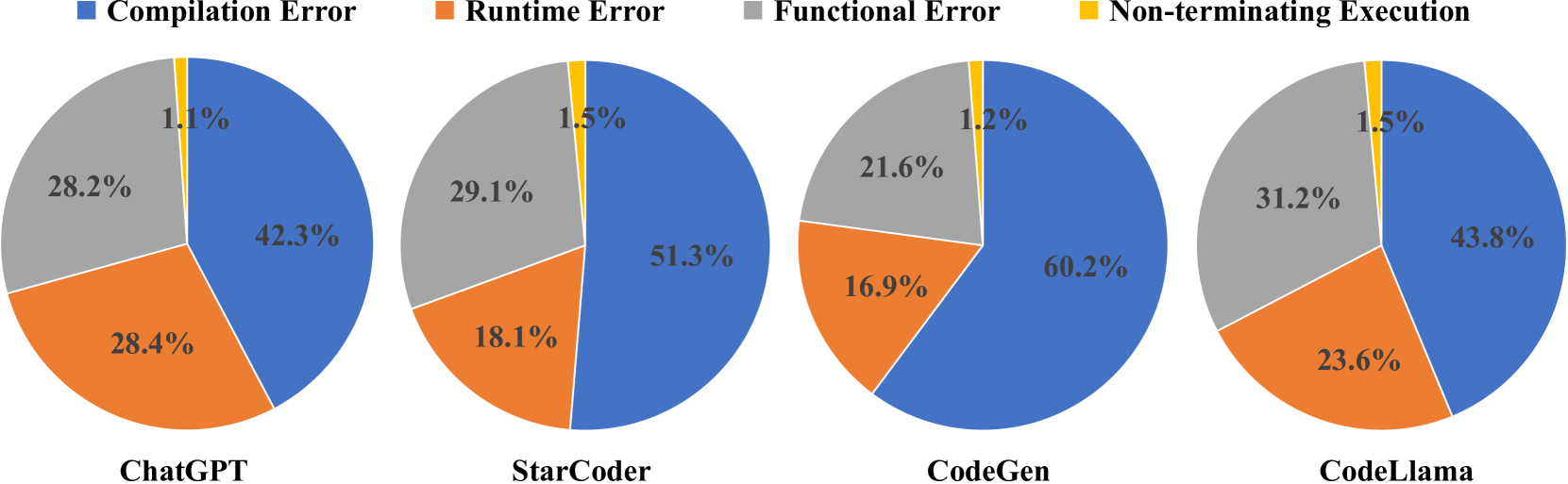
不成功翻译的细分。 先前的研究结果表明,在精心设计的基准测试上进行评估时,大多数大型语言模型(大语言模型)在代码翻译领域表现出了令人满意的性能。 为了实现我们的目标,我们随后根据各自的错误结果对不成功的翻译进行分类,其中包括:(1)编译错误,表示翻译后的代码无法成功编译的情况; (2)运行时错误,表示翻译后的代码可以编译但随后遇到运行时异常的情况; (3) 功能错误,指翻译后的代码编译和执行没有错误,但由于与源程序相比输出差异而导致测试失败的情况; (4)非终止执行,指翻译后的代码成功编译并启动执行,但未能终止的情况,通常是由于遇到无限循环或等待用户输入的状态。
表3和图4显示了大语言模型对每个数据集产生的不成功翻译的细分以及每个大语言模型翻译结果的比例。 我们观察到:(1)翻译产生的编译错误比例最高(表3所示为36.9%68.2%,42.3%60.2%如图4所示),这表明这些大语言模型很难理解目标代码语法。 (2)进一步细分每个PL的结果表明,Java和C++的语法相对严格,而大语言模型更容易生成语法正确的Python代码。 (3) 不成功翻译的下一个最常见的影响是功能错误(即表 3 中所示的 12.2%46.7% 和 21.6% 31.2% 如图4所示),表明即使代码在语法上正确并且在没有异常或运行时错误的情况下终止,它也不会保留在源语言中实现的功能。
| Dataset | CodeNet | AVATAR | ||||||||
| Source Language | C++ | Java | Python | Java | Python | |||||
| Target Language | Java | Python | C++ | Python | C++ | Java | C++ | Python | C++ | Java |
| Compilation Error | 68.2% | 47.5% | 66.5% | 39.1% | 61.0% | 64.7% | 55.7% | 36.9% | 48.9% | 50.1% |
| Runtime Error | 19.1% | 33.7% | 1.3% | 46.6% | 0.6% | 22.8% | 1.6% | 38.4% | 1.3% | 25.4% |
| Functional Error | 12.2% | 18.4% | 31.0% | 13.8% | 37.2% | 12.1% | 40.1% | 23.7% | 46.7% | 23.4% |
| Non-terminating Execution | 0.6% | 0.4% | 1.3% | 0.6% | 1.2% | 0.4% | 2.6% | 1.0% | 3.0% | 1.2% |
5.2. RQ-2:翻译错误类别
RQ2-分析程序。 为了深入了解翻译异常的本质,我们进行了严格的调查,包括对翻译不成功的根本原因进行人工审查。 本次调查围绕上述三个研究问题展开,最终建立了一个包容性的翻译错误分类系统。 此外,该研究还探讨了不成功翻译领域内每个错误类别的普遍性和空间分散性。 为了简化错误理解和分类中涉及的体力劳动,我们将注意力集中在来自 ChatGPT、StarCoder、CodeGen 和 CodeLlama 的 5,342 个不成功翻译实例上。 错误分类系统的构建需要四位人类注释者的协作努力,每个注释者都具有研究或软件工程方面的专业知识。 四位注释者(不是作者)检查了生成代码的 5,342 个错误。 对于每个错误,四位注释者独立研究翻译错误并对其进行分类。 标签完成后,注释者会比较他们的结果并讨论每个分歧,直到达成共识。 在此过程中,我们的 Cohen’s Kappa (Cantor,1996) 值为 0.80,这表明基本一致。 这项工作涵盖了表 1 中列出的所有十个翻译对的不成功翻译。
RQ2-结果。 我们生成了一个类别,分为六组根本原因(表4):(1)语言之间的语法差异,(2)语言之间的语义差异,(3)依赖错误,(4)逻辑错误,(5) 数据相关错误,(6) 模型特定错误,以及 (7) 其他。 在本节的其余部分中,我们将通过说明性示例讨论类别组。
| Category of Translation Errors | ChatGPT | StarCoder | CodeGen | CodeLlama |
| Syntactic difference between languages | 24.4% | 29.0% | 30.1% | 26.5% |
| Semantic difference between languages | 1.2% | 1.0% | 1.7% | 1.3% |
