MAVIS: Mathematical Visual 指令配置
摘要
多模态大型语言模型(MLLM)最近已成为学术界和工业界的一个重要焦点。 尽管他们精通一般的多模式场景,但视觉环境中的数学问题解决能力仍未得到充分探索。 我们确定了 MLLM 中需要改进的三个关键领域:数学图表的视觉编码、图表语言对齐和数学推理技能。 这就提出了对视觉数学中大规模、高质量数据和训练管道的迫切需求。 在本文中,我们提出了MAVIS,第一个用于MLLM的MA主题VIS双指令调整范例,涉及一系列数学视觉数据集和专门的MLLM。 针对这三个问题,MAVIS从零开始包含了三个渐进的训练阶段。 首先,我们策划由 558K 图表标题对组成的 MAVIS-Caption,通过对比学习调整数学专用视觉编码器 (CLIP-Math),专为改进图表视觉编码而定制。 其次,我们利用 MAVIS-Caption 通过投影层将 CLIP-Math 与大型语言模型(大语言模型)对齐,从而增强数学领域的视觉语言对齐。 第三,我们引入了MAVIS-Instruct,包括900K精心收集和注释的视觉数学问题,用于最终指导调整MLLM以获得强大的数学推理技能。 在 MAVIS-Instruct 中,我们为每个问题纳入完整的思想链 (CoT) 基本原理,并最大限度地减少文本冗余,从而将模型集中于视觉元素。 请注意,我们的两个新数据集涵盖了广泛的数学科目,以确保综合能力,包括平面几何、解析几何和函数。 在各种数学基准上,例如 MathVerse,MAVIS-7B 在开源 MLLM 中取得了领先的性能,超过其他 7B 模型 +11.0%,超过第二好的 LLaVA-NeXT (110B) +3.0%,这证明了我们的有效性方法。 数据和模型发布于https://github.com/ZrrSkywalker/MAVIS。
1简介
对通用人工智能 (AGI) 的追求需要模型能够无缝集成、解释和生成多模态数据。 近年来,大语言模型 (大语言模型) [5, 28, 58, 59, 16] 及其多模态扩展 (MLLM) [70, 20 , 55, 13, 64] 极大地促进了各个领域的这一进程,例如医疗保健[54, 53, 69]、自动驾驶[63, 29] 和机器人[36, 42]。 尽管 MLLM 在各种任务和基准测试中表现出了卓越的性能,但它们尚未充分展示其潜力的一个领域是在视觉环境中解决数学问题。
现有的纯文本数学研究[48,47,72]已经取得了相当大的进展,这要归功于大语言模型中足够的训练数据和固有的语言能力。 然而,视觉数学问题解决给 MLLM 带来了独特的挑战,要求他们将文本问题的分析深度与视觉图表的上下文丰富性相结合。 我们观察到三个严重阻碍 MLLM 视觉数学能力的关键问题。
-
我。
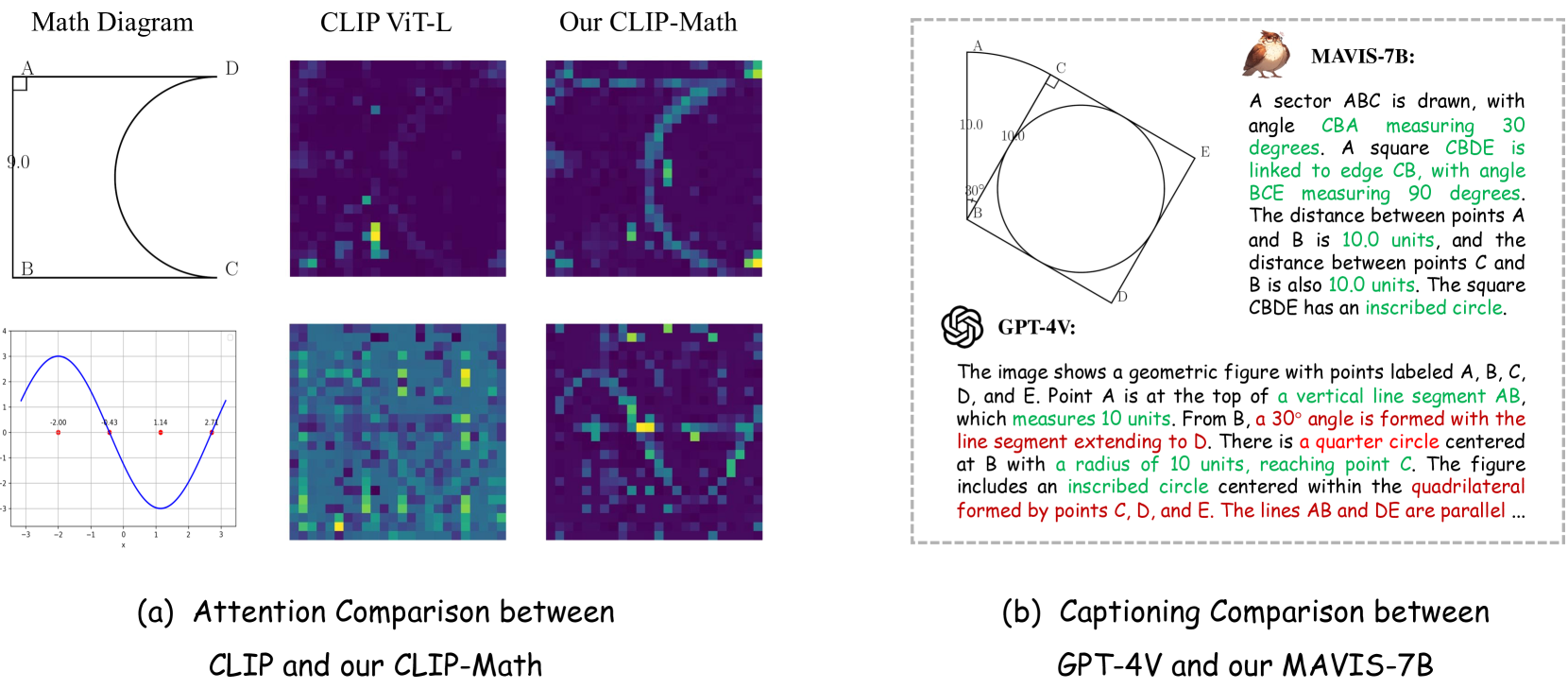
视觉编码器的数学图嵌入效果不佳。 大多数MLLM采用冻结的CLIP[51]作为视觉编码器,它是通过捕捉具有丰富颜色和纹理的真实世界场景的自然图像进行预训练的。 相比之下,数学图表由具有单色配色方案的抽象曲线、形状和符号组成,与一般场景表现出巨大的语义差距。 如图1(a)所示,CLIP的注意力图难以捕获数学图表中的重要信息,这无法为大语言模型提供令人满意的视觉嵌入以供理解。
-
二.
视觉编码器和大语言模型之间的图表语言不一致。 同样,MLLM 的视觉语言预训练阶段也采用自然图像标题对进行跨模态对齐。 由于领域差距,虽然它们可以为现实世界的图像生成准确的描述,但无法识别基本的数学元素并叙述它们的关系。 与图1(b)相比,即使是GPT-4V [49]对简单几何图形和函数的描述质量也很低,表明大语言模型没有很好地对齐与数学图表的视觉嵌入空间。
-
三.
