科学模拟智能代理主动学习的可行性研究
摘要
高性能科学模拟对于理解复杂系统很重要,但它会遇到计算挑战,尤其是在探索广泛的参数空间时。 人们对开发深度神经网络(DNN)作为能够加速模拟的替代模型越来越感兴趣。 然而,训练这些 DNN 代理的现有方法依赖于大量的模拟数据,这些数据是通过昂贵的计算启发式选择和生成的——这是文献中尚未探索的挑战。 在本文中,我们研究了将主动学习训练纳入 DNN 代理的潜力。 这允许智能、客观地选择训练模拟,减少生成大量模拟数据的需要以及 DNN 代理的性能对预定义训练模拟的依赖。 在为具有源的扩散方程构建 DNN 代理的问题背景下,我们考虑了两种不同的 DNN 架构,研究了基于多样性和不确定性的策略选择训练模拟的有效性。 结果为开发智能代理的高性能计算基础设施奠定了基础,该基础设施支持由主动学习策略引导的动态生成模拟数据,从而有可能提高科学模拟的效率。
关键字关键词机器学习深度学习主动学习扩散求解器代理建模编码器-解码器
1简介
高性能科学模拟对于增进我们对复杂系统的理解至关重要,并允许对从分子相互作用到气候模式和天体物理学等现象进行精确建模。 这些由高性能计算 (HPC) 实现的模拟可以获得以前仅通过观测数据无法获得的见解,从而使研究人员能够探索多种假设场景并预测相应的系统行为。
然而,尽管 HPC 取得了进步,但随着日益复杂的仿真模型的计算需求超出了系统的容量,特别是在探索广泛的参数空间时,就会出现限制。 机器学习和深度学习的最新发展激发了人们对为这些科学模拟创建有效的替代近似的兴趣。 对于模拟的某些内部组件或整个模拟,这些替代物可以将昂贵的科学模拟大大加速几个数量级[1,2,3]。 其中,基于深度神经网络 (DNN) 的代理已成为优化多维空间中高性能科学模拟的强大工具[4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]。 这些方法既解决了与广泛模拟相关的计算挑战,又有助于提高科学探究的效率和速度。
尽管最近取得了重大进展,但构建 DNN 代理的流行方法涉及使用涵盖输入参数空间边界的广泛模拟数据集来训练这些模型。 然而,生成这些数据的计算成本即使不是过高,也是昂贵的。 此外,训练数据可能在参数空间的某些区域包括冗余子集,而在其他区域则不足,其中这种训练模拟的变化可能会导致不同的最佳替代。
在本文中,我们研究了将主动学习集成到 DNN 代理模型训练中的潜力,以长期建立智能代理的 HPC 基础设施,该基础设施可以智能地选择动态生成针对 DNN 代理构建的最佳训练模拟。 深度主动学习通常在缺乏大量预标注数据的情况下使用,它可以选择性地查询少量数据的标签,以实现需要使用大量标签数据才能实现的 DNN 性能。 在高性能仿真的 DNN 代理构建设置中,这将能够智能探索参数空间并选择性执行仿真运行,而不是在仿真模型的参数空间中进行随机或均匀采样。 这解决了与生成大量模拟数据相关的资源挑战,并减少了 DNN 代理对使用临时假设预定义的训练模拟的依赖(以及因假设差异而产生的不一致)。
然而,在构建用于高性能模拟的 DNN 代理时,主动学习的潜力尚未得到系统探索,从而留下了两个关键的知识空白。 首先,目前尚不清楚在被称为获取函数的具有代表性的基于不确定性和多样性的策略中,哪种类型的数据选择策略对于构建 DNN 代理更有效。 其次,虽然架构选择被认为是 DNN 代理的一个重要主题,但 DNN 代理的不同架构如何影响主动学习的性能尚不清楚。
在本文中,我们试图在具有源的扩散方程的特定背景下对上述关键差距提供初步见解。 在科学中,我们通常对某些与时间有关的物理量的变化率以及这种变化率如何取决于环境感兴趣。 对该过程进行建模的最常见方法是通过偏微分方程。 这个概念支撑着无数的现象,例如热传导中的扩散方程、量子力学中的薛定谔方程、流体动力学中的纳维-斯托克斯方程以及从电磁学到金融和生物学等领域的其他模型。 这些问题的复杂性通常由其性质以及特定的初始条件和边界条件决定,其解决方案从简单的静态答案到复杂的动态响应各不相同。 在这里,我们重点关注一个这样的实例作为用例——有源场景中扩散方程的平稳解。 尽管扩散过程在各种系统中普遍存在,但它带来了巨大的计算挑战,特别是在参数变化很大的环境中求解稳态和时变方程时。 当源和汇数量等因素发生波动时,这些复杂性会变得更加复杂,从而增加了模拟的计算需求[15]。 DNN 已被提议作为 PDE 求解器[16]。 特别是,卷积神经网络的成功主要归功于卷积层固有的位置编码。 或者,首次提出用于图像分割的 U-Net[17] 也已被用作 PDE 求解器[18]。 我们以过去的成功为基础,研究了不同主动学习策略在为该问题构建 DNN 代理时的有效性,同时考虑了之前工作中报告的 CNN 和 U-Net 架构。
作为第一个概念验证,我们在模拟主动学习环境中进行了上述研究,其中训练模拟的选择是在基于均匀采样离线生成的大型模拟数据数据集上进行的的参数空间。 我们的研究结果表明,基于不确定性的训练模拟选择,尤其是基于 DNN 替代项预测损失的训练模拟选择,有可能通过较少的模拟来提高 DNN 替代项的准确性。 我们进一步发现,为给定的感兴趣的科学模拟确定合适的 DNN 架构对于发挥 DNN 代理主动学习的优势至关重要。 这些结果为智能代理高性能计算基础设施的设计和开发提供了重要基础,以支持由主动学习引导的动态生成模拟数据,以实现提高效率和效率的最终目标。用于科学模拟的 DNN 替代构建的效率。