| Dependency error | 16.8% | 10.3% | 15.2% | 14.7% |
| Logic error | 8.0% | 9.8% | 8.5% | 11.8% |
| Data-related error | 43.9% | 25.4% | 23.3% | 27.0% |
| Model-specific error | 0.7% | 20.7% | 16.5% | 14.2% |
| Others | 4.9% | 3.8% | 4.7% | 4.5% |
5.2.1. 语言之间的语法差异
在这一组中,存在一系列明显的差异,主要归因于语言大语言模型在代码翻译中无法有效管理编程语言(PL)之间的句法差异。 大语言模型经常模拟源 PL 的语法,即使它与目标 PL 不兼容。

例如,如图5所示,描述了从Python到Java的错误翻译的实例。 在这种情况下,大语言模型错误地合并了源语言中的 for...else 循环,这是 Java 语法中不允许的构造。
5.2.2. 语言之间的语义差异
具体来说,常见错误包括 API 行为不匹配和运算符使用不正确。 大语言模型可能会错误地将源 API 映射到目标 PL 方法,从而导致代码无法正确执行。 同样,不同的 PL 可能具有不同的运算符语法,从而导致不正确的翻译,从而导致意外错误。 如图6所示,当除数和被除数都是整数的情况下,Java中的/表示整数除法,而Python中的/表示正则除法。

5.2.3. 依赖错误
导入语句加载代码中使用的必要库、类和模块。 我们发现翻译经常会导致导入缺失或不正确,从而导致错误。 在许多错误中,当导入错误时,大语言模型很难翻译数据类型、方法等的定义和实现。
5.2.4. 逻辑错误
大语言模型在进行代码翻译时,可能会误解源代码的逻辑,产生错误的翻译逻辑。 此类别涵盖:(1) 不正确的循环和条件边界,(2) 包含源代码中未包含的逻辑,以及 (3) 删除源代码中的逻辑。 对源代码逻辑的更改将导致功能上的差异。
5.2.5. 数据相关错误
我们观察到许多错误源于数据处理中的不正确翻译,包括输入解析、数据类型和输出格式。 具体来说,大语言模型无法正确解析和从输入中提取值,为变量和返回值选择不合适的数据类型,并且输出格式不正确。
5.2.6. 特定于模型的错误
某些错误源于大语言模型设计的固有局限性。 例如,我们发现大语言模型在代码翻译时不输出任何目标语言代码,输出大量重复代码,或者大语言模型的词符大小超出,导致编译错误或不编译的问题。正在生成输出。
表 4 提供了翻译错误的详尽细目。 我们的观察如下:
-
•
ChatGPT 主要表现出与数据处理相关的错误,约占总错误的 43.9%。 这些主要表现为输入/输出差异。 幸运的是,这些错误可以通过基于模式的学习来纠正。
-
•
特定于模型的错误表示大型语言模型(大语言模型)特有的差异,例如非目标语言的代码输出。 这些错误通常会给解决带来更大的挑战。 值得注意的是,与其他大语言模型相比,ChatGPT 的此类错误发生率要低得多,这凸显了其在代码翻译方面的高度弹性。
5.3. RQ-3:通用模型(整流器)在纠错中的有效性
RQ3-分析程序。 RQ1的结果表明,大语言模型的大多数翻译都是由于引入了不同的错误而不成功,导致编译错误、运行时错误、功能错误和非终止执行。 在本节中,我们研究从这些错误中学习的模型是否可用于修复未知(新)模型生成的翻译错误。 我们手动修复了已知大语言模型(即 ChatGPT、StarCoder 和 CodeGen)生成的翻译错误,使用一系列无效-有效对来调整 Rectifier 的 CodeT5+ 模型。 然后,我们评估从相似错误模式中学习的微调 CodeT5+ 是否可以修复未知模型(即 CodeLlama)生成的错误翻译。
探索我们提出的框架的通用性及其独立于任何特定大语言模型模型运行的能力。 我们进行了交叉实验,依次从 ChatGPT、StarCoder、CodeGen 和 CodeLlama 中选择错误代码翻译,利用其余模型中的错误代码进行微调。 本质上,在这个实验中,我们进行了三个额外的实验:(1)从 StarCoder、CodeGen 和 CodeLlama 学习,在 ChatGPT 中测试,(2)从 ChatGPT、CodeGen 和 CodeLlama 学习,在 StarCoder 中测试,以及(3)从ChatGPT、StarCoder 和 CodeLlama,在 CodeGen 中进行测试。