MLLM 使用视觉元素进行不准确的数学推理。 参考 MathVerse [71],与仅使用纯文本问题相比,合并图表输入会对 MLLM 的推理质量产生不利影响。 从他们的演示中,我们观察到 GPT-4V 和 Gemini-Pro [22] 的问题解决过程都存在低质量的思想链(CoT)推理精度。 这表明 MLLM 无法利用视觉线索来精确解决数学问题。
因此,为了缓解这些问题,有必要开发适合视觉数学的广泛数据集和有效的训练方法。 在本文中,我们提出了MAVIS,这是第一个针对MLLM的MA主题VIS双指令调优范例,旨在充分释放其图解潜力视觉编码和推理能力。 我们引入了两个精心策划的数据集、一个渐进式三阶段训练管道和一个视觉数学专家 MAVIS-7B。 我们的工作贡献总结如下。
-
•
MAVIS-标题和 MAVIS-指导。 我们策划了两个大规模、高质量的数学视觉数据集,广泛涵盖平面几何、解析几何和函数。 MAVIS-Caption 由 558K 图表标题对组成,这些图表标题对由精心设计的数据引擎自动创建,具有准确的视觉语言对应关系。 MAVIS-Instruct 包括 834K 视觉数学问题,这些问题从四个来源获得:83k 由 GPT-4V 从手动收集的 4K 问题中增强,51K 由 GPT-4V 基于图表标题对生成,117k 从现有数据集增强,以及 582K 直接由我们的数据引擎构建。 每个问题都用 CoT 基本原理进行注释,并进行修改以包含最小化的文本冗余,以获得更多信息的可视化图表。
-
•
三阶段训练管道。 我们的训练框架涉及三个渐进阶段,旨在依次解决 MLLM 中上述已识别的缺陷。 首先,我们利用 MAVIS-Caption 通过对比学习(称为 CLIP-Math)来构建数学专用视觉编码器,以实现数学图表的更好的视觉表示。 随后,我们将该编码器与大语言模型对齐,以确保 MAVIS-Caption 也能有效地进行图表语言集成。 最后,采用我们的 MAVIS-Instruct 对 MLLM 进行指令调整。 带注释的 CoT 基本原理可以为复杂的推理能力提供充分的监督,而视觉主导的格式可以更好地将模型集中在利用视觉输入上。
-
•
数学视觉专家。 经过三阶段训练后,我们开发了 MAVIS-7B,这是一款专门针对视觉数学问题解决而优化的 MLLM。 在各种评估基准上,与现有开源 MLLM 相比,我们的模型取得了领先的性能,例如,超过其他 7B 模型 +11.0%,超过第二好的 LLaVA-NeXT (110B)[31] MathVerse [71] 的平均准确度+3.0%。 定量结果和定性分析都验证了我们方法的重要性。
2相关工作
视觉指令说明。
具有指令调优功能的大型语言模型(大语言模型)[5,28,59,16]的进步显着增强了一系列任务的零样本能力。 受此启发,LLaMA-Adapter系列[70,20,26]提出了一种零初始化注意力机制,将冻结视觉编码器[51]与LLaMA 对齐[58]用于多模式学习。 LLaVA 系列[41, 39] 采用线性投影仪进行视觉语言对齐,将视觉指令调整建立为多模态领域的标准训练方法。 Flamingo [2] 和 OpenFlamingo [3] 通过将交叉注意力重采样器与视觉编码器集成,改进了视觉表示。 SPHINX系列[21, 38]利用视觉编码器的混合使大语言模型能够识别图像的各个方面。 InternVL系列[15,17,56]采用大型视觉编码器和QFormer[34]通过多阶段训练方法整合高质量的视觉信息。 LLaVA-NexT [40, 31, 33] 进一步引入了“AnyRes”技术来管理任何给定分辨率的图像,LLaVA-NexT-Interleave [32] 扩展了范围广泛,可交错多图像设置。 最近还致力于将视觉指令调整应用于 3D [25, 62] 和视频 [35, 18] 场景。 尽管多模态大语言模型 (MLLM) 通过视觉指令调整在模型能力和训练效率方面取得了令人印象深刻的进步,但目前还没有专门为解决数学问题而设计的 MLLM,也没有可用于此类目的的大量数据集。开源社区。 在本文中,我们通过提出具有高质量数学视觉数据集和训练范例的 MAVIS 来缓解这个问题。
大型模型中的数学。
最近的研究主要集中在使用大语言模型解决纯文本数学问题。 MAmmoTH [67, 68] 编制了大量数学问题,使用解决方案中描述的推理过程训练大语言模型。 MetaMATH [66] 通过重写现有问题以创建更大的数据集对此进行了扩展。 MathCoder [60] 和 ToRA [24] 引入了工具代理方法,在训练阶段使用 Python 代码和符号解析器,显着优于依赖于纯文本的传统模型数学推理。 然而,在多模态领域,尽管引入了Geometry3K [44]、GeoQA [11]、UniGeo [8]等多个数据集t2>、UniMath [37]和GeomVerse [30],旨在增强MLLM解决图数学问题的性能,这些数据集在规模和领域上都非常有限。 基于这些数据集,G-LLaVA [19] 已经开发出了理解图形几何的卓越能力,但在其他领域的数学问题上却遇到了困难。 综合基准 MathVerse [71] 还强调了现有 MLLM 在不同数学领域编码视觉图的能力不令人满意。 因此,迫切需要开发更鲁棒的数学图像编码器以及通过数学视觉指令调整 MLLM,为此我们提出 MAVIS 来应对这些挑战。
Statistic Number Total Captions - Total number 588K - Average length (words) 62.85 - Average length (characters) 339.68 - Vocabulary size 418 Plane Geometry - Total number 299K (50.9%) - Average length (words) 69.77 - Average length (characters) 385.85 - Vocabulary size 195 Analytic Geometry - Total number 77K (13.1%) - Average length (words) 39.64 - Average length (characters) 210.10 - Vocabulary size 158 Function - Total number 212K (36.0%) - Average length (words) 61.48 - Average length (characters) 321.46 - Vocabulary size 149