2相关作品
扩散求解器: 鉴于扩散过程在各个领域的广泛存在,扩散求解器是科学计算不可或缺的一部分。 有限元和有限差分等传统数值方法因其在某些情况下的鲁棒性和高效性而成为该领域的基石[19, 20],并且在某些情况下,这些方法可以相当优化的[21]。 然而,这些方法的有效性通常取决于特定因素,例如问题的几何形状、固有对称性和问题参数(例如,扩散率场、衰减率场等),这些因素可以限制了它们在更复杂场景中的适用性。 为了应对这些限制,DNN 已成为有前途的替代品,为加速传统上由这些数值方法处理的模拟提供了潜力[22,23,24,25,26,27]。 尽管他们做出了承诺,但在这种情况下部署神经网络仍然具有挑战性。 训练时间延长、精选数据集稀缺以及缺乏物理原理集成等问题可能会严重影响其准确建模扩散过程的性能和可靠性[28]。 解决这些挑战对于在扩散求解器中有效集成神经网络、确保科学计算的速度和准确性至关重要。
本研究中检查的主动学习方法将有助于解决为学习扩散求解器管理大型模拟数据集的挑战,据我们所知,这些数据集尚未进行过研究。
深度主动学习(DAL): 主动学习是机器学习中的一个领域,它处理增量智能选择数据来查询标签,以实现高模型性能和低标注成本[29]。 在深度学习的背景下,这种实践被称为深度主动学习(DAL),它导致了各种数据选择策略的发展。 这些策略可以分为基于不确定性的方法、基于多样性的方法和混合方法。 基于不确定性的方法主动选择 DNN 最不确定的示例。 此类方法的示例包括 DNN 损失 [30, 31]、熵 [32, 33]、BALD [34, 35] 的估计,边际采样[36, 37],以及基于softmax输出的最小置信度采样[38]。 基于多样性的方法旨在找到有效代表数据分布的不同样本的子集。 这些方法通常依赖于核心集选择 [39, 40] 或基于密度的聚类 [41, 42] 来查找最能代表分布的示例。整个未标记的数据池。 混合方法结合了基于不确定性和基于多样性的方法的优点[43,44,45,46,47,48,49]。
这些方法大多数都是专门针对图像分类任务而衍生的,而它们对于构建用于科学模拟的 DNN 替代项的好处却鲜有研究。
代理建模中的主动学习: 最近出现的一些研究探索了主动学习在 DNN 替代科学模拟中的作用。 [50]中提出了贝叶斯主动学习,在训练神经过程作为科学模拟的替代模型时,使用预期信息增益来选择训练模拟,并在反应扩散、热和反应方面进行测试。当地流行病和流动模型。 [51]中提出了一种主动学习方法,以减少光子器件建模的光学表面组件的神经网络代理模型的模拟次数。 他们提出了一种基于集成训练的获取函数,该函数根据误差度量选择示例。 在[52]中,构建了一个 DNN 代理,以在求解 PDE 约束优化的背景下将 PDE 参数链接到可观测量,其中获取函数基于使用 DNN 代理的优化目标函数并选择低于公差设置的“k”参数。 [53] 中提出了一种双网络(分类器和回归器)物理信息主动学习系统,名为 ADEPT(等离子体湍流主动深度集成)。 该框架旨在训练回旋湍流的替代模型,其主要目标是最大限度地减少所需的数据量。 分类器屏幕从未标记的池中识别潜在的候选者,回归器的认知不确定性用于策略性地选择模拟示例。
这些作品中考虑的主动学习方法是专门针对特定应用而导出的,并与 DNN 架构的特定选择相关联;在后两种情况下,采集功能的设计进一步与使用科学模拟的特定优化目标联系在一起。 到目前为止,还缺乏关于不同数据选择策略对 DNN 代理构建的影响的系统研究,以及 DNN 架构的选择如何影响它们。
3 背景:扩散解算器
扩散过程普遍存在于无数系统中,对于生物现象建模至关重要,但也带来了巨大的计算挑战。 在环境参数变化很大的生物环境中,解决稳态和动态扩散方程变得特别复杂。 这种复杂性在涉及波动元素(例如不同数量的源和汇)的模拟中进一步加剧,这是生物系统中的常见情况。 这些因素显着增加了计算量,凸显了对高效且稳健的扩散求解器的需求。 在生物系统中,扩散通常是理解营养物质运输、细胞信号传导和组织生长等过程的关键,因此准确模拟这些过程的能力对于增进我们对复杂生物机制的理解至关重要。
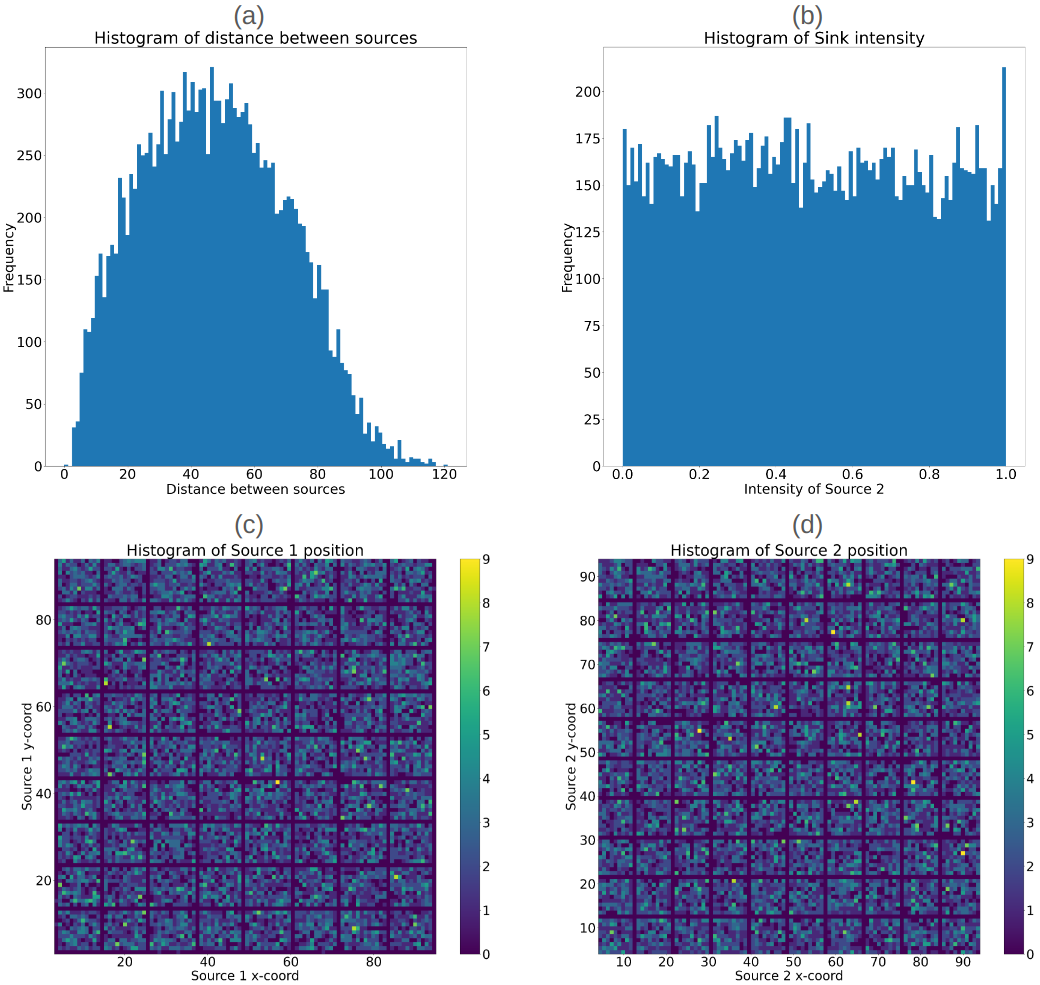
3.1数据生成
本文使用的数据源自生物多尺度建模[15],并对应于放置在具有充当汇的衰减率的晶格中的两个源。 为了从双源系统生成代表性初始条件和相应的稳态扩散场,我们考虑 100x100 晶格。 总共使用晶格中随机放置的两个源创建了 20k 个初始配置。 每个源的特征为 5 单位半径,其中一个源的恒定通量为 1,而其他源则具有随机分配的介于 0 和 1 之间的恒定通量值,并使用均匀分布随机分配。 晶格的其余部分的字段值为零。 对于每个初始条件,具有吸收边界条件的扩散方程的稳态解是使用 Julia [21] 中的微分方程包计算的。 我们将 表示为输入图像,表示两个源单元的初始条件布局, 表示输出图像,即扩散方程的预测稳态解。