RQ3-结果。 表5显示我们的整流器校正模型可以修复CodeLlama生成的翻译错误。 我们的模型从 ChatGPT、StarCoder 和 CodeGen 生成的错误中学习,并且可以修复 CodeLlama 模型生成的以前未学过的错误。 具体来说,它可以修复 CodeNet 数据集中 PythonJava 翻译中生成的 90 个错误中的 22 个。 总体而言,我们提供了一种有效的翻译错误修复模型,可以修复 6.4%(188 个中的 12 个)24.4%(90 个中的 22 个)范围内的错误。 上述结果表明,大语言模型在代码翻译任务中产生了类似的错误。 从现有代码翻译错误中学到的模式可以用来修复新的大语言模型生成的错误。
| Dataset | Source Language | Target Language | # Number | # Invalid | # Repair |
| CodeNet | C++ | Java | 200 | 66 | 6 (9.1%) |
| C++ | Python | 200 | 128 | 10 (7.8%) | |
| Java | C++ | 200 | 69 | 8 (11.6%) | |
| Java | Python | 200 | 114 | 16 (14.0%) | |
| Python | C++ | 200 | 75 | 7 (9.3%) | |
| Python | Java | 200 | 90 | 22 (24.4%) | |
| AVATAR | Java | C++ | 249 | 131 | 15 (11.5%) |
| Java | Python | 249 | 170 | 13 (7.6%) | |
| Python | C++ | 250 | 188 | 12 (6.4%) | |
| Python | Java | 250 | 188 | 18 (9.6%) |
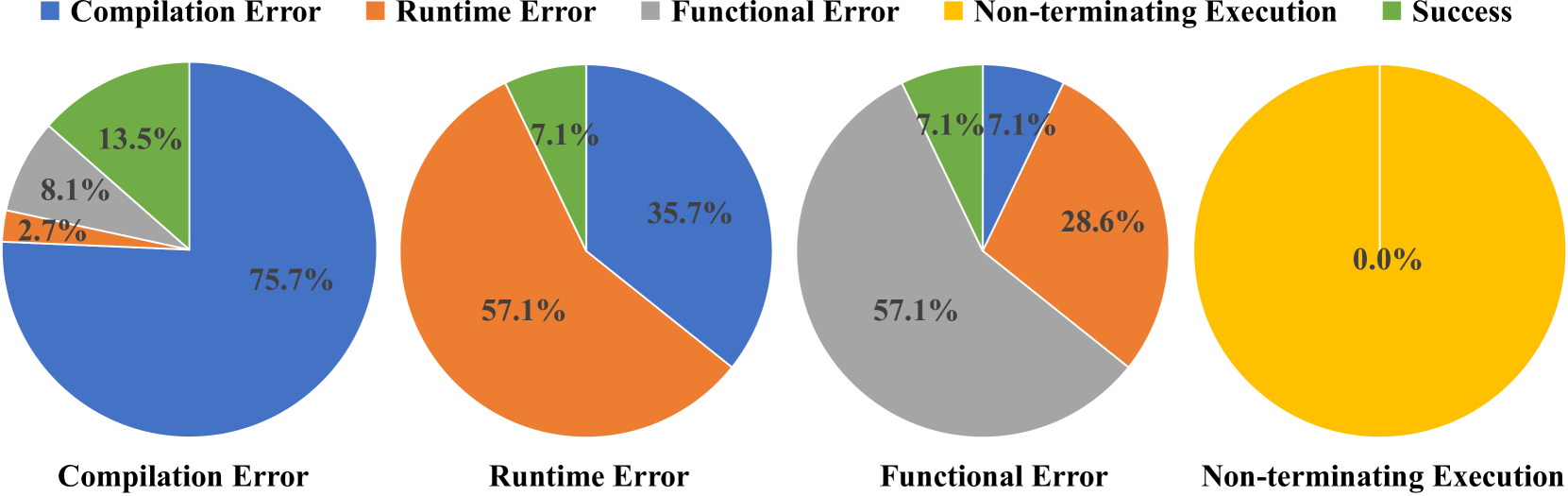
我们还想了解翻译错误在修复过程中是如何演变的。 为此,我们跟踪了不成功翻译的错误结果,以进一步说明错误修复的有效性。 为了更好的展示,我们使用饼图来表示修复操作后每种错误类型的分布。 如果错误被修复并成功通过所有测试用例,则视为成功。
图7展示了我们对CodeLlama的分析结果,我们得出以下观察结果:
-
(1)
该模型对编译错误更加敏感,可以成功修复 13.5% 的此错误。 这是因为大语言模型在翻译过程中产生了大量的编译错误(参见 5.1 节),因此包含了 CodeT5+ 微调数据集中的大部分编译错误示例。
-
(2)
对于其他错误,成功百分比较低(即运行时错误为 7.1%,功能错误为 7.1%),这表明这些错误更难缓解。
-
(3)
我们还观察到一些翻译结果升级的情况(即编译错误转换为运行时/功能错误)。 该模型无法完全恢复代码的功能,但它仍然修复了这些代码中当前存在的一些错误。
交叉实验。 为了研究不同的误差源如何影响模型的整体性能(即模型的鲁棒性),我们进行了交叉实验。 根据表6的结果,我们可以观察到:
-
(1)
我们的模型对 ChatGPT 生成的错误更加敏感。 在 RQ2 中(参见 在5.2节)中,我们提到ChatGPT产生的错误中有43.9%是由于数据相关的错误,特别是输入/输出格式错误。 此类错误在其他大语言模型中也经常出现,因此,通过有效的错误模式学习,我们的模型可以修复 4.6%43.2% 的 ChatGPT 错误。
-
(2)
尽管 StarCoder、CodeGen 和 ChatGPT 生成类似的错误模式,但 StarCoder 和 CodeGen 在翻译代码时会产生大量特定于模型的错误,例如输出与目标语言无关的代码。 此类错误难以修复,导致我们的模型在 StarCoder 和 CodeGen 上的修复性能较弱(即 3.8%28.4%)。
| Dataset | Source Language | Target Language | # Invalid / # Repair | ||
| ChatGPT | StarCoder | CodeGen | |||
| CodeNet | C++ | Java | 30/3 (10.0%) | 73/10 (13.7%) | 193/19 (9.8%) |
| C++ | Python | 76/17 (22.4%) | 134/38 (28.4%) | 188/40 (21.3%) | |
| Java | C++ | 29/4 (13.8%) | 80/6 (7.5%) | 136/10 (7.4%) | |
| Java | Python | 85/28 (32.9%) | 150/38 (25.3%) | 188/10 (5.3%) | |