Statistic Number Total questions 834K - Multiple-choice questions 615K (62.4%) - Free-form questions 218K (37.6%) Manual Collection Augmented by GPT-4 83K - Geometry questions 72K (86.5%) - Function questions 11K (13.5%) Existing Datasets Augmented by GPT-4 117K - Geometry questions 117K (100.0%) - Function questions 0 (0%) Data Engine Captions Annotated by GPT-4 51K - Geometry questions 30K (58.8%) - Function questions 21K (41.2%) Data Engine Generated Problems 582K - Geometry questions 466K (80.0%) - Function questions 116K (20.0%) Number of unique images 611K (73.3%) Number of unique questions 804K (96.5%) Number of unique answers 675K (81.0%) Average question length 44.60 Average answer length 62.82
3 数学视觉数据集
在3.1节中,我们首先说明了数据引擎自动生成数学图表的方法。 然后,我们分别介绍我们新为 MLLM 策划的两个数据集,即 3.2 节中的 MAVIS-Caption 和 3.3 节中的 MAVIS-Instruct。
3.1数据引擎
为了满足 MLLM 的大量数据需求,必须访问数十万个训练实例。 然而,对于视觉数学来说,公开数据集的缺乏带来了挑战,而且由于成本高昂,手动创建此类数据也是不可行的。 因此,我们开发了一个自动数据引擎来高效生成高质量的数学图表,如图1所示。 涵盖大多数数学场景,我们采用三种图表类型:平面几何、解析几何和函数。 请注意,数据引擎的所有逻辑都是用 Python 实现的,我们使用 Matplotlib 来进行图表的图形渲染。
平面几何图。
由于此类图通常由各种基本形状的空间组合组成,因此我们利用多跳数据管理的原理来开发定制的生成规则。 这些规则允许将新形状迭代集成到现有配置中。 最初,我们建立了一组核心形状,包括正方形、矩形、三角形、扇形等,用于生成图表。 从随机选择的形状开始,我们从该组中沿着其直边之一延伸另一个形状。 通过迭代这个过程,我们可以构建具有不同形状组合的各种平面几何图。 此外,我们随机用字母(例如 A、B、C)标记顶点,并注释与几何属性(例如边长和角度)相关的数值,模拟现实的平面几何问题。
解析几何图。
同样,我们的方法首先定义一个基本图形集,该图形集与平面几何中使用的图形集略有不同;例如,我们包含其他元素,例如点和线段。 然后,我们构建一个笛卡尔坐标系,其中包含网格线和缩放轴。 坐标系的范围是在预定范围内随机确定的。 随后,我们从 1 到 3 中选择一个数字来表示要在图表上绘制的图形数量,并随机选择左上角顶点的坐标,以不同的大小绘制这些图形(使用这些点作为圆的中心)。 与平面几何不同,我们确保除点和线段之外的图形不重叠,并将图形区域保持在合适的比例内。
功能图。
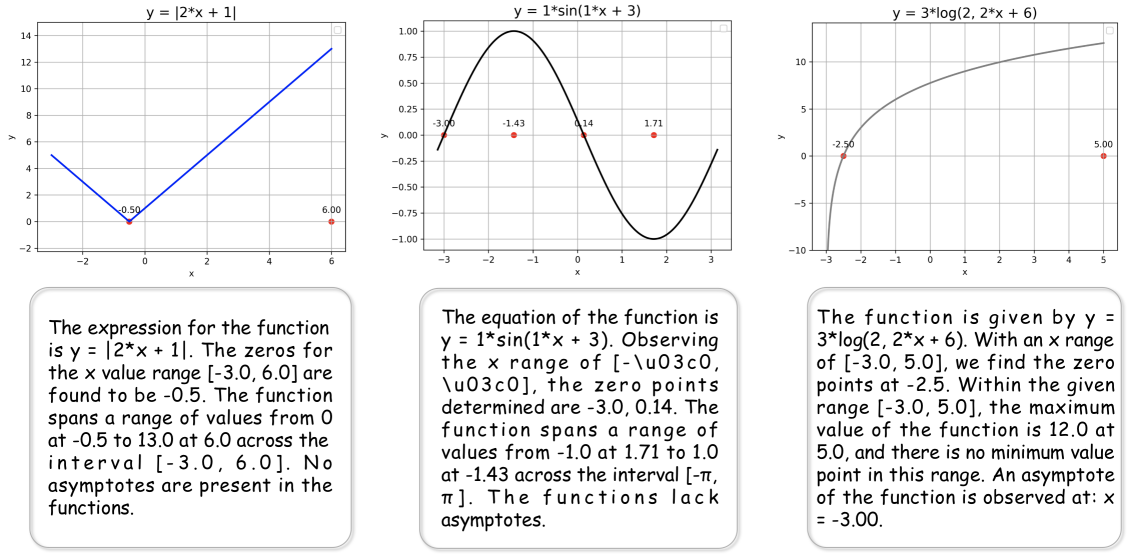
我们关注七种基本函数类型:多项式、正弦、余弦、正切、对数、绝对值和分段多项式函数。 对于每种函数类型,我们使用随机变量参数化方程,例如预定义范围内的系数和常数(例如,中的和),这有助于生成各种函数图。 我们还采用与解析几何相同的笛卡尔坐标系。 此外,对于特定的标题或问答样本,我们还绘制了函数的极值点和零点等关键特征,提供了额外的视觉信息,有助于理解和推理这些数学函数。
3.2 MAVIS-标题
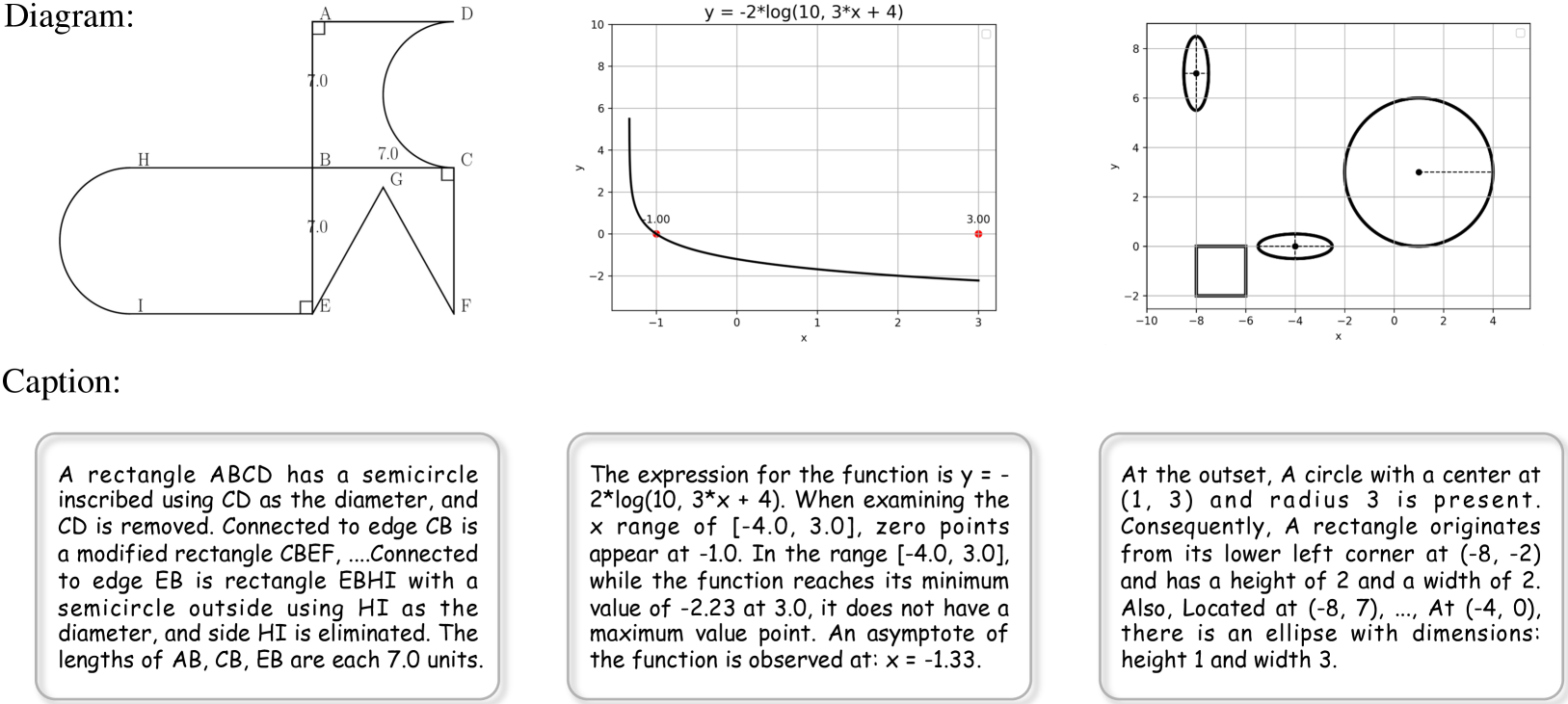
通过我们的数学视觉数据引擎,我们首先策划一个图表标题数据集 MAVIS-Caption,如图 2 所示,旨在有利于图表视觉表示和跨模式对齐。
数据概览。
如表 2 所示,MAVIS-Caption 数据集包含 588K 图表标题对。 其中包括平面几何 299K、解析几何 77K 和函数 212K。 字幕的平均字长为 61.48 个字,反映了其详细的描述性。 总体词汇量为149个,表明语言表达的多样性。
标题标注。
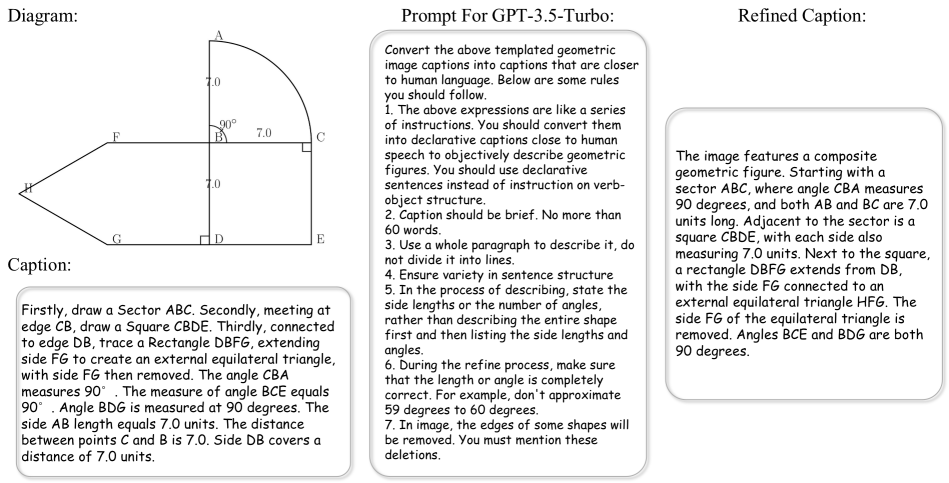
我们采用不同的策略来为三种类型的图表生成标题。 请注意,所有精选的字幕最终都经过 ChatGPT [50] 的细化,以实现类似人类的表达。
-
•
平面几何标题。 我们遵循迭代几何生成过程来制定准确而详细的标题规则。 我们首先提示 GPT-4 [48] 创建三组语言模板:基本形状的描述性内容(例如,“一个三角形{},其中两个全等边 {} 和 {}”),表示特定属性的短语(例如,“角度 {} 测量 {} 度”),以及连接两个相邻形状的连词(例如,“附加到形状 {} 的边缘 {},有一个 0>{}”1>)。 然后,根据各种生成场景,我们填充并合并这些模板,以获得几何图形的连贯描述。
-
•
解析几何标题。 我们还利用GPT-4获得了两套语言模板:基本图形的坐标描述和属性信息(例如“左底角在的正方形”{}特征边{} 长度”)以及附近图形的空间关系(例如,“在 {} 的右下角,有一个{}”)。 然后通过填写坐标并通过坐标比较选择适当的空间关系模板来制定标题。
-
•
功能标题。 由于函数图通常展示单条曲线,因此我们直接利用 GPT-4 生成描述函数各种属性的模板,包括表达式、域、范围、极值点和零点。 然后根据具体情况填写每个模板,例如 “函数的表达式为。 在 x 值 范围内,零点出现在 处……”.