扩散常数设置为,衰减率设置为,得到扩散长度。 该长度随着 的增加和 的减少而减少。 该长度的减小对应于场梯度的减小,如[54]中所述。 图1总结了一些关键参数的分布,包括两个源之间的距离(a)、一个源的强度(b)以及两个源的位置(c-d)。 数据的生成代码和数据可以参见[55, 15]。
3.2 DNN 代理
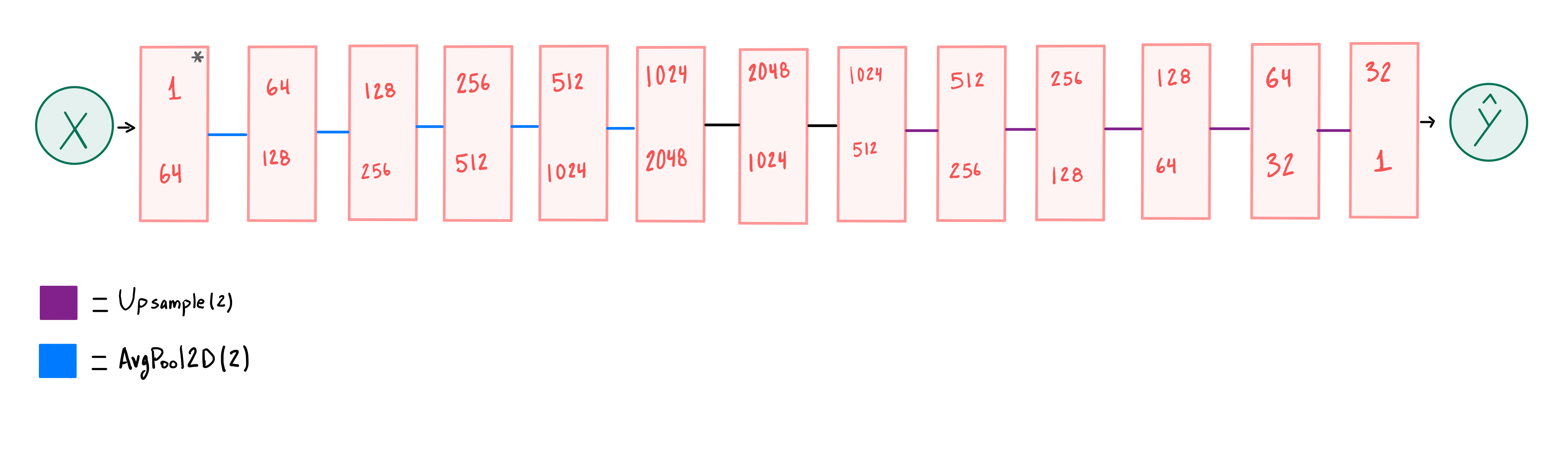
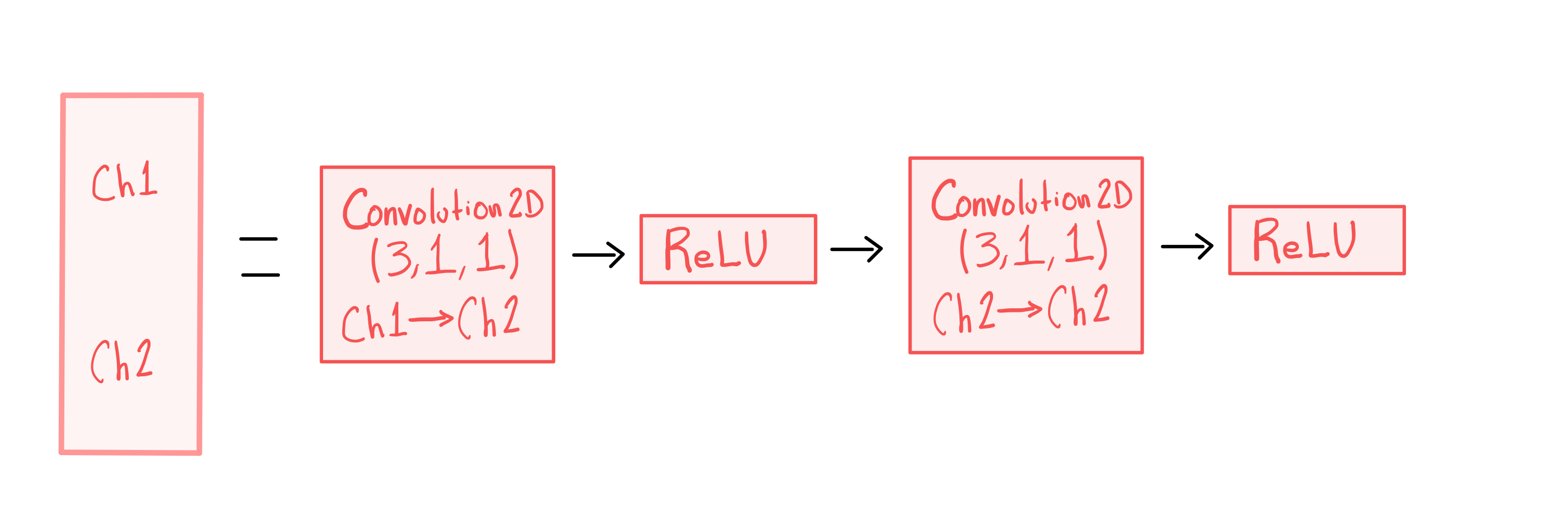
自动编码器的前六层执行平均池操作,在每一层之后按照{、、、、、、}的顺序将高度和宽度减半,同时在每一层之后按照{1、64、128、256、512、1024、2048}的顺序添加通道。 与[15]类似,接下来的六层减少了通道数量,同时以与上述相反的顺序增加了高度和宽度。
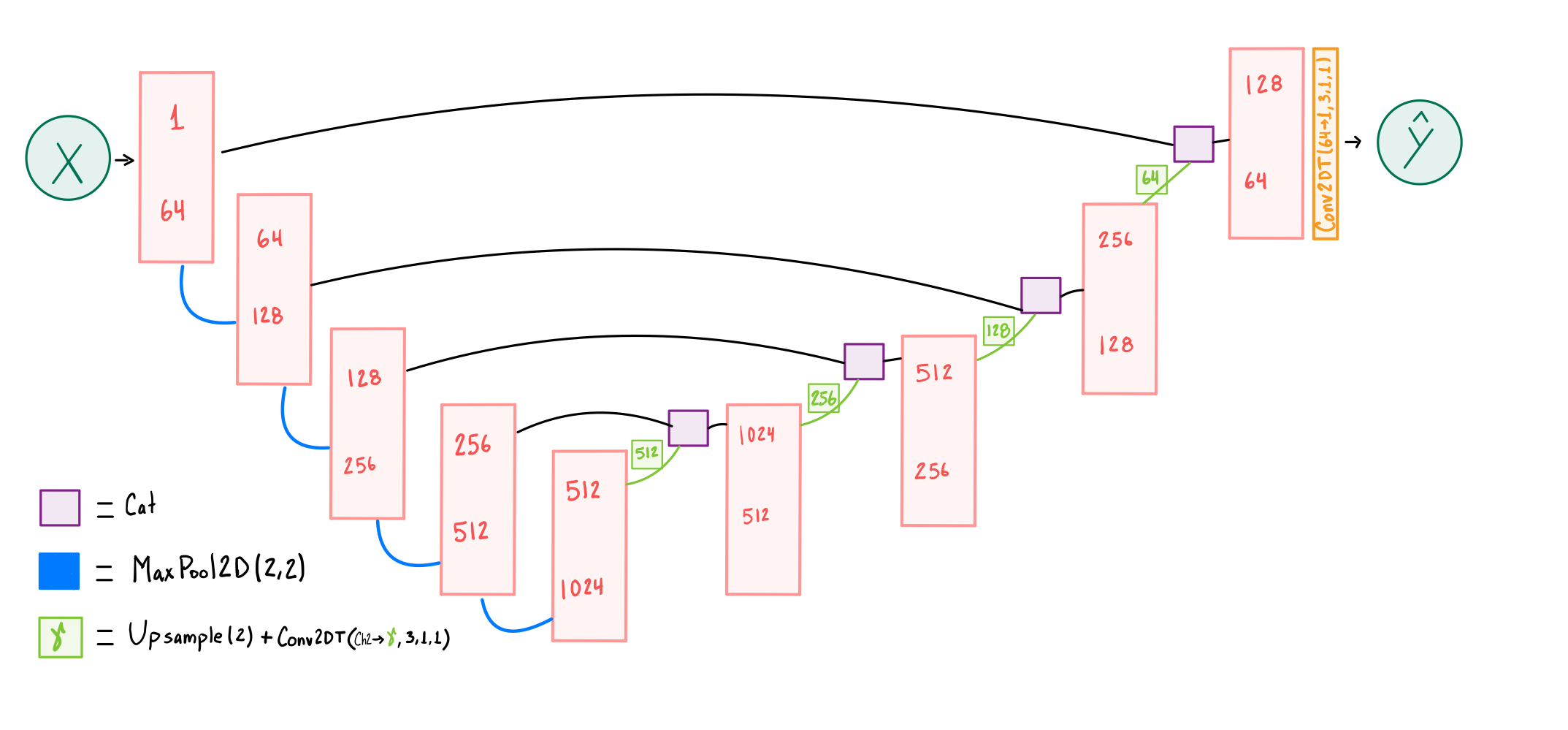
U-Net 的前四层执行最大池操作,与 CNN 自动编码器类似,按照{、、、和}的序列将高度和宽度减半,相应的通道为{1、64、128、256 和 512 },直到达到瓶颈,此时的大小为 ,通道为 。 随后的四层反转了这个过程,从瓶颈开始放大图像,并从缩小的一侧连接图像,以产生尺寸和通道与前面描述的相反的特征。 最后一层将通道数从 调整到 ,并将图像大小调整为 。
3.3 损失定义
输入图像中的一个源的强度为 1,而另一个源的强度为均匀分布的随机数。 两个源占据总图像空间的 2%,其余空间的强度为 0。 由于源和空间强度的分布不成比例,需要对源像素进行权重以避免高场值被冲掉。 因此,损失用指数权重来衡量,并用标量超参数 进行调节。
| (1) |
其中 设置为 1, 表示输入和目标元组。 在本文的其余部分中,我们将其称为加权平均绝对误差 (MAE)。 这里 表示内积, 是一个与 大小相同的酉向量,除了位置 等于一。 是一个向量,所有分量都等于 1,大小等于 。 那么 是对应于 中 位置的像素值的标量,而 则对应于所有 。 请注意,高像素值和低像素值将分别具有指数权重 和 。 这意味着与高像素相关的误差将比与低像素相关的误差具有更大的值。 损失函数是所有像素和给定数据集的平均值
4方法:扩散求解器的 DNN 代理的主动学习
4.1主动学习
令 为完整的输入和输出训练数据对,分为初始标记集 和剩余的未标记数据 。 我们最初使用 训练扩散代理模型,并评估 上的获取函数。 来自的大多数信息数据被标记并附加到,使得和。 该模型在标记数据上重新训练,并且该过程迭代,直到达到性能指标 或总标记数据大小达到 。
请注意,采集函数设计的一个重要考虑因素是,在选择样本来查询标签之前,样本的标签(在本例中为给定输入的模拟输出)不可用。 换句话说,采集目标不能利用样本的标签。 我们考虑三种主动学习获取函数并将它们与随机获取进行比较。 两个是基于不确定性的采集的代表,包括熵的使用[32]和DNN替代的估计损失[31]。 一种是考虑到训练样本多样性的采集的代表。
熵:
熵采样[32]选择模型最不确定的实例,通过网络“k”个输出预测的标准差来衡量。 我们使用 dropout 作为贝叶斯近似 [33] 来生成“k”个不同的输出预测并将熵评估为:
| (2) |
其中, 是 预测中的 像素, 是 的平均预测通过“k”次带有 dropout 的前向传递获得的像素, 是晶格中的像素总数。
时间输出差异 (TOD):
DNN 代理对新样本的损失是选择 DNN 最不确定的样本的另一个潜在标准:高损失样本有可能为 DNN 的优化提供更强的信号,而低损失样本则可能无法为 DNN 的优化提供更强的信号。对于 DNN 已经训练过的内容来说是多余的。 作为选择未标记数据样本的标准,未标记样本上的 DNN 损失无法根据实际标签(此处为模拟输出)计算,而必须进行估计。 遵循时间输出差异(TOD)测量[31],我们根据同一样本在不同学习迭代中的 DNN 输出差异来估计样本上的 DNN 损失:
| (3) |
其中 是模型 的输出之间的距离,其中参数 和 在 处评估,并且梯度优化步骤。 在我们的实验中,我们设置了。
为了支持 TOD 获得的结果,由于存在已经离线生成的模拟数据,我们还使用新样本的实际损失作为获取标准。 一旦我们在标记数据 上训练 DNN 代理,我们就会使用可用的模拟输出计算未标记数据 的损失,并选择 示例为下一次训练添加到 的最高损失。 请注意,这旨在为 TOD 的有效性提供参考,TOD 依赖于对未标记样本的 DNN 损失的估计,而不是在 DNN 代理主动学习期间使用的采集策略(因为真实损失在未标记样本上不可用)新样品)。
参数多样性:
为了在不查看模拟输出的情况下考虑训练模拟的多样性,我们通过用于生成模拟的参数来衡量多样性。 我们考虑输入初始条件中的六个参数,包括两个源()的坐标(cx和cy)、源之间的距离()和强度将第二个源 () 作为模型的重要标识符 ()。 在[39]之后,我们从未标记的数据创建一个核心集子集,以便选择与标记数据具有最大最小距离的示例。
| (4) |
我们从中选择具有最大计算参数多样性距离的示例。
4.2评估指标
加权MAE
我们通过计算损失来评估 DNN 代理的性能,即其加权平均绝对误差,如方程 1 中所定义。 每轮采集后,都会根据所有主动学习采集功能的测试数据计算度量。