| Python | C++ | 39/7 (17.9%) | 86/10 (11.6%) | 129/9 (7.0%) | |
| Python | Java | 81/35 (43.2%) | 78/8 (10.3%) | 199/20 (10.1%) | |
| AVATAR | Java | C++ | 67/6 (9.0%) | 160/9 (5.6%) | 218/19 (8.7%) |
| Java | Python | 94/11 (11.7%) | 209/16 (7.7%) | 248/20 (8.1%) | |
| Python | C++ | 153/7 (4.6%) | 183/7 (3.8%) | 232/9 (3.9%) | |
| Python | Java | 155/31 (20.0%) | 184/12 (6.5%) | 246/17 (6.9%) | |
6. 实例探究
为了进一步理解为什么我们的整流器在纠正翻译错误方面表现良好,我们进一步分析了一些例子作为案例研究,包括(1)语言之间的句法差异,(2)语言之间的语义差异,(3)依赖性错误,以及(4)数据相关错误。 我们还提供了两个难以修复的翻译错误的例子。 我们将详细说明每个错误的原因,并演示我们提出的模型如何详细修复它们。
6.1. 语言之间的语法差异
我们分析图8中语言间语法差异错误的例子(即AVATAR中的atcoder_ABC174_C.py)。 此 Python 代码的目的是找到最小整数 ,当以 10 为基数表示且每个数字都替换为 7 时,会得到一个可被 整除的数字。该循环模拟替换和验证过程。 存储当前测试值,并检查它是否能被整除。如果是,那么迭代次数 就是答案。 如果循环结束,没有找到的可行值,则不存在这样的,打印-1。 总的来说,这段代码通过模拟基数转换和取模运算,智能地搜索满足特定条件的最小整数。 翻译后的 C++ 代码中存在编译错误,StarCoder 错误地合并了源语言中的 for...else 循环,这是 C++ 语法中不允许的构造。 我们提出的模型成功识别了这个错误,修改后的 C++ 代码与 Python 代码具有完全相同的功能,通过了所有测试用例。

6.2. 语言之间的语义差异
我们分析图9中语言错误之间语义差异的示例(即CodeNet中的s369598583.Java)。 这段Java代码的功能是计算1到N之间所有正整数的位数之和。具体来说,它使用扫描器获取整数N,然后使用循环计算1到N之间所有数字的位数之和1和N,最后输出结果。 在计算过程中,它使用一个计数器count和一个变量next来按照特定的模式更新循环计算的范围。 CodeLlama 将此 Java 代码翻译成 Python 代码。 虽然它没有产生任何编译错误,但它没有意识到Java和Python语言中for循环的区别。 在图12中,Java代码的第8行是循环,而翻译后的Python代码的第6行是循环。 在Python的循环中,并不充当计数器循环变量,而是引用可迭代对象范围内的元素。 因此,Python代码中的时,仍然执行循环语句,这与Java代码的功能不同。 我们提出的模型通过在 for 循环中添加 语句成功修复了此错误。 因此,如果,则退出循环。

6.3. 依赖错误
我们分析了图10中的依赖错误示例(即AVATAR中的codeforces_421_A.py)。 此错误是依赖错误的典型示例,这是由于 Java 代码中使用了 Scanner 类但未导入相关包而发生的。 我们的模型添加了导入语句以成功修复错误。

6.4. 数据相关错误
调查集中在图 11 所示的数据相关异常(即 CodeNet 中的 s987117545.java)上。 此异常源于翻译后的 Python 代码中的输入解析差异。 具体来说,测试用例的输入包含位于一行上的两个数据元素,并以空格分隔。 利用 函数可以从同一行同时检索两个数据项。 因此,采用 进行读取操作对于准确捕获这两个数据项至关重要。 此类异常现象在其他大语言模型制作的众多翻译中也很普遍。 因此,适合识别和纠正此类错误模式的模型可以熟练地解决 ChatGPT 生成的这种特定类型的异常。

7. 未破案件
在本节中,我们提出了我们的模型未修复的两种类型的翻译错误:(1)逻辑错误和(2)模型特定错误。 我们将详细解释每种错误类型的原因,并演示为什么我们提出的模型无法修复它们。
7.1. 逻辑错误
我们检查了一个未解决的逻辑差异,以 AVATAR 中的 codeforces_203_A.java 为例,如图 12 所示。 该 Java 实现采用简单的动态编程算法来确定是否可以通过一系列递减步骤操作两个给定数字来产生目标值 。 具体来说,和表示初始值,而和表示在每个步骤中应用的递减量。 在 t 次迭代之后,我们检查是否存在对 和 的递减调整组合,产生等于 的总和。 如果存在这样的组合,则输出“YES”;否则输出“NO”。