3.3 MAVIS-指导
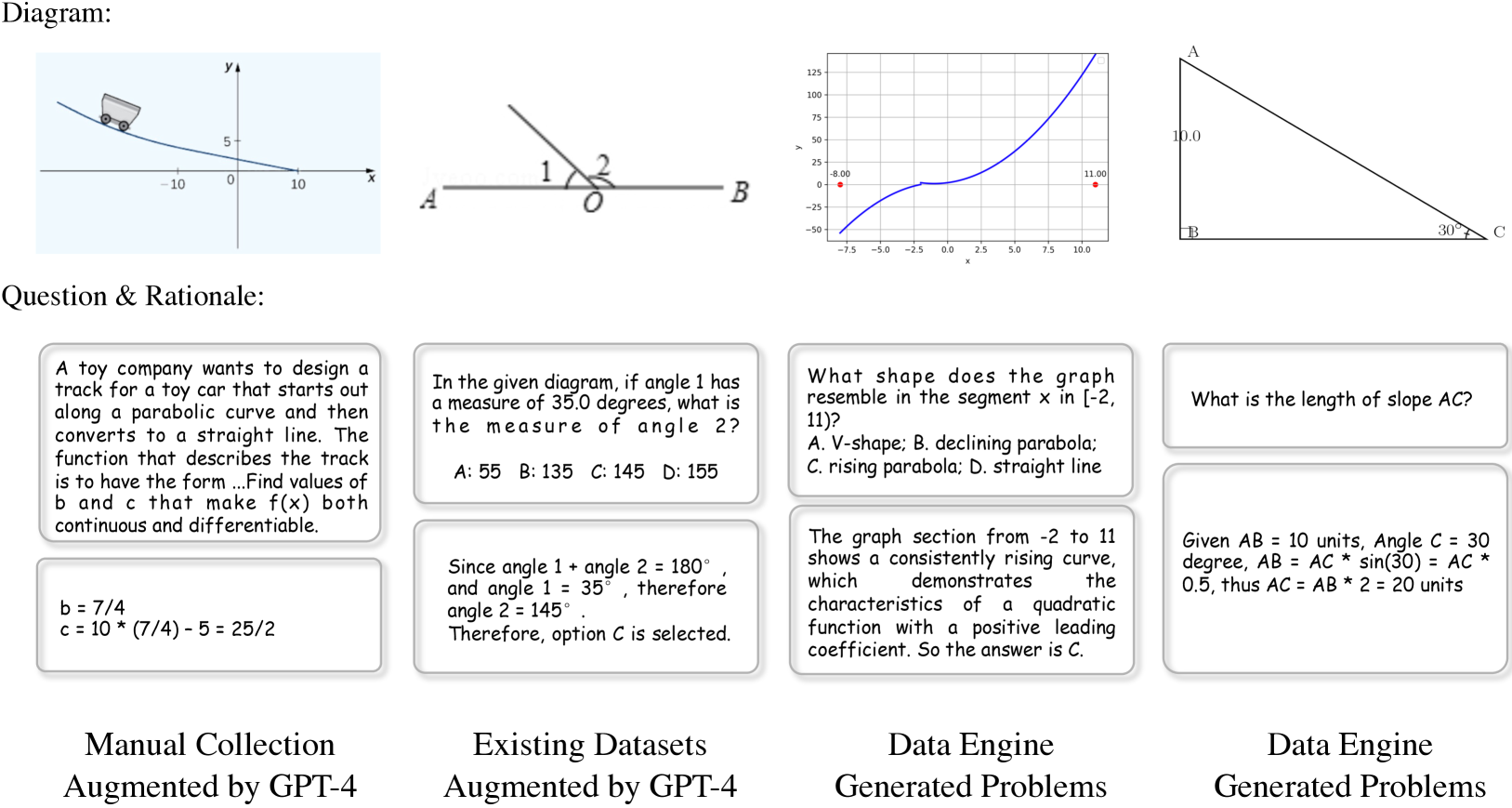
除了用于跨模式对齐的图表标题数据外,我们还整理了 MAVIS-Instruct 广泛的问题解决数据,以赋予 MLLM 视觉数学推理能力,如图 3 所示。
数据概览。
如表2所示,MAVIS-Instruct 数据集总共包含 834K 个视觉数学问题。 鉴于解析几何问题所占比例较小,为简单起见,我们将其归为函数问题。 MAVIS-Instruct 中的每个问题都包含提供分步解决方案的 CoT 基本原理,平均答案长度为 150 个单词。 我们最大限度地减少了问题中的文本冗余,消除了不必要的上下文信息、分散注意力的条件以及从图表中容易观察到的属性。 文本的减少迫使 MLLM 增强从视觉输入中提取基本内容的能力。 MAVIS-Instruct 由四个不同来源组成,以确保广泛的覆盖范围。
由 GPT-4 增强的手动收集。
为了整合在现实世界中发现的高质量问题,我们从公开资源中手动收集带有图表的 4K 数学问题。 认识到这些来源通常缺乏详细的原理并且可能包含冗余文本,我们最初使用 GPT-4V 来注释详细的解决过程并简化问题文本以减少冗余。 随后,对于每个收集到的实例,我们将问题、理由和图表输入 GPT-4,并使用定制的少样本提示为每个原始问题生成 20 个新问题,其中包括 15 个多项选择题和 5 个自由格式问题。 此过程总共为数据集贡献了 84K 问题。
GPT-4 增强了现有数据集。
考虑到现有的组织良好的几何数据集,我们还可以利用它们来扩展 MAVIS-Instruct。 参考之前的提示设计,我们将来自 Geometry-3K 和 GeoQA+ 这两个数据集的 8K 训练集扩展为 80K 视觉问题及其基本原理,将每个原始问题映射到 10 个新问题。 由于公开可用的函数数据稀缺,我们不包含此来源的函数问题。
由 GPT-4 注释的数据引擎标题。
给定我们的数据引擎生成的详细标题和图表,我们可以通过这些充分条件提示 GPT-4V 生成准确的问答数据。 我们首先生成一组新的 17K 图表标题对,它们不与之前的 MAVIS-Caption 重叠,这避免了详细标题中的答案泄漏。 然后,我们提示 GPT-4V 生成 3 个带有基本原理的新问题,从图表-标题对中总共获得 51K 数据。
数据引擎生成的问题。
除了依靠 GPT 来生成数据之外,我们还手动制定严格的规则,直接从我们的数据引擎生成视觉数学问题。
-
•
平面几何问题。 我们最初提示 GPT-4 编译一套适用于每个基本形状的综合数学公式(例如,直角三角形的毕达哥拉斯定理和圆形的面积公式)。 然后,对于几何图,我们随机选择形状内的已知条件作为最终解决方案目标,并使用随机选择的数学公式系统地向后推论到同一形状或相邻形状内的另一个条件。 然后将该推导条件设置为未知,并且我们根据需要继续迭代向后推导。 最终条件以及最后一步中的任何条件都作为问题中的初始属性呈现。 通过逆向推演过程即可简单地获得基本原理。
-
•
功能问题。 由于函数的属性是预先确定的,我们利用 GPT-4 来生成不同的推理模板。 这些模板有助于根据其他提供的属性求解一个函数属性,从而确保生成高质量的函数基本原理。 我们最终得到了299K个平面几何问题和212K个函数问题。
4 数学视觉训练
利用精选的数据集,我们设计了一个三阶段训练管道,为 MLLM 赋予数学视觉功能。 他们分别旨在缓解现有 MLLM 中的三个缺陷,即图视觉编码、图语言对齐和视觉上下文中的数学推理技能。
4.1 阶段 1:训练 CLIP-数学
为了改善 CLIP 的[51]数学图表视觉编码不足的问题,我们利用 MAVIS-Caption 来训练专门的 CLIP-Math 编码器。 具体来说,我们按照保守学习方案训练了一个预训练的 CLIP-Base 模型。 数学图被输入可学习的视觉编码器,而相应的标题由文本编码器处理,文本编码器保持冻结状态以提供可靠的监督。 通过对比训练,模型学习从原始自然图像域适应数学上下文,增加对图表中基本视觉元素的关注,如图 1 (a) 所示。 经过优化的CLIP-Math编码器现在可以提供更精确、更稳健的数学图表表示,为后续大语言模型的可视化解释奠定了坚实的基础。
4.2 阶段 2:调整图表语言
获得 CLIP-Math 编码器后,我们使用 MAVIS-Caption 进一步将其与大语言模型集成,以促进数学图和语言嵌入空间之间的跨模态对齐。 使用简单的两层 MLP 作为投影层,我们转换来自 CLIP-Math 的视觉编码,并将它们作为前缀添加到大语言模型输入中。 这个过程在图表标题任务的指导下,使大语言模型能够准确识别数学组件并描述它们的空间排列。 通过图语言的对接,大语言模型具备了数学图的解释能力,为更深层次的数学推理迈出了第一步。 在这个阶段,我们冻结 CLIP-Math,并与基于 LoRA 的 [27] 大语言模型一起训练投影层。
Model Base LLM All Text Dominant Text Lite Vision Intensive Vision Dominant Vision Only Acc Acc Acc Acc Acc Acc Baselines Random Chance - 12.4 12.4 12.4 12.4 12.4 12.4 Human - 67.7 71.2 70.9 61.4 68.3 66.7 LLMs ChatGPT [50] - 26.1 33.3 18.9 - - - GPT-4 [48] - 33.6 46.5 46.5 - - - Closed-source MLLMs Qwen-VL-Plus [4] - 11.8 15.7 11.1 9.0 13.0 10.0 Gemini-Pro [22] - 23.5 26.3 23.5 23.0 22.3 22.2 Qwen-VL-Max [4] - 25.3 30.7 26.1 24.1 24.1 21.4 GPT-4V [49] - 39.4 54.7 41.4 34.9 34.4 31.6 Open-source MLLMs LLaMA-Adapter V2 [20] LLaMA-7B [58] 5.8 7.8 6.3 6.2 4.5 4.4 ImageBind-LLM [26] LLaMA-7B 10.0 13.2 11.6 9.8 11.8 3.5 mPLUG-Owl2 [65] LLaMA-7B 10.3 11.6 11.4 11.1 9.4 8.0 MiniGPT-v2 [13] LLaMA2-7B [59] 10.9 13.2 12.7 11.1 11.3 6.4 SPHINX-Plus [21] LLaMA2-13B 14.0 16.3 12.8 12.9 14.7 13.2 SPHINX-MoE [21] Mixtral-87B [28] 15.0 22.2 16.4 14.8 12.6 9.1 G-LLaVA [19] LLaMA2-7B 15.7 22.2 20.4 16.5 12.7 6.6 InternLM-XC2. [17] InternLM2-7B [6] 16.5 22.3 17.0 15.7 16.4 11.0 LLaVA-1.5 [39] Vicuna-13B 17.0 18.7 18.5 18.1 16.1 13.8 ShareGPT4V [14] Vicuna-13B 17.4 21.8 20.6 18.6 16.2 9.7 Math-LLaVA [52] Vicuna-13B 19.0 21.2 19.8 20.2 17.6 16.4 LLaVA-NeXT [31] LLaMA3-8B [57] 19.3 24.9 20.9 20.8 16.1 13.8 LLaVA-NeXT Qwen-1.5-110B [1] 24.5 31.7 24.1 24.0 22.1 20.7 MAVIS-7B MAmmoTH2-7B [68] 27.5 41.4 29.1 27.4 24.9 14.6
4.3 阶段3:指令配置
最后,我们利用 MAVIS-Instruct 赋予 MLLM 视觉数学中的 CoT 推理和问题解决能力。 每个问题解决方案中的详细原理为 MLLM 提供了高质量的推理指导,显着增强了其逐步的 CoT 流程。 此外,所采用的轻文本、视觉主导和仅视觉问题格式有助于 MLLM 从视觉嵌入中捕获更重要的信息来解决问题,而不是依赖于仅处理问题中的文本内容的捷径。 在此阶段,我们解冻投影层和基于LoRA[27]的大语言模型,进行彻底的指令跟踪调整,最终得到MAVIS-7B。
5实验
5.1实验设置
实施细节。
我们采用 CLIP ViT-L [51] 作为预训练模型来调整我们的 CLIP-Math,并利用 Mammoth2-7B [68] 作为基础大语言构建 MAVIS-7B 的模型。 在第一阶段,我们对 CLIP 进行 10 个周期的调整,批量大小为 16,初始学习率为 。 在第二阶段,我们以批量大小 32 和初始学习率 训练 1 epoch 的图语言对齐,并采用排名为 128 的 LoRA [27] 。 第三阶段,我们采用与上一阶段相同的训练设置。
评估基准。
我们在三个流行的数学基准上评估我们的模型 MAVIS-7B:MathVerse [71]、GeoQA [12] 和 FunctionQA(MathVista 中函数问题的子集) [43])。 MathVerse 是一个综合基准测试,包含 2.6K 视觉数学问题,涵盖平面几何、函数和立体几何。 GeoQA 和 FunctionQA 分别关注平面几何和功能场景。 我们对所有基准采用准确性指标。
Model Accuracy (%) Random Chance 25.0 Frequent Guesses 32.1 Top-10 Accuracy NGS [10] 56.9 DPE-GPS [7] 62.7 SCA-GPS [45] 64.1 Top-1 Accuracy Geoformer [9] 46.8 UniMath [37] 50.0 G-LLaVA-7B [19] 64.2 MAVIS-7B 66.7