感兴趣区域MAE
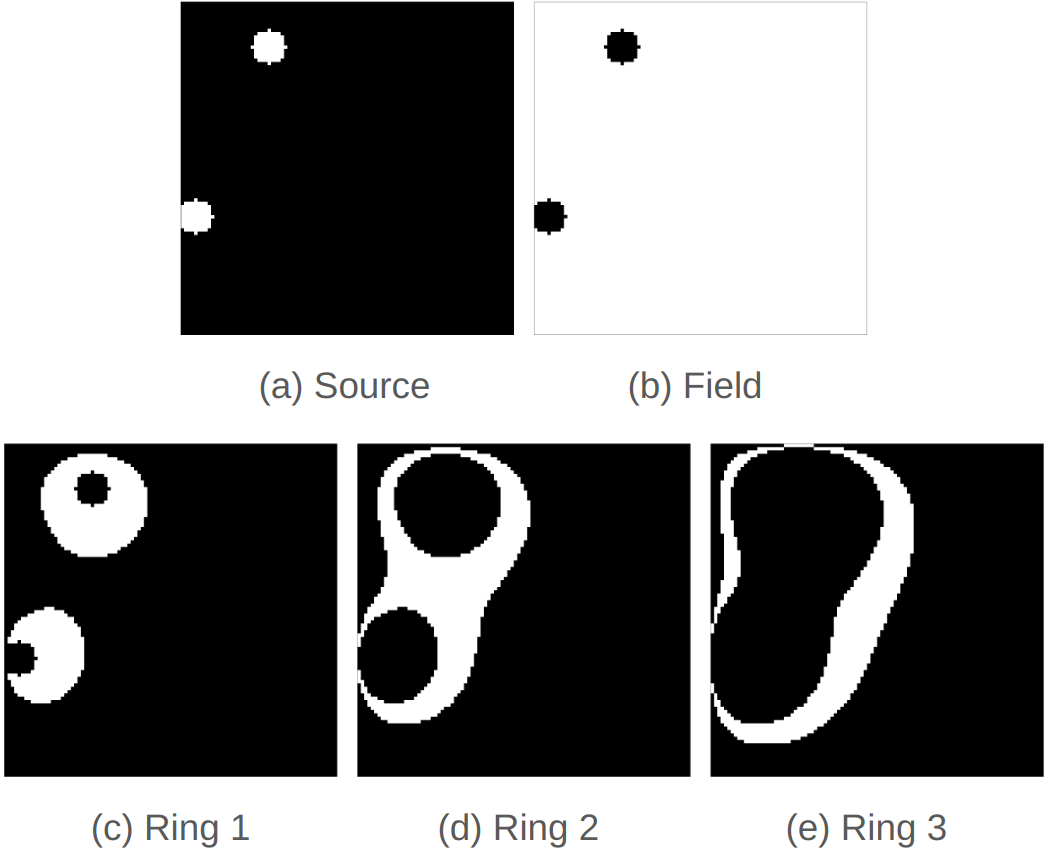
如前所述,源占据了总晶格空间的 2%,其中扩散图案从源发出并在场中迅速消失。 为了更好地理解主动学习对 DNN 代理准确性的影响,我们进一步检查了格子上不同感兴趣区域的 MAE,如图 4 所示:“源”和“场”的区域" 根据模拟的初始输入确定; “RINGS 1”、“RINGS 2”和“RINGS 3”的区域是基于使用范围 [0.2, 1.0]、[0.1, 0.2] 和 [0.05, 0.1],分别 - 代表到源的距离增加。
5实验
我们对3.1节中描述的双源数据进行了拆分。分为 16,000 个训练数据、4,000 个验证数据和 4,000 个测试数据。 我们训练了3.2节中定义的U-Net和CNN自动编码器结构。 我们将 16000 个训练数据分为初始 1000 个标记数据(具有可用模拟输出的样本)和 15000 个未标记池(没有模拟输出的样本)。 我们使用 4.1 中定义的 CNN 自动编码器的获取函数进行主动学习,并排除 U-Net 的熵获取函数,因为 前向传递的计算需求较大。 在每一轮采集中,都会选择新的未标记样本来查询模拟输出,并使用当前标记的数据集(输入-输出模拟 p 对)重新训练 DNN 代理。 重复此操作,直到所有 15000 个未标记样本都被标记。 在每一轮主动学习中,DNN 代理都经过 500 个 epoch 的训练,并根据最佳验证损失进行保存。 对于熵获取函数,在 CNN 自动编码器中,在第一和第二卷积层批量归一化后添加了 40% 的 dropout。 代码存储库可以在[56]中找到。
5.1主动学习习得功能比较
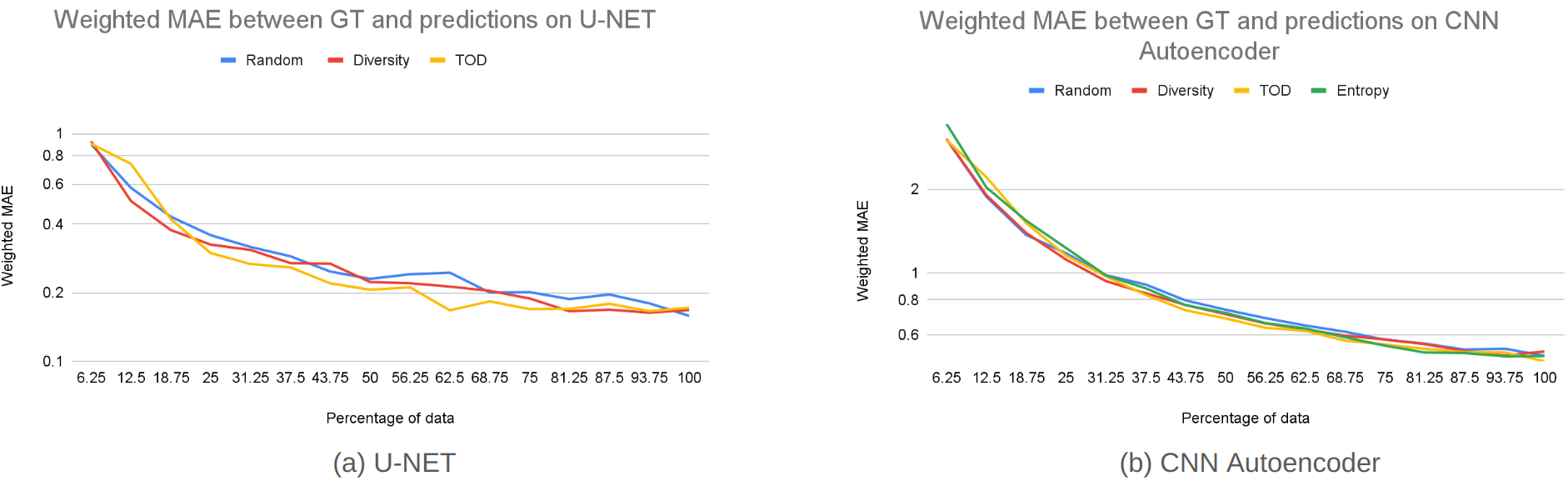
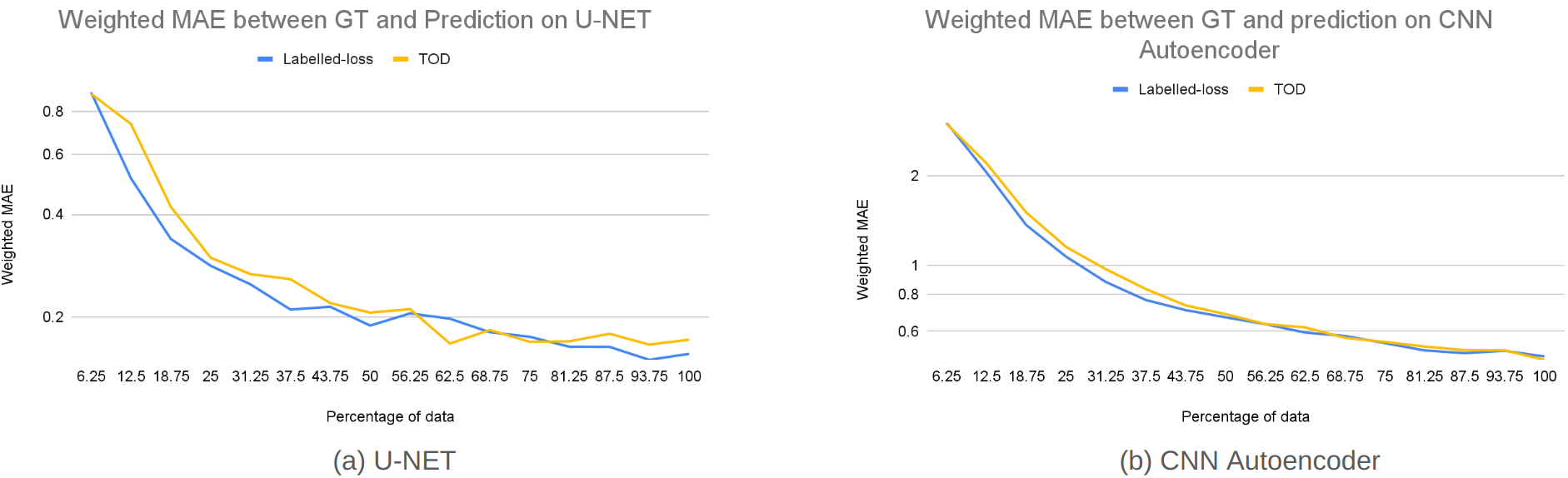
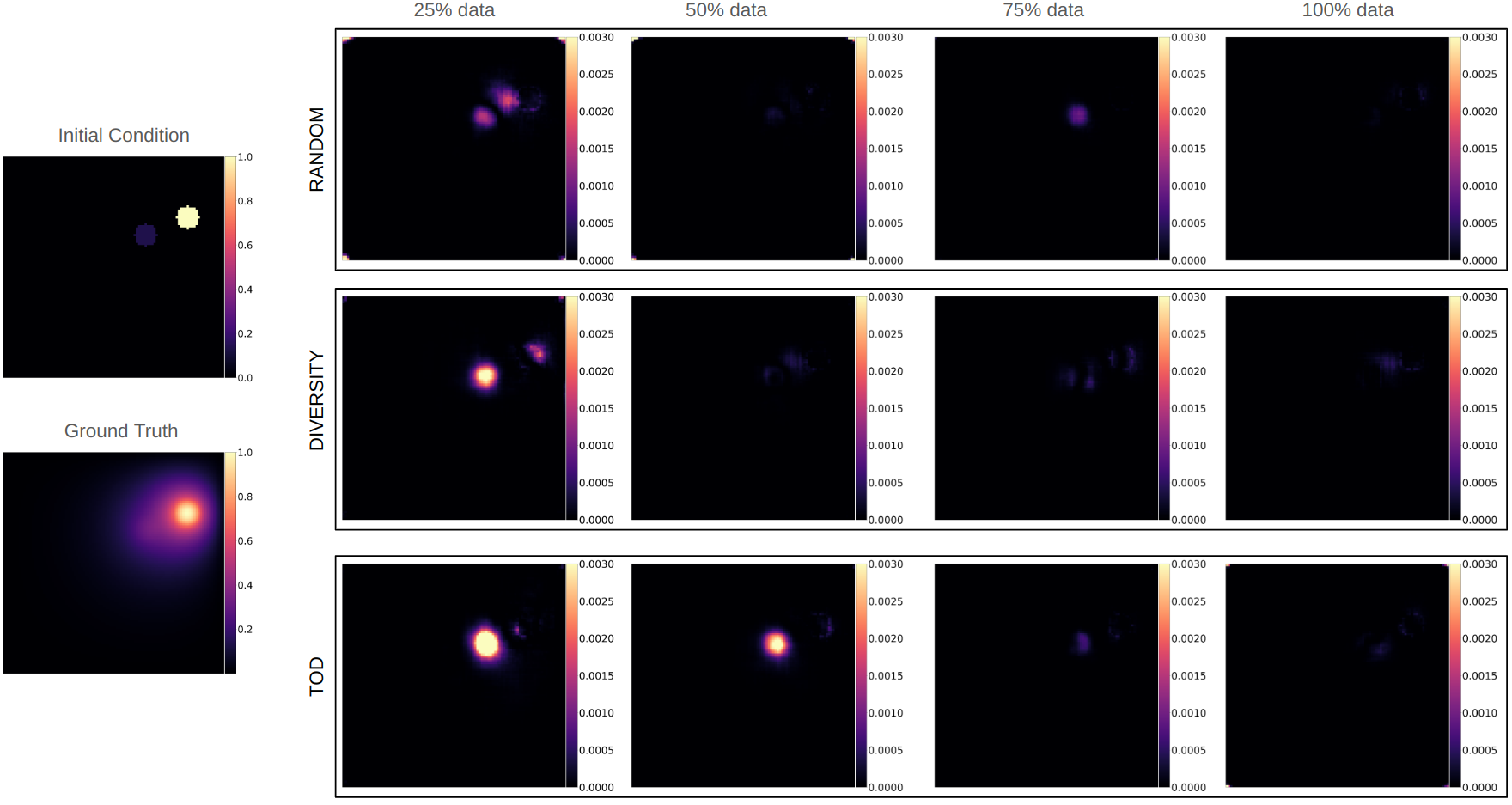
图6(a) 比较了不同采集函数在不同百分比的标记数据下的真实情况和 DNN 代理预测之间的加权 MAE,并针对 U-Net 架构的随机采集进行了评估。 如图所示,与使用相同数量的标记训练数据进行随机采集相比,主动选择 DNN 代理训练的模拟数据,特别是考虑代理的估计损失 (TOD),可以持续提高 DNN 性能。 请注意,尽管 TOD 依赖于 DNN 损失的估计,而没有模拟输出作为标签,但其性能与使用根据标签计算的实际 DNN 损失相当,如图 6(a) 所示。 相比之下,基于多样性的训练样本选择显示出有限的好处,其性能类似于或略好于随机采集。
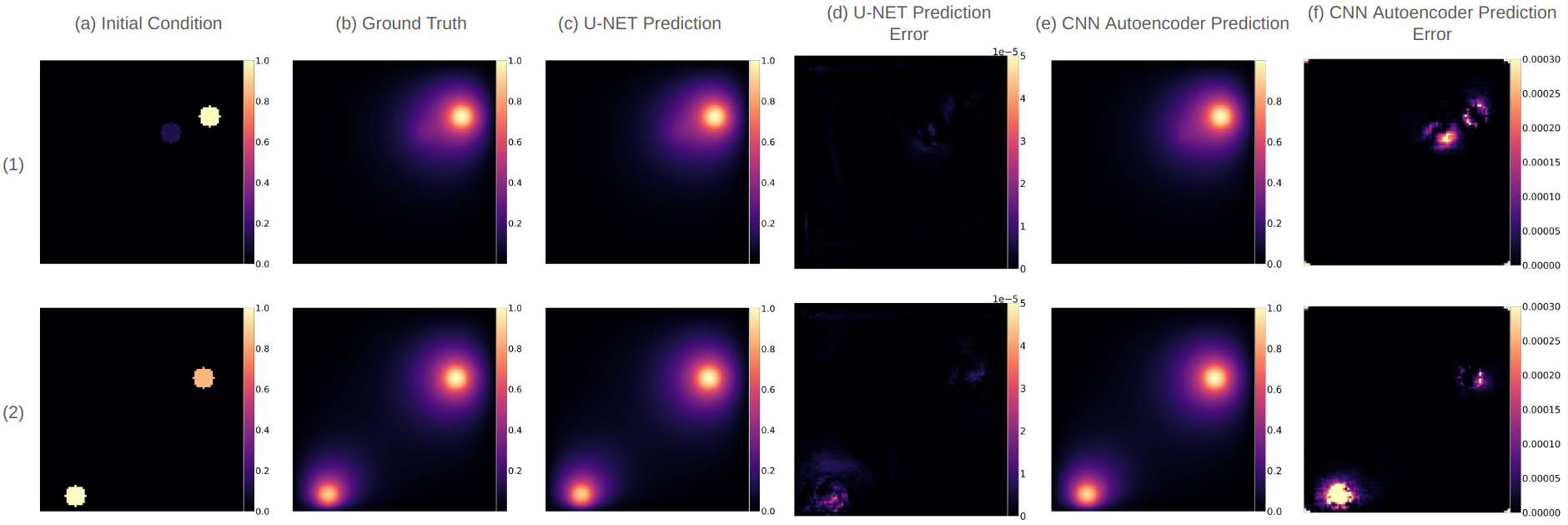
表 1 列出了模拟地面实况与 U-Net 测试数据预测之间的加权 MAE(按季度标记数据百分比计算),针对不同感兴趣区域进行计算,如图 4。 结果表明,在整个主动学习过程中,在相同数量的标记训练数据下,精心选择的训练模拟在所有习得策略中都实现了测试性能的提高(使用所有数据时除外):当使用标记数据的大小很小。 此外,这些改进在靠近源的区域(SRC、RING1)更为明显,那里的误差最高。 在 DNN 代理预测与 U-Net 架构上获得的真实模拟输出之间的绝对误差的视觉示例(图 7)中可以更好地理解这一观察结果。 正如预期的那样,在这三行中,随着训练数据的增加,错误逐渐减少。 然而值得注意的是,与随机训练相比,TOD 始终表现出较低的错误,特别是在靠近源的区域。
| Test Loss for U-Net | Test Loss for CNN Autoencoder | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DATA SIZES | DATA SIZES | |||||||||||
| 25% | 50% | 75% | 100% | 25% | 50% | 75% | 100% | |||||
| Random | 0.35784 | 0.23011 | 0.20112 | 0.15839 | Random | 1.17626 | 0.73720 | 0.57466 | 0.50335 | |||
| Diverse | 0.32529 | 0.22275 | 0.18868 | 0.16786 | Diverse | 1.11622 | 0.71032 | 0.57625 | 0.52171 | |||
| TOD | 0.29847 | 0.20616 | 0.16936 | 0.16616 | ALL | TOD | 1.15445 | 0.68581 | 0.55251 | 0.48098 | ||
| Entropy | 1.22860 | 0.71770 | 0.54734 | 0.50217 | ALL | |||||||
| Random | 4.92366 | 3.13306 | 2.75548 | 2.19644 | Random | 18.46547 | 11.72694 | 8.68628 | 7.60275 | |||