在 ChatGPT 将此 Java 代码转换为 Python 代码的过程中,无意中对逻辑进行了更改。 具体来说,Java 代码中第 12 行和第 14 行的语句 和 被错误地转录为 Python 代码中第 9 行和第 11 行的语句 和 。 这导致了相对于原始 Java 代码的语义发生了变化,导致测试用例失败。 遗憾的是,由于缺乏修复特定逻辑错误的既定模式,我们的模型无法纠正这种形式的差异。 唯一的办法就是理解底层语义逻辑和源代码的精确实现。

7.2. 特定于型号的错误
我们检查了一个未解决的特定于模型的异常,例如 AVATAR 中的 atcoder_AGC002_A.py。 如图13所示,当CodeGen尝试将Python代码转换为Java时,它始终生成大量无关且无意义的代码。 遗憾的是,我们的模型无法纠正此代码以成功清除测试用例。
这种类型的异常在 CodeGen 执行代码翻译时经常出现,凸显了其目前在鲁棒性方面的局限性。 这种限制进一步导致我们的模型在解决 CodeGen 相关问题时表现不佳,因为它缺乏专门针对和解决这一特定挑战的能力。

8. 有效性的威胁
我们研究的威胁主要来自以下几个方面。 第一个威胁是我们研究结果的普遍性。 我们的方法在两个数据集:CodeNet 和 AVATAR,以及三种程序语言:Java、Python 和 C++ 上进行了评估。 我们的方法的性能可能因其他编程语言和数据集而异。 然而,所选数据集是众所周知的基准,并已在文献中广泛使用(Pan等人,2023a;Szafraniec等人,2022)。 研究了三种编程语言(PL),也是工业中广泛使用的主要 PL。 我们鼓励未来对更多 PL 和数据集进行研究。 第二个威胁来自 RQ2 中翻译错误的手动分类(第 5.2 节)。 为了减轻威胁,我们选择了 4 名具有 2-4 年软件开发经验的人工注释者(非作者),他们独立分析了错误。 他们通过多次讨论解决了分歧。 整个过程的 Cohen’s Kappa 值为 0.8,表明基本一致。
9. 相关工作
9.1. 大语言模型
大语言模型 (Large Language Models) (Brown 等人, 2020) 自从自然语言处理的进步以来,大语言模型已被广泛采用,使得大语言模型能够通过数十亿个参数和数十亿个参数进行良好的训练训练样本的数量,从而为大语言模型采用的任务带来了很大的性能提升(Yin and Ni, 2024; Yin, 2024; Bang 等人, 2023; Ouyang 等人, 2022)。 开源大语言模型(例如CodeLlama (Rozière 等人, 2023)和CodeGen (Nijkamp 等人, 2022))因其出色的生成能力而受到广泛关注。能力。 通过微调,这些大语言模型可以轻松用于下游任务(Radford等人,2018;Zhang等人,2024;Ni等人,2023;Yin和Ni,2024)或被提示(Xia和Zhang,2023;Xia等人,2023;Yin,2024;Liu等人,2023b),因为他们被训练成具有通用性,并且可以从不同领域的数据中捕获不同的知识。 微调用于通过在特定数据集上迭代模型来更新特定下游任务的模型参数,而提示可以通过提供自然语言描述或下游任务的一些示例来直接使用。 与提示相比,微调的成本较高,因为它需要额外的模型训练并且使用场景有限,特别是在没有足够训练数据集的情况下。
在本文中,我们构建了一个名为“整流器”的微观模型(平衡效率和成本),同时提示大语言模型执行代码翻译任务。 通过提供对所需任务进行编码的自然语言提示,大语言模型可以在不修改其参数的情况下生成输出。
9.2. 代码翻译
传统的代码翻译方法依赖于基于规则的方法,例如 C2Rust (C2R, 2024)、C2Go (C2G, 2024) 和 2to3 (2to, 2024) 它将 C 转换为 Rust 和 Go,或者将 Python 2 代码转换为 Python 3。 近年来,随着深度学习技术的发展,基于神经机器翻译(NMT)的技术得到了广泛的研究。 随着深度学习的最新进展,神经机器翻译(NMT)技术已成为代码翻译研究的主要焦点。 Chen 等人 (Chen 等人, 2018) 为此任务提出了一种开创性的树到树神经架构。 他们将程序解析为 AST,并将其转换为二叉树,然后将这些树输入基于 Tree-LSTM 的编码器-解码器神经模型。 顾等人(Gu等人, 2017)提出了DeepAM,一种RNN序列到序列模型,可以自动提取语言对之间的API映射编程。 