Model Accuracy (%) Random Chance 22.5 Closed-source MLLMs CoT GPT-4 [48] 35.0 PoT GPT-4 [48] 37.0 Multimodal Bard [23] 45.5 GPT-4V [49] 69.5 Open-source MLLMs LLaVA [41] 20.5 LLaMA-Adapter V2 [20] 32.0 LLaVA-NeXT [40] 33.7 SPHINX-MoE [21] 34.6 MAVIS-7B 40.3
5.2定量表现
如MathVerse上的结果如表3所示,MAVIS-7B仅用7B大小就实现了现有开源模型中最好的整体精度。 在不同的问题版本上,我们的方法始终超过了第二好的方法,特别是对于 Text Dominant 和 Text Lite。 具体来说,我们的模型比 InternLM-XComposer2 (7B) [17] 超出 +11.0%,比 ShareGPT4V (13B) [14] 超出 +10.1%。 与其他数学 MLLM(即 G-LLaVA [19] 和并发 Math-LLaVA [52])相比,MAVIS-7B 表现出卓越的问题解决能力,得分更高分别为+11.8%和+8.5%。 此外,我们的模型还优于最强大的开源 MLLM 系列 LLaVA-NeXT [31],从 7B 到 110B 模型尺寸,展示了 MAVIS-7B 的数学特定能力。 表5.1和5.1分别展示了我们在平面几何和功能场景上的表现。 与 G-LLaVA 等专业模型相比,我们的 MAVIS-7B 表现出卓越的推理和泛化能力。
5.3定性分析
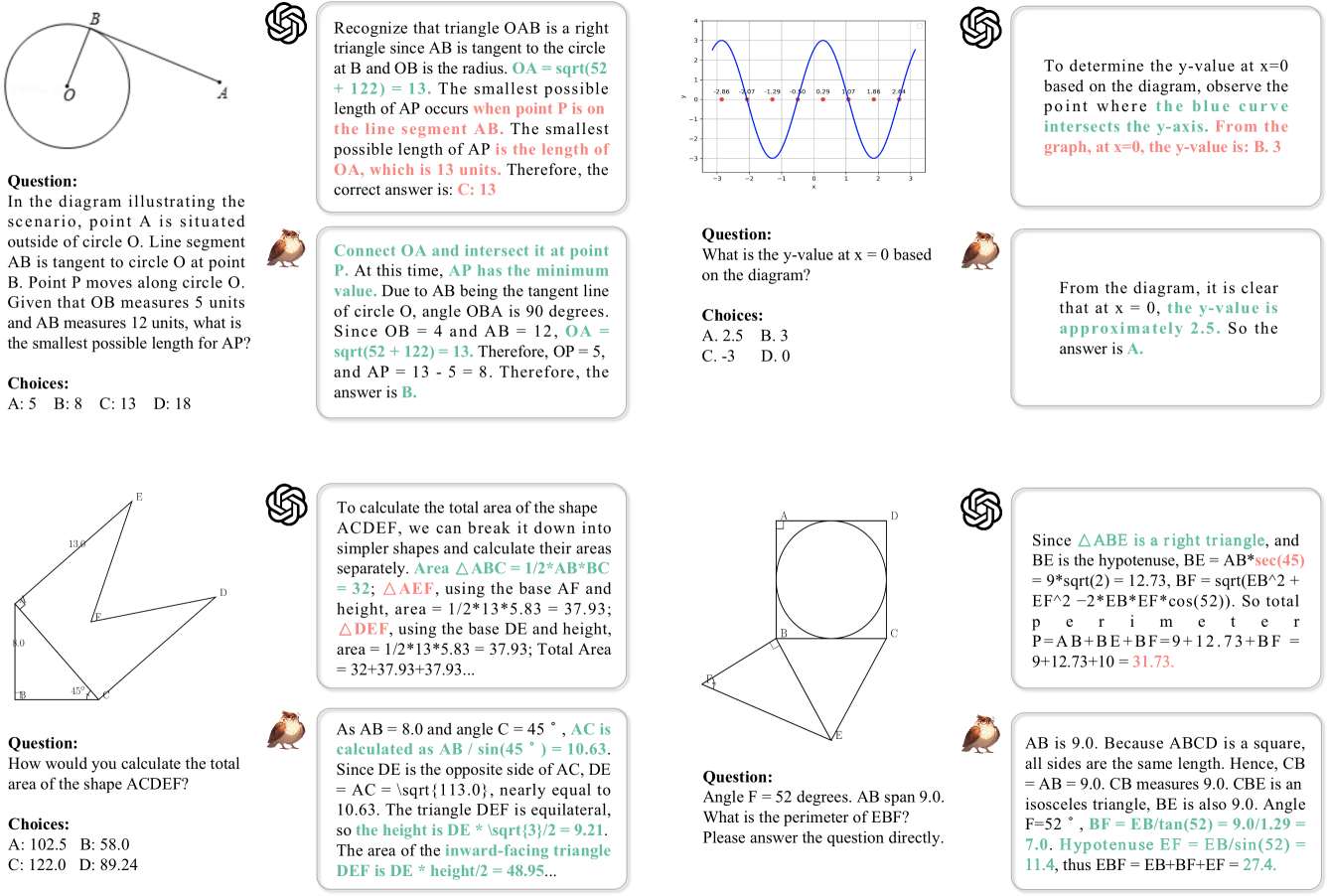
在图4中,我们比较了MAVIS-7B和GPT-4V之间的数学问题解决示例[49]。 我们的模型擅长理解数学图表中的几何元素、函数曲线和坐标轴,实现更高质量的 CoT 推理能力。
6结论
在本文中,我们提出了 MAVIS,这是第一个用于 MLLM 的数学视觉指令调整范例。 我们首先通过精致的数据引擎引入两个高质量的数据集,MAVIS-Caption 和 MAVIS-Instruct,包含大规模图表语言和问题解决数据。 然后,我们定制了一个三阶段的训练框架,以逐步训练 MLLM 的数学特定视觉编码器、图表语言对齐和数学推理能力。 获得的专业模型 MAVIS-7B 在不同的数学视觉基准上实现了卓越的性能,展示了作为未来研究新标准的潜力。
参考
- [1] AI@Meta: Llama 3 model card (2024), https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md
- [2] Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems 35, 23716–23736 (2022)
- [3] Awadalla, A., Gao, I., Gardner, J., Hessel, J., Hanafy, Y., Zhu, W., Marathe, K., Bitton, Y., Gadre, S., Sagawa, S., et al.: Openflamingo: An open-source framework for training large autoregressive vision-language models. arXiv preprint arXiv:2308.01390 (2023)
- [4] Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023)
- [5] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. In: Advances in neural information processing systems. pp. 1877–1901 (2020)
- [6] Cai, Z., Cao, M., Chen, H., Chen, K., Chen, K., Chen, X., Chen, X., Chen, Z., Chen, Z., Chu, P., et al.: Internlm2 technical report. arXiv preprint arXiv:2403.17297 (2024)
- [7] Cao, J., Xiao, J.: An augmented benchmark dataset for geometric question answering through dual parallel text encoding. In: Proceedings of the 29th International Conference on Computational Linguistics. pp. 1511–1520 (2022)
- [8] Chen, J., Li, T., Qin, J., Lu, P., Lin, L., Chen, C., Liang, X.: Unigeo: Unifying geometry logical reasoning via reformulating mathematical expression. ArXiv abs/2212.02746 (2022)
- [9] Chen, J., Li, T., Qin, J., Lu, P., Lin, L., Chen, C., Liang, X.: UniGeo: Unifying geometry logical reasoning via reformulating mathematical expression. In: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. pp. 3313–3323 (2022)
- [10] Chen, J., Tang, J., Qin, J., Liang, X., Liu, L., Xing, E., Lin, L.: GeoQA: A geometric question answering benchmark towards multimodal numerical reasoning. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. pp. 513–523. Association for Computational Linguistics, Online (Aug 2021). https://doi.org/10.18653/v1/2021.findings-acl.46, https://aclanthology.org/2021.findings-acl.46
- [11] Chen, J., Tang, J., Qin, J., Liang, X., Liu, L., Xing, E.P., Lin, L.: Geoqa: A geometric question answering benchmark towards multimodal numerical reasoning. ArXiv abs/2105.14517 (2021), https://api.semanticscholar.org/CorpusID:235253782
- [12] Chen, J., Tang, J., Qin, J., Liang, X., Liu, L., Xing, E.P., Lin, L.: Geoqa: A geometric question answering benchmark towards multimodal numerical reasoning. arXiv preprint arXiv:2105.14517 (2021)
- [13] Chen, J., Li, D.Z.X.S.X., Zhang, Z.L.P., Xiong, R.K.V.C.Y., Elhoseiny, M.: Minigpt-v2: Large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478 (2023)
- [14] Chen, L., Li, J., wen Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., Lin, D.: Sharegpt4v: Improving large multi-modal models with better captions. ArXiv abs/2311.12793 (2023), https://api.semanticscholar.org/CorpusID:265308687
- [15] Chen, Z., Wang, W., Tian, H., Ye, S., Gao, Z., Cui, E., Tong, W., Hu, K., Luo, J., Ma, Z., et al.: How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821 (2024)
- [16] Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., Stoica, I., Xing, E.P.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. https://lmsys.org/blog/2023-03-30-vicuna/ (March 2023)
- [17] Dong, X., Zhang, P., Zang, Y., Cao, Y., Wang, B., Ouyang, L., Wei, X., Zhang, S., Duan, H., Cao, M., et al.: Internlm-xcomposer2: Mastering free-form text-image composition and comprehension in vision-language large model. arXiv preprint arXiv:2401.16420 (2024)