| Diverse | 4.41641 | 2.96436 | 2.52532 | 2.17466 | Diverse | 18.03126 | 11.03576 | 8.59056 | 7.99048 | |||
| TOD | 3.58799 | 2.91486 | 2.07431 | 2.33184 | SRC | TOD | 18.29991 | 10.79857 | 8.45668 | 7.16640 | ||
| Entropy | 18.48527 | 11.08221 | 8.19734 | 7.73362 | SRC | |||||||
| Random | 1.48035 | 0.94344 | 0.84136 | 0.63358 | Random | 5.33343 | 3.30900 | 2.63469 | 2.31095 | |||
| Diverse | 1.41882 | 0.92979 | 0.79940 | 0.69533 | Diverse | 5.01338 | 3.22305 | 2.65821 | 2.36826 | |||
| TOD | 1.15558 | 0.82894 | 0.69378 | 0.67992 | RING1 | TOD | 5.02481 | 3.06267 | 2.51028 | 2.19476 | ||
| Entropy | 5.52691 | 3.20892 | 2.48799 | 2.27788 | RING1 | |||||||
| Random | 0.34664 | 0.23742 | 0.19985 | 0.17337 | Random | 0.90847 | 0.57265 | 0.45602 | 0.39152 | |||
| Diverse | 0.30417 | 0.23389 | 0.18549 | 0.17087 | Diverse | 0.86313 | 0.54783 | 0.44496 | 0.41255 | |||
| TOD | 0.37816 | 0.21057 | 0.19488 | 0.17043 | RING2 | TOD | 1.00724 | 0.54755 | 0.43630 | 0.38701 | ||
| Entropy | 1.03330 | 0.59488 | 0.44425 | 0.39372 | RING2 | |||||||
| Random | 0.14096 | 0.09395 | 0.07416 | 0.06339 | Random | 0.27176 | 0.17411 | 0.13709 | 0.11720 | |||
| Diverse | 0.11276 | 0.08636 | 0.06804 | 0.07206 | Diverse | 0.25081 | 0.16577 | 0.13732 | 0.12434 | |||
| TOD | 0.15077 | 0.08337 | 0.07653 | 0.06613 | RING3 | TOD | 0.30949 | 0.17163 | 0.13658 | 0.11916 | ||
| Entropy | 0.31644 | 0.18589 | 0.13581 | 0.12081 | RING3 | |||||||
| Random | 0.28301 | 0.18254 | 0.15927 | 0.12500 | Random | 0.89296 | 0.55713 | 0.44174 | 0.38700 | |||
| Diverse | 0.25827 | 0.17783 | 0.15039 | 0.13497 | Diverse | 0.83903 | 0.54113 | 0.44492 | 0.39932 | |||
| TOD | 0.24457 | 0.16177 | 0.13815 | 0.13069 | FIELD | TOD | 0.87351 | 0.52009 | 0.42297 | 0.37143 | ||
| Entropy | 0.94582 | 0.54786 | 0.42197 | 0.38366 | FIELD | |||||||
总体而言,TOD 能够使用较小的数据量 (50%) 来实现随机采集使用较高数据量 (75%) 时可以实现的性能。 请注意,当使用 100% 数据时,我们预计不同采集策略之间不会存在显着差异。
5.2架构对主动学习的影响
图8首先比较了使用100%数据时U-Net和CNN自动编码器获得的结果,这表明与U-Net相比,CNN自动编码器作为扩散方程的替代架构并不是最优的。
图6(b) 比较了不同采集函数中不同标记数据百分比下 CNN 自动编码器的加权 MAE。 与图6(a)相比,很明显,尽管使用相同的采集函数和数据集,但与CNN自动编码器相比,U-Net架构中主动学习带来的性能提升更为明显:性能增益由于 CNN 自动编码器的主动学习对于随机训练来说至多是微不足道的。 这种区别在表 1 中提供的定量数据中也很明显。 类似地,如图 9 所示,真实模拟和替代预测之间的绝对误差图的视觉示例所示,与我们之前在 U-Net 上的观察相比,获取功能始终保持相似。