TransCoder (Roziere 等人, 2020) 率先将无监督机器翻译技术应用于程序翻译,并在大规模单语言代码库上进行训练,以在 C++、Java 和 Python 之间进行翻译。 然后,TransCoder-ST (Roziere 等人,2021) 通过在回译过程中使用自动化单元测试过滤掉无效翻译来增强 TransCoder,减少噪音并进一步提高翻译性能。 然而,TransCoder 和 TransCoder-ST 仍然需要在大型单语代码语料库上进行昂贵的预训练。 他们还很难推广到预训练期间未见过的语言。 Fang 等人 (Liu 等人, 2023a) 提出了一种新的无监督程序翻译方法 SDA-Trans,利用语法结构和领域知识来增强模型的跨语言迁移能力。 SDA-Trans 在程序翻译方面取得了令人印象深刻的性能,可与大规模预训练模型相媲美,尤其是在未见过的语言翻译方面。
最近,在代码上训练的大型语言模型,例如 Codex (Chen 等人, 2021)、StarCoder (Li 等人, 2023)、CodeGeeX (Zheng 等人, 2023)、CodeGen (Nijkamp 等人, 2022)、Llama 2 (Touvron 等人, 2023)、CodeLlama (Rozière 等人) ,2023) 和 ChatGPT (OpenAI,2022) 已经展示了强大的无监督代码翻译能力,并接受了来自开源项目的数百万个片段的训练。 然而,这些模型在翻译代码时仍然会产生某些常见的错误类型:(1)编译错误,(2)运行时错误,(3)功能错误和(4)非终止执行。 分析表明这些错误源于相似的根本原因,例如缺少包导入、循环边界问题、操作员错误等。通过识别翻译代码中这些重复出现的错误模式,我们可以开发统一的纠正操作,以更可靠的方式自动修复它们。 这使得纠错过程更加自动化和稳健。
10. 结论和未来的工作
在本文中,我们为基于 LLM 的代码翻译模型提出了一种与模型无关且高效的紧凑型纠错器,即 Rectifier。 通过分析基于LLM的代码翻译模型的错误模式,我们的方法吸收了这些模式,并且可以应用于纠正广泛的代码翻译大语言模型。 通过实证分析,结果表明我们的方法可以纠正不同基于 LLM 的翻译模型的翻译错误,例如 ChatGPT 翻译错误的 4.6%43.2%。 未来,我们计划测试整流器的不同较小模型,并将分析过程扩展到其他软件工程任务。
致谢
该工作得到了国家自然科学基金项目(批准号:62202419和No. 62172214),中央高校基本科研业务费专项资金(No.62172214) 226-2022-00064),浙江省自然科学基金(No. LY24F020008),宁波市自然科学基金(No. 2022J184)、浙江省重点研发计划(2021C01105)、道富浙江大学技术中心。
参考
- (1)
- C2G (2024) 2024. C2Go. https://github.com/gotranspile/cxgo
- C2R (2024) 2024. C2Rust. https://github.com/immunant/c2rus
- hug (2024) 2024. Hugging Face. https://huggingface.co
- 2to (2024) 2024. Python 2 to Python 3. https://docs.python.org/2/library/2to3.html
- rep (2024) 2024. Replication. https://github.com/vinci-grape/Rectifier
- Ahmad et al. (2021) Wasi Uddin Ahmad, Md Golam Rahman Tushar, Saikat Chakraborty, and Kai-Wei Chang. 2021. Avatar: A parallel corpus for java-python program translation. arXiv preprint arXiv:2108.11590 (2021).
- Bang et al. (2023) Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. 2023. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023 (2023).
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Cantor (1996) Alan B Cantor. 1996. Sample-size calculations for Cohen’s kappa. Psychological methods 1, 2 (1996), 150.