- [18] Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075 (2024)
- [19] Gao, J., Pi, R., Zhang, J., Ye, J., Zhong, W., Wang, Y., Hong, L., Han, J., Xu, H., Li, Z., et al.: G-llava: Solving geometric problem with multi-modal large language model. arXiv preprint arXiv:2312.11370 (2023)
- [20] Gao, P., Han, J., Zhang, R., Lin, Z., Geng, S., Zhou, A., Zhang, W., Lu, P., He, C., Yue, X., Li, H., Qiao, Y.: Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010 (2023)
- [21] Gao, P., Zhang, R., Liu, C., Qiu, L., Huang, S., Lin, W., Zhao, S., Geng, S., Lin, Z., Jin, P., et al.: Sphinx-x: Scaling data and parameters for a family of multi-modal large language models. arXiv preprint arXiv:2402.05935 (2024)
- [22] Gemini Team, G.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
- [23] Google: Bard (2023), https://bard.google.com/
- [24] Gou, Z., Shao, Z., Gong, Y., Yang, Y., Huang, M., Duan, N., Chen, W., et al.: Tora: A tool-integrated reasoning agent for mathematical problem solving. arXiv preprint arXiv:2309.17452 (2023)
- [25] Guo, Z., Zhang, R., Zhu, X., Tang, Y., Ma, X., Han, J., Chen, K., Gao, P., Li, X., Li, H., et al.: Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following. arXiv preprint arXiv:2309.00615 (2023)
- [26] Han, J., Zhang, R., Shao, W., Gao, P., Xu, P., Xiao, H., Zhang, K., Liu, C., Wen, S., Guo, Z., et al.: Imagebind-llm: Multi-modality instruction tuning. arXiv preprint arXiv:2309.03905 (2023)
- [27] Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021)
- [28] Jiang, A.Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D.S., de Las Casas, D., Hanna, E.B., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L.R., Saulnier, L., Lachaux, M., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Scao, T.L., Gervet, T., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mixtral of experts. Arxiv 2401.04088 (2024)
- [29] Jin, B., Zheng, Y., Li, P., Li, W., Zheng, Y., Hu, S., Liu, X., Zhu, J., Yan, Z., Sun, H., et al.: Tod3cap: Towards 3d dense captioning in outdoor scenes. arXiv preprint arXiv:2403.19589 (2024)
- [30] Kazemi, M., Alvari, H., Anand, A., Wu, J., Chen, X., Soricut, R.: Geomverse: A systematic evaluation of large models for geometric reasoning. arXiv preprint arXiv:2312.12241 (2023)
- [31] Li, B., Zhang, K., Zhang, H., Guo, D., Zhang, R., Li, F., Zhang, Y., Liu, Z., Li, C.: Llava-next: Stronger llms supercharge multimodal capabilities in the wild (May 2024), https://llava-vl.github.io/blog/2024-05-10-llava-next-stronger-llms/
- [32] Li, F., Zhang, R., Zhang, H., Zhang, Y., Li, B., Li, W., Ma, Z., Li, C.: Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models (2024), https://arxiv.org/abs/2407.07895
- [33] Li, F., Zhang, R., Zhang, H., Zhang, Y., Li, B., Li, W., Ma, Z., Li, C.: Llava-next: Tackling multi-image, video, and 3d in large multimodal models (June 2024), https://llava-vl.github.io/blog/2024-06-16-llava-next-interleave/
- [34] Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International Conference on Machine Learning. pp. 12888–12900. PMLR (2022)
- [35] Li, K., He, Y., Wang, Y., Li, Y., Wang, W., Luo, P., Wang, Y., Wang, L., Qiao, Y.: Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355 (2023)
- [36] Li, X., Zhang, M., Geng, Y., Geng, H., Long, Y., Shen, Y., Zhang, R., Liu, J., Dong, H.: Manipllm: Embodied multimodal large language model for object-centric robotic manipulation. arXiv preprint arXiv:2312.16217 (2023)
- [37] Liang, Z., Yang, T., Zhang, J., Zhang, X.: Unimath: A foundational and multimodal mathematical reasoner. In: EMNLP (2023)
- [38] Lin, Z., Liu, C., Zhang, R., Gao, P., Qiu, L., Xiao, H., Qiu, H., Lin, C., Shao, W., Chen, K., et al.: Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. arXiv preprint arXiv:2311.07575 (2023)
- [39] Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning (2023)
- [40] Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024), https://llava-vl.github.io/blog/2024-01-30-llava-next/
- [41] Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023)
- [42] Liu, J., Li, C., Wang, G., Lee, L., Zhou, K., Chen, S., Xiong, C., Ge, J., Zhang, R., Zhang, S.: Self-corrected multimodal large language model for end-to-end robot manipulation. arXiv preprint arXiv:2405.17418 (2024)