这些结果表明了一个有趣且重要的发现:为了主动选择训练模拟以在 DNN 代理的构建中发挥作用,首先为代理确定合适的(如果不是最佳的)DNN 架构非常重要,因为架构的选择具有对各种采购职能的相对排名及其所能带来的利益产生重大影响。 有趣的是,这个结果与报道的一般 DAL 方法的系统评估一致[57, 58]。
6讨论
在本文中,我们研究了将主动学习集成到扩散求解器的 DNN 代理训练中的可行性。 我们的研究结果强调了两个关键观察结果。 首先,通过智能选择的模拟训练 DNN 代理有可能减少生成昂贵的模拟的要求并提高 DNN 代理的性能。 具体来说,对于智能 DNN 代理来说,专注于 DNN 代理在新样本上的预测训练损失的获取策略可能是最有前途的。 这鼓励在训练代理模型中使用主动学习,使用较少但信息丰富的数据,而不是预先注释的数据集。 其次,网络本身的选择会显着影响主动学习的收益:在相同的数据和获取策略下,主动学习在多大程度上改善了 DNN 代理训练,很大程度上取决于 DNN 架构的底层选择——CNN 自动编码器与 U-在这种情况下净。 这表明,要开发支持构建具有主动学习的智能代理的 HPC 基础设施,基础设施需要支持的另一个组件可能是在主动学习之前对 DNN 代理架构进行优化。
作为第一个概念验证可行性研究,未来的工作可以沿着以下方面进行改进。
应用程序和数据集规模的多样化
虽然我们当前的工作重点是扩散解算器代理的用例,其中两个源随机放置在 晶格上,但我们计划合并更大的模拟集。 该集合将在更大的网格上具有可变数量的源,捕获现实世界模拟中固有的随机性。 此外,我们认识到扩大应用范围的重要性,超越我们当前关注的范围,涵盖各种用例。
更广泛的采集功能
我们的研究目前包含三种独特的习得训练功能,作为探索将主动学习融入替代的基础。 由于主动学习领域的不断发展,我们未来的计划包括纳入额外的习得功能,利用证据不确定性和混合策略,结合不确定性和多样性的好处。
建筑影响的广泛探索
本研究中观察到的主动学习性能与架构之间的相互作用为了解最佳架构设计和训练数据选择在构建 DNN 代理中的重要性提供了重要的见解。 未来的工作将需要对更大的架构空间进行实证研究,甚至扩展到架构优化和网络架构搜索等领域。
向智能代理的过渡:主动学习引导的即时模拟
这项研究虽然基于离线生成的模拟数据,但为 DNN 代理主动学习的可行性和关键设计元素提供了重要见解。 作为我们研究轨迹的关键转变,我们正在从离线仿真转向在线场景,其中 HPC 模拟将通过主动学习来动态引导和执行。 虽然本研究中提出的方法框架通常只需进行很少的修改即可应用,但需要付出大量努力来建立 HPC 基础设施,以支持在执行高性能模拟、DNN 之间动态分配不同的 HPC 资源。 ,以及数据采集的决策——当前研究的令人兴奋的下一步。
7结论
我们提出了一项调查研究,强调了在扩散求解器代理模型中利用主动学习的好处。 我们通过实验表明,对于某些获取函数,使用较少数据(<50% 数据)的主动学习有望比使用较大数据量(>75% 数据)的随机训练有所改进。 这为下一步构建智能代理的 HPC 基础设施奠定了坚实的基础,其中训练模拟是在主动学习的指导下动态生成的,可能是在针对科学模拟进行优化的 DNN 架构上。手。
8致谢
这项工作得到了国家科学基金会资助的 NSF OAC-2212548 和 NSF OAC-2212550 的支持。
参考
- [1] Geoffrey Fox and Shantenu Jha. Learning everywhere: a taxonomy for the integration of machine learning and simulations. In 2019 15th International Conference on eScience (eScience), pages 439–448. IEEE, 2019.
- [2] Shantenu Jha and Geoffrey Fox. Understanding ml driven hpc: applications and infrastructure. In 2019 15th International Conference on eScience (eScience), pages 421–427. IEEE, 2019.
- [3] Geoffrey Fox, James A Glazier, JCS Kadupitiya, Vikram Jadhao, Minje Kim, Judy Qiu, James P Sluka, Endre Somogyi, Madhav Marathe, Abhijin Adiga, et al. Learning everywhere: Pervasive machine learning for effective high-performance computation. In 2019 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 422–429. IEEE, 2019.