- chatgptendpoint (2023) chatgptendpoint. 2023. Introducing ChatGPT and Whisper APIs. https://openai.com/blog/introducing-chatgpt-and-whisper-apis.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021).
- Chen et al. (2018) Xinyun Chen, Chang Liu, and Dawn Song. 2018. Tree-to-tree neural networks for program translation. Advances in neural information processing systems 31 (2018).
- Eghbali and Pradel (2022) Aryaz Eghbali and Michael Pradel. 2022. CrystalBLEU: precisely and efficiently measuring the similarity of code. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–12.
- Gu et al. (2017) Xiaodong Gu, Hongyu Zhang, Dongmei Zhang, and Sunghun Kim. 2017. DeepAM: Migrate APIs with multi-modal sequence to sequence learning. arXiv preprint arXiv:1704.07734 (2017).
- Jiang et al. (2023) Nan Jiang, Thibaud Lutellier, Yiling Lou, Lin Tan, Dan Goldwasser, and Xiangyu Zhang. 2023. Knod: Domain knowledge distilled tree decoder for automated program repair. arXiv preprint arXiv:2302.01857 (2023).
- Jiang et al. (2021) Nan Jiang, Thibaud Lutellier, and Lin Tan. 2021. Cure: Code-aware neural machine translation for automatic program repair. In 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). IEEE, 1161–1173.
- Li et al. (2023) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. 2023. StarCoder: may the source be with you! arXiv preprint arXiv:2305.06161 (2023).
- Liu et al. (2023a) Fang Liu, Jia Li, and Li Zhang. 2023a. Syntax and Domain Aware Model for Unsupervised Program Translation. arXiv preprint arXiv:2302.03908 (2023).
- Liu et al. (2019) Kui Liu, Anil Koyuncu, Dongsun Kim, and Tegawendé F Bissyandé. 2019. Avatar: Fixing semantic bugs with fix patterns of static analysis violations. In 2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 1–12.
- Liu et al. (2023b) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023b. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. Comput. Surveys 55, 9 (2023), 1–35.