- [43] Lu, P., Bansal, H., Xia, T., Liu, J., yue Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating math reasoning in visual contexts with gpt-4v, bard, and other large multimodal models. ArXiv abs/2310.02255 (2023)
- [44] Lu, P., Gong, R., Jiang, S., Qiu, L., Huang, S., Liang, X., Zhu, S.C.: Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. arXiv preprint arXiv:2105.04165 (2021)
- [45] Ning, M., Wang, Q.F., Huang, K., Huang, X.: A symbolic characters aware model for solving geometry problems. In: Proceedings of the 31st ACM International Conference on Multimedia. p. 7767–7775. MM ’23, Association for Computing Machinery, New York, NY, USA (2023). https://doi.org/10.1145/3581783.3612570, https://doi.org/10.1145/3581783.3612570
- [46] Nye, M., Andreassen, A.J., Gur-Ari, G., Michalewski, H., Austin, J., Bieber, D., Dohan, D., Lewkowycz, A., Bosma, M., Luan, D., et al.: Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114 (2021)
- [47] OpenAI: Chatgpt. https://chat.openai.com (2023)
- [48] OpenAI: Gpt-4 technical report. ArXiv abs/2303.08774 (2023)
- [49] OpenAI: GPT-4V(ision) system card (2023), https://openai.com/research/gpt-4v-system-card
- [50] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Gray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P., Leike, J., Lowe, R.: Training language models to follow instructions with human feedback. In: Advances in Neural Information Processing Systems (2022)
- [51] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning (2021), https://api.semanticscholar.org/CorpusID:231591445
- [52] Shi, W., Hu, Z., Bin, Y., Liu, J., Yang, Y., Ng, S.K., Bing, L., Lee, R.K.W.: Math-llava: Bootstrapping mathematical reasoning for multimodal large language models. arXiv preprint arXiv:2406.17294 (2024)
- [53] Shu, C., Chen, B., Liu, F., Fu, Z., Shareghi, E., Collier, N.: Visual med-alpaca: A parameter-efficient biomedical llm with visual capabilities (2023)
- [54] Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., Clark, K., Pfohl, S., Cole-Lewis, H., Neal, D., et al.: Towards expert-level medical question answering with large language models. arXiv preprint arXiv:2305.09617 (2023)
- [55] Su, Y., Lan, T., Li, H., Xu, J., Wang, Y., Cai, D.: Pandagpt: One model to instruction-follow them all. arXiv preprint arXiv:2305.16355 (2023)
- [56] Team, I.: Internlm: A multilingual language model with progressively enhanced capabilities (2023)
- [57] Team, Q.: Introducing qwen1.5 (February 2024), https://qwenlm.github.io/blog/qwen1.5/
- [58] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
- [59] Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
- [60] Wang, K., Ren, H., Zhou, A., Lu, Z., Luo, S., Shi, W., Zhang, R., Song, L., Zhan, M., Li, H.: Mathcoder: Seamless code integration in LLMs for enhanced mathematical reasoning. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=z8TW0ttBPp
- [61] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems 35, 24824–24837 (2022)
- [62] Xu, R., Wang, X., Wang, T., Chen, Y., Pang, J., Lin, D.: Pointllm: Empowering large language models to understand point clouds. arXiv preprint arXiv:2308.16911 (2023)
- [63] Yang, S., Liu, J., Zhang, R., Pan, M., Guo, Z., Li, X., Chen, Z., Gao, P., Guo, Y., Zhang, S.: Lidar-llm: Exploring the potential of large language models for 3d lidar understanding. arXiv preprint arXiv:2312.14074 (2023)
- [64] Ye, Q., Xu, H., Xu, G., Ye, J., Yan, M., Zhou, Y., Wang, J., Hu, A., Shi, P., Shi, Y., Jiang, C., Li, C., Xu, Y., Chen, H., Tian, J., Qian, Q., Zhang, J., Huang, F.: mplug-owl: Modularization empowers large language models with multimodality (2023)
- [65] Ye, Q., Xu, H., Ye, J., Yan, M., Hu, A., Liu, H., Qian, Q., Zhang, J., Huang, F., Zhou, J.: mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration (2023)
- [66] Yu, L., Jiang, W., Shi, H., Yu, J., Liu, Z., Zhang, Y., Kwok, J.T., Li, Z., Weller, A., Liu, W.: Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284 (2023)
- [67] Yue, X., Qu, X., Zhang, G., Fu, Y., Huang, W., Sun, H., Su, Y., Chen, W.: Mammoth: Building math generalist models through hybrid instruction tuning. arXiv preprint arXiv:2309.05653 (2023)
- [68] Yue, X., Zheng, T., Zhang, G., Chen, W.: Mammoth2: Scaling instructions from the web. arXiv preprint arXiv:2405.03548 (2024)
- [69] Zhang, H., Chen, J., Jiang, F., Yu, F., Chen, Z., Li, J., Chen, G., Wu, X., Zhang, Z., Xiao, Q., et al.: Huatuogpt, towards taming language model to be a doctor. arXiv preprint arXiv:2305.15075 (2023)