- [4] Muhammad Firmansyah Kasim, D Watson-Parris, L Deaconu, S Oliver, P Hatfield, Dustin H Froula, Gianluca Gregori, M Jarvis, S Khatiwala, J Korenaga, et al. Building high accuracy emulators for scientific simulations with deep neural architecture search. Machine Learning: Science and Technology, 3(1):015013, 2021.
- [5] Eugen Hruska, Vivekanandan Balasubramanian, Hyungro Lee, Shantenu Jha, and Cecilia Clementi. Extensible and scalable adaptive sampling on supercomputers. Journal of Chemical Theory and Computation, 16(12):7915–7925, 2020.
- [6] Hyungro Lee, Matteo Turilli, Shantenu Jha, Debsindhu Bhowmik, Heng Ma, and Arvind Ramanathan. Deepdrivemd: Deep-learning driven adaptive molecular simulations for protein folding. In 2019 IEEE/ACM Third Workshop on Deep Learning on Supercomputers (DLS), pages 12–19. IEEE, 2019.
- [7] Andreas Mardt, Luca Pasquali, Hao Wu, and Frank Noé. Vampnets for deep learning of molecular kinetics. Nature communications, 9(1):5, 2018.
- [8] Debsindhu Bhowmik, Shang Gao, Michael T Young, and Arvind Ramanathan. Deep clustering of protein folding simulations. BMC bioinformatics, 19:47–58, 2018.
- [9] Anh-Tien Ton, Francesco Gentile, Michael Hsing, Fuqiang Ban, and Artem Cherkasov. Rapid identification of potential inhibitors of sars-cov-2 main protease by deep docking of 1.3 billion compounds. Molecular informatics, 39(8):2000028, 2020.
- [10] Zhirui Liao, Ronghui You, Xiaodi Huang, Xiaojun Yao, Tao Huang, and Shanfeng Zhu. Deepdock: enhancing ligand-protein interaction prediction by a combination of ligand and structure information. In 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 311–317. IEEE, 2019.
- [11] Austin Clyde, Xiaotian Duan, and Rick Stevens. Regression enrichment surfaces: a simple analysis technique for virtual drug screening models. arXiv preprint arXiv:2006.01171, 2020.
- [12] Luning Sun, Han Gao, Shaowu Pan, and Jian-Xun Wang. Surrogate modeling for fluid flows based on physics-constrained deep learning without simulation data. Computer Methods in Applied Mechanics and Engineering, 361:112732, 2020.
- [13] Han Gao, Luning Sun, and Jian-Xun Wang. Phygeonet: Physics-informed geometry-adaptive convolutional neural networks for solving parameterized steady-state pdes on irregular domain. Journal of Computational Physics, 428:110079, 2021.