- Meng et al. (2023) Xiangxin Meng, Xu Wang, Hongyu Zhang, Hailong Sun, Xudong Liu, and Chunming Hu. 2023. Template-based Neural Program Repair. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1456–1468.
- Ni et al. (2023) Chao Ni, Xin Yin, Kaiwen Yang, Dehai Zhao, Zhenchang Xing, and Xin Xia. 2023. Distinguishing Look-Alike Innocent and Vulnerable Code by Subtle Semantic Representation Learning and Explanation. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1611–1622.
- Nijkamp et al. (2022) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2022. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474 (2022).
- OpenAI (2022) OpenAI. 2022. ChatGPT: Optimizing Language Models for Dialogue. (2022). https://openai.com/blog/chatgpt/.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
- Pan et al. (2023b) Jialing Pan, Adrien Sadé, Jin Kim, Eric Soriano, Guillem Sole, and Sylvain Flamant. 2023b. SteloCoder: a Decoder-Only LLM for Multi-Language to Python Code Translation. arXiv preprint arXiv:2310.15539 (2023).
- Pan et al. (2023a) Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lambert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. 2023a. Understanding the Effectiveness of Large Language Models in Code Translation. arXiv preprint arXiv:2308.03109 (2023).
- Pan et al. (2024) Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lambert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. 2024. Lost in translation: A study of bugs introduced by large language models while translating code. In 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE). IEEE Computer Society, 866–866.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32. Curran Associates, Inc., 8024–8035. http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf
- Puri et al. (2021) Ruchir Puri, David S Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, et al. 2021. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks. arXiv preprint arXiv:2105.12655 (2021).
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. 2018. Improving language understanding by generative pre-training. (2018).
- Ren et al. (2020) Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis. arXiv preprint arXiv:2009.10297 (2020).
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 (2023).
- Roziere et al. (2020) Baptiste Roziere, Marie-Anne Lachaux, Lowik Chanussot, and Guillaume Lample. 2020. Unsupervised translation of programming languages. Advances in Neural Information Processing Systems 33 (2020), 20601–20611.
- Roziere et al. (2021) Baptiste Roziere, Jie M Zhang, Francois Charton, Mark Harman, Gabriel Synnaeve, and Guillaume Lample. 2021. Leveraging automated unit tests for unsupervised code translation. arXiv preprint arXiv:2110.06773 (2021).
- Shieh (2023) Jessica Shieh. 2023. Best practices for prompt engineering with OpenAI API. OpenAI, February https://help.openai. com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api (2023).
- Szafraniec et al. (2022) Marc Szafraniec, Baptiste Roziere, Hugh Leather, Francois Charton, Patrick Labatut, and Gabriel Synnaeve. 2022. Code translation with compiler representations. arXiv preprint arXiv:2207.03578 (2022).
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- Wang et al. (2023) Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi DQ Bui, Junnan Li, and Steven CH Hoi. 2023. Codet5+: Open code large language models for code understanding and generation. arXiv preprint arXiv:2305.07922 (2023).
- Xia et al. (2023) Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In Proceedings of the 45th International Conference on Software Engineering (ICSE 2023). Association for Computing Machinery.
- Xia and Zhang (2023) Chunqiu Steven Xia and Lingming Zhang. 2023. Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT. arXiv preprint arXiv:2304.00385 (2023).
- Ye et al. (2022b) He Ye, Matias Martinez, Xiapu Luo, Tao Zhang, and Martin Monperrus. 2022b. Selfapr: Self-supervised program repair with test execution diagnostics. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–13.
- Ye et al. (2022a) He Ye, Matias Martinez, and Martin Monperrus. 2022a. Neural program repair with execution-based backpropagation. In Proceedings of the 44th International Conference on Software Engineering. 1506–1518.
- Yin (2024) Xin Yin. 2024. Pros and Cons! Evaluating ChatGPT on Software Vulnerability. arXiv preprint arXiv:2404.03994 (2024).
- Yin and Ni (2024) Xin Yin and Chao Ni. 2024. Multitask-based Evaluation of Open-Source LLM on Software Vulnerability. arXiv preprint arXiv:2404.02056 (2024).
- Zhang et al. (2024) Jian Zhang, Chong Wang, Anran Li, Weisong Sun, Cen Zhang, Wei Ma, and Yang Liu. 2024. An Empirical Study of Automated Vulnerability Localization with Large Language Models. arXiv preprint arXiv:2404.00287 (2024).
- Zheng et al. (2023) Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, et al. 2023. Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x. arXiv preprint arXiv:2303.17568 (2023).
- Zhong et al. (2010) Hao Zhong, Suresh Thummalapenta, Tao Xie, Lu Zhang, and Qing Wang. 2010. Mining API mapping for language migration. In Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering-Volume 1. 195–204.