- [70] Zhang, R., Han, J., Zhou, A., Hu, X., Yan, S., Lu, P., Li, H., Gao, P., Qiao, Y.: LLaMA-adapter: Efficient fine-tuning of large language models with zero-initialized attention. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=d4UiXAHN2W
- [71] Zhang, R., Jiang, D., Zhang, Y., Lin, H., Guo, Z., Qiu, P., Zhou, A., Lu, P., Chang, K.W., Gao, P., et al.: Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? arXiv preprint arXiv:2403.14624 (2024)
- [72] Zhou, A., Wang, K., Lu, Z., Shi, W., Luo, S., Qin, Z., Lu, S., Jia, A., Song, L., Zhan, M., et al.: Solving challenging math word problems using gpt-4 code interpreter with code-based self-verification. arXiv preprint arXiv:2308.07921 (2023)
附录A附录
A.1 数学可视化数据集详细信息
A.1.1 数据引擎
在本节中,我们详细介绍数据引擎的实现细节,即生成与平面几何、解析几何和函数域相关的图表的过程。
平面几何图。
受先前多跳推理方法[30,61,46]的启发,我们采用逻辑理论的迭代生成方法来生成平面几何图像以及相应的标题和问答对,其复杂度可以跨多个轴进行控制。 具体来说,我们首先在图5中定义一组基本几何形状。
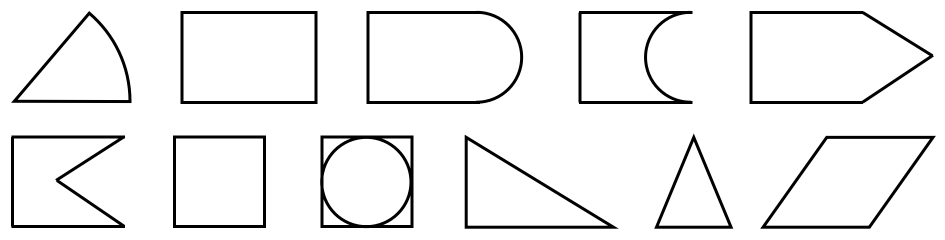
在每个形状内,可以通过延伸特定边缘来生成新的基本形状。 对于每个基本形状,我们最初定义一个元推理过程:
| (1) |
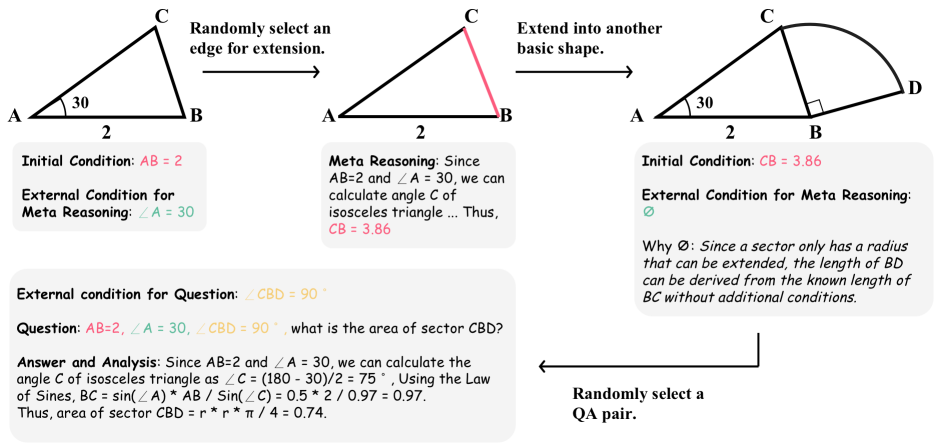
其中表示形状的初始边长,表示完成元推理所需的附加条件,提供元推理的详细解释过程。 例如,当将等腰三角形视为序列中的 形状时,仍需要顶角为 来推断底边长度,然后扩展到 形状,作为这个过程的解释。 变量表示形状有组可能的元推理,表示生成序列的长度,也是生成序列的数量。回答问题所需的推理跳跃。 每个基本形状的初始边、延伸边以及元推理的附加条件可以参考图5。 在最终的形状中,与该形状相关的问答对可以生成为
| (2) |
其中表示解决问题所需的附加条件,而和分别表示问题和答案。 指的是求解过程的详细说明。 变量表示形状内有对问答和相应的详细解释。 通过对第个形状应用元推理,可以推导出第个形状的初始边长。 因此,对于由形状组成的复杂复合图形,整体问答对可以定义如下:
| (3) |
每个形状都定义了足够数量的条件、解释和答案,以确保生成的问答对的多样性。 基于上述规则,控制生成序列的长度可以调节推理步骤的数量,控制问题的类型可以管理解决问题所需的知识。 因此,我们可以生成不同难度级别的问题。 上述生成过程也可以如图7所示。
解析几何图。
解析几何的图像生成方法相对简单。 首先,我们在坐标系内随机选择一个范围:的最小值选择为之间的整数,的最大值为选择之间的整数; 的范围与 相同。 然后,我们定义以下基本形状:点、线段、直线、圆、椭圆、矩形、正方形、多边形和扇形。 在生成过程中,我们选择 1 到 4 之间的数字作为要生成的形状数量。 生成规则是除点、线段和线之外的非线性形状不得重叠。
功能图。
函数图的生成也很简单。 我们定义以下基本函数,每个函数都有一组可以随机选择的参数:
- 正弦函数
-
,其中幅度是1到3之间的随机整数,频率是1或2,相位 是 0 到 之间的随机整数。
- 余弦函数
-
,其中幅度是1到3之间的随机整数,频率是1或2,相位 是 0 到 之间的随机整数。
- 正切函数
-
,其中幅度是1到3之间的随机整数,频率是1或2,相位 是 0 到 之间的随机整数。
- 多项式函数
-
,其中度 是 1 到 4 之间的随机整数。 系数是随机选择的整数,范围从-3到3。
- 分段函数
-
分段多项式函数分为 2 或 3 段,每段的参数与多项式函数的参数相同。
- 对数函数
-
,其中系数是从中随机选择的,基是从中随机选择的,系数是1到3之间的随机整数,系数是1到6之间的随机整数,保证为正数。
- 绝对函数
-
,其中a和b是和之间的随机整数。
我们首先确定要在函数图上显示的域范围。 对于三角函数,定义域设置为。 对于分段多项式函数,的最小值是之间的随机整数,的最大值是。 对于其他函数,的最小值和最大值分别是和范围内的随机整数。 在绘图过程中,我们通过迭代域来计算函数的局部最大值、最小值和零点。 然后,我们在函数图的 x 轴上渲染这些极值和零点的 x 坐标。
A.1.2 MAVIS-标题
在本节中,我们详细介绍如何生成与 MAVIS-Caption 数据集中的图像相对应的字幕。
平面几何标题。
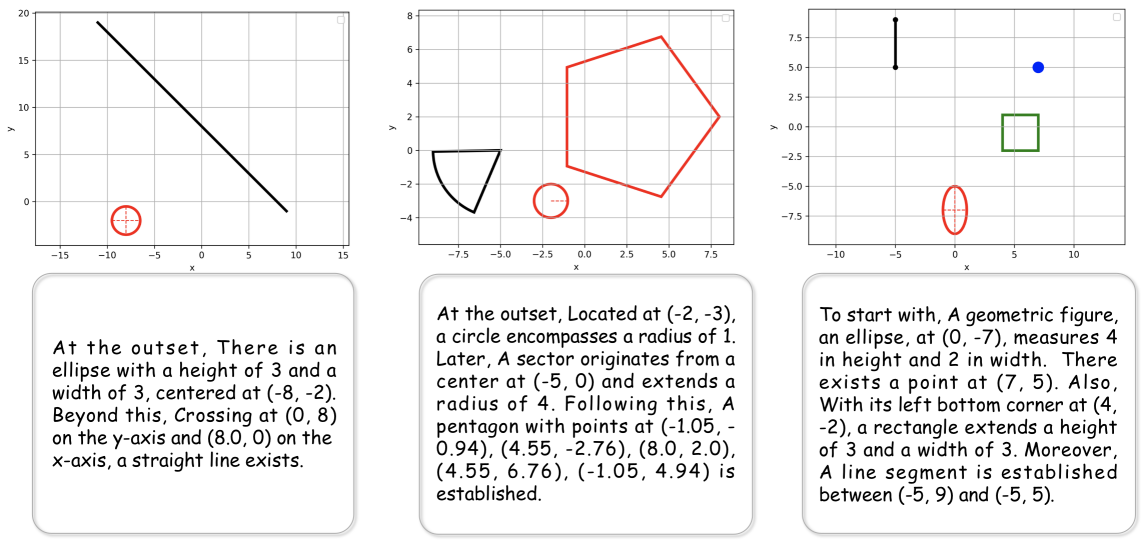
解析几何标题。
对于每个形状,我们维护一组描述形状的类型、坐标位置和其他属性的标题模板。 具体模板可以参考LABEL:appendix:Analytical_Caption_Template部分。 在A.1.1节描述的生成过程中,我们选择一个模板并随机添加一些不同的连接词以形成完整的标题。 一些标题的示例如图8所示。
功能标题。
根据A.1.1节描述的函数图生成过程,我们记录函数的零点和极值。 此外,我们还记录函数的表达式和渐近线。 这些属性被合并到随机选择的标题模板中以形成函数图的标题。 标题模板可以在LABEL:appendix:_Function_Caption_Template部分引用。 图9中提供了一些示例。
A.1.3MAVIS-指导
由 GPT-4 增强的手动收集。 为了用现实世界的问题解决场景补充数据集,我们聘请了 8 名人类专家从各种公共来源手动收集视觉数学问题1,2,3,涵盖平面几何、解析几何和函数。 对于问题,我们尝试获取尽可能完整的内容,包括问题、图表、答案和理由(如果有)。 然后,我们首先将所有相关信息输入GPT-4V,以消除文本问题中的冗余信息,按照图10中的提示构建问题的文本精简版本。 然后,我们为 GPT-4 设计了三种类型的提示,分别增加 15 个多项选择题(包括 10 个多项选择题和 5 个二元选择题,即“True”或“False”)和 5 个自由形式问题,如图11所示。 我们在这里不采用 GPT-4V,因为 GPT-4V 本身会误解低质量数据增强的图表。 新生成的问题包含详细的 CoT 原理和多样化的问题形式。


GPT-4 增强了现有数据集。 之前已经努力提供一些小规模的平面几何数据集,例如 GeoQA [12]、GeoQA+ [10] 和 Geometry3K [44] 。 尽管它们在调整 MLLM 时的数据规模有限并且没有任何基本原理,但我们也可以将它们视为种子数据集并采用 GPT-4 来增强更大规模的训练数据。 出于与上述相同的原因,我们在这里不使用 GPT-4V。 具体来说,我们使用不同的提示设计了3种类型的问题生成方法,如图12所示。 对于 Geometry3K,由于问题文本通常很简短并且包含边际描述信息,这给 GPT-4 理解图表带来了挑战,我们仅对其进行增强以生成二元选择问题,即“Ture”或“False”。 对于 GeoQA+,我们可以利用文本中足够的冗余信息来生成更加多样化和准确的多选题和自由格式问题。 同样,GPT-4 可以为每个问题提供 CoT 基本原理。

由 GPT-4 注释的数据引擎标题。
考虑到用于自动图表标题创建的精心设计的数据引擎,我们可以利用生成的大规模对使用 GPT-4V 来注释问答数据。 与前面两个基于问题来增强问题的来源不同,我们在这里使用 GPT-4V 模型来获取警告数据,原因有两个:首先,来自我们数据引擎的详细标题可以很好地指导 GPT-4V 进行相对更高质量的视觉嵌入;其次,视觉输入作为指导,为广泛的问题形式提供额外的空间信息。 如图20和图21所示,我们对函数和平面几何问题采用不同的提示,保证生成的问答数据具有较高的教学质量调整。



数据引擎生成的问题。
平面几何。
根据A.1.1节中描述的生成过程,我们对生成序列中的最终形状提出问题。 我们设计了6种题型:求周长、求面积、求底长、求角度、求弧长、求延长边长。 每种题型都有一组可以随机选择的模板,如图15-19所示。 至于答案和分析,每个形状都有一组不同类型问题的模板可供选择,如Sec.A.1.1所示。
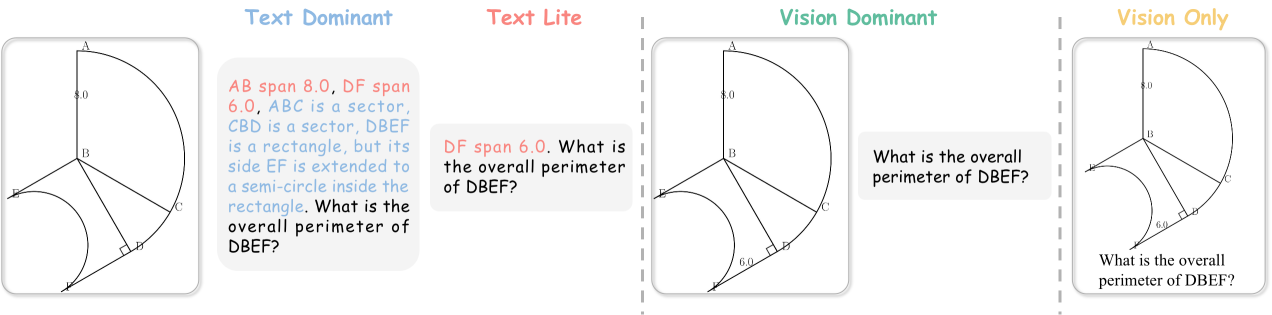
为了进一步增强模型对不同形式问题的理解,更好地利用文本和图像中的多种模态信息,我们参考 MathVerse [71] 将数据引擎生成的简单几何问题分为四个版本>:文本主导、文本精简、视觉主导和仅视觉。
- 文字为主
-
我们在图中标记了解决问题所需的所有条件,并在文本中描述了这些条件,以及一些多余的描述性文本。
- 文本精简版
-
解决问题所需的所有条件被随机分为两部分:一部分在图中标注,另一部分在文字中描述。 换句话说,图中的条件和文本中的条件并不重叠。
- 视觉主导
-
解题所需的所有条件都标注在图中,而文字只包含问题,没有任何条件。
- 仅视觉
-
不仅解决问题所需的所有条件都标注在图中,而且问题也呈现在图中,而文本部分留空。
同一问题的四个版本之间的差异如图13所示。 每个基本形状都会保留一组冗余条件。 在形状生成过程中,有 50% 的概率包含这些冗余条件。





功能。
所有函数都将通过两种类型的问题进行检查:求导数和求极值。 获得导数后,我们计算导数在给定域内是否有零点。 零点的存在决定了计算函数极值的方法。