- [14] Mustafa Mustafa, Deborah Bard, Wahid Bhimji, Zarija Lukić, Rami Al-Rfou, and Jan M Kratochvil. Cosmogan: creating high-fidelity weak lensing convergence maps using generative adversarial networks. Computational Astrophysics and Cosmology, 6(1):1–13, 2019.
- [15] J Quetzalcóatl Toledo-Marín, Geoffrey Fox, James P Sluka, and James A Glazier. Deep learning approaches to surrogates for solving the diffusion equation for mechanistic real-world simulations. Frontiers in Physiology, 12:667828, 2021.
- [16] Winfried van den Dool, Tijmen Blankevoort, Max Welling, and Yuki Asano. Efficient neural pde-solvers using quantization aware training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1423–1432, 2023.
- [17] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- [18] Jayesh K Gupta and Johannes Brandstetter. Towards multi-spatiotemporal-scale generalized pde modeling. arXiv preprint arXiv:2209.15616, 2022.
- [19] Jacob Fish Ted Belytschko. A first course in finite elements. 2007.
- [20] William E Schiesser. The numerical method of lines: integration of partial differential equations. Elsevier, 2012.
- [21] Christopher Rackauckas and Qing Nie. Differentialequations. jl–a performant and feature-rich ecosystem for solving differential equations in julia. Journal of open research software, 5(1), 2017.
- [22] Amir Barati Farimani, Joseph Gomes, and Vijay S Pande. Deep learning the physics of transport phenomena. arXiv preprint arXiv:1709.02432, 2017.
- [23] Jiequn Han, Arnulf Jentzen, and Weinan E. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences, 115(34):8505–8510, 2018.
- [24] Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895, 2020.
- [25] Haiyang He and Jay Pathak. An unsupervised learning approach to solving heat equations on chip based on auto encoder and image gradient. arXiv preprint arXiv:2007.09684, 2020.
- [26] Jared Willard, Xiaowei Jia, Shaoming Xu, Michael Steinbach, and Vipin Kumar. Integrating physics-based modeling with machine learning: A survey. arXiv preprint arXiv:2003.04919, 1(1):1–34, 2020.
- [27] Shengze Cai, Zhicheng Wang, Sifan Wang, Paris Perdikaris, and George Em Karniadakis. Physics-informed neural networks for heat transfer problems. Journal of Heat Transfer, 143(6):060801, 2021.
- [28] J Quetzalcoatl Toledo-Marin, James A Glazier, and Geoffrey Fox. Analyzing the performance of deep encoder-decoder networks as surrogates for a diffusion equation. arXiv preprint arXiv:2302.03786, 2023.
- [29] David A Cohn, Zoubin Ghahramani, and Michael I Jordan. Active learning with statistical models. Journal of artificial intelligence research, 4:129–145, 1996.
- [30] Donggeun Yoo and In So Kweon. Learning loss for active learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 93–102, 2019.
- [31] Siyu Huang, Tianyang Wang, Haoyi Xiong, Jun Huan, and Dejing Dou. Semi-supervised active learning with temporal output discrepancy. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3447–3456, 2021.
- [32] Ajay J Joshi, Fatih Porikli, and Nikolaos Papanikolopoulos. Multi-class active learning for image classification. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 2372–2379. IEEE, 2009.
- [33] Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning, pages 1050–1059. PMLR, 2016.
- [34] Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, and Máté Lengyel. Bayesian active learning for classification and preference learning. arXiv preprint arXiv:1112.5745, 2011.
- [35] Andreas Kirsch, Joost Van Amersfoort, and Yarin Gal. Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning. Advances in neural information processing systems, 32, 2019.
- [36] Dan Roth and Kevin Small. Margin-based active learning for structured output spaces. In Machine Learning: ECML 2006: 17th European Conference on Machine Learning Berlin, Germany, September 18-22, 2006 Proceedings 17, pages 413–424. Springer, 2006.
- [37] Tobias Scheffer, Christian Decomain, and Stefan Wrobel. Active hidden markov models for information extraction. In International Symposium on Intelligent Data Analysis, pages 309–318. Springer, 2001.
- [38] Burr Settles. Active learning literature survey. 2009.
- [39] Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. arXiv preprint arXiv:1708.00489, 2017.
- [40] Yonatan Geifman and Ran El-Yaniv. Deep active learning over the long tail. arXiv preprint arXiv:1711.00941, 2017.
- [41] Hieu T Nguyen and Arnold Smeulders. Active learning using pre-clustering. In Proceedings of the twenty-first international conference on Machine learning, page 79, 2004.
- [42] Min Wang, Fan Min, Zhi-Heng Zhang, and Yan-Xue Wu. Active learning through density clustering. Expert systems with applications, 85:305–317, 2017.
- [43] Keze Wang, Dongyu Zhang, Ya Li, Ruimao Zhang, and Liang Lin. Cost-effective active learning for deep image classification. IEEE Transactions on Circuits and Systems for Video Technology, 27(12):2591–2600, 2016.
- [44] Zongwei Zhou, Jae Shin, Lei Zhang, Suryakanth Gurudu, Michael Gotway, and Jianming Liang. Fine-tuning convolutional neural networks for biomedical image analysis: actively and incrementally. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7340–7351, 2017.
- [45] Lin Yang, Yizhe Zhang, Jianxu Chen, Siyuan Zhang, and Danny Z Chen. Suggestive annotation: A deep active learning framework for biomedical image segmentation. In Medical Image Computing and Computer Assisted Intervention- MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, September 11-13, 2017, Proceedings, Part III 20, pages 399–407. Springer, 2017.
- [46] Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds. arXiv preprint arXiv:1906.03671, 2019.
- [47] Changjian Shui, Fan Zhou, Christian Gagné, and Boyu Wang. Deep active learning: Unified and principled method for query and training. In International Conference on Artificial Intelligence and Statistics, pages 1308–1318. PMLR, 2020.
- [48] Haonan Wang, Wei Huang, Ziwei Wu, Hanghang Tong, Andrew J Margenot, and Jingrui He. Deep active learning by leveraging training dynamics. Advances in Neural Information Processing Systems, 35:25171–25184, 2022.
- [49] Seo Taek Kong, Soomin Jeon, Dongbin Na, Jaewon Lee, Hong-Seok Lee, and Kyu-Hwan Jung. A neural pre-conditioning active learning algorithm to reduce label complexity. Advances in Neural Information Processing Systems, 35:32842–32853, 2022.
- [50] Dongxia Wu, Ruijia Niu, Matteo Chinazzi, Alessandro Vespignani, Yi-An Ma, and Rose Yu. Deep bayesian active learning for accelerating stochastic simulation. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2559–2569, 2023.
- [51] Raphaël Pestourie, Youssef Mroueh, Thanh V Nguyen, Payel Das, and Steven G Johnson. Active learning of deep surrogates for pdes: application to metasurface design. npj Computational Materials, 6(1):164, 2020.
- [52] Kjetil O Lye, Siddhartha Mishra, Deep Ray, and Praveen Chandrashekar. Iterative surrogate model optimization (ismo): An active learning algorithm for pde constrained optimization with deep neural networks. Computer Methods in Applied Mechanics and Engineering, 374:113575, 2021.
- [53] L Zanisi, A Ho, T Madula, J Barr, J Citrin, S Pamela, J Buchanan, F Casson, V Gopakumar, et al. Efficient training sets for surrogate models of tokamak turbulence with active deep ensembles. arXiv preprint arXiv:2310.09024, 2023.
- [54] Andreĭ Nikolaevich Tikhonov and Aleksandr Andreevich Samarskii. Equations of mathematical physics. Courier Corporation, 2013.
- [55] J. Quetzalcoatl Toledo-Marin. Steady state diffusion equation. https://github.com/jquetzalcoatl/DiffSolver, 2023.
- [56] Pradeep Bajracharya. Active learning with diffusion surrogate. https://github.com/pb8294/active-diffusion, 2023.
- [57] Nathan Beck, Durga Sivasubramanian, Apurva Dani, Ganesh Ramakrishnan, and Rishabh Iyer. Effective evaluation of deep active learning on image classification tasks. arXiv preprint arXiv:2106.15324, 2021.
- [58] Prateek Munjal, Nasir Hayat, Munawar Hayat, Jamshid Sourati, and Shadab Khan. Towards robust and reproducible active learning using neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 223–232, 2022.